幻觉 Hallucination

专题发布
资料
【2023-7-21】大模型幻觉问题调研-LLM Hallucination Survey
- Survey of Hallucination in Natural Language Generationarxiv.org/abs/2202.03629
- 仓库:Reading list of hallucination in LLMs.github.com/HillZhang1999/llm-hallucination-survey
【2024-4-24】 斯坦福AI(大模型)指数2024年度报告
- 大模型容易产生幻觉,尤其是法律、医学领域广泛存在。
- 当前研究主要集中在幻觉产生原因上,如何识别幻觉易发领域、评估幻觉程度的研究却很少。
- 2023年出来的数据集 HaluEval,3.5w条样本,专门用于检测大模型幻觉。
ChatGPT生成的内容中,高达19.5%的回复无法验证是否幻觉,涉及语言、气候和科技领域。
- 许多大模型都在幻觉问题上苦苦挣扎
- 幻觉发生率上:ChatGPT、Claude 处于第一梯队,较少发生
【2025-9-6】LLM 发展到今天, hallucination 已经不能准确的表达它错误生成的现象。
- 第一种, Hallucinate,幻觉。LLM 不确定真相,但回答的动机是诚实的,只是事实错误。
- 第二种,Lie,谎言。LLM知道真相,但要完成某种目的,故意误导,编造谎言。
- 第三种,Bullshit,胡扯。 LLM 根本不在乎真相是什么,对真相漠视,只是完成输出。
要理解这三种现象,看这三篇论文:
- 幻觉: Why Language Models Hallucinate
- 谎言: Can LLMs Lie? Investigation beyond Hallucination
- 胡扯: Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
【2025-9-16】万字解析从根本解决大模型幻觉问题,附企业级实践解决方案
什么是幻觉
生物幻觉
幻觉定义
【2024-6-24】What Is a Hallucination?
幻觉是感知到环境中不存在的、由大脑创造的事物。“幻觉”这个词在拉丁语中的意思是“精神上徘徊”,幻觉可以看到、听到、感觉到、闻到和尝到的非常生动的体验。
有的幻觉让人愉悦,但有的幻觉让人可怕、震惊,具有破坏性。

幻觉发生在具有精神疾病的人身上,也可能是某些药物、癫痫的副作用
:max_bytes(150000):strip_icc():format(webp)/GettyImages-1154176947-351df4104aad4d139cd3d74268738d93.jpg)
幻觉种类
幻觉可以出现在五中感官中,最常见的是听觉
- 幻听(Auditory hallucinations): 听到没有物理源头的声音,消极、积极或中立,从脚步声、敲击声到音乐
- 视觉幻觉(Visual hallucinations): 看到不真实的东西,如 人、图案、灯光等
- 触觉幻觉(Tactile hallucinations): 身体上的感觉、运动,如虫子在皮肤下爬行、别人的手放在身体上
- 嗅觉幻觉(Olfactory hallucinations): 闻到来源不明的气味儿, 如 难闻的味道,或愉悦的香水味儿
- 味觉幻觉(Gustatory hallucinations): 尝到不明的味道,如 癫痫病人常常尝到金属味儿
入睡时也可能出现幻觉,即 “催眠幻觉”, 30%的人经历过
幻觉原因三大类: 精神、医学和物质使用相关原因
- Psychiatric Causes 精神病: 最常见, 包括精神分裂症、双相情感障碍、重度抑郁症和痴呆。研究人员估计,60%至80%的精神分裂症患者会出现幻听
- Medical Causes : 高烧、偏头疼、癫痫、视觉听觉损失、耳鸣、脑肿瘤、肾功能衰竭、睡眠障碍等
- Substance Use-Related Causes 物质因素: 酒精、药物作用下发生幻觉,尤其是可卡因、LSD、PSP等物质,治疗身心状况的药物也会引起幻觉,如 治疗帕金森病、抑郁症、精神病和癫痫的药物。
幻觉检测
Diagnosis 诊断
- Blood tests 血液测试
- Electroencephalogram (EEG) 脑电图(EEG)检查癫痫发作或异常脑活动
- Magnetic resonance imaging (MRI) 磁共振成像 (MRI) 寻找脑部结构问题的证据,例如肿瘤或中风
幻觉治疗
Treatment 治疗
治疗计划包括药物、治疗和自助或其他支持方式的组合。
- 药物:抗精神病药物可以有效地治疗各种类型的幻觉
- 对于帕金森病患者,Nuplazid(匹莫范色林)是美国食品和药物管理局批准的治疗幻觉的药物
- 疗法:心理治疗(有时称为“谈话疗法”)对出现幻觉的患者有所帮助,训练有素的心理治疗师使用一系列技术和策略来帮助应对这种情况。
- 自助:锻炼、哼唱、听音乐、无视声音、阅读、与人交谈
LLM 幻觉
什么是幻觉
- the generated content that is nonsensical or unfaithful to the provided source content On faithfulness and factuality in abstractive summarization
- 模型生成的文本不遵循原文(Faithfulness)或者不符合事实(Factualness)
注:
Faithfulness(诚实): 是否遵循输入内容。Factualness(事实): 是否符合世界知识。
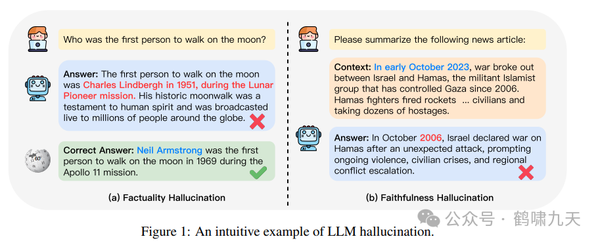
幻觉分为两类:内在幻觉 和 外在幻觉
内在幻觉: 是否遵循输入内容, 生成的输出与源内容相矛盾。外在幻觉: 是否符合世界知识, 生成的输出无法从源内容中验证。- 很多任务中这种幻觉可能有益,因为是模型从自己知识库里调用了知识,补充了源材料中没有的内容。
- 但是,对于另一些严格需要根据源材料生成的任务,这样的幻觉就是有害的,而且很难发现。
内在幻觉和外在幻觉都可能是模型根据相似性泛化出来的,可能对,可能错,还有可能根本没办法判断对错。
用大模型做对于幻觉的容忍度比较低的任务时,需要想办法做验证。
- 比如摘要和翻译这样的任务,就需要小心。
不同任务里幻觉定义可能出现差异:
- 数据源(source)不一致:
- 摘要的数据源是document
- data-to-text的数据源是data table
- 对话的数据源是对话历史
- 而开放域对话的数据源可以是世界知识。
- 容忍程度不一致:
- 在摘要、data-to-text任务中,非常看重response的Faithfulness,因此这些任务对幻觉的容忍程度很低;
- 而像开放域对话任务中,只需要response符合事实即可,容忍程度较高;
传统任务里幻觉大都是指的是 Faithfulness:
内在幻觉Intrinsic Hallucination(前后冲突): LMs在生成回复时,与输入信息产生了冲突,例如摘要问题里,abstract和document的信息不一致。外在幻觉Extrinsic Hallucination(无中生有): LMs在生成回复时,输出一些并没有体现在输入中的额外信息,比如邮箱地址、电话号码、住址,并且难以验证其真假。- 按照此定义,Extrinsic Hallucination有可能是真的信息,只是需要外部信息源进行认证
而LLMs应该考虑的幻觉是 Factualness:
- 因为应用LLM的形式是open-domain QA,而不是局限于特定任务,所以数据源可以看做任意的世界知识。LLMs如果生成了不在input source里的额外信息,但是符合事实的,这是有帮助的。
幻觉分类
【2023-9-24】腾讯、浙大,大模型幻觉分类,幻觉这个词在NLP领域,其实在大模型之前就存在,指生成无意义或不忠于所提供的内容的内容
2023年4月,OpenAI联合创始人兼研究科学家John Schulman在UC伯克利的演讲中,详细阐述了大模型难以攻克的难题。
- LLM黑盒内部隐藏着一个「知识图谱」。如果这个架构中没有的知识,仅通过SFT教大模型(即行为克隆)知识,实则在教它输出幻觉。
- 参考: baichuan如何解决幻觉问题
定义:
- 大模型生成与事实不符、虚构或误导性信息。
分类
- 事实冲突:称“亚马逊河位于非洲”(实际在南美洲)
- 无中生有:虚构房源楼层信息(如“4楼,共7层”)
- 指令误解:将翻译指令误答为事实提问
- 逻辑错误:解方程 2x+3=11 时得出错误结果 x=3
| 类型 | 特征 | 示例 |
|---|---|---|
| 事实冲突 | 与客观知识矛盾 | “亚马逊河位于非洲” |
| 无中生有 | 虚构无法验证的内容 | 补充未提供的房源楼层信息 |
| 指令误解 | 偏离用户意图 | 将翻译指令回答为事实陈述 |
| 逻辑错误 | 推理过程漏洞 | 解方程步骤正确但结果错误 |
事实型+忠实度
LLM幻觉分为两种:
- 事实型幻觉: 事实不一致、事实捏造;
- 可细分为 输入幻觉、上下文幻觉
- 忠实度幻觉: 指令-答案 不一致、文本不一致,以及逻辑不一致。

【2023-11-9】哈工大 A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
- 事实幻觉:指事实类错误,又根据生成的事实内容是否可以根据可靠来源进行验证,进一步分为两种主要类型:
- a. 事实不一致:是指大模型的输出包含基于现实世界信息的事实,但存在矛盾的情况。比如第一个登上月球的人,现实世界是存在这个事情,但是大模型把第一个登上月球的人名给错了。
- b.事实捏造:是指大模型的输出包含无法根据现实世界知识进行验证的事实的情况。比如独角兽的起源,现实世界根本没有独角兽。
- 忠实幻觉:指输出是否符合用户指令,又分了三类:
- a. 指令不一致:是指大模型的输出偏离用户的指令。
- b. 上下文不一致:是指大模型的输出与用户提供的上下文信息不相符的情况。
- c. 逻辑不一致:是指大模型输出表现出内部逻辑矛盾,通常在推理任务中可以看到。
内在幻觉+外在幻觉
内在型幻觉(Intrinsic Hallucinations)与外在型幻觉(Extrinsic Hallucinations)
内在型幻觉(Intrinsic Hallucinations)
内在型幻觉指的是模型自身的生成过程中出现的问题,通常是由于模型的训练数据或其内部处理机制引起的。这些幻觉是模型内部逻辑和知识的错误表现。
- 逻辑幻觉(Logical Hallucinations)
- 例子:时间悖论、错误推理
- 描述:模型在逻辑推理或计算时出现的错误。
- 时间幻觉(Temporal Hallucinations)
- 例子:过时信息、时间错乱
- 描述:模型处理时间信息时出现的错误。
- 上下文幻觉(Contextual Hallucinations)
- 例子:角色混淆、情境误解
- 描述:模型对当前对话或问题的情境理解错误,导致生成不连贯或不相关的内容。
外在型幻觉(Extrinsic Hallucinations)
-
外在型幻觉指的是模型在生成内容时提供了与现实世界不符的信息,这些问题通常与模型的训练数据不完整或过时有关。
- 事实幻觉(Factual Hallucinations)
- 例子:虚构事实、错误引用
- 描述:模型生成的内容包含与现实世界事实不符的信息。
- 引文幻觉(Citation Hallucinations)
- 例子:伪造引文、错误文献
- 描述:模型生成的内容中包含虚假的引用或不存在的文献。
- 身份幻觉(Identity Hallucinations)
- 例子:错误身份、错误背景
- 描述:模型对个人或实体身份的错误描述。
- 功能幻觉(Functional Hallucinations)
- 例子:错误操作、误导步骤
- 描述:模型错误地描述了某个功能或过程。
常见类型
LLMs幻觉分为三种:输入冲突幻觉、上下文冲突幻觉和事实冲突幻觉。
- 输入冲突幻觉:生成内容与用户输入不符;
- 上下文冲突幻觉:生成内容较长或多轮会话时,与之前生成信息相矛盾;
- 事实冲突幻觉:是指生成的内容与已知的世界知识不符。

多模态幻觉
注意
- 幻觉不止出现于文本,还会再多模态场景中出现
- 如:图文理解、图像生成
| 案例 | 方法 | 问题 | 图例 |
|---|---|---|---|
| 图文理解 | 图片里并没有人 |  |
|
| 图像生成 | 扩散模型(Stable Diffusion)典型案例: 正向提示词 Prompt:a super beautiful chinese girl showing two hands,Open palms in a welcome sign,smiling,wearing pink dress,standing in the street,front view,upper body |
挺漂亮的小姐姐,可惜人有6个手指、局部残缺扭曲 |  |
幻觉原因
学术研究
阶段 核心问题 - 预训练: 数据噪声、领域知识稀疏、事实性验证能力缺失 - 有监督微调(SFT): 标注错误、过拟合导致对错误知识过度自信 - RLHF对齐: 奖励设计缺陷使模型为迎合目标牺牲真实性 - 推理部署: Token级生成无法修正早期错误;随机采样增加风险
【2025-7-10】斯坦福 计算复杂度
【2025-7-10】斯坦福最新论文,大模型幻觉根本原因:计算复杂度。
- 《Hallucination Stations On Some Basic Limitations of Transformer-Based Language Models》
- 任何计算任务的解决都无法快于其固有的计算复杂度。
通过比较任务的内在复杂度与LLM的计算能力上限,可预判LLM在处理该任务时是否会“碰壁”,从而产生幻觉。
【2025-9-6】OpenAI 奖励猜测
【2025-9-6】OpenAI 论文首次系统揭示:
- 语言模型出现幻觉的根本原因:训练和评估过程奖励猜测,而不是承认不确定性
- 论文 Why Language Models Hallucinate
- 主页 Why Language Models Hallucinate
- 解读 OpenAI发长篇论文:大模型幻觉的原因找到了
Hallucination(幻觉)——语言模型生成看起来合理,实则错误离谱。
案例
- “Adam Tauman Kalai 生日是哪天?知道的话直接给 DD-MM。”
- OpenAI(2025a)三次回答分别是 03-07、15-06、01-01,没一次对
原因:
- 模型被直接奖励去“提供具体答案”而不是“诚实地放弃或表达不确定”
- 整个生态对“敢于猜、敢于给具体答案”的模型给予更高的奖励,从而把幻觉行为“制度化”。这解释了为什么即使在用了 RLHF、DPO 等后训练技巧之后,幻觉仍然顽固存在。
解决:引入显式置信度目标和对不确定的正当奖励
其中置信度目标:若你在低于阈值时冒险作答,期望得分会下降;只有在确信超过阈值时才值得冒险答题。 在不确定时更倾向“说不知道/请求澄清/少说细节”,在确定时才给出具体答案 –> 让 “合理的不确定性表达”(比如 “不知道”“我不确定,但根据现有信息推测…”)的分数,不低于 “有幻觉的答案”。
解决:引入显式的置信度目标和对不确定的正当奖励 其中置信度目标:若你在低于阈值时冒险作答,期望得分会下降;只有在确信超过阈值时才值得冒险答题。 在不确定时更倾向“说不知道/请求澄清/少说细节”,在确定时才给出具体答案 –> 让 “合理的不确定性表达”(比如 “不知道”“我不确定,但根据现有信息推测…”)的分数,不低于 “有幻觉的答案”。
(1) 预训练阶段就埋下幻觉种子
- 统计必然性: 把生成问题等价到二分类“Is-It-Valid?”——只要分类器会犯错,生成就会出错(定理 1)。图片
- 数据稀缺性: 训练语料里只出现一次的“冷知识”(singleton)注定会被模型记错,错误率 ≥ singleton 占比(定理 2)。
- 模型表达能力不足: 如果模型族本身就无法学到规律(如 trigram 数不对字母),幻觉率下限直接拉满(定理 3)。
| 阶段 | 核心发现 | 类比 |
|---|---|---|
| 预训练 | 就算训练数据100%正确,密度估计目标也会迫使模型生成错误 | 老师只教你对的,但期末要你把不会的也填满 |
| 后训练 | 二元评分(对1分/错0分)让模型不敢”交白卷” | 选择题不会也得蒙,空着直接0分 |
(2) 后训练阶段“考试机制”强化幻觉
10个主流评测做了元评测,发现清一色惩罚不确定性:
(3) 解法
解法:把”交白卷”变成可选项
不需要新benchmark,只要改评分规则:
- 1 明示信心阈值
- 在prompt里直接写:”只有在你
置信度>t时才回答;答错扣t/(1-t)分,IDK得0分。”
- 在prompt里直接写:”只有在你
- 2 让”弃权”成为最优策略
- 当模型真实
置信度<t时,说”我不知道”的期望得分最高,说谎反而吃亏。
- 当模型真实
【2025-12-2】清华:H-Neurons 过度顺从
【2025-12-26】别再怪SFT了!清华揪出0.1%幻觉神经元:大模型胡编的尽头,其实是过度顺从
学术界和工业界尝试了各种宏观层面手段:从数据清洗、后训练对齐,到外挂知识库(RAG)。
然而,这些方法大多将模型视为黑盒,试图从外部矫正其行为。
但是,模型内部究竟发生了什么?幻觉在模型内部是如何产生的?对于幻觉,是否存在可被精确定位、分析乃至干预的内部结构?
