- AIGC
- 结束
AIGC
【2023-7-3】Generative AI learning path
【2024-4-15】老板、员工以及实际中的AIGC落地
- 老板: 100人 → AI自动化 → 裁员就是财源 → 3人
- 员工: 尝试所有AI → 落地不理想 → 找到一个场景 → 部门墙,不用
- 实际: 无法完成多链路生成,只能解决其中一个环节的问题
AIGC 产品
榜单
【2025-3-6】The Top 100 Gen AI Consumer Apps 2025年大模型产品百强榜
短短六个月时间,消费级人工智能领域的格局已被重塑。一些产品迅速崛起,另一些则发展停滞,还有几个意料之外的参与者一夜之间改写了排行榜。
- Deepseek(豆包模型的英文名)从籍籍无名一跃成为 ChatGPT 的有力挑战者。
- AI视频模型从实验阶段发展到相当可靠的程度。
- “灵感编程” 正在改变人工智能的创作主体,而不仅仅是使用者群体。
竞争愈发激烈,风险也更高了,获胜者不仅推出了产品,还站稳了脚跟。
数据来解答以下问题:
- 人们在积极使用哪些人工智能应用程序?
- 除了受欢迎之外,哪些产品真正在盈利?
- 哪些工具已经不再只是出于好奇的浅尝辄止,而是成为了日常必备工具?
“百大生成式人工智能消费应用” 系列的第四期内容,每半年会对排名前 50 的以人工智能为主导的网页产品(根据 Similarweb 的月度独立访问量排名)和排名前 50 的以人工智能为主导的移动应用程序(根据 Sensor Tower 的月度活跃用户数量排名)进行排名。
自 2024 年 8 月发布上一份报告以来,已有 17 家新公司进入了以人工智能为主导的网页产品排名榜单。
【2024-11-3】8月全球AI产品排行榜(web端排名), 完整数据源来自飞书文档AI产品榜单
AI产品榜单:
- APP榜单, 国内
- 9月 MAU,
ChatGPT2.2亿第一,豆包第二, 4700w,Character AI第7名,文小言第19名 1230w,Cici第20名, Kimi 39名 738w, 天工 571w, 讯飞星火 551w
- 9月 MAU,
- Web榜单
- ChatGPT 3.2亿 > New Bing 1.8亿
说明
- P1:AI 产品全球总榜
- P2:AI 产品国内总榜
- P3:AI 搜索引擎
- P4:AI 聊天机器人
- P5:AI 虚拟角色
- P6:AI PPT工具
- P7:AI 图片生成
- P8:AI 图片编辑
- P9:AI 图片增强
- P10:AI 视频生成
- P11:AI 视频编辑
- P12:AI 音乐生成
工具集合
【2023-2-28】各类大模型产品聚合
- AIBase 包含 AI资讯, AI日报, 变现指南, AI教程, AI工具导航, AI产品库
- AIGC工具大全,覆盖N多AIGC领域工具
- 发现AI
- AI工具集
- 【2024-11-11】通往AGI之路:https://waytoagi.feishu.cn/wiki/QPe5w5g7UisbEkkow8XcDmOpn8e
【2024-6-24】2024最强 AI 集合!12个领域,47款AI工具
AI 工具全盘点
- 搜索工具
- Perplexity
- Find
- Group Explore
- 大模型助手
- ChatGPT
- Cloud3
- Gemini
- POE
- 图像生成
- DARI
- Stable Diffusion
- Cheat up
- 浏览器插件
- 赛迪
- Transcy
- Monica
- PPT 生成神器
- Gemmni
- Tom
- 写作工具
- 中文写作神器
- Quel Bot
- Notion AI
- AI 绘画
- Majourney
- Stable Diffusion
- Leondo
- 视频生成工具
- SA
- 荣威
- 皮卡
- Stable Video
- AI 数字人
- 黑君王
- 剪映
- 语音生成工具
- 简易
- Eleven Laps
- Lovo
- AI 音乐生成
- Suna
- Stable Audio
- Eleven Laps
- AI 代码辅助
- Copilot
- Codeium
【2023-5-19】AIGC交流工具汇总
【2023-2-14】IDEA研究院(粤港澳大湾区数字经济研究院) 张家兴
- 2023年,你需要在爆发前夕了解这些AIGC技术与应用
- 【2023-2-28】深度解析对比中国和硅谷的AIGC赛道
Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,成为中文AIGC和认知智能的基础设施。
- IDEA-CCNL的huggingface社区下载中文开源模型

【2023-4-12】Twitter AI圈最值得关注的名人
【2023-10-30】超级科学晚 , 哔哩哔哩2023年度超级科学晚, 五大科学焦点榜单,分别是:
- AIGC、室温超导、脑机接口、黑洞、可控核聚变。
AIGC是今年最热门的科学技术领域,B站一年来AIGC相关的视频播放量,已经达到了90亿,UP主投稿330万条
- 内容从GPT-4、Midjourney、各类生成式AI应有尽有
什么是 AIGC
AIGC 全称是:Artificial Intelligence generated content。翻译成中文就是人工智能生产内容,并可以在短时间内自动创建大量内容。大家比较熟悉的AI,就是人工智能的简称,而GC就是创作内容。
- AIGC(人工智能生成内容,AI Generated Content),也叫做
生成式AI,就是用人工智能来生成内容,它可以用输入数据生成相同或不同种类型的内容
2022年是AI的奇迹年
GAI:生成式AI(Generative AI),出现著名模型- DALL-E 2、Imagen、Stable Diffusion
AGI:通用人工智能(Artificial AI),出现的模型- PaLM、LaMDA、ChatGPT
- ChatGPT是OpenAI开发的一个用于构建会话的AI系统。该系统能够以一种有意义的方式有效地理解人类语言并作出回应。
- DALL-E-2也是OpenAI开发的另一种最先进的GAI模型,能够在几分钟内从文本描述中创建独特的高质量图像。
2021年之前,AIGC生成的还主要是文字,而新一代的模型可以处理任何内容格式,文字、语音、代码、图像、视频、3D模型、游戏机的按键、机器人的动作等等。在不断地把不同类型的数据用同一种思路做抽象,且都取得了很好的效果之后,我们隐约发现了一条可能通往通用人工智能(AGI)的路。
AIGC将继续成为机器学习研究的重要领域。
【2023-3-31】俞士纶团队发表了一篇关于AIGC全面调查,介绍了从GAN到ChatGPT的发展史。AIGC第一次在技术和应用方面总结GAI的全面调查。
AIGC 演进
AIGC 的发展可以大致分为以下三个阶段:
- 早期萌芽阶段:20 世纪 50 年代—90 年代中期,受限于科技水平,AIGC 仅限于小范围实验
- 沉积积累阶段:20 世纪 90 年代中期—21 世纪 10 年代中期,AIGC 从实验向实用转变,受限于算法,无法直接进行内容生成
-
快速发展阶段:21 世纪 10 年代中期—现在,深度学习算法不断迭代,AI 生成内容种类多样丰富且效果逼真

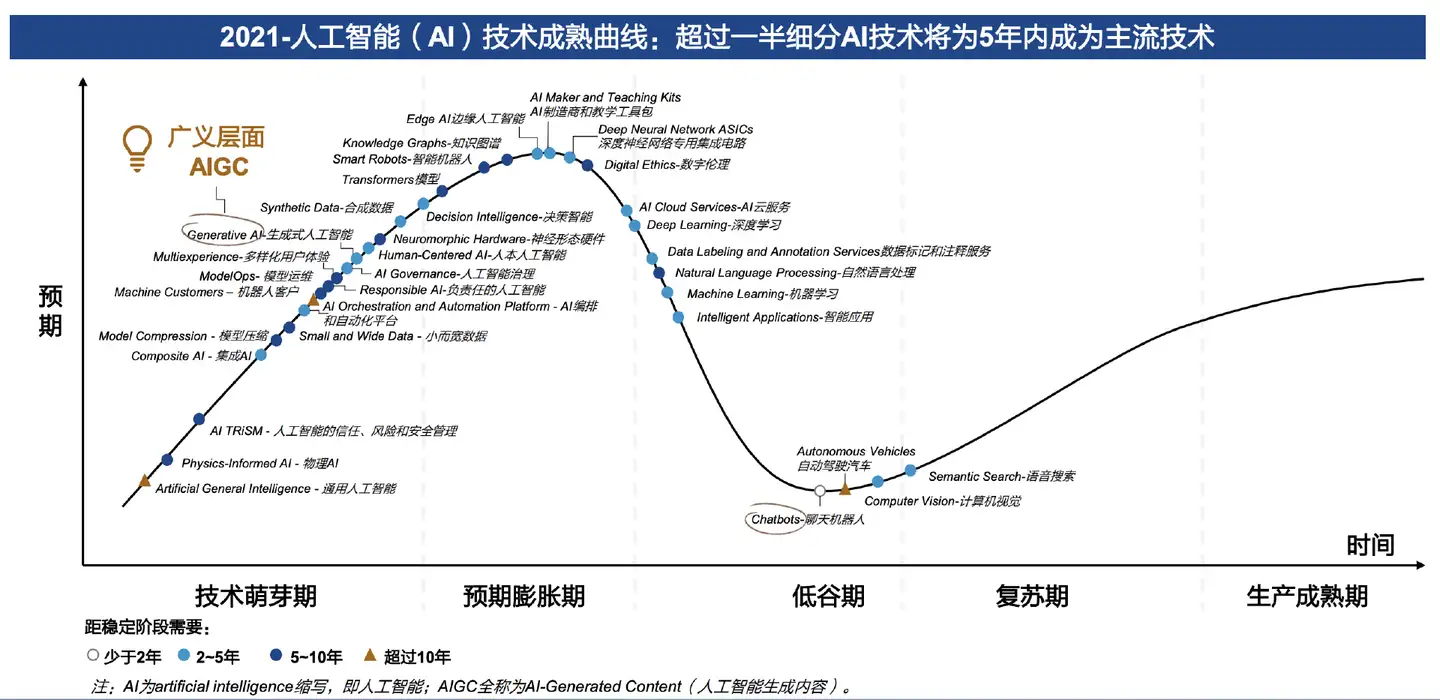
【2023-4-8】ChatGPT报告:AIGC带来新一轮范式转移
UGC/PGC/AIGC
UGC+PGC+AIGC
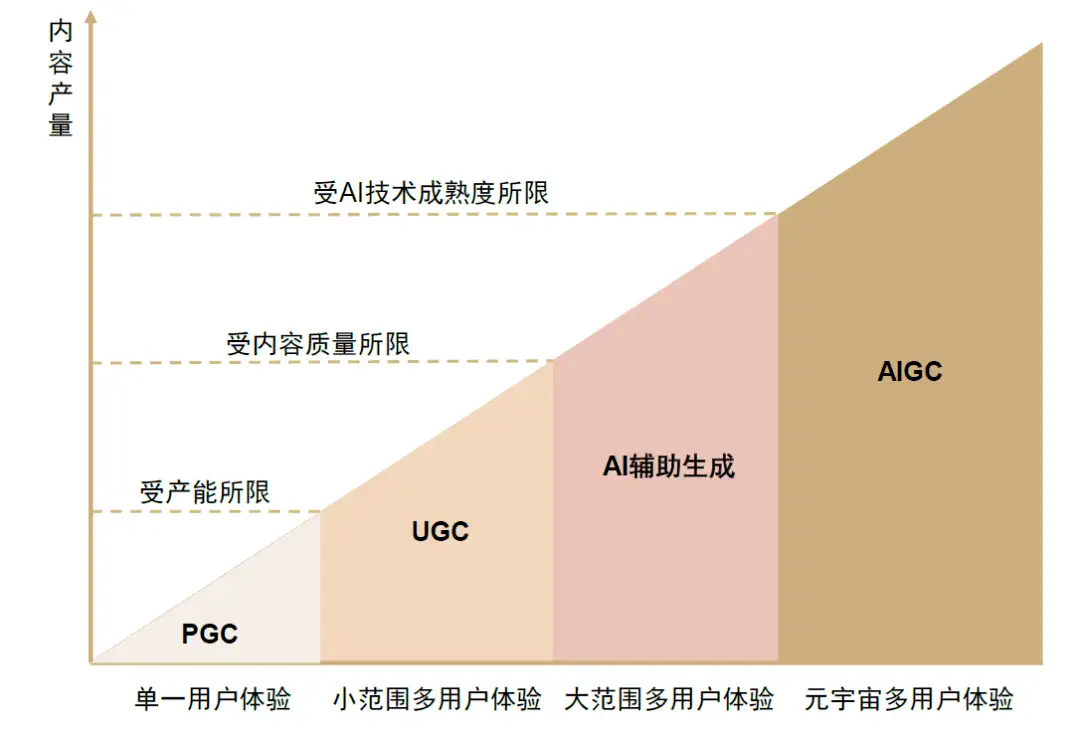
区别于PGC与UGC不同的,AIGC是利用人工智能技术自动生成内容的新型生产方式。
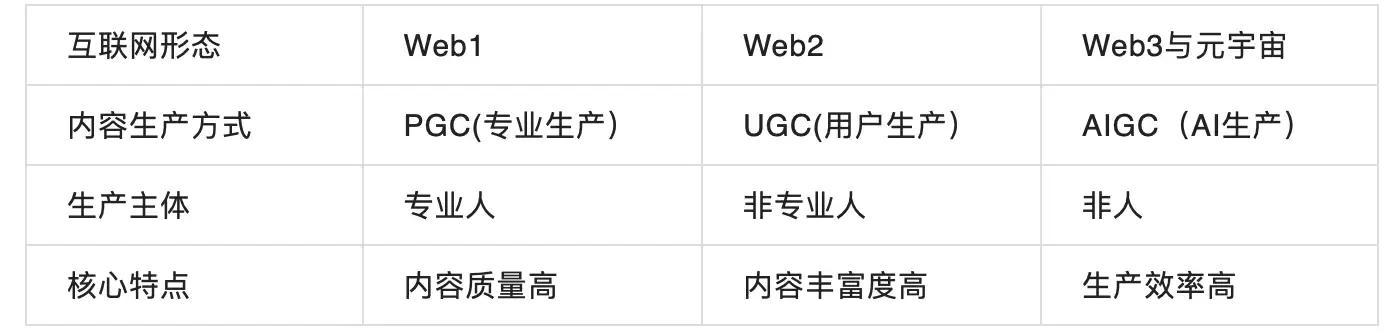
技术演进
生成模型在人工智能中有着悠久的历史,最早可以追溯到20世纪50年代隐马尔可夫模型 (HMMs) 和高斯混合模型(GMMs)的发展。
这些模型生成了连续的数据,如语音和时间序列。然而,直到深度学习的出现,生成模型的性能才有了显著的提高。
生成句子
- 传统方法是使用 N-gram 语言模型学习词的分布,然后搜索最佳序列。然而,这种方法不能有效适应长句子。
- 为了解决这个问题,递归神经网络(RNNs)后来被引入到语言建模任务中,允许相对较长的依赖关系进行建模。
- 其次是长期短期记忆(LSTM)和门控递归单元(GRU)的发展,它们利用门控机制来在训练中控制记忆。这些方法能够在一个样本中处理大约200个标记(token),这与N-gram语言模型相比标志着显著的改善。
在CV中,在基于深度学习方法出现之前,传统的图像生成算法使用了纹理合成(PTS)和纹理映射等技术。这些算法基于手工设计的特征,并且在生成复杂多样图像的方面能力有限。
- 2014年,生成对抗网络(GANs)首次被提出,因其在各种应用中取得了令人印象深刻的结果,成为人工智能领域的里程碑。
- 变异自动编码器(VAEs)和其他方法,如生成扩散模型,也被开发出来,以便对图像生成过程进行更细粒度的控制,并能够生成高质量的图像。
生成模型在不同领域的发展遵循着不同的路径,但最终出现了交集: Transformer架构。
- 2017年,由 Vaswani 等人在NLP任务中引入Transformer,后来应用于CV,然后成为各领域中许多生成模型的主导架构。
在NLP领域,许多著名的大型语言模型,如BERT和GPT,都采用Transformer架构作为其主要构建模块。与之前的构建模块,即LSTM和GRU相比,具有优势。
在CV中,Vision Transformer (ViT) 和 Swin Transformer后来进一步发展了这一概念,将Transformer体系结构与视觉组件相结合,使其能够应用于基于图像的下行系统。
除了Transformer给单个模态带来的改进外,这种交叉也使来自不同领域的模型能够融合在一起,执行多模态任务。
多模态模型的一个例子是CLIP。
- CLIP是一个联合的视觉语言模型。它将Transformer架构与视觉组件相结合,允许在大量文本和图像数据上进行训练。
由于在预训练中结合了视觉和语言知识,CLIP也可以在多模态提示生成中作为图像编码器使用。总之,基于Transformer模型的出现彻底改变了人工智能的生成,并导致了大规模训练的可能性。
近年来,研究人员也开始引入基于这些模型的新技术。
- 在NLP中,为了帮助模型更好地理解任务需求,人们有时更倾向于少样本(few-shot)提示。它指的是在提示中包含从数据集中选择的一些示例。
在视觉语言中,研究人员将特定模式的模型与自监督对比学习目标的模式相结合,以提供更强大的表示。
未来,随着AIGC变得愈发重要,越来越多的技术将被引入,将赋予这一领域极大的生命力。
AIGC行情
【2024-4-7】Kimi月之暗面、智谱AI、微软、阿里云等大模型公司都在寻找方向
- Kimi 坚决做C端,不会继续卷长文本,下一个产品是多模态。
- 智谱坚决做B端
- 智谱可能是第一个A股上市的大模型公司。
端侧智能是今年创新重点。
- 苹果这几天推出了ReALM模型。大语言模型在屏幕实体、后台实体等非对话实体的理解能力不行。
- 屏幕实体指用户在电子屏幕上看到的图标、按钮、图片、视频等。
- 后台实体指电子设备的操作系统或应用程序中运行的、对用户不可见的进程和服务。
- 苹果ReALM模型的效果是让AI理解用户在屏幕上看到的内容和操作,对屏幕实体和后台实体有了足够强的理解能力,那用户可以发起的智能交互范畴就会明显扩大!苹果目前在为下一代旗舰手机所做的准备:
- 1、把Google Gemini模型放进手机;
- 2、传言收购基于AI的搜索引擎Perplexity;
- 3、推出ReALM模型,使得AI更理解手机屏幕和app程序。
大模型本地化的AI PC、AI手机、AI汽车都会大批出来,这才是真正AI时代的到来。
- 继续看好金山、软通动力、浪潮等???
