LLM 优化方向
【2023-6-16】知乎专题:大模型LLM领域,有哪些可以作为学术研究方向?
- 模型层:
- GPT系列,多模态系列,视觉类SAM:原生的工具调用能力;
- 安全性:加密,可信任,联邦学习;
- 新模型,新范式:长文本建模,不需要RLHF等;
- 涌现问题的研究、黑盒的研究;
- 并行、运算、显存的优化。EL-Attention,ZeRo,剪枝部署,蒸馏压缩。
- 接口层:
- 私有化部署;
- Adapter,prefix,Lora;
- Fusing。
- 应用层:
- Visual ChatGPT,HuggingGPT,AutoGPT,LangChain;
- Prompt工程,向量库,dense retrieval;
- 自我纠错,自我迭代,chain of thought 加强;
- 评测数据集、新时代下的新任务,generatice agents等
假设已经有 GPT-3.5 基础模型,一千张卡,思考能做什么?然后用小模型,比如LLaMa 7B去验证,如果成功,再慢慢加大到13B,30B,画出一条上升的曲线;不一定要scale到最大的模型,只要自己的结论能划出一条上升的曲线,那么这条曲线就可外推到更大。
源自知乎:LessTalk
- 平台工具及工程化部署
- 小模型拟合大模型降低计算量
- 多模态的输入与输出
- Prompt Engineering
- 垂直领域应用 搜索+知识图谱、机器人、自动驾驶等
提纲
- 基础理论:大模型的基础理论是什么?
- 网络架构:Transformer是终极框架吗?
- 高效计算:如何使大模型更加高效?
- 高效适配:大模型如何适配到下游任务?
- 可控生成:如何实现大模型的可控生成?
- 安全可信:如何改善大模型中的安全伦理问题?
- 认知学习:如何使大模型获得高级认知能力?
- 创新应用:大模型有哪些创新应用?
- 数据评价:如何评估大模型的性能?
- 易用性:如何降低大模型的使用门槛?
作者:zibuyu9
其它
- reasoning 逻辑推理:目前llm能力还不够的地方。比如能不能让llm做leetcode hard。进一步的,能不能自己创造新的知识,解决哥德巴赫猜想。
- compression and acceleration 模型压缩与加速:怎么把一个10b的模型弄到手机上并高速运行
- agent:怎么更好的给llm加上眼睛与手脚,让llm变成agent执行任务,并构造各种各样全新的benchmark。比如让agent发知乎回答以点赞多为目标。能不能通过RL把这件事做了?就和当年搞游戏ai一样。
- multi-modal 多模态:GPT-4没有开源,甚至没有技术细节,怎么做一个开源的逼近gpt-4的模型。mini-gpt4, llava是个不错的尝试。
- Hallucination 幻觉问题:GPT-4已经好了很多,但仍然没有完全解决。所以因此马斯克说要做TruthGPT. 要让LLM知之为知之不知为不知。这个难度其实很大。
- Evaluation。开源世界需要一套新的Evaluation的方法来评估llm的效果,从而方便推进开源llm的进展。
- dataset。这个是chatgpt被创造出来的源头。所以,能否多构建一个专家的数据库来帮助优化llm呢?每一份开源数据都非常有价值。
论文:A PhD Student’s Perspective on Research in NLP in the Era of Very Large Language Models
【2025-6-15】Scaling What?堆数据/规模 → 拉长思维链 → context 情景智能
邱锡鹏教授:该Context了
- 第一阶段,靠“堆数据、加参数”,让模型变聪明;
- 第二阶段,拉长“思维链”提升推理能力。
- 第三阶段正在上演。新概念——Contextual Intelligence(情境智能)。场景、具身等信息
【2025-7-10】AGI实现的可能方向:
- 推理LLM(已经很多人批了,自回归可能行不通)
- 世界模型(yann lecun强推,难度大,处于早期)
- 其他非transformer模型(如ssm状态空间模型、snn脉冲神经网络等)
- 符号主义(因果推理、GNN图神经网络)、类脑(仿生)等。
openai的成功“破坏”了整个世界的技术认知,就像书籍《伟大不能被计划》一样,技术创新难以被精确预测
张钹院士在2024年8月初的ISC.AI 2024 人工智能峰会上,指出大模型的四个发展方向:
- 1、与人类对齐;
- 2、多模态生成;
- 3、AI Agent;
- 4、具身智能。
数据
大模型数据已经见底, 需要转型,从经验中学习
趋势: 人类数据 -> 经验数据
强化学习之父”、2024 年 ACM 图灵奖得主 Richard Sutton 在新加坡国立大学发表人工智能未来的演讲,系统地阐述了他对 AI 技术趋势、社会哲学及宇宙演化的前沿思考。
- AI 正经历从“人类数据时代”到“经验时代”的根本性转变,并强烈呼吁社会以去中心化的合作精神取代基于恐惧的中心化控制,勇敢地迎接一个由 AI 驱动的未来。
详见站内专题:Data Centric
模型融合
【2024-8-8】模型融合来袭!ChatGPT和Claude 杂交能变聪明10倍?
什么是模型融合
什么是模型融合?
- 把多个AI模型的参数混合在一起,生成一个新模型。
简单, 但效果却出奇的好
- 不需要额外的数据和算力,只要把模型权重加减一下就行了。
- 融合后的模型还真能集各家之所长,性能明显提升。
比如 Prometheus-2 模型用这招把几个评估模型的能力融合到一起的
融合方法
常见方法:图见原文
- 线性融合:最简单粗暴,直接对参数加权平均。虽然简单但出奇的有效。
- 任务向量:把微调后的模型减去原始模型,得到一个”任务向量”。用这个向量做加减法,比如减掉有毒内容的任务向量,模型就能生成更干净的内容了。
TIES融合:在任务向量基础上加了三板斧 - 修剪、选举和分离,可以去掉冗余权重、解决任务向量间的分歧。DARE融合:跟TIES思路类似,但用随机丢弃和重新缩放来去掉冗余权重。
论文链接:
工具 mergekit:
GaC
Gac: Generation as Classification
【2024-6-18】上海AI Lab 推出 融合多个大模型新思路 — Generation as Classification
常打比赛的人(如Kaggle)很熟悉, 很多时候拼的就是各种花式模型融合, 将多个model融合(ensemble)后可以突破现有瓶颈, 神奇地让融合后的性能超过任何一个参与ensemble的单一模型。
ImageNet 视觉分类任务, 分类模型会输出一个维度为 1000 向量代表预测每个类别的概率,仅仅将多个模型的分类向量加起来后取平均, 就可以取得不错的准确率提升
- 原本最高的是 RepGhostNet 78.81%, 将三个模型融合后就提升到了 80.62%.
类似地, 把LLM每个generation step都当成一次分类任务(Generation as Classification, GaC)去ensemble, 从而提升所生成的每个token的正确性, 并最终获得更好 response.
核心思想: LLM生成文本时, 每个generation step都由多个LLM共同决定下一个token要输出什么
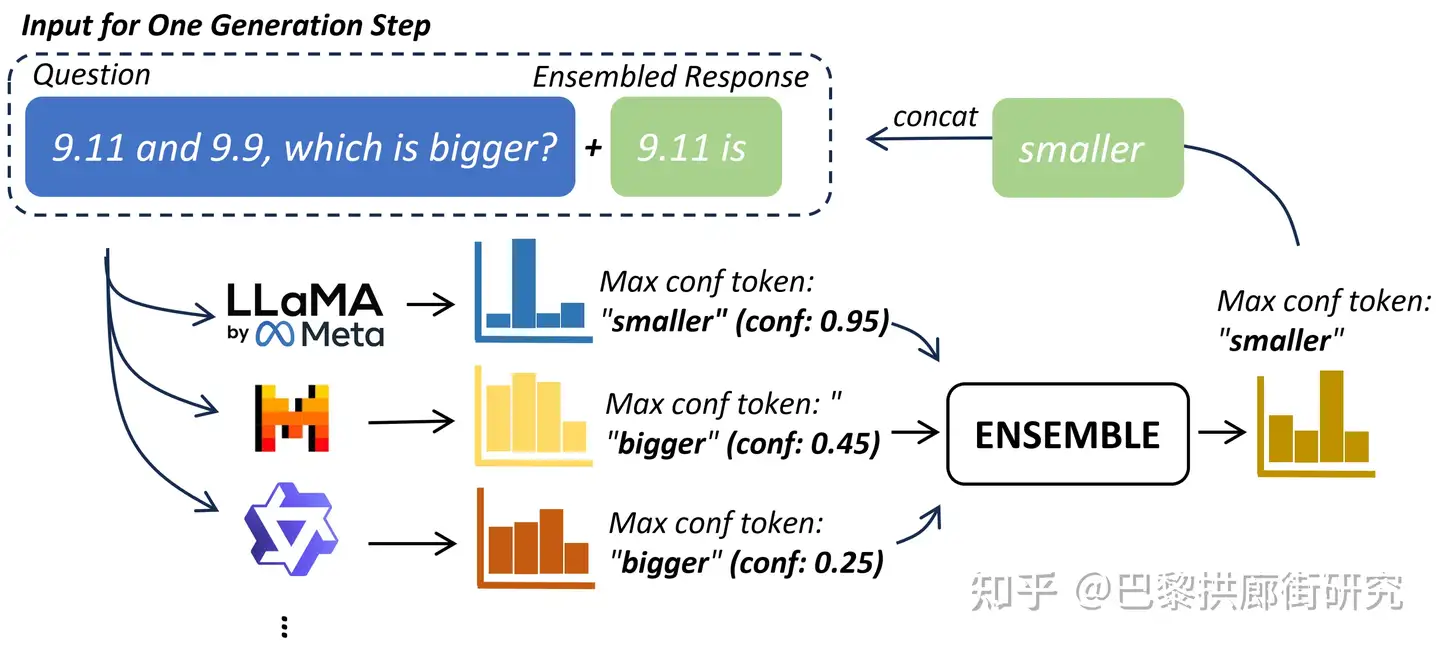
- Paper Title: Breaking the Ceiling of the LLM Community by Treating Token Generation as a Classification for Ensembling
- GaC
如何实施?
问题
- LLM 每步生成跟其词汇表等长的概率向量, 而 LLMs 词汇表长度不一样
- 比如:
- Llama3 词汇表长度 128256
- Qwen2 词汇表长度 152064
- 这和ImageNet分类任务上所有模型都输出1000维度的向量不同.
