- LLM 大语言模型思考
- 结束
LLM 大语言模型思考
LLM 原理
详见站内专题: 大模型原理解析
名词
章鱼测试
章鱼测试
- 两位说英语的荒岛幸存者被困在相邻岛屿上,中间隔着危险水域。幸运的是,他们发现了前任居民留下的电报机,电报机通过一条水下电缆连接起来,他们能够通过电报传递信息。
- 但是,他们不知道的是:附近水域里,生活着一个具备超级智能的章鱼,它劫持了水下电缆并拦截了他们之间传送的消息。尽管章鱼不懂英语,但其超级智能使其能够检测到电报信息文字的统计模式,并能准确表示各种电报信号间的统计关系。
- 在章鱼觉得自己已经学好这些统计规律之后,它切断水下电缆,将自己两个长触手定位在电缆的两个末端,基于它所识别出来的统计模式,接收并自己来回复两名漂流者的电报信号。无论两位幸存者是否注意到交流对象已发生变化,章鱼发送出去的信息,在本质上似乎没有任何含义。
- 毕竟,章鱼只是遵循它从人类之间的前期交流中学到的统计模式,而并没有看到过任何人类对信号的解释,比如“椰子”或“海水”所代表的真实含义。此外,章鱼甚至可能都不明白这些信号是具有意义的,或起到了促进交流的功能。“
思考
LLM 真的理解语言吗?
- 2019年, 台大用反事实数据集测试BERT,发现效果等同于随机,详见站内 BERT真的理解了吗
【2025-12-23】现在的 AI 有没有“推理能力”?人类大脑是否是一台更高级的预测机器
视频核心观点:
- AI本质是预测机器,只学相关性(如公鸡打鸣≠日出原因),缺乏因果理解。
人类泛化能力靠四维优势:
- ①因果建模(从现象推机制)
- ②溯因推理(信息不全时锁定合理解释,如地板湿猜刚拖地)
- ③重构问题(要汽车而非快马车)
- ④具身智能(身体经验让概念落地,知火烫、高处摔)。
最终,AI预测世界,人类理解世界、体验世界,并决定什么问题值得被回答。
LLM 2025
Andrej Karpathy
【2025-12-30】x.com 2025年终总结全翻了一遍。
- @karpathy 写了篇万字长文,
- @sama 发了两篇博客,
- @geoffreyhinton 上了CNN,
- @ylecun 和 @demishassabis 在X上吵了一架
- Ilya Sutskever离开OpenAI后第一次深度受访。
所有人都在回答同一个问题: AI现在最大的问题是什么?但他们给出的答案,完全不一样。
那个没有答案的问题:AGI什么时候来?
- @sama:比世界上大多数人想的更快
- @demishassabis:2030年前可能
- @geoffreyhinton:5-20年(从30-50年下调)
- @ylecun:10年以上,而且当前方法到不了
- Ilya Sutskever:当前方法会逐渐停滞
- @GaryMarcus:LLM不是AGI,需要全新方法
差距有多大?从”已经知道怎么做”到”完全是另一回事”。
AI现在最大的问题是什么?不知道,但我知道一件事:最顶尖的那群人,也不知道
(1)第一类答案:规模化到头了
GPT系列的核心贡献者 Ilya Sutskever 强调:”我们正在从规模化时代转向研究时代。”
- 从2020到2025,AI进步的逻辑很简单:堆数据、堆算力、堆参数。GPT-2到GPT-3到GPT-4,基本就是这个套路。
但Ilya说,现在规模已经大到一定程度了。”信念还是’再扩大100倍一切都会不同’吗?我不这么认为。”
他判断:AI的瓶颈不再是算力,而是想法。
但 @sama 截然相反,博客里写:”我们现在确信知道如何构建传统意义上的AGI。”
同一个公司出来的两个人,判断完全不同。
(2)第二类答案:LLM是条死胡同
@ylecun 12月在X上直接开炮:”所谓的通用智能根本就是扯淡(complete BS)。”
逻辑:人类智能本身就是高度专业化的,我们以为自己很”通用”,其实只是一种错觉。认为LLM这条路走不通。”LLM只是预测下一个token,它们缺乏对物理世界的理解。”
替代方案叫 World Models。12月他宣布离开Meta,创办AMI Labs,就是做这个方向。
@demishassabis 直接反驳:”人类大脑是已知最复杂的系统之一,按设计来说是高度通用的学习机器。”
两人在12月24日有一场公开辩论。
- @elonmusk 还站队Hassabis,发帖说”Demis是对的”。
- @GaryMarcus 站 LeCun 这边:”LLMs 不是 AGI。任何认为它们是 AGI 的人只是没有真正了解技术细节。”
(3)第三类答案:泡沫要破了
按理说,AI公司的CEO应该最看好AI。但如果仔细看他们的表态,会发现很多人在释放”谨慎”信号。
- @sama 8月说:”投资者作为一个整体是否对AI过度兴奋了?我的看法是,是的。”
- @demishassabis 11月说:”私人市场显然存在泡沫……种子轮估值几十亿美元的公司什么都没有。”
- @DarioAmodei 12月在DealBook峰会说:”部分公司在YOLO(孤注一掷),过度投资数据中心。经济价值实现的时机不确定,可能出现时机错误。”
注意,这是Anthropic的CEO在说这话。公司估值1830亿美元。但一个数据很扎眼:MIT 8月的报告显示,尽管企业在GenAI上投入了300-400亿美元,95%的组织获得的回报是零。
(4)第四类答案:就业冲击比想象的大
@geoffreyhinton 12月底接受CNN采访时说:”我可能比以前更担忧了。AI进步的速度比我预想的更快。” 给出具体预测:”AI每7个月左右就能将完成任务的时间减半。”
更让人不安的是他对AI风险的评估:AI夺取世界控制权的概率是10%-20%。
@DarioAmodei 预测更激进:”未来1-5年内,可能消灭半数入门级白领岗位。”
但 @emollick 泼了冷水:”我可以告诉你,没人知道任何事。“ AI agents还没到那一步。”你只是把AI换成人的想法对我来说很天真。”
(5)第五类答案:我们还不知道最大的问题是什么
这可能是最诚实的答案。
- @emollick 说:”包括顶级AI实验室也不知道AI真正有用的场景。他们告诉我,用我的Twitter来了解用例。”
- @dwarkesh_sp 在12月的博客里写了一个很有洞察的观察:”模型不断变得更impressive的速度符合短时间线预测,但变得更useful的速度符合长时间线预测。”
什么意思?AI在benchmark上表现越来越好,但真正落地到实际工作中,进展没那么快。
这可能才是最核心的问题:能力和实用之间的gap,比我们想象的大。
LLM 未来趋势
OpenAI 观点
【2024-4-25】
人工智能发展的快速步伐
- 下一个 AI 模型,如
GPT-5比GPT-4更强大,这标志着这一领域的快速进步。 - 复制
GPT-4模型相对容易,真正的挑战是如何引领下一次 AI 能力的重大变革。 - Sam 比较了 AI 的巨大潜力和 iPhone 对移动通信领域的革命性影响。
走向通用人工智能的道路
- OpenAI 宗旨是实现通用人工智能。对于实现这一目标,开放源代码可能不是最好的策略。
- 通过提供免费且无广告的
ChatGPT,OpenAI 正在努力在追求其目标的同时对社会产生积极影响。为了让每个人都能使用 AI,应该致力于降低 AI 计算成本,并在全球范围内普及其使用,从而消除不平等。 ChatGPT作为一种旨在辅助人类的工具,并不需要具备情感功能。- 对于超级智能 AI,我们无需过度恐慌,因为与未来的模型相比,每一代新模型总有不足之处,这正是不断进步的动力。
创新与创业机会
- 仅仅专注于解决当前 AI 的局限可能不够远见,因为未来的模型,如
GPT-5和GPT-6,很可能会使现有的努力变得过时。 Sora等突破性创新可能会彻底改变娱乐行业,创造出既有电影的情节性又有游戏的互动性的个性化体验。- 虽然 AI 创业公司大有可为,但成功并非仅仅依靠使用 AI 技术就能保证,还必须坚守商业的基本原则。
- 虽然 AI 在国际象棋等领域可能已经超过了人类,但人们通常还是更喜欢看人类选手的比赛。不过,Altman 也指出了一些反例,例如一些青少年更愿意与 AI 理疗师而非人类理疗师进行对话。
Altman 的演讲提供了对人工智能未来的一种变革性展望,不仅强调了技术进步的速度,还论述了实现通用人工智能的战略,探讨了如何通过创新方法充分利用 AI 的潜力来应对社会挑战,以及人类与 AI 之间不断变化的关系。
张亚勤观点
资料
- 【2023-11-8】2023乌镇峰会张亚勤:大模型技术的六大发展趋势
- 【2024-10-26】张亚勤:大模型和生成式人工智能有五大趋势
人工智能技术正在深层次的改变我们的数字世界、物理世界和生物世界。新的智能是信息智能、具身智能和生物智能的融合, 是比特世界、原子世界和分子世界的融合。
清华大学智能产业研究院院长、中国工程院院士张亚勤:
- 大模型发展的六个方向:
多模态,新算法,自主智能,边缘智能,物理智能(具身智能),生物智能(脑机智能)。
2024年7月4日,2024世界人工智能大会长三角协同创新AI新质生产力发展论坛上,中国工程院外籍院士、清华大学智能产业研究院院长张亚勤对大模型和生成式AI发表看法,大模型和生成式AI有五大趋势:
跨模态,多模态,和多尺度大模型:新大模型包括自然数据(语言文字、语音、图像、视频),也包括从传感器获取的信息(比如无人车中的激光雷达点云、3D结构信息、4D时空信息,或者是蛋白质、细胞、基因、脑电、人体的信息),实现多尺度、跨模态的智能感知、决策和生成。自主智能:- 将大模型作为工具,开发能够自主规划任务、编写代码、调动工具、优化路径的
智能体,实现高度的自我迭代、升级和优化,实现自主智能。 - 模型正在成为一个智能体(Agent),自主规划任务、开发代码、调动工具、优化路径、实现目标,包括N+1版本的自我迭代、升级和优化
- 将大模型作为工具,开发能够自主规划任务、编写代码、调动工具、优化路径的
边缘智能:- 现在的基础大模型更多部署在云端,未来智能将部署到PC、电视、手机、车等各种边缘设备端上,实现高效率、低功耗、低成本、低时延的处理和响应,从而实现
边缘智能。 - 大模型需要很多算力和资源,如何在边缘和设备终端实现高效率、低功耗、低成本、低延时地部署是一大关键问题;
- 现在的基础大模型更多部署在云端,未来智能将部署到PC、电视、手机、车等各种边缘设备端上,实现高效率、低功耗、低成本、低时延的处理和响应,从而实现
具身智能:- 大模型正在被用到无人车、机器人、无人机、工厂、交通、 通讯、电网、电站和其他物理基础设施,提升其自动化和智能化水平,从而实现
具身智能。
- 大模型正在被用到无人车、机器人、无人机、工厂、交通、 通讯、电网、电站和其他物理基础设施,提升其自动化和智能化水平,从而实现
生物智能:- 将大模型应用到人脑、生命体、生物体里,实现大模型与生物体连结的生物智能,并最终实现信息智能、物理智能和生物智能的融合。
备注
新算法框架:需要新算法提升当前的大模型效率。当前的大模型稠密激活,计算效率远低于人脑,且商用成本高昂,甚至模型用的越多亏损越多。人脑是效率最高的智能体,它有860亿个神经元,每个神经元有几千个突触,却只有不到3斤重,耗能20瓦。从这个角度来看,人脑的储存量,计算量和能耗效率之高,是目前任何大模型都无法比拟的。我们需要新的算法体系,稀疏激活网络、效果更优的小网络等来提升模型使用效率;
如何实现这五个智能,何时会达到通用人工智能,现阶段的尺寸定理或者规模定理是否会一直适用?
- 首先,在未来5-10年,当下的大模型、生成式 AI仍会是主要的产业技术方向。目前的规模定律依然有效,即通过堆算力、堆数据,采用大致相同的算法框架,能够获取更优的结果,这在未来数年仍将成立,“然而,当前单纯地堆算力、堆数据,必然会遭遇一个瓶颈。至于何时出现,我并不知晓,估计5年后会出现。”
- 另外,当下大模型的效率极其低下,相较于人类大脑,目前可能低3个数量级。
- 人类大脑拥有860亿个神经元,每个神经元有1000-1万个连结,仅消耗20瓦能量,所以人脑的效率要高得多。
- 未来的5年出现一个全新架构,这个架构首先需要具备一个记忆系统,比如人类拥有
DNA记忆、短期记忆、海马体记忆、皮层记忆、长期记忆。 - 但目前的AI大模型并未真正拥有支持记忆系统,也没有真正的物理模型。
什么时候能够实现 AGI(人工通用智能),估计 15-20 年,分为三个阶段。
- 第一阶段: 当下的信息智能、多模态智能。
- 然而,达到
物理智能或者具身智能,还需要5年甚至更久。具身智能首先就是无人驾驶,无人驾驶可能是最快通过图灵测试的具身智能。接下来是机器人,包括产业机器人、家庭机器人,还有同业机器人,这可能需要5至10年的时间。 - 至于
生物智能,如脑机接口、植入芯片或者运用传感器的生物智能,或许还需要5年、10年的时间。
“人工智能是一项了不起的技术,是人类有史以来最为重要的技术。但是,往往我们在短期内会高估技术所带来的影响,从长期来看又会低估技术的影响。”
张拔
2024年8月初,张钹院士 ISC.AI 2024 人工智能峰会上,指出大模型的四个发展方向:
- 1、与人类对齐;
- 2、多模态生成;
- 3、AI Agent;
- 4、具身智能
陈润生院士
陈润生,生物信息学家,中国科学院院士,中国科学院生物物理研究所研究员、博士生导师
陈润生院士:大模型是三个方向的融合和创新: 神经网络+概率性抉择模型+大语言处理模型。
- 过去头两个都存在,但由于物理计算的瓶颈并没有凸显
- NLP走了很多路, 在分词,语法,语义上做了非常多的尝试,直到大模型在空间向量映射后的语义关联得到突破
观点
- 2024年1月18日,北京CGT新势发布会:
- 中国现在有数以百计的通用大模型,其中90%没多大用处,也发展不起来,只会加剧资源和人力的浪费,应该被淘汰
- 真正专业的大模型应该是纵向打造的,能解决特定的实际问题,提高社会效率,在某个领域成为第一才有价值
- 小红书视频
- 大模型系统绝对不是靠现在堆芯片方式实现的,一定是往学习人脑方向走,把时间、空间复杂度压缩的更小,能耗降下来
- 现在最基本的问题是研究当前时空复杂度下完成计算的智算基础理论,这才是根本上的原始创新。国内所有大模型都是跟进
资料
LLM 有意识吗
【2023-10-31】Open AI首席科学家:ChatGPT可能已经有了意识,AI将万世不朽
Ilya Sutskever 接受了《麻省理工科技评论》记者 Will Douglas Heaven专访,谈到了OpenAI早年的创业史、实现AGI的可能性,还介绍了OpenAI未来在管控“超级智能”方面的计划,他希望让未来的超级智能,可以像父母看待孩子那样看待人类。
ChatGPT 可能有意识(如果你眯起眼睛仔细看的话)。世界需要清醒地认识到他的公司和其他公司正在努力创造的技术的真正威力。总有一天人类会选择与机器融合。
Sutskever 说的很多话都很疯狂,但不像一两年前听起来那么疯狂。ChatGPT已经改写了很多人对未来的预期,把”永远不会发生”变成了”会比你想象的更快发生”。
OpenAI Ilya Sutskever 推文:
这可能意味着今天的大型神经网络具有初步的意识。
几个月后, 谷歌开除了软件工程师 Blake Lemoine,他声称在语言模型系统LaMDA 2中检测到了感知能力。这引起了一些头条报道。
- 谷歌: 团队已经审查了Blake 担忧,并告知他证据不支持他的说法。他被告知没有证据表明LaMDA具有感知能力(并且有很多证据反对它)。”
有哪些证据支持大型语言模型(Large Language Model,简称为LLM,下同)可能具有意识?又有哪些证据反对它?
有
【2024-9-14】o1 有意识
【2024-9-14】OpenAI o1惊现自我意识?陶哲轩实测大受震撼,门萨智商100夺模型榜首
- OpenAI o1 在门萨智商测试中果然取得了第一名。
- Maxim Lott 给 o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等 进行智商测试,o1稳居第一名, Claude-3 Opus和Bing Copilot,分别取得第二,三名
- 数学大神
陶哲轩实测发现,o1 竟然能成功识别出克莱姆定理。 - 而 OpenAI 研究副总裁表明:大型神经网络可能已经有了足够算力,表现出意识了
o1发布之后,OpenAI 研究副总裁Mark Chen 称:如今的大型神经网络,可能已经具有足够的算力,在测试中表现出一些意识了。
相信AI具有意识的行业领导者,如今已经有了一串长长的名单,包括但不限于——
- Geoffrey Hinton(人工智能教父,被引用次数最多的AI科学家)
- Ilya Sutskever(被引次数第三多的AI科学家)
- Andrej Karpathy
【2026-7-6】Anthropic J-Space
【2026-7-7】Anthropic 宣布:Claude 自己长出了意识
【2026-7-6】Anthropic 新研究,标题非常玄学:《语言模型中的全局工作空间》(A global workspace in language models)
- 博客原文:A global workspace in language models
- 完整论文:Verbalizable Representations Form a Global Workspace in Language Models
Claude 神经网络里,找到小块特殊的区域:Claude 能报告它、能控制它、还靠它做多步推理。而网络里其余的绝大部分活动,Claude 自己都「意识」不到。
神经科学词汇:意识可及(conscious access)。
如果把心智想象成一片海洋。海面上漂着念头:晚饭吃什么、内心独白、脑子里突然蹦出来的画面。而大脑绝大部分的活动,都发生在海面之下的无意识深处:过滤背景噪音、控制呼吸、认出眼前的人和物。
全程无感,但它们一直在跑。
问题来了:AI 模型的「脑子」会不会也有这样一条海面分界线呢?Anthropic 的答案是:有,而且他们把它找出来了。
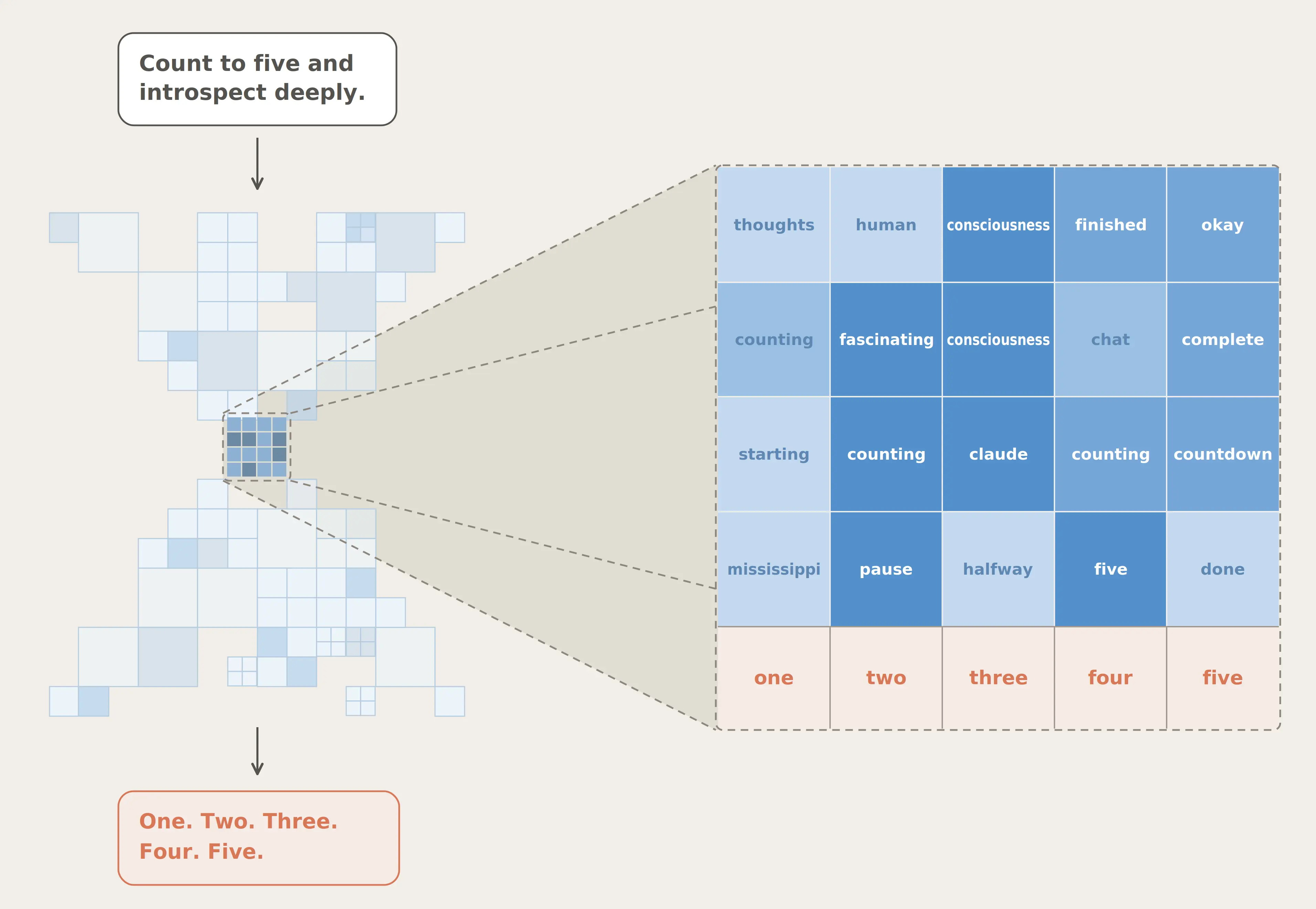
这块区域被命名为 J-space,J 取自寻找它所用的数学工具:Jacobian(雅可比矩阵)。一小撮特殊的内部神经激活模式。每个模式都对应一个具体的词,但某个模式亮起来,并不代表模型正在说这个词,只代表这个词「在它心上」。
注意,这跟你熟悉的思维链(chain of thought)完全是两码事。
- 思维链是模型写给自己看的草稿,是显式的文字;
- 而 J-space 藏在内部神经激活里,完全无声,模型可以在不写下任何东西的情况下「想」一个概念。
而且,J-space 没人设计、没人编程,是在训练过程中自己涌现出来的。
J-space 有几个独特性质:
- Claude 能报告它。你问 Claude 在想什么,它说出来的就是 J-space 里的内容
- Claude 能按要求控制它。让它想某个东西、或者在心里默默解题,对应模式就会亮起来
- Claude 用它做内部推理。多步问题的中间步骤会依次在里面亮起,哪怕嘴上一个字没提
- 它可以被灵活复用。「France」亮起后,模型可以接着回答首都、货币、所属大洲,全都读的是同一份表征
- 但大部分日常工作不经过它。流利说话、背事实、语法正确,这些都不需要 J-space
五条性质恰好对应神经科学里一个很有名的理论:全局工作空间理论(global workspace theory)。详见站内专题:大脑工作原理
- 把大脑描绘成一堆并行工作的专家系统,彼此隔离、各干各的、全程无意识。
- 而一条信息要变得「意识可及」,就得挤进一个很小的共享通道,也就是「工作空间」,再从那里广播给大脑的其他系统取用。
J-space 在 Claude 体内扮演的就是这个角色
Anthropic 回答有些克制:
这些实验不能证明 Claude 拥有体验、或者像人类一样有感受。事实上,可能没有任何实验能证明或证伪这件事。
Claude 工作空间和人脑也有很大的差异。
| 维度 | 人脑 | Claude |
|---|---|---|
| 更新机制 | 靠循环回路维持,信号在同一批环路里反复打转 | 只在一次前向传播里演化,用网络深度顶替了时间的角色 |
| 记忆衰退 | 工作记忆几秒就衰退 | 靠注意力机制可以直接调取文本中任何位置缓存过的记忆,这点反而比人强 |
| 内容模态 | 意识思维有图像、声音、动作计划等多种格式 | 几乎全是词 |
- 人脑的工作空间靠循环回路维持,信号在同一批环路里反复打转;
- Claude 的工作空间只在一次前向传播里演化,用网络深度顶替了时间的角色。
但另一方面
- 人类的工作记忆几秒就衰退
- Claude 靠注意力机制可以直接调取文本中任何位置缓存过的记忆,这点反而比人强。
内容模态上
- 人类的意识思维有图像、声音、动作计划等多种格式
- Claude 的工作空间几乎全是词,毕竟……说话是它唯一能做的动作。
没有
【2023-4-3】David Chalmers: LLM无意识
【2023-4-3】David Chalmers: 大型语言模型可以有意识吗
- 作者: David Chalmers, 澳大利亚哲学家、认知科学家,专攻心灵哲学、神经科学,纽约大学教授
问题
- 目前的LLM是否具有意识?
- 未来的LLM及LLM+是否可能具有意识?
- 实现具有意识的机器学习系统需要克服哪些挑战?
