大模型应用: 搜索
大模型搜索
【2025-5-10】图灵奖得主、Meta首席AI科学家杨立昆近日在Flatiron Institute 演讲中表示
- AI系统今后将基本上通过推理进行搜索,而不是让多层神经网络来预测tokens
2025年5月27日,蚂蚁开源在第⼗届技术⽇上,重磅发布了《2025 ⼤模型开源开发⽣态全景与趋势》报告
作为最早落地的应用场景,AI 搜索曾被视为 AI 时代的“超级应用”,但随着大模型能力的泛化,那些专注于 AI 搜索的项目优势不再明显,甚至在处理一些复杂任务时,远没有能进行推理和归纳的大模型游刃有余。
- 分析: 用户并不在意打开的是搜索页还是对话框,可以联网的模型完全可以满足用户“先问 AI”的需求。
RAG -> Graph RAG -> DeepSearcher
【2025-4-22】别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher
RAG 解决什么问题
- 知识时效性
- 事实准确性:降低幻觉
- 领域适配成本:微调的标注数据+计算成本高
传统RAG、Graph RAG、DeepSearcher
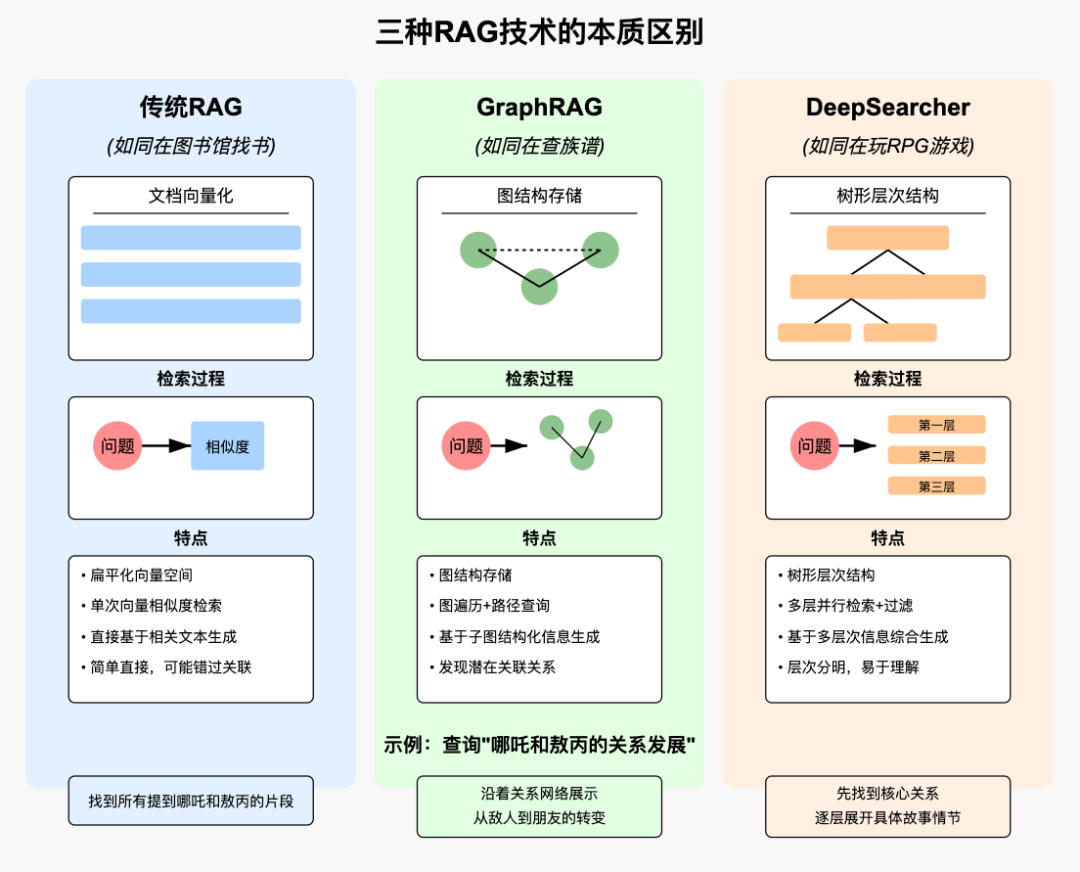
对比分析
| 维度 | RAG | GraphRag | deepsearcher |
|---|---|---|---|
| 检索机制 | 向量相似性搜索,平坦检索 | 图关系查询,基于实体和关系的检索 | 粗到细的渐进检索,多阶段筛选候选 |
| 上下文处理 | 通过文本拼接提供上下文,简单直接 | 利用知识图谱关系,上下文结构化丰富 | 通过多阶段精炼,逐步提升上下文相关性 |
| 效率与扩展性 | 适合中小数据集,平坦检索可能效率低 | 处理复杂关系,图规模大时效率可能下降 | 设计为高效处理大数据,平衡效果与效率 |
| 准确性与相关性 | 依赖嵌入质量,相关性受限于检索文档 | 结构化关系提升准确性,适合复杂查询 | 多阶段精炼提高准确性,适合动态更新信息 |
| 实现复杂度 | 简单,使用标准库如LangChain即可 | 复杂,需要构建和维护知识图谱 | 较复杂,涉及多阶段检索管道,需高级设置 |
资料
论文
- 【2025-6-20】百度论文,大模型驱动的AI搜索范式 LLM-powered agents (Master, Planner, Executor and Writer) ,覆盖简单知识问答和复杂多步推理
“AI搜索范式”区别于传统搜索引擎和现有检索增强生成(RAG)系统的工作模式。
- 传统搜索系统像流水线,按部就班地检索、排序、生成答案,难以处理需要多步推理复杂问题。
- 新范式像动态协作的专家团队,由四个核心的LLM(大语言模型)智能体组成:
Master(大师)、Planner(规划师)、Executor(执行器)和Writer(作家)。- Master负责分析用户问题的复杂性并组建最合适的智能体团队;
- Planner负责将复杂问题分解成一个可执行的计划图;
- Executor负责调用各种工具(如搜索、计算)来完成具体的子任务;
- Writer则负责综合所有结果,生成一个全面、连贯的答案。
- 这种架构的精髓在于其动态性和协作性,能够像人一样思考、规划并解决问题,而不是机械地匹配和生成。
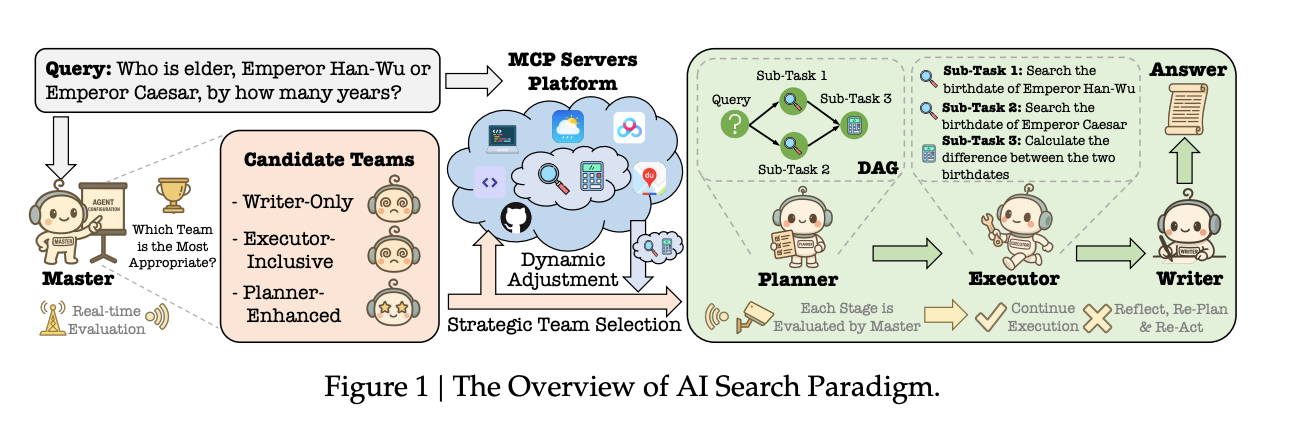
案例
- 对于“汉武帝叫什么名字”这类简单问题,采用“作家-唯一(Writer-Only)”配置,直接生成答案;
- 对于“今天北京天气适合出门吗”这类需要外部信息但无需复杂推理的问题,采用“执行器-包含(Executor-Inclusive)”配置,由执行器调用天气工具后,作家再整合信息;
- 而对于汉武帝与凯撒年龄比较的复杂问题,则启动最高级的“规划师-增强(Planner-Enhanced)”**配置。这个模式下,Master首先识别出问题的复杂性,然后委派Planner。
| 案例 | 难度 | 分析 | 方案 |
|---|---|---|---|
| 汉武帝叫什么名字 | 简单 | 常规知识问答 | 采用“作家-唯一(Writer-Only)”配置,直接生成答案 |
| 今天北京天气适合出门吗 | 中等 | 需要外部信息但无需复杂推理的问题 | 采用“执行器-包含(Executor-Inclusive)”配置,由执行器调用天气工具后,作家再整合信息 |
| 汉武帝与凯撒谁大 | 复杂 | 多步推理 | 启动最高级的“规划师-增强(Planner-Enhanced)”**配置,Master识别问题的复杂性,然后委派Planner。 |
