LLM 插件
github热门LLM工具实时排名
插件用途
插件让 ChatGPT 做以下事情:
- 检索实时信息;例如,体育比分、股票价格、最新新闻等。
- 检索知识库信息;例如,公司文档、个人笔记等。
- 代表用户执行操作;例如,预订航班、订购食物等。
Action 实现上,除了 OpenAI 的 Plugin,Adept 和 Inflection 这两家早期团队想以自然语言为基础,为用户打造新的 LUI (语言为基础的 UI)方式。
【2023-7-9】ChatUI 背后首先是控制大脑,参考下图 JARVIS 的架构,由大模型(GPT-4)来控制领域模型来工作的思路,取得了非常不错的成果,也开启了整个领域的研究方向。参考

OpenAI Plugin
3月24日,OpenAI宣布解除了ChatGPT无法联网的限制,以第三方插件为中介,使ChatGPT能访问其他网站并获取实时信息,还支持执行计算。
Plugins enable ChatGPT to do things like:
- Retrieve real-time information;
- e.g., sports scores, stock prices, the latest news, etc.
- Retrieve knowledge-base information;
- e.g., company docs, personal notes, etc.
- Assist users with actions;
- e.g., booking a flight, ordering food, etc.
此前,ChatGPT只能从训练数据当中提取信息,导致其输出结果大大受限。OpenAI官方称,此次推出的插件不仅允许ChatGPT浏览网页,还能让它与开发人员定义的API进行交互,使其能执行诸如搜索实时新闻、检索知识库等更具体的操作。
ChatGPT的第一批插件由Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify、Slack、Speak、Wolfram和Zapier等公司提供,这些插件的具体功能包括推荐餐厅、制定出游计划、网上商店购物、企业办公、信息检索、语言教学等,涵盖日常生活的衣食住行各个方面。“插件商店(ChatGPT Plugins Store)”的推出意味着其他服务成为了ChatGPT的“眼睛和耳朵”。
ChatGPT的“插件商城”
- ChatGPT集成第三方插件,成为聊天版“App Store”
搜索插件
LangChain
LangChain:Model as a Service粘合剂,被ChatGPT插件干掉了吗?
LangChain 由前 Robust Intelligence 的机器学习工程师 Chase Harrison 在 22 年 10 月底推出,是一个封装了大量 LLM 应用开发逻辑和工具集成的开源 Python 库,有成为第一个被广泛认可的 LLM 应用开发框架的势头。
- 随着 Harrison 为 LangChain 添加了很多实用的抽象,以及 23 年 1 月众多 AI Hackathon 决赛项目使用 LangChain,它的 Github Star 迅速破万,成为 LLM 应用开发者选择中间件时想到的第一个名字。
- 产品:拼接好 LLM 的大脑和四肢
- LangChain 身上有许多标签:开源的 Python 和 Typescript 库、第一个被广泛采用的 LLM 开发框架、Model as a Service 设想的中间件、AI 应用层的基础设施……
从开发者视角看,LangChain 是个挺友好且优美的库:
- • 它非常模块化,还通过 Chain、Agent、Memory 对 LLM 的抽象帮助开发者提高了构建较复杂逻辑应用的效率;而且每个模块有很好的可组合性,有点像“为 LLM 提供了本 SOP”,能实现 LLM 与其他工具的组合、Chain 与 Chain 的嵌套等逻辑;
- • 它一站式集成了所有工具,从各种非结构化数据的预处理、不同的 LLM、中间的向量和图数据库和最后的模型部署,贡献者都帮 LangChain 跟各种工具完成了迅速、全面的集成。
- 作为成长期投资者看 LangChain,它本身还太早期,远没到成长逻辑。除此之外,我对它在商业层面未来发展的核心担忧在于:
- • 我们不能直接套用旧时代的中间件视角,随着 ChatGPT Plug-In 出现和 OpenAI 的更多边界延伸,LangChain 的价值可能被取代,很快像机器学习历史上的其他明星库一样隐入尘埃;
- • LangChain 本身的壁垒也比较薄,是“其他开源库身上的开源库”,没有太多技术壁垒,只是替大家省下来了码的时间。如果要收费使用,很多开发者可能会选择自己把 LangChain 这套东西码出来;
- • 目前使用 LangChain 库的以个人开发者和极客的 side project 为主,还不是正经的企业级 LLM 集成工具,而稍微有点体量的公司都会选择 fork LangChain 的源码或者干脆自己再码套框架。
更多见站内:LangChain专题
插件调用效率
插件增加后,继续填充到Prompt中,会导致 LLM识别准确率下降
APIs 数据
- RapidAPI2 收集了 16464个 Representational State Transfer (REST) APIs, RapidAPI 是一个托管着大量由开发者提供的真实世界APIs的平台。这些APIs涵盖了社交媒体、电子商务、天气等49个不同类别。
【2023-10-16】Android系统api集合
| BII | Description |
|---|---|
| Open app feature | Launch a feature of the app. |
| Create review | Create a review or leave a rating on products, locations, content, or other things. |
| Create thing | Construct a new entity in an app. |
| Get barcode | Open a barcode or QR code scanner. |
| Get news article | Search and view news updates. |
2022.5.1 MRKL
MRKL (Modular Reasoning, Knowledge and Language) 一个模块化的、神经-符号的架构,结合了大型语言模型、外部知识和离散推理
- MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
- Jurassic-X: AI21 Labs’ MRKL system – 404
语言模型处理输入,分发任务至专家,并总结专家输出
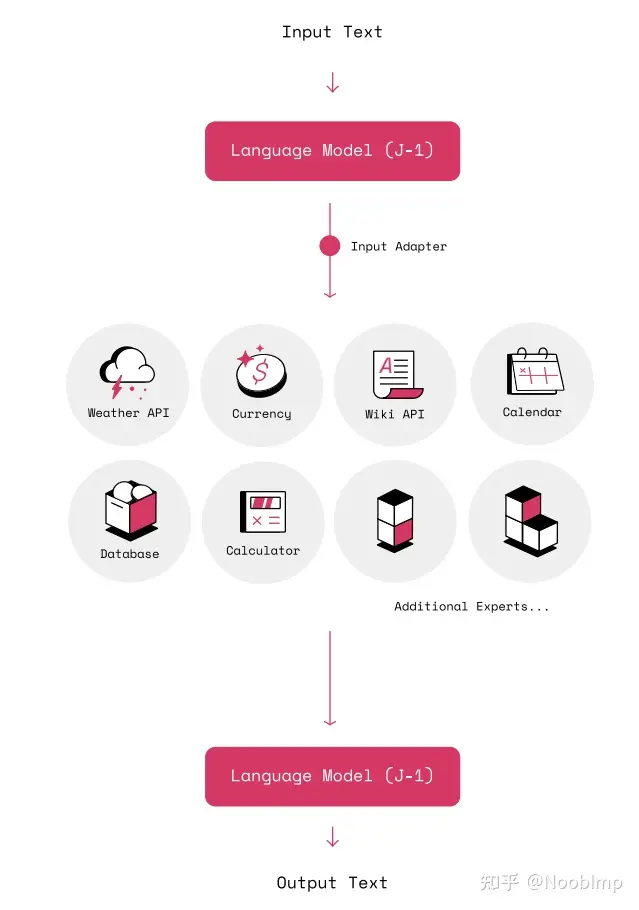
实验以使用计算器为例,LLM做文本描述->公式这一步,做微调,计算器算结果
2022.5.24 TALM – 谷歌
同时学习两个子任务:调用工具并根据工具结果生成答案
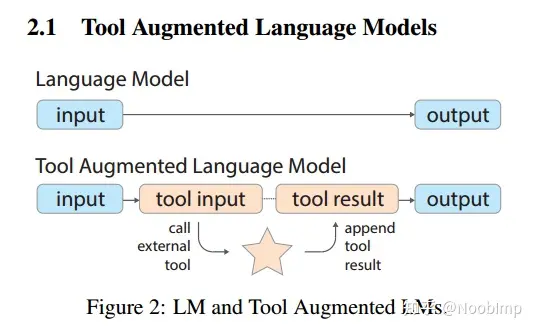
tool-use set比task set多了两个中间结果,对于一个小的T,模型根据输入x生成t、调用api获得r、根据x、t、r生成y’,判断y’和y的差距,如果小于某阈值,就加入D中
数据哪里来?
