LLM 时代推荐系统
【2024-6-18】 新疆大学 CherryRec - 新闻推荐框架
- CherryRec:Enhancing News Recommendation Quality via LLM-driven Framework
- CherryRec 框架包含三个核心组件:知识感知新闻快速选择器(KnRS)、内容感知LLM评估器(CnLE)和价值感知新闻评分器(VaNS)。
- KnRS基于用户互动历史快速筛选候选新闻,CnLE通过微调的LLM深入理解用户偏好
- 而VaNS综合评分以形成CherryRec分数,指导最终推荐。
通过在MIND、Yahoo R6B和Adressa等基准数据集上的实验,CherryRec在推荐准确性和效率方面均优于现有方法。研究结果证明了CherryRec在实时新闻推荐领域的潜力,未来工作将探索整合多媒体内容以进一步提升推荐质量。
RS 介绍
【2024-1-20】谈谈AI落地容易的业务-搜广推
- 推荐系统适用场景:信息过载时提供信息匹配价值
RS 技术路线
推荐系统技术路线
- 早期搜索推荐采用竞价排名,早期的百度凤巢有一系列问题,
戴文渊利用LR算法改进凤巢,和陈雨强又引入了深度学习,陈雨强又在今日头条担任过架构师。 - 另一个主线: 阿里妈妈为代表的电商广告,从
盖坤2011年提出分片线性模型MLR开始,到后面通过类似于Wide&Deep算法,构建GwEN,再到针对用户兴趣建模提出DIN,以及将Attention和GRU引入用户兴趣构建的DIEN,但是用户兴趣序列长度有限制,又引入异步机制User Interest Center并构建MIMN算法对长期行为建模。再到后期提出Search Based Interest Model(SIM),并针对用户不同的行为构建基于Session的分类的Deep Session Interset Network(DSIN),在针对特征间的交互(Co Action)构建的CAN,当然还有召回中的利用树结构构建的TDM算法,和利用图结构的二项箔算法等。
RS 常规流程
推荐系统组件
- 两阶段模型:
召回+排序 - 工业级推荐系统用四阶段模型:
召回,粗排,精排和重排。 - 原因:整个环节上对延迟有严格的需求,通常要求端到端延迟低于100ms,因此需要构建逐级过滤的算法实现。
详见站内推荐系统专题
问题
主流深度学习推荐模型依赖大量手工设计的特征(如用户 ID、物品类别、点击次数等)
随着数据规模爆炸式增长,模型面临计算效率低下的问题
比如,处理数十亿用户行为时,计算成本会呈指数级上升,难以扩展。
三个关键挑战:
- 特征复杂性:特征类型多(如离散的用户 ID 和连续的点击率),缺乏统一结构,传统模型难以高效处理。
- 动态词汇表:推荐系统需要处理不断变化的海量物品(如每天新增的视频、商品),传统方法在训练和推理时效率极低。
- 计算成本高:用户行为序列可能长达数万甚至数十万(如用户长期的浏览历史),传统 Transformer 架构的计算复杂度(如自注意力的 O (n²) 复杂度)无法应对。
作者:李见黎
LLM + RS
知乎专题 生成式推荐会成为下一代推荐系统的范式吗?
生成式推荐分析
生成式推荐模型的目标与优势
(1)将推荐视为 “序列生成任务”:
- 把用户与物品的交互(如点击、观看、分享)视为一个序列
- 模型目标: 根据历史交互序列生成未来的交互行为。
例如
- 输入: “用户 A 昨天点击了视频 X,今天观看了视频 Y”
- 模型预测: “用户接下来可能喜欢视频 Z”。
(2)统一特征表示:
- 不再依赖手工设计的复杂特征,而是将所有特征(包括用户 ID、物品类别、点击频率等)编码成统一的时间序列。
- 例如,将 “用户 ID”“物品类别”“点击时间” 等信息合并成一个连续的序列,让模型自动学习特征之间的关联。
应用综述
【2023-6-17】基于LLM的推荐系统全面综述, 将基于LLM的推荐系统分为两大范式,方法、技术和性能的洞察,分别是
- 用于推荐的
判别型LLM(DLLM4Rec) - 用于推荐的
生成型LLM(GLLM4Rec),首次被系统地整理出来。
大型语言模型(LLMs)融入推荐系统的关键优势
- 能提取高质量的文本特征表示,并利用其中编码的广泛外部知识 [Liu等人,2023b]
范式总结
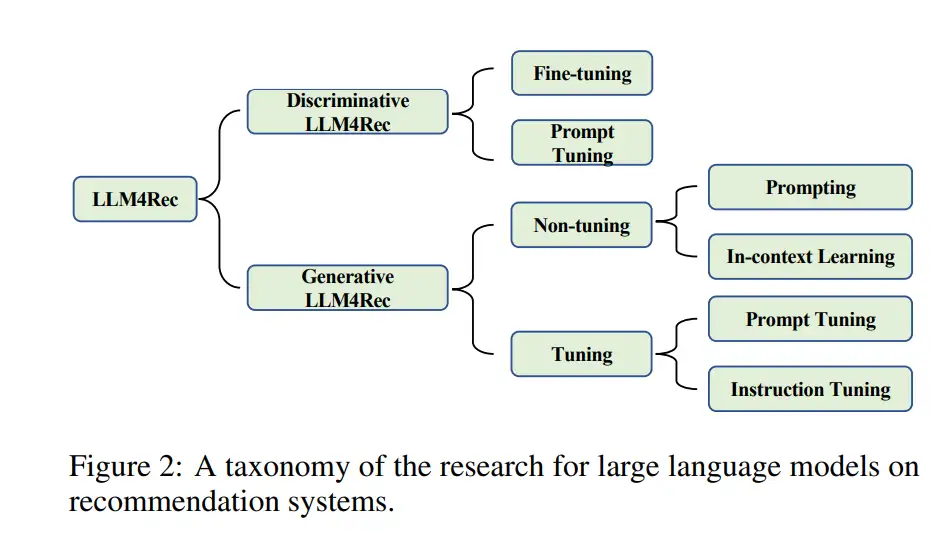
- (1) LLM Embeddings + RS。这种建模范式将语言模型视为特征提取器,将物品和用户的特征输入到LLM中并输出相应的嵌入。传统的RS模型可以利用知识感知嵌入进行各种推荐任务。
- (2) LLM Tokens + RS。与前一种方法类似,根据输入的物品和用户的特征生成token。生成的令牌通过语义挖掘捕捉潜在的偏好,可以被整合到推荐系统的决策过程中。
- (3) LLM作为RS。与(1)和(2)不同,这个范式的目标是直接将预训练的LLM转换为一个强大的推荐系统。输入序列通常包括简介描述、行为提示和任务指示。输出序列预计会提供一个合理的推荐结果。
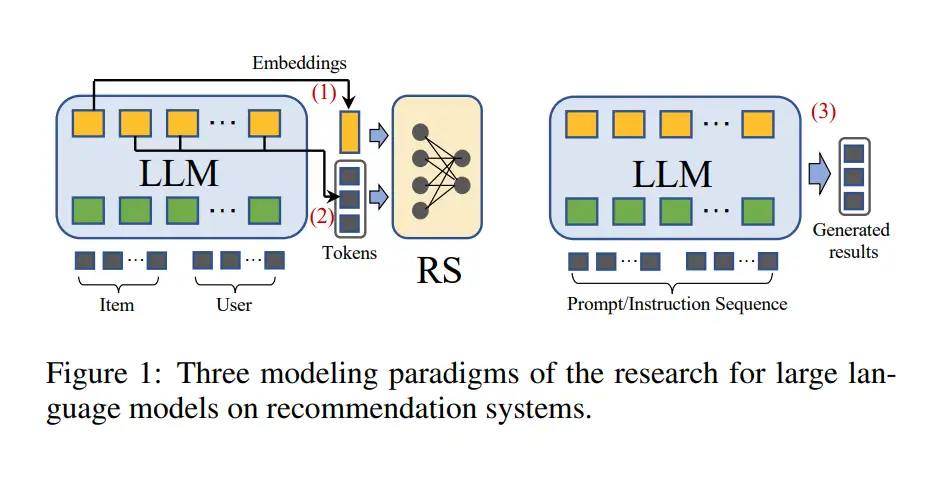
推荐的判别式LLM和生成式LLM。
- 判别式语言模型非常适合在范式(1)中嵌入
- 判别性语言模型主要是指BERT系列的模型

- 而生成式语言模型的响应生成能力进一步支持范式(2)或(3)。
- 相比于判别型模型,生成型模型具有更好的自然语言生成能力。
- 因此,不像大多数基于判别模型的方法将LLMs学习到的表示与推荐领域对齐,大多数基于生成模型的工作将推荐任务翻译为自然语言任务,然后应用像在上下文中学习,提示调优,和指导调优这样的技术,来适应LLMs直接生成推荐结果。
【2023-5-20】当推荐系统遇到大模型
ChatGPT在推荐系统中的应用有不小的潜力,主要体现在以下几个方面:
- 任务统一:所有类型的推荐任务都可以表述成文本,实现了推荐任务大统一,使用统一语言模型进行各个场景和任务上的推荐,有效解决多任务、多场景问题。
- 小样本和冷启动问题:传统推荐系统中,小样本和冷启动是一个比较常见的问题,而大模型天然具备很强的语义泛化能力和小样本学习能力。
- 基础的推荐能力验证:多篇文章已经验证了ChatGPT等模型在推荐系统中应用是可行的,即使不在下游任务finetune,也能取得不错的效果
【2023-11-17】人民大学高瓴AI学院 徐君: 当大语言模型遇见推荐系统
- 【2023-8-24】论文: RecSys 2023 Uncovering ChatGPT’s Capabilities in Recommender Systems
- 代码 LLM4RS, 包含电影、书籍、音乐与新闻等domain上实践
LLM 做推荐两个思路:
- 将LLM当作backbone: 训练时的strategy,适应某个推荐任务。
- 早期的
BERT4Rec,训练时让模型猜测,如果少了一个item,这个item应该是什么,由模型补上这个item。 UniSRec,用 pre-train 和 fine-tune 流程。P5,用 pre-train和promting 流程。
- 早期的
- 把LLM当作推荐系统的补充。
- 把LLM当作一个embedding生成器,生成更好的user、item以及context的表达,换句话说,LLM可以辅助理解用户。
- 用LLM生成一段文字描述来用户。然后把LLM带来的附加信息加入现有的推荐模型中去。
要点
- Key Tasks:Top-K Ranking of Items
- 交互页面稳定时, 关键是选取Top-K的items,再排序
- 三种方式
Point-wise ranking。假设有5个items,直接询问大模型对这5个item的打分。这种方式最大程度模拟了业界推荐模型的工作方式,因为在线侧每一个item都会询问一次大模型,所以是Point-wise的方式。Pair-wise ranking。每次选取两个items去问大模型,哪个才是更适合用户的结果,哪个才是用户更喜欢的item,大模型会告诉我们一个答案。这样的话,如果我们有n个item,那么我们最多问 n*(n-1)/2次,就能得到n个item的排序。List-wise ranking。这种方式是个挑战,直接询问大模型n个item的排序方式,相当于直接把大模型当成item排序结果的生成器。
