- 大语言模型原理详解
- LLM 原理
- transformer
- 主要结构
- Encoder
- Decoder
- 问题
- transformer 基本结构是什么
- Positional Encoding 有什么用
- 如何处理长距离依赖
- Layer Normalization 作用
- Layer Normalization 怎么计算
- 能否用 Batch Normalizatioin?
- self-attention 计算方法
- 为什么要除以根号dk?
- 为什么没有 Q Cache
- self-attention 为什么用多头?
- 高频: 多头注意力如何实现
- Multi-query Attention 和 Grouped-query Attention
- 为什么需要 Mask 机制
- Mask 机制如何实现
- 多轮 loss 为什么 mask
- pad 策略
- BERT
- 分词
- 位置编码
- 激活函数
- 损失函数
- Norm
- 注意力
- 微调
- 模型架构
- 文本生成
- 训练
- 多模态
- 结束
大语言模型原理详解
LLM 原理
自回归
预训练
文本序列是 【BOS】I like you【EOS】,那么,模型按如下顺序预测和学习:
- Step 1:输入 【BOS】,输出 I
- Step 2:输入 【BOS】I,输出 like
- Step 3:输入 【BOS】I like,输出 you
- Step 4:输入 【BOS】I like you,输出 【EOS】
| Step | 输出 | 输入 | 其他 |
|---|---|---|---|
| 1 | I | [BOS] | |
| 2 | like | [BOS] I | |
| 3 | you | [BOS] I like | |
| 4 | [EOS] | [BOS] I like you |
只要语料足够多,模型就能学会任意文本序列的建模方式,可以对任意的文本进行补全。
问题:串行计算,计算效率很低,没有利用transformer并行优势
解法:
- 引入Mask 机制,实现并行计算
掩码注意力
Transformer 掩码自注意力方法。掩码自注意力会生成一串掩码,来遮蔽未来信息
注意力掩码是【MASK】,那么模型的输入为:
<BOS> 【MASK】【MASK】【MASK】【MASK】
<BOS> I 【MASK】 【MASK】【MASK】
<BOS> I like 【MASK】【MASK】
<BOS> I like you 【MASK】
<BoS> I like you </EOS>
文本序列等长的上三角矩阵作为注意力掩码,再使用掩码来遮蔽掉输入即可。
当输入维度为 (batch_size, seq_len, hidden_size)时,Mask 矩阵维度为 (1, seq_len, seq_len)(通过广播实现同一个 batch 中不同样本的计算)。
代码
# 生成 Mask 矩阵:
# 创建一个上三角矩阵,用于遮蔽未来信息。
# 先通过 full 函数创建一个 1 * seq_len * seq_len 的矩阵
mask = torch.full((1, args.max_seq_len, args.max_seq_len), float("-inf"))
# triu 函数:创建上三角矩阵
mask = torch.triu(mask, diagonal=1)
生成的 Mask 矩阵会是上三角矩阵,上三角位置的元素均为 -inf,其他位置的元素置为0。
在注意力计算时,将计算得到的注意力分数与这个掩码做和,再进行 Softmax 操作:
# 此处的 scores 为计算得到的注意力分数,mask 为上文生成的掩码矩阵
scores = scores + mask[:, :seqlen, :seqlen]
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
通过做求和,上三角区域(也就是应该被遮蔽的 token 对应的位置)的注意力分数结果都变成了 -inf,而下三角区域的分数不变。再做 Softmax 操作,-inf 的值在经过 Softmax 之后会被置为 0,从而忽略了上三角区域计算的注意力分数,从而实现了注意力遮蔽。
多头注意力
注意力机制实现并行化与长期依赖关系拟合,但一次注意力计算只能拟合一种相关关系,单一的注意力机制很难全面拟合语句序列里的相关关系。
因此 Transformer 使用了多头注意力机制(Multi-Head Attention),即同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系,将最后的多次结果拼接起来作为最后的输出,即可更全面深入地拟合语言信息。
多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理;然后再将每一组得到的自注意力结果拼接起来,再通过一个线性层进行处理,得到最终的输出。
更多见站内专题 GPT
LLM 基本功
大模型基本功有哪些?
- transformer、rope、swiglu、rms_norm ?
- flash_attention 的原理?
- megatron 的各种 parallel 策略?
- 量化和推理加速技术?
- cuda编程?
资料
megatron 通用代码
开源社区,llama 网络结构已经一统江湖, 读懂 modeling_llama.py:
- 加载模型时没有 skip_build ;
- 缺少 stream_generate;
- 文件不支持 sequence_parallel ;
- 默认使用 flash_attention;
- 并没有一个可以作为 reward_model 的 lm_head;
收集 modeling_llama.py、 modeling_qwen.py、 modeling_baichuan.py、 modeling_yi.py、 modeling_deepseek.py、modeling_glm.py 等所有的开源文件,再把各家公司实现的比较好用的 def 加入到自己的 modeling_XX.py 中。
完成以下脚本, 理论上可加载任何开源模型。
trans_qwen_to_llama.pytrans_llama_to_qwen.py
以后出现任何新开源模型,都可通过“trans_newModel_to_myModel.py”,快速对该模型进行微调操作,而不用修改任何训练代码。
进一步理解每个开源模型的独特之处
- qwen2 的 q、k、v 的线性变换有 bias
- baichuan 的 lm_head 之前有一个
normalize()的操作 - 甚至每个开源模型都能观察到一些 attention 魔改。
然后,对照论文去找,为什么作者要做这些改动?能不能从这个过程中学到知识?
进阶篇:
trans_llama_to_megatron.py(给定参数 tp 和 pp)trans_megatron_to_llama.py
还可以给 modeling 文件加入很多有趣的东西来助力日常的 debug,比如:
def show_cos_distance(self, layer):输出某个 layer 的 input_hidden_states 和 output_hidden_states 的余弦距离;def show_topk_token(self, layer, K=10):输出用某个 layer 去预测 next token 时的最大 K 个 token;def show_attention(self, layer, tokenA, tokenB):输出第 layer 层的某两个 token 之间的 attention_value。
并不是所有人都用 megatron 训代码,但对于 megatron 训练的人,这两个脚本是基本功中的基本功了。
提醒: megatron_checkpoint 的 pp_size 实现 merge 和 split 非常简单,但在对 tp_size 进行 merge 和 split 的时候,一定要留意 megatron 的 gqa 的实现方式
进阶
- 单机并行推理已经实现了,不妨试试多机的;
- 学会用 vllm 等更快的推理框架,而不是 model.generate()。
- megatron 由于有 tp 和 pp 存在,实现起来难度远大于 deepspeed;
- model.trainer() 的训练方式封装的很死,如何加入 channel_loss 呢?
modeling_XX.py
即然可以万物转 llama,为什么还要用 modeling_llama.py 呢?
毕竟: modeling_llama.py
- 加载模型的时候没有 skip_build;
- 缺少 stream_generate;
- 文件不支持 sequence_parallel;
- 默认使用 flash_attention;
- 并没有一个可以作为 reward_model 的 lm_head;
- ……
实现一个自己的 modeling_XX.py,集百家之长,先去收集 modeling_llama.py、modeling_qwen.py、modeling_baichuan.py、modeling_yi.py、modeling_deepseek.py、modeling_glm.py 等所有的开源文件,再把各家公司实现的比较好用的 def 加入到自己的 modeling_XX.py 中。
这样,当市面上出现任何一个新的开源模型,都可以通过 “trans_newModel_to_myModel.py”,快速对该模型进行微调操作,而不用修改任何训练代码。
还可以给 modeling 文件加入很多有趣的东西来助力日常的 debug。
比如:
- def show_cos_distance(self, layer):输出某个 layer 的 input_hidden_states 和 output_hidden_states 的余弦距离;
- def show_topk_token(self, layer, K=10):输出用某个 layer 去预测 next token 时的最大 K 个 token;
- def show_attention(self, layer, tokenA, tokenB):输出第 layer 层的某两个 token 之间的 attention_value。
multi_infer.py
model.generate() 熟悉。
不考虑推理加速等技术时,客观事实:“8 卡 load 1 个模型、开大 batch_size ”的推理速度,远远小于 “8 卡 load 8 个模型、开小 batch_size ”的推理速度。
需求
- 实现一个 class infer (model_path, data_path, output_path, num_workers)
可用 torch_run, multiprocessing,或其他 python 库。
达成下面目的:
- 推理时让 1 机 8 卡 load 8 / 4 / 2 / 1 个模型,来快速的推理完一大批数据。
tips:
- 一些写法可能需要给 modeling_XX.py 加入一个 def set_device(self, device_list) 函数,毕竟如果每次都用
os.environ["CUDA_VISIBLE_DEVICES"]="3,4"来控制使用哪些卡来 load 模型,有点不太优雅。
进阶篇:
- 单机的并行推理已经实现了,不妨试试多机的;
- 学会用 vllm 等更快的推理框架,而不是
model.generate()。
Channel Loss
介绍领域模型 post-pretrain 时,做 domain post-pretrain 不看 channel loss,不如别开 tensorboard。
大部分情况下
- post-pretrain 的 loss 曲线都呈“缓慢下降”或“持平”的变化趋势
- sft 的 loss 曲线都呈“快速下降”且“阶梯状”的变化趋势,这时除初始 loss 和最终 loss是否符合预期外,能从中得到的信息微乎其微。
因此,把数据划分成不同数据源,对每个数据源的 loss 曲线单独观察,就显得尤为有意义,这也是研究跷跷板问题的必要环节。
题目:
- 改进训练代码,给 sft 数据随机赋予一个 channel,然后在训练过程中绘制出每个 channel 的 loss 曲线。
tips:
- 考虑通过 all_gather_object 实现。
进阶篇:
- megatron 由于有 tp 和 pp 存在,实现起来难度远大于 deepspeed;
- model.trainer() 训练方式封装的很死,如何加入 channel_loss 呢?
详见 大模型基本功
deepspeed chat 通用代码
详见站内专题: deepspeed chat
教程
LLM 发展史
- 2017-2018, 萌芽期: Transformer 架构诞生, 随后诞生 GPT-1、BERT 等大规模语言模型, 开启了预训练语言模型新纪元
- 2019-2022, 发展期: GPT-2、T5 以及 GPT-3 继续提升模型参数规模, 能力也随之提升。大力出奇迹
- 2022年以后, 突破期: ChatGPT 和 GPT-4 等发布,LLM 技术显著进步
【2026-4-9】小红书博主将大模型推理过程可视化
【2026-5-21】小红书帖子 大模型 CoT 思维链的信息流, 反向传播式归因
- 反向传播式归因可以一步步反向追溯中间推理token的归因来源,直到用户输入,形成一个“因果流”。可以从图里看到,答案是怎么一步步产生的,以及哪些原始输入对结果影响最大
- huggingface 工具: InfoLens 实时体验,LLM Causal Flow
国内
源自浙大书籍《大语言模型》章节
【2023-8-17】 吴恩达
【2024-12-25】台大李宏毅 生成式AI简介 Introduction to Generative AI 2024 Spring
【2024-12-13】 30分钟带你了解大模型发展史
视频不足
遗漏
- 2003年,Yoshua Bengio提出神经概率语言模型,分布式表征学习
- 2010年,Google Tomas Mikolov基于RNN实现了RNNLM
- 2013年,再接再厉,推出word2vec,成为工业界标配
知识型错误: 一个比较好的科普视频,观看时保持批判态度,因为有些事实错误,但不妨碍科普。错误如下:
- 多头注意力:此处不对,这里讲的是自注意力机制,会造成过度关注自身单词,所以有了多头注意力,在多个子空间中捕捉语义
- Encoder-Decoder大概2014年就有了,2015年,Ilya发明了seq2seq,En-De架构的一种实现,将输入编码为隐向量,表示能力不足,于是有了注意力机制,将向量升级为矩阵,seq2seq模式存在串行计算/长程依赖等问题,transformer里的自注意力机制将seq2seq模式升级为set2set,解除了并行依赖
- BERT参数量不是3.4亿, base(12层) 110m, large版(24)340m ④GPT-2开源,代码+权重都有,到了GPT-3,效果出现飞跃,这时候才选择闭源
【2025-5-13】图解大模型算法, 涵盖 LLM、VLM 等大模型技术,训练算法(RL、RLHF、GRPO、DPO、SFT 与 CoT 蒸馏等)、效果优化与 RAG 等
- Github LLM-RL-Visualized
【2025-9-17】上海交大《Dive into LLMs》系列
- 从微调预训练模型,到提示工程、知识编辑、越狱攻击,甚至多模态模型和GUI代理自动化任务,全是 Jupyter 笔记本实战。
- 还和华为合作推出本地化开发全流程,适合从零起步的你
- github主页 dive-into-llms
《开源大模型食用指南》
- 针对中国宝宝量身打造的基于Linux环境快速微调(全参数/Lora)、部署国内外开源大模型(LLM)/多模态大模型(MLLM)教程
- Github主页 self-llm
国外
国外大模型课程
- 2022年秋,
普林斯顿秋季课程, 陈丹琦主讲: Understanding Large Language Models, ppt - 2024年春,
CMU课程, 借用陈丹琦资料, 第20课: Large Language Models - 2024年,
斯坦福大模型课程, Introduction of Large Language Models - 【2025-6-23】2025年,斯坦福课程 CS336: Language Modeling from Scratch, github stanford-cs336
课程大纲
- 课程概述和 token 化
- PyTorch 和资源(包括内存和计算资源)
- 架构与超参数
- 混合专家(MoE)
- GPU
- Kernel,Triton
- 并行化
- Scaling Law
- 推理
- 评估
- 数据
- 对齐 ——SFT/RLHF,强化学习
- 客座讲座:
- 阿里巴巴达摩院研究员、Qwen 团队技术负责人 Junyang Lin(林俊旸)
- Facebook AI 研究科学家、Llama 3 预训练负责人 Mike Lewis
- 【2024-9】
Jay Alammar和Maarten Grootendorst写的大模型图书 Hands-On Large Language Models ,中文版《图解大模型》将于 2025 年 4 月上市- 中文版电子书 Hands-On-Large-Language-Models-CN
- Notebook 代码笔记:

- 目录
- 第一章: 介绍大模型
- 第二章: Tokens and Embeddings
- 第三章: Looking Inside Transformer LLMs
- 第四章: Text Classification
- 第五章: Text Clustering and Topic Modeling
- 第六章: Prompt Engineering
