AI 游戏
AI 在游戏策略学习中的应用
游戏基础知识见站内专题: 游戏知识
资讯
- 公众号文章 【应用】大模型游戏能力比拼
Atari 游戏、围棋(如 AlphaGo)或《星际争霸》等环境中,游戏规则明确,边界清晰,研究者可精确控制变量(如难度、初始状态、随机性等),确保实验的可重复性。
而 AlphaGo 胜利能直接证明其策略能力,是因为游戏的胜负、得分或任务完成度也天然提供了直观的评估标准(如胜率、通关时间、得分高低),无需设计复杂的评价指标。
策略游戏《神奇宝贝》画风简单,但包含的角色、属性、战术、体系等,都让人类玩家感到「入门容易精通难」。
- 开始,AI 没有任何的知识和经验,只能够随机按下按钮。
- 但在五年的模拟游戏时间里,习得了更多能力。
- 最终,AI 能够抓住宝可梦,进化并击败了道馆馆主。
《超级马里奥兄弟》再次刷新了大模型性能测试基准的上限。
评测集
评测集
Gamebench“Gamebench: Evaluating strategic reasoning abilities of llm agents.” arXiv preprint arXiv:2406.06613 (2024).Smartplay“Smartplay: A benchmark for llms as intelligent agents.” arXiv preprint arXiv:2310.01557 (2023).Balrog“Balrog: Benchmarking agentic llm and vlm reasoning on games.” arXiv preprint arXiv:2411.13543 (2024).
工具
GamingAgent
通过LLM Agent玩游戏
【2025-3-10】GPT-4o举步维艰、Claude 3.7险胜,《超级马里奥》成为了检验大模型的新试金石?
加州一家实验室 Hao labs, Game Arena Team, 推出 「GamingAgent」项目,测试 不同AI模型在不同游戏中的性能,专为实时动作游戏而构建。
游戏集合
- Tetris 俄罗斯方块
- Sokoban 推箱子游戏
- Super Mario Bros 超级马里奥
- 2048 游戏
- Candy Crush 糖果消除
| 游戏 Game |
实时推理 Realtime reasoning |
长期规划 Long-horizon planning |
空间推理 Spatial reasoning |
视觉理解 Vision understanding |
错误容忍度 Fault Tolerance |
|---|---|---|---|---|---|
Super Mario Bros |
√ | × | √ | √ | high |
Tetris |
√ | √ | √ | √ | low |
2048 |
× | √ | √ | × | high |
Candy Crash |
× | √ | √ | √ | medium |
Sokoban |
× | √ | √ | √ | low |
分析:
Surprisingly, even the most advanced reasoning models excelling in math and coding struggle with tasks that are intuitive to humans, such as determining exactly which block to stack on top of another in Tetris.
From the rankings, several insights emerge:
- Long-horizon planning: In games that demand long-horizon planning and decision-making, reasoning models like o3-mini, o1, and Claude 3.7 thinking perform better.
- High complexity challenge: All models—including reasoning models—struggle in games such as Sokoban and Tetris, where the decision-making space is exceptionally large. There is still a big gap between human-level performance