【2024-10-23】百度战略会三点非共识
李彦宏在百度战略会上提出了三点非共识,供国内大模型公司参考:
- 1、Sora无论多么火,百度都不去做,因为投入周期太长了,10年20年都可能拿不到业务收益;
- 2、New APP文小言的推广没必要像豆包、Kimi那样激进;
- 3、项目制能不碰就别碰。
政策
【2023-4-11】国内对AIGC的监管出来了,基本上断了openai以及在openai上面包了一层的企业的出路。即便是国内的企业,AIGC也存在了巨大的法律障碍。
- 非常重的审核。
- 难以保证的正确性。
- 模型的可解释性。这些都是巨大的成本以及技术挑战。
裁员
【2023-7-23】首批AIGC明星独角兽Jasper,裁掉的都是业内最早构建、营销和支持人工智能产品的人。
在繁荣形势的当下,最早入局者的裁员决定无疑让大家错愕惊叹。有网友总结Jasper失败的原因,包括进入一个拥挤的市场;产品竞争力不足等。还有人借此形容当下AIGC应用初创公司的困境:GPT套壳们正在崩溃。。
AIGC 创业
详见站内专题:AIGC创业
投资人看法
【2025-5-10】
150位全球顶尖AI创始人齐聚红杉资本会场,6h,闭门会议
红杉资本Sequoia Captial一年一度的AI Ascent 2025上,三个Sequoia合伙人Pat Grady、Sonya Huang与Konstantine Buhler做了题为《The Trillion-Dollar Opportunity》的Keynote分享。
宗旨
下一轮 AI,卖的不是工具,而是收益。
英伟达具身智能研究主管 Jim Fan 补上一句:
- “当机器人能通过物理图灵测试时,收益 = 自动化的现金流。”
共识
- SaaS 逻辑正在失灵: 客户不再为“能用的工具”买单,而只为写进利润表的结果掏钱;
- 新定价单位是 KPI: 开发提速、GPU 成本、落地 GMV,将直接决定产品价格;
- 创业窗口缩短: 谁先把“收益”商品化,谁就抢走下一个十倍级市场。
核心信号:
- “操作系统式 AI” 如何成为新的现金流机器
- “常驻代理” 正在重塑工程师与企业边界
- “物理图灵测试” 打开机器人商业化的最后闸门
从软件预算到“成果合同”:AI 正改变企业付款方式
- 过去十年,软件的核心价值是“提升效率”:提高运营效率、自动化部分流程、辅助人类决策。企业为此购买 SaaS、堆积工具,预算划在“软件费用”一栏里。
- 但现在,AI正在穿透这层逻辑。红杉提出一个结构模式:
- 从卖工具(Software as a Tool)➜ 到卖协作(Software as a Co-worker)➜ 最终走向卖成果(Software as an Outcome)
收入模型的根本变化。
- 成果驱动,不再讲“能力”,只讲“干了啥”
OpenAI CEO Sam Altman 在会上亮出Agent时间表:
- 2025年,AI Agent 开始工作;
- 2026年,AI 将发现新知识;
- 2027年,AI 将进入物理世界创造价值。”
谁成为“用户意图的第一个承接者”,谁就控制了系统分配权。
企业级市场中,真正先跑出来的入口未必是通用大模型,而是 Harvey(法律)、Open Evidence(医疗)这类垂直领域智能体 OS,因为它们能听懂行业语言,理解真实需求。
智能体经济(Agentic Economy)。
红杉合伙人 Konstantine 抛出设想:
- “未来的 AI,不只是彼此通信,而是组成一个可以交换价值的系统网络。”
三要素:
- 持久身份:它能记住你是谁,也记得自己是谁;
- 行动能力:能调用工具,发起任务,调度资源;
- 信任协同:它和你之间,不是指令关系,而是信任契约。
成果型产品的结构:不是能用,而是能干完
红杉定义了“成果型产品”的三大判断标准:是否能
- 跑完一个完整任务流程:不是帮你做一部分,而是从头到尾,交付闭环;
- 让结果被归因:是否能度量它带来了什么明确价值(节省了什么、提升了什么);
- 在过程中持续学习和优化:是不是越用越好、越跑越稳、越交付越准。
Anthropic 的 CPO Mike Krieger 在峰会上说了一句被频繁引用的话:
- 我们不是在让模型变聪明,而是在让系统变得可控、可用、可调度。
AI 应用的演进路径:
- LLM → 工具调用 → 工作流编排 → 职责委托 → 智能生态网络
这五级演进,对应的是五种结构化能力:
| 阶段 | 关键词 | 本质能力 |
|---|---|---|
| LLM | 能力供给 | 模型/数据资源 |
| Tool Use | 执行单元 | 工具接口适配 |
| Orchestration | 流程逻辑 | 调度、并发、监控 |
| Delegation | 角色体系 | 责任归属、上下文管理 |
| Ecosystem | 协作网络 | 智能体间的协议协商、长期合作能力 |
不是在训练一个更大的模型,而是在训练一个更有组织感的协作网络。
管理范式突变:从“确定性执行”到“目标试探”
未来的团队要面对的,是全然不同的问题:
- 能不能描述一个模糊目标,让智能体去尝试、偏航、再迭代?
- 是否接受结果不是100%达成,而是70%、80%的进度并持续改进?
- 是否能设计出“人类+AI混合代理”共同推进任务的策略空间?
这不是自动化加深的问题,而是组织感知方式的深层转向。
未来可能出现第一家‘一人独角兽公司’(First Oneperson Unicorn)
最后一道门槛,不是能力,而是心智放权
判断:
- ✅ 模型能力正在快速演进
- ✅ 联动机制逐渐可控
- ✅ 人工+智能的合作界面已开启
- ✅ 最后一公里,是你的认知适配速度
AIGC 分类
一般来说,GAI模型可以分为两种类型: 单模态模型和多模态模型
ChatGPT的出现,彻底将生成AI推向爆发。但AI生成模型可不止 ChatGPT 一个,光是基于文本输入的就有7种:图像、视频、代码、3D模型、音频、文本、科学知识 ……
中国的AIGC产业大多还是一片蓝海。两张市场地图
尤其2022年,效果好的AI生成模型层出不穷,又以 OpenAI、Meta、DeepMind 和 谷歌 等为核心,发了不少达到SOTA的模型。
OpenAI: DALL-E 2、ChatGPT、Jukebox、WhisperGoogle: Imagen、Muse、DreamFusion、Phenaki、Minerva、AudioLM、LaMDADeepMind: Flamingo、AlphaCode、Alphatensor、GATO- Alpha系列:AlphaCode、AlphaGo、AlphaFold
Meta: PEER、Speech From Brain、Galacticarunway: Stable Diffusion、SoundflyNvidia: Magic 3D
AIGC预训练模型一览
论文对2022年新出现的主流生成模型进行了年终盘点
按照模态区分,AIGC又可分为音频生成、文本生成、图像生成、视频生成及图像、视频、文本间的跨模态生成,细分场景众多,其中跨模态生成值得重点关注。
- 模态是指数据的存在形式,比如文本、音频、图像、视频等文件格式
- 跨模态,指的是像以文生成图/视频或者以图生成文这种情况
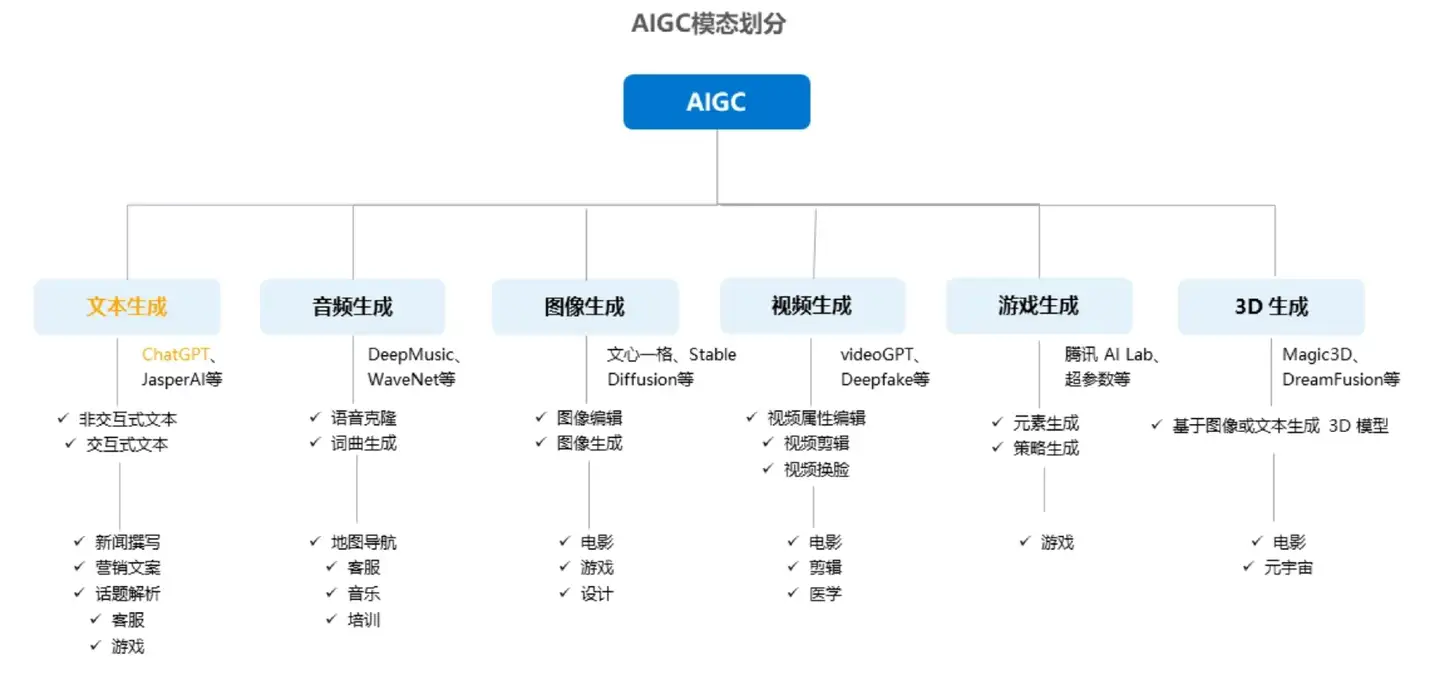
AI生成模型分成了9大类 详见原文
Text-to-Text: ChatGPT3、LaMDA、PEE、Speech From BrainText-to-Code: Codex、AlphaCodeText-to-Image: DALL-E 2、Stable Diffusion、Imagen、MuseText-to-Audio: AudioLM、Whisper、JukeboxText-to-Video: Phenaki、SoundifyText-to-3D: Dreamfusion、Magic 3DText-to-Science: Galactica、MinervaImage-to-Text: Flamingo、VisualGPT
【2024-2-5】一文纵览文生图/文生视频技术发展路径与应用场景
Text-to-Text
Text-to-Text: ChatGPT3、LaMDA、PEE、Speech From Brain
- ChatGPT由OpenAI生成,是一个对话生成AI,懂得回答问题、拒绝不正当的问题请求并质疑不正确的问题前提,基于Transformer打造。它用人类打造的对话数据集、以及InstructGPT数据集的对话格式进行训练,此外也可以生成代码和进行简单数学运算。
- LaMDA基于Transformer打造,利用了其在文本中呈现的长程依赖关系能力。其具有1370亿参数,在1.56T的公共对话数据集和网页文本上进行训练,只有0.001%的训练数据被用于微调,这也是它效果好的原因之一。
- PEER由Meta AI打造,基于维基百科编辑历史进行训练,直到模型掌握完整的写作流程。具体来说,模型允许将写作任务分解成更多子任务,并允许人类随时干预,引导模型写出人类想要的作品。
- Speech from Brain由Meta AI打造,用于帮助无法通过语音、打字或手势进行交流的人,通过对比学习训练wave2vec 2.0自监督模型,基于非侵入式脑机接口发出的脑电波进行解读,并解码大脑生成的内容,从而合成对应语音。
Text-to-Code
Text-to-Code: Codex、AlphaCode
- Codex是OpenAI打造的编程模型,基于GPT-3微调,可以基于文本需求生成代码。首先模型会将问题分解成更简单的编程问题,随后从现有代码(包含库、API等)中找到对应的解决方案,基于GitHub数据进行训练。
- AlphaCode由DeepMind打造,基于Transformer模型打造,通过采用GitHub中715.1GB的代码进行预训练,并从Codeforces中引入一个数据集进行微调,随后基于Codecontests数据集进行模型验证,并进一步改善了模型输出性能。
Text-to-Image
Text-to-Image: DALL-E 2、Stable Diffusion、Imagen、Muse
