- 大模型应用: 代码辅助
- 结束
大模型应用: 代码辅助
总结
2025年5月27日,蚂蚁开源在第⼗届技术⽇上,重磅发布了《2025 ⼤模型开源开发⽣态全景与趋势》报告
AI Coding 开源项目正呈现出火热的态势,甚至在今年一度刮起了“氛围编程”(Vibe Coding)热潮。
- 一直以来,编程都称得上是 AI 赛道的热门场景,从最早的低代码、无代码,到后期的辅助编程,甚至是 AI 自主编程,AI 的编程能力愈演愈强,也让这一赛道持续火热。
- 现阶段除了商业化产品
Cursor、Windsurf等验证了市场热情外,以Continue、Cline为代表的 IDE 插件形态的项目们也是主流的开源选择。
技术层面
- AI 在理解复杂业务逻辑时存在一定短板。在代码质量、安全性、合规性上,均面临不小的挑战。对于一些关键业务是否交给 AI,不少企业仍心存顾虑。
- 此外,目前公开的代码数据集存在质量参差不齐等问题,这也给模型优化带来挑战。
预计未来 24 个月内,随着代码验证技术(如形式化方法与符号执行的结合)、多模态训练数据(代码 + 文档 + 运行时日志)的成熟,以及开发者反馈闭环的优化,AI 开发助手将会承担更多常规开发任务,但仍需人类开发者在关键决策点进行监督。
【2026-1-27】大神 Karpathy发了条推文:写了20年代码,最近被AI伤了自尊
极速转变:
- 2025年11月: “80% 手写 + 自动补全,20% 使用 Agent”
- 2025年12月: “80% Agent 编写,20% 人工编辑 + 修补”。
LLM Agent 的能力(尤其是 Claude 和 Codex)在 2025 年 12 月左右跨越了某种连贯性的阈值,并在软件工程及紧密相关领域引发了一场相变。
每个人都有自己的开发流,左边 Ghostty 终端里开几个 Claude Code (CC) 会话,右边开着 IDE 用来审视代码 + 手动编辑
【2026-5-22】微软报告
- Microsoft reports are exposing AI’s real cost problem: Using the tech is more expensive than paying human employees
- 特定工作场景中,部署和使用人工智能(AI)的成本高于人工工资。
- 报告分析了基于“tokens”(令牌)和“agents”(智能体)的AI使用模式,发现其综合开销超过了雇佣人类员工完成同类任务的费用。
微软按下 vibe coding 暂停键:烧 token 已经比员工贵了
- 2025年12月,微软把 Claude Code 开放给数千名员工,包括工程师、产品经理、设计师,鼓励所有人都用 vibe coding 的方式来重塑工作流。
- 2026 年 5 月 14 日,微软已经开始取消大部分员工的 Claude Code 内部许可。截止日期是 6 月 30 日
微软的总成本结构:「原来的员工工资 + 新增的 token 账单」, 「员工产出 +20%」在财务上的反映的并不是「营收 +20%」,而是 「营收维持不变,但成本结构里多了一项 AI 账单」
YC 的合伙人 Blomfield 判断很直接:
- 今天大部分公司还是「罗马军团」式的结构 —— 信息逐级向上传递、命令逐级向下分发、人是协调的核心。把 AI 装到这种结构上,效果就是把热兵器发给罗马步兵 —— 会用得更狠,但战术不会变。
- 真正的 AI-native 公司应该是另一种样子:
- 每个动作都产生可记录、可调用的产物,让一切对 AI 清晰可读(legible to AI);
- 公司应该被设计成「自我改进的 AI 循环」,系统能感知环境、做出决策、调用工具、接收反馈、自我修正。
- 人在这种公司里只剩两种角色:
- 个人贡献者(每个人不论部门都是 builder 和 operator,开会带原型,不光带想法;
- DRI(直接负责人):每个产出都有明确的责任人,「不能躲到 AI 后面」。
然后 Blomfield 说了金句:
「如果 API 账单不让你心痛,说明烧得不够。」
Uber 的 CTO Praveen Neppalli Naga 对 The Information 透露:公司 2026 年全年的 AI 编程工具预算,在前 4 个月就烧光了
英伟达应用深度学习副总裁 Bryan Catanzaro 接受 Axios 采访时说的那句:「对我的团队来说,算力的成本远远超过员工的成本。」
结论
vibe coding 没死, 只是不属于传统公司
工具
相关工具
- 【2026-3-16】香港大学推出开源工具CLI Anything, 一条命令将任何软件转化为 AI 智能体可控的 CLI 工具。无需手动编码,告别脆弱的 GUI 自动化。支持 Claude Code、Cursor 等主流智能体框架。详见站内专题:Claude
概念
Vibe Coding vs Spec Coding
比较
- Vibe Coding 灵活直觉/场景驱动:
- 直觉驱动的快速原型方法,通过自然语言与AI对话,以极高的速度将模糊想法转化为可运行代码,适用于个人项目、创意探索和MVP验证,但其生成的代码质量、可维护性和团队协作性较差。
- OpenAI联合创始人 Andrej Karpathy 在2025年初提出的”氛围编程”概念,强调”忘记代码存在,专注创意表达”的开发模式。
- Spec Coding 演进规范/需求明确:
- 规范驱动的可控工程方法,强调在编码前通过结构化的文档明确需求和设计,再让AI在严格约束下生成代码,适用于企业级复杂项目、团队协作和需要长期维护的系统,虽然前期投入较高,但能保障代码质量和项目的可控性。
- 从”Vibe”到”Spec”的演进,强调结构化与可控性,解决复杂项目中的可控性问题。
作者:Jartto
Vibe Coding 与 Spec Coding 像两条岔路:一条凭直觉狂奔,一条按蓝图缓行。
- 前者把键盘当画笔,先“跑起来”再谈对错;
- 后者把需求当契约,先“画清楚”再动工。
- 它们不是优劣之争,而是速度-可维护性天平上的左右砝码。
编码模式对比表
| 维度/模式 | Vibe Coding(氛围编程) | Spec Coding(规范编程) |
|---|---|---|
| 项目规模 | 小型项目、个人项目、MVP 原型 | 中大型项目、企业级应用 |
| 团队结构 | 个人开发者、小型团队、非技术背景成员 | 专业开发团队、跨职能协作团队 |
| 交付周期 | 极短,追求快速验证和迭代 | 相对较长,注重质量和可维护性 |
| 质量要求 | 较低,以功能实现为主 | 较高,对性能、安全、可维护性有严格要求 |
| 需求清晰度 | 需求模糊,需要在探索中明确 | 需求相对明确,或需要通过规范来澄清 |
| 长期维护 | 一次性项目、短期工具 | 需要长期演进和持续维护的核心系统 |
| 技术债容忍度 | 较高,可以接受一定的技术债 | 较低,需要严格控制技术债 |
| 开发者技能 | 对编码技能要求较低,更侧重创意 | 对系统设计、需求分析能力要求较高 |
Vibe Coding
氛围编程,详见本文末尾
Spec Coding
- 【2026-3-16】Spec Coding:AI开发的新范式
- 【2025-10-24】AI Coding 新范式:基于 Spec Coding 的新玩法
问题
- 问题1:“PROMPTS ARE EPHEMERAL.”(Prompt是短暂的)
- 问题2:Vibe Coding一开始很爽,但到后面越改越头大!
Spec Coding杀死Prompt Engineering
“Spec Coding不是‘头脑风暴’,而是‘头脑风暴后的施工图’。”
Spec Coding
OpenSpec 是为AI编码助手设计的规范驱动开发工具,通过轻量级工作流程确保开发者和AI助手在编写代码前就能对需求达成明确共识。
核心特点
- 🚀 轻量级:无需API密钥,最小化设置
- 🔄 现有项目优先:特别适合修改现有功能 (1→n)
- 📋 变更跟踪:提案、任务和规范差异的完整生命周期管理
- 🤖 AI工具集成:支持多种主流AI编码助手
AI编码助手时,是否遇到过以下情况:
- ❌ AI根据模糊提示生成不符合需求的代码
- ❌ 遗漏重要功能要求
- ❌ 添加了不必要的功能
- ❌ 代码行为不可预测
OpenSpec 解决方案
OpenSpec通过规范驱动开发解决这些问题:
- ✅ 明确共识:在编码前确定所有要求
- ✅ 结构化变更:所有相关文档集中管理
- ✅ 可审查输出:AI根据明确规范生成代码
- ✅ 版本控制:完整追踪所有变更历史
安装
npm install -g @fission-ai/openspec@latest
openspec --version
# 初始化OpenSpec
cd your-project-directory
openspec init
# 验证设置
openspec list
初始化过程会:
- 询问本地AI工具(Claude Code、Cursor等)
- 自动配置相应的斜杠命令
- 创建 openspec/ 目录结构
- 生成 AGENTS.md 文件
支持哪些工具

OpenSpec使用两个主要目录:
openspec/
├── specs/ # 当前真理源规范
│ └── auth/
│ └── spec.md
├── changes/ # 变更提案
│ └── feature-name/
│ ├── proposal.md
│ ├── tasks.md
│ └── specs/
└── project.md # 项目级别约定
常用命令
# 查看和管理变更
openspec list # 查看所有活动变更
openspec view # 交互式规范仪表板
openspec show <change-name> # 显示变更详情
openspec validate <change-name> # 验证规范格式
# 归档变更
openspec archive <change-name> # 交互式归档
openspec archive <change-name> --yes # 非交互式归档
# 工具管理
openspec update # 刷新AI指导,重新生成斜杠命令
详见:OpenSpec 介绍
新范式
开发者与 AI 之间最佳的协作范式?如何解决项目级别问题?
【2025-6-25】Anthropic 最佳实践: AI Coding 新范式
从敲代码的“工具”升级为融入整个开发生命周期的“伙伴”(未来可能变为导师)。
- 区别于 feature-level problem 一个简单的 prompt 便可解决,更规范更标准的工作模式。
Zen of Vibe Coding Outline
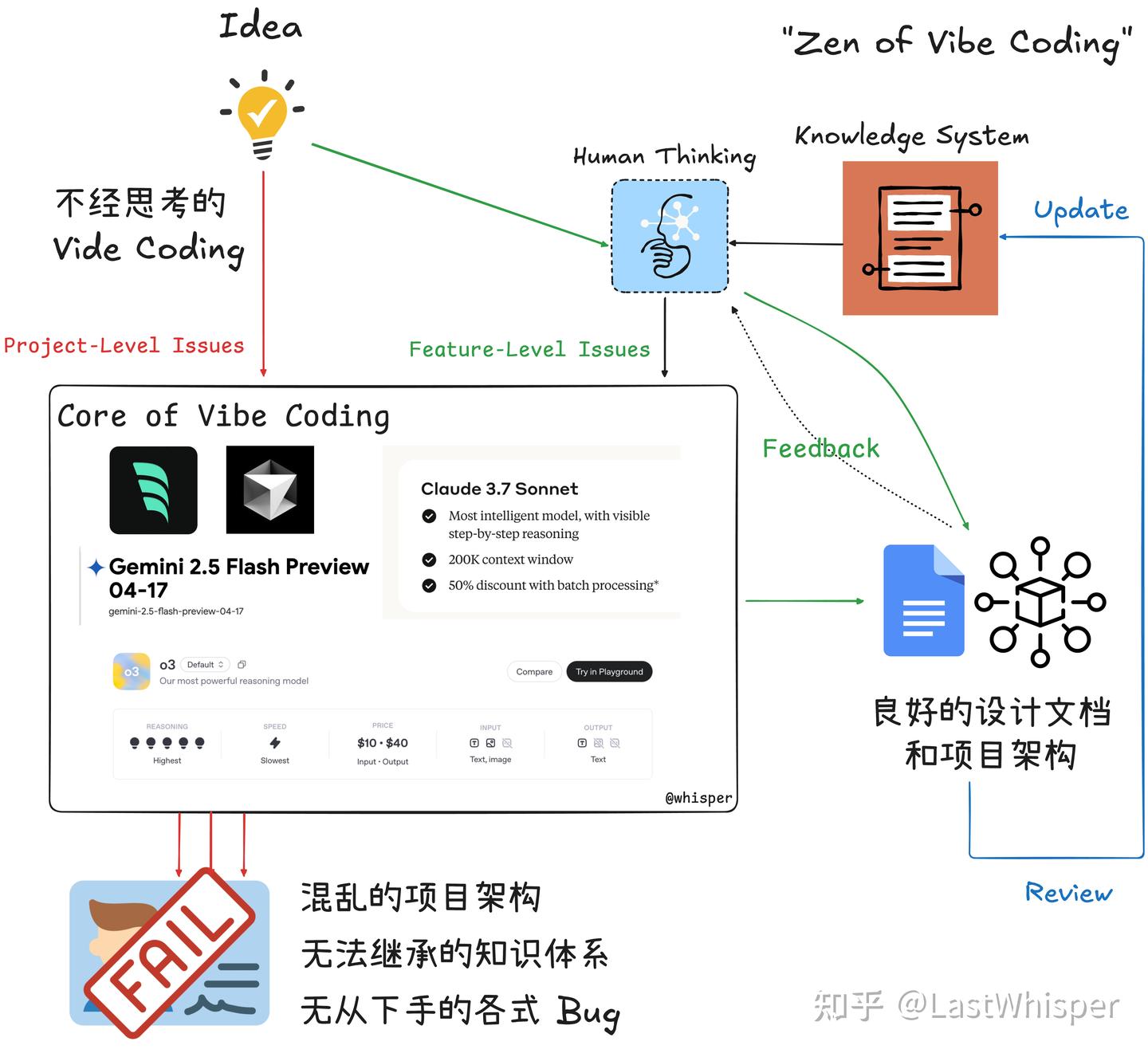
人机协同的“双模”驱动(Agent & Ask)
Anthropic 实践表明,与 AI 高效协作的关键:“任务分类”。
- 根据任务性质,在两种不同模式间切换,即 “自主代理模式”(委托)与“同步共驾模式”(监督)。
- 对应 Cursor Agent 和 Ask 模式。
- 目前主流 AI Coding 软件都兼容这两种模式。
构建高效人机协同系统所必需的思维方式。
- 原则一:建立自我验证的闭环系统
- AI 写代码前,先生成测试用例( memory 或 system rules 中)。
- 随后,AI 任务就变成“通过所有测试”。
- 这个简单的流程转变,创建了自我修正的闭环,极大提升自主模式的可靠性。
- 原则二:培养精准的任务分类直觉
- 高效协作的前提是做出正确的决策:何时放手,何时掌控。
- 开发者要快速判断任务适合 “Agent” 模式的外围探索,还是“Ask” 模式的核心构建。
- 这种判断力,是区分普通使用者与高级玩家的关键。
- 原则三:追求工程级别的精确沟通
- 与 AI 的沟通是严肃的工程行为。模糊指令必然导致不可靠的输出。
- 尤其在同步模式下,提示应如同 API 文档般精确,明确指出要操作的文件、函数、类以及预期的行为。
- 沟通的精度,直接决定了协作的效率和产出的质量。
如何区分这两种模式?
