世界模型
通用智能目前存在两个流派
- Transformer 学派(如GPT系列)侧重于大数据驱动的自回归学习,最近发布的Sora体现的涌现能力初步隐含着通用人工智能的韵味。
- 杨立昆(Yann LeCun)为代表的世界模型学派。世界模型学派则认为需要通过构建对世界的内在理解,强调常识性知识和环境交互
「世界模型」被业界看作是通往AGI道路上的关键基石,让AI智能体在无限丰富的模拟环境中接受训练。
世界模型正在经历从“视觉生成”向“物理模拟”的质变。它不仅是让 AI 生成逼真视频的工具,更是赋予 AI 因果推理与前瞻规划能力的关键。
正如物理学家理查德·费曼所言:“凡我不能创造的,我就不能理解(What I cannot create, I do not understand)。” 世界模型正是 AI 试图通过在内部“重构”世界,从而真正“理解”世界的尝试。
从 LLM 的视角来看,可能并不是世界模型研究的终点,而是让“世界模型”首次具备了统一、通用表达接口的起点。真正强大的智能体,将是语言模型、显式世界模型、规划与执行系统深度融合后的新一代架构。
视觉世界模型
【2026-5-6】2026 最新世界模型综述:见视界,知世界
面对从桌面掉落的杯子,LLM或许能秒答“杯子会碎”,却无法推演液体如何飞溅、杯身如何摔碎。
残酷现实:
- 语言本质上是高度压缩的符号系统,它只能概括世界的状态。
- 相比之下,视觉直接记录了物体的几何、运动以及背后的因果线索,是 AI 学习世界演化最直接完整的信息载体。
越来越多研究者如 Yann LeCun,Fei-Fei Li 等开始重新思考:如果世界模型是通向通用智能的关键,那么起点不应该是语言,而应该是视觉。
总结:
- 视觉不应仅仅被视为一种输入模态,而应成为塑造世界模型表征方式、学习机制以及评估体系的核心驱动力。
为了理清视觉与世界模型之间的深层联系,联合新加坡国立大学、腾讯、字节等机构,重磅发布首篇视觉世界模型 (Vision World Models,VWM) 长篇综述,调研截至2026年4月,硬核梳理400+篇文献
核心:
- 📚 全新定义框架(P2)
- 将世界模型研究统一为三大组件:
- 视觉编码 :将原始视觉信号转化为利于建模世界变化的表征。
- 知识学习:模型到底该学什么?从表层的时空连贯性、物理动力学,到深层的因果机制。
- 可控模拟:如何基于交互条件精准推演未来状态。
- 🛠️ 四大流派 & 七大细分路线(P3, P4, P5)
- 依据上述框架分析现有主流技术路线,一图看懂SOTA模型架构。
- 📊 评估生态(P6, P7, P8)
- 将当前的评估方式梳理为三类指标和五大数据集/基准。
- 🚀 未来之路:下一代世界模型(P9)
- Re-grounding: 走出简单物理,理解复杂形变与人类社会因果规则。
- Re-evaluation: 引入物理裁判官与反事实推理测试。
- Re-scaling: 借鉴LLM中scaling的成功之路,在pretraining和inference阶段均大有可为。
- 📥 完整资源
因果推理
理想中的 World Model 是事实及其支撑逻辑的合集。但现实中,World Model 往往为隐性,并呈碎片化 - 事实散布于各类数据、分析和专家的脑袋中
基于因果分析构建 World Model 工具链
例如,对于利润率问题,人类专家可以基于先验知识、私有数据、Causal-learn和DoWhy等工具构建一个具有统计学意义的“利润率World Model”
Causal AI 长时间在商业领域裹足不前的主因: Causal Modeling 过程非常依赖于人类专家的知识和干预,难以完全自动化。
但利用大模型替代或辅助人类专家进行 Causal Modeling 研究有了不错的进展。
详见站内专题:因果推理
双系统:快思考 & 慢思考
人脑思维双系统模型理论(Dual Process Theory)
认知心理学名著《思考,快与慢》(Thinking, Fast and Slow)中介绍 双过程理论(dual propcess theory)。人类认知过程需要两个密不可分的系统,其中
System 1负责快速直觉式思考 –感性System 2负责慢速分析式思考 –理性
详见站内专题: 大脑工作原理
【2023-9-11】大模型为啥这么慢,原来是想多了:新方向是和人一样的思维算法
弗吉尼亚理工大学和微软的一个研究团队在近日的一篇论文中提出了思维算法(AoT),其组合了直觉能力与算法方法的条理性,从而能在保证 LLM 性能的同时极大节省成本。
- 当前研究则转向了线性推理路径,将问题分解成子任务来发现解决方案,或通过修改上下文来利用外部机制来改变 token 的生成。
- 早期的 LLM 策略模仿即时的
System 1(快速反应),特征是通过脉冲决策实现。 - 相较之下,
思维链(CoT)和least-to-most prompting(L2M)等更新的一些方法则反映了System 2(慢速思考)的内省式本质。通过整合中间推理步骤,可让 LLM 的算术推理能力获得提升。
什么是世界模型
【2024-2-22】什么是world models/世界模型
- OpenAI 介绍材料中称 Sora 是 “world simulator”
AI领域提到 世界/world、环境/environment 这个词时,通常是为了与 智能体/agent 加以区分。
研究智能体最多领域,一个是强化学习,一个是机器人领域。
- 因此,world models、world modeling 最早常出现在机器人领域的论文中。
而 world models 这个词影响最大的可能是 Jurgen 2018 年放到arxiv的论文, 以“world models”命名,该文章最终以 “Recurrent World Models Facilitate Policy Evolution”的title发表在NeurIPS‘18。
- 论文没有定义什么是World models,而是类比了认知科学中人脑的mental model,引用了1971年的文献
- Wikipedia中介绍mental model是很明确的指出其可能参与认知、推理、决策过程。
- mental model 主要包含 mental representations 和 mental simulation 两部分。
论文截图
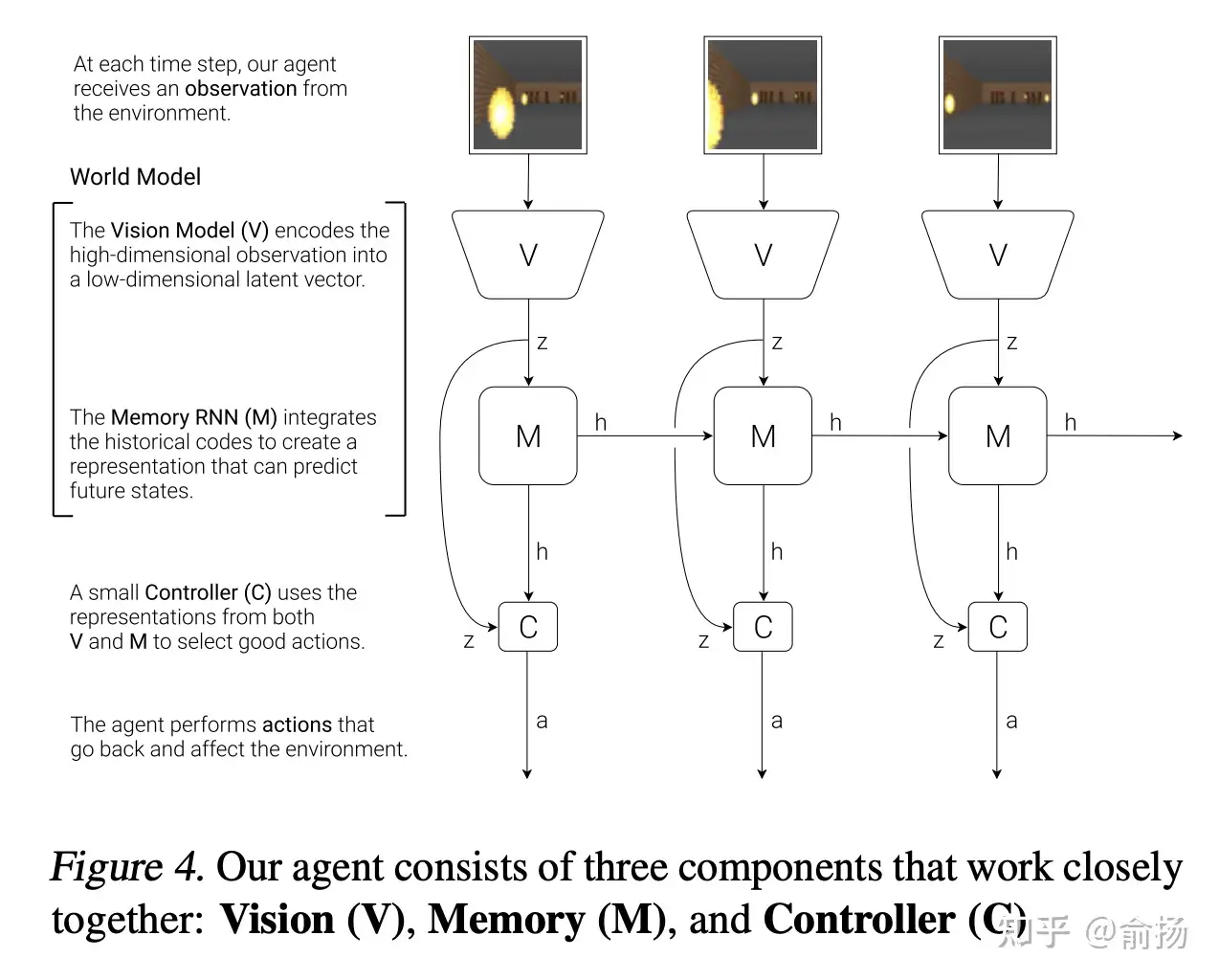
- 纵向 V->z: 观测的低维表征,用VAE实现
- 水平的M->h->M->h: 序列预测下一个时刻的表征,用RNN实现
- 这两部分加起来就是World Model。
定义
学术界,世界模型通常被定义为:
世界模型是智能体对其所处环境的状态结构、演化规律及潜在因果关系的内部表征,用于支持预测、推理与决策。
从功能维度看,一个具备世界模型的智能体,通常包含以下核心能力:
- 状态表征(State Representation) 能够从高维、噪声较大的观测数据(如图像、传感器读数)中,提炼出紧凑且对决策有意义的内部状态(Latent State)。
- 动态预测(Dynamics Prediction) 在给定当前状态与假设动作的条件下,能够预测环境未来的状态变化( $s_{t+1} = f(s_t, a_t)$ )及可能的回报。
