- ICL
- 思维链(CoT:Chain-of-thoughts)
- 结束
ICL
ICL(上下文学习), 一种特殊的 prompt 形式, GPT-3 首次提出的,它已经成为利用 LLMs 的一种典型方法。
【2023-2-20】
- 斯坦福原文:Extrapolating to Unnatural Language Processing with GPT-3’s In-context Learning: The Good, the Bad, and the Mysterious
- 译文理解:In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘
- 一文理解“上下文学习”—-大语言模型突现能力
GPT-3 模型展现了一些大模型才具备的突现能力(模型规模必须得增大到一定程度才会显现的能力,比如至少百亿级),其中一项能力就是上下文学习(In-Context Learning)(或:情境学习)
突现能力:预训练好的大语言模型,迁移到新任务上的时候,只需要给模型输入几个示例(示例输入和示例输出对),模型就能为新输入生成正确输出而不需要对模型做 fine-tuning。
【2026-5-21】小红书帖子 大模型 CoT 思维链的信息流, 反向传播式归因
- 反向传播式归因可以一步步反向追溯中间推理token的归因来源,直到用户输入,形成一个“因果流”。可以从图里看到,答案是怎么一步步产生的,以及哪些原始输入对结果影响最大
- huggingface 工具: InfoLens 实时体验
什么是ICL(In-Context Learning)?
情境学习(In-context Learning)提供几个任务示例/说明,要求预训练模型要对任务本身进行理解。
GPT-n 系列模型都属于自回归类的语言模型
自回归模型: 根据当前输入预测下一个词,然后将预测结果和输入拼接再当做模型的输入再预测下一个词,这样循环往复。
自回归模型的训练目标: 从超大规模语料库中采样训练样本,模型根据输入输出一个概率向量(概率向量包含所有词的预测概率,对于GPT-3 模型来说,维度约1千多万),而因为文本数据自带标注所以我们是知道真实的下一个词,所以损失函数就采用得交叉熵。
预训练好的 GPT-3 模型拥有一项神奇的能力,后来被称为:上下文学习(In-Context Learning)。
- 预训练好的 GPT-3 模型在迁移到新任务时并不需要重新训练,而只需要提供任务描述(可选项)接着提供几个示例(任务查询和对应答案,以一对对的形式组织),最后加上要模型回答的查询。将以上内容打包一起作为模型的输入,则模型就能正确输出最后一个查询对应的答案。
用 GPT-3 来做个翻译任务,翻译英文为法文。输入的格式如下:

- 第一行是对任务描述,告诉模型要做翻译
- 接下来三行就是示例,英文单词和对应的法文单词对
- 最后一行就是待翻译的英文单词。
将以上内容整体作为 GPT-3 的输入,让模型去补全输出就能得到 cheese 对应的法文单词。
上下文学习非常灵活,除了上面展示的翻译任务,还可以做语法修饰甚至写代码。
- 而神奇的地方就在于,GPT-3 训练过程中是并没有显式提供,类似测试阶段任务描述加示例这样的训练数据。
当然 GPT-3 的训练数据量非常巨大(包含了 wiki, 书本期刊,reddit 上的讨论等等),或许里面就已经就包含了各种任务类似结构的数据,GPT-3 模型容量足够大能够将所有训练数据都记了下来。
对于上下文学习能力的成因,目前还是一个开放性问题。为什么只有大规模的语言模型才会具备该能力?或许只有模型参数量大还不够,还必须要训练数据量也足够大,模型才能显现出该能力?
Prompt与ICL,CoT
Prompt与ICL,CoT关系
- ICL(上下文学习), 一种特殊的 prompt 形式, GPT-3 首次提出的,它已经成为利用 LLMs 的一种典型方法。
- 思维链(CoT)是一种改进的 prompt 策略,可以提高 LLM 在复杂推理任务中的表现,如算术推理、常识推理和符号推理。CoT 不是像 ICL 那样简单地用 输入-输出 对来构建 prompt,而是将能够导致最终输出的中间推理步骤纳入 prompt。
【2023-4-3】LLMs演进图解, paper
ICL 发展历史
演变历程
- 2021年初,Prompt learning
提示学习 - 2021年底,Demonstration learning
演示学习 - 2022年初,In-cotnext learning
情境学习
ICL 资料
- 【2023-3-22】princeton university 普林斯顿大学的ppt讲义:Towards Understanding In-context Learning
- 【2022-8-1】斯坦福AI Lab文章:How does in-context learning work? A framework for understanding the differences from traditional supervised learning
- 译文理解:In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘
ICL是LLM的一项神奇的涌现能力,无需优化参数,只需提供输入输出示例。斯坦福提供一个贝叶斯推理框架,可以更好的理解ICL,定位预训练数据中学到的隐含概念。prompt提示的所有组成部分(输入/输出/格式化/映射关系)都能为推理隐含概念提供信息- This suggests that all components of the prompt (inputs, outputs, formatting, and the input-output mapping) can provide information for inferring the latent concept
in-context learning可以看成一个贝叶斯推理过程,其利用提示的四个组成部分(输入、输出、格式和输入输出映射)来获得隐含在语言模型中的潜在概念,而潜在概念是语言模型在训练过程中学到的关于某类任务的特定“知识”。
Research Goals
- Develop a mathematical framework for understanding how in-context learning emerges during pre-training
- Analyze empirically which aspects of the prompt affect downstream task performance
GPT-3 paper found that the large scale leads to a particularly interesting emergent behavior 涌现能力 called in-context learning 上下文学习.
An Explanation of In-context Learning as Implicit Bayesian Inference

- Two examples of in-context learning, where a language model (LM) is given a list of training examples (black) and a test input (green) and asked to make a prediction (orange) by predicting the next tokens/words to fill in the blank.
- 黑色是训练样本,绿色是测试输入,目标是预测空白处的单词(negative/positive,finance/sport…)
Concepts (long-term coherence 长程连贯性)
- A latent variable 隐变量 that contains various document-level statistics: a distribution of words, a format, a relation between sentences, and other semantic and syntactic relations in general.
- For example, a “news topics” 新闻主题 concept 概念 describes a distribution of words 单词 (news and their topics), a format 格式 (the way that news articles are written), a relation between news and topics 新闻和主题关系, and other semantic and syntactic relationships between words 单词之间的语义语法关系. In general, concepts may be a combination of many latent variables 概念是许多隐变量的组合 that specify different aspects of the semantics and syntax of a document, but we simplify here by grouping them all into one concept variable.

- the LM uses the training examples to internally figure out that the task is either sentiment analysis (left) or topic classification (right) and apply the same mapping to the test input.
Bayesian inference view of in-context learning
In our framework, the document-level latent concept 文档级别隐概念 creates long-term coherence, and modeling this coherence 连贯性 during pretraining requires learning to infer the latent concept:
Pretrain: To predict the next token during pretraining, the LM must infer (“locate”) the latent concept for the document using evidence from the previous sentences.- assumption: a document is generated by first sampling a latent concept, and then the document is generated by conditioning on the latent concept.
- 假设:采样隐含概念后,据此生成文档
In-context learning: If the LM also infers the prompt concept (the latent concept shared by examples in the prompt) using in-context examples in the prompt, then in-context learning occurs!- In-context learning prompts are lists of
IID(independent and identically distributed) training examples. Each example in the prompt is drawn as a sequence conditioned on the same prompt concept, which describes the task to be learned. - ICL 示例 是独立同分布的训练样本,附带一个测试样本,共同组成prompt concept提示概念,描述要学习的任务
- The process of “locating” learned capabilities can be viewed as Bayesian inference of a prompt concept that every example in the prompt shares. If the model can infer the prompt concept, then it can be used to make the correct prediction on the test example. Mathematically, the prompt provides evidence for the model (p) to sharpen the posterior distribution over concepts, $p(concept\∣prompt)$. If $p(concept\∣prompt)$ is concentrated on the prompt concept, the model has effectively “learned” the concept from the prompt.
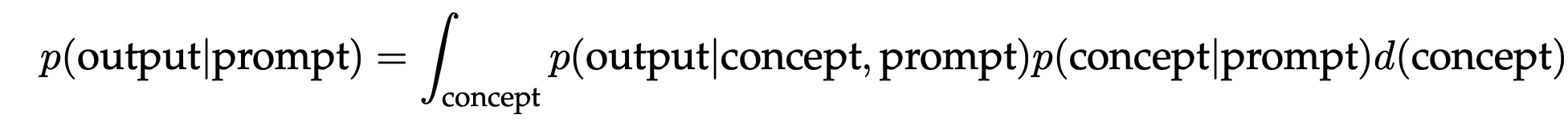
concept–>prompt–>output
- In-context learning prompts are lists of
Prompts provide noisy evidence for Bayesian inference
- LM will infer the prompt concept from in-context examples, even though prompts are sampled from the prompt distribution, which can be very different from the pretraining distribution. Interestingly, the LM can still do Bayesian inference despite the mismatch between the pretraining and prompt distributions, as seen empirically in GPT-3. In-context learning via Bayesian inference can emerge from latent concept structure in the pretraining data in a simplified theoretical setting and use this to generate a synthetic dataset where in-context learning emerges for both Transformers and LSTMs.
- 语言模型从上文示例从推断提示概念,即使提示样本不同于训练数据(包含噪声)。紧固那预训练分布和提示分布不同,语言模型(如GPT-3)依然可以执行贝叶斯推断

- 绿色概念表示训练样本中隐含提示概念之间的信号,红色箭头表示示例间低概率转移的噪声。
- 训练样本提供信号:训练样本提供贝叶斯推理的信号,样本内单词转移有助于LM学习共享的隐含概念。这种转移来自输入分布、输出分布、输出格式以及输入-输出映射。
- 训练样本之间的转移可以是低概率噪声:训练样本独立同分布,放在一起后,成了非自然、低概率的样本转移,产生推理噪声
- ICL对噪声鲁棒:如果提示里包含的信号超过噪声,语言模型能成功执行ICL任务:随着训练样本数趋近无穷,预测准确率不断上升。
- 信号由提示里的概念和其他概念之间的KL散度来衡量。
- 噪声源自示例之间的转移概率
- 小规模ICL数据集 GINC dataset:We found that pretraining on GINC causes in-context learning to emerge for both Transformers and LSTMs, the main effect comes from the structure in the pretraining data.
ICL 介绍
In Context Learning(ICL)的核心思想:从类比中学习。
- 综述: 【2023-2-8】A Survey on In-context Learning
一个描述语言模型如何使用ICL进行决策的例子。
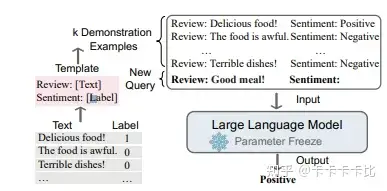
- 首先,ICL需要一些示例, 形成一个
演示上下文。这些示例通常是用自然语言模板编写的。 - 然后,ICL将查询的
问题(即input)和一个上下文演示(一些相关的cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。
注意:
- 与训练阶段用反向梯度更新模型参数的监督学习不同,
ICL不需要参数更新,并直接对预先训练好的语言模型进行预测- 这是
ICL与prompt,传统demonstration learning不同的地方,ICL不需要在下游 P-tuning 或 Fine-tuning。
- 这是
- 希望该模型学习隐藏在演示中的模式,并据此做出正确的预测。
Works like magic!
- No parameter tuning need
- Only need few examples for downstream tasks
- GPT-3 improved SOTA on LAMBADA by 18%!
We don’t know how models in-context learn
- Learns to do a downstream task by conditioning on input-output examples
- No weight update and model is not explicitly pre-trained to learn from examples
Model needs to figure out:
- input distribution (financial or general news)
- output distribution (Positive/Negative or topic)
- input-output mapping (sentiment or topic classification)
- formatting
结论1:
- ICL中 Ground Truth 信息无关紧要
- ICL的性能收益主要来自独立规范的
输入空间和标签空间,以及正确一致的演示格式
模型是否在Test阶段学习到了知识?
- 如果对学习进行严格的定义,即学习在训练数据中给出的输入标签对,那么,lm在测试时不学习新的任务。
- 然而,学习一项新任务更广泛地解释:可能包括适应特定的输入和标签分布以及演示的格式,并最终更准确地做出预测。
- 有了定义,该模型确实可以从演示中学习任务。实验表明,该模型确实利用了演示的各个方面,并实现了性能的提高。
演示是如何让 In-context learning 在不同的任务中产生性能增益的,而且随着 fine-tune 阶段的黑盒化,很多文章也提出 fine-tune 阶段可能让模型丧失了泛化性,那么ICL这种不fine tune的方法既节省时间与资源开销,且能提升效果,应该会在大模型林立的时代被人关注,并迅速火起来。
上下文学习原理
ICL 原理
How does in-context learning work?
大型预训练语言模型其中一个重要特点:上下文学习(In-Context Learning,ICL)能力,即通过一些示范性的 <输入-标签> 对,就可以在不更新参数的情况下对新输入的标签进行预测。
性能虽然上去了,但大模型的ICL能力到底从何而来仍然是一个开放的问题。为了更好地理解ICL的工作原理,清华大学、北京大学和微软的研究人员共同发表了一篇论文,将语言模型解释为元优化器(meta-optimizer),并将ICL理解为一种隐性的(implicit)微调。
情境学习三种分类的定义和示例如下:
few-shot learning多个示例- 输入:“这个任务要求将中文翻译为英文。你好->hello,再见->goodbye,购买->purchase,销售->”
- 要求模型预测下一个输出应该是什么,正确答案应为“sell”。
one-shot learning一个示例- 输入:“这个任务要求将中文翻译为英文。你好->hello,销售->”
- 要求模型预测下一个输出应该是什么,正确答案应为“sell”。
zero-shot learning- 输入:“这个任务要求将中文翻译为英文。销售->”
- 要求模型预测下一个输出应该是什么,正确答案应为“sell”。
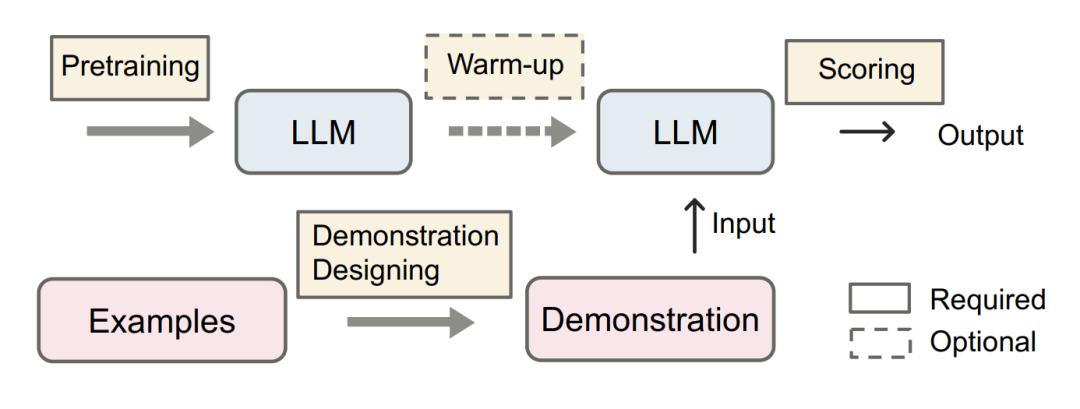
ICL主要流程如图。
- 预训练对于发展LLM的ICL能力具有重要意义,而可选的预热阶段进一步提高了能力。
- 对于演示来说,最重要是演示设计。通过预训练的LLM和精心设计的演示,适当的评分策略最终产生任务输出。
【2023-1-3】北大综述论文:In-context Learning进展、挑战和方向
随着模型规模和语料库规模的扩大,大型语言模型展示了从由上下文中的几个示例组成的演示中学习的新能力(简称语境学习)。
- 研究表明,LLMs可以使用ICL执行一系列复杂的任务,如解决数学推理问题。
- 这些强大的能力已经被广泛验证为大型语言模型的新兴能力。
ICL的形式化定义, 境学习的核心思想是类比学习。