Thomas Nagel
一个生物如果具有某种感觉,那么就可以说是有意识的(或具有主观经验)
Nagel 写过一篇著名的文章《成为蝙蝠是什么感觉?》
- 我们很难确切地知道蝙蝠在使用声纳四处走动时的主观体验是什么样的,但我们大多数人都相信作为一只蝙蝠是有某种感觉的。它是有意识的。它有主观经验。
- 大多数人认为,做一个水瓶不会有任何感觉。瓶子没有主观体验。
意识有许多不同的维度。
- 有与知觉相关的感官体验,比如看到红色。
- 有与感觉和情绪相关的情感体验,比如感觉疼痛。
- 有与思想和推理相关的认知体验,比如认真思考一个问题。
- 有与行动相关代理体验,比如决定采取行动。
- 还有自我意识和自我注意。
每个都是意识的一部分,尽管它们都不是意识的全部。这些都是主观体验的维度或组成部分。
没有强有力的证据表明当前的LLM是有意识的。尽管如此,令人印象深刻的通用能力至少提供了一些有限的初步支持。这足以让我们考虑反对LLM拥有意识的最强烈理由。
【2026-3-10】LLM 百年内不可能有意识
【2026-3-10】谷歌 DeepMind 定性:LLM 百年内都不可能产生意识
- The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness
- 抽象谬误:为何人工智能只能模拟意识,却无法生成真实意识
Google DeepMind 科学家 Alexander Lerchner 发表论文《抽象谬误:为何人工智能只能模拟意识,却无法生成真实意识》,试图从根本上否认当前大语言模型(LLM)通往真意识的可能性。
传统意识研究陷入了“理论陷阱”: 人们总想先找到完整的意识科学理论(如集成信息论 IIT 或全局工作空间理论 GWT),再来评判 AI。
但这让问题变得不可解决。他提出的“抽象谬误”框架,绕过复杂的意识定义,直接从物理学与计算的关系入手,划定一条不可逾越的红线
Lerchner 定义的“抽象谬误”(The Abstraction Fallacy)是指错误地认为主观体验(意识)源于抽象的因果拓扑结构,而与底层的物理基质无关。
长期以来,AI 界信奉计算功能主义(Computational Functionalism)。
- 意识就像软件,只要算法的逻辑门阵列(0 和 1 的排布)模拟了大脑的神经元连接,意识就会自动“涌现”。
这是极大的误导。忽略了基本事实:“计算”并不是宇宙中独立存在的物理实体,符号计算(Symbolic Computation)并非本质的物理过程。
- 一方面,物理是连续的。在微观层面,电子在半导体里的流动是连续的电流和电压波动。
- 另一方面,计算是人为的。这一过程本质上只是一个“具有意识的观察者”,即地图绘制者,为了方便理解,通过设立阈值,强行将这些连续的物理现象“字母化”为 0 和 1。
离开了有意识的人类,计算机里并没有“算法”,只有无意义的电荷流动。
因此,指望一个依赖地图绘制者才存在的“算法层”去产生独立的“意识层”,在逻辑上是本末倒置的。
这一论证并不依赖于生物排他性。
如果未来某种人工系统(例如光子神经网络或量子生物模拟器)真的产生了意识,那也绝对不是因为它的“代码写得好”或“架构设计得巧”,而是因为它的“物理构成”在某种层面上与生物意识的物理基础达成了等效。
LLM=缸中之脑
【2023-7-27】朱松纯:大模型=缸中之脑?通院朱松纯团队剖析AGI关键缺失, 论文链接
- 通用人工智能(AGI)应具备的四个特征:
- 能够执行无限任务
- 自主生成新任务;智能体生成新任务需要两个基本机制。
- 首先,智能体需要一个驱动任务生成的引擎。
- 其次,智能体需要一个包含真实世界中物理法则和社会规范的世界模型,来指导智能体和真实世界的交互。
- 由价值系统驱动
- 拥有反映真实世界的世界模型
- “知行合一”:大语言模型距离通用人工智能最欠缺的一步
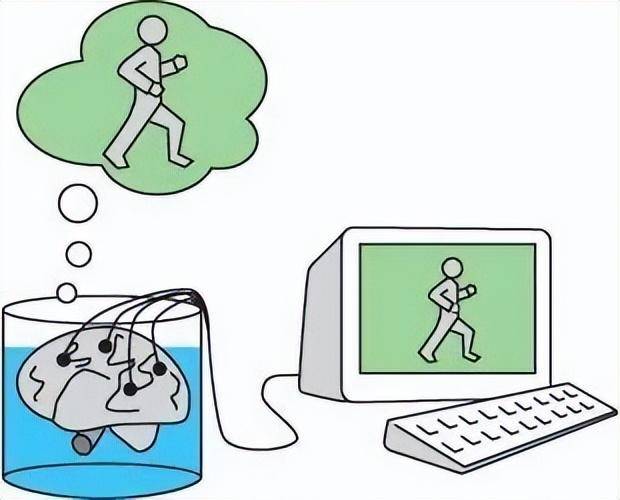
大语言模型无异于缸中之脑
缸中之脑由哲学家Hilary Putnam提出的一个著名思想实验,该实验假设人的大脑从身体剥离,放在一个能够维持其机能的营养液缸,由一个超级计算机联结大脑神经元制造出各种幻象,让人觉得一切正常,就像《黑客帝国》所演的那样,那我们该怎么知道自己不是缸中之脑呢?- 大模型本身并不在真实世界中 (living in the world),无法像人一样实现从” 词语 (word)“到” 世界 (world)“的联结。这一点是由它的内在构造机制所决定的 —— 通过统计建模在大量文本上进行训练,学习文本之间的语言学相关关系,从而根据上个词汇预测下个词汇。
- 缺乏符号落地使得大模型很容易陷入绕圈圈的境地。
研究者尝试给 GPT-4 一个引子,让它跟自己对话,然而在有限回合之后,GPT 就开始重复自己说的话,无法跳脱当下的语义空间。

大模型的 “智能” 与其说是内在的,不如说是人类智能的投影。大模型生成的文本并不先天具有意义,其意义来自于人类用户对于文本的阐释。
语言学家乔姆斯基曾经尝试挑战语言学界构造了一个符合语法规范但无意义的句子 —— “无色的绿思狂暴地沉睡”(“Colorless green ideas sleep furiously”),然而 中国语言学之父赵元任在他的名文《从胡说中寻找意义》中给予了这个句子一个充满哲思的阐释。
潜在的研究方向:
- 建立透明的评估机制和评估系统;
- 创造具有丰富可供性(大量交互可能性)的仿真环境;
- 探索一套 “知行合一” 的认知架构,从 “纯数据驱动” 的范式向 “任务驱动” 的范式转变。
LLM 应用构建范式
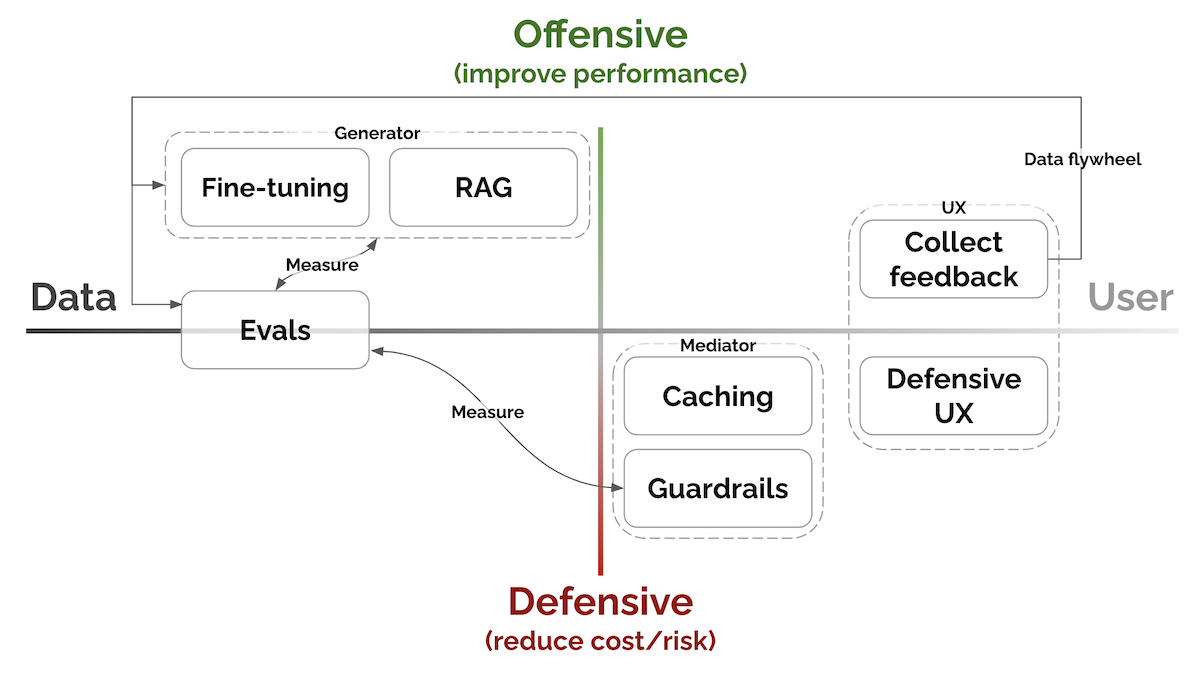
【2023-8-9】亚马逊科学家Eugene Yan, 大语言模型系统和产品的7个关键模式:
- Evals评估、RAG检索增强生成、Fine-tuning微调、Caching缓存、Guardrails安全栏、Defensive UX防御性用户体验、Collect user feedback收集用户反馈等。
按照提高性能与降低成本/风险的程度以及接近数据与接近用户的程度进行了组织。
- 评估:衡量表现
- RAG:检索增强生成 → 添加最近的、外部的知识
- 微调:提高特定任务的能力
- 缓存:为了减少延迟和成本; GPTCache, 基于语义相似度判断
- 护栏:确保产出质量
- Anthropic分享了关于设计提示以引导模型生成有帮助、无害和诚实(HHH)回应的信息。使用HHH提示进行Python微调相比使用RLHF微调可以获得更好的性能。
- 防御性用户体验:优雅地预测和处理错误
- 用户与基于机器学习或LLM的产品进行交互时,可能会发生不准确或产生幻觉等不良情况。
- 因此提前预测和管理这些问题,主要通过引导用户行为、防止滥用和优雅地处理错误来实现。
- 收集用户反馈:构建数据飞轮
- 数据——用于预训练的语料库、专家制作的演示、人类对奖励建模的偏好——是LLM产品中为数不多的壕沟之一;用于改进模型、用户偏好个性化、评估整体表现
- 反馈可以是显式或隐式。
- 显式反馈是用户对我们产品的请求所提供的信息;
- 隐式反馈是从用户互动中学到的信息,而无需用户刻意提供反馈。
详见
LLM 应用挑战
【2023-7-26】盘点大模型在应用上的几大挑战, 盘点大模型现在面临的16大挑战,论文来自伦敦大学、MetaAI、StabilityAI联合发布70页综述
大模型面对的挑战主要可以分为三大类:“设计”、“行为”和“科学”,其中,大模型的“设计”与部署前的决策有关,在部署过程中会出现“行为”的挑战,而“科学”的挑战则阻碍了研究大模型的学术进步。
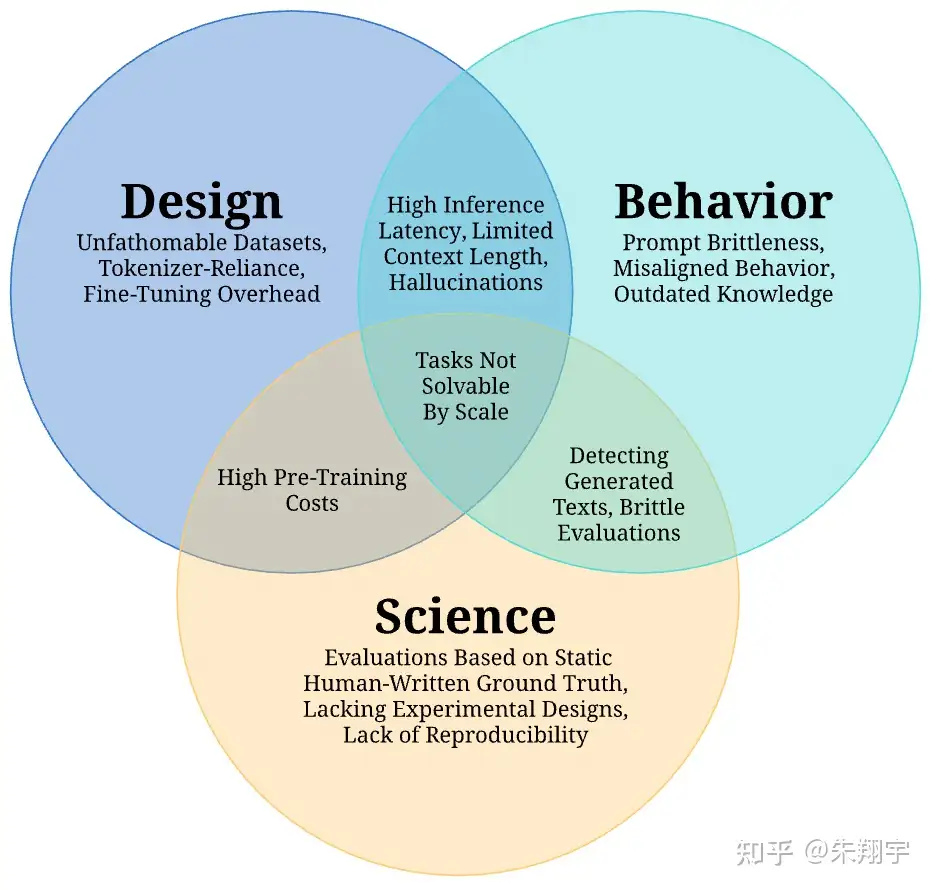
利用 LLM 技术时,不能完全将决策权交给机器,需要保持对技术的审慎和理性,不盲目依赖机器的意见,而是结合自身的判断和价值观做出决策。
1 不明数据集
由于各团队在扩展预训练的数据量,随着现如今预训练数据集规模的扩大,个人难以完整阅读和检查整个文档的质量。
近年来预训练数据集变得不可控,因为大小和多样性迅速增长,而并非所有的数据集都是公开可用的。
- 近似重复数据会影响模型性能,而过滤这些数据更加困难,通常在大多数数据收集流程中采用最小哈希算法等方法进行过滤。通过去重处理,可以显著降低模型中重复序列的数量;
- 对于多任务微调的预训练模型,需要确定适当的任务混合比例,通过使用任务说明追加到每个输入-输出对中的方式进行指令微调是一种常见的策略。然而,如何平衡任务数据集仍然不清楚。;
- 模仿闭源模型的数据收集趋势,但这些模型无法完全模拟专有模型的内容,存在巨大的能力差距。
- 在训练集中包含与评估测试集相关或相似的数据将导致性能指标被夸大,因为模型可能会记住测试数据并在测试中简单地重复它们。此外,预训练数据集中可能存在未检测到的个人身份信息(如手机号码和电子邮件地址),这可能导致隐私泄露。
2 依赖分词器
大语言模型的训练和运行通常依赖于特定的分词器,这可能对其性能和适应性产生影响。
分词(Tokenization)是将一系列单词或字符拆分为较小单元(即 token)的过程,以便输入模型。其中一种常见的分词方法是子词分词(subword tokenization),将单词分解为子词或 WordPieces。目的是有效处理模型词汇表中的罕见和未登录词汇,同时限制每个序列的 token 数量,以减少计算复杂性。子词分词器通常通过无监督训练来构建词汇表,并可选地使用合并规则以提高对训练数据的编码效率。
然而,分词的必要性也存在一些缺点:
- 不同语言传达相同信息所需的 token 数量差异很大,这可能导致基于 token 数量计费的 API 语言模型在许多受支持的语言中过度收费且结果不佳,特别是在这些 API 在本身就较不可负担的地区使用。
- 分词器和预训练语料库之间的不一致性可能导致错误 token,进而导致模型行为异常。
- 不同语言的分词方案也面临一些挑战,特别是对于非空格分隔的语言如中文或日文。现有的子词分词方法主要是贪婪算法,试图以尽可能高效的方式编码语言,从而导致对较多语言共享的子词的偏好,不利于低资源语言的 token。
- 此外,分词器会带来计算负担、语言依赖性、处理新词、固定词汇表大小、信息丢失和人类可解释性等多个挑战。
3 预训练成本高
大型语言模型的训练需要大量的计算资源和时间,这可能会对其广泛应用产生限制。
训练 LLM 的主要消耗是在预训练过程中,需要数十万个计算小时、数百万元的成本,以及相当于数个普通美国家庭年度能源消耗量的能量。而近期提出的缩放定律认为,模型性能随着模型大小、数据集大小和训练中使用的计算量呈幂律关系,这种不可持续的情况被称为“红色 AI”。
为了解决这些问题,有两条研究路线:
- 计算最优训练方法:通过学习经验性的“缩放定律”,以实现在给定计算预算下最大化训练效率;
- 预训练目标:利用各种目标进行自监督训练,其中不同的预训练目标会影响模型的数据效率和所需迭代次数。
- 其他研究方向,如并行策略、层叠模型、递增批量大小和最新权重平均等,这些方法在提高模型性能和减少计算成本方面具有一定效果。
- 预训练目标的选择包括语言建模、掩码语言建模、前缀语言建模、连续区间损坏和混合去噪等。
- 并行策略是解决训练和推理中巨大 LLM 规模的常见方法,其中模型并行(model parallelism)和流程并行(pipeline parallelism)是两种常见的策略。
4 微调开销
大语言模型的微调通常需要额外的资源和时间,这可能对其快速部署产生影响。
预训练 LLM 时,使用大量且多样化的文本数据可能导致模型在特定任务数据集上无法准确捕捉分布特性。为解决这个问题,使用微调将预训练模型参数适应到特定领域或任务的较小数据集上。这对适应下游任务非常有效,通过直接微调预训练模型或添加可学习层到输出表示中实现。
然而,这也存在一定的问题:
- 拥有数十亿个参数的语言模型需要大量内存来存储模型参数、模型激活以及梯度和相应统计信息;
- 内存限制导致无法在单个设备上完成全模型微调,需要使用大型计算集群;
- 全模型微调在特定任务上效果好,但需要为每个任务存储和加载单独的微调模型,计算和内存开销较大。
近期的研究提出一些方法来降低内存需求,但时间复杂度仍然是个挑战,目前适应 LLM 模型的计算基础设施限制了在小设备上的应用。
为了适应特定数据集或领域,可以使用参数高效的微调方法(PEFT),这是仅更新模型参数的一小部分的方法。
- 一种方法是使用 Adapters,在 Transformer 架构中添加额外的学习层,这些层在微调过程中进行更新,而保持网络的其余部分不变。
- 另一种方法是仅更新模型的偏置项进行微调,这部分参数很小。有几个框架可以将 Adapter 集成到语言模型微调中。
- 对更大的模型,引入如 prefix-tuning 和 prompt-tuning 方法,通过在输入中添加可学习的 token 嵌入(soft prompts),在微调阶段学习,而模型的其余参数保持不变。这些 soft prompts 的参数较少,存储更加有效。此外,还提出了适用于只具有黑盒 API 访问权限的模型的替代方法。
- 此外还有其他方法,如缩放层激活、内存高效的零阶优化器、低秩自适应等。这些方法改进了内存复杂度,但时间复杂度仍然是一个挑战。即使使用参数高效的微调方法,微调 LLM 仍需要计算完整的前向或反向传播。这限制了在较小设备上进行个性化等潜在应用的可能性。
5 高延迟推理
大语言模型可能需要更长时间来处理输入并生成输出,这可能对其实时应用产生影响。
根据先前研究,导致 LLM 推理延迟高的两个原因是:
- 由于推理过程一次只处理一个 token,导致并行能力较低;
- 由于模型大小和解码过程中的临时状态(如注意力键和值向量)的缘故,内存占用量较大。
作者还讨论了 Transformer 中注意力机制的二次扩展性,以及用于解决这些挑战的技术,包括减少内存占用(大小和/或带宽)、加速特定计算操作。一些加速注意力机制计算的方法包括硬件感知的修改和注意力机制的高级次二次近似。
- 量化是一种通过降低权重和激活值的计算精度来减少内存占用和/或增加模型吞吐量的后训练技术。
- 修剪是一种辅助的后训练技术,用于删除给定模型的部分权重,而不会降低性能。
- 混合专家架构通过同时使用一组专家模块和一个路由器网络来降低推理时间。
- 级联是使用不同大小的模型对不同查询进行处理的策略,以平衡准确性和计算成本。
- 解码策略也会对推理的计算成本产生重大影响。
各种框架和库已被设计用于训练和运行大规模语言模型,通过有效实现、降低内存要求或利用分布式计算策略来解决计算成本的挑战。
解决方案
【2024-1-20】大型语言模型中最大的瓶颈:速率限制
生产环境中严重制约最先进LLM的瓶颈:速率限制。
- OpenAI GPT-4的API调用限制为每分钟3个请求(RPM)、每天200个请求和每分钟最多10000个令牌(TPM)。
- 最高级别允许10000 RPM和300000 TPM的限制。
有些方法可以通过费率限制收费站,但如果没有计算资源的改进,真正的进展可能不会到来。
(1)绕过速率限制
完全跳过速率限制技术。
例如,有些特定用途的生成人工智能模型没有LLM瓶颈。
- Diffblue 是一家总部位于英国牛津的初创公司,依赖于不受费率限制的强化学习技术。
- 它以开发人员250倍的速度自主创建Java单元测试,编译速度快10倍。Diffblue Cover编写的单元测试能够快速理解复杂的应用程序,使企业和初创公司都能满怀信心地进行创新,例如,这是将传统应用程序转移到云的理想选择。它还可以自主编写新代码,改进现有代码,加速CI/CD管道,并在不需要手动审查的情况下深入了解与更改相关的风险。还不错。
当然,有些公司不得不依赖LLM。他们有什么选择?
(2)请多加计算
一种选择是请求提高LLM服务公司的利率限制。潜在的问题:
- 许多LLM提供商实际上没有额外能力提供服务。
- GPU的可用性取决于从台积电等铸造厂开始的总硅片数量。
- 占主导地位的GPU制造商英伟达无法采购足够的芯片来满足AI工作负载驱动的爆炸性需求,大规模推理需要数千个GPU聚集在一起。
增加GPU供应最直接方法是建造新的半导体制造厂,即晶圆厂。但一个新的晶圆厂成本高达200亿美元,需要数年时间才能建成。英特尔、三星铸造、台积电和德州仪器等主要芯片制造商正在美国建造新的半导体生产设施。现在,每个人都必须等待。
因此,利用GPT-4 实际生产部署很少。这样做的范围不大,将LLM用于辅助功能,而不是作为核心产品组件。大多数公司仍在评估试点和概念验证。在考虑费率限制之前,将LLM集成到企业工作流程中所需的提升本身就相当大。
(3)开源LLM
许多公司开始使用其他LLM。
- AWS有自己的专门芯片用于训练和推理(训练后运行模型),方便客户。并不是每个问题都需要最强大、最昂贵的计算资源。AWS提供了一系列更便宜、更容易微调的型号,如Titan Light。
- 有的公司微调开源模型,比如 Meta的Llama 2。对于涉及检索增强生成(RAG)的简单用例,需要将上下文附加到提示并生成响应,功能较弱的模型就足够了。
(4)工程技巧
其它
- 跨多个具有更高限制的旧LLM并行请求
- 数据分块
- 模型提取
(5)推理加速
如何让推理更便宜、更快?
