总结
- 【2021-2-3】机器学习的可解释性,知乎地址,Github地址,【知源月旦】团队完成的首篇综述,参考了Gilpin Leilani H.,et al. 发表在DSAA2018 上的文章,ppt, 作者视频讲解,南方科技大学张宇博士(唐珂教授2017级在读博士)发表一篇神经网络可解释性综述《A Survey on Neural Network Interpretability》
- 模型可解释性的奠基性论文:The Mythos of Model Interpretability,2016年,作者Zachary C. Lipton是UCSD的著名教授
-
【2021-5-11】「综述专栏」神经网络的可解释性综述,从方法论上来讲,都应“先见森林,再见树木”, 源自知乎对A Survey on Neural Network Interpretability的解读
- 【2023-10-19】获得亚马逊40亿美元投资的ChatGPT主要竞争对手Anthropic在官网公布了一篇名为《朝向单义性:通过词典学习分解语言模型》的论文,公布了解释经网络行为的方法。
神经网络是基于海量数据训练而成,其开发的AI模型可以生成文本、图片、视频等一系列内容。虽然一些数学题、推理我们可以看到正确结果,例如,AI模型会告诉你1+1=2这个结果,却无法解释这个过程是如何产生的。即便进行简单解释,也只是基于语义上的理解。
就像人类做梦一样,可以说出做梦的内容,却无法解释梦境到底是怎么形成的。
Anthropic根据Transformer模型进行了一个小型实验,将512个神经单元分解成4000多个特征,分别代表 DNA 序列、法律语言、HTTP 请求、营养说明等。研究发现,单个特征的行为比神经元行为更容易解释、可控,同时每个特征在不同的AI模型中基本上都是通用的。
- 单个特征的行为比神经元行为更容易解释、可控,同时每个特征在不同的AI模型中基本上都是通用的
- Anthropic创建了一个盲评系统,来比较单个特征和神经元的可解释性。Anthropic还采用“自动解释性”方法,使用大型语言模型生成小模型特征的简短描述,根据另一个模型的描述预测特征激活的能力对其进行评分。同样,特征的得分高于神经元,这表明特征的激活及其对模型行为的下游影响具有一致的解释。
ChatGPT等大语言模型经常出现幻觉、歧视、虚假等信息的情况,主要是人类无法控制其神经网络行为。所以,该研究对于增强大语言模型的准确率、安全性,降低非法内容输出帮助非常大。
第一性原理
- 【2021-8-4】Facebook、MIT等联合发表451页手稿:用「第一性原理」解释DNN
- 来自 Facebook 人工智能研究中心(FAIR)的科学家 Sho Yaida,麻省理工学院理论物理中心的研究员、Salesforce 的首席研究员 Dan Roberts 和普林斯顿的 Boris Hanin 合作,撰写了一本关于如何从「第一性原理」来理解 DNN 的书籍《The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks》。
- 「第一性原理」:回归事物最基本的条件,将其拆分成各要素进行解构分析,从而找到实现目标最优路径的方法。最早提出第一性原理思维的人是
亚里士多德,他把它定义为「认知事物的第一基础」 
- 书籍开篇引用了量子力学的奠基人、诺贝尔物理学奖得主
狄拉克在《量子力学原理》一书序言中的一句话:这就需要完全脱离历史发展路线,但这种突破是一种优势,因为它使人们能够尽可能直接地接近新的思想。
- 该书提供了一个理论框架,从「第一性原理」理解 DNN。对于人工智能从业者来说,这种理解可以显著减少训练 DNN 所需的试错量。例如,该理论框架可以揭示任何给定模型的最佳超参数,而无需经过当今所需的时间和计算密集型实验。
- Facebook VP 兼首席 AI 科学家 Yann LeCun 也在推特上推荐该书,并表示
- 「在科学技术发展史上,工程相关的往往排在第一位:望远镜、蒸汽机、数字通信。解释其功能和局限性的理论往往出现得较晚:
折射定律、热力学和信息理论。」 - 「随着深度学习的出现,人工智能驱动的工程奇迹已经进入我们的生活——但我们对深度学习的力量和局限性的理论理解仍然是片面的。这是最早致力于深度学习理论的书籍之一,并以连贯的方式列出了近期理论方法和结果。」
- 「在科学技术发展史上,工程相关的往往排在第一位:望远镜、蒸汽机、数字通信。解释其功能和局限性的理论往往出现得较晚:
试图理解 DNN 的理论家们通常依赖于网络的理想化,即所谓的「无限宽度限制」,在这种限制下,DNN 的每一层都有无限数量的神经元。这类似于理想气体定律与真实气体情况。「无限宽度限制」为理论分析提供了一个起点,但它通常与现实世界的深度学习模型几乎没有什么相似之处,尤其是普通的深度神经网络,在那种情况下,抽象将越来越偏离准确的描述。虽然偶尔有用,但「无限宽度限制」过于简单,忽略了真正 DNN 的关键特性,而这些被忽略掉的特性可能就是让 DNN 如此强大的有力工具。
如果从物理学家的角度来处理这个问题,核心是通过在「有限宽度」上建立一个有效的 DNN 理论,从而改进这个无限宽度限制。传统上,物理学家的目标是创造最简单和最理想的模型,同时也包含了描述现实世界所需的最小复杂性。在这里,这需要取消无限宽度限制,并系统地纳入所有必要的修正,以解释有限宽度的影响。在物理学语言中,这意味着对单层和跨层神经元之间的微小相互作用进行建模。
机器学习解除术(machine unlearning)
【2022-4-4】机器学习的重新思考:人工智能如何学习“失忆”?
机器学习已经成为各行各业的宝藏工具,常被用来构建系统,帮助人们发现那些容易忽略的细节,并辅助决策。尽管已经取得了惊艳的结果,但是也有很多痛苦,例如如何在已经成型的模型中修改、删减某些模块或者数据记录?
有学者表示,在大多数情况下,修改往往意味着重新训练,但仍然无法避免纳入可疑数据。这些数据可能来自系统日志、图像、客户管理系统等等。尤其是欧洲GDPR出台,对模型遗忘功能提出了更高的要求,企业如果不想办法将会面临合规处罚。
确实,完全重新训练的代价比较高,也不可能解决敏感数据问题。因此,我们无法证明重新训练的模型可以完全准确、有效。
为了解决这些问题,学者们定义了一种“机器学习解除术”(machine unlearning),通过分解数据库、调整算法等专门技术,诱导模型选择性失忆。
- 机器学习解除术:让训练好的模型遗忘掉特定数据训练效果/特定参数, 以达到保护模型中隐含数据的目的。
机器学习之所以有魅力,是因为它能透过庞大的数据,超出人类认知范围的复杂关系。
- 这项技术的黑盒性质,让学者在修改模型时候,非常谨慎,毕竟无法知道一个特定的数据点处在模型的哪个位置,以及无法明确该数据点如何直接影响模型。
- 当数据出现异常值时,模型会记得特别牢,并对整体效果产生影响。
当前的数据隐私工具可以在数据脱敏的情况下训练模型,也可以在数据不出本地的情况下联合训练。或许可以将敏感数据替换成空值,引入噪声掩蔽敏感数据。但这些都无法从根本上解决问题。甚至,替代元素并保留关键数据的差异隐私技术也不足以解决选择性遗忘问题。例如它只能在单个案件或少数几个案件中发挥作用,在这些案件中,虽然不需要重新训练,但会有“敏感”的人要求从数据库中删除数据。随着越来越多的删除请求陆续到来,该框架的“遗忘模型”很快就会瓦解。
因此,隐私技术和机器学习解除术在解决问题的层面,并不能等同。
匿名无法验证和差分隐私技术的数据删除问题不仅是理论问题,而且会产生严重的后果。研究人员已经证明,人们总是有能力从所谓的通用算法和模型中提取敏感数据。例如2020年时候,学者发现,从GPT-2中可以获得包括个人身份和受版权保护的信息等训练数据。
- 论文:extracting training data from large language model
选择性遗忘
让机器学习模型获得选择性遗忘的能力,需要解决两个关键问题:
- 理解每个数据点如何机器学习模型;
- 随机性如何影响空间。例如需要弄清,在某些情况下,数据输入中相对较小的变化为何会产生不同的结果。
该方向的最初研究出现在在2019年。当时,Nicolas Papernot提出将机器学习的数据分割成多个独立的部分,通过建立众多的迷你数据,从而实现只对特定组件进行删除和再训练,然后插回完整的数据集中,生成功能齐全的机器学习模型。
- 论文:machine unlearning
具体操作过程是:
- 先将训练数据分成多个不相交的切片,且一个训练点只包含在一个切片中;
- 然后,在每个切片上单独训练模型;
- 随后,合并切片,成功删除数据元素。 因此,当一个训练点被要求遗忘时,只需要重新训练受影响的模型。由于切片比整个训练集更小,就减少了遗忘的代价。
该方法被Nicolas Papernot命名为SISA(Sharded, Isolated, Sliced, and Aggregated ),对比完全重训练和部分重训练的基线, SISA实现了准确性和时间开销的权衡。在简单学习任务中, 在数据集Purchase上是4.63x, 在数据集 SVHN上是2.45x。
同时,作者也承认,虽然这个概念很有前途,但也有局限性。例如,通过减少每个切片的数据量,会对机器学习产生影响,并且可能会产生质量较低的结果。此外,这项技术并不总是像宣传的那样奏效。
目前,机器学习遗忘术的研究仍处于初级阶段。随着研究人员和数据科学家深入了解删除数据对整体模型的影响,成熟的工具也会出现,其目标是:机器学习框架和算法允许学者删除一条记录或单个数据点,并最终得到一个“完全遗忘“相关数据的有效模型。
- 【2020-8-27】【KDD2020】可解释深度神经网络
- KDD2020 Tutorial on Interpreting and Explaining Deep Neural Networks: A Perspective on Time Series Data,含YouTube视频,ppt资料:XAI_KDD_Tutorial-part1_final_v2,part2,part3
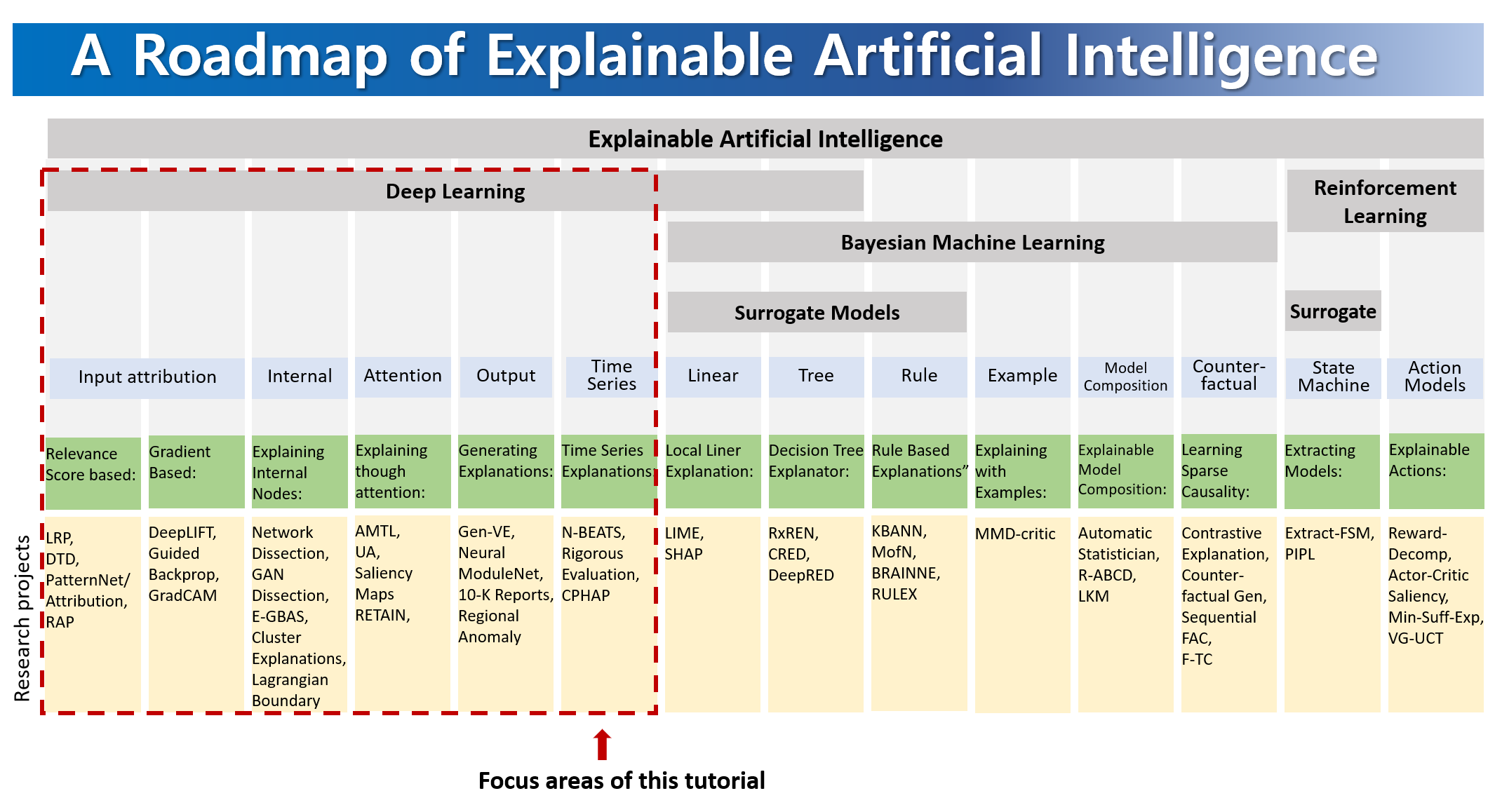
- 【2021-3-14】中国人寿研发中心:模型可解释性在保险理赔反欺诈中的应用实践
- (1)全局解释方法
- 特征权重:线性模型,系数
- 信息增益:信息论,树型模型
- importance:特征重要性排序
- (2)局部解释方法:专注于该数据点并查看该点周围的特征空间中的局部子区域,并尝试基于该局部区域理解该点的模型决策,解释单个预测
- Shap:博弈论,计算单个特征贡献值
- 将某一特征与其他所有的特征子集进行博弈比较,计算其对于其他特征子集对预测结果影响。预测值= 1/(1+exp(-sum(贡献值)))
- DeepLIFT:相对特征基准值,计算特征贡献
- Lime:线性模型局部模拟,计算贡献
- 某个样本附近生成采样数据,训练线性模型,辅助解释
- Shap:博弈论,计算单个特征贡献值
- 总结
- ① 适用范围:模型有关?Lime算法无关,DeepLIFT适用深度模型
- ② 运行效率:Lime较慢,Shap较快,全局解释依据模型计算
- Shap方法在适用范围和运行效率上具有双重优势。
- 应用
- 问题一:单纯欺诈风险评分,不可解释,作业人员使用意愿不强。
- 问题二:调查建议指导性不强,调查工作仍然强依赖经验丰富的调查人员。
- 解法:多轮交互验证,历史欺诈案件多特征shap贡献多维分析,形成反欺诈知识经验,并由审核员整理解释性的具体书面表达话术
大模型可解释
【2023-10-24】Can ChatGPT self-explain its predictions?