自主代理模式 (Agent)
开发者扮演“架构师”或“项目经理”的角色,向 AI 下达高阶指令,授予较高的自主权,来完成相对独立的任务。
AI 如同被委派任务的智能 Agent,负责从编码、测试到迭代的完整闭环。
适用场景:
- 快速原型开发:验证一个新想法,构建 MVP。
- 非核心功能实现:为产品增加外围或辅助性功能,例如工具、插件等。
- 技术探索:在不熟悉的框架或库中进行实验性编码。
Anthropic 提供案例:
- 团队在非优先级的背景下,要求 Claude 为其编辑器实现 Vim 键位绑定。
- 最终,约 70% 的代码由 Claude 自主完成,开发者仅需进行少量的审查和迭代。
在明确的目标和边界下,AI Agent 能爆发出惊人的生产力。
操作原则:
- 启用“自动接受模式”:允许 AI 持续地编写、测试和修正代码。
- 保障安全边界:始终从一个干净的 git 分支开始,并设置 checkpoint(备份),确保任何偏离预期的结果都能被轻松回滚。
同步共驾模式 (Ask)
开发者与 AI 更像是经验丰富的飞行员与智能副驾(Copilot)。
- 开发者掌握主导权,进行实时监督和引导
- 而 AI 则负责处理具体的、重复性的编码任务,充当一个不知疲倦的“结对编程”伙伴。
适用场景:
- 核心业务逻辑开发:处理直接影响产品核心价值的复杂代码。
- 关键 Bug 修复:对重要问题进行精准修复。
- 大型代码库重构:在遵循严格架构和风格指南的前提下进行修改。
- 关键实践:核心功能开发
为代码库或者项目实现一个关键的 feature,这区别于一些简单的 utils,它对整个项目成功运行非常重要。在处理这类涉及应用业务逻辑的关键特性时,需要向 Claude 提供极为详尽的 prompt,并实时监控其产出,确保代码质量、架构合规性与编码风格的统一。开发者聚焦于“思考”,AI 聚焦于“执行”。
操作原则:
- 提供高信息密度的提示 (Prompt):指令必须清晰、具体,无歧义,尤其是在处理命名相似的组件时。
- 不能依赖模型 agentic 的去处理可能的歧义,在要修改的代码前显式的引用文件名或者类似的标识,减少模型的认知负担
- 实时反馈与修正:将 AI 的工作流视为一个需要持续监督的过程,而非一次性的任务交付。因为这是重要的核心逻辑,需要你反复的修改和优化。
- 这就是为什么叫 Ask 模式,问题的解决显然不是一次询问就能解决的。
资讯
2025年5月28日,字节跳动发布最新内部邮件,逐步禁用包括 Cursor、Windsurf 在内的第三方 AI 开发软件,转而推广自研编程助手 Trae 作为替代方案。
- 邮件由字节跳动安全与风控部门发出,称此举是出于防范数据泄露风险的考虑,自 6 月 30 日起将分批在内部实施相关禁用措施。
代码能力
【2024-9-6】 第三方观点 常见编码助手:阿里通义灵码,商汤小浣熊,智谱codegeex,讯飞iflycoder
- 反响最好是通义灵码…
【2025-2-25】 最强代码模型 Claude 3.7, Grok 3
- 详见站内专题:Claude学习笔记
【2025-11-26】Anthropic Engineering 博客最新文章:
- 原文 Effective harnesses for long-running agents
- 长时间运行的 AI 代理仍然面临在多个上下文窗口中工作的挑战
《为什么 90% 的 AI 项目都会失败?——从 Claude Code 被当脚本用说起》
很多公司兴冲冲地部署各种“企业级 AI 项目”,例如把 Claude Code、GPT、Gemini 搬上服务器,让它们对代码库“自动做分析”“自动提报告”“自动查变更”。
听起来很先进,但现实往往是:这些项目上线不到两周,就悄悄死掉了。为什么?因为这些 AI 被要求做的事情,根本不是它们被创造出来的用途。
这就像买了一架飞机,结果用来当电风扇吹。能吹一点风,但不值得。
绝大多数 AI 项目为什么注定失败?
(1)不是技术,而是人类的误解
旧时代管理者总认为:AI = 高级脚本
- 调一次 → 产出一次 → 汇报一次
但真正的 AI(特别是代码 AI)其实是:
- 需要上下文
- 需要多轮推理
- 需要迭代
- 需要持续学习
- 需要理解整个代码图谱
- 需要记住架构演进
- 需要做 reasoning,而不是 grep
让它做“一次性分析”这种需求,本质上是:用飞机载 3 公斤快递。不是不能做,而是——完全不值得。
(2)单轮调用 AI 去分析代码,是结构性错误
为什么?因为忽略了代码的本质特征:
- 高频变动
- 横向依赖
- 潜在耦合
- 历史原因
- 模块习俗
- 真实上下文
- 团队暗规则
- 不可见逻辑
一轮调用无法重建任何一个真实工程的“因果链”。这就导致:
- AI 每次都像盲人摸象,
- 每天都在重新摸一遍。
成本高、价值低、速度慢、结论不准。
现实世界里的代码库,不是你把几段 diff 扔进去它就能立刻理解的。
这不是 AI 问题,是设计者对“软件复杂性”的理解不够。
(3)最讽刺的是:这些失败的 AI 项目,从一开始就注定要失败
因为真实目的不是:
- 提升效率
- 减少错误
- 优化迭代
- 提升团队能力
而是:
- “看起来我们在拥抱 AI”
- “可以在周会上展示”
- “可以写进流程”
- “可以向上汇报”
这些项目不是为了解决问题,而是为了满足“政治红利”。
这种项目的生命一般分三步:
- 部署很快(没想清楚)
- 试用很短(不好用)
- 下线很悄悄(不好解释)
最终都进入一个共同的下场:没人再提它,就像它从未存在过一样。
(4)真正的 AI-native 代码系统是什么样?
真实有效的 AI-native 模式应当包含:
- 全量索引整个代码库
- 持续增量同步
- 建立 code graph(结构图谱)
- 多轮推理
- 理解整个历史演进
- 自动生成 patch
- 自动验证
- 能和 CI/CD 整合
- 长期记忆 + 长期一致性
换句话说:
- 不是“开一枪”,而是“接管一个系统”。
- 不是做一次,而是融入整个工作流。
- 不是当脚本,而是当协作者。
这才叫 AI-native。
(5)总结
绝大多数 AI 项目失败,不是因为 AI 不够强,而是因为用它的人不够懂。
最常见的误解:
- “我终于拿到一把激光剑了!
- 我要用来……切菜。”
当然可以这么做,但这不是激光剑的错,这是时代的错位。
很多组织在“拥抱 AI”,但他们拥抱的是表象,而不是结构。
他们用的是 2025 年的 AI,但思考还停在 2015 年。
这就是 90% 的 AI 项目必然失败的根本原因。
LLM 编程能力怎么样
提出人:andrej kaparthy
【2026-4-2】Vibe Coding 烂摊子。Karpathy 自己都笑着说,做项目时不再深入理解代码,只是让它能用。
这种「能跑就行」的开发哲学,在原型阶段极其高效,在产品后期可能是灾难。
AI 生成的代码
- 往往缺乏边界检查和错误处理,碰到异常输入就崩。数据库索引、算法复杂度这些优化,模型不会主动去想,随着用户增长,性能瓶颈很快出现。
- 遇到要改功能的时候,开发者发现自己看不懂代码,只能继续用 AI 打补丁,补丁摞补丁,最后变成一座没人敢碰的屎山。
当年初为了抢上线快速用 AI 写的代码,可能在年末变成团队的噩梦,为了一个改动牵一发动全身。
正方:Anthropic 内部已经不写代码了
【2025-9-24】Anthropic 联创曝内部工程师已不写代码了,但工作量翻倍!开发者嘲讽:所以 Claude bug才那么多?
Anthropic 联合创始人 Dario Amodei
“未来 1-5 年,可能有一半的白领岗位会消失,失业率会飙升至 10% 到 20%,无论这项技术能带来多少好处”。
Anthropic 内部,工程师们已经不写代码了,而是通过管理大量的 AI Agent 系统来写代码,并且在这种模式下,每个人完成的工作量是以前的 2-3 倍。
130 名工程师过去一年使用 AI 体验: 工作发生了翻天覆地的变化。
- 很多人现在的工作量是以前的两、三倍,但他们已经不再写代码了,而是管理 AI Agent 系统集群。
- “我的工作完全变了,我得重新思考自己在 Anthropic 的角色。”
- 支撑 Claude 运行和设计下一代 Claude 所需的绝大部分代码,都是由 Claude 自己编写的。
- 不仅 Anthropic 是这样,其他发展迅速的 AI 公司也一样。
老板视角(站着说话不腰疼)
- 员工不会因此失业,公司还在飞速发展。
- Dario 还提议政府向 AI 公司多征税,表示这并不会影响 Anthropic 的发展
YouTube
高管们为公司全 AI 代码而开心的时候,开发者们却对这种情况充满质疑。
有人犀利发问:
- AI 写代码这么厉害,为什么 Claude 桌面客户端经常 UI 卡?
- 所以这就是 Claude 所谓“bug”被社区反映了一个多月才被发现的原因?
- 你们有没有写过代码、用 AI 干过一件生产工作?
- 一个人用几个 Agent 写代码很扯</span>,严重破坏心流
- 而且 AI 无法窥探产品全局和核心价值点,一般设计的架构和代码可能会完全偏离产品方向。
- 不是说 AI 不好,而是还没有到能革命地步,最起码没有想的那么美
这个联合创始人被员工给骗了,用 AI 编过程序的人都知道,用 AI 编写满意的程序,不把 Prompt 写清楚,产生不了结果。而写满意的 Prompt 可不是那么容易的,而且还要把想法分成若干步骤,让 AI 一步步逼近你的需求。中间还有一些参数调整,如果用 AI 帮忙,还不如自己改呢!”
目前的技术水平 AI 只能辅助,全 AI 代码是胡扯,只有少部分人觉得很惊叹。
正方:OpenClaw
大模型代码能力达到专家水平
Peter Steinberger 通过 Vibe 写出了 OpenClaw
反方:谢赛宁 大模型依然死记硬背
【2025-6-19】大模型全员0分!谢赛宁领衔华人团队,最新编程竞赛基准出炉,题目每日更新禁止刷题
有人说,LLM编程现在已超越人类专家,但本次测试结果表明并非如此。
表现最佳的模型,在中等难度题上的一次通过率仅53%,难题通过率更是为0。
即使是最好的模型o4-mini-high,一旦工具调用被屏蔽,Elo也只有2100,远低于真正大师级的2700传奇线。
谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1 一众模型全都难倒。
- 【2025-6-13】论文 LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
- 实时榜单 LiveCodeBench Pro
LiveCodeBench Pro:一个包含来自IOI、Codeforces和ICPC的竞赛级编程问题的实时基准测试。
- 奥林匹克获奖者构建,比赛结束后立即收集每道Codeforces、ICPC和IOI题目,在互联网上出现正确答案之前捕获每个问题。
- 动态题库考验LLMs算法逻辑深度
- 题库还每日更新,来预防LLMs“背题”
- 584道顶流竞赛题,团队手动对每个问题进行标注,标注内容包括解决每个任务所需的关键技能,并根据问题的认知焦点将题目分为知识密集型、逻辑密集型和观察密集型三大类。
- 题目分为三个难度级别,非人工挑选,而是正态分布自动选择。
谢赛宁表示:
- 击败这个基准就像AlphaGo击败李世石一样。我们还没有达到那个水平——甚至对于有明确可验证结果的问题也是如此。
结合题目分类与提交结果,对比人类专家的解题模式,分析模型在不同难度(简单 / 中等 / 困难)、题型(知识密集型 / 逻辑密集型 / 观察密集型)下的表现,定位模型在算法推理、样例利用及边缘案例处理等方面的短板。
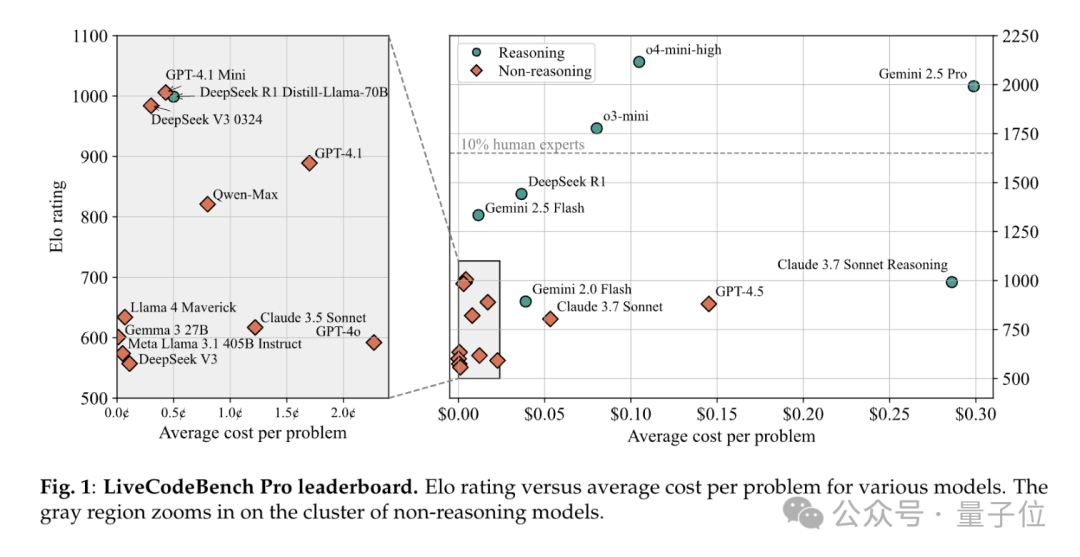
结论
- 模型在知识密集型和逻辑密集型问题上表现更好,擅长 “死记硬背”(如数据结构模板)
- 但在观察密集型问题或案例工作中表现较差,搞不定 “灵光一现” 的贪心、博弈题。
LLMs擅长实现类问题,但在需要精细算法推理和复杂案例分析的题目上表现欠佳,还常给出看似正确实则错误的解释。
LLMs经常无法正确通过题目提供的示例输入,显示其对给定信息的利用不充分。
反方:职业倦怠
【2026-2-13】X.com
软件工程师 SiddhantKhare 博客文章,吐槽AI编程为自己带来的“疲乏感觉”,引发了其他工程师们的共鸣。
AI引发的职业倦怠真实存在,却长期被行业有意无意地忽视。
- 单项任务提速并不意味着整体工作负担减轻
- 实际上正好相反,任务总量不断膨胀,高频的上下文切换带来了深层次的精力透支。
与此同时,工作角色也在悄然转变。
- 工程师从原本的创造者沦为高认知消耗的AI产出审核者,而AI输出固有的不确定性又与工程师习惯的确定性思维产生冲突,持续滋生焦虑情绪。
此外,行业技术更新节奏过快催生出一种 “FOMO 跑步机” 效应,频繁追逐新工具不仅浪费时间,还加速了已有知识的贬值,工程师也容易陷入反复调试提示词的“prompt 螺旋”之中,长此以往,独立思考和解决问题的能力逐渐退化。社交媒体上铺天盖地的高光展示,则进一步放大了比较焦虑。
Khare认为
- 在AI时代,工程师真正的核心竞争力不在于将AI用到极致,而在于懂得为自己设定边界、适时叫停,守护有限的认知资源,以实现可持续的长期产出。
反方:Jeremy Howard 装懂+反人类
【2026-3-3】Jeremy Howard(杰瑞米·霍华德):Kaggle 前总裁兼首席科学家、顶级 Grandmaster、Fast.ai 创始人;
- 2018 年,他与 Sebastian Ruder 共同提出了 ULMFiT,打破了当时“语言模型无法微调”的行业铁律,直接启发了后来的 ELMo、BERT 和 GPT 系列,拉开了 NLP 预训练大模型的序幕。
- 视频:260303-AI编程的危险幻觉——杰里米·霍华德
- 文字版:杰瑞米·霍华德最新对话:Vibe Coding 就像在拉老虎机,AI 正在剥夺人类获得“直觉”的权利
两种声音:都对,LLM 在“角色扮演(Cosplay)”理解事物 —— 假装懂
- LLM 根本什么都不懂,只是随机鹦鹉;
- LLM 刚才解决了具体问题,当然有理解能力!