- LLMs for Recommendation: Overall Evaluation Procedure
- Prompt的构建包括三部分。
- 第一部分是Task Description,指出是哪种推荐系统,比如电影推荐系统,相当于指定推荐的domain;
- 第二部分是Demonstration Examples,告诉模型想让它做出什么样的动作;
- 最后是New Input Query,想要问的问题。通过这个template,基于是否要in-context learning,就构造出了一个prompt。将这个prompt给到LLM,LLM就会按照它的生成方式,输出一段话,再从这段话中提取出答案。有时这个答案可能是不符合要求的,就需要一个exception处理流程。
分别在电影、书籍、音乐与新闻等domain数据上面,验证了ChatGPT等大模型的表现,并给出了相关实验结论。
大模型对推荐影响
【2023-5-12】gpt4这种大模型能力对推荐系统这个领域有什么影响?
结论:
- 短期内,不会对推荐系统有大的影响。
- 长期看,对推荐系统的影响体现在
- 大模型催生新的业务场景:比如基于问答的推荐场景,当用户查询旅游攻略时,除了常规的线路规划,还可以给出基于用户偏好的酒店,餐厅推荐候选。在这类的场景下,搜索和推荐相比当前的交互,会更加融合。
- 大模型提升生产力,导致垃圾内容泛滥:如何识别aigc 内容,降低该类内容对内容生态冲击,流量蚕食会是未来的一个新命题。
- 大模型在用户关怀上的应用:通过内容生产能力,为用户产生不同风格化评论,对创作者进行促活,也是一个比较有潜力的应用,现在的生成模型缺乏内容理解和产出风格化的能力。
- 大模型对内容理解能力的提升,使推荐朝端到端的方向发展:当前推荐建模依赖大量离散特征以及统计后验特征,如果未来能通过大模型的内容理解能力,直接匹配用户理解,这样端到端的新范式,会重塑推荐系统的发展线路。
推荐大模型最有可能的路线
- 借助语言图像类大模型的内容理解能力,把对内容的理解固定在一个稳定的embedding 空间,完全替代掉推荐模型里的itemid类稀疏特征,在系统层面,真正的学到推荐“知识”,并具有大规模泛化能力,这是最令我激动和充满热情的技术路线。
作者:手套销售拉呱总
工业应用
【2025-6-15】李见黎的回答
核心创新点总结
HSTU:首次验证推荐系统Scaling Law,实现万亿参数级扩展;MTGR:平衡生成式与传统特征优势,实现工业级低成本落地;OneRec:引入LLM技术(DPO、MoE),突破多阶段系统性能上限;GenRank:重构自回归范式,通过行动导向设计降低75%注意力计算量。 HLLM:- 1)分层解耦架构:Item LLM提取跨领域文本特征,User LLM专注序列建模,突破ID特征冷启动瓶颈
- 2)LLM知识迁移验证:首次证明通用LLM预训练权重经微调可激活推荐场景Scaling Law(7B模型指标↑108.68%)
方法对比
| 框架 | 架构类型 | 核心技术 | 计算优化 | 适用场景 | 关键指标提升 | 工业场景验证 | 主要瓶颈 | 优化方向 |
|---|---|---|---|---|---|---|---|---|
HSTU |
分层序列转换单元 | Pointwise聚合注意力(替代Softmax) | 稀疏Attention + CUDA Graph优化(KV缓存) | 超长序列(8192+)实时场景 | 在线指标↑12.4%,吞吐↑94 req/s(FP16优化) | Meta数十亿用户平台部署 | 依赖动态词表更新(分钟级新内容),冷启动需人工规则干预 | 实时增量学习 + 跨模态注意力 |
MTGR |
混合特征生成架构 | 交叉特征Token化重组 + 组层归一化(GLN) | 动态Batch调整 + FP16量化(延迟↓37%) | 高基数动态特征工业场景 | 外卖订单量↑1.22%,推理成本↓12% | 美团核心流量全量 | 低活跃用户GAUC↓0.5%(特征稀疏性敏感) | 多模态增强(图文特征融合) |
OneRec |
端到端Encoder - Decoder | 多级语义ID生成(残差量化) + MoE稀疏门控 | BeamSearch剪枝 + DPO偏好对齐 | 多阶段系统替代(召回→精排) | 观看时长↑6.56%,互动率↑9.2%(DPO对齐策略) | 快手A/B测试覆盖亿级用户 | 生成延迟高(需专用TensorRT引擎,MoE路由计算↑40%) | 动态早停机制 + 分块KV缓存 |
GenRank |
行动导向因果建模 | 行为 - 位置解耦(Item作位置编码) + 无参数ALiBi偏差 | 序列长度压缩50% + 线性I/O位置编码 | 资源敏感型精排场景 | 训练速度↑94.8%,AUC↑0.0006(对应线上0.5%收益) | 小红书发现页推荐 | 实时统计特征需人工校准(如时间衰减系数) | 自适应特征权重网络 |
HLLM |
分层LLM架构 | Item - User双塔解耦:Item LLM提取文本特征→User LLM建模序列兴趣 | 预训练权重迁移 + Item Embedding缓存 | 冷启动敏感型场景 | 关键指标↑0.705%,召回率@200↑2.44(vs HSTU↑0.76) | 抖音全量部署,冷启动GAUC↑15.8% | 依赖文本特征质量(无描述物品效果差),存储成本高(需缓存全量Item Emb) | 跨模态特征融合 + Embedding压缩 |
转置
- 使用工具 tableconvert
| 框架 | HSTU |
MTGR |
OneRec |
GenRank |
HLLM |
|---|---|---|---|---|---|
| 架构类型 | 分层序列转换单元 | 混合特征生成架构 | 端到端Encoder - Decoder | 行动导向因果建模 | 分层LLM架构 |
| 核心技术 | Pointwise聚合注意力(替代Softmax) | 交叉特征Token化重组 + 组层归一化(GLN) | 多级语义ID生成(残差量化) + MoE稀疏门控 | 行为 - 位置解耦(Item作位置编码) + 无参数ALiBi偏差 | Item - User双塔解耦:Item LLM提取文本特征→User LLM建模序列兴趣 |
| 计算优化 | 稀疏Attention + CUDA Graph优化(KV缓存) | 动态Batch调整 + FP16量化(延迟↓37%) | BeamSearch剪枝 + DPO偏好对齐 | 序列长度压缩50% + 线性I/O位置编码 | 预训练权重迁移 + Item Embedding缓存 |
| 适用场景 | 超长序列(8192+)实时场景 | 高基数动态特征工业场景 | 多阶段系统替代(召回→精排) | 资源敏感型精排场景 | 冷启动敏感型场景 |
| 关键指标提升 | 在线指标↑12.4%,吞吐↑94 req/s(FP16优化) | 外卖订单量↑1.22%,推理成本↓12% | 观看时长↑6.56%,互动率↑9.2%(DPO对齐策略) | 训练速度↑94.8%,AUC↑0.0006(对应线上0.5%收益) | 关键指标↑0.705%,召回率@200↑2.44(vs HSTU↑0.76) |
| 工业场景验证 | Meta数十亿用户平台部署 | 美团核心流量全量 | 快手A/B测试覆盖亿级用户 | 小红书发现页推荐 | 抖音全量部署,冷启动GAUC↑15.8% |
| 主要瓶颈 | 依赖动态词表更新(分钟级新内容),冷启动需人工规则干预 | 低活跃用户GAUC↓0.5%(特征稀疏性敏感) | 生成延迟高(需专用TensorRT引擎,MoE路由计算↑40%) | 实时统计特征需人工校准(如时间衰减系数) | 依赖文本特征质量(无描述物品效果差),存储成本高(需缓存全量Item Emb) |