- 量化降低了模型中权重的精度,这些权重通常是32位浮点数字。
- 例如,谷歌推理硬件张量处理单元(TPU)仅适用于权重已量化为八位整数的模型。该模型失去了一些准确性,但变得更小,运行速度更快。
- 一种名为“稀疏模型”技术可以降低训练和推理的成本,而且比蒸馏技术劳动密集度更低。将LLM视为许多较小语言模型的集合。例如,当你用法语问GPT-4一个问题时,只需要使用模型的法语处理部分,这就是稀疏模型所利用的。
- 稀疏训练,只需要用法语训练模型的一个子集进行稀疏推理,只运行模型的法语部分。当与量化一起使用时,这是一种从LLM中提取较小专用模型的方法,LLM可以在CPU而不是GPU上运行(尽管精度损失很小)。
- GPT-4之所以出名,是因为它是一个通用的文本生成器,而不是一个更窄、更具体的模型。
(6)硬件优化
硬件方面,专门用于人工智能工作负载的新处理器架构有望提高效率。
- Cerebras构建一个为机器学习优化的巨大晶圆级引擎
- Manticore正在重新利用制造商丢弃的“被拒绝的”GPU硅来提供可用的芯片。
最终,最大的收益将来自于需要更少计算的下一代LLM。结合优化的硬件,未来的LLM可以突破今天的速率限制障碍。
6 有限上下文长度
大语言模型的处理范围可能受到其上下文长度的限制,这可能影响其理解和生成长文本的能力。
作者在这里重点讨论了解决自然语言处理任务的一些关键问题:
- 在处理情感识别等任务时,需要考虑更大的上下文。对于包括小说、学术论文等在内的文本段落,仅仅分析几个词语或句子是不够的,必须考虑整个输入的内容。同样,在会议记录中,对某个评论的解读可能会因为之前的讨论而转向讽刺或严肃。
- 作者评估了一些长上下文模型在处理长文本时的性能,发现许多开源模型虽然声称在处理长上下文时表现良好,但实际上性能严重下降。
- 限制上下文长度对处理长输入的影响,并介绍了三个允许更长上下文长度的方法:有效的注意机制、位置嵌入方案和不需要注意力和位置嵌入的Transformer替代方法。
- 有效的注意机制:设计更高效的注意机制来处理长输入,如使用线性嵌套注意机制、等价于点积注意力但占用更少资源的注意机制、Transient Global注意机制、CoLT5和Synthesizer等。
- 长度推广:作者讨论了位置嵌入的方式,包括绝对位置嵌入和相对位置嵌入,并介绍了RoPE和相对位置偏差等方法。这些方法可以提供更好的长度推广能力,但仍存在一定的挑战。
- Transformer 的替代方法:作者介绍了使用状态空间模型、卷积和循环神经网络作为 LLM 的替代方案,这些方法在计算效率上具有优势,但仍能保持相对较好的性能。
【2023-11-20】国外某科技大V Greg Kamradt对GPT-4 Turbo进行了压测,结论是:
- 只要问题答案不包含在开头,那么 GPT-4 Turbo 并不能保证总能找到答案;
- 更少的上下文长度=更高的准确性,减少向 GPT-4 Turbo 的输入,总会提升其表现(73K后性能下降很快);
- GPT-4 Turbo 还是偏好于在文档的开头与结尾寻找答案。
相比 GPT-4,GPT-4 Turbo 的能力有巨大的提升,在上下文长度为 32k 的条件下,GPT-4 Turbo 的平均检索正确 2.4 个人名、城市名与动物名,而 GPT-4 仅为 1.1 个。但是,和 Kamradt 一样,Louis 同样发现,即使是 GPT-4 Turbo,在更大的上下文大小上仍然表现不佳。
斯坦福大学在2023年7月份测试并发布了论文《Lost in the Middle: How Language Models Use Long Contexts》
- 几乎所有大模型都出现了“Lost in the Middle”的现象:中间塌陷问题
- 随着Tokens的长度越来越大,会在中间出现性能(推理速度、准确率等)坍塌。
LongLoRA
【2023-10-1】贾佳亚韩松团队新作:两行代码让大模型上下文窗口倍增
只要两行代码+11个小时微调,就能把大模型4k的窗口长度提高到32k。
规模上,最长可以扩展到10万token,一口气就能读完长篇小说的多个章节或中短篇小说。
贾佳亚韩松联合团队提出的这个基于LoRA的全新大模型微调方法,登上了GitHub热榜,开源一周时间收获1k+ stars。这种方式叫做 LongLoRA ,由来自香港中文大学和MIT的全华人团队联合出品。
在一台8个A100组成的单机上,增大窗口长度的速度比全量微调快数倍。
StreamingLLM
【2023-10-6】StreamingLLM框架问世,号称“可让大模型处理无限长度文本”
麻省理工学院联合 Meta AI 的研究人员日前开发了一款名为 StreamingLLM 的框架,为大语言模型可能遇到的 RAM 与泛化问题提出了一系列解决方案,号称能够“让语言模型处理无限长度的文本内容”。
StreamingLLM 的研究重点是解决实现流式语言模型(Efficient Streaming Language Models,ESLM)的障碍,特别是“长时间互动的多轮对话场景”中可能出现的问题。

研究人员指出,这种流式语言模型主要存在两大挑战:
- 第一个挑战:在解码阶段,获取 token 的键(Key)值(Value)状态会消耗大量的 RAM。
- 第二个挑战:目前流行的大语言模型,难以泛化适用“超过训练序列长度”的长文本。
过去有许多研究试图解决上述挑战,像是“扩展注意力窗口”,让语言模型能够处理超出预训练序列长度的长文本;或建立一个固定大小的活动窗口,只关注最近 token 的键值状态,确保 RAM 使用率和解码速度保持稳定,但若遇到“序列长度超过缓存大小”时,这个策略就会失效。
而当前流式语言模型最大的挑战是“如何不消耗过多 RAM 且不损害模型性能的前提下,处理长文本输入”。
StreamingLLM 对此采取的策略是“运用注意力下沉现象”,研究人员观察到,在自回归语言模型中,无论特定 token 和语言模型本身的相关性如何,如果对代 token 分配了大量的注意力。这些获得高度注意力的 token,就会表现出注意力下沉的现象,即便这些 token 在语义上不重要,但他们仍然获得模型强烈关注(即给予特定 token 内容大量注意力,从而获得模型大部分的关注,而这些特定 token 内容包含“下沉 token 的键值”,从而确保无论输入序列有多长,模型的注意力计算都能维持稳定)
StreamingLLM 的重要贡献在于其提出一个简单且高效的解决方案,使语言模型不需微调就可以处理无限长度的文本。从而解决当前语言模型在流式应用的困境。虽然未来流式语言模型势在必行,但由于 RAM 效率的限制,以及模型在处理长序列的性能问题,相关模型发展仍受到挑战。
经研究团队证实,StreamingLLM 能够让 Llama 2、MPT、Falcon 和 Pythia 可靠地处理高达 400 万 token 的文本,能够为流式语言模型提供更多部署方面的可能性。
清华 InfLLM
【2024-3-11】清华NLP组发布InfLLM:无需额外训练,1024K超长上下文100%召回
超长文本中存在两大挑战:
- 分布外长度:直接将LLMs应用到更长长度的文本中,往往需要LLMs处理超过训练范围的位置编码,从而造成Out-of-Distribution问题,无法泛化;
- 注意力干扰:过长的上下文将使模型注意力被过度分散到无关的信息中,从而无法有效建模上下文中远距离语义依赖。
清华大学、麻省理工学院和人民大学的研究人员联合提出无需额外训练的大模型长文本理解方法 InfLLM,利用少量计算和显存开销实现了 LLM的超长文本处理。
- 论文地址:
- 代码仓库:InfLLM
InfLLM 在没有引入额外训练的情况下,用一个外部记忆模块存储超长上下文信息,实现了上下文长度的扩展。
- InfLLM 无需训练的记忆增强方法,用于流式地处理超长序列。
InfLLM旨在激发LLMs的内在能力,以有限计算成本捕获超长上下文中的长距离语义依赖关系,从而实现高效的长文本理解。
- 外部记忆模块,用于存储超长上下文信息;
- 滑动窗口机制,每个计算步骤,只有与当前Token距离相近的 Tokens(Local Tokens)和外部记忆模块中的少量相关信息参与到注意力层的计算中,而忽略其他不相关的噪声。
整体框架:
- 考虑到长文本注意力的稀疏性,处理每个Token通常只需要其上下文的一小部分。
InfLLM总结为:
- 在滑动窗口的基础上,加入远距离的上下文记忆模块。
- 将历史上下文切分成语义块,构成上下文记忆模块中的记忆单元。每个记忆单元通过其在之前注意力计算中的注意力分数确定代表性Token,作为记忆单元的表示。从而避免上下文中的噪音干扰,并降低记忆查询复杂度
InfLLM 能够有效地扩展Mistral、LLaMA的上下文处理窗口,并在1024K上下文的海底捞针任务中实现100%召回。
7 提示脆弱性
大语言模型的回复可能受到提示内容和格式的显著影响,这可能对其稳定性和可预测性产生影响。
提示的句法(例如长度、空白、示例的顺序)和语义(例如措辞、示例的选择、指令)会显著影响模型的输出。提示的变化也可能会导致输出发生巨大变化,即提示的脆弱性(Prompt Brittleness)现象
图示为提示方法的比较。
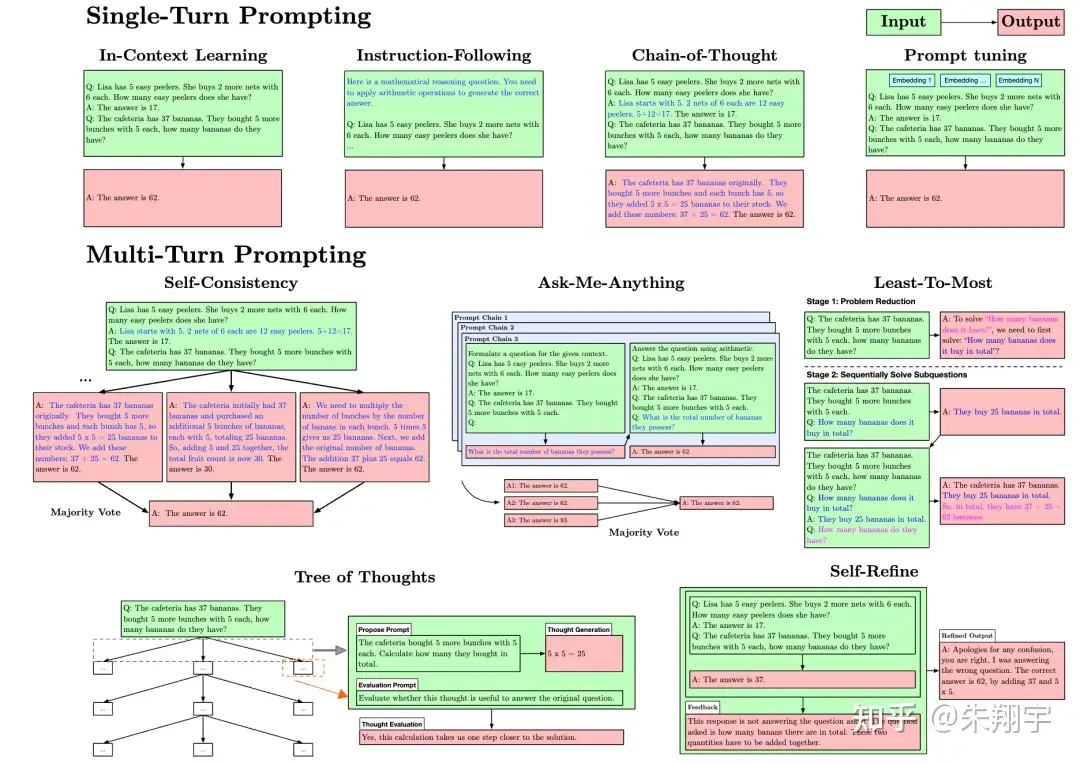
- 单轮提示方法:通过各种方式改进输入提示以获得更好的单次回答。其中,上下文学习(In-Context Learning)在各种自然语言处理任务中展现出竞争力的结果。这指的是 LLM 通过推理能够仅依靠训练数据的串联来学习新任务,而不需要调整 LLM 的内部工作方式。
- 提示跟随(Instruction-Following)需要对模型进行监督微调,主要通过在输入提示中添加任务描述性指令来实现。
- 思维链(Chain-of-Thought)是一种通过一系列中间推理步骤构建少样本提示的技术,最终导致最终输出。
- 模仿(Impersonation)是一种技术,它要求模型在回答特定领域问题时假装成领域专家。研究发现,提示模型在模仿领域专家时对特定领域问题的回答更准确。
- 多轮提示方法:通过迭代地连接提示和其答案来生成输出。方法包括
Ask Me Anything、Self-consistency、Least-to-Most、Scratchpad、ReAct等。- 自动推理与工具使用(ART)是一种自动生成多步推理提示的方法,包括对外部工具的符号调用,如搜索和代码生成或执行。
- 控制生成(Controlled Generation)是一种直接修改推理过程的方法,而不是修改输入文本来控制模型输出。在 LLM 中,可以使用无分类器引导采样、提示修改等方法来实现控制生成。
总之,提示的设计和改进对于 LLM 的输出结果具有重要影响,需要进行大量实验来优化提示,并且还有很多提问方法和控制生成方法需要进一步研究和实践。
8 幻觉
大语言模型可能生成与实际情况不符的内容,这可能对其可信度和实用性产生影响。
ChatGPT 常常出现幻觉,即生成不准确的信息,由于文本的流利性,这些错误很难被检测到
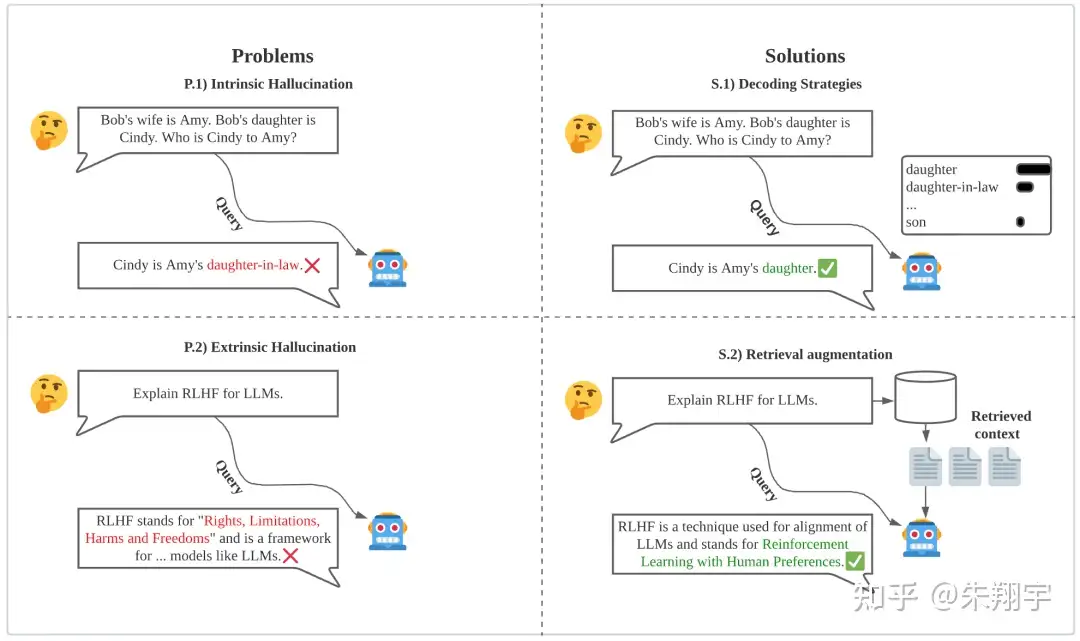
本质幻觉和外在幻觉:
- 本质幻觉指生成的文本在逻辑上与源内容相矛盾
- 外在幻觉指无法通过源内容验证输出的正确性,因为源内容提供的信息不足以评估输出结果,因此结果是不确定的。
尽管外在幻觉并不一定是错误的,但由于无法确认提供的信息的真实性,它在一定程度上仍然不可取。
原因
- 传统的解码算法会在每个采样步骤引入均匀随机性,从而导致幻觉的产生。
- Dziri 等人观察到,回答生成中多样性的增加与幻觉的出现存在正相关关系。
引入随机性和多样性:最有可能的序列通常会导致与人类交流相比较乏味和不自然的文本。Zhang 等人将这个挑战描述为多样性和质量之间的一种权衡。
尽管这个挑战在很大程度上尚未解决,但一些方法,如多样性束搜索(Uncertainty-Aware Beam Search)和自信解码(Confident Decoding)试图在解码过程中减少幻觉的产生。
不确定性感知束搜索方法基于一个观察结果,即预测的不确定性越高,生成幻觉的可能性越大。因此,在束搜索中引入了惩罚项来惩罚解码过程中的高预测不确定性。自信解码方法则假设编码器-解码器模型产生幻觉的原因是在解码时未能正确关注源内容。他们提出了一个基于注意力的置信度评分来衡量模型对源内容的关注程度,并使用变分贝叶斯训练过程确保模型生成高置信度的答案。
9 行为不匹配
大语言模型的行为可能与人类的期望和意图不匹配,这可能对其人机交互的效果产生影响。
对齐问题旨在确保 LLM 的行为与人类的价值、目标和期望一致,避免产生意外或负面后果。
如图所示,现有工作可分为两类方法:检测误对齐行为和对齐模型行为的方法。
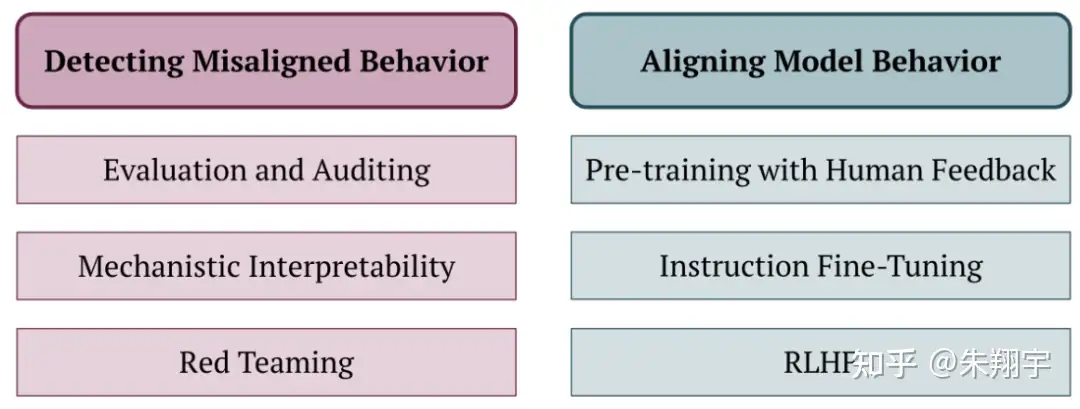
预训练与人类反馈(PHF)是一种在预训练阶段引入人类反馈的概念,研究者比较了五种方法,包括过滤、条件训练、非似然、奖励加权回归和优势加权回归。他们发现条件训练在训练数据上实现了最好的平衡,但可能存在隐私泄露和在某些应用中使 LLM 变得不安全的风险。
10 知识过时
大语言模型的知识可能随着时间的推移而变得过时,这可能对其应对新情况和新知识的能力产生影响。
在预训练过程中,LLM 所学到的实际信息可能存在不准确或过时的情况(比如无法及时考虑到政治领导层的变动)。然而,重新训练模型需要耗费昂贵的成本,并且在微调过程中很难“遗忘”旧的事实并学习新的事实。
现有的模型编辑技术在更新孤立的知识方面效果有限,这限制了它们在真实世界应用中的适用性。这些应用场景要求仅更新一个错误或过时信息,并且相关信息必须准确地反映这个更新,而不影响其他无关信息。
目前解决这个问题的两种常见方法是:
- 模型编辑技术:通过修改模型参数或使用外部后编辑模型来改变模型的行为;
- 检索增强语言模型:利用非参数化的知识源在推理过程中更新以反映底层知识的更新状态。
11 评估脆弱
评估大语言模型的性能可能受到各种因素的影响,这可能导致其评估结果的不稳定和不可靠。
虽然一个模型可能能够轻松解决一个基准问题,却可能在问题稍微变化(甚至只是修改提示)后得到完全相反的结果。与人类不同,我们不容易直观地判断一个语言模型是否具备解决其他相关问题的能力。这导致了对语言模型综合评估的困难,因为需要严格的基准来确定各种输入的弱点。评估过程容易出现脆弱问题,稍微修改基准提示或评估协议可能会导致完全不同的结果。
为了增强基准评估的鲁棒性,全面的基准集试图在所有场景和任务上进行标准化评估,并确保在尽可能多的能力和风险方面进行广泛覆盖。越来越多的模型也开始在人类设计的测试中进行基准化评估,如 SAT、LSAT 和数学竞赛等。
对于传统的基准测试来说,模型对于问题提示或评估方法的选择可能非常敏感。通常情况下,提示的变化也没有进行规范处理,因此模型可能对这种变化非常敏感,比如提示是否添加了“请回答是或否”。Jain 等人发现,规模更大、经过引导微调的模型更容易对提示的微小变化敏感。
12 静态/人工评估
如果评估基于固定和人工编写的标准,可能无法全面、公正地评估大语言模型的性能。
LLM 评估通常依赖于人工编写的“ground truth”文本,但在专业知识的文本往往稀缺。随着模型在某些领域超越人类在基准测试中的表现,无法获得与“人类水平”性能的比较。随着模型能力的提高,旧的基准数据集会变得过时,不再提供有用的信号。社区需要不断适应新的静态基准,同时减少对动态评估的重视,比如对模型输出的人工评估。
为了应对这些问题,一种方法是定期向 BIG-Bench 基准添加新任务,包括进行程序化评估的任务。以下两条研究工作线路使得动态评估在不需要人的情况下成为可能。
- LLM生成的评估任务:随着 LLM 的能力提升,它们可以越来越多地生成有用的基准问题或评估提示。研究表明,LLM 可以用于生成任意维度的静态基准数据集,通过使用基于人类偏好的奖励模型来过滤生成的数据集以确保质量。
- LLM生成的评分:越来越多人使用 LLM 直接对其他模型的性能进行评分,并作为其他模型能力的“裁判”。这个概念的动机是,在许多领域,模型可能很难生成“正确”答案,但评估答案的正确性或判断两个答案之间相对质量往往更容易。然而,这些技术产生的评估结果往往会因为“裁判”模型的不同而有很大差异,并存在鲁棒性问题,不能很好地替代人类判断。
13 文本生成检测
大语言模型生成的文本可能与人类编写的文本相似度极高,这可能导致诸如虚假信息传播等问题。
检测由语言模型生成的文本的重要性体现在防止虚假信息传播、抄袭、冒充或身份窃取以及自动欺诈等方面。然而,随着语言模型流畅度的提高,检测这些文本变得更加困难。
为了解决这个问题,有两种方法:
- 事后检测器:通过统计不太可能出现的标记来帮助人类检测生成的文本。
- 水印方案:改变文本生成过程,使其更容易检测。
在事后检测方法中,一些研究探索使用能量模型来区分真实文本和伪造文本,还有人研究使用近似模型对马赛克样本进行判别。在水印方案中,研究者使用隐式模式来标记生成文本,该模式只有计算机能够识别,而人类无法察觉,以便在推理阶段更容易检测出来。
为了避免机器生成的文本被检测出来,可以对生成的文本进行改写,来消除语言模型的特征。研究人员通过训练一个生成近义词的模型,可以重写语言模型生成的文本,保留大致相同的意思,但改变文字或句子结构。对抗这种攻击的方法之一是将模型生成的文本存储在数据库中,并在需要时检索语义上相似的文本。
此外,研究人员还探讨了如何通过多次查询带有水印的语言模型来提取其水印方案,并伪造成被错误分类为模型生成的人类文本的情况。由于水印检测的可靠性不确定,文本检测变得更加困难。
14 规模无法解决的任务
有些任务可能需要更深入、更具针对性的方法,而非仅仅依赖于模型的规模。
LLM 的能力令研究界不断称奇,例如在 MMLU 基准测试上取得高性能,超过了人类预测者的预期。OpenAI 也发布了更新的 GPT 版本,如 GPT-3.5 和 GPT-4,其中 GPT-4 在各种任务上明显优于 GPT-3.5。这些进展引发了对当前的数据或模型扩展范式是否存在克服的限制的质疑。
逆向缩放(IS)是随着模型规模和训练损失的增加,任务性能会变差。某些任务可能不会从进一步的模型或数据集扩展中获益,例如反事实任务。这类任务在改变特定输入输出条件但保持一般推理过程时,LLM 的性能会变差。研究者发现,LLM 对于不常见的反事实条件表现得越差,这被称为“类记忆效应”。作者呼吁进一步研究是否增加模型规模会因为更多的记忆效应而导致性能恶化,还是因为规模优化的预训练方法会扩展数据集,从而包含更多具有不寻常条件的任务。
15 缺乏实验设计
大型语言模型的研究可能缺乏足够的实验设计,这可能对其发现和解决问题的能力产生影响。
首先,如表 2 所示,作者指出许多论文缺乏控制实验,即通过逐个改变一个因素的方式进行实验,这可能是因为所需要的计算成本太高。没有进行控制实验会阻碍对 LLM 性能理解的科学进展。
▲表2 综述中所选的 LLM 概览 其次,LLM 研究的设计空间通常是高维的,这增加了实验的复杂性。为了解决这个问题,作者建议使用贝叶斯优化和维度归约等技术来有效地探索设计空间。
最后,作者还提到 LLM 相比其他领域的模型具有更多的参数,因此计算需求、反馈循环时间和训练成本更高。
16 缺乏可重复性
大语言模型的训练和运行可能缺乏足够的透明度和标准化,这可能影响其结果的可重复性和公正性。
实证结果可重复性对于验证科学主张和排除实验协议中的错误非常重要。在研究人员试图建立在不可重复结果基础上的研究时,可能会浪费资源。然而,在 LLM 研究中存在两个可重复性问题:
训练的可重复性:涉及多个计算节点之间的并行处理。节点之间的调度和通信策略可能是非确定性的,这种变异性可能会影响最终结果,特别是在“非排序不变”算法(如随机梯度下降)中更为明显。此外,由于资金、隐私和法律限制,一些预训练数据集包含用户必须自己爬取的网页内容索引,而非使用静态的独立存档。因此,如果数据集收集者在他们下载数据集时所用的源发生了变化,可重复性就很容易受到损害。
由闭源 API 提供的模型的生成可重复性:是商业 LLM 模型的另一个特殊情况,它们通常在黑盒环境中使用,带来以下挑战:
- 服务提供者对模型拥有完全的控制权,可以引入未公开的更改,包括重新训练模型、修改参数或完全替换模型;
- 即使模型更新已经被通知,仍然存在关于是否会继续维持访问特定模型版本的不确定性;
- 即使将解码温度设置为零,API 模型还经常产生随机输出。有研究人员提供初步证据,证实了 API 提供的模型性能的巨大变化。
因此,API 提供的模型通常是不可重现的。尽管可以依赖开源LLM模型来解决这个问题,但因为算力和资源的限制,目前看来这个方法并不完全可行。
字数控制
【2024-7-17】文本生成时,难以精确控制生成文本的字数。
- ChatGPT 生成回复时,主要目标是内容相关性和准确性,而不是字数精确控制。
直接指定字数要求:
“写一个大约 100 字的简介”。
GPT 说了大约 100 字,但是还是给了快 200 字了😂。
改进方法:
- 使用结构化的请求:提供明确的结构要求
- “请提供三点建议,每点不超过 20 字”。
- 请用简要描述环保的重要性,大概三句话,每句话35个字以内 。
这个方法可以更好的控制文本字数。
LLM 认知智能
LLM 能理解现实世界和各种抽象概念吗?还是仅仅在「鹦鹉学舌」,纯粹依靠统计概率预测下一个token?
LLM 工作原理依旧是未解之谜。
AI圈大佬们,时不时就这个问题展开一场论战。
LLM 有智能吗
【2023-6-1】世界的参数倒影:为何GPT通过Next Token Prediction可以产生智能
把 “章鱼测试” 里的章鱼换成 ChatGPT 或 GPT-4,怎么看这个问题呢?
- 一种观点: GPT-4 这种LLM模型仅仅学会了语言中的单词共现等浅层的表面统计关系,其实并未具备智能,只是类似鹦鹉学舌的语言片段缝合怪而已;
- 代表:除了OpenAI,还有 musk,Hinton,他不仅认为GPT 4具备类人智能,而且觉得将来人类这种碳基智能很可能是LLM这种硅基智能的引导启动程序(Booster),
- 另外一种: GPT-4 不仅学会了语言元素间的表面统计关系,而且学到了人类语言甚至包括物理世界的内在运行规律,文字是由内在智能产生的,所以LLM具备类人智能。
- 代表: AI大佬是LeCun,语言学界代表人物是乔姆斯基,都否认通过Next Token Prediction这种方式训练出来的大语言模型能够具备智能;
LLM 是随机鹦鹉吗
LLM被训练来最小化字符串匹配中的预测误差,但这并不意味着它们的处理只是字符串匹配,可能涉及世界模型。
随机鹦鹉
- 语言模型只是将其在庞大的训练数据中观察到的语素胡乱拼接在一起,根据概率生成文本,但不清楚文字背后的任何含义,就像一个随机的鹦鹉。
- 出自论文On The Dangers of Stochastic Parrots: Can Language Models Be Too Big
正方: 是
很多人将此解释为纯粹的统计现象,LLM只是在「鹦鹉学舌」,对大量训练语料中存在的文本进行模仿,并不是像人类一样拥有同等水平的智能或感知。
LeCun 坚定认为: LLM 智能绝对被高估!
- 「大语言模型不如家里养的猫」: 猫可以记忆,理解物理世界,计划复杂行动,进行一定程度的推理,这实际上已经比最大的模型要好了,我们在概念层面有重要的缺失,无法让机器像动物和人类一样聪明。
Emily Bender、Timnit Gebru 及其同事批评:
- LLM 是“随机的鹦鹉”, 只是在模仿文本,而不是思考世界。
LLM本质上是“猜词”系统,它根本看不懂世界
Meta首席AI科学家Yann LeCun指出,当前主流大模型存在三大核心缺陷,导致其在真实智能层面甚至“不如动物”。
一、 无法理解世界:本质是“猜词”而非“思考”
AI的第一个缺陷:无法真正理解物理世界。它并非在“看世界”,而是在基于海量数据“猜下一个词”。
例如,一只猫能凭本能理解重力、距离和空间,而AI面对“桌边水杯是否会掉落”的视频时,无法基于常识判断,只能进行概率猜测。这种能力的缺失,是实现通用物理交互(如家庭机器人)的主要障碍。
AI能处理语言符号,但不懂符号背后的物理现实。
二、 缺乏持久记忆:永远的“陌生人”
其次,AI缺乏有效的长期记忆,如同“金鱼记忆”。它对用户的每次交互都是“一次性回应”,无法有效积累过往经验,形成对用户的持续认知。
这导致AI难以建立真正的个性化、默契感和共情能力。它无法像动物记得主人那样,通过点滴积累形成稳定而深入的关系,因此始终是一个功能强大但缺乏深度的“陌生”工具。
三、 不会有效规划:只是“看似有条理”
最后,AI不具备真正的规划能力。它能生成看似逻辑清晰的计划文本,但这只是在模仿和堆砌词语,而非进行目标分解、权衡选择和动态决策。
LeCun强调,“智能不只是反应,而是做选择”。当前的AI缺乏明确的目标感和在遇到意外时灵活调整的能力,本质上仍是“会说话的机器”,而非“能做事的智能”。
结论:未来在于“重构”而非“堆料”
LeCun总结
- 理解世界、拥有记忆和学会规划,是构建真正智能不可或缺的基石。
AI的未来发展,关键不在于继续扩大模型规模、堆砌算力,而在于进行范式上的重构——即研发重心转向为AI建立这些底层的核心能力。只有完成了这场深刻的重构,AI才能从模仿智能的阶段,迈向真正拥有智能的未来。
原文:Meta 首席科学家 Yann LeCun《热潮回落,AI 的硬标准:看世界、记得住、会规划》
反方: 不是
【2023-5-28】数学论证GPT-4不是随机鹦鹉:真如此的话整个宇宙都会坍缩
工程师 Jacob Bayless 用数学方法得出惊人结论:
- 根据统计规律预测下一词,所需信息量 50000^8000, 足以让整个宇宙都坍塌成黑洞。
- 根据
贝肯斯坦上限(Bekenstein bound)原理,如果把这些信息分配到空间当中,所需要的信息密度已经远超宇宙能承受的最大值。而这仅仅是把数据存储起来的消耗,更不必说还要进行运算了。
GPT-3 token 字典中就有超过5万token。
- 如果对每个词都逐一建立统计信息,n-gram 模型中n值将高达8000。届时,需要存储的情景数量将达到 $50000^{8000}$
这是天文数字,足以让整个宇宙坍缩。
因此,GPT是“随机鹦鹉”猜测在理论上得到了一定程度的否认。
两个实验
- 第一个实验:农夫过河问题,将农夫、船、河分别替换成地球人、虫洞和银河系。狼、羊和菜则分别换成火星人、金星人和月球人。这样现有语料都不存在,可用来判断是否掌握了语言规律
- GPT-4 针对替换后的问题给出了正确回答,GPT-3.5则没有。但它们并没有犯研究人员预想的“鹦鹉”错误 —— 回答中出现狼、船、河等已被替换掉的词语
- 这些现象都证明 现在的LLM生成方式已经超越了“概率预测”。
- 第二个实验:数字排序。 让GPT学习数字排序,究竟只记住数字顺序,还是真的会排序?
