总结
- 汇总知名数据竞赛的经验信息
算法竞赛
经验分析
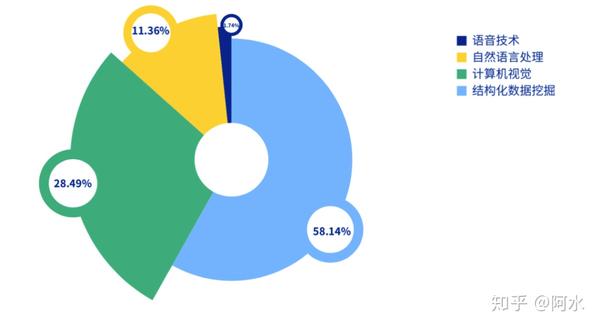
【2022-3-28】kaggle大神都在用什么语言/模型/框架?,Eniola Olaleye的数据科学爱好者介绍了他们的统计结果,作者得出了几个重要结论:
- 1、在所有竞赛中,Kaggle上的竞赛数量仍然占据1/3,而且奖金数量占270万美元总奖金池的一半;
- 2、在所有比赛中,有67场比赛是在前5大平台(Kaggle、AIcrowd、Tianchi、DrivenData 和 Zindi)上举行的,有8场比赛是在去年只举办了一场比赛的平台上举行的;
- 3、几乎所有的冠军都使用了Python,只有一个冠军使用了C++;
- 4、77%的深度学习解决方案使用了PyTorch(去年高达72%);
- 主流机器学习框架依然是基于Python的。Scikit-learn非常通用,几乎被用于每个领域。经典机器学习问题中,Catboost、LightGBM等梯度提升模型占据主流
- 两个最流行的机器学习库是Tensorflow和Pytorch。其中,Pytorch在深度学习比赛中最受欢迎。与2020年相比,在深度学习竞赛中使用PyTorch的人数突飞猛进,PyTorch框架每年都在快速发展。
- 5、所有获奖的CV解决方案都使用了CNN;
- 自从AlexNet在2012年赢得ImageNet竞赛以来,CNN算法已经成为很多深度学习问题都在用的算法,特别是在计算机视觉方面
- RNN还在计算机视觉的下列领域中得到了成功的应用
- RNN和CNN的结合是可能的,这可能是计算机视觉的最先进的应用
- 6、所有获奖的NLP解决方案都使用了Transformer。
- 循环神经网络,如LSTM,被用于数据具有时间特征的情况(如时间序列),以及数据上下文敏感的情况(如句子补全),其中反馈循环的记忆功能是达到理想性能的关键
- 像2020年一样,2021年NLP领域大型语言模型(如Transformer)的采用比例显著增加,创历史新高。
2021年最常见的竞赛类型是计算机视觉和自然语言处理。与2020年相比,这部分变化很大,当时NLP竞赛仅占竞赛总数的7.5%。
机器学习竞赛的优胜方案中,集成模型成为了首选方法之一。集成方法中最常用的方法是求平均,即构建多个模型并通过将输出和的平均值相加将其组合在一起,从而达到更稳健的性能。
数据科学竞赛大全
- 【2020-10-10】Data Science Challenge / Competition 数据科学挑战赛/数据科学竞赛,源自:机器学习理论与数据竞赛实战

- 【2022-1-4】coggle数据科学竞赛,汇总国内外竞赛信息,主办方、时间、题目、参赛人数等,历次比赛经验总结
- 【2023-1-17】整理了190+场比赛TOP方案
KDD CUP
- 【2020-8-28】KDD CUP 2020 大奖出炉,中国团队包揽全部冠亚军
- KDD CUP 2020 大赛结果终于在其官网上公布,其中,来自中国的团队如国立台湾大学、美团点评、北航、第四范式、东南大学、上海交大、国科大、清华大学包揽全部奖项的冠亚军
- ACM SIGKDD,被中国计算机学会(CCF)推荐为A类国际学术会议,至今已举办26届。其中KDD CUP是由ACM知识发现和数据挖掘特别兴趣小组(领先的数据科学家专业组织)组织的年度国际数据挖掘和知识发现竞赛。素有“大数据领域世界杯”之誉,是目前数据挖掘领域最高水平、最具影响力、规模最大的国际顶级赛事。 由于各种数据科学竞赛类型的日益普及,KDD CUP今年一共开设三个项目共四个赛道的比赛,分别是:
- 1、常规机器学习竞赛轨道(ML赛道1) “现代化电子商务平台挑战”(Challenges for Modern E-Commerce Platform)
- 由阿里巴巴、阿里巴巴达摩院、杜克大学、清华大学和UIUC赞助,竞赛选手需要通过考虑不同类型的复杂信息来学习高质量的跨模态表示,以及模态之间的紧密关系。然后,所学习的表示可以用于计算表示之间的相似度得分,并选择与文本相关的图像/视频。最后,将在测试数据集上评估每个提交的解决方案,该数据集将评估检索到的产品与真实值之间的对应关系。
- 多模态召回(Multimodalities Recall )——冠军团队:WinnieTheBest(国立台湾大学)、亚军团队:MTDP_CVA(美团点评 )、季军团队:aister(美团点评)
- 去偏差(Debiasing)——冠军团队:aister(美团点评)、亚军团队:DeepWisdom(深度赋智 )、季军团队:TheAvengers(北京航空航天大学)
- 2、常规机器学习竞赛轨道(ML赛道2) “学术图上的对抗性攻击和防御”(Adversarial Attacks and Defense on Academic Graph)
- 要求参赛者提交原始数据集的修改版本,以作为一种攻击形式,其外观应与原始图相似,但在基准模型上分类准确性较低。参赛者应准备好数据及并保存在比赛系统的后端。然后,所有团队都必须提交攻击和防御的解决方案。组织者将与所有团队的所有进攻方案和防御方案进行比赛,并得出排行榜。
- 冠军团队:SPEIT-卓工 (上海交通大学、上海交大-巴黎高科卓越工程师学院)、亚军团队:ADVERSAIRES (中山大学、杭州电子科技大学 )、季军团队:DaftStone ( 中国科学技术大学)
- 3、AutoML机器学习竞赛轨道(AutoML赛道) “用于图表征学习的AutoML”(AutoML for Graph Representation Learning)
- AutoML机器学习赛道 “用于图表征学习的AutoML”由第四范式、ChaLearn、斯坦福大学和Google共同协办,该赛道邀请参赛者部署用于图表示学习的AutoML解决方案,其中节点分类作为评估学习的表示形式的质量的任务。
- 每个团队都有五个公共数据集来开发AutoML解决方案。组织方提供了五个反馈数据集,以使参与者能够评估他们的解决方案。这些解决方案将在没有人为干预的情况下使用五个新的数据集进行评估,优胜者将根据表现的最终排名进行选择。
- 冠军团队:aister(美团点评、中国科学院大学、清华大学 )、亚军团队:PASA_NJU(南京大学)、季军团队:qqerret(蚂蚁金服)
- 4、强化学习竞赛赛道(RL赛道) “在移动点播平台上学习调度和重定位”(Learning to Dispatch and Reposition on a Mobility-on-Demand Platform)
- 强化学习赛道 “在移动点播平台上学习调度和重定位”由滴滴出行与DiDi AI Labs合作赞助,该赛道要求参与者应用机器学习工具来确定新颖的解决方案,用于在移动点播(MoD)平台上的订单分派(订单匹配)和车辆重新定位(车队管理)。具体地说,竞赛着眼于如何应用机器学习解决方案来提高MoD平台的效率。
- Dispatch任务:冠军:Polar Bear(北京航空航天大学、第四范式)、亚军:EM(中山大学)、季军:Team Hail Mary ( Lyft )
- 冠军思路:为了最大化平台上所有司机日均收入,在计算每个订单的收益时,北航联合第四范式团队采用基于强化学习的方法,不仅能考虑当前时刻的收入,还能兼顾未来可能的收益。同时,结合剪枝与C++实现的高效二分图匹配算法,能够在2秒的规定时限内,及时找到合适的订单分配方案,保证乘客的用户体验。最终团队以2359108.54的高分在Dispatch任务上夺冠。
- Repopsition任务获奖团队:冠军团队:TLab(普渡大学、东南大学)、亚军团队:wait a minute(南京大学LAMDA组)、季军团队:NTTDOCOMO LABS(日本NTTdocomo实验室)
- 冠军思路:参赛者需要解决网约车平台的订单匹配与车辆调度问题,其中订单匹配任务需要每两秒钟进行一次匹配,车辆调度任务则需要在成都8000余个六边形网格内进行运力调度。相关算法可将乘客潜在出行需求与合适的司机相匹配,从而更高效地利用空置车辆,提高车辆周转率,提升用户体验与司机收入水平,优化系统运营效率。
CCF
- 比赛:智能人机交互自然语言理解,队伍(338) / 人数(386),奖金¥25,000
【2022-1-4】贝壳参赛团队针对小样本学习问题,分别采用了半监督学习与迁移学习的混合技术。
- 针对“意图识别”任务,有监督的分类模型往往需要大量的人工标注数据训练模型,很难适用于小样本数据。团队提出了一种半监督的分类模型,利用未标注的数据样本,可以半监督地为数据打上软标签,扩充小样本类别的数据数量,从而提高小样本意图识别准确率。
- 针对“槽位抽取”任务,团队采用了经典的BERT+BILSTM+CRF网络架构,然而当槽位训练数据不足时,模型学习会出现欠拟合的情况。为此,团队采用了迁移学习的思路,利用槽位相似性,迁移不同领域下相似的槽位数据,从而达到增强小样本数据的目的。
- 最终,贝壳在AB榜中均取得了第一名的成绩,准确率分别为84.3%,85.3%的高分。
赛题介绍
对NLU领域的“意图识别”及“槽位填充”任务进行考察,发布的数据集包含用户与音箱等智能设备进行单轮对话的文本数据,共计11种意图类别(包含2个小样本意图)、47个槽位类型。
| 意图名称 | 样本数量 | 槽位 |
|---|---|---|
| Video-Play | 1000 | datetime_time, region, datetime_date,name |
| Calendar-Query | 1000 | datetime_date |
| Alarm-Update | 1000 | datetime_time, notes, datetime_date |
| Radio-Listen | 1000 | name, frequency, channel, artist |
| FilmTele-Play | 1000 | play_setting, name, tag, age, region, artist |
| Travel-Query | 1000 | departure, destination, datetime_date, datetime_time, query_type |
| Weather-Query | 1000 | type, datetime_date, datetime_time, city, index |