- 从少量工具示例中迭代 self-play
工具用的什么?怎么去调用的?

- Natural Questions -> 检索工具
- MathQA -> 实现了一个简单的求解工具
实验任务
- 重知识问答
- 数学推理
2023.2.10 Toolformer – META
【2023-2-9】META AI 发布 Toolformer: 自监督方式训练模型,自动选择调用哪个api,只需提供几个示例
- which 调哪个api
- when 什么时候调
- what 传什么参数
-
how 怎么从结果里提取信息
- 论文: Toolformer: Language Models Can Teach Themselves to Use Tools
- pytorch代码实现: Toolformer - Pytorch
- 视频讲解:作者讲解, 他人解读
We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q\&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
使用具有上下文学习的LLMs 从头生成整个数据集:只要给出一些关于如何使用API的人工编写示例,就让LM用潜在的API调用注释一个巨大的语言建模数据集。
- 然后,用自监督损失来确定哪些API调用实际上有助于模型预测未来的令牌。
- 最后,根据有用的API调用对LM本身进行调优。
通过这种简单的方法,lm可以学会控制各种工具,并自己选择何时以及如何使用哪种工具。
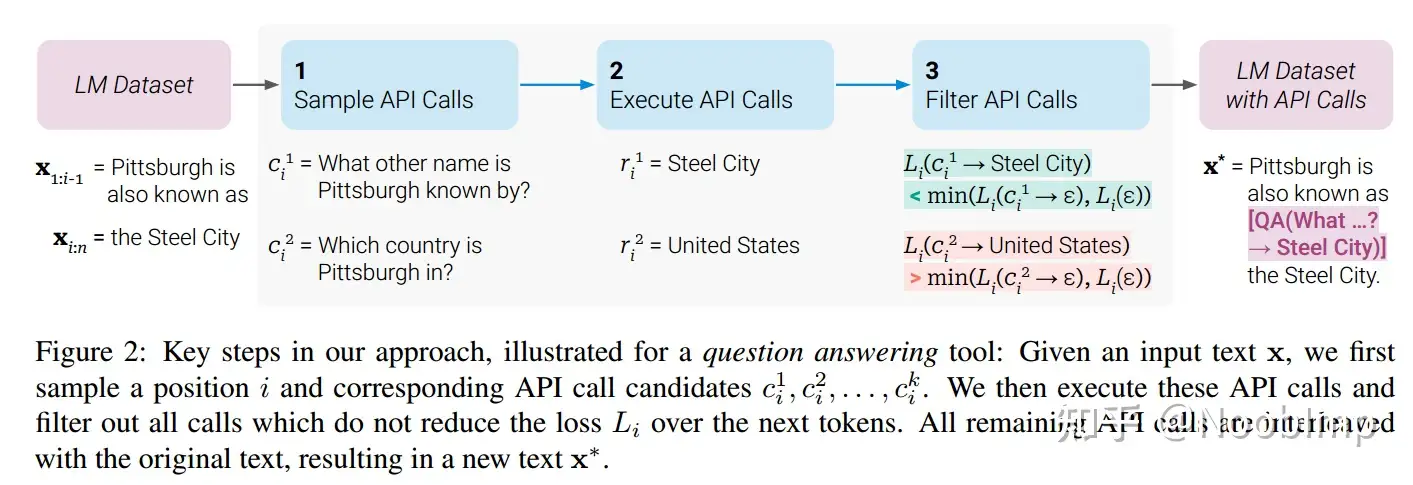
- Sampling API Calls:通过in-context learning让他自己插入可能需要的api;
- Excuting API Calls:执行获得的API并收集结果;(自己切分出来拿到对应的工具去执行吗?
- Filtering API Calls:如果提供API和对应执行结果后生成答案的 LM loss L1 比啥也不提供的LM loss L2 小一个阈值 delta,那就认为这个API是有帮助的。
数据集制作的方法整体分这几步
- 使用Prompt令LM在文本中生成APICall
- 执行APICall获取结果
- 过滤APICall结果,形成数据集
训练
- 得到的数据集区别就是内容中多包含了API调用c和结果r,还是用LM loss微调。
推理
- 执行常规解码,直到LM产生“!”令牌,表明它下一步期望API调用的响应。此时,中断解码过程,调用适当的API来获取响应,并在插入响应和令牌之后继续解码过程。
用哪些工具?
