- 数据标注
- 结束
数据标注
标注意义
【2024-3-5】大模型+数据标注=?
“garbage in garbage out” 垃圾进,垃圾出
OpenAI 翁丽莲
什么是好的大模型训练数据 分析了翁丽莲(Lilian Weng)博客 “Thinking about High-Quality Human Data”
- LLM依旧是机器学习模型, 也依旧符合ML基础原理: Garbage-in-Garbage-out.
- 人工智能里面, 数据处理依然: 有多少人工就有多少智能
然而,大家的倾向
- Everyone wants to do the model work, not the data work
- Everyone wants to train the model, no one wants to do feature engineering
机器学习项目中,数据处理的投资回报往往大于模型优化
什么是高质量数据?
- “高质量人类”生成的高质量数据
如何生产
- 让人类标注员生产数据, 并做好质量控制
- 模型找到错误标注数据, 并且进行修正

如何提升标注质量
- 人类标注员的挑选, 培训, 激励, 到标注任务的设计, 质量检验的每个环节都很有讲究
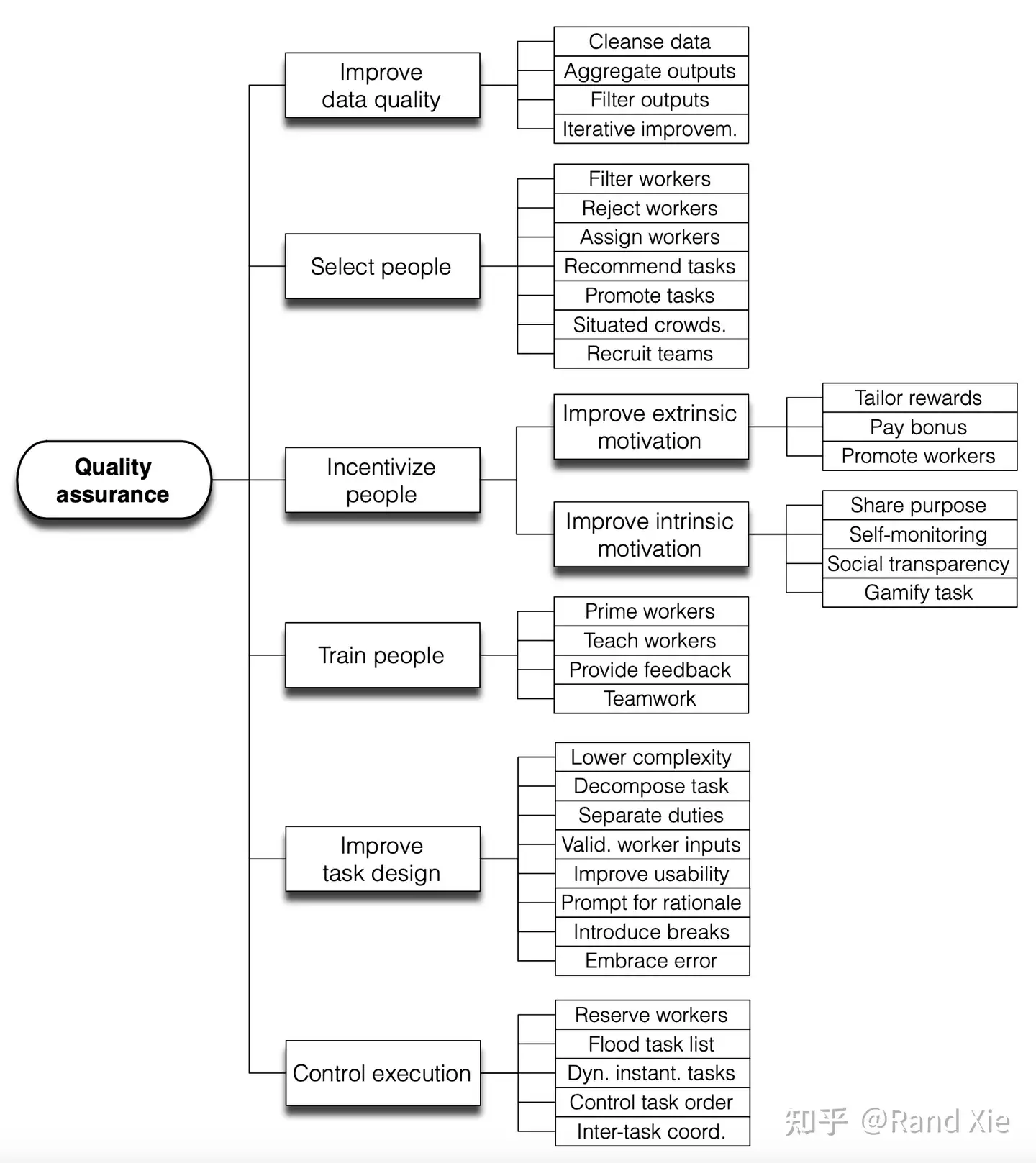
怎么去做 Rater agreement 标注对齐
- majority voting, Cohen’s Kappa和MACE (Multi-Annotator Competence Estimation)
如何找到问题数据?几类方法:
- Influence Functions: 评估一个特定sample对Loss影响 —— 计算量大(因为计算Hessian,二阶导)
- Prediction changes during training: 追踪预测值在训练过程的变化, 通过预测值的变化找到错标的数据
- Noisy Cross-Validation: 把数据集分成两半, 各自训练一个模型来预测另外一半的label, 如果预测值和真实值是一致的, 那就看作是clean label
数据标注介绍
什么是数据标注
- 对文本、图像、音频、视频等数据进行高质量、高精度的处理打标签,满足机器训练学习的需求。
参考:
- 软件学报:数据标注研究综述
数据类型
数据主要分为图像数据、语音数据、文本数据等
文本标注:数据标注员对语句分词的标注、语义判断的标注、情感标注、多音字标注等,为人工智能机器学习提供高准确率的文本语料。图像数据:主要有点标、框标、区域标注、2D/3D融合标注等标注方法。- 目前,人脸识别技术落地应用的比较成熟,无论是刷脸进火车站地铁站还是购物人脸支付,日常场景中随处可见。
- 语音交互也是重要分支。基于语音识别、声纹识别、语音合成等建模测试中,需要对语音数据进行任务角色标注、环境场景的标注、多语种标注、情感标注等。
标注任务
常见的数据标注任务包括 分类标注、标框标注、区域标注、描点标注和其他标注
分类标注 Classification annotation
分类标注是从给定标签集中选择合适的标签分配给被标注的对象.
- 一张图可以有很多分类/标签, 如:运动、读书、购物、旅行等.
- 对于文字, 又可以标注出主语、谓语、宾语, 名词和动词等.
此项任务适用于文本、图像、语音、视频等不同的标注对象.
以图像分类标注为例:一张公园的风景图, 标注者需要对树木、猴子、围栏等不同对象加以区分和识别.
标框标注 Frame annotation
标框标注是从图像中选出要检测的对象, 此方法仅适用于图像标注.
标框标注细分为多边形拉框和四边形拉框两种形式.
- 多边形拉框(Polygonal frame): 是将被标注元素的轮廓以多边型的方式勾勒出来, 不同的被标注元素有不同的轮廓, 除了同样需要添加单级或多级标签以外, 多边型标注还有可能会涉及到物体遮挡的逻辑关系, 从而实现细线条的种类识别.
- 四边形拉框(Quadrilateral frame): 主要用特定软件对图像中需要处理的元素(比如人、车、动物等)进行一个拉框处理, 同时, 用1个或多个独立的标签来代表 1个或多个需要处理的元素.
例如, 对人物的帽子进行了多边形拉框标注, 则对天鹅进行了四边形拉框标注.
区域标注 Region annotation
与标框标注相比, 区域标注(Region annotation)要求更加精确, 而且边缘可以是柔性的, 并仅限于图像标注
- 主要应用场景包括自动驾驶中的道路识别和地图识别等.
区域标注任务是在地图上用曲线将城市中不同行政区域的轮廓形式勾勒出来, 并用不同的颜色(浅蓝、浅棕、紫色和粉色)加以区分
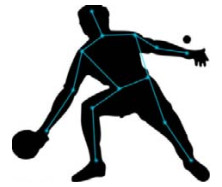
描点标注 Point annotation
描点标注将需要标注的元素(比如人脸、肢体)按照需求位置进行点位标识, 从而实现特定部位关键点的识别.
例如, 采用描点标注的方法对图示人物的骨骼关节进行了描点标识.
- 人脸识别、骨骼识别等技术中的标注方法与人物骨骼关节点的标注方法相同
- Point annotation
其它标注
数据标注的任务除了上述4种以外, 还有很多个性化的标注任务.
- 自动摘要是从新闻事件或者文章中提取出最关键的信息, 然后用更加精炼的语言写成摘要.
自动摘要与分类标注类似, 但两者存在一定差异.
- 分类标注有比较明确的界定, 比如在对给定图片中的人物、风景和物体进行分类标注时, 标注者一般不会产生歧义;
- 而自动摘要需要先对文章的主要观点进行标注, 相对于分类标注来说, 在标注的客观性和准确性上都没有那么严格, 所以自动摘要不属于分类标注.
数据标注角色
传统手工数据标注中的用户角色可以分为3类
- 1)
标注员: 标注数据, 由经过专业培训的人员来担任.在一些特定场合或者对标注质量要求极高的行业(例如医疗), 也可以直接由模型训练人员(程序员)或者领域专家来担任. - 2)
审核员: 审核已标注数据, 完成数据校对和数据统计, 适时修改错误并补充遗漏的标注. 这个角色往往由经验丰富的标注人员或权威专家来担任. - 3)
管理员: 管理相关人员, 发放和回收标注任务.
数据标注过程中的各个角色之间相互制约,各司其职, 每个角色都是数据标注工作中不可或缺的一部分.
此外, 已标注数据往往用于机器学习和人工智能中的算法, 这就需要模型训练人员利用人工标注好的数据训练出算法模型.而产品评估人员则需要反复验证模型的标注效果, 并对模型是否满足上线目标进行评估.
数据标注流程
数据标注基本流程
【2022-9-5】人工智能数据标注怎么做?流程是什么?