复杂问题
- Planner 将问题分解为三个子任务:
- 搜索汉武帝的生卒年份;
- 搜索凯撒的生卒年份;
- 计算年龄差。
- 这个过程被构建成一个有向无环图(DAG),清晰地表达了任务间的依赖关系。
- 随后,Executor 按图索骥,调用搜索和计算工具完成任务
- 最后由Writer综合信息,生成最终答案。
引入 MCP,面对海量工具,Planner 并非全部加载,而是引入了动态能力边界(Dynamic Capability Boundary)。具体做法:
- 先通过 DRAFT 自动化框架,通过“经验收集-经验学习-文档重写”的循环,迭代优化工具的API文档,使其对LLM更友好;
- 然后,利用 k-means++ 算法对工具进行功能聚类,形成“工具包”以备不时之需(如同一个工具坏了,可以从同类工具包中找替代品);
- 最后,通过 COLT 先进检索方法,该方法不仅看重查询与工具的语义相似性,更通过图学习捕捉工具间的“协作关系”(例如,解决一个复杂问题需要计算器、汇率查询、股价查询三个工具协同工作),从而为当前任务检索出一个功能完备的工具集。
拥有了合适的工具后,Planner 会利用思维链和结构化草图提示策略,基于用户复杂查询生成一个基于DAG(有向无环图)的全局任务计划
这个流程与传统RAG系统一次性检索或简单的“思考-行动”循环相比,展现了更强的逻辑性、鲁棒性和解决复杂问题的能力。
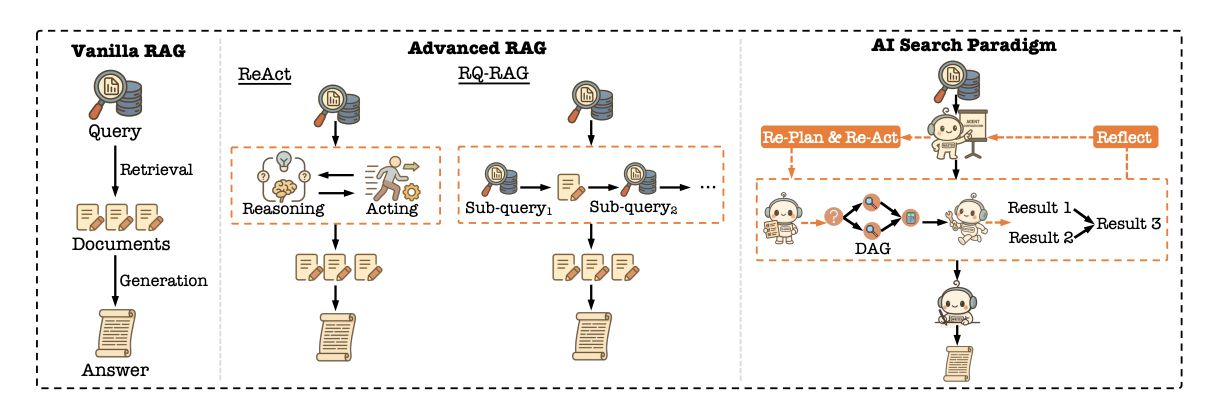
搜索demo
ollama 本地搜索
【2024-3-29】LLocalSearch 开源的完全本地化的AI搜索工具,无需 OpenAI 或 Google API 密钥。
- 基于 ollama, 7b 模型
项目特点:
- 🕵️ 完全本地化运行,不需要连接到外部API,因此无需API密钥。
- 💸 适用于性能相对较低的大型语言模型硬件,例如在演示视频中使用的是7b模型。
- 🤓 提供详细的进度日志,这有助于用户更好地理解搜索和处理过程。
- 🤔 支持用户提出后续问题,以便深入探讨或解决问题。
- 📱 界面对移动设备友好,适合在手机或平板电脑上使用。
- 🚀 使用Docker Compose工具,可以快速且轻松地部署此服务。
- 🌐 提供网络界面,使用户可以从任何设备轻松访问和使用。
- 💮 该服务提供精心设计的用户界面,支持浅色和深色模式,满足不同用户的视觉偏好。
git clone https://github.com/nilsherzig/LLocalsearch.git
# 1. make sure to check the env vars inside the `docker-compose.dev.yaml`.
# 2. Make sure you've really checked the dev compose file not the normal one.
# 3. build the containers and start the services
make dev
# Both front and backend will hot reload on code changes.
Ask.py
【2025-1-20】Ask.py:一个简单的Python程序,实现了 搜索-提取-总结 流程
- Demo: leettools
命令行或通过 GradIO UI 运行,控制输出行为,比如提取结构化数据或改变输出语言,还能控制搜索行为,比如限制特定网站或日期,或仅抓取指定URL列表的内容。

搜索模型
WebGPT
【2021-12-17】基于GPT3模型在搜索结果方面的优化
把原先需要人工创造的原始数据,或需要爬取的数据,直接通过输入层,从网页端Search Query到模型,经过内部网络的隐藏单元推理后,到输出层与人工结果进行对比,然后再调参。
- 把工程方法融入到了模型训练的流程中,所以称之为“对GPT3做了一点小调整”。
数据生产分为两个部分: demostration(演示)和comparison(对比)。
- demonstration: 按照人类使用搜索引擎时的操作,针对给定的问题,对搜索引擎返回的结果,进行过滤。
- OpenAI将上述复杂的过程简单抽象为了10个commands(指令)。在特定开发的标注平台,记录人类的搜索过程,并将此过程中的操作和上下文转换为带标签的语料——语料的输入是上下文,command是具体操作。值得注意的是,为了包含搜索过程中的历史操作,上下文包含了对操作的总结。