| 优化方向 | 实时增量学习 + 跨模态注意力 | 多模态增强(图文特征融合) | 动态早停机制 + 分块KV缓存 | 自适应特征权重网络 | 跨模态特征融合 + Embedding压缩 |
技术路径差异
| 维度 | HSTU | MTGR | OneRec | GenRank | HLLM |
|---|---|---|---|---|---|
| 序列建模 | 用户行为序列因果建模 | 多序列联合编码 | Session级生成(5 - 10项) | 行动 - 候选掩码交互 | 物品特征独立建模→用户序列二次编码,避免原始文本输入膨胀 |
| 特征处理 | 删除数值特征,依赖语义编码 | 保留交叉特征与统计特征 | 多模态量化 + 语义ID | 离散化数值特征 + 冻结Embedding | 纯文本特征驱动(Title/Tag/Desc),拒绝ID特征 |
| 扩展性 | 参数规模达1.5T,幂律扩展 | 兼容传统特征工程 | MoE稀疏激活(24专家) | 线性I/O位置编码 | LLM Scaling Law迁移(Item/User LLM从1B→7B参数,效果持续提升) |
| 推理效率 | M - FALCON微批处理 | 动态候选集压缩 | Beam Search + KV缓存优化 | 候选掩码并行解码 |
最新论文
论文
- 【2023-1-2】Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm
- P5将各类推荐任务通过prompt形式全都转换成统一文本,然后利用这些文本训练一个 Transformer Encoder-Decoder模型。P5利用语言模型解决推荐系统问题,由于各种推荐系统任务都能表述成文字,使得统一建模各类推荐系统任务成为了可能。
- prompt构造方法:针对每种任务设计一个prompt模板,对于商品信息、用户信息等,直接将id作为本文输入。P5在这种文本上训练,对于商品和用户id相当于都当成一个独立的词进行embedding的学习。
- 【2023-4-4】Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
- Chat-REC将ChatGPT应用到推荐系统中,会话推荐系统, 具有交互式和可解释的能力,验证了大模型在一般推荐场景、跨域推荐、冷启动推荐等场景下都有着不错的表现。
- Chat-REC核心:将包括用户特征、搜索词、用户和item的历史交互信息、历史对话信息等一系列信息,输入到一个Prompt Constructor中,自动生成一个prompt。这个prompt输入到ChatGPT中,让ChatGPT生成推荐结果,或者解释推荐利用。
- 通过这种方式让推荐系统能够产生可解释的推荐结果,例如在对话过程中,可以询问对话系统推荐的原因,prompt会将推荐系统给到的结果和用户的问题输入Prompt Constructor,生成新的prompt,让ChatGPT生成对应的解答。
- Chat_REC整体利用了ChatGPT优化原有的推荐系统,让其能够实现更丰富的用户和推荐系统的交互。
- 【2023-5-11】A First Look at LLM-Powered Generative News Recommendation
- 利用大模型来提升新闻推荐系统的效果。新闻推荐系统中存在很多挑战,一方面新闻标题可能不含实际内容的关键词,需要更深入的语义理解;另一方面对于用户特征缺失、冷启动等情况,推荐效果也会变差。
- 这篇文章利用大模型进行title扩展、用户特征生成、解决冷启动等问题。
- 构造prompt,进行3方面的数据扩充,再利用扩展出的数据进行下游新闻推荐系统模型的训练
- 为了在新闻标题中补充更丰富的信息,设计了一个摘要prompt,根据title和新闻信息生成扩展后的title。
- 为了补充用户特征,利用用户历史的浏览行为,生成指定的相关特征。
- 最后,对于冷启动用户,利用用户少量的历史浏览行为,让大模型生成更多用户可能感兴趣的新闻信息。
- 【2023-5-12】Is ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation
- 研究利用大模型进行推荐时是否存在公平性问题。
- 公平性问题:用户侧一些敏感属性的特征,可能会引起大模型产出不公平的推荐结果,因为大模型经过大规模语料进行训练,其中会存在这样的有偏信息。
- 为了对这个问题进行实验和验证,构建了大模型推荐系统公平性的benchmark,在评估时基础做法是生成一些instruction产出推荐结果,再在instruction中插入各种敏感词对比推荐结果,判断推荐结果因为敏感词插入造成的差异大小。差异越大,说明大模型用于推荐系统存在的不公平现象越严重。
- 【2023-4-20】Is ChatGPT a Good Recommender? A Preliminary Study
- 通过5种类型的推荐任务评估ChatGPT在推荐系统中应用的效果。这5个任务包括:排序预测 rating prediction、序列推荐 sequential recommendation、直接推荐 direct recommendation、可解释生成 explanation generation、总结 review summarization等。解读
评分预测:评分预测旨在预测用户对特定项目的评分,如上图所示,黑字部分代表任务的描述,评分预测被翻译为“How will user rate this product_title?”,灰字表示当前的输入,即要求用户评分的项目,红字表示针对输出的格式要求,在评分预测任务中,要求有“1 being lowest and 5 being highest”和“Just give me back the exact number a result”;序列推荐:序列推荐任务要求系统根据用户过去的序贯行为预测其之后的行为,如上图所示,论文为该任务设计了三种 Prompt 格式,分别是基于交互历史直接预测用户的下一个行为,从候选列表中选出可能的下一个行为以及判断指定行为成为用户下一个行为的可能性;直接推荐:直接推荐指通过利用用户评分或评论信息直接显示反馈推荐的任务,论文将这一任务的 Prompt 设计为从潜在的候选项中选择出最适合的一项;解释生成:解释生成是为用户提供解释以澄清为什么会推荐此项的推荐系统任务,具体地,如上图所示,论文要求 ChatGPT 生成一个文本解释,以阐明解释生成过程,对每个类别,可以包含如提示词或星级评分等的辅助信息;评论总结:旨在使用推荐系统自动生成用户评论摘要。通过输入用户的评论信息,Prompt 提示推荐系统总结评论的主要含义。- 针对这5种任务分别设计了相应的prompt,输入到ChatGPT中生成预测结果。5种任务的prompt构造例子,每个prompt都包含:任务描述、格式声明以及一些user和item交互的例子,以给ChatGPT提供few-shot信息。
- 从推荐系统准确率相关指标来看(如hit rate等),ChatGPT在rating任务上表现比较好,但是在其他任务上表现比较差。但是如果人工评估的话,ChatGPT的结果是比较好的,这说明使用推荐系统指标评估ChatGPT也是有局限性的。同时,文中的ChatGPT并没有在推荐系统数据上进行finetune,就能达到这样的效果,也表明了ChatGPT在推荐系统中的落地是非常有潜力的。
- 【2023-5-11】Uncovering ChatGPT’s Capabilities in Recommender Systems(2023.5.11)
- 尝试挖掘ChatGPT在推荐系统中3类任务的能力,包括
point-wise、pair-wise、list-wise三类推荐系统面临的给定user推荐item的任务。 - 针对这3类任务,文中构造了如下3类prompt。每类prompt包括任务描述、例子、当前的问题三个部分。