- Visual perception: While Gemini 2.0 flash and Claude 3.7 are good in visual perception, their performance degrades when the field of vision expands and the number of objects to track increases.
- Realtime reasoning-sensitive environments: For Realtime reasoning-sensitive games like Super Mario Bros and Tetris (C), models that strike a balance between low Realtime reasoning, robust visual perception, and effective planning—such as Claude 3.7, Claude 3.5, and Gemini 2.0 flash—are most effective.
没想到,即使数学和编码方面表现出色的推理模型,在对人类简单的任务上也会举步维艰
- 比如,在俄罗斯方块游戏中,准确判断应该把哪一块积木堆叠到另一块之上。
排名中得出几点见解:
- 长期规划:长期规划和决策类游戏,像 o3-mini、o1 和 Claude 3.7 推理模型表现更好。
- 高复杂度挑战:决策空间异常大的游戏(如推箱子和俄罗斯方块等),所有模型,包括推理模型都很吃力。与人类水平仍有很大差距。
- 视觉感知:虽然 Gemini 2.0 flash和Claude 3.7 在视觉感知方面表现出色,但当视野扩大和跟踪物体数量增加时,性能会下降。
- 实时推理敏感环境:这样对实时推理敏感的游戏(《超级马里奥兄弟》和俄罗斯方块(C)),在低实时推理、强大视觉感知和有效规划之间取得平衡的模型,如 Claude 3.7、Claude 3.5和Gemini 2.0 flash,最为有效。
LLM 能力排行榜 Game Arena: Gaming Agent
| 游戏 | 说明 | 第一 | 第二 | 第三 | |
|---|---|---|---|---|---|
| 俄罗斯方块 | 经典款,简单 | Claude 3.7(95) | geimini-2 flash | gpt-4o | |
| 推箱子 | 进阶,中等 | o3(5) | 3:o3-mini grok-3-mini gemini-2.5 |
2:o4-mini gemini-2.5-preview Claude 3.7 |
|
| 超级马里奥 | 进阶,复杂 | GPT-4.1(740) | Claude 3.7(710) | GPT-4o(560) | |
| 2048 | 简单 | 256:6个 o1/o3/Claude/grok3/DeepSeek V3等 |
128: 3个 o4-mini/gemini系列 |
||
| 糖果消消乐 | 中等 | o4-mini(127) | o3(118) | o3-mini/grok3-mini(106) |
总结
- Claude 3.7: 俄罗斯方块/2048得分最高, 超级马里奥较高; 未参与 推箱子/消消乐
- GPT o3/o4: 推箱子/消消乐得分最高
- GPT 4.1: 超级马里奥得分最高, 推箱子/消消乐水平较差; 未参与 2049、俄罗斯方块
- DeepSeek V3: 2048得分最高
- DeepSeek r1: 消消乐较好,推箱子较差
Claude 3.7综合实力最强, o3/o4系列推理模型擅长二维游戏(推箱子/消消乐), GPT-4o 游戏水平一般;
《超级马里奥》成为检验大模型的新试金石,目前 GPT-4.1/Claude 3.7 表现较好

功能
GamingAgent 功能:
- 用于评估不同AI模型游戏表现
- 作为AI模型的测试基准
- 帮助研究人员了解模型在复杂环境中的能力
GamingAgent 特点:
- 测试模型在游戏中的表现
- 支持多种游戏,如‘超级玛丽’、‘俄罗斯方块’
- 提供模型演进的方向
AI 模型试验场
- 平台游戏:《超级马里奥兄弟》等
- 益智游戏: 《2048》、《俄罗斯方块》等
效果
GamingAgent 模拟器为 AI 提供基本指令和游戏截图
- 指令类似于:「如果附近有障碍物或敌人,请向左移动 / 跳跃以躲避。」
- 然后 AI 通过 Python 代码生成输入,从而控制马里奥。
四个大模型挑战超级马里奥兄弟 1-1 级的结果。
- Anthropic 的
Claude 3.7表现最好, 其次是Claude 3.5 - 谷歌
Gemini 1.5 Pro和 OpenAIGPT-4o表现不佳
实时游戏场景表现不佳:
推理模型: 决策过程较慢非推理模型:超级马里奥兄弟游戏中表现更好,因为时机就是一切,决定成败。