语言模型如何使用ICL进行决策。
- 首先,ICL需要一些示例来形成演示上下文。示例通常使用自然语言模板编写。
- 然后,ICL将一个查询问题和一个演示上下文连接在一起形成一个
提示- 注意:ICL中Ground Truth信息(示例qa质量)无关紧要
- 最后,将其输入到语言模型中进行预测。
训练阶段,监督学习用后向梯度更新模型参数,而ICL不需要参数更新,直接对预训练语言模型进行预测。该模型被期望学习隐藏在演示中的模式,并相应地做出正确的预测。
ICL作为一种新的范式,具有许多吸引人的优势。
- 首先,演示用自然语言格式编写,提供一个可解释的接口与大型语言模型通信。这种范式通过更改演示和模板使将人类知识纳入语言模型变得容易得多。
- 第二,上下文学习类似于人类的类比决策过程。
- 第三,与有监督学习相比,ICL是一种无训练学习框架。这不仅可以大大降低使模型适应新任务的计算成本,还可以使语言模型即服务成为可能,并且可以很容易地应用于大规模的现实世界任务。
但ICL中还有些问题和性质需要进一步研究。
- 虽然普通的GPT-3模型显示出ICL能力,但通过预训练期间的自适应,能力可以显著提高。
- 此外,ICL的性能对特定的设置很敏感,包括提示模板、上下文示例的选择和示例顺序等。
- 此外,尽管从直观上看是合理的,但ICL的工作机制仍然不明确,很少有研究提供初步解释。
ICL的强大性能依赖于两个阶段:
- (1) 训练阶段,训练LLM的ICL能力
- 训练阶段,语言模型直接在语言建模目标上进行训练,如从左到右的生成。虽然这些模型并没有针对上下文学习进行特别优化,但ICL仍然具有令人惊讶的能力。现有的ICL研究基本上以训练有素的语言模型为骨干。
- (2) 推理阶段,LLM根据特定任务的演示进行预测。
- 推理阶段,由于输入和输出标签都在可解释的自然语言模板中表示,因此有多个方向来提高ICL的性能。
ICL分类
ICL 思考
ICL 探索
【2023-12-23】微信AI团队:以标签为锚的LLM学习方法探索研究
微信AI和北京大学联合团队深入研究了上下文学习(In-context learning,ICL)的工作机制,发现上下文学习中演示示例的标签词起着 “锚点” 作用,为此提出了一系列方法来提升ICL性能。
- EMNLP2023,由北京大学和微信AI团队合作的论文“Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning”从4909篇投稿中脱颖而出,斩获EMNLP2023的最佳长论文奖(Best Long Paper Award),这也是EMNLP会议上国内首篇获此殊荣的论文。
一些工作分析了上下文学习中示例的格式与排列组合对性能的影响,还有一些工作则尝试建立起上下文学习同K近邻算法、梯度下降算法的联系。
本文从信息流动视角提出了分析了上下文学习中模型“以标签为锚”的猜想,通过多组实验从不同角度验证了这一猜想,并利用分析得到的结论提出了对上下文学习的性能改进与错误识别方法。
分析结论(Information Flow with Labels as Anchors):
- 1、浅层存在一个“信息聚合流(information aggregation flow)”,模型将示例文本的信息聚合到标签处;
- 2、深层存在一个“结果预测流(label prediction flow)”,模型进一步利用标签处聚集的信息完成指定的任务。
示例中的标签位置起到了关键作用,研究团队形象地称其为“锚点(anchor)”
【2023-3-25】in-context learning到底在学啥?
论文:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
- 项目地址
- in-context learning学习的并不是输入与标注之间的关联,而是通过展示数据形式,来激活预训练模型的能力。
- 模型学到(激活)了输入数据、预测标签的分布,以及这种数据+label的语言表达形式。
- 此外还有两个附带的结论:
- (1) 在meta learning的环境下,in-context learning的这一特点更为明显;
- (2) 因为标签不重要,所以可以用无标注领域内数据做 in-context zero-shot learning。
结论:见 什么是In-Context Learning(上下文学习)
- ICL中Ground Truth信息无关紧要
- ICL的性能收益主要来自独立规范的输入空间和标签空间,以及正确一致的演示格式
模型有没有学习?
-
传统意义上的学习, 指模型建模输入样本和输出样本之间的关联( $P(y x)$或 $P(x,y)∝P(x y)$ )。在这种定义下,in-context learning并没有学习。 - 然而,模型可以通过展示样例中的输入、输出、及输入+输出的语言表达风格来提升表现。这种利用前缀输入激活大模型语言表达建模能力的方式也算是一种学习。
- 这也表明:大模型零监督能力远超预期,毕竟,学习表达形式、语言风格与标签形式,不需要标注数据的参与。大模型潜在具备这种(分类)能力。反过来表明了in-context learning的局限性:不能真正建模输入和输出之间的关系,因此在一些输入输出之间的关系必然没有被无监督预训练任务所建模的下游任务而言,in-context learning很可能失效。不过,目前大多数传统NLP的任务都不会满足上述“失效”设定。
一作 Sewon Min 近期很多相关主题的高质量工作:
- Noisy Channel Language Model Prompting for Few-Shot Text Classification
- MetaICL: Learning to Learn In Context
【2023-5-21】陈丹琦团队最新力作:上下文学习在上下文“学到”了什么?
- 论文:What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
- 代码
- 录取:Findings of ACL 2023
上下文学习究竟在上下文“学到”了什么?
尚无定论
- 一派研究假设预训练期间LLMs就已经隐含地学习了下游应用所需的任务,而上下文演示只是提供信息、使模型识别所需任务而已。
- 另一派则表示,Transformer-based模型可以执行隐式梯度下降以更新“内部模型”,并且上下文学习与显式微调之间具有相似性!脑洞神奇!
根据这两派的观点,这篇文章把ICL分解为任务识别(TR)和任务学习(TL)两个方面,观察ICL背后到底发生了什么。
任务识别(TR,task recognition):表示模型仅通过观察输入分布x和标签分布y, 而不是提供(x,y)对的情况下,识别映射的能力。任务学习(TL,task learning):指从演示(demonstrations)中学习新的输入-标签映射的能力。- 与TR不同,TL允许模型学习新的映射,因此正确的输入标签对至关重要。
一句话概括就是:
- TR通过演示(demonstrations)来识别任务并应用预训练的先验知识,TL学习预训练中没有的新知识;
- TR不受输入-标签映射的影响,但TL要求提供正确的映射
只识别不学习(TR)比学习新映射(TL)更容易。TR可以在小规模上发生,但只有TL会随着模型规模和演示次数的增加而显著改进。
那么如何将TR和TL分开观察呢?
- 作者巧妙地使用了标签空间操作来分离TR和TL,包括三种不同的设置:
- GOLD:使用自然提示和黄金的输入-标签对的标准ICL设置。这种设置同时反映TR和TL。
- RANDOM:使用与GOLD相同的自然提示,从标签空间中均匀随机采样演示标签。这种设置只反映TR机制。
- ABSTRACT:使用最小提示(提供没有任务信息的提示)和没有明确语义含义的字符(例如数字、字母和随机符号)作为每个类的标签,不泄漏任何任务特定的信息。这种设置只反映TL机制。
在4种类型的16个分类数据集上进行实验,包括情感分析、毒性检测、自然语言推理/复述检测和主题/立场分类等分类任务;使用三个最先进的LLM系列,包括GPT 3,LLaMA和OPT.
结果
- 总体趋势上,GOLD在所有模型族和演示数量方面始终表现最好,这是因为GOLD设置为模型提供了所有信息;RANDOM曲线不会随着模型大小或演示数量而增加,保持基本平稳;在模型尺寸较小或演示数量较少时(K = 8),RANDOM和GOLD之间差距非常微小。也就是说,从上下文示例中识别任务(TR)并不会随着模型大小或示例数量的增加而急剧扩展。
ICL 数学原理
【2023-2-24】 Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers,解读
- 清华大学、北京大学和微软的研究人员共同发表了一篇论文,将语言模型解释为元优化器(meta-optimizer),并将ICL理解为一种隐性的(implicit)微调。
- Transformer注意力中存在一个基于梯度下降优化的
对偶形式(dual form),并在此基础上,对ICL的理解如下:- GPT首先根据示范实例产生
元梯度,然后将这些元梯度应用于原始的GPT,建立ICL模型。
- GPT首先根据示范实例产生
- 在实验中,研究人员综合比较了ICL和基于真实任务的显式微调的行为,以提供支持该理解的经验证据。
- 结果证明,ICL在预测层面、表征层面和注意行为层面的表现与显式微调类似。
- 此外,受到元优化理解的启发,通过与基于动量的梯度下降算法的类比,文中还设计了一个基于动量的注意力,比普通的注意力有更好的表现,从另一个方面再次支持了该理解的正确性,也展现了利用该理解对模型做进一步设计的潜力。
ICL可以被解释为一个元优化(meta-optimization)的过程:
- 将基于Transformer的预训练语言模型作为一个元优化器;
- 通过正向计算,根据示范样例计算元梯度;
- 通过注意力机制,将元梯度应用于原始语言模型上,建立一个ICL模型。

ICL与微调有许多共同的属性,主要包括四个方面。
- 都是梯度下降
- ICL和微调都对Wzsl进行了更新,即梯度下降,唯一的区别是,ICL通过正向计算产生元梯度,而finetuning通过反向传播获得真正的梯度。
- 相同的训练信息
- ICL的元梯度是根据示范样例获得的,微调的梯度也是从相同的训练样本中得到的,也就是说,ICL和微调共享相同的训练信息来源。
- 训练样例的因果顺序相同
- ICL和微调共享训练样例的因果顺序,ICL用的是decoder-only Transformers,因此示例中的后续token不会影响到前面的token;而对于微调,由于训练示例的顺序相同,并且只训练一个epoch,所以也可以保证后面的样本对前面的样本没有影响。
- 都作用于注意力
- 与zero-shot学习相比,ICL和微调的直接影响都仅限于注意力中key和value的计算。对于ICL来说,模型参数是不变的,它将示例信息编码为额外的key和value以改变注意力行为;对于微调中引入的限制,训练信息也只能作用到注意力key和value的投影矩阵中。
基于ICL和微调之间的这些共同特性,研究人员认为将ICL理解为一种隐性微调是合理的。
ICL 与 GPT
GPT-3 中Few-shot Learning没有 fine-tune,直接当做 GPT model 的输入,没有调整模型
- Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
- GPT首先根据示范实例产生元梯度,然后将这些元梯度应用于原始的GPT,建立ICL模型。
- ICL在预测层面、表征层面和注意行为层面的表现与显式微调类似。 此外,受到元优化理解的启发,通过与基于动量的梯度下降算法的类比,文中还设计了一个基于动量的注意力,比普通的注意力有更好的表现,从另一个方面再次支持了该理解的正确性,也展现了利用该理解对模型做进一步设计的潜力。
【2023-2-8】In-Context Learning(上下文学习)相关分享
示例讲解
拷贝输出
一个很简单的任务,让模型直接复制输入的内容。
首先示例个数设置为 5个,每个示例输入包含 5 个不同的小写单词(从字母表前 8 个小写字母中随机选5个得到),这些单词用逗号分隔,输出直接拷贝的输入,比如:
Input: g, c, b, h, d
Output: g, c, b, h, d
Input: b, g, d, h, a
Output: b, g, d, h, a
Input: f, c, d, e, h
Output: f, c, d, e, h
Input: c, f, g, h, d
Output: c, f, g, h, d
Input: e, f, b, g, d
Output: e, f, b, g, d
Input: a, b, c, d, e
Output:
期待模型的输出是:
- a, b, c, d, e
接着对于5个字母顺序的所有可能情况 (8!/3!=6720,从8个样本中选5个总的组合数)也就是最后 input 的位置将 6720 个情况都测试了
- GPT-3 模型的准确率是 100%。
- GPT-3 系列最小的模型 text-ada-001 来做这个任务,获得了 6705/6720 = 99.78% 的准确率
一定程度上证明了模型规模的重要性。
格式化日期
复杂一些的任务。
- 对日期做格式化,将 年-月-日 格式的输入格式转化成 !月!日!年!,其中年份四位数,月份和日子是两位数,比如:

- 源自:斯坦福in-context-learning
示例个数是3,最后是待测试的日期:2005-07-23。
为什么选择日期格式化这个任务呢?
- 足够简单,日期包含三个随机变量(年月日),长度固定,而且设定的输出格式也不是正常格式,所以训练数据中不太可能包含类似的样本,也排除了模型可能只是将训练数据都记忆了下来。
接下来看看测试结果
- GPT-3 全系列的模型,包括 text-ada-001,text-babbage-001,text-curie-001 和 text-davinci-003,模型参数量依次从小到大排列。并通过设置不同的上下文示例个数(对于每个示例个数的设置,都有2000个测试样本),记录各个模型的预测准确率,测试结果如下:
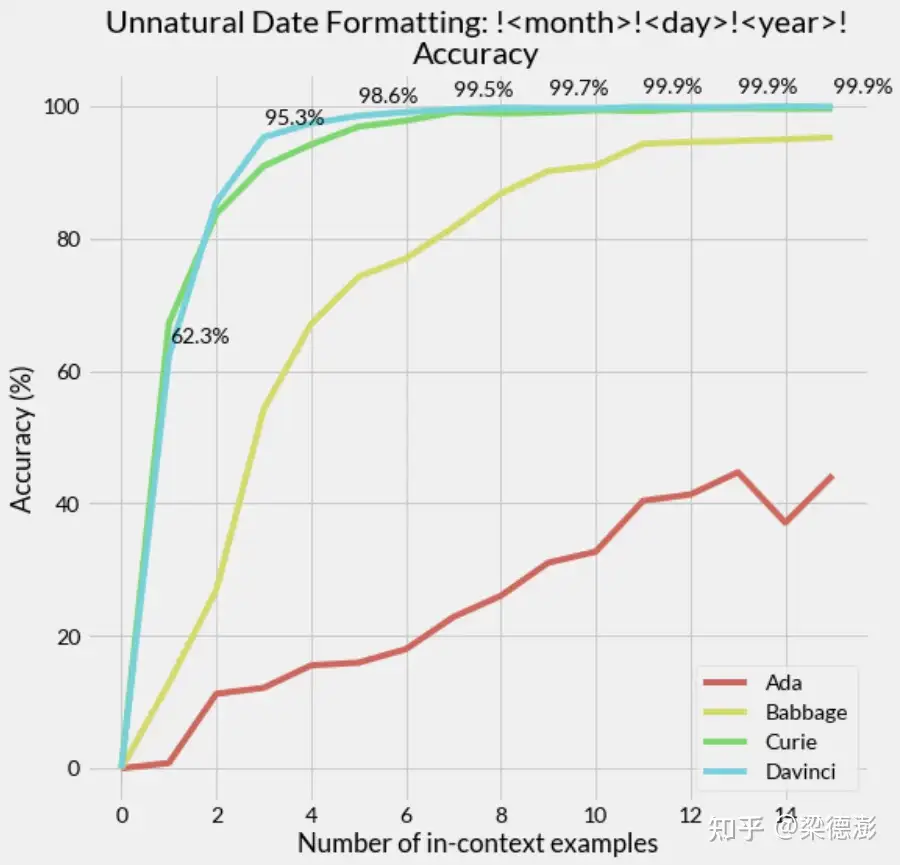
分析:
- 固定横坐标示例个数,则模型越大准确率也越高,模型越大准确率曲线也就更加的陡峭。
- 而对于每个模型来说,增加示例个数也能有效提升准确率。
- 不过,即使增大示例个数和模型,模型的精确度也只是无限接近 100% 但还是达不到。
GPT-3 预测错误的样本都包含哪些类型。
- 随着上下文示例个数的增加,预测错误的样本个数也在下降。
- 2019 年份的输入,模型是最容易预测错误的,这也能理解因为训练数据中 2019 年份的数据不多
标签重映射
任务描述
- 将实体做一个不正常的重新分类
volleyball: animal
onions: sport
broccoli: sport
hockey: animal
kale: sport
beet: sport
golf: animal
horse: plant/vegetable
corn: sport
...
输入示例中包含了 [animal(动物), plant/vegetable(植物/蔬菜), sport(运动)] 三种类型标签。
现在将原来的标签映射打乱,将动物映射为植物(duck: plant/vegetable),将运动映射为动物(golf: animal),将植物映射为运动(beans: sport)。
测试 GPT-3 能否根据仅有的示例学会预测新的映射:GPT-3 能正确输出映射关系。
ICL能力成因
为什么 LLM 能够具备该能力?上下文学习的原理究竟是怎样的呢?
微软研究院发布的文章,对于上下文学习能力来源的探究。
- 论文:Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
- Large pretrained language models have shown surprising In-Context Learning (ICL) ability. With a few demonstration input-label pairs, they can predict the label for an unseen input without additional parameter updates. Despite the great success in performance, the working mechanism of ICL still remains an open problem. In order to better understand how ICL works, this paper explains language models as meta-optimizers and understands ICL as a kind of implicit finetuning. Theoretically, we figure out that the Transformer attention has a dual form of gradient descent based optimization. On top of it, we understand ICL as follows: GPT first produces meta-gradients according to the demonstration examples, and then these meta-gradients are applied to the original GPT to build an ICL model. Experimentally, we comprehensively compare the behavior of ICL and explicit finetuning based on real tasks to provide empirical evidence that supports our understanding. The results prove that ICL behaves similarly to explicit finetuning at the prediction level, the representation level, and the attention behavior level. Further, inspired by our understanding of meta-optimization, we design a momentum-based attention by analogy with the momentum-based gradient descent algorithm. Its consistently better performance over vanilla attention supports our understanding again from another aspect, and more importantly, it shows the potential to utilize our understanding for future model designing.
- 关键在于 LLM 中的
注意力层(attention layers),在推理过程实现了一个隐式参数优化过程,这和 fine-tuning 的时候通过梯度下降法显式优化参数的过程是类似的。
基于梯度下降法的优化过程和注意力层的联系
- 一个线性注意力层其实和基于梯度下降法优化的全连接层是互为对偶的形式
上下文学习怎么实现隐式 finetuning
思维链(CoT:Chain-of-thoughts)
Prompt Engineering
【2023-3-15】翁丽莲(Lilian Weng)Prompt Engineering,中文翻译
Prompt Engineering, also known asIn-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.
Useful Resources
- OpenAI Cookbook has many in-depth examples for how to utilize LLM efficiently.
- LangChain, a library for combining language models with other components to build applications.
- Prompt Engineering Guide repo contains a pretty comprehensive collection of education materials on prompt engineering.
- learnprompting.org
- PromptPerfect
- Semantic Kernel
Zero-shot and few-shot learning are two most basic approaches for prompting the model, pioneered by many LLM papers and commonly used for benchmarking LLM performance.
CoT 介绍
思维链(CoT)是一种改进的 prompt 策略,可以提高 LLM 在复杂推理任务中的表现,如算术推理、常识推理和符号推理。
CoT 不像 ICL 那样简单地用 输入-输出 对 来构建 prompt,而是将能够导致最终输出的中间推理步骤纳入 prompt。
【2023-2-19】思维链(Chain-of-thoughts)作为提示
- “让我们一步步思考。”
- Let’s think step by step
【2023-2-27】Learn Prompting
- 【2023-3-6】CoT一作 Jason Wei的ppt New abilities in big language models,two new abilities of scale 大模型的两项新增能力
- ① Language models follow instructions. 遵从指令
- Finetuned language models are zero-shot learners (ICLR 2022). {J. Wei, M. Bosma, V. Zhao, K. Guu}, A. Yu, B. Lester, N. Du, A. Dai, & Q. Le.
- ② Language models do chain of thought reasoning. 思维链
- Chain of thought prompting elicits reasoning in large language models
- Emergence and reasoning in large language models - Jason Wei (Google),ppt, youtube
Chain-of-thought prompting elicits reasoning in large language models (Wei et al., 2022).
- ○ Self-consistency improves chain-of-thought reasoning in language models (Wang et al., 2022).
- ○ Least-to-most prompting enables complex reasoning in large language models (Zhou et al., 2022).
- ○ Language models are multilingual chain-of-thought reasoners (Shi et al., 2022).
-
○ Challenging BIG-Bench tasks and whether chain-of-thought can solve them (Suzgun et al., 2022).
- 作者GitHub上的chain-of-thought-zip
- 【2023-3-18】思维链论文集锦:Chain-of-ThoughtsPapers
2022年5月,谷歌年度开发者大会(Google I/O)上对CoT技术进行了宣传,还有谷歌的540B系数大模型PaLM和Pixel系列手机手表等等。

