Scaling Law 缩放定律
思考
需求:
- 训练10B模型,至少要多大数据?
- 1T数据能训练多大模型?
- 100张A100,应该用多少数据训一个多大模型,最终效果最好?
- 10B模型不满意,扩大到100B模型,效果能提升到多少?
以上这些问题都可以基于 Scaling Law 理论进行回答。
LLM 为什么都是 6b/13b/52b…
总结
scaling law 指导下,匹配当前的显卡资源和数据资源
最大尺寸版本确定的核心逻辑是: DeepMind 的 Chinchilla Scaling Law。
开发大模型时,清洗出来的开源数据数量是离散值。
- LLaMA-1 预训练时,从各种开源数据集凑够了 1.4T tokens,所以最大版本是70B,很接近
Chinchilla Scaling Law的计算结果。 - 用1024张A100,MFU=0.55情况下,训练时长大概是38天,这是一个比较可行的预训练方案。
- 至于更小版本选型比较随意,主要考虑调试时,计算量要控制在一个可控范围,比如一般会选择一个10^22 FLOPs计算量(差不多256卡两三天出结果)下的最优模型尺寸,因此最优尺寸肯定是在10B以内。由于一些矩阵维度的限制,一般都是6B,7B。
Chinchilla Scaling Law有些争议,正溯还是得看OpenAI文章Scaling laws for neural language models,过去一年内大家还是会follow这套理论。
LLM 一般都是基于Transormer结构,参数总和 = Embedding部分参数 + Transormer-Decoder部分参数
- Embedding 部分参数由词表大小和模型维度决定;
- Decoder 部分参数由模型层数和模型维度决定。
决定参数的几个因素有:词表大小、模型层数(深度)、模型维度(宽度)。
- 关于词表大小设置,越大的词表的压缩会更好,但可能导致模型训练不充分;越小的词表压缩会比较差,导致模型对长度需求较高。
- 关于层数设置问题,其实模型层数和维度具体设置成多少是最优的(但一般层数变大,维度也会变大),目前没有论文明确表明,但绝大多数感觉跟着GPT3的层数和维度来的。
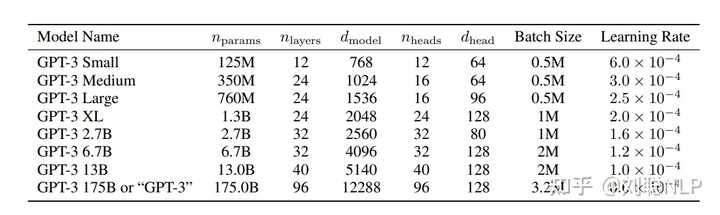
常见模型 6/7B 是32层、13B 是40层。
PS:由于GPT3模型先出,让OPT、Bloom等都是为了做开源的GPT3所提出的,因此参数规模是一致的。
- llama 为了对标GPT3,不过为了证明效果更好,也在中间多了
33B和65B规模。 130B只有GLM大模型是这个参数。
现在流传甚广的其实是6/7B(小)、13B(中),主要是由于更大的模型训练成本会更高,并且对于很多人来说13B的模型已经算顶配了(消费显卡跑得了)。
语言模型进化
【2024-8-10】大语言模型 Scaling Law:如何随着模型大小、训练数据和计算资源的增加而扩展
缩放定律
- 一个由三个关键部分组成的法则:
模型大小、训练数据和计算能力
过去几年,语言模型迅速发展壮大。
- 语言模型从 2018年的 BERT-base 的1.09亿参数规模,增长到 2022年的 PaLM 的5400亿参数。
- 每个模型不仅在模型规模上增加(即参数数量),还在训练令牌数量和训练计算量(以浮点运算或FLOPs计)上都有所增加。
| Time | Company | Model | Model Size #parameters |
Training data #tokens |
Training compute FLOPs |
Resources |
|---|---|---|---|---|---|---|
| 2018 | BERT-base |
109M | 250B | 1.6e20 | 64 TPU v2 for 4 days 16 v100 GPU for 33 hours |
|
| 2020 | OpenAI | GPT-3 |
175B | 300B | 3.1e23 | ~1000 x BERT-base |
| 2022 | PaLM |
540B | 780B | 2.5e24 | 64 TPU v4 for 2 months |
问题
- “这三个因素之间有什么关系?”
- 模型大小和训练数据对模型性能(即测试损失)的贡献是否相等?哪一个更重要?
- 如果将测试损失降低10%,我应该增加模型大小还是训练数据?需要增加多少?
幂律函数
幂律是两个量x和y之间的非线性关系,建模为:
- $ y = ax^k $
- $ logy = loga + klogx$
- 其中k和a是常数。
幂律曲线
import numpy as np
import matplotlib.pyplot as plt
def plot_power_law(k, x_range=(1, 100), num_points=100):
"""
Plot the power law function y = x^k for any non-zero k.
Parameters:
k (float): The exponent for the power law (can be positive or negative, but not zero).
x_range (tuple): The range of x values to plot (default is 0.1 to 10).
num_points (int): Number of points to calculate for a smooth curve.