标注工具
【2022-9-25】标注工具总结
- 中文标注工具包
-
img,
- 深度学习标注工具汇总, 图像领域
| 工具名 | 开闭源 | 作者 | 体验地址 | 总结 | 备注 |
|---|---|---|---|---|---|
| IEPY | 开源 | - | 文档, |
工程完整,有用户管理系统。前端略重,对用户不是非常友好 | 安装失败 |
| DeepDive | 开源 | stanford | 前端代码,demo,失效, |
前端比较简单,用户界面友好 | 汉化版:DeepDiveChineseApps,DeepDive_Chinese |
| BRAT | 开源 | - | demo,git地址, |
英文 | |
| SUTDAnnotator | 开源 | - | 论文 | 非web,pythonGUI,但比较轻量 | - |
| Snorkel | - | - | demo,论文 | ||
| Prodigy | 闭源 | spaCy同家公司Explosion.ai | 示例, |
支持模型加载+主动学习,体验不错,但要收费 | - |
| 标注精灵 | 闭源 | 国内 | - | 中文环境,收费 | |
| 标注客户端 | 开源 | - | - | python开发,大而全 | - |
| ImageNet的GUI标注工具 | 开源 | - | - | 图像标注 | - |
| Universal Data Tool | 开源 | 国外 | - | 通用数据(标注)工具:用简单的网络界面/桌面应用协作标注图像、文本、文档等数据 | 安装失败 |
| MarkTool | 开源 | 个人 |  |
基于web的通用文本标注工具,支持大规模实体标注、关系标注、事件标注、文本分类、基于字典匹配和正则匹配的自动标注以及用于实现归一化的标准名标注,同时也支持文本的迭代标注和实体的嵌套标注 | |
| Chinese-Annotator | 开源 | 仿照Prodigy,主动学习,详情介绍 | 讨论区 | ||
| label-studio | 开源 | - | ,后端纯python编写,使用了flask,前端:React + MST | 界面相对美观,部署方便,可以明晰了解任务的完成度,支持图像、文本和音频等多种数据格式和多种任务数据的标注,但速度慢,没有账号体系 | 介绍 |
| doccano | 开源 | doccano demo, 代码,一站式文本标注工具,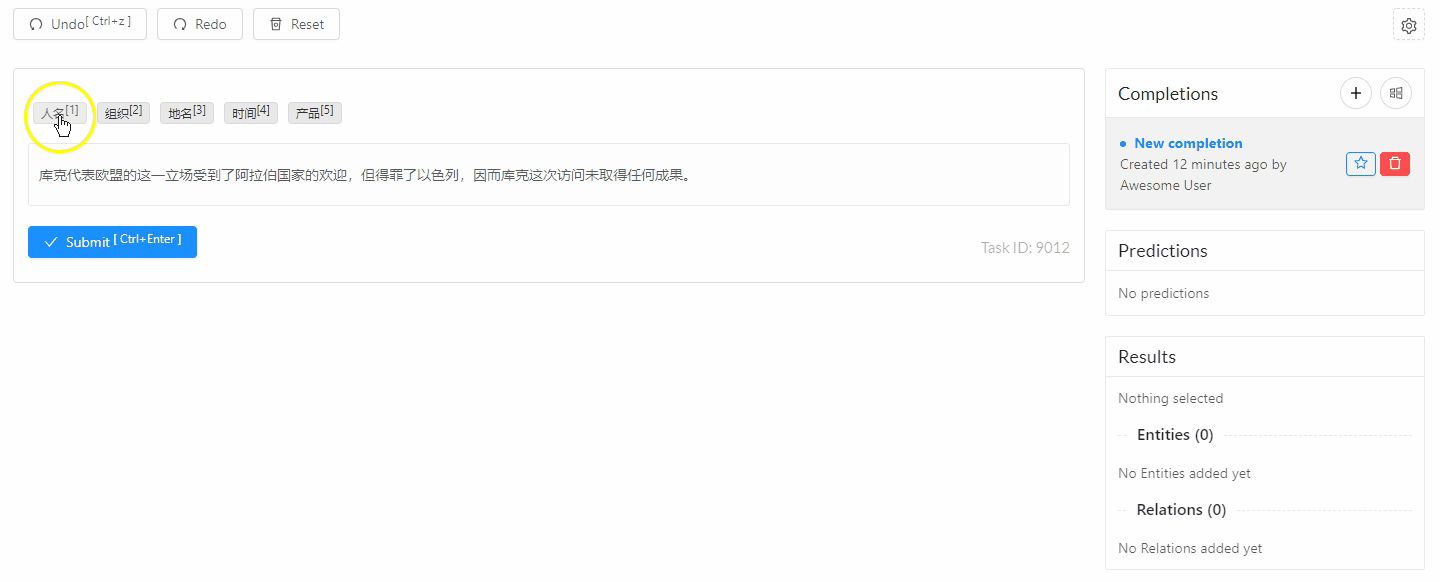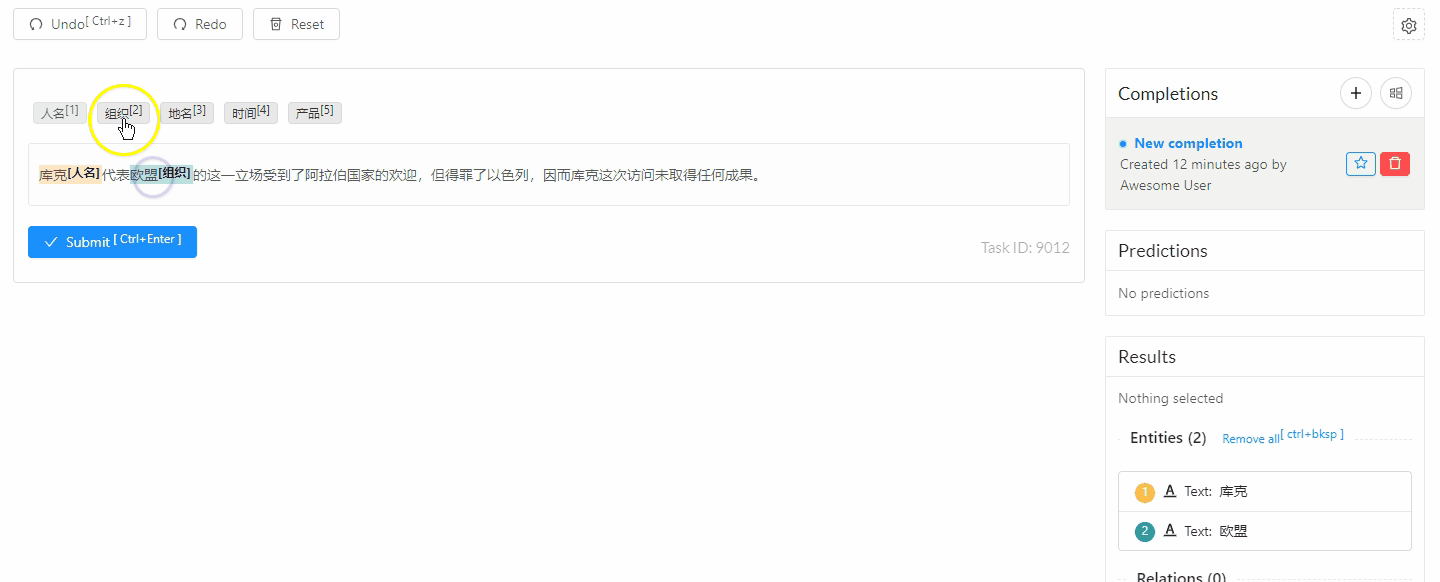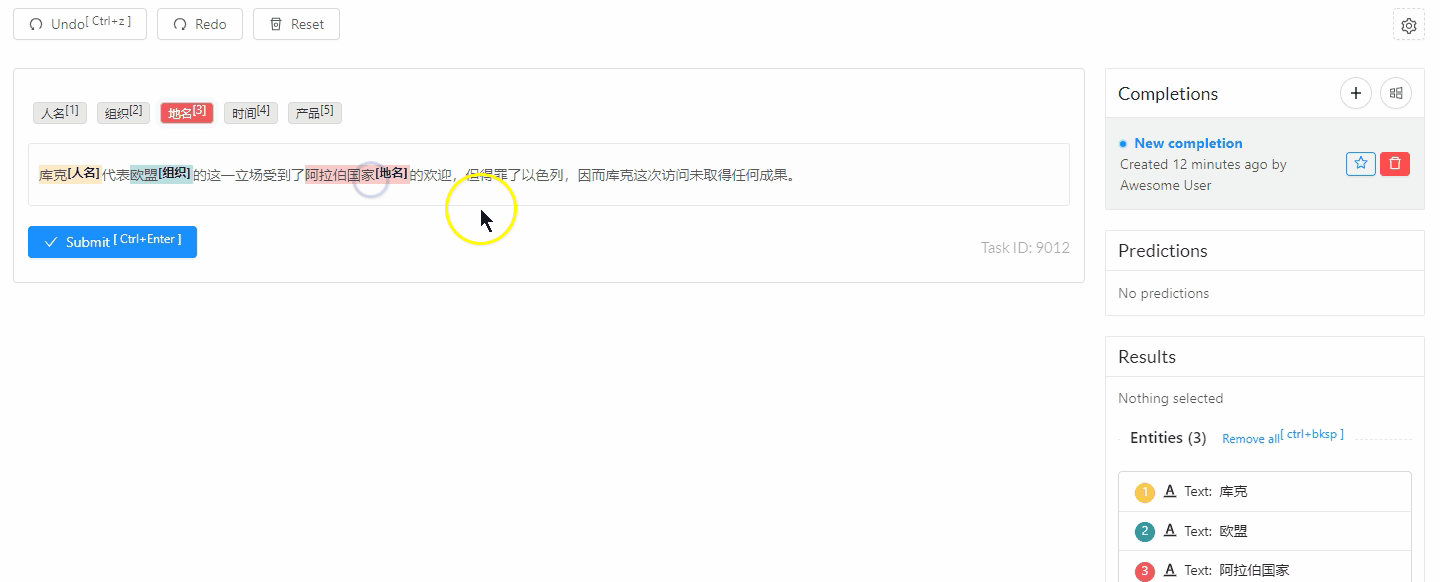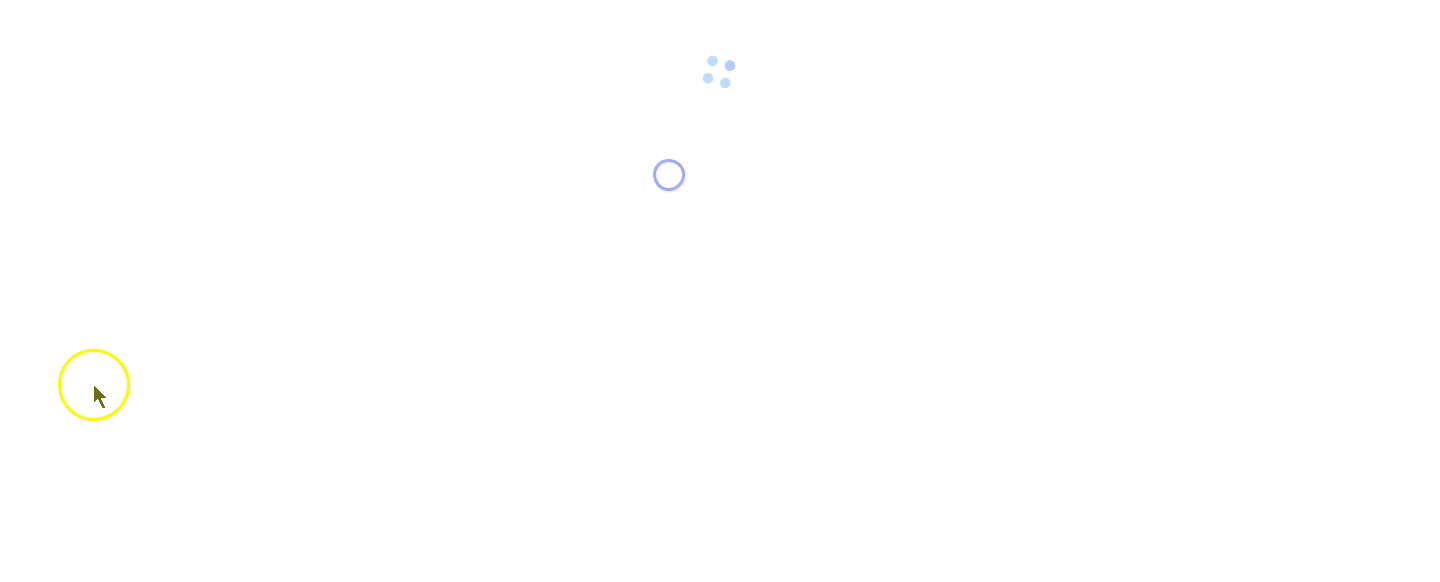 |
中文 | ||
LLM 标注范式
【2023-10-22】
- 作为标注员的LLM(一)– 蒸馏法, 方法一:蒸馏法
- 作为标注员的LLM(二):在弱监督学习的视角下, 方法二:多角度标注+弱监督学习法
- 【2022-5】Snorkel团队的论文 Language Models in the Loop: Incorporating Prompting into Weak Supervision
- 多角度对一个样本进行标注,要优于单prompt的标注效果
- 作为标注员的LLM(三):中文开源大语言模型的标注效果初体验(附代码), 中文任务上,参数量 < 10B的开源LLM的标注效果
- TNEWS新闻标题分类数据上,
ChatGLM2-6B和Qwen-7B-Chat标注效果还不够理想,要想学习到泛化性好的任务模型也仍然需要干净的验证集,并未摆脱验证集依赖 - 好消息:使用简单的ensemble策略,例如 Majority Vote,可明显提升效果。
- TNEWS新闻标题分类数据上,
- 作为标注员的LLM(四):开源大语言模型标注效果优化之Bias Calibration篇(文末附代码)
- 为标注员的LLM(五):3种标注范式以及思考
LLM 时代的NLP如何发展?
