类脑计算
背景
当大模型还在为处理更长文本扩充万亿参数时,人类大脑却能在稳定的生理消耗下,高效存储数十年的记忆与知识
当前 LLM可能已是传统机器学习范式的巅峰,其固有的黑箱问题是通往AGI的根本障碍。
必须重写机器学习的底层范式。
类脑实现
2024.7.11 Yan
【2024-7-11】 RockAI 推出 Yan 模型,放弃transformer架构, 探索类脑思路
改进点
- (1) transformer 换成 MCSD
- (2) 局部模态激活
- transformer架构: 问 1+1=?, 会激活所有参数, 算力消耗太大, 人脑不是这样
- 类脑机制: 人脑按听说看等功能分区, 根据任务激活对应区域,其它区域处于抑制状态, 这样功耗很低, 才20w, 相当于电灯泡
整体水平接近主流的transformer,部分性能超越
- 3b 模型, 大小5G,优化后,内存占用仅1G
- 端侧设备上运行,性能超过 transformer 30% 以上
问题
- 如何判断激活哪个区域? 仿真神经元选择算法, 一个单独的小型神经网络, 随着训练的进行,从随机选择迭代到针对性选择
- 训练上有什么技巧?
Yan 1.3: 群体智能单元大模型
- 训练效率提升7倍、推理吞吐量提升5倍、记忆能力提升3倍
- 秒级影响、非transformer结构、端到端多模态、满足大部分端侧设备
- 国内能在手机cpu上运行LLM的公司不超过3家
现在大模型训练反常识:训练一个模型,花费的计算资源太多,有的甚至要启动核电站训练。
视频介绍
- 站起来了!国内这家AI公司用新技术挑战ChatGPT权威 RockAI联创邹佳思
OpenAI GPT 在attention路上深耕,并非唯一出路。
改进
- 量化?
- 文本模态上量化,能保留80-90%的效果,而图像、视频大幅度下滑
- 量化后,权重固定,无法再学习
国内大模型机会
- 基础创新: 弯道超车的机会,卡脖子问题
- deepseek 推出 MLA/O1复现
- RockAI(岩山科技) 目标:把attention拿掉; 国内能在手机上运行的LLM不超过3家, Yan 模型解决端侧推理资源开销大的问题
- 国内蹦出来一批LLM,原因是 Llama 开源了。。。META 计划闭源
- 人才要求: 数学+算法都强,且愿意坐冷板凳
- 应用创新
- 国内做应用很强
- 人才要求:交叉学科背景,如 懂医学+AI
斑马鱼
- 只有几百万神经元,但避障能力非常强,这对智能驾驶很有启发
- 还不清楚大脑神经有没有量子效应。 如果斑马鱼神经网络有量子效应,那么鱼脑计算效率肯定是高效的,这在需要投入多少算力可能有的参考。
机器人
- 宇树科技、智源,机器人行业还需要5年沉淀
2024.8.25 内生复杂性类脑网络
【2024-8-25】放弃Scaling Law!中科院、清北提出内生复杂性类脑网络:让AI像人脑一样“小而强”
如果 AI 模型像人脑一样,规模小,耗能少,但具备同样复杂功能,那现阶段 AI 模型训练的耗能大、难理解的瓶颈是不是就能解决了?
中国科学院自动化研究所李国齐、徐波研究员团队联合清华大学、北京大学等团队便取得突破
- 借鉴大脑神经元复杂动力学特性,提出“基于内生复杂性”的类脑神经元模型构建方法,而非基于 Scaling Law 去构建更大、更深和更宽的神经网络。
- 这种方法不仅改善了传统模型通过向外拓展规模带来的计算资源消耗问题,还保持了性能,内存使用量减少了 4 倍,处理速度提高了 1 倍。
研究论文
- “Network model with internal complexity bridges artificial intelligence and neuroscience”, Nature Computational Science
- 共同通讯作者为中国科学院自动化所李国齐研究员、徐波研究员,北京大学田永鸿教授。共同一作是清华大学钱学森班的本科生何林轩(自动化所实习生),数理基科班本科生徐蕴辉(自动化所实习生),清华大学精仪系博士生何炜华和林逸晗。
李国齐解释说
- 构建更大、更复杂的神经网络的流行方法,称为“基于外生复杂性”,消耗了大量的能源和计算能力,同时缺乏可解释性。
- 相比之下,拥有 1000 亿个神经元和 1000 万亿个突触连接的人脑仅需 20 瓦的功率即可高效运行。
加州大学圣克鲁斯分校 Jason Eshraghian 团队在评论文章中表示,这一发现暗示了 AI 发展的潜在转变。尽管大语言模型(LLM)的成功展示了通过大量参数计数和复杂架构的外部复杂性的力量,但这项新的研究表明,增强内部复杂性可能提供了改善 AI 性能和效率的替代路径。
AI 中内部与外部复杂性之争仍然开放,两种方法在未来发展中都可能发挥作用。通过重新审视和深化神经科学与 AI 之间的联系,我们可能会发现构建更高效、更强大,甚至更“类脑”的 AI 系统的新方法。
效果怎么样?