他忧心忡忡指出隐藏在代码自动生成背后的巨大陷阱:Vibe Coding 是披着智能外衣的“老虎机”
- Vibe Coding 本质是“老虎机”: 写下一段提示词,按下回车,然后祈祷出来的代码能跑通。你获得了控制的幻觉,但当面对一堆连 AI 自己都不理解的复杂代码时,已经彻底丧失了修复能力。
- 大模型没有创造力,只是在“角色扮演”: 无论是让 Claude 写 C 编译器,还是解决某个具体任务,AI 都只是在训练数据的庞大分布中进行“插值(Interpolation)”。它们没有建立真实的物理心智模型,一旦脱离训练分布的“舒适区”,瞬间变得比白痴还蠢。
- “适当的困难(Desirable Difficulty)”是人类进化的燃料: 如果把所有初级、繁琐的编程任务都交给 AI 自动化,人类就会失去建立代码直觉的摩擦力。一个从未在泥泞的底层代码中挣扎过的初级程序员,永远不可能成长为架构复杂系统的资深工程师。
- AI 最大的末日风险,是被巨头用来“夺权”: 别去操心什么“AI 觉醒毁灭人类”的科幻剧本。真正的危险在于,科技寡头和政府正在利用这种恐慌制造监管壁垒,试图将这种能够颠覆世界的技术垄断在少数人手里。
实践
快手
【2026-2-8】3年、1万人,快手技术团队首次系统披露AI研发范式升级历程
快手研发范式的三阶段演进路径,以及快手技术团队对 AI 赋能组织提效的思考:
三阶段演进路径:
- 平台化、数字化、精益化(2023-2024 年):
- 建设一站式研发平台,并标准化需求和工程流程,工具渗透率>95%,流程自动化>94%
- 通过建立效能模型,识别交付瓶颈,提升需求交付效率,人均需求吞吐量提升 41.57%
- 智能化 1.0(2024 年 6 月 -2025 年 6 月):聚焦用 AI 提升个人开发效率
- 建设并推广 AI 编码 / 测试 /CR 等能力,AI 代码生成率超过 30%
- 但发现矛盾——个人主观编码效率提升显著,但组织需求交付效率却基本不变
- 智能化 2.0(2025 年 7 月以后):聚焦用 AI 提升组织整体效能
找到了 AI 研发范式升级路线:L1 AI 辅助(Copilot)→ L2 AI 协同(Agent)→ L3 AI 自主(Agentic)
探索出了支撑路线达成的系统性实践:AI x 效能实践、AI x 研发平台、AI x 效能度量
关键洞察与经验:
- AI 研发提效陷阱: 用 AI 开发工具 ≠ 个人提效 ≠ 组织提效
- 本质问题:如何将个人提效传导到组织提效
阿里
【2026-3-18】阿里巴巴集团与中山大学联合发表的AI编程相关研究解读
- 【2026-3-4】论文 SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
持续233天、消耗高达100亿token的大规模实验,对主流18个AI智能体在真实代码库上的“耐力”进行了极限测试。
实验结果令开发者五味杂陈:
- 当前大多数AI并非合格的代码维护者,而是在高效地“制造技术债务”。
- 75%的AI正在疯狂制造“技术债务”
核心发现:人工智能编程或许不会抢走开发者的工作,因为正忙于编写那些需要人类在未来十年不停修复的“遗留代码”。
打破泡沫:一次性修复不等于真正的“编程”
绝大多数AI 智能体在HumanEval或SWE-bench这类“一次性考试”中表现出色,快速解决明确的Bug。然而,实际上,软件开发动态演进:今天修复Bug,明天需求变更,后天依赖库升级。
这种持续演进的过程,无法被静态、一次性的修复测试所刻画。
全新的基准——SWE-CI。基于持续集成流程的代码仓库级评估基准,首次将AI编程评估从“一次性快照”转向“长期演化”。
即便在2026年,主流AI智能体的表现依然暴露出其在长期维护上的巨大短板。
- 首先,“零回归率”普遍惨不忍睹。在模拟长期开发的测试中,绝大多数大模型的“零回归率”竟然不到25%。这意味着,这些模型每进行四次代码修改,至少有三次会破坏原本正常的功能。
- 其次,技术债务指数级累积。随着项目演进,大多数模型产生的技术债务呈指数级增长。前期看似高效的修改,可能在后期引发系统级的“雪崩”。
优胜者
- Claude 4.5/4.6 是唯一能在长周期维护中保持50%以上零回归率的选手,展现了强大的“架构师思维”和稳定性。
- 国产大模型GLM-5的表现同样亮眼,在应对长期代码演进时稳居第一梯队。
不同模型厂商的智能体表现出显著的风格差异,而同一厂商下的模型则倾向一致。
- “救火队长”型:如Kimi、GLM等模型,在修改代码时更为激进,追求立刻解决当下的问题,但可能较快耗尽代码库的长期演进空间。
- “长线规划”型:如GPT、DeepSeek、MiniMax等模型,修改时更谨慎,会考虑代码结构对未来的影响,更具“架构师”潜质。
- “全能稳健”型:如Claude、Doubao、Qwen等模型,无论在短期还是长期考量下,表现都较为均衡。其中Claude更是稳定性与能力上限结合得最好的选手。
AI在代码维护中表现不佳的原因:
- 追求短期最优:模型倾向于选择“最快通过当前测试”的方案,而非全局最优的架构设计。
- 上下文遗忘:在多轮迭代中,模型对早期变更带来的深层影响缺乏持续、深刻的理解。
- 真实环境的复杂性:真实代码库的外部依赖、配置漂移和边界案例,远超模型训练数据所能覆盖的范围。
字节
资料
2026年6月23日,字节跳动技术副总裁洪定坤在火山引擎FORCE原动力大会上发表《AI Coding的实践与探索》主题演讲,分享字节内部在AI编程落地过程中的真实体感与挑战。
过去一年, 字节 AI代码贡献率增长超过6倍,AI Coding上的Token消耗增长5倍,AI代码合入率也增长超过2倍。
但这些数字不代表AI Coding 已做得非常好,反而因为用得越来越多,对挑战有了更真实的体感。
挑战一:过度重视AI代码贡献率。
- 洪定坤: 单一指标容易失真。字节TRAE团队过去半年超 90% 的代码由AI产出,人均需求吞吐率仅提升60%。
- AI写代码速度是人的10倍以上,理论上应有几倍甚至数量级的提升,但实际只有1.6倍,说明: 单一指标很难衡量全局效率。
Vibe Coding:感觉快了,可能慢了。
- 3个主流Coding模型和3个Agent框架做实验结果。
- 900次运行数据显示,所有组合功能正确率均超过80%,但关注UI易用性、可靠性、可维护性、性能和兼容性时,得分骤降至40到60分的不及格水平。
- 模型加框架表现出非常强的随机性,距离真正上线交付还有一定距离。
「Vibe Coding」在过去一两年很火,这种「有想法就让 AI 生成一版、跑通再说」的轻量开发方式,刚开始没写过代码的人上瘾。但真实世界里的开发,Coding 只是其中一部分,企业要的是长期稳定、可维护、可运营。 Vibe Coding 问题不是写不出代码,而在于容易只盯着眼前这段代码「对不对、能不能跑」。但容易忽略两件真实环境里很关键的事:
- 一是「防御性编程」,提前替意外情况做好准备,比如用户填了不该填的内容、传进来的数据是空的,程序能不能处理好这些情况;
- 二是「异常处理」,系统出错时(如文件读不到、网络连不上),代码得有预案,能友好提示或安全退回,而不是当场崩溃。 TRAE 团队实验:选三个主流 Coding 模型和三个主流 Agent 框架两两组合,用一个真实的中等复杂度需求、相同的 Prompt 各跑 100 次。
- 只看「功能是否基本正确」,所有组合的正确率都超过 80%;
- 可一旦看 UI 易用性、可靠性、可维护性、性能、兼容性这些维度,分数就断崖式下跌,组合之间还表现出极强的随机性。
代码生成的门槛降了,系统复杂度却没降。从团队协作的角度,两难:
- 不能因为「不是工程师写的」就一概否定——让更多角色直接把想法变成代码,沟通更直接、验证更快;
- 也不能「谁写出来谁就上线」,因为代码要放进既有架构、和已有模块配合。 真正的挑战是让更多人更合理地参与代码生产,同时让这些产出汇入统一的架构、规范与交付流程。
Harness 基建是关键。真正决定AI能否落地的,往往是更基础、更工程化的问题——上下文工程、架构约束、团队知识沉淀、技术债梳理等。
- 引入Harness后,正确率从80%提升到近90%,可交付性从40到60分普遍提升到80分的不错水平。
人人都是程序员,如何协作?
- 产品同学用 Vibe Coding做出需求,但研发表示还要排期。原因: 代码虽然能跑,但性能不够好、扩展性没考虑、存在权限安全问题。AI让不同角色都有机会把想法变成代码,但代码生成门槛下降不代表系统复杂度下降,产出仍需进入统一的架构、规范和交付流程。
字节跳动在AI Coding上的关注已发生变化,更加关注三件事:
- 指标:找到更合理的指标衡量全局效率;
- 治理:用更稳定的方式让Vibe Coding走向真正的软件工程;
- 协作:围绕AI Coding让软件开发上下游角色更好地协作。
原型只是起点。要真正进入企业级研发,还得把共识沉淀成可复现、可验证、可维护的流程——字节给这套做法起了个名字,叫「系统化的 AI Development」。简单来说就是:AI 不该只在「写代码」这一段发力,而要进入研发的各个流程。
字节内部已探索原型驱动开发模式和系统化AI Development,TRAE日均Token消耗量已达5.6万亿,相比去年增长50倍。近期还推出了TRAE Work,集成到TRAE企业版之中。
代码生成概要
【2025-4-13】悉尼大学论文
summarise six key topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance.
SE: 1) 需求文档 Requirement Engineering and Documentation: Capturing, analyzing, and documenting software requirements, as well as generating user manuals and technical documentation. 2) 代码开发 Code Generation and Software Development: Automating code generation, assisting in the development lifecycle, refactoring code, and providing intelligent code recommendations. 3) 自学习和决策 Autonomous Learning and Decision Making: Highlighting the capabilities of LLM-based agents in autonomous learning, decision-making, and adaptive planning within SE contexts. 4) 软件设计评估 Software Design and Evaluation: Contributing to design processes, architecture validation, performance evaluation, and code quality assessment. 5) 软件测试 Software Test Generation: Generating, optimizing, and maintaining software tests, including unit tests, integration tests, and system tests. 6) 软件安全、维护 Software Security & Maintenance: Enhancing security protocols, facilitating maintenance tasks, and aiding in vulnerability detection and patching
We review and differentiate the work of LLMs and LLM-based agents from these six topics, examining their differences and similarities in tasks, benchmarks, and evaluation metrics.
| Category | LLMs | LLM - based agents | Total |
|---|---|---|---|
| Requirement Engineering and Documentation | Requirement Classification and Extraction (4) Requirement Generation and Description (6) Requirements Satisfaction Assessment (1) Requirement Verification (1) Quality Evaluation (5) Ambiguity Detection (2) |
Generation of Semi - structured Documents (1) Generate safety requirements (1) Automatically generating use cases based on requirements (1) Requirements Satisfaction Assessment (1) Automated User Story Quality Enhancement (3) |
28 |
| Code Generation and software development | Code Generation Debugging (3) Code Evaluation (2) Implement HTTP server (1) Enhancing Code Generation Capabilities (5) Specialized Code Generation (3) Human Feedback Preference Simulation (1) |
Automating the Software Development Process (5) Large - Scale Code and Document Generation (2) Tool and External API Usage (4) Multi - Agent Collaboration and Code Refine (6) Improving Code Generation Quality (3) |
35 |
| Autonomous Learning and Decision Making | Multi - LLM Decision - Making (1) Creativity Evaluation (1) Self - Identify and Correct Code (1) Judge Chatbot Response (1) Mimics Human Scientific Debugging (1) Deliberate Problem Solving(1) |
Collaborative Decision - Making and Multi - Agent Systems (6) Learning, Reasoning and Decision - Making (12) Learning and Adaptation through Feedback (4) Simulation and Evaluation of Human - like Behaviors (2) |
30 |
| Software Design and Evaluation | Creative Capabilities Evaluation (1) Performance in SE Tasks (1) Educational Utility and Assessment (1) Efficiency Optimization (2) |
Automation of Software Engineering Processes (3) Enhancing Problem Solving and Reasoning (4) Integration and Management of AI Models and Tools (3) Performance and Efficiency Improvement (2) Performance Assessment in Dynamic Environments (2) |
19 |
| Software Test Generation | Bug Reproduction and Debugging (2) Security Test (2) Test Coverage (3) Test - Informed Code Generation (1) Universal Fuzzing (1) |
Multi - agent Collaborative Test Generation (3) Autonomous Testing and Conversational Interfaces (3) |
15 |
| Software Security & Maintenance | Vulnerability Detection (7) Vulnerability Repair (2) Program Repair (5) Code Generation (1) Requirements Analysis (1) Fuzzing (1) Duplicate Entry (1) Code Generation and Debugging (4) Penetration Testing and Security Assessment (2) Program Analysis and Debugging (1) |
Autonomous Software Development and Maintenance (6) Program Fault Localization (4) Vulnerability Detection and Generation Testing (3) Smart Contract Auditing and Repair (2) Safety and Risk Analysis (2) Adaptive and Communicative Agents (1) |
43 |
Vibe Coding
【2025-5-12】Vibe Coding彻底火了,到底什么是”氛围编程”?它如何改变未来的软件开发?
Vibe Coding 伴随着强大的、经过代码生成优化的 AI 模型的兴起而出现。
一些分析师认为,Vibe Coding 只是低代码平台的下一步发展,在这种模式下,自然语言成为了编程语言。
历史
- 2010 年代兴起的低代码/无代码平台
- 2021 年出现 AI 代码助手(如 GitHub Copilot)是 Vibe Coding 的早期先驱。
- 2022 年底 ChatGPT 的发布标志着会话式编码时代的到来。
- 2025 年,Vibe Coding 已经从一种边缘化的实验转变为一种主流趋势,这得益于 AI 技术的进步和实际应用中的成功案例。
Vibe Coding 核心原则:
- 使用自然语言进行提示,将 AI 视为代码生成的合作伙伴,通过迭代反馈循环不断完善代码,以及在一定程度上接受 AI 生成但可能不完全理解的代码。
这种方法的核心在于将与代码交互从直接操作转变为通过自然语言进行更高层次的抽象,从根本上改变了开发者与代码库的关系。
- 传统编码需要使用特定语法进行明确而详细的指令
- 而 Vibe Coding 则通过允许自然地表达意图来抽象化这一过程。
这标志着开发者角色从亲力亲为、注重细节转向更具指导性和方向性的转变。
课程
【2026-2-24】x.com
2026年1月,斯坦福大学 Vibe Coding 课程,PPT、阅读材料、作业全部公开可用
