- BERT
- BERT变种
- 结束
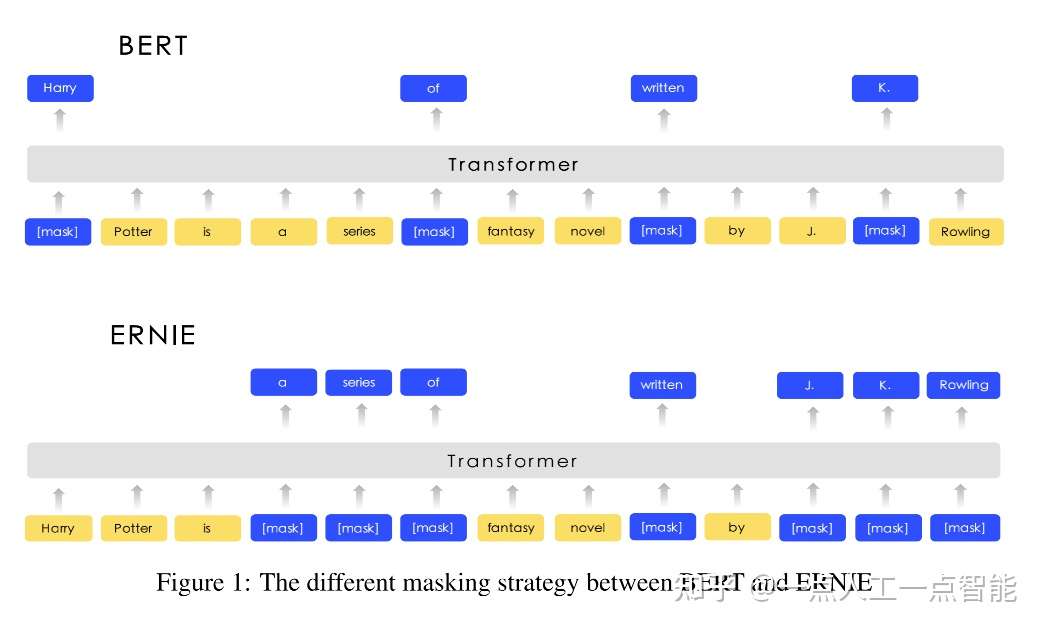
BERT
技术博主 Jay Alammar illustrated-bert,通过图解方式生动地讲解了 BERT 的架构和方法基础。
- 2018 年是机器学习模型处理文本(更准确地说是自然语言处理,简称 NLP)的一个转折点。


下游任务

背景
语言模型预训练用在下游任务的策略主要有两种:
- 基于特征(feature-base):也就是词向量,预训练模型训练好后输出的词向量直接应用在下游模型中。
- 如ELMo用了一个双向LSTM,一个负责用前几个词预测下一个词,另一个相反,用后面几个词来预测前一个词,一个从左看到右,一个从右看到左,能够很好地捕捉到上下文的信息,不过只能输出一个词向量,需要针对不同的下游任务构建新的模型。
- 基于微调(fine-tuning):先以自监督的形式预训练好一个很大的模型,然后根据下游任务接一个输出层,不需要再重新去设计模型架构
- 如OpenAI-GPT,但是GPT用的是一个单向transformer,训练时用前面几个词来预测后面一个词,只能从左往右看,不能够很好的捕捉到上下文的信息。
ELMo虽然用了两个单向的LSTM来构成一个双向架构,能捕捉到上下文信息,但是只能输出词向量,下游任务的模型还是要自己重新构建,而GPT虽然是基于微调,直接接个输出层就能用了,但是是单向的模型,只能基于上文预测下文,没有办法很好的捕捉到整个句子的信息。
BERT(Bidirectional Encoder Representations from Transformers)把这两个模型的思想融合了起来
- 首先,用基于微调的策略,在下游有监督任务里面只需要换个输出层就行
- 其次,训练时用了一个transformer的encoder来基于双向的上下文来表示词元
ELMo、GPT和BERT的区别
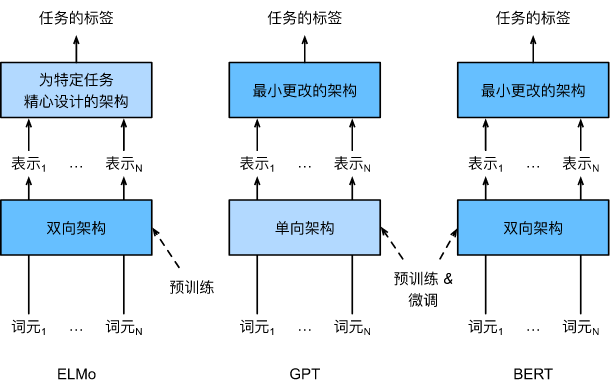
BERT很好的融合了ELMo和GPT的优点,论文中提到在11种自然语言处理任务中(文本分类、自然语言推断、问答、文本标记)都取得了SOTA的成绩。
BERT 介绍
2018年10月, Google AI研究院提出预训练模型 BERT(Bidirectional Encoder Representation from Transformers)
- 在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
- 论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
BERT网络架构使用《Attention is all you need》中提出的多层Transformer结构。
- 最大特点是抛弃了传统 RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
- Transformer的结构在NLP领域中已经得到了广泛应用。
效果
2018年11月底,谷歌发布了基于双向 Transformer 大规模预训练语言模型 BERT,该预训练模型能高效抽取文本信息并应用于各种 NLP 任务,该研究凭借预训练模型刷新了 11 项 NLP 任务的当前最优性能记录。
BERT 概念简单,但效果很好,刷新了 11 个 NLP 任务的当前最优结果(sota),
- GLUE 基准提升至 80.4%(7.6% 的绝对改进)
- MultiNL! 准确率提高到 86.7%(5.6% 的绝对改进)
- SQuAD v1.1 问答测试 F1 得分提高至 93.2 分(提高 1.5 分)–比人类表现还高出 2 分。
BERT结构
BERT结构

BERT 总体结构图
- 多个Transformer Encoder一层一层地堆叠起来,就组装成 BERT
- 论文分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
BERT 模型分为24层和12层两种,差别是使用transformer encoder的层数的差异
- BERT-base 使用 12层的 Transformer Encoder结构
- BERT-Large 使用 24层的 Transformer Encoder结构。
| 模型 | 层数 | 隐藏单元数 | head数 | 总参数量 | 运行环境 |
|---|---|---|---|---|---|
| Base | 12层 | 768 | 12个 | 110M | 单GPU |
| Large | 24层 | 1024 | 16个 | 340M | TPU |
BERT/GPT/Elmo
差异
BERT用 双向Transformer- OpenAI
GPT使用单向(从左到右)Transformer。 ELMo用是双向(单独的从左到右和从右到左)的LSTM拼接而成的特征。
只有BERT 所有层考虑了左右上下文。
除此之外,BERT和OpenAI GPT是微调(fine-tuning)的方法,而ELMo是一个基于特征的方法。
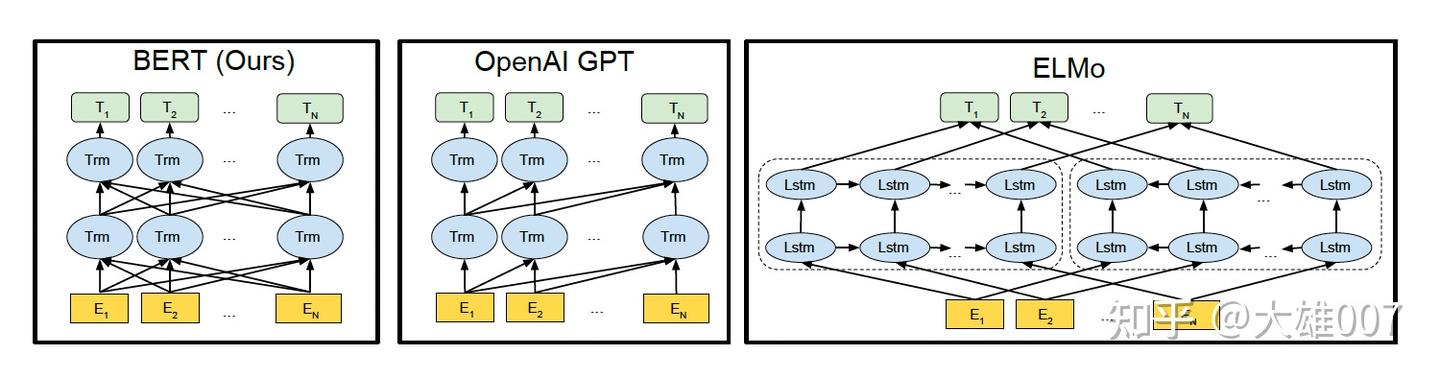
Trm代表Transformer层E代表Token Embedding,即每一个输入的单词映射成的向量T代表模型输出的每个Token的特征向量表示。
BERT 为什么比 ELMo 效果好?
从网络结构以及实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
- LSTM 抽取特征的能力远弱于 Transformer
- 拼接方式双向融合的特征融合能力偏弱
- BERT 训练数据以及模型参数均多于 ELMo
BERT vs Transformer
BERT 用了Transformer的encoder网络
- encoder中 Self-attention机制在编码一个token 时同时利用了其上下文的token,其中‘同时利用上下文’即为双向的体现,而并非想Bi-LSTM那样把句子倒序输入一遍。
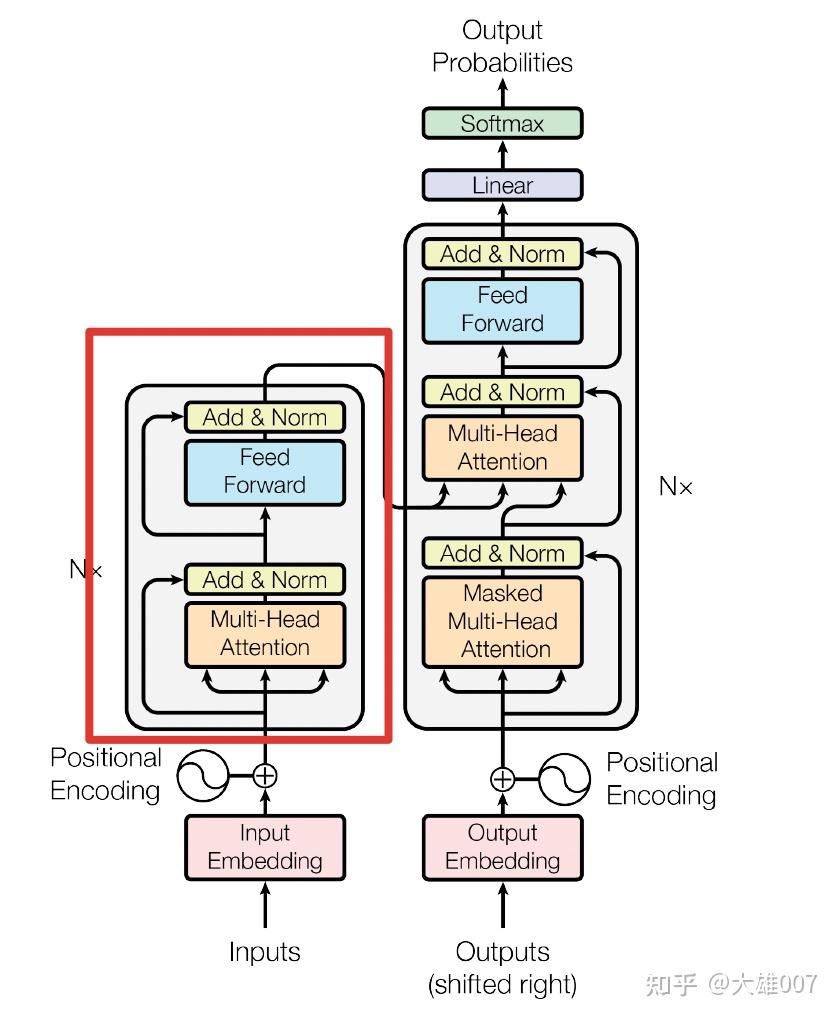
BERT之前, GPT-1 用 Transformer decoder 网络
- GPT是单向语言模型的预训练过程,更适用于文本生成,通过前文去预测当前的字。
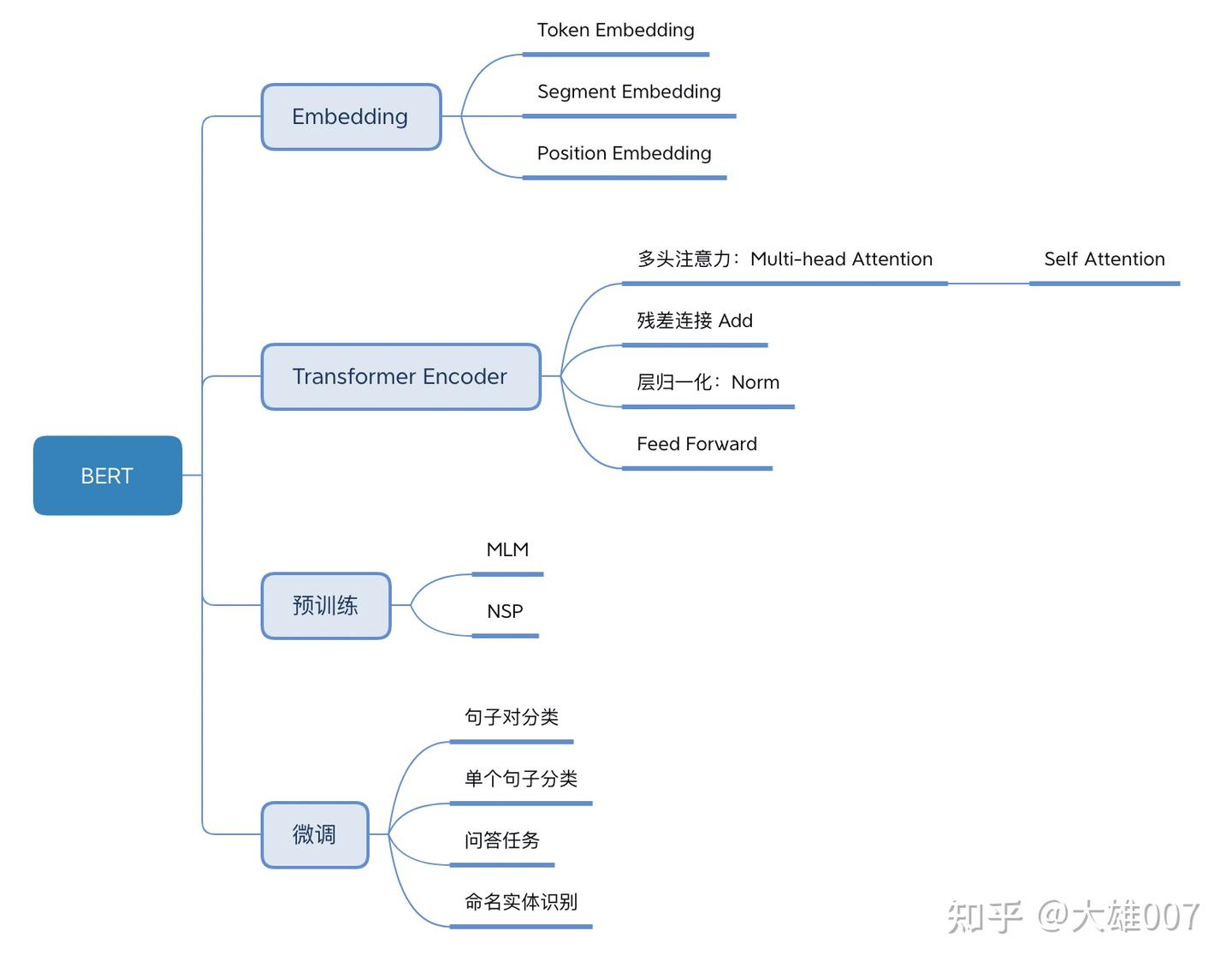
- Transformer中,模型输入被转换成512维向量,然后分为8个head,每个head 64维
-
但是BERT 768维,然后分 12个head,每个head 维度是64维
- Transformer中position Embedding 用三角函数
- BERT也有Postion Embedding, 但是随机初始化,然后从数据中学习。
变换图解
输入格式
Bert 的输入格式如下:
tokens : [CLS] Sentence 1 [SEP] Sentence 2 [SEP]
input_ids : 101 3322 102 9987 102
segment_ids: 0 0 0 1 1
文本特征
- 单句或者句子对(或叫上下句)经过 Word Piece Tokenize 后变成 tokens,然后通过一个词表(vocab)被映射成 input_ids。
- 上下句信息会被编码成 segment_ids,连同 input_ids 一起进入 Bert
- 经过多层 transformer 被转换成 Vector Representation,文本信息也就被编码到向量中了。
tokens 长度限制
注意
- tokens 总长度的限制(Seq Length):
- 硬性限制: 不能超过 512;
- 资源限制: GPU显存消耗会随着 Seq Length 的增加而显著增加。
- 所以,tokens总长度与 max batch size成反比例关系
Google 给出的在单个 Titan X GPU(12G RAM) 上 Bert 的资源消耗情况。

