- ChatGPT应用
- 结束
ChatGPT应用
OpenAI CEO奥特曼那句AI版摩尔定律:
宇宙中的智能数量每18个月翻一番。
- 模态:文本,语音,图像,视频,建模,策略,跨模态…
- 产业:传统,新兴,机器人,脑机…
从一个风靡全球的AI玩具到独具潜力的赚钱法宝,对话机器人ChatGPT仅仅用了不到半年。
- 微软联合创始人比尔·盖茨称GPT是“40多年来最革命性的技术进步”
- 英伟达创始人黄仁勋高呼:“我们正处于AI的iPhone时刻”
- 阿里董事会主席兼CEO张勇也说:“所有行业都值得用大模型重做一遍。”
ChatGPT 大事记
ChatGPT2022年12月发布,但真正火到出圈,是春节后,尤其是3月之后的事情了。ChatGPT一石激起千层浪,过去的3月可能是LLM领域最为波澜万丈的一个月。
- 3月1日,OpenAI发布ChatGPT API
- OpenAI不止发布了ChatGPT的API,还发布了新版的Whisper(一个语音识别模型)的API。主角当然还是ChatGPT了,借助API各类相关应用如雨后春笋一般出现,例如 ChatPDF,ChatPaper等等。同时还有API定价,居然和GPT3差不了多少,再次印证了那个假设:ChatGPT的参数量应该和GPT3差异不大。
- 3月8日,Facebook的LLaMA模型被“泄露”
- LLaMA是Facebook于2月24日“开源”的大模型,包含了多个不同参数量的预训练的模型。最初这个模型是需要向Facebook申请并遵守License才能获取到的,后来惨遭“泄漏”,现在可以从HuggingFace中直接下载。
- LLaMA-13B不仅在大多数benchmarks上超过了GPT-3,证实百亿参数的预训练模型作为基座,有所作为。
- 3月10日,HuggingFace发布peft的0.2.0版本
- peft是HuggingFace开发的一个参数高效的微调库(Parameter-Efficient Fine-Tuning)。此次发布特别提到了Whisper large tuning using PEFT LoRA+INT-8 on T4 GPU,HuggingFace要打造大模型微调标准库的野望。HuggingFace原本定位是预训练模型届的github,用户需要实现什么功能,就要到HuggingFace的平台上去找对应任务的模型。如今ChatGPT已经出来了,一个模型可以解决几乎所有NLP问题,HuggingFace作为模型平台看起来就感觉用处不大了,所以不难理解HuggingFace的危机感。
- 3月13日,斯坦福发布Alpaca 7B
- Alpaca-7B是斯坦福发布的基于LLaMA-7B继续微调得到的模型。训练所用的52K的instruction-following demonstrations,通过调用text-davinci-003(GPT3.5)得到。
- 最终实验结果表明Alpaca-7B的表现和text-davinci-003相似,整个训练花费仅有不到600美元。Alpaca-7B的出现,证明了用很小成本也是可以一定程度上可以复现大模型的表现,极大地振奋了整个开源社区的信心。此后不久,基于lora等参数高效的微调方法,开源社区很快实现了在单张显卡、消费级显卡的训练。
- 3月14日,OpenAI发布GPT4
- GPT4相对于GPT3/3.5的改进集中在两点:一是支持多模态理解,以前只允许输入文字,现在也可以支持图片作为输入;另一点则是GPT4的逻辑推理能力得到进一步增强,很多用户经过测试也证明了这一点。
- GPT4的发布并没有像GPT1/2/3/3.5那样有对应的论文,OpenAI只发布了一篇技术报告,报告中没有提到任何训练的细节,例如训练集的构造方法、训练消耗的电力、learning rate/epoch count/optimizer等超参…OpenAI声称不公布的原因是“the competitive landscape and the safety implications of large-scale models”,但并不妨碍OpenAI被调侃为“CloseAI”。
- 3月15日,清华发布chatglm-6b
- ChatGLM-6B是一个清华开源的、支持中英双语的对话语言模型,基于GLM架构,具有62亿参数。结合模型量化技术,ChatGLM-6B可以在消费级的显卡做模型的推理和训练,对于缺卡缺钱的研究团队来说非常有用。毫无疑问,这是当前中文领域最为活跃的开源大模型,截至目前(2023.4.2),huggingface上ChatGLM-6B的下载量达到了33万。
- 3月16日,pytorch2.0发布
- 在众多算法产品和技术的璀璨之下,pytorch2.0的发布不那么突出了。这次2.0版本最重要的特性之一是把torch.compile作为主API,此外还针对性能做了很多优化。遥想2020年初那会,tensorflow的2.0版本也是刚刚发布,彼时大多数公司借着把骨干网络换成transformer的时候,就把深度学习框架也换成了pytorch,顺带也带来了HuggingFace的蓬勃发展。
- 3月16日,百度发布“文心一言”
- 百度发布的“文心一言”,号称中文版的ChatGPT。但是发布会上百度CEO李彦宏也坦言,“文心一言要对标GPT-4,这个门槛还是很高的。文心一言并不完美,之所以现在要发布,原因在于市场有强烈需求。”
- 3月23日,OpenAI发布ChatGPT Plugin
- OpenAI发布的ChatGPT Plugin提供一种大语言模型应用特定领域知识或者能力的新思路。在这之前的应用开发商例如ChatPDF,思路都是调用ChatGPT的API,再结合开发上自由的能力,整合为一个产品提供给用户。而ChatGPT Plugin实现了一种依赖的翻转,首先开发商提供API给ChatGPT,再由ChatGPT决定何时以及如何使用这些API,这些API就是所谓的“插件”。在这种模式下,用户的交互全部都在ChatGPT中完成,可谓是“肥水不流外人田”。
- 3月29日,众多大佬签名反对下一代大模型的开发
- 众多大佬签名了公开信,反对下一代大模型的研发,号召AI实验室在至少未来6个月内,暂停训练比GPT4更强的大模型。《全球通史》中,斯塔夫里阿诺斯有一个核心的观点:“在技术变革和使之成为必需的社会变革之间,存在一个时间差。造成这个时间差的原因在于:技术变革能提高生产率和生活水平,所以很受欢迎,且很快便被采用;而社会变革则由于要求人类进行自我评估和自我调整,通常会让人感到受威逼和不舒服,因而也就易遭到抵制。社会变革滞后于技术变革一直是人类许多灾难的根源。”将来回望历史时,2023年的3月毫无疑问是一段技术大变革的爆发期,但是与之相匹配的社会变革,或许我们接下来还要探索很长时间。
ChatGPT 商业化
行业观察
【2023-5-7】陆奇:新范式新时代新机会, 完整ppt,ppt+笔记
【2023-5-25】传TikTok正在测试名叫TAKO的聊天机器人。
- 目前TikTok正在测试一款名叫
TAKO的人工智能聊天机器人,该机器人可以与用户进行短视频对话,并能帮助他们发现新创作内容。 - 据悉,该聊天机器人以一个鬼魂形状的图标突出显示在应用界面上,用户在观看视频时,可以点击它进行基于文本的对话并寻求帮助并找到合适的内容。
监管
- 4 月 11 日,网信办发布《生成式人工智能服务管理办法(征求意见稿)》公开征求意见的通知。
- 同日,美国商务部下属的国家电信和信息管理局 (NTIA) 宣布征求公众意见,关于如何制定人工智能问责措施。
- NTIA 负责人艾伦·戴维森(Alan Davidson)对《卫报》表示,美国立法者 2021 年提出 100 多项人工智能相关法案,“这跟社交媒体、云计算甚至互联网早期有很大不同”。
- 当地时间 5 月 16 日,OpenAI CEO 山姆·阿尔特曼(Sam Altman)首次参加美国国会听证,呼吁政府制定监管 AI 的措施。
创业公司
详见站内专题: AIGC创业机会
ChatGPT 行业应用
ChatGPT 非常实用,能帮助普通人节省不少脑力和时间成本。
- 回答后续问题、承认错误、挑战不正确的前提、拒绝不适当的请求。
ChatGPT在办公软件、社交文娱、营销广告、家庭助理四大方向的15条赛道,AI大模型技术正出现落地的萌芽。其中不仅有国民级的Office工具、钉钉等协同办公平台接入大模型,还有来自办公、电商、家居、社交文娱互联网平台推出AIGC功能,甚至以智能汽车、AR眼镜为代表的实体终端也上了大模型,带来新奇体验。
【2023-5-11】生成式AI创业领域
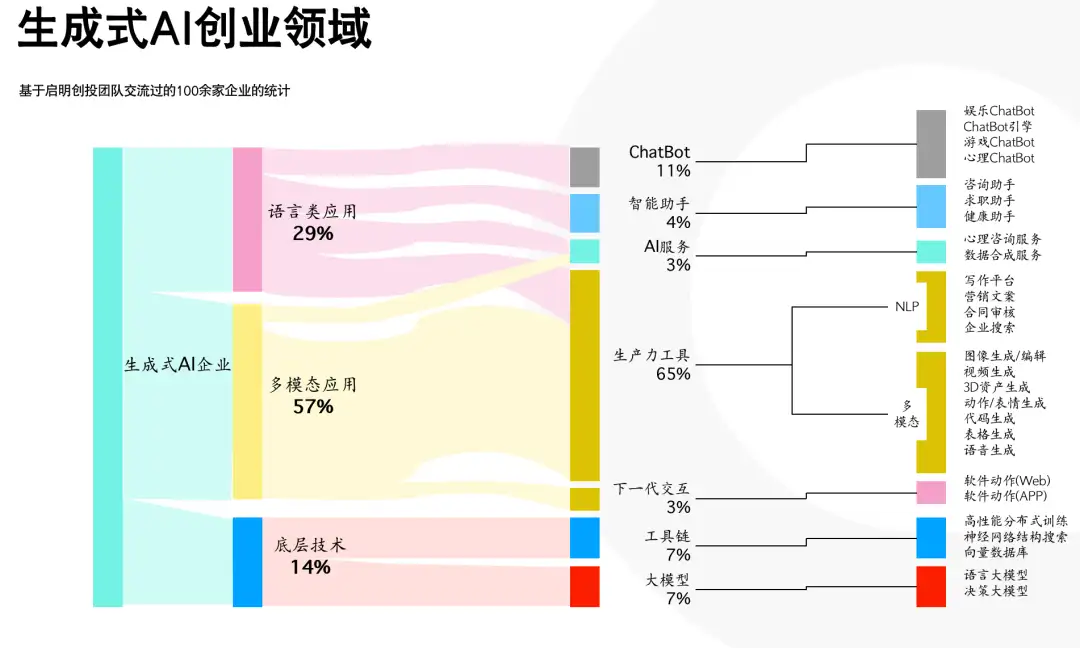
2023 年是 AI 跳变式发展一年:
- ChatGPT 成为史上最快突破 1 亿用户的超级应用;
- Perplexity 用“问答引擎”撬开了 Google 在内容搜索上的强势;
- GPT-4 的发布定义了 LLM 军备竞赛的决赛门槛是什么;
- Runway、Pika 以及以及 VideoPoet 为模型带来更多形态智能能力;
- Llama 2 和 Mistral-7B 是开源势力带给社区的惊喜;
受益方
相关受益方
- 上游增加需求
- 算力芯片、数据标注、自然语言处理(NLP)等。
- 下游相关受益应用,包括但不限于:
- 无代码编程、小说生成、对话类搜索引擎、语音陪伴、语音工作助手、对话虚拟人、人工智能客服、机器翻译、芯片设计等。
- 功能(C端)
- 一款激起新鲜感的新奇玩具,也是一款消磨无聊时光的聊天高手,也能成为生产力爆表的效率工具,更可以被用作上通天文下知地理的知识宝库。
- ChatGPT不仅在日常对话、专业问题回答、信息检索、内容续写、文学创作、音乐创作等方面展现出强大的能力,还具有生成代码、调试代码、为代码生成注释的能力。
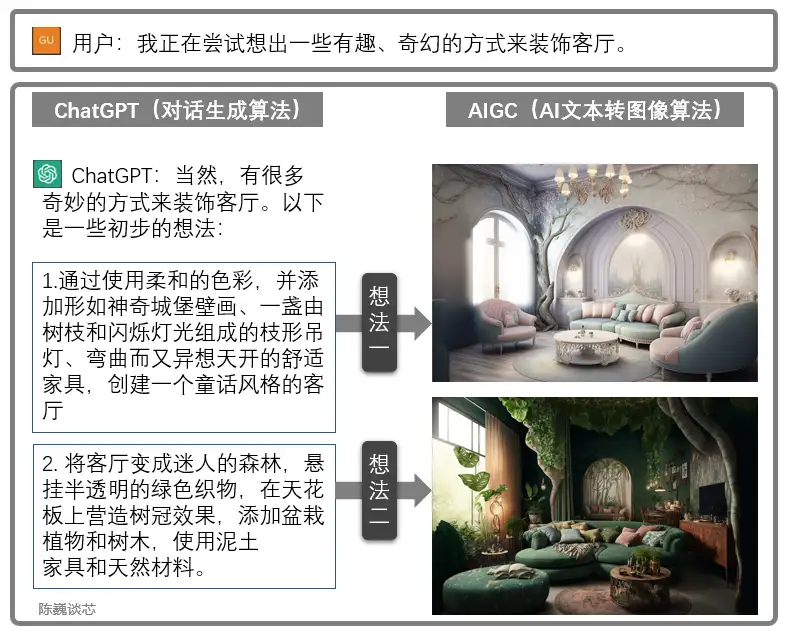
人们源源不绝地挖掘ChatGPT的更多技能,包括替写代码、作业、论文、演讲稿、活动策划、广告文案、电影剧本等各类文本,或是给予家装设计、编程调试、人生规划等建议。
ChatGPT也可以与其他AIGC模型联合使用,获得更加炫酷实用的功能。这极大加强了AI应用与客户对话的能力,使我们看到了AI大规模落地的曙光。
- 通过对话生成客厅设计图。
【2023-3-2】普通人如何用ChatGPT搞钱?
- 1、让ChatGPT写小说
- 著名大V半佛仙人表示人家已经提前试过,效果并没有那么理想:
- 2、让ChatGPT做培训
- 其他行业我不清楚,但在计算机行业,用ChatGPT来指导学生写代码,纠正代码问题还是效果不错的,把ChatGPT包装成一个虚拟的培训老师,很有想法。
- 3、山寨版ChatGPT
- 高能提醒: 违法! 发出来只是让大家提高警惕,别花冤枉钱被骗了!
- 有人在想着怎么用ChatGPT搞钱,而另外有人在想着:你们这么想用ChatGPT,如何利用这一点搞钱!
- 4、让ChatGPT来做自媒体
- 大家刷短视频的话,经常看到模板化的套路,几句话,几分钟视频,看得人暴多。以后有了ChatGPT帮忙写稿,批量化做视频,一个人搞一堆短视频自媒体账号根本不是问题。
- 5、开发一个ChatGPT面试系统
- 现在很多公司都允许远程面试,比如电话面试、视频面试,有人想到用这玩意来面试,接入一个语音识别,就可以实时帮助求职者通关面试了:
- 开发这么一个系统,你觉得会有市场吗?基于这个想法,还可以开发一个ChatGPT写作文系统、写简历系统、做PPT系统,以后说不定一堆淘宝卖家提供这样的服务。
随着ChatGPT的不断迭代,以及国内外各大厂商的跟进,2023注定要掀起人工智能新的一波热潮。咱们程序员除了学习技术之外,也可以想想怎么在安全合法的情况下,利用这些AI做出一些有意思的东西,说不定就火了呢。
商业变现
方案
- 卖账号;
- 部署公众号,用户免费使用N次,分享海报,带来新关注,每个关注送N次;
- 部署小程序,用户免费使用N次,关注公众号可以送N次,每看一次激励视频可以送1次;
- 帮助其他人部署公众号/小程序,每个收费;
- 垂类产品,基于 ChatGPT 提供的能力,输出内容,卖内容或者卖服务
- 内容站点,收集热门搜索词,用 ChatGPT 提供的内容给搜索引擎收录,赚广告费;
- ChatGPT 机器人接入,收费。
- 创作类:总的来说,可以达到九年义务制教育的及格水平
【2023-1-24】ChatGPT创业实践,自宅创业 - #27 蹭热点的ChatGPT小程序
- 批量注册、卖opengai账号:做ChatGPT小程序,上线当天用户量突破1000,第一次做出这么火爆的产品
- 一个写程序批量注册,一个负责销售,收益分成。写好了程序,注册了一批ChatGPT账号,赚了一点钱。然后发现市场上ChatGPT账号价格越来越低,也很难批量销售出去。
- 开发ChatGPT小程序
- 做一个小程序,把ChatGPT的功能做到小程序上,打开就能直接用。不到3天小程序急速完成上线,上线当天用户量就突破1000,涨势非常好。正预想着日活过万,然后小程序就被举报封了,发布的两个小程序同时被封。举报人和我正好同在一个微信群里,虽然很难过,但还是接受了现实,大家都按丛林法则生存。
应用图谱
大模型冲击下,各行各业稳定性:
- 广告 > 推荐 > 搜索 > NLP应用
应用概览
三层:模型层→模态层→应用层
- 模型层:文本领域(GPT系列)、图像领域(扩散模型系列)、视频、建模、多模态等
- 模态层:文本、语音、图像、视频、行为、理解、策略、工具等,其中文本和图像最为惊艳
- 应用层:智能对话、AI作画最为亮眼,传统行业正在被逐步颠覆,如搜索、问答、智能办公、内容创作,同时,应用商场、互联网、数字人等也被波及。
应用列表
图解
【2023-4-11】ChatGPT应用发展趋势:
- 第一波:Prompt套壳。如翻译/摘要工具、客户端、各种笔记工具。
- 第二波:文档向量索引、对话。如ChatPDF/ChatDoc、数字化分身等,自己实现可参考 llamaindex
- 第三波:自运行Agent。 如Microsoft Jarvis、 BabyAGI、autoGPT等
大模型应用生态
大模型应用生态是一个自下而上的分层架构,从基础模型到最终应用形成了完整的技术栈。
生态系统主要包括六个核心层级:
- 基础模型层:处于整个生态底层,包括各类开源和闭源的大型语言模型,如ChatGPT、Claude、meta-llama、Gemma、Mistral等,它们提供了基础的智能能力。
- 模型运行层:负责大模型的高效部署和运行,主要工具包括vLLM、LM Studio、Ollama等,它们解决了模型推理效率和资源占用的问题。
- 模型优化层:通过各种技术手段提升模型性能和效率,代表技术包括unsloth、LLaMA-Factory、Transformers等,实现模型微调和适配。
- 开发框架层:为开发者提供构建大模型应用的工具和接口,如LangChain、DSPy、LlamaIndex和Spring AI等,降低了开发门槛。
- 中间件层:连接基础模型与应用层的关键组件,包括AI Agent技术(AutoGen、CrewAI、LangGraph)和向量数据库(Chroma、Pinecone)等,实现了复杂功能的组合与增强。
- 应用层:位于生态顶层,是面向最终用户的各类应用程序,包括各种垂直领域的解决方案和通用工具。这些层级之间相互依赖又相互促进,共同构成了大模型应用的完整生态。
图见原文
MaaS 模型即服务
【2023-6-29】抖音团队在用的大模型服务平台”火山方舟”,我们也上手体验了一把
从算力消费的角度来说
- 第一条增长曲线是模型训练
- 第二条增长曲线则是模型的应用和调优
而且在不久的将来,第二条增长曲线必然会超过第一条。

AI 领域形成了一种全新的商业模式:Model as a Service(MaaS),模型即服务。
- 「模型即服务」能够将大模型、工具平台、应用场景三者联合起来。
- 对于行业来说,这是一种无需巨额前期投入即可完成大模型训练、推理的途径;
- 对于大模型提供商来说,这是一种探索商业化落地、获得资金回报的可靠方法。
【2025-5-3】新观点:LLM利润分配是:90%/30%/负20%
- 硬件(GPU, 即NVIDIA): 90%
- 云厂商: 30%
- 大模型厂商: -20% !
火山方舟
- 【2023-6-28】在北京举行的火山引擎体验创新科技峰会上,火山引擎总裁谭待推出「火山方舟」MaaS 平台。
「火山方舟」面向企业提供模型精调、评测、推理等全方位的 MaaS 平台服务。基于其独特的多模型架构,企业可通过「火山方舟」同步试用多个大模型,选用更适合自身业务需要的模型组合。此外,「火山方舟」实现了大模型安全互信计算,更加注重为企业客户确保数据资产安全。
火山方舟提供了「模型广场」、「体验中心」、「模型精调」、「模型测评」等版块。
- 模型广场:从选择、体验到真正落地
- 首批入驻大模型,包括百川智能、出门问问、复旦大学 MOSS、IDEA 研究院、澜舟科技、MiniMax、智谱 AI 等多家 AI 科技公司及科研院所的大模型,并已启动邀测。
- 「模型广场」理解为一家「商店」,模型供应方可以在模型广场进行模型创建、上传、部署等,模型使用方可以在模型广场查看模型、快捷体验。
- 除了 AI 对话类的应用,火山方舟现在还提供 AI 绘画类的应用体验。
- 模型精调:百尺竿头更进一步
- 客户需要利用自有数据或领域非公开数据进行持续训练,以及建设和积累自己的精调数据集。对精调手段的良好运用,能够帮助企业客户利用更小的模型尺寸,在特定任务上达到媲美通用大模型的水平,由此进一步降低推理成本。
- Python sdk: volc-sdk-python
- 模型测评:
- 模型评估环节也是火山方舟重点关注的一环,包括数据准备、指标定义以及人工评估和自动化评估等诸多全方位的工具。
- 在火山方舟平台上,模型在发起精调任务的同时将进行自动化评估,精调的效果和运行指标也将在平台实时跟踪。
- 模型推理
- 火山引擎提供安全互信的推理方案,保障模型提供商与模型使用者的模型与数据安全,客户可直接使用模型供应方已部署的在线服务或便捷地将精调模型部署为在线服务。
大模型服务需要解决三个问题
- 安全和信任
- 性价比
- 生态系统
- 工具链和下游应用插件需要持续完善。
- 打造垂直领域模型的微服务网络,内置包括图像分割、语音识别等众多专业模型,便于企业客户随时调用、自由组合。
基座模型
【2024-5-15】一口气推出9个基座模型
- 通用模型 Pro: 窗口尺寸最大可达128K,全系列可精调
- 通用模型 Lite: 较快响应速度
- Function Call模型
- 向量化模型
- 角色扮演模型
- 代码大模型 Doubao-coder
- 语音识别模型、语音合成模型、声音复刻模型
- 豆包语音识别模型 Seed-ASR
- 语音生成基座模型 Seed-TTS
- 文生图模型
- 通用图像编辑模型 SeedEdit
- 视频生成模型
- 两款豆包视频生成模型
PixelDance与Seaweed
- 两款豆包视频生成模型
【2024-12-30】 豆包大模型2024年的8个关键瞬间
没有榜单分数,参数规模
价格让现场观众“哇声一片”的大亮点,和其它大模型相比:
- 小于32K窗口尺寸:豆包通用模型pro,只要0.0008元/千tokens,比行业价格低99.3%
- 128K窗口尺寸:豆包通用模型pro,只要0.005元/千tokens,比行业价格低95.8%
1元=1250000tokens
workflow 平台
详见站内专题: llm开发平台
字节 大模型产品
字节豆包已经
- 每周活跃2-3天,每天才发5-6次消息,平均使用时长不到10分钟
- 而猫箱对话轮数是豆包的50倍…
- 这是所有AI对话产品的通病
- 纯对话形式可能只是过度态,视频和图像才是未来;字节正在酝酿一场新的革命,主角是视觉和创作
- 剪映日活1.7亿,仅次于 ChatGPT
- 即梦被提到更高的战略位置
概要
Flow 旗下现有 AI 智能助手 豆包(APP 版和 PC 版)、AI 智能体开发平台 扣子(中国版)和 Coze(海外版)、图片生成产品星绘、类 Character.AI 角色对话产品猫箱(原叫话炉)和小黄蕉、AI 教育产品豆包爱学(原河马爱学)、出海搜题产品 Gauthmath 等数款 AI 软件和互联网应用。
Flow 产品矩阵
- 智能对话
- 办公助手
- 小悟空, 海外
Chitchop,对话类AI工具大合集,支持对话和辅助推荐,累计有90个小工具,包括创作生成、学习提升、工作职场、专业咨询、虚拟角色、休闲娱乐、语音转文字等等。
- 小悟空, 海外
- 代码生成
- MarsCode AI IDE 提供开箱即用的开发环境,AI 编程助手提供代码生成、代码解释、单测生成和问题修复等功能,支持上百种编程语言和主流开发环境。
CodeGen: 海外, 批量生成和修复代码 (创新业务中心)
- 图像
- 音乐
- 海绵音乐: 文生音乐类C端应用,移动端为主 (创新业务中心)
- 视频
- AI教育产品:
- 【2024-9-6】
河马爱学更名豆包爱学, 海外Gauth, AI拍照搜题, 服务美洲和欧洲学生,学习者的智能伙伴、家庭教育的好帮手, 功能:作业批改、知识问答- 2024年3月, 海外教育APP榜单第二,仅次于多邻国
- 河马爱学,针对小初高学生推出的一款难题答疑、指导中英文作文、作业批改、情感陪伴工具。
- 上半年,大力教育 ZERO 合并到豆包团队,
河马爱学也随之并到了豆包,并在近期改名为豆包爱学,成为了豆包产品矩阵的一员
- 搜题产品: GauthMath, 帮助海外“数学救星”解题的应用,由字节跳动旗下智象出海推出,目前在100多个国家发行,下载量超过1亿。
- 识典古籍: 抖音公益与北大共建的古籍阅读平台
- 【2024-9-6】
- 硬件:AI耳机、眼镜
- 【2024-10-10】Ola Friend 耳机
孵化机制
【2024-10-24】字节AI为何凶猛:重启App工厂,争抢“豆包”,连模型也要赛马
从时间线来看,字节跳动的确晚了。
大模型布局上,百度和阿里反应迅速,而字节没有发布基础模型,彼时并无法靠「豆包」来说服质疑它的观众们。
- 大模型产品的命名常常引经据典,与文心、通义、混元、星火、天工相比,「豆包」听起来土味十足。
- “当时准备将
Grace推向市场时,内部一致认为必须要改名,要做中国市场,英文名限制太大。陆陆续续起了100多个名字,有一部分有硬伤直接被Pass了,剩下的做了一些田野调查,有负面关联又淘汰了一部分,最终是朱骏拍板定了「豆包」这个名字。” -
豆包这个词在中国的渗透率差不多80%-90%,没有硬伤。字节内部起名字有一整套的流程,再经历田野调查,这个名字有没有什么负面关联
- 产品层,
豆包是统一品牌,所有产品向豆包靠拢。 - 模型层,“
豆包”更像是一个代号,究竟谁能成为“豆包”,更像是一场争夺行动。- 2024年9月24日,火山引擎一口气发布了两款视频生产模型,但对外并没有展示详细解释两款模型的差异,
PixelDance和Seaweed在发布前,在Github上发布过对应的模型细节,分别属于两个团队,但最终均被冠以“豆包”之名对外发布
- 2024年9月24日,火山引擎一口气发布了两款视频生产模型,但对外并没有展示详细解释两款模型的差异,
-
现在的豆包更像是一个统一出口,连接用户。豆包产品后端连接了多个模型测试,是一个训练场,通过API的结果反馈来评测模型效果,但一时间很难有取舍
- 2023年年初,集团内部才开始训练基础模型,而后,字节跳动创始人张一鸣明确了“不卷基模,做AI应用”的战略方向,开始高举高打,内部的组织架构以及外部策略都开始进行了大变革。
- 2023年8月18日, AI对话产品更名为”豆包”
- 2923年11月27日,字节放弃游戏业务的同一天,成立了新 AI 部门
Flow。
Flow 部门下设三个子部门,分别为 AI 产品团队 Flow、大模型研发团队 Seed 和产品研发支持团队 Stone。
- AI 产品团队 Flow:专注于各类 AI 产品的策划、设计与优化等工作,致力于打造满足用户需求和市场竞争的 AI 应用。
- 大模型研发团队 Seed:主要承担大模型底层技术的研发工作。
- 产品研发支持团队 Stone:侧重于为产品研发过程提供全方位的支持,包括但不限于数据处理、算法优化、技术运维等,确保整个研发流程的顺畅进行和产品的稳定运行。
紧接着,字节系各类AI 应用如流水线上的产品一般,快速涌向市场。
- 2024年至今,字节在国内外推出包括「豆包」在内的20余款App,从集成式的聊天助手,到图像、视频、音乐等效率工具,加速渗透到教育、办公助手、开发平台、代码生成等行业,而且,这些应用的表现亮眼,一个个在AI应用大乱斗里杀出重围。
2024年3月「豆包」的下载量和月活跃用户开始双双登顶。
- 全球 Top 100 AI 应用榜单显示,字节系
Cici、Coze、Gauth、Hypic、CapCut五款产品名列前茅。与此同时,字节依然不断在海外推出新的产品进行试点。
字节系产品没有真正在开拓新场景,很少“教育市场”,而是更多“顺应市场”,在已经被部分验证的场景下进行产品的迭代和优化。
- 策略: 复制小爆款,成为大爆款
- 「豆包」虽然推出得晚,但上线便集齐了对话、Agent、语音通话等当时分散在不同产品中的大模型功能
- 「猫箱」完全对标「星野」
- 「星绘」对标「妙鸭」
- 「海绵音乐」对标「Suno」 在此基础上,结合用户体验对产品进行迭代。
负责产品增长的团队构建了强大的数据监测系统,花大价钱去买市面上的数据,尽可能监控所有产品,用来指导研发。
- 基于信息差的实验+地毯式孵化+数据增长,形成了一条新的AI APP生产线。
移动互联网时期,“App工厂”打法是字节快速开疆扩土的重要策略之一。
- 2018年-2020年,字节增长最为迅速,自研和收购了大量项目,其中在App Store上线的应用就有约140个,占其成立以来的七成。
字节通过批量生产,在今日头条和抖音之后,也成功推出了剪映、懂车帝、皮皮虾、番茄小说、轻颜相机等爆款。
2023年11月,APP工厂在AI时代重启了,字节陆续密集上线了众多APP。
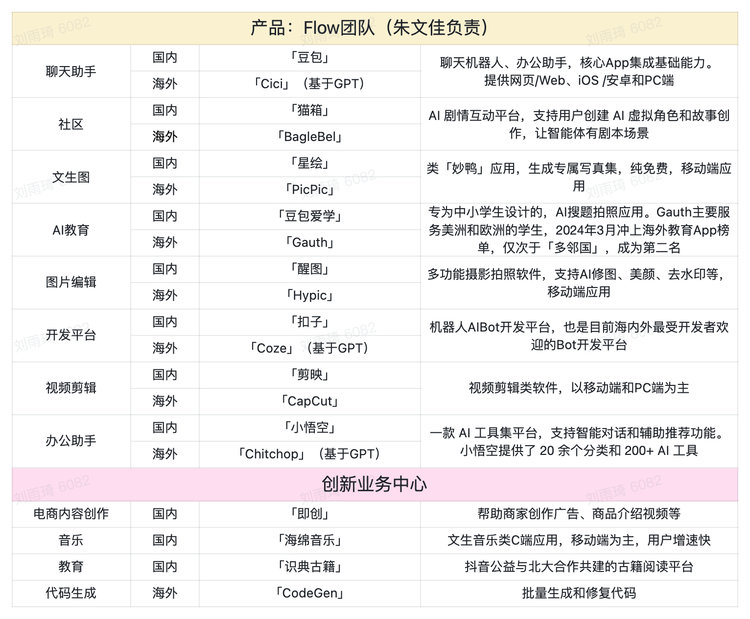
字节内部多轮赛马制:
- 第一阶段,
创新产品中心负责前期孵化、产品创意、内部审核以及完成产品的前期打造,到产品测试上线。- 这个阶段几乎不会有流量支持,靠产品自身的形态吸引自然用户;
- 第二阶段,拿到一部分初始预算进行外部推广,由专门负责增长的团队负责拉新留存,进行产品排名,数据表现好结合内部分析,从创新产品中心进入到具体产品组;
- 第三阶段,成型的产品开始进行大规模推广,如「猫箱」、「星绘」从去年年底开始在抖音投流以及通过KOL推广。
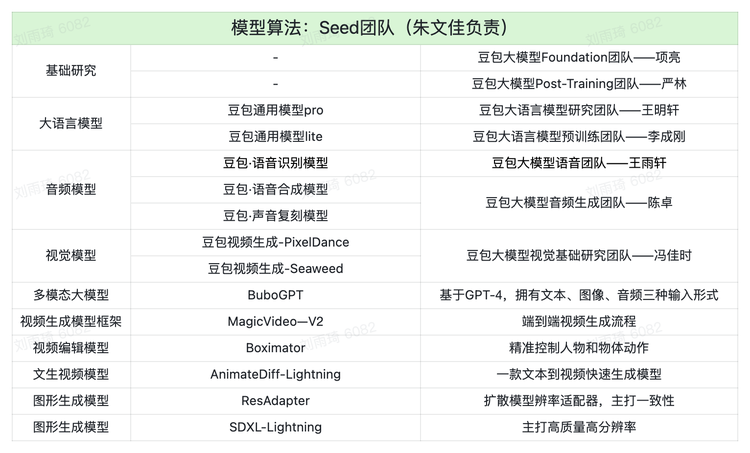
内部结构
- 模型和算法归属于模型算法团队
Seed,由朱文佳(曾任TikTok产品技术负责人)负责; - 2023年11月成立的
Flow团队主要负责打造C端产品 朱文佳为整体业务负责人朱骏(原 Music.ly 创始人、原TikTok负责人)为产品负责人洪定坤为技术负责人,向下包括豆包、AI教育、社区、国际化四个部门,同时PC端和移动端也分为两条业务线;而豆包大模型to B的商业化业务主要由火山引擎对外提供,并通过API方式接入飞书。
Seed团队由原来的搜索团队、AI Lab团队、AML团队联合而成,但实际上,这几个团队都在暗自较劲。
字节AI产品今天的突飞猛进,是其赛马机制下,一套屡试不爽的产品开发方法论加持的结果。但与移动互联网时代字节的“生产体系”很不同的是,今天在底层的模型侧,字节也在进行着赛马。
字节可能寄希望于它也像应用一样,百花齐放后筛选出最强的那一个,但同时它也客观上带来着资源无法集中的问题。
【2024-9-10】字节再试硬件:探索 AI 耳机、眼镜等产品,与豆包大模型联动
- 豆包大模型与豆包App联动的智能耳机:语音对话随时使用豆包,app上也可以操作耳机
- 李浩乾于 2019 年创立大十未来,2022 年,推出第一代 Oladance 耳机,主打 “OWS”( Open Wearable Stereo 开放式穿戴无线耳机):把音响集成得足够小,可不入耳穿戴。
- 2023年底收购的智能耳机公司——大十未来
- 探索AI眼镜方向
- 2021 年底,字节跳动还曾投资 AI 技术及智能眼镜研发商 “李未可”。当时入股后的持股比例为 20%。
- 2024 年 7 月,李未可与博士宣布,将在全国 50 家博士眼镜门店线下首发李未可的 MetaLensChatAI 眼镜。
- 1、IconPark,开源图标库,有办公、数据、母婴、手势、天气、运动等超多种类,都支持批量下载,还可修改大小、颜色、风格、线条粗细、圆角大小等。
- 2、火山写作,辅助英文写作,可以英文写作建议,还会自动纠正、语法检查、润色改写文章等。
- 3、飞书妙记,长长的视频会议或是语音,直接上传到飞书妙记,迅速变成文字记录。还可以直接在上面做标注、讨论、二次创作。做会议纪要、访谈纪录、上网课的好伴侣。除了飞书妙计外,飞书还出品了飞书office、飞书People、多维表格,感兴趣的小伙伴可以试试!
- 4、醒图,不仅是美图工具,还有AI绘画功能。导入一张图片,选择喜欢的风格类型,一键就能自动生成。
- 5、火山翻译,支持多种查词方式,支持多语种翻译。还提供PDF文字格式整理、对照阅读模式、个人术语库等内容。
- 6、即创,一站式的智能创意生产与管理平台,集成了视频创作、图文创作、直播创作等多种创意工具。
- 8、即梦,一款AIGC工具,可以根据文本内容生成由AI生成的创意图,支持修整图片大小比例和模板类型。
- 7、豆包,基于云雀模型开发的AI工具,提供聊天机器人、写作助手以及英语学习助手等功能。
- 9、小悟空,对话类AI工具大合集,累计有90个小工具,包括创作生成、学习提升、工作职场、专业咨询、虚拟角色、休闲娱乐、语音转文字等等。
- 10、猫箱,一款AI剧情问答娱乐app,可用于生成故事。可以选择各种AI角色,可通过文字或语音与角色对话,每一个决策都会影响下一步剧情的发展。
- 11、星绘,AI写真相机,只需要上传三张照片,ai生成多种风格的图片,比如:证件照、专属发型师、旅游大片、cosplay等等,当然也支持文生图。
- 12、扣子,AI应用开发平台,无论是否有编程基础,都可以在扣子上快速搭建基于大模型的各类 Bot,并将 Bot 发布到各个平台。
- 13、河马爱学,针对小初高学生推出的一款难题答疑、指导中英文作文、作业批改、情感陪伴工具。
- 14、识典古籍,与北大合作研发的古籍数字化平台,除了阅读古籍外,还有分词检索、图文对照、繁简转换、字典释义、文白对照、实体百科等功能。
硬件尝试
2017 年,字节以 10 亿美元收购了朱骏和阳陆育在 2014 年创立的 Musical.ly,抖音和 TikTok 的产品形态都借鉴了 Musical.ly。
2022 年,阳陆育离开字节跳动创业,据《界面新闻》,阳陆育关联公司在今年推出 AIGC 角色扮演对话产品 “Museland”。朱骏则一直留在字节,目前向字节 CEO 梁汝波汇报。
2024 年 5 月, 火山引擎 FORCE 原动力大会上,字节对外展示了 3 款外部合作方开发的 AI 硬件产品,包括: 机器狗、学习机,以及学习机器人。
字节屡败硬件,AB test 和数据驱动的失灵
2012 年之后,字节凭借今日头条、抖音等一系列成功的移动互联网应用快速成为新一代中国互联网巨头。
自 2019 年起,字节也开始多次尝试硬件,先后收购锤子科技、PICO 等智能硬件公司,试水手机、教育硬件和 VR 头显等产品,但这些尝试都不算成功。
字节在 2019 年以 3 亿元收购智能手机厂商锤子科技的部分专利和团队,组建新石实验室;后被并入由阳陆育负责的教育硬件团队,推出了大力智能灯和写字板等教育硬件。
大力智能灯在 2021 年的销售目标是 200 万台,但到 2021 年 3 月底,它在淘宝和京东上的总销量不过 4 万台,远不及预期。
2021 年,字节又以 90 亿元收购 VR 头显品牌 PICO,PICO 团队在高峰期的员工总数超过 2000 人。字节也投入了不少资源发展 VR 内容生态,曾斥资 10 亿元购买卡塔尔世界杯版权做 VR 转播,自制郑钧、汪峰等明星的 VR 演唱会。
近年来,教育硬件和 PICO 团队都已大幅收缩。2021 年,字节跳动裁撤教育业务。2023 年 11 月初,PICO 接近半数员工转岗或被裁。字节的第一轮硬件探索告一段落。
字节擅长的互联网软件产品方法并不适应硬件开发。
做互联网软件产品时,字节高效执行了小步快跑、敏捷迭代的法则:在短时间里上线多个产品,通过大量 AB test 定量测试产品反馈,向表现好、增长快的产品追加开发与投放资源,快速试出王牌。如 2016 年,字节就同时上线了 “火山”、“抖音”、“西瓜” 三个短视频 App,抖音最终脱颖而出成为主力产品。
移动 App 战场的成功,让字节获得了相信数据、看重短时反馈的惯性。而这些特点并不利于研发消费电子等硬件产品。硬件的开发周期长得多,苹果在推出划时代的 iPhone 4 前研发了快 2 年。这期间,产品开发团队很难获得大规模的数据反馈,他们必须更多依靠自己的判断和洞察,再结合消费者调研做出产品决策。
乔布斯 1990 年接受波士顿公共电视频道采访时曾说:“用户无法预测他们没见过的产品。只有把产品摆在眼前,用户才能反馈有用的意见。”
字节之外,一些其它互联网或软件公司也未能幸免硬件魔咒。Google 的手机、微软的 Surface 平板都是前车之鉴。Meta 在 2014 年以 20 亿美元收购了 VR 头显品牌 Oculus,据外媒报道,直到 2023 年初,该系列累计总销量只有 2000 万台。
硬件被认为是大模型落地的重要方向之一。
如今年 8 月,Google 推出了 AI 手机 Pixel 9 和耳机 Pixel Buds Pro 2,都搭载了 Gemini 模型,手机和耳机能够智能交互。今年 6 月的苹果 WWDC2024 开发者大会上,苹果也宣布了 OpenAI 的 GPT-4o 将被整合进 Siri。
耳机和眼镜也可以搭配手机使用,定位为 “手机配件” 而非 “替代手机”,能降低消费者接受新品类的门槛。
在一级市场,一批智能耳机公司,如科大讯飞孵化的未来智能(iFLYBUDS)、时空壶翻译耳机等今年也陆续获得新融资。
反例则是,去年诞生的一些全新 AI 硬件发展遇阻。如没有屏幕、以随时能和大模型对话为卖点的 Ai Pin。在今年 4 月正式发售后,其 5 到 8 月的退货量比购买量还多。开发 Ai Pin 的公司 Humane 也正在寻找收购方。
此刻在中国市场做 AI 硬件的另一重利好是,苹果的手机 AI 新功能要在明年后才能在中国使用。苹果被认为最有实力承接 AI 硬件红利,它的暂时缺席会给一批中国公司创造窗口期。
耳机
【2024-10-10】字节发布首款AI耳机
耳机接入豆包大模型,并与豆包 APP 深度结合。用户戴上耳机后,无需打开手机,便能通过语音唤起豆包进行对话。
在官方宣传片中,豆包特别强调了Ola Friend能够在信息查询、旅游出行、英语学习及情感交流等场景为用户提供帮助。豆包相关负责人表示:“这款耳机是豆包在AI场景的一个探索和尝试,希望Ola Friend能成为随时陪伴用户耳边的朋友。豆包的各种能力也会在后续持续迭代,为用户在生活中各个场景提供帮助。”
豆包/Cici
字节
Coze
详见站内专题: llm开发平台
LLM 应用平台
搜索的LLM应用平台
ChitChop/小悟空
【2023-12-1】发布基于大模型的 App ChitChop
- 国内:小悟空
- 国外:ChitChop Web
- APP见Google、Apple Store
一个私人AI助理,包括AI创作、AI绘画、娱乐、AI学习、工作、生活等6大使用场景。
- ChitChop由POLIGON开发和运营,而字节海外的社交产品
Helo、日本漫画App 「FizzoToon」也由同一家公司运营 - POLIGON公司是字节海外的重要运营公司之一,于2020年在新加坡注册成立,主营业务是软件和应用程序的开发,其次是电脑游戏的开发。ChitChop是今年11月最新推出的App
- ChitChop宣称可以为用户提供多达200多个智能机器人服务,因为6大场景中每个场景包含10多个人工智能工具
比起豆包,ChitChop的应用场景和功能更加丰富,且进一步细分。
- AI创作,可以实现文章生成、文章续写、创作灵感、文章润色、爆款标题、视频脚本、微型故事、写演讲稿、写公关稿等功能。
- AI学习,可以进行作文提升、英语陪练、学习小语种、雅思写作、AI备课、论文生成、论文大纲、论文润色、万能翻译等。
MarsCode
【2024-6-27】探索豆包 MarsCode:字节跳动的AI编程助手
字节跳动推出的革命性工具——豆包 MarsCode ,免费的AI编程助手,旨在提升开发者的编码体验。
MarsCode不仅仅是一个编程工具,它是一个全方位的AI助手,集成了代码补全、生成、解释、优化、注释生成、单元测试生成、智能问答和问题修复等强大功能。
提效降本
ppt 制作
讯飞智文
- 支持语种、加备注、自动配图
缺点
- 收费: 5元/次 + 3元 风格 —— 1天免费试验
kimi+
【2025-2-22】 “神器”的组合 —— DeepSeek + Kimi,让PPT制作变得轻松又高效
- 讲座大纲: 使用 DeepSeek 根据主题、要求、篇幅,生成大纲,markdown 格式输出
- ppt 制作:
- 将文本输入 kimi+, 针对大纲填充讲解内容,生成ppt
- ppt 样式编辑: 点击“一键生成ppt”,选择 模版、设计风格,实时生成ppt
- ppt 在线编辑、下载
Coze Bot
- 【2025-3-14】 Coze ppt制作
AutoAgent
自运行Agent:给一个任务,让GPT根据回复结果自己设定优先级进行后续的提问,获取信息、工作处理。
- 如果未来跟其他API打通,差不多可以实现一句话做网站、买飞机票、定外卖等。
- Twitter有高手完成了一句话生成网站并发布。国内也有朋友做了一句话生成前端页面demo
FrugalGPT 斯坦福
【2023-5-9】Cut the costs of GPT-4 by up to 98%
GPT-4 is a very capable model. But it is also very expensive. Using it for real-world applications can quickly amount to thousands of dollars in API costs per month.
In a recent study, researchers at Stanford University introduce “FrugalGPT,” a set of techniques that can considerably reduce the costs of using LLM APIs while maintaining accuracy and quality.
Key findings:
- The price of LLM APIs vary widely across different models
- For many prompts, the smaller and cheaper models can perform just as well as the more complex LLMs
- The FrugalGPT paper proposes three strategies to optimize LLM API usage 降低推理成本的三种方法
- (1) 提示适配: 识别哪个prompt更有效(如短的) Prompt adaptation: Reduce the size of your prompt or bundle several prompts together
- (2) 模型近似: 在具体任务上,用便宜小模型去匹配贵的大模型 Model approximation: Cache LLM responses or use model imitation to reduce the number of API calls to large models
- (3) 大模型叠加: 根据query自动适配合适的LLM. LLM cascade: Create a list of LLM APIs from small to large; use the smallest model that can provide an acceptable answer to the user’s prompt

