智能客服
客服行业
客服 vs 销售
ai客服 vs ai销售
【2025-6-15】区别:
- ai客服一次性解答
- ai销售具备长期记忆,多轮会话,逐步引导
人工客服
【2025-7-24】刘润:我在石家庄当客服
亲自去一线体验生活
- 2024年9月,我在上海送外卖。
- 大众认知: “大不了”,我就去送外卖。 外卖小哥是纯体力劳动。无需大脑介入。只要会“取餐,敲门,开小电驴”,就能干。
- 2025年3月,我在上海开滴滴
- 一名优秀的滴滴司机,需要像CEO一样思考战略,像CFO一样精算成本,像COO一样优化流程,像CMO一样经营客户。他们与算法博弈,与时间赛跑,让每一分钟价值最大化。
- 2025年7月,刘润:我在石家庄当客服
- 万一咨询行业被AI取代,怎么办?以后,就把这句话甩他脸上:开着滴滴送外卖啊!
海信客服中心在石家庄
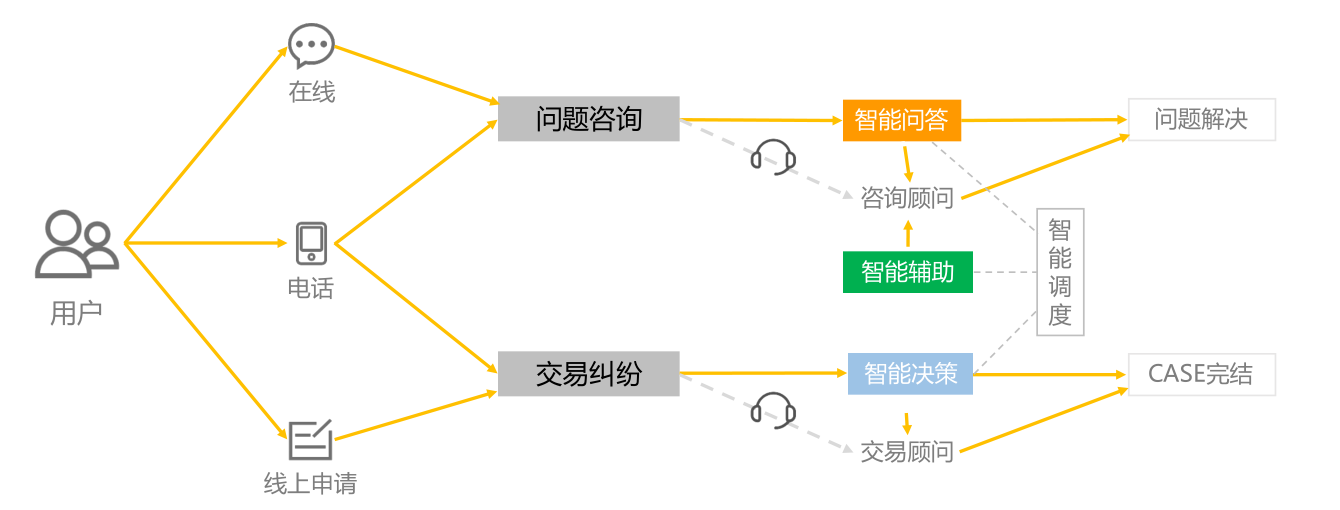
客服的三大能力,并发处理、化解情绪、穿针引线
并发能力:并发处理,点单时记住所有,送餐后彻底忘掉一切。脑子里只有最近的50单在循环- 热线客服1v1,在线客服1v10+,优秀客服最高同时和50个客户沟通
- 客户说完任何一句话,15秒之内必须看到回复,否则愤怒情绪已经升级为退货决定。
- 沟通必须结束在你的回复,而不是他的等待
化解情绪:帮客户结束战斗状态,要给对方一只“懒人沙发”,比如“感谢”- 大部分用户带着情绪进线,平均24岁的客服承受了太多,年离职率几乎50%以上
- 处理客户问题之前,要先处理好客户情绪。处理好客户情绪之前,要先处理好自己的情绪
- 服务业喊口号是为了提前发泄情绪,调整为最佳状态。服务业的微笑,是职业武装,也是心理防护
- 一句“您好”的背后,日均承接30+次愤怒、哭泣。客服是情绪的消防员,每天扑灭30场心理火灾。然后在15秒内切换回“平静模式”。
穿针引线:订单是针,客服是线。客服的工作是用针线把所有系统串起来,为客户问题找到答案- 千牛配备羚羊AI智能助手,提供智能辅助能力(智能提示、智能填单、情绪识别、外呼跟进等)
AI不是抢饭碗,而是“递筷子”。
- AI负责客服每天80%重复工作。剩下20%个性化工作,还是必须由人来完成 外呼是为了服务,而不是为了骚扰
- 客户越来越不喜欢接电话了,骚扰电话太多
- AI只允许在9-21点之间打给客户。只为他的订单而打。客户挂断后的15分钟内,不允许再打。
真正的专业,不是知道所有答案,而是能听懂所有问题
对客服的全新理解。
- 每次淘宝购物的“联系商家”背后,究竟是怎样一套体系。
- 看似简单的“亲亲”背后,究竟是怎样的辛苦。
- 为什么问候结尾的语气词永远是“嘛”,而不是“吗”。
今天的在线客服,和当时的电话客服,完全不同
- 热线客服: 单频处理一个客户的问题
- 在线客服: 客户用“淘宝”提问,你用“千牛”回答, 客户觉得在和你一对一聊天。但其实你电脑上开了10几个窗口。优秀的客服最高同时和50个客户沟通
要求
- 客户说完任何一句话,15秒之内,必须看到你的回复,否则愤怒情绪已经升级为退货决定。
- 沟通必须结束在你的回复。而不是他的等待
晨会结束,一起喊:
“好!很好!!非常好!!!”
为什么非要喊口号呢?不能有事说事,没事散会吗?
大部分催促发货的客户会着急并带着情绪进线,甚至说些难听的话。系统会自动过滤一些难听的话,甚至一些不雅的图。但这些平均24岁的小姑娘们,还是承受了太多。这也是为什么客服这个行业,年离职率几乎50%以上。
- 处理客户问题之前,要先处理好客户情绪。
- 处理好客户情绪之前,要先处理好自己的情绪。
50%以上离职率背后,可能是100%的情绪消耗。
服务行业喊口号唱歌,你觉得是个问题。但其实是解决方案。每天,她们都需要给自己打气,用自己饱满的情绪,去化解客户愤怒的情绪。
服务业的微笑,是职业武装,也是心理防护。
一句“您好”的背后,日均承接30+次愤怒、哭泣。客服是情绪的消防员,每天扑灭30场心理火灾。然后在15秒内切换回“平静模式”。
海信有电视、冰箱、空调…7大类产品。数百个SKU。每个SKU可能有200个不同的功能点。而且,商品、活动等信息时刻在变化。没有人可以记住所有。所以,这时你就需要快速切换。在功能文档里查。在物流系统里找。在话术表格里翻。在二级客服的钉钉群里问。然后把结果给到客户。
客服核心能力:
- 并发处理
- 化解情绪
- 穿针引线
订单是针,我们是线。我们的工作是用针线把所有系统串起来,为客户的问题找到答案。
千牛上配备了羚羊开发的AI智能助手,提供智能辅助能力
- AI 引导确认消费者是否成功修改预约配送时间,在确认消费者修改失败后,智能辅助页面又“自动”出现了一个按钮:智能填单。2-3分钟填写的表单。催发货、催派送,现在只需要10s
- AI Agent “自动”识别出了客户的投诉情绪。给出建议话术。你只要点一下“发送”按钮。一秒内,就可以回复客户。
AI不是抢饭碗,而是“递筷子”。
- AI负责客服每天80%的重复工作。剩下20%的个性化工作,还是必须由人来完成。
- 这时的客服不再是复制粘贴的机器了,而是有情绪、有创造性的人。那些繁琐、重复、没有创造价值的事情,都交给AI就行。
外呼是为了服务,而不是为了骚扰
今天的客户,越来越不喜欢接电话了,骚扰电话太多
- AI只允许在9-21点之间打给客户。只为他的订单而打。客户挂断后的15分钟内,不允许再打。
AI 功能: AI填单、AI识别、AI外呼、AI跟进。
真正的改进来自用户,而不是实验室的想象。带回客户的反馈,才是客服最大的价值。
| 指标 | 刘润 | 优秀员工 | 人工智能 |
|---|---|---|---|
| 每小时接待量 | 10 | 50 | 75 |
| 平均响应时间 | 83s | 15s以内 | 3s |
| 催发工单时长 | 3 - 4min | 2min | 10s |
| 退款操作时长 | 16.5min | 2.4min | 1s(秒级) |
敬畏那些被视为“简单工作”背后的深度和难度。客服的三大能力,并发处理、化解情绪、穿针引线。每一项,都是需要千锤百炼的技艺。
这个世界上,哪有什么真正的“感同身受”。每一次“我以为”的背后,都藏着一个“我不知道”。
【2025-7-24】视频
对话系统
详见站内对话系统知识专题
发展阶段
【2021-5-31】阿里小蜜:智能客服的几种模式
- 传统服务模式
- 经典服务模式
- 智能问答服务模式
- 【2021-5-8】智能客服终将被颠覆,进化为下一代智能服务, Mingke,智能对话领域创业者. 作者的相关文章:人工智障 2 : 你看到的 AI 与智能无关,2016-11,为什么现在的人工智能助理都像人工智障?