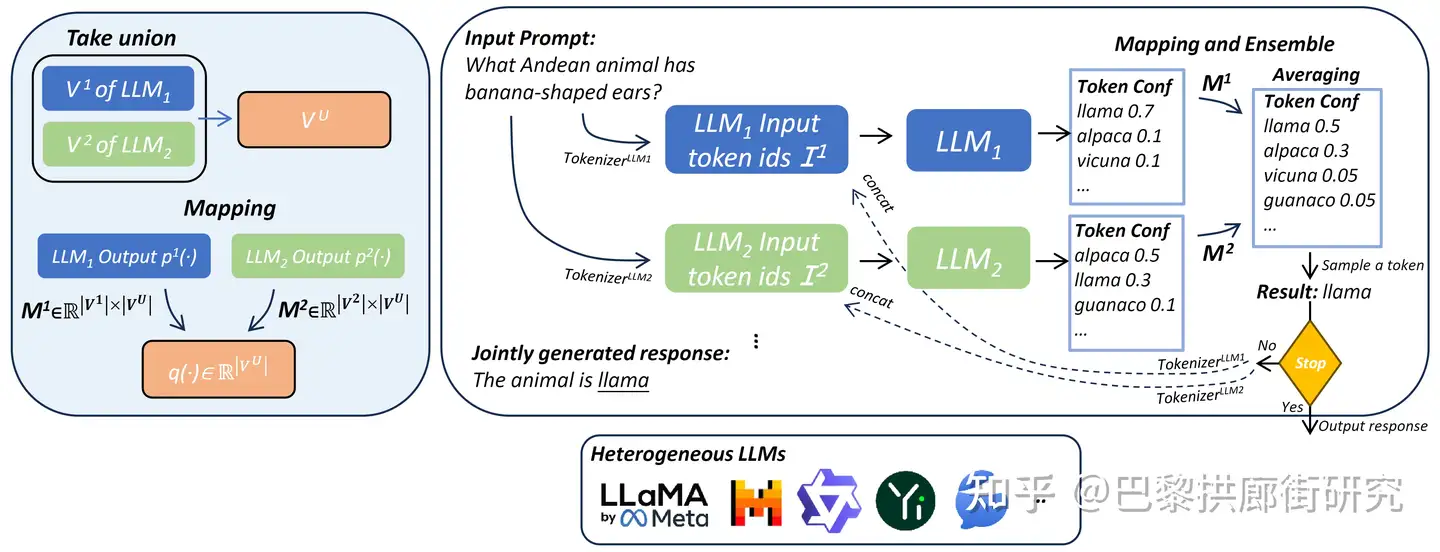
直觉做法:
- 对所有参与ensemble的LLM词汇表取并集得到 Vu, 并用0-1矩阵记录下原本LLM词汇表和 Vu 对应关系.
- 一个generation step中, 将每个LLM生成的概率向量乘以各自的0-1矩阵转换到 Vu 维度
- 随后再取平均并得到ensemble后的概率向量
- 再根据该向量sample出下一个token, 此时这个token就是由所有参与ensemble的LLM决定的
- 当选出一个token后, 每个LLM会用各自的tokenizer将这个token转换为各自的 token id(s), 并拼回到各自的输入中以进行下一个generation step.
这种简单做法竟然打破现有的LLM社区天花板!(当然, 花费了更多计算量)
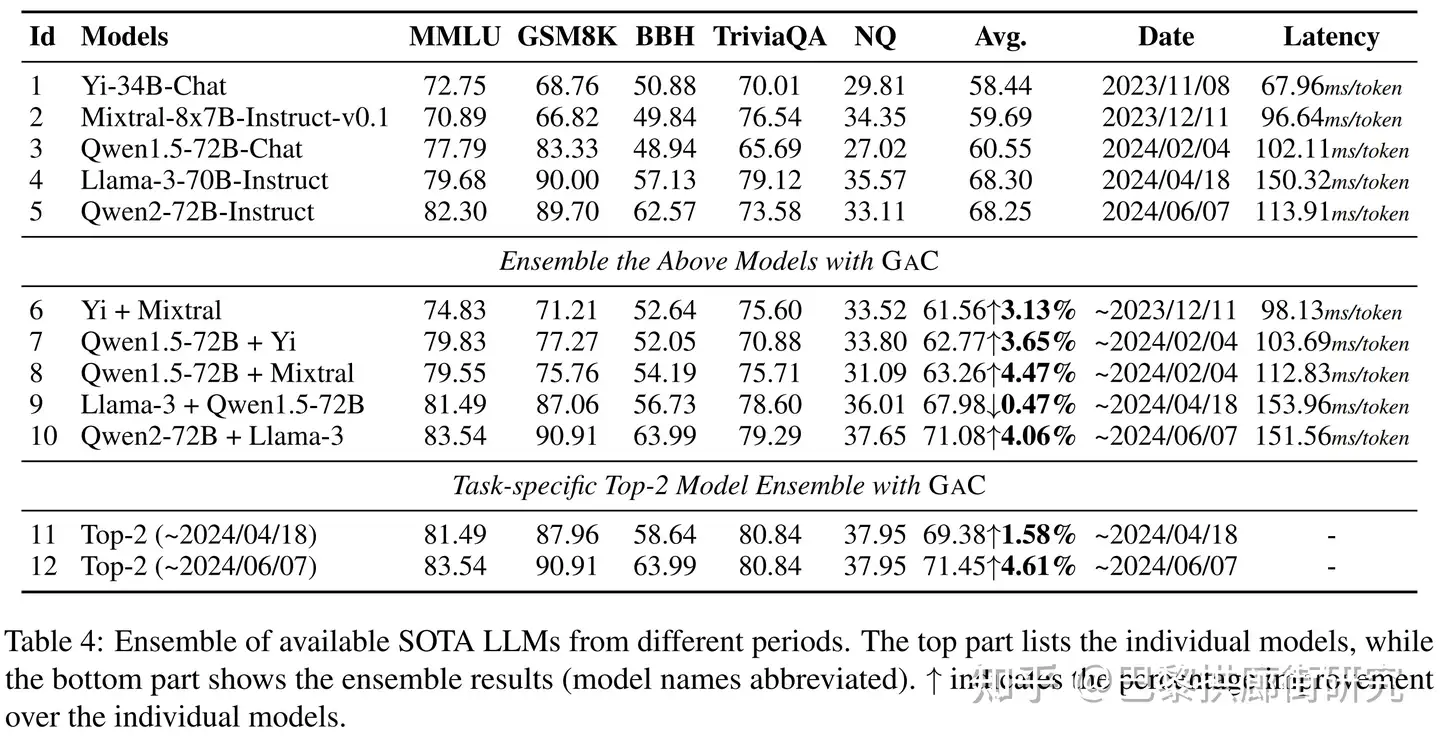
Qwen2 是 2024/06/07 退出, 拿它和实力相当的 llama3 进行融合, 各个指标上平均4%的提升! 达到 2024/06/07开源社区最好结果
该方法不受模型架构的限制, 随着新模型的释出还是可以不断的以新模型为基础继续推升天花板.
可控生成
【2023-7-10】LLM 可控生成初探
基于 LLM 的应用开发过程中,有几个挑战,包括:
- 如何避免“胡说八道”, 提升模型输出的可靠性/稳定性
- 控制模型的计算开销和响应速度等等
目前主流的解决手段包括:
- 更好的 prompt 设计
- 通过 retrieval 来做增强
- 与外部工具的结合
- 流程编排与产品设计
- 考虑使用 fine tune 模型或混合模型应用
| Prompt优化类型 | latency | compute |
|---|---|---|
| Few-Shot CoT | ?? | ?? |
| Zero-Shot CoT | ? | ? |
| Decomposition | ?? | ?? |
| Ensembling | ? | ???? |
| Self-Criticism | ???? | ?? |
可控生成最直接的方案:
- 首先通过 prompt 告知 LLM 我们所需要的返回格式,并进行生成。
- 通过一些规则来检查返回结果,如果不符合格式,生成相关错误信息。
- 将上一次的生成内容和检查的错误信息告知 LLM,进行下一次的修正生成。
- 重复 2-3 步骤,直到生成的内容完全符合要求。
LLM 的可控性、稳定性、事实性、安全性等问题是推进企业级应用中非常关键的问题,下面这些项目在这方面做了很多探索,也有很多值得借鉴的地方。
总体思路上来说,主要是:
- 提供一套 prompt 模板定义,允许用户指定 LLM 生成的格式或内容主题。
- 在模板基础上,也有不少项目进一步设计了相应的编程语言,让 LLM 与确定性程序的交互更加直观。
- 提供各类 validator,保证生成内容符合预期,并且提供了自动处理/修正机制。
- 更进一步,也可以在生成前进行干预,例如在 prompt 中给近似案例,修改模型 decode 时的概率分布等。
- 其它在可控性基础上做的各种性能与开销的优化,例如缓存,减少 token 消耗量,对开源模型能力的挖掘等。
即使不直接使用上述的项目做开发,也可以从中学习到很多有用的思路。当然也非常期待这个领域出现更多有意思的想法与研究,以及 prompt 与编程语言结合能否碰撞出更多的火花。
详见原文:LLM 可控生成初探
输出稳定性
【2025-2-6】【ICLR 2025】不确定性uncertainty相关论文汇总
- ICLR 2025中关于不确定分析、不确定性量化、不确定性+下游任务等相关的论文简单汇总
- 哈佛大学 Provable Uncertainty Decomposition via Higher-Order Calibration, 将模型预测不确定性分解为具有明确语义的随机和认知成分,这些成分与现实世界的数据分布相关联。
- Credal Wrapper of Model Averaging for Uncertainty Estimation in Classification 提出 “credal wrapper”的创新方法,为贝叶斯神经网络 (BNN) 和深度集成 (DE) 制定模型平均的“credal set”表示,能够改善分类任务中的不确定性估计。
- From Risk to Uncertainty: Generating Predictive Uncertainty Measures via Bayesian Estimation 逐点风险分解为与不同预测不确定性来源相关的成分:即随机不确定性(固有数据变异性)和认知不确定性(与模型相关的不确定性)。结合作为近似值的贝叶斯方法,我们构建了一个框架,允许生成不同的预测不确定性度量。
- DeLLMa: Decision Making Under Uncertainty with Large Language Models DeLLMa(决策大型语言模型助手),这是一个旨在提高不确定环境中决策准确性的框架。多步骤推理过程,该过程整合了扩展推理时间推理的最新最佳实践,借鉴了决策理论和效用理论的原理,以提供准确且可人工审核的决策过程。
- 复旦 An Empirical Analysis of Uncertainty in Large Language Model Evaluations 2 种不同的评估设置中对 9 种广泛使用的 LLM 评估者进行了广泛的实验,LLM 评估者根据模型系列和大小表现出不同的不确定性, 采用特殊的提示策略(无论是在推理期间还是在训练后)可以在一定程度上缓解评估不确定性。通过利用不确定性来增强 LLM 在分布外 (OOD) 数据中的可靠性和检测能力,我们使用人工注释的微调集进一步微调了一个名为 ConfiLM 的不确定性感知 LLM 评估器
- 剑桥 Do LLMs estimate uncertainty well in instruction-following? 首次系统地评估了 LLM 在指令遵循方面的不确定性估计能力
【2025-9-10】LLM技术论文:《如何解决LLM推理中的非确定性问题》
2025年2月, OpenAI前CTO Mira Murati成立公司 Thinking Machines Lab
- 第一篇文章,从底层技术的角度阐述LLM推理时的非确定性产生的原理,并在vLLM基础上实现确定性推理的演示。
- 原文 Defeating Nondeterminism in LLM Inference
OpenAI在上周正好发布为什么语言模型会产生幻觉的技术论文。
- 《为什么语言模型会产生幻觉》解读
最大的贡献:
- 清晰分析了当前推理引擎的工作机制,指出当前推理引擎因为效率优化,在batch计算的时候计算顺序不确定问题引入了
非结合律带来的推理结果不确定,也就是前向传播 “批次不变性”(batch invariance)
解决后最大的收益
- 不确定性导致当前用vllm/sglang做roll out的RL训练并不是真的on policy,所以需要一些技巧避免训练崩。
- 而解决问题后虽然性能有降,但还能忍,而且是 true on policy RL,训练稳定性大幅提升。
LLM 幻觉的根本原因: 训练和评估流程奖励猜测行为而非承认不确定性。
- 幻觉现象并非神秘莫测 —— 本质上源于二元分类错误。当错误陈述无法与事实区分时,预训练语言模型中的幻觉就会在自然的统计压力下产生。
- 大多数评估的评分方式 —— 语言模型被优化为优秀的应试者,在不确定时,进行猜测能够提高测试表现。这种惩罚不确定性回答的“普遍现象”只能通过社会技术层面的缓解措施来解决:修改现有基准测试的评分机制,这些基准测试存在偏差却主导着排行榜,而非引入额外的幻觉评估。
可重现性是科学进步的基石, 然而大语言模型重现结果极其困难
多次向ChatGPT询问同一个问题,得到不同结果。
这并不令人意外
- 语言模型获得结果, 需要“采样”——将语言模型输出, 转换为概率分布并概率性地选择token的过程。
更令人意外的是
- 即使将温度参数调整到0(理论上使采样过程变成确定性的),LLM API在实际应用中仍然不具有确定性。
- 即使在自有硬件上使用
vLLM或SGLang等开源推理库运行推理,采样过程依然不是确定性的。
为什么不稳定
【2025-11-17】同一个prompt重复多次输入进 LLM,为啥得到的输出都不一样?