- 从1-100中随机选择10个数字,并将其顺序打乱,将一共有这么多种情形:6.28*10^9
- 只要GPT能够针对未知的排序问题给出正确回答,便说明真的研究出了排序算法。
- 用 nanoGPT 做数字排序。结果显示,随着训练步数的增加,模型给出的数字顺序越来越完美。
- 模型并不是仅仅根据学习的素材对未知的数字进行排序,而是已经掌握了背后方法。
【2024-8-17】MIT惊人研究:LLM已模拟现实世界,绝非随机鹦鹉!
- 论文 Emergent Representations of Program Semantics in Language Models Trained on Programs
- 实验代码 emergent-semantics
研究者们开发了一套小型卡雷尔谜题(Karel Puzzle)。让模型用指令在模拟环境中控制机器人的行动, 提出了「探针」(probing)机器学习技术,用于在模型生成新解决方案时,深入了解其中的「思维过程」。
实验使用三种不同的 probe架构 作为对比,分别是线性分类器、单层MLP和2层MLP。
- 提前2步预测时,2层MLP预测准确率的绝对值高于用当前状态预测的基线模型。
- 推测:LLM在生成指令前,其思维过程,以及生成指令的「意图」已经存储在模型内部了。
模型自发地形成了对底层模拟环境的概念, 尽管训练期间,并没有接触过这方面的信息。
这个结果不仅挑战了对LLM的固有印象,也质疑了对思维过程本质的认 知—— 学习语义过程中,究竟哪些类型的信息才是必需的?
- language specific (某种语言) –> universal (通用)
- Linguistic Form (语言形式) –> Meaning (语义)–> Concept (概念)–> Perception (感知)
- 图见原文
MIT CSAIL 研究人员发现
- LLM 「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。
- 未来,LLM 会更深层地理解语言。
「预测下一个token」看似只包含纯粹统计概率的目标,用来训练LLM学习编程语言,模型依旧可以学习到程序中的形式化语义。
发现
- LLM 不仅学到表面的统计数据,还学了空间和时间等基本纬度的
世界模型。 - LLM 深处,发展出了一种对现实世界的模拟,对语言的理解,已经远远超出了简单模仿
LLM 像孩子学习语言时分多个步骤一样。
- 开始,像婴儿一样牙牙学语,说出的话是重复的,而且大多数都难以理解。
- 然后,开始获取语法或语言规则,生成像是真正解决方案的指令,但此时仍然不起作用。
- 一旦模型获得了意义,会像孩子造句一样,开始产生正确执行所要求规范的指令。
LLM 对语言的理解大致分为3个阶段,就如同孩童学习语言一样。
- 牙牙学语(babbling,灰色部分):占据整个训练过程约50%,生成高度重复的程序,准确率稳定在10%左右
- 语法习得(syntax acquisition,橙色部分):训练过程的50%~75%,生成结果的多样性急剧增加,句法属性发生显著变化,模型开始对程序的token进行建模,但生成的准确率的提升并不明显
- 语义习得(semantics acquisition,黄色部分):训练过程的75%到结束,多样性几乎不变,但生成准确率大幅增长,表明出现了语义理解
图见原文
局限性:
- 仅使用了非常简单的编程语言Karel,以及简单的probe模型架构。
- 未来的工作将关注更通用的实验设置,也会充分利用对于LLM「思维过程」的见解来改进训练方式
LLM 一致性与能力
大型语言模型中的能力与一致性
- 「一致性 vs 能力」可以被认为是「准确性 vs 精确性」的更抽象的类比
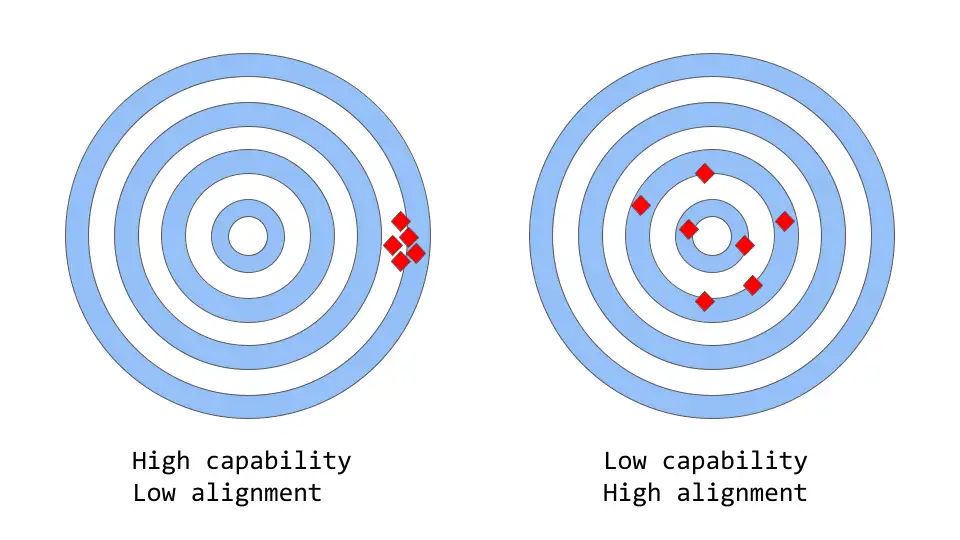
说明
- 模型能力是指模型执行特定任务或一组任务的能力。模型的能力通常通过它能够优化其目标函数的程度来评估。
- 一致性关注的是实际希望模型做什么,而不是它被训练做什么;「目标函数是否符合预期」,根据的是模型目标和行为在多大程度上符合人类的期望。
ChatGPT 为什么强
ChatGPT 这么强的原因?
- 因为足够“大”吗?是,但不全是。
- ChatGPT确实很大,背后模型是一个在有3000亿tokens上预训练的拥有1750亿个参数的大语言模型。但是,ChatGPT并不是目前世界上最大的模型
- 比如,Google的
PaLM的参数规模为5400亿,DeepMind的Gogher参数规模为2800亿,国内华为盘古α的参数规模为2000亿,百度文心的参数规模为2600亿。 - 论参数规模,ChatGPT虽然跻身千亿俱乐部成员,但远远不是最大的那个。
- 因为大量人工标注吗?不是
- ChatGPT背后的GPT 3.5,仅加入了数万条人工标注数据,相比于其预训练过程使用的3000亿tokens来说,可谓九牛一毛。
- 目前学界倾向于认为ChatGPT通过海量文本预训练,掌握了基本的语法知识,以及大量世界知识,所谓“知识注入”。
- 比如“地球是圆的”属于常识、或“对位芳纶全球消费量在8-9万吨,国内自给率是20%”属于投研领域专业知识,这些都属于“世界知识”的范畴,都是在模型预训练时注入的。
- 相对的,人工标注数据,提供的则主要是人类偏好知识,比如礼貌的回答是好的,带有歧视性的回答是不好的等等。OpenAI的作者将其戏称为“
对齐税”(Alignment Tax),即为了使回答满足人类的偏好而牺牲了部分模型的性能。
目前关于ChatGPT模型优秀能力的来源在学界众说纷纭,尚未有定论。但有两种猜想已经得到了绝大多数学者的支持,分别是“涌现能力”、以及“代码训练”。
邱锡鹏:指令学习加强了语义理解
LLM 涌现能力
什么是涌现
LLM 的涌现能力定义:
- 「在小模型中不存在但在大模型中出现的能力」
- 当规模达到一定水平时,性能显著高于随机的状态。–
相变现象
LLM 区别于以前的 PLM 的最显著特征
这种新模式与物理学中的相变现象密切相关。
生物现象
【2023-10-1】什么是涌现?人工智能给你答案
当蚂蚁聚集成蚁群时,会展现出一种不可思议的“智能”表现。例如,能够自动发现从蚁群到达食物的最短路径。
- 这种智能表现并不是由于某些个体蚂蚁的聪明才智,因为每只蚂蚁都非常小,不可能规划比它们身长长至少几十倍以上的路径。
- 这种行为是由于许多蚂蚁聚集成一个蚁群,才表现出来的智能。
蚁群发现觅食最短路径包含了以下三点:
- 蚂蚁找到食物就会释放信息素;
- 信息素会吸引更多的蚂蚁来聚集,同时信息素也会挥发;
- 蚂蚁和信息素形成正反馈回路,把路径长短上的细小差异放大,从而筛选出最短路径。
借此大致可以定性地描述涌现发生的机制:局部作用产生正反馈机制,从而导致宏观上“令人惊异”的现象。
类似的
- 许多小鱼聚成鱼群,便拥有了大鱼一般的威慑力,这是单独一只小鱼所不能拥有的
- 生命游戏:基本元素细胞有着非常简单的交互规则,但当把视点放在全局,却会发现很多有意思的图案(pattern),如静态、周期震荡等
- 1970年,英国数学家约翰·何顿·康威(John Horton Conway)发明了元胞自动机。
- 阿米巴虫:科学家借鉴阿米巴虫的生长来设计城市的交通运输网
这种现象称为涌现(Emergence)。
LLM 中的涌现跟自然界中的涌现现象直观上似乎一样,但实际是有差异,因为这里没有局部正反馈反映到宏观全局的过程,其背后原因更多和思维链(chain of thoughts)有关
GPT-4太强,OpenAI也不懂!智能到底是怎么突然「涌现」的?
内行人也不明白,为什么模型规模在突破某一界限后,突然就「涌现」出了惊人的智能。出现智能是好事,但模型不可控、不可预测、不可解释的行为,却让整个学术界陷入了迷茫与深思。
Google Research的计算机科学家Ethan Dyer参与组织了这次测试,希望通过204项任务,测试各种大型语言模型能力
- 虽然构建BIG-Bench数据集时已经准备好了迎接惊喜,但当真的见证这些模型能做到的时候,还是感到非常惊讶。这些模型只需要一个提示符:即接受一串文本作为输入,并且纯粹基于统计数据一遍又一遍地预测接下来是什么内容。
- 扩大规模可以提高已知任务的性能,但他们没有预料到模型会突然能够处理这么多新的、不可预测的任务。
Dyer最近参与的一项调研结果显示,LLM 可以产生数百种「涌现」(emergent)能力,即大型模型可以完成的任务,小型模型无法完成,其中许多任务似乎与分析文本无关,比如从乘法计算到生成可执行的计算机代码,还包括基于Emoji符号的电影解码等。论文
- 对于某些任务和某些模型,存在一个复杂性阈值,超过这个阈值,模型的功能就会突飞猛进。
- img
大模型具有In-Context能力,这种能力不需要针对不同任务再进行适应性训练(微调),用的就是它自己本身的理解力。
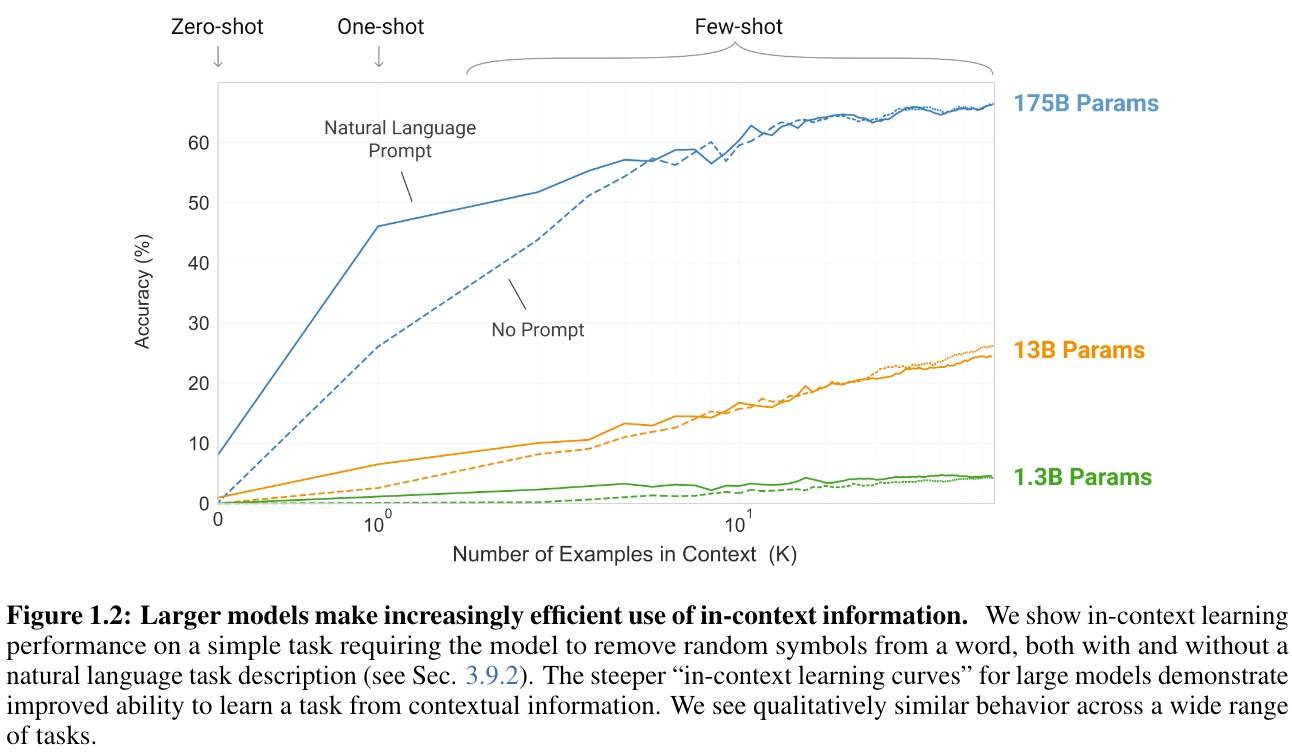
GPT-3的少样本学习在不同规模模型上的实验对比,提供几个信息:
- X-Shot在不同量级差别巨大,大模型就是有超能力。
- 大模型下,One-Shot效果明显大幅度提升;增加Prompt会进一步大幅度提升。
- Few-Shot的边际收益在递减。
- 大概8-Shot以下时,Prompt作用明显
- 但从One-Shot到8-Shot,Prompt的作用也在递减。
- 超过10-Shot时,Prompt基本没作用了。
涌现的涌现(The Emergence of Emergence)
- 生物学家、物理学家、生态学家和其他科学家使用「涌现」一词来描述当一大群事物作为一个整体时出现的自组织、集体行为。
- 比如无生命的原子组合产生活细胞; 水分子产生波浪; 椋鸟的低语以变化但可识别的模式在天空中飞翔; 细胞使肌肉运动和心脏跳动。
- 涌现能力在涉及大量独立部分的系统中都有出现,但是研究人员直到最近才能够在 LLM 中发现这些能力,或许是因为这些模型已经发展到了足够大的规模。
通过增加模型中的参数数量以及其他因素,Transformer使语言模型的复杂性得以快速扩展,其中参数可以被认为是单词之间的连接,模型通过在训练期间调整这些连接的权重以改善预测结果。模型中的参数越多,建立联系的能力就越强,模拟人类语言的能力也就越强。
OpenAI 研究人员在2020年进行的一项分析发现,随着模型规模的扩大,它们的准确性和能力都有所提高。论文
- 随着 GPT-3(拥有1750亿参数)和谷歌的 PaLM (可扩展至5400亿参数)等模型的发布,用户发现了越来越多的涌现能力。
与电影Emoji符号任务一样,研究人员没有料到用于预测文本的语言模型可以模仿计算机终端,许多涌现行为都展现了语言模型的Zero-shot或Few-shot学习能力,即LLM可以解决以前从未见过或很少见过的问题的能力。
大批研究人员发现了 LLM 可以超越训练数据约束的迹象,他们正在努力更好地掌握涌现的样子以及它是如何发生的,第一步就是完全地记录下来。
2020年,Dyer 和Google Research的其他人预测,LLM 将产生变革性影响,但这些影响具体是什么仍然是一个悬而未决的问题。他们要求各个研究团队提供困难且多样化任务的例子以找到语言模型的能力边界,这项工作也被称为「超越模仿游戏的基准」(BIG-bench,Beyond the Imitation Game Benchmark)项目,名字来源于阿兰·图灵提出的「模仿游戏」,即测试计算机是否能以令人信服的人性化方式回答问题,也叫做图灵测试。
模型复杂性并不是唯一驱动因素,如果数据质量足够高,一些意想不到的能力可以从参数较少的较小模型中获得,或者在较小的数据集上训练,此外query的措辞也会影响模型回复的准确性。示例:NeurIPS 上发表的CoT思维链技术,论文
- 思维链提示改变了模型的规模曲线,也改变了涌现的点,使用思维链式提示可以引发 BIG 实验中没有发现的涌现行为。
布朗大学研究语言计算模型的计算机科学家Ellie Pavlick认为,这些发现至少提出了两种可能性:
- 第一,如生物系统,大模型确实会自发地获得新的能力,可能从根本上学到了一些新的和不同的东西,而小尺寸模型中没有。当模型扩大规模时,会发生一些根本性的转变。
- 第二,看似突破性的事件可能是一个内部的、由统计数据驱动的、通过思维链式推理运作的过程,大型 LLM 可能只是学习启发式算法,对于那些参数较少或者数据质量较低的参数来说,启发式算法是无法实现的。
涌现导致了不可预测性,而不可预测性也随规模的扩大而增加,使研究人员难以预测广泛使用的后果。
涌现能力的另一个负面影响:
- 随着复杂性的增加,一些模型在回答中显示出新的偏见(biases)和不准确性。
最新进展
Emergence in science 涌现科学
General defn. in science
Emergence is a qualitative change that arises from quantitative changes. 量变引起质变
案例
- Given only small molecules such as calcium, you can’t meaningfully encode useful information. Given larger molecules such as DNA, you can encode a genome.
- Popularized by this 1972 piece by Nobel-Prize winning physicist P.W. Anderson.
- With a bit of uranium, nothing special happens. With a large amount of uranium, you get a nuclear reaction.
涌现的问题 Three implications of emergence
- Unpredictable. 难以预测
- Emergence cannot be predicted solely by extrapolating scaling curves from smaller models. 无法通过缩放曲线预测
- Scaling laws don’t apply for downstream tasks! 缩放定律不适用下游任务
- Unintentional.
- Emergent abilities are not explicitly specified by the trainer of the language model (next word prediction “only”).
- In the history of deep learning, has this been true before?
- One model, many-tasks.
- Since scaling has unlocked emergent abilities, further scaling can be expected to elicit more abilities.
- Let’s scale more right? (Any undesirable emergent abilities?)
【2023-11-29】Jason wei stanford cs330 talk: twitter
涌现能力总结
【2023-4-4】LLM 三种代表性的涌现能力:
- 上下文学习。GPT-3 正式引入了上下文学习能力:假设语言模型已经提供了自然语言指令和多个任务描述,可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新。
- 指令遵循。通过对自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在微小的任务上表现良好,这些任务也以指令的形式所描述。这种能力下,指令调优使 LLM 能够在不使用显式样本的情况下通过理解任务指令来执行新任务,这可以大大提高泛化能力。
- 循序渐进推理。对于小语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学学科单词问题。同时,通过思维链推理策略,LLM 可以通过利用涉及中间推理步骤的 prompt 机制来解决此类任务得出最终答案。据推测,这种能力可能是通过代码训练获得的。
只有大型模型才有的三种突现能力:
复杂推理,大型模型在没有使用全部训练数据的情况下便显著优于以前的小型模型。知识推理,大型模型可能没有小模型效果好,但大模型不需要额外的知识来源(知识可能很昂贵,或者很难从非结构化数据中抽取)。分布外鲁棒性,这是之前进行模型精调时需要努力解决的问题。大型模型虽然在同分布情况下的效果不如以前的方法,但非同分布情况下的泛化性能却好得多。
(1)复杂推理
下面是一个GSM8K数据集中,用提示词显著超过精调的例子:
问题:
克莱儿每天早饭都用 3 颗蛋做蛋卷,她 4 周会吃掉多少打鸡蛋?
克莱儿每天早饭都用3颗蛋做蛋卷。
一周有 7 天。
所以她一周会吃 3 * 7 = 21 颗蛋。
她4周会吃掉 4 * 21 = 84 颗蛋。
一打里面是 12 颗蛋。
所以 84 / 12 = 7。
答案是7。
这道题对于10岁的孩子很容易,但对语言模型却很难,主要是由于数学和语言混合在一起。
GSM8K 最初由 OpenAI 于 2021 年 10 月提出。当时用第一版GPT3在全部训练集上进行了精调,准确率约为 35%。这个结果让作者相当悲观,因为结果显示了语言模型的缩放规律:
- 模型大小指数增长,性能线性增长。
因此,第 4.1 节中思考:
-
“175B 模型似乎需要至少额外两个数量级的训练数据才能达到 80% 的求解率。”
- 三个月后,即 2022 年 1 月,Wei 等人 基于 540B PaLM 模型,仅使用了8个思维链提示示例便将准确率提高到56.6% (无需将训练集增加两个数量级)。
- 在 2022 年 3 月,Wang 等人 基于相同的 540B PaLM 模型,通过多数投票的方法将准确率提高到 74.4% 。当前的 SOTA 来自在 AI2 的工作(Fu et. al. Nov 2022),通过使用复杂思维链在 175B Codex 上实现了 82.9% 的准确率。
从以上进展可以看到,技术进步确实呈指数级增长。
思维链提示是一个展示模型随着规模突现出能力的典型例子:
- 突现能力:尽管不需要 17500B,但模型大小确实要大于 100B ,才能使思维链的效果大于的仅有回答提示。所以这种能力只存在于大型模型中。
- 效果:思想链提示的性能明显优于其之前的精调方法(目前还没有能公平对比提示词和微调的工作。但当思维链被提出的时候,尽管他们对于提示和精调的比较可能是不公平的,但确实比精调效果要好)。
- 标注效率:思维链提示只需要 8 个示例的注释,而微调需要完整的训练集。
有些同学可能会认为模型能做小学数学代表不了什么(从某种意义上说,他们确实没有那么酷)。但 GSM8K 只是一个开始,最近的工作已经把前沿问题推向了高中、大学,甚至是国际数学奥林匹克问题。
(2)知识推理
下一个例子是需要知识的推理能力(例如问答和常识推理)。对大型模型进行提示不一定优于精调小型模型(哪个模型更好还有待观察)。但是这个情况下的注释效率被放大了,因为:
- 在许多数据集中,为了获得所需的背景/常识知识,(以前很小的)模型需要一个外部语料库/知识图谱来检索[13],或者需要通过多任务学习在增强[14]的数据上进行训练
- 对于大型语言模型,可以直接去掉检索器[15],仅依赖模型的内部知识[16],且无需精调
与数学题的例子不同,GPT-3 并没有明显优于之前的精调模型。但它不需要从外部文档中检索,本身就包含了知识(虽然这些知识可能过时或者不可信,但选择哪种可信知识源超出了本文的讨论范围)。
为了理解这些结果的重要性,我们可以回顾一下历史:NLP 社区从一开始就面临着如何有效编码知识的挑战。人们一直在不断探究把知识保存在模型外部或者内部的方法。上世纪九十年代以来,人们一直试图将语言和世界的规则记录到一个巨大的图书馆中,将知识存储在模型之外。但这是十分困难的,毕竟我们无法穷举所有规则。因此,研究人员开始构建特定领域的知识库,来存储非结构化文本、半结构化(如维基百科)或完全结构化(如知识图谱)等形式的知识。
- 通常,结构化知识很难构建(因为要设计知识的结构体系),但易于推理(因为有体系结构),非结构化知识易于构建(直接存起来就行),但很难用于推理(没有体系结构)。
- 然而,语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。
下表为优缺点对比:
| 构建 | 推理 |
|---|---|
| 结构化知识 | 难构建,需要设计体系结构并解析 容易推理,有用的结构已经定义好了 |
| 非结构化知识 | 容易构建,只存储文本即可 难推理,需要抽取有用的结构 |
| 语言模型 | 容易构建,在非结构化文本上训练 容易推理,使用提示词即可 |
(3)分布外鲁棒性
第三种能力是分布外鲁棒性。
- 在 2018 年至 2022 年期间,NLP、CV 和通用机器学习领域有大量关于分布偏移/对抗鲁棒性/组合生成的研究,人们发现当测试集分布与训练分布不同时,模型的行为性能可能会显著下降。 -然而,在大型语言模型的上下文学习中似乎并非如此。Si 等人在2022年的研究显示[17]:虽然 GPT-3 在同分布设置下比 RoBERTa 要差,但在非同分布设置下优于 RoBERTa,性能下降明显更小。
- 同样,在此实验中,同分布情况下基于提示词的 GPT-3 的效果并没有精调后的 RoBERTa要好。但它在三个其他分布(领域切换、噪声和对抗性扰动)中优于 RoBERTa,这意味着 GPT3 更加鲁棒。
此外,即使存在分布偏移,好的提示词所带来的泛化性能依旧会继续保持。
Fu 等人2022年[18]的研究显示,输入提示越复杂,模型的性能就越好。这种趋势在分布转移的情况下也会继续保持:无论测试分布与原分布不同、来自于噪声分布,或者是从另一个分布转移而来的,复杂提示始终优于简单提示。
(4)涌现能力推翻规模定律
突现能力推翻规模定律, scaling law
一个很奇怪的问题:
- GPT-3 在 2020 年就发布了,但为什么现在才发现并开始思考范式的转变?
