NL2SQL
NL2SQL(Natural Language to SQL)是一项将用户的自然语句转为可执行 SQL 语句的技术,有很大的实际应用价值,对改善用户与数据库之间的交互方式有很大意义。
- NL2SQL问答不是基于问答对或者知识图谱知识库,它是基于结构化数据表进行智能问答,实现自然语言转SQL查询的功能
- 经典的NL2SQL方案中,基于Seq2Seq的X-SQL模型是十分常见的,该模型的思路是先通过 MT-DNN 对原始问题及字段名称进行编码,再在问题前面人为地添加一个 [CXT] 用于提取全局信息。

- 【2021-3-15】详见:百分点认知智能实验室:智能对话技术应用和实践
【2025-6-14】25年大模型应用方向:Text2SQL
介绍
Text2SQL 是一门将用户输入文本自动转换成SQL查询语言的技术
具体过程:
- 用户通过自然语言表达BI查询需求
- Text2SQL系统将需求转换成可执行的SQL语句
- 再由SQL引擎执行获取数据
- 最终通过可视化界面呈现给用户
学术上,Text2SQL 被称为 NL2SQL
NL2SQL 把自然语言“翻译”成机器能理解的SQL语句,在人机交互中有巨大的价值,解决了从中文人类语言到SQL这种计算机语言的转化问题,那些和你对话的AI系统们,就会变得更“聪明”,更容易理解你的问题并找到答案,App里的智能客服、家里的智能音箱们一问三不知的情况也会少很多。
在 CUI(Conversation User Interface)的大背景下,如何通过自然语言自由地查询数据库中的目标数据成为了新兴的研究热点。
肖仰华教授说,现在阻碍大数据价值变现的最大难题就是访问数据门槛太高,依赖数据库管理员写复杂的SQL,而且考虑到中文的表述更加多样,中文NL2SQL要比英文难很多。
NL2SQL 任务的本质是将用户的自然语言语句转化为计算机可以理解并执行的规范语义表示 (formal meaning representation),是语义分析 (Semantic Parsing) 领域的一个子任务。NL2SQL 是由自然语言生成 SQL,那么自然也有 NL2Bash、NL2Python、NL2Java 等类似的研究。
NL2Bash Dataset 一条数据:
# NL:
Search for the string ‘git’ in all the files under current directory tree without traversing into ‘.git’ folder and excluding files that have ‘git’ in their names.
# Bash:
find . -not -name ".git" -not -path "*.git*" -not –name "*git*" | xargs -I {} grep git {}
示例
示例:
- 用户可能会想知道「宝马的车总共卖了多少辆?」
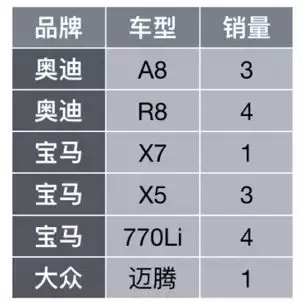
- 表格数据是信息在经过人为整理、归纳后的一种高效的结构化表达形式,信息的价值、密度和质量高于普通的文字文本。
- 其相应的 SQL 表达式是