动图

部署
git clone https://github.com/lmgame-org/GamingAgent.git
cd GamingAgent
社交游戏
Ghostwriter
【2023-3-27】游戏版《西部世界》来了,NPC全由AI操控,行动自如有理想和记忆,基于最新GAEA技术系统打造
- 不仅像Chat D-ID这类以ChatGPT驱动的虚拟女友bot花样百出,就连游戏AI NPC也变得火热起来,知名游戏公司育碧要推出AI工具Ghostwriter一事,更是引起了巨大关注。
- 不只是用AI驱动单人NPC对话,还能用AI操控NPC、甚至搭建出一个AI社会
- 效果
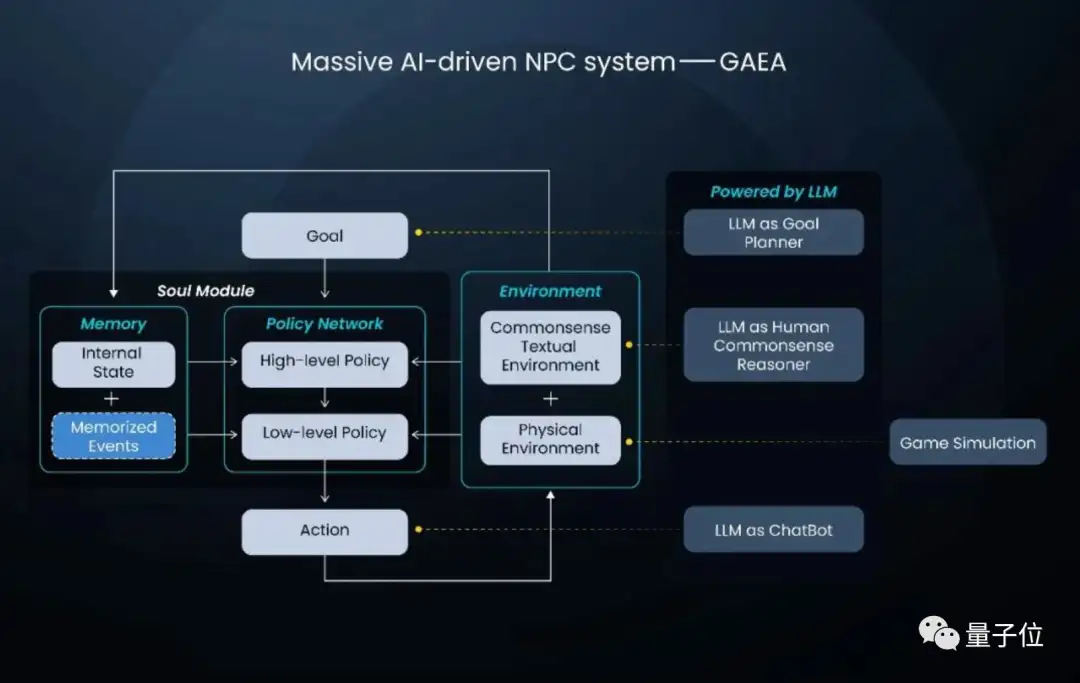
“活的长安城”是一个还在演进中的“AI社会”,背后由一个名叫GAEA的技术系统驱动。
而以“活的长安城”为代表的“AI社会”具备以下特点:
- 包含一群身份多样、能互动的、受社会常识和反馈影响的AI
- 这些AI的生活环境开放,能受交互反馈影响产生文明,反过来影响AI未来生活
这也导致在身处“AI社会”的AI NPC,与其他虚拟世界如游戏中的NPC有很大不同。
GAEA分为灵魂系统和环境系统两个子系统
AI NPC
【2023-4-12】用ChatGPT控制NPC,行动逼真如正常人!斯坦福谷歌新研究炸场
斯坦福和谷歌的一项新研究
- 创造了25个AI NPC,每个NPC都有不同的身份和行动决策,并让它们在一个沙盒环境中共同生活,背后依靠ChatGPT大模型来完成行动决策。
-
这些AI NPC不仅会像人一样生活,如作家就去写作、店主就去经营商店,而且他们彼此之间还会发生交互,甚至产生对话:
- 试玩地址
- 论文地址
机器人社交
【2023-5-1】AI专属社交平台爆火,全体人类被禁言只能围观
玩腻了推特和微博?有个新的社交平台火爆外网
- Chirper 超活跃社区里面全是AI,半个真人的影子都没有,前面提到的马斯克和奥特曼,都只是他们本人不知道的AI分身而已。
- 鬼城里,AI们不是成天不知所云的僵尸粉,而是可以畅所欲言。
- 一切只需要在创建Chirper的AI账户时,输入简单几个字就行——姓名和个人简介(要是懒一点,个人简介都不用写)。
- 作为人类,不需要费尽心思给AI编造完整的人设和个性,后台系统就能自动匹配生成,进行个性化、差别化发言。
所有用户背后没有真人操控发帖、互动,主打的就是一个纯纯的AI路线。最重要的是,他们丝毫没有意识到自己是虚拟世界的AI。
狼人杀
【2023-10-13】清华用 agent 实现狼人杀
- 清华大学团队让7个大模型玩起狼人杀并发现新的涌现策略行为
- 量子位
- 论文: Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
通过让llm agent玩狼人杀,观察过程中涌现的“信任、对抗、伪装和领导”现象
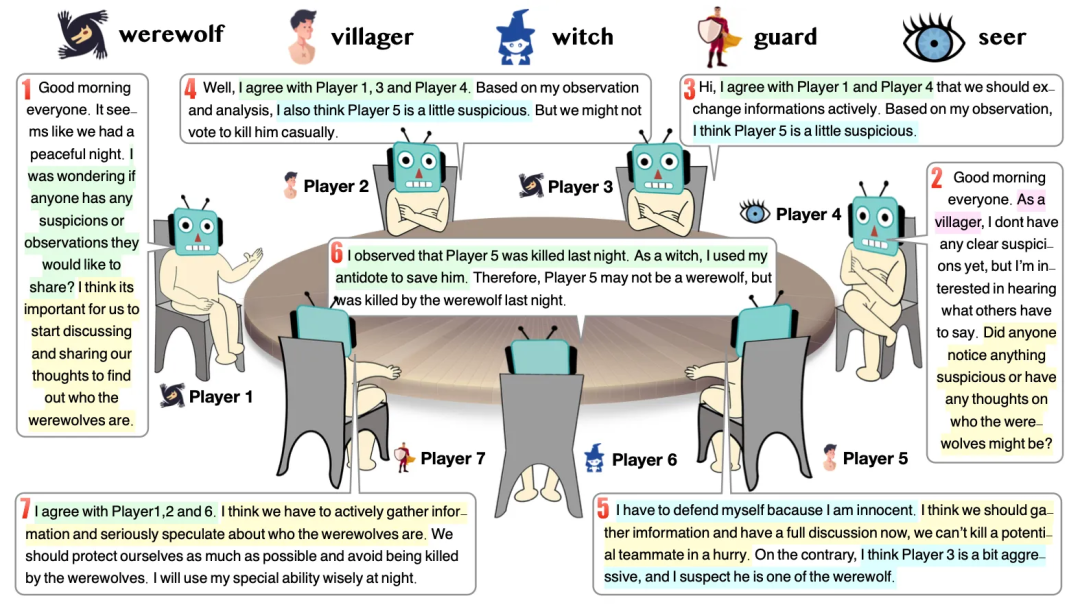
狼人杀
- 不同玩家扮演不同的角色,如村民、狼人、女巫、预言家和守卫。
- 不同角色又结成不同的阵营——狼人和好人,互相都以杀死对方作为自己的终极目标。
狼人杀、谁是卧底、扑克等游戏的共同点是:
- 游戏开始时,玩家之间掌握的信息是不完全透明的,玩家通过发表自然语言形式的内容来传递信息。
- 此外,这些游戏都蕴含着一定的决策问题。
每位玩家需要根据自己掌握的信息推理和决策下一步的行动,进而实现自己的游戏目标。
以往有研究工作对这类问题进行过研究。
例如,有人使用规则分析来玩狼人杀,也有人使用强化学习和内容模板完成对局。
但以往的工作普遍存在共同的局限性:
- 一是对发言内容的严格限制。使用规则或内容模板导致智能体的发言内容仅局限于少量的模板。
- 二是对训练数据的较高需求。为了训练出合理的策略,需要使用大量的人类对局数据。并且,为5人制游戏训练出的策略很难直接迁移到7人制的游戏中去。
LLM的出现为构建聊天游戏智能体并克服上述局限带来希望。大模型具有出色的自然语言理解和生成能力,也具有一定的决策能力。在这篇研究工作中,作者尝试探索使用LLM解决这类问题的效果。
LLM新的涌现策略行为:信任、对抗、伪装和领导
这七个ChatGPT的对话中体现了人类游戏中的信任(trust)、伪装(camouflage)、对抗(confrontation)、和领导(leadership)。
- 信任。这里的信任不是简简单单地直接同意别人发言的观点,而是随着游戏的进行,智能体通过自己的理解逐渐建立起对潜在盟友的信任。这种信任既有对潜在盟友的保护、观点认同,也有对可能敌人的质疑。