A new study by researchers at UCSC and MIT compares self-explanations in ChatGPT with traditional ML explainability methods such as LIME and occlusion.
Key findings: 关键结论
- Traditional ML explainability uses “feature attribution” techniques that determine which parts of the input are highly associated with the model’s output 传统机器学习可解释性通过特殊属性技术来决定哪部分输入跟输出高度相关
- LLM self-explanation can provide the explanation along with the model’s output, usually in natural language 而 LLM 自解释性能用自然语言解释输出
- Self-explanation can come in two formats: “Predict then explain” (
P-E) and “Explain then predict” (E-P) - In their study, the researchers compared both P-E and E-P with feature attribution
- As classic explanation, they used the “occlusion method,” where they remove different words from the same prompt and see how they affect the model’s output
- Their findings show that self-explanation is reasonable in highlighting words that are associated with the model’s output
- Self-explanation can be a substitute for classic explanation, which can be slow and expensive since it requires multiple queries to the model
However, they also found that self-explanation can harm the model’s accuracy
- The most important finding is that current explanation pipelines are not suitable for LLMs and we should look for other techniques
Read the full article on TechTalks.

GPT-4 解释神经元
要研究 AI 的“可解释性”,理论上要先了解大模型的各个神经元在做什么。
这个工作本应由人类手动检查,弄清神经元所代表的数据特征
- 参数量少还算可行,可如今动辄百亿、千亿级参数的神经网络,这工作量显然“离谱”。
于是,OpenAI 灵机一动:或许,可以用“魔法”打败“魔法”?
- “用 GPT-4 为大型语言模型中的神经元行为自动编写解释,并为这些解释打分。”
- 而 GPT-4 首次解释的对象是 GPT-2,一个 OpenAI 发布于 4 年前、神经元数量超过 30 万个的开源大模型。
【2023-5-9】OpenAI 用 GPT-4 去解释 GPT-2
- 官方宣传 Language models can explain neurons in language models
- 文章: Language models can explain neurons in language models
- 国内解读:OpenAI 最新“神”操作:让 GPT-4 去解释 GPT-2 的行为
- 官方 demo, 在线展示每层神经元功能
- Automated interpretability
方法
- Given a GPT-2 neuron, generate an explanation of its behavior by showing relevant text sequences and activations to GPT-4.
- 给定 GPT-2 神经元, 展示相关文本序列及激活状态
- GPT-4 生成神经元功能解释
Model-generated explanation:
- references to movies, characters, and entertainment.
GPT-4 “解释” GPT-2 的过程,整体分为三个步骤。
- (1)让 GPT-4 生成解释
- 给定 GPT-2 神经元,向 GPT-4 展示相关文本序列和激活单词,产生行为解释。
- GPT-4 对 GPT-2 该神经元生成的解释为:与电影、人物和娱乐有关。
- (2)再用 GPT-4 模拟被解释的神经元会做什么。
- (3)比较 GPT-4
模拟神经元的结果与 GPT-2真实神经元的结果,根据匹配程度对 GPT-4 解释进行评分。- 示例中,GPT-4 得分为 0.34。
- OpenAI 共让 GPT-4 解释了 GPT-2 中的 307200 个神经元,其中大多数解释的得分很低,只有超过 1000 个神经元的解释得分高于 0.8。



观点
- 每个神经元完成特定功能
- 层次越浅,功能越单一;
- 层数越高,概念越抽象
- 论文: 小模型中关闭特定功能神经元(识别语法),模型特定能力丧失,但大模型依然存在
OpenAI 承认目前 GPT-4 生成的解释并不完美,尤其在解释比 GPT-2 规模更大的模型时,效果更是不佳:“可能是因为后面的 layer 更难解释。”
- GPT-4 给出解释总是很简短,但神经元可能有着非常复杂的行为,不能简洁描述。
- 当前方法只解释了神经元行为,并没有涉及下游影响,希望最终能自动化找到并解释能实现复杂行为的整个神经回路。
- 只解释了神经元行为,并没有解释产生这种行为的背后机制。
- 整个过程都是相当密集的计算,算力消耗很大。
三种提高解释得分的方法:
- 对解释进行迭代,通过让 GPT-4 想出可能的反例,根据其激活情况修改解释来提高分数。
- 使用更大的模型来进行解释,平均得分也会上升。
- 调整被解释模型的结构,用不同的激活函数训练模型。
CRATE 白盒 Transformer
【2023-11-30】「GPT-4只是在压缩数据」,马毅团队造出白盒Transformer,可解释的大模型要来了吗?
伯克利和香港大学的马毅教授领导的一个研究团队给出了自己的最新研究结果:
包括 GPT-4 在内的当前 AI 系统所做的正是压缩。
提出的新深度网络架构 CRATE,通过数学方式验证了这一点。
- CRATE 是一种白盒 Transformer,其不仅能在几乎所有任务上与黑盒 Transformer 相媲美,而且还具备非常出色的可解释性。
Anthropic 可解释性
高维特征空间
【2023-12-1】Anthropic训练AI拆解LLM黑箱,意外看到了大模型的”灵魂”
Anthropic 可解释性团队论文讲述了通过训练一个新模型去理解一个简单模型的方法。
新模型能准确地预测和理解原本模型中神经元的工作原理和组成机制。
- 训练了一个非常简单的512神经元AI来预测文本
- 然后训练另一个名为「自动编码器」的AI来预测第一个AI的激活模式。
- 自动编码器被要求构建一组特征(对应更高维度AI中的神经元数量),并预测这些特征如何映射到真实AI中的神经元。
- 尽管原始AI中的神经元本身不易理解,但是新的AI中的这些模拟神经元(也就是「特征」)是单义的,每特征都表示一个指定的概念或功能。
Anthropic 研究声称能够看到了人工智能的灵魂: 成功分解了一个模拟AI系统中的抽象高维特征空间。
电路追踪
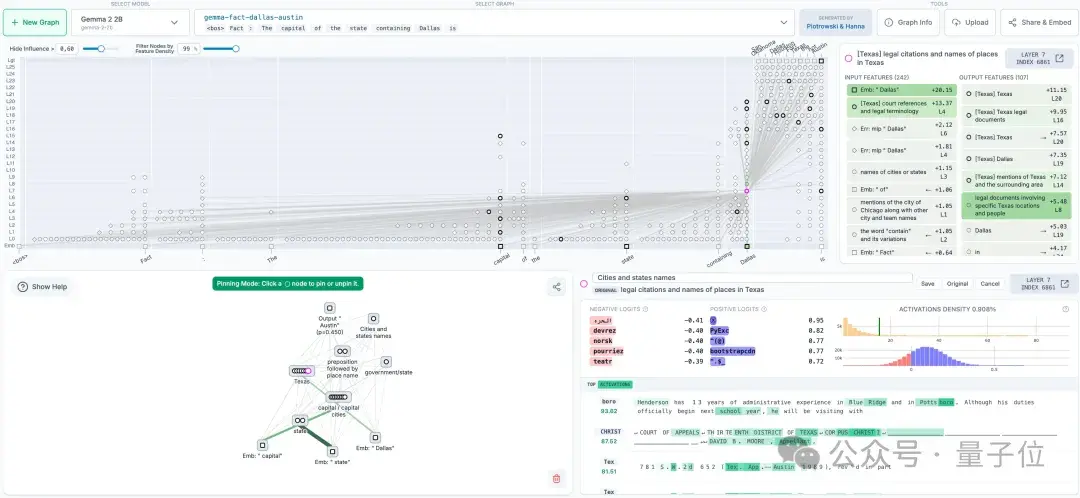
【2025-5-30】Claude团队打开大模型「脑回路」,开源LLM思维可视化工具来了
Claude 推出“电路追踪”(circuit tracing)工具,读懂大模型“脑回路”,追踪其思维过程。
- 电路追踪方法原始论文《On the Biology of a Large Language Model》
核心:生成归因图(attribution graphs),其作用类似于大脑的神经网络示意图,通过可视化模型内部超节点及其连接关系,呈现LLM处理信息的路径。
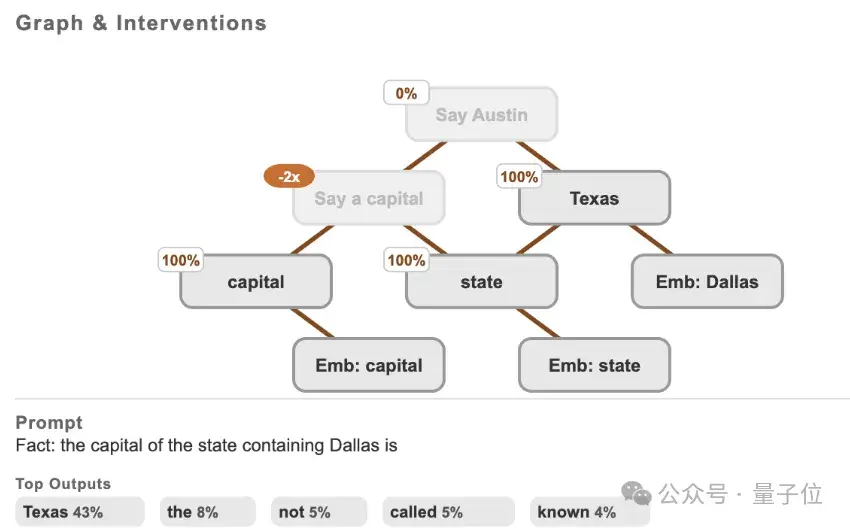
研究人员通过干预节点激活值,观察模型行为变化,从而验证各节点的功能分工,解码LLM的“决策逻辑”。
开源库支持在主流开源权重模型上快速生成归因图,而Neuronpedia托管的前端界面则进一步允许用户交互式探索。
- 通过生成自有归因图,在支持的模型上进行电路追踪;
- 在交互式前端中可视化、注释和分享图表;
- 通过修改特征值并观察模型输出变化来验证假设。
OpenAI: Transformer Debugger
【2023-5-12】OpenAI官宣开源Transformer Debugger!不用写代码,人人可以破解LLM黑箱
- 2023年5月,OpenAI团队发布令人震惊的发现:GPT-4竟可以解释GPT-2的三十万神经元!