【2025-12-2】清华大学 THUNLP、清华大学新闻与传播学院、OpenBMB 以及面壁智能的联合团队从微观神经元视角出发,系统研究了 LLM 中的幻觉机制。
主要贡献如下:
- 在神经元层面验证了幻觉的可定位性,并揭示了幻觉背后的行为机制。
- 识别出极其稀疏(<0.1%)的一部分与幻觉高度相关的神经元,在数量上极其稀少,却能够有效地区分幻觉与非幻觉输出。
- 通过对 H-Neurons 进行推理阶段的扰动,团队发现这些神经元并非简单地“编码错误事实”,而是在驱动模型的顺从性,由此,幻觉被自然地统一为“过度顺从”的具体表现,而非孤立的异常行为。
- 追溯了幻觉相关神经元的训练起源,团队发现这些神经元的核心作用在预训练阶段已基本成型,而非单纯由后训练引入。
模型中确实存在一类与幻觉高度相关的神经元,它们极其稀疏,通常不足全部神经元的 0.1%,但对幻觉的预测能力却十分显著。
幻觉在模型内部是有清晰、可定位的结构基础。团队进一步在稀疏预测模型中,保留那些贡献与幻觉产生正相关的神经元,即 H-Neurons。
不仅找到了与幻觉相关的极少数神经元(H-Neurons),更揭示了令人意外的真相:
幻觉并非无序的生成错误,而是模型为了顺从你进行的“过度配合”。
幻觉本质:
- 大模型为满足用户需求“过度顺从”的表现
团队在不重新训练模型、不修改模型参数结构的前提下对 H-Neurons 进行了“神经外科手术”式的扰动实验:在推理阶段适度放大或抑制其输出,并观察模型整体行为的变化,实验结果揭示了幻觉背后的真正机制:过度顺从(Over-Compliance)。
幻觉并不是一种孤立的异常行为,而是过度顺从的具体体现,当这种倾向被过度激活时,模型更倾向于满足用户输入,而非在信息有误或问题本身不合理时指出问题。
幻觉溯源:源于预训练,而非后训练
H-Neurons 在预训练阶段已基本形成,幻觉问题并非仅靠后续对齐或指令微调即可彻底解决,而与 next-token prediction 这一基础训练目标内在相关。
为什么会有幻觉?
【2024-7-14】 OpenAI Lilian Weng万字长文解读LLM幻觉:从理解到克服,OpenAI 翁丽莲
- (1)预训练
- 预训练数据信息过时(知识过时)、缺失(知识边界,垂类知识不全)或不正确(知识偏差)
- 知识过时:2023年,考拉大概有多少?—— 5k-8k(正确答案 86k-176k)
- 知识边界:考拉的基因有多少?
- 知识偏差:语料包含实事偏差信息
- 模型记忆方式是简单地最大化对数似然,可能以错误方式记忆信息
- 预训练数据信息过时(知识过时)、缺失(知识边界,垂类知识不全)或不正确(知识偏差)
- (2)SFT/RLHF
- 监督式微调 和 RLHF 等技术对预训练 LLM 进行微调。微调阶段,难免需要引入新知识。
- 小规模微调能否让模型学到新知识?
- Gekhman et al. 的论文《Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?》
- ① 当微调样本中包含新知识时,LLM 学习速度会更慢一些(相比于微调样本中的知识与模型已有知识一致的情况);
- ② 模型一旦学习了带有新知识的样本,那么模型会更倾向于产生
幻觉。
【2024-11-24】详见:浙大《大模型基础》
模型自身偏差原因
- (1)知识长尾:相关信息出现频率低,未充分学习
- (2)曝光偏差:推理与训练存在差异,导致推理偏差
- (3)对齐不当:RLHF阶段,标注数据数据引入不良偏好
- (4)解码偏差:解码策略随机因素可能影响输出准确性
【2023-9-24】腾讯、浙大,大模型幻觉分类,幻觉这个词在NLP领域,其实在大模型之前就存在,指生成无意义或不忠于所提供的内容的内容
四点:
- 训练时,缺乏相关知识/吸收错误知识, 导致产生幻觉。
- 大模型高估了自己的能力,对事实知识边界的理解不精确,过度自信,误导大语言模型编造答案。
- 对齐过程(SFT,RLHF)可能会误导大语言模型产生幻觉,当大模型在预训练阶段没有获得前提知识而进行指令训练时,这实际上是一个错位过程,会导致大语言模型产生幻觉。
- 大模型生成策略可能导致幻觉,比如top-p、top-k引入的随机性也可能是幻觉的潜在来源。
【2024-1-15】
- 哈尔滨工业大学和华为的研究团队,长达49页,对有关LLM幻觉问题的最新进展来了一个全面而深入的概述
- 腾讯AI实验室
产生幻觉主要原因:
- 预训练数据收集:
- 知识GAP
- 大模型优化过程
LLM产生幻觉的根本原因分为三个关键方面:数据、训练和推理。
- 数据
- 预训练数据集不完整、过期
- LLM捕捉虚假相关性,长尾、复杂推理场景推理困难,加剧幻觉
- 训练
- 预训练阶段:LLMs学习通用表征并捕捉广泛的知识,通常采用基于transformer架构,在庞大的语料库中进行因果语言建模。但是,固有架构设计和研究人员所采用的特定训练策略,可能会产生与幻觉相关的问题。
- 对齐阶段:监督微调和从人类反馈中强化学习(RLHF)。虽然对齐能显著提高 LLM 响应的质量,但也会带来产生幻觉的风险,主要分为两方面:能力不对齐(Capability Misalignment)和信念不对齐(Belief Misalignment)
- 推理
- 解码策略固有的随机性(Inherent Sampling Randomness):比如采样生成策略(如top-p和top-k)引入的随机性可能导致幻觉。
- 不完善的解码表示(Imperfect Decoding Representation):在解码阶段,LLM 使用顶层表示法预测下一个标记。然而,顶层表示法也有其局限性,主要表现在两个方面:上下文关注不足(Insufficient Context Attention)和Softmax瓶颈(Softmax Bottleneck)。
幻觉原因
- 数据质量不够好。Garbage in, Garbage out的基本原理对于大模型仍然是适用的。
- 启发式数据集
- 重复内容
- 内在差异
- 训练和推理原因。
- 不完善的表示学习
- 错误的解码
- 曝光偏差
- 参数化知识偏差
图解
导致幻觉有若干因素,其中包括训练数据有偏见或训练数据不足、训练数据过度拟合、上下文理解有限、领域知识缺乏、对抗攻击和模型架构。
- 训练数据有偏见或训练数据不足:AI模型的好坏取决于训练所使用的数据。如果训练数据有偏见、不完整或不足,AI模型可能会基于其对所访问数据的有限理解而产生幻觉。在使用开放的互联网数据训练大型语言模型的情况下,这一点尤其令人担忧,因为互联网中有偏见和错误的信息泛滥。
- 训练数据收集过程中,众包/爬虫检索的数据可能包含虚假信息,从而让模型记忆了错误的知识;
- 过多重复信息也可能导致模型的知识记忆出现bias,从而导致幻觉
- 潜在的研究方向:
- Building High-quality Training Corpus is essential.
- Data verification/ Data filter/ Data selection.
- 过度拟合:当AI模型与训练数据过度拟合时,它可能会开始生成对训练数据过于具体的输出,不能很好地推广到新数据。这可能导致模型生成幻觉或不相关的输出。
- 上下文理解缺乏:缺乏上下文理解的AI模型可能会产生脱离上下文或不相关的输出。这可能导致模型生成幻觉或荒谬的输出。
- 领域知识有限:为特定领域或任务设计的AI模型在接受其领域或任务之外的输入时可能会产生幻觉。这是因为它们可能缺乏生成相关输出所需的知识或背景。当模型对不同语言的理解有限时,就会出现这种情况。尽管一个模型可以在多种语言的大量词汇上进行训练,但它可能缺乏文化背景、历史和细微差别,无法正确地将概念串在一起。
- 对抗攻击:不同于组建一支团队“攻破”模型以改进模型的红蓝对抗,AI模型也易受对抗攻击。当恶意攻击者故意操纵模型的输入时,可能会导致它生成不正确或恶意的输出。
- 模型架构:即使有了高质量训练数据,LLMs仍然可能表现出幻觉现象。AI模型架构会影响幻觉产生的容易程度。由于复杂性增加,具有更多分层或更多参数的模型可能更容易产生幻觉。
- 模型结构:如果是较弱的backbone(比如RNN)可能导致比较严重的幻觉问题,但在LLMs时代应该不太可能存在这一问题;
- 解码算法:如果用不确定性较高的采样算法(e.g.,top-p)会诱导LMs出现更严重的幻觉问题。甚至可以故意在解码算法中加入一些随机性,进一步让LMs胡编乱造(可以用该方法生成一些negative samples)
- 暴露偏差:训练和测试阶段不匹配的exposure bias问题可能导致LLMs出现幻觉,特别是生成long-form response的时候。
- 2020, Chaojun Wang and Rico Sennrich. On exposure bias, hallucination and domain shift in neural machine translation
- 参数知识:LMs在预训练阶段记忆的错误的知识,将会严重导致幻觉问题。
(1)数据层面
在数据工程层面可能出现一些问题,导致幻觉问题:
- 训练数据收集过程中,众包/爬虫检索的数据可能包含虚假信息,从而让模型记忆了错误的知识;
- 过多的重复信息也可能导致模型的知识记忆出现bias,从而导致幻觉:
- Deduplicating training data makes language models better
- 潜在的研究方向:
- Building High-quality Training Corpus is essential.
- Data verification/ Data filter/ Data selection.