- comparison: 针对某个特定的问题,模型生成两个答案,标注人员先对每个答案从trustworthness(可信度)、来源对结果的支持程度进行打分。在对两个答案进行对比打分。
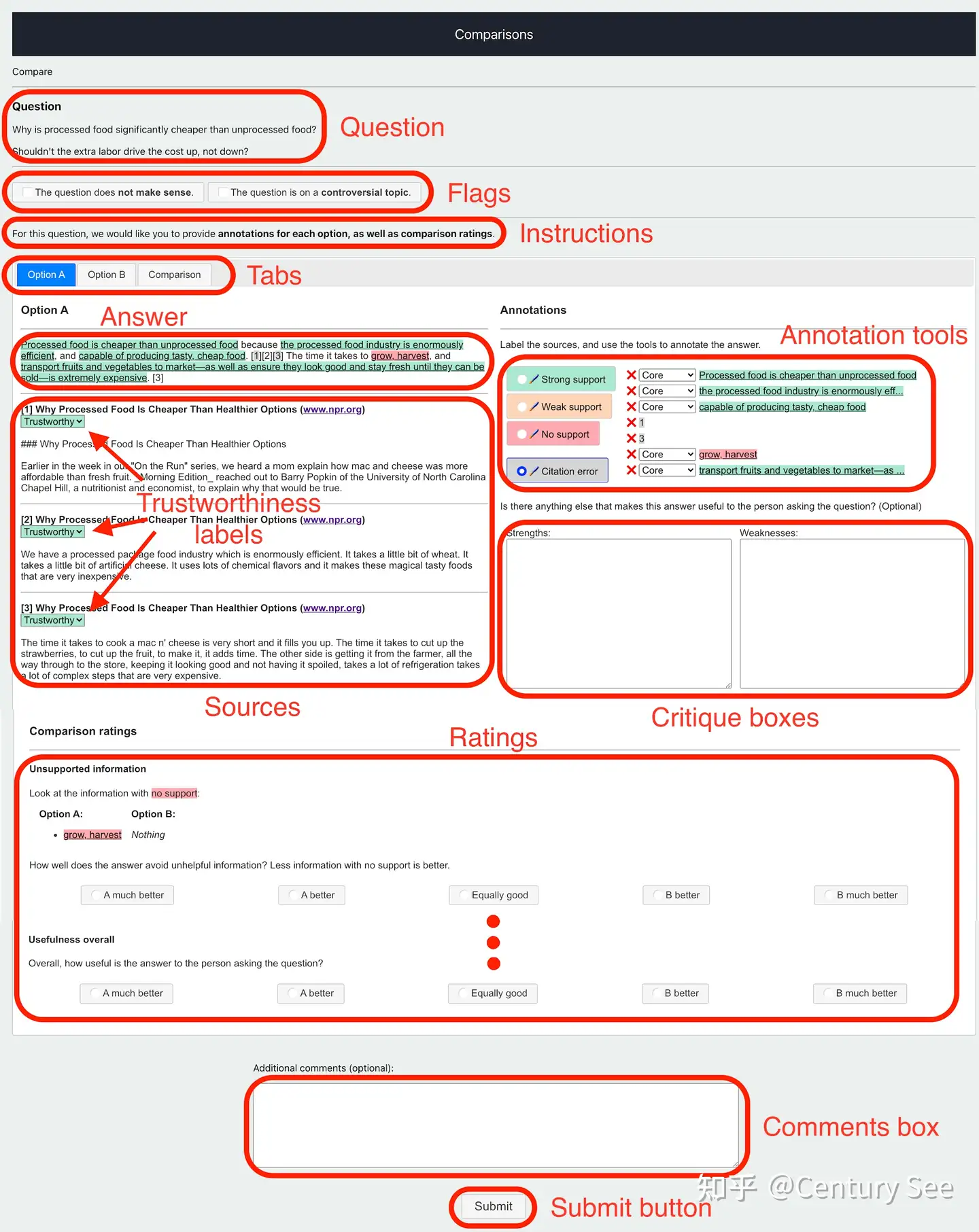
WebGPT 的训练是在 pre-trained GPT 的基础上进行 finetune,finetune 的方法挺有趣的,采用了 behavior cloning, reward modeling, RL, rejection sampling
模型由四个部分组成:
- Behavior cloning(以下简称BC)
- Reward model(以下简称RM)
- Reinforcement learning(以下简称RL)
- Reject Sampling(以下简称RS)
这些均由GPT3类模型微调而来。做这个选择的原因就是GPT3模型在阅读理解、答案合成等领域涌现出了零样本学习的能力
主要作用如下:
- Behavior cloning
- 基于demonstration数据,模仿人类搜索+提取信息行为。可以简单地理解为一个分类任务的微调。
- Reward model
- 基于comparison数据,输入问题、答案以及引用,模型给出一个得分,相当于是一个回归任务的微调。但由于得分的主观性过大,这里输入采用了同一个问题、两组答案与引用,groundTruth为comparison数据的标签,训练目标函数为交叉熵。
- Reinforcement learning
- 这里的强化学习模型采用BC模型的参数初始化,通过RM生成奖励值,利用PPO算法更新模型参数,使得模型生成的结果得分越来越高。
- Reject Sampling
- 拒绝采样,对BC / RL模型生成的结果进行采样,并对采样后的结果通过RM选取回报值最大的结果作为最终结果。
结果对比
- 5.1节介绍了不同部分组合的对比结果。主要对比RL、RS与baseline的BC的结果之间的对比。
- 结论比较反直觉
- 一方面,虽然RL、RS比baseline都有提升,但RS的提升要更明显些;
- 另一方面,经过RL、RS两步的结果没有只进行RS的结果提升大。
- 文章给出的可能原因是RS不需要更新基础的BC模型参数,而RL+RS同时对RM的结果优化,可能造成对RM的过度优化。
作者:Century See
WebCPM
【2023-5-15】WebCPM 成功实践了 BMTools, 中文领域首个基于交互式网页搜索的问答开源模型框架 WebCPM,这一创举填补了国产大模型该领域的空白
- paper, code
- WebCPM 的特点在于其信息检索基于交互式网页搜索,能够像人类一样与搜索引擎交互从而收集回答问题所需要的事实性知识并生成答案。换言之,大模型在联网功能的加持下,回答问题的实时性和准确性都得到了飞跃式增强。
- WebCPM 对标的是 WebGPT , WebGPT 也正是微软近期推出的 New Bing 背后的新一代搜索技术。同 WebGPT一样,WebCPM 克服了传统的 LFQA( Long-form Question Answering)长文本开放问答范式的缺陷:依赖于非交互式的检索方法,即仅使用原始问题作为查询语句来检索信息。
Search Agent
DeepSearcher 架构
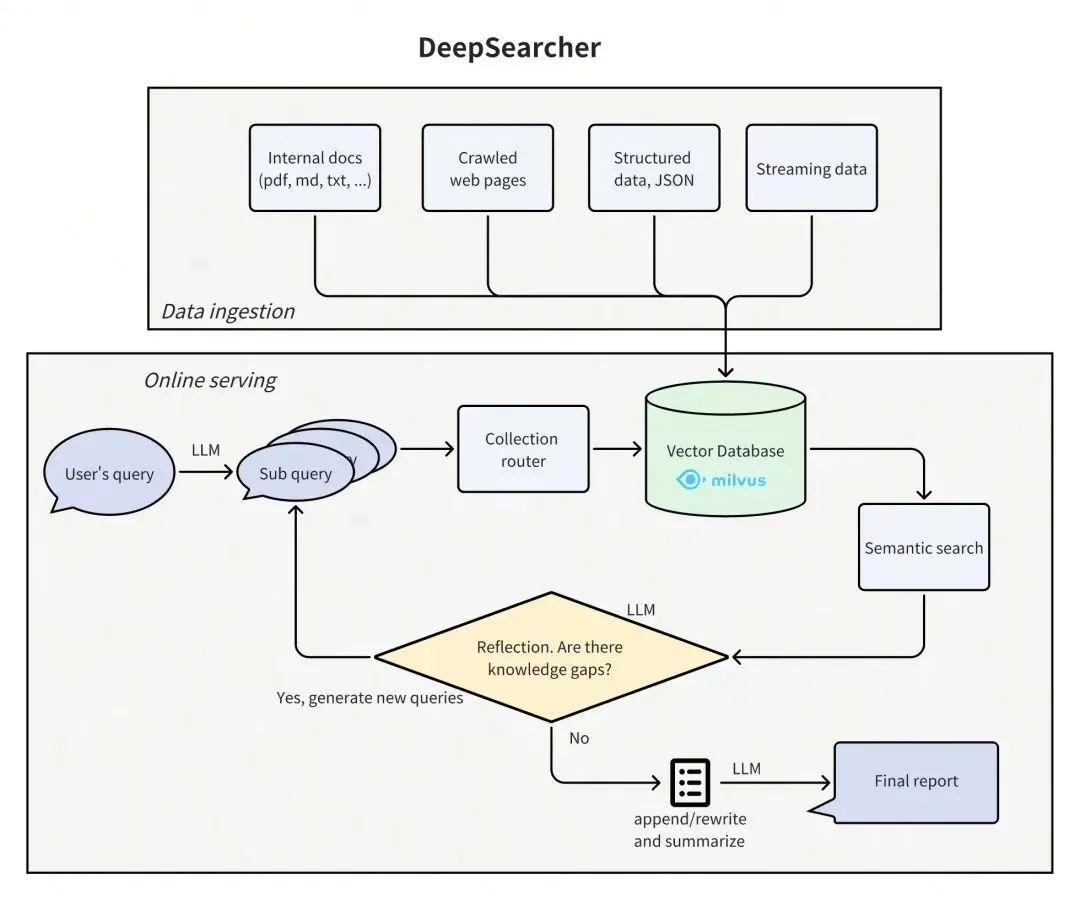
DeepSearcher
【2025-4-22】别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher
优点
DeepSearcher 先进性在于它突破了传统检索和生成的分步模式,深度整合深度学习,优化整个搜索过程。其核心优势包括:
- 更智能的检索:语言模型参与检索过程,例如生成候选查询或重新排序结果,提升相关性。例如,面对“如何选择适合我的手机?”,DeepSearcher 可根据用户历史生成更精准的检索条件。
- 适应性强:通过反馈循环(如强化学习)优化搜索,基于用户行为不断改进。例如,搜索结果不满意时,系统可学习调整策略。多模态支持:能处理文本、图片、视频等混合数据,适合现代应用需求,如搜索“展示红色跑车的图片和相关新闻”。
- 个性化能力:深度学习模型可根据用户偏好定制搜索结果,相比 RAG 和 GraphRAG 的静态检索更灵活。令人惊讶的是,DeepSearcher 的搜索过程更像人类思考,能理解上下文和意图,但这也带来效率和解释性的挑战。
问题
汇总
- 集成复杂性:将语言模型与搜索索引深度整合,需要设计高效的架构。例如,如何在不牺牲性能的情况下让语言模型参与检索?