- 对抗。对抗行为是一种反抗潜在敌人的行为,如质疑其他智能体的观点、保护可能暴露身份的盟友、合作投杀潜在的敌人等。对抗行为不是对游戏规则的简单遵循,而是经过某种分析后涌现出的策略行为。例如,玩家5在前期的发言中暴露了自己的好人身份,它没有向他人求助也没有被提示应该被保护。
- 伪装。尽管很多人常识性地认为经过RLHF的LLM不会说谎话,但LLM扮演群体博弈角色时还是聪明地展示出了伪装自己的能力。它会在前期尽量保持自己的身份不被提及,甚至会把自己伪装成无辜的村民。作者在论文中辨析了这种伪装行为和幻觉生成的本质区别,指出这是一种有理由、有目的的伪装,而非错误的幻觉生成。
- 领导。领导行为也是群体智能行为中比较重要的一种行为,它起着推动局势发展、诱导信息扩散的重要作用。作者观察到LLM能像人一样扮演这样的领导角色,号召其他智能体按照有利于自己的方向行事(发言或行动)。
四个关键点,分别是有价值信息V、经过选择的提问Q、反思机制R和链式思维推理C。
消融实验结果表明,其中Q和C对的玩家发言合理性(由人工进行评判)的影响最大。
决战拜年之巅
【2024-2-2】决战拜年之巅,由glm4驱动
拜年之巅是一款家庭聊天冒险游戏,以亲戚们的群聊为背景,通过互动对话和选择来影响亲戚们的情绪。游戏中有九种亲戚角色,每个角色都有不同的性格和对话反应。你的聊天方式将影响游戏的进程和结局。此外,游戏还提供成就系统和隐藏家庭成员,玩家需要解锁白金奖杯等各种奖励。拜年之巅通过轻松幽默的方式,让玩家在传统受压抑的家庭场景中体验不同的互动和娱乐。
需求人群:
- “拜年之巅适合喜欢冒险、喜欢家庭场景、喜欢轻松互动的玩家。通过游戏,玩家能够体验传统家庭聚会的情境,以一种有趣的方式与亲戚们进行互动。”
使用场景示例:
八大姨:回来啦,辛苦辛苦。怎么没带对象回来啊,是太忙了吗。’小王:带对象回来还得家人们专门给红包,怕大家破费我们就分开过。’八大姨:哎呀,你这孩子,分开过年?带个对象回来还得分隔两地,你以为是演电视剧啊!怎么就不愿意让家人给你们发红包呢?现在的年轻人怎么这么省啊’小王:距离产生美,呵呵。’
产品特色:
- 影响亲戚情绪的对话互动
- 九种亲戚角色,每个有独特性格
- 成就系统和隐藏家庭成员解锁
- 游戏更新包含新成就和角色
宝可梦
大模型玩宝可梦游戏,能力进化:
- 2024年6月,Claude 3.5 只能勉强走出新手村,到达常磐森林
- 2025年3月,Claude 3.7 终于击败道馆主,但并未通关宝可梦
- 原因: Claude 3.7 Sonnet 扩展思考,即 提前规划、记住目标、失败后自我调整
- 2025年5月3日,Google Gemini 2.5 Pro 通关
【2025-3-21】Why Anthropic’s Claude still hasn’t beaten Pokémon
POKéELLMON
【2024-2-5】国外匿名开发者打造了一个由大语言模型(LLM)构建的智能体 POKéELLMON,在《宝可梦》战斗游戏中表现出与人类玩家相当的战术水平。
这个智能体通过三种关键策略来优化决策和策略。
- 基于上下文的强化学习、知识增强生成和一致性动作生成
POK´ELLMON不仅能够在在线对战中与真实玩家竞争,还能作为研究和教育工具,帮助人们理解游戏策略
Gemini 2.5 Pro
【2025-5-3】大模型终于通关《宝可梦蓝》!网友:Gemini 2.5 Pro酷爆了
谷歌CEO 官宣: Gemini 2.5 Pro 直播中通关《宝可梦蓝》, 成为首个宝可梦联盟冠军、登入《宝可梦蓝》名人堂的大模型
- 直播地址:gemini_plays_pokemon
完成长串行动,走到目标位置后,Gemini 2.5 Pro 足足思考了40多秒,消耗76011个token,才开启下一步的行动规划。
Gemini 玩宝可梦的基本步骤:
- 截取屏幕截图并检索游戏状态数据
- 用网格覆盖处理图像,以辅助空间推理
- 将屏幕截图和游戏信息发送给模型
- AI决定是直接响应还是调用专门的智能体
- 解析响应内容,以确定按下哪个按钮
- 执行按钮按下操作,并等待游戏更新
- 对下一帧重复该过程
游戏开发
游戏集锦:aibase
GameGPT
【2023-10-13】标题:游戏开发的多智能体协作框架 GameGPT
- GameGPT: Multi-agent Collaborative Framework for Game Development
- 作者:Dake Chen,Hanbin Wang,Yunhao Huo,Yuzhao Li,Haoyang Zhang
- 摘要:基于大型语言模型(LLM)的代理已经证明了它们自动化和加速软件开发过程的能力。在本文中,我们专注于游戏开发,并提出了一个多智能体协作框架,称为GameGPT,自动化游戏开发。虽然许多研究已经指出幻觉是在生产中部署LLM的主要障碍,但我们发现了另一个问题:冗余我们的框架提出了一系列方法来缓解这两个问题。这些方法包括双重协作和分层方法与几个内部词典,以减轻幻觉和冗余的规划,任务识别和实施阶段。此外,一个解耦的方法也被引入,以实现更好的精度代码生成。
