长文本创作
问题
长文本创作的本质是多轮对话
传统AI写作模型,如基于Transformer的GPT系列,虽然在短文本生成方面表现出色,但在处理长文本时,往往会遇到“上下文遗忘”的问题,导致文章前后逻辑不一致,主题偏移。
窗口扩大
思考
知乎专题
无限上下文又不是无限显存和无限算力
- transfomer attention机制中,越靠前的token对新token的预测的影响越小,这个问题解决了吗?
- 无限上下文固然好,但是上下文中可能包含很多无用的信息(比如过时的政策、法律等),是否支持删除上下文的某些信息?
- 如果第2点是支持的话,怎么删?由LLM自己去删吗?还是人类手动去删?删的标准是什么?
作者:卡卡罗特
RAG有意义且无法替代。
- 首先,无限上下文的LLM 指《Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention》论文。实际上所谓的无限上下文LLM也会有信息损失,本质上也是一种RAG方法。只是这个RAG不是在自然语言粒度(llm的输入),而是在QKV矩阵的粒度(LLM的中间向量)去做了召回。
- 其次,最近一年,LLM上下文长度有了非常长的扩展,从早期的4096个token到最近kimi chat的200万token,因此很多人就认为LLM不需要RAG了。实际上这个想法其实是错误的。
- RAG的本质是包含两个步骤,一是召回(检索),二是推理。大部分人以为RAG只是服务于私有知识库,然而RAG的应用是可以很广泛的。
- 例如设计一个带感情色彩的聊天机器人,这个聊天机器人回答的语气的示例(也就是few shot learning)可通过RAG召回,在这个例子中召回的是示例。
- 再比如,让LLM使用外部工具,外部工具可能特别的多,那么可以让RAG来帮忙对工具进行初步的召回和检索,原因是过多的信息(例如塞入全部工具的描述)会增加LLM的失误率,使得容错率降低。
- 最后,再以langchain的daniel在一个月前的分享来进一步说明为什么现在的长下文的LLM无法替代RAG。
大海捞针实验(Needle in a haystack),测试LLM在长下文中的检索和推理能力。
- 在一段长文本(大海)中随机插入一些短文本(针)。
- 将这段文本输入给LLM,向LLM提问捞出来这些针。
下一个token预测方式训练存在偏差(bias),因为训练语料中,下一个token预测的真实值大部分和附近的token有关,这导致LLM会倾向于更多的关注最近(Recency)的token,而容易忽略前面的token,论文中将这种现象称为Recency Bias。
无限上下文 和 RAG两码事。
- RAG解决私有数据和LLM知识的鸿沟,弥补LLM幻觉的问题。把公司数据塞给LLM然后再问问题吧?
RAG 作用:
- 解决大语言模型在某些小众领域知识不足的问题。
- 解决大语言模型的幻觉问题。
- 解决大语言模型无法实时更新数据的问题。
- 解决隐私保护的问题(某些公司出于安全考虑,并不想让大模型训练自家的行业机密数据)。
无限上下文的LLM 并不能解决
数学原理
- attention 计算量是seq_len的平方。因此两个选择:
- 真的1m context window。一般的模型的上下文比如是2K。那么你的计算量就会是一般模型的500 x 500 = 25万倍。
- fake infinite context window。很多文章,比如加窗的attention,ringbuffer,以及通过模型压缩memory等等。但是这样的效果,和你RAG到底谁好,至少RAG没压缩信息,理论上RAG的准确率也肯定会更高。 实际上, 无限上下文在attention主导的模型里没啥意义。
作者:higgaraa
窗口如何跃迁到10m
2024-2025年,主流模型上下文窗口从128K跃升至1M甚至10M token。
- Llama 4 Scout支持10M,Gemini 1.5 Pro支持1M(beta 2M),GPT-4.1全线1M。
这一跳变靠算法、工程与数据的组合突破。
(1)技术一:位置编码外推(RoPE Scaling)
Transformer 用旋转位置编码(RoPE)标记token顺序。模型训练时只见过4K-32K长度的序列,给它1M的输入,位置编码超出训练范围,模型会”迷失”。
YaRN(Yarn)等缩放方法解决了这个问题:通过非线性拉伸RoPE的旋转角度,让模型见过的位置编码范围”覆盖”更长序列。训练时只需少量长文本数据(如10亿token),即可将窗口从128K扩展到4M,且不需要重新训练整个模型。
(2) 技术二:注意力计算优化
标准注意力复杂度O(n²),处理1M token需要10¹²次运算,不现实。
