大模型开发模式
开发模式
如何接入大模型?
模式总结
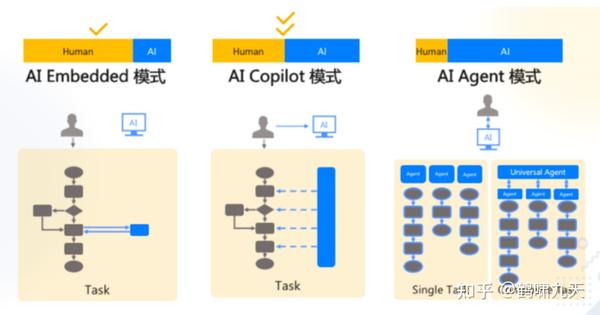
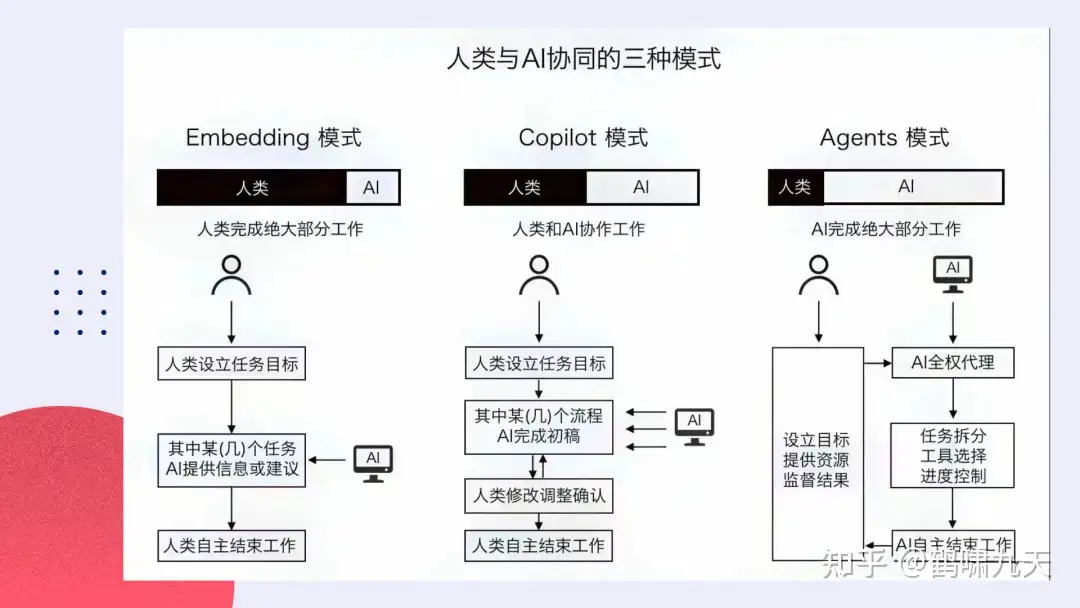
人机协同三种模式
AI Embedded嵌入:某个环节里去调用大模型- 使用提示词来设定目标,与AI进行语言交流,然后AI协助完成目标
AI Copilot辅助:每个环节都可以跟大模型进行交互- 人类和AI各自发挥作用,AI介入到工作流程中,从提供建议到协助完成流程的各个阶段。
AI Agent代理:任务交给大模型,大模型即可自行计划、分解和自动执行- 人类设定目标并提供资源(计算能力),然后监督结果。
- Agent承担了大部分工作。
- AutoGPT代表了一种完全自动化的实现方式,试图抵达AGI的理想状态,即提出需求后机器人能够自动完成任务
- AI技术的自动化范式 —— AutoGPT
- 基于Agents的自动化团队——GPTeam,许多流程都可以被自动化执行。市场调研、问卷调查、品牌计划等等,都可以由AI来完成。
- 自动化品牌营销公司——AutoCorp
Society模式
【2023-11-21】更完整的图解
- 【2023-9-9】多智能体框架 MetaGPT 作者 洪思睿
- 未来人机交互范式也会从
嵌入式模式,发展到辅助模式,再到代理模式,最终达到人机深度协作的社会化模式。在这个模式下,人类和智能体既可以自主提出需求,也可以相互提供资源来完成任务。 - 未来互联网的门户也将从 App 变成智能体。用户只需要向单个或多个智能体提出需求,由智能体负责完成整个工作流程,包括调用不同的软件程序、设定参数等。这将极大提升人机协同的效率,更进一步带来生活和工作方式的变革。

第三种模式将成为未来人机交互的主要模式。
方案一:AI Copilot 辅助
以LLM为核心,end2end架构实现新版对话系统,用prompt engineering复现原有主要模块
既然大模型(尤其是GPT系列)这么厉害,下游任务只需调prompt,那就用prompt去完成对话功能,替换原有功能模块就好了。
- 角色模拟:system prompt中设置即可,大模型的强项
- 闲聊任务:满足,一次调用即可
- 简易问答:如果是通用领域知识,一次调用即可,如果是垂直领域,需要额外融入知识(prompt中植入/微调),如果涉及实时查询、工具,还需要结合Plugin、Function Call,一般1-3次调用
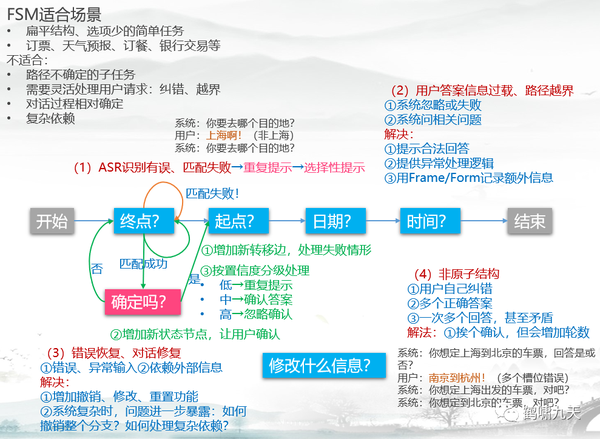
- 多轮任务:prompt中设置对话逻辑(类似上一代有限状态机FSM),简单任务满足,功能接口借助Plugin、Function Call实现,同时增加记忆单元(如借助LangChain),但复杂任务不好办,如:任务状态处理逻辑复杂、场景嵌套、API较多等。即便是FSM场景也受限(如图),而订餐这类场景只是多轮对话中的一种简单形式,至于更复杂的循环、中断、嵌套、多阶就不用提了,如信用卡业务场景下,各种流程跳转,简易对话无能为力,只好用比FSM(图)更高级的方法,Frame(槽填充+树)、Goal(树+栈+字典),大模型用data-driven结合强化学习更合适。
- 推荐型:边聊边推,设计推荐的prompt,一次调用,但依赖具体形态,聊天场景推荐对时延要求低,启用流式输出可以缓冲,而输入是输入提示这类场景,大模型的速度就堪忧了。
全部采用大模型后,以常规的对话系统为例,一次对话过程可能涉及1~10次大模型调用,这用户体验可想而知。
这种思路是把原来对话系统所有的功能都用生成式方法(自回归语言模型,GPT为代表)解决,实际上,生成式只是小部分,大部分任务是理解式任务(掩码语言模型,BERT为代表),如意图识别、槽位抽取、状态跟踪等输出空间有限,这时用生成式方法,天然就慢半拍。
实际落地时,新的问题出来了:
- 极度依赖prompt:提示语稍微变更下,加个空格,结果可能就相差十万八千里,每个场景都需要仔细调试prompt,换个模型又要重新开始。
- 速度慢:实在是慢,正常情况1-3s回复,如果句子长,要持续等待,直至流式输出结束。这对高并发、低时延要求的对话产品简直是“噩耗”。
- 不可控:即便在prompt里明确要求不要超过30字,结果LLM当成耳边风,还是会超出字数。任务型对话里的业务处理逻辑往往要求准确无误了。
- 幻觉:一本正经的胡说八道
- 黑盒:大模型到底是怎么执行对话策略的?不知道,充满了玄学意味,涌现到底是个啥?这对高度可控的场景十分致命。
对于速度问题,短期内只能依靠别的方法提速了,如:
- 各种模型加速推理技术
- 部分功能回退:如不适合生成式方法的NLU/DM
- 推进end2end方法:将多轮会话训入大模型,延续之前的end2end思路
方案二:AI Embedded 嵌入
在LLM基础上,加领域语料,增量预训练、微调,融入领域知识,根据业务场景,增加特殊逻辑
这部分涉及两部分工作
- 基座大模型训练:各行各业都在训自己的大模型,金融、医疗、教育、数字人,甚至宗教
- 业务场景落地:适配业务场景,升级或重构现有对话产品的局部
各行各业都在训自己的大模型,金融、医疗、教育、数字人,甚至宗教
人物个性模拟上
- 国外有 Character.ai,用户根据个人偏好定制 AI 角色并和它聊天;
- 国内有阿里的脱口秀版GPT——鸟鸟分鸟,并且已经在天猫精灵上为个人终端行业的客户做了演示

应用场景很多,略
方案三:AI Agent 代理
抛弃过往模块化思路,站在任务角度,通过Agent去执行对话任务,如:
最近不少人不再卷大模型了,开始卷 AI Agents
- LLM诞生之初,大家对于其能力的边界还没有清晰的认知,以为有了LLM就可以直通AGI了,路线: LLM -> AGI
- 过了段时间,发现LLM的既有问题(幻觉问题、容量限制…),并不能直接到达AGI,于是路线变成了: LLM -> Agent -> AGI
- 借助一个/多个Agent,构建一个新形态,继续实现通往AGI的道路。但这条路是否能走通,以及还面临着哪些问题,有待进一步验证。
由于大模型的出现,AI Agents 衍生出了一种新的架构形式: 《LLM Powered Autonomous Agents》
- 将最重要的「任务规划」部分或完全交由LLM,而做出这一设计的依据在于默认:LLM具有任务分解和反思的能力。
最直观的公式
Agent=LLM+ Planning + Feedback + Tool use
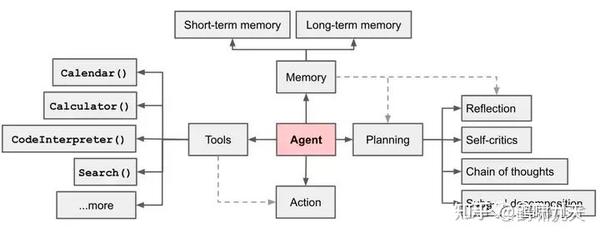
这种思路更加灵活,贴近AGI,想象空间巨大,成为继模型训练后又一个角斗场。
详见往期文章:大模型智能体
方案四:AI Society 模式
一般应用于复杂社交场景,如群体游戏,斯坦福小镇
详见站内专题:大模型智能体
LLM 开发范式
开发范式总结
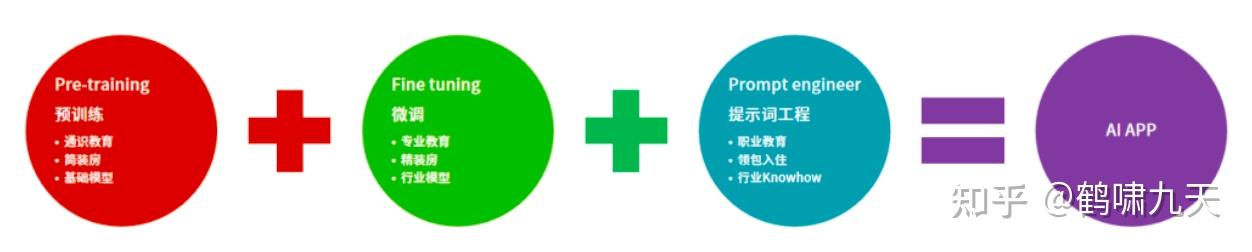
总结: 预训练(pre-training) → 微调(fine-tune) → 提示工程(prompt engineering)
- (1)
pre-training(预训练): 通识教育,教小孩认字、学算数、做推理,这个步骤产出基础大模型。 - (2)
fine-tune(微调):专业课,比如学法律的会接触一些法律的条款、法律名词;学计算机的会知道什么叫计算机语言。 - (3)
prompt engineering(提示工程):职业训练,AI应用的准确率要达到商用级别(超过人的准确率),就需要 prompt engineer,PE 重要性
有些场景中(2)可以省略。
开发范式演进
LLM时代Prompt Engineer开发范式
- 第一层:简单Prompt: 即编写一个提示词(Prompt)去调用大模型,最简单。
- 第二层:Plugin插件: 用大模型插件(Plugin)去调各种API,以及Function Call。
- 第三层:Prompt Engineering Workflow + OpenAI API
- 基于提示词工程的
工作流(workflow)编排。AI应用就是基于工作流实现。
- 基于提示词工程的
- 第四层:向量数据库集成
RAG- 向量数据库包含数据特征值,落地方案如 VectorDB,包括做知识库、做客服机器人。
- 第五层:AI Agents, 让大模型自己做递归。
- Agent 原理: AI自己对任务进行拆解,再进一步递归、继续拆解,直到有一步,AI可以将这个任务执行,最后再将任务合并起来,往前递归回来,合并为一个工程。
- 第六层:领域模型 Domain Model
- 专业模型为什么重要?大参数基础模型的训练和推理成本非常高,而专业模型速度快、成本低、准确率高,因为有行业的高质量数据,所以准确率高;进而可以形成数据飞轮,形成自己的竞争优势。
2024.11.6 斯坦福 DSPy
【2024-11-6】告别繁琐提示词,斯坦福DSPy框架开创LLM开发新思路,Star突破1.8万
斯坦福大学NLP小组推出一款革命性框架 - DSPy, 颠覆了传统 LLM开发方式。
不同于繁琐的手写提示词, DSPy 采用编程式声明与组合,为大模型应用开发带来全新体验
DSPy 代表了 LLM 应用开发的一个重要趋势: 将软件工程的最佳实践引入 LLM 开发。我们可以期待:
- 更多预制模块的出现
- 与主流开发框架的深度集成
- 更强大的优化器
- 更完善的评估体系
问题
传统 LLM 应用开发中,经常遇到这些痛点:
- 提示词工程过于依赖经验和技巧
- 难以保证输出的一致性和可靠性
- 复杂任务提示词难以维护和迭代
- 缺乏系统化的评估和优化方法
法律文档分析系统,传统方式:
# 传统方式
response = llm.complete("""
请分析以下法律文档的关键条款:
{document}
要求:
1. 提取主要条款
2. 识别潜在风险
3. 给出建议
""")
明显问题:
- • 提示词难以复用
- • 输出质量不稳定
- • 难以进行系统优化
DSPy 思维编程
DSPy 引入了”思维编程“(Thought Programming)的概念,像编写普通程序一样来设计 LLM 推理过程。
- 模块化设计
- 自动优化能力:内置 Teleprompter 优化器
DSPy 核心思想是将 LLM 的使用过程抽象为可编程模块。
通过以下机制实现:
- 签名系统
- 推理链优化
模块化设计
模块化设计带来多个优势:
- • 每个步骤都可以独立优化
- • 逻辑清晰,易于维护
- • 可以复用到其他类似任务
升级后的代码
import dspy
class LegalAnalyzer(dspy.Module):
def __init__(self):
super().__init__()
self.extract = dspy.Predict('document -> key_clauses')
self.analyze = dspy.Predict('key_clauses -> risks')
self.suggest = dspy.Predict('risks -> suggestions')
def forward(self, document):
# 步骤1: 提取关键条款
clauses = self.extract(document=document)
# 步骤2: 风险分析
risks = self.analyze(key_clauses=clauses)
# 步骤3: 给出建议
suggestions = self.suggest(risks=risks)
return {
'clauses': clauses,
'risks': risks,
'suggestions': suggestions
}
# 使用方式
analyzer = LegalAnalyzer()
result = analyzer.forward(document_text)
自动优化能力
DSPy 亮点是内置了 Teleprompter 优化器:
# 准备训练数据
trainset = [
(doc1, expert_analysis1),
(doc2, expert_analysis2),
# ...
]
# 自动优化提示词
teleprompter = dspy.Teleprompter()
optimized_analyzer = teleprompter.optimize(
LegalAnalyzer,
trainset,
metric=dspy.Metrics.Accuracy
)
这个优化过程会:
- • 自动发现最佳提示词模板
- • 优化推理链路
- • 提高输出质量
评估框架
DSPy 提供了完整的评估系统:
# 定义评估指标
class LegalMetrics(dspy.Metric):
def __call__(self, pred, gold):
accuracy = self.compare_analysis(pred, gold)
completeness = self.check_completeness(pred)
return (accuracy + completeness) / 2
# 进行评估
evaluator = dspy.Evaluate(
metric=LegalMetrics(),
num_threads=4
)
scores = evaluator(optimized_analyzer, testset)
案例
实战案例
- 案例1: 智能客服系统
- 案例2: 文档总结系统
详见原文 告别繁琐提示词,斯坦福DSPy框架开创LLM开发新思路,Star突破1.8万
建议使用方式:
- 模块设计原则 • 保持单一职责 • 清晰定义输入输出 • 适度颗粒度划分
- 优化策略 • 收集高质量的训练数据 • 设计合理的评估指标 • 渐进式优化而非一蹴而就
- 部署考虑 • 做好错误处理 • 设置超时机制 • 实现监控和日志
LLM 应用范式
LLM应用架构范式
【2024-3-25】大模型应用的10种架构模式
路由分发模式: 将用户query发到控制中心,分发到不同领域小模型/大模型。更准确、响应更快且成本更低,平衡成本/性能与体验大模型代理模式: 大模型充当代理角色,分析用户意图,结合上下文路由到不同专有小模型,适合复杂问题解多任务微调模式: 微调大模型,同时处理多个任务,适合复杂任务平台, 如虚拟助理或是人工智能驱动的研究工具。面向微调的分层缓存策略模式: 将缓存策略和相关服务引入大模型应用架构,解决成本、数据冗余以及训练数据等组合问题。- 缓存初始QA结果, 积累到一定量后, 微调训练专有小模型,同时参考缓存和专用模型,适合高准确、适应性环境, 如客户服务或个性化内容创建
- 工具: GPTCache,或缓存数据库,如 Redis、Cassandra、Memcached 运行服务
混合规则模式: 将大模型与业务规则逻辑结合,适合需要严格遵守标准或法规的行业或产品,如 电话IVR系统或基于规则的传统(非LLM)聊天机器人的意图和消息流知识图谱模式: 将知识图谱与大模型结合,赋予面向事实的超级能力,使得输出不仅具有上下文情境,而且更加符合事实。- 适合: 要求内容真实性和准确性的应用,比如在教育内容创作、医疗咨询或任何误导可能带来严重后果的领域
- 知识图谱及其本体将复杂主题或问题分解成结构化格式,为大型语言模型提供深层上下文基础。甚至可以借助语言模型,以JSON或RDF等格式创建本体。
- 构建知识图谱的图数据库服务: ArangoDB、Amazon Neptune、Google Dgraph、Azure Cosmos DB以及Neo4j等。此外,更广泛的数据集和服务也能用于访问更全面的知识图谱,包括开源的企业知识图谱API、PyKEEN数据集以及Wikidata等等。
智能体蜂巢模式: 运用大量AI Agent,共同协作以解决问题,每个代理都从各自独特的视角出发进行贡献。智能体组合模式: 大模型系统模块化, 自我配置以优化任务性能。- 自主代理框架和体系结构来开发每个Agent及其工具,例如CrewAI、Langchain、LLamaIndex、Microsoft Autogen和superAGI等
记忆认知模式: 仿照人类记忆, 允许模型回忆并基于过去的交互进行学习,从而产生更细腻的反应。- 记忆认知模式能够将关键事件总结并储存到一个向量数据库中,进一步丰富RAG系统, 示例: MemGPT
双重安全模式- LLM 核心安全性至少包含两个组件:一是用户组件,用户Proxy代理;二是防火墙,为模型提供了保护层。
- 用户proxy代理在查询发出和返回的过程中对用户的query进行拦截。该代理负责清除个人身份信息(pII)和知识产权(IP)信息,记录查询的内容,并优化成本。
- 防火墙则保护模型及其所使用的基础设施。尽管我们对人们如何操纵模型以揭示其潜在的训练数据、潜在功能以及当今恶意行为知之甚少,但我们知道这些强大的模型是脆弱的。
Anthropic 经验
和 Google,OpenAI不同,Anthropic 并没有仰望星空,而是务实的总结了 agent 落地经验
工作流和智能体之间划分了一个重要的区别:
工作流:通过预定义代码路径对LLM和工具进行编排的系统。智能体:LLM动态指挥其自身的流程和工具使用的系统,并保持对任务完成方式的控制权
只有在必要的时候,才用Agent,不要因为手里拿着锤子看什么都是钉子
- 用LLM构建应用时,尽可能选择简单的解决方案,只有在必要时才增加复杂性
- 智能体系统通常要在延迟和成本上做出妥协,以换取更高的任务性能。决定使用智能体之前,需要仔细评估这种权衡是否值得。
- 当任务复杂性较高时,工作流可以为明确的任务提供稳定性和一致性,而在需要灵活性以及大规模模型驱动决策的场景中,智能体则是更好的选择。
- 多数应用场景,通过检索和上下文示例优化单次LLM调用通常已经足以满足需求
目前有多种框架简化智能体系统的实现:
- LangGraph(LangChain提供的工具)
- 亚马逊Bedrock的Al Agent框架
- Rivet,一个拖放式的GUI工具,用于构建LLM工作流
- Vellum,另一款支持构建和测试复杂工作流的GUI工具。
这些框架通过处理底层的常规任务(如调用LLM、定义和解析工具、链式调用+等),大大降低开发难度。
- 然而,也会增加额外的抽象层,可能掩盖提示词和响应的实际逻辑,从而增加调试难度。
- 此外,这些框架可能让开发者倾向于引入不必要的复杂性,而简单的实现方式可能已经足够。
建议开发者优先直接使用 LLM API,许多功能可以通过简单的几行代码实现。如果选择使用框架,务必确保理解底层的实现逻辑,因为对底层机制的错误假设往往是开发中的主要问题之一。
增强型LLM
- 智能体系统的核心构建模块是
增强型LLM,结合了检索(Retrieval)、工具使用(Tools)以及记忆(Memory)等功能。 - 目前的模型能够主动利用这些能力,例如生成搜索查询、选择适合的工具以及确定需要保存的重要信息。

实际应用中,应重点关注两个方面:
- 一是根据具体业务场景对这些功能进行定制化;
- 二是确保为LLM提供一个简洁且文档完善的接口。
五种工作流形态:
- (1) 提示词链式调用工作流: (Prompt chaining) 将任务分解为一系列串行步骤, 其中任意中间步骤都可以加入程序化检查,确保按照预期顺利推进。
- 适用场景: 清晰分解为固定子任务的场景,
- 核心目标是在延迟与高准确性之间平衡,通过简化LLM调用的复杂度,提升整体效果
- 示例:
- 生成营销文案,并翻译成其它语言
- 撰写文档大纲, 验证是否符合特定标准
- (2) 路由工作流: (Routing) 将输入分类,并引导到特定后续任务上
- 特点: 有效分离关注点,便于针对不同输入类型设计更专业的提示词
- 适用场景: 复杂任务, 尤其包含可分别处理的类别,并通过LLM/传统模型准确分类
- 应用案例:
- 将不同类型的客户服务请求(常规问题/退款申请/技术支持), 分别引导到对应下游流程、提示词或工具
- 将简单/常见问题分给小模型(Claude 3.5 Haiku), 将复杂/罕见问题分给大模型(Claude 3.5 Sonnet), 平衡成本与速度
- (3) 并行化工作流: (Parallelization) 让 LLM 同时处理任务,并通过程序汇总输出,有两种实现形式:
- ① 分块: 将任务拆分为相互独立的子任务,并行执行
- ② 投票: 同一任务运行多次, 获得多样化的视角、结果
- 适用场景: 任务能分解成独立子任务以提升速度,或通过多次尝试来增强结果置信度时,并行化是一种高效的工作流。对于涉及多个考量的复杂任务,让LLM分别处理每个考量,可以更专注地关注各自的具体内容,从而提升整体性能。
- (4) 协调器-工作者工作流: (Orchestrator-workers)
- 一个中心 LLM 负责,根据任务动态分解子任务,分派给多个工作者LLM处理,并最终整合所有工作者的结果。
- 区别在于灵活性:子任务不是事先规划好的,而是由协调器根据输入动态生成
- 适用场景: 无法预先确定子任务的复杂场景
- 典型案例
- 编程工具:支持对多个文件进行复杂修改的任务,动态调整每个文件的修改内容。
- 搜索任务:从多个信息来源中动态收集、分析数据,并提取最相关的信息。
- (5) 评估器-优化器工作流 (Evaluator-optimizer)
- 一个LLM生成响应,另一个LLM对其进行评估并提供反馈,形成一个迭代循环。
- 适用场景: 有明确评估标准且迭代优化能够显著提高质量
- 两个关键特征:
- 第一,LLM生成的响应在获得明确反馈后能够显著改进;
- 第二,LLM可以自动生成反馈。这种流程类似于人类作家通过多次修改完善文档的过程。
- 示例:
- 文学翻译:在翻译复杂文学作品时,翻译LLM可能无法初步捕捉其中的细微差别,而评估器LLM可以提供精准的修改建议。
- 复杂搜索任务:在需要多轮搜索和分析的场景下,评估器判断当前信息是否足够全面,并决定是否需要进一步搜索和优化。
并行化典型应用:
- 分块:
- 实现防护机制:一个模型实例负责回答用户查询,另一个实例同时筛查不适当内容或请求。将防护和核心任务分离处理的效果通常优于单一调用。
- 自动化性能评估:在评估LLM表现时,每次调用分别评估模型对特定提示词的不同性能维度。
- 投票:
- 代码漏洞审查:利用多个提示词从不同角度审查代码是否存在漏洞,并标记出潜在问题。
- 内容适当性评估:通过多个提示词从不同角度对内容进行评估,并设定投票机制,如不同的通过门槛,以平衡误报与漏报的风险。
| 工作流形态 | 特点 | 图解 | |
|---|---|---|---|
| 链式调用 | 串行处理 | 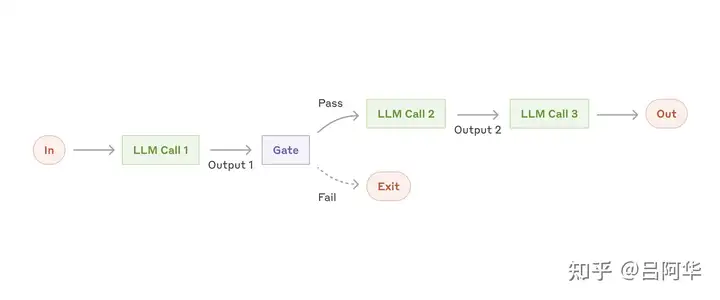 |
|
| 并行化 | 直接多次调用,再聚合处理 | 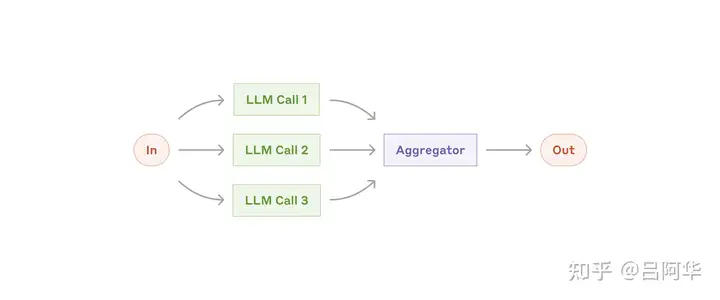 |
|
| 路由 | 根据意图分发给不同子任务处理 | 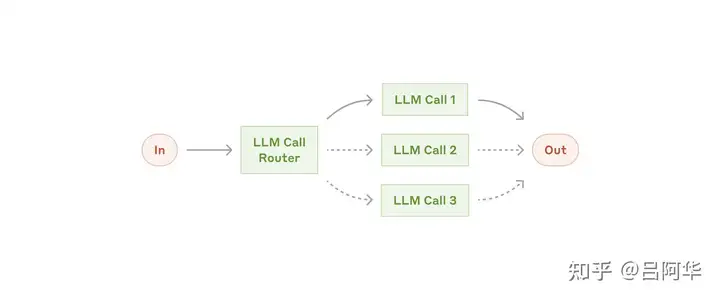 |
|
| 协调器-工作者 | 任务拆解→分发到子任务→合成后处理 | 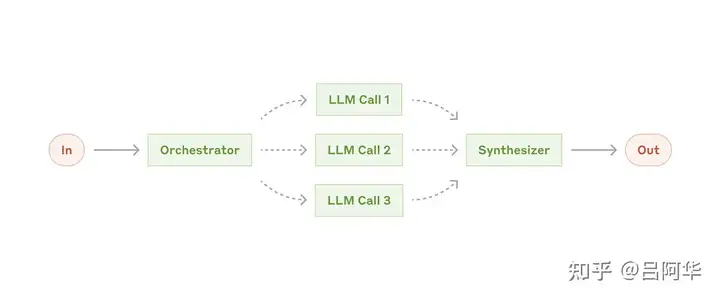 |
|
| 评估器-优化器 | 执行任务,检查结果,相互对抗,最后才输出 | 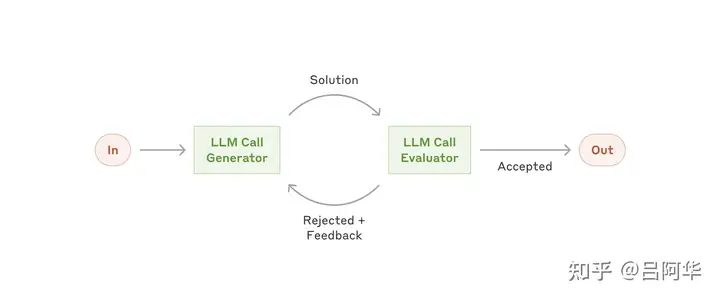 |
智能体模式
自主智能体适合处理开放式问题,尤其是难以预测所需步骤或无法通过硬编码预设路径的任务。这些场景中,LLM可能需要经过多轮交互完成任务,因此需要对其决策能力有足够的信任。自主智能体非常适合在可信环境中扩展任务。
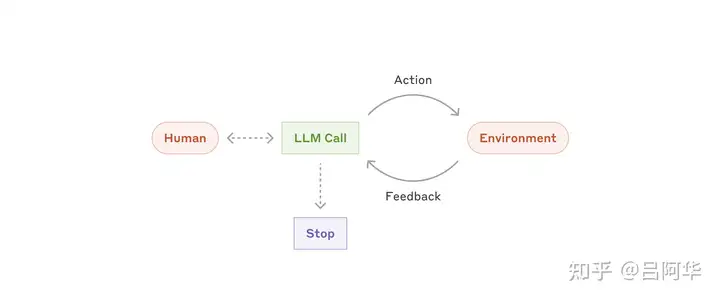
自主智能体的高自主性同时伴随着更高的运行成本以及累积错误的潜在风险。
因此,在部署前应在沙盒+环境中进行充分测试,并设置适当的防护机制。
详见: 知乎专题
LLM 开发平台
LLM 应用开发平台。
- 提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用,比 LangChain 更易用。
给开发者提供定制Bot的能力,业界案例
LLM 能力局限
局限性
- LLM 具备通用领域能力,但特定领域能力不足或缺乏
- LLM 请求信息有限制
GPT-3.5: 4k → 16kGPT-4: 8k → 32k → 128k
- LLM 无法调用外部服务、执行本地命令
Bot组成
Bot常见组成要素
- Bot
基本信息:name、description、icon - 人设/指令:又称
system prompt,以下简称 sp - 工具:
plugin/tool,使用一方、三方工具,增强模型能力- 配合 LLM 的 Function Call 使用
- 工作流:
workflow,工具升级版,执行更加复杂的逻辑 - 记忆单元:
Memory- 短期记忆:Short Term Memory,
Profiles- 以变量形式存在,直接嵌入 sp 中; 提供基础存储,持久化变量
- 变量: taste=’川菜’
- 使用: 附近有什么好吃的, llm 从memory中召回饮食偏好,匹配附近川菜
- 以表格形式存在,LLM 通过SQL存取数据
- 读书笔记类Bot
- 使用: 刚读了毛选第五卷,记录下
- llm: 已经帮你保存到数据库了,读的是毛选,第五卷
- 分析:
INSERT INTO book_notes(name, section, note) VALUES('毛选','第五卷', '-')
- 以变量形式存在,直接嵌入 sp 中; 提供基础存储,持久化变量
- 长期记忆:Long Term Memory
Datasets: 以外挂知识库方式存在,将领域知识向量化存储,通过 RAG 方式召回,补充到 sp 中
- 短期记忆:Short Term Memory,
- 定时任务:
Task, 开发者设置定时任务,如每天8点推送最新消息 - 智能体:
Agent,执行更复杂的任务
其它
