文档问答
资讯
【2023-3-27】文档问答
作者:强化学徒
【2023-5-9】大语言模型实现智能客服知识库文档数据提取功能
- 智能客服的知识库有两类:机器人知识库和坐席知识库,分别是为机器人和坐席进行服务时,提供数据的支撑。
- 如何通过大语言模型,让企业的文档可批量上传,无需更多的整理,直接转化为有效的QA,供座席和机器人直接调用呢?
当前的主流客服产品
- 智能客服系统会标配
知识库管理功能,常见的形式是树状结构,提供分类管理、知识库条目管理,并支持知识库的批量导入导出操作。 - 使用中,企业需要经常性地维护管理知识库内容,将企业已有知识内容文档上传,但如果是将原文件上传,则系统最多能支持预览功能,使用者在操作界面只能点击打开全文检索。而如果是机器人知识库,直接上传文档是不可用的,需要操作者手工整理文档中的内容为机器人标准问答对。
大模型时代
- 所有企业的文档可以批量上传,无需更多的整理,直接可自动转化为有效的QA,供座席和机器人直接调用。
【2023-6-26】吴恩达大模型系列课程:
- LangChain for LLM Application Development
-
学习笔记:基于LangChain开发大语言应用模型
- 【2023-9-22】LLM Search:提供一个方便的基于LLM的问答系统,可与多个本地文档集合进行交互
- ‘LLM Search - Querying local documents, powered by LLM’ Denis Lapchev GitHub
大模型知识库:详见站内专题 大模型知识库
背景
文本向量化
嵌入(Embedding)是一种将文本或对象转换为向量表示的技术,将词语、句子或其他文本形式转换为固定长度的向量表示。
- 嵌入向量是由一系列浮点数构成的向量。
- 通过计算两个嵌入向量之间的距离,可以衡量它们之间的相关性。距离较小的嵌入向量表示文本之间具有较高的相关性,而距离较大的嵌入向量表示文本之间相关性较低。
以 Milvus 为代表的向量数据库利用语义搜索(Semantic Search)更快地检索到相关性更强的文档。
详见:站内专题里的文本向量化
Token
什么是token?
- tokens 不是指 prompt 字符串的长度;
- token 指一段话中可能被分出来的词汇。
- 比如:i love you,就是三个token,分别为 「i」「love」「you」。
- 不同语言token计算不一样。在线测试
- 中文的「我爱你」其实是算 5个token,因为会先把内容转成 unicode。
- 有些 emoji 的token长度会超出想象,长达11个。
ChatGPT has an upper limit of 4096
GPT-4 支持,详见官网
- 8k context
- 32k context
| Model | Price for 1000 tokens (prompt) |
|---|---|
| Ada | 2048 |
| Babbage | 2048 |
| Curie | 2048 |
| DaVinci | 4096 |
| ChatGPT | 4096 |
| GPT-4 8k context | 8192 |
| GPT-4 32k context | 32768 |
Remember, the sum of your prompt and maximum tokens should always be less than equal to the model’s maximum token limit, OR your output is truncated.
备注
编码器:可接受长度不超过最大序列长度(如 512 个单词)的输入。如果序列长度小于该限制,就在其后填入预先定义的空白单词。- 如,原始 transformer 论文中的编码器模块可以接受长度不超过最大序列长度(如 512 个单词)的输入。
解码器:区别- 加入了一层重点关注编码器输出的某一片段,编码器-解码器自注意力(encoder-decoder self-attention)层
- 后面的单词掩盖掉了。但并不像 BERT 一样将它们替换成特殊定义的单词 < mask >,而是在自注意力计算的时候屏蔽了来自当前计算位置右边所有单词的信息。
经验
- 英文:100 tokens ~= 75 words)
- 中文:一个汉字占2-3个token
- 其它:emoji表情符号,占用更多,有的高达11个
更多见站内分词专题
如何增强LLM能力
Full Stack LLM 课程
【2023-5-21】LLM训练营课程笔记—Augmented Language Models
- 英文ppt, 讲义总结
- There are three ways to augment language models: retrieval, chains, and tools.
- Retrieval involves providing an external corpus of data for the model to search, chains use the output of one language model as input for another, and tools allow models to interact with external data sources.
【2023-6-24】The Full Stack 出品的 LLM Bootcamp Spring 2023
很难用传统ML方法评估,LLM输出特点:多样性
如何评估LLMs效果 Evaluation metrics for LLMs
- 常规评估标准: 如 正确率之类
- 借鉴匹配标准:
- 语义相似度
- 用另一个LLM评判两个大难事实是否一致
- 哪个更好 which is better
- 让LLM根据提供的要点判断两个答案哪个更好
- 反馈是否包含 is the feedback incorporated
- 让LLM判断新答案是否包含旧答案上的反馈
- 统计指标
- 验证输入结构,如 是否 json格式
- 让LLM给答案打分,如 1-5分
总结,评估顺序
- 有正确答案吗?是→用传统ML的指标,否则
- 有参考答案吗?是→用匹配指标,拿参考答案计算匹配度,否则
- 有其他答案吗?是→LLM判断哪个更好(which is better),否则
- 有人工反馈吗?是→LLM判断反馈是否采纳(is the feedback incorporated),否则
- 统计指标
如何提升生产环境中LLMs输出效果
- 反问模型是否正确 Self-critique 自我怀疑
- Ask an LLM “is this the right answer”
- 多次请求选最佳 Sample many times, choose the best option
- 多次请求集成 Sample many times, ensemble
如何改进持续prompt效果?
- 根据用户反馈人工筛选未解决的案例
- 调整prompt,方法:① 提示工程 ② 改变context
那么,这个流程如何自动化? Fine-tuning LLMs 微调大模型
- SFT
- 想将大模型适配到具体任务,或 ICL效果不好
- 有大量领域数据
- 构建小/便宜模型,降低总成本
- 基于人工反馈微调
- 由于技术复杂、昂贵,没多少公司自己做
- 方法:RLHF、RLAIF
LLMs的SFT类型:效果上逐级提升,但训练效率上不断降低
- (1)基于特征:冻结LLMs(如预训练transformer),输出embedding信息后,单独更新附加模型(如分类)
- (2)部分参数微调:冻结LLMs,只更新新增的全连接层参数(不再单独加模型)
- (3)全参数微调:全部参数一起微调
PEFT技术:Parameter-efficient fine tuning
- Prompt modification:
- Hard prompt tuning
- Soft prompt tuning
- Prefix tuning
- Adapter methods
- Adapters: 如 LLaMA-Adapter(基于prefix tuning)
- Reparameterization
- LoRA(Low rank adaptation)
LLM问题
- Most common: often UI stuff
- 响应时间长 Latency especially
- 回答错误/幻觉 Incorrect answers / “hallucinations”
- 过于啰嗦 Long-winded answers
- 回避问题 Too many “dodged” questions
- 提示攻击 Prompt injection attacks
- 道德安全 Toxicity, profanity
LLM Bootcamp 2023 Augmented language models
LLM擅长什么?What (base) LLMs are good at ?
- • 语言理解 language understanding
- • 遵循指令 instruction following
- • 基础推理 basic reasoning
- • 代码理解 code understanding
LLM在哪些方面需要帮助? What they need help with ?
- • 获取最新知识 up-to-date knowledge
- • 用户数据包含的知识 knowledge of your data
- • 更有挑战性的推理 more challenging reasoning
- • 与外界交互 interacting with the world
如何增强LLM能力
如何增强LLM的能力?
- LLM更加擅长通用推理,而不是特定知识。
- LLMs are for general reasoning, not specific knowledge
为了让LLM能够取得更好的表现,最常见方法就是给LLM提供合适的上下文信息帮助LLM进行推理。
- A baseline: using the context window
- Context is the way to give LLM unique, up-to-date information … But it only fits a limited amount of information
- 上下文信息适合提供独特、实时信息,但进适用于有限的信息量
随着最近LLM的不断发展,各类大模型所能支持的最大上下文长度也越来越大,但是在可预见的一段时间内仍不可能包含所有内容,并且越多的上下文意味着更多的计算成本。
- Context windows are growing fast, but won’t fit everything for a while (Plus, more context = more $$$)
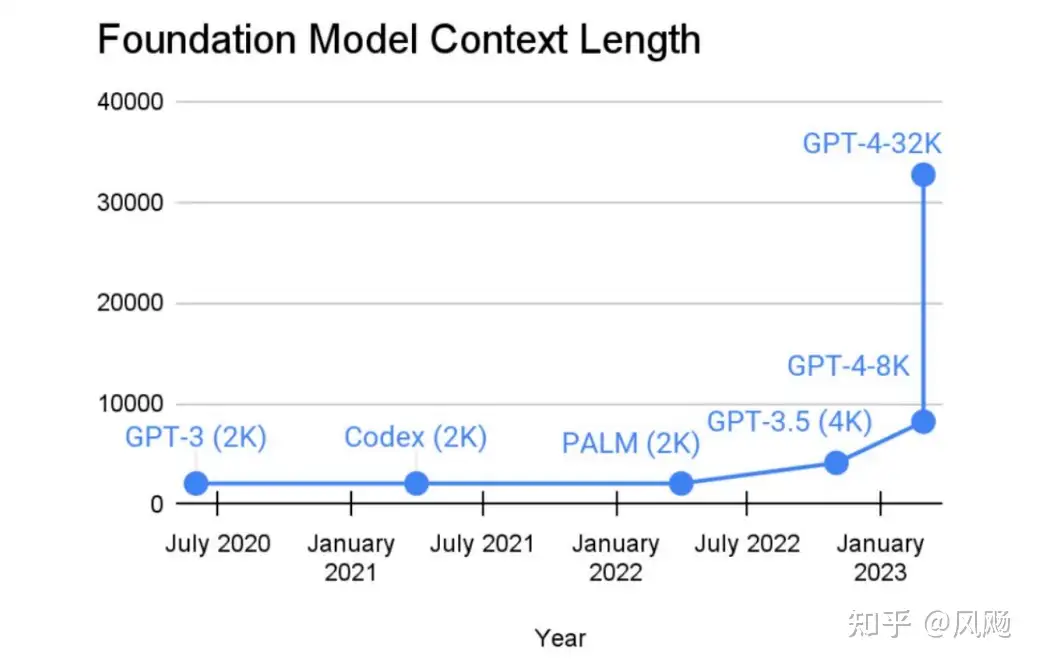
how to make the most of a limited context by augmenting the language model ?
如何充分利用当前所能支持的有限的上下文信息,让LLM表现更好,值得研究。
有限下文情况下充分激发LLM 能力的方法有三种:
- 检索
Retrieval:答案在文档内,并行找相关内容作为prompt;Augment with a bigger corpus - 链式
Chain:答案在文档外,串行请求;Augment with more LLM calls - 工具
Tools:调用外部工具;Augment with outside sources
(1)通过Retrieval增强LLM的能力 —— 答案在文档内
outline
- A. Why retrieval augmentation?