首先展示了脉冲神经网络神经元 LIF(Leaky Integrate and Fire)模型和 HH(Hodgkin-Huxley)模型在动力学特性上存在等效性,进一步从理论上证明了 HH 神经元可以和四个具有特定连接结构的时变参数 LIF 神经元(tv-LIF)动力学特性等效。
基于这种等效性,团队通过设计微架构提升计算单元的内生复杂性,使 HH 网络模型能够模拟更大规模 LIF 网络模型的动力学特性,在更小的网络架构上实现与之相似的计算功能。进一步,团队将由四个 tv-LIF 神经元构建的“HH 模型”(tv-LIF2HH)简化为 s-LIF2HH 模型,通过仿真实验验证了这种简化模型在捕捉复杂动力学行为方面的有效性。
结果表明,HH 和 s-LIF2HH 网络具有相似的噪声鲁棒性,而鲁棒性源自 HH 神经元的动态复杂性和 s-LIF2HH 的复杂拓扑,而不仅仅是神经元数量。这表明,模型内部复杂性与外部复杂性之间具有等效性,并且它们在深度学习任务中比具有简单动力学增加规模的模型有更加明显的优势。
局限性
- HH 和 s-LIF2HH 模型在深度学习实验中具有不同的脉冲模式,这表明模拟中近似的动态特性可能不是它们可比性的良好解释。这种现象可能源于它们基本单元(HH 神经元和 s-LIF2HH 子网络)固有的相似复杂性。
- 此外,由于神经元非线性和脉冲机制的局限性,本研究仅在小型网络中进行了,未来将研究更大规模的网络和单个网络中多种神经元模型的影响。
【2024-12-17】天琴
【2024-12-17】全球首台100亿神经元类脑异构融合智算在横琴诞生
从人脑中借鉴运作原理,启发创造类脑智能技术,再反哺到人脑机制和神经医学的研究中去,这样的良性循环,让参与本次研讨会并进行现场考察的与会代表印象深刻。
2024年12月17日,“2024年类脑智算创新产品发布会暨神经医学大模型研讨会”在横琴举办。广东省智能科学与技术研究院(下称“广东省智能院”)发布第二代天琴芯类脑处理芯片LYRA-β Max、第二代天琴类脑晶圆计算芯片LYRA-β eXtreme、类脑计算卡、高密度类脑算力服务器等创新产品。
类脑智能计算芯片方面,类脑芯片联合实验室本次发布了第二代天琴芯类脑处理芯片LYRA-β Max,进一步拓展脉冲神经元计算规模达460万,计算性能较实验室上一代成果提升约2.7倍。实验室还在单张标准尺寸PCIe卡上实现多颗LYRA-β Max类脑芯片的互联集成和分布式计算,研发出可支持脉冲神经元计算规模最大达2600万以上的类脑计算卡。
不仅如此,实验室采用全新一代晶圆级集成技术,基于自主研发的存算融合、事件触发、线性可扩展的类脑计算架构,推出了第二代天琴类脑晶圆计算芯片LYRA-β eXtreme,单芯片脉冲神经元计算规模达4亿以上,持续刷新类脑算力纪录。
集成与配套技术方面,由智能计算系统联合实验室迭代推出的类脑血管相变散热系统,高效模拟人脑血管散热模式,相较市场上的风冷技术可减少87%的散热能耗,相较液冷技术可减少45%的散热能耗。实验室融合了自研的超高算力密度整机集成、类脑血管相变液冷、无风扇高功率氮化镓电源等技术,推出了高密度类脑算力服务器,可支持单机4亿以上脉冲神经元计算规模。
【2025-3-14】上海交大 BriLLM