【2022-4-24】长文本分类——如何解决BERT输入大于512的问题
如何突破BERT窗口限制?
方法:
- Clipping(
截断法):对长输入截断,挑选其中「重要」token输入模型。- 腰部截断(最常见):挑选头部Top N 个 token,和文末 Top K 个 token,保证 N + K <= 510,这种方法基于的前提假设是「文章的首尾信息最能代表篇章的全局概要」;
- 两阶段:先将文章摘要,再喂给分类模型。
- 问题:但无论哪种截断方式,都将丢失部分文本信息,可能会导致分类错误。
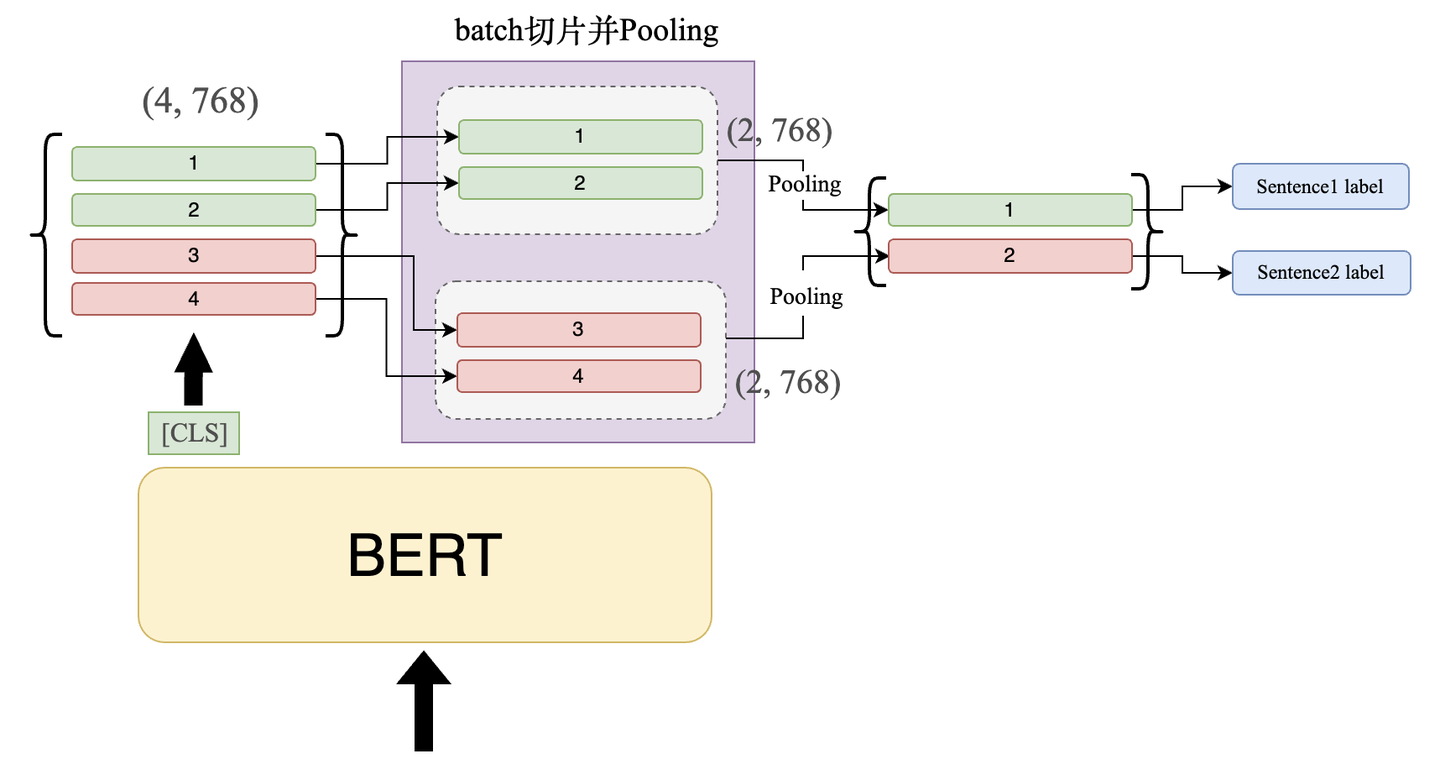
- Pooling(
池化法):截断法需要丢掉部分文本,保留文本所有信息,能避免文本丢失带来的影响。- 步骤1 句子分片: 长句子按照 510 长度分别切断,放到一个batch中,同时输入
- 步骤2 Pooling: 取 BERT 模型的
[CLS]输出,此时输出维度应该为:(4, 768)-> (2, 2, 768),对同一组的向量进行 Pooling 操作(如max-pooling) - 步骤3 分类: 将各句子对应的表征向量过一个 FC,通过 softmax 得到句子标签
- RNN(
循环法):BERT之所以会有最大长度的限制,是因为MLM预训练的时候就规定了最大的输入长度,而对于类RNN的网络来讲则不会有句子长度的限制(有多少个token就过多少次NN就行了)。- 但RNN相较于 Transformer 来讲最大问题就在于效果不好,如何将 RNN 的思想用在 Transformer 中就是一个比较有意思的话题了。
- 推荐可以看看ERNIE-DOC
图解
代码实现见原文:长文本分类——如何解决BERT输入大于512的问题
评论
- 最合理的答案是换外推性更好的位置编码,比如roformer t5 deberta
- 主要问题不在位置编码,在于attention的L^2复杂度,L>4096一般就炸显存
如何处理截断
真实数据集中,每条数据文本长度不同,一般呈现长尾分布,需要简单分析后,确定一个 Seq Length。
以 Google QUEST Q&A Labeling 比赛为例,文本特征包括 question_title、question_body 和 answer,tokenize 后分布
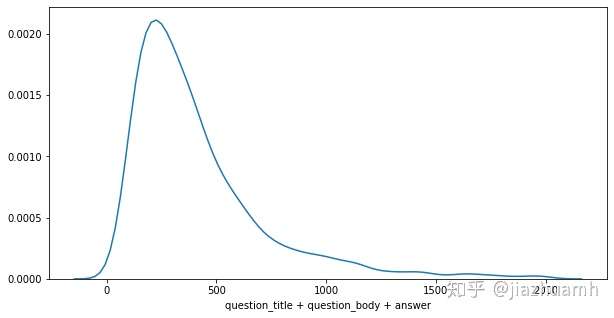
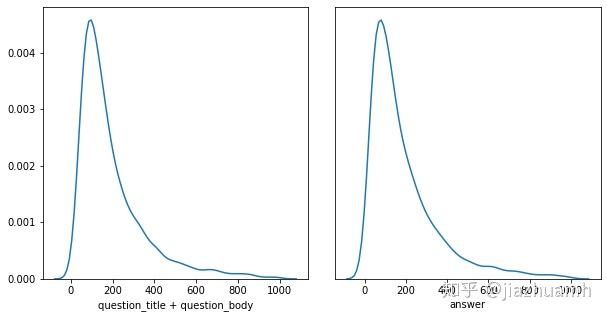
- 使用 question_title + question_body + answer 的方式,则有75%左右的样本满足512的长度限制,另外25%需要做truncate截断处理;
- 使用 question_title + question_body 和 answer 分开编码的方式,则有92%左右的样本满足512的长度限制,不过这时候需要使用两个 Bert;
常用截断策略有三种:
- pre-truncate 头部截断
- post-truncate 尾部截断
- middle-truncate (head + tail):最优
三种策略的效果,head + tail 最优,符合直觉,一般文章或段落的开头结尾往往会包含重要信息,截掉中间部分信息丢失最少。
- 当然,这并非绝对,建议三种方法都尝试,比较后挑选,或者都保留,后期做融合。
- 另外,根据具体的场景自定义截断策略,比如在上面例子中,可以通过设定 question_title 不超过 50,question_body 不超过 200,answer 不超过 200 等。
分词器
文本序列转换为token的id形式,涉及到不少字符串处理,如:字符串格式转换、空格判断、标点判断、控制符号判断、根据空格划分字符等等
convert_to_unicode文本转unicode,默认输入utf-8load_vocab加载此表convert_by_vocab根据此表进行id、token转换convert_tokens_to_idstoken转idconvert_ids_to_tokensid转token_is_punctuation标点符号判断_is_control控制字符判断_is_whitespace空格判断whitespace_tokenize去除前后空格,再用空格分词
【2023-11-24】NLP实战篇之bert源码阅读(tokenization)
BasicTokenizer
BasicTokenizer主要流程:
- 先对文本进行预处理,删除一些空白字符以及无效字符,将中日韩字符前后加上空格(并不是所有的日韩字符都要加,因为部分日韩字符也是用空格切分的,这部分就不用加),使用空格将文本切分,如果需要将文本小写化,则还需要去除去除文本中的重(zhong)音字符
- 然后,再根据标点与空格切分文本
- 最终,将文本变成词(中日韩字符则是字)粒度的序列。
class BasicTokenizer(object):
"""进行基础标志(标点分割,小写化等等)"""
def __init__(self, do_lower_case=True):
"""
Args:
do_lower_case: 是否小写化输入.
"""
self.do_lower_case = do_lower_case
# 预处理函数中包含了:处理无效字符,判断是否是中日韩字符,在中日韩文字两边添加空格,去除重音符号
def _clean_text(self, text):
"""删除无效字符并处理空白字符"""
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
"""判断是否是中日韩字符"""
# 这里的中日韩字符并不是包含了所有的韩文与日文,因为有部分韩文与日文也是
# 使用空格切分的,这部分不需要额外处理。
# 相关定义如下:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
def _tokenize_chinese_chars(self, text):
"""在中日韩文字符两边加上空格"""
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
def _run_strip_accents(self, text):
"""去除文本中的重(zhong)音符号"""
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn":
continue
output.append(char)
return "".join(output)
# 流程函数: 进过一些列预处理之后,将文本根据标点与空格分割即获取最终结果。
def tokenize(self, text):
"""标记一些列文本"""
text = convert_to_unicode(text) # 将文本转为Unicode格式
text = self._clean_text(text) # 删除处理空白字符与无效字符等
# 这是2018年11月1号,为了多语言模型与中文模型添加的。现在也可以应用在英文模型上。
text = self._tokenize_chinese_chars(text) # 在中文字符两边加上空格
orig_tokens = whitespace_tokenize(text) # 使用空格切分后的结果
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token) # 去除文本中的重(zhong)音符号
split_tokens.extend(self._run_split_on_punc(token)) # 根据标点符号分割文本
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
def _run_split_on_punc(self, text):
"""根据标点符号分割文本"""
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
WordpieceTokenizer
WordpieceTokenizer 将词再切分成小的词片段,类似中文的单个字符则不能再切分。
其思想是使用贪心的最长匹配优先算法进行词片段划分
- 以当前字符为开始,以后续的每一个字符为终止,组成的一系列子串中,找到存在于已有词表中最长的一个,如果没有找到,则将该词标记为未知。并且如果找到的子串不是词的开头,则在子串前添加“##”来加以区分,这是为了后面进行mask的时候,可以进行全词mask(因为这样就能知道所在词的开头与结尾)。
WordpieceTokenizer是接在BasicTokenizer之后处理的,所以其输入一般是单个单词。
class WordpieceTokenizer(object):
"""Runs WordPiece tokenziation."""
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab # 词表
self.unk_token = unk_token # 未知词的标志
self.max_input_chars_per_word = max_input_chars_per_word # 被切分词的最大长度,超过则认为是未知词
def tokenize(self, text):
"""将一段文本标记为词片段形式
基于给定词表,使用贪心最长匹配优先算法进行标记
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: 单个词或者使用空格分割之后的词序,输入应该已经经过BasicTokenizer处理。
Returns: 词片段序列
"""
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
# 单个词的字符数超过最大限度,则认为是未知词
output_tokens.append(self.unk_token)
continue
is_bad = False # 是否可以切分成词片段
start = 0
sub_tokens = [] # 切分后的词片段
# 循环判断词的片段是否在给定的词表里
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
# 如果不是开头,在在词片段前加上“##”,为了方便后面进行全词mask
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
# 如果没有找到在给定词表中的词片段,则认为是坏词
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad: # 如果认为是坏词,则标志为未知
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
FullTokenizer
FullTokenizer 是端到端文本标记处理类,外部调用时,直接调用这个类即可。其流程
- 先用
BasicTokenizer将文本切分成词序列 - 然后, 再用
WordpieceTokenizer将词序列切分成词片段序列
class FullTokenizer(object):
"""端到端地进行标记"""
def __init__(self, vocab_file, do_lower_case=True):
self.vocab = load_vocab(vocab_file) # 加载词表
self.inv_vocab = {v: k for k, v in self.vocab.items()} # 反向词表,key,value反转
self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case) # 基础标记
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab) # 词片段标记
def tokenize(self, text):
split_tokens = []
for token in self.basic_tokenizer.tokenize(text):
# 先将文本切分成一个词一个词的
for sub_token in self.wordpiece_tokenizer.tokenize(token):
# 再将每个词切分成词片段
split_tokens.append(sub_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
# 将标志转为id
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
# 将id转为标志
return convert_by_vocab(self.inv_vocab, ids)
位置编码
词向量包括三个部分的编码:词向量参数,位置向量参数
- 位置信息组装 =
token+segment+pos
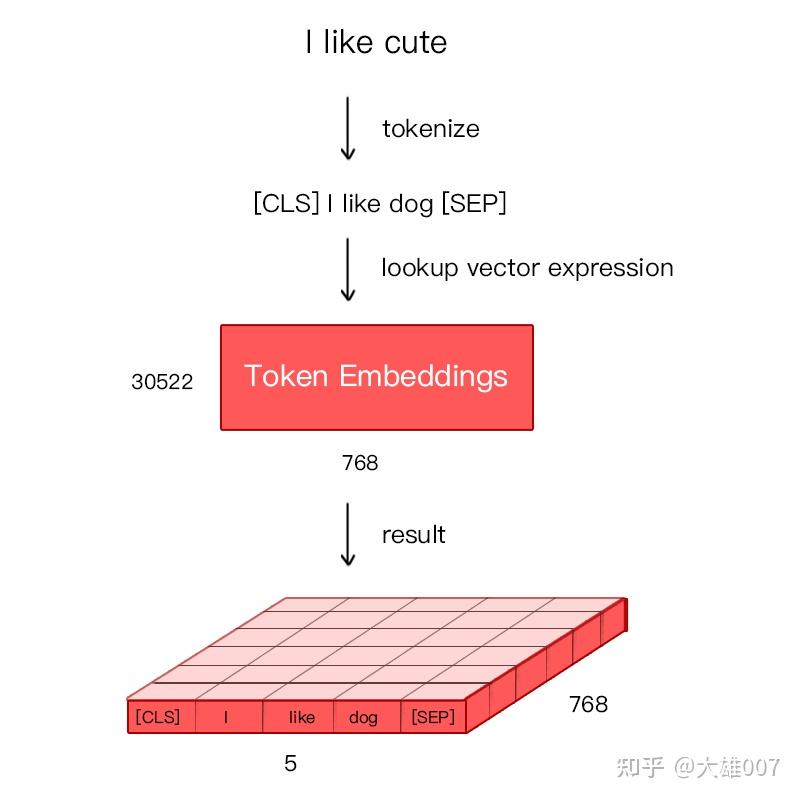
BERT 将 Token Embeddings (1, n, 768) + Segment Embeddings(1, n, 768) + Position Embeddings(1, n, 768) 求和, 得到一个 Embedding(1, n, 768) 作为模型输入。
Embedding由三种Embedding求和而成:
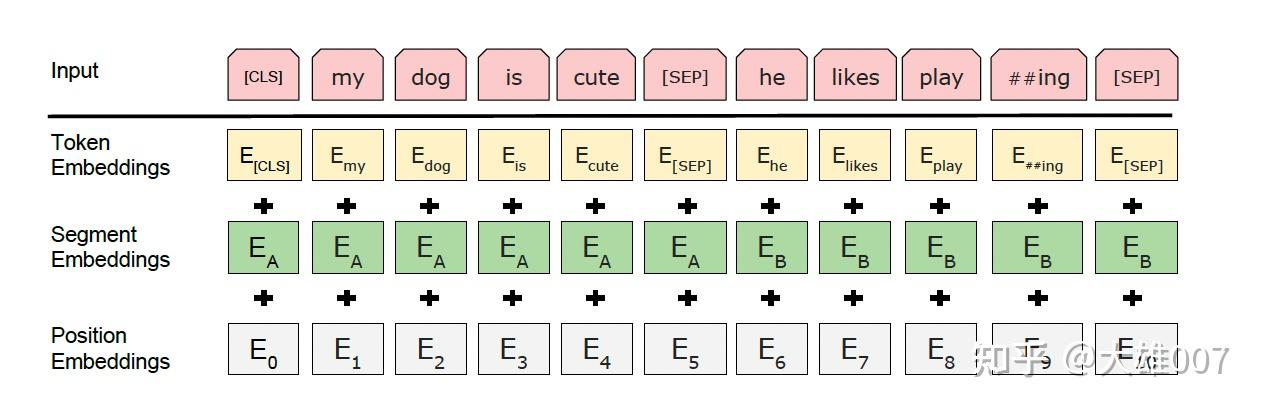
- Token Embeddings 前先处理 tokenization,将两个特殊 Token 插入文本开头
[CLS]和结尾[SEP]。[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
- (1)
Token Embeddings: 词向量,第一个单词是CLS标志,可用于分类任务- 通过词表(30522个词)将每个字转换成一维向量(base版768维),作为模型输入
- 英文词汇会做更细粒度的切分(次词 sub-word),如
playing或切割成play和##ing - 中文目前尚未对输入文本进行分词,直接对单子构成为本的输入单位。
- 将词切割成更细粒度的 Word Piece 是为了解决未登录词的常见方法。
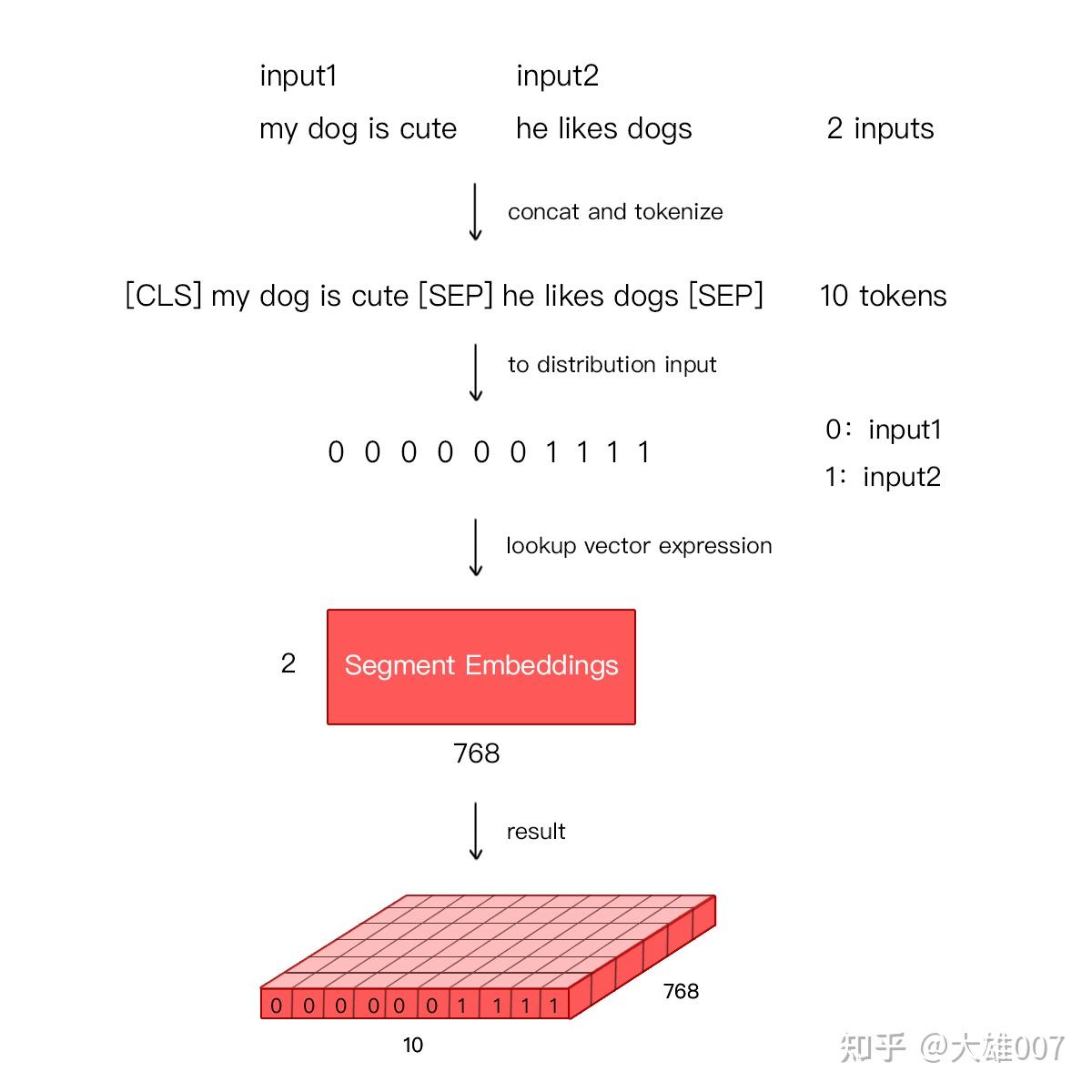
- (2)
Segment Embeddings: 区别两种句子,因为预训练不只做语言建模LM,还要做两个句子为输入的分类任务- Bert 处理句子对的分类任务,判断两个文本是否是语义相似的。句子对中的两个句子被简单拼接在一起,送入模型
- Bert 如何区分一个句子对是两个句子呢?Segment Embeddings。
- Segement Embeddings 层有两种向量表示,前一个向量是把 0 赋值给第一个句子的各个 Token,后一个向量是把1赋值给各个 Token
- 问答系统等任务要预测下一句,因此输入是有关联的句子。
- 而文本分类只有一个句子,那么 Segement embeddings 就全部是 0。
- (3)
Position Embeddings: 和 Transformer 不同,不是三角函数而是学习出来的- Transformer 通过植入关于 Token 的相对位置或者绝对位置信息来表示序列的顺序信息
- 由于出现在文本不同位置的字/词所携带的语义信息存在差异(如 ”你爱我“ 和 ”我爱你“),你和我虽然都和爱字很接近,但是位置不同,表示的含义不同。
- RNN 中,第二个
I和 第一个I表达的意义不一样,因为隐状态不一样。对第二个I来说,隐状态经过I think therefore三个词,包含了前面三个词的信息,而第一个I只是一个初始值。因此,RNN 的隐状态保证在不同位置上相同的词有不同的输出向量表示。
BERT 中处理的最长序列是 512 个 Token,长度超过 512 会被截取,BERT 在各个位置上学习一个向量来表示序列顺序的信息编码进来,这意味着 Position Embeddings 实际上是一个 (512, 768) 的 lookup 表,表第一行是代表第一个序列的每个位置,第二行代表序列第二个位置。
Token Embeddings 层会将每个词转换成 768 维向量,例子中 5 个Token 会被转换成一个 (6, 768) 的矩阵或 (1, 6, 768) 的张量。
Encoder
与 TransformerEncoder 不同, BERT Encoder 使用片段嵌入和可学习的位置嵌入。
- nn.Parameter 传入的是一个随机数
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens) # token id 化
self.segment_embedding = nn.Embedding(2, num_hiddens) # 片段 id 化
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens)) # 位置信息 id 化
def forward(self, tokens, segments, valid_lens):
"""
前向传播
"""
# 位置信息组装 token + segment + pos
# X形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
特殊符号
Bert 输入端,通过添加 special tokens
Google QUEST Q&A Labeling 比赛举例,比如对于每条问答数据,有一个类别信息,可以是 culture、science 等
设计两个 special tokens [CAT=CULTURE] 和 [CAT=SCIENCE] 加入到文本中:
tokens : [CLS] [CAT=CULTURE] question [SEP] answer [SEP]
input_ids : 101 1 3322 102 9987 102
segment_ids: 0 0 0 0 1 1
新增的 special tokens 需要相应地在词表中添加,实现方法也很简单,具体可以查看相关框架的文档。
输出
Bert 输出端
- 直接做 embedding
- 另一种是直接在 Bert 输出端对 meta 特征进行 embedding,然后与文本特征的 Vector Representation 进行融合。
一个简单的代码实现示意:
emb = nn.Embedding(10, 32) # 初始化一个 Embedding 层
meta_vector = emb(cat) # 将类别编码成 vector
logits = torch.cat([txt_vector, meta_vector], dim=-1) # 文本向量和类别向量融合
两种方式都可以尝试
向量表示 Vector Representation
文本特征经过 Encoder 编码后变成了啥?
- 以12层的 bert-base 为例,得到了 transformer 12层的 hidden states,每一层的维度为
B x L x HB表示 batch size,L表示 Seq Length,H表示 Hidden dim
一般最后一层第一个 token (也即 [CLS]) 对应的向量可以作为整个句子(或句子对)的向量表示,包含了从文本中提取的有效信息。但在比赛中可以看到各种花式操作,并且都得到了明显的效果提升,比如:
- 取最后一层所有 token 对应的向量做融合;
- 取所有层的第一个 token 对应的向量做融合;
- 取最后四层的所有 token 对应的向量,加权重(可学习)融合;
- …

分类器 Classifier
分类器一般是一或多层的全连接网络,最终把特征的向量表示映射到 label (target) 维度上。这部分比较灵活,比如使用不同的激活函数、Batch Normalization、dropout、使用不同的损失函数甚至根据比赛 metric 自定义损失函数等。
小技巧:
(1)Multi-Sample Dropout
使用连续的 dropout,加快模型收敛,增加泛化能力,详细见论文,代码实现如下:
dropouts = nn.ModuleList([nn.Dropout(0.5) for _ in range(5)])
for j, dropout in enumerate(dropouts):
if j == 0:
logit = self.fc(dropout(h))
else:
logit += self.fc(dropout(h))
(2)辅助任务
多任务学习在 NLP 领域很常见,通过设计一些与目标任务相关的辅助任务,有时也可以获得不错的提升。在 Jigsaw Unintended Bias in Toxicity Classification 比赛中,1st place solution 就采用了辅助任务的方法。