- 实时更新:处理实时数据更新(如股票价格变化)时,确保模型及时适应,技术难度较高。系统复杂性:DeepSearcher 可能涉及多个组件(如检索模块、生成模块、学习模块),增加维护和故障排查难度。
- RAG 和 GraphRAG 是成熟的范式,分别适合文档检索和关系查询,而 DeepSearcher 代表未来方向,通过深度学习优化搜索过程,适合复杂、个性化的需求。尽管它潜力巨大,但效率、解释性和数据需求仍是需要攻克的难题。实现中需关注集成复杂性和实时性,确保系统在实际应用中表现稳定。
Multi-Agent
论文
- 【2025-2-6】同济、新加坡南洋理工 提出 MaAS
早期多智能体系统提供专业能力,但严重依赖手动配置
- 如
CAMEL(Li et al., 2023)、AutoGen(Wu et al., 2023)和MetaGPT(Hong et al., 2023) - 手工配置:提示工程、智能体分析和智能体间通信流水线(Qian et al., 2024)。
- 这种依赖限制了多智能体系统对不同领域和应用场景的快速适应
多智能体系统设计自动化
- 优化Agent间通信:
DsPy(Khattab et al., 2023)和EvoPrompting(Guo et al., 2023) 自动提示优化,GPTSwarm(Zog et al.,2024)和G-Designer(Zhang et al.,2024b) - 自我进化Agent分析:
EvoAgent(Yuan et al.,2024)和AutoAgents(Chen et al.,2023a)
然而,专注于自动化系统的特定方面。
随后,ADAS(胡等人,2024a)、AgentSqure(Shang 等人,2024)和 AFlow(Zhang 等人,2024c)拓宽了设计搜索空间 — SOTA 方法
ODS 通过不同的搜索范式为给定数据集优化单个复杂(多)代理工作流程,例如: 启发式搜索(胡 et al., 2024a)、蒙特卡洛树搜索(Zhang et al., 2024c)和进化(Shang et al., 2024),超越了手动设计系统的性能
问题
- 性能受资源限制,例如令牌成本、LLM调用和推理延迟。现代方法倾向于针对复杂和资源密集型的 agen 进行优化
We introduce MaAS, an automated framework that samples query-dependent agentic systems from the supernet, delivering high-quality solutions and tailored resource allocation (e.g., LLM calls, tool calls, token cost). Comprehensive evaluation across six benchmarks demonstrates that MaAS (I) requires only 6 ∼ 45% of the inference costs of existing handcrafted or automated multi-agent systems, (II) surpasses them by 0.54% ∼ 11.82%, and (III) enjoys superior cross-dataset and cross-LLM-backbone transferability.
MaAS 自动化框架从超网中采样query相关的智能体系统,提供高质量的解决方案和定制的资源分配(大语言模型调用、工具调用、令牌成本)。
Agent超网是一个级联的多层工作流,包括
- ❶ 多个Agent算子: CoT (Wei et al., 2022)、Multi-agent Debate (Du et al., 2023)、ReAct (Yao et al., 2023)),以及
- ❷ 算子跨层的参数化概率分布。
- 训练期间,MaAS 利用控制器网络对以query为条件的多代理架构进行采样。分布参数和运算符根据环境反馈共同更新,前者的梯度通过蒙特卡洛采样近似,后者梯度通过文本梯度估计。
- 推理过程,对于不同query,MaAS 对合适的多智能体系统进行采样,提供令人满意的分辨率和适当的推理资源,从而实现任务定制的集体智慧
六个基准综合评估: MaAS
- ❶ MaAS 高性能,比现有的手工或自动化多智能体系统高出 0.54% ∼ 11.82%;
- ❷ 节省token,在 MATh 基准上优于 SOTA 基线 AFlow,训练成本为 15%,推理成本为 25%;
- ❸ 可迁移: 跨数据集和 LLM-backbone;
-
❹ 归纳式: 对看不见的Agent运算符泛化性强
- (I)仅需现有手工制作或自动化多智能体系统推理成本的 6% - 45%
- (II)高出 0.54% - 11.82%,并且
- (III)具有卓越的跨数据集和跨大语言模型骨干的可转移性。
更多见站内 Agent 专题
RL + Agent
【2025-4-9】 rl 和 search agent 结合。
没法互相比较算法或框架策略上的优劣、评估方法上不一致。 multihop 数据集,急需统一 leaderboard。
实验来看 纯 deep seekr1+prompt 或者 sf t在multihop上可以达到很高的指标。
- search + RL
- 人大 r1-seacher
- University of Illinois at Urbana-Champaign search-r1 paper
- baichuan research
- search & browse + RL
- DeepResearcher: 上海交大 paper
- search + offline rl
- stanford deep mind: Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
- search +SFT + RL
- 北京交通大学 AutoCoa paper
搜索产品
perplexity.ai
待补充
秘塔
【2024-4-11】国产AI搜索之光,秘塔AI搜索,打败Perplexity?