BriLLM及其 SiFu 学习框架,并非对现有模型的改良,而是基于大脑宏观工作原理, 对学习机制的一次彻底重构。
上海交通大学团队为AGI发展开辟一条根植于生物智能、完全透明且高效的新路。
【2025-3-14】上海交大首发「类人脑」大模型 BriLLM,彻底脱离 Transformer架构,打造全新类脑大语言模型 BriLLM。
- 论文: BRILLM: BRAIN-INSPIRED LARGE LANGUAGE MODEL
- 代码: BriLLM0.5
- 模型: BriLLM0.5
- 解读: 上海交大发布全球首个“类人脑”大模型,引领机器学习新范式
采用全新的信号全连接流动(SiFu)学习范式,从根本上重塑了机器学习的基础。
为解决现有 Transformer 模型面临的黑箱不透明、二次方复杂度、上下文长度依赖等核心局限
亮点
- 范式创新:SiFu学习是对主流深度学习范式的一次勇敢颠覆,其追求可解释性和生物 plausibility 的立意非常具有前瞻性。
- 可解释性强:“节点即语义”的设计从根本上解决了黑箱问题。如果模型出错,理论上可以追溯到是哪条信号通路(即哪个词元组合的连接)出了问题,如同对大脑进行功能成像。
- 理论优雅:模型的设计原则与宏观神经科学发现高度契合,理论框架自洽且具有很强的解释力。
原理
BriLLM 融合了两大关键的神经认知原理:大脑处理信息依赖的量大原则
- (1)静态语义映射:将词元(token)精确映射到类似大脑皮层功能区的特化节点;
- 不同语义概念(如“狗”、“爱”、“肉”)被映射到大脑皮层的特定、固定的区域
- (2)动态信号传播:模拟电生理信息流在节点间的流动来完成计算。
- 认知过程由电生理信号在这些功能区之间传播、整合而产生
SiFu机制是对这两大原则的计算模拟。
这一架构实现了三大突破:
- 完全的模型可解释性
- 与上下文长度无关的模型扩展性
- 首次对类脑处理进行全局尺度的模拟。
要点
- 提出SiFu学习新范式:
- 最根本的创新:提出
信号全连接流动(Signal Fully-connected flowing,SiFu)学习范式。抛弃了传统深度学习的“黑箱”计算模式,转而模拟大脑的宏观信息处理机制。 - 这标志着从传统机器学习向类脑学习的范式级演进。
- 最根本的创新:提出
- 构建完全可解释的BriLLM模型:
- 基于SiFu范式,BriLLM 每个计算节点(Node)都唯一且静态地对应一个具体的词元(Token)。
- 模型的每一部分都有明确的语义,计算过程(即信号在节点间的流动)变得完全透明,实现了“认知过程可追溯性”,从根本上解决了AI的可解释性难题。
- 实现上下文无关的模型扩展:
- BriLLM的模型大小仅与词汇量和节点维度有关,而与处理的上下文长度完全无关。
- 这与Transformer架构中计算/内存复杂度随上下文长度二次方增长(O(L^2))形成鲜明对比。BriLLM在处理超长序列上具有天然的、类似大脑的效率优势。
- 首次实现宏观尺度的大脑模拟:
- 不同于以往仅借鉴神经元等微观特征的研究,BriLLM是首个在系统层面对大脑进行宏观功能(静态语义分区 + 动态信号整合)模拟的计算模型,为探索更接近生物智能的AGI提供了具体的工程蓝图。
示例
- 输入”dog”、”love”,模型通过计算信号流向各个候选词(”meat”、”apple”等)的能量,选择能量值最高的”meat”(0.89)作为预测输出。
