- 文本分类 Text Classification
文本分类 Text Classification
总结
- 文本分类是自然语言处理的一个基本任务,试图推断出给定的文本(句子、文档等)的标签或标签集合。
- 文本分类算是NLP比较简单的任务之一,并且目前由于预训练语言模型的出现,现在文本分类直接上bert效果就挺好。
- 【2021-2-2】深度学习文本分类-模型&代码&技巧,NLP入门指南各类代码汇总
- 实际上,落地时主要还是和数据的博弈。数据决定模型的上限,大多数人工标注的准确率达到95%以上就很好了,而文本分类通常会对准确率的要求更高一些,与其苦苦调参想fancy的结构,不如好好看看badcase,做一些数据增强提升模型鲁棒性更实用。
- 【2021-8-5】深度学习文本分类模型综述+代码+技巧,文本分类方法快速选型导图
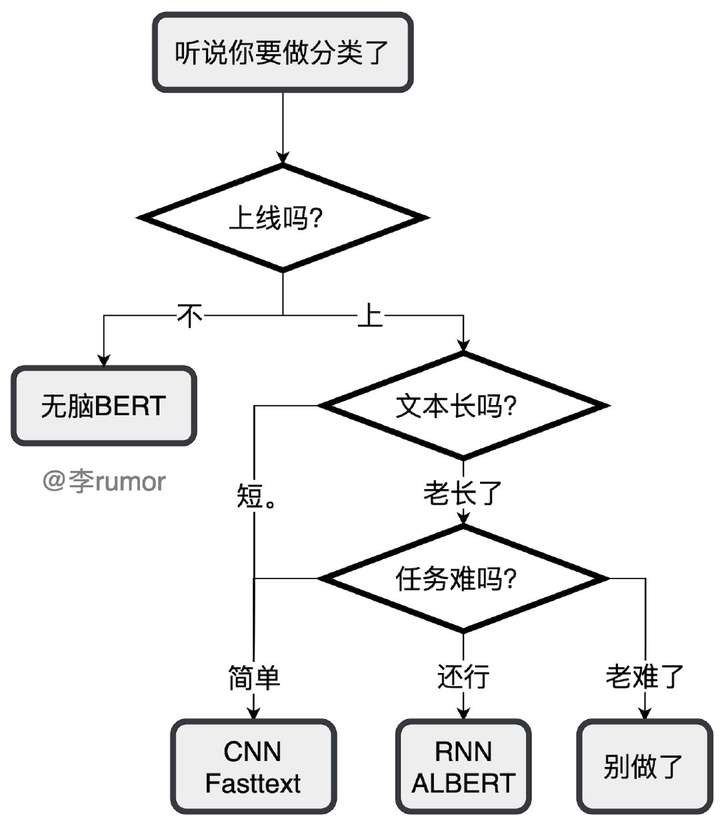
- 上线吗(不:BERT) → 文本长吗(短:TextCNN/FastText) → 任务难吗(还行:RNN/ALBERT) → 别做了
- 落地时主要还是和数据的博弈。数据决定模型的上限,大多数人工标注的准确率达到95%以上就很好了,而文本分类通常会对准确率的要求更高一些,与其苦苦调参想fancy的结构,不如好好看看badcase,做一些数据增强提升模型鲁棒性更实用。
- 【2021-9-16】NLP文本分类 落地实战五大利器, 从工业的角度浅谈实际落地中文本分类的种种常见问题和优化方案. 公开数据集讲解。
- Baseline用Roberta_base版本,把最后一层Transformer的输出进行mean和max后进行拼接,再连接全连接层,最后进行标签分类,由于Bert限制最大长度为512,对于长文本来说,可以通过「transfomrer-XL等改造模型」或者通过「截取字符」(从前面截取,或从中间截取,或从末尾截取)或「把文本进行分块」,分别输入模型中,再取概率平均,对于一般的任务,主要采用截取字符的方法,实现简单
- Micro F1值作为评价标准,分数,短文本 0.8932,长文本 0.5579,长文本由于标签类别多,加上标签数据不太充分,难度比短文本难不少。
提升方法
- (1)数据增强:EDA、对抗训练
- EDA(easy data augmentation)方法:同义词替换,回译,近音字替换,随机插入,随机交换,随机删除等等,效果最好的是「同义词替换」和「回译」
- 同义词替换:常用的同义词词表是哈工大的是nlpcda库
- 回译:把中文翻译成英文或法文或日本,再翻译回中文;
- 长文本并不适用于回译 → 改进:随机对长文本中的单句进行回译,而不是把整个长文本进行回译。)
- 注意:「增强后的样本要和实际预测的样本分布要相似」,这样才能得到比较好的正向效果。
- 对抗训练:对抗训练用于文本这几年基本成为算法比赛获奖方案的标配,如FGM、PGD、YOPO、FreeLB 等一些系列的思想。它属于数据增强的一部分,因为在深度学习进行文本分类中,无外乎将字或词映射成向量作为模型输入。
- EDA(easy data augmentation)方法:同义词替换,回译,近音字替换,随机插入,随机交换,随机删除等等,效果最好的是「同义词替换」和「回译」
- (2)数据去燥
- 算法工程师80%在洗数据,20%时间在跑模型;制约模型效果再上一步的,往往是数据质量,而不是模型,文本分类任务中,标注准确率95%就是非常好了
- 如何清洗标注数据?常用方法是根据业务规则来清洗、交叉验证清洗
- (3)类别不平衡
- 过采样、欠采样,推荐改造代价损失函数,因为前两者会带来噪声,后者不会,常用方法 focal loss
- (4)半监督学习:
- consistency loss
- sharpening predictions
- tsa
- confidence mask
- (5)模型轻量化
效果评测
- 短文本效果明显
| 方法 | 短文本 | 长文本 |
|---|---|---|
| baseline | 0.8932 | 0.5579 |
| +数据增强(同义词替换) | 0.8945 | 0.5742 |
| +FGM对抗训练 | 0.8970 | 0.5873 |
数据集
两个公开数据集:
- 今日头条的短文本分类
- 科大讯飞的长文本分类 数据集的下载见github的链接。
数据集的label个数、训练集、验证集和测试集的数量分布:
| 类目 | 短文本分类 | 长文本分类 |
|---|---|---|
| 标签个数 | 15个 | 119个 |
| 训练集数 | 229605条 | 10313条 |
| 验证集数 | 76534条 | 2211条 |
| 测试集数 | 76536条 | 2211条 |
可以看到:
- 短文本样本充足,20多W条训练数据只需分成15个类
- 长文本分类属于样本不足,1W条训练数据要分成119个类,其中数据集还有标签不平衡的问题。
短文本-头条
今日头条的短文本数据示例如下,通过新闻的标题对新闻进行分类
| label | text |
|---|---|
| 3 | 私募大佬跑起了谁 |
短文本分类的大部分数据都是很短的,经过EDA,发现99%以上的数据在40个字符以下
长文本-科大讯飞
长文本数据示例如下,通过APP的简介对APP进行类别分类,大部分数据长度在512以上,超过了Bert等模型的最大输入长度
| label | name | text |
|---|---|---|
| 16 | 射击游戏 | 星际激斗战斗重燃,《星空要塞》是一个基于未来科学背景的策略游戏。。。。 |
THUCNews-清华
- THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为 UTF-8 纯文本格式。
- 原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
- 使用THUCTC工具包在此数据集上进行评测,准确率可以达到88.6%。
不均衡问题
详见站内专题: 不均衡问题解法
文本增强
【2022-8-5】
pip install nlpcda
- 随机实体替换
- 近义词
- 近义近音字替换
- 随机字删除(内部细节:数字时间日期片段,内容不会删)
- NER类 BIO 数据增强
- 随机置换邻近的字:研表究明,汉字序顺并不定一影响文字的阅读理解«是乱序的
- 中文等价字替换(1 一 壹 ①,2 二 贰 ②)
- 翻译互转实现的增强
- 使用simbert做生成式相似句生成
经过细节特殊处理,比如不改变年月日数字,尽量保证不改变原文语义。即使改变也能被猜出来、能被猜出来、能被踩出来、能被菜粗来、被菜粗、能菜粗来。
资料
- 文本分类-基础算法
- 深度学习在文本分类中的应用
- 【2021-2-2】文本分类方法表格汇总
评估方法
不同类型的文本分类往往有不同的评价指标,具体如下:
- 二分类:accuracy,precision,recall,f1-score,…
- 多分类: Micro-Averaged-F1, Macro-Averaged-F1, …
- 多标签分类:Jaccard相似系数, …
- 为什么是jaccard?各类别不互(正交),不能用传统指标
实践经验
【2023-1-11】公司的数据集上
- BERT fine tune,精度82%,训练:30小时fune tune。serving:单GPU 5000词每秒;
- fasttext,精度81.5%,训练:1分钟,serving:单CPU 7万词每秒。
bert效果好一点,但落地成本也比较高,需要权衡一下。一般先用简单模型搭基线。
LLM 分类
【2023-9-20】使用 ChatGPT 进行 zero-shot 模型的自监督训练
ChatGPT 式的生成模型是目前阶段效果最好的 zero-shot 范式了。
但是大模型再美好,在部署成本和结果优化方面有些门槛。对于普通业务,用 LLM(Large Language Model)辅助小模型训练 是短期内更便于执行的落地方案。
模型冷启动阶段,由于缺乏标注数据,提升 zero-shot 方案的核心路线: 构造“伪样本”,构造尽可能多、尽可能准的伪样本。
两种情况
- 第一种: llm生成标签。有足量未标注数据,只需打上“伪标签”。
- 第二种: llm生成语料。无标注数据也不太够,在伪标签之外,还要用数据增强来构造“伪语料”。
zero-shot 分类
文本为 NLI(Natural Language Inference) 式的 zero-shot(推荐 huggingface 的 xlm-roberta-large-xnli,支持中文)。
zero-shot 分类 本质上这是一种迁移学习,用一个监督训练得到的双句 NLI 模型,完成单句文本分类任务。
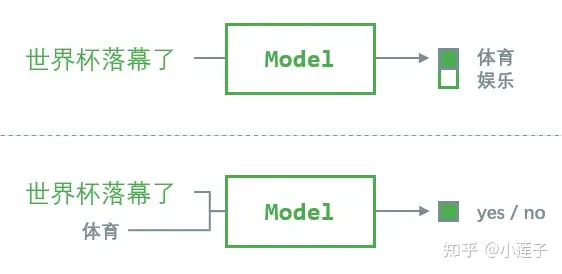
- premise(前提)= “世界杯落幕了”,使用模板 “这句话是关于{}的” 将标签“体育”转化为 hypothesis(假设)= “这句话是关于体育的”。由 NLI 模型给出判断,“是 / 否”。
- 当存在 N 个候选标签时,则构造 N 个 premise-hypothese 样本对,取“是”的概率最高的标签为输出标签。
2022 EMNLP
论文采用不同的 zero-shot 基座模型, 都开源。
- 2022 EMNLP, 传统优化路线
流程方法
- 取 1w 条无标注数据,用基座 NLI 模型打上伪标签。由于未经迭代的模型准确度有限,只取分类置信度最高的 1% 样本(100条左右)。在各个目标分类之上,top1 得分和 top2 得分的差距越大,此次预测的置信度越高。

GenCo
用到了 平替版 Alpaca-7B
- Generation-driven Contrastive Self-training for Zero-shot TextClassification with Instruction-tuned GPT
- code:GenCo
自训练的核心问题: 伪数据的筛选构造。
- 预测分数高的样本,准确度越高,噪声小,但是过于简单,引入的有效信息也很少;
- 预测分数低的样本,极有可能被打上错误的伪标签,但是往往是这类分类难度大的样本,更具备学习价值。
两者的取舍,对自训练效果有决定性的影响。
论文提出模型 GenCo,引入 ChatGPT 进行数据增强,这是一个让人眼前一亮的解决方案。
基座分类模型
- 借助
SimCSE,将 zero-shot 分类 转换为句向量对齐任务。对于一条样本 x 和对应标签 c,记 g(x, c) 为其编码向量的相似度(dot 或 cosine)。在所有候选标签中,g(x, c)为1的标签为文本分类的预测标签。
标签都是比较短的词语,不适合直接求语义向量。GenCo 用了两个 label-prompts 进行扩充,分别为:
lp1 = "Category:[label]"
lp2 = "It is about [label]"
然后对 lp1 和 lp2 的语义向量求平均值,作为标签向量。
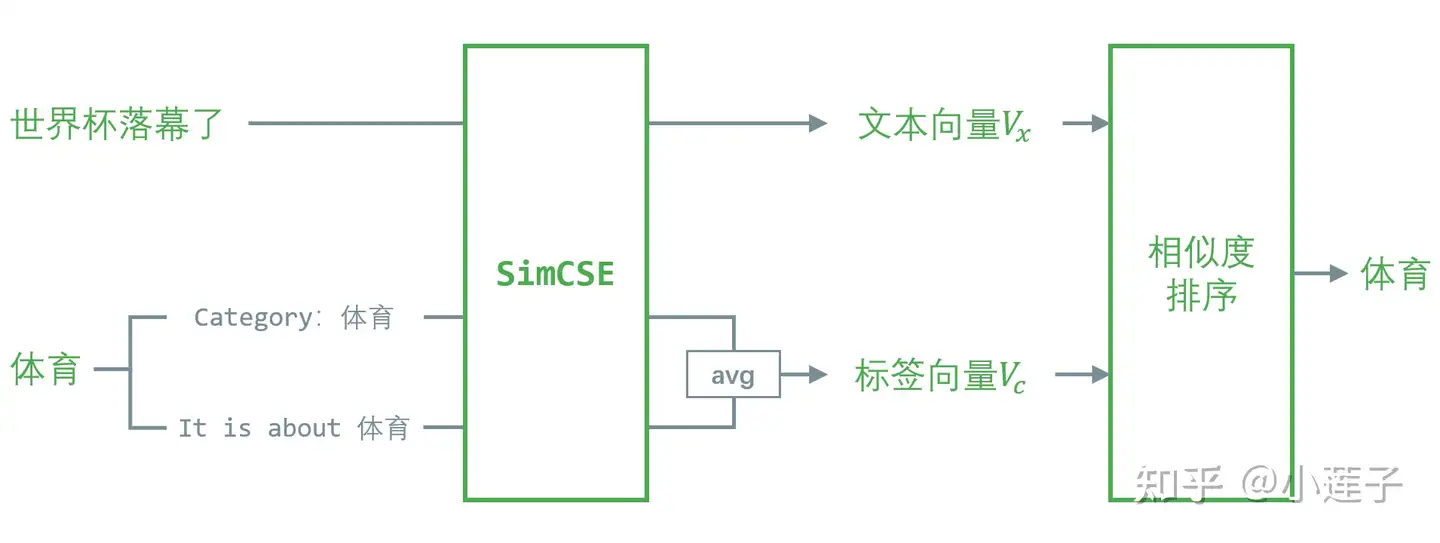
GenCo 的核心在于两次基于 Alpaca 的数据增强,出发点都是提升伪标签的预测准确度。

详见原文:
LLM 意图识别
详见站内专题:大模型意图识别专题
常规分类方法
TF-IDF
TF-IDF 通过高词频和低文档频率产生高权重,倾向于过滤常见词语,保留重要词语。
TF-IDF 基于词频(TF)和逆文档频率(IDF)来衡量词语在文档或语料库中的重要性,然后用此重要性对文本进行编码。
- tf-idf在nlp的比赛中仍然是一个强特征,合理使用就可以提分
代码
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
train_data = pd.read_csv(sys.argv[1],sep='|', names=["a","b","c","label"])
test_data = pd.read_csv(sys.argv[2],sep='|', names=["a","b","c","label"])
def pre_process(df):
df['real_path'] = df['c'].apply(lambda x:x.split("\\"))
df['real_path'] = df['real_path'].apply(lambda x:" ".join(x))
return df
train_data = pre_process(train_data) ## 训练集
test_data = pre_process(test_data) ## 测试集
data = train_data.append(test_data) ## 全集
#vectorizer = CountVectorizer()
#transformer = TfidfTransformer()
#tfidf = transformer.fit_transform(vectorizer.fit_transform(data['real_path']))
## add ngram feature
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=5000)
tfidf = tfidf.fit_transform(data['real_path'])
X_train = tfidf[:len(train_data)]
y_train = train_data['label'].values
X_test = tfidf[len(train_data):]
y_test = test_data['label'].values
print("\nthis is the RF Classifier:")
model = RandomForestClassifier()
model.fit(X_train,y_train)
y_predict = model.predict(X_test)
print("this is the precision:")
print(precision_score(y_predict, y_test))
print("this is the recall:")
print(recall_score(y_predict, y_test))
print(classification_report(y_predict, y_test))
BM25
BM25 是一种改进的文本检索算法,在 TF-IDF 基础上, 通过文档长度归一化和词项饱和度调整,更精确地评估词项重要性,优化了词频和逆文档频率的计算,并考虑了文档长度对评分的影响。
虽然不涉及词项上下文,但是 BM25 在处理大规模数据时表现优异,广泛应用于搜索引擎和信息检索系
BM25(Best Matching 25)是经典的信息检索算法,基于Okapi TF-IDF算法的改进版本,解决 Okapi TF-IDF 算法的一些不足之处。
其被广泛应用于信息检索领域的排名函数,用于估计文档D与用户查询Q之间的相关性。
一种基于概率检索框架的改进,特别是在处理长文档和短查询时表现出色。
BM25 核心思想
- 基于词频(TF)和逆文档频率(IDF)来,同时还引入了文档的长度信息来计算文档D和查询Q之间的相关性。
- TF-IDF 的改进: BM25 通过对文档中的每个词项引入饱和函数(saturation function)和文档长度因子,改进了 TF-IDF 的计算。让算法在衡量词与文档相关性时更加精准。
- 饱和函数: 在 BM25 中,对于词项的出现次数(TF),引入了一个饱和函数来调整其权重。这是为了防止某个词项在文档中出现次数过多导致权重过大。
实现方法:BM25算法详解与实践总结
【2025-11-14】豆包作答
BM25 算法的诞生分为初始理念提出和最终定型并命名两个关键时间节点
- 1976 年:初始核心理念提出
- 最早由信息检索领域先驱 Stephen Robertson 和 Karen Spärck Jones 在 1976 年提出,为 BM25 奠定了理论基础,属于算法的早期理念探索阶段,此时尚未形成最终被广泛应用的 BM25 完整形态。
- 1992 年左右:算法定型与标准化
- 经过多年迭代优化,到 1992 年前后,Stephen Robertson 等人(不同资料提及合作者包括 Hugo Zaragoza 等)对早期理念进行了完善,确定了文档长度归一化、可调参数等核心设计,最终形成了如今我们熟知的 BM25 算法。也有说法提到这一阶段该算法被正式命名为 BM25,且因首次在 Okapi 检索系统中实现,常被称为 Okapi BM25。
BM25变体
BM25优缺点
优点:
- BM25 广泛使用的排序算法,因为在生成相关搜索结果方面简单而有效。
- 同时考虑了词语频率和文档长度规范化,这有助于解决文档长度偏差的问题。
- 有效地处理大型文档集合,使其可针对实际搜索方案进行扩展。
缺点:
- BM25 不考虑查询和文档的语义含义或上下文,这可能会导致某些类型的查询排名不理想。
- 假定查询词之间的统计独立性,这在存在词语依赖关系的某些情况下可能并不成立。
- 严重依赖词语频率和文档长度,可能会忽略其他重要因素,如文档结构和相关性反馈。
N-Gram
- 单纯的char embedding所提供的特征比较单一,所以一般会加别的特征,n-gram就是其中的一个,可以通过字符级别的n-gram来。
- n-gram的优点:
- 为罕见的单词生成更好的单词向量:根据上面的字符级别的n-gram来说,即使这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量
- 在测试集上,即使单词没有出现在训练语料库中(OOV),仍然可以从字符级n-gram中构造单词的词向量,即字符级n-gram利用了单词的形态学信息。这个在形态学丰富的语言中挺有用。
- n-gram可以让模型学习到局部词序信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息
Word2vec
- 一篇浅显易懂的word2vec原理讲解
-
- 神经网络语言模型
- 神经网络语言模型包含两个非线性层,求解起来复杂度很高,于是出现了两种更高效的神经网络模型CBOW和Skip-Gram

CBOW
- CBOW 是 Continuous Bag-of-Words 的缩写,与神经网络语言模型不同的是,CBOW去掉了最耗时的非线性隐藏层

Skip-Gram
Skip-Gram的模型图与CBOW恰好相反
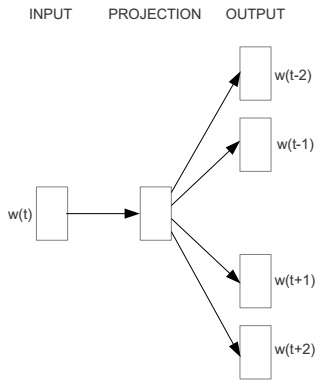
层次softmax
word2vec在预测词语并进行梯度传播时,最后一层是个多分类,会计算整个词典中每个词的概率。但这个词表往往是很大的,所以softmax本身的计算量非常大,但在反向传播时大部分参数的梯度都是0,造成了很大的资源浪费,间接降低了训练的速度。
由于softmax层非常昂贵,每次计算的复杂度为o(v) ,所以用层次softmax或者负采样来替换掉输出层,降低复杂度。
论文:《Bag of Tricks for Efficient Text Classification》
- FastText模型只有三层:输入层、隐含层、输出层(Hierarchical Softmax)。输入是多个单词的词向量,隐含层是对多个输入的词向量的叠加的平均,输出是一个特定的label。
- { x1, x2, x3 } -> hidden(平均) -> label
- drawio
层次softmax是一棵huffman树,树的叶子节点是训练文本中所有的词,非叶子节点都是一个逻辑回归二分类器,每个逻辑回归分类器的参数都不同
- 基于层次softmax的CBOW

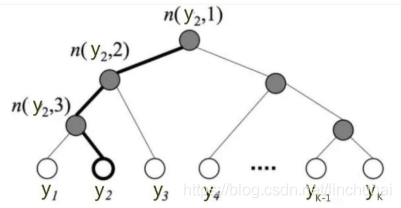
用Hierarchical Softmax来降低训练时间,首先根据每个label出现的概率,对所有的label,构造一棵赫夫曼树。如下图,若有n个label,则该赫夫曼树有n个叶结点,n-1个非叶结点, 每个非叶结点都对应一个参数Θ,其中每个叶节点都有一个唯一对应的赫夫曼编码(假设左子树为0,右子树为1),则图中叶节点y2的赫夫曼编码为001。
假设当前训练样本的标签为y2,y2的赫夫曼编码为001,则训练步骤如下:
- 从根结点n(y2,1)开始,赫夫曼编码当前为0,使用二分类,计算向左走的概率
- 走到n(y2,2)结点,赫夫曼编码当前为0,使用二分类,计算向左走的概率
- 走到n(y2,3)结点,赫夫曼编码当前为1,使用二分类,计算向右走的概率
- 最后走到了叶节点y2,则损失函数就是各个叶节点进行二分类的概率的乘积
- 根据损失函数,更新所走过的路径上的非叶结点的参数Θ 实质上就是从根节点开始,沿着Huffman树不断的进行二分类,并且不断的修正各中间向量Θ
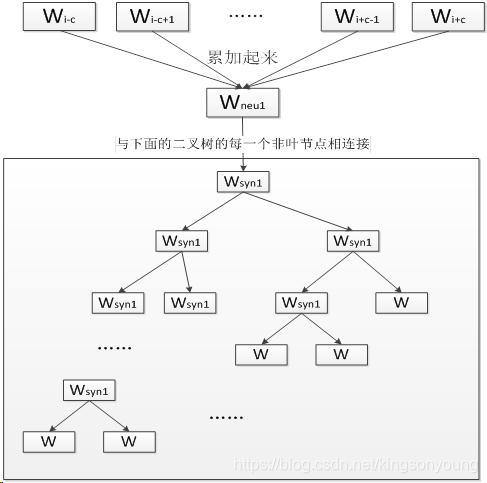
Hierarchical Softmax的核心思想就是将一次多分类,分解为多次二分类, 举个例子,有 [ 1,2,3,4,5,6,7,8 ] 这8个分类,想要判断词A属于哪个分类,我们可以一步步来,首先判断A是属于 [ 1,2,3,4 ]还是属于[ 5,6,7,8 ]。如果判断出属于[ 1,2,3,4 ],那么就进一步分析是属于[ 1,2 ]还是[ 3,4 ],以此类推。这样一来,就把时间复杂度从o(hN)降为o(hlogN)
结合Hierarchical Softmax的思想后,FastText模型如下图所示,其中hidden layer的节点与哈夫曼树的每个非叶节点进行连接
Pytorch实现FastText模型对AG_news数据集进行四分类预测(torchtext实现数据预处理)
负采样
负采样实际上是采样负例来帮助训练的手段,与层次softmax一样,用来提升模型的训练速度。
- 模型对正例的预测概率是越大越好,模型对负例的预测概率是越小越好。由于正例的数量少,很容易保证每个正例的预测概率尽可能大,而负例的数量特别多,所以负采样的思路就是根据某种负采样的策略随机挑选一些负例,然后保证挑选的这部分负例的预测概率尽可能小。
- 所以,负采样策略是对模型的效果影响很大,word2vec常用的负采样策略有均匀负采样、按词频率采样等等。
- 例如:原本词表有10000个词,传统方法对所有词进行softmax,会更新全部10000个词的参数;如果从词表中随机抽样5个负样本,再加上1个原始词,一共6个词,那么在此次梯度更新中就只更新这6个词的;更新数量为原来的1/20
negative sampling在以下几种情况可能会有不一样的结果。
- 1)样本信息过分冗余,通过negative sampling可以在相同机器资源的情况下提高训练速度,而且对效果影响很有限,这对于有限预算下是很重要的。
- 2)负样本不能有效反应用户真实意图的情况下,negative sampling可能会带来收益,比如有一些场景用户很可能大部分都没有看到而导致的负样本采集;
- 3)对于不同的问题也可能会不太一样,比如说implicit和explicit的问题,implict的feedback本身也是有折损的,也就是不点击不代表不喜欢,点击也不代表一定喜欢,需要考虑的信号就需要更仔细的看了。
作者:知乎链接
【2022-2-8】语言模型采样策略,源自论文:THE CURIOUS CASE OF NEURAL TEXT DeGENERATION
语言模型都是基于给定的一段文本,然后预测下一个token的概率。
- 给定”我喜欢美味的热”,模型可能会预测下一个token为: “狗” 80% 概率,饼干 5% 概率,等等。 基于这种模式,可以生成任意长度的序列。
- 比如,可以输入”我喜欢”, 模型可以输出一个token,”一个”, 一起得到”我喜欢一个”。然后在输入进模型可以得到下一个token的概率分布,可以一直循环这个过程。但是这样迭代下去最终会陷入死循环,或者偏离话题。
如果总是对最可能的单词进行采样,最终的结果可能变成:”我爱你爱我爱你爱我…” —— 退化(degenerate)问题
- 这不符合常理,但是语言模型中模型的大部分注意力仅集中在最新的一些token上。
- 另外,常用的采样方法是基于分布的采样。存在的问题是,如果有5万种可能的选择,即使最低的25000个token每个都不太可能,但是他们的概率加起来可能有30%。
- 这意味着,对于每个样本都有33%的概率完全偏离训练的结果。 由于前面提到的上下文一般较短,每个待生成的token比较依赖历史最近生成的文本,这样会导致误差不但传递放大。
解决方法:
- (1)Temperature sampling 退火采样
- temperature sampling是受统计热力学启发的,其中高温意味着更可能遇到低能态。 在概率模型中,logit起着能量的作用,可以通过将logit除以temperature, 然后在softmax,获得概率分布。
- 较低的temperature可以让模型对最佳选择越来越有信息,当temperature大于1,则会降低,0则相当于 argmax/max ,inf则相当于均匀采样。
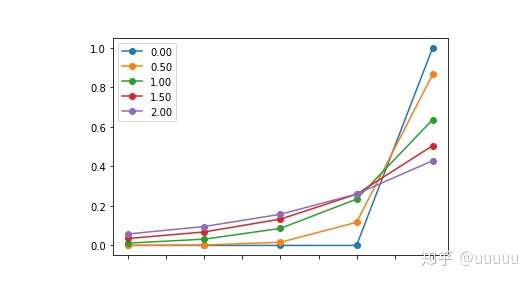
- (2)Top k sampling Top k采样
- Top k sampling表示对概率进行排序,然后对位置kth之后的概率转换成0
- 很显然,这样能提升长尾那部分概率的干扰,降低跑偏的可能性,但有些例子中,很多词确实是可以从合理范围采样(见下图broad distribution), 某些情况下,则不可以(narrow distribution)

- (3)Top p sampling Top p采样
- 为了解决top k问题,作者提出了top p sampling - aka nucleus sampling, 通过对概率分布进行累加,然后当累加的值超过设定的阈值p,则对之后的概率进行置0,在上面的例子里面,在broad distribution中,可能要去top 100个token才能达到0.9。在narrow distribution中,可能只需要 hot和 warm 2个token就可以达到0.9。通过这种方式,可以避免长尾部分的干扰,同时当top token的置信度不高的时候,仍旧保证多样性。
- 一般情况下,在训练的过程中,即使模型预测错了,也会人为的扭转成正确的token,然后结合之前的token,预测下一个token, 这就导致模型不会出现这种复合错误,在测试的时候,它需要使用自己生成的token,来预测,这可能是导致maximum likelihood sampling失效的原因。
- (4)自动选取超参-p&k
- 目标是通过top k 和 top p来最大化下一个预测最大概率的token为真实token。对于k, 可以直接找到真实token对应的sorted之后的index, 对于p, 可以看真实token对应的累计之后的位置。
- 比如”我喜欢吃热”,真实token是“狗”,而模型top 1置信度对应的token是”煎饼”,top 1对应的累加概率为60%,往低概率的token继续查找,如果发现”狗“对应的index是3,此时对应的累加概率是85%,这时候就找到了最优的p了。
超参搜索
- 如果是在训练集上评估模型,最好设置top k = 1, 但是模型结果的不确定性,可能真实答案是比较低的预测概率。而且,一个大的词表,比如5w, 可能有1半的词,在很多数据集上都不会出现,但是模型对这些不确定,通过top k或者top p的方法对这部分概率的置0,相当于合并了这些模型从来没见过的token。
代码
import torch
import torch.nn.functional as F
a = torch.tensor([1,2,3,4.])
## (1)退火采样
F.softmax(a, dim=0)
## tensor([0.0321, 0.0871, 0.2369, 0.6439])
F.softmax(a/.5, dim=0)
## tensor([0.0021, 0.0158, 0.1171, 0.8650])
F.softmax(a/1.5, dim=0)
## tensor([0.0708, 0.1378, 0.2685, 0.5229])
F.softmax(a/1e-6, dim=0)
## tensor([0., 0., 0., 1.])
## (2)top k/p采样计算
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
top_k = min(top_k, logits.size(-1))
if top_k > 0:
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
sorted_indices_to_remove = cumulative_probs >= top_p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = torch.zeros_like(logits, dtype=torch.uint8).scatter_(
dim=-1, index=sorted_indices, src=sorted_indices_to_remove )
logits[indices_to_remove] = filter_value
return logits
## 超参搜索
def best_k_p(logits, golden, verbose=False):
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
ks = (sorted_indices == golden).nonzero()[:, 1]
ps = cumulative_probs[sorted_indices == golden]
#print('top 5:', enc_.decode(sorted_indices[0, :5].tolist()))
return ks, ps
FastText —— 适合长文本
介绍
- 【2021-5-27】fasttext, 简介 ,Library for efficient text classification and representation learning
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比优点:
- 1、fastText在保持高精度的情况下加快了训练速度和测试速度
- 2、fastText不需要预训练好的词向量,fastText会自己训练词向量
- 3、fastText两个重要的优化:Hierarchical Softmax、N-gram
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
- 2016年,首次发布C++版的fastText,只支持命令行模式
- Bayu Aldi Yansyah开发了Python版本的工具包fasttext
- Facebook发布包含Python版本的fastText
- 2019年6月25日,Facebook融合两个工具包
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
- 模型架构: fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
- fastText模型架构和word2vec的CBOW模型架构非常相似, 只有三层:输入层、隐含层、输出层(Hierarchical Softmax)
- 输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。

- 层次softmax: 在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈夫曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
- 注意:分层softmax是完全softmax的一个近似,分层softmax在大数据集上高效的建立模型,但通常会以损失精度的几个百分点为代价
- N-gram特征: fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
安装
- fasttext 是一个有效的学习字词表达和句子分类的库。建立在现代 Mac OS 和 Linux 发行版上。因为它使用了 C++11 的特性,所以需要一个支持 C++11 的编译器,这些包括:gcc-4.8 或更高版本, clang-3.3 或更高版本;
- 注意
- 目前fastext仅在CPU上运行
- 仅用于离散数据集,连续数据集不可用,需要离散化
- 数据集中少量的拼写错误不影响结果
- 模型训练中出现NaN,原因可能是学习率太高,需要降低
- 因为优化算法异步随机梯度下降算法或Hogwild,所以每次得到的结果都会略有不同,如果想要fastText运行结果复现,则必须将参数thread设置为1
- 参考
## 下载后安装
pip install fasttext
## 直接安装(可能失败)
git clone https://github.com/facebookresearch/fastText.git
cd fastText
pip install .