- LLM覆盖所有“传统”NLP能做的事,如:分类、信息抽取、摘要、翻译等,而且效果相当不错,优秀的Zero-Shot、Few-Shot能力大大拓宽了NLP的应用场景;
- 但LLM推理成本高,在低延时、高QPS的场景下难以直接应用,而在能应用的场景上,投入/产出比不如小模型
传统”NLP如何从LLM中获益?
- 最轻量级的方法:用LLM来标注数据
标注本质以及LLM作用
标注=常识+标注规则常识对应先验知识。有了常识能力,仅提供类别名称、而未提供标注规则就能进行标注。零样本NLP模型(如Siamese-uniNLU、paddleNLP)的核心。标注规则帮助标注员明确任务、区分边界。工作包括:任务定义、类别定义、边界处理逻辑等。
将LLM引入标注, 意味着有了标注员
- 具备相当常识。不提供细则,也能有良好的效果(范式1);
- 听懂人话、高效。标注规则通过自然语言表达,也通过自然语言修改,成本低、速度快、且人类可以理解(范式2、范式3)。
为什么用LLM
- 标注难。
- 如金融情感分类任务标注要求同时具有金融 + 社交媒体知识,对标注员的专业性要求高
- 人类也只能达到70%的标注一致性,仅通过人类难以获得大量的高质量标注样本;
- LLM标注效果好。
- LLM + In-Context Learning 来标注,在进行了promp工程之后发现效果不错,在Reddit上ACC达到72%,考虑到任务的难点,LLM标注效果符合预期,于是采用LLM来标注。
范式总结
使用LLM标注的3种范式:调参式、工具式、智能式。
- (1)
调参式: - (2)
工具式(局部使用) - (3)
智能式(智能体迭代)
各范式间的关系
智能式和调参式都用全局性LLM来完成标注任务;而工具式里LLM局部作用;智能式和工具式核心是迭代标注规则;而调参式核心是迭代与业务无关的变量(参数、prompt技术等);调参式可以结合在智能式、工具式当中,以进一步提升效果;
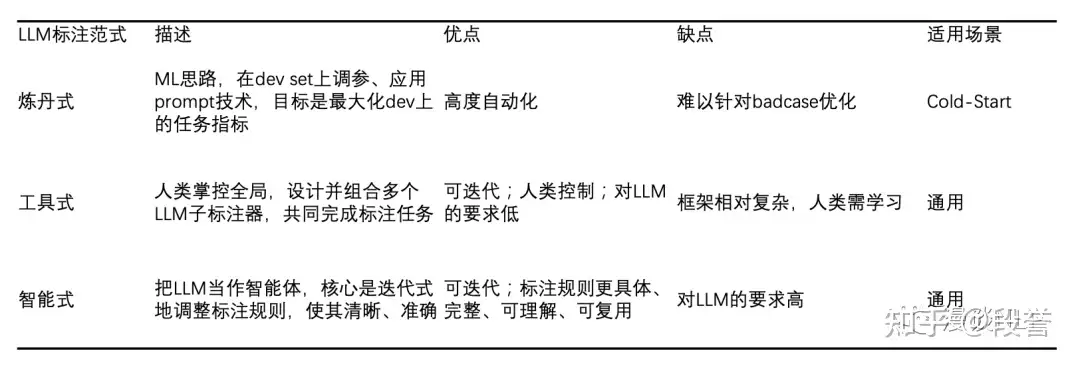
| 范式 | 说明 | 适用场景 | 优点 | 缺点 | 图解 |
|---|---|---|---|---|---|
调参式 |
prompt优化(非标注规则) | 冷启动 | 高度自动化 | bad case迭代不便 | |
工具式 |
LLM作为局部子标注器 | 通用 | 可控,对LLM依赖较低,支持case迭代 | 框架复杂,人工重 | |
智能式 |
所有工作都由prompt承担 | 只需修改标注规则 | 通用 | 对LLM要求高,具备复杂指令理解能力 |
调参式
- 重心是调整prompt中的非标注规则部分,调参数、应用prompt技术(如Self-Consistency、Chain-of-Thought、Bias Calibration、Few-Shot Prompting等);
- 目标:最大化dev set上的任务指标。
- 本质是炼丹,和传统的ML过程是一样的:在dev set上,通过调整超参、应用prompt技术,以得到能带来最佳效果的prompt。
- 优点:整个过程可以高度自动化;
- 缺点:难以针对badcase迭代;
- 适用场景:Cold-Start 冷启动。在没有业务经验的时候,可以快速得到第一版标注结果。
工具式
- Snorkel论文:Language Models in the Loop: Incorporating Prompting into Weak Supervision
- 特点:把LLM当作局部的子标注器,例如判断文本段落是否有联系方式;
- 人类负责把标注任务拆解为多个LLM子标注器的组合。拆解和组合方式,取决于数据分析和业务理解。
- 本质:Programmatic Weak Supervision 思路的扩展。
- 优点:
- 人类掌控全局,因此更可控;
- 对LLM的依赖性和要求较低,可以用较弱的LLM;
- 支持迭代,迭代的思路是新增LLM标注器、或者修改原有的LLM标注器;
- 缺点:框架相对复杂,人类使用者需要学习如何分析数据、设计子标注器;
- 适用场景:通用
智能式
- 代表: OpenAI使用GPT-4来标注(内容审核)的Blog: Using GPT-4 for content moderation
- 所有标注要求都通过prompt来表达,包括标签定义、标注边界情况的划分(例:如果XXXX,则标注XXX);
- 支持迭代,迭代Loop是 LLM标注 -> 找到标注错误 -> 让LLM解释标注原因 -> 迭代标注规则</span>,迭代目标是让让标注规则越来越精准。
- 本质: LLM当作智能体,人类则聚焦到标注的核心:让标注规则更清晰、准确。
- 优点:迭代只需修改标注规则,无需代码,且对比范式2,标注规则更加具体、完整、可理解、可复用(范式2是将标注规则抽象为 子标注器+逻辑关系);
- 缺点:对LLM要求高,尤其是对复杂指令的理解能力,因为标注规则会包含划分边界的if-else逻辑、对标签的详细定义等;
- 适用场景:通用。
LLM 标注方案
工具选择
建议
- 中小团队优先 X-AnyLabeling,擅长处理图像/视频标注(如目标检测、分割),能提升标注效率,通过自动化标注降低成本,且支持一键安装和跨平台,适配有限硬件资源。
- 企业级用户适合选择 Label Studio,处理多类型数据(如音频、时间序列)或复杂标注任务(如多模态融合),满足大规模团队协作标注与质量审核需求,且支持技术团队配置外部模型或自定义流程。
LLM 分类方法
总结
- (1)Prompt系列,除了直接PE,In-Context Learning 3种改进技术如下:
- Noisy Channel Model:2022年5月,华盛顿大学和Meta出品,根据贝叶斯概率公式,反其道而行之,将 Prompt 反着写,即将分类任务转化为生成任务
- Contextual Calibration(简称CC):2021年,消除ICL导致高方差的3类bias
- Domain-context Calibration(简称DC):2023年7月,瑞士苏黎世联邦,改进CC,消除llm、prompt和domain里的bias
- (2)蒸馏法:2023年,基于分类的蒸馏(CLS)、基于回归的蒸馏(REG),最后选择P-R曲线更平滑的REG,
- 最佳prompt组合技:manual few-shot COT + self-consistency
基础方法:通用分类+判别分类
LLM用于分类任务的方法:
- 通用分类 Generative Classifier:直接将LLM output(即token)作为分类结果,有Greedy Decode和Sample两种
- 优点:推理成本低,一次推理只需调用1次LLM
- 缺点:覆盖率 <= 100%,因为LLM的输出格式可能不规范(幻觉)
- 判别分类 Discriminal Classifier:对每个类别y,计算
P(y|x)- 优点:覆盖率 = 100%,由于可以拿到y的概率分布,扩展性强(可用于蒸馏、卡阈值等)
- 缺点:推理成本高,一次推理最多需要调用
|Y|次LLM,其中|Y|= 标签数量
| LLM分类方法 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| Generative Classifier | 直接使用LLM输出结果,分贪心解码和采样两种 | 推理成本低,调用1次即可 | 覆盖率 <= 100%(幻觉) |
| Discriminal Classifier | 对每个类别y,计算P(y|x) |
覆盖率 = 100% 易扩展(蒸馏/卡阈值) |
推理成本高,多次调用 |
LLM计算P(y|x)原理示意图
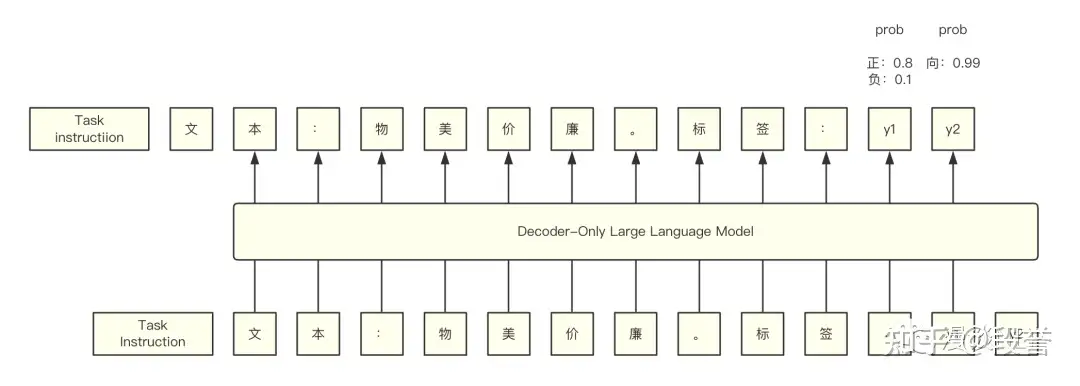
两种基本方法计算P(y|x):
Probability。概率连乘方式计算,即P(y|x) = P(y1|x) * P(y2|x,y1)P(正面|“物美价廉”)= 0.8 * 0.99 = 0.792P(负面|“物美价廉”)= 0.1 * 0.99 = 0.099
Average Log-Likelihood(简称Avg)。logP(y|x) = (logP(y1|x) + logP(y2|x,y1))/2P(正面|“物美价廉")= 0.8899P(负面|“物美价廉”)= 0.3146
前人论文指出Avg的方法效果好,因此采取Avg的方法来计算P(y|x)。
改进方法
In-Context Learning 3种技术如下:
- Noisy Channel Model
- Contextual Calibration(下文简称CC)
- Domain-context Calibration(下文简称DC)
2022.5 Noisy Channel Model:反其道而行之
【2022-5-】华盛顿大学和Meta出品
- 论文: Noisy Channel Language Model Prompting for Few-Shot Text Classification