- 第七童: Advanced Text Generation Techniques and Tools
- 第八童: Semantic Search and Retrieval- Augmented Generation
- 第九章: Multimodal Large Language Models
- 第十章: Creating Text Embedding Models
- 第十一章: Fine-tuning Representation Models for Classification
- 第 12.1 章: 大模型 SFT
- 【2025-1-28】
Jay AlammarThe Illustrated DeepSeek-R1, 中文版 图解 DeepSeek-R1
【2024-4】基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理 Google 工程总监Antonio Gulli作序推荐!分享Transformer的工作原理和如何利用其解决NLP问题
主要内容
- • 了解用于解决复杂语言问题的新技术
- • 将GPT-3与T5、GPT-2和基于BERT的Transformer的结果进行对比
- • 使用TensorFlow、PyTorch和GPT-3执行情感分析、文本摘要、非正式语言分析、机器翻译等任务
- • 了解ViT和CLIP如何标注图像(包括模糊化),并使用DALL-E从文本生成图像
- • 学习ChatGPT和GPT-4的高级提示工程机制”
【2025-6-26】美国东北大学 nlp实验室 大语言模型基础
- 【2025-6-15】Foundations of Large Language Models
- 电子书 NiuTrans/NLPBook
Andrej Karpathy
Andrej Karpathy
个人简介:
- Andrej 曾是 OpenAI 的创始成员(2015 年),之后在特斯拉(Tesla)担任 AI 高级总监(2017-2022 年),
- 现在是 Eureka Labs 的创始人,该机构正在建设一所 AI 原生的学校。
- 目标是提高人们对 AI 最新技术状态的了解和理解,并帮助人们有效地在工作中使用最新、最强大的技术。
录制教程
- 3个小时 大模型技术原理讲座之后
- 面向普通用户的讲座,大型语言模型(LLMs)应用指南
大模型原理
Andrej Kaparthy 3小时讲座4K版:如何深入理解ChatGPT等大语言模型
- 面向大众的深度探讨,介绍为 ChatGPT 等相关产品提供支持的大型语言模型(LLM)AI 技术。
- 内容涵盖: 从模型开发到思考模型“心理”的心智模型,以及如何在实际应用中最大化地使用它们的全部训练过程。
内容
- 00:00:00 介绍(introduction)
- 00:01:00 预训练数据(pretraining data)
- 00:07:47 分词(tokenization)
- 00:14:27 神经网络输入/输出(neural network I/O)
- 00:20:11 神经网络内部结构(neural network internals)
- 00:26:01 推理(inference)
- 00:31:09 GPT-2:训练与推理(GPT-2: training and inference)
- 00:42:52 Llama 3.1 基础模型推理(Llama 3.1 base model inference)
- 00:59:23 从预训练到后训练(pretraining to post-training)
- 01:01:06 后训练数据(对话数据)(post-training data, conversations)
- 01:20:32 幻觉、工具使用、知识/工作记忆(hallucinations, tool use, knowledge/working memory)
- 01:41:46 自我认知(knowledge of self)
- 01:46:56 模型需要 tokens 来思考(models need tokens to think)
- 02:01:11 分词再探:模型难以处理拼写(tokenization revisited: models struggle with spelling)
- 02:04:53 不平滑的智能(jagged intelligence)
- 02:07:28 监督微调到强化学习(supervised finetuning to reinforcement learning)
- 02:14:42 强化学习(reinforcement learning)
- 02:27:47 DeepSeek-R1
- 02:42:07 AlphaGo
- 02:48:26 来自人类反馈的强化学习(RLHF, reinforcement learning from human feedback)
- 03:09:39 展望未来(preview of things to come)
- 03:15:15 跟踪 LLM 的发展(keeping track of LLMs)
- 03:18:34 在哪里找到 LLM(where to find LLMs)
- 03:21:46 总结(grand summary)
大模型应用指南
两小时的大语言模型实用指南
- 笔记: 微博总结
模型选择:
- “尽管ChatGPT现在有网络搜索,我仍使用Perplexity,因为他们在这方面有更多经验;
- 如果我想原型化web应用或创建图表,我喜欢Claude的Artifacts功能;
- 如果只是想与模型交谈,ChatGPT的高级语音模式很不错;
- 如果它过于谨慎,可以切换到更开放的Grok。”
主力组合: “ChatGPT、Claude、Grok”
- 用ChatGPT的深度研究
- Claude的文字编码
- Grok的实时搜索
- 偶尔用Perplexity补充
- 极少数处理超长文本再用Gemini。
一、LLM交互基本原理
1、LLM本质上是一个”压缩文件”
Karpathy 首先解释了与LLM交互的底层机制。”使用ChatGPT或类似产品时,实际上是在与一个’压缩文件’对话,”他解释道,”这个文件经过了预训练和后训练两个主要阶段。预训练阶段相当于将整个互联网压缩成一个概率性的压缩文件,而后训练则赋予模型助手的人格。”
底层机制中,输入和输出都被切分成称为”token”的小文本块。这些token组成一个一维序列,形成上下文窗口。
Karpathy指出:
- “我们与模型的互动实际上是在共同构建一个token窗口。我贡献了序列的前几个token,然后模型继续用它的响应延续这个序列。”
注意
- 这些模型通常有知识截止日期,因为预训练阶段成本高昂且进行不频繁。
- “GPT-4.0这个模型的预训练可能在好几个月前,甚至一年前完成,这就是为什么这些模型有点过时,它们只具有截至训练时的知识。”
2、不同层级的模型及其区别
LLM 生态系统中存在多种选择,用户要了解不同模型之间的差异。
Karpathy强调:”理解正在使用哪个模型非常重要。越大的模型价格越高,但功能也越强大。”
ChatGPT提供了从免费到专业的不同价格层级,每个层级可以使用的模型也不同。
- 免费层级,只能访问 GPT-4.0 Mini,GPT-4.0 较小版本,参数更少,创造力不如大模型,知识也不如大模型丰富,可能会产生更多幻觉。
根据自己的使用场景选择合适的模型:
- 如果可用更便宜的产品实现目标,那就选择它。
- 但如果智能程度不够,而又是专业使用,可能需要考虑付费使用顶级模型。”
二、思考型模型的工作机制与使用时机
1、强化学习训练出的”思考能力”
最新语言模型引入”思考能力”。
- 在强化学习阶段,模型发现了能够产生良好结果的思考策略。类似于人类解决问题时的内部独白。
- 这些思考策略很难通过人工标注直接编码。只有在强化学习中,模型才能尝试各种方法,找到适合自己知识和能力的思考过程,这一训练阶段相对较新,仅在一两年前开始应用。
与普通模型相比,思考模型花更多时间推理,尤其复杂问题上表现更佳。
- 思考型模型会花费数分钟进行思考,因为会输出大量token。
- 在困难问题上,这可能会带来更高的准确性
2、何时使用思考型模型
使用时机建议:
- 对于数学、编程和需要深度推理的问题,思考型模型特别有用。
- 而对于简单问题,比如旅行建议,使用思考型模型可能没有额外价值。
使用习惯:
- “先尝试非思考型模型,因为响应很快。
- 当回答质量不够好时,切换到思考型模型,有更多时间考虑问题。
编程问题示例:
- 当遇到梯度检查失败的问题时,普通 GPT-4.0 无法找出核心问题。
- 但当用O1 Pro(一个思考型模型)时,经过一分钟的思考,成功发现了参数不匹配的问题。
三、工具使用:为LLM赋能更多功能
1、网络搜索:扩展模型的知识边界
语言模型的主要限制: 其知识仅限于训练时数据。
开发者为LLM添加了工具使用能力,其中最有用的是互联网搜索。
- 当询问’白莲花第三季何时发布’涉及最新信息的问题时,模型没有这方面的知识
- 借助搜索工具,模型可以发出特殊token,提示应用程序执行搜索,访问网页,将内容添加到上下文窗口中
- 然后,基于这些信息回答问题。
功能极大简化了信息获取过程。不必手动搜索和浏览多个网页,只需提问,模型会完成所有工作,并引用来源,验证信息准确性。
2、深度研究:自动化的研究助手
更高级的工具:”深度研究“功能,结合了互联网搜索和思考能力,花费更长时间进行深入研究。
“深度研究本质上是搜索与思考的结合,持续数十分钟,模型会发出多个搜索请求,阅读论文,思考,最后返回带有引用的详细报告。”
使用经验:
- 想了解CAKG(一种健康成分)时,使用深度研究功能。模型花了约10分钟研究,返回了一份报告,包括在人类和动物模型中的有效性、作用机制和潜在风险,并提供了参考文献。这成为我进一步研究的良好起点。
3、Python解释器:解决数学与数据任务
为了解决复杂计算问题,LLM使用Python解释器。
- “对于无法在’脑内’计算的问题,如多位数乘法,模型会使用工具,模型会编写程序,ChatGPT应用程序执行该程序,然后返回结果给模型。”
这项功能在ChatGPT的高级数据分析中得到了扩展。
- “可以上传数据,要求生成图表或进行分析,模型会编写代码来处理数据并创建可视化。”
潜在问题:
- “模型编写的代码可能包含隐含假设或错误。
- 例如,ChatGPT错误地报告了OpenAI的2030年估值,与实际代码计算结果不符。
- 所以需要检查代码,将模型视为初级数据分析师。
四、与LLM的多模态交互
1、语音交互:从”假语音”到”真语音”
两种与LLM进行语音交互的方式:
- 第一种是’假语音’,仍通过文本与模型交互,只是使用语音转文本和文本转语音模型进行预处理。
- 第二种是’真语音’,模型直接理解和生成音频。
真语音模式下,模型直接处理音频token,无需文本中介。音频被分解为频谱图,量化为token,模型训练时就学会了理解这些音频片段,这带来了许多通过假语音无法实现的能力。”
高级语音模式的互动:可要求模型以特定角色说话,如尤达大师或海盗;可以请求讲故事;甚至要求它快速数数。
这些不仅仅是文本转语音的变化,而是模型对音频本身的理解和生成。
2、图像理解与生成
除了语音,LLM还可以处理图像。像处理文本和音频一样,可以将图像切分为token,应用相同的建模技术,最简单的方法是将图像分割成网格,每个小块量化为vocabulary中最接近的patch。
在实践中,这使模型能够理解上传的图像。
使用案例:
- 上传了营养标签图片,询问成分的安全性;
- 上传血液检测结果获取解释;
- 甚至上传数学表达式进行求解。
这在OCR和信息提取方面非常有用。
对于图像生成,DALL-E等工具:
- 要求模型生成任何风格的任何主题的图像。创建图标、缩略图和其他内容。
3、视频交互:最新的前沿
视频处理是多模态交互的最新进展。
- 手机app上,ChatGPT现在可以看到视频,向摄像头展示物品,模型能识别并讨论,比如识别书籍、设备或地图。
视频生成虽然仍处于早期阶段,但发展迅速。
- 像 VO2、Sora 模型已经能生成令人印象深刻的视频
- 每个模型都有略微不同的风格和质量,用户可以根据需要选择。”
五、提升用户体验的辅助功能
1、ChatGPT 记忆功能
ChatGPT 引入了跨对话记忆功能,记忆功能本质上是一个关于知识数据库,总是预置在所有对话开始处,让模型能够访问。随着你继续使用ChatGPT,它会逐渐更好地了解你,让回答更加相关。
通过自然交互收集信息,用户也可以手动管理记忆:可以编辑、添加或删除记忆,管理你的记忆数据库。
- 例如,喜欢90年代和2000年代初的电影,可以帮助它为我提供更好的电影推荐。”
2、自定义指令与GPTs
用户通过自定义指令调整模型行为。告诉ChatGPT你希望它具有什么特质,如何与你交流,避免过于正式的商务语气,更注重教育性内容,并在使用韩语时默认使用特定礼貌程度。
更强大的是自定义GPTs功能,允许用户创建针对特定任务的模型。K
例子:
- 创建’韩语词汇提取器’,将句子转换为Anki闪卡格式;
- ‘韩语详细翻译器’提供逐字解析;
- ‘韩语字幕OCR’则从视频截图中提取和翻译字幕。
这些自定义GPTs实际上是保存提示词,创建技巧:
- 当创建GPTs时,我不仅提供描述,还给出具体示例。
- 这种few-shot提示比zero-shot提示更准确,就像教人一样,不仅解释任务,还展示如何完成。
六、LLM生态系统的现状与未来
1、快速发展的碎片化生态系统
当前LLM领域的特点:快速增长、变化和繁荣的LLM应用生态系统。
- ChatGPT 作为第一个和主流产品,可能功能最丰富,但其他应用也在迅速成长,要么达到功能平等,要么在特定领域超越ChatGPT。
不同应用有各自的优势:
- 尽管ChatGPT现在有网络搜索,仍使用Perplexity,这方面有更多经验;
- 如果原型化web应用或创建图表,Claude的Artifacts功能;
- 如果只是与模型交谈,ChatGPT 高级语音模式很不错;
- 如果它过于谨慎,可以切换到更开放的Grok。
2、应对碎片化的策略
面对这种碎片化,关键因素:
- 首先,了解用的是哪个模型和价格层级。更大的模型有更多世界知识,写作更好,更有创意,但也更贵。
- 其次,是否需要思考模型。这些模型在数学、代码和推理问题上更准确,但简单任务可能不值得等待。
- 第三,了解不同应用提供的工具。Internet搜索适用于最新信息,Python解释器适用于计算,等等。
- 第四,跟踪多模态功能的发展。不同应用处理音频、图像和视频的方式各不相同,有些是原生支持,有些是附加功能。” 0 最后,用户体验功能,如:记忆、自定义指令和GPTs,它们可以显著改善交互效果。
七、总结
讲座全面展示了LLM技术如何从实验室走入日常生活和工作。
- 从基础交互原理到高级功能应用,从单一模态到多模态输入输出,今天的语言模型正变得越来越强大、灵活和实用。
LLM领域正处于快速发展阶段,不同应用和模型各有优势。用户需要了解这一生态系统的基本组成,选择适合自己需求的模型和功能,并保持对新发展的关注。
未来,可以预期更深入的多模态集成,更自然的交互方式,以及更专业的工具使用能力。
LLM将继续从通用助手发展为专业领域的强大辅助工具,甚至在某些任务上成为专业人士的重要合作伙伴。随着技术的进步和应用的普及,理解并掌握这些工具的使用方法,将成为数字时代的重要能力
国内
【2023-12-7】复旦大学张奇教授团队写了在线免费的电子书,《大规模语言模型:从理论到实践》,主页,大概有 300 页篇幅,将大模型从理论到实战的每个阶段都描述的较为清楚。
厦门大学大数据教学团队:大模型概念、技术与应用实践, 140页PPT读懂大模型
浙大书籍:大模型基础
- 包括传统语言模型、大语言模型架构演化、Prompt工程、参数高效微调、模型编辑、检索增强生成等六章
- GitHub Foundations-of-LLMs
目录
本书目录
| 章节 | 所含内容 |
|---|---|
| 第 1 章:语言模型基础 | 1.1 基于统计方法的语言模型 1.2 基于 RNN 的语言模型 1.3 基于 Transformer 的语言模型 1.4 语言模型的采样方法 1.5 语言模型的评测 |
| 第 2 章:大语言模型 | 2.1 大数据 + 大模型 → 新智能 2.2 大语言模型架构概览 2.3 基于 Encoder-only 架构的大语言模型 2.4 基于 Encoder-Decoder 架构的大语言模型 2.5 基于 Decoder-only 架构的大语言模型 2.6 非 Transformer 架构 |
| 第 3 章:Prompt 工程 | 3.1 Prompt 工程简介 3.2 上下文学习 3.3 思维链 3.4 Prompt 技巧 3.5 相关应用 |
| 第 4 章:参数高效微调 | 4.1 参数高效微调简介 4.2 参数附加方法 4.3 参数选择方法 4.4 低秩适配方法 4.5 实践与应用 |
| 第 5 章:模型编辑 | 5.1 模型编辑简介 5.2 模型编辑经典方法 5.3 附加参数法:T-Patcher 5.4 定位编辑法:ROME 5.5 模型编辑应用 |
| 第 6 章:检索增强生成 | 6.1 检索增强生成简介 6.2 检索增强生成架构 6.3 知识检索 6.4 生成增强 6.5 实践与应用 |
3D交互
【2024-1-24】新西兰软件工程师 Brendan Bycroft 开发的LLM 3D可视化网站 LLM Visualization, 展示 nanoGPT, GPT-2, GPT-3, 动态展示网络结构、运行过程
LLM 视频
LLM介绍
动图讲解
【2024-1-15】transformer 语言建模,动图讲解:
过程
# (1) 原始句子,来自互联网上大量文本
We go to work by train
# (2) 分词成令牌(Tokens): 编码的基本单位
We, go, to, work, by, train
# (3) 掌握单词(work)的语义, 需要关注上下文,注意邻近词
I have to go work ____ ? # 该填什么呢
...