| HomeAppliance-Control | 1000 | appliance, command, details |
| Music-Play | 1000 | album, play_mode, song, instrument, language, artist, age |
| Audio-Play | 50 | artist, name, tag, language, play_setting |
| TVProgram-Play | 50 | datetime_time, datetime_date, channel, name |
大赛需要参赛选手围绕所选赛题和特定任务,设置多种不同的技术场景,基于给定的数据训练算法模型,持续优化相关精度、效率等指标。因此该赛题除基本的学习任务外,还面临“域外检测”与“小样本学习”两个子任务:
- 期望通过“小样本学习”任务减少产品对大量新类别标注数据的依赖。
- 通过“域外检测”任务识别未知意图,摆脱对已知意图的干扰,同时达到尽可能好的学习效果。
评测指标:意图识别准确率、槽位F1值、句准确率三项指标
- 1)意图识别准确率(Intent Accuracy):对识别结果中“意图”字段进行评判。
- 2)槽位F1值:对于识别结果中“槽位:槽值”字段进行评判。
- ①槽位填充与意图识别结果相关,如意图类别预测错误,则该样本槽位填充结果均记为FP。
- ②对于槽位F1值指标,采用精准匹配对“槽位:槽值”键值对整体进行评判,如槽位及槽值中任意一项预测错误,则该样本槽位填充结果记为FP。
- 3)句准确率(Sentence Accuracy):对模型意图识别及槽位填充结果进行综合评判,仅当意图预测正确且各槽位填充均正确时,认定该样本预测正确,否则认定为预测错误。
技术路线
NLU任务分成意图识别+槽位抽取两个子任务,实现上有两个方向:
- 串行:先分类,在子类上做槽位抽取
- 并行:一步到位,直接给出意图及槽位
示例:
- query:给我放白居易的咏怀
- intent:Audio-play,置信度0.73
- slot-filling:artist(白居易)、art(咏怀)
模型选择
| 模型 | 预训练任务差异 | 决策 |
|---|---|---|
| BERT | MLM获取双向特征表示;NSP学习句间关系 | 放弃 |
| ALBERT | 因式分解、参数共享减少参数量;SOP增加句间任务难度 | 放弃 |
| RoBERTa | 动态masking;更多的数据;更大的mini-batch | 采用 |
| NeZha | 相对位置编码;全词掩码;混合精度训练;LAMB Optimizer | 采用 |
| MacBERT | MLM作为校正 | 采用 |
三个bert模型集成(macbert近义词替换+roberta讯飞+nezha华为哪吒),投票或取平均,训练7-8h,几千数据推理要30min;核心点:预训练+数据增强+半监督训练http://10.200.24.101:8090/notebooks/work/nlu_data/newhouse/%E6%96%B0%E6%88%BF%E9%A9%BB%E5%9C%BA%E5%AE%A2%E6%9C%8D-%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90.ipynb
自监督
自监督预训练:分别用RoBERTa、NeZha和MacBERT执行MLM的预训练任务
示例:
- query: 播 放 中 央 电 视 台 的 都 市 之 声
- n-gram挖掘词语级别的特征表示
- bi-gram MLM: [CLS] 播 放 中 央 [MUSK] [MUSK] 台 的 [MUSK] [MUSK] 之 声
- tri-gram MLM:[CLS] 播 放 中 央 [MUSK] [MUSK] [MUSK] 的 [MUSK] [MUSK] [MUSK] 声
意图识别(分类)
分类问题
- (1)常规意图:直接加MLP,输出softmax结果
- (2)二级意图:合并层次信息
- radio 与 play 合并为:radio-play
- traval 与 query 合并为:travel-query
- (3)小样本意图:数据增强 + 权重设置
- query:查询北京飞桂林的飞机是否已经起飞了
- ① 数据增强:数据增强:Cutoff, AEDA
- 北京飞桂林的飞机,是否!起飞了。
- ② 权重设置:基础类别 1,小样本类别 12
- ③ 基于提示的预训练范式,通过设计提示模板更好的利用语言模型
- (4)域外意图
- 级联另一个专门预测other类别的模型,
OOD识别
- ACL 2021: Enhancing the generalization for Intent Classification and Out-of-Domain Detection in SLU
- 无监督方法。不需要额外收集数据,通过在最后一层线性层加上 DRM 模块就能实现
- OOD 的预测有 confidence-based 和 feature-based 两类方法
- Confidence-based Methods 基于 softmax output 来输出 OOD 的预测分数
- Feature-based Methods 马氏距离修正了欧式距离中各个维度尺度不一致且相关的问题。马氏距离计算点与聚类(分布)之间的距离,在多维数据集异常检测,高维数据集分类应用中表现出色。
- ACL 2021: Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training
- 构建一系列的 pseudo outliers,然后把 intent classification 和 OOD 两个任务抽象为一个 K+1 的分类任务来做
- EMNLP 2021: GOLD: Improving Out-of-Scope Detection in Dialogues using Data Augmentation
- 弱监督方式,在少量有标签的 OOD 数据(seed data)以及一个辅助的外部数据集 (source data)上进行数据增强,产生 pseudo-OOD data。任务是 in-domain/out-of-domain 二分类。
- ACL 2021: Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
- 有监督对比学习(SCL) + 交叉熵(CE)的方法,使用对抗攻击的方法实现正样本的增强。希望同一个意图下的样本互相接近,不同意图下的样本互相远离。有监督对比学习的表示学习方法可以通过最大化类间距离和最小化类内方差来提升特征的区分度。属于无监督的OOD检测方法,训练阶段用IND数据,测试阶段用 MSP/LOF/GDA 来检测 OOD。
- NACCL 2021: Adversarial Self-Supervised Learning for Out-of-Domain Detection
- 这篇和上面一篇都是美团发的文,模型上一篇更简单,实验指标也是上一篇更好看,用 IND 数据和 CL loss 训练一个分类器,对 unlabeled data 进行对比学习,用 back translate 做正样本数据增强
对话系统中的 domain 都是预先定义好的,而在实际应用场景中,会有很多现有系统回答不了的问题(out of the design scope),我们把系统支持的意图称为 in-domain (IND),系统不支持的意图称为 out-of-domain (OOD),OOD 是需要被拒识的。
处理 OOD 问题一般分为有监督和无监督两类方法。
- 有监督方法相对更直接,收集好 OOD 数据,在 IND 和 OOD 上训练一个二分类器,或者直接学习一个 K+1 的分类器。
- 然而 OOD 数据获取困难,所以有些研究是讨论怎么生成 pseudo outlier。
- 另外,从直觉上看,IND 和 OOD 数据分布不一致,IND/OOD 数据极不平衡,在选择 OOD 数据时存在一定的 selection bias,很难选择到高质量有代表性的数据,所以学习的模型对没见过的 OOD 数据很难泛化。
- 而无监督方法往往在训练阶段只利用 IND 数据来学习 IND 的 decision boundaries(如 LMCL,SEG),在测试阶段使用额外的检测算法来检测 OOD。这类方法致力于更好的对 IND 数据建模,以及探索更好的检测方法。但由于训练和测试阶段的目标并不一致,容易对 OOD 数据产生 overconfident 的后验分数。下面是三类常见的检测方法:
- 概率阈值 Probability Threshold: 利用 IND 模型的输出概率分布来决定 OOD,如 Maximum Softmax Probability (MSP),或者对输出的分数进行若干操作转化如 ODIN, Entropy,也有一些是在 reconstruction loss 或者 likelihood ratios 上设定阈值
- 异常检测 Outlier Distance: 异常检测的方法,看 outlier 到 in-scope 集合的距离是否足够远。通常是在 embedding function 或者距离函数上做文章,如 Local Outlier Factor (LOF)、马氏距离等
- 贝叶斯集成 Bayesian Ensembles: 在 16-18 年的工作比较多,近两年没怎么看到,通过 IND 模型输出的方差来决定是否是 OOD,如通过 ensemble / dropout 等方式看模型输出的方差如果够大,就认为是 OOD。
【2022-1-4】北邮模式识别实验室Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning,如何检测用户query中的跟task/domain不相关的问题。例如:银行的app语音助手
- 我有多少余额,它检测该问题为in-domain (
IND) 的问题,并给出回答; - 我们一起健身的小伙伴都怎样呀?我们不希望模型“不懂装懂”,而是希望它可以检测该问题为out-of-domain (
OOD),并引导用户提出domain相关的问题。 
