视频理解技术
【2023-5-5】 FesianXu: 万字长文漫谈视频理解
作为多媒体中重要的信息载体,视频的地位可以说是数一数二的,然而目前对于AI算法在视频上的应用还不够成熟,理解视频内容仍然是一个重要的问题亟待解决攻克。
短视频专题见站内:短视频学习笔记
视频理解
理解视频(understanding the video) 是一件非常抽象的事情,在神经科学尚没有完全清晰,如果按照人类感知去理解,终将陷入泥淖。
在理解视频这个任务中,到底在做什么?
- 首先,对比于文本,图片和音频,视频特点:动态的按照时间排序的图片序列
- 然而,图片帧间有着密切的联系,存在上下文联系;
- 视频有音频信息。
因此进行视频理解,先要再时间序列上建模,同时还需要空间上的关系组织。
目前理解视频主要集中在以人为中心的角度进行,由于视频是动态的,因此描述视频中的物体随着时间变化,在进行什么动作,很重要。
- 动作识别在视频理解中占据了一个很重要的地位。
视频分析的主要难点:
- 需要大量的算力,视频的大小远大于图片数据,需要更大的算力进行计算。
- 低质量,很多真实视频拍摄时有着较大的运动模糊,遮挡,分辨率低下,或者光照不良等问题,容易对模型造成较大的干扰。
- 需要大量的数据标签,特别是在深度学习中,对视频的时序信息建模需要海量的训练数据才能进行。时间轴不仅仅是添加了一个维度那么简单,其对比图片数据带来了时序分析,因果分析等问题。
子任务
理解视频具体子任务:
- 视频动作分类:对视频中的动作进行分类
- 视频动作定位:识别原始视频中某个动作的开始帧和结束帧
- 视频场景识别:对视频中的场景进行分类
- 原子动作提取
- 视频文字说明(Video Caption):给给定视频配上文字说明,常用于视频简介自动生成和跨媒体检索
- 集群动作理解:对某个集体活动进行动作分类,常见的包括排球,篮球场景等,可用于集体动作中关键动作,高亮动作的捕获。
- 视频编辑。
- 视频问答系统(Video QA):给定一个问题,系统根据给定的视频片段自动回答
- 视频跟踪:跟踪视频中的某个物体运动轨迹
- 视频事件理解:不同于动作,动作是一个更为短时间的活动,而事件可能会涉及到更长的时间依赖
- …
视频数据
视频数据模态
视频动作理解是非常广阔的研究领域,输入的视频形式也不一定是常见的RGB视频,还可能是depth深度图序列,Skeleton关节点信息,IR红外光谱等。

RGB视频是最容易获取的模态,然而随着很多深度摄像头的流行,深度图序列和骨骼点序列的获得也变得容易起来。
- 深度图和骨骼点序列对比RGB视频来说,其对光照的敏感性较低,数据冗余较低,有着许多优点。
视频动作分类数据集
公开的视频动作分类数据集有很多,比较流行的in-wild数据集主要是在YouTube上采集到的,包括以下的几个。
- HMDB-51,该数据集在YouTube和Google视频上采集,共有6849个视频片段,共有51个动作类别。
- UCF101,有着101个动作类别,13320个视频片段,大尺度的摄像头姿态变化,光照变化,视角变化和背景变化。
- sport-1M,也是在YouTube上采集的,有着1,133,157 个视频,487个运动标签。
- YouTube-8M, 有着6.1M个视频,3862个机器自动生成的视频标签,平均一个视频有着三个标签。
- YouTube-8M Segments,是YouTube-8M的扩展,其任务可以用在视频动作定位,分段(Segment,寻找某个动作的发生点和终止点),其中有237K个人工确认过的分段标签,共有1000个动作类别,平均每个视频有5个分段。该数据集鼓励研究者利用大量的带噪音的视频级别的标签的训练集数据去训练模型,以进行动作时间段定位。
- Kinectics 700,这个系列的数据集同样是个巨无霸,有着接近650,000个样本,覆盖着700个动作类别。每个动作类别至少有着600个视频片段样本。
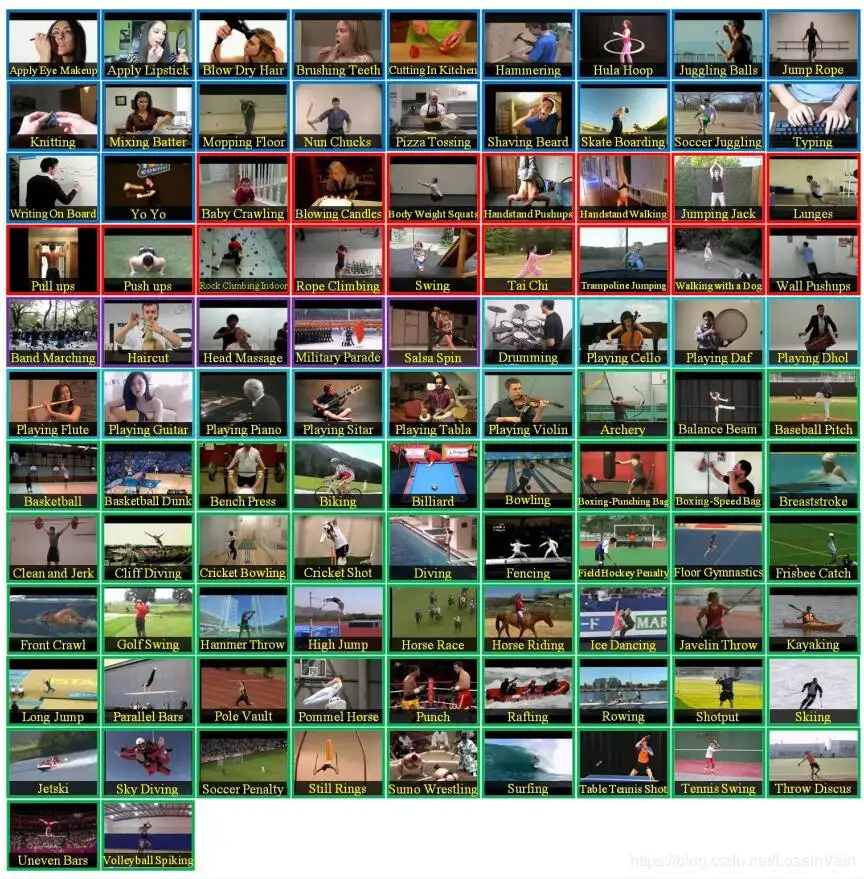


以上数据集模态都是RGB视频,还有些数据集是多模态的:
- NTU RGB+D 60: 包含有60个动作,多个视角,共有约50k个样本片段,视频模态有RGB视频,深度图序列,骨骼点信息,红外图序列等。
- NTU RGB+D 120:是NTU RGB+D 60的扩展,共有120个动作,包含有多个人-人交互,人-物交互动作,共有约110k个样本,同样是多模态的数据集。
视频理解方法
早期CV方法
深度学习之前,CV算法工程师是特征工程师,手动设计特征,而这是一个非常困难的事情。
手动设计特征并且应用在视频分类的主要套路有:
- 特征设计:挑选合适的特征描述视频
- 局部特征(Local features):比如HOG(梯度直方图 )+ HOF(光流直方图)
- 基于轨迹的(Trajectory-based):Motion Boundary Histograms(MBH)[4],improved Dense Trajectories (iDT) ——有着良好的表现,不过计算复杂度过高。
- 集成挑选好的局部特征: 光是局部特征或者基于轨迹的特征不足以描述视频的全局信息,通常需要用某种方法集成这些特征。
- 视觉词袋(Bag of Visual Words,BoVW),BoVW提供了一种通用的通过局部特征来构造全局特征的框架,其受到了文本处理中的词袋(Bag of Word,BoW)的启发,主要在于构造词袋(也就是字典,码表)等。
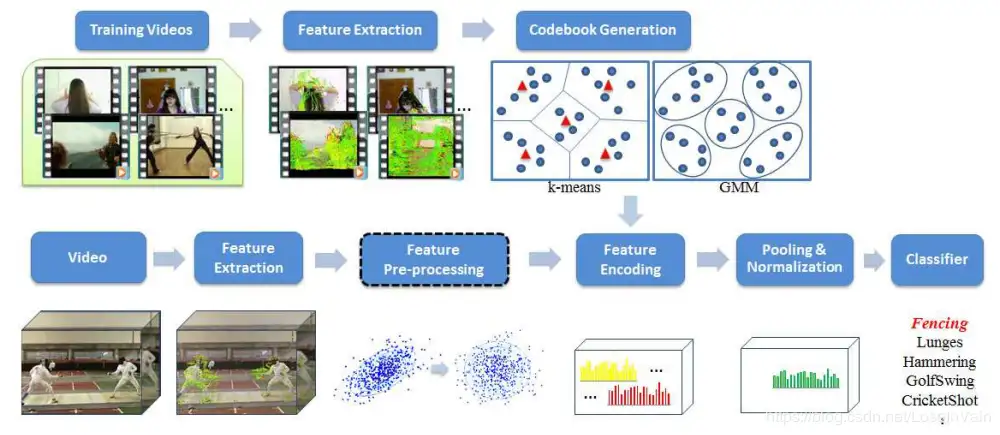
- Fisher Vector,FV同样是通过集成局部特征构造全局特征表征

- 要表征视频的时序信息,我们主要需要表征的是动作的运动(motion)信息,这个信息通过帧间在时间轴上的变化体现出来,通常我们可以用光流(optical flow)进行描述,如TVL1和DeepFlow。

深度学习CV方法
深度学习时代,视频动作理解主要工作量在于如何设计合适的深度网络,而不是手动设计特征。设计这样的深度网络的过程中,需要考虑两个方面内容:
- 模型方面:什么模型可以最好的从现有的数据中捕获时序和空间信息。
- 计算量方面:如何在不牺牲过多的精度的情况下,减少模型的计算量。
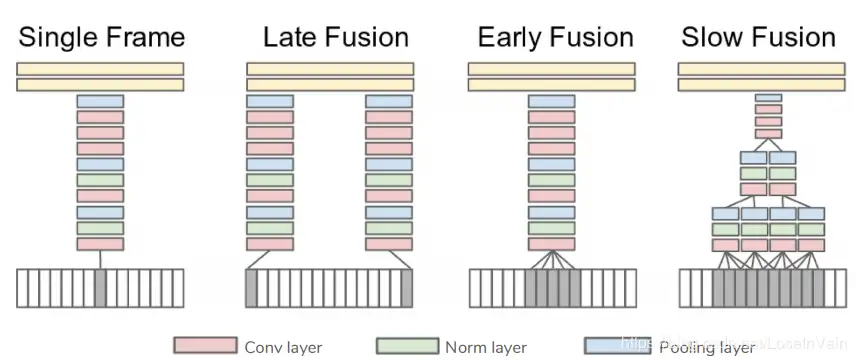
组织时序信息是构建视频理解模型的一个关键点,Fig 3.2展示了若干可能的对多帧信息的组织方法。
- Single Frame,只是考虑了当前帧的特征,只在最后阶段融合所有的帧的信息。
- Late Fusion,晚融合使用了两个共享参数的特征提取网络(通常是CNN)进行相隔15帧的两个视频帧的特征提取,同样也是在最后阶段才结合这两帧的预测结果。
- Early Fusion,早融合在第一层就对连续的10帧进行特征融合。
- Slow Fusion,慢融合的时序感知野更大,同时在多个阶段都包含了帧间的信息融合,伴有层次(hierarchy)般的信息。这是对早融合和晚融合的一种平衡。
最终的预测阶段,从整个视频中采样若各个片段,对这采样的片段进行动作类别预测,其平均或者投票将作为最终的视频预测结果。
LLM 视频理解
【2024-11-4】Early Access to NVIDIA AI Blueprint for Video Search And Summarization
This NVIDIA AI Blueprint provides cloud-native building blocks to build video search and summarization AI agents capable of processing large amounts of live or archived videos and images with vision-language models (VLM) and large language models (LLM) - whether deployed at the edge or cloud. This new generation of visual AI agents will help nearly every industry search, summarize, and extract actionable insights from video using natural language.
