信息抽取
【2023-9-19】阿里达摩院 信息抽取:从 PLM 到 LLM 的变迁
信息抽取介绍
信息抽取是自然语言处理(NLP)中一个非常传统且应用广泛的任务。它包含了许多小类的子任务,例如:
实体抽取(命名实体识别),识别文本中的人名、地名、组织名等。- 苹果公司CEO蒂姆库克的首部传记
细粒度的实体分类,比如 对于像特朗普这样的实体,在一些任务场景里,不仅要确定他是一个人,还要确定他是政治家,甚至是总统。实体链接:不仅要识别文本中片段,还要对标准化处理。例如,考虑姚明这个实体,可能存在多种含义,可能是一位作曲家,也可能是一位篮球明星。在给定上下文的情况下,要考虑如何更好地进行实体链接。关系抽取-
事件抽取 
信息抽取应用
信息抽取服务的应用范围非常广泛,包括 C 端、B 端和 G 端。
- C端,查询分析、文档分析和对话分析等。
- B端,结构化医疗信息、地址结构化和金融财报理解等。
- G端,利用信息抽取的能力智能辅助办公。
应用
- 智能化快递单:文本粘贴到快递单页面,通过系统自动识别来填充收货人的姓名、电话号码和地址等信息
- 电商:识别用户问题、商品标题或商品详情中与电商相关的关键词,并为它们打上标签,例如品牌、品类、属性和颜色等。

信息抽取技术
实体抽取这个基础通用任务,最常见的解法:建模为序列标注任务。
- 将输出结构信息转化为
BIOES序列,然后学习输入到输出的映射来训练模型。 - 一个通用的框架是基于 transformer 与 CRF 的组合。核心思想是对文本进行编码,并将编码信息输入到 CRF 层中,以预测输出序列。
信息抽取变更
- PLM 时代的信息抽取范式
- 少样本信息抽取研发
- LLM 时代的信息抽取范式
- 基于LLM的信息抽取范式

- 首先,在 PLM 时代我们更关注通过先进的算法来不断提高性能,特别是在给定一个任务的情况下,如何突破性能的极限,以优化结果。在这个领域,检索增强范式对于知识密集型任务可能会有很大的帮助,同时也是应对刷榜场景的有力工具。
- 其次,对于标注成本高昂的小样本场景,将标注量从成千上万的级别降低到百甚至十的级别。为了实现这一目标,利用信息检索进行数据增广,同时也可以利用已有模型的知识来优化下游模型。
- 现在,进入了 LLM 时代,其中一个关键研究方向是如何更高效地进行模型定制。一方面,我们可以利用大模型的 API 来设计更优的提示,以获得更好的性能。另一方面,我们可以创建任务特定的 LLM,这些 LLM 的规模较小,因此响应时间更短。
信息抽取效果
CoNLL-2003 Benchmark 任务
- 2018年左右,已经达到了一个很高的水平,约为93%的准确率。
- 然而过去几年,将准确率从93%提升到94%~95%已经变得困难很多。
学者开始关注如何在保持相同效果的情况下,进一步减少标注量的需求。
- 以前可能需要1w条标注数据才能达到90%的准确率
- 现在将标注量减少到5000条、2000条甚至1000条?
随着技术的发展,有望提高效率,特别是在大语言模型(LLM)时代。

PLM 时代
技术线整体来讲是信息增强式的抽取技术。
- 最早,提出了一种基于隐式增强的范式,该范式在多个任务上都取得了显著效果。
- 然后,提出了一种基于检索增强的范式,特别是在短文本方面,它对信息抽取任务有明显的提升效果。
- 将这个增强范式应用于国际比赛,取得了多个项目的冠军,其中包括了 SemEval 2022国际比赛,在其中拿下了10项冠军,并且获得了 best system paper。
- 随后将这种增强的范式不仅应用到文本上,还有其他的数据形态,比如图片,相关的2篇论文已经发表
- 另外,利用这种信息注入方式在 SemEval 2023竞赛中,也拿到9个子项第一的优异成绩
- 最近刚刚获知再次获得了 best system paper award。

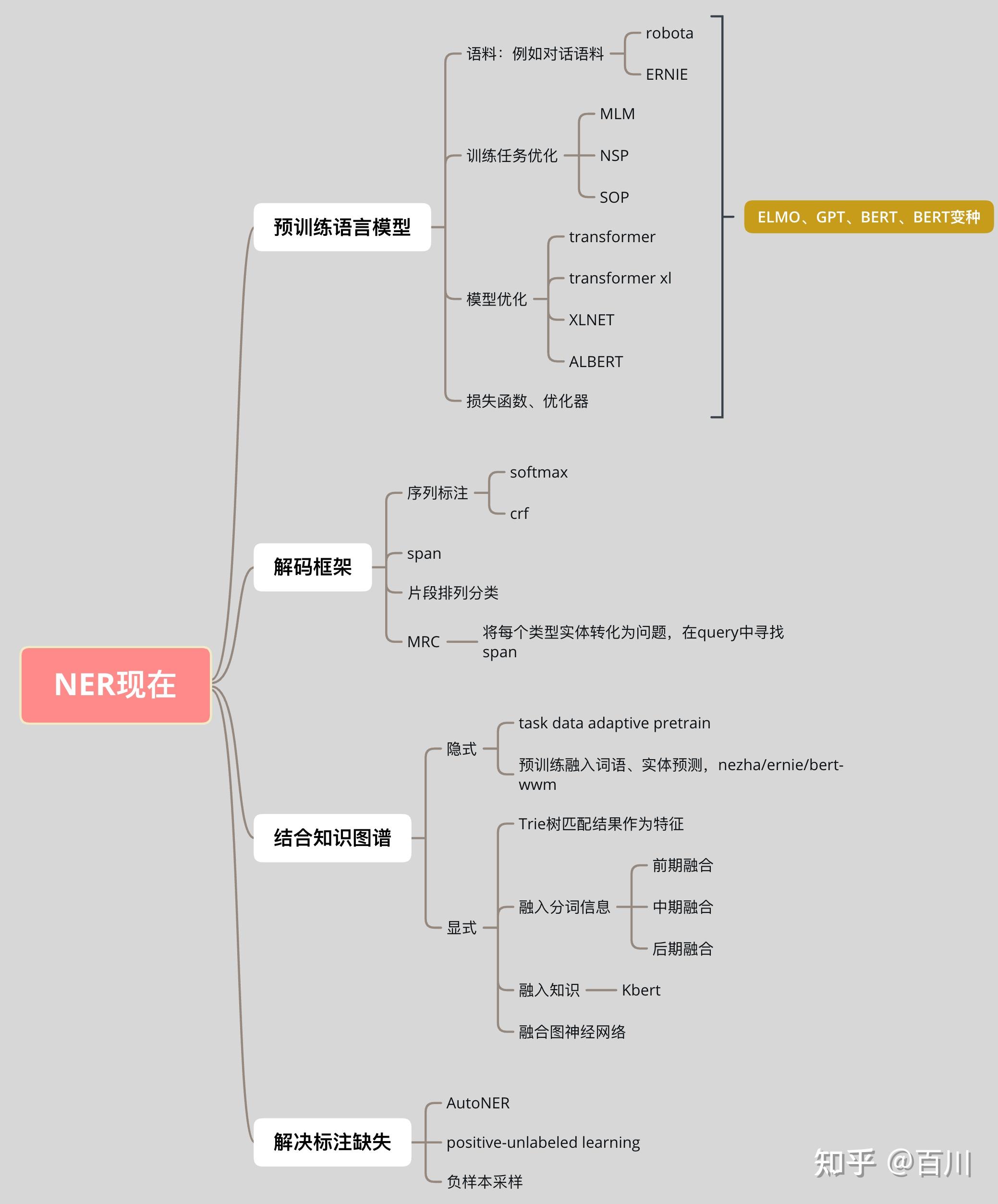
NER 命名实体识别
NER 定义
命名实体识别(NER, Named Entity Recognition),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
- 目标:识别序列中的人名、地名、组织机构名等实体。可以看做序列标注问题。
常见NER方法
NER 任务
NER 研究重点从常规的扁平命名实体识别(Flat NER)逐渐转向重叠命名实体识别(Nested/Overlapped NER)与非连续命名实体识别(Discontinuous NER)。这三类 NER 分别为:
Flat NER:抽取连续实体片段(或者包含对应的实体语义类型);Nested/Overlapped NER:抽取两个或多个实体片段之间有一部分的文字重叠;Discontinuous NER:所抽取的多个实体间存在多个片段,且片段之间不相连。
示例
- “aching in legs” 是一个扁平实体
- “aching in shoulders”是一个非连续实体,两者在“aching in”上重叠。
三种 NER 类型可概括为统一命名实体识别(Unified Named Entity Recognition,UNER)
总结

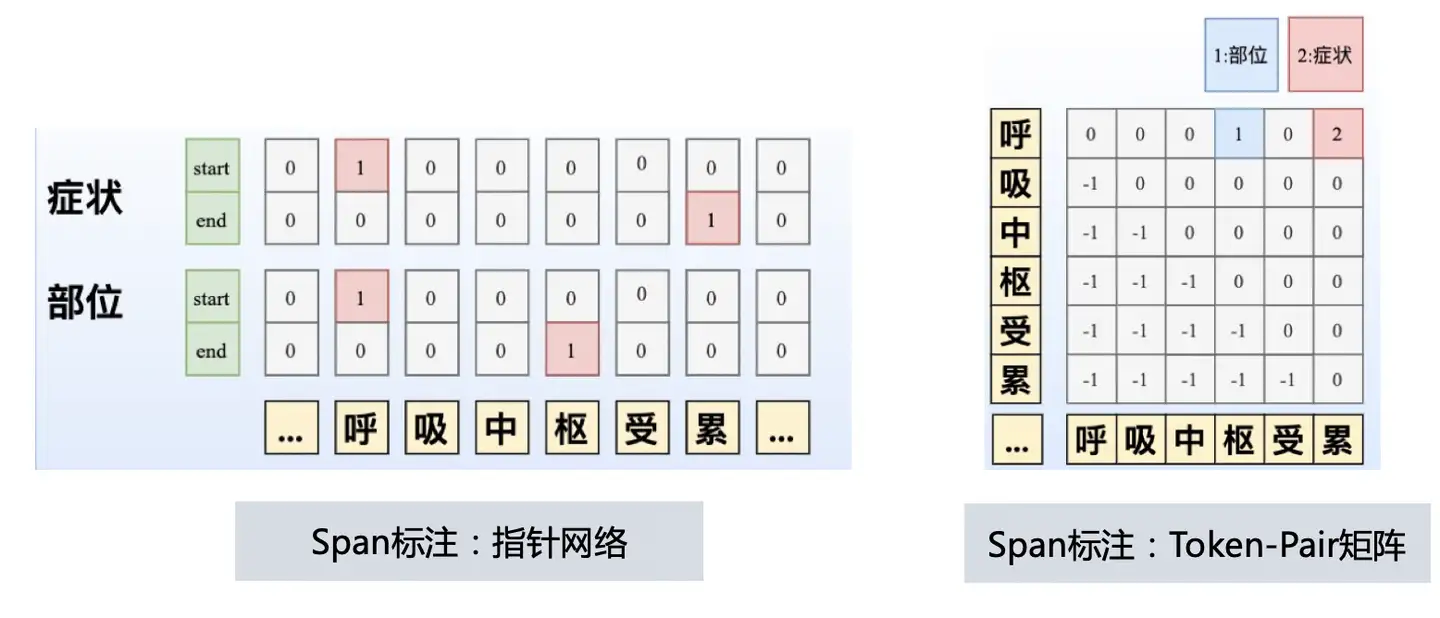
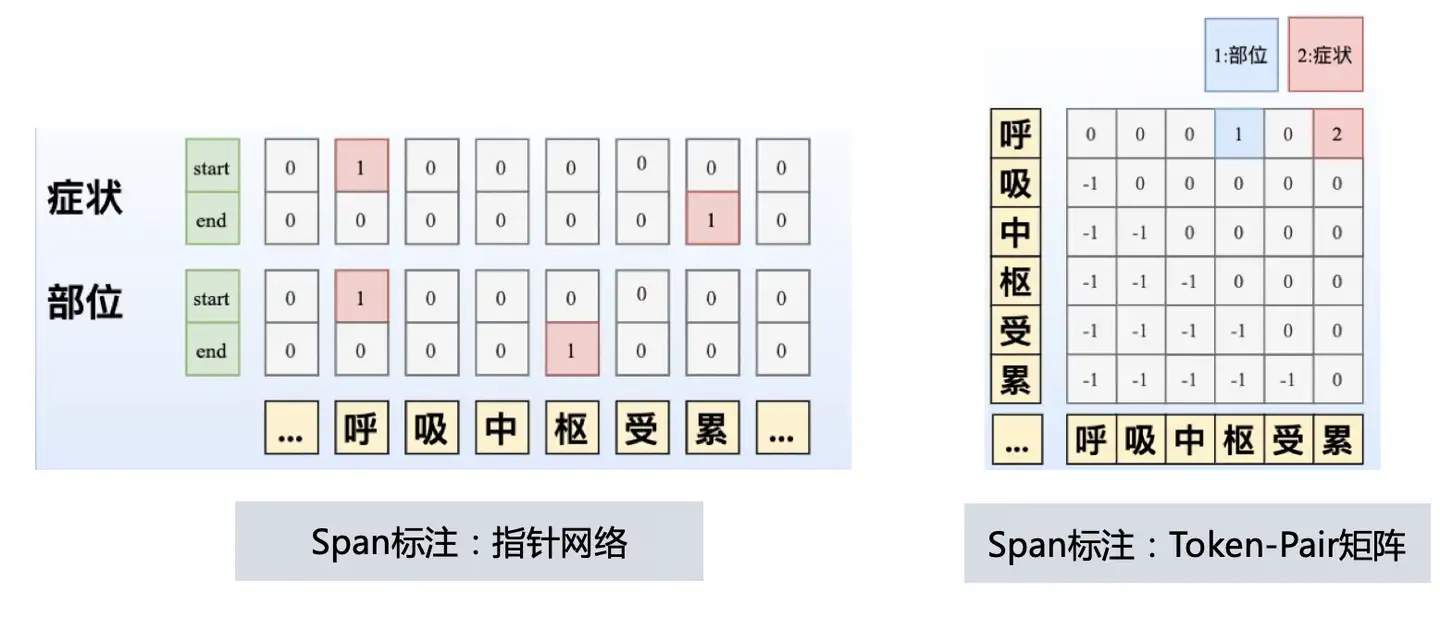
美妆场景NER,要识别商品标题中的品牌、品类、产品名,共三个实体