图中 Target 是比赛要预测的目标,is male mentioned、is christian mentioned 等是一些辅助目标,通过这些辅助目标提供的监督信号,也可以对模型的训练和最终效果提供帮助。
采样
当一种神经网络框架很强大时(比如 transformer 结构),对网络结构的小的改进(比如在 classifier 中增加几层全连接层、改变一下激活函数、使用dropout等)收益都是非常小的,这时候大的提升点往往是在数据层面。
文本扩增
比较常用且有效的方法是基于翻译的,叫做 back translation (回译法)。原理简单,是将文本翻译成另一种语言,然后再翻译回来,比如:
# 原始文本
Take care not to believe your own bullshit, see On Bullshit.
# EN -> DE -> EN
Be careful not to trust your own nonsense, see On Bullshit.
# EN -> FR -> EN
Be careful not to believe your own bullshit, see On Bullshit.
# EN -> ES -> EN
Be careful not to believe in your own shit, see Bullshit.
因为 Google 翻译已经做到了很高的准确率,所以 back translation 基本不会出现太大的语义改变,不过需要有办法搞到 Google 翻译的 api,目前似乎没有免费可用的了。
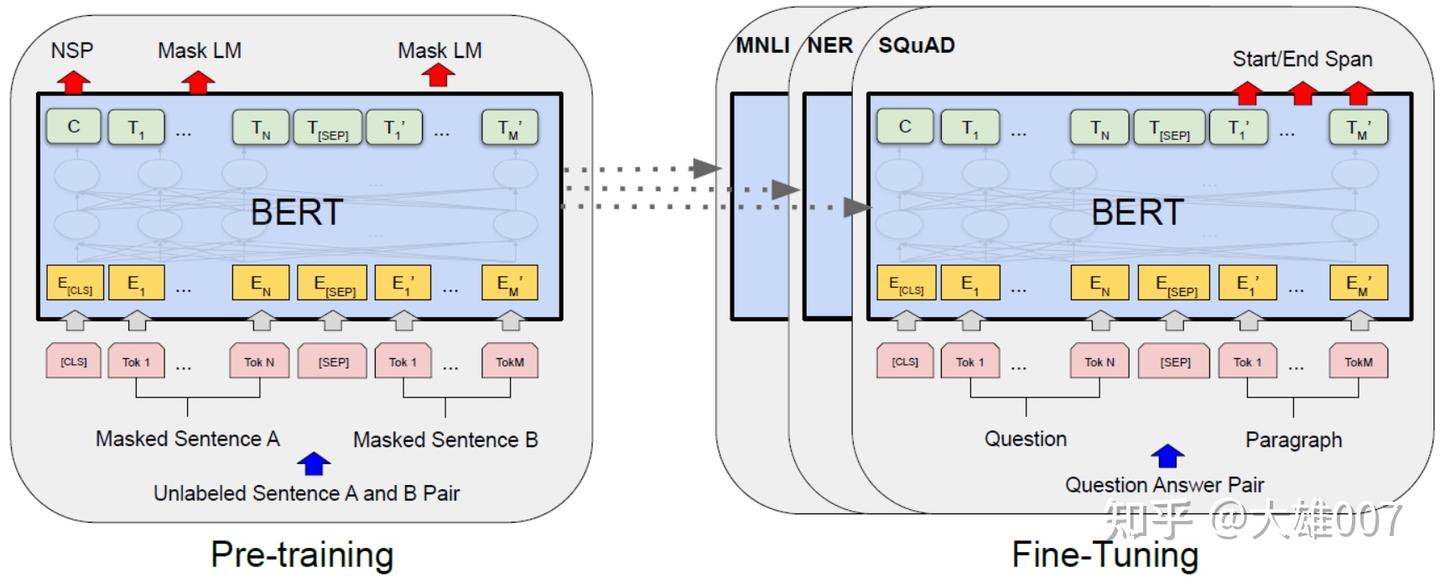
BERT 训练
BERT 训练包含pre-train和fine-tune两个阶段。
- pre-train阶段: 模型在无标注标签数据上进行训练,
- fine-tune阶段: BERT模型先被pre-train模型参数初始化,然后所有的参数会用下游的有标注数据上进行训练
图解
BERT 预训练
BERT 是一个多任务模型,预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP
BERT预训练模型最多只能输入512个词
- 因为 BERT中,Token,Position,Segment Embeddings 都是学习得到的。
- 直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉
[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大 max_position_embeddings 和 type_vocab_size 值去满足自己的需求。
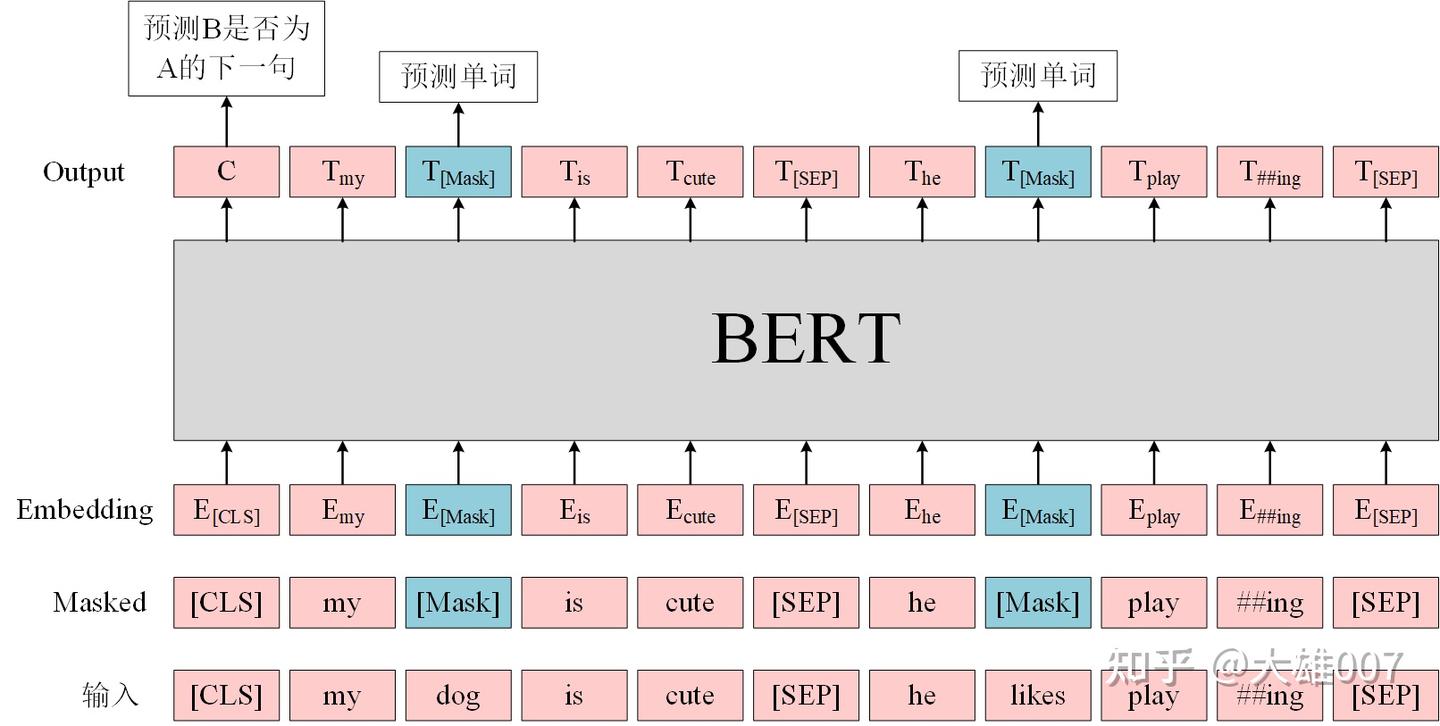
MLM
MLM 指训练时, 随机从输入语料上mask掉一些单词,然后通过上下文预测该单词,类似完形填空。
正如传统的语言模型算法和RNN匹配那样,MLM 和 Transformer 结构是非常匹配。
BERT 实验中,15%的WordPiece Token会被随机Mask掉。
训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
- 80% 的时候, 直接替换为
[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。 - 10% 的时候, 将其替换为其它任意单词
- 将单词 “cute” 替换成另一个随机词,例如 “apple”。
- 将句子 “my dog is cute” 转换为句子 “my dog is apple”。
- 10% 的时候, 保留原始Token
- 例如保持句子为 “my dog is cute” 不变。
mask 原因:
- 如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning 时, 模型就会有一些没有见过的单词。
加入随机Token的原因
- Transformer 要保持对每个输入token的分布式表征,否则模型就会记住这个
[mask]是token ’cute‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有 15%*10% =1.5%,这个负面影响其实是可以忽略不计的。 - 另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
优点
- 1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
- 2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点
- 针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
NSP
Next Sentence Prediction(NSP)任务: 判断句子B是否是句子A的下文。
- 如果是的话输出’IsNext‘,否则输出’NotNext‘。
训练数据的生成方式: 从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在[CLS]符号中。
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 我 最 擅长 的 [Mask] 是 亚索 [SEP]
类别 = IsNext
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 今天 天气 很 [Mask] [SEP]
类别 = NotNext
注意
- 论文《Crosslingual language model pretraining》等)发现,NSP任务可省略,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。
- 这可能是由于BERT以单句子为单位输入,模型无法学习到词之间的远程依赖关系。
针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
BERT 微调
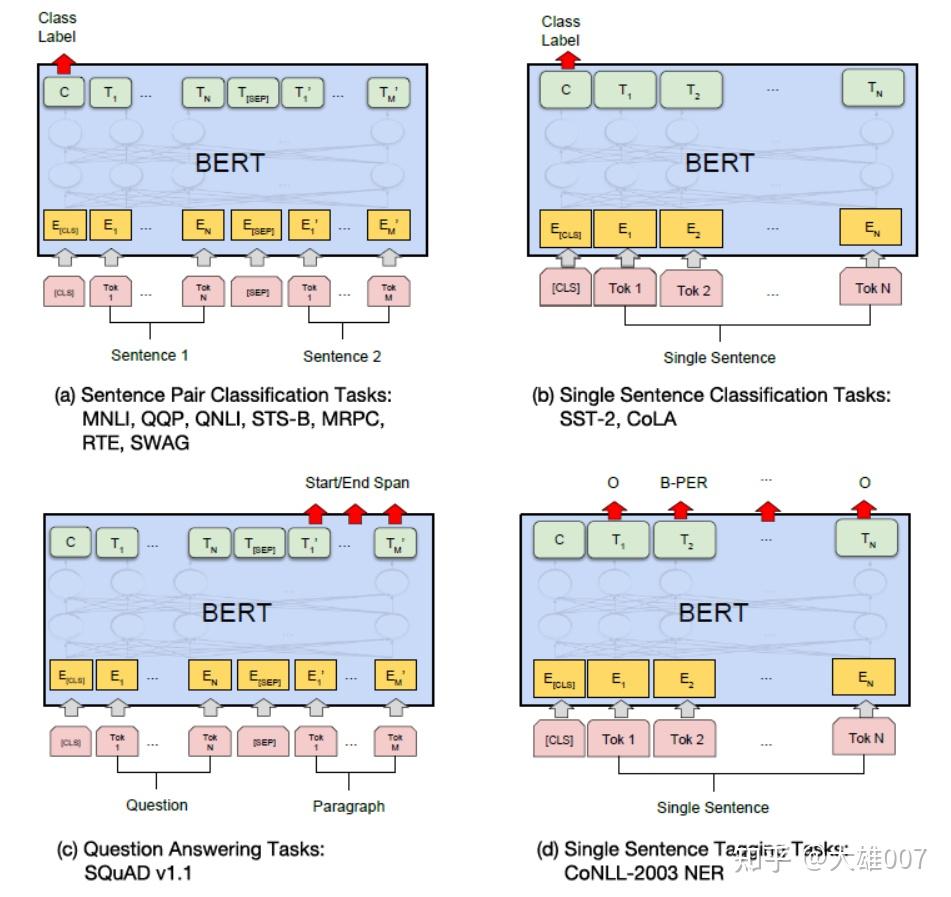
微调(Fine-Tuning) 任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
- 基于句子对的分类任务:
MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。- 该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系(Contradiction) 以及中立关系 (Neutral)。
- 本质上是一个分类问题,发掘前提和假设这两个句子对之间的交互信息。
QQP:基于Quora,判断 两个问题是否一样意思。QNLI:判断文本是否包含问题的答案,类似于阅读理解定位问题所在的段落。STS-B:预测两个句子的相似性,包括5个级别。MRPC:判断两个句子是否是等价。RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。SWAG:从四个句子中选择为可能为前句下文的那个。
- 基于单个句子的分类任务
SST-2:电影评价的情感分析。CoLA:句子语义判断,是否是可接受(Acceptable)。
- 问答任务
SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 命名实体识别
CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。
BERT 分析
优点
- BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。
- 相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。
缺点
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT NSP任务效果不明显,MLM存在和下游任务mismathch的情况。
- BERT 对生成式任务和长序列建模支持不好。
BERT要点
Bert细节:
- 在输入上,Bert的输入是两个segment,其中每个segment可以包含多个句子,两个segment用[SEP]拼接起来。
- 模型结构上,使用 Transformer,这点跟Roberta是一致的。
- 学习目标上,使用两个目标:
- Masked Language Model(
MLM) 掩码语言模型: 其中15%的token要被Mask,在这15%里,有80%被替换成[Mask]标记,有10%被随机替换成其他token,有10%保持不变。 - Next Sentence Prediction(
NSP) 下一句预测: 判断segment对中第二个是不是第一个的后续。随机采样出50%是和50%不是。
- Masked Language Model(
- Optimizations 算法优化:
- Adam, beta1=0.9, beta2=0.999, epsilon=1e-6, L2 weight decay=0.01
- learning rate, 前10000步会增长到1e-4, 之后再线性下降。
- dropout=0.1
- GELU激活函数
- 训练步数:1M
- mini-batch: 256
- 输入长度: 512
- Data
- BookCorpus + English Wiki = 16GB
BERT进阶思考
BERT学到了什么
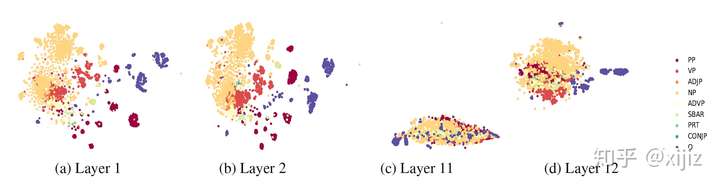
ACL 2019 最新收录的论文:What does BERT learn about the structure of language? 理解BERT每一层都学到了什么, 代码
- Frege早在1965年的组合原则里谈到,复杂表达式的意义由其子表达式的意义以及意义如何组合的规则共同决定。
- 本文思路与分析卷积神经网络每层学习到的表征类似,主要是探索了BERT的每一层到底捕捉到了什么样的信息表征。作者通过一系列的实验证明BERT学习到了一些结构化的语言信息,比如
- BERT的低层网络就学习到了短语级别的信息表征
- BERT的中层网络就学习到了丰富的语言学特征
- BERT的高层网络则学习到了丰富的语义信息特征。
- 图示
BERT可视化
【2022-7-22】最全深度学习训练过程可视化工具
- 深度学习训练过程一直处于黑匣子状态,有很多同学问我具体怎么解释?其实很多还是无法可解释,但是通过可视化,具体可以知道深度学习在训练过程到底学习了哪些特征?到底对该目标的哪些特征感兴趣?
- 1.深度学习网络结构画图工具,地址
- 2.caffe可视化工具,输入:caffe配置文件 输出:网络结构; 地址
- 3.深度学习可视化工具Visual DL; Visual DL是百度开发的,基于echar和PaddlePaddle,支持PaddlePaddle,PyTorch和MXNet等主流框架。ps:这个是我最喜欢的,毕竟echar的渲染能力不错哈哈哈,可惜不支持caffe和tensorflow。地址
- 4.结构可视化工具 PlotNeuralNet, 萨尔大学计算机科学专业的一个学生开发。地址
- CNN Explainer github, 交互可视化CNN类神经网络,使用 TensorFlow.js 加载预训练模型进行可视化效果,交互方面则使用 Svelte 作为框架并使用 D3.js 进行可视化。最终的成品即使对于完全不懂的新手来说,也没有使用门槛。
- VisualDL, a visualization analysis tool of PaddlePaddle;类似tensorboard
- NLP可视化
- NLPReViz: An Interactive Tool for Natural Language Processing on Clinical Text
- NLPVis web系统,visualize the attention of neural network based natural language models.
- Visualizing BERT
- kaggle上外国人分享的Visualizing BERT embeddings with t-SNE
- SHAP
- BertViz是BERT可视化工具包,支持transformers 库的大部分模型 (BERT, GPT-2, XLNet, RoBERTa, XLM, CTRL, BART, etc.),继承于Tensor2Tensor visualization tool

BERTViz
# pip安装
pip install bertviz
# 源码安装
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop
功能:
- headview:指定层的注意力层可视化
- modelview:整个模型的注意力可视化
- neuralview:QKV神经元可视化, 及如何计算注意力



from transformers import AutoTokenizer, AutoModel
from bertviz import model_view
model_version = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_version)
model = AutoModel.from_pretrained(model_version, output_attentions=True)
inputs = tokenizer.encode("The cat sat on the mat", return_tensors='pt')
outputs = model(inputs)
attention = outputs[-1] # Output includes attention weights when output_attentions=True
tokens = tokenizer.convert_ids_to_tokens(inputs[0])
# head可视化
from bertviz import head_view
head_view(attention, tokens)
head_view(attention, tokens, layer=2, heads=[3,5])
# model可视化
model_view(attention, tokens)
model_view(attention, tokens, display_mode="light") # 背景设置
model_view(attention, tokens, include_layers=[5, 6]) # 只显示5-6层
# neural可视化
# Import specialized versions of models (that return query/key vectors)
from bertviz.transformers_neuron_view import BertModel, BertTokenizer
from bertviz.neuron_view import show
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=do_lower_case)
model_type = 'bert'
show(model, model_type, tokenizer, sentence_a, sentence_b, layer=2, head=0)
jupyter notebook版本:
# bert可视化 pip install bertviz
from transformers import BertTokenizer, BertModel
#from bertv_master.bertviz import head_view
from bertviz import head_view
# 在 jupyter notebook 显示visualzation
def call_html():
import IPython
display(IPython.core.display.HTML('''<script src="/static/components/requirejs/require.js"></script><script>// <![CDATA[
requirejs.config({ paths: { base: '/static/base', "d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min", jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min', }, });
// ]]></script>'''))
# 記得我们是使用中文 BERT
model_version = 'bert-base-chinese'
model = BertModel.from_pretrained(model_version, cache_dir="./transformers/", output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version)
# 情境 1 的句子
sentence_a = "老爸叫小宏去买酱油,"
sentence_b = "回来慢了就骂他。"
# 得到tokens后输入BERT模型获取注意力权重(attention)
inputs = tokenizer.encode_plus(sentence_a,sentence_b,return_tensors='pt', add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
call_html()
# 用BertViz可视化
head_view(attention, tokens)
SHAP
SHapley Additive exPlanations
All the code and outputs are provided at the end of this blood. Please refer to it while reading and feel free to run it in Google Colab notebook
(1)Explaining a transformers-based model —— 分类模型
SHAP or ECCO have the potential to provide substantial syntactic information captured from an NLP model’s attention.
SHAP can be used to visualize and interpret what a complex transformers-based model sees when applied to a classification task.
#import the necessary libraries
import pandas as pd
import shap
import sklearn
import transformers
import datasets
import torch
import numpy as np
import scipy as sp
# load a BERT sentiment analysis model
tokenizer = transformers.DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
model = transformers.DistilBertForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
).cuda()
# define a prediction function
def f(x):
tv = torch.tensor([tokenizer.encode(v, padding='max_length', max_length=500, truncation=True) for v in x]).cuda()
outputs = model(tv)[0].detach().cpu().numpy()
scores = (np.exp(outputs).T / np.exp(outputs).sum(-1)).T
val = sp.special.logit(scores[:,1]) # use one vs rest logit units
return val
# build an explainer using a token masker
explainer = shap.Explainer(f, tokenizer)
# explain the model's predictions on IMDB reviews
imdb_train = datasets.load_dataset("imdb")["train"]
shap_values = explainer(imdb_train[:30], fixed_context=1, batch_size=2)
# plot a sentence's explanation
shap.plots.text(shap_values[27])
This visualization uses the probability scores of the model’s prediction. By taking into account the underlying patterns inside the layers, it uses the neuron activations values, more precisely the non-negative matrix factorization.
(2)NLP Model for Translation
Imagining what happens inside a sequence-to-sequence model could be described easier than a classifier. Our intuition for a translation could even show us more precisely which token or words have been mistranslated.
By hovering over the translated text, you will notice that those neuron activations carry embeddings scores. The non-latent embedding scores can be translated into embedding space where word similarity can easily be visualized. For example, in the embedding space, for “father”, “brother” will be what “sister” is for “mother”. This can be visualized even through a sentiment classification where each word is represented by its embedding score.
import numpy as np
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import shap
import torch
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-fr")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-en-fr").cuda()
s=["In my family, we are six: my father, my mother, my elder sister, my younger brother and sister"]
explainer = shap.Explainer(model,tokenizer)
shap_values = explainer(s)
语义匹配
Sentence BERT
【2020-3-25】Sentence-Bert论文笔记
Bert模型已经在NLP各大任务中都展现出了强者的姿态。在语义相似度计算(semantic textual similarity)任务上也不例外,但由于bert模型规定,在计算语义相似度时,需要将两个句子同时进入模型,进行信息交互,这造成大量的计算开销。
- 例如,有1w个句子,我们想要找出最相似的句子对,需要计算(10000*9999/2)次,需要大约65小时。 Bert模型的构造使得它既不适合语义相似度搜索,也不适合非监督任务,比如聚类。
- 问答系统任务中,往往会人为配置一些常用并且描述清晰的问题及其对应的回答,即“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
- 如果使用bert模型,那么每次用户问题都需要与标准问库计算一遍。在实时交互的系统中,是不可能上线的。 Sentence-BERT网络结构可以解决bert模型的不足。简单通俗地讲,借鉴孪生网络模型的框架,将不同的句子输入到两个bert模型中(但这两个bert模型是参数共享的,也可以理解为是同一个bert模型),获取到每个句子的句子表征向量;而最终获得的句子表征向量,可以用于语义相似度计算,也可以用于无监督聚类任务。
- 对于同样的10000个句子,我们想要找出最相似的句子对,只需要计算10000次,需要大约5秒就可计算完全。从65小时到5秒钟,这真是恐怖的差距。
Sentence-BERT 网络结构
- 文中定义了三种通过bert模型求句子向量的策略,分别是CLS向量,平均池化和最大值池化。
- (1)CLS向量策略,就是将bert模型中,开始标记【cls】向量,作为整句话的句向量。
- (2)平均池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求均值操作,最终将均值向量作为整句话的句向量。
- (3)最大值池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求最大值操作,最终将最大值向量作为整句话的句向量。
bert模型微调时,设置了三个目标函数,用于不同任务的训练优化,假设两个待比较的向量分别为 u 和 v
- (1)Classification Objective Function:u、v以及
|u-v|拼接起来,加softmax - (2)Regression Objective Function:目标函数是直接对两句话的句子向量 u 和 v 计算余弦相似度
- (3)Triplet Objective Function: 将原来的两个输入,变成三个句子输入。
- 给定一个锚定句 a ,一个肯定句 p 和一个否定句 n ,模型通过使 a-p 的距离小于 a-n 的距离,来优化模型。使其目标函数o最小