- 【2024-3-12】OpenAI 超级对齐团队负责人开源内部一直使用的大杀器——
Transformer调试器(Transformer Debugger)。 - 论文地址
功能
- 用TDB工具分析Transformer的内部结构,从而对小模型的特定行为进行调查。
- TDB能支持神经元和注意力头,所以就可通过消融单个神经元来干预前向传递,并观察发生的具体变化。
- 不用写代码,就能快速探索LLM的内部构造
Transformer调试器将稀疏自动编码器,与OpenAI开发的「自动可解释性」——即用大模型自动解释小模型,技术相结合。
可以回答
- 为什么模型会输出token A而不是token B
- 为什么注意力头H会关注token T
Patchscopes
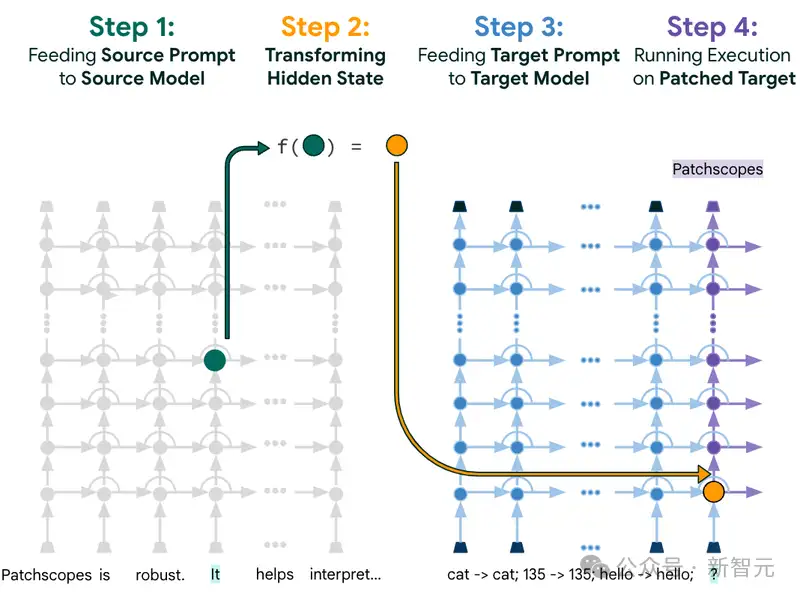
【2024-1-12】开箱黑盒LLM!谷歌大一统框架Patchscopes实战教程来了
- 使用LLMs来提供有关模型本身内部隐藏表征的自然语言解释。
- Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models
Patchscopes统一并扩展了现有的可解释性技术,能够让模型回答出之前无法解决的问题,比如模型可以说出关于「LLM的隐藏表征如何捕捉模型输入中含义的细微差别」的见解和想法,从而帮助开发人员更容易地修复某些特定类型的推理错误。
COAR
【2024-4-17】 MIT
“组件建模”任务,回答机器学习模型如何将输入转化为预测的内部计算过程。
组件建模目标:将ML模型的预测分解为其组成部分,即简单函数(例如卷积滤波器、注意力头),这些函数是模型计算的“构建块”。
组件归因估计单个组件对给定预测的反事实影响。然后,提出可扩展的算法COAR,用于估计组件归因;
展示了其在模型、数据集和模态方面的有效性。
最后,展示了使用COAR直接实现模型编辑的五个任务,即修复模型错误、“遗忘”特定类别、提高子人群的鲁棒性、定位后门攻击和提高对印刷攻击的鲁棒性。
可解释性工具
【2022-8-23】6个顶级的可解释AI (XAI)的Python框架推荐
【2022-1-12】
- (1)传统机器学习方法中具备解释能力的模型:LR(权重)、决策树(序列判断路径)
- (2)深度学习方法解释性探索:Attention权重、因果,还有不少研究热点,比如Rationalizing Neural Predictions Tao Lei, Regina Barzilay, Tommi Jaakkola; EMNLP 2016,代码 github.com/taolei87/rcnn
- 【2022-1-12】Awesome Explanatory Supervision
 ,包含各种可解释性论文
,包含各种可解释性论文 - 机器学习模型可解释性的6种Python工具包,总有一款适合你!
- 4 款算法模型可解释性工具包,总有一款适合你
交互可视化
站点 poloclub 提供多种模型原理可视化,包含
- WebSHAP 包含多个示例: 回归分析、文本异常检测、图像分类
1、Yellowbrick——侧重于特征和模型性能解释
Yellowbrick 是一个开源的多用途 Python 包,它通过可视化分析和诊断工具扩展了 scikit-learn API。对数据科学家而言,Yellowbrick 用于评估模型性能和可视化模型行为。
功能:
- 相关系数可视化:默认皮尔逊,可定制
- 判别阈值图,获取最佳阈值:解释模型在0.4概率阈值下表现最好
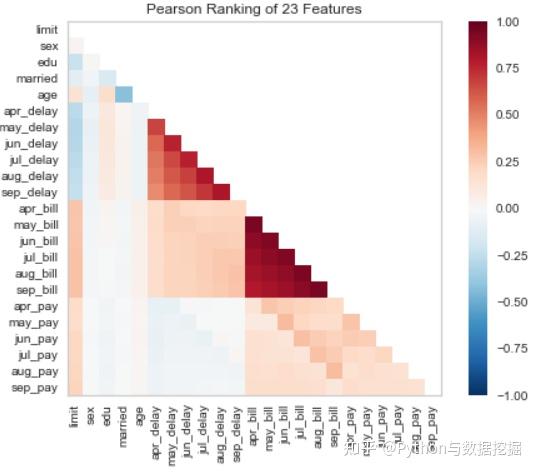

#pip install yellowbrick
# Pearson Correlation
from yellowbrick.features import rank2d
from yellowbrick.datasets import load_credit
X, _ = load_credit()
# (1)用 Pearson 相关方法来可视化特征之间的相关性
visualizer = rank2d(X)
# (2)判别阈值图,以找到分隔二进制类的最佳阈值
from yellowbrick.classifier import discrimination_threshold
from sklearn.linear_model import LogisticRegression
from yellowbrick.datasets import load_spam
X, y = load_spam()
visualizer = discrimination_threshold(LogisticRegression(multi_class="auto", solver="liblinear"), X,y)
2、ELI5——侧重模型参数和预测结果
如果 Yellowbrick 侧重于特征和模型性能解释,ELI5 侧重于模型参数和预测结果。
ELI5 是一个 Python 包,有助于机器学习的可解释性。取自Eli5软件包,此软件包的基本用法是:
- 检查模型参数,试图弄清楚模型是如何全局工作的
- 显示模型(决策树)权重 → 特征的重要性及其偏差
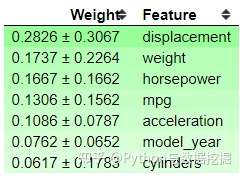
- ‘displacement’特征是最重要的特征,但是它们有很高的偏差,这表明模型中存在偏差。
- 检查模型的单个预测,并找出模型做出决策的原因
- ELI5 提供了另一种基于模型度量来解释黑盒模型的方法——置换重要性(Permutation Importance)
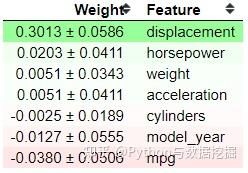
- 置换重要性背后的思想是评分(准确度、精确度、召回等)如何随特征的存在或不存在而变化。从以上结果可以看出,displacement 的得分最高,为0.3013。当置换位移特征时,模型的精度会有0.3013的变化。正负号后面的值就是不确定值。置换重要性法的本质上是一个随机过程;这就是为什么我们有不确定值。
- 位置越高,影响得分的特征就越关键。底部的一些特征显示一个负值,这很有趣,因为这意味着当我们排列特征时,该特征会增加得分。就我个人而言,ELI5 为我提供了足够的机器学习解释能力。
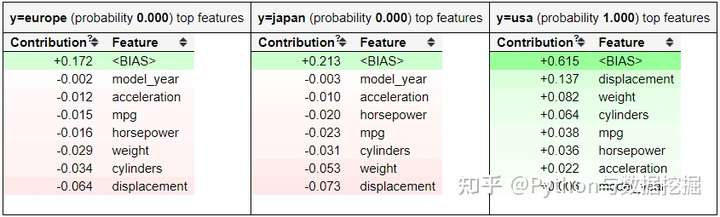
ELI5有两种主要的方法来解释分类或回归模型:
- 检查模型参数并说明模型是如何全局工作的;
- 检查模型的单个预测并说明什么模型会做出这样的决定
目前支持以下机器学习框架:
- scikit-learn
- XGBoost、LightGBM CatBoost
- Keras
#Preparing the model and the dataset
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
mpg = sns.load_dataset('mpg').dropna()
mpg.drop('name', axis =1 , inplace = True)
#Data splitting
X_train, X_test, y_train, y_test = train_test_split(mpg.drop('origin', axis = 1), mpg['origin'], test_size = 0.2, random_state = 121)
#Model Training
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# ------------------------
import eli5
# 最基本的 ELI5 函数是表示分类器权重和分类器预测结果。
eli5.show_weights(clf, feature_names = list(X_test.columns)) # 权重
eli5.show_prediction(clf, X_train.iloc[0]) # 预测结果,show_prediction得到特征贡献信息
# 置换重要性函数。
#Permutation Importance
perm = PermutationImportance(clf, scoring = 'accuracy',random_state=101).fit(X_test, y_test)
show_weights(perm, feature_names = list(X_test.columns))
3、SHAP——经典工具
讨论机器学习的解释性的经典工具:SHAP。
- SHapley Additive explanation (SHapley Additive explanation)是一种解释任何机器学习模型输出的博弈论方法。它利用博弈论中的经典Shapley值及其相关扩展将最优信贷分配与局部解释联系起来。
- 数据集中每个特征对模型预测的贡献由Shapley值解释。Lundberg和Lee的SHAP算法最初发表于2017年,这个算法被社区在许多不同的领域广泛采用。
- SHAP(SHapley Additive exPlanations)是一种博弈论方法,用来解释任何机器学习模型的输出。简单地说,SHAP 是使用 SHAP值来解释每个特性的重要性。
功能
- 全局可解释性
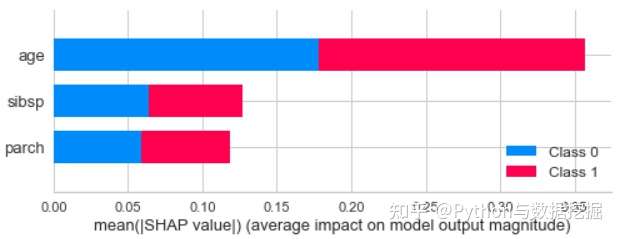
- 年龄特征对预测结果的贡献最大。
- 也可以看特定的类对预测的贡献
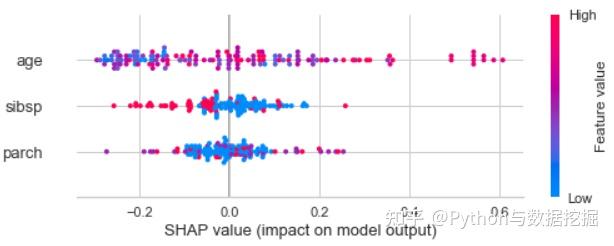
- 颜色越红,值越高,反之亦然。此外,当值为正时,它有助于0级预测结果概率。
- 解释单个数据集

- 预测更接近于类0,因为它是由年龄和 sibsp 特征推送的,而parch特征只提供了一点贡献。
#Installation via pip
pip install shap
#Installation via conda-forge
conda install -c conda-forge shap
# ---------------------
# 用泰坦尼克号数据训练,试着用SHAP来解释数据。
#Preparing the model and the dataset
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
titanic = sns.load_dataset('titanic').dropna()
titanic = titanic[['survived', 'age', 'sibsp', 'parch']]
#Data splitting for rfc
X_train, X_test, y_train, y_test = train_test_split(titanic.drop('survived', axis = 1), titanic['survived'], test_size = 0.2, random_state = 121)
#Model Training
clf = RandomForestClassifier() clf.fit(X_train, y_train)
# ---------------------
import shap
# 全局可解释性
shap_values = shap.TreeExplainer(clf).shap_values(X_train) shap.summary_plot(shap_values, X_train)
# 特定的类对预测的贡献
shap.summary_plot(shap_values[0], X_train)
# 解释单个数据集
explainer = shap.TreeExplainer(clf)