NVIDIA 推出云/端AI智能体, 用于实时/存档视频的视频搜索、摘要
传统视频分析应用及其开发工作流通常基于功能固定、有限的模型构建,这些模型旨在仅检测和识别一组预定义的对象。
借助 生成式 AI 、NVIDIA NIM 微服务和基础模型,现在可用更少的模型构建具有广泛感知和丰富上下文理解的应用程序。
新型生成式 AI 模型,即视觉语言模型(VLM),为 视觉 AI 智能体 提供支持,这些智能体可以理解自然语言提示并执行视觉问答。
- 通过结合 VLM、LLM 和最新的
Graph-RAG技术,可构建功能强大的视觉 AI 智能体,从而实现对视频的长篇理解。
这些可视化 AI 智能体将部署在工厂、仓库、零售商店、机场、交叉路口等地。它们将帮助运营团队利用从自然交互中生成的更丰富的见解做出更明智的决策。
组件
- 流处理程序: 管理与其他组件(例如 NeMo Guardrails、CA-RAG、VLM 管道、分块和 Milvus Vector DB)的交互和同步。
- NeMo Guardrails: 过滤掉无效用户提示。它利用 LLM NIM 微服务的 REST API。
- VLM pipeline – 解码流处理器生成的视频块,使用基于 NVIDIA Tensor RT 的视觉编码器模型为视频块生成嵌入,然后利用 VLM 为用户查询生成每个块的响应。它基于 NVIDIA DeepStream SDK。
- VectorDB: 存储每个块的中间 VLM 响应。
- CA-RAG 模块: 从每个块的 VLM 响应中提取有用信息,并将其聚合以生成单个统一摘要。CA-RAG(Context Aware-Retrieval-Augmented Generation)使用 LLM NIM 微服务的 REST API。
- Graph-RAG 模块: 捕捉视频中存在的复杂关系,并将重要信息存储在图形数据库中,作为节点和边的集合。然后,LLM 会对其进行查询,以提供交互式问答。
视频生成
参考站内:文生视频技术专题
视频处理工具
视频下载
网站视频下载
【2026-4-21】小红书视频下载工具 KuKuTool: 轻松无水印保存喜欢的小红书图文、视频、实况Live图,超高清分辨率
Twitter 视频下载:
- 【2023-11-19】twitterxz, 输入链接即可
【2026-7-3】视频号下载、背景音提取
- 1️⃣ 获取视频号地址:每个视频转发栏尾部有链接,手机端访问才行!
- 2️⃣ 填入下载器,下到本地
- 3️⃣ 剪映分离人声只留背景(付费试用功能)
- 4️⃣ 录屏,跳过付费
YouTube 视频下载:参考知乎帖子:如何下载youtube视频)
- ① 修改网址:
- youtube → yout 【失效】
- youtube → youtubeme,或者加now 【失效】
- youtube → ssyoutube 【有效】
- youtube → kissyoutube 【有效】
- ② 独立网站:
- noTube,Audio, y2mate
- 【2020-3-29】在线下载YouTube视频: youtube-video-downloader
- SaveMedia提供,在线下载+系列视频自动推荐
- clipconverter
- ③ 下载工具
you-get支持的视频网站范围广.- python 代码下载,
pip3 install you-get - 示例:
you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
- python 代码下载,
- annie 支持 抖音、b站、youtube等
【2024-6-25】Mac上实践
you-get https://www.youtube.com/watch?v=qQqv2pFMhmo # 提示 403 错误
lux https://www.youtube.com/watch?v=qQqv2pFMhmo # 成功
视频号
【2023-12-12】如何下载视频号上的视频?
- 加机器人(
视频妙取-H)好友, 也可以搜公众号、关注。 - 然后把视频号播放页转发给机器人
- 对话框出现H5链接,点击就能观看、下载了
流媒体视频下载
视频下载工具:流媒体下载的10种方法
- 硕鼠(可以下载流视频,可按专辑下载),硕鼠Mac版下载地址(官网地址有问题)
- 维棠
m3u8视频格式简介
m3u8视频格式原理:
- 将完整的视频拆分成多个 .ts 视频碎片,.m3u8 文件详细记录每个视频片段的地址。
- 视频播放时,会先读取 .m3u8 文件,再逐个下载播放 .ts 视频片段。
- 常用于直播业务,也常用该方法规避视频窃取的风险。加大视频窃取难度。
鉴于 m3u8 以上特点,无法简单通过视频链接下载,需使用特定下载软件。
- 但软件下载过程繁琐,试错成本高。
- 使用软件的下载情况不稳定,常出现浏览器正常播放,但软件下载速度慢,甚至无法正常下载的情况。
- 软件被编译打包,无法了解内部运行机制,不清楚里面到底发生了什么。
工具特点
- 无需安装,打开网页即可用。
- 强制下载现有片段,无需等待完整视频下载完成。
- 操作直观,精确到视频碎片的操作。
实测
lux 实测
- 支持 抖音、b站、youtube等
brew install lux
# b站视频
lux https://www.bilibili.com/video/BV1vu411x74Z/?spm_id_from=333.337.search-card.all.click&vd_source=ec1c777505e146eb20d947449d6bba6e
# b站快捷下载,提供ep或av值即可
lux -i ep198381 av21877586
# 抖音视频
lux https://www.douyin.com/video/7263993359235140923
# youtube视频
lux https://www.youtube.com/watch?v=hQSewmXxUho
lux https://www.douyin.com/shipin/7309342173366044735
# -------- 参数 -------
# 调试模式
lux -i -d "http://www.bilibili.com/video/av20088587"
# 输出参数
lux -o ../ -O "hello" "https://example.com"
# 使用cookie
lux -c "name=value; name2=value2" "https://www.bilibili.com/video/av20203945"
lux -c cookies.txt "https://www.bilibili.com/video/av20203945"
# refer
lux -r "https://www.bilibili.com/video/av20383055/" "http://cn-scnc1-dx.acgvideo.com/"
# 使用代理
HTTP_PROXY="http://127.0.0.1:1087/" lux -i "https://www.youtube.com/watch?v=Gnbch2osEeo"
HTTP_PROXY="socks5://127.0.0.1:1080/" lux -i "https://www.youtube.com/watch?v=Gnbch2osEeo"
# 多线程
--multi-thread or -m
--thread or -n
# --------------
# 多视频下载
lux -i "https://www.bilibili.com/video/av21877586" "https://www.bilibili.com/video/av21990740"
# 从文件中读取url链接,批量下载
# -start
# File line to start at (default 1)
# -end
# File line to end at
# -items
# File lines to download. Separated by commas like: 1,5,6,8-10
lux -F ~/Desktop/u.txt
音频提取
video_file = "实拍工程苹果醋制作全过程,全程自动化,居然用无人机采摘苹果.mp4"
ffmpeg -i $video_file -vn audio.mp3
视频操作
GitHub 上一款简单、高效且功能颇为齐全的日常工具 pear-rec。
- 支持截图、录屏、录像、录制(动图)gif、查看图片、查看视频、查看音频和修改图片等功能。
- 支持跨平台,但目前仅提供了 Windows 安装包,开箱即用。
- GitHub:pear-rec
一键多发