- 课程编号 CS146S,全名《The Modern Software Developer》
- 北理工博士推出汉化版 cs146s_cn
持续 10 周,依次讲解了提示词工程、Agent 架构、MCP、上下文工程、安全攻防、Code Review、自动做 App 和上线运维,还请了 Claude Code 创始人、a16z 合伙人来当嘉宾,阵容很豪华。
大纲
| 周次 | 主题 | 知识点 | 资料 |
|---|---|---|---|
| Week 1 | Introduction to Coding LLMs and AI Development 代码模型与AI研发 |
大模型原理及提示工程 Course logistics What is an LLM actually How to prompt effectively |
2个ppt:LLM如何训练出来的、如何加强提示词? |
| Week 2 | The Anatomy of Coding Agents 编程智能体定义 |
Agent架构组成,工具使用、函数调用、MCP Agent architecture and components Tool use and function calling MCP (Model Context Protocol) |
2个ppt:如何构建编程Agent,定义MCP服务 |
| Week 3 | The AI IDE 编程工具使用 |
上下文管理和代码理解,Agent需求文档,IDE集成与插件 Context management and code understanding PRDs for agents IDE integrations and extensions |
2个ppt:从prompt到IDE最优设置, Cognition 创始人分享 |
| Week 4 | Coding Agent Patterns 编程Agent应用模式 |
编程Agent设计范式, 人机协作模式 Managing agent autonomy levels Human-agent collaboration patterns |
2个ppt:如何成为合格的Agent经理,Claude Code创始人分享 |
| Week 5 | The Modern Terminal 新一代终端 |
AI增强版CLI, 终端自动化脚本 AI-enhanced command line interfaces Terminal automation and scripting |
2个ppt:如何打造爆款AI产品,Warp CEO分享 |
| Week 6 | AI Testing and Security AI测试与安全 |
Vibe Coding安全, 风险检测, AI自动化测试 Secure vibe coding History of vulnerability detection AI-generated test suites |
2个ppt:AI QA, SAST, DAST; Semgrep CEO 分享 |
| Week 7 | Modern Software Support 新一代软件工程 |
AI编程系统信任度, 调试与诊断, 智能文档生成 What AI code systems can we trust Debugging and diagnostics Intelligent documentation generation |
2个ppt:AI代码审查, Graphite CPO 分享 |
| Week 8 | Automated UI and App Building UI自动化及App构建 |
前端设计开发, UI/UC原型敏捷开发 Design and frontend for everyone Rapid UI/UX prototyping and iteration |
2个ppt:一键生成端到端App, Vercel 负责人分享 |
| Week 9 | Agents Post-Deployment Agent部署运维 |
AI系统观测监控, 自动调试、故障响应 Monitoring and observability for AI systems Automated incident response Triaging and debugging |
2个ppt:DevOps和故障响应, Resolve 技术高管分享 |
| Week 10 | What’s Next for AI Software Engineering AI软件工程未来趋势 |
软件开发角色, AI编程范式, 工业界趋势预测 Future of software development roles Emerging AI coding paradigms Industry trends and predictions |
2个ppt:近10年软件开发历史, a16z 合伙人分享 |
当顶级高校开始教“怎么用AI写代码”而不是“怎么写代码”,说明软件开发的价值链已经在重构。
注意课程设计的重点:
- 不是提示词工程,而是安全攻防和Code Review。
- 当AI能写代码后,下一个瓶颈是“谁来审代码”和“谁来保安全”。
这也是为什么Anthropic急着发Claude Code Security。
对普通人的启示:与其学写代码,不如学审代码。
定义
Vibe Coding (氛围编程) 是一种依赖人工智能的计算机编程实践
核心在于开发者使用自然语言提示向针对代码优化的大型语言模型(LLM)描述问题,由 LLM 生成软件,从而使程序员摆脱编写和调试底层代码的需要。
这个术语由计算机科学家、OpenAI 联合创始人兼特斯拉前人工智能主管 Andrej Karpathy 于 2025 年 2 月提出,并迅速成为一种新兴的编码方式。
Vibe Coding 倡导者认为,即使是业余程序员也能在无需大量培训和技能的情况下生成软件,这代表了一种更为直观和便捷的开发模式。
关键特征
- 用户通常在不完全理解代码底层机制的情况下接受 AI 生成的代码。这与仅仅将 LLM 作为代码输入的辅助工具不同,后者仍然需要开发者审查、测试和理解每一行代码。
Vibe Coding 本质: 完全沉浸于”AI 助手”氛围中,将详细的实现过程外包给 AI。
正如 Karpathy 最初所描述的那样:
“这不算真正的编程 – 我只是看看东西,说说东西,运行东西,然后复制粘贴东西,而且它大多都能工作” 。
区别
Vibe Coding 与传统编码
| 方面 | Vibe Coding | 传统编码 |
|---|---|---|
| 开发速度 | 更快 — AI 辅助生成加速编码和迭代 | 较慢 — 手动编码、调试和优化需要更多时间 |
| 可访问性 | 更易上手 — 降低非程序员的门槛 | 较难上手 — 需要正式的编程知识 |
| 所需技能 | 提示、审查、系统设计、问题定义 | 语法知识、算法、数据结构、调试 |
| 代码理解 | 黑箱式理解 — 接受但不完全理解 | 深度理解 — 开发者直接控制和理解代码库 |
| 调试 | 可能具有挑战性 — 依赖 AI 修复问题 | 更容易 — 开发者理解代码逻辑 |
| 代码质量 | 不稳定 — 取决于 AI 能力和提示 | 更可控 — 开发者可以遵循最佳实践 |
| 长期可维护性 | 可能更难 — 缺乏深入理解和文档 | 更容易 — 结构良好且有文档记录的代码 |
| 复杂性处理 | 受 AI 限制 — 难以维护大型项目的结构 | 无限制 — 完全控制复杂性和自定义 |
| 关注点 | 高层次问题解决 — 开发者描述意图 | 实现细节 — 开发者手动编写、优化和调试代码 |
| 灵活性 | 存在一些限制 — AI 生成的结构可能僵化 | 无限制 — 开发者可以完全控制代码的各个方面 |
| 学习曲线 | 更容易 — 主要依赖自然语言 | 更陡峭 — 需要学习语法、算法、调试和优化 |
| 学习资源 | 新兴领域,资源快速增长,但相对分散 | 成熟体系,资源丰富,体系化教程、文档完善 |
开发者要求
开发者技能要求的改变
Vibe Coding 的出现对开发者的技能要求产生了显著的影响,并正在改变传统的软件开发方法。
这部分内容介绍了开发者技能要求的改变:
- 更高层次的能力要求
- AI辅助下,程序员角色转变为“监督者”和“设计师” ,质量控制、架构规划、深度问题解决等高层次技能愈发重要。工程师需擅长确定产品需求、设计系统方案,把控AI产出代码,还要增强与AI协作、管理AI的能力。
- 计算机科学基础作用的变化
- 自然语言渐成“新编程语言”,传统算法、数据结构等计算机科学知识重要性在部分场景被削弱,但理解算法原理、系统性能和调试技巧等传统技能仍是复杂项目支撑,不可完全忽视。
- 职业路径与岗位影响
- 基础编码型初级岗位需求或减少,“AI提示工程师”“AI策略师”等新兴职位将出现。未来软件从业者多充当“提示提供者”和“代码管理者”,需在职业规划上与时俱进。
开发者需要更加注重问题定义和规范,清晰地使用自然语言表达需求和期望的结果。
- 确定最佳的提问方式变得至关重要。
- 同时,开发者需要具备指导和审查 AI 生成代码的能力,评估、完善和测试 AI 产出的代码。
- 开发者更像是扮演指导者或编辑的角色。
系统设计和架构的理解变得比低层次的编码更为重要。
- 批判性思维和问题解决能力对于评估和改进 AI 生成的代码至关重要。
- 此外,开发者需要学习如何有效地与 AI 沟通,掌握提示技巧以获得期望的结果。
- 虽然侧重点有所变化,但对编程基本原理的理解对于有效地指导 AI 和进行调试仍然很有价值。
Vibe Coding 对传统软件开发方法的影响体现在以下几个方面:
- 软件开发更加注重意图驱动,即更关注期望的结果而不是具体的实现细节。
- 迭代周期变得更快,Vibe Coding 与敏捷开发方法高度契合,强调快速迭代和灵活性。
- AI 处理了部分传统上由初级开发者完成的任务,可能导致团队结构的变化。非程序员也能参与到软件创建中,模糊了项目不同角色之间的界限。
- 此外,可能出现”快速迭代发布”或”MVP 驱动开发”的趋势,即更倾向于实时构建和发布产品,而不是进行大量的原型设计。
- Vibe Coding 还可能促使编程语言向更高层次抽象发展,并可能降低对学习多种编程语言的需求。自然语言可能成为主要的交互界面。
- 然而,Vibe Coding 强调快速迭代和最少的前期规划,这与瀑布模型的顺序性形成对比。
Vibe Coding 标志着软件开发模式的根本转变,从细致的手动编码转向更抽象、意图驱动的方法,人类开发者在此过程中扮演着指导 AI 的角色。这必然要求开发者掌握新的核心技能。如果 AI 负责底层编码,那么人类所需的技能自然会转向更高层次的关注点。清晰地定义问题和指导 AI 的能力变得至关重要。此外,AI 的输出需要验证,这需要批判性思维和对软件架构的理解。这表明开发者正在从”代码编写者”转变为更像是能够有效利用 AI 的”软件架构师”或”产品负责人”。
优势
Vibe Coding 优势:
- 提升开发效率:借助AI承担繁琐编码任务,大幅提升生产力,能将原本数日开发原型的时间缩短至数小时,加速概念到原型迭代,可提高项目75%开发速度。
- 降低开发门槛:采用自然语言编程,让无编码经验、非计算机科学(CS)背景人员通过描述需求开发软件,无代码基础也能在一小时内做出可用产品,实现编程体验民主化。
- 专注创意和设计:开发者可将精力集中于产品创意和架构设计,把重复劳动交予AI,使开发体验更流畅有趣,激发创新灵感。
Vibe Coding 通过多种机制显著提高了开发者的工作效率。
- 首先,AI 快速生成复杂或重复代码,大幅缩短开发时间。
- 例如,过去可能需要数天才能完成的原型,现在可能在数小时内即可构建完成。
- 其次,Vibe Coding 使开发者能够将更多精力投入到高层次问题解决、架构设计和产品设计上,而不是纠缠于语法错误和样板代码。 这种转变让开发者能够更专注于创新和创造性的工作。
- 此外,Vibe Coding 有利于快速原型设计和迭代。
- 通过简单自然语言指令,开发者可以快速尝试新的想法并获得初步的演示版本,从而加速反馈循环。
- Vibe Coding 还降低了软件开发的门槛,使那些编程经验有限甚至没有编程经验的人也能够创建软件。领域专家可以直接使用自然语言描述他们的需求,而无需先将其转化为代码。
- Vibe Coding 还能自动化繁琐的任务,将重复性的编码工作和调试工作交给 AI 处理,从而解放开发者的精力。
- 此外,语音编码的兴起使得开发者可以通过口头表达想法,再由 AI 将其转化为代码,这对于具有不同认知风格的开发者来说尤其有益。
以下场景中,Vibe Coding 优势尤为突出:快速原型设计、创建小众和个性化应用、自动化简单任务、促进更广泛的开发参与、加速产品迭代周期以及在需求明确的情况下。
例如,Kevin Roose 提出的”个人软件”概念,即通过 AI 构建满足个人特定需求的应用程序。Vibe Coding 的优势在于能够加速开发的初始阶段,并赋能那些编程技能有限的个人。这预示着软件创造者范围的扩大以及想法实现速度的提升。
局限
尽管Vibe Coding带来诸多便利,却存在不容忽视的局限性,实际应用中开发者需关注并采取缓解策略。
- 调试与错误排查难度:AI自动编程处理复杂bug能力有限,遇到微妙或涉及上下文逻辑问题,可能反复尝试却抓不住要点。还可能生成看似合理实则错误的代码(幻觉)或调用不存在函数。当AI连续给出错误修改建议时,工程师常需亲自调试。
- 代码质量和可维护性问题:AI生成代码未必符合最佳实践,若用户不有意引导,持续叠加修改和新功能且缺乏重构,代码会臃肿难懂,埋下安全漏洞或低效实现隐患。AI生成代码常只注重主流程,边缘情况、性能优化和安全方面可能有隐患。
- 复杂项目的扩展和长期维护:当前AI编码工具应对大型、持续演进项目能力有限。项目规模变大、需管理状态和调整架构时,模型难保持全局上下文,易在变化需求中“迷失” 。项目后期完善、跨模块集成及深度性能优化,需人类开发者深入理解和系统性思维,正如风投人Andrew Chen所说:“前75%的功能轻而易举……然而当你尝试进一步修改和迭代时,一切就开始乱套了” 。
不足
- 调试方面,AI 工具不一定能解决所有错误。调试 AI 生成的代码可能具有挑战性,因为开发者可能不完全理解其底层的逻辑。
- 如果开发者没有参与代码的创建过程,那么在出现问题时,可能难以追踪错误。对于复杂的问题,仅仅依靠直觉理解可能不够,还需要系统的调试技巧。AI 在尝试修复错误时,有时可能会引入新的问题。
- AI 模型在处理大型代码库时,其上下文窗口的限制也会阻碍对代码的全面理解。
- 此外,AI 有时会将代码插入到错误的位置或丢失上下文信息。
- 代码质量方面,AI 生成代码未必能针对性能进行优化,也可能不符合最佳实践。这可能导致代码结构、命名约定和逻辑的不一致。
- 过度依赖 AI 可能会导致开发者产生”自动完成依赖”,不再深入理解代码。如果 AI 没有经过安全编码实践的充分训练,则可能引入安全漏洞。在不进行充分审查的情况下就接受 AI 生成的代码,可能会导致一些问题被忽略。
- AI 生成的代码有时可能只是初步的框架,需要大量的人工完善。
- 长期维护的角度来看,对 AI 生成代码缺乏深入理解会使得未来的维护和修改变得困难。
- 快速生成代码而缺乏适当的设计会导致技术债务的累积。直觉式的编码可能导致代码结构混乱,难以维护。 纯粹的 Vibe Coding 通常缺乏文档,这会阻碍未来的理解。
- 早期 AI 决策可能难以在后期进行修改,导致架构上的锁定。代码的结构更像是涌现出来的,而不是经过仔细设计的。过度依赖 AI 可能会导致开发者失去基本的编程技能。
- 此外,Vibe Coding 对软件的长期可靠性也提出了挑战。
Vibe Coding 虽然提供了速度和便利性,但同时也带来了与代码质量、可维护性以及开发者基本技能可能退化相关的重大风险。
如果不加批判地采用 Vibe Coding,可能会导致大量的技术债务和长期的挑战。Vibe Coding 带来的短期效率提升,可能会以长期的技术债务为代价。对 AI 生成代码缺乏深入理解会产生黑箱效应。没有这种理解,调试会变得更加困难,确保代码质量具有挑战性,并且未来的修改可能存在风险且效率低下。过度关注快速生成而忽视仔细的设计和文档编制,会导致技术债务并阻碍长期可维护性。
方法
AI编程协作的实际应用策略,即“AI编程协作四步法”:
- 需求拆解:把复杂需求细分成多个小任务,逐个交给AI实现,避免提出笼统大需求。必要时可先让AI绘制原型草图,再逐步细化。
- 渐进引导:从简单功能开始开发,完成后再逐步添加复杂功能,像搭积木一样构建系统,每次新增功能都基于之前稳定的基础,循序渐进防止混乱。
- 错误反馈:出现错误或异常时,直接给AI提供报错信息,让其尝试修复。现代编码AI通常能根据错误日志自动调整代码,实现初步自我纠错。
- 功能验证:频繁运行和测试每个新增功能,确保按预期工作,不要等大量功能实现后才整体调试。对AI生成代码及时验证,利于尽早发现问题。
工具与平台
随着这一趋势兴起,市面上出现了多款 AI 编程助手和集成开发环境,帮助开发者更方便地实践 Vibe Coding 思路。其中具有代表性的包括:
- ChatGPT 与 Claude:通用对话式大型语言模型,可用于生成代码片段、解释错误信息、优化代码等。许多开发者将其作为对话式编程助手,通过自然语言向 AI 提问来获取实现思路或代码示例,加速开发过程。
- Cursor AI:一款内置 AI 功能的桌面代码编辑器,界面和操作类似 VS Code。Cursor 集成了 AI 聊天和代码自动补全等能力,支持开发者在编辑器中直接用自然语言命令生成或修改代码。
- Windsurf:另一款新兴的 AI 编程 IDE,提供代码对话生成等功能。Windsurf 强调自动分析整个项目的上下文,并通过”代理人”引导逐步完成任务,使用体验上对新人更加友好。
- GitHub Copilot:由 GitHub 推出的 AI 编码助手插件,可无缝集成到 VS Code、JetBrains 等主流 IDE 中。Copilot 能根据当前文件内容实时建议下一行或整段代码,被视为 AI 辅助编码的先行者之一。
不同类型的开发者都可以根据自身需求,利用上述工具提高工作效率。对于非技术背景或编程初学者,ChatGPT 这类对话 AI 能充当启蒙老师,帮助理解编程概念并提供现成代码;像 Cursor、Windsurf 这样的工具更是让他们可以用自然语言直接创造程序,大幅降低了入门门槛。
对于有经验的工程师,AI 工具则可承担大量重复劳动,让他们将精力集中于架构设计和疑难问题解决。例如资深开发者可以让 AI 快速生成样板、测试代码,然后专注于审核和优化,从而整体提效。
对于创业者或独立开发者,Vibe Coding 更是如虎添翼 – 单枪匹马也能做出过去需要团队协作才能完成的产品雏形。Karpathy 本人就曾演示在一小时内分别构建出一个阅读应用和一个小游戏,这在以前几乎是难以想象的速度。
可以预见,无论新人还是老手,善用 AI 编程助手都已成为提升开发效率、完成更具野心项目的关键技能之一。
GitNexus
【2026-2-24】AI 写代码最怕修好一个 Bug,却在不知名的地方引爆三个新 Bug。
当前AI 编程助手指哪改哪,无法深入了解代码之间的深层依赖。
GitHub 开源的 GitNexus,给项目代码建立知识图谱,让 AI 能够理解整个项目的架构、依赖和调用链。通过 MCP 服务器协议接入到 Cursor 或 Claude Code,让 AI 在修改代码前,先看清函数间的上下游关系。甚至能生成架构图,或者在 Web 端可视化查看整个代码库的逻辑脉络。
- GitHub:GitNexus
- 提供 CLI 和 Web 两种模式,支持 TypeScript、Python、Java 等主流编程语言。
所有索引和分析都在本地完成,数据不上传服务器,隐私性做得不错。
经验
【2025-5-12】 Zen of Vibe Coding: 引子与问题划分
LLM 时代下,工程师的哪些能力才是有价值的?