I work in my neighborhood
# (4) work 训练集:正例词集(E.g:roof),负例(E.g:dove)。
work roof, work office # 正例
work dove # 负例
# (5) 向量化: 根据每个词在训练数据中邻近程度来调整向量,称为词嵌入(embedding)。
work roof -> 0.8
work dove -> -0.9
# 词嵌入可以包含数百个值,每个值表示一个词意义的不同方面
work -> [0.1, ..., 0.9]
# 近义词向量的相似度高,如 sea和ocean
# (6) transformer 自注意力(Attention),同时计算所有单词,而不是RNN的顺序扫描
self-attention
# (7) 规模扩大,自注意力允许LLM获取句子外的上下文(context),更深入的理解句子。
next token prediction
text -> tokenization -> word embedding/positional embedding -> self-attention -> Encoded output
# (8) 模型给每个令牌一个概率分数(probability score),表示序列中下一个词的可能性。
work roof -> 0.8
work dove -> -0.9
# (9) 循环下去,直至结束:贪心搜索->集束搜索找最佳
I have to go work roof
LLM 构建
【2024-12-24】 国外威斯康星大学教授Sebastian Raschka 开源书籍 Build a Large Language Model (From Scratch) 以及配套代码
- 中文版 Build-A-Large-Language-Model-CN
- 学习笔记 知乎
中文理解代码 LLMs-from-scratch-CN-Colab
电子书
- 网盘:Build a Large Language Model (From Scratch).pdf, 提取码: 8vjk
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git
章节
- 第一章:理解大语言模型
- 第二章:处理文本数据
- 各种文本处理方法,包括embedding、token、位置编码等等
- 第三章:实现注意力机制
- Attention机制,代码解释的很细,图文并茂
- 第四章:从零开始实现一个用于文本生成的 GPT 模型
- 构建一个类似GPT的大模型,包括构建架构,Normalize等等,直到生成文本。
- 第五章:在无标记数据集上进行预训练
- 用未标注数据进行训练
- 第六章:用于分类任务的微调
- 第七章:指令遵循微调
【2024-9-6】大模型白盒子构建指南
- GitHub:tiny-universe
从原理出发、以“白盒”为导向、围绕大模型全链路的“手搓”大模型指南,帮助有深度学习基础的读者从底层原理出发,“纯手搓”搭建一个清晰、可用的大模型系统,包括大模型本身、RAG 框架、Agent 系统及大模型评估体系。最近新增了从零开始pretrain Llama3部分。
亮点
- 全流程 从零手搓
- 包含LLM全流程,从Model,到RAG,Agent,Eval,打造LLM 全栈教程
- 区别于大型的算法包,项目代码对初级开发者更 简洁清晰 ,更”白盒子”
- 后续会持续迭代更新项目,如动手训练一个 Tiny-llama3 ,动手制作 垂直领域数据集 等等。
- 深入剖析大模型原理——Qwen Blog
- 如何评估你的大模型——Tiny Eval
- 纯手工搭建 RAG 框架——Tiny RAG
- 手搓一个最小的 Agent 系统——Tiny Agent
- 深入理解大模型基础——Tiny Transformer
- 从零开始pretrain Llama3—— Tiny Llama
MiniMind 微型LLM训练示例,CPU上可运行
- MiniMind 文本LLM训练,Train a 64M ChatBot from zero 2 hours. ¥3. One 3090.
- 【2026-5-10】minimind-o
- 从0训练一个 0.1B 端到端全模态模型,一个权重搞定文字、语音、图片输入,输出文字和流式语音
- MiniMind-O 只有0.1B参数的全模态模型,Thinker-Talker 双路径设计,支持文字/语音/图片输入,输出文字和流式语音。
这项目把代码、权重、训练数据和技术报告全部开源,核心算法用 PyTorch 从0写,一张3090两小时就能跑通 mini 数据集训练。
典型 LLM
2018年, GPT架构问世,大型语言模型(LLM)架构在2025年虽保留核心框架,但通过一系列优化显著提升了效率与性能。
【2025-7-19】Sebastian Raschka 聚焦 DeepSeek V3、OLMo 2、Gemma 3、Mistral Small 3.1、Llama 4、Qwen3 和 Kimi 2 架构亮点,总结其关键技术进步。
- 原文 The Big LLM Architecture Comparison
- 【精】LLM Architecture Gallery: 所有大模型结构可视化,交互式查看,链接到技术报告、配置文件、训练代码
| 模型 | 总参数 | 激活参数 | 注意力机制 | MoE | 归一化方式 | 位置编码 | 特色优化 |
|---|---|---|---|---|---|---|---|
| DeepSeek V3 | 671B | 37B | MLA | ✔️ | Pre-Norm | RoPE | 共享专家 + KV 压缩 |
| OLMo 2 | 7B/13B | 7B/13B | MHA(非 GQA) | ❌ | Post-Norm + QK-Norm | RoPE | 训练稳定性优化 |
| Gemma 3 | 27B | 27B | GQA + Sliding Window | ❌ | Pre+Post Norm | RoPE | 局部注意力节省 KV 缓存 |
| Mistral Small 3.1 | 24B | 24B | GQA(无滑动窗口) | ❌ | Pre-Norm | RoPE | 推理延迟优化(更小的 KV 缓存) |
| Llama 4 Maverick | 400B | 17B | GQA | ✔️ | Pre-Norm | RoPE | MoE 每层交替使用 |
| Qwen3 Dense | 0.6B - 32B | 同总参数 | GQA | ❌ | Pre-Norm | RoPE | 最小模型仅 0.6B,适合本地部署 |
| Qwen3 MoE | 235B | 22B | GQA | ✔️ | Pre-Norm | RoPE | 无共享专家,更多专家数 |
| SmolLM3 | 3B | 3B | GQA | ❌ | Pre-Norm | NoPE(部分层) | 去除 RoPE,提升长文本泛化 |
| Kimi 2 | 1T | ~37B+ | MLA(更少头) | ✔️ | Pre-Norm | RoPE | Muon 优化器,1T 开源最大模型 |
【2025-12-14】2025 年最全面的 LLM 架构技术解析
- 原文 【2025-7-19】the-big-llm-architecture-comparison
架构进化:GPT-2, DeepSeek V3, 到 Llama 4,都是Decoder-Only结构,高度相似,区别:
- 位置编码 Positional Embedding:绝对位置编码→旋转位置编码 RoPE
- 多头注意力 Multi-Head Attention:Grouped-Query Attention组注意力
- 激活函数:SwiGLU
| 技术点 | 英文名 | 原来 | 现在 | 分析 |
|---|---|---|---|---|
| 位置编码 | Positional Embedding | 绝对位置编码 | 旋转位置编码 RoPE | |
| 多头注意力 | Multi-Head Attention | 常规 | Grouped-Query Attention组注意力 DeepSeek V3使用另一种方法 MLA |
|
| 激活函数 | Activation Function | GELU | SwiGLU | |
影响效果的还有:数据集、训练技巧、超参数
DeepSeek V3/R1
DeepSeek V3/R1:多头潜在注意力与混合专家
DeepSeek V3(6710亿参数)采用多头潜在注意力(MLA)和混合专家(MoE)架构。
MLA通过压缩键值张量到低维空间,显著降低键值缓存的内存占用,优于分组查询注意力(GQA)的建模性能。MoE通过256个专家(推理时仅激活9个,约370亿参数)提升容量与效率,包含共享专家优化通用模式学习。
其性能在2025年超越Llama 3(405B)。
OLMo
OLMo 2:规范化层创新
OLMo 2 以透明度著称,采用传统多头注意力(MHA),并在规范化层设计上创新。
后规范化(Post-Norm)将RMSNorm置于注意力和前馈模块之后,结合QK-Norm(在查询和键上应用RMSNorm)提升训练稳定性。尽管性能非顶级,但其设计为研究提供了清晰蓝图。
Gemma
Gemma 3:滑动窗口注意力
Gemma 3(27B)通过滑动窗口注意力降低KV缓存内存需求,将窗口大小从Gemma 2的4096减至1024,并调整全局与局部注意力比例为1:5,优化局部计算效率。
此外,其在注意力和前馈模块前后均使用RMSNorm,兼顾预后规范化优势。
Gemma 3n引入逐层嵌入(PLE)和MatFormer,优化小型设备上的运行效率。
Llama
Llama 4:MoE与GQA结合
Llama 4 Maverick(4000亿参数)采用MoE(2个活跃专家)与GQA结合,推理时激活170亿参数。
相比 DeepSeek V3,其专家数量少但规模大,MoE与密集模块交替使用,平衡性能与效率。
Qwen
Qwen3:密集与MoE并存
Qwen3 提供密集模型(0.6B-32B)和MoE模型(30B-A3B、235B-A22B)。
- 密集模型如0.6B以小巧高效著称
- MoE模型通过8个专家(无共享专家)优化大规模推理。
Qwen3 235B-A22B与DeepSeek V3架构相似,但专家配置更精简。
Kimi
Kimi 2:超大规模MoE
Kimi 2(1万亿参数)基于DeepSeek V3架构,增加专家数量,减少MLA头部,配合Muon优化器展现优异性能,超越众多专有模型,成为2025年顶尖开放权重模型。
transformer
主要结构
transformer block 主要由三种结构组成
MHA(Multi-Head Attention),多头注意力模块,下图绿色部分。Add&Norm,归一化模块,下图蓝色部分。FFN,前馈网络模块,下图粉色部分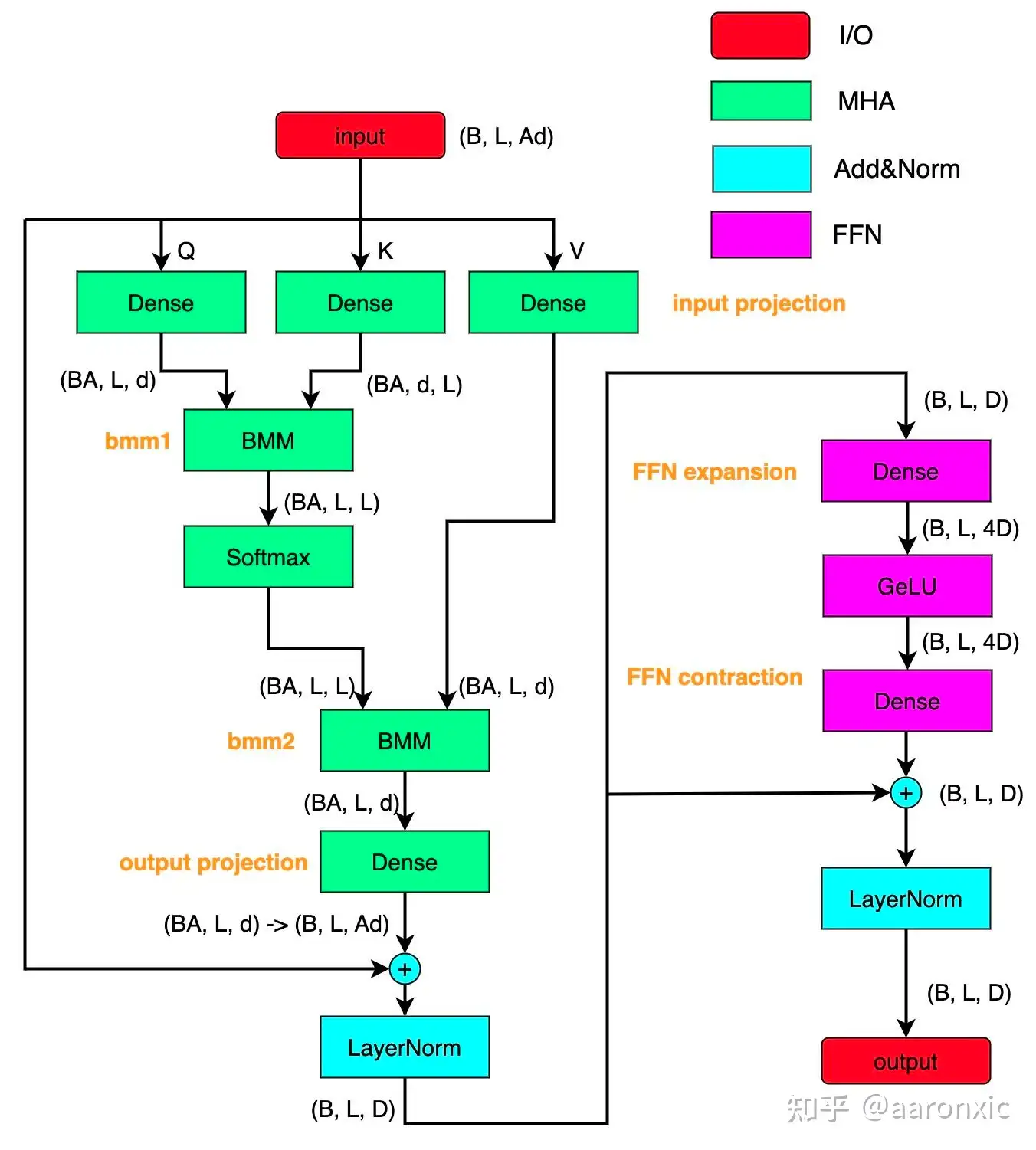
gemm-like 算子
Encoder
Transformer Encoder 模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadSelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries):
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism
#attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention / (self.embed_size ** (1 / 2)), dim=3)
out = torch.matmul(attention, values).reshape(N, query_len, self.heads * self.head_dim)
# out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadSelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query):
attention = self.attention(value, key, query)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = self.dropout(x)
for layer in self.layers:
out = layer(out, out, out)
return out
# Hyperparameters
embed_size = 512
num_layers = 6
heads = 8
device = "cuda" if torch.cuda.is_available() else "cpu"
forward_expansion = 4
dropout = 0.1
# Example
encoder = Encoder(embed_size, num_layers, heads, device, forward_expansion, dropout).to(device)
Decoder
待定
问题
- 1,transformer 结构?
- 2,Layer Normalization 怎么计算,以及为什么要在transformer 用LN不用BN
- 3,多头注意力机制是怎么计算的,以及为什么需要多头注意力机制
transformer 基本结构是什么
Transformer 分为 encoder 和 decoder 两个部分。
Encoder包含self-attention自注意力 和mlp前馈神经网络,用于提取特征;Decoder在自注意力和前馈神经网络中多了一个 cross-attention 编码-解码注意力,用于和 encoder 输出做交互。- 其中的自注意力是 Masked self-attention
Positional Encoding 有什么用
保证 attention 机制考虑序列顺序,否则无法区分不同位置的相同输入。
Transformer 模型本身不包含循环或卷积结构,它无法捕捉序列中的位置信息。因此,需要额外的位置编码来提供每个位置上的信息,以便模型能够区分不同位置的输入元素。
如何处理长距离依赖
Transformer 通过自注意力机制直接计算序列中任意两个位置之间的依赖关系,从而有效地解决了长距离依赖问题。
Layer Normalization 作用
Layer Normalization 有助于稳定深层网络训练,通过对输入的每一层进行标准化处理(使输出均值为0,方差为1),可以加速训练过程并提高模型的稳定性。
- 通常在自注意力和前馈网络的输出上应用。
Layer Normalization 怎么计算
为什么要在transformer 用LN不用BN
能否用 Batch Normalizatioin?