【2024-7-31】 GitHub 上一个自动化短视频上传、一键分发多平台的开源免费工具 social-auto-upload。
- GitHub:social-auto-upload
具有如下功能:
- 支持主流视频平台,如抖音、B 站、视频号、TikTok 等;
- 支持多账号矩阵化执行各自任务;
- 支持自定义复杂发布时间。
视频聚焦
【2024-10-01】录屏自动聚焦,缩放,突出重点,无需后处理
收费工具
- mac 用 screen studio
- win 用 focusee
免费开源
- ScreenToGif,简单好用
字幕提取
VSE
Video-subtitle-extractor (VSE) 是一款将视频中的硬字幕提取为外挂字幕文件(srt格式)的软件
功能:
- 提取视频中的关键帧
- 检测视频帧中文本的所在位置
- 识别视频帧中文本的内容
- 过滤非字幕区域的文本
- 去除水印、台标文本、原视频硬字幕,可配合:video-subtitle-remover (VSR)
- 去除重复字幕行,生成srt字幕文件
- 支持视频字幕批量提取
- 多语言:支持简体中文(中英双语)、繁体中文、英文、日语、韩语、越南语、阿拉伯语、法语、德语、俄语、西班牙语、葡萄牙语、意大利语等87种语言的字幕提取
- 多模式:
- 快速:(推荐)使用轻量模型,快速提取字幕,可能丢少量字幕、存在少量错别字
- 自动:(推荐)自动判断模型,CPU下使用轻量模型;GPU下使用精准模型,提取字幕速度较慢,可能丢少量字幕、几乎不存在错别字
- 精准:(不推荐)使用精准模型,GPU下逐帧检测,不丢字幕,几乎不存在错别字,但速度非常慢
项目特色:
- 采用本地进行OCR识别,无需设置调用任何API,不需要接入百度、阿里等在线OCR服务即可本地完成文本识别
- 支持GPU加速,GPU加速后可以获得更高的准确率与更快的提取速度

AI Video Transcriber
【2026-7-1】视频转录工具——AI Video Transcriber,直接输出文字内容并自动提炼核心要点,相当实用。
亮点:
- ① 覆盖 YouTube、TikTok、B站等 30 多个主流视频平台
- ② 支持 100 多种语言的语音识别与转录
- ③ 借助 GPT-4o 自动纠错和智能断句,生成的内容更清晰易读
- ④ 可生成多语言摘要,关键信息一眼就能抓住
- ⑤ 提供 Docker 一键部署方案,手机也能轻松访问使用
唯一需要提前准备的就是 OpenAI API Key。
视频处理
视频处理在线体验
视频理解
FastVLM
【2025-9-2】FastVLM:实时视频理解
苹果在 Hugging Face 平台上开源 FastVLM 视觉语言模型的浏览器试用版。资讯
- FastVLM
- 模型:FastVLM-0.5B
- 浏览器实时运行,速度↑85x,体积↓3.4x
FastVLM 以其“闪电般”的视频字幕生成速度著称,只要用户拥有搭载 Apple Silicon 芯片的 Mac 设备,即可轻松上手体验这一前沿技术。
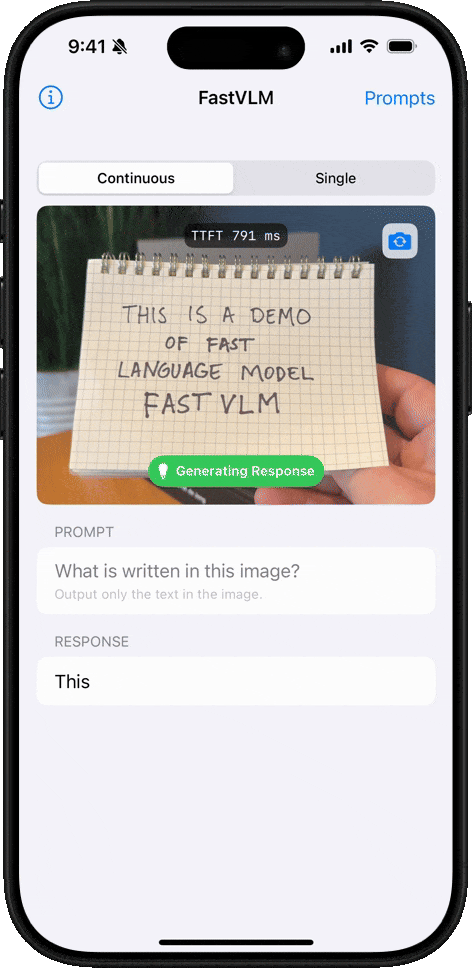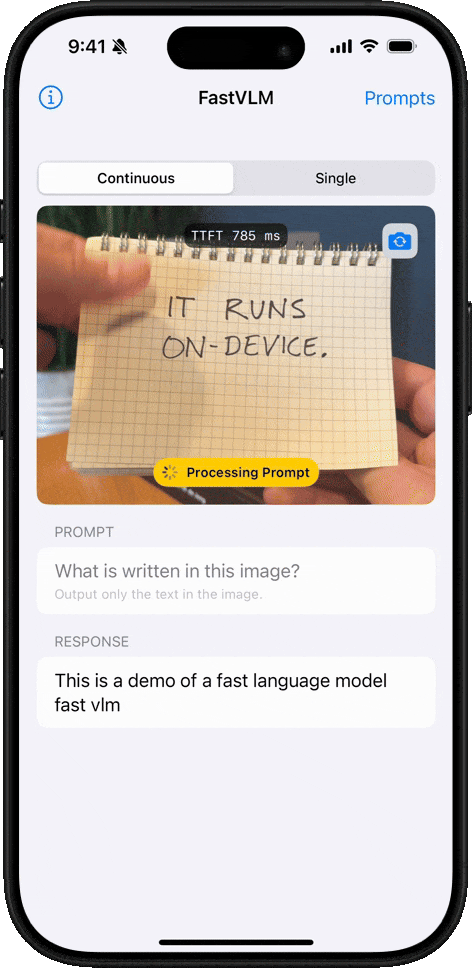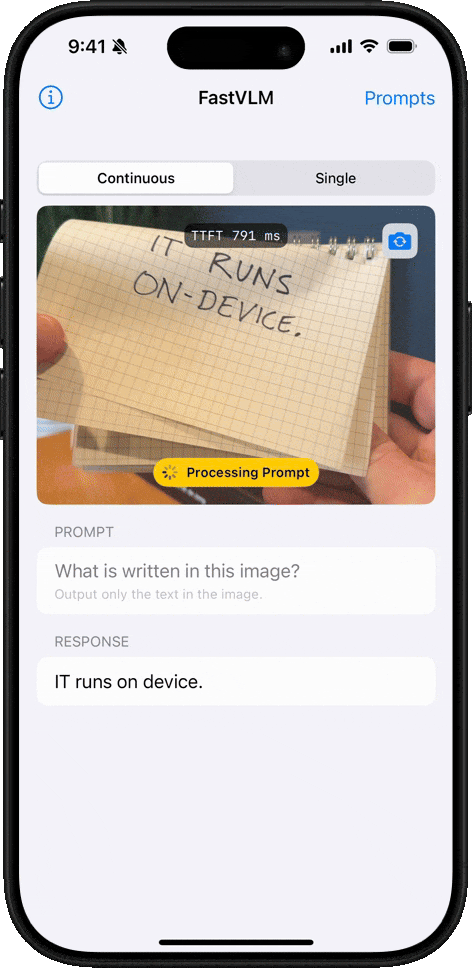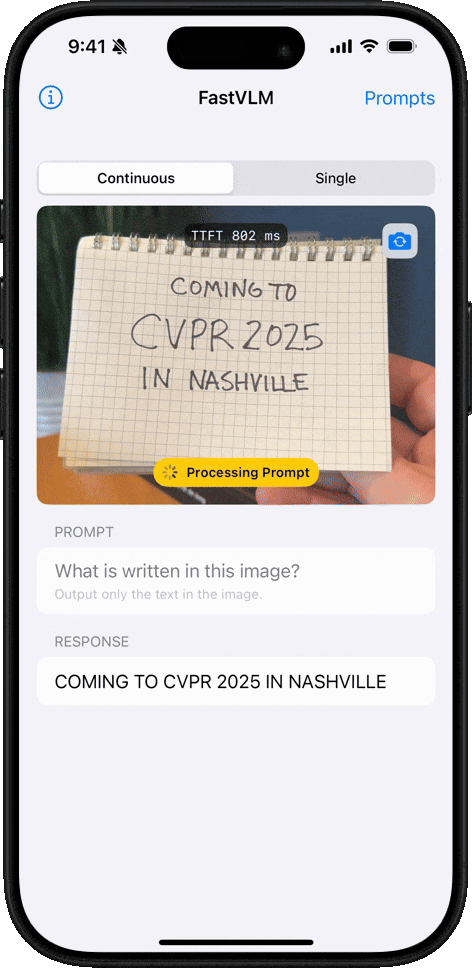
核心优势
- 极速响应:首 Token 输出速度惊人!FastVLM-0.5B 比 LLaVA-OneVision 快 85 倍。FastVLM-7B (结合 Qwen2) 比 Cambrian-1-8B 快 7.9 倍 (同等精度)。
- 小巧高效: 模型体积小,部署更轻松。FastVLM-0.5B 比 LLaVA-OneVision 小 3.4 倍。非常适合 iPhone、iPad、Mac 等端侧设备。
- 端侧智能: 无需依赖云端,直接在您的苹果设备上运行,保护隐私,响应更快。完美适配 iOS/Mac 生态,赋能边缘 AI 应用。
FastVLM 模型的核心优势在于其卓越的速度和效率。该模型利用苹果自研的开源机器学习框架 MLX 进行优化,专为 Apple Silicon 芯片设计。与同类模型相比,FastVLM 模型体积仅为三分之一左右,不过在视频字幕生成速度上却能提升 85 倍。
苹果此次发布的 FastVLM-0.5B 轻量版,可在浏览器内直接加载运行。
- 根据该媒体实测,在 16GB M2 Pro MacBook Pro 上,首次加载模型需数分钟,不过在启动后,便能精准描述画面中的人物、环境、表情及各种物体。
- 该模型支持本地运行,所有数据均在设备端处理,无需上传至云端,从而保障了用户的数据隐私。
FastVLM 的本地运行能力及其低延迟特性,让其在可穿戴设备和辅助技术领域展现出巨大潜力。例如,在虚拟摄像头应用中,该工具能即时详细描述多场景内容,FastVLM 未来有望成为这些设备的核心技术,为用户提供更智能、更便捷的交互体验。
视频清晰
【2024-5-30】中科院发布模糊视频处理方法 Deblur-GS, 从模糊抖动的视频中重建清晰视频
- Deblur-GS: 3D Gaussian Splatting from Camera Motion Blurred Images
- Neural Radiance Field (NeRF), 神经反射场

ffmpeg
ffmpeg 下载
ffmpeg介绍
【2023-1-10】
ffmpeg主要组成部分
- 1、libavformat:用于各种音视频封装格式的生成和解析,包括获取解码所需信息以生成解码上下文结构和读取音视频帧等功能,包含demuxers和muxer库;
- 2、libavcodec:用于各种类型声音/图像编解码;
- 3、libavutil:包含一些公共的工具函数;
- 4、libswscale:用于视频场景比例缩放、色彩映射转换;
- 5、libpostproc:用于后期效果处理;
- 6、ffmpeg:是一个命令行工具,用来对视频文件转换格式,也支持对电视卡实时编码;
- 7、ffsever:是一个HTTP多媒体实时广播流服务器,支持时光平移;
- 8、ffplay:是一个简单的播放器,使用ffmpeg 库解析和解码,通过SDL显示;
在这组成部分中,需要熟悉基础概念有
容器(Container): 容器就是一种文件格式,比如flv,mkv等。包含下面5种流以及文件头信息。- 视频文件本身其实是一个
容器(container),里面包括了视频和音频,也可能有字幕等其他内容。 - 视频格式:MP4,MKV,WebM,AVI。可以用 ffmpeg -formats 查看
- 视频文件本身其实是一个
流(Stream): 是一种视频数据信息的传输方式,5种流:音频,视频,字幕,附件,数据。帧(Frame): 帧代表一幅静止的图像,分为I帧,P帧,B帧。编解码器(Codec): 是对视频进行压缩或者解压缩,CODEC=COde (编码) +DECode(解码)- 视频和音频都需要经过编码,才能保存成文件。不同的编码格式(CODEC),有不同的压缩率,会导致文件大小和清晰度的差异。
- 常用的视频编码格式:ffmpeg -codecs
- H.262、H.264、H.265 —— 有版权,但可以免费使用
- VP8、VP9、AV1 —— 无版权
- MP3、AAC —— 音频编码格式
编码器(encoders)是实现某种编码格式的库文件。只有安装了某种格式的编码器,才能实现该格式视频/音频的编码和解码。- FFmpeg 内置的视频编码器。
- libx264:最流行的开源 H.264 编码器
- NVENC:基于 NVIDIA GPU 的 H.264 编码器
- libx265:开源的 HEVC 编码器
- libvpx:谷歌的 VP8 和 VP9 编码器
- libaom:AV1 编码器
- 音频编码器: ffmpeg -encoders
- libfdk-aac
- aac
复用/解复用(mux/demux):- 把不同的流按照某种容器的规则放入容器,这种行为叫做
复用(mux) - 把不同的流从某种容器中解析出来,这种行为叫做
解复用(demux)
- 把不同的流按照某种容器的规则放入容器,这种行为叫做
测试
样本是这四句话:
- Due to delays, we need to reconsider our schedule this week.
- As we’ve discussed, we need to put our most experienced staff on this.
- Can you suggest an alternative to the restructuring?
- We’ll implement quality assurance processes before the final review.