- 嵌套(Nested)
- 组间嵌套:如图中的“隔离妆前乳”,既属于品类,也属于产品名的一部分
- 组内嵌套:如上图的“妆前乳”,既是单独一个品类,也属于品类“隔离妆前乳”的一部分
- 不连续:
- 如图的“苏菲娜控油隔离妆前乳”是不连续的产品名,因为希望提取出的产品名是一个标准的产品名,因此中间一些无关的信息,如“限定款”不希望被抽取出来
NER 标注
NER tag 标注集
NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义为
| 标记 | 含义 |
|---|---|
| O | 这个词不是NE |
| S | 这个词单独构成一个NE |
| B | 这个词为一个NE的开始 |
| I | 这个词为一个NE的中间 |
| E | 这个词位一个NE的结尾 |
LTP中的NE 模块识别三种NE,分别如下:
| 标记 | 含义 |
|---|---|
| Nh | 人名 |
| Ni | 机构名 |
| Ns | 地名 |
- n/名词 np/人名(或nr)
ns/地名nt/机构名 nz/其它专名 - m/数词 q/量词 mq/数量词 t/时间词 f/方位词 s/处所词
- v/动词 a/形容词 d/副词 h/前接成分 k/后接成分
- i/习语 j/简称 r/代词 c/连词 p/介词 u/助词 y/语气助词
- e/叹词 o/拟声词 g/语素 w/标点 x/其它
完整版见:北大pkuseg tags.txt
序列标注模式
- 在序列标注中,我们想对一个序列的每一个元素(token)标注一个标签。一般来说,一个序列指的是一个句子,而一个元素(token)指的是句子中的一个词语或者一个字。比如信息提取问题可以认为是一个序列标注问题,如提取出会议时间、地点等。
- 不同的序列标注任务就是将目标句中的字或者词按照需求的方式标记,不同的结果取决于对样本数据的标注,一般序列的标注是要符合一定的标注标准的如(PKU数据标注规范)。
- 另外, 词性标注、分词都属于同一类问题,他们的区别主要是对序列中的token的标签标注的方式不同。
下面以命名实体识别来举例说明. 我们在进行命名实体识别时,通常对每个字进行标注。中文为单个字,英文为单词,空格分割。
标签类型的定义一般如下:
| 定义 | 全称 | 备注 |
|---|---|---|
| B | Begin | 实体片段的开始 |
| I | Intermediate | 实体片段的中间 |
| E | End | 实体片段的结束 |
| S | Single | 单个字的实体 |
| O | Other/Outside | 其他不属于任何实体的字符(包括标点等) |
常见的标签方案
常用的较为流行的标签方案有如下几种:
- IOB1: 标签I用于文本块中的字符,标签O用于文本块之外的字符,标签B用于在该文本块前面接续则一个同类型的文本块情况下的第一个字符。
- IOB2: 每个文本块都以标签B开始,除此之外,跟IOB1一样。
- IOE1: 标签I用于独立文本块中,标签E仅用于同类型文本块连续的情况,假如有两个同类型的文本块,那么标签E会被打在第一个文本块的最后一个字符。
- IOE2: 每个文本块都以标签E结尾,无论该文本块有多少个字符,除此之外,跟IOE1一样。
- START/END (也叫SBEIO、IOBES): 包含了全部的5种标签,文本块由单个字符组成的时候,使用S标签来表示,由一个以上的字符组成时,首字符总是使用B标签,尾字符总是使用E标签,中间的字符使用I标签。
- IO: 只使用I和O标签,显然,如果文本中有连续的同种类型实体的文本块,使用该标签方案不能够区分这种情况。
其中最常用的是BIO, BIOES, BMES
BIO标注模式
将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。
命名实体识别中每个token对应的标签集合如下:
LabelSet = {O, B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG}
其中,PER代表人名, LOC代表位置, ORG代表组织. B-PER、I-PER代表人名首字、人名非首字,B-LOC、I-LOC代表地名(位置)首字、地名(位置)非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分。