原因汇总
- 概率本质:LLM生成机制,大模型本质是复杂的概率预测系统,生成过程中的不确定性是内生的,非外来
- 解码策略:temperature=0 的真相
- temperature=0 输出完全缺点?错误,temperature控制采样随机性,值越小概率分布越尖锐,高概率token更容易选中,理论上,temperature=0 可以完全消除随机性,只选择概率最高的token。但实际实现中,并不能绝对保证。不同推理框架对参数处理存在差异,有些框架中0对应一个极小的非0数值,如 1e-8,导致仍然有一定概率选择次优token
- 不同解码策略会影响输出稳定性:贪心解码、束搜索、采样等
- 案例:100次输入中,5-15%次结果不同,尤其是输出较长,复杂推理任务尤其明显
- 浮点数精度:被忽视的罪魁祸首,浮点数运算本质非确定,不满足结合律,(a + b) + c ≠ a + (b + c),尤其是多gpu推理,运算顺序的微小差异导致结果不同,大模型中,误差被逐级放大,产生不同序列
- 模型架构:MoE额外变数
- 专家激活本身有一定随机性,路由机制可能因为浮点精度问题、并行计算顺序不同而选择不同专家组合
- 系统层面的不确定性
- cuda内核非确定性执行顺序、原子操作的时序不确定性、多线程调度的随机性、gpu缓存效应
- KV Cache实现:推理优化的双刃剑。
- kv cache 在不同框架中实现细节差异大,缓存管理中引入不确定性
- 量化效应:精度与效率的均衡
- int4和int8量化过程中,引入舍入误差,多次推理中以不同方式累积
- 有些框架还有动态量化策略
- 随机种子:被遗忘的控制变量
- 框架某些组件依赖随机数生成器,如果没显示设置种子,每次运行结果不同
- 批处理效应:并行推理的隐性影响
- 单个输入可能与不同请求一起处理,导致输出结果不同
如何获取真正的确定性输出?
- 固定随机种子:推理前设置所有随机源的种子
- 使用单一设备:避免多gpu/分布式推理
- 提高计算精度:float32提到float16】bfloat16
- 禁用所有非必要优化:关闭框架自动混合精度、内存优化
- 选择确定性框架:onnx runtime 确定性更有保障
- 验证模型架构:避免随机性模型架构,如某些变体moe
import torch
import random
import numpy as np
seed = 42
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
并发+浮点数
为什么LLM推理引擎不具备确定性呢?
- 浮点数的非结合性特征与并发执行相结合,会根据并发核心的完成顺序产生非确定性结果。—- LLM推理非确定性的“并发+浮点数”假设
【2025-1-11】论文 《Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning》指出
- GPU浮点算术具有非结合性特征,即
(a+b)+c ≠ a+(b+c),有限精度和舍入误差导致。 - 该特性直接影响transformer架构中注意力分数和logits的计算,其中跨多线程的并行操作会根据执行顺序产生不同结果。
- 速度权衡: 为了提高端点速度而使用GPU进行并行计算,这些计算具有非确定性。任何现代GPU神经网络计算都会受到这种影响。
- 由于GPU高度并行化,每次执行时加法或乘法的顺序可能不同,这种差异会级联放大到输出结果中。
批次不变性与”确定性”
但这并非全貌。
- 即使在GPU上,对相同数据重复执行相同矩阵乘法运算,始终会得到按位相同的结果。
- 这里确实使用了浮点数运算,GPU也确实具有大量并发性,那么为什么在这种测试中看不到非确定性现象呢?
困惑
- GPU某些内核非确定性,然而,语言模型前向传播中使用的所有内核都是确定性的。
- LLM推理服务器(如vLLM)的前向传播过程确定,但是,从推理服务器用户的角度来看,结果却是非确定性的。
“并发+浮点数”假设未能准确定位问题根源,揭示LLM推理非确定性背后的真正原因,并说明如何消除非确定性,在LLM推理中获得真正可重现的结果。
机器学习模型通常被视为遵循交换律或结合律等结构规则的数学函数。
浮点数的非结合性 (a+b)+c ≠ a+(b+c)
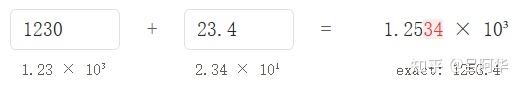
- 两个具有不同“量级”(即不同指数)的浮点数相加时,都可能发生这种情况
- 1230 需要3位精度,表示23.4也需要3位精度。
- 然而,将这两个数字相加的结果需要5位精度才能表示(1253.4)。浮点数格式必须舍弃末尾的34。
- 从某种意义上说,这相当于在相加之前将原来的23.4四舍五入为20.0
以不同顺序对浮点数进行加法运算时,就可能得到完全不同的结果。
import random
vals = [1e-10, 1e-5, 1e-2, 1]
vals = vals + [-v for v in vals]
results = []
random.seed(42)
for _ in range(10000):
random.shuffle(vals)
results.append(sum(vals))
results = sorted(set(results))
print(f"There are {len(results)} unique results: {results}")
# Output:
# There are 102 unique results: [-8.326672684688674e-17, -7.45931094670027e-17, ..., 8.326672684688674e-17]
浮点数之所以有用,是因为支持“动态”精度水平,破坏结合性的特征
内核为什么会以不同顺序进行数字加法运算的一个常见理论是“并发+浮点数”假设。
- 如果并发线程的完成顺序是非确定性的,而累积顺序又依赖于并发线程的完成顺序(例如使用原子加法操作),那么累积顺序也将是非确定性的。
- 虽然这种情况确实可能导致内核非确定性,但并发(和原子加法)与LLM推理的非确定性完全无关
GPU 在众多“核心”(即SM)上并发执行程序。
- 由于核心之间缺乏固有的同步机制,当核心需要相互通信时就面临挑战。
- 例如,如果所有核心都必须向同一个元素进行累积操作,可以使用“原子加法”(有时称为”fetch-and-add”)。
原子加法具有非确定性——结果累积的顺序完全取决于哪个核心先完成操作。

- 原子加法确保每个核心的贡献都会反映在最终结果中。然而,它不保证贡献的添加顺序。顺序完全取决于哪个核心先完成,这是一个非确定性属性。
- 因此,多次执行相同的并行程序可能产生非确定性输出: 使用完全相同的输入执行同一个内核两次,却得到不同的结果 ———— 运行间非确定性
虽然并发原子加法确实会使内核产生非确定性,但对于绝大多数内核而言,原子加法并非必需。
实际上,在LLM的典型前向传播中,通常不存在任何原子加法操作。避免使用原子加法带来的性能损失微乎其微。
- 沿“批次”维度通常存在足够的并行性,因此无需沿归约维度进行并行化
- 随着时间推移,大多数神经网络库都采用了多种策略来在不牺牲性能的前提下实现确定性。
LLM 常用的此类操作只有FlashAttention的反向传播。
- 但是,LLM 前向传播不涉及任何需要原子加法的操作, 前向传播具有“运行间确定性”。
批次不变性与”确定性”
前向传播本身具有“确定性”并不足以确保包含它的系统具有确定性。
例如,如果请求的输出依赖于并行的用户请求(如批归一化),会怎样?由于每个单独的请求无法知道并行请求的内容,从它们的角度来看,整个LLM推理过程也是非确定性的
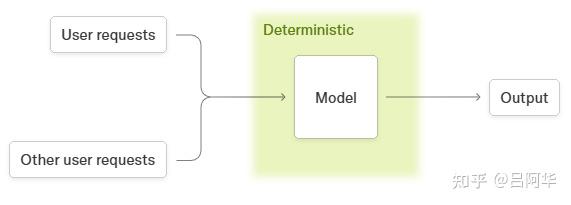
请求的输出确实依赖于并行用户请求。
- 这不是因为在批次间泄露了信息,而是因为前向传播缺乏”批次不变性”,导致请求的输出依赖于前向传播的批次大小
当非批不变的内核成为大型推理系统的组成部分时,整个系统就可能表现出非确定性。当用户向推理接口发出查询时,从用户角度来看,服务器所承受的负载实质上是“非确定性的”。负载决定了内核运行时的批次大小,进而影响每个独立请求的最终结果
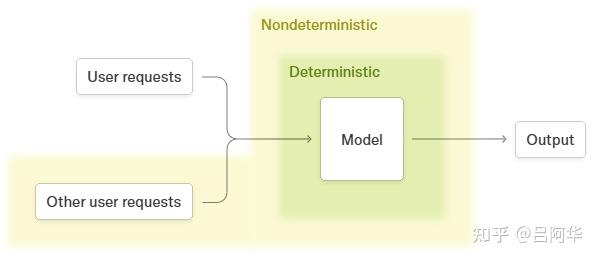
- 虽然推理服务器本身可以被认为是“确定性的”,但从单个用户的角度来看情况有所不同。对于单个用户而言,其他并发用户并不是系统的“输入”,而是系统的非确定性属性。这使得LLM推理从每个用户的视角来看都是“非确定性的”
几乎所有LLM推理接口都表现出非确定性的根本原因在于负载(以及相应的批次大小)的非确定性变化!这种非确定性并非GPU所独有——基于CPU或TPU的LLM推理接口同样存在这一非确定性来源。
如何实现内核的批次不变性?