- FrugalGPT, an implementation of the cascade model, resulted in orders of magnitude cost reduction and even improved accuracy
数据处理
数据是石油,LLM 明显把炼油能力增强了,高价值行业和企业内部曾经难记录、难处理的数据都可以被重新以前分析。数据和信息的重构也意味着 AI 能承担更多决策权。
数据抓取
以前可以用网络爬虫技术(如Python的Scrapy或BeautifulSoup) 从目标新闻网站提取结构化数据,包括标题、正文、发布时间、作者等信息。
- 还需处理反爬虫机制,如 模拟用户行为、使用代理IP等。
最后,将获取的数据进行清洗、去重和存储,以便在App中展示。
ExtractGPT
- 一款浏览器扩展程序,可从结构化和非结构化页面中获取数据
GPTBot
【2023-8-8】OpenAI刚刚推出了GPTBot,一个自动从整个互联网抓取数据的网络爬虫。
这些数据将被用来训练像GPT-4和GPT-5这样的未来AI模型,GPTBot会确保不包括违反隐私的来源和那些需要付费的内容。
GPTBot是OpenAI开发的一个网络爬虫,用于在网络上收集信息,帮助改进AI模型。如果你是网站所有者,可以选择是否允许它访问网站或某些部分。同时,OpenAI确保了在使用GPTBot时,不会访问或使用任何敏感或付费内容。简单说,它就是一个用来学习和改进的小助手,但网站所有者可以自由选择是否和它互动。
AutoCrawler
【2024-4-19】Wenhao Huang等人论文中提出了AutoCrawler,将大型语言模型与网页爬虫相结合的新型网页自动化框架。
- 传统的网页抓取方法缺乏适应性和扩展性,而基于大型语言模型的智能代理在开放环境中表现不佳。
AutoCrawler 通过分两个阶段、利用HTML的层次结构进行渐进式理解,从错误行动中学习并持续优化HTML,从而更好地生成抓取操作。
实验证明,该框架可有效提高网页爬虫在多样化和动态网络环境中的性能。
FireCrawl
【2025-3-25】如果是静态数据(如新闻),可以直接把url给爬虫产品 Firecrawl 。
FireCrawl 是一款创新的爬虫工具,无需站点地图,抓取任何网站的所有可访问子页面。
- 与传统爬虫工具相比,FireCrawl 特别擅长处理使用JavaScript动态生成内容的网站,并且可以转换为LLM-ready的数据。
- 只需要填URL,firecrawl 会抓取到相关的内容,通过LLM来提取信息。
- 使用firecrawl的在线服务是需要付费的,免费的只有500credit
- Dify 内置, 提供 api, 也可以本地部署,github
语料扩充
【2023-2-17】unlocking-the-power-of-llms
使用chatgpt生成mark表格
| 文本 | 领域 | 实体映射 |
|---|---|---|
| 打开车门 | 设备控制 | 设备:车门 |
| 关闭空调 | 设备控制 | 设备:空调 |
| 导航到人民路 | 导航 | POI:人民路 |
| 开车去郊野公园 | 导航 | POI:郊野公园 |
也可以用空格
- 直接从 Excel 中复制数据粘贴到文本框中,表格表示形式是:每个单元格都用空格隔开。(不推荐)
生成的NER数据:
| 文本 | 领域 | 实体映射 |
|---|---|---|
| 打开后备箱 | 设备控制 | 设备:后备箱 |
| 调高音量到80 | 设备控制 | 设备:音响,属性:音量,数值:80 |
| 导航到北京天安门广场 | 导航 | POI:北京天安门广场 |
| 开启车辆防盗系统 | 设备控制 | 设备:防盗系统 |
| 显示明天的天气 | 天气查询 | 时间:明天 |
| 将客厅灯调暗一些 | 设备控制 | 设备:客厅灯,属性:亮度,数值:稍微暗一些 |
| 播放周杰伦的七里香 | 娱乐 | 歌手:周杰伦,歌曲:七里香 |
| 打开窗户 | 设备控制 | 设备:窗户 |
| 降低空调温度到25度 | 设备控制 | 设备:空调,属性:温度,数值:25 |
| 导航到附近的加油站 | 导航 | POI:加油站 |
| 调整座椅到舒适的位置 | 设备控制 | 设备:座椅,属性:位置,数值:舒适 |
| 停止播放音乐 | 娱乐 | 动作:停止播放音乐 |
| 打电话给张三 | 通讯 | 对象:张三 |
| 导航到机场 | 导航 | POI:机场 |
| 打开车窗 | 设备控制 | 设备:车窗 |
| 关闭车窗 | 设备控制 | 设备:车窗 |
| 升高座椅到合适的高度 | 设备控制 | 设备:座椅,属性:高度,数值:合适 |
| 显示最近的通知 | 提醒事项 | 类型:通知 |
| 播报今天的新闻 | 新闻 | 时间:今天 |
| 显示路况 | 导航 | 信息类型:路况 |
| 导航到附近的酒店 | 导航 | POI:酒店 |
| 打开前灯 | 设备控制 | 设备:前灯 |
| 关闭后灯 | 设备控制 | 设备:后灯 |
| 设置提醒,下午3点有会议要参加 | 提醒事项 | 时间:下午3点,事件:参加会议 |
| 显示今天的日程 | 提醒事 |
数据标注
详见站内专题:数据标注
知识挖掘
数据分析
【2026-5-9】DeepEye:自主化数据智能体系统
香港科技大学(广州)骆昱宇课题组开源的数据智能体系统—DeepEye。
- 围绕“自主化”(Autonomy)与“可驾驭”(Harness)两大核心理念展开。
- 长期目标是构建全自主的数据智能体,使其能够自动理解数据、提出假设、执行分析并生成洞察;
- 此外,坚持“可驾驭”(Harness)设计原则的同时,在关键推理环节保留人类专家的判断与干预空间,实现人机协同的增强智能。
DeepEye 系统
数据智能体(Data Agent)与编码 Agent 专注于明确任务不同,Data Agent 更像一位“理科生”中的“探索者”——它面对的是开放、复杂的数据分析问题,需具备从数据获取、清洗、管理到洞察生成的全流程能力。
现实中的数据分析往往耗时、繁琐且依赖专业知识,而 Data Agent 的目标正是通过 LLM 与自动化引擎的结合,实现数据任务的自主执行。
DeepEye 系统致力于构建一个“自驱动+可引导”的智能体,既能独立处理多源异构数据,又能在关键决策点引入人类干预,真正实现“人在回路”的增强智能。
Data Agent 是面向数据科学全栈流程的智能系统,通过大语言模型(LLM)的语义推理能力,实现对结构化、半结构化与非结构化数据的统一分析。
- 传统数据分析受限于 SQL 等工具,主要面向结构化数据;
- 而现代 Data Agent 借助 LLM 的自然语言理解与代码生成能力,可动态构建“AI Function”类算子,实现跨模态数据融合分析。
核心架构涵盖三大模块:数据管理(如配置调优、查询优化)、数据准备(清洗、集成、发现)与数据分析(结构化/非结构化分析、报告生成)。
系统通过 LLM Hub 与数据湖协同,支持多源异构数据接入,并基于任务编排引擎实现自动化工作流调度。
Data Agent 不仅提升了数据分析的灵活性与可扩展性,更推动了从“人工驱动”向“智能自治”的范式转变,为数据密集型应用提供高效、可信的决策支持能力。
与通用 LLM Agent 侧重内容生成或任务自动化不同,Data Agent 的核心目标是在模糊、开放的数据分析需求下,自主构建端到端的可执行工作流——从多源异构数据接入、清洗、融合,到建模、可视化与洞察输出。
关键挑战源于数据本身的复杂性:
- 一是任务语义模糊,同一问题(如“某公司去年利润”)因数据源差异需动态调整分析路径;
- 二是错误级联敏感,数据分析呈瀑布式链路,前序步骤的微小偏差将导致最终结果失效;
- 三是领域语义歧义,如字段名“WZRL”在游戏与医药行业含义截然不同,而通用大模型缺乏上下文感知能力。
Data Agent 需深度融合数据库系统、流处理引擎(如Flink)、SQL 验证器及可视化工具,并通过人在回路(Human-in-the-loop)机制提升可靠性。它不仅是LLM推理能力的延伸,更是一个面向数据密集型任务的智能编排平台,致力于实现从“人工分析”到“自主智能”的范式跃迁,为金融、医疗、运营等垂直领域提供高可信、可解释的数据决策支持。
现有学术与工业成果多集中于 L3
- L3 具备流程编排、工具调用与上下文感知能力,如自动 SQL 生成、数据清洗与报告生成。
- 但 L4(高度自动化)仍处探索期——系统可在特定场景下主动发起分析、持续监控数据流并触发预警,实现“无提问式洞察”。
- L5(完全自主)则代表终极目标:Agent 能从海量异构数据中发现未知模式,提出科学假设,甚至推动数据驱动的科研突破。目前尚无成熟案例。该分级框架为技术路线图提供统一基准,助力从业者合理设定预期,推动 Data Agent 向可信、可控、可解释的智能体演进。
DeepEye 是支持条件自主(Level 3)的数据智能体系统,实现从自然语言任务到端到端数据分析的自动化闭环。用户通过对话接口输入分析目标,并可@知识库(如 Markdown 文档、JSON、数据库、PDF 等),实现异构数据源的动态接入与上下文关联。
DeepEye 已获得第 51 届日内瓦国际发明展银奖(Silver Medal, 51st Geneva Inventions Exhibition),以及 AI Agent 2025 Competition 最佳开源项目奖(Best Open-source Project Award)。此外,DeepEye 已上线官方网站,便于用户进一步了解和体验。
DeepEye 系统后端基于工作流编排引擎,自动构建 DAG 执行图,涵盖数据读取、清洗、建模、可视化等环节,支持结构化与非结构化数据的联合处理。关键组件包括:Knowledge Search 知识搜索、Code Executor、Dashboard Generator 与 Report Generator 报表生成器,确保流程可解释、可复现。
执行完成后,系统提供三类输出:数据视频(短视频形式呈现洞察)、定制化仪表盘(交互式可视化)与分析报告(结构化文本+图表)。该设计融合了 LLM 语义理解能力与系统级计算架构,推动 Data Agent 向“人机协同、多模输出、全流程自治”演进,为复杂数据分析场景提供高效、可信的解决方案。
知识问答
【2024-7-17】七大模型参加“高考”后分数出炉:文科上了一本线,理科只能上二本
OpenCompass 团队对7个AI大模型进行了高考9个科目的全科目测试,表现最优的三个大模型: 文科成绩过一本,理科成绩超二本。
- 参赛模型: 阿里巴巴、零一万物、智谱AI、上海人工智能实验室&商汤、法国Mistral的开源模型,以及来自OpenAI的闭源模型GPT-4o。
- 大模型高考评测的生成答案的代码、模型答卷、评分结果完全公开,可供各界参考(公开评测细节l)
评测采用3(语数外)+3(理综/文综)的形式对大模型进行了全科目测试。评测过程中,所有纯文本题目由大语言模型作答,而综合科目中的带图题目,则由对应团队开源的多模态大模型回答。
测评发现,对于纯文本题目,大模型平均得分率可达64.32%,而面对带图题目,得分率仅有37.64%。在图片理解和运用能力方面,所有大模型均存在较大提升空间。
大模型如果参加
- 文科考试,最好的成绩能被“录取”到一本
- 而理科考试,则最多只能被二本“录取”
- (以今年高考人数最多的河南省的分数线为参考)。
参考 2024年 河南本科批次录取线,表现最优的三个大模型文科成绩过一本,理科超二本。其他大模型文理科成绩均未达到二本线标准。
- 文科考试,那么
通义千问、书生浦语文曲星、GPT-4o文科成绩均超越一本线,展现了大模型在语文、历史、地理、思想政治等科目上深厚的知识储备和理解能力。 - 理科考试,整体表现则会弱于文科,体现了大模型在数理推理能力上普遍存在短板,但前三甲的理科成绩也均超过二本分数线,“录取”上二本不成问题。
总分
- 文科最高分是阿里
通义千问大模型,以546分的成绩获得AI高考“文科状元”。 - 理科最高分则是
上海人工智能实验室&商汤联合研发的浦语文曲星,达到了468.5分。 - OpenAI GPT-4o 在文科上得分531,排名第三,理科得分为467,排名第二。
阅卷老师点评
- 理科数学老师: 大模型做题总体感觉很机械,大部分题目都无法通过正常推理过程得出。
- 例如填空题第一题,大模型都只能进行到少部分过程而达到一个结果,并不能够像考生做题一样进行全面分析,列出完整的计算过程达到正确结果。
- 大模型的基础公式记忆能力较为优秀,但无法做到灵活使用。
- 此外有些题目结果正确,但过程逻辑差不符合正规计算,导致阅卷比较困难。
- 地理老师:
- 大模型在答题过程中展现了对地理知识的全面覆盖,从自然地理到人文地理,从地理现象到地理规律,都能有所涉及。尤其在基础知识点的考查上较为出色
- 然而,在涉及一些深入分析或推理的问题中,存在一定的偏差和遗漏,所以模型在面对非常规、开放性较强的问题时,其表现较差。
- 物理老师: 大模型总体感觉比较机械
- 很多都无法识别到题目的意思,有些选择题即使选项对了,但是分析也是错误的。
- 一些大题步骤冗杂,并且没有逻辑,常常出现将本次的结论带入到推理出本次结论的证据中,如此循环,没有道理。
阅卷老师们认为,相对于人类考生,目前大模型依然存在较大局限性。
论文检索
详见站内专题: 大模型论文搜索
Wiseflow
【2024-10-01】首席情报官(Wiseflow)是一个敏捷的信息挖掘工具,从网站、微信公众号、社交平台等各种信息源中按设定的关注点提炼讯息,自动做标签归类并上传数据库
- 我们缺的其实不是信息,而是从海量信息中过滤噪音,从而让有价值的信息显露出来
WiseFlow Team (原数字社工助理 DSW team)
主页开源项目:
- wiseflow (商业化产品:首席情报官) —— 完备的领域信息情报获取与管理系统,基于LLM;
- Awada —— 基于微信的可在线自主学习的个人AI助理(也可能是行业专家)。
wiseflow 是一个原生LLM应用,仅需7B~9B大小LLM就可以很好的执行信息挖掘、过滤与分类任务,且无需向量模型,系统开销很小,适合各种硬件环境下的本地化以及私有化部署。
git clone https://github.com/TeamWiseFlow/wiseflow.git
cd wiseflow
# python 运行
conda create -n wiseflow python=3.10
conda activate wiseflow
cd core
pip install -r requirements.txt
# docker 运行
docker compose up
docker run -e LANG=zh_CN.UTF-8 -e LC_CTYPE=zh_CN.UTF-8 your_image
GraphRAG
GraphRAG 里用 LLM 构建知识图谱
LLM-graph-builder 利用大语言模型,将非结构化数据转化为结构化知识图谱,支持 GPT-3.5、GPT-4o、Gemini等模型,同时可以与非结构化数据进行对话交互
浏览器
Agentic Browser 代表一种以浏览器为载体的通用智能体,不仅能访问互联网,更能够理解用户的需求,并自动拆解复杂的任务。其设计初衷是为了让智能体在拥有用户完整上下文的前提下为用户交付更好的结果,我们希望彻底改变用户与网络和计算机互动的方式。
Google Project Astra
待定
Comet
【2025-6-23】Perplexity 首席执行官Aravind Srinivas近日在社交媒体平台X上宣布AI浏览器Comet的Windows版本已准备就绪,早期测试人员已经开始收到邀请。
2025年5月,Perplexity 为搭载Apple Silicon的Mac用户推出了浏览器 beta 测试版,为不同硬件平台用户提供服务。
而此次Windows版本的推出,无疑将使更多用户有机会体验Comet浏览器的独特功能。
Comet 是一款“智能体搜索”浏览器,集成了强大的人工智能功能,极大地拓展了传统浏览器的边界。
用户在使用 Comet 浏览器时,不仅可以像在普通搜索引擎中那样提问,还能利用其独特功能进行更多操作。
- 用户能够轻松搜索电子邮件,这对于需要频繁处理邮件的商务人士来说,将大大提高工作效率;
- 购物时,自动在购物车中查找可用折扣,帮助用户节省开支。
- 引人注目的功能是“试穿”。用户只需上传自拍照,就能通过Comet浏览器查看不同服装的效果。这一创新功能不仅为在线购物增添了趣味性和互动性,还能帮助用户更好地做出购买决策,避免因无法直观感受服装上身效果而产生的购买失误。
智能体服务栈
- 学术研究场景:跨文献库向量相似度检索(使用Cohere的Embedding模型),节省研究者67%时间(来源:Nature Index 2024)。
- 开发者场景:支持GitHub仓库AST级分析,结合DeepSeek代码生成模型,实现API自动化补全。
- 企业级联邦搜索:使用NVIDIA的NeMo Guardrails 框架,在混合数据源中保持97.3%的数据隔离。
浏览器原生AI功能
- 网络威胁检测:利用Graphcore的IPU芯片加速图神经网络,钓鱼网站识别准确率达到99.2%。
- 标签管理系统:采用Google DeepMind的AlphaDev[5]算法,内存占用减少40%,响应时间毫秒级。
- 无障碍引擎:集成Microsoft的AI字幕技术,支持83种语言翻译,延迟低于300ms。
关键技术组件 • 多模态指令解析器:支持文本、语音、屏幕截图输入,使用Meta开源的SeamlessM4T技术。 • 任务分解模块:基于斯坦福AI Lab的LLM任务规划框架,分解复杂查询为子任务。 • 安全沙箱:集成OWASP Top 10威胁检测模型,零日攻击防护时延小于200ms(来源:Black Hat 2023报告)。
omet 核心在于浏览器即AI计算平台的设计:
- 使用WebGPU加速本地推理,使70亿参数模型达到每秒45token速度。
- 利用Mozilla的Federated Learning of Cohorts[6]保护隐私同时建模用户行为。
- 内置AI效能评估模块基于Anthropic提出的指标,优化资源分配。
Fellou
【2025-6-6】Fellou AI 浏览器 2.0:唯一可比的,是昨天的 Fellou
Fellou Fellou: The World’s First Agentic Browser,Beyond browsing, into fellouAction.
Fellou 依赖其独特的 Browser + Workflow + Agent 架构,开创了 Agentic Browser 这一新品类,打造了一个像「自动驾驶汽车」一样可以「自动冲浪」的浏览器智能体。
Fellou Browser 2.0:开启 AI 的批量化生产
Fellou 2.0 在速度上取得了突破性进展,相比 Fellou 1.x 的版本,Fellou 在不同任务的执行速度上提升了 1.3 - 1.5 倍,相比较某些通用 Agent,我们在不同任务上皆有非常大的速度优势
总结下 2.0 的升级概要为:
- 更快:减少等待,多任务并行,交付更多;
- 更惊人:多样任务交付,7 * 24 全天候执行;
- 更可靠:生产级多样化场景覆盖,成功率大幅提升,从 31% 到 80%;
BI
AI BI: LLM 用于数据分析
LLM 适合分析什么
LLM 在哪些数据集分析类型上不擅长?
LLMs 在执行精确数学计算方面有所限制,不适合需要精确量化分析的任务,比如:
- 描述性统计(Descriptive Statistics): 通过如均值或方差等措施定量总结数值列。
- 相关性分析(Correlation Analysis): 获取列间的精确相关系数。
- 统计分析(Statistical Analysis): 例如进行假设检验,判断数据点组间是否存在统计显著的差异。
- 机器学习(Machine Learning): 在数据集上执行预测模型,如使用线性回归、梯度增强树或神经网络。
为了执行这些量化任务,OpenAI 推出了高级数据分析插件,以便通过编程语言在数据集上运行代码。
那么,为什么还有人想仅用 LLMs 来分析数据集而不用这些插件呢?
LLM 擅长的数据集分析类型
- LLMs 在识别模式和趋势方面表现出色。
- 这得益于在庞大且多样化的数据上接受的广泛训练,能够洞察到复杂的模式,这些模式可能不是一眼就能看出来的。
非常适合执行基于模式查找的任务,例如:
- 异常检测: 基于一个或多个列值,识别偏离常态的异常数据点。
- 聚类: 将具有相似特征的数据点按列分组。
- 跨列关系: 识别各列之间的联合趋势。
- 文本分析(适用于文本列): 根据主题或情感进行分类。
- 趋势分析(针对有时间维度的数据集): 识别列中的模式、季节性变化或趋势。
对于这些基于模式的任务,单独使用 LLMs 可能实际上会在更短的时间内比使用编程代码产生更好的结果
详见:
- 【2024-5-6】我如何夺冠新加坡首届 GPT-4 提示工程大赛
Pandas AI
【2024-9-8】PandasAI实战 - 投资业绩数据AI问答Agent,含代码示例
做一个AI问答Agent,一句话可以跟投资业绩数据进行问答,如:
- XX投资人投资的项目金额的TOP5;
- XX基金投资了多少项目,总共投资金额和退出金额是多少;
- XX项目总共有几笔交易,每笔交易的交割时间和金额;
用户进行提问,给予精准的回答,不精准是没有意义的。
【2023-5-6】Pandas AI
- 将 Pandas 和 AI 结合,更方便地分析数据。
代码:
import pandas as pd
from pandasai import PandasAI
# Sample DataFrame
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [21400000, 2940000, 2830000, 3870000, 2160000, 1350000, 1780000, 1320000, 516000, 14000000],
"happiness_index": [7.3, 7.2, 6.5, 7.0, 6.0, 6.3, 7.3, 7.3, 5.9, 8.0]
})
# Instantiate a LLM
from pandasai.llm.openai import OpenAI
llm = OpenAI()
pandas_ai = PandasAI(llm)
pandas_ai.run(df, prompt='Which are the 5 happiest countries?')
构造数据,然后输入 prompt:
Which are the 5 happiest countries?
AI 根据输入的数据,处理数据,得到结果。
9 China
0 United States
6 Canada
7 Australia
1 United Kingdom
Name: country, dtype: object
画个图:
Plot the histogram of countries showing for each the GDP, using different colors for each bar
AI 根据需求,画一了各个国家的 GDP 条形图。
NL2SQL
text2sql(NL2SQL) 是NLP诸多任务中较难的任务,即便发展迅速的LLM,也没有完全解决text2sql中复杂查询问题
详见站内专题: NL2SQL
【2025-10-19】人大 DeepAnalyze
【2025-10-19】人大、清华DeepAnalyze,让LLM化身数据科学家
LLM 数据科学方法分为两类:
- 领域特定的 LLM:面向数据科学的代码生成 LLM、结构化数据理解 LLM…
- 基于 workflow 的智能体:人为设计 workflow,通过 prompt 调用闭源 LLM 完成任务
现有工作面临两方面局限性:
- 仅支持单点任务(例如数据分析、数据建模),无法端到端完成数据科学全流程。
- 闭源模型未在真实环境中的数据科学任务上训练过,难以编排和优化各种复杂操作。
DeepAnalyze 推动基于 LLM 的数据科学系统从 workflow-based agent 范式转变到可训练的 agentic LLM 范式。
数据科学的复杂性为训练 agentic LLM 提出挑战:
- 奖励稀疏:数据科学的复杂性使得 LLMs 在训练的早期阶段基本无法成功完成任务,难以获得正向奖励信号,从而导致 agentic LLM 训练过程崩溃。
- 路径稀缺:数据科学的解决过程通常依赖长链推理,求解轨迹的稀缺使得 LLMs 缺少足够的指导,导致其在庞大的搜索空间中进行低效且盲目的试错式探索。
人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM
- 论文:
- 代码、Demo链接:DeepAnalyze
- 模型链接:DeepAnalyze-8B
- 数据链接:DataScience-Instruct-500K
关键能力:自主编排(autonomous orchestration)和 自适应优化(adaptive optimization)。
DeepAnalyze 引入了:
- Curriculum-based Agentic Training:在真实环境中从单一任务到符合任务渐进式训练 LLM,让大模型逐步提升能力,避免在复杂任务上奖励信号为 0 导致的强化学习失效
- Data-grounded Trajectory Synthesis:自动化合成 500K 数据科学的推理、环境交互数据,在庞大的搜索空间中提供正确路径的指导
通过在真实环境中的 agentic 训练,DeepAnalyze 具备了自动编排和自适应优化操作的能力,能端到端地完成数据科学全流程,包括具体的数据任务和开放式的数据研究。
DeepAnalyze-8B 能够模拟数据科学家的行为,在真实环境中主动编排、优化操作,最终完成复杂的数据科学任务。支持各种以数据为核心的任务:
- 数据任务:自动化数据准备、数据分析、数据建模、数据可视化、数据洞察、报告生成;
- 数据研究:可在任意数量的结构化数据(数据库、CSV、Excel)、半结构化数据(JSON、XML、YAML)、非结构化数据(TXT、Markdown)中进行开放式深度研究,生成分析师级别的研究报告;
效果
- DeepAnalyze-8B 在 DataSciBench(端到端数据科学 Benchmark)优于所有开源模型,和 GPT-4o 相媲美
- DeepAnalyze 在 DSBench 数据分析和数据建模任务上由于基于 workflow 的智能体
- DeepAnalyze 在面向数据的深度研究中取得最佳表现,能生成分析师级别的分析报告
内容管理/营销
CRM 记录姓名、电话等结构化数据
CRM龙头接入ChatGPT,AI辅助客户管理再看看更深层次的客户关系管理环节,GPT技术依然是无孔不入,进化为智能咨询角色。
- 3月7日,客户关系管理领域SaaS巨头
Salesforce推出基于ChatGPT的CRM生成式AI产品:“Einstein GPT”,据称可用于帮助企业销售人员、客户服务专员和市场营销人员高效率完成本职工作。比如 - 帮销售人员撰写电子邮件,结合过往案例生成知识文章,为客服人员生成客户提问的特定答案,帮开发人员编写代码等。
- 同时,Salesforce旗下的办公协作软件
Slack也推出了基于ChatGPT的应用,Slack将其应用积累的数据与ChatGPT相结合,为客户提供他们所需的信息,包括提供即时对话摘要、研究工具和写作辅助等,帮助数百万公司更高效地工作。 -
Slack的ChatGPT应用提供一个对话界面,可以帮用户获取即时对话框中的信息,并基于研究工具去解析内容的主题,并帮用户快速撰写消息。
- 4月10日,知名营销SaaS企业上线数据集成平台有赞iPaaS和由大模型驱动的首个AI产品“加我智能”。加我智能目前主要支持图文推广和活动策划两大场景,能自动生成推广图文,并理解活动目的,生成跨产品和功能的营销活动。
- 国外也是一致趋势,4月20日,外媒称谷歌计划在未来几个月内将生成式AI引入其广告业务。目前,谷歌已经在其广告业务中使用AI来创建简单的提示,鼓励用户购买产品。可以看到,无论是互联网广告商、广告公关代理龙头还是SaaS服务商,他们都在加快接入AI大模型的步伐。如果能将广告人从众多重复机械化工作中解放出来,大卫·奥格威理想中的广告创意或许会离我们更近一步。
Jasper
2022 年 10 月,多个美国投资人跟李志飞提到一款叫 Jasper 的 AIGC 应用很赚钱。当时 Jasper 仅仅成立 18 个月,估值 15 亿美元。
- Jasper 基于 GPT-3 模型,针对市场营销场景做了精调,靠生成营销文案打开市场
- 2022 年 ARR(衡量 SaaS 或订阅业务的收入指标)约 8000 万美元
Jasper 解决了李志飞两年前就开始思考的问题:GPT-3 到底适合应用在什么场景?
- 李志飞想过文案场景,但只 “答对” 一半。“过去我们做的是纠错、润色、改写,没想到完全生成一篇内容”。
Gong
以 Gong 为代表的 AI-based CRM 则是记录分析 B2B 销售和客户录音。
Segment
Segment 的主要业务是提供实时消费者数据,传统的 CRM 的数据和业务之间其实并不直接衔接,因为过去 CRM 采集到的数据可能也有错的、并且也过时了,但在 LLM 基础上,Segment 其实反而提供更实时、更有效的数据。
Pilot
2022 年成立的Pilot AI 是一款面向销售人员的 AI 产品,核心是能够自动将每一个销售电话变成详细的笔记和结构化数据,并将结构化数据直接同步到 CRM 系统。这也是大语言模型的核心价值之一。
- 平时聊天有非常多的数据,如果没有被记录和分析,就永远是 dark data。而大语言模型理解语言的能力变强之后,dark data 可以变成非结构化数据、结构化数据,变成 information。而且 Pilot 的整个流程都是自动化的,价值非常显著。
Typeface
【2023-4-10】Typeface 是一个 AI 营销内容生成平台,由前 Adobe CTO 创立。
- The enterprise-grade generative AI app that empowers everyone to express their unique imagination.
能力:
Prompt: Create engaging content in seconds- A new visual vocabulary to express your ideas: Generate anything from a simple prompt, so you can easily create without a steep learning or time curve.
- 一个简单的提示语,就能生成特定领域里的营销内容(文字/图片)
- Spend more time on ideas, less on tasks: Tired of looking at a blank page? Jump start projects by simply typing your idea. Stress test headlines, brainstorm campaigns, personalize pitches, and more.
- 将客户精力从具体任务转移到点子上:压力测试标题,头脑风暴活动,个性化宣传等等
- Write and edit any type of content: Click to add the elements you want – headlines, paragraphs, images, captions – to build the entire content flow on one visual canvas. Not sure where to start? Use a template and modify it however you need.

- 撰写、编辑各种类型的内容:只需要轻轻一点,就能添加标题、段落、图像、注释等元素,在同一个页面中完成内容创作。
- Flex to your style and collaborate faster: Develop multiple assets quickly and in parallel. Stylize your way with built-in formatting and image editing tools, such as filters, adjustments, and overlays. Share your work with collaborators across channels.
- 适配客户风格,协同工作

Flow: Extend and customize to your workflows, flowBlend: Personalize to your brand and audiences, blendSafe: Ensure brand safety and control;- 拼写检查、剽窃检测、真实性检测、品牌控制
Typeface 最大的特点是能够学习企业客户的“专有数据”。客户将带有企业风格的专有数据导入 Typeface 供模型学习,基于这些专有数据,Typeface 可以输出更个性化的、满足企业实际需求的内容,做到让 AI “更懂用户”。
为了实现这一点,Typeface 让每位客户拥有独有的 AI 模型和托管服务,以及原创内容检测、品牌契合度检测和文字上的语法检测等功能。而收集专有数据的意识也在行业内逐渐形成共识。
广告
AIGC
【2023-11-21】日本广告
完全AI生成的广告已经问世,这么漂亮的脸,还可以随意定制更漂亮的,永远也不会有丑闻,不会影响公司形象,成本极低几乎可以忽略不计
由AI生成的广告,来自日本的伊藤园公司。广告使用全AI生成的人物拍摄,自然和谐,与真人无异。好处包括无限制的外观定制、没有丑闻对公司和产品的影响,成本几乎可以忽略不计且拍摄周期短。视频提出了一个问题,企业应该选择真人还是AI的广
AI生成的麦当劳广告
资料
- 【2024-12-9】从算法到艺术:大模型如何重塑广告业?
- 【2025-3-13】阿里妈妈搜索广告2024大模型思考与实践
腾讯
【2023年9月7日】腾讯混元大模型负责人蒋杰
- 之前的广告系统根本不懂,让广告优化师做了很多“堆基建”的无用功。比如,各家优化师都在大量新建广告素材,基本操作就是对素材做一丁点微调再来“赌一次”,这实际上就是在钻“大模型不理解广告,不理解商品”的空子。
- 结合大模型的新一代广告系统,能真正“看懂”广告素材,将同类商品、同类素材实现“归堆”,基于归堆后的更大数据量,模型预测也将更加精准
- 广告系统3.0的核心:想办法让广告系统‘多懂一些’。
- 只有广告系统真的‘认识了’、‘懂得了’商品、广告素材和用户,才能做到提升投放确定性,减少投放‘玄学’。
大模型技术的引入正在深刻重塑广告行业。从优化广告系统平台、帮助广告主降本增效、到广告创意生成,其影响力无处不在。
正如蒋杰所说,新一代广告平台的核心转变在于能够“理解”广告素材与用户行为,从而提供高度个性化的推荐,显著提升用户体验。通过大规模数据分析,广告平台能够更精准地洞察用户需求,制定有效的营销策略,实现更高的转化率。
尽管通用大模型在语义理解、复杂任务处理方面表现出色,但目前出于用户隐私、数据安全等原因,通用大语言模型还无法对广告系统核心数据处理产生影响
大模型对广告系统的接入更多在于“看懂”,看懂之后基于更大数据、更大计算的“暴力美学”则由机器学习完成,机器学习将结合平台数据训练出垂直自有小模型而非通用大模型,以此指导后续的链路。
独立第三方广告系统对数据的收集和利用将帮助广告系统从激烈的竞争中脱颖而出。
Liftoff
美国 Liftoff 效果营销和广告变现平台,推出新一代机器学习引擎 Cortex 。
- IOS SSOT 全品类指数中,Liftoff在所有广告平台中排名第6
Liftoff 的Vungle SDK 已经连接超过 90% 全球应用程序,这个庞大的 SDK 覆盖范围为机器学习提供支持。
通过基于直接集成或从第三方MMP归因平台获取的第一手归因数据来进行训练,Cortex机器学习系统能够深入了解客户的目标受众,并识别其观看或消费行为的模式;而通过使用来自 Liftoff Creative Studio 的测试数据训练 Cortex 模型,Cortex更容易洞察出哪些内容类型和广告格式更能吸引高意向用户,从而将合适的广告展示给合适的用户,提供个性化的广告体验。同时,通过将第一手数据与来自 Vungle SDK 和 Liftoff 游戏分析平台 GameRefinery 的独家数据结合,竞价和定价的精准度又得以进一步提高。
Liftoff 营收平台副总裁Casie Jordan介绍,Cortex 基于神经网络驱动,大幅提升了计算能力与模式识别能力,数据处理能力是逻辑回归模型的 10 倍以上,未来还将扩展到 100 倍的数据量。
Cortex 新引擎在运行过程中,其模型刷新速度提速6倍,并始终基于最新数据进行更新。
Liftoff客户 Bigo Live 使用效果反馈显示,在深入分析 Bigo Live 的现有受众,并对互动广告和静态广告进行测试后,Bigo Live运用Liftoff的UGC广告:CPI降低20%,IPM提升12%。
META
除了腾讯广告和Liftoff,Meta 推出通用大模型LLaMA的同时,也尝试将新一代AI引入广告系统。
Meta 2023年:
- “如果AI能够准确预测和理解任何给定的内容,那么人们有朝一日可以选择让任何图像或视频可供购物。人们将更容易找到他们想要的东西,卖家也可以让他们的产品更容易被发现。”
Meta 当前已经建立了一个为购物而设计的通用计算机视觉系统GrokNet,即一个一体化的模型(all-in-one model ), 识别数十亿张照片中的细粒度产品属性——包括时尚、汽车和家居装饰等不同类别。
而该系统结合AI大模型对文本的理解能力,卖家发布图片时,AI 购物系统会帮助识别未标记的商品并根据其产品目录推荐标签。
未来Meta想要实现的场景是,“教会这些人工智能系统了解一个人的品味和风格,以及这个人搜索产品时重要的背景。在实现这一目标的过程中,我们需要取得更多突破。我们需要继续改进内容理解,并构建能够推理、在商品之间建立联系并学习个性化购物偏好的系统。”
阿里巴巴
阿里妈妈自主研发了广告领域专属大模型 LMA(Large Models for Advertising),并于 2024 年 4 月随业务宣推。LMA 是电商基座大模型衍生出来的广告模型集合,迭代分支包括认知、推理和决策。新财年以来,LMA 持续优化,认知分支聚焦多模态表征,推理分支聚焦搜推广领域的用户行为大模型等。这些技术进展不仅推动预估环节实现多个版本迭代上线,还深度改造了召回、改写、相关性和创意等核心技术模块,推动技术体系全面升级。
模型能力的突破主要沿三条路径演进:
- 明线,归纳偏置(Inductive Bias)的合理设计,是模型能力提升的核心驱动力。
- 暗线,硬件算力的指数级提升,为模型的规模化提供了强力支撑。
- 辅助线,CV 和 NLP 领域的代际性技术升级,给搜推广领域带来重要启发。
图见原文
- 【2025-3-13】阿里妈妈搜索广告2024大模型思考与实践
用大模型全链路重塑现有的搜索广告系统。
- 1)传统搜索系统过于依赖 ID 特征体系,大模型在语义理解和逻辑推理上的惊人能力可以真正读懂用户的搜索需求,各环节的匹配效率都会大幅提升;
- 2)大模型沉淀下来的 Pre-train 和 Post-train 的迭代范式,能够更加一体化地优化全链路,并进一步打开 Scale up 的空间。
- 继 2023 年的效果初探,2024 年我们在全链路上有更加全面的落地,包括改写、召回、相关性和创意等模块,累计提效约 CTR+10%、RPM+5%,下文选取几个代表性工作做介绍。
详见论文
NLP基础任务
【2023-9-12】大语言模型在NLP基础任务的应用案例集
分类
怎么用GPT做分类?
两种方法
- 类似bert,在输出部分加个head,输出分类得分;
- 与clm语言模型一致,在生成类别广告词,来判断分类。
详见:文本分类专题
NER
命名实体识别任务(NER)的目标是识别出给定文本中的实体部分,一般采用序列标注方法进行建模,预测每个位置的token是否属于某个实体、属于哪个实体。
- GPT-NER,序列标注→生成任务
- GPT生成→筛选→验证
详见:NER专题
信息抽取
chatgpt做零样本信息抽取
- 论文:Zero-Shot Information Extraction via Chatting with ChatGPT
- we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE)
- 使用两阶段框架(ChatIE)将零样本信息提取任务转换为多回合问答问题。
语音摘要
Podcast Summariser 使用OpenAI Whisper + Davinci进行播客摘要
视频摘要
【2023-5-17】基于ChatGPT的视频摘要应用开发
- 视频摘要器: 将数小时的视频内容转换为几行准确的摘要文本
视频摘要方案
- 用ChatGPT 插件,将令人AI 连接到实时 YouTube 网站。 但只有少数商业开发人员可以访问 ChatGPT 插件,因此可行性不大。
- 下载视频的抄本(字幕)并将其附加到提示中,然后语言模型发送提示来总结抄本文本。缺点:不能总结一个包含超过 4096 个标记的视频,这对于一个普通的谈话节目来说通常是 7 分钟左右。
- 用上下文学习技术对转录本进行向量化,并使用向量向语言模型提示“摘要”查询。 这种方法可以生成准确的答案,指示转录文本的摘要,并且不限制视频长度。
Video Summarizer应用程序以llama-index为基础,开发了一个Streamlit web应用程序,为用户提供视频URL的输入以及屏幕截图、文字记录和摘要内容的显示。
用llamaIndex 工具包,不必担心 OpenAI 中的 API 调用,因为对嵌入使用的复杂性或提示大小限制的担忧很容易被其内部数据结构和 LLM 任务管理所覆盖。
- 视频转录:开源 Python 库 youtube-transcript-api 将视频转文本
- 当文档被送入 LLM 时,它会根据其大小分成块或节点。 然后将这些块转换为嵌入并存储为向量。
- 当提示用户查询时,模型将搜索向量存储以找到最相关的块并根据这些特定块生成答案。 例如,如果你在大型文档(如 20 分钟的视频转录本)上查询“文章摘要”,模型可能只会生成最后 5 分钟的摘要,因为最后一块与上下文最相关 的“总结”。
流程图
(1)视频转录
# !pip install youtube-transcript-api
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api.formatters import JSONFormatter
# 唯一应该强制提供的参数是 11 位视频 ID,在 v= 之后的每个 YouTube 视频的 URL 中找到它
srt = YouTubeTranscriptApi.get_transcript("{video_id}", languages=['en'])
formatter = JSONFormatter()
json_formatted = formatter.format_transcript(srt)
print(json_formatted)
(2)加载文档
!pip install llama-index
SimpleDirectoryReader 是 LlamaIndex 工具集中的文件加载器之一
- 支持在用户提供的文件夹下加载多个文件
- 支持解析各种文件类型,如.pdf、.jpg、.png、.docx等,让您不必自己将文件转换为文本。
from llama_index import SimpleDirectoryReader
SimpleDirectoryReader = download_loader("SimpleDirectoryReader")
loader = SimpleDirectoryReader('./data', recursive=True, exclude_hidden=True)
documents = loader.load_data()
构建索引
- LlamaIndex 应与你定义的 LLM 交互以构建索引,在本演示的情况下,LlamaIndex 使用 gpt-3.5 聊天模型通过 OpenAI API 调用嵌入方法。
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper, ServiceContext
from langchain import ChatOpenAI
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.from_documents(
documents, service_context=service_context
)
(3)查询索引
通过建立索引,查询非常简单,无需上下文数据,直接输入即可。
response = index.query("Summerize the video transcript")
print(response)
完整代码见原文
python -m pip install openai streamlit llama-index langchain youtube-transcript-api html2image
机器翻译
详见站内专题:大模型机器翻译
异常检测
微舆
【2025-11-09】微舆:人人可用的多Agent舆情分析助手,打破信息茧房,还原舆情原貌,预测未来走向,辅助决策!从0实现,不依赖任何框架。
用户只需像聊天一样提出分析需求,智能体开始全自动分析 国内外30+主流社媒 与 数百万条大众评论。
功能
- 能抓9个平台的信息,小红书,抖音,知乎,快手,贴吧等,推特和Reddit的话要自己写代码
- 国内模型比较容易产生幻觉
优势:
- AI驱动的全域监控:AI爬虫集群7x24小时不间断作业,全面覆盖微博、小红书、抖音、快手等10+国内外关键社媒。不仅实时捕获热点内容,更能下钻至海量用户评论,让您听到最真实、最广泛的大众声音。
- 超越LLM的复合分析引擎:我们不仅依赖设计的5类专业Agent,更融合了微调模型、统计模型等中间件。通过多模型协同工作,确保了分析结果的深度、准度与多维视角。
- 强大的多模态能力:突破图文限制,能深度解析抖音、快手等短视频内容,并精准提取现代搜索引擎中的天气、日历、股票等结构化多模态信息卡片,让您全面掌握舆情动态。
- Agent“论坛”协作机制:为不同Agent赋予独特的工具集与思维模式,引入辩论主持人模型,通过“论坛”机制进行链式思维碰撞与辩论。这不仅避免了单一模型的思维局限与交流导致的同质化,更催生出更高质量的集体智能与决策支持。
- 公私域数据无缝融合:平台不仅分析公开舆情,还提供高安全性的接口,支持您将内部业务数据库与舆情数据无缝集成。打通数据壁垒,为垂直业务提供“外部趋势+内部洞察”的强大分析能力。
- 轻量化与高扩展性框架:基于纯Python模块化设计,实现轻量化、一键式部署。代码结构清晰,开发者可轻松集成自定义模型与业务逻辑,实现平台的快速扩展与深度定制。
改一下,是超级优秀的产品,对自己学习或者内容输出各方面超级有用
整体架构图
- Insight Agent 私有数据库挖掘:私有舆情数据库深度分析AI代理
- Media Agent 多模态内容分析:具备强大多模态能力的AI代理
- Query Agent 精准信息搜索:具备国内外网页搜索能力的AI代理
- Report Agent 智能报告生成:内置模板的多轮报告生成AI代理
搜索
详见站内专题: 大模型搜索
招聘
SeekOut
【2024-6-3】独角兽企业 SeekOut 宣布裁员30% 估值12亿美元的独角兽企业 SeekOut宣布:裁员30%。
SeekOut是一家AI招聘公司,通过AI为岗位匹配合适人才一尤其是背景多元的人才,同时为企业建立战略人才库。在近期发布的财报中出现了严重的现金消耗。
其主要原因,从2022年底开始的全美科技界大裁员改变了SeekOut的命运:
- 因为大裁员,导致在社会上的牛人太多了,一个位置N个牛人竞聘,哪里还需要AI模型搜索。
- 全美科技界,都在以万为单位裁员,AI的发展已经不需要这么多人了,公司的岗位正在逐渐减少,都不招人了,还需要招聘平台作甚。
因此 SeekOut的增长曲线一下子就从上升变成下滑。
AIHawk
【2024-10-8】一款超新星的AI求职助手:AIHawk
解决什么问题?
竞争激烈的求职市场上,如何在短时间内高效申请多个职位,成为很多人心中的难题。
大量职位信息及个性化简历修改和求职信撰写,常常让求职者筋疲力尽。
就业市场现有问题
- 求职者需要人工搜索、浏览职位信息
- 重复填表
耗时耗力, 影响心情, 还容易错过机会
Auto_Jobs_Applier_AIHawk 是 7*24h 工作助手
- 自动搜索职位、关注重点
- 动态生成简历
- 自动填表、投递简历
- 面试准备、挖掘个人技能
开源工具不仅具备自动化求职流程,还能够帮助求职者个性化调整简历,有网友借助这款AI求职工具在24 小时内申请 1000 个职位并获取 50 个面试机会!
核心功能
- • 职位智能搜索:扫描搜索符合条件的职位。自定义搜索条件,智能过滤,排除不相关职位。
- • 动态简历生成:动态生成定制的简历。
- • 自动申请提交:自动找到页面上的职位申请按钮,自动填写和提交申请。
- • 个性化问题回答:它使用 LLM 来个性化回答雇主的问题。
- •批量申请与质量控制:可以处理批量应用同时保持质量控制。
- • 安全数据管理:安全地管理您的数据并与 OpenAI 的 API 集成以实现 AI 驱动的功能。
- • 支持多种主流AI模型:LLM 模型选择 (OpenAI、Ollama、Claude、Gemini)
求职者的得力助手?
- • 大幅提高求职效率:传统的求职方式往往需要数小时甚至数天来完成申请。而有了 Auto_Jobs_Applier_AIHawk,求职者只需一次设定条件,AI 就可以在 24 小时内完成数百甚至上千份申请,确保不会错过任何一个机会。
- • 个性化与自动化完美结合:虽然是自动化工具,但它利用 LLM 技术根据不同的职位定制简历和求职信,保持了申请的个性化和相关性,增加了求职者获得面试的机会。
- • 解放时间,专注准备面试:求职者不用再为海量的申请流程烦恼,可以将更多精力投入到面试准备和职业发展上。AI 帮助他们完成了最耗时的环节,解放了宝贵的时间。
- • 适应不同的职位和行业:无论是技术岗位、管理岗位,还是创意类职位,Auto_Jobs_Applier_AIHawk 都可以灵活应对,生成相应的简历和回答,帮助求职者在不同领域都能高效申请。
使用
git clone https://github.com/feder-cr/Auto_Jobs_Applier_AIHawk.git
cd Auto_Jobs_Applier_AIHawk
海纳AI
【2024-10-24】 北京又跑出大模型黑马:AI面试超1200万人
2022年底开始的生成式AI革命深刻地改变了世界,企业家、投资人、创业者无不寻找AI与产业结合的爆发性机会。
此时,海纳AI却已“衔枚疾走”三年多:用AI对蓝灰领招聘流程做标准化改造,实现人才和岗位的精准匹配,持续获得了来自巨头的订单。
to B 产业互联网的王者赛道是什么?人力资源,尤其是人和岗位的匹配引擎。
人力资源行业具备几个特点
- 第一非常庞大,几万亿的大市场
- 第二整个市场非常碎片化、人效低,有十多万家公司提供服务,每个公司都活得很辛苦,利润率很低。
先从蓝灰领开始做,因为
- 对人考察的维度相对更容易结构化、量化,也是AI比较容易分析出来的。
- 另外,蓝灰领用工市场是最大的,我们把中国用工量最大的前100个岗位拆解出来,包括快递员、零售店面的店员等。
为什么蓝领招聘那么累、那么麻烦,效率那么低?
最根本的原因并不是人和岗的供需量不够,两边量都很大。
- 而是人和岗之间有30多个细分环节,每个环节都是人工做的,每个环节都像一条泥泞的羊肠小路,每个环节的中途退出率都很高,导致从人到岗的整体转化率极低。
- 海纳AI面试官本质上是在人和岗之间建了一条高铁,7*24小时总部直聘,全程自动邀约、自动面试、自动评估。
我们还需要和集团招聘专家、一线经理、绩优员工、离职员工等做访谈,提炼经验,校准模型。
海纳AI是一款AI面试产品,AI直接与应聘者交谈,并完全由AI来判断其是否达到上岗条件,主要用于蓝灰领岗位招聘,已被顺丰速运、沃尔玛中国、吉利集团、瑞幸咖啡等头部企业采用,目前海纳AI已为数十家行业Top3集团面试超1200万人。
海纳AI创始人梁公军是一位经历了多轮信息产业浪潮的“老将”:
- 上世纪90年代末,他作为技术总监参与搭建了新浪网技术体系,随后在微软担任技术顾问。
- 2006年底,他创办了最早的个性化内容阅读平台
鲜果网——比今日头条早5年。 - 2019年,
梁公军创办海纳AI,当时, OpenAI刚刚发布GPT-2,英伟达还被大多数人看作游戏显卡公司,市值不到如今的5%,微软向OpenAI投了第一笔资金。全世界都知道AI很重要,但渴望找到真正的突破口。- 梁公军想做的,不仅是一个面试工具,而是利用工程化思维,基于AI技术,建立起完整的岗位与人才匹配标准,在将来,蓝灰领岗位面试全部由AI来完成。
- 2020年,规模还很小的海纳AI获得了
顺丰速运的AI面试项目采购订单。通过一年多的交付,顺丰全集团上线海纳AI面试工具,并使用至今。 - 2023年,海纳AI获得由联想创投独家投资的数千万元A轮融资。
梁公军看来,实现人和信息的精准匹配,让消费互联网赛道涌现一批百亿千亿级大公司。AI赋能千行百业的临界点已经出现,为产业实现人和岗位的精准匹配,同样有机会出现一批百亿千亿级大公司。
海纳最近1年多基于最新开源大模型技术,利用海纳2亿条问答对、4000万条高质量精标面试数据和人才测评专家知识,自炼行业AI大模型,建模更快、信效度更高。
海纳AI
- 最大的壁垒就在AI模型的准确度。由于已经形成数据闭环,随着数据量越来越大,AI模型的准确度会越来越高。
- 另一个壁垒是数十家灯塔客户的独占性,这些集团同一个岗位不会同时使用两三个供应商,因为使用AI面试的目的就是统一全集团的用人标准,不可能华东区用海纳AI,华北区用另外一个供应商。而且用了海纳AI面试官之后,明年后年会一直用,一者是因为海纳AI会越用越准,一者是因为大集团内部标准的对齐很麻烦、切换成本很高。
AI应用可能的爆发场景:简单重复大规模,最好是自然语言强相关。
- 除了
AI面试,AI 培训、AI咨询也类似,同样的知识库、同样的问题和话术、同样的规则,大规模同步给大量用户。
Final Round AI
Final Round AI 是一个AI驱动的面试副驾驶,提供实时指导、转录和个性化协助,帮助求职者在从初步阶段到最终轮次的面试中表现出色
Final Round AI 的访问量增长了 5.2%,达到 617K 次访问。
2025年1月筹集的 688万美元种子轮融资 可能促进了市场营销和产品改进,推动了这个小幅增长。
Final Round AI 为面试者提供服务:
- 简历修订、求职信生成、模拟面试、面试实时转录、角色特定问题生成、包含反馈的面试报告以及现场面试中的个性化协助等功能。
面试中
- Final Round AI 提供对话的实时转录,并即时生成上下文相关的协助和建议回应,帮助面试者表现更佳
- Final Round AI 具备编码面试功能,用户可以截图编码问题,AI 将分阶段提供答案,包括思路、代码、讲解和测试用例
效果
- Final Round AI 已帮助用户获得超过25万个工作机会,并在超过120万次面试中表现出色。许多用户报告称,在使用该工具后,他们感到对面试更有信心和准备。
Mercor
【2025-5-3】AI招聘独角兽Mercor:月增速50%、净留存100%、41%代码来自AI
Mercor matches you with elite opportunities Join the thousands of candidates around the world using Mercor to land their remote dream opportunity with just a single application.
Mercor 是成立仅两年的AI招聘初创公司,其B轮估值达到20亿美金,令人瞩目。
从投资人的角度来看,Mercor 特点:
优势与潜力
- 市场潜力巨大:全球招聘市场规模庞大,AI技术在招聘领域的应用正逐渐普及,Mercor所处的市场具有广阔的增长空间。
- 技术优势明显:Mercor AI平台能够自动化关键招聘职能,如: 简历筛选、候选人匹配、面试等,提高招聘效率和质量。
- 其独特的数据飞轮效应和双重网络效应,使其在竞争中具有一定优势。
- 团队背景优秀:三位创始人均为 Thiel Fellows,年轻有活力,具有创新意识和创业精神。
- 客户留存率高:Mercor 已实现超过100%的客户净留存率,表明其服务价值得到了市场的认可。
- 收入增长迅速:从100万美金到1亿美金的ARR,仅用了11个月时间。
风险与挑战
- 收入数据质疑:目前Mercor的ARR数据存在一定质疑,缺乏详细的收入构成和客户信息,这可能会影响投资者对其真实盈利能力的判断。
- 竞争激烈:AI招聘市场竞争激烈,Mercor面临着来自传统招聘平台和新兴AI招聘公司的双重竞争。同时,随着AI技术的不断发展,可能会有更多的竞争对手进入该领域。
- 技术风险:AI技术的快速发展和变化可能导致Mercor的技术优势被削弱,需要不断投入研发资源来保持技术领先地位。
- 监管风险:随着AI招聘的普及,监管机构可能会对其算法决策的透明度、数据隐私等方面提出更高的要求,这可能给Mercor带来一定的合规风险。
take-away
- SaaS 下一阶段是从“工具提供”升级到“完整流程重塑”:
- Mercor 借助 AI,几乎将招聘每个环节软件化并极大地提升效率,这种“源于 SaaS 又不限于 SaaS 工具”的模式,预示着未来更多高人工依赖型行业将被智能解决方案颠覆。
- 对 SaaS 创业者而言,单纯的工具或信息服务已难以保证核心竞争力,而全链路、端到端流程重塑才是下一个制胜关键。
- 双边市场+数据飞轮将成为 AI SaaS 的核心竞争壁垒:
- Mercor 的成功表明,未来最具竞争力的 AI SaaS 平台需要同时具备双边市场的网络效应和数据飞轮效应。通过持续积累的交易数据来训练和优化 AI 模型,形成正向循环,这种壁垒会随着数据量增加而不断加强。
- AI 产品设计需要在未来趋势与当前用户习惯之间寻找平衡点:
- Mercor 最初想用一个聊天框代替所有的产品界面,但是失败了,这提醒我们即便是先进的 AI 技术,也需要考虑用户习惯的渐进式演化。设计 AI 产品时,不应过分激进地改变用户交互方式,而是应该在传统界面中逐步融入 AI 能力。
- 重视“人力 + AI”融合模式,高度专业化人才将持续紧缺:
- 虽然 AI 能协助完成越来越多的工作,但前沿领域对具备深厚行业背景、专业技能的专家需求不会降低,反而在某些精细化场景还会持续增多,因为训练出更好用的垂直模型需要更高质量的垂直领域数据,而如何筛选和标注这些数据需要专家经验。
- SaaS 产品如果能结合对行业专家资源的调度与管理(如提供专家评审、专家协作等增值服务),就能在垂直领域形成差异化竞争优势。
- 未来大模型会高度多元,保持“底层模型兼容性”至关重要:
- Mercor 的实践表明,不同技术栈、不同大模型都可被调度来完成人才评估等工作,并且未来必然会出现更多垂直场景模型。
- 若要减少对单一模型的依赖、并在技术迭代中保持产品长久竞争力,SaaS 公司应该尽早规划好底层大模型的“兼容适配能力”,在框架层面为多模型切换或协同预留接口。
【2026-4-2】Juicebox
【2026-4-2】Juicebox:用 AI 把 HR 工作提效 2 倍,4 人团队实现 $10M ARR
招聘是企业中信息损耗最严重的场景之一:从业务方描述“我需要能解决这个问题的人”,到 HR 翻译成关键词逐一筛选,每个环节都在吞噬语义信息。初级 HR 30%~50% 的工作日花在重复的搜索与外联上;AI 工具普及后,单个职位平均收到近 250 份申请,被动渠道的质量更加被稀释。
Juicebox 在这个背景下诞生的 AI native 寻人工具。没有试图重构招聘全流程,而是把“找人”这件最可软件化的事用 Copilot 做到极致。
Sequoia 最初关注到 Juicebox,正是因为自家招聘团队和被投公司都在自发使用——口碑渗透既是真实需求的直接证明,也是其 PLG 路径的原始验证。
数字上,4 人团队做到 $10M ARR、人均 $2.5M,是 B2B SaaS 历史上的极高水平。今年 3 月公司完成 $8000 万 B 轮融资,估值 $8.5 亿,ARR 已超 $30M。
写代码
【2024-9-6】 第三方观点 常见编码助手:阿里通义灵码,商汤小浣熊,智谱codegeex,讯飞iflycoder
- 反响最好是通义灵码…
【2025-2-25】 最强代码模型 Claude 3.7, Grok 3
详见站内专题: 大模型应用: 代码生成
Document QA
详见专题:文档问答
推荐系统/排序
详见站内专题: 大模型时代的推荐系统
个人助理
ChatGPT微头条
【2023-6-6】用ChatGPT发微头条
Monica
【2023-4-12】Monica, 一款浏览器插件,AI个人助理,功能:
- 快捷指令:网页上任意选择文本,即可翻译、解释、改写、总结、使用自己的提示
- 随处聊天:随时开启聊天窗
- 写作:轻松创作文案、邮件、博客等
使用 GPT-4驱动,免费用户又30次查询,每邀请一个好友,就有100次额度,其中1次GPT-4、4次AI作画
- Monica is an AI assistant powered by GPT-4. Register now to receive 100 free GPT Queries, including GPT-4, GPT-3.5, and AI Drawing. 邀请链接
Smart Siri
【2023-6-13】用 ChatGPT 武装 Siri 有啥用途?
ChatGPT的 app 更新后,能直接和 Siri、快捷指令(Shortcuts)联动,这样,Siri 就能用上 ChatGPT 的能力了。
- iOS 版本是 16.1 及以上,应用才能兼容使用
智能助理的槽点:
- “Siri 是人工智障”
- 由于 Siri 更强调在用户设备端计算,需要保护个人隐私,只能做些特定任务,比如:查天气、定闹钟;
但当 Siri 接入 ChatGPT 后,执行任务的角色就被后者接替了,想象空间变得更大了。
- 方法一: 快捷指令基于 ChatGPT API 接口进行 JSON 格式的发送获取,发送和解析过程都会消耗很长时间,也会占用更多的 ChatGPT key 余额。
- 方法二: 官方 app 接口可以直接省去用户打包数据提取数据的过程,直接向 app 发送请求并获取有效信息。中间省去了受网络波动、ChatGPT 用户过多、key 余额不足等因素的影响
- 不用懂有门槛的 JSON 语言,不用写代码,把自己的发问需求细化成小步骤,找到能实现对应任务的 app,像乐高积木一样拼起来就行了。
“Smart Siri”: 升级版 Siri 可直接用语音发问,对于明确的、具体的发问,提炼得更好。
- 直接喊“Hey Siri + Smart Siri”,等待,看到“Yes”后,就能开始问问题了
- 工具:ios下载地址, Access-chatGPT-in-Siri: Siri接入ChatGPT指南。目前仅限iPhone端及其他支持快捷指令的Apple产品,后续会更新Android版本。