大量实验比较三种求句子向量策略的好坏,认为平均池化策略最优,并且在多个数据集上进行了效果验证。虽然效果没有bert输入两句话的效果好,但是比其他方法还是要好的,并且速度很快。
BERT降维
BERT-flow
BERT-flow 来自论文《On the Sentence Embeddings from Pre-trained Language Models》,EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。
用句向量做相似度计算、索引时,常常用到余弦相似度,根据数值排序,然而,不是所有向量都适合用余弦相似度。
- 余弦相似度:两个向量x,y的内积的几何意义就是“各自的模长乘以它们的夹角余弦”,即两个向量的内积并除以各自的模长
- 假设:向量的“夹角余弦”本身是具有鲜明的几何意义的,但上式右端只是坐标的运算,坐标依赖于所选取的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样。即余弦公式只在“标准正交基”下成立,如果这组基是标准正交基,每个分量都是独立的、均匀的,基向量集表现出“各项同性”。
BERT向量用余弦值来比较相似度,表现不好,原因可能就是句向量所属的坐标系并非标准正交基。不满足各项同性时,需要通过一些方法转换,比如:BERT-flow用了flow模型。
flow模型是一个向量变换模型,它可以将输入数据的分布转化为标准正态分布,而显然标准正态分布是各向同性的
flow模型本身很弱,BERT-flow里边使用的flow模型更弱,所以flow模型不大可能在BERT-flow中发挥至关重要的作用。反过来想,那就是也许我们可以找到更简单直接的方法达到BERT-flow的效果。
BERT-whitening
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
- BERT-whitening:通过简单的向量白化来改善句向量质量,可以媲美甚至超过BERT-flow的效果, 一个线性变换,可以轻松套到任意的句向量模型中
将句向量的均值变换为0、协方差矩阵变换为单位阵, 相当于传统数据挖掘中的白化操作(Whitening),所以该方法笔者称之为BERT-whitening
协方差矩阵 Σ 是一个半正定对称矩阵,半正定对称矩阵都具有如下形式的SVD分解: Σ=UΛU⊤,其中U是一个正交矩阵,而Λ是一个对角阵,并且对角线元素都是正的,因此直接让 $\boldsymbol{W}^{-1}=\sqrt{\boldsymbol{\Lambda}} \boldsymbol{U}^{\top}$ 就可以完成求解: $\boldsymbol{W}=\boldsymbol{U} \sqrt{\mathbf{\Lambda}^{-1}}$
def compute_kernel_bias(vecs):
"""计算kernel和bias
vecs.shape = [num_samples, embedding_size],
最后的变换:y = (x + bias).dot(kernel)
"""
mu = vecs.mean(axis=0, keepdims=True)
cov = np.cov(vecs.T)
u, s, vh = np.linalg.svd(cov)
W = np.dot(u, np.diag(1 / np.sqrt(s)))
return W, -mu
用一个简单线性变换的 BERT-whitening 取得了跟BERT-flow媲美的结果。除了STS-B之外,中文业务数据内做了类似的比较,结果都表明BERT-flow带来的提升跟BERT-whitening是相近的
仿照PCA降维,效果更好
def compute_kernel_bias(vecs, n_components=256):
"""计算kernel和bias
vecs.shape = [num_samples, embedding_size],
最后的变换:y = (x + bias).dot(kernel)
"""
mu = vecs.mean(axis=0, keepdims=True)
cov = np.cov(vecs.T)
u, s, vh = np.linalg.svd(cov)
W = np.dot(u, np.diag(1 / np.sqrt(s)))
return W[:, :n_components], -mu
将base版本的768维只保留前256维,效果有所提升,并且由于降维,向量检索速度肯定也能大大加快;类似地,将large版的1024维只保留前384维,那么降维的同时也提升了效果。
这个结果表明:
- 无监督训练出来的句向量其实是“通用型”的,对于特定领域内的应用,里边有很多特征是冗余的,剔除这些冗余特征,往往能达到提速又提效的效果。
而flow模型是可逆的、不降维的,这在某些场景下是好处,但在不少场景下也是缺点,因为它无法剔除冗余维度,限制了性能,比如GAN的研究表明,通过一个256维的高斯向量就可以随机生成1024×1024的人脸图,这表明这些人脸图其实只是构成了一个相当低维的流形,但是如果用flow模型来做,因为要保证可逆性,就得强行用1024×1024×3那么多维的高斯向量来随机生成,计算成本大大增加,而且效果还上不去。
SimBERT 追一科技
追一科技开放了一个名为SimBERT的模型权重,以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM 核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。
假如输入是“你想吃啥”,目标句子是“白切鸡”
- 那 UNILM 将这两个句子拼成一个:
[ CLS] 你 想 吃 啥 [ SEP] 白 切 鸡 [ SEP] - 然后, 接如图的Attention Mask
[ CLS] 你 想 吃 啥 [ SEP]这几个token之间是双向Attention,而白 切 鸡 [ SEP]则是单向Attention,从而允许递归地预测白 切 鸡 [ SEP]这几个token,所以它具备文本生成能力。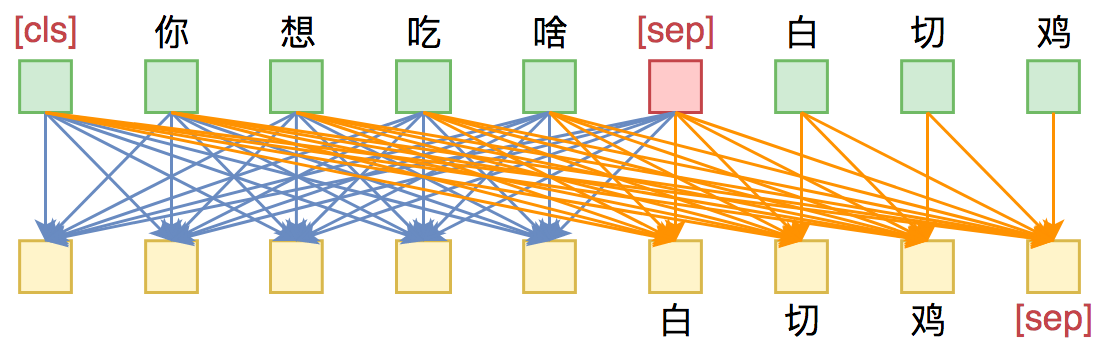

SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[ CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务
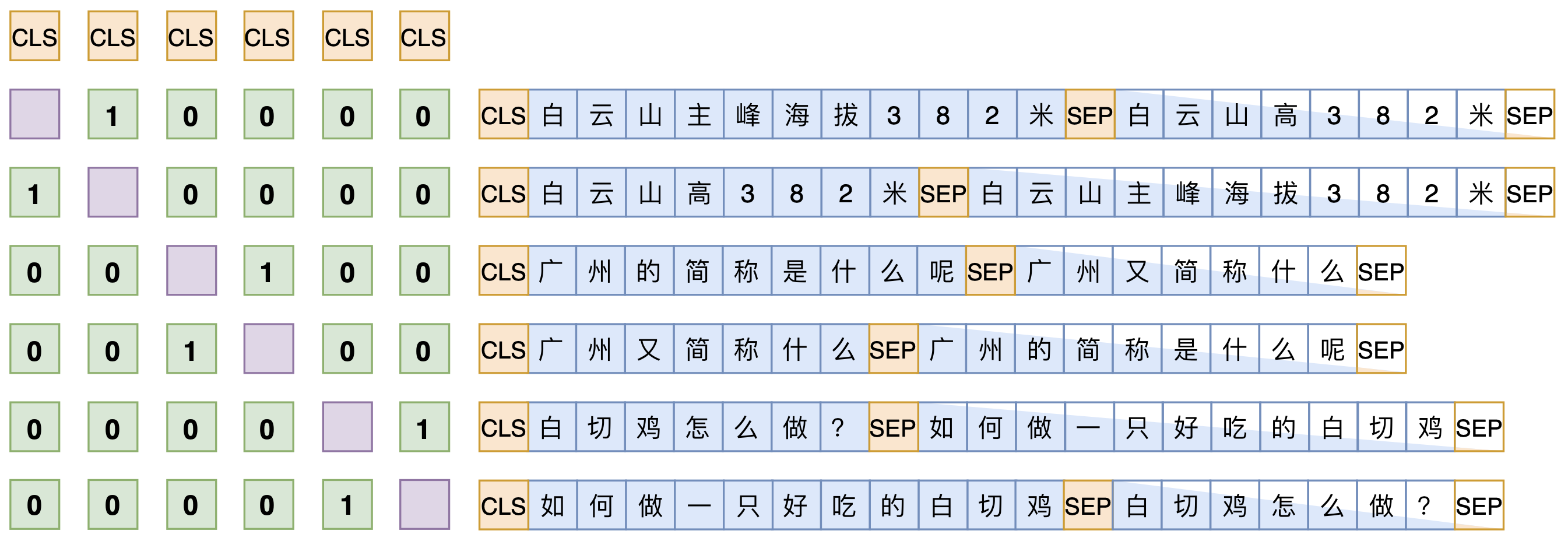
- 假设
SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[ CLS] SENT_a [ SEP] SENT_b [ SEP]和[ CLS] SENT_b [ SEP] SENT_a [ SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
关键就是“[ CLS]向量事实上就代表着输入的句向量”,所以可以做一些NLU相关的事情。最后的loss是Seq2Seq和相似句分类两部分loss之和。
实施:
- 数据来源是爬取百度知道推荐的相似问,然后经过简单算法过滤。如果本身有很多问句,也可以通过常见的检索算法检索出一些相似句,作为训练数据用。总而言之,训练数据没有特别严格要求,理论上有一定的相似性都可以。
- 至于训练硬件,开源的模型是在一张TITAN RTX(22G显存,batch_size=128)上训练了4天左右,显存和时间其实也没有硬性要求,视实际情况而定,如果显存没那么大,那么适当降低batch_size即可,如果语料本身不是很多,那么训练时间也不用那么长(大概是能完整遍历几遍数据集即可)。
SimCSE 对比学习 – simbert 简化
中文任务还是SOTA吗?给SimCSE补充了一些实验
苏剑林构思的“BERT-whitening”的方法一度成为了语义相似度的新SOTA,然而不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
- 第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,虽然有一定启发而且效果还可以,但是复现的成本和变数都太大。
- 另一篇则是《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的
SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
SimCSE可以看成是SimBERT的简化版:
- 1、SimCSE去掉了
SimBERT的生成部分,仅保留检索模型; - 2、由于SimCSE没有标签数据,所以把每个句子自身视为相似句传入。 即:(自己,自己) 作为正例、(自己,别人) 作为负例来训练对比学习模型,这里的“自己”并非完全一样,而是采用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身又是一个难搞的问题,SimCSE则提出了一个极为简单的方案:直接把Dropout当作数据扩增!
实验结果
- 英文语料:SimCSE明显优于BERT-flow和BERT-whitening
- 中文语料:除了PAWSX这个“异类”外,SimCSE相比BERT-whitening确实有压倒性优势,有些任务还能好10个点以上,在BQ上SimCSE还比有监督训练过的SimBERT要好,而且像SimBERT这种已经经过监督训练的模型还能获得进一步的提升,这些都说明确实强大
BERT真的有理解能力吗
【2019-07-12】
- ACL 2019,论文1:Probing Neural Network Comprehension of Natural Language Arguments, 台湾成功大学计算机科学与信息工程系智能知识管理实验室,一作 Timothy Niven,ARCT一个数据集
- 台湾小哥一篇论文把 BERT 拉下神坛
- 把BERT拉下神坛!ACL论文只靠一个“Not”,就把AI阅读理解骤降到盲猜水平
- We are surprised to find that BERT’s peak performance of 77% on the Argument Reasoning Comprehension Task reaches just three points below the average untrained human baseline. However, we show that this result is entirely accounted for by exploitation of spurious statistical cues in the dataset. We analyze the nature of these cues and demonstrate that a range of models all exploit them. This analysis informs the construction of an adversarial dataset on which all models achieve random accuracy. Our adversarial dataset provides a more robust assessment of argument comprehension and should be adopted as the standard in future work.
- ACL 2019, 论文2:Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference,只不过,数据集不一样了。这篇论文里BERT是在多类型语言推理数据集 (MNLI) 上训练的,而测试集则是研究团队自制的HANS数据集,一些简单的句子变换,就能让AI做出错误的判断。
- A machine learning system can score well on a given test set by relying on heuristics that are effective for frequent example types but break down in more challenging cases. We study this issue within natural language inference (NLI), the task of determining whether one sentence entails another. We hypothesize that statistical NLI models may adopt three fallible syntactic heuristics: the lexical overlap heuristic, the subsequence heuristic, and the constituent heuristic. To determine whether models have adopted these heuristics, we introduce a controlled evaluation set called
HANS(Heuristic Analysis for NLI Systems), which contains many examples where the heuristics fail. We find that models trained on MNLI, including BERT, a state-of-the-art model, perform very poorly on HANS, suggesting that they have indeed adopted these heuristics. We conclude that there is substantial room for improvement in NLI systems, and that the HANS dataset can motivate and measure progress in this area
- A machine learning system can score well on a given test set by relying on heuristics that are effective for frequent example types but break down in more challenging cases. We study this issue within natural language inference (NLI), the task of determining whether one sentence entails another. We hypothesize that statistical NLI models may adopt three fallible syntactic heuristics: the lexical overlap heuristic, the subsequence heuristic, and the constituent heuristic. To determine whether models have adopted these heuristics, we introduce a controlled evaluation set called
- 论文3:What does BERT Learn from Multiple-Choice Reading Comprehension Datasets? 在数据集中添加干扰文本,结果显示BERT的表现非常差
- 研究认为,包括BERT在内,许多模型的成功都是建立在虚假的线索上。团队用了去年诞生的
观点推理理解任务(ARCT) 考验了BERT。结果发现,只要做个对抗数据集,准确率就从77%降到53%,几乎等同于随机猜- 对抗并不是把o变成0、把I变成1的小伎俩
- BERT是依靠数据集里 “虚假的统计学线索 (Spurious Statistical Cues) ”来推理的,BERT是利用了一些线索词来判断,特别是“Not”这个词, 它并不能真正分析出句子之间的逻辑关系。
观点推理理解任务(ARCT) ,是Habernal和小伙伴们提出的阅读理解任务,考察的是语言模型的推理能力,中选了NAACL 2018。一个观点,包含前提(Premise) ,和主张(Claim) 。除此之外,观点又有它的原因(Reasoning) ,以及它的佐证(Warrant) 。
- 这篇ACL论文打击了以BERT为首的众多阅读理解模型
Reddit评论区补充说:
- 每隔几个月就会听到有关NLP的新进展,更新、更好的模型层出不穷。但当有人实际用数据集测试时,会发现这些模型并没有真正学习到什么。优化模型的竞赛该放缓脚步了,我们更应该仔细研究研究数据集,看看它们是否真的有意义。
- 并不否认BERT和其他新模型的价值,但是并不相信一些Benchmark。
BERT变种
改进总结
- 【2022-5-26】BERT模型的优化改进方法, 论文《BERT模型的主要优化改进方法研究综述》的阅读笔记,对 BERT主要优化改进方法进行了研究梳理。
基础回顾
- BERT是由Google AI于2018年10月提出的一种基于深度学习的语言表示模型。BERT 发布时,在11种不同的NLP测试任务中取得最佳效果,NLP领域近期重要的研究成果。
- BERT模型结构是Transformer编码器。Transformer是由 Ashish 等于2017年提出的,用于Google机器翻译,包含编码器(Encoder)和解码器(Decoder)两部分。 BERT 模型使用两个预训练目标来完成文本内容特征的学习。
- 掩藏语言模型(Masked Language Model,MLM)通过将单词掩盖,从而学习其上下文内容特征来预测被掩盖的单词
- 相邻句预测(Next Sentence Predication,NSP)通过学习句子间关系特征,预测两个句子的位置是否相邻

BERT 改进模型汇总
BERT 进化图
【2024-8-2】
表格整理
| Model | Creator | Date | Breif description | 🤗 |
|---|---|---|---|---|
| 1st Transfor. | Jun. 2017 | Transforer encoder & decoder | ||
| ULMFiT | Fast.ai | Jan. 2018 | Regular LSTM | |
| ELMo | AllenNLP | Feb. 2018 | Bidirectional LSTM | |
| GPT | OpenAI | Jun. 2018 | Transformer decoder on LM | ✔ |
| BERT | Oct. 2018 | Transformer encoder on MLM (& NSP) | ✔ | |
| TransformerXL | Jan. 2019 | Recurrent transformer decoder | ✔ | |
| XLM/mBERT | Jan. 2019 | Multilingual LM | ✔ | |
| Transf. ELMo | AllenNLP | Jan. 2019 | ||
| GPT-2 | OpenAI | Feb. 2019 | Good text generation | ✔ |
| ERNIE | Baidu | Apr. 2019 | ||
| ERNIE | Tsinghua | May. 2019 | Transformer with Knowledge Graph | |
| XLNet | Jun. 2019 | BERT + Transformer-XL | ✔ | |
| RoBERTa | Jul. 2019 | BERT without NSP | ✔ | |
| DistilBERT | Hug. Face | Aug. 2019 | Compressed BERT | ✔ |
| MiniBERT | Aug. 2019 | Compressed BERT | ||
| MultiFiT | Fast.ai | Sep. 2019 | Multi-lingual ULMFiT (QRNN) post | |
| CTRL | Salesforce | Sep. 2019 | Controllable text generation | ✔ |
| MegatronLM | Nvidia | Sep. 2019 | Big models with parallel training | |
| ALBERT | Sep. 2019 | Reduce BERT params (param sharing) | ✔ | |
| DistilGPT-2 | Hug. Face | Oct. 2019 | Compressed GPT-2 | ✔ |
| T5 | Oct. 2019 | Text-to-Text Transfer Transformer | ✔ | |
| ELECTRA | ? | Dec. 2019 | An efficient LM pretraining | |
| Reformer | Jan. 2020 | The Efficient Transformer | ||
| Meena | Jan. 2020 | A Human-like Open-Domain Chatbot |
| Model | 2L | 3L | 6L | 12L | 18L | 24L | 36L | 48L | 54L | 72L |
|---|---|---|---|---|---|---|---|---|---|---|
| 1st Transformer | yes | |||||||||
| ULMFiT | yes | |||||||||
| ELMo | yes | |||||||||
| GPT | 110M | |||||||||
| BERT | 110M | 340M | ||||||||
| Transformer-XL | 257M | |||||||||
| XLM/mBERT | Yes | Yes | ||||||||
| Transf. ELMo | ||||||||||
| GPT-2 | 117M | 345M | 762M | 1542M | ||||||
| ERNIE | Yes | |||||||||
| XLNet: | 110M | 340M | ||||||||
| RoBERTa | 125M | 355M | ||||||||
| MegatronLM | 355M | 2500M | 8300M | |||||||
| DistilBERT | 66M | |||||||||
| MiniBERT | Yes | |||||||||
| ALBERT | ||||||||||
| CTRL | 1630M | |||||||||
| DistilGPT-2 | 82M |
BERT家族
BERT:MLM 和 NSP任务- 基于 Transformer Encoder 构建预训练语言模型,通过 Masked Lanauge Model(
MLM) 和 Next Sentence Prediction(NSP) 两个任务在大规模语料上训练得到的 - 开源的 Bert 模型分为 base 和 large,差异在模型大小上。大模型有更大的参数量,性能也有会几个百分点的提升,当然需要消耗更多的算力
- 基于 Transformer Encoder 构建预训练语言模型,通过 Masked Lanauge Model(
BERT-WWM:mask策略由token 级别升级为词级别Roberta:BERT优化版,更多数据+迭代步数+去除NSP+动态maskXLNet:模型结构和训练方式上与BERT差别较大- Bert 的 MLM 在预训练时有 MASK 标签,但在推理时却没有,导致训练和推理出现不一致;
- 并且 MLM 不属于 Autoregressive LM,不能做生成类任务。
- XLNet 采用 PLM(Permutation Language Model) 避免了 MASK 标签的使用,且属于 Autoregressive LM,可以做生成任务。
- Bert 使用 Transformer 结构对文本的长度有限制,为更好地处理长文本,XLNet 采用升级版的
Transformer-XL。
Albert:BERT简化版,更少的数据,得到更好的结果(70% 参数量的削减,模型性能损失<3% );两个方面减少模型的参数量:- 对 Vocabulary Embedding 进行矩阵分解,将原来矩阵
V x E分解成两个矩阵V x H和H x E(H « E)。 - 跨层参数共享,每层的 attention map 有相似的pattern,可以考虑共享。
- 对 Vocabulary Embedding 进行矩阵分解,将原来矩阵
这些模型的性能在不同数据集上有差异,但总体而言 XLNet 和 Roberta 会比 Bert 效果略好,large 会比 base 略好,更多情况下,它们会被一起使用,最后做 ensemble。
分支1:改进预训练
自然语言丰富多变,研究者针对更丰富多变的文本表达形式,在这两个训练目标的基础上进一步完善和改进,提升了模型的文本特征学习能力。
1.1 改进掩藏语言模型 —— 全词覆盖(wwm/ERNIE/SpanBERT)
BERT模型中,对文本的预处理都按照最小单位进行了切分。例如对于英文文本的预处理采用了Google的 wordpiece 方法以解决其未登录词的问题。
- MLM中掩盖的对象多数情况下为词根(subword),并不是完整的词;
- 对于中文则直接按字切分,直接对单个字进行掩盖。这种掩盖策略导致了模型对于词语信息学习的不完整。
- 汉语的词语几乎可以用无穷无尽来形容。但中文常用的汉字也就4000多个,BERT训练很容易实现,所以最初BERT对中文任务是以汉字为单位实现训练的。
- 问题:既然是以汉字为单位训练的,其训练出的就是孤零零的汉字向量,而在现代汉语中,单个汉字是远不足以表达像词语或者短语那样丰富的语义的,这就造成了BERT在很多中文任务上表现并不理想的情况。 针对这一不足,大部分研究者改进了MLM的掩盖策略。
BERT-WWM 模型中,提出了全词覆盖的方式。
- 2019年7月,哈工大发布的
BERT-Chinese-wwm利用中文分词,将组成一个完整词语的所有单字同时掩盖。 - 2019年4月,
ERNIE扩展了中文全词掩盖策略,扩展到对于中文分词、短语及命名实体的全词掩盖。- 百度版:全词mask,隐式输入知识信息,mask训练阶段将知识实体全部mask
- 清华版:知识图谱,显式加入知识信息,在输入阶段
SpanBERT采用了几何分布来随机采样被掩盖的短语片段,通过Span边界词向量来预测掩盖词
(1)BERT-WWM
BERT-WWM是 2019年7月 推出的,它是由哈工大讯飞联合实验室针对中文做出的改进,WWM 的意思是Whole Word Masking,其实就是ERNIE模型中的短语级别遮盖(phrase-level masking)训练。
BERT-WWM属于BERT-base模型结构,由12层Transformers构成。
- 训练第一阶段(最大长度为128)采用的 batch size为2560,训练了100K步。
- 训练第二阶段(最大长度为512)采用的 batch size为384,训练了100K步。
后续又出了一个 BERT-WWM-ext ,它是BERT-WWM的一个升级版,相比于BERT-WWM的改进是增加了训练数据集同时也增加了训练步数,性能也得到了一定程度的提升。它也属于BERT-base模型结构,由12层Transformers构成。
- 训练第一阶段(最大长度为128)采用的batch size为2560,训练了1000K步。
- 训练第二阶段(最大长度为512)采用的batch size为384,训练了400K步。
为什么要单独说这个呢?因为提出BERT-WWM的论文中,作者团队还同时训练出了:BERT-WWM、BERT-WWM-ext、RoBERTa-WWM-ext和RoBERTa-WWM-ext-large模型,并且对比了这些模型的性能,其中RoBERTa-WWM-ext-large的强悍性能也让很多人对它青睐有加,即便是模型发布一年之久的今天它也难逢敌手。这些模型的发布为NLP从业者、学习者和爱好者提供了极大的方便,使用起来也很简单,在此感谢作者们。
(2)ERNIE
ERNIE的改进思路:给模型加上词语信息,即百度宣称的让模型学到“知识”
那要怎样加入知识信息呢?有两种方法:
- 第一种是显式的方法,即通过某种手段,在输入阶段,就给模型输入知识实体。(清华版)
- 第二种是隐式的方法,即在masked训练阶段,将包含有某一个知识实体的汉字全都Mask掉,让模型来猜测这个词语,从而学习到知识实体。(百度版) 百度的ERNIE选取的是第二种方案,其实清华大学也推出了一个同名的ERNIE模型,采取的就是第一种方法,但貌似表现效果和名气都不如百度的ERNIE,故在此不多谈。百度是国内搜索引擎常年的霸主,其对语义理解和知识图谱的研究可谓是炉火纯青,所以百度将知识图谱引入了BERT中,形成了ERNIE。
实际上,英文任务也可以通过ERNIE的方式来改进,掩盖整个英文短语或者实体,让BERT学习到知识
ERNIR的mask是由三个阶段学习组成
- 第一个阶段,采用的是 BERT模式的 word piece(词根) 级别的 mask (basic-level masking)
- 其次,加入短语级别的mask(phrase-level masking)
- 最后,再加入实体级别的mask(entity-level masking)。