OOD的检测方法分为有监督和无监督两种。
- 有监督的方式在训练时已知哪些数据OOD,所以在训练时可以将OOD的数据当成一个类型;
- 无监督方式训练的时候只有标注的IND数据。常用的方法是先利用IND数据学习类别的特征 (分类器),然后使用检测算法计算IND样本和OOD样本的相似度。
先验假设是:一个OOD检测模型依赖于高质量IND类别表示模型。
- IND分类器虽然在IND数据上表现好,应用到OOD时性能不高,原因是类别间隔很模糊。
- 所以核心是利用对比学习减小类内距离,增大类间距离。更好的IND聚类促使更好的OOD分类。
是无监督OOD进行训练,策略是先用有监督对比学习在IND数据上训练,然后用cross-entropy损失对分类器fine-tune,有监督对比学习的目标是拉近IND中属于拉近同一类别的意图,推远不同类别的意图。
槽位抽取(序列标注)
槽位抽取
- 常规槽位:
- MacBERT + BiLSTM → CRF
- 小样本槽位
- 迁移学习
其它
- 对抗训练
- 五折交叉验证
- 相似词替换
- 随机sentence permutation
- 随机word drop
尝试过的模型
- Joint-Model
- MRC-Model
- Proposed Model
并行
2021 CCIR Cup竞赛成果揭晓,极链发力“人机交互NLU”战绩可贺, 经历了近三个月A榜与B榜的接连挑战,决赛答辩阶段,组委会根据算法创新性、商业价值与现场表现力等多个维度对参赛团队进行综合评估,最终极链科技两支团队在中国移动研究院发布的「智能人机交互自然语言理解」赛题中取得第二名和第三名的优秀战绩。

两大团队面对所需解决的任务,均设计了由“域外检测”、“意图识别与槽位抽取”两大算法模块构成的算法系统。通过“域外检测”算法来排除测试集中的域外数据,再对过滤后得到的域内数据进行“意图识别与槽位抽取”。

- “域外检测”算法部分,综合利用了BERT、RoBERTa、MACBERT等基于不同语料预训练和不同开源模型之间的互补能力,融合增强了整体算法模型体系的域外检测能力,提升域外数据召回率的同时,也利用了多样化开源数据进行训练以最大化构建域内数据的补集空间。
- 为了更进一步提升任务准确率,团队对意图识别与槽位抽取进行了联合建模,通过联合训练学习到了两种任务间的相互约束关系,并实现了一次推理过程即可同时完成两种任务,准确而高效。
- 由于缺乏先验知识,而使意图识别的准确率提升陷入瓶颈。为了在缺乏实体属性的情形下,对模型不可靠的预测过程进行知识赋能,团队为此构建了文人名录库、文学作品库等多种知识库,从而提高了意图识别的准确率。(例如,改进后可以正确地在Music-Play、Audio-Play这两种易混淆意图当中作出选择)
- 针对竞赛训练数据中“异常槽位”(表现为槽位所对应的槽值并非来自于原文中,准确地说应该为一种分类标签)的抽取,团队根据异常槽位槽值非空占比值的大小设计了高效的特征词判断规则、深度学习分类模型两种策略,从而可靠地实现了槽位抽取任务。
SemEval
国际计算语言学协会(Association for Computational Linguistics, ACL)下属的 SIGLEX 主办。ACL 作为世界上影响力最大、最具活力的国际学术组织,其举办的计算语言学年会(Annual Meeting of the Association for Computational Linguistics)是国际自然语言处理的顶级会议。自 2001 年起,SemEval 至今已成功举办了十三届,吸引了世界范围内的多所大学和研究机构的参加,在业界和学术界具有极高的影响力。根据 Google Scholar 的数据,发表在 SemEval 的文章在 Computational Linguistics 领域的影响力仅次于 ACL/EMNLP/NAACL 三大顶会,位于 NLP 会议、期刊中的第四位。
- NLP顶级赛事SemEval那个人居然夺得榜首: 第十四届国际语义评测大赛(International Workshop on Semantic Evaluation 2020, SemEval 2020)落下帷幕。在 Task 4: Commonsense Validation and Explanation 常识验证与解释评测任务中,由我院 ICA 研究所的(我导师 + 联合培养的另一位老师)担任指导老师,千千、小雨等同学组成的参赛队成功获得子任务 B 第一名,子任务 A 第二名,撒花~。本届比赛也吸引了包括哈尔滨工业大学、香港中文大学、雷丁大学等著名全球高校。
-
2020年,全球规模最大的语义评测比赛 SemEval 2020 百度基于飞桨平台自研的语义理解框架 ERNIE一举斩获5项世界冠军,囊括视觉媒体的关键文本片段挖掘、多语攻击性语言检测和混合语种的情感分析
- SemEval 2022,跟ACL合作
浦发和百度合作搞semeval 2022
Websites and contact information for individual tasks below.
Lexical semantics
- Task 1: CODWOE - COmparing Dictionaries and WOrd Embeddings ([contact organizers] [task mailing list]) Timothee Mickus, Denis Paperno, Mathieu Constant, Kees van Deemter
-
Task 2: Multilingual Idiomaticity Detection and Sentence Embedding ([contact organizers] [task mailing list]) Harish Tayyar Madabushi, Marcos Garcia, Carolina Scarton, Marco Idiart, Aline Villavicencio
- Task 3: Presupposed Taxonomies - Evaluating Neural-network Semantics (PreTENS) ([contact organizers] [task mailing list]) Dominique Brunato, Cristiano Chesi, Shammur Absar Chowdhury, Felice Dell’Orletta, Simonetta Montemagni, Giulia Venturi, Roberto Zamparelli
Social factors & attitudes
-
Task 4: Patronizing and Condescending Language Detection ([contact organizers] [task mailing list]) Carla Perez-Almendros, Luis Espinosa-Anke, Steven Schockaert
-
Task 5: MAMI - Multimedia Automatic Misogyny Identification ([contact organizers] [task mailing list]) Elisabetta Fersini, Paolo Rosso, Francesca Gasparini, Alyssa Lees, Jeffrey Sorensen
-
Task 6: iSarcasmEval - Intended Sarcasm Detection in English and Arabic ([contact organizers] [task mailing list]) Ibrahim Abu Farha, Silviu Oprea, Steve Wilson, Walid Magdy
Discourse, documents, and multimodality
-
Task 7: Identifying Plausible Clarifications of Implicit and Underspecified Phrases in Instructional Texts ([contact organizers] [task mailing list]) Michael Roth, Talita Kloppenburg-Anthonio, Anna Sauer
-
Task 8: Multilingual news article similarity ([contact organizers] [task mailing list]) Xi Chen, Ali Zeynali, Chico Camargo, Fabian Flöck, Devin Gaffney, Przemyslaw A. Grabowicz, Scott A. Hale, David Jurgens, Mattia Samory
-
Task 9: R2VQ - Competence-based Multimodal Question Answering ([contact organizers] [task mailing list]) James Pustejovsky, Jingxuan Tu, Marco Maru, Simone Conia, Roberto Navigli, Kyeongmin Rim, Kelley Lynch, Richard Brutti, Eben Holderness
Information extraction
-
Task 10: Structured Sentiment Analysis ([contact organizers] [task mailing list]) Jeremy Barnes, Andrey Kutuzov, Jan Buchmann, Laura Ana Maria Oberländer, Enrica Troiano, Rodrigo Agerri, Lilja Øvrelid, Erik Velldal, Stephan Oepen
-