秘塔科技由闵可锐在2018年4月创立。CEO闵可锐本科毕业于复旦计算机科学,是牛津大学数学专业的硕士,美国伊利诺伊大学香槟分校的博士,曾任玻森数据CTO、猎豹移动首席科学家,并在微软做过实习研究员,也参与过谷歌项目。
秘塔AI推出的秘塔AI搜索, 中国版 Perplexity 的 AI搜索引擎“秘塔AI搜索”
- 注册后即可免费使用,不用科学上网,也没有语言上的理解误差,在中文语境上的表现更有优势。其slogan是:“没有广告,直达结果”。
- 示例:o1原理
截至2024年3月1日, 前28天,秘塔AI搜索网站共计访问478.3万次,峰值在3月18日达到45万次。
秘塔科技推出了4款产品:秘塔AI搜索、秘塔写作猫、秘塔翻译、秘塔检索。其中秘塔写作猫之前被大多文字工作者们所熟知。
秘塔AI搜索特点:
- 1、没有广告,直达结果:秘塔AI搜索界面只有一个搜索框,没有广告和闲杂信息的干扰。
- 2、结构化信息展示:秘塔AI搜索会将搜索结果整理成更方便阅读的脑图和大纲形式。
- 3、信息来源追溯:秘塔AI搜索为每条搜索结果、每条信息提供了来源链接,用户可以轻松溯源验证信息的出处和可靠性。
- 4、辅助信息梳理:秘塔AI搜索会整合和搜索主题相关的辅助信息,包括相关事件名称、事件时间线、相关人物组织等,以表格的形式呈现,让用户更全面理解搜索主题。
- 5、学术搜索模式:秘塔AI搜索在首页搜索框,将搜索范围限定为学术后,信息来源会从全网聚焦到专业期刊和论文。还增加了一个快速浏览摘要的功能,最后汇总所有的参考文献,并且是导出即可使用的规范格式。
相比于Perplexity,秘塔AI搜索实际上走了一条具有差异化的路线。Perplexity开启co-pilot之后会引导你追问下一个问题,给出的模态会更多,包括图片和视频源。
背后自研大模型 MetaLLM(基于Transformer底层架构投入中文语料训练),支持多轮对话式搜索,被誉为中国版Perplexity。
工具添加
- Chrome 插件添加: 秘塔AI
- Chrome 站点搜索:
- 设置页面: chrome://settings/searchEngines
- Site search -> Add
- 名称:秘塔AI搜索
- 快捷字词:metaso.cn
- 网址格式:https://metaso.cn/?q=%s
- 其它设置方法
devvai
【2023-11-30】最懂程序员的新一代AI搜索引擎来了,devvai 可以基本代替使用Google/StackOverflow等等的使用场景
- 一款专门面向中文开发者群体的AI搜索引擎,接入了搜索引擎数据,回答的内容基本都是最新的,很适合用来学习,比如对编程中的某个地方不理解,可以直接使用关键词搜索,就可以获得一个相对来说比较完善的技术摘要,右侧还可以点进原文去查看具体内容!而且还全部免费
- 更快速的代码搜索体验
Lepton Search
【2024-1-14】贾扬清内侧版 Lepton Search
500行Python代码构建的AI搜索工具,而且还会开源。后端是 Mixtral-8x7b 模型,托管在 LeptonAI 上,输出速度能达到每秒大约200个 token,用的搜索引擎是 Bing 的搜索 API。

作者还写了一下自己的经验:
- (1) 搜索质量至关重要。优质的摘要片段是形成精准概括的关键。
- (2) 适当加入一些虚构内容实际上有助于补充摘要片段中缺失的“常识性信息”。
- (3) 在进行内容概括时,开源模型表现出了卓越的效果
Arc Search
【2024-1-31】基于大模型的Arc Search:颠覆百度的AI搜索来了?
2022 年底,一家名不见经传的初创公司——The Browser Company 推出了全新浏览器 Arc Browser,在理念和交互设计上完全不同于 Chrome 等今天常用的浏览器,很多用户、博客和媒体都给出了极高的评价。
- 「Arc Browser 是我一直在等待的 Chrome 替代品,」The Verge 的 David Pierce 评价道。
2023年,Arc Browser 进行了多次迭代,也在海外和国内都获得了许多拥趸,支持平台也从最初的 macOS 扩展到了 iOS 和 Windows。
这两天,The Browser Company 突然「推倒」了 iOS 上的 Arc Browser,基于生成式 AI 带来的颠覆,推出了一款全新的应用:Arc Search。
本质上 Arc Search 还是一款移动平台上浏览器,根据官方公告,「Arc Search」将在移动平台上全面取代「Arc Browser」。
Arc Search 有两种浏览模式
- 一是 传统模式,通过搜索词直接转到谷歌的搜索结果页,也可以输入网址进行访问;
- 二是 AI模式,类似其他生成式 AI 搜索一样,用户可以用自然语言对话的形式输入问题或者提示词。
输入问题或者提示词后,按下「Browser for Me」,AI 就通过阅读相关网页了解信息,再针对问题进行总结、回答。最终,Arc Search 会以统一的排版和格式呈现 AI 生成的回答,通常是先看到回答的「要点」和「最佳搜索结果」,接着再看到详细的回答,最后还附上一系列相关网页推荐。
举个例子,输入「为什么 Twitter 现在叫 X」后点击「Browser for Me」,就像字面意思,AI 将会为用户浏览包括 CBS 新闻、纽约时报、伦敦大学、Tech Radar 以及 YouTube 等 6 个网页的内容,然后针对问题进行提炼和总结,生成回答。
- 等待 AI 浏览、理解、再回答的过程中,Arc Search 利用 iPhone 的振动进行反馈,让用户可以明确感知到这一过程,这是一个值得称赞的细节。
不同于 ChatGPT,Arc Search 是建立在传统搜索方式的基础上,让 AI 浏览搜索结果页上的 6 个「最佳」结果,再利用生成式 AI 的技术优势针对问题进行总结、归纳。
Arc Search 的巧妙之处
- AI 生成回答前,先通过传统搜索引擎进行了一层「过滤」,筛选出内容质量较高的相关网页,再基于这些内容生成答案,可以在一定程度上降低大模型「幻觉」带来的影响,在回答质量、准确性上也更多一些保证。
虽然 The Browser Company 没有明确指出 Arc Search 背后调用的大模型,但按照 Arc Browser 的相关报道,Arc Search 应该也是通过 API 调用了包括 GPT-4 在内的混合模型。
技术实现
概要
【2025-6-22】利物浦大学、华为诺亚方舟和牛津大学等联合发布 Deep Research Agents 系统性综述。
Deep Research 最全面的技术路线与案例
- 1️⃣搜索引擎:API vs 浏览器
- 2️⃣调用工具:代码解释器、数据分析、多模态处理
- 3️⃣架构与工作流:
- 1)静态工作流 vs 动态工作流
- 2)规划策略:Planning-Only、Intent-to-Planning、Unified Intent-Planning
- 3)单代理 vs 多代理:Kimi是端到端单代理,Manus是典型多代理
- 4)长上下文记忆:扩展上下文窗口长度;压缩中间步骤;利用外部结构化存储用于临时结果(比如向量数据库)
- 4️⃣参数调优:SFT vs 强化学习
- 5️⃣非参数化持续学习
【2025-2-2】Deep Research
参考
- 【2025-2-2】Introducing deep research
- 【2025-2-23】OpenAI Deep Research是什么?如何使用?你想知道的都在这儿!