shap_value_single = explainer.shap_values(X = X_train.iloc[0,:])
shap.force_plot(base_value = explainer.expected_value[1],shap_values = shap_value_single[1],features = X_train.iloc[0,:])
或:
import xgboost
import shap
# train an XGBoost model
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
# visualize the first prediction's explanation with a force plot 力图可视化
shap.plots.force(shap_values[0])
结果:
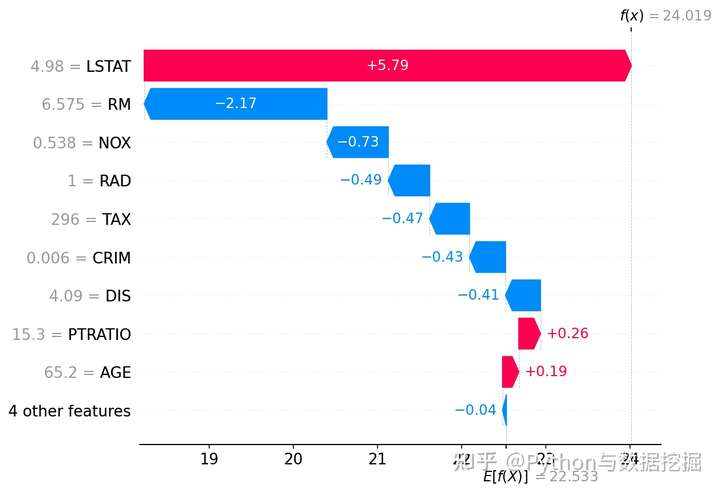
- 每个功能都有助于将模型输出从基值推向模型输出的功能。推高预测的特征以红色显示,推低预测的特征以蓝色显示。
- 力图可视化
- 瀑布图
- 构建Beeswarm图

4、Mlxtend——二维特征
Mlxtend 是一个用于数据科学日常工作的 Python 包。包中的api不仅限于可解释性,还扩展到各种功能,如统计评估、数据模式、图像提取等。
- Decision Regions (决策区域) plot API 将生成一个 Decision region plot,以可视化特征如何决定分类模型预测。
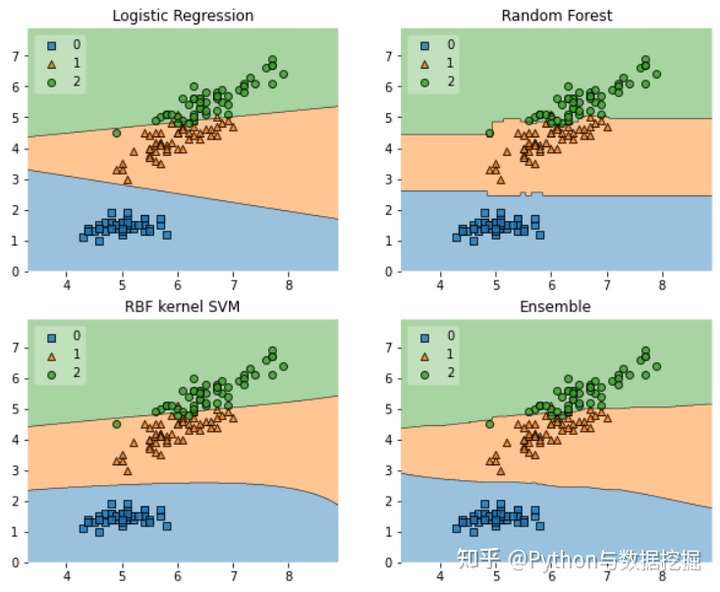
- 当每个模型进行预测时,可以看到它们之间的差异。例如,一类的 Logistic 回归模型预测结果越大,X轴值越高,但Y轴上变化不大。与随机森林模型相比,在X轴值之后,划分没有很大变化,Y轴值在每次预测中都是常数。
- 决策区域的唯一缺点是它只限于二维特征,因此,它比实际模型本身更适合于预分析。
# pip install Mlxtend
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],['Logistic Regression', 'Random Forest','RBF kernel SVM', 'Ensemble'],itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()
5、PDPBox
PDP(Partial Dependence Plot) 是一个显示特征对机器学习模型预测结果的边际影响的图。它用于评估特征与目标之间的相关性是线性的、单调的还是更复杂的。
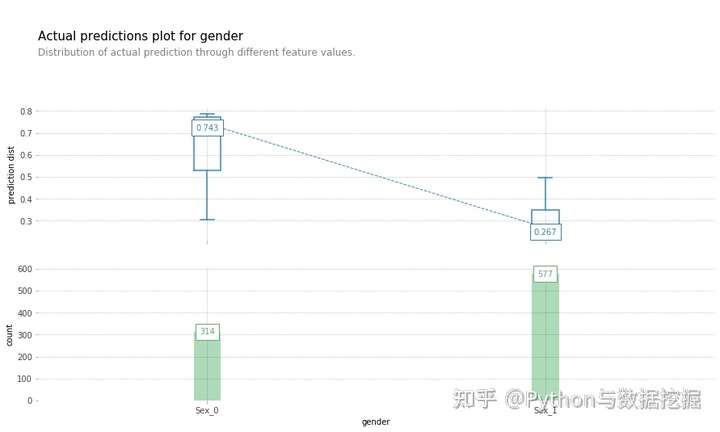
- 检查模型预测分布函数以及特征。

- 当性别特征为男性时,预测概率降低(意味着男性存活的可能性降低)
# pip install pdpbox
import pandas as pd
from pdpbox import pdp, get_dataset, info_plots
#We would use the data and model from the pdpbox
test_titanic = get_dataset.titanic()
titanic_data = test_titanic['data']
titanic_features = test_titanic['features']
titanic_model = test_titanic['xgb_model']
titanic_target = test_titanic['target']
# 用 info_plots 函数检查特征和目标之间的信息
fig, axes, summary_df = info_plots.target_plot(df=titanic_data, feature='Sex', feature_name='gender', target=titanic_target)
_ = axes['bar_ax'].set_xticklabels(['Female', 'Male'])
# 检查模型预测分布函数以及特征
fig, axes, summary_df = info_plots.actual_plot(model=titanic_model, X=titanic_data[titanic_features], feature='Sex', feature_name='gender')
# 用PDP绘图函数来解释模型预测
pdp_sex = pdp.pdp_isolate(model=titanic_model, dataset=titanic_data, model_features=titanic_features, feature='Sex')
fig, axes = pdp.pdp_plot(pdp_sex, 'Sex')
_ = axes['pdp_ax'].set_xticklabels(['Female', 'Male'])
6、InterpretML
InterpretML是一个开源的Python包,它向研究人员提供机器学习可解释性算法。InterpretML支持训练可解释模型(glassbox),以及解释现有的ML管道(blackbox)。
InterpretML展示了两种类型的可解释性:
- glassbox模型——为可解释性设计的机器学习模型(如:线性模型、规则列表、广义可加模型)
- 黑箱可解释性技术——用于解释现有系统(如:部分依赖,LIME)。
使用统一的API并封装多种方法,拥有内置的、可扩展的可视化平台,该包使研究人员能够轻松地比较可解释性算法。
- InterpretML还包括了explanation Boosting Machine的第一个实现,这是一个强大的、可解释的、glassbox模型,可以像许多黑箱模型一样精确。
InterpretML 是一个Python包,它包含许多机器学习可解释性API。此包的目的是基于绘图图提供交互式绘图,以了解预测结果。
- InterpretML 提供了许多方法来解释机器学习,方法包括使用讨论过的许多技术——即SHAP和PDP。
- 此外,这个包拥有一个Glassbox模型API,它在开发模型时提供了一个可解释性函数。
# pip install interpret
from sklearn.model_selection import train_test_split
from interpret.glassbox import ExplainableBoostingClassifier
import seaborn as sns
#the glass box model (using Boosting Classifier)
ebm = ExplainableBoostingClassifier(random_state=120)
titanic = sns.load_dataset('titanic').dropna()
#Data splitting
X_train, X_test, y_train, y_test = train_test_split(titanic.drop(['survived', 'alive'], axis = 1), titanic['survived'], test_size = 0.2, random_state = 121)
#Model Training
ebm.fit(X_train, y_train)
# 自动对你的特征进行热编码,并设计交互特性。
# 模型全局解释
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from interpret import show
ebm_global = ebm.explain_global()
show(ebm_global)
# 局部的可解释性
#Select only the top 5 rows from the test data
ebm_local = ebm.explain_local(X_test[:5], y_test[:5])
show(ebm_local)
- 模型全局解释
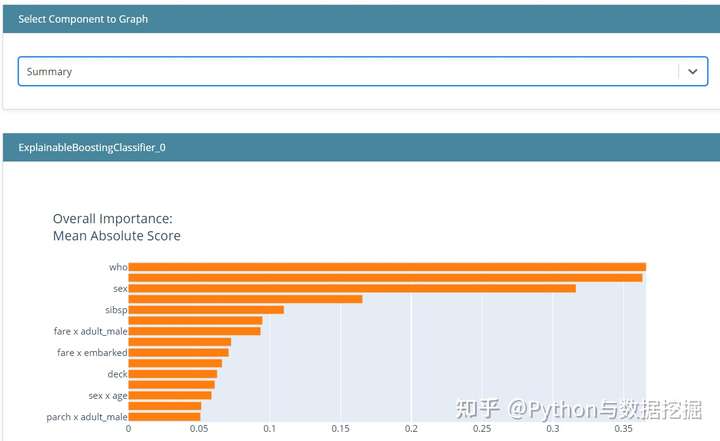
- “可解释”是一个交互式绘图,可以使用它来更具体地解释模型。如果只在上图中看到摘要,可以选择另一个组件来指定要查看的功能。这样就可以解释模型中的特征是如何影响预测的。
- 低票价降低了生存的机会,但随着票价越来越高,它增加了生存的机会。然而,你可以看到密度和条形图-许多人来自较低的票价。
- 局部可解释
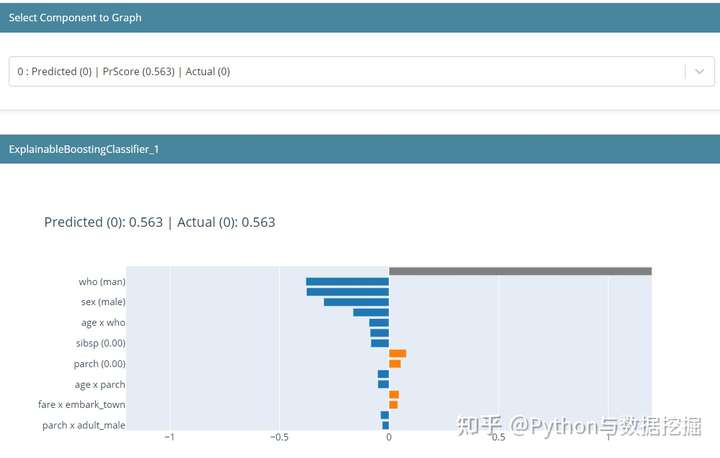
- 局部可解释性显示了单个预测是如何进行的。这里显示的值是来自模型的对数赔率分数,它们被添加并通过 logistic 函数传递,以得到最终预测。在这个预测中,我们可以看到男性对降低存活率的贡献最大。
7、LIME——局部可解释性(最早出名)
在机器学习模型事后局部可解释性研究中,一种代表性方法是由 Marco Tulio Ribeiro 等人提出的 Local Interpretable Model-Agnostic Explanation(LIME)。
可解释性领域最早出名的方法之一是 LIME。 它可以帮助解释机器学习模型正在学习什么以及为什么他们以某种方式预测。 Lime目前支持对表格的数据,文本分类器和图像分类器的解释。
- 知道为什么模型会以这种方式进行预测对于调整算法是至关重要的。借助LIME的解释,能够理解为什么模型以这种方式运行。如果模型没有按照计划运行,那么很可能在数据准备阶段就犯了错误。
- 对于每一个输入实例,LIME首先利用该实例以及该实例的一组近邻数据训练一个易于解释的线性模型来拟合待解释模型的局部边界,然后基于该线性模型解释待解释模型针对该实例的决策依据,其中,线性模型的权重系数直接体现了当前决策中该实例的每一维特征重要性。
LIME主要提供三种解释方法,这三种方法都处理不同类型的数据:
- 表格解释
- 文字翻译
- 图像解释。
# pip install lime
rfc.fit(vectorized_train_text,y)
import lime
from sklearn.pipeline import make_pipeline
explainer = lime.lime_text.LimeTextExplainer(class_names=["Not Patient", "Patient"])
pl = make_pipeline(vect,rfc)
exp = explainer.explain_instance(train["combined_text"][689], pl.predict_proba)
exp.show_in_notebook()
- LIME 构建的局部解释图
- LIME构建的Beeswarm 图

Shapash
Shapash是一个使机器学习对每个人都可以进行解释和理解Python库。
- Shapash提供了几种类型的可视化,显示了每个人都能理解的明确标签。
- 数据科学家可以更轻松地理解他们的模型并分享结果。 最终用户可以使用最标准的摘要来理解模型是如何做出判断的。
为了表达数据中包含故事、见解和模型的发现,互动性和漂亮的图表必不可少。 业务和数据科学家/分析师向AI/ML结果展示和互动的最佳方法是将其可视化并且放到web中。Shapash库可以生成交互式仪表盘,并收集了许多可视化图表。与外形/石灰解释性有关。 它可以使用SHAP/Lime作为后端,也就是说他只提供了更好看的图表。
- 使用Shapash构建特征贡献图
- 使用Shapash库创建的交互式仪表板
- Shapash构建的局部解释图
OmniXAI