- SELECT SUM(销量) FROM TABLE WHERE 品牌==’宝马‘
- NL2SQL结合用户想要查询的表格,将用户的问句转化为相应的 SQL 语句,从而得到答案「8」。
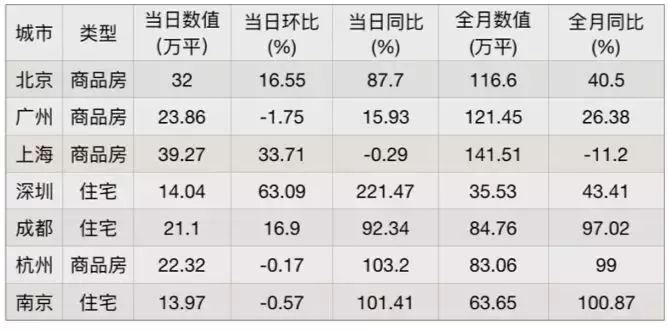
示例:
- 用户问:「哪些城市的全月销量同比超过了 50% 或者当日环比大于 25%?相应的房产类型和销售面积情况如何?」
- 表格
- SQL 语句
- select 城市, 类型, 全月数值 (万平) from table where 全月同比 (%) > 50 or 当日环比 (%) > 25
示例
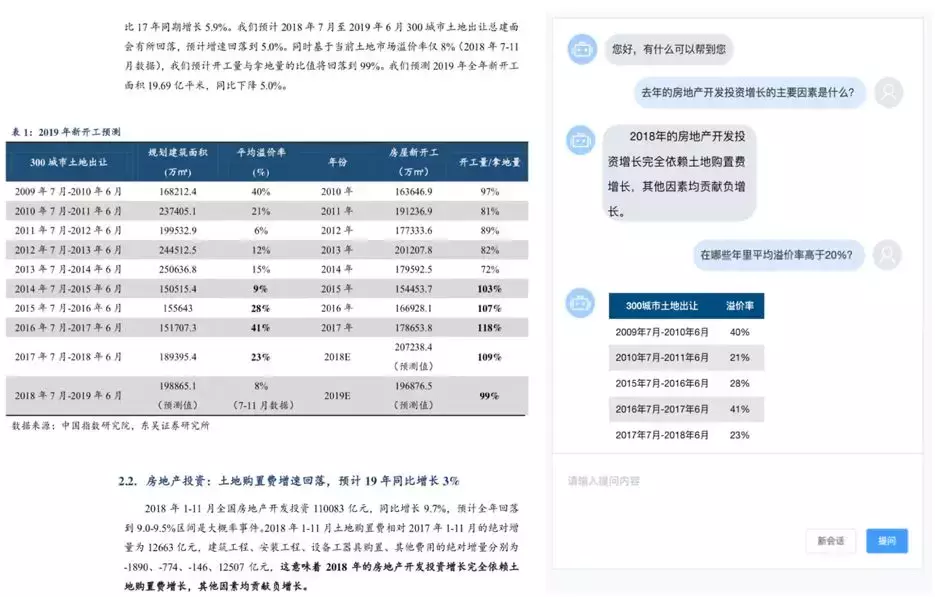
- 用户如果想问「在哪些年里平均溢价率高于 20%」这样的问题,依靠现有的机器阅读理解技术,在文本中是找不到答案的。而 NL2SQL 可以很好地弥补现有技术的不足,完善非结构化文本问答在真实落地场景中的应用,更充分地发掘此类结构化数据的价值。
广义来说,KBQA 也与 NL2SQL 技术有着千丝万缕的联系,其背后的做法也是将用户的自然语言转化为逻辑形式,只不过不同点在于前者转化的逻辑形式是 SPARQL,而不是 SQL。将生成的查询语句在知识图谱执行,直接得到用户的答案,进而提升算法引擎的用户体验。
-
- 人工智能时代如何高效发掘数据库的价值?NL2SQL值得你关注
- 【2019-10-14】中文自动转SQL刷新纪录,Kaggle大师带队拿下NL2SQL挑战赛冠军: 在追一科技主办的首届中文NL2SQL挑战赛上,又一项超越国外水平的NLP研究成果诞生了。在NL2SQL这项任务上,比赛中的最佳成绩达到了92.19%的准确率,超过英文NL2SQL数据集WikiSQL目前完全匹配精度86.0%,执行匹配精度91.8%的最高成绩。
资料
FinSQL 金融领域 Text2SQL 训练框架,包含提示构造、peft和输出校准
【2024-5-29】DB-GPT:蚂蚁开源的Text-to-SQL利器
- 代码 DB-GPT
DB-GPT 主要模块包括:
SMMF(服务化多模型管理框架):DB-GPT 的核心模块之一,SMMF 负责管理和调用各种大语言模型,它提供统一的接口,屏蔽了不同模型之间的差异,方便开发者灵活地选择和切换模型。Retrieval(检索):检索模块负责从知识库中检索相关信息。DB-GPT 的检索模块支持多知识库检索增强,可以同时检索多个知识库,并对检索结果进行排序和筛选,提高检索效率和准确性。Agents(智能体):Agents 模块是 DB-GPT 的智能化核心。DB-GPT 提供了数据驱动的 Multi-Agents 框架,开发者可以创建多个 Agents,并为每个 Agent 分配不同的角色和任务。Agents 可以互相协作,共同完成复杂的任务。Fine-tuning(微调):微调模块负责对大语言模型进行微调,使其更适应特定领域的任务。DB-GPT 提供了自动化微调框架,支持多种微调方法,并提供评估指标,帮助开发者找到最佳的微调方案。Connections(连接):连接模块负责连接各种数据源,包括数据库、数据仓库、Excel 等。DB-GPT 提供了统一的数据连接接口,方便开发者访问和处理不同类型的数据。Observability(可观测性):可观测性模块提供 DB-GPT 运行时的监控和日志信息,方便开发者了解 DB-GPT 的运行状态,及时发现和解决问题。Evaluation(评估):评估模块提供工具和指标,用于评估 DB-GPT 的性能和准确性。开发者可以使用评估模块对不同模型、不同参数配置进行比较,找到最佳的方案。