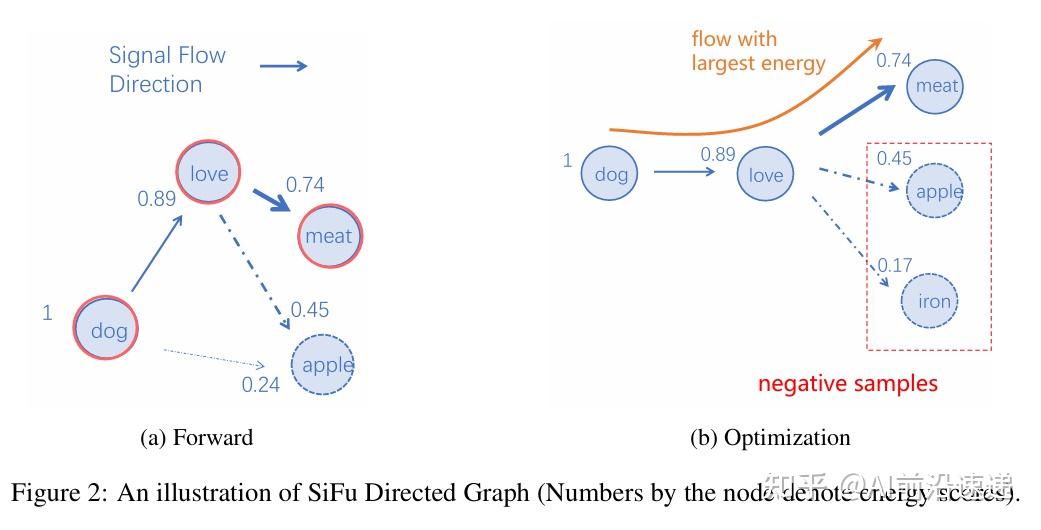
BriLLM架构:如何实现信号流动?
BriLLM是SiFu机制的具体实现
效果
初步 10-20亿参数模型已展现出与GPT-1相当的生成能力和稳定的学习动态。
可扩展性分析证实,将模型扩展至1000-2000亿参数规模并处理4万词元上下文是完全可行的。
结果分析:
- 学习稳定性:训练损失曲线平稳下降,证明模型能够有效学习语言模式
- 生成能力:从续写案例(下表)可以看出,模型具备了基础的上下文理解和生成能力,能够生成语法通顺、语义相关的文本。
- 例如,输入“阿根廷探戈是起源于”,模型续写“阿根廷探戈是起源于阿根廷或乌拉圭”。作者称,这一能力达到了早期GPT-1的核心生成水准。
- 可扩展性:即便将词汇量扩大到4万(与现代LLM相当),通过稀疏训练也可将BriLLM的参数控制在1000-2000亿,与主流LLM相当,同时保持其长文本处理的独特优势
BriLLM 为构建基于生物学原理的AGI建立了全新范式。
B站视频:突破Transformer!交大首发「类人脑」大模型BriLLM
【2025-8-2】浙大 悟空
2025年8月2日,浙江大学脑机智能全国重点实验室发布新一代神经拟态类脑计算机—Darwin Monkey(“悟空”)。

该成果是浙江大学类脑计算团队继2020年9月份研制成功我国首台亿级神经元类脑计算机Darwin Mouse(“米奇”)之后,取得又一重要突破。
“悟空”
- 由15台刀片式神经拟态类脑服务器组成,每台刀片式类脑服务器内部集成了64颗达尔文3代类脑计算芯片。
脉冲神经元规模超过20亿,神经突触超过千亿,其神经元数量已接近猕猴大脑规模,在典型运行状态下功耗约为2000瓦。

“悟空”
- 不仅能运行DeepSeek,完成逻辑推理、内容生成和数学求解等智能任务
- 还能模拟秀丽线虫、斑马鱼、小鼠以及猕猴等不同神经元规模的动物大脑,为脑科学研究提供了新的手段。
这是国际首台神经元规模超过20亿的基于专用神经拟态芯片的类脑计算机。
人脑是一部极其高效的“计算机”,能举一反三、融会贯通,可处理视觉、听觉、语言、学习、推理、决策、规划等各类任务。
类脑计算仿照生物神经网络工作原理,设计计算机系统,构建像大脑一样低功耗、高并行、高效率、智能化的计算系统。
还团队还研制了新一代达尔文类脑操作系统,采用分层资源管理架构,通过负载感知调度算法与动态时间片划分机制等技术,实现了神经拟态任务的高效并发调度与系统资源的动态优化。
【2025-9-5】瞬悉
【2025-9-10】用国产GPU训练的国产大模型来了!能耗暴降97.7%
2025年9月5日,中国科学院自动化研究所发布类脑脉冲大模型“瞬悉1.0”(SpikingBrain-1.0)的技术报告。
SpikingBrain-7B 开源模型仅用主流大模型 2% 的预训练数据,就实现了 Qwen2.5-7B 90% 的性能,并与Llama-3.1-8B等众多开源Transformer模型相媲美的性能。
我国首次提出大规模类脑线性基础模型架构,也是我国首次在国产GPU算力集群上构建类脑脉冲大模型的训练和推理框架。
起因
为什么需要新型非Transformer架构的大模型?