- 现阶段智能客服在理念方向和技术上都存在一定瓶颈。在未来,智能客服终将被颠覆,将进化为下一代智能服务 。Mingke 认为,一家智能客服公司要想快速建立起自己的核心壁垒,重点是更快地转型为智能服务公司。


智能客服是金融机构应用较多的 AI 产品,但是体验不佳,并非想象中的智能,甚至有些“智障”。一些智能客服产品与人对话时常常答非所问,对于一些金融专业词汇和知识等识别不准确、一遇到复杂的金融场景就“歇菜”…
资料
- 【2022-1-28】北京12345平台,公众号上嵌入的智能客服插件
- 【2021-6-15】浅谈智能客服机器人的产品设计
- 【2022-7-14】曾经,我对着AI客服喷了两分钟,它只回复了我的第一句话
- 接打快递、银行等电话时,遇到AI的情况越来越多了。和这些AI沟通,还得讲究一个技巧:要保持你一句我一句的标准节奏,不然难免变成“人工智障”。
- 比如话说一半卡壳停顿了,AI会以为你说完了,对着半句话给出莫名其妙的回复
- 如果在一句话中间打断它,也很少有AI能反应得过来
- 要是投诉时情绪比较激动,对着话筒一顿输出,AI可能只回复了第一句,甚至不听你的,跟你“抢话”。
- 谷歌在今年的I/O大会上终于提到这个问题,给出的初步解决方案演示还获得满场掌声。
- 国内其实有人(京东)关注这个问题比谷歌更早,京东集团副总裁、IEEE Fellow何晓冬博士看来,这既不属于语音识别问题,也不属于语义理解问题,学术研究中往往关注度不高。只有在落地实践中,这样的问题才会暴露出来,进而有机会解决。
- 在京东,何晓冬带领团队融合声学、语义、时间等多模态特征,开发了一系列人机交互场景的“话语权决策“(Turn taking)技术。这套技术在京东智能客服系统上每天有百万到千万级的咨询量,就相当于每天要做上千万次图灵测试,已经日趋成熟。
- 何晓冬提出“对话的本质是推理与决策”,语言只是其中一种表现形式。智能客服领域,决策推理能力还体现在如果遇到退换货、或者其他问题,言犀可以结合对业务场景深度的理解,以及RPA(机器人流程自动化)能力,特别情况下还通过优惠券等多种方式来补偿客户,或遇到复杂问题自动转接给人工客服处理。
- 通过解决客户服务实践中遇到的种种问题,一套语音语义技术被打磨得更实用,也更以人为本。
- 情感识别上,有业界首个大规模商用的情感系统,能识别生气、失望、愤怒、焦虑等7种情绪。
- 方言识别上,专门开发口音适配模型和算法,结合语音识别和语义理解联合建模保证精确性,已能识别粤语、四川话等多地方言。
- 接打快递、银行等电话时,遇到AI的情况越来越多了。和这些AI沟通,还得讲究一个技巧:要保持你一句我一句的标准节奏,不然难免变成“人工智障”。
- 【2022-10-21】智能客服搞笑吐槽视频,当战士遇到人工客服
LLM 与 ICS
大模型智能客服飞书文档总结
ICS 思考
【2024-3-4】杜玉姣,客服对话大模型-算法探索与落地
传统客服
- 劳动密集型
- FAQ问答为主
- 复杂问题靠人工
传统客服流程:用户进线(online/hotline) -> 定位问题 -> 解决问题 -> 结束服务 -> 创建工单
- 坐席对话阶段要解决 定位+解决 环节的问题
大模型有强大的理解、记忆和生成能力,弥补了传统客服的缺陷
客服分级
| 阶段 | 特点 | 说明 |
|---|---|---|
| L1 | 全人工操作 | 传统客服模式,所有工作都有坐席承担 |
| L2 | 机器辅助人类 | 智能客服模式,AI意图识别、话术推荐等,辅助坐席提效 |
| L3 | 人类辅助机器 | LLM为主坐席监督的全托管模式,Agent |
| L4 | 机器取代人类 | LLM独立承接用户诉求,坐席无需参与 |
LLM 客服
- 根据会话上文+当前问题,自动生成回复
- L2 形态下, 坐席点击采纳才发送
- L3 形态下, 坐席在旁边监督,超时未干预, 机器自动发送
挑战
- 领域知识注入: 领域知识库+SOP+话术模版
- 做法1:
CT(增量预训练)/SFT(监督微调) - 分析: 链路简单,但更新频率低,无法实时
- 做法2:
RAG外挂知识库 - 分析: 链路长,耗时多,可快速更新
- 做法1:
- 推理: 负责场景需要多步查询、思考
- 幻觉: 违背事实、不符合话术
- 知识更新: SOP 新增与更新
- 知识边界: 机器要有拒识能力,无法回答的问题流转给人工客服
LLM 对话系统的影响及变革见站内专题: llm时代的对话系统何去何从
传统客服
传统智能客服在回复上经常犯以下四大通病:
- 有限的理解能力
- 缺乏上下文感知
- 交互性和灵活性不足
- 个性化服务不足
经历了多年的“答非所问”、“一问三不知”,很多人已经厌倦了所谓的“智能客服”。哪怕是技术已经非常成熟、可以模拟真人发音的外呼机器人,也会因为“机感”重而被用户迅速挂机或转向人工客服。
智能客服似乎遇到了一道坎,在理解用户、和用户对话方面,始终无法实现真正的“智能”。
然而大模型技术的出现,让智能客服看到了前所未有的曙光——基于大模型特有的生成式技术和智能的涌现,让智能客服越来越逼近人们想象中的样子。
LLM 对 Chatbot 和 AI 客服影响
- 早期基于 rule-base 的 Chatbot 对答: 可控、可预测、可重复,但对话缺乏“人情味”,并且存在重复和循环对话的风险。
- 传统 Chatbot 架构和工具非常成熟,主要包括四个部分:
NLU自然语言理解,DM对话流程管理(对话流和响应消息,基于固定和硬编码逻辑)、信息抽象(预定每个对话的机器人响应)、知识库检索(知识库和语义相似性搜索)。 - 传统 Chatbot 唯一基于机器学习和 AI 模型的组件是 NLU 组件,负责根据模型预测意图和实体。
- 优点:有众多开源模型、占用空间小/无需过多资源、存在大量的命名实体语料库、有大量垂直行业的数据。后来的 Chatbot 采用更复杂的算法,包括自然语言处理(NLP)和机器学习,来提供动态和上下文相关的交互,从而解决早期基于模板的方法的缺点。
- Chatbot 后期, 出现 Voicebot。
- Voicebot 基本流程:
Voicebot=ASR(Automatic Speech Recognition) +Chatbot+TTS(Text To Speech)。 - 这些变化增加了复杂性,提供更好的对话效果、更长的对话时间和更多的对话轮次,以及更复杂的对话元素(如自我纠正、背景噪音等)。
- 然而,Voicebot 问题:有延迟问题、需要更复杂的流程、需要加翻译层、容易出现对话离题、用户打断对话难以解决等。
- Voicebot 基本流程:
开发者依然在渴望一个灵活且真正智能的对话管理系统。
LLM 对 ICS 影响
LLM 从开发到运行都颠覆了 Chatbot IDE 生态系统:
- 不仅加速了 Chatbot 的开发设计,大大提高了泛化能力;
- 而且在对话运行中实现上下文交互、灵活且智能回复。
- 但缺点:稳定性、可预测性较差,以及在某种程度上的可重复性弱。
大模型对智能客服影响
- 降低了技术门槛,大厂或者传统NLP企业的技术和数据壁垒不复存在。
- 过去训练模型的成本非常高,算法工程师的工资比较高、标注数据的成本也不低,训练用的显卡和机器成本也需要考虑。
- 这些条件备齐的情况下,达到85%准确率,如果再往上提升,需要付出数倍的时间和人力成本。
- 而现在只需要调用大模型接口,就达到业界最先进的技术水平,拉齐了大厂和小公司的技术实力。
- 同时语料数据或者垂直领域的数据积累带来的优势也随着大模型专业能力的提升也会逐渐减弱。
- 产品通用性增强:大模型产品通用性增强。可以支持跨场景、跨行业而无需复杂的定制功能,提升产品的标准化。
- 大模型智能体适用于很多场景,包括智能客服,只需要简单的配置就可以搭建出复杂的业务流程,这在之前的产品中需要非常复杂的规则逻辑。
- 现在只需要说清楚逻辑和定义,其他的交给大模型就可以了。
这些因素带来的就是产品门槛降低,更多的市场进入者,从而加剧竞争程度。一些专注于大模型智能体的产品也很容易渗透到智能客服市场,其通用性、简易性反而会受到一部分客户的欢迎。
LLM 如何升级 ICS
LLM 对 AI 客服行业的改变/颠覆, 分四个阶段:
- 第一,开发阶段加速。在 Chatbot/Voicebot 开发过程中用 LLM 加速 NLU 开发,此阶段使用 LLM 的好处是容错率较高,并且可以显著降低研发/人力成本。
- 例如,LLM可以在生成意图训练数据、检测命名实体等方面提升数据的准确性和开发效率,还可以通过描述流程生成流程框架,简化开发过程。
- 第二,Chatbot 运行阶段将 LLM 用于增强搜索、问答、文本编辑、对话管理等功能。
- 第三,多样化价值实现与责任承担。
- 鉴于 AI 客服直接面对客户的特性,错误输出可能导致重大损失和客户投诉。因此,企业需要一个既稳定、可审计的 LLM 来实现多样化的价值。另外,在一项企业对 LLM 态度的调查中,很多企业表示对 LLM 提供商托管和 API 访问的依赖带来了运营挑战。理想情况下,企业更希望在本地安装 LLM,以遵守个人身份信息和其他隐私保护法律。这将确保模型中传输和使用的数据路径能够接受全面审计。
- 因此,第三阶段 LLM 机会在于在数据隐私和审计安全的基础上,提供模型部署、定制化的 LLM Playground、无代码微调、托管、Agent、Orchestration 等多种价值机会。
- 第四阶段是 In-Context 数据利用。LLM 微调最好的起点就是企业内部的信息流(例如现有的客户对话),因此数据发现、数据设计、数据开发、数据传输也是 LLM 的机会。
个性化
【2023-6-30】用AIGC重构后的智能客服,能否淘到大模型时代的第一桶金?,未来中短期内 ChatGPT 产业化的方向大致有四类:即智能客服、文字模态的 AIGC 应用、代码开发相关工作以及图像生成。其中,最适合直接落地的项目就是智能客服类的工作。
基于大模型技术所构建的智能客服正在从根本上改变传统的人机交互过程
- 大模型自动生成对话流程让运营智能客服更高效,可以提升复杂缠绕问题解决率、人机交互感知程度,以及意图理解、流程构建、知识生成等运营内容的效率。
如果单从产品渗透率层面来看,智能客服早在过去七八年里就已经在电商、金融等等领域慢慢普及开来了。
大模型带来的两个核心改变
- 一个是开发智能客服产品的成本大幅度下降
- 2016 年左右做一个智能客服的原型产品要一个7-8人的小团队,耗时几个月的时间才能完成。
- 有了大模型,可能一个工程师2-3天就做出来了。
- 另一个就是用户体验的提升。
- 过去的智能客服产品虽然是“智能”但回答问题时“呆板”,内容大都预先写好的模版,能够回答的问题也有限。
- 现在大语言模型能够根据用户的问题和对应的标准答案,给出个性化答案,用户体验上已经不太容易分辨出是人工客户还是机器客服了,这一点上是很明显的提升。
大模型强大的自然语言生成能力将智能客服推向更加智能化、高效化和个性化的新局面。
问题
- 如何将 LLM 大语言模型与智能客服产品进行结合?
- 如何将大模型落地于 ToB SaaS 应用软件领域?
- 该如何着手搭建技术栈?
- 大模型产品将如何赋能智能客服产品?