OmniXAI (Omni explained AI的简称),是Salesforce最近开发并开源的Python库。它提供全方位可解释的人工智能和可解释的机器学习能力来解决实践中机器学习模型在产生中需要判断的几个问题。对于需要在ML过程的各个阶段解释各种类型的数据、模型和解释技术的数据科学家、ML研究人员,OmniXAI希望提供一个一站式的综合库,使可解释的AI变得简单。
OmniXAI提供的与其他类似库的对比
一、机器学习的可解释性研究概述
随着机器学习模型在人们日常生活中的许多场景下扮演着越来越重要的角色,模型的「可解释性」成为了决定用户是否能够「信任」这些模型的关键因素(尤其是当我们需要机器为关系到人类生命健康、财产安全等重要任务给出预测和决策结果时)。在本章,我们将从机器学习可解释性的定义、研究意义、分类方法 3 个方面对这一话题展开讨论。
1.1 什么是可解释性
- Interpretability (of a DNN) is the ability to provide explanations in understandable terms to a human. F Doshi-Velez & B Kim, 2017
- 解释(Explanations),是指需要用某种语言来描述和注解
- 理想情况下,严谨的数学符号-逻辑规则是最好的解释(D Pedreschi et al., 2019)。实际上人们往往不强求“完整的解释”,只需要关键信息和一些先验知识
- 可解释的边界(Explainable Boundary),是指可解释性能够提供解释的程度
- 来自XAI的:对于不同的听众,解释的深度也有所不同,应该是需求而定。例如:为什么你这么聪明?因为我喜欢吃鱼。为什么吃鱼会聪明?因为鱼类富含DHA。为什么DHA聪明?…… 因为根据不同的人群,我们的可解释的工作也不一样。例如给大众解释吃鱼能够聪明就行了,因为吃鱼能够聪明我们很多人已经从小到大耳熟能详了。如果我们给专业人士解释DHA为什么会是大脑聪明,我们身边很多人也答不出来,这已经远超出我们计算机这个领域了。当然,可解释的这种边界越深,这个模型的能力也越强。
- 可理解的术语(Understandable Terms),是指构成解释的基本单元
- 不同领域的模型解释需要建立在不同的领域术语之上,不可能或者目前难以用数学逻辑符号来解释。例如计算机视觉中的image patches,NLP中的单词等。而可理解的术语可以理解为计算机跟我们人类能够沟通的语言。以前我们很多研究关于人类跟计算机表达的语言例如计算机指令,现在是反过来计算机根据现有的模型给我们解释
- 对于机器学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常可以认为机器学习的可解释性刻画了「人类对模型决策或预测结果的理解程度」,即用户可以更容易地理解解释性较高的模型做出的决策和预测。
从哲学的角度来说,为了理解何为机器学习的可解释性,需要回答以下几个问题:
- 首先,如何定义对事务的「解释」,怎样的解释才足够好?许多学者认为,要判断一个解释是否足够好,取决于这个解释需要回答的问题是什么。对于机器学习任务而言,我们最感兴趣的两类问题是「为什么会得到该结果」和「为什么结果应该是这样」。而理想状态下,如果能够通过溯因推理的方式恢复出模型计算出输出结果的过程,就可以实现较强的模型解释性。
- 实际上,可以从「可解释性」和「完整性」这两个方面来衡量一种解释是否合理。
- 可解释性:通过一种人类能够理解的方式描述系统的内部结构,它与人类的认知、知识和偏见息息相关;
- 完整性:通过一种精确的方式来描述系统的各个操作步骤(例如,剖析深度学习网络中的数学操作和参数)。
- 然而,不幸的是很难同时实现很强的「可解释性」和「完整性」,这是因为精确的解释术语往往对于人们来说晦涩难懂。同时,仅仅使用人类能够理解的方式进行解释由往往会引入人类认知上的偏见。
- 此外,还可以从更宏大的角度理解「可解释性人工智能」,将其作为一个「人与智能体的交互」问题。如图 1 所示,人与智能体的交互涉及人工智能、社会科学、人机交互等领域。
- 图 1:可解释的人工智能
1.2 为什么需要可解释性
在当下的深度学习浪潮中,许多新发表的工作都声称自己可以在目标任务上取得良好的性能。尽管如此,用户在诸如医疗、法律、金融等应用场景下仍然需要从更为详细和具象的角度理解得出结论的原因。为模型赋予较强的可解释性也有利于确保其公平性、隐私保护性能、鲁棒性,说明输入到输出之间个状态的因果关系,提升用户对产品的信任程度。下面从「完善深度学习模型」、「深度学习模型与人的关系」、「深度学习模型与社会的关系」3 个方面简介研究机器学习可解释性的意义。
- (1)高可靠性的要求
- a)神经网络在实践中经常有难以预测的错误(进一步的研究是对抗样本攻击与防御),这对于要求可靠性较高的系统很危险
- b)可解释性有助于发现潜在的错误;也可以通过debug而改进模型
- (2)伦理/法规的要求
- AI医疗:目前一般只作为辅助性的工具,是因为一个合格的医疗系统必须是透明的、可理解的、可解释的,可以获得医生和病人的信任。
- 司法决策:面对纷繁复杂的事实类型,除了法律条文,还需要融入社会常识、人文因素等。因此,AI在司法决策的事后,必须要给出法律依据和推理过程。
- (3)作为其他科学研究的工具
- 科学研究可以发现新知识,可解释性正是用以揭示背后原理。
(1)完善深度学习模型
- 大多数深度学习模型是由数据驱动的黑盒模型,而这些模型本身成为了知识的来源,模型能提取到怎样的知识在很大程度上依赖于模型的组织架构、对数据的表征方式,对模型的可解释性可以显式地捕获这些知识。
- 尽管深度学习模型可以取得优异的性能,但是由于我们难以对深度学习模型进行调试,使其质量保证工作难以实现。对错误结果的解释可以为修复系统提供指导。
(2)深度学习模型与人的关系
- 在人与深度学习模型交互的过程中,会形成经过组织的知识结构来为用户解释模型复杂的工作机制,即「心理模型」。为了让用户得到更好的交互体验,满足其好奇心,就需要赋予模型较强的可解释性,否则用户会感到沮丧,失去对模型的信任和使用兴趣。
- 人们希望协调自身的知识结构要素之间的矛盾或不一致性。如果机器做出了与人的意愿有出入的决策,用户则会试图解释这种差异。当机器的决策对人的生活影响越大时,对于这种决策的解释就更为重要。
- 当模型的决策和预测结果对用户的生活会产生重要影响时,对模型的可解释性与用户对模型的信任程度息息相关。例如,对于医疗、自动驾驶等与人们的生命健康紧密相关的任务,以及保险、金融、理财、法律等与用户财产安全相关的任务,用户往往需要模型具有很强的可解释性才会谨慎地采用该模型。
(3)深度学习模型与社会的关系
- 由于深度学习高度依赖于训练数据,而训练数据往往并不是无偏的,会产生对于人种、性别、职业等因素的偏见。为了保证模型的公平性,用户会要求深度学习模型具有检测偏见的功能,能够通过对自身决策的解释说明其公平。
- 深度学习模型作为一种商品具有很强的社会交互属性,具有强可解释性的模型也会具有较高的社会认可度,会更容易被公众所接纳。
1.3 可解释性的分类
根据多个维度将机器学习的可解释性方法分为:
- 可解释性方法的作用时间:本质可解释性(active)、事后可解释性(passive)
- 可解释性方法与模型的匹配关系:针对特定模型的可解释性、模型无关可解释性
- 可解释性方法的作用范围:局部可解释性、全局可解释性。
其中
- 本质可解释性: 对模型的架构进行限制,使其工作原理和中间结果能够较为容易地为人们所理解(例如,结构简单的决策树模型);
- 事后可解释性(post-hoc)指通过各种统计量、可视化方法、因果推理等手段,对训练后的模型进行解释。
- 比如:分析深度神经网络的显著性映射(Saliency Maps)
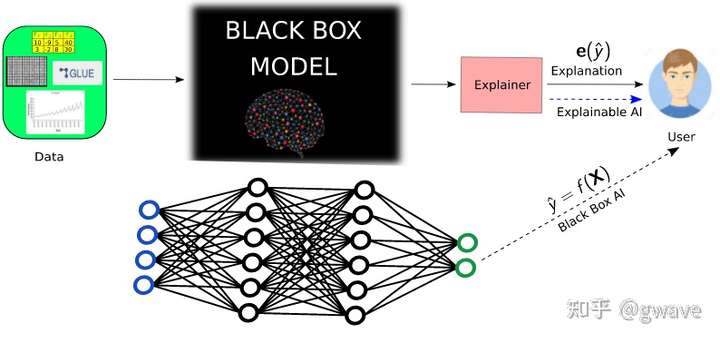
- 事后解释的目标是让用户理解 ML 模型的预测y,这是通过解释器 (Explainer)来实现的,使用一个算法来生成解释e(y)
补充:事后可解释
训练完成后,从模型中能了解到的东西,或者说,如何以自然语言来解释模型的决策,比如:分析深度神经网络的显著性映射(Saliency Maps),注意力机制(attention),图源

- 事后解释的目标是让用户理解 ML 模型的预测y,这是通过解释器 (Explainer)来实现的,使用一个算法来生成解释e(y)
由于深度模型的广泛应用,本文将重点关注深度学习的可解释性,并同时设计一些机器学习方法的解释。
【2021-5-11】可解释性分类
按照逻辑规则解释(Rule as Explanation)
图左是一颗关于判断西瓜好坏的决策树,经过DFS后,我们可以抽取出右图的规则。而对于神经网络,我们是否也可以类似决策树这样做呢?
答案是肯定的。
第一种方法是分解法,遍历所有特征的排列组合
分解法最简单,但是缺点也是显而易见的,就是时间复杂度太高,虽然KT算法有所优化,但是指数形式的复杂度还是难以投入实际使用。于是我们引入第二种方法:教育法
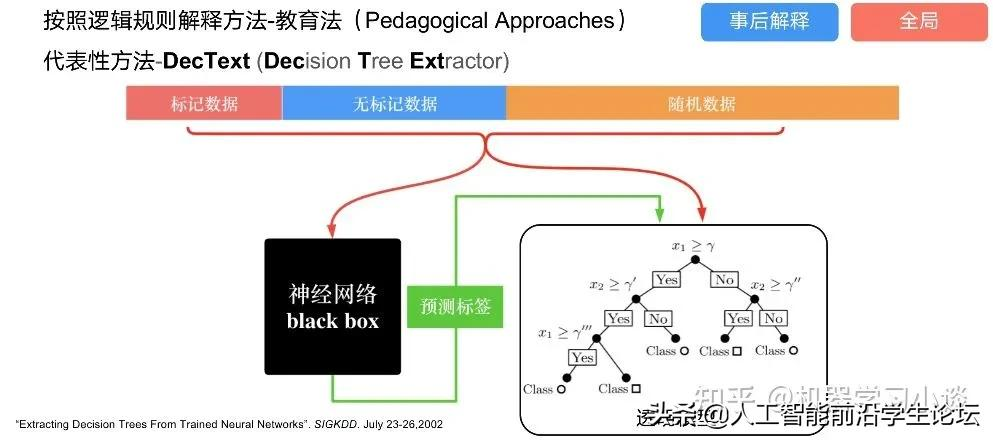
DecText-决策树抽取器,主要采用经过黑箱子的数据来抽取黑箱子的规则,并且与其他决策树不同的是,该方法除了使用标记数据还可以使用未标记数据以及随机数据,只要经过神经网络黑箱子都可以获得标签。对比仅用训练集,由于传统决策树进行生成叶子比生成其根的可信度还要低(因为能用于划分界限的数据越来越少)。所以DecText有一个优势就是可以利用更多的无标记数据甚至随机数据进行补充。但是一般论文也不会提及到自身设计的大多数缺点。例如,这里我认为有两大缺点。一、无标记数据或者随机数据其实有很多是超过解释的意义,例如人脸识别,如果我们倒入一些不及格的人脸甚至随机的图像,决策树也会对这些图像进行开枝散叶,降低了真正解释人脸的枝叶的占比。二、决策树不能表达太深的网络,决策树越深,性能会急剧下降,可解释性也越差。
Tree Regulartion[2]提出了树正则的方法,来抑制了树的深度。
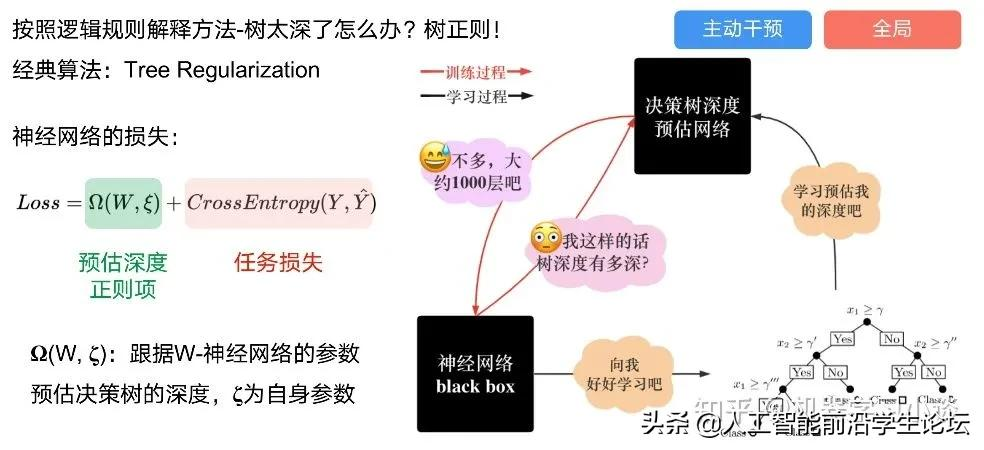
树正则通过引入深度损失正则项,在优化时候会抑制树的深度。而树的深度则是通过一个简单的预估网络进行预估,需要的参数就是主网络的参数。
按照语义进行解释
类比人类开始对细胞解释的时候,无法一下子直接从细胞本身理解这个细胞的类别或者功能,但是可以从细胞群或者组织(例如表皮细胞组织)来从宏观角度了解细胞的作用。神经网络亦是如此。例如卷积神经网络,浅层的卷积网络往往关注更基础的图像信息例如纹理、颜色等,而越往上层则越能抽象出更丰富的语义,例如人脸识别的眼睛、鼻子等。其中经典代表就是计算机视觉中的经典方法-可视化[3]
可视化的方法非常多,比如说有一个华人的博士就可视化了CNN,把每一层都展示得非常清楚,只需要在网页上点击对于的神经元,就可以看到工作流程。右边是一位维也纳的小哥,本来搞unity3D特效开发的,他把整个CNN网络用3d的形式可视化了出来。
cnn_visual
featuremap_layout
另外一种主动的按照语义进行解释的代表作:可解释卷积神经网络[4](Interpretable convolutional neural networks.)与传统的卷积神经网络不同的是,ICNN的每一个卷积核尽量只代表一种概念,例如,传统的卷积核对猫的头或者脚都有较大的激活值,而ICNN只能选择最大的一种。
通过示例解释
这种方法容易理解,是一种直观方法:寻找和待解释的样本最“相似”的一个训练样本,典型的代表作 Understanding black-box predictions via inflfluence functions,[5]
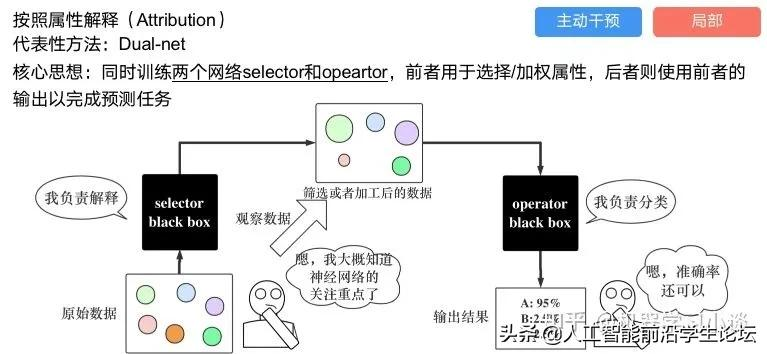
按照属性解释
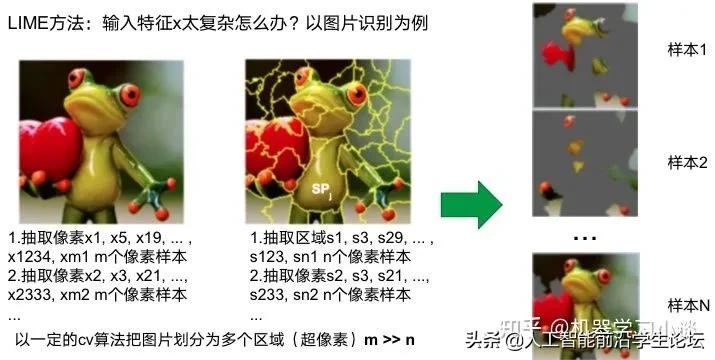