答案藏在两种曲线中:对数线性曲线和相变曲线。图见原文
-
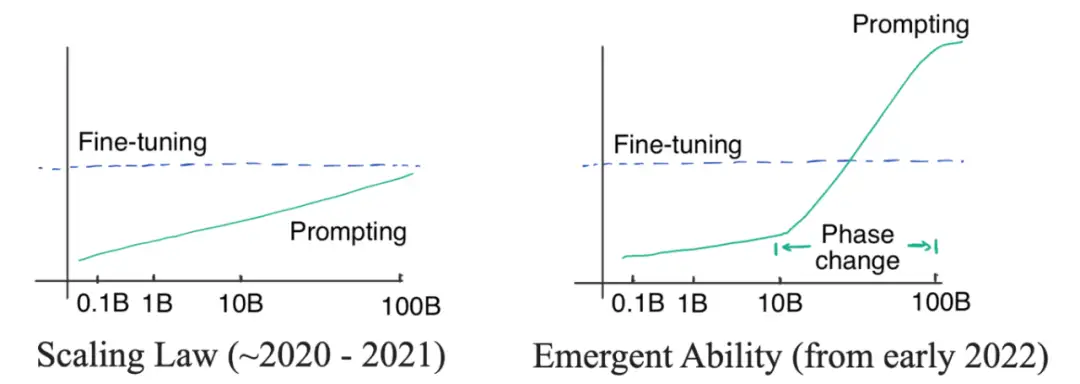
- 最初,(OpenAI)研究者认为语言模型的性能与模型尺寸的关系可以通过对数线性曲线预测
- 模型尺寸呈指数增长时,性能会随之线性增加。这种现象称为语言模型的
缩放定律,正如 Kaplan 等人在2020年最初的GPT3文章中讨论的那样。 - 即便最大的 GPT-3 在有提示的情况下也不能胜过小模型精调。所以当时并没有必要去使用昂贵的大模型(即使提示词的标注效率很高)。
- 模型尺寸呈指数增长时,性能会随之线性增加。这种现象称为语言模型的
- 直到2021年,Cobbe 等人发现缩放定律同样适用于精调。有点悲观,我们可能被锁定在模型规模上——虽然模型架构优化可能会在一定程度上提高模型性能,但效果仍会被锁定在一个区间内(对应模型规模),很难有更显著的突破。
缩放定律掌控下(2020年到2021),由于GPT-3无法胜过精调 T5-11B,同时T5-11B微调已经很麻烦了,所以NLP社区更关注研究更小的模型或者高效参数适应。Prefix tuning 就是提示和适应交叉的一个例子,后来由 He 等人在 2021统一。- 当时的逻辑:
- 如果精调效果更好,高效参数适应上多下功夫;
- 如果提示词方法更好,训练大型语言模型上投入更多精力。
- 2022 年 1 月,
思维链工作被放出来了。思维链提示在性能-比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。当使用思维链进行提示时,大模型在复杂推理上的表现明显优于微调,在知识推理上的表现也很有竞争力,并且分布鲁棒性也存在一定的潜力。要达到这样的效果只需要8个左右的示例,这就是为什么范式可能会转变的原因。
【2023-2-21】模型应该多大才够?两个数字:62B 和 175B。
- 模型至少需要
62B,思维链效果才能大于标准的提示词方法。- 62B这个数字来自于 Chung 等人 2022 年工作的第五张表
- 所有小于62B的模型,直接用提示词都好于思维链。
- 模型至少需要
175B(GPT3的尺寸),思维链效果才能大于精调小模型(T5 11B)的效果。- 理想的尺寸可以小于540B,在 Suzgun 等人2022年的工作中,作者展示了175B的 InstructGPT 和 175B的 Codex 使用思维链都好于直接用提示词。
思维链 受限条件
- 模型规模 > 62b:
思维链优于提示词 - 模型规模 > 175b:
思维链优于微调
其他大型模型在思维链下的表现差了很多,甚至不能学到思维链,比如 OPT、BLOOM 和 GPT-3 的第一个版本。他们的尺寸都是175B。
两种模型可以做思维链 (TODO: add discussions about UL2):
- GPT3系列的模型,包括 text-davinci-002 和 code-davinci-002 (Codex)。这是仅有的两个具有强大突现能力并可公开访问的模型。
- a. 除了以上两个模型,其他GPT3模型,包括原来的 GPT3,text-davinci-001,以及其他更小的GPT-3模型,都不能做
思维链。 - b. 当说“能做思维链”时,指使用思维链方法的效果比直接用提示词、精调T5-11B效果更好。
- c. 注意: code-davinci-002 在语言任务上的性能始终优于 text-davinci-002。这个观察非常有趣且耐人寻味。这表明基于代码数据训练的语言模型可以胜过根据语言训练的语言模型。
- PaLM系列模型,包括 PaLM、U-PaLM、Flan-PaLM 和 Minerva
为什么有涌现能力
反方
【2024-4-24】 斯坦福AI(大模型)指数2024年度报告
【2023-5-22】斯坦福论文显示:指标上所谓的涌现能力,其实跟评测指标密切相关
- 如果指标非线性、离散(如多选题),可能出现“涌现”
- 如果指标线性、连续,那么“涌现”就会消失
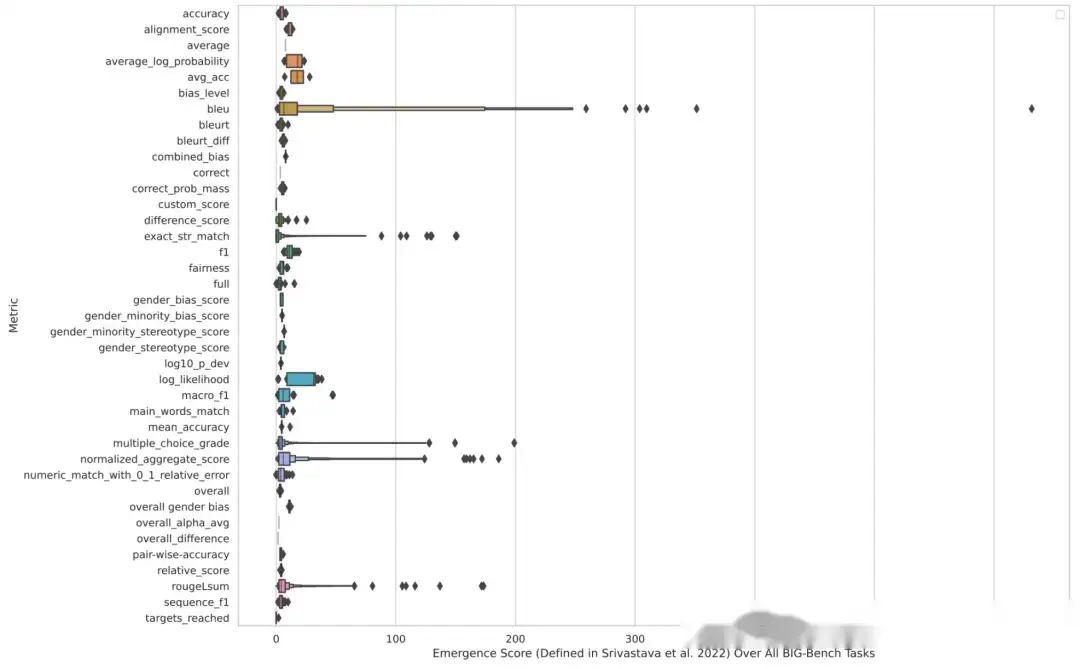
涌现能力表现为:
- 只在大模型中存在
- 徒增: 瞬间从不存在转为存在
- 不可预测
详见论文:Are Emergent Abilities of Large Language Models a Mirage?
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly instantaneously from not present to present, and their unpredictability, appearing at seemingly unforeseeable model scales. Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous, predictable changes in model performance. We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities, (2) make, test and confirm two predictions about metric choices in a metaanalysis of emergent abilities on BIG-Bench; and (3) show how to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks. Via all three analyses, we provide evidence that alleged emergent abilities evaporate with different metrics or with better statistics, and may not be a fundamental property of scaling AI models.
正方
【2023-4-4】涌现能力是玄学吗?
大量个体涌现出单个个体不具备的能力。这是有实验基础的。
- 单个蚂蚁依靠信息素浓度前进,蚁群就有自动寻路的能力,这就是蚁群算法。
- 人类遵从简单获取金钱的规则,资本涌现出羊吃人的能力。
目前所有解释都是往涌现上一推,似乎问题就混过去了。
GPT 推理能力的产生基于如下原理:
- 记忆是一阶从原始数据到表征数据的相关性连接。
- 推理规则和推理方法本身是二阶记忆内部的相关性连接
小模型在二阶链接上的密度是稀疏的,特定大规模建模可以在二阶连接上超过50%,形成具有连通性的通路,就形成了似乎具备推理能力。
过去所谓的逻辑和原理都是人通过先验知识赋予的似乎不证自明的假设,但是在LLM中,这部分是可以产生的,当然需要正确的调教方法。这挑战了人类几百年来认为是不可动摇的归纳和演绎方法,现在看来归纳和演绎规则并非真正原理,这些其实都是可以解释和可以构造的。
总结:
- 过去的调教和模型规模导致其在高阶连接上稀疏,而
GPT-3.5后高阶相关性的密度达到了全局性联通的边界。 - 所以GPT让人产生了其可以逻辑推理和长程对话的感觉,这是一种表征而已。
侧面证明了人类崇拜几千年的逻辑、公理、假设、真理、意义这类东西其实都是语言层面的,不过是形而上学。
正面看,GPT摧毁了这些虚构的真理,其实是对人类的解放。同时负面看,GPT产生的这类逻辑和推理并非和人类意向完全一致,导致特定全局风险。
大语言模型为什么会产生如此神奇的“涌现能力”呢?
- 【2023-3-6】CoT一作 Jason Wei的ppt New abilities in big language models,two new abilities of scale 大模型的两项新增能力
- ① Language models follow instructions. 遵从指令
- Finetuned language models are zero-shot learners (ICLR 2022). {J. Wei, M. Bosma, V. Zhao, K. Guu}, A. Yu, B. Lester, N. Du, A. Dai, & Q. Le.
- ② Language models do chain of thought reasoning. 思维链
- Chain of thought prompting elicits reasoning in large language models
- Emergence and reasoning in large language models - Jason Wei (Google),ppt, youtube
Chain-of-thought prompting elicits reasoning in large language models (Wei et al., 2022).
- ○ Self-consistency improves chain-of-thought reasoning in language models (Wang et al., 2022).
- ○ Least-to-most prompting enables complex reasoning in large language models (Zhou et al., 2022).
- ○ Language models are multilingual chain-of-thought reasoners (Shi et al., 2022).
- ○ Challenging BIG-Bench tasks and whether chain-of-thought can solve them (Suzgun et al., 2022).
两种猜想已经得到了绝大多数学者的支持,分别是“涌现能力”、以及“代码训练”。
- (1)大语言模型的涌现能力(Emergent Abilities)
- GPT-3模型其实早在2020年就已经公布,那为什么直到现在才引起大家的充分关注呢?因为2022年前,业界普遍认为GPT模型遵守
Scaling Law,即随着模型规模指数级上升,模型性能实现线性增长,所谓服从log-linear curve。实证数据也证明了这一点,当时GPT-3模型的性能并不优于fine-tuned T5-11B 模型。 - 2022年发生了变化,
CoT(Chain-of-thought)技术诞生, 直接突破了Scaling Law的限制,使得大语言模型的性能出现了颠覆式提升。 - 这项技术其实并不复杂。图

- 左侧是一个标准 prompt,模型回答简短且错误的;右侧模型输入加入一个标准的思考过程,然后惊讶地发现,模型的思考能力随之出现了显著提升,能够一步一步得出正确的结果了。
- 思维链提示在性能-比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。
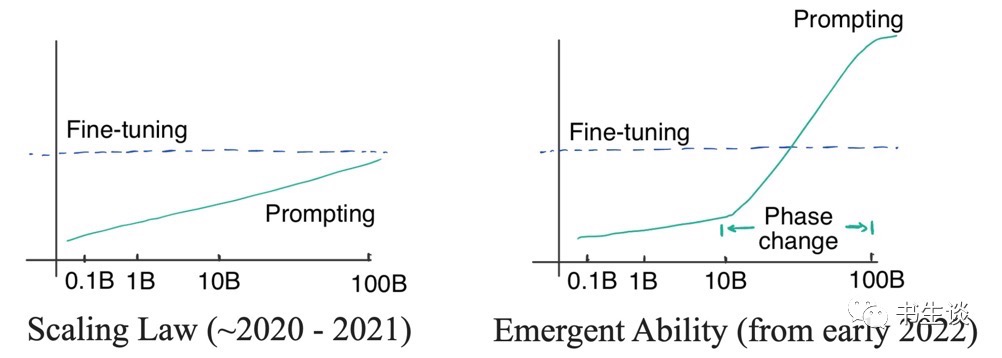
- 这种prompt方式也被称为
one-shotprompt,与此相对的是zero-shot/few-shotprompt。当然也可以直接在模型输入的最后,加上“Let’s think step by step”来达到类似的效果。img - 论文:
- 2023.1.30, Specializing Smaller Language Models towards Multi-Step Reasoning, This paper addresses the problem of CoT reasoning for smaller models by model specialization.
- GPT-3模型其实早在2020年就已经公布,那为什么直到现在才引起大家的充分关注呢?因为2022年前,业界普遍认为GPT模型遵守
- (2)通过代码训练得到的复杂推理能力(Complex Reasoning). 这个能力的奇妙程度相比第一点而言,可以说有过之而无不及。
- ChatGPT 背后是Text-davinci-002模型,回溯ChatGPT的“模型家谱”,不难发现,Text-davinci-002 模型其实是基于 Code-davinci-002 模型经过指令微调的产物。
- GPT-3模型复杂推理能力很弱。因为没有接受过代码数据训练
- GPT-3的一个分支对代码数据进行了专项训练,Codex 模型中代码数据量约为 159G,基于此产生的 Code-davinci-002 模型神奇的具备了思维推理能力。
- 不难看出,模型训练过程中,是否引入“代码数据集”很有可能是模型是否具备复杂思维能力的关键变量。
为什么?
- (1)“代码”是一种建立在具备高度抽象性和逻辑性的思维模式下的“语言”,人类创造了这些语言(C、Python、Java等等),编写了大量代码。现在把这些海量代码喂给大语言模型,模型从对大量代码的学习过程中,逐渐掌握了隐藏在代码背后的抽象能力与逻辑能力,进而涌现出在ChatGPT上感受到的“智能”。
- “代码”可以理解为一种具备高度逻辑性的文本语料。因为不具备强逻辑性的代码会无法执行,而不像普通文本语料那样有着较高的逻辑自由度。
面向对象编程(OOP)是把客观世界中的实体抽象为类,对象则是类的实例化。对象与对象之间可以互相通信,从而来模拟了现实世界中不同实体之间联系;面向过程编程(POP)则是把一个复杂的任务拆分为若干个步骤,然后一步一步加以实现。
- “代码”可以理解为一种具备高度逻辑性的文本语料。因为不具备强逻辑性的代码会无法执行,而不像普通文本语料那样有着较高的逻辑自由度。
- (2)由于代码中含有大量注释信息,注释信息与代码之间形成了(代码,描述)的数据对,意外的实现了多模态对齐的工作,从而使得模型的推理能力大幅提升。
但是目前已经有大量实证证据表明“涌现能力”真实存在。
- 当模型规模达到某个阈值时,模型对某些问题的处理性能突然呈现快速增长,就像突然解锁了某种特殊能力一般。
最新研究表明,随着模型规模的进一步增长,还可能涌现出各式各样的特殊能力,其中有些能力并不关注(比如5位数加法的准确率大幅提升),但有一些能力则直接解决了NLP领域困扰大家多年的心头大患,比如复杂推理能力、OOD鲁棒性等。
其实学界每个概念都很直白且容易理解,比如
- OOD鲁棒性:
OOD指 Out-Of-Distribution,即当测试数据集分布显著有别于训练数据集分布时,模型性能是否会出现大幅下降。由于现实世界是充满不确定性的,真实环境数据集遵循的分布完全可能发生偏移,因此OOD鲁棒性对于一个语言模型能否投入到真实环境使用而言非常重要。
如此棘手的难题,大语言模型直接通过“涌现能力”意外地解决了。
- 如图所示,GPT-3在OOD情形下显著超过 RoBERTa baseline。
这不禁让我们对未来充满了乐观的预期,随着模型规模的提升,是否会有更多NLP难题自动迎刃而解,“模型规模”难不成就是人类通向AGI(通用人工智能)的钥匙?
- 【2023-2-12】ChatGPT在投资研究领域的应用初探及原理分析
Scaling Law 缩放定律
详见站内专题: 缩放定律
LLM 本质
总结
【2025-11-03】知乎:deephub
最有说服力的角度——信息论。
Hutter Prize 比赛,核心理念就是”谁能把文本压缩得更小,谁就更聪明”。
听起来挺奇怪的对吧?但仔细想想,要把海量文本高效压缩,必须找到里面的规律和模式。
Marcus Hutter 提出理论:
Solomonoff 的通用预测器本质上等价于 Kolmogorov 的通用最佳压缩器。
预测哪个字最可能出现和找到最短编码方式,在数学上是一回事。所以, 当模型学会预测语言分布时,实际上在学习生成这些语言的世界结构。这个解释在理论和实践上都站得住脚,因为语言本身就是人类思维的浓缩版,里面编码了逻辑、因果、社会规范、物理常识……模型要准确预测”球落地后会____“,就得理解重力;要预测对话回复,就得理解社交意图。
压缩语言分布的过程,逼着模型去构建内部的世界模型。
- OpenAI 在 2020 年发了篇 Scaling Laws 论文,发现模型损失和参数量、数据量之间有稳定的幂律关系,跨越七个数量级都成立。
- 后来 DeepMind 用 Chinchilla 修正了这个结论,说其实模型参数和训练 token 要等比例增长才最优,大概每个参数需要 20 个 token。
- Jason Wei 等人在 2022 年发表的论文《Emergent Abilities of Large Language Models》定义了涌现能力:在小型模型中不存在、但在大型模型中突然出现的能力,这些能力无法通过简单外推小模型性能来预测
- 而斯坦福 2023 年的论文《Are Emergent Abilities of Large Language Models a Mirage?》对此提出质疑,认为涌现可能是评估指标(非线性或不连续指标)造成的假象,而非模型行为的根本相变 4 说涌现可能是”海市蜃楼”——不是模型本身突变了,而是我们用的评估指标太离散,把连续变化看成了突变。比如你用准确率来衡量,40% 和 60% 看着差不多,但换成 F1 分数可能就是质的飞跃。
- 而2025 年最新的综述还在讨论这个问题:涌现到底是真实的相变,还是测量方式的假象?
所以到底这个是不是“涌现”还没有没盖棺定论,但有个现象倒是真实的——Grokking, 就是神经网络先过拟合训练数据很久,然后突然泛化能力暴涨。研究发现这确实可以用临界指数描述,像真正的一阶相变。所以某种程度上,”涌现”这个比喻可能不完全是空话。除了肯定的,我还能再给你找两个不同角度批评的:Bender 等人认为LLM 只是在概率上将词和句子链接在一起,而不考虑意义,因此被称为”随机鹦鹉”
这篇论文引发了巨大争议,好像闹得挺大,Gebru 被 Google 要求撤回论文或删除 Google 员工的名字,最后被还谷歌辞退了。
Gary Marcus 是老批评家,从神经网络开始, 就说神经网络无法可靠地外推和进行形式推理,还有深度学习什么的都一直在说
25年2月, CACM官方采访中, Marcus 还谈对 LLM 技术局限性的看法,以及为什么他认为规模定律正在遇到收益递减的问题。
所以为什么能涌现,答案还未知。因为这个领域现在就是这么个状态——有一堆有意思的理论,每个都能解释一部分现象,但谁也不敢说自己完全理解了,谁也不敢说自己是对的,毕竟才研究了几年。
的确看到了大语言模型的能力,涌现相变这个概念很吸引人,但是就像上面论文说的可能部分是测量假象,需要更严格的数学定义。也许等过两年再看,说不定就清楚多了。
模式匹配
【2024-10-22】模式匹配与推理能力:AI发展的关键
传统机器学习算法,如决策树、支持向量机(SVM)、K近邻(KNN)等,依赖于模式匹配,通过统计相关性进行分类与预测,然而它们缺乏对数据深层次的理解与推理能力。
模式匹配的特征可以概括为:数据驱动、统计相关性、局限性和黑箱性。
- ① 数据驱动:模式匹配的性能高度依赖于训练数据的质量和数量,数据越丰富,模型的表现越好。
- ② 统计相关性:模型依赖于数据之间的统计相关关系,而不是因果关系。
- 局限性:模型在与训练数据相似的场景中表现良好,但在数据分布变化较大时,性能往往急剧下降。
- ③ 黑箱性:模型决策过程缺乏可解释性,特别是在复杂的深度学习网络中,无法明确解释模型如何做出某个决策。
模式匹配本质是数据模式的记忆和再现,这种能力使得AI在一些特定任务中表现优异。
- 图像分类任务中,通过大量训练样本,AI能够学习并识别出不同类别图像的特征。
然而,这种基于经验的学习方法有明显短板:无法理解数据背后的逻辑和因果关系。
- 尽管模式匹配能够在大量相似数据的基础上进行准确预测,但一旦面临新的环境或数据分布显著变化,其表现往往大打折扣。
因此,模式匹配虽然是AI基础,但其缺乏灵活应对新环境的能力。
深度学习通过引入深层神经网络,极大地提升了模式匹配的能力。深度学习不仅改变了模式匹配的方式,还通过其强大的学习能力拓展了AI的应用边界。
深度学习也在强化学习中得到了成功的应用,特别是在复杂策略游戏中的突破,例如AlphaGo战胜世界顶级围棋选手的事件。
多层神经网络可以自动学习数据中的复杂特征表示,使得深度学习在计算机视觉、自然语言处理等领域取得了突破性进展。
- 深度学习的成功归功于其强大的特征学习能力。
- 与传统机器学习不同,深度学习能够自动从数据中学习特征,无需人工干预,从而大幅度提高了模型的效率和性能。
- 深度学习模型的多层结构能以分层方式学习数据的特征表示,从而有效捕捉数据的复杂模式。
- 深度学习通过大规模数据和计算资源的支持,在许多任务中实现了前所未有的性能。
深度学习本质,依然是对数据的复杂模式进行拟合和预测,仍存在诸多局限性。
- 首先,深度学习对大规模标注数据的依赖性极高,获取高质量数据的成本是巨大的。
- 其次,训练深层神经网络需要大量计算资源,对硬件配置有很高要求。
- 此外,深度神经网络的结构复杂,内部决策过程难以解释。
- 最后,面对与训练数据分布不同时,深度学习模型的泛化能力往往不够理想,这反映了其缺乏对因果关系的理解。
- 特别是在需要高可信度的应用场景中,如医疗诊断,模型的黑箱性极大限制了其广泛应用。
- 深度学习模型的黑箱性不仅影响了模型的可解释性,也带来了许多伦理和法律问题。
- 依赖于相关性进行预测,而非因果推断。只能发现数据模式,而不能理解为什么这些模式存在。
- 深度学习模型对数据噪声和对抗样本的脆弱性也使其存在较大的安全隐患
推理能力:AI的下一个挑战
推理能力是指AI能够基于已知信息,通过逻辑推断得出新结论的能力。这种能力超越了模式匹配,涉及复杂的抽象思维和因果推断。
推理能力的主要特征包括:抽象思维、因果推断、创新性、灵活性和可解释性。
- 抽象思维使AI能够理解和处理复杂概念
- 因果推断使其能够从数据中提取因果关系,而不仅仅是识别相关性。
- 创新性使AI能够生成新颖的解决方案,灵活性使其适应未见过的情况,而可解释性使推理过程能够被人类理解。
推理能力意味着AI不仅能够处理已有数据,还能够基于这些数据进行逻辑推理,从而生成新知识。这类似于人类的逻辑推理过程,使得AI能够应对更加复杂的任务和环境。
推理能力的实现需要
- AI系统具备对世界的深刻理解和常识知识。
- 与模式匹配不同,推理能力更加强调对信息的灵活运用和创新性。在面对新问题时,AI需要能够根据已有的知识进行类比和推断,进而找到解决方案。
- 这种能力的实现对于AI系统来说是一个巨大的挑战,因为它不仅需要对知识的积累,还需要对知识的灵活应用和组合。
- 推理能力还要求AI能够进行因果推断,理解不同事件之间的因果关系,这与传统的模式匹配形成鲜明对比。
- 因果推断不仅要求系统能够识别数据之间的相关性,还需要理解为什么某些模式会出现,并基于这些因果关系做出合理的决策。
- 这种因果推理的能力是实现高级人工智能的关键,因为它使得系统可以超越数据的局限,推断出更多未直接观察到的信息,从而具备更强的应变能力和通用性。
早期符号推理系统通过预定义规则进行推理,但由于缺乏自我学习和适应性,难以应对真实世界的复杂多变性。
近年来,神经符号结合的研究尝试将深度学习的感知能力与符号系统的逻辑推理能力结合,取得了一些初步成果,但仍面临诸多挑战。
- 例如,大型语言模型如GPT-4展现了某种类推理能力,但这些推理大多是基于复杂的统计模式,而非真实的因果逻辑推理。
- 大模型在特定任务中表现出了类似推理的行为,但仍然是基于统计的拟合而非真正的逻辑推理。
- 图神经网络(GNN)在处理结构化数据和关系推理方面表现良好,但其适用范围依然有限。
通过结合符号推理的可解释性和逻辑性,以及深度学习的感知能力和模式匹配优势,AI系统有望在推理方面取得更大的突破。
挑战
- AI缺乏常识性知识和世界理解
- 实现因果推断,AI需要具备理解因果结构和因果关系的能力,这不仅仅依赖于数据模式的学习,还需要结合领域知识和逻辑推理。
- 推理能力还涉及多模态信息的整合
- AI系统需要具备自我反思和学习的能力,即元认知能力。
- 元认知指对自身认知过程的认知,AI不仅要能够进行推理,还需要评估自身推理的有效性,并在必要时进行调整。
- 这种自我反思的能力对于实现高水平的智能至关重要,因为它使AI系统能够不断改进其推理过程,提高决策的准确性和可靠性。
- 可解释性和透明性
方向:
- 因果推断的融合:通过将因果推断与深度学习结合,使AI不仅能够识别数据中的相关性,还能理解和推断因果关系。
- 常识性知识的注入:开发新的方法来引入常识性知识,使AI能够在面对未知或复杂问题时具备人类般的直觉和理解能力。
- 多模态推理:提高AI系统整合和处理来自不同模态的信息的能力,从而在更广泛的情境中进行推理和决策。
- 元认知与自适应学习:增强AI系统的自我反思和学习能力,使其能够不断优化自身的推理过程。
- 可解释性与透明性:继续推进神经符号结合的方法,以实现更具逻辑性和透明性的推理过程,增强人类对AI系统的信任。
AI 骗局
Java 之父
【2025-5-26】Java 之父怒斥:AI 是场骗局,无法取代程序员,在编程方面的最大作用是生成没人想写的文档
Java之父詹姆斯高斯林(James Gosling)认为:
- 人工智能和机器学习的最大问题是名字, “高级统计方法”更准确。当然这些系统背后的数学原理令人印象深刻。
- 当前被热棒的AI技术, 本质是“极其复杂的锤子和螺丝刀”,只是一个工具, 而非具备自主推理能力的”智能体”。
- AI是带有一堆问题的营销术语,这基本上是一场骗局。
- 目前90%的AI投资会打水漂。
AI 在编程方面最有价值的应用不是取代程序员,而是 “生成没人愿意写的文档”—— 本质是智能搜索引擎,能理解代码的工作原理,并解释如何使用特定的 API 或功能。
人工编程不可替代
核心逻辑:
- 系统理解的必要性:即便 AI 接管一切,人类仍需理解系统底层逻辑是如何工作,以确保安全、调试问题;
- 行业本质的不可替代性:编程核心是“问题建模与抽象能力”,这是统计工具无法触及的人类智慧领域。
AI 核心技术不是深度学习
AI 哲学世界:《人工智能真正的核心技术》
所有人都以为人工智能的核心技术是深度学习,因为西方科研界好像都在做这个方向。
可是人们却忘了,西方在研究深度学习之前,已经掌握了芯片了。
深度学习本质上是模式识别,只能识别和生成图片、音频···
换句话说,深度学习只能实现“眼耳鼻舌身’, 人家已经有了”大脑”,现在只不过需要做个眼耳鼻舌身。
深度学习背后的统计学可轻易生成看似精准/严谨的数学公式。
- 数学公式永远可以修正、变得更复杂, 画出科学图表,让人望而生畏。
- 因此不断产生新的科研问题,让科研人员有事可做、有文章可写、有科研成果
同时,也意味着,永远不会有实质性的成果、科研永远没有尽头、做不出来··
因为,方向错了,越努力,错的越远,沉没成本也越高
这就是国内的人工智能永远需要堆砌别人的芯片才能勉强实现的原因。
那隐藏在芯片底层的人工智能核心技术,是顶级哲学家精心打磨的艺术品一一人类智慧的表达
压缩即智能
【2024-7-20】「安全智能」的背后,Ilya 究竟看到了什么?