华院计算技术总监兼数字人事业部联合负责人贾皓文和中关村科金智能交互研发总监、中关村科金智能客服技术团队负责人王素文,探讨 AIGC 在智能客服产品中的落地及未来发展趋势。
大模型掀起一场“新革命”革命之前,还需要为其铺好每一段路,不能操之过急。比如
- 智能客服产品领域中,对话通常是限定于特定业务领域和任务驱动的需求。
- 但客户并不希望只是为了寻找⼀个超级智能、善解⼈意、会写会画的聊天机器⼈。对话内容必须在企业业务范畴内收敛,服务于客服和营销场景,解决和处理问题,不要浪费宝贵的资源。
- 直接将 ChatGPT 这类大模型引⼊客服领域⽽不加控制,其结果难免会让人失望。
构建一款能够实际应用于业务中的大模型并非容易事,通常需要完成多项步骤,包括大模型选型、数据采集清洗、模型训练、模型测试与评估、模型微调、部署应用等。
- (1)选择开源通用大模型
- 收集领域数据,用领域数据继续训练开源大模型(学术上叫知识注入),得到领域大模型
- 整理领域任务的指令集合(半自动生成),用这些指令数据对领域大模型进行指令微调
- 筛选优质的真实场景的客服多轮对话数据,继续微调领域大模型(使领域大模型的对话能力增强)
- 收集一些安全相关的问题(例如涉及到政治、敏感话题、歧视等),人工给出符合安全要求的答案,继续微调大模型(对齐到人类的价值观、规范)
- (2)模型部署,对接智能客服系统进行应用
- 数据准备:对话模型的训练数据应该具有足够的质量和多样性,以提高模型的泛化能力。对话数据可以通过爬虫、问答社区、对话记录等多种方式获得。在获得数据后,需要进行数据清洗和预处理,使得数据格式规范、数据质量高。
- 模型训练:在准备好训练数据后,开始训练大模型。
- 训练过程中需要选择合适的超参数,如学习率、批量大小、训练轮数等,以达到最佳的效果。
- 另外,可用分布式训练技术,以加速训练过程。
- 模型优化:模型训练完成后,需要对模型进行评估和优化,以提高模型的泛化能力和效果。
- 常见优化方法包括调整超参数、增加训练数据、使用正则化技术、剪枝模型等。另外,也可以通过模型蒸馏等技术,将大模型的知识转移给小模型,以提高小模型的效果。
- 对话生成:模型训练和优化完成后,就可以进行对话生成了。
- 对话生成可以通过两种方式实现:一种是使用单个模型进行对话生成,另一种是使用多个模型进行对话生成。
- 在使用单个模型进行对话生成时,需要对话模型具备记忆能力,即模型可以通过上下文信息,生成更加合理、连贯的对话回复。
- 在使用多个模型进行对话生成时,可以利用模型的多样性,生成更加丰富、多样的对话文本。
知识库
智能客服产品中最需要内容⽣产能⼒的地⽅,莫过于知识库。
智能客服产品都具备⼏类知识库:内部知识库、机器⼈知识库和外部知识库。
内部知识库:实时定位查询使⽤的知识库。由于企业的业务变化频繁,知识库的调整需要及时到位。传统的上传、编辑、整理等流程⾮常耗费⼯作量。引⼊大模型,可以协助⾼效智能的协助员⼯归类、⽣成知识库的类⽬及明细。同时,还可以增加对外部数据源的引⽤,并减少知识库的同步操作。⽤户在实际应⽤时,还可以给对知识点给出反馈,帮助知识库⾃动调节权重。机器⼈知识库是⽂本和语⾳机器⼈能够回答访客问题的核⼼所在。机器⼈知识库的有效内容对于机器⼈的表现⾄关重要。对于未知问题的整理,需要智能客服使⽤者⼤量投⼊⼯作量。借助⽤户反馈对未知问题进⾏⾃动整理和关联,能节省很多知识库维护者的⼯作。同时,通过多机器⼈组合的⽅式,在⼀通会话中接⼒棒⼀般服务于客户的不同场景,大模型专属机器⼈也可以在特定的场合发挥能⼒,并逐步替代⼀些以往模式僵化的问答型机器⼈。- 而
外部知识库需要整合在智能客服产品中,将已整理的知识内容转化为输出产物,更⽅便⽣成知识⽂章、图⽚、甚⾄⾳视频。基于 ChatGPT 的多模态的 AIGC 能⼒,可以快速⽣成⼀个个性化的知识空间。
利⽤大模型⾃⾝的⽣成能⼒,基于向量数据库、可信内容审核等技术,为智能客服提供优质的内容补充。
大语言模型在实际应用于智能客服场景中时仍存在一些挑战
- 它可能会生成错误或不准确的回答,尤其是对于复杂问题或特定领域知识,这就对智能化程度提出了更高的要求。未来的在线客服系不仅需要更高级的算法和机器学习技术,还需要更多精准的自然语言处理能力。这将对在技术上不太强大的企业形成巨大的压力。
- 此外,随着用户数量和访客量的增多,未来智能客服将需要处理超大规模并发请求。这需要系统在多种方面都拥有特殊的设计,如负载均衡、高可扩展性和高可用性等。
市面上很多对话机器人的回答单一固定,变化比较少,与真人对话还有差距,未来的智能客服系统将需要进一步加强对用户行为的自适应性和个性化服务。这就需要系统学习更多的用户数据和信息,并适应不同的用户行为,为他们提供更好的服务和体验。
如何提升用户体验就成为了智能客服供应商主攻的方向。从人性化服务、个性化服务和拟人化的对话交互方面进行改进。
- 首先是人性化服务。
- 在场景和意图理解精准的基础上,附加更有温度的对话语境,可以让机器人在拟人化上,再进一步,多模态情感计算是实现这一步的有效方法。目前,正在推进虚拟数字人客服进行人机交互对话,在此过程中结合情感计算,可识别用户通过视频、语音、文本所传递的情感表达,让智能客服在应对是作出相应情感反馈,打造具有情感理解、有温度的人机交互。这种多模态情感计算技术的实现方法主要是通过基于专家规则和基于机器学习两种。其中,基于机器学习的方法通过训练模型来自动学习情感状态的分类标准,可以更好地适应不同领域、不同语境下的情感表达,效果相对更优些。
- 其次,拟人化的对话型交互。
- 通过场景化设计优化,比如问题拆解、主题继承、多轮对话、上下文理解等等,机器人能够带来一种更加贴近自然对话场景的对话型交互模式。
- 第三是个性化服务。
- 根据客户画像千人千面提供个性化服务,从多角度出发进行语义理解,此外还要附加语音情绪判别。
- 大模型诞生后,无疑为智能客服领域注入了新的“营养剂”。这种“革新”体现在多个方面,包括座席辅助和座席提效、闲聊寒暄、话术优化建议、提供语料扩写等。
- 座席辅助和座席提效:过去的智能辅助更多局限于按单轮对话来完成,基于大模型的能力能够快速分析并生成面向客户侧的系统支撑策略,这种处理效率和结果,远超出依附纯规则或者纯知识库所能达到的效果;
- 闲聊寒暄:智能客服非常关键的基础能力,能够帮助企业对任意进线客户进行即时响应。过去的智能客服闲聊主要是将各类非业务相关的语料堆到素材库,并通过调取数据库已有的关键词进行内容的回复。如今可以充分借助大模型能力提供闲聊,在非业务领域上为座席和客服提供更多决策依据和参考;
- 话术优化建议:话术往往决定了客服的效果,话术回复不精准将直接导致用户的流失。通过大模型强大的内容生成能力,智能客服能够对话术进行不断地迭代和与优化,提升客户满意度;
- 提供语料扩写:在智能客服冷启动阶段,往往需要足够多的语料来丰富知识库的相似问法,以保证上线初期智能客服有足够高的解决率和场景覆盖率。以往的语料生成模型很难覆盖众多垂直行业和领域,大模型在通用领域中积累了足够的数据和语料,可以很好的弥补语料生成模型的不足,快速生成相似问法,解决智能客服冷启动语料不足,场景覆盖率低等问题。