"""
if k == 0:
raise ValueError("k cannot be zero")
# Generate x values
x = np.linspace(x_range[0], x_range[1], num_points)
# Calculate y values
y = x**k
# Create the plot
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'ro', label=f'y = x^{k}')
#plt.barh(x, y)
plt.title(f'Power Law: y = x^{k}')
plt.xlabel('x')
plt.ylabel('y')
plt.grid(True)
plt.legend()
plt.show()
plot_power_law(2) # y = x^2
plot_power_law(-0.5) # y = x^(-0.5)
三要素
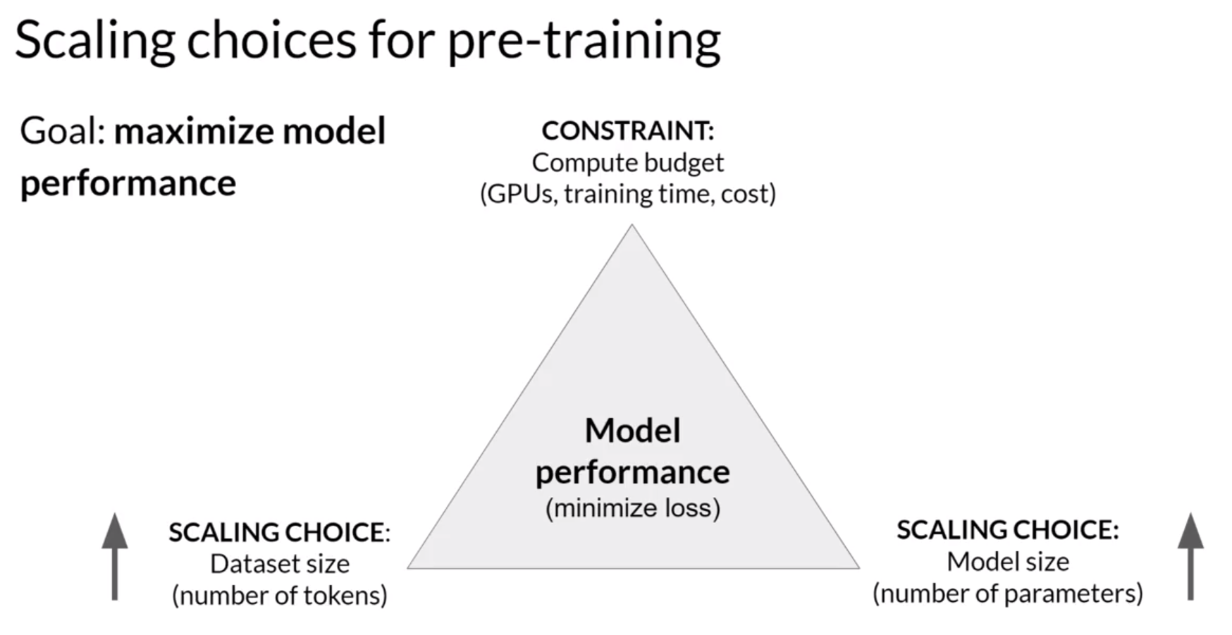
大语言模型的预训练,通常伴随着模型容量、数据量、训练成本的三方权衡博弈。
这种三角形式的拔河关系存在一些三元悖论,比如
- 分布式计算领域中的公认定理:
CAP理论: 分布式系统不可能同时满足一致性、可用性和分区容错性,最多只能同时满足其中2个条件。 - 大语言模型训练同样存在类似这种三元关系的探索,这就是
缩放定律(Scaling Laws)。
大语言模型预训练过程中,交叉熵损失(cross-entropy loss)是一种常用的性能衡量标准,用于评估模型预测输出与真实情况之间的差异。较低的交叉熵损失意味着模型的预测更准确。训练的过程也是追求损失值的最小化的过程。
什么是 Scaling Laws
Scaling Laws 意义:
- AI专业人士可以通过Scaling Laws预测大模型在
参数量、数据量以及训练计算量这三个因素变动时,损失值的变化。 - 这种预测能帮助一些关键的设计决策,比如在固定资源预算下,匹配模型的最佳大小和数据大小,而无需进行及其昂贵的试错。
规模化法则(缩放法则)(Scaling Law)指 模型性能与模型大小、数据集大小和计算资源等多种因素之间观察到的关系。
随着模型的扩展,这些关系遵循可预测模式。
规模化法则行为的关键因素如下:
- 模型大小:随着模型中参数数量的增加,性能通常会按照幂律改善。
- 数据集大小:更大的训练数据集通常带来更好的性能,也遵循幂律关系。
- 计算:用于训练的计算资源(浮点运算次数)与性能改善相关。
测试集损失与计算、数据集大小和模型参数之间遵循幂律关系(对数线性)
Training Compute= alpha *Model Size*Training Data- alpha ~ 6
每个参数和每个训练实例需要大约6次浮点运算(FLOPs)
- 前向传播中,需要恰好2次FLOPs将w与输入节点相乘,并将其添加到语言模型的计算图的输出节点中。(1次乘法和1次加法)
- 计算损失对w的梯度时,需要恰好2次FLOPs。
- 用损失的梯度更新参数w时,需要恰好2次FLOPs。
【2024-9-20】AI can’t cross this line and we don’t know why
Scaling Law 定义
主要有两个版本
OpenAI V.S DeepMind
更多见【2024-1-5】OpenAI与DeepMind的Scaling Laws之争
2020 OpenAI Scaling Law
OpenAI
“Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.”