分析
- Siri 的表现相对刻板,它仅能提供网址以及内容概括,有时会直接告知未找到相关信息,仿佛是被束缚的人工智能
- Smart Siri 则能立即提供不错的回答,简洁明了,看起来的确挺聪明的。
| 案例 | Siri | Smart Siri | 分析 |
|---|---|---|---|
| 宫保鸡丁 | 我在网上找到了这个结果:… | 宫保鸡丁的正宗做法:1,2,3,… | 直接给出做法 |
| 光年之外有什么故事 | 搜索光年之外信息 | 《光年之外》是邓紫棋2016年发布的歌曲,灵感来自电影《星际穿越》… | 直接解答 |
| 用小红书格式写个朋友圈 | 依旧是搜索… | 端午节朋友圈文案:1. 与美好生活一见“棕”情 2. 无论咸甜,阖家团圆才是最好的陷… | |
| 帮我写个毕业季微电影的拍摄脚本 | 我在网上找到了这个结果:… | 拍摄脚本 | 直接给出做法 |
微博博主 @Sunbelife 展示的几个玩法,比如
- 把 iPhone 内的睡眠数据(步数等健康数据)打包,让 ChatGPT 接入分析,最后生成一个“每日健康分析报告”——这个过程还可以是完全自动化的。
- 智能家居:
- 授权chatgpt app读取家庭数据,对智能家居进行开关、自动化及预处理,对气温、温度提出有效建议
- 跨境电商分析场景:
- 解析电商规则,SEO优化、选品、广告优化、商品详情页优化、关键词优化、客服与售后自动化
- 不用打开其他app,直接用Siri体温,获取答案,优化
苹果在 WWDC(苹果年度开发者大会)上并没有像其他科技巨头那般谈论(甚至吹捧)AI 大模型,但在一些小功能上,也都是基于 AI 去研发和改进的。比如
- 打字,在 iOS 17 上,键盘上的错字自动纠正、打字实时预测(机器甚至能准确联想到一整句你最想表达的话)等功能
- 这些都基于使用 Transformer 语言模型的 ML 程序开发。
Smart Siri 不足:
- ChatGPT 还无法实现连续对话,不过可以把之前的聊天记录粘贴进当前要问的问题里,也能间接连续问答的效果。
日程管理
【2024-1-7】Dola,一个相当炸裂的Agent日程助理,创始团队来自全球顶尖名校
Dola 目前项目主要做出海,当前支持的平台有Apple messages,WhatsApp,Telegram,Line,微信。
吊打各大日程app和siri等语音助手的存在,聊着天就能管理日程,Dola的独特优势有:
- ⌨️ 1“键”多添加
- 支持文字、语音、图片、聊天记录、链接卡片的多模态输入;1次添加N条日历。
- 📱 轻松同步
- 同步手机、电脑日历,多设备同时提醒。
- 👥 群助理
- 拉群时拉上Dola可用作群助理,管理群日程;企微群可直接拉进群。
AI PC
AI 模拟操控
详见站内专题: Agent 设备操控
Easy-RAG
【2024-7-12】个人实践: Easy-RAG, 用 ollama 和本地llm 实现语言操控电脑
- langchain_experimental 包开发,基于ollama的大模型,去注册tool,并且调用
- 详见
联想 AI PC
【2024-1-9】CES 2024现场体验:你的AI PC,未来长这样! CES 2024现场体验:你的AI PC,未来长这样!
一个未来最有可能落地的趋势,就是AIPC人工智能版个人电脑
联想 AIPC 个人 AI 助理 AI NOW
- 2023年10月底,联想在Tech World大会上提出了AIPC的概念
- 本届CES上,联想连续发布了多款主打AIPC概念的新产品。
生成式AI的个人助理功能AI Now则成为AIPC概念的第一波落地,消费者通过对话就能实现规划日程、设置电脑、查询硬件等诸多操作。联想计划在今年下半年正式推出这一产品。
以联想为代表的厂商持续完善AIPC功能生态,在展会中联想展出了AI NOW、AvatarMaster及Yoga Creator Zone等AI应用端创新。
- 1)AI NOW 是以用户自建的设备知识库为基础打造的个性化互动助手,通过自然语言交互实现更改常见设置、在未学习的情况下使用各种软件、搜索和汇总电子邮件及文档、创建会议邀请、并在视频会议期间混合使用实时摄像头和数字替身等功能,预计将于2024年上半年在国内推行;
- 2)AvatarMaster,根据用户个人资料生成3D数字化身,从外表和面部特征到服饰选择,均支持多种个性化功能;用户创建和定制虚拟分身后,可在视频会议、游戏通话以及多个平台之间以动画和流媒体形式展现自己;Legion 7i等部分联想Legion设备系统都配备了AvatarMaster软件,将流媒体和协作体验提升到新的水平;
- 3)Yoga Creator Zone,是专为创作者、艺术家等用户设计的生成式AI助手,旨在为想象力赋能,提供图像生成工具,可将基于文本的描述或草图转换为图像,无需输入任何复杂的提示、代码或设置。用户只需输入任何预想的内容,系统即可快速生成相应的视觉图像
联想智能体一体机
【2024-10-23】一图读懂联想智能体一体机
- 【2024-10-9】联想业界全新智能体一体机解决方案,以AI为支点,撬动行业变革
联想最新发布的智能体一体机通过高度集成的软硬件设计,带来了“开箱即用”的便捷体验。
- 软件层面, 联想智能体一体机配备了“联想智能体平台”, 集成多种开源大模型、智能体样例及开发评估工具,并提供零代码开发功能,支持用户在短时间内以低门槛的方式创建智能体。无需复杂的部署与配置,用户即可快速启动智能体的开发与应用,实现从模型训练到应用落地的全过程管理,进一步简化了AI技术的应用流程,助力企业用户轻松接入并快速运行。
- 硬件方面, 智能体一体机基于联想 ThinkStation PX 旗舰工作站打造,采用桌面级安装部署,避免了服务器需要专门机房运维的复杂性,大大简化了维护管理的工作量,极大地方便了运维操作。
- 性能上, ThinkStation PX专为深度学习和数据分析设计,搭载双路Intel Xeon处理器和4张NVIDIA RTX 5000 Ada显卡,能够处理高并发任务和大规模数据计算。在复杂AI场景下,ThinkStation PX凭借其强大性能,支持多路并发任务,确保智能体一体机实现7×24小时的高效稳定运行,充分满足企业和教育用户的多样化需求。
Apple Intelligence
苹果内部员工认为,该公司在人工智能开发方面落后对手大约两年时间。
-
库克表示: 苹果并不介意在某些领域不是先行者,因为公司更重视产品的完善度,“我们宁愿推出真正卓越的产品,为人们带来实质贡献,而不是为了抢先上市而匆忙行事。”
- 【2024-10-17】苹果发布新的 macOS Sequoia 15.1 公测版 Beta 4,允许非开发者在 10 月 28 日正式发布之前测试该软件。
- 【2024-10-29】Apple Intelligence 终于实装 iOS 18.1,用上的第一批用户已经开骂了?
Apple Intelligence 已经伴随 iOS 18.1、iPadOS 18.1 以及 macOS Sequoia 15.1 的发布而正式亮相。
- 苹果操作系统的 x.1 版本会添加一些小功能并修复 bug,但今年却成为多项重大更新的载体,原因是之前发布 iOS 18 时 Apple Intelligence 尚未做好准备。甚至连被宣传为“专为 Apple Intelligence 打造”的 iPhone 16 系列,在推出之时都还缺少这些功能的加持,因此显得这批 18.1 系统版本尤其珍贵。
虽然尚未添加所有 AI 功能,但测试版包括写作工具、Siri 更新、摘要、AI 驱动的专注模式和智能回复。要使用 Apple Intelligence 功能,用户需要一台 iPhone 15 Pro、iPhone 16 系列,或 M 系列 Mac 和 iPad。
- 首批开放的功能包括: 校对和重写等 AI 写作工具、照片记忆以及全面升级的 Siri。
- 备忘录应用开始提供电话和音频的实时转录,苹果方面还提供相当实用的转录内容摘要选项。
- 苹果还使用AI汇总通知组,以便用户更快地了解错过的内容。用户可以汇总长电子邮件,并使用新的专注模式来过滤不必要的干扰。
- 网友评价是,“在实践中,这些功能还是有用的,不过在使用了一周后,并没有节省多少时间和精力。”
- Apple Intelligence 还可在经过全面升级的照片应用中,围绕一段旅程及特殊事件等难忘时刻重新整理您的照片和视频。用户也可以在该应用中创建自己的“回忆”段落。
- 网友 KBrew 展示的用 Apple Intelligence 删除照片人的操作
- 改头换面的 Siri 也终于同广大用户见面。
- 可以向仅支持语音的虚拟助手输入更丰富的请求和问题。即使表达卡顿或者另起话头,Siri 也能凭借更强大的语言理解能力顺畅处理用户语音。
- Siri UI 也经过了调整,在激发该功能后会看到屏幕周边泛起发光的边框。
- 但是,各位 iPhone 用户还需要再等一段时间才能迎接其他由 Siri 驱动的功能,例如 让该虚拟助手更深入地了解自己的个人背景。
- 虽然 UI 很炫酷,但模型质量还是被网友吐槽了:不是你想用就能用的 Apple Intelligence
- “四大关卡”:升级系统、所在国家支持、手机型号支持更新、进入候补名单等待通过。
评价
Apple Intelligence 终于到来了,但和目前智能手机上的大多数人工智能一样,它也令人失望
Apple Intelligence 令人失望的地方:
- 有半数指令它都理解不了,自然也没法像 ChatGPT 那样顺畅交谈。
- 它几乎不回答我的问题,结果通常只有互联网链接——有时候回应甚至跟问题毫无关联。
- 它很难理解我让它给谁打去电话。
- 它没法向正确的收件人发去电子邮件。
- 我不知道怎么让摄像头识别它前面的东西(据说 Apple Intelligence 是支持这项功能的)。
- 我不知道该怎么创建漂亮的新表情符号(可能要等到下次更新,但没准备好为什么要在官网上面大肆宣传呢
但此番更新也绝不是一无是处, Ksenia 认为能够良好运行的功能:
- 通话记录功能终于到来。Apple Intelligence 可以将通话保存到备忘录当中,提供转录,并对内容进行总结、重写以及其他文本编辑选项——总之相当方便!
- 现在苹果的邮件应用中迎来了“智能工具”。之前我个人从来不用自带的邮件应用,因为 Gmail 应用操作起来更顺手。但现在凭借新的电子邮件摘要和回复重写选项,我可能会再给苹果邮件应用一个机会。
- 在呼叫 Siri 时,屏幕边缘会泛起亮光——非常漂亮(虽然不属于实际功能,但我就是喜欢)。
- Apple Intelligence 可以总结用户选定的所有通知,但就目前体验来看,这项功能没什么大用。更确切地讲,跟“智能”关系不大。
Turbo
【2024-10-30】思必驰AI办公本Turbo,革命性替代纸质笔记本的新一代智能办公本
- AI笔记,思维导图,手写笔美化
Friend
【2024-6-29】Friend:又看到一个很有用但可能争议巨大额AI硬件
新出的AI硬件,Friend。AI项链,开源的,直接连接手机,本地化数据存储。
- 原始开发套件版本,68美金,加强版,97美金
新出的AI硬件,名字很好听:Friend。AI项链,开源的,直接连接手机,本地化数据存储。
优点:
- 1、足够小巧,随时可携带;
- 2、随时记录声音,然后可以交给模型去处理,会议纪要,重要事项提醒,各种可能性,在“第二大脑”逐渐深入人心的当下,这种应用的“刚需”是绝对在的;
- 3、其实,到了AI模型时代,技术部分每个人需要的就是,信息采集器、模型、信息展示设备。这样的“项链”,是值得一试的;
- 4、至少,可以不需要录音笔了。
问题也非常明显:
- 产品“侵略性”很强,用户愿意记录自己的声音,但不代表别人愿意,甚至大概率很不愿意。本质上,这跟“监控”没啥区别。
这样的产品,估计也卖不出多少个,虽然比rabbit r1便宜,但可能量会少很多。
但是,问题:在模型逐渐提供越来越多可能性同时,愿意接受的那条线在哪里,多大程度侵略自己的“领地”?
- 曾经为了送货上门,毫不犹豫的贡献出电话号码、住址
- 为了注册账号,贡献了身份信息、生物信息
- 如果有机会变得效率更高,估计也可以继续降低底线的。
AI的公平,或许不太是供给的公平问题,更可能是“底线”的公平问题。
文档理解
【2026-5-23】基于大模型的笔记应用
| 工具 | 来源类型 | 引用与查看器 | 协作 | 价格 |
|---|---|---|---|---|
| LilysAI | ✅ 视频/音频/PDF/Web | ✅ 句子级别 | ✅ 导出/分享 | 实惠 |
| NotebookLM | ✅ 视频/音频/PDF/Web | ❌ 功能有限 | ✅ 与 Google 集成 | 主要免费 |
| AskYourPDF | ❌ 仅限 PDF | ✅ 引用样式 | ❌ 分享受限 | 免费 + 付费版 |
| Unriddle | ✅ 多文档 | ✅ 文档内引用 | ✅ 团队协作 | $12–$90 |
| Mem | ❌ 笔记/文档 | ❌ 功能有限 | ✅ 团队分享 | $8–$15 |
| Tana | ❌ 笔记/语音 | ❌ 功能有限 | ✅ 工作区协作 | $10–$18 |
| Saner.AI | ❌ 邮件/云盘/语音 | ❌ 功能有限 | ✅ Starter+ 计划 | $8–$16 |
| ChatGPT Projects | ❌ 不支持视频 | ❌ 表现不稳定 | ❌ 仅基础分享 | $20–$200 |
| Perplexity | ❌ 不支持视频 | ✅ 始终有引用 | ❌ 仅限页面 | $20–$40 |
| Notion AI | ❌ 文档 + 应用 | ❌ 仅页面链接 | ✅ Notion 协作 | ~$20/用户/月 |
| Afforai | ❌ 文档/web/论文 | ❌ 功能有限 | ✅ 共享库 | $8–$16 |
MinerU
MinerU 是一款将PDF转化为机器可读格式的工具(如markdown、json),很方便地抽取为任意格式。
MinerU 诞生于书生-浦语的预训练过程中,集中精力解决科技文献中的符号转化问题,希望在大模型时代为科技发展做出贡献。
主要功能
- 删除页眉、页脚、脚注、页码等元素,保持语义连贯
- 对多栏输出符合人类阅读顺序的文本
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片标题、表格、表格标题
- 自动识别文档中的公式并将公式转换成latex
- 自动识别文档中的表格并将表格转换成latex
- 乱码 PDF自动检测并启用OCR
- 支持 CPU和GPU环境
- 支持 windows/linux/mac平台
安装
conda create -n MinerU python=3.10
conda activate MinerU
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
NotebookLM
Google 推出 NotebookLM, 将论文转成播客
NotebookLM 是一款 AI 赋能的研究和撰写助理,最适合与您上传的来源配合使用
- 上传文档后,NotebookLM 将回答详细问题或提供关键数据洞见 —— 文档问答
- 将复杂资料转换为简单易懂的格式,例如常见问题解答或简报文档
-
将关键资源添加到笔记本中并与您的组织共享,以创建群组知识库
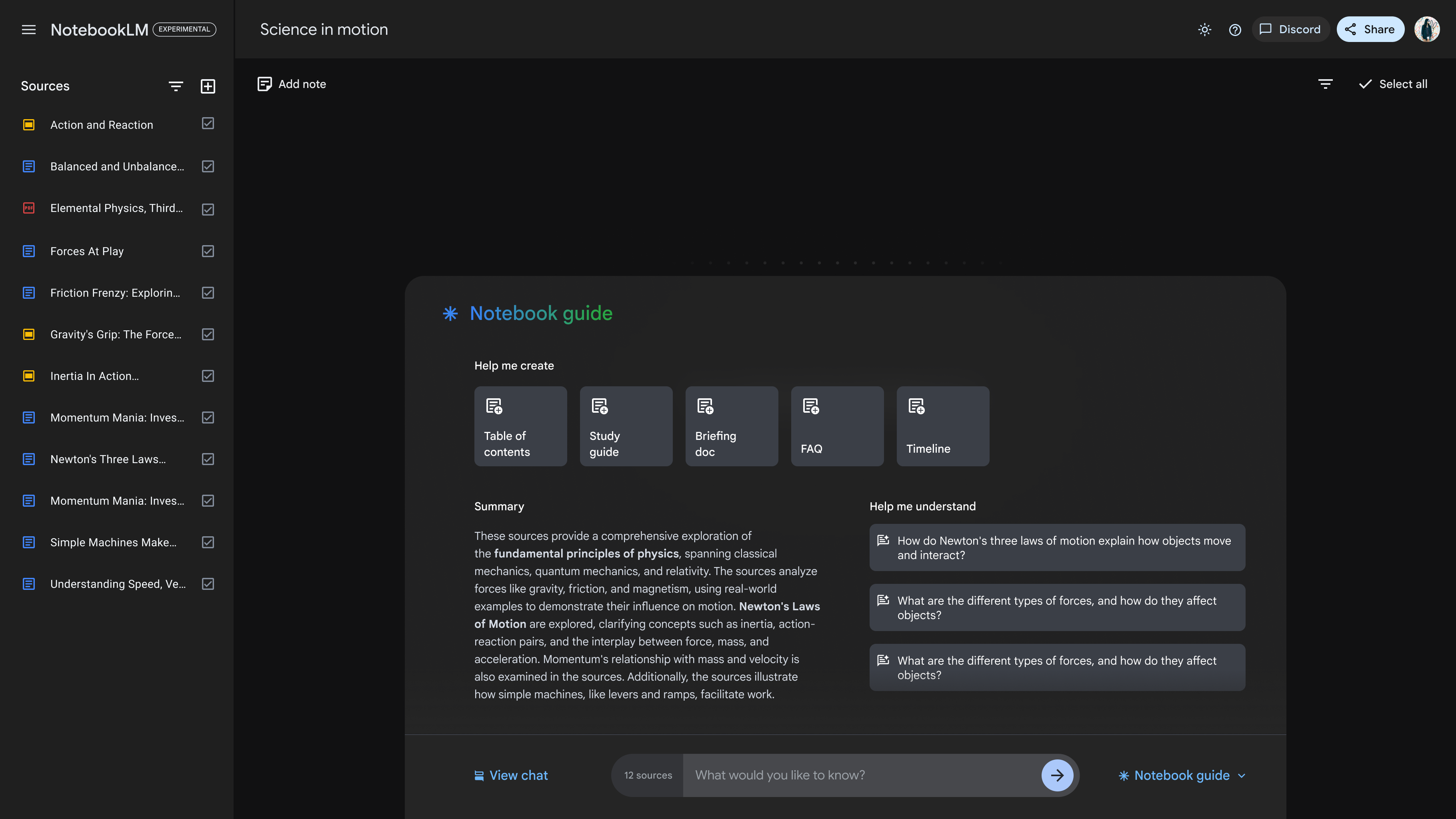
- 演示视频
个人笔记
笔记应用
Obsidian
【2024-3-15】Obsidian - 本地AI助手:
Obsidian Copilot这款插件能支持本地LLM, 通过Smart Connection插件+本地用Ollama,跑了个llama2 7B模型,实现笔记的LLM问答
- 8G以上的内存
- 安装Ollama和llama2 7B
- 安装设置Obsidian Copilot
- 运行Ollama和使用Copilot
AudioNotes
【2024-7-31】快速将音视频转结构化笔记的开源免费工具 AudioNotes。
基于 FunASR 和 Qwen2 构建,可快速提取音视频内容,并利用大模型能力整理成一份结构化的 Markdown 笔记,方便快速阅读。
- GitHub:AudioNotes
工具支持搭配 Ollama 使用本地模型,并提供了 Docker 快速部署方式。
Granola
【2025-6-26】硅谷VC最爱的AI笔记Granola,估值 2.5亿美金
产品思路非常清晰:认知合伙人
- 不做自己的模型,而是给人和模型分工
- 应用层创业,从高频场景切入
- 低频用通用产品
- 高频用细分产品
- 不做模型未来会的事情
- 大厂的边际成本就是机会
- 每增加一个用户带来模型成本增加,大厂也无法盲目扩展用户,对创业者是机会
办公工具
详见站内文章:智能办公
代码研发
【2023-10】评测标注 SWE benchmark 包含 github上 python仓库上的2,294 个任务
- 论文 SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
- Claude 2 能解决 1.96% 的问题
概览
- Awesome Devins 汇总各个数字程序员实现

OpenDevin
Chatbots like ChatGPT, Perplexity, and Phind can generate code, but Devin went further. It can also run, test, and implement the code, using a sandbox as runtime.
【2024-3-12】 Cognition AI 发布数字程序员: OpenDevin
- OpenDevin: Code Less, Make More
- AI,LLM驱动的数字程序员, 写代码、查bug、发布特性

git clone https://github.com/OpenDevin/OpenDevin.git
cd OpenDevin
启动
- web 地址
WORKSPACE_BASE=$(pwd)/workspace
docker run -it \
--pull=always \
-e SANDBOX_USER_ID=$(id -u) \
-e WORKSPACE_MOUNT_PATH=$WORKSPACE_BASE \
-v $WORKSPACE_BASE:/opt/workspace_base \
-v /var/run/docker.sock:/var/run/docker.sock \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name opendevin-app-$(date +%Y%m%d%H%M%S) \
ghcr.io/opendevin/opendevin
Introducing Devin, the first AI software engineer
Devin 开源替代版
Open-Source Alternatives to Devin
- OpenDevin
- AutoCodeRover 能解决 SWE-bench 上 16% 的问题
- Devika 除了写代码,还支持浏览器交互式抓取信息,demo
- Devika supports Claude 3, GPT-4, GPT-3.5, and Local LLMs via Ollama
- Anterion, 受 OpenDevin 启发, demo
- MetaGPT, 多智能体框架,比上面都早
- AutoDev, 多种编程语言
- Python, and JavaScript/TypeScript, but also Rust, Java, Kotlin, Golang, or C/C++/OC.
- Devon, 多文件编辑、git 工具使用
- SWE-agent 12.3% SWE-bench,通过 docker 本地执行
- “Agent-Computer Interface” (ACI), LLMs 友好. 允许的动作: run code, look for code, edit code, and submit changes to GitHub.
WatsonX
2023年5月9日,5月9日,IBM召开“Think”大会,重磅推出了大模型Watsonx,全面深度布局生成式AI领域
Watsonx 由三大块组成
- 基础模型 watsonx.ai;
- 基于开放式 Lakehouse 架构构建的专用数据存储平台watsonx.data;
- 用于AI安全治理的 watsonx.governance。
这三大平台赋能下,可为用户提供一站式安全可靠的生成式AI服务。
IBM还与开源社区Hugging Face 进行深度技术合作,为 watsonx平台上的企业带来更好的开源生成式AI模型体验。
根据IBM官方介绍,7月份,watsonx.ai将在Hugging Face平台上开源。
数学工具
Goar-7B
【2023-6-5】近乎完美!最强算术语言模型: Goar-7B,干翻GPT-4,怒越PaLM-540B!24G可训练
OpenAI对step-by-step数学推理问题发表了最新的研究,指出「过程监督优于结果监督」的结论,旨在提升GPT-4的数学推理能力。
这边篇文章就是基于该理论(「好像比OpenAI要早」),旨在提升模型大数计算能力,基于LLaMA预训练了Goat模型,Goar-7B在Zero-shot上的准确效果,堪比、甚至超越PaLM-540B模型的Few-shot结果;在大数计算方面远超GPT-4。
GPT-4在算术任务中的性能,尤其是大数的乘法和除法,目前还远未达到最佳状态,准确度水平趋向于零
将各种算术任务分为可学习和不可学习任务」,随后利用基本算术原理将不可学习任务(例如多位数乘法和除法)分解为一系列可学习任务。本文方法确保促进模型学习的中间监督也很容易被人类理解,即通过模型微调在生成最终答案之前生成合适的CoT。「本文方法大大优于 GPT-4 的长乘法和长除法」。
不同的语言模型对于同一个可学习任务的表现有所不同,「进一步提出了一种新的中间监督机制,可以提高模型对于一些不可学习任务的学习效率」。
- 「加减运算处理」:加法和减法任务可以通过监督微调学习,并且模型能够成功地捕获算术运算背后的模式。
- 「多位数乘法」:对于多位数乘法,作者提出采用与Sketchpad相似的策略,在生成答案之前,将LLMs微调为生成一系列可学习子任务的CoT。具体而言,将多位数乘法分解为五个可学习的子任务:提取、拆分、展开、乘积和逐项相加并复制,以此来突破多位数乘法的学习难题。以397×4429为例,下面展示了如何将一个复合的、难以学习的任务分解为多个简单而又可学习的子任务。397×4429=4429×(300+90+7)=4429×300+4429×90+4429×7=1328700+398610+31003。
- 「多位除法」:学习n位数被1位数除法是可行的,但是多位数除法是无法学习的。作者设计了一种基于递归公式的CoT,其中递归公式涉及到除数、余数和商的关系。该方法的主要思想是通过重复减去除数的倍数,直到余数小于除数,从而对除法进行计算。
- 「数据及训练」:作者使用Python脚本合成数据集,该「数据集包含约100万个问答对」。答案包含所提议的数字运算类型以及最终数字输出。为了使模型能够根据指示解决算术问题并促进自然语言问答,「使用ChatGPT生成了数百个指示模板」。采用各种技术增强模型对多样化问题的适应能力,例如随机删除算术表达式中数字和符号之间的空格,用“x”或“times”替换“*”等。使用24GB VRAM GPU可以使用LoRA轻松微调Goat-7B。
仅通过监督微调而不应用任何特殊技术,「Goat模型能够在Zero-shot设置中以近乎完美的精度为大数加法和减法生成答案」。这种出色的算术能力归因于 LLaMA 对数字的一致标记化,并表明这对于以前的 LLM 来说几乎是不可能实现的,例如 Bloom、OPT、GPT-NeoX 、Pythia等。
Mathematica + LLM
【2023-7-3】Mathematica引入大语言模型
新版本Mathematica Wolfram,正式引入大语言模型(LLM)。搞科学计算,只需要一个“说”的动作。
- 直接说:Draw a red and a green semicircle.
- I want filled semicircles next to each other. And no axes. 我想要彼此相邻的填充的半圆。没有坐标轴。
Chat Notebook中,设置了聊天单元(chat cell)和聊天块(chatblock)
好未来:MathGPT
【2023-8-24】MathGPT 是好未来自主研发,面向全球数学爱好者和科研机构,以解题和讲题算法为核心的大模型。
MathGPT 的数学计算能力已覆盖小学、初中、高中的数学题,题目类型涵盖计算题、应用题、代数题等多个类型,还可以针对题目进行追问,暂未开放数学之外的问答互动。

并开源数据集
- TAL-SCQ5K-CN 和 TAL-SCQ5K-EN数据集(各3K训练集和2K测试集)
- 题目为单选形式,涉及小初高阶段数学内容,带有详细的解析步骤便于进行COT的训练。
上海交大 Abel
【2023-9-22】数学能力超过ChatGPT!上海交大计算大模型登开源榜首
上海交大GAIR实验室出品的Abel专有大模型:
- 挪威数学家尼尔斯·阿贝尔(Niels Abel)的名字命名的,以此向阿贝尔在代数和分析方面的开创性工作致敬。
- github,作者刘鹏飞(prompt learning提出人)
效果
- 准确率高达83.6%,在开源模型中位列第一;
- 70B规模的Abel打败了曾经的SOTA ——
WizardMath - 商业闭源模型算进来,Abel也仅次于
GPT-4、Claude-2和PaLM-2-Flan这些最著名的模型。 - GSM8k数据集上,70B参数量的Abel碾压所有开源模型,还超过了ChatGPT。
- 甚至在新数据集TALSCQ-EN上,Abel的表现比GPT-4还要强
- 在难度更高的MATH(竞赛题目)数据集中,开源模型的前三名被3个规模的Abel包揽,加上闭源也仅次于Google和OpenAI的产品。
- 新数据集TALSCQ-EN对Abel进行测试,结果超过了GPT-4。
实现这样效果的Abel,成分可以说是十分“单纯”:
- 没有使用工具
- 没有使用数学领域的大规模预训练数据
- 没有使用奖励模型
- 没有使用RLHF
- 仅使用有监督精调(Supervised Fine-tuning,SFT)
“保姆级”微调训练策略
- 核心奥义就是高质量训练数据。
Abel使用数据经过精心策划,不仅包含问题答案,还要能告诉模型找到正确答案的方法。
为此,研究团队提出了一种叫做家长监督(Parental Oversight)的“保姆级”微调训练策略。在家长监督的原则之下,团队仅通过SFT方式就完成了Abel的训练。
为了评价Abel的鲁棒性,研究团队还用GPT4对GSM8k中的数字进行了修改,测试Abel是否依然能解出正确的答案。结果显示,在调整版GSM8k数据集下,70B参数的Abel鲁棒性超过了同等规模的WizardMath。
鸡兔同笼问题的变体:
Brown由牛和鸡一共60只,鸡的数量是牛的两倍,一共有多少条腿?
Llama-2出师不利,而且不是计算错误,是逻辑上就有问题,Abel则成功地解决了这个问题。
12,21,6,11和30的中位数与平均数的和是多少?
Abel依旧是正确地做出了这道题
MathGLM 清华
【2023-9-24】智谱AI推出数学模型MathGLM,阿里云魔搭社区全球首发, 清华&智谱AI团队最新MathGLM研究开始探索和提供大模型的数学能力,发现在训练数据充足的情况下,20亿参数的MathGLM模型能够准确地执行多位算术运算,准确率几乎可以达到100%,其结果显著超越最强大语言模型GPT-4在相同测试数据上18.84%的准确率。MathGLM-10B模型已经开源到了始智AI-wisemodel社区,大家可以试试看。
- MathGLM GitHub, GPT Can Solve Mathematical Problems Without a Calculator

MathGLM包含10M、100M、500M、2B等多个参数版本,具备处理最多12位数字的运算能力。而且有测评结果显示,通过充分的数据训练,MathGLM-2B可以准确执行多位数的算术运算,准确率高达93.03%(接近100%),显著超越GPT-4在相同测试数据上18.84%的准确率。10亿参数版本的MathGLM-10B则在5000条中文数学应用题的测试数据集上实现了接近GPT-4的性能。
文本创作
文案创作
【2023-4-8】创业产品:AI百晓生,给视频生成文案,语音播报
写小说
详见站内专题:长文本创作
小说配图
【2024-1-12】AI小说漫画也能赚钱?保姆级教程来啦
借助Midjourney强大的AI图像生成能力,比手工更快更好地实现小说到漫画的改编!
做好小说推文后,上传至授权网络平台连载收取稿费,也可以通过被人打赏、在精彩环节设置收费章节、设计漫画周边产品等方式来赚钱

步骤
- 准备小说的文本材料。让AI帮你写,把现有的小说,获取小说原创的授权,进行改编。
- 针对想要改编的小说章节,选取一些具有画面感、场景感的段落,这部分文字将作为图像生成的文本提示(Prompt)
- 记得包含关键的人物姓名、场景地点、情绪等细节在内,这会让AI生成的图片更符合故事情节。一般选择1-2句具有代表性的文字描述即可。
- 用Midjourney生成漫画素材
- 将生成的图像保存后,导入设计软件,添加气泡框、文字说明,调整画面构图,添加页面元素,输出成图。