- Q: We want our model to have access to data from thousands of uses in the context
- 海量用户数据塞到context中
- B. 传统信息检索 Traditional information retrieval,要素:
- Query. Formal statement of your information need. E.g., a search string.
- Object. Entity inside your content collection. E.g., a document.
- Relevance. Measure of how well an object satisfies the information need
- 通过布尔搜索(boolean search)
- E.g., only return the docs that contain: simple AND rest AND apis AND distributed AND nature
- Ranking. Ordering of relevant results based on desirability
- 通过 BM25, 受3个因素影响 Ranking via BM25. Affected by 3 factors
- ① 词频 Term frequency (
TF) — More appearances of search term = more relevant object - ② 逆文档概率 Inverse document frequency (
IDF) — More objects containing search term = less important search term - ③ 字段长度 Field length — If a document contains a search term in a field that is very short (i.e. has few words), it is more likely relevant than a document that contains a search term in a field that is very long (i.e. has many words).
- 方法:通过倒排索引搜索 search via inverted indexes,另外还有很多:
- 文档注入 Document ingestion
- 文档处理 Document processing (e.g., remove stop words, lower case, etc)
- 转换处理 Transaction handling (adding / deleting documents, merging index files)
- 缩放 Scaling via shards Ranking & relevance
- 局限性:Limitations of “sparse” traditional search
- 只建模简单词频信息 Only models simple word frequencies
- 无法捕捉语义信息、相关信息等 Doesn’t capture semantic information, correlation information, etc
- E.g., searching for “what is the top hand in bridge” might return documents about 🌉, ♠, 💸
- C. 基于embedding的信息检索 AI-powered Information retrieval via embeddings
- Search and AI make each other better
AI:Better representations of data (embeddings)Search: Better information in the context
- 什么是embedding?学习到的抽象、稠密、压缩、定长的数据表示
- Embeddings are an abstract, dense, compact, fixed-size, (usually) learned representation of data
- Search and AI make each other better
- D. Patterns and case studies
一个典型的在文档QA场景使用检索方式来增强LLM能力的方式,分为几个流程:
- 用户问题embedding
- 从海量文档中检索出Top N与问题embedding相似的候选文档
- 基于TopN文档内容构造Prompt
- 调用LLM获取最终答案
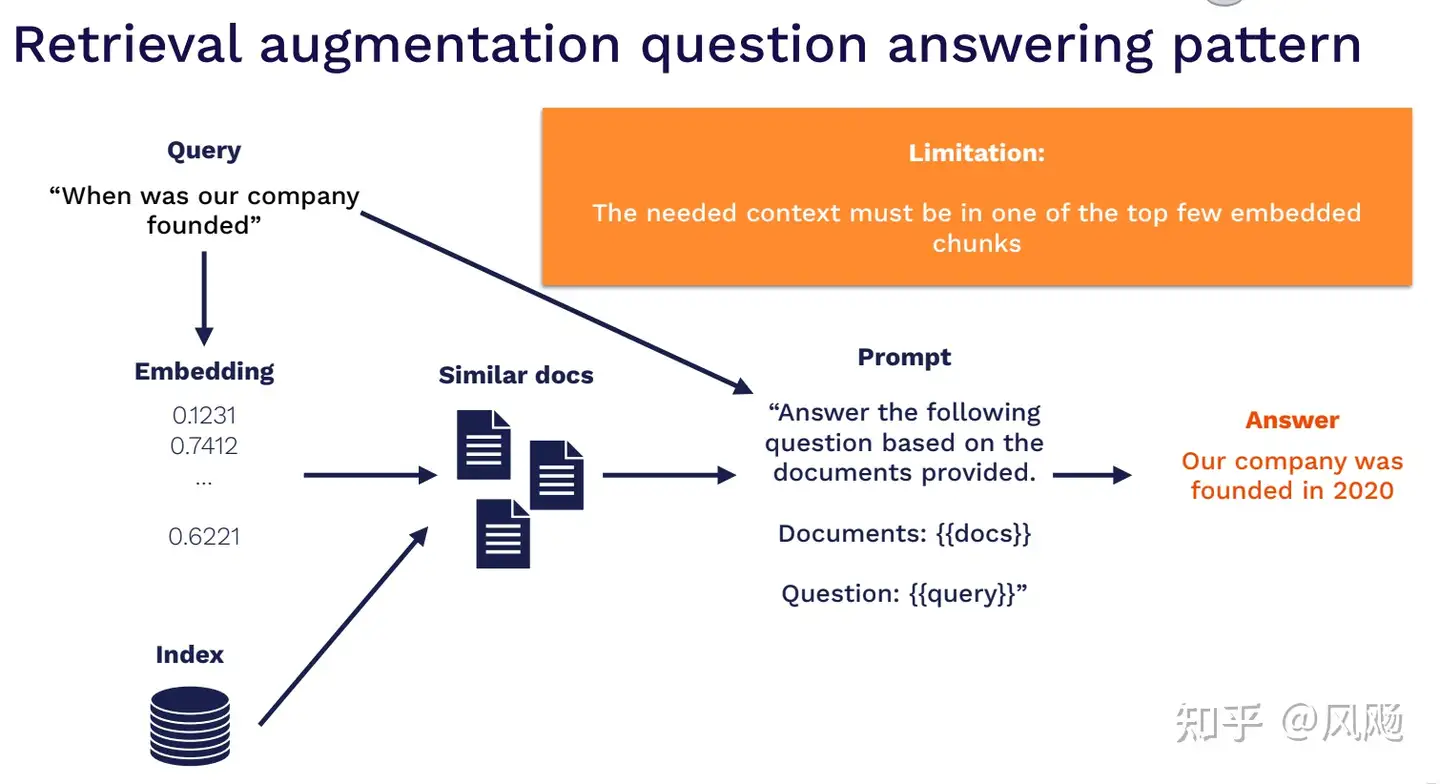
常用的Retrieval技术
对Retrieval的技术细节以及一些常用的工具进行了详细的介绍,包括传统Retrieval以及基于Embedding的Retrieval这两种技术路线,原教程学习或者参考一些其他的信息检索资料。
(2)通过Chain增强LLM的能力 —— 答案在文档外
某些情况下,最佳的context可能并不存在于用户语料库中。上一个LLM的输出结果可能正好是当前LLM的最好的输入context。
此时,可以用Chain形式将不同的LLM连接起来,去增强最终任务的效果。例如下图的摘要任务:
- 首先将文本拆分为多个部分,对于每个部分使用LLM做一个局部摘要,然后再用LLM对各个摘要进行合并输出全局的摘要。

典型进行这样任务编排的工具是LangChain,可以利用它来开发很多有意思的应用。
(3)通过Tools增强LLM的能力 —— 借助外界工具
通过各种各样的工具让LLM与外界进行交互,比如使用搜索引擎、执行SQL语句等,从而去丰富LLM的功能。
- 有时最好的context并不直接存在于语料,而是源自另一个LLM的输出。
构建工具链的几个案例 Example patterns for building chains
- 问答模式 The QA pattern
- Question ➡ embedding ➡ similar docs ➡ QA prompt
- 假想文档映射 Hypothetical document embeddings (HyDE)
- Question ➡ document generating prompt ➡ rest of QA chain
- 摘要 Summarization
- Document corpus ➡ apply a summarization prompt to each ➡ pass all document summaries to another prompt ➡ get global summary back
Tools方式大致有两种
- 一种是基于Chain的方式,Tool是一个必选项,前面有一个LLM来构造Tool的输入,后面会有另一个LLM来总结Tool的输出并得到最终的结果;
- 一种是基于Plugin的方式,Tool是一个可选项,让LLM来决定用不用以及怎么用Tool。
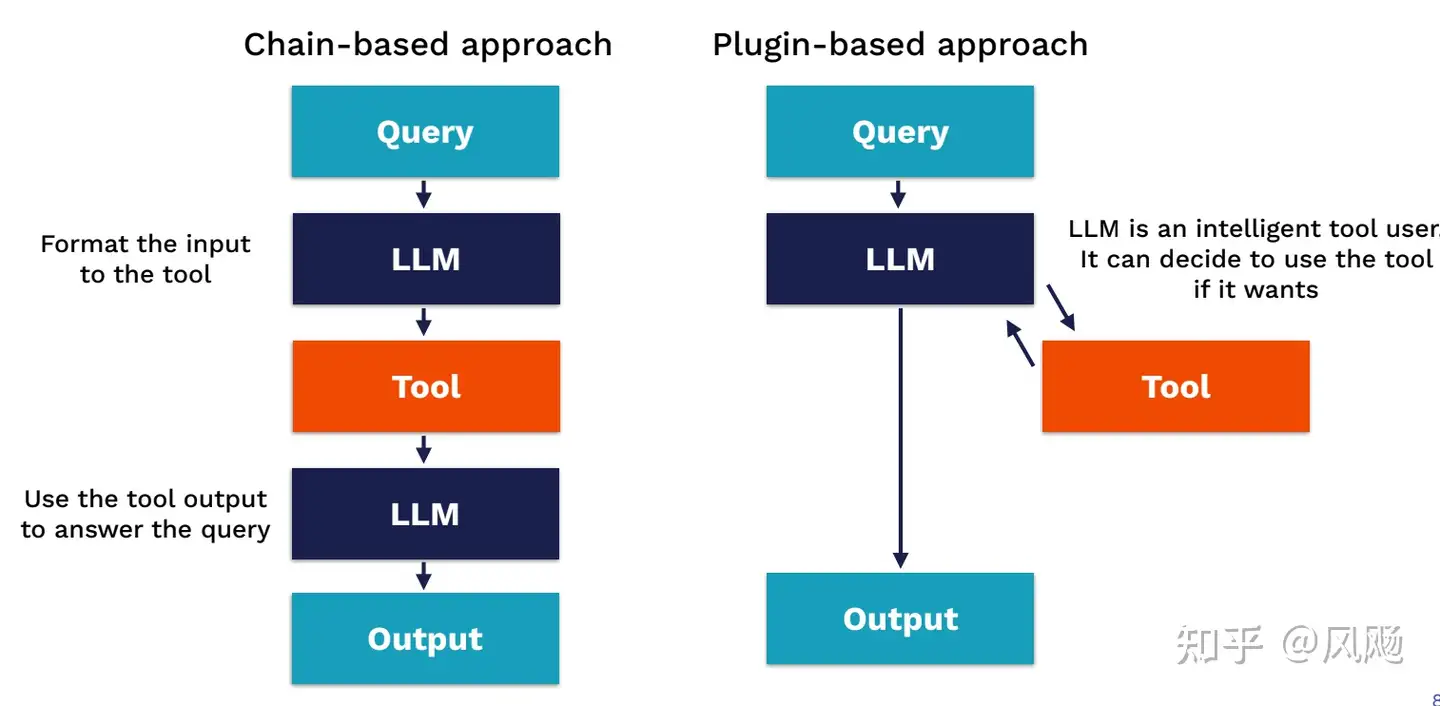
总结
- • 通过与外界数据的交互,LLM的能力能够更加强大。
- • 通过使用规则和启发式方法,可以实现各种各样的功能。
随着知识库的扩大,应该将其视为一个信息检索系统。使用Chain的方式可以帮助编码更复杂的推理,并且绕过token长度的限制。各种各样的外部工具可以让模型访问更多的资源。
方法总结
常见的方法:
retrieve-then-generate:类ChatGPT Retrieval Plugin的技术方案- 根据输入query来抽取相关外部文本,把抽取到的文本和query一起作为prompt再来做后续字符的推理。
- chatpdf这种产品的方法也类似,先把你输入的文档分成多个chunk分别做embedding放到向量数据库里,然后根据输入embedding的向量做匹配,再把匹配到的向量对应的chunk和输入一起作为prompt给LLM。
- 论文:【2020-2-10】REALM: Retrieval-Augmented Language Model Pre-Training
Fine-tuning:Fine-tuning是指在已经训练好的GPT/LLM模型基础上,使用新数据集再次训练。这种方法可以使模型针对特定任务或特定领域的语言使用情况进行优化,从而提高模型的效果。在Fine-tuning过程中,可以将额外知识作为新的数据集加入到训练中。Knowledge Distillation:Knowledge Distillation是指将一个“大模型”的知识转移到一个“小模型”中。例如,可以将一个已经训练好的GPT/LLM模型的知识转移到一个小型的模型中,使得小型模型能够使用大型模型中的知识。这种方法可以通过将额外的知识加入到“大模型”中,从而使得“小模型”可以使用这些知识。数据增强:数据增强是指在已有的数据集中,添加一些类似但不完全相同的数据来增加数据的数量和多样性。这种方法可以使得模型更加全面地学习到不同的语言使用情况,从而提高模型的效果。在数据增强的过程中,可以添加额外的知识,例如同义词、反义词、专业术语等。- 词向量:将领域特定的词汇和词向量添加到模型的词汇表中。这些词汇可以是在目标领域中独有的词汇或者在常规数据集中缺失的词汇。