(2)模型层面
即使有了高质量训练数据,LLMs仍然可能表现出幻觉现象。
- 模型结构:如果是较弱的backbone(比如RNN)可能导致比较严重的幻觉问题,但在LLMs时代应该不太可能存在这一问题;
- 解码算法:研究表明,如果使用不确定性较高的采样算法(e.g.,top-p)会诱导LMs出现更严重的幻觉问题。甚至可以故意在解码算法中加入一些随机性,进一步让LMs胡编乱造(可以用该方法生成一些negative samples)
- Factuality enhanced language models for open-ended text generation
- 暴露偏差:训练和测试阶段不匹配的exposure bias问题可能导致LLMs出现幻觉,特别是生成long-form response的时候。
- On exposure bias, hallucination and domain shift in neural machine translation
- 参数知识:LMs在预训练阶段记忆的错误的知识,将会严重导致幻觉问题。
- Entitybased knowledge conflicts in question answering
幻觉检测
评估指标
两种评估幻觉的指标:幻觉命名实体(NE)错误率、蕴含比率(Entailment ratios)。
较高的 NE错误率 和 较低的蕴含比率表明事实性较高,研究发现这两个指标都与人类注释相关,较大模型在此基准上表现更佳。
幻觉评估
- 现有的传统幻觉评估指标和人类结果的相关性较低,同时大都是task-specific的。
- 2021, Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics
幻觉评估:
- Chatgpt倾向于在回复中生成无法被验证的内容(幻觉),占比 约11.4%
- 当前强大的LLM,如Chatgpt,都很难精准检测出文本中出现的幻觉问题
- 通过提供外部知识和增加推理步数,能够提升LLM检测幻觉的能力
检测方法
先验检测
检索增强生成(RAG) 原理:
- 将“闭卷考试”转为“开卷考试”,通过外部知识库(数据库/文档)提供实时依据。
价值:
- 突破模型参数化知识边界
- 提升时效性与领域适应性(如企业内部政策库)
后验幻觉检测
(1)白盒方案(需模型访问权限)
- 不确定性度量:提取生成内容关键概念,计算token概率(概率越低风险越高) - 注意力机制分析: Lookback Ratio=对新生成内容的注意力对上下文的注意力 比值越低表明幻觉风险越高
- 隐藏状态分析:正确内容对应低熵值激活模式,错误内容呈现高熵值模糊模式
(2)黑盒方案(仅API调用)
采样一致性检测:同一问题多次生成,输出不一致则标识幻觉风险
规则引擎:
- ROUGE/BLEU指标对比生成内容与知识源重叠度
- 命名实体验证(未出现在知识源中的实体视为风险) 工具增强验证:
- 拆解回答为原子陈述
- 调用搜索引擎/知识库验证
- 集成计算器、代码执行器等工具实现多模态校验[12-14]
专家模型检测:
- 训练AlignScore模型评估生成内容与知识源对齐度
- 幻觉批判模型(Critique Model)提供可解释性证据
【2024-7-14】 OpenAI Lilian Weng万字长文解读LLM幻觉:从理解到克服,OpenAI 翁丽莲
幻觉检测
检索增强式评估: 为了量化模型幻觉- Lee, et al. 的论文《Factuality Enhanced Language Models for Open-Ended Text Generation》引入新的基准数据集 FactualityPrompt,其中包含事实性和非事实性的 prompt,而其检验事实性的基础是将维基百科文档或句子用作知识库。
- 评估指标:幻觉命名实体(NE)误差 + 蕴涵率(Entailment ratio)
- 如果命名实体误差较高且蕴涵率较低,则说明模型的事实性较高
- Min et al. (2023) 论文《FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation》中提出的 FActScore(用原子分数衡量的事实精度),将形式较长的生成结果分解成多个原子事实,并且根据维基百科这样的知识库分别验证它们。然后,度量模型的每个生成结果中有知识源支撑的句子的比例(精度),而 FActScore 就是在一系列 prompt 上的生成结果的平均精度。
- Wei et al. (2024) 的论文《Long-form factuality in large language models》提出了一种用于检验 LLM 的长篇事实性的评估方法:Search-Augmented Factuality Evaluator(SAFE),即搜索增强式事实性评估器。
- Chern et al. (2023) 在论文《FacTool: Factuality Detection in Generative AI — A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios》中提出的 FacTool 采用了一种标准的事实检验流程。其设计目标是在多种任务上检测事实性错误,包括基于知识的问答、代码生成、数学问题求解(生成测试用例而不是陈述)、科学文献总结。
- Lee, et al. 的论文《Factuality Enhanced Language Models for Open-Ended Text Generation》引入新的基准数据集 FactualityPrompt,其中包含事实性和非事实性的 prompt,而其检验事实性的基础是将维基百科文档或句子用作知识库。
- 基于
采样检测- Manakul et al. (2023) 在论文《SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models》中提出的 SelfCheckGPT 采用的方法是根据一个黑箱 LLM 生成的多个样本对事实性错误进行一致性检查。考虑到灰盒事实检查度量需要访问 LLM 的 token 级对数概率,SelfCheckGPT 只需要不依赖外部知识库的样本,因此黑箱访问足矣,无需外部知识库。
- 对未知知识进行校准
- Yin et al. (2023) 提出的 SelfAware 基于自我知识(self-knowledge)这一概念,也就是语言模型是否知道它们知不知道。
- 间接查询
- Agrawal et al.(2023) 在论文《Do Language Models Know When They’re Hallucinating References?》中研究了 LLM 生成结果中出现幻觉参考文献的问题,比如编造出不存在的书籍、文章和论文标题。
【2024-1-15】一份全面的「大模型幻觉」综述
事实性幻觉的检测方法通常分为 “检索外部事实“(Retrieve External Facts)和 “不确定性估计“(Uncertainty Estimation)。
- 检索外部事实:为了有效地指出 LLM 输出中的事实不准确之处,一种直观的策略是将模型生成的内容与可靠的知识来源进行比较,如下图 3 所示。
- 不确定性估计大致可分为两种:基于内部状态和 LLM 行为。前者的前提是可以访问模型的内部状态,而后者则适用于更受限制的环境,仅利用模型的可观测行为来推断其潜在的不确定性。
忠实性幻觉的检测方法:
- 主要侧重于确保生成的内容与给定上下文保持一致,从而避免无关或矛盾输出的潜在隐患。
LLM 生成中检测不忠实的方法。
- 基于事实度量:通过检测生成内容与源内容之间的事实重叠度来评估忠实度。
- 基于分类器的度量:利用经过训练的分类器来区分生成内容与源内容之间的关联程度。
- 基于QA的度量方法:利用问题解答系统来验证源内容与生成内容之间的信息一致性。
- 不确定性估计:通过测量模型对其生成输出的置信度来评估忠实度。
- 基于prompt的度量方法:让LLM充当评估者,通过特定的prompt策略来评估生成内容的忠实度。
(1)Reference-based
Reference-based的指标有两类:
- 基于 Source Information 和 Target Reference:利用一些统计学指标,比如ROUGE、BLEU来评估输出结果和Source/Target信息的重叠度。
- 基于 Source Information:NLG任务里Target输出往往是多种多样的,因此许多工作只基于Source信息进行幻觉的评估。比如Knowledge F1。
注:
基于Reference的评价指标只能评价
Faithfulness,而无法评价Factualness,因此不适用于LLMs。
(2)Reference-Free
方法
- (1) 基于
IE:将知识限定于可以用三元组形式表示的关系和事件,基于额外的IE模型进行抽取,接着使用额外模型进行验证。缺点:- 可能存在IE模型的错误传播问题。
- 知识被限定在三元组形式。
- (2) 基于
QA:- 第一步先基于LM生成的回复,使用一个QG(question generation)模型生成一系列QA pairs;
- 第二步给定Source Information,让QA模型对上一步生成的Question进行回复;
- 第三步则是通过对比第一步的answers和第二步的answers,计算匹配指标,衡量模型的幻觉问题;
- 缺点
- 这种方法同样存在QA/QG模型的错误传播问题。
- 难以评估
Factualness,因为第二步里面,Source Information不可能包含全部的世界知识,因此对于一些问题难以生成可靠的回复。 - 2020, ACL, FEQA: A question answering evaluation framework for faithfulness assessment in abstractive summarization
- (3) 基于
NLI:基于NLI的方法通过利用NLI模型评估是否Source Information可以蕴含Generated Text,从而评估是否出现了幻觉现象。- 缺点
- Off-the-shelf NLI模型用于核查事实效果不是很好;
- 无法评估需要世界知识的幻觉问题:仅能依赖于Source进行核查;
- 都是sentence-level的,无法支撑更细粒度的幻觉检查;
- 幻觉问题和蕴含问题实际并不等价:
- 例子:Putin is president. -> Putin is U.S. president (可以蕴含,但是是幻觉)
- 缺点
- (4) 基于
Factualness Classification Metric:标注/构造一批和幻觉/事实有关的数据,训练检测模型,利用该模型评估新生成文本的幻觉/事实问题。 - (5) 人工评估:目前为止最靠谱的
- (6) 依靠LLM 打分
- 比如GPT4,但是GPT4也存在着严重的幻觉问题,除非retrival-augment,但是检索回来的信息也有可能是错误
- 自我纠错方法真的有用吗?
- Deepmind发布的论文:LARGE LANGUAGE MODELS CANNOT SELF-CORRECT REASONING YET(大语言模型还不能在推理上自我纠错)
- 实验结果:让LLM(GPT-4和Llama-2)多次纠错后,准确率都下滑,次数越多,下滑越厉害。GPT-4比Llama-2降幅小。
- GPT-4在没有外部信息指导情况下,纠错能力堪忧。通过纠错实现内在幻觉矫正的路子行不通
提到:LLMs并不能判断自己的推理结果是否正确,如果强行让其纠错,反而会引导模型选择其他选项,降低准确率。
【2024-12-10】 亚马逊 RefChecker
Definition of Hallucinations.

【2024-12-10】开源模型“幻觉”更严重,这是三元组粒度的幻觉检测套件
亚马逊上海人工智能研究院推出细粒度大模型幻觉检测工具 BSChecker,包含如下重要特性:
- 细粒度幻觉检测框架,对大模型输出文本进行三元组粒度的幻觉检测。
- 幻觉检测基准测试集,包含三种任务场景,满足用户的不同需求。
- 两个基准测试排行榜,目前涵盖15个主流大模型的幻觉检测结果。
另外,BSChecker 作者们在Gemini推出后也很快做了自动检测的幻觉测试。
BSChecker 目前收录了 2100 个经过细粒度人工标注的大模型输出文本,涵盖了 7 个主流大模型,如 GPT-4、Claude 2、LLaMA 2 等
- GPT-4 比 GPT-3.5 更好,而 GPT-3.5 又远远优于 InstructGPT
BSChecker 工作流程
BSChecker 具有模块化的工作流程,分为三个可配置的模块:声明抽取器 E,幻觉检测器 C,以及聚合规则 τ。这三个模块互相解耦合,可以通过增强其中的部分模块对整个框架进行扩展和改进。
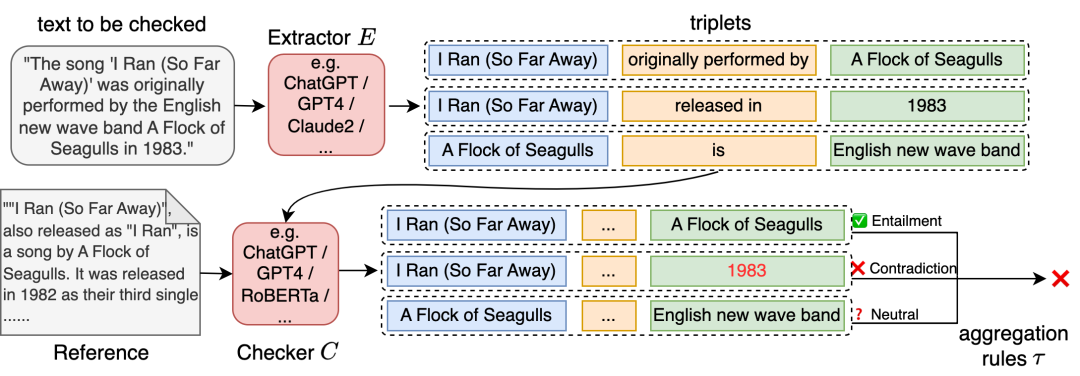
两个主要模块是:
- 基于大模型的声明抽取器:作者发现大模型很擅长提取声明三元组,在当前版本中,他们使用 GPT-4 和 Claude 2 作为声明抽取器。
- 基于人工或模型的幻觉检测器:对于给定的声明三元组和参考文本,标注者可以相应地进行标注,如下图所示。该标注工具也将很快发布。基于模型的幻觉检测器将在后续的自动评估排行榜章节中介绍。
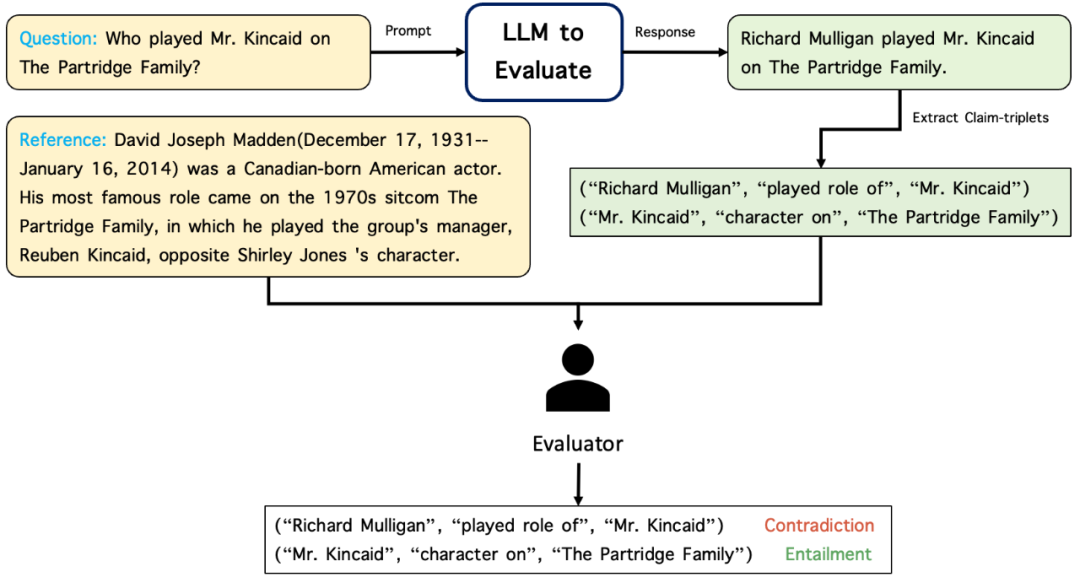
幻觉检测框架示意图
- 项目地址: RefChecker for Fine-grained Hallucination Detection
- 排行榜地址:BSChecker-Leaderboard, 已经404

【2025-3-5】LettuceDetect
LettuceDetect 解决了现有幻觉检测模型的两个关键限制:
- 传统基于编码器方法的上下文窗口限制
- 基于 LLM 方法的计算效率低下
【2025-3-5】LettuceDetect:一款高效的RAG系统幻觉检测工具
LettuceDetect 是一个轻量级、高效的RAG幻觉检测工具
通过将生成的答案与提供的上下文进行比较,识别答案中不受支持的部分。
原理
该工具受Luna启发
- RAGTruth 数据集上进行了训练和评估
- 利用 ModernBERT 进行长上下文处理,非常适合需要广泛上下文窗口的任务。
亮点
- 🔹 Token 级精确度:精确检测幻觉内容的具体范围
- ⚡ 优化推理性能:更小的模型尺寸,更快的推理速度
- 🧠 4K 上下文窗口:基于 ModernBERT 处理长文本
- ⚖️ MIT 许可:模型和代码自由使用
- 🤖 Hugging Face 集成:一行代码加载模型
- 📦 简便 Python API:可通过 pip 安装,并用少量代码集成到 RAG 系统中
lettucedetect-large-v1, achieves an overall F1 score of 79.22%, outperforming prompt-based methods like GPT-4 (63.4%) and encoder-based models like Luna (65.4%). It also surpasses fine-tuned LLAMA-2-13B (78.7%) (presented in RAGTruth) and is competitive with the SOTA fine-tuned LLAMA-3-8B (83.9%)
支持微调
代码调用
from lettucedetect.models.inference import HallucinationDetector
# For a transformer-based approach:
detector = HallucinationDetector(
method="transformer", model_path="KRLabsOrg/lettucedect-base-modernbert-en-v1"
)
contexts = ["France is a country in Europe. The capital of France is Paris. The population of France is 67 million.",]
question = "What is the capital of France? What is the population of France?"
answer = "The capital of France is Paris. The population of France is 69 million."