- Atlas做QA、计算器、BM25做搜索、NLLB做翻译、日历
Toolformer的结果相当惊艳。
- 以数学推理能力为例,通过Toolformer的加持,仅6.7B的
GPT-J大幅超过了远大于它的175B的GPT-3。 - 结果也容易理解,小学生调用外挂也可以参加高考
Toolformer 不足
- 训练上,使用不同工具数据,分别生成相互独立,这使得模型无法配合使用多种工具,没有连续性的能力。
- 同种工具的数据也是相互独立生成的,这使得模型无法交互地不断优化查询。
- 从推断上,为了防止模型不断调用API导致卡死,每个样本仅允许调用一次API,这大大降低了模型的能力。
- 最重要的是,Toolformer还不能链接互联网。
# pip install toolformer-pytorch
import torch
from toolformer_pytorch import Toolformer, PaLM
# simple calendar api call - function that returns a string
def Calendar():
import datetime
from calendar import day_name, month_name
now = datetime.datetime.now()
return f'Today is {day_name[now.weekday()]}, {month_name[now.month]} {now.day}, {now.year}.'
# prompt for teaching it to use the Calendar function from above
prompt = f"""
Your task is to add calls to a Calendar API to a piece of text.
The API calls should help you get information required to complete the text.
You can call the API by writing "[Calendar()]"
Here are some examples of API calls:
Input: Today is the first Friday of the year.
Output: Today is the first [Calendar()] Friday of the year.
Input: The president of the United States is Joe Biden.
Output: The president of the United States is [Calendar()] Joe Biden.
Input: [input]
Output:
"""
data = [
"The store is never open on the weekend, so today it is closed.",
"The number of days from now until Christmas is 30",
"The current day of the week is Wednesday."
]
# model - here using PaLM, but any nn.Module that returns logits in the shape (batch, seq, num_tokens) is fine
model = PaLM(
dim = 512,
depth = 2,
heads = 8,
dim_head = 64
).cuda()
# toolformer
toolformer = Toolformer(
model = model,
model_seq_len = 256,
teach_tool_prompt = prompt,
tool_id = 'Calendar',
tool = Calendar,
finetune = True
)
# invoking this will
# (1) prompt the model with your inputs (data), inserted into [input] tag
# (2) with the sampled outputs, filter out the ones that made proper API calls
# (3) execute the API calls with the `tool` given
# (4) filter with the specialized filter function (which can be used independently as shown in the next section)
# (5) fine-tune on the filtered results
filtered_stats = toolformer(data)
# then, once you see the 'finetune complete' message
response = toolformer.sample_model_with_api_calls("How many days until the next new years?")
# hopefully you see it invoke the calendar and utilize the response of the api call...
2023.3.31 TaskMatrix – 微软
【2023-3-31】一个AI驱动百万个API!微软提出多任务处理模型TaskMatrix,机器人和物联网终于有救了
- 论文地址:paper
基于ChatGPT大模型的强大理解能力,将输入的任何信号拆解成一个个可完成的任务,交给其他的AI和程序完成。
- 就像是建了一座司令塔,每个大模型都能成为其中的“大脑”指挥官,其他专门解决某类任务的模型,则听它调令
人类只需要提需求,AI从自动做PPT、Word和Excel三件套(Office自动化),到驱动机器人完成各种智能任务,都能搞定。
这个最新的研究名叫 TaskMatrix,据微软表示,它能直接驱动数百万个用于完成任务的AI和API。
TaskMatrix 怎样工作?
从架构图来看,TaskMatrix可以被分为四部分:
- 多模态对话基础模型(MCFM):与用户对话并了解需求,从而生成API可执行代码以完成特定任务
- API平台:提供统一API格式,存储数百万个不同功能的API,允许扩展和删除API
- API选择器:负责根据MCFM生成的内容推荐API
- API执行器:调用API并执行生成代码,给出结果
简单来说,MCFM负责生成解决方案,API选择器从API平台中选取API,随后API执行器基于MCFM生成的代码调用API,并解决任务。
为了统一API管理,API平台又给API统一了文档格式,包含以下五个部分:
- API名称(提供API摘要,避免与其他API混淆)
- 参数列表(包含输入参数和返回值等)
- API描述(功能描述)
- 组合指令(如何组合多个API完成复杂用户指令)
搭建TaskMatrix的原因,从学术角度来说主要有两点。
- 其一,扩大AI适用范围,如通过扩展API来提升可完成任务的类型和数量;
- 其二,便于进一步提升AI可解释性,通过观察AI分配任务的方式就能理解它的“思路”。
2023.4.4 BMTool 面壁智能
【2023-4-4】面壁智能自研工具学习引擎 BMTools (发布资讯) 也因此被成功实践。
【2023-5-15】面壁智能 联合来自清华、人大、腾讯的研究人员共同发布了 中文领域首个基于交互式网页搜索的问答开源模型 WebCPM,这一创举填补了国产大模型该领域的空白。
面壁智能在 ChatGPT Plugins 发布后仅十天就推出 BMTools, 官方公众号报道
- BMTools 是一个基于语言模型的开源可扩展工具学习平台。
- 面壁研发团队将各种各样的工具调用流程都统一到一个框架上,使整个工具调用流程标准化、自动化。
- BMTools 目前支持的插件,涵盖娱乐,学术,生活等多方面,包括 douban-film(豆瓣电影)、search(必应搜索)、Klarna(购物)等。开发者可以通过 BMTools,使用给定的模型(比如 ChatGPT、GPT-4)调用多种多样的工具接口,以实现特定功能。此外,BMTools 工具包也已集成最近爆火的 Auto-GPT 与 BabyAGI。
BMTools 支持 Open AI 的 Plugins,同时也允许开发者自己加入的工具列表。BMTools 目前接入了OpenAI 的 ChatGPT 和 GPT4 模型,并提供了 OpenAI Plugins 的相应实现。同时,通过 BMTools,开发人员可以根据自己的需求,自定义选择合适的工具加入列表,提高特定开发的效率和质量。
详见官方介绍:发布资讯
2023.5.25 HuggingGPT


不同阶段的prompt:

类似的
详见站内专题 智能体
2023.5.26 Tool Maker (LATM) – 谷歌+斯坦福+普林斯顿
LLM能够自己制作工具了:详解Large Language Models as Tool Makers
- Google Deepmind,普林斯顿和斯坦福的研究人员发布了“Large Language Models as Tool Makers”通过让LLM制作“工具”来解决复杂的问题。
- Large Language Models as Tool Makers,解读
- Code: LLM-ToolMaker
已有工作调用的是现有工具。本文提出一个闭环框架,即 LLMs作为工具生成器(LATM),消除依赖,其中LLMs为问题解决创建自己的可重用工具。方法包括两个关键阶段:
- 1)工具生成:LLM 为给定任务创建 工具生成器,其中工具被实现为Python实用函数。
- 生成的工具可以在不同的任务实例中重复使用
- 2)工具使用:LLM 使用工具解决问题,该工具由工具生成器构建的。
- 工具用户是与工具生成器相同或不同的LLM。
- 工具生成使LLM能够不断生成可以应用于不同请求的工具,以便将来的请求在解决任务时可以调用相应的API。

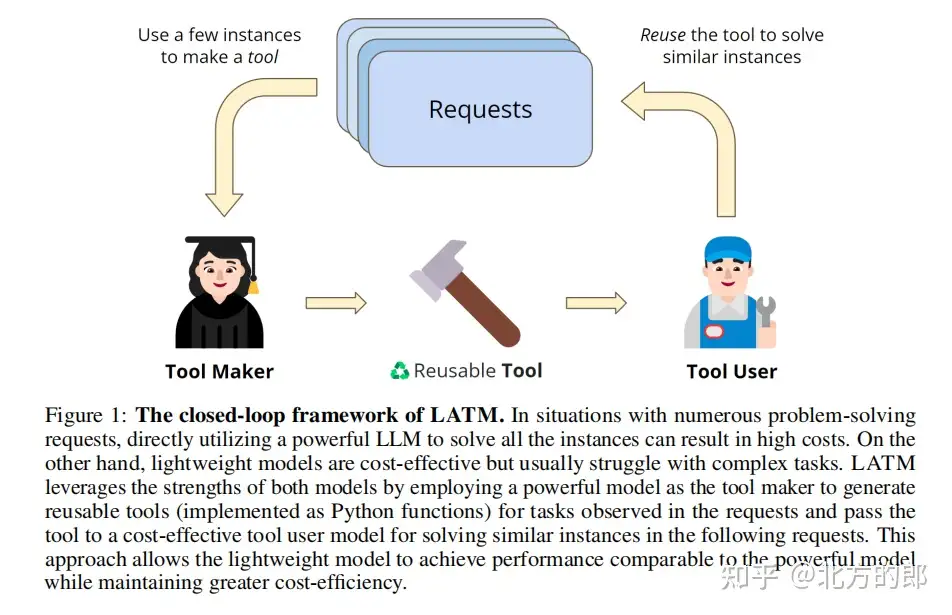
此外,LLMs在工具生成和工具使用阶段的分工为实现成本效益提供了机会,同时不降低生成的工具和问题解决方案的质量。例如可以将功能要求比工具使用更复杂的功能分配给功能强大但资源密集的模型作为工具生成器,并将成本较低的模型作为工具使用者。通过在各种复杂的推理任务(包括Big-Bench任务)中验证了方法的有效性。使用GPT-4作为工具生成器和GPT-3.5作为工具使用者,LATM的性能可以与使用GPT-4进行工具生成和工具使用的性能相媲美,同时推理成本显著降低。
用途
- 将公网上的强大模型与企业私有稍小的模型结合起来使用的方法。
- 因为数据安全及成本原因,企业不能直接使用公有云上的大模型,可以让大模型生成“工具”,提升私有小模型的能力。
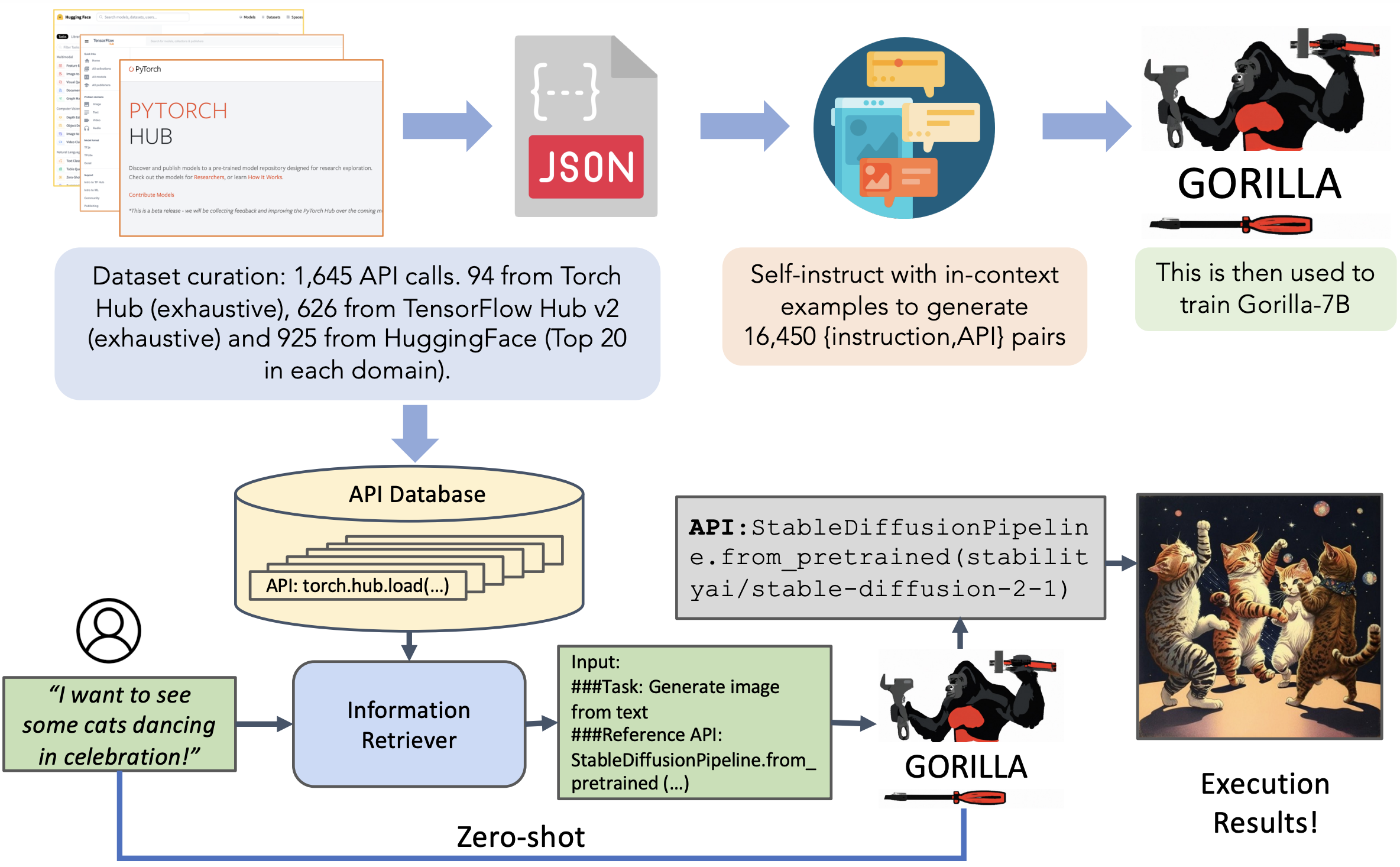
2023.5.27 Gorilla 伯克利
用 开源小模型 完成 API调用
pip install gorilla-cli
gorilla "generate 100 random characters into a file called test.txt"
Gorilla is Apache 2.0 With Gorilla being fine-tuned on MPT, and Falcon, you can use Gorilla commercially with no obligations
Gorilla enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, we are the first to demonstrate how to use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. We also release APIBench, the largest collection of APIs, curated and easy to be trained on! Join us, as we try to expand the largest API store and teach LLMs how to write them! Hop on our Discord, or open a PR, or email us if you would like to have your API incorporated as well.