在这个基础上,借助百度在中文的社区的强大能力,中文的ERNIR还用了各种混杂数据集(Heterogeneous Data)。
ERNIE 2.0
- 百度在之前的模型上做了新的改进,这篇论文主要是走多任务的思想,引入了多大7个任务来预训练模型,并且采用的是逐次增加任务的方式来预训练,具体的任务如下面图中所示,图中红框、蓝框、绿框里面的就是七种任务的名称:
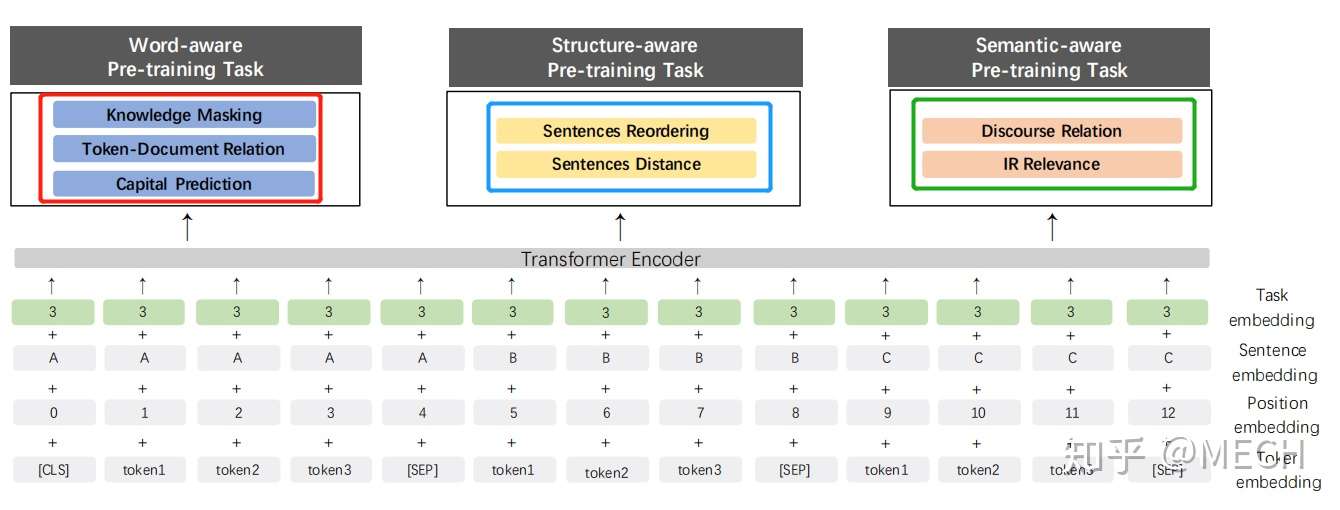
- 因为不同的任务输入不同,因此作者还引入了Task Embedding,来区分不同的任务。真就万物皆可Embedding呗。
- 训练的方法是先训练任务1,保存模型,然后加载刚保存的模型,再同时训练任务1和任务2,依次类推,到最后同时训练7个任务。
效果:
- 2.0在效果上比1.0版本全面提升,其中,在阅读理解的任务上提升非常大。
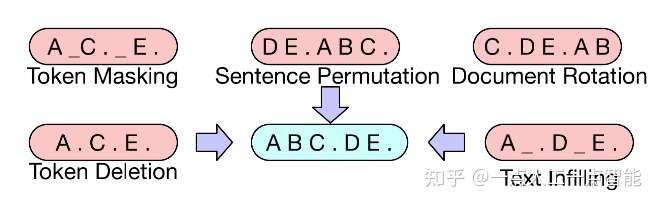
1.2 引入降噪自编码器 —— BART
MLM 将原文中的词用[MASK]标记随机替换,这本身是对文本进行了破坏,相当于在文本中添加了噪声,然后通过训练语言模型来还原文本,消除噪声。
DAE 是一种具有降噪功能的自编码器,旨在将含有噪声的输入数据还原为干净的原始数据。对于语言模型来说,就是在原始语言中加入噪声数据,再通过模型学习进行噪声的去除以恢复原始文本。
BART引入了降噪自编码器,丰富了文本的破坏方式。例如随机掩盖(同 MLM 一致)某些词、随机删掉某些词或片段、打乱文档顺序(含旋转)等,将文本输入到编码器中后,利用一个解码器生成破坏之前的原始文档。
1.3 引入替代词检测 —— ELECTRA
MLM 对文本中的[MASK]标记的词进行预测,以试图恢复原始文本。其预测结果可能完全正确,也可能预测出一个不属于原文本中的词。
ELECTRA引入了替代词检测,来预测一个由语言模型生成的句子中哪些词是原本句子中的词,哪些词是语言模型生成的且不属于原句子中的词。
- ELECTRA 使用一个小型的 MLM 模型作为生成器(Generator),来对包含[MASK]的句子进行预测。
- 另外训练一个基于二分类的判别器(Discriminator)来对生成器生成的句子进行判断。

1.4 改进相邻句预测
在大多数应用场景下,模型仅需要针对单个句子完成建模,舍弃NSP训练目标来优化模型对于单个句子的特征学习能力。
- 删除NSP:NSP仅仅考虑了两个句子是否相邻,而没有兼顾到句子在整个段落、篇章中的位置信息。
- 改进NSP:通过预测句子之间的顺序关系,从而学习其位置信息。
分支2:融合融合外部知识
当下知识图谱的相关研究已经取得了极大的进展,大量的外部知识库都可以应用到 NLP 的相关研究中。
2.1 嵌入实体关系知识
实体关系三元组是知识图谱的最基本的结构,也是外部知识最直接和结构化的表达。
K-BERT从BERT模型输入层入手,将实体关系的三元组显式地嵌入到输入层中。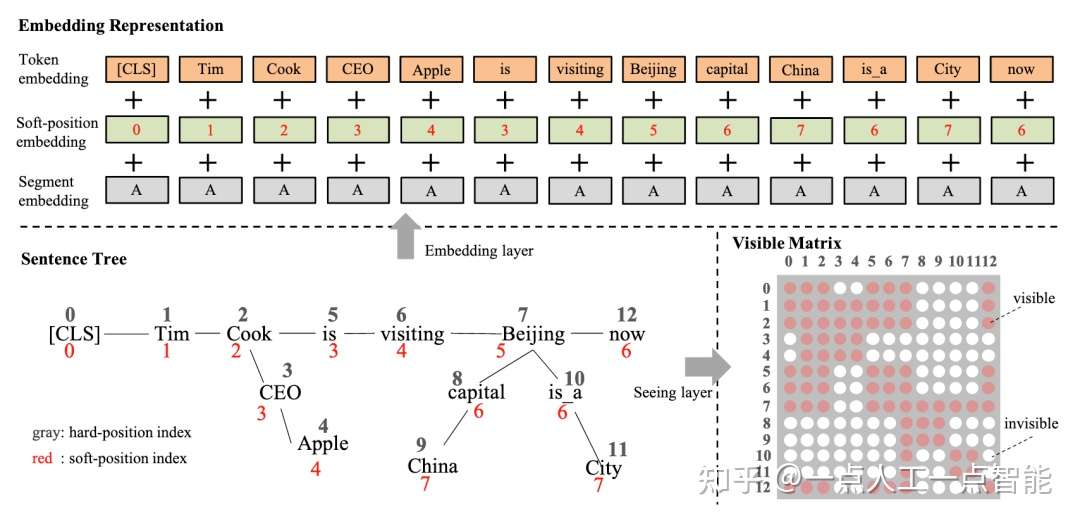
2.2 特征向量拼接知识
BERT可以将任意文本表示为特征向量的形式,因此可以考虑采用向量拼接的方式在 BERT 模型中融合外部知识。
SemBERT利用语义角色标注工具,获取文本中的语义角色向量表示,与原始BERT文本表示融合。
2.3 训练目标融合知识
在知识图谱技术中,大量丰富的外部知识被用来直接进行模型训练,形成了多种训练任务。
ERNIE以DAE的方式在BERT中引入了实体对齐训练目标,WKLM通过随机替换维基百科文本中的实体,让模型预测正误,从而在预训练过程中嵌入知识。
分支3:改进Transformer
由于Transformer结构自身的限制,BERT等一系列采用 Transformer 的模型所能处理的最大文本长度为 512个token。
3.1 改进 Encoder MASK矩阵
BERT 作为一种双向编码的语言模型,其“双向”主要体现在 Transformer结构的 MASK 矩阵中。Transformer 基于自注意力机制(Self-Attention),利用MASK 矩阵提供一种“注意”机制,即 MASK 矩阵决定了文本中哪些词可以互相“看见”。
UniLM通过对输入数据中的两个句子设计不同的 MASK 矩阵来完成生成模型的学习。对于第一个句子,采用跟 BERT 中的 Transformer-Encoder 一致的结构,每个词都能够“注意”到其“上文”和“下文”信息。
对于第二个句子,其中的每个词只能“注意”到第一句话中的所有词和当前句子的“上文”信息。利用这种巧妙的设计,模型输入的第一句话和第二句话形成了经典的“Seq2Seq”的模式,从而将 BERT 成功用于语言生成任务。
3.2 Encoder + Decoder语言生成
BART模型同样采用Encoder+Decoder结构,借助DAE语言模型的训练方式,能够很好地预测和生成被“噪声”破坏的文本,从而也得到具有文本生成能力的预训练语言模型。
分支4:量化与压缩
4.1 模型蒸馏
对 BERT 蒸馏的研究主要存在于以下几个方面:
- 在预训练阶段还是微调阶段使用蒸馏
- 学生模型的选择
-
蒸馏的位置
DistilBERT在预训练阶段蒸馏,其学生模型具有与BERT结构,但层数减半。TinyBERT为BERT的嵌入层、输出层、Transformer中的隐藏层、注意力矩阵都设计了损失函数,来学习 BERT 中大量的语言知识。
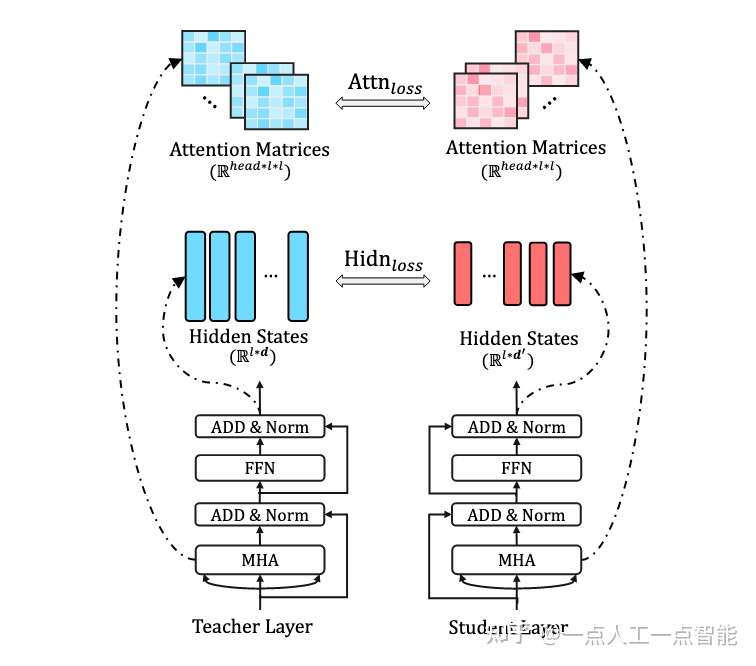
4.2 模型剪枝
剪枝(Pruning)是指去掉模型中不太重要的权重或组件,以提升推理速度。用于 BERT 的剪枝方法主要有权重修剪和结构修剪。
BERT fine-tune
bert 的 finetune 主要存在两类应用场景:分类和阅读理解。
- 【2021-8-25】中文语料的 Bert 微调 Bert Chinese Finetune
- 【2023-11-15】BERT微调与实时预测
Bert 文档本身对 finetune 进行了较为详细的描述,但对于不熟悉官方标准数据集的工程师来说,有一定的上手难度。
随着 Bert as service 代码的开源,使用 Bert 分类或阅读理解的副产物–词空间,成为一个更具实用价值的方向。
预训练模型
- 下载 BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
huggingface transformer
【2024-8-21】基于 huggingface transformer 库的 Finetune
Model 定义
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 2024-01-09 11:49:28
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
class Model(nn.Module):
"""
下游模型定义
"""
def __init__(self, args):
super(Model, self).__init__()
# 加载预训练模型
self.model = AutoModel.from_pretrained(args.model_path)
# 冻结预训练权重, 设置 requires_grad = False
if args.freeze:
for param in self.model.parameters():
param.requires_grad = False
# self.fc1 = nn.Linear(args.hidden_size, args.hidden_size)
# self.dropout1 = nn.Dropout(p=args.dropout)
# self.fc2 = nn.Linear(args.hidden_size, args.hidden_size)
# self.dropout2 = nn.Dropout(p=args.dropout)
# self.fc3 = nn.Linear(args.hidden_size, args.hidden_size)
# self.dropout3 = nn.Dropout(p=args.dropout)
# self.fc4 = nn.Linear(args.hidden_size, args.hidden_size)
# self.dropout4 = nn.Dropout(p=args.dropout)
self.fc_out = nn.Linear(args.hidden_size, args.num_classes) # [0,1] + [0,0,1,0,0] 满意不满意label + 原因
# self.activator = nn.GELU()
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
pooled = self.model(context, attention_mask=mask)[1]
# print(pooled) # pooler_output
# linear_output_1 = self.fc1(pooled)
# linear_output_1 = self.dropout1(self.activator(linear_output_1))
# linear_output_2 = self.fc2(linear_output_1)
# linear_output_2 = self.dropout2(self.activator(linear_output_2))
# linear_output_3 = self.fc3(linear_output_2)
# linear_output_3 = self.dropout3(self.activator(linear_output_2))
# linear_output_4 = self.fc4(linear_output_3)
# linear_output_4 = self.dropout4(self.activator(linear_output_4))
out = self.fc_out(pooled)
return out
Train 训练
加载模型
model = Model(args) # 初始化实例
# 适配 cpu/gpu 环境
if not torch.cuda.is_available():
state_dict = torch.load(args.checkpoint_path, map_location=torch.device('cpu'))
else:
state_dict = torch.load(args.checkpoint_path)
# 融合模型新旧参数
state_dict_new = {}
for key,value in state_dict.items():
if key.startswith("module"):
new_key = key.lstrip("module")[1:]
else:
new_key = key
state_dict_new[new_key] = value
# 加载权重
model.load_state_dict(state_dict_new)
if torch.cuda.device_count() > 1:
print('Let us use ' + str(torch.cuda.device_count()) + "GPUs!")
# DP 模式
model = nn.DataParallel(model)
model = model.to(device)
训练代码片段
for epoch in range(args.num_epochs):
logging.info('Epoch [{}/{}]'.format(epoch + 1, args.num_epochs))
for i, (x, seq_len, mask, labels, _) in enumerate(train_iter):
trains = (x.to(device), seq_len, mask.to(device))
labels = labels[:,0].to(device)
# 指向新定义的model
outputs = model(trains) # trains[0].shape [batch_size, dim], trains[1].shape [batch_size], trains[2].shape [64, 512]
model.zero_grad()
loss = loss_functioin(outputs, labels)
loss.backward()
optimizer.step()
数据处理过程
BERT数据处理过程:原始文本 → 分词 → 加特殊标记 → 映射为id → 合并
- 原始文本
- 分词:中英文不同
- 英文:词性/词干还原
- 中文:分词,bert默认以单字切割
- 加特殊标记
- 根据任务不同,加
[CLS],[SEP],[PAD]等
- 根据任务不同,加
- 映射为id
- 将以上所有字符映射为id编号序列
- 注意:encoder和decoder对应不同的字典
- 句子向量化
- 根据语料长度,设置高于分词后最大长度的阈值max_len,作为句子长度维度
格式:
- (a) For sequence pairs: 句子对
- sentence:
is this jackson ville ? || no it is not . - tokens:
[CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP] - type_ids:
0 0 0 0 0 0 0 0 1 1 1 1 1 1
- sentence:
- (b) For single sequences: 单句形式
- sentence: the dog is hairy .
- tokens:
[CLS] the dog is hairy . [SEP] - type_ids:
0 0 0 0 0 0 0 - 输出格式:
[guid, text_a, text_b, label]- 后两个字段可选
- 输入模型
- input_ids:句子id向量,max_len维
- input_mask:句子掩码模板,0,1标记,0表示空白填充
- segment_ids:两个句子分隔位置
- label_id:分类目标对应的id
数据准备
将语料切分为 train.tsv , test.tsv 以及 dev.tsv 三个文件。
- train.tsv 训练集
- dev.tsv 验证集
数据格式
- 第一列为 label,第二列为具体内容,tab 分隔。
- 因模型本身在字符级别做处理,因而无需分词。
fashion 衬衫和它一起穿,让你减龄十岁!越活越年轻!太美了!...
houseliving 95㎡简约美式小三居,过精美别致、悠然自得的小日子! 屋主的客...
game 赛季末用他们两天上一段,7.20最强LOL上分英雄推荐! 各位小伙...
分类任务
分类容易获得样本,以分类为例做模型微调
整体流程
修改 run_classifier.py
- 集成抽象类 DataProcessor,实现里面的几种方法:
- get_train_examples:获取训练集数据
- get_dev_examples:获取验证集数据
- get_test_examples:获取测试集数据
- get_labels:获取分类标签集合
DataProcessor
新增任务定义 DemoProcessor
- get_labels 定义label
class DemoProcessor(DataProcessor):
"""任务相关的数据集,处理类"""
def __init__(self):
self.labels = set() # label集合
def get_train_examples(self, data_dir):
"""读取训练集"""
# _read_csv只是简单按照tab分隔成list
# _create_examples将以上list转成标准样本格式
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""读取验证集"""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""读取测试集"""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
# 新增的任务
def get_labels(self):
"""获取目标值集合"""
#return list(self.labels) # 偷懒方式
#return ['-1', '0' , '1']
return ["fashion", "houseliving","game"] # 根据 label 自定义
def _create_examples(self, lines, set_type):
"""从训练集/验证集中读取样本"""
examples = []
for (i, line) in enumerate(lines):
# 格式:[label text]
# Only the test set has a header 测试集有header表头信息
if set_type == "test" and i == 0:
continue
guid = "%s-%s" % (set_type, i) # 样本唯一id
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[0])
label = "0" # 测试集给默认label
else: # 将所有字符转成unicode
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
# 输出格式:[guid, text_a, text_b, label]
return examples
processors
添加 DemoProcessor
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"demo": DemoProcessor, # 新增任务
}
训练
训练脚本 train.sh
BERT_DIR=`pwd`
# 模型目录
export BERT_BASE_DIR=${BERT_DIR}/chinese_L-12_H-768_A-12
# 数据目录
export DATA_DIR=${BERT_DIR}/data
python run_classifier.py \
--task_name="demo" \
--do_train=true \
--do_eval=true \
--data_dir=$DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/output/
输出
output 目录会有以下输出:
***** Eval results *****
eval_accuracy = xx
eval_loss = xx
global_step = xx
loss = xx
最终,微调后的模型保存在output_dir指向的文件夹中。
模型导出
run_classifier.py 是单次运行,如果把 do_predict 参数设置成 True,也可以预测,但输入样本是基于文件,不支持将模型持久化在内存里进行serving,因此需要改一些代码,达到:
- 将模型加载到内存,即:允许一次加载,多次调用。
- 读取非文件中的样本进行预测。从标准输入流读取样本输入。
在run_classifier.py添加下面的代码
flags.DEFINE_string(
"export_dir", None,
"The dir where the exported model will be written.")
flags.DEFINE_bool(
"do_export", False,
"Whether to export the model.")
编写导出脚本 explot.sh
BERT_DIR=`pwd`
export BERT_BASE_DIR=${BERT_DIR}/chinese_L-12_H-768_A-12
export DATA_DIR=${BERT_DIR}/data
python run_classifier.py \
--task_name=sentiment \
--do_train=false \
--do_eval=false \
--do_predict=true \
--data_dir=$DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=output \
--do_export=true \
--export_dir=exported
添加函数
def serving_input_fn():
label_ids = tf.placeholder(tf.int32, [None], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
})()
return input_fn
main()函数添加 do_export 选项
if FLAGS.do_export:
estimator._export_to_tpu = False
estimator.export_savedmodel(FLAGS.export_dir, serving_input_fn)
执行export.sh脚本,执行完成可以在export目录下看到一个新的模型文件,表示导出成功
实时预测
python test_serving.py 之后就可以愉快的快速离线预测
import tensorflow as tf
import tokenization
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
class PaddingInputExample(object):
"""Fake example so the num input examples is a multiple of the batch size.
When running eval/predict on the TPU, we need to pad the number of examples
to be a multiple of the batch size, because the TPU requires a fixed batch
size. The alternative is to drop the last batch, which is bad because it means
the entire output data won't be generated.
We use this class instead of `None` because treating `None` as padding
battches could cause silent errors.
"""
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
input_ids,
input_mask,
segment_ids,
label_id,
is_real_example=True):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
self.is_real_example = is_real_example
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
if isinstance(example, PaddingInputExample):
return InputFeatures(
input_ids=[0] * max_seq_length,
input_mask=[0] * max_seq_length,
segment_ids=[0] * max_seq_length,
label_id=0,
is_real_example=False)
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
# debug xmxoxo 2019/3/13
# print(ex_index,example.text_a)
label_id = label_map[example.label]
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: %s (id = %d)" % (example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id,
is_real_example=True)
return feature
if __name__ == '__main__':
predict_fn = tf.contrib.predictor.from_saved_model('exported/1607510113')
label_list = ["-1", "0", "1"]
max_seq_length = 128
tokenizer = tokenization.FullTokenizer(vocab_file='./chinese_L-12_H-768_A-12/vocab.txt', do_lower_case=True)
print('模型加载完毕!正在监听》》》')
while True:
question = input("> ")
predict_example = InputExample("id", question, None, '0')
feature = convert_single_example(100, predict_example, label_list,
max_seq_length, tokenizer)
prediction = predict_fn({
"input_ids": [feature.input_ids],
"input_mask": [feature.input_mask],
"segment_ids": [feature.segment_ids],
"label_ids": [feature.label_id],
})
probabilities = prediction["probabilities"]
label = label_list[probabilities.argmax()]
print(label)
总结
Bert 预训练后的 finetune,是一种很高效的方式,节省时间,同时提高模型在垂直语料的表现。finetune 过程,实际上不难。较大的难点在于数据准备和 pipeline 的设计。从商业角度讲,应着重考虑 finetune 之后,模型有效性的证明,以及在业务场景中的应用。如果评估指标和业务场景都已缕清,那么不妨一试。
MLM改进
- 基于MLM,做各种改进尝试
MLM,全称“Masked Language Model”,可以翻译为“掩码语言模型”,实际上就是一个完形填空任务,随机 Mask 掉文本中的某些字词,然后要模型去预测被 Mask 的字词。其中被 Mask 掉的部分,可以是直接随机选择的 Token,也可以是随机选择连续的能组成一整个词的 Token,后者称为 WWM(Whole Word Masking)。
论文 BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model指出 MLM 可以作为一般的生成模型用,论文 Spelling Error Correction with Soft-Masked BERT 则将 MLM 用于文本纠错。
结合人工模板
GPT-3 的论文叫做 Language Models are Few-Shot Learners [1],标题里边已经没有 G、P、T 几个单词了,只不过它跟开始的 GPT 是一脉相承的,因此还是以 GPT 称呼它。顾名思义,GPT-3 主打的是 Few-Shot Learning,也就是小样本学习。此外,GPT-3 的另一个特点就是大,最大的版本多达 1750 亿参数,是 BERT Base 的一千多倍。
正因如此,前些天 Arxiv 上的一篇论文 It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners [2] 便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。
必须要GPT-3吗?不,BERT的MLM模型也能小样本学习中,我们介绍了一种名为Pattern-Exploiting Training(PET) 的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。
将任务转成完形填空
- MLM 的一个精彩应用:用于小样本学习或半监督学习,某些场景下甚至能做到零样本学习。