## 编译安装
wget https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
unzip v0.1.0.zip
cd fastText-0.1.0
make
## 测试
./fasttext
使用
上述的命令包括:
- supervised: 训练一个监督分类器
- quantize:量化模型以减少内存使用量
- test:评估一个监督分类器
- predict:预测最有可能的标签
- predict-prob:用概率预测最可能的标签
- skipgram:训练一个 skipgram 模型
- cbow:训练一个 cbow 模型
- print-word-vectors:给定一个训练好的模型,打印出所有的单词向量
- print-sentence-vectors:给定一个训练好的模型,打印出所有的句子向量
- nn:查询最近邻居
- analogies:查找所有同类词
代码:
## ----- 官方版本 -------
import fastText
## and call:
fastText.train_supervised
fastText.train_unsupervised
## ----- 非官方版本 -------
import fasttext
## and call:
fasttext.cbow
fasttext.skipgram
fasttext.supervised
## ----- 官方融合版本 -------
import fasttext
## and call:
fasttext.train_supervised
fasttext.train_unsupervised
分类示例
fasttext在进行文本分类时,huffmax树叶子节点处是每一个类别标签的词向量。在训练过程中,训练语料的每一个词也会得到响应的词向量。输入为一个window 内的词对应的词向量,隐藏层为这几个词的线性相加。相加的结果作为该文档的向量。再通过softmax层得到预测标签。结合文档真实标签计算 loss,梯度与迭代更新词向量(优化词向量的表达)。
参数方面的建议:
- loss function 选用 hs(hierarchical softmax)要比 ns(negative sampling)训练速度更快,准确率也更高
- wordNgram 默认为1,建议设置为 2 或以上更好
- 如果词数不是很多,可以把 bucket 设置小一些,否则会预留太多的 bucket 使模型太大
功能
- supervised 进行模型训练
- quantize 量化模型以减少内存使用
- test 进行模型测试
- predict 预测最可能的标签等
注意:
- 小数据集时,记得调整一个参数 mincount(默认是5),不然会出不来词表。
- 中文的分词之后,用空格隔开,也同样可以放入训练。
- data.txt 是一个以 UTF-8 编码的训练文本文件
- 在默认情况下,单词向量将会考虑到 n-grams 的3 到 6 个字符。 在优化结束时,程序将保存 2 个文件: model.bin 和 model.vec
C++版本
编译成二进制文件,当做命令行使用
## 数据准备
## 无监督语料——wiki百科
wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
## wiki百科部分数据
mkdir data
wget -c http://mattmahoney.net/dc/enwik9.zip -P data
unzip data/enwik9.zip -d data
## 有监督语料——分类
wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz
tar xvzf cooking.stackexchange.tar.gz
head cooking.stackexchange.txt
## 数据集划分
head -n 12404 cooking.stackexchange.txt > cooking.train ## 训练集
tail -n 3000 cooking.stackexchange.txt > cooking.valid ## 验证集
## (1)训练
## -input命令选项指示训练数据
## -output选项指示的是保存的模型的位置
## (1.1)------- 无监督训练 --------
## skip-gram/cbow模型
mkdir result
./fasttext skipgram -input data/fil9 -output result/fil9
./fasttext cbow -input data/fil9 -output result/fil9
## 输出两个文件:
## ① fil9.bin是模型文件
## ② fil9.vec是词向量文件,每一行对应词汇表中的每个单词(按照词频降序排列)
## 218316 100 ## 第一行是单词数/向量维度
## the -0.10363 -0.063669 0.032436 -0.040798 0.53749 0.00097867 0.10083 0.24829 ...
## of -0.0083724 0.0059414 -0.046618 -0.072735 0.83007 0.038895 -0.13634 0.60063 ...
## one 0.32731 0.044409 -0.46484 0.14716 0.7431 0.24684 -0.11301 0.51721 0.73262 ...
## 模型量化压缩
./fasttext quantize -output model
## 打印词向量
echo "asparagus pidgey yellow" | ./fasttext print-word-vectors result/fil9.bin
## asparagus 0.46826 -0.20187 -0.29122 -0.17918 0.31289 -0.31679 0.17828 -0.04418 ...
## pidgey -0.16065 -0.45867 0.10565 0.036952 -0.11482 0.030053 0.12115 0.39725 ...
## 或,文件形式批量转换向量
./fasttext print-sentence-vectors model.bin < text.txt
## 查询单词
echo "enviroment" | ./fasttext print-word-vectors result/fil9.bin
## 最临近词向量查询,通过fastText提供的nn功能来实现,余弦相似度去衡量两个单词之间的相似度
$ ./fasttext nn result/fil9.bin ## 启动服务
## Pre-computing word vectors... done.
## 交互查询
## Query word? asparagus
## beetroot 0.812384
## tomato 0.806688
## horseradish 0.805928
## spinach 0.801483
## licorice 0.791697
## lingonberries 0.781507
## asparagales 0.780756
## lingonberry 0.778534
## celery 0.774529
## beets 0.773984
## 单词类比, analogies,柏林与德国的关系,类比到法国与巴黎
$ ./fasttext analogies result/fil9.bin
## Pre-computing word vectors... done.
## Query triplet (A - B + C)? berlin germany france
## paris 0.896462
## bourges 0.768954
## louveciennes 0.765569
## toulouse 0.761916
## valenciennes 0.760251
## montpellier 0.752747
## strasbourg 0.744487
## meudon 0.74143
## bordeaux 0.740635
## pigneaux 0.736122
## 模型调优
## ① 模型中最重要的两个参数是:词向量大小维度、subwords范围的大小,词向量维度越大,便能获得更多的信息但同时也需要更多的训练数据,同时如果它们过大,模型也就更难训练速度更慢,默认情况下使用的是100维的向量,但在100-300维都是常用到的调参范围。subwords是一个单词序列中包含最小(minn)到最大(maxn)之间的所有字符串(也即是n-grams),默认情况下我们接受3-6个字符串中间的所有子单词,但不同的语言可能有不同的合适范围
./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5 -dim 300
## ② 另外两个参数:epoch、learning rate、epoch根据训练数据量的不同,可以进行更改,epoch参数即是控制训练时在数据集上循环的次数,默认情况下在数据集上循环5次,但当数据集非常大时,我们也可以适当减少训练的次数,另一个参数学习率,学习率越高模型收敛的速度就越快,但存在对数据集过度拟合的风险,默认值时0.05,这是一个很好的折中,当然在训练过程中,也可以对其进行调参,可调范围是[0.01, 1]
./fasttext skipgram -input data/fil9 -output result/fil9 -epoch 1 -lr 0.5
## ③ fastText是多线程的,默认情况下使用12个线程,如果你的机器只有更少的CPU核数,也可以通过如下参数对使用的CPU核数进行调整
./fasttext skipgram -input data/fil9 -output result/fil9 -thread 4
## (1.2)----- 有监督训练 -------
./fasttext supervised -input cooking.train -output model_cooking
## 在训练结束后,文件model_cooking.bin是在当前目录中创建的,model_cooking.bin便是我们保存训练模型的文件
## (1.2.1) 模型优化:模型精准率从 12.4% 提升到了 59.9%
## ① 数据预处理:如 大小写统一,缩小词表规模
## 增加迭代次数
./fasttext supervised -input cooking.train -output model_cooking -epoch 25
## ② 设置学习率,一般 0.1~1.0
./fasttext supervised -input cooking.train -output model_cooking -lr 1.0
## 组合使用
./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25
## ③ 使用n-gram语言模型:上面默认使用uni-gram,丢失了词序信息,改成bi-gram重新训练
## 句子:Last donut of the night
## unigrams:last,donut,of,the,night
## bigrams:last donut,donut of,of the,the night
./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25 -wordNgrams 2
## ④ 训练提速:层次softmax,参数-loss
./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25 -wordNgrams 2 -bucket 200000 -dim 50 -loss hs
## Read 0M words
## Number of words: 9012
## Number of labels: 734
## Progress: 100.0% words/sec/thread: 2199406 lr: 0.000000 loss: 1.718807 eta: 0h0m
## (2)测试:
## 交互式测试,一次一句
## 输入:Which baking dish is best to bake a banana bread ?
## 结果:baking
./fasttext predict model_cooking.bin -
## 批量测试
./fasttext test model_cooking.bin cooking.valid
## N 3000
## P@1 0.124
## R@1 0.0541
## Number of examples: 3000
## 带概率的结果
./fasttext predict-prob model.bin test.txt k
C++代码调用
#include <iostream> // cin, cout, endl, getline
#include <sstream> // istringstream
#include <string> // string
#include <vector> // vector
#include <utility> // pair
#include "fasttext.h" // fasttext::FastText
using namespace std;
int main(int argc, char** argv) {
if (argc < 2){
cout << "<model>" << endl;
return 0;
}
// 新建一个模型对象
fasttext::FastText* model = new fasttext::FastText();
// 从模型文件中加载模型数据
model->loadModel(argv[1]);
string line;
std::vector< std::pair<float, std::string> > tags;
while (getline(cin, line)) {
// 从标准输入中读入一行(假设已经分好词)
istringstream iss(line);
tags.clear();
// 预测Top5个标签: 从iss中读入一行, 预测5个Top概率的标签, 输出到tags中,概率阈值为0.5
model->predictLine(iss, tags, 5, 0.5);
// 输出到标准输出
for (auto&& tag: tags) {
cout << tag.second << ":" << tag.first<< " ";
}
cout << endl;
}
delete model;
return 0;
}
Python版本
import fasttext
## ------- 无监督训练 -------
## ① skipgram model
model = fasttext.train_unsupervised('data.txt', model = 'skipgram')
#model = fasttext.skipgram('data.txt','model') ## 旧版非官方版本调用方法
## ② CBOW model
model = fasttext.train_unsupervised('data.txt', model = 'cbow')
#model = fasttext.cbow('data.txt','model') ## 旧版非官方版本调用方法
print(model) ## 存储位置
print(model.get_words()) ## 词表
print(model.words) ## 字典中的词汇列表
## 单词 'king' 的词向量
print(model['king'])
print(model.get_word_vector('to')) ## 对应词向量
## 保存模型
model.save_model('model.bin')
## 加载前面训练好的模型 model.bin
model = fasttext.load_model("model.bin")
## ---- 文本分类 ----
## 训练文本分类器
classifier = fasttext.train_supervised('data.train.txt','model')
## 还可以用 label_prefix 指定标签前缀
classifier = fasttext.train_supervised('data.train.txt','model',label_prefix = '__label__')
## 输出两个文件: model.bin 和 model.vec
## 量化压缩模型
model.quantize(input='data.train.txt',retrain=True) ## 数据集太小会报错 !!!
#接下来展示结果和存储新模型
print_result(*model.test(valid_data))
model.save_model("model.ftz") ## model.ftz 比model.bin 的大小 要小很多
## 加载模型
classifier = fasttext.load_model("model.bin",label_prefix = "__label__")
print(classifier.labels)
## ------ 预测 -------
## (1)单例预测
## model.predict(self,
## text, utf-8 字符串文本
## k=1, 返回标签的个数,可以理解为最大K项
## threshord=0.0) 概率阈值,大于才返回
texts = ["example very long text 1","example very longtext 2"]
labels = classifier.predict(texts[0]) ## 单词预测
labels = classifier.predict(texts) ## 并行预测
labels = classifier.predict(texts,k = 3) ## top k的预测结果
labels = classifier.predict_proba(texts) ## 含概率, 无效!