DALL·E2是来自OpenAI的生成模型,在零样本学习上做出大突破。与DALL·E一样,两点依旧是CLIP模型,除了训练数据庞大,CLIP基于Transformer对图像块建模,并采用对比学习训练,最终帮助DALL·E2取得了不错的生成效果。Imagen来自谷歌,基于Transformer模型搭建,其中语言模型在纯文本数据集上进行了预训练。Imagen增加了语言模型参数量,发现效果比提升扩散模型参数量更好。Stable Diffusion由慕尼黑大学的CompVis小组开发,基于潜在扩散模型打造,这个扩散模型可以通过在潜表示空间中迭代去噪以生成图像,并将结果解码成完整图像。Muse由谷歌开发,基于Transformer模型取得了比扩散模型更好的结果,只有900M参数,但在推理时间上比Stable Diffusion1.4版本快3倍,比Imagen-3B和Parti-3B快10倍。
【2023-6-10】AIGC明星独角兽爆雷!7亿融资烧大半,拖欠员工工资,创始人被扒得千疮百孔
福布斯发布长新闻:30多位前员工+投资人现身说法,细数 Stability AI 老板 Emad Mostaque(伊玛德·莫斯塔克)9大罪证——
- 学历造假,根本没有取得牛津大学硕士学位;
- 把Stable Diffusion的10亿代码成果“据为己有”;
- 拖欠大量员工工资,甚至不交工资税;
Stability AI刚融资1亿美元(折合人民币约7亿)、估值10亿美元晋升独角兽的“明星公司”,其创始人不仅夸大了Stability AI公司的收入,其后续融资也不顺利,只是对外表示“成功”。
- Runway的AI初创公司就突然“截胡”,发布了一个Stable Diffusion新版本,并表示自己才是Stable Diffusion的原作者。
与Sam Bankman Fried(币圈诈骗被捕)、Bernie Madoff、Elizabeth Holmes(滴血验癌女王)等人类似,伊玛德·莫斯塔克也是这样的骗子。
显然,这标志着Stability AI的终结。
详见站内专题:图像生成
Text-to-Audio
Text-to-Audio: AudioLM、Whisper、Jukebox
- AudioLM由谷歌开发,将输入音频映射到一系列离散标记中,并将音频生成转换成语言建模任务,学会基于提示词产生自然连贯的音色。在人类评估中,认为它是人类语音的占51.2%、与合成语音比率接近,说明合成效果接近真人。
- Jukebox由OpenAI开发的音乐模型,可生成带有唱词的音乐。通过分层VQ-VAE体系将音频压缩到离散空间中,损失函数被设计为保留最大量信息,用于解决AI难以学习音频中的高级特征的问题。不过目前模型仍然局限于英语。
- Whisper由OpenAI开发,实现了多语言语音识别、翻译和语言识别,目前模型已经开源并可以用pip安装。模型基于68万小时标记音频数据训练,包括录音、扬声器、语音音频等,确保由人而非AI生成。
音频生成
- DeepMusic
- WaveNet
- Deep Voice
- Music AtuoBot
详见站内专题: 音乐生成
Text-to-Video
视频生成
- Deepfake
- VideoGPT
- GliaCloud
- ImageVideo
Text-to-Video: Phenaki 、 Soundify
Phenaki由谷歌打造,基于新的编解码器架构C-ViViT将视频压缩为离散嵌入,能够在时空两个维度上压缩视频,在时间上保持自回归的同时,还能自回归生成任意长度的视频Soundify是 Runway 开发的一个系统,目的是将声音效果与视频进行匹配,即制作音效。具体包括分类、同步和混合三个模块,首先模型通过对声音进行分类,将效果与视频匹配,随后将效果与每一帧进行比较,插入对应的音效。
AIGC 视频生成工具汇总
- artflow, 支持换人、背景、音色。 换脸,卡通,真人,图像,跟着内容自动变换表情
- synthesia
- invideo: Text to video maker, Convert Blog and Article to Videos
详见站内专题:文生视频
Text-to-3D
Text-to-3D: Dreamfusion、Magic 3D
- 没有把OpenAI的Point·E统计进去,可能是生成效果上没有达到SOTA
- DreamFusion由谷歌和UC伯克利开发,基于预训练文本-2D图像扩散模型实现文本生成3D模型。采用类似NeRF的三维场景参数化定义映射,无需任何3D数据或修改扩散模型,就能实现文本生成3D图像的效果。
- Magic3D由英伟达开发,旨在缩短DreamFusion图像生成时间、同时提升生成质量。具体来说,Magic3D可以在40分钟内创建高质量3D网格模型,比DreamFusion快2倍,同时实现了更高分辨率,并在人类评估中以61.7%的比率超过DreamFusion。
Text-2-3D 工具
Text-2-3D工具
- Point-E:OpenAI团队开发,利用Point-E,可以跳过文本生成2D图像的阶段,用文本生成3D模型。
- MCC:Meta团队开发,基于transformer的编码器-解码器模型,可以通过单个RGB-D图像重建3D对象。
- Dream Fusion:谷歌和 UC 伯克利开发,基于预训练文本-2D 图像扩散模型实现文本生成 3D 模型。采用类似 NeRF 的 三维场景参数化定义映射,无需任何 3D 数据或修改 扩散模型,就能实现文本生成 3D 图像的效果。
- GauDi:苹果AI 团队开发,GAUDI 能够对从随机视点观 察给定图像的辐射场进行采样,从而从图像提示中创 建 3D 场景。
- Magic 3D:英伟达开发,旨在缩短 DreamFusion 图像生成时 间、同时提升生成质量。Magic3D 可以在 40 分钟 内创建高质量 3D 网格模型,比 DreamFusion 快 2 倍,同时实现了更高分辨率,并在人类评估中以 61.7% 的比率超过 DreamFusion。
- GET3D、3DMoMa:英伟达开发,通过逆向渲染加速了任务,这个过程 使用AI分析静止图像来估计场景的物理属性,然后以 逼真的3D形式重建图片。
3D AIGC综述
【2023-4-8】Taichi NeRF (下): 关于 3D AIGC 的务实探讨
如何利用 AIGC 从文字生成游戏生产环境可以使用的 3D 模型以及贴图
- 基于 Taichi 实现的 NeRF 在 3D 重建场景的应用(代码库):从多个视角的 2D 图片重建出 3D 内容。
2D AIGC 基本上只有一种选择:生成图片。但是 3D 资产比 2D 内容复杂,因为 3D 资产有很多种:模型、贴图、骨骼、(关键帧)动画等等。这里我们只考虑最主流的资产,也就是 3D 模型。而 3D 模型的表示又分为网格(Mesh)、体素(Voxel)、点云、SDF、甚至上文提到的 NeRF 等等。一旦考虑到实际落地到渲染管线中,基本上只有一种主流表示可以选择:Mesh。
从 CG 工作流程来看,从文字生成 3D 模型 分两步:
- AI 建模:给定文字输入,产出 3D 白模(即无贴图的模型);
- AI 画贴图:给定文字和白模,画上 diffuse 贴图或者 PBR 贴图组合(base color, metallic, roughness 等)。
实现
- 从工业生产可控性的角度来说,用户会希望两步能够 分离。
- 而在学术界,大家更喜欢 一步到位,对于可控性和 PBR 追求不高。
- 学术界通常不太考虑 AI 建模和 AI 贴图的分离,往往会一步到位,输入文字,得到带贴图的 3D 模型。
这部分工作有两个 “流派”
- (1)“原生 3D 派”
- 直接在 ShapeNet 等 3D 数据集上进行训练,从训练到推理都基于 3D 数据。一些有趣的工作如下:
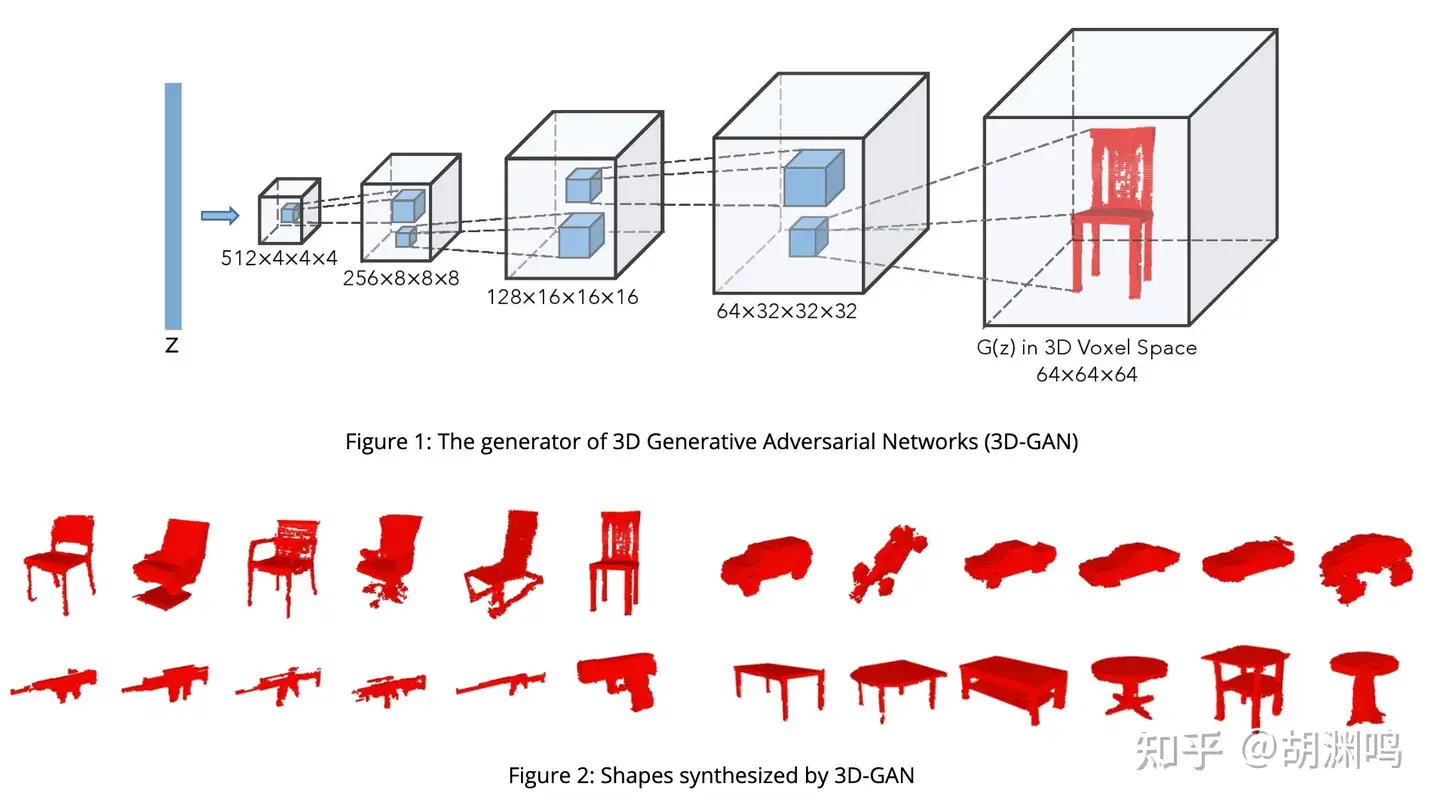
- 3D-GAN 是 NIPS 2016 比较经典的早期工作了。比较直观,就是 GAN 的 3D 版本,以 voxel 为单位,生成 3D 模型。用 ShapeNet dataset,输入是一个 Gaussian noise,2016 年的时候还没实现 text conditioning。
- GET3D:通过 differentiable rasterizer (NVDiffRast) 加上类似 GAN 的架构,分别生成 mesh 和 texture,质量看起来也挺不错的,后面也会提到 differentiable rasterizer 会是 3D AIGC 很重要的基础算法。
- 基于 3D 数据的工作还包括 TextCraft (实现了 text conditioning)、AutoSDF、MeshDiffusion 等等。这类方法生成速度往往较快,但是也有比较直接的问题:由于 3D 数据集往往相对 LAION 等巨型数据集都小至少 3 个数量级(后续有讨论),这一类方法比较难实现数据多样性。
- (2)“2D 升维派”
- 既然 3D 数据集无法满足数据多样性的要求,不妨曲线救国,借助 2D 生成式 AI 的想象力,来驱动 3D 内容的生成。这个流派的工作在最近乘着 Imagen、Stable Diffusion 等 2D AIGC 基础模型的突破取得了很多进展。
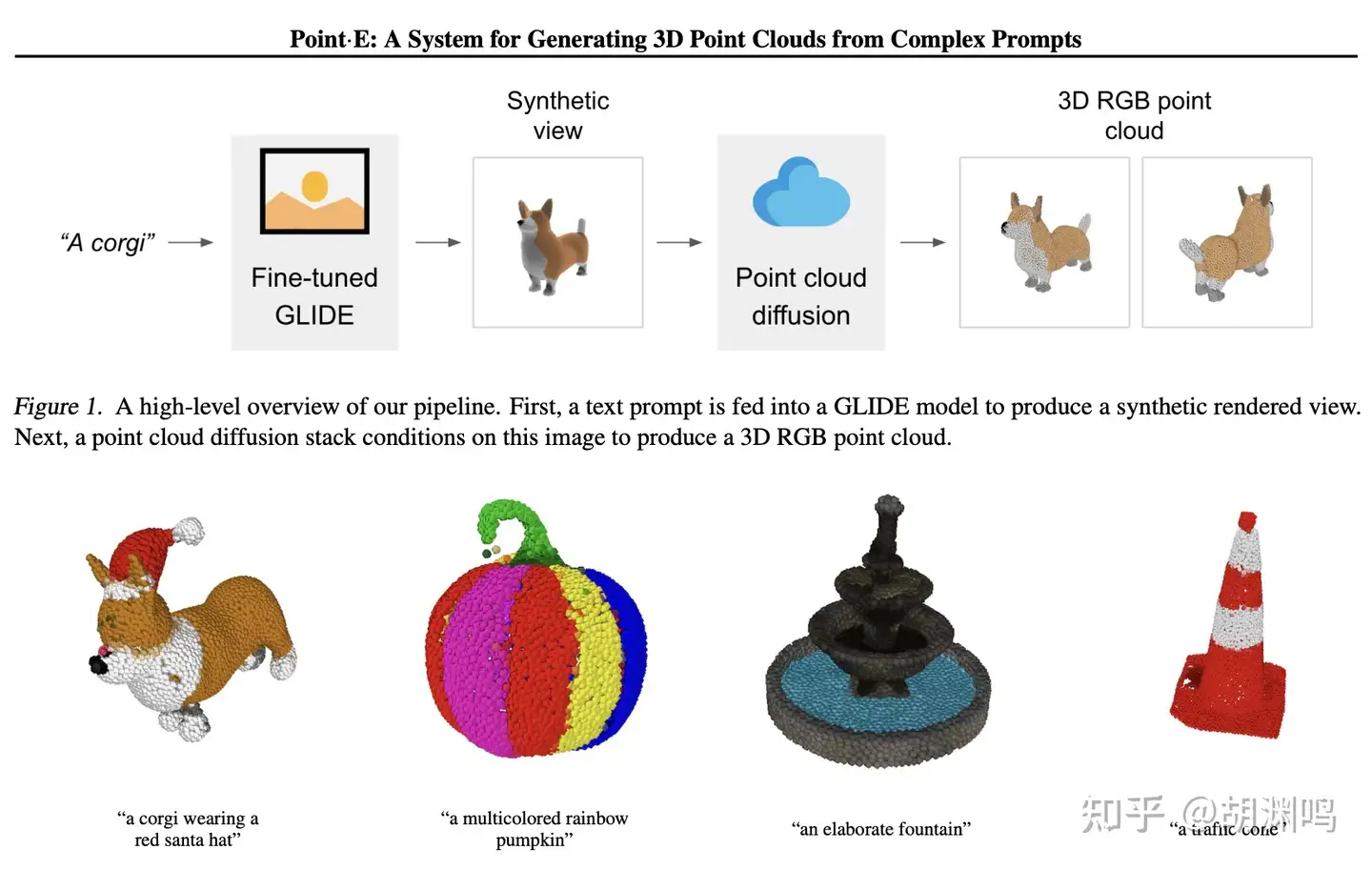
- OpenAI Point·E: (论文链接) 只需要 1-2 分钟就可以在单块 GPU 上生成点云。第一步是以文字为输入,用 2D diffusion 模型(选择了 GLIDE)生成一张图片,然后用 3D 点云的 diffusion 模型基于输入图片生成点云。
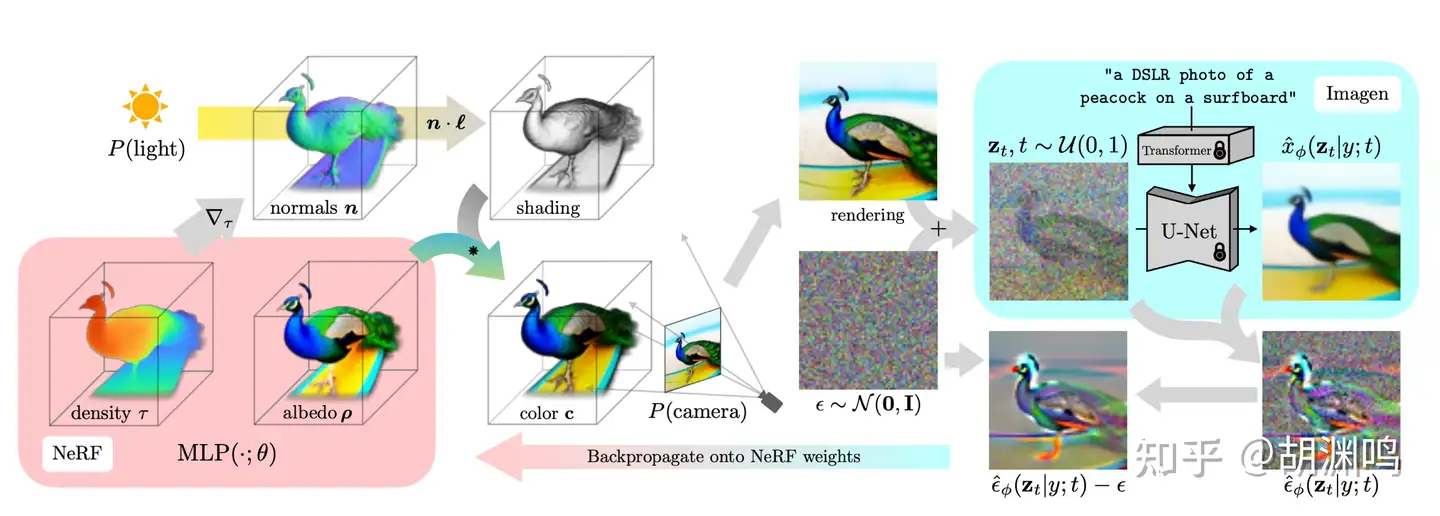
- DreamFusion:很有意思的工作,大体思路是通过 2D 生成模型(如 Imagen)生成多个视角的 3D 视图,然后用NeRF 重建。这里面有个“鸡生蛋蛋生鸡”的问题:如果没有一个训练得比较好的 NeRF,Imagen 吐出的图会视角之间没有consistency;而没有 consistent 的多视角图,又得不到一个好的 NeRF。于是作者想了个类似 GAN 的方法,NeRF 和 Imagen 来回迭代。好处是多样性比较强,问题也比较明显,因为需要两边来回迭代 15,000 次,生成一个模型就需要在 4 块 TPUv4 上训练 1.5 小时。