AWEL (Agentic Workflow Expression Language) 是 DB-GPT 中专门用于编排智能体工作流程的语言。它提供了一种简洁、灵活的方式来定义 Agents 之间的交互、数据流动以及任务执行顺序。
参考
任务
NL2SQL 任务目标: 将用户对某个数据库的自然语言问题转化为相应的SQL查询。
随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。
- 如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
现状:大语言模型虽然在不断的迭代过程中越来越强大,但类似商业智能企业级应用要远比分析一个 Excel 文件、总结一个 PDF 文件的问题要复杂的多:
- 数据结构复杂:企业信息系统的数据结构复杂性远远超过几个简单的 Excel 文件,一个大型企业应用可能存在几百上千个数据实体,所以在实际应用中,大型 BI 系统会在前端经过汇聚、简化与抽象成新的语义层,方便理解。
- 数据量较大:分析类应用以海量历史数据为主,即使一些数据在分析之前会经过多级汇总处理。这决定了无法在企业应用中把数据简单的脱机成文件进行分析处理。
- 分析需求复杂:企业应用的数据分析需求涵盖及时查询、到各个维度的报表与指标展现、数据的上下钻、潜在信息的挖掘等,很多需求有较复杂的后端处理逻辑。
这些特点决定了当前大语言模型在企业数据分析中的应用无法完全取代目前所有/部分的分析工具。
其合适的定位或许是:作为现有数据分析手段的一种有效补充,在部分需求场景下,给经营决策人员提供一种更易于使用与交互的分析工具。
范式
研究范式
- Supervised Fine-Tuning-Based Text2SQL(文本到SQL的监督微调):早期研究集中在用编码器-解码器神经网络模型,并通过
GRNN(图关系神经网络)增强编码器的表示能力,以及将SQL语法注入解码器以确保生成语法正确的SQL查询 - Prompting-Based Text2SQL(基于提示的文本到SQL方法):随着LLMs的出现,研究者开始探索使用少量文本到SQL示例作为提示,以实现无需微调参数的SOTA性能
【2025-6-14】25年大模型应用方向:Text2SQL
步骤
Text转换成SQL语句,往往分为两个步骤
- (1) Schema Linking:从原始DB schema中过滤出合适的信息(表、列等)供SQL生成使用,以降低Prompt的长度和处理难度
- 原因:数据库中表格和列的数量往往非常多;如果全部都采用,对生成步骤难度过大,而且往往也会超过Prompt最大长度
- 目标1:多个论文都提出独特的裁剪方法,以保证Question相关的表和列都可完整保留
- 目标2:为了推导SQL生成,哪些meta-data应该保留