print(labels)
## (2) 模型批量预测
## model.test(self,
## path, 文件路径
## k=1) 最大k项
## 返回:[N,p,r] 样本个数,精确率,召回率
## 使用 classifier.test 方法在测试数据集上评估模型
result = classifier.test("test.txt") ## 迭代输出返回内容
print("准确率:" , result.precision)
print("召回率:" , result.recall)
print("Number of examples:", result.nexamples)
论文及案例
- 论文Bag of Tricks for Efficient Text Classification提出一个快速进行文本分类的模型和一些trick。
- fastText模型架构
- fastText模型直接对所有进行embedded的特征取均值,作为文本的特征表示
- 特点
- 当类别数量较大时,使用Hierachical Softmax将N-gram融入特征中,并且使用Hashing trick[Weinberger et al.2009]提高效率
- 【2021-2-2】论文,代码, 2-2.FastText
- Fasttext是Facebook推出的一个便捷的工具,包含文本分类和词向量训练两个功能。
- Fasttext的分类思想:把输入转化为词向量,取平均,再经过线性分类器得到类别。输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类任务一起训练。
- fastText模型架构和word2vec的CBOW模型架构非常相似
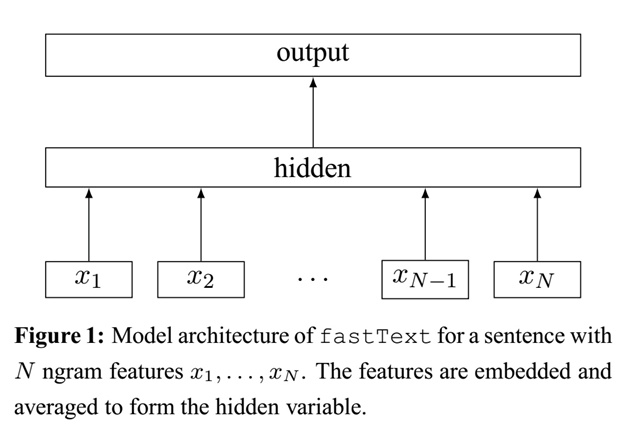
- fastText模型和CBOW一样也只有三层:输入层、隐含层、输出层(Hierarchical Softmax)。fasttext的隐藏层是把输入层的向量求平均。
- cbow是将每个词先用one-hot编码,然后再经过随机初始化的look-up table。
- fasttext也是相似,区别就是fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征,所以fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档。
- fastText作者的实现是句子中的单词再加上n-gram作为输入的。并且为了节省内存,n-gram需要经过哈希处理,哈希到同一个位置的不同n-gram是会共享一个embedding的。
- fastText单词的embedding跟常见的embedding方法没什么不同,都是先随机初始化,然后再通过反向传播学习参数,维度就是人工指定的一个超参数,是词向量的维度。不过有两点要注意的地方
- 第一是如果fastText的embedding是通过supervised的方式来训练一个文本分类器并同时学习embedding的话,那么这个embedding的学习过程就是有监督的,与word2vec等无监督的模型是有一定区别的;
- 第二是fastText还会学习n-gram(这里的n-gram其实有两种,分别是char-n-gram和word-n-gram)的embedding,这使得它可以在一定程度上捕捉词序信息。为了节省空间,fastText在原作者的实现中并不是每一个n-gram都学习一个单独的embedding,而是首先将n-gram进行hash,hash到同一个位置的多个n-gram是会共享一个embedding的。
- 字符级n-gram的引入,有以下几点好处:
- 对于像英语、芬兰语这种形态学比较丰富的语言,字符级的n-gram抓住了单词的形态学信息。在fasttext词向量中直接利用了构词学中的信息。
- 为罕见的单词生成更好的单词向量。根据上面的字符级别的n-gram来说,即使这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量
- 一定程度上解决了OOV问题。即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量。
- word-n-gram可以让模型学习到局部词序信息,可以在一定程度上捕捉词序信息。
- cbow先将词进行one-hot编码,其实在我看来就是构造了word2id词典,这样就可以通过lookup-table 查询到对应的词向量。
- 优点:
- 模型本身复杂度低,但效果不错,能快速产生任务的baseline
- Facebook使用C++进行实现,进一步提升了计算效率
- 采用了char-level的n-gram作为附加特征,比如paper的trigram是 [pap, ape, per],在将输入paper转为向量的同时也会把trigram转为向量一起参与计算。这样一方面解决了长尾词的OOV (out-of-vocabulary)问题,一方面利用n-gram特征提升了表现
- 当类别过多时,支持采用hierarchical softmax进行分类,提升效率
- 对于文本长且对速度要求高的场景,Fasttext是baseline首选。同时用它在无监督语料上训练词向量,进行文本表示也不错。不过想继续提升效果还需要更复杂的模型。
代码
import pandas as pd
import numpy as np
import fasttext
import sys
from sklearn.utils import shuffle
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
## 转换为FastText需要的格式
train_df = pd.read_csv(sys.argv[1], sep='\t', names=["label","text"])
train_df = shuffle(train_df)
test_df = pd.read_csv(sys.argv[2], sep='\t', names=["label","text"])
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].to_csv('train.csv', index=None, header=None, sep='\t')
test_df['label_ft'] = '__label__' + train_df['label'].astype(str)
test_df[['text','label_ft']].to_csv('test.csv', index=None, header=None, sep='\t')
#print(dir(fasttext))
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2,
verbose=2, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in test_df['text']]
val_pred = [int(x) for x in val_pred]
print("this is the precision:")
print(precision_score(test_df['label'].values,val_pred))
print("this is the recall:")
print(recall_score(test_df['label'].values,val_pred))
print(classification_report(test_df['label'].values,val_pred))
Pytorch实现FastText模型对AG_news数据集进行四分类预测(torchtext实现数据预处理)
训练
pytorch实现fastText:
## -*- coding: utf-8 -*-
import torch.nn as nn
from torch.nn import functional as F
class FastText(nn.Module):
def __init__(self, trial, vocab_size, class_num):
super(FastText, self).__init__()
self.embed_dim = trial.suggest_int("n_embedding", 200, 300, 50)
self.hidden_size = trial.suggest_int("hidden_size", 64, 128, 2)
self.dropout = nn.Dropout(0.5)
self.embed = nn.Embedding(vocab_size, self.embed_dim, padding_idx=1)
self.fc1 = nn.Linear(self.embed_dim, self.hidden_size)
self.fc2 = nn.Linear(self.hidden_size, class_num)
def forward(self, x):
embeds = self.embed(x)
out = embeds.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
logit = F.log_softmax(out, dim=1)
return logit
深度学习文本分类
- 汇总文本分类众多方法
CNN文本分类
TextCNN —— 适合中短文本
-

- TextCNN是Yoon Kim小哥在2014年提出的模型,开创了用CNN编码n-gram特征的先河
- 词向量
- 随机初始化 (CNN-rand)
- 预训练词向量进行初始化,在训练过程中固定 (CNN-static)
- 预训练词向量进行初始化,在训练过程中进行微调 (CNN-non-static)
- 多通道(CNN-multichannel):将固定的预训练词向量和微调的词向量分别当作一个通道(channel),卷积操作同时在这两个通道上进行,可以类比于图像RGB三通道。
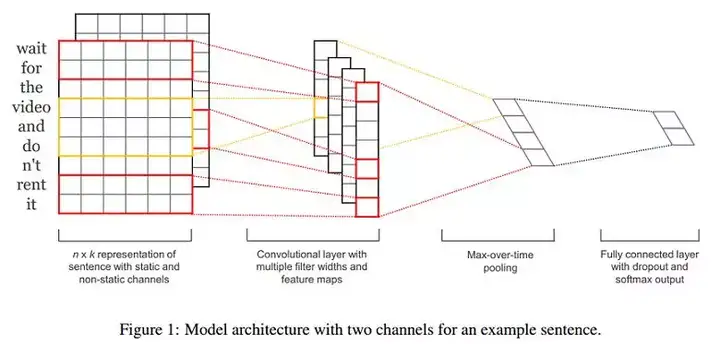
- 句长n=9,词向量维度k=6,filter有两种窗口大小(或者说kernel size),每种有2个,因此filter总个数m=4,其中:
- 一种的窗口大小h=2(红色框),卷积后的向量维度为n−h+1=8
- 另一种窗口大小h=3(黄色框),卷积后的向量维度为n−h+1=7
- 一些结论
- Multichannel vs. Single Channel Models: 虽然作者一开始认为多通道可以预防过拟合,从而应该表现更高,尤其是在小规模数据集上。但事 - 实是,单通道在一些语料上比多通道更好;
- Static vs. Non-static Representations: 在大部分的语料上,CNN-non-static都优于CNN-static,一个解释:预训练词向量可能认为‘good’ - 和‘bad’类似(可能它们有许多类似的上下文),但是对于情感分析任务,good和bad应该要有明显的区分,如果使用CNN-static就无法做调整了;
- Dropout可以提高2%–4%性能(performance);
- 对于不在预训练的word2vec中的词,使用均匀分布U[−a,a]随机初始化,并且调整a使得随机初始化的词向量和预训练的词向量保持相近的方差,可 - 以有微弱提升;
- 可以尝试其他的词向量预训练语料,如Wikipedia[Collobert et al. (2011)]
- Adadelta(Zeiler, 2012)和Adagrad(Duchi et al., 2011)可以得到相近的结果,但是所需epoch更少。
- 模型结构如图,图像中的卷积都是二维的,而TextCNN则使用「一维卷积」,即filter_size * embedding_dim,有一个维度和embedding相等。这样就能抽取filter_size个gram的信息。以1个样本为例,整体的前向逻辑是:
- 对词进行embedding,得到[seq_length, embedding_dim]
- 用N个卷积核,得到N个seq_length-filter_size+1长度的一维feature map
- 对feature map进行max-pooling(因为是时间维度的,也称max-over-time pooling),得到N个1x1的数值,拼接成一个N维向量,作为文本的句子表示
- 将N维向量压缩到类目个数的维度,过Softmax
- 优化:
- Filter尺寸:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
- Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可
- CNN的激活函数:可以尝试Identity、ReLU、tanh
- 正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了
- Embedding表:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练蒸馏BERT的logits,利用领域内无监督数据
- 加深全连接:原论文只使用了一层全连接,而加到3、4层左右效果会更好[2]
- TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用特征。另外再仔细想的话,TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,因为解决了词袋模型的稀疏性问题。
代码:pytorch
import sys
import torch
import pandas as pd
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from collections import Counter
from sklearn.utils import shuffle
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
train = pd.read_csv(sys.argv[1],sep='|',names=["a","b","c","label"])
test = pd.read_csv(sys.argv[2],sep='|',names=["a","b","c","label"])
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
## 3 words sentences (=sequence_length is 3)
train = shuffle(train)
word2idx = {}
sentences = list(train['c'].apply(lambda x:" ".join(x.split("\\"))))
labels = list(train['label'])
test_sentences = list(test['c'].apply(lambda x:" ".join(x.split("\\"))))
test_labels = list(test['label'])
## TextCNN Parameter
embedding_size = 300
sequence_length = max([len(each.split()) for each in sentences]) ## every sentences contains sequence_length(=3) words
num_classes = 2 ## 0 or 1
batch_size = 128
word_list = " ".join(sentences).split()
c = Counter(word_list)
word_list_common = list(Counter(el for el in c.elements() if c[el]>1))
word_list_common.append("UNK")
vocab = list(set(word_list_common))
word2idx = {w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
tmp_list = []
for each_word in sen.split():
try:
tmp_list.append(word2idx[each_word])
except:
tmp_list.append(word2idx['UNK'])
inputs.append(tmp_list)
#inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) ## To using Torch Softmax Loss function
pad_token = 0
padded_X = np.ones((len(inputs), sequence_length)) * pad_token
for i, x_len in enumerate([len(each) for each in inputs]):
sequence = inputs[i]
padded_X[i, 0:x_len] = sequence[:x_len]
inputs, targets = torch.LongTensor(padded_X), torch.LongTensor(labels)
return inputs, targets
input_batch, target_batch = make_data(sentences,labels)
input_batch_test, target_batch_test = make_data(test_sentences,test_labels)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 1
self.conv2 = nn.Conv2d(1, 1, (2, embedding_size))
self.conv3 = nn.Conv2d(1, 1, (3, embedding_size))
self.conv4 = nn.Conv2d(1, 1, (4, embedding_size))
## fc
#self.fc = nn.Linear(3 * output_channel, num_classes)
self.Max2_pool = nn.MaxPool2d((sequence_length-2+1, 1))
self.Max3_pool = nn.MaxPool2d((sequence_length-3+1, 1))
self.Max4_pool = nn.MaxPool2d((sequence_length-4+1, 1))
#self.fc = nn.Linear(7 * output_channel, num_classes)
self.linear1 = nn.Linear(6, 2)
def forward(self, x):
#'''
#X: [batch_size, sequence_length]
#'''
#batch_size = X.shape[0]
#embedding_X1 = self.W(X) ## [batch_size, sequence_length, embedding_size]
#embedding_X = embedding_X.unsqueeze(1) ## add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
#conved = self.conv(embedding_X) ## [batch_size, output_channel, 1, 1]