对于词性标注, 则可以用{B-NP, I-NP}给序列中的名词token打标签
BIOES标注模式
BIOES标注模式就是在BIO的基础上增加了单字符实体和字符实体的结束标识, 即
LabelSet = {O, B-PER, I-PER, E-PER, S-PER, B-LOC, I-LOC, E-LOC, S-LOC, B-ORG, I-ORG, E-ORG, S-ORG}
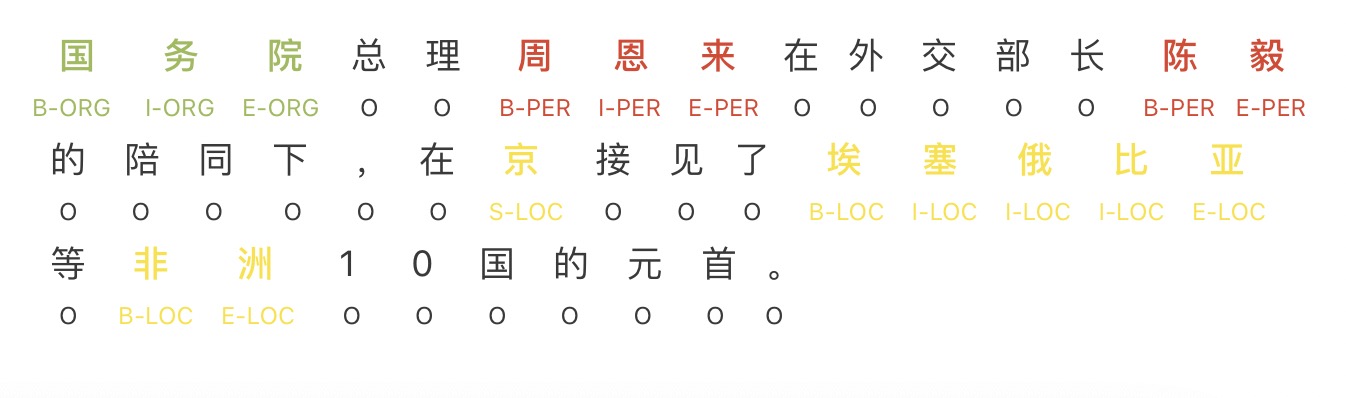
根据标注的复杂度, 还有会在其中添加其他的比如MISC之类的实体, 如
LabelSet = {O ,B-MISC, I-MISC, B-ORG ,I-ORG, B-PER ,I-PER, B-LOC ,I-LOC]。 其中,一般一共分为四大类:PER(人名),LOC(位置[地名]),ORG(组织)以及MISC(杂项),而且B表示开始,I表示中间,O表示不是实体。
其他类似的标注方式:
标注方式1:
LabelSet = {BA, MA, EA, BO, MO, EO, BP, MP, EP, O} 其中,
- BA代表这个汉字是地址首字,MA代表这个汉字是地址中间字,EA代表这个汉字是地址的尾字;
- BO代表这个汉字是机构名的首字,MO代表这个汉字是机构名称的中间字,EO代表这个汉字是机构名的尾字;
- BP代表这个汉字是人名首字,MP代表这个汉字是人名中间字,EP代表这个汉字是人名尾字,而O代表这个汉字不属于命名实体。
标注方式2:
LabelSet = {NA, SC, CC, SL, CL, SP, CP} 其中 NA = No entity, SC = Start Company, CC = Continue Company, SL = Start Location, CL = Continue Location, SP = Start Person, CP = Continue Person
上面两种标注方式与BIO和BIEOS类似, 只是使用不同的标签字符来标识而已.
BMES标注模式
评估方法
序列标注算法一般用conlleval.pl脚本实现,但这是用perl语言实现的。在Python中,也有相应的序列标注算法的模型效果评估的第三方模块,那就是seqeval,其官网网址, pip install seqeval==0.0.3
seqeval支持BIO,IOBES标注模式,可用于命名实体识别,词性标注,语义角色标注等任务的评估。
# -*- coding: utf-8 -*-
from seqeval.metrics import f1_score
from seqeval.metrics import precision_score
from seqeval.metrics import accuracy_score
from seqeval.metrics import recall_score
from seqeval.metrics import classification_report
y_true = ['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O', 'B-PER', 'I-PER']
y_pred = ['O', 'O', 'B-MISC', 'I-MISC', 'B-MISC', 'I-MISC', 'O', 'B-PER', 'I-PER']
print("accuary: ", accuracy_score(y_true, y_pred))
print("p: ", precision_score(y_true, y_pred))
print("r: ", recall_score(y_true, y_pred))
print("f1: ", f1_score(y_true, y_pred))
print("classification report: ")
print(classification_report(y_true, y_pred))
NER 数据集
- 【2022-6-16】中文NER数据集整理, NLPDataSet
- 【2023-9-25】中文命名实体识别(NER)数据集大盘点
总结
W2NER 数据集
| 数据集 | 语种 | 数量 | 主题 | 实体集合 |
|---|---|---|---|---|
| resume-zh | 中文 | 3819 | 简历实体 | {‘NAME’: 952, ‘CONT’: 260, ‘RACE’: 115, ‘TITLE’: 6308, ‘EDU’: 858, ‘ORG’: 4611, ‘PRO’: 287, ‘LOC’: 47} |
| weibo-zh | 中文 | 1350 | 微博语料 | {‘PER’: 1341, ‘LOC’: 107, ‘GPE’: 213, ‘ORG’: 225} |
| ontonotes4-zh | 中文 | 15736 | 未知 | {‘GPE’: 4962, ‘PER’: 4392, ‘LOC’: 928, ‘ORG’: 3090} |
| msra | 中文 | 46471 | 未知 | {‘NS’: 36517, ‘NT’: 20571, ‘NR’: 17615} |
| conll03 | 英文 | 17291 | 生物-蛋白质 | {‘ORG’: 7662, ‘MISC’: 4360, ‘PER’: 8442, ‘LOC’: 8977} |
| cadec | 英文 | 5340 | 未知 | {‘ADR’: 4428} |
【2022-6-16】将CMeEE数据集、IMCS21_task1数据集、CCKS2017_task2数据集、CCKS2018_task1数据集、CCKS2019_task1数据集、CLUENER2020数据集、MSRA数据集、NLPCC2018_task4数据集、CCFBDCI数据集、MMC数据集、WanChuang数据集、PeopleDairy1998数据集、PeopleDairy2004数据集、GAIIC2022_task2数据集、WeiBo数据集、ECommerce数据集、FinanceSina数据集、BoSon数据集、Resume数据集、Bank数据集、FNED数据集和DLNER数据集等22个数据集进行整理清洗,构建一个较完善的中文NER数据集。
- 数据集清洗时,仅进行了简单地规则清洗,并将格式进行了统一化,标签为“BIO”。
- 处理后数据集详细信息,见数据集描述。
- 数据集由NJUST-TB一起整理。
- 由于部分数据包含嵌套实体的情况,所以转换成BIO标签时,长实体会覆盖短实体。
- NLPDataSet
| 数据 | 原始数据/项目地址 | 原始数据描述 |
|---|---|---|
| CMeEE数据集 | 地址 | 中文医疗信息处理挑战榜CBLUE中医学实体识别数据集 |
| IMCS21_task1数据集 | 地址 | CCL2021第一届智能对话诊疗评测比赛命名实体识别数据集 |
| CCKS2017_task2数据集 | 地址 | CCKS2017面向电子病历的命名实体识别数据集 |
| CCKS2018_task1数据集 | 地址 | CCKS2018面向中文电子病历的命名实体识别数据集 |
| CCKS2019_task1数据集 | 地址 | CCKS2019面向中文电子病历的命名实体识别数据集 |
| CLUENER数据集 | 地址 | CLUENER2020数据集 |
| MSRA数据集 | 地址 | MSRA微软亚洲研究院开源命名实体识别数据集 |
| NLPCC2018_task4数据集 | 地址 | 任务型对话系统数据数据集 |
| CCFBDCI数据集 | 地址 | 中文命名实体识别算法鲁棒性评测数据集 |
| MMC数据集 | 地址 | 瑞金医院MMC人工智能辅助构建知识图谱大赛数据集 |
| WanChuang数据集 | 地址 | “万创杯”中医药天池大数据竞赛—智慧中医药应用创新挑战赛数据集 |
| PeopleDairy1998数据集 | 地址 | 人民日报1998数据集 |
| PeopleDairy2004数据集 | 地址 | 人民日报2004数据集 |
| GAIIC2022_task2数据集 | 地址 | 2022全球人工智能技术创新大赛-商品标题实体识别数据集 |
| WeiBo数据集 | 地址 | 社交媒体中文命名实体识别数据集 |
| ECommerce数据集 | 地址 | 面向电商的命名实体识别数据集 |
| FinanceSina数据集 | 地址 | 新浪财经爬取中文命名实体识别数据集 |
| BoSon数据集 | 地址 | 玻森中文命名实体识别数据集 |
| Resume数据集 | 地址 | 中国股市上市公司高管的简历 |
| Bank数据集 | 地址 | 银行借贷数据数据集 |
| FNED数据集 | 地址 | 高鲁棒性要求下的领域事件检测数据集 |
| DLNER数据集 | 地址 | 语篇级命名实体识别数据集 |
通用领域
Boson-NER
Boson提供的命名实体识别数据
- UTF-8进行编码,每行为一个段落标注,共包括2000段落。数据集共包含2000个段落
- 实体类型有六种,主要包括:时间、地点、人名、组织名、公司名、产品名。
该数据集查了出处网上都指向地址:https://bosonnlp.com/, 无法访问
CLUENER 细粒度-NER
由于公开访问获得的、高质量、细粒度的中文NER数据集较少,CLUE 基于清华大学开源的文本分类数据集THUCNEWS,选出部分数据进行细粒度命名实体标注,并对数据进行清洗,得到一个细粒度的NER数据集。
本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注得到。
- 训练集共计10748条,验证集共计1343条
- 数据分为10个标签类别,分别为:
地址(address),书名(book),公司(company),游戏(game),政府(government),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene),其中训练集共计10748条,验证集共计1343条。 - CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
- github: CLUENER2020
实体详情
- 地址(address): 省市区街号,路,街道,村等(如单独出现也标记)。地址是标记尽量完全的, 标记到最细。
- 书名(book): 小说,杂志,习题集,教科书,教辅,地图册,食谱,书店里能买到的一类书籍,包含电子书。
- 公司(company): 公司,集团,**银行(央行,中国人民银行除外,二者属于政府机构), 如:新东方,包含新华网/中国军网等。
- 游戏(game): 常见的游戏,注意有一些从小说,电视剧改编的游戏,要分析具体场景到底是不是游戏。
- 政府(government): 包括中央行政机关和地方行政机关两级。 中央行政机关有国务院、国务院组成部门(包括各部、委员会、中国人民银行和审计署)、国务院直属机构(如海关、税务、工商、环保总局等),军队等。
- 电影(movie): 电影,也包括拍的一些在电影院上映的纪录片,如果是根据书名改编成电影,要根据场景上下文着重区分下是电影名字还是书名。
- 姓名(name): 一般指人名,也包括小说里面的人物,宋江,武松,郭靖,小说里面的人物绰号:及时雨,花和尚,著名人物的别称,通过这个别称能对应到某个具体人物。
- 组织机构(organization): 篮球队,足球队,乐团,社团等,另外包含小说里面的帮派如:少林寺,丐帮,铁掌帮,武当,峨眉等。
- 职位(position): 古时候的职称:巡抚,知州,国师等。现代的总经理,记者,总裁,艺术家,收藏家等。
- 景点(scene): 常见旅游景点如:长沙公园,深圳动物园,海洋馆,植物园,黄河,长江等。
MSRA-NER
该数据集是 Microsoft Research Asia 「(MSRA)推出的关于中文命名实体识别的数据集」
- 关联论文:The Third International Chinese Language Processing Bakeoff: Word Segmentation and Named Entity Recognition
- GitHub:nlp_datasets
- 数据集地址
其中主要包括:地名、机构名和人名
- 标签策略: BIO。
- 其中训练数据集含有4.5万个句子,3.6万多个地名,2万多个机构名,1.7万多个人名;
- 测试数据集大概是训练数据集的十分之一,其中含有3.4k+个句子,2.8k+地名,1.3k+组织名,1.9k+人名。
目前Github最近一次更新是在2018年。
微博 NER
微博-NER
- 关联论文:Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings
- github
- BIO 标注
该数据集是「一个为NER标注的微博信息语料库」。相较于MSRA-NER该数据更加具体,其主要包括:
- 人名(具体名字和泛指名字)
- 地址(具体地址和泛指地址)
- 行政区
- 组织机构(特定机构和泛指名称)。
该语料库基于2013年11月~2014年12月期间从微博上采样的1890条信息标注完成
- 训练数据集1350条,开发数据集270条,测试数据集270条
在数量方面相较于MSRA-NER偏少。目前Github最近一次更新时间是在2018年。
人民日报(1998/2014)-NER
该数据集同样是「一个为NER标注数据集」,本NER数据集由人民日报语料库1998版和2014版生成,包含:
- 人名(PER)、地名(LOC)和机构名(ORG)3类常见的实体类型。
- 对于命名实体资料其主要包括:
人名、地名和机构名。 - 其中1998版本语料库训练数据集2W+条,开发数据集2.3k+条,测试数据集4.6k+条。
目前该数据集Github最近一次更新时间是在2018年。
特定领域
电商
电商NER–Taobao
电商NER数据集主要基于Taobao电商数据制作的一个命名实体数据集
- 该数据集包括了4大类(商品名称、商品型号、人名、地名)、9小类实体类别(电脑、汽车、日用品等)。
- 该数据集由阿里巴巴达摩院和新加坡科技设计大学联合提供。
- 训练数据集6000条,验证数据集998条,测试数据集1000条。
- Better Modeling of Incomplete Annotations for Named Entity Recognition
- github: ner_incomplete_annotation
最近Github更新时间是2022年。
商品标题2022-NER
GAIIC2022数据集主要出自2022全球人工智能技术创新大赛。主要背景是:京东商品标题包含了商品的大量关键信息,商品标题实体识别是NLP应用中的一项核心基础任务,能为多种下游场景所复用,从标题文本中准确抽取出商品相关实体能够提升检索、推荐等业务场景下的用户体验和平台效率。共有标注训练样本:4万条左右;无标注样本:100万条。实体共有52种类型,均已经过脱敏处理,用数字代号1至54表示(不包含27和45);其中“O”为非实体。标签中“B”代表一个实体的开始,“I”代表一个实体的中间或者结尾。“-”后的数字代号表示该字符的实体类型。
https://www.heywhale.com/home/competition/620b34ed28270b0017b823ad/content/2
文娱NER–Youku
文娱NER数据集主要是基于youku视频相关标题制作的,该数据集包括包括:3大类(娱乐明星名、影视名、音乐名)、9小类实体类别(例如:动漫、电影、影视、综艺等)
- 训练集8001条、验证集1000条、测试集1001条。
- 该数据集由阿里巴巴达摩院和新加坡科技设计大学联合提供。最近Github更新时间是2022年。
- Better Modeling of Incomplete Annotations for Named Entity Recognition
- github: ner_incomplete_annotation
简历 NER–新浪财经
该数据集基于新浪财经(Sina Finance4)收集了一个简历数据集, 包括中国股票市场上市公司高管的简历。随机选择了1027份简历摘要,并使用YEDDA系统手动标注了8种命名实体: [国籍(CONT)、教育背景(EDU)、地名(LOC)、人名(NAME)、组织名(ORG)、专业(PRO)、民族(RACE)、职称(TITLE)]。
- 该本数据集包括训练集(3821)、验证集(463)、测试集(477),实体类型包括,文本比较规范,实体识别模型效果通常F1 90%以上。
- Chinese NER Using Lattice LSTM
- github: LatticeLSTM
医学
中文医学 CMeEE-NER
CMeEE 数据集出自中文医疗信息处理挑战榜CBLUE。数据集将医学文本命名实体划分为九大类,包括:疾病(dis),临床表现(sym),药物(dru),医疗设备(equ),医疗程序(pro),身体(bod),医学检验项目(ite),微生物类(mic),科室(dep)。标注之前对文章进行自动分词处理,所有的医学实体均已正确切分,另外CMeEE-V2是对CMeEE的补充。
中医药应用2020-NER
该数据集主要是在2020年智慧中医药应用创新挑战赛中发布,该比赛主要由阿里和万科主办,旨在选出优秀的中医药人工智能大数据领域的应用创新解决方案。该数据集共1255条样本,13种类别,为药物剂型、疾病分组、人群、药品分组、中药功效、症状、疾病、药物成分、药物性味、食物分组、食物、证候和药品。
电子病历-NER
该数据集是由全国知识图谱与语义计算大会(CCKS)公布,2017年到2020年举办了四次关于电子病历命名实体识别(简称CNER Clinical Named Entity Recognition)的竞赛
- 对于给定的一组电子病历纯文本文档,任务的目标是识别并抽取出与医学临床相关的实体,并将它们归类到预先定义好的类别(pre-defined categories),比如症状,药品,手术等。其中主要包括CCKS2017-NER、CCKS2018-NER、CCKS2019-NER、CCKS2020-NER。
- 具体CCKS2017-NER数据集,共2229条样本,5种类别,为symp、dise、chec、body和cure;
- CCKS2018-NER数据集,共797条样本,5种类别,为症状和体征、检查和检验、治疗、疾病和诊断、身体部位;
- CCKS2019-NER数据集,共1379条样本,6种类别,为解剖部位、手术、疾病和诊断、药物、实验室检验、影像检查;
- CCKS2020-NER,共计1887条样本
诊疗对话2021-NER
在线问诊平台逐渐兴起,在线问诊是指医生通过对话和患者进行病情的交流、 疾病的诊断并且提供相关的医疗建议,医患对话理解旨在对问诊文本信息进行信息抽取,主要包括两个任务,分别是命名实体识别和症状检查识别。目前是从医患对话文本中识别出五类重要的医疗相关实体(Operation、Drug_Category、Medical_Examination、Symptom和Drug),数据包含2000多组对话,共98452条样本。
Link:http://www.fudan-disc.com/sharedtask/imcs21/index.html
瑞金MCC2018-NER
该数据集是由上海瑞金医院与阿里云联合发起主办AI大赛上发布的,其主要任务是通过糖尿病相关的教科书、研究论文来进行糖尿病文献挖掘并构建糖尿病知识图谱。该数据集共计3498条样本,18种类别,为Level、Method、Disease、Drug、Frequency、Amount、Operation、Pathogenesis、Test_items、Anatomy、Symptom、Duration、Treatment、Test_Value、ADE、Class、Test和Reason。
军事
军事装备试验鉴定-NER
该数据集源于军事科学院系统工程研究院在CCKS 2020中组织关于军事装备试验鉴定的命名实体识别评测
- 训练集和测试集分别为400条,平均长度150,最大长度358。
- 实体类型主要包括四大类:试验要素(如:RS-24弹道导弹、SPY-1D相控阵雷达)、性能指标(如测量精度、圆概率偏差、失效距离)、系统组成(如中波红外导引头、助推器、整流罩)、任务场景(如法国海军、导弹预警、恐怖袭击)。
- github: ccks_ner
FNED数据集合-NER
FNED数据集包含8种事件类型,共计1.3万个具有事件信息的句子(每个句子中包含一个事件),数据来源于公开军事新闻网站(如新浪军事、凤凰军事和网易军事等),标注信息包含事件提及(触发词、事件类型和事件元素)、实体提及(实体)和关系提及(头实体、尾实体和关系类型),其中8种事件类型,7种实体类型,8种关系类型。
Link:https://www.datafountain.cn/competitions/561/datasets
中国文学-NER
该数据集基于中国文学文章进行标注制作,共计包含726篇文章。一共定义了7个实体:物件、任务、地址、事件、计量单位、组织、出处等。
- A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text
- Chinese-Literature-NER-RE-Dataset
金融
银行借贷2021-NER
该数据集共10000条样本,4种类别,为BANK、COMMENTS_ADJ、COMMENTS_N和PRODUCT。
任务对话2018-NER
该数据集是NLPCC2018发布的比赛任务公布出来的,主要对应任务式对话任务4,该数据集共21352条样本,15种类别,为language、origin、theme、custom_destination、style、phone_num、destination、contact_name、age、singer、song、instrument、toplist、scene和emotion。
Link:http://tcci.ccf.org.cn/conference/2018/taskdata.php
CCIR2021-NER
全国信息检索学术会议(CCIR)由中国中文信息学会和中国计算机学会联合举办,则全国信息检索挑战杯(CCIR Cup)是由全国信息检索学术会议(CCIR)发起的技术评测比赛。数据集CCIR2021是该比赛发布的,旨在提高算法在中文命名实体识别方面鲁棒性,该数据数据集共15723条样本,4种类别,分别为LOC、GPE、ORG和PER。
https://www.datafountain.cn/competitions/510
NER 算法
NER任务归纳总结为三大研究范式:
序列标注范式阅读理解范式序列生成范式
NER 算法总结
信息抽取两大范式