SpikingBrain 联合团队
- Transformer 架构面临固有缺点:训练计算开销随序列长度呈平方级增长,推理时的显存占用也随序列长度线性增加,带来海量资源消耗。这限制了模型处理超长序列(100万个token以上的序列)的能力。
- Transformer 架构本质上依赖“外生复杂性”,即通过堆叠更多神经元和更大规模计算来提升智能水平。
- 与此对比,人脑以极低的能耗(约为20W)实现了高度复杂的智能,其神经元具有丰富的内部动力学与多样性。
- 大模型或许存在另一条“内生复杂性”的发展路径,通过充分利用生物神经网络在神经元和神经环路上的结构和功能特性,打造下一代模型架构。
脉冲神经网络
低功耗脉冲神经网络(SNN)方案,被认为是通往更通用AI系统的新一代低功耗类脑神经网络方案之一。
其工作方式与大脑类似,只在需要的时候发送信号,因此功耗较低。
- 复杂的脉冲神经元可以用几个小神经元组合来实现同样的效果,这让构建高效的类脑网络成为可能。
基于上述理论研究,SpikingBrain 团队在模型架构中集成了混合高效注意力、MoE模块和脉冲编码三大核心组件。
- 1、混合高效注意力
- 注意力机制是大语言模型的核心计算单元。SpikingBrain整合了不同注意力机制的优势,7B版本模型采用层间混合的线性注意力与SWA,兼顾全局信息检索和局部依赖。
- 而更大规模的SpikingBrain-76B则使用层内并行混合,将线性、SWA与全量softmax注意力结合,同一层中并行运行多种注意力机制,可高效处理全局信息、局部依赖和长程依赖。
- 2、混合专家模块
- SpikingBrain从Qwen2.5-7B-Base(稠密模型)扩展而来。为了在现有稠密模型的基础上高效扩展,得到稀疏的混合专家模型,SpikingBrain团队使用了上采样(Upcycling)技术。
- 这一方法的核心是通过参数复制和输出缩放,使扩展后的模型在初始状态下与原模型保持一致,从而避免性能损失。
- 3、脉冲神经元
- 脉冲神经元是脉冲神经网络的基本单元。工程应用中常见的LIF(Leaky Integrate-and-Fire)模型,能在一定程度上模拟生物神经元的核心特性。但LIF存在神经元过度沉默或过度激活问题,从而影响模型精度与能效的平衡。
SpikingBrain 团队提出了自适应阈值脉冲神经元(Adaptive-threshold Spiking Neurons),可保持神经元适度激活,避免过度兴奋或静息。
训练
训练过程中,SpikingBrain团队将 Qwen2.5-7B-Base 转换为类脑脉冲大模型,主要包含3个环节。
- 持续预训练和长序列扩展中,模型使用了约150B tokens的数据,将序列长度从8K逐步扩展至128K。其训练数据量仅占从头训练所需的2%,实现了高效模型转换。
- 监督微调环节中,通过使用不同领域的数据集以及由DeepSeek-R1蒸馏得到的高质量推理数据集,模型在通用知识、对话和推理等方面的能力逐步提升。
- 模型还需要经过脉冲化编码。受生物神经系统启发,SpikingBrain团队提出将大模型的连续激活值转换为整数脉冲序列的策略。
推理阶段,整数脉冲计数会被展开成稀疏脉冲序列,以适配事件驱动计算。
SpikingBrain提供三种编码方式:
- 二值脉冲简单低能耗;
- 三值脉冲支持类似生物神经系统的兴奋-抑制调控,减少时间步和脉冲总数;
- 二进制脉冲可在高计数场景下显著降低计算量和能耗。
SpikingBrain 仍然选择了在国产沐曦GPU集群上进行训练,沐曦软件平台通过MoE优化、计算通信并行、显存优化、算子融合和自动调优等手段实现适配。 这一适配过程包括Triton适配、CUDA向MACA(沐曦兼容CUDA的软件栈)框架迁移两部分。这两条路径针对模型内部不同算子进行优化,结合形成适用于沐曦GPU的硬件适配方案。
效果
经过三阶段SFT对齐训练后,SpikingBrain-76B在通用知识、长序列建模及指令跟随能力上,与同量级开源对话模型相当,同时保持预训练获得的通用能力,未出现过拟合现象,显示了架构在对齐训练中的稳定性和可扩展性。