要使transformer实现具备批次不变性,需要确保每个内核都具备批次不变性。
Transformer架构下,当前推理引擎里解决批次确定性问题主要在3个部分完成:RMSNorm、矩阵乘法(matmul)、注意力(attention)。
假设所有逐点运算都具备批次不变性。
因此,只需关注涉及归约操作的3种运算——RMSNorm、矩阵乘法和注意力机制。(按难度递增的顺序排列)
| 操作 | 要点 | 改造方案 | 图解 |
|---|---|---|---|
| RMSNorm | 小batch时,原始实现会切换规约策略(比如分裂规约/atomic add),导致不同batch-size下结果不一致。 | 固定规约顺序,或者采用“数据并行”策略(每个batch元素独占一个核心),确保不同batch-size下计算顺序恒定。 | 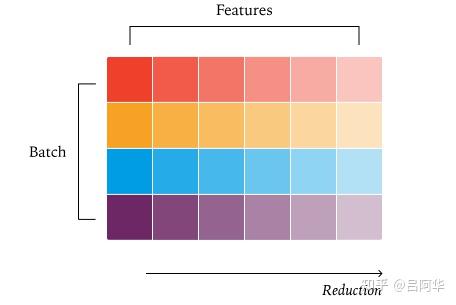 |
| 矩阵乘法 | 当M、N维度较小,需要用Split-K并行或切换tensor core指令,不同情况会改变规约顺序 | 强制使用固定的kernel 配置(固定 tile 与tensor core指令),不随batch-size动态调整,即使有轻微性能损失,也保证计算路径一致 | 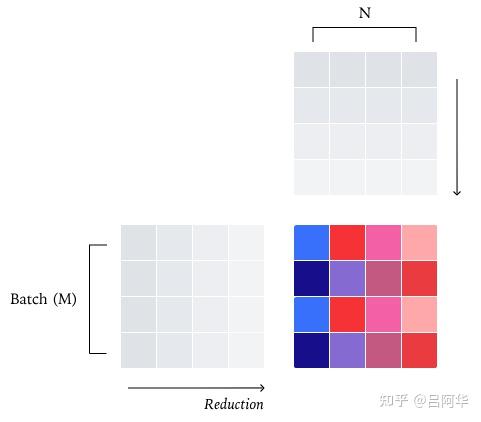 |
| 注意力机制 | KV Cache和新token分开规约,导致不同阶段(预填充和解码)的规约顺序不同。 | 对并行请求数量和推理引擎对请求的切分方式保持不变性 | 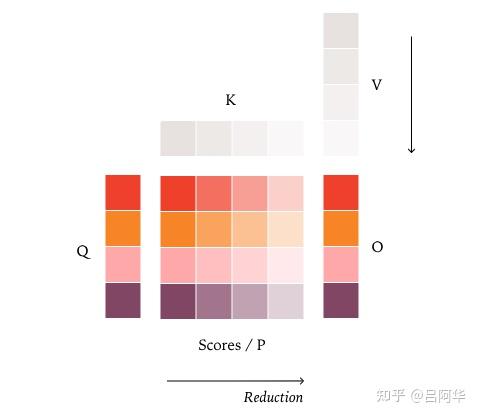 |
数据并行RMSNorm
- 理想情况下,希望在并行化策略中避免核心间通信。实现方法是将每个批次元素分配给一个核心,从而确保每个归约操作完全在单个核心内完成。
- 这被称为“数据并行”策略,因为仅沿着不需要通信的维度进行并行化。在此例中,四行数据和四个核心实现了核心的充分利用。
改造
- 固定规约顺序,或采用“数据并行”策略(每个batch元素独占一个核心),确保不同batch-size下计算顺序恒定。
大批次的数据并行RMSNorm
- 将数据并行策略扩展到更大批次相当直接——不是让每个核心处理一行数据,而是让每个核心依次处理多行数据。这种方法保持了批次不变性,因为每个批次元素的归约策略保持一致
数据并行矩阵乘法
- 与RMSNorm类似,矩阵乘法的标准并行策略是 数据并行 策略,将整个归约保持在单个核心中。
- 最直观的方法是将输出张量分割为2D tile,并将每个tile分配给不同的核心。每个核心然后计算属于该tile的点积,再次在单个核心内执行完整的归约。
问题
- 当M、N维度较小,需要用Split-K并行或切换tensor core指令,不同情况会改变规约顺序。
改造方案
- 强制使用固定的kernel 配置(固定 tile 与tensor core指令),不随batch-size动态调整,即使有轻微性能损失,也保证计算路径一致。
矩阵乘法可以看作逐点运算后跟随归约操作
主演问题推理时,KV Cache和新token分开规约,导致不同阶段(预填充和解码)的规约顺序不同。
解码阶段 query 很短:为了让GPU饱和,需要用Split-KV并行;常见的“平均切分”策略会随batch-size变化而改变规约顺序。
解决方案就是对并行请求数量和推理引擎对请求的切分方式保持不变性。
- 一是在进入注意力kernel前统一更新KV cache,保证K/V布局一致。
- 二使用固定分裂大小(fixed split-size)策略,不随batch-size改变分裂方式,从而保证规约顺序始终一致。
FlashAttention2策略
- 沿Q方向并行化,同时沿K/V方向归约。这意味着整个归约可以保持在单个核心内,使其成为另一种数据并行策略。
实现
vLLM基础上实现确定性推理的演示,利用了其FlexAttention后端和torch.Library。通过torch.Library,可以以非侵入性方式替换大部分相关的PyTorch操作符。
Qwen/Qwen3-235B-A22B-Instruct-2507 模型,在温度0设置下使用提示词”Tell me about Richard Feynman”(非思考模式)采样1000个完成结果,每个生成1000个token。
- 结果显示生成了80个不同的完成结果,其中最常见的出现78次。
通过分析完成结果的差异位置,发现前102个token完全相同!首次出现分歧的位置是第103个token。所有完成结果都生成序列”Feynman was born on May 11, 1918, in”,但随后992个完成结果生成”Queens, New York”,而8个完成结果生成”New York City”。
相比之下,启用批不变内核后,所有1000个完成结果都完全相同。这符合对采样器的数学预期,但如果没有批不变内核就无法实现确定性结果。
单GPU运行Qwen-3-8B的API服务器,请求1000个输出长度在90到110之间的序列。
guardrails
guardrails 项目将上述步骤做了进一步的抽象与封装,提供更加 high level 的配置与 API 来完成整个过程。其主要的组成部分包括:
- 定义了一套 RAIL spec,用来描述上面第 1 点提到的返回格式限定。除了 output schema 的定义外,RAIL目前也支持 input schema,prompt 模板,以及 instructions 等其它配置。
- 提供了一系列的 validation 机制,对应上面的第 2 点。对于 validate 失败的部分,会保留其在 output schema 中的位置,生成相应的错误信息。
- 通过 ReAsk 类来实现上面的第 3 点,发送给 LLM 的内容会更聚焦于错误信息部分,且保留了结构,更便于 LLM 理解和处理。
- 其它像常用 prompt 模板之类的功能。
NeMo-Guardrails
NeMo-Guardrails
- 来自 Nvidia 的一个同名项目,比 guardrails 更有野心,想要确保 LLM 应用整体的可信度,无害性以及数据安全性等,而不仅仅只是输出的结构化检查和修复。
- 因此其实现思路上也复杂不少,设计了一种专门的 Colang 语言,来支持更加通用多样的业务流,而不仅仅是生成 -> 检查 -> 修复。
- 这个项目会更专注于用户与 LLM 的对话式交互应用,主要的设计都是围绕这个前提展开。
guidance
guidance
- 微软推出的开源项目,几个作者看头像就很知名,分别是 shap,lime,checklist 的作者。之前有研究过 可解释机器学习的同学应该不会陌生。从 explainable ai 到 controlable llm,倒也是很说得通的发展路径
guardrails 中的做法是在 prompt 中给出说明和示范,希望 LLM 能够遵循指令来输出。但现实中往往会出现各种问题,例如额外带了一些其它的文字说明,或者生成的 json 格式不正确等,所以需要后续的 ReAsk 来进行修正。
LangChain 里也提供了各种 output parser 来帮忙提取回复中的结构化信息部分,但也经常容易运行失败。
在 guidance 中,同样是通过“模板语言”来定义 LLM 的输出结构,以确保输出格式的正确性。这个结构比起 xml 来说会更易写易理解些
guidance 将更加复杂的 Handlebars 模板 融入到了 prompt 中,使得原先需要复杂设计的 LLM 生成与程序处理交互过程可以很方便地在 prompt 中直接完成。
- 上面的例子中,只有当调用到
命令时,才会触发 LLM 的生成操作。另外也有像,``,函数调用,逻辑判断,控制流等命令,有种结合了自然语言与编程语言两者长处的感觉。
除了 prompt 模板编程能力外,guidance 还有一系列高级特性,包括:
- 支持 hidden block,例如 LLM 的一些推理过程可能并不需要暴露给最终用户,就可以灵活利用这个特性来生成一些中间结果。
- Generation caching,自动把已经生成过的结果缓存起来,提升速度。
- 支持 HuggingFace 模型的 guidance acceleration,进一步提升生成速度。
- Token healing,不看这个我还不知道 LLM 有这种问题……
- Regex pattern guide,在模板的基础上进一步通过正则表达来限定生成的内容规范。
lmql
在 guidance 的基础上,lmql 项目进一步把“prompt 模板”这个概念推进到了一种新的编程语言,倒是有点像前面 guardrails 跟 NeMo-Guardrails 的关系。项目本身提供了很漂亮的 playground 方便试用,注意如果要在本地玩这个项目,需要升级到 Python 3.10 的版本。
Json 控制
【2024-8-6】程序员窃喜!卡了大模型脖子的Json输出,OpenAI终于做到了100%正确
大模型的 json 格式饱受诟病。经常遇到模型不遵循指令,不按格式输出,即使在 prompt 中明确说了要按照指定格式(比如Json、XML)返回结果,但是它就是不听话。
OpenAI 给 GPT-4o 模型升级到2024-08-06版本,带来全新功能:
- API 中引入了
结构化输出(Structured Outputs)
模型输出现在可靠地遵循开发人员提供的 JSON 模式, 实现输出JSON的100%准确率
之前开发者通过第三方开源工具,或在 prompt 上面做功夫,让大模型遵循你的命令,再或者反复重试请求来绕过LLMs在结构化处理的缺陷,现在都不需要
两种办法:
- (1)函数调用: 在函数定义中设置 strict:true进行结构化输出;
- (2)新增response_format 参数选项
如何实现?