Tagging:信息抽取“第一范式”
主流信息抽取建模方式通常采取“抽取范式”(暂且称为“第一范式”),这种范式最显著的特征就是:需要给定offset、并进行Tagging(位置标记)。
比如,我们通常采取的Tagging方式有:
- 序列标注:对实体span内的每一个token进行标注,比如BIO或BIESO;
- Span标注:对实体span的start和end进行标注,比如可采取指针网络、Token-pair矩阵建模、片段枚举组合预测等方式。
主流方法大致可分类为四类:
- 基于序列标注的方法;
- Flat NER 的基准模型
- 给每一个 Token 一个标签(BIO)
- 基于超图的方法;
- 模型结构相对复杂,关注相对较少
- 基于序列到序列 seq2seq 的方法;
- 基于片段 span 的方法。
基于序列到序列(seq2seq)方法和基于片段(span)方法获得了当前最好的效果,社区最为流行的方法。
技术思路
-
- 简单的 NER 任务一般用
序列标注就可以解决 - 多类型 NER 效果较好的还是基于
Span的方法
具体可参见 JayJay 这篇:刷爆 3 路榜单,信息抽取冠军方案分享:嵌套 NER + 关系抽取 + 实体标准化
NER 范式
美妆NER的场景,要识别商品标题中的品牌、品类、产品名,共三个实体

嵌套(Nested)组间嵌套:
- 图中的“隔离妆前乳”,既属于品类,也属于产品名的一部分组内嵌套:如上图的“妆前乳”,既是单独一个品类,也属于品类“隔离妆前乳”的一部分
不连续
- “苏菲娜控油隔离妆前乳”就为不连续的产品名,因为这里希望提取出的产品名是一个标准的产品名,因此中间一些无关的信息,如“限定款”不希望被抽取出来
NER 算法绕不开BERT+CRF,经验显示,BERT+CRF 在当前数据集上效果与SOTA相差不大,但考虑到更好的效果:
- CRF虽然引入了无向图,但只约束了相连结点之间的关联,并没有从全局出发来考虑更复杂的业务场景:
- 如
Flat NER到Nested NER、不连续NER等复杂业务场景的不断涌现 - CRF是否还能优雅地解决问题, 更快的线上serving效率:CRF解码复杂度与输入文本长度呈线性关系
几种范式
- 范式一:
BERT+CRF解决 嵌套与不连续 问题- 方法:分层CRF和万能的标签

- 组间嵌套: 共享BERT,但训练多个CRF层
- 组内嵌套: 设计标签,如品类那行的N标签,表示处于某个品类的中间部分,同时也是某个品类的开头
- 不连续: 设计标签,如产品名那行的G标签,表示token处于不连续产品名的中间部分,这部分输出时是要舍弃的
- 范式二:
Multi-Head(token pairs based)- Multi-Head,用头token与尾token的来表示一段span(称为token pairs),再接一些交互层和分类层,得到Multi-head(多头)矩阵。

- Multi-Head能天然解决组间嵌套和组内嵌套问题
- 不连续; 设置head来相对优雅地解决,设置多一个“产品名中间”的head,把产品名中间也当成一种实体提取出来
- Multi-head 最终得到一个
[L,L,N]矩阵(忽略batch_size维度), 三种构建方式(乘性、加性、双仿射) - 相对位置信息对于Multi-head这种token pairs based的模式更为重要,一句话总结:告诉模型start token与end token之间的距离非常关键。
- 范式三:
BERT+MRC- NER任务当成机器阅读理解(MRC)任务来处理,把要提取的实体类型信息,显式地加入到输入中,如下图所示,预测的start和end即为对应实体的start和end。

- 统一信息抽取任务的范式, 三大任务(命名实体识别、关系识别、事件抽取)迁移时, 参数是完全可迁移
- 香侬科技的两篇论文:
- 《Entity-relation extraction as multi-turn question answering》
- 《A Unified MRC Framework for Named Entity Recognition》
- MRC比BERT+CRF和Multi-Head的优势
- 利用大量的数据来预热
- 把entitiy的信息encode到输入端(即question中),有助于模型更“懂”要抽取的实体
- 劣势: 计算效率太低,有N个entity type,就需要在BERT前向计算N次
- 范式四:
Span-based- 《 Span-based Joint Entity and Relation Extraction with Transformer Pre-training 》
- 区别于token pairs用头和尾token来表示这段span,span-based是用span的每个token做pooling来表示这段span,可以猜测的是,这种表征方式肯定要比token pairs要好。
- 但span-based貌似无法设计成并行的模式,时间复杂度太高!
范式二:Multi-Head
标签不平衡
- 多头矩阵存在大量的0标签,训练出来的模型很可能会高精确低召回,解决之道是通过改损失函数(如Focal Loss、Label Weight等)、负采样等方式来缓解这种不平衡。
- 推荐负采样,因为负采样还能缓解NER任务中的一大噪声——漏标。
多头中,损失函数的通常有两种选择
- Softmax:构造(实体类型数+1)个head的多头矩阵,其中一个head代表null entity,最后在head的维度上做softmax
- Sigmoid:构造(实体类型数)个head的多头矩阵,每个元素单独做sigmoid 通常来说,Softmax会比Sigmoid效果更好,训练速度更快,因为Softmax还融入了类间的互斥信息。
方案选择
- 场景一:想省心,就用
BERT+CRF吧,BERT+CRF好处是没有太多超参,只需要注意CRF层的学习率要比BERT调大一些,如大100倍左右 - 场景二:垂直领域,能获得的数据集有大量的漏标,尝试
Multi-Head+负采样方式,能缓解噪声的影响 - 场景三:有大量相似数据集,此时选择
BERT+MRC这种统一范式
作者:周星星
序列标注
序列标注方法比较常用,给每一个 Token 一个标签(BIO)
- 输入序列会使用已有的表征框架(如 CNN、LSTM、Transformer 等)表征成序列特征,之后 CRF 层经常会会引入以解决标签间关系特征。
- 对于多类型 NER,可以将「多分类」改为「多标签分类」或将多标签拼成一个标签。
- 前者不容易学习,而且预测出来的 BI 可能都不是一个类型的;
- 而后者则容易导致标签增加,且很稀疏。
- 虽有不少研究,比如
- 《A Neural Layered Model for Nested Named Entity Recognition》提到的动态堆叠平铺 NER 层来识别嵌套实体;
- 《Recognizing Continuous and Discontinuous Adverse Drug Reaction Mentions from Social Media Using LSTM-CRF》的 BIOHD 标注范式(H 表示多个实体共享的部分,D 表示不连续实体中不被其他实体共享的部分),注意 H 和 D 都是实体的 Label,标注时会和 BI 结合使用,如 DB,DI,HB,HI。但总的来说较难设计一个不错的标注 Scheme。