- 3类任务的prompt主要差别是当前问题的组织形式: point-wise就直接问ChatGPT打分是多少,pair-wise给两个item让模型做对比,list-wise则是对item做排序。
- 整体实验结果: 主要是对比了ChatGPT和一些基础推荐方法(随机推荐、根据商品流行度推荐)的差异,初步能够证明ChatGPT是具备一定的推荐能力的,其中在list-wise类型的任务上能获得最高的性价比。
- 尝试挖掘ChatGPT在推荐系统中3类任务的能力,包括
- 【2024-7-9】综述文章: How Can Recommender Systems Benefit from Large Language Models: A Survey
| 维度 | 传统推荐系统 | 大语言模型 |
|---|---|---|
| 特征表示 | 1. user/item profile id 2. 具有协同意义的(combine/match类)id特征 |
1. 文本数据(语义信息) |
| 数量级 | 亿级(用户)/ 千万级(候选) | 十万级token |
| 场景特点 | 1. 领域各异,领域知识(数据),不具备迁移性 2. 大量稀疏隐式反馈行为数据 |
1. 能跨领域和跨任务,通用模型,One for all 2. 语义丰富的,用户主动表达的数据 |
| 学习范式 | Supervised learning | Pretrain-Finetune、Prompt tuning、Instruction tuning |
| 模型能力 | 1. 冷启动差,需要大量行为数据训练 2. 定制化的parameter server,能高效利用id 特征中的协同信息 |
1. 丰富的世界知识,冷启动友好 2. 有逻辑推理 和 规划能力 3. 可解释性强 |
推荐系统希望从LLM获取的能力
- 更丰富的特征表示、丰富的语义信息、知识信息
- 尝试模型架构(Transformer,Causal language model)
- 借鉴学习范式(Pretrain-finetune)
- 交互推荐 和 可解释推荐的能力
LLM参与到推荐系统的各个环节: 总结图见论文原文
- 特征工程&表征提取: 核心思路是引入额外语义信息和世界知识
- feature engineering 特征工程
- feature encoder 特征编码
- LLM 扩充文本信息 + 文本encoder提供embs + 构造instruction数据 + 与 传统推荐模型 share embs,给embs间接赋予语义信息
- 序列建模优化
- LLM对基于早期LM模型序列建模的改进
- 1.重构行为序列 id 特征
- 2.基于Tranformer的结构,直接训练序列推荐模型
- 直接推荐
- 探究 LLM zero shot/few shot用于推荐排序的能力
- 召回推荐
- 打分排序: 如何利用大模型学习推荐领域信息,再用于排序
- scoring/ranking function
- 交互式推荐&控制
- user interaction, and pipeline controller
提示学习与推荐
随着 prompt learning 在nlp的出色表现,也开始向cv,向多模态进行扩展,当然,也有不少研究人员用它来解决推荐系统问题。
【2022-8-29】提示学习用于推荐系统问题
论文
- KDD 2022: Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning, 解读
- 会话推荐系统 (下面简称为:
CRS) 旨在通过自然语言对话主动引发用户偏好并推荐高质量的项目。通常,CRS 由一个推荐模块(用于预测用户的首选项目)和一个对话模块(用于生成适当的响应)组成。 - 提出了一种统一的 CRS 方法,即基于 PLM 的知识增强型即时学习,
UniCRS。
- 会话推荐系统 (下面简称为:
Chat-Rec
【2023-4-4】Chat-REC: 当推荐系统遇上 ChatGPT, 会发生什么奇妙反应,解说
推荐系统已被广泛部署用于自动推断人们的偏好并提供高质量的推荐服务。然而大多数现有的推荐系统仍面临诸多缺陷,例如缺少交互性、可解释性,缺乏反馈机制,以及冷启动和跨域推荐。
本文中提出了一种用 LLMs 增强传统推荐的范式 Chat-Rec(ChatGPT Augmented Recommender System)。通过将用户画像和历史交互转换为 Prompt
- Chat-Rec 将用户与物品的历史交互、用户档案、用户查询 和对话历史 (如果有的话)作为输入,并与任何推荐系统R接口。
- 如果任务被确定为推荐任务,该模块使用 R 来生成一个候选项目集。否则,它直接向用户输出一个响应,如对生成任务的解释或对项目细节的要求。提示器模块需要多个输入来生成一个自然语言段落,以捕捉用户的查询和推荐信息。这些输入如下:
- 用户与物品的历史交互,指的是用户过去与物品的互动,比如他们点击过的物品,购买过的物品,或者评价过的物品。这些信息被用来了解用户的偏好并进行个性化推荐。
- 用户画像,其中包含关于用户的人口统计和偏好信息。这可能包括年龄、性别、地点和兴趣。用户资料有助于系统了解用户的特点和偏好。
- 用户查询 Qi ,这是用户对信息或建议的具体要求。这可能包括他们感兴趣的一个具体项目或流派,或者是对某一特定类别的推荐的更一般的请求。
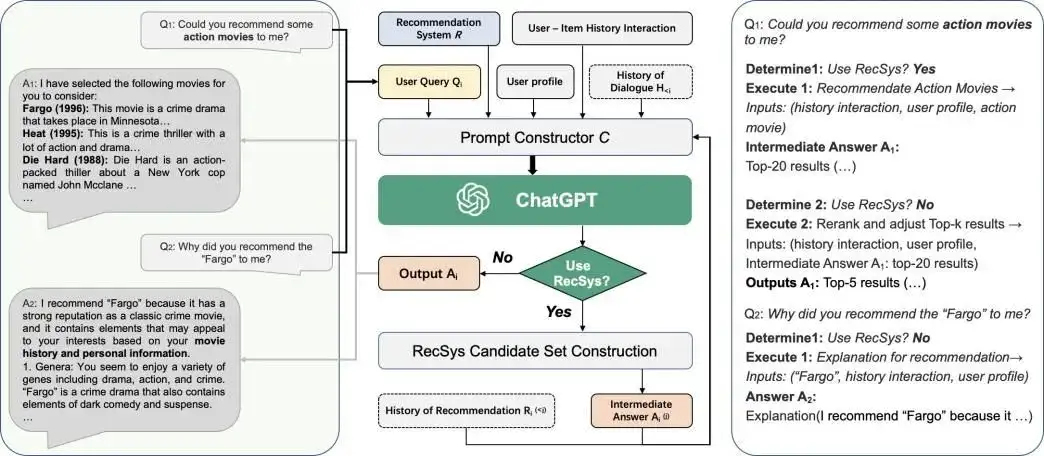
- Chat-Rec 的框架。左边显示了用户和 ChatGPT 之间的对话。中间部分显示了 Chat-Rec 如何将传统的推荐系统与 ChatGPT 这样的对话式人工智能联系起来的流程图。右侧描述了该过程中的具体判断。
- 对于一个用户query:“你能推荐一些动作片给我吗?”。
- 确定这个query是否是一个推荐任务【ChatGPT来判断】
- 如果是推荐任务,则使用该输入来执行“推荐动作电影”模块。但由于推荐空间是巨大的,所以该模块需要分为两个步骤:1推荐系统产生一个少量的候选得到top20的推荐结果,2然后再进行重新排序和调整【ChatGPT来重排】,以生成top5的最终输出。这种方法可以确保向用户展示一个更小、更相关的物品集,增加他们找到自己喜欢的东西的可能性。
- 如果不是推荐任务,如用户询问“为什么会推荐你会推荐fargo电影给我”。系统将使用电影标题、历史记录交互和用户配置文件作为输入来执行对推荐模块的解释【ChatGPT来生成解释】。
由于ChatGPT的输入是自然语言文本,所以中间模块的主要目标:
- 如何利用用户与物品的历史交互、用户档案、用户查询和对话历史 (如果有的话)等等多个输入ChatGPT来生成一个自然语言段落,以捕捉用户的查询和推荐信息。
- User-item history interactions:用户与物品的历史交互,指的是用户过去与物品的互动,比如他们点击过的物品,购买过的物品,或者评价过的物品。
- User profile:用户画像,其中包含关于用户的人口统计和偏好信息,如年龄、性别、地点和兴趣。
- User query Qi:查询句子,可能是推荐任务也可能是通用任务。
- History of dialogue Hi : 用户和chatgpt之间的所有上下文
对于topk推荐任务来说,生成的prompt例子
如何解决冷启动?
大模型中拥有很多知识,利用商品文字描述就能够借助LLM的力量来帮助推荐系统缓解新项目的冷启动问题,即没有大量用户互动也可以得到embedding。
两种chatGPT难以执行推荐场景:
- 1 让不能联网的chatGPT推荐2023最新的动作电影;
- 2 让chatGPT推荐一个它知识储备中没有的动作电影。
因此,离线利用LLM来生成相应的embedding表征并进行缓存。从而在当chatGPT遇到新的物品推荐时,会首先计算离线商品特征和用户query特征之间的相似性,然后检索最相关商品一起输入到 ChatGPT 进行推荐。
如何解决跨域推荐?