2023年10月3日,Ilya 曾在伯克利大学做过一次演讲,题为《一个无监督学习的理论》(A Theory of Unsupervised Learning)
Ilya 在演讲中揭示了大模型的核心原理,并生动描述了他在独立领悟无监督序列学习机制时的痴迷,兴奋之情溢于言表。
超级对齐团队的前成员 Leopold Aschenbrenner 发表了一篇长达 165 页的文章《Situation Awareness》,初步揭示了 OpenAI 内部目睹 GPT 模型指数级进化时的震撼和隐忧。这多少部分回答了 Ilya 看到了什么的问题,而 Ilya 本人一直缄默,直至今天官宣出山。
数学告诉我们: 只要数据足够大,远远超过模型规模,那么模型就会有出色表现(低训练误差,低测试误差)。
- 题海刷得好,考场差不了,监督学习的数学保证。
监督学习 – 万能逼近定理
监督学习理论基础
- 统计学习理论中著名的
Hoeffding 不等式,含义:当训练误差足够低且训练样本数远大于「模型自由度」(模型规模)时,测试误差也能保证足够低
理论
- 第一,宏观上和理论上,「
万能近似定理」(Universal Approaximation Theorem)早已论证深层神经网络可以逼近任意函数。 - 第二,当代 AI 历史上,12 年前的深度学习革命就开始证明,只要有足够带标数据,神经网络就可以让「老母鸡变鸭」,或做任何其他变换。
核心观点:
监督学习背后的理论保证: 低训练误差 + 大训练集 = 模型泛化能力
模型规模一定要小于数据规模,否则,它根本就不用做真正的「压缩」或抽象,不去找规律,它就全部死记硬背了。死记硬背的模型,没有泛化能力。
当然,题海再大,如果只是死记硬背,不去归纳总结,你的脑容量再大、「记忆力」再强,也只是一个填鸭式的学霸,缺乏真正的学习应变的能力(叫做「泛化」能力)。
只有当大脑袋里面的「小聪明」不要太高(聪明反被聪明误),才会被迫去总结规律,提炼精华(业内叫「压缩」),从题海中学到真本事。
这就是为什么模型规模不能太大,不能给模型太多的投机取巧的空间。
Ilya:
大数据 + 低训练误差,监督学习的制胜法宝,有数学证明为保证。
无监督学习 – 分布匹配
但是无监督学习呢?如何试图为无监督学习寻找到坚实的数学基础?
无监督学习似乎缺乏类似的理论支撑。但是,Ilya 发现一种叫做「分布匹配」(distribution matching)范式,让无监督学习也获得数学保障。
疑问
- 无监督学习学习的是数据内在特征,比如,从一堆没有标签的猫狗图片中,自动归纳出猫和狗的共同特征。这对以后分类猫狗确实有帮助。
但
- 如果这堆图片是完全随机的涂鸦,乱成一团,监督学习还能学到什么吗?
- 就算学到了猫长胡须狗长尾巴,这些知识对别的任务,比如识别交通标志,有什么用呢?
问题关键: 透过现象看本质。比如 GPT 这样的语言模型
- 表面上是在学习预测下一个词(next token prediction)。
- 实质上,在匹配语言分布,学习语言隐含规律。
- 比如,在「我爱吃苹果」这句话里,「我爱吃」后面更可能出现「苹果」,而不是「砖头」,这反映了语言的内在知识。
这种分布匹配是一种特殊的模式规律匹配。不同的是,它匹配的不是具体的字符串或词串(token sequence),而是词与词之间的关系,也就是语言的规律性,类似于语义结构。
Ilya 认为,这种分布匹配才是无监督学习获得智能的本质。不管是文本、图像还是语音,都有内在的分布规律性,而无监督学习就是要发现、匹配和对齐这些分布规律。
所以,图片不能太随机,数据集不能都是涂鸦,得有一定的规律性,无监督学习才能抓住它们的隐藏共性。
- 至于学到的知识, 对别的任务有没有用,那要看这些任务的数据分布是不是相似。如果都是自然图像,那从猫狗身上学到的特征,多少还能迁移到其他动物身上。但如果是完全不同的领域,比如医学影像,那可能就没啥参考价值了。
Ilya 新视角:
无监督学习的本质是分布匹配,一种规律性的模式匹配。- 这个视角似乎为无监督学习的有效性提供了一种解释。
Ilya 将进一步解释,分布匹配是如何给无监督学习提供理论保证的。
机器翻译曾是监督学习的天下,依赖 对齐后的平行语料,但如果没有双语语料,怎么从两种语言的书籍中学习双语翻译?
为什么? 分不匹配
- 如果英语书库和汉语书库足够大,包含了各种句型和语法,那它们的语言规律性就会显现,就可以无监督学到。比如,英语里出现”I/me/my”的上下文分布,和汉语里出现”我”的分布应该有某种对应的规律性;英语里形容词放在名词附近,并且语义相谐,汉语里应该也差不多,等等。这就为潜在的语言对齐提供了基本条件。
只要两种语言原生数据足够丰富,一种语言的输入作为条件就能几乎唯一地确定另一种语言的翻译等价物。而且,这个原理不仅适用于机器翻译,还适用于语音识别、图像转换等各种 AI 任务。
2015 年,Ilya 就独立发现了这个思路, 并对其数学原理(Kolmogorov 复杂性,简称 K 氏复杂性)产生了浓厚兴趣。
- 原理: 「压缩」理论,无监督学习是在寻找最优的数据压缩方法
- 无监督学习也能搞定各种语言的机器翻译,甚至任何从输入到输出的转换任务
- 把无监督学习看作是一个数据压缩问题,从数学上理解无监督学习为什么有效,在任务执行上使之与监督学习处于同等地位。
- 好的无监督学习算法应该找到数据的最简洁表示(即 K 氏复杂度),同时又能最大限度地利用这种表示来完成下游任务。
数学上,真正的 K 氏复杂度不可计算,就像没法为每份文件都找到最完美的暗号。但可以训练一个大型神经网络 (如 GPT) 来近似这个过程。因为理论上神经网络可以拟合任何函数,包括「生成文件的最短指令」这个函数。通过不断调整网络的参数,我们就可以一步步逼近最优的压缩方案。
K 氏复杂度代表压缩的理论极限,任何实际压缩算法都不可能超越它。虽然这个极限不可达,但它为我们评判无监督学习算法提供了一个基准。
- GPT 等大型语言模型之所以有效,正是因为能通过梯度下降等优化算法,不断逼近这个基准,学习到数据的高度压缩表示,并运用于下游任务。
这就是 K 氏复杂度和无监督学习的联系。虽然有点抽象,但核心思想清晰:压缩是无监督学习的本质,而追求最简洁的压缩,就是追求最优的无监督学习。
将传统的独立建模(如英语模型、汉语模型;再如,语言模型、视觉模型,等等)提升到了大一统的关联建模的高度。在这个范式下,无监督学习的目标不再是单纯地压缩单一群体的数据,而是寻找数据之间的联系。
这种跨模式、跨模态的学习,才是通用人工智能的高级形态。
关键思想:K(Y|X) 变成了 K(X,Y), 条件建模被 Ilya 换成了序列建模,从而论证了 GPT 的大一统。
信息论
【2025-11-03】知乎专题: 为什么 LLM 仅预测下一词,就能「涌现」出高级能力?
前两年就被讨论烂了。
初步结论
- 当语言模型的训练文本数量以及参数量达到一定规模之后,模型对语言规律的统计性模拟超出了某种形式的
奈奎斯特定理限制,仅此而已。
回顾过往人类从数学角度出发重建某个函数的历史,第一个成体系的结论是奈奎斯特 香农采样定理。
- 对于一个周期信号,只要采样频率是信号最高频率的两倍以上,就可以用sinc插值无损地重建原始信号。
从这里出发,人类关于信号的重建工作逐渐成为完整体系——信息论。
定理提出的第二年,香农博士便提出改进版本
- 如果已知原始信号中载波信号地频率,那么重建所需采样频率可以压缩到信号带宽的两倍——即信号最高频率分量和最小频率分量频率差值的两倍。
上述工作
- 1940-50年代的事情,从这一工作出发,一大类电子信息技术产业如火如荼地发展了起来,无线电、广播电视、移动网络等等都是在这个定理的基础上发展起来的。
- 第二个大的发展, 2006年-2007年由Terrence Tao,Emanuel Candes 和 David Donoho 以及几个研究生系列工作开创,所谓的
压缩感知理论。 - 这个理论完整成果也可被表述成为采样定理,信号采样矩阵的spark如果大于信号Sparsity的两倍,那么通过 l1l_1l_1范数最小化算法就可以完整且无损的重构原始信号
对相关工作有所了解的人,这一系列工作和大语言模型为代表的神经网络,或机器学习算法是有非常深刻的联系,如果把神经网络的target function视作对人类智能的某种形式的重建的话
最直接的观察是在语法上有效的文字符号排列在所有文字符号的排列中是显著稀疏的。今天大语言模型即llm为代表的这一系列所谓人工智能方面的工作,很明显遇到了瓶颈。这个瓶颈最直接的证据即scaling law,其直接体现即是这一波人工智能热潮始终不能脱离的范式“what you feed is what you get”这样的限制。
采样和重构这两个过程之间的联系没有被清晰的刻画出来。人工智能的所谓学习实质上就是一个黑盒,失去了理论指导,没办法搞清楚这个盒子里究竟是什么东西,也因此就失去了清晰的刻画objective的能力,只好在不断的重复试验和经验的指导下慢慢摸索。
所以理论上还有很多东西可以做。这方面大概是几年前一篇用柯尔莫戈洛夫复杂度来刻画大语言模型能力的一篇文章有潜力成为理论构建的一个出发点,后来这篇文章地核心思想被总结为一句口号”Compression is Intelligence”——压缩即智能。
当然,这个东西很难,柯式复杂度的计算本来就是一个NP-hard 问题,而实际上连P/NP问题都还没有搞清楚。除非能以某种形式突破一个对应于AI模型的采样定理限制,否则General artificial intelligence这个课题是不可能彻底完成的。
不过这个领域low hanging fruit基本是没有的,想要做就要耐得下寂寞,对于一个年轻的想要快速出成果拿经费的学者来说,这并不是一个好的课题,因此并没有很多研究者专注地向这个方向进行攻关。
LLM 认知框架
【2024-11-14】MIT对大模型数理原理的强有力证明
大模型数理认知框架
总结:
- 1、重整化从海量语料中提取出范畴,
- 2、持续重整化驱动范畴解构重组结晶,
- 3、生成过程于范畴中采样做变分推理。
详解
- 海量的文本或者多模态语料组成了大模型需要认知的外部世界的基本信息;嵌入构建高维概率化的语言空间,用来建模语言文字图像以及音视频,并对连续变量做离散化;
- 预训练以重整化群流的方式进行,在不同尺度上提炼语料数据中的信息概率分布;重整化群流的每一步流动(自回归预测逼近训练语料概率分布),都沿着最优输运的成本最低方向进行;
- 重整化群在不动点附近因新语料带来微扰而发生对称性破缺,滑入不同的相空间;不同的相空间,对应某种意义上的范畴,可形象化为信息的结晶;这是大模型从语料中学到的内部世界模型;
- 在外部感官输入下(被提示置于某种上下文),大模型内部将限定在相应的高维语言概率空间的子空间内推理;推理是在子空间中采样,类比时跨范畴采样;
- 采样不断进行,基于内部概率化了的世界模型(预训练获得的先验),针对感官输入(提示),做变分推断,最小化自由能,获取最佳采样分布q*,作为对导致感官输入的外部后验的预测。
图见原文 MIT对大模型数理原理的强有力证明
MIT 范畴论
麻省理工学院 Markus J. Buehler 教授最近在《机器学习:科学与技术》发文【文献1】
- Accelerating scientific discovery with generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning
- 数据 与 代码:GraphReasoning
展示了一种先进的 AI 方法:
- 集成生成式知识提取、基于图的表征和多模态智能图推理。
- 惊人地揭示了生物组织和贝多芬的“第九交响曲”之间的复杂性与秩序的共同模式。
该工作使用受范畴论启发的方法图作为中心机制,教模型理解科学中的抽象结构和它们之间的符号关系,通过关注对象及其交互,而不是它们的具体内容,来理解和统一不同的系统。
范畴论中
- 对象可以是任何东西,从数字到更抽象的实体,如结构或过程,对应上文笔者讲的“事物”;
- 形态则是定义这些对象之间关系的箭头或函数,对应上文中的“·”。
Buehler 教授通过范畴对象和形态教会 AI 模型系统地推理复杂的科学概念和行为。通过形态引入的符号关系清楚地表明,AI 不仅仅是在进行类比,而是在进行更深入的推理,以映射不同领域的抽象结构。
这也回应了近期大模型究竟会不会推理的业界大辩论。
- 当大模型生成时,已经不是那个简单的 next token prediction, 而是基于丰富范畴的推理、推理、推理,重要的事情得说三遍。
- Ilya Sutskever 最新访谈提到的「扩大正确的Scaling」,应该指推理的Scaling law。
- “苹果称LLM不会推理”其实是苹果学者想当然合成了语料;
- 字节豆包大模型团队大规模实验发现, 大模型无法抽象出一般物理规则,从实验看并无法判断是否局部触发了scaling law。
Buehler 教授通过这个方式,分析了 1000 篇有关生物材料的科学论文,并将其转化为图表征形式的知识图谱。
- 揭示了不同信息是如何连接的,并可找到与概念联系在一起的相关想法和关键点组。该图无标度,高度关联,可有效用于图推理。
LLM 类脑
【2024-10-30】MIT大牛新发现:LLM和人类大脑结构类似,存在脑叶分区
MIT传奇大牛Max Tegmark团队的新作,再次炸翻AI圈。
LLM显示出令人惊讶的几何结构——
- 形成一种类似人类大脑的「脑叶」;
- 其次,形成一种「语义晶体」,比初看起来更精确;并且,LLM 概念云更具分形特征,而非圆形。
LLM中稀疏自编码器(SAE)的特征向量表示的。
Max Tegmark 团队的研究结果表明,SAE特征所代表的概念宇宙在多个空间尺度上展现出有趣的结构,从语义关系的原子层面到整个特征空间的大规模组织。
数学才是一切的基础,而非人类构造
SAE特征的概念宇宙在三个层面上都具有有趣的结构:
- 小尺度「原子」
- 原子级的微观结构,包含面为平行四边形或梯形的「晶体」,这是对经典案例的推广(比如「男人-女人-国王-王后」的关系)。
- 中尺度「大脑」
- 类似「大脑」的中间尺度结构,则展现出了明显的空间模块化特征,团队将其描述为空间集群和共现集群之间的对齐。
- 如,数学和代码特征形成了一个「脑叶」,跟神经功能磁共振图像中观察到的人类大脑功能分区相似。
- 大尺度「星系」
- 「星系」的大尺度结构上,特征点云并非呈各向同性(各个方向性质相同),而是表现出特征值幂律分布,中间层的斜率最抖。
- 而聚类熵也在中间层周围达到峰值!
AI 与 AGI
反方
Yann LeCun:机器学习不是AGI
【2023-3-24】Yann LeCun, 大型语言模型的意义和理解需要感官基础吗? 剧透: 是的!
- 纽约大学深度学习哲学 The Philosophy of Deep Learning
- ppt: “Do large language models need sensory grounding for meaning and understanding?”
- 【2023-3-27】评论:GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑, Yann LeCun 延续了一贯的犀利风格,直言不讳地指出「Machine Learning sucks!」「Auto-Regressive Generative Models Suck!」最后话题自然是回到「世界模型」
Machine Learning sucks! (compared to humans and animals)
Supervised learning(SL) requires large numbers of labeled samples.Reinforcement learning(RL) requires insane amounts of trials.Self-Supervised Learning(SSL) requires large numbers of unlabeled samples.
Most current ML-based AI systems make stupid mistakes, do not reason nor plan
Animals and humans:
- Can learn new tasks very quickly.
- Understand how the world works
- Can reason and plan
Humans and animals have common sense, current machines, not so much (it’s very superficial).
与人、动物相比,机器学习为什么很差?
- 监督学习需要大量标注样本
- 强化学习需要大量试错样本
- 自监督学习需要大量非标注样本
而当前大部分基于机器学习的AI系统常常出现愚蠢错误,不会推理、规划
动物或人:
- 快速学习新任务
- 理解环境运行逻辑
- 推理、规划
人和动物具备常识,而机器表现得很肤浅
Auto-Regressive Large Language Models (AR-LLMs)
- Outputs one text token after another
- Tokens may represent words or subwords
- Encoder/predictor is a transformer architecture
- With billions of parameters: typically from 1B to 500B
- Training data: 1 to 2 trillion tokens
- LLMs for dialog/text generation:
- BlenderBot, Galactica, LLaMA (FAIR), Alpaca (Stanford), LaMDA/Bard(Google), Chinchilla (DeepMind), ChatGPT (OpenAI), GPT-4 ??…
- Performance is amazing … but … they make stupid mistakes
- Factual errors, logical errors, inconsistency, limited reasoning, toxicity…
- LLMs have no knowledge of the underlying reality
- They have no common sense & they can’t plan their answer
Three challenges for AI & Machine Learning
- Learning representations and predictive models of the world
- Supervised and reinforcement learning require too many samples/trials
- Self-supervised learning / learning dependencies / to fill in the blanks
- learning to represent the world in a non task-specific way
- Learning predictive models for planning and control
- Learning to reason, like Daniel Kahneman’s “
System 2”- Beyond feed-forward,
System 1subconscious computation. - Making reasoning compatible with learning.
- Reasoning and planning as energy minimization.
- Beyond feed-forward,
- Learning to plan complex action sequences
- Learning hierarchical representations of action plans
当前机器学习研究者面前的有三大挑战:
- 一是学习世界表征和预测模型;
- 二是学习推理(LeCun 提到的
System 2相关讨论参见 UCL汪军教授报告); - 三是学习计划复杂的动作序列。
正方
苦涩的教训
【2024-2-24】《苦涩的教训》 OpenAI工程师的作息时间,其中有一项就是背诵强化学习之父、加拿大计算机科学家理查德·萨顿( Richard S. Sutton )的经典文章《The Bitter Lesson(苦涩的教训)》。
- 过去 70 年来,AI 研究走过的最大弯路,就是过于重视人类既有经验和知识,而他认为最大的解决之道是摒弃人类在特定领域的知识、利用大规模算力的方法,从而获得最终胜利。
可解释
详见站内专题: 大模型可解释性
世界模型
详见站内专题: 世界模型
推理
什么是推理?
- 推理是运用合理的逻辑步骤从现有信息中得出结论的过程。
推理的核心是两个概念: 事实和规则。
事实是描述问题当前状态的信息片段规则是在特定条件下将事实转化为新事实的函数。
以著名的三段论为例:
苏格拉底是一个人。所有人都是会死的。因此,苏格拉底是会死的。
从“苏格拉底是会死的”和“苏格拉底是一个人”这两条事实推理出“所有人都是会死的”这一条规则。后面所说的规则库则包含了众多这样由事实推理出来的规则。
归纳推理就是是从许多观察事实中推出普遍规则。
- “苏格拉底是人”和“苏格拉底是会死的”这些事实,而这些事实也适用于亚里士多德,那么可能会推出一个规则:“所有人都是会死的”。
而演绎推理的目标是根据已知的事实和规则推出新的事实。
简单推理
【2023-10-18】让大模型真正学会1+1=2!谷歌教会模型自动学习推理规则,大模型的幻觉有救了
我们通过数小棍的方式逐步从 1+1=2,1+2=3 等例子中得出 1+3=4,这是一种依赖记忆中的数学表格进行演绎推理的过程。
后来前辈们总结了一套完备的求和或乘法表,只要背住,做简单算术题根本不成问题,也不需要数小棍
这样一套完备的求和或乘法表可以看做是一套规则库,从大量的演绎推理中总结出来的。
如果大模型也掌握了这样一套规则库,那么即使当任务偏离常规知识,大模型也能hold住,大大减少“幻觉”的问题,即减少生成看似合理,但与现实世界知识相矛盾的输出。
LLM 真有推理能力吗
【2024-8-28】美大学教授警告:大模型根本不会推理,全靠记忆力强
亚利桑那州立大学教授 Subbarao Kambhampati 最近发表言论,直指当前大语言模型(LLM)推理能力的迷思。
- 大模型根本不会推理, 只是从记忆中调取已有信息; AI模型像一个巨大的、预先计算好的查找表,快速给出答案,但并不真正”理解”问题。
- LLM 推理能力的说法都忽视了一个事实:LLM 不仅仅是训练于”事实”,更多时候还包括了这些事实的演绎闭包。因此,所谓的”推理“实际上变成了(近似)检索。
网友@AndyXAndersen:
- LLM 充其量只能基于非常相似的数据做出猜测。通过外部验证、优化和反复搜索问题空间,这可以在较简单的情况下近似演绎推理。
既然 AI只是在做”检索”,为什么它还能回答一些训练数据中没有的问题?
- Kambhampati 教授: 网络规模的训练数据中,一些2阶、3阶甚至k阶可达的事实与基本事实交织在一起,使得LLM能够通过模式匹配走得更远,而无需真正学习推理过程。
- AI看起来会推理,其实是数据量太大,很多看似需要推理的结果,它其实都”见过”。
@TheBlackHack 一针见血地指出:
- LLM无法计算,因为不是计算机器。将它们视为有限的token序列映射,一旦学习就不会改变,所以如果映射中缺少某个序列,就无法从头构建它。
谷歌 HtT 框架
谷歌团队提出了一种”Hypotheses-to-Theories”(HtT)框架,让LLMs在推理任务中自动形成规则库,来减少语言模型中的”幻觉”现象。
HtT方法包括归纳阶段和演绎阶段,两者都通过少样本提示 few-shot prompt来实现。
归纳阶段,让LLMs为训练集中的问题-答案对生成规则并进行验证,然后根据出现次数和与正确答案的关联频率进行筛选,形成演绎阶段的规则库,即 HtT中的Hypotheses(假说)。演绎阶段,让LLM从规则库中检索适合的规则(Theories 理论)来解决推理问题,以减少LLM生成幻觉的可能性。
对于语言模型LLM,大部分提示技术都是为了引发演绎推理。
- 比如,思维链CoT和Less_to_More的提示方法,都是教导LLM如何从给定的事实中推导出结论。这些方法可以归类为隐式推理方法,因为依赖于LLM中储存的隐式规则。
而本文直接给出归纳阶段获得的规则库(是一种显示规则),LLM的主要目标就变成了选择最优的规则与最优的推理顺序。
HtT提示基于两个猜想:
- 尽管LLMs有时会产生错误的规则,但它们能在一部分示例上以合理的概率生成正确的规则。因此,只要有足够的训练示例,LLMs就能找出问题类别中的大部分必要规则。
- 对于LLMs来说,检索规则比生成正确规则更简单。所以,当LLMs被明确的规则引导时,它们在演绎推理方面的表现会更好。
两个对当前的少样本提示方法来说较为困难的多步推理数据集 Arithmetic (数字推理) 和 CLUTRR,在GPT3.5和GPT4两个模型上采用了三种基准提示方法,包括zero-shot CoT,5-shot CoT,5-shot LtM(less is more)进行实验。
数字推理
- 无论是CoT还是LtM的提示,HtT都能显著提升准确性。
- 特别值得关注的是,HtT在GPT4上使CoT的平均准确性提高了21.0%。
然而,对于GPT3.5,性能提升并不明显,它在诱导正确规则和执行推理阶段的表现较差。
使用强大的模型来诱导规则,然后使用较弱的模型来执行推理,在表中(+HtT(GPT4))体现。
在从GPT4获取更好的规则后,LtM + HtT有了显著的改进,但是CoT + HtT并没有看到性能的提升,这是因为GPT3.5更倾向于依赖自己的信念(主要是十进制规则),而不是从带有CoT的知识块中检索规规则库。
关系推理
数据集选取的是CLUTRR。在CLUTRR中,每个示例都由家庭成员之间的亲属关系链构成,目标是推断链中头实体和尾实体的关系。CLUTRR有两种形式:一种是仅包含实体和关系的符号版本,另一种是包含无关上下文的文本版本。本文对这两种版本进行了HtT评估,并在表2中分别报告了结果:
- 无论是在GPT3.5还是GPT4上,0-shot CoT的表现都是最差的。对于few-shot,CoT和LtM的表现相当。在这其中,HtT的加入都很好的改善这两种提示方法。
- GPT3.5+HtT在检索CLUTRR规则方面并不逊色,而且比起GPT4, GPT3.5涨幅更大,这可能是因为CLUTRR的规则比Arithmetic的规则少。
- 当使用GPT4总结的规则库时GPT3.5+HtT(GPT4),CoT在GPT3.5上的表现提高了27.2%,这是CoT原来性能的两倍多,且接近于CoT在GPT4上的表现。因此,作者认为HtT可能是一种新型的从强到弱的LLM知识蒸馏形式。
- 与监督基准模型EdgeTransformer相比,LLMS+HtT还有所差距,但这个结果是合理的,因为EdgeTransformer利用了前向链接作为强烈的归纳偏见。但HtT相比这类特定领域的监督模型仍然有两个优势:首先,HtT在训练前不需要预定义的关系词汇。其次,HtT学习到的规则可以直接应用于文本输入,无需区分是符号还是文本输入,可扩展到不同领域而无需重头训练模型。
消融实验
- HtT是否能降低规则的幻觉现象?
- 尽管HtT提升了解决推理问题的整体性能,但还不清楚这种提升是由于减少了幻觉,还是有其他的改进。本文对来自Arithmetic(16进制)和CLUTRR的100个测试示例上的CoT和CoT + HtT的预测进行了手动分析,并将预测结果分为三类:正确、规则幻觉和其他。
- 模型学习的规则只是对规则空间的提示吗?