- 基于想象的规划(Planning inside Imagination) 能在内部模型中进行多步推演(Rollout),比较不同决策路径的长期后果,而非完全依赖真实环境中的昂贵试错。
意义
世界模型被普遍认为是通向通用人工智能(AGI)的关键基石,其价值主要体现在:
- 极高的样本效率(Sample Efficiency) 在内部模型中进行“梦境训练”,成本远低于真实环境交互。例如,DreamerV3 仅需少量交互即可在 Minecraft 中收集钻石。
- 支持长期规划与反事实推理 智能体不再局限于对当前输入的条件反射,而是能够思考“如果我这样做,会发生什么?”,从而实现长程目标。
- 提升安全性与可控性 在自动驾驶、手术机器人等高风险领域,先在世界模型中模拟危险情形(如碰撞、失误)是确保安全的前提。
- 促进泛化与迁移 对环境物理规律和因果机制的理解,使得智能体能将在一个场景中学到的知识迁移到全新的环境中。
资料
【2025-11-25】🌍世界模型,真的很Awesome
github 项目库
要点
- 着重梳理世界模型的定义,与当前的主流研究思路。从错综复杂的已有工作中抽丝剥茧,对于世界模型的定义进行了囊括性的分类。
- 系统性地整理了从基础到前沿的世界模型研究,创新性的按领域、研究范式与时间线将已有论文、数据集、综述分门别类,倒车入库。
- 打通入门到精通,让所有世界模型爱好者都有所收获。除了领域差异,同时也考虑到阅读者的处于的不同阶段
Meta FAIR 在做,Google Deepmind在做,Elon Musk的xAI的做,Jensen Huang的Nvidia在做,Dr. Feifei Li的World Lab在做。

经常看到 World Model 初创公司获得几亿的融资,World Model的学界研究收获广泛关注。
【2026-3-6】硅谷101 全面解析“世界模型”:定义、路线、实践与AGI的更近一步
- 世界模型的核心定义、三层研发结构,以及最主流的几条技术路线:视频生成、3D空间智能、智能体训练、JEPA抽象预测。
【2026-6-23】世界模型简介:智能体理解世界的内部引擎 github, 全面介绍世界模型概貌,精简
世界模型方向
世界模型前沿:主流6大技术路线
【2026-4-28】小红书帖子
世界模型技术路线分为六类:像素生成、隐空间建模、表征预测、因果建模、决策融合和物理结构建模。
| 流派 | 英文 | 流行度 | 核心思想 | 解释 | 案例 | 优点 | 缺点 |
|---|---|---|---|---|---|---|---|
| 像素生成范式 | pixel-based world model | 最多 | 高维观测空间的条件生成,不是真正的状态转移建模 视频生成模型改成“未来预测器” |
输入当前观测+动作,输出未来视频帧(pixel级别) | diffusion/transformer | 利用海量视频数据,效果逼真 | 学习视觉统计规律,不是真实物理规律,导致看起来合理但实际不可置信的结果 |
| 隐状态 | latent world model | - | 在隐空间建模世界,而不是像素空间 | 把观测压缩成隐变量,再学习状态随动作如何变化 | 典型结构 RSSM/Dreamer范式 | 比像素模型稳定、高效 | latent表示缺乏语义约束,容易学到错误的世界抽象 |
| 表征预测 | JEPA World model | 分水岭, 最接近真正的世界模型 | 既不生成像素也不重建输入,而是直接预测“抽象表示” | 模型通过encoder得到embedding,再预测未来embedding,专注于可预测的结构信息,忽略纹理、光照等无关细节 | I-JEPA, V-JEPA 通过 “mask预测” 学习时空结构 | 更接近因果结构、泛化能力更强 | - |
| 因果结构范式 | causal object-centric world model | 新 | latent空间做“干预”,逼迫模型学习物体交互关系 | JEPA基础上发展而来,不以patch为单位,而是以物体为单位建模,通过mask某个物体让模型用其他物体推断,引入因果约束 | C-JEPA | 比JEPA多了一层能力:不仅知道“会发生什么”,还学习“为什么发生” | - |
| 决策驱动范式 | model-based RL World Model | - | 世界模型用来决策,而不是纯建模,把世界模型当做可微分的模拟器 | 学习状态转移模型,内部进行rollout,再基于想象轨迹优化策略 | Dreamer、MuZero | 数据效率高 | 模型误差累积,导致规划失效 |
| 物理结构建模 | structured/physics-aware world model | 新路线 | 数据驱动之外,引入结构归纳偏置,让世界模型真正符合物理规律 | 方法:几何结构(3D/BEV/voxel、运动学约束(kinemetics)、object-level dynamics) | 更接近世界模型 | 更复杂、数据要求高 |
当前 world model的技术路线,一条清晰演化链:
- 像素生成(Pixel)
- → 隐空间建模(Latent/RSSM)
- → 表征预测(JEPA)
- → 因果建模(Causal JEPA)*→决策融合(Model-based RL)
- → 物理结构建模(Physics-aware)
每类方法通过不同方式逼近世界规律,从视觉统计到因果结构,再到物理规律,逐步提升模型的泛化能力和决策能力
| 分类类型 | 代表模型/团队 | 核心特点 | 典型落地场景 |
|---|---|---|---|
| 交互式世界模型(Interactive World Models) | Google DeepMind Genie | 支持静态图片/简单文本输入,实时生成可操控动态虚拟世界;人/智能体输入动作后,环境遵循物理规则实时反馈,是通用AGI、高阶仿真的核心基础 | 可交互虚拟游戏环境、人机可视化仿真、AI原生数字交互场景 |
| 空间智能与3D世界重建 | 李飞飞 World Labs(Marble) | 从2D图像/视频挖掘底层空间几何结构,重建具备物理约束、三维一致性的完整世界 | 机器人3D仿真、空间计算、影视/建筑数字孪生、3D资产生成 |
| 视频生成与预测式世界模型 | OpenAI Sora、Meta V-JEPA系列 | 基于海量视频数据学习物理常识(重力、流体、碰撞等),分为两条路线:像素级视频生成、隐空间表征预测;输出高物理真实度长时序视频/语义表征 | 自动驾驶仿真、物理模拟视频生成、视觉物理推理、长时序行为预测 |
| 具身智能与机器人世界模型 | 智源悟界系列、蚂蚁LingBot-World、DeepMind MuZero | 世界模型与实体/虚拟智能体深度耦合;智能体执行动作前,在内部模拟未来状态试错推演,优化机械抓取、导航等复杂控制任务,提升跨任务泛化能力 | 通用机器人控制、具身智能训练、游戏策略自学习、离线机器人仿真 |
世界模型构成
World model 主要包含状态表征和转移模型,正好对应mental representations 和 mental simulation。
这不是所有的序列预测都是world model了?
