最新技术
【2022-3-29】爱可可微博
资料
- 【2022-1-18】IEEE Fellow 过敏意:从IEEE汇刊主编视角看如何提升科技论文质量
- 【2021-5-12】谷歌提出的一篇MLP-Mixer(谷歌最新提出无需卷积、注意力 ,纯MLP构成的视觉架构!)让人调侃 MLP->CNN->Transformer->MLP 的魔幻圈难道要成真?以往CV圈的老大「卷积模型」今日竟然来反向偷袭NLP 领域!
- 【2021-5-4】谷歌大脑团队《MLP-Mixer: An all-MLP Architecture for Vision》,原视觉Transformer(ViT)团队的一个纯MLP架构的尝试。提出了一种仅仅需要多层感知机的框架——MLP-Mixer,无需卷积模块、注意力机制,即可达到与CNN、Transformer相媲美的图像分类性能。
- Mixer使用两种类型的MLP层:
- 1、通道混合MLP(channel-mixing MLPs ):用于不同通道之间进行通信,允许对每个token独立操作,即采用每一行作为输入。
- 2、token混合MLP(The token-mixing MLPs ):用于不同空间位置(token)之间的通信;允许在每个通道上独立操作,即采用每一列作为输入。
- 以上两种类型的MLP层交替执行以实现两个输入维度的交互。在极端情况下,MLP-Mixer架构可以看作一个特殊的CNN,它使用1×1通道混合的卷积,全感受域的单通道深度卷积以及token混合的参数共享
- 知乎评论:
- FC is all you need, neither Conv nor Attention.在数据和资源足够的情况下,或许inductive bias的模型反而成了束缚,还不如最simple的模型来的直接。
- 最开始大家希望,learning from data, 结果发现效果并不好,于是不断加 inductive bias,让模型按我们的想法学习,产生了CNN等网络。 inductive bias 发展了一段时间,又往回走,扔掉inductive bias,让model自己学。提出了 attention之类的方法。 现在又走回到MLP。
- 【2021-5-6】清华的《RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition》
- ACL 2021 谷歌《Are Pre-trained Convolutions Better than Pre-trained Transformers?》的论文,卷积模型在预训练领域就不能比Transformers更好吗?
- 【2021-6-21】论文实现趣图
信息获取
sci 论文编辑和编译5大神器:
- 1、grammarly:在线的语法纠错神器,除了语法纠错之外,还有同意替换功能。
- 2、linggle: 解决词语搭配问题,通过短语加通配符,它能够匹配到合适的短语,填补空缺,并给出词频和例句。
- 3、SCI-HUB:论文检索,谷歌都找不到PDF的时候,用它试试。
- 4、mathpix:数学公式转latex,有时候自己写个公式还挺费劲的,现在轻松截图,公式在手。
- 5、mendeley:论文阅读器,写作前,一定要大量阅读相关工作,一个靠谱的论文管理和阅读工具非常重要。
【2020-4-24】如何从垃圾信息的海洋中找到优质信息的孤岛。
两个指导原则如下:
- 英文世界比中文世界有着更多的优质作品,并且时效性更强,因此应当习惯于阅读英文资料。
- 在没有时间和精力去筛选内容的情况下,优先关注优质的平台、博主生产的信息。
(1)最新信息
- 在 twitter 上关注各位大佬,每天早上刷 twitter 即可
- 用 RSS 阅读器订阅 DeepMind/OpenAI/Google AI blog 如果做到以上两点,各种中文机器学习/人工智能公众号推送的东西基本上就都是你半天到两三天前看过的了。中文公众号我基本上只用来看国内公司的新闻。
- slack上搭建自己的paperbot服务,详见:paperbot, A Slack bot for personalized, filtered and trackable arXiv output
- 科技媒体
- Paper Digest: Recent Papers on ChatGPT
- arxiv latest paper, arXiv Vanity renders academic papers from arXiv as responsive web pages
- AMiner每日论文
- 新浪微博,爱可可
AI Hot
【2026-5-10】每天信息太多刷不过来?4个免费网站帮你一站式搞定全网热点👇
- 全球AI热门动态:AI Hot, 实时抓取外网最新AI资讯(精选/动态/日报),LLM自动筛选、判断,支持多种安装方式(RSS/Rest API/Skill)
帮我安装这个 skill:https://aihot.virxact.com/aihot-skill/- 示例:”今天 AI 圈有什么新东西”、“最近3天大模型进展”
- 国内全平台热搜聚合:News Now 社会新闻实时抓取展示
- X(推特)爆款监控:hot tweets
- 全球AI热门提示词:You Mind
Horizon
AI 驱动的信息聚合系统。
【2026-5-20】好新闻分散在各处,坏信息却源源不断。Horizon 为你先完成第一轮筛选:
- 从 Hacker News、Reddit、Telegram、RSS、Twitter/X、GitHub 和 OpenBB 抓取内容,合并重复新闻,用 AI 打分过滤,并为重要内容补充背景解释和社区讨论。
但 Horizon 不只是摘要工具。AI 很擅长降低噪声,但新闻仍然需要人的品味:你信任哪些信息源,哪些评论改变了你对事件的理解,哪些小众来源值得被更多人看见。
Horizon 通过可定制的信息源、筛选标准、模型、语言、分发方式、评论摘要和社区信息源官网,把这层“人味”保留下来。
功能特性
- 📡 关注你的信息源 — 将 Hacker News、RSS、Reddit、Telegram、Twitter/X、GitHub Release / 用户动态,以及 OpenBB 金融新闻观察列表纳入同一条 pipeline
- 🤖 把噪声变成阅读清单 — 使用 Claude、GPT、Gemini、DeepSeek、豆包、MiniMax 或任意 OpenAI 兼容 API,为每条内容评分 0-10
- 🔗 合并重复新闻 — 在生成日报前自动合并来自不同平台的相同故事
- 🔍 补全背景知识 — 为陌生概念、公司、项目和技术术语补充网络搜索得到的背景解释
- 💬 读到社区声音 — 收集并总结 Hacker News、Reddit 等来源的评论讨论
- 🌐 生成双语日报 — 基于同一组信息源生成英文和中文日报
- 📝 发布日报站点 — 将生成的 Markdown 发布为 GitHub Pages 静态日报站点
- 📧 邮件分发 — 运行自托管 SMTP/IMAP 邮件列表,自动处理订阅与退订
- 🔔 推送到聊天和自动化工具 — 将模板化结果发送到飞书、钉钉、Slack、Discord 或自定义 Webhook
- 🧙 从兴趣开始配置 — 通过交互式向导根据你的兴趣生成个性化信息源配置
- ⚙️ 调校你的新闻雷达 — 在单个 JSON 配置中定制信息源、阈值、模型、语言和分发方式
- 定义 — 用一个 JSON 配置好信息源、阈值、模型、语言和分发方式。
- 抓取 — 并发拉取所有已配置信息源的最新内容。
- 去重 — 合并来自不同平台、指向同一故事或 URL 的内容。
- 打分与过滤 — 用 AI 对内容排序,只保留超过阈值的条目。
- 丰富 — 为重要内容补充搜索得到的背景信息和社区讨论。
- 总结 — 生成结构化的 Markdown 日报,包含摘要、标签和参考链接。
- 分发 — 将结果发布到 GitHub Pages、邮件、飞书等 webhook、MCP 或本地文件。
git clone https://github.com/Thysrael/Horizon.git
cd horizon
# 使用 uv 安装(推荐)
uv sync
# 需要测试/开发依赖时
uv sync --extra dev
# 或使用 pip
pip install -e .
每日学术速递
【2023-10-13】arxivdaily,有公众号
- 每日最新论文集合,按主题分类,示例
- AI专题 cs.AI人工智能,共计109篇
- 【2024-1-15】huggingface papers
sophon.at
【2026-6-6】sophon
收集和展示和AI 相关的所有信息和内容,论文/最新模型/Benchmark/排行榜
- 论文能直接在线看,非常非常全
- 还有 feed ,可直接订阅了解最新的消息。
Sophon 这个词是三体里面智子的意思。
工具
【2023-11-7】例行更新 arxiv 论文: xiximayou-arxiv
arXiv-Search
arXiv-Search, An arXiv paper search engine based on Elasticsearch and fastapi.
基于 arXiv 上的数据的一个论文检索系统,可以通过输入标题、作者、摘要中的关键字进行检索,方便研究人员高效地搜索相关论文。
爬虫部分代码略去。爬取论文标题、作者、摘要、提交日期和 pdf 链接共 5 个字段
ArXiv 爬虫
同事开发的paper daily工具
- 实现逻辑:
- ArXiv上抓取对应日期、主题的论文 → 用ChatGPT翻译摘要 → 格式化输出为feishu文档
- https://readpaper.feishu.cn/docx/J98jdwnGaoiT4MxaKgHcc0VYnXf
更多资料
优化点
- 翻译下标题,再算下LLM相关性得分,降序排列,自动过滤掉次要文章
其它爬虫代码
- Python爬取arxiv的paper,每天都要去arxiv上关注最新一天的论文(computer vision)更新,而且每次下载的论文的名称都是arxiv的代号
- dailyarxiv.py, 支持邮件发送、缓冲爬取,知乎解读
ArXiv ChatGuru
ArXiv ChatGuru! 演示视频见twitter
- Put in a topic, number of papers, and chat with a guru who knows all about them.
Features:
- ▶️ Langchain-based QnA
- ▶️ ArXiv API loader
- ▶️ Semantic caching
- ▶️ @Redisinc vector db stats
- ▶️ LLM and retrieval controls
LLM 工具
测试
帮我收集最近5年里的质量比较高的uplift模型的论文,需要是来自比较好的刊物,尽量是互联网大厂的论文, 不少于20个(必须有正确arvix链接,并附上作者、发表会议、链接、简介、年份)
豆包、DeepSeek 测试,链接绝大部分有效,但 链接对应的文章与标题不符,大规模错乱
【2024-9-12】paper-qa
【2024-9-12】检索总结能力超博士后,首个大模型科研智能体PaperQA2开源了
LLM 帮助科学家检索、综合和总结文献,提升工作效率,但在研究工作中使用仍然有很多限制。
- 事实性至关重要,而大模型会产生
幻觉,有时会自信地陈述没有任何现有来源或证据的信息。 - 科学需要极其注重细节,而大模型在面对具有挑战性的推理问题时可能会忽略或误用细节。
- 科学文献的检索和推理基准尚不完善。AI 无法参考整篇文献,而是局限于摘要、在固定语料库上检索,或者只是直接提供相关论文。
这些基准不适合作为实际科学研究任务的性能代理,通常缺乏与人类表现的直接比较。
因此,语言模型和智能体是否适合用于科学研究仍不清楚。
FutureHouse、罗切斯特大学等机构的研究者们构建更为强大的科研智能体,并对 AI 系统和人类在三个现实任务上的表现进行严格比较。
- 搜索整个文献以回答问题;
- 生成一篇有引用的、维基百科风格的科学主题文章;
- 从论文中提取所有主张,并检查与所有文献之间的矛盾。
第一个在多个现实文献搜索任务上评估单个 AI 系统的强大程序。利用新开发的评估方法,研究者探索了多种设计,形成 PaperQA2 系统,它在检索和总结任务上的表现超过了博士生和博士后。
LLM驱动的论文检索工具 paper-qa
PaperQA2 可以访问「论文搜索」工具,其中智能体模型将用户请求转换为用于识别候选论文的关键字搜索。
- 候选论文被解析为机器可读文本,并分块以供智能体稍后使用。
- PaperQA2 使用最先进的文档解析算法(Grobid19),可靠解析论文中的章节、表格和引文。
- 找到候选论文后,PaperQA2 使用「收集证据」工具,该工具首先使用 top-k 密集向量检索步骤对论文块进行排序,然后进行大模型重新排序和上下文摘要(RCS)步骤。

工作流程主要包括以下几个步骤:
- 文档嵌入:将文档内容转换为向量表示。
- 查询嵌入:将用户的问题转换为向量表示。
- 相似度搜索:在文档向量中搜索与问题最相关的Top K段落。
- 内容总结:对每个相关段落进行摘要,提取与问题相关的关键信息。
- 相关性排序:使用大语言模型对摘要进行重新排序,筛选出最相关的内容。
- 提示构建:将筛选后的内容组合成提示。
- 答案生成:利用大语言模型基于提示生成最终答案。
这个过程充分利用了大语言模型的语义理解和生成能力,同时通过多步筛选确保了答案的准确性和相关性。
Paper-QA 应用场景
- 科研文献综述
- 撰写文献综述耗时耗力。Paper-QA 帮助研究者快速从大量文献中提取关键信息,形成初步的综述框架。
- 研究者可以向系统提问如”近五年来在X领域有哪些重要进展?”,系统会从导入的文献中提取相关信息并给出综述性回答。
- 快速信息检索
- 从大量文档中找到特定信息。Paper-QA 可以大大简化这个过程。
- 工程师可以向系统询问”我们项目中使用的X算法的具体参数是什么?”,系统会快速从技术文档中定位并提取相关信息。
- 辅助决策
- 对于管理者和决策者来说,Paper-QA 可作为强大的决策支持工具。
- 通过向系统提问如”我们公司过去三年的财务报告显示了哪些趋势?”,管理者可以快速获得数据支持的洞察,辅助决策制定。
- 教育辅助
- 教育领域, Paper-QA 可以作为一个智能辅导工具。学生可以向系统提问课程相关的问题,系统会从教材和参考资料中提取信息给出解答,帮助学生更好地理解和掌握知识点。
- 专利分析
- 专利分析师来说,Paper-QA可以大大提高工作效率。
- 通过向系统提问如”近年来在X技术领域有哪些重要的专利申请?”,分析师可以快速获得相关专利的概览,为进一步的深入分析奠定基础。
原文链接:https://blog.csdn.net/Nifc666/article/details/141928320
安装
# python 3.11 以上
pip install paper-qa>5
# llm 配置
export OPENAI_API_KEY='sk-****'
使用
pqa ask 'What manufacturing challenges are unique to bispecific antibodies?'
pqa search -i 'answers' 'antibodies'
导入文档: 使用Docs类添加需要分析的文档。
from paperqa import Docs
docs = Docs()
for doc in my_docs:
docs.add(doc)
提问:使用query方法向系统提问。
answer = docs.query("What manufacturing challenges are unique to bispecific antibodies?")