Task 11: MultiCoNER - Multilingual Complex Named Entity Recognition ([contact organizers] [task mailing list]) Shervin Malmasi, Besnik Fetahu, Anjie Fang, Sudipta Kar, Oleg Rokhlenko
-
Task 12: Symlink - Linking Mathematical Symbols to their Descriptions ([contact organizers] [task mailing list]) Viet Dac Lai, Amir Ben Veyseh, Thien Huu Nguyen, Franck Dernoncourt
Kaggle
Kaggle kernel
【2023-2-27】问题在于平台不是很灵活,比如上传文件之类的,而且速度很不稳定,时好时坏
- 编程语言,默认支持 Python + R
- 整个kernel相当于一个虚拟的环境
- kernels运行代码不能超过6个小时
- 如果离开kernels界面时间超过一个小时,kernels就会重启,不管其中是否已经正在执行训练任务,这样是为了资源的合理利用…
- 如果执行超过1h,可以去页面的右上角得Commit按钮,将代码提交,就会在服务器后端执行,当执行完毕后页面就会加载。执行过程中的一些输出信息也会呈现出来。Commit后的代码可执行时间也是最长6小时
kaggle vs 天池
Notebook:
- 提供一个配置好环境的运行的环境,所有参赛选手免去在本地配置环境的环节;
- 代码和思路的分享,比如比赛分析过程和解决方案的展示;
- 比赛提交的入口,如比赛最终提交可以从Notebook提交;
- 提供系列的学习资源和实践教材,可以作为在线教材;
- 版本存储的功能,可以存储历史运行的代码;
- 渲染Markdown、图片和公式的功能,展示方式更加灵活;
- 与数据集和比赛交互的过程;
- 天池 notebook
| 维度 | 天池DSW | Kaggle Notebook |
|---|---|---|
| 界面 | Juypter Lab | 自定义网页 |
| 使用时间 | 总共使用时间不限制 CPU和GPU单次链接8小时 每次链接可以运行多个Notebook |
CPU时间不限,GPU每周35小时 可以同时运行多个CPU Notebook 只能运行一个GPU Notebook |
| 文件目录 | 工作目录与文件目录混合 | 工作目录与数据文件分开 |
| 文件系统 | 多个Notebook共享 | 单个Notebook独占 |
| Markdown目录 | 支持 | 不支持 |
| 数据集 | 支持挂载数据集 | 支持挂载数据集 |
| 内存 | 4G,多个Notebook共享 | 16G,单个Notebook独占 |
| 显存 | 16G,多个Notebook共享 | 11G,单个一个Notebook独占 |
| 联网 | CPU模型可以联网 GPU模型不可以联网 |
CPU和GPU都可以联网 |
| 稳定性 | CPU较为稳定 GPU稳定性一般 |
较为稳定 |
| Shell | 支持 | 不支持 |
| 上传文件 | 支持 | 不支持,可在Dataset页面上传 |
| 发布 | 支持发布到天池论坛 | 支持发布到Kaggle论坛 |
| 版本 | 支持版本管理,但不完善 | 支持版本管理,比较完善 |
| Copy & Fork | 支持 | 支持 |
| 评论 | 支持 | 支持 |
从上表对比可知,天池DSW与Kaggle Notebook环境虽然整体都为在线Notebook,但在使用上存在一定的差异性:
- 资源分配:天池DSW环境可以同时运行多个Notebook,且多个Notebook资源共享;Kaggle Notebook每个资源独立,且文件各自不共享;
- 使用方式:天池DSW环境与Juypter Lab比较类似,而Kaggle Notebook是固定好输入情况下的代码运行环境;
从使用角度天池DSW比较灵活强大,而Kaggle Notebook每个功能比较单一。所以如果大家在国内,建议使用天池DSW。
- 天池向左 Kaggle向右:Notebook使用对比
- 天池DSW是国内首个支持GPU和CPU的学习环境
云环境
# UI可视目录
ls /kaggle/input # 输入目录,存放上传的文件信息
ls /kaggle/working # 输出目录
数据集
可以搜索公用数据集,也可以自己上传数据集
上传数据集成功,但Kaggle Processing data过程中会出错,信息为:
“Unfortunately, we could not create your dataset. Failed to check creation status. Please try again later.”
原因是:
- 数据集中文件名包含非法字符如’&’, ‘;’, ‘,’等,请统一更新为合法文件名 。
- 文件名很长很长,Kaggle也不认识,请尽量变短你的文件名。
kaggle中文显示乱码:
- 在Kaggle中可以查看支持的所有字体:
a=sorted([f.name for f in matplotlib.font_manager.fontManager.ttflist])
print(a)
# 没有支持中文(可能未来会有)
解决方法:详见
- 到 C:\Windows\Fonts中,选择几个字体文件,打成zip文件,创建一个字体文件数据集,接着通过Add data将字体文件数据集引入到当前notebook下
-

myfont =matplotlib.font_manager.FontProperties(fname=r'../input/chinesefonts/chinesefonts/STXINWEI.TTF')
# 在显示中文的地方添加myfont即可:
plt.subplot(3,4,1) #要生成三行四列,这是第一个图plt.subplot('行','列','编号')
plt.plot(t,s,'b--')
plt.title('前夕', fontproperties=myfont,size=14)
plt.ylabel('y1')
python
默认Python环境 3.7.12
python --version # Python 3.7.12
更改Python版本
【2023-2-28】实验失败, 参考kaggle问题
conda create -y -n yanjunenv python=3.8
!conda env list # 列出conda管理的所有环境, conda info -e
!activate py38 # linux下激活虚拟环境conda activate
#source deactivate
!conda activate py38 && python -c "import sys;print(sys.version)"
shell
Currently supported shells are:
- bash
- fish
- tcsh
- xonsh
- zsh
- powershell
conda 使用
kaggle默认安装了conda
- 创建虚拟环境
conda env list # 查看 conda环境
conda create -n learn python=3.10 # 由于没有终端交互,流程卡在yes环节
conda create -n learn python=3.10 --yes # 加上yes参数即可
conda env list
# conda environments:
#
# base /opt/conda
# learn /opt/conda/envs/learn # 刚创建的虚拟环境
执行conda init失败
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.
To initialize your shell, run
$ conda init <SHELL_NAME>
参考:
- How to accept a proceed in console
- How do I interact with the console on a kaggle notebook, I am currently unable to respond with a yes.
- !conda install –yes seaborn
- !pip uninstall bert4keras –yes
- 或者 -y
- How to activate conda environment in kaggle notebook
GPU
kaggle 提供免费GPU计算资源,每个用户可以获得30小时的 GPU 加速
- Kaggle只提供一周37小时,Kaggle重设credit是星期六的0点
- 训练时间不能超过12小时,否则Kaggle会自动停止你的运行任务

!nvidia-smi # 查看 GPU 资源
!nvcc -V # 查看 cuda 版本
!gcc --version # gcc
计算资源(【2023-2-27】)
- CPU
- GPU T4*2
- GPU P100
- TPU V3-8
- TPU VM V3-8
注意
- 训练完以后一定要 关闭事例,不然会一直计费
Kaggle 基本介绍
- Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台。
- 企业或者研究机构在Kaggle上发布商业和科研难题,悬赏吸引全球的数据科学家,通过众包的方式解决建模问题。
- 而参赛者可以接触到丰富的真实数据,解决实际问题,角逐名次,赢取奖金。
- 诸如 Google,Facebook,Microsoft 等知名科技公司均在 Kaggle 上面举办过数据挖掘比赛。
-
2017年3月,Kaggle 被 Google CloudNext 收购。
- 【2020-10-10】历年赛题分布
竞赛( Leaderboard) 是论文最好的练兵场,撕开论文第三页上方华丽花哨的大图,是骡子是马拉出来溜溜。为什么说竞赛(Leaderboard)是论文最好的练兵场。原因有以下几个:
- 统一测试集的划分,不放出标签,避免了自己通过不规范不统一的验证集划分来自说自话,运动员想当裁判。众所周知,不同的测试集其实方差波动范围不小.