#flatten = conved.view(batch_size, -1) ## [batch_size, output_channel*1*1]
#output = self.fc(flatten)
#return output
batch = x.shape[0]
## Convolution
x = self.W(x)
x = x.unsqueeze(1)
x11 = F.relu(self.conv2(x))
x12 = F.relu(self.conv2(x))
x21 = F.relu(self.conv3(x))
x22 = F.relu(self.conv3(x))
x31 = F.relu(self.conv4(x))
x32 = F.relu(self.conv4(x))
## Pooling
x11 = self.Max2_pool(x11)
x12 = self.Max2_pool(x12)
x21 = self.Max3_pool(x21)
x22 = self.Max3_pool(x22)
x31 = self.Max4_pool(x31)
x32 = self.Max4_pool(x32)
## capture and concatenate the features
x = torch.cat((x11, x12, x21, x22, x31, x32), -1)
x = x.view(batch, 1, -1)
## project the features to the labels
x = self.linear1(x)
x = x.view(-1, 2)
return x
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
## Training
for epoch in range(2):
for i,(batch_x, batch_y) in enumerate(loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (i + 1) % 100 == 0:
## print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
print('Epoch:', '%03d' % (epoch + 1), "data_batch:",i, 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
## test eval
### Test
### Predict
model = model.eval()
predict = model(input_batch_test).data.max(1, keepdim=True)[1]
print("this is the precision:")
print(precision_score(test_labels,predict))
print("this is the recall:")
print(recall_score(test_labels,predict))
print(classification_report(test_labels,predict))
DPCNN——TextCNN改进
- 论文,代码
- TextCNN有太浅和长距离依赖的问题,那直接多堆几层CNN是否可以呢?事情没想象的那么简单。
- 直到2017年,腾讯才提出了把TextCNN做到更深的DPCNN模型
- 在Region embedding时不采用CNN那样加权卷积的做法,而是对n个词进行pooling后再加个1x1的卷积,因为实验下来效果差不多,且作者认为前者的表示能力更强,容易过拟合
- 使用1/2池化层,用size=3 stride=2的卷积核,直接让模型可编码的sequence长度翻倍(自己在纸上画一下就get啦)
- 残差链接,参考ResNet,减缓梯度弥散问题
- 凭借以上一些精妙的改进,DPCNN相比TextCNN有1-2个百分点的提升。
RNN文本分类
- 思想:以双向LSTM 或GRU来获取句子的信息表征, 以最后一时刻的 h 作为句子特征输入到 softmax 中进行预测
- RNN用于文本分类
- 策略1:直接使用RNN的最后一个单元输出向量作为文本特征
- 策略2:使用双向RNN的两个方向的输出向量的连接(concatenate)或均值作为文本特征
- 策略3:将所有RNN单元的输出向量的均值pooling或者max-pooling作为文本特征
- 策略4:层次RNN+Attention, Hierarchical Attention Networks
TextRNN
import sys
import torch
import pandas as pd
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from collections import Counter
from sklearn.utils import shuffle
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
train = pd.read_csv(sys.argv[1],sep='|',names=["a","b","c","label"])
test = pd.read_csv(sys.argv[2],sep='|',names=["a","b","c","label"])
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
## 3 words sentences (=sequence_length is 3)
train = shuffle(train)
word2idx = {}
sentences = list(train['c'].apply(lambda x:" ".join(x.split("\\"))))
labels = list(train['label'])
test_sentences = list(test['c'].apply(lambda x:" ".join(x.split("\\"))))
test_labels = list(test['label'])
## TextRNN Parameter
embedding_size = 300
sequence_length = max([len(each.split()) for each in sentences]) ## every sentences contains sequence_length(=3) words
num_classes = 2 ## 0 or 1
batch_size = 128
word_list = " ".join(sentences).split()
c = Counter(word_list)
word_list_common = list(Counter(el for el in c.elements() if c[el]>1))
word_list_common.append("UNK")
vocab = list(set(word_list_common))
word2idx = {w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
tmp_list = []
for each_word in sen.split():
try:
tmp_list.append(word2idx[each_word])
except:
tmp_list.append(word2idx['UNK'])
inputs.append(tmp_list)
#inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) ## To using Torch Softmax Loss function
pad_token = 0
padded_X = np.ones((len(inputs), sequence_length)) * pad_token
for i, x_len in enumerate([len(each) for each in inputs]):
sequence = inputs[i]
padded_X[i, 0:x_len] = sequence[:x_len]
inputs, targets = torch.LongTensor(padded_X), torch.LongTensor(labels)
return inputs, targets
input_batch, target_batch = make_data(sentences,labels)
input_batch_test, target_batch_test = make_data(test_sentences,test_labels)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
self.lstm = nn.LSTM(300, 128, 2,bidirectional=True, batch_first=True)
## fc
self.fc = nn.Linear(128 * 2, 2)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
out = self.W(X) ## [batch_size, sequence_length, embedding_size]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :])
return out
model = TextRNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
## Training
for epoch in range(2):
for i,(batch_x, batch_y) in enumerate(loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (i + 1) % 100 == 0:
#print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
print('Epoch:', '%03d' % (epoch + 1), "data_batch:",i, 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
## test eval
### Test
### Predict
model = model.eval()
predict = model(input_batch_test).data.max(1, keepdim=True)[1]
print("this is the precision:")
print(precision_score(test_labels,predict))
print("this is the recall:")
print(recall_score(test_labels,predict))
print(classification_report(test_labels,predict))
Text-RCNN(RNN+CNN)用于文本分类
TextRCNN:一种结合RNN和CNN的模型,通过RNN捕获长依赖特性,通过CNN来对捕获文本中的重要部分,防止RNN有偏特点。
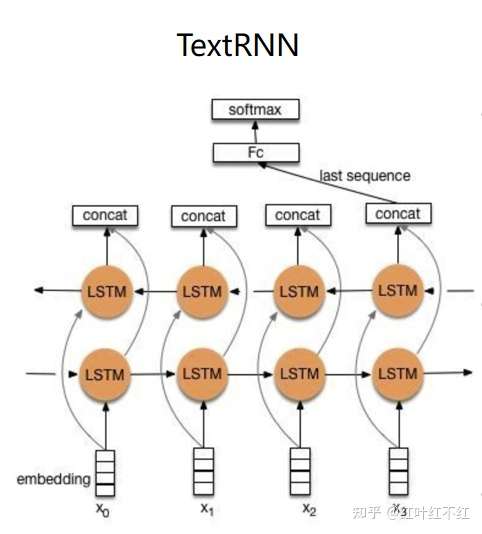
- 除了DPCNN那样增加感受野的方式,RNN也可以缓解长距离依赖的问题。
- 论文Recurrent Convolutional Neural Networks for Text Classification设计了一种RNN和CNN结合的模型用于文本分类。代码
- 一个很简单的思想看起来比 Transformer 还复杂,真的是有点醉

- RCNN相关总结
- NN vs. traditional methods: 在该论文的所有实验数据集上,神经网络比传统方法的效果都要好
- Convolution-based vs. RecursiveNN: 基于卷积的方法比基于递归神经网络的方法要好
- RCNN vs. CFG and C&J: The RCNN可以捕获更长的模式(patterns)
- RCNN vs. CNN: 在该论文的所有实验数据集上,RCNN比CNN更好
- CNNs使用固定的词窗口(window of words), 实验结果受窗口大小影响
- RCNNs使用循环结构捕获广泛的上下文信息
- 通过加入RNN,比纯CNN提升了1-2个百分点。
TextBiLSTM+Attention
- 论文,代码
- 文本分类的框架,就是
- 先基于上下文对token编码,然后pooling出句子表示再分类。
- 在最终池化时,max-pooling通常表现更好,因为文本分类经常是主题上的分类,从句子中一两个主要的词就可以得到结论,其他大多是噪声,对分类没有意义。而到更细粒度的分析时,max-pooling可能又把有用的特征去掉了,这时便可以用attention进行句子表示的融合
- 加attention的套路用到CNN编码器之后代替pooling也是可以的,从实验结果来看attention的加入可以提高2个点。如果是情感分析这种由句子整体决定分类结果的任务首选RNN。
一定要CNN/RNN吗
- 上述的深度学习方法通过引入CNN或RNN进行特征提取,可以达到比较好的效果,但是也存在一些问题,如参数较多导致训练时间过长,超参数较多模型调整麻烦等。下面两篇论文提出了一些简单的模型用于文本分类,并且在简单的模型上采用了一些优化策略。
深层无序组合方法
- 论文Deep Unordered Composition Rivals Syntactic Methods for Text Classification提出了NBOW(Neural Bag-of-Words)模型和DAN(Deep Averaging Networks)模型。对比了深层无序组合方法(Deep Unordered Composition)和句法方法(Syntactic Methods)应用在文本分类任务中的优缺点,强调深层无序组合方法的有效性、效率以及灵活性。
Neural Bag-of-Words Models
- 论文首先提出了一个最简单的无序模型Neural Bag-of-Words Models (NBOW model)。该模型直接将文本中所有词向量的平均值作为文本的表示,然后输入到softmax 层
Considering Syntax for Composition
- 一些考虑语法的方法:
- Recursive neural networks (RecNNs)
- 可以考虑一些复杂的语言学现象,如否定、转折等 (优点)
- 实现效果依赖输入序列(文本)的句法树(可能不适合长文本和不太规范的文本)
- 需要更多的训练时间
- Using a convolutional network instead of a RecNN
- 时间复杂度同样比较大,甚至更大(通过实验结果得出的结论,这取决于filter大小、个数等超参数的设置)
Deep Averaging Networks
- Deep Averaging Networks (DAN)是在NBOW model的基础上,通过增加多个隐藏层,增加网络的深度(Deep)。下图为带有两层隐藏层的DAN与RecNN模型的对比。
Word Dropout Improves Robustness
- 针对DAN模型,论文提出一种word dropout策略:在求平均词向量前,随机使得文本中的某些单词(token)失效。
HAN 注意力机制 (长文本【篇章级别】分类)
HAN:一种采用了attention机制的用于文本分类的分层注意力模型,attention机制让模型基于不同的单词和句子给予不同的注意力权重。模型主要有一个词序列编码器,一个词级注意力层,一个句子编码器和一个句子层注意力层,词和句上的结构基本类似。字编码阶段GRU将词向量通过隐层形式表征,再拼接前向和后向的隐藏表征,作为注意力层的输入,在注意力层选取一个query向量分别计算不同单词的权重,作为词的attention权重。结果作为句子表征阶段的输入,句子表征重复单词阶段的两个步骤,最后的句子的表征能用来做下游的分类任务。该模型在长文本有相对不错的效果,且因为attention的存在,能对词和句子有着相对不错的解释。
- 论文,代码
- 以上方法都是句子级别的分类,虽然用到长文本、篇章级也是可以的,但速度精度都会下降,于是有研究者提出了层次注意力分类框架,即Hierarchical Attention。先对每个句子用 BiGRU+Att 编码得到句向量,再对句向量用 BiGRU+Att 得到doc级别的表示进行分类
- 哈工大团队提出 Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. Duyu Tang, Bing Qin , Ting Liu. In EMNLP, 2015,该文章提出了一种层次神经网络的结构做篇章级别的情感分析,取得了很好的效果
- 2016年另外一个团队提出了HAN网络,也是使用层次神经网络的结构做篇章级别的文本分析。并且和上篇论文有很多相似之处。文章利用word att ention 和 sentence attention来更好的实现加权平均,取得了很好的效果
- Hierarchical Attention Networks for Document Classification. Zichao Yang1, Diyi Yang1, Chris Dyer and et al. In NAACL-HLT, 2016
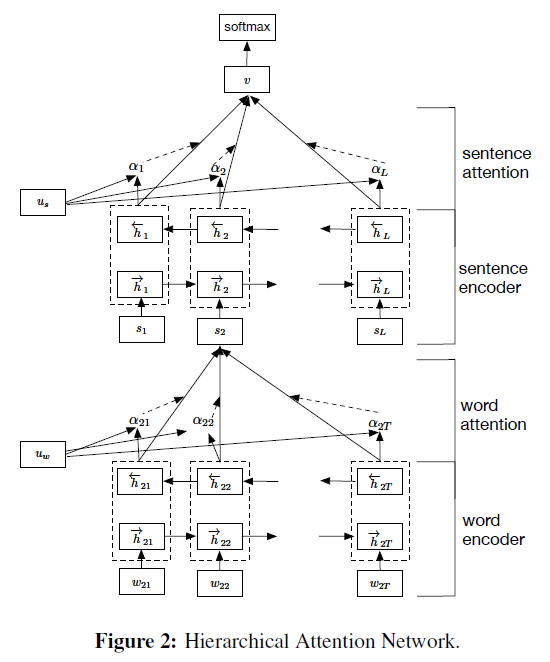
- 首先是词语到句子级别的,利用词向量,通过双向GRU,对一句话中的词抽取特征
- 考虑到在每个句子中,各个词对句子信息的贡献不同。随后作者利用word attention 来对BI-GRU抽取的词特征加权求和,生成句子表示(句向量);
- 然后是句子到文章级别的,一篇文章有多个句子,把它们看成是一个时间序,使用双向GRU对所有句子进行整合,生成新的句向量;
- 对句向量使用sentence attention ,具体过程和word attention相似,获得文章表示
- 最后,用Softmax做分类。
- 方法很符合直觉,不过实验结果来看比起avg、max池化只高了不到1个点(狗头,真要是很大的doc分类,好好清洗下,fasttext其实也能顶的
transformer
BERT
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding,双向的Transformers的Encoder,是谷歌于2018年10月提出的。主要是一种预训练的模型,通过双向transformer实现的,通过mask的机制,随机遮挡部分的单词进行词向量的预训练,同时在每个位置token表征的时候引入了token向量,segment向量和position向量相结合的方式,能更全面的语义进行表征,同时通过mask的机制使得单次的训练中,词向量的学习过程能同时引入前后文的信息,而不是通过双向RNN那种生硬拼接的方式,从结果上来说,该模型的效果在很多任务上表现显著。
BERT分类
【2022-10-26】How to Fine-Tune BERT for Text Classification?, code
BERT加速
【2022-10-26】BERT文本分类最佳解决方案
- BERT文本分类指的是在[CLS]后面接一个 FFN + softmax,然后用标记数据微调BERT参数。
- BERT文本分类微调可以说是多分类的sota模型了。但是,在生产应用中,推理速度一直是个瓶颈。