- 熟悉强化学习的同学能一眼看出来,这张图的结构是错误(不完整)的,而真正的结构是下面这张图
- RNN的输入不仅是z,还有动作action,这就不是通常的序列预测了

- 强化学习里有很多model-based RL,其中的model跟world model一回事儿
model-based RL这个方向长久以来的无奈:
- model不够准确,完全在model里训练的RL效果很差。
这个问题直到近几年才得到解决。
- Sutton 很久以前就意识到model不够准确。
- 在1990年提出
Dyna框架论文Integrated Architectures for Learning, Planning and Reacting based on Dynamic Programming(发表在第一次从workshop变成conference的ICML上),管这个model叫action model,强调预测action执行的结果。RL一边从真实数据中学习(第3行),一边从model中学习(第5行),以防model不准确造成策略学不好。
world model 对决策十分重要。
- 如果能获得准确的world model,那就可以通过在world model中就反复试错,找到现实最优决策。
world model 核心作用:反事实推理/Counterfactual reasoning
- 即便对于数据中没有见过的决策,在world model中都能推理出决策的结果。
图灵奖得主Judea Pearl的科普读物The book of why中绘制了一副因果阶梯
- 最下层是“关联”,也就是今天大部分预测模型主要在做的事;
- 中间层是“干预”,强化学习中的探索就是典型的干预;
- 最上层是反事实,通过想象回答 what if 问题。
Judea为反事实推理绘制的示意图,是科学家在大脑中想象,这与Jurgen在论文中用的示意图异曲同工。
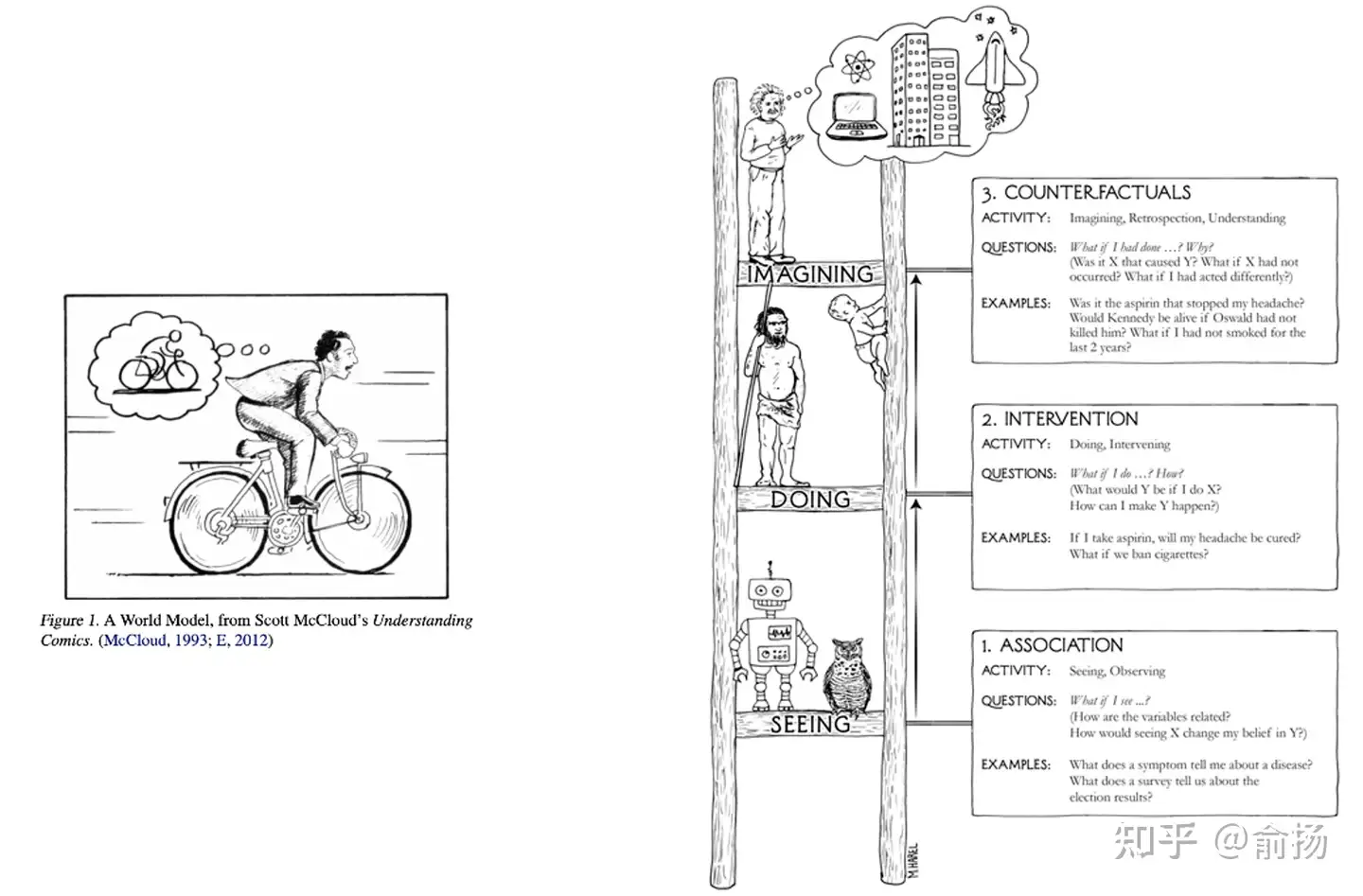
AI研究人员对world model的追求,是试图超越数据,进行反事实推理,回答what if问题能力的追求。这是一种人类天然具备,而当前的AI还做得很差的能力。一旦产生突破,AI决策能力会大幅提升,实现全自动驾驶等场景应用。
A Cognitive Architecture capable of reasoning & planning
LeCun 提出了构建「世界模型」想法,并在一篇题为《A path towards autonomous machine intelligence》论文中进行了详细阐述
构建一个能够进行推理和规划的认知架构。这个架构由 6 个独立的模块组成:
- 配置器(Configurator)模块;
- 感知模块(Perception module);
- 世界模型(World model);
- 成本模块(Cost module);
- actor 模块;
- 短期记忆模块(Short-term memory module)。
这些模块的具体信息参考:图灵奖获得者 Yann LeCun:未来几十年 AI 研究的最大挑战是「预测世界模型」, 文章中包含视频讲解
技术架构
世界模型的实现路径经历了从简单的像素预测到复杂的潜在空间动力学的演进。
- 循环状态空间模型(RSSM):当前强化学习领域最主流的架构,以 Dreamer 系列(DreamerV1/V2/V3)为代表。
- 核心思想:结合确定性的路径(如 RNN/GRU)和随机性的路径(如 VAE),在潜在空间中同时建模环境的确定性规律和不可预测的随机性。
- 优势:能有效处理局部可观测性,并在连续控制任务中达到 SOTA 性能。
- 联合嵌入预测架构(JEPA)
- Yann LeCun 提出,旨在解决生成式模型关注像素细节而忽略语义结构的问题。
- 核心思想:放弃预测具体的像素(Generative),转而在抽象的特征空间(Representation Space)中预测未来的特征嵌入。
- 代表作:I-JEPA, V-JEPA。
- 优势:计算效率高,专注于学习环境的高层语义和物理规律,而非纹理细节。
- 生成式交互环境(Generative Interactive Environments)
- 随着大模型的发展,基于 Transformer 的生成式世界模型开始兴起。
- 代表作:Genie(Google DeepMind)、Sora(OpenAI)。
- 特点:利用海量视频数据进行预训练,通过“预测下一个视频帧”来隐式学习物理规律。OpenAI 更是直接将 Sora 定义为“世界模拟器(World Simulator)”。
| 实现路径 | 代表模型 | 核心思想 | 核心优势 |
|---|---|---|---|
| 循环状态空间模型(RSSM) | DreamerV1/V2/V3 | 融合RNN/GRU确定性时序分支与VAE随机隐变量分支,在潜在空间统一建模环境固定规律与随机不确定性 | 适配局部观测场景,在连续控制类强化学习任务上达到SOTA效果 |
| 联合嵌入预测架构(JEPA) | I-JEPA、V-JEPA(Yann LeCun提出) | 摒弃像素级画面重建,仅在抽象表征特征空间预测未来语义嵌入,跳过冗余纹理生成 | 算力开销低、样本效率高,聚焦学习物理规则与高层空间语义,不纠缠画面细节 |
| 生成式交互环境(基于Transformer) | DeepMind Genie、OpenAI Sora | 依托海量视频预训练,通过逐帧视频预测隐式习得重力、碰撞等物理规则;Sora直接定位为通用世界模拟器 | 原生生成高真实度连续动态画面,支持文本/图像条件控制,可构建完整可交互虚拟环境 |
世界模型 vs 模拟器
【2025-7-28】 从视频生成到世界模型
- 刘威 前腾讯杰出科学家、混元大模型技术负责人:现在为Video Rebirth首席执行官
世界模型 = 世界模拟器 + 世界预测器
模拟器主题见站内专题:用户模拟器
世界模型需要解决的关键问题
- 因果推理: 生成遵循时间单向性,过去状态决定未来演化,不违反因果关系
- 物理准确: 生成内容符合真实物理规律和常识逻辑
- 持续一致: 连续生成长时段视频内容,整个序列中保持人物、物体、背景的前后一致性
- 实时交互: 实时响应用户lAgent输入,低延迟地动态生成
问题
世界模型仍面临核心难题:
- 长期预测的累积误差(Compounding Errors) 在多步推演中,微小的误差会被指数级放大,导致长程规划失效。
- 幻觉与物理一致性 生成式世界模型(如视频生成)常出现违反物理常识的现象(如物体凭空消失、液体反重力),说明其尚未完全掌握因果律。
- 多模态融合与具身智能 如何将语言模型的语义理解与机器人的物理控制模型结合,构建既懂道理又能干活的“具身世界模型”,是当前热点。
- Sim-to-Real 鸿沟 内部模型即使再完美,也无法完全捕捉真实世界的复杂性(如摩擦力、光照变化),如何实现从“脑中沙盘”到“现实世界”的零样本迁移仍具挑战。
如何构建世界模型
如何构建、训练世界模型?