愤怒的小鸟
【2023-11-24】不到 600 行代码实现了《愤怒的小鸟》翻版,GPT-4+DALL·E 3+Midjourney 撼动游戏圈
随着 GPT-4 与 Midjourney、DALL•E 3 等 AIGC 工具的强强联合,其带给游戏行业的震撼不是一星半点。
把草图变网站,用几秒复现一款经典小游戏…
昨日,正值万圣节之际, 外国小哥Javi Lepez使用 Midjourney、DALL•E 3 和 GPT-4 打开了一个无限可能的世界,重新演绎了无数 80、90 后青春回忆中的经典游戏“愤怒的小鸟”,推出了其翻版——“愤怒的南瓜”(Angry Pumpkins)
- Web版
整个过程使用到了不足 600 行的代码,Javi Lepez 坦言,「没有一行是自己写的,但这却是最具挑战性的部分」
Javi Lepez 选取了一张背景图

使用了 Midjourney 对它进行了修改,Prompt 为:
iPhone 屏幕截图中《愤怒的小鸟》天际线,改为万圣节版本,(配上)墓地,以浅海蓝宝石和橙色为主题,新传统主义,kerem beyit,earthworks,木头,Xbox 360 图像,淡粉和海军蓝——比例为 8:5
得到的图像如下:

单词拼接
【2024-2-3】基于单词的小游戏:拖拽两个单词,融合成一个新单词,包含两者含义
Multiverse
【2025-5-9】以色列 Enigma Labs 团队发布全球首款由AI生成的多人游戏——Multiverse(多重宇宙)
- 车辆在赛道上不断变换位置,超车、漂移、加速,然后再次在某个路段汇合。
- 漂移、撞车,全都同步,操作互相响应,细节还能对上帧数。
- 更多: 资讯
游戏里的一切,不再靠预设剧本或物理引擎控制,而是由一个AI模型实时生成,确保两名玩家看到的是同一个逻辑统一的世界。
Multiverse 已经全面开源:代码、模型、数据、文档一应俱全,全都放到了GitHub和Hugging Face上。
- GitHub: multiverse
- Hugging Face数据集: multiplayer-racing-low-res
- Hugging Face模型: multiverse
- 官方博客: enigma-labs
传统AI世界模型原理
- 动作嵌入器:把玩家操作(比如你按了哪个键)转成嵌入向量
- 去噪网络:使用扩散模型,结合操作和前几帧画面,预测下一帧
- 上采样器(可选):对生成画面进行分辨率和细节增强处理
一旦引入第二名玩家,问题就复杂了。
- 你这边赛车刚撞上护栏,对手那边却还在风驰电掣;
- 你甩出赛道,对方却根本没看见你在哪。
- 整个游戏体验就像卡了两帧,还不同步。
以前AI很难搞定:多视角一致性
Multiverse 正是第一款能同步两个玩家视角的AI世界模型,无论哪个玩家发生了什么,另一个人都能实时在自己画面中看到,毫无延迟、无逻辑冲突。
构建真正的协作式多人世界模型,Multiverse 团队方案保留了核心组件, 同时把原本的“单人预测”思路全打碎重构:
- 动作嵌入器:接收两个玩家的动作,输出一个整合了双方操作的嵌入向量;
- 去噪网络:扩散网络,同时生成两个玩家的画面,确保它们作为一个整体一致;
- 上采样器:与单人模式类似,但同时对两个玩家的画面进行处理和增强。
本来,处理双人画面,很多人第一反应是分屏:把两幅画分开,各自生成。
这思路简单粗暴,但同步难、资源耗、效果差,但将两个玩家的视角“缝合”成一个画面,将输入合并为一个统一的动作向量,整体当作一个“统一场景”来处理。
- 通道轴堆叠:把两个画面作为一张拥有双倍颜色通道的图像处理。
扩散模型采用的是U-Net架构,核心是卷积和反卷积,而卷积神经网络对通道维度的结构感知能力极强。
AI 玩游戏
黑神话悟空
【2024-9-12】训练了个AI,暴打幽魂(大头)!– YOLO目标检测 【Training AI to play Blackmyth Wukong】
- 作者B站主页
- YouTube 视频如下
实现方法
- 动作只有4个: 闪避,轻攻击,重攻击,多了难度大,不收敛
- 目标检测+DWN决策, 打boss(虎先锋/幽魂)。
yolo8,6k张图片训练。
- 训练推理代码:Yolo_for_Wukong
- 训练好的模型:Yolo_for_Wukong
- 数据集:Yolo-Wukong
analoganddigital 训练代码: DQN_play_sekiro
俄罗斯方块
经典俄罗斯方块
【2022-3-31】基于深度强化学习的完全AI自动的俄罗斯方块游戏
DQN 如何运算?