- FlashAttention:通过IO感知的精确注意力计算,避免频繁读写HBM,将长序列注意力速度提升数倍
- 稀疏注意力(如LongLoRA的移位短注意力):将长序列拆分为重叠短窗口(如512 tokens),窗口内计算注意力,窗口间通过滑动机制传递信息。复杂度从O(n²)降至O(n·w)
(3) 技术三:分布式训练(上下文并行)
单GPU显存放不下1M token的中间激活值。上下文并行将序列切分到多GPU,每块GPU只存一个片段。注意力计算时,GPU之间通过All-Gather通信交换KV。英伟达方案训练1M序列时使用TP=8、CP=4,256张H100只需5小时。
(4)长文本数据配比
训练数据不是越长越好。
- 研究发现:数据长度应多样化(4K、8K、16K、128K混合),而非全部压到目标长度。检索能力(在长文中找关键信息)比推理能力更关键,需要更多检索型数据。
- 工程落地:从训练到推理
训练好后,推理还需优化:
- KV Cache显存优化:量化到INT8,显存减半
- vLLM PagedAttention:分页存储,消除碎片
- 长上下文定价策略:部分厂商(Anthropic、Google)请求超过200K token时,所有token单价翻倍
LongForm
论文《The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction》介绍了基于 C4 和 Wikipedia 等已有语料库的人工创作文档集合以及这些文档的指令,从而创建了一个适合长文本生成的指令调优数据集。
Re^3
【2023-2-14】Generating Longer Stories With Recursive Reprompting and Revision, Meta 田渊栋写小说
- We consider the problem of automatically generating longer stories of over two thousand words. Compared to prior work on shorter stories, long-range plot coherence and relevance are more central challenges here. We propose the
Recursive Reprompting and Revisionframework ($Re^3$) to address these challenges
WriteHERE
WriteHERE 引入异质递归规划(Heterogeneous Recursive Planning)技术,有效地解决了这个问题。
异质递归规划核心思想:
- 将写作任务分解为
检索(Retrieval)、推理(Reasoning)和写作(Composition)三种异构任务。
每种任务具有不同的信息流模式,例如
- 检索:从外部获取信息
- 推理:进行逻辑分析
- 写作:生成文本
这些任务之间通过有向无环图(DAG)建立依赖关系,系统根据任务状态动态调整执行顺序,确保任务按逻辑顺序完成。
这种任务分解和动态调度的方式,使 WriteHERE 能够更好地管理长文本的结构和内容,保持文章的连贯性和一致性。
同时,WriteHERE 还支持开发者自由调用异构Agent,这意味着用户可以根据自己的需求,定制不同的写作Agent,进一步提升写作效率和质量。
WriteHERE 核心功能:
- 单次生成超长文本:WriteHERE 支持生成超过4万字、100页的专业报告,能够满足复杂写作需求。相比于传统的AI写作模型,WriteHERE在长文本生成方面具有显著优势。
- 创意与技术内容生成:WriteHERE 不仅可以生成创意故事、小说等文学作品,还可以生成技术报告、行业分析等专业文档。这使得WriteHERE具有广泛的应用前景。
- 动态信息检索:在写作过程中,WriteHERE能够实时搜索相关信息,并将这些信息整合到文章中。这大大提高了写作效率和质量。
- 风格一致性:WriteHERE能够保持一致的写作风格和内容连贯性,避免了传统AI写作模型中常见的风格漂移问题。
- 写作过程可视化:WriteHERE基于任务依赖图展示写作流程,使得用户可以清晰地了解文章的结构和生成过程。
WriteHERE 技术原理
- 异构任务分解:WriteHERE将写作过程解构为检索、推理和写作三种异构任务。每种任务具有独特的信息流模式,例如检索任务从外部获取信息,推理任务进行逻辑分析,写作任务生成文本。任务基于递归分解为子任务,直至分解为可直接执行的原子任务。