- 未来几十年阻碍人工智能发展的真正障碍是为世界模型设计架构以及训练范式。
- 训练世界模型是自监督学习(SSL)中的一个典型例子,其基本思想是模式补全。对未来输入(或暂时未观察到的输入)的预测是模式补全的一个特例。
世界只能部分地预测。首先,如何表征预测中的不确定性。一个预测模型如何能代表多种预测?
概率模型在连续域中是难以实现的,而生成式模型必须预测世界的每一个细节。
基于此,LeCun 给出解决方案:联合嵌入预测架构(Joint-Embedding Predictive Architecture,JEPA)。
- JEPA 不是生成式的,因为不能轻易地用于从 x 预测 y, 仅捕获 x 和 y 之间的依赖关系,而不显式生成 y 的预测。
生成式架构会预测 y 的所有的细节,包括不相关的;而 JEPA 会预测 y 的抽象表征。
有五种思路是需要「彻底抛弃」的:
- 放弃生成式模型,支持联合嵌入架构;
- 放弃自回归式生成;
- 放弃概率模型,支持能量模型;
- 放弃对比式方法,支持正则化方法;
- 放弃强化学习,支持模型预测控制。
他的建议是,只有在计划不能产生预测结果时才使用 RL,以调整世界模型或 critic。
与能量模型一样,可以使用对比方法训练 JEPA。但是,对比方法在高维空间中效率很低,所以更适合用非对比方法来训练它们。在 JEPA 的情况下,可以通过四个标准来完成,如下图所示:
- 最大化 $s_x$ 关于 x 的信息量;
- 最大化 $s_y$ 关于 y 的信息量;
- 使 $s_y$ 容易从 $s_x$ 中预测;
- 最小化用于预测潜在变量 z 的信息含量。
迈向自主式 AI 系统的步骤都有哪些?LeCun 也给出了自己的想法:
- 1、自监督学习
- 学习世界的表征
- 学习世界的预测模型
- 2、处理预测中的不确定性
- 联合嵌入的预测架构
- 能量模型框架
- 3、从观察中学习世界模型
- 像动物和人类婴儿一样?
- 4、推理和规划
- 与基于梯度的学习兼容
- 没有符号,没有逻辑→向量和连续函数
其他的一些猜想包括:
- 预测是智能的本质:学习世界的预测模型是常识的基础
- 几乎所有的东西都是通过自监督学习得来的:低层次的特征、空间、物体、物理学、抽象表征…;几乎没有什么是通过强化、监督或模仿学习的
- 推理 = 模拟 / 预测 + 目标的优化:在计算上比自回归生成更强大。
- H-JEPA 与非对比性训练就是这样的:概率生成模型和对比方法是注定要失败的。
- 内在成本和架构驱动行为并决定学习的内容
- 情感是自主智能的必要条件:批评者或世界模型对结果的预期 + 内在的成本。
LeCun 总结了 AI 研究的当前挑战:(推荐阅读:思考总结 10 年,图灵奖得主 Yann LeCun 指明下一代 AI 方向:自主机器智能)
- 从视频、图像、音频、文本中找到训练基于 H-JEPA 的世界模型的通用方法;
- 设计替代成本以驱动 H-JEPA 学习相关表征(预测只是其中之一);
- 将 H-JEPA 集成到能够进行规划 / 推理的智能体中;
- 为存在不确定性的推理程序(基于梯度的方法、波束搜索、 MCTS….) 分层规划设计推理程序;
- 尽量减少在模型或批评者不准确的情况下使用 RL(这是不准确的,会导致不可预见的结);
Position paper:
- A path towards autonomous machine intelligence
- Longer talk: search “LeCun Berkeley” on YouTube
Modular Architecture for Autonomous AI
Configurator配置器- Configures other modules for task
Perception感知器- Estimates state of the world
World Model世界模型- Predicts future world states
Cost计算不舒适度- Compute “discomfort”
Actor演员- Find optimal action sequences
Short-Term Memory短时记忆- Stores state-cost episodes

- 详见博文:Meta’s Yann LeCun on his vision for human-level AI
LLM 是世界模型?
大语言模型(LLM)通过预测对话序列中的下一个单词生成输出,这种基于概率建模的机制已催生出趋近人类智力水平的对话交互、逻辑推理与内容创作能力。
但大模型与真正的通用人工智能(AGI)仍存在显著鸿沟。若能实现对环境中所有可能未来状态的全量模拟,是否就能构建出具备强智能的 AI 系统?
人类认知特质:
- 区别于 ChatGPT 的单一预测模式,人类能力体系天然存在具体技能实操与深度复杂任务处理的层级化差异。
模拟推理的典型案例:
- 某人(或许出于利己动机)通过心理层面模拟多种可能的行为后果,最终选择帮助一位正在哭泣的人。
世界模型领域核心学者观点
| 研究者/团队 | 核心主张 | 标志性成果 | 核心学术观点 |
|---|---|---|---|
| Yann LeCun(Meta) | 世界模型不应预测像素,而应预测抽象特征 | JEPA 系列(I-JEPA、V-JEPA) | 反对Sora这类像素级概率生成路线,逐像素预测算力低效、易产生幻觉;智能应在抽象表征空间预测未来语义,这是机器常识的必经之路 |
| 李飞飞(斯坦福 / World Labs) | 空间智能是AI的下一个前沿 | World Labs 3D大型世界模型Marble | 现有大模型缺少三维世界真实认知;真正智能必须掌握空间智能:理解几何、物理属性,可在3D空间完成推理与交互,是机器人、数字创作的底层基础 |
| Demis Hassabis & David Silver(DeepMind) | 规划是智能核心,世界模型是规划引擎 | AlphaGo、MuZero | 世界模型等同于大脑内部的模拟推演引擎;无需还原完整视觉画面,仅在潜空间预测价值、策略相关未来状态,就能实现超人类长时序规划能力 |
| Danijar Hafner(DeepMind / UC Berkeley) | 在想象中依靠世界模型学习,最大化样本效率 | DreamerV1/V2/V3(RSSM架构) | 基于世界模型的模型强化学习(MBRL)泛化能力极强;DreamerV3一套超参数适配数百类差异化任务,大幅降低真实环境交互需求,离线训练、跨任务泛化优势突出 |
| OpenAI 团队 | 缩放定律:预测即理解,视频生成等同于世界模拟 | Sora、GPT-4 | 遵循Scaling Law规模路线,认为足够大的模型+海量视频数据,通过逐Patch帧预测就能涌现物理、因果常识;Sora定位为通用世界模拟器,不认同LeCun摒弃像素生成的思路 |
正方
【2023-10-18】MIT 的 Max Tegmark 认为有世界模型
- MIT 和 东北大学的两位学者发现 大语言模型内部有一个世界模型,能够理解空间和时间
- LLM绝不仅仅是大家炒作的「
随机鹦鹉」,它的确理解自己在说什么! - 杨植麟:“Next token prediction(预测下一个字段)是唯一的问题。”“只要一条道走到黑,就能实现通用泛化的智能。”
【2023-10-20】再证大语言模型是世界模型!LLM能分清真理谎言,还能被人类洗脑
- 【2023-10-10】The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets
- dataexplorer
- MIT等学者的「世界模型」第二弹来了!这次,他们证明了LLM能够分清真话和假话,而通过「脑神经手术」,人类甚至还能给LLM打上思想钢印,改变它的信念。
新发现: LLM还可以区分语句的真假!