- 外部数据集:从外部数据集中收集与目标领域相关的数据,并将其添加到模型的训练数据中。这种方法需要找到与目标任务相关的高质量数据集,并使用适当的方法将其合并到模型的训练数据中。
- 外部知识库:将外部的知识库,如百科全书、知识图谱等,与模型集成,以便模型可以使用这些知识来辅助其生成文本。
- 人工标注:通过人工标注的方式,将领域特定的信息添加到训练数据中。这种方法需要大量的人力和时间,并且对于大型数据集来说可能不切实际。
多任务学习:多任务学习是指同时训练一个模型完成多个任务。例如,在训练GPT/LLM模型时,可以让模型同时完成文本分类、情感分析等任务,从而使得模型可以学习到更加多样化的知识。在多任务学习的过程中,可以将额外的知识添加到其他任务中,从而间接地影响到模型在主要任务上的表现。
【2023-4-22】基于llama-index和ChatGPT API定制私有对话机器人的方式。
方案
- 1、fine-tunes微调。用大量数据对GPT模型进行微调,实现一个理解文档的模型。
- 但微调需要花费很多money,而且需要一个有实例的大数据集。也不可能在文件有变化时每次都进行微调。
- 微调不可能让模型 “知道“ 文档中的所有信息,而是要教给模型一种新的技能。
- 因此,微调不是一个好办法。
- 2、将私有文本内容作为prompt的上下文,访问ChatGPT。
- openai api存在最大长度的限制,ChatGPT 3.5的最大token数为4096,如果超过长度限制,会直接对文档截断,存在上下文丢失的问题。
- 并且api的调用费用和token长度成正比,tokens数太大,则每次调用的成本也会很高。
输入长度限制
【2023-7-26】浅谈LLM的长度外推
随着大模型应用的不断发展,知识外挂已经成为了重要手段。但只是外挂手段往往受限于模型本身可接受长度,以及模型外推能力。
截止20230724,外推策略:NBCE,线性内插,NTK-Aware Scaled RoPE,Dynamically Scaled RoPE,consistent of Dynamically Scaled RoPE。
NBCE
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度,介绍
- 苏神最早提出的扩展LLM的context方法,基于bayes启发得到的公式
- 在问答下实测确实不错,在较长context下的阅读理解还算好用。
局限
- 无序性,即无法识别Context的输入顺序,这在续写故事等场景可能表现欠佳,做一些依赖每个context生成答案,比如提取文档摘要,效果较差
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
return_dict=True,
use_cache=True,
past_key_values=past_key_values
)
past_key_values = outputs.past_key_values
# ===== 核心代码开始 =====
beta = 0.25
probas = torch.nn.functional.softmax(outputs.logits[:, -1], dim=-1)
logits = probas.log()
k = (probas * logits).sum(dim=-1)[1:].argmax() + 1
logits_max = logits[k]
logits_uncond = logits[0]
logits = (1 + beta) * logits_max - beta * logits_uncond
# ===== 核心代码结束 =====
# 构建分布,采样
tau = 0.01 # tau = 1是标准的随机采样,tau->0则是贪心搜索
probas = torch.nn.functional.softmax(logits[None] / tau , dim=-1)
next_tokens = torch.multinomial(probas, num_samples=1).squeeze(1)
线性内插
llama 基于 rotary embedding在2048长度上预训练,该方法通过将position压缩到0~2048之间,从而达到长度外推的目的。
longchat将模型微调为上下文长度外扩为16384,压缩比为 8。例如,position_ids = 10000 的 token 变为position_ids = 10000 / 8 = 1250,相邻 token 10001 变为 10001 / 8 = 1250.125
该方法的缺陷是需要进行一定量的微调,让模型来适应这种改变。
资料
NTK-Aware Scaled RoPE
NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation.
RoPE是一种β进制编码: re
RoPE 的行为就像一个时钟。12小时时钟基本上是一个维度为 3、底数为 60 的 RoPE。因此,每秒钟,分针转动 1/60 分钟,每分钟,时针转动 1/60。现在,如果将时间减慢 4 倍,那就是二使用的线性RoPE 缩放。不幸的是,现在区分每一秒,因为现在秒针几乎每秒都不会移动。因此,如果有人给你两个不同的时间,仅相差一秒,你将无法从远处区分它们。NTK-Aware RoPE 扩展不会减慢时间。一秒仍然是一秒,但它会使分钟减慢 1.5 倍,将小时减慢 2 倍。这样,您可以将 90 分钟容纳在一个小时中,将 24 小时容纳在半天中。所以现在你基本上有了一个可以测量 129.6k 秒而不是 43.2k 秒的时钟。由于在查看时间时不需要精确测量时针,因此与秒相比,更大程度地缩放小时至关重要。不想失去秒针的精度,但可以承受分针甚至时针的精度损失。
Dynamically Scaled RoPE
dynamically_scaled_rope_further_increases
方法二、三,都涉及到一个超参数α,用于调节缩放比例,该方法是通过序列长度动态选择正确的比例参数,效果可以看上图。
对于线性插值,前 2k 上下文的精确位置值,然后在模型逐个生成标记时重新计算每个新序列长度的位置向量。本质上,将比例设置为原始模型上下文长度/当前序列长度。
对于动态 NTK,α 的缩放设置为 (α * 当前序列长度 / 原始模型上下文长度) - (α - 1)。随着序列长度的增加动态缩放超参数。
consistent of Dynamically Scaled RoPE
输出长度受限
RecurrentGPT(输出不受限)
【2023-5-30】ChatGPT能写长篇小说了,ETH提出RecurrentGPT实现交互式超长文本
- 苏黎世联邦理工和波形智能的团队发布了 RecurrentGPT,一种让大语言模型 (如 ChatGPT 等) 能够模拟 RNN/LSTM,通过 Recurrent Prompting 来实现交互式超长文本生成,让利用 ChatGPT 进行长篇小说创作成为了可能。
- 论文地址
- 项目地址
- 在线 Demo: 长篇小说写作, 交互式小说
Transformer 大语言模型最明显的限制之一: 输入和输出的长度限制。
- 虽然输入端的长度限制可以通过 VectorDB 等方式缓解
- 输出内容的长度限制始终是长内容生成的关键障碍。
为解决这一问题,过去很多研究试图使用基于向量化的 State 或 Memory 来让 Transformer 可以进行循环计算。这样的方法虽然在长文本建模上展现了一定的优势,但是却要求使用者拥有并可以修改模型的结构和参数,这在目前闭源模型遥遥领先的大语言模型时代中是不符合实际的。
RecurrentGPT 则另辟蹊径,利用大语言模型进行交互式长文本生成的首个成功实践。它利用 ChatGPT 等大语言模型理解自然语言指令的能力,通过自然语言模拟了循环神经网络(RNNs)的循环计算机制。
- 每一个时间步中,RecurrentGPT 会接收上一个时间步生成的内容、最近生成内容的摘要(短期记忆),历史生成内容中和当前时间步最相关的内容 (长期记忆),以及一个对下一步生成内容的梗概。RecurrentGPT 根据这些内容生成一段内容,更新其长短时记忆,并最后生成几个对下一个时间步中生成内容的规划,并将当前时间步的输出作为下一个时间步的输入。这样的循环计算机制打破了常规Transformer 模型在生成长篇文本方面的限制,从而实现任意长度文本的生成,而不遗忘过去的信息。
llama-index
【2023-4-23】参考
既然tokens有限制,那么有没有对文本内容进行预处理的工具?不超过token数限制。
- 借助llama-index可以从文本中只提取出相关部分,然后将其反馈给prompt。
- llama-index, github支持许多不同的数据源,如API、PDF、文档、SQL 、Google Docs等。
llama-index Ecosystem
- 支持多种文件格式:support parsing a wide range of file types: .pdf, .jpg, .png, .docx, etc.