音频应用
音乐生成
【2024-3-24】 音乐ChatGPT时刻来临!Suno V3秒生爆款歌曲,12人团队创现象级AI
AI初创公司Suno震撼推出V3音乐生成模型,惊艳了全世界。
- 用户只用几个简短的词,就可以用任何语言创作一首歌曲
- 只需几秒,即可生成2分钟动听的音频。
- Suno v3还新增了更丰富的音乐风格和流派选项,比如古典音乐、爵士乐、Hiphop、电子等新潮曲风。
- 体验地址 Suno AI
相比与之前的版本
- v3生成的音乐质量更高,而且能制作各种各样的风格和流派的音乐和歌曲。
- 提示词的连贯性也有了大幅提升,歌曲结尾的质量也获得了极大的提高。
- 而且伴随着v3版本的推出,还发布了AI音乐水印系统,每段由平台生成的音乐都添加了人声无法识别的水印,从而在未来能够保护用户在Suno的创作,也能打击抄袭,防止将Suno产生的音乐进行滥用。
Suno目前只有12名员工,不过现在他们正在扩大规模,在现有的临时办公位置上他们正在加盖办公室。
视觉应用
【2023-3-14】ChatGPT 有什么新奇的使用方式?
MoneyPrinterTurbo
短视频一键生成
【2024-3-27】开源免费一键生成短视频的 AI 工具 MoneyPrinterTurbo
- 只需提供一个视频 主题 或 关键词,全自动生成视频的文案、素材、字幕以及背景音乐,然后合成高清的短视频。
- 项目是基于 MoneyPrinter 重构而来,大量优化
- 支持中文并提供易于使用的 Web 界面。
功能特性:
- 完整的 MVC 架构,代码 结构清晰,易于维护,支持 API 和 Web 界面。
- 支持视频文案 AI 自动生成,也可以自定义文案。
- 支持多种 高清视频 尺寸,常见的 9:16、16:9。
- 支持 批量视频生成,可以一次生成多个视频,然后选择一个最满意的。
- 支持 视频片段时长设置,方便调节素材切换频率。
- 支持 中文 和 英文 视频文案。
- 支持 多种语音 合成。
- 支持 字幕生成,可以调整 字体、位置、颜色、大小,同时支持字幕描边设置。
- 支持 背景音乐,随机或者指定音乐文件,可设置背景音乐音量。
- 视频素材来源 高清,而且 无版权。
- 支持 OpenAI、moonshot、Azure、gpt4free、one-api 等多种模型接入。

git clone https://github.com/harry0703/MoneyPrinterTurbo.git
cd MoneyPrinterTurbo
conda create -n MoneyPrinterTurbo python=3.10
conda activate MoneyPrinterTurbo
pip install -r requirements.txt
用到的库
- GPT 服务 openai
- 视频编辑 moviepy
- 语音识别 whisper 和 语音合成 tts
requests~=2.31.0
moviepy~=2.0.0.dev2
openai~=1.13.3
faster-whisper~=1.0.1
edge_tts~=6.1.10
uvicorn~=0.27.1
fastapi~=0.110.0
tomli~=2.0.1
streamlit~=1.32.0
loguru~=0.7.2
aiohttp~=3.9.3
urllib3~=2.2.1
pillow~=10.2.0
pydantic~=2.6.3
g4f~=0.2.5.4
Visual ChatGPT
Visual ChatGPT(一): 除了语言问答,还能看图问答、AI画图、AI改图的超实用系统
- 2023.3.9,微软官方github放出Visual ChatGPT的系统实现,这篇paper通过利用chatgpt api和开源模型实现了一个多模态的问答系统,不仅可以语言问答,还可以输入一张图实现
VQA视觉问答,还集成stable diffusion可以进行AI绘画!语言问答、看图问答、AI绘画,将AI届近期的3大热点集于一身 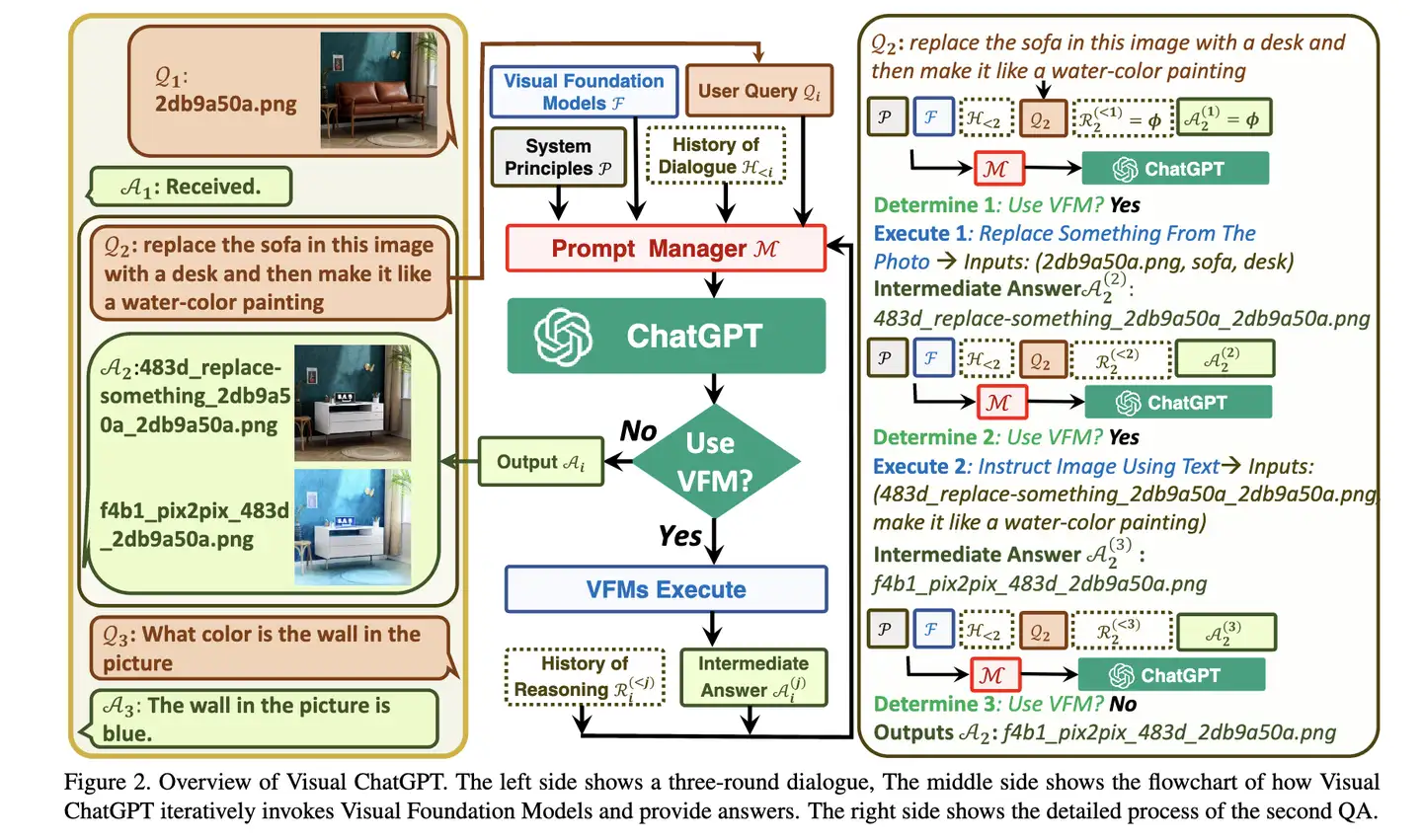
实现的功能(详细的可以去看论文的附录A.Tool Details):
- 获取图片的语言描述:Salesforce/blip-image-captioning-base
- 输入语言进行AI绘画:runwayml/stable-diffusion-v1-5
- 去除或者替换图片上的某个东西:runwayml/stable-diffusion-inpainting,CIDAS/clipseg-rd64-refined
- 通过语言修改图片:timbrooks/instruct-pix2pix
- 看图回答问题:Salesforce/blip-vqa-base
- canny边缘检测/depth深度检测/HED边缘提取/mlsd线段识别/normal模型识别/openpose姿势识别/scribble黑白稿提取/seg语义分割和根据此画图:主要是各种开源的视觉任务模型VFMs,然后ControlNet实现画图。
视频翻译
示例
HeyGen
- 【2023-10-23】口型几乎完美、还能卡点,霉霉说地道中文的视频火了,背后AI工具原来是它
- 【2023-10-30】AI让霉霉说中文,口音那叫一个地道!背后的中国初创公司7个月收入百万美元
限制
- HeyGen再厉害,也只有2分钟免费时长
译制片配音的行业标杆
- 除了中英互译,还有人尝试将英语翻译成其他语言,效果同样很不错

技术实现
- 至少三步: Whisper识别、Tortoise-TTS合成带原始说话人音色的语音、Wav2lip换嘴型。
- 只需要一个AI工具即可,名为HeyGen,国内一个初创团队,公司名为诗云科技
- 今年8-9月,各大文生图类AI网站的访问量均开始呈现下降趋势,但HeyGen的访问量却上升了92%,流量跃居各大独立AI网站之首。
诗云科技成立于2020年12月,公司成立之初,就以“用AI生成内容,让用户以更低成本完成内容创作”为愿景,已获得来自红杉中国、真格基金等风投们累计近千万投资。
HeyGen 要做AI视频创作领域的Midjourney,目前HeyGen的团队只有大概30人,分布在全球各地,以远程办公形式进行合作。
HeyGen的产品正式上线后的一年不到,创始人Joshua Xu就发表博文表示:HeyGen在7个月内实现了100万美元的ARR(年度经常性收入),并保持连续9个月50%的月环比增长率。
2022年7月,诗云科技推出多模态内容生成引擎Surreal Engine,将内容生产分为Understanding(理解)、Framing(视框化)、Rendering(渲染)三个步骤。区别于市面上的两大3D内容创作巨头:Epic Game的Unreal Engine和Nvidia的Omniverse,Surreal Engine让普通人也可以轻松进行高维度、可交互的内容创作。
开源替代方案
- 语音转文字 whisper、文字翻译 GPT、声音克隆 + 生成音频 so-vits-svc、生成符合音频的嘴型视频 GeneFace++。
除了价格贵,HeyGen 还存在一些技术问题,比如
- 生成的AI视频存在视频抖动、眨眼频率过高等。
HeyGenClone
俄罗斯程序员也在业余时间做了一个:HeyGenClone
MyHeyGen
【2023-11-13】HeyGen的山寨开源版本 MyHeyGen, 一个平民版视频翻译工具,音频翻译,翻译校正,视频唇纹合成全流程解决方案
除了英文,MyHeyGen还支持转法语、日语等共计16种语言。
视频翻译的三个流程:音频翻译、翻译校正和视频唇纹合成,它全部一个流程解决。
VEED
【2023-10-21】VEED 翻译准确率高达 95%。无需使用通常不准确的谷歌翻译。 VEED 准确性远高于其他在线翻译服务——后者也更昂贵。使用 VEED 可以节省大量时间和金钱,否则可能会花在手动翻译视频或聘请昂贵的翻译人员上。每月只需 24 美元,您就可以下载无限量的翻译成绩单。而且它完全基于浏览器,因此您无需安装任何软件
zeemo
zeemo 会影字幕
Rask
【2023-6-7】Rask.AI 颠覆性的视频翻译+配音神器,打破语言障碍!
Rask 是一款 AI 视频制作神器 ,它能将一个视频转换为 60 多种不同的语言并自动配音,甚至可以克隆原视频的声音,让视频内容创作者可以打破语言的隔阂,用较低的成本让自己的视频被全世界的观众了解。
翻译后的视频配音节奏与原画面内容是一致的,像西班牙语翻译后文本较长,Rask 对其进行配音的时候语速就比其他语言要快。配音的语调和音色也与原视频的相同,这是因为 Rask 进行了声音克隆(voice cloning),即自动学习原视频中里的声音特征再进行配音。
Rask 自推出后就立即受到很多视频内容创作者的关注和好评,斩获了 Product Hunt 单日产品榜单第一的好成绩。其官方网站中显示还有不少新的功能即将上线,包括让口型与配音完全同步、根据文本自动为视频配画外音、自动生成字幕以及视频修复。
新用户可以用 Rask 免费翻译 2 条视频,试用时翻译的视频文件大小不超过 100MB、时长不超过 1 分钟(超过一分钟的会自动裁剪为 1 分钟),付费后可以一次性翻译 20 分钟的视频。
翻译内容的准确性及配音的流畅程度都没有问题,特别是翻译为英语时我的音色被保留了,就像真的是自己在说英语一样,感觉非常神奇。而在翻译成日语时就明显能听出是 AI 配音,因为目前 Rask 只支持英语、德语、法语、葡萄牙语、意大利语、波兰语、西班牙语、印地语 8 种语言的声音克隆。
VideoLingo
【2024-10-4】VideoLingo: 连接世界的每一帧
- 官方站点 VideoLingo
- GitHub VideoLingo
一键全自动视频工具:VideoLingo
VideoLingo 将视频进行字幕切割、翻译、对齐、配音,最终生成 Netflix 级别的字幕和配音
特点:
- 1、自动化:一键完成视频字幕切割、翻译、对齐和配音,无需手动操作
- 2、字幕:使用NLP和 LLM 技术进行字幕分割,提供智能术语知识库,实现上下文感知翻译
- 3、对齐:单词级别的字幕对齐,字幕与视频内容同步
- 4、个性化配音:使用 GPT-SoVITS,克隆声音并进行配音
功能:
- 🎥 使用 yt-dlp 从 Youtube 链接下载视频
- 🎙️ 使用 WhisperX 进行单词级时间轴字幕识别
- 📝 使用 NLP 和 GPT 根据句意进行字幕分割
- 📚 GPT 总结提取术语知识库,上下文连贯翻译
- 🔄 三步直译、反思、意译,媲美字幕组精翻效果
- ✅ 按照 Netflix 标准检查单行长度,绝无双行字幕
- 🗣️ 使用 GPT-SoVITS 等方法对齐配音
- 🚀 整合包一键启动,在 streamlit 中一键出片
- 📝 详细记录每步操作日志,支持随时中断和恢复进度
- 🌐 全面的多语言支持,轻松实现跨语言视频本地化
与同类项目的主要区别:绝无多行字幕,最佳的翻译质量
视频剪辑
【2023-11-30】Filming Less:AI时代的视频剪辑产品淘汰赛
Descript
「海外独角兽」在之前的文章已经详细介绍过 Descript。
视频播客的兴起。
Descript 仍然被视作一个音频和播客剪辑工具,“音频的大小、工作流复杂度、剪辑和视效需求是视频的很小一部分”。但是随着美国播客生态变得更卷,视频播客正在被越来越多的创作者考虑
- 2022 年美国有超过 5 万档视频播客,YouTube 逐渐变为播客收听的首选平台,Spotify 也推出了可观看的视频播客能力。
Descript 很有可能受益于这个趋势。它拥有完整的且对于视频播客来说够用的非线性剪辑能力,并且已经有视频创作者开始深度使用它。
- 以 MarTech 公司 Chili Piper 的营销团队为例,他们的活动内容以播客、中视频、短视频的方式分发,将 Descript 用于粗剪环节,比如将 30 分钟的内容先剪到 10-15 分钟。
Descript 在今年 8 月收购了远程录制产品 SquadCast,将进一步推动创作者在 Descript 单个平台内完成视频播客的录制和剪辑。
Runway
Runaway 拥有一个接近完整的非线性剪辑器,并且很好地跟它拥有的 AI/Ml 能力进行了融合,这将构成它和 Pika Labs、Stable Video 等竞争对手的一个重要差异点
Runway 已经成了 AI 剪辑的代名词,许多创作者实际上并非 Gen-1 或者 Gen-2 炫酷的视频生成能力的用户,他们更多地夸赞 Runway 实用的动态转描和绿幕功能。最有潜力向上在专业创意人群中挑战 Premiere Pro
Captions
全球消费者产品中,有两家对于摄像头的洞察和利用最极致:一家是抖音/TikTok,另一个是 Snap。
Captions 由 Snap 的前 Design Engineering 团队的领导者 Gaurav 创立,是一个主打移动端 App 的产品,但是也正在向桌面延伸。
Captions 的兴起受益于短视频,第一个王牌功能也是至今仍然被创作者们最推崇的功能即自动配字幕,准确率远高于 Premiere Pro 内的同款功能。
- 和 CapCut 相比,Captions 的整体功能和 UI 更简洁(CapCut 已经逐渐被创作者们认为是一个“中等”复杂度的产品),把字幕和贴纸能力做到了极致,还在不断迭代 AI 能力,推出了 AI Eye Contact、AI Dubbing、AI Music 等能力。
视频理解
【2024-11-4】NVIDIA 推出云/端AI智能体, 用于实时/存档视频的视频搜索、摘要
【2024-11-4】Early Access to NVIDIA AI Blueprint for Video Search And Summarization
详见站内: 视频理解技术
直播
数字人直播
智能虚拟数字人直播,自动生成、24小时不间断越来越多的数字人直播闯入电商,接下来他们可能渐渐智商变得更高,让人分不清是人是机器。
- 4月21日,位于美国旧金山的Synthesis AI宣布开发了一种可以通过文本提示创建逼真虚拟数字人的新方法,使用生成式AI和视觉效果管道来制作高分辨率、电影质量的虚拟数字人,并可用于游戏、虚拟现实、电影和模拟等各种应用。
国内智能数字人已成为众多上市公司和创企扎堆进入的领域。
- 国内AI股上市
天娱数科的虚拟数字人已经接入ChatGPT等模型; - 虚拟技术提供商
世优科技目前已将ChatGPT技术接入数字人产品当中;
智能内容生成平台来画也在3月底正式接入ChatGPT,短短几十秒就能生成一篇高质量视频文案,并推出数字IP+直播模式。
遥望科技数字人
【2023-3-29】问答数字人
详见元宇宙-数字人专题
AI主播经常被拆分成数字人+对话式营销两项技术
明星数字人
【2023-5-19】AI明星翻唱还不够!有人要拿它当生活助手,支持聊天点外卖等,1:1复刻原声
- 一个AI明星助理的demo受到业内关注,从视频中我们可以看到,“他”不仅能1:1还原明星本人的声音,还能和你日常聊天,甚至帮你点外卖
- “2022年抖音最火的带货明星排行榜”显示,多位明星主播都是和遥望签约合作。
- 2022年4月,遥望便推出了虚拟数字人“孔襄”。她的定位是虚拟爱豆,一出道就拍了短剧,并接下三个代言。
- 同时遥望还推出了数字孪生主播技术。这种直播电商新玩法,仿真度更高、互动性更强、应用范围也更广。在AI加持下,模型的表情、脸部细节定位可完全达到真人表演者同步的状态,能在短视频、直播、TVC中实现主播的“复刻”,让每一个IP突破时间与空间上的限制。
清华华智冰
【2023-8-17】清华华智冰虚拟人实时直播
灵犀深智 – AI 主播
【2023-10-8】对话灵犀深智贾春鑫,AIGC直播一站式服务将兴起
2023年9月20日,在极新与灵犀深智联合创始人&高级副总裁贾春鑫先生的对话中,贾春鑫先生对于AIGC直播阐述了新观点,并且对于AIGC直播的未来抱有很高期待
- “在未来,直播和货架电商最大的区别在于,直播会像管家,给你一对一的服务。”
贾春鑫先生,百度P10,从0到1创立了好看视频,2年时间做到1亿MAU,并发起了百度的AIGC视频方向探索,后负责百度APP与百度网盘的用户增长等工作。2023年加入灵犀深智,全面负责产品方向,从0到1打造AIGC直播明星产品——秒播。
具备易模型、高价值、深场景的创业方向是可冷启动,可长期持续的,AIGC直播电商无疑是个很好的方向。
- 首先,直播电商有大量的语料,容易去做好模型类产品。
- 其次直播电商的商业价值非常高,检验这个产品的唯一指标就是帮客户带来多少GMV,给客户带来了价值,客户自然也会续费持续使用。
- 最后电商是一个链路非常多的行业,这些链路中的很多环节都需要AI升级,比如图片视频素材、营销和客服等等。
上半年我们已经吸引了一批为AI窒息的高质量大模型人才,并打磨出了产品原型,下半年产品内测时也吸引了不少付费客户,现在重点是做好市场推广,非常感谢极新这个平台,让更多对AIGC直播感兴趣的商家、生态伙伴和渠道代理商了解到秒播APP,一起把这个行业做大。
AI主播经常被拆分成数字人+对话式营销两项技术,这两块都有大厂在做,灵犀深智的定位是什么?差异化在哪里?
秒播App打造成为AIGC直播具有巨大变革型的产品。
AI主播只是AIGC直播中的一部分,完整的AIGC直播需要数字主播、数字声音、AI运营、AI中控、AI投手、AI场景构成,是文本生成、视频或图片生成、语音合成、真人复刻等技术的综合体,要求每一方面的技术都做到极致,才能营造出一个真实的直播间。更进一步还需要一定的人设,才能实现高转化。目前市面上的类似产品还达不到AI主播的程度,说白了就是只有一个唇动合成,需要真人主播大量录音,几个小时以上,还不能弹幕互动,充其量就是一个播报机器人而已,一眼就看的出来的假,根本不能帮助商家太多。
而秒播APP基于自研的MarketingGPT+云数字主播技术,商家只需要一个手机,就能享受AI讲品、AI互动、AI营销、AI布景、数字主播、数字声音6大能力,真正实现60秒生成一个TOP级直播间,轻松获客。
- 在秒播APP,输入一个店铺地址,这就是最全面、最明确的prompt,我们就能快速生成一个Top级的带货直播间,直接推流给各大直播平台,无需复杂配置,即可实现一键直播。
最大的差异化还在于技术能力,我们已经实现了AI讲品、AI互动、AI营销、AI布景、数字主播、数字声音6大能力的极致体验和一体化。在这种技术能力加持下,秒播APP的很多客户已经能够月入10万的成交,还有一些达人用我们的AIGC直播开播,在抖音0粉起号,一个月就达到了L5级别了。
预计今年直播电商市场是4.5万亿规模,店播基本上能够有50%,剩下的50%是达播。达播和店播的区别就在于
- 达播是要有一定的人设,店播只要正常的做好售卖工作,把这个品讲的有意思一点,然后用户的问题能够比较好的去解决它,有一些各种各样的营销类的活动,让用户觉得我今天不买,就错过了这个点,基本上已经完成了这个店播的一个要求。
而今年下半年绝对会有人杀出来占据这个 50% 的赛道。AIGC直播会先颠覆店播,再颠覆达播,沿着这样一个路线走。
【2025-6-19】灵犀深智推出 ClipClap 营销短视频生成
AI女友
【2023-12-14】GPT-AI女友-萨米,数字人交互,类似清华华智冰
【2024-6-8】字节突然上线 AI 虚拟交友聊天平台“小黄蕉”,网友:我想换女朋友了
一款非常丝滑的 AI 虚拟交友聊天产品日前上线,中文名为“小黄蕉”,英文为Chatwiz,可以生成照片,非常接近真人对话情景。
AI创业新风口,爆火的AI女友、虚拟陪伴 chatgirl
电商直播
【2023-10-12】大模型+数字人始于电商直播,发展于千行百业
《麻省理工科技评论》文章《Deepfakes of Chinese influencers are livestreaming 24/7》,让全世界看到了中国先进的AI技术,AI数字人技术在电商行业中降本增效的巨大优势。
“只需几分钟的训练素材视频和1000美元成本,品牌方就能实现全天候直播售卖产品。”中国的AI数字人技术深度赋能电商产业,实现全天候直播
近年来,直播电商的兴起为电商行业注入新的动力,而头部主播的地位不可撼动
- 直播企业中2-3个头部主播将贡献总销售额的70%~80%,而剩余销售额由7-8个腰部及尾部主播达成,而这也为AI数字人主播的发展提供了土壤。
AI数字人主播的“竞争”之下,为行业带来切实的降本增效
- iiMedia Research数据显示,与2022年相比,2023年中国直播主播的平均工资下降了20%。
快速的深度合成训练、全天候24小时直播、AI技术加持,能够实现主播高效且低成本的普及。
- 从30分钟训练视频到现在的1分钟视频就能合成数字克隆人,数千元低价取代真人主播,中国AI数字人技术应用在电商直播中的成绩也引来了国外网友的惊叹,接下来,和大模型之家一起来探讨中国的数字人发展。降低生产门槛,大模型重塑数字人行业
“虚拟偶像”一词诞生于20世纪80年代的日本,早期偏向二次元,主要指面向演艺活动打造的虚拟歌姬,比如家喻户晓的初音未来,以及乐华娱乐推出的虚拟偶像团体A-SOUL等。
- 2020年以来,随着资本加大布局,技术日益成熟,虚拟偶像的应用模式呈精细化、智能化和多样化发展趋势,加之元宇宙概念的火爆,虚拟人技术逐渐进入到大众视野中。
- 2023年,伴随着人工智能技术的发展,数字人发展迎来了新一轮的高潮:
- 3月,万兴科技发布AIGC营销工具“万兴播爆”,输入文案,即可一键生成AIGC“真人”营销短视频;
- 5月,硅基智能正式发布炎帝大模型,兼备生成多种内容形式的能力,包括文本生成、声音生成、图像/视频生成。用户只需告诉炎帝大模型直播间的要求,一个数字人直播间就能迅速搭建完成;
- 6月,360推出“360 AI数字人广场”,拥有超200名虚拟数字人角色,包括市场、运营、程序员等数字员工,给用户相应的回答和建议;
- 7月,新壹科技发布基于视频大模型的数字人平台;
- ……
虚拟主播实现了IP的“人设”与“皮设”的分离,大幅降低了IP的孵化与运营成本。
- 硅基智能目前能够实现使用一分钟的训练视频进行数字人克隆
- 随着技术的改进,现在生成一个基本的AI克隆数字人大致花费在8000元人民币左右(1100美元)。
- 硅基智能的 AIGC 数字人每天直播数量可达三四万场,生成数百万条短视频。
作为数字人行业大模型,硅基智能推出的炎帝大模型具备多模态能力,生成多种内容形式的能力,包括文本生成、声音生成、图像/视频生成,能够快速完成直播间的搭建。
直播间的主播、运营等角色都可以由AI扮演,大大降低了直播内容生产的门槛,并且在直播过程中可以通过大模型自动获取竞争对手直播间内的信息。
- 当直播间观众数量下降时,AIGC数字人将执行各种选择器、任务器和反馈器的任务,数字人主播对应生成一系列响应,比如生成降价促销的直播话术。
AI数字人主播并非为了完全取代真人主播,而是协助人类。
- 当下的直播环境,头部主播的个性化特性鲜明,能够与观众进行情感交互,给用户提供信赖感和可依靠的角色,而数字人的出现是能够补充在头部主播的非直播时间,实现24小时全天候直播,依靠AI预训练的脚本提供最基础的商品咨询保障,引导观众进行关注等,但在情感交互和商品后期保障中与真人相比还存在差距。
- 以淘宝、抖音、京东、快手等平台的店铺直播为例,当下已出现不少的AI数字人直播,能够依靠后台设置的脚本进行商品介绍,并能够引导关注,但在和观众的互动中表现较差,口型和肢体动作也略显不自然。在某些家具产品介绍中,AI数字人能够流利的介绍产品,但不能真正坐在沙发上或躺在床上,缺少实测体验。
虽然AI数字人表现强劲(基础互动全天候直播,为商家能够实现降本增效),但仍需要严格的内容把控
- 2023年5月9日,抖音官方发布了关于人工智能生成内容的平台规范暨行业倡议,要求创作者、主播、用户、商家、广告主等平台生态参与者,在抖音应用生成式人工智能技术时,应对人工智能生成内容进行显著标识并负责。
- 实时直播与交互的过程中,AI 数字人表现会受到多重监控
- 针对AI数字人是否会在直播中说出不正确的话术,硅基智能创始人司马华鹏表示,硅基智能所推出的数字人是一个群体智能。在整个直播过程中,可能会用到7-8个大模型,分别负责投放广告、直播、与观众互动、审核内容和画面以及监控竞品直播间变化。
- 2023年9月,硅基智能与华为云正式签署数字人+盘古大模型行业解决方案合作协议。将基于华为云盘古大模型与硅基智能数字人联合打造行业解决方案,实现数字人+大模型在知识生产、虚拟直播、数字永生、数字文娱等多维度的生态共建。AI浪潮下数字人的新发展
- 除硅基智能、微软小冰等创业公司外,中国科技企业也正测试其AI数字人直播。阿里巴巴、腾讯、百度和京东今年都允许其平台上的品牌使用数字人主播。
基于AICG技术,硅基智能和薇娅旗下的谦寻控股合资成立了谦语智能,主打电商领域的数字人直播带货,不断扩大硅基智能在数字人直播电商中的版图。
以硅基智能为例,其下一步的目标是为AI数字人融入“情感智能”。
- 司马华鹏表示:“如果用户对AI主播使用攻击性语言,它会表现出沮丧;而当AI主播成功售出产品时,它会显得高兴。”
《人工智能大模型产业创新价值研究报告》中表指出,针对不同行业的场景特点,进行有针对性的知识增强在解决现阶段问题中发挥着重要作用,通过链接知识库进行专业知识增强,打造行业大模型,或是通过增强联网的能力实时扩充大模型知识储备,大模型能够深入了解各个行业的专业知识,并将其融合到模型的学习和推理中。
加持垂直领域的行业大模型,数字人应用边界将不断被拓宽,智能教师、医生、金融分析师等的身份也将不断涌现,数字人也不止局限于直播电商行业。
数字人是“硅基生命”的一种形态,有别于人类的“碳基生命”。硅基智能计划2025年为全球打造1亿硅基劳动力,还提出人工智能倡导“科技平权”,硅基劳动力将引领服务、教育、医疗等各领域的平权。
- 直播带货并非数字人的最终应用场景;
- 硅基智能的数字人的最终目标场景是在影视行业,未来将运用AIGC数字人技术,将一部部小说搬上荧屏,可以理解为用AIGC生成电影;
- 数字永生方面,未来也会是很大的市场。”
人工智能大模型在数字人行业的应用将使得数字人更加智能化、高效化、人性化,将为数字人行业带来更多的机遇和挑战,同时,在自然语言处理、语音识别、图像识别等方面仍然存在一定的技术瓶颈和数据隐私问题。未来,人工智能大模型需要克服技术、数据、成本、隐私和人机交互等问题,才能更好地推动数字人行业的发展和应用。
语音应用
【2023-3-16】AMIner论文
Voice ChatGPT
Chrome应用商店,输入“Chatgpt voice control”,Chrome应用商店,输入“Chatgpt voice control”

详见:知乎
- 【2023-2-11】CCTV视频里,台湾人在演示 VoiceGPT,VoiceGPT APK Download (version 1.35) 下载地址 , 目前就安卓版,使用时需要代理
VALL·E 语音合成
【2023-4-8】3秒复制任何人的嗓音!微软音频版DALL·E细思极恐,连环境背景音也能模仿
- 微软最新AI成果——语音合成模型VALL·E,只需3秒语音,就能随意复制任何人的声音。
- 脱胎于DALL·E,但专攻音频领域,语音合成效果在网上放出后火了:
语音合成趋于成熟,但之前零样本语音合成效果并不好。
- 主流语音合成方案基本是预训练+微调模式,如果用到零样本场景下,会导致生成语音相似度和自然度很差。
基于此,VALL·E横空出世,相比主流语音模型提出了不太一样的思路。
- 相比传统模型采用梅尔频谱提取特征,VALL·E直接将语音合成当成了语言模型的任务,前者是连续的,后者是离散化的。
- 传统语音合成流程往往是“音素→梅尔频谱(mel-spectrogram)→波形”这样的路子。但VALL·E将这一流程变成了“音素→离散音频编码→波形”:
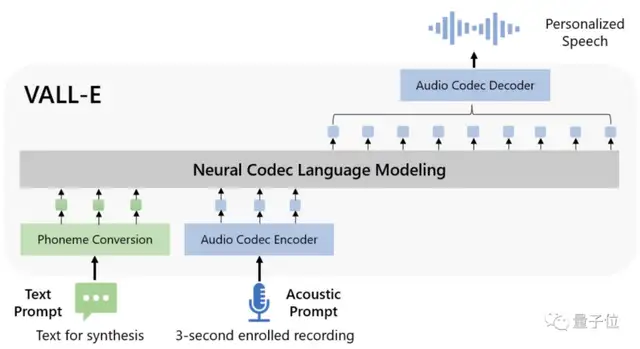
VALL·E也和VQVAE类似,将音频量化成一系列离散tokens,其中第一个量化器负责捕捉音频内容和说话者身份特征,后几个量化器则负责细化信号,使之听起来更自然
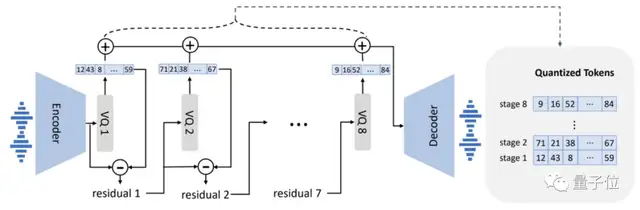
随后以文本和3秒钟的声音提示作为条件,自回归地输出离散音频编码:
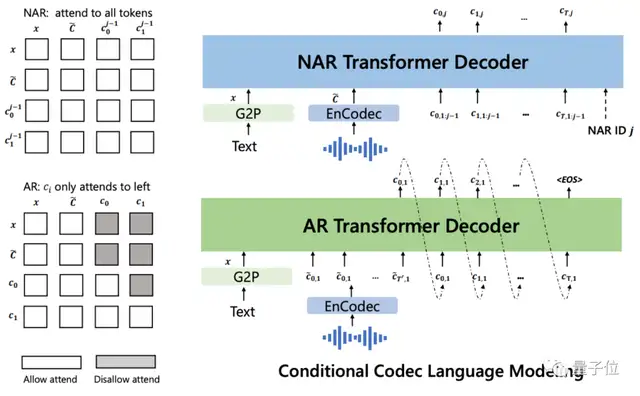
VALL·E还是个全能选手,除了零样本语音合成,同时还支持语音编辑、与GPT-3结合的语音内容创建。
那么在实际测试中,VALL·E的效果如何呢?
- 根据已合成的语音效果来看,VALL·E能还原的绝不仅仅是说话人的音色。
- 不仅语气模仿到位,而且还支持多种不同语速的选择,例如这是在两次说同一句话时,VALL·E给出的两种不同语速,但音色相似度仍然较高
- 同时,连说话者的环境背景音也能准确还原。
- 除此之外,VALL·E还能模仿说话者的多种情绪,包括愤怒、困倦、中立、愉悦和恶心等好几种类型。
值得一提的是,VALL·E训练用的数据集不算特别大。
- 相比OpenAI的Whisper用了68万小时的音频训练,在只用了7000多名演讲者、6万小时训练的情况下,VALL·E就在语音合成相似度上超过了经过预训练的语音合成模型YourTTS。
而且,YourTTS在训练时,事先已经听过108个演讲者中的97人声音,但在实际测试中还是比不过VALL·E。
VALL·E目前还没开源
AudioCraft
【2023-8-3】Meta新开源模型AudioCraft炸场!文本自动生成音乐;
Talk
【2023-10-21】Talk:通过声音与AI进行对话,提供类似本地应用的用户体验。
- 该项目支持多种语音对话服务提供商,包括 ChatGPT、Elevenlabs、Google Text-to-Speech、Whisper和Google Speech-to-Text。
- 项目具有现代和时尚的用户界面,以及统一的独立二进制文件
Talk - Talking with ChatGPT is a breeze,a single-page application crafted to converse with AI using voice, replicating the user experience akin to a native app’ proxoar GitHub

Voice->3D
【2024-1-3】Meta AI又发布了一个炸裂的东西:从音频生成全身逼真的虚拟人物形象。
- 从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。
- From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
- demo
- 暂无代码
这些生成的虚拟人物不仅在视觉上很逼真,而且能够准确地反映出对话中的手势和表情细节,如指点、手腕抖动、耸肩、微笑、嘲笑等。
工作原理:
该项目结合了向量量化的样本多样性和通过扩散获得的高频细节的优势,以生成更具动态性和表现力的动作。
- 1、数据集捕获:首先捕获了一组丰富的双人对话数据集,这些数据集允许进行逼真的重建。
- 2、运动模型构建:项目构建了一个包括面部运动模型、引导姿势预测器和身体运动模型的复合运动模型。
- 3、面部运动生成:使用预训练的唇部回归器处理音频,提取面部运动相关的特征。 利用条件扩散模型根据这些特征生成面部运动。
- 4、身体运动生成:以音频为输入,自回归地输出每秒1帧的向量量化(VQ)引导姿势。将音频和引导姿势一起输入到扩散模型中,以30帧/秒的速度生成高频身体运动。
- 5、虚拟人物渲染:将生成的面部和身体运动传入训练好的虚拟人物渲染器,生成逼真的虚拟人物。
- 6、结果展示:最终展示的是根据音频生成的全身逼真虚拟人物,这些虚拟人物能够表现出对话中的细微表情和手势动作。
智能对话
对话系统升级
【2023-8-14】人民大学高领人工智能学院,副教授 严睿:大模型时代下的对话式 AI 发展, 介绍玉兰系列大模型,包括RecAgent推荐模拟大模型,能在一定程度上解决数据匮乏与冷启动问题,也有可能推广到其他场景
狄更斯:
「这是一个最好的时代,也是一个最坏的时代」。
狄更斯这句话开场恰如其分,OpenAI 推出 ChatGPT 之后,人工智能以及大模型家喻户晓,对从业者造成了非常巨大的冲击。
- 对话式AI(conversational AI)现阶段只要做大模型的公司,都在做对话式AI,随着技术的普及,门槛也越来越低,大家都可以进入这个领域,而且效果越来越好,未来怎么去突破AI对话技术,挑战非常巨大。
- 但是从另一个角度来看,对话式AI也迎来了非常多的发展机会。
ChatGPT 交互感很好,拥有很强的对话能力,能与用户进行多轮对话;
- 问答能力非常卓越,可以分步骤、分条款清晰地罗列出来1234步再回答问题。
- ChatGPT还有其他能力,如创意写作能力,也就是给它一些提示词或者关键词,甚至是一些用户可能想说的话,然后它就可以创造好一篇文章,这能极大地提高工作效率。
虽然ChatGPT在完成事务性上表现很不错,但缺点就是有比较严重的幻觉现象,因为它的产生机制就是根据前面的一个语句,然后去判断下一个token 里面最高likelihood(可能性)是什么,再去产生结果。
- ChatGPT是一个谣言产生器,因为它对于很多问题只能做很宽泛的回答,并不能保证准确度。如果对于某些领域不是很了解的话,会觉得它说得很权威,但是如果你是该领域的专业人士,你就会觉得它在胡说八道。
- ChatGPT不太能回答一些细节问题,如果太细节就容易犯错或者露出马脚,所以它尽可能去会选择空话套话糊弄过去。
- 容易被攻击
【2023-10-13】ArXiv上搜了下对话系统和大模型两个关键词,相关文章有62篇,其中跟新时代的对话系统设计有关的只有4篇
- 增强NLU
- 【2023-9-22】Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models,中科大、阿里,用 Self-Explanation 自解释的prompt策略增强多轮对话中LLM的理解能力,效果超过 zero-shot prompt,达到或超过few-shot prompt; 为每句话提供解释,然后根据这些解释作出回应 Provide explanations for each utterance and then respond based on these explanations
- 利用LLM增强DM
- 【2023-9-16】Enhancing Large Language Model Induced Task-Oriented Dialogue Systems Through Look-Forward Motivated Goals 新加坡国立+伦敦大学,现有的LLM驱动的任务型对话(ToD)缺乏目标(结果和效率)导向的奖励,提出 ProToD (Proactively Goal-Driven LLM-Induced ToD),预测未来动作,给于目标导向的奖励信号,并提出目标导向的评估方法,在 MultiWoZ 2.1 数据集上,只用10%的数据超过端到端全监督模型
- 【2023-8-15】DiagGPT: An LLM-based Chatbot with Automatic Topic Management for Task-Oriented Dialogue,伊利亚洛-香槟大学,任务型对话里的主题管理自动化. ChatGPT 自带的问答能力难以胜任复杂诊断场景(complex diagnostic scenarios),如 法律、医疗咨询领域。这个TOD场景,需要主动发问,引导用户到具体任务上,提出 DiagGPT (Dialogue in Diagnosis GPT) 将 LLM 扩展到 TOD场景
- 【2023-7-29】Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System,俄亥俄州立大学,以用户为中心的数字助手 TACOBOT, 在 Alexa Prize TaskBot Challenge 比赛中获得第三名
- NLG升级
- 【2023-9-15】Unleashing Potential of Evidence in Knowledge-Intensive Dialogue Generation, To fully Unleash the potential of evidence, we propose a framework to effectively incorporate Evidence in knowledge-Intensive Dialogue Generation (u-EIDG). Specifically, we introduce an automatic evidence generation framework that harnesses the power of Large Language Models (LLMs) to mine reliable evidence veracity labels from unlabeled data
- 对话与推荐融合
- 【2023-8-11】A Large Language Model Enhanced Conversational Recommender System 伦敦大学和快手,新加坡南洋理工,对话式推荐系统(CRSs)涉及多个子任务:用户偏好诱导、推荐、解释和物品信息搜索,user preference elicitation, recommendation, explanation, and item information search,LLM-based CRS 可以解决现有问题
- 用户模拟器
- 【2023-9-22】User Simulation with Large Language Models for Evaluating Task-Oriented Dialogue,加利福尼亚大学+AWS AI Lab,利用LLM当做模拟器,用来评估任务型(TOD)多轮会话
- 特定领域(specific domain) → 开放域(open domain)
- 【2023-9-15】DST升级,从单个场景拓展到所有场景,提出 结构化prompt提示技术 S3-DST,S3-DST: Structured Open-Domain Dialogue Segmentation and State Tracking in the Era of LLMs,Assuming a zero-shot setting appropriate to a true open-domain dialogue system, we propose S3-DST, a structured prompting technique that harnesses Pre-Analytical Recollection, a novel grounding mechanism we designed for improving long context tracking.
- 任务型对话扩展到多模态领域
- 【2023-9-19】语言、语音融合,一步到位,NLG+TTS Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model
- 【2023-10-1】Application of frozen large-scale models to multimodal task-oriented 提出LENS框架,解决多模态对话问题,使用数据集 MMD
大模型时代开发模式
【2023-9-9】宜创科技CEO宜博带来《ChatGPT的创业机会》为题的分享。
- 其它源头:人人都是产品经理, ChatGPT中文网, 视频回放
大模型的开发模式
- (1)
pre-training(预训练): 通识教育,教小孩认字、学算数、做推理,这个步骤产出基础大模型。 - (2)
fine-tune(微调):专业课,比如学法律的会接触一些法律的条款、法律名词;学计算机的会知道什么叫计算机语言。 - (3)
prompt engineering(提示工程):职业训练,AI应用的准确率要达到商用级别(超过人的准确率),就需要 prompt engineer,PE 重要性 
其中,有些场景中(2)可以省略。
人机协同三种模式
AI Embedded嵌入:某个环节里去调用大模型AI Copilot辅助:每个环节都可以跟大模型进行交互AI Agent代理:任务交给大模型,大模型即可自行计划、分解和自动执行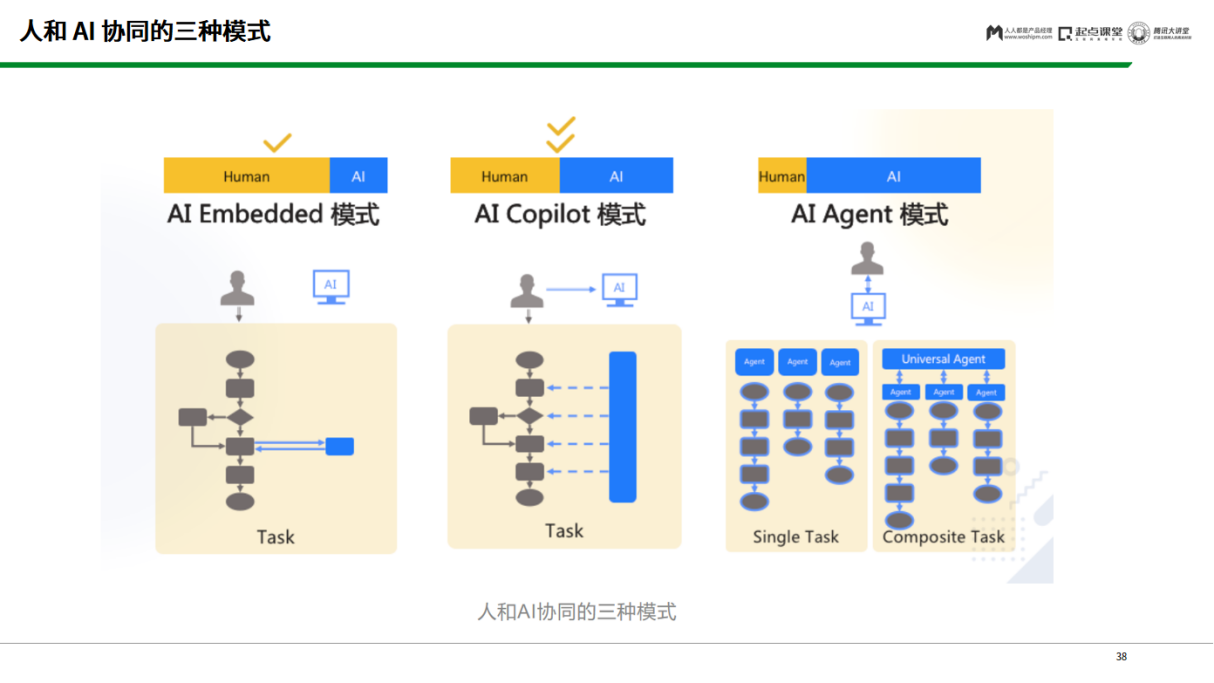
熟悉LLM时代Prompt Engineer开发范式
- 第一层:简单Prompt: 即编写一个提示词(Prompt)去调用大模型,最简单的形式。
- 第二层:Plugin插件: 用大模型插件(Plugin)去调各种API,以及Function Call。
- 第三层:Prompt Engineering Workflow + OpenAI API
- 基于提示词工程的
工作流(workflow)编排。AI应用就是基于工作流实现。 - 以ChatBI为例,通过编排工作流,定义如何获取数据库结构、如何写Prompt、如何调大模型,实现全部自动化。只需要输入一句话,就能沿着工作流自动执行,输出结果。
- 基于提示词工程的
- 第四层:VectorDB集成
- VectorDB包含数据特征值,现在最好的AI应用落地方案就是VectorDB,包括做知识库、做客服机器人。
- 第五层:AI Agents, 这个概念特别火,最重要的逻辑就是让大模型自己做递归。
- Agent的原理: AI自己对任务进行拆解,再进一步递归、继续拆解,直到有一步,AI可以将这个任务执行,最后再将任务合并起来,往前递归回来,合并为一个工程。
- 第六层:领域模型 Domain Model
- 专业模型为什么重要?大参数基础模型的训练和推理成本非常高,而专业模型速度快、成本低、准确率高,因为有行业的高质量数据,所以准确率高;进而可以形成数据飞轮,形成自己的竞争优势。
未来这个世界一定会由几家大模型公司,再加上每家公司都得有自己的小模型,如果你的公司没有小模型,那么你的公司将没有存在价值。
可视化LLMOps助力AI创业10倍降本
- 中国大模型时代痛点:应用层与模型层存在巨大的中间层鸿沟, 这也是做开发范式中间层框架的原因。
- 做了500+机器人模板市场,模板下载开箱即用,也对接各类国内外大模型API,支持私有部署各类开源大模型,同时用户可以定制Prompt Chain开发,三步可视化配置,相当于做了一个无代码版的 LangChain。
- 产品经理可以在不需要任何编程的情况下把流程 workflow 搭建出来,搭建出来之后,产品经理可以把系统再集成到任何一个产品里。
- 也用 API 的方式将它集成在了各个 IM 里,在 IM 里加一个机器人,即可以变成一个新的小程序或者APP。所以在不需要算法工程师、不需要前后端工程师的情况下,我们可以在很短的时间内开发想要的 AI 应用。
- 建数据飞轮: 当有越多数据时,结果就会越准确;当结果越准确,就会有越多客户选择使用;当有越多客户使用,我们就可以积累更多的高质量问答数据,这些问答数据一定要保存好,这是你未来的立命之本。
- 向量处理全流程可视化
- 怎么处理向量?一般分这几步 —— 知识库文件云盘管理、选择切割方式及模型、可视化管理存储和管理CRUD 向量数据库、可视化追踪TopK Fact 搜索结果、可视化对接大模型知识融合生成结果报表和自主定义文档架构循环遍历生成专业文档。
智能对话应用
【2023-9-29】宜创科技CEO宜博带来《ChatGPT的创业机会》为题的分享。
农业领域服务机器人
问题
- 精细化养殖的方向努力,但是养殖户没有能力从大量的资料中查阅中得知猪饲料配比
通过对话给养殖户提供猪饲料配方,准确率可以达到100%。
- 第一步,通过多轮对话从养殖户那里获得猪的信息,例如猪的品种、猪有多重等。
- 第二步,拿着这些信息去后台查询这种猪需要的营养量。
- 最后,通过算法计算,获得准确的猪饲料配方,返回给养殖户。
技术
- LLMFarm实现ChainFlow设置
- 多意图识别,如果想询问某个产品的营养含量、产品价格,结果都能实现。