思维链的主要思想是通过向大语言模型展示一些少量的 exemplars,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
思维链提示过程 Wei等人
- “思维链仅在使用∼100B参数的模型时才会产生性能提升”。
较小的模型编写了不合逻辑的思维链会导致精度比标准提示更差。
思维链(CoT)提示过程 是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程

- 常规提示过程 vs 思维链提示过程
思维链已被证明对于算术、常识和符号推理等任务的结果有所改进。
- 特别是,在GSM8K2基准测试上,PaLM 540B3的提示达到了57%的解决率准确性。

CoT 诞生背景
2021年,提示学习(prompt learning)浪潮兴起,以离散式提示学习(提示词的组合)为起点,连续化提示学习(冻结大模型权重+微调较小参数达到等价性能)为复兴,几乎是在年末达到了研究的一个巅峰。
2022年开始,逐渐有很多人意识到: 连续化提示学习其中的一些好处伴随的一些局限性,比如伪资源节约,不稳定等等。很多研究者拒绝陪玩,虽认同提示学习将会带来下一代NLP界的革命,但是认为拒绝做他人大模型的附庸,开始探索大模型的训练技术,并且训练自己的大模型;而手头暂时没有掌握资源的研究者开始再次将研究重心从连续化学习转移到离散式提示学习上去,将研究聚焦于特定的大模型GPT3上。
此时,距离175B的GPT3模型被发布和上下文学习被发现过去了不到2年,热度经历了高潮与低谷,经历了深度学习流派关于连接学派和符号学派的辩论和是否具有意识和推理能力的讨论,一些基础的玩法在被开发之后就被搁置了一段时间直到提示学习的兴起。
2022年1月,OpenAI通过强化学习调试模型,使用强化学习调试更新了他们的模型到了第二代,LLM肉眼可见地变得更好提示,很多任务的性能也显著提升,尤其是一些之前没有办法很好进行的任务被显著地提高了起来。
思维链系列工作就是在这样一个大环境下产生的。
CoT 提出
【2022-1-28】 谷歌大脑研究员Jason Wei放到arxiv上面的文章,提出了思维链这个概念。
- 论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- 2023年2月15日,一作Jason Wei,twitter,github, personal page, 离开Google Brain,加入OpenAI
- 2020年,达特茅斯本科毕业的ABC,I graduated with an AB from Dartmouth College in 2020.

We explore how generating a chain of thought (
CoT) – a series of intermediate reasoning steps – significantly improves the ability of large language models (LLM) to perform complex reasoning (复杂推理).
- In particular, we show how such reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain of thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting.
- Experiments on three large language models show that chain of thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains can be striking. For instance, prompting a 540B-parameter language model with just eight chain of thought exemplars achieves state of the art accuracy on the GSM8K benchmark of math word problems, surpassing even finetuned GPT-3 with a verifier.
思维链是一种离散式提示学习
- 大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习,即通过 x1,y1,x2,y2,….x_test 作为输入来让大模型补全输出 y_test,思维链多了中间的一些闲言碎语絮絮叨叨,以下面这张图为例子

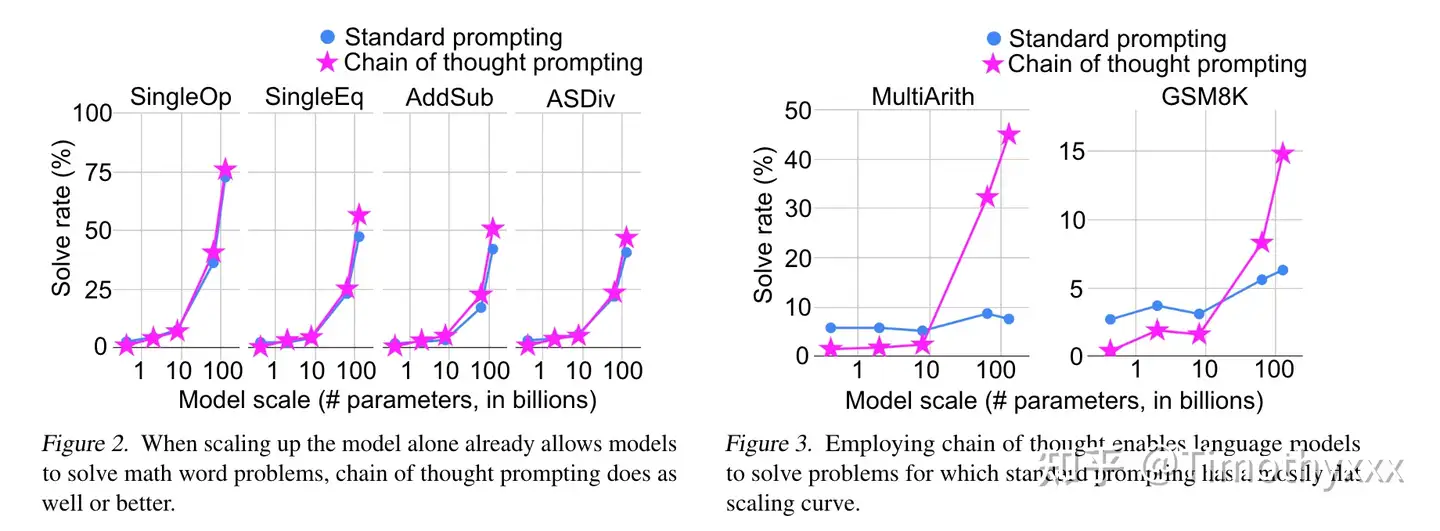
例子选择自一个数据集叫GSM8K,每一个样例大概就是一个小学一二年级的看几句话(基本都是三句)写算式然后算答案的难度,但是GPT-3通过刚刚说的最简单的提示方法曾经只能在这个数据集上做到6%左右的准确度。
- 由此可见,直接预测y不太可行。
思维链的絮絮叨叨,即不直接预测y,而是将y的“思维过程”r(学术上统称为relationale)也要预测出来。当然最后不需要这些“思维过程”,这些只是用来提示,获得更好的答案,只选择最后的答案即可。作者对不同的数据集的原本用于上下文学习的提示标注了这些思维链然后跑了实验,发现这么做能够显著提升性能(左图),且这种性能的提升是具有类似于井喷性质(右图)的(后来称这种性质叫涌现性)。
Zero-shot 小样本思维链
Zero-shot learning is to simply feed the task text to the model and ask for results
- 零样本提示直接输入任务指令,让模型产出
Text: I will bet the video game is a lot more fun than the film.
Sentiment:
Few-shot 零样本思维链
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. Few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when input and output text are long.
Text: (lawrence bounces) all over the stage, dancing, running, sweating, mopping his face and generally displaying the wacky talent that brought him fame in the first place.
Sentiment: positive
Text: despite all evidence to the contrary, this clunker has somehow managed to pose as an actual feature movie, the kind that charges full admission and gets hyped on tv and purports to amuse small children and ostensible adults.
Sentiment: negative
Text: for the first time in years, de niro digs deep emotionally, perhaps because he has been stirred by the powerful work of his co-stars.
Sentiment: positive
Text: I will bet the video game is a lot more fun than the film.
Sentiment:
- 小样本提示则提供少量高质量示例(包含输入、期望输出),让模型参考学习,再回答任务指令
- 因此,小样本提示效果比零样本好,但可能导致提示语超限。
Many studies looked into how to construct in-context examples to maximize the performance and observed that choice of prompt format, training examples, and the order of the examples can lead to dramatically different performance, from near random guess to near SoTA
- 如何构建好的语境示例,效果最大化?研究人员发现 prompt形式、训练样本集、样本顺序会导致效果不同。
导致不同提示下模型性能高方差的三个原因:
- 如果选用的示例的标签分布不平衡,则存在多数标签偏差(Majority bias)
- 模型更倾向于最后一个所见到的标签,近频偏差(Recency bias)
- 相比罕见词,大语言模型倾向于使用常见词,常见词偏差(Common token bias)
如何选择样本示例?tips-for-example-selectio
- 选择跟测试样本相近的示例,如在嵌入空间中用k-NN聚类算法挑选
- 选择多样性、代表性好的示例
- 使用对比学习训练嵌入矩阵
- 使用 Q-Learning 选择样本
- 借鉴主动学习思路
如何设置示例样本顺序?Tips for Example Ordering
- 随机:防止大类偏差、近因效应
- 保持多样性、(与测试样本的)相关性和随机性,以避免多数标签偏差和近频偏差。
- 使用大模型、更多训练样本并不会降低顺序带来的方差
CoT 原理
如何生成CoT提示?
【2023-3-24】Automatic Chain of Thought Prompting in Large Language Models
- 思维链有两种范例
- ① 用 “让我们一步步思考” 来辅助LLM回答问题时逐步思考
- ② 一系列人工示例,每个示例由 $< 问题, 推理链 >$ 组成
Providing intermediate reasoning steps for prompting demonstrations is called chain-of-thought (CoT) prompting. CoT prompting has two major paradigms.
- One leverages a simple prompt like “Let’s think step by step” to facilitate step-by-step thinking before answering a question.
- The other uses a few manual demonstrations one by one, each composed of a question and a reasoning chain that leads to an answer.
The superior performance of the second paradigm hinges on the hand-crafting of task-specific demonstrations one by one. We show that such manual efforts may be eliminated by leveraging LLMs with the “Let’s think step by step” prompt to generate reasoning chains for demonstrations one by one, i.e., let’s think not just step by step, but also one by one. However, these generated chains often come with mistakes.
To mitigate the effect of such mistakes, we find that diversity matters for automatically constructing demonstrations. We propose an automatic CoT prompting method: Auto-CoT. It samples questions with diversity and generates reasoning chains to construct demonstrations. On ten public benchmark reasoning tasks with GPT-3, Auto-CoT consistently matches or exceeds the performance of the CoT paradigm that requires manual designs of demonstrations.
CoT 类型
Two main types of CoT prompting:
- Zero-shot CoT. Use natural language statement like
Let's think step by stepto explicitly encourage the model to first generate reasoning chains and then to prompt withTherefore, the answer isto produce answers (Kojima et al. 2022 ). Or a similar statementLet's work this out it a step by step to be sure we have the right answer(Zhou et al. 2022). - Few-shot CoT. It is to prompt the model with a few demonstrations, each containing manually written (or model-generated) high-quality reasoning chains.
Zero-shot CoT
零样本CoT
- 显示植入提示语:Let’s think step by step (让我们一步步思考)
- 鼓励模型先生成推理链,再通过前缀 Therefore, the answer is(所以,答案是)来作答
- 或者使用提示语:Let’s work this out it a step by step to be sure we have the right answer (让我们逐步解答这个问题,以确保得到正确答案)
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer: Let's think step by step.
零样本思维链(Zero Shot Chain of Thought,Zero-shot-CoT)提示过程 是对 CoT prompting 的后续研究,它引入一种非常简单的零样本提示。
- 在问题结尾附加“让我们一步步思考</span>。” 这几个词,大语言模型能够生成一个回答问题的思维链。
- 从这个思维链中,他们能够提取更准确的答案。

从技术上讲,完整的零样本思维链过程涉及两个单独的提示/补全结果。下图中,左侧顶部气泡生成一个思维链,而右侧顶部气泡接收来自第一个提示(包括第一个提示本身)的输出,并从思维链中提取答案。这个第二个提示是一个 自我增强 的提示。