—— 2023年2月14日《Planning for AGI and beyond》
谷歌收购 DeepMind 后,为避免谷歌在AI领域形成垄断,埃隆·马斯克和其他科技行业人物于2015年决定创建OpenAI。
OpenAI 作为一个有声望的非营利组织,致力于开发能够推动社会进步的AI技术。不同于 DeepMind 像一个精于解决棋盘上复杂战术的大师,专注于解决那些有明确规则和目标的难题,OpenAI更像是一个擅长语言艺术的诗人,致力于让机器理解和生成自然的人类语言。
从坚持初期被外界难以理解的GPT路线信仰,直到拥有1750亿参数的GPT-3问世,OpenAI展示了其在生成式模型上无与伦比的能力,引领了另一个AI时代。类比Deepmind和谷歌的关联,OpenAI与科技巨头微软牵手,展开了深度的战略合作,进一步推进AI技术的发展。
OpenAI 发布
- 【2020-1-23】论文 Scaling Laws for Neural Language Models
- OpenAI 官方文章 Scaling laws for neural language models
- 解读
- 【2020-11-6】第二篇文章 OpenAI Scaling Paper: Scaling Laws for Autoregressive Generative Modeling, 解析大模型中的Scaling Law
核心结论
- 对于 Decoder-only 模型,计算量
C(Flops), 模型参数量N, 数据大小D(token数),三者满足:C ≈ 6ND - 模型最终性能主要与计算量
C,模型参数量N和数据大小D三者相关,而与模型结构(层数/深度/宽度)基本无关。 - 计算量
C,模型参数量N和数据大小D,当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系 - 为了提升模型性能,模型参数量
N和数据大小D需要同步放大,但模型和数据分别放大的比例还存在争议。 - Scaling Law 不仅适用于语言模型,还适用于其他模态以及跨模态的任务
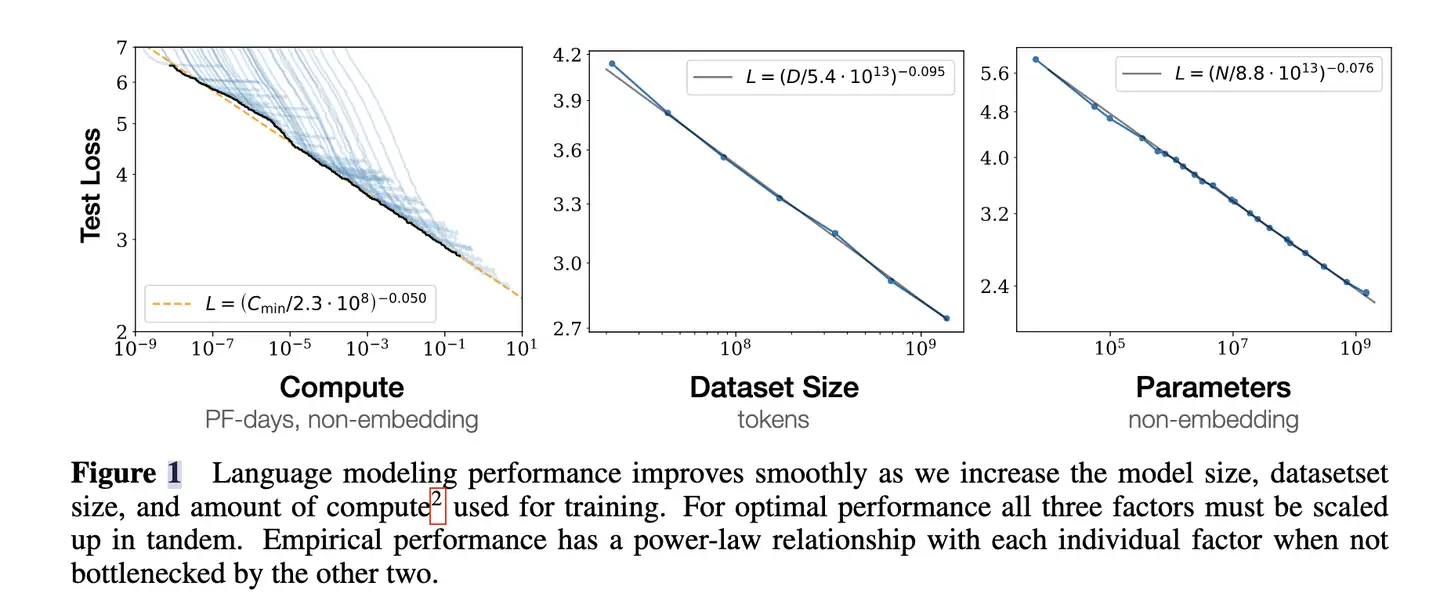
论文首次提出模拟神经语言模型的模型性能(Loss)与模型大小、数据集大小和训练计算量的关系。
- 三者中任何一个因素受限时,Loss与其之间存在
幂律关系。 - 注:
幂律指一个变量与另一个变量的某个幂次成正比。体现在图表中,当两个轴都是对数时,图像呈现为直线
总结:
- 影响模型性能的三个要素之间,每个参数会受到另外两个参数的影响。
- 当没有其他两个瓶颈时,性能会急剧上升,影响程度为:
计算量>参数»数据集大小 - 固定计算预算训练时,最佳性能可通过训练参数量非常大的模型并在远离收敛前停止(Early Stopping)来实现。
- 更大的模型在样本效率方面表现更好,能以更少的优化步骤和使用更少的数据量达到相同的性能水平。
- 实际应用中,应该优先考虑训练较大的模型。
因为这项研究,OpenAI 有了在数据和参数规模上 Scaling-up 信心,在同年四月后,火爆全球的GPT3问世。
2022 Chinchilla Scaling Law 数据不变
DeepMind
We’re a team of scientists, engineers, ethicists and more, committed to solving intelligence, to advance science and benefit humanity.