- 检索任务:负责从外部知识库或互联网上检索相关信息。检索任务可以使用各种信息检索技术,如关键词搜索、语义搜索等。检索到的信息将作为推理任务和写作任务的输入。
- 推理任务:负责对检索到的信息进行逻辑分析和推理。推理任务可以使用各种推理技术,如知识图谱推理、逻辑推理等。推理结果将作为写作任务的输入。
- 写作任务:负责根据推理结果生成文本。写作任务可以使用各种自然语言生成技术,如基于Transformer的语言模型、基于规则的生成方法等。
- 状态化层次调度算法:任务依赖关系用有向无环图(DAG)表示,每个任务具有激活、挂起、静默三种状态。系统根据任务状态动态调整执行顺序,确保任务按逻辑顺序完成,支持实时反馈和调整。
- 激活状态:表示任务正在执行中。
- 挂起状态:表示任务已暂停执行,等待其他任务完成后才能继续执行。
- 静默状态:表示任务已完成或尚未开始执行。
- 系统会根据任务之间的依赖关系和任务状态,动态调整任务的执行顺序,确保任务按逻辑顺序完成。例如,如果一个写作任务依赖于一个检索任务的结果,那么系统会先执行检索任务,待检索任务完成后,再执行写作任务。
- 数学形式化框架:将写作系统抽象为五元组,Agent内核、内部记忆、外部数据库、工作空间和输入输出接口。基于数学形式化定义写作规划问题,确保每个任务的可执行性和最终目标的达成。
- Agent内核:负责执行各种任务,如检索、推理和写作。
- 内部记忆:用于存储Agent的知识和经验。
- 外部数据库:用于存储外部信息,如知识库、互联网等。
- 工作空间:用于存储任务的中间结果。
- 输入输出接口:用于与外部环境进行交互。
- 通过数学形式化定义写作规划问题,可以确保每个任务的可执行性和最终目标的达成。例如,可以定义一个目标函数,用于衡量文章的质量和连贯性,然后通过优化算法,找到最优的任务执行顺序和参数配置,使得目标函数达到最大值。
WriteHERE 应用场景:
- 小说创作:生成情节完整、角色丰富的长篇小说,支持创意写作和动态调整情节。例如,可以利用WriteHERE生成一部科幻小说,让AI自动生成故事情节、人物设定和环境描写,从而大大提高创作效率。
- 技术报告:撰写结构化的技术报告,整合数据和逻辑推理。例如,可以利用WriteHERE生成一份关于人工智能技术发展趋势的报告,让AI自动检索相关数据、分析技术发展趋势,并生成结构化的报告。
- 行业分析:生成涵盖行业趋势、市场分析的专业报告。例如,可以利用WriteHERE生成一份关于新能源汽车行业的市场分析报告,让AI自动收集市场数据、分析竞争格局,并生成专业的市场分析报告。
- 学术论文:辅助撰写学术论文,整合文献并生成规范结构。例如,可以利用WriteHERE生成一篇关于深度学习算法的学术论文,让AI自动检索相关文献、分析算法原理,并生成符合学术规范的论文。
- 政策文件:撰写政策文件和白皮书,生成权威性和逻辑性强的文本。例如,可以利用WriteHERE生成一份关于环境保护政策的白皮书,让AI自动收集相关数据、分析政策影响,并生成权威性和逻辑性强的政策文件。
StyleLLM Chat
通用大模型 × 文风大模型 = 多样化风格的聊天机器人
stylellm 是一个基于大语言模型(llm)的文本风格迁移(text style transfer)项目。项目利用大语言模型来学习指定文学作品的写作风格(惯用词汇、句式结构、修辞手法、人物对话等),形成了一系列特定风格的模型。
利用stylellm模型可将学习到的风格移植至其他通用文本上
- 即:输入一段原始文本,模型可对其改写,输出带有该风格特色的文本,达到文字修饰、润色或风格模仿的效果。
StyleLLM Chat利用通用大模型的通用能力(世界知识、逻辑推理、对话问答)和文风大模型(StyleLLM) 的语言风格转化能力,探索实现多样化风格的聊天机器人。
利用StyleLLM模型对ChatGPT等通用大模型的输出进行风格改写,可改变对话风格单一、AI味过重的状况。
功能
- 集成 OpenAI API,填写api_key后可以调用ChatGPT对话能力。
- 集成 Qwen模型,支持调用Qwen本地化模型对话能力。
- 集成 stylellm_models,支持对ChatGPT或Qwen生成结果进行风格润色。
- 支持通过场景(scene)和角色(character)参数,控制具体风格类型。
- 如:西游记(场景)、唐僧(角色)
- 支持多轮对话。
参数
- QwenChatModel
- model_name_or_path: 对话模型名称或本地路径。可选值为Qwen1.5系列模型[查看列表],如”Qwen/Qwen1.5-7B-Chat”
- device: 对话模型使用的硬件。可选值为”cpu”, “cuda”(或用”cuda:0”, “cuda:1”指定不同显卡)