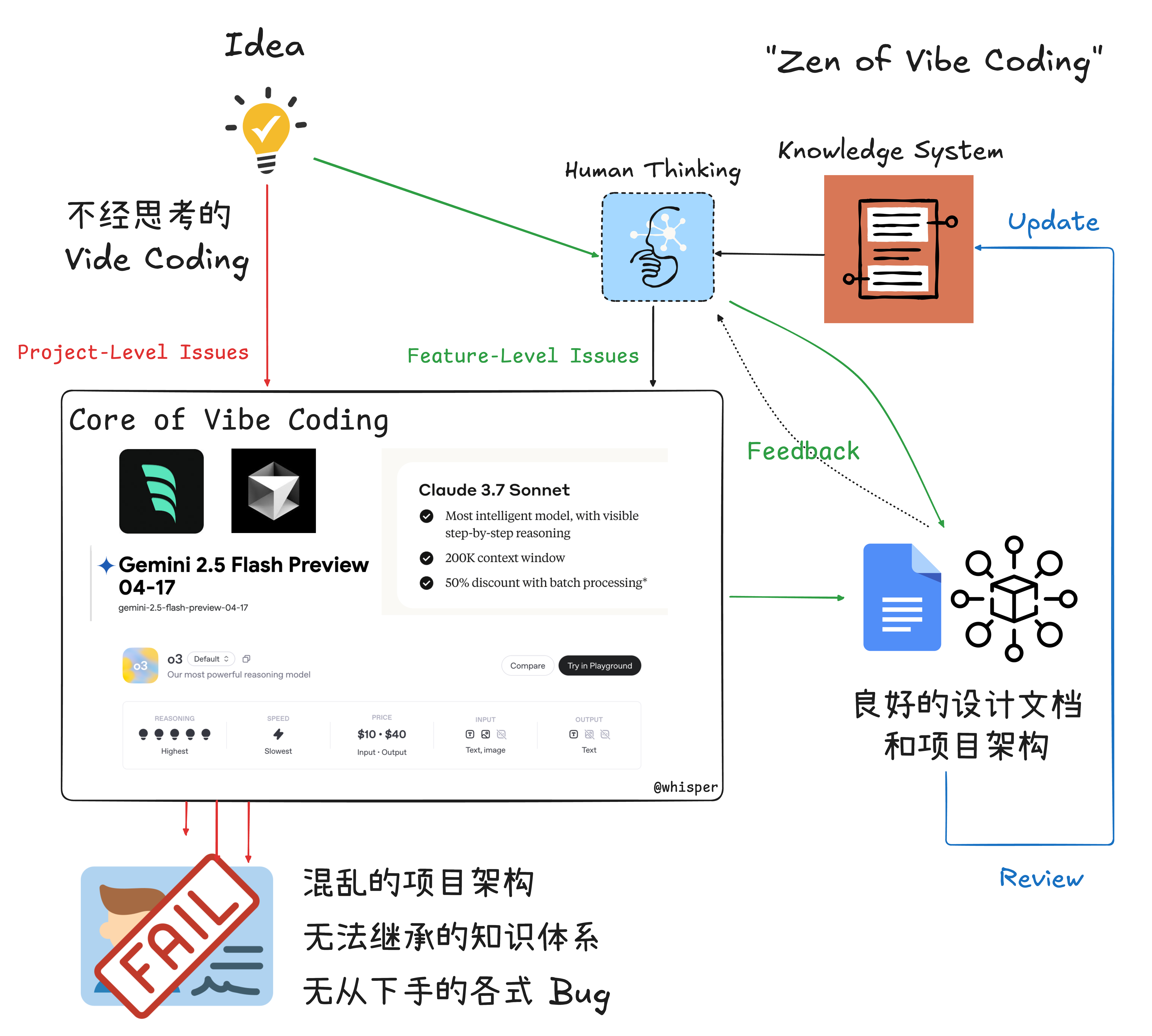
Vibe Coding 体验,几个小时内实现了 0 到 0.7,但之后可能会遇到:
- 折腾了几天从 0.7 实现到了 0.8 (进度非线性)
- 折腾了几天从 0.7 实现到了 0.5 (花费时间但反作用)
- 有好几个版本的 0.7+- 但是不知道如何选择 (工具灾难)
对于问题1/2 可以把问题分为:
- Project-Level,整体项目相关的,涉及多个/复杂/耦合的问题。特点是需求比较模糊,可以继续细分与讨论,比如“设计具有某个功能的插件/应用”。
- Feature-Level,具体功能相关的,涉及单个/少数/独立的问题。特点是需求比较清晰,可以参考大部分 GitHub 中的 issue,比如“修复某个因为 XX 导致的 bug”。
- Project-Level 可以通过拆解得到多个
- Feature-Level 问题 ➡️ Feature-Level 是原属于 Junior 工程师的任务 ➡️ 当前 LLM 更擅长解决 Feature-Level 问题。
🥕结论:
- Project-Level 需要人主动思考与细致规划,拆解为多个 Feature-Level 问题,再由 Vibe Coding 解决,这样高效不少。
代码辅助工具
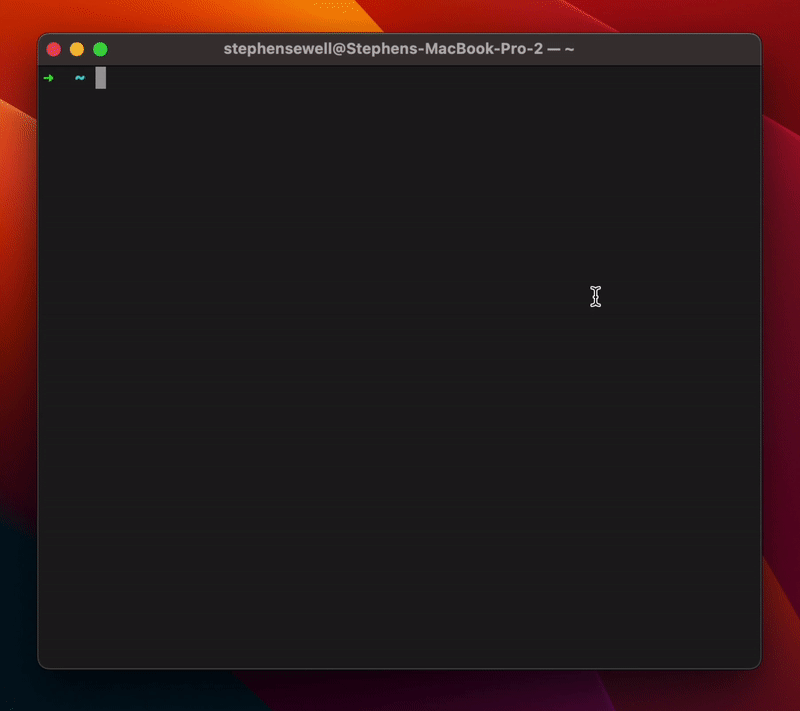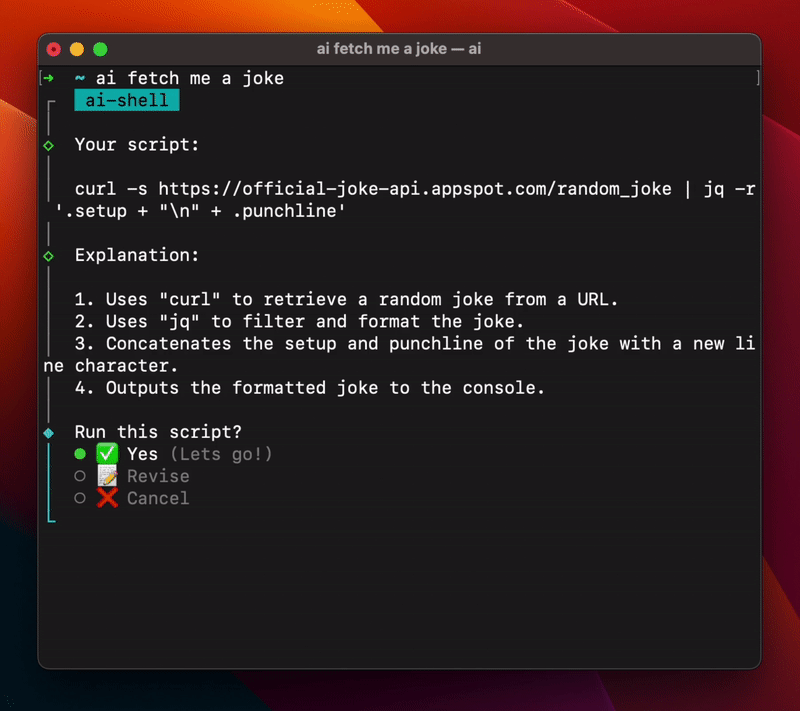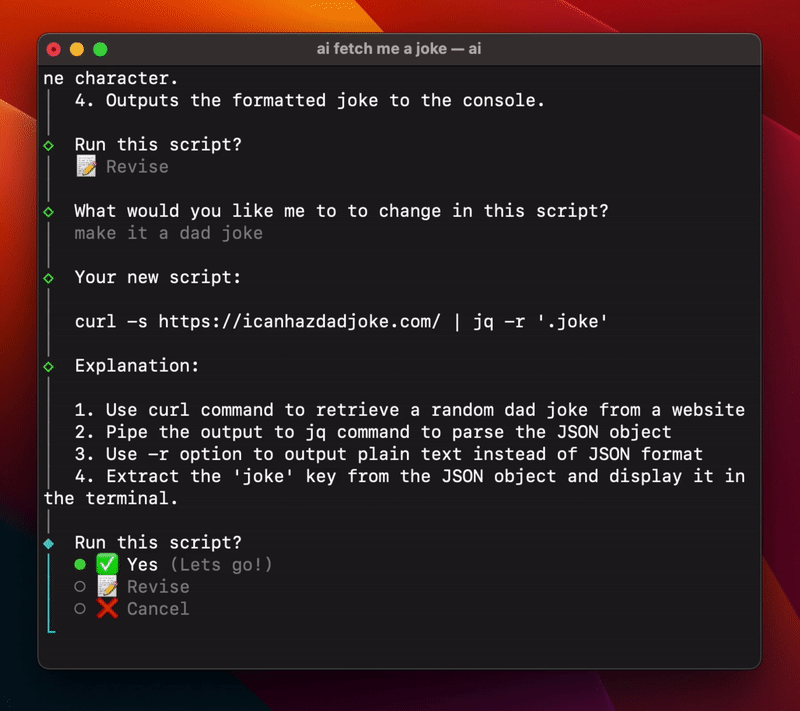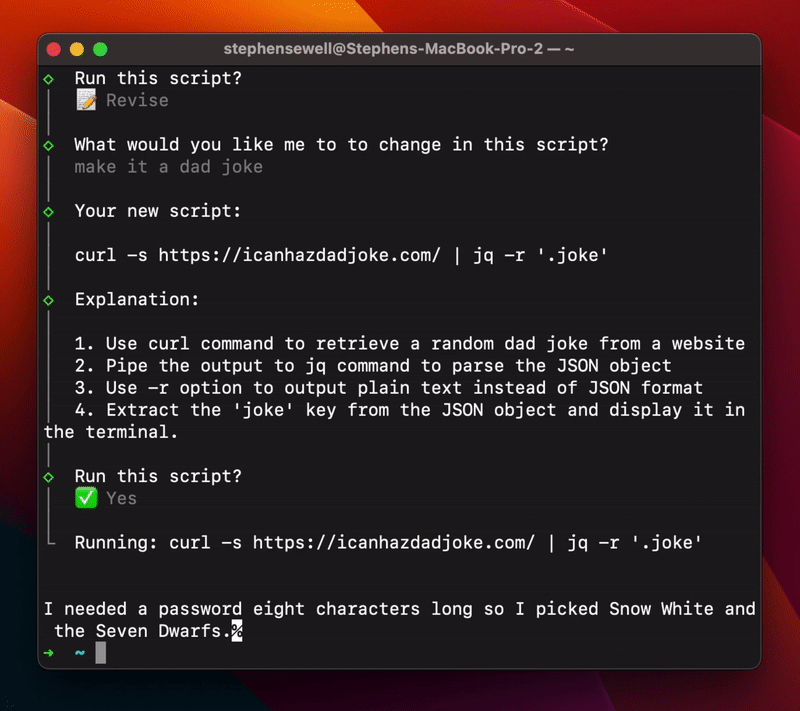
AI Shell
AI Shell 将自然语言转换为Shell命令的CLI工具。受 GitHub Copilot X CLI 启发,但AI Shell是开源的,为所有人提供服务。
用户只需安装 AI Shell 并从OpenAI获取API密钥,便可使用该工具。
Cursor
【2024-11-16】10几个人如何构建20多亿的cursor,Lex 对 Cursor 团队访谈
- 视频版 Cursor CEO访谈
- 文章介绍
- 【2024-10-31】Cursor:如何构建 AI Coding 最佳实践?
AI coding 是模型推理能力增加之后的下一个竞争高地。
- Github Copilot 是第一个 LLM-driven 的消费级应用
除了模型厂商、AI Labs 之外,这个领域的参与者也有着 Cursor 这样的初创团队
作为一个 LLM-first IDE,Cursor 在今年迅速出圈
- 一方面: 底层模型
Claude Sonnet 3.5模型 coding 能力提升带来的体验升级 - 另一方面: 团队在 AI Coding UI/UX 上的持续投入。
技术选型
- 刚开始用 Vim 做代码编辑。当时还没有 Neovim,只有 Vim 和一个终端。
- 2021 年 Copilot 发布时,由于 Copilot 只能在 VS Code 上使用,所以 Cursor 转用 VS Code 了。
- Copilot 和 VS Code 组合使用体验特别好,所以即便很喜欢 Vim,还是转向了 VS Code。
- 开发 Cursor 之前,VS Code 都是默认编辑器。
Cursor 是怎么做预测的?Cursor 延迟很低, Tab 健能做下一步动作预测(next action prediction)
背后的技术细节
- 训练了专门MoE小模型: 这些模型很依赖 pre-fill tokens
- 这些模型面对的是非常长的 prompt,需要处理很多代码行,但是实际生成的 token 并不多。这种情况下使用稀疏模型(Sparse Model)就很合适,一种 MoE 模型。这个突破显著提高了模型处理长上下文时的性能。
- 基于推测解码(Speculative Decoding)构建了推测编辑(Speculative Edits)。
这两个因素是 Cursor 生成质量高、速度快的关键。
没有哪个模型能在所有方面的表现都比其他模型更好,包括速度、代码编辑能力、处理大量代码的能力、上下文长度和代码能力等等。不过,整体上表现最好的模型是 Sonnet,这也是共识。
大量和 prompt 相关的信息,包括文档、添加的文件和对话历史等。
问题:在 context window 有限的情况下,该如何筛选和组织这些信息?