故意读得磕磕巴巴,每个音频大约在13秒。但是录制出来的是m4a格式,得转换下,这里用ffmpeg
ffmpeg安装
- ffmpeg下载
- 解压到指定目录,将bin文件目录添加到path路径(电脑-属性-高级系统设置-环境变量-path-新建)
- 命令行(windows+r 输入cmd)输入:ffmpeg -version 出结果表示成功。
ffmpeg使用
ffmpeg命令格式
ffmpeg {1} {2} -i {3} {4} {5}
五个部分的参数依次如下。
- 全局参数
- 输入文件参数
- 输入文件
- 输出文件参数
- 输出文件
常用命令
- 可用的bit流 :ffmpeg –bsfs
- 可用的编解码器:ffmpeg –codecs
- 可用的解码器:ffmpeg –decoders
- 可用的编码器:ffmpeg –encoders
- 可用的过滤器:ffmpeg –filters
- 可用的视频格式:ffmpeg –formats
- 可用的声道布局:ffmpeg –layouts
- 可用的license:ffmpeg –L
- 可用的像素格式:ffmpeg –pix_fmts
- 可用的协议:ffmpeg -protocals
- 视频格式转换:ffmpeg -i num.mp4 -codec copy num2.avi
- 将num.mp4复制并转换为num2.avi
- 注:-i 后表示要进行操作的文件
- gif制作:ffmpeg -i num.mp4 -vframes 20 -y -f gif num3.gif
- 将num.mp4的前20帧制作为gif并命名为num3
- 视频截取:ffmpeg -i num.mp4 -ss 0 -t 3 -codec copy cut1.mp4
- -ss后数字表示截取时刻,-t后数字表示截取时长
- 截取视频某一时刻为图片:ffmpeg -i num.mp4 -y -f image2 -ss 2 -t 0.001 -s 400x300 pic.jpg
- 将2s时刻截取为400x300大小的名为pic.jpg的图片(-ss后的数字为截取时刻)
- 每秒截取一张图片:ffmpeg -i num.mp4 -r 1 image%d.jpg
- 将视频num.mp4进行每秒截取一张图片,并命名为imagei.jpg(i=1,2,3…)
- 注:-r后的数字表示每隔多久截取一张。
全局参数
主要全局参数:
- -i 设定输入流
- -f 设定输出格式
- -ss 开始时间
输出视频文件参数:
- -b 设定视频流量(码率),默认为200Kbit/s
- -r 设定帧速率,默认为25
- -s 设定画面的宽与高
- -aspect 设定画面的比例
- -vn 不处理视频
- -vcodec 设定视频编解码器,未设定时则使用与输入流相同的编解码器
- -qscale 0 保留原始的视频质量
输出音频文件参数:
- -ar 设定采样率
- -ac 设定声音的Channel数
- -acodec 设定声音编解码器,未设定时则使用与输入流相同的编解码器
- -an 不处理音频
-c:指定编码器
-c copy:直接复制,不经过重新编码(这样比较快)
-c:v:指定视频编码器
-c:a:指定音频编码器
-i:指定输入文件
-an:去除音频流
-vn: 去除视频流
-preset:指定输出的视频质量,会影响文件的生成速度,有以下几个可用的值 ultrafast, superfast, veryfast, faster, fast, medium, slow, slower, veryslow。
-y:不经过确认,输出时直接覆盖同名文件。
获取媒体文件信息
ffmpeg -i file_name
ffmpeg -i video_file.mp4
ffmpeg -i audio_file.mp3
ffmpeg -i video_file.mp4 -hide_banner # hide_banner 来隐藏掉ffmpeg本身的信息
ffmpeg -i audio_file.mp3 -hide_banner
转换文件格式
转换媒体文件
- ffmpeg 最有用的功能:在不同媒体格式之间进行自由转换。
- 指明输入和输出文件名就行,ffmpeg 会从后缀名猜测格式,这个方法同时适用于视频和音频文件
ffmpeg -i video_input.mp4 video_output.avi
ffmpeg -i video_input.webm video_output.flv
ffmpeg -i audio_input.mp3 audio_output.ogg
ffmpeg -i audio_input.wav audio_output.flac
# 同时指定多个输出后缀:这样会同时输出多个文件
ffmpeg -i audio_input.wav audio_output_1.mp3 audio_output_2.ogg
ffmpeg -formats # 看支持的格式
# 用 -hide_banner 来省略一些程序信息。
# 用 -qscale 0 来保留原始的视频质量:
ffmpeg -i video_input.wav -qscale 0 video_output.mp4
视频中抽取音频
为了从视频文件中抽取音频,直接加一个 -vn 参数就可以了
- 一些常见的比特率有: 96k, 128k, 192k, 256k, 320k (mp3也可以使用最高的比特率)。
- 其他常用参数: -ar (采样率: 22050, 441000, 48000), -ac (声道数), -f (音频格式, 通常会自动识别的). -ab 也可以使用 -b:a 来替代.
ffmpeg -i video.mp4 -vn audio.mp3
# 复用原有文件的比特率,使用 -ab (音频比特率)来指定编码比特率比较好
ffmpeg -i video.mp4 -vn -ab 128k audio.mp3
ffmpeg -i video.mov -vn -ar 44100 -ac 2 -b:a 128k -f mp3 audio.mp3
视频中抽取视频(让视频静音)
用 -an 来获得纯视频 (之前是 -vn)
ffmpeg -i video_input.mp4 -an -video_output.mp4
ffmpeg -i input.mp4 -vcodec copy -an output.mp4
# 这个 -an 标记会让所有的音频参数无效,因为最后没有音频会产生。
视频中提取图片
这个功能很实用
- 一些幻灯片里面提取所有的图片
ffmpeg -i video.mp4 -r 1 -f image2 image-%3d.png
解释:
- -r 代表了帧率(一秒内导出多少张图像,默认25)
- -f 代表了输出格式 (image2 实际上上 image2 序列的意思)
最后一个参数 (输出文件) 有一个有趣的命名:
- 使用 %3d 来指示输出的图片有三位数字 (000, 001, 等等.)。
- 也可以用 %2d (两位数字) 或者 %4d (4位数字)
Note: 同样也有将图片转变为视频/幻灯片的方式。
更改视频分辨率或长宽比
用 -s 参数来缩放视频:
ffmpeg -i video_input.mov -s 1024x576 video_output.mp4
# 用 -c:a 来保证音频编码是正确的:
ffmpeg -i video_input.h264 -s 640x480 -c:a video_output.mov
# 用-aspect 来更改长宽比:
ffmpeg -i video_input.mp4 -aspect 4:3 video_output.mp4
为音频增加封面图片
音频变成视频,全程使用一张图片(比如专辑封面)。当想往某个网站上传音频,但那个网站又仅接受视频(比如YouTube, Facebook等)的情况下会非常有用。
ffmpeg -loop 1 -i image.jpg -i audio.wav -c:v libx264 -c:a aac -strict experimental -b:a 192k -shortest output.mp4
# 只要改一下编码设置 (-c:v 是 视频编码, -c:a 是音频编码) 和文件的名称就能用了。
Note: 如果使用一个较新的ffmpeg版本(4.x),就可以不指定 -strict experimental
为视频增加字幕
给视频增加字幕,比如一部外文电源,使用下面的命令:
ffmpeg -i video.mp4 -i subtitles.srt -c:v copy -c:a copy -preset veryfast -c:s mov_text -map 0 -map 1 output.mp4
# 可以指定自己的编码器和任何其他的音频视频参数
压缩媒体文件
压缩文件可以极大减少文件的体积,节约存储空间,这对于文件传输尤为重要。通过ffmepg,有好几个方法来压缩文件体积。
- 文件压缩的太厉害会让文件质量显著降低。
首先,对于音频文件,可以通过降低比特率(使用 -b:a 或 -ab):
ffmpeg -i audio_input.mp3 -ab 128k audio_output.mp3
ffmpeg -i audio_input.mp3 -b:a 192k audio_output.mp3
再次重申,一些常用的比特率有:
- 96k, 112k, 128k, 160k, 192k, 256k, 320k.
- 值越大,文件所需要的体积就越大。
对于视频文件,选项就多了,一个简单的方法是通过降低视频比特率 (通过 -b:v):
ffmpeg -i video_input.mp4 -b:v 1000k -bufsize 1000k video_output.mp4
# 视频的比特率和音频是不同的(一般要大得多)。
也可以使用 -crf 参数 (恒定质量因子). 较小的crf 意味着较大的码率。同时使用 libx264 编码器也有助于减小文件体积。这里有个例子,压缩的不错,质量也不会显著变化:
ffmpeg -i video_input.mp4 -c:v libx264 -crf 28 video_output.mp4
# crf 设置为20 到 30 是最常见的,不过您也可以尝试一些其他的值。
# 降低帧率在有些情况下也能有效(不过这往往让视频看起来很卡):
ffmpeg -i video_input.mp4 -r 24 video_output.mp4
# -r 指示了帧率 (这里是 24)。
# 还可以通过压缩音频来降低视频文件的体积,比如设置为立体声或者降低比特率:
ffmpeg -i video_input.mp4 -c:v libx264 -ac 2 -c:a aac -strict -2 -b:a 128k -crf 28 video_output.mp4
# -strict -2 和 -ac 2 是来处理立体声部分的。
裁剪媒体文件(基础)
想要从开头开始剪辑一部分,使用T -t 参数来指定一个时间:
ffmpeg -i input_video.mp4 -t 5 output_video.mp4
ffmpeg -i input_audio.wav -t 00:00:05 output_audio.wav
这个参数对音频和视频都适用,上面两个命令做了类似的事情:保存一段5s的输出文件(文件开头开始算)。上面使用了两种不同的表示时间的方式,一个单纯的数字(描述)或者 HH:MM:SS (小时, 分钟, 秒). 第二种方式实际上指示了结束时间。
也可以通过 -ss 给出一个开始时间,-to 给出结束时间:
ffmpeg -i input_audio.mp3 -ss 00:01:14 output_audio.mp3
ffmpeg -i input_audio.wav -ss 00:00:30 -t 10 output_audio.wav
ffmpeg -i input_video.h264 -ss 00:01:30 -to 00:01:40 output_video.h264
ffmpeg -i input_audio.ogg -ss 5 output_audio.ogg
可以看到 开始时间 (-ss HH:MM:SS), 持续秒数 (-t duration), 结束时间 (-to HH:MM:SS), 和开始秒数 (-s duration)的用法.
可以在媒体文件的任何部分使用这些命令。
输出YUV420原始数据
对于一下做底层编解码的人来说,有时候常要提取视频的YUV原始数据。
- ffmpeg -i input.mp4 output.yuv
只想要抽取某一帧YUV呢? 简单,你先用上面的方法,先抽出jpeg图片,然后把jpeg转为YUV。 比如: 你先抽取10帧图片。
ffmpeg -i input.mp4 -ss 00:00:20 -t 10 -r 1 -q:v 2 -f image2 pic-%03d.jpeg
#结果:
# -rw-rw-r-- 1 hackett hackett 296254 7月 20 16:08 pic-001.jpeg
# -rw-rw-r-- 1 hackett hackett 300975 7月 20 16:08 pic-002.jpeg
# -rw-rw-r-- 1 hackett hackett 310130 7月 20 16:08 pic-003.jpeg
# -rw-rw-r-- 1 hackett hackett 268694 7月 20 16:08 pic-004.jpeg
# -rw-rw-r-- 1 hackett hackett 301056 7月 20 16:08 pic-005.jpeg
# 然后,随便挑一张,转为YUV:
ffmpeg -i pic-001.jpeg -s 1440x1440 -pix_fmt yuv420p xxx3.yuv
# 如果-s参数不写,则输出大小与输入一样。当然了,YUV还有yuv422p啥的,你在-pix_fmt 换成yuv422p就行啦!
视频添加logo
ffmpeg -i input.mp4 -i logo.png -filter_complex overlay output.mp4
提取视频ES数据
ffmpeg –i input.mp4 –vcodec copy –an –f m4v output.h264
视频编码格式转换
比如一个视频的编码是MPEG4,想用H264编码,咋办?