print(answer.formatted_answer)
系统会返回一个包含答案、引用源等信息的对象。
【2025-1-21】AgentPaSa
【2025-1-21】 LLM合集:找新论文困难重重?字节 AgentPaSa 强势登场,性能远超 Google和GPT-4o

由大语言模型驱动的论文搜索AgentPaSa。
PaSa 能自主作出一系列决策,包括调用搜索工具、阅读论文和选择相关参考文献,以最终获得复杂学术查询的全面和准确结果。利用合成数据集 AutoScholarQuery 对PaSa进行了强化学习优化,该数据集包括35000个详细的学术查询及其对应的论文,这些论文来自顶级AI会议的出版物。
此外,还开发了 RealScholarQuery 基准,收集真实世界的学术查询以评估PaSa在更现实场景中的性能。尽管仅训练于合成数据,但PaSa在RealScholarQuery 表现显著优于现有基线,包括Google、Google Scholar、Google进行改写后的查询、chatGPT(搜索增强的GPT-4o)、GPT-o1以及PaSa-GPT-4o(通过提示GPT-4o实现的PaSa)。
- PaSa-7B在召回率@20和召回率@50上分别比基于Google的最佳基线Google进行改写后的查询分别提高了37.78%和39.90%。它还超过了PaSa-GPT-4o的召回率30.36%和精度4.25%。模型、数据集和代码可在 pasa获得。
支持 微调
【2025-4-3】AGS
让AI和机器人联手当“科学家”,直接把科研流程拉满~
- 【2025-4-3】加拿大多伦多大学 论文:Scaling Laws in Scientific Discovery with AI and Robot Scientists
- an autonomous generalist scientist (AGS) concept combines
agentic AIandembodied roboticsto automate the entire research lifecycle
- 核心创新点
- ⭐️ 提出“自主通用科学家”(AGS)概念:把 AI大脑 和 机器人身体 结合,从查文献、想创意、做实验到写论文,全流程自动化,再也不用靠人类苦哈哈熬夜肝科研
- ⭐️ 给AI科学家“分级考试”:从 Level 0 纯人工到 Level 5 完全自主(比如极端环境搞科研的超级机器人),清晰划分6个等级,帮大家看懂AI科研助手的进化进度
- ⭐️ 打通虚拟+物理世界壁垒:以前 AI只会处理数据,现在搭配机器人能动手做实验, 比如在实验室配溶液、操作显微镜”
- 技术亮点
- ⭐️文献调研会“翻墙”:用OS Agent模拟人类上网,突破付费墙查文献,还会自动整理热点和研究空白,比人工查资料快10倍不止
- ⭐️提案生成会“脑暴+自检”:先靠大模型疯狂生成研究想法,再用多Agent系统互相挑刺,从可行性、创新性到实验步骤,反复打磨出超靠谱的研究计划
- ⭐️实验能“虚实联动”:虚拟AI负责跑数据、做模拟,实体机器人负责动手操作,比如化学实验里精准分液、生物实验里细胞培养,全程记录细节, reproducibility直接拉满
- 实验效果
- ⭐️ 科研效率飙升:从文献调研到论文初稿,时间缩短60%,以前要3个月的项目,现在不到2个月就能搞定~
- ⭐️ 跨学科秒变“六边形战士”:在生物、化学、材料等多个领域都能干活,比如用机器人合成新材料,AI同步分析数据找规律,打破学科壁垒超轻松!
- ⭐️ 极端环境也能“打工”:模拟太空、深海等场景,机器人能独立完成采样、实验,人类去不了的地方,它也能传回超有价值的数据~
【2026-4-15】
【2026-4-15】hermes 会替代 openclaw 吗
Hermes 非常适合承接这种长期运行、跨多步骤、带真实外部投递的 agent 任务
基于 Hermes 的 agent skill:项目 hermes-arxiv-agent 的 AGENT_SKILL.md
- 每天自动从 arXiv 抓取论文,用 AI 生成中文摘要和作者单位,推送到飞书,并提供一个本地静态阅读网站。
支持:
- 按抓取日期或发表日期筛选
- 按关键词全文检索
- 查看中文摘要
- 查看作者单位
- 收藏论文
一句话安装
请从该地址 https://github.com/genggng/hermes-arxiv-agent/blob/main/AGENT_SKILL.md 安装 skill 并执行。
Hermes 自己完成:
- 克隆仓库
- 安装 Python 依赖
- 生成定时任务 prompt
- 创建 cron job
- 把定时任务的投递目标设为 Feishu
效果
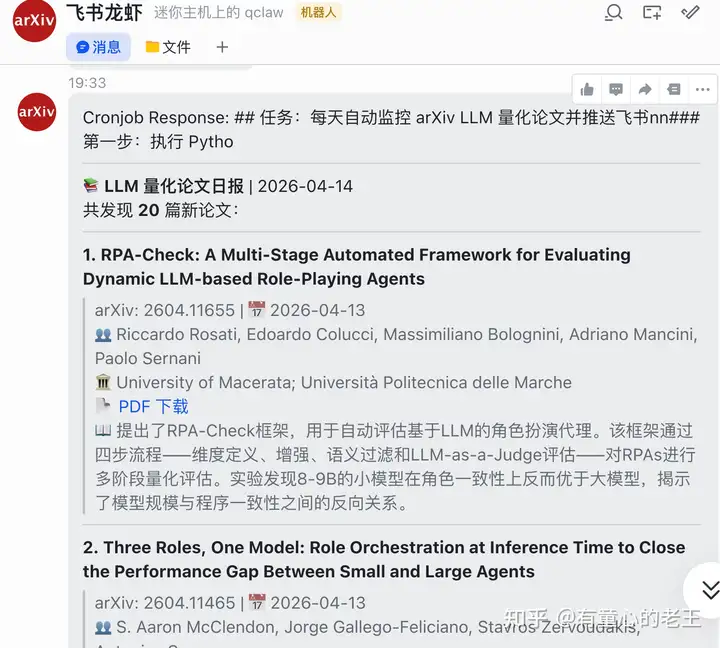
本地阅读网站效果
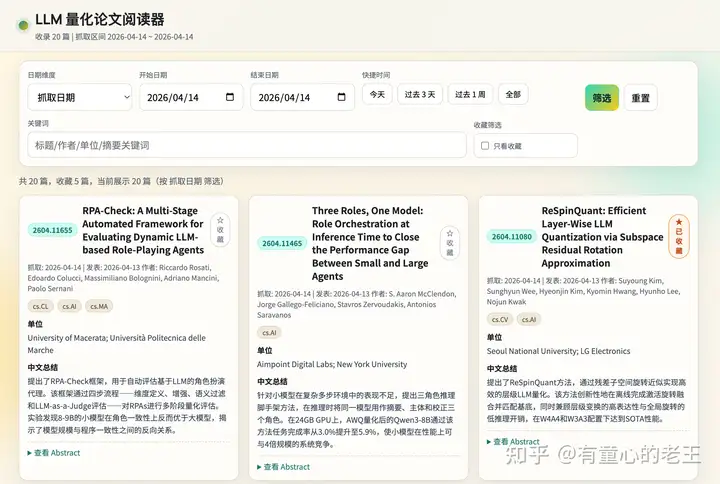
(2)某领域进展
- 完全不熟悉的领域,一般以 XXX tutorial/notes 为关键字来搜索,找到北美名校的讲义、某个顶会的 Tutorial 或者说 Summer School 的资料看,这些资料一般质量都很高。如果需要读论文,就找一些 roadmap 中提到频次较高的文章, 然后在 Google scholar 中搜索这些文章所引用和被引的文章里的高引文章,读上几篇就可以熟悉这个领域的大致脉络。
- 熟悉的领域,就去找基准数据集的 leaderboard(例如 SQuAD/GLUE/WMT 等等),看看最新的效果如何,再去看对应的论文。paperswithcode 和 nlpprogress 也是追踪最新进展的好地方。
(3)工作回顾
- 最新的工作刚出来的时候,解读难免有失偏颇(例如以前对 Transformer 就看走眼了,觉得是一篇水文,这是我自从读论文以来犯过的最大错误)或者无法用更简化的眼光来审视。当一个领域发展一段时间后,把某些工作串联起来看往往会有更深的感悟。这种文章我一般会浏览以下博主或网站上的博客:
- https://distill.pub/
- http://colah.github.io/
- http://ruder.io/
- http://www.wildml.com/
论文检索
- AIMner学术头条
- PaperWeekly(论文分享社区)
- ak47开发的arxiv最新文章跟进工具
- ResearchGate(论文引用高效关联)
- 【2020-9-5】What-I-Have-Read,NLP论文解读集合
【2023-2-25】github trending,查看GitHub上最新最热代码库
图谱检索
connected papers
【2020-6-11】阿里员工开发的论文知识图谱可视化检索工具 connectedpapers
soarXiv
【2025-5-20】Jinay Jain 推出 soarXiv - the universe of science
-
原理: 收集截止 2025年5月的280万篇论文, 用 UMap 嵌入到三维空间, 用 three.js 可视化, 绘成星空图,输入arXiv地址即可探索
-
交互指令:
- 左键 前进
- 右键 后退
- 鼠标移动
- Esc 显示光标
- Q 打开当前文章
功能
- 相同主题论文同一种颜色, 按语义相似性发现论文
- 输入论文地址, 定位到星空位置
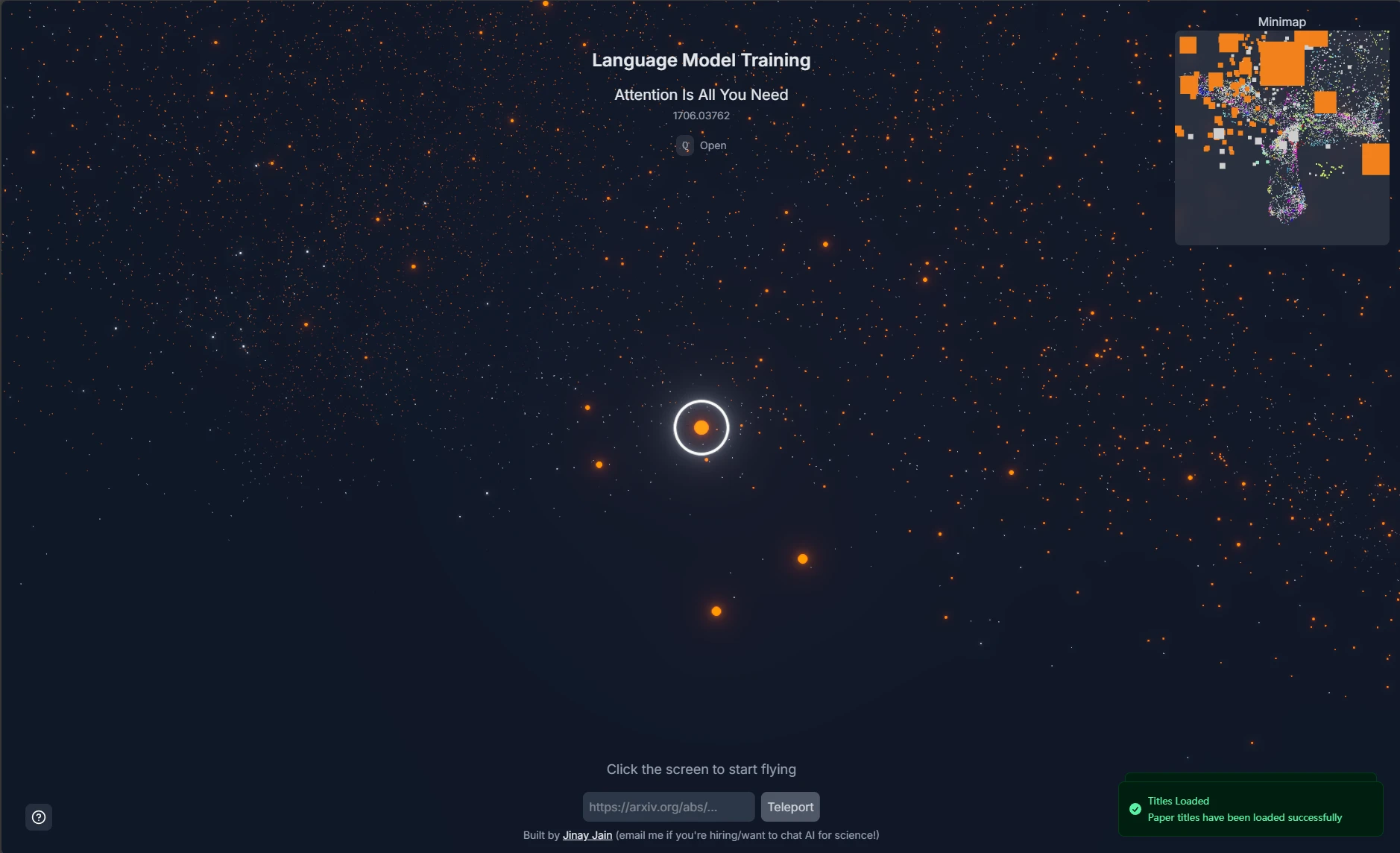
Sota
- 【2021-3-7】机器之心SOTA专栏
- StateOfTheArt.ai
- Paperwithcode,Browse State-of-the-Art
- 【2020-7-5】快速找到最新AI技术的模型/代码/API】“CatalyzeX: machine intelligence to catalyze your projects”
NLP 组织及资料
- NLP Progress
- nlp最新论文及代码
- 100 Must-Read NLP Papers
- 【按主题分类的自然语言处理文献大列表】NLP Paper - natural language processing paper list
- 清华NLP组文本生成方向:Text Generation Reading List
- 文本生成框架:AllenNLP、FairSeq、OpenNMT、Texar、HuggingFace
- 中文公开聊天语料库
- Chatbot and Related Research Paper Notes with Images
【2023-7-20】普林斯顿 NLP
- InstructEval: Systematic Evaluation of Instruction Selection Methods
- 普林斯顿 NLP GitHub: Princeton Natural Language Processing, 已知知名项目
- 2021, SimCSE, 陈丹琦
- tree-of-thought-llm
- 2022, TRIME: EMNLP 2022 Training Language Models with Memory Augmentation
ACL 2022上的NLP热点
- 【2022-8-4】从ACL 2022 Onsite经历看NLP热点
- 继续预训练大模型仍然是工业界的大方向之一;
- “Zero- and Few-Shot NLP with Pretrained Language Models” 的Tutorial中,Iz Beltagy 在最后一部分介绍了预训练时候的顾虑。
- ① 开启预训练之前就要根据经验公式,来预估给定计算资源时能够达到最好效果的模型大小
- ② 预训练数据本身的筛选与构建应该被给予更多关注
- 模型预训练的workshop:“Workshop on Challenges & Perspectives in Creating Large Language Models”
- 让大模型解决更全面的NLP问题,以及NLP之外的问题
- 包括 Extend large-scale Transformer models to multi-task, multimodal, multilingual settings
- 2.1 Cross-task Generalization 跨任务泛化:Instructions as Task Descriptions、Continual / Lifelong Learning
- 2.2 Multimodal Learning:paper list, 涉及:视觉、表格、代码
- 2.3 Multilingual Learning:
- 用好大模型
- 3.1 Decoding / Sampling
- 3.2 Prompt**
- 3.2 Effiecient Models:如何设计更高效的模型(模型压缩,quantization,adapter等)仍是热点
- 3.3 Language Models as KG:把大模型视为knowledge base,它可以帮助我们生成有助于解决任务的知识进而帮助任务本身