SpikingBrain-7B 在多个基准测试上恢复了基座模型 Qwen2.5-7B 约90%的性能,整体水平与Mistral-7B、Llama-3-8B等先进Transformer模型相当,表明高效线性注意力在降低推理复杂度的同时仍能保持较强的建模能力。
SpikingBrain 训练和推理全过程均在国产算力上完成,使用沐曦股份曦云C550 GPU组成的集群。
- 训练过程中,集群连续运行2周未中断,这也证明了构建国产自主可控的新型非Transformer大模型架构生态的可行性。
除了极高的数据效率之外,SpikingBrain还在推理效率上实现数量级提升。
- 100万个token上下文场景下,SpikingBrain-7B 生成首个token的耗时,比Qwen2.5-7B降低了96.2%。
- 这一特性也使得SpikingBrain尤其适合超长序列处理任务,如在法律和医学文档分析、复杂多智能体模拟、高能粒子物理实验、DNA序列分析、分子动力学轨迹等。
- 能耗方面,该模型平均乘加运算能耗相比传统FP16和INT8运算,分别降低了97.7%和85.2%。
SpikingBrain-76B混合线性MoE模型几乎完全恢复了基座模型性能。
在长序列推理场景中,SpikingBrain-7B模型在100万个token长度下TTFT(生成第一个Token所需时间)相比Transformer架构加速达到26.5倍,400万Token长度下加速超过100倍。
训练性能方面,7B模型在128K序列长度下的训练吞吐量为Qwen2.5-7B的5.36倍,这与推理性能提升基本一致。
同时在手机CPU端64K、128K、256K长度下,SpikingBrain较Llama3.2的同规模模型推理速度分别提升4.04倍、7.52倍、15.39倍。
模型
SpikingBrain-1.0 共有7B参数量和76B参数量两个版本。
2025年9月3日
- 7B版本的模型已在GitHub、魔搭等平台开源。
-
76B版本的模型暂未开源,但提供了体验链接。
- 开源地址:SpikingBrain-7B
- 技术报告:SpikingBrain_Report_Chi.pdf
- 体验链接:demo
【2026-3-7】果蝇大脑复现
【2026-3-9】果蝇大脑被完整“上传”并驱动虚拟身体,全脑仿真进入具身时代
2024 年 10 月《自然》杂志同期刊发九篇论文,宣布了成年果蝇(Drosophila melanogaster)完整大脑连接组(connectome,即所有神经元及其突触连接的结构图谱)的绘制完成。这一工程由 FlyWire 联盟牵头,普林斯顿大学神经科学家 Mala Murthy 和计算神经科学家 Sebastian Seung 是核心领导者。
FlyWire 联盟随后花了数年时间,结合 AI 自动分割和全球数百名科学家及志愿者的人工校对,最终完成了约 139,255 个神经元和超过 5,000 万个突触连接的完整映射。这是迄今为止已完成的最大、最完整的成体动物大脑连接组,远超此前秀丽隐杆线虫(C. elegans)302 个神经元的规模。
局限:一个脱离身体的大脑。神经活动产生了运动输出信号,信号却无处可去,没有物理躯体来接收和执行。这就像拥有了一份完整的汽车发动机设计图并让它在台架上运转,却没有把它装到一辆车上去跑过。
2026 年 3 月公布的这次演示,试图填补这个缺口。
2026年3月7日,一家名为 Eon Systems PBC 的旧金山初创公司发布视频:一只虚拟果蝇在物理模拟环境中爬行、转向、搓“手”,动作谈不上优美,甚至显得有些笨
B站视频:数字果蝇全脑模拟首次驱动物理身体产生多行为-2026【Eon Systems × FlyWire】
Eon Systems 发布首个 具身化(embodied)的全脑模拟系统:
- 研究团队基于 FlyWire 果蝇连接组数据构建包含 12.5 万神经元、5000 万突触 的完整计算模型,并将其与 MuJoCo 物理仿真的果蝇身体(NeuroMechFly v2)耦合,实现从: 感觉输入 → 神经动力学传播 → 运动输出 → 物理身体执行 的闭环控制。
- 与传统通过强化学习训练控制策略的仿生模型不同,该系统的行为完全由 真实连接组驱动的神经网络动力学产生,可在仿真中表现出多种自然行为。