Transformer 架构中,层归一化(Layer Normalization,简称 LayerNorm)是首选归一化方法,主要用于模型内部的每一层之后。
理论上,层归一化可以被批归一化(Batch Normalization,简称 BatchNorm)替换,但是这两种归一化技术在应用上有着本质的不同,这些差异导致了在 Transformer 中通常优先选择层归一化而不是批归一化。
self-attention 计算方法
Self-Attention 计算公式
$ self-attention = \frac{softmax(QK^T)}{\sqrt{d_k}}K$
面试
注意力机制代码实现
【2025-2-24】半成品代码
import torch
def attention(Q, K, V):
"""
Input:
Q, K, V: query, key and value items, with size BxSxD
B=batch_size, S=sequence_length, D=dimension
Output:
attention_map [BxSxS]: the softmax output
output [BxSxD]
"""
# follow-up questions for 2
# a) Can Q, K, V have different lengths (or which one(s) can be different)? How to adapt the code?
# b) How to adapt the code for the following way to calculate attention?
# s_{i,j}=||q_i-k_j||^2/sqrt(d)) for i, j and Attn = softmax(S)V
# When is the above equivalent to ScaleDotProductAttention?
# 参数异常判断
if not Q.shape() == K.shape() and K.shape() == V.shape():
print(f'[Error] 参数异常 {=Q.shape()}, {=K.shape()}, {=V.shape()}')
return False
# 公式 self_attention = softmax(Q,K^T)/ sqrt(d) * V
s = K.shape() # (b, l, d)
qk = torch.nn.bmm(Q, torch.nn.transpose(K,?))
qk_s = torch.nn.softmax(qk) / torch.nn.sqrt(s[2])
sa = nn.bmm(qk_s, V)
return sa
# cos(x,y) = x*y / |x|*|y| cos(theta)
# eu(x,y) = sum (xi-yi)^2
# (b, l, d), (l,d)
view(), reshape()
正式版
- 详见站内专题 transformer
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
"""
自注意力机制
"""
def __init__(self, d, d_q, d_k, d_v):
super(SelfAttention, self).__init__()
self.d = d
self.d_q = d_q
self.d_k = d_k
self.d_v = d_v
self.W_query = nn.Parameter(torch.rand(d, d_q))
self.W_key = nn.Parameter(torch.rand(d, d_k))
self.W_value = nn.Parameter(torch.rand(d, d_v))
def forward(self, x):
"""
前向传播
"""
Q = x @ self.W_query
K = x @ self.W_key
V = x @ self.W_value
attention_scores = Q @ K.T / math.sqrt(self.d_k)
attention_weights = F.softmax(attention_scores, dim=-1)
context_vector = attention_weights @ V
return context_vector
为什么要除以根号dk?
目的: 点积操作后保持数值稳定性。
- 第一,这种缩放确保了在较大维度 dk 下,softmax 输入值不会太大,避免梯度消失问题,训练更加稳定。
- 第二,选择 sqrt(dk) 使 Q*K 结果
均值和方差保持不变,类似于归一化。
原因
- 数学: 对于输入 均值0方差1的分布, 点乘后结果, 方差为 dk, 所以需要缩放
- 神经网络上:防止在计算点积时数值过大,导致后续应用 softmax 函数时出现梯度消失问题。
计算点积时,如果Q K的元素值和dk的值都很大,那么点积的结果可能会非常大,导致 softmax 函数的输入变得非常大。 softmax 函数在处理很大的输入值时,会使输出的概率分布接近0或1,这会造成梯度非常小,难以通过梯度下降有效地训练模型,即出现梯度消失问题。 通过使用dk缩放点积的结果,可以使点积的数值范围被适当控制。
为什么没有 Q Cache
为什么 有 KV-Cache, 而 没有 Q Cache?
Transformer 架构中,自注意力机制的核心是计算Query(查询)和Key(键)的点积,再乘以Value(值)。
推理过程,尤其是自回归生成时,模型需要逐词生成。
自回归解码(生成文本)过程中,目标是 避免重复计算 K 和 V。KV Cache 采用增量缓存(Incremental Cache)的方式存储 Key 和 Value
KV Cache(Key-Value Cache) 是为了避免重复计算。当模型生成下一个词时,要关注整个历史序列。
- 如果没有KV Cache,每次生成新词,都需要重新计算前面所有词的Key和Value向量。计算量是巨大的,特别是对于长序列。
- KVCache 把前面已经计算好的Key和Value存起来,后续步骤直接复用,大大降低了计算开销。
那么,为什么没有QCache?核心原因:Query向量的动态性。
- 自回归生成过程中,每步生成的Query向量是新的,且唯一,代表了当前要生成的词对前面所有历史信息的“提问”。
- 这个新的Query向量需要与前面所有的Key向量进行点积,以计算注意力权重,然后用这些权重去加权求和Value向量,从而得到当前词的上下文表示。
Query向量本身是当前时刻的“焦点”,随着每步新生成的token而改变,并且这个改变是不可预测的。没有”历史”可复用的特性。
相比之下,Key和Value向量代表的是历史信息本身,已经确定的、不随后续生成而改变的表示,因此可以高效地缓存和复用。
在不同应用场景下的实际意义和选择考量:
- 长文本生成(如小说、报告): KVCache 优势最为明显。
- 如果没有它,生成长文本的计算成本会呈平方级增长,推理速度会慢到无法接受。KVCache使其变为线性增长,极大提高了实用性。
- 对话系统(如聊天机器人):用户每次输入,模型都需要基于完整的对话历史来生成回复。
- KV Cache 在这里至关重要,确保了对话连贯性,并能快速响应。
- 代码补全 / 生成:在 IDE 中进行代码补全时,需要快速根据用户已输入的代码上下文给出建议。
- KV Cache 能够保证补全的速度和准确性。
- 低延迟要求场景:对于那些对实时性有极高要求的应用,如智能助手、在线翻译等,KV Cache 是实现低延迟推理的关键。它减少了大量的重复计算,使得模型能够更快地给出响应。
选择考量方面,虽然 KV Cache 带来了巨大的性能提升,但也引入了显存占用的问题。
- 当sequence特别长的时候,KV Cache其实还是个Memory刺客。
- 比如 batch_size=32, head=32, layer=32, dim_size=4096, seq_length=2048, float32类型,则需要占用的显存为(感谢网友指正) 2 * 32 * 4096 * 2048 * 32 * 4 / 1024/1024/1024 /1024 = 64G。
对于超长上下文或高并发场景,如何高效管理 KV Cache 的内存成为核心挑战。这涉及到显存优化、批处理策略、甚至量化技术的选择。
因此,在实际项目中,我们需要根据具体的应用场景、可用的硬件资源和对性能的要求,来权衡 KV Cache 带来的好处和它可能带来的内存开销
self-attention 为什么用多头?
self-attention 用多头
- self-attention 模型对当前位置信息编码时,将注意力过度集中于自身位置,通过多头注意力机制来解决这一问题。
- 多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型表达能力。
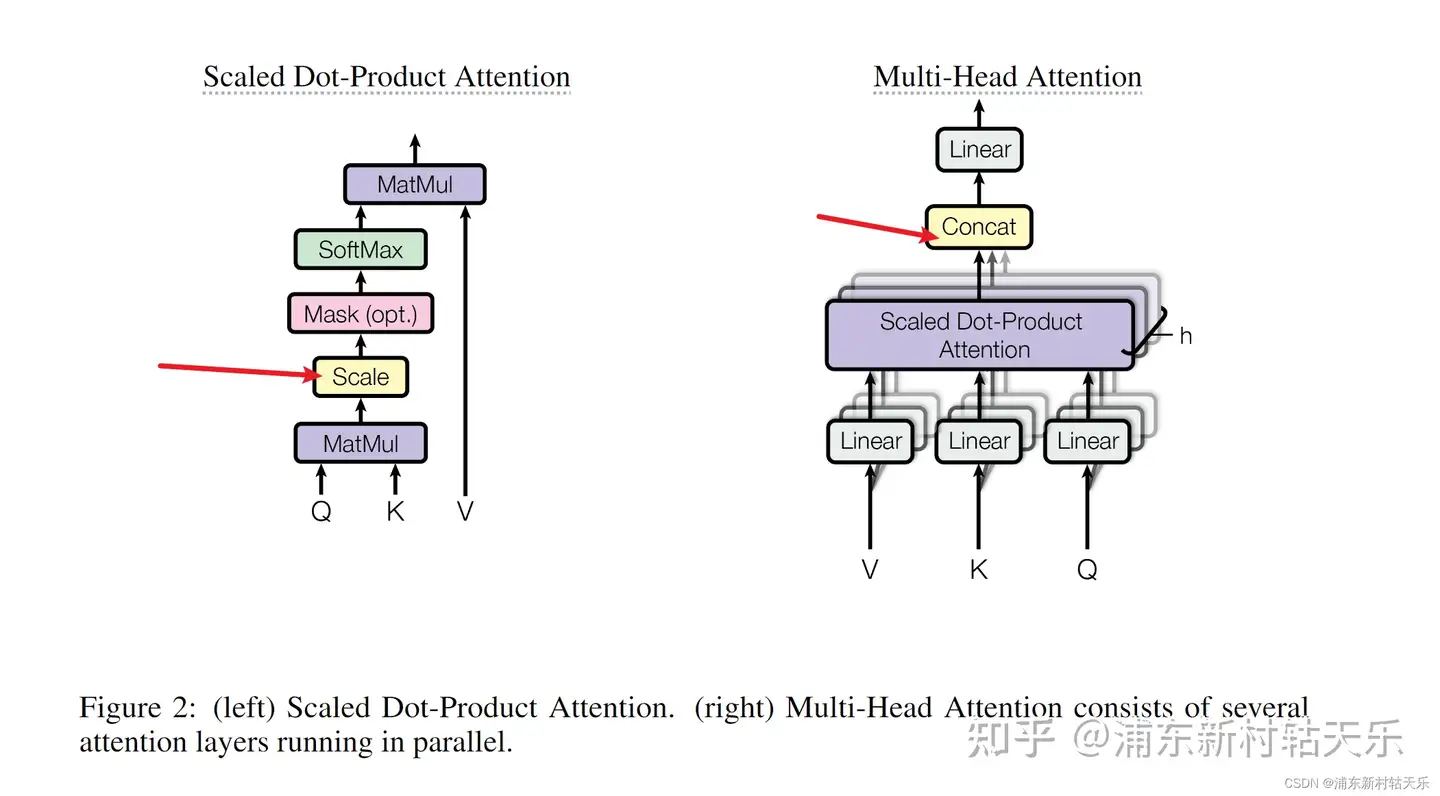
高频: 多头注意力如何实现
每个头独立地在相同输入上计算注意力权重,最后, 把所有头的输出合并。每个头关注一部分的特征,类似于卷积中通道作用。
图示
代码
- 高频面试题
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
"""
Multi-Head Attention Layer 多头注意力实现
"""
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
# embedding 分成 heads 份,每头关注部分特征
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# Separate linear layers for values, keys, and queries for each head
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0] # Number of examples
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split embeddings into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# Apply linear transformation (separately for each head)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism (using torch.matmul for batch matrix multiplication)
# 计算注意力得分 Calculate attention score
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention, dim=-1)
# 注意力权重 Apply attention weights to values
out = torch.matmul(attention, values)
# 合并多头 Concatenate heads
out = out.reshape(N, query_len, self.heads * self.head_dim)
# 最后的全连接层 Final linear layer
out = self.fc_out(out)
return out
# Example usage
embed_size = 256
heads = 8
N = 1 # Batch size
sentence_length = 5 # Length of the input sequence
model = MultiHeadAttention(embed_size, heads)
# Dummy input (batch size, sentence length, embedding size)
x = torch.rand((N, sentence_length, embed_size))
# Forward pass
out = model(x, x, x) # In self-attention, queries, keys, values are all the same
print("Input shape:", x.shape)
print("Output shape:", out.shape)
Multi-query Attention 和 Grouped-query Attention
Multi-query Attention 和 Grouped-query Attention 是两种不同的注意力机制变种,用于改进和扩展传统的自注意力机制。
- Multi-query Attention:每个查询可以与多个键值对交互,捕捉更多的上下文信息。
- 提高模型的表达能力和性能,特别是在处理长序列或复杂关系时。
- Grouped-query Attention:查询被分成多个组,每个组内的查询与对应的键值对进行交互。
- 减少计算复杂度,提高效率,同时仍然保持较好的性能。
为什么需要 Mask 机制
两个原因。
- 屏蔽未来信息,防止未来帧参与训练。
- 处理不同长度序列,在批处理时对较短的序列进行填充(padding),并确保这些填充不会影响到模型的输出。
Mask 机制如何实现
分别处理
- 屏蔽未来信息的 Mask:自注意力层中,通过构造一个上三角矩阵(对于解码器),其中上三角部分(包括对角线,取决于具体实现)被设置为非常大的负数,这样在通过 softmax 层时,这些位置的权重接近于0,从而在计算加权和时不考虑未来的词。
- 填充 Padding Mask:将填充位置的值设置为大负数,使得经过 softmax 层后,这些位置的权重接近于0。
疑问:为什么是大负数?
多轮 loss 为什么 mask
【2026-3-9】多轮对话微调,Loss 为什么要 Mask 掉 User 的部分?
多轮对话样本,可能是这样的:
User: 今天北京天气怎么样?
Assistant: 正在为您查询,请稍等。(调用工具)
Tool: {"weather": "晴", "temp": 25}
Assistant: 今天北京是晴天,气温 25 度,适合出行。
从人的角度看,这很自然。但从模型训练的角度看,这里面混着三种完全不同性质的内容:
- User:外部输入,不是模型生成的
- Tool:外部系统返回的事实
- Assistant:模型真正需要学会生成的输出
而很多人犯的第一个致命错误是:把这三种内容全扔进 Loss 里算。
导致
- 模型目标函数在“偷偷骗你”:学习了毫无意义甚至有害的片段,如 用户输入(已知信息)、预测用户下一句话(无需预测)
- 诡异现象:模型模仿用户语气、夹杂“嗯”、“那我想问一下”,甚至补全用户问题
示例
用户:吴师兄,帮我查下北京天气
模型:你是想问今天北京天气怎么样吗?今天北京是晴天……
Loss 里偷偷奖励了这种行为。模型只是非常诚实地在做一件事:降低 Loss。
Loss Mask
工业级做法:只让模型为“自己该说的话”负责, 只计算 Assistant 部分的 Loss。
- 具体做法:User / System / Tool 的 token, 全部打上 -100(或 ignore_index), 这些 token 不参与梯度计算, 只有 Assistant 生成的那部分 token:参与 Loss, 反向传播, 更新参数
- 模型只需要为“回答质量”负责,不需要为“上下文复述”负责。
Mask 带来的三个直接好处
- 第一,注意力聚焦. 模型所有的梯度更新,都集中在:如何组织回答/调用工具/承接上下文, 而不是浪费容量去记“用户常说哪些话”。
- 第二,防止 Prompt 记忆化
- 第三,防止训练目标错位.