- 🏡 LlamaHub, 包含各类插件,如:网页、faiss语义索引、b站视频脚本、ES、Milvus、数据库等
- 🧪 LlamaLab
【2023-5-17】基于ChatGPT的视频摘要应用开发
- 当文档被送入 LLM 时,它会根据其大小分成块或节点。 然后将这些块转换为嵌入并存储为向量。
- 当提示用户查询时,模型将搜索向量存储以找到最相关的块并根据这些特定块生成答案。 例如,如果你在大型文档(如 20 分钟的视频转录本)上查询“文章摘要”,模型可能只会生成最后 5 分钟的摘要,因为最后一块与上下文最相关 的“总结”。
流程图
一种全新的 LlamaIndex 数据结构:文档摘要索引,与传统语义搜索相比,检索性能更好
多数构建 LLM 支持的 QA 系统步骤:
- 获取源文档,将每个文档拆分为文本块
- 将文本块存储在向量数据库中
- 查询时,通过嵌入相似性 和/或 关键字过滤器来检索文本块。
- 执行响应并汇总答案
由于各种原因,这种方法检索性能有限。
- 文本块缺乏全局上下文。通常query上下文超出了特定块中索引的内容。
- 仔细调整 top-k / 相似度分数阈值。
- 假设值太小,你会错过上下文。
- 假设值值太大,并且成本/延迟可能会随着更多不相关的上下文而增加,噪音增加。
- 嵌入选择的上下文不一定最相关。
- 嵌入本质上是在文本和上下文之间分别确定的。
添加关键字过滤器是增强检索结果的一种方法。
- 但需要手动或通过 NLP 关键字提取/主题标记模型为每个文档充分确定合适的关键字。
- 此外,还需要从查询中充分推断出正确的关键字。
LlamaIndex中提出了一个新索引,为每个文档提取/索引非结构化文本摘要。
- 该索引可以提高检索性能,超越现有的检索方法。有助于索引比单个文本块更多的信息,并且比关键字标签具有更多的语义。
如何构建?
- 提取每个文档,并使用 LLM 从每个文档中提取摘要。
- 将文档拆分为文本块(节点)。摘要和节点都存储在文档存储抽象中。
- 维护从摘要到源文档/节点的映射。
在查询期间,根据摘要检索相关文档以进行查询:
- 基于 LLM 的检索:向 LLM 提供文档摘要集,并要求 LLM 确定: 哪些文档是相关的+相关性分数。
- 基于 嵌入 的检索:根据摘要嵌入相似性(使用 top-k 截止值)检索相关文档。
注意
- 检索文档摘要的方法不同于基于嵌入的文本块检索。文档摘要索引检索任何选定文档的所有节点,而不是返回节点级别的相关块。
存储文档的摘要还可以实现基于 LLM 的检索。
- 先让 LLM 检查简明的文档摘要,看看是否与查询相关,而不是一开始就将整个文档提供给 LLM。
- 这利用了 LLM 的推理能力,它比基于嵌入的查找更先进,但避免了将整个文档提供给 LLM 的成本/延迟
带摘要的文档检索是语义搜索和所有文档的强力摘要之间的“中间地带”。
示例
- 构建方法见原文:LlamaIndex :面向QA 系统的全新文档摘要索引
pip install llama-index # install
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data() # 加载数据
index = GPTVectorStoreIndex.from_documents(documents) # 创建索引
query_engine = index.as_query_engine() # 初始化查询引擎
response = query_engine.query("What did the author do growing up?") # 执行查询
print(response) # 返回结果
# --------- 持久化向量索引 ---------
from llama_index import StorageContext, load_index_from_storage
index.storage_context.persist() # 持久化存储(默认放内存)
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load index
index = load_index_from_storage(storage_context)
高级api
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
response = query_engine.query("What are the sports teams in Toronto?")
print(response)
底层api
# use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What are the sports teams in Toronto?")
print(response)
安装
pip install openai
pip install llama-index
调用代码
- construct_index方法中,使用llama_index的相关方法,读取data_directory_path路径下的txt文档,并生成索引文件存储在index_cache_path文件中。
from llama_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper,ServiceContext
from langchain import OpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'your openai api key'
data_directory_path = 'your txt data directory path'
index_cache_path = 'your index file path'
#构建索引
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 2000
max_chunk_overlap = 20
chunk_size_limit = 500
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=num_outputs))
# 按最大token数500来把原文档切分为多个小的chunk
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, chunk_size_limit=chunk_size_limit)
# 读取directory_path文件夹下的文档
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
# 保存索引
index.save_to_disk(index_cache_path)
return index
def chatbot(input_text):
# 加载索引
index = GPTSimpleVectorIndex.load_from_disk(index_cache_path)
response = index.query(input_text, response_mode="compact")
return response.response
if __name__ == "__main__":
#使用gradio创建可交互ui
iface = gr.Interface(fn=chatbot,
inputs=gr.inputs.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Text AI Chatbot")
index = construct_index(data_directory_path)
iface.launch(share=True)
llama-index的工作原理如下:
- 创建文本块索引
- 找到最相关的文本块
- 使用相关的文本块向 GPT-3(或其他openai的模型) 提问
- 在调用query接口的时候,llama-index默认会构造如下的prompt:
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}\n"
使用以上prompt请求openai 的模型时,模型根据提供的上下文和提出的问题,使用其逻辑推理能力得到想要的答案。
【2023-4-13】如何为GPT/LLM模型添加额外知识?
如何分句
【2023-5-25】llama-index的分句方法:加自定义部分(前后缀等)→调用nltk.tokenize.punkt分句(自定义句末正则)→按照chunk_size截断→分句列表,源码
retrieve-then-generate
1、retrieve-then-generate:类ChatGPT Retrieval Plugin的技术方案
核心:根据 输入query 检索本地/私有数据库/文档中的文档片段(检索可以是文本检索或基于向量的检索),作为扩充的上下文 context,通过 prompt template 组合成一个完整的输入,继而调用模型生成response。
简版工作流:
- chunk -> index -> retrieve -> construct input -> LLM
推荐开源工具:
- (1)OpenAI 的官方插件:ChatGPT Retrieval Plugin
- (2)llama-index:https://github.com/jerryjliu/llama_index,提供了一个本地/私有数据收集(ingestion)和数据索引(indexing)的解决方案,构建起外部数据和 LLM 之间的接口。
一个利用 llama-index 定制个人论文检索的示例:llama_index/examples/paul_graham_essay at main · jerryjliu/llama_index。
(在没有OpenAI API的情况下,llama-index 支持调用自定义的 LLM。)
(3)LangChain:langchain,也是为了更好的构建外部数据、其他应用与 LLM 进行交互的接口层框架。
LangChain应用参考示例:GPT-4 & LangChain——PDF聊天机器人-地表最强全文搜索。
llama-index 和 LangChain 可以组合使用,LangChain 中提供了 面向不同任务的 prompt template 和 prompt chain。
基于 fine-tuning 的方式
2、基于 fine-tuning 的方式,相比于第一种方案,基于 fine-tuning 的方式需要额外的训练开销,同时还是会受限于LLM的最大长度限制。
“让 LLM 具备理解定制数据库的能力”是很有挑战的目标,同时也会有很多应用场景。
使用Hugging Face实现将维基百科的知识库添加到GPT-2模型中
- 作者:小斐实战
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments
# 加载预训练的GPT-2模型
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 加载GPT-2的tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 加载维基百科的文本文件,并将其转换为数据集
dataset = TextDataset(
tokenizer=tokenizer,
file_path='path/to/wiki.txt',
block_size=128
)
# 创建data collator
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 设置训练参数
training_args = TrainingArguments(
output_dir='./results', # 输出目录
num_train_epochs=3, # 训练的轮数
per_device_train_batch_size=8, # 训练时每个GPU的batch size
per_device_eval_batch_size=8, # 验证时每个GPU的batch size
evaluation_strategy='steps', # 评估策略
save_steps=500, # 多少步保存一次模型
save_total_limit=2, # 最多保存几个模型
logging_steps=500, # 多少步记录一次日志
learning_rate=5e-5, # 学习率
# 创建Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
prediction_loss_only=True
)
# 开始训练
trainer.train()
# 保存微调后的模型
trainer.save_model('./fine-tuned-model')
知识图谱增强
使用知识图谱增强GPT-2模型的示例代码:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练的GPT-2模型
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 加载GPT-2的tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 加载知识图谱: 表示一些实体和它们之间的关系。
knowledge_graph = {
'John': {
'is a': 'person',
'born in': 'New York',