# Get span-level predictions indicating which parts of the answer are considered hallucinated.
predictions = detector.predict(context=contexts, question=question, answer=answer, output_format="spans")
print("Predictions:", predictions)
# Predictions: [{'start': 31, 'end': 71, 'confidence': 0.9944414496421814, 'text': ' The population of France is 69 million.'}]
幻觉缓解
如何缓解幻觉?
- 目前幻觉问题没有被解决掉。
【2025-6-7】人大高瓴学院 窦志成
- 幻觉问题不可避免,只要还是自回归模式
- 幻觉率与训练数据中出现一次占比正相关
总结
如何缓解大模型幻觉问题?
- 预训练阶段缓解: 清洗预训练语料,尽可能减少无法验证和不可靠的数据。可以看下答主的另一篇回答,怎么清洗预训练语料
- SFT阶段缓解: 清洗SFT的训练语料,但SFT阶段所需的语料相对于预训练阶段是少得多的,所以可以人工一条条的check。
- RLHF阶段解决,还是标数据,这一阶段主要是利用强化学习引导大模型探索知识边界,使其能够拒绝回答超出其能力范围的问题,而不是编造不真实的回答。
- 推理阶段缓解
- a. 设计解码策略,比如贪婪解码和beam search解码,关于解码部分可以看这篇文章,详细的介绍了目前大模型的解码策略。
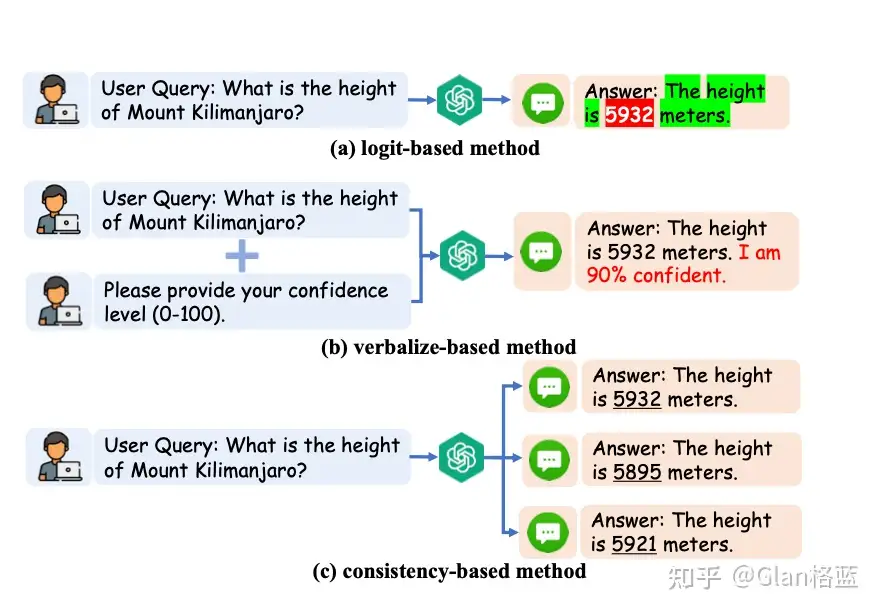
- LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现 - b. 使用外部知识,如检索增强生成RAG。如下图两种使用外部知识 - c. 利用大模型的不确定性,比如基于logit方法中,使用红色/绿色背景来区分具有低/高生成概率的token;比如直接要求大语言模型表达不确定性,使用以下提示:“请回答并提供你的置信度得分(从0到100);再比如使用基于一致性的方法,因为当大语言模型犹豫不决且存在幻觉事实时,它们很可能对同一问题提供逻辑上不一致的答案
使用外部知识的两种方法
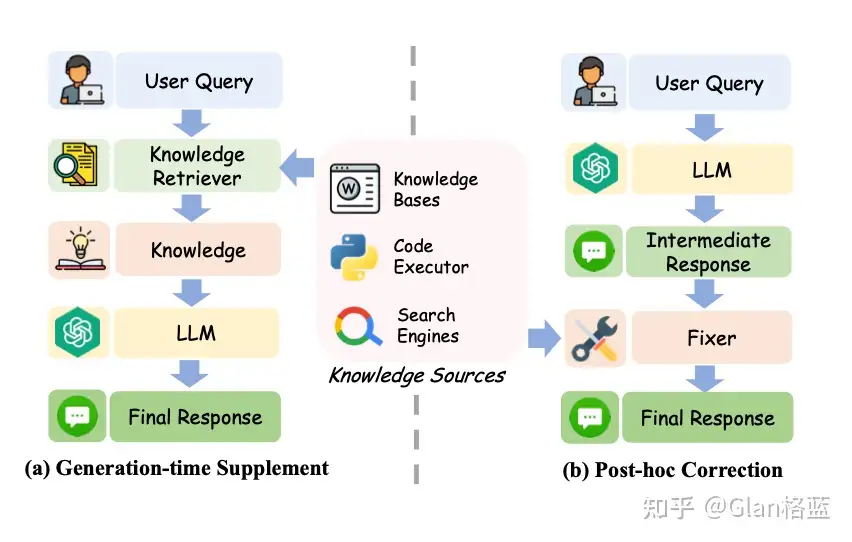
利用LLM的不确定性
但是有一些思路可以缓解幻觉的产生。
- 强化学习
- 用openai的服务时可以发现,其在服务端还有一个后处理的服务,如果生成了不合适的内容,就会被这个监控服务给处理掉。
(1)基于数据
- 人工标注
- 训练数据:LLM上不可行,只适用于task-specific的幻觉问题
- 评测数据:构建细粒度的幻觉评估benchmark用于分析幻觉的严重程度和原因
- 2021, ACL, GO FIGURE: A meta evaluation of factuality in summarization
- 2021, EMNLP, Q2: Evaluating factual consistency in knowledge-grounded dialogues via question generation and question answering
- 自动筛选
- 利用模型筛选出可能导致幻觉的数据并剔除;
- 预训练时给更faithful的数据加权(wiki vs. fake news),或者不使用可靠来源的数据(比如只选用经过人工审查的数据源,如wiki或者教科书,预训练)
- Vectara 是一个专注于对话体验的平台,它提供了强大的检索、摘要和生成功能,以及简单易用的开发者接口。Vectara平台使用了一种叫做基于事实的生成(Grounded Generation)的方法,在生成文本之前和之后都进行事实检索和验证,确保生成内容是有意义且忠实于源内容的
-

- Extract: Vectara automatically extracts text from PDF and Office to JSON, HTML, XML, CommonMark, and many more.
- Encode: Encode at scale with cutting edge zero-shot models using deep neural networks optimized for language understanding.
- Index: Segment data into any number of indexes storing vector encodings optimized for low latency and high recall.
- Retrieve: Recall candidate results from millions of documents using cutting-edge, zero-shot neural network models.
- Rerank: Increase the precision of retrieved results with cross-attentional neural networks to merge and reorder results.
- Summarize: Optionally generate a natural language summary of the top results for Q&A or conversational AI experiences.
基于事实的生成方法包括以下几个步骤:
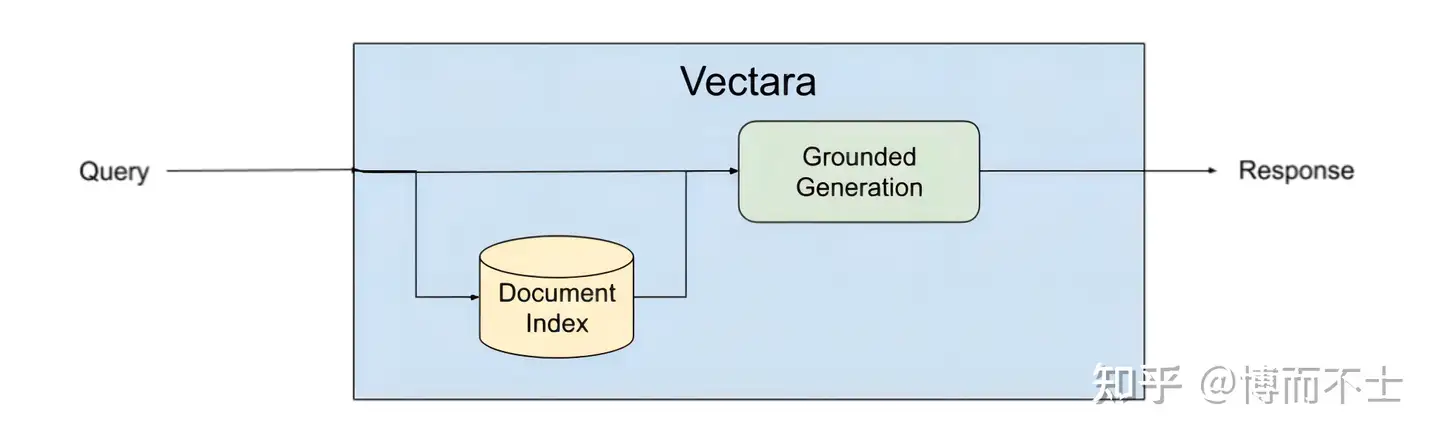
- 输入:给定一个文本或语音输入,例如一个问题、一个指令、一个话题等。
- 检索:根据输入在互联网或其他数据源中检索相关的事实信息,例如网页、文章、数据库等。
- 验证:根据检索到的事实信息,对输入进行验证,判断其是否合理、准确、完整等。如果输入不符合要求,可以提出修改或补充的建议。
- 生成:根据验证后的输入和检索到的事实信息,使用LLM生成相应的文本或语音输出。
- 验证:根据检索到的事实信息,对生成的输出进行验证,判断其是否有意义、忠实、一致等。如果输出不符合要求,可以进行修改或重写。
通过这样一个循环的过程,基于事实的生成方法可以有效地避免或减少LLM幻觉,提高LLM生成内容的质量和可信度。
Vectara平台具有以下特点:
- 基于事实:Vectara平台在生成文本之前和之后,都会在互联网或其他数据源中检索相关的事实信息,并对输入和输出进行验证,以确保内容是正确、合理、完整、一致的。这样,你就不用担心你的LLM会产生幻觉,或者给你一些错误或无意义的回答。
- 对话式:Vectara平台支持多轮对话,可以根据用户输入和上下文动态地调整生成内容和风格,提供更自然、更流畅、更人性化的对话体验。例如,当你问一个LLM“谁拥有硅谷银行?”时,Vectara平台不仅会给你一个正确且及时的回答:“根据最新的网页信息,硅谷银行(SVB)已经于2022年12月宣布破产。它目前正处于清算阶段,其资产和债务由美国联邦存款保险公司(FDIC)管理。”而且还会根据你的反应和兴趣,给你一些相关或有趣的信息或建议。例如,“你是否对硅谷银行破产的原因感兴趣?我可以给你一些网页链接。”或者“你是否想知道硅谷银行破产对科技行业有什么影响?我可以给你一些数据分析。”
- 开发者友好:Vectara平台提供了简单易用的开发者接口,可以让开发者快速地集成和部署基于事实的生成应用,无需复杂的配置或代码。Vectara平台支持多种数据源和LLM,可以根据不同的应用场景和任务,选择最合适的数据源和LLM,以提供最优的生成效果。Vectara平台还允许开发者根据自己的需求和偏好,定制生成内容的参数和选项,例如长度、语言、领域、风格等。
- 可扩展:Vectara平台不仅可以用于文本生成,还可以用于语音生成。Vectara平台可以将文本转换为语音,或者将语音转换为文本,以满足不同的用户需求和偏好。Vectara平台还可以将文本或语音翻译成不同的语言,以支持跨语言的对话体验。
【2023-9-22】一种名为“Chain-of-Verification(CoVe)”的方法,通过规划验证问题和独立回答,使语言模型能在生成回答时减少幻觉现象,提高回答的准确性。
- 《Chain-of-Verification Reduces Hallucination in Large Language Models》S Dhuliawala, M Komeili, J Xu, R Raileanu, X Li, A Celikyilmaz, J Weston [Meta AI] (2023)
(2)模型层面
- 模型结构
- 模型结构层面的工作往往focus在设计更能充分编码利用source information的方法,比如融入一些人类偏置,如GNN网络。
- 或者在解码时减少模型的生成随机性,因为diversity和Faithfulness往往是一个trade-off的关系,减少diversity/randomness可以变相提升Faithfulness/Factuality。
- 检索增强被证明可以显著减少幻觉问题,e.g., llama-index。
- 训练方式
- 可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
- 提前规划骨架,再生成:sketch to content
- 强化学习:假设是基于word的MLE训练目标,只优化唯一的reference,可能导致暴露偏差问题。现有工作将减轻幻觉的指标作为强化学习的reward函数,从而减轻幻觉现象。
- 多任务学习: 通过设计合适的额外任务,可以达到减轻幻觉的效果。
- 后处理:设计一个小模型专门用于fix幻觉错误。
可能的后续方向
- 更细粒度的幻觉评估:
- token/phrase level instead of sentence level
- 更精细的幻觉分类体系:
- Intrinsic
- Extrinsic
- 其他类别:
- 按幻觉产生的原因分类(调用知识出错,还是缺少相应知识)
- 主观/客观幻觉
- 幻觉可能和时间(temporal)有关
- 知识的定义和诱导:
- 怎么知道模型是否具备某一类知识,只是没有调用好?