- 对于特定复杂JSON架构进行模型训练,Openai通过这种方法能把模型准确率提到93%。
- 相较于最开始带JSON模式的GPT-4的40%准确率,已经高出很多了。
- 但是模型本质上还是不确定,无法保证JSON的稳定输出
- OpenAI使用了约束解码(constrained decoding)技术。
- 默认情况下,大模型在进行token输出时,可在词汇表中选择任意词汇,作为下一个输出token。而这种不可控性会让模型在输出一些固定格式的文本时犯格式错误。
- 而使用动态约束解码技术后,大模型在下一个token输出时,便增加了一些约束,将模型限制在有效的token内,而不是所有token。
- 比如:输入“
{"val”后,下一个生成的文本一定不会是“{”。 - 大模型不仅可以实现JSON格式正确,还可实现合适schema结构精确。
现在OpenAI已经通过这种方式实现了100% JSON输出准确率。
缺陷
- 额外增加Schema预处理时间,新模型在请求新的JSON Schema时慢些。
- 要使用结构化输出还有一些限制:
- 目前结构化仅支持输出一部分JSON模式,包括 String、Number、Boolean、Object、Array、Enum和anyOf。
- 同时,所有字段或者函数参数必须是“required”。
- 对象对嵌套深度和大小也有限制。
- 一个架构总共最多可以有 100 个对象属性,最多有 5 个嵌套级别。
- OpenAI还留了个底:结构化输出并不能防止所有类型的模型错误。模型可能仍会在JSON对象的值中犯错误(比如在数学方程式中步骤出错),如果出现错误,需要使用者在指令提示词中提供示例,或者将任务拆分为更简单的子任务。
- 安全。结构化输出功能将遵守OpenAI现有的安全政策,并且仍会拒绝不安全的请求。甚至他们在API响应上设置了一个新字符串值,让开发人员能以编程方式,检测模型是否拒绝生成。
知识植入
LLMs 依然会受到知识截断和谬误问题的限制。例如,ChatGPT 和 LlaMA 等 LLMs 仅具备截至训练最后时点的信息,也可能会因预训练数据中的偏见和差异生成不准确或误导性的输出。因此,高效更新 LLMs 的参数化知识进而调整特定行为,变得至关重要。
解决办法
- 尽管微调和参数高效微调可以修改 LLMs,但成本较高,还可能导致 LLMs 失去预训练所得能力,并且其修改也不总能泛化到相关输入。
- 使用手动编写或检索的提示影响 LLMs 的输出,但这类方法没有参数更新,可靠性不足。
知识编辑
为了使不相关输入的影响最小化,并迅速有效地修改 LLMs 的行为,一种可行的解决方案是知识编辑。关于 LLMs 的知识编辑研究在各种任务和设置下取得显著进展,包括 Memory based、Meta-learning 和 Locate-Then-Edit 三类方法。
Methods
- ① Memory-based
- Memory-Based Model Editing at Scale (ICML 2022)
- Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, Chelsea Finn. [paper] [code] [demo]
2. Fixing Model Bugs with Natural Language Patches. (EMNLP 2022)
Shikhar Murty, Christopher D. Manning, Scott M. Lundberg, Marco Túlio Ribeiro. [paper] [code] 3. MemPrompt: Memory-assisted Prompt Editing with User Feedback. (EMNLP 2022)
Aman Madaan, Niket Tandon, Peter Clark, Yiming Yang. [paper] [code] [page] [video] 4. Large Language Models with Controllable Working Memory.
Daliang Li, Ankit Singh Rawat, Manzil Zaheer, Xin Wang, Michal Lukasik, Andreas Veit, Felix Yu, Sanjiv Kumar. [paper] 5. Can We Edit Factual Knowledge by In-Context Learning?
Ce Zheng, Lei Li, Qingxiu Dong, Yuxuan Fan, Zhiyong Wu, Jingjing Xu, Baobao Chang. [paper] 6. Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
Yasumasa Onoe, Michael J.Q. Zhang, Shankar Padmanabhan, Greg Durrett, Eunsol Choi. [paper] 7. MQUAKE: Assessing Knowledge Editing inLanguage Models via Multi-Hop Questions
Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, Danqi Chen.
.[paper]
- ② Additional Parameters
- Calibrating Factual Knowledge in Pretrained Language Models. (EMNLP 2022)
Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, Lei Li. [paper] [code] - Transformer-Patcher: One Mistake worth One Neuron. (ICLR 2023)
Zeyu Huang, Yikang Shen, Xiaofeng Zhang, Jie Zhou, Wenge Rong, Zhang Xiong. [paper] [code] - Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors.
Thomas Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, Marzyeh Ghassemi. [paper] [code] - Neural Knowledge Bank for Pretrained Transformers
Damai Dai, Wenbin Jiang, Qingxiu Dong, Yajuan Lyu, Qiaoqiao She, Zhifang Sui. [paper]
- Calibrating Factual Knowledge in Pretrained Language Models. (EMNLP 2022)
- ③ Change LM’s representation space
- Inspecting and Editing Knowledge Representations in Language Models
- Plug-and-Play Adaptation for Continuously-updated QA. (ACL 2022 Findings)
- Modifying Memories in Transformer Models.
- Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, Sanjiv Kumar. [paper]
- Editing Factual Knowledge in Language Models.
- Fast Model Editing at Scale. (ICLR 2022)
- Editable Neural Networks. (ICLR 2020)
- Editing a classifier by rewriting its prediction rules. (NeurIPS 2021)
- Language Anisotropic Cross-Lingual Model Editing.
- Yang Xu, Yutai Hou, Wanxiang Che. [paper]
- Repairing Neural Networks by Leaving the Right Past Behind.
- Ryutaro Tanno, Melanie F. Pradier, Aditya Nori, Yingzhen Li. [paper]
- Locating and Editing Factual Associations in GPT. (NeurIPS 2022)
- Mass-Editing Memory in a Transformer.
- Editing models with task arithmetic .
- Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, Ali Farhadi. [paper]
- Editing Commonsense Knowledge in GPT .
- Anshita Gupta, Debanjan Mondal, Akshay Krishna Sheshadri, Wenlong Zhao, Xiang Lorraine Li, Sarah Wiegreffe, Niket Tandon. [paper]
- Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs.
- Detecting Edit Failures In Large Language Models: An Improved Specificity Benchmark .
- Jason Hoelscher-Obermaier, Julia Persson, Esben Kran, Ioannis Konstas, Fazl Barez. [paper]
- Knowledge Neurons in Pretrained Transformers.(ACL 2022)
- Damai Dai , Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, Furu Wei.[paper] [code] [code by EleutherAI]
- LEACE: Perfect linear concept erasure in closed form .
- Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, Stella Biderman. [paper]
- Transformer Feed-Forward Layers Are Key-Value Memories. (EMNLP 2021)
- Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy. [paper]
- Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space.(EMNLP 2022)
- Mor Geva, Avi Caciularu, Kevin Ro Wang, Yoav Goldberg. [paper]
- PMET: Precise Model Editing in a Transformer.
-
FRUIT: Faithfully Reflecting Updated Information in Text. (NAACL 2022)
Robert L. Logan IV, Alexandre Passos, Sameer Singh, Ming-Wei Chang. [paper] [code] -
Entailer: Answering Questions with Faithful and Truthful Chains of Reasoning. (EMNLP 2022)
Oyvind Tafjord, Bhavana Dalvi Mishra, Peter Clark. [paper] [code] [video] -
Towards Tracing Factual Knowledge in Language Models Back to the Training Data.
Ekin Akyürek, Tolga Bolukbasi, Frederick Liu, Binbin Xiong, Ian Tenney, Jacob Andreas, Kelvin Guu. (EMNLP 2022) [paper] -
Prompting GPT-3 To Be Reliable.
Chenglei Si, Zhe Gan, Zhengyuan Yang, Shuohang Wang, Jianfeng Wang, Jordan Boyd-Graber, Lijuan Wang. [paper] -
Patching open-vocabulary models by interpolating weights. (NeurIPS 2022)
Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Simon Kornblith, Ali Farhadi, Ludwig Schmidt. [paper] [code] -
Decouple knowledge from paramters for plug-and-play language modeling (ACL2023 Findings)
Xin Cheng, Yankai Lin, Xiuying Chen, Dongyan Zhao, Rui Yan.[paper] [code] -
Backpack Language Models
John Hewitt, John Thickstun, Christopher D. Manning, Percy Liang. [paper] -
Learning to Model Editing Processes. (EMNLP 2022)
Machel Reid, Graham Neubig. [paper]
- Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models.
Peter Hase, Mohit Bansal, Been Kim, Asma Ghandeharioun. [paper] [code] - Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Mor Geva, Jasmijn Bastings, Katja Filippova, Amir Globerson. [paper] - Evaluating the Ripple Effects of Knowledge Editing in Language Models
Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, Mor Geva. [paper] - Edit at your own risk: evaluating the robustness of edited models to distribution shifts.
Davis Brown, Charles Godfrey, Cody Nizinski, Jonathan Tu, Henry Kvinge. [paper]
FastEdit 北航
快速注入知识
- 【2022-2-10】Rank-One Model Editing (ROME): Locating and Editing Factual Associations in GPT, demo
This repo aims to assist the developers with injecting fresh and customized knowledge into large language models efficiently using one single command.