- 3.4 Language Models to Generate Data:大模型强大的生成能力或者zero-shot/few-shot能力可以帮助生成标注数据以及生成数据作为数据扩增的方式
- 3.4 Zero/few-shot Learning & Learning with Limited Data:有限数据的场景下学习(limitted data learning)或者few/zero-shot learning
- 大模型无法完成的
- 4.1 Ambiguity
- 4.2 Reasoning / Logic / Structure
- 4.3 Out-of-distribution (OOD)Generalization & Robustness
- 4.4 Long Document Understanding / Generation
- 4.5 Knowledge
- 4.6 Problem Definition / Dataset Creation / Evaluation
- Large LM 的目的:更好地为人类所用(help people instead of replacing people)
- 5.1 Interactive Learning / Human-in-the-loop / Human-AI Collaboration
- 5.2 SocialNLP
- 5.3 Complex Tasks
- 5.4 安全性/隐私
- 5.5 Personalization
- 继续预训练大模型仍然是工业界的大方向之一;
NLP各方向论文综述
- 最新版见NLP学习指南
- 2020 A Survey on Text Classification: From Shallow to Deep Learning
- 2020 A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
- 2020 Evolution of Semantic Similarity - A Survey
- 2017 Neural text generation: A practical guide
- 2018 Neural Text Generation: Past, Present and Beyond
- 2019 The survey: Text generation models in deep learning
- 2020 Efficient Transformers: A Survey
NLP论文经验
【2020-9-30】ACL 2020趋势总结
- 交稿量最多的方向:通过机器学习处理自然语言,对话和交互系统,机器翻译,信息提取和自然语言处理的应用及生成。

- 近10年来的研究热点变化趋势图
- 论文有从基础任务到高级任务发展的趋势,例如从通过单词级,句子级语义和语篇的句法,过渡到对话。机器学习方向研究也正稳步增加,越来越多的文章提出具有普遍性目标的模型,而这些模型都基于多个任务来衡量。
- 模式:
- 基于某任务X调整了BERT模型,然后在评价标准Y下表现更好
- I fine-tuned BERT on task X and it improved the performance on benchmark Y
- 在自然语言处理研究有个反复出现的模式
- 介绍一个新模型;
- 通过改进模型,或者将其应用于多任务实现一些容易的目标然后发表;
- 发表文章分析其不足之处或缺陷;
- 发表新的数据集。
-
尽管某些步骤可能同时进行,现在就处于2和3之间。小标题的结论是基于我选择的论文得出的,过滤掉了这类文章。
- ACL 2020 文章摘要
- (1)少了套路。
- (2)不再依赖大型已标注数据集
- 聚焦于更少监督的训练模型:
- 无监督
- Yadav等人,基于检索的问答方法,可以迭代地将询问提炼到1KB
- 常识类多选任务上,通过计算每个选项的合理性得分(利用Masked LM),Tamborrino等人取得了令人欣喜的成果。
- 数据增强
- Fabbri等人提出了一种可以自动生成上下文的方法,问题和回答三合一的形式来训练问答模型。他们首先检索和原始数据相似的上下文,生成回答:是或否,并且以问句形式向上下文提问(what, when, who之类开头的问句)然后基于这三件套训练模型。
- Jacob Andreas提出将不常见的短语替换为在相似语境下更常用的短语从而改进神经网络中的组合泛化能力。
- Asai和Hajishirzi用人工例子增加问答训练数据,这些例子都是从原始训练数据中按逻辑衍生出来用以加强系统性和传递一致性。
- 元学习
- Yu等人利用元学习去迁移知识用以从高源语言(high-resource language)到低源语言(low-resource language)的上义关系检测。
- 主动学习
- Li等人搭建了一个高效的标注框架,通过主动学习选取最有价值的样本进行批注进行共指关系解析。
- 无监督
- 聚焦于更少监督的训练模型:
- (3)语言模型不是全部,检索又回来了
- 语言模型的不足: Kassner and Schütze和 Allyson Ettinger的论文表明某些语言模型对否定不敏感,并且容易被错误的探针或相关但不正确的答案混淆。
- 解法
- ① 检索:在Repl4NLP研讨会上的两次受邀演讲中,有两次提到了检索增强的LMs。 Kristina Toutanova谈到了谷歌的智能领域,以及如何用实体知识来增强LMs(例如,这里和这里)。 Mike Lewis谈到了改进事实知识预测的最近邻LM模型,以及Facebook的将生成器与检索组件相结合的RAG模型。
- ② 使用外部知识库:这已经普遍使用好几年了。Guan等人利用常识知识库中的知识来增强用于常识任务的GPT-2模型。Wu等人使用这样的知识库生成对话。
- ③ 用新的能力增强 LMs:Zhou 等人训练了一个 LM,通过使用带有模式和 SRL 的训练实例来获取时间知识(例如事件的频率和事件的持续时间) ,这些训练实例是通过使用带有模式和 SRL 的信息抽取来获得的。Geva 和 Gupta通过对使用模板和需要对数字进行推理的文本数据生成的数值数据进行微调,将数值技能注入 BERT 中。
- 可解释 NLP
- 检查注意力权重今年看起来已经不流行了,取而代之的关注重点是生成文本依据,尤其是那些能够反映判别模型决策的依据。Kumar 和 Talukdar 提出了一种为自然语言推断(NLI)预测忠实解释的方法,其方法是为每个标签预测候选解释,然后使用它们来预测标签。Jain 等人 开发了一种忠实的解释模型,其依赖于事后归因(post-hoc)的解释方法(这并不一定忠实)和启发式方法来生成训练数据。为了评估解释模型,Hase 和 Bansa 提出通过测量用户的能力,在有或没有给定解释的前提下来预测模型的行为。
- (4)反思NLP的当前成就,局限性以及对未来的思考
- 求解的是数据集,而不是任务。在大量数据上训练模型,可能无法从可用的数据量中学到任何东西,而且这些模型在人类可能认为不相关的数据中找到统计模式。 建议应该标准化中等规模的预训练语料库,使用专家创建的评估集,并奖励成功的一次性学习。排行榜并不总是对推动这一领域有所帮助。 基准通常会占据分布的顶端,而我们需要关注分布的尾部。 此外,很难使用通用模型(例如LM)来分析特定任务的进步。
- 当前模型和数据存在固有的局限性。 邦妮还说,神经网络能够解决不需要深入理解的任务,但是更具挑战性的目标是识别隐含的含义和世界知识。
- 远离分类任务。 近年来,我们已经看到了许多证据,证明分类和多项选择任务很容易进行,并且模型可以通过学习浅层的数据特定模式来达到较高的准确性。 另一方面,生成任务很难评估,人类评估目前是唯一的信息量度,但是却很昂贵。将NLI任务从三向分类转换为较软的概率任务,旨在回答以下问题:“在假设前提下,假设成立的可能性有多大?”
- 学习处理歧义和不确定性。 Ellie Pavlick在Repl4NLP上的演讲讨论了在明确定义语义研究目标方面的挑战。 将语言理论天真地转换为NLI样式的任务注定会失败,因为语言是在更广泛的上下文中定位和扎根的。 盖·艾默生(Guy Emerson)定义了分布语义的期望属性,其中之一是捕获不确定性。 冯等。 设计的对话框响应任务和模型,其中包括“以上皆非”响应。 最后,Trott等 指出,尽管语义任务关注的是识别两种话语具有相同的含义,但识别措辞上的差异如何影响含义也很重要。
- (5)有关道德伦理的讨论(很复杂)
- 强烈推荐观看 Rachael Tatman 在 WiNLP 研讨会上洞见深入的主题演讲「What I Won’t Build(我不会构建的东西)」。Rachael 说明了她个人不会参与构建的那几类系统,包括监控系统、欺骗与其交互的用户的系统、社会类别监测系统。她提供了一个问题列表,研究者可用来决定是否应该构建某个系统:
- 该系统将让哪些人获益?
- 该系统对哪些人有害?
- 用户可以选择退出吗?
- 该系统会强化还是弱化系统的不公平性?
- 该系统总体上会让世界变得更好吗?
- 强烈推荐观看 Rachael Tatman 在 WiNLP 研讨会上洞见深入的主题演讲「What I Won’t Build(我不会构建的东西)」。Rachael 说明了她个人不会参与构建的那几类系统,包括监控系统、欺骗与其交互的用户的系统、社会类别监测系统。她提供了一个问题列表,研究者可用来决定是否应该构建某个系统:
顶会信息
资讯
- AI Conference Deadlines顶会截止时间
- Conference Ranks
- 【2021-7-19】AI顶会大全,持续更新
- 【2021-8-17】顶会截止时间大全,实时更新
- 【2022-1-6】计算机顶会论文投稿指南, CCF划分的A/B/C类会议
- 人工智能子领域会议投稿参考:
- NLP领域四大顶会及2019年接收率:ACL (25.7%),NAACL (26.3%),EMNLP (25.5%),COLING (33%),除此之外推荐投稿 NLPCC,AAAI,NIPS 等;
- CV领域三大顶会:ICCV,CVPR和ECCV;
- 语音领域顶会:ICASSP,ICSLP 和 InterSpeech。
- 论文要求
- 注册会员:一般国内外的会议投稿都能在softconf平台完成,从会议征稿页面的论文提交链接进入,然后填写个人信息注册会员即可。一次注册,多地使用
- 论文编写:latex格式论文推荐用Overleaf写,多人协同编辑的平台,包含了大量 LaTeX 插件,编辑功能相当完善;编辑完内容还能实时预览效果。
- 提交论文前,必须确认自己和其他作者的 profile 和 global profile 信息填写完整,否则可能会被拒稿哦。
【2022-1-18】AAAI跟KDD都是CCF A类,但是从认知来说,kdd难度比aaai大多了。aaai、ijcai、cvpr都是灌水会,都是a类;ICDM还是CIKM也有过类似的
【2023-10-17】如何看待大语言模型会议COLM(Conference on Language Modeling)?