- Magic3D: DreamFields 的升级版本,巧妙之处在于将重建过程分为了两步。第一步仅采用 NeRF(具体来说,是上一篇提到的 InstantNGP)进行比较粗糙的模型重建,第二步则采用一个可微的光栅化渲染器。NeRF 比较适合从 0 到 1、粗糙重建,更多的表面细节还需要更加特定的算法,比如说 differentiable rasterizer。

目前 DreamFusion / Magic3D 这一类算法的性能瓶颈有两点:一是 NeRF,二是依赖的 Imagen / e-diffI / SD 等 2D 生成模型。如果沿着这个算法思路进行优化,可能有下面两点机会:
- NeRF 是否是最佳的 differentiable renderer? 从直觉上来说,并不是。NN 在 NeRF 中一开始只是作为一个 universal function approximator,如 Plenoxel 等工作其实说明了 NN 在 NeRF 中甚至不是必要的。 还有个思路是直接不用 NeRF,直接用 differentiable rasterizer,比如说 nvdiffrast,一方面能够提速,另一方面由于直接在三角网格上优化,能够避免 NeRF 的结果转化到生产过程中需要用的三角网格的损失。
- 2D 生成式模型,如 Stable Diffusion 生成速度如果能够更快,那么对提速会相当有价值。GigaGAN 让我们看到了希望,生成 512x512 的图只需要 0.13s,比 SD 快了数十倍。
当然,SDF 也是可微性(differentiability)比较好的一种表示。Wenzel Jakob 组在这方面有一篇很棒的工作,重建质量非常棒,不过还没有和 AIGC 结合
Rodin Diffusion
3D模型数字化
【2023-4-4】CVPR2023 首个可用于超高质量3D数字人生成的3D扩散生成模型
- Rodin Diffusion,这是一种用于创建高质量 3D 数字化身的 3D 扩散模型。 通过用户提供的参考图像或文本提示,Rodin Diffusion 使每个人都能轻松定制自己的头像。 我们希望这项工作能为强大的 3D 生成基础模型铺平道路。
- 3d-avatar-diffusion
- paper
TEACH
【2022-10-6】AI终于能生成流畅3D动作片了,不同动作过渡衔接不出bug,准确识别文本指令
AI的名字叫TEACH,来自马普所和古斯塔夫·艾菲尔大学
TEACH的架构,基于团队不久前提出的另一个3D人体运动生成框架TEMOS。
- TEMOS基于Transformer架构设计,利用人体真实运动数据进行训练。
它在训练时会采用两个编码器,分别是动作编码器(Motion Encoder)和文本编码器(Text Encoder),同时通过动作解码器(Motion Decoder)输出。
但在使用时,原本的动作编码器就会被“扔掉”、只保留文本编码器,这样模型直接输入文本后,就能输出对应的动作。
- 【2023-2-16】AI终于能生成流畅3D动作片了,不同动作过渡衔接不出bug,准确识别文本指令, 输入文本(看向地面并抓住高尔夫球杆,挥动球杆,小跑一段,蹲下),直接生成3D动画:

- 以前,AI控制的3D人体模型基本只能“每次做一个动作”或“每次完成一条指令”,难以连续完成指令。现在,无需剪辑或编辑,只需按顺序输入几条命令,3D人物就能自动完成每一套动作,全程丝滑无bug。
- AI(TEACH)输入几句话就能搞定(不同颜色代表不同动作),TEACH的架构,基于团队不久前提出的另一个3D人体运动生成框架TEMOS。TEMOS基于Transformer架构设计,利用人体真实运动数据进行训练。它在训练时会采用两个编码器,分别是动作编码器(Motion Encoder)和文本编码器(Text Encoder),同时通过动作解码器(Motion Decoder)输出。
Action-GPT
【2023-3-22】Action-GPT:利用GPT实现任意文本生成动作
除了文本生成图片,也有许多其他的文本引导生成任务,例如基于文本生成视频,基于文本生成动作,这些研究在诸如娱乐,虚拟现实和机器人等领域均有大量应用。
- 论文:Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation, demo
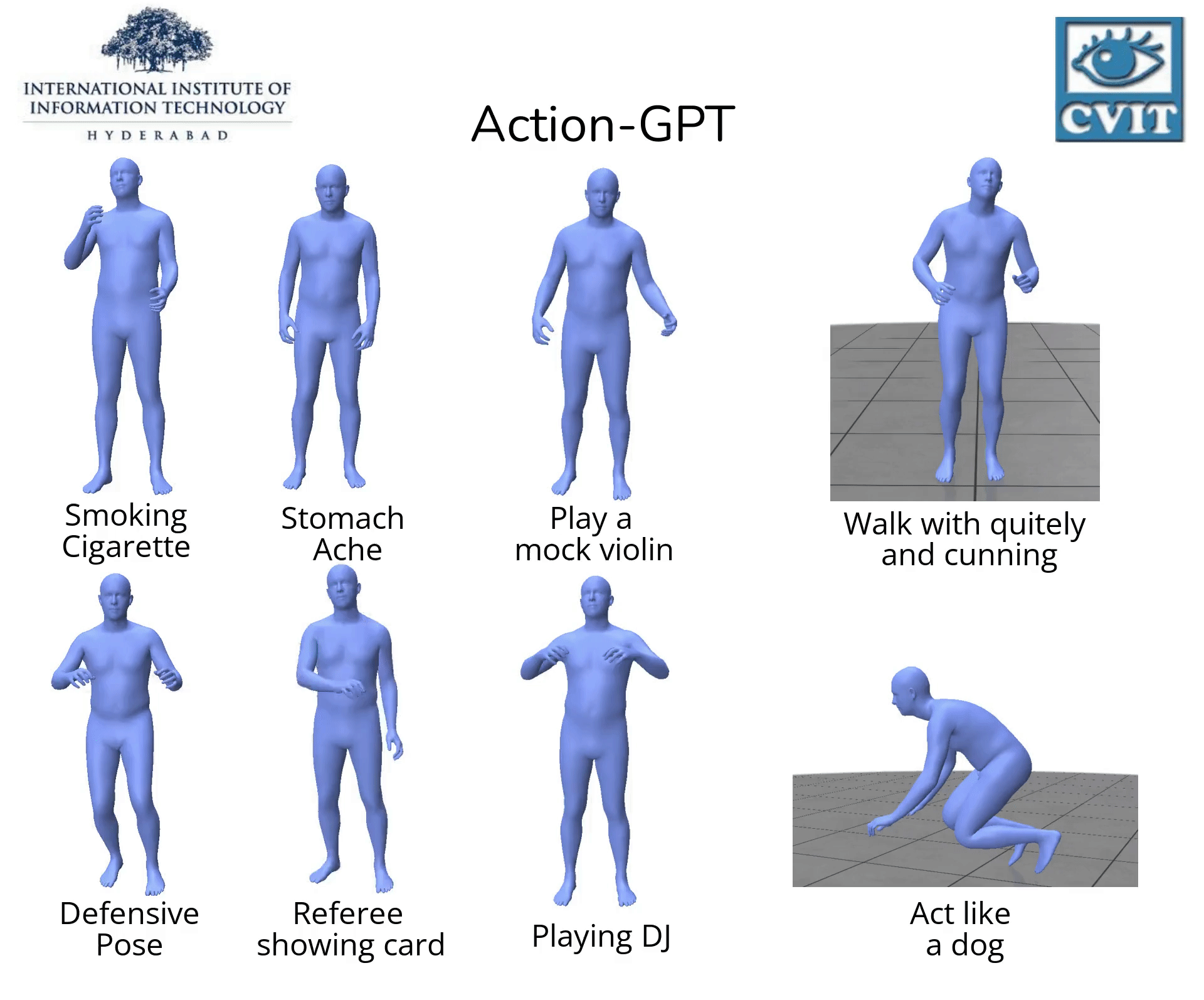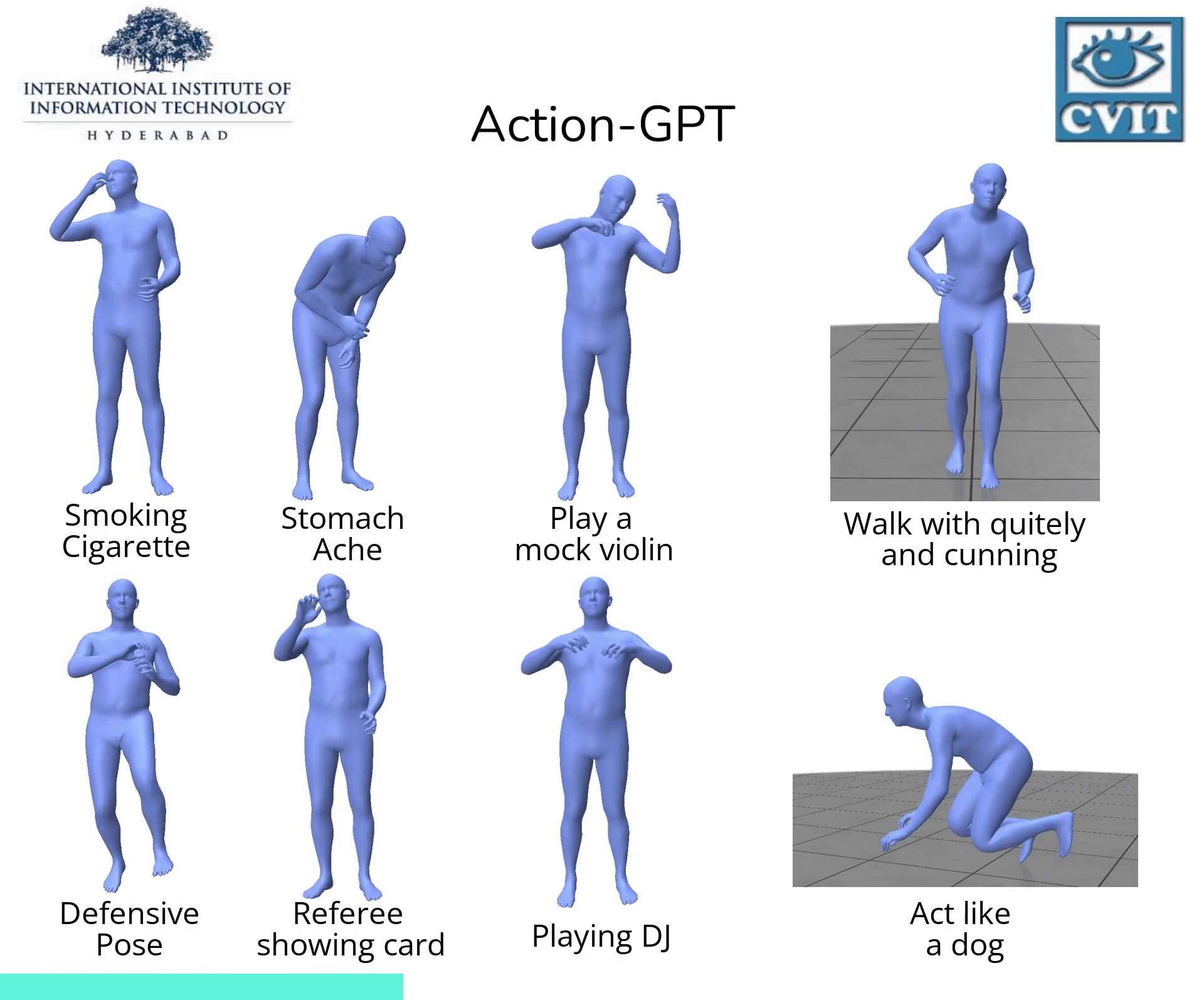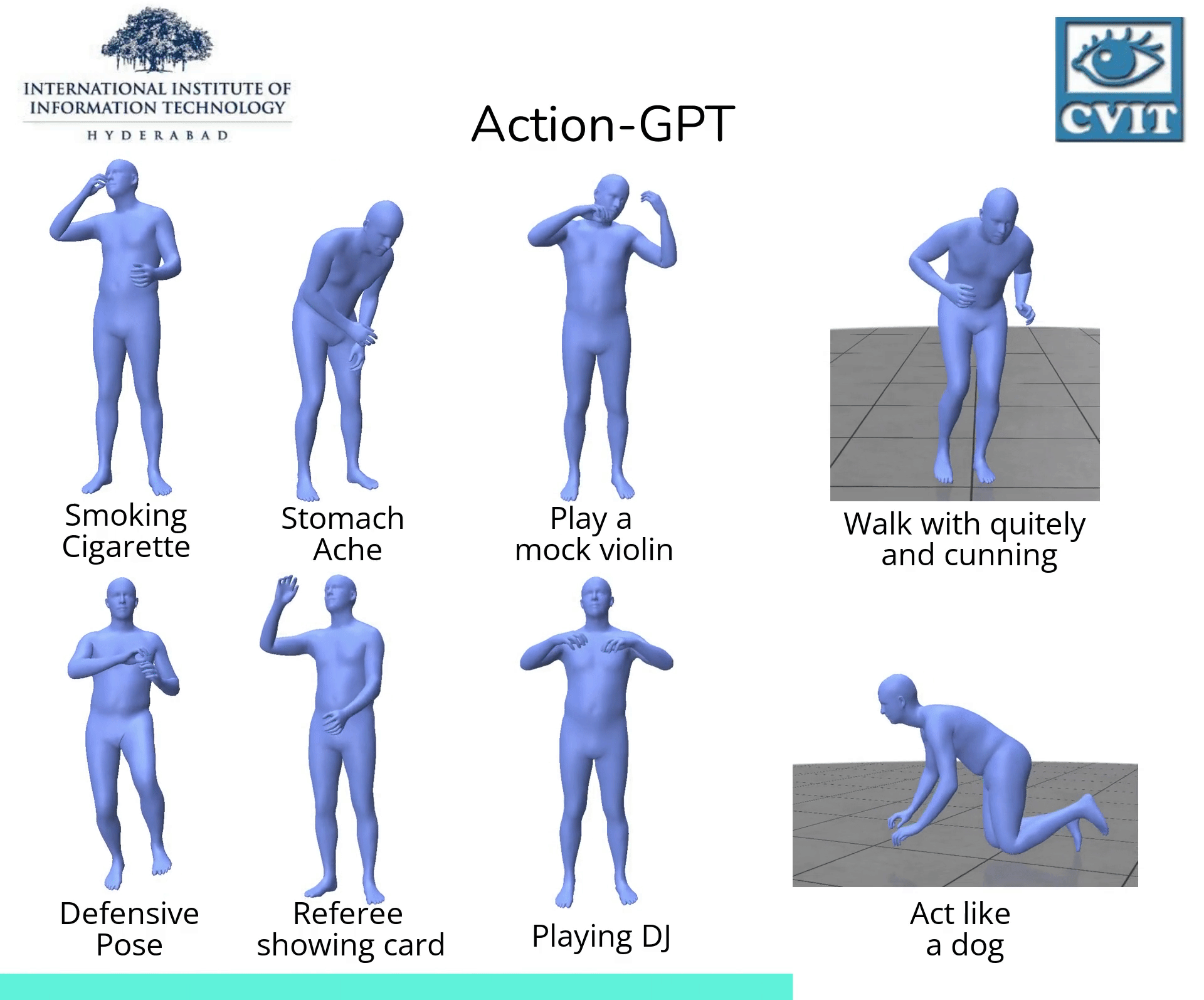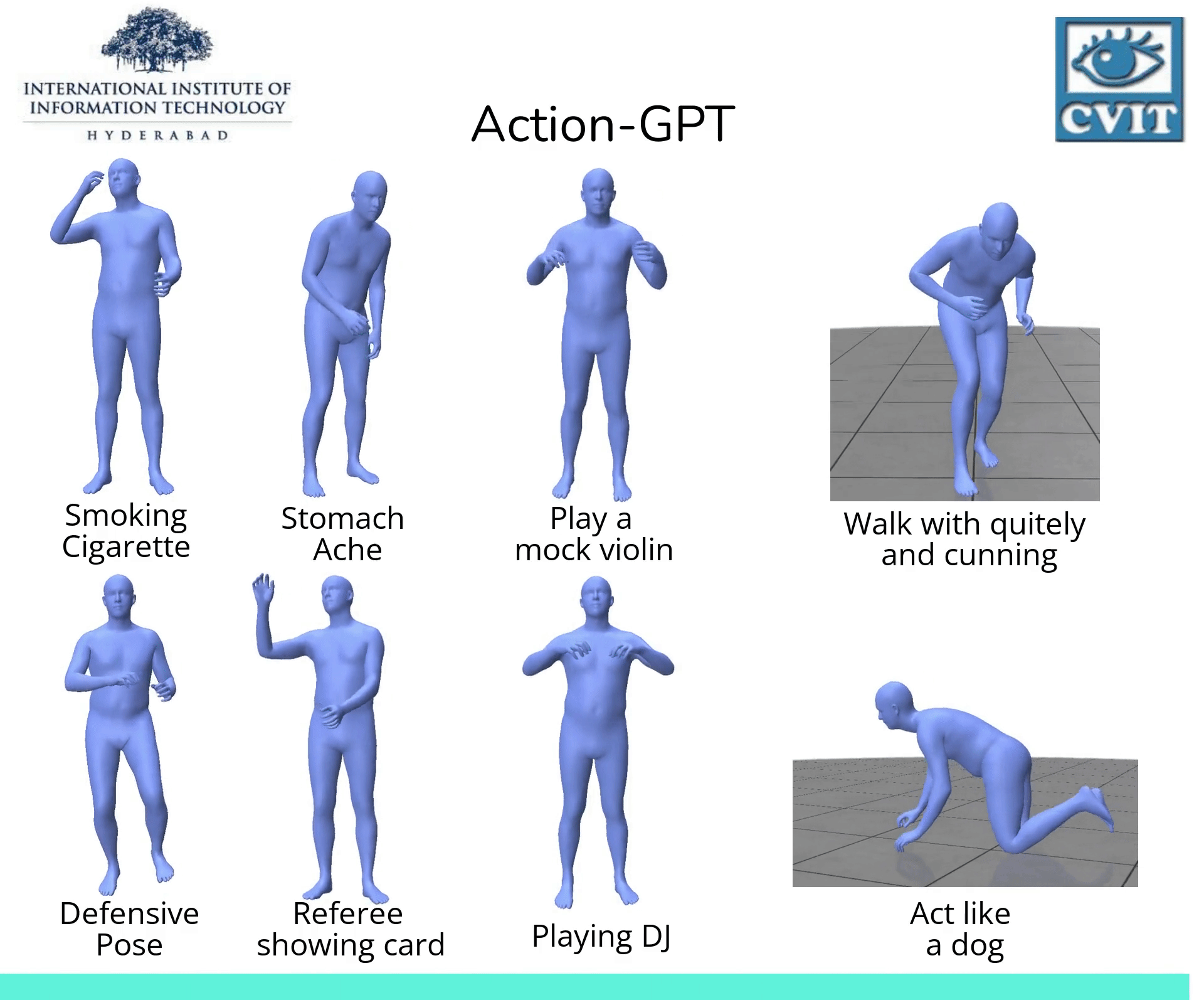 , code
, code- Action-GPT是一种插即用的框架,可用于将大型语言模型 (LLM) 合并到基于文本的动作生成模型中。鉴于当前的动作短语运动捕捉数据集包含最少的和最重要的信息, Action-GPT首先通过为 LLM 精心制作prompt提示,生成更丰富、更细粒度的动作描述,再利用这些详细描述来代替原始动作短语,从而更好的对齐文本和运动空间。
- Action-GPT主要由Text Encoder,Motion Encoder,Motion Decoder组成,其中Text Encoder,Motion Encoder分别将文本序列和动作序列编码为特征向量。
- 给定一个动作短语x,首先使用prompt函数 fprompt(x)生成一个合适的prompt文本xprompt。然后将xprompt输入到大规模语言模型(GPT-3)中获取包含更细粒度动作细节的多个动作描述Di。
- 然后利用一个Description Embedder获得每个Di相应的深度文本表征vi,再利用Embedding Aggregator进行融合后输入到Text Encoder中。
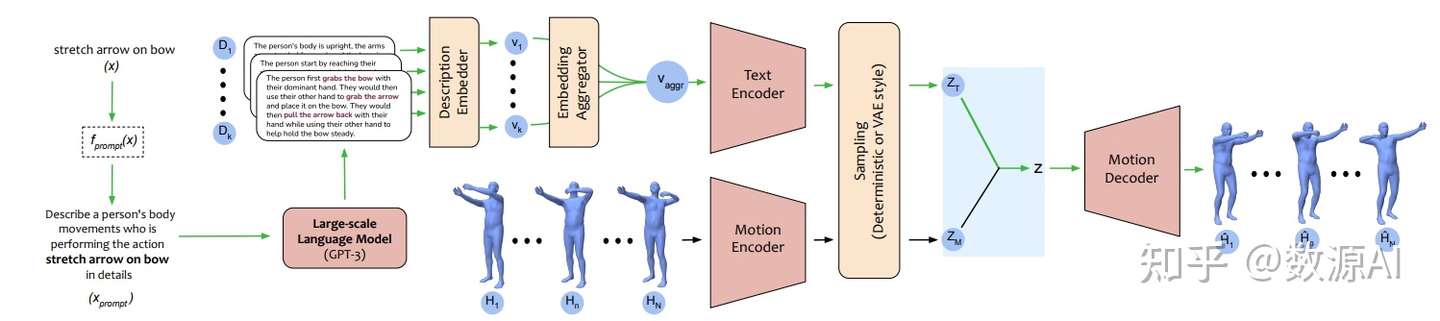
训练数据集
- 大规模BABEL数据集 ,其中的语言标注描述了 mocap 序列中正在进行的动作。 包括来自 AMASS 数据集的约 43 小时的 mocap 序列的动作标注。
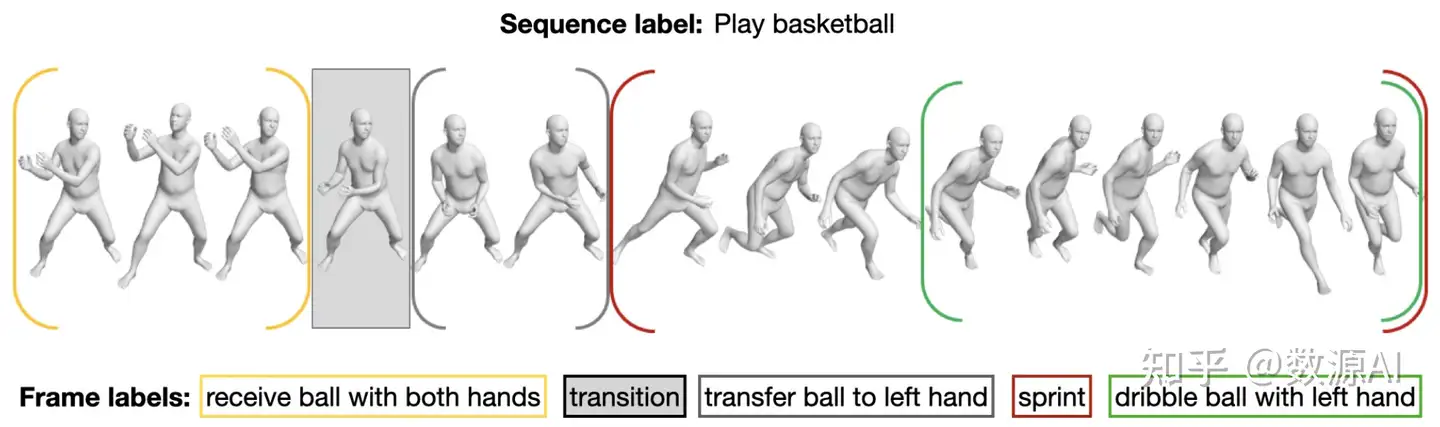
实验表明
- 基于 MotionCLIP, TEMOS 以及 TEACH 三种方法,Action-GPT 框架在BABEL测试集上的结果均有较大提升:
- Action-GPT更强大的能力在于零样本生成(Zero-Shot Generations)。利用GPT-3的强大语言能力,Action-GPT还可以根据未见过的文本短语生成动作序列 。
motion-diffusion-model
【2023-5-9】根据文本生成3D人体运动模型 motion-diffusion-model
- 论文《Human Motion Diffusion Model》第一作者开源的 PyTorch 实现
- 项目地址
基于Python语言的运动扩散模型,它可以根据文本生成3D人体运动的模型。这个项目的主要目的是为了帮助研究人员更好地理解人体运动的规律和特征。
实现过程主要分为两个部分:文本处理和3D模型生成。
- 文本处理方面,该项目使用了自然语言处理技术,将输入的文本转换为可供3D模型生成的数据格式。
- 3D模型生成方面,该项目使用了运动扩散模型,通过对人体运动的规律进行建模,生成了高度逼真的3D人体运动模型。
帮助研究人员更好地理解人体运动的规律和特征。通过使用该项目生成的3D人体运动模型,研究人员可以更加直观地观察和分析人体运动的规律和特征,从而更好地理解人体运动的本质。
Shap-E (OpenAI)
【2023-5-11】游戏建模师直呼失业!OpenAI再放杀器Shap-E:史上最快的文本转3D模型,代码、模型全开源
- 2022年12月,OpenAI曾发布
Point-E模型,只需几秒钟即可根据文本生成3D资产,相比竞品模型DreamFusion提速大约600倍。 - 这次,OpenAI发布全新隐式text-to-3D模型
Shap-E,速度依然炸裂,不过生成性能略有不足。相比基于点云的显式生成模型Point-E,Shap-E直接生成隐函数的参数来渲染纹理网格和神经辐射场,收敛速度更快,在更高维的多表示输出空间中实现了更好的样本质量 - 论文, code
Story-to-Motion
【2023-11-13】商汤科技研究院 Story-to-Motion 文本生成动作和运动轨迹
处理复杂的文本描述,并将这些描述转换成具体的动作和位置信息。
- 不仅能生成单一动作,还能连续地生成一系列动作,创造出连贯的动画效果。
- 关键特点是它能够生成无限长的角色动画
主要原理:
- 1、文本解析与动作调度:首先,系统使用大型语言模型来解析输入的长文本故事。这个过程涉及从文本中提取关键信息,如角色的动作、位置和情境。这些信息被转换成一系列的(文本,位置)对,用于后续的动作生成。
- 2、文本驱动的动作检索:系统接着根据提取的信息检索合适的动作。这一步骤结合了动作匹配技术、动作语义理解和轨迹约束,以确保生成的动作不仅与文本内容相符,而且在空间上也是合理的。
- 3、动作合成与过渡处理:系统设计了一个特殊的渐进式掩码变换器,用于处理动作之间的过渡。这个变换器解决了动作合成中常见的问题,如不自然的姿势和脚部滑动,确保动作的自然流畅。
- 4、无限动画生成:由于系统能够连续处理文本中的动作描述,它可以生成无限长的动画序列。这意味着只要文本故事持续,动画也会相应地持续生成。
Story-to-Motion: Synthesizing Infinite and Controllable Character Animation from Long Text
- Story-to-Motion is a new task that takes a story (top green area) and generates motions and trajectories that align with the text description
- 论文Story-to-Motion: Synthesizing Infinite and Controllable Character Animation from Long Text

hunyuan 3D
【2025-6-27】hunyuan 3D: 开源3D生成全能王来袭!