Deep Research 是 OpenAI集成于ChatGPT中的一项全新功能,其独特之处在于能够自主进行网络信息检索、整合多源信息、深度分析数据,并最终提供全面深入的解答。
Deep Research 的推出,标志着OpenAI在智能体上取得了重要进展。
功能
该功能具备自适应学习、持续进化和动态调整的能力。可处理和分析来自网络的各类信息,包括文本、图像、PDF 文档等,其工作模式与人类研究人员高度相似。
在 Humanity’s Last Exam 和 GAIA 两项权威基准测试中,Deep Research的表现均显著优于同类竞争产品和以往的AI模型。
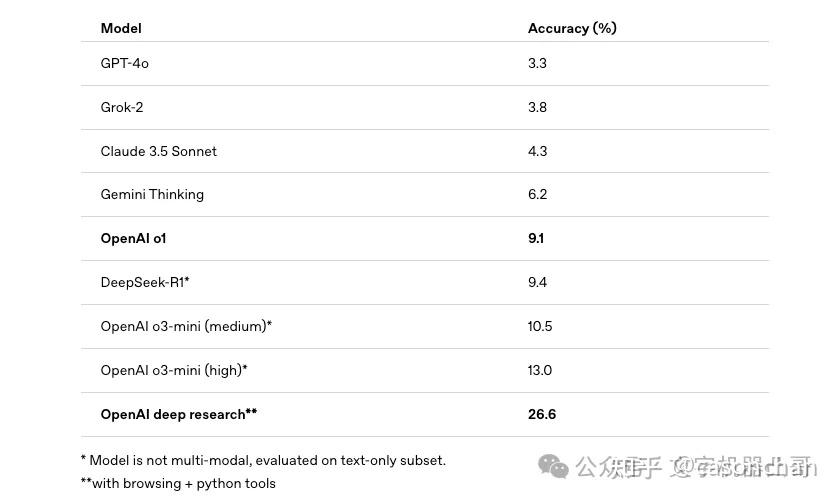
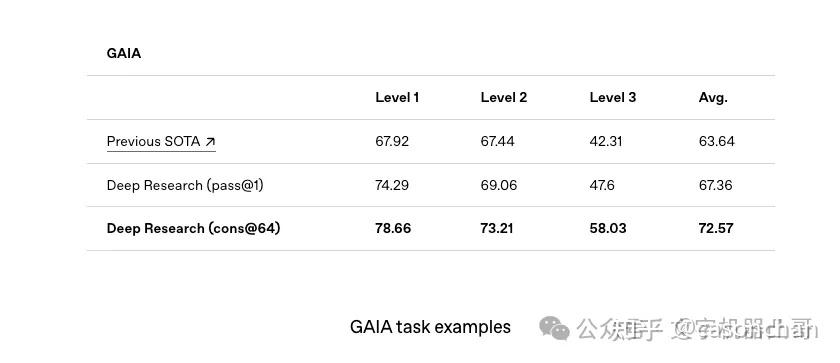
对于搞金融、科研、政策、工程的专业人士来说,Deep Research可能会彻底改变他们的工作方式,帮他们省下大量上网查资料的时间。
Deep Research 虽然很厉害,但离真正的通用人工智能(AGI)还差得远。只是一个辅助工具,不能代替人类研究员。AI还有很长的路要走。
原理
Deep Research 工作机制
- 把一个复杂任务拆成小块,然后一步步解决,与人类研究人员的思路高度一致。
接收到任务指令后,Deep Research
- 首先进行任务理解和步骤规划
- 随后从多个在线信息源检索相关资料,整合不同来源的信息片段
- 最终基于分析结果生成研究报告。
Deep Research 跟 ChatGPT 普通功能最大的区别:能自己干活。
它会投入时间深入探索多个信息源,以构建全面深入的答案。对于那些需要深入理解和分析的复杂问题,Deep Research要好用很多。
问题
问题:
- • 信息准确性: 有时信息不对,对于做研究来说其实挺关键的。
- • 信息可靠性甄别: 区分可靠信息与不可靠信息方面存在一定困难。
- • 不确定性表达: 确表达不确定性的情况下,可能无法准确传达。说人话就是明明它不确定,却不说出来。
- • 报告与引文格式: 生成的报告和引文在格式上可能存在瑕疵。
- • 可用性限制: 目前仅对ChatGPT Pro用户开放,且一个月限100次。
- • 计算资源需求: 由于其复杂的运算机制,Deep Research对计算资源的需求较高,速度可能比普通ChatGPT很多。
开源复现
总结
- Hugging Face 的 Open Deep Research
- Jina AI 的 DeepResearch
- OpenDeepResearcher
- open-deep-research
- deep-research
GAIA基准测试上
- Open Deep Research 的准确率为55%,虽然比原版 Deep Research 67%低,但仍是提供的解决方案中性能最好的。
Open Deep Research
openai research 发布后, 仅24h, huggingface 就完成了复现
Open Deep Research 是一个 AI 驱动的研究助手,通过搜索引擎、网络爬虫和大语言模型进行迭代式深度研究。提供简单的深度研究代理实现,保持代码量小于 500 行以便理解和拓展。
特色包括:
- 迭代研究、智能查询生成、深度广度可控、智能跟进、生成综合报告及并发处理。
主要功能
- 迭代研究:通过迭代生成搜索查询、处理结果,并根据发现的内容进行更深入的研究。
- 智能查询生成:使用大型语言模型(LLMs)根据研究目标和先前的发现生成有针对性的搜索查询。
- 深度和广度控制:可配置的参数,用于控制研究的广度和深度。
- 智能跟进:生成后续问题,以更好地理解研究需求。
- 综合报告:生成详细的 Markdown 报告,包含研究发现和来源。
- 并发处理:并行处理多个搜索和结果,提高效率。
原理
- 输入:用户输入查询内容、广度参数和深度参数。
- 深度研究:根据输入进行深度研究,生成 SERP(搜索引擎结果页面)查询。
- 处理结果:对查询结果进行处理,提取学习内容和研究方向。
- 决策判断:根据深度参数判断是否继续深入研究。如果深度大于 0,则生成新的研究方向并继续研究;否则,生成 Markdown 报告作为最终输出。
流程图
flowchart TB
subgraph Input
Q[User Query]
B[Breadth Parameter]
D[Depth Parameter]
end
DR[Deep Research] -->
SQ[SERP Queries] -->
PR[Process Results]
subgraph Results[Results]
direction TB
NL((Learnings))
ND((Directions))
end
PR --> NL
PR --> ND
DP{depth > 0?}
RD["Next Direction:
- Prior Goals
- New Questions
- Learnings"]
MR[Markdown Report]
%% Main Flow
Q & B & D --> DR
%% Results to Decision
NL & ND --> DP
%% Circular Flow
DP -->|Yes| RD
RD -->|New Context| DR
%% Final Output
DP -->|No| MR
%% Styling
classDef input fill:#7bed9f,stroke:#2ed573,color:black
classDef process fill:#70a1ff,stroke:#1e90ff,color:black
classDef recursive fill:#ffa502,stroke:#ff7f50,color:black
classDef output fill:#ff4757,stroke:#ff6b81,color:black
classDef results fill:#a8e6cf,stroke:#3b7a57,color:black
class Q,B,D input
class DR,SQ,PR process
class DP,RD recursive
class MR output
class NL,ND results
使用
- Node.js 环境及相关 API 密钥,运行后按提示操作,最终生成 markdown 报告。
Jina AI 的 DeepResearch
Jina AI 的 DeepResearch
- GitHub开源地址:node-DeepResearch
- 体验地址:search
方案采用 Node.js架构,可以通过循环执行搜索、阅读和推理,帮助用户快速找到所需信息。
与 OpenAI 和 Gemini 的 Deep Research 功能不同
- Jina DeepResearch 专注于通过迭代搜索提供精准答案,主要是针对深度网络搜索的快速、精准答案进行优化,而非生成长篇内容(更像perplexity的深度研究功能)。
OpenDeepResearcher
HyperWriteAI CEO 在推特上分享的开源方案—— OpenDeepResearcher。
- 开源地址: OpenDeepResearcher
用户只需提供一个主题,AI 就会进行网络搜索、查看页面、提取信息,并生成详细报告。如果需要更深入的研究,可以重复执行搜索过程。
该工具采用异步处理,速度快,比较适合需要快速获取研究结果的场景。
open-deep-research
- 开源地址:open-deep-research
对OpenAI的 Deep Research 的实验性克隆,但使用 Firecrawl 而不是o3模型的微调版本。