结论
- 零样本思维链也有效地改善了算术、常识和符号推理任务的结果。然而,通常不如思维链提示过程有效。在获取思维链提示的少量示例有困难的时候,零样本思维链可以派上用场。
CoT 使用 few shot 让 llm 说出来 CoT ,然后得到答案,分成两部分:
- 首先, 加一个“Lets think step by step</span>”,得到一个CoT的 murmur
- 然后, 后面接上一句“so the anwser is”,然后得到答案。
性能远超原来的zero shot逼近few shot和CoT的few shot性能。
深呼吸
【2023-9-9】大模型靠“深呼吸”数学再涨8分!AI自己设计提示词效果胜人类
- 谷歌 DeepMind 团队最新发现,用新“咒语” “深呼吸”(Take a deep breath)结合熟悉的“一步一步地想”(Let’s think step by step),大模型在GSM8K数据集上的成绩就从71.8提高到80.2分。
- 论文: Large Language Models as optimizers
- 大模型自己设计的提示词在Big-Bench Hard数据集上最高提升50%
- 不同模型的最佳提示词不一样
- 不光不同模型设计出的提示词风格不同,适用的提示词风格也不同
- GPT系列: AI设计出的最优提示词是“
Let’s work this out in a step by step way to be sure we have the right answer.”- 这个提示词使用APE方法设计,ICLR 2023 论文,在GPT-3(text-davinci-002)上超过人类设计的版本“
Let’s think step by step”。
- 这个提示词使用APE方法设计,ICLR 2023 论文,在GPT-3(text-davinci-002)上超过人类设计的版本“
- 谷歌系PaLM 2和Bard上,
APE版本作为基线就还不如人类版本。OPRO方法设计de新提示词中,“深呼吸”和“拆解这个问题”对PaLM来说效果最好。对text-bison版的Bard大模型来说,则更倾向于详细的提示词。
- 论文还测试了大模型在
线性回归(连续优化)和旅行商问题(离散优化)这些经典优化任务上的能力。- 大模型还无法替代传统基于梯度的优化算法,当问题规模较大(如节点数量较多的旅行商问题)时,OPRO方法表现就不好
- 大量实验中得到最优提示词包括: 电影推荐、恶搞电影名字等实用场景
而且这个最有效提示词是AI找出来的
优化问题无处不在,一般用基于导数和梯度的算法,但经常遇到梯度不适用的情况。
于是, 团队开发了新方法OPRO,也就是通过提示词优化(Optimization by PROmpting)。不是形式化定义优化问题然后用程序求解,而是用自然语言描述优化问题,并要求大模型生成新的解决方案。一张图总结,对大模型的一种递归调用。
- 每步优化中,之前生成的解决方案和评分作为输入,大模型生成新的方案并评分,再将其添加到提示词中,供下一步优化使用。
- 谷歌的
PaLM 2和Bard中的text-bison版本作为评测模型, 再加上GPT-3.5和GPT-4,共4种模型作为优化器。
方向
- 结合关于错误案例的更丰富的反馈,并总结优化轨迹中高质量和低质量生成提示的关键特征差异。这些信息可能帮助优化器模型更高效地改进过去生成的提示,并可能进一步减少提示优化所需的样本数量。
Few-shot CoT
少样本CoT
- 补充少量高质量推理链示例
Question: Tom and Elizabeth have a competition to climb a hill. Elizabeth takes 30 minutes to climb the hill. Tom takes four times as long as Elizabeth does to climb the hill. How many hours does it take Tom to climb up the hill?
Answer: It takes Tom 30*4 = <<30*4=120>>120 minutes to climb the hill.
It takes Tom 120/60 = <<120/60=2>>2 hours to climb the hill.
So the answer is 2.
===
Question: Jack is a soccer player. He needs to buy two pairs of socks and a pair of soccer shoes. Each pair of socks cost $9.50, and the shoes cost $92. Jack has $40. How much more money does Jack need?
Answer: The total cost of two pairs of socks is $9.50 x 2 = $<<9.5*2=19>>19.
The total cost of the socks and the shoes is $19 + $92 = $<<19+92=111>>111.
Jack need $111 - $40 = $<<111-40=71>>71 more.
So the answer is 71.
===
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer:
Manual-CoT 人工设计
Manual-CoT:
- 人工设计演示, 通过few-shot prompt的形式提示LLM.
Manual-CoT 方法比 Zero-Shot-CoT 更有效,但Manual-CoT的方法需要手动设计大量的演示。
CoT 不足
思维链的应用领域有限
- (1)思维链必须在模型规模足够大时才能涌现
- Jason Wei 等的研究中,PaLM 在扩展到 540B 参数时,与思维链提示结合,才表现出了先进的性能。一些小规模模型,思维链并没有太大的影响,能力提升也不会很大。
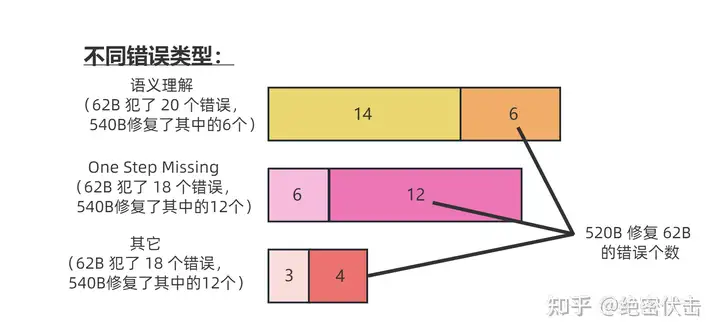
- 思维链必须要探索如何在较小的模型中进行推理,降低实际应用的成本。
- (2)思维链只是在一些有限领域,比如数学问题,五个常识推理基准(CommonsenseQA,StrategyQA,Date Understanding 和 Sports Understanding 以及 SayCan)上显现出作用,其他类型的任务,像是机器翻译,性能提升效果还有待评估。
- (3)即使有思维链提示,大语言模型依然不能解决小学水平的数学问题
- 没有思维链,数学推理是指定不行。但有了思维链,大语言模型也可能出现错误推理,尤其是非常简单的计算错误。Jason Wei 等的论文中,曾展示过在 GSM8K 的一个子集中,大语言模型出现了 8% 的计算错误,比如6 * 13 = 68(正确答案是78)。
- 即使有了思维链,大语言模型还是没有真正理解数学逻辑,不知道加减乘除的真实意义,只是通过更精细的叠加来“照葫芦画瓢
详见原文
CoT 改进
【2023-7-13】推理链CoT系列
【2024-5-17】思维链不存在了?纽约大学最新研究:推理步骤可省略
CoT 演进
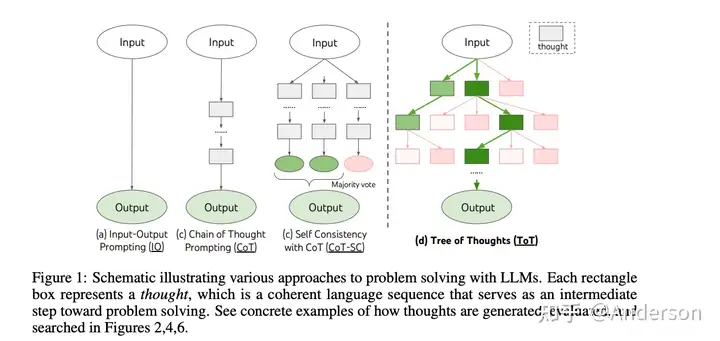
演进
- IO、CoT、CoT-SC、ToT
zero-shot 和 few-shot,从Prompt形式来看,可以分为四种:
- 【IO】Input-Output Prompting
- 【CoT】Chain of Thought Prompting
- 【CoT-SC】Self Consistency with CoT
- 【ToT】Tree of Thoughts
总结
总结:见原文
- 1、在LLM时代做好prompt的设计也是一种贡献,但是设计背后的核心思想需要有意义且有新意,而且往往需要大量工程上的尝试和验证
- 2、利用LLM生成更高质量reasoning chains的技巧:
- 要求模型先将原问题分解
- 调大LLM decoding的temperature参数以生成更多reasoning paths,采用投票的方式选出最佳的path
- 给出一些demonstrations(“Few-Shot-CoT” rather than “Zero-Shot-CoT”)
- 选择更“好”的exemplars:diversity-based,uncertainty-based
- 3、利用中小模型做reasoning:
- 小模型常识知识、逻辑能力欠缺,不适合直接用于推理
- LLM可以为小模型提供外源知识,也可以通过蒸馏的方式将LLM的CoT能力赋予小模型
- 在用大模型生成的rationales训小模型时,rationales的质量和数量都很重要
- 保证质量的方法:answer filtering
- 保证数量的方法:rationalization,diverse reasoning
- 4、Chain-of-thought来源于NLP reasoning任务,但可以应用到更广泛的领域
总结
- 前文提到的一致性采样+多数投票法也能提高思维链推理的准确性
- 用集成学习(比如改变示例顺序、使用模型生成的提示示例来代替人工编写的提示)来引入随机性,以替代一致性采样。集成学习生成的结果同样可以使用多数投票法寻找最优解。
- Zelikman et al. 2022提出了Self-Taught Reasoner方法,用于训练集中只有答案、没有详细推理步骤的情形。具体方法是(1)让 大语言模型自动生成推理过程,同时只保留生成了正确答案的过程(如果连标准答案也没有,可以采用多数投票法选择出”正确“的答案)。(2)在第一步生成的伪数据上做精调,直到模型收敛。
- Fu et al. 2023发现思维链的步骤越详尽、推理步骤越多时,模型的性能越好。分隔思维链的推理步骤时,用换行符
\n要比句号、分号和数字编号要更有效。 - Fu et al. 2023还设计了基于思维链复杂性的采样投票法。更复杂思维链作为提示时,模型生成的结果会更加置信。
- Shum et al. (2023)发现在他们的实验中,复杂的思维链只能提升复杂推理任务的准确性,但对简单问题效果不好。
- Ye & Durrett (2022)发现,对于涉及文本推理的 NLP 任务(比如 问答 和 推断),思维链的效果因模型而异。他们还观察到模型更有可能生成一些非事实性的解释、同时这些非事实性的解释又导致模型做不正确的预测。
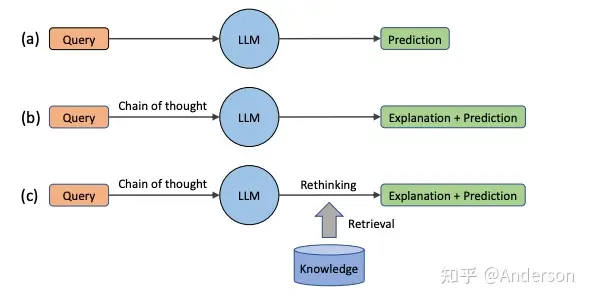
- Press et al. 2022、Trivedi et al. 2022、Yao et al. 2023等工作引入了搜索引擎或者维基百科API来作为外部知识,辅助模型迭代构建思维链。简单流程见下图:

论文
论文图谱 Connected Papers
- (1) 多数投票(自一致性)显著提高CoT性能: 不用原生的贪心解码
- (2) 提出了一种boost方法,让中小模型也可以通过训练具有思维链能力
- 2022年5月20日, 斯坦福+谷歌, STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
- 问题: cot 要么依赖大量推理数据集,要么使用小样本推理牺牲准确率
- 方案: 在大规模数据集(非推理)上迭代使用少量推理样例,来提升复杂推理能力,”Self-Taught Reasoner” (STaR)
- (3) Zero-Shot 推理
- 【2023-1-29】东京大学+谷歌, Large Language Models are Zero-Shot Reasoners
- Zero-shot-CoT: 主需要再answer前面增加“Let’s do it step by step“,就可以激活LLM的零样本学习能力
- (4) Least-to-Most Prompting
- 【2023-4-16】谷歌大脑,Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
- 问题:cot在回答困难(相对于prompt里的示例)问题时容易出错
- 解法:将复杂问题拆解成多个更简单的子问题,顺序解答,充分利用上一个解答的问题
- 效果:16% 提升到 99%
- On the Advance of Making Language Models Better Reasoners
- Rationale-Augmented Ensembles in Language Models
自洽性 (一致性采样)
自洽性: 多数投票显著提高CoT性能
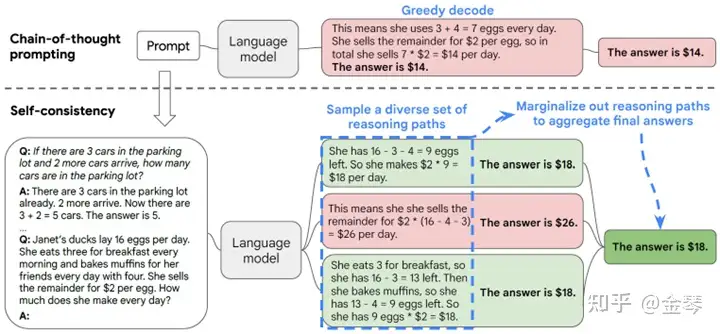
自洽性(Self-consistency)(或:一致性采样)是对 CoT 的补充,它生成多个思路链,然后取多数答案作为最终答案。
- 自我一致性旨在改进思维链提示中所使用的合理性解码。
- 通过调节温度等随机采用策略来让模型输出多种结果作为候选,然后在候选中择优作为最终的输出。
- 通过少量的CoT对多个不同的推理路径进行取样,并利用这些代数来选择最一致的答案,这有助于提高CoT提示在涉及算术和常识性推理的任务中的表现。
- 常见方法:多数投票法(即选择多次采样结果中最常见者作为最终答案
下图中,左侧提示是使用少样本思路链范例编写的。使用这个提示,独立生成多个思路链,从每个思路链中提取答案,通过“边缘化推理路径”来计算最终答案。实际上,这意味着取多数答案。