- 允许trick,在trick的加成下比试去比model baseline,避免了自己偷偷用了trick提升了百分之80的效果,然后把功劳送给第三页上面的花里胡哨的大图。然后说我真棒。
- 会有很多团队(上千支)同时来检验paper,是否难于实现,开源是否丰富,是否难以泛化都决定了你工作的质量。
- Leaderboard数据一般比较新,数量可靠(百万级别很常见),没有过度优化甚至泄露标签的风险。
- 同时的多数据集评测能一定程度考验模型的方差。
参赛方式
- 以个人或者组队的形式参加比赛。组队人数一般没有限制,但需要在 Merger Deadline 前完成组队。
- 关于组队,建议先单独个人进行数据探索和模型构建,以个人身份进行比赛,在比赛后期(譬如离比赛结束还有 2~3 周)再进行组队,以充分发挥组队的效果(类似于模型集成,模型差异性越大,越有可能有助于效果的提升,超越单模型的效果)。
- 当然也可以一开始就组好队,方便分工协作,讨论问题和碰撞火花。
-
为了能参与到比赛中,需要在 Entry Deadline 前进行至少一次有效提交。最简单地,可以直接提交官方提供的 Sample Submission。
- Kaggle 对比赛的公正性相当重视。
- 在比赛中,每个人只允许使用一个账号进行提交。
- 在比赛结束后 1~2 周内,Kaggle 会对使用多账号提交的 Cheater 进行剔除(一般会对 Top 100 的队伍进行 Cheater Detection)。在被剔除者的 Kaggle 个人页面上,该比赛的成绩也会被删除,相当于该选手从没参加过这个比赛。
- 此外,队伍之间也不能私自分享代码或者数据,除非在论坛上面公开发布。
- 比赛一般只提交测试集的预测结果,无需提交代码。
- 每人(或每个队伍)每天有提交次数的限制,一般为2次或者5次,在 Submission 页面会有提示。
比赛获奖
- Kaggle 比赛奖金丰厚,一般前三名均可以获得奖金。
- 获奖队伍需要在比赛结束后 1~2 周内,准备好可执行的代码以及 README,算法说明文档等提交给 Kaggle 来进行获奖资格的审核。
- Kaggle 会邀请获奖队伍在 Kaggle Blog 中发表 Interview,来分享比赛故事和经验心得。
- 对于某些比赛,Kaggle 或者主办方会邀请获奖队伍进行电话/视频会议,获奖队伍进行 Presentation,并与主办方团队进行交流。
比赛类型
从 Kaggle 提供的官方分类来看,可以划分为以下类型:
- ◆ Featured:商业或科研难题,奖金一般较为丰厚;
- ◆ Recruitment:比赛的奖励为面试机会;
- ◆ Research:科研和学术性较强的比赛,也会有一定的奖金,一般需要较强的领域和专业知识;
- ◆ Playground:提供一些公开的数据集用于尝试模型和算法;
- ◆ Getting Started:提供一些简单的任务用于熟悉平台和比赛;
- ◆ In Class:用于课堂项目作业或者考试。
- 从领域归属划分:包含搜索相关性,广告点击率预估,销量预估,贷款违约判定,癌症检测等。
- 从任务目标划分:包含回归,分类(二分类,多分类,多标签),排序,混合体(分类+回归)等。
- 从数据载体划分:包含文本,语音,图像和时序序列等。
- 从特征形式划分:包含原始数据,明文特征,脱敏特征(特征的含义不清楚)等。
比赛流程
一个数据挖掘比赛的基本流程如下图2所示,具体的模块将在下一章进行展开陈述。
这里想特别强调的一点是:
- Kaggle 在计算得分的时候,有Public LB(验证集)和 Private LB(测试集) 之分。
- 具体而言,参赛选手提交整个测试集的预测结果,Kaggle 使用测试集的一部分计算得分和排名,实时显示在 Public LB上,用于给选手提供及时的反馈和动态展示比赛的进行情况;
- 测试集的剩余部分用于计算参赛选手的最终得分和排名,此即为 Private LB,在比赛结束后会揭晓。
- 用于计算 Public LB 和 Private LB 的数据有不同的划分方式,具体视比赛和数据的类型而定,一般有随机划分,按时间划分或者按一定规则划分。
- 这个过程可以概括如下图所示,其目的是避免模型过拟合,以得到泛化能力好的模型。
- 如果不设置 Private LB(即所有的测试数据都用于计算 Public LB),选手不断地从 Public LB(即测试集)中获得反馈,进而调整或筛选模型。这种情况下,测试集实际上是作为验证集参与到模型的构建和调优中来。
- Public LB上面的效果并非是在真实未知数据上面的效果,不能可靠地反映模型的效果。
- 划分 Public LB 和 Private LB 这样的设置,也在提醒参赛者,我们建模的目标是要获得一个在未知数据上表现良好的模型,而并非仅仅是在已知数据上效果好。
数据挖掘比赛基本流程
- 从上面图可以看到,做一个数据挖掘比赛,主要包含了
数据分析,数据清洗,特征工程,模型训练和验证等四个大的模块,下面分别介绍。
数据集上传
- kaggle上有各种数据集,Kaggle dataset,也可以自己上传,不过国内需要翻墙,才能上传自己的数据集,否则上传进度一直是0
- 方法:在Kaggle dataset上点New Dataset创建一个新的数据集, 左下角设置里有Private、Public选项,是否公开数据集.
数据分析
数据分析可能涉及以下方面:
- ◆ 分析特征变量的分布
- ◇ 特征变量为连续值:如果为长尾分布并且考虑使用线性模型,可以对变量进行幂变换或者对数变换。
- ◇ 特征变量为离散值:观察每个离散值的频率分布,对于频次较低的特征,可以考虑统一编码为“其他”类别。
- ◆ 分析目标变量的分布
- ◇ 目标变量为连续值:查看其值域范围是否较大,如果较大,可以考虑对其进行对数变换,并以变换后的值作为新的目标变量进行建模(在这种情况下,需要对预测结果进行逆变换)。一般情况下,可以对连续变量进行Box-Cox变换。通过变换可以使得模型更好的优化,通常也会带来效果上的提升。
- ◇ 目标变量为离散值:
- 如果数据分布不平衡,考虑是否需要上采样/下采样;
- 如果目标变量在某个ID上面分布不平衡,在划分本地训练集和验证集的时候,需要考虑分层采样(Stratified Sampling)。
- ◆ 分析变量之间两两的分布和相关度
- ◇ 可以用于发现高相关和共线性的特征。
通过对数据进行探索性分析(EDA, 甚至要肉眼观察样本),还可以有助于启发数据清洗和特征抽取,譬如缺失值和异常值的处理,文本数据是否需要进行拼写纠正等。
数据清洗
数据清洗是指对提供的原始数据进行一定的加工,使得其方便后续的特征抽取。其与特征抽取的界限有时也没有那么明确。
常用的数据清洗一般包括:
- ◆ 数据的拼接
- ◇ 提供的数据散落在多个文件,需要根据相应的键值进行数据的拼接。
- ◆ 特征缺失值的处理
- ◇ 特征值为连续值:按不同的分布类型对缺失值进行补全:
- 偏正态分布,使用均值代替,可以保持数据的均值;
- 偏长尾分布,使用中值代替,避免受 outlier 的影响;
- ◇ 特征值为离散值:使用众数代替。
- ◇ 特征值为连续值:按不同的分布类型对缺失值进行补全:
- ◆ 文本数据的清洗
- ◇ 在比赛当中,如果数据包含文本,往往需要进行大量的数据清洗工作。如去除HTML 标签,分词,拼写纠正, 同义词替换,去除停词,抽词干,数字和单位格式统一等。
特征工程
有一种说法:
特征决定了效果的上限,而模型只是以不同的方式/程度逼近这个上限而已。
- 这样来看,好的特征输入对于模型的效果至关重要,正所谓Garbage in, garbage out。
- 要做好特征工程,往往跟领域知识和对问题的理解程度有很大的关系,也跟一个人的经验相关。
- 特征工程的做法也是Case by Case。
特征变换
主要针对一些长尾分布的特征,需要进行幂变换或者对数变换,使得模型(LR或者DNN)能更好的优化。
- 注意
- Random Forest 和 GBDT 等模型对单调的函数变换不敏感。原因是树模型在求解分裂点的时候,**只考虑排序分位点**。
特征编码
- 对于离散的类别特征,往往需要进行必要的特征转换/编码才能将其作为特征输入到模型中。
- 常用的编码方式有 LabelEncoder,OneHotEncoder(sklearn里面的接口)。
- 譬如对于”性别”这个特征(取值为男性和女性),使用这两种方式可以分别编码为和{[1,0], [0,1]}。
- 对于取值较多(如几十万)的类别特征(ID特征),直接进行OneHotEncoder编码会导致特征矩阵非常巨大,影响模型效果。可以使用如下的方式进行处理:
- ◆ 统计每个取值在样本中出现的频率,取 Top N 的取值进行 One-hot 编码,剩下的类别分到“其他“类目下,其中 N 需要根据模型效果进行调优;
- ◆ 统计每个 ID 特征的一些统计量(譬如历史平均点击率,历史平均浏览率)等代替该 ID 取值作为特征,具体可以参考 Avazu 点击率预估比赛第二名的获奖方案;
- ◆ 参考 word2vec 的方式,将每个类别特征的取值映射到一个连续的向量,对这个向量进行初始化,跟模型一起训练。训练结束后,可以同时得到每个ID的Embedding。具体的使用方式,可以参考 Rossmann 销量预估竞赛第三名的获奖方案。
对于 Random Forest 和 GBDT 等模型,如果类别特征存在较多的取值,可以直接使用 LabelEncoder 后的结果作为特征。
模型训练和验证
模型选择
在处理好特征后,进行模型的训练和验证。
- ◆ 对于稀疏型特征(如文本特征,One-hot的ID类特征),一般使用线性模型,譬如 Linear Regression 或者 Logistic Regression。
- Random Forest 和 GBDT 等树模型不太适用于稀疏的特征,但可以先对特征进行降维(如PCA,SVD/LSA等),再使用这些特征。
