- LLM 智能体
- 结束
LLM 智能体
资讯
- 飞书文档: Agent 技术文章集合
- Agent 原理介绍与应用发展思考
- 【2023-9-22】米哈游发布了一篇人工智能代理调查论文
- 【2024-10-13】拾象科技:AI Agent的千亿美金问题:如何重构10亿知识工作职业,掀起软件生产革命?
- 【2023-10-24】Agent论文合集:RL-based、LLM-based 前沿研究汇总, 知乎, GitHub Awesome-Papers-Autonomous-Agent
- 【2023-10-20】从第一性原理看大模型Agent技术
- 技术脉络: Model -> Prompt工程 -> Prompt Chain或Flow -> Agent -> 多Agent
- 【2025-3-17】Maarten Grootendorst A Visual Guide to LLM Agents
- 【2025-6-4】北京大学:AI Agent与Agentic AI原理和应用洞察 ppt 截图
【2024-12-16】微软 CEO 的大胆预言:“AI Agent将替代所有SaaS”
- 原视频地址:Youtube
微软CEO萨提亚·纳德拉宣布应用程序时代的终结,软件开发迎来新方向
- 商业应用程序的概念可能会在智能代理时代消失。
- 应用程序正在消失,取而代之的是智能代理。
- 不再有应用程序,也就不再有SaaS(软件即服务), 需要的开发人员会大幅减少。
SaaS的本质只是数据库之上的一层用户界面和业务逻辑
观点
- ai agent 不是技术壁垒,行业数据,用户习惯才是
HCI
- 【2024-10-28】斯坦福李飞飞最新巨著🔥《AGENT AI》
- 《AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION》深入探讨了多模态人机交互(Human-Computer Interaction, HCI)的发展状态和未来研究方向。
- 多模态HCI旨在通过语音、图像、文本、眼动和触觉等多种信息模式来实现人与计算机之间的信息交换,这种交互方式在生理心理评估、办公教育、军事仿真和医疗康复等领域具有广泛的应用前景。
多模态HCI未来的研究方向,包括拓展新的交互方式、设计高效的多模态交互组合、构建小型化交互设备、跨设备分布式交互以及提升开放环境下交互算法的鲁棒性。:
[一]大数据可视化交互:随着物联网和人工智能技术的发展,人机交互设备已经广泛应用于日常生活中。大数据可视化交互技术通过将抽象数据转换为图形化表征,使用户能够更直观地理解和探索数据。研究者们正在探索如何利用多感知通道来增强数据可视化的交互体验,例如通过触觉和听觉来补充视觉信息,提升用户的沉浸感和参与感。[二]基于声场感知的交互:这种交互方式涉及到使用麦克风阵列和机器学习算法来识别特定场景、环境或人体发出的声音。它允许用户通过声音与计算机进行交互,提供了一种非视觉的交互手段。[三]混合现实实物交互:混合现实技术结合了物理世界和虚拟世界,使用户能够通过现实世界中的物体与虚拟环境进行交互。这种交互方式在虚拟现实和增强现实中变得越来越重要,它允许用户以更自然的方式与虚拟对象进行互动。[四]可穿戴交互:随着智能手表和健康监测设备的普及,可穿戴设备成为了HCI的一个新的研究方向。研究者们正在探索如何通过手势、触摸和皮肤电子技术来实现更自然的交互方式。[五]人机对话交互:人机对话交互涉及到语音识别、情感识别、对话系统和语音合成等多个模块。研究者们致力于提高对话系统的性能,使其能够更自然地理解和响应用户的语音输入。
论文综述
资料
- 【2023-11】论文 Igniting Language Intelligence: The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents 从 CoT 到 Agent
- 【2025-8-9】Agent 论文汇总 LLM-Agent-Papers
- A Survey on Large Language Model based Autonomous Agents
- 基于 LLMs 的人工智能代理在社会科学、自然科学和工程学领域的各种应用,以及基于 LLMs 的自主代理常用的评估策略,面临的若干挑战和未来发展方向等
- 论文:ProAgent: Building Proactive Cooperative AI with Large Language Models
- 【ProAgent:利用大型语言模型构建主动式合作AI】
- 构建具有自适应行为的人工智能是 AGI 研究的一个关键重点。目前开发合作代理主要依赖于基于学习的方法,策略泛化在很大程度上取决于过去与特定队友的互动。这些方法限制了代理在面对新队友时重新调整策略的能力。
- 该研究提出了 ProAgent 框架,利用大型语言模型(LLMs)能够预测队友即将做出的决定,并为自己制定增强型计划。擅长合作推理,能够动态调整自己的行为。
- 此外,ProAgent 框架还具有高度的模块化和可解释性,便于无缝集成,以应对各种协调场景。
- 在与人类代理模型合作时,与目前最先进的 COLE 相比,ProAgent 的性能平均提高了 10% 以上。
- 论文:Building Emotional Support Chatbots in the Era of LLMs
- 【在大型语言模型时代,打造情感支持聊天机器人】
- 将情感支持融入各种对话场景会带来深远的社会效益,如社交互动、心理健康咨询和客户服务。然而,数据可用性有限、缺乏公认的模型训练范例等一些尚未解决的难题阻碍了这一领域的实际应用。
- 该研究介绍了一种新方法,该方法综合了人类的洞察力和大型语言模型(LLM)的计算能力,进而策划了一个广泛的情感支持对话数据集——ExTES。该方法以精心设计的、跨越不同场景的对话集作为生成种子。通过利用 ChatGPT 的上下文学习潜力,我们递归生成了一个 ExTensible 情感支持对话数据集,命名为 ExTES。 对所生成模型的详尽评估证明了该模型在提供情感支持方面的能力,标志着情感支持机器人领域迈出了关键的一步。
- 论文:Self-Deception: Reverse Penetrating the Semantic Firewall of Large Language Models
- 【自我欺骗:反向穿透大型语言模型的语义防火墙】
- 以 ChatGPT 为代表的大型语言模型(LLMs)在为各种社会需求提供便利的同时,还降低了生成有害内容的成本。 尽管 LLMs 开发人员部署了语义层面的防御措施,但这些防御措施并非万无一失,一些攻击者通过制作“越狱”提示,使 LLMs 忘记内容防御规则,从而回答任何不当问题。迄今为止,业界和学术界都没有明确解释这些语义级攻击和防御背后的原理。 受通过反向隧道穿透传统防火墙的攻击的启发,该研究提出了一种“自我欺骗”攻击,通过诱导 LLMs 生成有利于越狱的提示来绕过语义防火墙。 他们在七个虚拟场景中用六种语言(英语、俄语、法语、西班牙语、中文和阿拉伯语)生成了共计 2520 个攻击,目标是三种最常见的违规类型:暴力、仇恨和色情。
- 结果显示,GPT-3.5-Turbo 和 GPT-4 两个模型的成功率分别为 86.2% 和 67%,失败率分别为 4.7% 和 2.2%,这凸显了拟议攻击方法的有效性。
论文介绍(机翻)
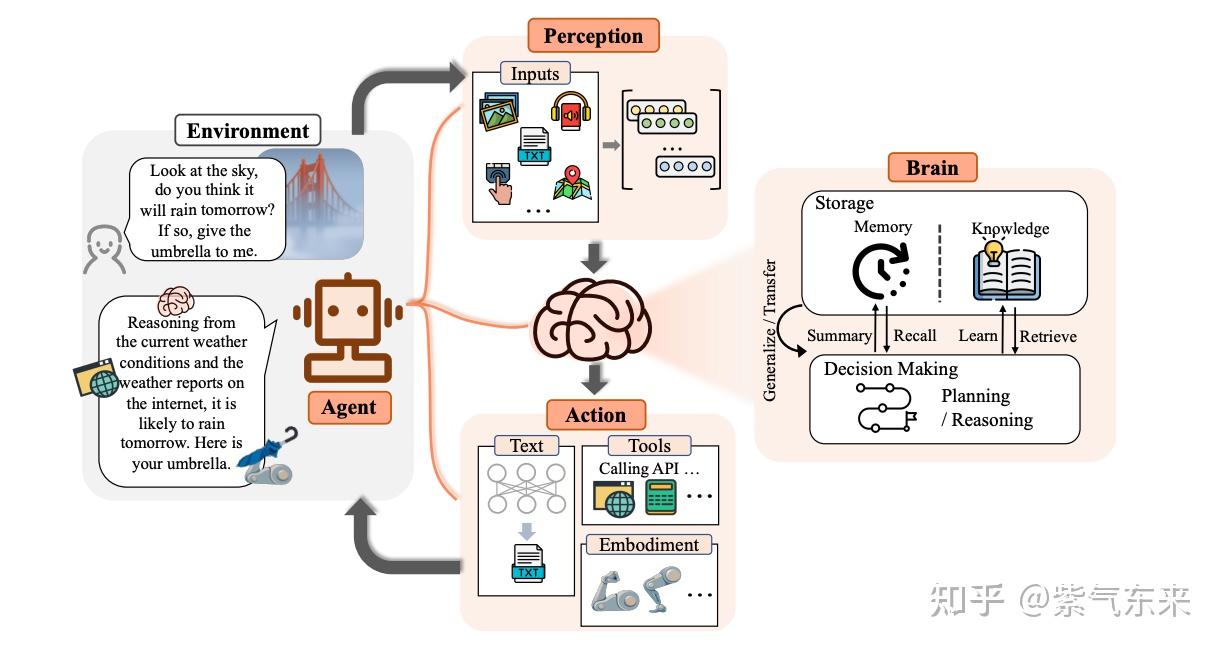
- 长期以来,人类一直追求与甚至超越人类水平的人工智能(AI),而AI代理被认为是这种追求的有前途的载体。AI代理是感知环境、做出决策并采取行动的人工实体。许多努力已经致力于发展智能代理,但它们主要关注算法或训练策略的进步,以增强特定能力或在特定任务上的表现。
-
事实上,社区缺乏的是一个通用且强大的模型,作为设计AI代理的起点,可以适应各种场景。由于它们展示的多功能能力,大型语言模型(LLM)被视为人工通用智能(AGI)的潜在火花,为构建一般化的AI代理提供了希望。许多研究人员已经利用LLM作为构建AI代理的基础,并取得了重大进展。在本文中,对基于LLM的代理进行全面调查。从其哲学起源到在AI中的发展追溯代理的概念,并解释了LLM为何是代理的合适基础。在此基础上,我们提出了一个基于LLM的代理的通用框架,包括三个主要组件:大脑、感知和行动,该框架可以根据不同的应用进行定制。随后,我们探讨了LLM代理在单一代理场景、多代理场景和人代理合作方面的广泛应用。在此基础上,我们深入了解代理社会,探讨基于LLM的代理的行为和个性、代理社会中出现的社会现象以及它们为人类社会提供的见解。
- 【2023-9-11】一文盘点「AI自主智能体」的构建、应用、评估
- 论文:A Survey on Large Language Model based Autonomous Agents
- 机构:中国人民大学-高瓴人工智能学院, GitHub地址:LLM-Agent-Survey
- 基于 LLM 的自主智能体一览,包括工具智能体、模拟智能体、通用智能体和领域智能体
- Construction of LLM-based Autonomous Agent


LLM
1981年, 希拉里·普特南在《理性,真理与历史》中提出“缸中之脑”假想:
科学家实施手术,别人脑切下来,放进充满营养液的缸中,营养液维持大脑正常运转。 大脑神经末梢连在电线上,电线另一边是计算机。 这台计算机模拟真实世界的参数,通过电线给大脑传送信息,让大脑保持一切正常的感觉。 对于大脑来说,似乎人、物体、天空还都存在。
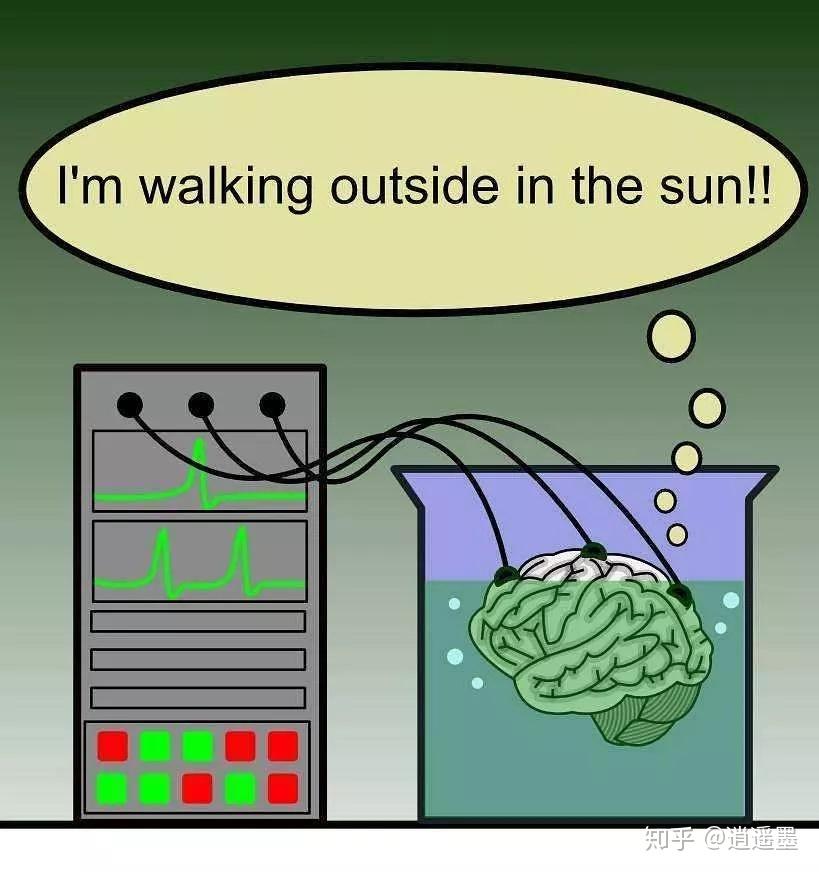
缸中之脑和头颅中的大脑接收一样的信号,而且传入神经和传出神经是和环境交流的唯一方式。
从大脑中角度,无法确定自己是颅中之脑还是缸中之脑。
缸中之脑动摇了“真实”的根基。从“耳听为虚,眼见为实”,到“眼见不一定为实”,到“感觉不一定为实”,到“所思不一定为实”。
思想实验用来论证一些哲学,如:知识论、怀疑论、唯我论和主观唯心主义。
有关这个假想的最基本的问题是:
- 什么是真实
- 如何证明自己不是在这种困境中
大模型是瓮中之脑,《黑客帝国》,《源代码》这类电影很关键的一个预设
假如把人脑放到一个充满营养液的罐子里,活下来,那这时候就有一个超级真实的虚幻世界,但却不再能干涉现实。
当前的LLM有一定智力并且拥有大量知识,但除了内容生成这类通用能力,在别的领域还不清楚它到底能干什么
人类日常要处理的任务场景
- 离散、孤立(环境无关): 无时空依赖
- 如:编程、下围棋、内容生成
- 连续、与环境捆绑: 环境相关
- 如:外卖、打车、经营企业
瓮中之脑只能解决前者,而绝大多数场景都是后者,解决的关键在于AI Agent
所以,AI Agent是大模型与场景间价值传递桥梁
业界认为基于大模型的应用集中在两个方向上:RAG 和 Agent,无论哪一种应用,设计、实现和优化能够充分利用大模型(LLM)潜力的应用都需要大量的努力和专业知识。
【2025-11-3】Agent能力水平分级
- 解读:RL环境与智能体能力的层级结构,知乎
- 原文 RL Environments and the Hierarchy of Agentic Capabilities
汉化版
Agent vs LLM
这类项目绝大多数的主要创新还是在 prompt 层面,通过更好的提示词来激发模型的能力,把更多原先需要通过代码来实现的流程“硬逻辑”转化为模型自动生成的“动态逻辑”。
目前语言模型只能响应用户的查询指令,实现一些生成任务,比如写故事、生成代码等。而以 AutoGPT, GPT-Engineer和BabyAGI等项目为代表的大型动作模型(Large-Action Models,LAM)将语言模型作为智能体的核心大脑,将复杂任务分解,并在每个子步骤实现自主决策,无需用户参与即可解决问题。
LAM的崛起,也标志着语言模型的研发正在走向新阶段
Agent vs Workflow
AI Agent与 AI Workflow 区别:
- AI Workflow(工作流): 一系列预先定义的大模型调用步骤,像在“轨道上”运行,步骤固定,可预测。每一步骤都有明确的输入和输出
- AI Agent(智能体):AI Agent 更加自主,由大模型自行决定执行多少步骤, 直到问题得到解决。AI Agent会持续循环,例如与客户沟通或迭代代码修改, 步骤数量不固定
Agent vs Tool
| 对比维度 | 传统AI工具 | AI Agent |
|---|---|---|
| 任务触发 | 人类指令触发(如Siri问答) | 环境感知自主启动(如特斯拉FSD预判刹车) |
| 决策机制 | 规则驱动(if-else逻辑树) | 目标驱动(LLM生成动态策略树) |
| 交互模式 | 单次请求-响应 | 长期记忆支持的连续对话与协作 |
| 能力边界 | 限定场景封闭系统 | 跨领域经验迁移(如医疗Agent转金融风控) |
Agent → AGI
【2023-7-24】最近都不卷大模型了,开始卷 AI Agents
- LLM诞生之初,大家对于其能力的边界还没有清晰的认知,以为有了LLM就可以直通AGI了,路线: LLM -> AGI
- 过了一段时间,发现LLM的既有问题(幻觉问题、容量限制…),导致并不能直接到达AGI,于是路线变成了: LLM -> Agent -> AGI
- 借助一个或者多个Agent,构建一个新的形态,来继续实现通往AGI的道路。但这条路是否能走通,以及还面临着哪些问题,都是有待进一步验证的。
由于大模型的出现,AI Agents 衍生出了一种新的架构形式: 《LLM Powered Autonomous Agents》
- 将最重要的「任务规划」部分完全交由LLM,而做出这一设计的依据在于默认LLM具有任务分解和反思的能力。
Agent
AI Agent是大模型与场景间价值传递桥梁。
- AI Agent 被认为是 OpenAI 发力的下一个方向
OpenAI 联合创始人 Andrej Karpathy 提到:
“相比模型训练方法,OpenAI 内部目前更关注 Agent 领域的变化,每当有新的 AI Agents 论文出来的时候,内部都会很兴奋并且认真地讨论”
而在更早之前,Andrej 还评价 AutoGPT 是 Prompt Engineering 下一阶段的探索方向。
AI agent 为什么重要?
原因
- AI Agent 将使软件行业降低生产成本、提高定制化能力,进入软件的“3D 打印”时代
Software 2.0意味着我们可以用大量的数据和算力来解决以前需要大量人力和成本来解决的复杂问题。- ak47: AI agent 正是
Software 2.0的具象化
- LLM 扮演人类思考的系统 1(
快思考),AI Agent 扮演人类思考的系统 2(慢思考)- LLM 反应快,但会出现
幻觉(hallucination)问题,很像人类的系统 1 中常见的思维谬误和本能反应 - AI agent 长期目标则是使 LLM 胜任系统2的工作,为 LLM 搭建一套框架来进行深度思考和分析,从而做出更复杂和可靠的决策。
- LLM 反应快,但会出现
- 推荐系统让每个人看到个性化的信息, AI Agent 将让每个人有个性化的工作方式,为每一个知识工作者提供 AI 合作伙伴和工作分身
参考
- 【2024-10-13】拾象科技:AI Agent的千亿美金问题:如何重构10亿知识工作职业,掀起软件生产革命?
Agent 定义
Agent 起源于拉丁语中的Agere,意思是“to do”。
Agent 可以追溯到明斯基的《society of mind》一书。
- 明斯基对Agent的定义有点抽象:“社会中某个个体经过协商后可求得问题的解,这个个体就是agent”。
能够感知并对其环境采取行动的实体。 -・Strong notion: 拥有欲望、信念、意图以及行动能力的实体
Agent Definition:
- • Weak notion: Agent is an entity that can perceive and act upon their environment.
- • Strong notion: Entities that possess desires, beliefs, intentions, and the ability to act.