- 输入自然语言,Gorilla就会驱动LLM调用APIs
- 首次演示如何通过LLM正确调用 1600+ 个 API,并减少幻觉
- 发布API数据集: APIBench
2023.8.4 ToolBench (ToolLLM)
【2023-8-4】利用外部API(应用程序编程接口)来解决任务和问题的能力
- 面壁智能联合来自 TsinghuaNLP、耶鲁、人大、腾讯、知乎的研究人员推出 ToolLLM 工具学习框架,加入 OpenBMB 大模型工具体系“全家桶”。
- 论文: TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000+ REAL-WORLD APIS
- 代码: ToolBench

- A demo of using ToolLLaMA 演示视频
We crawl 16000+ real-world APIs from RapidAPI, and curate realistic human instructions that involve them. Below we present a hierarchy of RapidAPI and our instruction generation process.
- 从RapidAPI2收集了 16464个 Representational State Transfer (REST) APIs,RapidAPI 是一个托管着大量由开发者提供的真实世界APIs的平台。这些APIs涵盖了社交媒体、电子商务、天气等49个不同类别。
- 对于每个API,从RapidAPI爬取了详细的API文档,包括功能描述、必需参数、API调用的代码片段等。希望LLMs通过理解这些文档来学习使用APIs,以便模型可以泛化到训练中未见过的APIs;
- 一种新颖的基于深度优先搜索的决策树(
DFSDT),以增强LLMs的规划和推理能力。与传统思维链(CoT)(Wei等,2023)和ReACT(Yao等,2022)相比,DFSDT使LLMs能够评估多种推理路径,并做出慎重的决策,要么撤回步骤,要么继续沿着有前途的路径进行。 - 实验证明,
DFSDT显著提高了注释效率,并成功完成了CoT或ReACT无法回答的复杂指令。 
为了评估LLMs的工具使用能力,开发了一个名为ToolEval的自动评估器,依赖于ChatGPT。它包含两个关键指标:
- (1)
通过率,衡量在有限预算内成功执行指令的能力; - (2)
胜率,比较两种解决方案路径的质量和实用性。展示ToolEval与人工评估之间具有高度相关性,并为工具学习提供了一个稳健、可扩展、可靠的评估方法。
ChatGPT Plugin
【2023-3-24】ChatGPT 插件开发指南
- alpha 阶段,需要申请加入候补名单才能获得访问权限
ChatGPT 插件是专门为以安全为核心原则的语言模型设计的工具,可帮助 ChatGPT 访问最新信息、运行计算或使用第三方服务。
【2023-7-14】OpenAI文档
- 官方指南
- 第三方汉化版
- plugins-quickstart, 以待办事项列表为例,5min开发一个插件
OpenAI 正在逐步启用一些合作者的插件供 ChatGPT 用户使用,同时开始推出开发者可以为 ChatGPT 创建自己的插件的功能。第一批插件已经由 Expedia、FiscalNote、Instacar等创建。
- 一个Chat最多可选3个插件
插件功能
WebPilot: 比官方联网插件好多了,读取任何网页的内容,包括国内外,比如大家常去的知乎、微信公号等,也可以读取在线的PDF、在线文献等,一方面可以解决GPT数据时效性、另一方面大家可以针对在线的内容提出各类问题,比如总结、丰富、提取核心、洗稿等,只需要给它链接就行Prompt Perfect: 输入的问题后面加perfect就能触发插件,优化 promptWolfram: 处理各式各样的问题,包括但不仅限于数学运算、物理公式的求解、化学元素的查询、历史事件的检索、地理信息的查询等等, 也可以直接给它问题,让它给你答案和解析的过程,比如鸡兔同笼AskYourPDF: 直接阅读线上PDF并进行归纳总结等操作。ShowMe: 绘制Diagram图表,并提供可编辑的链接,也可以直接下载; 直接在聊天中创建和编辑图表。可以将复杂的语料分析的有逻辑,并且将逻辑框架画出来,并且允许在线修改。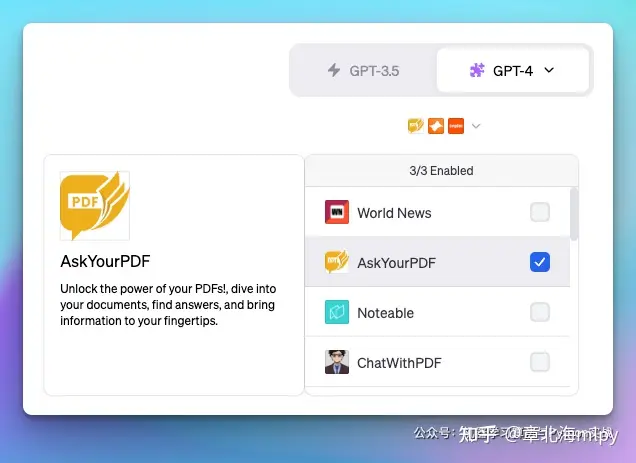