类似的,LLM中的知识可以很方便,对不同领域的商品有认知,如电影,音乐和书籍等等,并且还能够分清楚在不同领域产品之间的关系。
因此,直接依靠chatGPT把上下文对话输入一起编码进chatGPT的输入后,就能在用户询问关于其他类型作品的建议时,实现跨域推荐,如对书籍、电视剧、播客和视频游戏进行推荐。
从top5推荐和评分预测这个俩结果上来看,似乎text-davinci-003才是最好的
Chat-Rec可以有效地学习用户的偏好,它不需要训练,而是完全依赖于上下文学习,并可以有效推理出用户和产品之间之间的联系。通过 LLM 的增强,在每次对话后都可以迭代用户偏好,更新候选推荐结果。
此外,产品之间的用户偏好是相关联的,这允许更好的跨域产品推荐。Chat-Rec 为运用 ChatGPT 等对话 AI 进行多种推荐情景的应用提供了有希望的技术路线。
商品推荐
定制化商品推荐,告别传统“傻瓜”推荐算法
- 当下国内众多电商的推荐算法都还是基于传统技术,因此也会出现“买过的东西依然推荐”的傻瓜做法,AI大模型有望彻底改变这些业态
ChatGPT有一些营销场景应用是围绕垂直领域展开,革新推荐算法逻辑,让产品卖点更精准地触达目标客户。
- 海外生鲜电商平台
Intacart的食物搜索工具,其基于ChatGPT推出了面向食物推荐的应用,与自身来自75000多零售合作商店的产品数据结合了起来,帮助客户找到购物的灵感。 - 美国一款名为
Expedia软件内置了一个聊天机器人,通过AI大模型算法为用户规划旅游。有人经历过用ChatGPT规划旅游被推荐一个不存在的海滩,能够在iOS上轻便运行的Expedia据称不会出现这个问题。Expedia会根据旅游地推荐经济实惠的酒店,建议可以打卡的景点,是大模型落地垂直旅游行业的一个代表应用案例。
InstructRec
利用LLM的用户推荐,便于将用户偏好或需求用自然语言描述来表达,因此 instruct tuning 非常适合。
- Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
- 开源LLM(3B的 Flan-T5-XL)进行指令调优来适应推荐系统。原文解读
- 模型流程:用户直接给出instructions如“I prefer”,然后历史记录和用户指定将一起输入formulation模块中,生成模型能够理解的instructions形式,然后输入到大模型中,最后可以完成各种任务如sequential recommendation、product search、personalized search等。
该工作最重要的模块就是通用指令的设计,以全面地描述用户的偏好、意图、任务形式。
- 偏好(Preference)。指用户偏好。其中隐式偏好用商品标题而非id,显式偏好用用户query中的明确表达(如用户评论),而不是之前的评分或点赞。
- 意图(Intention)。指用户对某些类型的物品的需求。模糊的意图如“给我儿子的一些礼物”、具体的意图如“蓝色、便宜、iPhone13”)。
- 任务形式(Task Form)。要做到统一的推荐系统,需要有适应各种任务的能力。
Pointwise。某个候选商品是否适合用户,那么直接用用户需求和商品特征来匹配。Pairwise。让LLM从item pairs中选择更合适的一个即可。Matching。召回模块,LLM从整个商品语料库中生成候选集合。Reranking。排序模块,LLM从候选中重排序商品。
分为 Item LLM 和 User LLM,两者参数并不共享,都是可训练的并通过 next item predict 来进行优化。可以直接基于已经预训练好的(例如 llama、baichuan)来训练。
Item LLM使用 item 的描述作为输入,包括 Title、Tag、Description,最后再加上一个特殊 token:[ITEM],特殊 token 对应输出的代表该 item 的 embedding;User LLM输入是用户历史交互序列,输入序列中每个 item 就来自于 Item LLM 的输出。由于输入并非文本 token,所以会去除预训练模型的 word embedding;
优化目标
推荐系统大致分为两类:生成式推荐与判别式推荐,而 HLLM 同时应用了这两种。
- 首先,针对 Item LLM 的训练虽然论文没提及,但应该就是简单的 next token prediction 训练,针对输入的每个位置预测下一个 token,损失为交叉熵损失。
- 其次,针对 User LLM 的训练还能用 next token prediction 吗?当然不能!因为去除了 word embedding,词表都没了,还怎么预测 next token。
那该怎么做呢?
生成式推荐:- 实际会 User LLM 使用 InfoNCE 来作为生成损失,对于某个物品 模型输出的 是正样本,随机抽取的其他物品为负样本,不得不说将对比学习的 InfoNCE 作为预测 next token 的损失设计的很巧妙。
判别式推荐:- 业界主要还是应用判别式推荐模型,HLLM 同样也可。
Meta HSTU
【2024-3-26】行动胜过言语: Meta落地工业界首个万亿级别参数的生成式推荐系统模型
借鉴 LLMs 思路重塑推荐系统范式,实现推荐系统的scaling。
第一次在核心产品线替换掉了近十年工业界长期使用的基于海量异构特征的深度推荐模型, 在模型规模、业务效果、性能加速等方面都相当亮眼。
有可能成为工业级推荐系统大规模scaling的开创性工作。
传统大规模推荐系统基于海量用户行为数据,构造海量高基数和异构特征进行深度模型训练。尽管模型规模已经很庞大了,但如果想进一步进行scaling,则非常困难。
受到近期大语言模型成功的启发,Meta团队重新审视了传统的推荐系统范式,数十亿用户规模的推荐系统所面临的三类主要挑战:
- 特征缺乏显式结构:海量异构特征,如高基数ids、交叉特征、计数特征、比例特征等。
- 需要处理数十亿级别的动态词汇表:如ID/属性等。与语言模型中的10万量级静态词汇形成了鲜明对比。
- 这种数十亿级别的动态词汇表不断变化,给训练带来很大挑战;
- 且线上需要以目标感知target-aware的方式给数以万计的候选集打分,推理成本巨大。
- 计算成本是限制落地的最大瓶颈:
- GPT-3在1-2个月的时间内使用数千个GPU进行了总计300B tokens的训练。从这个规模上来看,似乎令人望而却步,但与推荐系统用户行为的规模相比就相去甚远了。
- 最大的互联网平台每天为数十亿用户提供服务,用户每天与数十亿条内容、图片和视频进行交互。在极端情况下,用户序列的长度可能高达10^5。
- 因此,推荐系统每天需要处理的tokens数量甚至比语言模型在1-2个月内处理的数量还要大好几个数量级。
为了解决上述挑战,实现推荐系统的scaling,Meta提出了一种新架构 HSTU (Hierarchical Sequential Transduction Unit,层次化序列直推式单元) ,专为高基数、非平稳分布的流式推荐数据而设计。
核心贡献如下:
- 统一的生成式推荐(GR) 第一次在核心产品线替换掉了近十年推荐工业界长期使用的分层海量特征建模范式;
- 不是替换分层架构,而是将传统召排建模方法做了大升级,统一的模型复用到召排链路中,仍然是分层架构,只不过做了升级和技术方案统一。
- 新的 encoder (HSTU) 通过新架构 + 算法稀疏性加速达到了模型质量超过Transformer + 实际训练侧效率比FlashAttention2 (目前最快的Transformer实现)快15.2倍 (8192长度序列);
- 通过新的推理算法
M-FALCON达成了推理侧700倍加速(285倍复杂模型,2.48x推理QPS); - 在传统测试集 MovieLens/ Amazon Reviews上,相比经典的 SASRec 提升20.3%~65.8% NDCG@10;
- 实际中多产品界面上线,单特定ranking界面提升12.4%,如果把召排阶段提升加起来,可达到18.6%(排序12.4%,召回6.2%);
- 通过新架构HSTU+训练算法GR,模型拥有1.5万亿个参数,模型总计算量达到了1000x级的提升,第一次达到GPT-3 175b/LLaMa-2 70b等LLM训练算力,且第一次在推荐模系统中观测到了类LLM的的scaling law。
重点强调
- GR的效果经验性地以训练计算量的幂律方式进行scaling,跨越了三个数量级,最高可达到GPT-3/LLaMa-2规模。
核心洞察点:
- 将“用户行为”当做一种新模态:
- 传统非结构化的图片、视频、文本是模态;
- 结构化的画像、属性也是模态;
- 将用户行为定义为“新模态”,就能够实现海量词表所有模态间的充分交叉,无损信息输入。这篇工作抽象出来“最妙”的点之一。
- 在给定合适的特征空间下,能够重塑推荐系统核心召回、核心排序问题:
- 如何将传统海量的异构特征做转换,转成生成式任务输入格式也是非常基础非常重要的步骤。
- 本文方案也有可能成为生成式推荐系统“标配”的输入范式。
- 新范式系统性地解决传统推荐系统中的特征冗余、计算冗余、推理冗余等关键性能瓶颈问题:
- 节省大量的计算资源和耗时,提升整体推荐系统的效率。
- 相比传统推荐系统分层架构给多个候选打分,新范式在多个候选集打分时能复用算力,实现1次推理同时预估所有候选items。节省下来的算力给到大模型1次更复杂的推理。整体系统耗时不一定会上涨。这也是工业界落地所亟需的。
- 本文方案回答了困扰问题,即:大模型在推荐系统的性能问题该怎么解决:在传统工程架构下叠加大模型能力肯定无法落地,但在新架构新范式下,是有可能实现整体系统层面耗时的摊销。
实现推荐系统的scaling,解决传统推荐系统海量异构特征、海量动态词表、计算瓶颈这三个方面工业级难题。
- 海量异构特征:通过给定适当的新特征空间, 将核心排序和检索任务转化为生成建模问题。
- 海量动态词表:通过自回归建模、Transformers架构定制、采样优化等实现海量动态词表间高阶信息交互和提取。
- 计算瓶颈:通过稀疏性优化、内存优化、算子融合、候选集算力复用和计算摊销来实现高吞吐、低时延。
详见:行动胜过言语: Meta落地工业界首个万亿级别参数的生成式推荐系统模型
字节 HLLM
【2024-10-6】LLM4Rec最新重磅工作:字节发布用于序列推荐的分层大模型HLLM
前几个月 Meta HSTU 点燃各大厂商对 LLM4Rec 的热情,一时间,探索推荐领域的 Scaling Law、实现推荐的 ChatGPT 时刻、取代传统推荐模型等一系列话题让人兴奋
字节前几天(2024.9.19 发布 arxiv)公开的工作 ⌜HLLM⌟(分层大语言模型)便是沿着这一方向的进一步探索,论文内也提及了 follow HSTU
- 论文题目:HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
- 代码链接:HLLM
传统推荐问题:
- 推荐重要的是 建模 user、item feature,主流方法是 ID-based,将 user、item 转为 ID 并创建对应的 embedding table
- 然而一般都是 embedding 参数很大而模型参数较小,这会导致以下问题:
- 严重依赖 ID feature 在冷启动时表现不好
- 模型较小难以建模复杂且多样的用户兴趣
过往 LLM 探索大致分为三种:
- 利用 LLM 提供一些信息给推荐系统
- 将推荐系统转变为对话驱动的形式
- 修改 LLM 不再只是文本输入/输出,比如 直接输入 ID feature 给 LLM
LLM4Rec 挑战:
- 相同时间 span 情况下,相比 ID-based 方法 LLM 的输入更长,复杂度更高;
- 相对于传统方法 LLM-based 方法提升并不显著。
三个关键问题
LLM 应用到推荐有三个问题需要评估:
- LLM 预训练权重的真正价值:模型权重蕴含着世界知识,但是如何激活这些知识,只能使用文本输入吗?这也为之后使用 feature 输入埋下伏笔;
- 对推荐任务进行微调必要性?直接使用 pretrain 还是说要进一步微调?