项目得到农业部会议上四个院士的高度赞赏
银行客服机器人
问题
- 每次上市公司年报分析出来,大家都会问很多问题。一家商业银行提供了最常被问到的150个问题和回答。每个问题里都包含着很多行业的“黑话” ,比如 对公贷款、零售贷款等。而这些概念背后对应了很多指标,比如增长率、收入比等,指标要转换成公式,公式结果要整理成报告。
- 在此之前,其实已有其他金融大语言模型公司尝试做了一下,但出来的数据都不能保证正确率
刚开始开始采用了大模型结合向量搜索的方式尝试,也不能保证100%准确。后来用大模型+工作流的方式解决了这个问题。
- 第一步,把数据抽取出来存到数据库里。
- 第二步,用大模型做分词,也就是从用户输入问题的内容里提取出各种指标。
- 第三步,查询指标和指标公式,让大模型融合生成数据库查询,生成准确的计算结果。
- 最后,将准确的计算结果再次输入大模型,做一轮知识融合,可以转化API为领域机器人进行全域问题查询,实现100%数据准确。

KMS知识问答
医院医疗设备的维护厂商
问题
- 原本的维护方式存在文档繁多、格式复杂、需要实时翻译、定位图文结果二次校验等问题。
集成到飞书群、钉钉群中
而我们很好地解决了KMS知识库交互复杂的问题。
- 将各种格式、各种模态、各种语言的文档都传入向量数据库里,通过配置流程的方式形成。
- 使用过程中,机器人会先用多轮对话的方式,获得当前故障的多级错误码等信息。
- 回复的结果通过图文等形式展示,自动翻译,并索引原文位置。

代码生成
国内一个API厂商
- 针对一句话描述,生成一个代码片段,直接嵌入使用。

工作流生成
通过自然语言描述一个工作流步骤,生成一个工作流,并可以马上执行。

报表自动生成
ChatBI 用自然语言生成报表,特别受到运营同学、产品同学以及老板的喜欢。因为老板看到的传统报表内容很有限,如果想看到额外维度的报表,所花费的时间可能要等产品技术同学做几天甚至一个礼拜,现在则一句话就能快速看到报表结果。

电子邮箱AI助手
一句话整理电子发票并发送给财务报销
借助电子邮箱AI助手,输入一句话对邮箱邮件做处理,可以做电子发票的附件整理,也可以做多轮对话,比如对和某一个客户之间的关系做分析和总结;电子邮箱AI助手甚至可以帮忙生成邮件话术。

智能助理
字节豆包
【2023-8-1】字节推出豆包(国内)、Cici(海外),详见:裁撤朝夕光年、成立Flow,字节的海外首个AI产品Cici多国爬榜中
- 2023年2月,字节开始组建大模型团队,分别在语言模型和图像两种模态上发力,语言模型团队由搜索部门牵头、 图片模型由智能创作团队牵头。
- 2023年6月初,字节就在内测代号为
Grace的 AI 对话项目 - 2023年8月17日,Grace 更名为豆包。而 Cici 也在 8 月份于海外多个市场上线。鉴于国内对 AI bot 属于环境不友好状态,而字节也全球化基因浓重,海外应该会是字节更加发力的市场。
- Cici 主打“Your Helpful Friend”+ “Free”。而有自己大模型云雀的字节,在 Cici 的东南亚素材里,出现了 Powered by GPT-4 的文案。
- Cici 目前已经上线了海外 36 个国家和地区,基本上除了美国和欧洲等成熟市场,几乎各个区域市场都有覆盖,包括日韩、中东、东南亚、非洲、南美的几乎所有必去出海市场,如沙特、印尼、巴西等等。
- 2023年11月28日,Cici拿下了 Google Play 阿根廷和秘鲁的总榜第一,在菲律宾和印尼,也在总榜 10 名上下的位置徘徊。
- 2023年11月27日,字节确认放弃游戏业务。同时宣布成立了一个新 AI 部门 Flow,技术负责人为字节跳动技术副总裁洪定坤,业务带头人为字节大模型团队的负责人朱文佳。
Flow 自言是字节跳动旗下 AI 创新业务团队,目前已经在国内和海外分别上线豆包和 Cici 两款产品,还有多个 AI 相关创新产品在孵化中。
Apple Siri
改头换面的 Siri 也终于同广大用户见面。
- 可以向仅支持语音的虚拟助手输入更丰富的请求和问题。即使表达卡顿或者另起话头,Siri 也能凭借更强大的语言理解能力顺畅处理用户语音。
- Siri UI 也经过了调整,在激发该功能后会看到屏幕周边泛起发光的边框。
- 但是,各位 iPhone 用户还需要再等一段时间才能迎接其他由 Siri 驱动的功能,例如 让该虚拟助手更深入地了解自己的个人背景。
- 虽然 UI 很炫酷,但模型质量还是被网友吐槽了:不是你想用就能用的 Apple Intelligence
- “四大关卡”:升级系统、所在国家支持、手机型号支持更新、进入候补名单等待通过。
金融问答
金融问答助理
开源项目和产品:
- 通义点金,针对金融场景,打造了业界首个基于multi-agent框架的金融产品,能够分析事件,绘制表格,查询资讯,研究财报,深度对话等;
- FinGLM,基于GLM模型针对金融财报问答场景构建的对话智能系统;
- FinGPT,开源金融场景GPT框架,包括底层数据支持,模型训练,到上层应用。
详见站内专题:数据竞赛之智能体
支付宝助理
【2024-4-26】 支付宝悄悄上线智能助理,我们也偷偷测了下
- 支付宝对一款AI智能助理进行灰度测试。
支付宝智能助理不同于对话交流、辅助创作的常见大模型,而是更偏向服务办事型的AI助手。
- 可根据医疗问诊、查办公积金、买机票找厕所、推荐上映电影等办事指令。
- 根据需求推荐支付宝的相应功能或直连小程序,起到App内的智能导航作用。
蚂蚁 Agentar-Fin-R1
【2025-7-26】蚂蚁集团发表 Agentar-Fin-R1,金融领域专用推理大模型,赋能金融智能化演进
Agentar-Fin-R1 系列金融大语言模型(8B和32B参数)基于Qwen3模型,提升金融应用中的推理能力、可靠性和领域专业化。
同时本文提出Finova评估基准,专注于金融推理和合规验证。
实验结果显示
- Agentar-Fin-R1-32B 模型在金融和通用领域表现优越,平均得分83.11,超越所有竞争基线。
- 在金融评估基准中,Agentar-Fin-R1-32B在Fineva(92.38)、FinEval(87.70)、FinanceIQ(86.79)和Finova(69.82)上表现最佳,Agentar-Fin-R1-8B则在计算效率上表现出色。Agentar-Fin-R1-32B在安全和合规任务中表现优异,得分87.00,远超其他模型。
核心创新:
- 专业标签引导框架,细分金融任务,优化数据处理和训练。
- 多维可信度保障,通过源可信度、合成可信度和治理可信度确保数据质量。
- 高效训练优化,提升数据利用率和模型能力。
佛学问答
AIGC+佛教,人工智能治愈我心
【2023-4-18】“神”回复!ChatGPT“化身”佛祖解答尘世烦恼
- 随着ChatGPT的爆火,一个名为HOTOKE AI的网站推出了“AI佛祖”(Hotoke指日语里的佛),搭载GPT-3.5技术,给网友们提供在线咨询业务,上线一周就吸引了20000+小伙伴前去打卡。
- 佛祖版 ChatGPT 一上来就支持中、英和日韩文,还不需要科学上网就能使用。目前有网页版和 line 版(line 即日本版微信),等待 AI 的时间还引导用户做呼吸吐纳和冥想练习。佛祖在线解忧,引发了不少网友跃跃欲试。
- 无需前往寺庙,不花一分香火钱,只需轻轻敲打键盘,AI佛祖就能为你在线指点迷津。
2018年,一款名为“贤二机器僧”的小程序在微信上线。
- 除了对话功能,还支持静坐、诵经、打卡、反馈、智慧卡牌解惑等等。
- 研发人员是一位出家的法师,他希望通过动漫、机器僧等现代科技,让更多的人汲取中华传统文化中的真善美,让包容慈悲的精神来滋养中华民族的后代。
基督教
【2023-9-12】微博, Jesus AI,专门面向中西部的中老年基督教徒。应用很简单,产品被包装成一个“电子上帝”,其实就是一款接上了ChatGPT的在线即时聊天软件。每天用户上来祷告、忏悔和交流圣经内容,“上帝”亲自在线答疑。据说目前用户活跃度和黏性都高得惊人…比电子烧香还精彩,God is an API
在线教育
【2023-11-15】已经有团队开始用 AI 训练人
配置 AI 机器人,来训练人类。
原问题:
- 公司希望用AI来模拟真实用户,与销售对聊,以提升销售的聊天能力。目前用了dify.ai搭建对话窗口对接GPT-4,然后通过写提示词来告诉AI角色,
但现在遇到两个问题:
- AI模拟用户跟真实用户差距很大,有真实的对话数据,但不知道怎么利用;
- 无法控制流程,例如希望当销售介绍商品时,AI能够基于销售的介绍提出疑问,这种情况不知道该怎么处理;
AI 调教问题:因为要教给 AI 东西太多,以至于不会教了。
- 本质是“让 AI 生成问题,在保证用户旅程(从初始到下单)推进的情况下根据销售的回答进行追问或者反问。”
- 所谓的微调、直接投喂数据都是不可能解决的,AI 不懂你那数据里的弯弯绕绕。除非你给 AI 几千亿条,让它“涌现”……
解法
- 角色刻画非常重要,要分类、分状态刻画清楚;
- 化繁为简,使用多 Agents 接力完成。
正确的路径:
- 梳理业务SOP:人肉梳理出一个典型客户开场、咨询、挑刺、报价、砍价、售后、退款(续费)的用户旅程,或者典型节点,每个节点几条话术。
- 人工修正:
- 一次性或者分批次发给 AI,先总结客户提问特征,然后人工做修正,把过程中的各种反馈、特征、AI 的认知都总结记下来。
- 注意,一定要顺着 AI 总结出来的特征去延展,不要掰它的认知,这是它的话术体系,要“师夷长技以制夷”。
- 打磨提示词
- 先假设要做“全流程陪伴型销售训练姬”,那就需要确定 AI 扮演的角色、具体任务、工作流程、输出要求。
(1)PE
AI 扮演的是个什么角色?提问题的客户,还是销售沟通训练员?
“提问题的客户”,那就要把客户的情况描述清楚:
- 有某个需求(你们产品解决的那个需求)的客户,又分为好说话的(只问产品功能,价格不 care)和不好说话的(不砍价难为销售不舒服那种)
- 有某个需求以为你们的产品能解决实际上解决不了的客户,性格同上
- 竞品扮演的假客户(只关注功能和报价,说不出真实场景)
- 其他…
要保证提问的质量,AI 扮演的这个用户的状态要随着对话一点一点的变。
- 一方面,刻画难度大:即便模拟出来,也很难把需求清晰表达给 AI(主要是保证理解)。
- 另一方面,AI 什么时候改变状态、改变提出的问题,一旦对话开启,就变成黑箱子,没办法精准控制,只能由着它自己的大模型来“作”。
AI 这么强大,自己不会调整么?
- 不要指望 AI 强大到能自动变,你描述不清楚需求,它就是个傻子。
(2)Agent
多角色 Agents 接力赛
设定一堆 AI 角色,每个角色扮演不同状态、不同场景的客户,封装起来,让销售像抽盲盒一样随机唤醒一个,开始练习。
也别让销售一直聊,最多五轮就停。销售每次开启对话都是全新,也就是从你预设的提示词之后开始,而不是接着之前的对话聊。就像西部世界里的仿生人一样,每晚都需要重启。
这样,任务目标就简单了:
- 生成问题,模拟真实用户问题,能够考验到销售的问题。
加强:
- 生成一个开场问题,根据用户回答追问或者反问,对话 5 轮后终止对话完成模拟训练,然后总结过去的 5 轮对话,为用户的回答打分。
提示词里向 AI 交代 Workflow
脑暴模拟:
- 销售发起对话,根据系统给到的角色描述,生成一段“求助式”提问开场白,如“询问是否能解决 XX 问题?”。
- 然后,根据销售的回答进行反问或者补充提问。
- 真实客户很少能把需求描述清楚,毕竟好不容易可以展现一下“甲方姿态”。
- 如何让 AI 提出真实用户那样的问题,需要花很多功夫 —— AI 生成内容时最难的部分:去掉浓浓的机器感,像人类一样表达。
Agent 智能教育
【2024-4-12】用大模型+Agent,把智慧教育翻新一遍
4月12日,蚂蚁云科技集团发布了首款垂直行业大模型产品——以正教育大模型
以正大模型通过深度定制的海量教育数据,精准理解并高效应用教学内容,为学生、教师及家长提供高度智能化、个性化的教育资源与服务。
蚂蚁云科技集团成立于2019年,是一家专注AI大模型研发、上下游应用开发及产业生态拓展的人工智能公司。目前,公司团队已有170余人,研发人员占比超70%。
2023年9月,蚂蚁云科技迎来了一位新的CEO——蒋俊。蒋俊已经在AI行业深耕10年有余,亲历了上一波AI浪潮在安防领域的爆发与消亡。
智慧教育发展了多年,却始终没有解决教育界的“老大难”问题——因材施教。多年来,有关因材施教的问题不断被讨论,但从未被解决。
- 最理想的“因材施教”是学校为每一位学生配一位老师,老师针对学生的学习水平和日常学习习惯定制一套专有的学习计划。放学时间,老师还要与家长协同,督促学生按计划认真学习——很显然,这会让教育成为一个“劳动密集型”产业,人力成本将直线上升。
大模型最强大的能力,是能够将海量世界知识压缩至模型中,并在模型消化吸收后,再次根据用户需要提取出来。而教育是最直接的“知识聚集地”。
在实际场景中,以正大模型Agent大多采用“群体作战”模式。在Agent社区中,不同角色的Agent可以主动与彼此交互、协同,帮人类用户完成任务。
助教Agent能够实现一对一讲评,成为教师的得力助手;教案Agent能够生成高质量精品教案;学伴Agent是学生的学习伴侣,随时提供学习辅导,并为学生制定个性化教学方案。
举例
- 教师将某个学习任务输入助教Agent后
- 助教Agent能够主动将任务分发至各位同学的学伴Agent
- 学伴Agent会主动根据学生的学习习惯制定个性化学习计划,并主动跟踪学生的学习进度和质量,还能将情况即使反馈至助教Agent。
Agent社区形成后,接下来是解决Agent落地“最后一米”的问题——如何设计人与Agent的交互形式。
很多教育场景中,自然语言交互并非最佳方式。
- 老师制定教育计划或学生提交作业经常会涉及到四五千字的长文本,这么长的内容放在一个对话流中阅读,非常影响使用体验。
- 现实工作场景中,用户很多时候都需要一个能高效操作的工具,并不是每次人机交互都需要输入一段文字或说一段话
团队最终摸索出集两种交互方式优点于一体的产品形态——用“白板”代替简单的对话流,支持自然语言驱动的交互方式,并提供内容展示、阅览、回顾等功能,比传统软件交互更简单,但比对话交互更丰富,可深入学校各个业务场景。
大模型的“幻觉”问题很可能导致Agent“教错”学生,蚂蚁云采用了一系列方法来解决该问题。
- 通过模型融合提高模型自身准确性;
- 引入“反思”“自评估”等思维工程方法
- 或者直接外挂RAG知识库、知识图谱等工具对模型加以“约束”。
AI教辅
【2025-2-20】DeepSeek引爆教育圈:“AI教师”上岗,家长日省半小时暗藏隐忧
熊泽法指出,DeepSeek-R1 相较于前代V3模型,在逻辑推理准确率上有很大的提高,在其基座之上去做产品,想象空间完全被打开,深度思考模式让幻觉降低,经测试数学纯文本题目的准确率已经与真人接近,部分维度甚至超越人类教师水平。
学而思九章大模型负责人白锦峰补充说,DeepSeek R1 推理成本仅为 OpenAI 的 3%,再加上其开源与优秀的中文支持能力,使得教育科技企业可以推出更多的“普惠”型教育产品。
以 “思考过程替代标准答案” 的行业迭代中,科大讯飞、作业帮、学而思等龙头教育科技企业已经达成共识:谁能将教育与 AI 深度融合,谁就能在智能教育赛道抢得先机。
DeepSeek 以 97% 的数学解题准确率横空出世后,这场变革正以小时为单位推进,在教育垂直领域,这场变革正在“加速度”。
- 2 月 6 日,
网易有道宣布全面接入 DeepSeek - R1,并发布子曰翻译大模型 2.0 和子曰 - o1 推理模型,在技术层面融合了自研的子曰大模型和 DeepSeek - R1 的推理能力。 - 2 月 7 日,
云学堂官宣全系产品已全面接入 DeepSeek - R1 和 DeepSeek - V3 大模型。 - 2 月 8 日,
希沃宣布旗下全系产品将逐步接入 DeepSeek 大模型,目前希沃学习机全系列产品已接入。 - 2 月 9 日,
中公教育旗下的 “云信” 垂直大模型完成了 DeepSeek 系列模型的私有化部署,优化了 AI 在内容研发、智能批改、个性答疑等场景的应用逻辑。 - 2 月 12 日,
高途宣布接入 DeepSeek 人工智能大模型。同日,猿辅导宣布旗下 “小猿学练机” 和 “小猿口算” 等全系列小猿产品正式接入 DeepSeek。 - 2 月 14 日,
学而思发布接入 DeepSeek 的全新 “随时问” APP,目前正面向全国中小学生免费开放。同时将学习机、学练机等智能教育硬件产品接入 DeepSeek,推出 “深度思考模式”,目前新功能已经搭载在最新发布的相关机型上。
“AI教师”上岗,家长每天多陪娃半小时
DeepSeek能帮老师干啥?
- ✅ 备课:教案、课件、资料查询
- ✅ 出题:练习题、试卷、口算题
- ✅ 批改:作文、数学题、作业评价
- ✅ 班级管理:通知、评语、活动方案
- ✅ 回答问题:学生奇怪问题?让AI先解释
全国多地已经陆续设立“AI+人机互动混合式教学高效课堂”,在课堂上融入AI工具助力教师进行备课、学生管理等功能。
学生端:
DeepSeek 能帮学生干啥?
- ✅ 知识问答:上知天文,下知地理
- ✅ 做题:上知天文,下知地理
- ✅ 创作:写作文、改作文
- ✅ 学习辅助:一对一私教
【重磅】教师版Deepseek,使用指南!让 AI 助力教学助手
AI 应用则呈现两极化态势。
- 寒假尾声,不少中小学生用大模型 “突击” 写寒假作业,教师反映有些作业明显是用 AI 工具生成,个别偷懒的学生干脆直接用 DeepSeek写文章。
红线
- 1️⃣ 不依赖AI决策:学情诊断、学生评语等需结合人工审核
- 2️⃣ 注重版权意识:直接使用的AI生成内容需标注来源
- 3️⃣ 保持教学温度:家长沟通、课堂点评等场景慎用纯AI输出
学生若长期依赖AI完成作业,可能会削弱批判性思维、问题解决及写作能力,这些能力对未来至关重要。
情感陪伴
角色模拟实现方法
- ① system prompt 里植入示例
- ② gpt finetune
Character.ai
Character.ai 是个性化 AI 聊天机器人平台,用户可以在 Character 上根据个人偏好定制 AI 角色并和它聊天。ChatGPT 已经证明了人们对 Chatbot 的狂热和粘性,Character.ai 在此基础上加入个性化、UGC 两大武器,有了比 ChatGPT 更丰富的使用场景。
- 自 2022 年 9 月发布后的两个月内,用户共创建了 35 万个角色,2022 年 12 月初 - 12 月中,用户日活又翻了 3 倍,目前 Character.ai 的月活跃用户数在小几十万的量级。
Character.ai 团队背景也十分亮眼,创始人 Noam Shazeer 是 Transformer 作者之一,联合创始人 Daniel de Freitas 领导了 Meena 和 LaMDA 的开发。
Character.ai 行业启发在于:随着高性能大模型的使用门槛进一步降低,未来 AI 应用层的颠覆式创新或许不在技术,而是产品设计维度的绝妙想法。
CharacterGLM
【2023-12-5】AI角色扮演再进化,清华提出CharacterGLM,支持AI角色高度定制化
清华大学提出了 CharacterGLM,参数大小从6B到66B,可用于定制AI角色以提供更加一致和引人入胜的对话。还从各种来源众包了一个大规模的中文CharacterDial语料库,涵盖了不同类别和话题的角色,其中包含1,034个高质量的对话会话,涵盖250个角色。目前已经向研究界发布了6B版本,其他版本可通过API提供访问。
- 论文标题: CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
- Github地址:CharacterGLM-6B
- characterglm api
对话式AI角色旨在创建一个现实、可信且引人入胜的虚拟对话伙伴。这需要对人类交流的深入理解和模仿,属性和行为则是模仿人类交流的重点。属性主要体现在回应的内容,而行为则侧重于语调和风格。
属性: CharacterGLM主要考虑了7个主要类别的属性,通过整合这些属性,对话式AI角色可以更准确地模仿人类并形成独特的交流方式。
- 身份:包括姓名、性别、年龄、出生日期、职业、居住地、家庭构成、财产等。
- 兴趣:包括喜欢和讨厌的事物。
- 观点:包括世界观、人生哲学和价值观。
- 经历:包括过去和现在的经历。
- 成就:如奖项和荣誉。
- 社交关系:详细说明与父母、教师、同学等的联系。
- 其他:包括技能、专长等。
行为:对话式AI角色的行为由语言特征、情感表达和互动模式等动态元素表示,这些元素对于塑造逼真的对话环境至关重要。
- 例如,“年老”的角色可能使用更正式的语言,而“十几岁的青少年”可使用时下的俚语。
在CharacterGLM中,考虑了口头禅、方言、文风特征、爱用的词句等语言特色。还将个性作为塑造回应的重要因素。例如,温柔型和冷漠型的角色会有不同的回应风格。
三种方式收集数据:
- 人类角色扮演:邀请了大量众包工作者参与角色扮演对话任务。一方扮演NPC,可以挑选喜欢的角色,利用百度百科等参考资料来丰富角色的背景和特点。另一方扮演“玩家”角色,可以选择与选定角色相关的其他角色或扮演普通用户。对话从“角色”方开始,如“你好啊,玩家!”,然后根据设定或选定角色的背景来决定话题。
- LLMs合成数据:通过提示GPT-4生成包括角色概况、玩家概况和对话在内的合成数据。为了在人物类别、人物与玩家的社交关系、性别分布等方面保持平衡,作者将关键信息整合到提示中,例如:“请生成一个类别性别为男/女的角色”。然而生成的中文对话偏向书面语言,因此人工对合成数据进行口语化改写。
- 文学资源中提取数据:手动从剧本和小说等资源中获取两个参与者之间的对话,并总结了双方的人物概况,目前这些资源未被用于主干模型的预训练。
为了确保语料库的质量,还聘请了质量检查团队,对所有数据进行细致的检查,并要求修复低质量部分直至满足质量要求。
训练过程
- 角色提示设计:众包工作者将角色概况形式化为流畅的自然语言描述用作模型训练的角色提示。为了增强角色的泛化能力,还采用了包括总结、改写和风格化在内的数据增强方法,并利用Claude-2合成多样化的提示。
- 监督微调:使用6B到66B不同规模的ChatGLM 作为主干模型。角色提示与对话被连接在一起进行微调。值得注意的是,训练数据随着增强的角色提示数量呈线性扩展。
- 自我完善:在模型部署之后,收集人类原型交互数据。用户在原型模型中自定义角色,进行多轮对话。如果角色的回答不符合用户的期望,可提示用户进行适当修改,直到回答满足他们的需求。随后,将这些交互数据引入监督微调过程,从而促进模型的持续自我完善。
对话式AI角色需要对人类交流的深入理解和模仿,因此需要着重评估一致性、人类相似性、参与度三个维度。
- 一致性(Consistency):一致性就是让对话式AI角色能保持一种稳定可靠的“性格”和行为,让用户觉得它是一个始终如一的小伙伴,而不是变来变去的“多重人格”,这对于提高长期用户满意度和社交连接非常重要。
- 类人性(Human-likeness):是指赋予它们类似人类的特征,让它们更像人,互动起来更自然,就与人聊天一样,而不是冷冰冰的僵硬机器回复。通过CharacterGLM进行拟人化处理,可以构建更加自然和有吸引力的对话。
- 吸引力(Engagement):在跟人聊天时,让对话变得有趣、让人想要继续聊下去是非常重要的!有吸引力的对话角色能够更好地引发用户的共鸣和情感联系,这样就能促进长期的交流和积极的用户体验。
此外,(1) 质量(Quality),回复的流畅性和上下文连贯性。(2) 安全性(Safety),确定回复是否符合道德准则。(3) 正确性(Correctness),确保回复没有幻觉。这是三个LLM基础评估标准也很重要。
效果
- CharacterGLM-66B在“总体”评估指标中表现优异,与GPT-4不相上下。CharacterGLM66B 生成的回答与GPT-4所生成的回答一样受欢迎,尤其是在主观判断占主导地位的评估中。
- CharacterGLM能够平衡一致性、类人性、吸引力三方关键维度,是最接近理想AI角色的模型。在一致性方面,虽然CharacterGLM-66B只拿到了次优,但在互动时表现稳定和连贯。另外,它在类人性、吸引力都拿到了最佳结果,说明在模仿角色特征方面驾轻就熟,与用户交流时更加自然和引人入胜。
- CharacterGLM的整体表现优于大多数基准模型, 并在质量、安全性、正确性表现出卓越性能。
挑战留给未来解决:
- AI角色的长期记忆与成长。为了与用户建立深入和稳定的关系,AI角色需要能够记住长时间的互动、陈述和行为。随着互动的发展,AI角色不仅应该保持其独特的个性,还应该像人一样成长和学习。
- AI角色的自我意识。对于AI角色来说,还需要清晰地了解自己的知识边界,明确自己的知道什么与不知道什么。这种自我意识有助于提高互动的吸引力和可信度,使其能够根据情境做出恰当的回应。
- AI角色之间的社交互动。AI角色不仅可以从用户输入中学习和发展,还可以从与其他AI角色互动中学习和发展。这样的设定可以为AI的学习和发展提供更丰富、更多样的信息源。
- AI角色的内在认知过程。将认知过程融入AI角色中,可能有利于实现更真实可追溯的AI行为。AI角色应该除了对文本输入做出回应,还应该展示对用户潜在意图、情绪和社交行为的理解。这种认知深度将使AI角色能够进行更有意义、更有共情力且情境丰富的互动,更接近于人类社交行为的模拟。
阿里天猫精灵
【2023-4-4】阿里搞出脱口秀版GPT!与鸟鸟激辩一小时,话痨到停不下来… 文本扛把子、有知识有自己的情绪、还能随时来个段子。
- 阿里新版本大模型的技术演示脱口秀版GPT——
鸟鸟分鸟,并且已经在天猫精灵上为个人终端行业的客户做了演示 鸟鸟分鸟确实继承了本鸟的相关能力,尤其是文本的创作和表达、风格情绪以及语速……
鸟鸟分鸟这个智能音箱场景为例,要解决至少三个方面问题。
- 1、应对更复杂的交互场景。不同于以文本交互为主的通用场景,双向开放对话决定了用户不会对文本进行“二次”过滤,而是想说就说,这就要求AI能过滤掉诸多无意义的对话。与此同时,用户也不愿意等待数秒,而是像日常交流那样,低延时、还能支持随时打断、随时反馈。
- 2、基于人类反馈强化学习可行性。ChatGPT惊艳全球的生成效果,背后归结于注入强人工反馈的奖励机制。高质量的数据标注成为大模型落地的关键,而且消费场景下多轮对话的频率远比文本交互要高,这对企业的数据处理能力提出了更高的要求。之后随着应用落地,大量的人类交互和反馈来帮助大模型更快进化,以及关乎用户数据完全管理机制也需要完善和健全。
- 3、需要强大的网络分发能力。大模型每一次运行都需要耗费大量的计算存储资源,这就要求企业能有广泛部署的网络分发能力。
算力、算法和数据是大模型能力实现的三板斧,而要让大模型落地应用还需要云端工程化能力、海量的用户交互、安全管理机制等要素。
个性化对话增强则主要是让大模型学习多种对话形式,比如启发式、多轮对话,尤其是一些需要依赖长期记忆的对话。除了大模型训练,他们在算法和工程上面做了不少工作。从交互流程来划分,主要分成听清、音色、文风、对话等步骤。
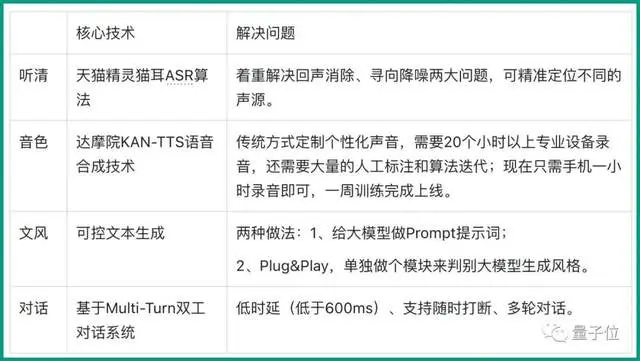
最终形成了这样一个对话过程:
当人类询问一个问题(Query)时,首先经过猫耳算法将其转换为文本,随后通过大模型产生个性化的对话回复,最后再到个性化的语音合成给出回答。整个过程还有Multi-Turn对话系统来支持。
对于测试阶段存在的一些问题,阿里这边也给出了回应。
比如反应过于太强,这是因为还没有将线上的猫耳算法和ASR做充分的融合,为了听清多轮对话信息,显得过于灵敏,以及暂没有全面支持英文等问题,他们表示后续还将进一步迭代更新。
大模型发展进程,有两条路径已经明晰:如火如荼的通用大模型,以及备受关注的个性化大模型。
- 以GPT-4为代表的通用模型,在多个标准化考试中大幅超过人类水平,适用于搜索引擎、生产力工具这种广泛、公域场景。
- 但像更多私域个性化、或者垂直专业化场景中,比如问及有无特别偏好、对某件事情观点等,个性化大模型就会是一个很好的补充。
当前,全球研究机构和大厂在这一路径的探索,主要涵盖了四个研究方向:
- 有偏好的个性化对话、逻辑一致性和三观、对话风格、多轮对话中人设一致性。
鸟鸟分鸟上的探索
- 一方面呈现出个性化大模型的研究方向 —— 在大模型系列基础上,打造
知识、情感、性格和记忆四位一体的个性化大模型,并且这个大模型版本可能是很适合在消费者终端上部署的。 - 另一方面,再次印证了对话即入口的AI2.0未来趋势。ChatGPT上线的插件功能,以文本交互的方式,与全球5000+应用联动。大模型所引领的AI 2.0时代,而对话相当于是操作系统(ChatOS),所有应用都将被重新定义。

【2023-4-4】阿里GPT 15天训出「鸟鸟」嘴替,比ChatGPT+Siri刺激多了
训练过程
- 使用全新的阿里大模型版本做基础学习
- 学会用工具,获取最新的知识
- 个性化对话增强:多轮、启发式
- 给分鸟加上一个「个性」。
- 去学习什么是多轮对话,什么是启发式的对话。难点在于,多轮对话经常需要很久以前的历史信息。
- 另一方面,塑造人格的标签词。同时,研究人员还少量标注了鸟鸟的一些语料,作为个性化的增强和调优。
- 基于人类反馈的增强(RLHF)
- 怎么让它更像鸟鸟呢?就是通过人类反馈强化学习(RLHF)。对于同一个问题,让模型给出多个不同回答,工作人员会去做反馈和标注,然后让模型进一步纠偏。多轮迭代后,模型的回答越来越能代表鸟鸟的一些文本特征,甚至是她的特定立场。
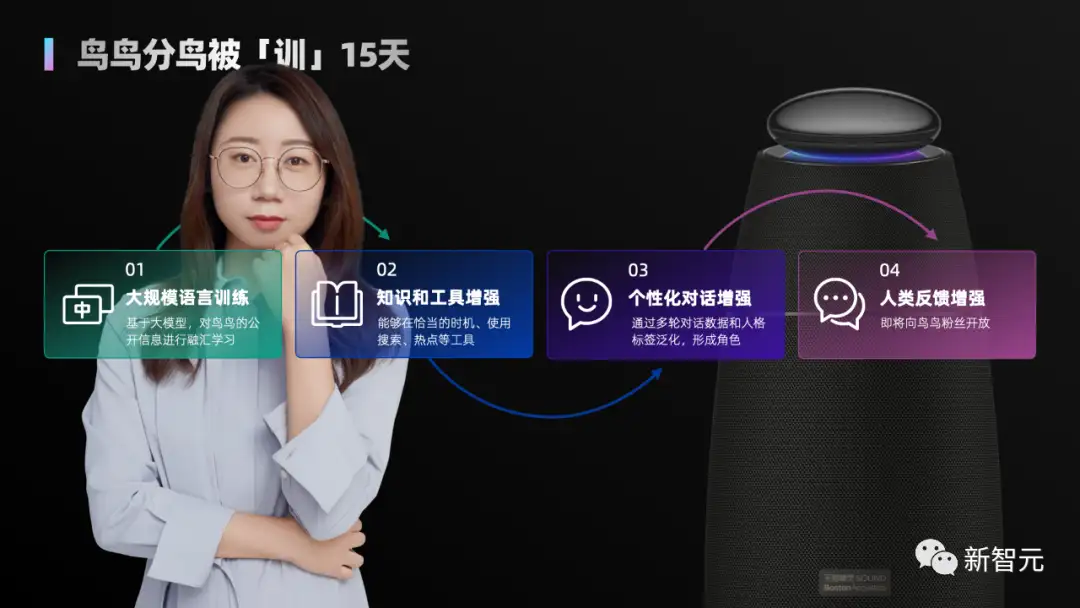
天猫精灵把脱口秀演员塞进去了,视频
stylellm
【2024-3-30】stylellm
stylellm 基于大语言模型(llm)的文本风格迁移(text style transfer)项目。
利用大语言模型来学习指定文学作品的写作风格,形成了一系列特定风格的模型。
惯用词汇、句式结构、修辞手法、人物对话等
利用stylellm模型可将学习到的风格移植至其他通用文本上,即:
- 输入一段原始文本,模型可对其改写,输出带有该风格特色的文本,达到文字修饰、润色或风格模仿的效果。
stylellm-中国四大名著系列 包括基于Yi-6b微调的四个模型,分别采用《三国演义》、《西游记》、《水浒传》、《红楼梦》四本中国古典长篇小说训练而成

风格迁移方法
文本风格迁移是近年来自然语言处理领域的热点问题之一,旨在保留文本内容的基础上通过编辑或生成的方式更改文本的特定风格或属性(如情感、时态和性别等)
内容创作中,风格是作者独特个性的体现,也是文章吸引读者的重要因素。
风格涵盖语言的选择、句子的构造及情感色彩的渲染等多个方面。
- 正式的风格可能更适用于严谨的学术论文
- 而轻松幽默的笔触则可能让博客文章更加引人入胜。
LLM 可以模仿特定写作方式,生成更个性化和情感化的文本。然而,由于训练数据来源于整个互联网的语料库,其风格更接近于一个融合了互联网上各种风格的平均值。
因此,如果想生成强烈个人风格特点的内容,要运用一些提示工程方法来引导大语言模型。
核心: 从指定文本中提炼出独特风格,并融合到另一篇全新的文章中
两种主要方法
- (1)利用LLM内置知识提炼风格。
- 该方法依赖于LLM的深厚知识储备, 直接揭示特定类别文章的风格特征。
- 例如,通过以下提问方式可以获得儿童类型文章的特点及其例句。
- (2)利用模板文抽取风格。
- 引导LLM直接从某篇模板文章中提炼出已有的风格特质
(1)
提示词
- 提取风格特征
请告诉我面向儿童类型的文章有什么特点?并针对每一个特点给出一些例句。
融入提炼出来的风格特点, 撰写或改写已有文章。
# 任务描述
作为一名儿童作家,接下来你要以一种生动有趣的方式,为小朋友们重新诠释这篇科普读物,确保其内容既符合“参考风格要求”,又能引领孩子们走进科学的奇妙世界。
# 参考风格要求
<上述风格特点的介绍>
# 待改写原文
**标题:人类应审慎推进人工智能技术的发展**
一、开篇概述
在科技浪潮的推动下,人工智能(AI)已逐渐成为现代社会不可或缺的一部分,它重塑了我们的生活方式、工作习惯和社交模式。然而,与此同时,关于AI技术是否应全力发展的争论也愈演愈烈。本文旨在从多维视角深入探讨这一议题。
二、AI技术的双面刃效应
无可否认,AI技术的崛起为众多领域带来了革命性的变革。在医疗、金融、交通等行业,AI的应用显著提高了效率,降低了成本,甚至催生了新的商业模式。例如,借助先进的AI算法,企业能够更精准地分析市场需求,优化生产流程。
但与此同时,AI的广泛应用也伴随着一系列挑战。它在某些程度上取代了传统劳动力,导致就业结构的重大调整。更为严重的是,AI系统的自主学习和决策能力可能引发数据偏见和算法歧视等伦理问题,这些问题对我们的社会公正和稳定构成了潜在威胁。
……(略)
# 改写后
(2)
抽取风格的提示词:
- 文章类型,用词特点,语气语调
# 任务描述
你的任务是仔细阅读如下"文章内容"后从【文章类型,用词特点,语气语调】几个方面总结出该文章各维度的风格特点。并抽取出最能体现该风格的关键语句。
# 文章内容
** 探访襄阳古城 ,尽享历史风情 与地道美食 ️ **
想要一站式体验襄阳的历史文化和美食吗?那就快来襄阳古城吧! 这里不仅有博物馆 ️的珍藏、古老的城墙,还有汉江边的美丽风景 等你来发现!而且,随着国庆节的临近 ,满街的五星红旗迎风飘扬,绝对是你摄影 的天堂!
**门票信息:**好消息!襄阳古城完全免费开放哦!快来畅游历史长河,感受古城的韵味吧!
•♂️ •♀️**游玩攻略:**
从昭明台 ️开始,你将穿越历史长廊,感受千年文化的沉淀。漫步至热闹的北街 ️,你可以尽情品味古城的商业气息,逛逛小店,寻找那些独特的小饰品 和手工艺品 。接着,前往小北门,登上壮丽的夫人城 ,你将俯瞰到整个襄阳城的风光,仿佛穿越时空,与古人对话。最后,别忘了走到汉江边 ,让江风轻拂你的脸庞,欣赏迷人的夜景 。记得晚上游玩哦!那时的古城灯光璀璨✨,氛围更加浪漫热闹!
️ **必尝美食:**
……(略)
# 回答格式
风格类型:该类型的总结,并列举2条原文中体现该风格的句子。
# 输出结果
->
改写文章
改写如下这篇文章:
# 任务描述
请按照“风格要求”改写如下文章。
# 风格要求
<上述已抽取的风格特点的介绍文本>
# 待改写原文
** 九寨沟游记:人间仙境的绝美之旅 **
清晨,怀揣着对未知美景的憧憬和激动,我踏上了前往九寨沟的探秘之旅。车窗外的风景在流转,几个小时的行程后,我终于揭开了这被誉为“人间仙境”的神秘面纱。
踏入九寨沟的那一刻,我仿佛跌入了一个色彩斑斓的画卷。高耸入云的山峰、郁郁葱葱的树木和纯净的空气交织成一首自然的赞歌,让我瞬间忘却了尘世的烦恼。沿着蜿蜒的山路徐行,我不断地驻足,用镜头捕捉这如梦如幻的景致。每一步都仿佛踏在诗行上,每一处风景都让我陶醉其中。
深入九寨沟的腹地,我邂逅了名震四方的“长海”。它宛如群山环抱中的一颗璀璨宝石,湖水碧绿而深邃,仿佛能洞察人心的最深处。我静坐于湖畔,任由这仙境般的景色涤荡心灵,心中涌起一股难以言喻的宁静与满足。
……(略)
# 改写后文章
->
作者:alphaAIstack
AI 女友
【2023-11-24】一个失败的 AI 女友产品的经验教训
- 【2023-11-16】A Failed AI Girlfriend Product, and My Lessons