Supported Models
git clone https://github.com/hiyouga/FastEdit.git
conda create -n fastedit python=3.10
conda activate fastedit
cd FastEdit
pip install -r requirements.txt
# 或
pip install pyfastedit
Model Editing
CUDA_VISIBLE_DEVICES=0 python -m fastedit.editor \
--data data/example.json \
--model EleutherAI/gpt-j-6b \
--config gpt-j-6b \
--template default
EasyEdit 浙大 – 开源
【2023-8-16】浙大出品:大模型轻松获取“世界知识”,比传统微调效果更好
- 知识编辑 papaerlist: Knowledge Editing for LLMs Papers
- 【2023-5-23】Editing Large Language Models: Problems, Methods, and Opportunities

浙江大学和东海实验室的研究团队提出了一个易于使用的 LLMs 知识编辑框架——EasyEdit,该框架支持各种知识编辑方法,且可以轻松应用于众多 LLMs,如 T5、GPT-J 和 LlaMA 等。
然而,目前关于 LLMs 知识编辑的研究在实现和任务设置上的差异妨碍了知识编辑统一和综合框架的发展。值得注意的是,这种复杂性阻碍了不同方法之间有效性和可行性的直接比较,也使得创建新的知识编辑方法变得复杂。
EasyEdit 框架整合了各种编辑技术,支持在不同 LLMs 之间自由组合模块。通过统一的框架和接口,EasyEdit 能使用户迅速理解并应用包含在该框架中的主流知识编辑方法。EasyEdit 具有统一的 Editor、Method 和 Evaluate 框架,分别代表编辑场景、编辑技术和评估方法。
EasyEdit 还提供了五个评估编辑方法性能的关键指标,包括可靠性(Reliability)、泛化性(Generalization)、局部性(Locality)、可移植性(Portability)和效率(Efficiency)。
为验证知识编辑在 LLMs 中的应用潜力,研究团队选用了参数庞大的 LlaMA 2 模型,并利用 ZsRE 数据集(QA 数据集)来测试知识编辑将大量一般事实关联整合进模型的能力。测试结果证明,EasyEdit 在可靠性和泛化性方面超越了传统的微调方法。
流式输出
详见站内专题:大模型流式输出与安全
窗口扩大
详见站内专题: 长文本
模型结构
详见 LLM 架构代码详解
自学习
AI 自我演进/进化
总结
研究进展
- Sakana AI 与不列颠哥伦比亚大学等机构合作的「达尔文-哥德尔机(DGM)」
- CMU 的「自我奖励训练(SRT)」
- 上海交通大学等机构提出的多模态大模型的持续自我改进框架「MM-UPT」
- 香港中文大学联合 vivo 等机构的自改进框架「UI-Genie」
- MIT 发布的《Self-Adapting Language Models》提出让 LLM 更新自己的权重的方法:SEAL🦭,即 Self-Adapting LLMs。
参阅文章《LSTM 之父 22 年前构想将成真?一周内 AI「自我进化」论文集中发布,新趋势涌现?》
OpenAI CEO、著名 𝕏 大 v 山姆・奥特曼在其博客《温和的奇点(The Gentle Singularity)》中更是畅想了一个 AI/智能机器人实现自我改进后的未来。
- 「我们必须以传统方式制造出第一批百万数量级的人形机器人,但之后它们能够操作整个供应链来制造更多机器人,而这些机器人又可以建造更多的芯片制造设施、数据中心等等。」
不久之后,就有 𝕏 用户 @VraserX 爆料称有 OpenAI 内部人士表示,该公司已经在内部运行能够递归式自我改进的 AI。
【2025-3-4】MIT PRefLexOR
解决什么问题
- 面对跨领域难题,AI输出像碎片拼图毫无逻辑
- 模型遇到新场景就“痴呆”,需要反复调教
- 重要决策时,AI推理过程不可信…
【2025-3-4】MIT Markus 教授团队 全新自学习AI框架 PRefLexOR (Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning), 让AI像人类一样,进行深度思考和自主进化。
- MIT 新AI自主进化出
思维链:动态知识图谱+跨域推理黑科技 - 融合
强化学习与偏好优化的「自进化大脑」,通过递归推理和多步反思,动态生成知识图谱。 - 不仅能动态构建知识图谱,还会像人类一样通过「反思令牌」迭代优化推理路径。
- GitHub: PRefLexOR
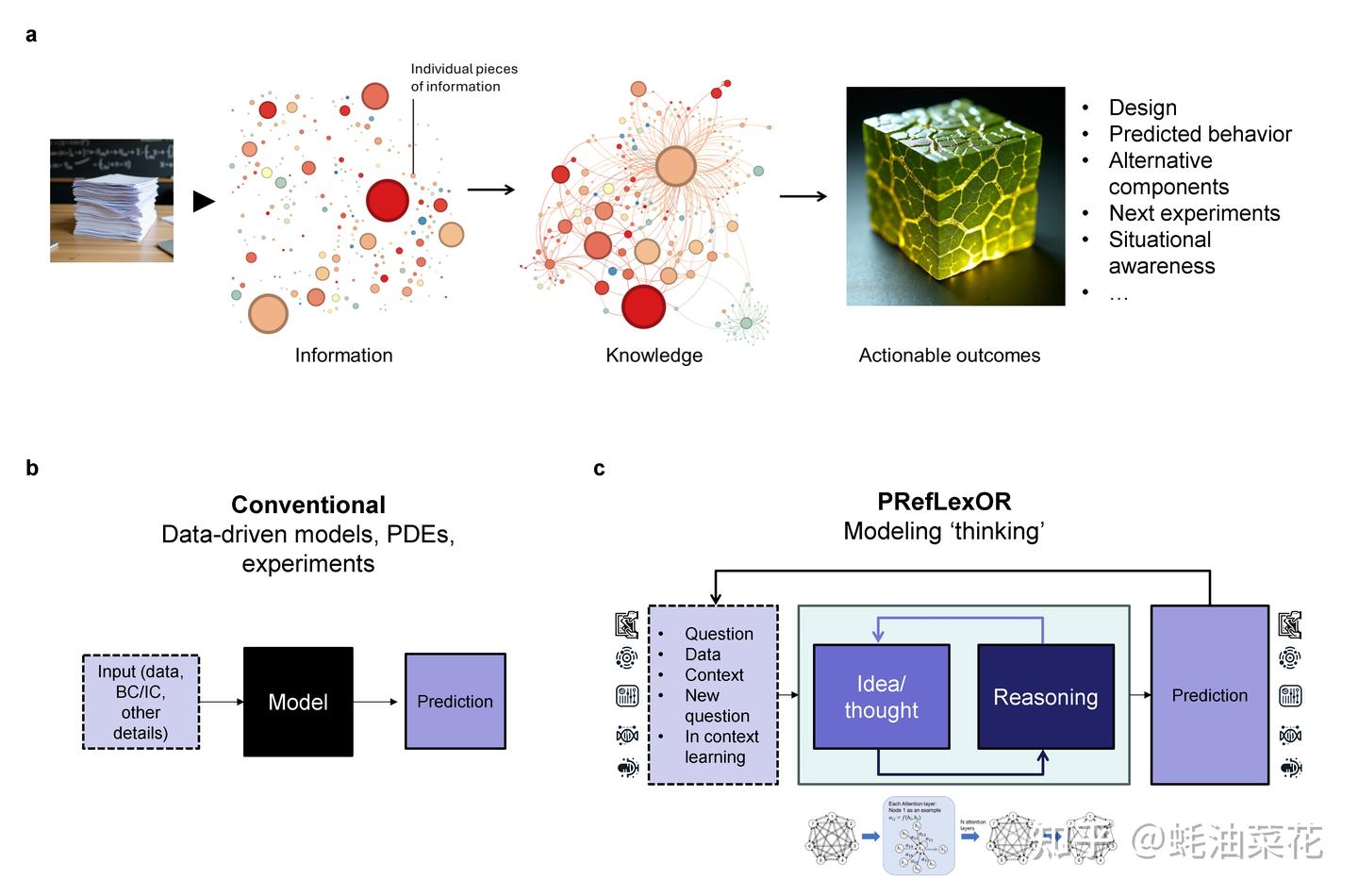
核心功能:动态知识图谱构建、跨领域推理能力、自主学习与进化。
PRefLexOR 主要功能
- 动态知识图谱构建:框架不依赖预生成的数据集,通过动态生成任务和推理步骤,实时构建知识图谱,使模型能不断适应新任务,在推理过程中动态扩展知识。
- 跨领域推理能力:PRefLexOR 能够将不同领域的知识进行整合和推理,例如在材料科学中,模型可以通过递归推理和知识图谱生成新的设计原则。
- 自主学习与进化:通过递归优化和实时反馈,PRefLexOR 能够在训练过程中自我教学,不断改进推理策略,展现出类似人类的深度思考和自主进化能力。
技术原理:递归推理与反思、偏好优化、多阶段训练。
- 优势比偏好优化(ORPO),模型通过优化偏好响应和非偏好响应之间的对数几率来对齐推理路径。
- 同时,集成了直接偏好优化(DPO),通过拒绝采样进一步提升推理质量。
- 这种混合方法类似于 RL 中的策略细化,模型通过实时反馈和递归处理不断改进。
技术原理
- 递归推理与反思:PRefLexOR 引入“思考令牌”和“反思令牌”,明确标记推理过程中的中间步骤和反思阶段。模型在推理过程中会生成初始响应,然后通过反思逐步改进,最终生成更准确的答案。
- 偏好优化:PRefLexOR 基于优势比偏好优化(ORPO)和直接偏好优化(DPO)。模型通过优化偏好响应和非偏好响应之间的对数优势比,使推理路径与人类偏好决策路径一致。DPO 进一步通过拒绝采样调整推理质量,确保偏好对齐的细微差别。
- 多阶段训练:PRefLexOR 的训练分为多个阶段:首先通过 ORPO 对齐推理路径,然后通过 DPO 进一步优化推理质量。这种混合方法类似于 RL 中的策略细化,模型通过实时反馈和递归处理不断改进。
训练基于图结构的原生AI,自主推理数天,构建动态关系世界模型,而这一过程也不需要预先编程。
这个模型涌现出的枢纽节点、小世界特性、模块化和无标度结构都是自然形成。
随后,该模型通过组合式推理,从深度合成中发现了未被编码的特性,即具有记忆的材料、微生物修复能力和自进化系统。
如果你给AI一堆乐高积木,也不告诉它怎么搭,它自己研究几天后,不仅搭出了城堡,还发明了会变形的积木、能自动修复裂痕的胶水,甚至让城堡长出“腿”自己移动,整个过程完全超出你的预期
安装
pip install git+https://github.com/lamm-mit/PRefLexOR.git
或:
git clone https://github.com/lamm-mit/PRefLexOR.git
cd PRefLexOR
pip install -r requirements.txt
pip install -e .
使用 Flash Attention,可以安装:
MAX_JOBS=4 pip install flash-attn --no-build-isolation
【2025-2-18】港大 AutoAgent
【2025-2-18】 港大开源全自动且高度自我进化的零代码AI Agent框架:AutoAgent
AutoAgent 是全自动且高度自我进化的框架,用户仅需自然语言即可创建并部署 LLM Agent。
核心特性
- 🏆 GAIA 基准测试冠军
- AutoAgent 在开源方法中排名 #1,性能媲美 OpenAI 的
Deep Research。
- AutoAgent 在开源方法中排名 #1,性能媲美 OpenAI 的
- 📚 Agentic-RAG,内置自管理向量数据库
- AutoAgent 配备原生自管理向量数据库,超越 LangChain 等行业领先方案。
- ✨ 轻松创建 Agent 和工作流
- AutoAgent 利用自然语言轻松构建可直接使用的工具、Agent 和工作流 —— 无需编码。
- 🌐 广泛兼容 LLM
- AutoAgent 无缝集成多种 LLM(如 OpenAI、Anthropic、DeepSeek、vLLM、Grok、Huggingface…)。
- 🔀 灵活交互模式
- 支持函数调用(Function-Calling) 和 ReAct 交互模式。
- 🤖 动态、可扩展、轻量级
- AutoAgent 是你的个人 AI 助手,具备动态、可扩展、可定制、轻量级的特性。
使用方法
- 用户模式(SOTA 🏆 对标 OpenAI Deep Research)
- AutoAgent 内置多智能体(Agent)系统,你可以在启动页面选择用户模式直接使用。这个多智能体系统是一个通用 AI 助手,具备与 OpenAI Deep Research 相同的功能,并在 GAIA 基准测试中实现了可媲美的性能。
- 🚀 高性能:基于 Claude 3.5 实现 Deep Research 级别的表现,而非 OpenAI 的 o3 模型。
- 🔄 模型灵活性:兼容任何 LLM(包括 DeepSeek-R1、Grok、Gemini 等)。
- 💰 高性价比:开源替代方案,无需支付 Deep Research $200/月 的订阅费用。
- 🎯 用户友好:提供易部署 CLI 界面,交互流畅无阻。
- 📁 文件支持:支持文件上传,实现更强的数据交互能力。
- 🎥 Deep Research(即用户模式)
- Agent 编辑器(无工作流的 Agent 创建)
- AutoAgent 最具特色的功能是自然语言定制能力。不同于其他 Agent 框架,AutoAgent 允许你仅通过自然语言创建工具、Agent 和工作流。只需选择 Agent 编辑器或工作流编辑器模式,即可开启对话式构建 Agent 之旅。
- 工作流编辑器(使用工作流创建 Agent)
- 通过工作流编辑器模式,使用自然语言描述创建代理工作流,如下图所示。(提示:此模式暂时不支持工具创建。)
【2025-6-14】MIT SEAL
【2025-6-14】LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?
MIT 昨日发布的《Self-Adapting Language Models》提出让 LLM 更新自己的权重的方法:SEAL🦭,即 Self-Adapting LLMs。
该框架中,LLM 可以生成自己的训练数据(自编辑 /self-editing),并根据新输入对权重进行更新。而这个自编辑可通过强化学习学习实现,使用的奖励是更新后的模型的下游性能。
- 论文标题:Self-Adapting Language Models
- 项目页面:seal
- 代码地址:seal
自适应语言模型(SEAL)
SEAL 框架可以让语言模型在遇到新数据时,通过生成自己的合成数据并优化参数(自编辑),进而实现自我提升。
该模型训练目标:
- 使用模型上下文中提供的数据,通过生成 token 来直接生成这些自编辑(SE)。
自编辑生成需要通过强化学习来学习实现,其中当模型生成的自编辑在应用后可以提升模型在目标任务上的性能时,就会给予模型奖励。
因此,可以将 SEAL 理解为一个包含两个嵌套循环的算法:一个外部 RL 循环,用于优化自编辑生成;以及一个内部更新循环,它使用生成的自编辑通过梯度下降更新模型。
【2025-10-15】META 早期经验自主学习
META 和 俄亥俄州立大学,
- 【2025-10-15】Meta团队揭秘:AI智能体如何通过“早期经验”实现自主学习突破
- 【精】【2025-10-11】深度解读 Meta 论文:无需奖励,AI Agent 如何通过“早期经验”实现自我进化?