—— DeepMind
DeepMind 成立于2010年, 并于2015年被谷歌收购,是 Alphabet Inc. 子公司。
- 该公司专注于开发能模仿人类学习和解决复杂问题能力的AI系统。
- 作为 Alphabet Inc.的一部分,DeepMind在保持高度独立的同时,也在利用谷歌的强大能力推动AI研究的发展。
DeepMind 在技术上取得了显著成就,包括
- 开发
AlphaGo,击败世界围棋冠军李世石的AI系统,展示了深度强化学习和神经网络的潜力,开启了一个AI时代。 AlphaFold,这是一个革命性的用于准确预测蛋白质折叠的工具,对生物信息学界产生了深远影响。DeepMind用AI进行蛋白质折叠预测的突破,将帮助我们更好地理解生命最根本的根基,并帮助研究人员应对新的和更难的难题,包括应对疾病和环境可持续发展。
【2022-3-29】 DeepMind 发表论文
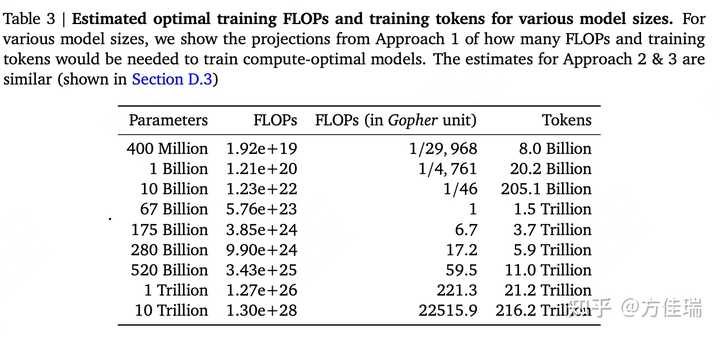
- Training Compute-Optimal Large Language Models 根据
Scaling Law,给定计算量(FLOPS)训练出来的最优模型(达到最好模型效果)的训练数据集的token数和模型参数数目是确定的。 - Gopher 模型计算量预算是 5.76 × 10^23 FLOPs,那么达到最优效果的参数量是 63B,数据集中Token数目为1.4T。
Deepmind 的 Hoffmann 等人团队提出与OpenAI截然不同的观点。
- OpenAI 建议在计算预算增加了10倍情况下,如果想保持效果,模型大小应增加5.5倍,而训练token数量仅需增加1.8倍。
- Deepmind 则认为模型大小和训练token数都应该按相等比例进行扩展,即都扩大3倍左右。
该团队还暗示许多像 GPT-3这样的千亿参数大语言模型实际上都过度参数化,超过了实现良好的语言理解所需,并训练不足。
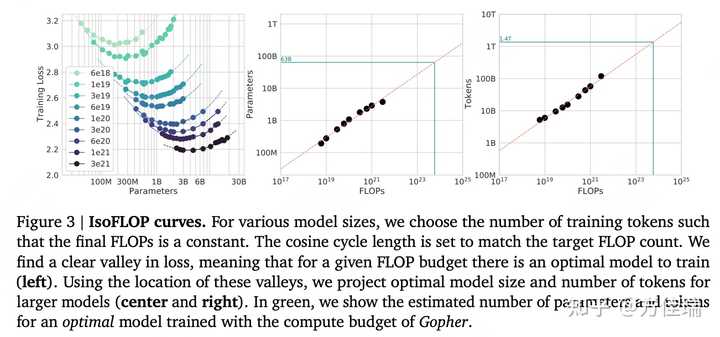
结论:
- 对于给定FLOP预算,损失函数有明显的谷底值:
- 模型太小时,在较少数据上训练较大模型将是一种改进;
- 模型太大时,在更多数据上训练的较小模型将是一种改进。
- 给定计算量下,数据量和模型参数量之间的选择平衡存在一个最优解。
- 计算成本达到最优情况下,模型大小和训练数据 (token) 数量应该等比例进行缩放,即:如果模型的大小加倍,那么训练数据的数量也应该加倍。
- 给定参数量模型,最佳训练数据集大小约为模型参数的20倍。
- 比如,对于一个7B模型,理想训练数据集大小应该约为 140B tokens。
大模型训练要更加关注数据集的扩展,但是只有数据是高质量的时候,更大数据集的益处才能体现出来。
大语言模型发展的一个新方向
- 从一味追求模型规模的增加,变成了优化模型规模和数据量的比例。
保持训练数据不变的情况下,扩大模型大小,当前的大型语言模型实际上训练不足
作者训练了从7000万到超过160亿参数的400多个语言模型,这些模型使用的训练令牌从50亿到5000亿不等,并得出结论:
- 对于计算优化的训练,模型大小和训练令牌数量应该同等规模化。
经验预测公式,将模型大小和训练数据与模型性能联系起来。
L(N,D) = A/N^α + B/D^β + E- N 是参数数量(即模型大小),D 是训练令牌。
- 符号 L(N,D) 指一个拥有 N 个参数并且在 D 个令牌上训练的模型的性能或测试损失。
- E 是一个常数,代表不可约减的损失,即模型在完美训练的情况下能够达到的最小损失。它考虑了模型所训练的任务的固有难度和数据中的噪声。
常数 A 和 B 以及指数 α 和 β 通过实验和数据拟合经验性地确定。
- α≈0.50 和 β≈0.50。
- 主要发现: 每翻倍增加模型大小时,训练令牌的数量也应该翻倍,以实现计算最优训练
边际效益递减
- 随着模型规模的增大,每增加相同数量的参数/计算资源,获得的性能提升逐渐减少的现象。
这是 Scaling Law 中非常关键的一个方面,它对于理解和决策模型设计及其部署策略有着重要的指导意义。
原因和表现
- 对数关系:很多研究中观察到,模型性能(如测试集上的准确率或其他指标)与模型大小(通常是参数数量或计算复杂度)呈对数关系。随着模型规模的扩大,要获得同样幅度的性能提升,需要的资源增加将更为显著。
- 资源效率的降低:当模型规模达到一定阶段后,继续增加模型的大小,其性能提升不再明显,而相对应的训练成本、时间和能源消耗却显著增加。这种现象表明,从成本效益角度出发,模型规模的无限扩大并不合理。
- 技术挑战:较大的模型更难训练,可能会面临梯度消失或爆炸、过拟合等问题,这些技术挑战也限制了模型性能的持续提升。
应对策略
- 模型和算法创新:通过改进模型架构、优化算法或引入新的训练技术(如稀疏化、量化等),可以在不显著增加参数的情况下提高模型的效率和效果。
多任务学习和迁移学习:利用多任务学习和迁移学习技术可以提高模型的泛化能力,使得模型在多个任务上具有更好的性能,这种方式可以在一定程度上克服单一任务上的边际效益递减问题。- 选择适当的规模:根据应用场景的实际需求和可用资源,选择合适的模型规模,避免资源的浪费,实现性能与成本的最优平衡。
缩放法则对AI研究者和工程师具有重大意义:
- 平衡规模化:Chinchilla 强调了同时对模型大小和训练数据进行等比例规模化以达到最佳性能的重要性。这挑战了之前仅增加模型大小的重点。
- 资源分配:理解这些关系可以更有效地分配计算资源,可能导致更具成本效益和环境可持续的人工智能发展。
- 性能预测:这些法则使研究人员能够根据可用资源做出有根据的模型性能预测,帮助设定现实的目标和期望。
Scaling Law 观点
Ilya
【2024-9-5】Ilya 的公司 SSI 将以与OpenAI不同的方式, 继续 Scaling:
每个人都只是在说
Scaling Hypothesis,每个人都忽略了问:我们在Scaling什么?