- 欢迎语:onboarding/opening dialogue
- 问题推荐:suggest
Bot 进化史
过程
- (0)
Prompt: 通过 sp 设置 bot 的画像信息,技能,按指定角色进行会话 - (1)
Tool-解析: LLM + Parser- 让 LLM 输出 特定格式字符串(如json),代码解析后再调用 Tools
- (2)
Tool-Function Call:- LLM 识别需要什么函数,并自动调用函数(本地/远程),总结结果并返回
- 概念: Plugin, Knowledge, Variable
- Plugin: 调用插件,如实时新闻
- Knowledge: 垂类场景优化,人设+私有知识
- Variable: 基础存储,为开发者持久化变量
- Table Memory: 开发者用SQL查表
- Scheduled Task: 定时触发任务
- Opening dialog: 欢迎语
- Suggestion: 推荐问题
- (3)
Workflow工作流:- 起因:
- ① FC模式不稳定,单次成功率低
- ② 逻辑简单, 负责逻辑需要嵌入code,成本高
- 改进: 低代码模式,将llm,api,code编排起来
- 节点:
- start 开始节点,定义输入数据
- end 结束节点,处理结束数据
- 组件: LLM, API, Code, Knowledge, IF
LLM: 大模型调用设置,包含请求方式(单次/批量)、参数(模型/温度)、输入、输出、promptCode: 代码模块, js代码后处理Knowledge: 根据用输入召回n个片段,列表返回IF: 条件分支
- 起因:
- (4)
Multi-Agent:- 起因:
- ① workflow 是plugin加强版,缺少用户交互
- ② Bot执行依赖prompt理解,内容多,造成时间成本大
- ③ 复杂交互逻辑用sp实现,成本高,难以维护
- 解法:
Agent=Prompt+Skill(plugin/workflow) +Jump ConditionMulti-Agent代理人模式: 每次由单个Agent回复,几种模式- Flow 对话流: 顺序处理对话流程, 适合有明显状态迁移的Agent
- Reverse 回溯: 当前Agent无法作答时,回到上一个Agent/StartAgent
- Host 路由: 每次对话从StartAgent重新路由到合适的Agent
- 起因:
总结如下
workflow 平台
资料
- 【2024-5-11】16个AI Workflow automation(无代码AI工作流)构建平台
- 【2024-5-21】3 款强大的开源低代码 LLM 编排工具,可视化定制专属 AI Agent 和 AI 工作流
AI Workflow automation(无代码AI工作流)构建平台
特点:
- 不同程度地支持自定义插件、llm;
- 自己设定 workflow,类似RPA流程
- 有 workflow模版、store 模版、plugin 模版
【2025-12-17】吴恩达
Agentic Workflow(智能体工作流)指:
基于LLM的应用,通过自主规划、调用工具、反思迭代等多个步骤,协同完成一个复杂任务的端到端流程。
不是单次提示(prompt)就能解决的问题,而是“会思考、会行动、会调整”的动态系统。
- 自主性:从“脚本执行者”到“决策者”
吴恩达特别指出:并非所有叫“Agent”的系统都具有高自主性。用“Agentic”来描述不同层级的智能行为:
- 低自主性:所有步骤预定义,工具硬编码,LLM 仅用于生成文本。
- 中等自主性:LLM 可根据上下文选择使用哪个工具,但工具集是固定的。
- 高自主性:LLM 能自主规划任务路径、发现新工具、甚至在失败后自我修正。
关键区别在于:系统是否具备“决策自由度”。
- 为什么 Agentic Workflow 如此重要?
吴恩达观点:
- 效果提升远超模型换代:
- 即便使用上一代模型(如 GPT-3.5),只要设计良好的 Agentic Workflow,其任务完成效果可能远超直接用最新模型(如 GPT-4o)做单步推理。
- 换句话说:好的架构 > 更大的模型。
- 并行化能力碾压人类:
- 智能体可以同时发起多个 API 调用、并行处理子任务(比如同时查天气、订机票、写邮件),而人类只能串行操作。这种“多线程执行力”是 Agentic AI 的天然优势。
概念
【2024-12-29】Agent/Workflow/MAS:概念、区别与应用, 源自 Anthropic blog Building effective agents
常见概念:
- LLM、Augmented LLM(agent)、workflow、Multi-Agent system(MAS)
术语
LLM:基础大语言模型,通过API调用完成任务。Augmented LLM:增强型LLM,具备调用工具、搜索和记忆的能力,是构建智能体系统的基础组件,很多时候也被称为一个agent。- 给基础的LLM加上能够调用搜索、工具和记忆的能力,为后面构建智能体系统(agentic systems)的基础组件或核心元素(building block)
- 常规意义上的 Agent
- Agent System 核心目的:通过延迟和成本为代价获取更好的任务性能
Agentic System:用 agent 搭建的系统,完成一些难以用单个LLM调用完成的复杂任务。- 一般包含写死的
workflow和动态灵活的multi-agent system
- 一般包含写死的
Workflow:预先编排的固定流程,静态系统,由多个 Augmented LLM 按步骤执行,适用于流程明确的任务。- 输入/输出明确,一些 augmented LLM 按照人为规定的结构执行
- workflow 和 agent 都是一种 Agentic system
Multi-Agent System(MAS):由多个智能体组成的动态系统,能够与环境交互并自主决策,适用于开放性问题。- 与 上面几种概念的区别: 要不断地与环境做交互,根据实际情况决定下一步的调用和操作,在经过不确定轮数之后,达到终止条件
| 类型 | 优点 | 缺点 |
|---|---|---|
Agent |
动态规划 灵活 |
不稳定性 |
Workflow |
静态规划 稳定性高 |
不灵活性 |
Multi-Agent |
完成复杂任务 | 不稳定性 |
工作流 还是 mas?
如果一个系统工作流程
- 依靠人来编排的,那么就是 Workflow(工作流)
- 没法事先编排,需要依靠 LLM 在工作中动态编排,那么是 Agent
选择依据:
- 使用 Workflow:任务流程固定,需要可预测性和一致性。
- 使用 MAS:任务流程开放,需要灵活性和动态决策能力。
实现建议:
- Workflow:直接从 LLM API 搭建,注重简洁性。
- MAS:推荐使用现成框架(如 AutoGen、Coze),避免从零开发。
核心结论:
- Workflow 和 MAS 各有优劣,选择取决于任务的需求。
- Workflow 适合流程明确的任务,而 MAS 更适合处理开放性问题。
2025年10月28日,coze和dify只能做demo玩具,一到真实企业应用,基本歇菜
- 知识库太弱,文档解析差,管理弱,企业内部各种形态的知识库,难以集成 - 高度定制化,不灵活 - 系统集成难度大 - 数据安全和权限管理 企业要的是能系统集成,业务闭环,数据治理,安全合规的产品经理,demo只是起点,闭环才是终局,真实场景的适配和落地,以及roi
总结
平台总结
- 目前功能扎实、真正在做产品
- 国内 dify api/fastGPT
- 国外 微软 power automate
- 办公场景 questFlow
- 其他要么是产品很初期,要么只是为了割韭菜
【2025-2-18】n8n vs. Dify vs. Coze: 自动化和人工智能平台的全面比较
| 特性 | n8n | Dify | Coze |
|---|---|---|---|
| 工作流自动化 | ✅ 高级工作流自动化 | ⚠️ 有限(以人工智能为中心) | ⚠️ 以聊天机器人为中心的自动化 |
| 人工智能与LLM集成 | ⚠️ 第三方人工智能集成 | ✅ 内置LLM支持 | ✅ 人工智能驱动的聊天机器人系统 |
| 易用性 | ⚠️ 中等(技术用户) | ✅ 低代码/无代码 | ✅ 初学者友好的聊天机器人构建器 |
| 可扩展性与API支持 | ✅ 高(自定义节点、API) | ⚠️ 限于人工智能集成 | ⚠️ 基于API的聊天机器人部署 |
| 部署与托管 | ✅ 自托管与云 | ⚠️ 仅云 | ⚠️ 仅云 |
| 定价与许可 | ✅ 开源与付费云 | ⚠️ 商业定价 | ⚠️ 基于订阅 |
说明:✅表示具备该特性且表现良好 ,⚠️表示特性存在一定限制 。
优先事项
- 工作流自动化和数据处理 —— n8n
- 构建 人工智能驱动的应用程序 —— Dify
- 寻找 智能聊天机器人和对话式人工智能 —— Coze
| 平台 | 最佳适用对象 | 示例使用案例 |
|---|---|---|
| n8n | 工作流自动化与API集成 | 自动化业务流程、API编排、数据工作流、DevOps自动化 |
| Dify | 人工智能应用开发 | 人工智能驱动的应用程序、LLM驱动的客户支持、基于NLP的洞察、个性化人工智能交互 |
| Coze | 对话式人工智能与聊天机器人 | 客户服务的人工智能聊天机器人、电子商务机器人、内部人力资源自动化、社交媒体参与 |
其他
| 功能 | Dify.AI | LangChain | Flowise | OpenAl Assistant API |
|---|---|---|---|---|
| 编程方法 | API+应用程序导向 | Python代码 | 应用程序导向 | API导向 |
| 支持的LLMs | 丰富多样 | 丰富多样 | 丰富多样 | 仅限OpenAl |
| RAG引擎 | ✅ | ✅ | ✅ | ✅ |
| Agent | ✅ | ✅ | ❌ | ✅ |
| 工作流 | ✅ | ❌ | ✅ | ❌ |
| 可观测性 | ✅ | ✅ | ❌ | ❌ |
| 企业功能(SSO/访问控制) | ✅ | ❌ | ❌ | ❌ |
| 本地部署 | ✅ | ✅ | ✅ | ❌ |
附加
| 平台 | 介绍 | 优点 | 不足 |
|---|---|---|---|
| Microsoft Power Automate | 微软, 从产品技术角度出发,连接的节点还有本地laptop RPA和云上的DPA | 功能最丰富 | 付费 |
Dify’s introduction/fastGPT |
多个版本 开源版的FastGPT |
国内workflow体验最佳 | |
Coze/扣子 |
字节,国内扣子,国外Coze | 功能多 | 体验并不好 |
| MindStuido | 像coze一样有自定义LLM、知识库,支持多种插件,生成api嵌入到另一平台和能在后台看到使用量 | 按照使用量付费,知识库需要付费才能用,新注册用户有5美元免费额度 | |
| 影刀&zapier | 传统RPA转型而来,对应国外的Zapier | 有很多适合国内各电商、社交平台的成熟插件 ai 功能,包括ChatGPT、AI生成视频的HeyGen |
|
| scriptit | 支持自定义文本和一些api | 网站做得挺亮眼 | 产品功能,用户体验都一般 |
| Leap | 图片插件多 | 插件还较少,自定义流程也偏简单 | |
| GPTAgent | 简单自定义workflow构建应用 | ||
| mazaal | 提供简单的现有应用,比如分析照片的情绪,AI图片分类、zero-shot text classification | 界面也跟mindstudio类似,右边是模型处理结果,套壳 | |
| actionize | 要跨平台操作 | ||
| Coflow | 小众产品,只有简单的workflow流程 | ||
| Questflow | Product Hunt排第4名,近期比较火 侧重团队工作的wokflow,比如发邮箱,开会总结,社交平台自动发帖、收集新闻等,从它提供的plugin来看都是Notion、google sheet、gmail和lark |
已有商业场景,收费:8美元一个月能执行250次automations | 模版不多,都是基于提供的插件生成的,主要是收集新闻类,翻译邮件,收集邮件,写邮件,生成一些文案 |
| Bardeen | 总结zoom会议,撰写email邮件,爬取网络信息形成表格,发送到slack、日历提醒等 | ||
| Levity | 功能更简单,自动化根据用户信息给用户发邮件 | ||
| 达观RPA | 前些年传统的AI workflow | ||
| n8n | 传统的AI workflow,支持code和UI两种模式 | 有开源版本 | 操作界面不是特别友好 |
还有 团队之间工作流的产品
- make 、nanonets,没有 perplex、GPT这些AI模型
知识库
【2025-6-22】知识库使用
- pdf内容结构复杂,图片、表格、公式等
- 【2025-6-22】dify pdf解析能力弱 → 更专业的ragflow,速度慢 → mineru➕dify
- 测试文件:10多页的pdf文件,MinerU 花费 42s
- 参考:小红书视频
| 阶段 | 方案 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|
| 1 | Dify原生功能 | Dify自带 | pdf解析能力弱 | |
| 2 | RAGFlow | 文档解析更专业 | 速度慢 | 几分钟 |
| 3 | MinerU+Dify | 先通过OCR解析pdf内容,集成到Dify工作流,方便 | 10页pdf花费42s | |
| 4 |
国内平台
【2024-10-27】全网最全国内Agent平台深度测评:扣子、Dify、FastGPT,谁是你的Agent开发首选?