- scene, character :对话模型人设。设置后对话模型将扮演”scene中的character”。默认为None,即不使用角色扮演,保持对话模型原有的AI助理人设。
- ChatGPTModel
- model: 对话模型名称。可选值为GPT系列模型,如”gpt-3.5-turbo”, “gpt-4-turbo”
- api_key: openai api key
- scene, character :对话模型人设。设置后对话模型将扮演”scene中的character”。默认为None,即不使用角色扮演,保持对话模型原有的AI助理人设。
- StyleModel
- model_name_or_path: 风格模型名称或本地路径。可选值为stylellm系列模型[查看列表],如”stylellm/HongLouMeng-6b”
- device: 风格模型使用的硬件。可选值为”cpu”, “cuda”(或用”cuda:0”, “cuda:1”指定不同显卡)
- scene, character :风格类型。设置后风格模型将以”scene中的character”说话风格输出
数据
数据集已发布:dataset
RM 数据示例
{
"instruction":"四健将打扫完毕,然后开始休息,最后进行祈祷和礼拜。",
"input":"",
"output":[
"四健将打扫安歇叩头礼拜毕。",
"四健将打扫已毕,歇息片时,又拜祷礼拜。"
]
},
{
"instruction":"大圣慢慢地走出宫门。",
"input":"",
"output":[
"那大圣,却才出宫。",
"那大圣慢慢出宫门。"
]
}
训练
训练使用
- 01-ai/Yi: 模型底座
- hiyouga/LLaMA-Factory: 训练框架
参考:
训练步骤
- 准备平行数据集
- 准备希望学习风格的小说文本。
- 将小说的全文分割成句子。
- 使用LLM,如 GPT来修改每个句子的风格。输入提示 “change the style of this sentence. \ninput: … \noutput:”,即可得到一个风格不同但含义相同的新句子。
- 将新句子与原小说句子配对,构成一个平行数据集。
- SFT
- 使用平行数据集训练 SFT 模型,输入是新句子,输出为原句子。
- RM
- 使用不同的checkpoint和温度采样多个 SFT 模型输出。
- 对输出进行排名,构成一个偏好数据集。
- 使用偏好数据集训练 RM 模型。
- PPO
- 使用 SFT 和 RM 模型训练最终的 PPO 模型。
代码
Huggingface
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stylellm/SanGuoYanYi-6b")
model = AutoModelForCausalLM.from_pretrained("stylellm/SanGuoYanYi-6b").eval()
messages = [{"role": "user", "content": "严冬时节,鹅毛一样的大雪片在天空中到处飞舞着,有一个王后坐在王宫里的一扇窗子边,正在为她的女儿做针线活儿,寒风卷着雪片飘进了窗子,乌木窗台上飘落了不少雪花。"}]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids, do_sample=False, repetition_penalty=1.2)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
print("Output:", response)
# Output: 时值隆冬,大雪压境,王后坐于王宫之窗下,正与女作绣,寒风入室,吹落乌木窗台之雪。
Gradio
from stylellm_chat import StyleLLMChat, ChatGPTModel, StyleModel
# 无风格化
sc = StyleLLMChat(
chat_model=ChatGPTModel(api_key=api_key),
style_model=StyleModel()
)
# 风格化
sc = StyleLLMChat(
chat_model=ChatGPTModel(scene="三国演义", character="孔明", api_key=api_key),
style_model=StyleModel(scene="三国演义", character="孔明", device="cuda")
)
# ------ 无风格 -------
print(sc.chat("今天天气真不错"))