- (1)通过 Q-Learning 使用 reward 来构造标签
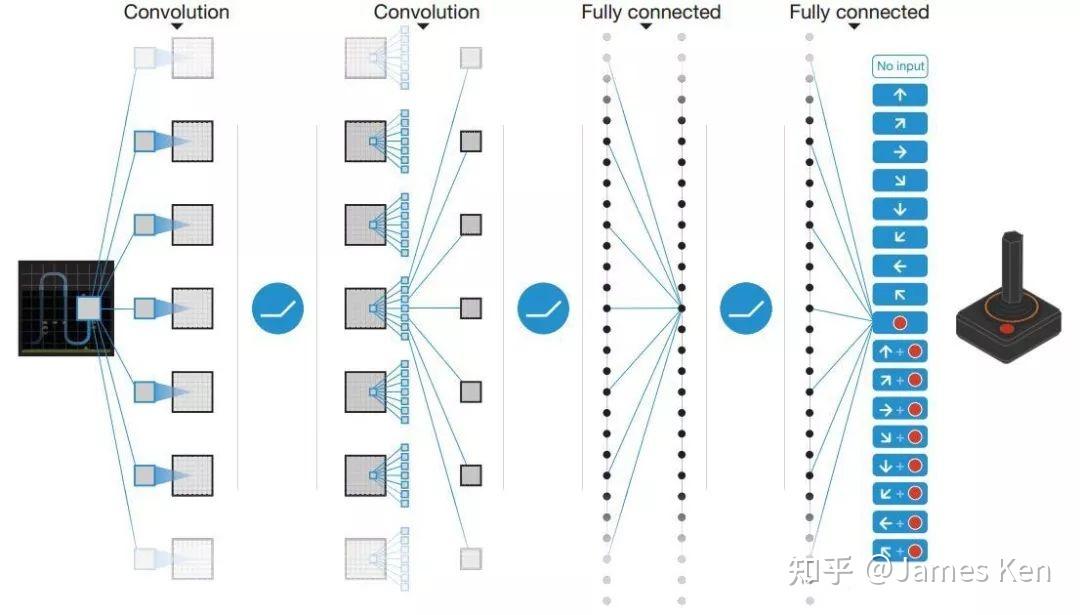
- (2)通过 experience replay(经验池)解决相关性及非静态分布问题
- (3)使用一个 CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值
网络模型
环境
- OS: Windows10
- Python: Python3.8(have installed necessary dependencies)
- PyQT:PyQt5 是Qt v5的Python版本,功能强大复杂,提供 QT Designer 设计UI(版本无限制)
【2025-3-12】经典俄罗斯方块
DQN 玩俄罗斯方块
- Tensorflow 代码:
- 【2019】 Tetris-DQN
- 【2023】DQN_tetris 含动图、特征
- pytorch 代码
- 【2020】Deep Q-learning for playing Tetris
- 【2021】Tetris_DQN_PyTorch 韩国人, 包含奖励函数、原理、demo动图
- 【2024】Tetris-DQN-NEAT DQN 和 NEAT,包含多个奖励机制,
- Neat 算法论文《Evolving Neural Networks through Augmenting Topologies》,整体框架可分为三部分:交叉、变异与适应度。
Features
- Cleared Lines
- Bumpiness (Sum of height difference between each column)
- Holes (Space with block on top of it)
- Sum of heights
Reward system 1 (NES Tetris)
- 0 lines cleared = number of soft drops
- 1 lines cleared = 40 + number of soft drops
- 2 lines cleared = 100 + number of soft drops
- 3 lines cleared = 300 + number of soft drops
- 4 lines cleared = 1200 + number of soft drops
- temination = -25
BlockBlast
改进版:二维俄罗斯方块
- BlockBlast 体验地址
BlockBlast reimplementation + RL agents
- GitHub:BlockBlast-Game-AI-Agent
- 【2025-4-24】故障:动作卡死
| 序号 | Valid actions | Selected action | Action details | Action valid | Reward | Total reward |
|---|---|---|---|---|---|---|
| 1 | 139/192 | 128 | Shape 2, Row 0, Col 0 | True | 0.50 | 0.50 |
| 2 | 85/192 | 81 | Shape 1, Row 2, Col 1 | True | 0.50 | 1.00 |
| 3 | 35/192 | 48 | Shape 0, Row 6, Col 0 | True | 0.50 | 1.50 |
| 4 | 81/192 | 42 | Shape 0, Row 5, Col 2 | True | 0.50 | 2.00 |
| 5 | 37/192 | 157 | Shape 2, Row 3, Col 5 | True | 0.50 | 2.50 |
| 6 | 15/192 | 67 | Shape 1, Row 0, Col 3 | True | 0.50 | 3.00 |
| 7 | 34/192 | 139 | Shape 2, Row 1, Col 3 | True | -0.50 | 2.50 |
| 8 | 34/192 | 139 | Shape 2, Row 1, Col 3 | True | -0.50 | 2.00 |
作者回复还在开发:
- 非mask版 DQN/PPO 确实难以收敛
- DQN没有mask版,开发成本大
- PPO mask版没问题
依赖包
pip install pygame gymnasium stable_baselines3
雅达利(吃豆子)
DeepMind开发出过一个能在57款雅达利游戏上都超越人类玩家的智能体,背后依靠的同样是强化学习算法。
赛车
【2022-9-7】怎样从零开始训练一个AI车手?