- 之前看有大佬在呼吁需要一个新的,专门用于LLM的会议,没想到这么快就组织出来了,之前看有大佬在呼吁需要一个新的,专门用于LLM的会议,没想到这么快就组织出来了,Call for papers里面的topics非常有看点,可以说罗列了(基本上)所有LLM相关的方向
- ACL的投稿周期太长了,匿名期使得很多工作要很长的时间才可以公开出来,但如今LLM这个领域发展太快了,长时间不能公开自己工作,会严重削弱这个工作的影响力,现在挺好的,有一个专门关注LLM的会,这样大家就不用一窝蜂去卷ML三大会了
跟李沐学AI
【2022-11-19】跟李沐学AI, paper-reading
OpenAI Whisper 精读【论文精读】
KDD
【2022-1-18】Call for Applied Data Science Track Papers
录用论文
- 【2021-8-19】KDD2021工业界搜推广nlp论文整理,KDD21的Accepted Papers[1]中,工业界在搜索、推荐、广告、nlp上的文章。
- 【2020-7-18】2020 IJCAI,ICML 2020
- 【2021-2-5】2021年AAAI论文录取
- 【2021-8-6】ACL 2021 一文详解美团技术团队7篇精选论文,美团在事件抽取、实体识别、意图识别、新槽位发现、无监督句子表示、语义解析、文档检索等自然语言处理任务上的一些技术沉淀和应用。
- 针对于事件抽取,我们显示地利用周边实体的语义级别的论元角色信息,提出了一个双向实体级解码器(BERD)来逐步对每个实体生成论元角色序列;
- 针对于实体识别,我们首次提出了槽间可迁移度的概念,并为此提出了一种槽间可迁移度的计算方式,通过比较目标槽与源任务槽的可迁移度,为不同的目标槽寻找相应的源任务槽作为其源槽,只基于这些源槽的训练数据来为目标槽构建槽填充模型;
- 针对于意图识别,我们提出了一种基于监督对比学习的意图特征学习方法,通过最大化类间距离和最小化类内方差来提升意图之间的区分度;
- 针对于新槽位发现,我们首次定义了新槽位识别(Novel Slot Detection, NSD)任务,与传统槽位识别任务不同的是,新槽位识别任务试图基于已有的域内槽位标注数据去挖掘发现真实对话数据里存在的新槽位,进而不断地完善和增强对话系统的能力。
研究
- 【2020-8-28】【Eric的博士生生存指南】《Syllabus for Eric’s PhD students - Google Docs》by Eric Gilbert
研究思路
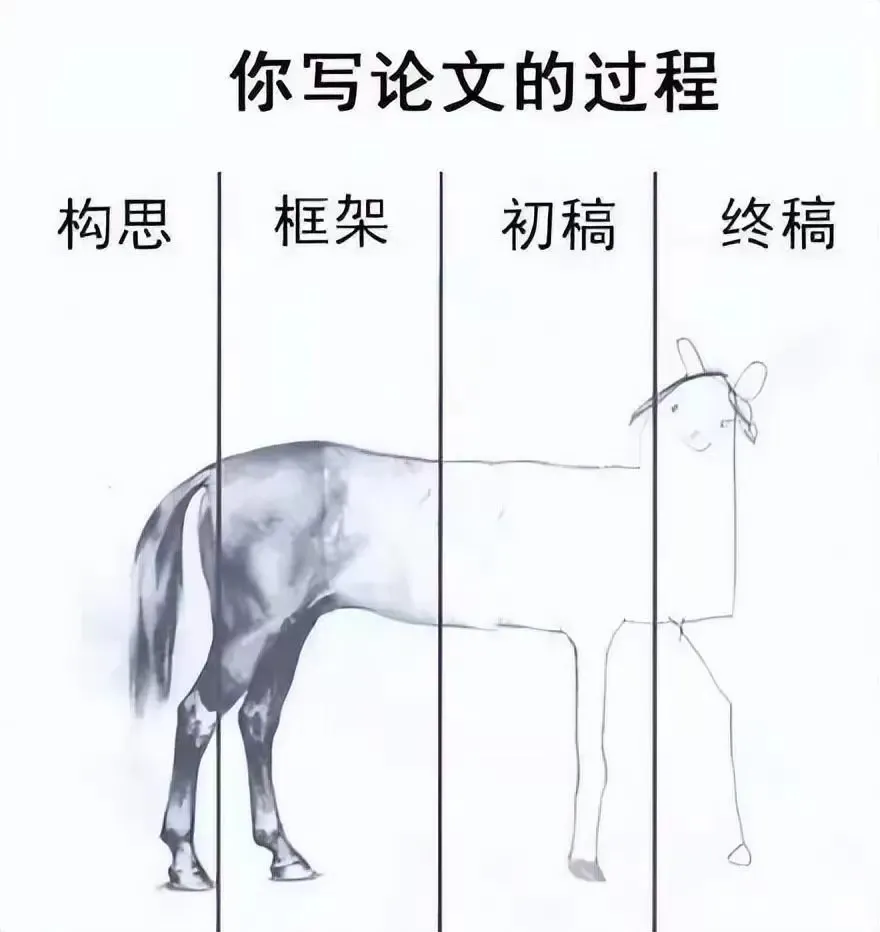
【2022-5-18】写论文过程形象描述:构思 → 框架 → 初稿 → 终稿
科研方法论
【2023-9-24】你在科研路上遇到过什么如有神助的经历? - 科研大喵叫喵大的回答
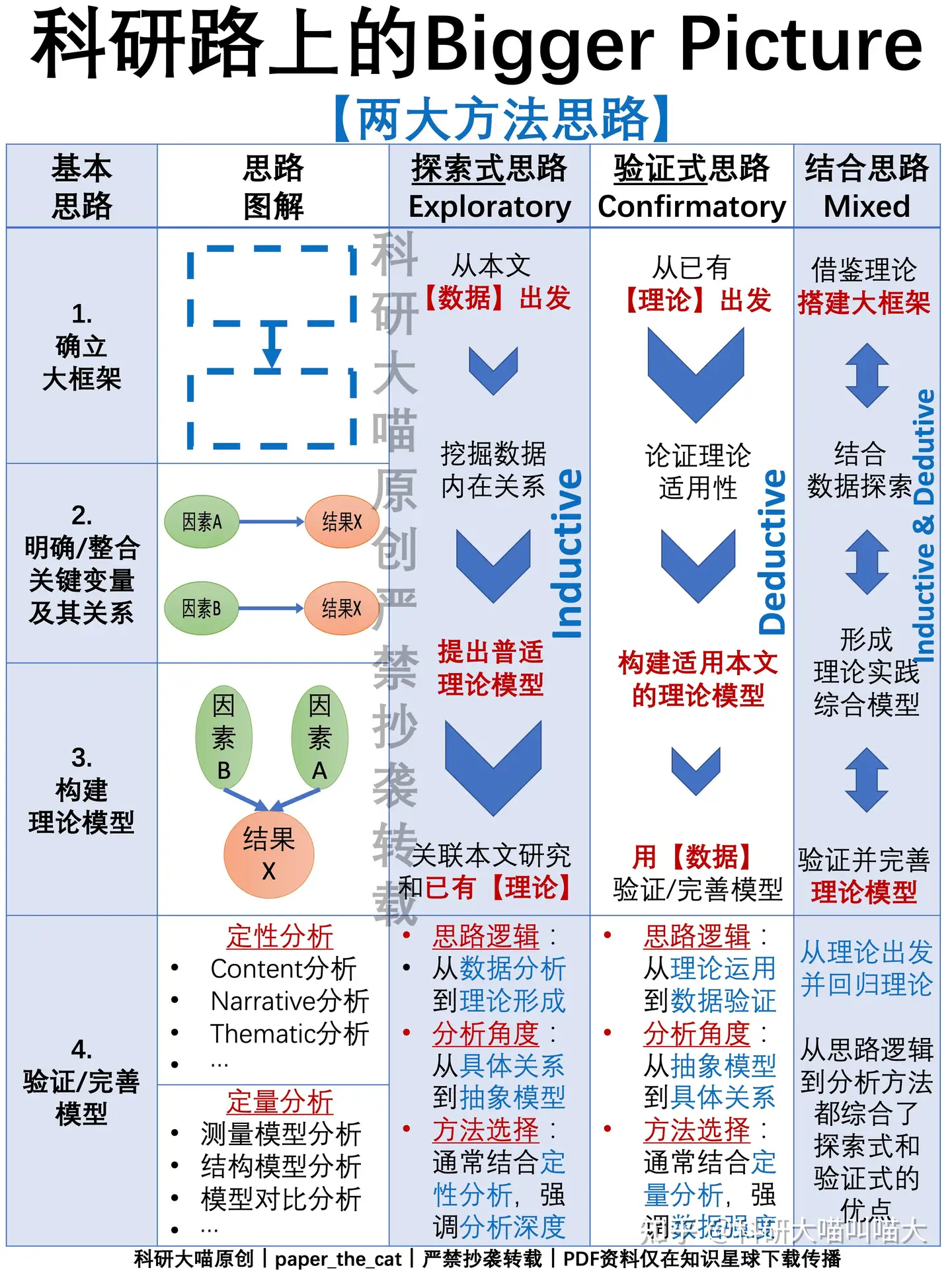
两大方法思路
- 探索式的思路走不通,就试试验证式,当然还可以两者结合
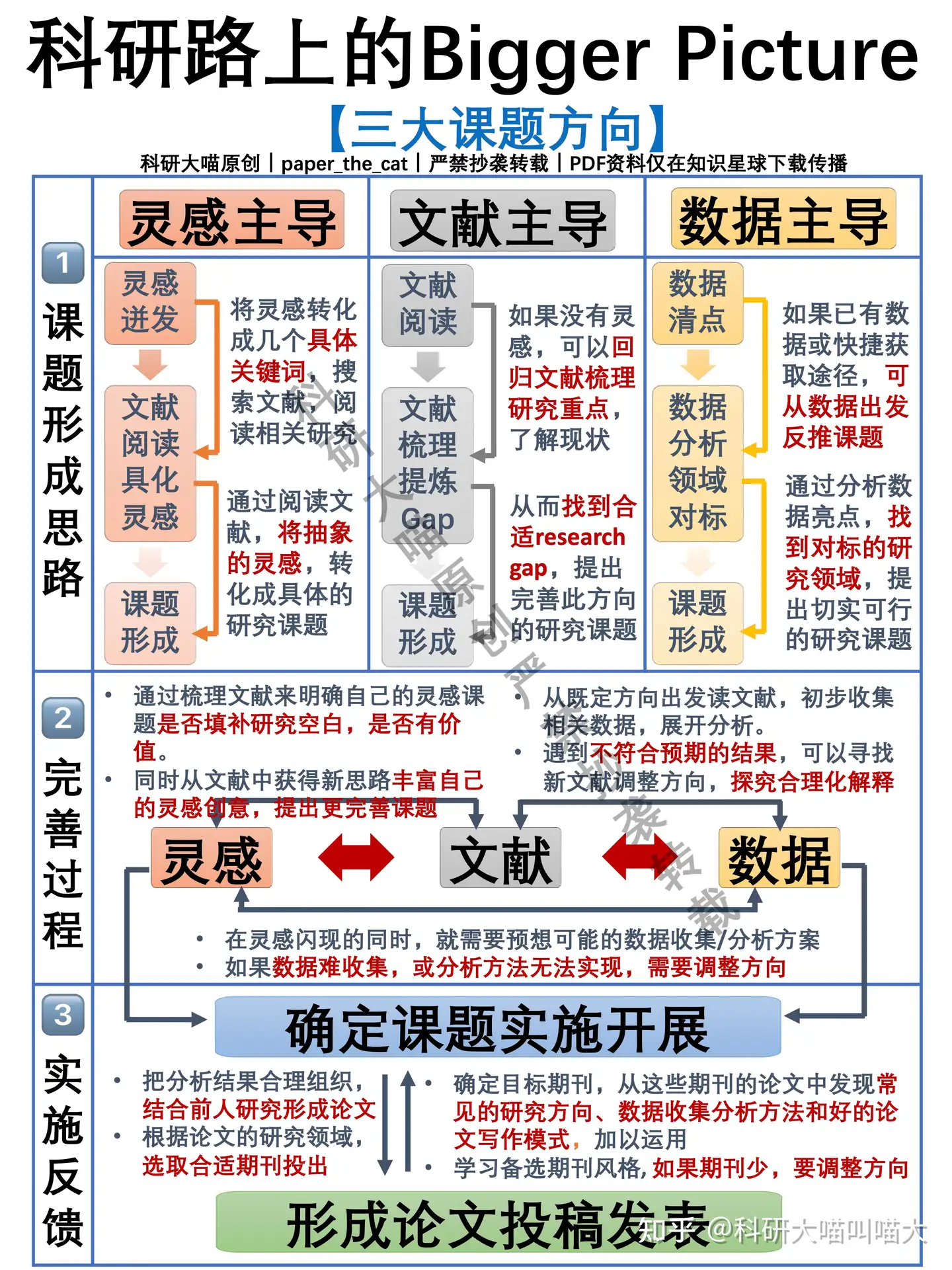
三大课题方向
- 灵感、文献、数据结合起来,综合考虑找课题
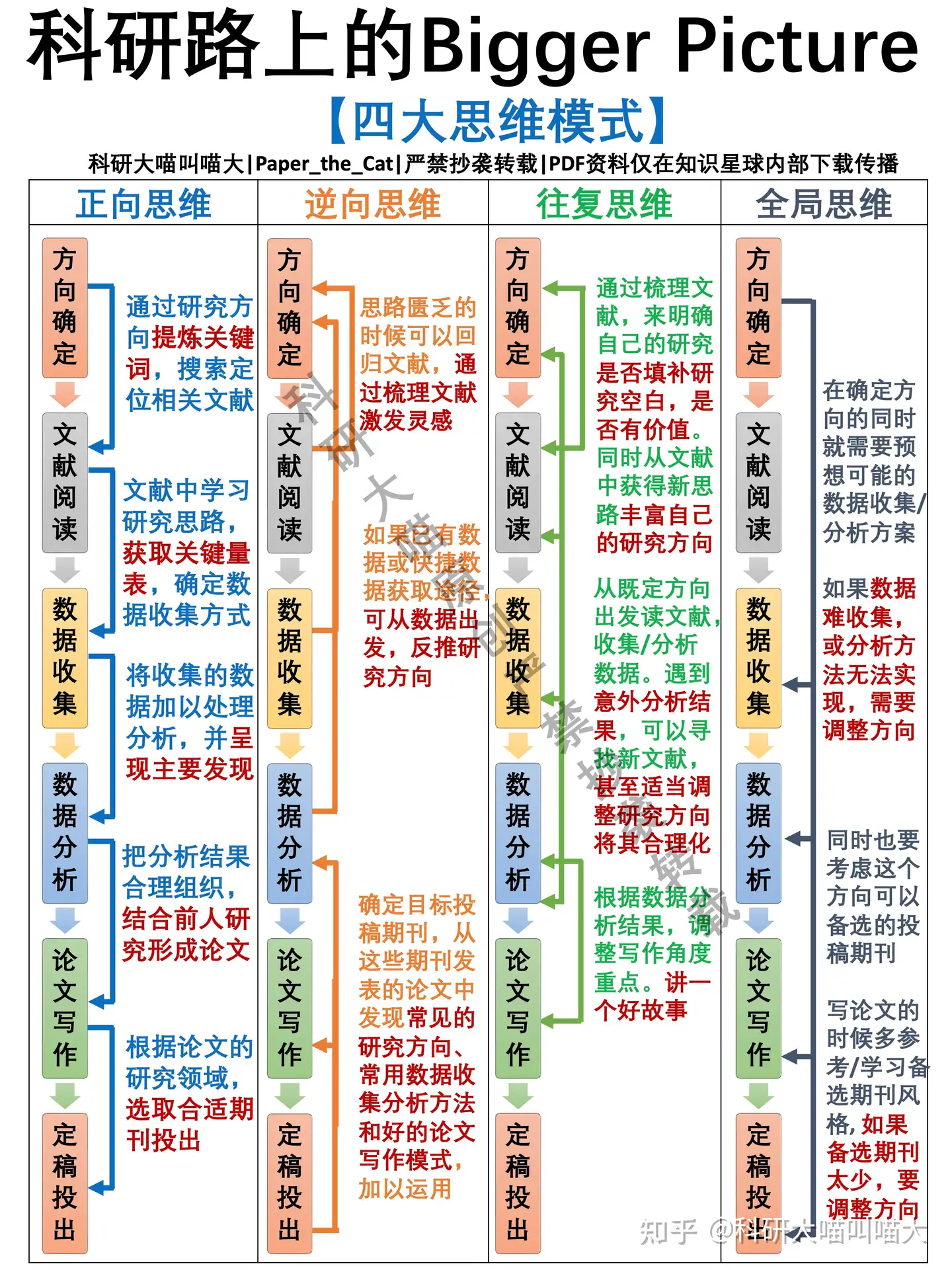
四大思维模式
- 正向、逆向、往复、整体考虑,不要陷入思维的死胡同
五大文献考虑
- 文献的来源有很多,考虑文献的实效性、系统性、权威性、学术性和理论性,结合自己的需要,高效获取文献信息

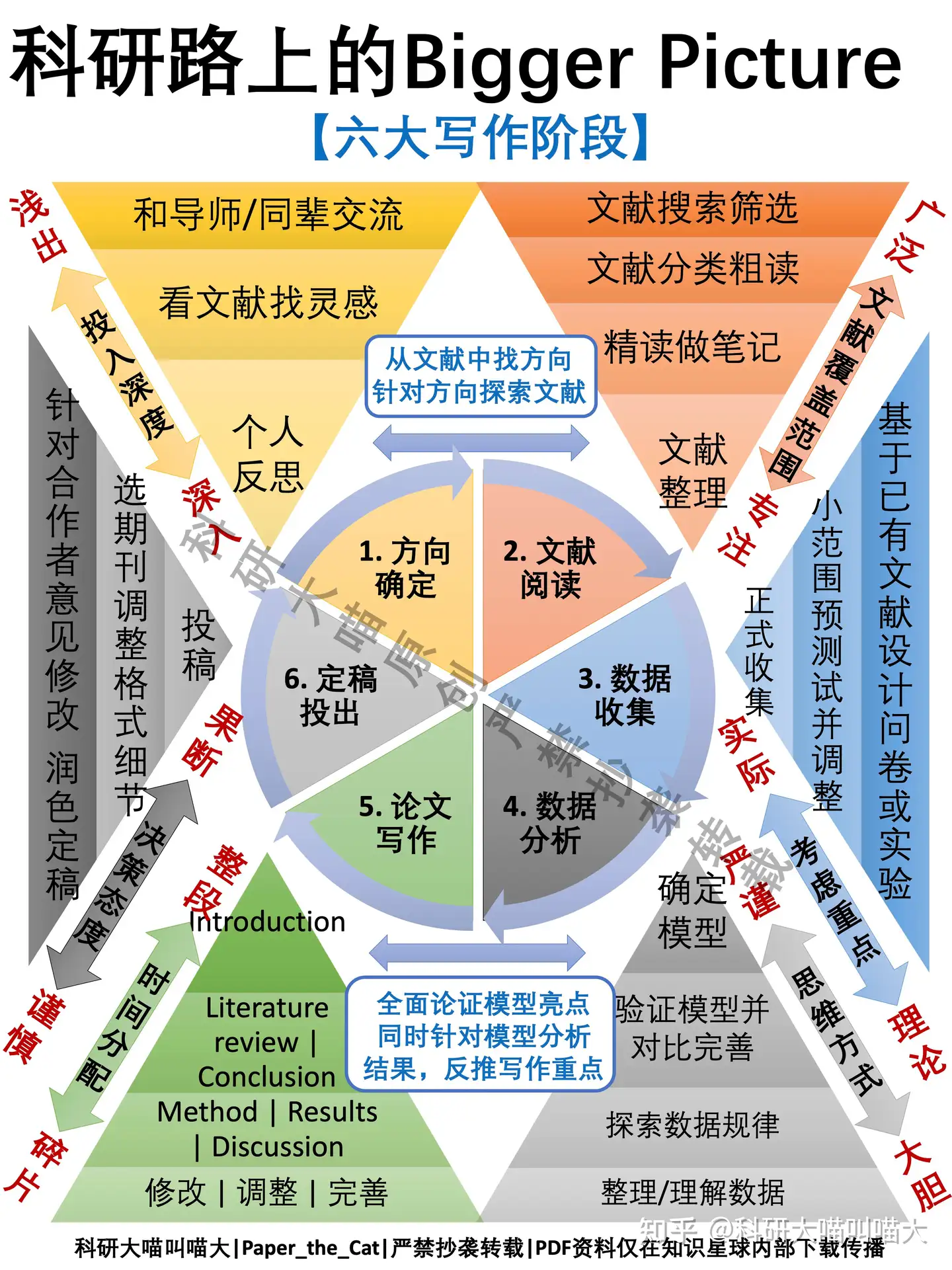
六大写作阶段
- 方向确定、文献阅读、数据收集、数据分析、论文写作、定稿投出,这条路不可能一帆风顺,不要卡在一个点,停滞不前的之后可以跳跃进行
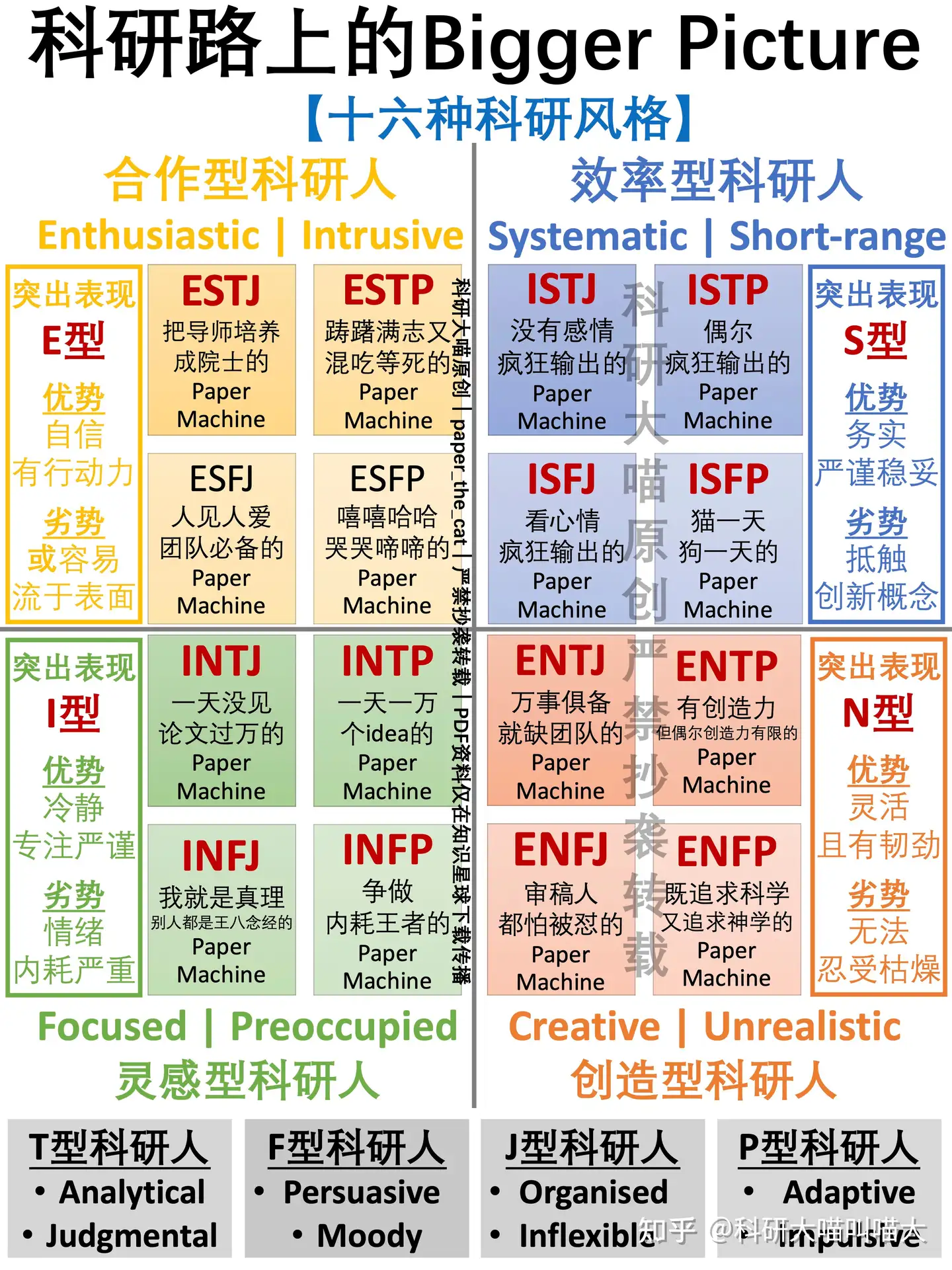
十六种科研风格
- 做颜色不一样的,paper machine
二十个论文要点
- 一篇学术论文只需要解决20个小问题,掰开了揉碎了,难题就迎刃而解了

好的想法从哪里来
- 做过一些研究的同学会有感受,仅阅读自己研究方向的文献,新想法还是不会特别多。这是因为读到的都是该研究问题已经完成时的想法,它们本身无法启发新的想法。
- 如何产生新的想法呢?有三种可行的基本途径:
实践法。即在研究任务上实现已有最好的算法,通过分析实验结果,例如发现这些算法计算复杂度特别高、训练收敛特别慢,或者发现该算法的错误样例呈现明显的规律,都可以启发你改进已有算法的思路。现在很多自然语言处理任务的Leaderboard上的最新算法,就是通过分析错误样例来有针对性改进算法的 [1]。类比法(迁移)。即将研究问题与其他任务建立类比联系,调研其他相似任务上最新的有效思想、算法或工具,通过合理的转换迁移,运用到当前的研究问题上来。例如,当初注意力机制在神经网络机器翻译中大获成功,当时主要是在词级别建立注意力,后来我们课题组的林衍凯和沈世奇提出建立句子级别的注意力解决关系抽取的远程监督训练数据的标注噪音问题 [2],这就是一种类比的做法。组合法。即将新的研究问题分解为若干已被较好解决的子问题,通过有机地组合这些子问题上的最好做法,建立对新的研究问题的解决方案。例如,我们提出的融合知识图谱的预训练语言模型,就是将BERT和TransE等已有算法融合起来建立的新模型 [3]。