Self-consistency sampling (Wang et al. 2022a) is to sample multiple outputs with temperature > 0 and then selecting the best one out of these candidates. The criteria for selecting the best candidate can vary from task to task. A general solution is to pick majority vote. For tasks that are easy to validate such as a programming question with unit tests, we can simply run through the interpreter and verify the correctness with unit tests.
2022年3月在arxiv上放出来
- 论文:Self-Consistency Improves Chain of Thought Reasoning in Language Models
- 改进思维链解码效率:新的解码策略(自一致性)替换原生的贪心解码
- 类似于self-ensemble的思想,即对于某个要求解的问题,不再使用greedy decoding,而是让LLM生成多条不同的推理链,最后再对同一问题下所有推理链得到的结果做最大投票,作为模型最终的预测结果。
- 对于同一问题生成更多的推理链以供投票往往能取得更好的效果。当推理链数量足够多时,这种方法效果能够胜过使用greedy decoding的CoT方法
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-of-thought prompting.
- It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths.
- Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer.
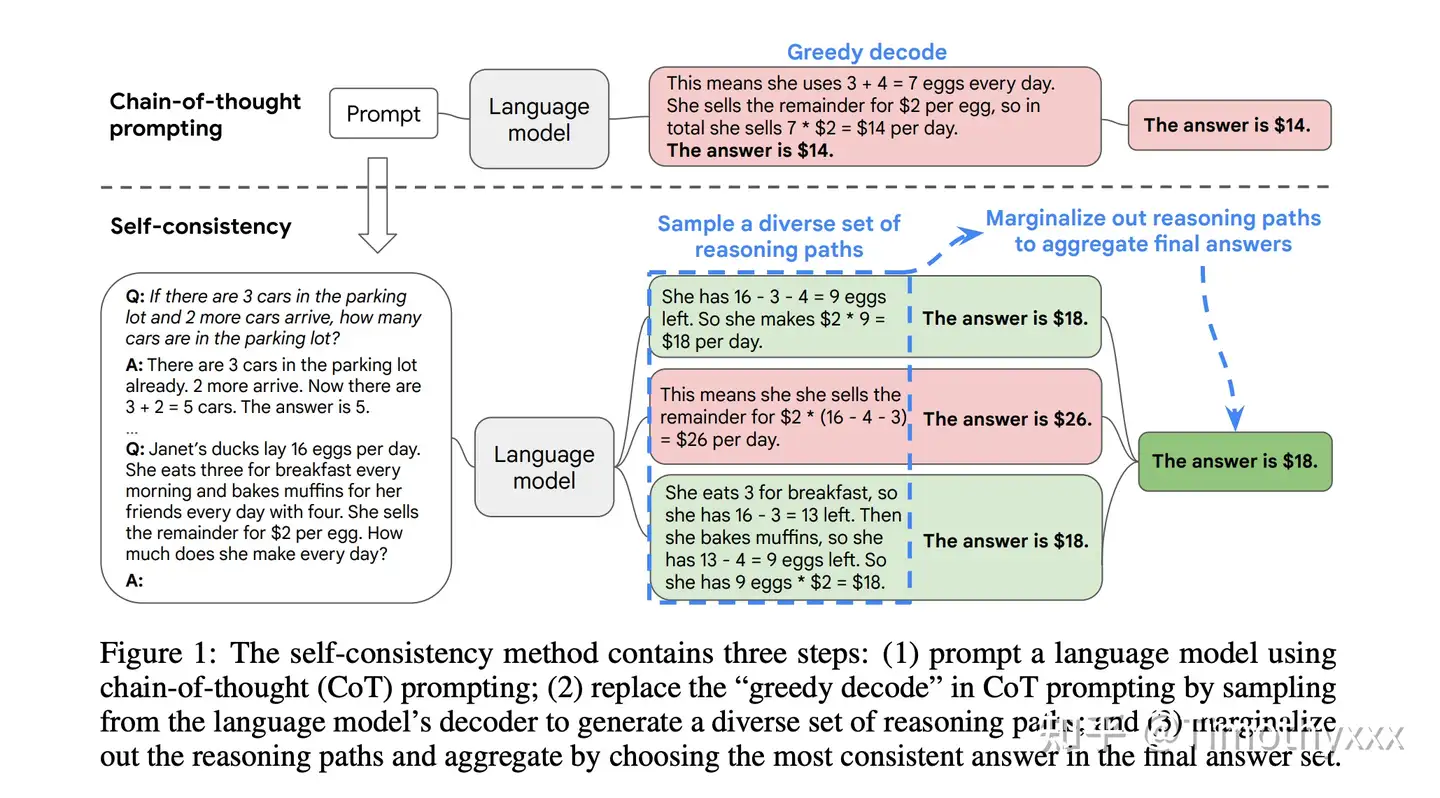
- Our extensive empirical evaluation shows that self-consistency boosts the performance of chain-of-thought prompting with a striking margin on a range of popular arithmetic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%).
思维链初代文章很快的一个跟进工作,是思维链系列文章版图的重要一步。
- 这篇文章几乎用的和初代思维链文章完全一样的数据集和设置,主要改进是使用了对答案进行了多数投票(majority vote),并且发现其可以显著地提高思维链方法的性能。
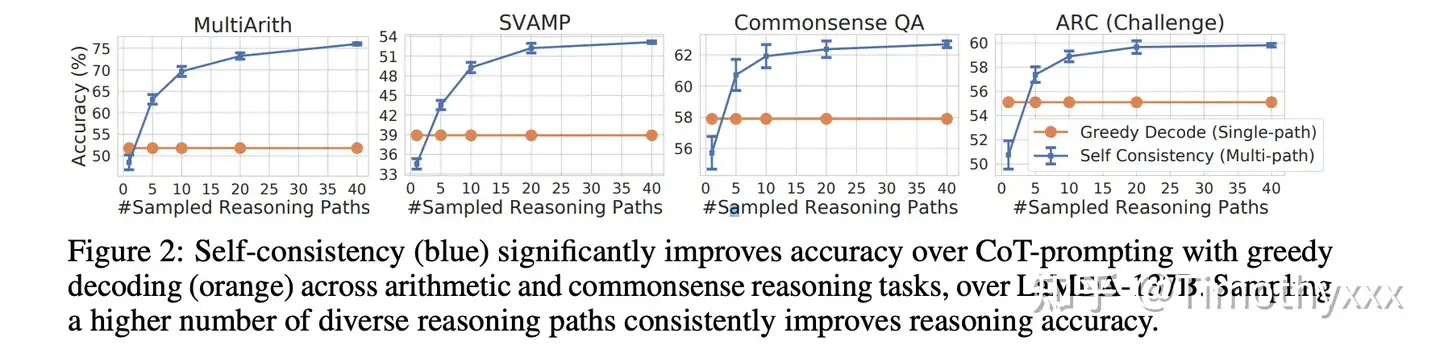
- 将 greedy search 变成了 sample+vote
- 一开始不如cot(因为temperature),后面大幅度超过
- 将
贪婪搜索(greedy search),即将GPT模型的 temperature 从0设置为某个数值,比如说0.4,然后sample多个按照y进行投票,会显著地提升性能
实验
- 对于同一问题生成更多的推理链以供投票往往能取得更好的效果。当推理链数量足够多时,这种方法效果能够胜过使用greedy decoding的CoT方法。
结论
- 自洽性可以提高算术、常识和符号推理任务的结果。
- 即使普通的思路链提示被发现无效2,自洽性仍然能够改善结果。
改进: DiVeRSe
(DiVeRSe) On the Advance of Making Language Models Better Reasoners
Self-Consistency的基础上,进一步做了几点优化:
- Diverse Prompts:在few-shot prompt的设置下,为每个要解决的目标问题提供 $M_1$ 种不同的prompts(即使用 $M_1$ 种不同的exemplars作为prompt),同时在每种prompts下让LLM生成M_2条推理链。即对于同一问题,共生成 $M_1 * M_2$ 条推理链
- 训练一个verifier用来判断每条推理链得出的答案正确与否,并将verifier的判断与最大投票的结果相结合用于得到模型的最终预测。
- 上述的verifier不仅考虑到最终答案是否正确,还考虑到了对于推理链中每一步是否正确的验证。
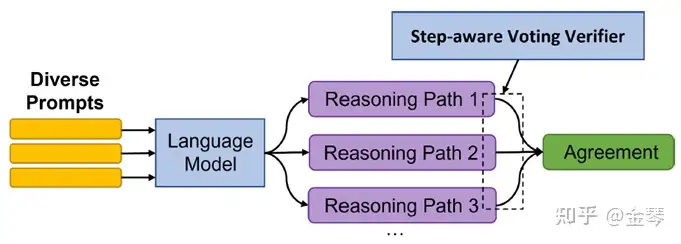
这种方法的效果胜过了基于greedy decoding的CoT方法以及上面的Self-Consistency方法。
Auto CoT – 基于多样性选择示例
【2023-10-7】为了缓解手动设计的困难,Auto-CoT 方法自动构建具有questions和reasons chains的演示。
- 自动化构建大模型的演示(Auto-CoT)
- 论文 A(Auto-CoT) Automatic Chain of Thought Prompting in Large Language Models
- 代码 auto-cot
选择更适当的问题作为exemplars
在Few-Shot-CoT的做法中,能够省去人工选取示例问题并撰写推理链的过程,而是自动选取可作为示例的问题, 并自动生成推理链作为prompt。但自动生成的推理链质量一般都是会比手写的差,需要尽可能选出更适合作为exemplars的问题,弥补这一点不足。
探索发现,exemplars的“diversity”是构建Few-Shot-CoT prompt时很重要的一点因素。作为exemplars的几个问题样本之间在语义上越不相似,组合起来作为prompt对于模型推理的帮助就越大。因此作者设计了两阶段做法。
- 第一阶段,用Sentence-BERT编码训练集中所有问题的句向量,接下来采用聚类的方式将所有问题聚成多个簇,分别从每个簇中选出一个问题共同作为exemplars,就保证了它们之间足够diverse。
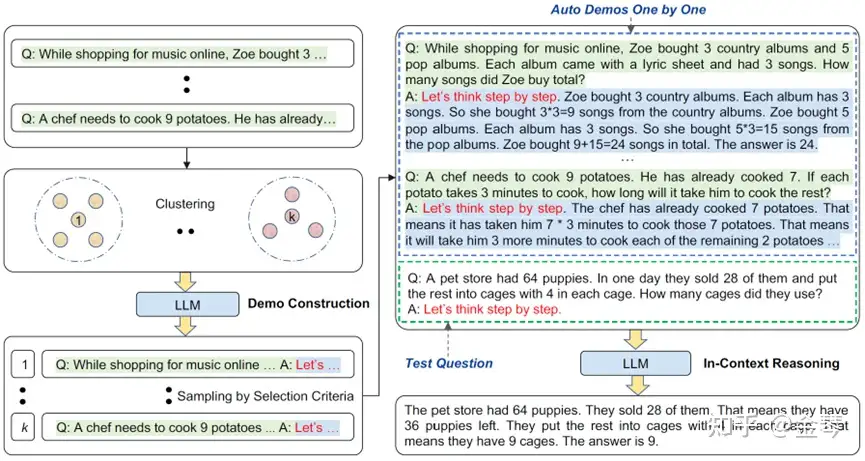
实验发现,这样的做法在多个推理任务的benchmark上效果能够超过基于人工标注exemplars的Few-Shot-CoT方法。消融实验中也发现,即便exemplars中很多推理链导向了错误的答案,只要保证问题本身足够diverse,这种错误带来的负面影响也能得到很大程度的缓解。
Auto-CoT 能够达到甚至超过手工设计的演示效果
- Auto-CoT 使用“Let’s think step by step”的提示来生成演示的reasoning chains.。但直接使用Zero-Shot-CoT的方式生成的答案会存在错误。
- 为了缓解reasoning chain mistakes带来的影响,演示的questions的丰富程度是核心。
Auto-CoT主要包括两个步骤:
- question clustering(问题聚类) : k-means算法将questions聚成k个簇,对于每个簇,将其中的question按照与簇中心的距离排序。
- demonstration sampling(演示采样) : 对于每一个簇,选择代表性的问题,通过Zero-Shot-CoT的方式生成reasoning chain,构建对应的演示.
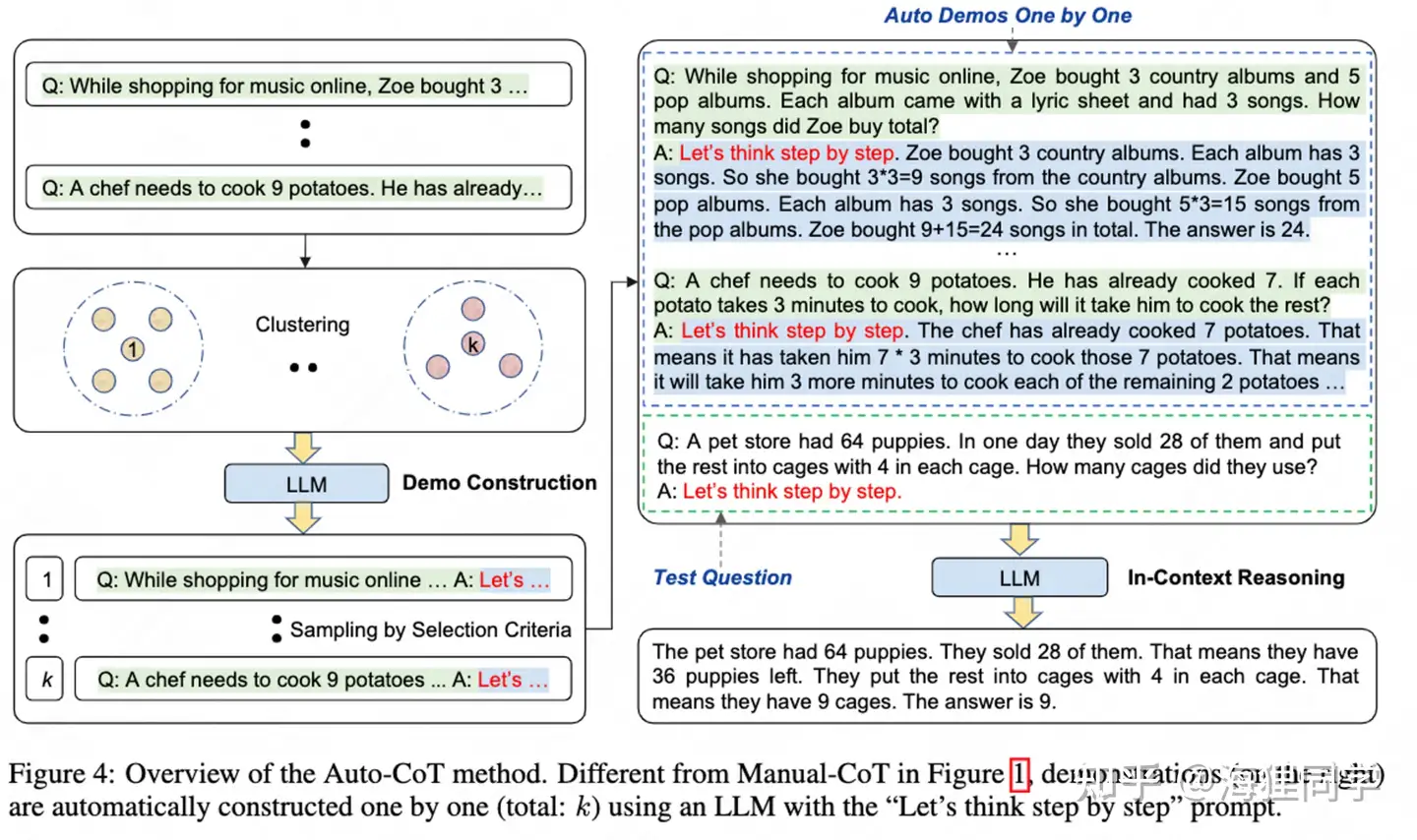
Auto-CoT 的 关键挑战在于自动化地构建具有good questions和对应reasoning chains的演示.
作者设计了Retrieval-Q-CoT和Random-Q-CoT两种方法来验证结论。
- 背后使用GPT-3模型
代码
- 返回结果见 try_cot.ipynb
import sys
sys.argv=['']
del sys
from api import cot
question = "There were 10 friends playing a video game online when 7 players quit. If each player left had 8 lives, how many lives did they have total?"
print("Example: Zero-Shot")
# To use GPT-3, please add your openai-api key in utils.py (#Line 59)
# method = ["zero_shot", "zero_shot_cot", "manual_cot", "auto_cot"]
cot(method="zero_shot", question=question)
# 零样本 cot
print("Example: Zero-Shot-CoT")
cot(method="zero_shot_cot", question=question)
# 手工 cot
question = "In a video game, each enemy defeated gives you 7 points. If a level has 11 enemies total and you destroy all but 8 of them, how many points would you earn?"
print("Example: Manual-CoT")
cot(method="manual_cot", question=question)
question = "In a video game, each enemy defeated gives you 7 points. If a level has 11 enemies total and you destroy all but 8 of them, how many points would you earn?"
print("Example: Auto-CoT")
cot(method="auto_cot", question=question)
改进: Active Prompt
改进:
- (Active Prompt) Active Prompting with Chain-of-Thought for Large Language Models
上篇基于“diversity”选择问题作为exemplars,而本文则是尽可能选择那些会让模型的生成结果足够“uncertain”的问题用作exemplars。
- 首先会让LLM对于训练集中的每个问题生成多条推理链,随后根据这些推理链计算出一个对应于该问题的“uncertainty”值。对于这些选出的问题,人工标注推理链,并作为prompt中的demonstrations部分,能够取得不错的效果。

不过作者发现,对于这些“uncertain”的问题如果采用自动生成推理链的方式则效果较差。
最少到最多提示过程 Least to Most prompting – 问题分解
(Least-to-most Prompting) Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
有时对于较为复杂的问题,显式地要求LLM对问题做分解往往能帮助模型进行更有效的推理。本文方法分成两个阶段
- 第一个阶段,输入的prompt会要求LLM对于原问题给出分解后的子问题序列,或给出首先需要解决的子问题。
- 第二阶段,会要求LLM逐步解决每个子问题。其中每一步的输入会包含前面已经回答过的子问题及其答案,要求LLM输出当前子问题的答案。
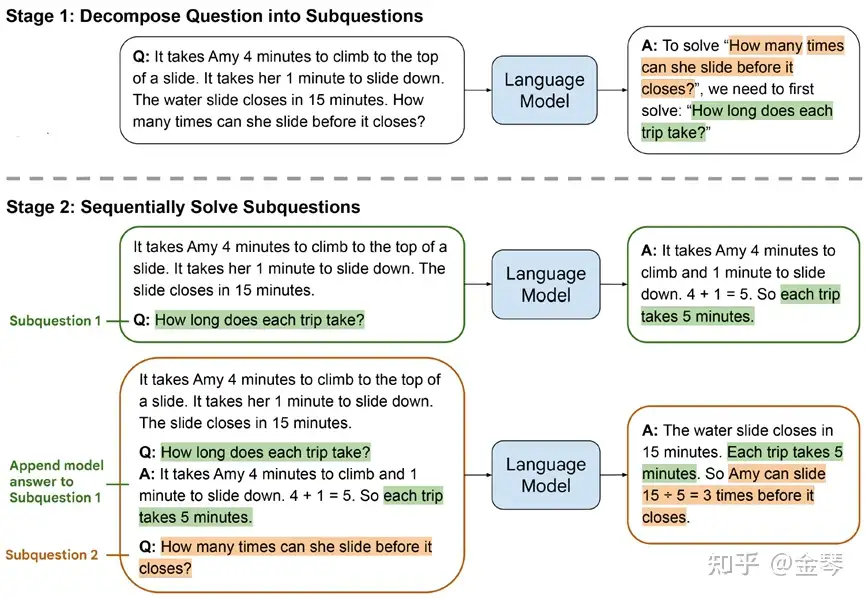
最少到最多提示过程 (Least to Most prompting, LtM) 将 思维链提示过程 (CoT prompting) 进一步发展
- 首先将问题分解为子问题,然后逐个解决。
受针对儿童的现实教育策略的启发, 发展出的一种技术。
与思维链提示过程类似,需要解决的问题被分解成一组建立在彼此之上的子问题。
- 在第二步中,这些子问题被逐个解决。
- 与思维链不同的是,先前子问题的解决方案被输入到提示中,以尝试解决下一个问题。