归根结底,提高对话质量的核心还是理解客户和用户场景,以及能够搭建出衡量得失的数据框架。这两个组合之下,会有一个循环反馈的过程,就能够通过正常的产品迭代达到好的效果,并且能够衡量出来 ROI 和对实际业务的共享。
LLM 客服
智能客服业界落地案例:
- 2023年3月,电商saas服务商Shopify集成ChatGPT
- 2023年12月,成立于2014年的Kore.ai完成1.5亿D轮融资,估值8亿
- 2023年底,德国创业公司Cognigy AI推出AI Copilot,用llm重新定义企业Agent协助,rise联络中心,AI改造传统客服;2024年6月,融资1亿美金
- 2023年成立的Bland AI 支持语音克隆、多语言支持、无限呼叫
- 国内,阿里小蜜已完成llm全方位升级重构,传统nlu+fsm方案退出
- sierra 融资较多
【2026-3-17】Top 8 AI agents for customer service : Tested & reviewed (2026)
详见转内专题 LLM智能客服案例
商业应用
智能客服行业
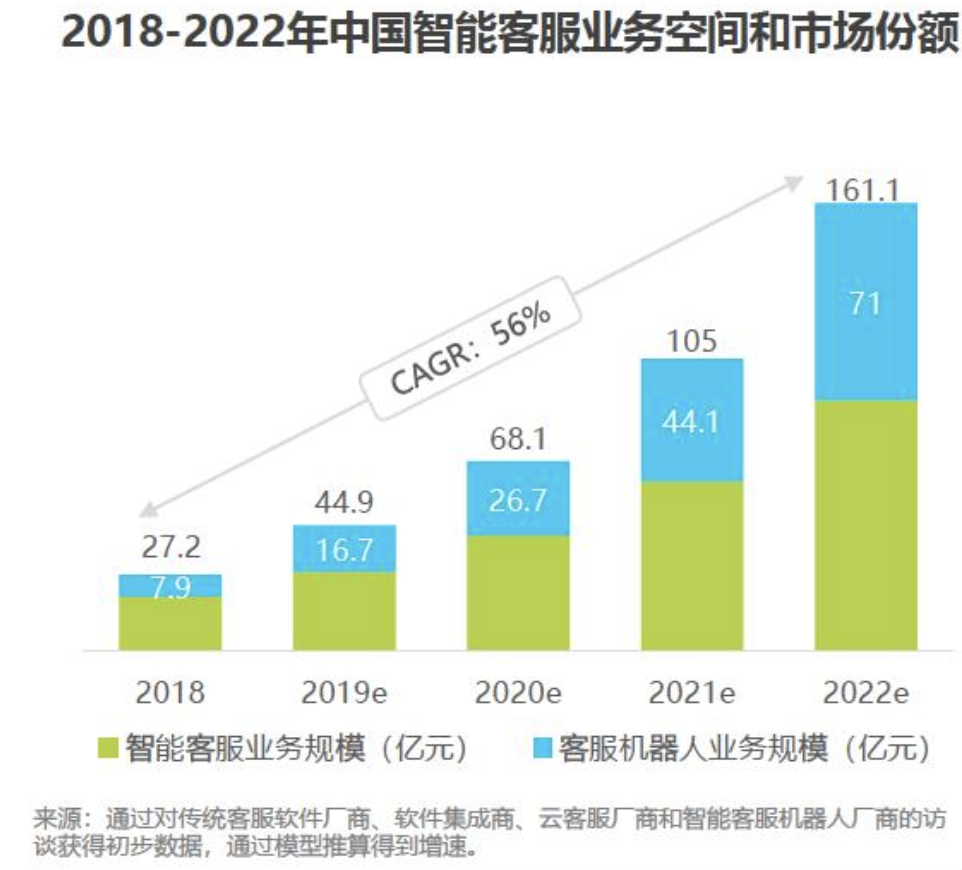
- 中国客服行业正处在云客服+智能客服机器人的阶段,2018年智能客服业务规模达到27.2亿元,以NLP技术为主的客服机器人业务规模为7.9亿元。预计2022年智能客服机器人的业务规模将为71亿元。以上数据来源于艾瑞咨询 image
竹间智能
2024年年初,智能客服明星公司竹间智能突发消息:停工停产6个月。
- 公司业务的持续亏损,入不敷出。即便将国内金融大企业收入囊中,在大模型爆发的时代,依然没能扭亏为盈。
智能客服领域
- 一方面是传统NLP公司承受着盈利压力
- 另一方面是涌现出的初创公司借着大模型和AI智能体的东风,进入赛道。
峰答
【2025-9-25】北大、川大团队推出峰答AI客服,客服省心神器,AI全天值守,完全免费,不止于自动回复,更是随每一次对话自我进化的店铺大脑
蜂答智能客服系统专为电商平台设计,轻松应对各种服务挑战
- 全平台店铺统一管理: 集成多电商平台,一键登录全局掌控,多店运营高效管理。
- 智能学习引擎: AI自主学习商品数据,对话式学习一键导入知识,多店响应统一,咨询秒级回复。
- 三分钟回复率保障: 精确匹配优先,秒级响应命中问题,全天候维护三分钟回复率,满足平台考核。
- 恶意用户智能识别: 智能识别高风险客户,实时预警干预,规避恶意差评,海量订单服务质量稳定。
- 多媒体内容回复: 支持图片视频回复,根据知识库标记自动发送素材,提升沟通效果和用户体验。
- 智能提醒系统: 转人工声音提醒,不错过任何转人工会话,智能识别需求,提示人工介入。
要点
- 商品识别即刻精准
- 上下文理解深度共情
- 连续追问衔接丝滑
- 差评、投诉、退货等信息还会自动分流给人工处理
- 一键管理多家电商平台:淘宝、京东、拼多多、抖音、咸鱼
拼多多客服
拼多多智能客服开源实现
- Coze API
- Customer-Agent
技术架构
- 前端界面: qfluentwidgets
- 后端逻辑: Python
- AI集成: Coze API
- 数据存储: SQLite + JSON
- 浏览器自动化: Playwright
git clone https://github.com/JC0v0/Customer-Agent.git
cd Customer-Agent
pip install uv
uv venv
uv sync
# 安装浏览器驱动
uv run playwright install chrome
# 启动系统
python app.py
服务场景
- 服务场景有:
智能机器人、智能语音导航IVR、智能外呼/营销、智能质检等。- 总结:机器人、IVR、外呼/营销和质检
- 以下是阿里云对外公布的智能客服应用框架 image

智能客服给B端企业带来的价值:降低人工成本(一般来讲能节省10%客服运营成本)、提高工作效率、提供更精准作业回答等。
而智能客服最大的隐性价值在于实际场景中得到的标准化数据积累,可以在挖掘客服价值信息中起到降本增效的作用,后续还可以作精准营销和产品升级。
- 问答型和任务型机器人的优化目标在于:用最短的对话轮次,满足用户的需求。
- 用户的诉求是:通过最短路径,获得精准、直接的答案以及很好地完成任务
银行客服机器人
【2022-5-4】银行机器人快宝:
- 【快宝】快宝解锁新表情,在线征名 https://www.bilibili.com/video/BV1eZ4y1j7VH
- 【快宝】快宝的日常怼人 https://www.bilibili.com/video/BV1rC4y147oc/
- 【快宝】不能欺负快宝哦!会被爸爸揍的! https://www.bilibili.com/video/BV1Fi4y187z8/
- 【安安】客户:你先跳个舞我就办个信用卡 安安:不!您先办卡我在跳舞
- 评论:我亲戚就是干这个的,在四线城市工资2700元。这机器人70万一台,客户每年还要缴5万元维护费,有两种模式,一个是人工后台聊天,一个是像天猫精灵那种大数据,上班时间我老姨就陪人聊天,下班或者中午吃饭就换另外一种AI模式或者直接关机,但AI模式像天猫精灵那种比较智障,说话没有感情,由于大数据你问他天文地理或者加减乘除他都知道,但随机应变自我学习完全不行,人的大脑神经细胞,中枢神经极为复杂。网上这些特别厉害的机器人都是后台人工在和你聊天,你不信问他个3位数的乘法它一定回答不上来。另外网上这些小视频比较短,其实现实中长时间对话会出现磕巴,不利索,断断续续的情况,毕竟能做到像新闻联播主持人一样就不会干这个了
图书馆机器人
产品架构
客服机器人目前被大量使用在电商、金融、银行等系统中,所以我们以银行业务为例分析使用客服的业务场景后,将用户的问答归为下面几类:
- 1)常见问题。如:手机银行转账限额多少。
- 2)咨询理财/贷款产品和服务。比如某个基金的赎回时间,或者更精准的问题:哪款产品预期收益率最高?
- 3)个人信息查询或业务办理。比如查询余额、转账业务、购买理财产品、申请贷款等。
- 4)聊天/寒暄。银行业务场景下,一般都是起兜底作用的寒暄。
应用中通常会包含不同类型的机器人,那到底当用户输入问题后,应该选择哪类型机器人,这就是智能路由机器人(Route-Bot)的工作了。看下图的基于场景的产品架构图(此图来源于 关于对话机器人,你需要了解这些技术)

路由机器人在对用户问题的意图识别后,会结合历史背景,决定把问题发送给哪些机器人,以及将最终使用哪个机器人的答案作为提供给用户的最终答复。
根据上面关于银行业务的问题划分,需要用到机器人类型有:
- 检索型对话机器人FAQ-Bot
- 知识图谱型机器人KG-Bot
- 任务型机器人Task-Bot
- 用于寒暄的闲聊型机器人
检索型机器人FAQ-Bot
在客服处理的问题中70%都是简单的问答业务,只要找到QA知识库中与用户当前问句语义最相近的标准问句,取出答案给用户就可以了。FAQ-Bot就是处理这类问题的。在没有使用深度学习算法之前,通常采用检索+NLP技术处理。
- (1)适用场景:解答非用户个性化的问题,返回的是静态知识,无需调用接口返回答案。
- (2)处理流程:

- 1)用户提出问题:“怎样才能使用刷脸转账”
- 2)本体识别:用户问题分析后,识别出本体为“刷脸转账”
- 3)计算FAQ相似度:问题与知识库里的标准问题根据相似度计算后召回,例如:
- Q1: “如何使用刷脸转账?”,相似度0.56;
- Q2: “使用刷脸转账的前提条件有哪些?”, 相似度0.92 。
- 4)候选答案排序:Q2-Q1
- 5)若阀值设定为0.9,Q2达到阀值,返回Q2问题的答案。如果有多个答案都到达阀值,选相似度最高的标准问题的答案返回给用户。如果都没有达到阀值的,但达到推荐阀值的答案有几个的,显示推荐的答案。
- 6)本体继承:把“刷脸转账”继承至下文
- 7)继续提问:用户问“怎么刷”,话题继承。
- (3)知识库的设计
- FAQ-Bot是基于知识库匹配算法设计的,所以首先需要搭建本体知识库,通过新增和维护机器人知识库,来提升机器人问答的准确率和用户体验。下图是云小蜜的知识库管理页面
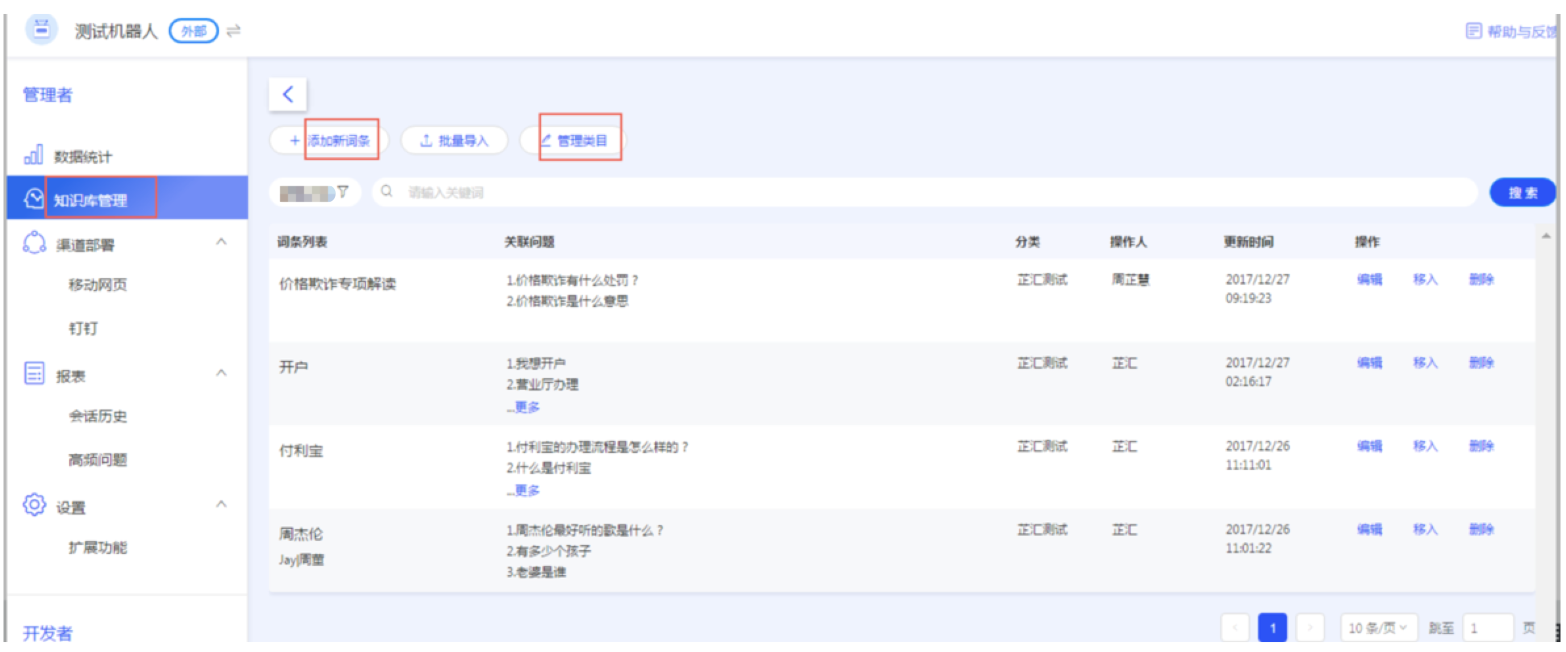
- 1)它的层级结构是:类目—> 词条, 这里的词条就可以理解为本体,它是关键词的模板。所以当用户问“如何开户”时,识别出来的本体/词条就是“开户”。
- 2)每个词条需要维护的信息有:同义词、关联问题、相似问题、分类等。其中分类主要用于知识点的管理,当某一分类下数据量较大时,分类还可以作为算法聚类的一个标记,认为分类下的问题相关度高,在检索匹配时作为一个计算因子
- 3)本体识别,可看作一个文本分类问题。
- QA语料添加与维护,可以分为三个阶段:
- ① 机器人上线前,处理已有QA。
- 若业务上线前,客户已经有一定的原始用户语料积累,比如通过线上客服渠道或者论坛等积累的问答对,或者有大量用户咨询的问题。可以使用聚类工具自动聚类后,再人工进行调整。知识库应该提供“批量导入”的功能(银行业务的场景基本都有原始的线上数据,可以通过爬取这些数据后做清洗,提炼出高频问题,然后进行优先处理)
- ② 冷启动阶段,人工添加+NLP手段扩充语料。前期没有标注数据的,需要人工手动标注数据。但因为问题和候选答案包含的词通常都很少,此时可以利用同义词、复述句对问题和候选答案进行扩展和改写。
- 功能上:在编辑界面支持“增加同义词”、“新增相似问句”的功能(如小蜜的划词功能)
- 算法上:用词表示工具,如Word2vec、Glove、 Fasttext来获得每个词的向量表示,然后使用词向量计算每对词之间的相似性,获得同义词候选集; 也可通过已经存在的结构化知识源如WordNet、HowNet等获得同义词; 相似问句方面,系统可以使用自动聚类的方式推荐相似问句。
- ③ 机器人上线后,人工标注迭代。
- 系统上线后,对于回流数据(没有答案的、机器推荐而用户没有点击的、机器回答错误的、用户不满意的问题等)进行诊断,系统将这些语料先做聚类,然后由标注人员作统一处理。具体处理方式可以有:答案纠错、标注到已有问题的相似问题里、新增知识/词条、标注为负训练样本、优化词条和问题标题/关键词等。从产品层面上,应该提供知识库的“badcase标注”功能,以及提供测试模拟窗口功能(测试demo也是一般平台都会有)
- ① 机器人上线前,处理已有QA。
- (4)语义相似度计算:通常根据训练方式不同,从前期无标注数据到有一定量标注数据,语义相似度的算法也向深度学习迭代:
- 1)无监督学习:冷启动阶段没有足够标注数据时,通常使用无监督学习算法。将用户问句和标准问题作降维得到向量表示,用余弦相似度等方法计算出句子间语义相似度(值越靠近1说明越相似)
- 2)监督学习:机器人上线后经过用户问题和重新标注过程,积累了一定的数据后,通常可使用深度学习算法。如基于RNN的语言模型。用RNN训练出来的语言模型,采用其隐层状态作为词向量,将词向量代入其他需要word embedding的问答匹配方法中,经验证,可以取得比原方法更优秀的表现。
- (5)阀值
- 1)关注阀值的可配置性:从产品层面输入阀值后,改变相对应的输出结果。如果阀值配得过高,会影响召回率;太低又会影响准确率。要根据业务场景做权衡。
- 2)在云小蜜中,还设置了问题推荐的阀值。处理逻辑是:当结果达到直出阀值,直接给出答案; 未达到直出阀值,但达到推荐阀值的,给出几个推荐回答; 未达到推荐阀值的,给出无答案回复。无答案回复可以进入配置后台进行配置。

- 小蜜的这个推荐阀值是基于机器阅读理解模型训练的,目前设计是在知识库的词条中进行维护,添加段落,模型会自动列出将关联问题和答案。但此模型与领域相关,向其他领域快速扩展是一个比较大的挑战。
- (6)信息咨询型多轮对话
- 简单问答中除了单轮对话外,也多轮对话的情况。这类咨询型多轮与任务型多轮有所区分。以下类型的多轮对话情况在FAQ-Bot中处理
- 1)情况1:条件挖掘。用户提问“如何开户?” ,机器人会返回“开户”的条件相关的提问“请问是希望通过下面哪个渠道办理:手机、网站、营业厅”,用户作出回答后,机器人返回答案。这个对话虽然是多轮,但不涉及用户的个性化信息,还是用语义匹配来实现。
- 2)情况2:话题继承。如用户提问“怎样才能用刷脸转账”,话题“刷脸转账”被记录下来了,若用户问“怎么刷”,机器人应该识别到是同一话题下的关联问题,并返回相应答案。
知识图谱型机器人KG-Bot
知识图谱,拥有知识推断能力,能更直接回答用户的问题。
举个例子:
- 百度查询春节还剩多少天,会直接以卡片的形式显示答案“距今还有140天”,而不是给出一堆文档/网页的集合让用户自己去筛选和计算
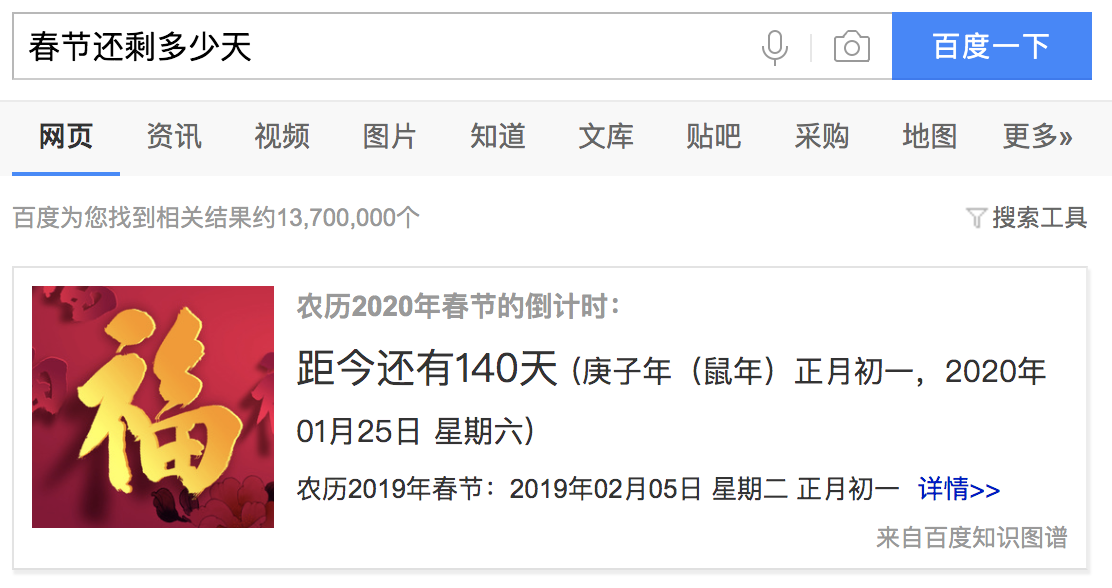
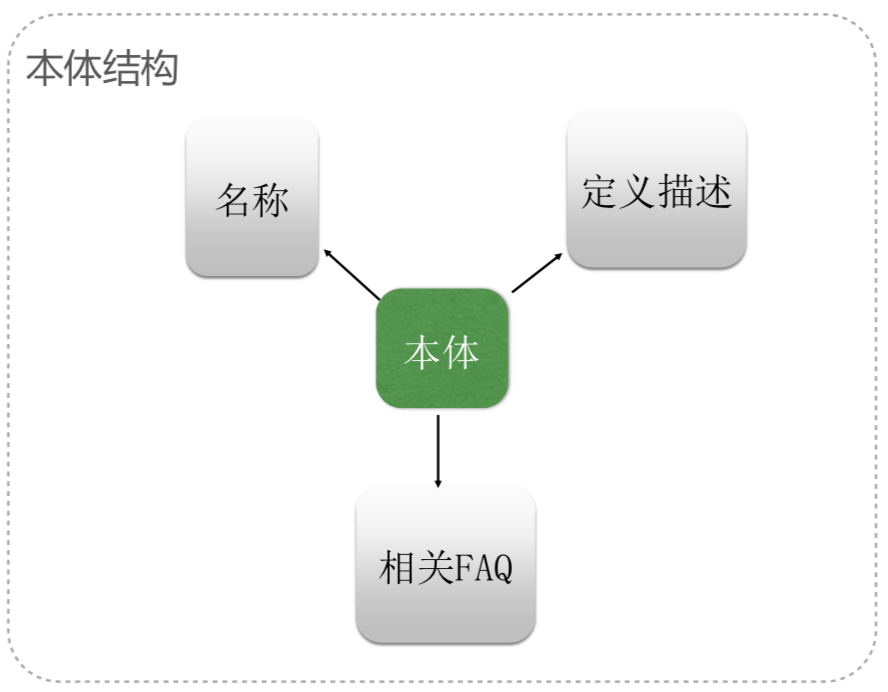
知识图谱的逻辑结构,它分为两个层次:数据层和模式层。
- 数据层一般存在两种三元组作为事实的表达方式。这两种三元组为:“实体—关系—实体”(SPO)、“实体—属性—值”。知识图谱结构示例图:

FAQ-bot解决了大部分的简单问句,但它无法解决更精准更复杂的问题。而知识图谱的优势在于:
- 1)在对话结构和流程的设计中支持实体间的上下文会话识别与推理
- 2)且通常在一般型问答的准确率相对比较高(当然具备推理型场景的需要特殊的设计,会有些复杂。)
基于这些优势,用知识图谱可推理的问题种类有如下(以下来源于百度AI赋能的搜索和对话交互报告):
- 『主语+谓词』:刘德华的老婆
- 『谓词+取值范围』:180cm以上的男明星
- 『谓词+排名』:世界第五/第八/第十高峰
- 多步推理:谢霆锋的爸爸的儿子的前妻的年龄
但有些问句需要先对其进行 句法分析,才能确定如何查询知识图谱。如“谢霆锋的儿子是谁”
KG-Bot有两大难点:
- 1)知识图谱的构建: 关于知识图谱的构建可参考上面文章链接,简单的构建流程是:
- 数据爬取—>数据解析(实体、关系、属性)—>数据插入—>关系建立。
- 2)把用户问题转化为知识图谱上的查询语言。
- 转化为查询语言的实现流程可以简化为:意图识别—>实体识别—>属性识别—>问题分类
任务型机器人Task-Bot
任务型bot顾名思义是为用户完成某项任务,这类用户问题通常是需要调用第三方接口返回结果的。目标是在多轮交互中不断理解用户的意图,和根据用户的意图结果优化排序的结果和交互的过程。