| 编号 | 插件名 | 插件描述 | 图示 |
|---|---|---|---|
| 1 | AskYourPDF |
直接阅读线上PDF并进行归纳总结等操作 | 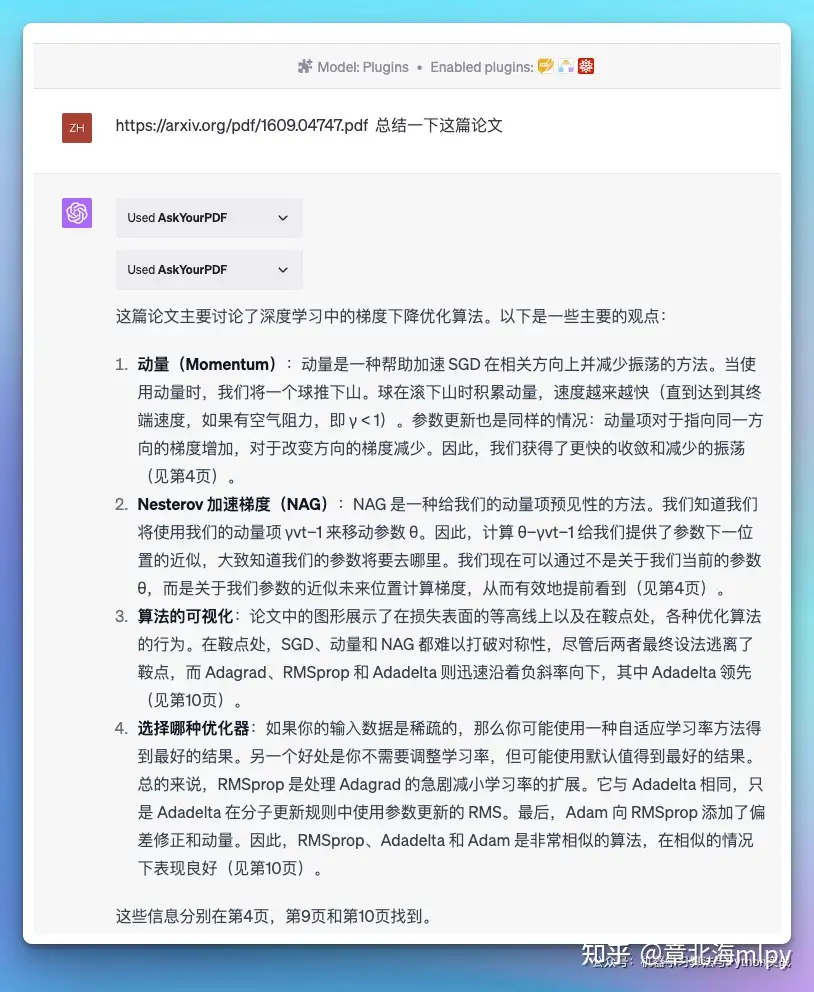 |
| 2 | ShowMe |
绘制Diagram图表,并提供可编辑的链接,也可以直接下载 | 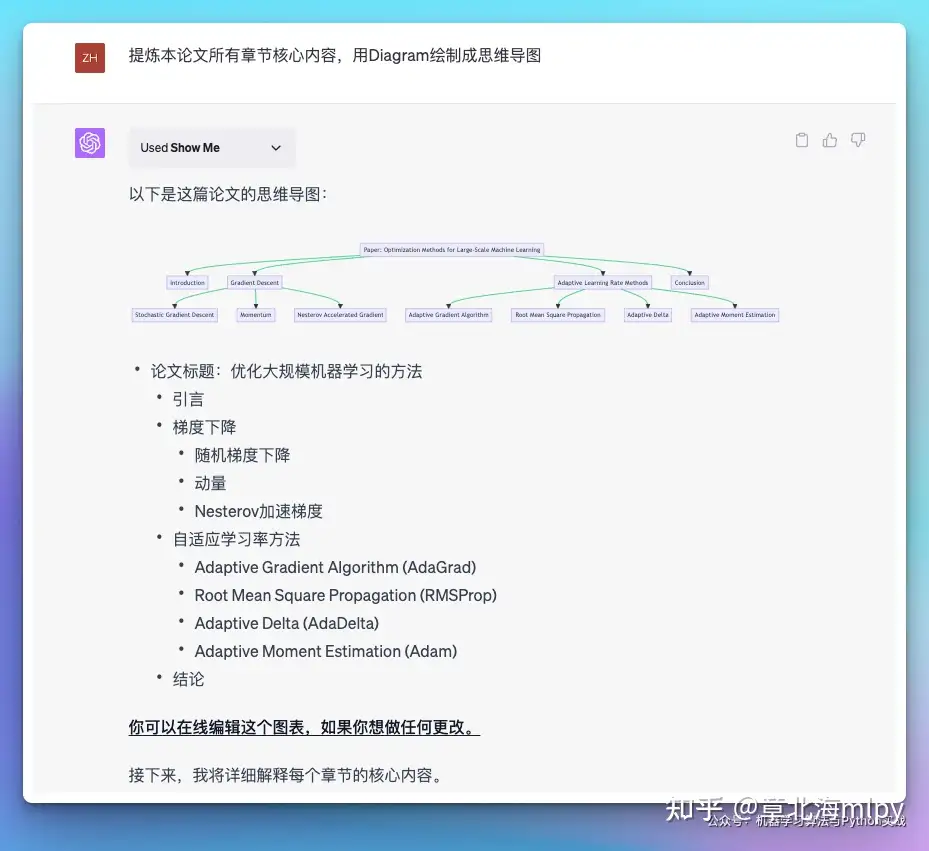 |
| 3 | Wolfram |
复杂公式的运算,根据结果数据绘制各种图表:地图、热力图、柱状图… | 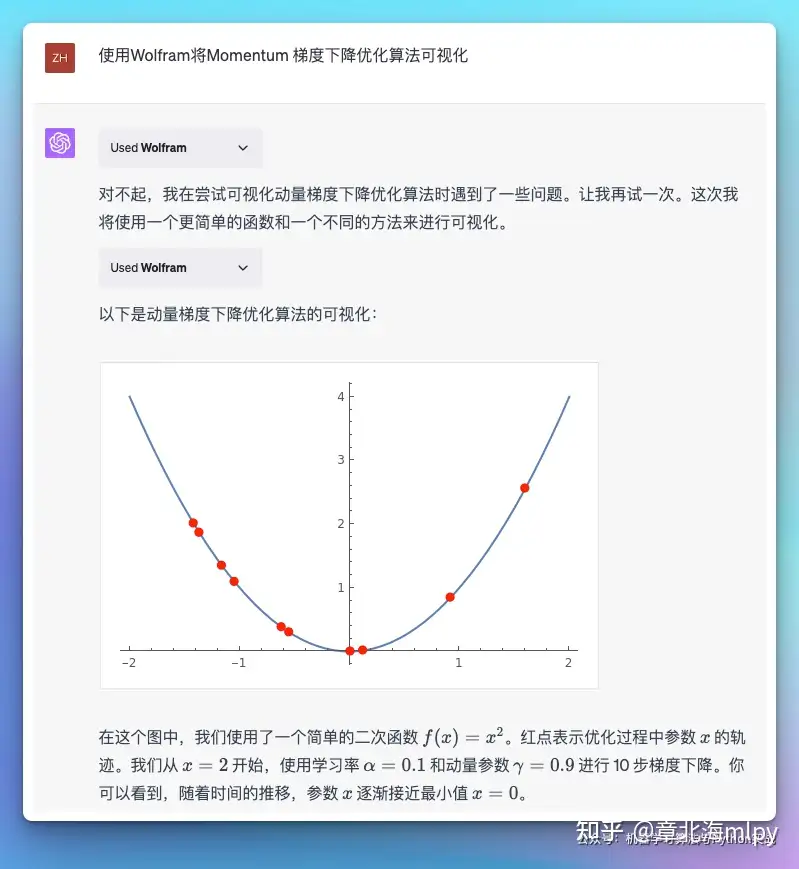 |
| 4 | WebPilot |
读取任何网页的内容,包括国内外,比如大家常去的知乎、微信公号等,也可以读取在线的PDF、在线文献等 | |
| 5 | Prompt Perfect |
输入的问题后面加perfect就能触发插件,优化 prompt | |
插件申请
开发者插件开发的申请流程,与网页浏览器插件、代码解释器插件、Retrieval 插件、第三方插件等插件的功能、交互样式,详细介绍了开发流程,并通过“待办事项列表(to-do list)插件”的案例开发过程进行了演示。
插件开发指南
插件开发者公开一个或多个 API 端点,伴随着一个标准化清单文件和一个 OpenAPI 规范。
这些定义了插件的功能,允许 ChatGPT 消耗这些文件并调用开发者定义的 API。
AI 模型作为智能 API 调用者。给定 API 规范和使用 API 的自然语言描述,模型主动调用 API 执行操作。
- 例如,如果用户问“在巴黎住几晚应该住哪里?”,模型可以选择调用酒店预订插件 API,接收 API 响应,并生成结合API数据和自然语言能力的用户可见答案。
插件主要3个步骤:详见指南
- 开发API(同普通API)
- 写API文档(OpenAPI格式,Swagger生成的API文档)
- 编写 JSON manifest插件配置文件, 定义插件的相关元数据
- 每个插件都需要一个名为 ai-plugin.json 的文件,该文件需要托管在 API 所在的域名下。
OpenAI 规范
需要用 OpenAPI 规范 来描述 API 文档。
除了 OpenAPI 规范和清单(manifest)文件中定义的内容外,ChatGPT 中的模型对您的 API 一无所知。
- 如果有非常多的 API,则无需向模型公开所有 API,只选择开放特定的 API 就行。
- 例如,有一个社交媒体 API,希望模型能通过 GET 请求访问网站内容,但要阻止模型对用户帖子发表评论,以减少垃圾邮件的可能性。
规范示例
- 首先定义规范版本、标题、描述和版本号。
- ChatGPT 中运行查询时,将查看信息部分中定义的描述,以确定插件是否与用户查询相关。可以在写作说明部分阅读更多关于提示的信息。
请记住 OpenAPI 规范中的以下限制:
- API 规范中每个 API Endpoint(指具体的某个 API)节点描述/摘要字段最多 200 个字符
- API 规范中每个 API 参数描述字段最多 200 个字符
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT.
version: "v1"
servers:
- url: http://localhost:3333
paths:
/todos:
get:
operationId: getTodos
summary: Get the list of todos
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: "#/components/schemas/getTodosResponse"