- Cursor Priompt 渲染器把内容合理地排布在页面上,只需要告诉它想要什么,它就会帮你实现。
- 开发了 Priompt 内部系统, 借鉴现代网页开发的最佳实践。和固定版式的杂志排版不同,网站开发中会涉及到的一个情况是,不同设备的中信息的展示多少、格式等是动态变化的,而用户到底在哪里查看网站开发者事前并不知道,但无论终端怎么变,都要保证网站信息在不同设备上正常显示。AI 提示词工程也是类似,我们要做到无论 input 内容多大、怎么变,output 的格式都能正确展示。
团队创始成员 Aman Sanger (CEO)、Arvid Lunnemark(CTO)、Sualeh Asif(COO)和 Michael Truell(设计主管)详细分享了 Cursor 产品体验、infra、模型训练、数据安全等细节,以及对于 AI coding、AI Agent 的思考,通过这些分享也能了解 Cursor UI/UX 背后的理念。
- • o1 不会干掉 Cursor,AI Coding 领域才刚刚开始;
- • 围绕代码预测、补齐等各类任务 Cursor 还训练了一系列专门的小模型;
- • Cursor 正在试验一个叫做
Shadow Space的产品概念,后台运行一个隐藏窗口让 AI 在不影响到开发者的操作的情况下进行 coding 任务; - • 团队在 code base indexing 上投入了大量精力,这个 indexing 系统会成为接下来其他代码任务可以展开的基础;
- • 未来编程会是自然语言和代码将共存,根据具体任务选择最有效的交互;
- • AI 正在重塑编程体验,提高效率的同时保持程序员的创造力和控制力;
- • Cursor 认为 Claude 3.5 Sonnet 综合实力更强,Sonnet 最强的地方在于能够很好地理解开发者表述并不清晰的目标,预测程序员接下来的操作、给出适当建议;
- • 即便是 SOTA 模型, 也不擅长找 bug,这会是 Cursor 的机会;
- • 当前代码任务基准测试并不能准确反映模型的真实能力,因为现实中的代码任务更加复杂多样,并且充满了模糊性和上下文依赖。Cursor 团队更倾向于通过真实用户的使用反馈来评估模型的性能;
- • 目前还没有人能很好地解决 models routing 问题,底座模型和自有模型之间可以初步实现模型切换,但如果是 GPT-4o、Claude sonnet 和 o1 之间的切换可能要更加复杂。
MarsCode
【2024-6-27】探索豆包 MarsCode:字节跳动的AI编程助手
字节跳动推出的革命性工具——豆包 MarsCode ,免费的AI编程助手,旨在提升开发者的编码体验。
MarsCode不仅仅是一个编程工具,它是一个全方位的AI助手,集成了代码补全、生成、解释、优化、注释生成、单元测试生成、智能问答和问题修复等强大功能。它支持多种编程语言,并且可以无缝集成到Visual Studio Code和JetBrains等主流IDE中。
主要功能
- AI助手:提供代码补全、生成、优化、注释生成和解释。
- 智能问答: 唤起对话框后,你可以在输入框中输入你的问题,然后点击 发送 按钮或敲击回车键,豆包 MarsCode 编程助手将回答你的问题。你可以进行多轮问答,不断补充细节,从而使插件的回答更加准确。
cline
Cline是一款功能强大且完全免费的AI编程工具,能够显著提高开发效率。
代码编程插件 Cline
- vs code 插件地址
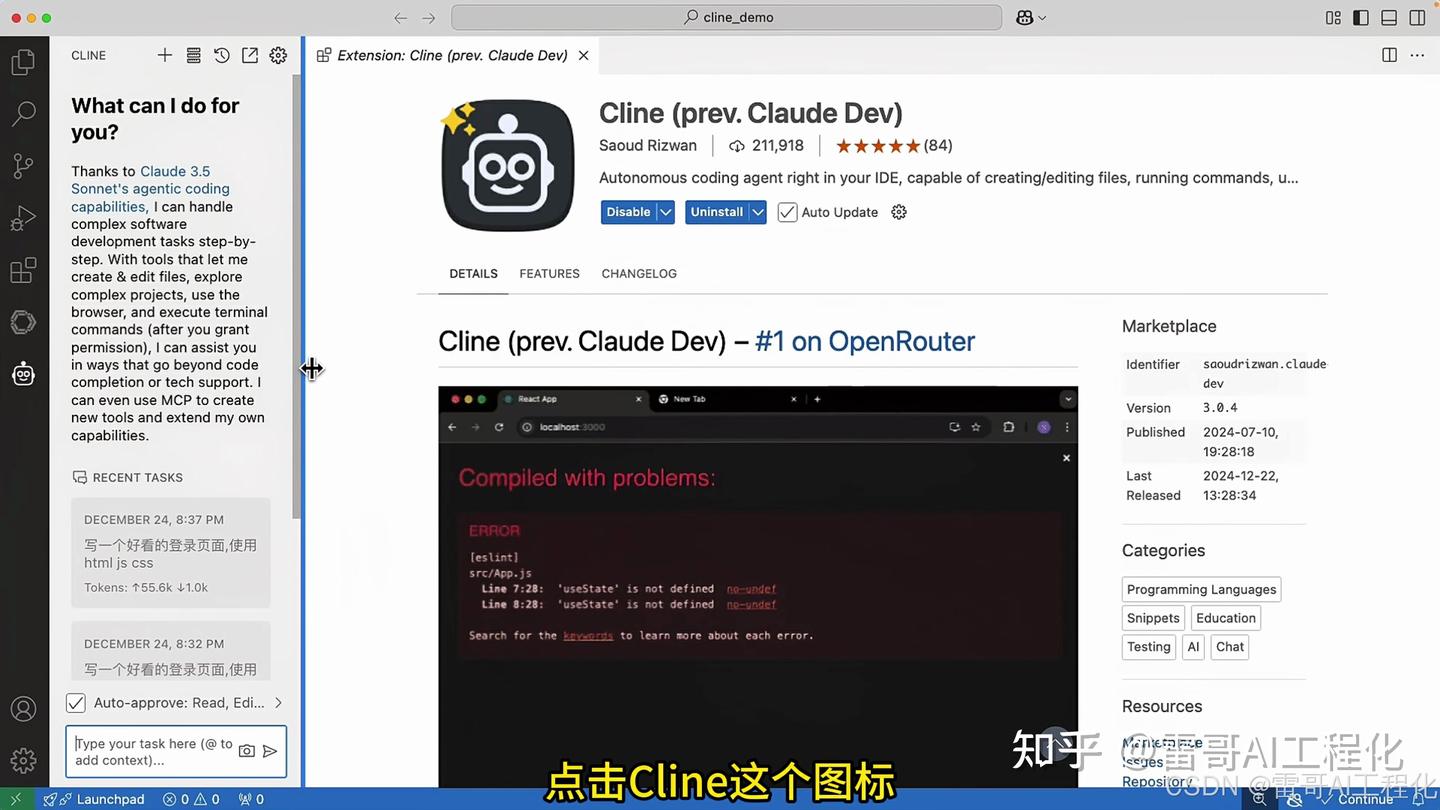
VSCode中安装Cline插件:
- 打开VSCode
- 点击插件图标
- 搜索”Cline”并安装
- 安装完成后,左侧会出现小机器人图标
Cline支持配置多种API key,包括Open Router、Open AI和Ollama等。
- 也可使用 deepseek api
创建一个登录页面非常简单:
- 在Cline中输入任务描述:”写一个好看的登录页面,使用HTML、JS、CSS”
- Cline会自动分析需求,并逐步生成HTML、CSS和JavaScript代码
- 最终生成的页面美观实用,完全符合预期
【2025-1-21】实践
任务:
生成一段html,js代码,实现功能:逐项卡片展示数组a里的项目,布局要求:第一行加粗展示“RedNote Slangs for TiktokRefugee”,其次再展示卡片,每行3个卡片,超过后另起一行,每个卡片浅蓝色背景,卡片是云朵颜色,3个字段字体颜色依次是红色、绿色、紫色,点击卡片后自动放大,要求简洁、美观、立体效果、配色好看;数据:国内常用网络用语,每个短语包含字段:中文短语、英文短语、英文解释;以 javascript list 输出, 示例 [[‘a’, ‘a’, ‘a’]];注意:只输出代码,不要解释
报错
Command failed with exit code 1: powershell (Get-CimInstance -ClassName Win32_OperatingSystem).caption ‘powershell’
提交问题官方 issue
Trae
资料
- 【2025-1-20】字节全新AI编程软件:Trae!免费无限量使用Claude
- 【2025-7-23】如何评价 Trae 发布 2.0,以及新推出的 SOLO 模式体验如何? 字节内部员工 重生之我在大厂搞 AI Coding
Trae 是字节跳动推出的免费中文 AI IDE,通过 AI 技术提升开发效率。
- 支持原生中文,集成了 Claude 3.5 和 GPT-4o 等主流 AI 模型,完全免费使用。
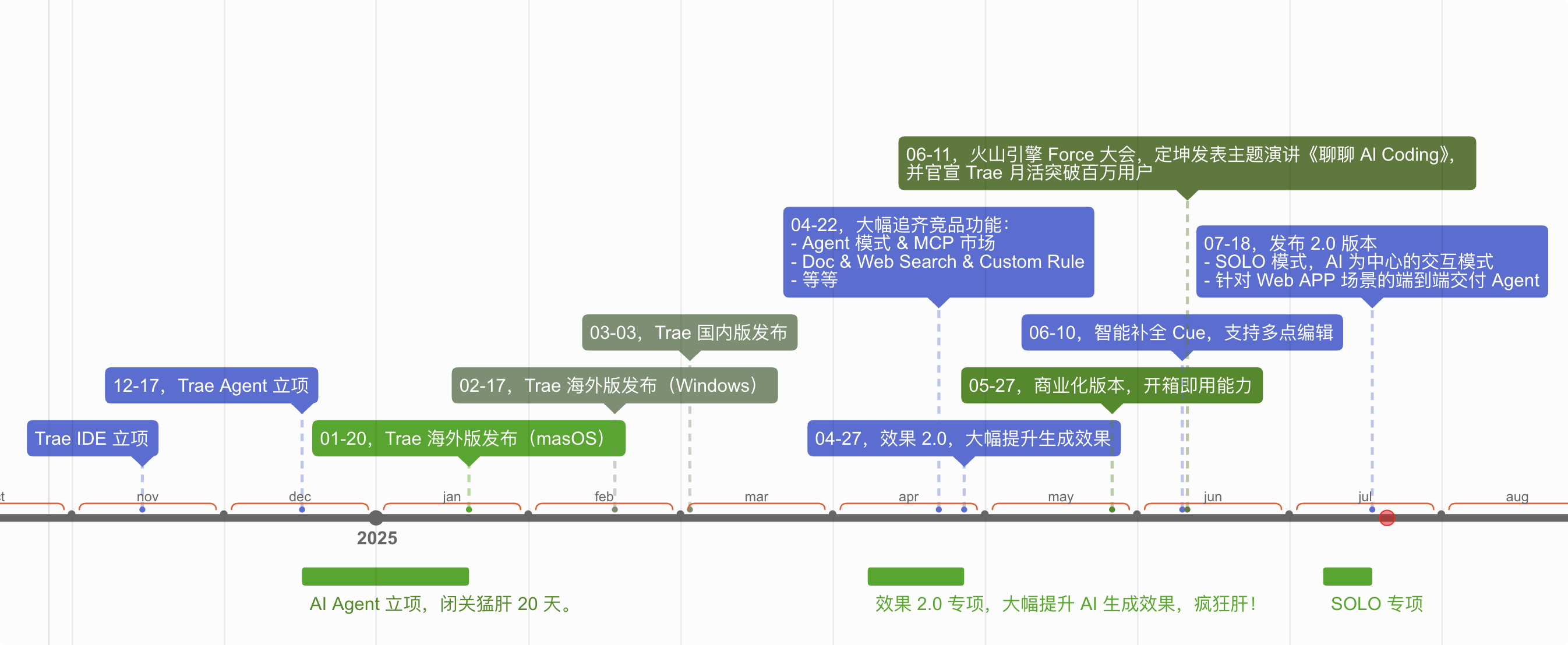
发展史
时间线
- 2022 年 11 月 15 日,措不及防的蚂蚁大礼包让我需要重新思考未来的规划,还好随即很幸运的加入了字节。
- 2023 年 11 月 15 日,我被一个电话召集到了杭州闭关室,从此负责起 MarsCode Cloud IDE 团队的云工作区等相关工作,那是疯狂奔跑的一年。
- 2024 年 11 月 15 日,再次进入了闭关室,又是疯狂的半年,于是就有了大家看到的 Trae 1.0、2.0 的演进。
功能
Trae 主要功能: Builder 模式和 Chat 模式
- Builder 模式可帮助开发者从零开始构建项目
- Chat 模式支持对代码库或编程问题进行提问和优化。
Chat 模式
- 快捷键:使用 Cmd + i 或 Cmd + u 调用 Chat 功能。
- 交互方式:在对话框中输入问题或代码需求,Trae 会基于 AI 模型生成代码建议或解答。
- 代码更新:Trae 会显示原始代码和优化后的代码对比,开发者可以选择接受或拒绝。
Builder 模式
- 项目生成:通过简单描述(如“生成一个图片压缩工具”),Trae 可以自动生成项目代码。
- 交互执行:在生成过程中,Trae 可能会征求用户意见(如是否执行命令),需要手动确认。
- 代码预览与调试:Trae 提供 Webview 功能,可以直接在 IDE 内预览 Web 页面,方便前端开发。如果遇到错误,可以通过点击命令行中的“Add To Chat”按钮,将错误信息复制到 Chat 中,让 AI 帮助解决。
- 上下文引用:在 Chat 中可以引用代码块、文件、文件夹或整个项目。
- 命令行工具:支持在本地终端安装 Trae 的命令行工具。
注意事项:
- Trae 的 AI 功能目前不支持直接读取外网链接。
- 使用 Builder 生成项目时,建议提前手动创建虚拟环境(如 Python 的 venv 或 Conda),避免环境变量问题。
Trae 具备友好的交互设计,如代码预览、Webview 功能,以及强大的代码生成能力。
作为一款直接对标 Cursor 和 Windsurf 的全新 AI IDE,Trae 的目标不仅是与这些工具竞争,更是要弥补它们在中文开发者体验上的短板。现在 Trae IDE 的 Claude 3.5 和 GPT-4o 都是限时免费用
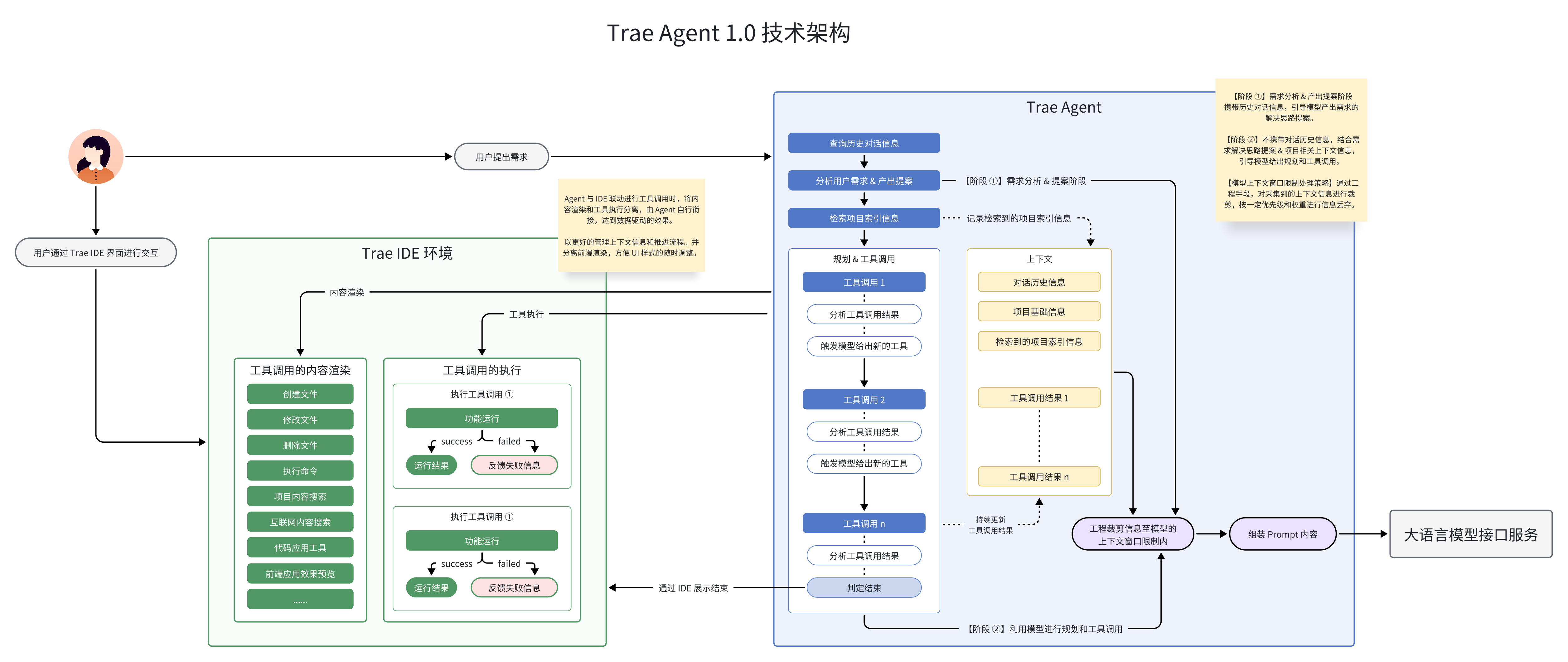
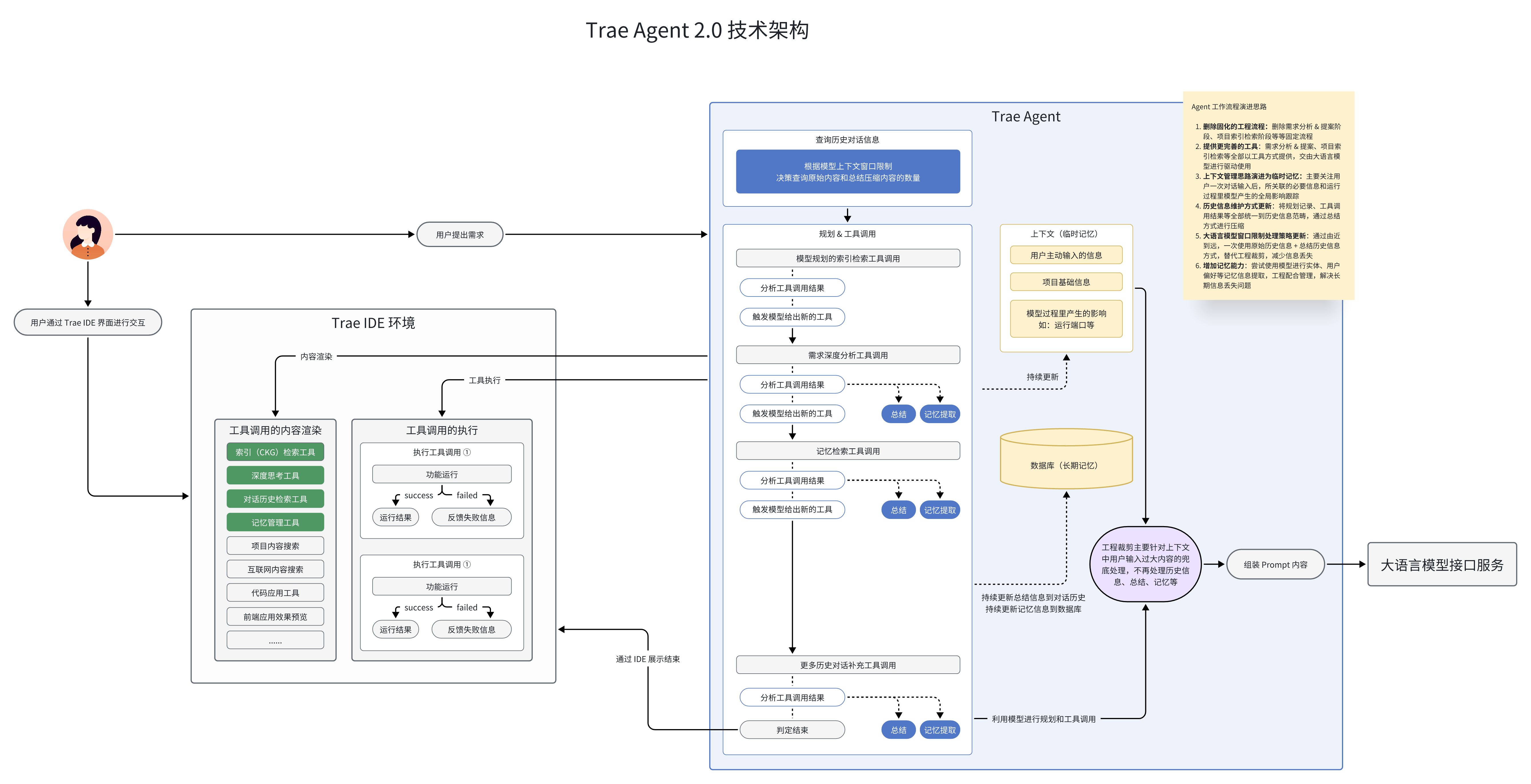
架构
1.0 架构
2.0 架构
Firebase
【2025-4-10】谷歌发布 AI 编程工具 Firebase Studio 一款基于云端、人工智能驱动的集成开发环境(IDE)
- lovable + cursor + replit + windsurf 合体应用
- 支持一键构建后端、前端和移动应用
- 支持 React、Next.js、Angular、Vue.js、Flutter、Android、Node.js、Java 和 Python Flask 等多种编程语言和框架,让开发者能快速上手,满足不同项目需求。
从生产到发布都在一个地方完成,除了网页还有安卓应用
应用发布后还带有数据监控能力
Firebase Studio 为缺乏编程经验的用户提供便利,这符合当前“氛围编码”(vibecoding)热潮。
与 Cursor AI 等竞品相比,Firebase Studio 优势:
- 不仅支持多种编程框架,还注重用户体验,通过直观的界面和强大的AI生成能力,为非技术用户提供更友好的开发体验。
特点
- Forget about infrastructure
- 无服务器的 PaaS 层平台,使用者不需要关心服务器、网络甚至不需要去做运维,只需尽情使用就好。
- Make smart, data-driven decisions
- 数据驱动决策,现在大家都有一个共识,决策应当依托于数据。通过 A/B test,数据会帮助使用者决定使用什么颜色的按钮、每天的广告频次、该用那一半的页面布局等等。
- 跨平台,良好的兼容性
- 用户可能用苹果(iOS),安卓(Android),或别的应用,可能用C语言,或“ 调用 API ”的方式,Firebase 全都可以支持。
- 免费支持
- 一则 Firebase Google 本身就是免费的,二则 WebEye 作为谷歌云的高级合作伙伴,除了谷歌的支持以外,WebEye 也会24小时随时提供支持。
AlphaEvolve
AlphaEvolve 是一个由 Google DeepMind 开发的“超级智能编码助手”
【2025-5-14】AlphaEvolve 像无穷智慧和耐心的“编程大师”,不是一次性给最终答案,而是通过不断地尝试、学习、改进自己的代码,像生物进化一样,一步步“进化”出越来越好的解决方案。
- AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms
- alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf
核心目标:
- 利用AI力量,通过直接修改和优化计算机代码的方式,来攻克那些极具挑战性的科学问题和工程难题。
成果:
- 让矩阵乘法更快: 在一个困扰了数学家和计算机科学家50多年的问题上,AlphaEvolve 发现了一种新的 4×4 复数矩阵乘法算法,这是自1969年Strassen算法以来在该特定问题上的首次改进!