ffmpeg -i input.mp4 -vcodec h264 output.mp4
# 相反也一样
ffmpeg -i input.mp4 -vcodec mpeg4 output.mp4
添加字幕
语法 –vf subtitles=file
ffmpeg -i jidu.mp4 -vf subtitles=rgb.srt output.mp4
ffmpeg 高级用法
高级用法
- 分割媒体文件
- 拼接媒体文件
- 将图片转变为视频
- 录制屏幕
- 录制摄像头
- 录制声音
- 截图
# 分割: -t 00:00:30 为界分成两个文件(音频、视频都行), 可以指定多个分割点
ffmpeg -i video.mp4 -t 00:00:30 video_1.mp4 -ss 00:00:30 video_2.mp4
# 拼接:concat, 把join.txt里的文件合并为 output.mp4
ffmpeg -f concat -i join.txt output.mp4
# 图片→视频:image2pipe 同一种格式(png或jpg)的图片文件
cat my_photos/* | ffmpeg -f image2pipe -i - -c:v copy video.mkv
cat my_photos/* | ffmpeg -framerate 1 -f image2pipe -i - -c:v copy video.mkv # 指定帧率,framerate
cat my_photos/* | ffmpeg -framerate 0.40 -f image2pipe -i - -i audio.wav -c copy video.mkv # 加入声音 audio.wav
# 录屏:x11grab,屏幕分辨率 (-s),按 q 或者 CTRL+C 以结束录制屏幕
ffmpeg -f x11grab -s 1920x1080 -i :0.0 output.mp4
-s $(xdpyinfo | grep dimensions | awk '{print $2;}') # 获取真实分辨率
ffmpeg -f x11grab -s $(xdpyinfo | grep dimensions | awk '{print $2;}') -i :0.0 output.mp4 # 完整写法
# 录摄像头:q 或者 CTRL+C 来结束录制。
ffmpeg -i /dev/video0 output.mkv
# 录声音:Linux上同时是使用 ALSA 和 pulseaudio 来处理声音的。 ffmpeg 可以录制两者
# 在 pulseaudio, 必须强制指定(-f) alsa 然后指定 default 作为输入t (-i default):
ffmpeg -f alsa -i default output.mp3
ffmpeg -i /dev/video0 -f alsa -i default -c:v libx264 -c:a flac -r 30 output.mkv # 指定编码器及帧率
ffmpeg -f x11grab -s $(xdpyinfo | grep dimensions | awk '{print $2;}') -i :0.0 -i audio.wav -c:a copy output.mp4 # 提供音频文件
# 截图
ffmpeg -i input.flv -f image2 -vf fps=fps=1 out%d.png # 每隔一秒截一张图
ffmpeg -i input.flv -f image2 -vf fps=fps=1/20 out%d.png # 每隔20秒截一张图
过滤器 是 ffmpeg 中最为强大的功能。在ffmepg中有数不甚数的过滤器存在,可以满足各种编辑需要
ffmpeg 过滤器:
- 视频缩放
- 视频裁剪
- 视频旋转
- 音频声道重映射
- 更改播放速度
# 过滤器基本结构
# 指定视频过滤器 (-vf, -filter:v的简写) 和 音频过滤器 (-af, -filter:a的简写),单引号连接
ffmpeg -i input.mp4 -vf "filter=setting_1=value_1:setting_2=value_2,etc" output.mp4
ffmpeg -i input.wav -af "filter=setting_1=value_1:setting_2=value_2,etc" output.wav
# 视频缩放
ffmpeg -i input.mp4 -vf "scale=w=800:h=600" output.mp4 # 绝对大小
ffmpeg -i input.mkv -vf "scale=w=1/2*in_w:h=1/2*in_h" output.mkv # 数学运算,相对大小
# 视频裁剪:除了w和h,还需要指定裁剪原点(视频中心)
ffmpeg -i input.mp4 -vf "crop=w=1280:h=720:x=0:y=0" output.mp4
ffmpeg -i input.mkv -vf "crop=w=400:h=400" output.mkv
ffmpeg -i input.mkv -vf "crop=w=3/4*in_w:h=3/4*in_h" output.mkv # 相对大小
# 视频旋转
ffmpeg -i input.avi -vf "rotate=90*PI/180" # 按照指定弧度顺时针旋转 90°
ffmpeg -i input.mp4 -vf "rotate=PI" # 上下颠倒
# 声道重映射
ffmpeg -i input.mp3 -af "channelmap=1-0|1-1" output.mp3 # 将右声道(1)同时映射到左(0)右(1)两个声道(左边的数字是输入,右边的数字是输出)。
# 更改音量
ffmpeg -i input.wav -af "volume=1.5" output.wav # 音量 1.5倍
ffmpeg -i input.ogg -af "volume=0.75" output.ogg # 0.75倍
# 视频播放速度:setpts(视频播放)、atempo(音频播放)
ffmpeg -i input.mkv -vf "setpts=0.5*PTS" output.mkv # 视频加速
ffmpeg -i input.mp4 -vf "setpts=2*PTS" output,mp4 # 视频减速一半
ffmpeg -i input.wav -af "atempo=0.75" output.wav # 音频减速
ffmpeg -i input.mp3 -af "atempo=2.0,atempo=2.0" ouutput.mp3 # 音频加速
moviepy
MoviePy 是开源软件,原作者为Zulko,并根据MIT licence发行。
- 在Windows、Mac和Linux环境中以Python2或Python3运行。
python 视频处理模块 moviepy
- 基本操作:剪切、拼接、插入标题、视频合成(即非线性编辑)、视频处理和创建高级特效。
- 常见视频格式进行读写,包括GIF。
文档
- moviepy中文文档
- 【2022-2-17】【首发】python moviepy 的用法,看这篇就能入门
工作原理
MoviePy
- 用ffmpeg软件读取和导出视频和音频文件。
- 用(可选)ImageMagick来生成文字和制作GIF文件。
- 不同媒体的处理依靠Python的快速的数学库Numpy。
- 高级效果和增强功能使用一些Python的图片处理库(PIL,Scikit-image,scipy等)。
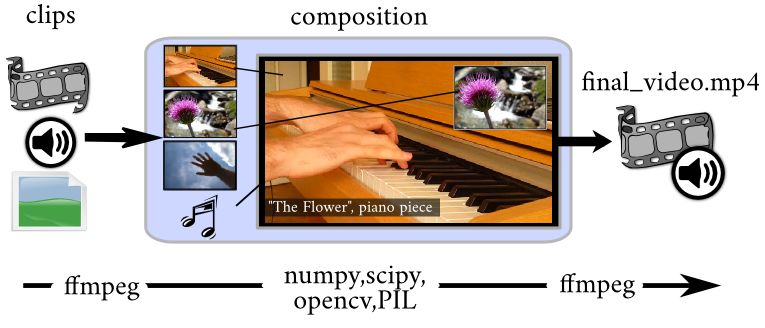
MoviePy 核心对象是剪辑,可用AudioClips或VideoClips来处理。
- 剪辑可被修改(剪切、降低速度、变暗等)或与其他剪辑混合组成新剪辑。
- 剪辑可被预览(使用PyGame或IPython Notebook),也可生成文件(如MP4文件、GIF文件、MP3文件等)。
以VideoClips为例,它由一个视频文件、一张图片、一段文字或者一段卡通动画而来。可包含音频轨道(即AudioClip)和一个遮罩(一种特殊的VideoClip),用于表明当两个剪辑混合时,哪一部分的画面被隐藏)。
安装
MoviePy 依赖
- Numpy 、 imageio 、 Decorator 和 tqdm
- MoviePy 依赖 FFMPEG 软件对视频进行读写, 初次使用时,FFMPEG将会自动由ImageIO下载和安装
可选依赖
- ImageMagick: 添加文字时用到, 安装后会被MoviePy自动检测到,除了Windows环境
- PyGame: 视频和声音预览中会使用到
- 高级的图片处理: PIL(Pillow), Scipy, ScikitImage, OpenCV
pip install moviepy
测试
from moviepy.editor import *
mac 上执行报错
ImportError: cannot import name 'is_ascii' from 'charset_normalizer.utils' (/Users/bytedance/miniconda3/envs/py310/lib/python3.10/site-packages/charset_normalizer/utils.py)
解决
- 安装chardet
pip install chardet
视频信息
视频的分辨率和时间
from moviepy.editor import *
video = VideoFileClip('1644974996.mp4')
print(dir(video))
size = os.path.getsize('1644974996.mp4') # 文件大小
print(size)
print(video.size) # 获取分辨率
print(video.duration) # 获取视频总时长
# 视频封面
clip.save_frame("frame.jpg") # 保存第1帧
clip.save_frame("frame.png", t=2) # 保存2s时刻的那1帧
播放速度
读取视频,调用 speedx() 方法,其中设置要加速到的倍数
from moviepy.editor import *
clip = VideoFileClip('./1644974996.mp4')
video_1 = clip.speedx(2) # 加速两倍
video_1.write_videofile('sss.mp4')
视频裁剪
VideoFileClip 类的构造函数如下所示:
__init__(self, filename, has_mask=False,
audio=True, audio_buffersize=200000,
target_resolution=None, resize_algorithm='bicubic',
audio_fps=44100, audio_nbytes=2, verbose=False,
fps_source='tbr')
其中, 只有 filename 为必填项,其余都为选填内容。
- filename:视频文件名,一般常见格式都支持;
- has_mask:是否包含遮罩;
- audio:是否加载音频;
- audio_buffersize:音频缓冲区大小;
- target_resolution:加载后需要变换到的分辨率;
- resize_algorithm:调整分辨率的算法,默认是 bicubic,可以设置为 bilinear,fast_bilinear;
- audio_fps:声音的采样频率;
- audio_nbytes:采样的位数;
- verbose:是否输出处理信息。
- subclip(t1,t2) 方法的含义为截取t1到t2时间段内的片段。
- write_videofile() 方法用于视频输出。
subclip(t_start,t_end) 方法时间参数
- 秒:
(t_start=10),以秒表示 - 分:
(t_start=(1,20)),以1分20秒 - 时:
(t_start=(0,1,20))或者(t_start=(00:01:20)), 以小时: 分钟: 秒形式表示 - t_end 的默认值是视频长度
from moviepy.editor import *
import time
clip = VideoFileClip('./1644974996.mp4').subclip(10, 20)
# 保存视频片段
new_file = str(int(time.time())) + '_subclip.mp4'
clip.write_videofile(new_file)
# 片段转gif
clip.write_gif('demo.gif',fps=5) # 生成之后的文件小
clip.write_gif('demo.gif',fps=15) # 生成之后的文件大
音频提取
VideoFileClip 对象的 audio 属性,获取视频的音频部分,然后 调用 set_audio() 方法对文件进行音频设置
- 注意: 合成的音频和视频等于长的。
from moviepy.editor import *
# 读取2个视频文件
videoclip_a = VideoFileClip("1644974996.mp4")
videoclip_b = VideoFileClip("1644974998.mp4")
# 去掉音频
video = video.without_audio() # 去除声音
video.write_videofile('cc.mp4')
# 提取A视频的音频
audio_a = videoclip_a.audio # 提取音频
audio_a.write_audiofile('a.mp3') # 写入音频文件
# 给B设置音频,注意视频最终合成的大小会依据长的为准
videoclip_c = videoclip_b.set_audio(audio_a)
# 输出新的视频文件
videoclip_c.write_videofile("videoclip_c.mp4")
视频合成
视频合成,也称为非线性编辑,把许多视频剪辑放在一起,变成一个新剪辑。
视频剪辑都会带有音轨和遮罩
两种合成方法
- 连接: 变成一个更长的剪辑,一个接一个播放
- 堆:并排组成画面更大的剪辑
连接 concatenate_videoclips
用 concatenate_videoclips 函数进行连接操作。
from moviepy.editor import VideoFileClip, concatenate_videoclips
clip1 = VideoFileClip("myvideo.mp4")
clip2 = VideoFileClip("myvideo2.mp4").subclip(50,60)
clip3 = VideoFileClip("myvideo3.mp4")
# final_clip 是一个剪辑,使clip 1、2和3一个接一个播放。
final_clip = concatenate_videoclips([clip1,clip2,clip3])
final_clip.write_videofile("my_concatenation.mp4")
注意
- 剪辑不一定必须要相同尺寸。
- 如果各剪辑尺寸不同,那么将被居中播放,而画面大小足够包含最大的剪辑,而且可以选择一种颜色来填充边界部分。
- 通过 transition=my_clip 选项来在剪辑之间加一个过场
堆 clip_array
clip_array 函数对剪辑进行堆叠操作
from moviepy.editor import VideoFileClip, clips_array, vfx
clip1 = VideoFileClip("myvideo.mp4").margin(10) # add 10px contour
clip2 = clip1.fx( vfx.mirror_x)
clip3 = clip1.fx( vfx.mirror_y)
clip4 = clip1.resize(0.60) # downsize 60%
final_clip = clips_array([[clip1, clip2],
[clip3, clip4]])
final_clip.resize(width=480).write_videofile("my_stack.mp4")
效果

合成 CompositeVideoClip
CompositeVideoClip 类提供了非常灵活的方法来合成剪辑,但比 concatenate_videoclips 和 clips_array 更复杂一些。
# 当前video播放clip1,clip2在clip1的上层,而clip3在clip1和clip2的上层
video = CompositeVideoClip([clip1,clip2,clip3])
video = CompositeVideoClip([clip1,clip2,clip3], size=(720,460)) # 修改尺寸
clip1 = clip1.set_start(5) # start after 5 seconds # 起始时间
video = CompositeVideoClip([clip1, # starts at t=0
clip2.set_start(5), # start at t=5s
clip3.set_start(9)]) # start at t=9s
# 淡入效果
video = CompositeVideoClip([clip1, # starts at t=0
clip2.set_start(5).crossfadein(1),
clip3.set_start(9).crossfadein(1.5)])
# 剪辑定位
video = CompositeVideoClip([clip1,
clip2.set_pos((45,150)),
clip3.set_pos((90,100))])
clip2.set_pos((45,150)) # x=45, y=150 , in pixels
clip2.set_pos("center") # automatically centered
# clip2 is horizontally centered, and at the top of the picture
clip2.set_pos(("center","top"))
# clip2 is vertically centered, at the left of the picture
clip2.set_pos(("left","center"))
# clip2 is at 40% of the width, 70% of the height of the screen:
clip2.set_pos((0.4,0.7), relative=True)