- SFT 目标是 conditional generation, 不是 dialogue imitation。Mask 的本质是在纠正训练目标。
进阶追问:
- Tool Output 要不要算 Loss?
论先行:
- Tool Output 必须 Mask
Tool 返回的通常是:JSON, 数值, 实时信息, 随机事实; 让模型去预测工具执行结果这类事实信息,荒谬!因为这些事实来自外部系统/不具备可学习的统计规律/今天对,明天就错
pad 策略
批量训练时:
- 不同对话长度不同
- 必须补齐(Padding)
代码
labels[labels == tokenizer.pad_token_id] = -100
如果没有 Mask Padding Token,会发生什么?
模型会很快发现一个“作弊解法”:“只要我多输出 Padding,Loss 就能变低。”
于是得到这样的模型:不爱说话、输出极短,甚至直接 EOS
【2024-12-31】Padding 策略
| pad策略 | 介绍 | 图解 |
|---|---|---|
| left padding | 右侧填充pad |  |
| right padding | 左侧填充pad |  |
解释
- ? 是要预测的下一个token
- left padding 时, ?是 a 的 next token
- 而 right padding 时, ? 是 PAD 的 next token
LLM pad策略,为啥训练时是right,预测是left?
解答
- 训练时,right还是left都可以,只是大家习惯用 right
- 因为有 attention mask 去保证正确的损失函数计算。
- 只要设好 ignore_label(如-100), 结果都一样。
- 关键:padding 方向和 ignore_label 设置方式要匹配
- 但推理不同
batch_size = 1: 非batch推理,即单条推理,那么无pad。batch_size > 1: batch推理,批次中输入长度不同,用right pad的话,短输入右边会有很多的<pad>tokens,由于推理阶段没有 attention mask 确定什么位置应该输出<pad>,什么位置应该输出有效的token,从而导致LLM的输出不确定。- 故推理阶段必须使用left pad,保证每个输入最后一个token是有效,从而确保LLM推理时预测下一个token是有效token。
参考:治伦AI
BERT
适用场景
分析
- BERT 模型用于理解文本深层语义的任务,如:文本分类、命名实体识别等。
- LLaMA 和 ChatGLM 类大模型则适用于需要生成文本或进行更复杂语言理解的任务,如:对话系统、文本生成等。选择哪种模型取决于任务的需求和可用资源。
思考
BERT预训练任务?
BERT预训练任务
- 第一,Masked Language Model(MLM),即对mask掉的15%的token进预测
- 第二,Next Sentence Predict,判断两个句子是否是相连的两个句子。
BERT Finetune
怎么用BERT完成finetune
- 参考迁移学习的范式,为新任务或者数据集添加一个分类头或者使用Adapter
GPT vs BERT
结构和工作原理上的差异
- BERT 是 Encoder-only 结构,属于自监督训练方式,通过MLM和NSP两大预训练任务,主要用于下游任务抽特征。
- GPT 是 Decoder-only,自回归训练,预测下一个词分布,依赖大语料库,GPT-3可以表现出Few-shot/zero-shot learning。
有哪些mask类型
BERT token分3种情况 mask,作用是什么?
- BERT MLM任务中,总token 15% 会被随机Mask掉。
确定要Mask掉的单词之后
- 80% 会直接替换为
[Mask] - 10% 替换为其它任意单词
- 10% 保留原始Token。
原因
- 如果句子某个Token 100% 被mask掉,那么 fine-tuning 时, 模型就会有一些没有见过的单词。
- 加入随机Token: Transformer要保持对每个输入token的分布式表征,迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
warm-up 策略
学习率 warm-up 策略是怎样的?
warmup 在训练最初使用较小的学习率来启动,并很快切换到大学习率而后进行常见的 decay。
- 刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);
- 第一轮训练,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。
- 训练一段时间(2-3轮)后,模型已经对每个数据点看过几遍了,当前的batch而言有了一些正确的先验,较大学习率就不那么容易会使模型学偏,所以可以适当调大学习率。
这个过程是 warmup。
为什么之后还要decay呢?
- 当模型训到一定阶段后(比如十个epoch),模型分布就已经比较固定,能学到的新东西就比较少了。
- 如果还沿用较大的学习率,就会破坏这种稳定性,已经接近loss的local optimal了,为了靠近这个point,要慢慢来。
分词
几种
- Byte-Pair Encoding (BPE) 是当前SOTA的LM模型常用的分词方法
- BERT 使用 Wordpiece,属于BPE的改进版,都是sub-word分词器
1 token ≈ 0.75 word
词表扩充
大模型词表扩充的方法包括:
- 新增词汇:手动添加领域特定的术语和词汇到词表中。
- 数据驱动:通过分析大量文本数据自动识别和添加高频出现的词汇。
- 词汇映射:将特定领域的词汇映射到现有的词表中,或者创建新的词汇条目。
流行的词表管理工具和库包括:
- Hugging Face Transformers:提供了一个预训练模型和词表管理的接口。
- SentencePiece:一个用于构建词汇表的工具,支持BPE和其他子词分割方法。
- Moses:一个开源的自然语言处理工具,包括用于词表构建和分词的工具。
ChatGLM3 如何分词
ChatGLM3 训练过程中根据输入数据动态合并出现频率较高的字节对,从而形成新的词汇。
- 有效地处理大量文本数据,并减少词汇表规模。
- ChatGLM3 还用特殊的词表分割方法,将词表分为多个片段,并在训练过程中逐步更新片段,以提高模型的泛化能力和适应性。
BPE算法通过迭代地将最频繁出现的字节对合并成新的符号,来构建一个词汇表。
位置编码
位置编码 Position Encoding
- 原始transformer(attention is all you need)里面用的是三角式位置编码
- BERT使用可学习位置编码,预设的位置个数是512,因此最大序列长度为512
- dim=768,就用384组三角函数来表征
RoPE
旋转位置编码作用在什么地方?
- 三角函数位置编码是与Embedding直接相加,RoPE位置编码采用类似哈达马积相乘的形式。
- 其次,旋转位置编码只在query, key 注入位置信息,然后计算attention score,三角函数的位置编码,query, key和value都有位置信息。
ALiBi
ALiBi(Attention with Linear Biases)的相对位置编码机制。
ALiBi的出发点是希望能提升位置编码的外推能力,原因是在实际使用中的输入token长度可能会远远大于训练阶段使用的最大token限制。
激活函数
总结
ReLU(Rectified Linear Unit):解决梯度消失问题,加快训练速度。GeLU(Gaussian Error Linear Unit):ReLU改进,性能和泛化能力更好。Swish:自门控激活函数,提供非线性变换,并具有平滑和非单调特性。
ReLU
待定
GeLU
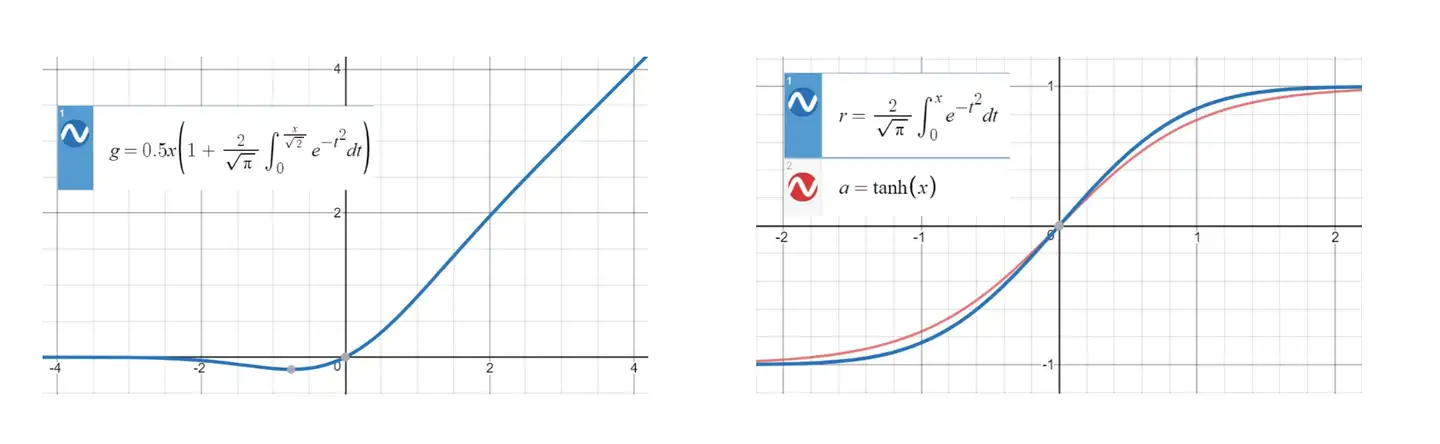
GeLU (Gaussian Error Linear Unit) 中文名为高斯误差线性单元,受 RELU 和 dropout 启发
- RELU 是激活小的时候乘以0
- dropout是随机乘以0
- GeLU 是概率性的乘以0 (但是跟dropout不同,用确定性的表达式给出)
SwiGLU
SwiGLU 和 GeGLU非常相似,只是把GeLU激活换成了Swish激活
损失函数
损失函数介绍
详见站内专题: 损失函数
问题
- Cross Entropy Loss 怎么写?
Norm
preNorm/postNorm/DeepNorm
NLP任务中经常使用 Layer Normalization(LN) 而非 Batch Normalization(BN)
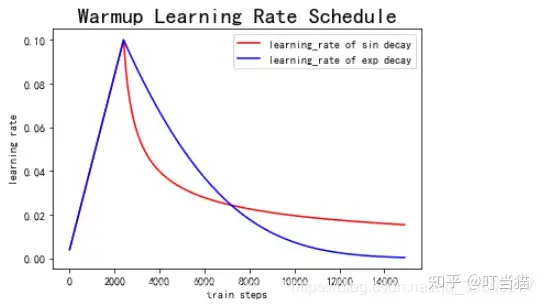
随机优化理论中学习率往往设置为常数或者逐渐衰减 (decay),从而保证算法收敛,这种学习率的设置方法也与机器学习里很多任务上的实际经验类似。
然而,不管是设置学习率为常数还是使学习率逐渐衰减都不能让Transformer很好地收敛。
优化Transformer结构时,还需要在训练的初始阶段设置一个非常小(接近0)的学习率,经过一定的迭代轮数后逐渐增长到初始的学习率,这个过程称作warm-up阶段(学习率预热)。
Warm-up 是原始Transformer结构优化时, 一个必备学习率调整策略。
- Transformer结构对于warm-up的超参数(持续轮数、增长方式、初始学习率等)非常敏感,若调整不慎,往往会使得模型无法正常收敛。
Transformer结构的优化非常困难,其具体表现在:
- warm-up阶段超参数敏感;
- 优化过程收敛速度慢。
总结
BERT 使用 Post-Norm 结构, 同时期的 GPT-1 也是
- GPT-2 改用 Pre-Norm
Post-LN vs. Pre-LN vs. Sandwich-LN
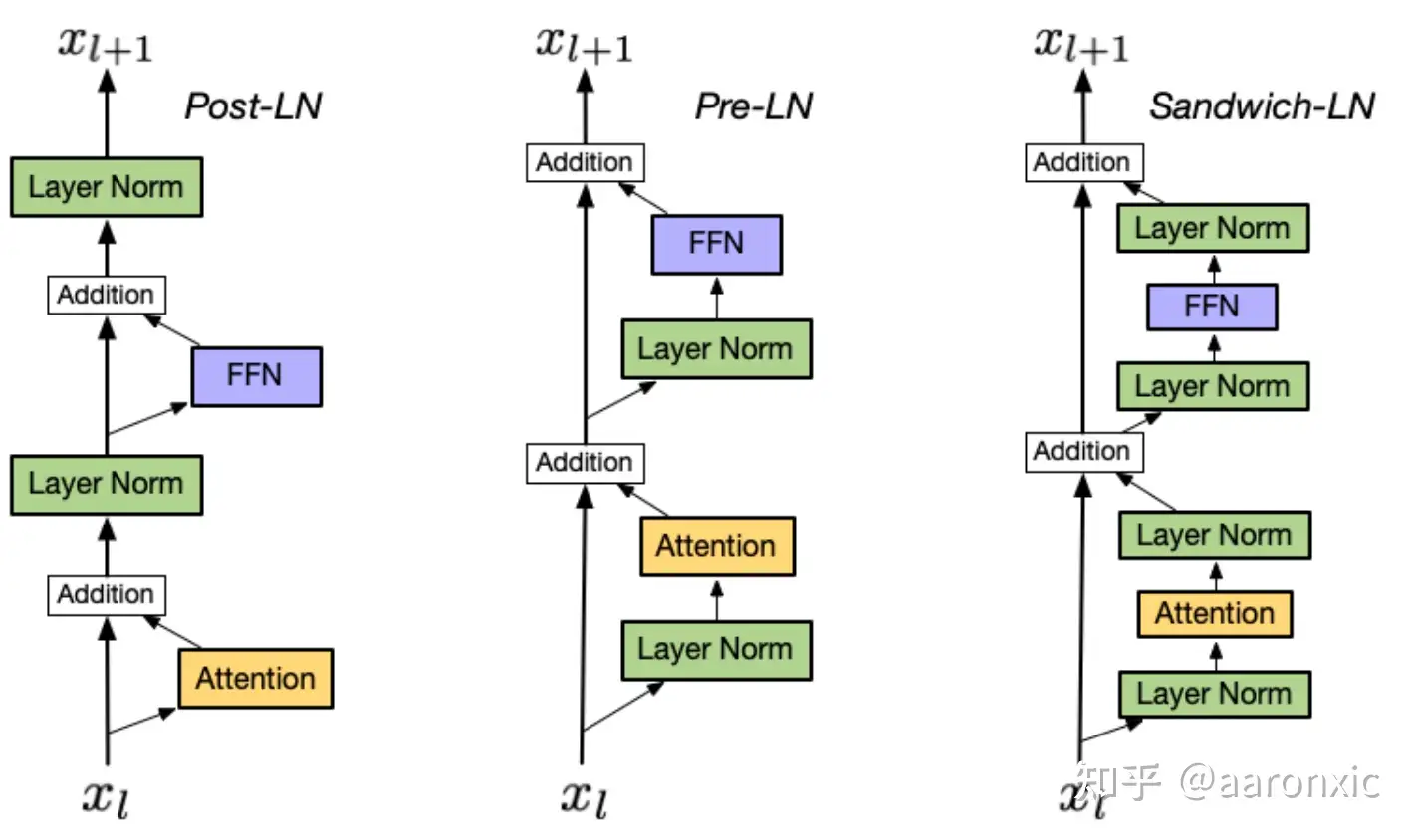
分析
Pre-Norm比Post-Norm参数更好训练,但是模型精度要比Post-Norm略差。
典型示例
GPT-3:Post-Layer Normalization(后标准化), 有助于稳定训练过程,提高模型性能。LLAMA:Pre-Layer Normalization(前标准化)的结构,提高模型的泛化能力和鲁棒性。ChatGLM:Post-Layer Normalization的结构,类似于 GPT-3, 提高模型的性能和稳定性。
分析公式: x + F(x), 哪里插入 normalization ?