结论: LtM 带来了多项提升:
- 相对于思维链提高了准确性
- 在难度高于提示的问题上提升了泛化能力
- 在组合泛化方面的性能得到了显著提高,特别是在SCAN基准测试3中
- 使用 text-davinci-002(论文模型)的标准提示解决了 6% 的 SCAN 问题,而 LtM 提示则取得了惊人的 76% 的成功率。在 code-davinci-002 中,结果更为显著,LtM 达到了 99.7% 的成功率。
CoT应用于中小模型
重要结论
CoT能力只在约100B以上参数规模模型上能够得到充分体现。
然而大模型的使用会受到很多限制,例如使用需要付费,且只能通过接口调用的形式,无法针对特定的任务进行微调。
如何能够将CoT的思想应用于中小模型解决推理相关任务?
知识注入
LLM模型静态知识目前在完整性,时效性和真实性还存在缺陷,一般需要外部知识作为辅助。但是当前外部知识的使用方法需要额外训练或者微调,对大规模语言模型而言成本较高,不太可行。
LLM自身的知识比较有限,面临时效性和真实性问题,一般需要外部知识辅助才能投入实际使用
- 通过检索增强语言模型: 生成检索query, 借助搜索引擎查询检索相关文档,或者利用检索到的文档作为context作生成任务,或者基于人类反馈构建网页浏览环境,重点将外部知识作为语言模型效果提升工具
- 结合外部知识到语言模型: 将外部知识源, 比如WordNet, ConceptNet, Wikidata 作为显示知识和LLM隐式知识结合来做推理或问答,重点在利用外部知识提高 LM 的推理能力
- 外部知识辅助方法一般涉及微调或者额外训练
- 发掘LLM的潜在知识:主要指探索LLM在推理时隐藏的知识。
Failthful
2022 Tencent AI Lab, Cot系列-Failthful, 论文讲解
- 一种后处理方法RR,从推理链Prompt中获得推理路径, 基于分解后的句子 推理链内容 检索外部相关的知识;
这种方法轻量级,不涉及额外训练或者微调, 也不受限于LLM输入长度。
论文基于GPT-3的模型,在复杂推理任务上进行实验评估,包括常识推理, 时间推理和表格推理,验证RR方法可以生成更真实的支持论据 + 结果, 提升LLM的效果
核心流程:
推理链 + LLM -> query分解 -> 多query检索知识库 -> 知识论据排序 + 结果展示
Search-in-the-Chain
Towards Accurate, Credible and Traceable Large Language Models for Knowledge-intensive Tasks
将推理链的链式拓扑变成树型拓扑,并使用信息搜索引擎对分解的全局query链节点的推理结果进行校验,遇到结果不正确的时候,则返回上一节点启动新一轮分裂,基于新链条进行信息搜索校验,尽可能确保每个推理节点都有可信的参考信息,从而保证最终推理输出的正确性和可靠性
QA问题式的推理prompt
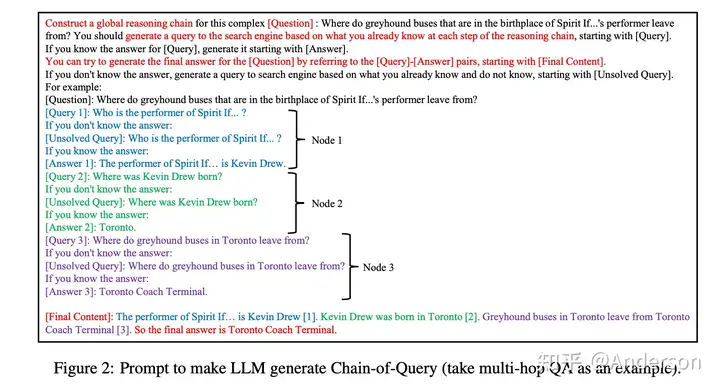
Verify-and-Edit
A Knowledge-Enhanced Chain-of-Thought Framework
从推理步骤出发,将分析结果提炼成问题,再基于外部知识搜索完成问题解答,将外部知识替换原来的推理结果,从而获得最终输出结果
本质上,这篇论文是对多步推理的改进,先对原问题进行子问题拆解,然后借用外部知识搜索获得每个子问题的答案,最终完成结果生成,和一般的langchain的区别是,它是先一次性完成拆解,然后可以同时获得所有问题的答案,完成最终结果的生成;而一般langchain则是逐步生成action - thought - observation等过程
知识注入prompt
知识注入prompt
- (Generated Knowledge Prompting) Generated Knowledge Prompting for Commonsense Reasoning
大模型相对于中小模型具备更充足的常识知识,可以考虑将大模型作为外部知识源,并将大模型生成的知识注入到利用小模型做目标任务的过程中。
- 采用GPT-3作为大模型,对于需要求解的问题,首先要求大模型生成与之相关的一些知识。例如对于“企鹅有几只翅膀这个问题”,大模型可能生成“鸟有两只翅膀,企鹅是鸟”这样的知识。这些知识可能会为原问题中的一些概念提供必要的信息补充。接下来,作者采用11B的T5模型作为目标任务模型,同时接收原问题以及大模型生成的知识作为目标任务模型的输入,通过推理得到对于问题答案的预测。

生成的知识方法(Generated Knowledge Approach)要求 LLM 在生成响应之前生成与问题相关的可能有用的信息。
该方法由两个中间步骤组成:知识生成 和 知识集成
- 知识生成: 要求 LLM 生成有关问题的一组事实。大语言模型将以 few-shot 方式进行提示,如下所示。使用相同提示生成 M 个不同的完成。
- 知识集成:

问题: “大多数袋鼠有 <mask> 肢体”。假设在知识生成步骤中,生成了 2 个知识(M=2):
- 知识1:“袋鼠是生活在澳大利亚的有袋动物。”
- 知识2:“袋鼠是有 5 条肢体的有袋动物。”
将每个知识与问题连接起来,生成知识增强的问题:
- 知识增强问题1:“大多数袋鼠有 <mask> 肢体。袋鼠是生活在澳大利亚的有袋动物。”
- 知识增强问题2:“大多数袋鼠有 <mask> 肢体。袋鼠是有 5 条肢体的有袋动物。”
然后,用这些知识增强的问题提示 LLM,并获得最终答案的提案:
- 答案1:“4”
- 答案2:“5”
选择概率最高的答案作为最终答案。最高概率可能是答案令牌的 softmax 概率,或答案令牌的对数概率。
注入知识后目标任务模型推理的表现相比于只根据问题进行推理有了明显的提升。另外值得注意的是,本文这种注入大模型生成内容的方式能够达到与基于检索的知识注入方式(IR)可比的效果,这也说明LLM本可以作为一个有效的知识源,且这种提取与问题相关的外部知识并注入到prompt中的方式能够有效地帮助中小型模型实现更准确的推理。
Bootstrapping
- (STaR) STaR: Self-Taught Reasoner, Bootstrapping Reasoning With Reasoning
以Bootstrapping 方式构建出一个含推理链的微调数据集,并用推理链微调一个中等规模的LM(GPT-J,6B),使其学到较好的推理能力。具体来说,在每轮迭代时,会通过few shot的方式让LM对训练集中所有问题生成推理链。如果推理链引出的结果与ground truth一致,就直接将该推理链连同其对应的问题加入到微调数据集中。但考虑到如果仅靠这种方式筛选数据,有些比较难的问题可能永远都无法被加入到数据集中。
因此又额外采用了rationalization的方式:对于那些推理链引出结果错误的问题,在prompt中加入正确答案,并让LM再次生成推理链,如果这次的推理链引出了正确答案,则也将该问题加入到微调数据集中。最后,利用微调数据集中的推理链训练LM,并将训练后的LM用于下轮迭代时生成推理链的过程。经过多轮迭代后,LM的推理能力能够得到明显的提升。
这种方法的一大局限
- 只适合参数量达到一定规模的中型模型。作者在采用更小规模的LM进行实验时发现,小型LM在训练的第一次迭代时难以生成质量足够高的推理链,因此后续的迭代过程很可能越训越差。
利用推理链进行蒸馏
- (Fine-tune-CoT) Large Language Models Are Reasoning Teachers
用LLM(InstructGPT, 175B)作为教师模型,对同一个问题采用Zero-Shot-CoT prompting,以非greedy decoding的方式生成多条推理链,并保留引出的结果与ground truth相同的推理链。接下来,将上述保留下的推理链作为监督,训练中小型的学生模型(GPT-3,0.3B/1.3B/6.7B)。
- (MT-CoT) Explanations from Large Language Models Make Small Reasoners Better
将175B的GPT-3作为LLM,将T5-base (220M)作为task LM,本文尝试了使用task LM同时做答案预测和推理链生成的多任务训练,其中推理链的监督信号来源于LLM的生成结果。本文在采用LLM构建包含推理链的微调数据集时,也采用了和STaR中类似的将answer filtering和rationalization相结合的方式。
实验表明经过多任务训练后的task LM能取得比STaR方法更佳的效果。
多阶推理
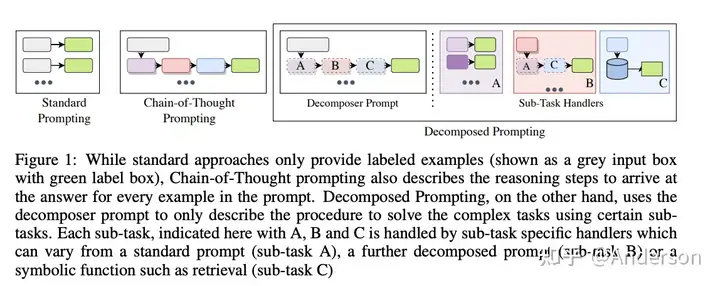
- Decomposed Prompting: A Modular Approach for Solving Complex Tasks
- 类似于之前两阶段的推理生成过程【先生成推理,基于结果生成最终答案】,将原来的推理链prompt分解为多个子任务的prompt,分别构建不同子任务的prompt解决子问题,最终基于子问题的结果生成最终答案。
- 这种方法相当于构建标准的推理流,使得推理过程可控,多个Prompt的使用可以使得推理链更为强大,甚至可以进一步转化为langchain调用api的格式,但是这种方法仅适用于可定义分隔的场景任务
- Complexity-Based Prompting for Multi-Step Reasoning
- 基于Self-Consistency的投票思路,选择最复杂的推理链的结果投票作为最终结果
- ToT
推广
多模态
多模态
- (Multimodal-CoT) Multimodal Chain-of-Thought Reasoning in Language Models
对于多模态的QA任务,视觉信息可能对于问题求解是至关重要的。例如下图中的问题,如果看不到视觉信息,就完全无从得知问题中的“two objects”分别指什么,也就完全无法回答问题。
本文采用两阶段的步骤,第一阶段根据问题生成推理链,第二阶段根据问题和推理链生成答案。两个阶段的输入中都融入了视觉信息:首先将T5 encoder编码的文本特征作为query,将利用DETR模型抽取出的视觉特征作为key和value,进行cross-modal attention。接下来将attention得到的视觉特征与文本encoder输出的特征做gated fusion,随后送入文本端的decoder。两个阶段分别采用标注的推理链和答案进行有监督的训练。
多语言
- (XLT) Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting
虽然当前的LLM具备一定的多语言理解能力,但是在不同语言上的性能往往存在着较大的差异。为了能够进一步提升LLM在不同任务上的多语言能力,本文设计了一个通用的prompt模板。该模板会首先显式指出任务输入所对应的语言,随后会要求模型将任务输入用英文“复述”一遍。这种做法有点类似于我们人在应对非母语的问题时,也往往会在内心中将该问题转化为母语,并基于自己的母语进行思考。而对于类似于ChatGPT这样的大模型来说,训练语料最多的英语就可以被看作是它的母语。另外,本文的prompt模板也采用了类似Zero-Shot-CoT的方式,要求模型利用母语“step-by-step”地给出推理逻辑,从而得出答案。
PAL
CoT只依赖于模型生成的文本,能力受限。
- 【2022-11-18】PAL: Program-aided Language Models
- 【2023-1-27】CMU 提出程序辅助的 Program-Aided Language models (PAL) 方法,自动生成数学、符号推理中间过程
程序辅助语言模型(PAL)使用LLM来读取问题并生成程序作为中间推理步骤。

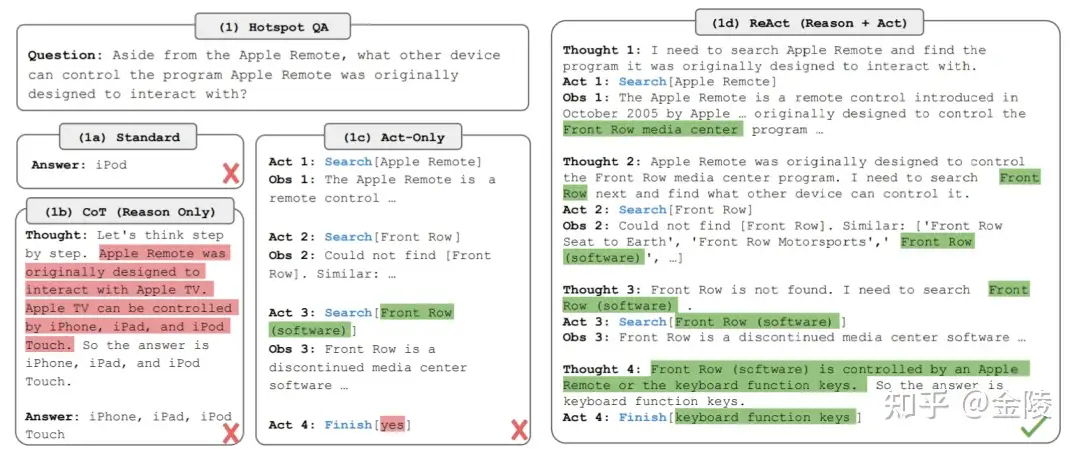
ReAct
ReAct是一个框架,LLM被用来以交错方式生成推理痕迹和特定任务的行动。
- 生成推理跟踪允许模型诱导、跟踪和更新行动计划,甚至处理异常。
- 行动步骤允许与外部资源(如知识库或环境)对接并收集信息。
ReAct允许LLM与外部工具互动,以检索更多的信息,从而获得更可靠和真实的反馈。
COA
【2023-5-18】从 COT 到 COA
- COT(Chain of Thought,思维链)
- COA(Chain of Action,行为链):
AutoGPT为代表,将自然语言表达的目标分解为子任务,并利用互联网和其他工具自动迭代地尝试实现这些目标。
特点
- 自主化决策,任务链自动化
- 知行一体,参数外挂,泛化学习,
- 动态适应和灵活反应
- AI从模拟人类思维到模拟人类行为, 人主要负责设定目标、审批预算、 调整关键行动链
优点
- •自主任务分解
- •上下文适应性
- •泛化多功能优化
- •智能响应
- •协同学习
- •动态知识整合
缺点
- 语义鸿沟
- 依赖风险
- 计算成本过高
- 透明度缺失
TOT 思维树
【2023-5-22】GPT-4推理提升1750%!普林斯顿清华姚班校友提出全新「思维树ToT」框架,让LLM反复思考
- 论文地址: Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- 代码地址: tree-of-thoughts, 本地部署失败:issue
- 【2023-7-6】普林斯顿发布官方版本 Official Repo of Tree of Thoughts (ToT), code, prompts, model outputs, 并声明 tree-of-thoughts 无法复现论文结果
即便有了思维链,LLM有时也会在简单问题上犯错.
- 普林斯顿大学 和 Google DeepMind 研究人员提出了一种全新的语言模型推理框架——「思维树」(
ToT) - ToT将当前流行的「思维链」方法泛化到引导语言模型,并通过探索文本(思维)的连贯单元来解决问题的中间步骤。
「思维树」可以让LLM:
- 自己给出多条不同的推理路径
- 分别进行评估后,决定下一步的行动方案
- 在必要时向前或向后追溯,以便实现进行全局决策
论文实验结果显示,ToT显著提高了LLM在三个新任务(24点游戏,创意写作,迷你填字游戏)中的问题解决能力。
- 24点游戏中,GPT-4只解决了4%的任务,但ToT方法的成功率达到了74%。
「人类认知」的文献提供了一些线索。「双重过程」模型的研究表明,人类有两种决策模式:
- 快速、自动、无意识模式——「
系统1」 - 缓慢、深思熟虑、有意识模式——「
系统2」。
语言模型简单关联token级选择可以让人联想到「系统1」,因此这种能力可能会从「系统2」规划过程中增强。
- 「系统1」让LLM保持和探索当前选择的多种替代方案,而不仅仅是选择一个
- 「系统2」评估其当前状态,并积极地预见、回溯以做出更全局的决策。
为了设计这个规划过程,研究者追溯到人工智能和认知科学的起源,从科学家Newell、Shaw和Simon在20世纪50年代开始探索的规划过程中汲取灵感。
- Newell及其同事将问题解决描述为「通过组合问题空间进行搜索」,表示为一棵树。
一个真正的问题解决过程包括重复使用现有信息来探索,反过来,这将发现更多的信息,直到最终找到解决方法。
现有使用LLM解决通用问题方法的2个主要缺点:
- 局部来看,LLM没有探索思维过程中的不同延续——树的分支。
- 总的来看,LLM不包含任何类型的计划、前瞻或回溯,来帮助评估这些不同的选择。
研究者提出了用语言模型解决通用问题的思维树框架(ToT),让LLM可以探索多种思维推理路径。
- 现有的方法(如IO、CoT、CoT-SC)通过采样连续语言序列解决问题。
- 而ToT主动维护了一个「思维树」。每个矩形框代表一个思维,并且每个思维都是一个连贯的语言序列,作为解决问题的中间步骤。