- 目标3:尽量不改变原始的schema,采用原始表结构等
- (2) SQL Generation:让大模型利用复杂的推理能力生成正确的SQL
- SFT-Based:如何SFT出领域专属的小模型,达到或者超过大模型的效果,又如何迁移到新的领域
- Prompt-Based:怎么构建合适的Prompt,引导LLM输出正确的SQL
Schema Linking
Schema Linking:选择最合适的表和列
模式链接在文本到SQL过程中起着关键作用,旨在识别自然语言问题中引用的数据库模式(如表和列)以及数据库值
基于Prompt的多代理协作
基于LLMs的Text2SQL方法在处理“巨大数据库”和需要多步推理的复杂用户问题时性能会显著下降
为了应对这些挑战,MAC-SQL框架通过以下几个关键组件来提高Text2SQL解析的有效性:
- 分解器代理:负责将复杂的文本问题分解为更简单的子问题,并通过少量的COT推理来逐步解决这些问题
- 选择器代理:将大型数据库分解为更小的子数据库,减少无关信息的干扰,防止Prompt超上下文
- 细化器代理:使用外部工具执行SQL查询,获取反馈,并迭代修正错误的SQL查询
SQL Generation
- SFT-Based
- Prompt-Based
分类
大模型应用大概分为四类:
| 分类 | 典型产品/形态 | 特点 |
|---|---|---|
| Text2Text | ChatGPT 等文本生成模型 | 侧重内容创作和问答,输出范围宽泛 |
| Text2Code | Cursor、Tabnine、Trae 等代码助手 | 生成开放式代码片段,灵活度高但约束弱 |
| Text2SQL | 各类自然语言查询 BI / 数据助手 | 生成受限于 SQL 语法与库结构的查询 |
| Text2API/Tool | 各类 Agent 系统 | 通过自然语言调用外部 API / 工具完成任务 |
局限
- Text2Text:输出维度过于宽泛,难以在高可靠的商业场景中形成可量化收益,更多用于知识问答这类轻量级应用
- Text2Code:
- 结果为“开放集”,变量命名、风格多样,难以统一约束
- 业务价值难衡量:几行—几十行代码往往不是项目瓶颈,ROI 不易评估
- Text2API / Tool
- 需要手工梳理并维护 API 调用规范,前期集成成本高
- 逻辑大多复用既有系统,LLM 仅“包了一层壳”,增量价值有限
- 对权限、安全、容错要求高,落地门槛显著
【2025-6-14】25年大模型应用方向:Text2SQL
难点
【2026-4-29】NL2SQL 五大难点:
- 自然语言歧义大、口语化严重
- 表名字段名与自然语言语义不匹配
- 多表 JOIN 关系难以自动推断
- SQL 语法严谨,复杂逻辑极易生成错误
- 大规模 Schema、领域专有名词、小样本难落地
落地工程难点(最影响体验)
- 超大规模 Schema 难以处理
- 上百张表、上千字段 → 模型无法全部输入
- 必须做字段检索 + 过滤,但检索错了就全错
- 领域专有名词无法泛化
- 金融、电商、医疗、政务术语各不相同
- 通用大模型容易 “理解偏差”
- 零样本 / 小样本表现差
- 企业里没有那么多标注数据
- 小领域泛化能力不足