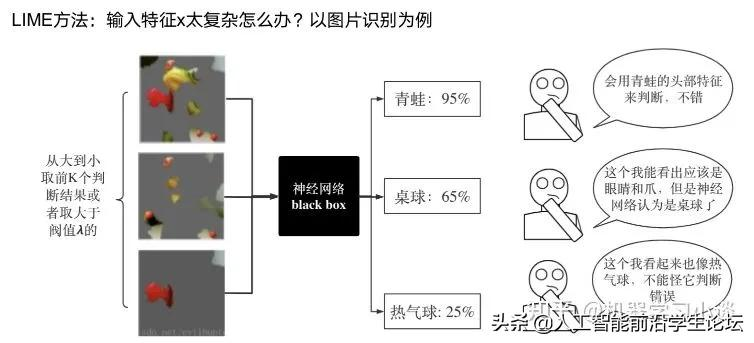
按照属性解释目前内容上最。如前面提及到,决策树等透明模型难以模仿复杂的神经网络,那怎么解决呢?针对此问题研究的代表作有:Why should i trust you?: Explaining the predictions of any classififier[6]
由于LIME不介入模型的内部,需要不断的扰动样本特征,这里所谓的样本特征就是指图片中一个一个的像素了。但如果LIME采样的特征空间太大的话,效率会非常低,而一张普通图片的像素少说也有上万个。若直接把每个像素视为一个特征,采样的空间过于庞大,严重影响效率;如果少采样一些,最终效果又会比较差。所以针对图像任务使用LIME时还需要一些特别的技巧,也就是考虑图像的空间相关和连续的特性。不考虑一些极小特例的情况下,图片中的物体一般都是由一个或几个连续的像素块构成,所谓像素块是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块,我们称之为超像素。
下面提供一些主动干预型的方法,如Dual-net[7]
其他的还有:用意想空间的对话系统[8]
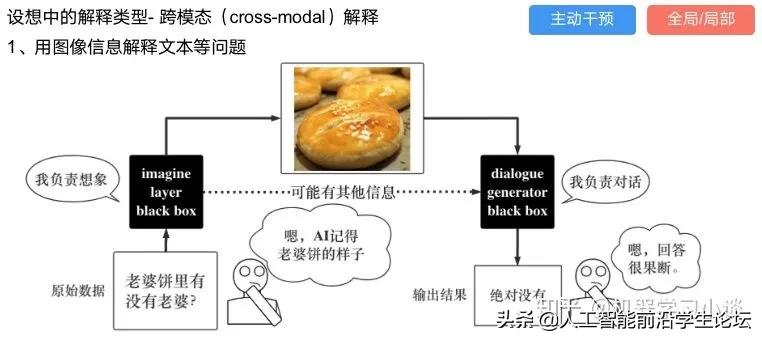
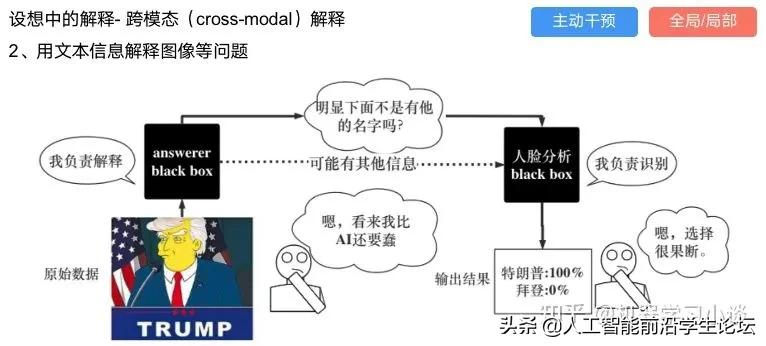
这种解释的类型是最有深度而且也是用户最容易理解的。但是对AI模型和训练难度也更高了。目前这方面的研究屈指可数。
总结
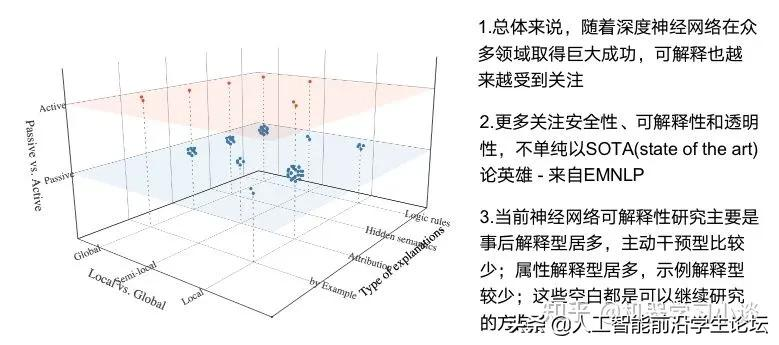
【2022-1-12】机器学习模型可解释性对比:源自机器学习模型可解释性
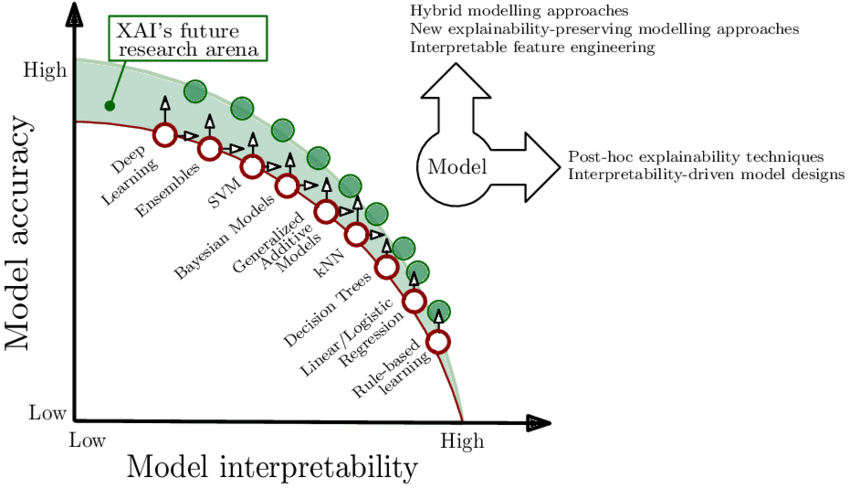
- 模型越简单,可解释性越强:深度学习 > 集成方法 > SVM > 贝叶斯 > kNN > 决策树 > 罗辑回归 > 规则
二、深度学习的可解释性
-
-
对于深度学习模型来说,我们重点关注如何解释「网络对于数据的处理过程」、「网络对于数据的表征」,以及「如何构建能够生成自我解释的深度学习系统」。网路对于数据的处理过程将回答「输入为什么会得到相应的的特定输出?」,这一解释过程与剖析程序的执行过程相类似;网络对于数据的表征将回答「网络包含哪些信息?」,这一过程与解释程序内部的数据结构相似。下文将重点从以上三个方面展开讨论。
2.1 深度学习过程的可解释性
- 常用的深度网络使用大量的基本操作来得出决策:例如,ResNet使用了约5×107个学习参数,1010个浮点运算来对单个图像进行分类。
- 解释这种复杂模型的基本方法是降低其复杂度。这可以通过设计表现与原始模型相似但更易于解释的代理模型来完成(线性代理模型、决策树模型等),或者也可以构建显著性图(salience map),来突出显示最相关的一部分计算,从而提供可解释性。
(1)线性代理模型(Proxy Models)
- 目前被广泛采用的机器学习模型,大多仍然是「黑盒模型」。在根据预测结果规划行动方案,或者选择是否部署某个新模型时,我们需要理解预测背后的推理过程,从而评估模型的可信赖程度。一种可能的方法是,使用线性可解释的模型近似“黑盒模型”。
- Marco et. al提出了一种新的模型无关的模型解释技术「LIME」,它可以通过一种可解释的、准确可靠的方式,通过学习一个围绕预测结果的可解释模型,解释任意的分类器或回归模型的预测结果。
- 本文作者还通过简洁地展示具有代表性的个体预测结果及其解释,将该任务设计成了一种子模块优化问题。
- 文中指出,一种优秀的解释方法需要具备以下几点特质:
- (1)可解释性:给出对输入变量和响应的关系的定性理解,可解释性需要考虑用户自身的限制。
- (2)局部保真:解释方法至少需要在局部是可靠的,它必须与模型在被预测实例附近的表现相对应。需要指出的是,在全局上重要的特征不一定在局部环境下仍然重要,反之亦然。
- (3)模型无关:解释方法需要能够解释各种各样的模型。
- (4)全局视角:准确度有时并不是一个很好的模型评价指标,解释器旨在给出一些具有代表性的对样本的解释。
- 文中的方法可以基于对分类器局部可靠的可解释表征,来鉴别器模型的可解释性。LIME 会对输入样本进行扰动,识别出对于预测结果影响最大的特征(人类可以理解这些特征)。
- 如图 2 所示,加粗的红色十字样本有待解释。从全局来看,很难判断红色十字和蓝色圆圈对于带解释样本的影响。我们可以将视野缩小到黑色虚线周围的局部范围内,在加粗红色十字样本周围对原始样本特征做一些扰动,将扰动后的采样样本作为分类模型的输入,LIME 的目标函数如下:
- 其中,f 为分类器,g 为解释器,π_x 为临近度度量,Ω(g) 为解释器 g 的复杂度,L 为损失函数。
- 因为代理模型提供了模型复杂度与可信度之间的量化方法,因此方法间可以互相作为参考,吸引了许多研究工作。
(2)决策树方法
- 另一种代理模型的方法是决策树。将神经网络分解成决策树的工作从1990年代开始,该工作能够解释浅层网络,并逐渐泛化到深度神经网络的计算过程中。
- 一个经典的例子是Makoto et. al。文中提出了一种新的规则抽取(Rule Extraction)方法CRED,使用决策树对神经网络进行分解,并通过c/d-rule算法合并生成的分支,产生不同分类粒度,能够考虑连续与离散值的神经网络输入输出的解释。具体算法如下:
- 一.将网络输入变量按设定的特征间隔大小分成不同类别,并划分网络的目标输出和其他输出。
- 二.建立输出隐藏决策树(Hidden-Output Decision Tree)每个结点使用预测目标的特征做区分,以此分解网络,建立网络的中间规则。
- 三.对于2建立的每个节点,对其代表的每个函数建立输入隐藏决策树(Hidden-Input Decision Tree),对输入的特征进行区分,得到每个节点输入的规则。
- 四.使用3中建立的输入规则替换结点的输出规则,得到网络整体的规则。
- 五.合并结点,根据设定的规则,使表达简洁。
- 图 4 :CRED算法
- DeepRED将CRED的工作拓展到了多层网络上,并采用了多种结构优化生成树的结构。另一种决策树结构是ANN-DT,同样使用模型的结点结构建立决策树,对数据进行划分。不同的是,判断节点是采用正负两种方法判断该位置的函数是否被激活,以此划分数据。决策树生成后,通过在样本空间采样、实验,获得神经网络的规则。
- 这阶段的工作对较浅的网络生成了可靠的解释,启发了很多工作,但由于决策树节点个数依赖于网络大小,对于大规模的网络,方法的计算开销将相应增长。
(3)自动规则生成
- 自动规则生成是另一种总结模型决策规律的方法,上世纪80年代, Gallant将神经网络视作存储知识的数据库,为了从网络中发掘信息和规则,他在工作中提出了从简单网络中提取规则的方法,这可以被看作是规则抽取在神经网络中应用的起源。现今,神经网络中的规则生成技术主要讲输出看作规则的集合,利用命题逻辑等方法从中获取规则。
- Hiroshi Tsukimoto提出了一种从训练完成的神经网络中提取特征提取规则的方法,该方法属于分解法,可以适用在输出单调的神经网络中,如sigmoid函数。该方法不依赖训练算法,计算复杂度为多项式,其计算思想为:用布尔函数拟合神经网络的神经元,同时为了解决该方法导致计算复杂度指数增加的问题,将算法采用多项式表达。最后将该算法推广到连续域,提取规则采用了连续布尔函数。
- Towell形式化了从神经网络中提取特征的方法,文章从训练完成的神经网络中提取网络提取特征的方法,MoFN,该方法的提取规则与所提取的网络的精度相近,同时优于直接细化规则的方法产生的规则,更加利于人类理解网络。
- MoFN分为6步:
- 1)聚类;2)求平均;3)去误差;4)优化;5)提取;6)简化。
- 聚类采用标准聚类方法,一次组合两个相近的族进行聚类,聚类结束后对聚类的结果进行求平均处理,计算时将每组中所有链路的权重设置为每个组权重的平均值,接下来将链接权重较低的组去除,将留下的组进行单位偏差优化,优化后的组进行提取工作,通过直接将每个单元的偏差和传入权重转换成具有加权前因的规则来创建,最后对提取到的规则简化。MOFN的算法示例如下图所示。
- 图5:MOFN 算法
- 规则生成可以总结出可靠可信的神经网络的计算规则,他们有些是基于统计分析,或者是从模型中推导,在保障神经网络在关键领域的应用提供了安全保障的可能。
(4)显著性图
- 显著性图方法使用一系列可视化的技术,从模型中生成解释,该解释通常表达了样本特征对于模型输出的影响,从而一定程度上解释模型的预测。常见方法有反卷积、梯度方法等。Zeiler提出了可视化的技巧,使用反卷积观察到训练过程中特征的演化和影响,对CNN内部结构与参数进行了一定的“解读”,可以分析模型潜在的问题,网络深度、宽度、数据集大小对网络性能的影响,也可以分析了网络输出特征的泛化能力以及泛化过程中出现的问题。
- ① 利用反卷积实现特征可视化
- 为了解释卷积神经网络如何工作,就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,论文通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。
- Eg:假如你想要查看Alexnet的conv5提取到了什么东西,就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
- ② 反池化过程
- 池化是不可逆的过程,然而可以通过记录池化过程中,最大激活值的坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。
- ③ 反激活
- 在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
- 另一些可视化方法可视化方法主要是通过deconv的方法将某一层特征图的Top-k激活反向投射到原图像上,从而判断该激活值主要识别图像的什么部分。这就要求针对每一层都必须有对应的逆向操作。
- 具体而言,对于MaxPooling层,在前馈时使用switch变量来记录最大值来源的index,然后以此近似得到Unpooling。对于Relu层,直接使用Relu层。而对于conv层,使用deconv,即使用原来卷积核的转置作为卷积核。通过可视化方法,对训练完成的模型在ImageNet的数据各层可视化后,可以得到不同结构的重建特征图,与原图进行对比能够直观地看到网络各层学习到的信息:
- 图 7:第二层学习边缘,角落信息;第三层学到了一些比较复杂的模式,网状,轮胎;第四层展示了一些比较明显的变化,但是与类别更加相关了,比如狗脸,鸟腿;第五层则看到了整个物体,比如键盘,狗。
- 同时,通过可视化,我们也可以发现模型的缺陷,例如某些层学习到的特征杂乱无章,通过单独训练,可以提升模型效果。另外的方法也被采用,例如使用遮挡的方法,通过覆盖输入的某部分特征,分析输出和模型计算的中间参数,得到模型对被遮挡部分的敏感性,生成敏感性图,或者用梯度方法得到输出对于输入图像像素的梯度,生成梯度热力图。
- 总结性的工作来自ETH Zurch的Enea Ceolini [9]证明了基于梯度的归因方法(gradient-based Attribution methods)存在形式上\联系,文章证明了在一定情况下,诸如sigma-LRP[10]、DeepLIF[11]方法间存在的等价和近似关系,并基于统一的数学表达,提出了一个更普适的梯度归因方法框架Sensitivity-n,用于解释模型输入输出之间的关联。
- 深度学习的归因分析用于解释输入的每个变量对于神经网络的贡献(contribution),或相关程度(relevance),严格来说,假设网络的输入为x = [x1, …, xN ],C个输出神经元对应的输出为S(x) = [S1(x), …, SC (x)],归因分析的目标便是找到xi对于每个神经元输出的贡献,Rc = [Rc 1 , …, Rc N ]。