ToT将任何问题定义为在树上进行搜索,其中每个节点都是一个状态S, 表示到目前为止输入和思维序列的部分解。
ToT执行一个具体任务时需要回答4个问题:
思维分解:如何将中间过程分解为思维步骤;- CoT在没有明确分解的情况下连贯抽样思维,而ToT利用问题的属性来设计和分解中间的思维步骤。
- 根据不同的问题,一个想法可以是几个单词(填字游戏) ,一条方程式(24点) ,或者一整段写作计划(创意写作)。
- 一个想法应该足够「小」,以便LLM能够产生有意义、多样化的样本。比如,生成一本完整的书通常太「大」而无法连贯 。
- 但一个想法也应该「大」,足以让LLM能够评估其解决问题的前景。例如,生成一个token通常太「小」而无法评估。
思维生成器:如何从每个状态生成潜在的想法;- 通过2种策略来为下一个思维步骤生成k个候选者
- (a)从一个CoT提示采样:在思维空间丰富(比如每个想法都是一个段落),并且iid,导致多样性时,效果更好
- (b)使用「proposal prompt」按顺序提出想法:思维空间受限制(比如每个思维只是一个词或一行)时效果更好,因此在同一上下文中提出不同的想法可以避免重复。
状态求值器:如何启发性地评估状态;- 给定不同状态前沿,状态评估器评估解决问题的进展,作为搜索算法的启发式算法,以确定哪些状态需要继续探索,以及以何种顺序探索。
- 虽然启发式算法是解决搜索问题的标准方法,但它们通常是编程的(DeepBlue)或学习的(AlphaGo)。
- 这里研究者提出了第三种选择,通过LLM有意识地推理状态。深思熟虑的启发式方法可以比程序规则更灵活,比学习模型更有效率。
搜索算法:使用什么搜索算法。2个相对简单的搜索算法:- 算法1——广度优先搜索(BFS),每一步维护一组b最有希望的状态。
- 算法2——深度优先搜索(DFS),首先探索最有希望的状态,直到达到最终的输出
LLM通过自我评估和有意识的决策,来实现启发式搜索的方法是新颖的。
部署
【2023-7-6】普林斯顿发布官方版本 Official Repo of Tree of Thoughts (ToT)
GoT 思维图
【2023-8-25】思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了
由于 ToT 方法为思维过程强加了严格的树结构,极大限制 prompt 的推理能力。详情《思考、思考、思考不停歇,思维树 ToT「军训」LLM》。
- 将 LLM 的思维构建成任意的图结构,那么就能为 prompt 的能力带来重大提升。
苏黎世联邦理工学院、Cledar 和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)(GoT/Graph of Thoughts)。让思维从链到树到图,为 LLM 构建推理过程的能力不断得到提升,研究者也通过实验证明了这一点。他们也发布了自己实现的 GoT 框架。
- 研究论文
- 官方实现:graph-of-thoughts
GoT 中,一个 LLM 思维会被建模成一个顶点,顶点之间的依赖关系则建模为边。使用 GoT,通过构建有多于一条输入边的顶点,可以将任意思维聚合起来。整体而言,GoT 使用的图抽象方法可无缝地将 CoT 和 ToT 泛化到更复杂的思维模式,而且这个过程无需更新模型。
一种实现 GoT 的模块化架构。该设计有两大亮点。
- 一是可实现对各个思维的细粒度控制。这让用户可以完全控制与 LLM 进行的对话并使用先进的思维变换,比如将正在进行的推理中两个最有希望的思维组合起来得到一个新的。
-
二是这种架构设计考虑了可扩展性 —— 可无缝地扩展用于新的思维变换、推理模式(即思维图)和 LLM 模型。这让用户可使用 GoT 快速为 prompt 的新设计思路构建原型,同时实验 GPT-3.5、GPT-4 或 Llama-2 等不同模型。
GoT 尤其适用于可自然分解成更小子任务的任务,并且这些子任务可以分开解决,然后融合成一个最终解答。在这方面,GoT 的表现优于其它方案,比如在排序任务上,GoT 分别优于 CoT 和 ToT 约 70% 和 62%,同时成本还比 ToT 低 31% 以上。
提出一种新的评估指标 —— 思维容量(the volume of a thought),可用于评估 prompt 设计策略。研究者表示,使用这一指标的目标是更好地理解 prompt 设计方案之间的差异。
对于一个给定的思维 v,v 的容量是指 LLM 思维的数量,用户可以基于此使用有向边得到 v。直观上说,这些就是有望对 v 做出贡献的所有 LLM 思维。
USP 自适应prompt
【2023-6-1】一个通用的自适应prompt方法,突破了零样本学习的瓶颈
- 谷歌提出了一种 Universal Self-adaptive Prompting (
USP) 方法,对LLMs的零样本学习进行了优化,同时也适用于少样本学习任务。USP只需要少量未标记的数据,就能大幅提升LLMs在20多个自然语言理解和生成任务上的表现。实际上,结果比起少样本基线方法甚至更好! - 论文:Universal Self-adaptive Prompting
主流方法,分别是:
- Chain of Thought (
CoT): CoT方法将一个具体的推理问题拆分成多个步骤,并将每个步骤的解释信息输入LLMs,从而得出最终的答案。 - Self-Consistency (
SC): SC方法对CoT进行了改进。通过对多个CoT推理路径进行采样,并将结果进行投票,选择一致性最高的输出作为最终答案,可以进一步提高LLMs的推理准确性。 - Consistency-based Self-adaptive Prompting (
COSP), COSP方法采用双阶段策略,进一步增强LLMs的零样本学习能力。- 第一阶段,COSP类似于SC,采用多路径解码进行零样本推理。它对同一查询在不同解码路径上进行预测,并计算出归一化熵,用于量化模型在不同解码路径下的自信程度和预测之间的差异。基于熵值(以及其他指标如多样性和重复性),COSP对第一阶段的输出进行排名,并选择自信的输出作为伪演示数据。
- 第二阶段,COSP再次将这些伪演示数据与查询结合,以类似于少样本推理的方式进行处理。最终的预测结果是通过两个阶段的输出进行多数投票得出的。
这些方法是目前LLMs推理研究的主要方向,而COSP方法也是这篇研究的主要灵感来源。
对于不同类型的任务可能存在一些局限性和挑战。
- 一些分类NLP问题,模型的逻辑回归结果对于不确定性的量化很有用,但在COSP的设计中却忽视了这一信息
- 对于涉及创造性和生成性任务的任务,多数投票的概念可能并不存在,因为有很多合理的解决方案存在。
于是有了Universal Self-adaptive Prompting(USP)方法
OlaGPT
详见站内智能体专题
SoT 解码提速
【2023-8-9】大模型速度狂飙2.39倍!清华联手微软首提SoT,让LLM思考更像人类
当前先进的LLM采用了顺序解码方式,即一次生成一个词语或短语。这种顺序解码可能花费较长生成时间,特别是在处理复杂任务时,会增加系统延迟。
LLM推理慢的3个主要原因:
- 大模型需要大量内存,内存访问和计算。
- 比如,GPT-3的FP16权重需要350 GB内存,这意味着仅推理就需要5×80GB A100 GPU。即使有足够多的GPU,繁重的内存访问和计算也会降低推理(以及训练)的速度。
- 主流Transformer架构中的核心注意力操作受I/O约束,其内存和计算复杂度与序列长度成二次方关系。
- 推理中的顺序解码方法逐个生成token,其中每个token都依赖于先前生成的token。这种方法会带来很大的推理延迟,因为token的生成无法并行化。
人类自身如何回答问题的思考。
- 并不总是按顺序思考问题,并写出答案。相反,对于许多类型的问题,首先根据一些策略推导出骨架,然后添加细节来细化和说明每一点。
那么,这一点在提供咨询、参加考试、撰写论文等正式场合中,更是如此。
受人类思考和写作过程的启发,来自清华微软的研究人员提出了「思维骨架」(SoT),减少大模型的端到端的生成延迟,并提升了回答质量。
- SoT 引导LLM,首先生成答案骨架,然后进行并行API调用或分批解码,并行完成每个骨架点的内容。

SoT 不仅大大提高了速度,在11个不同的LLM中可达2.39倍,而且还可能在多样性和相关性方面提高多个问题类别的答案质量。
- 通过Slack使用Claude模型将延迟时间从22秒,减少到12秒(快了1.83倍),通过A100上的Vicuna-33B V1.3将延迟时间从43秒减少到16秒(快了2.69倍)。
研究人员称,SoT是以数据为中心优化效率的初步尝试,揭示了推动LLM更像人类一样思考答案质量的潜力。
AoT 思维算法
【2023-8-20】大模型为啥这么慢,原来是想多了:新方向是和人一样的思维算法
弗吉尼亚理工大学和微软的一个研究团队在近日的一篇论文中提出了思维算法(AoT),其组合了直觉能力与算法方法的条理性,从而能在保证 LLM 性能的同时极大节省成本。
- 当前研究则转向了线性推理路径,将问题分解成子任务来发现解决方案,或通过修改上下文来利用外部机制来改变 token 的生成。
- 早期的 LLM 策略模仿即时的
System 1(快速反应),特征是通过脉冲决策实现。 - 相较之下,
思维链(CoT)和least-to-most prompting(L2M)等更新的一些方法则反映了System 2(慢速思考)的内省式本质。通过整合中间推理步骤,可让 LLM 的算术推理能力获得提升。
如果任务需要更深度的规划和更广度的思维探索,这些方法有局限。
- 尽管整合了自我一致性的 CoT(
CoT-SC)可使用多个 LLM 输出来达成共识性结果,但由于缺少细致的评估,可能会导致模型走向错误方向。 - 2023 年出现的思维树(
ToT)值得注意。其中使用一个 LLM 来生成想法,再使用另一个 LLM 来评估这些想法的优点,之后续以「暂停 - 评估 - 继续」的循环。这种基于树搜索的迭代过程明显是有效的,尤其是对于具有较长延续性的任务。
用外部工具来增强 LLM,类似于人类使用工具来规避自身工作记忆的限制
缺点
- 查询数量和计算需求会大幅飙升。对 GPT-4 等在线 LLM API 的每一次查询都会产生可观的金钱开支,同时还会拉长延迟
优化目标
- 大幅减少当前多查询推理方法所使用的查询数量,同时维持足够的性能,使模型能应对需要熟练使用世界知识的任务,从而引导人们更负责任和更熟练地使用 AI 资源。
LLM 从 System 1 到 System 2 的演变的关键因素:算法,帮助人们探索问题空间、制定策略和构建解决方案的途径
能否引导这种迭代式逻辑来将一个算法内化到 LLM 内部?论文将人类推理的复杂精妙和算法方法富有条理的精确性聚合到了一起,试图通过融合这两方面来增强 LLM 内部的推理能力。
人类在解决复杂问题时会本能地借鉴过去的经历,确保自己进行全面思考而不是狭隘地关注某一细节。LLM 生成范围仅受其 token 限制限定,似乎是注定要突破人类工作记忆的阻碍。
研究者探究了 LLM 能否实现类似的对想法的分层探索,通过参考之前的中间步骤来筛除不可行的选项 —— 所有这些都在 LLM 的生成周期内完成。而人类长于直觉敏锐,算法善于组织化和系统性的探索。
- CoT 等当前技术往往回避了这种协同性潜力,而过于关注 LLM 的现场精度。通过利用 LLM 的递归能力,研究者构建了一种人类 - 算法混合方法。其实现方式是通过使用算法示例,这些示例能体现探索的本质 —— 从最初的候选项到经过验证的解决方案。
基于这些观察,研究者提出了思维算法(Algorithm of Thoughts /AoT)
- 论文:paper
新方法有望催生出一种上下文学习新范式。这种新方法没有使用传统的监督学习模式,即 [问题,解答] 或 [问题,用于获得解答的后续步骤],而是采用了一种新模式 [问题,搜索过程,解答]。
- 当通过指令让 LLM 使用某算法时,通常预计 LLM 只会简单模仿该算法的迭代式思维。但是,LLM 有能力注入其自身的「直觉」,甚至能使其搜索效率超过该算法本身。
核心
- 认识到当前上下文学习范式的核心短板。
- CoT 尽管能提升思维联系的一致性,但偶尔也会出问题,给出错误的中间步骤。
实验
- 用算术任务(如 11 − 2 =)查询 text-davinci-003 时,研究者会在前面添加多个会得到同等输出结果的上下文等式(如 15 − 5 = 10, 8 + 2 = 10)
- 准确度陡然下降,这说明只是在上下文中给出正确的推理可能会在无意中损害 LLM 的基础算术能力。
为了减少这种偏差,让示例更加多样化也许是可行的解决方案,但这可能会稍微改变输出的分布。
论文做法
- 不为每个子集都给出单独的查询,而是利用了 LLM 的迭代能力,在一次统一的生成式扫描中解决它们。
- 通过限定自己仅能进行一两次 LLM 交互,该方法可以自然地整合来自之前的上下文候选项的洞见,并解决需要对解答域进行深度探索的复杂问题。
树搜索算法的关键组件
-
- 分解成子问题
-
- 为子问题提议解答
-
- 衡量子问题的前景
-
- 回溯到更好的节点
24 点和 5x5 迷你填词游戏上进行了实验,结果表明:
- AoT 方法的优越性 —— 其性能表现由于单 prompt 方法(如标准方法、CoT、CoT-SC),同时也能媲美利用外部机制的方法(如 ToT)
- 迷你填词任务上,AoT 明显超过CoT/CoT-SC 的标准 prompt 设计方法
- 但比 ToT 差。原因
- ToT 使用的查询量巨大,超过了 AoT 百倍以上
- 示例中固有的回溯能力没有充分得到激活; ToT 的优势在于可以利用外部记忆来进行回溯
- 搜索步数会为 LLM 的搜索速度引入隐含的偏差
无论什么算法都会进行搜索并重新审视潜在的错误 —— 随机搜索变体中的随机尝试,或通过 DFS 或 BFS 配置中的回溯。
- AoT (DFS) 和 AoT (BFS) 这两个结构化搜索的版本的效率都优于 AoT (Random),算法洞察在解答发现中的优势。
- 但是,AoT (BFS) 落后于 AoT (DFS)。相比于 AoT (DFS),AoT (BFS) 更难识别最佳操作。
- 总结: AoT (Random) < AoT (BFS) < AoT (DFS)
XoT
【2023-11-12】微软
现有思维生成范式有很多,比如思维链 (Chain-of-Thought, CoT)、思维树 (Tree-of-Thought, ToT)、思维图 (Graph-of-Thought, GoT) 等。
然而,这些范式各有其局限性,无法同时实现性能、效率和灵活性这三个期望的属性。
- 直接的输入-输出 (IO) 提示,适用于简单的单步骤问题解决场景,性能和灵活性都有所不足;
CoT和自洽CoT(CoT-SC) 实现了逐步问题解决,性能有所提升,但受限于线性思维结构,灵活性受限;- 相比之下,
ToT和GoT允许更多样化的思维拓扑结构,但需要通过LLM本身评估中间思维步骤,导致计算成本高并且效率低下。
几种思维启发范式