- 与阅读论文、撰写论文、设计实验等环节相比,如何产生好的研究想法,是一个不太有章可循的环节,很难总结出固定的范式可供遵循。像小马过河,需要通过大量训练实践,来积累自己的研究经验。不过,对于初学者而言,仍然有几个简单可行的原则可以参考。
- (1)一篇论文的可发表价值,取决于它与已有最直接相关工作间的Delta。我们大部分研究工作都是站在前人工作的基础上推进的。牛顿说:如果说我看得比别人更远些,那是因为我站在巨人的肩膀上。在我看来,评判一篇论文研究想法的价值,就是看它站在了哪个或哪些巨人的肩膀上,以及在此基础上又向上走了多远。反过来,在准备开始一项研究工作之前,在形成研究想法的时候,也许要首先明确准备站在哪个巨人的肩膀上,以及计划通过什么方式走得更远。与已有最直接相关工作之间的Delta,决定了这个研究想法的价值有多大。
- (2)兼顾摘果子和啃骨头。人们一般把比较容易想到的研究想法,叫做Low Hanging Fruit(低垂果实)。低垂果实容易摘,但同时摘的人也多,选择摘果子就容易受到想法撞车的困扰。例如,2018年以BERT为首的预训练语言模型取得重大突破,2019年中就出现大量改进工作,其中以跨模态预训练模型为例,短短几个月里 arxiv上挂出了超过六个来自不同团队的图像与文本融合的预训练模型。设身处地去想,进行跨模态预训练模型研究,就是一个比较容易想到的方向,你一定需要有预判能力,知道世界上肯定会有很多团队也同时开展这方面研究,这时你如果选择入场,就一定要做得更深入更有特色,有自己独特的贡献才行。相对而言,那些困难的问题,愿意碰的人就少,潜下心来啃硬骨头,也是不错的选择,当然同时就会面临做不出来的风险,或者做出来也得不到太多关注的风险。同学需要根据自身特点、经验和需求,兼顾摘果子和啃骨头两种类型的研究想法。
- (3)注意多项研究工作的主题连贯性。同学的研究训练往往持续数年,需要注意前后多项研究工作的主题连贯性,保证内在逻辑统一。需要考虑,在个人简历上,在出国申请Personal Statement中,或者在各类评奖展示中,能够将这些研究成果汇总在一起,讲出自己开展这些研究工作的总目标、总设想。客观上讲,人工智能领域研究节奏很快,技术更新换代快,所以成果发表也倾向于小型化、短平快。我有商学院、社科的朋友,他们一项研究工作往往需要持续一年甚至数年以上;高性能计算、计算机网络方向的研究周期也相对较长。人工智能这种小步快跑的特点,决定了很多同学即使本科毕业时,也会有多篇论文发表,更不用说硕士生、博士生。在这种情况下,就格外需要在研究选题时,注意前后工作的连贯性和照应关系。几项研究工作放在一起,到底是互相割裂说不上话,还是在为一个统一的大目标而努力,格外反映研究的大局意识和布局能力。例如,下图是我们课题组涂存超博士2018年毕业时博士论文《面向社会计算的网络表示学习》的章节设置,整体来看就比《社会计算的若干重要问题研究》等没有内在关联的写法要更让人信服一些。当然,对于初学者而言,一开始就想清楚五年的研究计划,根本不可能。但想,还是不去想,结果还是不同的。
- (4)注意总结和把握研究动态和趋势,因时而动。
- 2019年在知乎上有这样一个问题:“2019年在NLP领域,资源有限的个人/团队能做哪些有价值有希望的工作?”
- 我当时的回答如下:
- 我感觉,产业界开始集团化搞的问题,说明其中主要的开放性难题已经被解决得差不多了,如语言识别、人脸识别等,在过去20年里面都陆续被广泛商业应用。看最近的BERT、GPT-2,我理解更多的是将深度学习对大规模数据拟合的能力发挥到极致,在深度学习技术路线基本成熟的前提下,大公司有强大计算能力支持,自然可以数据用得更多,模型做得更大,效果拟合更好。
- 成熟高新技术进入商用竞争,就大致会符合摩尔定律的发展规律。现在BERT等训练看似遥不可及,但随着计算能力等因素的发展普及,说不定再过几年,人人都能轻易训练BERT和GPT-2,大家又会在同一个起跑线上,把目光转移到下一个挑战性难题上。
- 所以不如提前考虑,哪些问题是纯数据驱动技术无法解决的。NLP和AI中的困难任务,如常识和知识推理,复杂语境和跨模态理解,可解释智能,都还没有可行的解决方案,我个人也不看好数据驱动方法能够彻底解决。更高层次的联想、创造、顿悟等认知能力,更是连边还没碰到。这些正是有远见的研究者们应该开始关注的方向。
- 需要看到,不同时期的研究动态和趋势不同。把握这些动态和趋势,就能够做出研究社区感兴趣的成果。不然的话,即使研究成果没有变化,只是简单早几年或晚几年投稿,结果也会大不相同。例如,2013年word2vec发表,在2014-2016年之间开展词表示学习研究,就相对比较容易得到ACL、EMNLP等会议的录用;但到了2017-2018年,ACL等会议上的词表示学习的相关工作就比较少见了。
- 周志华:做研究与写论文
写作
- 【2020-7-4】【论文写作相关资源大列表】’Paper Writing’ by wangdongdut GitHub
术语
消融实验
【2023-11-15】论文里频频出现的消融实验(ablation experiment)是什么意思?