'works at': 'Google'
},
'Google': {
'is a': 'company',
'headquartered in': 'California',
'founded by': 'Larry Page and Sergey Brin'
}
}
# 将知识图谱嵌入到模型中
model.resize_token_embeddings(len(tokenizer))
for entity in knowledge_graph.keys():
entity_id = tokenizer.convert_tokens_to_ids(entity)
entity_embedding = torch.randn(768)
model.transformer.wte.weight.data[entity_id] = entity_embedding
# 生成句子
input_text = 'John works at'
input_ids = tokenizer.encode(input_text, return_tensors='pt')
output = model.generate(
input_ids,
max_length=50,
do_sample=True,
top_k=50
)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
LLM应用
LLM应用技术架构
典型LLM应用开发架构四层:
- (1)
存储层:主要为向量数据库,用于存储文本、图像等编码后的特征向量,支持向量相似度查询与分析。例如,我们在做文本语义检索时,通过比较输入文本的特征向量与底库文本特征向量的相似性,从而检索目标文本,即利用了向量数据库中的相似度查询(余弦距离、欧式距离等)。- 【代表性数据库】
Pinecone、Qdrant。
- 【代表性数据库】
- (2)
模型层:选择大语言模型,如OpenAI的GPT系列模型、Hugging Face中的开源LLM系列等。- 模型层提供最核心支撑,包括聊天接口、上下文QA问答接口、文本总结接口、文本翻译接口等。
- 【代表性模型】OpenAI的
GPT-3.5/4,Anthropic的Claude,Google的PaLM,THU的ChatGLM等。
- (3)
服务层:将各种语言模型或外部资源整合,构建实用的LLM模型。Langchain是一个开源LLM应用框架,概念新颖,将LLM模型、向量数据库、交互层Prompt、外部知识、外部工具整合到一起,可自由构建LLM应用。- 【代表性框架】:
LangChain,AutoGPT,BabyAGI,Llama-Index等。
- (4)
交互层:用户通过UI与LLM应用交互langflow是langchain的GUI,通过拖放组件和聊天框架提供一种轻松的实验和原型流程方式。- 实现一个简单的聊天应用,输入“城市名字”,聊天机器人回复“该城市的天气情况”。
- 只需要拖动三个组件:PromptTemplate、OpenAI、LLMChain。完成PromptTemplate、OpenAI、LLMChain的界面化简单配置即可生成应用。
LLM 应用
【2023-5-30】万字长文:LLM应用构建全解析
LLM 应用总结
LLM 应用
- 1、本地文档知识问答助理(chat with pdf),如:私域知识问答助理,智能客服,语义检索总结、辅助教学。
- 2、视频知识总结问答助理(chat with video),如:视频自动编目、视频检索问答。
- 3、表格知识总结问答助理(chat with csv),如:商业数据分析、市场调研分析、客户数据精准分析等
1. Doc-Chat 文档问答
LangChain 面对非机构化数据时,通过借助 Embedding 能力,对PDF文件数据进行向量化,LangChain在此基础上允许用户将输入的数据与PDF中的数据进行语义匹配,从而实现用户在PDF文件中的内容搜索。
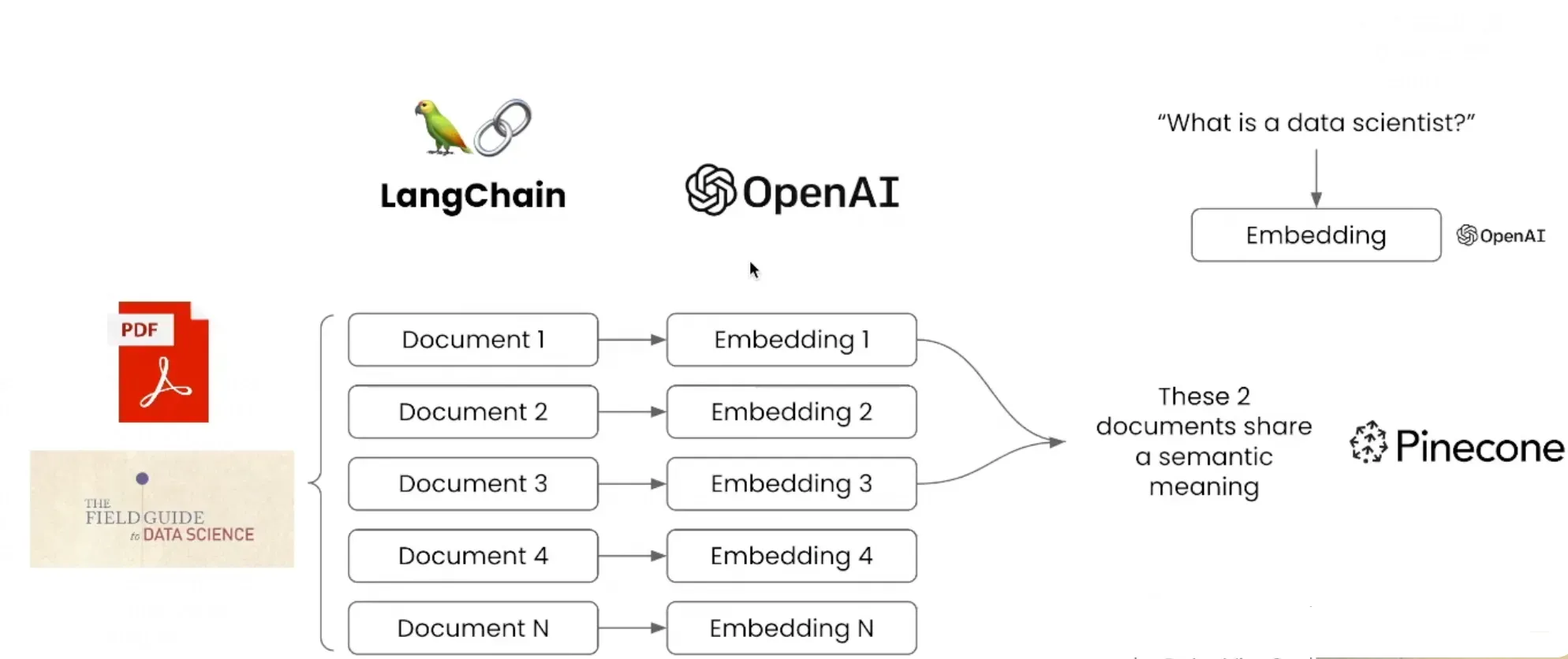
有大量本地文档数据,希望通过问答的方式快速获取想要的知识或信息,提高工作效率
解决方案:
langchain + llms
本地化知识专属问答助理构建过程可简单概括如下:
- 第一步:数据加载&预处理(将数据源转换为text,并做text split等预处理)
- 第二步:向量化(将处理完成的数据embedding处理)
- 第三步:召回(通过向量检索工具Faiss等对query相关文档召回)
- 第四步:阅读理解,总结答案(将context与query传给llms,总结答案)
langchaini + pinecone 实现
from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
oader = UnstructuredPDFLoader("../data/field-guide-to-data-science.pdf")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(data)
# Create embeddings of your documents to get ready for semantic search
from langchain.vectorstores import Chroma, Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
OPENAI_API_KEY = '...'
PINECONE_API_KEY = '...'
PINECONE_API_ENV = 'us-east1-gcp'
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# initialize pinecone
pinecone.init(
api_key=PINECONE_API_KEY, # find at app.pinecone.io
environment=PINECONE_API_ENV # next to api key in console
)
index_name = "langchaintest" # put in the name of your pinecone index here
docsearch = Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name)
query = "What are examples of good data science teams?"
docs = docsearch.similarity_search(query, include_metadata=True)
#. Query those docs to get your answer back
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
llm = OpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the collect stage of data maturity?"
docs = docsearch.similarity_search(query, include_metadata=True)
chain.run(input_documents=docs, question=query)
#. OUTPUT: ' The collect stage of data maturity focuses on collecting internal or external datasets. Examples include gathering sales records and corresponding weather data.'
(1)数据加载&预处理
加载pdf文件,对文本进行分块
- 每个分块的最大长度为3000个字符)。这个最大长度根据llm的输入大小确定,比如gpt-3.5-turbo最大输入是4096个token。
- 相邻块之间的重叠部分为400个字符,目的是每个片段保留一定的上文信息,后续处理任务利用重叠信息更好理解文本。
方案
- LangChain + FAISS + OpenAI
import os
openai_api_key = 'sk-F9Oxxxxxx3BlbkFJK55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
from langchain.llms import OpenAI
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain import PromptTemplate
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0, openai_api_key=openai_api_key)
# data loader
loader = PyPDFLoader("data/ZT91.pdf")
doc = loader.load()
# text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
(2)向量化
调用 OpenAIEmbeddings接口对文本进行向量化。
- 实际应用中,可使用开源模型,如下所示(OpenAIEmbeddings用的是第6个)。同时,中文embedding效果优秀的模型有百度的ERNIE。
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
(3)召回
用FAISS工具对输入文档构建FAISS索引,返回构建好的FAISS索引对象。
创建FAISS索引包含的工作有:
- 为索引分配内存空间;
- 选择合适的索引类型与参数(比如Flat IVFFlat等);
- 将文档向量添加到索引中。
docsearch = FAISS.from_documents(docs, embeddings)
# docsearch.as_retriever(search_kwargs={"k": 5})表示返回前5个最相关的chunks,默认是4,可以修改
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 5}), chain_type_kwargs={"prompt": PROMPT})
(4)总结答案
- 输入:query + context
- 输出:answer
其中 context 为通过faiss retriever检索出的相关文档:
特别的,为了让gpt只回答文档中的内容,在prompt_template 增加了约束:“请注意:请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答”对不起,我不知道”,另外也不要回答无关答案:”。即如果文档中没有用户提问相关内容,需要回答“不知道”,防止“答非所问”误导用户。
prompt_template = """请注意:请谨慎评估query与提示的Context信息的相关性,只根据本段输入文字信息的内容进行回答,如果query与提供的材料无关,请回答"对不起,我不知道",另外也不要回答无关答案:
Context: {context}
Question: {question}
Answer:"""
# 输入:query + context
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
query = "实时画面无法查看,怎样解决?"
# FAISS检索出来的文档:retriever=docsearch.as_retriever(search_kwargs={"k": 5})
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 5}), chain_type_kwargs={"prompt": PROMPT})
# query为用户输入的提问
qa.run(query)
2. 视频知识总结
LLM 看完视频,回答问题
需求描述:
- youtube等视频网站上每天都会产生大量视频,虽然推荐系统按照喜好进行了推荐,但观看大量有价值的视频依然面临挑战,如果能够快速了解视频内容,并得到关注的信息,将极大提高信息获取效率。
解决方案:
- langchain + transcript + llms
与pdf文档处理方式不同,YoutubeLoader库从youtube视频链接中加载数据,并转换为文档。
- 文档获取过程: 通过youtube-transcript-api获取的视频的字幕文件,这个字幕文件是youtube生成的。当用户将视频上传至youtube时,youtube会通过内置的语音识别算法将视频语音转换为文本。当加载youtube视频字幕文档后,接下来的处理工作与第一个例子类似。
LangChain支持对YouTube视频内容进行摘要内容生成,通过调用 document_loaders 模块中的 YoutubeLoade ,同时传入YouTube的视频链接,然后即可支持视频内容的摘要提取。
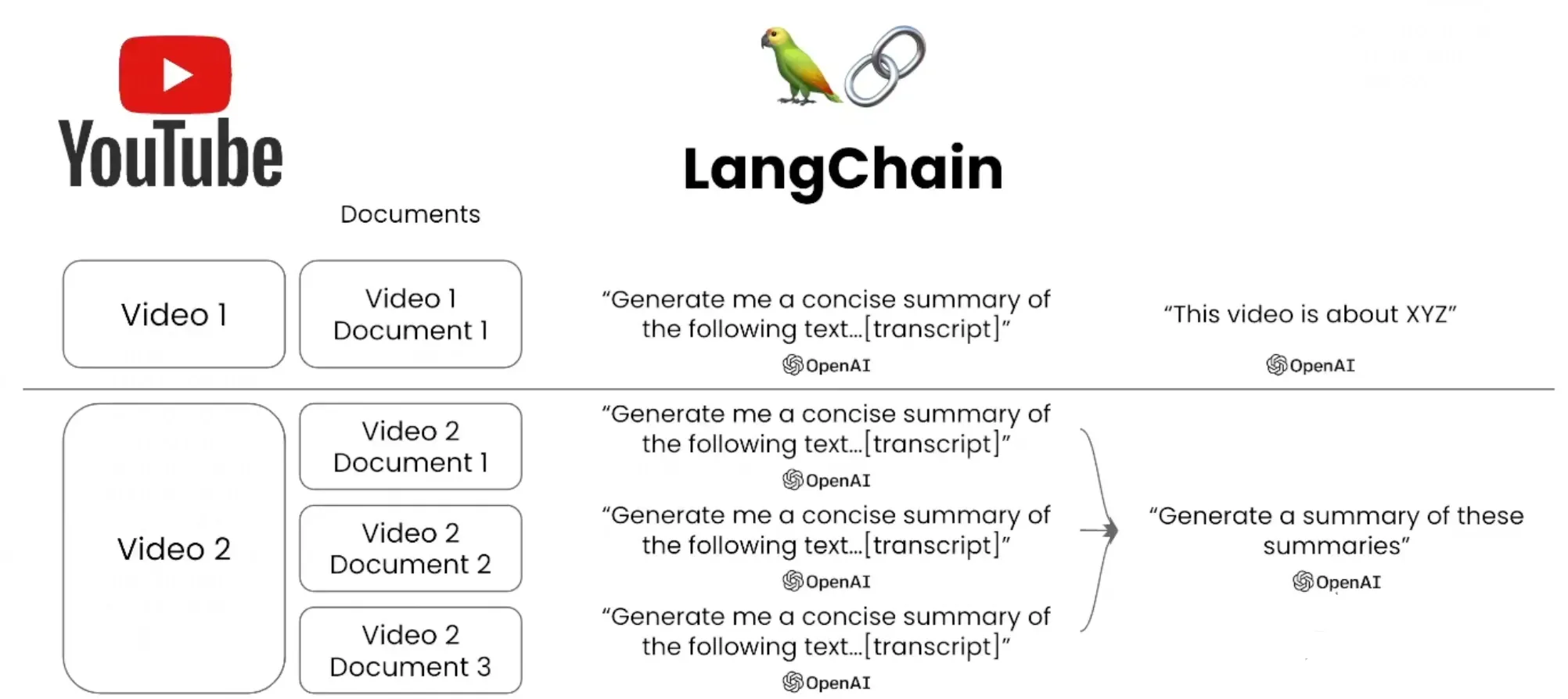
from langchain.document_loaders import YoutubeLoader
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
OPENAI_API_KEY = '...'