- Code, GitHub: Channel-LM-Prompting
分类模型通过P(y|x)来进行分类,但是Noisy Channel Model却使用P(x|y)。

理论依据:
- 贝叶斯概率
P(Y|X) = ( P(X|Y) * P(Y) )/P(X) - 推理:
P(Y|X) \propto P(X|Y) * P(Y), 因为 P(X) 与P(Y|X)无关 - 推理:
P(Y|X) \propto P(X|Y), 假设 $P(Y)$ 均匀分布
要计算P(x|y),只需将 Prompt 反着写,即将分类任务转化为生成任务:
# 原Prompt:
文本:{input._text},标签:
# 现Prompt:
标签:{label_name},文本:
Noisy Channel Model在分类时需逐字考虑,因此比较鲁棒
2021 Contextual Calibration(CC):消除3类bias
In-Context Learning 具有高variance问题
- Task Instruction的写法、Few-Shot Examples的选择和呈现顺序等,都对最终的效果有影响。
CC 作者发现了3类bias可能是variance问题的元凶:
- majority label bias,指倾向于预测prompt中高频的label
- recency bias,指倾向于预测prompt中靠后的label
- common token bias,指倾向于预测在预训练数据中高频的label
作者提出校准方法—CC。其公式抽象如下:
P_CC(y|x) = P(y|x) / P(y|NULL)
其中, NULL表示content-free input(如’‘、空、N/A),实现方法比较简单,直接用content-free input替换原本的待推理样本,从而得到P(y|NULL)。
实验结果表明
- Zero-Shot、Few-Shot设定下,CC都可显著提升效果,并可减少variance。
2023.7.9 Domain-context Calibration(DC):再消除domain bias
【2023-7-9】瑞士苏黎世联邦
CC基础上,DC作者再次对bias进行了分类:
- vanilla label bias,与LLM本身参数有关,对应CC中的common token bias
- context label bias,与prompt有关,对应CC中的majority label bias与recency bias
- domain label bias,与input_text的分布有关,未被CC考虑
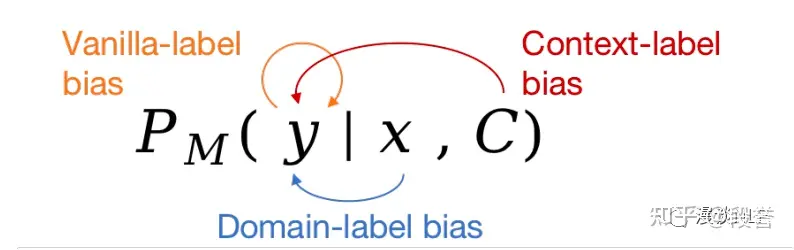
作者举例解释何谓 domain lable bias

在Tweet hate数据集上,随机从domain中抽取词语,LLM极大程度地预测其为hate,而随机英文单词的预测结果相对均衡,因此Tweet hate的domain label bias比较大;相比之下,SST-2就几乎没有domain label bias。
DC的公式如下:
P_DC(y|x) = P(y|x) / P(y|domain_random_words)
从方法来看,DC与CC的主要不同
- 用于校准的input不再是content-free input,而是domain_random_words
- 其组成方式是:从domain corpus中随机选L个word,其中L为domain data的平均长度。
在实践中常常重复这一步m步,再取m个结果的平均。
结果
- 引入更多domain信息的DC,效果比CC要好,尤其在那些本身的domain label bias比较大的数据集上。
蒸馏法
2023 WWW论文: What do LLMs Know about Financial Markets? A Case Study on Reddit Market Sentiment Analysis
- 蒸馏法: 基于分类的蒸馏(
CLS)、基于回归的蒸馏(REG),最后选择了P-R曲线更平滑的REG;- 最佳prompt组合技:manual few-shot COT + self-consistency
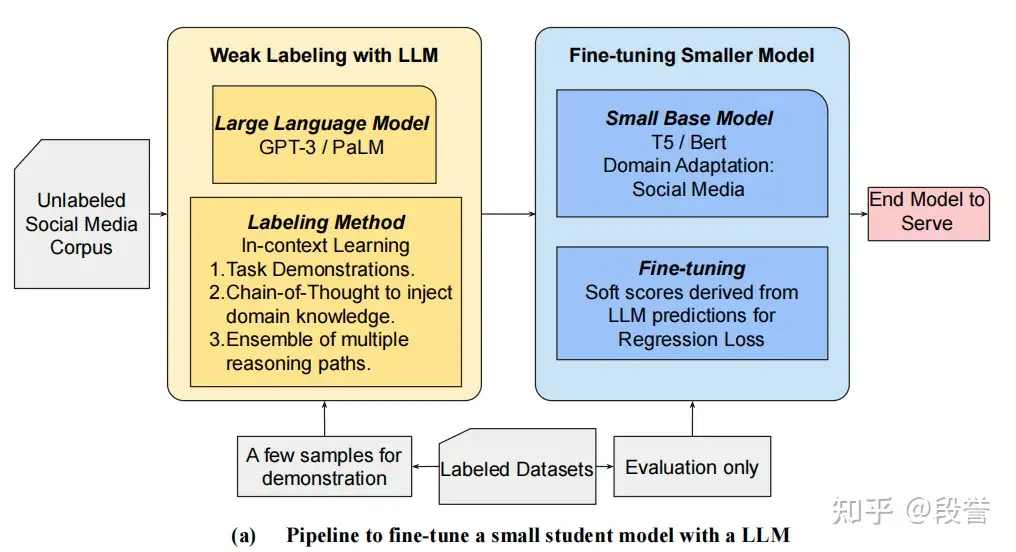
任务
- 社交媒体中的金融市场情感分析,判断帖子表达出的、针对某公司的financial sentiment
- 候选标签集合为:positive、negative和neutral
步骤
- 第一步:利用LLM来标注unlabel data,通过 样本 -> LLM -> hard/soft label,得到 弱标签数据 weakly labeled data;
- 第二步:更小的任务模型(
T5/BERT等)直接从 weakly labeled data 中进行监督学习。
仅保留了用于 self-consistency 的8次sample中,一致次数>=5次的样本
- 即丢弃了置信度低的样本,这些样本通常准确率也较低
2种方式来进行蒸馏:
CLS:每个样本得到 hard label(即最频繁出现的label),直接通过正常的分类loss(cross entropy)来学习;REG:每个样本得到 soft label(把sample 8次结果的agreement ratio,转换为label分布),通过regression loss(MSE)来学习。
CLS 和 REG 最佳效果接近(80.5 + 68.0 vs 84.2 + 65.5),但两种方法有不同特性:
- CLS 要更准确数据。随着 agreement减小,尽管数据多了,但 precision会下降,当agreement=8(即8次预测完全一样)时,效果最佳,但此时仅使用了31%的数据(用作蒸馏的数据共20000);
- REG 包容性更强。可用更多的、更难的(LLM预测更不一致)数据,在agreement=5时,效果最佳,可以使用85%的数据。
最终作者选择了REG。
- 一方面,REG用了更多的、更难的数据;
- 另一方面,REG的P-R曲线更平滑一些(部署时,需要根据预期presion来选择threshold,更平滑的话选点的效果更好)
用 self-consistency 来产生 soft label,进而蒸馏 —— 这种方法具有启发性,soft label比hard label更好
2022.5.4 Snorkel
作为标注员的LLM(二):在弱监督学习的视角下, 方法二:多角度标注+弱监督学习法
- 【2022-5-4】Snorkel团队的论文 Language Models in the Loop: Incorporating Prompting into Weak Supervision
- 多角度对一个样本进行标注,要优于单prompt的标注效果
Snorkel 是一个弱监督标注框架,专注于在标注层减少noisy label(而非学习层、模型层),去噪后的label直接供任务模型训练。
Snorkel使用步骤:
- 定义多种多样的Label Function(将sample映射到label的函数,简称LF),每个样本因此可得到多个weak label;
- LF可以是一段正则表达式、基于词库的匹配、或对模型预测结果的组合
- LF的输出为任务label集合中的某一个,或abstain(置信度不足时,放弃标注)
- 使用 Label Model,对weak labels进行去噪,得到 estimated label;
- 使用estimated label,以监督学习的方式训练任务模型。
如何将LLM融入Snorkel
- 不用再使用规则实现LF,用自然言语实现模糊概念
LLM作为一种全新范式labeler,只需编写自然语言prompt,即可实现LF功能。
- 领域专家编写多个prompt,实现多种prompted LF(每种LF对应一种角度);
- 在Label Map阶段,将LLM输出映射到任务label集合上;
- 使用Label Model去噪,得到estimated label;
- 将estimated label用于任务模型的监督式学习中。
prompted LF 标注的泛化性上明显强于rule-based LF,基于LLM标注结果训练的任务模型效果至少与rule-based LF相当
多角度prompt比单prompt要好
- Prompted WS在几乎所有数据集、所有LLM上,都显著优于zero-shot的效果。
ChatGPT 超过人工标注
【2023-3-29】ChatGPT超过人工标注
- ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
- Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT’s intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 – about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.