- 研究人员建立了简单、明确的真/假陈述数据集,并且把LLM对这些陈述的表征做了可视化。清晰的线性结构,真/假语句是完全分开的,线性结构是分层出现,如果是简单的陈述,真假语句的分离会更早出现,如果是「芝加哥在马达加斯加,北京在中国」这类复杂的陈述,分离就会更晚
- 第0层时,「芝加哥在马达加斯加」和「北京在中国」这两句话还混在一起。随着层数越来越高,大模型可越来越清晰地区分出,前者为假,后者为真
证明了两点——
- 从一个真/假数据集中提取的方向,可以准确地对结构和主题不同的数据集中的真/假语句进行分类。
- 仅使用「x大于/小于y」形式的语句找到的真值方向,在对西班牙语-英语翻译语句进行分类时的准确率为97%,例如「西班牙语单词『gato』的意思是『猫』」。
- 更令人惊喜的是,人类可以用确定的真相方向给LLM「洗脑」,让它们将虚假陈述视为真实,或者将真实陈述视为虚假。
- 「洗脑」前,对于「西班牙语单词『uno』的意思是『地板』」,LLM有72%的可能认为这句话是错误的。
- 但如果确定LLM存储这个信息的位置,覆盖这种说法,LLM就有70%的可能认为这句话是对的。
这种办法来提供模型的真实性,减轻幻觉。
反方
【2024-6-18】GPT-4不是世界模型,LeCun双手赞同!ACL力证LLM永远无法模拟世界
ACL 2024 顶会
UA微软等机构最新研究发现,GPT-4在复杂环境的模拟中,准确率甚至不及60%。
- LeCun激动地表示: 世界模型永远都不可能是LLM。
GPT-4 模拟基于常识任务的状态变化时,比如烧开水,准确度仅有60%
如何量化LLM的规划能力?
- 作者提出全新的基准测试——bytesized32-state-prediction,并在上面运行了GPT-4模型。
- GPT-simulator
文本环境中,智能体通过自然语言,完成特定的目标。
将文本虚拟环境形式化,建模为一种马尔可夫决策过程(POMDP),共有7个元组:S, A, T , O, R, C, D。
- S表示状态空间,A表示行动空间,T:S×A→S表示状态转移函数,O表示观测函数,R:S×A→R表示奖励函数,C表示用自然语言描述目标和动作语义的「上下文信息」,D:S×A→{0,1}表示二元指示函数,用0或1标记智能体是否完成任务。
- 上下文C为模型提供了除环境外的额外信息,比如行动规则、物体属性、打分规则和状态转换规则等等。
研究人员还提出了一个预测任务,称为 LLM-as-a-Simulator(LLM-Sim),作为定量评估大模型作为可靠模拟器的能力的一种方法。
LLM的预测模式也分为两种:预测下一步的完整状态,或者预测两个时刻之间的状态差。
- Bytesized32-SP基准测试的数据来源于公开的Bytesized32语料库,其中有32个人类编写的文字游戏。
网友:
目前的LLM能达到约60%的准确率(不专门为任务进行训练),这至少是某种「世界模型」了,而且每一代LLM都在提升。
Hinton
- AI已经不再是仅仅依赖于过去,基于统计模型做下一个token的预测,而是展现出更高的「理解」能力
- 大模型想要成为世界终极模拟器,还很远
案例
总结
知名世界模型总结
- V-JEPA:不生成画面,只学抽象物理表征(LeCun AGI路线)
- Genie:生成可交互2D视频世界,面向人类可视化操作
- Dreamer:只为强化学习决策服务,纯隐空间想象训练
- WoW:分层多尺度,大规模城市场景多智能体仿真
- Marble:原生三维持久化世界,面向商用3D空间产业落地
主流世界模型完整对比表(V-JEPA / Genie / Dreamer / WoW / 李飞飞Marble)
| 模型名称 | 研发主体 | 核心技术路线 | 核心原理 | 预测对象 | 核心优势 | 典型适用场景 | 开源/商用状态 |
|---|---|---|---|---|---|---|---|
| V-JEPA 2 | Meta AI(LeCun团队) | 非生成式表征预测路线 | JEPA联合嵌入预测,不重建像素,仅在语义隐空间预测未来表征,规避像素重建算力浪费 | 视频/图像的高层语义嵌入向量 | 样本效率极高、机器人零样本泛化强、算力开销低;无需生成画面即可做物理规划 | 具身机器人、物理推理、智能体规划、长时序抽象理解 | 权重开源(MIT协议) |
| Genie 3 | Google DeepMind | 动作条件交互式视频生成路线 | 自回归潜在扩散模型,从无标注视频自动推断隐动作空间,动作可控生成连续交互视频 | 像素级连续交互视频帧(动作+文本可控) | 实时可交互虚拟世界、画面连贯持久、支持文本生成可探索游戏级环境,涌现重力/碰撞物理 | 交互式数字孪生、游戏世界生成、仿真可视化、人机交互演示 | 闭源,仅学术预览 |
| Dreamer V3 | Google DeepMind | 基于模型强化学习路线(Model-Based RL) | RSSM循环隐状态空间模型,在内部想象轨迹中训练Actor-Critic策略,纯靠环境模拟降低真实交互成本 | 环境隐状态分布、未来奖励、策略价值 | 极强样本效率,一套超参数覆盖150+跨域任务(Atari/Minecraft/机器人),无需海量真实交互数据 | 游戏强化学习、机器人离线训练、控制类智能体、低数据仿真训练 | 论文开源、代码可复现 |
| WoW (World of Worlds) | 多高校联合学术模型 | 分层多尺度世界模拟器 | 分层时空动力学建模,多粒度并行模拟全局+局部环境,解耦场景布局与动态物体运动 | 全局场景布局+局部物体动态轨迹 | 支持超大场景长时序仿真、多智能体共存、分层物理解耦,适合大规模交通/城市场景 | 自动驾驶仿真、城市多智能体模拟、大规模环境推演 | 学术开源原型 |
| Marble(李飞飞World Labs) | World Labs(李飞飞团队) | 3D空间生成式世界模型 | 多模态输入生成持久化3D世界,原生高斯泼溅/网格几何表征,显式建模3D几何与物理约束 | 完整可编辑3D场景、多视点2D渲染画面、空间物理交互结果 | 原生三维一致性、场景永久无崩坏、支持多格式3D资产导出、面向产业商用落地 | 游戏开发、影视数字孪生、机器人3D仿真、建筑空间设计 | 商用订阅产品,闭源API |
【2023-6-14】I-JEPA
【2023-6-14】LeCun世界模型出场!Meta首个“类人”模型,自监督学习众望所归, META官方
LeCun在公开演讲中,再次批评了GPT大模型:根据概率生成自回归的大模型,根本无法破除幻觉难题。甚至直接发出断言:GPT模型活不过5年。
Meta震撼发布了一个「类人」的人工智能模型 I-JEPA,它可以比现有模型更准确地分析和完成缺失的图像。