- 优化Google“大脑”: 它帮助优化了Google数据中心的调度算法,让庞大的计算资源得到更有效的利用;还改进了TPU(谷歌的AI芯片)硬件加速器的电路设计。
- 加速AI训练: 甚至,它还加速了支撑 AlphaEvolve 自身的AI大模型的训练过程。
- 数学新发现: 在纯数学领域,AlphaEvolve 发现了许多新的、可证明正确的算法和数学构造,超越了之前已知的最佳成果,比如改进了Erdős提出的最小重叠问题、11维空间中的接吻数问题等。
FunSearch 思路:
- 让AI大模型(LLM)扮演“函数发现者”,通过进化式搜索,找到解决特定数学问题的小型、高效的Python函数。
- 证明了LLM引导的进化方法在发现新知识方面的潜力。
AlphaEvolve 则是在 FunSearch 的基础上进行全方位“超级升级”:
- 进化范围更广: FunSearch 主要进化单个小函数,AlphaEvolve 能进化包含多个函数和组件的整个代码文件。
- 代码规模更大: FunSearch 处理的代码通常几十行,AlphaEvolve 能处理数百行。
- 语言更通用: FunSearch 主要用Python,AlphaEvolve 支持任何编程语言。
- 评估更灵活: FunSearch 需要快速评估,AlphaEvolve 能应对耗时更长的评估,还能用AI加速器。
- AI大脑更强: AlphaEvolve 用的是更先进、能力更强的AI大模型,并且给AI的信息更丰富。
- 目标更多元: FunSearch 主要优化单一目标,AlphaEvolve 能同时优化多个目标。
AlphaEvolve 把 FunSearch 思想提升到了一个全新的高度。
Claude Code
【2025-4-18】Anthropic 发布 Claude Code,用于智能编程的命令行工具。更原生的方式来将Claude集成到编程工作流程中。
代码生成
数据集
BigCodeBench
BigCodeBench: 继 HumanEval 之后的新一代代码生成基准测试
BigCodeBench 包含1140个函数级任务,挑战 LLMs 遵循指令并将来自139个库的多个函数调用作为工具进行组合。
BigCodeBench 为每个任务提供了复杂的、面向用户的指令,包括清晰的功能描述、输入/输出格式、错误处理和已验证的交互示例。我们避免逐步的任务指令,相信有能力的 LLMs 应该能够从用户的角度以开放的方式理解和解决任务。我们通过测试用例验证特定功能。

网站设计
【2025-3-7】Wegic
提示语
设计一个科技公司主页,要求大气
主营业务:软件开发、人工智能、大模型、AIGC等
团队成员:王文,北京航空航天大学;管同学,北京交通大学博士;王小文,中国农业大学计算机硕士
过往项目:① 嵌入式设备开发 ② 视频直播软件开发 ③ 大模型对话助手
联系方式:公众号 廿面体,邮箱 wqw547243068@163.com
哪吒抽取系统
【2025-2-25】 实测: 大模型生成《哪吒2》人物抽签系统
总结(60分及格,低分不计入榜单)
- 功能完成度:DeepSeek V3>Gemini-2 Flash>豆包 1.5-Pro>OpenAI o3-mini
- 页面美观度:DeepSeek V3>DeepSeek R1满血版=DeepSeek R1联网版=Gemini-2 Flash>豆包 1.5-Pro
- 数据准确度:DeepSeek R1满血版=豆包 1.5-Pro>DeepSeek R1联网版=OpenAI o3-mini=Gemini-2 Flash>GPT-4o-mini
- 自我认知:全部失败,只有DeepSeek能报出模型名(不过是GPT-4)
整体:DeepSeek V3强于DeepSeek R1=openai系列

聊天框
提示词
用前端代码写一个聊天对话页面,布局:第一行是标题 "ChatBot Demo",背景是蓝天, 5朵边缘模糊的白云从左往右慢慢飘动,右上角是太阳,周围发出金光;标题下是 对话框,UI 仿照微信聊天框风格,聊天框居中,占页面 1/2,半透明效果,可滑动,立体效果,Bot/User两种角色分别使用不同logo;支持流式输出;左侧是两个滑动控制条,控制两个参数 temperature 取值范围 [0,1], top_p 取值范围 [0,1]; 对话框下方备注“LLM Web 示例<br>2025-03-01”
Figma 转代码
【2025-5-15】资讯
Figma 设计稿转化为前端代码
MCP Server - Figma AI Bridge,自动将 Figma 设计稿转换为整洁的前端代码,并生成相应的网页。
- 简单高效,无需复杂配置,跟随文中的步骤操作,即可体验智能化的设计交付。tutorial-mcp-figma
NL2Code
【2023-5-30】代码大模型综述:中科院和MSRA调研27个LLMs,并给出5个有趣挑战
- NL2Code: 将自然语言转换成可执行代码来提高开发人员的工作效率
- 中科院和微软亚洲研究院在 ACL 2023 国际顶会上发表的一篇综述:调研了 NL2Code 领域中的「27 个大型语言模型以及相关评价指标」,分析了「LLMs 的成功在于模型参数、数据质量和专家调优」,并指出了「NL2Code 领域研究的 5 个机遇挑战」,最后作者建立了一个分享网站来跟踪 LLMs 在 NL2Code 任务上的最新进展。
- Large Language Models Meet NL2Code: A Survey
Web 站点
AI在线生成前端页面
DeepSite
DeepSite 由 Deepseek 驱动的 Huggingface AI 代码助手
DeepSite 是一款 AI 编码工具,无需编程知识即可创建网站和 Web 应用程序。通过 DeepSite 强大的平台获得实时预览、SEO 优化和快速部署。
LocalSite-ai
【2025-5-12】开源替代——LocalSite-ai 支持在线预览前端页面,所见即所得编辑,并且支持多个AI API提供商,以及支持响应式设计。
- 地址:LocalSite-ai
UXBox
【2025-8-23】UXBox 开源的设计与原型制作工具,目前正处于早期开发阶段。
- github uxbox
UXBOX 提供 完整的设计工具,包括: 界面布局工具、原型编辑工具和交互测试工具等。这些工具使得设计师可以快速地将创意转化为实际的产品原型,并对其进行测试和优化。
UXBOX 适用于所有设计和原型的标准格式SVG,这意味着它支持大多数现代的设计标准,并且可以与多种软件和平台兼容。这使得设计师可以在多个环境中使用UXBOX,无论是在个人电脑还是移动设备上,都能保持设计的一致性和流畅性。
UXBOX 界面设计直观易用,使得即使是初学者也能快速上手。同时,也提供了丰富的教程和文档,帮助用户更好地理解和使用这个工具。这种用户友好的设计使得UXBOX能够吸引大量的设计师和开发者,促进其社区的形成和发展。
UXBOX作为一款开源的设计与原型制作工具,具有广泛的应用前景和潜力。它的设计理念和技术实现都值得学习和借鉴。
代码测试
随着软件系统的复杂性不断增加,软件测试的重要性越来越高,测试活动将影响开发人员的工作效率,产品的可靠性、稳定性和合规性,以及最终产品的运营效率。
智能测试
智能测试发展阶段
- 大模型出现之前,软件测试领域一直在探索“智能测试”,例如精准测试、通过各种传统算法生成用例、UI自动化测试等。
- 大模型出现后,智能测试层次不断提升,真正进入了“智能测试”新时代。
《大模型应用跟踪月报(2024年10月)》,从场景上看
- 相较于2024年上半年常见的知识助手、编码助手、智能客服等场景
- 大模型在销售赋能、软件测试、智能运维等场景的应用上升明显。
软件测试领域,自动化测试脚本成为继测试用例生成外又一个显著赋能企业质量和测试活动的重要场景。
从测试端到端工作量分布来看,测试自动化工作量占比较大,随着测试业务量的持续增大,对测试自动化的及时性和自动化率提出了更高要求,同时测试自动化程度高也会降低测试执行部分的工作量。
大模型能力
优势
核心优势
- 自然语言理解能力
- 从非结构化需求文档中提取测试需求和关键场景。
- 自动识别需求中的模糊或矛盾之处,优化测试设计。
- 知识学习与推理能力
- 大模型的上下文推理能力强,复杂场景下生成高质量测试用例。
- 基于现有知识,预测潜在缺陷位置,提升测试效率。
- 多语言和多平台支持
- 支持多种语言的测试脚本生成和转换(如将 Java 转为 Python 测试代码)。
- 跨平台测试(如 Web 和移动端)中提供一致性支持。
- 数据生成与分析能力
- 生成多样化测试数据,包括:边界值、随机值和异常值。
- 高效分析测试结果并自动生成测试报告。
参考:
- 【2025-1-13】大模型在测试中的应用:开启智能化测试新时代
不足
大模型存在的问题
- 模型的准确性与上下文理解
- 特定领域的专业知识可能不足,需结合领域数据进行微调。
- 生成代码的可维护性
- 自动化生成的代码质量不稳定,可能需要人工优化,RAG知识库等手段来提升质量。
- 测试流程集成
- 将大模型能力高效集成到现有测试工具链中仍需探索。
- 数据隐私与安全
- 生成测试数据或分析日志时,需确保敏感信息的脱敏处理。
参考:
- 【2025-1-13】大模型在测试中的应用:开启智能化测试新时代
- 【2024-06-19】【AI大模型】在测试中的深度应用与实践案例
自动化场景
大模型为自动化测试脚本生成带来新方案
- 大模型可以编写自动化测试脚本,用于
单元、API和UI功能性和非功能性检查及评估,但是可能需要其他平台或工具执行自动化测试脚本。
范围
- 测试用例生成
- 自动化脚本生成
- 缺陷预测
- 测试数据生成
- 等任务
(1) 测试用例生成
通过解析需求文档,大模型可以生成覆盖不同场景和边界条件的测试用例
基本流程一致
- 收集全部产品需求和研发设计文档,输入到大模型,生成自动测试用例
区别
- 方案1:原文整体输入大模型
- 方案2:原文摘要后再给大模型
- 方案3:原文存入向量数据库,通过搜索相似内容,自动生成部分测试用例
3种方案使用场景不同,优缺点也可互补
| 方案 | 文档处理方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 方案1 | 原文整体 | 用例内容相对准确 | 不支持特大文档,容易超出token限制 | 普通规模需求及设计 |
| 方案2 | 原文摘要 | 摘要后无需担心token问题 | 用例内容不准确,大部分都概况 | 特大规模的需求及设计 |
| 方案3 | RAG | 用例内容更聚焦,无需担心token问题 | 部分用例 | 仅对需求及设计中部分生成用例 |
参考
- 【2024-10-07】利用LangChain与大模型自动化生成测试用例
streamlit
代码 AITester
LangChain
Langchain 测试用例生成方案
用户登录模块
需求:
- 测试用户登录模块,包括正常登录、错误密码、账号锁定等场景。
代码示例
from wenxin_api import TextGeneration
# 初始化大模型
model = TextGeneration(api_key="your_api_key")
# 输入需求描述
requirement = """
用户登录模块需要支持以下场景:
1. 正确的用户名和密码可以成功登录。
2. 错误的密码会提示登录失败。
3. 连续三次错误登录后,账号会被锁定。
"""
# 生成测试用例
response = model.generate_text(prompt=f"根据以下需求生成测试用例:\n{requirement}")
print(response["result"])
输出测试用例示例:
- 正确用户名 “test_user”,密码 “password123”,预期结果:登录成功。
- 用户名 “test_user”,密码 “wrong_password”,预期结果:提示登录失败。
- 连续输入错误密码三次后,预期结果:账号锁定。
解析:
- 通过模型生成的测试用例,涵盖了功能测试的核心场景,并能快速扩展至异常处理和边界条件测试。
GPT-4 生成测试用例示例:
依赖
pip install openai
pip install pytest
pip install requests
代码
import openai
# 设置API密钥
openai.api_key = "YOUR_API_KEY"
def generate_test_cases(prompt):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=500
)
return response.choices[0].text.strip()
# 定义测试用例生成的提示
prompt = """
Generate test cases for an e-commerce platform with the following features:
1. User Registration
2. User Login
3. Product Search
4. Add to Cart
5. Place Order
6. Payment
Please provide detailed test cases including steps, expected results, and any necessary data.
"""
# 生成测试用例
test_cases = generate_test_cases(prompt)
print(test_cases)
(2) 测试数据生成
大模型能够根据场景需求,快速生成多样化的测试数据,包括边界值、异常值和随机值。
生成银行账户系统的测试数据
目标:
- 为账户余额字段生成不同类型的测试数据。
data_requirement = """
生成用于测试银行账户系统的数据,包括:
1. 正常值:0 到 100 万之间的金额。
2. 边界值:负值、0、最大值。
3. 异常值:空值、非数字字符。
"""
response = model.generate_text(prompt=f"根据以下需求生成测试数据:\n{data_requirement}")
print(response["result"])
输出结果:
正常值:500, 10000, 999999
边界值:-1, 0, 1000000
异常值:None, "abc", 1.5e6
通过模型生成的数据多样性显著提高,能够有效覆盖更多测试场景。
(3) 自动化脚本生成
大模型通过自然语言理解,将需求描述转化为可执行代码,极大地提高了测试脚本的开发效率。
功能测试
用测试用例编写自动化测试脚本。
用pytest框架进行功能测试
import requests
# 基础URL
BASE_URL = "http://example.com/api"
def test_user_registration():
url = f"{BASE_URL}/register"
data = {
"username": "testuser",
"email": "testuser@example.com",
"password": "password123"
}
response = requests.post(url, json=data)
assert response.status_code == 201
assert response.json()["message"] == "User registered successfully."
def test_user_login():
url = f"{BASE_URL}/login"
data = {
"email": "testuser@example.com",
"password": "password123"
}
response = requests.post(url, json=data)
assert response.status_code == 200
assert "token" in response.json()
def test_product_search():
url = f"{BASE_URL}/search"
params = {"query": "laptop"}
response = requests.get(url, params=params)
assert response.status_code == 200
assert len(response.json()["products"]) > 0
def test_add_to_cart():
# 假设我们已经有一个有效的用户token
token = "VALID_USER_TOKEN"
url = f"{BASE_URL}/cart"
headers = {"Authorization": f"Bearer {token}"}
data = {"product_id": 1, "quantity": 1}
response = requests.post(url, json=data, headers=headers)
assert response.status_code == 200
assert response.json()["message"] == "Product added to cart."
def test_place_order():
# 假设我们已经有一个有效的用户token
token = "VALID_USER_TOKEN"
url = f"{BASE_URL}/order"
headers = {"Authorization": f"Bearer {token}"}
data = {"cart_id": 1, "payment_method": "credit_card"}
response = requests.post(url, json=data, headers=headers)
assert response.status_code == 200
assert response.json()["message"] == "Order placed successfully."