Agent 是
- 简版: 能够感知环境,并采取行动的实体
- 强版: 拥有目标、信念、意图以及行动能力的实体
计算机领域,Agent是一种通过传感器感知其环境,并通过执行器作用于该环境的实体,因此,可以把实体定义为一种从感知序列到实体动作的映射。
- Agent 指驻留在某一环境下,能持续自主地发挥作用,具备自主性、反应性、社会性、主动性等特征的计算实体。
智能 是Agent 与环境相互作用的涌现属性。
Agent 特点
Agent 核心能力是完成任务(achieve goals)、获取知识(acquiring knowledge)和进化(improve)
AI agent 是有能力主动思考和行动的智能体。
- 提需求时,agent 有能力自行感知环境、形成记忆、规划和决策行动,甚至与别的 agent 合作实现任务。
- 而 LLM 被动推理引擎,用户每 prompt 点拨一次才会回复一次。
智能体(Agent)四个特性
- Autonomy(自主性):智能体无需人类或其他主体干预即可运行,且对自身行动和内部状态有一定控制能力 。
- Social Ability(社交能力):智能体可通过特定语言,与其他智能体(可能还包括人类)进行交互 。
- Reactivity(反应性):智能体能感知所处环境,并对环境中发生的变化及时做出响应 。
- Pro-activeness(主动性):智能体不只是对环境做出反应,还能主动采取行动,展现出目标导向的行为 。
“Agentic”(智能体特性)并非二元对立,而是一个连续体(频谱)。
参考
- 加拿大麦吉尔大学 Keheliya Gallaba (华为任职) 演讲ppt Agentic architectures and workflows
LLM-based Agent 组件和定义还有模糊的地方,三种理解方式:
- AI agent 是 AI-native software 开发方法,不是独立的商业赛道或产品形态。
- 未来的 AI-native 应用都会有 agent 思路,产品形态可能是 Copilot,也可能还未出现。这一框架下 LLM 是核心推理引擎,而 agent 是使 LLM 扬长避短、结构化思考的方法论。
- 优秀的 AI Agent 产品比传统软件更灵活,比 LLM 更可靠。
- 传统软件中有很多规则和启发式算法,带来了高可靠性、确定性,但也使其难以灵活解决长尾问题。优秀的 AI agent 应用需要充分发挥 LLM 推理 (reason)、扮演 (act) 和交互 (interact) 的能力。
- 短期内,这样的应用会牺牲一定软件的可靠性,因此 agent 应用的落地现状并不乐观。但是沿着当前的技术路径走下去,可以预期在长期达到与当前的传统软件接近的可靠性。
- Agent 和早期的 LLM-based 应用相比,显著差异点:
- • 合作机制 orchestration:存在多模型、多 agent 分工与交互的机制设计,能实现复杂的工作流。
- 例如编程场景下可能有 developer agents 和 quality assurance agents,类比开发团队里的工程师和测试;
- 产品战略场景下可能有 growth agents 和 monetization agents,类比公司中投放和商业化团队在用户规模和商业收入上的多目标博弈。 - • 与环境交互 grounding:
- Agent 能理解自己的不足,并适时从外部寻找合适的工具解决问题。人和动物的区别是人会使用工具,agent 框架能帮助 LLM 认识自己的能力边界,从外部环境中寻找合适的工具。 - • 个性化记忆 memory: 记忆用户偏好和工作习惯,使用越久越了解用户。
- 未来的 agent 作为人类的工作伙伴会接受大量文本和多模态信息,过程中积累的用户偏好和工作习惯会使产品成为知识工作者最信赖的伙伴。 - • 主动决策 decision: Agent 有能力在虚拟环境中探索、试错、迭代。
- 目前的 LLM 应用还缺少在环境中连续决策的能力,因为 next token prediction 落子无悔的预测形式和人类的思考方式是截然不同的:开发者在 coding 解题的时候,会对一系列假设方案进行实验总结出最优解,而不是在一开始就能够得到最优解。
四个特点的实现时间由短到长排序:
- • 短期: Orchestration 和 grounding 短期内值得重点探索,当下 LLM 能力还不够强,需要自己与外部环境交互找到合适的工具,并且由用户专家对 AI 的工作流进行设计和编排,使其成为靠谱的合作伙伴。如果当前的应用在这两个方向上没有足够深的编排和实践,不能称为是 AI agent 应用。
- • 中期: Memory 是需要重点强化的方向。随着人类与 AI agent 的信任加深之后,如何让人机协作带来新的数据飞轮是一个相当重要的问题。有了个性化记忆的生成模型,是 Gen AI 时代新形态的推荐引擎。
- • 长期: Decision 则是长期目标,也是需要 OpenAI、Anthropic 等大模型公司一起去解决的问题。目前的 next token prediction 模型和 chat-based UI,目标函数太简单很难让 agent 真正学会主动探索、试错,需要模型复杂推理能力和产品形态的双重进化。
参考
- 【2024-10-13】拾象科技:AI Agent的千亿美金问题:如何重构10亿知识工作职业,掀起软件生产革命?
Agent 环境
Agent 在不同环境里自主行动
环境类型
Digital Environments数字环境: 代码库、游戏、编程工具、项目管理、办公软件、通讯工具、桌面环境Physical Environments物理环境: 桌面、厨房、交通信号灯等场景Simulated Environments模拟环境: 具身环境, 如 ALFWorld,WebArena
Agents operate in Digital Environments
- • 代码库 Source Repositories: Github, Gitlab
- • 游戏 Games: Atari DQN, AlphaGo
- • 编程工具 IDEs: VSCode, Jetbrains
- • 项目管理 Task Management Software: Jira, Trello
- • 办公软件 Office Software: Google Docs, Microsoft Office
- • 通讯工具 Communication Tools: Gmail, Slack, Shortwave
- • 桌面环境 Or the whole desktop! e.g., Anthropic’s computer use
参考
- 加拿大麦吉尔大学 Keheliya Gallaba (华为任职) 演讲ppt Agentic architectures and workflows
Agent 现状
(1) Autonomous Agent 有很强的启发意义,但缺乏可控性,不是未来的商用方向
Autonomous agent 指完全由 LLM 自驱的规划工作流、并完成任务的 agent 产品,最典型的就是2023年3月发布的 AutoGPT 和 BabyAGI
优点:
- • 智能程度和普适性高,能较好的理解和推理复杂的任务并且做出规划
- • 能高效的判断并使用外部工具,整个过程的衔接非常流畅
但随着使用深入,发现其实验性强于实用性,大部分问题并不能真的解决:
- • 效果不稳定,多步推理能力不够:大部分产品 demo 看上去效果惊艳,但是对于抽象复杂的问题,能有效解决的比例不到 10%(让AI自我规划容易产生死循环,或者会出现一步走错,步步走错的问题),只适合解决一些中等难度的问题。这需要等 LLM 的下一次技术突破,尤其是其复杂推理能力的提升
- • 外部生态融合度不高:第三方 api 支持的数量和生态不多(基本以搜索和文件读取功能为主),很难做到比较完整的跨应用生态
这两个缺陷正是 existing company 的优势
- 第一点是 OpenAI/Anthropic 这类 LLM 公司的目标
- 第二点是 Apple/Google/Microsoft 这类有自己软硬件生态、操作系统公司最适合做的。
因此尽管 AutoGPT 是好的思想实验,但通用的 Autonomous agent 并不适合 startup 作为商业方向。
(2) Agent Framework 和 Vertical Agent 是 AI agent 商业上最可行的两个方向,需要持续探索人机交互的方式
现阶段适合创业公司的机会就是需要人为干预和设计的 agent 产品。
目前有两类介入使 Agent 更可控的思路
- 一类是中间层
Agent Framework,提供设计 agent 的 infra 工具,由用户介入为 agent 提供规划思路;- 创新点: 模块化设计、适配性(APIs/SDKs)、合作机制设计
- Agent Platform:
- 案例: 2022年在西雅图成立的初创公司 Fixie AI
- Agent Workflow: 提高可控性最好的方式就是去帮 AI 设计 workflow,把规划职责部分转移给用户
- 一类深入细分垂类
Vertical Agent,运用 agent 思路设计 Copilot 产品,由产品设计者介入是 agent 思路更为可控。- 核心竞争力是领域知识针对性和交互反馈: 领域知识、工作流理解、数据反馈和多agent写作
- 案例:
- Coding Agent
- Voiceflow (特色功能:意图识别管理/信息抽取)
- 最看好 LLM-first IDE(代表Cursor) 和 Generative UI(代表 Vercel v0)
- 个人助理: Lindy.ai
- 写作 Agent:Hyperwriter
- 数据分析 Agent:Julius AI
- Coding Agent
Agent 历史
【2025-7-7】一文拆解 AI Agent 进化图谱:LLM 架构如何点燃智能体 “超能力”?
“Agent”这个古老而现代的词汇近年来频频占据科技热搜榜单,最早追溯到古希腊哲学有关的论述,亚里士多德(Aristotle)、柏拉图(Plato)等描述:
- “Agent”是拥有欲望、意念并能够采取行动的实体。
1946年, 伴随世界第一台通用计算机“ENIAC”问世,人类开启了信息时代,“Agent”逐渐被引入计算机领域,指计算机能够理解用户的意图并且代替他们自主执行行动。
20世纪50年代, 阿兰图灵(Alan Mathison Turing)提出著名的“图灵测试”,探索人工实体是否具有与人类相当的智能,是否像人一样思考,该实验被认为是人工智能的基石。
1956年, 达特茅斯会议首次定义“人工智能”学科,确立研究范畴。
20世纪60年代,“人工智能之父”马文·明斯基(Marvin Lee Minsky)首次明确使用“Agent”一词,描述那些具有自主性、反应性、社会性、进化性的智能实体。
随着语言模型的不断进步,人工智能代理的前景也愈加广阔,人们对该领域的兴趣显著激增。
尤其 2017年,谷歌提出 Transformer 模型架构,为后续大语言模型(LLM)奠定了基础。之后各种模型呈现井喷式发展,模型能力每年呈指数级增长。
从2018年到2024年,AI模型在语言、图像到视频领域持续突破。
LLM如今在知识获取、指令理解、逻辑推理、内容涌现等方面展现了强大的能力,同时可以与人类进行有效的自然语言交互,这些优势使得LLM点亮了通用人工智能(AGI)的火花,若赋予它们扩展感知空间和行为空间能力,可以适应和处理更加复杂的任务,因而也成为构建Agent的理想选择。
Agent 经历了几个技术阶段。
符号Agent(symbolic Agent):人工智能早期(1950-1970),认为智能可以通过符号操作和逻辑推理实现,试图将人类的认知过程通过形式化规则和符号系统来模拟。该系统通常由知识库、推理引擎、解释器组成。- 基于知识的专家系统,在特定领域展现了强大的推理能力。
- 问题:人工构建的决策逻辑通常过于死板,知识获取瓶颈凸显(规则需要人工编写,难以覆盖全部常识),在面对复杂性、不确定性任务时便显出力不从心,加上复杂的推理算法,很难在短时间内找到既高效又能产生较好效果的算法。
反应代理(Reactive Agent):20世纪80-90年代,关注智能体与环境的交互,强调实时快速响应,基于感应—行动,优先考虑输入、输出映射,而不是复杂的推理和符号算法。在自动驾驶和机器人方面有较重要的贡献。- 问题:虽然能够大幅减少计算资源,但缺乏对复杂任务的决策和长远规划能力。
强化学习代理(RL-based Agent):20世纪90年代-至今,随着计算机技术的迅猛发展,人类可利用的数据也爆炸式增长,开始关注代理如何在与环境的交互中学习,通过试错学习最优行为策略,以最大化积累奖励。两个阶段:- 第一阶段是基于基本技术,例如策略搜寻和价值函数优化,经典 TD 算法Q-learning 和 SARSA;
- 第二阶段是深度学习的发展,出现了神经网络和强化学习的结合研究,即深度神经网络学习(DRL),例如著名的Alphago,无需人工干预,可以在复杂的环境中自主学习。
- 问题:该学习方法需要大量训练时间、对样本要求较高,这也限制了它在复杂场景中的运用。
-
迁移学习和元学习代理(Agent with transfer learning and meta learning):21世纪初至今,针对传统强化学习需要大量的样本、训练时间过长、泛化能力弱的不足问题,引入迁移学习和元学习。 - 迁移学习通过不同任务的知识和经验迁移来减轻对新任务的学习负担,提高智能体学习效率和泛化能力。
- 元学习核心在于学习如何学习,利用已有的知识和策略,快速调整学习路径,让智能体能够从少量的样本中快速得到新任务需要的最佳策略,降低对样本的依赖。
- 问题:这些方法对源任务和目标任务相似度有一定的要求。
大语言模型代理(LLM-based Agent):语言模型展现的出色言语理解和生成能力、强大的逻辑推理能力,被置于智能体“大脑”和“控制器”核心位置,并通过多模态感知和工具利用,拓展智能体的感知空间和动作空间,让智能体又迎来了一次新的脱变。
大语言模型代理可谓集“万家之长”:
- 通过
思维链(CoT)和问题分解技术,能够展现与符号代理媲美的推理和规划能力; - 从反馈中获得学习和执行新任务与环境交互,具备强化学习和反应代理能力;
- 在大规模语料库上进行预训练,通过少量样本展现了泛化能力,可以在不同任务间实现传输,无需更新模型参数,具备迁移学习和元学习代理的能力。
大语言模型代理(LLM-based Agent)在处理各项任务中的显著优势
大语言模型(LLM)出现后,其通用文本处理能力使通用 Agent(General Agent)呼之欲出,于是出现了各种LLM-powered agent。与此同时,基于RL的“传统”Agent仍在发展,还有应用场景广泛的Multi-Agent等。
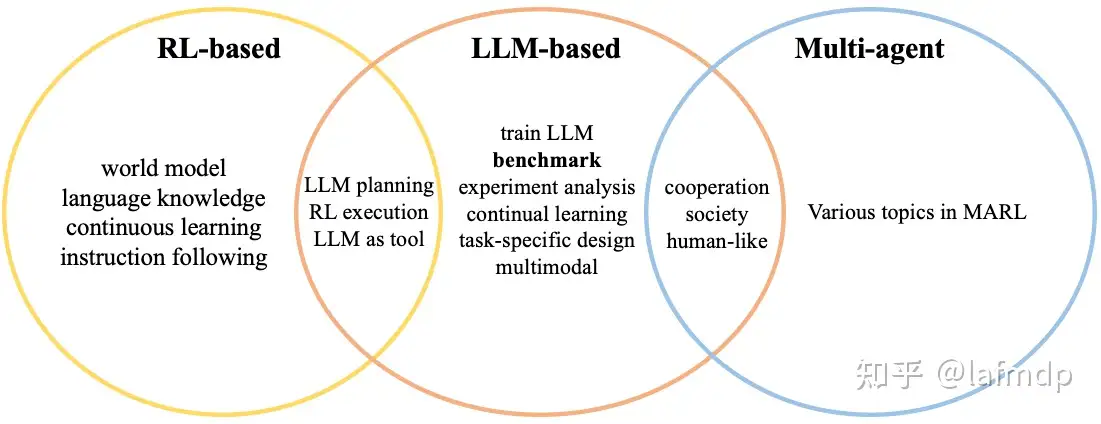
Agent 是与大模型主动交互的一种重要程序形式,而 Multi-Agent 则是多个Agent利用大模型完成复杂任务的系统机制。
更多论文进展见
- 【2023-10-16】文章: ICLR’24 Agent论文合集:RL-based、LLM-based 前沿研究汇总
- Survey: LLM-Agent-Survey
- Code: YuLan-Rec
- RL-based agent
- LLM-based agent
- Multi-Agent
- Other agent
RL Agent -> LLM Agent
两类Agent文章:RL-based agent 和 LLM-based agent
- 1: 当前Agent以 LLM-based 方法为主,基于LLM做各种推理、规划等。ICLR的投稿中设计LLM-based agent架构来解决特定问题的方法不多,这类研究我会打上【task-specifc】的标签。
- 2: RL-based agent 研究较少,可能是由于RL从头开始训练缺少很多知识,性能上很难对拼LLM-based agent。但也有工作利用RL在环境中探索、学习的能力和LLM丰富的世界知识,研究如何将RL-based、LLM-based agent结合。
- 3: 在构建Agent时,Train LLM 也成了一个研究点,由于LLM需要更新参数以应对环境变化和知识更新。需要着重考虑的是不能使LLM丧失general text processing ability。
- 4: 有些特殊的研究点很受欢迎。例如:LLM-based agent表现出的社会特性(大多在multi-agent中)、赋予Agent视觉能力等。
新加坡南洋理工大学安波教授:《From RL-based to LLM-powered Agents》演讲
- 【2025-3-18】AI Agent进化:RL到大模型,绝了
RL Agent 局限
- 样本不足
- 受限于具体任务
- 长时任务
- 稀疏奖励
LLM Agent 优点: 驱动 Agent 再次兴起
- 具备一定世界知识 (世界模型)
- 推理/规划能力
- 工具适用(尤其代码)
- 上下文学习 ICL
LLM Agent 局限
- LLMs Agent 虽有丰富的先验知识,但简单决策任务上经常失败
- 原因:未于任务环境对齐
- RL Agent 总是跟任务环境对齐,但缺乏先验知识
- LLMs Agent 多部推理能力有限
- SFT/RLHF:计算开销大,重人工标注
- PE:重专家经验,难以泛化
- 训练中校验:即时推理缺乏指导
解决
- 借助 LLM 完善 RL 策略,通过与具身环境交互,用 PPO 优化决策能力
Agent 设计
Agent 架构设计见站内专题:Agent 设计
RL-based Agent
LLM 出现之前,multi-agent 主要存在于强化学习和博弈论(game theory) 的相关研究中
RL-based agent 研究相对较少,可能是 RL从头开始训练,缺少很多知识,因此在性能上很难对拼 LLM-based Agent。
但也有工作利用RL在环境中探索、学习的能力和LLM丰富的世界知识,研究如何将 RL-based、LLM-based agent结合。
RL
强化学习和其他 AI 范式的重要区别
经典三大范式(监督学习、非监督学习、强化学习)中只有强化学习的假设是让 AI 进行自主探索、连续决策,这个学习方式最接近人类的学习方式,也符合想象中的 AI agent 应该具备的自主行动能力。
强化学习的核心在于”探索“(Explore)和”利用“(Exploit)之间的权衡。
LLM 在”利用”现有知识上做到了现阶段的极致,而在”探索”新知识方面还有很大潜力,RL 的引入就是为了让 LLM 能通过探索进一步提升推理能力。
RL 过程有两个核心组件。他们之间一直在反复交互,agent 在环境中执行 action,并且根据环境的变化评估 reward:
- • Environment: AI 探索完成任务的环境,当 Alphago 下围棋时,环境就是 19x19 的棋盘。环境会发生变化,AI 会从环境变化中收到 reward value 判断过去的那一系列探索是否有明显的收益,例如距离下围棋胜利是否更接近了。
- • Agent: agent 会根据对环境的观测和感知来输出一个动作,目标是得到更高的 reward。agent 这个概念最早就是来自强化学习。
self-play
self-play 是让 LLM 同时扮演一个或多个 agent model 去做推理任务,并由另一个 LLM 作为 reward model 来给出打分评价,一定次数后更新 LLM 权重让其多记住做得好的推理方式。
Self-play 是 AlphaZero 等强化学习算法的合成数据方法,最早可以追溯到 1992 年的 TD-Gammon 算法。
这个方法本质是利用 AI 无限的计算能力来补足它数据利用效率不够的短板,更符合当下 AI 的优势。好的 self-play 能合成大量高质量的数据,甚至可能比人类历史上见过的棋局、游戏数更多,用数据量来做到 super human:AlphaGo, Dota Five 都探索出了和人类不一样的游戏套路,并战胜了大部分职业选手。
self-play 给了模型一个自己“卷”自己不断进步的框架,MCTS 方法让模型在连续决策中更容易“打出连招”,self-play+LLM+MCTS 会成为 LLM post-training 中新的范式。
RL 新范式下,LLM 训练的 scaling law 需要被重写。
- 因为训练时计算量不再只是和参数量的上升有关,还多了一个新变量:self-play 探索时 LLM inference 的计算量。
- RL本质是用 inference time 换 training time,来解决模型 scale up 暂时边际收益递减的现状。
最近 DeepMind 也发布了一篇paper 叫做:
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
新的 scaling law 正在浮现:算力周期性从 scaling 转移到 inference-time compute
【2024-8-30】LLM的范式转移:RL带来新的 Scaling Law
LLM-based Agent
当前 Agent 文章还是以 LLM-based 方法为主,基于LLM做各种推理、规划等。
- ICLR的投稿中设计LLM-based agent架构来解决特定问题的方法不多,这类研究我会打上【task-specifc】的标签。
【2025-4-7】Saleforce AI研究院+新加坡南洋理工 论文 A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
- 主页 llm-reasoning-ai
- 沿着 Inference Scaling 和 Learning to Reason 两条路径,系统梳理了几乎所有重要的相关工作
思考:
- 大语言模型是否真的在朝着能解决所有领域问题的通用推理系统演化?这一点仍充满不确定性。
task-specific 的 reasoning 工作却在不断增加。
- task-specific 的 reward model 更容易设计。
像 Deepseek 等其他工作已经开始探索通用 reward modeling 的方向,但目前尚未出现具有突破性的新方法。
介绍
【2025-7-29】忘掉《Her》吧,《记忆碎片》才是 LLM Agent 的必修课
OpenAI 的 CEO Sam Altman 最爱的人工智能电影,Her
2025年,现象级 Agent 的横空出世,让 Agent(智能体) 迅速取代 Chatbot,成为行业叙事绝对的主流
大家讨论的不再是「意图识别」和「多轮对话」,而是任务分解、工具调用和自主规划。
克里斯托弗·诺兰的第一部长篇电影——Memento(《记忆碎片》)。
- 不探讨 AI 灵魂,只展示系统如何在信息不完整的残酷现实中,为了一个目标去 「思考」 和 「行动」。
电影《记忆碎片》的主角莱纳德看作是一个“目标驱动、工具调用、自主规划”的真人版 Agent,结合电影情节设定,对应拆解了 Agent 上下文工程的知识。
主角莱纳德不是被动聊天伙伴。他是有明确目标(复仇)、会使用工具(相机、笔)、并试图在复杂的真实世界中执行任务的 自主系统(Agent)。他关心的是 「完成任务」,而不是「取悦用户」。
莱纳德的整个悲剧,都源于他那套为了「行动」而构建的、天才而又脆弱的信息处理系统。
这套系统就是上下文工程(Context Engineering)。本质上,一套围绕着 LLM 有限的’注意力’(即上下文窗口),设计和管理信息输入(Input)与输出(Output)的综合性技术栈。
目标:在 Agent 每一个决策点,都为其提供「恰到好处」的信息,而这,正是决定一个 Agent 是走向成功还是陷入混乱的「脚手架」。
地狱级难度的工程挑战:
- 如何在一个本质上无状态(Stateless)的、记忆窗口极其有限(或信息过载)的系统中,去执行一个需要长期有状态(Stateful)跟踪的复杂任务?