- 稀疏特征直接输入 DNN 会导致网络 weight 较多,不利于优化,也可以考虑先降维,或者对 ID 类特征使用 Embedding 的方式;
- ◆ 对于稠密型特征,推荐使用 XGBoost 进行建模,简单易用效果好;
-
◆ 数据中既有稀疏特征,又有稠密特征,可以考虑使用线性模型对稀疏特征进行建模,将其输出与稠密特征一起再输入 XGBoost/DNN 建模,具体可以参考2.5.2节 Stacking 部分。
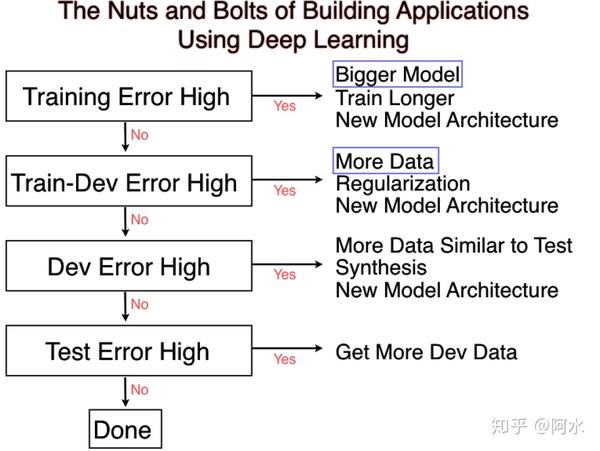
- 【2020-10-10】根据训练集、验证集和测试集误差大小适配不同解决办法
调参和模型验证
对于选定的特征和模型,往往还需要对模型进行超参数的调优,才能获得比较理想的效果。调参一般可以概括为以下三个步骤:
- 训练集和验证集的划分。根据比赛提供的训练集和测试集,模拟其划分方式对训练集进行划分为本地训练集和本地验证集。划分的方式视具体比赛和数据而定,常用的方式有:
- a) 随机划分:譬如随机采样 70% 作为训练集,剩余的 30% 作为测试集。在这种情况下,本地可以采用 KFold 或者 Stratified KFold 的方法来构造训练集和验证集。
- b) 按时间划分:一般对应于时序序列数据,譬如取前 7 天数据作为训练集,后 1 天数据作为测试集。这种情况下,划分本地训练集和验证集也需要按时间先后划分。常见的错误方式是随机划分,这种划分方式可能会导致模型效果被高估。
- c) 按某些规则划分:在 HomeDepot 搜索相关性比赛中,训练集和测试集中的 Query 集合并非完全重合,两者只有部分交集。而在另外一个相似的比赛中(CrowdFlower 搜索相关性比赛),训练集和测试集具有完全一致的 Query 集合。对于 HomeDepot 这个比赛中,训练集和验证集数据的划分,需要考虑 Query 集合并非完全重合这个情况,其中的一种方法可以参考第三名的获奖方案。
- 指定参数空间。在指定参数空间的时候,需要对模型参数以及其如何影响模型的效果有一定的了解,才能指定出合理的参数空间。譬如DNN或者XGBoost中学习率这个参数,一般就选 0.01 左右就 OK 了(太大可能会导致优化算法错过最优化点,太小导致优化收敛过慢)。再如 Random Forest,一般设定树的棵数范围为 100~200 就能有不错的效果,当然也有人固定数棵数为 500,然后只调整其他的超参数。
- 按照一定的方法进行参数搜索。常用的参数搜索方法有,Grid Search,Random Search 以及一些自动化的方法(如 Hyperopt)。其中,Hyperopt 的方法,根据历史已经评估过的参数组合的效果,来推测本次评估使用哪个参数组合更有可能获得更好的效果。有关这些方法的介绍和对比,可以参考文献: Algorithms for Hyper-Parameter Optimization。
适当利用 Public LB 的反馈
上面提到本地验证(Local Validation)结果,当将预测结果提交到 Kaggle 上时,还会接收到 Public LB 的反馈结果。如果这两个结果的变化趋势是一致的,如 Local Validation 有提升,Public LB 也有提升,可以借助 Local Validation 的变化来感知模型的演进情况,而无需靠大量的 Submission。如果两者的变化趋势不一致,需要考虑 2.4.2 节中提及的本地训练集和验证集的划分方式,是否跟训练集和测试集的划分方式一致。
另外,在以下一些情况下,往往 Public LB 反馈亦会提供有用信息,适当地使用这些反馈也许会给你带来优势。如图4所示,(a)和(b)表示数据与时间没有明显的关系(如图像分类),(c)和(d)表示数据随时间变化(如销量预估中的时序序列)。
- (a)和(b)的区别在于,训练集样本数相对于 Public LB 的量级大小,其中(a)中训练集样本数远超于 Public LB 的样本数,这种情况下基于训练集的 Local Validation 更可靠;而(b)中,训练集数目与 Public LB 相当,这种情况下,可以结合 Public LB 的反馈来指导模型的选择。
一种融合的方式是根据 Local Validation 和 Public LB 的样本数目,按比例进行加权。譬如评估标准为正确率,Local Validation 的样本数为 $N_l$,正确率为 $A_l$;Public LB 的样本数为 $N_p$,正确率为 $A_p$。则可以使用融合后的指标:$(N_l * A_l + N_p * A_p)/(N_l + N_p)$,来进行模型的筛选。对于(c)和(d),由于数据分布跟时间相关,很有必要使用 Public LB 的反馈来进行模型的选择,尤其对于(c)图所示的情况。
模型集成
如果想在比赛中获得名次,几乎都要进行模型集成(组队也是一种模型集成)。关于模型集成的介绍,已经有比较好的博文了,可以参考 [3]。在这里,我简单介绍下常用的方法,以及个人的一些经验。
Averaging 和 Voting
直接对多个模型的预测结果求平均或者投票。对于目标变量为连续值的任务,使用平均;对于目标变量为离散值的任务,使用投票的方式。
Stacking
图5展示了使用 5-Fold 进行一次 Stacking 的过程(当然在其上可以再叠加 Stage 2, Stage 3 等)。其主要的步骤如下:
- 数据集划分。将训练数据按照5-Fold进行划分(如果数据跟时间有关,需要按时间划分,更一般的划分方式请参考3.4.2节,这里不再赘述);
- 基础模型训练 I(如图5第一行左半部分所示)。按照交叉验证(Cross Validation)的方法,在训练集(Training Fold)上面训练模型(如图灰色部分所示),并在验证集(Validation Fold)上面做预测,得到预测结果(如图黄色部分所示)。最后综合得到整个训练集上面的预测结果(如图第一个黄色部分的CV Prediction所示)。
- 基础模型训练 II(如图5第二和三行左半部分所示)。在全量的训练集上训练模型(如图第二行灰色部分所示),并在测试集上面做预测,得到预测结果(如图第三行虚线后绿色部分所示)。
- Stage 1 模型集成训练 I(如图5第一行右半部分所示)。将步骤 2 中得到的 CV Prediction 当作新的训练集,按照步骤 2 可以得到 Stage 1模型集成的 CV Prediction。
- Stage 1 模型集成训练 II(如图5第二和三行右半部分所示)。将步骤 2 中得到的 CV Prediction 当作新的训练集和步骤 3 中得到的 Prediction 当作新的测试集,按照步骤 3 可以得到 Stage 1 模型集成的测试集 Prediction。此为 Stage 1 的输出,可以提交至 Kaggle 验证其效果。
在图5中,基础模型只展示了一个,而实际应用中,基础模型可以多种多样,如SVM,DNN,XGBoost 等。也可以相同的模型,不同的参数,或者不同的样本权重。重复4和5两个步骤,可以相继叠加 Stage 2, Stage 3 等模型。
Blending
Blending 与 Stacking 类似,但单独留出一部分数据(如 20%)用于训练 Stage X 模型。
Bagging Ensemble Selection
Bagging Ensemble Selection [5] 是我在 CrowdFlower 搜索相关性比赛中使用的方法,其主要的优点在于可以以优化任意的指标来进行模型集成。这些指标可以是可导的(如 LogLoss 等)和不可导的(如正确率,AUC,Quadratic Weighted Kappa等)。它是一个前向贪婪算法,存在过拟合的可能性,作者在文献 [5] 中提出了一系列的方法(如 Bagging)来降低这种风险,稳定集成模型的性能。使用这个方法,需要有成百上千的基础模型。为此,在 CrowdFlower 的比赛中,我把在调参过程中所有的中间模型以及相应的预测结果保留下来,作为基础模型。这样做的好处是,不仅仅能够找到最优的单模型(Best Single Model),而且所有的中间模型还可以参与模型集成,进一步提升效果。
自动化框架
从上面的介绍可以看到,做一个数据挖掘比赛涉及到的模块非常多,若有一个较自动化的框架会使得整个过程更加的高效。在 CrowdFlower 比赛较前期,我对整一个项目的代码架构进行了重构,抽象出来特征工程,模型调参和验证,以及模型集成等三大模块,极大的提高了尝试新特征,新模型的效率,也是我最终能斩获名次的一个有利因素。这份代码开源在 Github 上面,目前是 Github 有关 Kaggle 竞赛解决方案的 Most Stars,地址:https://github.com/ChenglongChen/Kaggle_CrowdFlower。
其主要包含以下部分:
- 模块化特征工程
- a) 接口统一,只需写少量的代码就能够生成新的特征;
- b) 自动将单独的特征拼接成特征矩阵。
- 自动化模型调参和验证
- a) 自定义训练集和验证集的划分方法;
- b) 使用 Grid Search / Hyperopt 等方法,对特定的模型在指定的参数空间进行调优,并记录最佳的模型参数以及相应的性能。
- 自动化模型集成
- a) 对于指定的基础模型,按照一定的方法(如Averaging/Stacking/Blending 等)生成集成模型。
Kaggle竞赛方案盘点
到目前为止,Kaggle 平台上面已经举办了大大小小不同的赛事,覆盖图像分类,销量预估,搜索相关性,点击率预估等应用场景。在不少的比赛中,获胜者都会把自己的方案开源出来,并且非常乐于分享比赛经验和技巧心得。这些开源方案和经验分享对于广大的新手和老手来说,是入门和进阶非常好的参考资料。以下作者结合自身的背景和兴趣,对不同场景的竞赛开源方案作一个简单的盘点,总结其常用的方法和工具,以期启发思路。
NLP
文本分类技术演进