BERT文本分类最佳解决方案(之一)就是用 TensorFlow 2 进行训练,再用 TensorRT 进行推理。
- 在RTX 3090单卡上,单条文本耗时可达4.00毫秒。
keras加成的tf2变得非常好用了,丝滑程度不输Pytorch。
- 训练BERT分类模型的代码库是bert-classification-train-tf2,该代码库使用简单,只需要准备标记数据即可。
- TensorRT是在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。
- 利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。
BERT分类模型推理的代码库是bert-classification-inference-trt。
运行结束后,最后两行显示:
- 准确率: 94.92%
- 平均每条文本耗时: 4.00毫秒
基于TensorRT推理,准确率有1个百分点的损失
对比
- fasttex 训练好的模型在测试集上的准确率是92.9%,比TensorRT预测结果小2个百分点,比BERT微调训练小3个百分点
XLNet
XLNet:是一种通用化自动回归 BERT 式预训练语言模型,可通过最大限度地提高针对因式分解顺序的所有排列的预期可能性,实现学习双向上下文,乱排序可以不用显现mask来学习到双向上下文的信息,防止类似mask操作导致的finetune数据和预训练数据分布不一致,和mask的token之间存在相互依赖关系。为了防止训练过程中标签泄露的问题,引入了Two-Stream Self-Attention机制,XLNet在Pre-train時分為兩個stream,Content stream負責學習上下文,而Query stream這個角色就是用來代替< Mask>token,其負責把Content stream產生的representation拿來做預測,且引入了Transformer-XL,该方法能克服Transformer中长依赖的学习问题。
GNN 图神经网络
TextGCN
TextGCN:一种文本分类的图神经网络方法。第一次将整个语料库建模为异构图,并研究用图形神经网络联合学习词和文档嵌入。
通过图表征的方式进行建模,将文档和单词通过异构图的形式进行构建,边的权重是单词在文档中的TFIDF值,最后将文档表征作为下游的分类应用。
最新研究
- 根据github repo: state-of-the-art-result-for-machine-learning-problems ,下面两篇论文提出的模型可以在文本分类取得最优的结果(让AI当法官比赛第一名使用了论文Learning Structured Text Representations中的模型):
- Learning Structured Text Representations
- Attentive Convolution
- 论文Multi-Task Label Embedding for Text Classification 认为标签与标签之间有可能有联系,所以不是像之前的深度学习模型把标签看成one-hot vector,而是对每个标签进行embedding学习,以提高文本分类的精度。
- 其他模型
- BERT
- Capsule Network被证明在多标签迁移的任务上性能远超CNN和LSTM,但这方面的研究在18年以后就很少了。
- TextGCN 则可以学到更多的global信息,用在半监督场景中,但碰到较长的需要序列信息的文本表现就会差些
层次分类 HTC
什么是层次分类
【2023-11-1】
实际问题中,标签之间具有层次结构,
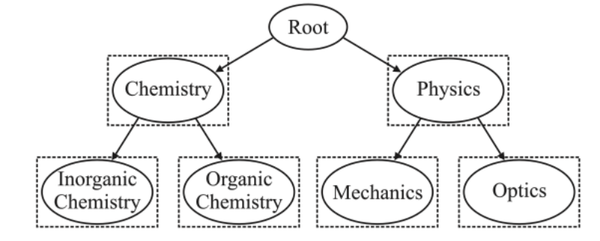
- 一个标签可以被特殊化为子类或者被一个父类所包含,层次多标签正如图所示
- Chemistry有着两个子类。这些类标签以层次结构(Hierarchical Structure)的形式存储,这就是层次多标签分类(Hierarchical-Multilabel-Text-Classification,hmtc)问题。
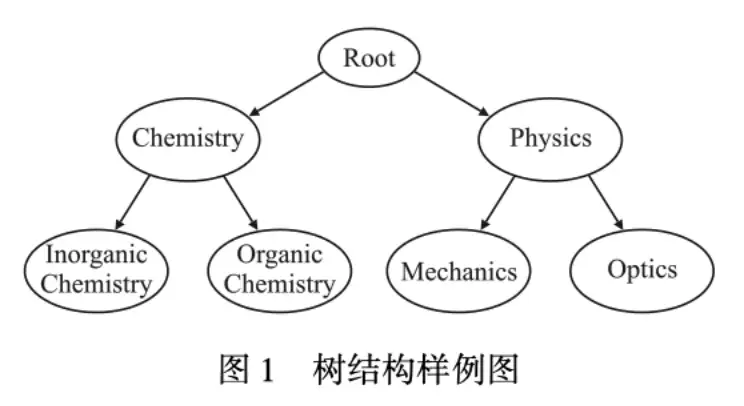
文本分类包含:二分类、多分类。
多分类包括:多标签分类和层次标签分类。
层次标签概念:
- 一级标签包含二级标签,二级标签包含三级标签。
多标签 vs 层次
标准多标签和层次多标签的不同
- 多标签称为标准平面多标签任务
- 层次多标签分类和标准平面多标签分类对比如下:
- 层次标签是以预定义的层次结构存储的,这带来了不同层级以及相同层级之间的标签之间的内在关系,而对于平面多分类问题不用考虑这种关联关系。
- 如何学习和利用这些不同层级的关系、并对分类结果从层级关系遵循性的角度进行评价成为了层次多标签分类问题的难点和挑战。
多标签分类
多标签分类见站内专题: albert-多标签实践
【2023-11-15】多标签文本分类 ALBERT
标签两两之间的关系:有的 independent,有的 non independent。
假设个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食。
- 一个人的爱好有这其中的一个或者多个 —— 多标签分类任务
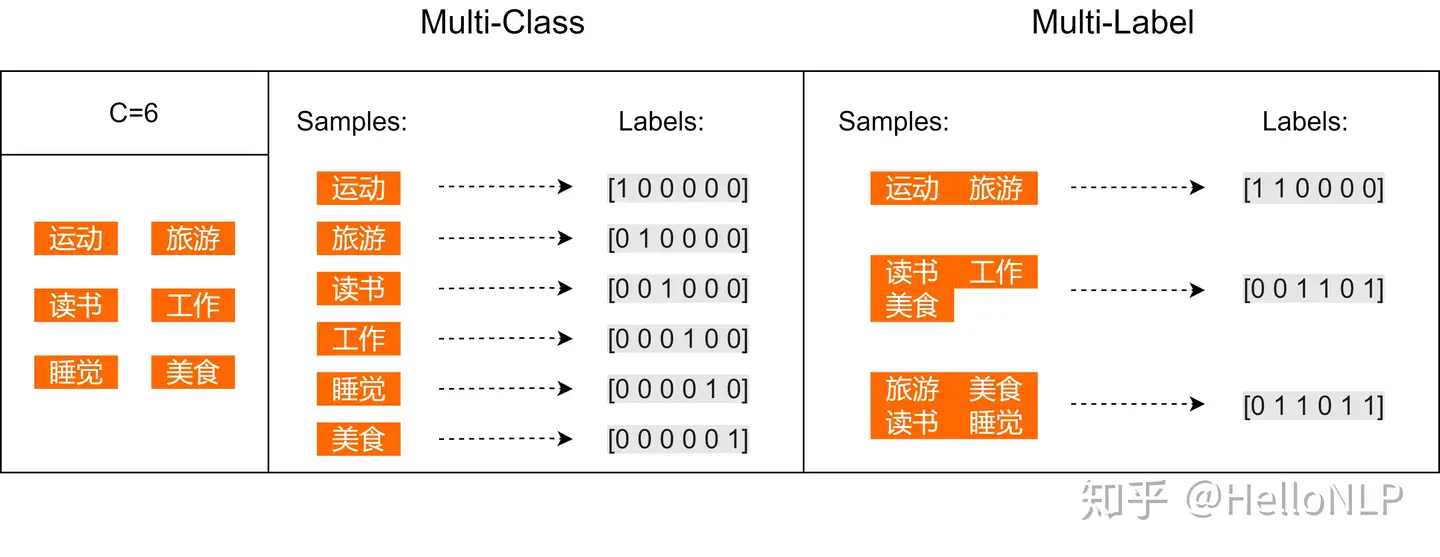
多标签分类评估指标
【2024-5-17】sklearn中多标签分类场景下的常见的模型评估指标
多标签分类最常见的指标如下:原文,含代码实现
- Precision at k (P@K): 仅考虑前k个元素正确预测的数量除以每个预测类别的前k个元素。值的范围在 0 到 1 之间。
- Avg precision at k (AP@K):
- Mean avg precision at k (MAP@K)
- Sampled F1 Score: 先计算数据中每个实例的 F1 分数,然后计算 F1 分数的平均值
- Log Loss: 对数损失,又名逻辑损失或交叉熵损失。这种误差损失衡量方式其实就是在逻辑回归中用来衡量预测概率与真实标签之间误差的方法。
多标签分类评估指标
- (1) 完全正确
- 绝对匹配率(Exact Match Ratio)
- 对于每一个样本,只有预测值与真实值完全相同才算预测正确,只要有一个类别的预测结果有差异都算没有预测正确。
- 0-1损失(Zero-One Loss)
- 绝对准确率是完全预测正确的样本占总样本数的比例,而0-1损失计算的是完全预测错误的样本占总样本的比例。
- 绝对匹配率(Exact Match Ratio)
- (2) 部分正确
- 绝对匹配率 和 0-1损失 在计算结果时都没有考虑部分正确的情况,显然是不准确。
- 例如,假设正确标签为
[1,0,0,1],模型预测的标签为[1,0,1,0]。尽管模型没有预测对全部的标签,但是预测对了一部分。 - 将部分预测正确的结果也考虑进去。Sklearn 提供了在多标签分类场景下的
精确率(Precision)、召回率(Recall)和F1值计算方法。 Hamming Score: 为针对多标签分类场景下另一种求取准确率的方法。- Hamming Score其实计算的是所有样本的平均准确率。而对于每个样本来说,准确率就是预测正确的标签数在整个预测为正确和真实为正确标签数中的占比。
Hamming Loss:
import numpy as np
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
## 绝对匹配率
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true,y_pred)) ## 0.33333333
print(accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))) ## 0.5
## 0-1 损失
from sklearn.metrics import zero_one_loss
print(zero_one_loss(y_true,y_pred)) ## 0.66666
Hamming Score
import numpy as np
def hamming_score(y_true, y_pred, normalize=True, sample_weight=None):
'''
Compute the Hamming score (a.k.a. label-based accuracy) for the multi-label case
http://stackoverflow.com/q/32239577/395857
'''
acc_list = []
for i in range(y_true.shape[0]):
set_true = set(np.where(y_true[i])[0] )
set_pred = set(np.where(y_pred[i])[0] )
tmp_a = None
if len(set_true) == 0 and len(set_pred) == 0:
tmp_a = 1
else:
tmp_a = len(set_true.intersection(set_pred))/float(len(set_true.union(set_pred)) )
acc_list.append(tmp_a)
return np.mean(acc_list)
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
print('Hamming score: {0}'.format(hamming_score(y_true, y_pred))) ## 0.5277
海明距离(Hamming Loss)
Hamming Loss 衡量所有样本中,预测错的标签数在整个标签标签数中的占比。
- 所以,对于Hamming Loss损失来说,其值越小表示模型的表现结果越好。取值在0~1之间。距离为0说明预测结果与真实结果完全相同,距离为1就说明模型与想要的结果完全就是背道而驰。
def Hamming_Loss(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
## 单个样本的标签数
p = np.size(y_true[i] == y_pred[i])
## np.count_nonzero用于统计数组中非零元素的个数
## 单个样本中预测正确的样本数
q = np.count_nonzero(y_true[i] == y_pred[i])
print(f"{p}-->{q}")
count += p - q
print(f"样本数:{y_true.shape[0]}, 标签数:{y_true.shape[1]}") ## 样本数:3, 标签数:4
return count / (y_true.shape[0] * y_true.shape[1])
print(Hamming_Loss(y_true, y_pred)) ## 0.4166
sklearn中的实现方法如下:
from sklearn.metrics import hamming_loss
print(hamming_loss(y_true, y_pred))## 0.4166
print(hamming_loss(np.array([[0, 1], [1, 1]]), np.zeros((2, 2)))) ## 0.75
tensorflow 实现
常规文本分类中的交叉熵为 tf.nn.softmax_cross_entropy_with_logits;
多标签文本分类中,交叉熵则为 tf.nn.sigmoid_cross_entropy_with_logits
原因:
tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立而不互斥。这适用于多标签分类问题。tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是独立且互斥(每个条目恰好在一个类中)。这适用多分类问题。
代码
pytorch 实现
【2024-5-9】对应的pytorch实现 MultiLabelSoftMarginLoss
BCEWithLogitsLoss=MultiLabelSoftMarginLossBCEWithLogitsLoss= One Sigmoid Layer +BCELoss(solved numerically unstable problem)- 参考 What is the difference between BCEWithLogitsLoss and MultiLabelSoftMarginLoss
MultiLabelSoftMargin 计算方法跟 BCEWithLogitsLoss 一样
- 唯一区别: BCEWithLogitsLoss 有参数‘weight’,而 MultiLabelSoftMarginLoss 没有
x = Variable(torch.randn(10, 3))
y = Variable(torch.FloatTensor(10, 3).random_(2))
## double the loss for class 1
class_weight = torch.FloatTensor([1.0, 2.0, 1.0])
## double the loss for last sample
element_weight = torch.FloatTensor([1.0]*9 + [2.0]).view(-1, 1)
element_weight = element_weight.repeat(1, 3)
bce_criterion = nn.BCEWithLogitsLoss(weight=None, reduce=False)
multi_criterion = nn.MultiLabelSoftMarginLoss(weight=None, reduce=False)
bce_criterion_class = nn.BCEWithLogitsLoss(weight=class_weight, reduce=False)
multi_criterion_class = nn.MultiLabelSoftMarginLoss(weight=class_weight, reduce=False)
bce_criterion_element = nn.BCEWithLogitsLoss(weight=element_weight, reduce=False)
multi_criterion_element = nn.MultiLabelSoftMarginLoss(weight=element_weight, reduce=False)
bce_loss = bce_criterion(x, y)
multi_loss = multi_criterion(x, y)
bce_loss_class = bce_criterion_class(x, y)
multi_loss_class = multi_criterion_class(x, y)
bce_loss_element = bce_criterion_element(x, y)
multi_loss_element = multi_criterion_element(x, y)
print(bce_loss - multi_loss)
print(bce_loss_class - multi_loss_class)
print(bce_loss_element - multi_loss_element)
BCEWithLogitsLoss :
bce loss
- b这里指的是binary,用于二分类问题
- pytorch 使用 nn.BCELoss时,要在该层前面加上Sigmoid函数
criterion = nn.BCELoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)#0或1
pre = nn.Sigmoid()(input)
loss = criterion(pre, target)
top k bce loss:
- 在所有类别中找出前k个error最高的数据,然后拿出来进行求bce loss
def BCE_loss(results, labels, topk=10):
error = torch.abs(labels - torch.sigmoid(results))#one_hot_target
error = error.topk(topk, 1, True, True)[0].contiguous()
target_error = torch.zeros_like(error).float()
error_loss = nn.BCELoss(reduce='mean')(error, target_error)
return error_loss
if __name__ == '__main__':
results = torch.randn((4, 4))
target = torch.empty((4,4)).random_(2)
print(BCE_loss(results, target,2))
BCEWithLogitsLoss(自带sigmoid)
下面这个代码是输出多个类别,只有一个类别是正例子,对所有类别×相应的权重然后平均或者sum.这个方法可以用于多分类;
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
#1为标签所在位置
target_bce = target
## inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none')
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean')
## forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
输出只有一个类别,然后用bce,只能用于二分类
import torch
import torch.nn as nn
import math
m = nn.Sigmoid()
loss = nn.BCELoss(size_average=False, reduce=False)
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
lossinput = m(input)
output = loss(lossinput, target)
print("输入值:")
print(lossinput)
print("输出的目标值:")
print(target)
print("计算loss的结果:")
print(output)
print("自己计算的第一个loss:")
print(-(target[0]*math.log(lossinput[0])+(1-target[0])*math.log(1-lossinput[0])))
层次多标签任务
任务简介:
与多标签分类类似,给定一个文档样本可以有一个或者多个类标签与之对应,不同的是这些标签是以层次结构存储的
- 层次结构中低的标签受到层级较高的标签的约束
- 层次结构在带来类标签之间层次关系的同时,也带来了计算复杂等更具有挑战性的特点。
处理流程:
一般来说,层次多标签任务涉及到数据集获取、文本预处理、文本表示、特征降维、层次结构标签表示、分类器设计、结果输出等工作,其中文本预处理、文本表示、特征降维、层次结构标签表示、分类器设计比较重要,流程如下图所示。

(1)文本预处理
文本预处理是处理文本分类任务的重要过程,通过文本预处理可以抽取文本中的重要信息,去除不必要的内容。
文本预处理的一般步骤是固定的,包括