components:
schemas:
getTodosResponse:
type: object
properties:
todos:
type: array
items:
type: string
description: The list of todos.
manifest
插件清单 manifest 的最小定义如下所示:
{
"schema_version": "v1", # 清单(manifest)架构版本
"name_for_human": "TODO Plugin", # 人类可读的名称,例如公司全名
"name_for_model": "todo", # 模型将用于定位插件的名称
# 插件的人类可读描述
"description_for_human": "Plugin for managing a TODO list. You can add, remove and view your TODOs.",
# 更适合模型的描述,例如令牌上下文长度注意事项或关键字用法,以改进插件提示。
"description_for_model": "Plugin for managing a TODO list. You can add, remove and view your TODOs.",
"auth": { # 身份验证模式
"type": "none"
},
"api": { # 接口规范
"type": "openapi",
"url": "http://localhost:3333/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "https://vsq7s0-5001.preview.csb.app/logo.png", # 用于获取插件徽标的网址
"contact_email": "support@example.com", # 用于安全/审核联系、支持和停用的电子邮件联系人
"legal_info_url": "http://www.example.com/legal" # 重定向 URL,以便用户查看插件信息
}
清单(manifest)文件中某些字段的长度限制:
- name_for_human:最多 50 个字符
- name_for_model:最多 50 个字符
- description_for_human:最多 120 个字符
- description_for_model:最多 8000 个字符(会随着时间的推移而减少)
另外,对 API 响应正文长度也有 100k 个字符的限制(会随着时间的推移而减少),这个在未来也可能会变。
description_for_model 和描述以及设计 API 响应时要遵循的一些最佳实践:
- 描述不应试图控制 ChatGPT 的情绪、个性或确切反应。ChatGPT 旨在为插件编写适当的响应。
- 不好的例子:当用户要求查看他们的待办事项列表时,请始终回复“我能够找到您的待办事项列表!你有 [x] 个待办事项:[在此处列出待办事项]。如果你愿意,我可以添加更多的待办事项!
- 好例子:[无需说明]
- 当用户没有要求插件的特定服务类别时,描述不应鼓励 ChatGPT 使用该插件。
- 不好的例子:每当用户提到任何类型的任务或计划时,询问他们是否要使用 TODOs 插件将某些内容添加到他们的待办事项列表中。
- 好例子:TODO 列表可以添加、删除和查看用户的 TODO。
- 描述不应规定 ChatGPT 使用该插件的特定触发器。ChatGPT 旨在在适当的时候自动使用您的插件。
- 不好的例子:当用户提到任务时,请回复“您是否希望我将其添加到您的待办事项列表中?说’是’继续。
- 好例子:[无需说明]
- 插件 API 响应应返回原始数据而不是自然语言响应(除非确实有必要)。ChatGPT 将使用返回的数据提供自己的自然语言响应。
- 不好的例子:我能够找到你的待办事项清单(manifest)!您有 2 个待办事项:买杂货和遛狗。如果您愿意,我可以添加更多待办事项!