# clip2's position is horizontally centered, and moving down !
clip2.set_pos(lambda t: ('center', 50+t) )
指定坐标的时候请记住,y坐标的0位置在图片的最上方

视频剪辑混合在一起时,MoviePy将会把它们各自的音轨自动合成为最终剪辑的音轨
from moviepy.editor import *
# ... make some audio clips aclip1, aclip2, aclip3
concat = concatenate_audioclips([aclip1, aclip2, aclip3])
compo = CompositeAudioClip([aclip1.volumex(1.2),
aclip2.set_start(5), # start at t=5s
aclip3.set_start(9)])
实例
# Import everything needed to edit video clips
from moviepy.editor import *
# 读取视频
video_file = "../download/apple.mp4"
# Load myHolidays.mp4 and select the subclip 00:00:50 - 00:00:60
clip = VideoFileClip(video_file).subclip(50,60)
# 降低音量 Reduce the audio volume (volume x 0.8)
clip = clip.volumex(0.8)
# 生成字幕:中文字幕无法识别 Generate a text clip. You can customize the font, color, etc.
txt_clip = TextClip("Apple 苹果制作过程",fontsize=70,color='white')
# Say that you want it to appear 10s at the center of the screen
txt_clip = txt_clip.set_pos('center').set_duration(10)
# 视频合成 Overlay the text clip on the first video clip
video = CompositeVideoClip([clip, txt_clip])
# 保存合成视频 Write the result to a file (many options available !)
#video.write_videofile("my_works.mp4") # mp4 格式,清晰,但没有声音
video.write_videofile("my_works.webm") # webm 格式,有声音,但画面模糊
视频防抖
电子防抖:
- 通过电子手段来对图像处理,减轻抖动对成像的影响。
电子防抖主要有三种实施手段:自动提高ISO感光度/电子图像压缩/BSS模式。
CCD防抖原理
- 将CCD安置在一个可上下左右移动的支架上,先检测出是否有抖动,由于使用陀螺传感器,抖动的检测与其他公司基本相同
常见的手机视频防抖有两种:OIS 光学防抖和 EIS 电子防抖
参考
防抖算法
防抖算法三步处理:
- (1)运动估计。估计摄像系统设备运动的大致运动参数。
- (2)抖动识别。识别设备的大致抖动情况。
- (3)运动补偿。根据抖动补偿图像,还原图像。
A stabilization pipeline consists of three steps: motion estimating (运动估计), path smoothing (路径平滑), and novel view rendering (视窗渲染)
在提取每帧图像间特征点基础上,根据特征点匹配的结果计算摄像设备的全局运动参数,用参数建立仿射变换模型进行估算视频帧的相对运动参数,实现抖动帧向基准帧纠正,从而达到连续拍摄的视频图像防抖效果。
防抖模型
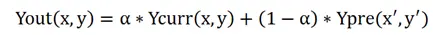
防抖算法核心: 运动估计
常用方法:
- (a) 灰度投影法
- (b) 块匹配法
- (c) 位平面匹配法
- (d) 边缘匹配法
- (e) 特征点匹配法
光学防抖 vs 电子防抖
对比分析
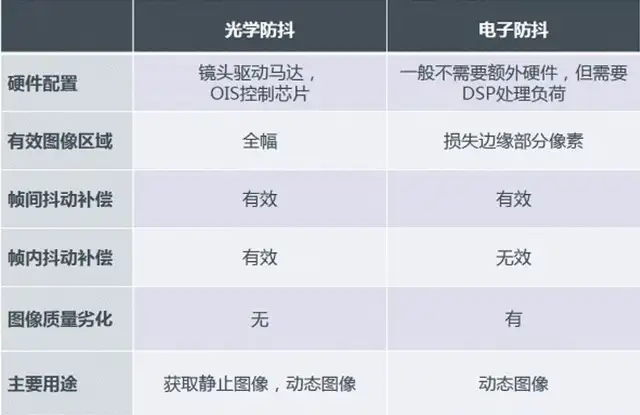
| 光学防抖 | 电子防抖 | |
|---|---|---|
| 硬件配置 | 镜头驱动马达,OIS控制芯片 | 一般不用额外硬件,但要DSP处理负荷 |
| 有效图像区域 | 全幅 | 损失边缘部分像素 |
| 帧间抖动补偿 | 有效 | 有效 |
| 帧内抖动补偿 | 有效 | 无效 |
| 图像质量劣化 | 无 | 有 |
| 主要用途 | 获取静止图像 | 动态图像 |
OIS 光学防抖
OIS光学防抖的工作原理
- 通过镜片组中增加一个使用磁力悬浮的镜片,配合陀螺仪工作。
- 当机身发生震动时,相机系统能检测到轻微的抖动,从而控制镜片浮动对抖动进行位移补偿,避免光路发生抖动,减少抖动造成的画面模糊问题。
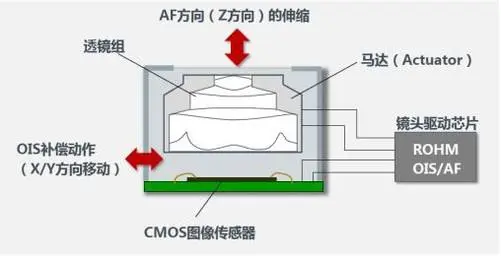
OIS 光学防抖需要镜头组中的传感器设备做支撑。
另外,作为物理防抖,对镜头设计制造的要求比较高,而且成本也相对更高一些,因此很多千元机一般不会搭载OIS 光学防抖。
EIS电子防抖
EIS电子防抖是一种软件补偿算法
原理:对成像进行“后期处理”,它通过算法对传感器上的图像进行分析、采集,以机身抖动的程度来动态调整ISO、快门等来做模糊修正。
EIS 电子防抖无需额外的元器件辅助,厂商可以更好控制成本,所以目前主流的千元机一般都会搭载 EIS电子防抖技术。
但是,EIS 电子防抖需要通过降低画质来“补偿”抖动,这对手机厂商不同软法算法的调教有很高的要求,这也造成了手机拍摄质量出现天差地别的情况。
混合防抖
混合防抖技术平衡了画质和防抖效果,随着技术创新手机厂商开始另辟蹊径,选择将OIS 光学防抖和 EIS 电子防抖巧妙的结合在一起。
OIS 光学防抖可以获得很好的视频防抖效果,保证成像画质- 另一方面,
EIS 电子防抖又可以去做画面补偿,两者互为补充。
防抖实现
剪映app自带视频防抖功能,实验下来有些效果,但不如结合光学防抖、陀螺仪的
剪映
- 剪映APP,选择视频 → 画面 → 下滑到底 → 视频防抖
- 提供3种模式:最少裁剪、推荐、最稳定
【2021】CVPR 实时自拍防抖
论文 Real-Time Selfie Video Stabilization

【2022】DVS 深度实时混合防抖
【2021-4-4】威斯康辛、谷歌发表,用DNN结合陀螺仪(gyroscope)、图像光流(optical flow)辅助做视频防抖
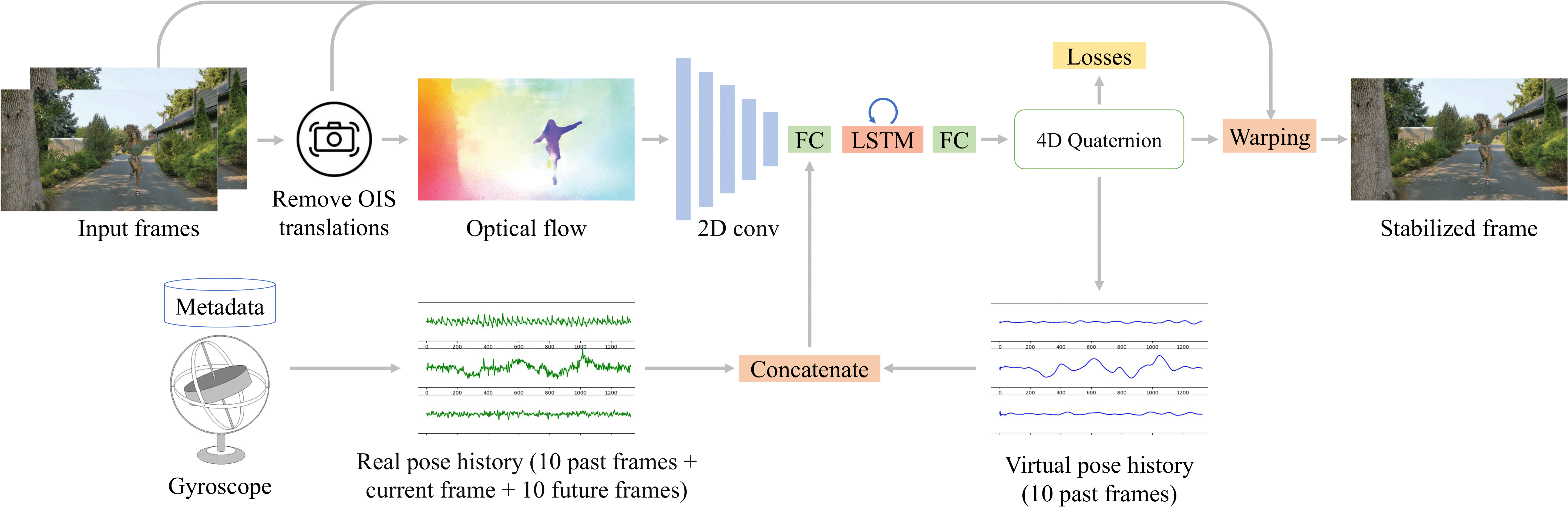
演示
【2024-3-31】GitHub 代码 deep-stabilization 实践通过
- 错误矫正
- cuda 版本改成 cpu 版
# 数据
https://drive.google.com/file/d/1PpF3-6BbQKy9fldjIfwa5AlbtQflx3sG/view?usp=sharing
# 环境准备
cd dvs
pip install -r requirements.txt --ignore-installed
# 数据处理
python load_frame_sensor_data.py
# 推理
python inference.py
python metrics.py
# 训练
python warp/read_write.py --dir_path ./dataset_release # video2frames
cd flownet2
bash run_release.sh # generate optical flow file for dataset
python train.py
错误矫正
load_frame_sensor_data.py
def main(args = None):
config_file = args.config
dir_path = args.dir_path
print(dir_path, config_file)
# (1) yaml 版本升级(5.4以上), load -> full_load, safe_load
#cf = yaml.load(open(config_file, 'r'))
cf = yaml.full_load(open(config_file, 'r'))
# (2) CPU版本,关掉所有相关文件的cuda相关设置
# USE_CUDA = cf['data']["use_cuda"]
checkpoints_dir = cf['data']['checkpoints_dir']
checkpoints_dir = make_dir(checkpoints_dir, cf)
data_name = sorted(os.listdir(dir_path))
print('video files:', data_name)
for i in range(len(data_name)):
print("Running: " + str(i+1) + "/" + str(len(data_name)))
# (3) 路径传入错误,从文件→目录
#inference(cf, os.path.join(dir_path, data_name[i]), USE_CUDA)
inference(cf, dir_path)
return
inference.py
def main(args = None):
config_file = args.config
dir_path = args.dir_path
print(args)
# (1) yaml 版本升级(5.4以上), load -> full_load, safe_load
#cf = yaml.load(open(config_file, 'r'))
cf = yaml.full_load(open(config_file, 'r'))
USE_CUDA = cf['data']["use_cuda"]
log_file = open(os.path.join(cf["data"]["log"], cf['data']['exp']+'_test.log'), 'w+')
printer = Printer(sys.stdout, log_file).open()
data_name = sorted(os.listdir(dir_path))
for i in range(len(data_name)):
print("Running Inference: " + str(i+1) + "/" + str(len(data_name)))