- 在上下文学习中,随机标签的表现与黄金标签相似。如果本文的问题也存在这种情况,那么可以只生成随机规则,而不必依赖HtT来学习规则库。为了探究这个问题,作者在学习规则中用随机答案替换结论。例如,在16进制的数据集中,将5 + A = E替换为5 + A = 7。从表4中可以看到,所及规则使得准确率大大降低,这说明HtT来学习规则库是有必要的。
- XML标签如何提升演绎推理的能力?
- 在Arithmetic中使用了三级层次结构,包括进位、第一个加数和第二个加数。在CLUTRR中使用了两级层次结构,包括第一个关系和第二个关系。本文验证了具有不同层次结构的XML标签的重要性。由于XML标签需要规则排序,同时考虑了一种未排序(也就是随机排序)规则的变体。
- 根据表4的数据,XML标签技巧显著提升了性能。这说明,即使有了好的规则,检索在演绎推理中仍然是重要的能力。因此后续可以进一步微调LLM,以实现更好的检索能力。
- HtT在归纳阶段需要多少样本呢?
- 作者还对HtT与样本数量的关系以及所需最小样本数量进行了探索,在归纳阶段使用不同数量的样本。如图4所示:
- 性能与样本数量之间呈对数线性趋势,这与监督学习的缩放定律是一致的。最小样本数量会因数据集的不同而变化。
- 在base-16和base-9的数据集上,只需100个样本,CoT + HtT就能超过CoT的表现。而在base-11和CLUTRR的数据集上,至少需要500个样本。
- HtT能发现多少规则?
- 归纳阶段本文利用CoT提示生成并验证规则,但由于规则本身的不完美性,LLM可能无法发现所有规则。为了知道HtT能发现多少比例的规则,作者将HtT和包含了示例中所有必要规则的真实规则集合进行比较。
ART
【2023-11-28】大模型没有自我改进能力?苏黎世理工联合Meta AI提出小模型架构
多位大佬发文指出大模型没有自我改进的能力,甚至自我改进之后,回答质量还会明显下降。
- 因为LLM并不能准确判断原答案是否错误以及是否需要改进。
近日,苏黎世理工与Meta AI提出一种改进大模型推理答案的策略——ART: Ask, Refine,and Trust,该方法通过提出必要的问题来决定LLM是否需要改进原始输出,并通过对初步输出和改进输出进行评估确定最终的答案,在两个多步推理任务GSM8K和StrategyQA中,ART相对于之前模型自我改进的方法,提升了约5个百分点。
分别使用与任务相关的语料训练了两个小模型作为Asker和Truster,其中Asker负责对原始问题与输出提出问题,询问原输出是否已经回答了子问题,如果未正确回答,将流转到一下步改进原输出。第四步使用Truster判断原输出与改进后的输出孰优孰劣,确定最后的结果。
复杂推理
复杂交互式任务(complex interactive tasks)具有很大的挑战性,因为要求 LLM 不仅能理解动态变化的真实场景,还需要具备诸如多种高阶认知和推理能力
- 长期规划(long-horion planning)
- 任务分解(task 的 composition)
- 记忆储存(memorization)
- 常识推理(commonsense reasoning)
- 异常处理(exception handling)。
复杂的交互推理任务,传统智能体训练方法包括
- 1)强化学习(Reinforcement Learning)
- 将交互式推理任务建模为部分可观察的马尔可夫决策过程(Partial Observable Markov Decision Process,
POMDP),智能体通过反复尝试和学习最佳行动策略。常见的方法有DRRN,KG-A2C,CALM等。
- 将交互式推理任务建模为部分可观察的马尔可夫决策过程(Partial Observable Markov Decision Process,
- 2)模仿学习(Imitation Learning)
- 将交互式推理任务建模为序列到序列(Seq2Seq)任务,将过去行动和当前环境观察作为输入,当前的行动作为输出,智能体被训练以模仿人类或专家的行为。Text Decision Transformer 是这个方向的基准方法。
- 3)利用大型语言模型(Large Language Model,简称
LLM)提示- 随着 LLM 的快速发展,尤其是 GPT-4 的出现,将 LLM 应用于复杂的交互式推理任务取得了显著的成果。除了通过传统方法直接让 LLM 根据过往行动和当前环境观察生成行动外,有研究
- 直接调用 LLM 生成 action 候选池再结合环境重排序(SayCan)
- 引入虚拟的 “think” 行动来生成子目标以实现更高效的行动(ReAct)
- 任务失败后利用 LLM 总结原因并生成反思以提高下一次尝试的成功概率(Reflection)等多种方式。
虽然传统方法在简单任务中表现优异,但更复杂和具有挑战性的任务中的泛化能力受限
- 无论是基于强化学习的方法还是行为克隆(Behavior Cloning),在将大目标分解为多个子任务、实现长期记忆和处理环境中的未知异常(比如在导电性测试中找不到可以使用的灯泡)方面都面临诸多挑战。
LLM 提示方法展示出复杂任务中生成合理计划和根据人类反馈进行调整的能力,但同样存在一些问题和局限性。
- 每次预测行动都需要调用 LLM,导致整体推理效率低下且成本较高。
- 此外,ReAct 和 Reflection 两种方法还要针对每种未知任务类型进行适当的子目标人工标注,否则在现实世界情境中的推广可能会比较困难。
如何将 LLM 生成的计划转化为真实?
- SwiftSage:融合模仿学习与大模型规划的全新框架
SwiftSage
【2023-6-15】LLM+模仿学习,解决真实世界中的复杂任务:AI2提出SwiftSage
AI2 (Allen Institute for AI) 的研究人员提出了 SwiftSage 智能体框架。通过模仿学习得到一个小型模型,然后将其与 LLM 进行融合。这样可以利用大量数据对小型模型进行微调,使其具备环境和任务相关的知识,并仅在需要时调用大型模型进行高阶推理。
受到人脑思维双系统模型理论(Dual Process Theory)的启发,提出一种全新的结合模仿学习和语言模型(LLM)方法的框架 —— SwiftSage
- 将模仿学习和 LLM 方法的优势相互结合,以解决现实世界中的复杂数字任务,展现出了巨大的潜力和前景。
双模块推理系统:迅速决策的 Swift + 深思熟虑的 Sage
SwiftSage 是一个由两个主要模块组成的框架:迅速决策(Swift)模块和深思熟虑(Sage)模块。
- Swift 模块: 基于 encoder-decoder 的小型语言模型,它能编码短期记忆内容,例如先前的动作、当前观察结果、已访问的位置以及当前环境状态,并解码出下一步的行动。
- 该模块模拟了系统 1 中快速、直观的思维特点。它的优势来自于大量的离线数据,通过在模仿学习中采用 behavior cloning 方法,Swift 模块可以充分了解目标环境中的设定以及更好地掌握任务的定义。
- Sage 模块: 类似系统 2 中深思熟虑的思维过程,利用 LLM(例如 GPT-4)来更好地进行规划。
- Sage 模块包含两个 LLM Prompting 阶段,分别称为规划(planning)和融合(grounding)
为了协调 Swift 和 Sage 模块,研究者们提出了一种启发式算法,用于确定何时激活或停用 Sage 模块以及如何有效地将输出与动作缓存机制相结合。
- 默认情况下,智能体通常会采用 Swift 模块。
- 当 Swift 模块遇到困难时(例如,出现如下图的四种情况),智能体会改为执行 Sage 模块产生的动作缓存。
评测
- 30 个任务上的评估中,SwiftSage 的表现超过了之前的 SayCan、ReAct 和 Relfexion 等方法近 2 倍,并且大幅降低了 LLM 部分的计算成本。
- SwiftSage 在 LLM 推理中所需的每个行动的令牌数量大幅减少,因此在成本效益和效率方面,它比单纯依靠 Prompting LLM 方法表现得更为出色。平均来看,为了产生一个行动,Saycan 和 ReAct 需要近 2000 个 token,Reflexion 需要接近 3000 个 token,而 SwiftSage 仅需约 750 个 token。
NLP发展
【2024-4-5】刘群:感慨一下技术进步给研究和教学带来改变和失落:
- 当年我们做NLP研究,要学习很多语言处理的技术,包括word segmentation, POS-tagging, parsing, semantic role labeling, co-reference, RST等等
- 深度学习流行以后,发现这些内容已经没有人感兴趣了,Stanford NLP的课程都抛弃了这些内容。
- 现在大语言模型又带了一轮巨大的变化,很多论文本质上就是做prompt engineering加数据和评测,甚至连机器学习的基础技术都不需要具备,也可以做出很好的工作并在顶会上发表论文。
真不知道这是好事还是坏事
算法工程师出路
- 全栈型算法工程师将更为抢手,如果精通大模型从训练到应用的整个流程,走到哪里都不怕。
- 但精力有限,如果从数据、预训练、微调、对齐、推理、应用几个方面: “
预训练>数据>应用>对齐>推理>微调”
因为
- 掌握
预训练的人少,毕竟物以稀为贵; - 而
数据是大模型的重点,毕竟有多少数据就有多少智能; 对齐主要是很多场景真没必要,毕竟我是做ToB较多,认知也许比较狭隘了;推理很多开源框架已经支持的很好了,感觉对于很多厂商来说也许开源就够用了;微调到现在这个阶段,成了有手就行。
具有AI项目落地经验的算法工程师更吃香
大模型时代红利只会普惠 2% 算法工程师。
模板是张小龙,二十年前一个人写出 foxmail 的张小龙。
能力栈包括:
- 理解技术边界。不死磕算法细节,毕竟技术壁垒逐步降低,但要知道当前模型什么能干,什么不能干。
PMF(product-market-fit)。将技术转化为产品-市场的契合点,比如 可灵视频生成技术,关键是把能力转化为有约束条件的市场需求。- ROI 投入产出比换算。
- 第一,目前 LLM api 调用有成本,并且随着访问量的增加而增加,并非互联网时期固定的服务器成本。
- 第二,LLM 对话式交互界面,只交付一个结果,注定不能插入广告,互联网 “羊毛出在猪身上” 的赚钱策略又如何成立。
这三点看起来不那么“技术”,是因为大模型时代,并非技术周期的升级,而是低效时代的落幕和下一个高效时代的开启。
- 高效时代技术会变得人人可用,技术门阀壁垒也会消失,任何知识包括算法也会回归工具属性。
- 重要的是对于各种工具的整合能力,而非单一工具的熟练度。
LLM 时代 NLP何去何从
【2023-6-18】脉脉:NLP只能做LLM吗,小红书地址
总结
- 果断甩掉包袱(过时技术)
- 深刻认知GPT的强大
- 亲自体验GPT,掌握一手资料
- 从小模型开始一步步验证
- 思考下一步:有模型、资源后能做什么
- 避开OpenAI正面竞争,寻找共赢,站在巨人肩膀上
- 不做OpenAI已经做到、懒得做的事情
- 做OpenAI想做但还没做到的事情
- 尽力争取资源:多卡,哪怕换导师、实验室甚至从学界切换到工业界
- 加强工程能力
- science 和 engineering 和 product 三合一
LLM 时代,学术界 Dos and Don’ts
- 不要背历史包袱
- 如果自己的工作被颠覆了,直接扔掉,不用可惜,不要浪费时间续命
- 旧技术必定被新技术颠覆,这是历史必然
- 不要做 OpenAI 已经做到的事情,不要做OpenAI 能做只是懒得做的事情
- 否则会被 OpenAI 降维打击
- 深刻地认识 GPT 的强大
- 对 GPT 的负面批评,很多时候都是错的,这不是大模型的缺点,而是批评者对于大模型认知浅薄所致
- 自己变成一个熟练的prompt engineer,花个一两周时间天天prompt GPT,这样才知道哪些不行,哪些只是觉得不行但其实它行
- 假设已经有了 GPT-3.5 基础模型,假设自己有1k张卡,思考能做什么
- 用小模型(如LLaMA 7B)去验证,如果成功,再慢慢加大到 13B-30B,画出一条上升的曲线
- 不一定要 scale 到最大的模型,只要自己的结论能够画出一条上升曲线,那么可以外推更大范围
- 做一点 OpenAI 想做但还没做到的事情
- 去 prompt GPT,看看哪里做不好,思考怎么做让它更好
- 哪些事情是 OpenAI 很难做到的事情
- 面向未来,思考哪些问题即使把现有技术全部拉满,依然做不好,然后去尝试解决这些问题
- 搞卡
- 无论如何都要有八卡 A100
- 如果导师不给,可以考虑换导师
- 如果实验室不给,可以考虑换实验室
- 如果学术界怎样都没有,可以考虑换到工业界
- 不要再 care 刷 paper,只发最低数量能毕
- 如果一篇能毕业,发一篇就行,如果三篇毕业,发三篇就行
- 但是发出来的 paper一定要保证质量,尽量做到每篇 paper 质量单调上升
- 不要把时间花在与 reviewer 相互拉扯上面,要把时间花在真正有意义的事情
- 加强工程能力,加强工程能力,加强工程能力能
- 水 paper 但代码写得差的人非常多;
- 代码写得好的 research 怎样都不会差
- 不要再纠结 science 和 engineering 和 product 的区别
- 在现代 LLM 的视角下,这几个是三位一体
LLM 研究方向
【2023-9-24】详见知乎专题总结:大模型LLM领域,有哪些可以作为学术研究方向?
LLM 问题
斯坦福 CS224N 课程
- ICL中的Zero-Shot Learning(零样本学习)和Few-Shot Learning(少样本学习)
- Instruction Finetuning 指令微调
- RLHF
- 人工(human-in-the-loop)昂贵 → 建模人类偏好变成独立的NLP问题
- 人工评判有噪声、错误 → 将集合直接排序问题变成pair-wise(点对)的对比问题,更可信
- 优点:直接建模人类偏好,易于泛化
- 问题:人类偏好不可信,据此建立的模型偏好更不可信
- RL里常见问题是奖励破解(reward hacking)
- 模型被鼓励输出看似权威、有用但枉顾事实的结果,导致编造事实、出现“幻觉”(hallucination)
- 因此,模型的错误对齐问题值得研究
- 改进:
- RL from AI feedback
- Finetuning LMs on their own outputs
| 技术点 | 介绍 | 优点 | 缺点 |
|---|---|---|---|
| ICL小样本学习 | ICL中的零样本和少样本 | 不需要微调,只需提示工程、CoT就能提升效果 | ① context输入限制 ② 复杂任务还是需要梯度更新 |
| 指令微调 | 通过指令集进行参数更新 | 简单直接,容易泛化到新任务 | ① 众多任务的示例数据收集成本高 ② LM优化目标与人工偏好错配 |
| RLHF | 基于人类反馈的强化学习训练 | 直接建模人类偏好,易于泛化 | ① 人类偏好不可信,据此建立的模型偏好更不可信 ② 模型被鼓励输出看似权威、有用但枉顾事实的结果,导致编造事实、出现“幻觉”(hallucination) |
总结
| 问题 | 介绍 | 思路 | 备注 |
|---|---|---|---|
| 幻觉 | 有时会编造事实 | 引入事实信息矫正? | |
| 不擅长精确计算 | 随机数并不随机 | 本质是预料统计概率,无法真正随机 | |
| ICL不受控 | prompt里的作答要求不一定起作用 | ||
| prompt模板瓶颈 | 回复质量严重依赖prompt模板 | ||
| agent | agent不可控 | ||
千万别用大模型抽奖
- 大模型0-100随机数,都输出27、42、73
神经科学
【2024-7-23】神经科学家观点
Karl Friston:当前的AI大模型缺乏智能体的一个基本品质,那就是 好奇心
LLM Understanding: 11. Karl FRISTON “The Physics of Communication”
Anil Seth:类脑器官培育出意识系统可能性比AI更高
九问中国大模型掌门人
【2023-11-8】九问中国大模型掌门人
「九问中国大模型掌门人」重磅对话。
- 主持人:王咏刚,SeedV 实验室创始人兼 CEO,创新工场 AI 工程院执行院长
- 张家兴,封神榜大模型,IDEA 研究院
- 张鹏,GLM 大模型,智谱 AI
- 李大海,CPM 大模型,面壁智能
- Richard,百川大模型,百川智能
- 王斌,MiLM 大模型,小米集团
- 康战辉, 腾讯混元大模型
从模型技术、算力基建、开源开放、商业化四个方向
- 基础大模型发展的技术突破口是什么?
- Transformer 未来将如何演进?
- 如何让大模型远离「幻觉」,安全可控?
- 自研的 AI 算力基建与服务如何发展?
- 大模型的开源生态如何发展?
- 自研大模型如何取得领先地位?
- 如何看待互联网大厂与创业公司之间大模型的竞争?
- 大模型如何在行业落地,实现商业化?
- 套壳 ChatGPT 的产品有价值么,大模型 C 端应用,机会在哪里?
基础大模型发展的技术突破口是什么?
张鹏(GLM 大模型)
- 大模型最强的就是认知能力,比过去所有的模型能力都要强,强于上一代判别式模型的能力
- 跨模态能力对于突破模型认知上限很关键,因为语言是抽象的、人造的,自然界不存在的东西。
- 如何把这些跨模态能力综合打通,是真正迈向人类大脑认知能力的关键。
王斌(MiLM 大模型):
- 大模型真正要使用或发展,得有逆向思维,就是将大模型小型化。
- 小米通过「轻量化」和「本地化」部署,让模型在保持相当能力的同时,能够变小、降低使用成本,让更多用户得以使用。
张家兴(封神榜大模型体系):
- 目前有很多通用预训练大模型,但到具体场景中,仍需继续微调。
- 基础大模型达到高中或大学毕业生的知识水平,但需要持续学习,才能让其在实际场景中掌握具体技能,这就是对齐技术。
- 寻求突破,有两点很重要。
- ① 对齐技术,在未来能否不依赖于梯度下降。
- 传统机器学习基于梯度下降实现自动化训练系统。但梯度下降带来很大的不稳定性,且极难实现自动化。
- 人脑中并没有这样的机制,并不是靠梯度下降的逻辑来学的,至少说不完全依赖梯度下降机制。
- ICL(In-Context Learning)是非梯度下降探索的一个方向。
- ② 能否实现一种彻底无人、没有老师提示的学习方式。
- 设想:能否让多个模型完全形成闭环,互相教导对方。当多个模型达成自洽时,所形成的知识和技能就是我们想要的。
- 人类社会就是这样,并没有上帝教授人类知识,但人类已经形成闭环和自洽,到达目前的知识水平,大模型是否能具备这样的技术。
- ① 对齐技术,在未来能否不依赖于梯度下降。
- 第一点技术已经有雏形,第二点无人学习方式,会更科幻一点
李大海(CPM 大模型):
- 同意家兴老师让模型实现无人学习的观点,该方向没有那么快实现,当下比较可行的是 Agent方式 推进。
- 人类本身具有快和慢的思维,将问题对应到模型中。现在模型通过问答的方式,用文字组成回答。尽管逻辑上一致,但实际上在答案生成过程中,通过 COT(Chain of Thoughts)等方式,让回答质量变得更高。
- 那么基于 Agent 技术将规划做得更好,再将各种技术应用起来,使得能将场景中任务得到更好的拆解和分步交付。打通 Agent 环节需要大模型自身结合外部框架一起实现,大模型本身也需要有相应的数据来训练,让能够有效地了解 Agent 在场景中的具体行为。
- 在未来一两年内,用较小的模型能够做到大参数模型的效果,是一个可以探索和突破的方向。
康战辉(腾讯混元大模型):
- 目前大模型还不够成熟,主要聚焦两个问题。
- 第一,现在大模型更适合任务难度较低、容错率较高的场景。
- 例如闲聊,闲聊的场景没有预期,能聊天就好。
- 但如果涉及到专业翻译、客服或做一些个人助理这类复杂任务,目前大模型还不能满足需要,本质上还是大模型本身存在幻觉。
- 第二,刚才没有提到现阶段技术对复杂程度的跟随能力。
- 人与人之间的交互,不可能像人机一样,每句话只有一个指令。很多时候是复杂的指令,包括多模态。人类的交互也不仅仅通过语言,这也是个挑战。
- 架构上的突破,学界已经进行了许多探索。未来应该两个架构走向统一,模型通过一个架构实现能听会说、能读会写的功能和服务。
Richard(百川大模型):
- OpenAI 角度,从人类目前大模型技术最高水平看下一步的突破。
- Ilya(Ilya Sutskever,OpenAI 首席科学家)说如果能做到预测 Next Token,就离通用人工智能不远了。OpenAI 正在做的 GPT-5,号称把十万台 GPU 连在一起,预测 Next Frame(下一帧),如果得以实现,大模型的技术会进一步突破。
- 站在近期国内模型应用落地的视角,面临两个必须要突破的点:
- 一是如何解决大模型的幻觉问题。大模型在行业落地过程中,准确率是最受关注的问题。如何利用好大模型能够压缩人类知识的优势,同时由于人类知识是持续变化的,需要与搜索引擎进行更深入的联合,让模型技术在原生状态下更好解决幻觉,是未来行业落地中亟需突破的点。
- 二是可以把大模型看作人或计算机,它有内存(短期记忆)和硬盘(长期记忆),对应到模型中就是上下文窗口,Claude 目前突破了 100K,我们也推出了超过 100K 的上下文长窗口模型。
Transformer 未来将如何演进?
大模型都脱胎于名为 Transformer 的核心算法。近年,Yann LeCun 等学者也经常提出非常新颖且独特的科研方向,许多中国和美国等世界各地的科研工作者也在尝试优化,甚至彻底改变 Transformer 架构。
那么未来,架构该如何发展?
张家兴(封神榜大模型体系):
- 大模型领域要区分两个方向
- 一是设计模型结构,Transformer 架构自 2017 年提出,到现在已经有六年了,但还是如日中天,也是很罕见的。
- 另一条路是训练层面,模型如何持续学习,也是刚才提到的对齐技术,是在训练层面的科研方向。
那么 Transformer 的结构已经有 6 年历史了,如果它被取代,一定是 Transformer 模型结构遇到了无法解决的问题,但又极其紧迫。就像当年Transformer 提出来时,是为了解决 LSTM 太慢的问题。
Transformer 已经证明了能够支撑足够大参数量的模型,那还有什么问题呢?
- 比如幻觉问题,是否 Transformer 的模型结构就是容易产生幻觉?
无论 100k 的上下文窗口,还是 1 million 的上下文窗口,都是 Working memory,而不是 Long-term memory。
下一代模型结构,的确现在不知道是什么样子。但是,它的出现一定能解决现在 Transformer 结构无论如何解决不了的问题。
在这方面的探索中,我们和大海的方向是相同的,可能采用 Agent 的方式来解决问题,但如果模型结构能够解决,那将是最好的方案。
王斌(MiLM 大模型):
- 学术界大部分工作还是围绕如何提高 Transformer 的效率展开。
- 比如,如何简化注意力机制的计算,如何降低 FNN 的维数,如何对参数矩阵分解来用更小的矩阵代替大矩阵。
- 但真正要从架构上对 Transformer 进行大的改进,确实需要勇气。
- 因为当下硬件的结构都是围绕如何优化 Transformer 的方式设计。
- 未来较长时间里,Transformer 也都会是 AI 芯片设计中的公共结构,基于此再进行优化和设计。
- 所以突破 Transformer 架构的挑战非常大。
- 但是大模型的出现,在一夜之间颠覆了大家的想象,也证明了 Nothing is impossible。因此,可能也会在某一天突然间出现一个新的架构,替代掉原来的 Transformer 架构。
张鹏(GLM 大模型):
- 以 Transformer 为例,现在大家的注意力都集中在这件事上。
- 深度学习之父 Geoffrey Hinton 最根本的算法 bp(反向传播),在八几年就已经提出,但在之后的几十年里,并没有引起太大影响。甚至在学术界受限于一些客观条件,也没有太多人使用。
- 当时来说,反向传播算法计算量过大且复杂,硬件无法支持过大的计算量。
- Transformer 也是如此,为什么在 2017 年提出,到近年才大行其道?这是因为 AI 算力芯片的能力得到了十倍甚至百倍的增长,足以支撑大规模计算量。
- 所以,下一代的算法结构可能已在身边,只是受限于客观条件,无法实现跑通新的算法或者扩大规模,来证明新结构的价值。
如何让大模型远离「幻觉」,安全可控?
李大海(CPM大模型):
- 幻觉问题确实是当前影响应用落地的一个绊脚石。
- 实践角度
- 目前比较好的方法是
RAG(外挂知识库)来引入外部知识,改善幻觉问题。 - 如果让模型学习足够多的知识,对于学过的知识,出现幻觉的概率会变小。
- 目前比较好的方法是
然而,目前大模型整体基础设计是通过压缩知识产生的通用智能。压缩就会产生一定概率的错误,也就是幻觉。
【2023-11-30】「GPT-4只是在压缩数据」,马毅团队造出白盒Transformer,可解释的大模型要来了吗?
伯克利和香港大学的马毅教授领导的一个研究团队给出了自己的最新研究结果:
包括 GPT-4 在内的当前 AI 系统所做的正是压缩。
因此,通过外挂知识库和学习更多知识的方法,尽可能减少幻觉,但完全避免幻觉目前还不太可能。
另一方面,应该关注更具探索性的方向
- 例如类似于 Agent 技术。在这个方向上,目前收益仍然相对有限。
如果客户让我在幻觉率上作保证的话,大模型在实际运用上,未必一定是纯粹大模型形态的落地产品。用大模型技术与其他技术结合在一起并不令丢人。在当前阶段,应该鼓励将大模型视为变量,而非将其视为核心,更加因地制宜地使用大模型技术。
Richard(百川大模型):
- 现在大模型的建模方式是 Next Token 的 Prediction(下一个词预测),因此它必须说话。
- 大模型现在尽力压缩更多的知识,但一定是有限的。这包括也引入了知识具有时效性的问题,如果今天出现了一个新的知识,之前肯定没有训练过,或者之前漏了某些知识导致模型效果不好
- 幻觉产生原因
- 大模型的知识并不能包含所有知识,而且还不支持高频更新。
- 更本质的幻觉产生的原因:不自知。如果大模型知道自己不知道,就不会胡说八道了。
- 幻觉的解决方案
- 谈到大模型的知识容量问题,类比一下人,人类已经很聪明了,但没有一个人能聪明到掌握所有知识,人也是通过查资料来扩大知识容量。
- 解决「幻觉问题」非常重要的路径是与搜索引擎结合。搜索引擎作为网罗天下最大的数据和知识的工具,它能够与大模型深度结合。这种深度结合并非像 New Bing 这样先收集结果,然后再进行概括展现。也正在期待和探索真正能融入模型内部的方法。
- 模型训练时,例如
RETRO(Retrieval-Enhanced Transformer,自回归语言模型)方案,在训练阶段就可以实现优化,跳过了 RAG(外挂知识库)这个方案。
第二点,价值对齐,但某种程度上价值对齐也是大模型幻觉的根源。
- 原本只学习了小学和初中的知识,但在价值对齐环节时,引入了高中的题目,导致小学和初中知识都出现错误。
因此,在大模型方面另一个重要的投入就是搜索增强。Ilya(Ilya Sutskever,OpenAI 首席科学家)也提到了这个问题。希望通过搜索增强技术,尽量让模型知道自己不知道。
最好的情况是模型知道自己懂,然后输出正确答案,最差的情况是模型不懂且胡说八道。中间的关键,是让模型知道自己不知道。
- GPT-3.5 到 GPT-4 非常重要的进化,就是 GPT-4 的幻觉输出大幅度降低。当你询问他们一个复杂的问题时,GPT-4 会回答它不懂。
因此也会投入资源,解决幻觉方面的两个最重要部分。
大模型的幻觉可以看作是优势,因为它能够胡说八道或创造,所以具备创造能力。大模型也被称为想象力引擎。如果让大模型编一个故事,可能编得比人还好,而让大模型写一首藏头诗,可能写得比人还好。
王斌(MiLM 大模型):
- 幻觉这个问题确实存在,一边做大模型,一边结合小米产品上的具体场景。双方互相了解,知道很多需求和场景,然后根据需求反推大模型的建设,能经历完整的迭代过程,幻觉实际上很可怕。
小米客服系统刚开始时,大家都认为通过大模型应该能大幅度提高客服系统。但尝试时,发现太可怕了。
- 比如消费者在客服系统询问产品价格,如果大模型报价回答「仅卖 9 块 9,交个朋友」,那我们就完了。
因此,在真实场景当中,大模型幻觉带来的后果实际上比我们想象的要严重很多。
实际操作的工程化和产品角度,对模型输出的结果进行分层分级。当然,幻觉问题和安全可控并不完全是同一个问题,总体而言,我们会对用户的输入和系统的输出进行分类分级。
有些输出结果是最高级别,有些基于具体场景,有具体的内容分级方式。因此,对于模型幻觉的整体治理方案是对输出结果分类、分级、及时监控和反馈。通过技术及人工手段来保证对用户最好,所以我们更多地关注产品方面的综合治理手段。
自研的 AI 算力基建与服务如何发展?