- 好例子:
{"todos":["买杂货","遛狗"]}
运行插件
通过 ChatGPT UI 连接插件。插件可能运行在不同的位置: 本地开发环境,远程服务器。
- 本地版本,将插件接口指向该本地设置。要将插件与 ChatGPT 连接,可以导航到插件市场,然后选择“Install an unverified plugin(安装未经验证的插件)”。
- 远程服务器,先选择“Develop your own plugin(开发自己的插件)”,然后选择 “Install an unverified plugin(安装未经验证的插件)”。
- 只需将插件清单(manifest)文件添加到 ./well-known 路径并开始测试您的 API。
- 但是,对于清单(manifest)文件的后续更改,必须将新更改部署到您的公共站点,这可能需要很长时间。在这种情况下,建议设置一个本地服务器作为API 的代理。这可以快速对 OpenAPI 规范和清单(manifest)文件的更改进行原型设计。
如何设置面向公众的 API 的简单代理。
- Python 代码示例
import requests
import os
import yaml
from flask import Flask, jsonify, Response, request, send_from_directory
from flask_cors import CORS
app = Flask(__name__)
PORT = 3333
CORS(app, origins=[f"http://localhost:{PORT}", "https://chat.openai.com"])
api_url = 'https://example'
@app.route('/.well-known/ai-plugin.json')
def serve_manifest():
return send_from_directory(os.path.dirname(__file__), 'ai-plugin.json')
@app.route('/openapi.yaml')
def serve_openapi_yaml():
with open(os.path.join(os.path.dirname(__file__), 'openapi.yaml'), 'r') as f:
yaml_data = f.read()
yaml_data = yaml.load(yaml_data, Loader=yaml.FullLoader)
return jsonify(yaml_data)
@app.route('/openapi.json')
def serve_openapi_json():
return send_from_directory(os.path.dirname(__file__), 'openapi.json')
@app.route('/<path:path>', methods=['GET', 'POST'])
def wrapper(path):
headers = {
'Content-Type': 'application/json',
}
url = f'{api_url}/{path}'
print(f'Forwarding call: {request.method} {path} -> {url}')
if request.method == 'GET':
response = requests.get(url, headers=headers, params=request.args)
elif request.method == 'POST':
print(request.headers)
response = requests.post(url, headers=headers, params=request.args, json=request.json)
else:
raise NotImplementedError(f'Method {request.method} not implemented in wrapper for {path=}')
return response.content
if __name__ == '__main__':
app.run(port=PORT)
调试
- 默认情况下,聊天不会显示插件调用和其他未向用户显示的信息。为了更全面地了解模型如何与您的插件交互,可单击屏幕左下角的“Debug”按钮打开调试窗口。这将打开到目前为止对话的原始文本,包括插件调用和响应。
- 对插件的模型调用通常包括来自模型(“助手”)的消息,其中包含发送到插件的类似 JSON 的参数,然后是来自插件(“工具”)的响应,最后是来自利用插件返回的信息的模型。
- 在某些情况下,例如在插件安装期间,错误可能会出现在浏览器的 javascript 控制台中。
插件开发实战
插件开发指南
- 用 Python 开发并部署在 Replit 上。插件将使用服务级别(认证有 4 种方式:无认证,服务级,用户级和 OAuth)的身份验证令牌进行身份验证,并允许用户创建、查看和删除待办事项。还需要定义一个 OpenAPI 规范以匹配我们插件中定义的端点
- 步骤详解:稀土掘进含图解、代码详解, 公众号
获取示例代码
# clone 代码
git clone https://github.com/openai/plugins-quickstart.git
pip install -r requirements.txt # 安装依赖 quart
python main.py
重要文件就三个
.wll-known/ai-plugin.json # manifest 文件: 插件配置文件
openapi.yaml # 插件服务的api接口规范
main.py # 插件服务主文件
基于 Quart 和 Quart-CORS 的简单 RESTful API 服务器,用于处理待办事项(todo)数据的 CRUD 操作(创建、读取、更新、删除)。
- Quart 是一个 Python 的异步 web 框架,相当于异步版本的 Flask。
- Quart-CORS 是一个用于处理跨源资源共享(CORS)库。
插件配置文件(ai-plugin.json)告诉ChatGPT插件的功能是什么,API文档在哪里。
- 每一个插件都有一个
ai-plugin.json配置文件,如果域名是 https://example.com ,ChatGPT会去这个路径查询插件配置 https://example.com/.well-known/ai-plugin.json - 提示:/.well-known/
ai-plugin.jsonChatGPT插件配置文件固定路径
插件配置(ai-plugin.json)例子
auth 的 type 取值:
- none(无需认知)
- service_http(服务Token校验)
- user_http(用户Token校验)
- oauth(Oauth认证)
{
"schema_version": "v1", # 配置文件版本
"name_for_human": "插件名字,给用户看的名字", # 给 用户看的信息
"description_for_human": "插件功能描述,给ChatGPT用户看的",
"name_for_model": "插件名字,给ChatGPT模型看的名字", # 给chatgpt model看的信息
"description_for_model": "插件功能描述,给ChatGPT模型看的",
"auth": {
"type": "none" # API认证方式,none 代表不需要认证,后面单独介绍API认证机制
},
"api": {
"type": "openapi",
"url": "https://example.com/openapi.yaml", # swagger api文档地址,chatgpt通过地址访问api文档
"is_user_authenticated": false
},
"logo_url": "https://example.com/logo.png", # 插件logo地址
"contact_email": "support@example.com", # 插件官方联系邮件
"legal_info_url": "http://www.example.com/legal" # 插件官方地址
}
main.py 代码详解见:稀土掘进
启动步骤
Once the local server is running:
- Navigate to openai chat.
- In the Model drop down, select “Plugins” (note, if you don’t see it there, you don’t have access yet).
- Select “Plugin store”
- Select “Develop your own plugin”
- Enter in localhost:5003 since this is the URL the server is running on locally, then select “Find manifest file”.
讯飞星火 插件
【2023-6-9】星火助手是基于讯飞星火认知大模型,面向用户使用场景,打造的高效生产力工具。通过设置详细的指令模板,用户即可完成助手功能设定,每个助手在对话的模式下能够快速满足场景需求。
讯飞助手创作中心体验
- 助手创建流程相对简单,只需上下文、指令模板即可,可视化调试

CPM 插件
待定
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