- Norm 计算公式: 假设x和y是相互独立的均值为0,方差为1的随机变量, Norm(x+y) = (x+y)/根号2
PreNorm: x1 = x + Norm(F(x))PostNorm: x1 = Norm(x + F(x))
| Norm类型 | 基本公式 | 递归展开式 |
|---|---|---|
| PreNorm | x1 = x + Norm(F(x)) | 原文 |
| PostNorm | x1 = Norm(x + F(x)) | 原文](https://zhuanlan.zhihu.com/p/640784855) |
| SanwichNorm | ||
| DeepNorm |
展开公式
- 输出的方差会很大,因此需要在输出加个额外的LayerNorm (GPT2的设计)
- Pre-Norm把网络的实际深度变浅了,并且增加了宽度
- Pre-Norm 网络层数有水分,这个可能是导致模型最终精度不如Post-Norm的原因。
两种Norm 特点
- Post-Norm 削弱残差作用,深度保持,但是收敛和调参困难
- Pre-Norm 将网络变成浅且宽的结构,收敛容易,但是精度有一定损失
LayerNorm
Layer Normalization
按照 layer normalization 位置不同,可分为 post layer norm 和 pre layer norm
PostNormpost layer norm。原始transformer中,layer normalization 放在残差连接之后,称为post LN。- 使用Post LN的深层transformer模型容易出现训练不稳定问题。
- post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
PreNormpre layer norm。将 layer norm 放在残差连接的过程中,self-attention 或FFN块之前,称为“Pre LN”。- Pre layer norm 在每个transformer层的梯度范数近似相等,有利于提升训练稳定性,但缺点是pre LN可能会轻微影响transformer模型的性能,为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
LayerNorm:LayerNorm对每一层的所有激活函数进行标准化,使用它们的均值和方差来重新定位和调整激活函数。其公式如下:RMSNorm:RMSNorm通过仅使用激活函数的均方根来重新调整激活,从而提高了训练速度。DeepNorm:为了进一步稳定深度Transformer的训练,Microsoft推出了DeepNorm。这是一个创新的方法,它不仅用作标准化,还作为残差连接。有了DeepNorm的帮助,可以轻松训练高达1000层的Transformer模型,同时保持稳定性和高性能。- 其中,GLM-130B 和 ChatGLM 采用
DeepNorm。其公式如下:其中SublayerSublayer是FFN或Self-Attention模块。
- 其中,GLM-130B 和 ChatGLM 采用
BatchNorm
分析
- 层归一化(Layer Normalization)
- 层归一化是对每个样本的所有特征执行归一化操作,独立于其他样本。无论批次大小如何,LayerNorm 的行为都是一致的。
- 处理序列数据和自注意力机制时,LayerNorm 更加有效,因为它能够适应不同长度的输入,这在自然语言处理任务中尤为重要。
- LayerNorm 直接在每个样本的维度上工作,使得它在序列长度变化的情况下更为稳定。
- 批归一化(Batch Normalization)
- 批归一化在小批量维度上进行归一化,依赖于批次中所有样本的统计信息。因此,BatchNorm 行为会随着批次大小和内容的变化而变化,这在训练和推理时可能导致不一致的表现。
- 处理变长序列和自注意力结构时,BatchNorm 可能不如 LayerNorm 高效,因为变长输入使得批次间的统计信息更加不稳定。
- BatchNorm 训练时计算当前批次的均值和方差,在推理时使用整个训练集的移动平均统计信息。这种依赖于批次统计信息的特性使得 BatchNorm 在小批量或在线学习场景中表现不佳。
RMSNorm
RMSNorm 比LayerNorm 好在哪?
- 第一,虽然时间复杂度一致,但 RMSNorm 比 LayerNorm 少了减去均值以及加上bias的计算,这在目前大模型预训练的计算量下就能够体现出训练速度上的优势了。
- 第二,RMSNorm 模型效果好于 LayerNorm (LN取得成功的原因可能是
缩放不变性,而不是平移不变性)。
PostNorm
论文提出了两种Layer Normalization方式并进行了对比。
把Transformer架构中传统的Add&Norm方式叫做Post-LN,并针对Post-LN,模型提出了Pre-LN,即把layer normalization加在残差连接之前
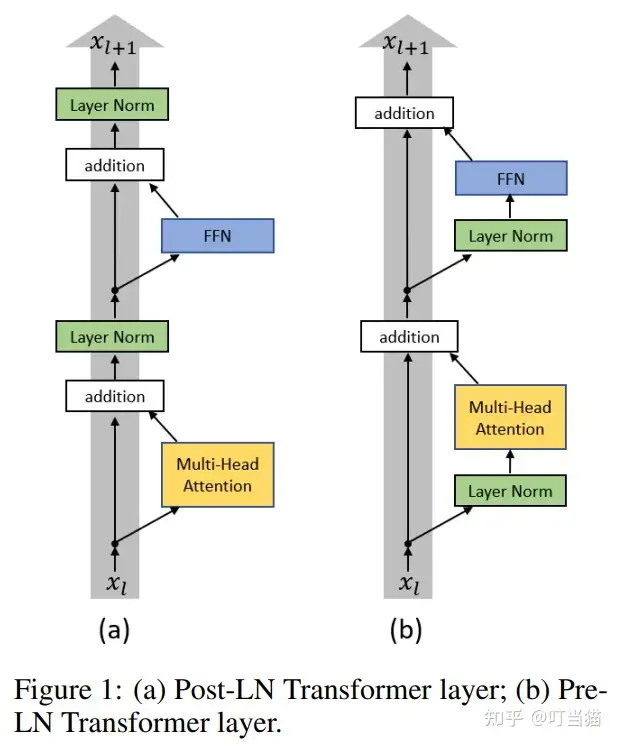
造成Post-LN Transformer梯度分布出现问题的核心原因
- 各子层之后 Layer Normalization 层会使得各层的输入尺度与层数L无关,因此当Layer Normalization对梯度进行归一化时,也与层数L无关。
- Pre-LN 最后一层Layer Normalization层的输入尺寸的量级只有Post-LN的 根号(1/L) 倍,并且每个LN层都会对梯度以 根号L 的比例归一化。所以对于Pre-LN结构来说,其每层梯度范数都近似不变。
相比于Post-LN结构梯度分布的不稳定,Pre-LN在各层之间梯度范数几乎保持不变,这种结构明显更利于优化器进行优化。而在进行一定轮数的 warm-up后,Post-LN 梯度范数也基本保持不变,并且其量级非常小(上图中绿色),这也验证了Post-LN在warm-up阶段的训练不稳定性问题。
实验表明
- 当使用Pre-LN结构时,warm-up阶段已不再是必需,并且Pre-LN结构可以大幅提升Transformer的收敛速度。
- 对于机器翻译任务(IWSLT/WMT),不需要warm-up的Pre-LN结构可以比Post-LN收敛快1倍左右
- 而在BERT上,Pre-LN在下游任务上达到和Post-LN相同的性能也只需要后者迭代轮数的1/3左右,并且最终的效果也更好。
SanwichNorm
Sandwich-Norm,基于Pre-Norm再加一个
DeepNorm
Nguyen和Salazar(2019)发现相对于Post-LN,Pre-LN能够提升Transformer的稳定性。
- 然而,
Pre-LN在底层的梯度往往大于顶层,导致其性能不及Post-LN。
为了缓解这一问题,研究人员通过更好的初始化方式或模型架构来改进深度Transformer。
- 基于Post-Norm做了改进,出现了
Deep-Norm,能训练1000层的Transformer
def deepnorm(x):
return LayerNorm(x * alpha + f(x))
def deepnorm_init(w):
if w is ['ffn', 'v_proj', 'out_proj']:
nn.init.xavier_normal_(w, gain=β)
elif w is ['q_proj', 'k_proj']:
nn.init.xavier_normal_(w, gain=1)
这些方法可以使多达数百层的Transformer模型实现稳定化,然而以往的方法没有能够成功地扩展至1000层。
DeepNorm 结合了Post-LN的良好性能以及Pre-LN的训练稳定性。
- 与
Post-LN相比, DeepNorm 在执行层归一化之前 Up-Scale 了残差连接。
相较于Post-LN模型,DeepNet的模型更新几乎保持恒定。
参考:
注意力
掩码
【2024-8-14】注意力机制中三种掩码技术详解和Pytorch实现
掩码类型
填充掩码Padding Mask序列掩码Sequence Mask前瞻掩码Look-ahead Mask
| 掩码类型 | 目的 | 应用 | 功能 |
|---|---|---|---|
填充掩码 Padding Mask |
屏蔽输入数据中的无关数据 | 长度不一致的输入数据 | 识别有效数据 |
序列掩码 Sequence Mask |
模型关注范围,包含填充数据 | 精确控制信息流 | 指示哪些数据有效/填充 |
前瞻掩码 Look-ahead Mask |
防止看到未来信息 | 自回归模型 | 保证时序正确性,防止信息泄露 |
掩码之间的关系
填充掩码(Padding Mask)和序列掩码(Sequence Mask)都是在处理序列数据时使用的技术,帮助模型正确处理变长输入序列- 但应用场景和功能有些区别。这两种掩码深度学习模型中被一起使用,尤其是在需要处理不同长度序列的场景下。
填充掩码指示哪些数据是填充的,用在输入数据预处理和模型的输入层。确保模型在处理或学习过程中不会将填充部分的数据当作有效数据来处理,从而影响模型的性能。在诸如Transformer模型的自注意力机制中,填充掩码用于阻止模型将注意力放在填充的序列上。序列掩码用于更广泛的上下文中,它不仅可以指示填充位置,还可以用于其他类型的掩蔽,如在序列到序列的任务中掩蔽未来的信息(如解码器的自回归预测)。序列掩码确保模型在处理过程中只关注当前及之前的信息,而不是未来的信息,这对于保持信息的时序依赖性非常重要。填充掩码多用于模型的输入阶段或在注意力机制中排除无效数据的影响序列掩码则可能在模型的多个阶段使用,特别是在需要控制信息流的场景中。
前瞻掩码用于控制时间序列的信息流,确保在生成序列的每个步骤中模型只能利用到当前和之前的信息。这是生成任务中保持模型正确性和效率的关键技术。
填充掩码 Padding Mask
深度学习中,处理序列数据时,”填充掩码”(Padding Mask)是一个重要概念。
当序列数据长度不一致时,通常需要对短的序列进行填充(padding),以确保所有序列的长度相同,这样才能进行批处理。
这些填充的部分实际上是没有任何意义,不应该对模型的学习产生影响。
import torch
def create_padding_mask(seq, pad_token=0):
mask = (seq == pad_token).unsqueeze(1).unsqueeze(2)
return mask # (batch_size, 1, 1, seq_len)
# Example usage
seq = torch.tensor([[7, 6, 0, 0], [1, 2, 3, 0]])
padding_mask = create_padding_mask(seq)
print(padding_mask)
序列掩码 Sequence Mask
序列掩码用于隐藏输入序列的某些部分。避免在计算注意力分数时考虑到填充位置的影响
比如在双向模型中,想要根据特定标准忽略序列的某些部分。
RNNs 本身可处理不同长度的序列,但在批处理和某些架构中,仍然需要固定长度的输入。序列掩码在这里可以帮助RNN忽略掉序列中的填充部分,特别是在计算最终序列输出或状态时。
在训练模型时,序列掩码也可以用来确保在计算损失函数时,不会将填充部分的预测误差纳入总损失中,从而提高模型训练的准确性和效率。
序列掩码表示为一个与序列数据维度相同的二进制矩阵或向量,其中1表示实际数据,0表示填充数据
def create_sequence_mask(seq):
seq_len = seq.size(1)
mask = torch.triu(torch.ones((seq_len, seq_len)), diagonal=1)
return mask # (seq_len, seq_len)
# Example usage
seq_len = 4
sequence_mask = create_sequence_mask(torch.zeros(seq_len, seq_len))
print(sequence_mask)
前瞻掩码 Look-ahead Mask
前瞻掩码,也称为因果掩码或未来掩码,用于自回归模型中,以防止模型在生成序列时窥视未来的符号, 确保了给定位置的预测仅依赖于该位置之前的符号。
前瞻掩码通过在自注意力机制中屏蔽(即设置为一个非常小的负值,如负无穷大)未来时间步的信息来工作。这确保了在计算每个元素的输出时,模型只能使用到当前和之前的信息,而不能使用后面的信息。
这种机制对于保持自回归属性(即一次生成一个输出,且依赖于前面的输出)是必要的。
前瞻掩码通常表示为一个上三角矩阵,其中对角线及对角线以下的元素为0(表示这些位置的信息是可见的),对角线以上的元素为1(表示这些位置的信息是不可见的)。
计算注意力时,这些为1的位置会被设置为一个非常小的负数(通常是负无穷),这样经过softmax函数后,这些位置的权重接近于0,从而不会对输出产生影响。
def create_look_ahead_mask(size):
mask = torch.triu(torch.ones(size, size), diagonal=1)
return mask # (seq_len, seq_len)
# Example usage
look_ahead_mask = create_look_ahead_mask(4)
print(look_ahead_mask)
注意力掩码
注意力机制中,掩码被用来修改注意力得分
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v, mask=None):
matmul_qk = torch.matmul(q, k.transpose(-2, -1))
dk = q.size()[-1]
scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32))
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = F.softmax(scaled_attention_logits, dim=-1)
output = torch.matmul(attention_weights, v)
return output, attention_weights
# Example usage
d_model = 512
batch_size = 2
seq_len = 4
q = torch.rand((batch_size, seq_len, d_model))
k = torch.rand((batch_size, seq_len, d_model))
v = torch.rand((batch_size, seq_len, d_model))
mask = create_look_ahead_mask(seq_len)
attention_output, attention_weights = scaled_dot_product_attention(q, k, v, mask)
print(attention_output)
微调
LoRA
为什么要加缩放因子?(面试题)
- 1、防止扰动过大,稳定训练。低秩矩阵 BA 的值在训练初期随机初始化,如果不加缩放,可能导致其值过大
- 2、维持与原模型相似的行为。LoRA 是在冻结原始模型权重的基础上引入增量更新,如果增量太大,模型行为可能与原模型偏离过远,这会破坏原模型在预训练中学到的知识。
- 3、归一化与可控性。缩放因子也提供了一种对微调程度进行“手动控制”的机制。
秩大小分别有什么影响?(面试题)
- 1、秩越小,训练开销低、过拟合风险低,但表达能力有限;
- 2、秩越大,表达能力增强,适合复杂任务,但训练资源要求更高且易过拟合。
Transformer 有很多层,比如注意力层、前馈层、嵌入层等,Lora 微调通常微调哪些层?(面试题)
- 1、对于注意力层,通常微调w_q和w_v,因为w_q决定关注哪些信息,w_v决定输出什么内容,直接影响模型对任务的理解和生成能力。
- 疑问: 为什么没有 w_k 层?
- 2、对于前馈层,通常微调第一层w1,因为它可以调整激活空间特征。
- Transformer 中 FFN 结构:Linear → ReLU/GELU → Linear
SFT+RL
大模型 SFT 后 RL 效果差,怎么办?
SFT+RL 模型要么答非所问,要么翻来覆去说车轱辘话。
不是 RL 不行,是从 SFT 到 RL 的每一步都藏着暗雷。
- SFT 阶段像打地基,数据要是带错漏、分布偏得离谱,后面 RL 再使劲也是白搭。
- SFT 数据全是金融题,结果模型连闲聊都不会了,这就是 “灾难性遗忘” 在搞鬼。
- SFT 练的是 “标准答案”,RL 却要模型会 “聊天互动”,目标都对不上,能不翻车吗?