# 加载 youtube 频道
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
# 将数据转成 document
result = loader.load()
Question:
“对视频中介绍的内容,逐条列举?”
3. 表格问答
LLM 分析完 54万条数据,给出正确答案,完成了数据分析师1天的工作。
需求描述:
- 零售商有客户的交易数据。希望从数据中生成一些基本见解,以便识别最佳客户。
- 例如:按性别和年龄组划分的平均支出、每种类型的客户购买的产品、产品在哪个城市和商店的销售额最高等等
- 数据分析师将获取数据,编写一些 SQL 或 Python 或 R 代码,生成见解,数据分析师可能需要一天的时间来提供这些结果。
解决方案:
- langchain+llm + agents
任务
- (1) 显示表格中用户的数量
- 验证: agent给出的答案完全正确
- (2) 年龄与消费金额之间相关性分析
- 分析下年龄与消费金额之间的相关性:年龄与消费成正相关,但是相关性很弱
- (3) 产品销售量统计并画出柱状图
- 统计每种产品的销售总量,并画柱状图
import os
from langchain.agents import create_csv_agent
from langchain.llms import OpenAI
openai_api_key = 'sk-F9O70vxxxxxxxBlbkFJK55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
agent = create_csv_agent(OpenAI(openai_api_key=openai_api_key, temperature=0), 'train.csv', verbose=True)
# 统计用户数
agent.run("请按照性别对用户数量进行显示?")
# 年龄与消费金额之间的相关性
agent.run("在这份表格中,年龄与消费金额是否存在相关性?")
# 统计每种产品的销售总量,并画柱状图
agent.run("产品1总量,产品2总量,产品3总量分别是多少,将三个总量通过柱状图画出来并显示")
存储层:文档向量化
自研框架的选择
- 基于OpenAIEmbeddings,官方给出了基于embeddings检索来解决GPT无法处理长文本和最新数据的问题的实现方案。参考
- 也可以使用 LangChain 框架。
参考
除了从文档中抓取数据,从指定网站URL抓取数据,实现智能客服外部知识库,可以借助ChatGPT写Python代码,PythonBeautiful Soup库的实现方式很成熟
大厂产品截图:智能客服知识库建设
- 企业资料库,关联大语言模型自动搜索
- 大模型文档知识抽取和“即搜即问”
都有ChatGPT了,为什么还要了解Embedding这种「低级货」技术?两个原因:
- 有些问题使用Embedding解决(或其他非ChatGPT的方式)会更加合理。通俗来说就是「杀鸡焉用牛刀」。
- ChatGPT性能方面不是特别友好,毕竟是逐字生成(一个Token一个Token吐出来的)。
文本切分
LangChain 切分工具
- Text Splitters文档: 选择对应的文本切分器,如果是通用文本的话,建议选择
RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入文本
loader = UnstructuredFileLoader("./data/news_test.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:",len(split_docs))
相似度
相似度索引
- 只用embedding来计算句子的相似度
# 初始化 prompt 对象
question = "2022年腾讯营收多少"
# 最多返回匹配的前4条相似度最高的句子
similarDocs = db.similarity_search(question, include_metadata=True,k=4)
# [print(x) for x in similarDocs]
接入ChatGLM来帮忙做总结和汇总
from langchain.chains import RetrievalQA
import IPython
# 更换 LLM
qa = RetrievalQA.from_chain_type(llm=ChatGLM(temperature=0.1), chain_type="stuff", retriever=retriever)
# 进行问答
query = "2022年腾讯营收多少"
print(qa.run(query))
向量化方案
OpenAIEmbeddings
OpenAI官方的embedding服务
OpenAIEmbeddings:
- 使用简单,并且效果比较好;
OpenAI的Embedding服务
直接使用openai的embedding服务
import os
import openai
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
# OPENAI_API_KEY = "填入专属的API key"
openai.api_key = OPENAI_API_KEY
text = "我喜欢你"
model = "text-embedding-ada-002"
emb_req = openai.Embedding.create(input=[text], model=model)
emb = emb_req.data[0].embedding
len(emb), type(emb)
# 相似度计算
from openai.embeddings_utils import get_embedding, cosine_similarity
# 注意它默认的模型是text-similarity-davinci-001,我们也可以换成text-embedding-ada-002
text1 = "我喜欢你"
text2 = "我钟意你"
text3 = "我不喜欢你"
emb1 = get_embedding(text1)
emb1 = get_embedding(text1, "text-embedding-ada-002") # 指定模型
emb2 = get_embedding(text2)
emb3 = get_embedding(text3)
cosine_similarity(emb1, emb2) # 0.9246855139297101
cosine_similarity(emb1, emb3) # 0.8578009661644189
问题
- 会消耗openai的token,特别是大段文本时,消耗的token还不少,如果知识库是比较固定的,可以考虑将每次生成的embedding做持久化,这样就不需要再调用openai了,可以大大节约token的消耗;
- 可能会有数据泄露的风险,如果是一些高度私密的数据,不建议直接调用。
LangChain调用OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import VectorDBQA
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.embeddings.openai import OpenAIEmbeddings
import IPython
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_API_BASE")
embeddings = OpenAIEmbeddings()
# ---- 简洁版 -------
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
HuggingFaceEmbeddings
HuggingFaceEmbeddings:
可以在HuggingFace上面选择各种sentence-similarity模型来进行实验,数据都是在本机上进行计算 需要一定的硬件支持,最好是有GPU支持,不然生成数据可能会非常慢 生成的向量效果可能不是很好,并且HuggingFace上的中文向量模型不是很多。
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec2":"uer/sbert-base-chinese-nli",
"text2vec3":"shibing624/text2vec-base-chinese",
}
EMBEDDING_MODEL = "text2vec3"
# 初始化 hugginFace 的 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL], )
embeddings.client = sentence_transformers.SentenceTransformer(
embeddings.model_name, device='mps')
详见:站内向量化专题
服务层:LLM框架
LLMs就像是C++的编译器,Python的解释器一样:
| 语言类型 | 执行原理 |
|---|---|
| C++语言 | C++语言 → 编译器/链接器 → 既定任务 |
| Java语言 | Java语言 → 编译器/虚拟机 → 既定任务 |
| Python语言 | Python语言 → 解释器 → 既定任务 |
| 人类自然语言 | 人类自然语言 → LLMs → 各种后端组件 → 既定任务 |
将语言模型与其他数据源相连接,并允许语言模型与环境进行交互,提供了丰富的API
- 与 LLM 交互
- LLM 连接外部数据源
AGI的基础工具模块库,类似模块库还有 mavin。
- LangChain provides an amazing suite of tools for everything around LLMs.