国内外bot framework平台,如dialogflow、Alexa Skills Kit、Luis.ai、DuerOS、UNIT、Dui.ai中关于任务型机器人的设计思想大体相似。具体我的上篇文章点亮技能人机对话系统全面理解讲开放平台体验中也有讲到,这里不再细讲。
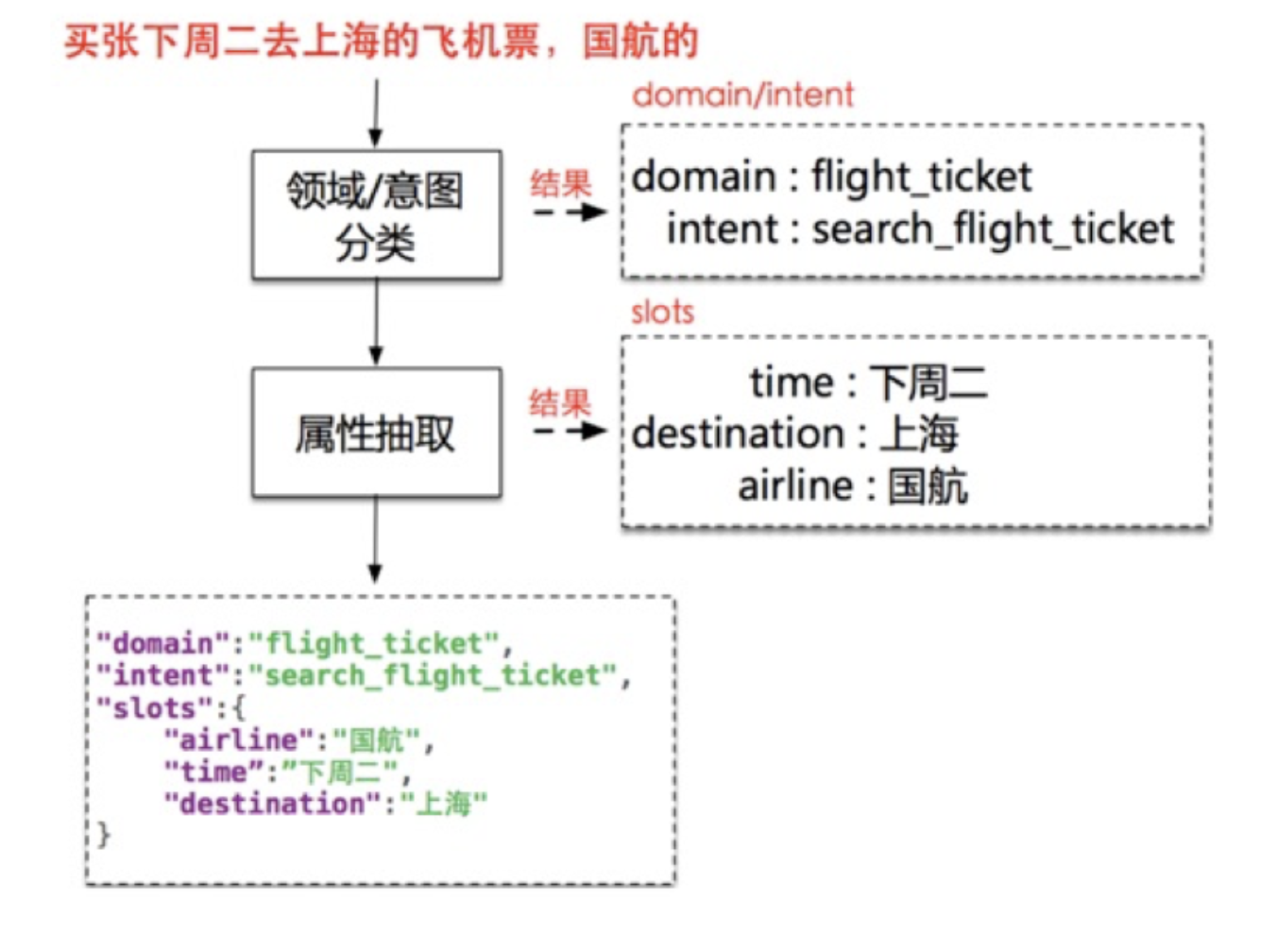
任务型场景的三个要素是:领域、意图、参数
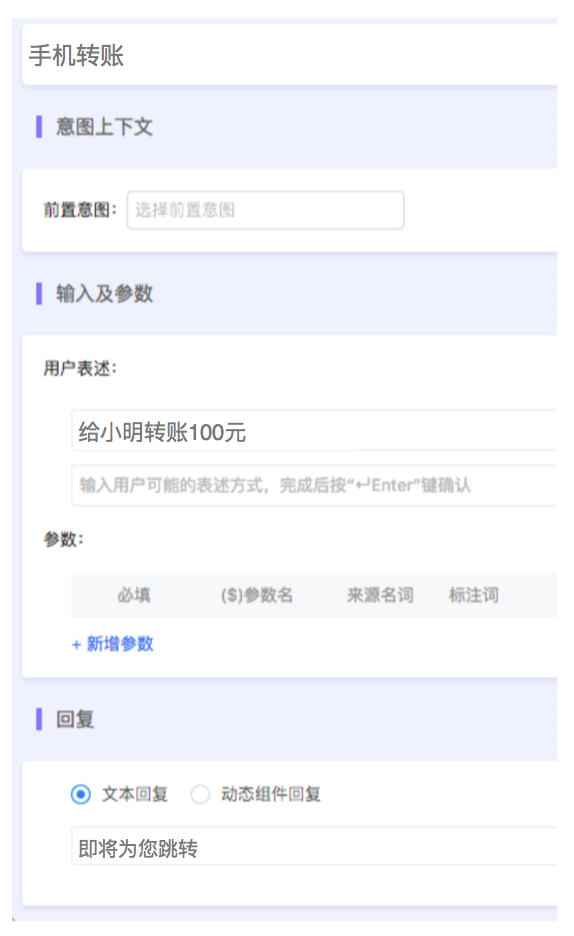
小蜜任务型多轮对话交互设计中,配置“手机转账”意图页面例子
- 意图的配置中包含的要素有:意图上下文(即语境)、用户表述、参数(含追问提示语句)、回复。
闲聊型机器人Chat-Bot
闲聊型bot的风格是娱乐风趣,对答案的准确性要求较低,知识的数据来源也是全部领域。 还是银行为例子,银行业务是垂直的领域,对问答准确性要求极高,要求智能客服机器人也是要严肃、负责的。所以闲聊型在此类场景优先级放在后面。在设计bot产品前,就要定义好产品边界和分析业务需求,来选择会用到的bot类型。
智能客服为什么不好用
智能客服体验不好,很多人第一反应是 NLP 的水平不行。建议再试试这家的人工客服体验如何,如果人工的体验还不错,那么才是智能客服的问题。往往很多公司的客服体系本身的体验就差,原因是不去、也无法解决用户的具体问题。如《人工智障 2》里提到的很多对话智能产品,不关注服务的闭环,只关注对话管理,就没有太大商业价值。
(1)从产品价值定位来看,人工客服行业经过了多年发展,自身的演进却有限,从使用电话开始到现在,基本没有颠覆式创新。
- 主要原因是大多人工客服系统在价值设计上并不帮助用户解决具体问题,只提供业务的规则。主流智能客服只是在复刻人工运营的思路,体验上也不会有颠覆性的差异,无非是把原来由人力提供的低价值,变为由机器来提供低价值。但在用户端,这些低价值的服务不解决当前的用户需求,甚至比人工的价值更低。
- 主流“智能客服”的产品 owner 是客服部门,做产品定义的也就是客服部门自己。但客服只负责管理用户生命周期中的一个阶段的事情,通常是比较靠后的售后。而当用户提出的问题与其他阶段的数据有关时,数据往往由其他部门负责,客服们就很难去有效处理。以此定位打造出来的智能客服,能有的系统权限也就是过去人工客服有的系统权限。因此,抛开技术的上限,业务上能做什么的上限就这样被限定了。而实际上用户往往是带着具体问题来的,这些问题又分散到不同的业务系统当中,所以单是数据权限,就决定了系统的价值上限。
(2)从业务数据的治理和使用角度看,大多数客服系统都只是从客服系统读出数据,提供给用户,这些查询类工作与具体业务相关度低。 这时,用户需要自己去思考自身所处的条件是否满足客服提供的信息和业务规则,并依据自身判断去进行下一步的操作。这类的客服系统,无论是人驱动的还是人工智能驱动的,很少进行具体用户数据的写入,它不能改变这一个用户和服务提供方之间的状态,所以用户能感知的价值低,用起来很累,这也是绝大多数智能客服的现状。
(3)最后才是技术问题。 智能客服大都把技术栈堆在前端,关注自然语言理解、填槽、知识图谱,这些每家都差不多。这几项单拉出来都没有太多差异,大厂都做的挺好的,创业公司也没啥区别。而以目前的技术上限来看,这样的定位就是在挑战机器最不擅长的部分,反而在机器擅长的方面没有发挥出来。
为什么用户感觉”智障”的核心原因,是因为用户不会去区分识别出错还是服务能力不足。 就算能识别用户的发问,只要不能处理服务的交付,用户也会觉得蠢。“我不能理解你的问题”和“我无法处理你的问题”,对用户来说是一样的智障。我认为自动完成高质量的服务闭环与交付才是内核,再用对话系统对内核进行“包裹”,完成交互。 所以与其说技术到了瓶颈,不如说做技术实现的人在这件事儿的整体理念上还停留在过去,继而限制了技术的施展。
以现在的技术而言,如果上面这些方向不做出改变,技术能改变的部分也很有限。
与”智能客服“对应的是”智能服务“,尽管都是对话系统的应用,但却是两种不同定位的产品。好比两个人都能讲话,但能做的事儿都不同。如果说智能客服是对标人工客服的,那么智能服务对标的是移动时代APP。 这是面向下一代 B2C 服务的理念,即对专业服务的智能化,可以理解为:以用户为中心,覆盖“用户完整生命周期”,管理用户与服务提供方的关系状态的变化。 甚至从“还不是客户”的阶段开始,比如对于航空公司,还没注册的用户,也在其服务范围内。
智能服务的 owner 不一定是客服部门,很有可能是在具体的业务部门。业务覆盖的范围,则是用户使用一个企业的所有产品或服务。产品定义上要解决的核心问题不是对话,而是服务交付。
对智能服务的产品定位而言,不能只给用户提供静态信息,比如各种公司规则,没人愿意看。它需要帮助用户完成信息搜集、分析情况、套用业务规则、然后给出预测结果,如果用户愿意,并直接操作后台,完成数据写入。所以智能服务,一方面在强调完整用户生命周期的管理,另一方面则强调帮助用户直接解决整个任务。
行业应用现状如何
- InfoQ::最近几年,银行等金融机构纷纷部署智能客服产品,似乎不用上就落后了
跟风很正常,早期是有一定规模的公司都需要这个服务,长远从行业整体来看,会逐步普及,大家早晚都会用。大概在 2017、2018 年,对话系统刚火起来的时候,跟风现象比较明显。现在更理性一些了,有些企业的智能客服系统上线后不久又被下线推倒重做,冷静下来后,他们开始反思前面掉过的“坑”。
用对话系统来做客服,在方向上是否出了问题?技术的边界在哪里?DevOps 方法论上是否还能沿用传统软件开发的套路?该整体业务是外包还是把工具拆出来找供应商做然后自己运营?选方案的时候 happy path 的 poc 一时爽,上生产了,后期运维成本巨高又怎么办?行业开始思考这类问题了,只是目前还比较早期,方案上没有”统一解”。
传统金融机构为什么这么积极地想要拥抱智能客服?
Mingke: 当前金融机构对智能客服的核心需求就是降本增效,尤其是在一些采用量较大的场景,如高频问题自动回答、外呼、回访等客单价比较低的业务中,能够代替低端人工客服的重复操作。
但这个成本减下来是有前置条件的,就是用户不得不用,不用智能客服就根本没客服。 一旦开放选择给用户的时候,很多人一上来就直接转人工了。这都是智能客服自身定位的瓶颈带来的问题。两端的价值 — 企业提供商业服务价值和用户使用服务的价值,还没有充分发挥出来,还有很多很多空间。
而有少部分头部企业是为了试图打造下一代智能金融服务,有接触过一些产品方向,也确实值得期待。理念上走在前面,确实想拉开服务的差异性,服务的对象更偏用户而不是业务、指标卡在如何提升服务质量上。这类案例往往强调人机结合;他们数字化程度高;组织结构转型更敏捷;服务对企业核心业务的价值明显;在战略上面向未来做规划;对核心业务系统的连接比较多,承载一些业务的战略转型,比如打造好的智能服务,还可以分发到其他渠道和终端上,完成从自动获客到交易闭环。放到智能终端上,还可以拓客;而如果做的是智能客服,分发到智能音箱上,或者集成进车机里就根本没有意义了。
- InfoQ:您怎么看待它们宣传口径中的“高回答准确率”?