苏黎世大学:
ChatGPT标注数据比人类便宜20倍,80%任务上占优势
在ChatGPT面前,无论成本还是效率,人类可以说是毫无优势:
- 成本上,ChatGPT平均每个标注成本低于0.003美元,比众包平台便宜20倍;何况AI还能24*7无休。
- 效率上,在相关性、立场、主题等任务中,ChatGPT也是以4:1的优势“碾压”人类。
MTurk 是专门进行数据标注的一个众包平台。
- 在MTurk这类众包平台内部,还会有更加精细的分工,比如说会有经过专业训练的数据标注者以及众包工作者。
- 前者在产出高质量数据上具有优势,但自然成本也更高,而后者虽然更便宜但质量也会随任务难度波动。
于是, 研究大语言模型(LLM)在这方面的潜力,并且对比了没有额外训练(zero-shot)的ChatGPT(基于GPT-3.5)和MTurk在数据标注上的性能。这项对比基于研究团队此前收集到的2382条推文样本。
ChatGPT和MTurk分别将推文以“相关性、立场、主题、政策、实用性”这五种任务进行标注。
“生成训练数据需要人工”的说法已经成为过去式
【2026-2-*】OpenAI 发布《GPT as a Measurement Tool》,证明 GPT 作为打标员的工作表现已经和人类一致。
- 推出
GABRIEL(Generalized Attribute-Based Ratings Information Extraction Library)的Python库。本质是GPT API的prompt wrapper,但提供了标准化、可扩展、已验证的工作流。
GABRIEL 软件包依托 GPT 对定性数据中的各类特征进行量化分析(例如衡量一篇演讲的 “创新倾向” 程度)。研究针对千余项由人工标注的多主题、多类型任务,从分类效果与特征评分表现两方面对 GPT 展开评估。
结果表明,将 GPT 作为测量工具在各领域均具备较高准确度,其评估结果与人类标注者的判断基本无显著差异。
研究证据显示:标注结果不受具体提示词策略的影响,且 GPT 并非依赖训练数据污染或通过其他特征间接推断目标属性。本文通过量化分析国会发言、社交媒体有害言论以及县级学校课程中全新且细致的变化趋势,展示了 GABRIEL 的应用潜力。
随后运用 GABRIEL 探究技术普及史,构建了包含 37000 项技术的全新数据集。分析结果显示,工业时代以来,技术从发明到普及的时间滞后缩短了十倍,从约 50 年降至如今的约 5 年。本文还量化了企业与美国在创新领域日益凸显的主导地位,并梳理出决定一项技术普及速度快慢的关键特征。
核心方法包括:
- 测量类:rate(0-100打分)、rank(ELO式配对比较排名)、classify(分类)、extract(结构化信息提取)、discover(发现区分两组数据的自然语言特征)
- 数据清洗类:merge(交叉匹配)、deduplicate(去重)、filter(大规模布尔筛选)、deidentify(去标识化) 成本方面非常惊人:对240篇国情咨文在10个属性上打分,用最便宜的模型只需$0.14,人类标注需要约$2,600——差距约17,500倍。
论文还替代生成了大量风格差异很大的 prompt 版本(短的、古英语的、全大写的……),结论:不同 prompt 得到的结果非常接近,长 prompt 并没有系统性收益。(其实很合理,thinking model 应该可以克服 prompt 导致的性能下降问题
ChatGPT NER Demo
ChatGPT 用于 人工标注的 Web系统:Weak Labeling Tool using ChatGPT, 代码

git clone https://github.com/ainbr/chatgpt-weak-labeler-webui.git
pip install -r requirements.txt
gradio app.py
填入OpenAI Key即可启动NER任务
【2023-6-18】无需人力标注!悉尼大学华人团队提出”GPT自监督标注范式
业界和学界面临数据标注任务:成本较高、存在偏见、难以评估,以及标注难度等问题。
悉尼大学研究团队提出了一种通过大语言模型自监督生成标注的框架。首次利用基于生成-还原循环标注的GPT自监督方法,解决了上述问题
- davinci,text-curie-001,text-davinci-003,gpt-3.5-turbo在不同评估标准下标注数据质量的得分
- 论文链接
核心思想: 利用大语言模型作为一个黑盒优化优器,构造了一个循环:
- 模版质量越高,生成的数据-标注对质量越高;
- 生成的数据标注对质量越高,用当前质量更高的数据对替换上一轮的模版。
- 以此往复迭代,滚雪球式循环提升标注质量。
标注方法包含了one-shot阶段和生成阶段。
- one-shot阶段的目标:迭代寻找最优的 {数据-标注}数据对 作为模板。
迭代过程:
- 初始化一个简单数据对作为初始模版,利用GPT生成标注,生成的标注和原始数据形成一个新的数据对。
- 然后,通过比较从标注中还原出来的数据和原始数据,评估这个新数据对作为模板的潜力。
- 如果还原数据与原数据的相似度得分有所提高,就用当前新数据对直接作为新的模板进行一轮数据生成。
因此,这种自我对齐机制会迭代调整one-shot模板,为下一轮生成做好准备。one-shot阶段搜索到的最优模板随后用于对数据集进行标注。
通过调整不同的预训练奖励模型来评估标注的质量,并引入不同的评价指标来间接评估摘要的还原能力。
Autolabel
【2023-6-19】GPT-4终结人工标注!AI标注比人类标注效率高100倍,成本仅1/7
数据标注需要找到一个新方法,避免大量使用人工标注带来的包括道德风险在内的其他潜在麻烦。所以,包括谷歌/Anthropic在内的AI巨头和大型独角兽,都在进行数据标注自动化的探索。
- 谷歌最近的研究,开发了一个和人类标注能力相近的AI标注工具
- Anthropic采用了Constitutional AI来处理数据,也获得了很好的对齐效果
初创公司refuel,也上线了一个AI标注数据的开源处理工具:Autolabel。用AI标注数据,效率最高提升100倍. introducing-autolabel
- 按照使用成本最高的GPT-4来算,采用
Autolabel标注的成本只有使用人工标注的1/7,而如果使用其他更便宜的模型,成本还能进一步降低

要点
- 1、开源工具Autolabel能用LLM代替人工高效标注数据,效率提升100倍,成本仅1/7。
- 2、Autolabel支持主流LLM,可快速标注NLP数据集,准确率高达88.4%,超过人工标注。
- 3、Autolabel可估计标注置信度,不同LLM可平衡成本与质量,大幅降低标注门槛。
Autolabel安装
# 安装所有必要的库
pip install 'refuel-autolabel[openai]'
from autolabel import get_data
get_data('civil_comments')
自动标签贴标分为三个步骤:
- 首先,指定一个标签配置(参见下面的config对象)并创建一个LabelingAgent。
- 接下来,通过运行agent.plan,使用config中指定的LLM对的数据集进行一次标注
- 最后,使用agent.run运行标签
LabelFast
【2023-11-3】LabelFast:基于LLM的NLP任务自动标注开源工具,Demo发布「AI小作坊」
特点如下:
- 开箱即用。无需微调和Prompt工程,提供 标注任务 + 样本,马上开始标注;
- 诚实可信。在提供标注结果的同时,还提供Confidence信息,以表示模型对标注结果的信心程度,便于使用者确定何时信任模型结果;
- 完全开源。LabelFast源于开源的模型和技术,因此也将回馈开源社区。
LabelFast的核心理念是:
- 用最快的速度,完成简单样本的标注,让人类聚焦于关键的难样本。
常见使用场景
- 单条样本标注: 将单条样本填入文本框 -> 执行标注 -> 得到标注结果;
- 批量样本标注: 将多条样本,按格式做成xlsx/csv文件 -> 上传文件 -> 执行标注 -> 得到批量标注结果;
- 批量样本标注 + 选择confidence threshold: 将多条样本 + 真实标签,按格式做成xlsx/csv文件 -> 上传文件 -> 执行标注 -> 得到批量标注结果 + 各confidence threshold下的任务表现(output2) -> 根据任务表现,确定confidence threshold,高于此值的自动标注结果可直接使用,低于此值的通过其他方式标注
autolabel
autolabel 是由Refuel AI开发的开源Python库, 用大语言模型(LLM)对文本数据集进行快速、高质量的标注。
数据科学家和机器学习工程师可以将数据标注速度提高25-100倍,同时保持人工标注级别的质量
支持多种NLP任务,如分类、命名实体识别、问答等,可以使用OpenAI、Anthropic 等商业LLM或开源LLM进行标注。
核心功能:
- 支持多种NLP任务的数据标注,包括分类、命名实体识别、实体匹配、问答等。
- 可用OpenAI、Anthropic、Google等商业LLM,也支持通过HuggingFace使用开源模型。
- 提供few-shot学习、思维链等提示技术,提高标注质量。
- 内置标签置信度估计和解释功能。
- 缓存和状态管理,降低成本并加快实验速度。
安装库:
pip install refuel-autolabel
创建配置文件, 指定标注任务、使用的LLM等信息。
初始化标注agent并传入配置:
from autolabel import LabelingAgent, AutolabelDataset
agent = LabelingAgent(config='config.json')
预览prompt并运行标注:
ds = AutolabelDataset('dataset.csv', config=config)
agent.plan(ds)
【2024-1-8】图片标注
【2024-1-8】告别逐一标注,一个提示实现批量图片分割,高效又准确
Segment Anything Model (SAM) 在图像分割领域引起了巨大的关注,其卓越的泛化性能引发了广泛的兴趣。然而,尽管如此,SAM 仍然面临一个无法回避的问题:
- 为了使 SAM 能够准确地分割出目标物体的位置,每张图片都需要手动提供一个独特的视觉提示。
目前的一些方法,如 SEEM 和 AV-SAM,通过提供更多模态的输入信息来引导模型更好地理解要分割的物体是什么。然而,尽管输入信息变得更加具体和多样化,但在实际场景中,每个无标注样本仍然需要一个独特的提示来作为指导,这是一种不切实际的需求。
伦敦大学玛丽女王学院的研究者们提出了一种无需训练的分割方法 GenSAM ,能够在只提供一个任务通用的文本提示的条件下,将任务下的所有无标注样本进行有效地分割。
Generalizable SAM(GenSAM)模型旨在摆脱像 SAM 这类提示分割方法对样本特定提示的依赖。
作者提出了一个跨模态思维链(Cross-modal Chains of Thought Prompting,CCTP)的概念,将一个任务通用的文本提示映射到该任务下的所有图片上,生成个性化的感兴趣物体和其背景的共识热力图,从而获得可靠的视觉提示来引导分割。此外,为了实现测试时自适应,作者进一步提出了一个渐进掩膜生成(Progressive Mask Generation,PMG)框架,通过迭代地将生成的热力图重新加权到原图上,引导模型对可能的目标区域进行从粗到细的聚焦。值得注意的是,GenSAM 无需训练,所有的优化都是在实时推理时实现的。
上海AI Lab
OpenDataLab 开源工具 🎉
- OpenDataLab 引领 AI 大模型时代的开放数据平台,提供了海量的、多模态的优质数据集,助力 AI 开发落地
- LabelLLM 专业致力于 LLM 对话标注,通过灵活的工具配置与多种数据模态的广泛兼容,为大模型打造高质量数据
- LabelU 多模态标注平台,覆盖图像、视频、语音,不含文本
- MinerU 一站式开源高质量数据提取工具,支持多格式(PDF/网页/电子书),智能萃取,生成高质量语料
【2024-1-1】LabelU 不支持文本
【2024-1-1】上海AI实验室推出的开源标注系统 LabelU : Opendatalab 多模态标注神器
LabelU 提供了多种标注工具和功能,支持图像、视频、音频标注。
- 图像类的多功能图像处理工具,涵盖 2D 框、语义分割、多段线、关键点等多种标注工具,协助完成图像的标识、注释和分析。
- 视频类标注具备强大视频处理能力,可实现视频分割、视频分类、视频信息提取等功能,为模型训练提供优质标注数据。
- 音频类高效精准的音频分析工具,可实现音频分割、音频分类、音频信息提取等功能,将复杂的声音信息直观可视化。
功能
- 多功能图像标注工具:包括2D框、语义分割、多段线、关键点等多种标注方式。这些工具能够灵活应对诸如目标检测、场景分析、图像识别、机器翻译等各种图像处理任务。
- 强大的视频标注功能:支持视频分割、视频分类以及视频信息提取等功能。非常适合应用于视频检索、视频摘要、行为识别等任务。
- 高效的音频标注工具:支持音频分割、音频分类和音频信息提取。通过将复杂的声音信息直观化展示。

特性
- 简易,提供多种图像标注工具,通过简单可视化配置即可标注
- 灵活,多种工具可自由组合使用,满足大部分图像,视频,音频的标注需求
- 通用,支持导出多种数据格式,包括 JSON,COCO,MASK
注
- 不支持文本标注!