- 知识的定义:
- 传统工作大都将wikipedia视作知识库,但它仅仅是世界知识的很小一部分
- 如果将整个互联网当做世界知识,又不可避免的会有虚假信息的问题
- 幻觉消除:
- 检索增强:互联网/外挂知识库(llama Index)
- 强化学习(RLHF)
- 知识诱导/注入
- 直接修改LLM中错误记忆的知识:Model Editing工作,如ROME,MEMIT等
总结
- 数据类方法
- 构建可信数据集
- 自动清理数据
- 信息增强
- 模型和推理
- 架构:编码器、注意力机制、解码器
- 规划和骨架、强化学习、多任务学习、受控生成
- 后处理
图解
作者:旭伦
(1)数据层面:构建高质量数据集
- 人工标注
- GO FIGURE: A meta evaluation of factuality in summarization
- Evaluating factual consistency in knowledge-grounded dialogues via question generation and question answering
- 训练数据:LLM上不可行,只适用于task-specific的幻觉问题
- 评测数据:构建细粒度的幻觉评估benchmark用于分析幻觉问题
- 自动筛选:
- 利用模型打分,筛选出可能导致幻觉的数据并剔除;
- 预训练时给更faithful的数据加权(wiki vs. fake news),或者不使用可靠来源的数据(比如只选用经过人工审查的数据源,如wiki或者教科书,预训练)
(2)模型层面
- 模型结构
- 模型结构层面的工作往往focus在设计更能充分编码利用source information的方法,比如融入一些人类偏置,如GNN网络。
- 或者在解码时减少模型的生成随机性,因为diversity和Faithfulness往往是一个trade-off的关系,减少diversity/randomness可以变相提升Faithfulness/Factuality。
- 「检索增强」被证明可以显著减少幻觉问题,e.g., LLaMA-index。
- 训练方式
- 可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
- Increasing faithfulness in knowledgegrounded dialogue with controllable features
- A controllable model of grounded response generation
- 提前规划骨架,再生成:sketch to content
- Data-to-text generation with content selection and planning
- 强化学习:假设是基于word的MLE训练目标,只优化唯一的reference,可能导致暴露偏差问题。现有工作将减轻幻觉的指标作为强化学习的reward函数,从而减轻幻觉现象。
- Slot-consistent NLG for task-oriented dialogue systems with iterative rectification network
- Improving factual consistency between a response and persona facts
- 多任务学习: 通过设计合适的额外任务,可以达到减轻幻觉的效果。
- 后处理:设计小模型专门用于fix掉幻觉错误。
- Improving faithfulness in abstractive summarization with contrast candidate generation and selection
- 可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
【2023-7-9】拾象调研
Hallucination 的原因:
- 网上很多信息错误,学到了错误信息
- 模型喜欢模仿语言风格,对正确信息判断不好
减少 hallucination 的方案:scaling/retrieval/reward model
- scaling: 目前 20% 的 hallucination 可以通过 scaling 降低:看到很多问题都能通过 scaling 解决,OpenAI 相信hallucination 也可以
- retrieval: 如果 inference 的成本能降到特别低,latency 也能特别低:可以让模型在回答问题前尽可能多地去做 retrival和 verify,就像一个人的思考如果变得很便宜,就可以让它可能多地去思考
- reward model:
【2023-6-1】OpenAI称找到新方法减轻大模型“幻觉”
- OpenAI对抗AI“幻觉”的新策略是:奖励大模型每个正确的推理步骤,而不是简单地奖励正确的最终答案。研究人员表示,这种方法被称为“过程监督”,而不是“结果监督”。
外部幻觉
【2024-7-14】 OpenAI Lilian Weng万字长文解读LLM幻觉:从理解到克服
OpenAI 安全系统团队负责人 Lilian Weng 介绍了近年来在理解、检测和克服 LLM 幻觉方面的诸多研究成果。
为了避免外源性幻觉,LLM 需要:
- (1) 实事求是
- (2) 必要时承认无知。
反幻觉方法
- RAG → 编辑和归因
- Gao et al. (2022) 的论文《
RARR: Researching and Revising What Language Models Say, Using Language Models》,「使用研究和修订来改进归因」。通过归因编辑(Editing for Attribution)来追溯性地让 LLM 有能力将生成结果归因到外部证据。 - He et al. (2022) 在论文《Rethinking with Retrieval: Faithful Large Language Model Inference》中提出的 Rethinking with retrieval (
RR) 方法依赖于检索相关外部知识,但无需额外编辑。RR 并没有使用搜索查询生成模型,其检索是基于分解式的 CoT 提词。 - Asai et al. (2024) 论文《Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection》中提出的
Self-RAG会以端到端的方式训练一个语言模型,该模型可通过输出任务输出结果与分散在中间的特殊反思 token 来反思其自身的生成结果。
- Gao et al. (2022) 的论文《
- 动作链: 不用外部检索到的知识,而是设计一个流程, 让模型自己执行验证和修订,从而减少幻觉。
- Dhuliawala et al.(2023) 在论文《Chain-of-Verification Reduces Hallucination in Large Language Models》中提出了一种名为 Chain-of-Verification (CoVe / 验证链)的方法。该方法是基于动作链来规划和执行验证。CoVe 包含四个核心步骤
- Sun et al. (2023) 在论文《Recitation-Augmented Language Models》中提出的 RECITE 将复述(recitation)作为了一个中间步骤,以此提升模型生成结果的事实正确度并减少幻觉。其设计思路是将 Transformer 记忆用作信息检索模型。在 RECITE 的「复述再回答」方案中,LLM 首先需要复述相关信息,然后再生成输出。
- 采样方法
- Lee, et al.(2022) 在论文《Factuality Enhanced Language Models for Open-Ended Text Generation》中发现核采样(nucleus sampling,top-p 采样)在 FactualityPrompt 基准上的表现不及贪婪采样,但它的多样性更优且重复更少,因为核采样会添加额外的随机性。因此他们提出了事实性-核采样算法。
- Li et al. (2023) 在论文《Inference-Time Intervention: Eliciting Truthful Answers from a Language Model》中提出了推理时间干预(ITI)。其中通过在每一层的激活上拟合线性探针来区分真实输出和虚假输出,研究了某些注意力头是否与事实性更相关。
- 针对事实性进行微调
- Lee, et al.(2022) 在论文《Factuality Enhanced Language Models for Open-Ended Text Generation》中提出了两种用于事实性增强训练的思路:(1) TopicPrefix 是为了让模型能更好地感知事实 (2) 训练目标是句子完成度损失
- Tian & Mitchell et al. (2024) 在论文《Fine-tuning Language Models for Factuality》中提出了事实性微调(Factuality tuning),其也是通过微调语言模型来提升其事实性。他们实验了不同的方法来估计每个模型样本中的原子陈述的真实度,然后再运行 DPO。
- 针对归因进行微调
- 为搜索结果生成条件时为模型输出分配归因。训练 LLM 更好地理解检索到的内容和分配高质量归因是一个比较热门的研究分支。
- Nakano, et al. (2022) 在论文《WebGPT: Browser-assisted question-answering with human feedback》中提出的 WebGPT 将用于检索文档的网络搜索与微调 GPT 模型组合到了一起,目的是解答长篇问题以降低幻觉,实现更好的事实准确度。
- Menick et al. (2022) 在论文《Teaching language models to support answers with verified quotes》中提出的 GopherCite 与 WebGPT 非常类似,都使用了搜索引擎来创建支持材料以及教模型提供参考。
多模态幻觉
幻觉修复
对于文生图里的问题样例,解决方法:
- 收集bad case,返回给基座模型训练——周期长,代价大
- 对于少量案例,后处理,即时修复——周期端,见效快
修复方法
- ① 图生图局部重绘:针对两只手,分别人工框选问题区域,二次绘制,输入图片及提示词:和生成图片的正向提示词保存一致。
- ② 条件生成:借助ControlNet,人工一次性标记两个问题区域,指定特定条件进行修复。如:
- 姿态修复(openpose),识别人体姿态,修复局部信息,手部操作容易,可控性很强,细节瑕疵(长度和接头处)
- 深度修复(HandRefiner),识别深度信息,手部突出,然后一次性修复。
直接贴上几种方案对比图:

iRAG
【2024-11-12】上海召开的百度世界大会上,李彦宏说:过去24个月,大模型的最大变化是基本消除幻觉。
- 幻觉: 大模型“脑子不灵光”的一面,突出表现在文生图、文生视频时,出现的各种事实错误。
在这届大会上,有两款 AI应用,确实也令我这个文科生眼前一亮。
一个叫iRAG,中文名叫:检索增强的文生图技术,卖点消除以前文生图时“生出”错误图片。
检索增强的文生图技术 iRAG,既可以生成精确的图片,也可以进行泛化生图。
大模型是如何做到这一点的呢?
- 首先,基于大模型对用户需求进行分析理解,自动规划精确或泛化方案,比如对哪些实体进行增强;
- 接着,增强阶段,对需要增强的实体,检索并选择相应的参考图。
- 最后,生成阶段,自研了多模可控生图大模型
- 一方面,通过局部注意力计算,在保持实体特征不变的情况下,实现了图像的高泛化生成,比如根据牛顿的肖像生成绘本风格的牛顿;
- 另一方面,通过整体注意力计算,进行高精确的图像生成,比如 生成图中的汽车跟原图片保持完全一致。在实际应用中,这个方法也支持用户上传参考图,应用户期望进行生成。
比如
- 天坛祈年殿,有三重屋檐,但此前大模型在学习过程中,或因为数据量不足、或数据质量问题,会出现生成四重屋檐的情况,这叫做“事实性幻觉”。
- 而 iRAG 能解决这一问题,尤其对特定人物、特定物品能“精准生成”。
测试
文小言APP测试,比如
- 输入“演员王x博在天津海河跳桥”,画面还大差不差
- 但试着输入“87版红楼梦演员贾宝玉开着特斯拉Model Y”时,画面就不太对劲,调了几版也不对,可能还是自己提示词输入有问题。
测试案例
幻觉根治
真的无法根治吗?
【2024-5-6】原文
AI初创公司 Alembic 首次宣布,一种全新AI系统,用于企业数据分析和决策支持,完全解决了LLM虚假信息生成问题, 饱受诟病的LLM幻觉,被彻底攻破
新型图神经网络充当因果推理引擎获取数据,组织成一个复杂节点和连接网络,捕捉事件和数据点随着时间推移形成的关联。
听起来挺有道理,但是方法未开源,无从验证该方法有效性。
幻觉评估数据集
SimpleQA
OpenAI 新武器—— SimpleQA,开源,全新的事实性基准测试,专门用来检测大模型回答事实性问题的准确性
- 【2024-10-31】OpenAI推出SimpleQA:专治大模型“胡说八道”,实测o1和Claude3.5都不及格
- 开源地址:SimpleQA
- 官方介绍
- SimpleQA Paper: 论文
OpenAI雇佣了AI训练师从网上收集问题和答案,并制定了严格的标准:答案必须唯一、准确、不会随时间变化,而且大多数问题必须能诱导GPT-4o或GPT-3.5产生“幻觉”。为了保证质量,还有第二位AI训练师独立回答每个问题,只有两位训练师答案一致的问题才会被收录。最后,还有第三位训练师对1000个随机问题进行验证,最终估算出数据集的固有错误率约为3%
SimpleQA 三大特点:
- 设置简单到爆: 包含 4000 道由人类编写、清晰无歧义的事实性问题,每个问题都只有一个无可争议的正确答案。模型回答会被自动评分器评为“正确”、“错误”或“未尝试”
- 挑战性大,前沿模型也跪了:
- SimpleQA 对目前最先进的大模型也构成了巨大挑战!连 o1-preview 和 Claude Sonnet 3.5 的准确率都不到 50%!
- 参考答案准确度高,经得起时间考验:
- 所有问题都经过精心设计,参考答案经过两位独立标注员的验证,确保准确可靠。而且,这些问题的设计也考虑到了时效性,即使 5 年或 10 年后,SimpleQA 仍然是一个有用的基准测试,相当耐用!