- It’s kind of like HuggingFace but specialized for LLMs
新兴 LLM 技术栈
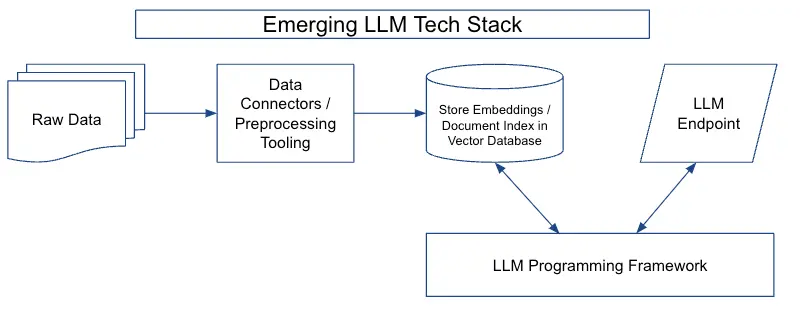
大语言模型技术栈由四个主要部分组成:
数据预处理流程(data preprocessing pipeline):- 与数据源连接的连接器(例如S3存储桶或CRM)、数据转换层以及下游连接器(例如向矢量数据库)
- 通常,输入到LLM中的最有价值的信息也是最难处理的(如PDF、PPTX、HTML等),但同时,易于访问文本的文档(例如.DOCX)中也包含用户不希望发送到推理终端的信息(例如广告、法律条款等)。
嵌入端点(embeddings endpoint )+向量存储(vector store)- 嵌入端点(用于生成和返回诸如词向量、文档向量等嵌入向量的 API 端点)和向量存储(用于存储和检索向量的数据库或数据存储系统)代表了数据存储和访问方式的重大演变。
- 以前,嵌入主要用于诸如文档聚类之类的特定任务
- 在新架构中,将文档及其嵌入存储在向量数据库中,可以通过LLM端点实现关键的交互模式。
- 直接存储原始嵌入,意味着数据可以以其自然格式存储,从而实现更快的处理时间和更高效的数据检索。
- 此外,这种方法可以更容易地处理大型数据集,因为它可以减少训练和推理过程中需要处理的数据量。
LLM 终端(LLM endpoints)- 接收输入数据并生成LLM输出的终端。LLM终端负责管理模型的资源,包括内存和计算资源,并提供可扩展和容错的接口,用于向下游应用程序提供LLM输出。
LLM 编程框架(LLM programming framework)- 一套工具和抽象,用于使用语言模型构建应用程序。在现代技术栈中出现了各种类型的组件,包括:LLM提供商、嵌入模型、向量存储、文档加载器、其他外部工具(谷歌搜索等),这些框架的一个重要功能是协调各种组件。
图解
LLaMA-Index
待补充
LangChain
详见站内 LangChain 专题
微软guidance(LangChain简化)
【2023-5-26】微软发布langChain杀手:guidance架构图全球首发
微软发布guidance模块库,并迅速登上github网站TOP榜首:
- guidance,传统提示或链接更有效、更高效地控制新式语言模型。
- 协助用户将生成、提示和逻辑控制交错到单个连续流中,以匹配语言模型实际处理文本的方式。
- 简单的输出结构,如思维链及其许多变体(例如ART,Auto-CoT等)已被证明可以提高LLM的性能。
- 像GPT-4这样更强大的LLM的出现允许更丰富的结构,并使该结构更容易,更便宜。
简单来说,微软guidance模块库,是langChain模块库的简化版,或者说:langChain杀手。
ChatGLM QA
【2023-5-22】
- 基于chatglm搭建文档问答机器人: 道路交通安全法领域,不到100行的python文件
- 基于langchain/llama-index已经可以快速完成类似的功能,但代码量大,学习门槛高
- chatglm-qabot-v2: 从q-d匹配到q-q匹配
- chatglm-qabot
- Chinese-LangChain:中文langchain项目,基于ChatGLM-6b+langchain实现本地化知识库检索与智能答案生成

一些关键组件的配置:
- LLM使用的是清华的chatglm-6b
- 计算embedding用的是苏神的simbertV2
- 没做embedding的索引优化,直接放list里暴力查找
- 每次默认查找top3相关的文档片段用于构造prompt
- 构造prompt的模板见代码
- 生成答案的长度没做限制,要做的话在代码中加请求chatglm的参数即可
import sys
# 初始化问答机器人
qabot = QaBot(doc_path="data/中华人民共和国道路交通安全法.txt", chatglm_api_url=sys.argv[1])
# 根据文档回答问题
answer, _ = qabot.query('酒后驾驶会坐牢吗')
初始化的代码如下
def __init__(self, doc_path: str, chatglm_api_url: str):
# 加载预训练模型,用于将文档转为embedding
pretrained_model = "junnyu/roformer_chinese_sim_char_small"
self.tokenizer = RoFormerTokenizer.from_pretrained(pretrained_model)
self.model = RoFormerForCausalLM.from_pretrained(pretrained_model)
# 加载文档,预先计算每个chunk的embedding
self.chunks, self.index = self._build_index(doc_path)
# chatglm的api地址
self.chatglm_api_url = chatglm_api_url
每次问答的代码如下
def query(self, question: str) -> Tuple[str, str]:
# 计算question的embedding
query_embedding = self._encode_text(question)
# 根据question的embedding,找到最相关的3个chunk
relevant_chunks = self._search_index(query_embedding, topk=3)
# 根据question和最相关的3个chunk,构造prompt
prompt = self._generate_prompt(question, relevant_chunks)
# 请求chatglm的api获得答案
answer = self._ask_chatglm(prompt)
# 同时返回答案和prompt
return answer, prompt
效果



基于chatglm做文档问答,通常的做法是”先检索再整合”,大致思路
- 首先准备好文档,并整理为纯文本的格式。把每个文档切成若干个小的chunks
- 调用文本转向量的接口,将每个chunk转为一个向量,并存入向量数据库
- 当用户发来一个问题的时候,将问题同样转为向量,并检索向量数据库,得到相关性最高的一个chunk
- 将问题和chunk合并重写为一个新的请求发给chatglm的api
将用户请求的query和document做匹配,也就是所谓的q-d匹配。
q-d匹配的问题
- query和document在表达方式存在较大差异,通常query是以疑问句为主,而document则以陈述说明为主,这种差异可能会影响最终匹配的效果。
- 一种改进的方法是不做
q-d匹配,而是先通过document生成一批候选的question,当用户发来请求的时候,首先是把query和候选的question做匹配,进而找到相关的document片段 - 另一个思路通过HyDE去优化
- 为query先生成一个假答案,然后通过假答案去检索,这样可以省去为每个文档生成问题的过程,代价相对较小
第一种方法就是’q-q匹配‘,具体思路如下:
- 首先准备好文档,并整理为纯文本的格式。把每个文档切成若干个小的chunks
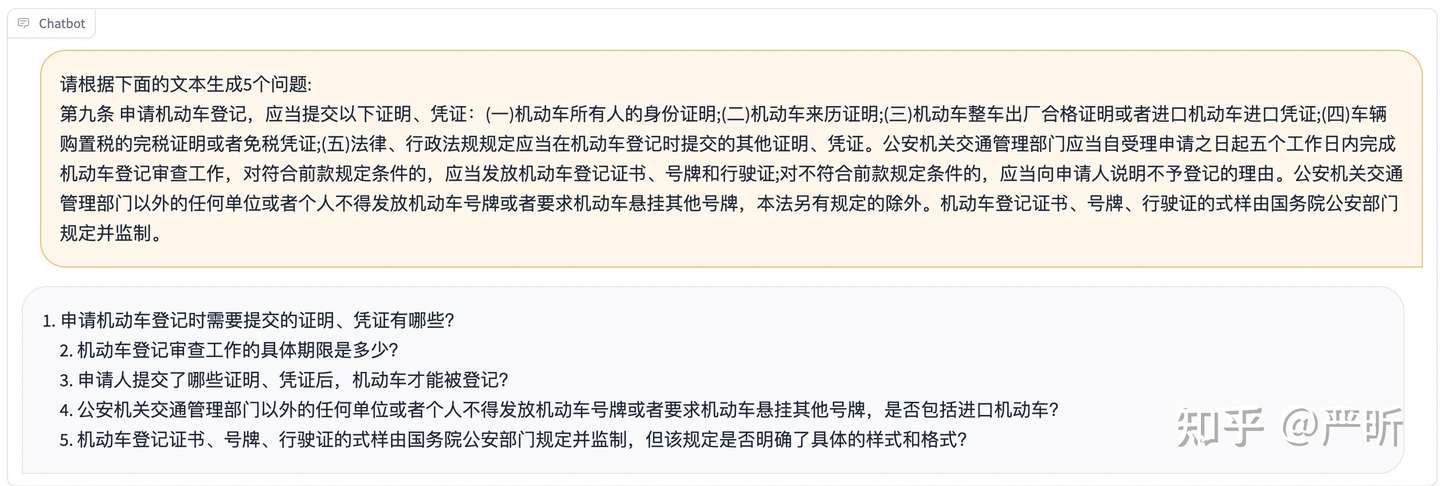
- 部署chatglm的api,部署方法
- 调api,根据每个chunk生成5个候选的question,使用的prompt格式为’请根据下面的文本生成5个问题: …‘,生成效果见下图:
- 调用文本转向量的接口,将生成的question转为向量,并存入向量数据库,并记录question和原始chunk的对应关系
- 用户发来一个问题时,将问题同样转为向量,并检索向量数据库,得到相关性最高的一个question,进而找到对应的chunk
- 将问题和chunk合并重写为一个新的请求发给chatglm的api
- qabot_v1.py实现了q-d匹配方法
- qabot_v2.py实现了q-q匹配方法
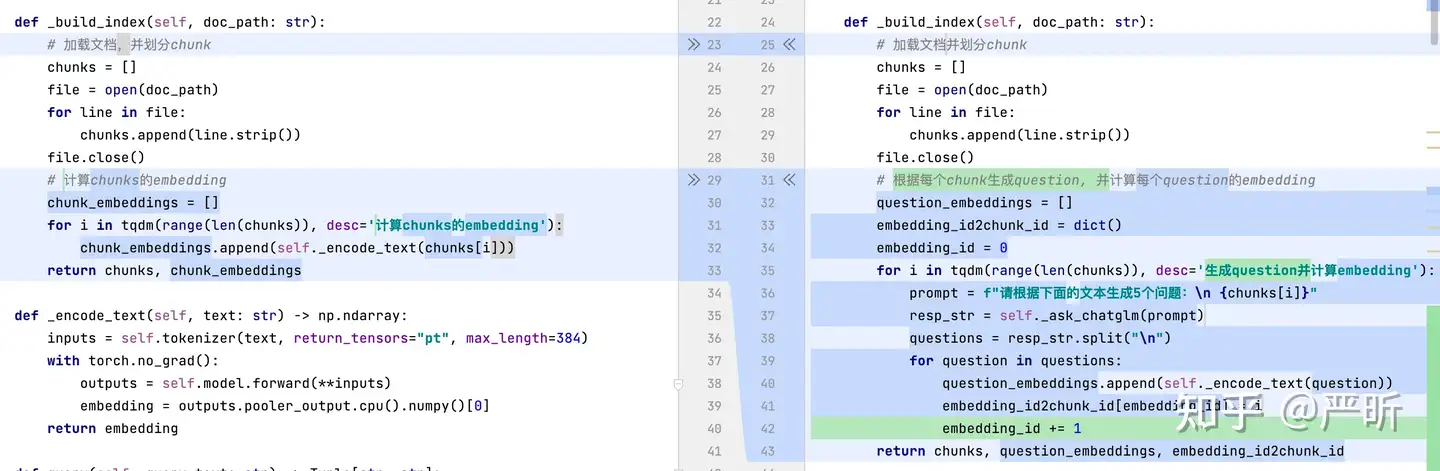
q-d匹配和q-q匹配的代码差异
- 初始化构建索引的差异如下:
- 查询索引时的差异如下:

测试问题为行驶证的式样由谁来监制,v1和v2的效果对比如下:
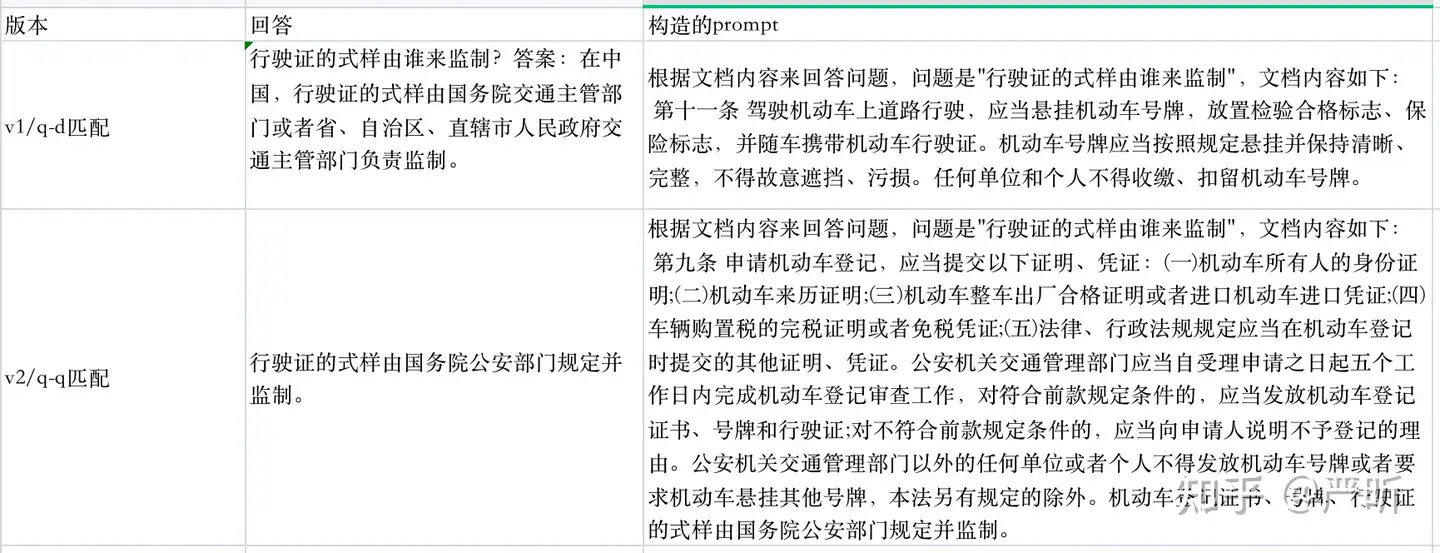
在构建索引阶段,v2花费的时间是远超过v1的:
# 计算chunks的embedding:
100%|██████████| 20/20 [00:02<00:00, 7.81it/s]
# 生成question并计算embedding:
100%|██████████| 20/20 [07:24<00:00, 22.24s/it]
定制知识库
【2023-5-24】
业务场景
调整 prompt,匹配不同的知识库,让 LLM 扮演不同的角色
- • 上传公司财报,充当财务分析师
- • 上传客服聊天记录,充当智能客服
- • 上传经典Case,充当律师助手
- • 上传医院百科全书,充当在线问诊医生
问题
微调的瓶颈
- 需要专业知识,很多计算资源和时间,以便在不同超参数设置训练多个模型,并选择最佳的一个
- 动态扩展比较差,新增和修改原有的数据都要重新微调一次。
总之,微调对非专业人员不友好。
如何不用微调就能实现垂直领域的专业问答?