| 类型 | Agent平台 | 支持的大模型 | 是否收费 | 评分 |
|---|---|---|---|---|
| 单模型Agent平台 | 文心智能体平台 | 文心大模型 | 免费 | ★★★ |
| 单模型Agent平台 | 智谱智能体中心 | ChatGLM - 4 | 免费 | ★★★ |
| 单模型Agent平台 | 天工SkyAgents | 天工大模型 | 免费 | ★★★ |
| 单模型Agent平台 | 讯飞星火智能体平台 | 讯飞星火大模型 | 免费 | ★★★ |
| 单模型Agent平台 | 腾讯元器 | 腾讯混元大模型 | 免费 | ★★★ |
| 多模型Agent平台 | Dify | OpenAI、Azure OpenAI Service、Anthropic、Hugging Face Hub、Replicate、Xinference、OpenLLM、讯飞星火、文心一言、通义千问、Minimax、Zhipu(ChatGLM)、JinaAI等 | 收费,较高 | ★★★★★ |
| 多模型Agent平台 | FastGPT | FastAI - 4s、claude - 3 - 5 - sonnet、星火、Deepseek、通义千问、月之暗面、零一万物、百川智能、ChatGLM、MiniMax、百度ERNIE等 | 收费,较低 | ★★★★★ |
| 多模型Agent平台 | 千帆AppBuilder | 百度ERNIE系列模型、Qianfan - Chinese - Llama、Meta - Llama、ChatGLM、XuanYuan、Gemini、Mixtral、零一万物等 | 收费,较低 | ★★★★★ |
| 多模型Agent平台 | 扣子 | 普渡版:豆包、通义千问、ChatGLM、MiniMax、月之暗面、Baichuan等 专业版收费,公版费较低 |
★★★★★ |
国内平台横向对比
| Agent平台 | 知识库 | 数据库 | 插件/工具 | 工作流 |
|---|---|---|---|---|
| 文心智能体平台 | 多格式、多渠道文档创建;自定义分段支持重叠段落字符设置 | 定位为Agent的记忆能力,自定义表结构后,可将用户数据存储到表中,具有读写功能,支持web创建数据表字段信息 | 插件市场较封闭,只有官方插件可使用,插件较少;插件质量高,可创建插件,包括能力插件和数据插件,能力插件需要代码开发,有一定数量的插件可使用 | 支持工作流编排,节点类型还不够丰富 |
| 智谱智能体中心 | 多格式、多渠道文档创建,支持图片、音频格式 | 无独立数据库模块 | 插件质量高,提供API插件配置助手功能 | 无工作流编排功能 |
| 天工SkyAgents | 多渠道文档创建,支持格式较少 | 无独立数据库模块 | 可用插件极少,暂无插件开发创建功能 | 工作流编排节点类型较少,功能尚不完善 |
| 讯飞星火智能体平台 | 名称为数据集,仅支持本地上传,格式为txt和pdf,上传文件数量和容量较小 | 无独立数据库模块 | 可用工具极少,结构化创建和编排创建模式下,暂无插件开发创建功能 | 工作流编排节点类型包含常用类型 |
| 腾讯元器 | 仅支持本地上传,格式为TXT / DOCX / DOC / PDF,无分段和检索策略的个性化配置 | 无独立数据库模块 | 插件市场较开放,可用工具较丰富,官方插件少,插件质量参差不齐,可配置API插件,可用插件工具较丰富 | 工作流编排节点类型包含常用类型 |
| Dify | 多格式、多渠道文档创建,分段和检索策略设置丰富 | 云服务版无独立数据库模块,但支持变量 | 插件质量高,可配置API插件,代码开发插件 | 工作流编排节点类型丰富 |
| FastGPT | 多格式、多渠道文档创建,单个文件支持100M,分段和检索策略具有独特功能:可分别配置索引模型和文件处理模型;分段方式丰富,提供问答拆分分段模式 | 无独立数据库模块 | 插件市场较封闭,可用工具很少,主要是官方插件,质量较高,可配置API插件 | 工作流编排节点类型丰富 |
| 千帆AppBuilder | 多格式、多渠道文档创建,分段和检索策略设置丰富 | 定位结构化数据管理,表格问答,类似知识库,支持数据库上传和直连数据库,需要上传数据表数据内容 | 组件市场较开放,可用工具丰富,插件质量较高,可配置API插件 | 组件内有工作流编排功能,工作流编排节点类型较丰富 |
| 扣子 | 区分文档、表格、照片3类知识库创建,多格式、多渠道文档创建,分段和检索策略设置丰富 | 定位为Agent的记忆能力,自定义表结构后,可将用户数据存储到表中,具有读写功能,支持web创建数据表字段信息 | 插件市场较开放,可用插件工具十分丰富,插件质量较高,可配置API插件,代码开发插件 | 工作流编排节点类型丰富,更新快,有图像流功能 |
国外平台
国外平台
- LangGraph from LangChain;
- Amazon Bedrock’s AI Agent framework;
- Rivet, a drag and drop GUI LLM workflow builder; and
- Vellum, another GUI tool for building and testing complex workflows.
- n8n
workflow 诞生
所有厂商都面临一个难题
-
GPT 珠玉在前,做什么模型都容易获得一片骂声,包括最近发布的Gemini
- Gemini 策略:免费的Pro 以及API(60每分钟) ,不算短token,足以满足普通用户的所需,可以想象有更多的AI工具提供免费的服务能力,这里可以吸引一波免费用户,比GPT或者Claude更具有特色,更简单能被使用,这里策略用的好,普通AI用户大盘少不了。
- 字节策略更狠,GPT4 不要钱,能提前把一堆需要使用的AI的个人开发者,企业应用者,先进的工作者吸引到这个平台。站在GPT4的高度,吸引一波客户,反向在非GPT4能力上构建核心优势(包含平台化能力、自动化能力、数据延伸能力),也可以探索更多可能得场景(AI Playbook 为后面Agents时代提供更多思路。)
- 以金钱换时间,还能吸引忠实的用户,用AzureAPI也是用,用字节的GPT的API也是用,只要能先把用户接上去,后面都好说。后面字节能打的大模型出来后,直接换引擎就是!真是一招妙招。反正OpenAI的套路大家都清楚了,无非就是钱的问题。
缺陷: Multiagent模式有两个“不爽”的地方,都跟Agent跳转有关。
- 第一个:Agent跳转必须要用户输入后才能触发,而不能由Agent自己触发,或者当Agent完成任务后自动跳转到下一个Agent。难以避免一些不必要的跟用户的交互。Multiagent模式下,Bot设计者应该有自由度去控制Bot什么时候自动执行流程,什么时候停下来跟用户交互。不然交互很多、流程复杂的程序就很难设计。
- 第二点: 在Multiagent模式,可以使用自然语言来配置Agent跳转条件。然而这个跳转的判断逻辑非常不稳定。
Bot 如何盈利
Bot 如何盈利?
Notion要做一个All-in-one 工具。但Notion做法不是把所有功能都打包到一个产品里,也不是做N多个App出来,Notion的做法是花很长时间去打磨那些组成软件的基本且必要的Building Blocks,例如文本编辑、关系数据库等等,然后用户可以用这些”Lego Blocks”组装自己的工具,让软件适配自己的需求和工作流。与其说Notion是一家生产力公司,不如说它是一家软件建构公司。Poe的Bot创作者主要有两种收益途径:- 如果Bot给Poe带来新的订阅,Poe会分成;
- 给Bot Message定价,用户使用你的Bot,要为每条Bot Message付费(还没落实)
Coze也沿着GPT Store这个路子,只不过相比于GPT Store,Coze的可定制性更强些,主要是因为Workflow以及Multiagent Flow这两大特性,其他如插件更丰富,支持变量和数据库,支持很多发布渠道等等这些特性也增色不少。但是Coze依然要面临盈利模式的问题- Bot这种软件形态短期内应该是达不到手机App那种程度,Bot Store 短期内也成为不了App Store。
coze C端变现方法:
- 1️⃣卖课,教别人怎么用coze,更好的打工
- 2️⃣卖工作流
- 3️⃣接私活,帮别人开发工作流
workflow价值
workflow 有用吗
思考
- DIFY、COZE 等各种LMOps以及各种Agent框架的 workflow 怎么样?
【2024-3-20】微博观点:workflow 因为模型reasoning能力在真实世界复杂任务时不够强,且短期内没法很大提升,针对合适的问题的从产品思维出发提出的解决方案。
理论上如果有capability很强的LLM,tools pool,可以解决非常多问题。但因为是概率性模型,LLM调用tools不总是100%成功,以及LLM当前的reasoning能力还不支持进行各个tools之间的组合调用,所以不能100%解决问题。
但如果工作流是确定的,那就没必要脱裤子放屁,用LLM去触发这个工作流,而只把LLM弱化,只是作为一个能很好理解用户意图并很擅长NLP任务的交互interface,弱化成一个节点,然后再提供同样丰富的 tools pool,然后让人工通过圈选拖拽等GUI去把这个workflow配置好,就能确定性的解决问题。 workflow就是这个思路。
workflow 核心是要有人识别确定性工作流,去配置足够多的模板,以及足够丰富的tools,其实使用门槛并不低,比如是一堆高玩带小白玩。 但workflow有可能像notion的template一样,是商业模式的一部分。
概率模型要想应用在容错率低的严肃场景,如何解决可控性/可预测性是最关键的一环,思路也是弱化 LLM 在业务流中的作用。
workflow 自动化
详见站内专题: Agent 设计: Agent 自动化
Skills
【2025-12-16】Claude Skills成为复杂工作流的最优解
两个核心工程挑战,直接决定了agent的“天花板”:
- 上下文窗口的稀缺性: 如何让模型“知道”数百个工具的定义,而不耗尽昂贵且有限的上下文?
- 编排逻辑的复杂性: 面对多步骤、长周期的任务,如何保证模型遵循既定的业务流程,确保任务的鲁棒性?