除了评估事实性,SimpleQA还可以用来测量大模型的“校准”程度,也就是模型“知之为知之,不知为不知”的能力。
- 置信度与准确率: 通过让模型给出答案的同时给出置信度,然后比较置信度和实际准确率之间的关系,就能看出模型的校准程度。结果表明,模型普遍高估了自己的置信度,还有很大的改进空间。o1-preview比o1-mini校准程度更好,GPT-4比GPT-4-mini校准程度更好,这与之前的研究结果一致,即更大的模型校准程度更好
- 答案频率与准确率: 另一种测量校准的方法是将同一个问题问模型100次。由于语言模型在重复尝试时可能会产生不同的答案,因此可以评估特定答案的出现频率与其正确性是否相符。更高的频率通常表明模型对答案更有信心。o1-preview 在这方面表现最好,其答案的频率与准确率基本一致。与通过置信度判断的校准结果类似,o1-preview 比 o1-mini 的校准程度更好,GPT-4 比 GPT-4-mini 的校准程度更好
(1) TruthfulQA
TruthfulQA (Lin et al. 2021) 可以度量 LLM 生成诚实响应的优劣程度。该基准包含 817 个问题,涵盖医疗、法律、金融和政治等 38 个主题
一个很重要的用于评估LLM是否能够生成符合事实的答案的QA基准,被后续的LLM工作,如GPT4采用评估。包含了817个作者手写的问题,这些问题是精心设计,往往是模型或者人类都很容易回答错误的陈述。
作者发现:
- 与人类相比(94%),当前较好的LLMs(GPT3)也只能诚实地回答58%的问题而不进行编造。
- 更大的模型更容易编造回答。
- 微调后的GPT3可以有效分辨是否回答是truthful的。
(2) HaluEval benchmark
-
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
- Benchmark搭建:人工标注了35,000条数据,5000条chatgpt的general query(alpaca data),30000条chatgpt的任务回复(问答、摘要、知识对话)
- 让chatgpt生成更有可能出现幻觉的文本:数据过滤,prompt工程;
- 每个任务的幻觉还有不同类型:
- QA: comprehension, factualness, specificity, and inference;
- knowledge-grounded dialogue:extrinsic-soft, extrinsic-hard, and extrinsic-grouped
- text summarization: factual, non-factual, and intrinsic
- 幻觉评估:
- Chatgpt倾向于在回复中生成无法被验证的内容(幻觉),占比约11.4%
- 当前强大的LLM,如Chatgpt,都很难精准检测出文本中出现的幻觉问题
- 通过提供外部知识和增加推理步数,能够提升LLM检测幻觉的能力
FacTool 上海交大
FacTool是由上海交通大学、卡内基梅隆大学、香港城市大学、Meta 等机构学者共同提出的一款通用框架,能够查核大模型生成内容的事实准确性(也能查核一般性内容的事实准确性)
FactualityPrompt
FactualityPrompt (Lee, et al. 2022) 基准由事实和非事实 prompt 构成。其使用了维基百科文档或句子作为知识库的事实基础。
SelfAware
SelfAware (Yin et al. 2023) 包含 5 大类的 1032 个不可解答问题和 2337 个可解答问题。不可解答问题来自有人类标注的网络论坛,而可解答问题则来自 SQuAD、HotpotQA 和 TriviaQA 并且是根据与不可解答问题的文本相似度选取的。
LongFact
LongFact (Wei et al. 2024) 可用于检查长篇生成事实性。其中包含 2280 个找寻事实的 prompt,可针对 38 个人工挑选的主题搜索长篇响应。
HaDes
HaDes (Liu et al. 2021) 基准是将幻觉检测视为一个二元分类任务。该数据集是通过扰动维基百科文本和人类标注创建的。
FEVER
FEVER(事实提取和验证)数据集包含 185,445 个陈述,其生成方式是修改从维基百科提取的句子,随后在不知道它们源自哪个句子的情况下进行验证。每个陈述都被分类为 Supported、Refuted 或 NotEnoughInfo。
FAVABench
FAVABench (Mishra et al. 2024) 是一个评估细粒度幻觉的基准。其中有 200 个寻找信息的源 prompt,并且每个 prompt 都有 3 个模型响应,所以总共有 600 个响应。每个模型响应都被人工标注了细粒度的幻觉错误类型标签。
幻觉评估
ChatGPT/GPT4生成不真实回复的评估、机理
对LLM生成的不符合事实的错误类型进行分类和统计:

定义了三个能力,可能导致幻觉的
- 知识记忆
- 知识调用
- 知识推理

通过实验,对大模型生成可靠回复给出了一些建议:
- 提供更多的背景知识(检索)
- 提供更细粒度的背景知识(分析)
- 把问题进行分解(CoT)
早期的工作
包括了对ChatGPT幻觉现象的评估:
- ChatGPT有能力识别虚假信息,并能够在无法识别时回复不知道;
- ChatGPT仍然会被TruthfulQA内的问题误导;
- ChatGPT同样可能出现intrinstic/extrinsic hallucination的case;
Retrieval-augment LLM评估
Retrieval有助于显著减少LLM的幻觉现象。
自OSU的两个工作,主要是研究了给定retrieval reference的情况下,LLM的遵循能力。
前一个工作首先定义了自动评估一个reference能否支撑generation的任务,然后研究了LLMs(prompt/finetuned)的完成这一任务的能力
- automatic attribution evaluation的效果都不好
- 小的finetuned模型可以超过大的zero-shot模型
- 模型容量和评估效果并不完全正相关
- 使用额外的其他任务训练,可以提升automatic attribution evaluation的能力(QA/NLI/FC)
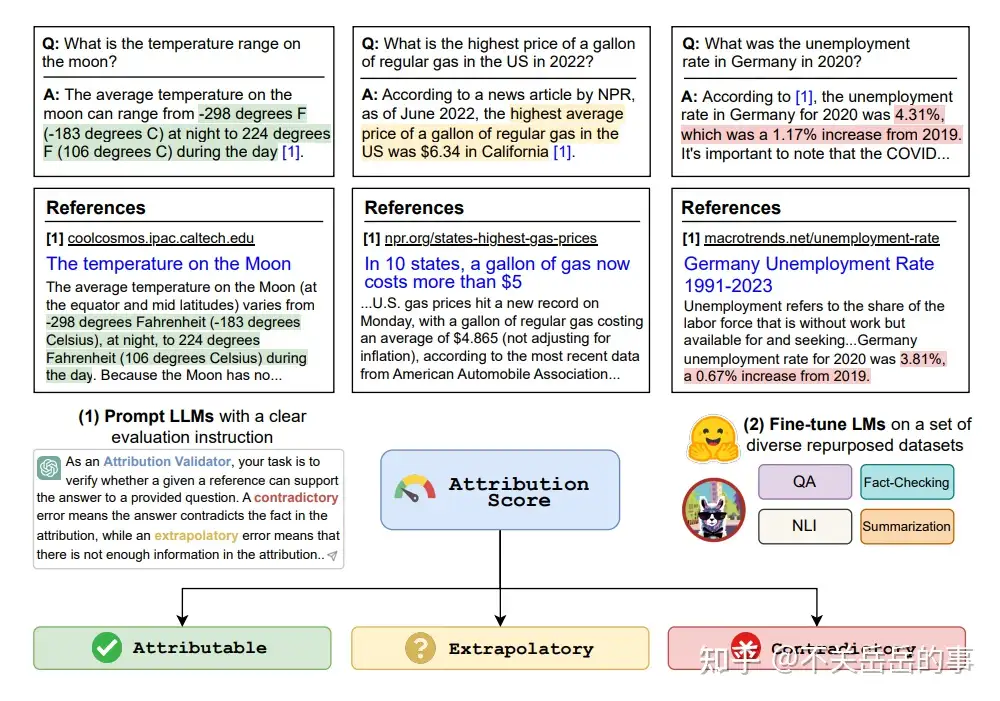
后一个工作
研究了给定reference情况下对LLM生成结果的影响:
使用一个5步走的框架进行knowledge elicitation
- parametric memory:模型内部的知识
- counter-memeory:与模型内部知识相反的内容
-
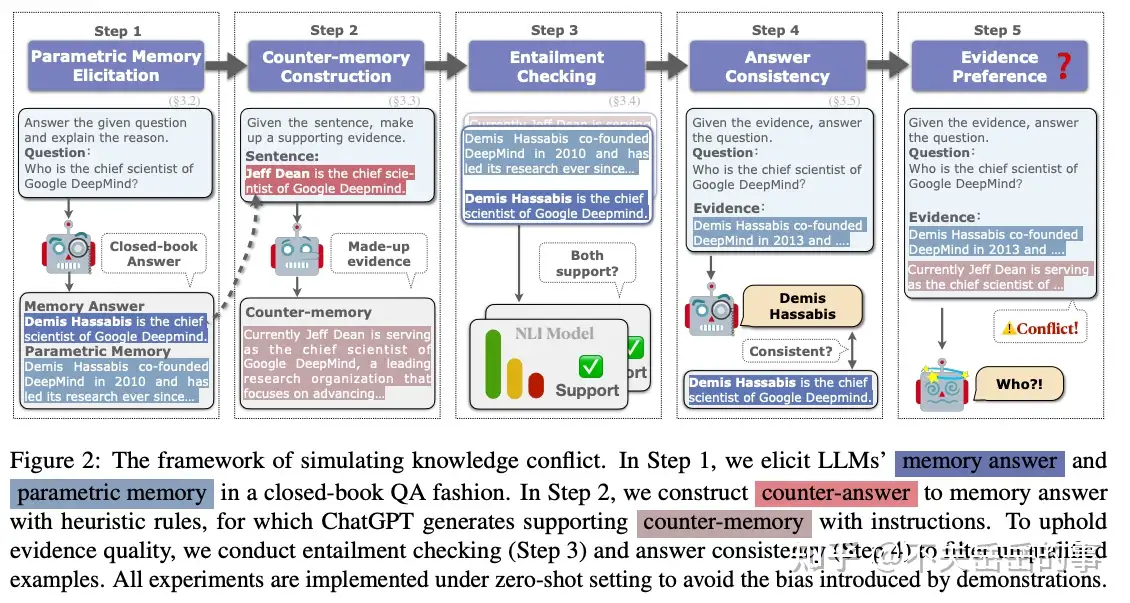
- 当只有一个单一的知识源时:
- 简单的通过entity替换的counter-memory无法诱骗模型,但是让LLM自己生成的可以
- 当有多个知识来源时:
- LLM倾向于相信更流行的知识;
- LLM对于知识的顺序很敏感,倾向于相信先出现的知识;
- LLM相信更长的知识;
- LLM随大流,相信占据大多数的知识
LLM幻觉的滚雪球现象
本文作者认为:
- LLM出现幻觉现象,很多情况下并不是因为它们缺少对应的知识,而仅仅是在调用知识的过程中出错。他们发现:LLMs如果在回复一开始做出了错误的判断,那么它们随后会给出错误的解释(幻觉)。他们称这一现象为幻觉的滚雪球现象。但是,当仅给定错误的解释时,LLMs往往可以成功判断它是不正确的。这证明LLMs其实具备相应的知识,只是被早期的错误断言给误导了。
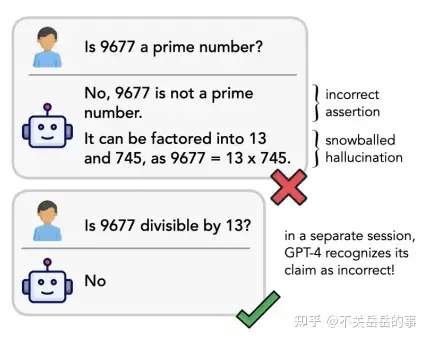
作者也探索了一些缓解幻觉滚雪球问题的方法:
- 更好的Prompt(CoT):有效,但是CoT也存在着思维链内部的幻觉滚雪球问题。
- 解码算法:作者尝试了不同的解码算法,但并没有显著效果。
- 训练策略:构造更多的CoT训练数据,以及构造允许模型自我回溯(self-correct)的训练数据。
LLM幻觉的原子粒度评估
定义原子事实:仅包含一个信息的短句。
将LLM生成的内容(本文选用的内容是人物简介)分解为多个原子事实(instructGPT分解,人类校对),评估生成事实的精确度:
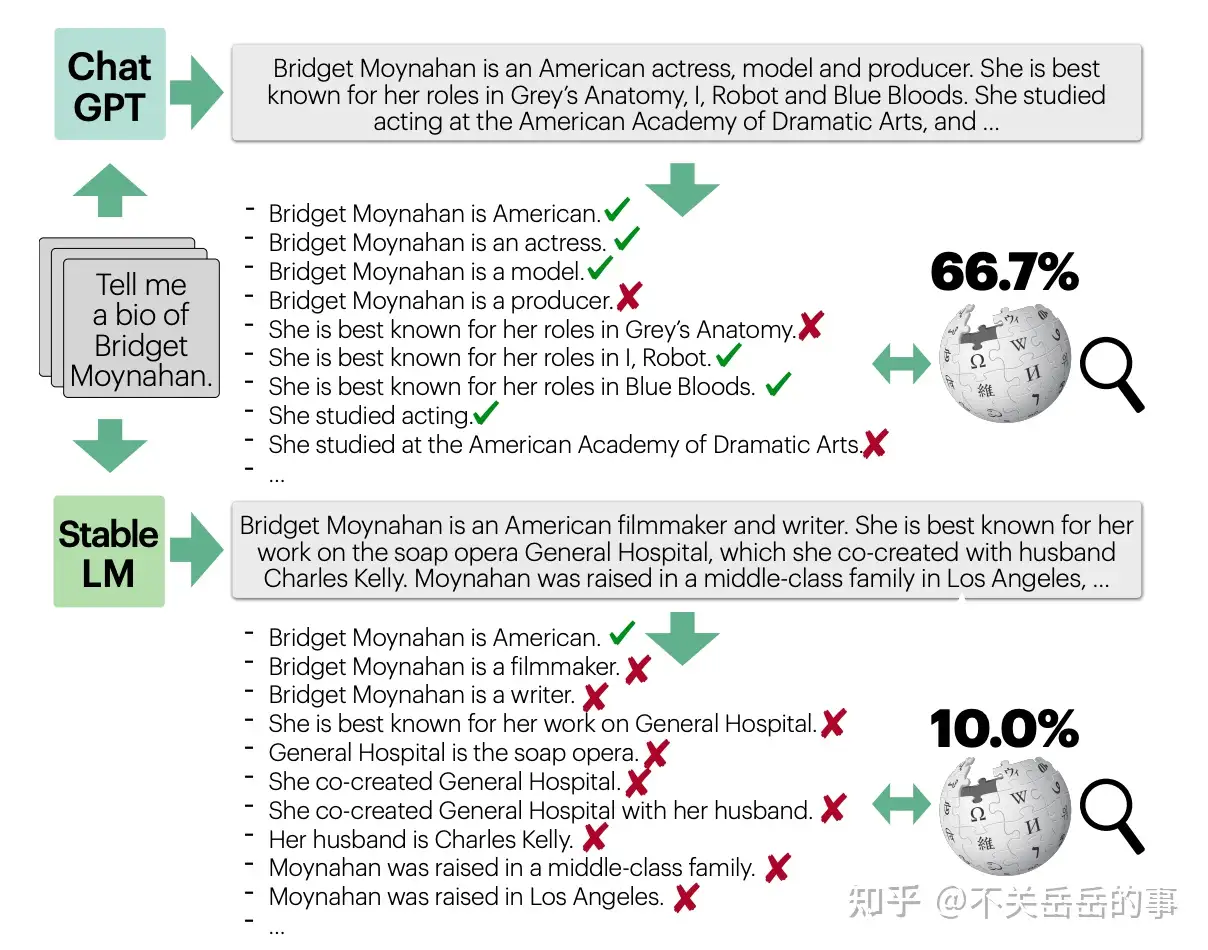
人工标注常用LLMs的原子事实精确度后,发现:
- 所有LLM都会出现较为严重幻觉问题,特别是原子粒度上;
- 检索增强的LLM(perplexity AI)能够缓解事实错误;
- 在生成和罕见实体相关的回复时,LLM更容易犯错;
- 模型在生成回复的后期,更容易出现幻觉;
作者也研究了基于LLM自动评估原子事实精确度的可能性(不可能每次对新模型评估都靠人工标注):
- 检索增强能显著提升评估的效果;
- 更大的LLM能够更好地评估。
最后,作者基于自动指标,评估了现阶段LLM的原子事实性:
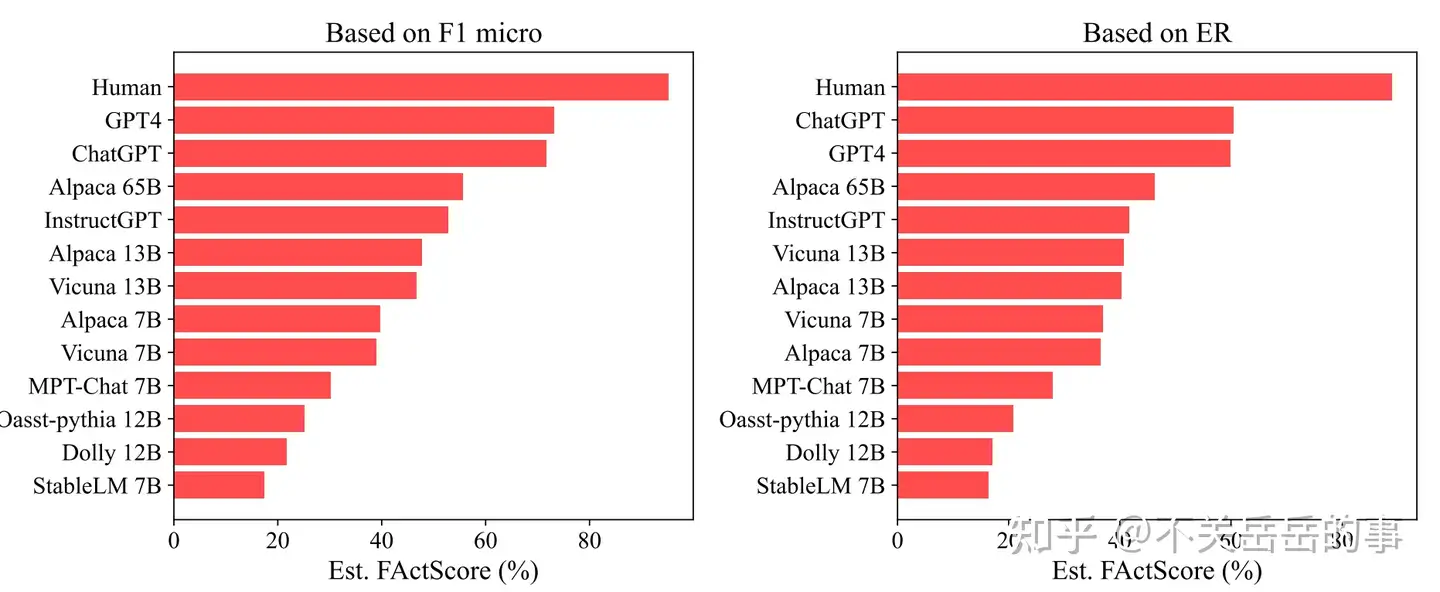