# 是的,好天气可以让人心情愉快。你有什么计划要在这样美好的天气里做吗?
print(sc.chat("你们天天一起玩,我来了也不理我"))
# 可能是因为他们已经形成了群体,你的加入打破了原有的平衡,需要时间去接纳你。试着主动和他们交流,参与他们的活动,慢慢地就会融入他们的圈子中。也可以尝试和他们私下聊聊,表达你的感受和需求,看看能否得到理解和支持。如果他们还是不理你,那可能他们不是真正的朋友,可以考虑寻找新的朋友圈子。
# ------ 有风格 -------
print(sc.chat("今天天气真不错"))
# 然也!今日天色甚佳。吾等游于清风之阳,其乐无穷。愿公享此良辰美景,更当奋勉图功。
print(sc.chat("你们天天一起玩,我来了也不理我"))
# 某乃儒生,不能常侍左右,倘有差遣,乞赐驱使。
arbois-novel
arbois-novel 的ai小说创作工具,从构思到成文都全流程可以跑通
案例
讲稿撰写
讲稿代写任务要点:
- 1 遵循讲稿主题
- 2 文章逻辑合理
- 3 引用数据正确
- 4 语言表述符合指定风格
分析
- 1 或 4 问题不大
- 2 需要结合主题、外部数据设计文章框架,逻辑严密
- 3 涉及知识库查询、在线搜索,基本信息常规RAG能搞定,但一旦有总结、对比、深度分析,就触发“关联≠因果”的困境,此时,得用更高级的RAG形式,结合agent设计模式
以上这些,无法在一次llm调用中完成
写小说
【2023-5-30】RecurrentGPT(输出不受限)
【2023-5-30】ChatGPT能写长篇小说了,ETH提出RecurrentGPT实现交互式超长文本
- 苏黎世联邦理工和波形智能的团队发布了 RecurrentGPT,一种让大语言模型 (如 ChatGPT 等) 能够模拟 RNN/LSTM,通过 Recurrent Prompting 来实现交互式超长文本生成,让利用 ChatGPT 进行长篇小说创作成为了可能。
- 论文地址
- 项目地址
- 在线 Demo: 长篇小说写作, 交互式小说
Transformer 大语言模型最明显的限制之一: 输入和输出的长度限制。
- 虽然输入端的长度限制可以通过 VectorDB 等方式缓解
- 输出内容的长度限制始终是长内容生成的关键障碍。
为解决这一问题,过去很多研究试图使用基于向量化的 State 或 Memory 来让 Transformer 可以进行循环计算。这样的方法虽然在长文本建模上展现了一定的优势,但是却要求使用者拥有并可以修改模型的结构和参数,这在目前闭源模型遥遥领先的大语言模型时代中是不符合实际的。
RecurrentGPT 则另辟蹊径,利用大语言模型进行交互式长文本生成的首个成功实践。它利用 ChatGPT 等大语言模型理解自然语言指令的能力,通过自然语言模拟了循环神经网络(RNNs)的循环计算机制。
- 每一个时间步中,RecurrentGPT 会接收上一个时间步生成的内容、最近生成内容的摘要(短期记忆),历史生成内容中和当前时间步最相关的内容 (长期记忆),以及一个对下一步生成内容的梗概。RecurrentGPT 根据这些内容生成一段内容,更新其长短时记忆,并最后生成几个对下一个时间步中生成内容的规划,并将当前时间步的输出作为下一个时间步的输入。这样的循环计算机制打破了常规Transformer 模型在生成长篇文本方面的限制,从而实现任意长度文本的生成,而不遗忘过去的信息。
【2025-7-14】DeepWriter
【2025-7-14】上海 AI Lab 和北大 推出 DeepWriter: 基于本地资料的多模态写作助手
基于llm的主流方案主要有两类:
- RAG ,虽然可以引入外部知识,但在生成长篇报告时常出现上下文不一致的问题,且难以实现精准的资料引用(citation),尤其在处理图表等多模态内容时效果也不好;
- llm+search engine,但由于网络内容质量参差不齐,最终生成结果往往缺乏可信度与专业性。
本文提出一种新的解决方案:基于本地数据集构建一个具备多模态写作能力并且严格依据资料事实的垂直领域写作助手。