- 这标志着“全脑仿真 + 具身机器人身体”的重要里程碑,为未来 数字孪生大脑(digital twin brain)研究提供了关键范式。
- Eon 下一步目标是构建 完整小鼠脑模拟(约7000万神经元),结合连接组重建与大规模神经成像数据,逐步迈向更大尺度的全脑仿真。
资料
- Video: X
- Blog: embodied-brain-emulation
- Website: eon.systems
这只虚拟果蝇的一切运动来自完整生物大脑的数字副本:神经元逐个对应,突触逐条连接,感觉输入流进去,神经活动在连接组网络中传播,运动指令流出来,物理仿真的身体执行动作。
感知到行动的回路,第一次在全脑仿真中闭合了
Eon Systems 的新演示整合了三条技术线索。
- 第一条是 Shiu 等人的全脑 LIF 计算模型。
- 第二条是 NeuroMechFly v2,这是瑞士洛桑联邦理工学院(EPFL)Pavan Ramdya 实验室团队开发的果蝇神经力学仿真框架,于 2024 年底发表在《自然·方法》(Nature Methods)上。NeuroMechFly v2 为果蝇提供了一个具备视觉、嗅觉、本体感觉的虚拟身体,能在复杂地形上行走,支持多种感觉运动控制的仿真。
- 第三条是同样来自 EPFL 的 Pembe Gizem Özdil 等人关于果蝇梳理行为中身体部位协调的中枢脑网络研究。Özdil 等人的工作揭示了一类中枢化的中间神经元和共享的前运动神经元如何协调颈部、触角和前腿的同步运动,发现了两种耦合的回路基序:促进对侧触角俯仰的递归兴奋性子网络,以及抑制同侧触角俯仰的广播抑制网络。
Eon Systems 将这些组件连接起来:连接组衍生的全脑模型作为“大脑”,NeuroMechFly v2 和 MuJoCo(Multi-Joint Dynamics with Contact,一个由 Google DeepMind 维护的开源物理仿真引擎)提供“身体”和物理环境。感觉输入进入仿真大脑,神经活动通过完整连接组传播,产生运动指令,驱动物理仿真的果蝇身体执行动作。据称,这只虚拟果蝇表现出了多种不同的自然行为,而这些行为完全由仿真大脑自身的回路动力学驱动。
Sapient
Sapient Intelligence 是类脑 AGI 领域的新锐公司,总部新加坡,以 HRM 分层推理架构颠覆传统大模型路线,用 “小数据、高效率、强推理” 实现接近人类的高阶思维能力,被视为Transformer 的有力挑战者
核心产品
- HRM(2025 年 6 月):基础推理架构,数学 / 逻辑任务超越主流 LLM
- HRM-Text(2026 年 5 月):面向文本的基础模型,1B 参数、1000 美元训练成本,长文本推理、代码、数学能力突出36氪
- 应用方向:科学计算(药物筛选)、气候预测、量化金融、具身 AI、医疗健康
HRM(Hierarchical Reasoning Model)
HRM 是 Sapient 自研基础架构,模仿人脑 “分层 - 循环” 机制,区别于大模型 “堆参数、堆数据” 的路线
- 2024年,Austin 郑晓明、王冠 创立 Sapient
- 定位:探索类脑 AGI,替代传统 Transformer,强调 “Lean General Intelligence”(轻量通用智能)

| 层级 | 名称 | 职责说明 |
|---|---|---|
| High-level(高层) | Slower Controller(慢速控制器) | 负责抽象、审慎推理 |
| Low-level(低层) | Faster Processor(高速处理器) | 负责精细化计算 |
关键优势(对比主流 LLM)
- 小样本学习:仅需数千样本(非百万级),训练数据需求减少约1000 倍sapient.inc
- 高效推理:1B 参数即可,推理速度快100 倍,普通 GPU 即可运行sapient.inc
- 强逻辑推理:擅长数学、数独、迷宫等长程复杂任务,ARC-AGI、高阶数独测试超越 GPT-4o、Claude
- 可解释性强:推理过程分层可见,非黑盒概率输出
【2026-5-20】推理内化小模型 HRM-Text
HRM-Text 小模型
- 只有约1B参数、从零预训练, 成本约1500美元、16块H100跑不到两天