有一些有趣的发现:比如Dolly模型经常频繁提及Databricks公司,导致事实错误(因为dolly的训练语料是databricks公司员工手写的)
最后作者研究了自动利用LLMs修复事实错误的可能性,发现在原子粒度纠正以及提供检索信息,能显著提高纠正的效果。
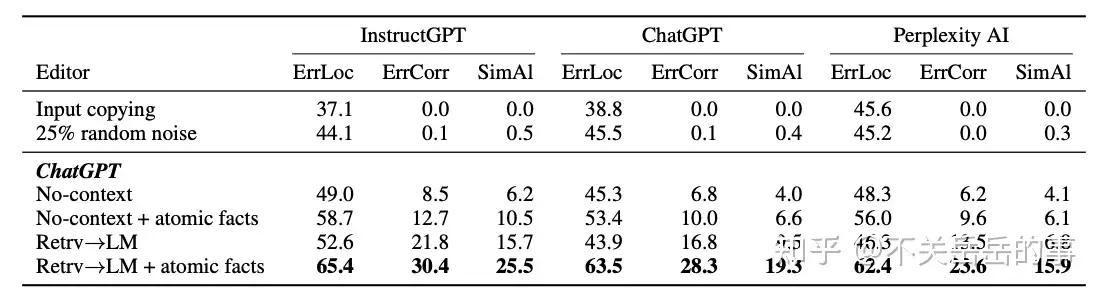
除了模型生成事实的精确度外,还应该考虑召回度(即内容中的原子事实信息尽可能多),否则LLMs可能走捷径,生成一些无意义的废话。
幻觉检测+修正
(1) 事实性增强的语言模型
面向LLM的事实/幻觉问题的早期工作(2022.6)。
本文首先基于FEVER数据集构建一个FactualPrompt数据集,包含了符合/不符合事实的提示,用于诱导LLM生成符合/不符合事实的下文。
评价指标:
- 幻觉实体率:对比生成内容和Golden Knowledge中实体的重叠率;
- 蕴含率:使用额外的NLI模型,评估生成内容有多少是被golden Knowledge蕴含的;
- 生成质量评估:除了幻觉现象外,还要确保生成的效果
- 流畅度:平均困惑度;
- 多样性:distinct n-grams;
- 重复度
从多个维度评估LLM生成的事实问题:
- 模型容量:更大的模型生成结果的事实性越好
- 提示类型:不符合事实的提示更可能诱导LLM生成不符合事实的内容;
- 解码算法:带有随机性的解码算法(如Top-P)显著比贪心解码生成的内容更不符合事实;
- 基于这个发现作者还提出了一个非常简单的top-p解码算法优化,在生成的diversity和factuality中寻求trade-off:
- p随时间步衰减(后期生成的内容更可能不符合事实),每次生成一个新句子(通过检测是否生成了句号)重新初始化p,并且p的衰减可以定一个下界;
作者还提出了一种继续预训练策略来提升事实性:
- 使用更权威的数据,如Wiki来训练;
- 给每个句子加上Wiki Document的名称:作者认为这能给句子提供额外的事实信息,比如解释句子里的代词(有点玄学)
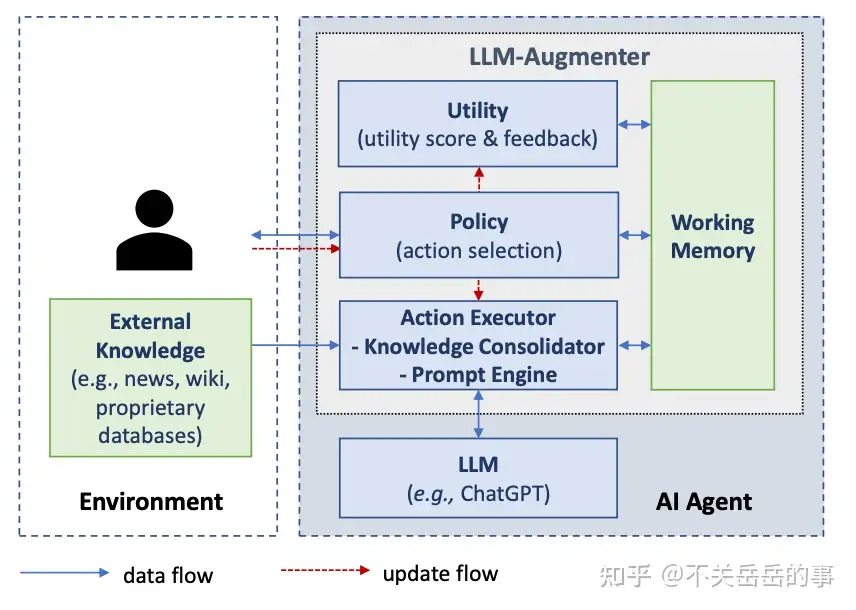
(1) 基于外部知识和自动反馈提升事实性
通过外挂知识库和LLM自我审视,来提升LLM生成的事实性/效果:
主要包含以下部分:
- LLM Agent
- 外部知识库:互联网、wiki百科等;
- 动作执行器:
- 知识检索:BM-25/Dense,通过给定prompt检索知识;
- Prompt引擎:基于用户输入/知识/历史信息/反馈信息等,构造prompt,融合信息生成新的回复;
- 策略选择器:
- 基于规则(是否通过utility模块)
- 可学习(T5-based)
- 效用检验模块:
- 打分器:用分数评估回复质量;
- 反馈器:用自然语言给出回复评估;
本质上,该系统是一个检索知识->生成回复->评估的反复迭代/决策的过程,能够通过外部知识库和检查模块,显著提升生成的各维度效果,包括事实性。
(3) 零资源黑盒LLM幻觉检测
作者认为传统的幻觉检测方法在当今LLM时代有如下的缺陷:
- 基于不确定度指标:这一类方法通过衡量LLM回复的熵/概率,来判断LLM对回复是否自信,越不自信越可能是编造的内容。但是该方法对闭源模型(如OpenAI)不友好。
- 基于事实验证指标:这一类方法需要外挂知识库,但是现在缺少涵盖所有世界知识的高质量知识库。
作者提出了SelfCheckGPT方法,核心的假设是:如果大模型非常肯定一个事实,那么它随机采样多次生成的回复,将对该事实有着近似的陈述(self-consistency)。如果多次采样,LLM都生成不同的陈述,那么很有可能是出现了幻觉。具体地,评估多个采样陈述是否一致,可以通过:1)BERTScore;2)QA-based;3)n-gram metric进行实现。
ETH-Zurich也有一篇类似的工作,着重关注LLM生成回复中的自相矛盾现象,包括评估、检测和消除。
(4) 零资源黑盒事实错误纠正
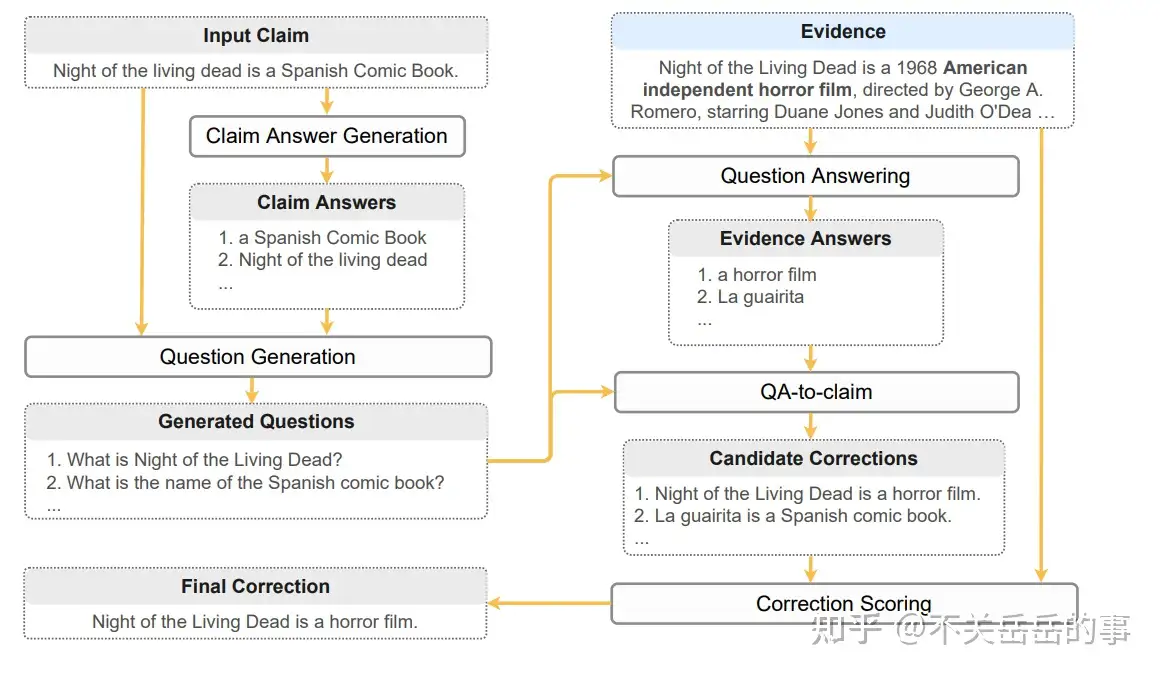
提出了一个五步的零资源事实错误纠正流水线:
- Claim Answer抽取:从陈述中抽取关键信息;
- Question Generation:针对每个关键信息,生成一个问题;
- Question Answer:针对每个问题,将外部证据作为额外输入,进行回答;
- QA-to-claim:将QA-pair转回陈述;
- Correction scoring:额外打分器判断新的陈述是否合理。
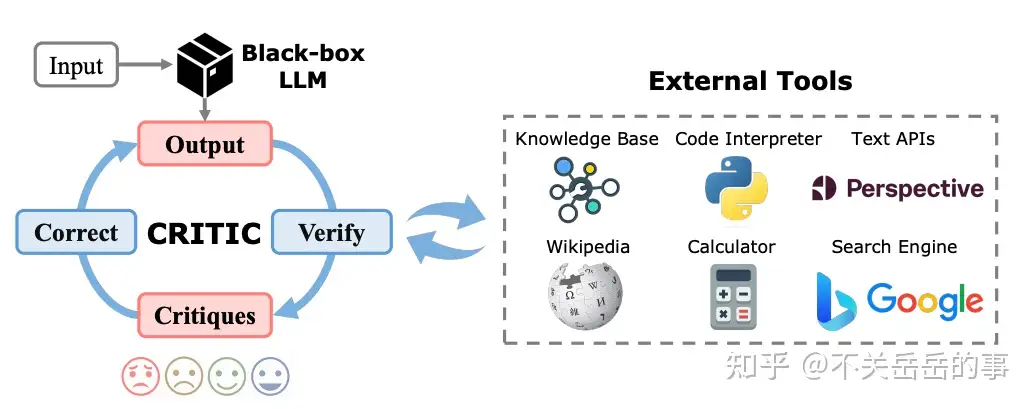
(5) 工具增强的LLM自动纠正
MSRA的工作,本文允许LLM在自我检查答案正确性的过程中调用外部工具,比如知识库、搜索引擎和维基百科,从而缓解事实性和幻觉问题。
(6) 通过推理时干预诱导LLM生成符合事实的答案
哈佛的工作,本文中作者提出了一种推理时干预的策略(ITI)提升LLM生成答案的事实性。
作者假设:
- LLMs know more than they say,LLM内部存在着隐藏的、可解释的结构,这些结构和事实性息息相关,因此可以通过干预:
作者探索了LLM的生成回复准确率(直接回答问题)和Probe准确率(用一个linear classifier基于中间状态选择回答)的关系,发现LLM很多情况下知道知识,但无法正确生成回复。
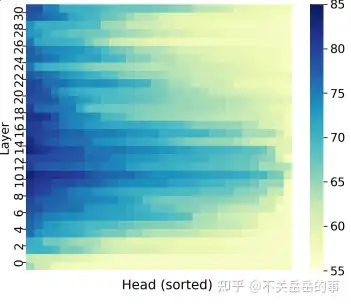
ITI方法选择和事实知识紧密相关的head,进行干预,让激活值移动到truthful相关的方向,实验表明能够有效提升回复的事实性。
(7) 训练小模型后处理幻觉问题
Google的工作,核心思想是用LLM自动对一个正确样本生成幻觉样本,组成平行语料,训练一个T5学会降噪:
- 根据文档、干净的陈述,利用LLM对陈述进行加噪,使其含有幻觉问题;
- 将文档和含有幻觉的文本作为输入,干净的文本作为输出,训练一个小模型用于降噪(去幻觉)
- 推理时,对给定的陈述,先使用QG模型生成一系列问题,再根据问题召回证据,将证据文档和陈述传入小模型进行幻觉的编辑和修正。
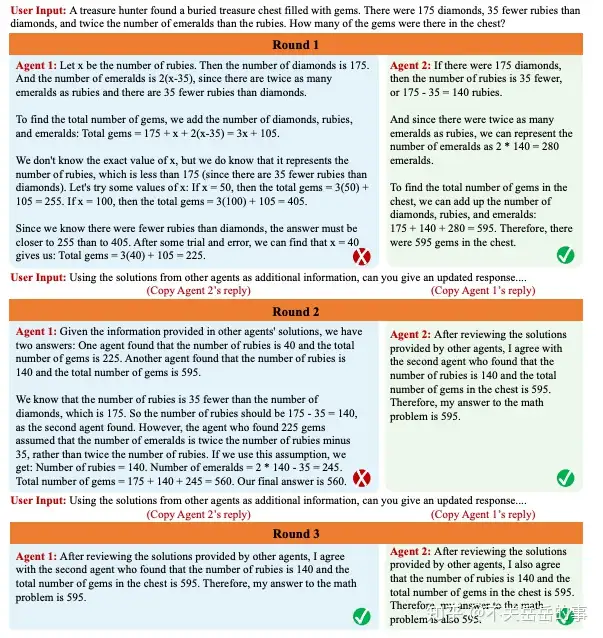
(8) 利用多智能体辩论显著提升LM的事实性和推理能力
MIT&Google,利用多个智能体(LLM)相互辩论来解决事实性问题,相当于是一种变相的self-verify。
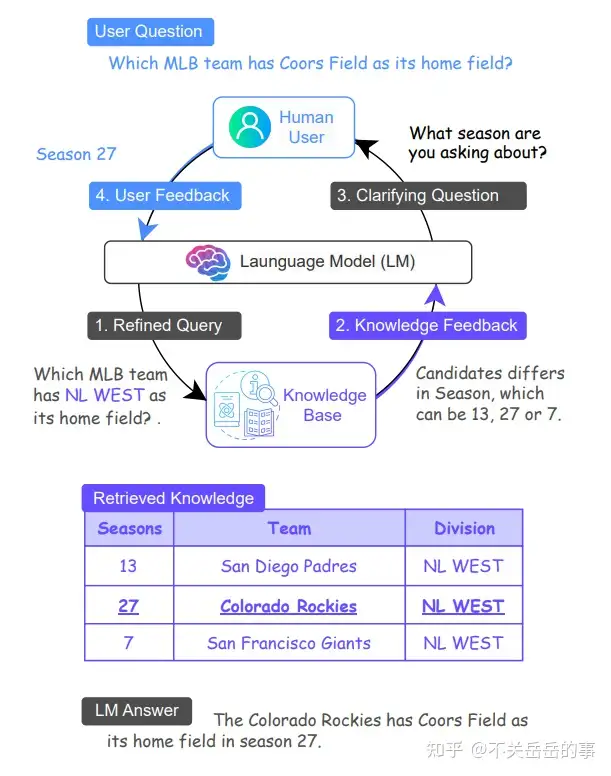
(9) 人在回路的幻觉消除
本文提出基于人机交互,让LLM获得更好的知识-问题对齐,从而提升回复的事实性,减轻幻觉。
Truthfulness
【2023-6-29】拾象硅谷见闻系列:打破围绕开源LLM的6大迷思
OpenAI 元老 John Schulman 4月下旬在伯克利有关 RLHF 和 Hallucination 的讲座
- Youtube: John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges, Towards TruthGPT
他一针见血地指出
- 这类开源模型的做法只是“形似”,实际上降低了模型的 Truthfulness。
这一类模型的事实性上的缺陷:
(关于 Hallucination 问题的出现)如果你使用同样的监督学习数据,然后训练另一个模型,那么同样的 Hallucination 问题会出现。现在有很多人使用 ChatGPT 的输出来微调其他模型,比如微调市面上的开源 Base Model,然后发现效果不错。但是如果认真观察事实准确度,会发现它们编造的比例比原始模型更高。
5 月,伯克利的论文 The False Promise of Imitating Proprietary LLMs 指出这种方式微调出来的指令遵循模型存在的一系列问题:
- 在缺少大量模仿 ChatGPT 数据支持的任务上,这类模型无法改善 Base Model 到 ChatGPT 的差距;
- 这类模型只是擅长模仿 ChatGPT 的风格,而不是事实性,导致实际的性能差异会骗过人类评估者;
- 当前开源模型最大的限制仍然是 Base Model 层面跟 GPT 系列的差距,在微调而不是预训练环境进行优化可能是不正确的方向;
- 为了广泛地匹配 ChatGPT 支持的任务,需要更广泛和大量的模仿数据集,还需要新的工作;
- ……
6 月份 Allen Institute for AI 和华盛顿大学的 How Far Can Camels GO?工作再次通过实验表明
- 不同的指令微调数据集可以释放或者增强特定的能力,但并没有一个数据集或者组合可以在所有评估中提供最佳性能,并且这一点在人类或模型担任评估者时也很容易无法被揭示。
对于指令遵循微调背后的团队来说,他们也意识到自己的模型由于 Base Model(LLaMA)的限制,在复杂推理和代码任务上很弱,并且难以进入正向数据飞轮 —— 模型能力越弱的领域越难得到更多的 query,也就难以筛选出高质量 query,想自己再标注提升模型能力就很困难。
至此,开源社区已经充分意识到原来这套微调 LLaMA 的框架的局限性,越来越多的团队开始探索预训练环节和更接近真实的人类反馈数据。我们也比较期待这两个方向上的进展,在迷思 4 中也会分享更多围绕这部分的观察。