- 有些人可以长时间工作,但他们只是以更快的速度走同样路径,这不是我们的风格。
- 但如果做些不同的事情,那么你就有可能做出一些特别的事情。
证伪
【2024-4-1】Scaling Law 被证伪,谷歌研究人员实锤研究力挺小模型更高效
Scaling Law 再次被 OpenAI带火,人们坚信:“模型越大,效果越好”
但谷歌研究院和约翰霍普金斯大学的研究人员对人工智能 (AI) 模型在图像生成任务中的效率有了新的认识:并非“越大越好”
实验设计 12 个文本到图像 LDM,其参数数量从 3900 万到惊人的 50 亿不等。
然后,这些模型在各种任务上进行了评估,包括文本到图像的生成、超分辨率和主题驱动的合成。
- 给定推理预算下(相同的采样成本)运行时,较小模型可胜过较大的模型。
- 当计算资源有限时,更紧凑的模型可能比较大、资源密集的模型能够生成更高质量的图像。
- 这为在模型规模上加速LDMs提供了一个有前景的方向。
- 采样效率在多个维度上是一致的
国内
国内讨论 Scaling Laws 论文不多。目前部分公开资料: 百川智能 Baichuan2 和 北京理工大学的明德大模型(MindLLM)论文中讲述了自己对scaling law的尝试。
两者在真正着手训练数十亿或者百亿参数的大语言模型之前,训练多个小型模型为训练更大的模型拟合拓展规律。
- 在同一套(足够大)的训练集上,采用一致的超参数设置,独立训练每个模型,收集训练的计算量和最终损失。
- 而后以OpenAI论文中结论的幂律关系拟合,预测出期望参数量模型的训练损失。
百川做法在开始训练7B和13B参数量模型前,设计大小从1000万到30亿不等的7个模型,采用一致的超参数,在高达1Ttoken的数据集上进行训练。
基于不同模型的损失,拟合出了训练浮点运算次数(flops)到训练损失的映射,并基于此预测了最终大参数模型的训练损失。
Baichuan2 缩放定律:
- 使用1万亿个token训练从1000万到30亿参数不等的7个模型,对给定训练浮点运算次数(flops)时的训练损失进行幂律拟合(蓝线),从而预测了在2.6万亿token上训练 Baichuan2-7B 和 Baichaun2-13B的损失。拟合过程精确预测了最终模型的损失(两颗星标记)
明德大模型团队的关注点与百川相似,在训练3B模型前,在10b Tokens 上训练了参数量从1000万到5亿的5个模型,通过分析各个模型的最终损失,同样基于幂律公式,建立从训练浮点运算次数(FLOPs)到目标损失的映射,以此预测最终大参数模型的训练损失。
MindLLM 缩放定律:
- 100亿token的数据集上训练参数从1000万到5亿参数的5个模型。通过对训练浮点运算次数(FLOPs)和损失幂律拟合,预测使用5000亿token的数据集训练MindLLM-3B的最终训练损失。该拟合过程准确预测了模型的最终损失,用星星标记。