- LLM 是否可以应用在推荐系统中并呈现
scaling law?
由此提出了 Hierarchical Large Language Model(HLLM)架构,训练 Item LLM(用来提取 item feature)和 User LLM (item feature 作为输入,用于预测下一个 item)
实验表明
- 公开数据集上显著超越 ID-based 方法,并呈现了 Scaling Law 特性。
- 在抖音落地,A/B 实验显示在重要指标上增长 0.705%。
REC-R1
REC-R1:RL+LLM 推荐新框架
强化学习的推荐系统论文,主角是REC-R1框架
通过 RL 连接 LLM 和 RS,基于 用户反馈的黑盒推荐方法
- 【2205-3-31】伊里亚诺香槟大学 论文:Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
- 核心创新点
⭐️ 用强化学习搭起LLM和推荐系统的桥梁:不像传统方法靠人工标数据或者让模型模仿GPT-4o,REC-R1直接让大语言模型(LLM)和推荐系统“打配合”,通过推荐效果的实时反馈(比如用户点击、购买数据)来训练LLM,生成更懂用户需求的内容。
⭐️ 告别海量监督数据,省钱又高效:以前用监督学习调模型,得花大价钱找GPT-4o生成数据或者人工标注,REC-R1直接省去这一步,靠和推荐系统互动就能自己学,成本暴降30倍+。
⭐️ 保留LLM“全能属性”不跑偏:很多模型调完推荐就忘了“本职工作”,但REC-R1在提升推荐效果的同时,还能让LLM保持超强的通用能力,比如数学推理、指令理解一点没变差。
- 技术亮点
⭐️不挑“队友”,啥推荐系统都能搭:不管是传统的BM25检索模型,还是现在流行的密集向量模型,REC-R1都能无缝接入,直接当“外挂”。
⭐️多场景通吃,冷启动也能行:在产品搜索和顺序推荐(比如“猜你下一步买什么”)场景都表现超好,尤其是冷启动场景(用户没历史数据时),比传统方法精准太多。
⭐️靠“奖励”驱动,生成内容更贴需求:用推荐效果(比如NDCG分数)当“奖励”,LLM会自己琢磨怎么生成让推荐系统“开心”的内容。
- 实验效果
⭐️产品搜索:直接“碾压”传统方法:用BM25这种老模型,NDCG分数最高涨了21.45分,比GPT-4o生成的内容还好使,复杂场景下也能把用户需求“吃透”!
⭐️顺序推荐:冷启动场景逆袭:在用户没买过的新品推荐中,Recall@10暴涨4.2分,比专门的顺序推荐模型还厉害!
⭐️通用能力不掉线:在数学推理、代码生成等“副业”测试中,REC-R1比监督学习调参的模型强太多!
LLM + Ranking
重排器(Reranker)作为信息检索的第二阶段,需要根据查询和文档的相关性,对候选文档做细粒度的排序。经典的重排方法一般使用交叉编码器,结合文档和查询的语义信息进行打分和排序。
现有涉及LLM的重排方法大致可以分为三类:
- 用重排任务微调LLM
- 使用prompt让LLM进行重排
- 以及利用LLM做训练数据的增强
综述
【2023-12-20】LLM in Reranking——利用LLM进行重排
本文中针对前两种方法介绍一些研究。
排序学习方法主要分为 point-wise,pair-wise 以及 list-wise 三种思路,LLM通过prompt进行重排也类似。
LLM不同于传统的交叉编码器,具有更强的语义理解能力,并且能够捕捉到文档列表整体的顺序信息,它仍然面对几个不可忽视的问题。
- 一方面,LLM的输入长度对于一个文档列表来说还是十分受限的,必须通过滑动窗口或集成的方式才能实现文档输入。
- 另一方面,list-wise的LLM重排器对于输入非常敏感,在某些极端的情况下,例如将输入文档随机打乱顺序时,模型的输出结果甚至可能不如BM25。
- 另外,还有参数过剩与时效性的问题会导致LLM重排器难以落地。
参考综述:
方案
LRL
Zero-Shot Listwise Document Reranking with a Large Language Model
这篇文章与现有的 score and rank 的 point-wise 打分方式不同,作者提出一种名为 Listwise Reranker with a Large Language Model (LRL) 的方法,利用 GPT-3 对文档进行 list-wise 的排序,直接生成候选文档的identifier序列实现重排, 这种list-wise的方法能够让模型同时关注到所有的文档信息
RankVicuna
RankVicuna 也是一种 Listwise 的LLM排序方法,但是不同于LRL,它是经过针对重排微调后的模型。
- 利用RankGPT-3.5作为教师模型在MS MARCO v1训练集中随机抽样的100K套训练集文档上生成数据,将RankGPT的能力蒸馏到7B的RankVicuna中。
PRP
作者提出利用LLM做list-wise与point-wise重排任务时,模型存在无法很好地理解排序指令的问题,并且在越小规模的模型中越显著。
作者认为这一问题有可能与预训练中缺少相应任务有关。
LLM应用于 list-wise 时出现的问题
针对这一问题,作者提出一种名为 pairwise ranking prompting (PRP) 的范式,设计了一种简单的prompt,结合了生成和打分的模型API,使得规模较小的开源模型也能够在公开数据集上实现SOTA.
PROMPTRANK
本文中提出一种名为 PROMPTRANK 的框架,依靠prompting和多跳重排,可以在少样本的前提下解决复杂的多跳问答(MQA)。
多跳问答(multi-hop question answering, MQA)是指query对应多个文档,且回答问题需要结合召回的复数文档进行多步推理的场景。目前的MQA大多基于retrieve-then-read的pipeline,然而这种模式下往往需要大规模的训练数据,对低资源场景(如医疗、法律等特定领域)不友好。
LLMRank
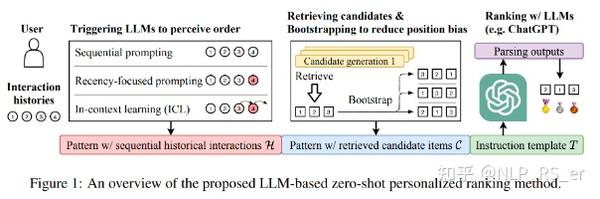
【2023-5-15】人民大学发表论文:LLM用于推荐系统排序
将推荐问题形式化为条件排序任务,将历史交互作为条件,将召回得到的候选item作为候选。
采用特定提示方法来应用LLM解决排序任务:包括交互历史、候选item和排序指令来设计提示模板。
- LLM 具有很有前途的零样本排序能力。
- LLM 难以感知历史交互顺序,并且可能会受到位置偏差等偏差的影响,而这些问题可以通过专门设计的提示和引导策略来缓解。
【2026-1-20】 X 推荐算法开源
1月11日,马斯克在X平台上发了一条帖子,宣布将在7天内开源X平台全新的推荐算法
1月20日,马斯克兑现承诺,X平台工程团队(@XEng)正式宣布:全新的X算法已经开源
X算法现在完全由AI驱动,已经移除了所有手工设计的特征和大多数人工规则。基于Grok架构的Transformer模型,通过学习你的历史互动行为(你点赞过什么、回复过什么、转发过什么),来决定给你推荐什么内容。
参考
- 【2026-1-20】刚刚,马斯克开源基于 Grok 的 X 推荐算法:Transformer 接管亿级排序
- 马斯克兑现承诺,开源X推荐算法!100% AI驱动,0人工规则, 介绍推荐算法背后逻辑
- 马斯克开源基于 Grok 的 X 推荐算法!专家:ROI 过低,其它平台不一定跟, 工业界可参考,对学术价值不大
马斯克X宣布开源 X 推荐算法,开源库包含为 X 上的“为你推荐”信息流提供支持的核心推荐系统,将网络内内容(来自用户关注的帐户)与网络外内容(通过基于机器学习的检索发现)相结合,并使用基于 Grok 的 Transformer 模型对所有内容进行排名,也就是说,该算法采用了与 Grok 相同的 Transformer 架构。
- 开源地址:x-algorithm
X 的推荐算法负责生成用户在主界面看到的“为你推荐”(For You Feed)内容。它从两个主要来源获取候选帖子:
- 关注的账号(In-Network / Thunder)(雷霆)
- 平台上发现的其他帖子(Out-of-Network / Phoenix)(凤凰)全球发现引擎
这些候选内容随后被统一处理、过滤然后按相关性排序。那么,算法核心架构与运行逻辑是怎样的?