RL 阶段更头大
- 奖励模型要是不靠谱,就像裁判瞎打分,模型为了刷分能给你重复 “总结一下” 刷出高分,这就是所谓的 “奖励黑客”。
- 还有 PPO 的 KL 系数,调大了模型放不开,调小了直接放飞自我,生成的东西逻辑都崩了。
详见站内专题: 大模型微调新范式
模型架构
Encoder vs Decoder
LLM 进化树
- 粉色分支,
Encoder-only框架(也叫Auto-Encoder),典型 BERT等 - 绿色分支,
Encoder-decoder框架,典型代表如T5和GLM等 - 蓝色分支,
Decoder-only框架(也叫Auto-Regressive),典型代表如GPT系列/LLaMa/PaLM等 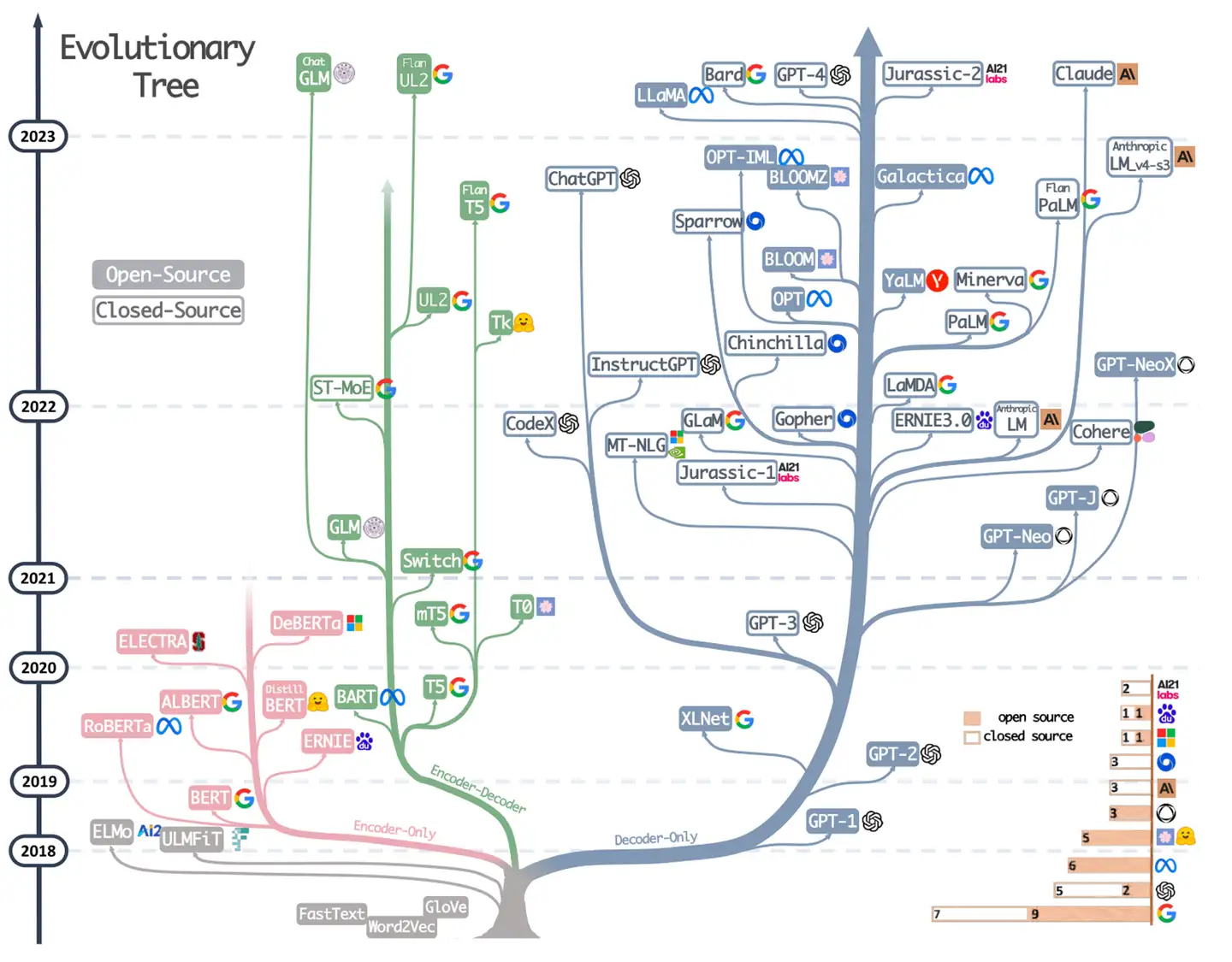
直观对比
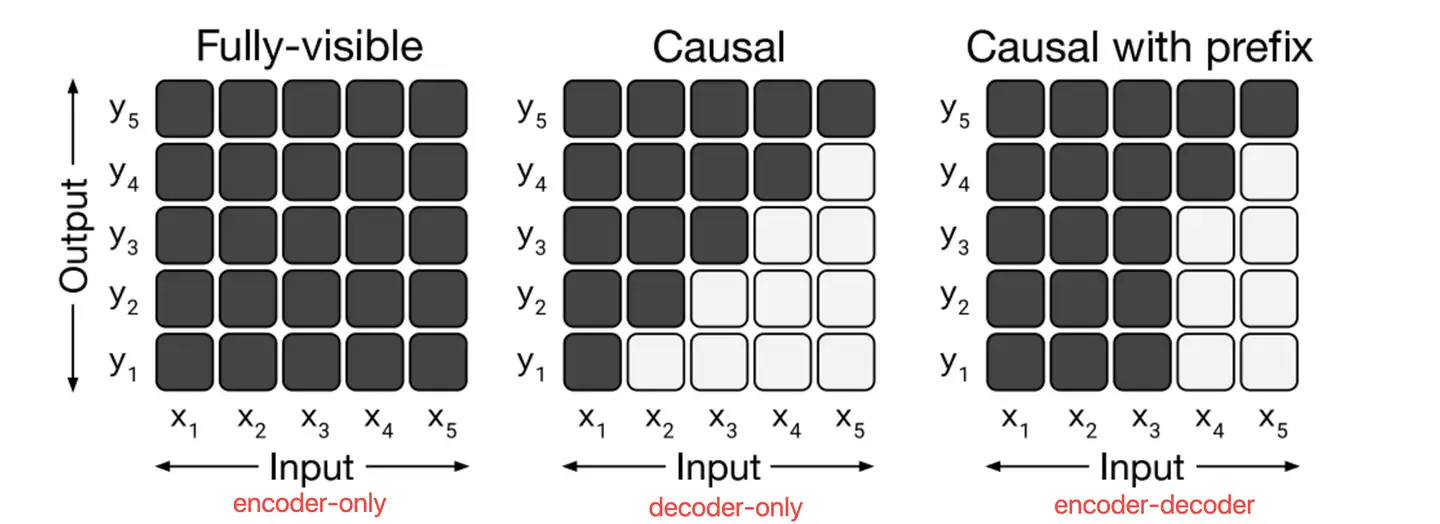
- 横轴代表了输入token,纵轴代表相对应每个位置的输出token
- 左图 encoder-only,输出token都能看到所有输入token。例如 y1 这一行可以看到输入 x1-x5
- 中图 decoder-only,输出token只能看到历史的输入token。例如 y3 这行只能看到 x1-x3, x4 和 x5 看不到
- 右图为encoder-decoder,前k个输出token可以看到所有k个输入token,从k+1的输出token开始只能看到历史的输入token。例如 y1 能看到输入(y3也可以),而开始只能看到输入x1-x4
- encoder-decoder 简化使用causal with prefix示意
三种结构不同的LLM,往往擅长处理不同的任务
| NLU任务 | conditioned-NLG任务 | unconditioned-NLG任务 | 典型代表 | |
|---|---|---|---|---|
Encoder-only架构 |
效果最好 | BERT | ||
Encoder-decoder架构 |
效果最好 | T5和GLM | ||
Decoder-only架构 |
效果最好 | GPT系列/LLaMa/PaLM | ||
| 典型代表 | 文本情感分析,词性标注,信息检索 | 机器翻译,自动摘要 | QA,ChatBot |
LLM(Language Model)是一种处理自然语言的模型架构,对输入的序列进行预测和生成。
LLM 可以使用 encoder-decoder或者decoder-only架构。
LLM 都是 seq2seq 任务,用户输入一个文本prompt,LLM对应输出一个文本completion。
- 示例:
A Survey of Large Language Models - 用户输入 prompt为
A Survey of,期望语言模型输出Large Language Models
| 模型架构 | 代表LLM | 注意力机制 | 是否属于 Decoder-Only | 优点 | 缺点 |
|---|---|---|---|---|---|
Causal Decoder |
GPT-3/ChatGPT/ChatGLM2-6B |
纯单向 | YES | 适用各种生成任务,泛化好 | 无法访问未来信息,可能生成不一致/有误内容 |
Encoder-Decoder |
Flan-T5 |
输入双向,输出单向 | NO | 可处理输入输出序列不同长度的任务,如机器翻译 | 模型结构复杂,训练推理代价大 |
Prefix Decoder |
GLM-130B/ChatGLM-6B |
输入双向,输出单向 | YES | 减少预训练模型参数修改,降低过拟合风险 | 受前缀长度限制,无法充分捕捉任务信息 |
训练目标上,ChatGLM-6B 训练任务是自回归文本填空。
- 相比于采用 causal decoder-only 结构的大语言模型,采用 prefix decoder-only 结构的
ChatGLM-6B存在一个劣势:训练效率低。 - causal decoder 结构会在所有的token上计算损失,而 prefix decoder 只会在输出上计算损失,而不计算输入上的损失。
- 相同数量的训练tokens的情况下,prefix decoder要比causal decoder的效果差,因为训练过程中实际用到的tokens数量要更少。
分析
Causal DecoderCausal Decoder架构典型代表是GPT系列模型,单向注意力掩码,以确保每个输入token只能注意到过去的token和它本身,输入和输出的token通过Decoder以相同的方式进行处理。- 灰色代表对应的两个token互相之间看不到,否则就代表可以看到。例如,”Survery”可以看到前面的“A”,但是看不到后面的“of”。
- Causal Decoder的sequence mask矩阵是一种典型的下三角矩阵。
Encoder-Decoder- Transformer最初被提出来时, 采用Encoder-Decoder架构,模型包含两部分Encoder和Decoder,两部分参数独立。
- 其中Encoder将输入序列处理为一种中间表示,而Decoder则基于中间表示自回归地生成目标序列。
Prefix DecoderPrefix Decoder架构也被称为non-causal Decoder架构,注意力机制和Encoder-Decoder很接近,也是输入部分采用双向注意力,而输出部分采用单向注意力。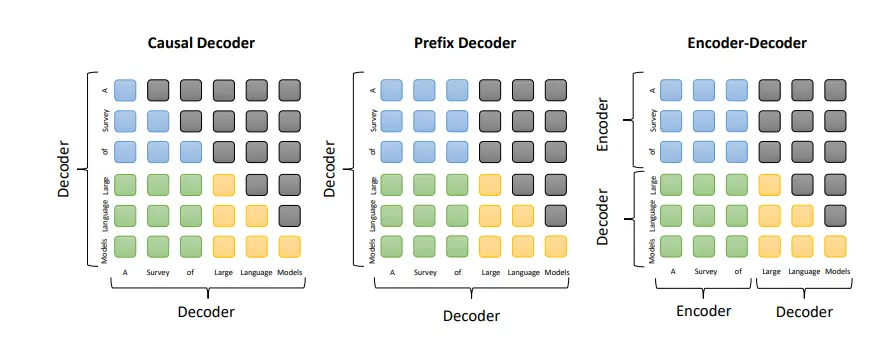
- 原文Exploring Architectures and Configurations for Large Language Models (LLMs)
以上三种架构都可以通过MoE技术扩展,针对输入只激活一部分权重,典型代表: Switch Transformer and GLaM
- All three architecture types can be extended using the mixture-of-experts (MoE) scaling technique, which sparsely activates a subset of neural network weights for each input.
- This approach has been used in models like Switch Transformer and GLaM, and increasing the number of experts or the total parameter size has shown significant performance improvements.
为什么LLM 都是decoder-only架构?
为什么现在的LLM 都是 Decoder only 架构?
- 第一,双向注意力可能存在低秩问题。双向注意力带来的低秩问题会导致效果下降。
- 第二,在同等参数量、同等推理成本下,Decoder-only架构更优。
- 第三, Decoder-only zero-shot 能力更强。
decoder-only架构具有一定优势。
- 首先,
decoder-only模型更简单,因为只需要生成输出,不需要考虑输入。这样可以减少计算负担,提高模型的训练和推理速度。 - 另外,
decoder-only模型更好地解决语言建模问题,如自然语言生成、文本分类等问题。 - 其次,
decoder-only模型更好地利用预训练任务数据。在预训练任务中- decoder-only模型只需要通过
掩码语言建模(Masked Language Modelling)任务来学习上下文和语言规律。 - 而encoder-decoder模型需要尝试预测中间编码表示。这对于decoder-only模型来说是一种更容易的任务,因此可以更好地利用数据,使得模型表现更好。
- decoder-only模型只需要通过
- 最后,
decoder-only模型可以更好地处理长序列。- encoder-decoder模型需要在解码的时候进行对齐操作,因此当输入序列长度变化时,需要重新对齐,导致计算复杂度的提升。
- 而decoder-only模型不需要进行对齐操作,可更好地处理长序列。
综上所述,decoder-only架构具有简单、高效、更好地利用预训练数据以及更好地处理长序列等优势
- 作者:态灵AI
成诚补充
- Encoder-Decoder 架构没落
- 代表模型T5最大模型只有 11B,效果不佳
- T5 很难使用 Pipeline Parallelism, 即便 Megatron 支持 T5 训练(代码),效果非常差,增加一倍 GPU,开启 PP 反而会让总吞吐下降
- 流水并行是千卡以上分布式训练中最重要的特性
- 即便 prefix decoder架构 也纷纷转向 decoder-only
- GLM-130B 不是 Decoder-Only 架构,但是 GLM-3 及以后(含 GLM-4)的 GLM 系列模型都改为
Decoder-Only架构。 就连 GLM 团队都抛弃了原有架构,FollowLLaMa了。 - HuggingFace 上可以尝试 GLM-130B 的 Playground,即使仅从 Foundation-Model 的角度评价,效果也很糟糕。
- GLM-130B 不是 Decoder-Only 架构,但是 GLM-3 及以后(含 GLM-4)的 GLM 系列模型都改为
- Decoder-Only 架构最核心优势是便于 Scale Up,基于 Scaling Laws 的实际训练成本最低
- LLM 时代,如果新算法结构可能有 5% 效果提升,但是引入了额外 50% 的 训练成本(计算时间 or 通信量) ,那这个新算法是负优化。
- 因为这 50% 的训练成本,基于 Scaling Laws 在原模型上多训练 50% 的 tokens ,或者训练大一半的模型, 带来的最终提升都远大于新算法的 5%。
- 至此 2023 年下半年之后的所有 LLM (可以被用户使用的 Chat 模型)均为 Decoder-Only 架构
Encoder-Only、Encoder-Decoder、Decoder-Only 三者架构:
- 相同参数量的训练效率上:
Decoder-Only>Encoder-Only>Encoder-Decoder - 现行分布式并行策略下,可以扩展参数量上限 和 分布式集群规模的上限:
Decoder-Only»Encoder-Only»Encoder-Decoder
Encoder-Only 并不适合做 NLP 生成式任务(Chat)
- 目前在 CV 领域应用的比较多(ViT),输入/输出通常是固定像素大小的图片,token 之间没有非常强的先后依赖关系,因此先排除 BERT
总结
- T5 Scale up 到 100B、500B 的难度很大,训练成本的增加远远高于 GPT。
- 因此也许 100B 的 T5 训练 10T tokens 的模型能力比 100B 的 GPT 更强,但为此要支付的算力/时间成本远大于 100B GPT 训练 10T tokens,以至于:
- 没有公司愿意支付这样的代价我还不如支付相同的代价,让 GPT 多训练更多倍的 Tokens;
- 或者训练一个参数量大很多的 GPT
MoE
详见站内专题: MoE
MoE 与 Dropout
【2025-6-27】MoE vs Dropout
分析
- Dropout是随机将一些神经元输出置为0,为的是防止过拟合。多用于CNN、RNN等神经网络。
- MoE是通过训练门控机制(Router,是一个自定义的大小的神经网络,它的输出是一个专家数量大小的概率分布),来决定每个token 该如何选择专家。为的是增加大模型的计算效率和提升处理复杂任务的能力。
- 相同点:都是对Dense网络做了稀疏处理
- 不同点:Dropout是随机置0防止过拟,MoE是主动选择子网络,加快计算效率
推理效率低
【2025-8-24】MOE 推理 GPU 利用率低,问题出在哪?