- 可解释性差、不可控
- 模型为什么生成错 SQL?不知道
- 无法做规则修正 → 企业不敢用
- 隐私与安全风险
- 生成恶意 SQL
- 越权查询、数据泄露
效果评估难点(业界至今没完美方案)
- 语法正确 ≠ 语义正确
- 结果正确 ≠ 生成的 SQL 最优
- 没有统一的自动评估指标
- EX 准确率(执行结果匹配)
- CX 准确率(组件匹配)
- 都有缺陷
应用
应用场景包括:
- 及时数据查询。提供对运营或统计数据的简单自定义查询,当然你只需要使用自然语言。
- 传统 BI 工具能力的升级。很多传统 BI 工具会定义一个抽象的语义层,其本身的意义之一就是为了让数据分析对业务人员更友好。而大模型天然具有强大的语义理解能力,因此将传统 BI 中的一些功能进化到基于自然语言的交互式分析,是非常水到渠成的。
- 简单的数据挖掘与洞察。在某些场景下的交互式数据挖掘与洞察,可以利用大语言模型的 Code 生成能力与算法实现对数据隐藏模式的发现。
工业界,Text2SQL 相关产品还处于探索期,远远未达到成熟期,例如
- 网易推出了ChatBI的产品
- 快手提出kwaiBI系统等。
未能在工业界产出新的生产力,改变BI的行业游戏规则
开源产品 Chat2DB 、supersonic 等可支持快速构建Demo,验证产品原型
数据集
text2sql 常用数据集与方法
中文 text-to-SQL数据集:
- CSpider (Min et al., 2019a)
- TableQA (Sun et al., 2020)
- DuSQL (Wang et al., 2020c)
- ESQL (Chen et al., 2021a)
- Chase https://xjtu-intsoft.github.io/chase/
NL2SQL 方向已经有 WikiSQL、Spider、WikiTableQuestions、ATIS 等诸多公开数据集。不同数据集都有各自的特点,这里简单介绍一下这四个数据集。
- (1) WikiSQL 是 Salesforce 在 2017 年提出的大型标注 NL2SQL 数据集,也是目前规模最大的 NL2SQL 数据集。它包含了 24,241 张表、80,645 条自然语言问句及相应的 SQL 语句。下图是其中的一条数据样例,包括一个 table、一条 SQL 语句及该条 SQL 语句所对应的自然语言语句。已经有 18 次公开提交。由于 SQL 的形式较为简单,该数据集不涉及高级用法,Question 所对应的正确表格已经给定,不需要联合多张表格,这些简化使得强监督模型已经可以在 WikiSQL 上达到执行 91.8% 的执行准确率。
- (2) Spider 是耶鲁大学 2018 年新提出的一个较大规模的 NL2SQL 数据集。该数据集包含了 10,181 条自然语言问句、分布在 200 个独立数据库中的 5,693 条 SQL,内容覆盖了 138 个不同的领域。虽然在数据数量上不如 WikiSQL,但 Spider 引入了更多的 SQL 用法,例如 Group By、Order By、Having,甚至需要 Join 不同表,这更贴近真实场景,也带来了更高的难度。因此目前在该榜单上只有 8 次提交,在不考虑条件判断中 value 的情况下,准确率最高只有 54.7,可见这个数据集的难度非常大。