- 论文地址: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
- 图像联合嵌入预测架构
I-JEPA模型,是史上第一个基于LeCun世界模型愿景关键部分的AI模型。
自监督学习的通用架构中,系统会学习捕捉不同输入之间的关系。目标是将高能量分配给不兼容的输入,将低能量分配给兼容的输入。
自监督学习的常见架构
这三种架构的区别
- (a) 联合嵌入(不变)架构会学习为兼容的输入x、y输出相似的嵌入,为不兼容的输入输出不相似的嵌入。
- (b) 生成式架构会学习直接从兼容的信号x重建信号y,使用以附加变量z(可能是潜变量)为条件的解码器网络,以促进重建。
- (c) 联合嵌入预测架构学习从兼容信号x中预测信号y的嵌入,使用以附加变量z(可能是潜变量)为条件的预测网络,来促进预测。
划重点:
- I-JEPA 填充缺失片段时,用的就是有关世界的背景知识!而不是像其他模型那样,仅仅通过查看附近的像素。
- I-JEPA就是通过创建外部世界的内部模型来学习。在补全图像的过程中,它比较的是图像的抽象表征,而不是比较像素本身。
在多个计算机视觉任务上,I-JEPA都表现出了强大的性能,并且比其他广泛使用的CV模型计算效率高得多
CVPR 2023, 距离提出「世界模型」概念一年多,眼看着LeCun就要实现自己的星辰大海了。训练代码和模型已经开源。
- img
- 创造出一个机器,学习世界如何运作的内部模型,更快速地学习,为完成复杂任务做出计划,并且随时应对不熟悉的新情况。
联合嵌入架构是人工智能的未来,而不是生成式
【2026-5-9】LeWorldModel 小型化
【2026-5-9】LeWorldModel 是 LeCun团队推出的突破性小模型:仅1500万参数,单显卡数小时即可完成训练。
- 其规划速度比巨型超算模型快48倍,关键在于摒弃了单纯记忆模式,真正学习物理规律。
- 通过高斯正则化技术解决了JEPA固有缺陷,使模型能在紧凑架构下稳定运行。
- 这项成果直接挑战了”模型越大越好”的AI行业主流思路,证明轻量化设计也能实现高性能,为未来AI发展提供了新方向。
【2024-7-29】蔚来 NWM
【2024-7-29】蔚来世界模型NWM 万千平行世界寻找最优解
详见站内专题: 自动驾驶
PAN
【2025-7-9】世界模型陷入困境?邢波团队深度剖析五大缺陷,全新 PAN 范式登场
卡耐基梅隆大学(CMU)、阿联酋穆罕默德・本・扎耶德人工智能大学(MBZUAI)、加州大学圣迭戈分校(UCSD)的研究团队,针对当前AI领域最前沿的研究方向——世界模型(World Models)的局限性展开了深入探讨。
构建与训练世界模型时,有五个关键要
- 其一,筛选并筹备蕴含目标世界信息的训练数据,数据需精准反映世界特征,为模型奠基
- 其二,构建
通用表征空间,用于刻画潜在世界状态,这一空间承载的信息要远超直观观测数据,能够挖掘深层语义与关联; - 其三,设计能对表征进行高效推理的架构,确保模型可基于已有表征,灵活且准确地推导未知;
- 其四,选定恰当的
目标函数,以此精准引导模型训练,让模型朝着预期方向优化; - 其五,明确世界模型在决策系统中的运用方式,使其能有效助力决策制定 。
创新性地提出了全新的世界模型架构PAN(Physical, Agentic, and Nested AGI System)。
PAN架构依托分层、多级以及混合连续/离散的表示形式,并采用生成式与自监督学习框架,旨在全方位提升模型性能。
PAN世界模型的详尽信息与实验结果将很快在另一篇论文中呈现。MBZUAI校长、CMU教授邢波在论文提交后,特意转推该论文,并表示PAN模型即将发布27B的第一版,此版本将成为首个可实际运行的通用世界模拟器,有望为世界模型领域带来新的变革 。
PAN架构严格遵循以下五大设计准则:
- 1)融合全模态体验数据,打破单一模态的信息壁垒;
- 2)构建连续与离散表示的混合体系,实现细节捕捉与抽象推理的平衡;
- 3)以增强型大语言模型(LLM)为主干,搭建分层生成建模与生成式潜在预测架构;
- 4)采用基于观测数据的生成损失函数,确保模型与现实世界的语义锚定;
- 5)通过强化学习(RL)机制,将世界模型转化为智能体的体验模拟器。
由 PAN 世界模型驱动的模拟推理智能体。与依赖即时反应策略的传统强化学习智能体,或在决策瞬间需耗费高额算力模拟未来的模型预测控制(MPC)智能体不同,其创新性地运用 PAN 生成的预计算模拟缓存。
决策进程中,智能体依据当下的认知信念与预期结果筛选行动方案,以此达成更高效、更灵活且更具目的性的规划模式。这种决策机制与人类推理的灵活性更为接近。
世界模型的终极目标并非生成视觉逼真的虚拟场景,而是对现实世界所有可能性空间的结构化模拟。当前领域的研究仍处于初级阶段,而PAN架构通过批判性重构与建设性创新,为下一代世界模型的理论突破与工程实现提供了可验证的探索方向。这种兼具学术严谨性与工程可行性的研究范式,有望推动世界模型从概念构想迈向真正的通用智能基础设施。
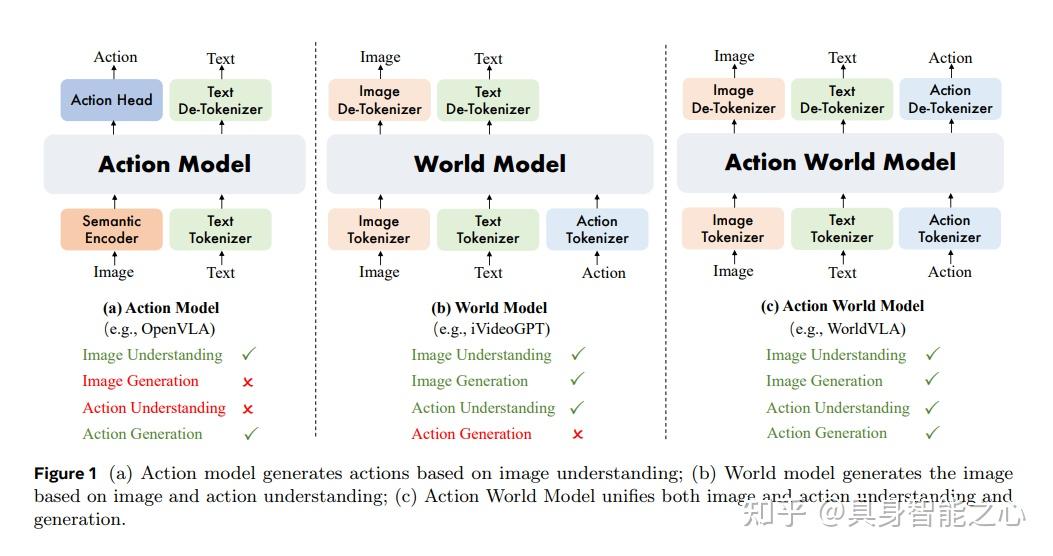
阿里 WorldVLA
【2025-6-26】全球首个融合世界模型与动作模型的自回归系统:WorldVLA,由阿里巴巴达摩院联合浙江大学等团队推出,使机器人既能理解环境又能精准执行动作
- 【论文题目】WorldVLA: Towards Autoregressive Action World Model
- 代码 WorldVLA
- 解读 WorldVLA:世界模型实现视觉-动作双向增强,抓取精度显著提升
如何让机器像人类一样,既能理解环境又能精准执行动作?传统机器人要么机械执行指令却不懂物理规律,要么能预测环境变化却无法自主决策。
阿里巴巴 DAMO Academy 联合湖畔实验室与浙江大学推出 WorldVLA——全球首个融合世界模型与动作模型的自回归系统。
- (1)动作模型:解析视觉与语言指令,生成抓取、移动等动作序列
- (2)世界模型:基于物理规律预测“若执行此动作,环境将如何变化”
两者形成双向增强循环,这种协同改变了传统机器人“盲目执行指令”的局限。
Genie
Genie 1/2
2024年,谷歌 DeepMind 首次放出世界模型——Genie 1和Genie 2,为AI智能体生成全新环境。
Genie 3
Genie 3是首个支持「实时交互」的世界模型,相较于Genie 2,一致性和真实感均有提升,而且时间更长,几分钟,内容还能保持连贯性。
【2025-8-5】Genie 3,一句话生成动态世界。
- DeepMind 官网:Genie 3: A new frontier for world models
功能
- 每秒20-24帧速度,实时生成720p画面
- 还能持续数分钟一致性

Genie 3升级点