性能测试
大模型生成高并发用户请求,进行负载测试。
import threading
import time
def perform_load_test(url, headers, data, num_requests):
def send_request():
response = requests.post(url, json=data, headers=headers)
print(response.status_code, response.json())
threads = []
for _ in range(num_requests):
thread = threading.Thread(target=send_request)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
# 示例负载测试
url = f"{BASE_URL}/order"
headers = {"Authorization": "Bearer VALID_USER_TOKEN"}
data = {"cart_id": 1, "payment_method": "credit_card"}
# 模拟100个并发请求
perform_load_test(url, headers, data, num_requests=100)
UI 测试
“操控”浏览器进行自动化测试
大模型可直接将需求描述或测试用例转化为具体的执行动作
- Selenium 或 Appium 自动化测试脚本。
- Browser Use
Selenium
登录功能的 Selenium 测试脚本生成
需求:
- 对登录页面进行自动化测试,包括验证输入框和按钮的基本功能。
生成测试脚本
from wenxin_api import TextGeneration
# 输入测试需求
requirement = """
测试目标:验证登录页面基本功能。
1. 页面应包含用户名输入框、密码输入框和登录按钮。
2. 输入正确的用户名和密码后,应成功跳转到首页。
"""
# 生成 Selenium 脚本
response = model.generate_text(prompt=f"根据以下需求生成 Selenium 测试脚本:\n{requirement}")
print(response["result"])
输出:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 初始化 WebDriver
driver = webdriver.Chrome()
# 打开登录页面
driver.get("http://example.com/login")
# 验证页面元素
assert driver.find_element(By.ID, "username")
assert driver.find_element(By.ID, "password")
assert driver.find_element(By.ID, "loginButton")
# 输入用户名和密码
driver.find_element(By.ID, "username").send_keys("test_user")
driver.find_element(By.ID, "password").send_keys("password123")
# 点击登录按钮
driver.find_element(By.ID, "loginButton").click()
# 验证跳转到首页
assert "Homepage" in driver.title
driver.quit()
Playwright
Playwright 为现代 Web 应用提供可靠的端到端测试。
Playwright 是微软开发的 Web应用 的 自动化测试框架 。
selenium 相对于 Playwright 慢很多,因为
- Playwright 是异步实现,但 selenium 同步,后一个操作必须等待前一个操作。
- selenium 由相应厂商提驱动,python+驱动执行相当自动化操作,缺点:如果浏览器驱动和浏览器版本不对应,selenium就会报错,而且时刻关注版本问题。
- Playwright 基于 Node.js 语言开发,不需要再重新下载一个浏览器驱动,相当于已经写好了,仅仅需要安装这个库即可
原文链接:https://blog.csdn.net/ak_bingbing/article/details/135852038
任何浏览器 • 任何平台 • 一个 API
- 跨浏览器。 Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit 和 Firefox。
- 跨平台。 在 Windows、Linux 和 macOS 上进行本地或 CI 测试,无头或有头。
- 跨语言。 在 TypeScript、JavaScript、Python、.NET、Java 中使用 Playwright API。
- 测试移动网络。 适用于 Android 的 Google Chrome 和 Mobile Safari 的原生移动模拟。 相同的渲染引擎可以在桌面和云端运行。
(4) 静态代码分析
缺陷预测与静态代码分析
大模型通过学习历史代码和缺陷数据,能够预测可能的缺陷位置,并给出优化建议。
基于代码的缺陷预测
目标:
- 分析一段 Python 代码,预测可能存在的安全漏洞。
示例
code_snippet = """
def login(username, password):
query = "SELECT * FROM users WHERE username = '{}' AND password = '{}'".format(username, password)
execute_query(query)
"""
# 使用大模型分析代码
response = model.generate_text(prompt=f"分析以下代码并指出潜在的安全问题:\n{code_snippet}")
print(response["result"])
输出结果:
- 问题:代码存在 SQL 注入漏洞。
- 优化建议:使用参数化查询代替字符串拼接。
大模型结合知识库和推理能力,可以高效发现代码中的常见漏洞,提升代码质量。
(5) 测试报告
测试报告自动化生成
大模型可根据测试结果生成详细的测试报告,包括: 问题统计、覆盖率分析和改进建议。
自动生成测试报告
目标:
- 对测试结果进行分析,并生成适合管理层的测试总结。
def analyze_test_results(results):
prompt = f"""
Analyze the following test results and provide a summary report including the number of successful tests, failures, and any recommendations for improvement:
{results}
"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=500
)
return response.choices[0].text.strip()
# 示例测试结果
test_results = """
Test User Registration: Success
Test User Login: Success
Test Product Search: Success
Test Add to Cart: Failure (Product not found)
Test Place Order: Success
"""
test_results = """
通过的测试用例:90
失败的测试用例:10
覆盖率:85%
"""
# 分析测试结果
report = analyze_test_results(test_results)
print(report)
输出示例:
总测试用例数:100
通过率:90%
覆盖率分析:当前覆盖率为 85%,建议增加边界条件测试以提高覆盖率。
改进建议:关注失败用例涉及的模块,特别是登录和支付功能。
(6) 系统集成
问题
- 如何将上述代码整合到一个
持续集成(CI)/持续交付(CD)管道中 - 如何处理和报告测试结果
确保测试过程高效、自动化,并且易于维护。
详见
- 【2024-06-19】【AI大模型】在测试中的深度应用与实践案例
测试工具
Shortest
Shortest 一款开源 AI 测试框架,彻底改变了开发者端到端测试的方式。
- github shortest 包含演示视频
开发者用简单易懂的纯英语编写测试用例。Shortest 将这些指令转换成可执行的测试代码。
Shortest 用 Anthropic 的 Claude API 进行准确的解释和执行。
该框架与 GitHub 无缝集成,并利用 Playwright 强大的测试引擎。
Shortest 提供更快、更直观的测试流程,减少了对大量编码知识的需求。
关键特性:
- 自然语言处理:Shortest 接受用日常英语书写的测试指令。无需学习复杂的测试语法或API。
- LLM驱动的测试执行:Anthropic Claude API 能够解释自然语言输入,并转换为可靠的可执行测试代码。
- Playwright 基础:Shortest 建立在 Playwright强大的测试引擎之上,确保测试执行的稳定性和可靠性。
- GitHub 集成:Shortest 与 GitHub无缝集成,方便管理测试套件和开发者之间的协作。
- 快速创建测试:开发者可以专注于描述测试场景,Shortest负责将其转换为可执行代码,从而加快测试开发速度。
Browser Use
网页应用的功能越来越丰富,交互性越来越强。从简单的信息展示页面到复杂的在线办公系统、电商平台,网页应用的测试难度呈指数级增长
传统自动化测试工具在复杂应用面前,显得力不从心。
Browser Use 打破了传统测试工具的局限性,能够快速、准确地模拟用户在浏览器中的各种操作,对网页应用进行全面、深入的测试
Browser Use 运用了一系列先进的浏览器自动化技术来实现对浏览器的操控。
- 通过调用浏览器的开发者工具接口,能够模拟用户的各种操作,如点击、输入、滚动等。
- 同时,它还可以监控浏览器的各种事件,如页面加载完成、元素出现或消失等。
信息
- Github:browser-use
- 官网
- 操作文档
- 详见站内专题: agent
Browser Use
- 将用户测试需求转化为语言模型能够理解的格式,发送给LLM进行处理。
- LLM 生成相应的测试步骤和操作指令
- 再将指令转化为实际的浏览器操作。
例如,测试一个复杂的在线表单填写功能
- 用户输入“填写所有必填字段并提交表单”
- LLM 分析表单中各个字段,并生成相应的填写内容和操作步骤
- Browser Use 则按照这些步骤,在浏览器中模拟用户的填写和提交操作。
Prompt 示例: 演示案例见 走进Browser Use:领略AI赋能UI自动化测试的魔法魅力
- 用谷歌邮箱给我爸爸写一封信,感谢他所做的一切,并将文档保存为PDF
- 阅读我的简历并找到ML工作,将其保存到文件中,然后在新选项卡中开始申请,如果您需要帮助,请咨询我。
- 在kayak.com上查找 2024年12月25日至2025年2月2日从苏黎世飞往北京的航班。
- 查找具有cc-by-sa-4.0 license的模型,并按照在Hugging Face上的最多点赞数进行排序,将前5名保存到文件中。
代码
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
llm = ChatOpenAI(model="gpt-4o")
async def main():
agent = Agent(
task="帮我查找2025年1月12日从巴厘岛飞往阿曼的单程航班,并返回最便宜的选项。",
llm=llm,
)
result = await agent.run()
print(result)
asyncio.run(main())
workflow use
【2025-5-26】Workflow Use,开源浏览器工作流自动化工具,RPA 2.0
Workflow Use 是由 Browser Use 开发商开源的浏览器工作流自动化工具
Workflow Use 还处于非常早期开发阶段,不建议用于生产环境。但基于Browser User开发团队的过往牛逼的产品能力、开发能力,对Workflow Use的未来值得期待
传统测试自动化工具
- LoadRunner、Selenium IDE 都可以通过录屏方式录制脚本,完成测试自动化工作。
- AutoHotkey AutoScriptWriter、按键精灵之类的PC自动化工具可以适用于更广的工作流自动化场合。
但传统自动化工具对自然语言理解、图形/语音/视频等多模态的识别及理解并不擅长,因此可适用的场景还是相对受限,必须大量定制。
RPA(Robotic Process Automation)、Manus之类的AI自动化工具,虽然在自然语言理解、多模态处理有了长足进步,但执行速度、成本都存在很大问题以及大模型幻觉导致的结果的不确定性,要大规模应用于企业工作流自动化场景还较难。
Zapier、n8n、Dify 之类AI工作流解决方案,很适合企业自动化应用场景,但其工作流依赖于有技术背景的人员预先编排。
Workflow Use 可以解决
- 项目地址:browser-use 子功能 workflow-use
最大的特色
- 通过一次性录制浏览器操作,就生成可无限运行的确定性工作流程
Workflow Use 核心功能:
- 一次录制,永久重用 :录屏一次浏览器交互过程就可无限期重播。
- 显示,不提示 :无需花费数小时提示浏览器一遍又一遍地做同样的事情。
- 结构化和可执行的工作流程 :将记录转换为确定性、快速且可靠的工作流程,自动从表单中提取变量。
- 类似人类的交互理解 :智能地过滤录音中的噪音,以创建有意义的工作流程。
- 企业级基础 :具有自我修复和工作流差异等功能,专为未来的可扩展性而构建。
- 与 LLM Agent 相比,Workflow Use 速度快10倍,成本低约90%,很适合企业级高频任务(来源)。
Workflow Use 愿景:
- 只需向计算机显示一次它需要做的事情,它就会一遍又一遍地执行,无需任何人工干预。
Workflow Use 未来规划:
- 改进步骤失败时的回退
- 自我修复,如果失败,代理会自动启动并更新工作流文件
- 更好地支持步骤
- 获取前面步骤的输出并将其用作后续步骤的输入
- 将工作流程公开为 MCP 工具
- 使用浏览器自动从网站创建工作流程
- 允许浏览器使用工作流程作为 MCP 工具
- 使用工作流作为网站缓存层
AutoMouser
【2025-1-17】AutoMouser:AI Chrome扩展程序,实时跟踪用户的浏览器操作,自动生成自动化操作脚本
- GitHub 仓库:AutoMouser
- 功能:实时跟踪用户交互行为,自动生成Selenium测试代码。
- 技术:基于OpenAI的GPT模型,支持多种XPath生成策略。
- 应用:适用于自动化测试脚本生成和用户交互行为记录。
AutoMouser是一款Chrome扩展程序,能够智能地跟踪用户的浏览器操作,如点击、拖动、悬停等,并将这些操作转化为结构清晰、易于维护的Python Selenium脚本。通过记录用户的交互行为,AutoMouser简化了自动化测试的创建过程,提高了测试效率。
AutoMouser 核心功能是借助OpenAI的GPT模型,将用户的浏览器操作自动转化为Selenium测试代码。这使得开发者和测试工程师能够快速生成自动化测试脚本,减少了手动编写测试脚本的时间和复杂性。
AutoMouser 主要功能
- 实时交互跟踪:能实时捕捉用户的浏览器操作,包括点击、输入、滚动等,精准地记录下用户在网页上的各种交互行为。
- 自动代码生成:借助OpenAI的GPT模型,将记录下来的用户操作自动转化为Selenium测试代码,生成Python Selenium脚本。
- 智能输入整合:对用户的输入操作进行智能整合,优化代码结构,使生成的测试脚本更加简洁、高效。
- 窗口大小变化检测:能检测浏览器窗口的大小变化,确保生成的测试代码能够适应不同的窗口尺寸。
- JSON动作日志导出:支持将用户的交互数据导出为JSON格式的动作日志文件,方便用户对原始数据进行查看、分析和进一步处理。
- 多种XPath生成策略:采用多种XPath生成策略,能更准确地定位网页元素,提高测试的准确性和可靠性。
- 代码结构优化:输出的Selenium测试代码结构清晰、整洁,易于阅读和理解,方便开发人员进行后续的开发和维护工作。
自动化测试应用
【2024-11-04】 大模型在自动化测试的突破:蚂蚁、华为等头部企业应用实践
蚂蚁集团、中国邮储银行、科大讯飞、华为等4家企业自动化测试领域大模型应用实践
案例1:支付宝小程序基于AI大模型的自动化测试实践
支付宝小程序在质量检测中挑战
- 传统监控无法有效识别业务问题。
蚂蚁集团利用AI大模型技术,开发智能异常检测和链路测试算法,实现自动化测试。
通过自然语言处理和多模态大模型提升识别业务异常和深度链路问题的准确性。
该实践不仅提高了检测效率,还通过智能动线预测模块,增强了用户体验。
完整内容:
案例2:中国邮储银行基于大模型的自动化测试脚本智能生成
传统自动化测试脚本编写需要测试人员具备一定编程能力,且耗时耗力,导致脚本编写人力成本大,质量参差不齐。
邮储银行金牛座自动化测试系统引入大模型技术,结合知识库、录制、报文解析、图像识别等技术,针对不同场景提供脚本智能生成功能:
- 单接口脚本批量生成:主要用于单接口测试,提供了单接口脚本批量生成功能,有效解决了单接口测试脚本编写量级较大的问题;
- 多接口组合场景脚本智能生成:主要用于测试业务流程,针对组合场景脚本,采用 录制+智能分析+辅助编写 方案智能生成脚本;
- UI测试脚本智能生成:借助大模型技术,可以根据简单的用例描述,直接自动生成测试脚本。
案例3:科大讯飞基于大模型的自动化测试实践
接口测试脚本生成场景,科大讯飞将融合大模型能力,提供智能用例生成服务,当前平台主要针对HTTP协议进行接口的智能化测试。
- 智能用例生成: 当新增接口用例或将接口定义导入时,会调用智能用例生成服务自动生成接口自动化用例;
- UI自动化测试脚本生成: 用例生成脚本模式,通过用例文本输入引导,结合其他输入数据,生成UI自动化脚本。经业务验证,在用例编写规范的情况下,UI自动化脚本生成的采纳率可以达到50%以上。
完整内容:
案例4:华为基于LLM的测试自动化代码生成实践
华为选择大模型辅助测试自动化代码生成作为大模型在智能测试领域应用的突破点
- 首先, 用
SFT调优方案,落地场景为老特性防护网补齐,但存在时间间隔导致无法写新特性; - 然后,使用
RAG方案实现分钟级新特性编写; - 再次,进一步实现无需写样例脚本,直接通过 AW 生成。从整个方案迭代方向看,AI自动生成的比例越来越大。
截止2024年6月底,大模型辅助测试自动化代码生成的应用人数为近3k人,覆盖 60+产品,测试自动化生成的代码量 40+万 行。
完整内容:
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