Mingke: 这个和对话轮数一样,对服务本身没有太大意义, 这属于对话系统的基本功,而不是智能服务的差异点。 识别准确,不表示回答正确;回答正确不表示服务正确,比如”正确的废话“。一个系统能听懂你的问题,但是就不帮你把事情解决掉,对用户并没有价值,对 B 端也完成不了闭环。
要做服务,就直接用评价服务的体系,比如 FCR 即”用户首次接触就完成服务的比例“;再加上 CSS 和 NPS 等。 目前绝大多数智能客服体系,在这几个值上的体现都是惨不忍睹的,属于不敢公开的类型。如果 AI 的 FCR 做到 80-85% 就比较厉害了,当然与真人专家是不能比的,好的品牌通常要 95% 以上。
现在很多大厂、小厂的方案都一味只关注识别准确率,其开发思路还都停留在“分不清对话用来干什么”这个阶段,目前这很普遍。一个具体表现是,没有把”对话session” 和 “服务session” 分清楚,以为一次对话就是一次服务。而对智能服务而言,一次完整的服务闭环,可由多次对话(就是多个对话 session)组成,甚至跨模态和终端。那么管理对话的,就应该是服务本身,而非对话本身。
在下一代的智能服务设计的结构中,对话系统和服务系统需要被拆分开来,即”交互“和”交付“分拆。 当前主流方案当中基本都没有拆分,所以会给人留下印象,对话系统好不好用,是靠识别的准确率来判断的。但是仅仅做到在语言上是正确的,而无法完成服务的交付,则对两方的最终价值不大。
智能服务的精华在于专业级服务的自动完成,称为 BSPA(Business Service Process Automation)。如果说 RPA 是机器模拟人在界面上的反复操作,那么 BSPA 就是机器模拟人在业务决策时的反复思考。而对话系统扮演的角色,只是一种交互方式,来包裹业务决策的模型。在完成服务的前提下,交互轮次越少越好。 有些案例,甚至无须用户开口,就能预判需求,直接给出结果。你看这个过程根本不存在自然语言处理的准确率的问题,而是推荐系统是否好用的问题。
举个例子,你要选择一个理财顾问,有人说的天花乱坠,但是就是不帮你赚钱;而另一个话不多,交互少,但能准确 get 到你的需求,就是能赚钱,你选择哪一个?因此,产品的核心评判是在于业务先要准确完成,哪怕语言不那么准确,只要业务准确了,依然能保证给用户传达价值,用户依然会买单。
所以,当你选择只用”识别率”评价对话系统的时候,你就已经选择了价值有限、且机器不那么擅长的定位了,这种选择就类似”让中文老师帮你做理财“。
- InfoQ:金融机构希望 AI 能够代替人工,降本增效,据您了解,目前应用上智能客服产品后,达到的“降本增效”水平是多少,可否用数据说明下?
Mingke: 降谁的本,增谁的效?智能客服仅提供 QA,只关注识别率,那么降本增效的对象就是只负责不停说话的基础客服。这个部分其实我不太关心,因为产品玩不出什么花样,而且商业价值低。这些业务早就被外包出去了,在这个定位的智能客服,抢的是传统客服外包行业的盘子。
更大的盘子是整个用户生命周期的专业服务全流程,强调专业服务的端到端的自动完成。此时降本增效的对象是核心业务的操盘人员,他们往往是 in house 的雇员;专业领域的水平高;本身就是核心业务或者离核心业务非常近;系统操作权限更高;招募、培训、管理、以及运营成本也会更高。但是 AI 与这类角色并不是替代关系,而是强力辅助让人变得越来越专业,数量越来越少就能开展大规模的高质量服务。
智能服务的核心指标是 BSPA rate,意味着一个服务从提出到完成,所需要的所有服务状态改变和交互,都自动完成。从用户角度看,就是一个服务有没有从头到尾的自动完成,而且有些服务类型可能是过去单靠人力无法完成的。
目前主流智能金融客服大部分时间是只读系统的数据,然后“打回”给用户。有的能读系统数据已经不错了,有些连读业务系统数据的权限都没有,能读的内容只是知识图谱制作的一些抽象规则,就无法实现服务的闭环。哪怕看上去有挺好的数据也都是围绕对话的,本质上也是“自嗨”,可以哄哄领导拿点明年的预算。一个例子就是在服务系统里加入端到端的“尬聊”机器人,凡是不能处理的对话,都扔过去,用户怎么说都能兜住,就是不解决问题。表面上看说了很多话了,session 数量还占比很高,看上去是不是降本增效了?但是该解决的问题依旧没解决。
在能够把服务完成的理想情况下,完成一个服务为目标,应能够为用户预判需求并提供更好的服务,减少交互,增加交付。有一些金融服务的项目在比较优秀的数字化基础上,BSPA rate 能跑到 88%,这已经是比较高的水平了。 以此为例,在 business case 上可以预设到至少 50% 的实际成本降低。
另一个容易被忽略但真实存在的价值,是 knowledge transfer 的成本。 人工客服的人员更换非常频繁,对新人员的训练需要专业人员反反复复去教,好不容易教会一批,过几个月走了,又换一批。这种重复劳动也让专业人员干起来很不开心,而培训 BSPA 型的系统,则是一个一次性的事情,可以在每个版本的 BSPA 模型上不断提升服务和推理能力的水平。专业能力是由系统来沉淀,而不是跟着一帮待不长的客服人员走的。
比如,我曾经接到过欧洲企业的需求,要打造 AI trainer,让这个 AI 培训师专门来培训不停流失又新入职的真人服务顾问。我跟他们说,既然都把行业知识训练给 AI 了,为什么不直接用来给终端客户呢?当然这与部门设计的根本利益也有关,由此可见在将来,智能服务的潜力还可能会改变一些更底层的商业形态。
- InfoQ:您觉得,用智能客服“替代”人工这件事靠谱吗?
Mingke: 这不靠谱。以目前的技术来看,不必过分担心基于统计的 AI 应用会整体上取代人,因为缺少通用推理能力。
从另一个角度来看,如果有一天低成本跨域推理的能力真出现了,被代替的也远不止初级客服了。所以我认为在可预见的将来也就是在未来 5 到 10 年里,Hybrid Intelligence(混合智能)才是发展的核心方向。 在这个方向上,一些基础客服,比如数据读写权限低、决策权限低的、照着手册念剧本的,确实会率先会被自动化系统取代,而且这个部分可能是 99.9% 的取代。GPT-3 的中文版出现后,应该会有一波相关的升级,会加速这个级别的取代过程。
但业务能力再往上提高时,现在的智能客服就不行了。一方面是金融场景受限于当前的合规,有些关键决策流程必须有人参与;另一方面是基于行业的深度和复杂的推理, 在这些场景下,智能客服就很难操作,需要具备完善领域能力的智能服务来处理。再往上走,遇到有些非结构化因素混杂在决策过程中,如投诉,这在贷款逾期的情况下经常遇到,这些问题往往伴随着用户情绪的管理,投诉和冲突的消解等等,这些类似问题还是交给真人专家去解决比较好。
不可能被全面取代的是专业服务的专家,他们可以做基于推理的业务决策,能处理长尾问题,有核心业务系统的权限。 对于这些同事,AI 价值是在辅助工具上,比如不需要死记硬背很多东西,用自然语言做检索、自动核审、即时方案生成、协助决策等。而人更擅长去解决长尾以及纠纷解决等对语言能力要求很高、业务条件复杂、还缺少数据支持的业务。机器擅长的交给机器,人擅长的交给人。
智能客服没有壁垒?
- InfoQ:当下智能客服公司的技术和产品是否存在同质化较严重的情况?
Mingke: 目前主流的智能客服基本都差不多,同质化非常严重,无论是传统金融行业从供应商那里拿的方案,还是包括互联网大厂、金融科技自己的 in house 方案。现阶段,各金融机构所部署的智能客服产品,基本都属于同一大类的产品,也就是 FAQ 加上基于知识图谱的 info retrieval,再好一点的做些填槽和逻辑树来管对话流。
有些加入一些自我感觉良好的 feature,比如端到端的闲聊或者所谓的情绪处理,基本都是无关紧要的噱头,不构成实际的竞争差异。整体覆盖范围与企业的核心业务结合的紧密程度基本都不够,在用户角度,体验和价值都没什么差别。
- InfoQ:作为一家智能客服公司的的核心壁垒应该是什么?
Mingke:在解决方案上,我不觉得智能客服本身有技术壁垒。
在智能服务方面,壁垒更多,特别是对特定领域的深挖,会不断积累一些基于领域的问题解决方案,在成为行业解决方案之后,这些积累会有比较明显的壁垒效果。 在以后一个企业在提出业务需求的时候,会遇到两种方案:
- 一个是智能客服,拿过来做话术配置,主要在售后问答的场景;
- 另一个是某某领域的智能解决方案,已经对业务领域做过预训练了,拿过来做业务系统的对接,主要应对完整的获客和个性化服务交付。
产品上的壁垒会逐步从“理”转到“文”,比拼的不是技术实现,而是谁的服务设计更好。 跟移动时代类似,当人人都会做 APP 的时候,就开始比拼谁的产品好了,再后面拼运营和资本。
- InfoQ:目前,智能客服在金融行业的落地概况是怎么样的?现在这些智能客服公司的赚钱能力怎么样?
Mingke: 智能客服落地项目还是很多的,水平参差不齐,使用量多多少少是有的。
据我了解,现在业内智能客服主流的做法是围绕问答展开的。 也就是刚刚提到的 info retrieval,FAQ,还有基于 KB 的 QA 这些。这样做的好处是落地很快,系统集成少,也不需要跨部门,针对业务领域的开发少。不好的地方也明显,就是体验差,专业水平低,用户价值少。这类系统比较适合大规模跨行业的做,尽管每个领域的专业程度低,但是优势在快和便宜上,有总比没有好。
这类系统比较适合对服务不那么看重的企业,比如小企业,其用户本身对服务期望也不高。另一类适用的是大企业,但优质服务本身不是它的核心竞争力,甚至有没有服务都不影响它赚钱,大家平时生活中也经常遇到。对这个定位的智能客服公司而言,就是渠道和销售驱动,因为技术上几乎没有壁垒,那价格和渠道战是必须的,没必要谈产品。
另一种做法是专精在特定的行业领域做深,也就是智能服务的方向。 这意味着,识别模型与架构、对话管理、业务服务建模、知识图谱、内外系统集成、跨部门运维协同,这些方面都需要深入行业打造。这个方向的核心价值在于,把专业人士从重复做类似的问题解决中解放出来,去解决那些提升服务质量的难题。最终商业价值和用户体验,都不是前一种方案可以相提并论的。在一套完善方案的基础上,可分发到不同渠道,文本电话智能终端等等。但是部署和训练成本高,跨域复用非常难。比较适合打造一套行业方案,供多个市场和语言来使用,增加复用。因此合适的客户可能是大型企业,非常在意服务质量,用户基数大,business case 才好建。
从 VC 普遍关注的短期增长来看,铺人去做项目带来的增长比较适合前一类的方案,但是在后面可能在各个领域遇到挑战。从长远上看,我比较看好在领域内“深挖”的做法。行业与行业间存在领域的壁垒,越往行业深挖,越不可能出现“一家通吃”的现象,因此未来的趋势可能会是一家公司擅长某些领域。往后,未来不同领域的公司间的合作、融合、兼并也或将出现。
- InfoQ:对金融领域的智能客服来说,它的变现能力、商业化能力怎么样?