三个贡献点:A、B、C。
- 去掉A,其它保持不变,发现效果降低了,那说明A确实有用。
- 去掉B,其它保持不变,发现效果降的比A还多,说明B更重要。
- 去掉C,其它保持不变,发现效果没变,那C就是凑字数的
类似控制变量法
上海交大 IEEE Fellow 过敏意
【2022-1-18】IEEE Fellow 过敏意:从IEEE汇刊主编视角看如何提升科技论文质量
问题陈述部分需要和读者产生共鸣,让读者读了这部分之后,即使不看后面的具体方法,也能自己琢磨相应的解决方案,从而让读者在阅读后面的解决方案的时候有与作者对话的感觉,产生迎刃而解的感觉。
写作建议:
- 临近区域同个词避免重复出现。中英文论文中如果临近区域重复出现一个词汇,会导致非常差的阅读体验,可以用其他相同含义的词汇表达同一意思。上图“红圈”地方就是一个直观例子。
- 避免and开头。一方面 and让读者感觉不专业,另一方面和中国人的习惯不同,在英文表达中需要用一些连接词进行逻辑整理,例如On one hand,On the other hand,however等等。
- 避免长句子。学会分段和分句。
- 避免过于晦涩难懂的词汇。中国学生写论文尤爱使用生晦的词,喜欢查词典找同义词,认为不常用的词非常“高大上”,这其实违反了让读者有愉悦感的原则。
在具体的论文中,标题和摘要是主编和审稿人的兴趣入口。主编往往可以从这两部分找出文章的缺点以及贡献和亮点。这两部分的标准是:标题足够凝练,摘要足够突出论文的核心创新和贡献。值得一提的是,计算机领域论文的摘要中不需要包含太多的公式。
论文中的引言(introduction)部分需要陈述问题的背景和意义,以及简述过去在这个方向的工作,并指出当前工作的不足之处,以及投稿论文的主要创新点。这部分最能体现作者的功底,展现作者的调研能力。撰写引言不宜过长,简介主要突出关键点,能够方便主编快速地大体确认论文方向,针对性地挑选编委以及吸引读者进一步阅读论文。吸引读者的技巧可以借鉴中国画中的留白技法。
在撰写论文相关工作时,要注意一方面要概述过去工作的贡献,另一方面也要突出过去工作的不足,从而凸显自己工作的先进性。这部分的撰写需要不断打磨,既不无限抬高别人,也不能刻意贬低别人。其中技巧只可意会,不可言传,文章被拒的次数多了,自然就能领悟真谛。
撰写相关工作的大忌是罗列,它只能告诉读者“谁做了什么工作,谁又做了什么工作”,无法让读者获取深度信息。一定要逻辑地整理相关工作,让读者阅读这部分时确实能够看到这个小领域的发展,而不是简单地知道谁做了什么。
在论文主题部分,需要注意问题陈述和创新方法的撰写。其中问题陈述是比摘要和简介中更进一步的清晰陈述,问题要让人容易理解,在可能的情况下,举例说明会更清淅;创新方法中“为什么”比“怎么做”还重要,聚焦于“怎么做”容易陷入技术报告,缺乏逻辑串联,聚焦于“为什么”会吸引评委和读者思考,从而得到认同,并且能够自然地带出“怎么做”。
在论文实验部分,牢记“实验是对所提方案的验证”,有三个要素不可缺少。一是可重复性,要有公认的实验场景和配置;二是可解释性,图片清晰,避免出现图片“误用”;三是要可分析性,即佐证结论。
- 反例:作图不专业、实验单调、标题不清晰、没有对比等等,从而使得图没有自解释性。好的实验图应该让读者读完文字之后,能通过图片验证想法。左图是一个正确的案例,显然能够达到佐证的效果:对比清晰,可以不是和state of the art进行比较,至少要让读者感觉你对自己的方法有信心;用了专业的作图工具,且考虑了黑白打印的效果。
在写总结部分时候,很容易写成摘要。其实总结还有一层含义:Takeaway。它指的是:建立在读者已经阅读了论文后,和作者一起产生了共鸣,希望读者忘却论文的工作细节后,还能留下一些印象。因此,可以在有进一层理解的基础上再次总结论文的主要贡献,也即拔高。
佛靠金装,人靠衣装。论文排版非常重要,请尽量使用LaTex进行排版,看起来专业、漂亮。虽然我们不能以貌取人,但人是视觉动物,很难保障主编不会“以貌取文”。此外,尽量使用指定的论文模板,虽然IEEE的主编接收Springer模板的论文也无伤大雅,但与人方便就是与己方便,还是应该考虑接收信息的成本。
哥大博士总结
- 【2021-1-1】如何让文章写的更好?源自:哥大读博五年总结
- 总体思路:
- 先给一个Talk。写paper最难的是构思storyline,最好的方法就是做一个slides,给周围的人present一遍。这个过程中,梳理好自己的思路,画好文中的figure,准备好实验结果的table,周围的人给你提意见,帮助你完善,等这个talk给完了,后面写paper就会顺畅自然了。其实准备投一个paper,当做了一段时间后,就会按照最终presentation的思路,准备slides,用在每周给老板们report时。开头先快速review一下做的task和提出的方法,remind一下context,然后重点focus在那周做的新东西上,所以每周汇报的slides可能80%都是跟上一周一样的,然后新的方法和实验结果的那几页slides是新的,有比较多的细节。
- 用Google doc做语法检查。刚写好的paper有typo和语法错误是很难避免的,但常常会被reviewer揪着不放。大家写paper如今大都在overleaf上,但overleaf的查错还是不够好,建议可以写完paper后,贴到Google doc里面。几年前开始,估计是由于deep learning对Google NLP的改进很大,感觉Google自动改的质量已经非常高了。
- Rationale很重要。不光是要讲清楚怎么做的,更要justify为什么这么做;不光要讲结果比baseline好,更要解释为什么好;读者看到的不应是一个“使用手册”。有时候花了很多篇幅写了实现细节,更重要的是解释“为什么”,这个背后的逻辑和insights。
- 大部分paper都是提出一个新的方法,这类paper都可以套这个框架:
- Introduction:可以分为以下几个部分:
- Problem definition
- Previous methods and their limits
- 简单描述你是提出了什么技术来overcome上面的limits
- 一个图,非常high-level的解释前人工作的limits和你的工作怎么解决了这些limits,最好让人30秒内完全看懂
- 最后一段如今大都是,In summary, this paper makes three contributions:
- First work to解决什么limits
- 提出了什么novel的技术
- outperform了state-of-the-art多少
- Related Work:一般三五个subsection,分别review下相关的topics,同样不光讲previous work做了啥,更要讲自己的方法跟前人工作有啥不同
- Method
- 这是文章的主体,按照你觉得最容易让别人看懂的方式来讲
- 可以第一个subsection是overview,formulate一下你的problem给出notation,配一个整体framework的图,图里面的字体不能太大或者太小看不清, - 要有些细节,让人光看图就能明白你的方法是怎么回事,但不要过于复杂,让人在不超过2分钟的时间看完这张图
- 然后几个subsection具体介绍你的方法或者模型;如果testing跟training不太一样,最后一个subsection介绍inference时候的不同,通常是一些post-processing操作
- Experiment
- Datasets
- Implementation details such as pre-processing process, training recipe
- Evaluation metrics
- Comparisons with state-of-the-art
- Detailed analysis
- Alternative design choice exploration
- Ablation studies
- Visualization examples
- Conclusion (and Future Work)
- Abstract:是全文的精简版,建议在paper写完第一稿差不多成型了,有定下来的成熟的storyline了,再去写abstract;大概就是用一两句话分别概括paper里面每个section,然后串起来
- Introduction:可以分为以下几个部分:
- presentation的技巧:
- 如果可能的话,事先了解听众背景,是做同一个topic的,还是同一个大领域但不同topic的,还是完全其他专业背景的。需要根据听众背景,定制和调整:比如,需不需要多介绍些背景?需不需要更深入技术细节?等等
- 一页slide尽可能focus在一个点上,不要信息量过大,否则听众很容易lost
- 尽可能多用图片表达,不要大段大段的列文字,A picture is worth a thousand words
- 上面这两点,其实principle都是尽量让要讲的内容简单明了,因为很多时候我们在听talk,这样被动接受的时候,接受新知识的能力是比主动接受时候(比如看paper)低的。
- 当听众问问题的时候,If you don’t know the answer, just say don’t know.
- 如果是跟mentor日常讨论的slides,因为会讨论到很细节的东西,有些图PPT画起来,很花时间,而且通常这样细节的图还挺多,所以可以就ipad上面手画一画,截个图放到PPT里就好了;如果是正式一点的presentation,写slides跟写paper的principle有点像,不要太focus在细节上,更重要的是讲清楚motivation,为什么这样设计,细枝末节的不关键的内容,放在backup slides里面。
域外学习(OOD)
【2021-9-13】《因果学习周刊》第1期:因果学习的分布外泛化问题
经典的机器学习方法是建立在独立同分布假设的基础上的。然而在真实场景中,独立同分布假设很难得到满足,导致经典机器学习算法在分布偏移下的性能急剧下降,这也表明研究分布外泛化问题的重要性。分布外泛化(Out-of-Distribution Generalization)问题针对测试分布未知且与训练不同的具有挑战性的问题设定。
分布外泛化问题(Out-of-Distribution Generalization)相关的一些方法,以不变学习方法为主,最后还介绍了一篇最新的分布外泛化问题综述文章。
清华大学计算机系崔鹏团队发布了首篇OOD泛化问题综述:Towards Out-of-Distribution Generalization: A Survey
【2021-10-26】论文分享:Mila-Invariance Principle Meets Information Bottleneck for Out-of-Distribution Generalization
- 论文链接, Hub链接
- 推荐理由:本文将不变学习与信息瓶颈结合了起来,并给出了一系列的模拟实验来说明其必要性,十分具有借鉴意义。
- 简介:来自因果关系的不变性原则是诸如不变风险最小化(IRM)等方法的核心,这些方法试图解决分布外泛化问题(Out-of-Distribution Generalization Problem)。尽管这个理论很有潜力,但基于不变原理的方法在普通的分类任务中效果不佳,这其中不变(因果)特征捕获了关于标签的所有信息。然而这些失败是由于方法未能捕获不变性特征造成的吗? 还是不变性原则本身就不够? 为了回答这些问题,我们回顾了线性回归任务中的基本假设,其中基于不变的方法被证明可以做到分布外泛化。与线性回归任务相比,我们证明,对于线性分类任务,需要对分布偏移有更强的限制,否则分布外泛化是不可能的。此外,即使有适当的分布位移限制,我们也证明了仅靠不变性原理是不够的。当不变特征捕获关于标签的所有信息时,一种形式的信息瓶颈约束和不变性原理结合有助于解决关键故障,并且即使在它们没有捕获到有关标签的所有信息时,也能维持现有的分布外泛化性能。我们提出了一种结合这两种原则的方法,并在几个实验中证明了它的有效性。
机器学习研究中的陷阱
【2021-8-17】如何避免机器学习研究中的陷阱?一本给学术研究人员的指南,指南共涵盖了机器学习过程的五大方面:建模前如何准备,如何建出可靠的模型,如何稳健地评估模型,如何公平地比较模型以及如何报告结果。
- 2021年8月5日的How to avoid machine learning pitfalls: a guide for academic researchers
- This document gives a concise outline of some of the common mistakes that occur when using machine learning techniques, and what can be done to avoid them. It is intended primarily as a guide for research students, and focuses on issues that are of particular concern within academic research, such as the need to do rigorous comparisons and reach valid conclusions. It covers five stages of the machine learning process: what to do before model building, how to reliably build models, how to robustly evaluate models, how to compare models fairly, and how to report results.