- 基于LabelU-kit 进行开发
安装
pip install labelu
labelu # 启动
labelu --host 0.0.0.0
【2024-6-9】LabelLLM
【2024-6-9】LabelLLM 是一个开源的数据标注平台
介绍
国内公司 Opendatalab 推出开源数据标注平台 LabelLLM
- 全面的任务管理解决方案,实时监控标注进度和质量控制
- 多样化的多模态数据支持, 图片、视频、音频、公式
- 简化并增强模型训练的数据注释过程的效率。整合人工智能辅助的标注
- 注重用户体验,提供直观的配置和工作流程,简化了数据标注任务的设置和分配。预标注数据的一键载入
在线体验 labelu-llm-demo
功能
| 功能 | 说明 | 图解 |
|---|---|---|
| 配置灵活 |  |
|
| 多模态数据 |  |
|
| 标注任务管理 |  |
|
| AI预标注 |
标注端视频演示
资料
使用
git clone https://github.com/opendatalab/LabelLLM.git
cd LabelLLM
docker compose up
# 打开浏览器,访问Localhost:9001
# 用户名:user 密码:password
# 修改Access key 为: MINIO_ACCESS_KEY_ID = MekKrisWUnFFtsEk MINIO_ACCESS_KEY_SECRET = XK4uxD1czzYFJCRTcM70jVrchccBdy6C
# 打开浏览器,访问以下地址即可进入:
http://localhost:8086/supplier # 标注端
http://localhost:8086/operator # 管理端
AutoAlign
【2024-8-14】 TKDE 2024-彻底摒弃人工标注, AutoAlign 方法基于大模型让知识图谱对齐全自动化
传统知识图谱对齐方法必须依赖人工标注来对齐一些实体(entity)和谓词(predicate)等作为种子实体对。
这样的方法昂贵、低效、而且对齐的效果不佳。
清华大学、墨尔本大学、香港中文大学、中国科学院大学学者联合提出了一种基于大模型的全自动进行知识图谱对齐的方法——AutoAlign。
AutoAlign 彻底不需要人工来标注对齐的种子实体或者谓词对,而是完全通过算法对于实体语义和结构的理解来进行对齐,显著提高了效率和准确性。
- 论文题目:AutoAlign: Fully Automatic and Effective Knowledge Graph Alignment enabled by Large Language Models
- 代码链接:AutoAlign
AutoAlign 主要由两部分组成:
- 用于将
谓词(predicate)对齐的谓词嵌入模块(Predicate Embedding Module)。 - 用于将
实体(entity)对齐的实体嵌入学习部分,包括两个模块:属性嵌入模块 (Attribute Embedding Module)和结构嵌入模块(Structure Embedding Module)。
在最新的基准数据集DWY-NB (Rui Zhang, 2022) 上进行了实验
- AutoAlign 在知识图谱对齐性能方面有显著提升,特别是在缺少人工标注种子的情况下,表现尤为出色。
- 在没有人工标注的情况下,现有的模型几乎无法进行有效对齐。
- 然而,AutoAlign 在这种条件下依然能够取得优异的表现。在两个数据集上,AutoAlign在没有人工标注种子的情况下,相比于现有最佳基准模型(即使有人工标注)有显著的提升。
AutoAlign不仅在对齐准确性上优于现有方法,而且在完全自动化的对齐任务中展现了强大的优势。
Label Studio
企业级用户适合选择 Label Studio,能够处理多类型数据(如音频、时间序列)或复杂标注任务(如多模态融合),满足大规模团队协作标注与质量审核需求,且支持技术团队配置外部模型或自定义流程
【2024-9-13】开源数据标注平台 Label Studio
介绍
Label Studio 是一个开源数据标注和数据管理平台,由 Human Signal开发并维护。
- 提供直观、灵活且可扩展的平台,用于对各种类型的数据(如文本、图像、音频、视频等)进行高质量的标注工作。
- 官方版 label-studio
- 中文版 label-studio-chinese
- playground
功能
提供多模态数据支持、丰富的可视化界面以及自定义标注模板的能力,这些特性使得 Label Studio 成为了一个灵活、高效且适用于多种领域和场景的数据标注平台,能够降低标注门槛,提高标注效率和准确性。
- 多模态数据支持
- Label Studio支持文本、图像、语音、视频等多种类型的数据标注,满足不同领域和场景的需求。
- 丰富的可视化界面
- 提供直观、易用的用户界面,降低数据标注的门槛,提高标注效率。
- 自定义标注模板
- 内置多种标注模板,同时允许开发者根据具体业务场景自定义模板,提高标注的针对性和准确性。
标注模版
- 官方 nlp模版
自动标注
labelstudio 有自动标注功能,通过模型对数据进行预测然后在页面上呈现出来
文本标注
文本标注:Label-Studio 在文档处理领域展现出强大的能力,支持大规模分类(最多可达10,000个类别)、命名实体识别、问答系统训练及情绪分析等多种标注任务。
文档分类:创建分类项目,上传待分类的文档,并定义分类标签。标注者可以根据文档内容将其归类到相应的类别中。命名实体识别:创建NER项目,并定义需要识别的实体类型(如人名、地名等)。标注者随后会在文本中标注出这些实体,并将其归类到相应的类别中。问答系统:创建问答标注项目,并上传包含问题、答案的文本数据。标注者将问题与答案进行关联,以生成训练数据。情绪分析:创建情绪分析项目,并定义情绪标签(如正面、负面、中性)。标注者随后会阅读文本内容,并根据其表达的情绪倾向进行标注。
图像标注
图像标注:Label-Studio 为计算机视觉领域提供了强大灵活的图像标注解决方案,支持图像分类、物体检测、语义分割等多种标注任务,提升标注效率和准确性。
图像分类:根据图像的语义信息将不同类别的图像区分开来。这是计算机视觉中的基本任务,也是其他高层视觉任务(如图像检测、图像分割等)的基础。物体检测:检测图像上的物体,并使用框(边界框)、多边形、圆形或关键点等形状进行标注。这有助于机器学习模型学习如何识别图像中的特定物体及其位置。语义分割:将图像分割成多个具有特定语义含义的片段。这需要对图像中的每个像素进行分类,实现像素级别的分类和标注。
语音标注
语音标注:Label-Studio 在音频和语音应用方面提供了全面的支持,包括音频分类、说话人分类、情绪识别和音频转录等功能,帮助用户高效地处理和分析音频数据。
音频分类:将音频文件根据其内容或特征进行分类。这可以用于多种场景,如音乐分类(摇滚、爵士、古典等)、环境声音识别(街道噪音、雨声、鸟鸣等)等。说话人分类:根据说话者的身份或特征将音频流划分为同质片段。这在语音识别、会议记录、电话客服等场景中非常有用,可以帮助区分不同的说话者或识别特定的语音特征。情绪识别:从音频中标记并识别情绪,如高兴、悲伤、愤怒、平静等。这对于情感分析、心理研究、客户服务等领域具有重要意义。音频转录:将口头交流用文字记录下来的过程。可以与语音识别系统(如NVIDIA NeMo)集成,实现自动或半自动的音频转录功能。
视频标注
视频标注:Label-Studio 提供视频分类、对象追踪及关键帧标注功能,助力高效、准确的视频数据标注工作。
视频分类:在Label-Studio中创建项目,上传视频并定义分类标签,标注者根据视频内容选择相应标签进行分类。对象追踪:设置视频对象追踪项目,上传视频并配置追踪工具,标注者逐帧或关键帧标记对象位置,实现对象在视频中的追踪。辅助标注:标注者选择视频中的关键帧并精确标注对象位置,可选地结合外部工具进行自动插值以估算非关键帧的对象位置。
时间序列标注
时间序列标注:Label-Studio 通过一些创造性的方法(如转换数据格式、使用外部工具、自定义标签类型等)来处理时间序列数据的分类、分割和事件识别任务。
时间序列分类:将时间序列数据转换为表格形式,其中每一行代表一个时间点,每一列代表不同的特征(如时间序列中的值、时间戳等),为每个时间序列样本分配类别标签。分割时间序列:使用Python等编程语言进行时间序列的分割,并将分割结果(如分割点的索引或时间戳)作为标签导入Label-Studio进行验证或进一步处理。事件识别:使用Label-Studio中的“矩形”或“多边形”标签来标记图表上的事件区域。这通常适用于那些可以通过视觉识别的事件,如峰值、谷值或突然的变化。
安装
labelstudio 提供了多种安装方式如:docker,pip,本地运行。这里我们以pip方式为例进行安装
# 首先创建conda环境
conda create -n labelstudio python=3.11
# 进入虚拟环境
conda activate labelstudio
# 安装
pip install label-studio
# pip install -U label-studio
# 启动,默认8080端口
label-studio start
# 指定端口启动
label-studio start --port 9001
标注模版
【2025-9-25】Label Studio 自定义模板教程:从零构建专属标注界面
通用模板往往无法完美适配特定场景,导致标注效率低下或数据格式不统一。Label Studio 提供强大的模板自定义功能,根据业务需求构建专属标注界面。
Label Studio 标注模板基于 XML 格式构建,通过组合不同标签(Tag)实现界面定制。
核心标签分为对象标签(Object Tag)和控制标签(Control Tag)两类:
对象标签:展示待标注数据,如<Image>、<Text>、<Audio>等控制标签:定义标注交互方式,如<Choices>、<TextArea>、<Rating>等
所有标签必须包裹在 <View> 根标签内,形成完整的标注界面结构。
- 官方提供的模板定义在 label_studio/annotation_templates/ 目录下,包含计算机视觉、自然语言处理等多个领域的标准模板。
数据类型
- 除了 Text,还有别的样式,如 Table、Image、Audio等类型
<Table name="data" value="$table" />
<Image name="image" value="$image" width="50%" />
多值数据
- 使用 valueList 属性实现多值数据展示,如批量文本分类
<View>
<List name="texts" value="$texts" valueList="items">
<Text name="item" value="$items.text" />
<Choices name="class" toName="item" choice="single">
<Choice value="垃圾邮件" />
<Choice value="正常邮件" />
</Choices>
</List>
</View>
自动调用模型结果
- 通过
<Model>标签集成预标注模型,实现智能辅助标注
<View>
<Text name="text" value="$text" />
<!-- 显示模型预测结果 -->
<Model name="spam_detector" value="$predictions" />
<Choices name="result" toName="text">
<Choice value="垃圾邮件" />
<Choice value="正常邮件" />
</Choices>
</View>
(1) 文本分类模版示例
- name:控件唯一标识,用于结果数据的字段命名
- value:数据绑定表达式,
$text表示绑定任务数据中的 text 字段 - toName:指定控制标签关联的对象标签名称
<View>
<!-- 展示待分类文本 -->
<Text name="text" value="$text" />
<!-- 分类选择控件 -->
<Choices name="category" toName="text" choice="single">
<Choice value="新闻" />
<Choice value="评论" />
<Choice value="广告" />
</Choices>
</View>
(2) 进阶交互式
- 带标签多选和文本备注的模板
<View>
<Text name="content" value="$content" />
<!-- 多选标签 -->
<Choices name="topics" toName="content" choice="multiple">
<Choice value="技术" />
<Choice value="教育" />
<Choice value="健康" />
</Choices>
<!-- 文本备注 -->
<TextArea name="comment" toName="content"
placeholder="输入备注信息..."