Mingke: 金融应该算是智能客服商业化比较好的领域。相较其他领域,金融领域的数字化相对成熟,实施难度较低,总体经济体量较大。金融领域是智能客服头一批落地场景,再往后演进成为智能金融服务的条件相对充分。
- InfoQ:对创企来说,在金融场景下落地,当下面临着哪些挑战?您在推进做项目的时候,有没有一些”踩坑”的地方?
Mingke: 无论是智能客服还是智能服务,要想把体验做好为前提,对话系统在金融企业里落地的挑战也挺多的。
- 在产品方面,有监管与数据问题。 因为做智能服务会牵涉到数据的使用,如果智能客服只给用户提供基于知识图谱的 QA 那还好一些,系统不需要详细了解用户。对数据的监管,最后都会限制产品的用户体验。 有些整体的操作,同一个企业的服务,放在中国市场可行,但是一旦放在欧洲市场就可能过不了 GDPR,用户体验甚至价值都会因此妥协。
- 在监管下,行业里一家机构能用的核心业务数据,别家差不多也能给。专业领域上实质不会有太多质的差别,比如”利息”,大家能给用户的点数都是那么多。但是从用户管理角度来看,专业领域的基础差不多,只是面向用户的服务传递可以做很多差异,就可能给用户差异化的体验。可以理解为,银行之间,利息能给的都一样,而且不是银行能决定的,但基于这个如何做出不同服务却各有招数。
- BU(业务团队)与 IT(IT 团队)协作。 因为智能客服业务总体较新,且有很多分支,行业里可靠的评价方法尚未成型。企业内部的业务部门(BU)和 IT 部门;该如何管理这种新项目;如何进行跨部门配合;以及如何评判成果等方面都要做好协调;是以业务为中心来设计还是以用户为中心来设计?最好能提前沟通好。
- CUI 产品与 GUI 产品的 DevOps 方面。 落地智能客服的企业,十有八九会遇到“上线快,运维坑”的情况。就是上线之后,再来改业务的技能,增加新的 usecase,覆盖更多的用户的新表达(比如疫情对业务的影响),维护这些对话管理的成本非常高,而且效果往往都很差。然后,预算 call 在 CR 和运维上的成本会慢慢高于实施的成本,最后项目就慢慢“崩”坏了。这不是某一家厂商的问题,也不是金融场景的问题,而是整个对话智能行业的问题。不仅仅是智能客服,如果你做一个智能助理,拿去 2C,这个问题甚至比智能客服还要严重的多。
这涉及到一个对话系统的本质问题,也是目前被行业忽视的,就是该如何设计一套对话系统? 这个问题具体表现在,如果你去看一家(企业)的对话产品的产品文档,如果还在用 excel 记录对话文本再配以流程图或者树状图,那么你的项目就一定会遇到上面的问题。
智能客服将进化为下一代智能服务
- InfoQ:2016-2017 年,可以说是智能客服行业创业投资都比较热的发展时期,最近这两年,由于一些问题凸显,业界对于这个行业的盈利能力等也或多或少有所质疑,您怎么看待,这个行业的发展历程?
Mingke: 现在的技术正在颠覆“在固定时间和地点上班”这些企业(作为服务提供方)运营的基本概念了。实际上一些行业领先的企业,已经开始重新思考,面向未来的下一代的服务体系是什么。 就好像改变马车的不是更多的马,最终彻底颠覆客服的也不是智能客服,而是智能服务,范围从技术选择、产品形态到商业模式。
智能客服的技术门槛低,价格和渠道拼到一定程度,这个行业可能就没什么钱可赚了,对每一家而言都是如此。 做不出什么差异化,生存状况堪忧。这时就需要有一些新的东西来破局,行业会进化到“分垂直领域”阶段,因为领域自带壁垒,慢慢就形成专业服务的智能化,而不是客服的智能化。
- InfoQ:有没有可能会在技术上实现很大的突破,从而让智能客服迎来了一个大升级?
Mingke: 产品升级肯定有,技术的突破是有的。包括这两天非常火的 GPT-3 也是,对有些场景是挺有帮助的。比如对只回答静态规则的智能客服而言,有团队可能过去在这个方面做了很多自研的各种栈,可能会被 GPT3 维度碾压。只是一旦业务要求要回复结果精准,对生成过程需要可被解释,特别是在金融服务里,就不能直接拿 GPT3 来用。就算是 GPT-30,你问它”我银行账户里还有多少钱?” 它会根据统计模型给你一个答案,这个数字不是从银行系统取出来的,你敢信?
一旦这个跨域推理有突破,就会改变一切,不只是智能客服、智能助理,甚至人类社会的整体经济形态都会发生本质的变化。只是在眼前以深度学习为核心范式的前提下,想要解决跨域做推理的问题,在自然语言处理领域理论上是不现实的。 所以只要这个底层的逻辑依然成立,就有很多 solution 上做选择的空间了,有行业壁垒的公司会逐渐击穿那些做浅层的智能客服公司。中期真正比拼的是,对领域的熟悉程度、专业程度、建模的颗粒度等。
- InfoQ:到领域里深耕,如何判定一家创业公司做到行业的专家了?
Mingke: 这里面很重要的一点与 AI 自身特点类似,就是做领域的推理,因为我们没有办法用一种功能技术建出一个对所有事情都能做推理的系统,我们现在只能模拟一些做推理的结果。而用人力去模拟每一个领域的推理结果,就意味着成本的极速增加。评价一个系统或一家公司,在某一领域的深挖程度是否有足够多价值,它能不能产生壁垒点,主要是判断它能否在该领域做更多复杂的推理,且对用户更有价值。 其实行业里也有在特定领域做的挺好的,比如一些领域的电商做的智能客服,对企业客户确实省下不少钱,对自己也赚了钱,就是终端用户不满意,但是总比没有好,也是一个慢慢发展的方向。
- InfoQ:尚不成熟的智能客服行业之所以火爆起来,这里面是否有炒作的成分在?
Mingke:有炒作,无论是来自于自身还是媒体的宣传,夸大效果,或者给出 “大饼”的时候不提实现成本,都会导致最后落地不了。不止是智能客服,整个 AI 行业都存在炒作现象,这是不太好的一点。
- InfoQ:2020 年以来,因为新冠疫情的影响,很多线下的银行网点加快了收缩、关闭的步伐,对此您有什么看法?
Mingke: 疫情期间,服务人员与用户的当面沟通减少,确实会加速远程办公、协同工具等智能服务发展。所谓智能服务是指让更多系统、机器能提供自动服务,个性化程度更高。当企业在一些场景下,不能线下面对面开展服务时,线上的需求就明显增加。人机混合的智能服务是未来,疫情会加速这个进程。
在接下来 1-3 年,我认为银行业应该会有“管钱助理”这种级别的智能服务出现。 终端用户只认一家银行的 logo,说话提出需求就自动获得完善服务,或者被主动推送合适的服务,不合适就不用,这也是自然语言交互。而不是现在各个部门的客服汇总在一起,甚至一个 app 里就有多个部门的客服入口和对话窗口。
- InfoQ:您为什么对于智能客服 / 助理持批判和怀疑态度?
Mingke: 其实我对用对话系统做智能客服或者智能助理本身并没有偏见,我本身也是对话智能的创业者,也在用前面提到的所有技术为客户提供服务,智能客服的项目和智能服务的项目都在做。可能有朋友在《人工智障 2》一文中看到我对深度学习对语言的处理表示悲观,其实更多的 我是想让大家比较实际的看到技术的边界,然后基于此来考虑如何打造真正传达价值的产品。
如果说批判,则是针对最开始提到的问题:当前系统远不如宣传那么好。以及类似的行业泡沫、炒作现象,当前 AI 不应该被不合理的神化或者被放大。
- InfoQ:对于接下来,智能客服以及智能客服在金融场景下的技术和应用的发展趋势,您有什么看法?
Mingke: 每一个行业都会诞生属于这个领域的智能服务,金融领域是首当其冲的。这些智能化之后,服务首先会覆盖售后的部分,也就是目前智能客服主要的用例,继而逐步颠覆智能客服,然后向用户生命周期的前面延伸,直至全面覆盖。
这个抽象过程也是深挖行业、场景的过程,行业逐步会分化。 我们本身就是例子,我们现在就在为这样的企业提供面向未来的服务设计,其中包括一些大家耳熟能详的品牌。尤其对于那些数字化程度较高的企业,差不多 1-2 年就可以看到到处开花的效果了。
与这个过程伴随出现的,还有配套的工具、平台、基础设施,以及其他“卖水给掘金者”的业务,都会纷纷出现。下一个时代可能是属于智能服务的,看上去像是由 to B 开始的,巅峰的时候可能是全面 to C。智能服务是我认为 AI to C 的方向最有可能出现的做法。 所以我对未来是非常期待的,如果有对这个行业感兴趣的小伙伴欢迎跟我讨论或者加入这个行业。
国外智能客服平台
【2022-1-16】
serviceNow智能客服平台演示-Automate customer service with Now Intelligence, See Now Intelligence powering self-service 自助, automation 自动 and service improvement with Virtual Agent 虚拟助手, Predictive Intelligence and Performance Analytics.
- Watch videos instantly
- Experience a live in-depth demo
NLU terminology NLU专业术语
In NLU parlance, these terms identify the key language components the system uses to classify, parse, and otherwise process natural language content.
- Intent 意图
- Something a user wants to do or what you want your application to handle, such as granting access.
- Utterance 发言
- A natural language example of a user intent. For example, a text string in an incident’s short description, a chat entry, or an email subject line. Utterances are used to build and train intents and should therefore not include several or ambiguous meanings or intents.
- Entity 实体
- The object of, or context for, an action. For example: a laptop, a user role, or a priority level.
- System defined entity 系统定义实体
- These are predefined in an instance and have highly reusable meanings, such as date, time, and location.
- User defined entity 用户自定义实体
- These are created in the system by users and can be built from words in the utterances they create.
- Common Entity 公共实体
- A context commonly used and extracted via a pre-defined entity model, such as currency, organization, people, or quantity.
- Vocabulary 词库,如近义词
- Vocabulary is used to define or overwrite word meanings. For example, you can assign the synonym “Microsoft” to the acronym “MS”.
NLU Model
- A collection of utterance examples and their associated intents and entities that the system uses as a reference to infer intents and entities in a new utterance. You can create default models tailored 特制的 to business unit consumers, such as an ITSM Model, a CSM Model, a Federal Model, or a Boeing Model.
- This image illustrates how Natural Language Understanding processes and renders utterance examples into intents and entities in the system.

NLU Workbench
- Use the NLU Workbench to create morphological representations of human language. These models enable you to create intents and entities expressed in natural language utterances. Any ServiceNow application can invoke an NLU model to get an inference of intents and entities in a given utterance.
- Using the nlu_admin role, you build your models in the NLU Workbench, where you create, train, test, and publish them iteratively.

 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