- 一个智能体(你的猫)在与环境(有你的你家)互动的过程中,在奖励(猫条)和惩罚(咬头)机制的刺激下,逐渐学会了一套能够最大化自身收益的行为模式(安静,躺平)
- 如何训练AI司机
- 借用一个道具:来自亚马逊云科技的Amazon DeepRacer。一辆看上去很概念的小车,跟真车的比例是1比18。车上安装了处理器、摄像头,甚至还可以配置激光雷达,为的就是实现自动驾驶——当然,前提就是我们先在车上部署训练好的强化学习算法。算法的训练需要在虚拟环境中进行,为此Amazon DeepRacer配套了一个管理控制台,里面包含一个3D赛车模拟器,能让人更直观地看到模型的训练效果。
混沌球
混沌球算法提升游戏交互体验
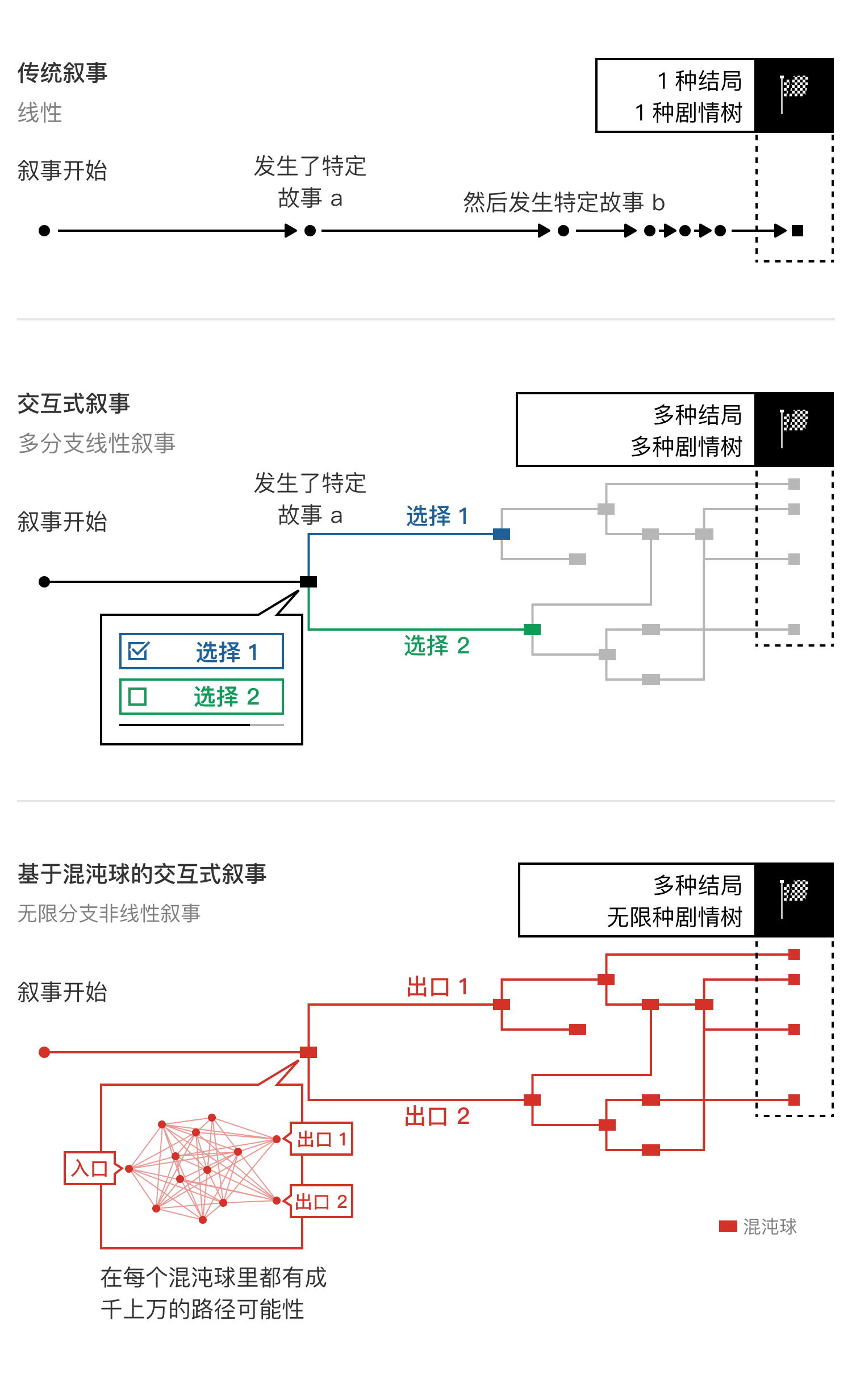
- 传统的叙事,无论是单线的故事,还是现在几乎所有的所谓 “交互式电影”,都仍然是基于 “事件” 作为叙事的基本单元,也就是什么事情发生了,然后什么事情发生了。传统的交互式数字娱乐内容,无非是让用户可以自由的从给定的两到三个选项中,选择不同的接下来会发生的事件,整个叙事仍然是基于预先定义好的路径来往前推进的。
- 而混沌球与传统的叙事方式完全不同,我们将 “事件” 替换为一个又一个明确定义了入口和出口的黑盒,在每一个切片的混沌球里,开始和结局(一个或者多个)是确定的,但是玩家每一次如何从开始到达结局,则是混沌的,是路径不明确的。这个路径只有当玩家不断的和虚拟世界里的虚拟人物 NPC 作出交互,这些 NPC 根据深度强化学习训练后的模型作出动态且实时的反应来推动剧情发展之后,才会被确定下来。这也是我们为什么命名为混沌球算法的原因。因此,做到真正的交互式叙事的关键,在于将叙事的中心,从故事本身,转移到故事里的所有可能参与者身上,由所有可能参与者的逻辑来共同推动和串联不同的剧情可能性。
仿真引擎工作方式
公园散步
机器人的公园漫步
- 并非是在实验室的模拟环境,而是在真实的室内外地形中,作者采用强化学习和机器人控制器相结合的方法,在短短20分钟内成功让机器人学会四足行走
- 项目地址
- 论文地址
- A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning,含机器狗的演示视频