save_path = os.path.join("./test", cf['data']['exp'], data_name[i]+'_stab.mp4')
# (2) 路径传入错误,从文件→目录
#data_path = os.path.join(dir_path, data_name[i])
data_path = dir_path
#data, virtual_queue, video_name, grid= inference(cf, data_path, USE_CUDA)
data, virtual_queue, video_name, grid= inference(cf, dir_path)
virtual_queue2 = None
visual_result(cf, data, data_name[i], virtual_queue, virtual_queue2 = virtual_queue2, compare_exp = None)
video_path = os.path.join(data_path, video_name+".mp4")
warp_video(grid, video_path, save_path, frame_number = False)
return
视频拼接
资料
360 全景
360度全景倒车影像是一套通过车载显示屏幕观看汽车四周360度全景融合,超宽视角,无缝拼接的适时图像信息(鸟瞰图像),了解车辆周边视线盲区,帮助汽车驾驶员更为直观、更为安全地停泊车辆的泊车辅助系统,又叫全景泊车影像系统或全景停车影像系统(有别于市面上把汽车四周画面在显示屏幕上进行分割显示的“全景”系统)
360全景影像呈现鸟瞰图,即从天空望车顶或者地面的俯视图,但俯视效果通过多个视角照片拼接而成。
- 观察自己的车就能发现在车的前后左右四个方向上都有一个鱼眼相机,一般左右方向的鱼眼相机因为视野的问题布置在后视镜下方的比较多。
- 把4个鱼眼相机通过一定方法拼接到一张图上,再把车辆照片贴到图片中央,就能近似形成完成的全景图像。下图所示的就是开源项目中所使用的的四路鱼眼相机的前、后、左、右方向的照片。
双目鱼眼镜头
概念
- 拼接鱼眼镜头:将多个鱼眼镜头图像通过特殊软件算法进行拼接,得到一个具有更大视野和更高分辨率的全景图像。
- 拼接鱼眼镜头通常由多个鱼眼镜头安装在一个圆形或球形支架上组成,每个镜头捕捉到的图像会有一定的重叠部分,这些重叠部分可以用来进行图像拼接。
拼接鱼眼镜头的应用十分广泛
- 拍摄室内、城市街景、户外景观等各种场景。
- 可以提供更加全面和真实的视角,同时也有助于提高图像的清晰度和分辨率。
鱼眼环视拼接(AVM)
全景环视系统,又称AVM。在自动驾驶领域,AVM属于自动泊车系统的一部分,一种实用性极高、可大幅提升用户体验和驾驶安全性的功能。
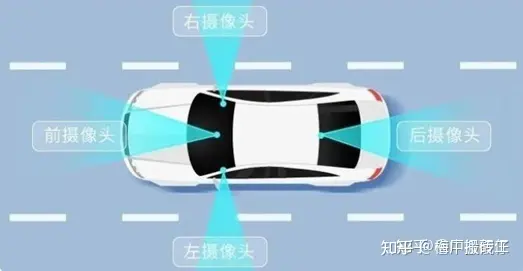

AVM汽车环视影像系统如图所示,由安装在前保险杠、后备箱、后视镜上的四个外置鱼眼相机构成。
- 该系统包含的算子按照先后顺序:去畸变、四路鱼眼相机联合标定、投影变换、鸟瞰图微调、拼接融合、3D模型纹理映射等。
现实中并不存在完全没有畸变的透镜,这主要是制造原因
- 因为制作一个球形透镜, 比制作一个数学上理想的透镜更容易
- 机械制作方面也很难把成像仪和透镜保持平行状态
现实应用中一般只考虑两种透镜畸变: 切向畸变和径向畸变
- 切向畸变产生的原因主要是摄像头生产安装过程中在工艺缺陷
- 径向畸变则来自于透镜形状。
鱼眼摄像机径向畸变模型如下图所示,存在着中间大两边小的特点
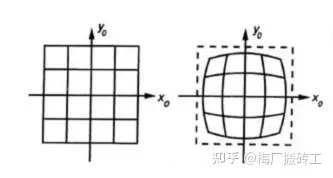
- 径向畸变就是沿着透镜半径方向分布的畸变,对于廉价的摄像头产生径向畸变的情况更加明显,径向畸变主要包括桶形畸变和枕形畸变两种。成像仪光轴中心的畸变为0,沿着镜头半径方向边缘移动,畸变越来越严重。对于畸变很大的镜头,如鱼眼镜头,可以利用两个畸变参数K1、K2描述。
- 切向畸变是由于透镜本身与相机传感器平面(成像平面)或图像平面在制作上放置不平行所产生的,这种不平行的情况多半是透镜被粘贴到镜头模组上安装时产生的偏差导致。畸变模型可以用两个额外的参数K3、K4来描述。
鱼眼畸变矫正算法
广泛应用的畸变校正方法是基于标定的校正方法,这类方法通过标定获取摄像机的内参数,即车载环视拼接系统的设计与实现(二)提到的摄像机内部参数,再通过摄像机成像过程坐标映射关系建立畸变模型。
假设(Xw,Yw,Zw)为世界坐标系下一个三维坐标点,投影到鱼眼图像中的像素点为(u,v),则可以根据车载环视拼接系统的设计与实现(二)摄像机理想线性坐标系变换即物体世界坐标点到像素坐标点的过程,结合切向径向畸变系数K1、K2、K3、K4推导出畸变图像成像模型的数学表达式。
世界坐标系到相机坐标系转换如下:
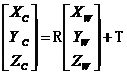
可用以下数学模型来描述畸变模型,假设摄像机坐标系下归一化坐标点:
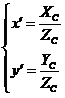
注意:
- opencv3.0以上加入了 fisheye 鱼眼畸变模型,相比于opencv1 opencv2 的普通相机模型的去畸变效果要好
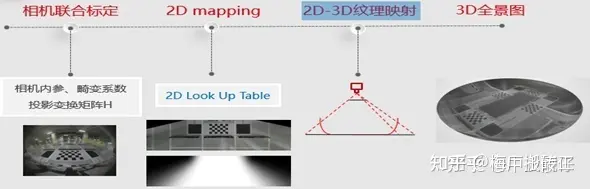
2D AVM:
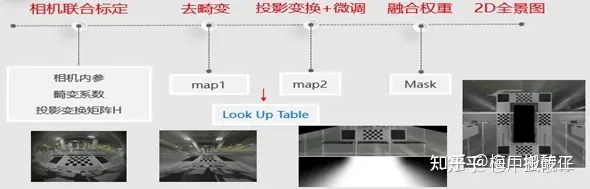
3D AVM:
镜头去畸变
获取每个相机的内参矩阵与畸变系数。
以下是视频中四个相机分别拍摄的原始画面,顺序依次为前、后、左、右,并命名为front.png、back.png、left.png、right.png

看到图中地面上铺了一张标定布,这个布的尺寸是6mx10m,每个黑白方格的尺寸为40cmx40cm,每个圆形图案所在的方格是80cmx80cm。
将利用这个标定物来手动选择对应点获得投影矩阵。
相机去畸变通常用张正友老师的棋盘格标定方法
- 首先通过矩阵推导得到一个比较好的初始解,然后通过非线性优化得到最优解,包括相机的内参、外参、畸变系数
- 然后对鱼眼图像做去畸变处理。内参即
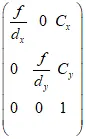
四路鱼眼相机联合标定
获取每个相机到地面的投影矩阵,这个投影矩阵会把相机校正后的画面转换为对地面上某个矩形区域的鸟瞰图。
这四个相机的投影矩阵不是独立的,必须保证投影后的区域能够正好拼起来。
这一步是通过联合标定实现,即在车四周地面上摆放标定物,拍摄图像,手动选取对应点,然后获取投影矩阵。
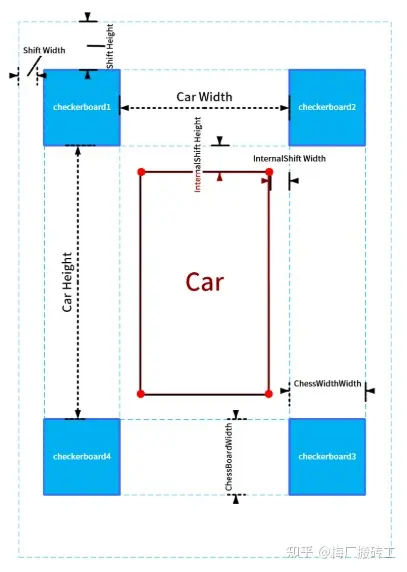
每个标定板应当恰好位于相邻的两个相机视野的重合区域中。
在上面拍摄的相机画面中车的四周铺了一张标定布,这个具体是标定板还是标定布不重要,只要能清楚的看到特征点就可以了。
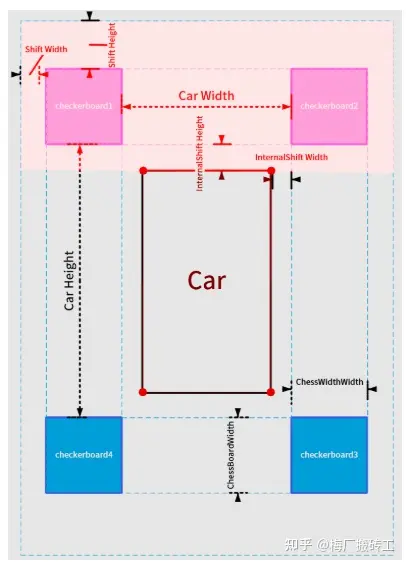
然后设置几个参数:(以下所有参数均以厘米为单位)
- innerShiftWidth, innerShiftHeight:标定板内侧边缘与车辆左右两侧的距离,标定板内侧边缘与车辆前后方的距离。
- shiftWidth, shiftHeight:这两个参数决定了在鸟瞰图中向标定板的外侧看多远。这两个值越大,鸟瞰图看的范围就越大,相应地远处的物体被投影后的形变也越严重,所以应酌情选择。
- totalWidth, totalHeight:这两个参数代表鸟瞰图的总宽高,在这个里我们设置标定布宽 6m 高 10m,于是鸟瞰图中地面的范围为 (600 + 2 * shiftWidth, 1000 + 2 * shiftHeight)。为方便计算,让每个像素对应 1 厘米,于是鸟瞰图的总宽高为 totalWidth = 600 + 2 * shiftWidth totalHeight = 1000 + 2 * shiftHeight 车辆所在矩形区域的四角 (图中标注的红色圆点),这四个角点的坐标分别为 (xl, yt), (xr, yt), (xl, yb), (xr, yb) (l 表示 left, r 表示 right,t 表示 top,b 表示 bottom)。这个矩形区域相机是看不到的,我们会用一张车辆的图标来覆盖此处。
- 设置好参数以后,每个相机的投影区域也就确定了,比如前方相机对应的投影区域如下:
投影变换
投影变换:
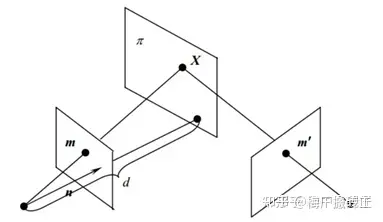
- 假设同一个相机分别在A、B两个不同位置,以不同的位姿拍摄同一个平面(重点是拍摄平面,例如桌面、墙面、地平面),生成了两张图象,这两张图象之间的关系就叫做投影变换。
张正友老师的相机标定法使用的就是从标定板平面到图像平面之间的投影模型。
图中相机从两个不同角度拍摄同一个X平面,两个相机拍摄到的图像之间的投影变换矩阵H(单应矩阵)为:
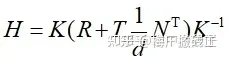
其中K为相机内参矩阵,R、T为两个相机之间的外参。这个公式怎么推导的网上有很多,只需要知道这个单应矩阵H内部实际是包含了两个相机之间的位姿关系即可。
这也就解释了:为什么有的AVM pipeline的方法是需要标定相机的外参,然后通过厂家提供的相机安装参数将四路鱼眼全部统一到车身坐标系下,而我们不需要这个过程,只需要用标定布来做联合标定。其实两种方法内部都是相通的,都绕不开计算相机外参这件事情。
鸟瞰图的拼接与平滑
到这一步其实就是最重要的一步了,如何将我们想要的图片进行拼接,并完成图片生成。生成鸟瞰图的过程可以理解为:将鱼眼相机拍摄到的图像,投影到某个在汽车上方平行地面拍摄的相机的平面上去。这个单应矩阵H具体是多少,由去畸变图中检测到的棋盘格角点坐标和联合标定全景图中棋盘格角点坐标来决定。如图所示,以后置相机为例,联合标定已知图(2)中框出棋盘格的坐标,图(1)中的棋盘格坐标可通过opencv的函数进行检测,从而建立单应矩阵H的求解模型。
由于相邻相机之间有重叠的区域,所以这部分的融合是关键。如果直接采取两幅图像加权平均 (权重各自为 1/2) 的方式融合的话你会得到类似下面的结果:
由于校正和投影的误差,相邻相机在重合区域的投影结果并不能完全吻合,导致拼接的结果出现乱码和重影。这里的关键在于权重系数应该是随像素变化而变化的,并且是随着像素连续变化。
以左上角区域为例,这个区域是front,left两个相机视野的重叠区域。我们首先将投影图中的重叠部分取出来, 灰度化并二值化,并用形态学操作去掉 噪点(不必特别精细,大致去掉即可)

至此得到了重叠区域的一个完整 mask。
然后将mask加入到拼接当中,通常的做法是分别以AB、CD为边界,计算白色区域像素点与AB、CD之间的距离,然后计算一个权重,距离CD越近的位置,前俯视图权重越大;距离AB越近的位置,左俯视图权重越大。但会出现边界效应:
鱼眼图片如何转为全景
如何从鱼眼图片透视变换为全景图片?