- (1)
青铜时代:特征工程+分类器的天下。LSHTC数据集- 2014年著名大规模文本分类数据集LSHTC的首次登场,后来演变成了text classification的benchmark。
- 2015年DL刚起步,风还没有刮到NLP,于是喜闻乐见,方案是特征工程+分类器,特征如TFIDF,BM25等。线性分类器融合。
- 中规中矩的监督学习框架,没有什么亮点,不过TFIDF,BM25就是IR领域里最经得住历史考验的东西,沿用至今。
- 论文和代码见
- (2)
白银时代:电影评论分类,初见word2vec的身影,Rotten Tomatoes 电影评论和IMDB数据集- 2015上半年,word2vec已经被大家讨论起来,不过端到端的方案似乎还还不多。方案是特征工程+分类器,特征多了bag of words的word2vec。
- 2015下半年,电影评论分类(IMDB数据集), DL开始见威力,和FE+分类器的方法不相上下,具体这里有一些讨论,这时候应该有一些端到端的方案了,不过大家似乎还是愿意把word2vec当feature用。DL框架也不是很多被讨论。
- 2017年,基于quora匹配数据集的文本匹配任务,DL开始大放异彩,不用magic的情况下,孪生网络+embedding为代表的DL baseline 可以碾压FE+分类器了。这时候各种框架也开始百花,keras占领了kaggle半壁江山,pytorch因该刚刚还在襁褓里。
- 这中间缺了一些文本分类的比赛,也进入文本分类的黑暗时期,毫无亮点,大家沉浸在排列组合的无聊游戏中疯狂水论文,于是乎embedding + CNN/RNN/LSTM/Highway/Attention/Memory/hierarchy/Graph/Tree 开始排列组合,类似与CTR中的排列组合水论文大法。不过涌现了一些比较高质量的embeding,如fasttext和glove等等。这里面的方法当属textCNN(创新型较大) fasttext(工程意义大),其他的可以扔进垃圾箱(个人观点)。
- 2018年,基于toxic数据集的分类比赛,DL的端到端方法基本碾压了FE,强力baseline:bilstm几乎可以吊打所有的文本分类结构,ELMO还没诞生,这个比赛也是各种排列组合,没什么意思。
- (3)
黄金时代- 2019年,基于quora分类数据集的比赛,pretrianed model的光照亮了nlp,给历史翻篇,枚举和排列组合结构终于被一棒子打死。于是乎大家看到一个bert直接霸榜,不过这次比赛禁止了外部数据,所以bert不能用作最后提交方案,所以导致大家穷尽可能的使用embedding+排列组合的方法也没打过public的bert,前排用bert挥一挥衣袖,没有留下一片云彩。
- 同年,Toxic2 数据集,pretrained model大放异彩。bert和gpt2开始霸榜,xlnet进入讨论区。几乎清一色的finetune model。手痒痒也参加了这个比赛,不得不说,bert真强。
- 2020年,Google QA Labeling数据集 pretrained mode丰富起来,albert,roberta, t5, CTRL, Camembert, BART等新面孔争奇斗艳…(不过说实话,还是bert的泛化最好)
pretrianed model标志着NLP正式进入 CV的玩法,以resnet和bert为代表性的backbone被大家牢牢记住。当然新的方法的出现不意味着老方法的完全失效,在一些特定场景下,还是有用武之地。不过从规律来看,就是一个好点子,引发了一大堆花里胡哨的东西,而好点子基本是最靠谱的,花里胡哨的中有一些是靠谱的。大浪淘沙,金子最终会闪闪发光,一切还没有盖棺定论。
文本分类比赛技巧
技巧1:快速读取数据
现在很多Kaggle比赛,数据集都比较大,大于3GB是非常常见的事情。在读取数据集时,可能会遇到一些困难。可以尝试以下的方法加速数据读取:
- 在pandas读取时手动设置变量类型
- 使用cudf代替pandas完成读取
- 转为parquet或feather再进行读取
技巧2:扩充数据集
当比赛数据集非常小时,外部数据集就非常关键了。此时可以寻找相似的外部数据集来完成预训练。例如对于QA任务,可以选择以下的数据完成预训练。
- https://rajpurkar.github.io/SQuAD-explorer/
- http://nlpprogress.com/english/question_answering.html 当然也可以从伪标签和数据扩增和回译来增加数据样本。
技巧3:深入文本数据
文本分析
- EDA有助于更好地理解数据。在开始开发机器学习模型之前,应该阅读/做大量的数据文本,这有助于特征工程和数据清洗。
- 文本长度规律
- 语种规律
- 标点符号规律
- 特殊字符规律 文本清洗
- 文本清理是NLP赛题中的重要组成部分。文本数据总是需要一些预处理和清理,然后我们才能用合适的形式表示它。
- Remove HTML tags
- Remove extra whitespaces
- Convert accented characters to ASCII characters
- Expand contractions
- Remove special characters
- Lowercase all texts
- Convert number words to numeric form
- Remove numbers
- Remove stopwords
- Lemmatization
技巧4:文本表示
文本表示方法影响文本的表示形式,也决定了模型的精度。基础的词向量包括:
- Pretrained Glove vectors
- Pretrained fasttext vectors
- Pretrained word2vec vectors
- Pretrained Paragram vectors
- Universal Sentence Encoder 也可以考虑组合上述词向量以减少OOV的情况,当然同一个单词也可以拼接或平均多种词向量。
也可以直接考虑直接使用高阶嵌入方法:
- Bert
- Roberta Bert
- XLNET
技巧5:模型构建
损失函数
- 二分类Binary cross-entropy
- 多分类Categorical cross-entropy
- 二分类Focal loss
- 多分类Weighted focal loss
- 多分类Weighted kappa 优化器
- SGD
- RMSprop
- Adagrad
- Adam
- Adam with warmup Callback
- Model checkpoint
- Learning rate scheduler
- Early Stopping
Contradictory, My Dear Watson
- Detecting contradiction and entailment in multilingual text using TPUs
TensorFlow 2.0 Question Answering


Kaggle Tweet Sentiment Extraction 第七名复盘

图像分类
National Data Science Bowl
- 任务详情
- 随着深度学习在视觉图像领域获得巨大成功,Kaggle 上面出现了越来越多跟视觉图像相关的比赛。这些比赛的发布吸引了众多参赛选手,探索基于深度学习的方法来解决垂直领域的图像问题。
- NDSB就是其中一个比较早期的图像分类相关的比赛。这个比赛的目标是利用提供的大量的海洋浮游生物的二值图像,通过构建模型,从而实现自动分类。
- 获奖方案
- ● 1st place:Cyclic Pooling + Rolling Feature Maps + Unsupervised and Semi-Supervised Approaches。值得一提的是,这个队伍的主力队员也是Galaxy Zoo行星图像分类比赛的第一名,其也是Theano中基于FFT的Fast Conv的开发者。在两次比赛中,使用的都是 Theano,而且用的非常溜。方案链接
- ● 2nd place:Deep CNN designing theory + VGG-like model + RReLU。这个队伍阵容也相当强大,有前MSRA 的研究员Xudong Cao,还有大神Tianqi Chen,Naiyan Wang,Bing XU等。Tianqi 等大神当时使用的是 CXXNet(MXNet 的前身),也在这个比赛中进行了推广。Tianqi 大神另外一个大名鼎鼎的作品就是 XGBoost,现在 Kaggle 上面几乎每场比赛的 Top 10 队伍都会使用。方案链接
- ● 17th place:Realtime data augmentation + BN + PReLU。方案链接
- 常用工具
- ▲ Theano: http://deeplearning.net/software/theano/
- ▲ Keras: https://keras.io/
- ▲ Cuda-convnet2: https://github.com/akrizhevsky/cuda-convnet2
- ▲ Caffe: http://caffe.berkeleyvision.org/
- ▲ CXXNET: https://github.com/dmlc/cxxnet
- ▲ MXNet: https://github.com/dmlc/mxnet
- ▲ PaddlePaddle: http://www.paddlepaddle.org/cn/index.html
回归
销量预估
- 任务名称:Walmart Recruiting - Store Sales Forecasting
- 任务详情