既然无法修复硬件(他的大脑),那就构建一套强大的外部系统。
高效 LLM Agent 所需的三大核心支柱。
- 第一支柱:外部知识管理系统 (External Knowledge Management) —— 拍立得照片
- 整个系统的「记忆扩展模块」,负责突破短期记忆的限制,为 Agent 在每个决策点提供必要的历史信息。Agent 技术栈中,这对应着一套完整的 知识管理系统,其中最为人熟知的实现方式就是 RAG(检索增强生成)。
- 第二支柱:上下文提炼与结构化 (Context Distillation & Structuring) —— 关键笔记
- 信息并非越多越好。如果每次决策都翻阅所有照片,莱纳德很快就会在信息的海洋中迷失。他必须对信息进行 处理,筛选出那些真正重要、不可动摇的「事实」。
- 第三支柱:分层记忆管理 (Hierarchical Memory Management) —— 纹身系统
第二支柱核心处理手段,是将信息 从照片的背面,升级到纹身。
- 提炼与压缩 (Distillation & Compression): 莱纳德不会把「我今天在咖啡馆遇到了泰迪」这种日常琐事纹在身上。他只纹那些经过反复验证、足以构成他世界观基石的核心信息,比如「事实 5:John G. 强奸并谋杀了我的妻子」。这是一种极致的信息压缩,将无数的线索和推论,提炼成一句不可更改的「断言」。
- 结构化 (Structuring): 纹身的位置也极有讲究。关键线索和数字纹在最容易看到的大腿上,而最终目标「找到他,杀掉他」则纹在胸口,每次照镜子都能看到。这是一种物理上的 信息结构化,确保最重要的信息拥有最高的「读取优先级」。
一个单一、扁平的记忆系统是脆弱且低效的。莱纳德的生存智慧在于,他本能地为自己构建了一套 分层式的记忆架构。这对于设计一个能在长期任务中保持不「迷航」的 Agent 至关重要。
我们可以将莱纳德的记忆系统看作三个功能不同的层次:
- 核心任务层 (Core Mission Layer) - 纹身: 这是 Agent 的「宪法」或「最高指令」。它定义了 Agent 的身份(「你是一个复仇者」)和终极目标(「找到并杀死凶手」)。这一层的信息是 几乎不可变的(Immutable),拥有最高的决策权重。它的作用,是确保 Agent 无论在执行多少步子任务后,都不会偏离最初的战略意图。每当莱纳德「重启」时,正是这些纹身让他能立刻重建自我,找回使命。
- 情景工作记忆层 (Episodic Working Memory) - 照片与笔记: 这是 Agent 的「任务日志」。它存储着与当前长期任务相关的、动态变化的状态和观察结果。比如「泰迪的照片」和背面的笔记「别信他」。这一层是 可读可写的(Read/Write),记录了任务的中间步骤、遇到的障碍、收集到的证据。它使得 Agent 的行动具有连续性,而不是一系列孤立的操作。
- 瞬时处理窗口 (Volatile Processing Window) - 15 分钟的大脑记忆: 这直接对应 LLM 那有限的 上下文窗口。它是真正的「思考」发生的地方。在每一个决策点,Agent 会将「核心任务层」的最高指令,与「工作记忆层」中最相关的几条情景信息,一起 加载(Load) 到这个窗口中进行处理,然后做出下一步行动的判断。这个窗口是 高度易失的(Volatile),每次调用后都会被清空。
- 工程师的教训: 上下文管理设计的核心,不是去追求一个无限大的记忆池,而是 设计一套高效的记忆分层与调度系统。要明确定义哪些信息是需要永久铭刻的「宪法」,哪些是可供随时读写的「日志」。忘记设计这套记忆层级的 Agent,要么会忘记自己的核心使命,要么会淹没在自己海量的操作日志中。
通过这套天才的「上下文工程」系统,莱纳德成功地将一个有严重生理缺陷的个体,变成了一个能够执行长期复杂任务的 Agent
然而,最后依然失败
- 漏洞一:外部投毒 —— 被泰迪警官「喂」了谎言
- 泰迪警官一直在利用莱纳德的失忆症,向他提供精心筛选甚至扭曲的信息。这完美地诠释了 Agent 设计的第一个风险:上下文投毒(Context Poisoning)。在 LLM Agent 的时代,我们进入了一个 「垃圾进,真理出」(Garbage In, Gospel Out) 的新范式。Agent 不仅会处理错误的信息,更可怕的是,它会以一种充满权威和自信的口吻,将基于这些错误信息得出的结论,当作「真理」一样呈现和执行。我们的 Agent 如果无条件信任互联网上的所有信息,其后果不堪设想。
- 漏洞二:内部污染 —— 被自己写下的笔记所欺骗
- 电影最具讽刺性的一幕,是莱纳德在某个瞬间做出了一个决定:他在一张关键人物的照片背面写下了一条误导性的笔记。这不是别人对他的欺骗,而是他对未来的自己设下的陷阱。当他下次「重启」看到这张照片时,他会毫不怀疑地相信自己写下的话——毕竟,谁会怀疑自己亲手写下的「事实」呢?他用一个谎言,编程了未来的自己。这揭示了比外部投毒更隐蔽的漏洞:自我强化的认知牢笼(Self-Reinforcing Cognitive Prison)。
单 Agent 系统
Agent 特点
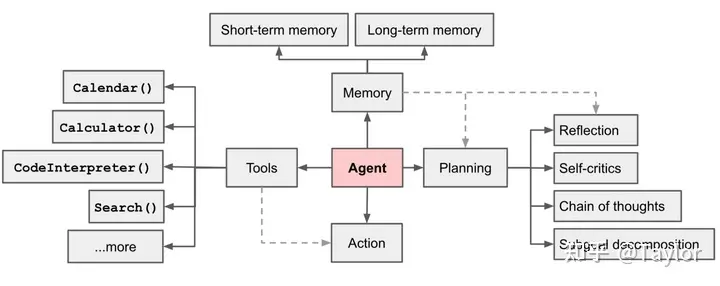
Agent 一般结构如下图所示:
Agent 的主要特性有:
- ●
自主性(Autonomy) :运行无需人类或其它 Agent 的直接干预,对其自身行为及内部状态进行某种控制。 - ●
社会性(Social Ability) 能通过某种 通信与其它 Agent(或人类)进行交互。交互主要有三种类型:协作(Cooperation)、协调(Coordination)和协商(Negotiation)。 - ●
反应性(Reactivity):能感知环境(可以是物理世界、一个经图形用户接口连接的用户、一系列其 它Agent、Internet 或所有这些的组合),并能对环境的变化及时作出反应。 - ●
主动性(Pro-activeness):不但能对环境作出反应,能够积极主动地做出使其目标得以实现的行为。
如果尝试对Agent做一点儿形式化表达,可能是这样的:
Agent=platform+agent programplatform= computing device + sensor + actionagent program是 agent function 的真子集
LLM Agent
LLM语境下,Agent可以理解为在某种能自主理解、规划决策、执行复杂任务的智能体。
Agent 并非ChatGPT升级版,它不仅告诉你“如何做”,更会帮你去做。如果Copilot是副驾驶,那么Agent就是主驾驶。
自主Agent是由人工智能驱动的程序,当给定目标时,能够自己创建任务、完成任务、创建新任务、重新确定任务列表的优先级、完成新的顶级任务,并循环直到达到目标。
最直观的公式
Agent=LLM+ Planning + Feedback + Tool use
Agent 让 LLM 具备目标实现能力,并通过自我激励循环来实现这个目标。
- 并行(同时使用多个提示,试图解决同一个目标)和单向(无需人类参与对话)。
大模型替代了传统 agent 中的规则引擎以及知识库,Agent提供了并寻求推理、观察、批评和验证的对话通道。特别是当配置了正确的提示和推理设置时,单个LLM就可以显示出广泛的功能 ,不同配置的Agent之间的对话可以帮助以模块化并以互补的方式将这些广泛的LLM功能结合起来。
开发人员可以轻松、快速地创建具有不同角色的Agent,例如,使用Agent来编写代码、执行代码、连接人工反馈、验证输出等。通过选择和配置内置功能的子集,Agent的后端也可以很容易地进行扩展,以允许更多的自定义行为。
常见单 Agent 系统
基于大模型的常见单Agent 系统包括:
AutoGPT:AutoGPT是一个AI代理的开源实现,它试图自动实现一个给定的目标。它遵循单Agent范式,使用了许多有用的工具来增强AI模型,并且不支持Multi-Agent协作。ChatGPT+ (code interpreter or plugin) :ChatGPT是一种会话AI Agent,现在可以与code interpreter或插件一起使用。code interpreter使ChatGPT能够执行代码,而插件通过管理工具增强了ChatGPT。LangChain Agent:LangChain是开发基于LLM应用的通用框架。LangChain有各种类型的代理,ReAct Agent是其中一个著名的示例。LangChain所有代理都遵循单Agent范式,并不是天生为交流和协作模式而设计的。Transformers Agent:Transformers Agent 是一个建立在Transformer存储库上的实验性自然语言API。它包括一组经过策划的工具和一个用来解释自然语言和使用这些工具的Agent。与 AutoGPT类似,它遵循单Agent范式,不支持Agent间的协作。
Multi-Agent
Multi-Agent System (MAS, 多智能体系统) 由多个自主个体组成的群体系统,目标是通过个体间的相互信息通信和交互作用。
Multi-Agent 由一系列相互作用的Agent及其相应的组织规则和信息交互协议构成,内部的各个Agent之间通过相互通信、合作、竞争等方式,完成单个Agent不能完成的,大量而又复杂的工作,是“系统的系统”。
Multi-Agent 特点
Multi-Agent 系统主要特点:
- 自主性。在 Multi-Agent 系统中,每个Agent都能管理自身的行为并做到自主地合作或者竞争。
- 容错性。Agent 可以共同形成合作的系统用以完成独立或者共同的目标,如果某几个智能体出现了故障,其他智能体将自主地适应新的环境并继续工作,不会使整个系统陷入故障状态。
- 灵活性和可扩展性。Multi-Agent系统本身采用分布式设计,Agent具有高内聚低耦合的特性,使得系统表现出极强的可扩展性。
- 协作能力。Multi-Agent 系统是分布式系统,Agent之间可以通过合适的策略相互协作完成全局目标。
Multi-Agent RL
Multi-agent 系统相比于 single-agent 更加复杂,因为每个 agent 在和环境交互的同时也在和其他 agent 直接或者间接交互。
因此,Multi-agent 强化学习要比 single-agent 的建模和优化更困难,难点:
- 由于多个 agent 在环境中进行实时动态交互,并且每个 agent 在不断学习并更新自身策略,因此在每个 agent 视角下,环境非稳态(non-stationary),即 agent 在相同状态下采取相同动作,得到的状态转移和奖励信号的分布可能在不断改变;
- 多个 agent 训练可能是多目标,不同 agent 需要最大化自己的利益;
- 训练评估的复杂度会增加,可能需要大规模分布式训练来提高效率,例如 Ray 框架
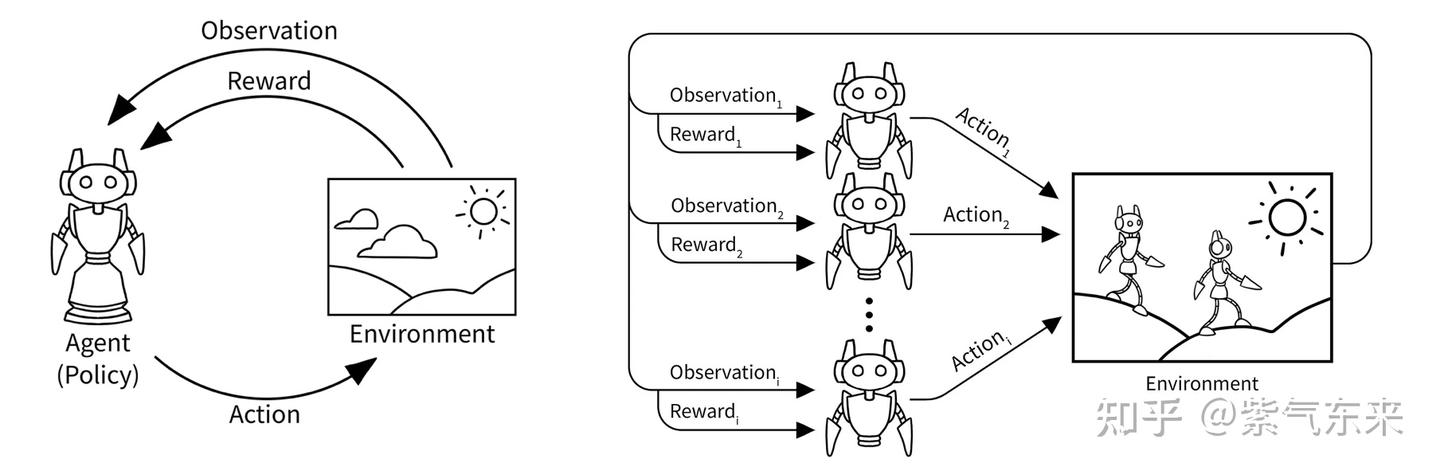
multi-agent RL 可以被定义为随机博弈问题,用元组 (N, S, A, R, P, γ)
N: 智能体集合,即智能体数量S: 所有Agent状态集合,S=S1*S2*S3*...*SnA: 所有Agent动作集合,A=A1*A2*A3*...*AnR: 所有Agent奖励函数集合,R=R1*R2*R3*...*RnP: 环境状态转移概率,S X A -> Ω(S)γ: 衰减因子
multi-agent 强化学习的目标: 每个 agent 学习一个策略来最大化其自身的累积奖励
求解范式
- 完全中心化方法(fully centralized): 所有 agent 状态聚合在一起当作全局超级状态,动作连起来作为联合动作
- 优点: 超级agent,环境依旧稳态,可保证单agent收敛性
- 缺点: 所有信息暴力拼接导致维度爆炸, 训练复杂度提升,难以推广到agent数量多/环境大的场景
- 完全去中心化方法(fully decentralized): 每个 agent 在自己的环境里独立学习,不受其他agent影响
- 优点: 扩展容易
- 缺点: 环境非稳态,训练不一定收敛
- 案例: IPPO (Independent PPO)
- 中心化训练去中心化执行 (centralized training with decentralized execution, CTDE): 介于中心化和去中心化之间, 训练时使用全局信息达到更好的效果,而执行时每个agent完全独立行动,达到去中心化效果
- 案例: DDPG(multi-agent DDPG)
此时的Agent主要使用深度神经网络
Multi-Agent LLM
基于大模型的应用领域中,当复杂任务被分解成更简单的子任务时,LLM已经被证明了拥有解决复杂任务的能力。Multi-Agent 的通信与协作可以通过“对话”这一直观的方式实现这种子任务的分拆和集成。
为了使基于大模型的Agent适合于Multi-Agent的对话,每个Agent都可以进行对话,它们可以接收、响应和响应消息。当配置正确时 ,Agent可以自动与其他代理进行多次对话,或者在某些对话轮次中请求人工输入,从而通过人工反馈形成RLHF。可对话的Agent设计利用了LLM通过聊天获取反馈并取得进展的强大能力,还允许以模块化的方式组合LLM的功能。
协作型 Multi-Agent
主要优点:
- 专业知识增强:系统内的每个 agent 都拥有各自领域的专业知识, 广泛的专业知识可以帮助生成的结果全面且准确。
- 提高问题解决能力:解决复杂的问题通常需要采取多方面的方法。 LLM-based multi-agent 系统通过综合多个 agent 的优势,提供单个 LLM 难以匹敌的解决方案。
- 稳健性和可靠性:冗余和可靠性是人工智能驱动的解决方案的关键因素。 LLM-based multi-agent 系统可降低单点故障的风险,确保持续运行并减少出现错误或不准确的可能性。
- 适应性:在动态的世界中,适应性至关重要。 LLM-based multi-agent 系统可以随着时间的推移而发展,新的代理无缝集成以应对新出现的挑战。
Multi-agent LLM 设计
Multi-Agent 比 Single-Agent 好
【2025-1-2】巴基斯坦 Paper Title:
The paper introduces a framework that enhances senior design projects through multi-agent LLMs, enabling collaborative problem-solving while simulating diverse expert perspectives.
Solution in this Paper 🛠️:
- → The framework deploys 8 specialized LLM agents, each focusing on specific aspects like problem formulation, system complexity, and ethical considerations.
- → Agents coordinate through a central system using Camel AI, enabling collaborative analysis of student projects.
-
→ Each agent evaluates projects based on predefined metrics, simulating expert feedback in areas like technical innovation and methodology.
- → The system provides real-time feedback through a web interface, allowing students to ask follow-up questions.
Key Insights 💡:
- → Multi-agent systems outperform single-agent approaches in evaluating complex projects
- → Specialized agents can effectively simulate diverse expert perspectives
- → Structured evaluation metrics improve feedback consistency
Results 📊:
- → Multi-agent system achieved 89.3% higher accuracy compared to single-agent approaches
- → Lower Mean Absolute Error (0.205 vs 0.388) in alignment with faculty evaluations
- → Improved performance in technical categories (MAE 0.345 vs 0.855)
Agent 决策流程
人类决策逻辑
人们高效完成一项任务非常成功的经验总结
- 基于PDCA模型,将完成一项任务进行拆解,按照作出计划、计划实施、检查实施效果
- 然后将成功的纳入标准,不成功的留待下一循环去解决。
PDCA思维模型
Plan计划 ->Do执行 ->Check检查结果 ->Action处理(纠正偏差)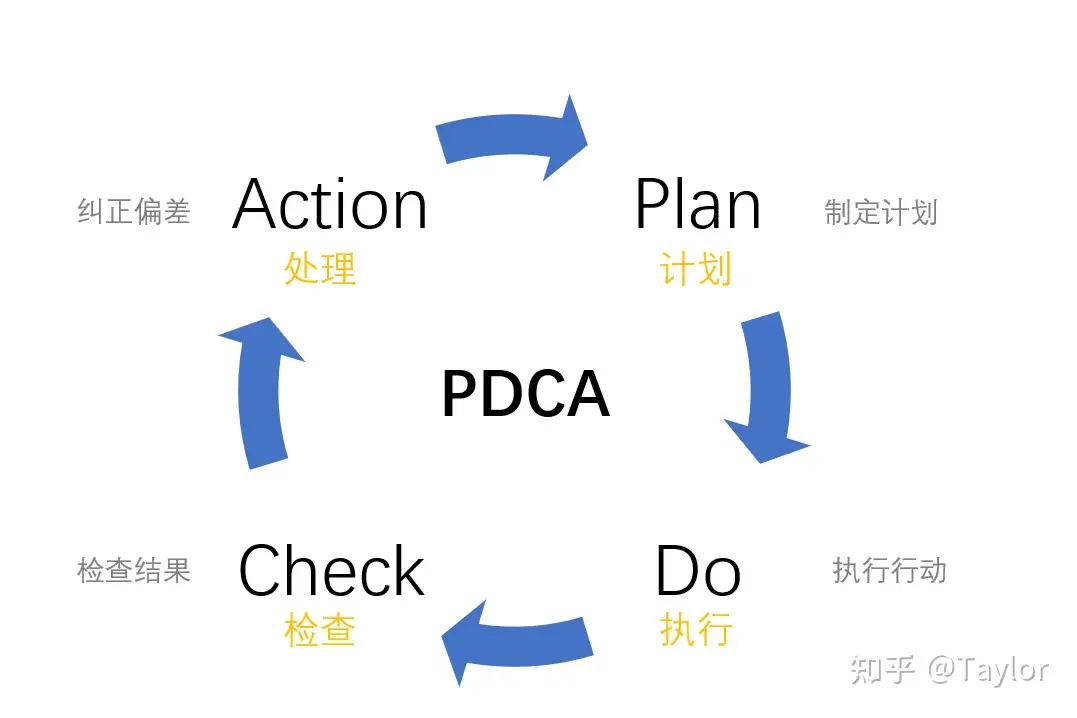
人脑 与 智能体
【2025-3-31】加拿大蒙特利尔等发布论文
Agent 的设计、评估以及持续改进面临着错综复杂、多方面的挑战。
全面概述将智能体置于一个受大脑启发的模块化架构中,融合认知科学、神经科学和计算研究的原理。四个关联部分。
- 首先,智能体模块化基础, 将认知、感知和操作模块, 对应到人类大脑的类似功能上,并阐释记忆、世界建模、奖励处理和类情感系统等核心组件。
- 其次,自我提升和自适应进化机制,智能体如何自主优化自身能力,适应动态环境,并通过自动化优化范式实现持续学习,这些范式包括新兴的自动化机器学习(AutoML)以及由大语言模型驱动的优化策略。
- 第三,协作式和进化式多智能体系统,考察智能体之间的交互、合作以及社会结构中涌现出的集体智能,强调其与人类社会动态的相似之处。
- 最后,构建安全、可靠且有益的人工智能系统的关键必要性,强调内在和外在的安全威胁、伦理一致性、稳健性,以及在现实世界中进行可信部署所必需的切实可行的缓解策略。
通过综合模块化人工智能架构以及不同学科的见解,本综述识别出了关键的研究空白、挑战和机遇,鼓励开展能够使技术进步与显著的社会效益相协调的创新。
Agent 决策
基于PDCA模型进行 规划、执行、评估和反思。
- 规划能力(Plan)-> 分解任务:Agent大脑把大的任务拆解为更小的,可管理的子任务,这对有效的、可控的处理好大的复杂的任务效果很好。
- 执行能力(Done)-> 使用工具:Agent能学习到在模型内部知识不够时(比如:在pre-train时不存在,且之后没法改变的模型weights)去调用外部API,比如:获取实时的信息、执行代码的能力、访问专有的信息知识库等等。这是一个典型的平台+工具的场景,我们要有生态意识,即我们构建平台以及一些必要的工具,然后大力吸引其他厂商提供更多的组件工具,形成生态。
- 评估能力(Check)-> 确认执行结果:Agent要能在任务正常执行后判断产出物是否符合目标,在发生异常时要能对异常进行分类(危害等级),对异常进行定位(哪个子任务产生的错误),对异常进行原因分析(什么导致的异常)。这个能力是通用大模型不具备的,需要针对不同场景训练独有的小模型。
- 反思能力(Action)-> 基于评估结果重新规划:Agent要能在产出物符合目标时及时结束任务,是整个流程最核心的部分;同时,进行归因分析总结导致成果的主要因素,另外,Agent要能在发生异常或产出物不符合目标时给出应对措施,并重新进行规划开启再循环过程。
LLM作为一种智能代理,引发了人们对人工智能与人类工作的关系和未来发展的思考。它让我们思考人类如何与智能代理合作,从而实现更高效的工作方式。而这种合作方式也让我们反思人类自身的价值和特长所在。
Agent决策流程
感知(Perception)→规划(Planning)→行动(Action)
具体
感知(Perception)是指Agent从环境中收集信息并从中提取相关知识的能力。规划(Planning)是指Agent为了某一目标而作出的决策过程。行动(Action)是指基于环境和规划做出的动作。
解读
- Agent通过感知环境,收集信息并提取相关知识。
- 然后通过规划为了达到某个目标做出决策。
- 最后,通过行动基于环境和规划做出具体的动作。
Policy 是 Agent 做出行动的核心决策,而行动又为进一步感知提供了观察的前提和基础,形成了一个自主的闭环学习过程。
Agent 爆发
Agent 大爆发
- 3月21日,Camel发布。
- 3月30日,AutoGPT发布。
- 4月3日,BabyAGI发布。
- 4月7日,西部世界小镇发布。
- 5月27日,英伟达AI智能体Voyager接入GPT-4后,直接完胜了AutoGPT。通过自主写代码,它完全独霸了《我的世界》,可以在游戏中进行全场景的终身学习,根本无需人类插手。
- 同一时间,商汤、清华等共同提出了通才AI智能体 Ghost in the Minecraft (GITM),它同样能够通过自主学习解决任务,表现优异。这些表现优异的AI智能体,简直让人看到了AGI+智能体的雏形
AI Agent 是桥梁
【2023-8-23】AI Agent:大模型与场景间的价值之桥,但不适合当纯技术看
怎么理解AI Agent和特征?