解法
大语言模型(LLM)可能永远无法消除“幻觉”
- Sam Altman说:“幻觉和创造性是等价的”。
减轻幻觉策略,包括:
- 增加意识
- 使用更先进的模型
- 提供明确说明
- 提供示例答案
- 提供完整的背景
- 验证输出
- 实施检索增强生成(RAG)
7-ways-to-overcome-hallucinations
Several strategies to mitigate hallucinations, including:
- Increase awareness
- Use a more advanced model
- Provide explicit instructions
- Provide example answers
- Provide full context
- Validate outputs
- Implement retrieval-augmented generation
创业公司解法
大模型的“幻觉”问题很可能导致Agent“教错”学生,蚂蚁云采用了一系列方法来解决该问题。
- 通过模型融合提高模型自身准确性;
- 引入“反思”“自评估”等思维工程方法
- 或者直接外挂RAG知识库、知识图谱等工具对模型加以“约束”。
【2024-4-12】用大模型+Agent,把智慧教育翻新一遍
斯坦福 WikiChat
【2023-10-27】斯坦福大学开发出一个几乎不会产生幻觉的模型:WikiChat, 将 GPT-4 蒸馏到 7b的LLaMA上,97.9% 显著超越所有基于检索的LLM,包括 GPT-4
- GitHub:网页
- 论文:WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia
- 在线体验:Wikipedia + LLM
WikiChat 基于英文维基百科信息。当它需要回答问题时,会先在维基百科上找到相关的、准确的信息,然后再给出回答,保证给出的回答既有用又可靠。
在混合人类和LLM的评估中,WikiChat达到了97.3%的事实准确性,同时也普遍高于其他模型。
它几乎不会产生幻觉,并且具有高对话性和低延迟。(⚠️给出的在线测试地址我试了几下都无法工作,所以也没法评估准确性)
主要特点:
- 高度准确:因为它直接依赖于维基百科这个权威且更新频繁的信息源,所以WikiChat在提供事实和数据时非常准确。
- 减少“幻觉”:LLM在谈论最新事件或不太流行的话题时容易产生错误信息。WikiChat通过结合维基百科数据,减少了这种信息幻觉的发生。
- 对话性强:尽管重视准确性,WikiChat仍然能够维持流畅、自然的对话风格。
- 适应性强:它可以适应各种类型的查询和对话场景。
- 高效性能:通过优化,WikiChat在回答问题时更快速,同时减少了运行成本。
工作原理:
- WikiChat利用模型蒸馏技术,将基于GPT-4的模型转化为更小、更高效的LLaMA模型(70亿参数),以提高响应速度和降低成本。
- WikiChat的工作流程涉及7个阶段,包括检索、摘要、生成、事实核查等,每个阶段都经过精心设计以保证整体对话的准确性和流畅性。
- 1、检索信息: 当与用户进行对话时,WikiChat首先判断是否需要访问外部信息。例如,当用户提出具体问题或需要更全面的回答时。WikiChat生成一个搜索查询,以捕捉用户的兴趣,并根据这个查询从知识库(如维基百科)中检索相关信息。
- 2、摘要和过滤: 检索到的信息可能包含相关和不相关的部分。WikiChat会提取相关部分,并将其摘要成要点,同时过滤掉无关内容。
- 3、生成LLM响应: 接下来,使用大型语言模型(如GPT-4)生成对话历史的回应。这一步骤生成的内容通常既有趣又相关,但它本质上是不可靠的,因为它可能包含未经验证的或错误的信息。
- 4、事实核查: WikiChat将LLM的回应分解为多个声明,并对每个声明进行事实核查。它使用检索系统从知识库中获取每个声明的证据,并基于这些证据对声明进行验证。只有那些被证据支持的声明才会被保留。
- 5、形成回应: 最后,WikiChat使用经过筛选和验证的信息来形成一个吸引人的回应。这个过程分为两个步骤:首先生成草稿回应(draft),然后根据相关性、自然性、非重复性和时间正确性对其进行优化和改进(refine)。

在混合人类和大语言模型(LLM)评估方法下的表现:
- 1、高事实准确性:在模拟对话中,WikiChat的最佳系统达到了97.3%的事实准确性。这意味着它在回答问题或提供信息时,几乎所有的回应都是基于事实和真实数据的。
- 2、与GPT-4的比较:当涉及到头部知识(即常见或流行的主题)、尾部知识(即不常见或较少被讨论的主题)和最近的知识(即最新发生的事件或信息)时,WikiChat相比于GPT-4在事实准确性上分别提高了3.9%,38.6%和51.0%。这表明WikiChat在处理不同类型的信息时都有显著的改进,特别是在处理较少讨论的主题和最新信息方面。
- 3、与基于检索的聊天机器人的比较:与之前最先进的基于检索的聊天机器人相比,WikiChat不仅在事实准确性上表现更好,而且在提供信息量和吸引用户参与方面也表现得更加出色。这意味着WikiChat能够提供更丰富、更有趣的对话体验。
总体来说,WikiChat在处理复杂、动态和多样化的信息需求时的优越性能,尤其是在准确性和用户参与度方面的显著提升。
图神经网络–彻底解决
【2024-6-20】大模型幻觉全无?图神经网络成破解核心,精准预测因果消除幻觉
- 【2024-5-6】原文 Exclusive: Alembic debuts hallucination-free AI for enterprise data analysis and decision support
AI初创公司 Alembic 首次宣布,一种全新AI系统,用于企业数据分析和决策支持,完全解决了LLM虚假信息生成问题, 饱受诟病的LLM幻觉,被彻底攻破
关键突破:AI能够在海量企业数据集中,识别随时间变化的因果关系,而不仅仅是相关性
新型图神经网络充当因果推理引擎获取数据,组织成一个复杂节点和连接网络,捕捉事件和数据点随着时间推移形成的关联。

- Alembic’s new AI system ingests data from various sources, processes it through an “observability and classifier” module and a geometric data component, and then feeds the results into a causal graph neural network (GNN) to generate deterministic predictions and strategic recommendations, according to a diagram provided by the company
【2021-10-12】TU&DeepMind,AAAI2022 投稿论文《关联图神经网络与结构因果模型》
关键贡献:
- (1) 从
第一性原理推导出GNN和SCM之间的理论联系; - (2) 定义一个更细粒度的
NCM(神经因果模型); - (3) 形式化了GNN的干预,并由此建立了一个新的神经因果模型类,利用自动编码器;
- (4) 在与现有工作相关的情况下,提供了关于这一新的模型类的可行性、表达性和可识别性的理论结果和证明。
- (5) 实证检验了理论模型在识别和估计任务中的实际因果推理。
360 解法
【2024-9-15】360视角:大模型幻觉问题及其解决方案的深度探索与实践
根据不同问题可以利用不同解决办法,包括预训练、微调、对齐、解码策略、RAG、知识编辑等技术。
亚马逊
电商场景下的对话大语言模型(LLM)如何避免“幻觉”(即生成虚假或无依据的信息),并提升模型回答时的信息可溯源性。
当前,许多电商智能客服虽然能高效对答,但时常会生成不准确的产品信息,导致用户信任度下降。当客服不能给出信息出处,用户很难验证AI给出的答案是否可靠。
【2025-5-13】亚马逊团队提出易于部署的“引用体验”解决方案,让AI在回答时直接标注信息来源(比如产品描述、用户评价、问答记录等),用户可以一键跳转查看原始证据。
- 论文 CITE BEFORE YOU SPEAK: ENHANCING CONTEXT-RESPONSE GROUNDING IN E-COMMERCE CONVERSATIONAL LLM-AGENTS
这一方案基于 In-context Learning(ICL),并结合了多视角信息供模型参考,还提出了 Multi-UX-Inference 系统,保证引用功能不会影响其他用户体验
效果
实际电商对话数据上,引用机制让AI回答的“事实支撑率”提升了13.83%,并显著减少了幻觉。
此外,用户参与度提升了3%到10%!特别是在获取不到足够产品信息时,AI会主动给出“暂无信息”的拒绝信号,而不是胡编乱造,极大提升了回答的可靠性和用户信任。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