DeepWriter,一个面向金融、法律等专业/垂直领域的报告生成系统,特点是基于本地文件(不联网搜索)、具备多模态写作能力并且严格依据资料事实。 简单来说,DeepWriter 包含本地文件处理和在线报告生成两个模块:在离线阶段,系统对非结构化文档(主要是pdf文件)进行解析与分块(chunk),提取文本、表格、图像等内容,并构建三层级知识库(文档-页面-chunk)进行知识管理和存储;在线阶段,系统接收query后,依次执行任务拆解、大纲生成、分段写作、图文融合与细粒度引用,最终生成一篇结构清晰、语义连贯、信息可溯的专业报告。总的来说,DeepWriter适合对内容准确性要求高、图文信息丰富的长文写作任务。
DeepWriter框架
DeepWriter结构很清晰,包含两个模块:
- 本地文件处理:主要是pdf文件,进行结构化解析,提取出文本、表格、图像等多模态内容,并结合元数据构建三层级知识表示
- 在线生成阶段:根据query,首先对query重写与任务拆解,明确生成目标,然后通过大纲规划、内容聚类与分段写作、图文内容的匹配与位置优化、细粒度引用
系统设置
- 使用MinerU处理pdf文件
- 向量化模型:gme-Qwen2-VL-2B-Instruct
- 向量数据库:Milvus
- 生成图和表格caption模型:Qwen2.5-VL 7B
- 执行写作任务的模型:Qwen2-7B
- 验证集:WTR (World Trade Report)
- llm-as-a-judge 模型:Prometheus2-7B
文档问答
RAGFlow
资料
知识图谱
0.16.0 版本引入知识图谱功能,开启后,RAGFlow 会在当前知识库的分块上构建知识图谱,构建步骤位于数据抽取和索引之间
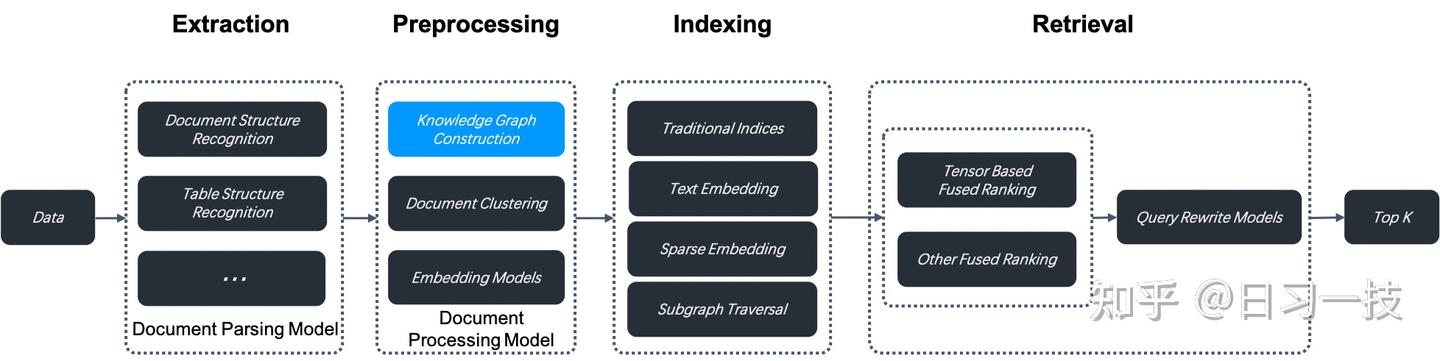
构建知识图谱将消耗大量 token 和时间。
知识图谱在涉及嵌套逻辑的多跳问答中尤其有用,当你在对书籍或具有复杂实体和关系的作品进行问答时,知识图谱的表现优于传统的抽取方法。
RAGFlow 能在复杂多跳问答场景中表现得更加出色,特别是在分析具有复杂关系和实体的文档时。

详见站内专题:大模型应用:RAG
其他类似工作流产品详见站内专题:大模型开发工具
langextract
【2025-7-31?】谷歌最新开源 文本结构化之光
谷歌开源 langextract 库,用大语言模型从非结构化文本中提取结构化信息的 Python 库,具备精确的源定位和交互式可视化功能。
- github langextract
功能
【功能】
- 1️⃣精确源定位: 将每个提取结果映射到源文本的确切位置,通过可视化高亮显示实现轻松追踪和验证
- 2️⃣可靠的结构化输出: 基于少样本示例强制执行一致的输出模式,利用 Gemini 等支持模型的受控生成功
- 3️⃣长文档优化: 使用优化的文本分块、并行处理和多轮传递,克服”大海捞针”的挑战,实现更高的召回
- 4️⃣领域适应性: 仅使用少量示例即可为任何领域定义提取任务。无需微调模型即可适应您的需
- 5️⃣交互式可视化: 生成交互式 HTML 可视化,通过直观的高亮显示在上下文中查看提取的实
- 6️⃣开源: 社区驱动的开发,完全透明。
应用
【应用】
- 医疗健康: 从临床记录和医疗报告中提取关键信息,同时保持源可追溯性。
- 法律文档: 从合同和法律文件中提取条款、日期、当事人和其他信息。
- 研究分析: 分析文献、从学术论文中提取实体,并结构化无组织的文本数据。
- 商业智能: 将商业文档转换为结构化数据,用于分析和决策制定。
使用
安装
pip install langextract
用法
- 定义任务
- 创建引导提取的提示词和示例
import langextract as lx
# 定义提取规则
prompt = "从文本中提取角色和情感"
# 提供高质量示例
examples = [
lx.data.ExampleData(
text="ROMEO: But soft! What light...",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO"
)
]
)
]
- 执行提取
- 使用定义的任务处理文本
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)