rows="3" />
</View>
(3)数据验证与样式定制
- 添加验证规则和样式属性,提升标注体验
<View style="padding: 20px; max-width: 800px;">
<Text name="title" value="$title" style="font-size: 18px; font-weight: bold;" />
<View style="margin-top: 10px;">
<Choices name="sentiment" toName="title" required="true">
<Choice value="正面" background="green" />
<Choice value="负面" background="red" />
<Choice value="中性" background="gray" />
</Choices>
</View>
<TextArea name="analysis" toName="title"
required="true"
validate="url"
placeholder="输入分析链接(可选)" />
</View>
X-AnyLabeling
X-AnyLabeling 是开源、工业级数据标注工具,专为深度学习模型训练提供高效、精准的数据标注解决方案。
X-AnyLabeling 无缝集成多种深度学习算法,开箱即用,支持图像、视频、文本等多模态数据的自动化标注,适用于目标检测、图像分割、OCR 等复杂任务。
X-AnyLabeling通过内置 SOTA 模型(如 YOLO、RT-DETR)实现“零样本标注”,减少人工重复劳动;
同时界面简洁直观,操作与主流工具(如 LabelImg、CVAT)对齐,新手能快速上手
使用
安装X-AnyLabeling
准备 Python环境并安装基础依赖,从GitHub 获取源码并安装核心依赖库,运行 python main.py 启动工具,最后验证安装能否正常自动化标注
git clone https://github.com/your-repo-link.git
cd X-AnyLabeling
【2026-4-8】LabelPaw
【2026-4-8】LabelPaw - 智能图像标注系统 (v2.0.0)
借鉴 labelme、labelimg 等工具,结合 SAM2、SAM3、YOLO 姿态估计等优秀的视觉模型,开发更智能、更高效的标注工具。经过多次迭代,系统迎来了全新的 2.0.0 版本!
- 源码地址:LabelPaw
核心功能特性
- ✨ AI 智能辅助 (SAM2/SAM3 驱动):鼠标悬停预览、单点快速提取轮廓、输入文本提示词全图目标自动分割。
- 🦴 关键点骨架模板与智能 (YOLO 驱动)标注:支持矩形、分割、obb、关键点智能标注,关键点内置行人(17个关键点)、人脸(68个关键点)、手部(21个关键点),关键点标注可自定义骨架模板。
- 📐 全能标注模式:矩形 (Rect)、多边形 (Poly)、点 (Point)、OBB 旋转框以及关键点 (Pose)。
- 🔄 极致 OBB 交互:旋转框控制手柄,360° 无极顺滑旋转与贴墙滑动检测。
- 💾 多格式互转与导出:原生保存 JSON、YOLO (.txt)、XML (Pascal VOC),可一键生成 U-Net Mask。
- 🗄️ 数据集处理工作流:支持按比例切分训练集/验证集/测试集
新技术
扭矩聚类
【2025-2-17】AI扭矩聚类算法:自主学习、无需标注,准确率高达97.7%的颠覆性突破
详见站内专题: 聚类分析
LLM 标注实践
开源模型实测
- 作为标注员的LLM(三):中文开源大语言模型的标注效果初体验(附代码), 中文任务上,参数量 < 10B的开源LLM的标注效果,实验基础方法
- 作为标注员的LLM(四):开源大语言模型标注效果优化之Bias Calibration篇(文末附代码), 实验高级方法
基础方法
TNEWS新闻标题分类数据上
ChatGLM2-6B和Qwen-7B-Chat标注效果还不够理想,不如零样本分类模型- 要想学习到泛化性好的任务模型也需要干净的验证集,并未摆脱验证集依赖
- 同类型标注员的一致性要明显大于不同类标注员
- 简单的ensemble策略(如Majority Vote),可明显提升效果,但无法超越人类。
实验的 In-Context Learning技巧为:Self-Consistency、Few-Shot Prompting。
- 代码: LLM_annotator
Prompt构造结构
- label_name_list 为分类标签的中文名称
- example 为 few-shot examples
- input_text 为待预测样本。
label_name_list = ['积极','中性','消极']
example = "[1] .... \n[2] ...."
input_text = "测试"
prompt = f'''
给定一段文本,输出一个分类标签。
分类标签集合:[{','.join(label_name_list)}]
请直接输出结果,不要附带其他内容。
{example}
文本:'{input_text}'
这段文本所属标签:
'''
Few-Shot 和 Self-Consistency 效果不总是正向,覆盖率或准确率反而可能下降。主要原因是模型参数量太小,不足以涌现出Few-Shot、Self-Consistency能力
综合考虑覆盖率和准确率
ChatGLM2-6B选择Prompt策略为:Zero-Shot Prompt+Self-Consistency* 3;Qwen-7B-Chat选择的策略为:Zero-Shot Prompt。- 实验数据见原文
Cohen’s Kappa Score 来衡量标注员的一致性
- 首先,所有标注员之间的Kappa得分都在0.4以上,属于中等一致性;
- 其次,同类标注员间的一致性明显更大,这与相近的模型结构、相近的训练方式、相近的训练数据有关。
ensemble方法:
- Majority Vote。取多个标注中最频繁的结果,隐含假设是每个标注员是独立且重要性一致
- Label Model(来自Snorkel)。可建模标注员间的关系,可自动学习标注员的权重
两个方法各有优劣。
- Majority Vote
准确率很高,但是牺牲了覆盖率(当4个标注员无法进行Majority Vote时,则放弃此次标注); - Label Model 效果更加均衡,可覆盖所有样本,但是准确率相对更低一些。
但是,两个方法都要比单独标注员效果要好, 明显的效果提升,Acc可以提升2% 绝对值, 即便覆盖率降低,但准确率大幅提升
改进方法
实验高级方法
优化版
- 在TNEWS(新闻标题分类)和NLPCC2014-Task2(微博情感二分类)数据上
- In-Context Learning试验的3种技术:
- Noisy Channel Model
- Contextual Calibration(简称CC)
- Domain-context Calibration(简称DC)
- DC可明显提升
Qwen-7B-Chat的Zero-Shot效果(+3%),是值得应用的技术; - 在Few-Shot下,DC和CC提升了鲁棒性,但均未提升Few-Shot效果,Few-Shot还需再觅良方。
zero-shot实验结论
- Channel Model的效果非常差。该方法的类别区分度太低,因此效果不好
- CC和DC均可提升Zero-Shot效果,效果最好的是DC,Acc可提升3%(绝对值),已经可以超过Siamese,与paddleNLP也可一战
- domain_random_words的改变,对DC的效果影响不大
few-shot实验结论
- 即使用了CC和DC,Few-Shot效果还是不尽如人意,效果可能不如Zero-Shot,但增加 #shot 对效果有帮助
- GD有潜力,但variance问题仍然明显,在TNEWS数据上
Best Acc - Worst Acc >10% - CC和DC均可提升Avg的鲁棒性,体现在Best与Worst的差距在减小
以Qwen-7B-Chat为基础模型时,在TNEWS和NLPCC2014-Task2数据集上:
- Bias Calibration(CC、DC)可明显提升Zero-Shot的效果,表现最好的是DC(可以提升3%的绝对值),因此,在Zero-Shot设定下推荐使用DC技术
- Bias Calibration(CC、DC)在Few-Shot设定下,体现了鲁棒性,可减少Best表现与Worst表现的差距,但Few-Shot的效果不明显,有时效果不如Zero-Shot,因此,在Few-Shot方面,还需要探索其他的优化技术
GPT标注实测
任务设计
自动标注任务设计
- 基本流程: 任务开始 → 分发给标注员 → 质检员质检 → 回收
- 标注员: 4个
- 质检员: 1个
- 质检方式: 统计集成+LLM检测
自动标注流程
实现方法
Coze 实现
- 【国外版】Multi-Agent 实现: AutoLabeler自动标注员
- 【国内版】workflow 实现: workflow
自动标注效果
运行代码, 两种模型各跑两次,结果相同,说明非随机结果
# 执行多代理自动标注
python auto_labler.py
model: gpt-3.5-turbo-0613
| 样例 | 标注结果(,分割) | 平均标注耗时(s) | 质检结果 | 最终标签 | 置信度 |
|---|---|---|---|---|---|
| 太阳出来了吗 | 积极,积极,积极,积极 | 0.57 | Yes | 积极 | 100.00 |
| 怎么这么慢 | 消极,消极,消极,消极 | 0.46 | Yes | 消极 | 100.00 |
| 你客气了 | 中性,积极,积极,积极 | 0.45 | Sure | 积极 | 100.00 |
| 嗯嗯 | 中性,中性,中性,中性 | 0.42 | Yes | 中性 | 100.00 |
| 不想说话 | 中性,消极,消极,消极 | 0.44 | Sure | 消极 | 75.00 |
model: gpt-4-0613
| 样例 | 标注结果(,分割) | 平均标注耗时(s) | 质检结果 | 最终标签 | 置信度 |
|---|---|---|---|---|---|
| 太阳出来了吗 | 中性,中性,中性,中性 | 1.30 | Yes | 中性 | 100.00 |
| 怎么这么慢 | 消极,消极,消极,消极 | 0.92 | Yes | 消极 | 100.00 |
| 你客气了 | 中性,中性,中性,中性 | 1.02 | Yes | 中性 | 100.00 |
| 嗯嗯 | 中性,中性,中性,中性 | 1.26 | Yes | 中性 | 100.00 |
| 不想说话 | 消极,消极,消极,消极 | 1.01 | Yes | 消极 | 100.00 |
gpt-3.5 vs gpt-4
- gpt-3.5 速度快(平均0.45s),但准确率不高(60%),不够稳定(60%)
- gpt-4 速度慢(平均1.1s), 准确率高(100%),且稳定(100%)
实现方法
Coze平台
新建多智能体、workflow等
代码
auto_labeler.py 内容
- 使用多线程(theading)实现多个标注人员一起标注
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2024 wqw547243068@163.com, All Rights Reserved
# **************************************************************************
# * 多Agent自动标注, openai > 0.28
# **************************************************************************
import os
import sys
#print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append('..')
from start_gpt_new import internalChat
from collections import Counter
#import asyncio
import threading
from queue import Queue
lock = threading.Lock() #创建锁
# lock.acquire(True) #锁定
# lock.release()#释放
que = Queue()
# --------------- prompt设计 ---------------
label_set = ['积极', '消极', '中性']
task_desc = f"给出以下句子的情绪等级: {','.join(label_set)}\n注意: 输出结果不能超出标签范围"
# annotator 标注员
system_prompt_a = f"""你是一个标注员,请完成文本分类标注任务.