李开复零一万物团队的黄文灏,在知乎上关于Yi大模型的回答也较有代表性:”Scaling Law is all you need:很多人都认为scaling law 就是用来算最优的数据和参数量的一个公式,但其实scaling law能做的事情远不止如此。
为了真正理解scaling law
- 第一件事就是忘记Chinchilla Scaling Law
- 然后打开 OpenAI 的 Scaling Law的paper,再把paper中OpenAI引用自己的更早的paper都详细的读几十遍”。
更多见【2024-1-5】OpenAI与DeepMind的Scaling Laws之争
应用
GPT-4
GPT4报告中 Scaling Law曲线,计算量C和模型性能满足幂律关系
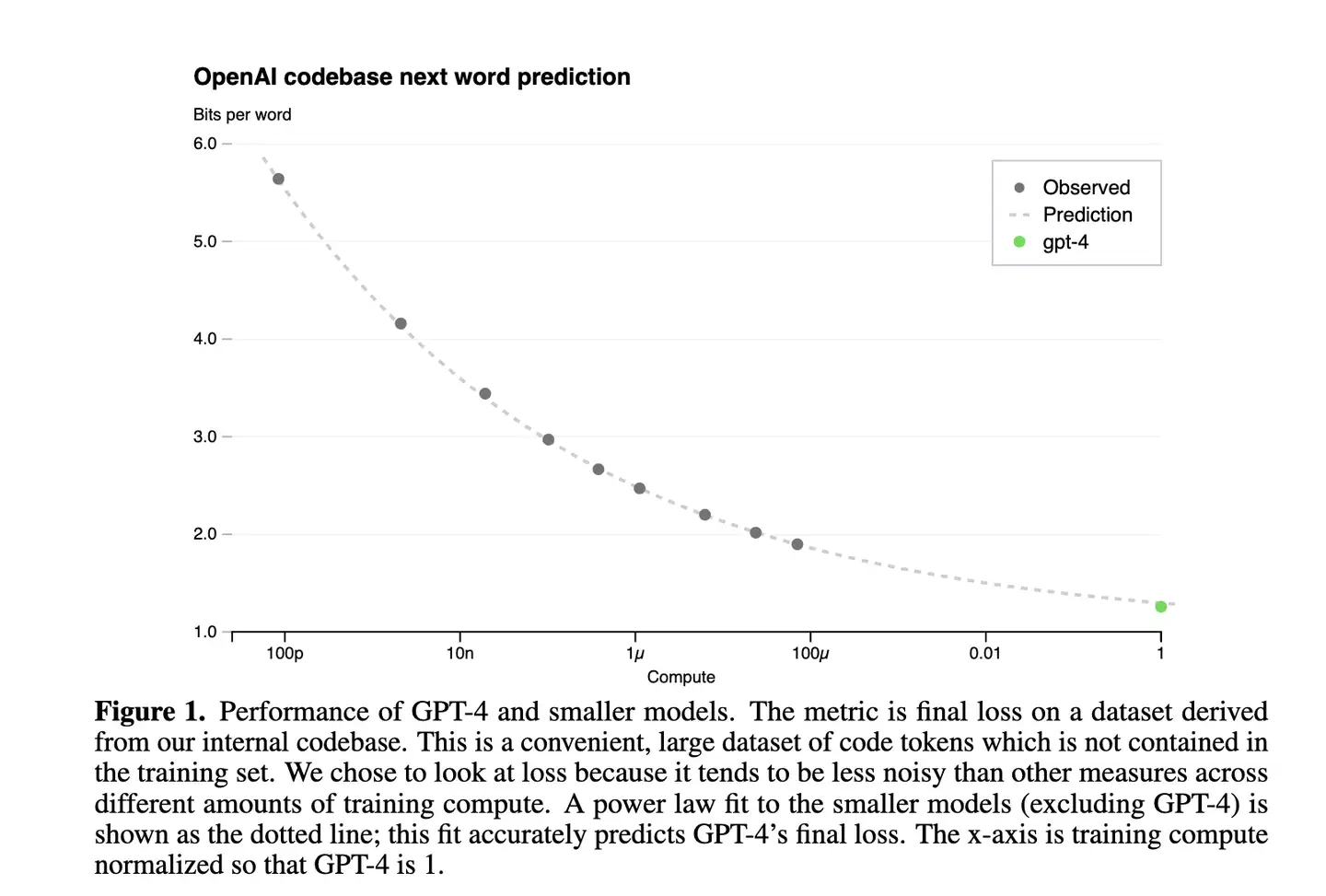
- 横轴是归一化之后的计算量,假设GPT4计算量为1。基于10,000倍小的计算规模,能预测最终GPT4的性能。
- 纵轴是”Bits for words”, 交叉熵单位。在计算交叉熵时,如果使用以 2 为底的对数,
交叉熵单位是 “bits per word”,与信息论中的比特(bit)概念相符。所以这个值越低,说明模型的性能越好。
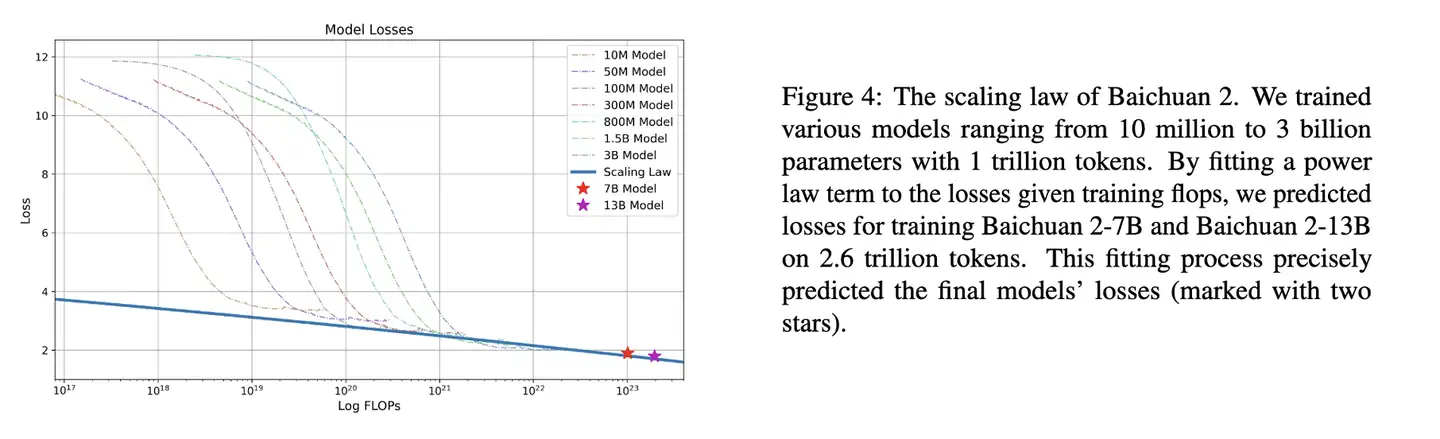
Baichuan2
Baichuan2 技术报告中的 Scaling Law曲线。
基于10M~3B 模型在1T数据上训练的性能,可预测出最后7B模型和13B模型在2.6T数据上的性能
幂律定律
- 模型参数固定,无限堆数据并不能无限提升模型性能,模型最终性能会慢慢趋向一个固定值
实验数据
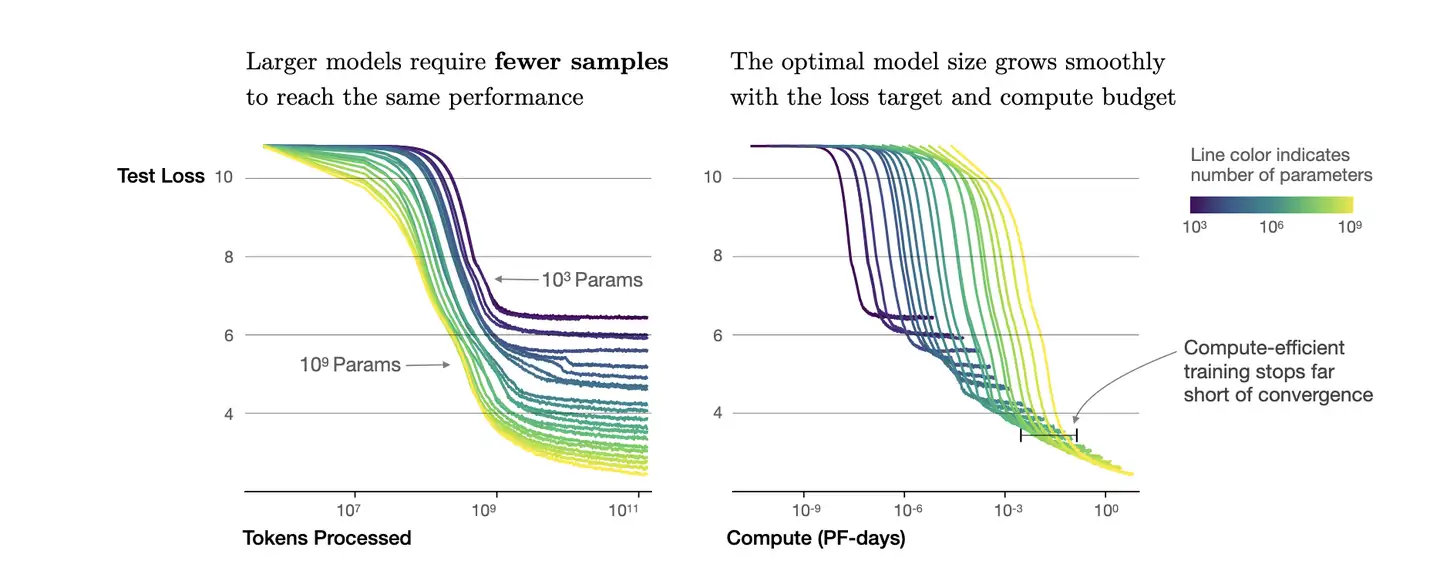
如何计算
如果模型参数量为 10^3(紫色线),数量达到10^9,模型基本收敛。继续增加数据,产生的计算量,没有同样计算量下提升模型参数量带来的收益大(计算效率更优)。
根据 C=6ND ,进一步转换成模型参数与计算量关系,即:
- 模型参数为 10^3,计算量为
6*10^12Flops,即7*10^(-8)PF-days时, 基本收敛。右图中紫色线拐点。
Baichuan 实验
- 中英场景下,7B 模型收敛时的算力是 10^23 FLOPS,对应数据量应该是 $ D=\frac{10^23}{6710^9}=2.3T $
计算效率最优时,模型参数与计算量幂次成线性关系,数据量大小也与计算量幂次成线性关系。
观点
- OpenAI 认为模型规模更重要,即 a=0.73, b=0.27
- 而 DeepMind 在 Chinchilla工作和Google在PaLM工作中都验证了 a=b=0.5 ,即模型和数据同等重要。