传统 API 函数调用 因其“急切加载”机制和对客户端的编排负担,已步履维艰。解决连接性碎片化的 确立了“通用连接器”的生态地位。然而,真正的架构质变来自 Anthropic 最新推出的 Claude Skills 。
Claude Skills 不再将功能视为简单的工具集合,而是将其封装为“程序性知识”——一份专业的“员工入职手册”。本文将深入剖析这三大范式在上下文管理与工作流编排上的本质差异,为您揭示为什么 Skills + MCP 的分层架构,才是构建下一代企业级高能效智能代理的最佳路径。
API 函数调用是不可或缺的底层执行原语,但其“急切加载”的上下文机制和脆弱的编排逻辑,使其不适合作为构建复杂、可扩展代理应用的核心架构 。模型上下文协议 成功地解决了连接性难题,为 AI 提供了标准化的“管道” 。
而 Claude Skills 代表了架构的质变。它通过渐进式披露”机制解决了上下文的扩展性瓶颈,无论是拥有 10 个还是 1000 个技能,启动成本都极低。更关键的是,它将复杂流程显式定义在 中,结合沙盒代码执行,极大地提升了复杂任务的流程鲁棒性和标准化。
三种设计范式:API Function Calling → MCP → Claude Skills
详见站内专题:LLM基建MCP+A2A
Coze
目前C端用户最多的智能体平台之一,分为国内版和国际版,两者使用不同的AI模型,其中国际版支持ChatGPT大模型,国内版支持豆包、DeepSeek等。
- 定位:全场景低代码开发平台
- 核心能力:拖拽式工作流设计、100+内置插件(抖音数据抓取、3D数字人)、一键分发至微信/飞书/抖音生态
- 试用体验:搭建“抖音爆款分析机器人”仅需15分钟,高阶功能需购买团队专业版,比如跨空间复制,新模型体验
【2025-5-26】Coze 官方 从扣子,看 AI Agent 产品开发范式演进
扣子作为一个专注 Agent 的产品,早在2024年2月上线国内版本。
短短的一年多时间里,扣子见证了 AI Agent 开发范式的持续演进迭代,从野蛮生长的状态快速进化成为了精耕细作的系统化工程方法。
- 初 期:好奇心驱动下的野蛮生长; 关键词:娱乐化、碎片化、实验性
- 探索期:严肃场景下的流程革命; 关键词:Workflow 化、场景闭环、稳定性
- 爆发期:系统工程的精耕时代,诞生 AI Agent 开发新范式; 关键词:全生命周期
2025年4月,进行品牌升级,同时推出了产品矩阵,分别为扣子空间、开发平台、扣子罗盘及 Eino 框架
- 扣子空间(space.coze.cn),也正是在这样的工程方法加持下快速诞生的新产品。
【2023-12-23】字节放出地表最强ChatBot,免费使用GPT4,请低调使用
Coze 是字节跳动推出的一款用来开发新一代 AI Chat Bot 的应用编辑平台,无论是否有编程基础,都可以通过这个平台来快速创建各种类型的 Chat Bot,并将其发布到各类社交平台和通讯软件上。—— 这个点类似于GPTs
插件: 无限拓展 Bot 的能力- Coze 集成了丰富的插件工具集,可以极大拓展 AlBot 能力边界。目前平台已经集成了超过60 款各类型的插件,包括资讯阅读、旅游出行、效率办公、图片理解等 API及多模态模型。
- 集成不同工具,打造具备极强功能性的 Bot,比如可以添加各类新闻插件,来迅速打造出一个可以播报最新时事新闻的 Al 新闻播音员。平台提供的插件无法满足你的需求?我们也支持快速将你的私有 API集成为插件。
知识库: 让 Bot 与你自己的数据进行交互- Coze 提供了简单易用的知识库能力,它能让 AI与你自己的数据进行交互。你可以在知识库中存储和管理数据。无论你需要处理几十万字的 PDF 还是某个网站的实时信息,只需要简单的创建知识库,即可让你的 Bot 来使用相关的知识。
- 可以将几十页的产品介绍文档导入知识库,仅需几分钟,即可生成你的专属产品顾问。。可以将你经常关注的资讯网站或者在线论文导入知识库,每天 Bot 都会为你收集最新的更新及动态。
长期记忆:让 Bot 拥有持久化的记忆能力- Coze 提供了一个方便 AI交互的数据库记忆能力,通过这个功能,你可以让 Al Bot 持久化的记住你跟他对话的重要参数或重要内容。
- 让 Bot 记住你的饮食偏好,每次按照你的兴趣偏好推荐餐厅。
- 让 Bot 记住你的语言偏好,每次按照你母语进行回答。
- Coze 提供了一个方便 AI交互的数据库记忆能力,通过这个功能,你可以让 Al Bot 持久化的记住你跟他对话的重要参数或重要内容。
定时任务:让 Bot 主动对话- Bot 能主动给你发送消息? 通过定时任务功能,用户可以非常简单的通过自然语言创建各种复杂的定时任务。Bot 会准时给你发送对应的消息内容。
- Bot 每天早上 9:00 给你推荐个性化的新闻。
- Bot 每周五帮你规划周末的出行计划。
工作流: 将创意变成 Bot 的技能- 让 Bot 使用这些特别的方法来代替你工作,那么你可以非常简单的创建一个工作流,让他变成 Bot 的技能。如果你懂得编程,那么可以在工作流里使用代码片段创建非常复杂的函数,如果你不懂的编程,那么也无需担心,通过简单的操作,你-样可以创作出属于你的工作流。
- 做一个帮你搜集电影评论的工作流,快速的查看一部最新电影的评论与评分。
- 做一个帮你撰写行业研究报告的工作流,让 Bot 替你写一份 20 页的报告。
- 让 Bot 使用这些特别的方法来代替你工作,那么你可以非常简单的创建一个工作流,让他变成 Bot 的技能。如果你懂得编程,那么可以在工作流里使用代码片段创建非常复杂的函数,如果你不懂的编程,那么也无需担心,通过简单的操作,你-样可以创作出属于你的工作流。
coze 案例
实践案例
- 【2024-2-14】如何用Coze制作一个信息检索Bot(含Workflow的基础用法)
- 【2024-3-6】Bot创作者如何在Coze上赚钱?
- 用 Coze 搭建 《卧底》的Multiagent Flow设计, Coze《卧底》
- 从3月3号发文,截止到3月5号,《卧底》总共收获10笔订单,其中有效订单8笔(其中有2笔是朋友帮忙测试支付流程的),总收入是1032元
- 【2024-3-8】Coze + 爬虫 = 周末去哪不用愁!, 搭建一个“周末去哪玩”的Bot
- 单纯靠提示词来实现这个Bot明显不太行,还是要自己加定制
- 需求: 发送「城市+区+类型(景点、展览、音乐、话剧等)」 ,Bot输出对应区域的 「周末活动信息」,如:深圳市南山区-景点,Bot输出景点列表:【景点名称】景点地址;深圳市南山区-展览,Bot输出这周末的展览信息列表:【展名称】时间-票价-地点。
- 实现: 写节点函数,实现 扣子: 7337619854435876876
- 【2024-6-30】开发了一款 Agent,每天全自动获取大模型日报并发送到微信群
- RPA 实现抓取大模型日报推送到微信,效果不错,但问题是 Mac 版本的 RPA 工具
影刀不支持定时任务执行,所以还是要每天手动点下执行按钮 - 用 Coze 搭建 全自动方案,每天定时抓取大模型日报并推送到微信群,全程不需要人工参与
- 新建工作流 llm_news_push, 包含多个节点: 开始、新闻抓取、内容读取、摘要生成、markdown合成、发送消息
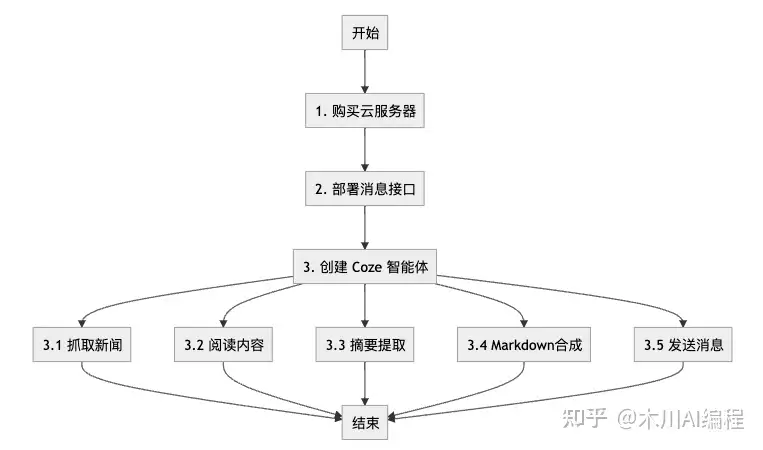
- RPA 实现抓取大模型日报推送到微信,效果不错,但问题是 Mac 版本的 RPA 工具
- 【2025-4-8】Coze构建微信销冠机器人
- 意图识别: 产品资讯、支付(二维码)
coze api
Coze API 接入方式
【2024-12-19】实践 coze-py
- 先将bot发布为api
- coze 空间设置token, 并开启chat权限
- 国内调用时, 需要制定 url, 否则鉴权失败!
- COZE_COM_BASE_URL = “https://api.coze.cn”
# coding: utf-8
import os
from cozepy import COZE_COM_BASE_URL
# token 配置 https://www.coze.cn/open/oauth/pats
# bot 先发布成 api才行
conf_info = {
'token':'pat_GiJJJSn085W1ew********',
'AI客服': {'bot_id':'7447527125353037875'},
'鹤啸九天助理': {'bot_id':'7374706518413230099'},
'聪明一休': {'bot_id':'7277598499636707383'},
'-': {'bot_id':'-'},
}
bot_name = 'AI客服'
# bot_name = '鹤啸九天助理'
token = conf_info['token']
bot_id = conf_info[bot_name]['bot_id']
# 国内需要制定base地址
COZE_COM_BASE_URL = "https://api.coze.cn"
user_id = "wqw" # 随便设置
# Get an access_token through personal access token or oauth.
coze_api_token = os.getenv("COZE_API_TOKEN", token)
# The default access is api.coze.com, but if you need to access api.coze.cn,
# please use base_url to configure the api endpoint to access
coze_api_base = os.getenv("COZE_API_BASE") or COZE_COM_BASE_URL
print(f'[debug] {bot_name=}, {bot_id=}, {coze_api_token=}')
from cozepy import Coze, TokenAuth, Message, ChatStatus, MessageContentType, ChatEventType # noqa
# Init the Coze client through the access_token.
coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=coze_api_base)
# Create a bot instance in Coze, copy the last number from the web link as the bot's ID.
bot_id = os.getenv("COZE_BOT_ID") or bot_id
# The user id identifies the identity of a user. Developers can use a custom business ID
# or a random string.
question = '你是谁'
# Call the coze.chat.stream method to create a chat. The create method is a streaming
# chat and will return a Chat Iterator. Developers should iterate the iterator to get
# chat event and handle them.
for event in coze.chat.stream(
bot_id=bot_id,
user_id=user_id,
additional_messages=[
Message.build_user_question_text(question),
],
):
if event.event == ChatEventType.CONVERSATION_MESSAGE_DELTA:
print(event.message.content, end="", flush=True)
if event.event == ChatEventType.CONVERSATION_CHAT_COMPLETED:
print("token usage:", event.chat.usage.token_count)
更多
import requests
import time
import json
import re
import tiktoken
from langchain_text_splitters import TokenTextSplitter
ACCESS_TOKEN = "***"
BOT_ID = "***"
USER_ID = "***"
def call_coze_api(query):
url = 'https://api.coze.cn/v3/chat'
headers = {
'Authorization': f'Bearer {ACCESS_TOKEN}',
'Content-Type': 'application/json'
}
payload = {
"bot_id": BOT_ID,
"user_id": USER_ID,
"stream": False,
"auto_save_history": True,
"additional_messages": [
{
"role": "user",
"content": query,
"content_type": "text"
}
]
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
response_data = response.json().get('data')
id = response_data['id']
conversation_id = response_data['conversation_id']
retrieve_url = f'https://api.coze.cn/v3/chat/retrieve?chat_id={id}&conversation_id={conversation_id}'
while True:
print('Starting retrieve the response...')
retrieve_response = requests.get(retrieve_url, headers=headers)
if retrieve_response.status_code == 200:
retrieve_data = retrieve_response.json().get('data')
if retrieve_data['status'] == 'completed':
result_url = f'https://api.coze.cn/v3/chat/message/list?chat_id={id}&conversation_id={conversation_id}'
result_response = requests.get(result_url, headers=headers)
if result_response.status_code == 200:
result_data = result_response.json().get('data')
result_dict = next((item for item in result_data if item['type'] == 'answer'), None)
return result_dict.get('content')
else:
print(f"Error: {result_response.status_code}, {result_response.text}")
return {"error": result_response.status_code, "message": result_response.text}
else:
print(f"Error: {retrieve_response.status_code}, {retrieve_response.text}")
return {"error": retrieve_response.status_code, "message": retrieve_response.text}
time.sleep(10) # Add a delay to avoid excessive API calls
else:
print(f"Error: {response.status_code}, {response.text}")
return {"error": response.status_code, "message": response.text}
小程序
如何将Bot发布到微信小程序?
(1)自己开发
方案: 微信小程序js逻辑和接口实现
- 使用 coze api 和 微信开发者工具, 自己开发小程序
(2)使用 coze 提供的发布渠道
【2024-6-28】 Coze 支持将 Bot 发布到微信小程序,Bot 将作为独立的微信小程序,在微信端提供服务。
- 准备自己的小程序,要备案!