- (3) WikiTableQuestions 是斯坦福大学于 2015 年提出的一个针对维基百科中那些半结构化表格问答的数据集,包含了 22,033 条真实问句以及 2,108 张表格。由于数据的来源是维基百科,因此表格中的数据是真实且没有经过归一化的,一个 cell 内可能包含多个实体或含义,比如「Beijing, China」或「200 km」;同时,为了很好地泛化到其它领域的数据,该数据集测试集中的表格主题和实体之间的关系都是在训练集中没有见到过的。下图是该数据集中的一条示例,数据阐述的方式展现出作者想要体现的问答元素。
- (4) The Air Travel Information System (ATIS) 是一个年代较为久远的经典数据集,由德克萨斯仪器公司在 1990 年提出。该数据集获取自关系型数据库 Official Airline Guide (OAG, 1990),包含 27 张表以及不到 2,000 次的问询,每次问询平均 7 轮,93% 的情况下需要联合 3 张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。下图是取自该数据集的一条样例,可以看出比之前介绍的数据集更有难度。

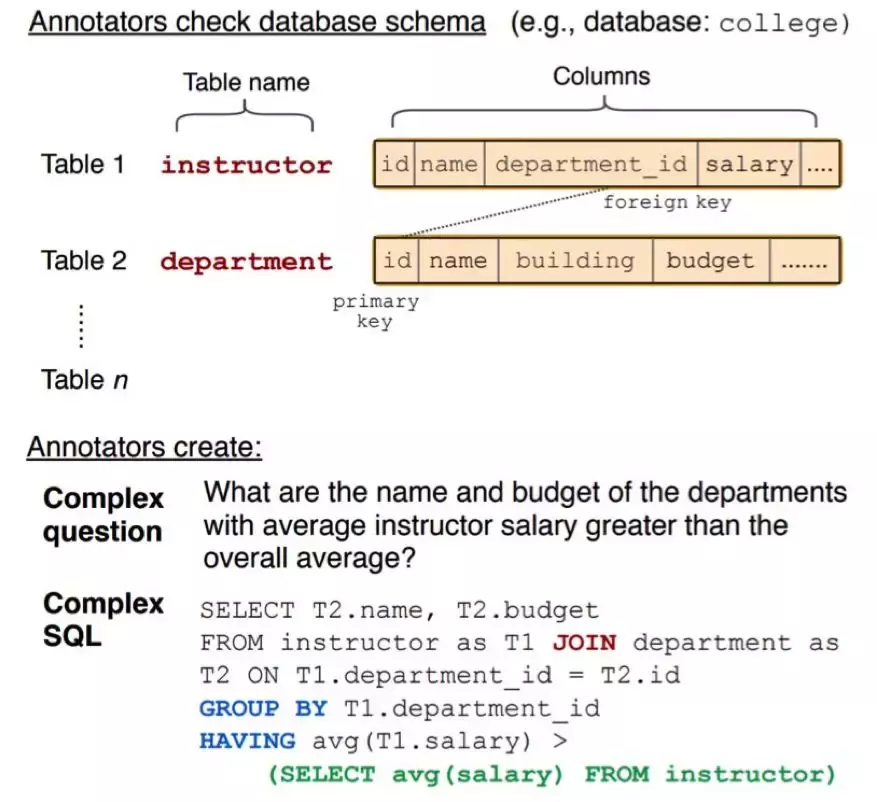
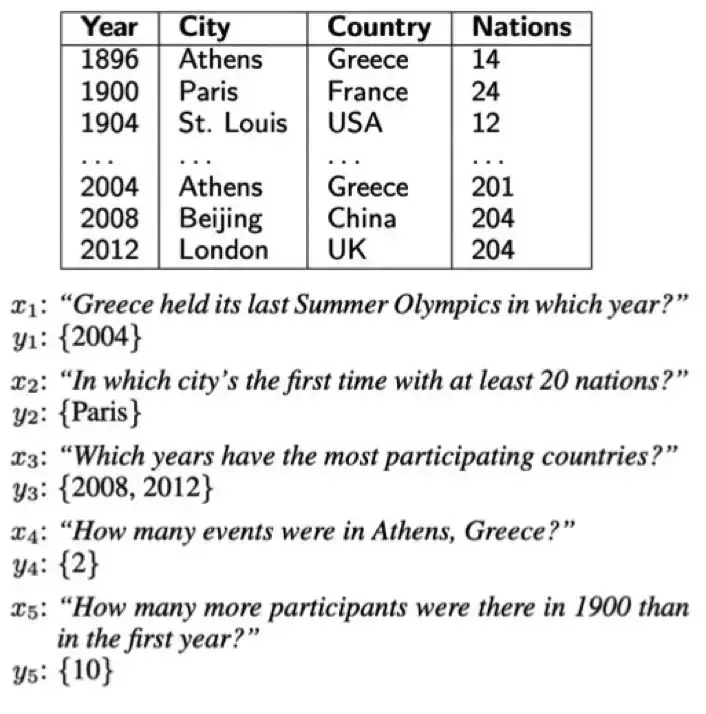

技术方案
具体做法
- 在深度学习端到端解决方案流行之前,这一领域的解决方案主要是通过高质量的语法树和词典来构建语义解析器,再将自然语言语句转化为相应的 SQL。
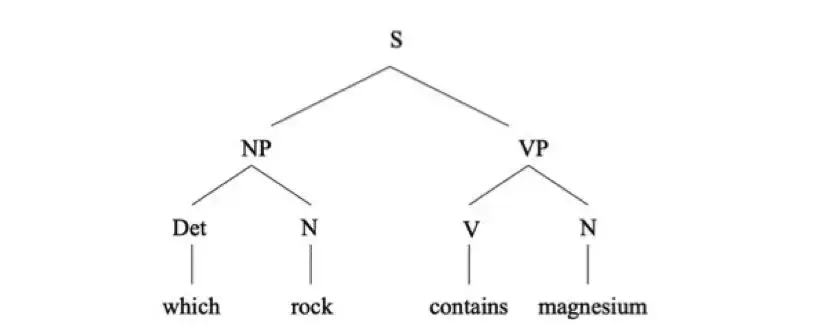
kaggle比赛
中文自动转SQL刷新纪录, 追一科技主办的首届中文NL2SQL挑战赛上,又一项超越国外水平的NLP研究成果诞生了。在NL2SQL这项任务上,比赛中的最佳成绩达到了92.19%的准确率,超过英文NL2SQL数据集WikiSQL目前完全匹配精度86.0%,执行匹配精度91.8%的最高成绩。
- WikiSQL排行榜上的第一名、来自微软Dynamics 365团队的X-SQL有一些问题,模型框架不完全适配,在value抽取上colume特征不显著,容易抽取混乱。针对这些问题,冠军团队提出了M-SQL,将原本X-SQL的6个子任务改为8个子任务,并且增加三个子模型,S-num、Value抽取、Value匹配,一次性将query中含有的所有Value抽取出来,并对value和数据库表字段的隶属关系进行判断。之后进行了一些细节提升,比如在数据预处理方面,将数据、年份、单位、日期、同义词进行修正,统一query的范式;在query信息表达方面,用XLS标记替换CLS标记,这样在线下验证集上准确率提高了0.3个百分点。用到的预训练模型,则是哈工大发布的BERT-wwm-ext模型。
- 冠军团队方案
- 参考资料:天池比赛, WikiSQL
基础方案
三种基础技术方案介绍
- 自然语言转数据分析的 API,