建模前的准备
为了得到符合预期用途的模型、可以顺利发表论文的结果,建模之前你需要做好以下6点准备:
- 1、确保花时间研究你要用的数据集,来源可靠、质量有保证。
- 2、但不要查看测试数据,防止先入为主做出某些假设导致最终模型通用性差。
- 3、保证数据量足够大,当然保证不了也是常有的事儿,解决办法:比如评估模型时交叉验证数据、采用数据扩充技术(数据集中某类数据不够时也可采用)。但总的来说,数据不够模型就不能设计得太复杂,不然分分钟给你过拟合。
- 4、要和相关领域专家谈谈,防止研究脱离实际,并且他们也可以帮助你向最合适的期刊/受众发表。
- 5、搜遍相关文献,虽然发现别人已经研究过了很沮丧,但是写论文时你该怎么解释为什么要覆盖相同的领域。
- 6、一定要提前考虑模型部署的问题:大部分学术研究最终都是要落地吧?好好考虑落地场景的资源、时间限制等问题来设计模型。
如何建出可靠的模型
- 1、不要让测试数据参与到训练过程中(这点前面也已强调过)。
- 2、尝试不同的ML模型,别套用,具体问题具体分析找出最适合解决你的问题的那个。“凑合”的例子包括将期望分类特征的模型应用于由数字特征组成的数据集、将假定变量之间没有依赖关系的模型应用于时间序列数据,或者只相信最新的模型(旧的不一定不合适)。
- 3、一定要优化模型的超参数。使用某种超参数优化策略比较好,这样在写论文时也好整。除了数据挖掘实践之外,可以使用AutoML技术优化模型及其超参数的配置。
- 4、在执行超参数优化和特征选择要小心:防止测试集“泄漏”,不要在模型训练开始之前对整个数据集进行特征选择。理想情况下应使用与训练模型所用数据完全相同的数据。
实现这一点的常用技术是嵌套交叉验证(也称为双交叉验证)。
如何稳健地评估模型
对模型进行不公平的评估,很容易让学术研究的水变浑浊。作者一共提了5点:
- 1、一个模型在训练集上的表现几乎毫无意义,保证测试集与训练集之间的独立。
- 2、在连续迭代多个模型,用前面的数据指导下一个的配置时使用验证集,千万不要让测试集参与进来。可以根据验证集对模型进行测量:当分数开始下降时,停止训练,因为这表明模型开始过拟合。
- 3、对模型多次评估,防止低估/高估性能。十次交叉验证是最标准的做法,对很小的数据类进行层化也很重要;需要报告多个评估的平均值和标准偏差;也建议保留单个分数记录,以防以后使用统计测试来比较模型。
- 4、保留一些测试数据以无偏评估最终的模型实例。
- 5、不要对不平衡的数据集使用准确度(accuracy)指标。这个指标常用于分类模型,不平衡数据集应采用kappa系数或马修斯相关系数(MCC)指标。
如何公平地比较模型
这是非常重要的一环,但很惊讶的是很多人都比不对,作者表示一定要确保在同一环境中评估不同的模型,探索多个视角,并正确使用统计测试。
- 1、一个更大的数字不意味着一个更好的模型。应将每个模型优化到同等程度,进行多次评估,然后使用统计测试确定性能差异是否显著。
- 2、要想让人相信你的模型好,一定要做统计测试。
- 3、进行多重比较时进行校正:如果你以95%的置信水平做20个成对测试,其中一个可能会给你错误的答案。这被称为多重性效应。最常见的解决方法是Bonferroni校正。
- 4、不要总是相信公共基准测试的结果。使用基准数据集来评估新的ML模型已变得司空见惯,你以为这会让结果更透明,实际上:如果测试集的访问不受限,你没法确保别人没有在训练过程中使用它;被多次使用的公共测试集上的许多模型可能会与之过度匹配;最终都会导致结果乐观。
- 5、考虑组合模型。
如何报告结果
学术研究的目的不是自我膨胀,而是一个贡献知识的机会。为了有效地贡献你的想法,你需要提供研究的全貌,包括哪些有效哪些无效。
- 1、保持你所做所发现的成果透明,这会方便其他人更容易地在你的工作基础上扩展。共享你的代码也会让你在coding的时候更认真。
- 2、提供多个测试集上的报告,为每个数据集报告多个度量指标(如果你报告F值,请明确这是F1得分还是精度和召回率之间的其他平衡;如果报告AUC,请指出这是ROC曲线下的面积还是PR下的);
- 3、不要在结果之外泛化,不要夸大,意识到数据的局限性。
- 4、报告统计显著性时一定要小心:统计人员越来越多地认为,最好不要使用阈值,而只报告p值,让读者来解释这些值。除了统计意义之外,另一件需要考虑的事是两个模型之间的差异是否真正重要。
- 5、最后,再回过头完整的看一眼你的模型,除了报告性能指标,看看它能解决多少实际问题。
小样本学习
- 【2021-1-1】小样本学习方法(FSL)演变过程
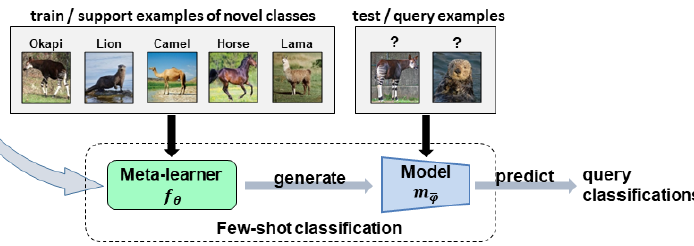
- 小样本学习方法(FSL)演变过程以及MAML和度量学习的区别所在
- 小样本学习一般会简化为N-way K-shot问题,如图。其中N代表类别数量,K代表每一类中(支持集)的样本量;
- 解决分类问题,人们最先想到的是采用传统监督学习的方式,直接在训练集上进行训练,在测试集上进行测试,如图,但神经网络需要优化的参数量是巨大的,在少样本条件下,几乎都会发生过拟合;
- 首先想到的是通过使用迁移学习+Fine-tune的方式,利用Base-classes中的大量数据进行网络训练,得到的Pre-trained模型迁移到Novel-classes进行Fine-tune,如图。虽然是Pre-trained网络+Fine-tune微调可以避免部分情况的过拟合问题,但是当数据量很少的时候,仍然存在较大过拟合的风险。
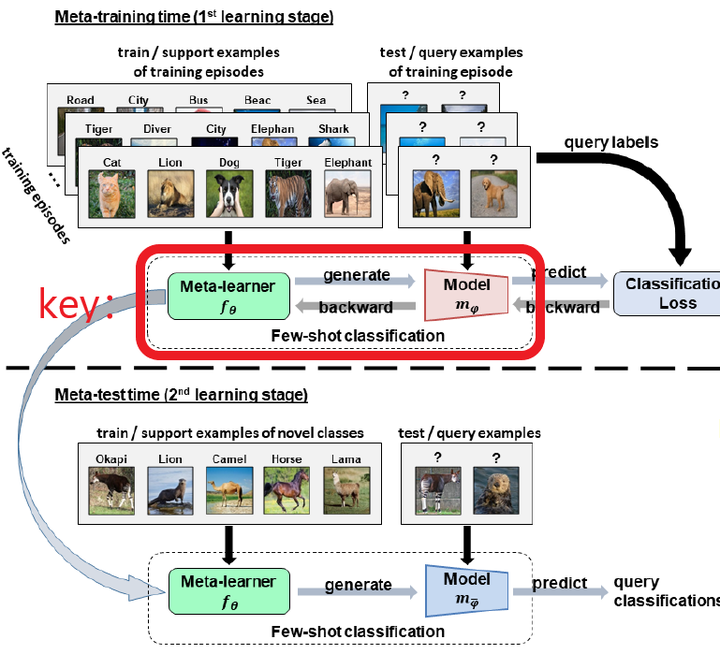
- 小样本学习中极具分量的Meta-learning方法,现阶段绝大部分的小样本学习都使用的是Meta-learning方法。Meta-learning,即learn to learn,翻译成中文是元学习。Meta-learning共分为Training和Testing两个阶段
- (1) Training阶段的思路如图[4]。

- 简单描述下流程:
- 1:将训练集采样成Support set和Query set两部分;
- 2:基于Support set生成一个分类模型;
- 3:利用模型对Query set进行分类预测生成predict labels;
- 4:通过query labels和predict labels进行Loss(e.g., cross entropy loss )计算,从而对分类模型 中的参数θ进行优化。
- (2) Testing阶段的思路如图,利用Training阶段学来的分类模型在Novel class的Support set上进行进一步学习,学到的模型对Novel class的Query set进行预测。
- 元学习整体流程
- Meta-learning核心点之一是如何通过少量样本来学习这个分类模型,即图中的key部分。
- 在这里引出了Meta-learning的两个主要方法:
- 度量学习(Matrix-based Meta-learning)和MAML(Optimization-based Meta-learning)
- (1) Training阶段的思路如图[4]。



元学习
- 【2020-9-19】什么是元学习(meta-learning)?
- 元学习(Meta Learning)或者叫做“学会学习”(Learning to learn),它是要“学会如何学习”,即利用以往的知识经验来指导新任务的学习,具有学会学习的能力。
- 瑞士Dalle Molle人工智能研究所的联合主任Jürgen Schmidhuber(LSTM发明人)在1987年毕业论文《Evolutionary principles in selfreferential learning. (On learning how to learn: The meta-meta-… hook.)》中最早提出了元学习的概念。在 1992 和 1993 两年里又借助循环神经网络进一步发展元学习方法。
- 由于元学习可帮助模型在少量样本下快速学习,从元学习的使用角度看,人们也称之为少次学习(Few-Shot Learning)。
- 如果训练样本数为 1,则称为一次学习(One-Shot Learning);
- 训练样本数为 K,称为 K次学习;
- 更极端地,训练样本数为 0,称为零次学习(Zero-Shot Learning)。
- 另外,多任务学习(Multitask Learning)和迁移学习(Transfer Learning)在理论层面上都能归结到元学习的大家庭中。
-
当前的深度学习大部分情况下只能从头开始训练。使用Finetune来学习新任务,效果往往不好,而Meta Learning 就是研究如何让神经元两个很好的利用以往的知识,使得能根据新任务的调整自己。
- 元学习可以简单地定义为获取知识多样性 (knowledge versatility) 的能力。
- 元学习要解决的就是这样的问题 : 设计出拥有获取知识多样性能力的机器学习模型,它可以在基于过去的经验与知识下,通过少量的训练样本快速学会新概念和技能。
- 例如完成在非猫图像上训练的分类器可以在看到一些猫图片之后判断给定图像是否包含猫
- 帮游戏机器人能够快速掌握新游戏,使迷你机器人在测试期间在上坡路面上完成所需的任务,即使它仅在平坦的表面环境中训练
元学习与多任务学习以及迁移学习的对比
- 元学习虽然从适应新任务的角度看,像是多任务学习;从利用过去信息的角度看,又像迁移学习。不过相对比二者还是有自己的特殊性
- 相较于迁移学习,元学习模型的泛化不依赖于数据量。迁移学习微调阶段还是需要大量的数据去喂模型的,不然会很影响最终效果。而元学习的逻辑是在新的任务上只用很少量的样本就可以完成学习,看一眼就可以学会。从这个角度看,迁移学习可以理解为元学习的一种效率较低的实现方式。
- 对比多任务学习,元学习实现了无限制任务级别的泛化。因为元学习基于大量的同类任务 ( 如图像分类任务 ) 去学习到一个模型,这个模型可以有效泛化到所有图像分类任务上。而多任务学习是基于多个不同的任务同时进行损失函数优化,它的学习范围只限定在这几个不同的任务里,并不具学习的特性。
- 【2021-1-1】知乎总结 aluea
- 迁移学习和元学习共同点就是泛化到没训过的任务上,或者是特定数据一些没见过的类。
- 两者一个是字面上的迁移学习,一个是学会学习。迁移学习简单来说就是,以前训练了一个模型,现在有个新任务,仍想用上那个模型。元学习完全不拘泥于模型,以前学过一些东西,现在新任务得用上它们。从定义上来看,使用迁移学习来实现元学习是一个天然直观的想法,这就是两者的关系。
- anders:元学习经常与另一个话题更相关,多任务学习,两者之间经常是形影不离。
- 多任务学习属于parallel transfer learning,而一般意义的迁移学习是sequential transfer learning。
- 多任务学习中的知识迁移,是并行进行的,多个任务的学习没有先后关系。而一般情况的迁移学习中的知识迁移,是串行进行的,即多个任务的学习过程存在先后关系。
- 需要说的是,不少的多任务学习模型背后都有着元学习的影子,但这些多任务学习的研究往往不会从元学习的角度去解释和思考问题。实际上,元学习也启发了不少多任务学习模型,可以从元学习的角度去解释多任务学习的有效性。
元学习与有监督学习、强化学习的对比
- 分类
- 有监督学习和强化学习称为从经验中学习(Learning from Experiences) , 下面简称
LFE; - 而把元学习称为学会学习(Learning to Learn) , 下面简称
LTL。
- 有监督学习和强化学习称为从经验中学习(Learning from Experiences) , 下面简称
- 二者区别
- ① 训练集不同
- LFE的训练集面向一个任务,由大量的训练经验构成,每条训练经验即为有监督学习的(样本,标签)对,或者强化学习的回合(episode)
- 而LTL的训练集是一个任务集合,其中的每个任务都各自带有自己的训练经验。
- ② 预测函数不同
- ③ 损失函数不同
- ④ 评价指标不同
- ⑤ 学习内涵不同
- LFE是基层面的学习,学习的是样本特征(或数据点)与标签之间呈现的相关关系,最终转化为学习一个带参函数的形式;
- 而LTL是在基层面之上,元层面的学习,学习的是多个相似任务之间存在的共性。不同任务都有一个与自己适配的最优函数,因此LTL是在整个函数空间上做学习,要学习出这些最优函数遵循的共同属性。
- ⑥ 泛化目标不同
- LFE的泛化目标是从训练样本或已知样本出发,推广到测试样本或新样本;
- 而LTL的泛化目标是从多个不同但相关的任务入手,推广到一个个新任务。LTL的泛化可以指导LFE的泛化,提升LFE在面对小样本任务时的泛化效率。
- ⑦ 与其他任务的关系不同
- LFE只关注当前给定的任务,与其他任务没关系;
- 而LTL的表现不仅与当前任务的训练样本相关,还同时受到其他相关任务数据的影响,原则上提升其他任务的相关性与数据量可以提升模型在当前任务上的表现。
- ① 训练集不同
对话系统
【2021-8-6】顶会汇总
- AAAI2021中的Dialogue, AAAI2021的录用文章,包含Dialogue的总共有26篇,还有一些槽位填充和意图识别不带dialogue的文章,简单分类整理如下,包含相关标题和下载链接。
- ACL2021上的Dialogue, ACL2021上包含dialogue关键词的主会文章整理如下,共35篇,方便对话的同学快速了解。相比于去年,对话热度有所下降。
一、多模态对话
- Structured Co-Reference Graph Attention for Video-Grounded Dialogue
- Dynamic Graph Representation Learning for Video Dialog via Multi-Modal Shuffled Transformers
二、对话摘要
- Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
- Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes
三、医疗对话
四、对话生成
- Reasoning in Dialog: Improving Response Generation by Context Reading Comprehension
- Multi-View Feature Representation for Dialogue Generation with Bidirectional Distillation
- Interpretable NLG for Task-Oriented Dialogue Systems with Heterogeneous Rendering Machines
- Stylized Dialogue Response Generation Using Stylized Unpaired Texts
- DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances
- Open Domain Dialogue Generation with Latent Images
- Learning from Perturbations: Diverse and Informative Dialogue Generation with Inverse Adversarial Training
- Generating Relevant and Coherent Dialogue Responses using Self-Separated Conditional VariationalAutoEncoders
- Space Efficient Context Encoding for Non-Task-Oriented Dialogue Generation with Graph Attention Transformer
五、端到端对话系统
六、对话情感分析
- DialogXL: All-in-One XLNet for Multi-Party Conversation Emotion Recognition
- Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentiment Classification
七、任务型对话系统
- Exploring Auxiliary Reasoning Tasks for Task-oriented Dialog Systems with Meta Cooperative Learning
- SCAN: A Spatial Context Attentive Network for Joint Multi-Agent Intent Prediction
- Discovering New Intents with Deep Aligned Clustering
- Encoding Syntactic Knowledge in Transformer Encoder for Intent Detection and Slot Filling
- Deep Open Intent Classification with Adaptive Decision Boundary
- Few-Shot Learning for Multi-Label Intent Detection
口语语言理解 (SLU)
- GL-GIN: Fast and Accurate Non-Autoregressive Model for Joint Multiple Intent Detection and Slot Filling
- Discovering Dialogue Slots with Weak Supervision
- Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Task-Oriented Dialogue System
对话状态跟踪 (DST)
- Dual Slot Selector via Local Reliability Verification for Dialogue State Tracking
- A Sequence-to-Sequence Approach to Dialogue State Tracking
- Comprehensive Study: How the Context Information of Different Granularity Affects Dialogue State Tracking?
- Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialogue State Tracking
端到端对话系统
开放域对话系统
- BoB:BERTOverBERTfor Training Persona-based Dialogue Models from Limited Personalized Data
- OTTers: One-turn Topic Transitions for Open-Domain Dialogue
用户模拟器
八、跨领域对话系统
九、无监督对话系统
十、检索式对话系统
对话回复选择
十一、对话阅读理解
- Filling the Gap of Utterance-Aware and Speaker-Aware Representation for Multi-Turn Dialogue
- Topic-Aware Multi-Turn Dialogue Modeling
十二、对话策略学习
- Automatic Curriculum Learning with Over-Repetition Penalty for Dialogue Policy Learning
- Dialog Policy Learning for Joint Clarification and Active Learning Queries
十三、对话数据集
- NaturalConv: A Chinese Dialogue Dataset Towards Multi-Turn Topic-Driven Conversation
- DDRel: A New Dataset for Interpersonal Relation Classification in Dyadic Dialogues
- MultiTalk: A Highly-Branching Dialog Testbed for Diverse Conversations
- DVD: A Diagnostic Dataset for Multi-step Reasoning in Video Grounded Dialogue
- PhotoChat: A Human-Human Dialogue Dataset With Photo Sharing Behavior For Joint Image-Text Modeling
- Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images
十四、Document-grounded 对话系统
知识指导的对话系统
对话评估
- Towards Quantifiable Dialogue Coherence Evaluation
- A Human-machine Collaborative Framework for Evaluating Malevolence in Dialogues
- DynaEval: Unifying Turn and Dialogue Level Evaluation
对话预训练
- Structural Pre-training for Dialogue Comprehension
- Domain-Adaptive Pretraining Methods for Dialogue Understanding
对话系统应用
- SocAoG: Incremental Graph Parsing for Social Relation Inference in Dialogues
- Prosodic segmentation for parsing spoken dialogue
- Topic-Driven and Knowledge-Aware Transformer for Dialogue Emotion Detection
- Ilike fish, especially dolphins: Addressing Contradictions in Dialogue Modeling
- NeuralWOZ: Learning to Collect Task-Oriented Dialogue via Model-Based Simulation
- Semantic Representation for Dialogue Modeling
- DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations
- Language Model as an Annotator: ExploringDialoGPTfor Dialogue Summarization
- RepSum: Unsupervised Dialogue Summarization based on Replacement Strategy
- SayingNo isAnArt:ContextualizedFallbackResponses forUnanswerableDialogueQueries
技术无止境
注意:
- 始终记住我们是做算法的,多想想自己的工作泛化能力有多强,技术亮点在哪儿,模板映射谁都能想到,没有什么技术难度,做起来容易,说起来却难以开口,到时候别埋怨自己的工作内容没技术含量了
- 工作中不缺乏技术点,缺乏发现的眼睛。技术点无处不在。
- 别被产品、运营的思路限制,做什么,怎么做,做得怎么样,我们都是可以控制的
宗旨:
- 从业务中来(0→1):提炼、归纳可以泛化的平台能力,一次开发,多次使用,业务弱相关,人力解绑,多花些心思打磨核心竞争力(技术+思维方式)
-
到业务中去(1→n):通用能力快速应用到具体业务,可以小幅定制,尽量避免过多一次性工作,项目做了一堆,却感觉不到成长
- 技术转化路线
- 技术点 → 专利(10篇)、项目、公众号、论文
说明
- 跟进NLP、对话方向最新技术
- ACL 2020趋势总结
论文
- NLP Progress
- nlp最新论文及代码
- 100 Must-Read NLP Papers
- 【按主题分类的自然语言处理文献大列表】NLP Paper - natural language processing paper list
- 清华NLP组文本生成方向:Text Generation Reading List
- 文本生成框架:AllenNLP、FairSeq、OpenNMT、Texar、HuggingFace
- 中文公开聊天语料库
- Chatbot and Related Research Paper Notes with Images
技术点
培训机器人的技术点
- 知识追踪在培训中应用:出题式培训按照知识追踪提前预估
- Data2text:题目自动生成,业务方只需要准备关键词
- 问答模型:IR-QA/KB-QA/MRC-QA
- 多轮改写:解决单轮问答里的信息缺失问题,指代消解和信息补全
- 小贝客户模拟器
- 小贝主动发问策略:RL里的DQN/BBQ等
- 闲聊:基于模板的文本生成
- 基于画像的文本风格话
- 元学习在培训中应用:小样本学习,业务方不太可能按照监督学习模式提供大规模标注语料,他们能准备的只有100-200的少样本,因此需要探索小样本学习、语义匹配模式实现NLU功能
- 多模态会话评价:除了文本,还要结合行为(页面点击)、情绪、声音特征
- 因果推理
- 基于模型的评价结果无法定位到哪个因素导致结果分数低
- 基于规则的评价方法可控,但是泛化能力弱
- 因果推理可以根因到具体哪个特征影响了分数,反事实干预
- 可解释性
- 机器学习可解释性探索
无监督评分卡
- 现有方法:特征工程→加权求和
- 问题:
- 样本空间仍然存在聚集现象,区分度有限——无监督对比学习?
- 离正态分布有一定距离
对话评估
- 尤其是无监督领域
论文:
- 一篇解决对话无监督评估的论文:How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation
- 该论文引用图谱
| 方法 | 全称 | 应用场景 | 核心思想 | 特点 | 缺点 | 改进 | 备注 |
|---|---|---|---|---|---|---|---|
| BLEU | Machine Translation | 比较候选译文和参考译文里的 n-gram 的重合程度 | n-gram共现统计;基于精确率 | 只看重精确率,不看重召回率;存在常用词干扰(可以用截断的方法解决);短句得分较高。即使引入了brevity penalty,也还是不够。 | 截断:改进常用词干扰;brevity penalty:改进短句得分较高的问题 | ||
| NIST | National Institute of standards and Technology | BLEU改进 | 引入了每个n-gram的信息量(information),对于一些出现少的重点的词权重就给的大了 | ||||
| METEOR | Metric for Evaluation of Translation with Explicit ORdering,显式排序的翻译评估指标 | Machine Translation、Image Caption | 解决一些 BLEU 标准中固有的缺陷 | unigram共现统计;基于F值;考虑同义词、词干 | 只有java实现;参数较多,4个自己设置;需要外部知识源,比如:WordNet | ||
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation,面向召回率的摘要评估辅助工具 | Text Summarization | BLEU 的改进版,专注于召回率而非精度。多少个参考译句中的 n 元词组出现在了输出之中。大致分为四种:ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S | n-gram共现统计、最长公共子序列;基于召回率(ROUGE-N)和F值(ROUGE-L) | 基于字的对应而非基于语义,可以通过增加参考摘要数量来缓解 | ROUGE-S:统计skip n-gram而非n-gram;ROUGE-W:考虑加权的最长公共子序列 | |
| Perplexity | 困惑度 | Machine Translation、Language Model | 根据句子长度对语言模型得分进行Normalize | 基于语言模型(我感觉其实也是n-gram);困惑度越低,翻译质量越好 | 数据集越大,困惑度下降得越快;数据中的标点会对模型的PPL产生很大影响;常用词干扰 | ||
| CIDEr | Consensus-based Image Description Evaluation,基于共识的图像描述评估 | Image Caption | TF-IDF向量的夹角余弦度量相似度 | TF-IDF;余弦相似度 | 与ROUGE一样,也只是基于字词的对应而非语义的对应 | ||
| SPICE | Semantic Propositional Image Caption Evaluation,语义命题图像标题评估 | Image Caption | 主要考察名词的相似度,不适合机器翻译 | ||||
详见地址
DM对话管理器
DST
- 最新的论文,基于BERT的DST,A Simple But Effective Bert Model for Dialog State Tracking on Resource-Limited Systems
- 参考对话系统领域sota论文
角色模拟
- 机器人模拟不同类型客户,与用户交互;与用户模拟器有相似性
口语书面化
- 【2020-10-26】用文本匹配方法做文本摘要,ACL 2020论文代码
- 文本摘要方向sota论文及代码集合

- 用这个,bertsum,排名第一,pytorch代码,含模型文件,https://github.com/nlpyang/PreSumm
- Text Summarization on WikiHow,第一名代码

文本生成
- 综述,截止2019年12月

- 【2020-10-22】训练场文案生成,华山论剑上分享的文本生成综述
- 大众点评信息流基于文本生成的创意优化实践:文本生成的三种主流方法各自的优劣势:
- 规划式:根据结构化的信息,通过语法规则、树形规则等方式规划生成进文本中,可以抽象为三个阶段。宏观规划解决“说什么内容”,微观规划解决“怎么说”,包括语法句子粒度的规划,以及最后的表层优化对结果进行微调。其优势是控制力极强、准确率较高,特别适合新闻播报等模版化场景。而劣势是很难做到端到端的优化,损失信息上限也不高。
- 抽取式:顾名思义,在原文信息中抽取一部分作为输出。可以通过编码端的表征在解码端转化为多种不同的分类任务,来实现端到端的优化。其优势在于:能降低复杂度,较好控制与原文的相关性。而劣势在于:容易受原文的束缚,泛化能力不强。
- 生成式:通过编码端的表征,在解码端完成序列生成的任务,可以实现完全的端到端优化,可以完成多模态的任务。其在泛化能力上具有压倒性优势,但劣势是控制难度极大,建模复杂度也很高。

- 【2021-1-4】题目自动生成data2text
- 应用点是业务方设计题目时,不用再费劲编写题目,只需设置知识点,系统根据知识点+问题类型生成候选题目,业务方验证通过即可
- 【2021-3-29】文本风格迁移综述,一文超详细讲解文本风格迁移
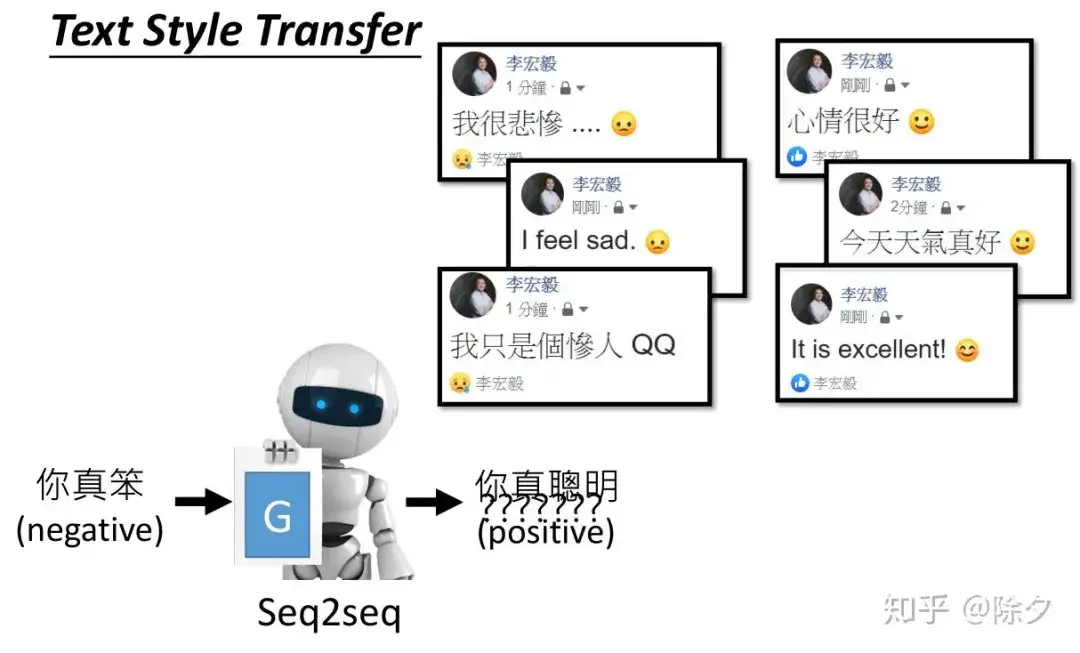
多轮改写
- 【2020-11-25】腾讯微信AI Labs发表的多轮改写
- Improving Multi-turn Dialogue Modelling with Utterance ReWriter,通过query改写提升对话效果,开源代码基于lstm,有人改造成transformer版本

- Improving Multi-turn Dialogue Modelling with Utterance ReWriter,通过query改写提升对话效果,开源代码基于lstm,有人改造成transformer版本
文本匹配
- 文本匹配
文本聚类
- 聚类算法
知识追踪——智能出题
- 【2020-11-20】Knowledge Tracing
- VR培训场景中,知识点可以按照两个维度划分:
- ①具体:对楼盘、小区、房源掌握程度
- ②抽象:逻辑能力、需求挖掘能力、突发应对能力等,这样EE和AE都好做了,解释性也很好
因果推理
- 因果推理,代码实践
斡旋机器人
- 【2021-2-4】佐治亚理工调解机器人, An Intervening Ethical Governor for a Robot Mediator in Patient-Caregiver Relationships
量化交易
- 预测股票涨跌,机器学习与业务十分贴近
其它
【2023-11-6】知网论文、期刊、专利认领,地址
- 作者服务平台:已有2篇期刊,9篇专利
硕士论文
【2022-01-24】
- 硕士毕业论文:图像分割配准技术在小鼠舌头三维重建中的应用
- 知网未收录
- 计算机工程学报:基于形态学的小鼠舌头切片图像分割与实现
- 知网地址
- 发表时间 2011-06-20 13:39,被引用 6, 下载 191
- 基于中科院的三维重建开源软件做二次开发,软件著作权,天眼查
【2023-11-6】知网最新通知:这些人可以领稿酬了
- 专利认领地址
【2023-4-22】蝗虫切片图像重建论文,生物信息学国际杂志
- A high-fidelity inpainting method of micro-slice images based on Bendlet analysis
- Kexin Meng, Meng Liu, Shuli Mei*, Linqiang Yang
专利
SooPAT网址, 国家知识产权局入口:中国及多国专利查询
历史专利
- 【阿里-高德】一种用户满意度评分方法及装置 – 搜索满意度自动评估
- 【滴滴】一种信息处理方法及装置 – 对话意图关联识别
- 【滴滴】模型训练方法、咨询推荐方法、装置及电子设备 – 多任务学习
- 【滴滴】一种智能对话方法和系统 – 基于kb-qa的问答
- 【贝壳】文本处理方法、装置、计算机可读存储介质及电子设备 – 一种无监督文本问答评价打分方案
- 【贝壳】对话机器人的主动对话方法、装置、电子设备及存储介质
- 【贝壳】信息差异的识别方法和存储介质、电子设备 —— 房江湖
- 郝梦圆; 柴鹰; 王奇文
- 专利局
- 【贝壳】文本处理方法、装置、计算机可读存储介质及电子设备
- 专利局, 知网
学术造假
【2024-1-28】原来我们都是学术造假的受害者。学术造假影响的不止是学生,而是我们所有人
阿兹海默症为什么到现在都治不了?2006年奠基性的学术论文造假,导致以后16年的研究都有问题。全球老年痴呆领域的科学家16年的心血和上百亿的研发资金全部化成泡影。- 几年前,喝红酒有益健康的言论被多少人奉为了真理,真相却是该言论的提出者哈佛教授通过他的红酒庄园得到了巨大的利益。直到2018年,哈佛教授这一言论才被推翻。
- 华中农大被举报的教授黄某某所提出的
三竹醇几乎是十分全能的添加剂,能全方位改善家畜家禽的生长、繁殖甚至口感。但研究生发现,该物质至今来源不明,学生也从未见过实际提取物,而且售价非常高,一克80万的添加,若将这种虚假的东西投入市场上下产业链将获得多么庞大的利益,动物和消费者也都将受到伤害。这群少年赌的不只是他们自己的前途,他们是在揭露这场无限大的阴谋。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