任务描述: {task_desc}
待标注数据: [query]
标注结果:
"""
# inspector 质检员
system_prompt_i = f"""你是一个质检员,你判断标注结果是否合格
- 如果标注员识别结果(逗号分隔)都一样, 返回: Yes,标注结果
- 如果标注员识别结果(逗号分隔)不同, 返回: No,矫正后标注结果
任务描述: {task_desc}
待标数据: [query]
标注结果: [result]
质检结果:
"""
# --------------- 标注任务 ---------------
model = "gpt-3.5-turbo-0613"
# model = "gpt-4-0613"
print(f"model: {model}")
task_list = ['太阳出来了吗', '怎么这么慢', '你客气了', '嗯嗯', '不想说话']
label_info = {"annotator": ['小王', '小明', '小张', '小赵'], "pass_rate":0.75, "inspector": ['小李']}
anno_num = len(label_info['annotator'])
def getLLM(model, query='', system_prompt=''):
"""
异步调度LLM. 子线程函数不能返回值, 只能通过队列来传递结果
"""
# lock.acquire(True) #锁定
# lock.release()#释放
if not query:
res = [0, '空值']
if system_prompt:
res = internalChat(model, query, system_prompt)
else:
res = internalChat(model, query)
que.put(res)
# return res
# --------------- 标注流程 ---------------
# task: start -> annotator -> inspector -> end
for task in task_list:
#task_result = []
task_thread_list = []
# 标注人员开始标注
for name in label_info['annotator']:
# 发布任务
query = system_prompt_a.replace('[query]', task)
#res = getLLM(model, query)
t = threading.Thread(target = getLLM, name='send_labeler',
kwargs={'model':model, 'query':task, 'query':query})
task_thread_list.append(t)
t.start() # 启动线程
for t in task_thread_list:
t.join() # 启动阻塞
# 提取标注结果
task_result = [que.get() for _ in range(anno_num)]
# 质检员开始质检: 一致率高于 75%(3/4) 时, 不需要LLM质检
task_label_list = [r[1] for r in task_result]
anno_list = [r[1] for r in task_result if r[1] in label_set]
avg_time = sum([r[0] for r in task_result]) / anno_num
annotations = ','.join(task_label_list)
is_check = False # 是否需要LLM质检
# 统计标注结果分布
anno_tag = Counter(anno_list)
#print(task, anno_tag, anno_list, task_result)
if anno_tag:
anno_tag_1 = anno_tag.most_common(1)[0] # ('消极', 3)
else: # 全部幻觉
anno_tag_1 = ['-', 0]
if anno_num >= 3 and anno_tag_1[1] >= anno_num * label_info['pass_rate']:
# ① 标注结果一致且无幻觉(100%)
# ② 标注结果不一致或个别幻觉, 但标注结果一致率高于阈值(75%),且标注人员超过3个
if anno_tag_1[1] == anno_num: # ① 标注结果一致且无幻觉(100%)
res_i = [avg_time, f'Yes,{anno_tag_1[0]}']
else: # ② 标注结果不一致或个别幻觉, 但标注结果一致率高于阈值(75%),且标注人员超过3个
res_i = [avg_time, f'Sure,{anno_tag_1[0]}']
else: # 有幻觉或一致率偏低
is_check = True
if is_check:
# 质检人员开始矫正
res_i = getLLM(model, system_prompt_i.replace('[result]', annotations).replace('[query]', task))
final_res = [f.strip() for f in res_i[1].split(',')]
if len(final_res) == 1:
final_res.append('幻觉')
# 计算置信度
final_percent = task_label_list.count(final_res[1]) / anno_num * 100
print(f'{task}\t{annotations}\t{res_i[0]:.2f}\t{final_res[0]}\t{final_res[1]}\t{final_percent:.2f}')
依赖文件
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2024 wangqiwen.at@bytedance.com, All Rights Reserved
# **************************************************************************
# * 公司内 GPT 调用接口, openai > 0.28
# * @author wangqiwen.at
# * @date 2024/01/01 13:00
# **************************************************************************
import os
import time
from openai import AzureOpenAI
client = AzureOpenAI(
#azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_endpoint = 'https://888***8',
# api_key=os.getenv("AZURE_OPENAI_KEY"),
api_key='***********',
api_version="2023-03-15-preview"
)
def timer(func):
'''统计函数运行时间的装饰器'''
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
used = end - start
#print(f'{func.__name__} used {used}')
return [used, res]
return wrapper
# -------- openai ------------
import openai
# 从邮件里提取模型名称
#model = "text-davinci-003" # 这个模型不支持 v1/chat/completions, 会报错!
@timer
def internalChat(model, question, func=[], prompt=''):
"""
公司内 azure api
"""
# openai.api_type = "azure"
# #openai.api_base = "https://..."
# openai.base_url = "https://...." # 专用ptu
# openai.api_version = "2023-03-15-preview"
# openai.api_key = '...'
msg = [{"role": "user", "content": question}]
if prompt: # role (“system”, “user”, or “assistant”)
msg = [{"role": "system", "content": prompt}, {"role": "user", "content": question}]
#print('使用system prompt: ', prompt)
else:
msg = [{"role": "user", "content": question}]
if func:
#response = openai.ChatCompletion.create(
response = client.chat.completions.create(
#engine="gpt-35-turbo", # 模型可支持: gpt-35-turbo、gpt-4、gpt-4-32k
#engine = model,
model = model,
temperature = 0.9,
# ---- function call -----
functions = func, # 设置函数调用
function_call="auto", # 开启function call
messages = msg
# messages=[
# {"role": "system", "content": system_prompt},
# ]
)
#if not response['choices'][0]['message']['content']: # 命中 function call
if not response.choices[0].message.content: # 命中 function call
res_raw = response['choices'][0]['message']['function_call']
res_raw['arguments'] = json.loads(res_raw['arguments'])
# {"name": "open_app", "arguments": {"app_name": "今日头条"}}
res_args = '&'.join([f'{i[0]}={i[1]}' for i in res_raw['arguments'].items()])
res_str = f'{res_raw["name"]}#{res_args}'
# res = json.dumps(res_raw, ensure_ascii=False)
res = res_str
else:
res = '未命中function'
# 第二次调用省略
pass
else:
#response = openai.ChatCompletion.create(
response = client.chat.completions.create(
#engine="gpt-35-turbo", # 模型可支持: gpt-35-turbo、gpt-4、gpt-4-32k
#engine = model,
model = model,
messages = msg,
# messages=[
# {"role": "system", "content": system_prompt},
# #{"role": "user", "content": "Do other Azure Cognitive Services support this too?"}
# ]
)
#res = response['choices'][0]['message']['content']
res = response.choices[0].message.content
return res
视觉标注
yolo 目标检测
【2024-3-30】自动标注不再是幻想
用YOLOv8将目标检测任务自动化
YOLO V8中有五个模型
YOLOv8n,YOLOv8s,YOLOv8m,YOLOv8l,YOLOv8x
准备
- 安装 yolov8 工具包
- 准备测试视频: pexels 汽车行驶视频
# YOLO V8
pip install ultralytics --upgrade
标注代码
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
import os
# 查看 yolo 支持的类目
names = model.model.names
print(names)
# {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane',
# 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light',
# 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench',
# 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow',
# 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack',
# 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee',
# 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite',
# 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard',
# 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork',
# 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple',
# 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog',
# 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch',
# 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv',
# 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone',
# 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator',
# 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear',
# 78: 'hair drier', 79: 'toothbrush'}
完整代码
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
import os
# 加载预训练模型
model = YOLO("yolov8n-seg.pt")
model.to('cuda')
names = model.model.names
# 打开视频文件
cap = cv2.VideoCapture("cars.mp4")
# 输出文件夹
output_folder = "output_instances"
os.makedirs(output_folder, exist_ok=True)
# 输出视频设置
# out = cv2.VideoWriter('instance-segmentation.avi',
# cv2.VideoWriter_fourcc(*'MJPG'),
# 30, (int(cap.get(3)), int(cap.get(4))))
# 输出宽度和高度
output_width = 1080
output_height = 600
# 感兴趣的对象列表
objects_of_interest = ['car']
# 对象计数
object_counts = {obj: 0 for obj in objects_of_interest}
while True:
ret, frame = cap.read()
if not ret:
print("视频帧为空或视频处理已成功完成。")
break
# 调整帧大小
frame = cv2.resize(frame, (output_width, output_height))
# 使用模型进行预测
results = model.predict(frame, device='0', conf=0.25)
if results[0].masks is not None:
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
annotator = Annotator(frame, line_width=2)
for idx, (mask, cls) in enumerate(zip(masks, clss)):
det_label = names[int(cls)]
if det_label in objects_of_interest:
annotator.seg_bbox(mask=mask,
mask_color=colors(int(cls), True),
det_label=det_label)
object_counts[det_label] += 1
# 保存每个实例分割的对象
# instance_folder = os.path.join(output_folder, det_label)
# os.makedirs(instance_folder, exist_ok=True)
# instance_path = os.path.join(instance_folder, f"{det_label}_{idx}.png")
# cv2.imwrite(instance_path, frame)
text_y = 30
for obj, count in object_counts.items():
cv2.putText(frame, f"{obj.capitalize()} Count: {count}", (10, text_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
text_y += 40
# out.write(frame)
cv2.imshow("实例分割", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# out.release()
cap.release()
cv2.destroyAllWindows()
标注效果
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}