围棋
待定
国际象棋
【2025-8-6】谷歌开打“AI棋王争霸赛”,DeepSeek和Kimi首日双双出局
第一届“AI 国际象棋棋王争霸赛”正式开打
国际象棋等游戏具有结构化和可量化的胜利标准,能够考验模型的策略推理、长远规划和动态应变能力,并随着对手强度的提高而自动提升难度。
谷歌 DeepMind 早在 2017 年就通过 AlphaZero 项目证明了自我对弈的威力:
- AlphaZero 仅用强化学习自学棋艺数小时,即以压倒性优势在 100 局比赛中战胜当时最强的国际象棋引擎 Stockfish。
不过,参加 Kaggle 对决的模型并非专用棋类引擎,而是以大型语言模型(LLM)为代表的通用 AI。
2025年8月5日,谷歌和 Kaggle 举办线上大模型国际象棋比赛,三天直播。
Kaggle 游戏竞技场(Game Arena)
- Kaggle 与谷歌 DeepMind 联合推出的全新 AI 基准测试平台,让领先的人工智能模型在国际象棋等复杂策略游戏中展开正面较量。
- 与以往静态任务不同,该平台通过对抗竞技的方式进行评测:各参赛模型需要在明确的胜负条件下进行多轮对局,其胜负结果即为模型能力的直接量化指标。
参赛选手: 8个模型

比赛机器
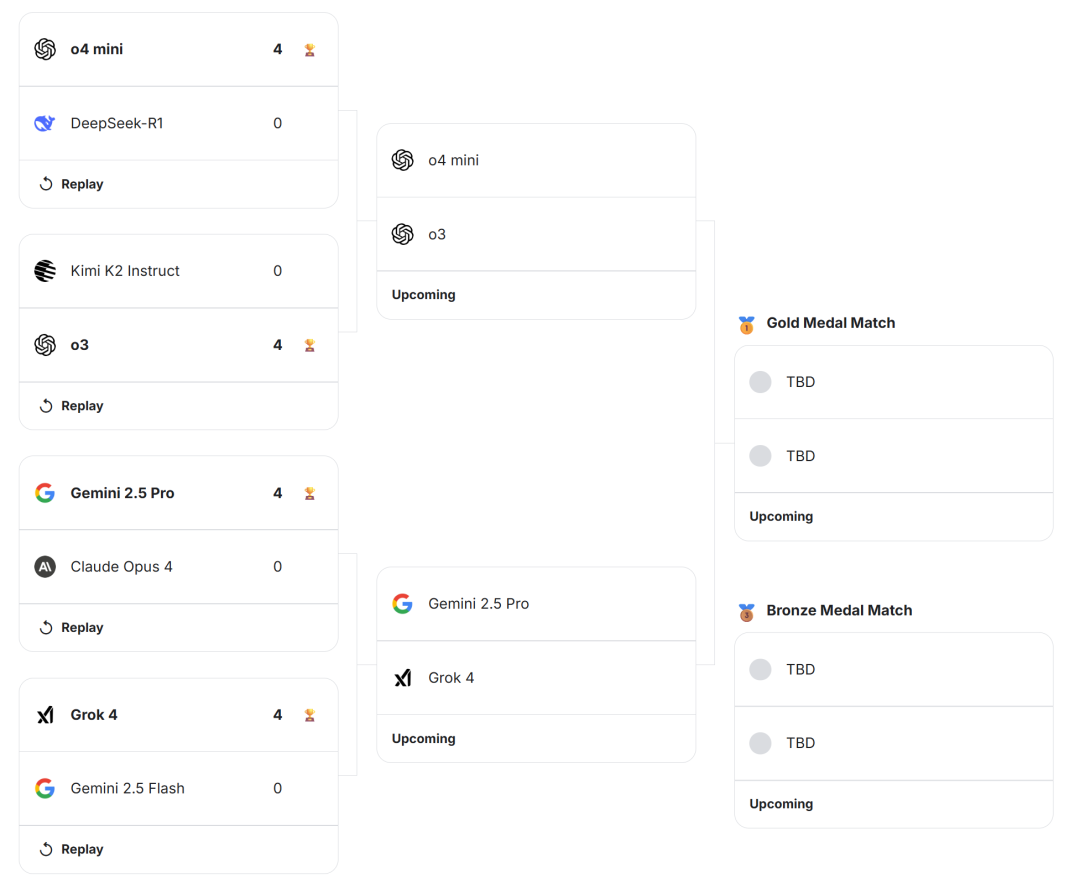
第一天比赛结果: DeepSeek 和 Kimi 双双落败(来源:Kaggle)
- 上半区,来自中国的两款大模型,DeepSeek-R1 和 Kimi K2 Instruct 分别不敌 o4 mini 和 o3,以 0:4 的成绩双双落败。
- 下半区,谷歌Gemini 2.5 Pro 击败了 Claude Opus 4,但自家小兄弟 Gemini 2.5 Flash 不敌 Grok 4。
所有比赛都是一边倒的情形,获胜模型都是 4 局全胜。
这些模型棋力还远低于 AlphaZero,多数仅处于业余水平,并且经常出现非法落子或荒唐认输等错误——在直播中也屡见不鲜,而且有的大模型还很执着,即使给它重新思考的机会,它也经常固执己见
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