Span – 分类、MRC 任务
基于 Span 的方法将 NER 问题转为 Span 级别的分类问题,具体方法包括:
- 枚举所有可能的 Span,然后判断是否是有效的 Mention。
- 使用 Biaffine Attention 来判断一个 Span 是 Mention 的概率。
- 将 NER 问题转为
MRC任务,提取实体作为答案 Span。 - 两阶段方法:使用一个过滤器和回归器生成 Span 的建议,然后进行分类。
- 将不连续的 NER 转为从基于 Span 的实体片段图中找到完整的子图。
本方法由于全枚举的性质,受到最大跨度长度和相当大的模型复杂度的影响,尤其是对于长跨度实体。
超图
基于超图的方法首次在《Joint Mention Extraction and Classification with Mention Hypergraphs》中提出,用于解决重叠 NER 问题(指数表示可能的 Mention),后续也被用于不连续实体。
- 但本方法在推理时容易被虚假结构和结构歧义问题影响。
Seq2Seq – 生成
Seq2Seq 方法是生成方法,在《Multilingual Language Processing From Bytes》中被首次提出,输入句子,输出所有实体的开始位置、Span 长度和标签。其他后续应用包括:
- 使用增强的 BILOU 范式解决重叠 NER 问题。
- 基于 BART 通过 Seq2Seq+指针网络生成所有可能的实体开始-结束位置和类型序列。
本方法存在解码效率和架构固有的暴露偏差问题。
exposure bias 问题
- 训练时使用上一时间步的真实值作为输入;
- 而预测时,由于没有标签值,只能使用上一时间步的预测作为输入。
- 由于模型都是把上一时间步正确的值作为输入,所以模型不具备对上一时间步的纠错能力。如果某一时间步出现误差,则这个误差会一直向后传播。
基于词典和规则的方法
- 利用词典,通过词典的先验信息,匹配出句子中的潜在实体,通过一些规则进行筛选。
- 或者利用句式模板,抽取实体,例如模板“播放歌曲${song}”,就可以将query=“播放歌曲七里香”中的 song= 七里香 抽取出来。 具体匹配方法:
- 正向最大匹配:从前往后依次匹配子句是否是词语,以最长的优先。
- 反向最大匹配:从后往前依次匹配子句是否是词语,以最长的优先。
- 双向最大匹配
- 覆盖 token 最多的匹配。
- 句子包含实体和切分后的片段,这种片段+实体个数最少的。
原理比较简单,直接看代码
机器学习方法 CRF
CRF,原理可以参考:Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
深度学习语义编码器 Bi-LSTM-CRF
(1)BI-LSTM-CRF模型可以有效地利用过去和未来的输入特征。借助 CRF 层, 它还可以使用句子级别的标记信息。BI-LSTM-CRF 模型在 POS(词性标注),chunking(语义组块标注)和 NER(命名实体识别)数据集上取得了当时的 SOTA 效果。同时 BI-LSTM-CRF 模型是健壮的,相比之前模型对词嵌入依赖更小。
论文Bidirectional LSTM-CRF Models for Sequence Tagging中对比了 5 种模型:LSTM、BI-LSTM、CRF、LSTM-CRF、BI-LSTM-CRF,LSTM:通过输入门,遗忘门和输出门实现记忆单元,能够有效利用上文的输入特征。BI-LSTM:可以获取时间步的上下文输入特征。CRF:使用功能句子级标签信息,精度高。
比较经典的模型,BERT 之前很长一段时间的范式,小数据集仍然可以使用
(2)stack-LSTM & char-embedding
Neural Architectures for Named Entity Recognition stack-LSTM :stack-LSTM 直接构建多词的命名实体。Stack-LSTM 在 LSTM 中加入一个栈指针。模型包含 chunking 和 NER(命名实体识别)。
(3)CNN + BI-LSTM + CRF
通过 CNN 获取字符级的词表示。CNN 是一个非常有效的方式去抽取词的形态信息(例如词的前缀和后缀)进行编码的方法
(4)IDCNN
针对 Bi-LSTM 解码速度较慢的问题,本文提出 ID-CNNs 网络来代替 Bi-LSTM,在保证和 Bi-LSTM-CRF 相当的正确率,且带来了 14-20 倍的提速。句子级别的解码提速 8 倍相比于 Bi- LSTM-CRF。
(5)胶囊网络
Joint Slot Filling and Intent Detection via Capsule Neural Networks [7]
Git: https://github.com/czhang99/Capsule-NLU
NLU 中两个重要的任务,Intent detection 和 slot filling,当前的无论 pipline 或者联合训练的方法,没有显示地对字、槽位、意图三者之间的层次关系建模。本文提出将胶囊网络和 dynamic routing-by-agreement 应用于 slot filling 和 intent detection 联合任务。
- 使用层次话的胶囊网络来封装字、槽位、意图之间的层次关系。
- 提出 rerouting 的动态路由方案建模 slot filling。
(6)Transformer
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [10]
直说吧,就是 BERT,bert 之前万年 bilstm+crf,bert 之后,基本没它什么事儿了,bert 原理不多赘述,应用在 NER 任务上也很简单,直接看图,每个 token 的输出直接分类即可
深度学习-语义特征
(1)char-embedding
Neural Architectures for Named Entity Recognition,将英文字符拆解为字母,将词语的每个字母作为一个序列编码,编码器可以使用 rnn,cnn 等。
(2)Attending to Characters in Neural Sequence Labeling Models
Attending to Characters in Neural Sequence Labeling Models,使用了单词或字符级别 embedding 组合,并在两种 embedding 之间使用 attention 机制“灵活地选取信息”,而之前模型是直接将两种 embedding concat。char-embedding 学习的是所有词语之间更通用的表示,而 word-embedding 学习的是特特定词语信息。对于频繁出现的单词,可以直接学习出单词表示,二者也会更相似。
(3)Radical-Level Features(中文部首)
Character-Based LSTM-CRF with Radical-LevelFeatures for Chinese Named Entity Recognition 也是一种 char embedding 方法,将每个中文字拆分为各个部首,例如“朝”会被拆分为字符:十、日、十、月。后面结构都类似。
(4) n-gram prefixes and suffixes
Named Entity Recognition with Character-Level Models 提取每个词语的前缀和后缀作为词语的特征,例如:“aspirin” 提取出 3-gram 的前后缀:{“asp”, “rin”}. 包含两个参数:n、T。n 表示 n-gram size,T 是阈值,表示该后缀或者前缀至少在语料库中出现过 T 次。
多任务联合学习
(1)联合分词学习
Improving Named Entity Recognition for Chinese Social Mediawith Word Segmentation Representation Learning [15]
将中文分词 和 NER 任务联合起来。使用预测的分割标签作为特征作为 NER 的输入之一,为 NER 系统提供更丰富的边界信息。分词语料目前是很丰富的。如果目标域数据量比较小,不妨用分词的语料作为源域,来预训练一个底层编码器,然后再在目标域数据上联合分词任务 fine-tuning。
(2)联合意图学习
slot-gated
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction,slot-gated 这篇文章提出了 slot-gate 将槽位和意图的关系建模,同时使用了 attention 方法,所以介绍这篇文章直接一起介绍 attention,之前 attention 相关的就不介绍了。
(3)BERT for Joint Intent Classification and Slot Filling
BERT for Joint Intent Classification and Slot Filling 原理如图,底层编码器使用了 BERT,token 的输出向量接 softmax 预测序列标签,cls 向量预测意图。
bert 之后,似乎之前的一些优化都变成了奇技淫巧,那么就没有新的方法了吗?bert 之前实体识别都是以序列标注(sequence labeling)来识别,没有其他的解码方式吗?
NER 优化
- Q1、如何快速有效地提升NER性能(非模型迭代)?
- Q2、如何在模型层面提升NER性能?
- Q3、如何构建引入词汇信息(词向量)的NER?
- Q4、如何解决NER实体span过长的问题?
- Q5、如何客观看待BERT在NER中的作用?
- Q6、如何冷启动NER任务?
- Q7、如何有效解决低资源NER问题?
- Q8、如何缓解NER标注数据的噪声问题?
- Q9、如何克服NER中的类别不平衡问题?
- Q10、如何对NER任务进行领域迁移?
- Q11、如何让NER系统变得“透明”且健壮?
- Q12、如何解决低耗时场景下的NER任务?
OOV问题
一般将 NER 视为分类/预测 问题,那如何处理不在训练语料库中的名称实体?
- “詹姆斯出生在英国” –> James 被标记为
PERSON,England 被标记为LOCATION。
NER Tagger 的目标是在给定一组预先指定的类的情况下,学习可用于对单词(或更一般地,标记)进行分类的语言模式。这些类是在训练之前定义的并且保持不变。类,例如:PERSON, DATETIME, ORGANIZATION, … 你可以命名它。
但是输入了另一个完全奇怪的句子
- “Fyonair 来自 Fuabalada”。 —> 人类可以理解 Fyonair 是一个人(或者也许是童话中的公主),而 Fuabalada 是她来自的土地。
一个好的 NER 标注器将学习一种语言结构,并识别出 “Fyonair is from Fuabalada land.” 遵循一些语言规则和规律,并且从这些规律(在训练期间自主学习)中,分类器可以将 Fyonair class PERSON 和 Fuabalada class 归类 LOCATION。
如果它不包含在数十亿的语料库和令牌中,模型将如何识别它?
- 【2021-9-8】ACL2021 一种巧妙解决NER覆盖和不连续问题的方法
- 稍微复杂些问题:一种带有覆盖和不连续(Overlapped and Discontinuous)的命名实体识别任务。前人只是要么解决覆盖问题,要么解决不连续问题,但是本文提出一种联合解决这两种问题的span-based方法。
- 两个步骤构建模型:
- 通过列举所有可能的text span来识别出实体片段(entity fragments);
- 在这些entity fragments上预测是两种关系overlapping or succession。
- 这样,我们不仅可以识别Discontinuous的实体,同时也可以对Overlapped的实体进行双重检查。
- 通过上述方法轻松将NER装换成RE(Relation Extraction)任务。最终实验在很多数据集上比如CLEF, GENIA and ACE05上展现除了很强劲的性能。
无监督 NER
深度学习模型比其他具有非常大数据集(所谓的“大数据”)的模型更好地工作。
- 在小型数据集上,它们并不是非常有用。
无监督学习能完成这个任务吗?
NER 标记是一项有监督的任务。
- 需要一组标记示例的训练集来为此训练模型。
但是,可以做一些无监督的工作来稍微提高模型的性能。
从 Geron 的书中摘录了一段有用的段落:
假设要处理一项没有太多标记训练数据的复杂任务
- 如果您可以收集大量未标记的训练数据,则可以尝试使用它来训练无监督模型,例如自动编码器或生成对抗网络, 然后您可以重用
自动编码器的较低层或GAN鉴别器的较低层,在顶部添加任务的输出层,并使用监督学习微调最终网络(即标签训练示例)。
Geoffrey Hinton 和他的团队在 2006 年使用的正是这种技术,并导致了神经网络的复兴和深度学习的成功。
(有史以来最好的机器学习书籍,恕我直言。)
这种无监督预训练是我能想到的将无监督模型用于 NER 的唯一方法。
【2022-10-14】BERT的无监督NER
- 采用BERT(bert-large-cased)无监督NER的标记句子样本,没有进行微调。 这些例子中突出了采用这种方法(BERT)标记的几个实体类型。 标记500个句子可以生成大约1000个独特的实体类型——其中一些映射到如上所示的合成标签。Bert-large-cased模型无法区分GENE和PROTE IN,因为这些实体的描述符与屏蔽词的预测分布落在同一尾部区域(无法将它们与基本词汇表中的词汇区分开来)。 区分这些密切相关的实体可能需要对特定领域的语料库进行MLM微调,或者使用scratch中自定义词汇进行预训练
如果要问术语(术语指文章中的单词和短语)的实体类型到底是什么,即使我们以前从未见过这个术语,但是也可以通过这个术语的发音和/或从这个术语的句子结构中猜出它来。 即,
(1) 术语的子词结构为它的实体类型提供了线索。
- Nonenbury is a _____
- Nonenbury是_____
这是一个杜撰的城市名称,但从它的后缀“bury”可以猜出这可能是一个地点。此时,即便没有任何其上下文,术语的后缀也给出了实体类型的线索。
(2)句子结构提供了术语的实体类型的线索。
- He flew from _____ to Chester
- 他从_____飞到切斯特
在这里,句子上下文给出了实体类型的线索,未知的术语是一个地点。即便以前从未见过它(例如:Nonenbury) ,但也可以猜测出句子中的空白处是一个地点(如:Nonenbury)。
详见原文:BERT的无监督NER
ACL2021 NER 小量强标签和大量弱标签结合的命名实体识别
- 弱监督在NLP里认证是有用的
- 现有工作:深度NER模型 + 只有弱监督
- 实际场景:既有小量强标签数据,又有大量弱标签数据
- 实际问题:两者简单/加权组合,未能提升性能(弱标签有大量噪声)
- 提出一个新的三阶段计算框架:针 NEEDLE (Noise-aware wEakly supErviseD continuaL prEtraining)
- 弱标签补全
- 噪声感知损失函数
- 最终在强标签数据上微调
- 三份生物医学数据集上达到SOTA
W2NER – 2022 sota
- 【2023-9-8】NER统一模型:刷爆14个中英文数据SOTA
- 【2022-7-17】统一NER为词词关系分类, 论文讲解, W2NER 代码
AAAI 2022 ,武汉大学论文刷新了14个中英文数据集的SOTA
- paper: Unified Named Entity Recognition as Word-Word Relation Classification,基于词对关系建模的统一命名实体识别系统
- code:
- 官方 W2NER
- 第三方
- 整合成一个文件 task_sequence_labeling_ner_W2NER
- 新增 predict 文件: W2NER_predict,修改了 data_loader.py ,新增 predict.py 文件
【2023-9-25】W2NER_predict,这个代码库版本依然有缺陷,更改数据集时报错
size mismatch for predictor.biaffine.weight: copying a param with shape torch.Size([11, 513, 513]) from checkpoint, the shape in current model is torch.Size([10, 513, 513]).
size mismatch for predictor.linear.weight: copying a param with shape torch.Size([11, 288]) from checkpoint, the shape in current model is torch.Size([10, 288]).
size mismatch for predictor.linear.bias: copying a param with shape torch.Size([11]) from checkpoint, the shape in current model is torch.Size([10]).
原因:
- data_loader.py 里 新增的函数 load_data_bert_predict 把词表写死了,更换数据集时,label信息 依然是 resume-zh 的标签,导致维度不匹配
解决:
- ① 直接更改 写死的 label 信息list → 会触发新的bug
- ② 升级代码,自动从数据集中计算 label 信息
# ----------- old --------------
def load_data_bert_predict(texts, config):
if isinstance(texts, str):
texts = [texts]
# with open('./data/{}/train.json'.format(config.dataset), 'r', encoding='utf 8') as f:
# train_data = json.load(f)
# with open('./data/{}/dev.json'.format(config.dataset), 'r', encoding='utf 8') as f:
# dev_data = json.load(f)
# with open('./data/{}/test.json'.format(config.dataset), 'r', encoding='utf 8') as f:
# test_data = json.load(f)
tokenizer = AutoTokenizer.from_pretrained(config.bert_name, cache_dir="./cache/")
vocab = Vocabulary()
# train_ent_num = fill_vocab(vocab, train_data)
# dev_ent_num = fill_vocab(vocab, dev_data)
# test_ent_num = fill_vocab(vocab, test_data)
label2id = {'<pad>': 0, '<suc>': 1, 'name': 2, 'cont': 3, 'race': 4, 'title': 5, 'edu': 6, 'org': 7, 'pro': 8, 'loc': 9} # 此处写死了,导致换数据集时,维度不匹配,报错!
id2label = {v:k for k,v in label2id.items()}
vocab.label2id = label2id
vocab.id2label = id2label
print(dict(vocab.label2id))
# ----------- new --------------
def load_data_bert_predict(texts, config):
if isinstance(texts, str):
texts = [texts]
with open('./data/{}/train.json'.format(config.dataset), 'r', encoding='utf-8') as f:
train_data = json.load(f)
with open('./data/{}/dev.json'.format(config.dataset), 'r', encoding='utf-8') as f:
dev_data = json.load(f)
with open('./data/{}/test.json'.format(config.dataset), 'r', encoding='utf-8') as f:
test_data = json.load(f)
tokenizer = AutoTokenizer.from_pretrained(config.bert_name, cache_dir="./cache/")
vocab = Vocabulary()
train_ent_num = fill_vocab(vocab, train_data)
dev_ent_num = fill_vocab(vocab, dev_data)
test_ent_num = fill_vocab(vocab, test_data)
print(dict(vocab.label2id))
创新点
- 利用统一的
Word-Pair标记方式建模不同类型的NER任务,并将NER统一模型称之为W2NER。 - 采用一种模型框架同时将三种不同类型的 NER 同时建模,即端到端抽取出所有的类型的实体。四种 NER 方法均可以被设计为支持统一命名实体识别的模型。
I am having aching/eiking/ in legs and shoulder
NER任务三种类型:Flat(平铺)、overlapped(重叠或嵌套)、discontinuous(不连续)
- 1)扁平实体;Flat —— aching in legs
- 2)嵌套实体;overlapped
- 3)非连续实体;discontinuous —— aching in shoulders
当前sota 以 基于 Span 和 Seq2Seq 模型,这两种方法很少关注边界,可能会导致后续的偏移
NER的相关建模方式主要包括:
- 序列标注:对实体span内的每一个token进行标注,比如BIO或BIESO;
- Span标注:对实体span的start和end进行标注,比如可采取指针网络、Token-pair矩阵建模、片段枚举组合预测等方式。
- 序列生成:以
Seq2Seq方式进行,序列输出的文本除了label信息,Span必须出现在原文中- 生成式统一建模时对解码进行限制(受限解码)。
邱锡鹏课题组就曾对NER进行统一建模,直接生成输入文本中word的索引。 A Unified Generative Framework for Various NER Subtasks
本文采取 Word-Pair 标记方式,是 Token-Pair 一种拓展:即建模Word和Word之间的关系
将 UNER 任务转化成一种词对关系分类任务,提出了一种新的 UNER 架构(NER as Word-Word Relation Classification),名为 W²NER。
- 构造一个 2D 的词词关系网格,然后使用多粒度 2D 卷积,以更好地细化网格表示。最后,使用一个共同预测器来推理词-词关系
W2NER模型将NER任务转换预测word-word(备注:中文是字-字)的关系类别,统一处理扁平实体、重叠实体和非连续实体三种NER任务,即一招通吃。
假设输入的句子 X 由 N 个token 或 word组成,即 X={x1, x2, ..., xn}, 模型对每个word pair (xi, xj) 中的两个word的关系类别R进行预测,其中 R∈{None, NNW, THW-*}。
Tag标记 具体说明如下:
- ①、
None:表示两个word之间没有关系,不属于同一个实体 - ②、
NNW:即 Next-Neighboring-Word 邻接关系,表示这两个word是在同一个实体中相邻位置; - ③、
THW-*:即 Tail-Head-Word-* 头尾关系,表示这两个word是在同一实体中,且分别是实体的结尾和开始。用THW-*来判断实体的类别和边界,并附带实体的label信息。
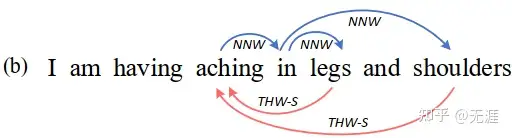
例子中包含两个实体:aching in legs 和 aching in shoulders,可以通过 NNW 关系(aching→in)、(in→legs)和(in→shoulders)和 THW 关系(legs→aching,Symptom)和(shoulders→aching,Symptom)解码得出。
NNW 和 THW 关系还暗示 NER 的其他影响,比如
- NNW 关系将同一不连续的实体片段关联起来(如 aching in 和 shoulders),也有利于识别实体词(相邻的)和非实体词(不相邻的)。
- THW 关系有助于识别实体的边界
为了得到(b)中的关系,将句子按word维度构建二维矩阵,通过W2NER模型,预测word-word的关系

通过上述的两种Tag标记方式连接任意两个Word,就可以解决如上图中各种复杂的实体抽取:(ABCD分别是一个Word)
- a): AB和CD代表两个扁平实体;
- b): 实体BC嵌套在实体ABC中;
- c): 实体ABC嵌套在非连续实体ABD;
- d): 两个非连续实体ACD和BCE;