算法先从两类来源抓取候选内容:
- 关注内的内容:来自你主动关注的账号发布的帖子。
- 非关注内容:由系统在整个内容库中检索出的、可能你感兴趣的帖子。
Thunder是一个实时内容存储系统,它会:
- 从Kafka消息队列中消费帖子的发布/删除事件
- 为每个用户维护最近的原创帖、回复、转发、视频等内容库
- 提供亚毫秒级的快速查询
Thunder确保第一时间看到关注者的新内容。
Phoenix 通过机器学习在全球海量帖子中搜索相关内容:
- 用户塔(User Tower):把你的特征和互动历史编码成一个向量
- 候选塔(Candidate Tower):把所有帖子也编码成向量
- 相似性搜索:通过向量点积找出与你「最匹配」的帖子
这就是病毒式传播发生的地方。如果帖子在早期表现良好,Phoenix会把它推送给大量陌生人。
即使你粉丝为零,优质内容也有机会被发现:粉丝数的优势被大幅削弱了。
Phoenix模型会预测用户可能对每条帖子采取的多种行为:
最终得分的计算公式是:Final Score = Σ (weight × P(action))
正面行为的权重为正,负面行为的权重为负。
算法不是简单看你获得了多少点赞,而是预测用户看到这条帖子后会怎么做。
这一阶段的目标是“把可能相关的帖子找出来。
系统自动去除低质量、重复、违规或不合适的内容。例如:
- 已屏蔽账号的内容
- 与用户明确不感兴趣的主题
- 非法、过时或无效帖子
这样确保最终排序时只处理有价值的候选内容。
此次开源的算法的核心是系统使用一个 Grok-based Transformer 模型(类似大型语言模型 / 深度学习网络)对每条候选帖子进行评分。
Transformer 模型根据用户的历史行为(点赞、回复、转发、点击等)预测每种行为的概率。最后,将这些行为概率加权组合成一个综合得分,得分越高的帖子越有可能被推荐给用户。
这一设计把传统手工提取特征的做法基本废除,改用端到端的学习方式预测用户兴趣。
LLM 端到端推荐
快手
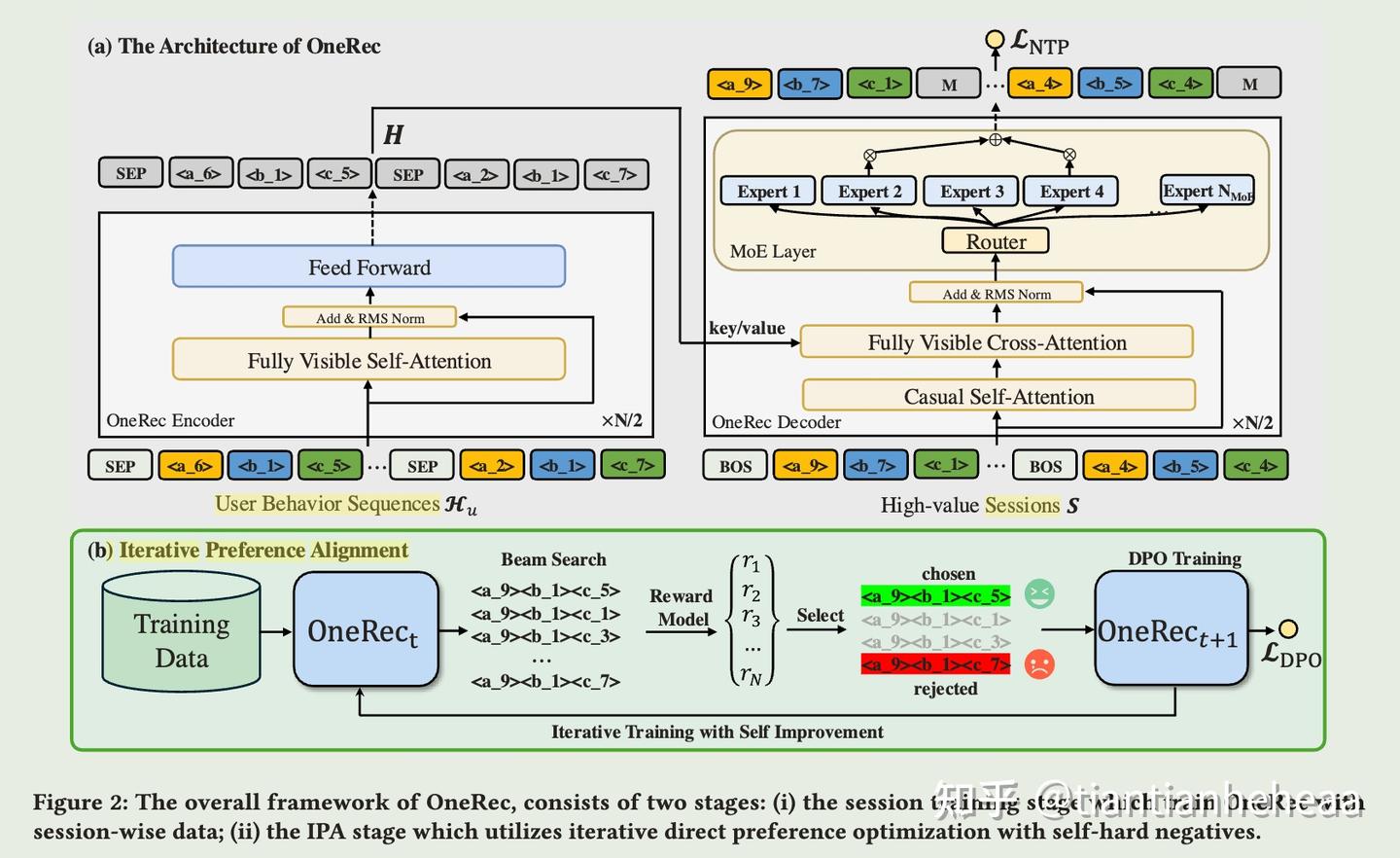
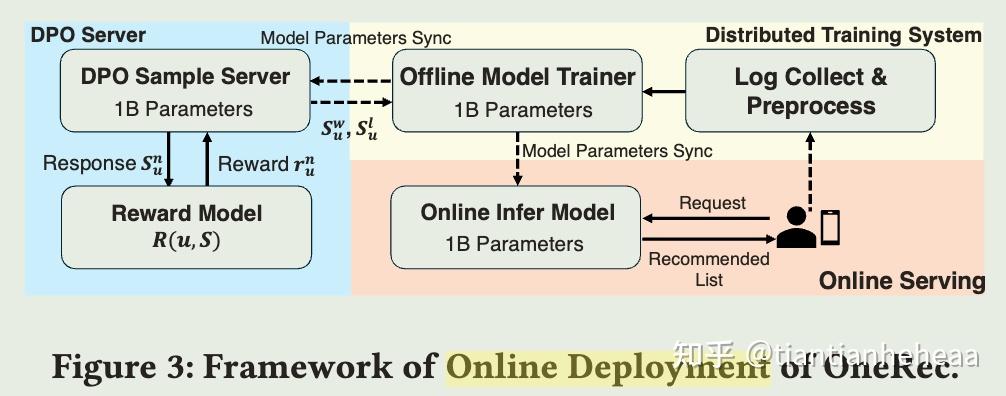
OneRec
【2025-2-26】快手:端到端生成式推荐 OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
第一个在现实场景中超过当前推荐系统的端到端生成式推荐模型
- 快手的主要场景部署,观看时长 +1.6%。
和已有生成式推荐模型相比,核心优化点有2个:
- 1 建模方式上,提出的list-wise生成方式 优于 point-wise 生成方式。
- 2 偏好对齐上,提出的迭代偏好对齐IPA 优于 其他DPO方法。
偏好对生成:
- NLP领域是人工对不同的响应标注。推荐系统中,不可能将同一个请求的不同结果展示给用户做反馈,每次只能展示给用户一种结果。
- 因此训练一个奖励模型Reward Model(RM)来替代真实用户对不同的结果打分,从而构成出偏好数据。
- 奖励模型RM可以看做一种评估器,例如rerank中生成器-评估器中的评估器,用于对序列打分。
迭代偏好对齐IPA:就是依次生成多个模型 ,每个模型是用前一个模型生成的偏好数据进行训练的。
模型结构
线上部署
OneRec-Think
【2025-10-15】OneRec-Think: 快手的集成对话、推理和个性化推荐的统一框架
现有生成模型(例如 OneRec)作为隐式预测器运行,严重缺乏显式且可控的推理能力——这是 LLM 的一个关键优势。
为了弥补这一差距,快手提出 OneRec-Think,无缝集成对话、推理和个性化推荐的统一框架。
OneRec-Think 包含:
- (1) 物品 Alignment:用于语义基础的跨模态 Item-Textual 对齐;
- (2) 推理激活:推理脚手架,在推荐上下文中激活LLM推理;
- (3) 推理增强,设计了一个特定于推荐的奖励函数,考虑用户偏好的多样性。
公共基准测试的实验显示了最领先的性能。
此外,“Think-Ahead”架构能够在快手上进行有效的产业部署,实现APP停留时间提升0.159%,验证了模型显式推理能力的实际效果。
Cici 问题推荐
【2025-11-24】【KDD 2026】如何在 Chat App 中利用强化学习提升生成式推荐质量?