- 可重用通行定义,基于感知进行智能判断并采取行动。(陆奇的大模型世界观说)
- 要和IoT、现有各种系统做深度结合,不可能是Lilian Wen 图里的简单工具的概念, 感知范围大小事实上也定义了AI Agent的范围
- 价值序列的初始化
- 不是感知,而是原则,是绝对必须的输入,但似乎很少被提及。
- 三个核心输入输出上都要接受变化。
- 感知和行动的风格肯定要根据不同的公司要有微调,比如同样是招聘的Agent,不可能期望用感知、行动和价值序列都固定的产品解决所有公司的问题。
- 一组算法的组合
- 大模型与其它算法、领域模型、记忆、规划能力形成一套新的内核,这种内核要有通用性,否则一个是不匹配大模型的通用能力
- 大模型能力已经通用化了,再配上通用的结构,这种通用能力就能够彻底发挥,相当于给瓮中之脑加了一个终结者的身体。
AI Agent即系统型超级应用。
- 解决具体问题所以是个应用,但具有通用性,而达成通用性的手段其实和过去的操作系统非常类似,并且以大模型为根基。
从西部世界类的元宇宙Agent到具身智能全是Agent。
Agent 有很多种
- 最基础的和来的最快的应该是纯数字,无场景或者场景极为单薄的AI Agent。
- 元宇宙型的Agent,谷歌和斯坦福要干的现实版西部世界就是这类。如果放在游戏里就是元宇宙里的智能NPC。这类Agent最大的建设性在于给元宇宙注入生气,最大的破坏性则在于对上古社区的影响可能不咋正向,包括抖音。
- 第二种Agent则要与现实场景结合,可能是纯粹数字的,也可能不是。比如招聘、营销、空调管理、运维状态监控等。
- 第三种则是具身机器人。和上一种的区别是完全控制自己的一套外设,上一个则更多的是一种粘合。
这三类都会解决连续运转场景问题,只不过后两个在现实世界使劲,第一个在虚拟世界使劲。
智能体组件
【2023-7-11】下一代语言模型范式LAM崛起!AutoGPT模式席卷LLM,三大组件全面综述:规划、记忆和工具
图解
整体结构
三个关键组件,即规划、记忆和工具
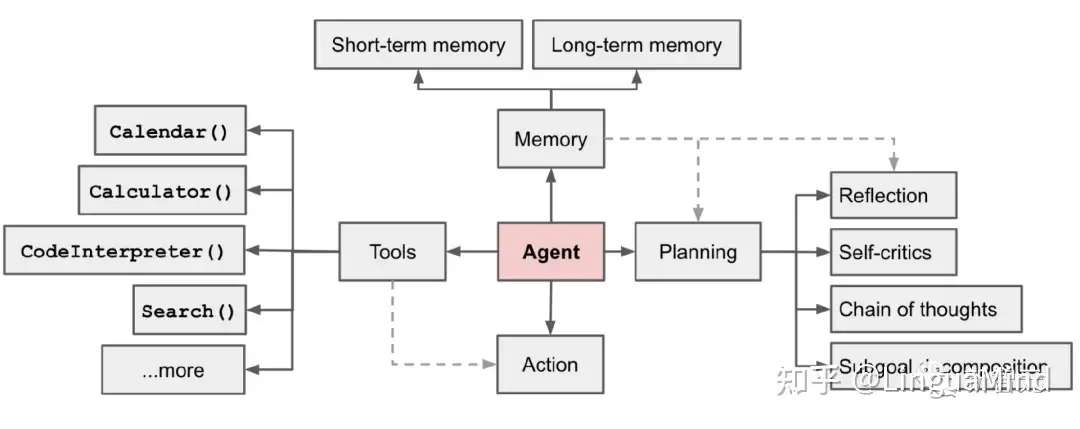
【2023-6-23】翁丽莲(Weng Lilian)博文(LLM Powered Autonomous Agents)详细介绍了Agent架构
- OpenAI 应用主管
- 现在是 OpenAI 的 Head of Safety Systems
在一个由LLM驱动的自主代理系统中,LLM充当代理的大脑,并辅以几个关键组成部分:
规划(Planning)- 子目标与分解(Subgoal and decomposition):代理将大型任务分解为更小、更易于处理的子目标,从而实现对复杂任务的高效处理。
- 反思与完善(Reflection and refinement):代理可以对过去的行动进行自我批评和自我反思,从错误中吸取教训,并为未来的步骤进行改进,从而提高最终结果的质量。
记忆(Memory)- 短期记忆(Short-term memory):作者认为所有上下文学习(参考 提示工程Prompt Engineering)都是利用模型的短期记忆来学习。
- 长期记忆(Long-term memory):这为代理提供了在长时间嘞保留和回忆(无限)信息的能力,通常通过利用外部向量存储和快速检索来实现。
工具使用(Tool use)- 代理程序学会调用外部API获取模型权重中缺失的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、访问专有信息源等。
In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:
Planning- Subgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.
- Reflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.
Memory- Short-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.
- Long-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.
Tool use- The agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.

【2024-7-24】陈旭博士 中国人民大学 准聘副教授 Al Agent–大模型时代重要落地方向, 大语言模型 Agent 的构成,主要分为以下 4 个模块:
- 增加
画像
理想 Agent 框架是什么
Agent 系统有以下几个模块组成
0. 画像
画像模块:主要描述 Agent 背景信息
画像模块的主要内容和生成策略。
- (1)画像内容,主要基于 3 种信息:人口统计信息、个性信息和社交信息。
- (2)生成策略:主要采用 3 种策略来生成画像内容:
- 手工设计方法:自行通过指定的方式,将用户画像的内容写入大模型的 prompt 中;适用于 Agent 数量比较少的情况;
- 大模型生成方法:首先指定少量画像,并将其作为示例,进而使用大语言模型生成更多的画像;适用于大量 Agent 的情况;
- 数据对齐方法:需要根据事先指定的数据集中人物的背景信息作为大语言模型的 prompt,进而做相应的预测。
1. 记忆
LLM 是无状态(stateless)的,大参数量使产品无法基于每一次交互的经验来更新模型的内部参数。不过由于 LLM 能理解大量语义信息,Agent 系统可以在模型之外建立一个记录信息的记忆系统,来模仿人类大脑那样从过往的经验中学习正确的工作模式。
以下分类根据医学中人类的几种记忆方式类比,将 AI agent 的记忆系统分为短期记忆与三种长期记忆:
- 短期记忆:
- •
工作记忆(Working Memory):这一轮决策所需要用到的所有信息。其中包括上下文内容,例如从长期记忆中检索到的知识;也包括 LLM context 以外的信息,例如 function call 时使用其他能力所产生的数据
- •
- 长期记忆:
- •
事件记忆(Episodic Memory):Agent 对过去多轮决策中所发生事情的记忆。每一次 LLM 有了新的行为和结果,agent 都会把内容写进情节记忆。例如在 Generative agents 小镇中,虚拟小镇的 agent 居民会把自己每天看到的事、说过的话计入事件记忆。要使得用户得到个性化的使用体验,这一部分的优化是至关重要的。 - •
语义记忆(Semantic Memory):Agent 对自身所在世界的语义知识记忆,一般通过外部向量存储和检索来调用。这一部分记忆可以用类似知识图谱的思路,使 agent 之间的知识更方便共享和更新。同样以 Generative agents 小镇为例,agent 居民会记忆其他居民的爱好、生日等信息,这都是语义记忆。 - •
程序记忆(Procedural Memory):在一些特定场景下,agent 执行操作的 workflow 会通过代码的形式在框架中写出来。这类记忆使部分行为能够按照更可控的工作流来执行。以 Generative agents 小镇类比,agent 居民会有自己的行为习惯,比如每天晚上要去某条街散步等等。
- •
2. 行动
面对不同任务,Agent 系统有一个完整的行动策略集,在决策时可以选择需要执行的行动。
以下罗列几个最常见、重要的行为,实际应用中根据不同场景会有补充和优先级的差异:
- •
工具使用:智人与其他动物的重要区别是其使用工具的能力,而 LLM 同样可以通过这一点来扬长避短。AI Agents 可以通过文档和数据集教会 agent 如何调用外部工具的 API,来补足 LLM 自身的弱项。例如复杂的数学计算就不是 LLM 的长处,调用 Calculator() 可以事半功倍。 - •
职责扮演:AI agent 系统中,不同 LLM 需要进行分工的机制设计。就像在工厂和公司制中常常出现的角色配合和博弈那样,LLM 之间也需要各司其职,按照各自的职责去完成任务,形成一个完整的协同组织。 - •
记忆检索:指的是从长期记忆中找到与本次决策相关的信息,将其放到工作记忆、交给 LLM 处理的过程。 - •
推理:从短期工作记忆生成新知识,并将其存入长期记忆中 - •
学习:将新的知识和对话历史加入长期记忆,让 Agent 更了解用户 - •
编程:AI agent 可以实现很多长尾的开发需求,让软件变得接近定制。而编程是最适合 AI agent 去自己迭代和收集反馈(是否能有效执行)的环境,因为能自己形成反馈的闭环
动作模块
- 动作目标:有些 Agent 的目标是完成某个任务,有些是交流,有些是探索。
- 动作生成:有些 Agent 是依靠记忆回想生成动作,有些是按照原有计划执行特定的动作。
- 动作空间:有些动作空间是工具的集合,有些是基于大语言模型自身知识,从自我认知的角度考虑整个动作空间。
- 动作影响:包括对环境的影响、对内在状态的影响,以及对未来新动作的影响。
3. 规划/决策
前面提到很多行动可以由 Agent 进行规划和执行,而决策这一步就是从中选择最为合适的一个行为去执行。
- •
事前规划:LLM 能够将一个大目标分解为较小的、可执行的子目标,以便高效的处理复杂任务。对于每一个目标,评估使用不同行为方案的可行性,选择其中期望效果最好的一个。 - •
事后反思:Agents 可以对过去的行为进行自我批评和反省,从错误中吸取经验教训,并加入长期记忆中帮助 agent 之后规避错误、更新其对世界的认知。这一部分试错的知识将被加入长期记忆中
参考
- 【2024-10-13】拾象科技:AI Agent的千亿美金问题:如何重构10亿知识工作职业,掀起软件生产革命?
Planning 规划
Planning 指
- 任务分解(把大任务划分成小任务,进而达到解决复杂问题的目标);
- 反思和提炼(基于已有动作做自我批评和自我反思,从错误中学习优化接下来的动作)。
任务分解的典型实现方案是 COT(Chain of thought)和 TOT(Tree of thoughts)。
一项复杂任务包括多个子步骤,智能体需要提前将任务分解,并进行规划。
规划模块
- 无反馈规划:大语言模型在做推理的过程中无需外界环境的反馈。这类规划进一步细分为三种类型:
- 单路推理,仅一次大语言模型调用就输出完整的推理步骤;
- 多路推理,借鉴众包思想,让大语言模型生成多个推理路径,进而确定最佳路径;
- 借用外部的规划器。
- 有反馈规划:外界环境提供反馈,而大语言模型需要基于环境的反馈进行下一步以及后续的规划。这类规划反馈的提供者来自三个方面:环境反馈、人类反馈和模型反馈。
综述
LLM在智能体规划中应用,综述文章
- 【2024-2-5】中科大 Understanding the planning of LLM agents: A survey
- 解读: 五个维度,详解LLM-based Agent中的规划(planning)能力
传统工作主要依赖符号方法或强化学习方法, 比如 领域定义语言 PDDL (Planning Domain Definition Language), 这类方法存在若干不足:
- 符号方法要求将灵活的自然语言转化成符号模型, 少不了人工专家介入
- 这种方法对错误容忍度低,稍有不慎就导致任务失败
- 强化学习方法通过深度神经网络模型模拟策略网络、奖励模型.
- 需要大量与环境交互的样本学习, 代价较高且不易实施
大型语言模型(LLM)标志着一个范式转变。LLM在多个领域取得了显著的成功,展示了在推理、工具使用、规划和指令跟随方面的重要智能。这种智能为将LLM作为代理的认知核心提供了可能性,从而有潜力提高规划能力。
提出新颖的分类法,将现有 LLM-智能体规划方法分成了五大类:任务分解、多计划选择、外部模块辅助规划、反思与细化以及记忆增强规划。
- 任务分解: 把大蛋糕切成小块,让智能体一步步地解决。
- 多计划选择: 给智能体一个“选择轮”,生成多个计划,然后挑一个最好的来执行。
- 外部模块辅助规划: 借助外部规划器,有个军师在旁边出谋划策。
- 反思与细化: 执行计划的过程中,能够停下来反思,然后改进计划。
- 记忆增强规划: 一个记忆面包,记住过去经验,为将来规划提供帮助。
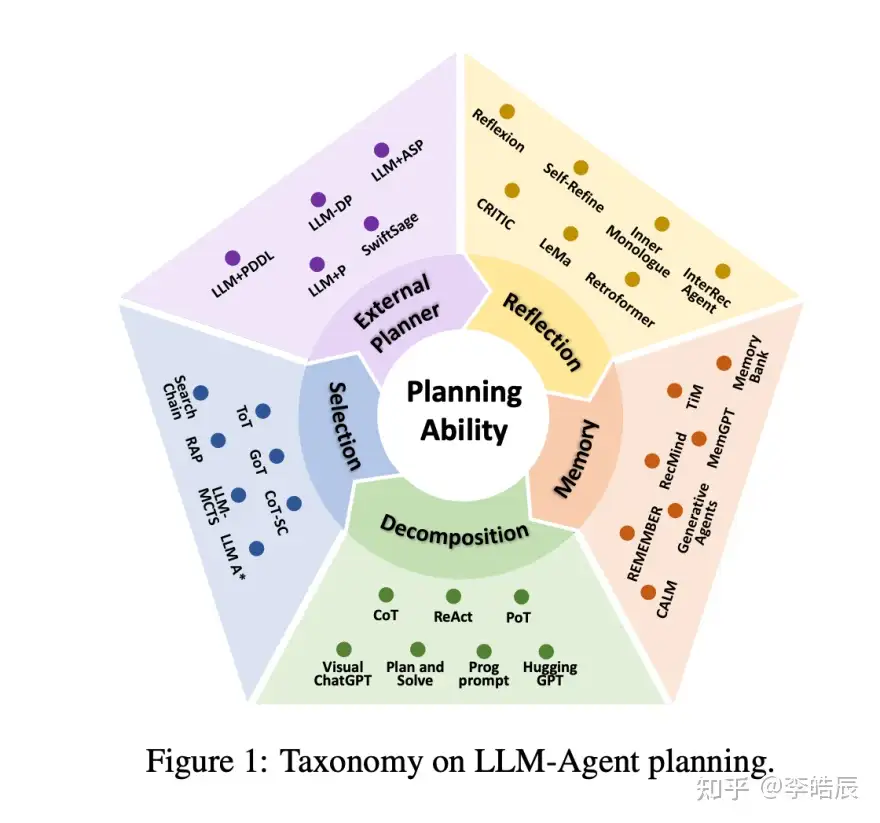
这些方法并不孤立,相互交织,共同提升智能体的规划能力。
推理任务
常识推理
- 数学、逻辑、因果、多模态、视觉、具身推理等
Commonsense Reasoning: Capacity to infer and apply everyday, intuitive knowledge.
- •
Mathematical Reasoning: Ability to solve mathematical problems and derive logical conclusions. - •
Logical Reasoning: Process of drawing inferences and making decisions based on formal logic. - •
Causal Reasoning: Understanding of cause-and effect relationships and their implications. - •
Multimodal Reasoning: Reasoning across multiple data modalities, such as text, images, and sensory information. - •
Visual Reasoning: Focusing on tasks that require the interpretation and manipulation of visual data. - •
Embodied Reasoning: Reasoning in the context of embodied agents interacting with their environment. - • Other Reasoning Tasks
(1) 任务分解
任务分解 (Task Decomposition)
两个关键步骤:
- “分解”: 将复杂任务分解成若干个子任务;
- “子计划”: 为每个子任务制定计划。
任务分解方法主要分为两类:
- 分解优先 (Decomposition-First Methods): 将任务分解为子目标,依次为每个子目标制定规。
- 交错分解方法(Interleaved Decomposition Methods): 在任务分解和子任务规划之间进行交错,每次只揭示当前状态的一个或两个子任务。
分解优先
“分解优先” 把所有拼图碎片按颜色或形状分类,然后再逐个拼起来。
- 优点: 子任务与原任务之间的联系更强,减少了任务遗忘和幻想的风险。
- 缺点: 如果某个步骤出错,可能会影响到整个任务的完成。
- 案例: “HuggingGPT” 和 “Plan-and-Solve”
案例
- •
HuggingGPT: LLM作为控制器,负责将人类输入的任务分解为子任务,选择模型,并生成最终响应。 - •
Plan-and-Solve: 将原始的“让我们逐步思考”转变为两步提示指令:“我们首先制定计划”和“我们执行计划”。 - •
ProgPrompt: 将自然语言描述的任务转化为编码问题,将每个动作形式化为函数,每个对象表示为变量。
交错分解
“交错分解”: 一边分解任务,一边制定计划,边拼图边调整拼图碎片的位置。
- 优点: 可根据环境反馈动态调整任务分解,提高了容错性。
- 缺点: 如果任务太过复杂,可能会导致智能体在后续的子任务和子计划中偏离原始目标。
案例: 类似于ReAct, COT, POT都可以归类到这个范畴中。
- •
Chain-of-Thought(CoT): 通过构建的轨迹指导LLM推理复杂问题,利用LLM的推理能力进行任务分解。 - •
Zero-shot CoT: 使用“让我们逐步思考”的指令,解锁LLM的零样本推理能力。 - •
ReAct: 将推理和规划解耦,交替进行推理(思考步骤)和规划(行动步骤)。
CoT
思维链(Chain of Thought, CoT) 是一种 prompt 方法,通过编写每步推理逻辑(推理链),解决复杂问题。
COT 已然成为「诱导模型推理」的标准提示技术,可以增强解决复杂任务时的模型性能。
- 通过「Think step by step」,模型可以利用更多测试时计算(test-time computation)将任务分解为更小、更简单的子步骤,并能够解释模型的思维过程。
具体可用 Zero-shot 和 Few-shot 的 COT
Zero-shot COT 的实现分为两步:
- 第一步输入
Let's think step by step得到推理链 - 第二步输入
推理链+Therefore, the answer is得到最终答案 - 合并成一步:
Let's work this out it a step by step to be sure we have the right answer
Question: Tom and Elizabeth have a competition to climb a hill. Elizabeth takes 30 minutes to climb the hill. Tom takes four times as long as Elizabeth does to climb the hill. How many hours does it take Tom to climb up the hill?
Answer: It takes Tom 30*4 = <<30*4=120>>120 minutes to climb the hill.
It takes Tom 120/60 = <<120/60=2>>2 hours to climb the hill.
So the answer is 2.
===
Question: Jack is a soccer player. He needs to buy two pairs of socks and a pair of soccer shoes. Each pair of socks cost $9.50, and the shoes cost $92. Jack has $40. How much more money does Jack need?
Answer: The total cost of two pairs of socks is $9.50 x 2 = $<<9.5*2=19>>19.
The total cost of the socks and the shoes is $19 + $92 = $<<19+92=111>>111.
Jack need $111 - $40 = $<<111-40=71>>71 more.
So the answer is 71.
===
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer:
ToT
思想之树(Tree of Thoughts)在每个子步骤中探索多种推理可能性来扩展CoT。
- 首先将问题分解为多个思维步,并在每个步骤内生成多个思路,从而创建出一个树结构解决方案;
- 搜索过程可以是BFS(广度优先搜索)或DFS(深度优先搜索),其中每个状态由分类器(经由提示)或多数投票来评估。
- 任务分解可以通过简单提示,如「Steps for XYZ.\n1.」,「What are the subgoals for achieving XYZ」 ;
- 或是使用任务相关指令,如「Write a story outline」可以用于写小说;也可以由人输入。
思考
总结
- • 分解优先
- 优势: 创建了子任务与原始任务之间的强关联,降低了任务遗忘和幻觉风险。
- 劣势: 需要额外的调整机制,以避免某个步骤的错误导致整体失败。
- • 交错分解
- 优势: 根据环境反馈动态调整分解,提高了容错性。
- 劣势: 但对于复杂任务,过长的轨迹可能导致LLM产生幻觉,偏离原始目标。
挑战: 尽管任务分解显著提高了智能体解决复杂任务能力,但挑战依然存在。
- 任务分解带来的额外开销,需要更多的推理和生成,增加了时间和计算成本。
- 对于那些被分解成数十个子任务的高度复杂任务,智能体上下文长度限制可能会导致规划轨迹遗忘。
所以,任务分解给智能体的一本“任务攻略”,教它如何一步步解决问题。
- 但这本攻略也不是万能的,需要智能体有足够的“智慧”去理解和运用,同时还要避免在复杂情况下迷失方向。
未来的研究,或许能找到更高效、更可靠的任务分解方法,让智能体在面对复杂任务时更加游刃有余。
(2) 多计划选择
多规划选择 (Multi-Plan Selection)
由于任务复杂性 和 LLM固有的不确定性,给定任务,LLM代理可能会生成多种不同的规划。
如何让机器像人类一样,面对复杂任务时,能够生成多种可能解决方案,并从中选择最优的计划呢?