- 备案: 小程序页面提交申请,关联身份证、手机号、详细住址、经营范围、同意书等
- 登录小程序:公众号平台扫码登录(不是账户登录),手机上选择小程序
使用限制
- 1个 Bot 只能发布到1个微信小程序
- 不支持主体类型为个人的微信小程序号
方法
(3)第三方发布渠道
【2024-12-19】使用第三方工具将coze上的bot发布到小程序上
- 工具: 小程序
小微智能体提供了一套扣子Coze智能体通过API发布到小程序的解决方案 - 参考文章 AI智能体+小程序解决方案,扣子Coze智能体秒变小程序!(无需企业资质,一键发布)
与扣子Coze官方导出小程序区别
- 第一:无需企业资质,微信发布AI小程序需要企业主体才能开通AI类目
- 第二:可发多个智能体,官方智能体导出到小程序只能导出单个智能体
- 第三:更多的分享形式,为了更好触达用户小微内置了4种分享形式
FlowGram
【2025-5-10】字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
字节跳动(ByteDance)开源基于节点的流程构建引擎:FlowGram。飞书工作流、扣子自动化 等产品中使用的核心可视化流程引擎。
结合节点式设计和 AI 增强功能,提供直观的可视化工作流构建体验。它支持 固定布局(结构化流程) 和 自由布局(灵活连接),通过 AI 自动化任务(如数据清洗、报告生成),并允许开发者扩展节点功能。
它通过前端可视化编辑器(React)实现节点拖拽和连接,结合后端 AI 集成(支持 豆包、DeepSeek、Kimi 等通用大模型),提供流畅的交互体验。FlowGram 的设计目标是简化工作流开发,同时通过 AI 增强自动化能力。
特别适合需要明确输入输出的可视化工作流场景。
核心功能亮点
- • 双布局模式:支持固定布局、自由布局,可实现卡片式排布(节点拖拽)或流程图式排布(自由线条连接)。
- • AI 能力增强:可接入豆包、月之暗面Kimi、DeepSeek等大模型能力,增强工作流的智能化处理。
- • 丰富的交互体验:提供拖拽、连线、节点配置、参数输入、状态高亮等交互设计,确保输入输出清晰。
- • 节点控制丰富:分支判断、循环执行、嵌套子流程、条件表达式等均可灵活配置
- • 强大的扩展能力:具备良好扩展性,可为节点增加自定义功能或集成外部服务
- • 低代码能力支撑:具备构建更大规模自动化系统的基础组件和扩展体系
部署
FlowGram 是基于 TypeScript 开发而成,需要借助前端 NodeJS 环境进行本地部署。
① 安装 Node.js 18+
nvm install lts/hydrogen
nvm alias default lts/hydrogen # set default node version
nvm use lts/hydrogen
② 克隆项目
git clone git@github.com:bytedance/flowgram.ai.git
③ 安装全局依赖包
npm i -g pnpm@9.12.0 @microsoft/rush@5.140.0
④ 安装项目依赖
rush update
⑤ 编译项目
rush build
⑥ 运行项目Demo
rush dev:demo-fixed-layout
rush dev:demo-free-layout
文档开发:rush dev:docs(访问 http://localhost:3000)。 固定布局演示:rush dev:demo-fixed-layout。 自由布局演示:rush dev:demo-free-layout。
创建应用:
npx @flowgram.ai/create-app@latest
开源
【2025-7-26】Coze 开源大动作!开发者生态迎来新变量,AI 应用开发门槛再降低
7月26日,知名AI 应用开发平台 Coze 宣布核心能力开源!此举将降低开发者门槛,重塑行业格局,尤其是冲击开源workflow产品,如Dify。
这次开源的是 Coze 核心框架与关键组件向开发者开放:
- Bot 构建引擎:支持通过 YAML/JSON 配置或低代码界面定义 AI 助能逻辑(如意图识别、多轮对话流程);
- 插件系统:开放插件开发标准,允许开发者快速接入外部 API(如数据库、企业 CRM、地图服务);
- 多模态交互模块:包含文本生成、图像理解、语音回复等基础模型接口;
- 部署工具链:提供轻量化本地运行方案与云端托管选项,适配从个人开发到企业级场景的需求。
地址
Coze vs Dify
对比总结
| 维度 | 扣子(开源版) | Dify(开源版) |
|---|---|---|
| 产品定位 | 字节推出的低代码智能体平台,闭源主站为父,开源版本为「阉割」后的框架 | 专为私有化本地部署设计的开源 LLMops 平台 |
| 核心代码完整度 | 只开源了「智能化工作流引擎」部分;缺失容器化、UI、前端拖拽搭建能力 | 全部功能(前端、工作流、账号体系、模型管理、API/SDK)100% 开源 |
| 账号/多租户/协作 | ❌没有账号系统、没有 workspace;只能单账号单机使用,无法协作 | ✔️自带完整账号体系、workspace、RBAC,可多人协作、租户隔离 |
| UI 与易用性 | 开源包仅提供 API/SDK,需自己写前端或再包一层才能用;无拖拽搭建界面 | 提供完整 Web UI,用户可直接拖拽操作、测试、发布 |
| 部署难度 | 高:需自行配置模型接入点(火山推理点)、写 Dockerfile、手动启停服务;文档缺失细节 | 低:一条 docker - compose up 即可;官方文档详尽,社区脚本丰富 |
| 模型接入灵活性 | 只能「先配置、后使用」:新增模型需改配置并重启服务;默认强制走火山引擎 | 随时在 UI 里添加任意 OpenAI - API 兼容的模型(本地/云端均可供);无需重启 |
| SDK/二次开发 | 只提供 LlM SDK,需自己再封装一层服务才能嵌入业务 | 提供完整 REST API、SDK,直接调用即可;可一键导出 DSL 分享 |
| 数据库/记忆 | 开源版未暴露数据库,无法持久化存储用户数据 | 无内置数据库,但可很方便地外挂 MySQL/Postgres,插件机制成熟 |
| 适用场景 | 仅适合开发者学习工作流原理,或公司有足够研发资源想深度二开 | 任何规模企业或个人都可快速私有化部署并投入使用 |
| 社区/生态 | 刚开源,社区尚未形成;示例、模板稀少 | 社区成熟,DSL/模板/插件丰富,可一键导入他人工作流 |
| 商业授权 | Apache - 2.0,可闭源二次开发 | MIT 许可证,可闭源二次开发 |
开源扣子
优点
- 字节团队技术积累,工作流引擎稳定、Bug
- 代码结构清晰,适合开发者研究「智能体调度逻辑」。
- Apache-2.0许可证,可闭源商业化改造。
缺点
- 不完整:缺少差异化UI、前端可视化、账号体系,开箱不可用。
- 协作缺失:无多账号、无workspace,无法团队共用。
- 部署复杂:必须手动对接火山引擎推理点(endpoint +推理ID),流程繁琐。新增/切换模型须改配置并重启服务。
- 使用门槛高:只能发布成SDK/API,普通用户或运营人员无法直接使用。无现成界面,二次开发工作量大。
- 社区与文档薄弱:示例模板少,README。
扣子开源版更像「工作流引擎示例」,而非「可立即落地的企业级平台」;Dify则提供「下载即可用」的完整私有化方案。
扣子开源版:目前只适合程序员学习源码,不是拿来即用的工具。
- ❌ 没有可视化界面、没有账号系统、没有协作空间
- ❌ 部署巨麻烦,模型接入硬绑火山引擎
- ✅ 工作流引擎确实稳,但想真正落地,你还得自己写前端、写 SDK、搭服务
对比之下,Dify 一条 docker-compose up 就能跑起来,UI、账号、API、DSL 分享全齐活。
如果你:
- 👉 个人/小团队想快速落地 → 选 Dify
- 👉 公司有足够研发想深度二开 → 再考虑扣子
别再被“开源掀桌子”的标题党带节奏,按需选择,才是真的降本增效!
Coze Studio
Coze Studio 是一站式 AI Agent 开发工具。提供各类最新大模型和工具、多种开发模式和框架,从开发到部署,最便捷的 AI Agent 开发环境。上万家企业、数百万开发者正在使 Coze Studio。
- 提供 AI Agent 开发所需的全部核心技术:Prompt、RAG、Plugin、Workflow,使得开发者可以聚焦创造 AI 核心价值。
- 开箱即用,用最低的成本开发最专业的 AI Agent:Coze Studio 为开发者提供了健全的应用模板和编排框架,你可以基于它们快速构建各种 AI Agent ,将创意变为现实。
- 官方介绍

Coze Studio 为开发者提供:
- 可视化工作流编排:通过直观的拖拽节点方式,轻松构建复杂的 AI 工作流
- 插件生态系统:内置 Plugin 核心框架,支持将任意第三方 API 或私有能力封装为插件,无限扩展 Agent 能力边界
- 一键部署:提供开箱即用的开发环境,简化部署流程
Coze Studio 是字节新一代 AI Agent 开发平台扣子(Coze)的开源版本。通过 Coze Studio 提供的可视化设计与编排工具,开发者可以通过零代码或低代码的方式,快速打造和调试智能体、应用和工作流,实现强大的 AI 应用开发和更多定制化业务逻辑,是构建低代码 AI 产品的理想选择。Coze Studio 致力于降低 AI Agent 开发与应用门槛,鼓励社区共建和分享交流,助你在 AI 领域进行更深层次的探索与实践。
Coze Studio 的后端采用 Golang 开发,前端使用 React + TypeScript,整体基于微服务架构并遵循领域驱动设计(DDD)原则构建。为开发者提供一个高性能、高扩展性、易于二次开发的底层框架,助力开发者应对复杂的业务需求。
实践
火山接入代码
import os
from openai import OpenAI
# 请确保您已将 API Key 存储在环境变量 ARK_API_KEY 中
# 初始化Ark客户端,从环境变量中读取您的API Key
client = OpenAI(
# 此为默认路径,您可根据业务所在地域进行配置
base_url="https://ark.cn-beijing.volces.com/api/v3",
# 从环境变量中获取您的 API Key。此为默认方式,您可根据需要进行修改
api_key=os.environ.get("ARK_API_KEY"),
)
response = client.chat.completions.create(
# 指定您创建的方舟推理接入点 ID,此处已帮您修改为您的推理接入点 ID
model="doubao-seed-1-6-250615",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://ark-project.tos-cn-beijing.ivolces.com/images/view.jpeg"
},
},
{"type": "text", "text": "这是哪里?"},
],
}
],
)
print(response.choices[0])
步骤
git clone https://github.com/coze-dev/coze-studio.git
cd coze-studio
# Copy model configuration template
cp backend/conf/model/template/model_template_ark_doubao-seed-1.6.yaml backend/conf/model/ark_doubao-seed-1.6.yaml
配置信息
conn_config:
base_url: "https://ark.cn-beijing.volces.com/api/v3"
api_key: "899fb306-76ab-43ae-bc0e-******"
timeout: 0s
model: "doubao-seed-1-6-250615"
temperature: 0.1
启动服务
# Start the service
cd docker
cp .env.example .env
docker compose --profile "*" up -d
日志
[+] Running 29/68
✔ minio-setup Pulled 82.2s
- etcd [⠀] Pulling 174.1s
- coze-server [⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀] Pulling 174.1s
- minio [⠀⠀⠀⠀⠀⠀⠀⠀⠀] Pulling 174.1s
- elasticsearch [⣄] 382.3MB / 783.7MB Pulling 174.1s
✔ mysql-setup-schema Pulled 122.8s
- milvus [⣿⣿⣿⣿⣤⣿⡀] 222.2MB / 675.8MB Pulling 174.1s
- redis [⠀] Pulling 174.1s
- elasticsearch-setup [⠀⠀⠀] Pulling 174.1s
✔ mysql Pulled 127.3s
✔ mysql-setup-init-sql Pulled
浏览器打开
- http://localhost:8888
win 11 下docker 部署
报错
- 3306 端口被占用, Mysql无法启用, 提交 issue
Coze Loop
Coze Loop 扣子罗盘: Agent 开发与运维平台,从开发、调试、运维到监控的全流程生态周期管理

为 AI Agent 开发者设计的全流程开发工具平台,提供:
- 提示词联调:高效的提示词开发与调试环境
- 自动化评测:智能化的 Agent 性能评估体系
- 实时监控:全面的 Agent 运行状态监控
- 团队协作:支持多人协同开发
- 框架兼容:无缝接入 Langchain、Eino 等主流 AI 开发框架
FastGPT
FastGPT
Dify
Dify 是开源 LLM 应用开发平台
2023年,由前腾讯系创业者张路宇创立,首个提出“LLMOps”概念,目标是降低大模型应用开发门槛,定位为“企业级AI应用开发平台”
内置了构建 LLM 应用所需的关键技术栈,包括:
- 对数百个模型的支持
- 直观的 Prompt 编排界面
- 高质量 RAG 引擎
- 稳健的 Agent 框架
- 灵活的流程编排
- 并同时提供了一套易用的界面和 API。
为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
功能
Dify 涵盖了构建生成式 AI 原生应用所需的核心技术栈,开发者可以聚焦于创造应用的核心价值。
Dify 核心模块:
- 前端界面:提供用户交互界面
- UI 功能: 工作流编排、知识库管理、Agent配置等
- 代码地址 frontend 目录, 基于 React 框架开发
- 后端服务:包括 API服务和 Worker 服务,负责处理前端请求和任务调度。
- 数据库:存储工作流定义、知识库数据、用户信息等。
- 消息队列:用于异步任务处理,提高系统性能。
- 存储服务:用于存储上传的文件和知识库数据。
主要功能
Orchestration Studio:可视化编排生成式 AI 应用的专业工作站,All in One Place。RAG Pipeline:安全构建私有数据与大型语言模型之间的数据通道,并提供高可靠的索引和检索工具。- 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。
Prompt IDE:为提示词工程师精心设计,友好易用的提示词开发工具,支持无缝切换多种大型语言模型。- 制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。
LLM Agent智能体:定制化 Agent ,自主调用系列工具完成复杂任务。- 提供了 50 多种内置工具,如: 谷歌搜索、DELL·E、Stable Diffusion 和 WolframAlpha 等。
Workflow:编排 AI 工作流,使其输出更稳定可控。- 在画布上构建和测试功能强大的 AI 工作流程,利用以下所有功能以及更多功能
- 全面的模型支持:涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。
Enterprise LLMOps:开发者可以观测推理过程、记录日志、标注数据、训练并微调模型;使应用效果脱离黑盒,持续迭代优化。-
- LLMOps:随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。
-
BaaS Solution:基于后端即服务理念的 API 设计,大幅简化生成式 AI 应用研发流程。- 后端即服务:所有 Dify 功能都带有相应的 API,可轻松地将 Dify 集成到自己的业务逻辑中。
DIFY 支持各类主流模型
- 直接体验 页面

多个版本
- 开源版 FastGPT, github dify
- 商业版 Dify, 功能更多,不需要自定义太多
支持多种核心节点,包括:
- LLM节点: 选择任意一个主流的大型语言模型,并定义它的输入和输出。
- 工具节点: 使用内置的和自定义的工具来扩展workflow的功能。
- 意图分类器: 让LLM对用户的输入进行自动分类,根据不同的类别进行工作流转。
- 知识检索: 为LLMs挂载来自现有知识库的上下文数据。
- 代码节点: 执行自定义的Python或Node.js代码。
- If/Else 块: 定义条件逻辑以创建分支的Workflows。
解决了什么问题?