- 分词(一般英语单词已经分词,而对中文需要进行分词)
- 词干提取(去除单词的不同词性表示,得到一致的单词表示)
- 删除停用词等。
(2)文本表示
文本是非结构化数据,而拟合训练的模型输入一般需要的是结构化数据,所以在上面的文本预处理阶段后,一般采用以向量的形式来表示文本,准确的向量文本表示可以在很大程度上提升模型的效果。常用的文本向量化的方法主要有两种:第1种是离散的表示,常见的有独热编码模型等;第2种是分布式的表示,比如有BERT、Word2vec等等。
(3)特征降维
由于向量空间模型来描述的文本向量通常具有较高的维度,这对于后续的分类任务来说,将带来效率低下和精确性下降的危害。在文本分类中,特征降维可以分为基于特征选择和基于特征提取的方法。
(4)层次结构标签表示
由于层次多标签分类问题对应的标签体系是存储在层次结构中的,所以越来越多的混合方法不仅考虑了文本提供的信息,也对层次结构标签进行了相应的表示,未来的方法也将会越来越重视标签的表示来提高模型性能。
(5)分类器设计
由于层次结构标签体系下,标签之间具有结构关系语义,因此,其分类器的设计也与一般的分类器不同,本次分享也将重点对分类器的设计进行讨论。
评估指标
层次多标签评估指标
平面方法的评价指标并不能体现层次多标签问题的特点,对层次分类的评价指标。
- 平面方法中,总要使用
精准率和召回率; - 而对于预测类别和实际类别处于层次中不同位置予以不同的关注,从而考虑了标签的层次结构的特性。
主要可分为:hP、hR和hF
- h精准度(hierarchical-precision,hP): 对部分正确的分类给予信任,对距离更远的预测错误更大的惩罚,对更高层次的预测错误更大的惩罚,hP的值越大,说明模型预测为真的样本更多的为正例。
- h召回率(hierarchical-Recall,hR): hR的值越大,说明模型将更多为真的样本预测正确
- hFβ
- hP和hR分别从真实样本和预测为真的样本出发,考虑不够全面,所以有指出可以将二者结合起来,就变成了 hFβ
- 一般将β取为1,表示将hP和hR赋予同等重要的权重
难点
挑战:
- (1)合适的文本表示方式
- 文本一般是非结构化或者半结构化数据,而分类模型的输入一般是结构化的向量或者张量等,所以怎样将文本进行编码表示,以尽可能保留文本中单词和单词、单词和句子以及句子和句子的顺序和语义关系信息是文本分类的第一步,也是很关键的一步。
- (2)层次标签结构语义表示
- 层次多标签文本分类中,标签之间具有的天然层次依赖关系,例如父—子关系、祖先—后代关系等,这些关系有着不同权重的依赖,它们也叫做标签的层次约束,文本和这些标签具有不同层次不同的关联如何利用它们之间的关系以及标签之间的关系是一个挑战,以树或者DAG(有向无环图)结构进行建模是目前普遍使用的方法。不过,这些方法相对简单,对标签之间以及文本和标签的复杂语义关联刻画并不充分。
- (3)缺乏合适的评估指标
- 层次多标签分类问题中,很多研究者提出了自己的评估指标,有的仅仅是自己在使用,有的沿用了多标签分类中的评估指标,比如精准率、召回率、F1值等。但是很显然,普通的多标签分类的评价指标不能很好地评价层次多标签分类问题,因为在预测时,如果预测结果是真实标签的兄弟、父亲或者后代节点时,这些错误的严重程度应该是不同的,而上述指标等却不能体现出这些差异,但是从文本分类的角度来看,预测出错的程度又是相同的,所以,对于什么样的评估指标才能正确反映HMTC中的算法模型性能还没有公认的定论。
- (4)分类器的设计
- 分类器不仅要关注于文本的层次关系,而且要关注不同层次不同标签和文本的关系,分类器如何利用文本的层次关系以及文本和标签之间的关系,利用的程度有多深,这些都是需要研究的难点,当然这也取决于具体的任务。
层次多标签解法
根据是否利用层次类标签信息以及如何利用层次信息,可以将层次多标签分类算法主要分为非层次方法和层次方法,其中非层次方法又可以叫做平面方法;而层次方法主要可以分为3种,分别是局部方法、全局方法以及它们的组合,即混合方法,如下图所示:
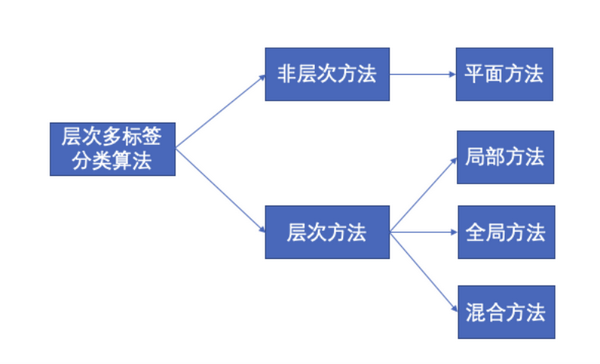
非层次方法
(1)平面方法
平面方法忽略层次标签之间的依赖关系,将其转换为平面的多标签分类问题,然后再使用多标签分类的方法进行处理,对于层次标签的内部标签节点,以层次约束为准则,任何被归类为子标签的样本都自动被归类于其所有祖先标签节点。
在平面方法中,最重要的不是分类器设计,而是文本表示,在文本分类(一)和文本分类(二)中从技术演化过程详细分析了文本表示方法,但是需要注意的是将层次多标签问题转换为平面多标签任务是最差的方法,因为它忽略了层次分类中各类别之间的依赖关系,这种依赖关系不仅存在于不同层级之间,也存在于同一层级的不同类之间,平面方法没有考虑这些特点,那么我们来看看层次方法是如何解决这些问题的。
层次方法
分为
- 局部、全局和混合
(1)局部方法
局部方法是利用分而治之的思想,将整个分类问题转换成多个局部的子问题,通过解决多个子问题,在层次结构上建立多个局部分类器,最后再将这些分类结果组合起来为全局的分类结果。
根据使用局部信息的不同,局部方法可以划分为不同的策略,主要有
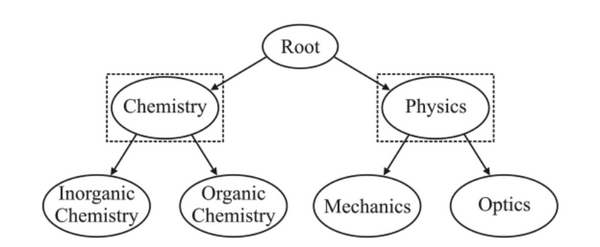
- LCN (LocalClassNode)
- LCPN(LoealCassifierParentNode)
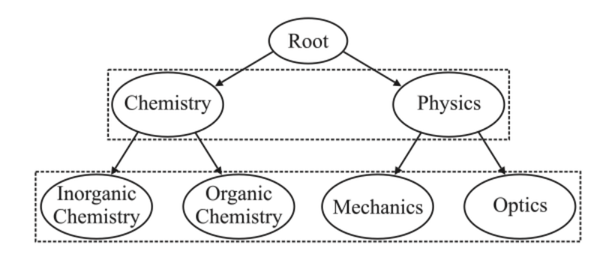
- LCL(LocalClassLevel)
这三种策略使用的分类器个数不同,另外使用的局部标签依赖信息也不尽相同。
首先,我们先看下图的LCN方法,它对于每个节点来进行分类。
其次,我们看下图的LCPN方法,它对于父节点的子类来进行分类。
最后,LCL使用了同一层级的关系,实现不同层次类的预测。
以上三种方法也有着相似的处理流程:
- 在测试阶段却都是以自上而下(Top-Down)的范式进行的从根节点开始,只有被当前的分类器预测为正的样本才会被传递给其子节点的分类器,依此类推,直至到达叶子节点分类器
但是它存在一定的问题:
- 错误传播问题:需要注意的是,随着类层次向叶子方向移动,错误分类也有着向下传播的风险
- 模型计算消耗巨大:因为涉及到的分类器过多,模型的参数量会巨大。
(2)全局方法
全局方法利用整体的信息,在层次结构上只建立一个分类器来同时处理所有的类别。大多数全局方法是基于平面方法修改得来的。近年来,全局方法大部分是以神经网络实现的,当然也有基于传统机器学习方法的,所以本节从这两种大类入手。
① 传统机器学习中,一般采取基于决策树或者基于集成的方法
- 决策树思想:
决策树以树形结构为架构,在面对分类问题时,通过信息增益或者信息增益比等以各个特征对实例样本进行分类的过程,即通过树形结构的模型,在每一层上对特征值进行判断,递归到叶子节点的决策过程。
- 决策树举例:
C4.5算法原本是平面的决策树算法,不能用于层次分类,有文章提出的HMC4.5方法,基于C4.5对计算类熵的方法进行了修改:在C4.5原始的算法中,每次都是选取信息增益比最大的属性作为当前分类的子树根节点,但是HMC4.5使用所有类的熵的和,相当于描述属于一个示例的所有类的信息量之和。该模型将整个层次归纳为一个决策树,归纳过程较为复杂,但是会生成一组简单的规则。
- 集成思想:
集成学习的思想是将若干个子学习器(分类器&回归器)通过某种策略(Bagging、Boosting)组合之后产生一个新学习器。
- 集成举例:
AdaBoost的全局方法,针对DAG(有向无环图)结构采用非强制性叶节点预测:先对文本数据进行预处理,然后结合适配的AdaBoost进行数据集上的规则学习,最后对样本进行测试且对预测不一致进行处理:对不一致的节点,考虑其所有祖先类的预测置信度,如果它们的置信度足够高,那么就将其所有祖先类来标记实例,否则去除掉该不一致的类标记。
② 神经网络的方法一般采取基于图表示学习、注意力机制等方式进行学习
- 图表示学习思路:
层次多标签分类存在结构信息,而图这种表达形式能够挖掘结构信息实现层次分类任务,因此图表示学习为层次分类任务提供了良好的解决思路。
- 图表示学习举例:
图表示模型首先对文本以词共现矩阵将文本转换为图,可以使用对节点的邻居节点进行卷积等操作实现图嵌入,这种思想类似图像或者普通文本一样进行交替卷积、池化操作,最后通过全连接层进行分类预测,并可以为标签之间的层次关系设置损失函数,并和网络模型最后的交叉熵函数共同加权作为损失函数,在全局的层次上考虑层次关系。
- 基于注意力机制的思路:
注意力机制就是把注意力放在重要的信息上,在文本分类情境下,就是将和层次结构各层最关联的文本内容利用注意力机制,对文本语义表示的不同部分分配不同的权重来突出实现的。
- 基于注意力机制举例:
基于注意力的模型同时也可以和上述图表示学习进行结合,将文本和标签使用图表示后,将文本以BERT和双向GRU进行上下文语义信息抽取,并通过多头注意力机制,将标签的图表示作为查询,文档作为键值对,让标签的层次信息融入到文本表示输出中,抽取文本的不同部分和标签层次中各个层次、各个类别之间的关系信息。
(3)混合方法
为了结合局部方法和全局方法的优势,可以在利用层次结构局部信息的同时也利用全局信息,最后对这两部分进行统一处理,这类方法叫做混合方法。
- HMCN混合模型
- 简介
以HMCN混合模型进行分析,它是第一个结合局部和全局信息进行层次分类的基于神经网络的HMTC方法,可以适用在树结构或者DAG(有向无环图)结构。
- 模型类型
它有两个类型,分别是前馈版本HMCN-F和递归版本HMCN-R,二者的主要区别在于前者需要训练更多的参数,而后者因为在层级之间共享权重矩阵并且使用类LSTM结构对层次信息进行编码,在关联相邻层次结构的同时也减少了需要训练的参数,并且随着层级越多递归版本的优势越大。
- 总体思路
HMCN模型在标签层级结构的每一层都会输出局部预测以及最后的全局预测,而最终的预测是各个局部预测的连接以及全局预测的加权组合而成;此外,各层的输入结合了上层的激活和重用输入特征,从而在原始特征和给定层级之间建立紧密的联系;对于预测不一致的情况,则通过在优化局部和全局损失函数的同时加上惩罚层次违规来保存预测遵循层级制约。以HMCN-F为例,其模型结构如下:

Seq2Tree
【2022-9-19】层次文本分类 Seq2Tree:用seq2seq方式解决HTC问题
大部分模型不考虑层次文本分类的路径问题,直接进行标签预测,导致可能出现上下层label冲突
用T5-Base作为backbone来实现「seq2Tree」,主要做了两部分的设定和改造:
- 「DFS based label linearization」: 这部分主要是为了适配seq2seq,「对样本的gold label进行序列化改造」。具体就是提出了一个基于DFS的标签线性化方法,因为一般层次标签体系都是树,而用DFS可以保证能够访问到同一条path内从上到下的所有节点。
- 「Seq2Tree with Constrained Decoding」: 就是在decoding的时候,利用层次标签体系和当前步预测出来的label「对下一步的label的值域进行限制」,避免下一个预测出来的label不在可能的路径上。
HFT-CNN
论文
- HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization
论文思想:
- 文本分类标签是多层的。一级包含二级,二级包含三级。
- 一级标签上训练textcnn模型,记为model1
- 二级标签上训练textcnn模型,记为model2,其中model2的embedding laber和convolutional layer用了model1的这些参数,在上面做finetune,其他参数随机初始化进行训练。如果有更多的下级标签,就继续往下这样做。
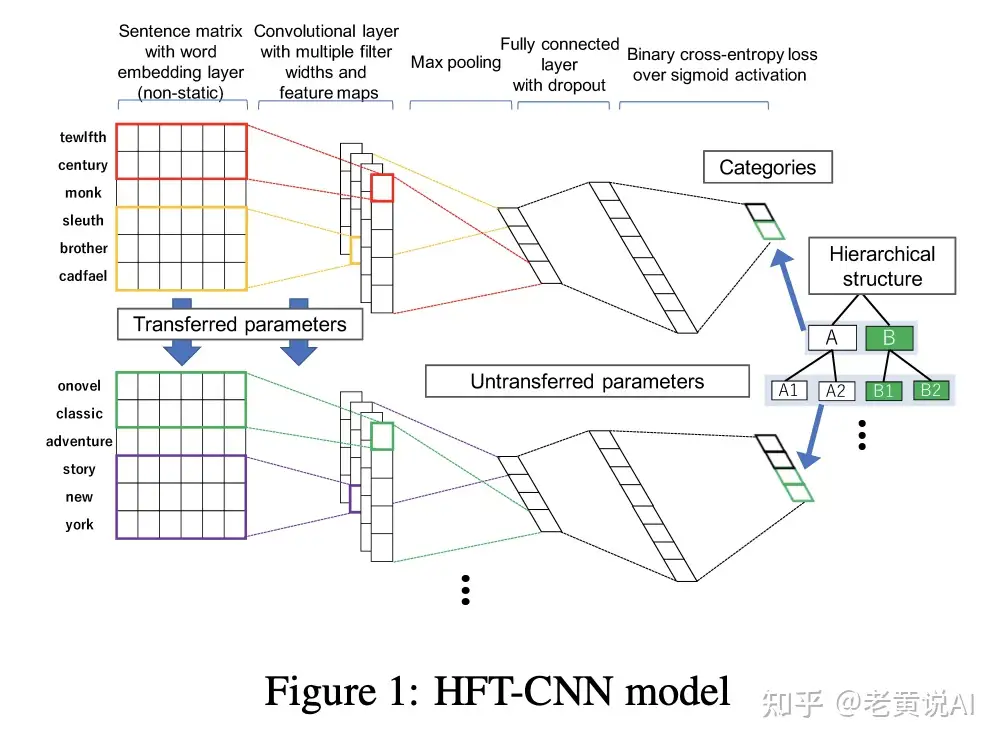
HGCLR – ACL 2022
- 论文:Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification
- 代码: https://github.com/wzh9969/contrastive-htc
当前HTC的很多模型都是将 text 和 标签层次结构分开编码,然后在分类之前再进行组合,然后预测。
- 提升点: 让文本特征和层次标签特征做充分的交互,用交互后获得的表征做预测,但是之前的模型有个问题,对于所有的文本来说,层次标签特征都是一样的,作者们认为这个交互的程度不够,对于文本来说,交互后变成了label specific text feature,但label feature并没有任何改变,没有触及灵魂,最好让他们相互交融。
思路
- 「把层次标签结构融入到 Text Encoder中,最终学到的就是一个 Text Encoder」,直接用 Text Encoder的结果进行多标签文本分类预测。
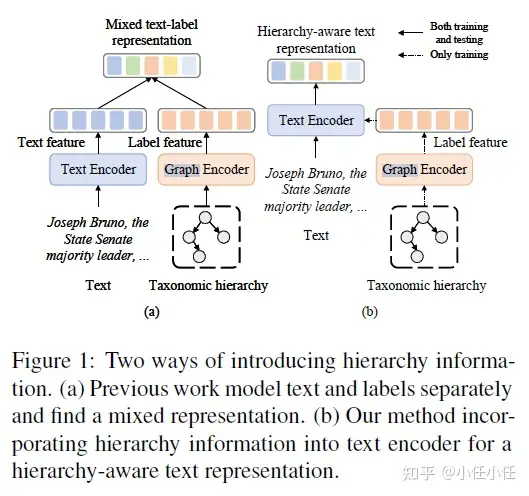
经验总结
一、问题拆解和数据
参考:工业界文本分类避坑指南
Q1 构建文本分类标签体系有哪些坑?
在我们在做真实的业务问题的时候,不像给定一个数据集,标签就是定死的。如何确定一个合理的分类标签体现其实是十分关键的。这个阶段一定要做数据充分的探索性分析。图省事吃大亏。
下面几个基本的原则:
- 稀疏程度合理。 一般正常的分类体系都是符合一个长尾分布,大概可以分为主要类A,主要类B,xxx,其他类。softmax based分类模型还是主要解决这部分样本比较多的问题。有个小技巧,按照业务上出现问题的频度,分类空间最好预留其他方便迭代。
- 类间可分,类内聚集。 不要搞一些分不开的类,最后发现学出来的两个结果,置信度都不高,对我们没有什么意义的。
- 标签的关系明确。 是多分类问题呢,还是多类别问题呢,还是层级分类呢?不同的问题有对应不同的方法,尤其是层级分类,坑比较多,这里先不展开了。
Q2 初期监督数据不够?
标注数据总需要一定的时间,这时候除了用规则,词典之类的方法外,或者fewshot learnig的一些思路解决问题,大体的思路是两种。
- Fewshot Learning 把分类问题转化为匹配或者相似度学习的问题,减小分类空间学习的难度,问一个小孩这个水果是啥比,总要比,选择一个最像的水果要简单。
- 迁移学习 Bert在小数据上表现其实挺出色的,除了慢一点,似乎没有其他毛病了。 上两个阶段大概只需要几千条数据就可以跑起来了。
Q3 如何高效地积累标注数据?
有了前面起步的baseline,我们至少可以扔到线上把模型跑着了,然后人工标注数据怎么积累又是一个问题,不同的样本对于我们当前的价值是不一样的,类别空间会扩充以及长尾标注样本数量不足是两个最常见的问题。大体的原则是通过不确定性度量和多样性度量两个角度,来选取对当前模型增量送训样本最优价值的样本。
- 不确定的样本 典型的特点是模型输出的置信度不高,没有把握判断是哪一个类别,这种样本需要人工给出真实的类别,指导学习。 baseline可以用熵来度量。
- 不一样的样本 典型的特点就是一些与积累数据分布有差异的,玩比赛的常用的adversrial validation,也是一个简单高效的办法。 学术界在度量分布差异的时候,总喜欢从数学的角度提出一些奇奇怪怪的指标,甚至还有结合ugly的聚类去做。而adversrial validation直接从监督学习的视角出发,让模型来自动学习给定标签的分布差异,从而有一定的区分能力。并且,这个过程中,特征重要性和预测的置信度两个结果分别完成了特征选择,样本粒度的分度度量置信度评价。看一下uber这篇论文,在concept drift detection里面,这也是一种神器。本质原理都是一样的,只不过concept drift detectio里,我们用的是特征重要性反馈,在分布度量里,我们用的是结果的置信度。
https://paperswithcode.com/paper/adversarial-validation-approach-to-conceptpaperswithcode.com
Q4 如何发现新的类别,扩充类别空间?
有一些方法还挺不错的,推荐ACL2019的那个论文 Deep Unknown Intent Detection with Margin Loss
https://arxiv.org/abs/1906.00434arxiv.org
,非常简洁明了。我们在Kaggle Bengali的比赛里面也用了类似的方法检测新类别,不过用的是arcface异曲同工吧,都是margin softmax,简单又效果非常好。具体可以前情回顾:
https://zhuanlan.zhihu.com/p/114131221zhuanlan.zhihu.com
本质上都是找出,与已知类别不相似(分布差异较大)的样本,其实用前面的adversrial validation也可以解决,实测margin softmax效果更好一点。
二、算法抽象和选型
Q5 文本分类任务有哪些难点?
文本分类的难点也是自然语言的难点,其根本原因是自然语言文本各个层次上广泛存在的各种各样的歧义性或多义性(ambiguity)和演化的问题,下面典型的例子:
- 输入层面:短文本->长文本和超长文本
- 标签层面:复杂语义识别,如阴阳怪气
- 时间演化:川普VS 川普,开车VS开车
- 上下文:美食论坛苹果小米黑莓 VS手机论坛苹果小米黑莓
Q6 如何定义一个文本分类问题的难度?
典型难度排序:主题分类-情感分类-意图识别-细粒度情感识别-复杂语义识别(如阴阳怪气)
- 数据量 典型的例子:one/zero shot VS 海量
- 非线性 典型的例子 :阴阳怪气 VS 垃圾邮件
- 类间距离 典型的例子: 细粒度的情感分类 VS 正负情感倾向
Q7 文本分类的算法选型推荐?
算法选型的出发点就是权衡各种约束,考虑模型的天花板能力,选择合适的模型。一般对应任务的难度,权衡计算时效,选择合适的模型。除了忽略一些比千分点的场景,比如竞赛和论文,一般这块在确定算法选型后,就没啥油水了,建议少花精力。有经验的算法工程师,一定能人脑搜索出一个当前选型下的最优结构。一个特别经典的建议大家试一下,concat_emb-> spartial dropout(0.2)->LSTM ->LSTM->concat(maxpool,meanpool)->FC。
结合前面的任务难度定义,推荐的算法选型行为
- Fasttext(垃圾邮件/主题分类) 特别简单的任务,要求速度
- TextCNN(主题分类/领域识别) 比较简单的任务,类别可能比较多,要求速度
- LSTM(情感分类/意图识别) 稍微复杂的任务
- Bert(细粒度情感/阴阳怪气/小样本识别)难任务
Q8 如何确定验证集和评价方法?
这是个老大难的问题,特别是实际应用中,由于文本分类符合一个长尾分布,常见类别的识别能力其实一般比较ok,长尾识别的稀烂,如果单纯看准确度的话,是个还不错的模型,但你不能说他好吧。对应着指标就是acc很高,macro-f1很低。
- 确定各类别错分的代价 特别是在类别较细或者层级标签的时候,如果在一颗子树上的标签,犯错的成本并不高。要是完全截然相反的类别,犯错的代价就特别大。这里建议通过惩罚矩阵的方法,构建细粒度的惩罚代价。
- 合理采样的验证集 真实的标签分布可能过于不均衡,建议掐头补尾,这样的验证集评价往往更有区分度。
- 模型语义压测 各种花里胡哨的变体输入,未纠错的文本都来一套,实在不行,上adversrial attack 攻击一下。
三、细节策略和实现
Q9 如何处理溢出词表词(OOV)?
这个在前Bert时代是一个挺关键的问题,以前回答过,还可以参考。从数据中来到数据中去, 要么想办法还原次干,找到可以替换的词向量。要么从sub-word的层次学习出语义,参考Bert BPE的方法。很早很早念书的时候,还没有Bert做过一些文本分类的比赛,在一些任务上搞定OOV提分还是很大的。给之前回答过的一个前Bert时代方法的链接。
Word Embedding 如何处理未登录词?www.zhihu.com
Q10 文本分类模型演进的明线和暗线?