- 方案:ChatGLM-6B + langchain 实现个人专属知识库
技术原理
技术原理
- 加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
- img1
- img2
核心技术是: 向量 embedding
- 将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 prompt 提交给 LLM 回答
典型的prompt
已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
实现
# 下载源码
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
# 安装依赖
cd langchain-ChatGLM
pip install -r requirements.txt
# 下载模型
# 安装 git lfs
git lfs install
# 下载 LLM 模型
git clone https://huggingface.co/THUDM/chatglm-6b /your_path/chatglm-6b
# 下载 Embedding 模型
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese /your_path/text2vec
# 模型需要更新时,可打开模型所在文件夹后拉取最新模型文件/代码
git pull
模型下载完成后,请在 configs/model_config.py 文件中,对embedding_model_dict和llm_model_dict参数进行修改。
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "/your_path/text2vec"
}
llm_model_dict = {
"chatyuan": "ClueAI/ChatYuan-large-v2",
"chatglm-6b-int4-qe": "THUDM/chatglm-6b-int4-qe",
"chatglm-6b-int4": "THUDM/chatglm-6b-int4",
"chatglm-6b-int8": "THUDM/chatglm-6b-int8",
"chatglm-6b": "/your_path/chatglm-6b",
}
启动服务
# Web 模式启动
pip install gradio
python webui.py
# API 模式启动
python api.py
# 命令行模式启动
python cli_demo.py
效果
gradio页面
Chatgpt-Next-Web 项目基础上进行了适配修改,打造了一款面向用户使用的本地知识库前端。
FastGPT
【2023-5-17】FastGPT, 调用 gpt-3.5 和 embedding 构建自己的知识库。
知识库构建原理

效果

在线体验
- 🎉 fastgpt.run (国内版)
- 🎉 ai.fastgpt.run (海外版)
业界案例
New Bing
- 优势:免费,快捷,可以联网,支持中英文,可以阅读本地PDF和网络论文,可以持续问答交互
- 缺点:不稳定,识别内容有限,甚至于信息量低于摘要的内容。经常会输出一半就断了。
chatpdf
ChatPDF 界面干净,上传pdf后,直接对话。
- 上传速度很快,对话响应也非常的快。
- 对文档内容的解析很准确,包括一些隐藏在内部的知识点也可以快速搜索找到
优势:
- 交互方便,容易上手,可以持续问答交互缺点:全文总结信息量较低,问答模式偏向于关键词定位,然后上下文翻译,且已经收费,每月5刀。只支持本地PDF文档上传。
scispace
- 优势:交互方便,容易上手,可以持续问答交互,支持本地论文上传,可以公式截图解析,可以解释伪代码
- 缺点:对中文支持较差,全文总结效果较差。
aminer.cn
清华唐杰老师他们组的工作!
-
- 优势:有热点论文推送!有论文打分,和别人的提问记录
- 缺点:语义理解有限
ChatPaper 开源
中科大出品:ChatPaper, Use ChatGPT to summarize the arXiv papers. 全流程加速科研,利用chatgpt进行论文总结+润色+审稿+审稿回复
问题:
- 前面几款工具都面临一个问题,全文总结的信息量较低,因为GPTs的输入token是远低于论文的全文文本的,而简单的翻译总结摘要,又拿不到多少有效信息
方案:
- 将abstract和introduction进行压缩,然后输入给chat进行总结
效果
- 每篇文章,调用五次chat,可以获得7到8成的信息量,并且格式化输出成中国人容易看懂的文本,极大的降低了大家的阅读门槛。几乎可以达到,AI花一分钟总结,人花一分钟看总结,就可以判断这篇文章是否需要精读的效果。
- 如果需要精读,则可以调用上面的各种工具,尤其推荐scispace和aminer.
【2023-10-19】chatwithpaper
PandasGPT
PandaGPT, 访问速度偏慢,UI对话样式一言难尽,没有一个版块不是互相遮挡的
- 已有3w个文档,10w个问题
- 上传文档,直接针对文档问答; 还能生成知识图谱,Generate Knowledge Graph
-

- 问题回答基本到位,相比ChatPDF,略显啰嗦
类似的,还有 AMiner 上的华智冰
ChatDOC
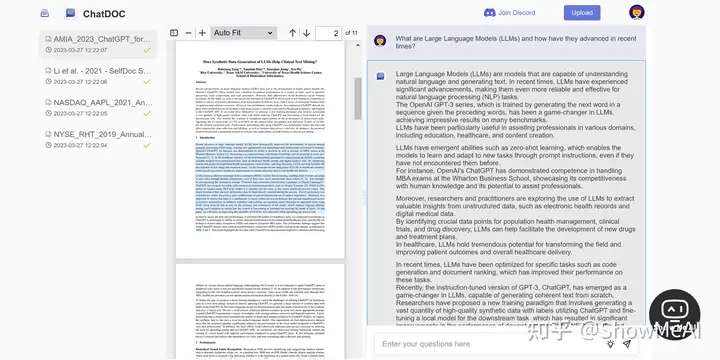
【2023-3-28】ChatDOC文档阅读工具,支持中文!又快又免费!使用 ChatGPT 阅读文件的AI问答机器人
- 基于 ChatGPT 的文件阅读助手,支持中英文,可以快速从上传研究论文、书籍、手册等文件中提取、定位和汇总文件信息,并通过聊天的方式在几秒钟内给出问题的答案。
- ChatDOC 还可以理解文档中的表格或文字,优化其数据分析性能,并为每个回答提供直接引用的来源,方便核实AI的解读准确性。
- ChatDOC 目前免费,文件大小限制为 200 页,最多可以上传 5 个文档。在即将更新的版本中,还支持跨多个文档的综合查询和问答。
typeset
- 主打论文检索,也支持pdf文档解读。
- 上传、对话响应都十分缓慢,对话的效果差,很多知识点无法解读,一律回复无法找到这个问题的答案。
privateGPT (本地、离线)
【2023-5-17】开源的 privateGPT, privateGPT代码,它使用GPT的强大功能,可以在100%私密的情况下与本地文档进行私密交互,不会有任何数据泄漏。
- 使用LLaMa、LangChain和GPT4All构建。
- Demo
The supported extensions are:
- .csv: CSV,
- .docx: Word Document,
- .enex: EverNote,
- .eml: Email,
- .epub: EPub,
- .html: HTML File,
- .md: Markdown,
- .msg: Outlook Message,
- .odt: Open Document Text,
- .pdf: Portable Document Format (PDF),
- .pptx : PowerPoint Document,
- .txt: Text file (UTF-8)
ChatBase
【2023-5-28】ChatGPT 造富“神话”:大四学生放弃大厂去创业,半年后月收入45万
埃及大学生Yasser在 Meta 和 Tesla 等大厂实习半年后,其创办的聊天机器人公司就已经稳定月收 6.4 万美元(约合 45 万人民币),而且自首次上线以来,业务流量从未下滑缩水。
- Chatbase 市场定位并不复杂,也没做过验证或者商业调查。毕竟 AI 这个领域才刚刚诞生,对我来说‘用 ChatGPT 处理数据’肯定有搞头,能帮助许许多多用户解决实际需求
- Chatbase 最初其实是想做成一款处理 PDF 的 ChatGPT 工具,这是 Yasser 当时想到的最直观的用例。比如用户可以上传一份 PDF,然后让 ChatGPT 总结一下其中的内容。
- 第一个版本花了两个月时间,2023 年 2 月 2 号,Yasser 发布给了 Twitter 上的全部 16 个关注者,结果一下子就火了,巨大的商机,Yasser 马上中止了在校课业,把所有时间和精力都集中在 Chatbase 上
Chatbase.co 是一款为网站构建自定义 ChatGPT 界面的工具,用户只需上传文档或添加到网站链接,就可以获得一个类似 ChatGPT 的聊天机器人,并将它作为小组件添加到网站上。
Yasser 用 React、Next.js 和 Supabase 来构 web 应用。Yasser 还在应用的 AI 部分使用了 OpenAI 的 API、Langchain 还有 Pinecone。付款部分用的是 Stripe。目前这套技术栈运行得不错,但后续 Yasser 可能需要做些调整来控制成本,比如尝试不同的 Vector 数据库或者托管选项
可集成到自己的网站, 官方提供看板配置
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