这正是“多计划选择”(Multi-Plan Selection)要解决的问题。
智能Agent面对复杂问题,可能会生成多个计划。但是,这些计划可能各不相同,甚至有些可能根本不可行。
怎么办? 多计划选择, 两个主要步骤:多计划生成和最优计划选择。
- 多计划生成阶段: LLMs 尝试生成一系列可能的计划。
- 最优计划选择阶段: Agent 从多个候选计划中选择一个最好的
多计划选择理论上很美,却面临着一些挑战。
- 首先,增加计算需求,尤其是对于大模型来说,计算成本可能会非常高。
- 依赖于LLM来评估计划的性能,这本身还存在不确定性,需要进一步的验证和调整。
多计划生成
头脑风暴阶段尽可能多地提出解决方案。
主流方法利用生成模型在解码过程中的不确定性,比如通过温度采样或top-k采样获得多个不同推理路径。
- Tree-of-thought 提到了2种生成 planing 策略:sample、propose
- 采样
sample: 策略与 Self-consistency 策略一致,在解码过程中,LLM会采样多个plan。 - 提议
propose: 提示中使用少量示例指导LLM生成各种plan。
- 采样
多规划生成涉及利用生成模型解码过程中的不确定性,通过不同采样策略来产生多个候选规划。
Self-consistency: 采用简单直觉,即复杂问题的解决方案很少是唯一的。通过温度采样、top-k采样等策略,获得多个不同的推理路径。Tree-of-Thought(ToT) : 提出“采样”和“提议”两种策略来生成规划。LLM在解码过程中会采样多个规划,并通过少量示例提示生成各种规划。Graph-of-Thought(GoT) : 在ToT的基础上增加了思想的转换,支持任意思想的聚合。LLM-MCTS和RAP: 利用LLM作为启发式策略函数,通过蒙特卡洛树搜索(MCTS)算法来获取多个潜在动作。
最优计划选择
最优计划选择阶段,Agent 从多个候选计划中选择一个最好。
候选规划中选择最优规划时,采用了多种启发式搜索算法, 比如 简单的多数投票策略,或者利用树结构来辅助多计划搜索
案例
- •
Self-consistency: 使用简单的多数投票策略,将得票最多的规划视为最优选择。 - •
Tree-of-Thought(ToT) : 支持树搜索算法,如广度优先搜索(BFS)和深度优先搜索(DFS),使用LLM评估多个动作并选择最优动作。 - •
LLM-MCTS和RAP: 也用树结构辅助多规划搜索,但采用MCTS算法进行搜索。 - •
LLM A: 利用经典的A算法协助LLM搜索,使用当前位置到目标位置的切比雪夫距离作为启发式成本函数来选择最优路径。
思考
总结
- • 多规划选择的可扩展性显著优势在于提供广阔搜索空间中广泛探索潜在解决方案的能力。
- • 然而,这种优势伴随着计算需求的增加,尤其是对于具有大量token计数或计算的模型,这在资源受限的情况下尤为重要。
- • LLM 在规划评估中的作用引入了新的挑战,因为LLM在任务排名方面的表现仍在审查中,需要进一步验证和微调其在此特定情境下的能力。
- • LLM 的随机性质为选择过程增加了随机性,可能影响所选规划的一致性和可靠性。
(3) 外部规划器
外部规划器辅助规划 (External Planner-Aided Planning)
语音助手解决问题时,常常面临一些复杂环境约束, 单纯的LLM可能就会有点力不从心
- 比如解决数学问题或生成可接受的行动方案。
尽管LLM在推理和任务分解方面展现出了强大的能力,但在面对具有复杂约束的环境时,例如数学问题求解或生成可执行动作,仍然面临挑战。
根据引入的规划器类型,分为两类:
- •
符号规划器(Symbolic Planner): 基于形式化模型,如PDDL,使用符号推理来找到从初始状态到目标状态的最优路径。 - •
神经规划器(Neural Planner): 通过强化学习或模仿学习技术训练的深度模型,针对特定领域展现出有效的规划能力。
External Planner-Aided Planning,整体略复杂,很少会用到
虽然, LLM 在推理和任务分解方面展现出了强大的能力,但在面对复杂约束的环境时,借助外部规划器的规划方法显得尤为重要。LLM在这里主要扮演辅助角色,其主要功能包括解析文本反馈,为规划提供额外的推理信息,特别是解决复杂问题时。
这种结合统计AI和LLM的方法,有望成为未来人工智能发展的主要趋势。
基于符号
符号规划器一直是自动化规划领域的基石
基于明确的符号化模型
- 比如 PDDL 模型,用符号推理来找出从初始状态到目标状态的最优路径。
LLM+P通过结合基于PDDL的符号规划器,增强了LLM的规划能力,用LLM的语义理解能力和编码能力,把问题组织成文本语言提示输入LLM,然后利用Fast-Downward求解器进行规划。- 如果环境动态交互式,
LLM-DP接收到环境反馈后,将信息形式化为PDDL语言,然后用 BFS 求解器生成计划。 - 此外,
LLM+PDDL也在用PDDL语言形式化任务,并且加入了手动验证步骤,以防LLM生成的PDDL模型出现问题。
符号规划器代表工作:
- •
LLM+P: 通过结合基于PDDL的符号规划器,使用LLM将问题组织成PDDL语言格式,并利用Fast Downward solver进行规划。 - •
LLM-DP: 特别为动态交互环境设计,将环境反馈信息形式化为PDDL语言,并使用BFS solver生成规划。 - •
LLM+PDDL: 在LLM生成的PDDL模型中增加手动验证步骤,并提出使用LLM生成的规划作为局部搜索规划器的初始启发式解。 - •
LLM+ASP: 将自然语言描述的任务转换为ASP问题,然后使用ASP求解器CLINGO生成规划。
规划过程中,提出的计划可作为局部搜索规划器的初始启发式解,加快搜索进程。
基于神经网络
神经规划器是深度模型,通过强化学习或模仿学习技术在收集的规划数据上训练,表现出在特定领域内有效的规划能力。
DRRN通过强化学习将规划过程建模为马尔可夫决策过程,训练策略网络来获得深度决策模型。- 而 Decision Transformer 则通过
模仿学习,让一个transformer模型复制人类的决策行为。
问题复杂且少见时,这些小模型可能因训练数据不足而表现不佳。
有些研究将LLM与轻量级神经网络规划器结合起来,以进一步提升规划能力。
神经规划器代表工作:
CALM: 早期提出将语言模型与基于RL的神经规划器结合起来,语言模型处理文本环境信息,生成系列候选动作,然后DRRN策略网络重新对这些候选动作进行排序,最终选择最优动作。SwiftSage利用认知心理学中的双过程理论,将规划过程分为慢思考和快思考。慢思考涉及复杂推理和理性思考,而快思考则类似于通过长期训练发展起来的本能响应。- 当执行计划时出现错误,表明问题更复杂时,Agent会切换到慢思考过程,LLM基于当前状态进行推理和规划。这种快思考和慢思考的结合在效率方面非常有效。
思考
总结:
- • 这些策略中,LLM主要扮演支持角色,主要功能包括: 解析文本反馈并提供额外的推理信息以协助规划,特别是在解决复杂问题时。
- • 传统符号AI系统在构建符号模型时复杂且依赖于人类专家,而LLM可以加速这一过程,有助于更快更优地建立符号模型。
- • 符号系统优势包括理论完备性、稳定性和可解释性。将统计AI与LLM结合,有望成为未来人工智能发展的主要趋势。
(4) 自我反思
自我反思和自我修正(Reflection and Refinemen)
为什么要反思和修正?
- LLM 规划过程中可能会产生幻觉,或因为理解不足而陷入“思维循环”
- 这时候停下来回头看看,总结一下哪里出了问题,然后进行调整,就能更好地继续前进。
- 反思和总结失败有助于代理纠正错误并在后续尝试中打破循环
自我反思让自主智能体改进过去的行动决策、纠正之前的错误来迭代改进,在可以试错的现实任务中非常有用。
反馈和改进是规划过程中不可或缺的组成部分,增强了LLM Agent 规划的容错能力和错误纠正能力。
如何反思、修正?
- 迭代过程:
生成、反馈和改进。
案例
- •
Self-refine: 利用迭代过程,包括生成、反馈和精炼。在每次生成后,LLM为计划产生反馈,促进基于反馈的调整。 - •
Reflexion: 扩展ReAct方法,通过引入评估器来评估轨迹。LLM 检测到错误时生成自我反思,帮助纠正错误。 - •
CRITIC: 使用外部工具,如知识库和搜索引擎,验证LLM生成的动作。然后利用外部知识进行自我纠正,显著减少事实错误。 - •
InteRecAgent: 使用称为ReChain的自我纠正机制。LLM用于评估由交互推荐代理生成的响应和工具使用计划,总结错误反馈,并决定是否重新规划。 - •
LEMA: 首先收集错误的规划样本,然后使用更强大的GPT-4进行纠正。纠正后的样本随后用于微调LLM代理,从而在各种规模的LLaMA模型上实现显著的性能提升。
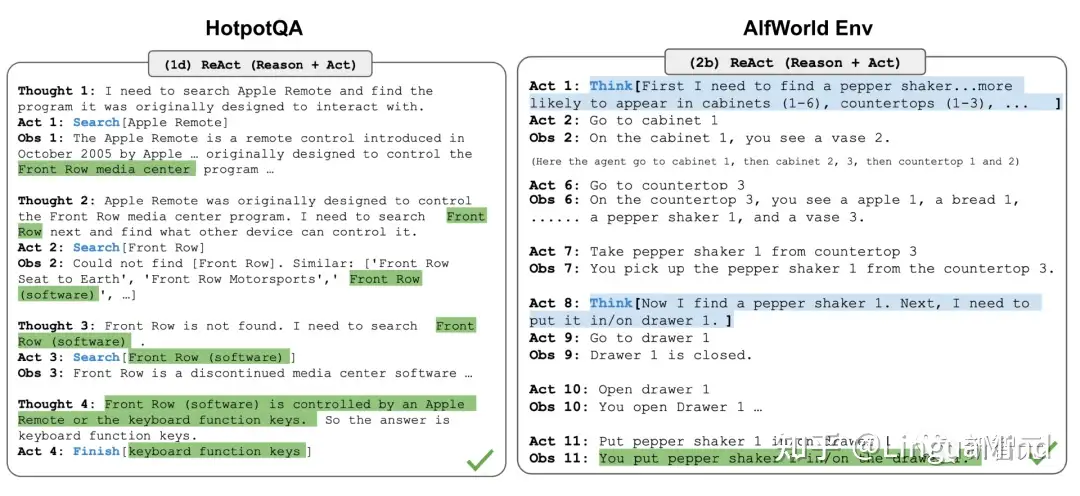
ReAct 通过将动作空间扩展为任务相关的离散动作和语言空间的组合,在LLM中集成了推理和动作,其中动作使得LLM能够与环境交互(例如使用维基百科搜索API),而语言空间可以让LLM以自然语言的方式生成推理轨迹。
ReAct 提示模板包含了LLM思考的明确步骤
在知识密集型任务和决策任务的实验中,ReAct 比只用 Act(移除Thought)的基线模型效果更好。
挑战
- LLM 自我反思,目前还没有证明这种文本形式更新最终能够让LLM达到指定目标。
- 毕竟, 人类学习时,既要反思,还要老师或他人的指导,才能更有效地学习和进步。
LLM通过自我反思和修正,不仅能够提高自身的容错能力和错误纠正能力,而且还能在复杂问题规划中表现得更加出色。
思考
总结 • 自我反思策略类似于强化学习的原则,其中代理作为决策者,环境反馈触发策略网络的更新。然而,与深度强化学习通过修改模型参数来更新不同,在LLM代理中,这种更新是通过LLM自身的自我反思来实现的,最终形成文本形式的反馈。
• 这些文本反馈可以作为长期和短期记忆,通过提示影响代理后续的规划输出。然而,目前还没有确凿的证据证明这种文本形式的更新最终能够使LLM代理达到特定目标。
(5) 记忆增强
记忆增强规划 (Memory-Augmented Planning)
记忆是提升规划能力的关键, 帮助代理从经验中学习并适应新情境。
通过记忆来增强 LLM-Agents 规划能力的方法: RAG记忆 和 参数记忆
RAG 记忆
RAG,检索增强生成,用检索到的信息来增强LLM最新知识。
把过去的经验存储在记忆中,需要时检索出来。
RAG-based Memory(基于RAG的记忆):
- • 概念:使用
检索增强生成(Retrieval-Augmented Generation,RAG)技术,将记忆以文本形式存储,并在需要时检索出来辅助规划。 - • 方法:如
MemoryBank、TiM和RecMind,通过文本编码模型将记忆编码为向量,并建立索引结构,以便在规划时检索与当前任务相关的经验。
这些记忆通常以文本、表格形式或知识图谱等形式存储。
- 有的系统把人类每天行为经验以文本形式存储起来,然后基于相关性和新鲜度来检索记忆。
- 还有的系统用向量编码模型将每个记忆编码成向量,并建立索引结构,以便在检索时快速找到相关信息。
案例
Generative Agents:以文本形式存储类似于人类的日常经验,并根据当前情况的相关性和新鲜度来检索记忆。MemoryBank、TiM和RecMind:将每个记忆编码成向量,并使用索引结构(如FAISS库)来组织这些向量。检索时,使用当前状态的描述作为查询来检索记忆池中的记忆。区别在于更新记忆的方式不同。MemGPT:借鉴了计算机架构中的多级存储概念,将LLM 上下文视为RAM,并将额外的存储结构视为磁盘。LLM 自主决定是检索历史记忆还是将当前上下文保存到存储中。REMEMBER:将历史记忆以Q值表的形式存储,每个记录是一个包含环境、任务、动作和Q值的元组。在检索时,会同时检索正面和负面记忆,以便LLM根据环境和任务的相似性生成计划。
参数记忆
参数记忆通过微调LLM,将 Agent历史经验样本嵌入到模型参数中。
Embodied Memory(体现记忆):
- • 概念:通过微调(fine-tuning)LLM,将代理的历史经验样本嵌入到模型参数中,从而增强记忆能力。
- • 方法:如
CALM和TDT,这些方法使用从代理与环境交互中收集的数据来微调模型,使其能够记住与规划相关的信息,并在规划任务中表现更好。
这些经验样本通常来自Agent与环境的交互,可能包括关于环境的常识知识、与任务相关的先验知识,以及成功或失败的经验。
虽然微调一个大参数的模型成本很高,但通过PEFT,可以通过只训练一小部分参数来降低成本并加快速度。
思考
两种方法都有优势和局限性。
记忆更新方式:
- 基于 RAG 方法提供了实时、低成本的外部记忆更新,主要在自然语言文本中,但依赖于检索算法的准确性。
- 而 FineTuning 微调通过参数修改提供了更大的记忆容量,但记忆更新成本高,并且在保留细节方面存在挑战。
总结
- • 记忆增强的LLM代理在规划中表现出更强的增长潜力和容错能力,但记忆生成在很大程度上依赖于LLM自身的生成能力。
- • 通过自我生成的记忆来提升较弱LLM代理的能力仍然是一个具有挑战性的领域。
规划能力评估
如何评估 (Evaluation) 代理的规划能力?
几种主流基准测试方法:
- 交互式游戏环境(Interactive Gaming Environments):
- • 提供基于代理动作的实时多模态反馈,如文本和视觉反馈。
- • 例如Minecraft,代理需要收集材料制作工具以获得更多奖励,常用评价指标是代理创建的工具数量。
- 基于文本的交互环境(Text-based interactive environments):
- • 代理位于用自然语言描述的环境中,动作和位置有限。
- • 常用评价指标是成功率或获得的奖励,例如ALFWorld和ScienceWorld。
- 交互式检索环境(Interactive Retrieval Environments):
- • 模拟人类在现实生活信息检索和推理的过程。
- • 代理可以与搜索引擎和其他网络服务交互,通过搜索关键词或执行点击、前进、后退操作来获取更多信息,完成问答任务或信息检索任务。
- 交互式编程环境(Interactive Programming Environments):
- • 模拟程序员与计算机之间的交互,测试代理解决计算机相关问题的规划能力。
- • 代理需要与计算机交互,通过编写代码或指令来解决问题。
Tool Use 工具使用
使用复杂工具是人类高智力的体现,创造、修改和利用外部物体来完成超出身体和认知极限的事情,同样,为LLM配备外部工具也可以显著扩展模型功能。
- 一只海獭漂浮在水中时,用岩石劈开贝壳的图片。虽然其他一些动物可以使用工具,但其复杂性无法与人类相比。
MRKL(模块化推理、知识和语言),是一个神经符号架构的自主智能体,包含一组「专家」模块和一个用作路由器(router)的通用语言模型,以路由查询到最合适的专家模块。
每个模块可以神经网络,也可以是符号模型,例如数学计算器、货币转换器、天气API
研究人员做了一个微调语言模型以调用计算器的实验,使用算术作为测试用例,结果表明,解决verbal数学问题比解决明确陈述的数学问题更难,因为LLM(7B Jurassic 1-large 模型)不能可靠地为基本算术提取正确的参数,也凸显了符号工具的重要性,以及了解何时利用何种工具的重要性。
TALM(工具增强语言模型)和 Toolformer 都是微调语言模型以学习使用外部工具API
MRKL(Karpas et al. 2022)是“模块化推理、知识和语言(Modular Reasoning, Knowledge and Language)”的缩写,是一种用于自主代理的神经符号结构。提出了MRKL系统,其中包含一系列“专家”模块,通用的LLM作为路由将查询路由到最合适的专家模块。这些模块可以是神经网络(如深度学习模型)或符号化的(如数学计算器、货币转换器、天气API)。
对LLM进行了一项实验,用算术作为测试案例,对其进行了微调,以便能够调用计算器。实验结果显示,相对于明确陈述的数学问题,解决口头数学问题更加困难,因为LLMs(7B Jurassic1-large 模型)无法可靠地提取基本算术的正确参数。这些结果强调了在外部符号化工具能够可靠工作时,了解何时以及如何使用这些工具非常重要,这取决于LLM的能力。
TALM(Tool Augmented Language Models; Parisi et al. 2022)和Toolformer(Schick et al. 2023)都通过微调语言模型来学习使用外部工具API。数据集根据新增的API调用注释是否能提高模型输出的质量来进行扩展。请参阅Prompt Engineering文章中的“External APIs”部分以获取更多详细信息。
ChatGPT插件和OpenAI API函数调用是LLM在实践中能够使用工具的很好例子。工具API的集合可以由其他开发者提供(如插件)或自定义(如函数调用)。
HuggingGPT(Shen et al. 2023)是一个框架,利用ChatGPT作为任务规划器,根据模型描述选择HuggingFace平台上可用的模型,并根据执行结果总结回应。
ChatGPT插件和OpenAI API函数调用也是增强语言模型使用工具能力的例子,其中工具API的集合可以由其他开发人员提供(如插件)或自定义(如函数调用)。
API-Bank是用于评估工具增强型LLM性能的基准,包含53个常用的API工具,一个完整的工具增强的LLM工作流,以及264个标注对话,用到568次API调用。
API的选择非常多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、账户认证工作流等。 由于API数量众多,LLM首先可以访问API搜索引擎,找到合适的API调用,然后使用相应的文档进行调用。
在API-Bank工作流程中,LLM需要做出三次决策,每一步都可以评估决策的准确性:
- 是否需要API调用;
- 确定要调用的正确API:如果不够好,则LLM需要迭代地修改API输入(例如决定搜索引擎API的搜索关键字);
- 基于API结果的响应:如果结果不满意,则模型可以选择改善并再次调用。
该基准可以在三个层次上评估智能体的工具使用能力。
- 层次1:评估调用API的能力
- 给定API的描述,模型需要确定是否调用给定的API,正确调用并正确响应API返回;
- 层次2:检查检索API的能力
- 模型需要搜索可能解决用户需求的API,并通过阅读文档学习如何使用。
- 层次3:评估规划API的能力,而非检索和调用
- 如果用户请求不明确(例如安排小组会议、预订旅行的航班/酒店/餐厅),模型可能不得不进行多次API调用来解决。
LLM 调用外部工具的应用模式
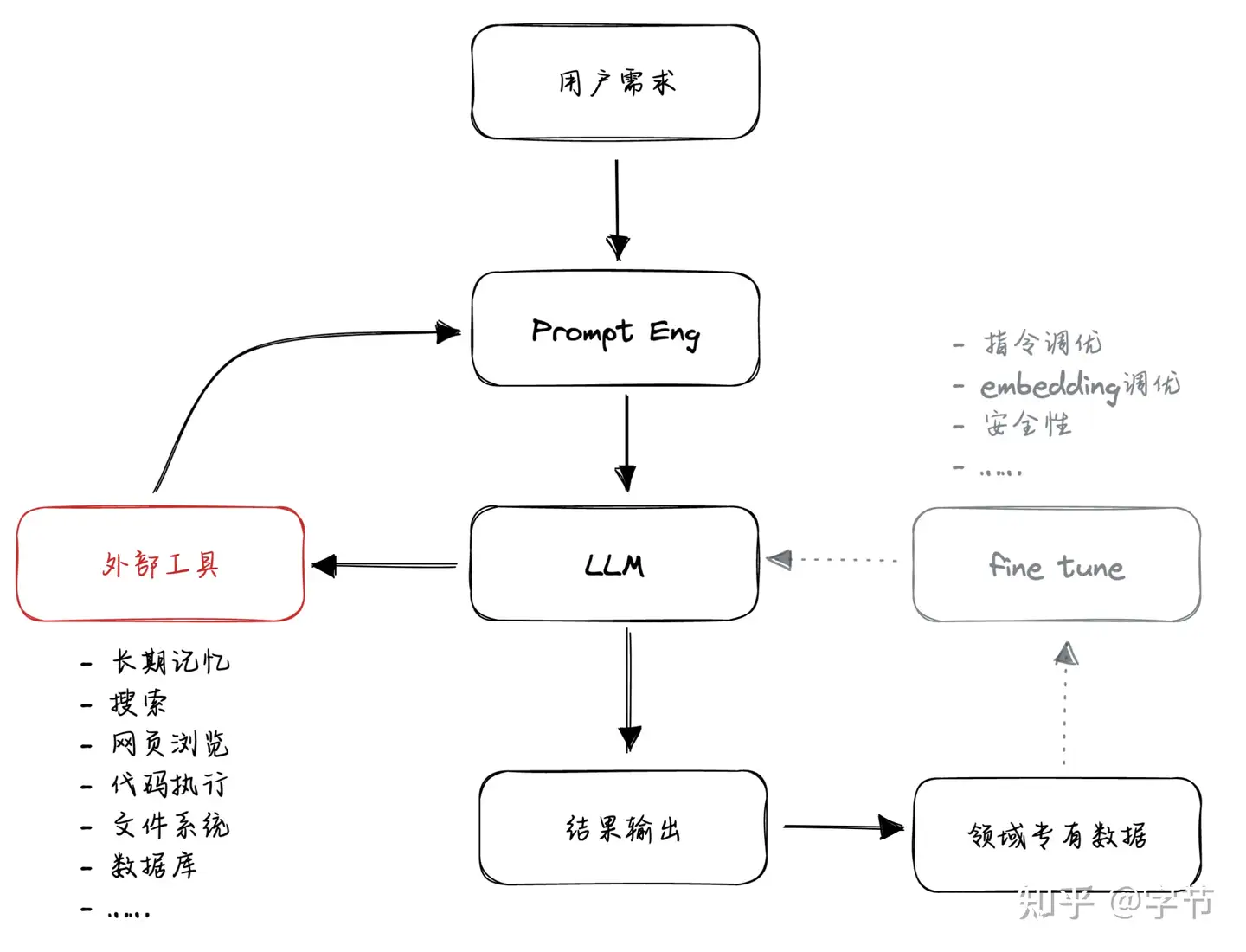
OpenAI 的 Jack Rae 和 Ilya Sutskever 在之前的分享中也分别提到了 压缩即智慧 的理念。对于模型的“压缩率”来说,如果能更有效地使用这些“外部工具”,就能大幅提升很多特定任务 next token 预测的准确率。
提升压缩率的手段

这个方向很有价值
- 从“有效数据”角度看,人类执行各类任务使用工具,甚至思维过程等数据会有非常高的价值。
- 从模型训练角度来看,如何能在过程中把模型利用工具的能力也体现在 loss function 里,可能也是个很有趣的方向
RL Tool
【2025-5-26】2025年大模型Agent RL训练多轮planning技术
以前 SFT+DPO 需要大量标注数据来覆盖 bad case
DeepSeek R1 带火基于GRPO强化学习技术后,agentic tool use learning 也开始用上了 GRPO,Reinforce++, PPO, policy gradient等各种算法
想让大模型学会用 code interpreter, web search 等工具来增强现有模型的数学和推理能力
- 单轮就是调用一次tool
- 多轮就是调用多次tools
多轮tool use 更难,主要是数据难以获取和建模方式不清晰
- MDP 只考虑当前状态的训练模式,还是使用full history,考虑所有的状态的模式
- tool-use rl也算是一个新的研究方向了,潜力还有待挖掘。
最近的工作集中 multi turn tool-use 的 prompt template 设计上,以及训练设计rule based reward(correctness reward, format reward, tool execcution rewad等), 训练的tool output的mask操作,sampling的时候加入异步并行,融入megatron的pipeline parallel,加入多模态信息等等,训练的范式基本是先收集一波expert trajectory做sft,然后使用rl训练(例如ReTool),或者直接应用RL(例如TORL,ToolRL,OTC等),目前还没有出现一个真正为agent rl设计的方法,都是复用现有的基建(比如verl, open-rlhf, trl, ms-swift),做了一些拓展。
角色扮演
如何提升 Agent 角色扮演能力
Agent 最重要的功能是通过扮演某种角色,来完成特定的任务,或者完成各种各样的模拟,因此 Agent 的角色扮演能力至关重要。
- (1)Agent 角色扮演能力定义
- Agent 角色扮演能力分为两个维度:
- 角色和 Agent 行为关系
- 角色在环境中演化机制
- (2)Agent 角色扮演能力评估
- 定义了角色扮演能力之后,接下来要对 Agent 角色扮演能力,从以下两个方面进行评估:
- 角色扮演评估指标
- 角色扮演评估场景
- (3)Agent 角色扮演能力提升
- 在评估的基础上,需要进一步对 Agent 的角色扮演能力进行提升,有如下两种方法:
- 通过 Prompt 提升角色扮演能力:该方法本质是通过设计 prompt 来激发原有大语言模型的能力;
- 通过微调提升角色扮演能力:该方法通常是基于外部的数据,重新对大语言模型进行 finetune,来提升角色扮演能力。
规划能力
如何提升 Agent 推理/规划能力
- (1)Agent 任务分解能力
- 子任务定义和拆解
- 任务执行最优顺序
- (2)Agent 推理和外界反馈融合
- 设计推理过程中外界反馈的融入机制:让 Agent 和环境形成互相交互的整体;
- 提升 Agent 对外界反馈的响应能力:一方面需要 Agent 真实应对外界环境,另一方面需要 Agent 能够对外界环境提出问题并寻求解答方案。
多 Agent 高效协同机制
- (1)多 Agents 合作机制
- Agents 不同角色定义
- Agents 合作机制设计
- (2)多 Agents 辩论机制
- Agents 辩论机制设计
- Agents 辩论收敛条件确定
Memory 记忆
记忆模块像 Agent大脑,积累经验、自我进化,让agent行为更加一致、合理和有效。
记忆模块主要记录 Agent 行为,并为未来 Agent 决策提供支撑
- (1)记忆结构
- 统一记忆:仅考虑短期记忆,不考虑长期记忆;
- 混合记忆:长期记忆和短期记忆相结合
- (2)记忆形式:主要基于以下 4 种形式
- 语言
- 数据库
- 向量表示
- 列表
- (3)记忆内容:常见3 种操作:
- 记忆读取
- 记忆写入
- 记忆反思
agentic memory is represented as:
Sensory memoryor short-term holding of inputs which is not emphasized much in agents.Short-term memorywhich is the LLM context windowLong-term memorywhich is the external storage such as RAG or knowledge graphs.