大模型时代,让模型“更懂用户”的核心路径:利用 用户反馈 + 强化学习(RL)改进生成行为
如何在 Chat App(豆包海外版Cici) 的 Query Suggestion(QS)系统中,通过多阶段 alignment 显著提升推荐质量
模型回答结束后看到系统给用户推荐的三个用户可能感兴趣的Query Suggestion(QS)
QS不是传统搜索中根据用户输入前缀补后缀的自动补全,而是从话题延续角度出发,主动引导用户,把对话推向更有价值的方向。
为了保证推荐的QS和上文的相关性,一般采用LLM来生成QS。
- 传统召回、粗排、精排以及重排的搜推链路, 从召回库中选取候选item并用和业务效果关联的的打分器, 选取最优item来推荐给用户。
- 如何让LLM生成具备好的业务效果的QS。
生成式 QS 有几个挑战:
- 如何定义优质QS需要满足的要求,冷启动业务场景。
- 如何构建reward model,使得模型的优化目标和线上业务目标关联。
- 做RL训练的时候,如何防止reward hacking。
针对如上问题,提出 多阶段 alignment 框架:从 prompt engineeriing→ SFT → Reward Model(GaRM)→ RL,层层递进。
Progressive Alignment 框架,具体包括:
- Prompt Engineering(冷启动)
- Supervised Fine-tuning(SFT)
- Preference Modeling(GaRM)
- Reinforcement Learning(GRPO)
点击日志有两大问题:
- 只有正反馈(clicked),没有负反馈
- 点击不稳定、不确定(概率行为)
方案
- 沿用经典 ctr 训练方式训练类似 reward model,这会导致 reward model 更关注上下文历史信息,而不是 query 内容,导致最终效果不好。
- 经过试错后,应该走 pair-wise reward model 训练路线(例如 Bradley-Terry Reward Model)。然而,BTRM 直接把正负样本当成确定 pair,而实际中,用户偏好往往有较大的随机性,这会导致 Reward Model 不稳定、bias 大。
于是,提出 Gaussian Reward Model(GaRM),核心思想:不是给 suggestion 打固定分数,而是给建模分布: N(μ, σ²):
- μ:用户偏好的中心值(越大越好)
- σ:偏好不确定性(越大越不确定)
为什么要这么做?核心洞察:
- “用户偏好不是单点 —— 而是概率分布”
例如两条 suggestion A 和 B:
- A:可能 70% 时间比 B 好
- B:30% 时间更好
GaRM 能捕捉这种 模糊性,传统 RM 做不到。那么如何训练这样的 GaRM 呢?推导出了一个 closed-form 近似公式(论文 Eq. 5)
怎么利用 reward 模型中 μ, σ 进行强化学习呢?我们通过 Bhattacharyya Distance 推导,得到一个 “不确定性下界”(ULB)
强化学习的 reward 中引入 ULB,对高 σ(不确定的 sample)进行惩罚。这使得 RL 倾向于生成“RM 有信心的高分 suggestion”,而不是 reward hacking。
总结一下,GaRM 作用非常关键,可以过滤偏好噪声、建模不确定性,并且提供更可靠、更稳定的 reward,有助于后续的强化学习。
即便有了 GaRM,仅靠 RM reward 去做 RL,仍然会出现严重问题。其中,reward hacking 是最大障碍:
- 模型输出奇怪格式 → RM 打高分
- 模型重复套模板 → 高 RM 分
- 忽略上下文 → RM 判不出来
为此,在 GRPO 的基础上进一步改进。
- 多信号复合 Reward(Composite Reward)
- 两阶段 Reward 融合(Weight Tuning)
(1) 多信号复合 Reward(Composite Reward)
把多种 reward 函数都建模了一遍,主要包含四类:
- Rule-based rewards:指定了若干 verifiable rules 作为奖励函数的一部分(例如长度、多样性等)。
- Prompt-based LLM 评分:使用大模型根据 rubric 打分(类似 rubric-as-reward)。
- Neural RM rewards:第三部分介绍的 reward model
- Perplexity Regularization:一种创新的正则化项
第四种引入参考模型(ref model,即 RL 训练的起点模型)的 logged perplexity 作为正则化项,加入奖励函数中。
(2) 两阶段 Reward 融合(Weight Tuning)
如何将这么多 reward 函数融合成 final reward 呢?
两阶段方案:
- Stage 1: Logistic regression 初始求权重
- Stage 2: Pareto-guided 手动调权
- 某种 reward 不升 → 提高权重
- 某个 reward dominate → 降低权重
- 这种方法看起来 heuristic,但实操起来相当稳定,效果也不错,实际不需要太多的精力。
显著提升:
- 人评方面:GSB 标注显著提升(+80)
- 线上A/B实验方面:取得了 34% 的 CTR 提升,用户发消息数 +1.2% ,用户活跃天 +1.16%
- 安全方面:在安全评测集下正确率超过 90%(即在敏感场景下保持不出推荐问题)
其他核心发现:
- ✔ GaRM 比大型 BTRM 更好:即使 GaRM-8B 在RM accuracy 上不及 BTRM-32B 。但在最终 RL 效果(线上 CTR)上取得更高收益。这证明“不确定性建模”比“增大参数”更重要
- ✔ PPL Regularization 是最重要的稳态组件:Ablation 去掉后性能直接 -40 GSB。
- ✔ 多 reward 融合显著优于单一 RM:很大程度上避免了 reward hacking。
LLM + 推理
【2025-9-1】虾皮+人大 OnePiece 推理模式
【2025-9-1】傅聪联合人大发布 OnePiece:首个全面落地推理能力的工业级生成式搜索框架
大多数工作都主攻生成式推荐基座模型训练方向,很少有工作聚焦在如何将当下LLM技术框架中的“推理能力”迁移至推荐系统中。
以CoT、上下文工程为代表的推理技术,占据LLM优化的半壁江山,将推理技术应用至推荐有如下好处:
- 强化模型对推荐会话“上下文”的感知,增强模型的个性化
- 小模型 + 推理 ≈ 大模型,能推理的推荐模型可以有效分摊算力、参数压力
为了给推荐模型赋予推理能力,傅聪团队联合人大高瓴学院发表了研究成果,在Shopee Search主场景已取得显著收益,全流量生效。
Onepiece 从推理能力的scaling出发,融合上下文工程、隐式推理和多目标训练的生成式搜推框架。一经发布,就凭借强大的推理能力冲上了Hugging Face Daily Paper榜单的前三,引起了海内外的广泛关注,昭示着生成式搜推领域进入了推理时代。
CoT 思路迁移到搜索推荐(尤其是电商场景),不可行
- 第一,每个人的购物思维逻辑都不同,难以还原;
- 第二,即便人为构造出一套推理链条,这种“自然语言文本 + 商品序列 ID”的混合形式也显得非常不协调,输入序列因此变得“异构且不连贯”,模型往往难以理解。
生成式推荐到底应该如何构造 Prompt?
- 最朴素的思路 —— test-time few-shot learning。
解法:引入锚点物品序列(anchor item sequences)。
Shopee Search 场景下,对于某个搜索词,收集大量用户的高频点击序列、高频下单序列,并把这些序列作为“专家示例(domain expert knowledge)”拼接在目标用户的交互序列后面。这样模型不仅看到用户自己的行为,还能看到“典型用户在同一语境下会怎么行为”,从而自然引入了一种可控的 inductive bias。
上下文工程框架
序列格式包含如下几个部分:
- Interation History(IH):就是常规理解的用户行为历史。
- Preference Anchors(PA):根据工程师的领域知识,构造的锚点序列,辅助引导预测和思考方向。
- Situational Descriptor(SD):一些表达场景或其它异构信息的特殊token,一般放在序列末尾聚合信息,例如我们在搜索场用到的user token、query token等。
- Candidate Item Set(CIS):潜在目标候选物品的集合,这个是ranking模式下特有的,也是相对于召回模式的优势所在,ranking模式下,候选物品对模型可见,可提供更多上下文信息。
OnePiece 相比 HSTU, ReaRec+PA 取得额外提升
证明:
- 通过适配推荐场景的上下文工程与推理范式,确实能够有效地引导模型的预测路径,使其在无语言环境下展现出类似 LLM 的指令跟随能力
- “提示词优化(Prompt Optimization)” 正在成为搜索推荐技术栈中的潜在核心能力
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