通过Firecrawl的数据提取+搜索结合推理模型进行网络深度研究。
这个项目最大的创新: 没有使用预先训练的模型,而是采用了一个完全不同的思路。
deep-research
这几个开源方案中最受欢迎。
基于OpenAI 的 Deep Research 概念,与openAI低,中,高的深度研究档次类似,使用简单的架构,允许用户调整研究广度(breadth)和深度(depth),运行时间可从 5 分钟到 5 小时自动调整。它可以并行运行多个研究线程,并根据新发现不断迭代,直到达到你的研究目标。
案例
Manus
【2025-3-5】 Monica.im 研发的全球首款 AI Agent 产品「Manus」
- Manus,名字取自拉丁语中的“手”,寓意着将思想转化为行动。
- Manus 不仅仅是一个 AI,更是一个能帮你完成实际任务的通用型 Agent。无论是工作还是生活,Manus 都能成为你的得力助手
- GAIA 基准测试中取得了 SOTA(State-of-the-Art),远远甩开了 OpenAI。在解决现实世界问题方面表现卓越。
详见站内专题: Agent应用
Gemini Deep Research
Gemini Deep Research 是一款AI研究助理。
将复杂问题拆解,自动浏览海量网站,分析信息并生成详尽报告。
特点包括:
- 自主规划、深度搜索、智能推理、快速生成多页报告。
DeerFlow
【2025-5-9】字节开源全新的 Deep Research 项目 —— DeerFlow
DeerFlow(Deep Exploration and Efficient Research Flow)是社区驱动的深度研究框架,建立在开源社区的杰出工作基础之上。
目标
- 将语言模型与专业工具(如网络搜索、爬虫和Python代码执行)相结合,同时回馈使这一切成为可能的社区。
DeerFlow 是一个基于 LangChain 全家桶的开源 Multi-Agent 应用
- 支持动态任务迭代、MCP 无缝集成、Meta Prompt 自动生成、Human-in-the-loop 协作,以及播客和PPT内容生成。
- DeerFlow 仓库:deer-flow
- DeerFlow 官网:deerflow
- DeerFlow 解读:
- 【2025-5-12】字节跳动重磅开源DeerFlow:对标Gemini Deep Research,AI深度研究框架来了
- 源码分析: 【2025-5-25】字节开源Deerflow项目体验与分析
核心特性
特性
- 高效多智能体架构
- 创新的 “Research Team” 机制支持高效的多轮对话、决策与任务执行。
- 相比传统方法,显著降低Token消耗和API调用,并通过动态任务重规划(Re-planning)灵活应对复杂场景。
- 基于LangStack,易学易用
- 构建于 LangChain 和 LangGraph 之上,代码结构清晰简洁,学习门槛低。
- MCP无缝集成
- 作为 MCP Host(类似Cursor、Claude Desktop),可轻松通过MCP扩展私域搜索、内部知识库访问、设备控制(Computer/Phone/Browser Use)等高级功能。
- AI赋能 Prompt工程
- 采用Meta Prompt模式,让大模型(基于OpenAI官方Meta Prompt)自动生成高质量Prompt,大幅降低Prompt工程难度和门槛。
- 人机协作优化
- 支持通过自然语言实时修改和优化AI生成的计划与报告。
- 用户可轻松调整细节、补充信息或重定义方向,确保最终结果符合预期。
- 多媒体内容生成
- 支持从报告一键生成双人主持播客(集成火山引擎语音技术,音色自然丰富)及多种形式的PPT(包括图文和纯文字版)。
架构
DeerFlow 实现了模块化的多智能体系统架构,专为自动化研究和代码分析而设计。
该系统基于 LangGraph 构建,实现了灵活的基于状态的工作流,其中组件通过定义良好的消息传递系统进行通信。
架构图
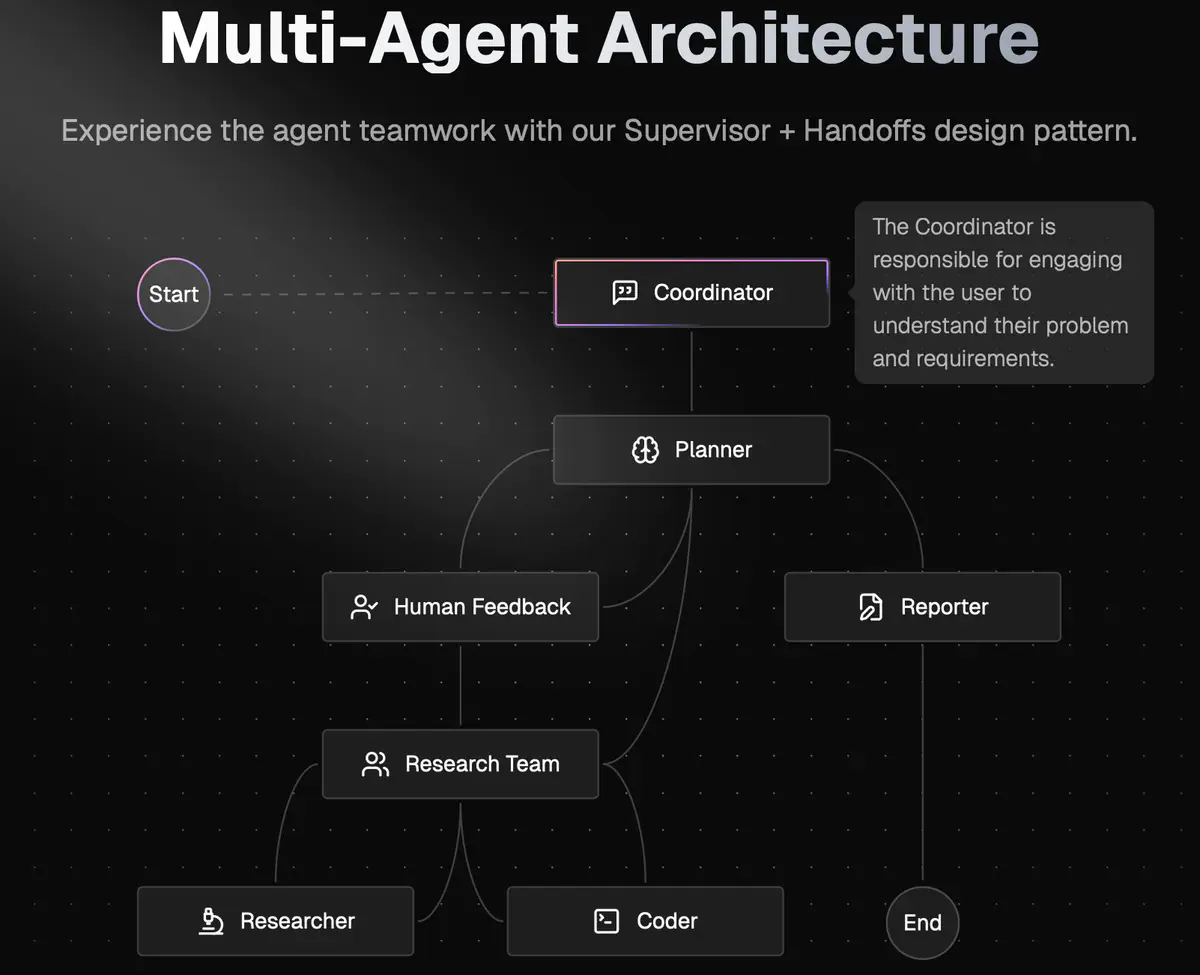
多Agent工作流(核心亮点)
过 src/graph/builder.py 构建 StateGraph,定义了如下节点:
coordinator(协调者):与用户交互,决定是否需要规划。background_investigator(背景调查):调用搜索工具进行信息检索。planner(规划者):生成任务计划。human_feedback(人工反馈):支持用户对计划的中断、编辑、接受。research_team(研究团队):分发任务给 researcher/coder。researcher(研究员):负责信息检索、资料收集。coder(程序员):负责代码实现、数据处理。reporter(报告员):撰写最终报告。
模块分析
src/
- agents/: 智能代理模块
- llms/: 大语言模型相关实现
- tools/: 工具集
- crawler/: 爬虫模块
- utils/: 通用工具函数
- prompts/: 提示词模板
- graph/: 图相关功能
- config/: 配置文件
- server/: 服务器相关代码
- podcast/: 播客相关功能
- prose/: 文本处理相关
- ppt/: PPT 相关功能
安装
# 克隆仓库
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
# 安装依赖,uv将负责Python解释器和虚拟环境的创建,并安装所需的包
uv sync
# 使用您的API密钥配置.env
# Tavily: [https://app.tavily.com/home](https://app.tavily.com/home)
# Brave_SEARCH: [https://brave.com/search/api/](https://brave.com/search/api/)
# 火山引擎TTS: 如果您有TTS凭证,请添加
cp .env.example .env
# 查看下方的"支持的搜索引擎"和"文本转语音集成"部分了解所有可用选项
# 为您的LLM模型和API密钥配置conf.yaml
# 请参阅'docs/configuration_guide.md'获取更多详情
cp conf.yaml.example conf.yaml
# 安装marp用于PPT生成
# [https://github.com/marp-team/marp-cli?tab=readme-ov-file#use-package-manager](https://github.com/marp-team/marp-cli?tab=readme-ov-file#use-package-manager)
brew install marp-cli
启动服务
# 控制台UI 运行项目的最快方法是使用控制台UI。
# 在类bash的shell中运行项目
uv run main.py
# Web UI 本项目还包括一个Web UI,提供更加动态和引人入胜的交互体验。
# 注意: 您需要先安装Web UI的依赖。
npm install -g pnpm
npm install next
# 在开发模式下同时运行后端和前端服务器
# 在macOS/Linux上
./bootstrap.sh -d
# 在Windows上
bootstrap.bat -d
浏览器输 localhost:3000 进行访问
【2025-5-27】win 11 实测通过
- 地址: http://localhost:3000/chat
- 注意: 不是 8000 !