text2API- 类似现有的一些 BI 工具会基于自己的语义层开放出独立的 API 用于扩展应用,因此如果把自然语言转成对这些数据分析 API 的调用,是一种很自然的实现方式。当然完全也可以自己实现这个 API 层。
- 特点是受到 API 层的制约,在后面我们会分析。
- 自然语言转关系数据库 SQL,
text2SQL- 目前最受关注的一种大模型能力(本质上也是一种特殊的 text2code)。由于 SQL 是一种相对标准化的数据库查询语言,且完全由数据库自身来解释执行,因此把自然语言转成 SQL 是最简单合理、实现路径最短的一种解决方案。
- 自然语言转数据分析的语言代码,即
text2Code- 即代码解释器方案。让 AI 自己编写代码(通常是 Python)然后自动在本地或者沙箱中运行后获得分析结果。当然目前的 Code Interpreter 大多是针对本地数据的分析处理(如 csv 文件),因此在面对企业应用中的数据库内数据时,需要在使用场景上做特别考虑。
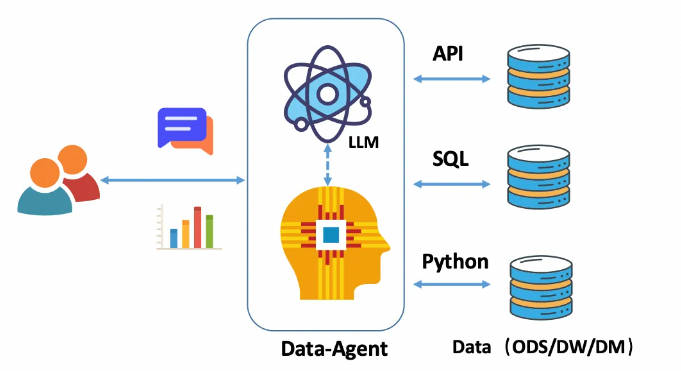
案例
tableQA
功能支持从多个 csvs 检测(csvs 也可以从 Amazon s3 读取)支持 FuzzyString 实现。即,可以自动检测查询中不完整的列值并在查询中填写。支持数据库 - SQLite、Postgresql、MySQL、Amazon RDS(Postgresql、MySQL)。开放域,无需培训。为定制体验添加手动模式在未提供模式的情况下自动生成模式数据可视化。
支持的SQL操作
- SELECT
- one column
- multiple columns
- all columns
- aggregate functions
- distinct select
- count-select
- sum-select
- avg-select
- min-select
- max-select
- WHERE
- one condition
- multiple conditions
- operators
- equal operator
- greater-than operator
- less-than operator
- between operator
LLM
text2sql(NL2SQL) 是NLP诸多任务中较难的任务,即便发展迅速的LLM,也没有完全解决text2sql中复杂查询问题
方案
解法 (参考)
- LLM 前处理
- RAT-SQL RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers, 基于Encoding + relation self attention
- LGESQL
- LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
- 基于Relation Graph, 虽然RATSQL等融合了关系信息,但目前仍有两点限制:① 无法发现有效的源路径(RATSQL是预先定义好的关系)② 相邻两个点,无法区分是不是local,即同一个表内。
- UnifiedSKG 逐渐过渡到LLM思路
- UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