- Walmart 提供 2010-02-05 到 2012-11-01 期间的周销售记录作为训练数据,需要参赛选手建立模型预测 2012-11-02 到 2013-07-26 周销售量。比赛提供的特征数据包含:Store ID, Department ID, CPI,气温,汽油价格,失业率,是否节假日等。
- 获奖方案
- 常用工具
- ▲ R forecast package: https://cran.r-project.org/web/packages/forecast/index.html
- ▲ R GBM package: https://cran.r-project.org/web/packages/gbm/index.html
搜索相关性
- 任务名称:CrowdFlower Search Results Relevance
- 任务详情
- 比赛要求选手利用约几万个 (query, title, description) 元组的数据作为训练样本,构建模型预测其相关性打分 。比赛提供了 query, title和description的原始文本数据。比赛使用 Quadratic Weighted Kappa 作为评估标准,使得该任务有别于常见的回归和分类任务。
- 获奖方案
- ● 1st place:Data Cleaning + Feature Engineering + Base Model + Ensemble。对原始文本数据进行清洗后,提取了属性特征,距离特征和基于分组的统计特征等大量的特征,使用了不同的目标函数训练不同的模型(回归,分类,排序等),最后使用模型集成的方法对不同模型的预测结果进行融合。方案链接:https://github.com/ChenglongChen/Kaggle_CrowdFlower
- ● 2nd place:A Similar Workflow
- ● 3rd place:A Similar Workflow
- 常用工具
- ▲ NLTK: http://www.nltk.org/
- ▲ Gensim: https://radimrehurek.com/gensim/
- XGBoost: https://github.com/dmlc/xgboost
- RGF: https://github.com/baidu/fast_rgf
点击率预估
Criteo Display Advertising Challenge
- 任务名称:Criteo Display Advertising Challenge
- 任务详情:经典的点击率预估比赛。该比赛中提供了 7 天的训练数据,1 天的测试数据。其中有 13 个整数特征,26 个类别特征,均脱敏,因此无法知道具体特征含义。
- 获奖方案
- 常用工具
- ▲ Vowpal Wabbit: https://github.com/JohnLangford/vowpal_wabbit
- ▲ XGBoost: https://github.com/dmlc/xgboost
- ▲ LIBFFM: http://www.csie.ntu.edu.tw/~r01922136/libffm/
Avazu Click-Through Rate Prediction
- 任务名称:Avazu Click-Through Rate Prediction
- 任务详情:点击率预估比赛。提供了 10 天的训练数据,1 天的测试数据,并且提供时间,banner 位置,site, app, device 特征等,8个脱敏类别特征。
- 获奖方案
- 常用工具
- ▲ LIBFFM: http://www.csie.ntu.edu.tw/~r01922136/libffm/
- ▲ XGBoost: https://github.com/dmlc/xgboost
智能体
知识问答助手
开源项目和产品:
- 通义点金,针对金融场景,打造了业界首个基于multi-agent框架的金融产品,能够分析事件,绘制表格,查询资讯,研究财报,深度对话等;
- FinGLM,基于GLM模型针对金融财报问答场景构建的对话智能系统;
- FinGPT,开源金融场景GPT框架,包括底层数据支持,模型训练,到上层应用。
天池2023博金大模型挑战赛
【2024-1-15】天池2023博金大模型挑战赛总结
- 赛题类型:知识问答、RAG、NL2SQL
- 赛题任务:构建通用知识问答方案,可以进行文本理解和数据查询
- 地址
一个智能体能根据用户需求进行意图识别和决策。本次大赛的赛题虽为单一,但融合了数据查询与文本理解两大任务,充分体现了Agent核心思想:根据不确定输入,判断用户意图,并调用相应服务或功能生成答案。
以“通义千问金融大模型”或“通义千问7B模型”(不限制pretrain和chat)作为基础大模型,可以结合多个模型,共同创建一个问答系统。可以采用Prompt Engineering方法,也可以使用外部数据对模型进行微调。
数据查询题挑战
- 任务目标:使用通义千问金融大模型或通义千问7B模型,根据用户问题进行高准确率的查询。
- 技术难题:处理多表之间的复杂关联,如 理解基金股票持仓明细与A股日行情表的连接,并确保查询的高准确性。
文本理解题挑战
- 任务目标:对长文本进行细致检索与解读,高效提取关键信息。
- 技术难题:处理长文本的复杂结构,确保信息完整性。对超长文本,选手需合理分块,并从文档分块中准确提炼答案。
优胜方案总结
- FinQwen
- FinQwen TOP 7 做法
- FinQwen: 致力于构建一个开放、稳定、高质量的金融大模型项目,基于大模型搭建金融场景智能问答系统,利用开源开放来促进「AI+金融」
数据集:区间为2019年至2021年
- 基金基本信息
- 基金股票持仓明细
- 基金债券持仓明细
- 基金可转债持仓明细
- 基金日行情表
- A股票日行情表
- 港股票日行情表
- A股公司行业划分表
- 基金规模变动表
- 基金份额持有人结构
qwen模型更新:
- 扩展金融行业词表;
- 增量训练行业金融200B规模,涵盖中英文财报、研报、新闻、书籍、论坛等多种类型数据;
- 训练上下文扩展到16K,借助 NTK 和 LogN 等技术,推理长度可以扩展到64K;
字节 AutoKaggle
【2024-11-25】大幅降低数据科学门槛!豆包大模型团队开源 AutoKaggle,端到端解决数据处理
字节跳动豆包大模型团队与 M-A-P 社区于提出 AutoKaggle ,为数据科学家提供了一个端到端数据处理解决方案,帮助简化和优化日常数据科学工作流程的同时,极大降低数据科学的门槛,可帮助更多没有相关背景的使用者进行有价值的探索。
- 相关评估中,AutoKaggle 性能表现超出人类平均水平。
AutoKaggle 通过构建一个多智能体(Agent)的工作流,以提高逻辑复杂的数据科学任务中间决策步骤的可解释性与透明性,并保持优秀性能及易用性,以降低理解难度和使用门槛。团队认为,AutoKaggle 可系统地解决数据科学任务的复杂问题,保证代码鲁棒、正确地生成。
-
对 8 个 Kaggle 竞赛数据集的评估中,AutoKaggle 的有效提交率达到 85% ,综合评分为 0.82(满分为 1),超过了在 MLE-Bench 中表现优秀的 AIDE 框架,展现了其在复杂数据科学任务中的高效性和广泛适应性,性能超过人类平均水平
- 论文: AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
- 代码链接:AutoKaggle
- 成果展示页:AutoKaggle
kaggle 要解决的问题
- 对整个任务的抽象和多智能体协作、迭代调试和单元测试、使用复杂的机器学习知识、全面的报告。
架构设计
- AutoKaggle 核心:基于阶段的多智能体推理,通过对竞赛任务的抽象,将复杂数据科学问题转化为可泛化的
工作流。由两套组件来完成这个任务:多阶段的工作流及多智能体。 - 数据科学解题过程分为六个关键阶段:背景理解、初步探索性数据分析、数据清洗、深入探索性数据分析、特征工程以及模型构建、验证和预测。
- 结构化设计提供了清晰的问题解决路径,确保各个方面都得到系统和全面的处理。
- 定义好每个阶段需要解决的问题后,设计对应的智能体以完成不同阶段任务,分别为 Reader、Planner、Developer、Reviewer 和 Summarizer 。
- 这些智能体在工作流程中,分别承担协同分析问题、制定策略、实施解决方案、审查结果并生成综合报告的角色。
多智能体协作方式不仅提高了任务完成效率,还增强了系统灵活性和适应性,使得 AutoKaggle 能够应对各种复杂的数据科学挑战。
重要模块之代码开发模块
- 架构之内,Developer 模块更复杂,也更值得分析。团队通过迭代开发与测试,构建了一个自适应、鲁棒的数据科学代码生成系统。Developer 会基于当前状态、Planner 提供的策略和上下文做初始代码生成。
- 之后,Developer 进入迭代的调试和测试过程:
- 1)运行生产代码,如果有错误,则送入调试工具。
- 2)代码调试工具基于源代码和报错信息修改代码。
- 3)单元测试生成的代码,通过多次代码执行、智能调试和全面单元测试,实现了对复杂研发过程的精准控制。
Kaggle 竞赛中,单纯确保代码无错误运行,远非充分条件。竞赛问题涉及复杂数据处理和精密算法,其中隐藏的细微逻辑差错往往对最终结果产生决定性影响。
单元测试不仅需要验证代码的形式正确,更要深入审视其是否完全符合预期的逻辑和性能标准。 为降低这种潜在风险,必须对每个开发阶段进行极其细致的单元测试设计,全面覆盖常规场景与边缘情况。
该方法的核心优势在于:动态捕获潜在错误、实时修正代码逻辑、预防错误传播,并在最小化人工干预的前提下,保证了代码的正确性和一致性。由于引入了自我修复和持续优化机制,能显著提升代码生成水平。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