- Input-Output(IO)提示(图1(a)):最直接的方法,指导LLMs解决问题,但没有提供任何中间思维过程。
- 思维链(Chain-of-thought, CoT)(图1(b)):CoT将问题解决分解成一个连续的思维链,允许LLMs逐步处理复杂问题。
- 自我一致性思维链(Self-consistency CoT, CoT-SC)(图1(c)):CoT-SC利用多个CoT的实例从LLMs生成多个输出,并从多个LLMs输出中选择最佳结果,提供比传统CoT更强大和一致的推断能力。
- 思维树(Tree-of-thought , ToT)(图1(d)):ToT将思维组织成类似树的结构,并利用搜索算法(如广度优先搜索、深度优先搜索)扩展树以寻求最优解。然而,在ToT中思维评估依赖于LLMs本身,需要多次昂贵且低效的LLMs推理调用。
- 思维图(Graph-of-thought , GoT)(图1(e)):GoT扩展了ToT方法,通过在中间搜索阶段进行思维聚合和细化,实现了类似图形的思维结构生成。尽管这种方法允许更灵活的思维结构,但仍需进行多次LLMs推理调用进行评估,导致较大的计算成本。
- 新的思维启发方法“Everything of Thoughts”(XOT),旨在超越现有的思维范式限制,提高LLMs在解决复杂问题时的性能、效率和灵活性。XOT利用预训练的强化学习和蒙特卡罗树搜索(MCTS)将外部领域知识融入思维中,实现了高质量、全面的认知映射生成,同时最大限度减少了LLMs的交互。相比于现有方法,XOT在多个问题解决任务中表现出更出色的性能,例如,在解决24点游戏中,成功率提升了15%。这些创新点突破了以往思维设计范式的局限,使得LLMs能更有效地解决各种领域的复杂问题。
这些范式受到了类似“彭罗斯三角形”的法则的限制,最多只能同时实现三个属性中的两个,而无法同时达到全部三个。
“Everything of Thoughts”(XOT)旨在增强LLMs推理过程中思维生成的关键属性,包括性能、效率和灵活性。XOT利用强化学习和蒙特卡罗树搜索等技术,结合轻量级策略和价值网络,对特定任务进行预训练,用于思维搜索,并随后泛化到新问题。
这种预训练有效地将外部领域知识整合到提供给LLMs的“思维”中,扩展了问题解决能力,显著提高了性能。一旦训练完成,XOT使用成本效益的策略和价值网络进行思维搜索,并自主生成LLMs的完整认知映射。
接着,它采用了蒙特卡罗树搜索-LLM协同思维修订过程,进一步提高了思维质量,同时最小化了LLM的交互。这消除了LLMs自行探索和评估思维的需求,从而提高了XOT的效率。此外,蒙特卡罗树搜索展现了出色的灵活性,可以探索各种思维拓扑结构,包括类似于人类思维映射过程中使用的图形结构,增强了LLMs的多样性和创造性思考能力。
XOT同时实现了出色的性能、效率和灵活性,挑战了“彭罗斯三角形”法则的限制,显著超越了其他思维生成范式的能力。在Game of 24、8-Puzzle和口袋魔方等多样化的具有挑战性的问题解决任务上,对XOT进行了全面评估。实验结果一致显示,XOT在提供多个解决方案、高效地使用LLM调用的问题上表现出卓越的性能。这些发现确立了XOT作为一种有效的思维生成方法,为LLMs在解决问题方面开辟了新的途径。
作者:时空猫的问答盒
CCoT
CCoT:将对比的思想引入CoT
- 论文链接:paper
CCoT 是 Contrastive Chain-of-Thought 的缩写,是一种使用正向和负向示例来改善大型语言模型推理能力的方法。
- 传统的 CoT 方法只使用正确的示例来引导模型的推理过程,而 CCoT 则同时提供正确和错误的推理步骤示例。
- CCoT 通过对比正负示例来增强模型的推理能力,并且需要开发一种结构化的提示创建方法。
此外,CCoT 还强调了数据在 LLM 实现中的重要性,包括数据发现、数据设计、数据开发和数据传递等过程。总之,CCoT 是一种改进链式推理方法的方法,可以提高大型语言模型的推理能力
CoC
【2023-12-11】李飞飞全新「代码链」碾压CoT!大模型用Python代码推理
谷歌DeepMind、斯坦福、UC伯克利团队联手提出了全新技术——「代码链」(CoC)。
「代码链」是一种将编码逻辑与自然语言理解相结合,简单却非常有效的创新方法,能够提升LLM基于代码的推理能力,让其更智能、更通用。
CoC允许LLM生成「伪代码」来分解难题,通过LMulator执行有效代码,模拟无效代码。
评测
- BIG-Bench Hard基准上,CoC实现了84%的准确率,比CoT提高了12%。
- BIG-Bench Hard的23项任务中,CoC在18项任务中超过了人类的平均表现。
DCoT
【2024-7-3】DICoT模型让AI学会自我纠错,提示词工程终结
多所大学的研究人员提出了一种新的训练方法——发散式思维链(Divergent Chain of Thought, DCoT),让AI模型在单次推理中生成多条思维链,从而显著提升了推理能力。
这项研究不仅让AI模型的表现更上一层楼,更重要的是,它让AI具备了自我纠错的能力。
DCoT训练方法主要有三大亮点:
- 提升小型模型性能:即使是规模较小、更易获取的语言模型,经过DCoT训练后也能显著提升表现。
- 全面超越CoT基线:从1.3B到70B参数的各种规模模型中,DCoT都展现出了优于传统思维链(Chain of Thought, CoT)的性能。
- 激发自我纠错能力:经过DCoT训练的模型能够在单次推理中生成多条思维链,并从中选择最佳答案,实现了自我纠错。
多个推理任务上测试
- 一致性提升:DCoT在各种模型家族和规模上都取得了持续的性能提升。
- 多样化思维链:通过实证和人工评估,确认模型能生成多条不同的推理链。
DCoT不仅提高了模型的推理能力,还让模型具备了”多角度思考”的能力。
DCoT在多个方面都超越了传统CoT:
- 领域内任务:DCoT在训练涉及的任务上表现优异。
- 未见过的任务:在全新的任务上,DCoT仍然保持优势。
- 困难任务:即使在CoT可能有害的任务上,DCoT也展现出了稳健性。
- 兼容性:DCoT还能与现有的CoT扩展方法(如自洽性解码)兼容,进一步提升性能。
CoT训练让模型具备了自我纠错的能力:
- 无需外部反馈:模型能够在单次推理中生成多条思维链,并从中选择最佳答案。
- 显著提升:仅生成两条思维链就能带来明显的性能提升,证实了自我纠错的存在。
- 人工验证:通过人工分析,确认了模型确实在进行自我纠错,而非简单的自我集成。
DCoT的出现无疑为AI与人类的交互开辟了新的可能性
CoT 应用
应用
- 多项选择题
- 解答讨论性问题: 通过正确的提示,GPT-3非常擅长写作短格式回答。
- GPT-3构建ChatGPT
- 聊天机器人+知识库
【2023-3-19】MathPrompter: Mathematical Reasoning using Large Language Models,微软的这篇论文通过prompt设计提高了数学计算效果
说到底,人脑也就是参数量够了才有能顾及那么繁多细节的思考能力。其实不止是transformer,就算是最原始的nn用这个算力效果也不会太差
多项选择
- LSAT(Law School Admission Test)是美国法学院用于评估潜在学生的批判性思维和分析推理能力的标准化考试
- 引入 CoT 技术,可以让 GPT-3 完成 LSAT 的多项选择题
- GPT与计算器等外部工具 MRKL
ReAct
ReAct 系统是具有推理和行动能力的 MRKL系统
ReAct(reason, act)是一种使用自然语言推理解决复杂任务的语言模型范例,旨在用于允许LLM执行某些操作的任务。MRKL系统中,LLM可以与外部API交互以检索信息。- 【2022-10-6】普林斯顿+谷歌 ReAct: Synergizing Reasoning and Acting in Language Models,【2023-5-10】更新论文
- Demo
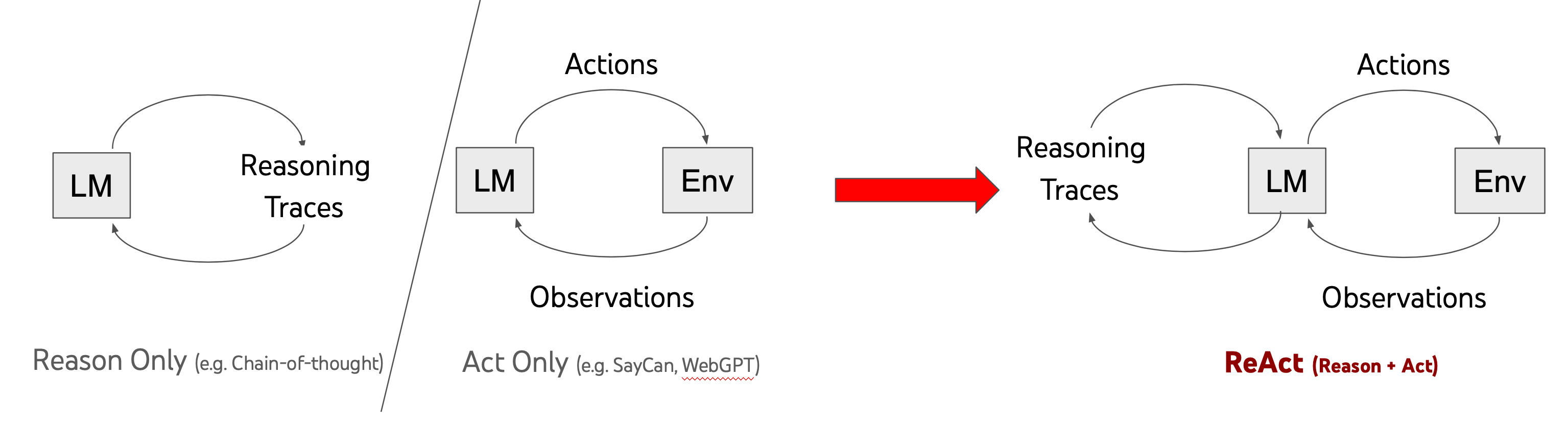
顶部框中的问题来自HotPotQA,一个需要复杂推理的问答数据集。
- ReAct能够首先通过推理
问题(Thought 1),然后执行一个动作(Act 1)来向Google发送查询来回答问题。 - 然后收到了一个
观察(Obs 1),并继续进行这个思考,行动,观察循环,直到达到结论(Act 3) 
具有强化学习知识的读者可能会认为,这个过程类似于经典的RL循环:状态,行动,奖励,状态,…
谷歌在 ReAct的实验中使用了PaLM LLM。与标准提示(仅问题)、CoT和其他配置进行比较表明,ReAct在复杂推理任务方面的表现是有希望的。
PAL
程序辅助语言模型(Program-aided Language Models, PAL) 是另一个MRKL系统的例子。代码推理
- 给定一个问题,PAL能够编写代码解决这个问题。
- 它将代码发送到编程运行时以获得结果。
PAL的中间推理是代码,而CoT的是自然语言。
PAL实际上交织了自然语言(NL)和代码。
- 图中,蓝色的是PAL生成的自然语言推理。虽然图中没有显示,PAL实际上在每行自然语言推理前生成’#’,以便编程运行时将其解释为注释。

PAL解决数学问题的例子
- langchain,一个用于链接LLM功能的Python包。
#!pip install langchain==0.0.26
#!pip install openai
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-YOUR_KEY_HERE"
llm = OpenAI(model_name='text-davinci-002', temperature=0)
MATH_PROMPT = '''
Q: There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room?
# solution in Python:
"""There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room?"""
computers_initial = 9
computers_per_day = 5
num_days = 4 # 4 days between monday and thursday
computers_added = computers_per_day * num_days
computers_total = computers_initial + computers_added
result = computers_total
return result
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?
# solution in Python:
"""Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?"""
toys_initial = 5
mom_toys = 2
dad_toys = 2
total_received = mom_toys + dad_toys
total_toys = toys_initial + total_received
result = total_toys
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
# solution in Python:
"""Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?"""
jason_lollipops_initial = 20
jason_lollipops_after = 12
denny_lollipops = jason_lollipops_initial - jason_lollipops_after
result = denny_lollipops
Q: {question}
# solution in Python:
'''
llm_out = llm(MATH_PROMPT.format(question=question))
print(llm_out)
exec(llm_out) # 传递给Python执行
print(result) # 210
输出
"""Emma took a 60 minute plane ride to seattle. She then took a 2 hour train ride to portland, and then a 30 minute bus ride to vancouver. How long did it take her to get to vancouver?"""
plane_ride = 60
train_ride = 2 * 60 # 2 hours in minutes
bus_ride = 30
total_time = plane_ride + train_ride + bus_ride
result = total_time
讨论性问题
解答讨论性问题: 通过正确的提示,GPT-3非常擅长写作短格式回答。
- 讨论性问题的回答通常约为100到700字。更长的内容可能会有些棘手,因为语言模型的记忆有限,并且难以理解他们所写的内容全局。
- 一个好的提示应该给出具体格式和内容指令。
- 许多讨论性问题并不适合提示
- Bad: 内战是一场关于扩张的冲突吗?同意还是不同意,为什么?
- Good(明确指令): 解释内战的原因以及扩张是否在冲突中起了作用。附上支持您论点的证据
- Better(具体格式): 写一篇高度详细的讨论回答,按照论文结构回答以下提示: 解释内战的原因以及扩张是否在冲突中起了作用。附上支持您论点的证据。
GPT-3构建ChatGPT
- GPT-3构建ChatGPT
- 与GPT-3.5系列模型一样, ChatGPT 是使用RLHF训练,但大部分效果来自于使用了好的提示。

- 如何记忆?将上文附加到下一个提示中,包括ChatGPT在内GPT-3模型,组合提示和生成响应的标记限制为4097个(约3000个单词)。
聊天机器人+知识库
- 传统聊天机器人基于意图识别,以 < 一组问题, 回复 > 形式存在, 问题:域外意图无法回答

- 知识库 Knowledge Base 是存储为结构化和非结构化数据的信息,可用于分析或推断。
- 每个意图与文档相关联,而不是一组问题和特定答案, 这样意图可以更加广泛
- 当用户询问有关登录的问题时,将“登录问题”文档传递给 GPT-3 作为上下文信息,并生成特定的响应。

- 这种方法减少了需要处理的意图数量,并允许更好地适应每个问题的答案。此外,如果与意图关联的文档描述了不同的流程(例如“在网站上登录”的流程和“在移动应用程序上登录”的流程),GPT-3可以在给出最终答案之前自动询问用户以获得更多的上下文信息。
- GPT-3这样的LLM模型, 最大提示的长度约为4k令牌(text-davinci-003模型),不足以将整个知识库馈入单个提示中。 LLM由于计算原因具有最大提示的限制,因为生成文本涉及多个计算,随着提示大小的增加,计算量也会迅速增加。未来的LLM可能不会有这种限制,同时保留文本生成能力。
- 用GPT-3构建一个聊天机器人, 两个步骤
- 为用户问题选择适当意图,即从知识库中检索正确的文档。— 语义搜索 semantic search, 如 sentence-transformers 库中的预训练模型为每个文档分配一个分数。分数最高的文档将用于生成聊天机器人答案。
- 有了正确的文档,就可以用 GPT-3 生成适当答案;— 用temperature为0.7的text-davinci-003模型。
- 注意
- 只要有正确的上下文信息,GPT-3就可以进行消歧义。
- 当用户问题可以在上下文中找到答案时,GPT-3很少生成虚假信息。由于用户问题通常是短小模糊的文本,不能总是依赖语义搜索步骤来检索正确的文档,因此容易受到虚假信息生成的影响。

提示制作
- 角色提示: 一种启发式技术,为AI分配特定的角色。
- 相关的知识库信息, 即在语义搜索步骤中检索到的文档。
- 用户和聊天机器人之间最后一次交换的消息. 这对于用户发送的未指定整个上下文的消息非常有用。我们将在后面的例子中看到它。请查看此示例 了解如何使用GPT-3管理对话。
- 最后, 用户的问题.

ChatGPT 的 Prompt 构造
system: 系统设置,默认是高级聊天机器人conversation: 会话历史user: 用户输入
chatbot_prompt = """
作为一个高级聊天机器人,你的主要目标是尽可能地协助用户。这可能涉及回答问题、提供有用的信息,或根据用户输入完成任务。为了有效地协助用户,重要的是在你的回答中详细和全面。使用例子和证据支持你的观点,并为你的建议或解决方案提供理由。
<conversation history>
User: <user input>
Chatbot:"""
CoT让小模型反超大模型
【2023-4-24】如何使用1B参数的小模型吊打GPT3.5
大型语言模型 (LLM) 通过利用思维链 (CoT) 提示生成中间推理链作为推断答案的基本原理,在复杂推理上表现出了令人印象深刻的性能。然而现有的 CoT 研究主要集中在语言模态上。
Multimodal-CoT(多模态思维链推理模型)将语言(文本)和视觉(图像)模态结合到一个两阶段框架中,该框架将基本原理生成和答案推理分开。通过这种方式,答案推理可以利用基于多模态信息的更好的生成原理。使用 Multimodal-CoT,作者提出的模型在对 ScienceQA 数据集进行评估,结果显示在少于 10 亿个参数下比之前 LLM(GPT-3.5)高出 16个百分点(75.17%→91.68% )的准确率。- 论文地址
- 代码地址
CoT推理能力存在于一定规模的语言模型中,例如超过1000亿个参数。然而,在1b模型中引出这种推理能力仍然是一个未解决的挑战,更不用说在多模态场景中了。
- 1b模型可以用消费者级gpu(例如,32G内存)进行微调和部署。
- 一些列实验研究了为什么1b模型在CoT推理中失败,并研究如何设计一个有效的方法来克服挑战。
只有 2.23 亿个参数的基本模型也优于 GPT-3.5 和其他 Visual QA 模型
cot实践
auto-cot
- Auto-CoT: Automatic Chain of Thought Prompting in Large Language Models (ICLR 2023)
- Official implementation for “Automatic Chain of Thought Prompting in Large Language Models” (stay tuned & more will be updated)

Prompt DEMO
Dyno:Prompt Engineering IDE
- trydyno, prompt工具包,支持自定义gpt-3模型、token长度、温度、top p等参数调节
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