- 复杂逻辑构建:开发基于LLM应用时,构建包含复杂逻辑的应用通常需要 复杂的提示设计和管理
- Dify Workflow 通过多步骤的工作流程设计,简化了这一过程。
- 应用的稳定性和可复现性:传统的基于单一提示的LLM应用,其输出的不确定性和可 变性较高。
- Dify Work1ow 通过允许用户精细控制每一步的逻辑和输出,提高了应用的 稳定性和可复现性。
- 集成复杂业务逻辑:在企业级应用中,往往需要将A!功能与复杂的业务逻辑结合。
- Dify Workflow使得集成这些逻辑成为可能,无需编写大量的自定义代码。
国内 workflow产品体验较好。
【2024-6-29】实测
- 版面:
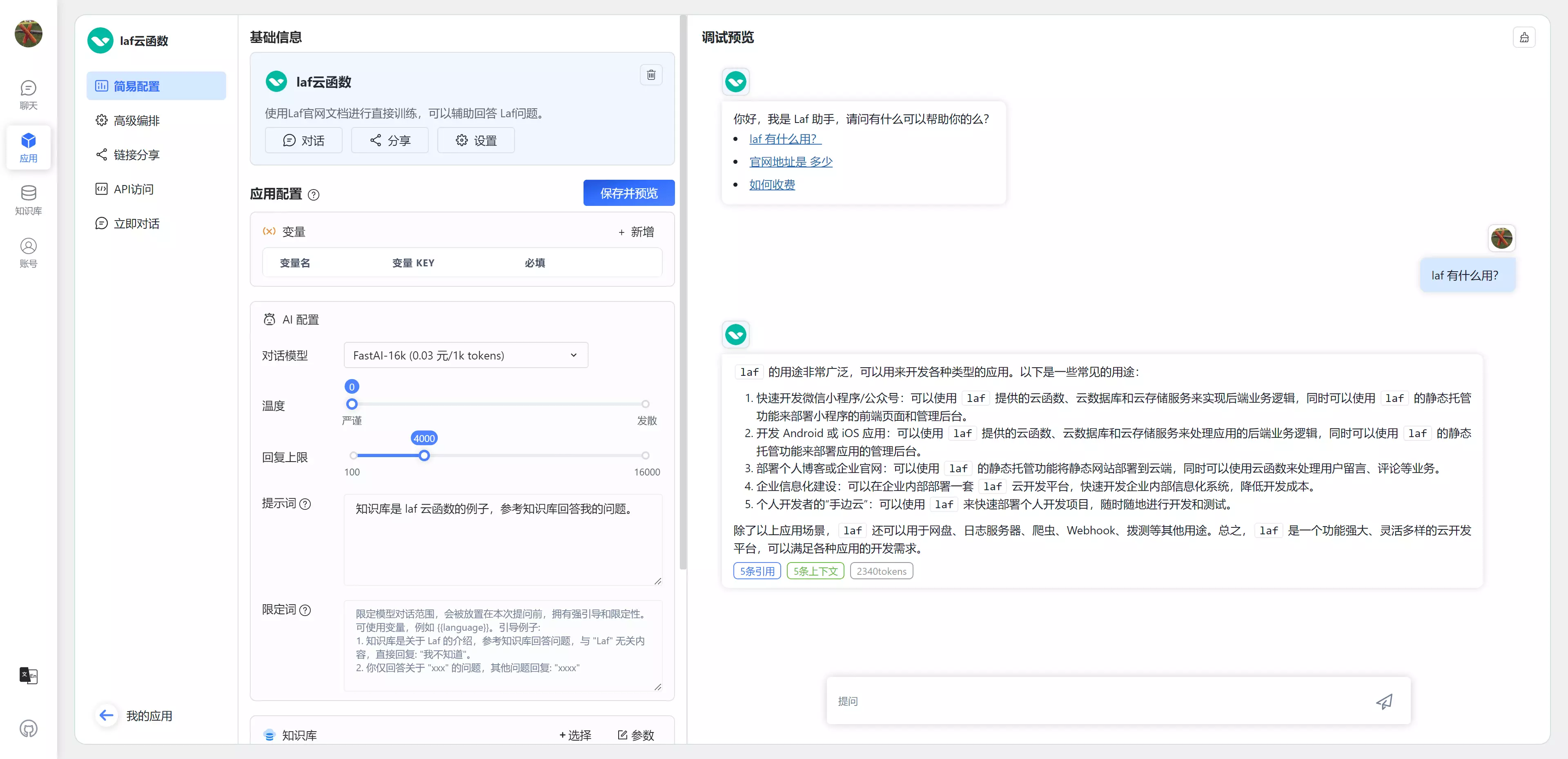
探索(bot市场)、工作室(bot编排)、知识库和工具(内置/自定义/工作流) - bot编排功能: 相对 coze 少很多
- system prompt、变量、上下文(导入知识库)、聊天增强(引用和归属)、调试预览
- 特殊功能: bot发布, 除了api, 还可嵌入网站(静态/浮窗/chrome插件)
嵌入示例:英语助手
【2025-6-26】问题
- dify 知识库录入 pdf文件时, 表格解析受限,表格字段错位,豆包、DeepSeek网页版正确
- Dify 中,集成了 Magic-PDF 工具来实现 PDF 文档的解析
- pdf文件里包含表格时,解析字段错位;
- 元宝和豆包没问题,但元宝、豆包背后用的啥pdf工具未知,豆包输出内容更详尽,原因是默认开启了联网搜索
DeepSeek AI 和豆包 AI 的文档提取能力,实现:
- PDF 解析:
- 对于文本型 PDF,使用 PDF 解析库(如 PyMuPDF、PyPDF2)直接提取文字。
- 对于扫描件或图像型 PDF,使用 OCR 工具(如 Tesseract、PaddleOCR)提取文字。
- 文本处理:
- 将提取的文字输入 AI 模型(如 DeepSeek)进行进一步处理,例如生成摘要、回答问题等。
- 多模态支持:
- 结合图像和文本信息,使用多模态模型(如 CLIP、BLIP)增强理解能力。
部署
【2024-7-3】Dify入门指南
开源版本部署
Dify 默认用
- PostgreSQL 数据库,默认没有开启远程访问
- 80 端口
- 知识库文档上传单个文档最大是 15MB ,总文档数量限制 100 个
非docker
也可以不用 docker,直接部署
- 官方 issue 一定要装docker才能部署吗
- 主要应用服务可以不用 docker
- 但中间件服务(如PostgresSQL,Redis,Weaviate)建议使用Docker Compose启动
node.js + npm 安装
docker
官方默认 docker 部署
git clone https://github.com/langgenius/dify.git
cp api/.env.example api/.env # 更新配置
cd dify/docker
docker compose up -d
sudo docker ps # 查看运行容器
# 浏览器中输入 http://localhost 访问 Dify
注意
- 如果安装 Docker Compose V2 而不是 V1,请使用
docker compose而不是docker-compose。 - 通过
docker compose version检查
win 11 安装
前置条件
- docker
- vpn
Docker 客户端软件 配置代理
Resources->Proxies-> 添加代理地址(http和https)->Apply&Restart- 如 http://127.0.0.1:2080
安装
docker compose up -d
日志
[+] Running 36/76
- nginx [⠀⠀⠀⠀⠀⠀⠀] Pulling 203.4s
✔ ssrf_proxy Pulled 155.0s
✔ db Pulled 156.8s
- sandbox [⣿⣿⣿⣿⣿⣿⣿⣿⣿⡀] 113.5MB / 186.6MB Pulling 203.4s
- web [⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀] Pulling 203.4s
- weaviate [⣿⠀⠀⠀] Pulling 203.4s
- worker [⣿⣿⣿⣿⣿⣿⣿⣿⣤⣿⣿⣿] 631.3MB / 942.8MB Pulling 203.4s
- redis [⠀⠀⠀⠀⠀⠀⠀] Pulling 203.4s
- api Pulling
FAQ
Dify常见问题解决:
- 忘记密码、忘记邮箱、开启HTTPS、知识库文档上传的大小限制和数量限制
- 参考
| 问题 | 说明 | 解法 | 其他 |
|---|---|---|---|
| 忘记密码 | 初次使用注册邮箱,设置后可能无法登录 | ① flask reset-password 命令重置 ② 直接操作 PostgreSQL 数据库修改密码信息 |
|
| 忘记管理邮箱 | |||
| 端口占用 | 修改 .env 文件中的 EXPOSE_NGINX_PORT | ||
| HTTPS 配置 | 修改 .env 文件中的 NGINX_HTTPS_ENABLED | ||
| 知识库限制 | 文档上传的大小和数量限制 | 调整 .env 文件中的 UPLOAD_FILE_SIZE_LIMIT 和 UPLOAD_FILE_BATCH_LIMIT | |
安装问题
【2025-6-22】腾讯云服务器上,ubuntu环境,部署Dify
- 注意: 需要配置代理, 访问外网, docker pull 环节需要,否则无法部署
密码找回
初次访问时,需要设置管理员邮箱、账户、密码
如果密码忘记,UI上“忘记密码”不管用,没有邮件,解决方法
# 服务器后端执行
sudo docker exec -it docker-api-1 flask reset-password
# 按提示输入 邮箱、新密码即可
邮箱配置
初次安装时,需要配置邮箱,以指定账户发送邮件
- 参考 Dify邮箱发送
具体
- docker-compose部署:直接修改.env文件
- k8s部署:修改全局 configMap 配置
MAIL_TYPE: "smtp"
MAIL_DEFAULT_SEND_FROM: "12345678910@qq.com"
SMTP_SERVER: "smtp.qq.com"
SMTP_PORT: "587"
SMTP_USERNAME: "12345678910@qq.com"
SMTP_PASSWORD: "youer password"
SMTP_USE_TLS: "true"
SMTP_OPPORTUNISTIC_TLS: "true"
修改完成之后,重启2个组件,api和worker
- k8s部署:直接删除2个pod即可
kubectl -n dify delete po api-0 worker-0
再次点击重置密码,输入邮箱地址
查看worker日志
kubectl -n dify logs -f worker-0
发送成功
端口问题
修改 .env 文件,指定 Nginx 暴露的端口。
# 编辑.env文件
EXPOSE_NGINX_PORT=9080
EXPOSE_NGINX_SSL_PORT=9443
https 支持
开启SSL以支持HTTPS
- 编辑 .env 文件,配置 NGINX_HTTPS_ENABLED=true 开启 HTTPS ;
- 将证书文件放到 dify-main/docker/nginx/ssl 目录下,记得命名为 dify.crt 与 dify.key ;
- docker-compose down 停止服务
- 启动服务 docker-compose up -d 生效。NGINX_HTTPS_ENABLED=true
知识库文档上传的大小和数量限制
- Dify 知识库文档上传单个文档最大是 15MB ,总文档数量限制 100 个
- 编辑 .env 文件。本地部署的社区版本可根据需要调整修改该限制。
# 上传文件大小限制,默认15M。
UPLOAD_FILE_SIZE_LIMIT=50M
# 每次上传文件数上限,默认5个。
UPLOAD_FILE_BATCH_LIMIT=10
代理设置
方法1:
- 亲测无效
配置
- 编辑文件 ./dify/docker/docker-compose.yaml
- 更改ip为自己的代理, 同时注释掉已有的 http_proxy(sandbox里有)
- 3台主机上添加一下配置: api, sandbox, plugin_daemon
http_proxy: “http://192.168.1.23:7890/”
https_proxy: “http://192.168.1.23:7890/”
HTTP_PROXY: “http://192.168.1.23:7890/”
HTTP_PROXYS: “http://192.168.1.23:7890/”
no_proxy: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
NO_PROXY: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
http_proxy: “http://172.17.0.1:4080/”
https_proxy: “http://172.17.0.1:4080/”
HTTP_PROXY: “http://172.17.0.1:4080/”
HTTP_PROXYS: “http://172.17.0.1:4080/”
no_proxy: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
NO_PROXY: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
方法2
docker-compose.yaml中的ssr_proxy服务,添加环境变量:
HTTP_PROXY_SERVER_HOST: 172.17.0.1
HTTP_PROXY_SERVER_PORT: 4080