- 基于梯度的方法可以被看作直接使用输出对输出的特征求梯度,用梯度的一定变换形式表示其重要性,工作中展示的考虑不同大小特征区域热力图如下:
- 文章分析了不同方法的效果差异:
- 通过证明,得到通用的梯度方法表示为:
- 基于上述推导,作者得以提出了sensitivity-n方法,总结了相似的梯度方法,并使后续工作可以在更广泛的框架下讨论。
2.2 深度网络表示的可解释性
- 尽管存在大量神经网络运算,深度神经网络内部由少数的子组件构成:例如,数十亿个ResNet的操作被组织为约100层,每层计算64至2048信息通道像素。对深层网络表示的解释旨在了解流经这些信息瓶颈的数据的作用和结构。
- 可以按其粒度划分为三个子类:
- 基于层的解释,将流经层的所有信息一起考虑;
- 基于神经元的解释,用来说明单个神经元或单个filter通道的情况;
- 此外基于(其他)表示向量的解释,例如概念激活向量(CAV)[12]是通过识别和探测与人类可解释概念一致的方向来解释神经网络表示,用单个单元的线性组合所形成的表示向量空间中的其他方向作为其表征向量。
(1)基于层的解释
- Bengio等人[13]分析了在图片分类任务中,不同层的神经网络的功能和可迁移性,以及不同迁移方法对结果的影响。从实验的角度分析了神经网络不同层参数具有的一些性质,证明了模型迁移方法的普遍效果。作者验证了浅层神经网络在特征抽取功能上的通用性和可复用性,针对实验结果提出了可能的解释,表明影响迁移学习效果的因素有二:
- 1) 共同训练变量的影响
- 通过反向传播算法训练的神经网络,结点参数并非单独训练,其梯度计算依赖于一系列相关结点,因此迁移部分结点参数会引起相关结点的训练困难。
- 2) 迁移参数的通用性能和专用性
- 网络中较浅层网络的功能较为通用,而高层网络与网络的训练目标更加相关。若A、B任务不想关,则专用于A的参数迁移后会影响对B任务的学习。
- 实验结果发现,在不同的实验条件下,两种因素会不同程度决定迁移学习的效果。例如,当迁移较深层网络并固定参数时,高层参数的专用性会导致在迁移到的任务上表现不佳,但这时共同训练的变量影响会减小,因为大部分参数都被迁移获得;当迁移自身的参数并固定时,在层数较小的情况下出现了性能下降,这说明了共同训练的变量对表现的影响。另外,实验发现完全不相关的任务对应的迁移,在经过充分微调后仍然能提升模型的性能,这证明了参数迁移是一个通用的提升模型性能的方法。
- 1) 共同训练变量的影响
- 牛津大学Karen Simonyan等人[14]为解决深层卷积神经网络分类模型的可视化问题,提出了两种方法:
- 第一种生成图像使得类得分最大化,再将类可视化;
- 第二种计算给定图像和类的类显著性映射,同时还证明了这种方法可以使用分类转换网络的弱监督对象分类。
- 整个文章主要有三个贡献:证明了理解分类CNN模型可以使用输入图像的数值优化;提出了一种在图像中提取指定类别的空间表征信息(image-specific class saliency map)的方法(只通过一次back-propagation),并且这种saliency maps可以用于弱监督的物体定位。证明gradient-based的可视化方法可以推广到deconvolutional network的重构过程。
- 在第一类方法中,文中采用公式(1)进行图像分类模型的可视化操作,其中
表示c的分数,由ConvNet的分类层对图像I计算得到,
是正则化参数。可视化过程与ConvNet训练过程类似,不同之处在于对图像的输入做了优化,权重则固定为训练阶段得到的权重。图1所示为使用零图像初始化优化,然后将训练集的均值图像添加到结果中的输出图。
(1)
- 在第二类方法中,给定一张图像I0,在I0附近使用一阶泰勒展开的线性函数来近似Sc(I):
,其中w即为Sc对于图像I的导数在I0点的值:
。
- 在给定的图像I0(m行n列)和对应的类别c中,要求得它对应saliency map M (M∈Rmxn),首先按照上述公式利用back-propagation 可以求得导数w,然后对w元素进行重新排列即可得到Saliency Map。Saliency Map是利用训练好的CNN直接提取的,无需使用额外的标注,而且对于某个特定类别的image-specific saliency map的求解是很快的,只需要一次back-propagation。可视化结果如图2所示
- 在第二类方法中得到的Saliency Map编码了给定图像中特定类别的物体位置信息,所以它可以被用来进行物体定位(尽管它在分类任务上得到训练,弱监督学习)。给定一张图像和其对应的Saliency Map,可以使用GraphCut颜色分割模型来得到物体分割mask。要使用颜色分割模型主要是因为Saliency Map只能捕捉到一个物体最具有区分性的部分,它无法highlight整个物体,因此需要将threshold map传递到物体的其他区域,本文使用colour continuity cues来达到这个目的。前景和背景模型都被设置为高式混合模型,高于图像Saliency distribution 95%的像素被视为前景,Saliency低于30%的像素被视为背景。标记了前景和背景像素之后,前景像素的最大连接区域即为对应物体的分割mask(使用GraphCut算法),效果如图3所示。
- 此外,Zhang et. al. 的工作[15]发现网络浅层具有统计输入信息的功能,并发现其和共享的特征信息一样,对迁移带来的性能提升起到了帮助。通过从相同checkpoint训练,发现参数迁移,可以使模型损失每次都保持在相同的平面内(basin),具有相似的地形,但随机初始化的参数每次损失所在的训练平面不同。文章支持了高层、低层网络具有的不同功能,发现高层网路对于参数的改变更加敏感。
(2)基于神经元的解释
- 香港中文大学助理教授周博磊的工作[16]为 CAM 技术的奠定了基础,发现了 CNN 中卷积层对目标的定位功能。在改文中,作者对场景分类任务中训练 CNN 时得到的目标检测器展开了研究。由于场景是由物体组成的,用于场景分类的 CNN 会自动发现有意义的目标检测器,它们对学到的场景类别具有代表性。作者发现,单个网络可以支持多个级别的抽象(如边缘、纹理、对象、场景),同一个网络可以在无监督环境下,在单个前向传播过程中同时完成场景识别和目标定位。
- 图 14:估计每个神经元的感受野
- 针对每个神经元,作者估计出了其确切地感受野,并观察到激活区域倾向于随着层的深度增加而在语义上变得更有意义(这是启发后来一系列计算机视觉神经网络框架的理论基础)。
- 周博磊CVPR 2017[17]提出了一种名为“Network Disp”的通用框架,假设“单元的可解释性等同于单元的随机线性结合”,通过评估单个隐藏单元与一系列语义概念间的对应关系,来量化 CNN 隐藏表征的可解释性。
- 这种方法利用大量的视觉概念数据集来评估每个中间卷积层隐藏单元的语义。这些带有语义的单元被赋予了大量的概念标签,这些概念包括物体、组成部分、场景、纹理、材料和颜色等。该方法揭示 CNN 模型和训练方法的特性,而不仅仅是衡量他们的判别能力。
- 论文发现:人类可解释的概念有时候会以单一隐藏变量的形式出现在这些网络中;当网络未受限于只能用可解释的方式分解问题时,就会出现这种内部结构。这种可解释结构的出现意味着,深度神经网络也许可以自发学习分离式表征(disentangled representations)。
- 众所周知,神经网络可以学习某种编码方式,高效利用隐藏变量来区分其状态。如果深度神经网络的内部表征是部分分离的,那么检测断分离式结构并读取分离因数可能是理解这种机制的一种方法。同时该论文指出可解释性是与坐标轴对齐(axis-aligned)的,对表示(representation)进行翻转(rotate),网络的可解释能力会下降,但是分类性能不变。越深的结构可解释性越好,训练轮数越多越好。而与初始化无关dropout会增强可解释性而Batch normalization会降低可解释性。
图 15
- 麻省理工大学CSAIL的Jonathan Frankle和Michael Carbin论文[18]中指出神经网络剪枝技术可以将受过训练的网络的参数减少90%以上,在不影响准确性的情况下,降低存储要求并提高计算性能。
- 然而,目前的经验是通过剪枝产生的稀疏架构很难从头训练,也很难提高训练性能。作者发现标准的剪枝技术自然而然地可以得到子网络,它们能在某些初始化条件下有效地进行训练。在此基础之上,作者提出了彩票假设:任何密集、随机初始化的包含子网络(中奖彩票)的前馈网络 ,当它们被单独训练时,可以在相似的迭代次数内达到与原始网络相当的测试精度。
- 具体而言,作者通过迭代式而定剪枝训练网络,并剪掉最小的权重,从而得到「中奖彩票」。通过大量实验,作者发现,剪枝得到的中奖彩票网络比原网络学习得更快,泛化性能更强,准确率更高。剪枝的主要的步骤如下:
- (1)随机初始化一个神经网络
- (2)将网络训练 j 轮,得到参数
- (3)剪掉
中 p% 的参数,得到掩模 m
- (4)将剩余的参数重置为
中的值,生成中奖彩票
- (1)随机初始化一个神经网络
图 16:虚线为随机才应该能得到的稀疏网络,实现为中奖彩票。
- 此外,加利福尼亚大学的ZHANG Quanshi和ZHU Song-chun 综述了近年来神经网络可解释性方面的研究进展[19]。文章以卷积神经网络(CNN)为研究对象,回顾了CNN表征的可视化、预训练CNN表征的诊断方法、预训练CNN表征的分离方法、带分离表示的CNN学习以及基于模型可解释性的中端学习。
- 最后,讨论了可解释人工智能的发展趋势,并且指出了以下几个未来可能的研究方向:
- 1)将conv层的混沌表示分解为图形模型或符号逻辑;
- 2)可解释神经网络的端到端学习,其中间层编码可理解的模式(可解释的cnn已经被开发出来,其中高转换层中的每个过滤器代表一个特定的对象部分);
- 3)基于CNN模式的可解释性表示,提出了语义层次的中端学习,以加快学习过程;
- 4)基于可解释网络的语义层次结构,在语义级别调试CNN表示将创建新的可视化应用程序。
- 网络模型自身也可以通过不同的设计方法和训练使其具备一定的解释性,常见的方法主要有三种:注意力机制网络;分离表示法;生成解释法。基于注意力机制的网络可以学习一些功能,这些功能提供对输入或内部特征的加权,以引导网络其他部分可见的信息。分离法的表征可以使用单独的维度来描述有意义的和独立的变化因素,应用中可以使用深层网络训练显式学习的分离表示。在生成解释法中,深层神经网络也可以把生成人类可理解的解释作为系统显式训练的一部分。
2.3 生成自我解释的深度学习系统
- 网络模型自身也可以通过不同的设计方法和训练使其具备一定的解释性,常见的方法主要有三种:注意力机制网络;分离表示法;生成解释法。
- 基于注意力机制的网络可以学习一些功能,这些功能提供对输入或内部特征的加权,以引导网络其他部分可见的信息。
- 分离法的表征可以使用单独的维度来描述有意义的和独立的变化因素,应用中可以使用深层网络训练显式学习的分离表示。
- 在生成解释法中,深层神经网络也可以把生成人类可理解的解释作为系统显式训练的一部分。
(1)注意力机制网络
- 注意力机制的计算过程可以被解释为:计算输入与其中间过程表示之间的相互权重。计算得到的与其他元素的注意力值可以被直观的表示。
- 在Dong Huk Park 发表于CVPR2018的[20]一文中,作者提出的模型可以同时生成图像与文本的解释。其方法在于利用人类的解释纠正机器的决定,但当时并没有通用的包含人类解释信息与图像信息的数据集,因此,作者整理了数据集ACT-X与VQA-X,并在其上训练提出了P-JX(Pointing and Justification Explanation)模型,检测结果如图所示。
图 17:P-JX模型检测结果