- LLM 后处理
LoRA
【2024-1-26】MLX 上使用 LoRA / QLoRA 微调 Text2SQL:对比使用 LoRA 和 QLoRA 基于 Mistral-7B 微调的效果
- 相同 Iteration 次数下 QLoRA 不如 LoRA 的效果
- Prompt tokens/sec: QLoRA 是 LoRA 的 1.79 倍
- Generation tokens/sec: QLoRA 是 LoRA 的 8.87 倍
| 方式 | 更新参数量 | 微调耗时(600步) | 内存占用 | 模型大小 | 测试困惑度(PPL) | 测试交叉熵(Loss) |
|---|---|---|---|---|---|---|
| LoRA | 2.35/万 (1.704M / 7243.436M * 10000) | 20 分 26 秒 | 46G | 13G | 3.863 | 1.351 |
| QLoRA | 13.70/万(1.704M / 1244.041M * 10000) | 23 分 40 秒 | 46G | 4G | 4.040 | 1.396 |
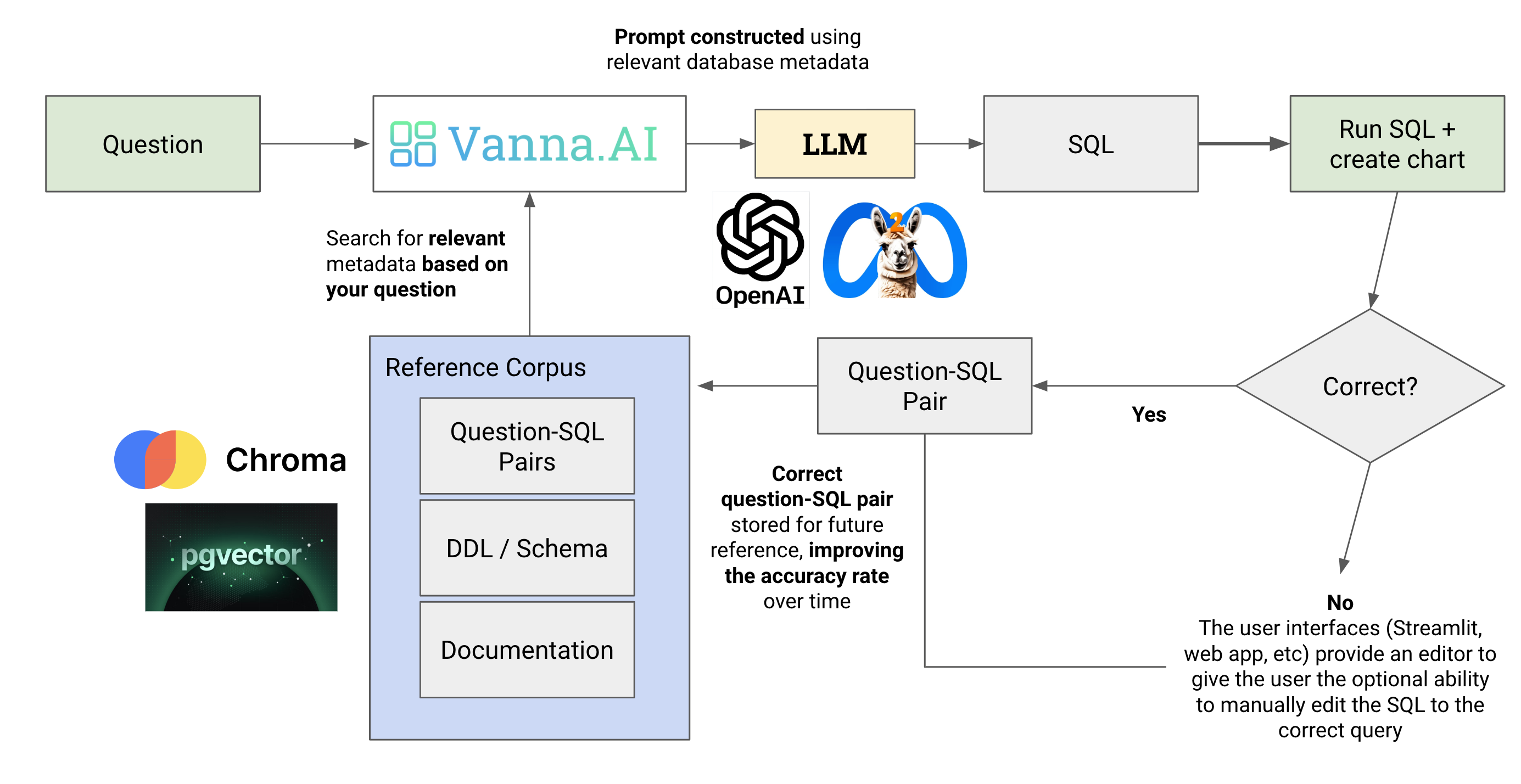
vanna-ai
vanna-ai 工作原理
- Train a RAG “model” on your data.
- 准备数据:DLL, Document, SQL语句
- 生成 embedding
- 存储embedding和metadata
- Ask questions.
- question → 生产 embedding → 找相关的数据 → 构建 prompt,发送给LLM → SQL语句
# pip install vanna
import vanna as vn
# --------- 训练 -------
# Train with DDL Statements
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
# Train with Documentation
vn.train(documentation="Our business defines XYZ as ...")
# Train with SQL
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
# --------- Asking questions -----------
vn.ask("What are the top 10 customers by sales?")
返回
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
ChatExcel
【2024-2-4】北京大学出的4款免费神器
ChatExcel 通过自然语言操作excel表格

PyGWalker
【2024-10-6】PyGWalker 将 pandas DataFrame 数据交互可视化
- 支持 NL2SQL, 新建特征变量, 实时编辑数据点
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