假定计算量整体放大10倍
- OpenAI 认为模型参数更重要,模型应放大 10^0.73=5.32 倍,数据放大 10^0.27=1.86 倍;
- DeepMind和Google认为模型参数量与数据同等重要,两者都应该分别放大 10^0.5=3.16 倍。
最好在自己的数据上做实验来获得你场景下的a,b
MindLLM
MindLLM 技术报告中 Scaling Law曲线。
基于10M~500M 模型在10B数据上训练的性能,预测出最后3B模型在500B数据上的性能。
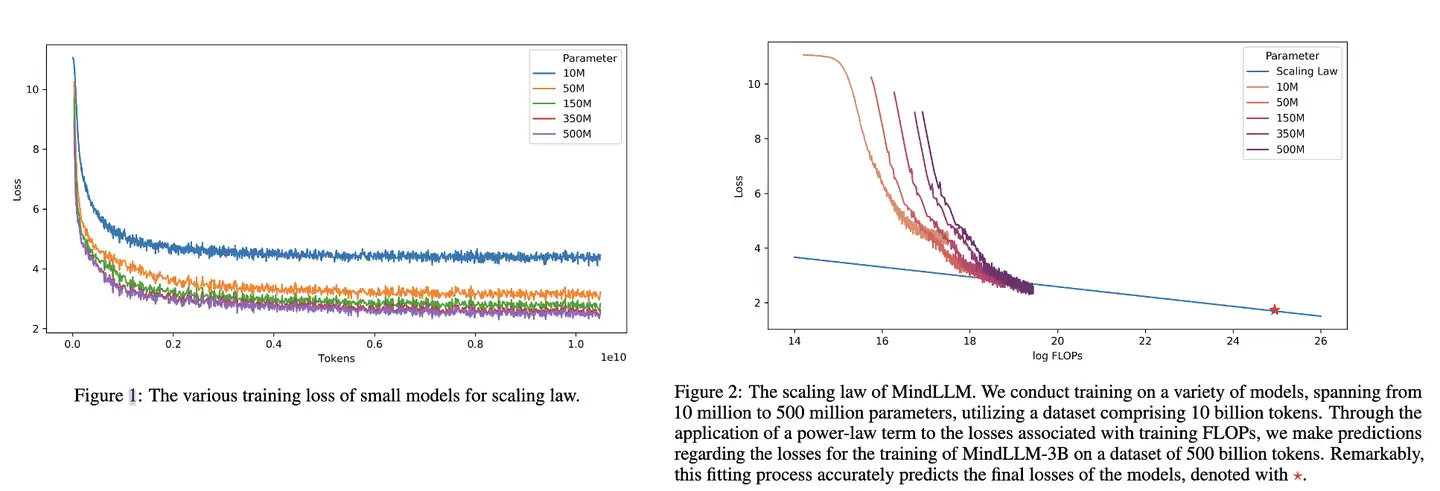
LLaMA
LLaMA: 反Scaling Law 大模型
假设遵循计算效率最优来研发LLM,那么根据 Scaling Law,给定模型大小,可推算出最优计算量,进一步根据最优计算量就能推算出需要的token数量,然后训练就行。
但是计算效率最优是针对训练阶段而言,并不是推理阶段,实际应用中推理阶段效率更实用。
Meta 在 LLaMA 的观点是:
- 给定模型目标性能,并不需要用最优的计算效率在最快时间训练好模型,而应该在更大规模的数据上,训练一个相对更小模型,这样的模型在推理阶段的成本更低,尽管训练阶段的效率不是最优的(同样的算力其实能获得更优的模型,但是模型尺寸也会更大)。
- 根据 Scaling Law,10B模型只需200B数据,但是7B模型性能在1T数据后还能继续提升。
所以, LLaMA 重点是训练一系列语言模型,通过使用更多数据,让模型在有限推理资源下有最佳的性能。
- 确定模型尺寸后,Scaling Law 给到的只是最优数据量,一个至少的数据量,实际在训练中观察在各个指标上的性能表现,只要还在继续增长,就可以持续增加训练数据。
改进
内生复杂性类脑网络
【2024-8-25】放弃Scaling Law!中科院、清北提出内生复杂性类脑网络:让AI像人脑一样“小而强”
如果 AI 模型像人脑一样,规模小,耗能少,但具备同样复杂功能,那现阶段 AI 模型训练的耗能大、难理解的瓶颈是不是就能解决了?
中国科学院自动化研究所李国齐、徐波研究员团队联合清华大学、北京大学等团队便取得突破
- 借鉴大脑神经元复杂动力学特性,提出“基于内生复杂性”的类脑神经元模型构建方法,而非基于 Scaling Law 去构建更大、更深和更宽的神经网络。
- 这种方法不仅改善了传统模型通过向外拓展规模带来的计算资源消耗问题,还保持了性能,内存使用量减少了 4 倍,处理速度提高了 1 倍。
研究论文
- “Network model with internal complexity bridges artificial intelligence and neuroscience”, Nature Computational Science