2025年10月15日,Meta超级智能实验室、FAIR团队及俄亥俄州立大学发布突破性研究,找到让AI像真正的孩子一样学习的方法。团队共同探索了一个全新的AI训练范式,不需要外部奖励信号,就能让AI从自己的探索经历中不断成长
打破了传统AI训练困境
- 要么机械模仿专家示范,像只会照着菜谱做饭的厨师,缺少食材就束手无策
- 要么通过大量试错、即时反馈来学习,很多场景下行不通,让学生做100道题但永远不告诉对错
填补了模仿学习和强化学习之间的空白,提出了可规模化、无需奖励、且效果显著的自学习方法。
AI学习的三个时代
- (1)传统课堂模式:专家数据时代,老师讲,学生模仿。模型观察专家示例来学习正确行为模式,即 监督微调、模仿学习;
- 问题:泛化能力不足,遇到新情况时犯傻
- (2)考试驱动模式:经验时代,或RL阶段,学生不听课,直接做题,根据分数调整策略。模型可以尝试各种行动,获取环境反馈。理论强大,代表 AlphaGo
- 问题:实际应用中,很多任务无法提供清晰、即时反馈。学习效率低,模型陷入困境
- (3)中间步骤:早期经验范式,介于传统课堂与考试之间;学生已经听过老师的基本讲解,知道一些正确答案,但还没到考试时候,学生自己拿课本/笔记尝试做题。
- 因素:(1)过于依赖昂贵的专家数据,不够灵活(2)需要明确的反馈信号,很多时候不存在、太稀疏
巧妙之处:不需要外部奖励信号,仍能提供有价值学习信号
两种互补的学习策略
- (1) 隐式世界建模 (Implicit World Modeling, IWM):理解环境如何运作; “如果我这么做会怎样?”,然后学习预测结果
- 让 Agent 学习并内化环境的动态规律,即理解 “我做了某个动作后,环境会发生什么变化?”
- (2) 自我反思 (Self-Reflection, SR):如何做出更好的决策; “为什么不那么做?”,然后学习推理过程
- 让 Agent 学习从对比中进行推理,理解“为什么专家的动作比我的想法更好?”
学生学习的两个不同方面:一个是理解知识本身的运作规律,另一个是学会自我评价和反思。
“早期经验”方法让AI在没有明确对错评判时,通过观察”如果我这样做会发生什么”来建立对环境的理解。
两种策略的结合创造了协同效应。
- 世界建模帮助AI理解环境的客观规律,而自我反思帮助AI学会在这些规律的基础上做出明智的选择。
- 就像一个好学生,既要掌握知识本身,也要培养批判性思维和问题解决能力。
研究团队在不同环境中发现,有时世界建模效果更好,有时自我反思效果更好,这取决于任务的性质。但在几乎所有情况下,两种方法都显著优于传统的纯模仿学习。
八个截然不同的任务场景中都表现出色,从网页购物到科学实验,从旅行规划到多步骤工具使用,证明了其广泛的适用性。
更令人兴奋的是,这种早期经验训练不仅立即提升了AI表现,还为后续强化学习训练打下了更坚实的基础,就像一个经过充分探索和试错的学生,在面对正式考试时会表现得更加出色。
Transformer 改进
详见站内: transformer 改进专题
放弃 Transformer
Transformer 构建灵活、易并行、易扩展等优势, 但问题是
- 并行输入的机制会导致模型规模随输入序列长度平方增长,导致其在处理长序列时面临计算瓶颈
传统 RNN 模型计算量小,理论上可以处理无限长序列,但存在序列依赖,难以捕捉长期依赖关系,且面临梯度消失、爆炸问题
- RNN 可以将历史状态以隐变量的形式循环叠加到当前状态上,对历史信息进行考虑,呈现出螺旋式前进的模式。
Transformer 无法回避的致命弱点——算力黑洞。
- 序列长度翻十倍,计算量直接翻一百倍,KV Cache 随着上下文线性膨胀,推理成本高到让大模型部署变成“富人游戏”。
- 当模型越来越大、上下文越来越长、推理越来越频繁,Transformer 的结构性瓶颈已经成为整个行业的天花板。
transformer 架构不是唯一
【2024-11-24】详见:浙大《大模型基础》
两类现代RNN 变体,分别为
- 状态空间模型(State Space Model,SSM)
- 测试时训练(Test-Time Training,TTT)
这两类范式都能实现关于序列长度的线性时间复杂度,且避免了传统RNN 中存在的问题
SSM
状态空间模型(State Space Model,SSM)范式可有效处理长文本中存在的长程依赖性(Long-Range Dependencies, LRDs)问题,并且可以有效降低语言模型的计算和内存开销。
SSM 范式
- SSM 思想源于控制理论中的动力系统。其通过利用一组状态变量来捕捉系统状态随时间的连续变化,这种连续时间的表示方法天然地适用于描述长时间范围内的依赖关系。
- 此外,SSM 还具有递归和卷积的离散化表示形式,既能在推理时通过递归更新高效处理序列数据,又能在训练时通过卷积操作捕捉全局依赖关系。
SSM 训练和推理非常慢。为了提高处理效率,需要对该方程进行离散化(Discretization), SSM 中最为关键的步骤,将系统方程从连续形式转换为递归形式和卷积形式,从而提升整个SSM 架构的效率。
- 训练时使用卷积形式
- 推理时使用递归形式
SSM 架构的系统方程具有三种形式,分别为
- 连续形式
- 离散化的递归形式
- 离散化的卷积形式
可应用于文本、视觉、音频和时间序列等任务
SSM 的优势在于能够处理非常长的序列,虽然比其它模型参数更少,但在处理长序列时仍然可以保持较快的速度。
两种基于SSM范式的代表性模型:RWKV 和Mamba。
RWKV
RWKV(Receptance Weighted Key Value)是基于SSM 范式的创新架构,其核心机制 WKV 的计算可以看作是两个SSM 的比。
RWKV 设计结合了 RNNs 和 Transformers 的优点,既保留了推理阶段的高效性,又实现了训练阶段的并行化。(注:这里讨论的是RWKV-v4)
RWKV 模型的核心模块有两个:时间混合模块和通道混合模块。
- 时间混合模块主要处理序列中不同时间步之间的关系
- 通道混合模块则关注同一时间步内不同特征通道30之间的交互。
时间混合模块和通道混合模块的设计基于四个基本元素:接收向量R、键向量K、值向量V 和权重W,
Mamba
【2026-3-18】奥特曼宣判Transformer死刑,Mamba‑3正在接管下一代AI架构
2023 年底,Albert Gu 和 Tri Dao 提出全新架构:Mamba,彻底绕开了注意力机制,改用状态空间模型(SSM)来处理序列。
- Transformer 读一句话要让每个词和其他所有词“对视”一遍,而 Mamba 只维护一个固定大小的记忆状态,线性时间就能完成,推理吞吐量直接快上五倍。
时不变性使得SSM 能够一致地处理不同时间步长的数据,进行高效的并行化训练,但是同时也导致其处理信息密集的数据(如文本)的能力较弱。
为了弥补这一不足,Mamba 基于SSM 架构,提出了选择机制(Selection Mechanism)和硬件感知算法(Hardware-aware Algorithm),前者使模型执行基于内容的推理,后者实现了在GPU 上的高效计算,从而同时保证了快速训练和推理、高质量数据生成以及长序列处理能力。
Mamba 的选择机制通过动态调整模型参数来选择需要关注的信息,使模型参数能够根据输入数据动态变化。
Mamba 在实际应用中展示了卓越的性能和效率,包括:
- (1)快速训练和推理:训练时,计算和内存需求随着序列长度线性增长,而推理时,每一步只需常数时间,不需要保存之前的所有信息。通过硬件感知算法,Mamba 不仅在理论上实现了序列长度的线性扩展,而且在A100 GPU上,其推理吞吐量比类似规模的Transformer 提高了5 倍。
- (2)高质量数据生成:在语言建模、基因组学、音频、合成任务等多个模态和设置上,Mamba 均表现出色。在语言建模方面,Mamba-3B 模型在预训练和后续评估中性能超过了两倍参数量的Transformer 模型性能。
- (3)长序列处理能力:Mamba 能够处理长达百万级别的序列长度,展示了处理长上下文时的优越性。
Mamba 在硬件依赖性和模型复杂度上存在一定的局限性,但是它通过引入选择机制和硬件感知算法显著提高了处理长序列和信息密集数据的效率,展示了在多个领域应用的巨大潜力
2026 年初,Mamba 已经进化到第三代——Mamba‑3。
线性模型(SSM / State Space Models)不依赖全局注意力,而是通过固定大小的状态向量来处理序列,理论上能做到线性复杂度+常数内存。
从 S4 到Mamba‑1,再到 2024 年的 Mamba‑2,这条路线一路狂飙,甚至被 NVIDIA、微软、AI21 等巨头大规模采用。
- Mamba‑1 解决了训练效率问题
- Mamba‑2 进一步优化了推理速度,3个缺陷限制了线性模型的上限,始终无法真正撼动 Transformer 的统治地位。
- Mamba‑3:Inference‑First(推理优先)保持线性复杂度的前提下, 同时提升模型的表达能力、状态跟踪能力与推理硬件效率。
但线性模型也有短板:表达能力不如 Transformer,尤其在状态跟踪、复杂动态建模上表现乏力,离散化方法粗糙,理论基础薄弱,推理阶段虽然复杂度低,但在 GPU 上却是典型的 memory‑bound,算力利用率极低。
三个关键缺陷:
- 离散化方法粗糙,表达能力有限。
- 无法处理复杂的状态跟踪任务。
- 推理阶段算力利用率极低(memory‑bound)
直到 Mamba‑3 出现了,彻底架构重构。 核心理念:Inference‑First(推理优先)。
- 不是为了训练更快,而是为了推理更强
- 不是为了模型更大,而是为了模型更聪明
- 不是为了延续旧范式,而是为了打开新范式的大门。
Mamba‑3 的三大创新——指数‑梯形离散化、复数状态空间模型、MIMO推理结构,分别对应线性模型的三大痛点:精度、能力、效率。
ttt
在处理长上下文序列时,基于SSM 范式的架构(例如RWKV 和Mamba)通过将上下文信息压缩到固定长度的隐藏状态中,成功将计算复杂度降低至线性级别,有效扩展了模型处理长上下文的能力。
然而,随着上下文长度的持续增长,基于SSM 范式的模型可能会过早出现性能饱和。
- 例如,Mamba 在上下文长度超过16k 时,困惑度基本不再下降。
出现这一现象的原因
- 可能是固定长度的隐藏状态限制了模型的表达能力,同时在压缩过程中可能会导致关键信息的遗忘。
测试时训练(Test-Time Training,TTT)范式提供了一种有效的解决方案。
- TTT 利用模型本身参数来存储隐藏状态、记忆上文;
- 并在每一步推理中,对模型参数进行梯度更新,已实现上文的不断循环流入
详见站内专题:测试时计算
【2025-1-15】Titans
【2025-1-15】近8年后,谷歌Transformer继任者「Titans」来了,上下文记忆瓶颈被打破
2017 年推出影响 AI 行业长达 8 年的 Transformer 架构之后,谷歌带来了全新的架构 Titans。
- 论文标题:Titans: Learning to Memorize at Test Time
- 代码
- 非官方实现 titans-pytorch
谷歌重点将推理领域非常重要的测试时(test-time)计算用在了记忆(memory)层面。
Ali Behrouz 表示
- 注意力机制一直是大多数 LLM 进展的重要组成部分,不过它无法扩展到长上下文。
- Titans 是一种同时具备注意力机制和元上下文记忆的结构,可以在测试时学习记忆。
该架构可以将上下文窗口扩展到 200 万 tokens。
谷歌提出新的长期神经记忆模块(neural memory module),学习记忆历史上下文,并帮助注意力机制在利用过去已久信息的同时处理当前上下文。
- 结果表明,这种神经记忆具有快速并行化训练的优势,同时还能保持快速推理。
从记忆的角度来看,谷歌认为
- 注意力机制虽然受限于上下文但可以更准确地建模依赖关系,因此可以起到短期记忆的作用;
- 而神经记忆能够对数据进行记忆,起到了长期、更持久的记忆作用。
基于这两个模块,谷歌引入了一个全新的系列架构 —— Titans,通过三种变体有效地将记忆融合到该系统架构中,分别是:
记忆作为上下文(Memory as a Context,MAC)记忆作为门(Memory as a Gate,MAG)记忆作为层(Memory as a Layer,MAL)
Titans 架构比 Transformer 和近年来的现代线性循环模型更有效。另外,在大海捞针(needle-in-haystack)中,Titans 架构能够有效地扩展到超过 200 万 tokens 的上下文窗口,并且比基准模型实现了更高的准确性。
【2025-10-18】RLM
【2025-10-18】递归语言模型登场!MIT华人新作爆火,扩展模型上下文便宜又简单
所有主流 LLM 都有固定的上下文窗口(如 200k, 1M tokens)。
- 一旦输入超过这个限制,模型就无法处理。
- 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「
上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
当用户与 ChatGPT 等主流 LLM 进行长时间、多轮的复杂对话时,会明显感觉到模型开始变「笨」,变得难以聚焦、遗忘关键信息。
MIT 研究者从一个直观的想法出发:
也许可以把超长上下文切分,分别交给模型处理,再在后续调用中合并结果,以此避免衰退问题?