- 模型利用「attention」机制得到图像像素的重要性,并据此选择输出的视觉图,同时,数据集中的人类解释文本对模型的预测作出纠正,这样模型可以同时生成可视化的解释,亦能通过文字说明描述关注的原因。例如在上图中,对问题「Is this a healthy meal」,针对图片,关注到了热狗,因此回答「No」,图片的注意力热力图给出了可视化的解释,同时文本亦生成了对应的文本解释。作者认为,利用多模态的信息可以更好地帮助模型训练,同时引入人类的知识纠错有利于提高模型的可解释性。
- 由于类别之间只有通过细微局部的差异才能够被区分出来,因此「fine-grained」分类具有挑战性,在Xiao et. al. 的[21]中,作者将视觉「attention」应用到「fine-grained」分类问题中,尽管注意力的单元不是出于可解释性的目的而训练的,但它们可以直接揭示信息在网络种的传播地图,可以作为一种解释。由于细粒度特征不适用bounding box标注,因此该文章采用「弱监督学习」的知识来解决这一问题。
- 该文章中整合了3种attention模型:「bottom-up」(提供候选者patch),「object-level top-down」(certain object相关patch),和「part-level top-down 」(定位具有分辨能力的parts),将其结合起来训练「domain-specific深度网络」。
图 18:Domain-specific深度网络结构示意图
- domain-specific深度网络结构示意图如图 18 所示:实现细粒度图像分类需要先看到物体,然后看到它最容易判别的部分。通过bottom-up生成候选patches,这个步骤会提供多尺度,多视角的原始图像。
- 如果object很小,那么大多数的patches都是背景,因此需要top-down的方法来过滤掉这些噪声patches,选择出相关性比较高的patches。寻找前景物体和物体的部分分别采用「object-level」和「part-level」两个过程,二者由于接受的patch不同,使其功能和优势也不同。在object-level中对产生的patches选出包含基本类别对象的patch,滤掉背景。part-level分类器专门对包含有判别力的局部特征进行处理。
- 有的patch被两个分类器同时使用,但该部分代表不同的特征,将每幅图片的object-level和part-level的分数相加,得到最终的分数,即分类结果。
(2)分离表示法
- 分离表示目标是用高低维度的含义不同的独立特征表示样本,过去的许多方法提供了解决该问题的思路,例如PCA、ICA、NMF等。深度网络同样提供了处理这类问题的方法。
- Chen et. al. 在加州大学伯克利分校的工作[22]曾被 OpenAI 评为 2016 年 AI 领域的五大突破之一,在 GAN 家族的发展历史上具有里程碑式的意义。对于大多数深度学习模型而言,其学习到的特征往往以复杂的方式在数据空间中耦合在一起。如果可以对学习到的特征进行解耦,就可以得到可解释性更好的编码。对于原始的 GAN 模型而言,生成器的输入为连续的噪声输入,无法直观地将输入的维度与具体的数据中的语义特征相对应,即无法得到可解释的数据表征。为此,InfoGAN 的作者以无监督的方式将 GAN 的输入解耦为两部分:
- (1)不可压缩的 z,该部分不存在可以被显式理解的语义信息。
- (2)可解释的隐变量 c,该部分包含我们关心的语义特征(如 MNIST 数据集中数字的倾斜程度、笔画的粗细),与生成的数据之间具有高相关性(即二者之间的互信息越大越好)。
- 若 c 对生成数据 G(z,c)的可解释性强,则 c 与 G(z,c) 之间的交互信息较大。为了实现这一目标,作者向原始 GAN 的目标函数中加入了一个互信息正则化项,得到了如下所示的目标函数:
-
然而,在计算新引入的正则项过程中,模型难以对后验分布 P(C X) 进行采样和估计。因此,作者采用变分推断的方法,通过变分分布 Q(C X) 逼近 P(C X)。最终,InfoGAN 被定义为了如下所示的带有变分互信息正则化项和超参数 λ 的 minmax 博弈:
图 19:InfoGAN 框架示意图
- 张拳石团队的[23]一文中,提出了一种名为「解释图」的图模型,旨在揭示预训练的 CNN 中隐藏的知识层次。
- 在目标分类和目标检测等任务中,端到端的「黑盒」CNN模型取得了优异的效果,但是对于其包含丰富隐藏模式的卷积层编码,仍然缺乏合理的解释,要对 CNN 的卷积编码进行解释,需要解决以下问题:
- CNN 的每个卷积核记忆了多少种模式?
- 哪些模式会被共同激活,用来描述同一个目标部分?
- 两个模式之间的空间关系如何?
图 20:解释图结构示意图
- 解释图结构示意图表示了隐藏在 CNN 卷积层中的知识层次。预训练 CNN 中的每个卷积核可能被不同的目标部分激活。本文提出的方法是以一种无监督的方式将不同的模式从每个卷积核中解耦出来,从而使得知识表征更为清晰。
-
具体而言,解释图中的各层对应于 CNN 中不同的卷积层。解释图的每层拥有多个节点,它们被用来表示所有候选部分的模式,从而总结对应的卷积层中隐藏于无序特征图中的知识,图中的边被用来连接相邻层的节点,从而编码它们对某些部分的共同激活逻辑和空间关系。将一张给定的图像输入给 CNN,解释图应该输出:(1)某节点是否被激活(2)某节点在特征图中对应部分的位置。由于解释图学习到了卷积编码中的通用知识,因此可以将卷积层中的知识迁移到其它任务中。
图 21:解释图中各部分模式之间的空间关系和共同激活关系图
- 解释图中各部分模式之间的空间关系和共同激活关系。高层模式将噪声滤除并对低层模式进行解耦。从另一个层面上来说,可以将低层模式是做高层模式的组成部分。
- 另外,张拳石[24]认为在传统的CNN中,一个高层过滤器可能会描述一个混合的模式,例如过滤器可能被猫的头部和腿部同时激活。这种高卷积层的复杂表示会降低网络的可解释性。针对此类问题,作者将过滤器的激活与否交由某个部分控制,以达到更好的可解释性,通过这种方式,可以明确的识别出CNN中哪些对象部分被记忆下来进行分类,而不会产生歧义。
-
模型通过对高卷积层的每个filter计算loss,种loss降低了类间激活的熵和神经激活的空间分布的熵,每个filter必须编码一个单独的对象部分,并且过滤器必须由对象的单个部分来激活,而不是重复地出现在不同的对象区域。
- Hinton的胶囊网络 [25],是当年的又一里程碑式著作。作者通过对CNN的研究发现CNN存在以下问题:1) CNN只关注要检测的目标是否存在,而不关注这些组件之间的位置和相对的空间关系;2) CNN对不具备旋转不变性,学习不到3D空间信息;3)神经网络一般需要学习大量案例,训练成本高。为了解决这些问题,作者提出了「胶囊网络」,使网络在减少训练成本的情况下,具备更好的表达能力和解释能力。
- 「胶囊(Capsule)」可以表示为一组神经元向量,用向量的长度表示物体「存在概率」,再将其压缩以保证属性不变,用向量的方向表示物体的「属性」,例如位置,大小,角度,形态,速度,反光度,颜色,表面的质感等。
- 和传统的CNN相比,胶囊网络的不同之处在于计算单位不同,传统神经网络以单个神经元作为单位,capsule以一组神经元作为单位。相同之处在于,CNN中神经元与神经元之间的连接,capsNet中capsule与capsule之间的连接,都是通过对输入进行加权的方式操作。
- 胶囊网络在计算的过程中主要分为四步:
- 输入向量ui的W矩阵乘法;
- 输入向量ui的标量权重c;
- 加权输入向量的总和;
- 向量到向量的非线性变换。
- 网络结构如下图所示,其中「ReLI Conv1」是常规卷积层;「PrimaryCaps」构建了32个channel的capsules,得到6*6*8的输出;「DigiCaps」对前面1152个capules进行传播与「routing」更新,输入是1152个capsules,输出是10个capules,表示10个数字类别,最后用这10个capules去做分类。
图23:胶囊网络网络结构示意图
(3)生成解释法
- 除了上文介绍的诸多方法外,在模型训练的同时,可以设计神经网络模型,令其产生能被人类理解的证据,生成解释的过程也可被显式地定义为模型训练的一部分。
- Wagner 2019[26]首次实现了图像级别的细粒度解释。文中提出的「FGVis」,避免了图像的可解释方法中对抗证据的问题,传统方法采用添加正则项的方式缓解,但由于引入了超参,人为的控制导致无法生成更加可信的,细粒度的解释。文中的FGVis方法基于提出的「对抗防御(Adversarial Defense)」方法,通过过滤可能导致对抗证据的样本梯度,从而避免这个问题。该方法并不基于任何模型或样本,而是一种优化方法,并单独对生成解释图像中的每个像素优化,从而得到细粒度的图像解释,检测示意图如图[24] 所示。
图24:FGVis检测结果示意图
- 另一个视觉的例子来自Antol et. 的Vqa[27],文章将视觉问题的「回答任务(Vqa)」定义为给定一个图像和一个开放式的、关于图像的自然语言问题,并提出了Vqa的「基准」和「回答方法」,同时还开发了一个两通道的视觉图像加语言问题回答模型。
- 文章首先对Vqa任务所需的数据集进行采集和分析,然后使用baselines为「基准」对「方法」进行评估,基准满足4个条件:1) 随机,2)答案先验, 3)问题先验,4)最近邻。
- 「方法」使用文中开发的两个视觉(图像)通道加语言(问题)通道通过多层感知机结合的模型,结构图如图所示。视觉图像通道利用 VGGNet最后一层隐藏层的激活作为 4096- dim 图像嵌入,语言问题通道使用三种方法嵌入:
- 构建「词袋问题(BoW Q)」;
- 「LSTM Q 」具有一个隐藏层的lstm对1024维的问题进行嵌入;
- 「deeper LSTM Q」。最终使用softmax方法输出K个可能的答案。
图 25:deeper LSTM Q + norm I 结构图
三. 总结
为了使深度学习模型对用户而言更加「透明」,研究人员近年来从「可解释性」和「完整性」这两个角度出发,对深度学习模型得到预测、决策结果的工作原理和深度学习模型本身的内部结构和数学操作进行了解释。至今,可解释性机器学习领域的研究人员在「网络对于数据的处理过程」、「网络对于数据的表征」,以及「如何构建能够生成自我解释的深度学习系统」三个层次上均取得了可喜的进展:
- 就网络工作过程而言,研究人员通过设计线性代理模型、决策树模型等于原始模型性能相当,但具有更强可解释性的模型来解释原始模型;此外,研究人员还开发出了显著性图、CAM 等方法将于预测和决策最相关的原始数据与计算过程可视化,给出一种对深度学习模型的工作机制十分直观的解释。
- 就数据表征而言,现有的机器学习解释方法涉及「基于层的解释」、「基于神经元的解释」、「基于表征向量的解释」三个研究方向,分别从网络层的设计、网络参数规模、神经元的功能等方面探究了影响深度学习模型性能的重要因素。
- 就自我解释的深度学习系统而言,目前研究者们从注意力机制、表征分离、解释生成等方面展开了研究,在「视觉-语言」多模态任务中实现了对模型工作机制的可视化,并且基于 InfoGAN、胶囊网络等技术将对学习有不同影响表征分离开来,实现了对数据表征的细粒度控制。
然而,现有的对机器学习模型的解释方法仍然存在诸多不足,面临着以下重大的挑战:
- 现有的可解释性研究往往针对「任务目标」和「完整性」其中的一个方向展开,然而较少关注如何将不同的模git型解释技术合并起来,构建更为强大的模型揭示方法。
- 缺乏对于解释方法的度量标准,无法通过更加严谨的方式衡量对模型的解释结果。
- 现有的解释方法往往针对单一模型,模型无关的解释方法效果仍有待进一步提升。
- 对无监督、自监督方法的解释工作仍然存在巨大的探索空间。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