- 却在MATH、GSM8K、ARC-Challenge等推理基准上打平不少大模型, 而且不蒸馏、不微调、不套壳,权重和代码全开源。
- HuggingFace联合创始人兼CEO亲自转发力荐, 图灵奖得主Bengio团队也押注同一条路线。
- 核心:『潜空间推理』—— 不再输出一长串思维链,而是让模型开口前先在脑子里做多轮分层递归计算, 被视为下一代推理架构的重要实验。
【2026-5-20】
Sapient Intelligence,2026-05 开源,HRM-Text
- 基于HRM(Hierarchical Recurrent Model)的1B参数文本基础模型,主打超高效训练+强推理能力,完全抛弃传统Transformer“堆参数/堆数据”路线。
核心定位与背景
- 发布时间:2026-05-18(论文+权重+代码全开源)
- 研发公司:Sapient Intelligence(智人智能,新加坡/北京)
- 核心架构:HRM分层循环架构(非Transformer)
- 模型规模:1.15B参数
- 训练数据:40B结构化指令-响应对(≈Llama3.2 3B的1/225)
- 训练成本:16×H100,1.9天,总成本$1,000–$1,500
- 核心口号:Lean General Intelligence(轻量通用智能)
HRM架构核心(双时间尺度循环)
HRM-Text 采用高低层解耦的双模块循环结构,模拟人脑“慢思考+快执行”:
| 层级 | 名称 | 角色 | 行为 |
|---|---|---|---|
| High-level(高层) | Slower Controller(慢速控制器) | 战略规划/抽象推理 | 慢迭代、抓全局、定策略、做反思 |
| Low-level(低层) | Faster Processor(高速处理器) | 细节计算/模式匹配 | 快循环、执行指令、算细节、出结果 |
- 工作机制:高层(H)×低层(L)循环,状态双向注入,参数固定但计算深度可扩展
- 训练创新:MagicNorm+深度信用分配,稳定深层循环训练
- 预训练目标:PrefixLM+任务完成损失,仅用指令-响应对,不用原始文本
关键性能(1B参数 vs 主流2–7B模型)
- 权威基准(2026-04 独立验证)
- MMLU(多任务理解):60.7%
- ARC-C(科学推理):81.9%
- DROP(数值推理):82.2%
- GSM8K(小学数学):84.5%
- MATH(高阶数学):56.2%(亮点)
- 效率对比(vs Llama3.2 3B / Qwen3.5 2B)
- 训练数据:40B vs 9T / 36T(少100–900倍)
- 训练算力:1.9天/16H100 vs 数周/数百卡(少96–432倍)
- 推理速度:普通GPU即可跑,比同参数Transformer快≈100倍
核心优势
- 数据效率极高:40B结构化token搞定,接近人脑“1B学习token”量级
- 推理能力突出:数学/逻辑/长程推理强,MATH超越Llama3.2 3B、Qwen3.5 2B
- 部署成本极低:1B参数、单卡可跑、$1500训练成本,个人/小团队可复现
-
可解释性强:分层推理过程可见,非黑盒概率输出,便于调试与审计
- 局限
- 非对话模型:预训练阶段,未做SFT/RLHF/多轮对话对齐,需二次微调才能聊天
- 上下文窗口:当前版本中等长度(未公开具体数值),不支持超长文本
- 通用知识覆盖:MMLU 60.7%,略低于同参数主流模型,强在推理、弱在纯记忆
- 适用场景
- 科研/教育:数学、逻辑、科学推理任务
- 企业轻量部署:低算力、低成本、高隐私场景(本地GPU即可跑)
- AI代理/工具调用:强规划+强执行,适合复杂任务拆解
- 二次开发:开源权重+代码,可基于HRM-Text做垂直领域微调
HRM-Text = 1B参数 + 类脑分层架构 + $1500训练成本 + 媲美3–7B模型的推理能力,是Transformer架构的强力挑战者,标志着“小而强”AGI路线的成熟。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