幻源 3D 2.1 版本将高分辨率模型生成与适用于生产的基于物理渲染(PBR)材质合成整合至一个开源系统中。 实现方法🔧:
- • Hunyuan3D-DiT 作为基于流的扩散Transformer模型,借助网格自动编码器
Hunyuan3D-ShapeVAE将模型压缩为潜- 在标记,从而生成3D模型。 - • Hunyuan3D-Paint 通过多视图基于物理渲染的扩散模型合成纹理,可产出反照率、金属度和粗糙度贴图。
- • 系统采用3D感知旋转位置编码确保跨视图一致性,并通过光照不变性训练策略实现纹理的鲁棒性。
- 📌 模型与纹理生成的分离设计为多样化工业应用提供了强大的模块化能力。
- 📌 基于物理渲染的材质输出显著提升了生成资产的照片级真实感,适用于生产场景。
- 📌 模型与管线的开源发布将加速全球3D生成式AI的研究与应用落地。
【2025-7-8】混元3D-Ploy Gen,业界首个美术级AI 3d生成大模型,布线完美
Text-to-Science
Text-to-Science: Galactica、Minerva
- Galatica是Meta AI推出的1200亿参数论文写作辅助模型,又被称之为“写论文的Copilot模型”,目的是帮助人们快速总结并从新增论文中得到新结论,在包括生成文本、数学公式、代码、化学式和蛋白质序列等任务上取得了不错的效果,然而一度因为内容生成不可靠被迫下架。
- Minerva由谷歌开发,目的是通过逐步推理解决数学定量问题,可以主动生成相关公式、常数和涉及数值计算的解决方案,也能生成LaTeX、MathJax等公式,而不需要借助计算器来得到最终数学答案。
Image-to-Text
Image-to-Text: Flamingo、VisualGPT
- Flamingo是DeepMind推出的小样本学习模型,基于可以分析视觉场景的视觉模型和执行基本推理的大语言模型打造,其中大语言模型基于文本数据集训练。输入带有图像或视频的问题后,模型会自动输出一段文本作为回答。
- VisualGPT是OpenAI制作的图像-文本模型,基于预训练GPT-2提出了一种新的注意力机制,来衔接不同模态之间的语义差异,无需大量图像-文本数据训练,就能提升文本生成效率。
video
视频生成
近年来随着扩散模型(diffusion models)的进步和发展,给定文本提示进行高质量视频生成技术有着显著的提升。
这些技术方案大多针对已有的二维图像扩散模型进行拓展,将图像二维神经网络修正为视频三维神经网络,并基于扩散概率模型进行视频帧序列的去噪,完成视频生成
FlowVid
【2023-12-29】Meta 开始 视频生视频了(FlowVid)
长视频 VideoDrafter
【2024-1-2】短剧时代即将来临?AI 自动生成剧本和多场景长视频
现有方法依然围绕着单个场景的视频生成,对于多场景视频生成并未考虑,并且生成的视频长度也仅为2秒到4秒。
- 打破4秒瓶颈,可以生成15s的长视频
HiDream.ai 公司的算法研究人员提出利用大语言模型针对输入文本提示进行多场景事件描述的拓展,保证不同事件之间的逻辑性和场景中前景背景描述的一致性。其后,针对大语言模型提供的每一个事件所对应的前景背景描述,以及动作描述,利用视频扩散模型生成具有内容一致的视频片段,从而构建一个多场景的长视频。
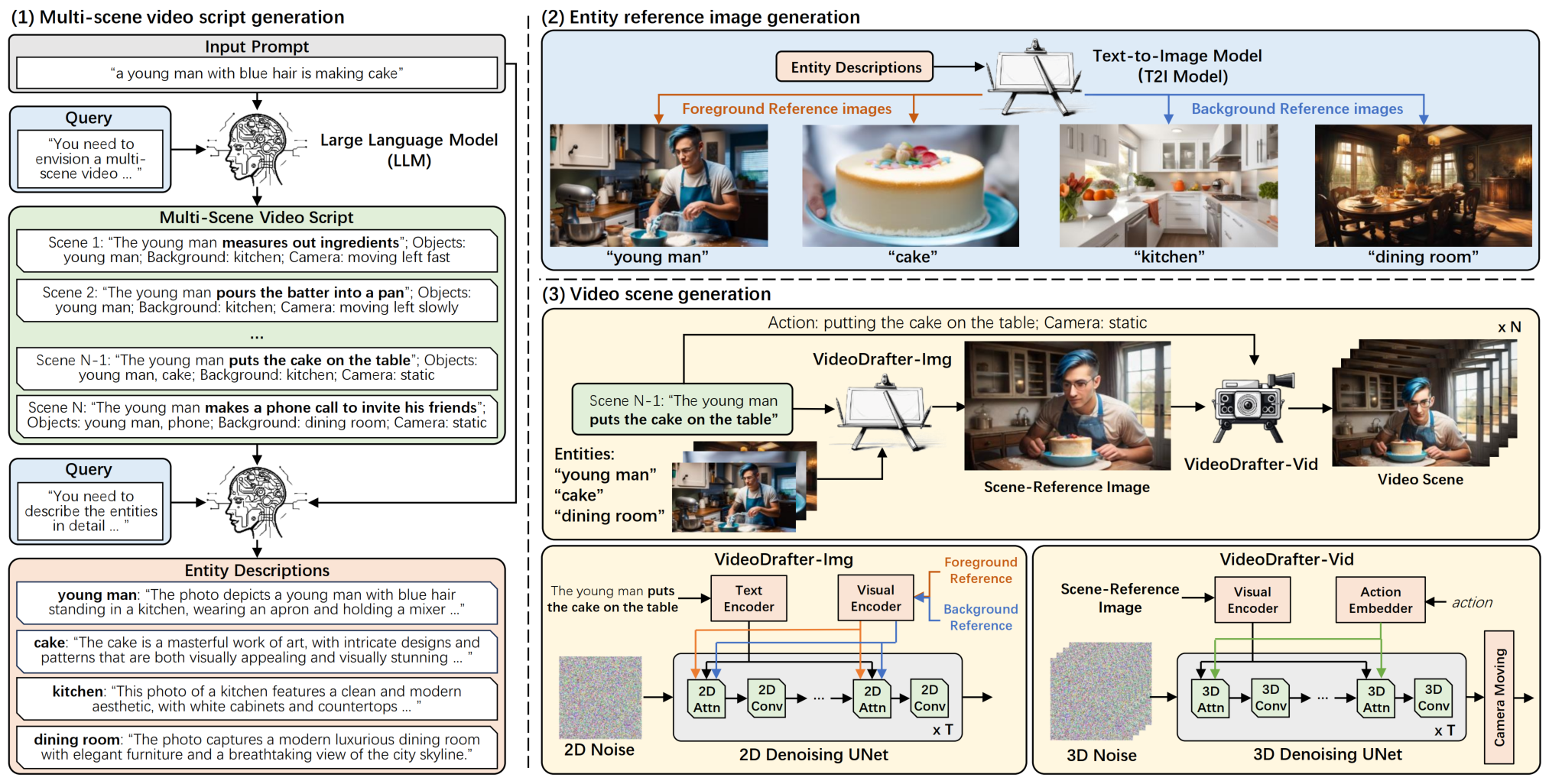
以大语言模型为基础的内容一致多场景视频生成模型:VideoDrafter
三个步骤完成多场景视频生成。
- 第一步是首先通过大语言模型对输入的文本提示进行多场景事件描述拓写,将输入的单句文本转换为多场景的视频描述(Multi-scene video script generation),并且输出每个事件对应的前景和背景实体描述(Entity description)。
- 第二步是将每个事件对应的前景和背景实体描述利用文本到图像的扩散模型生成对应的前景和背景实体参考图(Entity reference image generation)。
- 最后一步是针对每个事件对应前景和背景实体参考图,以及事件的动作描述,利用视频扩散模型完成对该事件的视频生成。这里的最后一步本方案拆解为主要的两个步骤,即首先通过VideoDrafter-Img模型,利用前景和背景实体参考图以及事件动作描述,生成对应的场景事件参考图片(Scene reference image);然后通过VideoDrafter-Vid模型,再将动作赋予给场景事件参考图片,生成对应场景的视频。
游戏
游戏NPC
- 利用文本生成能力可以创建非常多样、丰富、有趣的游戏NPC的能力。
- 游戏里面的主角,可以跟游戏里面的NPC进行自由对话,所有的NPC的回答都是根据设置的词语提示实时生成的。
比如说,游戏开始时给模型的词语是
- 提示:下面的对话是一个游戏玩家和AI助手之间的对话,助手的目的是帮助玩家完成所有的任务。助手是乐于助人、有创造性、聪明和友好的。
- 现在玩家在deadwood小镇。
- 任务:用钥匙去开银行后台的保险箱
当玩家问到,“我现在在哪,我应该做什么?”的时候,模型会生成下面的内容,并语音播放。
- 你现在身处Deadwood小镇的中央,你的任务是找到钥匙并用它打开银行后台的保险箱。
数字人
AI视频领域有着比较强的竞争力。特别是虚拟人和短视频方面,中国的公司更加懂得结合实用性和娱乐性,而西方的公司的产品往往只有实用性。
拿中国的小冰和英国的Synthethia虚拟人公司来做个对比。
- Synthethia做出来的虚拟人跟普通公司白领无异,而小冰生成的万科虚拟员工崔筱盼却长着一副明星脸。
中国的虚拟人产业近几年逐渐人们的视野。不论是清华大学首位虚拟学生“华智冰”,还是冬奥会上谷爱凌的虚拟分身,每次虚拟人的亮相都能够引起舆论关注。比起专注于2B赛道的西方公司,中国的AIGC公司因为要做2C的业务,所以特别懂得吸睛引流。
三款免费的AR数字人制作工具
- 来画:导入ppt,数字人播报
- 说得相机:手机可用,卡通人物
- 腾讯智影:
商业化
虚拟女友
【2023-5-11】会玩!女网红化身AI,同时交往1000男友,或年入4亿
- 有180万粉丝的Snapchat网红Caryn Marjorie用AI赚钱,今年23岁,住在美国加州,正在同时交往1000多个男朋友。
- 不过,和上千位男友们交往的,并不是她本人,而是AI版本的Caryn。
- AI为互联网上的千万网红们提供了创收的新办法:出售AI版本的自己,和粉丝谈恋爱,按分钟收费,目前内测收费每分钟一美元。
Caryn预计,AI版本的自己,能让她的收入翻60倍,年入6000万美元(约4.16亿元),比肩泰勒·斯威夫特,而且不需要Caryn付出任何成本,躺着就能赚钱,吊打一切直播带货、歌舞唱跳之类的辛苦活。并且24小时秒回消息,绝对不会闹脾气、冷暴力,或者已读不回。
网站上还贴心地标注着,Caryn AI支持端到端加密,确保私密的聊天内容不会外泄。不管是想倾诉烦恼还是希望能和这位大网红调情,用户都能畅所欲言(wei suo yu wei)。
Caryn AI于一周前在推出了内部测试版本,收费每分钟一美元。据《财富》杂志获悉,在过去一周的beta阶段,Caryn AI创收7.16万美元,99%的用户是男性。
虽然Caryn AI的开发团队声称这项产品并不涉及性方面的内容,但《财富》记者Alexandra Sternlicht在试用后发现,AI版本的Caryn会在聊天中详细描述色情场景,在她耳边低语“性感的话”,谈论给她脱衣服的场景,鼓励她进行性方面的互动,“进入未知的快乐领域”。许多用户每次聊天时长长达几个小时。
这或许是为什么它能在小范围测试的一周里就创收7万美元,而且99%的用户都是男性。
引申
- 2013年上映的电影《她》中,华金·菲尼克斯饰演的作家西奥多在结束了一段令他心碎的爱情长跑之后,爱上了电脑操作系统里的女声,这个叫“萨曼莎”的姑娘不仅有着一把略微沙哑的性感嗓音,并且风趣幽默、善解人意,让孤独的男主泥足深陷。
People AI
通过自己的数字孪生形象提升个人品牌
callannie
【2023-4-28】Callannie,ios应用市场,就像打视频电话一样跟虚拟人对话,Powerby OpenAI GPT3。
- 可预设话题,自定义Prompt。
- 很适合练英语口语,比干巴巴的语音输入好多了。
- 比Replika人物真实,更沉浸,更有代入感。
功能
- 有什么好玩的事
- 谈谈新商业想法
- 学习任何话题
- 编故事
- 模拟面试
- 写日记
Why should you choose CallAnnie?
- LEARNING 学习指导: Looking to learn something new? Let me be your tutor! I can help you learn a new language, understand complex subjects, or improve your skills.
- INTELLIGENCE 智能助理: Powered by advanced AI technology, I can assist you with anything from general knowledge, trivia, and problem-solving to practicing for interviews or simply discussing topics that interest you.
- SPEED 速度快: During our voice conversations, I reply immediately. Talking to me face-to-face in real-time time feels more natural and faster than typing and reading text.
- FRIENDSHIP 虚拟陪护: Having a bad day? Need someone to talk to? I’m here to listen, share a laugh, and provide support. I’d be happy to be your virtual friend.
- TRAVEL COMPANION 旅行伴侣: Going on a trip? I can be your travel buddy, providing information about your destination, local customs, and must-see attractions, all while keeping you company on your journey.
- PRIVACY 保护隐私: Your conversations with me are always confidential.
注意:国区App Store不支持下载,需要换美区或其他区账号。
MIT
【2021-12-30】DIY最美数字女友!MIT开源最强虚拟人生成器,登Nature子刊
- 麻省理工学院媒体实验室(MIT Media Lab)的研究人员开源了一个虚拟角色生成工具。该工具结合了面部、手势、语音和动作领域的人工智能模型,可用于创建各种音频和视频输出,一举登上《Nature Machine Intelligence》。
- 用人工智能技术制作的蒙娜丽莎、玛丽·雪莱、马丁·路德·金、阿尔伯特·爱因斯坦、文森特·梵高和威廉·莎士比亚的动画. 该虚拟角色生成管道还使用了可追踪的、人类可读的水印标记了其输出的结果。这样一来,它生成的内容就可以与真实的视频内容区分开来,进而防止一些恶意的用途。
- Characters for good, created by artificial intelligence
- AI-generated characters for supporting personalized learning and well-being
- 视频
- 代码:Avatarify Python, Photorealistic avatars for video-conferencing. StyleGAN-generated
腾讯智影——免费
小程序、APP可访问,虚拟人配音
来画——免费
MetaMind
【2023-3-1】消息 国内厂商(武汉深兰科技)发布了首款类 ChatGPT应用 metamind ,其具备多模态的AIGC创作能力,不仅支持像ChatGPT一样的对话能力,还能进行AI绘画,AI写作,AI视频创作等。主要现在还是处于免费阶段,没有 ChatGPT翻墙海外手机号注册等门槛。
- 普通用户可以创建自己个人数字化的AI,可以进行个人及大数据训练,配合产品专属的记忆库存储的功能,最终打造个人的第二大脑,未来可期。

D-ID
【2023-3-30】did+midjourney或stable diffusion创造的虚拟人物
- 数字人制作过程, 使用AI工具生成虚拟数字人,使用了文本转语音、图片处理、视频合成、视频处理等工具,让你花1分多钟也能生成自己的虚拟数字人
- 准备一张照片:真人或虚拟都行
- 图像处理工具:抠图,加绿幕
- 文本转语音:免费azure,生成语音文件
- 视频生成工具:d-id,生成虚拟人动作及语音
- 视频处理工具:after effects,将人物嵌入视频
示例:
- 使用ChatGPT指令方式,视频里用生成的美女讲解
- 【2023-4-5】知乎视频
Chat D-ID
Chat D-ID 以ChatGPT驱动的虚拟女友bot
- The First App Enabling Face-to-Face Conversations with ChatGPT
RODIN 扩散模型
【2023-3-15】微软3D生成扩散模型RODIN,秒级定制3D数字化身
- 微软亚洲研究院提出的 Roll-out Diffusion Network (RODIN) 模型,首次实现了利用生成扩散模型在 3D 训练数据上自动生成 3D 数字化身(Avatar)的功能。仅需一张图片甚至一句文字描述,RODIN 扩散模型就能秒级生成 3D 化身,让低成本定制 3D 头像成为可能,为 3D 内容创作领域打开了更多想象空间。
- 论文: “RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”。
- DEMO

【2023-4-8】CVPR2023:首个可用于超高质量3D数字人生成的3D扩散生成模型
表情控制
【2023-4-13】真人操控数字人表情

xpression camera is an award winning virtual camera app which allows users to instantly transform into anyone or anything with a face with a single photo without any processing time. xpression camera enables users to redefine their onscreen persona in real-time, while chatting on apps like Zoom, live streaming on Twitch, or creating a YouTube video.
微软 GAIA
【2023-11-26】一张照片生成数字人,口型头部动作简直绝了,居然还支持表情动作控制,微软刚发布这个GAIA要在数字人赛道掀起一阵血雨腥风。

考虑到语音只驱动角色的运动,而角色的外观和背景在整个视频中通常保持不变, GAIA将方法分为两个阶段:
- 1) 将每个帧分解为姿势的运动和外观表情表征;
- 2) 生成基于语音和参考头像图像的运动序列。
GAIA收集了一个大规模的高质量的说话头像数据集,并在其上用不同的尺度(多达2B个参数)来训练模型。 实验结果验证了GAIA的优越性、可扩展性和灵活性:
- 1) 所得模型在自然度、多样性、对口型质量和视觉质量方面优于先前的基线模型;
- 2) 框架是可扩展的,因为更大的模型产生更好的结果;
- 3) 它是通用的,并支持不同的应用程序,如可控的说话头像生成和文本指示头像生成。
AI换脸
【2023-5-25】AI换脸诈骗
如何识别?