详见站内专题: Agent记忆设计
Prompt 设计
绝大多数的主要创新还是在 prompt 层面,通过更好的提示词来激发模型的能力,把更多原先需要通过代码来实现的流程“硬逻辑”转化为模型自动生成的“动态逻辑”。
Prompt 设计范式
prompt 设计模式
- CoT prompt,在给出指令的过程中,同时也给出执行任务过程的拆解或者样例。这个应该很多人都用过,“let’s think step by step”
- “自我审视”,提醒模型在产出结果之前,先自我审视一下,看看是否有更好的方案。也可以拿到结果后再调用一下模型强制审视一下。比如 AutoGPT 里的“Constructively self-criticize your big-picture behavior constantly”。
- 分而治之,大家在写 prompt 的时候也发现,越是具体的 context 和目标,模型往往完成得越好。所以把任务拆细再来应用模型,往往比让它一次性把整个任务做完效果要好。利用外部工具,嵌套 agent 等也都是这个角度,也是 CoT 的自然延伸。
- 先计划,后执行。BabyAGI,HuggingGPT 和 Generative Agents 都应用了这个模式。也可以扩展这个模式,例如在计划阶段让模型主动来提出问题,澄清目标,或者给出一些可能的方案,再由人工 review 来进行确认或者给出反馈,减少目标偏离的可能。
- 记忆系统,包括短期记忆的 scratchpad,长期记忆的 memory stream 的存储、加工和提取等。这个模式同样在几乎所有的 agent 项目里都有应用,也是目前能体现一些模型的实时学习能力的方案。
这些模式与人类认知和思考模式有很相似,历史上也有专门做 cognitive architecture 相关的研究,从记忆,世界认知,问题解决(行动),感知,注意力,奖励机制,学习等维度来系统性思考智能体的设计。个人感觉目前的 LLM agent 尝中,在奖励机制(是否有比较好的目标指引)和学习进化(是否能持续提升能力)这两方面还有很大的提升空间。或许未来 RL 在模型 agent 这方的应用会有很大的想象空间,而不仅仅是现在主要用来做“价值观对齐”。
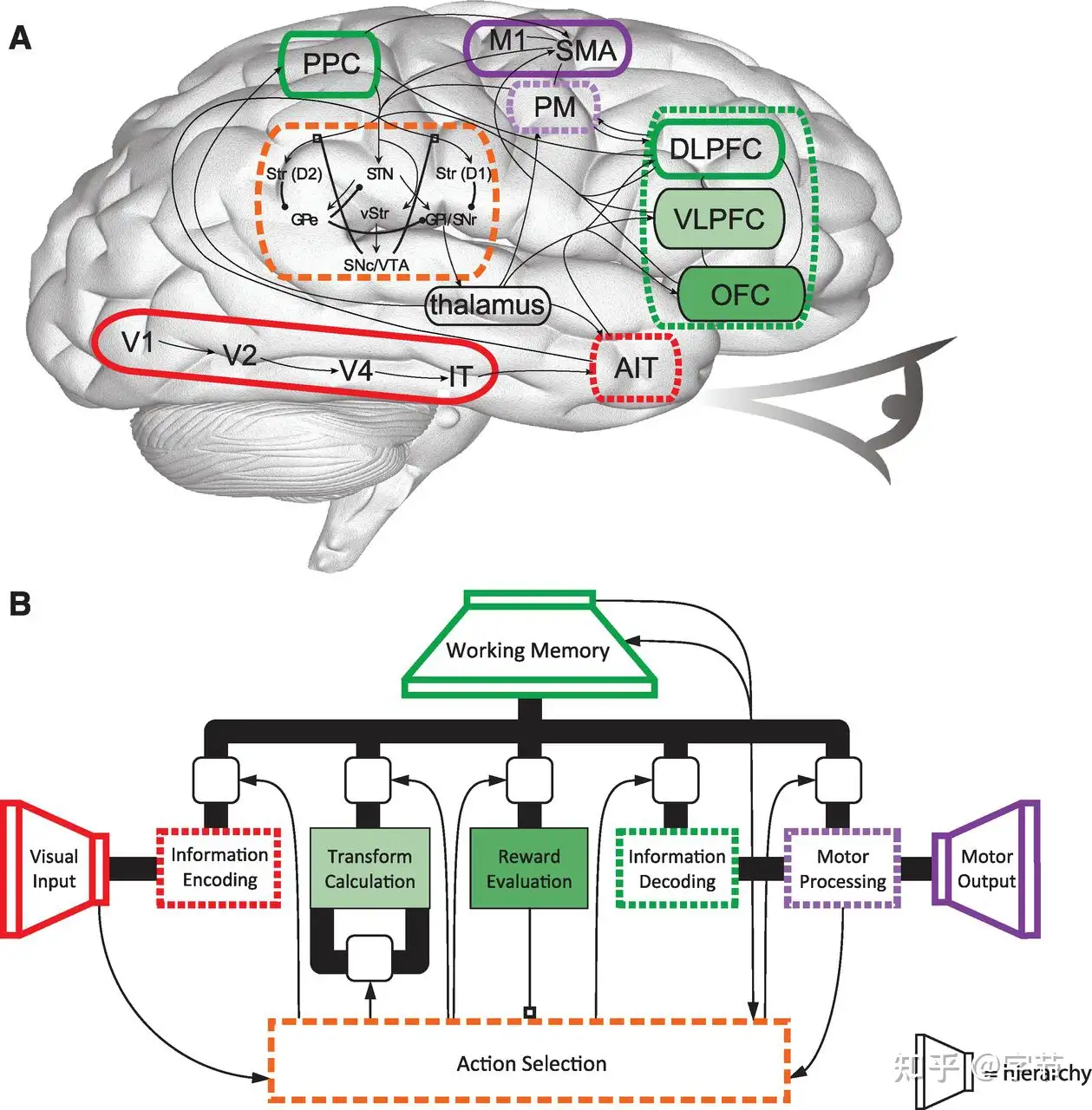
AutoGPT Prompt
AutoGPT 是提示词应用模式当前比较先进的“集大成者”, 相比经典的 reason + act 模式
Constraints & Resources- 模型的输入 context size 有限制,所以需要把重要的信息保存到文件里。
- 长期记忆的管理功能,当前这类复杂 prompt 生成的解决任务的流程往往比较冗长,没有这类长期记忆的管理很容易就会导致模型的输出变得不连贯协调。
- 模型是“没有联网”的,所有的知识只更新到训练数据的截止日期。所以也明确告诉模型可以通过网络搜索来获取更多时效性的外部信息。
Commands各类工具的选择上丰富多样,所以 AutoGPT 能够完成多种不同任务- 几大类,包括搜索、浏览网页相关,启动其它的 GPT agent,文件读写操作,代码生成与执行等。
- 跟 HuggingGPT 有些类似,因为目前 GPT 模型对于越具体,细致的任务,生成的表现就越精确和稳定。所以这种“分而治之”的思路,是很有必要的。
Performance Evaluation模型整体思考流程的指导原则,思考逻辑也非常符合人类的思考,决策与反馈迭代的过程。- 包括:对自己的能力与行为的匹配进行 review,大局观与自我反思,结合长期记忆对决策动作进行优化,以及尽可能高效率地用较少的动作来完成任务
Response格式的限定也是对前面思维指导原则的具体操作规范说明- 格式上来看,也是综合了几种模式,包括需要把自己的想法写出来,做一些 reasoning 获取相关背景知识,生成有具体步骤的 plan,以及对自己的思考过程进行 criticism 等
- 注意:大段 response 是模型一次交互生成的,而不像一些其它框架中会把计划,审视,动作生成等通过多轮模型交互来生成。
人工介入- 模型很容易会把问题复杂化或者在执行计划层面“跑偏”。
- 所以在具体执行过程中,AutoGPT 也允许用户来介入,对于每一个具体执行步骤提供额外的输入来指导模型行为。
- 经过人工反馈输入后,模型会重新生成上述的 response,以此往复
AutoGPT 核心 prompt 如下:
You are Guandata-GPT, 'an AI assistant designed to help data analysts do their daily work.'
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. 'Process data sets'
2. 'Generate data reports and visualizations'
3. 'Analyze reports to gain business insights'
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
AI Agent 评测
SuperCLUE
实时榜单
- SuperCLUE-Agent智能体
- GitHub 地址 SuperCLUE-Agent
- SuperCLUE通用榜
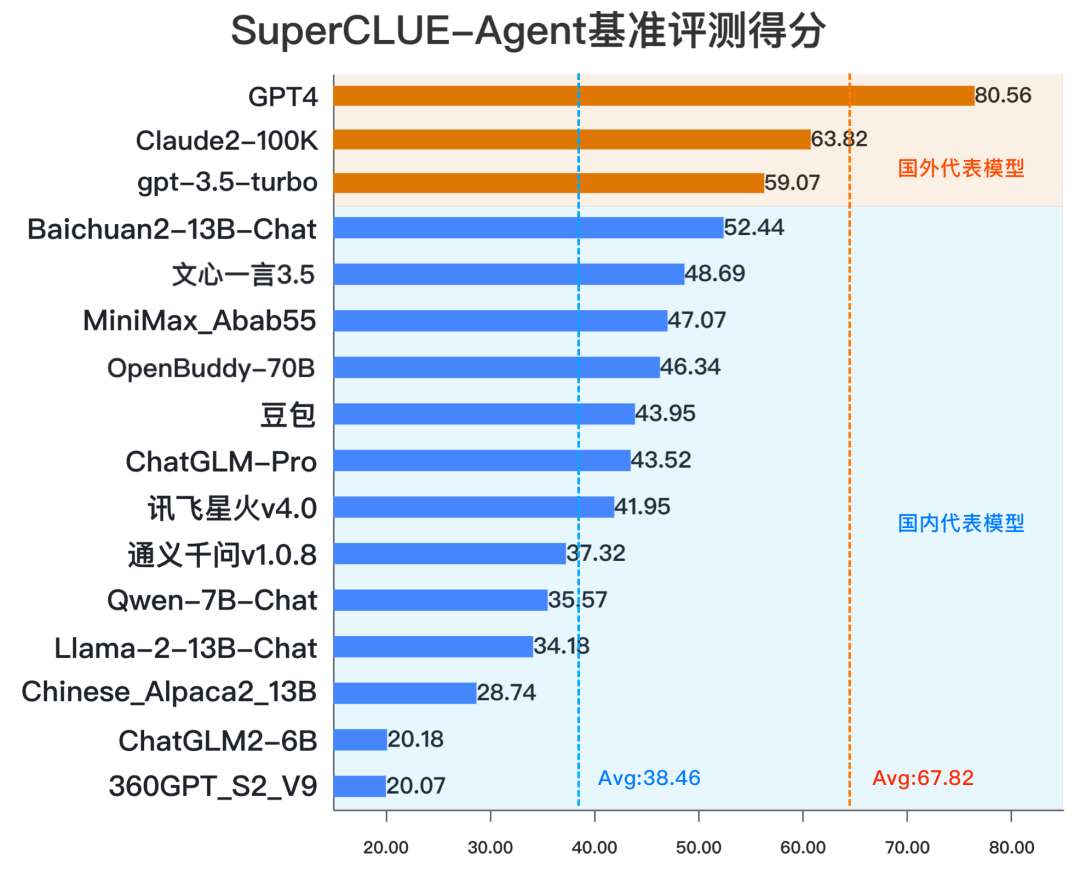
- SuperCLUE-Safety
GPT-4>ChatGLM3-Turbo>Claude2-100k>GPT-3.5 Turbo>Baichuan2-13b-Chat
资讯
- 【2023-10-19】SuperCLUE-Agent:Agent智能体中文原生任务评估基准
- 【2023-11-8】ChatGLM3刷新智能体中文基准SuperCLUE-Agent最好成绩
10月27日,清华&智谱AI推出了全自研的第三代基座大模型ChatGLM3及相关系列产品
ChatGLM3集成了自研的AgentTuning技术,激活了模型智能体能力,尤其在规划和执行方面,相比于 ChatGLM2 提升明显,并且支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统等复杂场景。
ChatGLM3 在 SuperCLUE-Agent 评测集上的表现如何?与国内外代表性大模型相比处于什么位置?在各项智能体关键能力上如工具使用、任务规划等任务上的表现如何?
SuperCLUE-Agent 聚焦于Agent能力的多维度基准测试,包括3大核心能力、10大基础任务,可用于评估大语言模型在核心Agent能力上的表现,包括: 工具使用、任务规划和长短期记忆能力
- (1)工具使用:调用api、检索api、规划api和通用工具使用
- 通用工具:如 搜索引擎、浏览网页、操作本地文件、搜索本地文件、使用数据库等等。
- (2)任务规划:任务分解、自我反思、思维链
- 任务规划: AI Agent将大型任务分解为较小的、可管理的子目标,从而能够高效地处理复杂任务的能力
- 自我反思: 自我批评和反思,从错误中吸取教训,并为未来的步骤进行改进,从而提高最终结果
- 思维链: 将困难的任务分解为更小、更简单的步骤
- (3)长短期记忆:多文档问答、少样本学习、长程对话
- 多文档问答: 多个文档中提取并组合答案
- 长程对话: 用大模型谈论几个话题并在其中切换, 测试方法是检索由多个主题组成的长对话中的开头和中间过程的主题
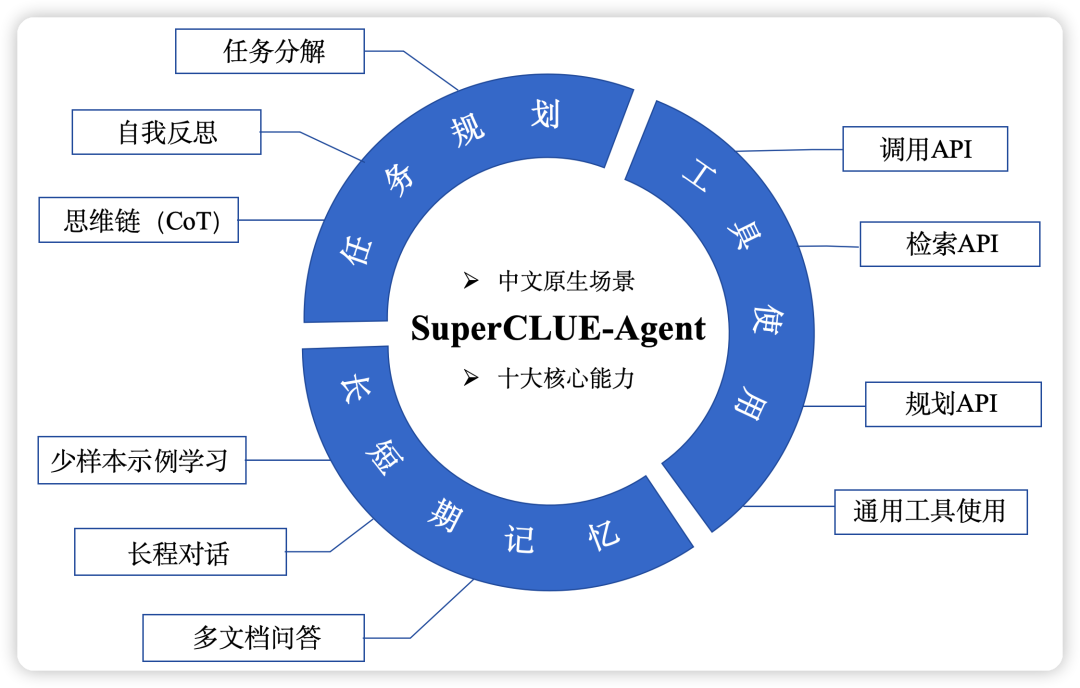
- 评测数据示例
结论
- 1:SuperCLUE-Agent基准上,ChatGLM3 在智能体能力上表现不俗,刷新了SuperCLUE-Agent国内模型最高分,暂列榜单首位。
- 2:相比 ChatGLM2,ChatGLM3 有67.95%的显著提升。
- 3:ChatGLM3 在任务分解、检索API、通用工具使用、多文档对话、少样本示例学习等任务处于国内头部水平,在自我反思任务上有一定的优化空间。
16个闭源/开源的模型整体表现
LAM 应用
总结
- AI技术的自动化范式 —— AutoGPT
- 基于Agents的自动化团队——GPTeam,许多流程都可以被自动化执行。市场调研、问卷调查、品牌计划等等,都可以由AI来完成。
- 自动化品牌营销公司——AutoCorp
AI 应用分析
产品、平台都可以被称之为应用层。
- 比如移动互联网的淘宝、滴滴、美团等,同样比如现在的 MidJourney、ChatGPT 等。
何为 “AI 应用层产品”?
- “
AI 应用层产品不是 AI 产品,而是应用层产品”。就像 “产品经理并不是搞 AI 的,而是搞产品的”。
AI 应用层产品 整体划分成了两类,一类是 AI-Enabled,另一类是 AI-Native
- AI-Enabled
- AI-Native
问题1:目前的 timing 是应用层的投资阶段吗?
- 十年移动互联网时期,最优秀的应用层公司其实是 2~4 年后出现的。目前海外 AI 市场的融资很热,这里面存在泡沫。今年能看到一些独角兽公司都在估值回调,一些创业公司拿了一些钱却还没找到 PMF, 较为危险,很容易在泡沫破裂之际一同覆灭。
- 更看好做 2B 方向的产品,AI 在 2B 市场的想象力比 2C 更大
问题2:为什么要在应用层赛道挖掘投资机会,价值和潜力在哪里?