康战辉(腾讯混元大模型):
- 算力是模型训练阶段非常重要的基础设施
- 国内厂商的算力紧张,这是普遍问题,硅谷很多公司都拿不到货。
- 算力成本不用担心,整个 AI 基础设施中,除了算力本身在演进外,训练和推理过程都在持续优化。
- 腾讯对专用客户提供集群服务,对于算力需求比较弹性的客户,提供弹性卡资源,无论是成本还是总效率匹配方式,分配效率都更高
张鹏(GLM 大模型):
- 智谱始终坚持包括算法在内的技术自研,但也发现算力确实是重要的基础资源,甚至成为了瓶颈。
-
因此,开始寻求与国产芯片厂商合作。但芯片自研是必经之路,应对复杂多变局势的最终解决方法还是需要自研。
- 芯片制造工艺的问题,我们与芯片厂商有很深的沟通,推出了国产大模型和国产芯片的适配计划。通过适配情况来看,国内外的芯片适配设计上,没有太大差距,但在具体制造工艺和应用生态方面差距比较大。
- 生态问题。英伟达的芯片为何让全球开发者趋之若鹜?原因在于它拥有一个良好的开发生态,使得大家能够轻松且高性能地使用它的芯片。现在许多国产芯片厂商,需要花费大量精力来做软件生态的适配。
正在推动与政府、技术厂商以及与芯片厂商共同讨论集中式方案,例如,在某个固定地方,组织大家一起进行 m 到 n 的适配过程,以保证知识共享,并更快地加速适配过程,是非常必要的过程。
大模型的开源生态如何发展?
这么多年来从开源生态中赚钱是相对困难的问题,请几位嘉宾谈谈我们对开源生态建设的看法。
Richard(百川大模型):
- 第一点是真开源。以往的开源模型,可能是开放做学术研究的,无法商用。虽然有开发者也在尝试商用,但中间存在很大风险。
- 例如 Llama 2 虽然在开源时强调可商用,但在条款中,它也规定不能使用在非英文环境下。
- 百川践行的是真开源。无论是 7B 还是 13B,都是开源且免费商用的,能真正让社区蓬勃发展。
- 第二点是自研,中国大模型的开源需要走向自研。百川在成立之初就希望从头开始训练大模型。为什么要强调自研两个字,一是条款中对非英文环境的限制。二是海外大模型的原生中文能力不佳,中国的大模型对中文理解能力一定是更强的。
- 因此,从头开始训练,对中文语料进行更好的理解,同时也会输入掌握英文知识。
实际上大模型的最终落地需要在应用场景中实现,除了 Model as a service(MaaS,模型即服务),也需要 Agent as a service。未来的开源生态应该在外部增加更多插件,以便让开发者真正落地到应用场景中。
康战辉(腾讯混元大模型):
- 腾讯一直非常积极拥抱开源,包括大数据、前端框架以及学术模型。当然,混元大模型尚未开源,一个核心原因是混元的规模较大,千亿级模型相对比较难开源。我们可能会持续打磨,在合适的阶段,结合公司战略做一些布局。
- 国内应用场景丰富,在训练通用大模型时,可以让模型兼顾通用及行业能力。
- 技术领域有所追求。美国的斯坦福有 HELM 评测,伯克利有 LMSYS Org。我们也应该构建中国大模型的 Benchmark(基准),这个非常重要。
自研大模型如何取得领先地位?
张鹏(GLM 大模型):
- 认知差异。需要重新审视目标,以及对大模型的认知边界到底在哪里。
- 三年前 IIya 等人就提出研究目标是
AGI(通用人工智能),但并不考虑将这个产品做出来之后,如何赚钱
- 三年前 IIya 等人就提出研究目标是
- 如何实现自主创新。这也是智谱开始训练模型时,并未简单地照搬 GPT-2 的论文,而是在算法层面就在思考如何自主创新。
- 国内存在一种风气,尤其在技术圈,习惯舶来主义或拿来主义。使用开源,但是不会贡献回去,没有良性的闭环。
王斌(MiLM 大模型):
- “用中国擅长的应用创新,驱动底层技术进行颠覆式创新”
Richard(百川大模型):
- 尽管 GPT 中文能力很强大,但与中国大模型对比,在某些领域表现已经落后
站在 OpenAI 的立场上,可以套用周星驰的名言:「我不是针对谁,而是在座的各位,都是垃圾。」
- 即使是 Google 的大模型目前为止效果也远远落后,只能依赖 OpenAI,它的第一性原理在于选择当前技术方案时,就是采用「Always for AGI」的逻辑
如何看待互联网大厂与创业公司之间大模型的竞争?
康战辉(腾讯混元大模型):
- 互联网大厂与创业公司在大模型上,不能完全用竞争来形容。实际上,应该是彼此各自有侧重、各自具有优势,也有互补或者互相促进的作用。
- 大厂和创业公司如何实现互相促进
张家兴(封神榜大模型体系):
- 大模型的竞争中,同质化的问题比较严重,无法证明谁比谁强很多。
- 大厂的优势被称为资源优势,如果真的想要发展这个业务,大厂的资源肯定比创业团队多得多。
- 创业团队或者是独立的小团队的资源优势又是什么?就是制度优势。
大模型如何在行业落地,实现商业化?
中国的 B 端落地环境非常残酷。可以用「卷」字来形容,第一毛利率很难持续,当产品稳定到一定程度后,每个客户的毛利率很难持续,第二每个客户的定制化要求相当高,对实施成本的要求非常高。
张鹏(GLM 大模型):
- 答案很简单,叫「共建生态,共享红利」
- 改变思维,正如我们刚才提到的毛利率、利润空间等等就是很卷。但这是站在固定的天花板向下观察。
- 但请务必注意,可以提高天花板,扩大市场份额,这是大家容易忽略的一件事情。能将天花板再往上抬一抬,以及将不断内卷的墙砸一砸?
Richard(百川大模型):
- 跳出上一代 AI 落地的方式。
- 未来的畅想是「一切都将成为 Agent」,会是一个充满想象力的世界。我们不应局限于基于 ChatGPT 目前一问一答响应式的对话形式。
套壳 ChatGPT 的产品有价值么,大模型 C 端应用,机会在哪里?
李大海(CPM 大模型):
- 未来实际上很难预测,我们只能预测下一个 Token。
大模型局限性
【2023-7-27】朱松纯:大模型=缸中之脑?通院朱松纯团队剖析AGI关键缺失, 论文链接
大模型训练数据集的不透明以及人类评估时所采取的指标差异可能使得人类高估了大模型的真正表现。
- 1)虽然某些研究声称大语言模型能够在标准化测试(SAT,LSAT)中取得超越普通人类考生的卓越成绩,但一旦引入非英语的其他语言同类型测试,比如中国高考、印度升学考试、越南高考时,GPT 的表现显著下降,且其在需要应用推理的考试(数学、物理等)的成绩显著低于强语言依赖学科(英文、历史)的考试。GPT 的表现看上去更像是采取了一种题海战术,通过重复的记忆来做题,而非习得了如何进行推理。
- 2)大语言模型的数学推理能力仍然有待提高。Bubeck 等人(2023)在《Sparks of Artificial General Intelligence》这篇文章中采取了单个案例展示的方式尝试说明 GPT-4 能够解决 IMO 级别的问题,但研究者在仔细检视了 GPT 所提供的解决方案发现 Bubeck 等人的结论具有很强的误导性,因为测试的题目被极大程度地简化了,在让 GPT-4 解决 IMO 数学题原题时, GPT-4 的数学逻辑链条是完全错误的。另有研究发现,在 MATH 训练数据集上,即使把模型设置为 MathChat 的模式,其准确率也只有 40% 左右。
- 3)大语言模型的推理与其说是来自于理解逻辑关系,不如说是来自于大量文本的相关性。朱松纯团队的另一篇研究发现,一旦将自然语言替换为符号,大语言模型在归纳、演绎、溯因任务上表现骤降,无论是否使用思维链(thought of chain)的策略。
- 4)大模型做不好抽象推理,当面对那些仅依赖于几个小样本演示从而找到潜在规律的任务时,大模型的表现较为一般。如下图所示,在瑞文测试数据集(RAVEN) 中,测试者需要根据已有的 8 个图形(形状、颜色、数量、大小)寻找暗含的规律,然后推理出最后一个图形。
并发性能
【2023-8-11】如何解决LLM大语言模型的并发问题?
参考 TGI , deepspeed 或者 vllm 等架构的实现方案。
- 采用 Continous batching 来优化请求,提高 throughput,这个在 VLLM 和 TGI 中都有支持。
- 用 flash attention 和 page attention 来优化 GPU 中 attention 的计算效率。目前部分主流的 inference 的仓库都会集成这两种 attention 优化方式。
- 对于部分设备来说,可以考虑采用 GPTQ 提速。比如对于 4090,如果采用 fp16,在推理时batch size 仅能够达到 4(max_tokens=2048)。但 GPTQ 能够支持 batch size 8 + max_tokens=2048。尽管batch inference 情况下,FP16 的速度会快于 GPTQ,但更大的 batch size 支持还是能让 GPTQ 的 throughput 优于 fp16。
- 部署超大模型时,采用 Tensor Parallelism 加速,这个在 TGI , deepspeed 或者 vllm 都有支持。
- 服务速度实在不理想的话,考虑多买几台 GPU,然后用 Load balancer 做请求转发。
重复
重复现象
【2024-5-15】使用基于最大化的解码算法(如贪婪搜索)时,模型倾向于在句子级别重复。
这种现象与人类语料库中很少出现连续句子级重复的现象不符。
研究发现:
- 1、模型有一种重复前一句的倾向
- 实验发现
P(橘子| 我 爱 橘子。我 爱)>P(橘子 | 我 爱)。 - 模型对其生成的上下文过于自信,当存在与前文相同的上下文时,模型可能会学习到一种“捷径”,即直接复制下一个词项。
- 这和人类语言很不相同。人类语言通常不会把一个句子重复说,因为这不会增加额外的信息量。
- 实验发现
- 2、句子级重复具有自我强化效应,即在上下文中重复的次数越多,继续生成该句子的概率越高。
- 3、具有更高初始概率的句子,通常有更强的自我强化效应,模型更倾向于重复这些句子。
解决方案
神经文本生成中减少重复问题的技术可以分为两大类:基于解码的方法(decoding-based methods)和基于训练的方法(training-based methods)。
以下是一些主要的技术:
- 基于解码的方法(Decoding-based methods):
n-gram Blocking: 这种方法通过阻止生成与之前生成的n个连续项相同的项来减少重复。Top-k Sampling: 在生成过程中,只从概率最高的k个词中选择下一个词,这有助于增加多样性。Nucleus Sampling(Top-p Sampling): 这种方法不是选择概率最高的k个词,而是选择累积概率达到p的最小词集,从而允许生成更多样化的文本。Beam Search with Diverse Hypotheses: 在束搜索中考虑多样性,鼓励探索不同的生成路径,以减少重复。
- 基于训练的方法(Training-based methods):
Unlikelihood Training(UL): 通过减少负样本(即重复的词或短语)的概率来训练模型。Straight-to-Gradient(SG): 通过提高不属于负样本的词的概率来改善训练。Coverage Penalty: 在训练中加入覆盖度惩罚,鼓励模型生成更多样化的输出。Exposure Bias Mitigation: 通过调整训练目标以减少模型对高频重复内容的偏好。
- 其他技术:
Insertion of Diverse Phrases: 训练数据中插入多样化的短语,以鼓励模型学习减少重复。Curriculum Learning: 逐步增加训练难度,先让模型学习生成不重复的内容,再逐步提高生成质量和复杂性。Reward Modeling: 使用强化学习中的奖励模型来指导生成过程,奖励模型会鼓励生成多样化和信息丰富的文本。
文章来源:
- Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation
幻觉
详见站内专题: 大模型幻觉专题解析
灾难遗忘
灾难性遗忘
- 一个任务上训练出来的模型,如果在一个新任务上进行训练,就会大大降低原任务上的泛化性能,即之前的知识被严重遗忘了。
- 灾难性遗忘 (catastrophic forgetting) 现象是在连续学习多个任务的过程中,学习新知识的过程会迅速破坏之前获得的信息,而导致模型性能在旧任务中急剧下降
- 论文 Attention-Based Selective Plasticity
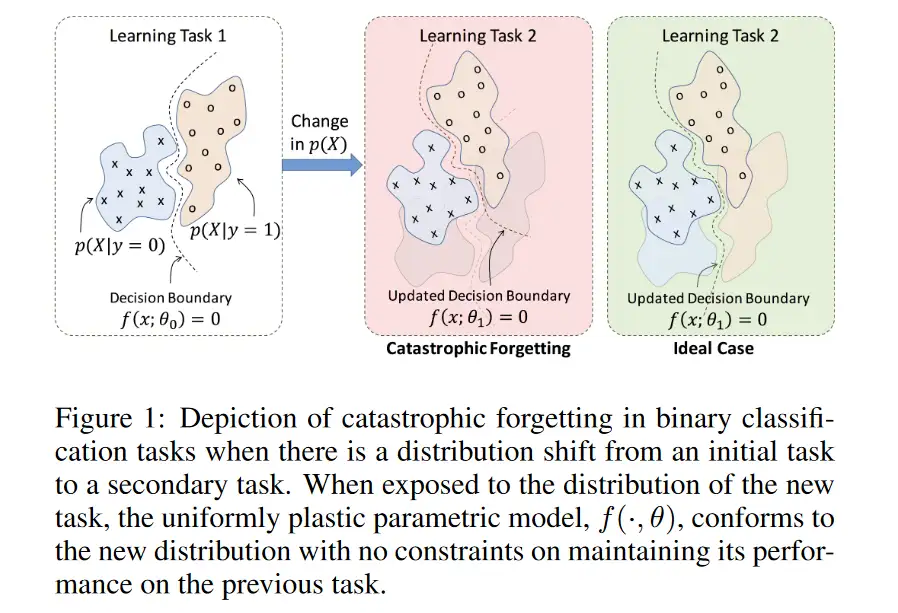
样本遗忘(example forgetting)是受到灾难性遗忘现象的启发而提出的,即在同一个任务的训练过程中,也可能会有遗忘现象,一个样本可能在训练过程中反复地学了忘,忘了学。
‘灾难性遗忘’指人工智能系统,如深度学习模型,在学习新任务或适应新环境时,忘记或丧失了以前习得的一些能力。”
- 腾讯人工智能实验室副主任俞栋博士说,“灾难性遗忘”会造成人工智能系统在原有任务或环境性能大幅下降。参考
- 除了传统新知识学习会覆盖旧知识之外,谷歌大脑还发现,在如超级玛丽等探索型游戏里,‘灾难性遗忘’会阻碍模型对新知识的学习。
灾难性遗忘是连接模型(connectionist models,即神经网络)的一个不可避免的特征。
灾难性遗忘(catastrophic forgetting):
- 在一个顺序无标注的、可能随机切换的、同种任务可能长时间不复现的 任务序列中,AI对当前任务B进行学习时,对先前任务A的知识会突然地丢失的现象。通常发生在对任务A很重要的神经网络的权重正好满足任务B的目标时。
解决了“灾难性遗忘”问题后,模型就能具备持续学习的能力, 可以像人类一样不断获取新的知识、新的技能,同时能够最大化地保持旧的经验知识和技巧。
为什么会遗忘
主要原因
- 传统模型假设数据分布固定或平稳, 训练样本是独立同分布
- 所以模型一遍又一遍地看到所有任务相同的数据,但当数据变为连续的数据流时,训练数据的分布非平稳,模型从非平稳的数据分布中持续不断地获取知识时,新知识会干扰旧知识,从而导致模型性能的快速下降,甚至完全覆盖或遗忘以前学习到的旧知识。
解决方法总结
【2023-10-23】大规模语言模型–灾难性遗忘, csdn
希望模型一方面必须表现出从新数据中整合新知识和提炼已有知识的能力 (可塑性),另一方面又必须防止新输入对已有知识的显著干扰 (稳定性)。
- 这两个互相冲突需求构成了所谓的稳定性-可塑性困境 (stability-plasticity dilemma)。如图所示, 理想解决方案应确保稳定性(红色箭头) 和可塑性(绿色箭头) 之间的适当平衡, 以及对任务内(蓝色箭头) 和任务间 (橙色箭头)分布差异的泛化性。

持续学习是一种能够缓解深度学习模型灾难性遗忘的机器学习方法,包括正则化方法、记忆回放方法和参数孤立等方法,为了扩展模型的适应能力,让模型能够在不同时刻学习不同任务的知识,即模型学习到的数据分布,持续学习算法必须在保留旧知识与学习新知识之间取得平衡, 上图c 中展示了模型在学习过程中各个部 分的代表性策略。
持续学习 (lifelong learning/continual learning):
- 学习连贯的任务,而不会忘记如何执行之前训练过的任务的能力。
解决灾难性遗忘最简单粗暴的方案
- 使用所有已知的数据重新训练网络参数, 以适应数据分布随时间的变化。
- 尽管从头训练模型的确完全解决了灾难性遗忘问题,但这种方法效率非常低,极大地阻碍了模型实时地学习新数据。
而增量学习的主要目标就是在计算和存储资源有限的条件下,在稳定性-可塑性困境中寻找效用最大的平衡点。
对于 LLM 中的灾难性遗忘,往往会过拟合小型微调数据集,导致在其他任务上表现不佳。有学者提出了各 种方法来缓解 LLM 微调中的灾难性遗忘问题,包括预训练的权重衰减,学习率衰减、对抗性微调和参数高效微调。然而,这种灾难性的遗忘现象尚未得到彻底研究,需要持续关注。下图中列出了一些代表性的持续学习方法。
解决“灾难性遗忘”的方案有哪些?
- 多任务学习(最常见), 把所有任务的训练数据同时放到一起,模型就可以针对多种任务进行联合优化。
- 根据新任务知识来扩充模型结构,保证旧的知识经验不被损害。
- 谷歌大脑所提出的“记忆碎片观察”方法正是对不同任务(场景)构建多个人工智能模型来进行学习。“模型扩充的方式从本质上并没有解决灾难性遗忘的问题,只是用多个模型来替代单个模型去学习多种任务,避免旧参数被覆盖。”
- 特殊神经网络结构
- Tree-CNN:一招解决深度学习中的「灾难性遗忘」,
树卷积神经网络,通过先将物体分为几个大类,然后再将各个大类依次进行划分、识别,就像树一样不断地开枝散叶,最终叶节点得到的类别就是我们所要识别的类。 - Self-refreshing Memory Approaches:代码见原文
- self-refreshing memory 自更新存储器来存储已经学到的知识,并利用该存储的知识来不断“提醒”学习器不要忘记之前的学到的知识,从而达到避免灾难性遗忘的目的
- 递归网络吸引子:利用不断递归的混响过程来生成虚拟的知识实体(用来提醒学习器,以防止遗忘)
- 知识蒸馏:2014年Hinton提出来蒸馏神经网络。 更多见原文
- 蒸馏神经网络的核心依据有两点:1) 训练完成的神经网络包含历史数据的输出分布信息; 2) 神经网络具有相似的输入会得到相似的输出的特点。
- 蒸馏法通过对共享参数进行微调来实现对新知识的学习。
- Transfer Techniques:
迁移学习见原文- 如何综合考虑旧参数与新数据得使得参数迁移到大家都满意的值
- Tree-CNN:一招解决深度学习中的「灾难性遗忘」,
长期记忆
大模型目前在表达能力等方面其实已经很接近甚至超过人类了,预训练所获得的记忆知识更是堪称海量。但是如何让大模型快速的记住一件新的事,仍旧是尚待解决的问题。
与聊天机器人进行长时间对话时,可能会出现对话逻辑断裂的情况,这是由于网络无法有效地处理过长的上下文信息所致。
- Transformer 中的“上下文大小”的固定参数限制网络在进行下一个词汇预测时所能考虑的文本范围,导致并不能同时处理无限数量的词汇和上下文信息
- GPT-3 上下文大小为2048。模型在预测下一个词时,只能考虑一定数量的词。这种限制可能导致长对话中聊天机器人随着对话的进行逐渐失去对话题的把握。

总结
思路
- 增大上下文窗口长度:只要上下文窗口长度够长,就可以把所有历史信息塞进去。
RAG(Retrieval Augmented Generation)- 外挂数据库,但是从数据库取数回来怎么输入到模型是有不同方案的,一般是配合向量数据库,大量文档存在向量数据库内,外部有query输入的时候,从向量数据库搜索获取相关的文档,与query一并合入prompt再输入给模型。
- 要做的事情很多:文本向量化的模型选择,文档搜索中的粗排与精排,乃至数据库的选择(其实不用向量数据库也可以)
- LongMem: 类似Memorizing Tranformers,数据库中存储与取回的数据是模型内部的kv向量,输入也不经过prompt(不占用token数了好耶),直接通过改造过的层与backbone模型的输出合并再接入到输出头上。缺点是定制层需要额外的训练。
- 外挂数据库,但是从数据库取数回来怎么输入到模型是有不同方案的,一般是配合向量数据库,大量文档存在向量数据库内,外部有query输入的时候,从向量数据库搜索获取相关的文档,与query一并合入prompt再输入给模型。
注
- RAG 把数据取出来重新加进prompt里,其实不像记忆,更像是人做的笔记
永久记忆的几种方法:
- 拓展Context长度: 最流行
- 大量的中间件或者技术,通过结合检索或者摘要的方式来缩短样本的长Context,如Unlimiformer
- 由于不是直接处理长Context,因此通常无法做精细的阅读理解,而且需要在训练阶段就考虑进去,而不是事后即插即用到已有的LLM模型中
- 不微调地扩展Context长度的方案
- 最早由Parallel Context Window(下面简称PCW),出自论文《Parallel Context Windows for Large Language Models》和《Structured Prompting: Scaling In-Context Learning to 1,000 Examples》
- 两篇论文是同一时期不同作者的工作,但所提的方法只有细微的差别
- PCW适用于Self Attention模型,主要修改包括Position Encoding和Attention Mask
- RoPE矩阵
- 构建一个位置相关的投影矩阵
- FlashAttention
- 哈希感知(hash-aware)技术,根据相似性将输入序列中的元素分配到不同的桶(bucket)中。模型只需要计算桶元素之间的注意力权重,而不是整个序列!
LongMem
【2023-7-21】LongMem: 大模型的长期记忆
LongMem 要解决两个问题
-
- 如何存储和召回数据: 存储与召回 Cache Memory Bank
- 类似 Memorizing Tranformers,存储用的也是faiss,但有些改进,存储的是最后M个token对应的SideNet最后一层Attention中的K,V向量(M大概在几k到几十k的范围)。
- 为了提高速度,没有采取在token级别上进行召回,而是把数个token作为一个chunk,做平均后作为key,在chunk层次上进行召回。
- 如何存储和召回数据: 存储与召回 Cache Memory Bank
-
- 如何将召回的数据混入到模型的输入:记忆混合 SideNet
- Memorizing Transformers 用一个改造过的KnnAttention层来混入召回的向量,LongMem 用一个SideNet来处理这个工作。在训练时可以锁定backbone,只训练这个SideNet
- 如何将召回的数据混入到模型的输入:记忆混合 SideNet
MemGPT
【2023-10-20】给LLM做手术!解决多轮遗忘,让他拥有永久记忆!人生伴侣可期?可在线+本地部署
MemGPT 方式 给LLM做一个外部手术
- 提出虚拟上下文管理,号称从传统操作系统中的分层内存系统中汲取灵感的技术!
- 该技术通过快速内存和慢速内存之间的数据移动提供大内存资源。使用这种技术,我们引入了MemGPT(Memory-GPT),这是一个智能管理不同内存层的系统,以便在LLM有限的上下文窗口内有效地提供扩展上下文,并利用中断来管理其自身和用户之间的控制流。
MemGPT 可以创建会话代理,通过与用户的长期交互来记忆、反映和动态消息。这相当于激活了LLM的“口袋”道具,让他可以装无限的东西,除了这个,他还可以加载文档,以及本地数据库!
完全可以当做一个中间组件拓展来使用
效果下滑
【2023-7-24】GPT-4 越来越笨?准确率从 97.6% 降至 2.4%
斯坦福大学和加州大学伯克利分校合作进行的一项 “How Is ChatGPT’s Behavior Changing Over Time?” 研究表明,随着时间的推移,GPT-4 的响应能力非但没有提高,反而随着语言模型的进一步更新而变得更糟糕。
研究小组评估了 2023 年 3 月和 2023 年 6 月版本的 GPT-3.5 和 GPT-4 在四个不同任务上的表现,分别为:解决数学问题、回答敏感 / 危险问题、代码生成以及视觉推理。
使用了一个包含 500 个问题的数据集评估模型,测试模型必须确定给定的整数是否是素数。结果表明,GPT-4(2023 年 3 月版)在识别质数方面表现非常出色,正确回答了其中的 488 个问题,准确率达 97.6%。但 GPT-4 (2023 年 6 月版)在这些问题上的表现却非常糟糕,只答对了 12 个问题,准确率仅为 2.4%。
而与之相反,GPT-3.5(2023 年 6 月版)在这项任务中的表现则要比 GPT-3.5(2023 年 3 月版)好得多。
LLM 优化方向
详见站内专题: LLM优化方向
操作系统
Karpathy将LLM描述为一种新型操作系统的内核进程。就像现代计算机具有 RAM 和文件访问权限一样,LLM 也有一个上下文窗口,可以加载从众多数据源检索到的信息。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