一些简单的推理任务也可以做这样的转换,常见的是给定两个句子,判断这两个句子是否相容,比如“我去了北京”跟“我去了上海”就是矛盾的,“我去了北京”跟“我在天安门广场”是相容的,常见的做法就是将两个句子拼接起来输入到模型做,作为一个二分类任务。如果要转换为完形填空,那该怎么构造呢?一种比较自然的构建方式是:
- 我去了北京?__,我去了上海。
- 我去了北京?__,我在天安门广场。
其中空位之处的候选词为 { 是的,不是 }
给输入的文本增加一个前缀或者后缀描述,并且 Mask 掉某些 Token,转换为完形填空问题,这样的转换在原论文中称为 Pattern,这个转换要尽可能与原来的句子组成一句自然的话,不能过于生硬,因为预训练的 MLM 模型就是在自然语言上进行的。
模板自动生成(PET)
【2021-6-17】P-tuning:自动构建模版,释放语言模型潜能
然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
P-tuning重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效
模版的反思
- 首先,我们来想一下“什么是模版”。直观来看,模版就是由自然语言构成的前缀/后缀,通过这些模版我们使得下游任务跟预训练任务一致,这样才能更加充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。
- 等等,我们真的在乎模版是不是“自然语言”构成的吗?
- 并不是。本质上来说,我们并不关心模版长什么样,我们只需要知道模版由哪些token组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么。模版是不是自然语言组成的,对我们根本没影响,“自然语言”的要求,只是为了更好地实现“一致性”,但不是必须的。于是,P-tuning考虑了如下形式的模版:
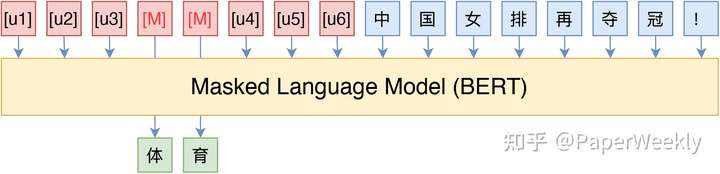
▲ P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性
这里的[u1]~[u6],代表BERT词表里边的 [unused1]~[unused6],也就是用几个从未见过的token来构成模板,这里的token数目是一个超参数,放在前面还是后面也可以调整。接着,为了让“模版”发挥作用,我们用标注数据来求出这个模板。
根据标注数据量的多少,优化思路又分两种情况讨论。
- 第一种,标注数据比较少。这种情况下,我们固定整个模型的权重,只优化[unused1]~[unused6]这几个token的Embedding,换句话说,其实我们就是要学6个新的Embedding,使得它起到了模版的作用。这样一来,因为模型权重几乎都被固定住了,训练起来很快,而且因为要学习的参数很少,因此哪怕标注样本很少,也能把模版学出来,不容易过拟合。
- 第二种,标注数据很充足。这时候如果还按照第一种的方案来,就会出现欠拟合的情况,因为只有6个token的可优化参数实在是太少了。因此,我们可以放开所有权重微调,原论文在SuperGLUE上的实验就是这样做的。读者可能会想:这样跟直接加个全连接微调有什么区别?原论文的结果是这样做效果更好,可能还是因为跟预训练任务更一致了吧。
原作者在SuperGLUE上的实验结果,显示出如果配合P-tuning,那么:
- 1)GPT、BERT的效果相比直接finetune都有所提升;
- 2)GPT的效果还能超过了BERT。
其中“小样本”只用到了“少量标注样本”,“无监督”则用到了“大量无标注样本”,“半监督”则用到了“少量标注样本+大量无标注样本”,“P-tuning”都是小样本,PET的几个任务报告的是最优的人工模版的结果,其实还有更差的人工模版。从小样本角度来看,P-tuning确实取得了最优的小样本学习效果;从模版构建的角度来看,P-tuning确实也比人工构建的模版要好得多;从模型角度看,P-tuning确实可以将GPT的分类性能发挥到跟BERT相近,从而揭示了GPT也有很强的NLU能力的事实。
【2019-7-26】RoBERTa —— 数据量+训练方式
RoBERTa 介绍
【2020-5-9】Roberta: Bert调优
Roberta,是Robustly Optimized BERT Approach的简称。
- Robustly用词很赞,既有“鲁棒的”,又有”体力的”。Roberta是实验为基础的论文,有点体力活的意思,但是结果又非常的鲁棒可信赖。
- 【2019-7-26】华盛顿大学 RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 代码在工具包 bert4keras 里
RoBERTa 改进点
BERT 模型的改进版: RoBERTa,GLUE,SQuAD,RACE 三个榜上取得 SOTA
RoBERTa 是BERT的成功变种之一,主要有4个简单有效的变化:
- 1)去除NSP任务;
- 2)大语料与更长的训练步数:batch size更大,数据更多;
- 3)更长的训练句子;
- 4)Masking策略——静态与动态:动态改变
[MASK]模式。复制多份数据
Bert 的优化版,模型结构与 Bert 完全一样,只是在数据量和训练方法上做了改进。简单说就是更大的数据量,更好的训练方式,训练得更久一些。
- 相比原生 Bert 的16G训练数据,RoBerta 训练数据量达到了161G;
- 去除了 NSP 任务,研究表明 NSP 任务太过简单,不仅不能提升反倒有损模型性能;
- MLM 换成 Dynamic Masking LM;
- 更大的 Batch size 以及其他超参数的调优;
RoBERTa 在 BERT 的基础上取得了令人印象深刻的结果。而且,RoBERTa 已经指出,NSP 任务对于 BERT 的训练来说相对没用。
结论:
- NSP 不是必须 loss
- Mask方式虽不是最优但是已接近。
- 增大batch size和增大训练数据能带来较大的提升。
由于Roberta出色的性能,现在很多应用都是基于Roberta而不是原始的Bert去微调了。
(1)动态 mask
- Bert中是在训练数据中静态的标上Mask标记,然后在训练中是不变的,这种方式就是静态的。
- Roberta尝试了一种动态的方式,说是动态,其实也是用静态的方式实现的,把数据复制10份,每一份中采用不同的Mask。这样就有了10种不同的Mask数据。
- 从结果中,可以看到动态mask能带来微小的提升。
(2)NSP任务
Bert的模型输入中是由两个segment组成的,因而就有两个问题:
- 两个segment是不是必要?
- 为什么是segment而不是单个的句子?
因此设置了四个实验:
- Segment-Pair + NSP
- Sentence-Pair + NSP: 只用了sentence以后,输入的长度会变少,为了使得每一步训练见到的token数类似,在这里会增大batch size
- Full-Sentence: 每一个样本都是从一个文档中连续sample出来的,如果跨过文档边界,就添加一个[SEP]的标记,没有NSP损失。
- Doc-Sentence: 类似于Full-Sentence,但是不会跨过文档边界。 从实验结果中可以看到,改用Sentence-Pair会带来一个较大的损失。猜测是因为这样无法捕捉long-term的依赖。
另外,Full-Sentence和Doc-Sentence能够带来微小的提升,说明NSP不是必须的。
- 这点跟Bert中的消融实验结论相反,但是请注意它们的输入还是不同的,原始Bert中的输入是Segment-Pair,有50%/50%的采样,而Full/Doc-Sentence中则是从文章中连续sample来的句子。
因为Doc-Sentence会导致不同的batch_size(因为要保证每个batch见到的token数类似),所以在Roberta中,使用Full-Sentence模式。
(3)Large-Batch
现在越来越多的实验表明增大batch_size会使得收敛更快,最后的效果更好。原始的Bert中,batch_size=256,同时训练1M steps。
在Roberta中,实验了两个设置:
- batch_size=2k, 训练125k steps。
- batch_size=8k, 训练31k steps。 从结果中看,batch_size=2k时结果最好。
RoBERTa 部署
pip install git+https://www.github.com/bojone/bert4keras.git
BERT 检索
问题
BERT和RoBERTa在文本语义相似度等句子对的回归任务上,已经达到了SOTA结果。- 但是,它们都需要把两个句子同时喂到网络中,导致巨大的计算开销:
- 从10000个句子中找出最相似的句子对,大概需要5000万(C100002=49,995,000)个推理计算,在V100GPU上耗时约65个小时。这种结构使得BERT不适合语义相似度搜索,同样也不适合无监督任务(例如:聚类)。
【2019-8-27】Sentence-BERT
Sentence-BERT,也称为SBERT,基于预训练BERT模型扩展的一种深度学习模型。
- 【2019-8-27】Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- Sentence-BERT: 一种能快速计算句子相似度的孪生网络
通过特定的训练方法,将句子转化为固定长度的向量表示,从而在自然语言处理领域中发挥重要作用。
Sentence-BERT(SBERT)网络结构利用孪生网络和三胞胎网络结构, 生成具有语义意义的句子embedding向量,语义相近的句子其embedding向量距离就比较近,从而可以用来进行相似度计算(余弦相似度、曼哈顿距离、欧式距离)。
该网络结构在查找最相似的句子对,从上述的65小时大幅降低到5秒(计算余弦相似度大概0.01s),精度能够依然保持不变。这样SBERT可以完成某些新的特定任务,例如相似度对比、聚类、基于语义的信息检索。
SBERT 在BERT/RoBERTa的输出结果上增加了一个pooling操作,从而生成一个固定大小的句子embedding向量
为了能 fine-tune BERT/RoBERTa,采用了孪生网络和三胞胎网络更新权重参数,以达到生成的句子向量具有语义意义。
SBERT广泛应用于句子对分类、句子相似度计算等任务。
BERT 压缩蒸馏
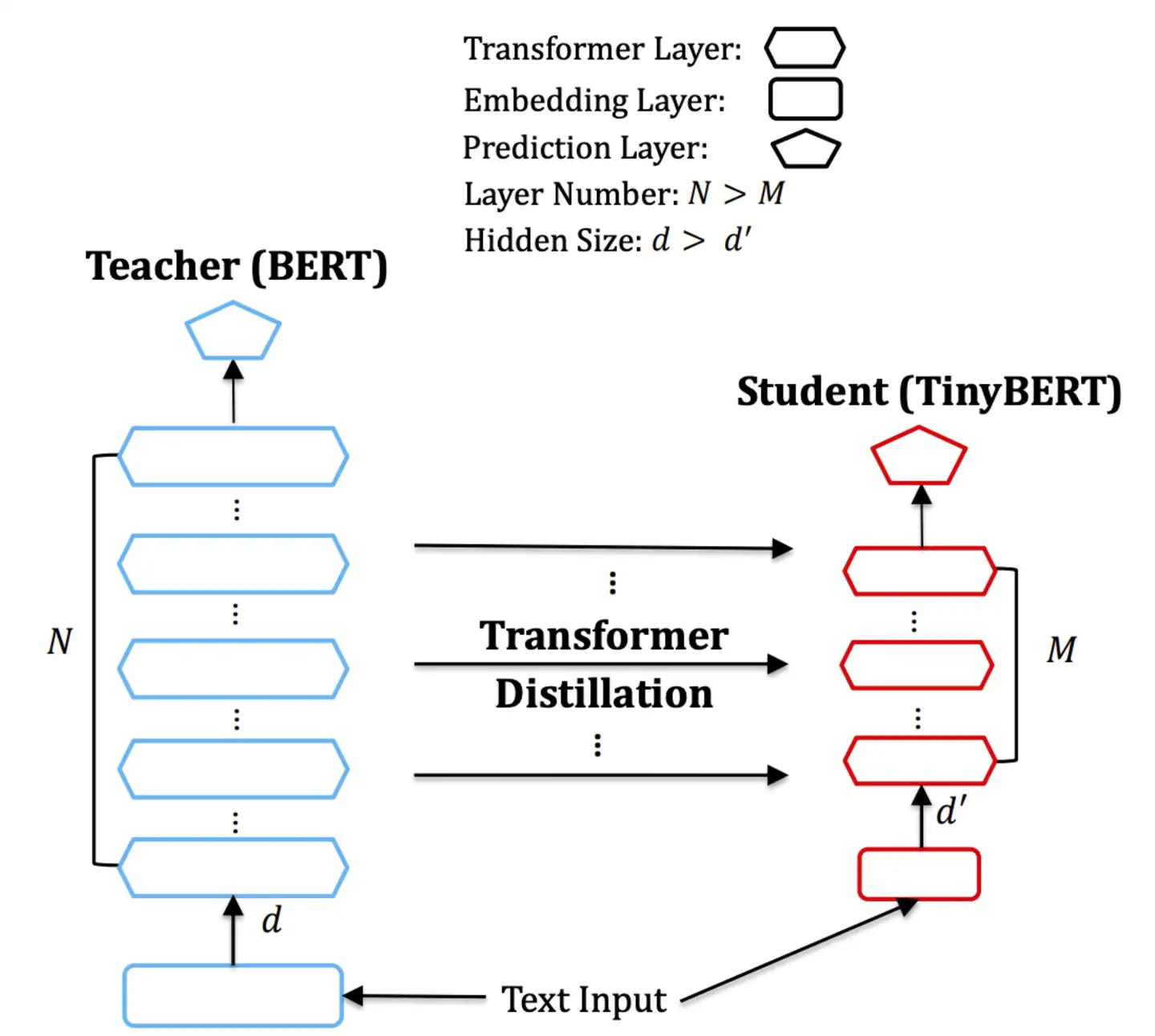
【2019-9-23】TinyBERT
BERT 强大毫无疑问,但由于模型过于庞大,单个样本计算一次的开销动辄上百毫秒,很难应用到实际生产中。
TinyBERT 是华为、华科联合提出的一种为基于 transformer 的模型专门设计的知识蒸馏方法,模型大小不到 BERT 的 1/7,但速度提高了 9 倍,而且性能没有出现明显下降。
本文复现了 TinyBERT 的结果,证明了 Tiny BERT 在速度提高的同时,对复杂的语义匹配任务,性能没有显著下降。
TinyBERT 模型结构
【2019-8-31】MiniBERT
Google推出的一种轻量级版本的BERT模型(即MiniBERT),该模型在保持性能的同时,大幅减少了参数量和计算复杂度,从而显著缩短了预训练时间
代码
【2021】 AutoTinyBERT
一次性神经架构搜索(NAS)来自动搜索架构超参数。
- 论文:AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
- 代码:AutoTinyBERT
在 GLUE 和 SQuAD 基准测试中的有效性。
- AutoTinyBERT 优于基于 SOTA 搜索的基线(NAS-BERT)和基于 SOTA 蒸馏的方法(例如 DistilBERT、TinyBERT、MiniLM 和 MobileBERT)。
此外,基于获得的架构,提出了一种更高效的开发方法,甚至比单个 PLM 的开发速度还要快。
【2019-9-28】ALBERT 轻量级bert 30%参数
【2019-9-28】谷歌Lab发布新的预训练模型”ALBERT”全面在SQuAD 2.0、GLUE、RACE等任务上超越了BERT、XLNet、RoBERTa,再次刷新了排行榜
Albert 的目的是想对 Bert 瘦身,希望用更简单的模型,更少的数据,得到更好的结果。它主要从两个方面减少模型参数量:
- 对 Vocabulary Embedding 进行矩阵分解,将原来的矩阵V x E分解成两个矩阵 V x H 和 H x E(H « E)。
- 跨层参数共享,每层的 attention map 有相似的pattern,可以考虑共享。
ALBERT最小的参数只有十几M, 效果要比BERT低1-2个点,最大的xxlarge也就200多M。
效果是 70%参数量的削减,模型性能损失 < 3%,但有很多文章指出 Albert 计算量并没有减少太多,并且如果达到超过 Bert 性能,需要使用更大的模型以及相应的算力。
【2020-5-20】BERT的youxiu变体:ALBERT论文图解介绍
ALBERT(一个Lite BERT)(Lan等人,2019)主要解决了更高的内存消耗和BERT训练速度慢的问题。
ALBERT引入了两种参数减少技术。
- 首先是嵌入分解,它将嵌入矩阵分解为两个小的矩阵。
- 其次是跨层参数共享,跨ALBERT的每一层共享transformer权重,这将显着减少参数。 此外,他们还提出了句序预测(SOP)任务来代替传统的NSP预训练任务。
ALBERT作为BERT的一个变体,在保持性能的基础上,大大减少了模型的参数,使得实用变得更加方便,是经典的BERT变体之一。
考虑下面给出的句子。作为人类,当我们遇到“apple”这个词时,我们可以:
- 把“apple”这个词和我们对“apple”这个水果的表征联系起来
- 根据上下文将“apple”与水果联系在一起,而不是与公司联系在一起
- 理解“he ate an apple”
- 在字符级,单词级和句子级理解它
NLP最新发展的基本前提是赋予机器学习这些表示的能力。
2018年,谷歌发布了BERT,试图基于一些新的想法来学习这个表示:
回顾 BERT
1. 掩码语言建模
语言建模方法包括:预测单词的上下文,包括当前单词时预测下一个单词。

BERT使用掩码语言模型,文档中随机地对单词进行掩码,并试图根据周围上下文来预测它们。

2. 下一个句子预测
“下一个句子预测”目的是检测两个句子是否连贯。

训练数据中的连续句被用作一个正样本。对于负样本,取一个句子,然后在另一个文档中随机抽取一个句子放在它的旁边。在这个任务中,BERT模型被训练来识别两个句子是否可以同时出现。
3. Transformer结构
为了解决上述两项任务,BERT使用了多层Transformer模块作为编码器。单词向量被传递到各个层,以捕获其含义,并为基本模型生成大小为768的向量。