上图更清晰的展示了扁平实体(aching in legs)和非连续实体(aching in shoulders)的连接方式。
模型结构
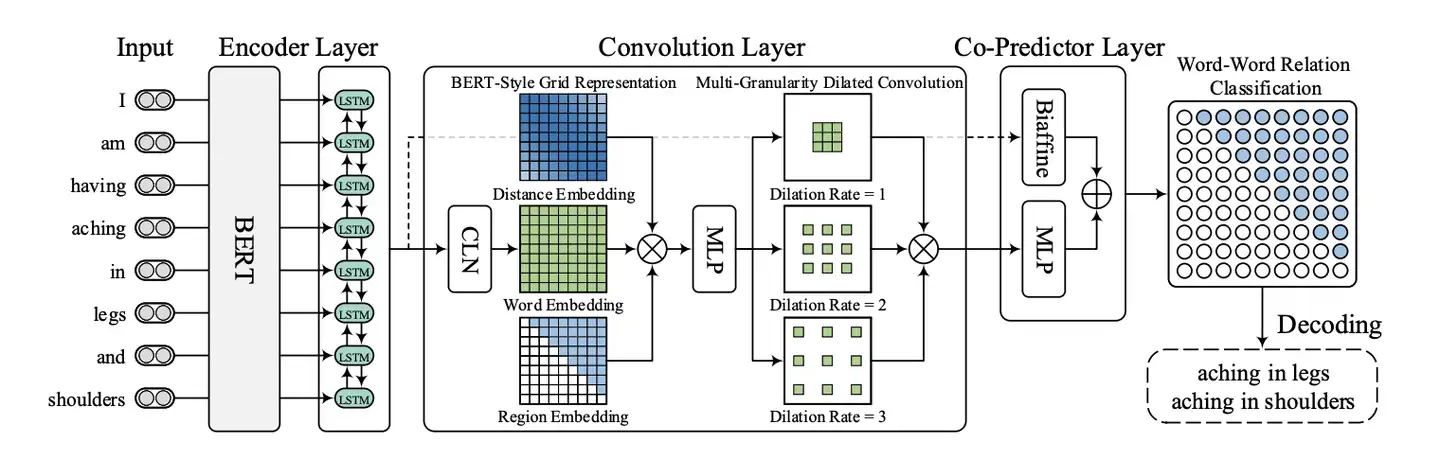
具体解释如下:
- 输入的sentence经过EncodeLayer(BERT+BiLSTM)得到word_reps,shape为[batch_size, cur_batch_max_sentence_length, lstm_hidden_size];
- 将word_reps经过Conditional Layer Normalization(简称CLN)层,得到cln;cln的shape为[batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, lstm_hidden_size],表示word pair的embedding;
- 将word pair的distance_embedding、所在三角区域的region_embedding和word_embedding按最后一个维度拼接起来,得到的conv_inputs,shape为[batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, dist_emb_size + type_emb_size + lstm_hidden_size];
- 将conv_inputs经过卷积层(核为1*1的常规二维卷积 + 核为3*3的多层空洞卷积),得到conv_outputs,shape为[batch_size, output_height = cur_batch_max_sentence_length, output_width = cur_batch_max_sentence_length, conv_hidden_size * 3],这里的3表示空洞卷积的层数;
- 将卷积层的输出conv_outputs经过CoPredictor层(由Biaffine + MLP组成),得到output,output的shape为[batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, label_num],label_num表示word-word关系类别的个数;
源码解释
从输入句子到预测句子的word pair中两个word的关系类别,整个过程如下图所示:

1、从输入句子得到BertModel所需的bert_inputs/input_ids和attention_mask
整个过程如下图所示:
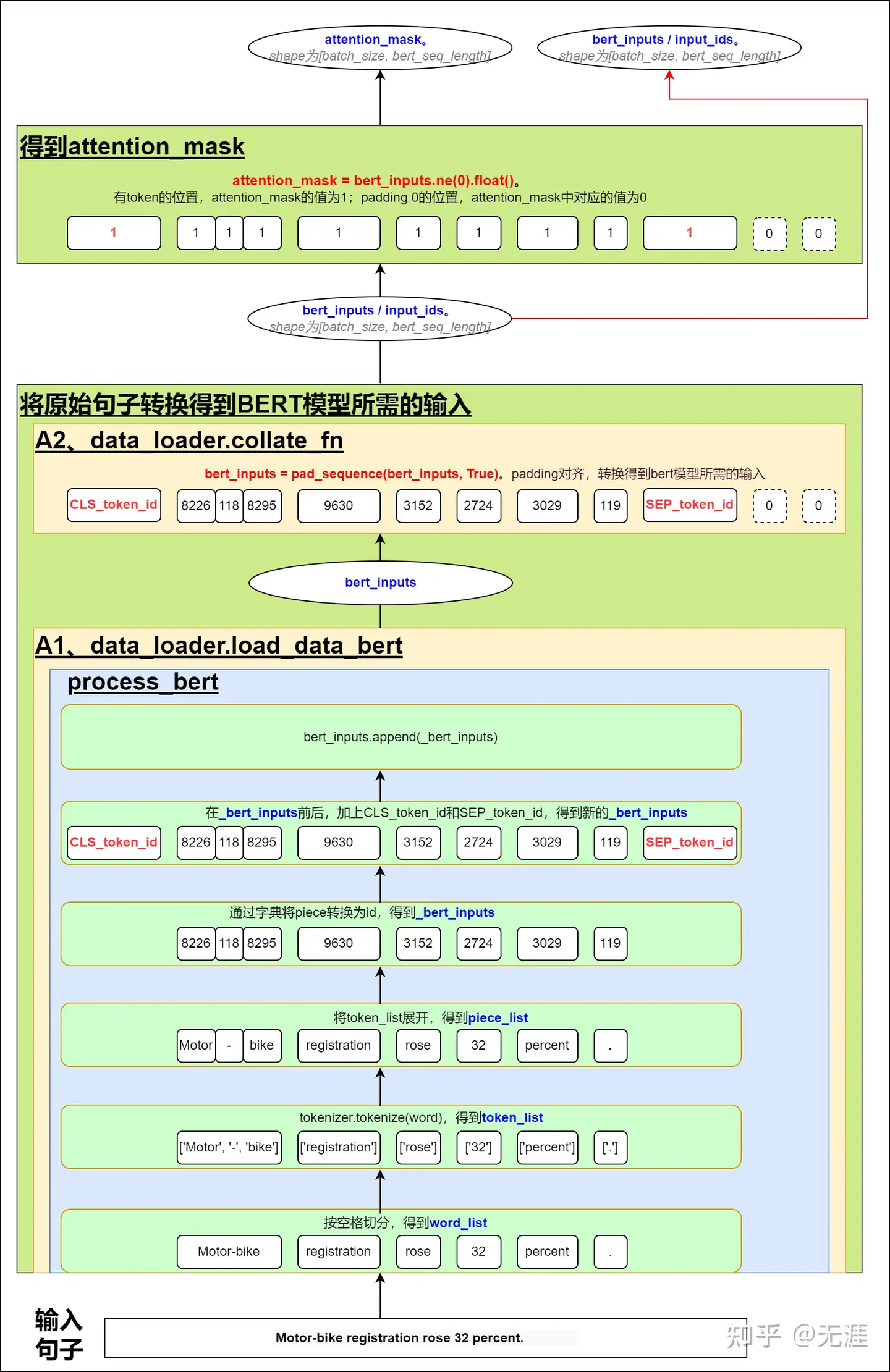
在data_loader.load_data_bert的process_bert中,将输入的句子,经过一系列切分处理后,得到piece_list,再将piece_list转换为对应id组成_bert_inputs。然后在_bert_inputs前后分别加上CLS_token_id和SEP_token_id,得到新的_bert_inputs。再执行bert_inputs.append(_bert_inputs)得到bert_inputs。
在data_loader.collate_fn中,对bert_inputs进行padding,得到bert模型所需的输入bert_inputs/input_dis。
再根据padding后的bert_inputs,得到attention_mask,具体方案是通过比较bert_inputs中的token_id是否不等于0。即padding 0的位置,token_id为0,则attention_mask中对应的值为0;非padding 0的位置,attention_mask的值为1;
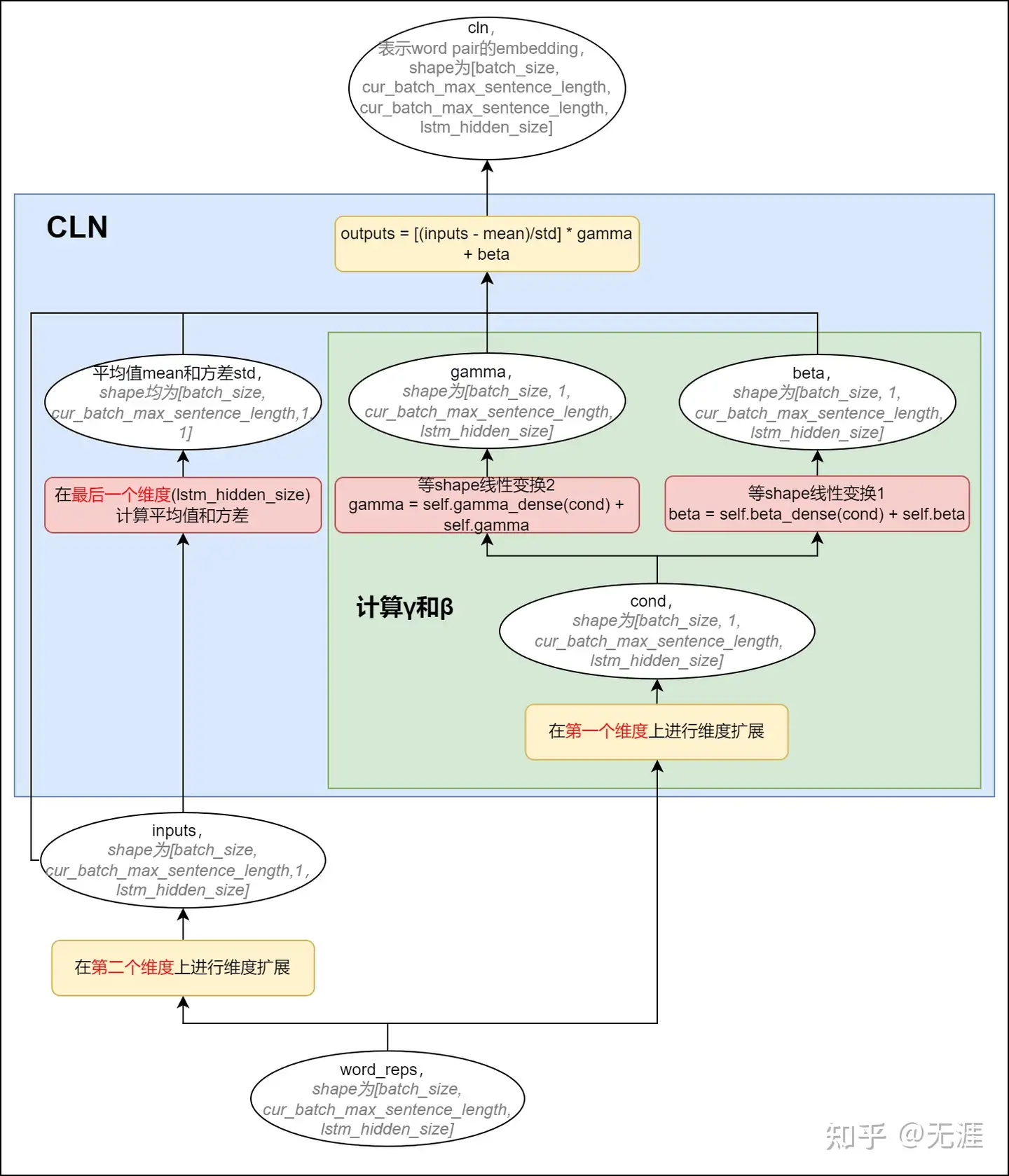
2、Conditional Layer Normalization
通过conditional layer normalization获取word pair中word-word的embedding。
示例讲解
# 样例: 8个单词、6个单词
train_sample = ['I am having aching in legs and shoulder', '常建良,男,']
# (1)训练数据集:
# 包含两个 NER: CONT(aching in legs和aching in shoulder), NAME(常建良)
# label → id: 1(相邻), 2(NAME), 3(CONT)
inp = [
{'ner': [{'index': [3, 4, 5], 'type': 'CONT'}, {'index': [3, 4, 7], 'type': 'CONT'}],
'sentence': ['i', 'am', 'having', 'aching', 'in', 'legs', 'and', 'shoulders'],
'word': []},
{'ner': [{'index': [0, 1, 2], 'type': 'NAME'}],
'sentence': ['常', '建', '良', ',', '男', ','],
'word': [[0], [1, 2], [3], [4], [5]]}
]
# (2)bert input
# tokens(按空格分开后再执行 tokenize)
[['i'], ['am'], ['ha', '##ving'], ['ac', '##hing'], ['in'], ['le', '##gs'], ['and'], ['sh', '##ould', '##ers']]
[['常'], ['建'], ['良'], [','], ['男'], [',']]
# pieces(将上面的tokens打平)
['i', 'am', 'ha', '##ving', 'ac', '##hing', 'in', 'le', '##gs', 'and', 'sh', '##ould', '##ers'] # 13个token
['常', '建', '良', ',', '男', ','] # 6个token
# bert_inputs
tensor([[101,151,8413,11643,10369,9226,10716,8217,8983,9726,8256,11167,11734,8755,102],[101,2382,2456,5679,8024,4511,8024,102,0,0,0,0,0,0,0]])
# (3) 标签矩阵:grid_labels Bx8x8
# 第一个矩阵:左上三角的三个 1 就表示 NNW,右下三角的 3 则表示 THW(就是对应的类型:CONT),是实体尾部
# shape 大小根据句子的长度(词数)来确定:第一句话长度为 8,第二句为 6,所以第二句会 Padding
tensor([ # 第一句:8个单词 ['i', 'am', 'having', 'aching', 'in', 'legs', 'and', 'shoulders']
[[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0], # 4,5
[0, 0, 0, 0, 0, 1, 0, 1], # 4,5,6; 4,5,7
[0, 0, 0, 3, 0, 0, 0, 0], # 边界 4+6, 标注label 3
[0, 0, 0, 0, 0, 0, 0, 0], # 边界 4+7, 标注label 3
[0, 0, 0, 3, 0, 0, 0, 0]],
# 第二句: 6个单词 ['常', '建', '良', ',', '男', ','],补两个0,对齐8个
[[0, 1, 0, 0, 0, 0, 0, 0], # 常, 建 相邻
[0, 0, 1, 0, 0, 0, 0, 0], # 建, 良 相邻
[2, 0, 0, 0, 0, 0, 0, 0], # 边界 1+3, 标注label 2
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]
])
# ner
for entity in instance["ner"]:
index = entity["index"]
for i in range(len(index) - 1):
grid_labels[index[i], index[i + 1]] = 1
grid_labels[index[-1], index[0]] = type_id
# grid_mask2d 和 grid_labels 对应,将其中 Padding 的部分 Mask 住
# Bx8x8
tensor([[[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True]],
[[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, False, False],
[False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False]]])
# pieces2word扩展,针对子词的,中文一般一个 Token 就是一个字(词),英文可能几个 Token 合成一个词。因为在 NER 时并不是针对子词,而是针对一个个独立的词的,所以这块需要单独标记。
# 注意:和前面的 tokens 结合起来看。这里的首尾各增加了 BERT 的特殊标记
# 中文
array([[False, True, False, False, False, False, False, False],
[False, False, True, False, False, False, False, False],
[False, False, False, True, False, False, False, False],
[False, False, False, False, True, False, False, False],
[False, False, False, False, False, True, False, False],
[False, False, False, False, False, False, True, False]])
# 英文
array([[False, True, False, False, False, False, False, False, False, False],
[False, False, True, False, False, False, False, False, False, False],
[False, False, False, True, True, False, False, False, False, False],
[False, False, False, False, False, True, True, False, False, False],
[False, False, False, False, False, False, False, True, False, False],
[False, False, False, False, False, False, False, False, True, True],
[False, False, False, False, False, False, False, False, False, False],
[False, False, False, False, False, False, False, False, False, False]])
# 位置编码:dist_inputs,根据词对的相对距离设计了 20 个 Embedding,并根据前后顺序与距离的 2 进制(2**0, 2**1, 2**2, ...)进行分配
# Bx8x8
tensor([[[19, 10, 11, 11, 12, 12, 12, 12],
[ 1, 19, 10, 11, 11, 12, 12, 12],
[ 2, 1, 19, 10, 11, 11, 12, 12],
[ 2, 2, 1, 19, 10, 11, 11, 12],
[ 3, 2, 2, 1, 19, 10, 11, 11],
[ 3, 3, 2, 2, 1, 19, 10, 11],
[ 3, 3, 3, 2, 2, 1, 19, 10],
[ 3, 3, 3, 3, 2, 2, 1, 19]],
[[19, 10, 11, 11, 12, 12, 0, 0],
[ 1, 19, 10, 11, 11, 12, 0, 0],
[ 2, 1, 19, 10, 11, 11, 0, 0],
[ 2, 2, 1, 19, 10, 11, 0, 0],
[ 3, 2, 2, 1, 19, 10, 0, 0],
[ 3, 3, 2, 2, 1, 19, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0]]])
# 代码
# 相对位置最大相差 9,句子长度可达 2**10,不过代码中将其限制到了 1000
dis2idx = np.zeros((1000))
dis2idx[1] = 1
dis2idx[2:] = 2
dis2idx[4:] = 3
dis2idx[8:] = 4
dis2idx[16:] = 5
dis2idx[32:] = 6
dis2idx[64:] = 7
dis2idx[128:] = 8
dis2idx[256:] = 9
length = 10 # 长度
dist_inputs = np.zeros((length, length), dtype=np.int_)
for k in range(length):
dist_inputs[k, :] += k
dist_inputs[:, k] -= k
for i in range(length):
for j in range(length):
if dist_inputs[i, j] < 0:
dist_inputs[i, j] = dis2idx[-dist_inputs[i, j]] + 9
else:
dist_inputs[i, j] = dis2idx[dist_inputs[i, j]]
# 对角线
dist_inputs[dist_inputs == 0] = 19
#最后是 entity_text,其实就是实体对应的 index 和实体类型的 id,这个用于评估
# [{'3-4-5-#-3', '3-4-7-#-3'}, {'0-1-2-#-2'}]
# 输入中还少了一个(在模型内部实现)用来区分上下三角的 reg_inputs,它等于对 grid_mask 下三角 Mask 与 grid_mask 之和
tril_mask = torch.tril(grid_mask2d.clone().long())
reg_inputs = tril_mask + grid_mask2d.clone().long()
# 具体实例
# tril_mask
tensor([[[1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1]],
[[1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]])
# gird_mask2d
tensor([[[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]],
[[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]])
# reg_inputs
tensor([[[2, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 1],
[2, 2, 2, 2, 2, 2, 2, 2]],
[[2, 1, 1, 1, 1, 1, 0, 0],
[2, 2, 1, 1, 1, 1, 0, 0],
[2, 2, 2, 1, 1, 1, 0, 0],
[2, 2, 2, 2, 1, 1, 0, 0],
[2, 2, 2, 2, 2, 1, 0, 0],
[2, 2, 2, 2, 2, 2, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]])
# 注意: reg_inputs 的值域是 {0, 1, 2},分别代表 Padding,上三角和下三角区域。
# ------- 输出 -------
# 最终输出的 logits 的 shape 为 B x SeqLen x SeqLen x LabelNum,换到本例中就是 2x8x8x10,取 argmax 后则变成 2x8x8 。
# 如果是训练阶段,logits 会和 grid_labels 一起计算损失,损失函数为交叉熵。
criterion = nn.CrossEntropyLoss()
# outputs 2x8x8x10, gird_labels 2x8x8, grid_mask2d 2x8x8
loss = criterion(outputs[grid_mask2d], grid_labels[grid_mask2d])
#注意这里用 grid_mask2d 将 Padding 的全部丢掉。
# 记录预测值时也用同样的方法操作:
# 2x8x8
pred = torch.argmax(outputs, -1)
y_true = grid_labels[grid_mask2d].contiguous().view(-1)
y_pred = pred[grid_mask2d].contiguous().view(-1)
# --------- 解码 -------
# 最后来看一下如何进行解码,官方代码如下(略作修改):
from collections import defaultdict
def decode(outputs, length):
decode_entities = []
for index, (instance, l) in enumerate(zip(outputs, length)):
# 获取实体和类型的index
forward_dict = defaultdict(list)
head_dict = defaultdict(set)
ht_type_dict = {}
for i in range(l):
for j in range(i + 1, l):
if instance[i, j] == 1:
forward_dict[i].append(j)
for i in range(l):
for j in range(i, l):
if instance[j, i] > 1:
ht_type_dict[(i, j)] = instance[j, i].numpy().tolist()
head_dict[i].add(j)
# 递归执行解码
predicts = []
def find_entity(key, entity, tails):
entity.append(key)
if key not in forward_dict:
if key in tails:
typ = ht_type_dict[(entity[0], entity[-1])]
predicts.append((entity.copy(), typ))
entity.pop()
return
else:
if key in tails:
typ = ht_type_dict[(entity[0], entity[-1])]
predicts.append((entity.copy(), typ))
for k in forward_dict[key]:
find_entity(k, entity, tails)
entity.pop()
for head in head_dict:
find_entity(head, [], head_dict[head])
decode_entities.append(predicts)
return decode_entities
# 上面的例子结果为:
pred_labels = torch.argmax(outputs, -1)
decode(pred_labels, sent_length)
# [[], [([0, 1, 2], 2)]]
# 由于模型没有使用英文数据集,所以第一个句子无结果。
整个模型在输入构造方面可谓设计颇多,但每一个又有其独特的意义,而且最后整体效果确实不错。
- 词信息其实并没有使用到训练过程中,与作者沟通后主要出于两个方面考虑。
- 第一,本文主要为了证明模型在三种不同类型 NER 任务及中英文数据上的普遍性,所以提供的其实是一个兼容的方案,并没有针对这块单独设计和处理;
- 第二,实验结果证明即使在没有分词和词典知识的情况下效果依然不错。
- 因此,如果在中文任务上,可以结合词信息和位置编码进行更多的尝试。
更多解读见原文
SOTA结果
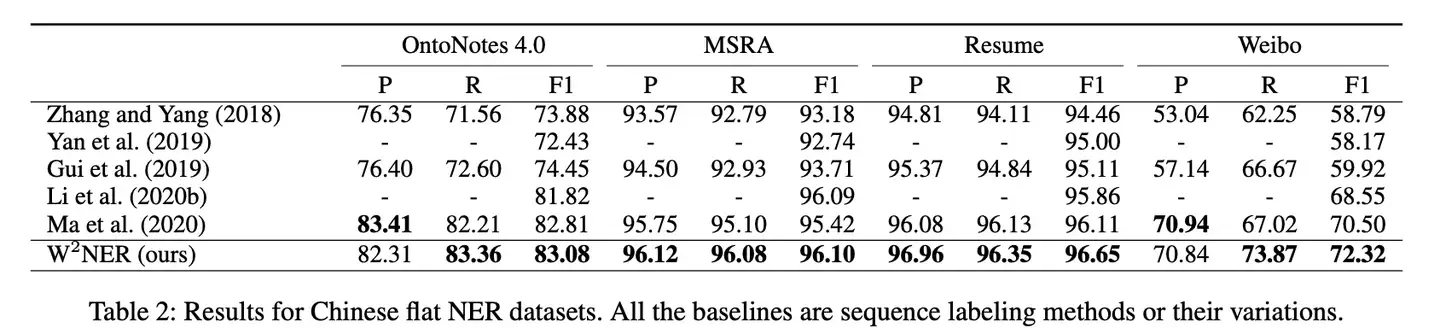
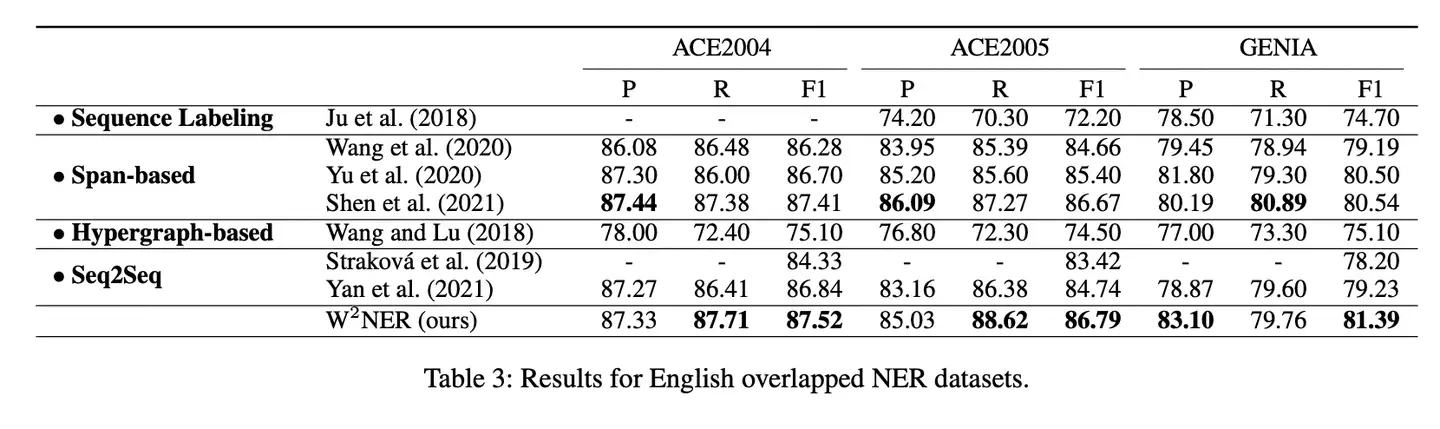
- 1、中文NER取得了SOTA
- 2、英文NER取得了SOTA