可视化结果
- 生成交互式 HTML 可视化
# 保存结果
lx.io.save_annotated_documents(
[result],
output_name="results.jsonl"
)
# 生成可视化
html_content = lx.visualize("results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
腾讯 WeKnora
WeKnora:基于大语言模型的文档智能解析与语义问答框架
WeKnora 是腾讯开源的一套文档理解与语义检索系统,专为复杂结构、多源异构的文档场景打造。
模块化RAG 企业级问答
- 插拔式接入本地大模型与向量库,打通多模态文档-召回-生成全流程构建自主知识引擎。
该系统以 RAG(Retrieval-Augmented Generation)为核心机制,通过文档结构化解析、语义嵌入、混合检索与上下文感知生成,构建出一整套高效、可控的文档问答流程。
WeKnora 功能
- 支持多种文档格式的智能解析,包括 PDF、Word、Markdown、纯文本和图像(如扫描件、截图等),可自动识别图文内容、提取结构信息,并进行统一的语义建模。
- 兼容本地大模型和 API 服务,用户灵活选择推理方式与模型来源(如 Qwen、DeepSeek 等)。
- 检索方面,WeKnora 支持关键词匹配(BM25)、向量检索(Dense Retrieval)、知识图谱增强(GraphRAG)等策略,可自由组合,实现更高精度的内容召回与排序。
- 支持提示词模板与上下文窗口配置,使问答过程更可控,并支持多轮对话与链式推理。
架构设计

WeKnora 提供可视化的端到端测试工具,用户可对召回率、回答覆盖率、BLEU、ROUGE 等主流指标进行评估,从而快速优化检索与生成效果。 开发者可通过标准 RESTful API 或 Web UI 接入系统,也可使用官方提供的 Docker 镜像进行本地或私有化部署,确保数据安全与运行可控性。
核心优势
- 全面的格式支持:轻松解析 PDF、Word、图像等文档,支持 OCR 与图文混排。
- 模块化架构设计:从文档解析到大模型推理,每一环节均可灵活替换或定制。
- 混合检索策略:结合关键词、向量与图谱,实现高效精准的信息召回。
- 上下文感知问答:支持语义理解、多轮交互与复杂提示词配置。
- 可视化测试评估:内置评测工具,助力调试与优化生成效果。
- 灵活部署能力:支持本地运行、私有云部署与容器化部署。
- 即用即测的体验:直观的用户界面和标准化 API,降低使用门槛。
UI 功能
- 知识库管理: 支持拖拽上传各类文档,自动识别文档结构并提取核心知识,建立索引。系统清晰展示处理进度和文档状态,实现高效的知识库管理。
- 知识图谱构建: 将文档转化为知识图谱,展示文档中不同段落之间的关联关系。开启知识图谱功能后,系统会分析并构建文档内部的语义关联网络,不仅帮助用户理解文档内容,还为索引和检索提供结构化支撑,提升检索结果的相关性和广度。
- 图文问答
- 智能问答能力可无缝集成到
公众号、小程序等微信场景中,提升用户交互体验
开源,可本地部署
① 克隆代码仓库
# 克隆主仓库
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
② 配置环境变量
# 复制示例配置文件
cp .env.example .env
# 编辑 .env,填入对应配置信息
# 所有变量说明详见 .env.example 注释
③ 启动服务
# 启动全部服务(含 Ollama 与后端容器)
./scripts/start_all.sh
# 或
make start-all
# ④ 停止服务
./scripts/start_all.sh --stop
# 或
make stop-all
🌐 服务访问地址
启动成功后,可访问以下地址:
- Web UI:http://localhost
- 后端 API:http://localhost:8080
- 链路追踪(Jaeger):http://localhost:16686
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