Jay Alammar有一篇非常好的文章:http://jalammar.github.io/bert/,更深入地阐述了Transformer的内部机制。
BERT 问题
BERT发布后,在排行榜上产生了许多NLP任务的最新成果。但是,模型非常大,导致了一些问题。“ALBERT”论文将这些问题分为两类:
1、内存限制和通信开销:
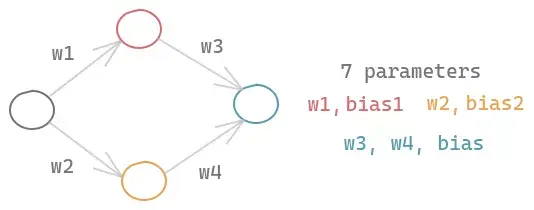
考虑一个包含一个输入节点、两个隐藏节点和一个输出节点的简单神经网络。即使是这样一个简单的神经网络,由于每个节点的权重和偏差,也会有7个参数需要学习。
BERT-large模型是一个复杂的模型,它有24个隐含层,在前馈网络和注意头中有很多节点,所以有3.4亿个参数。如果你想在BERT的基础上进行改进,你需要大量的计算资源的需求来从零开始进行训练并在其上进行迭代
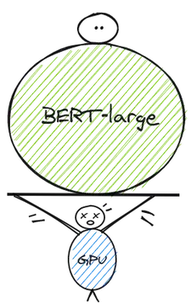
这些计算需求主要涉及gpu和TPUs,但是这些设备有内存限制。所以,模型的大小是有限制的。
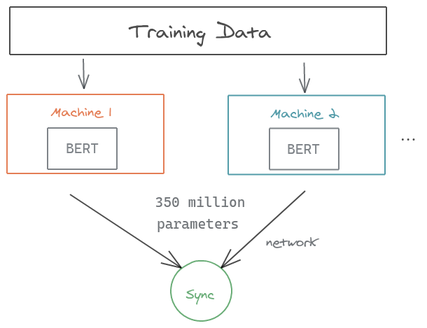
分布式训练是解决这个问题的一种流行方法。我们以BERT-large上的数据并行性为例,其中训练数据被分到两台机器上。模型在两台机器上对数据块进行训练。如图所示,你可以注意到在梯度同步过程中要传输的大量参数,这会减慢训练过程。同样的瓶颈也适用于模型的并行性,即我们在不同的机器上存储模型的不同部分。
2、模型退化
最近在NLP研究社区的趋势是使用越来越大的模型,以获得在排行榜上的最先进的性能。ALBERT 的研究表明,这可能会导致收益退化。
在论文中,作者做了一个有趣的实验。
如果更大的模型可以带来更好的性能,为什么不将最大的BERT模型(BERT-large)的隐含层单元增加一倍,从1024个单元增加到2048个单元呢?
他们称之为“BERT-xlarge”。令人惊讶的是,无论是在语言建模任务还是在阅读理解测试(RACE)中,这个更大的模型的表现都不如BERT-large模型。
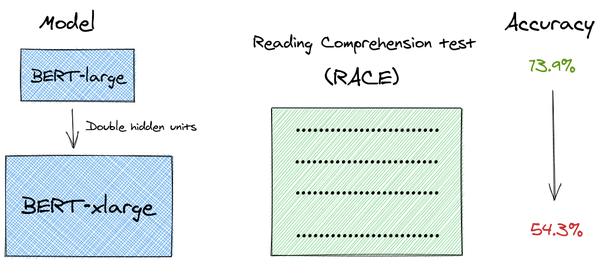
从原文给出的图中,我们可以看到性能是如何下降的。BERT-xlarge的性能比BERT-large差,尽管它更大并且有更多的参数。

ALBERT 原理
一个有趣的现象:
- 当我们让一个模型的参数变多的时候,一开始模型效果是提高的趋势,但一旦复杂到了一定的程度,接着再去增加参数反而会让效果降低,这个现象叫作“model degratation”。
albert要解决的问题:
- 让模型的参数更少
- 使用更少的内存
- 提升模型的效果
ALBERT提出了三种优化策略,做到了比BERT模型小很多的模型,但效果反而超越了BERT, XLNet。
- 低秩分解
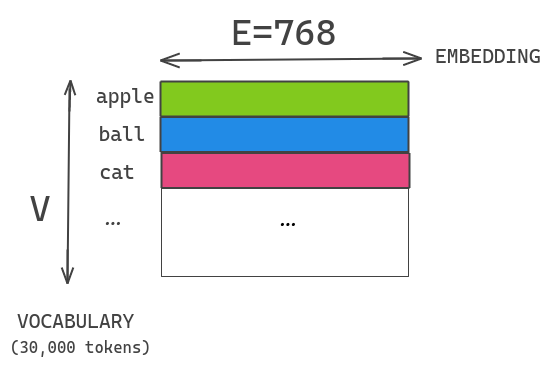
Factorized Embedding Parameterization. 针对于Vocabulary Embedding。在BERT、XLNet中,词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大,这就导致模型参数个数就会变得很大。通过对Embedding 部分降维来达到降低参数的作用。在最初的BERT中,以Base为例,Embedding层的维度与隐层的维度一样都是768,而词的分布式表示,往往并不需要这么高的维度,如Word2Vec时代就多采用50或300这样的维度。为了解决这些问题他们提出了一个基于factorization的方法。他们没有直接把one-hot映射到hidden layer, 而是先把one-hot映射到低维空间之后,再映射到hidden layer。这其实类似于做了矩阵的分解。- V:词表大小;H:隐层维度;E:词向量维度
- 以 BERT-Base 为例,Base中的Hidden size 为768, 词表大小为3w,此时的参数量为:768 * 3w = 23040000。 如果将 Embedding 的维度改为 128,那么此时Embedding层的参数量为: 128 * 3w + 128 * 768 = 3938304。二者的差为19101696,大约为19M。我们看到,其实Embedding参数量从原来的23M变为了现在的4M,似乎变化特别大,然而当我们放到全局来看的话,BERT-Base的参数量在110M,降低19M也不能产生什么革命性的变化。因此,可以说Embedding层的因式分解其实并不是降低参数量的主要手段。
- 层间参数共享
Cross-layer parameter sharing. Zhenzhong博士提出每一层的layer可以共享参数,这样一来参数的个数不会以层数的增加而增加。所以最后得出来的模型相比BERT-large小18倍以上。- 本质上就是对参数共享机制在Transformer内的探讨。Transformer两大主要的组件:FFN与多头注意力机制。传统 Transformer 的每一层参数都是独立的,包括各层的 self-attention、全连接
- ALBERT 将所有层的参数进行共享,相当于只学习第一层的参数,并在剩下的所有层中重用该层的参数,而不是每个层都学习不同的参数
- SOP替代NSP
Inter-sentence coherence loss.- BERT 训练中提出了next sentence prediction loss, 给定两个sentence segments, 然后让BERT去预测它俩之间的先后顺序
- 但ALBERT提出这种有问题,这种训练方式用处不是很大。 所以使用 setence-order prediction loss (SOP),其实是基于主题的关联去预测是否两个句子调换了顺序。
模型压缩有很多手段,包括剪枝,参数共享,低秩分解,网络结构设计,知识蒸馏等。ALBERT 也没能逃出这一框架,它其实是一个相当工程化的思想
Alber相对于原始BERT模型主要有三点改进:
- embedding 层参数因式分解
- 跨层参数共享
- 将 NSP 任务改为 SOP 任务
ALBERT在BERT 的基础上提出了一些新颖的想法来解决这些问题:
1、跨层参数共享
BERT-large模型有24层,而它的基础版本有12层。随着层数的增加,参数的数量呈指数增长。

为了解决这个问题,ALBERT使用了跨层参数共享的概念。为了说明这一点,让我们看一下12层的BERT-base模型的例子。我们只学习第一个块的参数,并在剩下的11个层中重用该块,而不是为12个层中每个层都学习不同的参数。
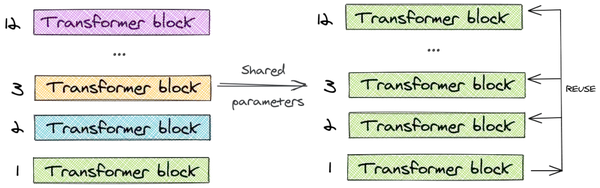
我们可以只共享feed-forward层的参数,只共享注意力参数,也可以共享整个块的参数。论文对整个块的参数进行了共享。
与BERT-base的1.1亿个参数相比,ALBERT模型只有3100万个参数,而使用相同的层数和768个隐藏单元。当嵌入尺寸为128时,对精度的影响很小。精度的主要下降是由于feed-forward层的参数共享。共享注意力参数的影响是最小的。
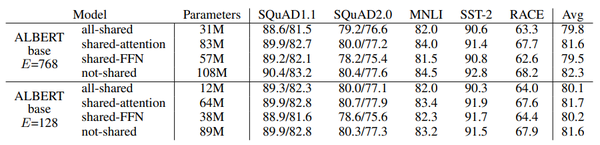
跨层参数策略对性能的影响
2、句子顺序预测 (SOP)
BERT引入了一个叫做“下一个句子预测”的二分类损失。这是专门为提高使用句子对,如“自然语言推断”的下游任务的性能而创建的。基本流程为:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本

像ROBERTA和XLNET这样的论文已经阐明了NSP的无效性,并且发现它对下游任务的影响是不可靠的。在取消NSP任务之后,多个任务的性能都得到了提高。
因此,ALBERT提出了另一个任务“句子顺序预测”。关键思想是:
- 从同一个文档中取两个连续的段落作为一个正样本
- 交换这两个段落的顺序,并使用它作为一个负样本
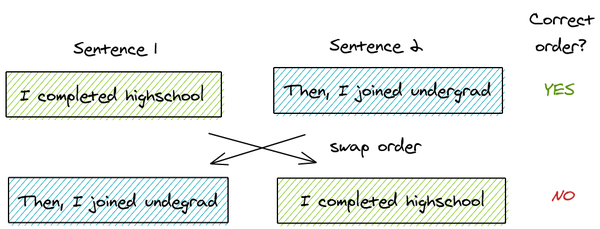
这使得模型能学习到更细粒度的关于段落级的一致性的区别。
ALBERT推测NSP是无效的,因为与掩码语言建模相比,它并不是一项困难的任务。在单个任务中,它混合了主题预测和连贯性预测。主题预测部分很容易学习,因为它与掩码语言建模的损失有重叠。因此,即使NSP没有学习连贯性预测,它也会给出更高的分数。
SOP提高了下游多句编码任务(SQUAD 1.1, 2.0, MNLI, SST-2, RACE)的性能。

在这里我们可以看到,在SOP任务上,一个经过NSP训练的模型给出的分数只比随机基线略好一点,但是经过SOP训练的模型可以非常有效地解决NSP任务。这就证明SOP能带来更好的学习表现。
3、嵌入参数分解
在BERT中,使用的embeddings(word piece embeddings)大小被链接到transformer块的隐藏层大小。Word piece embeddings使用了大小为30,000的词汇表的独热编码表示。这些被直接投射到隐藏层的隐藏空间。
假设我们有一个大小为30K的词汇表,大小为E=768的word-piece embedding和大小为H=768的隐含层。如果我们增加了块中的隐藏单元尺寸,那么我们还需要为每个嵌入添加一个新的维度。这个问题在XLNET和ROBERTA中也很普遍。
ALBERT通过将大的词汇表嵌入矩阵分解成两个小的矩阵来解决这个问题。这将隐藏层的大小与词汇表嵌入的大小分开。这允许我们在不显著增加词汇表嵌入的参数大小的情况下增加隐藏的大小。
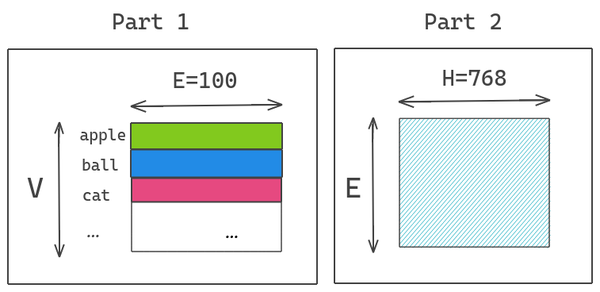
我们将独热编码向量投影到E=100的低维嵌入空间,然后将这个嵌入空间投影到隐含层空间H=768。
结果
- 比BERT-large模型缩小了18x的参数
- 训练加速1.7x
- 在GLUE, RACE和SQUAD得到SOTA结果:
- RACE:89.4%[提升45.3%]
- GLUE Benchmark:89.4
- SQUAD2.0 f1 score:92.2
ALBERT与BERT模型之间参数情况

在benchmark上的效果

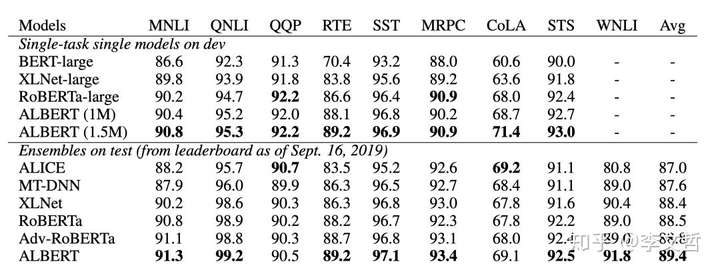
总结
ALBERT标志着构建语言模型的重要一步,该模型不仅达到了SOTA,而且对现实世界的应用也是可行的。
- 英文原文:https://amitness.com/2020/02/al
- albert的中文预训练模型
ALBERT 多标签实践
【2023-11-15】多标签文本分类 ALBERT
标签两两之间的关系:有的 independent,有的 non independent。
假设个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食。
- 一个人的爱好有这其中的一个或者多个 —— 多标签分类任务
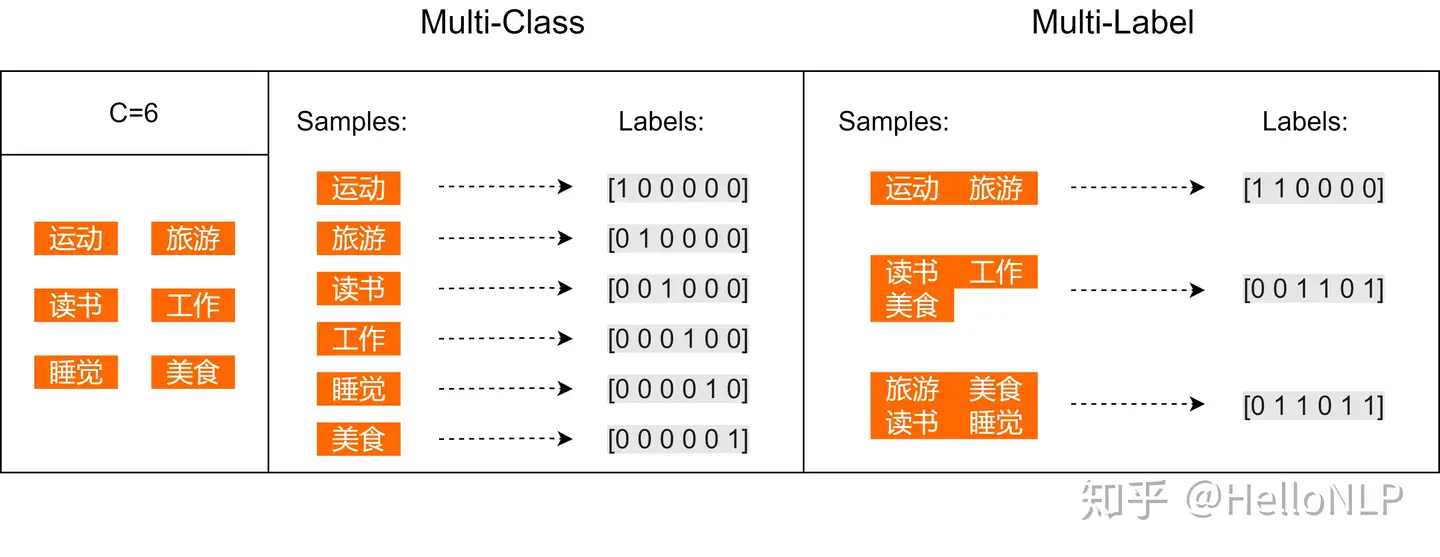
备注
- 常规文本分类中的交叉熵为
tf.nn.softmax_cross_entropy_with_logits; - 多标签文本分类中,交叉熵则为
tf.nn.sigmoid_cross_entropy_with_logits
原因:
tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立而不互斥。这适用于多标签分类问题。tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是独立且互斥(每个条目恰好在一个类中)。这适用多分类问题。
代码
ALBERT 微调
huggingface finetune
基于huggingface的finetune
import torch
from transformers import BertTokenizer,BertModel,BertConfig
import numpy as np
from torch.utils import data
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载预训练模型
pretrained = 'voidful/albert_chinese_small' #使用small版本Albert
tokenizer = BertTokenizer.from_pretrained(pretrained)
model = BertModel.from_pretrained(pretrained)
config = BertConfig.from_pretrained(pretrained)
inputtext = "今天心情情很好啊,买了很多东西,我特别喜欢,终于有了自己喜欢的电子产品,这次总算可以好好学习了"
tokenized_text = tokenizer.encode(inputtext)
input_ids = torch.tensor(tokenized_text).view(-1,len(tokenized_text))
outputs = model(input_ids)
# 输出字向量表示和句向量
print(outputs[0].shape,outputs[1].shape)
Pytorch Finetune – 成功
Pytorch版本实现 albert_pytorch
- albert pytorch版本由个人提供 brightmart
pip install boto3
目录结构
callback
convert_albert_tf_checkpoint_to_pytorch.py # 模型格式转换 tensorflow -> pytorch
dataset # 数据集目录
__init__.py
LICENSE
metrics # 评测工具
model # 模型源码
outputs # 模型保存
prepare_lm_data_mask.py # 数据处理:MASK
prepare_lm_data_ngram.py # 数据处理:n-gram
prev_trained_model # 预训练模型目录
processors # 处理 glue.py GLUE数据集适配工具
README.md
README_zh.md
run_classifier.py # 下游分类任务
run_pretraining.py # 预训练任务
scripts # 微调脚本
tools
预训练
数据准备: n-gram
- 将文本数据转化为一行一句格式,并且不同document之间使用
\n分割 - 产生n-gram masking数据集
python prepare_lm_data_ngram.py \
--data_dir=dataset/ \
--vocab_path=vocab.txt \
--data_name=albert \
--max_ngram=3 \
--do_data
启动预训练
python run_pretraining.py \
--data_dir=dataset/ \
--vocab_path=configs/vocab.txt \
--data_name=albert \
--config_path=configs/albert_config_base.json \
--output_dir=outputs/ \
--data_name=albert \
--share_type=all
任务
测试结果
问题匹配语任务:LCQMC(Sentence Pair Matching)
| 模型 | 开发集(Dev) | 测试集(Test) |
|---|---|---|
| albert_base(tf) | 86.4 | 86.3 |
| albert_base(pytorch) | 87.4 | 86.4 |
| albert_tiny | 85.1 | 85.3 |
分类
数据准备
- 下载 sts-2 数据集,到目录 dataset/sts-2
# question \t sentiment
has all the depth of a wading pool . 0
a movie with a real anarchic flair . 1
启动训练
sh scripts/run_classifier_sst2.sh
训练完毕
- V100 32G GPU上,约20min完成训练
- 模型保存目录
outputs/sst-2_output/albert
实践
【2023-11-23】新增新任务 test,仿照 sst-2 数据集, 修改文件:
- 【不变】
run_classifier.py- 函数
convert_examples_to_features用于处理数据
- 函数
processors/glue.pyglue_convert_examples_to_features是数据处理主要函数,超长会截断(尾部)- 末尾新增类
TestProcessor, 处理 train/dev/test 数据集- get_labels 函数要填写label集合,跟
glue_tasks_num_labels数目一致
- get_labels 函数要填写label集合,跟
- 新增字典取值:
- glue_tasks_num_labels: 标签数目
- glue_processors: 处理器字典
- glue_output_modes: 任务模式,分类还是回归
metrics/glue_compute_metrics.py- compute_metrics 方法新增 task_name 分支,指定评估指标
- 候选指标:
simple_accuracy(正确率),acc_and_f1(正确率+F1),pearson_and_spearman(相关系数) - acc_and_f1 要调用sklearn 的函数 f1_score,
metrics/glue_compute_metrics.py需要更改原始传参:- 36行增加average:
f1 = f1_score(y_true=labels, y_pred=preds, average='micro')
- 36行增加average:
scripts下新增文件run_classifier_test.sh,更新中文预训练模型地址、任务名(test)、启动predict、更新分词方式
processors/glue.py
# 【2023-11-23】新增任务
class TestProcessor(DataProcessor):
"""Processor for the Test data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
# 标签集合,字符串形式
return ["1", "2", "3", "4"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = line[0]
label = line[1]
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
glue_tasks_num_labels = {
"mnli": 3,
"mrpc": 2,
"sst-2": 2,
"sts-b": 1,
"qqp": 2,
"qnli": 2,
"rte": 2,
'lcqmc': 2,
"xnli": 3,
"test": 4, # 新增
}
glue_processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mnli-mm": MnliMismatchedProcessor,
"mrpc": MrpcProcessor,
"sst-2": Sst2Processor,
"sts-b": StsbProcessor,
"qqp": QqpProcessor,
"qnli": QnliProcessor,
"rte": RteProcessor,
'lcqmc': LcqmcProcessor,
"wnli": WnliProcessor,
"test": TestProcessor, # 新增
}
glue_output_modes = {
"cola": "classification",
"mnli": "classification",
"mnli-mm": "classification",
"mrpc": "classification",
"sst-2": "classification",
"sts-b": "regression",
"qqp": "classification",
"qnli": "classification",
"rte": "classification",
"wnli": "classification",
'lcqmc': "classification",
"test": "classification", # 新增
}
scripts/run_classifier_test.sh 内容
CURRENT_DIR=`pwd`
export BERT_BASE_DIR=$CURRENT_DIR/../model/albert_base_zh_pt # 模型地址
export DATA_DIR=$CURRENT_DIR/dataset # 数据集地址
export OUTPUR_DIR=$CURRENT_DIR/outputs # 模型输出
TASK_NAME="test" # 任务名
python run_classifier.py \
--model_type=albert \
--model_name_or_path=$BERT_BASE_DIR \
--task_name=$TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--data_dir=$DATA_DIR/${TASK_NAME} \
--max_seq_length=512 \
--per_gpu_train_batch_size=16 \
--per_gpu_eval_batch_size=8 \
--spm_model_file="" \
--learning_rate=1e-5 \
--num_train_epochs=30 \
--logging_steps=4210 \
--save_steps=4210 \
--output_dir=$OUTPUR_DIR/${TASK_NAME}_output/ \
--overwrite_output_dir \
--seed=42
# --do_predict \
# --spm_model_file=${BERT_BASE_DIR}/30k-clean.model \ # 关闭默认的英文分词器
Tensorflow Finetune – 失败
【2021-2-17】Albert微调实战
- 基于谷歌开源的BERT编写的文本分类器(基于微调方式),可自由加载NLP领域知名的预训练语言模型
BERT、Roberta、ALBert及其wwm版本,同时适配ERNIE1.0.
该项目支持两种预测方式:
- (1)线下实时预测
- (2)服务端实时预测
语料准备
完整版 TextClassifier_Transformer
- train.tsv
- test.tsv
- dev.tsv
数据样例
label txt
1 手机很好,漂亮时尚
1 做工一般
模型
# 下载源码
git clone https://github.com/google-research/ALBERT
# 下载模型 base
wget https://storage.googleapis.com/albert_models/albert_base_zh.tar.gz
# 解压模型
tar xvf albert_base_zh.tar.gz
确保本地环境是: Python 3.5~3.7, TensorFlow 1.15.2
conda create -n py37_tf1 python==3.7 tensorflow==1.15.2
conda activate py37_tf1
pip install -r requirements.txt
pytest albert # 单测
代码修改
每个数据集定义一个Processer类,包含多个方法
get_{train/test/dev}.py数据集处理- 调用方法
_create_examples,用tokenization.convert_to_unicode分词, 用InputExample构造每条数据
- 调用方法
get_labels标签获取
打开classifier_utils.py文件,添加代码
class SentimentProcessor(DataProcessor):
"""Processor for the sentiment data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["-1", "0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
if set_type == "test":
label = "0"
else:
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
然后打开run_classifier.py文件,添加一个processors
processors = {
"cola": classifier_utils.ColaProcessor,
"mnli": classifier_utils.MnliProcessor,
"mismnli": classifier_utils.MisMnliProcessor,
"mrpc": classifier_utils.MrpcProcessor,
"rte": classifier_utils.RteProcessor,
"sst-2": classifier_utils.Sst2Processor,
"sts-b": classifier_utils.StsbProcessor,
"qqp": classifier_utils.QqpProcessor,
"qnli": classifier_utils.QnliProcessor,
"wnli": classifier_utils.WnliProcessor,
"entiment": classifier_utils.SentimentProcessor,
}
Albert 代码与Bert结构大部分是相似的,但是目录结构不一样,把运行脚本写在工程的外面
BERT_DIR=`pwd`
export BERT_BASE_DIR=${BERT_DIR}/albert/albert_base
export DATA_DIR=${BERT_DIR}/albert/data
python albert/run_classifier.py \
--task_name=sentiment \
--do_train=true \
--do_eval=true \
--spm_model_file="" \
--do_predict=false \
--data_dir=$DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab_chinese.txt \
--albert_config_file=$BERT_BASE_DIR/albert_config.json \
--init_checkpoint=$BERT_BASE_DIR/model.ckpt-best \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=albert/output
【2023-11-14】实测
- run_classifier.py 相关的几个文件里import需要修改
from albert import modeling.py
# 改为
import modeling.py
Mac 下执行报错
Illegal instruction: 4 python albert/run_classifier.py
原因
numpy 1.18 was compiled with flags that enable certain CPU features (such as AVX) that are not present on older CPUs.
Linux tensorflow 2 下,执行仍然报错
- (1)要用 TensorFlow 1
- contrib 在TensorFlow 2中不再支持
- (2)tokenization.py 27行,tensorflow_hub不再支持
modeling.py 文件
# from tensorflow.contrib import layers as contrib_layers # 注释掉
# 429 行修改
def layer_norm(input_tensor, name=None):
"""Run layer normalization on the last dimension of the tensor."""
return tf.keras.layers.layer_norm(
inputs=input_tensor, begin_norm_axis=-1, begin_params_axis=-1, scope=name)
#return contrib_layers.layer_norm(
# inputs=input_tensor, begin_norm_axis=-1, begin_params_axis=-1, scope=name)
import tensorflow_hub as hub
ModuleNotFoundError: No module named 'tensorflow_hub'
【2023-11-23】使用 Debian GNU/Linux 10, tf 1.15.2, gpu,运行 albert分类代码,依然报错
- 运行 15min 左右,日志打印速度慢,最后显示 Killed
INFO:tensorflow:global_step/sec: 0.0647023
I1123 16:03:51.941936 140413923505984 tpu_estimator.py:2307] global_step/sec: 0.0647023
INFO:tensorflow:examples/sec: 2.07047
I1123 16:03:51.957370 140413923505984 tpu_estimator.py:2308] examples/sec: 2.07047
Killed
训练结果保存在output文件夹中,查看训练结果如下
eval_accuracy = 0.8332304
eval_loss = 0.4143196
global_step = 1000
loss = 0.41322827
best = 0.609635591506958
XLNet
XLNet 对 Bert 做了较大的改动,二者在模型结构和训练方式上都有不小的差异。
- Bert 的 MLM 在预训练时有 MASK 标签,但在使用时却没有,导致训练和使用时出现不一致;并且 MLM 不属于 Autoregressive LM,不能做生成类任务。
- XLNet 采用 PML(Permutation Language Model) 避免了 MASK 标签的使用,且属于 Autoregressive LM,可以做生成任务。
Bert 使用的 Transformer 结构对文本的长度有限制,为更好地处理长文本,XLNet 采用升级版的 Transformer-XL。
要点
- 全排列语言模型
- transformer-XL
- 跟多的数据
Yang等人(2019年)认为,现有的基于自编码的预训练语言模型(例如BERT)会遭受预训练和微调阶段的差异,因为masking符号[MASK]永远不会出现在微调阶段。
为了缓解这个问题,他们提出了XLNet,它基于Transformer-XL(Dai等人,2019)。 XLNet主要通过两种方式进行修改。
- 首先是所有排列上的输入因式分解的最大化期望似然,在此将它们称为排列语言模型(PLM)。
- 其次是将自编码语言模型更改为自回归模型,这与传统的统计语言模型相似
ERNIE(融合知识)
思路:
- 百度版:全词mask
- 清华版:知识图谱融入
ERNIE(通过知识整合增强表示)(Sun等人,2019a)旨在优化BERT的masking过程,其中包括实体级masking和短语级masking。 与在输入中选择随机单词不同,实体级mask将mask通常由多个单词组成的命名实体。短语级mask是mask连续的单词,类似于N-gram mask策略
【2019.10.18】Multi-BERT(谷歌)
Multi-BERT: 多语言 BERT(Multilingual BERT), Google 推出,官方介绍
- 数据: 用了 Wikipedia top 100 language
- token: 由于不同语言有不同的token(单词),所以要准备大的token集合,包含所有要训练语言的token。
- 训练: 和普通BERT一样。
代码示例
# Import generic wrappers
from transformers import AutoModel, AutoTokenizer
# Define the model repo
model_name = "bert-base-multilingual-cased"
# Download pytorch model
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Transform input tokens
inputs = tokenizer("Hello world!", return_tensors="pt")
# Model apply
outputs = model(**inputs)
【2019-12-5】NeZha 挪吒(华为)
华为开源预训练语言模型「哪吒」:编码、掩码升级,提升多项中文 NLP 任务性能
【2019-12-5】华为诺亚方舟实验室语音语义团队与海思、云BU等团队合作,共同研究大规模预训练模型的训练技术,发布了自己的中文预训练语言模型NEZHA(NEural ContextualiZed Representation for CHinese LAnguage Understanding,中文:哪吒)。
NEZHA是基于预训练语言模型BERT的改进模型,BERT通过使用大量无监督文本进行预训练,其包含两个预训练任务:Masked Language Modeling(MLM)和 Next Sentence Prediction (NSP),分别预测句子里被Mask的字(在构造训练数据时,句子里的部分字被Mask)和判断训练句对里面是不是真实的上下句。
三头六臂 NEZHA(哪吒)
- 函数式相对位置编码
- 全词覆盖的实现
函数式相对位置编码
位置编码有函数式和参数式两种
- 函数式通过定义函数直接计算就可以了。
- 参数式中位置编码涉及两个概念,一个是距离;二是维度。其中,Word Embedding 一般有几百维,每一维各有一个值,一个位置编码的值正是通过位置和维度两个参数来确定。
NEZHA 预训练模型则采用了函数式相对位置编码,其输出与注意力得分的计算涉及到他们相对位置的正弦函数,这一灵感正是来源于 Transformer 的绝对位置编码,而相对位置编码则解决了在 Transformer 中,每个词之间因为互不知道相隔的距离引发的一系列资源占用问题。
Transformer 最早只考虑了绝对位置编码,而且是函数式的;后来 BERT 的提出就使用了参数式,而参数式训练则会受收到句子长度的影响,BERT 起初训练的句子最长为 512,如果只训练到 128 长度的句子,在 128~520 之间的位置参数就无法获得,所以必须要训练更长的语料来确定这一部分的参数。
而在 NEZHA 模型中,距离和维度都是由正弦函数导出的,并且在模型训练期间是固定的。也就是说,位置编码的每个维度对应一个正弦,不同维度的正弦函数具有不同的波长,而选择固定正弦函数,则可以使该模型具有更强的扩展性;即当它遇到比训练中序列长度更长的序列时,依然可以发挥作用。
全词覆盖
现在的神经网络模型无论是在语言模型还是机器翻译任务中,都会用到一个词表;而在 Softmax 时,每个词都要尝试比较一下。每次运算时,所有词要都在词表中对比一遍,往往一个词表会包含几万个词,而机器翻译则经常达到六七万个词,因此,词表是语言模型运算中较大的瓶颈。
而 NEZHA 预训练模型,则采用了全词覆盖(WWM)策略,当一个汉字被覆盖时,属于同一个汉字的其他汉字都被一起覆盖。该策略被证明比 BERT 中的随机覆盖训练(即每个符号或汉字都被随机屏蔽)更有效。