针对上文提出来的文本分类的难点,其演进路径大概也是从统计机器学习,词向量+深度学习,预训练语言模型的发展。
- 明线:统计-机器学习-深度学习-更深的深度学习
- 暗线1:简单表达-语义表达-上下文语义表达
- 暗线2:特征输入粒度 从词到subword
- 暗线3:预训练权重从输入层扩展到网络结构内部
关于路线的演进,这里有个前几天画的思维导图:部分截图如
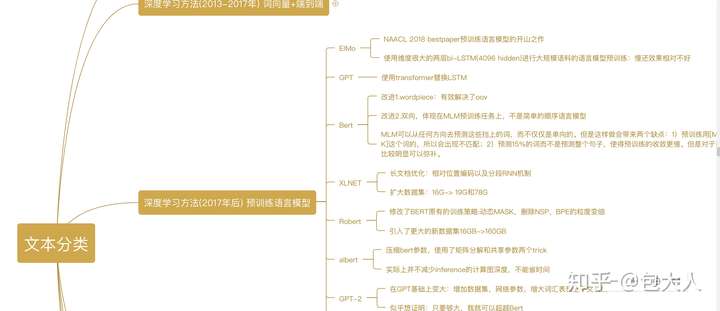
思维导图部分截图
完整的链接可以点击:
| [ppt | ProcessOn免费在线作图,在线流程图,在线思维导图www.processon.com ](https://link.zhihu.com/?target=https%3A//www.processon.com/view/link/566249a3e4b026a7ca234a71%23map) ](https://link.zhihu.com/?target=https%3A//www.processon.com/view/link/566249a3e4b026a7ca234a71%23map) |
Q11 策略和算法怎么结合?
算法工程师不能老鄙视规则,
- 串行式 典型的代表是,规则捕捉-分类-匹配兜底,大概这样的流程会比较合理,规则部分负责解决高频,和bad/hard case,分类负责解决长尾中的头部, 匹配负责解决长尾。这样的优点是,效率很高,往往大部分case很快就过完了。
- 并行式 规则,分类,匹配都过,然后进行归一化后的置信度进行PK,有点类似于广告竞价,这样的好处是能充分融合多重策略,结果更可靠。
Q12 有哪些可以刷分的奇技淫巧?
可以尝试的点还蛮多的,搜索空间特别大,感兴趣的可以试试,不保证都有效。这部分的方法大多需要在算法选型敲定后,在模型结构上下功夫,需要遍历一些搜索空间。不建议花太大的经理,具体可以参照之前的回答,而且有了bert之后,他们越来越不重要了,也就没有补充Bert上面的一些操作了:
在文本分类任务中,有哪些论文中很少提及却对性能有重要影响的tricks?www.zhihu.com
Q13 模型inference资源限制下,如何挑战算法选型的天花板
玩比赛的经常遇到过这个问题,典型的场景Kaggle上要求提交模型,更换测试数据,只给两个小时的推断时间。
除此之外,我们在工业界耗时严格的场景下,Bert总表示遗憾,效果虽好,但是臣妾做不到啊。想要TextCNN的速度,又想要逼近Bert的效果。

这时候模型蒸馏就派上用场了,模型蒸馏在Kaggle一些线上推断比赛的top solotion必不可少的。Hinton给的baseline是这样的,通过teacher model产出soft-target。然后student同时学习hard target和teacher model的soft-target。不过要注意的是,用的时候不要leak,先用KFold产出soft-target的oof,然后和GroundTruth一起给student训练。在不少开源代码里看到leak soft-target的情况,用teacher摸过训练标签的样本给student学习。
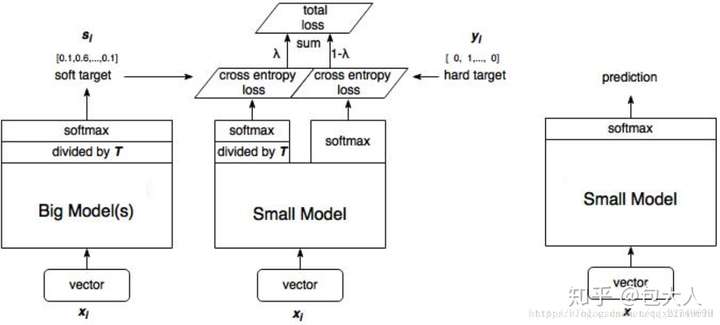
比赛经验
Google QUEST Q&A Labeling
【2022-6-3】新手入门 Kaggle NLP类比赛总结
- 最初是跟着教程跑入门赛 Bag of Words Meets Bags of Popcorn 入坑 kaggle NLP 类比赛, 被一步步的文本预处理搞得心累
- 后来 BERT 横空出世,文本预处理已不再重要,NLP 类比赛变得像传统挖掘类比赛一样简单,现成的开源框架加上 kaggle 平台上免费的 GPU 资源,似乎已经没什么障碍了
BERT家族
BERT 类模型的使用方法是预训练 + finetune
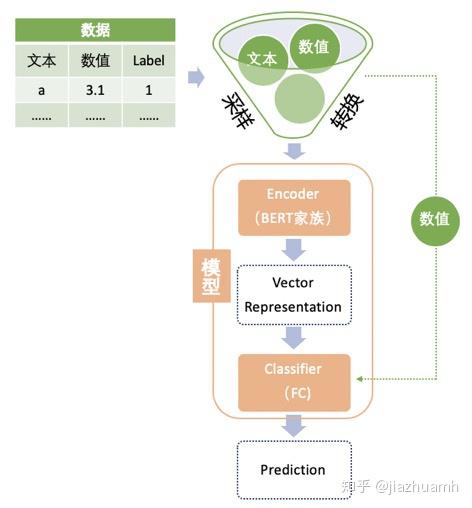
- 绿色的数据部分,主要包括对数据进行采样,转换成 BERT 输入的格式。
- NLP 类比赛中的数据大致可分为文本数据和非文本数据
- 文本数据为主,一般以句子、段落或篇章的形式存在;
- 非文本数据是指数值变量或分类变量,这类变量的处理方法与传统挖掘类比赛一样,因为不是重点,不需要太复杂的处理或转换,并且一般只是作为补充信息被整合到 BERT 模型中,不妨称它们为 meta 特征。
- NLP 类比赛中的数据大致可分为文本数据和非文本数据
- 粉色的是模型部分,拆成了两块 Encoder 和 Classifier,在实际使用中其实是放在同一个神经网络里的。拆开表示主要是因为
- Encoder 部分就是预训练语言模型,不论是网络结构还是权重都是现成的,直接拿来用,基本不需要做改动;
- 而 Classifier 部分是随着任务的不同而改变的,它一般是一层或多层全连接网络(FCNN)。
- 大致的流程是文本特征(也可以有 meta 特征)经过 Encoder 层会被编码成向量表示(Vector Representation),再通过 Classifier 得到最终的预测结果。
- meta 特征既能以 special tokens 的方式和文本特征一起进入 Encoder 进行编码;也可以不过 Encoder 而在 Classifier 部分进行 Embedding,然后与文本的 Vector Representation 进行融合后作为 Classifier 的输入。
BERT家族
BERT:MLM 和 NSP任务- 基于 Transformer Encoder来构建的预训练语言模型,它是通过 Masked Lanauge Model(MLM) 和 Next Sentence Prediction(NSP) 两个任务在大规模语料上训练得到的
- 开源的 Bert 模型分为 base 和 large,它们的差异在模型大小上。大模型有更大的参数量,性能也有会几个百分点的提升,当然需要消耗更多的算力
BERT-WWM:mask策略由token 级别升级为词级别Roberta:BERT优化版,更多数据+迭代步数+去除NSP+动态maskXLNet:模型结构和训练方式上与BERT差别较大- Bert 的 MLM 在预训练时有 MASK 标签,但在推理时却没有,导致训练和推理出现不一致;并且 MLM 不属于 Autoregressive LM,不能做生成类任务。
- XLNet 采用 PML(Permutation Language Model) 避免了 MASK 标签的使用,且属于 Autoregressive LM,可以做生成任务。
- Bert 使用的 Transformer 结构对文本的长度有限制,为更好地处理长文本,XLNet 采用升级版的 Transformer-XL。
Albert:BERT简化版,更少的数据,得到更好的结果(70% 参数量的削减,模型性能损失<3% );两个方面减少模型的参数量:- 对 Vocabulary Embedding 进行矩阵分解,将原来的矩阵V x E分解成两个矩阵V x H和H x E(H « E)。
- 跨层参数共享,每层的 attention map 有相似的pattern,可以考虑共享。
这些模型的性能在不同的数据集上有差异,需要试了才知道哪个表现更好,但总体而言 XLNet 和 Roberta 会比 Bert 效果略好,large 会比 base 略好,更多情况下,它们会被一起使用,最后做 ensemble。
Encoder
Encoder 都是基于 transformer 结构的预训练语言模型,包括了 Bert 及其后继者 Bert-WWM()、Roberta、XLNet、Albert 等,统称为 BERT 家族。
它们不仅在结构上很相似,而且在使用方法上更是高度一致,可以在 huggingface/transformers 全家桶中直接调用
硬负采样 Hard negative sampling
在 NLP 问答任务中,需要从一篇文章中寻找答案,一种常用的建模方法是将文章分割成多个 segment,分别与问题构成句子对,然后做二分类。这时候只有一个正样本,其他都是负样本,如果不对负样本做下采样的话,数据集会非常庞大,并且模型看到的多数都是负例。下采样可以减小数据集规模,从而节省模型训练的时间和资源消耗,这样才有可能尝试更多的模型和策略。
那么该使用什么样的下采样策略呢?最简单的可以直接随机下采样,当然有更好的选择,这里推荐使用 hard negative sampling, 它的思想是保留那些对模型而言比较“难”的负样本,这样可以增加难度,迫使模型学到更多有用的特征。
对负样本“难易”程度的衡量多是基于一些启发式规则,比如
- 与正样本比较接近的可能更有迷惑性,因此可以通过定义句子间距离,保留那些与正样本“距离”比较近的负样本。
- 再比如可以先用一个简单、运算量小的模型对训练集做预测,把那些容易预测错的负样本作为“难”的保留下来。
伪标签 Pseudo-labeling
伪标注是一种半监督方法,在众多比赛中被验证有效而广泛使用,步骤如下:
- 训练集上训练得到 model1;
- 使用 model1 在测试集上做预测得到有伪标签的测试集;
- 使用训练集+带伪标签的测试集训练得最终模型 model2;
伪标签数据可以作为训练数据而被加入到训练集中,是因为神经网络模型有一定的容错能力。需要注意的是伪标签数据质量可能会很差,在使用过程中要多加小心,比如不要用在 validation set 中。
Ensemble
打比赛的小伙伴对 Ensemble 应该不会陌生,在经验分享中看到有人只靠从 Public Kernal 中筛选一些得分高的模型,稍做修改后融合在一起就能拿到铜牌,足见 Ensemble 的威力。
在挖掘类比赛中经常见到复杂的 Ensemble 策略,多个模型做 blending,然后再 stacking 好几层,以至于有时候自己都搞不清最终的提交是由哪些模型融合而来的。但在 NLP 比赛中,Ensemble 会简单很多,一个重要的原因是深度模型都很大,最终提交会有资源限制,没法跑太多模型。
常用的 Ensemble 策略其实就是多个模型的输出求 average(算数平均、几何平均或秩平均)。
因为深度模型消耗的运算资源大,并且结果有很大的随机性,因此出现了一些适合深度模型的 Ensemble 方法。
- SWA(Stochastic Weight Averaging) 通过对训练过程中多个时间点的模型权重求平均达到集成的效果,基本不增加运算量,详细原理可以参考论文
- Checkpoint / Seed / Fold average
- 因为深度模型的随机性,同样的模型结构,使用不同的随机种子、KFold 分割、训练过程中的检查点,都可以做 average 提升模型的泛化能力。
情感分析
情感分析方法
- 目前舆情分析还是处于初级阶段。目前舆情分析还停留在以表层计量为主,配以浅层句子级情感分析和主题挖掘技术的分析。对于深层次事件演化以及对象级情感分析依旧还处于初级阶段。
- 【2021-3-14】情感分析五要素:(entity,aspect,opinion,holder,time), entity + aspect -> target
- 示例:我觉得华为手机拍照非常牛逼。 → (华为手机,拍照,正面,我,\)
- 【2021-3-14】情感分析五要素:(entity,aspect,opinion,holder,time), entity + aspect -> target
情感分析进阶
- 【2022-12-4】脉脉 NLP中的情感分析是不是有点low啊?就是个sentence分类问题,再具体就是token classification,分为3类,positive,neu,negative,这情感分析是不是简单了点?
- 情感分析主要还是针对业务场景看case设计策略+标注。这玩意儿模型真没啥好做的,随便一个文本分类模型都大差不差,剩下的讽刺、多重否定的难case,靠模型讲故事还行,真上线提升很有限
- (1)情感工作不只是这种大粒度的,还有小粒度的,如憎恶,埋怨,嫌弃,鄙视等等。
- (2)再者,情感分类只是最开始的一部分工作,紧接着后面还有情感归因,接着情绪安抚,结合安抚的对话生成等等。
- 深入点:情感词抽取、三元组抽取、情感原因抽取
情感分析实践
- 【2020-11-23】大连理工工具包cncenti,github地址
## [github地址](https://github.com/thunderhit/cnsenti)
## !pip install cnsenti -i https://pypi.tuna.tsinghua.edu.cn/simple/
from cnsenti import Sentiment
senti = Sentiment()
## 使用字典
## senti = Sentiment(pos='正面词自定义.txt',
## neg='负面词自定义.txt',
## merge=True,
## encoding='utf-8')
test_text= '我好开心啊,非常非常非常高兴!今天我得了一百分,我很兴奋开心,愉快,开心'
print('句子:', test_text)
## 情感词统计,默认使用Hownet词典
result = senti.sentiment_count(test_text)
print('情感词统计:', result)
## 精准的计算文本的情感信息。相比于sentiment_count只统计文本正负情感词个数,sentiment_calculate还考虑了
## 情感词前是否有强度副词的修饰作用
## 情感词前是否有否定词的情感语义反转作用
result2 = senti.sentiment_calculate(test_text)
print('情感词统计-精准:', result2)
from cnsenti import Emotion
emotion = Emotion()
test_text = '我好开心啊,非常非常非常高兴!今天我得了一百分,我很兴奋开心,愉快,开心'
## 情绪统计
result3 = emotion.emotion_count(test_text)
print('情感计算:', result3)
【2022-6-2】实际案例,调用情绪识别接口
import requests
import json
url = f'http://test.speech.analysis.ke.com/inspections/capability'
### headers中添加上content-type这个参数,指定为json格式
headers = {'Content-Type': 'application/json'}
text = "测!!"
data = {"biz_id":"utopia","app_id":"utopia","create_time":"2021-07-29 15:51:06",
"sentence":[
{"sentence_id":1,"text":"谢谢"},
{"sentence_id":2,"text":"你好"},
{"sentence_id":3,"text":"不好"},
{"sentence_id":4,"text":"怎么搞的"},
{"sentence_id":5,"text":"这也太慢了吧"},
{"sentence_id":6,"text":"妈的,到底管不管"},
#{"sentence_id"2,"text":f"{text}"}
],
"capability_id":"new_zhuangxiu_emotion_capability",
"audio_key":"","extend":{"context":[]}}
### post的时候,将data字典形式的参数用json包转换成json格式。
response = requests.post(url=url,data=json.dumps(data),headers=headers)
print(data)
## 接口说明:http://weapons.ke.com/project/6424/interface/api/632026
## 表扬>交流>中性>抱怨>不满>愤怒
## pos_appr 应该是 positive_appraisal
## pos_comm 应该是 positive_communication
## neu_neut 应该是neutral_neutral
## neg_comp 应该是 negative_complaint
## neg_dis 应该是negative_disappointed
## neg_angr 应该是negative_angry
type_info = {"pos_appr":"(正向)表扬型",
"pos_comm":"(正向)交流型",
"neu_neut":"中性型",
"neg_comp":"(负向)抱怨型",
"neg_dis":"(负向)不满型",
"neg_angr":"(负向)愤怒型"
}
res = eval(response.text)
print('-'*20)
print(res.keys())
print(res)
print('-'*20)
print('\n'.join(['%s\t%s\t%s\t%s'%(i['result'][0]['text'],i['result'][0]['type'], type_info.get(i['result'][0]['type'],'未知'), i['result'][0]['confidence']) for i in res['sentence']]))
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