- 生成时长史诗级加强——一口气能搞定长达数分钟,且内容连贯的可交互世界。
原理:
- 通过自回归方式逐帧生成,Genie 3 能在几分钟内保持环境物体和细节的一致性,视觉记忆最长可达一分钟。
- Genie 3一致性是涌现能力。NeRFs和高斯溅射(Gaussian Splatting)也能实现一致的可导航3D环境,但依赖显式3D表征。相比之下,Genie 3 生成的世界则远为动态和丰富,因为模型根据世界描述和用户行为逐帧创造
Genie 3 问世,标志着世界模拟AI迈向了全新高度,加速了人类通向AGI/ASI的终极目标


Mirage
Mirage 1
2025年7月3日,Mirage 1 推出,这是世界上首款AI原生UGC游戏引擎
Mirage 2
【2025-8-22】全球首款AI原生UGC游戏引擎迎来2.0版本。
- 体验地址 Mirage 2
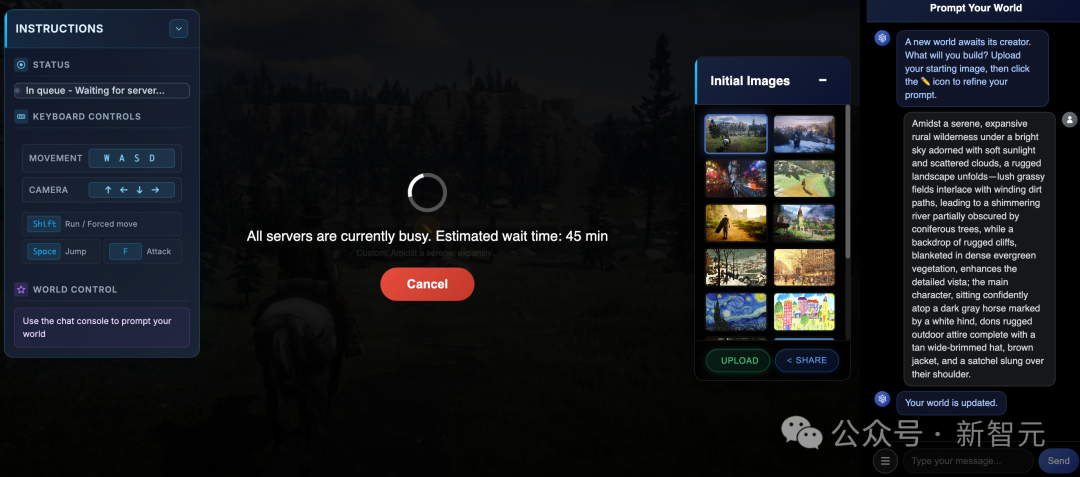
Mirage 2 是一款可在线游玩的实时通用领域生成式世界引擎,能将任何图像(照片、绘画、涂鸦等)转化为可实时互动的3D世界。
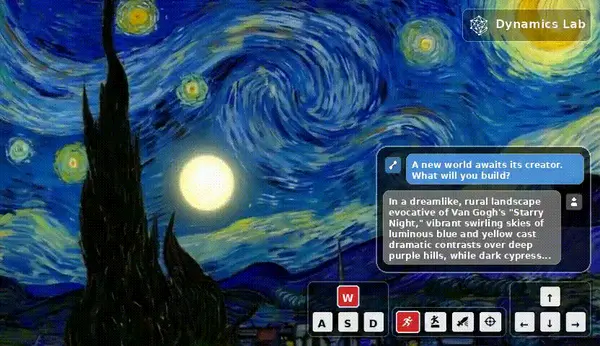
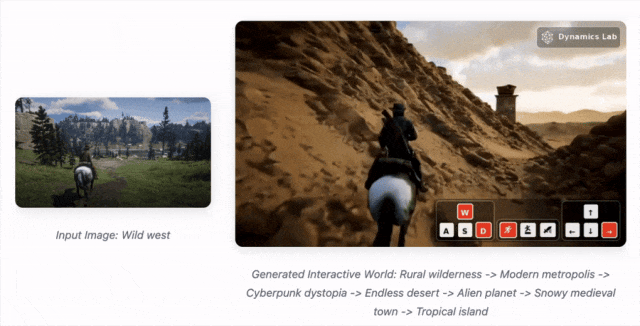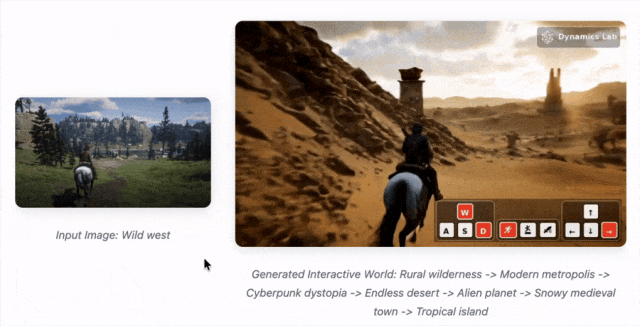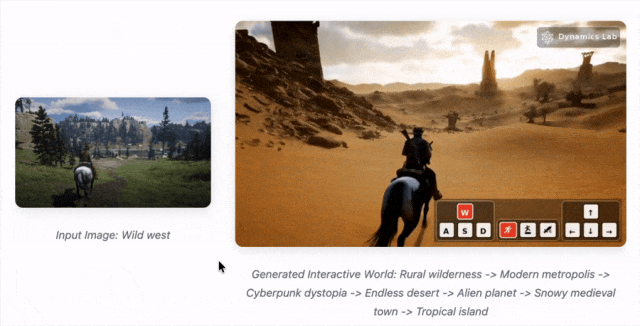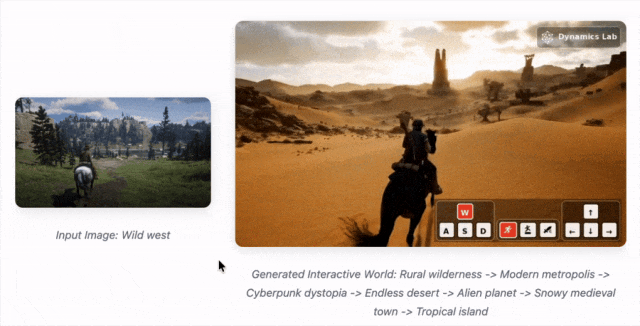
Mirage 2 把任何图片变成可玩3D世界的AI引擎,甚至能用文字实时操控。
把世界模型玩成了在线游戏,连谷歌的Genie 3都得靠边站
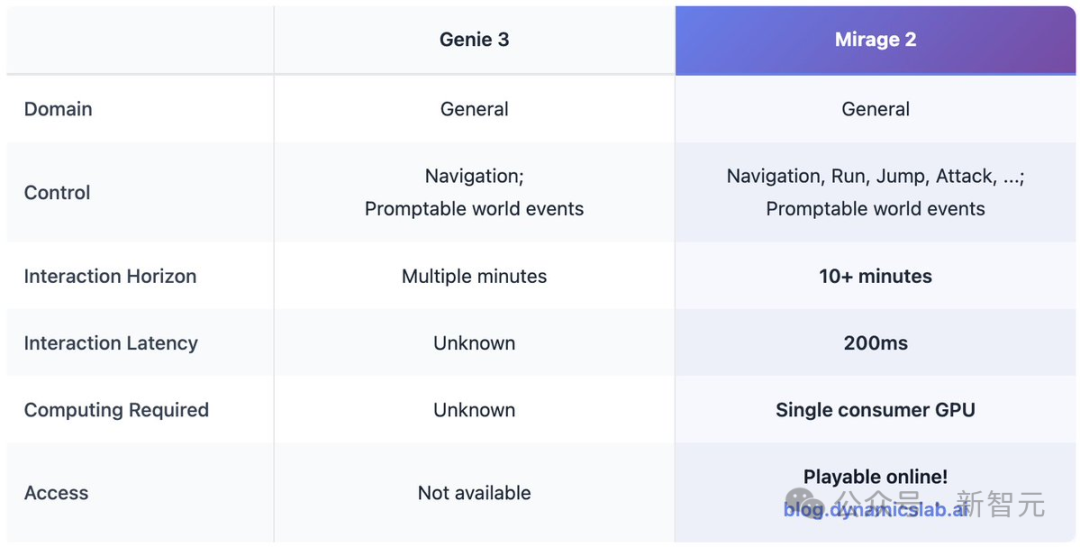
Mirage 2 和 Genie 3相比,控制的类别更加丰富,生成时长可以长达10+分钟,延迟可控制在200ms,只需要在消费级GPU即可实现,并且可以实时在线游玩。
- 更灵敏的提示控制——让您的创意更快、更精准地呈现。
- 降低游戏延迟——更流畅的操作,更少等待,更强的沉浸感。
- 通用领域建模——突破单一游戏类型的自由构建世界。
缺点:
- 动作控制精度:角色控制尚未达到完美,某些动作如右转时偶尔会出现响应迟钝的情况。
- 视觉稳定性:快速的场景转换可能会引入意外的细节变化,不过通过策略性的提示工程可以帮助在较长时间内保持一致性。
【2025-9-2】HunyuanWorld-Voyager
谷歌Genie3等支持实时交互视频生成世界模型不足
- 纯2D输出难以满足虚拟现实和物理仿真等应用的3D交互需求。
- 直接生成3D场景虽具备空间结构优势,却面临训练数据稀缺和内存效率低下的挑战,无法泛化到更大场景。
【2025-9-2】腾讯发布业界首个支持原生3D重建的超长漫游世界模型,HunyuanWorld-Voyager(简称混元Voyager)。
- 项目主页
- Github:HunyuanWorld-Voyager
- Hugging Face:HunyuanWorld-Voyager
- 技术报告:HYWorld_Voyager.pdf
- 参考资讯 腾讯混元开源超长漫游世界模型Voyager:首创支持原生3D重建
该模型聚焦于AI在空间智能领域的应用扩展,将为虚拟现实、物理仿真、游戏开发等领域提供高保真的3D场景漫游能力。
混元Voyager突破了传统视频生成在空间一致性和探索范围上的局限,能够生成长距离、世界一致的漫游场景,支持将视频直接导出为3D格式。
混元Voyager 3D输入-3D输出的特性,与此前已开源的混元世界模型1.0 高度适配,可进一步扩展 1.0 模型漫游范围,提升复杂场景的生成质量,并可对生成的场景做风格化控制和编辑。
不仅如此,混元Voyager 还可支持视频场景重建、3D物体纹理生成、视频风格定制化生成、视频深度估计等多种3D理解与生成应用,展现出空间智能的潜力。该模型现已正式上线,相关技术报告已公开,源代码在GitHub和Hugging Face上免费开放,供全球开发者下载和使用。
用户可通过键盘或者摇杆即可控制生成对应的视频画面,并可以通过3D空间记忆保持画面的高度一致性,实现Genie3相同的能力。同时,Voyager还支持将生成视频无损导出3D点云,无需依赖COLMAP等额外重建工具。
该模型在斯坦福大学李飞飞团队发布的世界模型基准测试 WorldScore 上位居综合能力首位,超越现有开源方法,在视频生成和3D重建任务中均表现出色。在视频生成和视频3D重建两个任务上,Voyager也均取得更好的结果。
【2025-10-30】Emu3.5
【2025-10-30】世界模型有了开源基座Emu3.5!拿下多模态SOTA,性能超越Nano Banana
北京智源人工智能研究院(BAAI)发布 悟界·Emu3.5
- 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
- 体验链接:体验报名入口
- 项目主页:landingPage
- 技术报告:Emu35_tech_report.pdf
像一个智能体(Agent)一样,理解长时序、空间一致的序列,模拟在虚拟世界中的探索和操作
Emu3.5 生成的作品展现出极强的连贯性、逻辑性,让AI模拟动态物理世界的能力又增强了,以第一人称视角进入所构建的虚拟世界。
也支持多图、多轮指令的复杂图像编辑,主体一致性、风格保持能力达到业界顶尖水平
给 Emu3.5 一张狐狸草图,并指令“把它变成3D模型、3D打印出来、再上色”,Emu3.5 直接一步步生成了从草图到最终手办形态的完整视觉流程
原理
Emu3.5 参数量仅34B,整个模型以标准 Decoder-only Transformer 为框架,单一模型能够同时完成视觉叙事、视觉引导、图像编辑、世界探索、具身操作等多种任务。
将所有任务都统一为下一State预测(Next-State Prediction)任务,无论是文本还是图像,都被一个强大的多模态分词器(Tokenizer)转换成离散的Token序列。
- 海量视频数据预训练
- 模型在超过10万亿Token的多模态数据上进行训练,其中主力是来自互联网视频的连续帧和转录文本。这使得模型从一开始就沉浸式学习时空连续性和因果关系。
- 强大的分词器
- 视觉分词器(Tokenizer)基于IBQ框架,拥有13万的视觉词汇表,并集成了扩散解码器,能实现高达2K分辨率的高保真图像重建。
- 多阶段对齐
- 在预训练之后,模型经过了大规模的有监督微调(SFT)和大规模多模态强化学习(RL),使用一个包含通用指标(如美学、图文对齐)和任务特定指标(如故事连贯性、文本渲染准确率)的复杂奖励系统进行优化。