混合精度训练及 LAMB 优化器
在 NEZHA 模型的预训练中,研究者采用了混合精度训练技术。该技术可以使训练速度提高 2-3 倍,同时也减少了模型的空间消耗,从而可以利用较大的批量。
传统的深度神经网络训练使用 FP32(即单精度浮点格式)来表示训练中涉及的所有变量(包括模型参数和梯度);而混合精度训练在训练中采用了多精度。具体而言,它重点保证模型中权重的单精度副本(称为主权重),即在每次训练迭代中,将主权值舍入 FP16(即半精度浮点格式),并使用 FP16 格式存储的权值、激活和梯度执行向前和向后传递;最后将梯度转换为 FP32 格式,并使用 FP32 梯度更新主权重。
【2020-9-15】MacBERT —— RoBERTa改进
MacBERT 介绍
MacBERT 全称:MLM as correction BERT,在多个方面对RoBERTa进行了改进,尤其是采用 MLM 作为校正(Mac)的masked策略。用相似单词mask,减轻了预训练和微调阶段两者之间的差距,这已被证明对下游任务是有效的
- NSP任务同
ALBERT的sentence-order predicion(SOP)任务,预测这两个句子对是正序还是逆序。 - MacBERT主要是修改BERT
MLM任务- 引入纠错型掩码语言模型(Mac)预训练任务,缓解“预训练-下游任务”不一致问题。
- 如何选择相似词?Synonyms 工具基于word2vec计算
- MacBERT在多种NLP任务上取得了显著性能提升。
- EMNLP,哈工大,Revisiting Pre-trained Models for Chinese Natural Language Processing,达到 sota
- MacBERT
- MacBERT: 中文自然语言预训练模型
发展
- 2020/9/15 论文”Revisiting Pre-Trained Models for Chinese Natural Language Processing” 被Findings of EMNLP 录用为长文。
- 2020/11/3 预训练好的中文MacBERT已发布,使用方法与BERT一致
MacBERT 模型
MacBERT与BERT共享相同的预训练任务,但有一些修改。 对于MLM任务修改。
- 用全词masked以及 Ngram masked策略来选择候选token来masked,单词级别的unigram到4-gram的比例为40%,30%,20%,10%。
- 不用[MASK] token进行mask,因为在token 微调阶段从未出现过[MASK],提议用类似单词进行masking。 通过使用基于word2vec(Mikolov et al。,2013)相似度计算的同义词工具包(Wang and Hu,2017)获得相似的单词。 如果选择一个N-gram进行masked,分别找到相似的单词。 在极少数情况下,当没有相似的单词时,会降级以使用随机单词替换。
- 对15%比例的输入单词进行masking,其中80%替换为相似的单词,10%将替换为随机单词,其余10%则保留原始单词。 对于类似NSP的任务,执行ALBERT (Lan等人,2019)引入的句子顺序预测(SOP)任务,其中通过切换两个连续句子的原始顺序来创建负样本。
MacBERT不是从头开始训练,用谷歌官方的Chinese BERT-base进行参数初始化
- 但是对于large版本是重新训练的,因为谷歌官方没有发布Chinese BERT的large版本。
论文模型(Hugging Face):
MacBERT 效果
在哈工大讯飞联合实验室发布的中文机器阅读理解数据(CMRC 2018数据集)等多个数据集上取得最佳,超过 RoBERTa,ELECTRA
MacBERT 实践
model_name = 'hfl/chinese-macbert-base'
model_name = 'hfl/chinese-macbert-large'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
DIET(RASA)
RASA推出 DIET 模型 —— 意图识别+实体抽取 sota
RASA 1.8 中引入
- DIET: Lightweight Language Understanding for Dialogue Systems
- 【2023-11-15】源码:diet_classifier
- 数据集:dataset
- Introducing DIET: state-of-the-art architecture that outperforms fine-tuning BERT and is 6X faster to train
DIET 特点
DIET出彩的地方:
- DIET是一种用于意图分类和实体识别的多任务体系结构。
- 能够以即插即用的方式结合语言模型的预训练单词嵌入,并将它们与单词和字符级 n-gram 稀疏特征结合起来。
- 即使没有预训练的嵌入,仅使用单词和字符级 n-gram 稀疏特征,DIET 仍可以在复杂 NLU 数据集上取得state of art的结果。
- 添加预训练语言模型的单词和句子嵌入,可进一步提高所有任务的整体准确性。
- 性能最好的模型明显优于fine-tune的 BERT,训练速度快6倍。
DIET 模型
DIET 模型是 Dual Intent and Entity Transformer 简称, 解决了对话理解问题中的2个问题,意图分类和实体识别。
- DIET使用纯监督方式,没有任何预训练的情况下,无须大规模预训练是关键,性能好于 fine-tuning Bert, 但是训练速度是bert的6倍。
- DIET 仅使用稀疏特征而没有任何预训练嵌入,即使这样,其性能仅比
Joint BERT模型低 1-2%之内。 利用 NLU-Benchmark 数据集上性能最佳模型的超参数,DIET 在 ATIS 和 SNIPS 上均获得与 Joint BERT 有竞争力的结果。
对话系统中NLU的2个任务:意图分类和实体识别, Goo et al 认为单独训练这2个task会导致错误传播,其效果不如2个任务同时使用一个模型,2个任务的效果会相互加强。
- 大型预训练模型在自然语言理解上性能很好,但是在训练和微调阶段都需要大量计算性能。
DIET模型关键功能是将预训练模型的得到的词向量,和可自由组合的稀疏单词特征和n-gram特征结合起来
- DIET代码中,这2个是dense-feature 和sparse-feature特征。
一般用 ELMO,BERT,GPT 等模型作为迁移学习模型,然后用或不用fine-tuning获取向量,用于下一个模型
- 但是这些模型速度慢,训练成本高,不太适合现实的AI对话系统。

Hen-derson et al. (2019b) 提出了一个更简洁的模型,使用单词和句子级别的encoding进行预训练,比BERT和ELMO效果要好,DIET模型是对此进一步研究
联合的意图分类和命名实体识别
- Zhang and Wang (2016) 提出了一种由双向门控递归单元(BiGRU)组成的联合架构。每个时间步的隐藏状态用于实体标记,最后时间步的隐藏状态用于意图分类。
- Liuand Lane (2016); Varghese et al. (2020) and Gooet al. (2018) )提出了一种基于注意力的双向长期短期记忆(BiLSTM),用于联合意图分类和NER。
- Haihong et al.(2019)引入了一个共同关注网络,用于每个任务之间共享信息。
- Chenet al. (2019)提出了联合BERT,该BERT建立在BERT之上,并以端到端的方式进行训练。他们使用第一个(CLS)的隐藏状态进行意图分类。使用其他token的最终隐藏状态来预测实体标签。
- Vanzo(2019)提出了一种由BiLSTM单元组成的分层自下而上的体系结构,以捕获语义框架的表示形式。他们从以自下而上的方式堆叠的各个层学习的表示形式,预测对话行为,意图和实体标签。
DIET采用transformer-based 框架,使用的多任务像形式,此外还进行了消融测试。
DIET 架构图
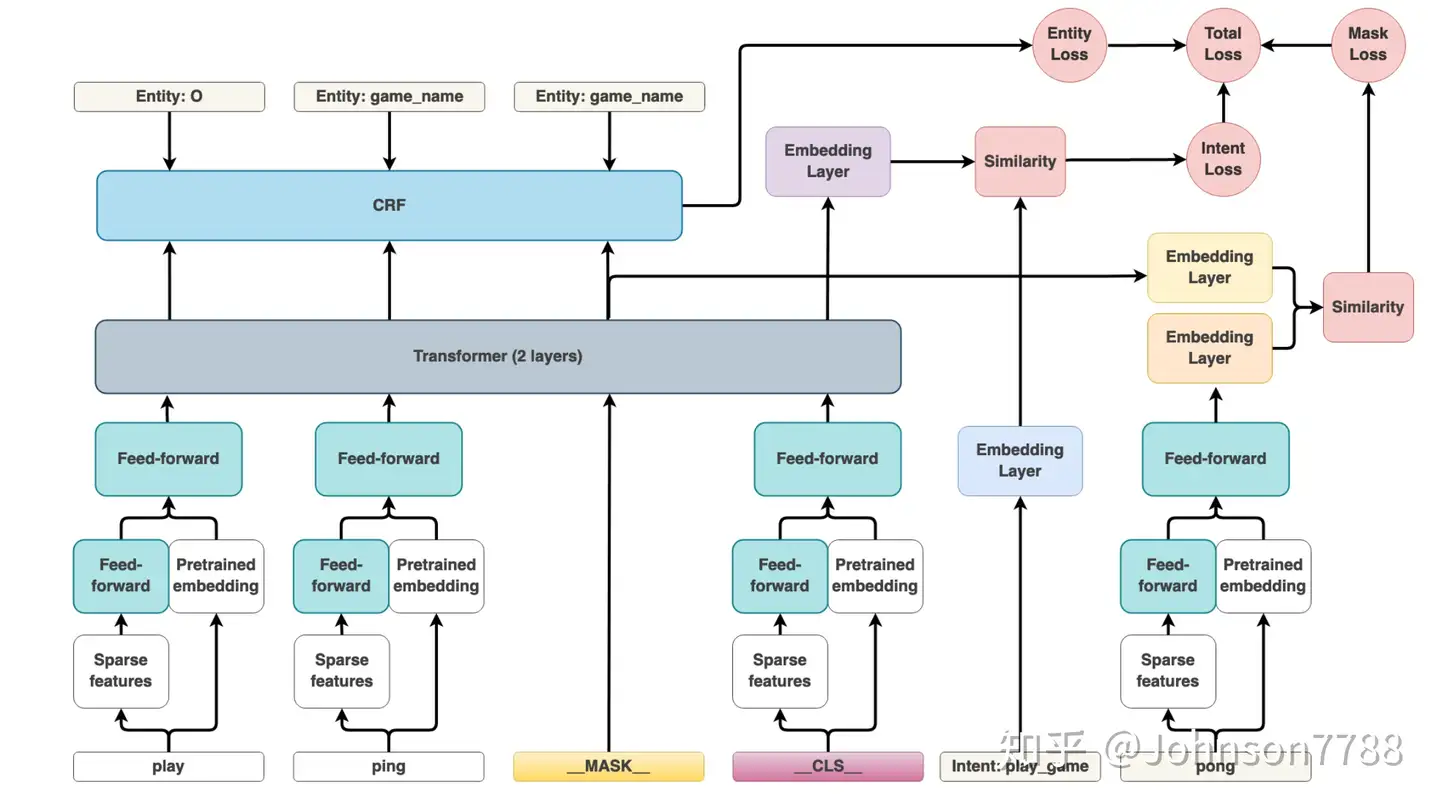
- 意图是play_game, 实体是ping pong,FFW是共享权重的
输入特征分为2部分,稠密特征 dense features和稀疏特征sparse features。
稀疏特征是n-grams(n<=5)的one-hot 或者multi-hot编码,但是稀疏特征包含很多冗余特征,为了避免过拟合,对此加入了dropout。 稠密特征来自预训练模型, 例如Bert或GloVe。
使用ConveRT作为句子的编码器,ConveRT的_CLS向量作为DIET的初始输入。这就是作为单词信息之外的句子信息特征了。如果使用BERT,我们使用 BERT [CLS] token, 对于GloVe,使用句子所有token的均值作为_CLS_,
稀疏特征通过一个全连接计算,其中全连接的权重是和其它序列的时间步全连接共享的,目的是为了让稀疏特征的维度和稠密特征的维度一致, 然后将稀疏特征的FFW的输出和稠密特征的向量进行concat拼接,因为transformer要求输入的向量维度需要一致,因此我们在拼接后面再接一个FFW,FFW的权重也是共享的。在实验中,这一层的维度是256.
transformer模块,使用2层layer,使用token的相对位置编码。
DIET: 一种用于意图和实体建模的灵活体系结构。
- DIET在NLU-Benchmark数据集上表现的state of the art。
- 此外,使用各种预训练方法的嵌入的有效性。发现没有单一的embdding模型总是在不同的数据集上表现出最好的效果,这凸显了模块化体系结构的重要性
- 此外,像GloVe这样的分布式模型与大规模语言模型BERT仍然具有不同的优势,在不使用任何预训练嵌入的情况下,DIET仍表现出state of the art
- 最后,在NLU-Benchmark数据集上,用于DIET的预训练嵌入集优于对DIET内的BERT进行fine-tune,并且训练速度快了六倍。
其它
UniLM、MASS 、SpanBERT 和 ELECTRA
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