- 共同通讯作者为中国科学院自动化所李国齐研究员、徐波研究员,北京大学田永鸿教授。共同一作是清华大学钱学森班的本科生何林轩(自动化所实习生),数理基科班本科生徐蕴辉(自动化所实习生),清华大学精仪系博士生何炜华和林逸晗。
李国齐解释说
- 构建更大、更复杂的神经网络的流行方法,称为“基于外生复杂性”,消耗了大量的能源和计算能力,同时缺乏可解释性。
- 相比之下,拥有 1000 亿个神经元和 1000 万亿个突触连接的人脑仅需 20 瓦的功率即可高效运行。
加州大学圣克鲁斯分校 Jason Eshraghian 团队在评论文章中表示,这一发现暗示了 AI 发展的潜在转变。尽管大语言模型(LLM)的成功展示了通过大量参数计数和复杂架构的外部复杂性的力量,但这项新的研究表明,增强内部复杂性可能提供了改善 AI 性能和效率的替代路径。
AI 中内部与外部复杂性之争仍然开放,两种方法在未来发展中都可能发挥作用。通过重新审视和深化神经科学与 AI 之间的联系,我们可能会发现构建更高效、更强大,甚至更“类脑”的 AI 系统的新方法。
效果怎么样?
首先展示了脉冲神经网络神经元 LIF(Leaky Integrate and Fire)模型和 HH(Hodgkin-Huxley)模型在动力学特性上存在等效性,进一步从理论上证明了 HH 神经元可以和四个具有特定连接结构的时变参数 LIF 神经元(tv-LIF)动力学特性等效。
基于这种等效性,团队通过设计微架构提升计算单元的内生复杂性,使 HH 网络模型能够模拟更大规模 LIF 网络模型的动力学特性,在更小的网络架构上实现与之相似的计算功能。进一步,团队将由四个 tv-LIF 神经元构建的“HH 模型”(tv-LIF2HH)简化为 s-LIF2HH 模型,通过仿真实验验证了这种简化模型在捕捉复杂动力学行为方面的有效性。
结果表明,HH 和 s-LIF2HH 网络具有相似的噪声鲁棒性,而鲁棒性源自 HH 神经元的动态复杂性和 s-LIF2HH 的复杂拓扑,而不仅仅是神经元数量。这表明,模型内部复杂性与外部复杂性之间具有等效性,并且它们在深度学习任务中比具有简单动力学增加规模的模型有更加明显的优势。
局限性
- HH 和 s-LIF2HH 模型在深度学习实验中具有不同的脉冲模式,这表明模拟中近似的动态特性可能不是它们可比性的良好解释。这种现象可能源于它们基本单元(HH 神经元和 s-LIF2HH 子网络)固有的相似复杂性。
- 此外,由于神经元非线性和脉冲机制的局限性,本研究仅在小型网络中进行了,未来将研究更大规模的网络和单个网络中多种神经元模型的影响。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}