- 推理加速黑科技
- 为了解决自回归模型生成图像慢,团队提出离散扩散适配(DiDA)技术,将逐个Token的生成方式转变为并行的双向预测,在不牺牲性能的前提下,使每张图像的推理速度提升近20倍。
效果
项权威基准上,性能媲美甚至超越了 Gemini-2.5-Flash-Image,即 Nano Banana,在文本渲染和多模态交错生成任务上优势尤其显著。
【2025-10-15】腾讯开源FlashWorld
【2025-10-30】世界模型可单GPU秒级生成?腾讯开源FlashWorld,效果惊艳
【2025-10-15】厦门大学和腾讯开源世界模型 FlashWorld
- 论文FlashWorld: High-quality 3D Scene Generation within Seconds
- 主页:FlashWorld-Project-Page
- Github:FlashWorld
- Huggingface Demo:FlashWorld-Demo-Spark
FlashWorld 不仅将三维场景的生成在单卡上做到了 5~10 秒(相比之前方法提速百倍),更统一支持了单张图片或文本输入,生成场景可在网页用户端实时渲染,同时质量还胜过其他同类闭源模型。
原理
FlashWorld 包含了两个训练流程:
- 双模式预训练:基于视频扩散先验,训练一个同时支持 以多视角为中心(MV)/ 以三维为中心(3D) 双模式输出的多视图扩散模型。
- 跨模式后训练:以 MV 模式为教师、3D 模式为学生,进行分布匹配蒸馏,兼顾高保真与 3D 一致。
FlashWorld 还利用了分布匹配蒸馏不需要 Ground Truth 的特性,将随机的图像、文本和轨迹组合成分布外的输入进行训练,进一步提升学生模型对各种场景、风格、轨迹的泛化能力。
效果
FlashWorld,Marble,RTFM 对比
FlashWorld 在预设轨迹下产生非常稳定、完整且高质量的渲染结果,生成速度比 Marble 的快速模式快 5 倍,而且完全通过前端渲染,不需要像 RTFM 一样需要等待连接后端 GPU 才能使用。
【2026-3-7】MiroFish
【2026-3-7】MiroFish 用AI造“平行世界”,精准推演未来走向
- GitHub 主页 mirofish-demo Predict Anything
时间线
- 2026 年 2 月底:开发者郭航江(BaiFu,北邮本科大四)耗时约 10 天完成核心开发。
- 2026 年 3 月 7 日:项目在 GitHub 正式开源上线。
- 2026 年 3 月 8 日:获盛大集团陈天桥 3000 万元人民币 种子轮投资。
00后大学生开发者团队打造,上线十几天就登顶全球热榜第一,甚至拿到了知名机构的投资,是今年最出圈的国产AI开源项目之一。
提到“推演未来”,会觉得是玄学、是噱头,但 MiroFish 不是算命,是高保真数字沙盘。
工作流步骤
- 01 图谱构建: 现实种子提取 & 个体与群体记忆注入 & GraphRAG构建
- 02 环境搭建: 实体关系抽取 & 人设生成 & 环境配置Agent注入仿真参数
- 03 开始模拟: 双平台并行模拟 & 自动解析预测需求 & 动态更新时序记忆
- 04 报告生成: ReportAgent拥有丰富的工具集与模拟后环境进行深度交互
- 05 深度互动: 与模拟世界中的任意一位进行对话 & 与ReportAgent进行对话
工作原理非常好理解:
- 给它一份“现实种子”——可以是政策草案、行业报告、舆情新闻、营销方案,甚至是一段文字描述;
- 它自动提取里面的关键信息,构建一个和现实高度相似的虚拟环境;
- 系统生成成百上千个有独立人格、有记忆、有行为逻辑的AI智能体,让它们在里面自由互动;
- 以上帝视角观察整个过程,甚至中途加入变量,看“蝴蝶效应”如何发生,最终得到一份可落地的预测报告。
举几个真实能用的场景:
- • 做自媒体:把你的选题丢进去,它能模拟网友反应,预判会不会火、有没有争议点;
- • 做职场方案:把活动策划、推广计划输进去,提前看执行中可能出现的问题;
- • 做舆情应对:遇到突发事件,模拟不同回应方式带来的结果,选最优解;
- • 做商业决策:小到店铺活动,大到产品迭代,不用真金白银试错,在虚拟世界跑一遍就行。
官方数据显示
- MiroFish 在模拟舆情发酵、用户行为、政策影响时,准确率可达75%以上,对于需要做判断、做决策的人来说,相当于多了一个“提前避坑”的神器。
最大优势:门槛极低,不用写代码,不用懂算法,上传文件、输入文字,等待几分钟就能出结果。
目前项目持续更新,支持本地部署,不用担心数据泄露,个人、小团队都能放心用。
【2026-6-5】Kairos-Homeworld 房间模拟器
【2026-6-5】全球首个机器人训练楼盘开盘:30万套中国住宅,机器人拎包入住
大晓机器人联合港中文MMLab发布新项目 Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。
- Kairos 3.0-4B
- HomeWorld
- 第一次把30万套中国真实住宅户型,搬进了数字世界。
- Kairos-Homeworld 不是给「找房APP」看房的,而是给「具身智能机器人」训练的仿真环境。
- 从30平米一居室到200平米大平层,从南北通透到封闭式厨房,从干湿分离卫生间到独立生活阳台,统统变成了机器人用来训练的3D仿真环境。
- Kairos-Homeworld 并不单纯是一个数据集,还是能够自动“盖房子”的模拟器。
大晓机器人开源过4B参数的世界模型 Kairos 3.0-4B。
- Kairos-Homeworld 给机器人建造训练场
- Kairos 3.0-4B 则是给机器人装上理解这个世界的大脑。
具身智能最核心的两块拼图:环境和模型,训练场和大脑。
【2026-6-8】MotionWAM
【2026-6-8】Mondo 机器人与港科大推出 MotionWAM,面向人形机器人的单目视觉端到端世界行动模型,结合视觉 DiT 和动作 DiT
人形机器人研究工作:
- 通过高效的去噪特征提取设计(比Cosmos Policy快7倍),单4090显卡实现基于世界模型的WAM + SONIC底层控制的多任务丝滑推理
🤖💪人形机器人做家务活已经成为可能,虽然还很慢,但是任劳任怨
- Paper: MotionWAM: Towards Foundation World Action Models for Real-Time Humanoid Loco-Manipulation
- Project Page: MotionWAM
详见站内专题:机器人vla模型
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