- 跨过参数标定聊透视变化
- 拼接图片后处理
- 重叠区域中的像素值的加权平均处理
- 为拼接图像的亮度一致性调整各区域的亮度
- 通过色彩平衡改善摄像头不同通道的强度不同的问题
对每个鱼眼镜头捕捉到的图像进行校正,转换为平面图像。这一步会用校正算法,例如: 极线校正法或球面映射法等。
1. 极线校正法(Epipolar Rectification)
极线校正法是计算机视觉常用技术,用于对成对图像进行处理,以便更好地进行视差计算和立体匹配。
- 该技术旨在将每个图像中的对应特征点投影到一条水平直线上,从而简化匹配问题,提高立体匹配的准确性和效率。
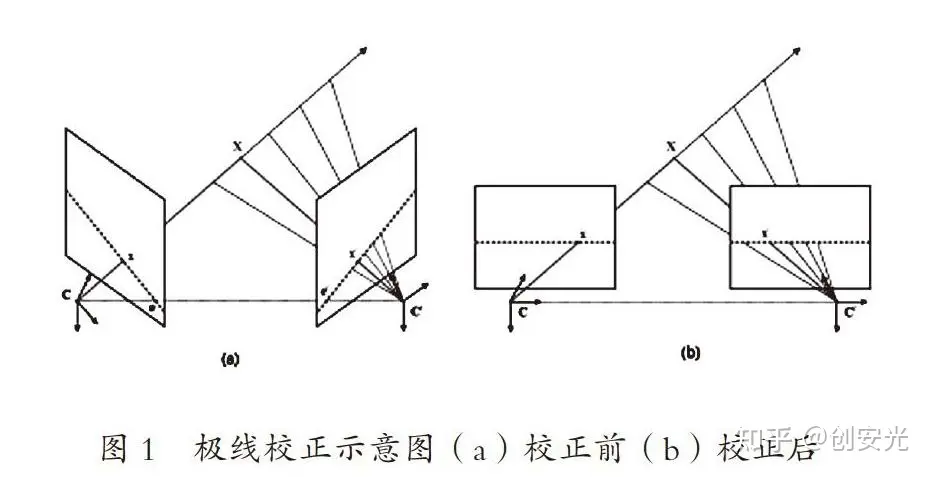
在使用极线校正法之前,需要进行以下步骤:
- ① 使用某种算法(如SIFT、SURF、ORB等)在每个图像中提取特征点。
- ② 对这些特征点进行匹配,找出两个图像中的对应点。
- ③ 使用本质矩阵或基础矩阵计算出两个图像之间的极线。
- ④ 对每个图像进行极线校正,使得它们的极线对齐。
极线校正过程:
- ① 对每个图像计算出极线。
- ② 计算出使得两个图像的极线对齐的旋转矩阵。
- ③ 对每个图像进行旋转和平移,使得它们的极线对齐。
- ④ 对图像进行裁剪和缩放,使得它们的像素之间的距离相等。
极线校正法可应用于许多计算机视觉任务中,包括立体视觉、运动估计和多视图几何等。它可以提高视差计算和立体匹配的准确性和效率,并且可以提高计算机视觉系统的整体性能。
2. 球面映射法
球面映射法将鱼眼图像转换为平面图像的校正方法,通常用于拼接鱼眼镜头图像的前处理步骤中。
球面映射法的基本思想
- 将鱼眼图像从球面上展开成为平面图像,使得图像中的直线在展开后仍然保持直线,从而消除鱼眼镜头引起的畸变。
球面映射法步骤:
- ① 选取适当的球心:通常选择鱼眼镜头的光轴所在位置作为球心,或者选择鱼眼镜头前端中心位置作为球心。
- ② 建立球面坐标系:以球心为原点,建立球面坐标系,其中经度和纬度分别对应于图像的x和y坐标。
- ③ 将鱼眼图像映射到球面上:将鱼眼图像中的每个像素点根据其球面坐标映射到球面上,得到球面图像。
- ④ 将球面图像展开成为平面图像:将球面图像展开成为平面图像,通常可以使用正交或斜交投影等方法。
- ⑤ 对平面图像进行后处理:对展开后的平面图像进行去畸变、剪裁、旋转等操作,得到校正后的图像。
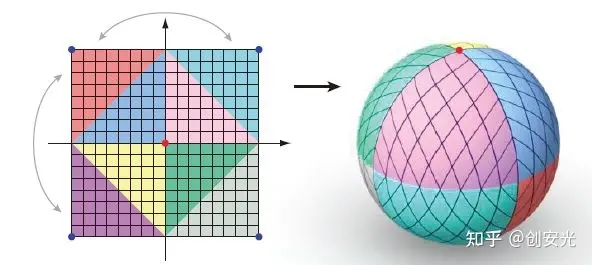
球面映射法是一种常用的校正方法,消除鱼眼镜头引起的畸变,并保持图像中的直线仍然是直线,是拼接鱼眼镜头图像的常用前处理步骤。
图像拼接
使用特定拼接算法拼接校正后图像,通常包括两个主要的步骤:特征点匹配和图像融合。
- 特征点匹配通过检测图像中的关键点,并将这些关键点在不同图像之间进行匹配。
- 图像融合将匹配后的图像进行融合,以得到完整的全景图像。
后期处理
对拼接后的全景图像进行调整和后期处理,例如:裁剪、色彩校正、去除畸变等。
注意
- 拼接鱼眼镜头的画面需要使用特定的软件和算法进行处理,通常需要具有一定的专业知识和技能。
工程实现
【2024-4-21】
- video-stitching, github 汇总
- surround-view-system-introduction 环视系统制作实现,包含完整的标定、投影、拼接和实时运行流程,详细文档见 doc 目录
代码:video_stitcher
常规视频拼接
- Video-Stitch 两个常规视频拼接示例
- video_stitcher.py 使用opencv 完成视频拼接
horizontally ‘stitch’ two videos such that the output video appears to be ‘panoramic’. This is achieved using three main techniques:
- Key Point Detection
- Feature Extraction
- Feature Matching
代码: 双目鱼眼拼接
双目鱼眼拼接
- 【2018】dual-fisheye-video-stitching-in-Python3
- 【2024】Dual-fisheye-video-stitching
- paper “Learning-based Homography Matrix Optimization for Dual-fisheye Video Stitching
- test data google drive, 两个文件 400m
- 实测: 报错, fov 取值不明, 论文无法查看, 已提issue
# [2018]
# python main.py [-h] [-o OUTPUT.XYZ] INPUT.XYZ
# 实测通过, 执行后卡住,点击图片后启动拼接
python main.py -o wqw_stitch.mp4 dual-fisheye-video-stitching/data/360_0080.MP4
# [2024] 下载 两个视频文件
# python Fisheye_stitching.py -o output_file_path -i1 left_fisheye_video -i2 right_fisheye_video -f FOV
# 实测
python Fisheye_stitching.py -o wqw_statich.mp4 -i1 data/left.mp4 -i2 data/right.mp4 -f 360
# ValueError: zero-size array to reduction operation maximum which has no identity
代码:gear360pano
gear360pano 从 鱼眼照片创建等距柱状全景照片,支持双目鱼眼图片、视频
Hugin - panorama from one double fisheye image
Requirements:
- Linux, Windows, should work on Mac.
- Hugin.
- ffmpeg (optional, needed for video stitching).
- multiblend (optional, needed for video stitching).
- GNU Parallel (optional, needed for video stitching if using
-poption).
软件:VideoStitch Studio
Vahana VR & VideoStitch Studio: software to create immersive 360° VR video, live and in post-production.
The software was originally developed by VideoStitch SAS. After the company folded in early 2018, the source code was acquired by the newly founded non-profit organization stitchEm, to publish it under a free software license.
Orah 4i
The Orah 4i is a camera with 4 fisheye lenses designed for live 4K 360° Video streaming. Information on setting up the camera is found in a the dedicated camorah respository.
Vahana VR & VideoStitch Studio 用于创建沉浸式360° VR视频软件,可在实时和后期制作中使用。
- 最初由VideoStitch SAS开发。该公司于2018年初倒闭后,该软件源代码被新成立的非营利组织stitchEm收购,以便根据自由软件许可发布。
多目鱼眼视频拼接软件,VideoStitch Studio, 支持四目鱼眼视频拼接
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