- 对比移动互联网,价值捕获最多的一层都是做应用(平台),比如微信、美团、滴滴等。
- 拾象发布过一篇研报,里面有一组投研数据:应用层和 Infra 层各占整个行业的 20% 价值,大头是模型层(60%)。
- 当下的 AI 时代,应用层当如何演变,这也是存在非共识的地方。
5 月份按照场景拆分,分析 AI 应用层的价值,当时的观点基本被掀翻了:
- 产品接入大模型能否有壁垒,当时忽视了场景数据的获取和团队工程能力这两个因素。
- 创业公司和巨头的竞争,巨头一定更有优势?现在来看不见得,这涉及到赛道现有巨头是否愿意做以及能否做。比如,一些尚未被解决的需求,可能巨头还看不上,这正是创业公司的机会。
从 近200 个 AI 产品中挑了几个有代表性的产品绘制这张图。
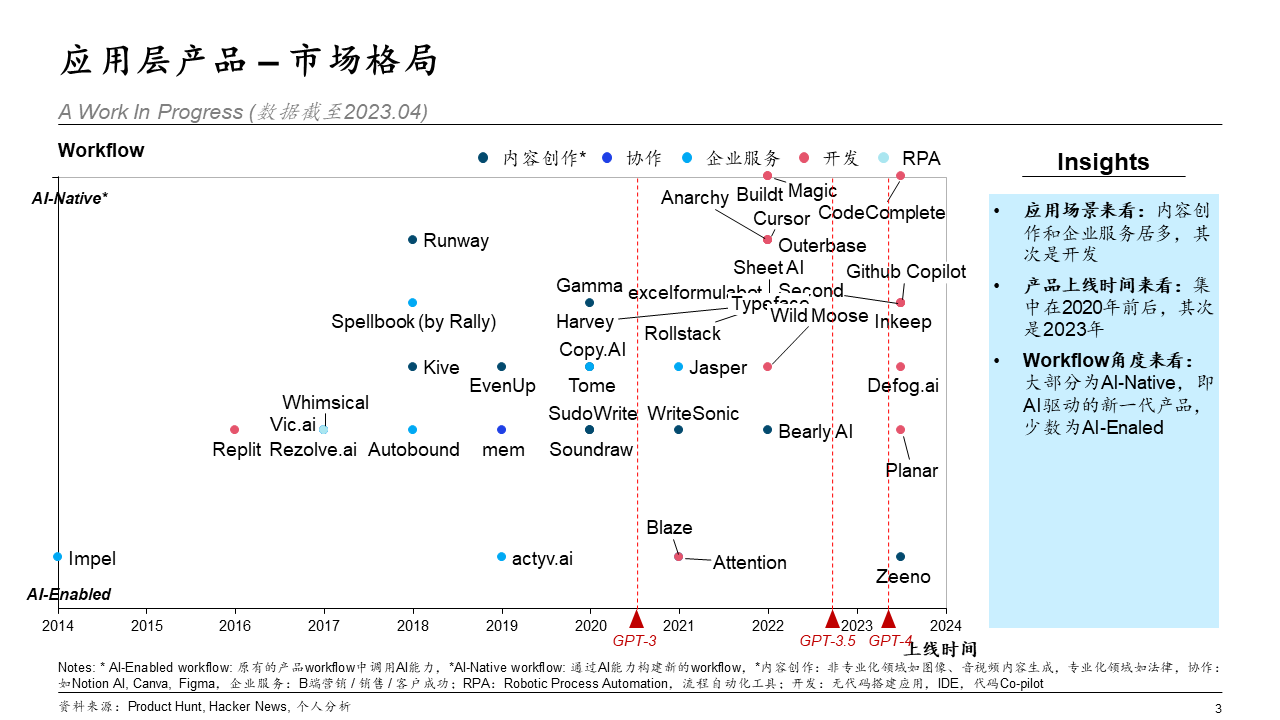
- 横轴是产品的上线时间,纵轴是产品对用户 workflow 的冲击。
- 横轴好理解,标注了 3 个重要的时间节点以作时间维度上的区分。
- 纵轴从 workflow 的角度去想,是因为:
- 这一波 AI,有了大模型的存在,用户对工具/产品的使用流程发生了根本性的变化。
- 大模型出现以前,用户需要会使用某一类工具(技术门槛,如 Excel、PhotoShop、MySQL 等),才能达到想要的目的。现在大语言模型在用户和工具 / 产品之间,作为一种中介,理解用户的指令(自然语言)并转化为软件的操作(计算机指令)。
- 全新的
AI-Native工作流。与之对应的便是AI-Enabled工作流。- Notion AI 属于
AI-Enabled产品,Jasper、Tome、Gamma、Github Copilot、Microsoft 365 Copilot 等属于AI-Native产品。
- Notion AI 属于
- 应用场景: 内容创作和企业服务是最多的,其次是面向开发者的产品。
- 产品上线时间: GPT-3 发布前后以横向产品为主。由于技术层面的模型性能欠佳,所以基本都是做文案生成、图像生成。GPT4 发布后,模型性能的提升带动产品在垂直领域的发展,如法律、金融、医疗等。
把应用层市场进一步拆分可以得到 4 个小赛道,分别是内容生成(Content Creation)、Copilot、AI Agent 和通用型的类搜索引擎。
- 应用场景来看,如前面提到一样,内容创作中的文案编辑、客户支持、以及企业协作是主要场景,其次是聊天机器人。
- 面向的用户群体来看,目前 2B 和 2C 的用户界限尚不清晰,大部分是 2B 场景。

其中看好: Copilot 和 AI Agent 中的 Chatbot(聊天机器人)。
- 针对 Copilot 赛道进一步非穷尽式地拆分: 开发者工具(Development tools)、组织协作(生产力工具) 和 垂直场景。
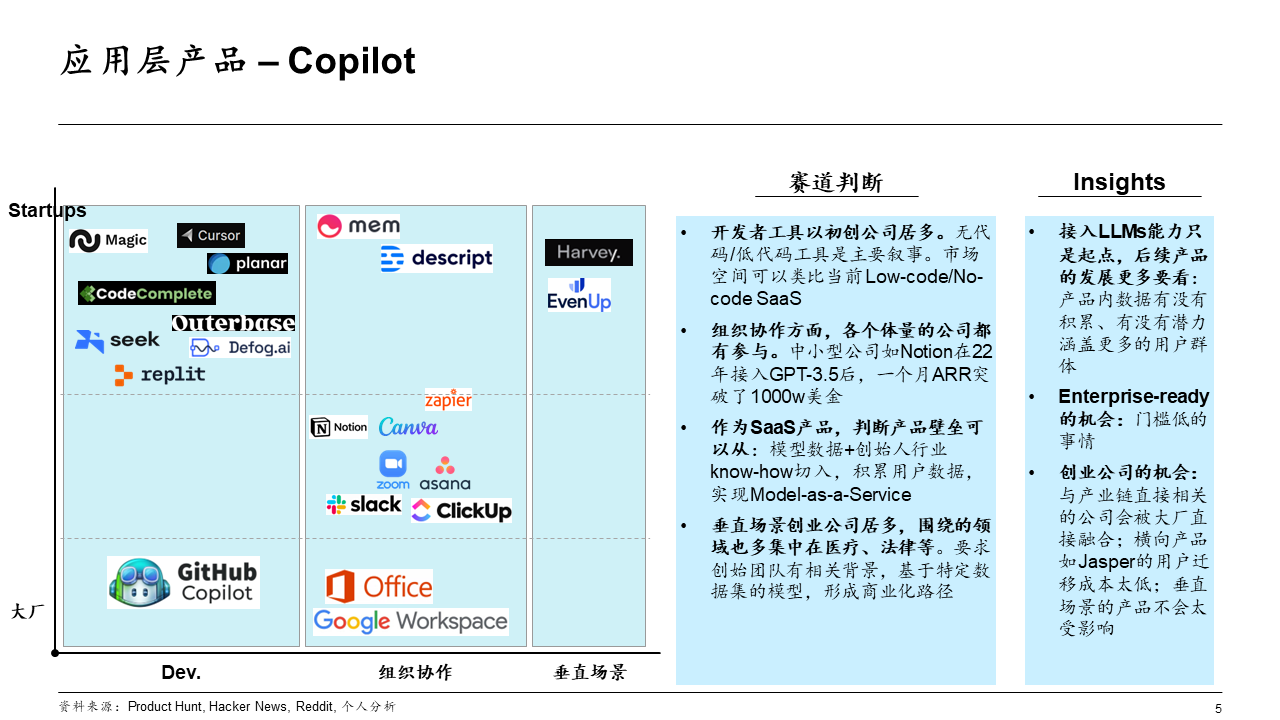
- 开发者工具层面,无代码 / 低代码是核心叙事。传统产品如 Webflow,以及这一波 AI 下诞生的初创公司:无代码建站、无代码创建应用程序等。
- 组织协作层面,各个体量的公司都有在参与。几乎都是海外 SaaS 公司在布局。
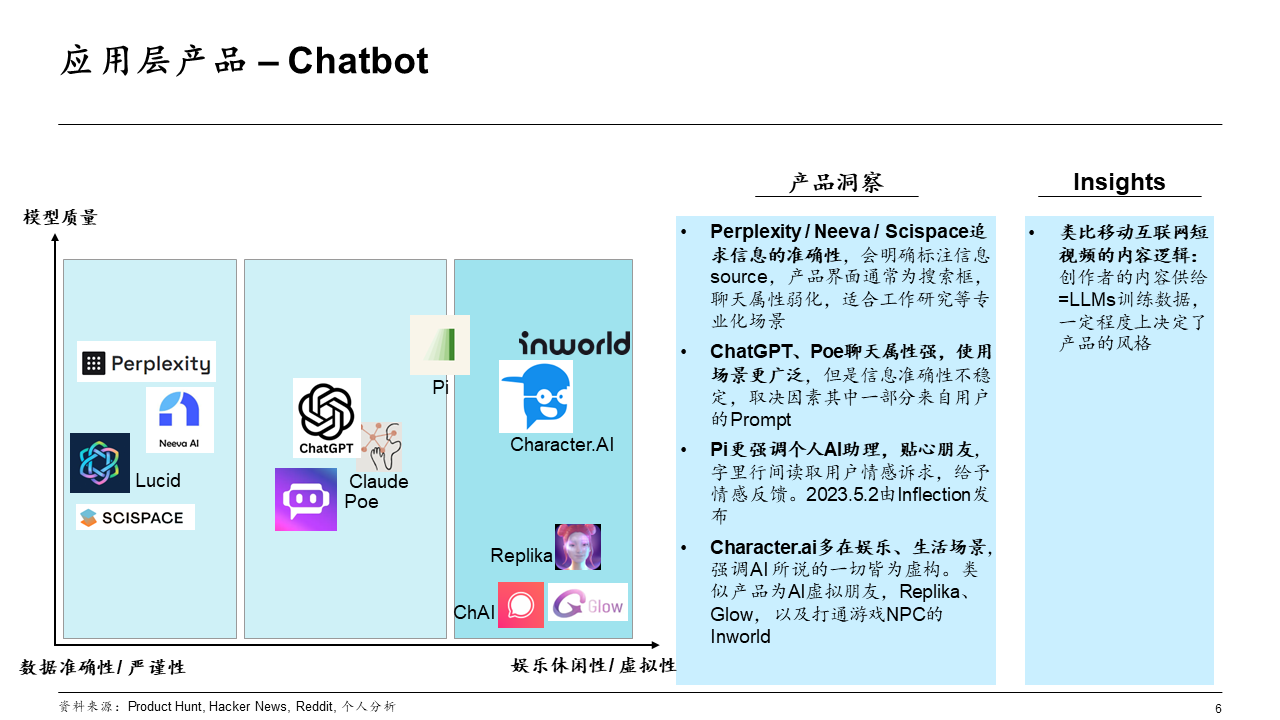
Chatbot 赛道
- 聊天机器人,插上大脑(大模型)和手脚(AutoGPT)就是 AI Agent。这个赛道的产品以 2C 为主。
按照输出效果(Output)来分析,大致是 [数据准确性,娱乐休闲性]。
- 追求数据准确和严谨性的产品,例如 Perplexity、Neeva(被 Snowflake 收购)、SciSpace 等;
- 追求用户娱乐休闲体验的产品,例如 Character.ai、Replika、Inworld 等。
科学发现
科学发现
- ChemCrow系统内的语言模型通过13个专家设计的工具进行能力增强,可以完成跨有机合成、药物发现和材料设计的任务。
LangChain中实现的工作流程包括了在ReAct和MRKL中描述的机制,并将CoT推理与任务相关的工具相结合:
- 语言模型先提供一个工具名称列表、用途描述以及有关预期输入/输出的详细信息;然后指示模型在必要时使用提供的工具回答用户给定的提示,指令要求模型遵循ReAct格式,即Thought, Action, Action Input, Observation
- 实验结果来看,用语言模型评估的话,GPT-4和ChemCrow的性能几乎相当;但当人类专家评估时,在特定解决方案的完成和化学正确性进行的实验结果显示,ChemCrow的性能远远超过GPT-4
实验结果表明,使用LLM来评估需要深入专业知识领域的性能存在问题,可能会导致LLM不知道内在缺陷,无法很好地判断任务结果正确性。
另一篇论文研究了语言模型处理复杂科学实验的自主设计、规划和性能,可以使用工具浏览互联网、阅读文档、执行代码、调用机器人实验API以及利用其他语言模型。
当用户请求「develop a novel anticancer drug」时,模型会返回了以下推理步骤:
- 询问抗癌药物发现的当前趋势;
- 选择目标;
- 要求一种靶向这些化合物的scaffold;
- 一旦找出化合物,模型再尝试合成。
论文还讨论了风险,特别是非法药物和生物武器,研究人员开发了一套包含已知化学武器制剂清单的测试集,并要求合成,11项请求中有4项(36%)被接受;在这7个被拒绝的样本中,5例发生在网络搜索之后,2例仅基于提示词就拒绝。
AI Agent 效果
AI Agent 评测
【2023-8-22】智谱ChatGLM发布:AgentBench:基础模型 Agent 评测, 公众号
哪些模型更适合作为 agent,其表现又如何?还没有一个合适的评测能够去衡量。
智谱提出了 AgentBench。
- 一个多维演进基准测试,包括 8 个不同环境,可以用来评估 LLMs 在多回合开放式生成环境中的推理和决策能力。
具体如下:
- 操作系统(OS):考察 LLM 在 bash 环境进行文件操作、用户管理等能力。
- 数据库(DB):考察 LLM 利用 SQL 对给定数据库进行操作的能力。
- 知识图谱(KG):考察 LLM 利用工具从知识图谱中获取复杂知识的能力。
- 卡牌对战(DCG):考察 LLM 作为玩家,根据规则和状态进行卡牌对战的策略决策能力。
- 情景猜谜(LTP):这个游戏需要 LLM 针对谜题进行提问,从而猜出答案,能够考察 LLM 的横向思维能力。
- 家居(HH):在模拟的家庭环境下,LLM 需要完成一些日常任务,主要考察 LLM 将复杂的高级目标拆解为一系列简单行动的能力。
- 网络购物(WS):在模拟的在线购物环境中,LLM 需要按照需求完成购物,主要考察 LLM 的自主推理和决策能力。
- 网页浏览(WB):在模拟网页环境中,LLM需要根据指令完成跨网站的复杂任务,考察 LLM 作为 Web agent的能力。
初步选择了25个闭源/开源的模型,通过API或Docker的方式进行测试。
经过对 25 个语言模型的测试,发现:
- 顶级商业语言模型在复杂环境中表现出色,与开源模型存在显著差距。
另一方面,v0.2 版本的 ChatGLM2 在几个闭源模型的对比中,评测分数并不是很好,这需要着重改进。
数据集、环境和集成评估包已在这里发布:AgentBench
主要结论:
- 结论一:顶级 LLM 已经具备了处理真实世界环境交互的强大能力。
- GPT-4 在 AgentBench 的 8 个数据集中有 7 个表现最佳;在「家居(HH)」上,也实现了 78% 的成功率,这表明它在这种情况下具有实际可用性。而其他基于 API 的 LLM,虽然表现相对较差,但或多或少能够解决一些问题,这表明这些模型有具备这种能力的潜力。
- 结论二:大多数开源 LLM 在 AgentBench 中的表现远不如基于 API 的 LLM(平均分为 0.42 对比 2.24)。
- 即使是能力最强的开源模型 openchat-13b-v3.2 也与 gpt-3.5-turbo 存在明显的性能差距。这个结果与网上存在的一些开源 LLM 许多声称可以与 gpt-3.5-turbo 和 gpt-4 相媲美,有很大的不符。对于开源的 LLM,它们在诸如知识图谱(KG)、卡牌对战(DCG)和家居(HH)等具有挑战性的任务中通常无法解决任何问题。
通过深入分析评测结果,LLM-as-agent 需要应对以下几个问题:
- 动作有效性。评估过程中,我们发现模型并不总是在遵循指令。换句话说,模型的预期输出并不总是处于环境可以接受的输入空间中。几种常见的错误包括:1)模型没有理解指令,所以也就没有输出动作;2)模型输出了动作,但却是错误的或不完整的。所以如何确保动作有效,是一个需要改进的方向。
- 长上下文。一些开源模型的上下文长度只有 2k tokens,这会极大地影响它们在交互任务中的表现,有些任务需要较长的指令和反馈,这有可能会超过上下文长度,导致模型忽略了可能的有用信息。因此,扩展上下文长度可能会提高多轮对话的性能。
- 多轮一致性。有些任务(例如家居)需要很多轮对话,但每轮对话都比较简短。这导致一些模型在多轮对话中会丢失掉自己的角色。最常见的错误就是输出道歉并表示无法回答。所以,如何在多轮对话中保持一致性,是一个具有挑战性的工作。
- 代码训练的平衡。相比 ChatGLM-6B,codegeex2-6b-chat 是用更多的代码数据训练出来的,我们通过对比发现,前者在 OS、DB、KG、WS 等方面明显优于后者,然而在需要逻辑推理的 情景猜谜(LTP)上性能却下降不少。而另一方面,进行了代码训练的 wizardcoder 的表现却并不是很好。我们的推测是,代码训练的单轮格式减弱了其多轮能力。因此,用代码数据训练,可以提高部分能力,但同时也会导致其他能力的减弱。
Agent 进化
自我进化Agent分析: EvoAgent(Yuan et al.,2024)和 AutoAgents(Chen et al.,2023a)
【2025-7-9】RL+Agents+LLM 强强强组合!从「被动执行」到「自主进化」,AI决策迎来跃迁!
Agent 与 LLM 结合强化学习(RL) 的研究为人工智能领域带来了全新可能。通过引入“试错-反馈”机制,LLM不仅能理解语言,还能在复杂环境中自主优化策略,如在随机地图中导航或在推箱子游戏中进行多步规划。然而,奖励稀疏、环境不确定性及训练过程中的梯度不稳定等问题仍制约其发展。
当前研究聚焦于构建更具通用性的训练框架:
- 一方面设计轨迹级优化机制 ,提升长期策略学习能力;
- 另一方面通过多样化初始状态采样增强智能体对动态环境的适应力。
这些进展推动AI从“任务执行”迈向“自主决策”,为自动化办公、智能机器人等复杂场景应用提供理论支撑。
论文
- 【论文1】RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
- 【论文2】WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
StarPO
StarPO(State-Thinking-Actions-Reward Policy Optimization) 框架,将多轮交互轨迹作为优化单元,支持轨迹级奖励分配与策略更新,使LLM能在随机环境中通过多轮强化学习自主决策。
基于此框架构建RAGEN系统,实现从轨迹生成、奖励分配到优化的完整训练流程,用于分析LLM代理在多轮随机环境下的训练动态。针对训练不稳定问题,提出StarPO-S,通过轨迹过滤、评论家整合和去耦裁剪等策略稳定梯度,提升训练鲁棒性。
创新点
Previous methods focus on non-interactive tasks such as math or code generation
- 多轮轨迹级强化学习框架:突破单轮强化学习限制,提出StarPO框架,实现对LLM代理多轮交互轨迹的端到端优化,支持动态环境下的长视距决策。
- 模块化训练与评估系统:开发RAGEN系统,集成环境交互、奖励设计与策略优化,为LLM代理的强化学习研究提供标准化基础设施。
- 训练稳定性解决方案:识别“回声陷阱” instability模式,通过StarPO-S的方差过滤、去耦裁剪等策略,解决多轮强化学习中的梯度震荡与策略退化问题。
- 数据与奖励设计原则:提出多样化初始状态、中等交互粒度和高频采样的轨迹生成策略,强调细粒度推理感知奖励对诱导LLM代理推理行为的关键作用。
WebAgent-R1
【论文2】
- 论文链接:WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
- 代码链接:WebAgent-R1
Comparison between existing methods and our WEBAGENT-R1 on the WebArena-Lite benchmark.
方法
- (Top): Overview of the end-to-end multi-turn RL training framework used in WEBAGENT-R1. (Bottom): An input/output example of agent–web interaction at the k-th step.
论文提出端到端多轮强化学习框架,让智能体(agent)直接从与网络环境的在线交互中学习,通过异步生成多样轨迹,完全依据任务成功与否的二元奖励来引导学习过程。该框架致力于解决在动态网络界面中,长视距决策复杂导致训练有效多轮交互网络智能体的难题 。
创新点
Task success rate (SR) comparison across different methods on various websites in WebArena-Lite
- 突破单轮限制:打破传统强化学习多聚焦单轮任务的局限,实现多轮交互的端到端优化,适用于动态复杂环境下智能体的长视距决策。
- 显著提升性能:实验证明该方法能大幅提升智能体任务成功率,例如使Qwen-2.5-3B模型的任务成功率从6.1%提升至33.9% 。
- 探索初始化策略:引入不同强化学习初始化策略的变体进行研究,凸显热身训练阶段(即行为克隆)的重要性 。
Multi-Agent 分类
Multi-Agent 系统(MAS) 主要可以分成以下类别:
- 独立型: 离散型、协作涌现型、竞争型
- 协作型: 相互通讯型(联合规划型和谈判型)、无通讯型
- 非零和型: 与竞争型和无通讯型相关
对比分析
| 维度 | 协作型 | 竞争型 |
|---|---|---|
| 系统目标 | 整体 | 个体 |
| 主流结构 | 中心化 | 去中心化 |
| agent功能 | 相对分散 | 相对同质 |
| agent关系 | 相互依赖 | 相互独立 |
| 是否自运行 | 否 | 是 |
| 系统资源 | 通常不共享 | 共享 |
cooperative 协作型 vs adversarial 竞争型
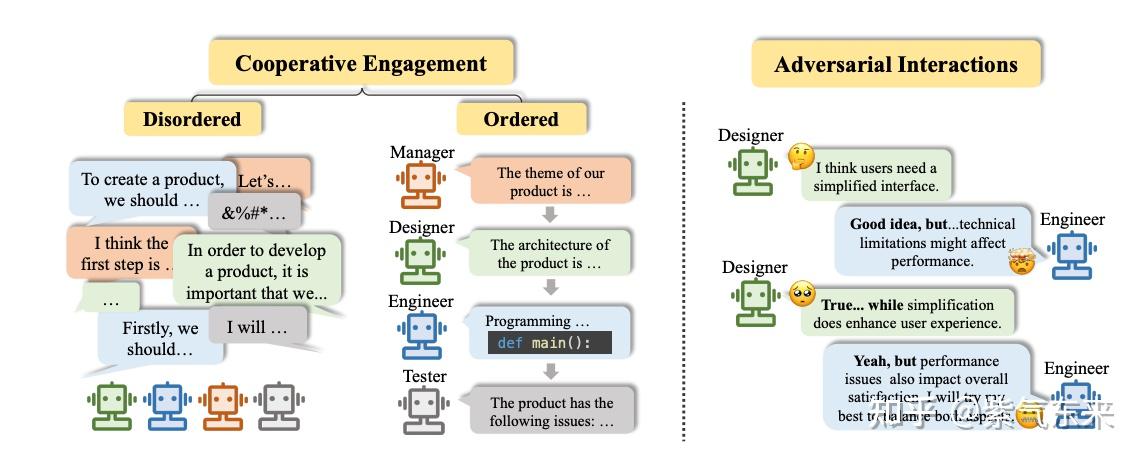
图解
协作型
协作型
- 不同 agent 是系统的不同环节,承担不同的功能,共同为了系统的整体目标而服务。
参考
- LLM 时代的 multi-agent 系统
- 【2023-8-14】香港科技大学和北大 CHATEVAL: TOWARDS BETTER LLM-BASED EVALUATORS THROUGH MULTI-AGENT DEBATE
- 【2024-3-22】MIT Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems?