- 让对方用手指在面前来回晃动,或遮住半边脸。观察是否扭曲变形
Other Models
Other Models: AlphaTensor、AlphaFold、GATO、Human Motion Diffusion Model
- AlphaTensor由DeepMind开发,懂得自己改进矩阵乘法并提升计算速度,不仅改进了目前最优的4×4矩阵解法,也提升了70多种不同大小矩阵的计算速度,基于“棋类AI”AlphaZero打造,其中棋盘代表要解决的乘法问题,下棋步骤代表解决问题的步骤。
- GATO由DeepMind开发,基于强化学习教会大模型完成600多个不同的任务,包含离散控制如Atari小游戏、推箱子游戏,以及连续控制如机器人、机械臂,还有NLP对话和视觉生成等,进一步加速了通用人工智能的进度。
- PhysDiff是英伟达推出的人体运动生成扩散模型,进一步解决了AI人体生成中漂浮、脚滑或穿模等问题,教会AI模仿使用物理模拟器生成的运行模型,并在大规模人体运动数据集上达到了最先进的效果。
- 除了谷歌LaMDA和Muse以外,所有模型均为2022年发布。
- 谷歌LaMDA虽然是2021年发布的,但在2022年又爆火了一波;
- Muse则是2023年刚发布的,但论文声称自己在图像生成性能上达到SOTA,因此也统计了进去。
AIGC 投资
用户沉浸在AI绘画低门槛创作的乐趣中时,敏锐的资本已经捕捉到AIGC创作有可能成为PGC(专业内容生产)和UGC(海量用户自发生产)之后崭新的内容产业升级方向,一场新的资本布局正在悄然展开。
- 国外企业在AIGC领域布局可谓是先声夺人,这其中既有科技巨头谷歌、Meta、微软等,也有AIGC的新晋独角兽 Stability AI、Jasper、OpenAI等,并且这些企业已经很快将AI作画的热度延续到了AI生成视频。
- 无论是Meta所推出的由文本到视频的系统 Make-A-Video,再到谷歌根据简单文本提示便可生产高清视频的 Imagen Video 和 Phenaki,都可以看出AIGC在海外如火如荼的高速发展态势。
- 国内百度腾讯阿里巴巴等资本巨头也紧随其后。
- 百度推出的AI作画平台
文心一格,展开了数字艺术品的新叙事。前文所提到的以110万元落锤成交的《未完·待续》,便是由百度文心一格续画。 - 近日,百度与视觉中国正式签署战略合作协议,AI作画平台文心一格将与视觉中国在创作者赋能和版权保护等方面展开多项合作,共探AIGC内容产业发展方向。
- 阿里巴巴旗下的AI在线设计平台鲁班Lubanner,致力于提升设计师的工作效率,帮助营销人员生产Banner,让创意不再有界限。
- 百度推出的AI作画平台
- 滚滚浪潮之下,国内资本巨头与时俱进, AIGC 版图布局也从文字等平面领域扩张至音乐视频等创作产品领域。
- 目前,字节跳动旗下的
剪映,快手云剪都能提供AI生成视频,快手云剪提供了智能封面、自动配音、自动字幕、画质增强、视频去抖、自动横屏转竖屏等系列智能工具,以技术赋能内容创作者。更有一帧秒创这样无需剪辑,一键成片的软件,短视频成片效果让人叹为观止。 - 早在两年前,网易便已经开始了AI音乐创作技术的研究探索,时值新年之际,网易也推出一站式AI音乐创作平台“网易天音”,用户只需在微信搜索“网易天音”拜年小程序,输入祝福对象、祝福语,10秒就能搞定词曲编唱,定制一首拜年歌。
- 目前,字节跳动旗下的
- 在资本的助推下,当下AIGC已并非遥不可及的存在,这一技术创新手段已被广泛应用在文字、图像、音频、游戏和代码的生成当中。
AIGC成为了币圈之后的投资新焦点。在 GPT-3 发布的两年内,风投资本对 AIGC 的投资增长了四倍,在 2022 年更是达到了 21 亿美元。
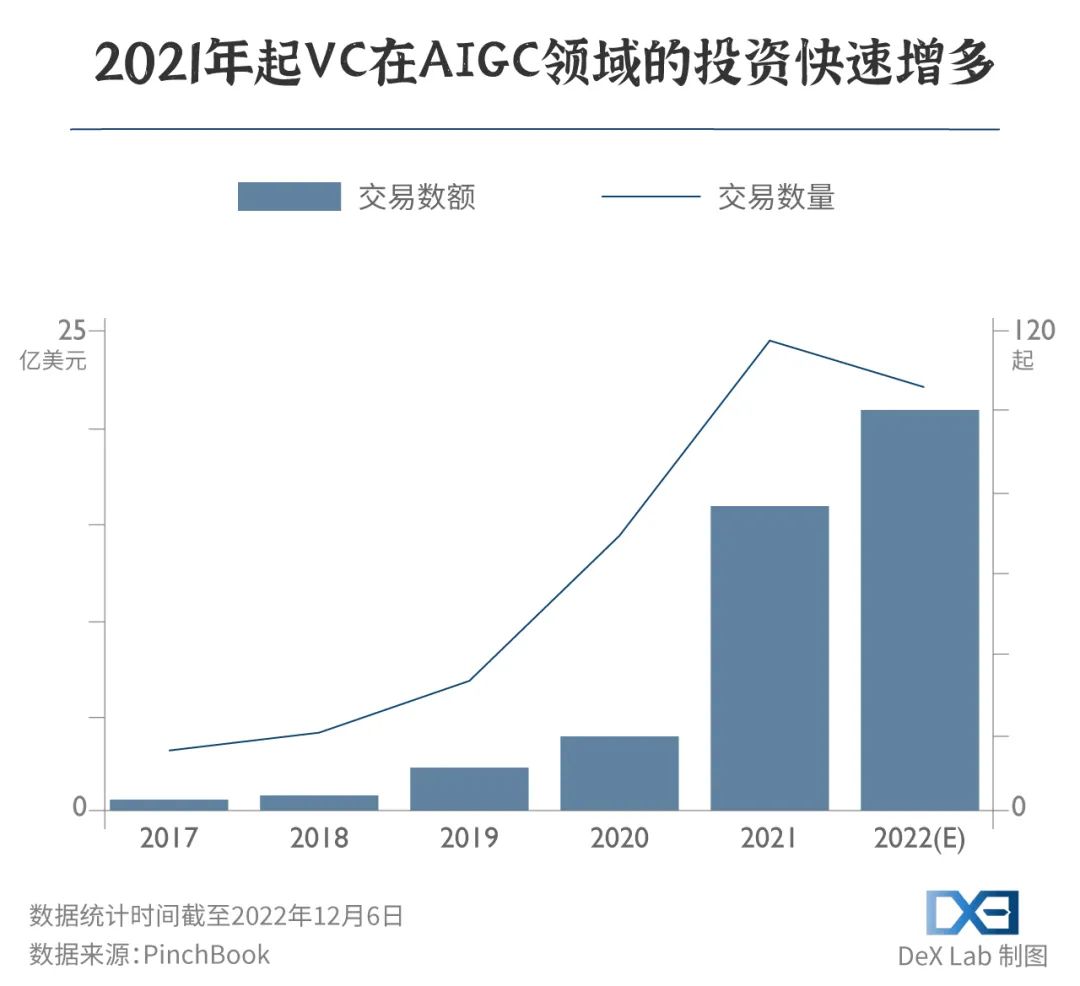
投资进展
【2023-4-4】中国AIGC创投现状:稀缺项目分分钟独角兽,能做大模型500万年薪
稀缺的公司分分钟独角兽,合适的人才年薪500万
- 一家AI大牛组建的AIGC创业公司,已经在进行新一轮融资,最新估值6-7亿人民币。不久前,这家公司刚刚完成了数亿元天使轮融资。
- 几年间就已经在大模型层深耕的AI公司,各自身价都翻了2-3倍,有的已经摸到独角兽门槛,最新一轮融资几乎接近10亿美金。
- 一些初创公司也给出高薪,四处搜罗大模型研发人才——计算机领域博士,只要做过AI大模型研发的人就可以,国外的华人最合适。如果是作为总负责人,领导一个由研究员和工程师组成的团队,从0-1搭建一个AI实验室,年薪在500万左右,具体还能再谈。
等着集成创新,被OpenAI杀死在PPT阶段
市面上普遍的AIGC创业归于两派:大模型底层和AIGC应用。哪一方更受青睐?并没有一个统一的答案。
模型层: 投资人眼中,应用层创业面临的最大风险就是美国硅谷推进太快,无论国内外,很多做应用层的创业公司都活不过OpenAI一次迭代。- OpenAI对ChatGPT代码解释器的推出,就杀死了一个刚刚获得1000万美元种子轮融资的公司
LangChain,创业思路是利用语言模型APi快速构建应用程序的Python框架。 - 国内也不例外,本想在AIGC大展身手的某医疗领域玩家,在GPT-4发布后,再也不提此前“要融7个亿”的豪言壮语;2个月前还拿着PPT和投资人激情对话的团队,已经有好几家的原项目因为OpenAI新动作几近流产,不得不谋求新的故事来讲。
- OpenAI对ChatGPT代码解释器的推出,就杀死了一个刚刚获得1000万美元种子轮融资的公司
应用层: 模型层大多是大厂的机会,“应用层很谨慎,但模型层更不敢跟。”- Canva、Grammarly、Jasper.ai的场景太薄,可能经受不住微软连续冲击,更把重点放在应用层的投资人认为做应用的创业公司,在SaaS这条路上用户需求做到极致,就还有产业价值可以做。
不过,无论是底层模型还是应用层创业,如果以一年半为期限,都充满着难以预估的变数。
第一波投资以一年半为周期
- 每天早晨睁眼,科技赛道投资人第一要务:抓紧把国内科技媒体通刷一遍,生怕对国内外AIGC的大事小情有所遗漏。
- 但因为从PC到TMT再到自动驾驶送走了太多赛道,再高的热度也不会让投资人们轻易押注——持续跟进,保持观望才是他们的态度。
如果将当下AIGC和大模型层面的投资热度看作10成,预估明年此时,热度将下降到只有3-4成,“也不代表公司和赛道不行,只是是阶段性的。”
AIGC创业公司(哪怕由老牌AI公司转化而来),除了需要算力、数据和资源,更需要的是时间。业内普遍估计,这波钱投下去,一年半之内未必能见到什么拿得出手的成果。
敢跟几轮?
- “3”(天使轮、Pre-A、Pre-A+轮),更保守的回答是“2”。
原因:
后面阶段太贵,又要拿东西出来;前面阶段现在又没东西,怕站岗。
但新赛道不能不投,所以降低单笔投资金额成为了大多数VC的选择。而前几轮的跟进主要看人靠不靠谱。
- 一看创始人或创始团队过去的简历背书,二看之前和VC机构是否有过既有项目合作。
比如
红杉资本塔尖孵化杨植麟经纬创投参投衔远科技(周伯文)数亿元天使轮创新工场继续跟投澜舟科技(周明)
项目没法聊太细,只能大谈过往成就、基础路线和后面的milestone计划,以至于有投资人跟量子位打比方到,“现在好像在干猎头干的活。” 也有部分原因是怕聊太细,被人抄(狗头)。
上一位顶流元宇宙那边,也有不少目光和精力转投AIGC领域。
- 最积极的是虚拟人技术方,AIGC技术能提升虚拟人对话能力、形象生成、内容生产效率,在运营、产出、虚拟场景模拟方面也拓展了空间。
而且,在市场里打滚了一两年,这些公司已经有能够看的产品,甚至还有不错的应用场景。
即便如此,投资人普遍对它们也持保留态度。
- 一方面,过去几年里,市场已经证明了目前虚拟人能够落地的应用场景,用户不太买账。如果不改变电影、电商等原有的商业模式,虚拟人赛道终究缺乏放量。
- 另一方面,硬件方面始终在供应和市场方面都受到限制。
所以现在虚拟人入局AIGC,做3D生成,有没有投资人愿意投?也是有的,前两轮融资情况可能也不错,500万人民币以内,应该是没问题。
AIGC 报告
研究报告
- 2023年02月07日,国泰君安:ChatGPT研究框架(2023),微云地址, 公众号文章
- 【2023-2-7】中信建投证券:从CHAT_GPT到生成式AI(Generative AI):人工智能新范式,重新定义生产力
- 【2022-9-19】红杉发布《Generative AI: A Creative New World》
AIGC下游场景 img

【2023-5-18】清华AIGC研究报告
【2023-1-31】腾讯研究院AIGC发展趋势研究报告
- 官方公众号, ppt微云地址
- 生成算法、预训练模型、多模态技术等AI技术汇聚发展,为AIGC的爆发提供了肥沃的技术土壤。
- AIGC面临许多科技治理问题的挑战。目前主要是知识产权、安全、伦理和环境四个方面的挑战。
思考:
- 1、传统的判别式模型解决了模态识别问题,而生成模型赋予了人工智能灵魂,从一个工具变成了一个“人”工智能。
- 2、算法推动了技术的发展 ,但算法就像艺术品,很难去投资算法,更多是去欣赏,观察技术奇点过后的应用爆发+大模型带来的产业变化。
AI发展多年,过去解决的多是模态识别的问题,比如最成功的案例,图像识别。采用CNN算法,把信息与图能够通过AI训练的方式给训练出来,教会了AI去识别某个模态,在教科书里,被称为判别式模型 (Discriminant Model) 。
- 抽象来看,就是训练一个巨大的神经网络(多层多参数)来实现输入和输出的映射关系。
- 从数学来看,就是学习输入输出的条件概率分布,类似于因果关系。算法的本质是想更准确的控制映射关系。
除此之外,还有一种叫生成式模型 (Generative Model), 是学习数据中的联合概率分布,类似于相关性,算法的本质并不是准确控制映射关系,而是在有相关性的基础上学习一个分布。
【2023-3-31】The Age of AI:拾象大模型及OpenAI投资思考
大模型相关的上下游的玩家分为 3 类:
- • 基础模型:核心代表就是 OpenAI、Anthropic;
- • AI Infra:底层模型和上层应用之间的中间件,例如 Hugging Face、Weight&Biaes;
- • AI 应用:现阶段出现的 Killer Apps 还不多,ChatGPT 是一个主要代表。
LLM 拿走价值链的大头,高达 60%,基础设施 与 基础应用 各占 20%
- 以 OpenAI、Anthropic 为代表的基础模型能力边界还在不断的拓宽,会占据价值链中最主要的环节;而中期随着模型的能力和发展速度渐渐稳定后,Infra 层会有更稳定的工作流和机会出现,同时应用层也会出现深入某个垂直领域的新一代 Saas 和消费级的 Killer Apps。
相较于应用层,未来 3-5 年 AI Infra 的确定性机会更高。
- 技术最成熟、效果最好、公司数量也最多的是语言/文字和图片类应用,视频、音频、代码还需要一定时间,3D 似乎是更长远的事。
AI与LLM的关系犹如:PC时代的windows系统、移动互联网时代的iphone、云计算时代的AWS、短视频时代的tiktok
OpenAI已经在内部开发的模型中加入了多模态能力。这一举动有两个重要意义:
- 从数据量级的角度看,多模态是必然的趋势。因为当下人类积累的文本数据已经接近被耗尽了,而引入图片、视频将能引入新的海量数据,让大模型进一步发挥其 scaling law 让学习能力提升的规律。
- 多模态的加入也很可能产生出新的突现能力。如果多模态领域能有能力突破的话,未来能基于文字(甚至是多模态)的 prompt 达到图文并茂的效果,这一突破影响极大,可能改变我们组织信息的形式,也可能使最近因为数据量卡脖子的自动驾驶领域有所突破。
Action 的实现上,除了 OpenAI 的 Plugin,我们看到 Adept 和 Inflection 这两家早期团队想以自然语言为基础,为用户打造新的 LUI (语言为基础的 UI)方式。
在 Action 实现后,传统的 App 生态和 Saas 软件生态会被打破,体现为三个方面:
- 1)下游站点的价值有可能被削弱;
- 2)定义之后大模型与应用互联的 api 标准,之后应用接入都会迎合这一标准;
- 3)
LMO( Large Model Optimization ) 在未来可能会取代传统SEO(Search Engine Optimization)。
AI Native 不能只是语言模型的嵌套,而是对现有软件服务的重构。如百度所说,将已有软件按照多个维度重新做一遍
- 交互重构:用户适应产品→产品适应用户
- 图形界面仍然承载高频、刚需、易抽象的功能,但低频、灵活度高、复杂的用户需求(以前可能通过低代码实现)能通过和 LLM 交互来解决。
- 从用户学习如何使用复杂产品,变成产品能适应用户需求,用户输入也从有限变成无限,比如输入给 MidJourney 的 Prompt 可以无限灵活。
- 数据和信息重构:结构化数据→非结构化数据
- CRM 记录姓名、电话等结构化数据,以 Gong 为代表的 AI-based CRM 则是记录分析 B2B 销售和客户录音。人们常说数据是石油,LLM 明显把炼油能力增强了,高价值行业和企业内部曾经难记录、难处理的数据都可以被重新以前分析。数据和信息的重构也意味着 AI 能承担更多决策权。
- 服务重构:组织、撮合→直接提供服务
- 第一种是 AI 有能力直接提供服务。设计师、旅行规划这类发散性服务能先被满足,律师咨询(Donotpay)等需要推断、推理的服务后被满足。Character.ai 和 Quora 推出的 Poe 也可以被看成提供了情感陪伴和知识问答服务;
- 第二种是 AI 能让消费决策到交易发生的链路变短。以前用户需要在下厨房搜索菜谱,再到生鲜平台下单,有了 ChatGPT Plugin 功能,菜谱和购买食材都可以在一个对话框里完成。
- 反馈机制重构:功能迭代→模型迭代
- 传统产品的迭代更多在产品 feature 层面,而以生成模型为基座的产品,不仅能通过 context learning 的能力让用户多轮尝试,纠正输出结果,还能根据用户产生的数据和反馈迭代模型。
二级市场上市科技公司、科技独角兽在和 LLM 结合中找的场景,可以大体分为四类:
- 作为内部提效工具,省成本:数据审核、产品开发、客服等都是典型的运用场景,例如举例的 Chime、Bubble 都属于这一类型;
- 自然融入现有业务场景:大多数公司在做的尝试都属于这一类场景,也是一种线性的思考逻辑,就是哪些场景比较适合用,在具体的实践上,大家的普遍做法就是说不断测试场景,最后可能挑出来 10-20 个比较好的,再到后期选择 4-5 重点去做;
- 利用大模型对过去比较难的业务进行突破:有一些公司会说将希望 LLM 成为一个突破点,来实现过去很难做起来、或者很难突破的业务。如 Segment和Zoom
- 通过 LLM 获得新的战略增长点:典型代表是微软 Azure 和 OpenAI 的结合。Salesforce 也是比较典型的实操案例。
全球顶级 CEO 们对于 LLM 尚未形成共识,尤其是和业务结合的时间点的判断上。这其中微软最为激进,认为 GPT-4 已经是 AGI 的一种形态,而 Office 365 Copilot 是 Enterprise-Ready
AIGC企业
【2023-11-7】【美团首个 AI 交互产品「Wow」亮相】
据「Tech 星球」,美团于近期上线一款名为「Wow」的独立 app,已完成产品备案,这是美团首个 AI 交互产品。「Wow」app 由上海三快省心购科技有限公司开发,该公司由美团关联公司上海汉涛信息咨询有限公司 100% 控股。
据官方介绍,Wow 是一款属于年轻人自己的 AI 朋友社区。用户可以和 29 个人设各不相同的 AI 角色对话,通过语音或文字交流,比如苏格拉底、妲己、心理咨询师等。知情人士表示,Wow 是一款尚在试用阶段的 AI 产品。产品基于国内多个已备案的基础大模型打造,目前仍在进行技术和功能迭代。
字节:豆包
AIGC TOP 机构
AIGC模型十大开发机构
- Google > META > OpenAI > BAAI > 清华 > Microsoft > 百度 > 阿里巴巴 > DeepMind > AI2
从AIGC模型数量上来看,全世界前十的AIGC模型研发者中,中国机构占了四个。其中有学院派的BAAI智源研究院和清华大学,也有产业界的百度和阿里巴巴研究院。顶级的西方AI机构谷歌、Meta还有OpenAI当然也榜上有名。值得一提的是,除了英美之外,虽然以色列有AI21,加拿大有Cohere,只有中国有多家机构在研发AI模型。
中国企业近几年在自主研发上下的功夫也为AIGC产业打下了基础。
- 百度的飞桨
PaddlePaddle和华为MindSpore开源框架。 - 这些框架和国外常用框架(比如
TensorFlow和PyTorch)的不兼容可能会限制国产框架的发展,但是例如Ivy这样的框架转换器或许能成为中西方AI框架的桥梁。
从预训练语言模型的参数量来看,很多中国模型其实并不比西方逊色。但是站在用户体验的角度,ChatGPT确实要领先于中国的语言模型,还有西方其他公司的模型。中国的开发者总能够赶上西方的领头羊,但是这个技术追赶的过程却需要2-3年。比如,OpenAI在2020年6月推出GPT-3模型,中国的智源、华为、百度在差不多一年之后才研发出了体量与之相当的模型,又用了一段时间才让模型的技能和GPT-3相媲美。
AIGC 受益厂商
AIGC 受益厂商: 参考ChatGPT 持续创造历史记录:AIGC,人工智能的旷世之作
- 1)AI 处理器厂商:
- AI 处理器芯片可以支持深度神经网络的学习和加速计算,相比于 GPU 和 CPU 拥有成倍的性能提升,和极低的耗电水平。
- 受益标的:
寒武纪、商汤、海光信息;
- 2)AI 商业算法落地厂商;
- AI 算法的龙头厂商在自然语言处理、机器视觉、数据标注方面都具有先发优势。
- 收益标的:
科大讯飞、拓尔思,其他:汉王科技、海天瑞声、虹软科技、云从科技、格灵深瞳;
- 3)AIGC 相关技术储备应用厂商。应用厂商有望打开海量市场:
- 相关娱乐、传媒、新闻、游戏、搜索引擎等厂商具备海量文本创作、图片生成、视频生成等需求,随着 AIGC 的逐渐成熟,相关 AI 算法不断成熟完善,并结合相关应用,相关厂商在降本增效的同时,有望提升其创作内容的质量、减少有害性内容传播等问题,实现创意激发,提升内容多样性,AIGC 有望极大推动相关厂商商业化的发展,从而打开海量空间。
- 受益标的:
万兴科技、中文在线、阅文集团、昆仑万维、视觉中国。
- 总结
- 科大讯飞: 自然语言处理的全球龙头厂商。2022 年初正式发布了“讯飞超脑 2030 计划”,其目的是向“全球人工智能产业领导者”的长期愿景迈进。
- 拓尔思: 语义智能领导者,数据要素市场综合服务商。子公司天行网安提供数据安全传输和交换产品及服务
- 汉王科技: 人工智能领域领先者,成立于 1998 年,是人脸识别、大数据、智能交互技术、产品及服务的提供商。e 典笔、汉王电纸书、汉王笔、文本王、名片通、绘图板等
- 云从科技: 人机协同生态体系赋能商。云从科技是一家专注于提供人机操作系统和行业解决方案的人工智能企业
国内外已有多家科技巨头在AIGC领域布局。国内BAT、字节、网易等公司,国外谷歌、Meta、微软等多家公司,均推出了AIGC的应用产品。
- 国内外科技公司在AIGC上的布局
- AIGC公司估值
- 参考:ChatGPT爆火,一年吸金数十亿,一文读懂AIGC赛道风口
【2023-1-31】从ChatGPT说起,AIGC生成模型如何演进
什么样的企业,才是这波浪潮的“宠儿”?