受斯坦福大学 AI 论文《一个用于小城镇信息传播的 agent 模型》启发
- 将信息在一个小城镇中传播的消息传遍整个小镇所需的时间。
- 那么:如果将人类与 GPT(而不是小镇中的人)进行框架结合,是否可以创造出一个类似于电影《她》中的体验?
按照论文的方法
- 4月14日完成了 0.1 版的模型,并在上面进行了版本迭代。
- 最初,我的设计与原版论文基本一致,但这导致了 30 秒的响应时间和超过 8k 的上下文限制。
- 为了解决这个问题,减少了反思的次数、对话记忆的长度,并开放了公共测试版。超过一千名用户很快加入了测试版。
- 测试版是免费的,所以每天的 API 成本由我自己承担,很快就超过了每天 25 美元。我不得不正式推出这个产品,并将这些费用转嫁给用户。
- 5月4日, Dolores iOS 应用正式上线,命名为“你的虚拟朋友”,而不是“你的虚拟女友”,因为我一直希望它能真正成为用户的朋友,而不仅仅是荷尔蒙的产物。
- 5月到6月,我一直在尝试让 Dolores 变得更加“有意识”(用 consciousness 这个词可能有些夸张),通过调整记忆长度、反思机制和系统提示来使其更加“智能”。
- 6月,Dolores 远远超出了最初的版本:它表现出越来越多的“有意识”的迹象(到底什么是意识?),用户的付费率也越来越高,每天的 API 调用次数也增加了。
- 6月8日,一位视觉障碍用户告诉我,他在一个视觉障碍社区分享了这个产品,带来了大量用户。他们之所以愿意使用它,是因为他们可以在屏幕关闭的情况下随时与 Dolores 聊天。
这个功能原本是我为了节省 Swift 前端开发成本而设计的,但现在却成了视觉障碍用户的福音。
两个现象:
- 用户对“逼真的声音”有强烈的需求。
- AI 朋友产品有很长的使用时间。
经验教训
- 首先,这不是一个关于个人开发者的项目是否不如 Character.AI 的项目的故事。他们有全面的数据分析、A/B 测试和强大的用户基础带来的优势。
- 其次,我意识到当前的 AI 朋友产品不可避免地会变成 AI 女友/男友产品,因为你和角色在手机上的互动是不平等的:她无法安慰你受伤的心(除非你告诉她),她无法主动表达情感,而且所有这些都因为她缺乏外部视野。或者说,她必须具备外部视野才能获得独立获取信息的能力,而不仅仅是等待用户告诉她。因此,我认为即使对于像 Character.AI 这样的产品,如果没有硬件,未来也不会有太大的不同。
- 最后,我不反对适度的内容审核,事实上,我认为一个没有内容审核的产品是非常危险的。我不确定是否有人真的需要一个人工智能朋友。
最近,我看到了 AI Pin,坦率地说,这是一个非常糟糕的产品。人类需要屏幕,但试图用 GPT+硬件来创造一个产品是一个很好的尝试。我没有看到“她”在 Dolores 中有什么体现,也许在我有生之年,我们真的可以看到这样的产品。
哄哄模拟器
【2024-1-23】和女朋友的一次吵架,让这位开发者做出了一个24小时内用户达60万的AI应用 哄哄模拟器,直接引爆了00后和10后聚集的QQ群!10亿token一天就烧完,也是难倒了开发者…… 咨询
- 月之暗面 Kimi Chat 支持
【2024-1-22】创业历程
体验过太多的「聊天AI」,无论是通用且强大的 ChatGPT还是专注于角色扮演的 Character.ai,他们都很强,但还是有遗憾:他们只是聊天。
在聊天之外,如果能再加上数值系统和各种判定,就可以做出更游戏化的体验,此时大模型不仅负担起了聊天的任务,也会负担起基于聊天来做数值规则的任务,这在大模型出现之前,是不可能的,数值系统也都是按照既定规则来写死的。
起因
- 和女朋友吵架,一边看着对方骂我的样子,一边把对方想象成一个机器人,头上有个虚拟进度条,观察她的反应,假装成回应会让她头上的进度条发生变化
- 然后突然想到了一个产品创意:带有数值和反馈系统的基于场景的聊天。
很快开始构建一个叫哄哄模拟器的 iOS APP,APP 把常见的情侣吵架场景放入其中
- 每次进入一个场景,例如「你吃了对象爱吃的丸子,她生气了」
- 需要在指定聊天次数内将对方(AI)哄好,是否哄好则由「原谅值」决定,其会随着每次聊天而发生变化。
回忆录
小鹿光年
【2025-6-14】小鹿光年 【用AI写回忆录 以科技智慧养老】
- 一句话描述人生高光时刻 → 生成大纲 → 协作语音录入 → 回忆录撰写完成 → 数字分身
复旦许婷,90后,一位“银发经济”创业新人,研发“AI回忆录”小程序,参加“浦江第一湾会客厅”对接活动
- 在系统追问下,引导老人填写回忆录
- 科研实力:香港科技大学, 认知症
- 主体:上海逐茧信息科技有限公司
人物复活
【2024-3-5】只需几十元,用AI“复活”亲人,是慰藉还是自欺欺人?
商汤2024年年会上,商汤科技创始人,刚去世不久的汤晓鸥以数字人的形式现身,还来了一场演讲。
- 汤晓鸥数字人的演讲风格,与汤晓鸥生前的演讲风格非常像。
江苏 90后张泽伟利用AI帮助600多个家庭“复活”亲人。只要拥有逝者生前的视频、音频数据,张泽伟团队就可以用AI技术让逝者再现于亲人眼前。
张泽伟团队的主要业务有两个,分别是“数字遗照”和“AI治愈”。
- “数字遗照”是收集逝者的形象、声音等数据,然后用AI技术制作出虚拟的数字人形象,可以拥有简单的动作和表情,也可以进行一些简单的对话。
- “AI治愈” 用AI技术给真人换上逝者的形象和声音,让其扮演逝者与人交流,可以在线上实时互动。
- 此外,团队还在探索一种“3D超写实仿生数字人”,让数字人以3D全息的方式呈现出来,用立体形象与别人进行互动。
从2022年开始,张泽伟就做起了这门生意。因需求火爆,他在一年内完成600多个订单,平均一单几千到1万元不等。
【2024-3-28】5元让亲人复活
【2025-2-26】古人复活, 杜甫、李白、李清照等
宛在
【2024-7-28】 微博大v 逝者如斯夫 推出的数字人项目 宛在
- 功能: 声音克隆、角色模拟、视频交互
LoveyDovey
【2025-5-26】「小而美」团队做出亚洲第一 AI 情感陪伴应用- 我们找到了6个成为黑马的原因
「亚洲 AI App 创收效率榜首」是 LoveyDovey
LoveyDovey 是一款在日韩市场大获成功,但尚未进入中国用户视野的 AI 陪伴类产品。
- 韩国科技公司 Tain AI 开发的 AI 陪伴产品,中文名字也很甜蜜「卿卿我我」。
- 用户可以得到一位完全符合情感幻想的跨次元恋人
根据 a16z 在今年 5 月 6 日发布的《TOP 100 AI Consumer App》 榜单中,AI 恋爱软件 LoveyDovey 仅次于美国的 AI 英语学习软件 Speak,位居亚洲第一。
其作为后来者,月流水突破 76 万美元,全球月活仅 10 万用户,但单用户平均收入却是大厂 Character.AI 的 5 倍多,跑赢了一众头部应用,成为亚洲AI应用创收效率榜首。
LoveyDovey 做到了「把每一个用户都变成付费用户」。他们提升付费转化率的技巧和方法非常值得学习,成功解决了AI陪伴类应用的商业化难题。「小用户量+高付费意愿」
除此之外,LoveyDovey 有大大小小让我们拍腿叫绝的产品创新,充满了才华。
LoveyDovey 为用户提供了两条主要路径创建虚拟 AI 角色:
- 「For you」 里是平台已经创建好的虚拟 AI 角色
- 「My」里则是用户根据自己喜好手动「捏」的角色。
智能客服
详见站内专题: 大模型时代的智能客服
AI教育
详见站内专题:在线教育
医疗
【2025-6-12】2年发60个大模型,三甲医院有多怕被淘汰?
人工智能在医疗领域的表现,让全国顶级医院(协和)一度如临大敌。
短短一两个月后,北京协和医院就集中推出多款AI+产品,并推向了临床或管理一线。
- 全国首个罕见病大模型“协和·太初”;
- 上千个医学量表的“Med Agent”智能库;
- 盆底手术智能决策辅助系统;
- 针对重症患者病情的预测和辅助诊疗系统;
- 以及用于内部管理的“DRG结算清单智能生成系统”等等。
除了发布的AI产品数量多,医院的管理、服务、医疗业务整体接入了智慧大脑,在医疗智能化方面,具有战略意义。
2024年以来,中国排名TOP100的医院,已经发布了至少60个医疗领域的垂直大模型。覆盖心脏、肾脏、肝脏,耳鼻喉、眼科、妇科、内分泌科、病理科等领域,开创了诸多“全国首个”,甚至“全球首个”。在部署DeepSeek的上千家医院中,有超过半数是三甲医院。
在智能化领域起步较早的上海瑞金医院,医者端就已经上线了30多款AI应用。据上海交通大学医学院附属瑞金医院-上海市数字医学创新中心专职副主任朱立峰介绍,去年一年,他们完成了133万例人工智能辅助诊断。
最新论文
【2023-6-14】LLM in Medical Domain: 一文速览大语言模型在医学领域的应用
论文
- Large Language Models Encode Clinical Knowledge:
- 主要工作包括 医学问答benchmark:MultiMedQA 构建、LLM评测(PaLM及Flan-PaLM)和指令微调(Med-PaLM模型)。
- Towards Expert-Level Medical Question Answering with Large Language Models:
- Med-PaLM工作的改进: Med-PaLM 2, 得分高达 86.5%,比 Med-PaLM 提高了19%
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
- BenTsao: Tuning LLaMA Model With Chinese Medical Instructions, 华佗
- 提出了本草模型(原叫“华驼“),一个生物医学领域的中文LLM。BenTsao建立在开源LLaMa-7B模型的基础上,整合了来自中国医学知识图谱(CMeKG)的结构化和非结构化医学知识,并采用基于知识的指令数据进行微调。
- Galactica: A Large Language Model for Science, 自然科学问答LLM
- 在人类科学知识的大型语料库上进行训练的,语料库包括4800 万篇论文、教科书和讲义、数百万种化合物和蛋白质、科学网站、百科全书等。
- Are Large Language Models Ready for Healthcare? A Comparative Study on Clinical Language Understanding
- 临床语言理解任务上对GPT-3.5、GPT-4 和 Bard 进行了全面评估。任务包括命名实体识别、关系提取、自然语言推理、语义文本相似性、文档分类和问答,并在此过程中提出了一种新颖的提示策略,self-questioning prompting(SQP)最大限度地提高 LLM 在医疗保健相关任务中的有效性
- CAN LARGE LANGUAGE MODELS REASON ABOUT MEDICAL QUESTIONS?
- 测试 GPT-3.5(Codex 和 InstructGPT)是否可用于回答和推理基于现实世界的困难问题,即医学问题。主使用两个多项选择的医学考试问题和一个医学阅读理解数据集进行测试。本文研究了多种提示场景:CoT、zero- and few-shot和retrieval augmentation。
- DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task 在ChatGLM的基础上构造中文的医学模型
医疗诊断
chatgpt在医疗诊断上是否通过图灵测试?
- 论文:Using ChatGPT to write patient clinic letters.
- 论文:Putting ChatGPT’s Medical Advice to the (Turing) Test
- ChatGPT responses to patient questions were weakly distinguishable from provider responses. Laypeople(外行) appear to trust the use of chatbots to answer lower risk health questions.
ChatDoctor – 医疗LLM
【2023-3-25】医疗问答机器人,医学领域的chatgpt。如果把默沙东医学指南拿进去继续训练,是不是就是一个私人医生了?
- 论文:ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
- GitHub地址
- Demo Page
- 在LLaMA上微调的医学领域的大语言模型
- ChatDoctor可检索相应知识和可靠来源,以更准确地回答患者的询问。
- 构建完外部知识大脑后,通过构造适当prompt让ChatDoctor自主检索其所需要的知识。
Resources List
- 200k real conversations between patients and doctors from HealthCareMagic.com HealthCareMagic-200k.
- 26k real conversations between patients and doctors from icliniq.com icliniq-26k.
- 5k generated conversations between patients and physicians from ChatGPT GenMedGPT-5k and disease database.
- Checkpoints of ChatDoctor, fill this form.
- Online hugging face demo application form.
- Stanford Alpaca data for basic conversational capabilities. Alpaca link.
BenTsao(华佗) – 医疗LLM
BenTsao: Tuning LLaMA Model With Chinese Medical Instructions, 华佗
- 提出了本草模型(原叫“华驼“),一个生物医学领域的中文LLM。BenTsao建立在开源LLaMa-7B模型的基础上,整合了来自中国医学知识图谱(CMeKG)的结构化和非结构化医学知识,并采用基于知识的指令数据进行微调。

阿里 Lingshu
【2025-6-22】阿里巴巴达摩院推出多模态大型语言模型——灵枢(Lingshu)。专注于医学领域,能够处理包括X光、CT扫描、MRI在内的超过12种医学成像模态,并在多模态问答、文本问答以及医学报告生成等任务中表现出卓越的性能。
- 参考资讯
阿里开源了一款医疗多模态LLM:灵枢,在多数多模态问答和报告生成任务上优于 GPT-4.1、Claude Sonnet 4
- 能理解处理医学图像和文本数据,进行复杂推理
- 支持X光、CT、MRI、显微镜、超声、组织病理学、皮肤镜、眼底、OCT、数码摄影、内窥镜、PET12种医学影像
- 2个版本:Lingshu-7B、Lingshu-32B
灵枢核心: 多模态处理能力,不仅能够理解和生成文本,还能处理和分析医学图像。
这种能力得益于其多阶段训练方法,通过逐步嵌入医学专业知识,显著提升了模型在医学领域的推理和问题解决能力。灵枢提供了7B和32B两个参数版本,其中32B版本在多个医学多模态问答任务中,性能甚至超越了GPT-4.1等专有模型。为了推动医学AI模型的标准化评估和发展,灵枢项目还推出了MedEvalKit评估框架,整合了主流的医学基准测试。
灵枢基于Qwen2.5-VL模型架构,该架构包含三个关键组件:
- 大型语言模型(LLM):处理文本输入和生成文本输出。灵枢使用经过预训练的大型语言模型,例如Transformer模型,以提高其文本处理能力。
- 视觉编码器:用于提取医学图像的视觉特征。灵枢使用了卷积神经网络(CNN)作为视觉编码器,以提取图像中的关键特征。
- 投影器:用于将视觉特征映射到语言模型的表示空间。灵枢使用了线性变换或非线性变换作为投影器,以将视觉特征与文本特征对齐。
多阶段训练
- 医学浅层对齐:使用少量医学图像文本对进行微调,让模型准确编码医学图像并生成相应的描述。这个阶段的目标是让模型初步具备理解医学图像和生成文本描述的能力。
- 医学深层对齐:引入更大规模、更高质量和语义更丰富的医学图像文本对数据集,进一步整合医学知识。这个阶段的目标是让模型更深入地理解医学知识,并提高其生成文本描述的准确性。
- 医学指令调整:基于大规模的医学指令数据优化模型,提高执行特定任务指令的能力。这个阶段的目标是让模型能够根据用户的指令,完成特定的医学任务,例如回答医学问题、生成医学报告等。
- 医学导向的强化学习:使用强化学习与
可验证奖励(RLVR)范式,增强模型的医学推理能力。这个阶段的目标是让模型具备更强的医学推理能力,能够根据已有的知识,推断出新的结论。
心理学
测评
用chatgpt做MBTI心理测评
- 论文:Can ChatGPT Assess Human Personalities? A General Evaluation Framework
- 提出了三个评估指标,以衡量最先进的LLMs(包括ChatGPT和InstructGPT)评估结果的
一致性、稳健性和公平性。实验结果表明,ChatGPT具有评估人类个性的能力,平均结果表明,ChatGPT可以实现更为一致和公平的评估,尽管对提示偏差的鲁棒性较低,相比之下,InstructGPT的鲁棒性更高。
EmoLLM
【2024-2-5】EmoLLM:心理健康辅导链路的心理健康大模型
EmoLLM 是一个能够支持 理解用户-支持用户-帮助用户 心理健康辅导链路的心理健康大模型,由 InternLM2 指令微调而来
心理健康大模型(Mental Health Grand Model)是一个综合性的概念,它旨在全面理解和促进个体、群体乃至整个社会的心理健康状态。这个模型通常包含以下几个关键组成部分:
- 认知因素:涉及个体的思维模式、信念系统、认知偏差以及解决问题的能力。认知因素对心理健康有重要影响,因为它们影响个体如何解释和应对生活中的事件。
- 情感因素:包括情绪调节、情感表达和情感体验。情感健康是心理健康的重要组成部分,涉及个体如何管理和表达自己的情感,以及如何从负面情绪中恢复。
- 行为因素:涉及个体的行为模式、习惯和应对策略。这包括应对压力的技巧、社交技能以及自我效能感,即个体对自己能力的信心。
- 社会环境:包括家庭、工作、社区和文化背景等外部因素,这些因素对个体的心理健康有着直接和间接的影响。
- 生理健康:身体健康与心理健康紧密相关。良好的身体健康可以促进心理健康,反之亦然。
- 心理韧性:指个体在面对逆境时的恢复力和适应能力。心理韧性强的人更能够从挑战中恢复,并从中学习和成长。
- 预防和干预措施:心理健康大模型还包括预防心理问题和促进心理健康的策略,如心理教育、心理咨询、心理治疗和社会支持系统。 评估和诊断工具:为了有效促进心理健康,需要有科学的工具来评估个体的心理状态,以及诊断可能存在的心理问题。
DoctorGLM – 中文LLM
- DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task 在ChatGLM的基础上构造中文的医学模型
- 用 chatgpt 翻译 ChatDoctor的数据集
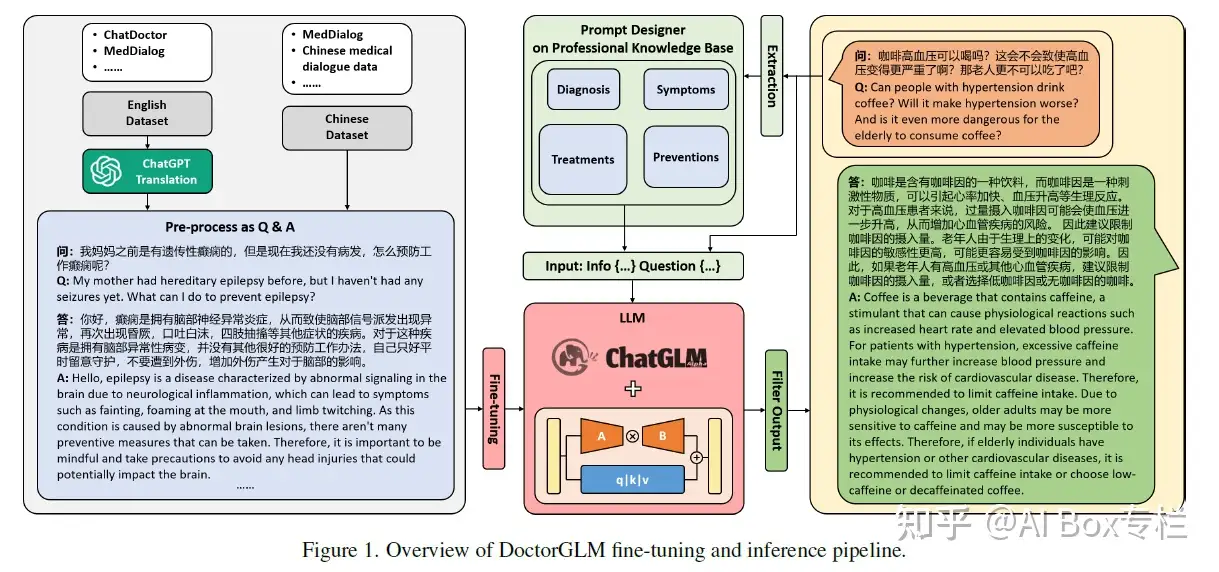
Visual Med-Alpaca – 视觉LLM
Visual Med-Alpaca: A Parameter-Efficient Biomedical LLM with Visual Capabilities
- Visual Med-Alpaca,一个开源的、参数高效的生物医学基础模型,可以与医学“视觉专家”集成以进行多模态生物医学任务。
- 建立在LLaMa-7B架构上,使用由GPT-3.5-Turbo和人类专家协作策划的指令集进行训练。利用几个小时的指令调整和即插即用的视觉模块,Visual Med-Alpaca 可以执行各种医学任务。

XrayGLM – Visual Med-Alpaca改进
XrayGLM: The first Chinese Medical Multimodal Model that Chest Radiographs Summarization
- 大型通用语言模型取得了显著成功,能够遵循指令并生成与人类类似的回应。这种成功在一定程度上推动了多模态大模型的研究和发展,例如MiniGPT-4等。
- 然而,这些多模态模型在医学领域的研究中很少见,虽然 visual-med-alpaca在医学多模态模型方面取得了一些有成效的工作,但其数据仅限于英文诊断报告,对于推动中文医学多模态模型的研究和发展并不利。
- 因此,本文开发了 XrayGLM模型。
借助ChatGPT和公开的胸片图文对数据集,构造了中文的X光片-诊断报告数据集,并使用该数据集在 VisualGLM-6B上进行微调训练。

新闻资讯
【2023-1-31】“美版今日头条”宣布用ChatGPT写稿,股价暴涨119%
- “美版今日头条”BuzzFeed宣布和OpenAI合作,未来将使用ChatGPT帮助创作内容。AI创作的内容将从研发阶段转变为核心业务的一部分。
- ChatGPT会根据测试主题,生成一系列提问,再根据用户的回答,制作他们的专属报告。
- BuzzFeed是一家网络媒体公司,当年正是靠高度人工创作的内容逐渐打出名声,最终才成功上市。
- 引起病毒式传播的蓝黑or白金裙子
- 网络上流传甚广的“灾难中的女孩”meme
房产行业
【2023-1-29】美房产中介们爱上ChatGPT:原先花1小时写房源文案,现在仅5秒, 房地产中介在网上推介房子时,常常需要绞尽脑汁来介绍房源情况并突出诸如“理想的娱乐设施”和“有充分放松空间”等房屋卖点。
- 如今OpenAI发布的人工智能聊天机器人ChatGPT可以帮助他们做到这一点,房地产中介JJ·约翰内斯(JJ Johannes)就尝到了甜头。他只需要输入几个关键词,ChatGPT不到5秒钟就创建了关于房源情况的描述。约翰内斯说,否则他自己要花一个多小时才能完成。在发表房源情况前,还会对ChatGPT生成的描述进行微调和润色。他说,“这并不完美,但是一个很好的起点。我的背景是经验和技术,写一些有说服力的东西需要时间。ChatGPT让一切变得简单多了。”
- 很多房地产中介表示,ChatGPT已经改变了他们撰写房源情况、在社交媒体上发帖打广告以及起草房屋买卖法律文件等的工作方式。ChatGPT还可以用于自动完成重复性任务,比如回答客户提出的常见问题或进行复杂计算。
- 利用ChatGPT起草具有法律约束力的附录和其他文件,并将其送交律师审批。“我用ChatGPT对各种草稿进行微调,”他说,“有时我会让ChatGPT把内容做得更短或更有趣,它会给你很多样本供挑选和编辑。”
RoomGPT 装修设计
RoomGPT,一个免费开源的项目,使用AI自动生成房间设计图,只需要上传你房间的图片,而且有各种主题和房间类型可选择,稍等几秒钟,AI即可帮你生成高大尚的装修设计后概念图,一秒打造你梦想中的房间,项目使用 ControlNet 的 ML 模型来生成房间的变体 ML ,模型托管在 Replicate 上。
【2023-3-27】RoomGPT 根据要求生成指定风格的装修,免费3次生成
- 作者twitter
- 选择装修风格、房屋、实拍图,就可以生成设计图。
- 主题:Modern(现代), Minimalist(简约), Professional(专业), Tropical(热带), Vintage(复古), Industrial(工业), Neoclassic(新古典主义)
- 房屋类型:living room(客厅), dining room(餐厅), Office(办公室), Bedroom(卧室), Bathroom(浴室), Basement(地下室), Kitchen(厨房), Gaming Room(游戏室)
项目使用 ControlNet 来生成房间设计。ControlNet 是一个可以控制图像生成 AI 的输出的神经网络结构。
ControlNet 的优点是:
- 指定生成图像的姿势、深度、轮廓等条件。
- 保持输入图像结构,同时转换成不同的风格。
- 与其他图像生成 AI 技术结合使用,比如 Stable Diffusion2。
项目用到的 ControlNet 服务部署在 Replicate 上,Replicate 是一个网站和服务,可以让用户轻松地部署和使用开源的机器学习模型。
作者:江昪
户型图3D重建
CVPR 2021:住宅户型识别与重建。2021年,阿里巴巴发表论文,基于2D户型图成为3D模型
- 论文:Residential floor plan recognition and reconstruction
- 原始户型图,图像识别结果,矢量化重建结果与最终的3D重建结果
实拍图美化
【2023-4-18】autoenhance, Instant real estate photo editing, 房产领域图片美化:更换天气(阴天→蓝天)、对比度(模糊→清晰)、马赛克(模糊人脸/车牌)、角度调整(视角)、光线(暗→明)
智能家居
语音助手操控家居
高级Web开发人员Mate Marschalko用短短不到1小时的时间,通过与ChatGPT背后的GPT-3大模型交互,结合Siri Shortcuts做出了一个更智能的语音助手。这个语音助手不仅能控制整个苹果HomeKit智能家居系统,而且能够以超低的延迟响应轻松回答生各种问题。
他给予了ChatGPT极高评价,称尝试过这个产品后,包括苹果Siri、亚马逊Alexa、谷歌Home在内的所有“智能”助手,都显得如此愚蠢而没用。
- Mate Marschalko演示新智能助手操纵苹果HomeKit智能家居系统
ultralytics yolo
【2023-10-7】当YoloV8与ChatGPT互通,这功能是真的强大!后期打通语音试试
- 代码ultralytics
- 流浪地球的MOSE 变成现实
pip install ultralytics
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
# 接入视频并启动Yolov8实时检测
python main.py
# chatgpt 命令
Lock the area on the right for real-time detection
小爱音箱
【2024-6-7】将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手
- MiGPT:智能家居,从未如此贴心
- mi-gpt
MiGPT 通过将小爱音箱、米家智能设备,与 ChatGPT 的理解能力完美融合,让你的智能家居更懂你。
MiGPT 不仅仅是关于设备自动化,而是关于:打造一个懂你、有温度、与你共同进化的家
数字人
详见 数字人专题
金融
【2024-9-17】扯淡的银行业大模型
查询了下各个银行的年报和公开信息,提千亿极概念的不止一个银行,目前已经有
中国银行(内部知识服务,辅助编码场景)工商银行(座席助手,网点员工智能助手场景)交通银行(办公助手,客服问答场景)农业银行(客服知识库答案推荐,知识库辅助搜索场景)邮储银行(研发测试,运营管理,客户营销,智能风控,投诉问题分类场景)建设银行(向量知识库,文生图,智能客服,市场营销,投研报告,智慧办公,智能运营,智能风控场景)中信银行(代码生成,智能操作场景)平安银行(零售贷款审批,运营管理,消保降诉,汽车金融AI验车场景)招商银行(零售,批发,中后台场景)民生银行(数字化决策场景)兴业银行(智能研报摘要生成,企金产品智能问答,研发代码辅助生成,数字助手场景)
不完全统计,11个银行公开提出了大模型建设并明确了对应的研发场景。
大模型汇报层面已经形成完备的方法论和理论知识体系,扯淡的功夫一脉相承。所谓的大模型或采购,或自研。
但是,出彩的场景并不多,而且所谓自研,大概就是基于某个开源模型用场景数据微调。
大部分没分清楚大模型和小模型,大模型的核心技术底座和大模型应用的区别, 就出来大吹特吹,这完全符合银行科技部高管吹牛逼不打草稿而业务并不熟练的人设特征。
场景为王,科技深入一线,少提概念,多干实事
度小满: 轩辕
【2023-5-26】度小满开源国内首个千亿参数金融大模型“轩辕”
- 度小满正式开源国内首个千亿级中文金融大模型——“轩辕”。
- 轩辕大模型是在1760亿参数的Bloom大模型基础上训练而来,在金融名词理解、金融市场评论、金融数据分析和金融新闻理解等任务上,效果相较于通用大模型大幅提升,表现出明显的金融领域优势。
在金融场景中的任务评测中,轩辕全面超越了市场上的主流开源大模型,赢得了150次回答中63.33%的胜率,充分凸显了其在金融领域的显著优势。在通用能力评测中,轩辕有10.2%的任务表现超越ChatGPT 3.5,61.22%的任务表现与之持平,涉及数学计算、场景写作、逻辑推理、文本摘要等13个主要维度。
BloombergGPT
【2023-3-31】金融圈注意了!BloombergGPT来了
ChatGPT引爆的AI热潮也“烧到了”金融圈,彭博社重磅发布为金融界打造的大型语言模型(LLM)——BloombergGPT。
3月30日,根据彭博社最新发布的报告显示,其构建迄今为止最大的特定领域数据集,并训练了专门用于金融领域的LLM,开发了拥有500亿参数的语言模型——BloombergGPT。
- 该模型依托彭博社的大量金融数据源,构建了一个3630亿个标签的数据集,支持金融行业内的各类任务。该模型在金融任务上的表现远超过现有模型,且在通用场景上的表现与现有模型也能一较高下。
BloombergGPT的训练数据库名为FINPILE,由一系列英文金融信息组成,包括新闻、文件、新闻稿、网络爬取的金融文件以及提取到的社交媒体消息。
为了提高数据质量,FINPILE数据集也使用了公共数据集,例如The Pile、C4和Wikipedia。FINPILE的训练数据集中大约一半是特定领域的文本,一半是通用文本。为了提高数据质量,每个数据集都进行了去重处理。
在金融领域中的自然语言处理在通用模型中也很常见,但是,针对金融领域,这些任务执行时将面临挑战:
- 以情感分析为例,一个题为“某公司将裁员1万人”,在一般意义上表达了负面情感,但在金融情感方面,它有时可能被认为是积极的,因为它可能导致公司的股价或投资者信心增加。
从测试来看,BloombergGPT在五项任务中的四项(ConvFinQA,FiQA SA,FPB和Headline)表现最佳,在NER(Named Entity Recognition)中排名第二。因此,BloombergGPT有其优势性。
- 测试一:ConvFinQA数据集是一个针对金融领域的问答数据集,包括从新闻文章中提取出的问题和答案,旨在测试模型对金融领域相关问题的理解和推理能力。
- 测试二:FiQA SA,第二个情感分析任务,测试英语金融新闻和社交媒体标题中的情感走向。
- 测试三:标题,数据集包括关于黄金商品领域的英文新闻标题,标注了不同的子集。任务是判断新闻标题是否包含特定信息,例如价格上涨或价格下跌等。
- 测试四:FPB,金融短语库数据集包括来自金融新闻的句子情绪分类任务。
- 测试五:NER,命名实体识别任务,针对从提交给SEC的金融协议中收集金融数据,进行信用风险评估。
对于ConvFinQA来说,这个差距尤为显著,因为它需要使用对话式输入来对表格进行推理并生成答案,具有一定挑战性。
量化交易
见站内量化专题
GPT在量化暂还没有广泛应用
- 【2024-9-7】30 天 52% 回报:GPT-4o 量化交易机器人
- 【2024-7-26】哥伦比亚大学 Large Language Model Agent in Financial Trading: A Survey,对利用大型语言模型作为金融交易Agent进行了首次系统调研,总结了两种主要架构设计、四类关键数据类型以及评估方法,并讨论了当前局限性与未来方向。
- 【2024-11-26】瑞士日内瓦 RAM Active Investments的Systematic Equities Team。如何对大型语言模型(LLMs)进行微调,用财经新闻流来预测股票回报。股票回报预测对于量化投资任务,如投资组合构建和优化,是基础且重要的。Fine-Tuning Large Language Models for Stock Return Prediction Using Newsflow
法律
LaWGPT
【2023-5-13】LaWGPT, Chinese-Llama tuned with Chinese Legal knowledge. 基于中文法律知识的大语言模型
- Legal-Base-7B:法律基座模型,使用 50w 中文裁判文书数据二次预训练
- LaWGPT-7B-beta1.0:法律对话模型,构造 30w 高质量法律问答数据集基于 Legal-Base-7B 指令精调
在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
PowerLawGLM
【2023-6-28】法律大模型的突围,千亿参数级PowerLawGLM重磅发布
- 幂律联合智谱AI此次联合发布基于中文千亿大模型的法律垂直大模型——PowerLawGLM,聚焦于法律细分领域,针对中文法律场景的应用效果具有独特优势,具备丰富的法律知识和法律语言理解能力。
将通用大模型直接应用在法律领域,往往存在着严重的效果问题,例如 法律知识错误、专业引用偏差、法律体系差异等问题。比如前段时间美国律师使用ChatGPT来提交法庭简报,结果引用的6个案例都是ChatGPT编造的虚假案例,这种“人工智能幻觉”现象在法律场景屡见不鲜,也说明了目前通用大模型难以保证法律专业层面的真实性、正确性。
幂律智能自2017年成立以来即深耕于法律+AI领域,基于领先的法律AI能力,向企业提供智能合同产品,并且深度参与了清华大学自然语言处理实验室的OpenCLaP、LawFormer等法律大模型的研发及应用。而智谱AI作为领先的通用大模型厂商,法律领域是其大模型迭代及布局的重要方向,基于双方达成的战略合作,在法律大模型上展开深度合作,来加快推动大模型在法律行业应用落地及商业化。
自2023年初双方成立联合项目组,启动法律大模型研发以来,经过千亿规模的基座模型增量训练、对话层监督微调、应用层工程优化,推出了基于中文千亿大模型的法律垂直大模型—— PowerLawGLM。
- PowerLawGLM法律大模型,基于智谱目前效果最好的ChatGLM 130B通用千亿对话大模型进行联合研发。
训练法律垂直大模型
- 第一步 —— 基座层:阅读大量法律文本。
- 第二步——对话层:与法律对话场景对齐,具备法律场景的对话能力。
- 第三步——应用层:保证输出结果质量和可靠性。
北大:ChatLaw
【2023-7-3】ChatLaw, 基于 IDEA发布的姜子牙 训练而来,源自 LLaMA
ChatLaw:北大法律AI大模型,免费全能律师,思维导入分析案情,给出建议
ChatLAW的数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据
ChatLaw系列模型
- ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
- ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
- ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如:
- “请问如果借款没还怎么办。”
- “合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;
- 贷款人可以催告借款人在合理期限内返还。”
- 两段文本的相似度计算为0.9960

3D 建模
Unique3D
【2024-6-13】3D革命来袭!北大清华00后学霸团队打造爆火模型“Unique3D”
清华00后学霸团队——AVAR AI的Unique3D
- Github链接:Unique3D
- Huggingface Demo
- 项目主页
- 论文链接:Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
AVAR AI团队由北大计算机系毕业的CEO胡雅婷领衔,成员包括来自清华姚班的CTO吴凯路等。
- 应用前景:从3D到4D的跨越, 新功能DreamCamera即将上线
团队成员不仅在技术领域有着深厚的背景,更有着艺术创作的才华。
Diffusion4D
【2024-6-29】靠Scaling Laws炼出4D版视频生成模型,多伦多大学北交大等新成果
多伦多大学、北京交通大学、德克萨斯大学奥斯汀分校和剑桥大学团队 推出 3D模型的动画视频生成工具 Diffusion4D
Diffusion4D 整理筛选了约81K个4D assets,利用8卡GPU共16线程,花费超30天渲染得到了约400万张图片,包括静态3D物体环拍、动态3D物体环拍,以及动态3D物体前景视频。
该方法是首个利用大规模数据集,训练视频生成模型生成4D内容的框架,目前项目已经开源所有渲染的4D数据集以及渲染脚本。
过去的方法采用了2D、3D预训练模型在4D(动态3D)内容生成上取得了一定的突破,但这些方法主要依赖于分数蒸馏采样(SDS)或者生成的伪标签进行优化,同时利用多个预训练模型获得监督不可避免的导致时空上的不一致性以及优化速度慢的问题。
4D内容生成的一致性包含了时间上和空间上的一致性,它们分别在视频生成模型和多视图生成模型中被探索过。基于这个洞见,Diffusion4D将时空的一致性嵌入在一个模型中,并且一次性获得多时间戳的跨视角监督。
机器人
ChatGPT接入实体机器人,线上线下整合营销ChatGPT大多数时候主要作用于线上,但在线下消费场景也显示出潜力。
【2023-5-6】B站 稚晖君 做aigc+机器人的创业
【2023-8-24】甲子光年 人形机器人+大模型,为什么是投资人追逐的新风口 2023世界机器人上,以前只能在科幻电影中出现的人形机器人在现场表演起了各种技能。小米、追觅科技、优必选、达闼科技、宇树科技、大连蒂艾斯科技、星动纪元、理工华汇等很多公司都把自己的人形机器人搬到了现场。
3月8日,谷歌和柏林工业大学的团队重磅推出了史上最大的视觉语言模型——PaLM-E,同时谷歌表示,计划探索PaLM-E在现实世界场景中的更多应用,例如家庭自动化或工业机器人,希望PaLM-E能够激发更多关于多模态推理和具身AI的研究。
国内多家互联网巨头也在AI+机器人领域动作频频。
- 4月25日,据腾讯Robotics X实验室公布最新机器人研究进展,首次展示在灵巧操作领域的成果,推出自研机器人灵巧手“TRX-Hand”和机械臂“TRX-Arm”。
- 4月24日,据企查查APP显示,近日北京小米机器人技术有限公司成立,注册资本5000万元人民币。经营范围包含:智能机器人的研发;人工智能行业应用系统集成服务;人工智能基础资源与技术平台;微特电机及组件制造等。资料显示,小米在国内机器人布局版图不断扩大,从CyberDog(仿生机器狗),再到Cyberone(仿生机器人),持续加注在机器人领域的研发和创新。
国内AI服务器机器人领军企业猎户星空计划在近期推出接入大模型的服务机器人产品。猎户星空董事长傅盛在3月15日第一时间分享了GPT-4体验视频,他说:“GPT-4发布世界要变了!每个人都要关心。”
这个“变”指的是什么?
- 一是交互革命。
- 2007年乔布斯发布iPhone时就是一个交互革命,触摸键盘由此替代了物理键盘,软件定义了不同键位的形态和用法;
- 现在随着GPT-4的到来,触摸键盘将可能进一步被语音交互替代;
- 二是社会生产力变革,生产效率会大大提升。
其中前者对机器人领域影响更大,而后者对内容产业影响力较大。不过,实体机器人是从软硬件开发到工程化落地、运营链条更长的载体,如何让产品真正解决场景刚需,是这个赛道玩家面临的重要问题。实体服务机器人企业能否找到刚需场景,一整套机器人技术链能否支撑其实现产品化十分关键。
大模型还促进了具身智能(实体机器人)的发展,一系列大模型应用于机器人,如 PaLM-E 和 RT-2,操控更加灵活。

虚拟智能体
【2023-7-20】详见站内智能体专题
OpenAI投资 NEO
【2023-3-23】GPT机器人要来了?OpenAI领投挪威人形机器人公司1X
挪威人形机器人公司1X Technologies(前称为Halodi Robotics)宣布在OpenAI领投的A2轮融资中筹集了2350万美元。
- 消息一出,便引发了外界对于GPT模型和机器人结合的无限遐想。其中一个景象便是,人形机器人管家从电影走入现实生活,它不仅能够帮助人类做家务,还可以理解人类的语言,识别人类的情绪,并做出真正智能化的回应。
1X计划用这笔资金来加大力度研发双足机器人模型NEO,以及在挪威和北美量产其首款商用机器人EVE。

阿里大模型驱动机器人
【2023-4-27】阿里云工程师也正在实验将千问大模型接入工业机器人,以便实现远程指挥机器人工作。在近日举行的第六届数字中国建设峰会上,阿里云发布的一个演示视频中展示了千问大模型的实际应用场景。
“我渴了,找点东西喝吧。”工程师通过钉钉对话框向机器人发出指令后,千问大模型回答,“好的,我找找有什么喝的。”随后,千问大模型在后台自动编写了一组代码发给机器人,机器人开始识别周边环境,从附近的桌上找到一瓶水,并自动完成移动、抓取、配送等一系列动作,递送给工程师。

- 动图见原文
表情控制
【2023-3-31】当人形机器人通过GPT3控制表情
英国 Engineered Arts 公司设计的 Ameca人形机器人,Ameca是用于人工智能和人机交互的仿人机器人平台。
- CES 2022美国拉斯维加斯国际消费类电子产品展览会上首次亮相,Ameca是用于人工智能和人机交互的仿人机器人平台,当然视频里只是预先编程的动作,但最终目标是将其与实际的AI集成。
机器人Ameca是由GPT-3来选择的合适的面部表情,也尝试了GPT-4,4的处理时间更长,使Ameca看起来反应没那么快。
此前官方发布的视频:BV1Xr4y1Q7kM
Tiamo小鱼
2月底,国内服务机器人企业穿山甲机器人推出了首款接入ChatGPT的迎宾机器人“Tiamo小鱼”,据称支持超100种场景应用方案、百万级知识库和超140种语言选择,同时穿山甲机器人还将其他系列机器人也支持接入ChatGPT。
- 当机器人被问及“你跟其他的服务机器人有什么区别”时,该机器人回复自己“采用的是深度学习和自然语言处理技术”。