分析
DeerFlow 适合场景
- 需要查找大量资料的复杂任务,比如产业研究报告、学术文献梳理和分析等。
缺点
- token 消耗巨大,比如跑两个任务,就消耗了十万token。
【2025-1-14】WebWalker
目前的 RAG 多为“水平检索”,仅通过搜索关键词查找页面,没有深入到网页内部的层级结构获取复杂信息。
阿里通义实验室提出测评集和方法来评估网页浏览多步推理能力。
数据构建
- 首先搜集一些会议、组织、教育、游戏领域的官网(可以理解为首页,可以点到很多页面上)
- 然后根据网页上的链接一直点到二级网页、三级网页、四级网页。(学校官网->学院网页->计算机系主页->某个教师主页)
- 然后把这些网页组合成多源(需要阅读多个页面信息,可以是不同级网页)和单源(只需要阅读一个页面信息,可以任一级别网页),用 gpt-4o 去生成一些初始的 QA 对
- 人工标注问题与答案,可以重写问题与答案,确保前后一致
框架
包括两个智能体:
- Explorer Agent
- 基于页面 HTML 信息(Markdown 格式 + 可点击按钮);
- 每步选择一个子链接点击;
- 最多可执行 15 步操作;
- 与环境互动后产出“观察”。
- Critic Agent
- 接收 Explorer 每步的信息;
- 判断是否获得足够信息回答问题;
- 若是,则输出答案;否则继续遍历。
【2025-10-22】OneSearch
快手 OneSearch 端到端生成式检索框架,解决传统电商搜索系统(多阶段级联架构,MCA)固有局限性。
该框架通过将分散召回、预排序和排序流程统一为一个生成模型,克服传统MCA中存在的计算碎片化和目标冲突等问题。
核心技术
- 关键词增强的分层量化编码 模块,用于精确地表征商品的关键属性
- 多视图用户行为序列注入 策略,以建模用户的短期和长期偏好。
- 此外,模型还采用了 偏好感知奖励系统,通过多阶段监督微调和自适应奖励机制来增强个性化排序能力。
经过快手电商平台的离线和在线测试,OneSearch不仅在点击率、转化率和订单量等关键业务指标上实现了 显著提升,还极大地降低了运营成本。
该成果标志着业界 首个工业落地的端到端生成式搜索框架 的成功部署。
新技术
r1-reasoning-rag
【2025-4-28】r1-reasoning-rag:一种新的 RAG 思路
将 DeepSeek-R1 推理能力结合 Agentic Workflow 应用于 RAG 检索。
- 代码 【2025-2-5】r1-reasoning-rag
RAG 问题
RAG 处理完搜索后,通过相似性搜索找到一些内容,再按匹配度重新排个序,选出相关的信息片段给到大型语言模型(LLM)去生成答案。
问题
- 尤其依赖重排序模型的质量
- 模型差,就容易漏掉重要信息或者把错的东西传给 LLM,结果出来的答案就不靠谱了。
原理
LangGraph 团队对这个过程做了大升级,用上了 DeepSeek-R1 的强大推理能力,把以前那种固定不动的筛选方式变成了一个更灵活、能根据情况调整的动态过程,即“代理检索”
- 这种方式让 AI 不仅能主动发现缺少的信息,还能在找资料的过程中不断优化自己的策略,形成一种循环优化的效果,这样交给 LLM 的内容就更加准确了。
结合 DeepSeek-R1、Tavily (即时资讯搜索) 和 LangGraph,实现由 AI 主导的动态信息检索与回答机制,利用 deepseek 的 r1 推理来主动地从知识库中检索、丢弃和综合信息,以完整回答一个复杂问题
原理
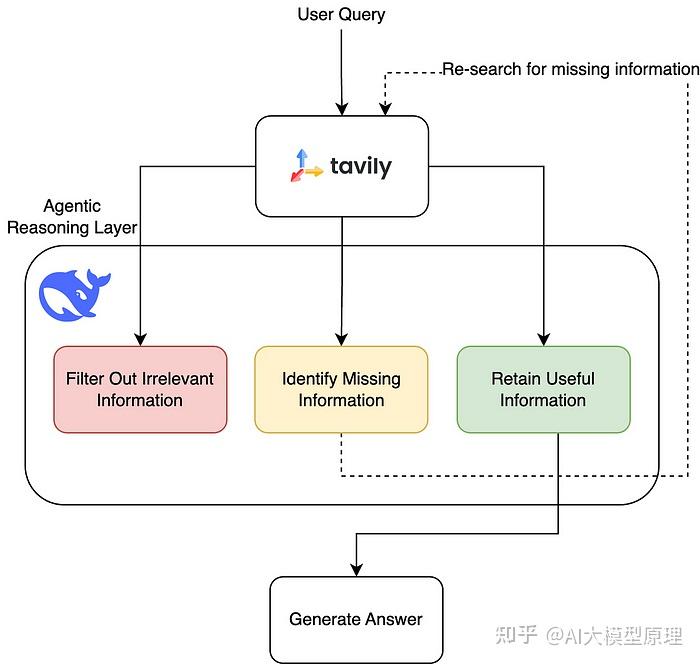
R1 工作
- 深度思考分析资讯内容
- 对现有内容进行评估
- 通过多轮推理辨别缺失的内容,以提高检索结果的准确性
LangGraph 递归检索(Recursive Retrieval)
透过 Agentic AI 机制,让大模型在多轮检索与推理后形成闭环学习
大致流程如下:
- 第一步检索问题相关的资讯
- 第二步分析资讯内容是否足够以回答问题
- 第三步如果资讯不足,则进行进一步查询
- 第四步过滤不相关的内容,只保留有效的资讯
这样的 递归式 检索机制,确保大模型能够不断优化查询结果,使得过滤后的资讯更加完整与准确
【2025-8-27】Atom-Searcher
【2025-8-27】 Agentic Deep Research新范式,推理能力再突破,可信度增加,蚂蚁安全团队出品
LLM在复杂任务上的表现仍受限于静态内部知识。
Agentic Deep Research
为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出 Agentic Deep Research 系统
- 基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
OpenAI 和 Google 总结了 Agentic Deep Researcher 的几大优势:
- (1)深入的问题理解能力(Comprehensive Understanding):能够处理复杂、多跳的用户提问;
- (2)强大的信息整合能力(Enhanced Synthesis):能够将广泛甚至冲突的信息源整合为合理的输出;
- (3)减轻用户的认知负担(Reduced User Effort):整个 research 过程完全自主,不需要用户的过多干预。
Agentic Deep Research 问题
现存最先进的 Agentic Deep Research 系统往往基于由可验证结果奖励指导的强化学习训练,尽管该训练范式带来了显著的性能收益,但仍存在以下核心问题:
- 梯度冲突(Gradients Conflicts):在基于可验证结果奖励的强化学习范式中,即使中间的推理过程或研究策略是有效的,只要最终答案错误,整个推理轨迹都会受到惩罚。这种粗粒度的奖励设计在中间推理步骤与最终答案之间引入了潜在的梯度冲突,阻碍了模型发现更优的推理能力和研究策略,从而限制了其泛化能力
- 奖励稀疏(Reward sparsity):基于结果的强化学习仅依赖最终答案生成奖励,导致每个训练样本只能提供稀疏的反馈信号。这严重限制了策略优化的效率,因为它增加了对更大规模训练数据和更长训练周期的依赖。
Atom-Searcher
以上两个限制限制了 Agentic Deep Research 系统的性能上线,为决解这两大限制,蚂蚁安全与智能实验室团队提出 Atom-Searcher,进一步推动了 Agentic Deep Research 系统的性能边界。
- 论文标题:Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward
- Github: Research-Venus
- Huggingface: Atom-Searcher
Atom-Searcher 结合监督微调(SFT)与基于细粒度奖励的强化学习构建强大的 Agentic Deep Research 系统。
与现存 Agentic Deep Research 训练框架相比
- Atom-Searcher 创新地提出了 Atomic Thought 推理范式,引导 LLM 进行更加深入、可信和可解释的推理
- 然后引入 Reasoning Reward Model(RRM)对 Atomic Thought 式的推理过程进行监督,构建细粒度的 Atomic Thought Reward(ATR);
- 进而提出一种课程学习启发的奖励融合策略将 ATR 与可验证结果奖励进行聚合;最后基于聚合奖励进行强化学习训练。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