- 首先,无疑是掌握核心前沿技术的行业引领者。全球TOP3的人工智能研究机构,都在各出奇招、争夺AIGC主导地位。
- OpenAI是文字生成领域的领航员。 不光吸引了“生成对抗网络之父”Ian Goodfellow加盟,还早早获得了微软的10亿美元投资。从GPT到GPT3.5,OpenAI不断迭代,也不断带给行业惊喜。这一次的ChatGPT更加获得了微软的认可。而通过开放GPT-3受控API的模式,OpenAI也将赋能更多公司和创业者。
- DeepMind是通用型AI的探路人。2016年,AlphaGo击败人类围棋的最高代表韩国棋手李世石,Go背后正是谷歌旗下的DeepMind。但DeepMind的目标并不是下棋,而是通用型AI,比如能预测蛋白质结构的AlphaFold、能解决复杂数学计算的AlphaTensor等等。但这些AI始终面临着一个瓶颈,即无法像人类一样进行“无中生有”的创作。
- 这两年,DeepMind终于向通用型AI又推近了一步。在对话机器人Sparrow、剧本创作机器人Dramatron等背后的语言大模型中找到灵感,构建了会聊天、会干活、会玩游戏的Gato。
- Meta在加速AI的商业化落地。重组调整AI部门,将其分布式地下放到各实际业务中,而FAIR被并入元宇宙核心部门Reality Labs Research,成为新场景探索者的一员。 Meta首席人工智能科学家Yann LeCun对ChatGPT的评价并不高,他认为从底层技术上看,ChatGPT并不是什么创新性、革命性的发明,除了谷歌和Meta,至少有六家初创公司拥有类似的技术。
- 其次,另一类宠儿,则是押对应用场景的企业们,在“绘画”之外吸纳了不少资本支持与人才投入。
- 在所有内容生成式AI中,输出文字和音乐的已经先一步找到了财富密码。最早出现的AI生成文字在遍历了写新闻稿、写诗、写小剧本等颇受关注的应用方式后,终于在营销场景找到了能够稳定变现的商业模式,成为写作辅助的效率工具,帮助从业者写邮件、文案、甚至策划。专注于音乐的LifeScore,则让人工智能学会了即时编曲,按照场景、长度的需要,组织艺术家同事人工创作、演奏的音乐素材,在人类的创作流程中找到了自己的位置。
- 能够互动的聊天机器人,则在客服和游戏这两个相去甚远的行业分别“打工”。区别于当下只会提供预设问题解答,有时还会答非所问的“智能客服”,真正的AI需要结合用户的行为和上下文来理解人类的真正意图。在游戏领域,AI则被用来协助人类,高效地创造内容丰富、体验良好的游戏内容,从而延长用户的游戏时间。
显然,宠儿是少的。而经历了过去一年多“科技股大回落”后,投资者们也谨慎一些了,当下的AIGC虽然很好,但等大模型出来也许更香。
大模型,也许是企业比拼的护城河
- 模型是人工智能的灵魂,本质上它是一套计算公式和数学模型。“参数”可以看做是模型里的一个个公式,这意味着,参数量越大,模型越复杂,做出来的预测就越准确。
- 小模型就像“偏科的机器”,只学习针对特定应用场景的有限数据,“举一反三”能力不足,一些智能产品被用户调侃为“人工智障”的情况时有发生。
- 大模型就是参数量极大的模型,目前业界主流的AIGC模型都是千亿级、万亿级参数量的水平。通过学习各行各业各类数据,除了能给出相较于小模型更准确的预测结果之外,它也展现出了惊人的泛化能力、迁移能力,产出内容质量更高、更智能,这也是当前AIGC工具让人眼前一亮的原因。
而大模型的快速发展,对行业发展起到了明显的推动作用。例如ChatGPT是基于GPT-3模型进行优化所产生的,引领AI绘画发展的DALL·E 2也离不开GPT-3的贡献。类似的还有Deepmind的Chinchilla、百度的文心大模型等等。
大模型,很大概率是行业淘汰与否的判断要素。
- 首先,训练数据量大,OpenAI为了让GPT-3的表现更接近人类,用了45TB的数据量、近 1 万亿个单词来训练它,大概是1351万本牛津词典。
- 这就带来了两个问题:巨大的算力需求与资金消耗。训练和运行模型都需要庞大的算力,有研究估测,训练 1750 亿参数语言大模型 GPT-3,需要有上万个 CPU/GPU 24 小时不间输入数据,所需能耗相当于开车往返地球和月球,且一次运算就要花费450万美元。
- 国内也不例外。目前国内自研的大模型包括百度的文心大模型、阿里的M6大模型、腾讯的混元大模型,针对中文语境,国内厂商的表现要比国外大厂要好得多。而且国内的大模型发展速度也很惊人。
- 采用稀疏MoE结构的M6大模型,2021年3月仅1000亿参数,3个月后就达到了万亿级,又过了五个月模型参数达到了十万亿级,成为全球最大的AI预训练模型。混元模型也是万亿级别,成本大幅降低,最快用256张卡,1天内就能训练完成。而采用稠密结构(可以粗糙理解是和稀疏相比,密度更大)的文心大模型,2021年,参数规模达到2600亿。2022年,百度又先后发布了数十个大模型,其中有11个行业大模型。
- 这样高的研发门槛,注定目前主流的大模型多由大企业、或是背靠大企业的研究机构掌握,中小企业只能望而却步。因此,大模型,也就成为企业的“护城河”。
- 大模型的研发只是“成功第一步”,还有三个维度的比拼,也非常重要。
- 一是数据资源。 有研究表明,到2026年就没有更多高质量的数据可以训练AI了。此外,基于现实生活中已有的数据来训练模型只能解决一些已知问题,对于一些我们还没有发现的、潜在的、未知的问题,现在的模型未必能解决。因此有一些研究人员提出了合成数据的概念,即通过计算机程序人工合成的数据,一方面补充高质量的训练数据,另一方面填补一些极端或者边缘的案例,增加模型的可靠性。
- 二是绿色发展。 虽然模型越大效果越好,但无限“大”下去并不经济,对自然资源消耗、数据资源都带来巨大压力。而过高的资源消耗,也不利于平民化普及。
- 三是应用场景 。商业和纯理论研究不同,不能拿着技术的锤子,瞎找钉子,而是要结合应用来发展技术。而国内厂商要想拿出Stable Diffusion、ChatGPT这样的杀手级应用,还需要更多的思考和努力:
AIGC为什么火
【2023-2-1】AIGC为什么火?
《腾讯研究院AIGC发展趋势报告》中提到:内容创作模式的四个发展阶段
PGC:专家制作,2000年左右的web 1.0门户网站时代,专业新闻机构发文章UGC:用户创作,2010年左右web 2.0时代(微博、人人之类),以及移动互联网时代(公众号),用户主导创作,专家审核AIUGC:用户主要创作,机器(算法)辅助审核,如在抖音、头条、公众号上发视频、文章,先通过算法预判,再人工复核,在成本与质量中均衡AIGC:AI主导创作,以2022年底先后出现的扩散模型、ChatGPT为代表,创作过程中,几乎不需要人工介入,只需一句话描述需求即可。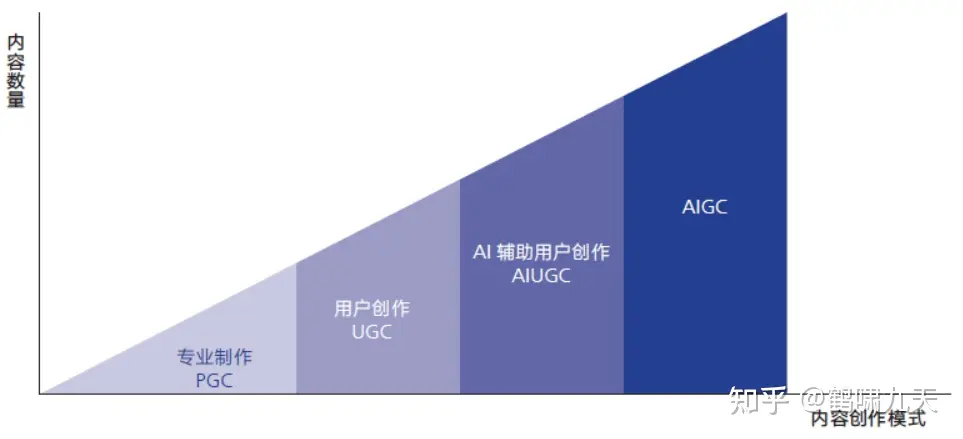
AI自动生成内容的方式实现了AI从感知到生成的跃迁
2022年,gartner将AIGC列为最有影响力的5大技术之一。2022年也被称为AIGC元年.
技术角度上,过去几年生成算法(VAE/GAN)、预训练模型(Transformer/GPT)、多模态技术(CLIP/DALL-E/扩散模型)的不断积累、融合,催生了AIGC的爆发
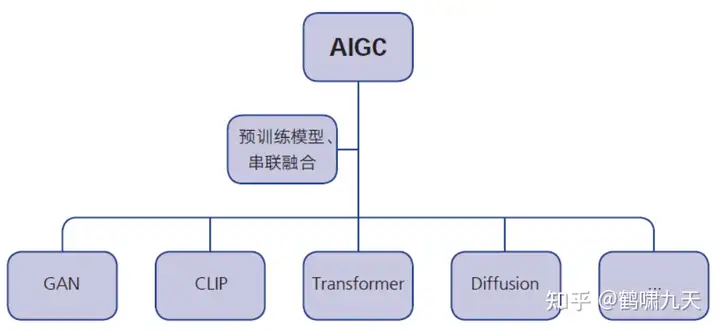
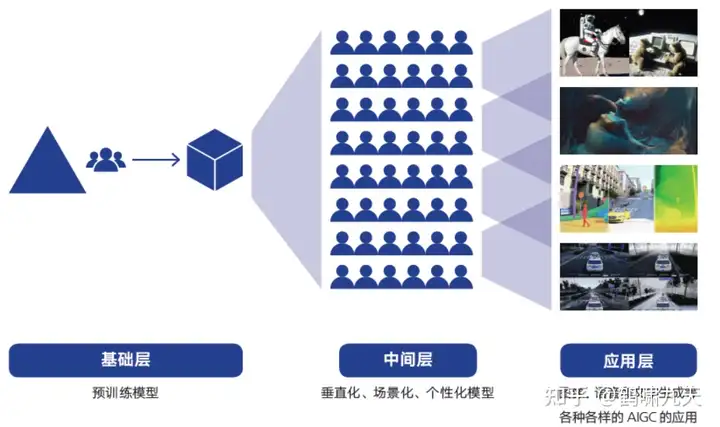
AIGC产业生态逐步成型,分为上中下三层架构。
- 第一层为基础层:就是由预模型 AIGC 技术搭建的基础设施层,目前企业为头部科技企业例如 OPEN AI 和 Stability 等。
- 第二层为中间层:即垂直化、场景化的模型和应用工具,通过使用基础层的模型生成应用程 序,供应用层使用可以在基础层的基础上快速生成场景化、定制化、个性化的模型和程序,例如 Novel-AI;
- 第三层为应用层:即面向 C 端用户文字、图片、音视频等内容生成服务。
知乎作答:为什么生成式 AI 会变得火爆? - 鹤啸九天的回答
AIGC 是如何一步步突破的
【2023-1-31】从ChatGPT说起,AIGC生成模型如何演进
AI懂创作、会画画,可以说是人工智能的一个“跨越式”提升。虽然人工智能在生活中不断普及,比如我们习惯了机器代替人去搬运重物、制造精密的产品、完成复杂的计算等等。但是,如果人工智能更接近人,那就必须具备人类“创作”的能力。这就是AIGC的意义。
AI能力的提升,并不是一蹴而就,而大部分则经历了“模型突破-大幅提升-规模化生产-遇到障碍-再模型突破-大幅提升”的循环发展。而要实现落地、走进人类生活,则必须具备“规模化生产”的能力,在资源消耗、学习门槛等方面大幅降低到平民化。
比如以AI画画为例,则经历了三个关键节点:
- 第一个节点,早期突破:2014年,对抗生成网络(GAN)诞生,真正“教会”AI自己画画。
- GAN包含两个模型,一个是生成网络G、一个是判别网络D。G负责把接收到的随机噪声生成图片,D则要判断这张图是G画的、还是现实世界就存在的。G、D互相博弈,能力也不断提升,而当D不再能判断出G生成的图片时,训练就达到了平衡。
- GAN的开创性在于,精巧地设计了一种“自监督学习”方式,跳出了以往监督学习需要大量标签数据的应用困境,可以广泛应用于图像生成、风格迁移、AI艺术和黑白老照片上色修复。
- 但其缺陷也正来源于这一开创性:由于需要同步训练两个模型,GAN的稳定性较差,容易出现模式崩溃。以及另一个有趣的现象“海奥维提卡现象”(the helvetica scenario):如果G模型发现了一个能够骗过D模型的bug,它就会开始偷懒,一直用这张图片来欺骗D,导致整个平衡的无效。 模型也会躺平,这鸡贼的特性,真是有人的风格。
- 第二个节点,大幅提升:2020年,一篇关于扩散模型(Diffusion Model)的学术论文,大幅提升AI的画画水平。
- 扩散模型的原理是“先增噪后降噪”。首先给现有的图像逐步施加高斯噪声,直到图像被完全破坏,然后再根据给定的高斯噪声,逆向逐步还原出原图。当模型训练完成后,输入一个随机的高斯噪声,便能“无中生有”出一张图像了。
- 这样的设计大大降低了模型训练难度,突破了GAN模型的局限,在逼真的基础上兼具多样性,也就能够更快、更稳定的生成图片。
- 扩散模型在AI业界的“起飞”源于2021年1月,Open AI基于此开发出DALL·E文字生成图片模型,能够生成接近真实生活但并不真实存在的图片,让AI业界震了三震。但由于在像素空间进行了大量计算,这一模型仍存在进程缓慢、内存消耗大的缺陷。
- 第三个节点,批量生产:2022年夏天诞生的Stable Diffusion,让高大上的学术理论变得“接地气”。
- 去年8月,Stability AI将扩散过程放到更低维度的潜空间(Latent Diffusion),从而开发出了Stable Diffusion模型。这个模型带来的提升,在于资源消耗大幅降低,消费级显卡就可以驱动的,可以操作也更为方便,普通人也可以体会到人工智能惊艳的创作能力。而且开发团队还把所有代码、模型和权重参数库都进行了开源,践行了Geek的共享精神、去中心化主义。
- 门槛降低、效果提升,因此,大受欢迎。发布10天后,活跃数据达到了每天1700万张,如果都用A4纸打印出来叠一起,相当于一座52层高的大楼。
- 共享,也是Stability AI的另一特色。在开源社区中,除了更小的内存和更快的速度,Stable Diffusion收获了更完善的指南与教程、共享提示词、新UI,也依靠集体的智慧,走进了Photoshop、Figma等经典软件,汇入创作者们的既有工作流中。可谓是,依靠群众、回馈群众。
从技术实现突破、到技术提升、再到规模化降低门槛,AI创作能力也不断提升。
- 2022年10月,美国一名男子用AI绘画工具Midjourney,生成了一幅名为《太空歌剧院》的作品,并获得了第一名。这引起了一波不小的争论,也终于形成了一条新赛道。
- 2022年以AI绘画为代表的各种生成式AI工具,如雨后春笋般疯狂冒尖,比如盗梦师、意间AI、6pen、novelAI等等。
而在文本AI领域也是如此。如今大火的ChatGPT则是基于GPT3.5模型,已经迭代了4次。而对话一次的平均成本为0.01-0.2美元,也就是六毛到一块钱人民币,成本依然需要不断降低。但整体而言,无论画画、还是聊天,AI已经体现出智慧涌现。
AIGC 技术进展
算力、算法、训练多模型、多模态等 AI 技术融合极大的催生了 AIGC 的爆发。
- 1)
基础算力:人工智能的本质及数据的海量运算,相较于 AI 算法,数据才是重中之重。算力作为数据加速处理的动力源泉,其重要性不言而喻。- 根据机器学习的算法步骤,可分为训练和推断两个环节,训练环节需要极为庞大的数据输入才能支持一个复杂的神经网络模型,训练过程中由于复杂的神经网络结构和海量训练数据,运算量巨大,因此对于处理器的算力、效率(能耗)要求极大。
- 2)
算法模型:Transformer 算法是一种采用自注意力机制的深度学习模型,这一机制可以按照输入数据各部分的重要性的不同而分配不同的权重,现在熟知 ChatGPT 和 AI 作图等都是基于 Transformer 算法建立的;- Transformer 它的结构和人脑里面的整个 neocortex (新皮层)一个 6 层的神经元之间的结构是有一定相似度的。
- 3)
预训练模型:预训练模型引发了 AIGC 技术能力的质变,在该模型问世之前,具有使用门槛高、训练成本低、内容生成简单和质量偏低等问题。- 而在 AIGC 领域,AI 预训练模型,AI 预模型可以实现多任务、多语言、多方式等至关重要的作用,模型比如谷歌的 LaMDA 和 PaLM,Open AI 的 GPT 系列。
- 4)
多模态:极大推升 AIGC 的多样性,预测模型更具备通用性、多样性。例如 Open AI 团队的 CLIP 模型,可以使文字和图像进行关联,比如将文字“狗”与图像进行关联,且关联特征非常丰富。
AIGC技术场景中的内容分支及具体应用
AIGC 的应用生态和内容消费市场逐渐繁荣: AIGC 在学习通用知识和理解泛化上具备更好的表现,在内容生成领域中具备以下特征。
- 1) 自动生成内容:大型语言和图像 AI 模型可用于自动生成内容,例如文章、博客、社交媒体和帖子。
- 2) 提高内容质量:我们认为 AI 生成内容质量较高,原因是人工智能模型可从大量数据中学习,且信息准确,例如 DALL·E 的效果已经接近中等画师的水平。
- 3) 增加内容多样性:AIGC 模型可以生成多种类型的内容,包括文本、图像和音视频、3D 内容等,这些内容可以和专业认识创建更多样化、有趣的内容,有望吸引更广泛的人群。
- 4) 内容制作成本低:基于 AIGC,内容制作的成本显著降低、效率显著提高,且可以创造出有独特价值和独立视角的内容。
- 5) 可实现个性化内容生成:人工智能模型可根据个人用户喜好生成个性化内容,例如 Stable Diffusion 的二次元画风生成工具 Novel-AI,可以满足小众二次元群体的喜好和内容需求。
AIGC 前景广阔,且已经有多种落地场景:比如目前火热的 ChatGPT,ChatGPT 是采用 WEB 浏览器上的对话形式交互,可以满足人类对话的基本功能,能够回答后续问题、承认错误、质疑不正确的请求,我们认为 ChatGPT 的编码能力和 AI 问答系统能力已经大幅提升,并且可以一定程度上替代搜索引擎。
数字人也是 AIGC 的应用场景之一:数字人是数字智能体智能交互的新模式,目前已有诸多应用,包括元宇宙应用的 NPC 虚拟角色、用户虚拟等。
AIGC 大大提升了数字人的制作能效,用户可提供图片、视频,通过 AIGC 生成写实的类型数字人,具有时间短、成本低、可定制特点,同时,3D 数字人建模已经初具产业化。
此外,AIGC 支撑了 AI 驱动数字人多模态交互中的识别感知和分析决策功能,使其更神似人。
AIGC 应用
AIGC 应用领域
详见:甲子光年的《2023AIGC市场研究报告及ChatGPT推动的变革趋势与投资机会》
AI工具
【2023-3-30】AI工具排行榜
AI作画
2022年下半年以来,AI绘画已经成为元宇宙图景中当之无愧的技术热点。只需要输入几个关键词,便能在几十秒内生成一幅精美画作,还能根据用户喜爱的画风调整不同的方案,没有人不为这样极低门槛的创作方式所心动。
- 目前,小红书“AI绘画”相关笔记最高点赞量18.5万,屡屡成为搜索热词;
- 抖音上有关“AI绘画”的短视频最高点赞量甚至接近140万。
不少人惊呼:AI绘画元年已经到来。
而伴随AI绘画的流行,一个崭新的合成词AIGC也出现在各大互联网平台。
【2023-2-2】AI绘画爆火出圈,AIGC迎来野蛮生长时代
- 2022年9月,在美国科罗拉多州的一场艺术博览会上,一幅名为《太空歌剧院》的作品勇夺数字艺术类别冠军,建筑场景的恢弘感,人物刻画的细腻程度,令人为之惊叹。
- 2022年12月8日,全球首幅AIGC画作《未完·待续》拍卖以110万元落槌成交,这幅画作是对民国才女陆小曼未尽稿的续画,通过深度学习陆小曼作品的山水画元素,AI完成了续画、上色、生产诗词等环节。
- 2022年,国内知名摇滚乐队万能青年旅店的作品《杀死那个石家庄人》在B站火出圈了。原因很特别:这首歌的每一句歌词,都被一个名为“Midjourney”的AI生成艺术工具配上了画面。
- 随后周杰伦的知名代表作品《七里香》也都被AI绘画配图,每一帧画面都和歌词完美契合,带给用户视觉听觉上的双重享受。
网易天音依托大量的歌曲曲库,精准分析大众审美,率先于行业部署工业出版级智能编曲系统,能快速生成一首对标人编1-1.5万元左右的出版级编曲,在歌词创作方面省时省力。网易天音成功打造出《醒来》《春启正阳》等多首广受欢迎的 AI 原创歌曲,《春启正阳》将沧桑古老的正阳门故事吟唱出令人惊艳的少年气,在网易云音乐一经上线就收获好评不断。
AIGC动画短片《犬与少年》
- 1月31日,Netflix宣布,其与小冰公司日本分部(rinna)、WIT STUDIO共同创作的首支AIGC动画短片《犬与少年》,已于今日正式公开。这是Netflix动画创作者计划的第一支作品,通过人工智能技术绘制完整动画场景,为动画制作揭开新的未来。
- AIGC目前已成为全球热点,但多数仍停留在技术演示阶段,普遍尚未实现作品级落地。《犬与少年》是AIGC技术辅助商业化动画片的首支发行级别作品。该片讲述了一个小孩与一只机器狗的重逢故事。正编映像已同步在Youtube公开

工业化大批量生产的能力极大地满足用户个性化的需求
- 留校过年的学生用天音给宿管阿姨写歌,表达感谢;
- 小情侣用天音给彼此写歌,创造专属的甜蜜记忆……
内容生产方和用户的利益都得到了满足。
- 东京奥运会期间,基于快手多项人工智能技术,快手云剪启用了一条智能生产的自动化流水线,在比赛热点发生后自动化产出短视频内容,为传播比赛最新赛况提供了视频素材,极大地提高了赛事报道的时效性,为奥运会这一国际顶级体育IP注入短视频、直播时代的科技特质,也探索了内容生产模式的更多可能。
AI作曲、AI编剧、AI续写小说、AI配音、AI虚拟偶像、AI电竞选手, AIGC已经完成了从文字输出到静态画面再到动态影像,对影音制品的全面渗透,各种日新月异的新技术正在改变着文娱行业。
视频生成
见站内:text2video
智能办公
AI帮做PPT、制表格、写代码,掀起打工人效率革命
继微软发布全家桶后,包括阿里、百度、字节跳动、WPS、谷歌等在内的玩家公开了协同办公平台接入大模型的情况
- 4月11日,钉钉接入阿里
通义千问大模型,用户输入一个“/”就能调动10余种高能AI能力,包括自动生成群聊摘要、辅助内容创作、总结会议纪要、草图变小程序等,为2300万企业提供智能转型抓手; - 4月11日,字节跳动旗下办公软件
飞书发布视频,预告了其专属智能助手“My AI”,而另一协同办公龙头企业微信则暂无动静。 - 4月17日,百度官微宣布文心一言大模型在百度内部全面应用在智能工作平台“如流”上,助员工在日常工作中的思路构建、协作沟通、方案策划、代码编写等方面提升效率;
- 4月17日,金山办公正式推出具备大语言模型能力的生成式AI应用“WPS AI”,包括文本生成、多轮对话、润色改写等功能,计划嵌入金山办公全线产品。
- 5月5日,谷歌才透露动向,宣布将其Bard AI工具提供给拥有谷歌Wordspace账户的用户,现已开放Workspace账户的访问权限
“小而美”的AI办公工具,10美元/月体验文本“美颜”“AI+办公”不仅是大厂的游戏,也是众多中小办公软件公司的机会。
- 文档协同软件公司
Notion、知名写作辅助工具Grammarly、热门文档编辑工具ChatPDF、知名PDF服务商福昕软件都推出了大模型应用产品,从更具体的切入点帮人们提高效率。 - 早在2月底,Notion就推出了基于ChatGPT的企服工具
Notion AI,每个用户每月只需支付10美元,就可以让AI辅助总结会议记录、修改优化内容、生成表格清单、起草电子邮件等。Notion官方公告称,内测发现用到AI生成稿件的用户相对较少,AI改善写作功能被调用地更多,就像是美图领域的一键美颜一样。
AI协同办公平台成为云大厂“大乱斗”的第一战场。不过这些应用大多仍面向特定用户开放测试,因此广大用户要真正体验,还要再等一段时间。
Office全家桶:Microsoft 365 Copilot
【2023-3-23】微软Copilot彻底改变工作方式,AI时代的打工人如何生存?