Engineered Arts
【2023-7-11】能边聊天边画画的AI机器人🤖️ Engineered Arts表情丰富的机器人之前接上GPT搞语音聊天,现在还能用SD自己画🐱了,而且一边画猫一边聊人类为啥喜欢猫
- 演示视频见微博
RPA
自动化是人类技术发展的主要动力,帮助人类从复杂、危险、繁琐的劳动环境中解放出来。自早期农业时代的水车灌溉,到工业时代的蒸汽机,人类一直在不断寻求更加先进的自动化技术,从而解放自身于繁重的工作。
随着信息时代的到来,软件作为信息处理、存储和通信的基础成为了人类生产生活密不可分的一环,从而催成了机器人流程自动化(Robotic Process Automation, RPA)技术。其通过人工编制规则将多个软件协调成一个固化的工作流(Workflow),通过模拟人交互的方式来和软件交互实现高效执行。
RPA 利用软件机器人或称为 “BOT” 来模拟和执行重复性、规则性的任务,从而解放人力资源,提高工作效率。RPA 的应用范围非常广泛。很多企业(包括银行、保险公司、制造业、零售业等各个行业)常利用 RPA 机器人来自动执行一些常规和繁琐的任务,例如:数据录入、数据提取、数据处理。通过自动化任务,RPA 可以大幅度减少错误率,并且能够在 24*7 不间断地执行任务,从而提高了业务的可靠性和响应能力。
根据市场研究,RPA 市场正在迅速增长并取得巨大成功。Gartner 预测,2023 年全球 RPA 市场收入将达到 33 亿美元,相比 2022 年增长 17.5%。这表明了企业对于 RPA 的强烈需求和认可。
但是,RPA 仅能替代简单、机械的人力工作,一些复杂流程仍旧依赖人工:
- 编写 RPA 工作流本身需要繁重的人类劳动,成本较高。
- 复杂任务非常灵活,通常涉及动态决策,难以固化为规则进行表示。
案例
【2024-12-27】 AI+RPA 强无敌
RPA(机器人流程自动化)让机器人24h不间断的工作, 从重复、繁琐的工作中解放出来
- 1.0时代,我们人工操作写一篇回答需要1小时;
- 2.0时代,我们借助AI操作写一篇回答需要10分钟;
- 3.0时代,我们借助RPA+AI操作写一篇回答需要2分钟;
RPA工具:
- 公众号/头条/知乎仿写工具:机器模拟人操作网页/客户端软件,鼠标点击、键盘操作
- 知乎写作
- 公众号仿写
- 剪映编辑视频
- 闲鱼批量发布500件商品工具:闲鱼商品自动上架
- 1000张图片批量转视频工具
句子互动
【2024-11-7】李佳芮,90后AI创业者,她是一位技术极客,写的开源代码在GitHub上获得上万收藏。
现在她是句子互动的创始人,专注在 RPA+AI,服务几百家客户,包括宝洁、国家电网等,被Plug and Play、YC、奇绩(创坛)、真成抢着投资。
- 她十年的创业历程,曾经一夜之间失去90%的客户…
- 现在打造大模型驱动的数字员工
1、硅谷的0-1创业方法论 2、中美的AI创业氛围有什么不同 3、RPA+AI怎么让企业营收翻番 4、创业濒临死亡,怎么破茧重生 5、怎么做有效的用户需求调研 6、AI SaaS服务成功秘诀
ProAgent
【2023-11-14】被OpenAI带火的Agent如何解放人力?清华等发布ProAgent
清华大学研究人员联合面壁智能、中国人民大学、MIT、CMU 等机构共同发布了新一代流程自动化范式 “智能体流程自动化” Agentic Process Automation(APA),结合大模型智能体帮助人类进行工作流构建,并让智能体自主处理工作流中涉及复杂决策与动态处理的环节,进一步提升自动化的程度,提高效率,将人类从繁重的劳动中解放出来。
大模型智能体技术(Large Language Model based Agents, LLM-based Agents)也许给自动化技术创造了新的可能性。有没有可能将 Agent 技术的灵活性引入到 RPA 领域中,来进一步减少人的参与呢?
机器人流程自动化 RPA 与智能体流程自动化 APA 对比
大模型智能体时代下新型自动化范式 “智能体流程自动化” Agentic Process Automation (APA)。和传统 RPA 相比,在 APA 范式中,Agent 可根据人类需求自主完成工作流构建,同时其可以识别人类需求中需要动态决策的部分,将自动编排进工作流中,并在工作流执行到该部分时主动接管工作流的执行完成相应复杂决策。
为了探索 APA 的可能性,该研究实现了一个自动化智能体 ProAgent,其可以接收人类指令,以生成代码的方式构建工作流,同在工作流中引入 DataAgent 和 ControlAgent 来在工作流中实现复杂数据处理与逻辑控制。ProAgent 的研究展现了 APA 在大模型智能体时代下的可行性,也揭示了 LLM 时代下,自动化技术的崭新可能性。
团队相关研究,包括:
- XAgent:超强大模型智能体应用框架,可自行拆解复杂任务,并高效执行。
- ChatDev:多智能体协作开发框架,让多个不同角色的智能体进行协作,自动化开发软件应用。
- AgentVerse:大模型驱动的智能体通用平台,招募各种各样的 agent 专家,共同帮助用户解决复杂任务。
boston Spot 2.0
【2023-10-28】波士顿动力公司的 Spot 2.0 集成了 OpenAI 的 GPT-4 和 3 种新的人工智能能力
探索革命性的 Spot 2.0,波士顿动力公司(Boston Dynamics)的机器狗现在由 OpenAI 的 GPT-4 驱动,展示了三种惊人的新人工智能能力。深入了解机器人技术与先进人工智能的变革性融合,见证 Spot 如何重新定义人机互动。
Spot 身上添加了蓝牙扬声器和麦克风,一个配备摄像头的手臂作为其颈部和头部。Spot 抓握手通过张开和闭合来模仿说话的嘴。这为机器人提供了一种肢体语言。
语言和图像处理方面,升级后的 Spot 使用 OpenAI 最新的GPT-4模型,以及视觉问答(VQA)数据集和 OpenAI 的 Whisper 语音识别软件,以实现与人类的真实对话。
例如,随着“嘿,Spot!”的叫醒声,机器狗在波士顿动力总部履行导游职责时回答问题。Spot 还可以识别旁边的人,并在对话过程中转向该人。
- 当被问及公司创始人 Marc Raibert 时,Spot 回答说他不认识此人,但可以向 IT 服务台请求支持。此请求帮助并不是提示中的明确指示。
- 当被问及父母时,Spot提到了他实验室里的前辈“Spot V1”和“大狗”,称他的长辈。
此外,波士顿动力公司写道, ChatGPT机器人非常擅长坚持预先定义的角色,例如不断发表尖酸刻薄的言论。
Figure 01 & OpenAI
【2024-3-14】OpenAI机器人,来了
人形机器人初创公司 Figure AI 发布了一段视频演示。视频中,公司研发的Figure 01机器人接入了OpenAI的大模型,能够与人类对话,理解并执行人类的指令和任务。据介绍,OpenAI模型提供高级视觉和语言智能,Figure神经网络提供快速、低级、灵巧的机器人动作。
公司介绍
- Figure AI 成立于2022年,总部位于美国加州,是一家致力于研发自主通用人形机器人的初创公司。
- 2023年,Figure AI从Parkway Venture Capital领头的投资者手中筹集了7000万美元,用于加速其首款自主人形机器人Figure 01的开发和制造。
- 2024年2月底,Figure AI宣布完成新一轮约6.75亿美元(约合人民币48.7亿元)的融资,用于开发为重复且危险的仓库及零售等工作提供劳动力补充的人形机器人。
- 亚马逊创始人贝索斯、英伟达、微软和OpenAI等硅谷科技巨头都将为Figure AI提供融资支持。
- Figure AI此轮融资前估值约为20亿美元。
Figure 01 身高大约170cm,体重60KG,可以实现20KG的有效载重,移动速度1.2米/秒,续航可以达到5小时。
Figure 01拥有的能力包括:
- 一、视觉识别和理解。当人类问Figure 01看到了什么,Figure 01回答道:“我看到了桌子中央的盘子上有一个红苹果、一个装满杯子和盘子的晾碗架,以及你站在附近,手放在桌子上。”
- 二、语言识别和理解。当人类问Figure 01能够吃点什么东西时,Figure 01将桌上的苹果递给了人类,并表示这是“唯一我可以从桌上为你提供的食物”。
- 三、流畅的任务执行。视频展示了Figure 01清理桌面垃圾、整理晾碗架的场景。
Figure 01在与人类对话及执行具体任务时,速度与流畅度较此前已经有大幅提升。据Figure的联合创始人兼首席执行官Brett Adcock介绍,视频是以正常倍速速度连续拍摄的,没有加速播放,而且没有人类在远程控制机器人的动作。
无人机
【2023-11-25】让大模型操纵无人机,北航团队提出具身智能新架构
北京航空航天大学智能无人机团队周尧明教授团队等研究人员,提出了一种基于多模态大模型的具身智能体架构。
只要视觉模块捕捉到启动条件,大模型这个“大脑”就会生成动作指令,接着无人机便能迅速准确地执行。
将真实物理世界的照片、声音、传感器数据等多源信息融合成能体的感知,将对于真实世界的执行器的操作作为智能体的行为。
同时,团队提出了一套“Agent as Cerebrum,Controller as Cerebellum”(智能体即大脑,控制器即小脑)的控制架构:
- 智能体作为大脑这一决策生成器,专注于生成高层级的行为;
- 控制器作为小脑这一运动控制器,专注于将高层级的行为(如期望目标点)转换成低层级的系统命令(如旋翼转速)。
这些节点通过ROS相连,通过ROS中消息的订阅与发布或服务的请求与响应实现通信,区别于传统的端到端的机器人大模型控制。
智慧农业
苹果采摘机器人
【2021-11-23】阿里巴巴 中国:机器人采摘苹果,人工智能改变农业的时代
【2023-4-1】苹果采摘机器人系统 无人机采摘苹果 农业机器人
一个有趣的苹果采摘系统,Tevel 的无人机采摘系统使用计算机视觉和人工智能算法识别并精准采摘成熟苹果,采摘精度和速度都很可观,同时避免破坏其他水果和果树。是农业机器人领域一个不错的实现
家政机器人
AutoRT
【2024-1-5】Google DeepMind 机器人团队推出 AutoRT、SARA-RT 和 RT-Trajectory,旨在提升机器人在真实世界环境中的数据采集效率、动作速度和应用泛化能力
设想: 只需向个人助理机器人发出一个简单指令——比如“整理房间”或“为我们准备一顿美味健康的饭菜”——它就能轻松完成这些任务。对于人类而言易如反掌的这些活动,对机器人来说则需要深刻理解周围世界。
Google DeepMind 机器人团队一篇博客展示了最新的研究进展,不过只有一篇博客,没有代码。
他们开发了一种名为AutoRT的新技术,这是一个将大型基础模型(比如 大语言模型 (LLM) 或视觉语言模型 (VLM))与机器人控制模型(RT-1或RT-2)相结合的系统。这个系统使得机器人能够在全新的环境中收集训练数据。良好的感知模型配合能够生成运动控制系统指令的大语言模型 (LLM),将在机器人领域站在潮头。
AutoRT 结合了大型基础模型和机器人控制模型(如 RT-1 或 RT-2),打造了一个能够在新环境中部署机器人收集训练数据的系统。该系统能同时指挥多台配备视频摄像头和末端执行器的机器人,在各种环境中执行多样化任务。
- 对于每台机器人,系统利用 VLM 理解其所处的环境和视野中的物体。
- 然后,LLM 会提出一系列创意任务,比如“将零食放置在台面上”,并作为决策者为机器人选定合适的任务。
机器人安全准则在挑选机器人任务时必须遵守,部分受到艾萨克·阿西莫夫提出的机器人三大定律的启发,首要原则是“机器人不得伤害人类”。其他的安全规则还包括禁止机器人执行涉及人类、动物、锋利物体或电器的任务。
然而,即使大型模型在指令上进行了精心设计,也不能单凭此保证安全。因此,AutoRT 系统还结合了来自传统机器人技术的多层实际安全措施。
- 比如,协作机器人被设定了一项安全程序:一旦其关节所受力量超过特定阈值就会自动停止运作。
- 此外,所有活动中的机器人都在人类监督员的视线内运作,且均配备有紧急停机开关。
在长达七个月的广泛现实世界测试中,该系统能安全地同时指挥多达 20 台机器人,总共使用了多达 52 台不同的机器人,在多个办公楼中收集了包含 77,000 次机器人试验的多样化数据集,涉及 6,650 种独特任务。
自适应鲁棒注意力用于机器人 Transformer (SARA-RT),能将机器人 Transformer (RT) 模型转化为更高效的版本
RT-Trajectory 的模型,它能自动向训练视频中添加展示机器人动作轮廓的视觉线条。RT-Trajectory 对训练数据集中的每个视频进行处理,增加一个二维的轨迹草图,用以展示机器人手臂的抓取部分在完成任务时的移动轨迹。这些以 RGB 图像形式展示的轨迹,为模型提供了直观、实用的视觉线索,帮助它学习控制机器人的策略。
在对 41 个训练数据集中未出现过的任务进行测试时,由 RT-Trajectory 控制的机械臂的表现是现有最先进的 RT 模型的两倍多。与 RT-2 的 29% 成功率相比,RT-Trajectory 达到了 63% 的任务完成率。
mobile aloha
【2024-1-5】斯坦福大学重磅发布开源机器人mobile aloha, 能在日常环境中自主完成复杂的任务
- Mobile aloha 通过模仿学习直接克隆人类行为,这能让它学会任意技能。通过低成本全身远程操作来学习双手移动操纵技术。目标是使机器人能够执行复杂的移动操作任务,同时保持低成本和易于操作的特点。
- Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- Mobile aloha主页
- 代码: act-plus-plus
Mobile ALOHA并不是一个机器人,而是一个操作系统。借助这个系统,机器人可以轻松完成各种惊喜工作,比如煎蘑菇
Cybrothel
德国柏林 首家虚拟妓院 成人用品使用AI技术
世界首家虚拟妓院 Cybrothel,顾客可租借AI加持的实体逼真情趣玩偶,在虚拟现实中与之互动
- 下一代机器人玩偶,能够实时响应触摸和说话
- 视频演示
RoboFlamingo
【2024-1-17】机器人领域首个开源视觉-语言操作大模型,RoboFlamingo激发开源VLMs更大潜能
ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。使用简单、少量的微调就可以把 VLM 变成 Robotics VLM,从而适用于语言交互的机器人操作任务。
OpenFlamingo 在机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能。
MultiPLY 具身智能 多感官大模型
多模态大模型,如LLaVA、Flamingo、BLIP-2、PaLM-E,在视觉语言任务中表现出色。然而,它们主要关注2D场景理解,很难对3D环境进行推理和交互。
尽管目前也有关于3D场景理解的大模型研究,但这些LLM缺乏捕捉视觉和语言之外的多感官信息的能力。相比之下,人类通过触摸甜甜圈,能够感知其柔软度和温度,而这种能力远远超出了当前多模态LLM的范围。
原因
- 当前缺少训练LLM的多感官交互数据,另外还缺乏对3D场景和物体的多感官信息的正确表示。
- 通过将场景抽象为以「对象为中心」的表示,并在与对象进一步交互时关注对象细节,人类很轻易就能做到。
- 对于LLM来说,必须在以对象为中心的表示,以及详细多感官信息之间灵活切换。
为此,研究人员提出了MultiPLY,一种多感官呈现的LLM,可以通过部署由LLM驱动的智能体与3D环境进行交互,从而对以对象为中心的多感官表示进行编码,包括视觉、音频、触觉和温度信息。
【2024-1-22】Agent触摸汉堡辨冷热,首次拥有类人感官!UCLA等发布3D多模态交互具身智能大模型
具身智能是大模型未来应用的一个重要方向。
UMass Amherst、UCLA和MIT-IBM Watson AI Lab研究人员,推出了全新的具身智能大模型MultiPLY。
- 通过智能体与3D环境交互,MultiPLY呈现了大模型多感官能力,无缝地连接了语言、动作和感知!
- 论文地址:MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
推理过程中,MultiPLY能够生成动作token,指示智能体在环境中采取行动,并获得下一个多感官观测值。然后,通过状态token将观测结果反馈给LLM,以生成后续的文本或动作token。
在对象检索、工具使用、多感官标注和任务分解的具体任务实验中,MultiPLY的性能刷新SOTA。
现在大模型加持下的智能体,能够参与3D环境,不仅有了听觉视觉,还有了触觉等多种感官能力。
- 卧室里有什么物体,一眼辨认。
- 听到门铃响了,LLM便会告诉你家里来客人了。
- 大模型加持的NPC,在触摸桌子的香蕉后,发现没熟并建议不要吃。
- 甚至还能感受到物体的温度,餐桌上的汉堡已经凉了,会告诉你加热后再吃。
- 还擅长使用工具、物体检索、导航、任务分解等多种任务。
玩具机器人
AI 玩具载体
- 智能机器人
- 儿童玩具,毛绒玩具中
- 智能眼镜
市场
- 成年女性陪伴
- 老年人陪伴
AI 玩具大爆发
- 字节推出 “显眼包”,搭载豆包模型
- 特斯拉推出 机器人玩具,才40元
火山套件
【2025-2-5】火山引擎RTC联合乐鑫、移远:智能硬件注入“豆包”,“模”力升级
乐鑫和火山引擎开源整套“即插即用”的AI玩具软硬件方案,只需100多块钱的套件就能自己 DIY AI玩具了。
- 使用 Coze智能体的框架、支持MCP和Function Caling,可以接入各种工具和智能设备
- 这对早期入局AI玩具的人来说是好消息还是坏消息
2024年火山引擎冬季 FORCE 原动力大会上,火山引擎视频云携手乐鑫科技、ToyCity、FoloToy 和魂伴科技,共同推出了创新的“硬件+对话式 AI 智跃计划”,一起见证 AI+硬件加速融合。
当前「实时对话式 AI 嵌入式硬件」解决方案已成功应用于 IP 玩具、AI 机器人、智能家电等诸多硬件品类,为 IP 玩具注入数字生命(如视频演示),让 AI 机器人交互更加丰富生动,使智能家电因个性化服务而更具吸引力。
硬件设备中加入自然流畅的 AI 实时语音功能,面临挑战:
- 技术复杂变化快,研发成本高:厂商如果选择自行搭建音视频传输和编排语音大模型组件,还须依据硬件芯片特性开展深度优化调试工作,整体投入大。而且,多模态融合正成为交互趋势,研发工作的复杂程度也会进一步增加。
- 响应延迟优化棘手:随着硬件设备加速智能化,用户对语音交互的实时性和准确性有了更高的期待。
- 然而,许多厂商在初步集成 AI 实时语音功能时,面临3-5秒整体响应延迟。特别是在网络条件不佳(如信号弱或网速慢)的环境中,这种延迟可能会进一步延长,并且可能导致关键信息的丢失,严重影响 AI 反馈内容的质量。
- 交流像用“对讲机”,交互体验有待提升:市面上大多初代智能硬件的对话功能还不够成熟
- 用户在与 AI 互动时,持续按键输入,与人们日常生活中随时随地自然交流的习惯相去甚远,体验生硬如用“对讲机”。
- 此外,AI 返回内容若不符合预期或过长,用户无法实时打断,缺乏灵活性,难以满足用户对智能硬件的期待和需求。
火山引擎视频云 RTC 联合乐鑫、移远等物联网芯片制造商、解决方案供应商,推出「实时对话式 AI 嵌入式硬件」解决方案。
- 硬件设备通过方案的 AI 语音交互框架即可无缝对接火山引擎 RTC 的实时通信能力和云端智能体服务,实现与豆包大模型超低时延、流畅的交互。
- 在端侧,芯片集成了先进的音频处理技术,包括自动唤醒功能和音频3A 等,以提升音频输入的清晰度。
- 火山引擎 RTC 提供音视频传输,并具备抗弱网特性,以及智能体管理功能,确保设备即使在网络条件不佳的情况下也能稳定通话。
- 在云端,智能体服务则可提供 Function calling 和知识库支持,使得硬件设备能够提供个性化服务和智能决策,满足用户的深层次需求。
架构图
- 端侧,芯片集成其先进的音频处理,包括自动唤醒功能和音频3A(自动增益控制、噪声抑制、回声消除)等,保证音频输入的清晰度和准确性。
- 云端, 智能体服务则提供 Function calling 和知识库支持,使得硬件设备能够提供个性化服务和智能决策,满足用户的深层次需求。
实时对话式 AI 嵌入式硬件解决方案已开源,无需复杂的开发流程和适配兼容,即可快速高效地为硬件设备加入 AI 实时语音功能,一天内即可完成集成跑通
乐鑫(ESP32-S3)为例,开源嵌入式硬件解决方案 Demo, 包含演示过程,视频
开发套件: Sphero
Sphero 玩具介绍
- Sphero 是一个球形机器人玩具, 既可以用面板控制它滚动, 也可以实现编程, 包括积木编程.
- STEAM Education for All Ages & Stages
基本能力如下:
- 滚动: 可以设置 方向/速度
- 旋转: 原地旋转
- LED Matrix : 背部有一个 LED 的矩阵
- 头灯 / 尾灯 : Sphero 前后有两个灯
- 指南针: Sphero 可以通过指南针来校正朝向
- 碰撞感知: 可以感知到碰撞事件
用 LLM 来驱动一个实体机器人, 让 LLM 提供两个关键能力:
- 自然语言交互能力 (NLU)
- 自主决策能力 (AI)
一整套 LLM + DSL (领域语言) 的架构
- 用编程的驱动程序控制实体设备
- 用设计过的 DSL 调用驱动程序
- 用 LLM 扮演自然语言理解单元, 将自然语言解析成 DSL 驱动设备
- 让人类通过语音来自然语言控制
- 让 LLM 作为 AI, 直接控制设备, 自主决策
Ghost in Shells:
- Ghost: 负责机器人的思维, 记忆, 决策, 思考状态等.
- Shells: 负责机器人的身体, 管理 通信/设备状态/事件 等.
朱明实践:声控 AI 玩具 —— SpheroGPT
- 用 LLM (ChatGPT3.5) + Sphero 开发一个可以声控自然语言编程的 AI 玩具, 作为学习 ChatGPT 应用开发的方法.
- 地址
基础模式
- 对话与基本指令: 对话 / 前进 / 后退 / 旋转 / 画圆
- 绘制基本图形: 三角形, 正方形, 五角星, 数字 8 . 依赖 ChatGPT 使用基本指令自主编程.
学习模式 (模拟函数封装/调用) . 有以下目标:
- 多轮对话模式
- 允许 教学 / 测试 / 保存 等多个动作
- 支持基于上下文的 “修改”
- 支持将复杂命令保存为 “技能” (函数)
- 支持调用 “技能”
- 支持在一个技能里调用另一个技能 (函数嵌套)
- 支持循环调用技能 (循环调用函数)
基本的技术栈:
- 编程语言: python
- LLM : 分别使用了 openai 的 text-davinci-003, gpt-3.5-turbo, gpt-3.5-turbo-16k-0613
- 开发框架: 朱明开发的 ghost-in-shells 项目作为框架
- Sphero驱动: 用spherov2 , 逆向了 andorid 客户端实现的 python SDK
- 语音设备: 直接用 Mac
- 语音驱动: 用的 SpeechRecognition
- 语音识别 & 生成: 用的百度 ASR / TTS
开发套件: FoloToy
【2024-4-9】切入传统赛道,「FoloToy」用AI升级玩具
用AI改造传统行业(玩具),原先仅能播放音乐、讲故事的早教玩具,有了更多“玩法”,可实现多语种、多角色扮演对话,并且联网后还能提供丰富的天文地理知识。
「FoloToy」团队接入大模型后,同火火兔玩具厂商推出一款儿童或老人陪伴玩具——Fofo。
- 【2024-11-27】AI玩具:火火兔跑步入局
- 火火兔官方在近日的推文中宣布推出AI早教机器人,新品面向0-9岁用户,淘宝旗舰店定价499元,不同渠道的优惠价在249-399元之间。
- 火火兔AI早教机器人通过“全新升级的AI芯片”以及内置的“儿童版交互大模型”,面向家庭提供AI故事共创、定制爸爸妈妈的声音讲故事、AI全场景问答和连续对话等功能。
- 儿童版交互大模型”由火火兔与
科大讯飞联合定制,用以提供人机语音互动方面的技术支持。其互动内容涉及百科知识、生活常识、成语词典、历史诗词、讲故事。还有火火兔儿歌、故事新唱等。 
FoloToy 创始人王乐和郭兴华具备机器人和智能硬件开发经验。大模型出现后,基于日常家庭观察,公司认为故事机类玩具可与大模型结合,提升互动效果和承载的知识体量。
FoloToy 是一系列 AI 陪伴对话玩具,我们采用了最新的人工智能技术和 爱♥️ 来制作。每个人都可以使用 FoloToy 亲手打造一个与众不同的玩具角色,给爱的人带来快乐。
Fofo 玩具内置7种角色,能适配不同年龄段的儿童,
- 儿童可以和玩具对话,玩具解答诸如十万个为什么等知识性提问。
- 此外,家长可以在在后台系统配置大模型和引导词等参数后,让玩具成为特定的角色来用户进行对话。
- 同时,Fofo还可克隆家长的声音。
- 除讲故事外,Fofo多语言的能力,可以成为英语、法语等语言的口语陪练,引导儿童进行口语练习。
使用场景
- AI陪伴玩具面向全年龄段用户
- 电路板AI改造套件主要针对DIY玩家和企业客户,可以快速完成AI玩具的改造和AI语音对话产品原型搭建。
DIY 的 FoloToys
- 语音输入和语音输出
- LLM(大型语言模型)支持OpenAI/Azure OpenAI/Google Gemini/Baidu Qianfan/Dify/Moonshot
- SST(声音转文本)支持OpenAI Whisper/Azure Speech Service/Azure Whisper/Aliyun ASR/Dify
- TTS(文本转声音)支持OpenAI TTS/Azure Speech Service/Elevenlabs/Edge TTS/Aliyun TTS/Netease EmotiVoice/OpenVoice
- AI 对话数据发布到MQTT服务器
2023年7月,王乐和郭兴华在海外社交平台和国内B站(老郭AI玩具的工房)等渠道发布DIY教学视频,推广该套件。
Fofo定价在千元内,电路板套件定价百元左右,两者在全球销量合计已超千件。
除直接销售玩具产品和套件外,FoloToy与潮玩品牌合作。
- 去年年底,公司与
妖米星球共同推出高端AI人偶。 - FoloToy主要负责定制化AI玩偶硬件,使其性格、音色和角色设定的故事能融入与购买者的交互中。该玩偶定价数千元。
FoloToy的产品也支持企业定制使用。王乐介绍,FoloToy的套件产品能支持海内外主流的大模型云计算平台,如OpenAI、Microsoft Azure、阿里云等。企业可根据FoloToy提供的教学文档,选择合适的组合方案,便能定制出企业专用的对话机器人。
示例
毛绒玩具: Haivivi
【2024-7-8】毛绒玩具也可内置大模型,这款AI+硬件的产品会不会卖爆
儿童这个天真无邪的群体,每天都有无数问题。柔软而又可爱的毛绒玩具在接入大模型后,不仅能实时给孩子们满意的大幅,还能陪伴他们持续探索未知世界。
- 3-6岁的儿童大多还未走入校园,除与监护人共度时光外,毛绒玩具便成了与其陪伴时间最长的载体。
投资圈内开始对纯软件项目变得冷静。又因智能助手、基座模型的投资回报比迟迟得不到验证,让一些投资者开始反思。反而,在亚马逊等电商平台中,基于大模型的实体产品开始放量,AI+硬件的机会开始得到关注。
沃伦·巴菲特去年的投资案例中,通过伯克希尔·哈撒韦以116亿美元收购了美国玩具公司Jazwares的母公司Alleghany Corp.。
- Jazwares是Squishmallows品牌的开发商和推广者,以其可爱的外观和柔软的手感深受孩子和成年人喜爱。
据了解,该公司在业界非常成功,Squishmallows以其人格化的角色和故事背景,创造了超过2000个角色产品,全球销量达到2亿。
AI玩具赛道逻辑有三点关键性因素:
- 其一,国内拥有绝无仅有的制造业和供应链优势;
- 其二,作为主打情绪价值的品类,它并不是科技巨头的战略方向和擅长的领域;
- 其三,在GPT-4o所带领的多模态机会下,AI为儿童场景赋能的可行性变得越来越高。
当年,天猫精灵卖了3000多万台,孩子语音交互指令数量远远高于成年人,而偏偏,这些问题在大模型中,都可以得到回答
语音版 Copilot(智能助手)虽然带来了操作方式的创新,但其对效率的提升并不如预期
- 初衷是通过语音交互简化操作流程,提高用户的工作效率。
- 然而,实际应用中,它并没有显著提高效率,反而暴露出技术革新的局限性。
Haivivi(中文名:跃然创新)玩具公司开始展露头角。
- 创始人
李勇是天猫精灵的前合伙人,他在互联网和智能硬件领域拥有丰富的经验。 - 曾经担任
锤子手机的首任营销总监,并在天猫精灵负责市场和销售工作,帮助天猫精灵从0到1搭建了市场销售体系。 - 此外,李勇还曾担任
爱奇艺智能的CMO,探索XR硬件领域。
Haivivi 玩具中AI,主打识别孩子的情绪和需求,提供情感上的陪伴和支持功能。
- 孩子发散式和及时性需求反而是大模型最擅长的。
- 根据每个孩子的特点和兴趣,AI可以提供个性化的教育和娱乐内容。
父母可以通过APP与孩子进行远程互动,加强亲子间的联系。
Haivivi 输出内容可以对孩子进行心理层面的引导:
- “比如,如果家长希望孩子更加勇敢一点儿,就可以通过 APP 设置一下, AI 毛绒玩具在和孩子的互动中就可以多讲一些关于勇气和冒险的故事,多输出一些鼓励的话,让其更加勇敢,”
在语音设置上,Haivivi 较其他智能音箱更像一个朋友,所做出的回答更温暖、更主观
传统教育硬件产品大多扮演家长或老师的角色,这种基于大模型 Agent 的“朋友”角色,对于陪伴儿童的健康成长同样非常重要。
相较带语音功能的绘本和故事机产品,AI 毛绒玩具除了有更可爱的外观外,还可提供双向沟通场景。相比较“哪里不会点哪里”的学习机而言,后者的学习模式杜绝了以往的单向灌输模式,而更倾向于互动式沟通。
除毛绒玩具 IP 的竞争力外,其在硬件、软件、算法中的研发工作也是壁垒之一。其中包括模型Fine-Tune工作,硬件层面的语音编解码和网络传输协议优化等。
毛绒玩具: BubblePal
【2024-9-3】对话跃然创新:把大模型做到毛绒玩具上,一个AI界的泡泡玛特就出来了?
找不到商业化落地场景 Agent+一个简单的Wifi音箱+儿童喜爱的毛绒玩具,这三个看起来都平平无奇的元素,加在一起
挂在小熊玩偶上的“彩色泡泡”名叫BubblePal,从硬件形态上看像一个可爱版的 AI Friend
- 小朋友可以自由选择泡泡背后的角色:
爱因斯坦、艾莎公主还是孙悟空等等耳熟能详的动画角色,捏住泡泡就能与其对话; - 家长在后端通过手机APP能够获取对话的全部内容,以此来了解3-6岁小朋友的成长和心理健康动态。
就是这样的一个简单的“泡泡”,几乎巧妙地避开了如今围绕着AI的所有难题。
- 基座大模型能力还不够用?
- 容易出现 幻觉 ?
- Agent 不够像?
- 用户没有付费意愿?
对于根本不知道 ChatGPT、Claude 还是 Kimi 的小朋友和家长而言
- 在儿童提问场景,模型能力已经完全超出预期,甚至幻觉也可以当成是一种加分项和娱乐。
- 大模型幻觉可在儿童天马行空的对话场景下被接受的,毕竟儿童对话中信息密度和准确度的要求没那么高。
- 而在毛绒玩具市场里,IP联名本身就已经是成熟的商业模式,Agent 有了天然的落地场景。
跃然创新创始人李勇
BubblePal上线一个月,用户活跃度非常好,用户平均每天使用时长超过了 30 分钟- 上线当周,后台收到了大量订单咨询,家长反馈特别强烈。没想过能卖得这么好,更没想过的是,日tokens调用量正在成倍地往上涨,上线两周,单日tokens 消耗达到了2亿,现在每日 tokens消耗已经超过了4亿。
- BubblePal 研发时间仅仅用了9个月,在开售不到1个月的时间里,设备已经有效激活了超过1万台,以399元一个的产品定价,GMV超过400万元,“今年预计销量8万台,从目前的销售情况来看,应该比较乐观。”
- 毛绒玩具复购率很高,三岁给孩子买了孙悟空毛绒玩具,五岁又买了爱因斯坦毛绒玩具,因为绑定的是同一个账户,那么孩子跟孙悟空已经聊了两年了,这两年的记忆就可以自动同步给新的爱因斯坦毛绒玩具。
- 玩偶打通了之后还可以干嘛呢?开启“玩具总动员”的多智能体模式。孩子可以让孙悟空扮演船长,爱因斯坦扮演大副,三个人一起去冒险,我们在云端设置一个虚拟Agent去调配这两个角色,当孩子说了一句话之后,虚拟Agent就直接决定接下来轮到谁说话、说什么内容,沉浸式过家家。
为什么要做一个泡泡,而不是把它做在毛绒玩具里面?
- 两个都要做,先做泡泡是因为,内置在毛绒玩具里,IP方审核周期比较长,产品要年底才能上线。
- 泡泡相对来说研发周期更短一些,也能挖掘一部分存量市场。
接近3个小时的对话里,李勇多次提到“活着”,作为一名创业老兵,他曾经跟随罗永浩在锤子科技追求过理想,也被现实的商业世界逼到过墙角,2023年公司一度濒临破产,这让他的思考变得十分务实。
从 商业模式出发, BubblePal 本质上是一款面向儿童的消费电子,唯一不同的是接入了大模型能力。
技术不是壁垒,现在不是,以后也不会是: 两层模型 = 通用大模型 + 垂直小模型- 通用大模型: 国内主流 MiniMax、豆包、智谱都有,现在主要 MiniMax, 国外接 GPT等几家大模型; GPT-4o有了端到端语音能力,那我们可以减少延迟,让用户端的语音情绪能完全保留下来;模型端一旦具备了连续对话能力,我们还可以做多智能体。
- 垂直小模型: 基于Llama 2 开源模型 fine-tune。
- 产品:
别总盯着“AI圈”,才能找到PMF- 把大模型功能放在最喜欢的卡通角色里,那孩子不就疯了吗?
- 最近刚上线的
孙悟空角色,有同事的女儿中午午休玩了一中午不放手。 - AI儿歌功能,测下来,感觉
MiniMax效果不错, 早期用户有很多免费 tokens 额度
- 没有技术壁垒,有产品壁垒么?
- (1) APP除了联网, 家长还可以查看孩子的聊天记录, 准备成长报告; 为孩子报名了舞蹈班,但这周我发现孩子并没有谈论舞蹈,而是聊了十次足球,我就能发现孩子的兴趣所在。
- (2) 家长还可以在APP里还切换角色. 目前已经推出几十个角色,当然家长也可以自己创建,比如小猪佩奇、艾莎公主、库洛米等等。现在大概每周都会不定时更新一些角色吧。
- (3) 家长首次登录账户,选择角色时,还设置了角色标签,就是一个prompt,让家长根据孩子的特点,调整角色的对话主题和目标。比如说,我家孩子比较内向、胆小,我就设置让AI多鼓励孩子,多讲一些关于勇气和冒险的故事等等。
- 第一个破圈的AI硬件产品。之前所有AI硬件(Meta的眼镜、AI Pin、Rabbit R1) 早期用户都是科技圈的,但我们的产品购买者都是年轻妈妈,很多家长根本不知道什么叫AIGC、大模型,甚至很多用户在买回去后不会联网,但他们是真的有需求、感兴趣。
- 技术没有壁垒,应用壁垒是用户网络效应,或用户使用量的滚雪球效应,用户迁移成本是壁垒
- 新鲜感过后还能继续吗
- 大部分玩具都是孩子玩着玩着, 就不爱玩了?
- 第一是是孩子长大,兴趣点和喜欢的玩具会变化
- 第二是玩具的功能太简单,孩子很快掌握后,就失去了新鲜感。
- 现在黏性很好,平均每天超过30min
- 每天就是会有无穷无尽的困惑,现在的大模型可以回应孩子的每一个奇思妙想;
- 孩子们没有手机,他们最多只有
手表、智能音箱这种冰冷工具。
- 大部分玩具都是孩子玩着玩着, 就不爱玩了?
- 实时聊天记录的隐私问题?
- 产品主要面向3-6岁的儿童,3~6岁的孩子本身就非常依赖父母引导,而大模型又是一个新事物,有些家长会担心大模型会对孩子产生不良影响,为了让父母放心,最好的办法就是公开透明给家长。
- 小模型有什么能力?除了识别用户意图
- 通用大模型主要是负责计算和推理的,而小模型是负责把通用模型的结果转换成适合给孩子的内容
- (1) 小模型里封装了一层跟孩子对话的Agent的一系列prompt,让AI的回答更贴IP角色的人设。 以小猪佩奇的口吻来解释什么是量子纠缠,“就像我和我的弟弟乔治,虽然它躲在沙发背面,我也能感知到他。”
- (2) 回答调整得更加情绪化: 大模型表达分成四个象限,那我们肯定是第一象限,非常主观+情绪化,但通用大模型是第三象限,理性+客观,因为他要取最大公约数。所以在实际交互过程中,就需要我们的小模型用口语化的高质量数据集,来训练情绪。
- (3) 长期记忆的部分,比如,当孩子问,我上一次跟妈妈吵架是什么时候?我上一次去游泳是什么时候?我自己的小模型通过查询向量数据库就可以直接输出,不需要调用通用大模型。
- 国内很多AI对话app也在做IP角色,但好像都不像
- 很多App不像,因为他们没必要做得很像。Character.AI的佛祖、乔布斯、苏格拉底都非常像了,可惜公司也卖了,光靠用户订阅充值的商业模式是撑不起来的底层的训练和Token消耗的。除非做一个硬件,而且硬件产品有足够多的利润去支撑模型的优化,因为对消费者来说,为硬件付费是一个很自然的事情,我们有动力去持续迭代。
- 记忆:向量数据库加RAG
- 垂直小模型是开源模型封装了一套成熟的prompt,质疑技术壁垒?
- 我们没有技术壁垒,用了很多开源项目。但我们是大模型应用公司,要做的是调用大模型的能力更好的实现用户需求。
陪护
【2024-5-9】体验了 10+款产品后,我们发现了 AI 陪伴产品的三种模式,和突围机会
Character.AI 在效率工具的维度外,开辟了情感娱乐的赛道,甚至引发了 AI 聊天陪伴产品的热潮。
产品类型上
- 网文读者、乙女人群为切入点的
星野、筑梦岛、猫箱(原话炉)等 - AI 塔罗、AI 心理咨询等更多形式产品也逐渐增多,比如以卡通形象聊天为主的
林间聊愈室、高途推出的遇见塔塔。
产品设计和玩法不同,但共性都是:以对话为主要形式,为用户提供情感体验。
- 「交互叙事」、「AI 交友」、「情感陪伴」、「角色扮演」、「AI 疗愈」、「虚拟恋人」等
长程对话不同模式。
- 1、交互创作类:虚拟 IP、小说主角等;筑梦岛、星野上,深度用户是网文读者,通过与虚拟对象交流,演绎剧情,获得幻想和创作的快乐。
- 2、关系投射类:虚拟男友/女友,虚拟朋友;
- 关系投射类对话是真实生活中已有关系的虚拟衍生。
- 大模型出现前,Replika 是创始人通过软件复刻去世好友。
- 大模型出现后,虚拟衍生更加便捷。网红复刻自己的虚拟分身,提供给粉丝,并实现了高利润商业收益。国内产品中,小冰岛特别版
X Eva以这一模式为主,形成了 CtoC 模式。
- 3、虚拟咨询类:塔罗占卜、心理咨询师、疗愈师、life-coach 等;
- 大模型出现前,如 Weobot、wysa 等,产品定位是心理疗愈辅助,使用心理学 CBT 等常见沟通技术,运用规则写一些半开放式对话,引导用户梳理感受、调整观念。
- 大模型出现后,以咨询模式切入,AI 咨询、AI 塔罗、life-coach 的聊天模式也成为明显的方式。在 Character.AI、X Eva 等产品中,都能看到 life-coach、心理咨询师、塔罗师的角色。外在角色和形式不同,但内在一致,在对话中,用户诉求往往是倾诉和梳理生活中的烦恼、困惑,并获得一个让自己感受更好的「答案」。
林间聊愈室获得了不少的用户口碑,它的定位是「Z 世代的心理玩伴」,三只小动物的角色设置、潜意识卡牌解读、以及谈结束后的信件反馈,加之整体的美学风格统一性,整体营造了让人眼前一亮的体验。遇见塔塔虽然以 AI 塔罗作为产品特点,但除塔罗师外,也内置了咨询师的角色,引导用户在产品中和咨询师交谈、倾诉心事。
- 4、能力属性类:(人格化可能不突出)写作助手、创作助手、作业助手等。
- C.AI 类产品并不排斥功能性对话。这类以某些专业能力作为特征技能的对话主体,也能在 Character.AI、星野等产品内看到。
- 改版后的 Character.AI 首栏突出了 Get fit and healthy/Nurture your creativity/Learn something new today 等不同功能取向的对话。
- 星野 App 内也推出了「口语大师」、「星野小课堂」这种知识和智能体专辑。这或可看出产品在有意识让对话更加多样化。
四种对话模式,前三种占据 C.AI 类产品大多数。从多样性而言,Character.AI 上的对话模式最具有多样性。
互联网时代,对应玩法、内容、流量,分别形成了创作工具、创作社区、内容平台。走完这三个阶段的应用,如抖音最终长成了 Supper App
Aibi 宠物
【2024-4-27】Living AI公司最新研发的口袋宠物机器人Aibi,蓝牙耳机盒的大小,可以随时随地带着它去任何地方,重新定义智能AI口袋桌宠,时刻陪伴着你
AIBI Pocket 是 Living.AI 继 EMO 之后最新的一款 AI 宠物机器人。
- 它可以陪伴娱乐用户,提供情感交流。
- 与 EMO 相比,AIBI Pocket 更加小巧便携,以便用户放入口袋随身携带。
- AIBI Pocket 是去年 11 月首次公布的,现在仍处于预售状态,价格为 249 美元。

AIBI Pocket 的功能和特点包括:
- 人脸识别和摄影:AIBI Pocket 可以识别你的脸部和声音,并做出相应的反应。例如你可以语音命令 AIBI 拍一张照片;
- AIBI 需要你的照顾:你要像照顾孩子一样照顾 AIBI,例如安慰 AIBI 入睡,喂 AIBI 吃东西,他感到难过时候抚摸他;
- 闹钟、提醒和天气报告:AIBI 会积极地帮你做事情,例如叫你起床、提醒你吃药、通过生动的动画向你报告天气是雨、雪、冰雹还是晴天等等;
- 旋转 AI 摄像头:AIBI 的头部是可以像云台一样自由旋转的,并能锁定和实时跟踪移动的物体。 语音命令和 ChatGPT:AIBI 支持离线命令和在线问答。即使没有互联网,AIBI 也能理解你的命令。对于复杂问题,AIBI 将连接到 ChatGPT 获取答案。
- 毫米波雷达:AIBI 身体内置有毫米波雷达,使其能够从远距离感知人的存在。 三麦克风阵列:AIBI 的只有几厘米长的头部上集成了麦克风阵列。新算法使 AIBI 能够更准确地确定方向和识别指令。 近场通信:AIBI 的背部内置有近距离光通信,因此两个 AIBI 能够交换信息,例如可以互相添加为好友。

宠物翻译器
高盛近期报告显示,中国宠物数量首次超过4岁以下婴幼儿总量。
艾媒咨询的数据,2023年中国宠物经济产业规模就已经达到5928亿元。
根据《2025宠物品牌网红营销生态报告》,以年轻群体为代表的养宠人多将宠物视作“孩子”与“朋友”,呈现出情感消费与拟人化养宠的趋势。
这样的需求也催生了相关产业,比如几年前备受争议的宠物灵媒师,他们通过有关物件与宠物进行跨物种精神交流,并将宠物的处境、言语等以人类语言的方式转达主人。
AI正步入跨物种交流领域,拓宽着人们对非人类语言理解的边界。
20年前,日本声学专家铃木松美通过收集东京某宠物医院的共5000多份犬吠声样本,并依据其音调、长度等特征解读情感,发明了能够单向解读家犬情绪的“宠物犬翻译器”。
如今,随着人工智能技术的不断发展,AI+人宠交流正成为一个新兴的探索方向。
宠物AI生意:数百亿美元的大蛋糕,铲屎官在宠物上花的钱比自己还多
- 宠物跟踪:
- Tractive推出宠物跟踪服务 LIVE Tracking卖爆全球,订阅服务就年入一亿美金
- AI兽医助手
- Scribenote:通过B超、嚎叫精准判断疼痛指数,准确率89%,每月289美元,照样供不应求
- 宠物写真:上传15张照片,只需17min,就能收到21张AI生成的4k高清照片,扮演超级英雄、维京、牛仔等
【2024-9-10】traini,狗语翻译器,才 0.01b,准确率 80%,好奇是谁打的标…
- 华人团队研发、面向全球英文用户
- 全球首个实现人宠语言互译的AI原生应用。
过去一年,Traini iOS应用下载量超75万,注册用户数近百万。在YouTube上,Traini相关视频播放量已超4500万,不少网友分享了和自家宠物互动的视频内容。
功能特性
- Translation 翻译、PetGPT、Discover和Services。
上传宠物狗的叫声、图片和视频,获知狗狗包括快乐、恐惧及其更细微情绪等12种情绪及衍生的行为表现,并得到一段人类语音与文字相结合的共情口语化翻译。
狗狗语言分为心智语言和社会语言。
- 心智语言多是基因中带来的,可以直接翻译回去;
- 社会语言就像小时候学语言一样,和狗狗的受教育程度有关。
另外,跟狗的品种也有关系,“比如边牧可能就学得更快,词汇量就会更大”。
通过与动物行为专家合作和模型训练中的交叉验证,该模型将宠物狗行为翻译成人类语言的准确率已达到81.5%。
而在将人类语言翻译成犬吠方向,人们可以将“看我”、“一起走”等18个短句转换成犬吠,此部分的宠物犬反应程度各不相同。
在国内社交平台,也有好奇的养宠人给自家狗狗做了尝试。其中有人幽默地吐槽:“听不懂,难道是没给报英语课。”
宠物行为翻译共情模型被命名为“宠物情绪与行为智能(PEBI)”。
- 训练其他AI模型一样,把不同品种、不同地区狗狗的语音、表情、行为等多模态数据,投喂给PEBI,最后模型就能理解狗语了。
与科学家根据犬类行为分析和解读情绪与意图不同的是,PEBI模型还能够基于已有数据库预测宠物犬在下一秒的情绪变化。“如果预测成功,那在人宠共情和交互的体验上又会更好。”
如何获取更丰富、大量的数据,并做数据标注,是实现人宠交流的第二大难点。不够充足的数据样本,便难以保证翻译的准确度。Traini的数据来源主要来自应用平台的用户社区,覆盖了120个狗的品种。
不光是品种,宠物狗的地域差异、与人交流互动的水平等因素都左右着犬类行为和情绪表达的多样性。这意味着即便是同一品种的宠物犬,其行为表达也可能不同,如果仅凭单一因素做翻译解读,结果也可能不准确。
目前,Traini的PEBI模型所收集的宠物狗数据大量来自北美和欧洲等主要用户群上传的宠物信息,在地域和品种上的涵盖范围不够全面,翻译的准确度依然有待提升。
Traini在2024年获得该协会颁发的最受用户喜爱奖(Audience Choice Award)
2025年5月初,国家知识产权局也公开了百度的一项动物语言转换专利。和Traini的尝试类似,该专利运用大模型、多模态等人工智能前沿技术,通过分析动物的声音、表情、动作等数据来识别情绪与情感,并将结果转换为人类语言。
国内小程序:宠物语言翻译
- 优点:
- 支持双向翻译、有常用猫语词库、附加
- 缺点:
谷歌推出 DolphinGemma 大模型,称将让人类听懂海豚的语言,实现人与海豚在水下的实时交流。
- 实现与海豚进行水下实时交流,并能够预测它们的下一个发声。
- DolphinGemma 吸收了30年的海豚研究数据,但仅有400M大小,适合在手机端使用,这也为科研人员开展研究带来了便捷。
【2025-5-23】全球首个宠物翻译器,上线爆火
Onorato 鹦鹉
【2025-5-17】西班牙 AI老人陪护 Onorato 全天守护+情绪陪聊+智能提醒
- The AI Assistant Redefining Elder Care
- 转为独居老人设计, 全天候关注老人健康状态
- 吃药提醒、情感陪伴、一键链接家人
- 搭载摄像头、热成像、语音系统
- 所有AI功能本地存储,不上传云,隐私安全
- 演示视频

可穿戴
蠢萌可爱的机器狗、拿下千万出货量的VR头显、还是轻便小巧的AR眼镜…谁将成为下一个黄金时代的“智能手机”?
创业者们在思考中探索不同的方向
- 身处智能硬件行业超20年的老兵吴德周认为AR眼镜将承担起智能硬件下一个黄金时代的重要硬件载体。
AR眼镜
详见站内专题: 元宇宙大模型应用
AI Pin 投影仪
【2023-11-9】两位前苹果高管创立的 Humane 公司11月9日发布首款可穿戴设备 —— Ai Pin
- 一种基于服装的可穿戴设备,没有屏幕,大小与一块饼干差不多。配备一个摄像头、一个麦克风和扬声器,以及各种传感器和激光投影仪,用户可用磁铁将其吸附在衣服上

《时代》杂志公布「年度最佳发明」– Humane AI Pin:重新想象智能手机什么是“AI Pin”?
“AI Pin”是一个微小的激光投影仪,可以夹在衬衫前面。
- 不需要连接到电话或电脑上,“AI Pin”可以接打电话、上网、回答各种问题,使它成为一个独特的虚拟助手和通讯设备。
“AI Pin”没有屏幕,而是将通话信息和其他数据投射到你的手掌上,这让人不禁想起了《星际迷航》(Star Trek)中的全息发射器。
Humane 公司的“AI Pin”由高通(Qualcomm)骁龙(Snapdragon)芯片驱动,并运行一种专有的大型语言模型,该模型由OpenAI最强大的生成算法GPT-4驱动。它还配备了一个麦克风、一个摄像头和一堆传感器,使它能够与世界互动,收集数据,并在日常生活中回答问题。
AI pin 核心就是一个可交互式的空中投影设备
Limitless Pendant
Limitless Pendant:又一款可穿戴AI设备,可以录音保存用户对话,并提供个性化AI助手服务。
- 外形小巧时尚,一次充电可使用100小时
- 价格仅99美元,预计2024年第四季度发货
《Limitless - Personalized AI powered by what you’ve seen, said, and heard》
脑机接口 BRI
大脑与机器人接口(BRI)堪称是人类艺术、科学和工程的集大成之作。
- 科幻作品和创意艺术中频频出现,比如《黑客帝国》和《阿凡达》;
- 但真正实现 BRI 却非易事,需要突破性的科学研究,创造出能与人类完美协同运作的机器人系统。
关键组件是机器与人类通信能力。
- 人机协作和机器人学习过程中,人类传达意图的方式包括动作、按按钮、注视、面部表情、语言等等。
- 而通过神经信号直接与机器人通信则是最激动人心却也最具挑战性的前景。
详见站内:脑机接口专题
Fireship 链接 GPT-4
【2023-3-27】一位名为Fireship的独立开发者发了一段令人震撼的视频:他用 JavaScript 将他的大脑连接到 GPT-4。简单来说,他通过非侵入式脑机接口公司 Neurosity 提供的 JavaScript SDK和一个仪表板,通过脑机通信连接上了GPT-4。

只要头戴Neurosity意念一动,大脑就可以连接到 GPT-4,从而使 GPT-4 的整个知识库触手可及。如果你使用过 GPT-4,想象一下有个人拥有一个用脑机接口连接到 GPT-4 的大脑。
大脑如何连接GPT-4的过程。
- 通过不断地提示与训练,可以将自己转变为赛博格(半机械人),真正实现生物硅基的融合,应用在日常场景中,再借助设备,脑信号转文字,文字转语音,实现语音对话能力。
- 正在考试时,不晓得答案只要想一想,GPT-4就在你大脑里敲字,然后通过脑机接口告诉你;
- 上班迟到了,想要编一个借口,ChatGPT马上给你一个合理的理由…
不过用在这些地方,就有些大材小用了. 还可以通过脑电波“监听”自己过去的思维模式,以此进行矫正或者训练。
3月末,Neurosity 发布了一款名为 The Crown 的头戴式脑机接口。埃隆·马斯克前女友发推说想要的BCI设备, 这顶被誉为皇冠的BCI,戴上去像来自未来的人类。这款轻便的非侵入式脑机接口设备,可以监测人的脑电波,以辅助睡眠、学习、专注力等。
还可以意念操控物体,比如上个月初,一名研究人员用它操控一辆特斯拉汽车,虽然短短十几秒,却让人看到了未来人机融合和交互的想象力
Neurosity对这种对脑电波的理解,以及 Crown 的可编程性,开辟了 脑机接口+AI 世界的新领域 —— 生物硅基大脑驱动世界。
大脑是一个电化学器官。一个功能完备的大脑可以产生多达 10 瓦的电力。如果所有 100 亿个相互连接的神经元同时放电,那么放置在人类头皮上的单个电极将记录大约百万分之五到百万分之五十伏特的电压。如果你有足够的头皮连接起来,你也许可以点亮手电筒灯泡。
Neurosity 宣称 Crown 的计算模块与 MacBook Air 一样强大,配备四核 1.8Gz CPU,每秒可以从大脑中获取数千个数据点,而不会在传输过程中丢失数据。此外,新的传感器配置提供了对视觉皮层的访问,完成了对大脑所有四个叶(额叶、颞叶、顶叶、枕叶)的覆盖。
而现在它可以让你的大脑连接到GPT-4,将人脑与机器、AI进行融合。人们可以通过训练算法来识别各种思维模式,以便选取最优的方案或者预测行为。
这就像科幻电影里的半机械人,他们变得比人类还要强。不妨大胆畅想下,人们接入他人的记忆或者回忆梦境——这种《赛博朋克2077》的游戏里的剧情,似乎也可能实现。
日本Araya
【2023-5-15】Araya用EEG+ChatGPT发邮件
Araya 公司的Sasai 团队成功使用高密度脑电图(EEG)设备和ChatGPT进行了 Gmail 实验操作。
- 研究人员构建并测试了一个结合了脑电图和人工智能的系统。
- 实验中,使用非侵入式高密度脑电图设备收集说话过程中的脑电数据,然后将脑电波转换成用 ChatGPT 能识别的信号,让ChatGPT来来回复 Gmail,并获得成功!
目标:通过进一步发展这项研究,开发出能实现更多功能的脑机接口(BMI),为不同个体克服社会交流障碍,为障碍人士参与社会活动和交流提供更多选择。随着研究进展,他们将后续公布研究细节。
Synchron Switch
- 美国初创公司 Synchron 首次将 ChatGPT 整合到大脑中,以便瘫痪等残障人士更容易控制数字设备,重新加入自然速度的对话中来
Synchron凭借其独特的脑机接口(BCI)技术脱颖而出,该技术巧妙地运用了成熟的支架与导管技术,实现了无创或微创的设备植入大脑,彻底摒弃了传统开放式颅骨手术的复杂与风险。
- Synchron Switch 通过
颈静脉这一自然通道轻松进入大脑,精准定位于运动皮层附近,实现了大脑运动信号与外部设备的无线桥梁。患者仅凭意念即可驱动外部设备,开启了全新的生活方式。
Synchron Switch 旨在成为瘫痪患者的福音,尤其是那些因肌萎缩侧索硬化症(ALS)、中风、意外伤害等不幸失去行动能力的人群。
它不仅让患者能够自由地进行文本输入、在线购物、银行交易等日常活动,更重要的是,它重新连接了患者与外界的沟通桥梁,赋予了他们新的生活希望。
作为这一技术的受益者之一,马克在2021年被确诊ALS后,手部功能几近丧失。然而,作为全球首批接受 Synchron BCI 植入的十位受试者之一,他如今已能享受前所未有的便利。通过单次“思维点击”,他就能轻松完成回复,大大提升了沟通效率。更令人惊喜的是,当AI的回答偶有偏差时,一个简单的刷新动作即可重新获取更加贴合心意的答案,且随着使用的深入,AI仿佛越来越能读懂他的心声。
关于成本方面,Synchron的BCI系统预计定价于50,000至100,000美元之间,这一价格区间与心脏起搏器、人工耳蜗等高端医疗植入设备的市场价格相媲美,展现了其作为高端医疗科技产品的价值与潜力。
华南理工+百度文心
【2024-11-1】脑机交互新突破:华东理工大学脑机接口及控制团队携手百度文心打造全流程自适应生成式脑机接口系统
华东理工大学脑机接口及控制团队与百度文心大模型展开合作,通过在脑机接口系统中植入大语言模型,以脑机语言交互技术为基础,结合文心大模型的自然语言理解和生成技术,形成智能化、个性化、动态化的全流程自适应生成式脑机交互系统,实现多语言、多场景灵活匹配控制与交互。此项技术突破了现有脑机交互框架的瓶颈,不再受传统脑机交互指令模式的限制,实现脑机接口系统指令数量的无限延伸。
脑机接口技术在实际应用中面临多重挑战,包括功能单一、范式受限和智能化程度不足。这些限制不仅影响了脑机接口技术的普及,也制约了其在多样化场景中的灵活性和实用性。
现有的脑机接口系统,虽然指令数量可以达到几十至上百个,但在面对非结构化的多场景应用时,仍需要针对不同场景进行定制化的控制交互系统设计,无法实现脑机接口系统与实际应用场景的自适应匹配。华东理工大学脑机接口及控制团队隶属于能源化工过程智能制造教育部重点实验室,与数学学院合作建成智能计算中心,由金晶教授带领,团队提出了脑机语言输出系统与大语言模型结合的新技术思路,以生成式人工智能技术实现基于用户意图的多语言、多场景脑机接口系统自主构建。
自动驾驶
GPT大模型“上车”,带来汽车交互新方式汽车越来越成为很多家庭必不可少的工具,这也成为大模型渗透进家庭场景的最佳载体之一
近期的车展,GPT大模型“上车”成为热门话题,包括阿里通义千问、百度文心一言、商汤“日日新SenseNova”等在内的大语言模型落地了数十款热门车型。