TweebankNLP-NER
【2020.5.10】MIT 推出 TweebankNLP bertweet-tb2_ewt-pos-tagging
the state-of-the-art Twitter POS tagging model (with 95.38% Accuracy) on Tweebank V2’s NER benchmark (also called Tweebank-NER), trained on the corpus combining both Tweebank-NER and English-EWT training data.
- Tweebank-NER, an English NER corpus based on Tweebank V2 (TB2)
- refer to this our paper and github page
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("TweebankNLP/bertweet-tb2_ewt-pos-tagging")
model = AutoModelForTokenClassification.from_pretrained("TweebankNLP/bertweet-tb2_ewt-pos-tagging")
Google NER 本地
Google ml-kit 工具包提供多种识别能力:OCR、人脸检测、图片加标签、目标检测跟踪、姿势检测以及图片分类
NLP类API功能: 语种识别、翻译、智能回复、实体提取
- NER, 支持功能如下:
| 实体 | 示例 |
|---|---|
| 地址 | 马萨诸塞州剑桥市第三大街 350 号 |
| 日期-时间 | 2019 年 9 月 29 日,明天明天下午 6 点见面 |
| 电子邮件地址 | entity-extraction@google.com |
| 航班号(仅限 IATA 航班代码) | LX37 |
| IBAN | CH52 0483 0000 0000 0000 9 |
| ISBN(仅限版本 13) | 978-1101904190 |
| 货币/货币(仅限阿拉伯数字) | 12 美元、25 美元 |
| 付款 / 信用卡 | 4111 1111 1111 1111 |
| 电话号码 | (555) 225-3556 |
| 12345 | |
| 跟踪编号(标准化国际格式) | 1Z204E380338943508 |
| 网址 | www.google.com https://zh.wikipedia.org/wiki/Platypus |
API 侧重于精确率而非识别。为了确保检测准确性,特定实体的某些实例可能漏掉。大多数实体都可以跨语言和语言区域进行检测
工程实现
实体识别NER
- 3-1. Bert-MRC
- 3-2. Bert-CRF
- 【2023-9-14】NER 序列标注方法实现总结:sequence_labeling, 包含 task_sequence_labeling_ner_W2NER
NER 算法代码
代码库包含各种序列标注算法实现
- sequence_labeling
- task_sequence_labeling_cws_crf.py
- task_sequence_labeling_ner_CNN_Nested_NER.py 嵌套 NER
- task_sequence_labeling_ner_W2NER.py 2022 NER sota, 任务统一
- task_sequence_labeling_ner_cascade_crf.py NER
- task_sequence_labeling_ner_crf.py
- task_sequence_labeling_ner_crf_add_posseg.py
- task_sequence_labeling_ner_crf_freeze.py
- task_sequence_labeling_ner_efficient_global_pointer.py
- task_sequence_labeling_ner_global_pointer.py
- task_sequence_labeling_ner_lear.py
- task_sequence_labeling_ner_mrc.py MRC实现NER
- task_sequence_labeling_ner_span.py
- task_sequence_labeling_ner_tplinker_plus.py
实体正则表达式
正则可视化
正则可视化展示
- 工具地址:ToolTT在线工具箱
- wangwl
电话号码
手机号码
# 精确匹配11位
/^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$/
# 模糊匹配11位
/^1[3456789]\d{9}$/
座机号码
# 座机号码
/^(0\d{2,3})-?(\d{7,8})$/
# 国内电话号码(0511-4405222、021-87888822):
\d{3}-\d{8}|\d{4}-\d{7}
人名
人名
- 其中,{2,4}控制可输入字符长度
# 人名--中文
/^[\u4e00-\u9fa5]{2,4}$/
# 中文字符的正则表达式:
[\u4e00-\u9fa5]
邮箱
邮箱/邮编
/^\w+@[a-z0-9]+\.[a-z]{2,4}$/
/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/
/^([a-zA-Z\d])(\w|\-)+@[a-zA-Z\d]+\.[a-zA-Z]{2,4}$/
# 腾讯QQ号:(腾讯QQ号从10000开始)
[1-9][0-9]{4,}
# 中国邮政编码:
[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
证件
身份证号码
# 简单校验
/(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)/
# 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X
/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$/
# 港澳身份证
/^([A-Z]\d{6,10}(\w1)?)$/
URL
网址
/^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/|www\.)(([A-Za-z0-9-~]+)\.)+([A-Za-z0-9-~\/])+$/
# 域名
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
# 内部url,两种
[a-zA-z]+://[^\s]*
^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
# IPv4地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
时间日期
日期
# 日期格式:
^\d{4}-\d{1,2}-\d{1,2}
# 一年的12个月(01~09和1~12):
^(0?[1-9]|1[0-2])$
# 一个月的31天(01~09和1~31):
^((0?[1-9])|((1|2)[0-9])|30|31)$
货币
货币
- 钱的输入格式有四种钱: “10000.00” 和 “10,000.00”, 和没有 “分” 的 “10000” 和 “10,000”:
^[1-9][0-9]*$
时间/日期识别
【2023-9-25】NLP实体命名识别之时间识别
地址识别
地址是日常生活中一种重要的文本信息,诸多场景需要和地址打交道,如电商购物、外卖配送、水电气开户等。
邮寄地址识别
【2022-2-28】邮寄地址识别(BiLSTM+CRF)
- address_ner
- BiLSTM+CRF实现该任务的开发
数据集:
- 训练集 19722 条
- 测试集 2994 条
确定的实体
- 1、省份
- 2、城市
- 3、区县
- 4、具体地址
- 5、收件人
- 6、收件人联系电话
项目亮点
- 1、对省、市、区全称和简称做了较完整的收集,构建的训练集数据基本覆盖全国省市区。
- 2、对全国采用姓氏做了较完整的收集,构建的训练集数据基本覆盖全国姓氏。
- 3、对城市和区县的邮政编码进行整理,返回报文中包含邮政编码。
# 测试
http://127.0.0.1:5033/base/address/predict?text=北京市大兴区312国道西侧 修昊14975916791
# 测试集
新疆维吾尔自治区P\阿勒泰地区C\哈巴河县D\解放南路1号院2号楼2号底商1室A\ O\宋魏娜R\18483487955T\
王永侠R\15585439189T\ O\新疆维吾尔自治区P\阿勒泰地区C\青河县D\锦逸路97号C3栋3层299号A\
新疆维吾尔自治区P\阿勒泰地区C\吉木乃县D\仙女镇龙川北路西侧广源世纪商业中心141室A\ O\崔宏生R\14736513341T\
孙国群R\17831222383T\ O\新疆维吾尔自治区P\石河子市D\柏加镇双源村湖田组414号A\
地址解析
地址要素解析是将地址文本拆分成独立语义的要素,并对这些要素进行类型识别的过程
地址结构化解析
- 天池比赛:地址结构化解析数据集
# 输入:
浙江省杭州市余杭区五常街道文一西路969号淘宝城5号楼
# 输出:21类标签类型
Province=浙江省
city=杭州市
district=余杭区
town=五常街道
road=文一西路
road_number=969号
poi=淘宝城
house_number=5号楼
addressparser
- PyPI version Downloads MIT Python3 Python2.7 GitHub issues Wechat Group
- 中文地址提取工具,支持中国三级区划地址(省、市、区)提取和级联映射,支持地址目的地热力图绘制。
- 适配python2和python3。
- Demo
#pip install addressparser
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
import addressparser
df = addressparser.transform(location_str)
#df = addressparser.transform(location_str, pos_sensitive=True) # 带位置索引
#df = addressparser.transform(location_str, cut=True) # 切词模式, jieba
print(df)
# 绘制热力图,pyecharts
from addressparser import drawer
drawer.echarts_draw(processed, "echarts.html")
效果
["徐汇区虹漕路461号58号楼5楼", "福建泉州市洛江区万安塘西工业区"]
# ↓ 转换
|省 |市 |区 |地名 |
|上海市|上海市|徐汇区|虹漕路461号58号楼5楼 |
|福建省|泉州市|洛江区|万安塘西工业区 |
数据集:中国行政区划地名
数据源:
- 爬取自国家统计局,中华人民共和国民政局全国行政区划查询平台
- 数据文件存储在:addressparser/resources/pca.csv,数据为2021年统计用区划代码和城乡划分代码(截止时间:2021-10-31,发布时间:2021-12-30)
业界经验
美团
【202-7-23】美团搜索中NER技术的探索与实践

LLM NER
LLM 对 NER 影响
论断:
- “All NLP Tasks Are Generation Tasks”
NLPer都不会陌生。
- Seq2Seq框架提出的那一天, 就得到这样的认知:所有的NLP任务都可以转化为生成任务。
- 遗憾:2017年至2019年间,Seq2Seq虽然在解决信息抽取问题上有过一些工作、但终究没有形成“大气候”。
- 而随着生成式预训练语言模型的强大,Seq2Seq(准确地讲是Text-to-Text)“王者归来”,有了不少有趣有效的工作。
宾夕法尼亚大学 Dan Roth 教授等在《Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey》一文中,将 生成式统一建模作为当今NLP的三大主流范式之一
- 论文指出:随着 「生成式预训练模型」 的日益强大(如T5、BART),如上图所示,通过T5所有NLP任务都可转化为“Text-to-Text”方式建模。
作者:JayJay
GPT-NER
【2023-6-5】如何用GPT大模型解决NER任务?
北大、香农科技、浙大、亚马逊、南洋理工等多个机构近期联合发表的工作,利用GPT这类预训练大模型解决NER问题。
GPT等大模型在众多NLP任务中都取得了非常显著的效果,但是在NER上效果却并不理想。造成大模型解决NER问题效果一般的核心原因
- NER任务和GPT训练方式的差异。
- GPT本质上是一个生成模型,而NER一般被当作序列标注任务(也可以是阅读理解、生成任务)
因此将GPT应用到NER中,一个必须解决的问题: 如何将NER任务转换成生成任务。
论文提出了GPT-NER,将NER任务通过prompt转换成生成式任务,用预训练大模型解决NER问题。
GPT-NER的整体思路
- 将NER这种序列标注任务,通过prompt转换成一个生成任务,输入到大模型中,让其生成初步的NER打标结果。
由于大模型存在幻觉问题,对于一些非实体结果也经常打出NER标签, 使用大模型自己来验证生成的结果是否准确。整体来看,GPT-NER包括初步结果生成和结果验证两个部分,这两个步骤都由大模型自身完成。
- (1) 序列标注转换为生成任务
- (2) 样例选择
- (3)生成结果验证
详情
(1) 序列标注转换为生成任务
整个GPT的输入包含3个主要部分:
- Task Description:用来描述任务,例如输入I am an exelent linquist,设置场景,让模型进行角色扮演,知道自己要从语言学专业角度进行NER打标;
- Few-shot Demonstration:给一些NER任务的示例,用来指导GPT生成的样本格式。每个样例由Input和Output组成。对于输出的格式,一种直观方法是直接输出LOC O O O这种NER打标序列。但是这种输出对GPT非常不友好。因此文中采用的输出格式为,将原来句子中的Tagging部分两侧使用@@##特殊符号进行标记;
- Input Sentence:即待标注的样本。
Prompt 样例

(2) 样例选择
Demonstration的引入相当于是在做few-shot learning,目标是希望找到一个和当前输入句子尽可能相似的文本,这样才能让待预测任务更多借鉴输入样例的知识,实现准确预测。
那么如何寻找合适的样例呢?提出了一种基于样本表示向量+KNN检索的样例选择方法,整体流程如下。

- 最基础的方法是使用一个文本表示模型(比如
SimCSE,基于对比学习训练的句子级别表示模型)产出句子向量,计算和当前输入样本相似度,检索最相似的几个句子作为样例。然而,问题是 NER是一个token级别的序列标注任务,使用整句语义检索可能导致检索出来的句子确实语义比较像,但是NER任务上可借鉴的信息不多。 - 因此,文中提出了一种token级别的检索任务,使用一个训练好的NER模型得到每个token的表示,然后根据token表示进行KNN检索出高相关的token,将包含这些token的句子作为候选样例。Token的NER向量相似的,说明在NER任务上有相似的上下文,更有可能与待预测样本在NER角度相关。
(3)生成结果验证
大模型幻觉现象是一个常见问题。在NER任务上,大模型经常会给非实体的词标记为实体。文中增加了一个验证模块,将上一步生成的初步NER结果,修改prompt的形式,再次输入到大模型进行一次验证。
- 整个Prompt也是由 Task Description、Demonstration、Input Sentence 三个部分组成,下图是一个文中的示例。在样例选择上,也使用了类似的基于NER模型token级别表示的KNN检索方法。

GPT-NER能够达到和有监督模型基本持平的效果。并且本文用的是GPT3模型,随着大模型版本的进一步迭代,GPT-NER这类方法有望取代传统的有监督NER方法。
Mistral NER
【2024-3-22】大模型做NER, 微调大型语言模型进行命名实体识别
个人可识别信息(Personal Identifiable Information,PII)是指可以用于识别、联系或定位个人身份的数据或信息。这些信息可以单独使用或结合其他信息,使得可以辨认特定的个人。PII通常包括但不限于以下内容:全名,电子邮件地址,身份证号码,驾驶证号码,社会安全号码,银行账号,生日,地址
微调LLM主要有以下2个方面的挑战:
- 调优的LLM不应该产生命名实体的幻觉。从一组受控的实体标签中进行检测。
- 微调LLM应该生成结构良好输出。LLM输出不应包含无关信息(例如,解释为什么检测到某些实体)。因为输出中的额外令牌导致每个输入的推理成本更高。并且下游任务也无法使用。
NER数据集,广泛采用BIO格式。
微调 mistral /Mistral-7B-Instruct-v0.2 模型。
- 添加了自定义的损失掩码
- 大约800个训练数据样本,大约400个测试样本和大约400个验证样本。
- 训练了3轮的模型,并在测试集上取得了相当高的精度/召回率/F1(96%以上)。
字符串标注方法超过了生成JSON编码方法
- 虽然JSON的格式是正确的,但在预测正确的’start_position’和’end_position’字符索引方面结果并不好。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