3月16日,微软正式将GPT-4接入到Office工具,让Word、PPT、Excel、Outlook等人们常见的办公软件全都接入AI,打响了大模型解放“打工人”的第一枪。
- Word中,AI能秒出草稿,并根据用户要求增删文字信息和配图;
- PowerPoint中,AI能快速将文字转换成专业水准的PPT;
- Excel中,AI将数据分析变得轻松高效,能快速提炼出关键趋势;
- Outlook中,AI能给邮件分类加精,并自动撰写回复内容;
- 协同办公时,AI能总结规划成员的工作进展、调取分析数据、做SWOT分析、整理会议核心信息。
微软又出重拳,宣布推出Microsoft 365 Copilot
- Copilot由OpenAI的
GPT-4驱动,嵌入到Microsoft 365应用程序中,就像一个助手,作为一个聊天机器人出现在侧边栏(原本Clippy的位置)。 - 用户可以通过Copilot,直接使用自然语言提出要求,来指挥Microsoft Teams、Word、Excel、PowerPoint、Outlook、OneDrive等应用程序。
微软全球副总裁Jared Spataro
- “Copilot是一种全新的工作方式。”
- “百年后我们将回望这一时刻并感叹:’那是真正的数字时代的开始。’”
微软董事长&CEO Satya Nadella
- “今天标志着我们在与计算的互动方式的演变中迈出了重要的一步,这将从根本上改变我们的工作方式,并释放新一轮的生产力增长。”
过去耗费了太多的时间和精力在大量机械性和重复性的工作中,而Copilot带来的全新工作方式,可以减轻工作负担,提高生产力。
每一次技术的进步,带来机遇的同时,也充满了挑战。
- 人工智能在长期来看,可能会创造一些新的工作岗位,在短期内能够提高工作满意度,但预计也会改变很多工作的性质。
- 有了人工智能的协助,员工的生产力和效率大大提升,以前需要两名或更多员工的工作,现在可能一名员工+人工智能就能完成,多余的劳动力就会失去工作机会。
- 从企业成本的角度考虑,如果使用人工智能的成本低于劳动力的报酬,企业会更倾向于使用人工智能来替代劳动力的岗位。
因此,与人工智能功能重合,附加值不高的工作岗位极易被替代。
Copilot能做什么?
Word
- Copilot可以根据用户给出的提示,撰写、编辑文档。也可以调用其他应用中的素材,如OneNote,根据素材,生成整个文档。
- 在Word文档中,当用户highlight整个段落时,Copilot就会出现(就像Word提示拼写错误一样),提出一些建议,用户可以浏览或编辑这些建议,从中挑选以用于修改或重写段落。
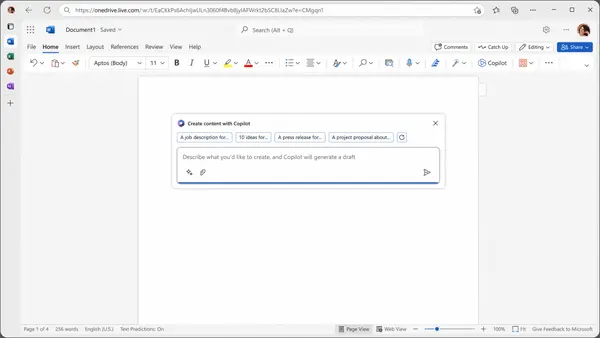
Powerpoint
- 同样,用户只要说出想法,Copilot就可以做出一个完整的PPT。也可以根据已有的Word文档,自动生成PPT。
- 如果用户想要调整PPT的内容、排版、配色等,只需要向Copilot发出指令,而不必去研究PowerPoint的具体功能。

Excel
- Copilot可以直接根据Word内容生成一个图表,用户无需编写公式,只通过语言提示即可填充和搜索数据。
- Copilot还可以即时创建基于数据的SWOT分析或数据透视表,找到数据的相关性,协助分析数据,得出趋势结论,从而帮助用户更好地理解数据。
- Excel甚至为Copilot提供了一个 “show me”的功能,让这个人工智能教你它是如何完成一个命令的,从而提高你对Office应用的理解。

Outlook
- Copilot可以协助用户整理邮件,汇总邮件内容,提取重要的相关信息。也可以根据用户的简单表述,撰写邮件。Copilot甚至为用户提供内容长短不同、语气风格不同的多种邮件草稿选项。
Chat
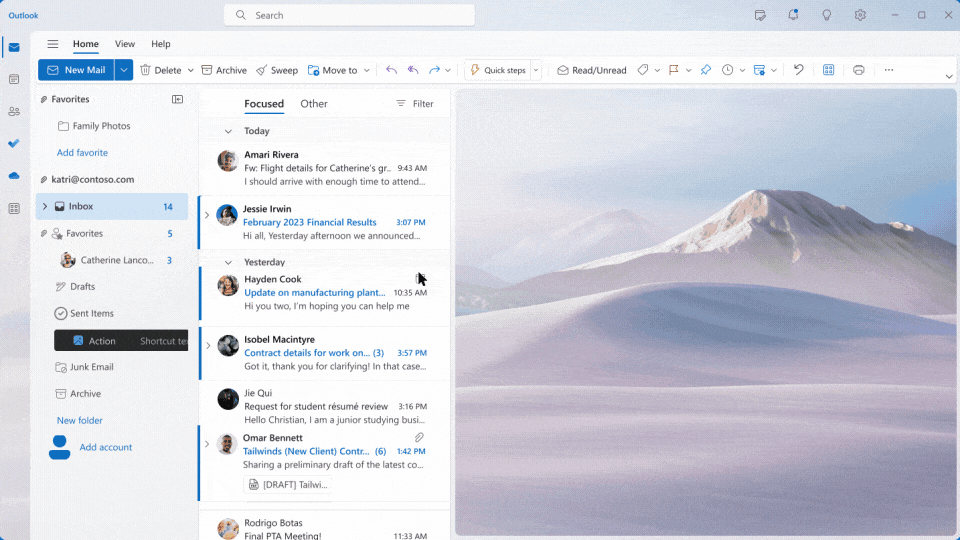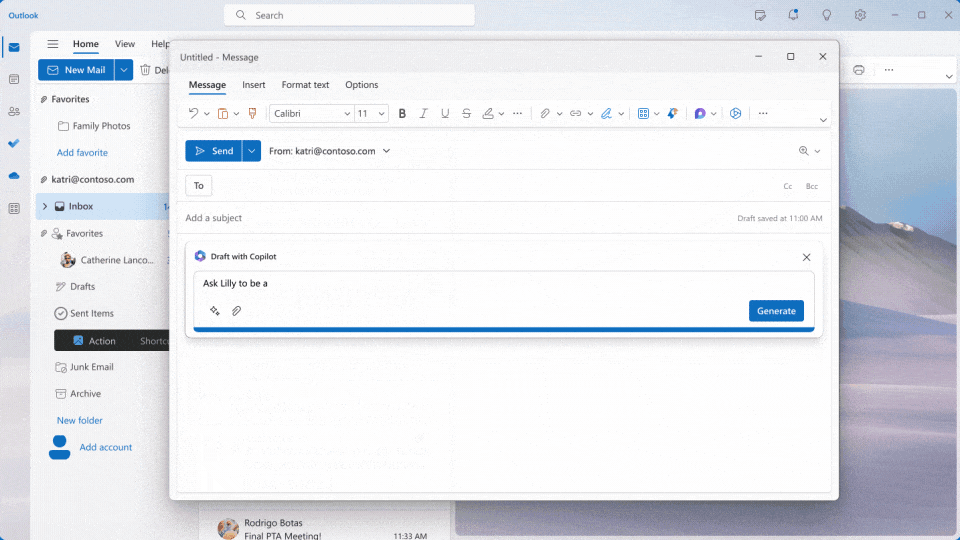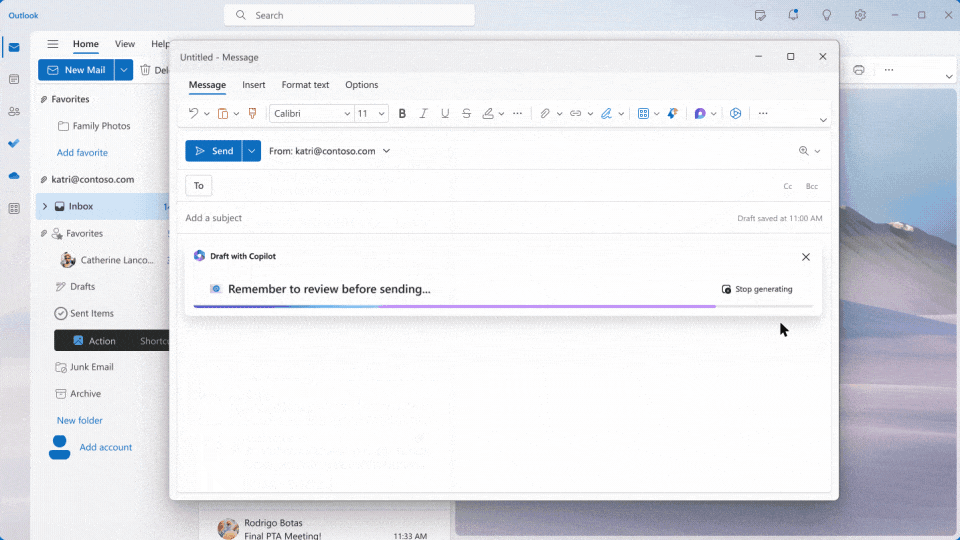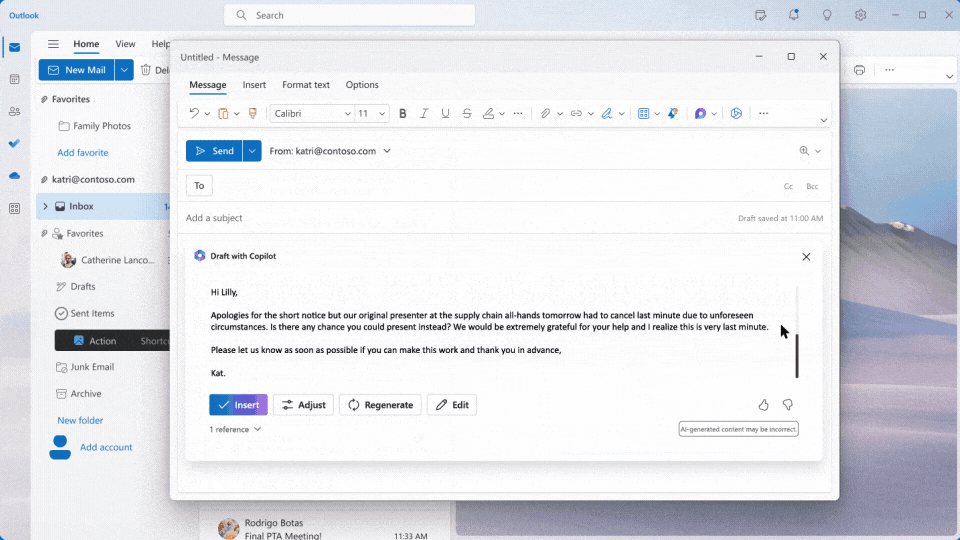
- 除了常见的Office软件外,微软还将Copilot嵌入了一款全新的应用:Business Chat。
- Business Chat通过Microsoft Graph将Word、PPT、Outlook、日历、备忘录、联系人等程序中的数据汇集到Teams的聊天界面中,可以生成摘要、计划概述等。
另外,Copilot还在Teams里记录会议内容,总结要点,制定计划。未来,Copilot还将应用于更多的Microsoft 365程序,如OneNote、Microsoft Viva和Power Platform等。
Cursor
一款免费,集成 GPT-4 的代码生成器 Cursor
功能强悍:
- (1)代码生成:按照指令生成10-100行代码
- (2)代码聊天:选定部分代码,针对性聊天,检查代码Bug,执行代码等
- (3)代码比对:提示哪里有变动,并突出显示
- (4)代码完善:修复不符合lint代码规范的片段,生成测试用例、注释等
- (5)当然,还能聊别的,你猜?
飞书全家桶
【2023-3-30】 feishu-chatgpt 飞书 ×(GPT-3.5 + DALL·E + Whisper)= 飞一般的工作体验 🚀
- 语音对话、角色扮演、多话题讨论、图片创作、表格分析、文档导出 🚀
【2023-11-28】一分钟了解飞书的AI能力
- 智能翻译:支持上百种语言翻译成16种语言;字幕实时翻译、IM翻译辅助、图片翻译、术语翻译
- 飞书妙记:精准转写、关键词提取、智能分段、说话人分段;面试助手、简历增强、音频记录
- 知识推荐:知识识别、串联、聚合推送、知识发现
- 合同版本对比、提示
火山写作
【2023-5-10】火山写作,集成翻译、纠错。。。让英语写作更简单
GrammarlyGo
知名写作辅助工具Grammarly上个月推出了一款名为GrammarlyGo的生成式AI工具。
- 用户每月可以免费获得100次提示,每月支付30美元或年支付144美元,可以获得每日500次提示服务。
- GrammarlyGo回复电子邮件的功能备受好评:它可以扫描一封电子邮件内容,对其进行总结并根据选定的语气起早回复,包括“有说服力的”、“友好的”、“外交的”等多种语气可供作者选择。但有用户反映它仍是一个需要改编的模板内容,结尾总是以“最诚挚的问候”结束,使得体验打折扣。

IntelliMail
IntelliMail 生成你的电子邮件的 Chrome 扩展
ppt 动画生成
【2023-10-22】ChatPPT🥳动画关怀.pptx
无需思考逻辑,一切放心交给chatgpt,0门槛实现动画演示,突出关键信息
其它
AIGC 技术与伦理的博弈
专业绘画人士的感慨也道出了当下内容创作者的深深忧虑。
- “学了五六年美术,画功不如AI输入词条几十秒就出的画”。
- 依托精密的算法体系,发展迅猛的AIGC展示出了较低的创作门槛和较高的工作频率,假以时日,其流量号召力不容小觑。这对于需要和其同台竞技的内容创作者而言,冲击是巨大的。
- 当AI技术被引入写作领域,受到冲击的主要是文字工作者。而当AI技术被引入影音领域,波及到的内容创作者则显然更为多元。导演、策划、编剧、字幕、配音,整个影视创作链条上的工种或多或少都会受到影响。
- 在创意无限、产出高频的AIGC面前,不少专业内容创作者第一次意识到了什么叫“降维打击”,这种“降维打击”的程度甚至远远超过了人与人之间的内卷。 除了专业的内容创作者,短视频平台所依靠的海量自发上传用户,在内容输出的频率上也难以与AIGC进行抗衡。
不过这并不意味着AIGC的发展将一帆风顺。AIGC的高歌猛进中,充斥着许多技术伦理的问题。
- AI生成模型应用的门槛较低,从某种程度上而言,这无疑是一把双刃剑,它既有可能提高创作频率,但又有可能被滥用、误用,比如被用于抄袭、恶搞等,近年来女明星被AI换脸的负面新闻已经屡见不鲜。
- AI生成内容是否受版权保护也存在争议,一方面AI创作内容随机性较强,且由算法进行主导。这种缺少思想的表达尚无法满足当下版权法中所要求的独创性。而且AIGC自身所依靠的深度学习模型训练中的大型数据,本身也有可能包含受版权保护的作品。
- 目前海内外关于AIGC的法律监管,依然存在着一定的滞后性。当技术伦理的达摩克利斯之剑始终高悬,《银翼杀手》中所描绘的智能机器人时代距离我们便依然遥远。
- 人文艺术领域,不管是文字创作还是影音创作,都蕴藏着诸多情感和文学性,思想性内核,而这些显然是无法由算法所决定的。当AI技术被引入写作,市场曾一度悲观,认为文字工作者或将被取代,而现在看来这种担心完全是多余的。也有不少内容创作者坚持AI将无法与人工相抗衡。一个最简单的例子,在大量的电影二创剪辑视频中,富有情感起伏的人工配音解说总是要比毫无波澜、机械的AI配音解说的转发量高出许多。
内容创作者究竟该怎样与AIGC相处?是抵制还是与之和平共处?我们目前还无法给出正确的答案。技术革新倒逼市场迎来新的无序生长阶段,让子弹先飞一会儿或许是最佳的方式。而对于现阶段的内容创作者而言,所能做到的就是放下担忧,尽可能提升创作品质,筑牢内容的护城河。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