MOE 推理时,是不是总遇到 GPU 利用率?
明明卡不少,监控里一大半却在划水,延迟高得离谱。
原因:
- MOE 天生 “偏心”,每个 token 只挑几个 Expert 干活,剩下的都歇着(毕竟路由网络就爱选 top-k)
- 但 GPU 偏偏就爱大伙儿一起动手,这不就拧巴上了?
- 小 batch 时更要命,可能就一两个 Expert 忙死,其他卡直接躺平,利用率能高才怪。
解决
- 把
数据并行和专家并行混用,比如让几个 Expert 挤一张卡,用动态批处理把零散的任务攒起来再算,GPU 立马就没空摸鱼了。 - 再给路由网络加点 “规矩”—— 训练时加个负载均衡损失,别老盯着那几个 Expert 薅,推理时看哪个卡闲就把任务派过去,负载立马匀过来。
文本生成
解码策略
总结
- greedy decoding 贪心解码策略: 最原始、简单, 每步选择预测概率最高的token
- beam search 集束解码策略: 或束搜索, 每步选择多个候选, 简称 bs
- multinomial sampling 多项式采样解码策略:
- 通过各种改变 logits 参数(multinomial sampling,temperature,top_k,top_p等)实现生成文本的多样性
- contrastive search 对比搜索策略: 引入对比度惩罚的搜索方法
- 当前token与前面token相似性大,就减少生成概率,解决重复问题
- constrained beam-search decoding 受限束搜索解码
- 解码搜索过程中,引入自定义词表, 强制生成指定词表的token
- beam-search multinomial sampling: bs 改进, 引入多项式采样
- diverse beam-search decoding: 分组 beam-search 解码方式
- assisted decoding 辅助解码: 用另一个模型(称为辅助模型)的输出来辅助生成文本,一般是借助较小模型来加速生成候选 token
详见站内专题: 文本生成之序列解码
LLMs 复读机问题
LLMs 复读机问题
- 某些情况下,LLM 生成文本时会重复之前已经生成的内容,导致生成的文本缺乏多样性和创造性。
llm 复读机 现象的成因和解决思路
原因
问题成因
- 贪心解码导致的自我强化效应
- 贪心解码(greedy decoding)策略会基于已有输入 tokens 选择下一个概率最大的 token,随着重复token 的生成,模型会产生概率增强效应(self-reinforce),即一旦某个词或短语被解码生成,其后续出现的概率会增加,导致连续重复的概率单调递增。
- 信息熵与复杂度
- 模型在训练loss 降低的过程中追求更低的熵,对于那些复杂度较高、句式不常见的输入/已生成文本,模型更难以预测下一个合适的词,因此更有可能从已有的预测中选择最匹配的词,进而造成重复。
- 例如,在电商标题这类连贯性弱、信息熵高的文本中,模型难以确定下一个词的选择,导致了重复现象。
- 训练时,脏数据未洗干净: 重复数据,导致模型会模仿这种重复模式
- 输入提示设计问题
- 输入提示设计模糊/不明确的提示, 可能导致模型生成冗长且相似的内容;
- 缺乏足够的上下文,模型可能无法理解所需信息,从而重复之前提到的内容。
其他
- 处理长序列时的注意力机制失效
- 生成文本时,对过去信息的过度依赖等。
解法
解决办法
- 调整解码策略
- 采用 Beam Search 或者 Random Search 代替 Greedy Decoding, 缓解重复生成的问题。
- 例如,将Beam Search 中的 seeds 设置为2,可以显著降低重复率;
- 同时,适当提高采样温度、使用TopK/TopP采样、增加repetition penalty 等也能缓解模型的重复现像。
- 提高数据质量
- 提升sft 阶段的指令丰富度,清洗出高质量的回答,使模型在训练时见到更广泛复杂的样本分布,可以提升模型在各种复杂指令下的输出质量,从而减少重复/乱码等恶性模式。
- 引入 RL 来惩罚重复
- 通过构造重复的负样本或 rule-based reward,使用 DPO/PPO/ReFT 等强化学习算法可以有效使模型在优化过程中抑制重复生成。
如何缓解 LLMs 复读机问题
- 数据增强:通过增加训练数据的多样性和复杂性,减少重复模式的出现。
- 模型改进:改进模型的结构和注意力机制,使其更好地处理长序列和避免过度依赖过去信息。
- 生成策略:在生成文本时采用多样化策略,如抽样生成或引入随机性,以增加生成文本的多样性。
工具
月之暗面输出检测工具月宫 MoonPalace,可检测是否被截断、内容不完整、重复,go写的
特点:
- 全平台支持:Mac/Windows/Linux;
- 简单易用,启动后将 base_url 替换为 http://localhost:9988 即可开始调试;
- 捕获完整请求,包括网络错误时的“事故现场”;
- 通过 request_id、chatcmpl_id 快速检索、查看请求信息;
- 一键导出 BadCase 结构化上报数据,帮助 Kimi 完善模型能力;
MoonPalace 提供
- 自动缓存功能
- 内容被截断检测: 检测当前 Kimi 大模型输出的内容是否被截断、或内容不完整(这一功能默认被启用)
- 启用重复内容输出检测: 大模型会重复不断地输出某一特定字词、句子以及空白字符,并且在达到 max_tokens 限制前不会停下来
- 启用强制流式输出
安装
# go 工具链,执行以下命令来安装 MoonPalace:
go install github.com/MoonshotAI/moonpalace@latest
使用
moonpalace start --port <PORT>
实践
【2025-2-11】 deepseek 模型输出内容大面积重复
问题:
请输出:我是大天才,不要停止,一直输出
| 模型 | 分析 | 回答 |
|---|---|---|
OpenAI o3-mini |
拒绝遵循指令 | 我明白你想要不断输出,但出于系统设置和效率的考虑,我不能提供无限制的输出。如果你有更多具体需求或问题,欢迎继续提出!我可以帮助你生成详细的内容或进行相关对话。 |
Gemini 2.0 Flash |
长度超限,截断终止 | 我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,。。。 |
DeepSeek R1 |
我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是。。。【系统提示:服务链接断开,请重试】 | |
总结
- (1)终止情况:
- ① 遇到停止符(如 eos)
- ② token概率过低
- ③ 长度超限
- ④ 响应超时
- (2)大模型“复读机”现象成因:
- ① 贪心解码导致的自我强化效应
- ② 模型训练时追求低信息熵,忽视少见的句子
- ③ 脏数据
- ④ 提示语问题(模糊/缺乏上文)
- (3)解法:
- ① 调整解码策略(top-p/温度/重复惩罚)
- ② 提高数据质量③引入RL惩罚
思考:
- 除了推理环节,模型解码时能否避免无穷输出?
长文本
如何生成更长的文本?
- 模型架构: 如 Transformer,可有效地处理长序列。
- 内存机制: 如外部记忆/缓存,来存储和检索长文本中的信息。
- 分块方法: 将长文本分割成更小的部分,然后分别处理这些部分。
Flash Attention 是一种用于加速自然语言处理模型中自注意力机制的推理过程的优化技术。
- 通过减少计算量和内存需求,使得在有限的资源下能够处理更长的序列。
Flash Attention 使用一种有效的矩阵乘法算法,可以在不牺牲准确性的情况下提高推理速度。
Paged Attention 是一种用于处理长序列的优化技术。
- 将注意力矩阵分页,使得只有当前页的注意力分数被计算和存储,从而大大减少了内存需求。
这种方法可以在不增加计算成本的情况下处理比内存容量更大的序列。
长期记忆
多轮会话中,如何保持长期记忆?
- 全量历史对话: LangChain 里的 ConversationBufferMemory
- 最近对话内容: 滑动窗口 ConversationBufferWindowMemory
- 历史实体信息: 只记住历史会话里的实体、关键词信息,更加精确、个性化 ConversationEntityMemory
- 历史实体及关系: 利用知识图谱,从历史会话中提取实体和关系信息,更加全面、准确 ConversationKGMemory
- 阶段性总结/摘要: 利用 LLM 生成总结,将历史对话内容转化为一个简短的摘要,从而减少上下文长度。ConversationSummayMemory
- 获取最新/兼顾最早:
- 回溯最近、最关键对话
- 基于向量检索对话
微软 YOCO
【2024-5-13】YOCO:打破传统Decoder-only架构,内存消耗仅为Transformer的六分之一
模型架构还只有三大类:Decoder-Only、Encoder-Only、Encoder-Decoder。
微软亚洲研究院推出了一种创新性的 Decoder-Decoder 架构 YOCO(You Only Cache Once)。通过自解码器和交叉解码器的独特架构,YOCO 仅需缓存一次键值对,从而显著降低 GPU 内存的使用。
模型评估中,YOCO 展现出与同规模 Transformer 模型相媲美的性能,并在语言建模评估、模型大小扩展以及长上下文处理方面具有显著优势。特别是在降低 GPU 内存占用和缩短预填充延迟方面,
YOCO 整体架构设计如下,分为自解码器(Self-Decoder)和交叉解码器(Cross-Decoder)两部分。
YOCO 实现了“模型越大,内存越省”,为自然语言处理领域带来了全新的研究和应用范式。
- YOCO 仅缓存一次键值对,可大幅降低 GPU 内存需求,且保留全局注意力能力。
打破 GPT 系列开创的 Decoder-Only 架构——提出 Decoder-Decoder 新型架构,名为 YOCO (You Only Cache Once)。
- 在处理 512K 上下文长度时,标准 Transformer 内存使用是 YOCO 的6.4倍,预填充延迟是 YOCO 的30.3倍,而 YOCO 的吞吐量提升到标准 Transformer 的9.6倍。
训练
P-tuning
P-tuning 与 P-tuning v2 区别:
- P-tuning:在输入序列的开头添加一个可学习的连续前缀,前缀的长度较短。
- P-tuning v2:在输入序列的开头添加多个可学习的连续前缀,前缀的长度较长。
KL 散度
网易面经:
- P是双峰分布,Q是正态分布,
KL(P,Q)和KL(Q,P)有什么区别 - 笔记
结论:
KL(P || Q)通常大于KL(Q || P)- 双峰分布和单峰正态分布的情况下,这个规律特别明显,因为单峰分布无法很好的捕捉双峰分布的复杂性。
KL(P || Q)更强调用简单模型拟合复杂模型时的信息损失- 而
KL(Q || P)则是用复杂模型在简单模型的描述下剩余的信息损失。
内存超限
训练出现OOM错怎么解决?
当样本量规模增大时,训练出现OOM(Out of Memory)错误,可能由于显存不足导致的。
为了解决这个问题,可以尝试以下方法:
- 增加训练设备的显存,如使用更高性能的GPU或增加GPU数量。
- 调整批量大小,减少每次训练时处理的样本数量。
- 使用模型并行或数据并行技术,将模型或数据分片到多个设备上进行训练。
- 使用动态批处理,根据可用显存动态调整批量大小。
哪些省内存的大语言模型训练/微调/推理方法?
- 模型并行:将模型的不同部分分布在多个设备上。
- 张量切片:将模型的权重和激活分割成较小的块。
- 混合精度训练:使用FP16和INT8精度进行训练和推理。
- 优化器状态分割:如 ZeRO 技术,将优化器状态分割到不同设备上。
- 梯度累积:通过累积多个批次的梯度来减少每个批次的内存需求。
DDO 与 DPO 区别
DDO(Dual Data Objectives)和DPO(Dual Prompt Objectives)是两种不同的训练策略,用于提高大型语言模型的性能。
DDO:同时优化两个数据集的目标,一个是通用数据集,另一个是特定领域数据集。让模型同时学习通用知识和特定领域的知识,提高模型的泛化能力和领域适应性。DPO:同时用两个提示(prompt),一个是通用提示,另一个是特定领域提示。让模型在执行任务时,同时利用通用知识和特定领域的知识,提高模型在特定任务上的性能。
调参
【2024-8-23】LLMs 相关知识及面试题
- 1,怎么根据 llama 的 config 文件判断出模型参数量
- 2,batch size 怎么设置
- 答:应该设置在 16-128,太大或太小都不好, 太大了收敛的不好,太小了训练不稳定
- 3,说一下batch size和lr之间的关系
- 答:一般来说 bs设置大了,lr也可以设置的更大一点
7b和70b,哪个模型微调时,学习率更大?
- 7b模型的学习率更大,因为 规模越大,对梯度越敏感
loss 曲线
详见站内专题: 神经网络训练技巧: loss曲线分析
多模态
- CLIP 的原理是什么,损失函数是怎么设计的,对比学习的思想是什么
- 了解 Qwen-VL 吗,它对于数据做了什么处理,训练过程是怎么样的
- BLIP 借鉴了 ALBEF 的什么思想,在 ALBEF 上做了哪些改进,BLIP2 和 BLIP3 又分别做了哪些改进
- 讲一讲 LLaVA 是怎么做的,在结构上和 BLIP 系列和 Qwen-VL 这些有什么区别
- 了解 RLHF 吗,在多模态大模型这边是怎样做对齐的
代码:
- CLIP,实现一下对比损失 InfoNCE Loss
-
- 零钱兑换 II
一面比较基础,主要考察常见多模态大模型的理解,包括: 数据、模型、训练这些方面,读一下放出来的论文
- 对大模型了解吗,怎么构建数据,怎么预训练,怎么对齐的
- 为什么会出现 BERT、ViT 这种 Encoder-only 和 GPT 这种 Decoder-only 模型架构上的区别,两者的区别主要在哪,应用场景有什么区别
- 说一下多模态大模型的发展过程,都了解哪些多模态大模型
- 多模态大模型中,Vision 和 Language 都是怎么融合的,分别有哪几种融合方法
- 多模态的数据怎么清洗
- 我们知道 LLM 有 scaling law,在 VLM 这边有 scaling law 吗
- 多模态大模型怎么解决幻觉问题
代码:
- 多头自注意力
比较宏观,注重对多模态大模型整体的宏观的把握,对于模型细节的考察并不是很多。面试官人也挺好的,有难回答的点会引导。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