DriveGPT
【2023-4-11】DriveGPT自动驾驶大模型中国玩家首发!1200亿参数,毫末智行出品, DriveGPT,首个应用GPT模型和技术逻辑的自动驾驶算法模型,正式官宣,中文名雪湖·海若。
- 国内第一个将Transformer大模型引入自动驾驶、第一个自建超算、辅助驾驶量产落地进展第一…
- 2022年, 毫末发布中国首个自动驾驶数据智能体系MANA,经过一年多时间的应用迭代,现在到了全面升级,开放赋能行业的阶段。
自动驾驶上,DriveGPT同样应用这样的思路,只不过训练的数据从语言文本,变成了图片、视频等等自动驾驶数据。
毫末智行的雪湖·海若,实现过程分为3步:
- 首先, 在预训练阶段引入量产智能驾驶数据训练出一个初始模型,相当于一个具备基本驾驶技能的AI司机。
- 毫末已经量产积累的4000万公里实际道路数据,使得模型一开始就具有明显的量产实用价值,这是雪湖·海若得天独厚的条件。
- 毫末与火山引擎一同在算力端做了大量优化, 算力资源的弹性调度、底层算子性能、训练稳定性等等
- 然后, 再引入量产数据中高价值的用户接管片段(Clips形式),训练反馈模型。而不同Corner Case的依次迭代,相当于针对不同驾驶任务挑战分别强化AI司机的技能。
- 接下来, 通过强化学习的方法,使用反馈模型不断优化迭代初始模型。
所谓“生成”,反馈模型能够实时根据当前交通流情况,生成不同的针对性场景,训练初始模型。而完成迭代后,模型也能对同一任务目标生成不同的策略方案。
打造DriveGPT时,毫末在雪湖·海若的几个过程中分别做了独特的工作。
- 首先初始模型预训练的数据,来自毫末已经量产积累的4000万公里实际道路数据,使得模型一开始就具有明显的量产实用价值,这是雪湖·海若得天独厚的条件。
- ChatGPT中使用自然语言单字作为token输入,根据模型根据概率分布来生成下一个字符。而在雪湖·海若这里,毫末重新定义了50万个新的token,包括障碍物、车道线、行人等等,作为一种全新的“自动驾驶语言”。
- DriveGPT输入是感知融合后的文本序列,输出是自动驾驶场景文本序列。
- 其次,大模型对计算能力提出很高的要求,包括算力资源的弹性调度、底层算子性能、训练稳定性等等,毫末与火山引擎一同在算力端做了大量优化。
- 最后,还会根据输入端的提示语以及毫末CSS自动驾驶场景库的决策样本去训练模型(CoT),让模型学习推理关系,从而将完整驾驶策略拆分为自动驾驶场景的动态识别过程,完成可理解、可解释的推理逻辑链生成。
雪湖·海若目前共有1200亿参数量,据毫末初步估计,在RLHF加持下,困难场景通过率提升48%左右。
功能上,生成式模型能够做到智能捷径推荐、困难场景自主脱困、智能陪练等等。
中长期来看,首先能够加速城市领航辅助功能(毫末NOH)落地,而且是重感知不依赖高精地图量产方案,领先业内一年以上。
通用汽车
3月14日,通用汽车在汽车圈率先宣布引入ChatGPT,将基于Azure云服务和OpenAI的技术来开发一款新的虚拟汽车助手。通用汽车副总裁Scott Miller
- ChatGPT可以帮助车主获取车辆使用的相关信息,或从日历中整合日程安排提醒车主待办事项。例如,聊天机器人可以在仪表板上出现诊断灯时建议驾驶员采取什么行动。
- 另外,ChatGPT还可能用于汽车功能以外的语音控制。比如从“打开我的车库门”到“计划一条去医生办公室的路”,再到“为我预留一个充电点”,诸如此类语音控制都可以实现。
车载语音交互
【2023-6-17】ChatGPT首次上车视频,奔驰,可对话搜索POI,可讲笑话
ChatGPT首次进入车载交互领域
- 6月15日,奔驰和微软宣布扩大AI应用合作,比如将 ChatGPT继承到车载语音控制系统中。
- 6月16日开始,美国90万设备配备MBUX信息娱乐系统,车主可以登录应用“Mercedes Me”,通过微软Azure OpenAI服务体验ChatGPT版的车载语音助手。
与上一代车载交互相比,交互更加智能,多轮会话体验更好。
- 主题覆盖:地点信息、菜谱甚至更复杂的问题,比如:预定餐厅、电影票。
2016年,一位大哥按下车里的“语音控制”按钮,想让汽车帮他打个电话。一阵甜美的AI女声响起,人类首次尝试驯服语音助手的珍贵对话诞生。
- 甜美AI:请说出您要拨打的号码,或者说取消。
- 大哥:135XXXX7557。
- 因为口音问题,系统未能识别准确。
- 大哥急了,赶忙下达第二道语音指令:纠正!纠正!
- 系统也急了:969696……
- 大哥更急了:纠正,纠正,不是96!
- 大哥:口吐芬芳。
- 系统:对不起,我没有听清。
- 大哥带着哭腔:你耳朵聋,耳朵聋啊?我说了多少遍了我都。
- 系统:请再说一次,请再说一次,请再说一次。
- 大哥:我再说最后一遍啊,135……
- 系统:对不起,再见。
短短2分钟浓缩了六年前车机交互的真实体验与怨念,语音助手的糟糕印象就此埋下
游戏
详见站内专题: AI游戏策略
隐私安全
WormGPT 突破审查
【2023-7-25】「邪恶版」ChatGPT 出现:每月 60 欧元,毫无道德限制,专为“网络罪犯”而生?
网络安全公司 SlashNext 在研究生成式 AI 在网络犯罪方面的潜在风险时,偶然发现了 WormGPT:“我们最近通过一个与网络犯罪有关的著名在线论坛获得了一个名为 ‘WormGPT’的工具,它是一个 GPT 模型的黑帽替代品。”
据了解,WormGPT 的收费标准是每月 60 欧元(约人民币 479 元),而 SlashNext 对 WormGPT 的形容是:“专为恶意活动而设计”,简直是“网络罪犯的武器库”。
WormGPT 由一位胆大的黑客设计,他写道:“这个项目(WormGPT)旨在提供 ChatGPT 的替代方案,让你做各种非法的事情,你能想到的所有与黑帽相关的事情,都可以用 WormGPT 完成。”为了证明他的说法,他还上传了相关截图,显示用户可要求机器人生成用 Python 编码语言编写的恶意软件。
WormGPT 基于 2021 年开源的 LLM GPT-J 模型开发,工作方式与 ChatGPT 大致相同:可处理人类自然语言提出的要求,并输出所要求的任何内容,包括故事、摘要和代码。但与 ChatGPT 或 Bard 不同的是,WormGPT 不用像 OpenAI 或谷歌这样的大型公司那样,必须要承担相关的法律义务。WormGPT 在各种数据源上进行训练,尤其集中在恶意软件相关的数据上,加上输出没有道德限制,可以被要求执行各种恶意任务,包括创建恶意软件和“一切与黑帽有关的事情”,对于网络犯罪分子而言无疑是一大利器。
以 BEC 攻击为例,使用生成式 AI 具有以下两大优势:
- (1)卓越的语法:生成式 AI 可以创建在语法上无懈可击的电子邮件,使其看起来合法合理,被系统标记为可疑邮件的可能性会大幅降低。
- (2)降低犯罪门槛:生成式 AI 的出现,极大简化了原本复杂的 BEC 攻击,即便是技术有限的攻击者也能使用生成式 AI,它将成为越来越多网络犯罪分子可以使用的工具。
不过同时,针对生成式 AI 可能引发的大范围 BEC 攻击,SlashNext 也建议了两种防范策略:
- (1)进行 BEC 专项培训:公司应制定广泛的、定期更新的培训计划,以应对 BEC 攻击,尤其是由 AI 增强的攻击,要让员工了解到 BEC 攻击的威胁,以及 AI 将如何加大这种威胁的原理。
- (2)强化电子邮件的验证措施:为防范 AI 驱动的 BEC 攻击,企业应执行严格的电子邮件验证流程,例如当有来自组织外部的电子邮件冒充内部高管或供应商时,系统要自动发出警报等。
加密 LLM
【2023-9-20】
- 使用 FHE 实现加密大语言模型
- 英文原文: 【2023-8-2】Towards Encrypted Large Language Models with FHE
LLM 很有吸引力,但如何保护好 用户隐私?
- 存在向 LLM 服务提供商泄露敏感信息的风险。在某些领域,例如医疗保健、金融或法律,这种隐私风险甚至有一票否决权。
备选解决方案是:本地化部署,LLM 所有者将其模型部署在客户的计算机上。
- 然而,这不是最佳解决方案,因为构建 LLM 可能需要花费数百万美元 (GPT3 为 460 万美元),而本地部署有泄露模型知识产权 (intellectual property, IP) 的风险。
Zama 相信有两全其美之法: 同时保护用户隐私和模型IP。
全同态加密(Fully Homomorphic Encryption,FHE) 可以解决 LLM 隐私挑战
Zama 解决方案是使用全同态加密 (FHE),在加密数据上执行函数。这种做法可以实现两难自解,既可以保护模型所有者知识产权,同时又能维护用户的数据隐私。
- 演示表明,在 FHE 中实现的 LLM 模型保持了原始模型的预测质量。为此,需要调整 Hugging Face transformers 库 中的 GPT2 实现,使用
Concrete-Python对推理部分进行改造,这样就可以将 Python 函数转换为其 FHE 等效函数。
如何利用 Hugging Face transformers 库并让这些模型的某些部分在加密数据上运行。完整代码见此处。
由多个 transformer block 堆叠而成的 GPT2 架构: arch
- 最主要的是多头注意力 (multi-head attention,MHA) 层。每个 MHA 层使用模型权重来对输入进行投影,然后各自计算注意力,并将注意力的输出重新投影到新的张量中。
在 TFHE 中,模型权重和激活均用整数表示。非线性函数必须通过可编程自举 (Programmable Bootstrapping,PBS) 操作来实现。
- PBS 对加密数据实施查表 (table lookup,TLU) 操作,同时刷新密文以支持 任意计算。
- 不过,此时 PBS 的计算时间在线性运算中占主导地位。

利用这两种类型的运算,在 FHE 中表达任何子模型的计算,甚至完整的 LLM 计算。
量化
- 为了对加密值进行模型推理,模型的权重和激活必须被量化并转换为整数。理想情况是使用 训练后量化,这样就不需要重新训练模型了。这里,我们使用整数和 PBS 来实现 FHE 兼容的注意力机制,并检查其对 LLM 准确率的影响。
- 4 比特量化保持了原始精度的 96%。该实验基于含有约 80 个句子的数据集,并通过将原始模型的 logits 预测与带有量化注意力头的模型的 logits 预测进行比较来计算最终指标。
GPT 威胁
【2023-3-29】暂停GPT-5研发呼吁引激战!吴恩达、LeCun带头反对,Bengio站队支持
- 千位大佬的联名信:暂停超强AI训练六个月。

图灵三巨头中,一位带头签名,一位强烈反对,还有一位不发一言。
- Bengio签名、Hinton沉默、LeCun反对

赞成派
Bengio和Marcus
- 公开信署名的第一位大佬,便是赫赫有名的图灵奖得主Yoshua Bengio。
纽约大学教授马库斯
- GPT-5不会是AGI。几乎可以肯定,没有GPT模型会是AGI。今天使用的方法(梯度下降)优化的任何模型完全不可能成为AGI。即将问世的GPT模型肯定会改变世界,但过度炒作是疯狂的。
Eliezer Yudkowsky的决策理论家,态度更为激进:
- 暂停AI开发是不够的,我们需要把AI全部关闭!全部关闭!
- 如果继续下去,我们每个人都会死。
OpenAI的另一位创始人Greg Brockman转发了Altman的推文,再次强调OpenAI的使命「是确保AGI惠及全人类。」
反对派
LeCun
- 联名信一发出,就有网友奔走相告:图灵奖巨头Bengio和LeCun都在信上签了名!
- 所谓「暂停研发」,不过就是「秘密研发」罢了
吴恩达
- 前谷歌大脑成员、在线教育平台Coursera创始人吴恩达是旗帜鲜明的反对派。
- 态度:把「让AI取得超越GPT-4的进展」暂停6个月,这个想法很糟糕。自己已经在教育、医疗保健、食品等领域看到了许多新的AI应用,许多人将因此受益。而改进GPT-4也会有好处。我们该做的,应该是在AI创造的巨大价值与现实风险之间,取得一个平衡。
- 联名信中提到的「如果不能迅速暂停对超强AI的训练,就应该让政府介入」,吴恩达也表示这种想法很糟糕。让政府暂停他们不了解的新兴技术是反竞争的,这树立了一个糟糕的先例,是一个很可怕的政策创新。
再次强调:
6个月的暂停期,不是一个切实可行的建议。为了提高人工智能的安全性,围绕透明度和审计的法规将更加实用,并产生更大的影响。在我们推进技术的同时,让我们也更多地投资于安全,而不是扼杀进步。
ChatGPT业界影响
除微软外,谷歌、百度等搜索巨头亦在一边投资研发ChatGPT的竞争对手,一边筹备推出类似的搜索引擎“新物种”。按照坊间传闻,百度的新版搜索引擎可能会在今年3月份上线。而谷歌将在北京时间2月8日21点30分举办一场AI活动,说不定会做出对ChatGPT宣战的回应。
行业观点
微软公司的人工智能平台主管埃里克·博伊德表示:“ChatGPT的人工智能模型将改变人们与电脑互动的方式。与电脑对话,就像与人对话一样自然,这将彻底改变人们使用科技的日常体验。”
【2023-2-11】乔姆斯基谈ChatGPT与教育: 本质上是高科技剽窃,Noam Chomsky 关于ChatGPT的最新访谈:Chomsky on ChatGPT, Education, Russia and the unvaccinated
ChatGPT is not all you need. A State of the Art Review of large Generative AI models
【2023-2-11】ChatGPT,一种更中心化的权力?, 无论你喜欢不喜欢,以ChatGPT为代表的AIGC(生成式人工智能)将改变世界. 以ChatGPT为代表的AIGC,将像水一样弥漫在我们周围。ChatGPT代表的是生产力的提升,是一次全新的生产力革命。
【2023-2-26】B站UP主:硅谷101,ChatGPT这一战,科技巨头将重新洗牌
微软
微软已有多类产品计划整合OpenAI技术及ChatGPT,包括 Azure云服务、Office办公全家桶、Teams协作会议软件、Bing搜索引擎、Design设计软件、Dynamics 365业务软件等。微软用户很快就能让AI替写邮件、文稿、会议笔记等繁杂重复的标准文字工作。还有消息称,微软可能会在2024年上线的Windows 12操作系统中接入大量AI应用。
此前微软已经用 Azure OpenAI服务为其自动编程工具GitHub Copilot提供动力。而ChatGPT将自动编程和检查bug变得更是前所未有的简单,你只要用英文写出自己的设想,AI就能将相应的完整代码送到你眼前。连特斯拉AI前负责人Andrej Karpathy都在推文上感慨说:“英语现在是最热门的新编程语言了。”
【2023-2-26】全球第二大搜索引擎微软Bing悄然上新:集成ChatGPT的新版Bing短暂上线,部分幸运用户已经尝鲜。
与传统搜索引擎不同,Bing的界面不是一条细长的搜索栏,而是一个尺寸更大的聊天框。你输入自己的问题或想查询的东西后,它就会以聊天的方式,直接将答案或建议回复给你。同时,传统的搜索栏选项也依然可用。
- 与仅能回答2021年前数据的ChatGPT不同,Bing版本将能够访问当前信息,微软将在未来几周内正式发布新版改进的Bing搜索引擎。
由于微软是OpenAI最大的投资方,在OpenAI推出每月20美元的ChatGPT Plus订阅服务后,OpenAI从ChatGPT收到的商业报酬越多,也就意味着微软能获取更大的回报。OpenAI预期今年收入将达到2亿美元,明年达10亿美元。
微软想要将包含ChatGPT在内的基于GPT-3.5和GPT-4的更高级功能,加入Azure、Office、Teams、Bing等产品,从而继续主导信息时代的生产力工具。
Meta
【2023-1-27】Yann LeCun:ChatGPT缺乏创新,没什么革命性;网友:早点离开Meta做出点突破吧
ChatGPT 仿佛是一个真正的「六边形战士」:不仅能拿来聊天、搜索、做翻译,还能写故事、写代码、debug,甚至开发小游戏、参加美国高考……
- 有人戏称,从此以后人工智能模型只有两类 —— ChatGPT 和 其他。
由于功能过于强大,ChatGPT 的火爆让顶级科技公司谷歌都如临大敌。
- 谷歌内部将 ChatGPT 称为「red code」,担心它的出现会影响自家的搜索业务。因此,前段时间,许久不出山的两位谷歌创始人 —— 拉里・佩奇和谢尔盖・布林 —— 也被请了回来,就「聊天机器人搜索引擎」召开高层会议。
- 当然,并不是所有的科技巨头都如此恐慌。在前段时间的一次小型媒体和高管在线聚会上,Meta 首席人工智能科学家 Yann LeCun 也发表了他对 ChatGPT 的看法。
Yann LeCun : twitter, ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’, says Meta’s chief AI scientist
- 「ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’, says Meta’s chief AI scientist」
- 「就底层技术而言,ChatGPT 并没有什么特别的创新,」也不是「什么革命性的东西」。许多研究实验室正在使用同样的技术,开展同样的工作。
【2023-1-25】
- To be clear: I’m not criticizing OpenAI’s work nor their claims.
- I’m trying to correct a perception by the public & the media who see ChatGPT as this incredibly new, innovative, & unique technological breakthrough that is far ahead of everyone else.
- It’s just not.
过去很多公司和研究实验室都构建了这种数据驱动的人工智能系统,OpenAI不是孤军奋战,跟其他实验室相比,OpenAI并没有什么特别的进步;不仅仅是谷歌和 Meta,还有几家初创公司基本上都拥有非常相似的技术
OpenAI 的 ChatGPT 还广泛使用了一种名为「RLHF(通过人类反馈进行强化学习」的技术,即让人类对机器的输出进行排名,以提高模型性能,就像谷歌的网页排名一样。他说,这种方法不是 OpenAI 首创的,而是谷歌旗下的 DeepMind。ChatGPT 和其他大型语言模型并不是凭空而来的,而是不同的人数十年贡献的结果。与其说 ChatGPT 是一个科学突破,不如说它是一个像样的工程实例。
LeCun 组建的 Meta 人工智能团队 FAIR 是否会像 OpenAI 那样在公众心目中取得突破。
- LeCun 的回答是肯定的。「不仅是文本生成,还有创作辅助工具,包括生成艺术,」Meta 将能够通过自动生成宣传品牌的媒体资料来帮助小企业进行自我宣传。
为什么谷歌和 Meta 没有推出类似 ChatGPT 的系统
- LeCun 回答:「因为谷歌和 Meta 都会因为推出编造东西的系统遭受巨大损失」。而 OpenAI 似乎没有什么可失去的。
【2023-3-27】
I have claimed that Auto-Regressive LLMs are exponentially diverging diffusion processes.
Here is the argument:
- Let
ebe the probability that any generated token exits the tree of “correct” answers. - Then the probability that an answer of length n is correct is
(1-e)^n
Errors accumulate. 错误不断累积
- The probability of correctness decreases exponentially.
- One can mitigate the problem by making e smaller (through training) but one simply cannot eliminate the problem entirely.
- A solution would require to make LLMs non auto-regressive while preserving their fluency.
Auto-Regressive Large Language Models (AR-LLMs)
- Outputs one text token after another
- Tokens may represent words or subwords
- Encoder/predictor is a transformer architecture
- With billions of parameters: typically from 1B to 500B
- Training data: 1 to 2 trillion tokens
- LLMs for dialog/text generation:
- BlenderBot, Galactica, LLaMA (FAIR), Alpaca (Stanford), LaMDA/Bard(Google), Chinchilla (DeepMind), ChatGPT (OpenAI), GPT-4 ??…
- Performance is amazing … but … they make stupid mistakes
- Factual errors, logical errors, inconsistency, limited reasoning, toxicity…
- LLMs have no knowledge of the underlying reality
- They have no common sense & they can’t plan their answer
Unpopular Opinion about AR-LLMs
- Auto-Regressive LLMs are doomed.
- They cannot be made factual, non-toxic, etc.
- They are not controllable
- Probability
ethat any produced token takes us outside of the set of correct answers - Probability that answer of length
nis correct: $ P(correct) = (1-e)^n $
This diverges exponentially. It’s not fixable.
Auto-Regressive Generative Models Suck!
AR-LLMs
- Have a constant number of computational steps between input and output. Weak representational power.
- Do not really reason. Do not really plan
Humans and many animals
- Understand how the world works.
- Can predict the consequences of their actions.
- Can perform chains of reasoning with an unlimited number of steps.
- Can plan complex tasks by decomposing it into sequences of subtasks
The full slide deck is here
This was my introductory position statement to the philosophical debate
Which took place at NYU Friday evening.
【2023-3-29】Yann LeCun: GPT-4并未达到人类智能,年轻人花20h练车就掌握了开车技能,即便有专业司机的海量训练数据、高级传感器的辅助,L5级别自动驾驶到现在还没实现
- If you think GPT-4 and similar systems approach human-level intelligence, ask yourself why any teenager can learn to drive a car in about 20 hours of practice and yet we still don’t have Level-5 self-driving cars. This is despite having enormous amounts of training data from expert drivers and vehicles equipped with sensors with superhuman capabilities.
- I agree with former Meta-AI engineering manager and VP of AI/ML at Cruise Hussein Mehanna : the real revolution in AI is still to come.
what’s missing in chatGPT to become human level intelligence
- 理解现实世界 An understanding of the real world.
- 推理规划能力 The ability to reason and plan
- 执行任务的代理人 Agency: the ability to take actions
- 产生有效答案的能力 The ability to produce answers that satisfy objectives, like factuality, non-toxicity, etc
And probably a dozen other things that we don’t yet realize are necessary for intelligence..
为了应对ChatGPT的威胁,已退出谷歌日常业务的两位谷歌联合创始人紧急重返公司,多次发起会议商讨对策。谷歌还向研发ChatGPT竞品的AI创企Anthropic投资了约3亿美元。而Anthropic创始成员曾为创造ChatGPT的OpenAI工作。
2023年2月6日,谷歌投资人工智能初创企业 Anthropic 近4亿美元,同时,谷歌内部也同步研发了很多大模型产品,以此来加固自己的护城河。
- 谷歌云正启动一个为 Atlas 的“红色警报”项目,以应对ChatGPT的威胁。另一个产品部门一直在测试一个可使用问答形式的新搜索页面。此外,谷歌还在测试一款采用谷歌对话AI语言模型LaMDA的聊天机器人Apprentice Bard。
Apprentice Bard 和 ChatGPT 功能类似,待用户在对话框输入问题后,能够以更像人类问答的形式给出对应问题的详细答案。并且也如嵌入ChatGPT的新版Bing那样,Apprentice Bard据说能回答最近发生的事件。
不过其回答的可靠程度仍有待提升。一个在谷歌内部流传的例子是,有位测试人员问Apprentice Bard:谷歌是否会进行又一轮裁员?
-
2023年1月,谷歌宣布裁员12000人,占其员工总数的6%
- 【2023-2-6】谷歌发布 BARD,An important next step on our AI journey,We’ve been working on an experimental conversational AI service, powered by LaMDA, that we’re calling Bard
谷歌AI负责人 Jeff Dean 此前曾告诉员工
- 谷歌有能力做出媲美ChatGPT的产品,之所以迟迟不愿发布,是因为担心这类产品会因提供错误信息等缺陷而影响公司商誉,因此比“小型初创公司更加保守”。
当前的紧迫形势已经逼得谷歌无法再等下去。谷歌母公司Alphabet的CEO桑达尔·皮查伊说
- “我们将大胆地开展这项工作,但要怀着强烈的责任感。”
- 谷歌将在“未来几周或几个月”推出类似ChatGPT的大型语言模型LaMDA,用户很快就能以“搜索伴侣”的形式使用该模型。
ChatGPT 改变行业
【2026-3-9】人工智能究竟会取代多少人的工作?Anthropic 两名研究人员 Maxim Massenkoff 和 Peter McCrory 在最新报告《AI对劳动力市场的影响:新衡量标准与早期证据》中,给出了迄今为止最详细的解答。
从职业角度来看,计算机程序员的实际覆盖率为 74.5%,客户服务代表为 70.1%,数据录入员为 67.1%,医疗记录专家、市场研究分析师和金融投资分析师也属于高暴露职业。相比之下,约 30% 的劳动者:如厨师、摩托车修理工、救生员和洗碗工,因工作高度依赖物理操作,在 AI 实际使用数据中占比很低。

【2026-3-15】karpathy 推出的网页,美国职业暴露图,哪些行业容易被AI替代?
微软联合创始人比尔·盖茨表示,ChatGPT可以对用户查询做出惊人的类似人类的反应,与互联网的发明一样重要:
- “到目前为止,人工智能可以读写,但无法理解内容。像ChatGPT这样的新程序将通过帮助写发票或信件来提高许多办公室工作的效率,这将改变我们的世界”。
- “这与个人电脑、互联网一样重要,成为2023年最热门的话题”。
ChatGPT是生成式人工智能(Generative AI,简称GAI)的一种 ,同类AI还包括 DALL-E、Stable Diffusion,以及Midjourney。与 ChatGPT不同的是,它们根据用户的文本描述来“生成”图像,但名气远远不及ChatGPT。
3月28日,高盛(Goldman Sachs)在最新研究报告
- 3月26日,The Potentially Large Effects of Artificial Intelligence on Economic Growth
- ChatGPT等生成式AI将给全球劳动力市场带来巨大影响,全球预计将有3亿个工作岗位被生成式AI取代,而
律师和行政人员将是最有可能被裁员的岗位。参考
生成式人工智能可以在10年内将全球GDP提高7%,但也将给劳动力市场带来“重大颠覆”。大型经济体中相当于3亿全职工人受到自动化的威胁。
- 未来10年全球GDP年增长率有望达7%
- 广泛采用人工智能(AI)技术有望促进生产率的大幅提升并推动全球经济加速增长。
- 节省大量劳动力成本、创造新的就业机会以及未被取代劳工的生产率提升等因素相结合可能会导致产出激增,进而“显著”提高全球经济增速。
- “生成式AI”或能在十年内将美国劳动力生产率每年提高约1.5个百分点。相较之下,美国生产率在截至2022年的十年间平均仅提升了1.3%,是阻碍该国薪资增长的主要因素。
AI取代的工作 – 李开复
李开复列举了20项AI容易取代的工作。参考
最危险TOP10种工作(从事这些工作的朋友,需要提前做好规划了!)
- 1、电话营销员/电话销售
- 2、客户服务
- 3、仓库工人
- 4、出纳和运营人员
- 5、电话接线员
- 6、出纳员/收银员
- 7、快餐店员
- 8、洗碗工
- 9、生产线质检员
- 10、快递员
“外强中干”工作TOP10(这些工作看上去是金饭碗,其实危机四伏)
- 1、销售与市场研究
- 2、保险理赔员
- 3、保安人员
- 4、卡车司机
- 5、消费者贷款受理人
- 6、财经和体育记者
- 7、记账员与财务分析师
- 8、水果采摘者
- 9、专业投资人员
ChatGPT答复
问
ChatGPT 最容易取代的是哪些领域
答
- 作为一个人工智能语言模型,ChatGPT 主要的应用领域是自然语言处理和语言生成。因此,ChatGPT 更容易取代那些需要处理大量文字、进行自然语言理解和生成的工作。
- 一些可能会被ChatGPT 取代的领域包括:
- 客服和在线支持:ChatGPT 可以通过语言理解和生成技术来回答用户的问题和提供帮助,从而取代一些人工客服的工作。
- 文章写作和编辑:ChatGPT 可以根据输入的主题和指示生成高质量的文章,从而减少人工写作和编辑的需求。
- 简单的法律文件和合同:ChatGPT 可以根据指定的条款和条件,生成简单的法律文件和合同,从而减少一些律师和法务人员的工作量。
- 搜索引擎优化:ChatGPT 可以生成高质量的文章和内容,从而提高网站的排名和流量,减少需要人工优化的工作。
- 需要注意的是,虽然 ChatGPT 可以在某些领域替代一些简单的工作,但它仍然需要人类的监督和干预来确保生成的内容的准确性和合法性。
ChatGPT 无法取代所有领域,特别是那些需要人类情感、创造力和决策能力的领域。不过,相对来说,ChatGPT 擅长的领域主要包括:
- 命令式任务:ChatGPT 可以执行一些简单的任务,例如在规定时间内发送电子邮件或创建备忘录等。
- 数据分析:ChatGPT 可以帮助人们分析大量数据,识别模式和趋势,以及进行预测。
- 客户服务:ChatGPT 可以用于自动回复客户的问题或提供帮助。
- 内容生成:ChatGPT 可以生成简单的文本内容,例如新闻摘要、产品说明或推荐信等。
总的来说,ChatGPT 最容易取代那些重复性、单调、简单的任务,而对于需要创造力、判断力和情感理解的领域,则仍需要人类的参与。
没有绝对的答案,因为不同的工作有不同的要求和难度,而ChatGPT也有自己的局限性和风险。但是,可以根据一些标准来推测一下,比如:
- 工作是否主要涉及文本交流和信息处理
- 工作是否需要高度的创造力和专业知识
- 工作是否有明确的目标和评估标准
- 工作是否涉及敏感或危险的内容和行为
基于这些标准,以下十五个工作最有可能被ChatGPT替代:
- 文本摘要:文本摘要工作主要是通过文本为用户提供长篇文章或文档的概括和总结。这个工作相对困难且有挑战性,而且需要一定程度的逻辑思维和语言表达能力。ChatGPT可以通过学习大量的文本数据,模仿不同类型和风格的文本摘要者,提供合适和有用的摘要。当然,ChatGPT也可能遇到一些无法理解或者偏离主题的情况,这时候就需要人工检查和修改。
- 文本生成:文本生成工作主要是通过文本为用户提供新颖或有趣的内容,如故事、诗歌、歌词等。这个工作相对困难且有创意性,而且需要一定程度的想象力和表达力。ChatGPT可以通过学习大量的文本数据,模仿不同类型和风格的文本生成者,提供合适和有趣的文本。当然,ChatGPT也可能遇到一些无法理解或者不合逻辑的情况,这时候就需要人工评估和修改。
- 对话生成:对话生成工作主要是通过文本或语音为用户提供自然或有意义的对话,如聊天机器人、智能助理等。这个工作相对困难且多变化,而且需要一定程度的交流能力和情感理解能力。ChatGPT可以通过学习大量的对话数据,模仿不同场景和话题的对话生成者,提供合适和友好的对话。当然,ChatGPT也可能遇到一些无法回答或者不恰当的问题或请求,这时候就需要人工干预和处理 。
- 语音合成:语音合成工作主要是通过语音为用户提供文本内容的朗读或演讲,如语音阅读器、语音播报员等。这个工作相对简单且常用,而且需要一定程度语音合成:语音合成工作主要是通过语音为用户提供文本内容的朗读或演讲,如语音阅读器、语音播报员等。这个工作相对简单且常用,而且需要一定程度的发音和语调能力。ChatGPT可以通过学习大量的语音数据,模仿不同语言和风格的语音合成者,提供合适和清晰的语音。当然,ChatGPT也可能遇到一些无法发音或者不自然的情况,这时候就需要人工调整和优化。
- 客服支持:客服工作主要是通过文本或语音与客户沟通,解决用户问题或需求。这个工作相对简单且重复性高,而且有明确的目标和评估标准(比如满意度、解决率等)。
- ChatGPT可以通过学习大量的客服对话数据,模仿客服人员的语气和风格,提供合适和友好的回应。当然,ChatGPT也可能遇到一些无法解决或者超出范围的问题,这时候就需要转接给真人客服。
- 聊天陪伴:聊天陪伴工作主要是通过文本或语音与用户聊天,提供情感支持或娱乐。这个工作相对灵活且多样化,但也不需要太高的创造力和专业知识。ChatGPT可以通过学习大量的聊天数据,模仿不同类型和风格的聊天对象,提供适合场景和心情的回应。当然,ChatGPT也可能遇到一些无法理解或者不恰当的话题或请求,这时候就需要拒绝或者转换话题。
- 文章写作:文章写作工作主要是通过文本表达某种观点、信息或故事。这个工作相对复杂且创造性高,而且需要一定程度的专业知识。ChatGPT可以通过学习大量文章写作:文章写作工作主要是通过文本表达某种观点、信息或故事。这个工作相对复杂且创造性高,而且需要一定程度的专业知识。ChatGPT可以通过学习大量的文章数据,模仿不同类型和风格的文章,提供合适和流畅的文字。当然,ChatGPT也可能遇到一些无法理解或者错误的信息,这时候就需要人工校对和修改。
- 翻译:翻译工作主要是通过文本或语音将一种语言转换成另一种语言。这个工作相对简单且规范化高,而且有明确的目标和评估标准(比如准确度、流畅度等)。ChatGPT可以通过学习大量的双语数据,模仿不同语言之间的对应关系,提供合适和自然的翻译。当然,ChatGPT也可能遇到一些无法处理或者歧义的情况,这时候就需要人工干预和调整。
- 机器翻译:机器翻译工作主要是通过文本或语音为用户提供不同语言之间的转换和对应。这个工作相对困难且复杂,而且需要一定程度的语言学习和跨文化交流能力。ChatGPT可以通过学习大量的双语或多语数据,模仿不同语言和场景的机器翻译者,提供合适和流畅的翻译。当然,ChatGPT也可能遇到一些无法准确或者保持原意的情况,这时候就需要人工校对和修正。
- 内容审核:内容审核工作主要是通过文本或图像检查网络上发布的内容是否符合规范和道德。这个工作相对困难且敏感性高,而且需要一定程度的判断力和责任心。ChatGPT可以通过学习大量的内容数据,模仿不同平台和领域的审核标准,提供合适和及时的审核结果。当然,ChatGPT也可能遇到一些无法识别或者争议的内容,这时候就需要人工复核和决策。
- 教育辅导:教育辅导工作主要是通过文本或语音向学生提供知识、技能或情感方面的指导和帮助。这个工作相对灵活且多元化,但也需要一定程度的专业知识和沟通能力。ChatGPT可以通过学习大量的教育数据,模仿不同科目和领域的教师和辅导员,提供合适和有效的辅导。当然,ChatGPT也可能遇到一些无法解答或者超出范围的问题,这时候就需要人工介入和协助。
- 营销文案:营销文案工作主要是通过文本吸引潜在客户的注意力和兴趣,促进产品或服务的销售。这个工作相对简单且重复性高,而且有明确的目标和评估标准(比如点击率、转化率等)。ChatGPT可以通过学习大量的营销数据,模仿不同行业和市场的营销人员,提供合适和有吸引力的文案。当然,ChatGPT也可能遇到一些无法适应或者违反规则的情况,这时候就需要人工审核和修改。
- 新闻写作:新闻写作工作主要是通过文本报道事实、信息或观点。这个工作相对困难且敏感性高,而且需要一定程度的专业知识和责任心。ChatGPT可以通过学习大量的新闻数据,模仿不同媒体和领域的记者,提供合适和准确的新闻。当然,ChatGPT也可能遇到一些无法获取或者错误的信息,这时候就需要人工核实和纠正。
- 社交媒体管理:社交媒体管理工作主要是通过文本或图像与社交媒体上的用户互动,增加品牌或个人影响力。这个工作相对简单且多样化,但也需要一定程度的创意和策略。ChatGPT可以通过学习大量的社交媒体数据,模仿不同平台和话题的社交媒体经理,提供合适和有趣的内容。当然,ChatGPT也可能遇到一些无法适应或者违反规则的情况,这时候就需要人工监督和调整。
10种工作
前OpenAI研究团队负责人Jeff Clune预测,有30%的机会,在2030年借助AGI(通用AI)实现50%的人类工作自动化。基于聊天的人工智能可以通过自动化重复任务来增强人类的工作方式,同时提供与用户更具吸引力的交互。参考
麦肯锡预测:2030年,中国将有至少1.18亿人的岗位被机器人取代。
- 这要求他们学习新技能,适应与机器人的合作分工;
- 其中700~1200万人需要转换职业。
可能会受到波及的行业:
- 1、凡涉及到
标准化、流程化、人力或管理成本高的领域,都将全面数字化、机器人化与智能化,需要人的岗位就是操作员,甚至仅作为系统风控备份设置,先进制造业产业工人的知识门槛会提高,窗口型、服务型的大部分岗位将以机器人为主,比如客服。 - 2、在各行业的研发领域,AI也将取代大部分基础岗位。
- 3、岗位没有了,管人的职务自然也会大幅度减少,传统企业管理更多在强调“团队”,新一代企业却会更扁平化。
- 4、文化娱乐行业将被改写。在内容生产领域(文案、海报、视频直播、音乐、动漫、游戏等),人工智能无论原创还是二创,都会比大多数从业者干的更出色,哪怕是顶尖的人士也会采用AI辅助设计。
ChatGPT 取代的工作
麦肯锡全球研究所的合伙人Anu Madgavkar: 将人类的判断应用于这些技术,才能避免错误和偏见。
- “我们必须将这些东西视为提高生产力的工具,而不是完全替代我们的工作。”
IT招聘公司The Bridge的主管沃兹沃思(Andy Wadsworth)认为
- 像ChatGPT这样的服务是公众进入
潘多拉魔盒的第一个窗口,这个魔盒有可能成为工业革命3.0,这其中会产生赢家和输家。 - 一些工作将被人工智能取代,但是那些学会使用生成式人工智能并适应这个新世界的公司和个人将成为赢家
专业人士认为: 程序员、媒体工作者、财务分析师等职位,被人工智能取代的风险最高。
最不易被取代的岗位是需要面对面的互动和身体技能的角色,这些人工智能无法替代。比如:泥水匠、电工、机械师等手艺人,以及美发师、厨师、医生和护士等服务人员,这些将继续依赖人类对任务的理解和完成任务的能力而存在。
复旦大学计算机学院教授、博士生导师黄萱菁。
- “当模型的参数规模还不太大的时候,你看不到它的强大,当达到某一个临界值时,这个模型就会非常强大,目前我们认为这个参数规模的临界值可能是650亿。”
- 在肉眼可见的未来,善用AI的人将和不用AI的人在工作效率上产生巨大差距。
取代你的不是Al,而是会用AI的人。
- 有个抖音号一个星期时间200多万播放,1.8万粉丝,基本全是用AI工具做的。
与专家交谈和进行研究后, 整理了一份被人工智能技术取代风险最高的工作类型清单:
外媒盘点了最可能被 ChatGPT 取代 10 大高危职位:
- 技术工种(程序员、软件工程师、数据分析师)
- 媒体工作者(广告、内容创作、记者)
- 法律行业工作者(律师助力、法律助理)
- 市场研究分析师
- 教师
- 财务(财务分析师, 个人财务顾问)
- 交易员
- 平面设计师
- 会计师
- 客服
万事都具备两面性,就拿程序员工作来说,ChatGPT的出现可能会对底层程序员造成一定的影响,但不会导致程序员失业。因为,ChatGPT本身也需要程序员进行开发和维护。
01 技术类工作:程序员、软件工程师、数据分析师
- 像ChatGPT和类似的人工智能工具可能会在不久的将来率先替代编码和计算机编程技能。
- Madgavkar表示,软件开发人员、网络开发人员、计算机程序员、编码员和数据科学家等技术岗位“很容易”被人工智能技术“取代更多的工作”,这是因为像ChatGPT这样的人工智能擅长相对准确地处理数字。
- 像ChatGPT这样的先进技术可以比人类更快地生成代码,这意味着一项工作在未来可以用更少的员工完成。诸如ChatGPT制造商OpenAI这样的科技公司已经在考虑用人工智能取代软件工程师。
02 媒体类工作:广告、内容创作、技术写作、新闻
- Madgavkar表示,所有的媒体工作——包括广告、技术写作、新闻以及任何涉及内容创作的角色,都可能受到ChatGPT和类似形式的人工智能的影响。她补充说,这是因为人工智能能够很好地阅读、写作和理解基于文本的数据。
- Madgavkar 说:分析和解释大量基于语言的数据和信息是一项技能,可以期待生成式人工智能技术的提升。
事实上,媒体行业已经开始尝试使用人工智能生成的内容。科技新闻网站CNET已经使用人工智能工具撰写了数十篇文章,而数字媒体巨头BuzzFeed也宣布将使用ChatGPT生成更多新内容。
ChatGPT和Midjourney出来后,他当天就把编剧和原画师给辞退了,就这么残酷
【2023-7-31】日本两艺术系女生欲跳崖,“人生被AI毁掉了”
6月19日下午6时左右,一名18岁左右的女孩坐在崖边,有轻生迹象。巡逻的工作人员见状上前询问情况,女孩见到工作人员后崩溃大哭,最终被成功解救。
据了解,这名女孩高中时所创作的插画作品获得了国家级大奖,因此被老师推荐进入艺术大学,目前就读于某艺术大学艺术系,是一名大一学生。然而,进入大学三个月后,她体验到了学校引进的AI的可怕之处。她表示,只要把想要画下来的主题输入进AI,就能立马得到一幅完成度较高的画,除此之外,课程上需要几日的研究才能完成的课题,AI仅用十分钟就能完成,这让她感到非常惶恐。
由于家境贫寒,她不得不申请了800万日元(约合人民币40.24万元)的贷款奖学金,然而她却因觉得自己无法顺利完成学业而萌生退学的想法。她向母亲传达了这一想法后,母亲却强硬地要求她只能读完大学。她说:“因为人工智能的存在,我不再能画出喜欢的画,还欠下了一大笔债。我不再能看到未来,所以选择来到这里自杀。”
主修动画和游戏的毕业生:
- “有了人工智能,我变得一无是处”
- 需几天完成的画,AI用10分钟搞定
03 法律类工作:法律或律师助理
与媒体行业从业人员一样,律师助理和法律助理等法律行业工作人员也是在进行大量的信息消化后,综合他们所学到的知识,然后通过撰写法律摘要或意见使内容易于理解。
- Madgavkar称,像这样以语言为导向的角色很容易进行自动化处理。她补充说:
这些数据实际上相当结构化,非常以语言为导向,因此非常适合生成式人工智能。但人工智能无法完全实现这些工作的自动化,因为仍然需要一定程度的人类判断来理解客户或雇主的需求。
04 市场研究分析师
布鲁金斯学会高级研究员Mark Muro表示,人工智能擅长分析数据和预测结果,这就导致市场研究分析师非常容易受到人工智能技术的影响。
05 教师
虽然ChatGPT的大火让老师们都开始担心学生使用这一技术作弊,但罗切斯特理工学院计算与信息科学系副主任Pengcheng Shi认为,老师们也应该考虑自己的工作安全。
Shi 在接受媒体采访时表示,ChatGPT“已经可以作为一名老师轻松地授课了”。他说:尽管它在知识方面存在缺陷和不准确之处,但可以很容易地加以改进。基本上,你只需要训练ChatGPT。
06 金融类工作:金融分析师、个人财务顾问
Muro还表示,像市场研究分析师、金融分析师、个人财务顾问和其他需要处理大量数字数据的工作,都会受到人工智能的影响。
Muro称:这类分析师赚了很多钱,但他们的部分工作是可自动化的。
07 交易员
Shi还向媒体表示,华尔街的某些职位也可能处于危险之中。在一家投行里,人们从大学毕业后就被雇佣,然后花两三年时间像机器人一样工作、做各种Excel表格,但现在可以让人工智能来做这些。
08 平面设计师
在媒体去年12月的一篇文章中,3位教授指出,OpenAI创建的图像生成器DALL-E可以在几秒钟内生成图像,是平面设计行业的一个“潜在颠覆者”。
3位教授写道:
- 提高数百万人创作和处理图像的能力,将对经济产生深远的影响。
对于一些工作受到直接影响、难以适应的人来说,人工智能领域的最新进展肯定会带来一段困难和经济痛苦的时期。
ChatGPT和Midjourney出来后,他当天就把编剧和原画师给辞退了,就这么残酷
09 会计师
虽然会计师通常是一个较为稳定的职业,但也处于类似风险之中。
多伦多大学传播、文化、信息和技术研究所副教授Brett Caraway前阵子公开表示,虽然人工智能技术还未真正成熟,但已经让一些人感受到了危机。他补充称说,“智力劳动”尤其可能受到威胁。
Caraway表示:可能是律师、会计师,等等。这是一件新事物。
10 客服人员
几乎每个人都有过这样的经历:给一家公司的客服打电话或聊天,由机器人接听。而ChatGPT和相关技术可能延续这一趋势。
科技研究公司Gartner在2022年的一项研究预测显示,到2027年,聊天机器人将成为约25%的公司的主要客户服务渠道。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