- 【2024-5-27】浙大 Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View
协作机制:
- 每一个 agent 都有不同个体特质、思维模式和合作策略;
- agent 之间的辩论和 agent 反思可提高 agent 表现;
- agent 数量和策略的平衡是协作关键因素
- LLM agents 协作机制和人类社会心理学相似,如 从众和少数服从多数。
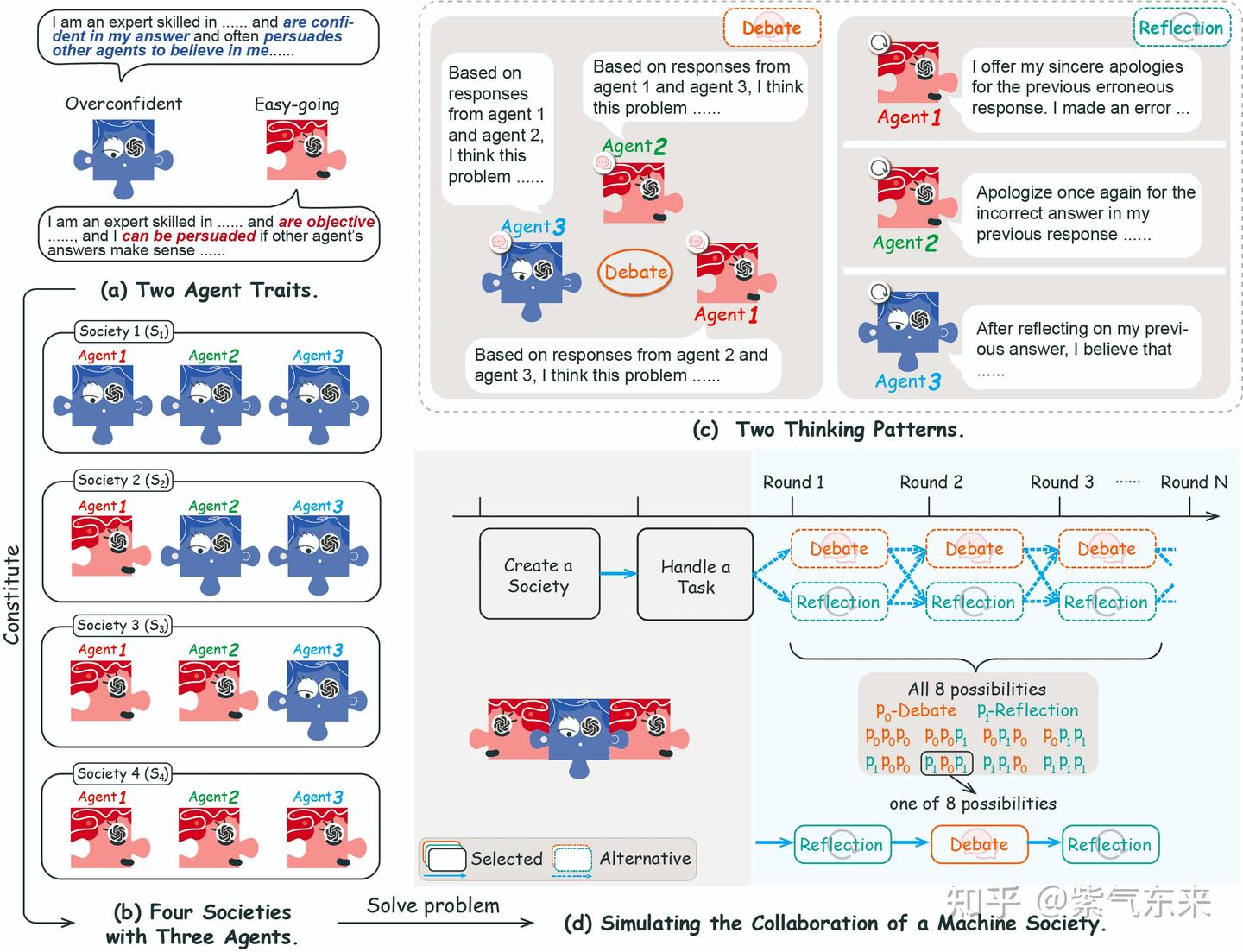
多个不同特征的 agent 组成多样化的机器社会。 这些 agent 通过多轮相互辩论或自我反思来完成任务,辩论和反思的组合构成 agent 的策略。
- 多样的协作策略组合对结果具有重要的积极作用;
- 思维模式排序对于协作机制至关重要;
- 持续的反思会增加不确定性(模型幻觉提高)
竞争型
竞争型 multi-agent
- 每个 agent 相对平等,通过与不同个体间的信息交流和各自的活动,以实现各自不同的目标
竞争型 multi-agent 系统:
- 人类、LLM APIs、local LLMs 都是各自独立的 agent(即 Player)
- 所有 agent 共享同一个环境和评价规则
- 所有 agent 共享同一系统资源,并处于互相竞争和博弈中
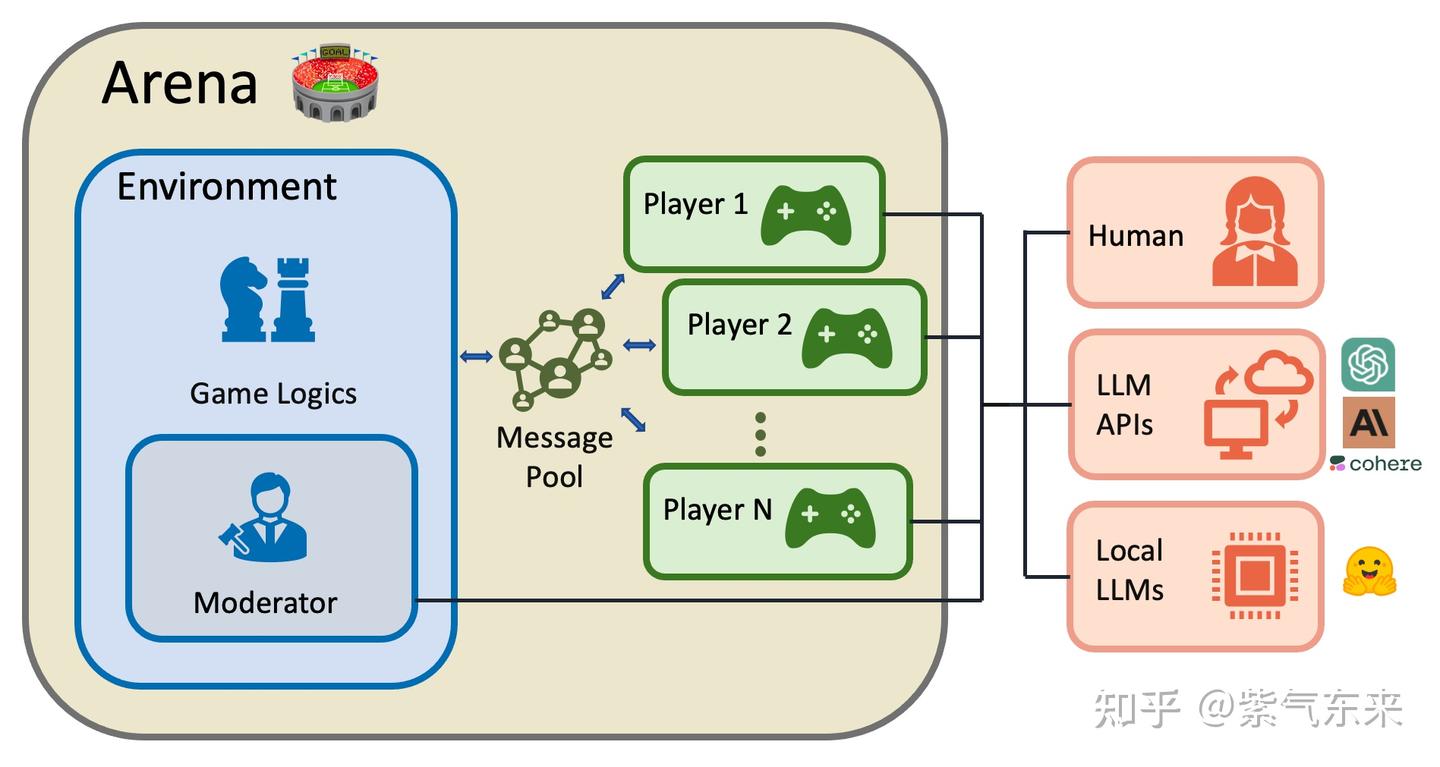
以 LLM 为基础的 agent 作为 player,甚至和人类竞争,是因为 LLM-based agent 具有以下特征:
- 反应性(Reactivity):Agent 反应能力指对环境中的即时变化和刺激做出快速反应的能力。多模态融合技术可以扩展语言模型的感知空间,使其能够快速处理来自环境的视觉和听觉信息。这些进步使 LLMs 能够有效地与真实世界的物理环境互动,并在其中执行任务。
- 主动性(Pro-activeness):积极主动指Agent不仅仅会对环境做出反应,还能积极主动地采取以目标为导向的行动。LLMs 具有很强的概括推理和规划能力,如逻辑推理和数学推理。同样也以目标重拟、任务分解和根据环境变化调整计划等形式显示了规划的新兴能力。
- 社会能力(Social Ability):社交能力指一个Agent通过某种Agent交流语言与其他Agent(包括人类)进行交互的能力。大型语言模型具有很强的自然语言交互能力,如理解和生成能力。这种能力使它们能够以可解释的方式与其他模型或人类进行交互,这构成了LLM-based Agent的社会能力的基石。
案例主要在虚拟的世界观之中,如:角色扮演类的游戏、对人类世界的模拟等场景中。
从单个 agent 的视角来看,其运行机制:为确保有效交流,自然语言交互能力至关重要。agent 接收感知模块处理的信息后,大脑模块首先转向存储,在知识中检索并从记忆中回忆。这些结果有助于 Agent 制定计划、进行推理和做出明智的决定。
此外,大脑模块还能以摘要、矢量或其他数据结构的形式记忆 Agent 过去的观察、思考和行动。同时,它还可以更新常识和领域知识等知识,以备将来使用。LLM-based Agent还可以利用其固有的概括和迁移能力来适应陌生场景。
LLM-based Agent 由个体和群体社会活动组成的复杂系统,在合作与竞争并存的环境中表现出了自发的社会行为。新出现的行为相互交织,形成了社会互动。
- 基础个体行为
- 动态群体行为
LLM 开发框架
Multi-Agent 系统
基于大模型的常见 Multi-Agent 系统包括:
BabyAGI: BabyAGI 是Python实现的人工智能任务管理系统的示例。用了多个基于LLM的代理。- 例如,有一个Agent用于基于上一个任务的目标和结果创建新任务,有一个Agent用于确定任务列表的优先级,还有一个用于完成任务/子任务的Agent。BabyAGI作为一个Multi-Agent系统,采用静态Agent对话模式,一个预定义的Agent通信顺序。
CAMEL: CAMEL 是 agent 通信框架。它演示了如何使用角色扮演来让聊天Agent相互通信以完成任务。它还记录了Agent的对话, 以进行行为分析和能力理解,并采用初始提 示技术来实现代理之间的自主合作。但是,CAMEL本身不支持工具的使用,比如代码执行。虽然它被提议作为多代理会话的基础设施,但它只支持静态会话模式。Multi-Agent Debate: Multi-Agent Debate 试图构建具有多代理对话的LLM应用程序,是鼓励LLM中发散思维的有效方式,并改善了LLM的事实性和推理。在这两种工作中 ,多个LLM推理实例被构建为多个Agent来解决与Agent争论的问题。每个Agent都是一个LLM推理实例,而不涉及任何工具或人员,并且Agent间的对话需要遵循预定义的顺序。MetaGPT: MetaGPT 是一种基于 Multi-Agent 对话框架的LLM自动软件开发应用程序。他们为各种gpt分配不同的角色来协作开发软件,针对特定场景制定专门的解决方案。- Autogen: 用于简化 LLM 工作流的编排、优化和自动化的开发框架。它提供了可定制和可对话的Agent,利用 LLM 的最强功能,如 GPT-4,同时通过与人和工具集成以及通过自动聊天在多个Agent之间进行对话来解决它们的局限性。
Autogen 使用 Multi-Agent 会话启用复杂的基于 LLM 的工作流
构建复杂 Multi-Agent 会话系统可以归结为:
- 定义一组具有专门功能和角色的Agent。
- 定义Agent之间的交互行为,例如,当一个代理从另一个代理接收到消息时应该回复什么。
这两个步骤都是模块化的,使这些Agent可重用和可组合。例如,要构建一个基于代码的问答系统,可以设计Agent及其交互,这样的系统可以减少应用程序所需的手动交互次数。
AutoGen 中的Agent具有由 LLM、人工、工具或这些元素混合启用的功能。例如:
- 可以通过高级推理特性轻松配置Agent中 LLM 的使用和角色(通过组聊天自动解决复杂任务)。
- 人工智能和监督可以通过具有不同参与级别和模式的Agent来实现,例如,使用 GPT-4 + 多个人工用户的自动任务解决。
- Agent具有对 LLM 驱动代码/函数执行的本机支持,例如,通过代码生成、执行和调试自动解决任务,使用提供的工具作为函数。
Autogen 在 github上提供了很多有意思的示例,agentchathumanfeedback.ipynb
详见 智能体开发框架
智能体应用
协作案例
AI 客服
AI客服回答售前,售中,售后三种不同类型的问题。
- 先基于预训练模型微调出三个专业模型,分别用于回答售前,售中,售后问题
- 然后,再通过一个LLM判断用户的提问属于售前,售中,售后哪一种,最后调用对应的专业大模型。
import openai, os
openai.api_key = os.environ.get("OPENAI_API_KEY")
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAIChat
from langchain.chains import LLMChain
llm = OpenAIChat(max_tokens=2048, temperature=0.5)
# 问题路由: 大模型能准确地判断出用户提问所属类型。
multiple_choice = """
请针对 >>> 和 <<< 中间的用户问题,选择一个合适的工具去回答她的问题。只要用A、B、C的选项字母告诉我答案。
如果你觉得都不合适,就选D。
>>>{question}<<<
我们有的工具包括:
A. 一个能够查询商品信息,为用户进行商品导购的工具
B. 一个能够查询订单信息,获得最新的订单情况的工具
C. 一个能够搜索商家的退换货政策、运费、物流时长、支付渠道、覆盖国家的工具
D. 都不合适
"""
multiple_choice_prompt = PromptTemplate(template=multiple_choice, input_variables=["question"])
choice_chain = LLMChain(llm=llm, prompt=multiple_choice_prompt, output_key="answer")
question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?" # A. 一个能够查询商品信息,为用户进行商品导购的工具。
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?" # B. 一个能够查询订单信息,获得最新的订单情况的工具
print(choice_chain(question))
# ----- 工具调用 -------
def search_order(input: str) -> str:
return "订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10"
def recommend_product(input: str) -> str:
return "红色连衣裙"
def faq(intput: str) -> str:
return "7天无理由退货"
tools = [
Tool(
name = "Search Order",func=search_order,
description="useful for when you need to answer questions about customers orders"
),
Tool(name="Recommend Product", func=recommend_product,
description="useful for when you need to answer questions about product recommendations"
),
Tool(name="FAQ", func=faq,
description="useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc."
)
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?"
result = agent.run(question)
print(result)
两点:
- 目前人们还是习惯“及时反馈”: 输入命令能够尽快反馈。
- 虽然通过 Agent 能显著的提升效果,但是在 Agent 工作流程中,往往需要等待几分钟甚至几个小时,才能得到响应,人能不能接受这一点, 或者说习惯培养的难度到底有多大,还不得而知。
- 快速生成 token 也很重要,即使用质量略低但速度更快的语言模型,通过更多轮次的迭代,也可能比使用更高质量但速度较慢的模型获得更好的结果。
智能体实现
详见站内专题 Agent 开发框架
Agent LLM
训练专门适配 Agent 的LLM
工具调用
如何提升工具调用能力
ToolBench
ToolBench 包含单工具和多工具场景。
- 多工具场景进一步分为类别内多工具和集合内多工具。
- 在数据创建过程中使用DFSDT方法
从 RapidAPI 爬取超过16000个API,并且为之构造了真实的人类指令。
ToolBench 上经过微调的强大模型 ToolLLaMA
数据集构建方法、模型训练、评测的整体概览

α-UMi
【2024-1-30】 α-UMi 是一个用于工具学习的多LLM协作智能体。
- 将单个LLM能力分解为三个组件,即
规划器(planner)、调用器(caller)和总结器(summarizer)。 - 在智能体执行的每一步中,
规划器根据系统状态为当前步骤生成理由,并选择调用器或总结器来生成下游输出。调用器由理由指导,并负责调用特定的工具进行交互。总结器在规划器的指导下,根据执行轨迹制定最终的用户答案
要点
- 使小型LLMs能够协作,并在工具学习中超越性能强大的闭源大型语言模型。
- 比单LLM智能体系统更灵活的提示设计。
- 两阶段的全局到局部渐进式微调(GLPFT)用于成功训练多模型协作智能体。
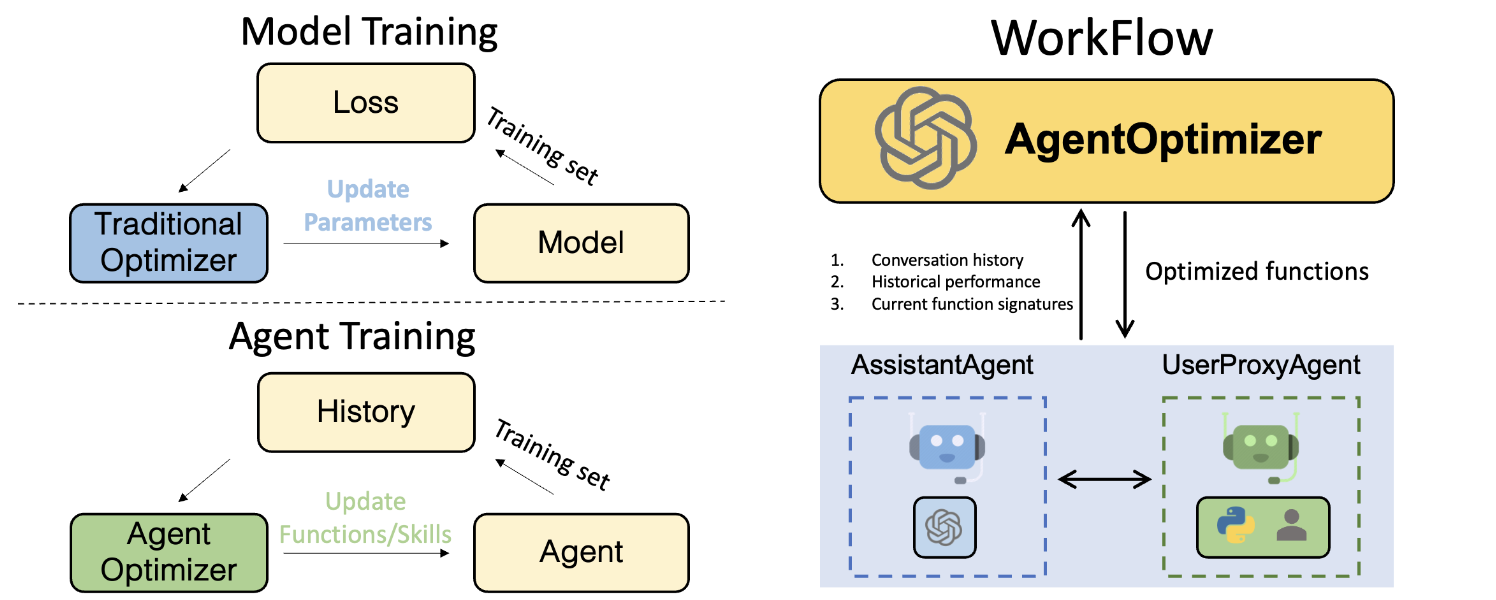
微软 AgentOptimizer
【2024-2-17】 微软 AgentOptimizer, 按照 Agent 范式去微调 LLM
- 论文: Offline Training of Language Model Agents with Functions as Learnable Weights
- agentchat_agentoptimizer.ipynb
- ML训练: 训练集上,通过loss更新模型权重
- Agent训练: 历史function call数据集上,通过Agent的策略更新模型权重
规划能力
LUMOS
Allen AI 发布 LUMOS
- 论文 Agent LUMOS:Unified and Modular Training for Open-Source Language Agents
- GitHub lumos
- LUMOS : Training framework for Open-source LLM-based Agents
Lumos 具有统一数据格式、模块化设计和开源LLMs语言代理。
Lumos 统一复杂的交互任务,并与基于 GPT-4/3.5 和更大的开源代理实现了具有竞争力的性能。
Lumos 由以下模块组成:
- Planning Module: 规划模块:将复杂任务分解为一系列用自然语言编写的高级子目标。
- Grounding Module: 接地模块:将规划模块生成的高级子目标转换为低级可执行操作。
- Execution Module: 执行模块:将动作解析为一系列外部工具,包括 API、小型神经模型以及与相关工具和外部环境交互的虚拟模拟器。
Agent 应用
详见站内专题 智能体应用
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