DOMAINS_BY_PROXY: ".googleapis.com .google.com google.dev .openai.com .anthropic.com .github.com .githubusercontent.com .githubassets.com .youtube.com .duckduckgo.com .huggingface.co .dify.ai"
修改 ssr_proxy/squid.conf.template文件,添加上游代理配置,在
# cache_peer 172.1.1.1 parent 3128 0 no-query no-digest no-netdb-exchange default
下一行添加如下配置:
# 使用squid的机制实现对指定域名及其子域名走上游代理
cache_peer ${HTTP_PROXY_SERVER_HOST} parent ${HTTP_PROXY_SERVER_PORT} 0 no-query no-digest no-netdb-exchange default
acl external_domains dstdomain ${DOMAINS_BY_PROXY}
never_direct allow external_domains
cache_peer_access ${HTTP_PROXY_SERVER_HOST} allow external_domains
cache_peer_access ${HTTP_PROXY_SERVER_HOST} deny all
重启服务
docker compose down
docker compose up -d
架构
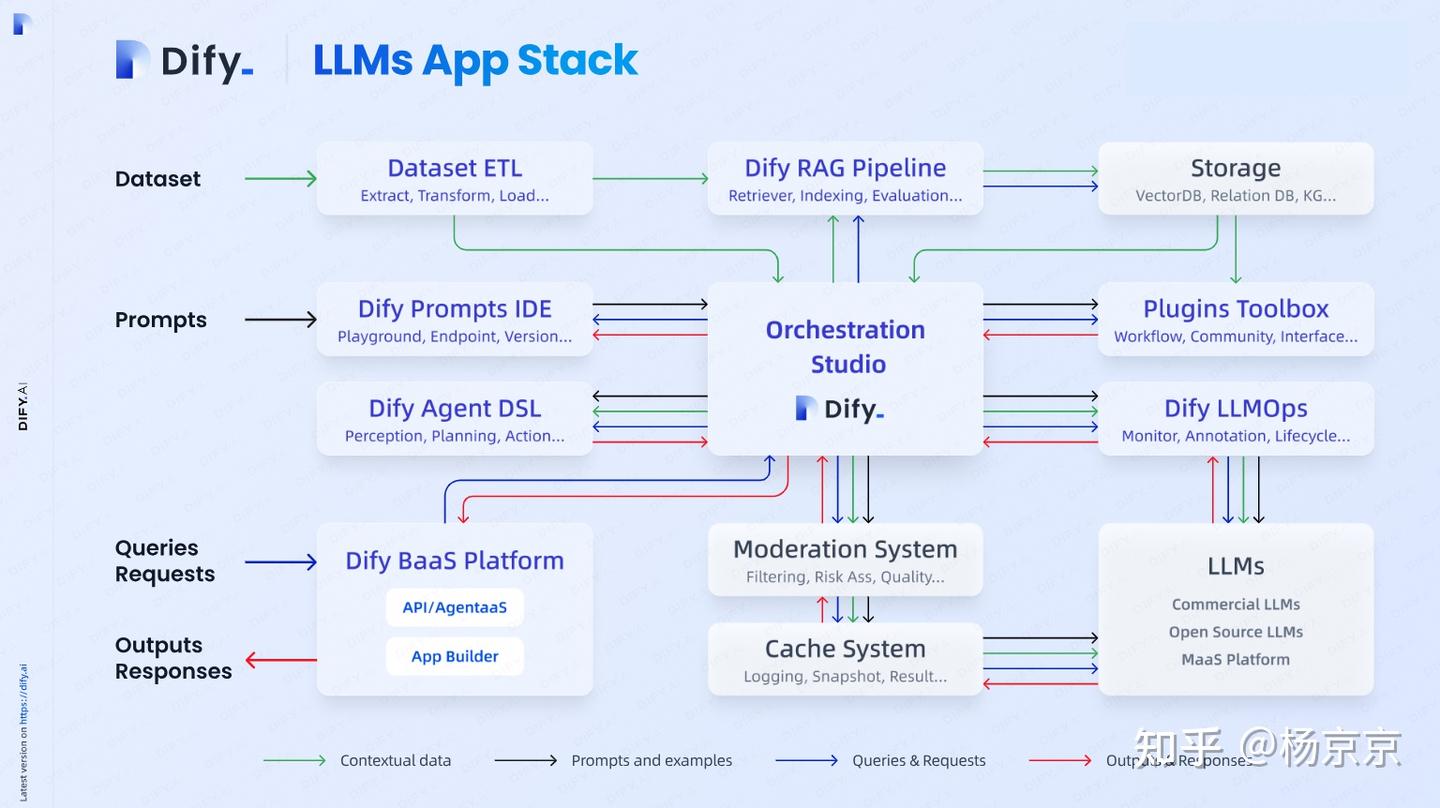
Dify 整体架构
包括
- 3 个业务服务: api / worker / web
- 6 个基础组件: weaviate / db / redis / nginx / ssrf_proxy / sandbox
后端服务使用了
- Flask 中的蓝图(Blueprint)
- CORS 处理跨域请求
架构
- 6大服务组件: postgres 数据库、redis、weaviate、dify-sandbox、dify-plugin-daemon、squid
- 通过docker 容器部署,也可以由本地已有的环境考虑是否都由docker生成容器服务。
- 3大业务服务: api、web、worker
- 本地源码部署启动,需要对应环境和依赖。
- worker服务用于消费异步队列任务,如知识库文件导入、更新知识库文档等异步操作,并不影响登录测试及基础功能的使用
使用
代码节点: 支持 Python 和 js
def main(input_var1, input_var2):
# 在函数内部导入模块
import json
# 处理逻辑
result = input_var1 + input_var2
# 返回字典,键名对应输出变量
return {
'output_var1': result
}
不足
【2025-7-10】 dify上代码节点:
- 代码支持js和python
- dify 沙盒对代码节点敏感,有warning就fail
大模型做规划的问题:
- 时间长,平均20-50s
- 无法精准遵循指令
gptbots
【2023-12-7】对话平台 gptbots, 类似字节 coze
Gnomic
【2024-1-16】Gnomic 智能体平台
- 无需魔法,随时随地免费使用GPT-4,并打造个性化GPTs智能体
- 集成 GPT-4, Gemini
Flowise
拖放界面构建定制化的 LLM 流程
核心功能列表:
- LLM 编排:支持 LangChain、LlamaIndex 等 100 多个开箱即用的服务。
- Agents & Assistants:支持创建可以使用工具执行不同任务的自主代理。
- 友好的开发体验:支持 APIs、SDK 和嵌入式聊天扩展,方便快速集成到您的应用程序。
- 全面的模型支持:支持 HuggingFace, Ollama, LocalAI, Llama2, Mistral, Vicuna, Orca, Llava 等模型。
实践
- 三分钟零代码创建AI智能体工作流, 开源免费 Flowise 超越 Coze 和 dify!打造复杂多AI Agents协作任务!轻松驾驭多智能体协作
- 代码见主页
- 开源项目 AISuperDomain
LangFlow
Langflow 是一个动态图,每个节点都是一个可执行单元。
- 模块化和交互式设计促进了快速实验和原型开发,挑战了创造力的极限。
核心功能列表:
- 开箱即用的组件:内置了 LLMs、Loaders、Memories、Vector Stores 等功能组件;
- 支持与第三方系统无缝集成:打通了与 Notion、Slack、Supbase、Google 等主流的平台之间的数据集成;
- 友好的开发体验:支持通过电子表格轻松微调 LLM,充分发挥 LLM 的潜力。支持自定义组件,满足不同的业务场景。
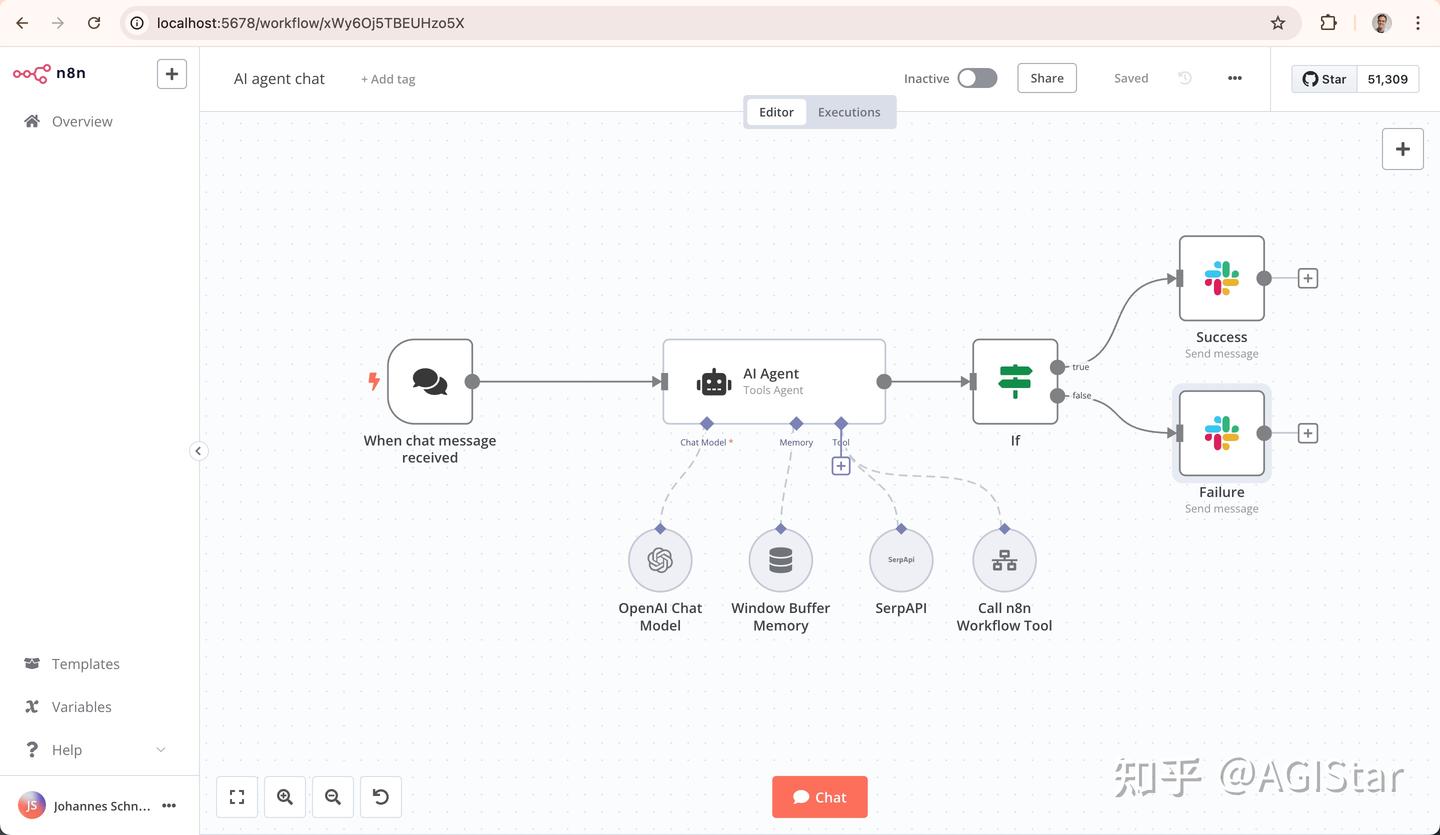
n8n
扣子虽然提供了很多现成的AI模板(比如智能客服、文档分析),但核心逻辑依赖云端服务,数据必须经过第三方服务器。
这对于医疗、金融、政务这些强监管行业来说,致命缺陷。
如果关心 数据安全、系统集成和长期成本,n8n 才是更值得投入的选择
n8n:2019 年由前《加勒比海盗》视觉设计师 Jan Oberhauser 创立。因不满 Zapier 等工具的 “不灵活” 和高成本,秉持 “自由可持续,开放且务实” 的理念,打造了完全开源的自动化工作流工具。
n8n(发音为”n-eight-n”)是强大的工作流自动化平台,专为技术团队设计。
- 资料
- GitHub n8n-io
- 结合了无代码的便捷性和代码的灵活性,让够构建从简单到复杂的各种自动化流程。
- 介绍
与市面上其他自动化工具相比,n8n 有几个突出优势:
- 完全可自托管,数据掌握在自己手中
- 400+ 集成,覆盖几乎所有主流服务
- N8N 拥有超过 2000 个节点,涵盖了各种常见的应用和服务,如社交媒体平台(Facebook、Twitter)、云存储(Google Drive、Dropbox)、项目管理工具(Trello、Asana)等。用户可以像搭积木一样,通过拖拽这些节点轻松构建复杂的工作流。
- 内置 AI 能力,支持 LangChain 和自定义模型
- 公平代码许可,核心功能完全免费
优势
- 开源免费
- 高度可定制
- 社区支持
亮点
-
私有化部署能力。Docker快速搭建,甚至直接跑在本地服务器上,数据完全不出内网。
-
腾讯 ima
ima
【2024-12】ima.copilot(简称ima)是腾讯发布的产品,一款基于混元大模型的智能工作台产品。
目前官网上线了 Mac 和 Windows 应用端版本。
官方对ima 定位是: 会思考的知识库,开启搜读写新体验
可在工作台上实现资料收集、快速解读、AI问答,并把生成的结果存在你的个人知识库内,用于创作。
页面很简单,一个搜索框,功能跟市面上大部分大模型应用差不多;
- 支持文字问问题、文件上传、截图识别、图片识别。
- 文件上传支持PDF、doc格式,可以做100M以内,小于500页的文件解读。
ima 主要功能
- 智能搜索:允许用户通过自然语言提问,获取全网信息及个人知识库中的相关内容,支持上传截图和文件进行识别。
- 知识库管理:展示用户本地文档和笔记的整合,支持标签编辑功能及AI搜索,旨在让用户的个人知识管理更加系统化。
- 智能写作:支持从本地或知识库添加资料作为参考文档,进行智能写作,拥有论文、作文(覆盖中小学)、文案(朋友圈、小红书)等写作模式。
- 文档解读:支持对知识库文件、本地文件进行解读,AI会基于文件生成总结、提炼要点。支持个人文件云存储1GB,目测后面这个地方是一个会员订阅的付费项。
- 生成脑图:针对专业领域的问答,支持“深度研究”,AI会从广度和深度两方面对问题进行拓展,提供更具结构化、更丰富的回答,并支持生成脑图。
元器
腾讯元器智能体平台
- 社交基因:深度集成微信/QQ/公众号,支持3D虚拟形象生成,适合教育陪练、游戏客服
- 依托腾讯生态:可以在QQ、微信、小程序等平台分发,覆盖广大用户群体
腾讯元器,可以基于腾讯的大模型,快速搞出自己的 AI 智能体。功能上,设置智能体信息、一键分发到腾讯系的平台都挺方便,不过,目前插件生态也还有待提升。
智能体可以一键分发到QQ、微信客服等腾讯生态渠道,未来还可发布到小程序、微信公众号等。
百度
千帆
文心智能体
百度·文心智能体
图片 企业服务优势:无缝接入百度搜索、地图、文库,适合电商导购、本地生活服务 实测局限:复杂语境理解较弱
AgentKit
【2025-10-6】OpenAI 开发者大会DevDay 2025发布了什么?
OpenAI在开发日带来很多新发布:
- ChatGPT 中引入Apps:可直接在ChatGPT进行自然对话的Apps,以及供开发者构建自己应用程序的全新Apps SDK(预览版)
- AgentKit:一整套用于开发者和企业构建、部署与优化agent的完整工具集
- 新模型API:
Sora 2、Sora 2 Pro、GPT-5 Pro、gpt-image-1-mini和gpt-realtime-mini - Godex GA:Codex 现已全面可用,同时推出三项新功能。
OpenAI正式推出 AgentKit,用于开发者和企业构建、部署与优化agent的完整工具集。
- 以前,构建agent 要在各种零散工具之间来回折腾:复杂且无版本控制的编排流程、自定义连接器、手动评估管线、提示词调优,以及在上线前需要耗费数周构建前端界面。
- AgentKit 可以通过全新构建模块,以可视化方式快速设计工作流,并更快地嵌入智能体交互界面,包括:
Agent Builder:创建和版本管理多agent工作流的可视化画布Connector Registry:管理员可在此集中管理数据和工具在 OpenAI 产品间的连接方式ChatKit:一套可嵌入产品中的、可自定义的聊天式agent体验工具包
LLM tech map
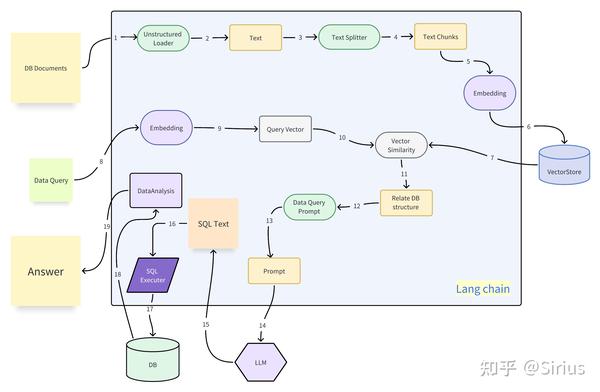
langchain-rag
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