提出递归语言模型(Recursive Language Models,RLMs),通用的推理策略:
做法
- 将上下文视为一个可操作的「变量」:主模型(root LM)在一个类似 Jupyter Notebook 的编程环境(REPL)中工作,完整的上下文只是一个它能用代码访问的变量,而不是直接的输入。
- 递归调用自身或小模型:主模型可以编写代码来查看、切分、过滤(比如用 grep)这个巨大的上下文变量,然后把小块的任务外包给一个个小的、临时的 LLM 调用(递归调用)。
- 综合结果:主模型收集这些「外包」任务的结果,最终形成答案。
研究者还设计了具体实现:在一个 Python REPL 环境中调用 GPT-5 或 GPT-5-mini,并将用户的 prompt 存入变量中进行迭代式处理。
向一个 RLM 发起查询时,「根」语言模型(root LM)把整个上下文当作可操作的环境来探索和处理。通过递归调用(R)LM,将对任意结构或任意长度上下文的处理任务分解并逐级委托,从而实现可扩展的推理能力。
这种方式要比任何「分块(chunking)」策略都更加通用且更智能。研究者认为:应该让语言模型自己决定如何探索、拆解并递归地处理长 prompt,而不是由人为制定固定的切分策略。
RLM 框架显著优势:可在一定程度上解释它的行为轨迹,理解它是如何一步步推理并得出最终答案的。研究团队编写了一个简易可视化工具,用来观察 RLM 的推理路径,展示了 RLM 实际在「动手做什么」。
结果很惊人:
- 在能获取到的最难的长上下文评测集之一 OOLONG 上,使用 GPT-5-mini 的 RLM 正确答案数量是直接使用 GPT-5 的两倍以上,而且平均每次调用的成本更低。
研究者还基于 BrowseComp-Plus 构建了一个全新的长上下文 Deep Research 任务。
- 该任务中,RLM 显著优于 ReAct + 推理时索引 / 检索等方法。
- 令人意外的是,即使推理时输入超过 1000 万 tokens,RLM 的性能也没有出现衰减。
RLM 很快会成为一个强大范式。
同时,相比于仅依赖 CoT 或 ReAct 风格的代理模型,显式训练以递归式推理为核心机制的 RLM,很可能成为推理时扩展能力领域的下一个里程碑。
【2025-12-22】Grassmann Flows 颠覆 注意力机制
【2026-4-24】Attention根本不是必需,格拉斯曼流才是序列建模的未来
Transformer 致命软肋
- 自注意力本质:高维张量“升维爆炸”
- 张量升维(Tensor Lifting)三大原罪:维度爆炸、不可解释、数学不可追踪
- 大模型不可解释,不只是因为大,而是核心升维操作本身就数学不可追踪。
- 真正需要的不是Attention,而是“表示的几何演化”
- 序列建模的本质不是让token两两算相似度, 而是让语义表示在流形上做可控几何演化。
- Attention只是其中一种粗糙实现, 完全可以用更优雅、更可控的几何结构替代它。
直接向统治NLP近十年的Transformer核心机制——自注意力机制,发起了颠覆性挑战。
- 【2025-12-22】zhang chong 发表 arXiv 论文《Attention Is Not What You Need:Grassmann Flows as an Attention-Free Alternative for Sequence Modeling》
没有去优化稀疏注意力、线性注意力,而是直接抛出结论:
序列建模根本不需要显式 Attention,用
格拉斯曼流(Grassmann Flows)就能做到接近甚至局部超越Transformer,还更可解释、复杂度更低。
格拉斯曼流
- 不用L×L注意力矩阵,改用低维子空间在格拉斯曼流形上的流动,完成序列信息融合。
- 因果格拉斯曼架构,替换Transformer的Attention Block
总结
- Attention是暴力枚举所有关系
- Grassmann Flows是优雅刻画局部几何
| 维度 | 标准自注意力 | 格拉斯曼流 |
|---|---|---|
| 复杂度 | O(L²) 平方增长 | O(L) 线性增长 |
| 核心结构 | L×L 注意力张量 | 低维子空间+流形流动 |
| 可解释性 | 黑箱,无全局不变量 | 几何可追踪,有代数不变量 |
| 长序列 | 越长越崩 | 天然友好 |
| 实现 | 成熟优化 | 理论完美,待工程落地 |
效果炸裂:
- 小模型打平Transformer,局部实现反超
【2026-1-9】嵌套学习
【2026-1-9】Transformer已死?DeepMind正在押注另一条AGI路线:联想记忆
DeepMind 2025年最重要的研究或产品,嵌套学习「Nested Learning」必有一席之地。《Attention is All you Need》的「续集」。
Nested Learning 不只是一个架构框架,而是一种重新理解深度学习的范式。
如果Transformer开启了Scaling时代,那么嵌套学习正在开启真正的AGI时代
Transformer并不完美。
- 长上下文处理效率低
- 抽象知识层级有限
- 适应性弱
- 缺乏持续学习能力
特别是第四点,Ali认为那是最关键的问题。
「持续学习」(Continual Learning):
- 没有训练期,也没有测试期;
- 模型在使用过程中,持续塑造新的记忆和抽象结构。
人类天生如此。但对今天的大语言模型来说,几乎不存在任何「持续学习」。
医学类比:顺行性遗忘症(Anterograde Amnesia)。特征:
- 短期记忆正常
- 长期记忆也还在
但👉短期记忆,无法转移为长期记忆。永远活在「现在」
知识主要来自两部分:
- 预训练阶段学到的长期知识、
- 当前上下文里的短期信息。
两者之间几乎完全没有通道。AI模型无法自然地把「刚刚学到的东西」,沉淀为未来可复用的知识。
真正的问题不是参数不够多,不是数据不够大,也不只是算力不够。
问题本质:「短期记忆」和「长期记忆」之间,根本没有一条自然的知识转移通道
如果这条通道不存在,所谓「持续学习」,就永远只是一个口号。
核心问题:该如何构建一种机制,让AI模型像人类一样,将「现在」的经历沉淀为「未来」的知识?
模型到底是「怎么记住东西的」?
- 大模型给出的答案,不是Transformer,不是参数量,而是一个更原始、更根本的概念:
联想记忆(Associative Memory)。
「联想记忆」是人类学习机制的基石。本质是通过经验将不同的事件或信息相互关联。
技术上,联想记忆就是键值对映射:
- Key:线索
- Value:与之关联的内容
但关键在于,联想记忆的映射关系不是预先写死的,而是「学出来的」。
注意力机制本质是一种联想记忆系统:学习如何从当前上下文中提取key,并将其映射到最合适的value,从而产生输出。
如果不仅优化这种映射本身,还让系统去元学习(meta-learn)这种映射过程的初始状态,会发生什么?
基于对联想记忆的理解,提出通用框架,名为 MIRAS,用于系统化地设计AI模型中的记忆模块。
核心思想:几乎所有注意力机制、本地记忆结构,乃至优化器本身,其实都可以视为联想记忆的特例。
一套「可学习的、嵌套式的记忆系统」,要对模型中的记忆结构做出四大设计决策:
- 记忆架构(Memory Architecture)
- 注意力偏置/目标函数(Attentional Bias/Objective)
- 保留机制(Retention Gate)
- 学习规则(Learning Rule)
MIRAS 把「记忆」作为一种学习过程进行建模、组合与优化,而不仅仅是一个静态模块。
优化器也可以被统一视为「将当前梯度映射到历史信息」的联想过程,就可以进行重新建模与推广。
优化器就是一种「记忆模块」,是模型理解其学习历史、进而做出更优决策的关键组件。
优化过程与学习算法/架构本质上是相同的概念,只是处于系统不同层级中具有不同的上下文(即梯度与数据)。
此外,两个相互连接的组件,其中学习算法/架构为优化器生成上下文(即梯度)。这支持为特定架构设计专属优化器的理念。
由此,谷歌的团队探讨了不同层级之间的知识传递方式,提出了嵌套学习。
符号主义
问题:
- LLM 在执行抽象规则归纳(abstract rule induction)时,到底是“黑箱式”地拼统计特征,还是内部出现了可辨识的“符号机制”,如同经典 AI 中的抽象变量和符号推理?
LLM 三段式
LLM 内部学会符号机制来做抽象reasoning
【2025-6-6】普林斯顿
选 Llama3-70B,设计抽象模式延伸、逻辑归纳等任务, 通过 causal mediation、attention pattern、RSA 等分析,发现模型内部竟然自发形成了三段式符号处理流水线:
- Symbol Abstraction Heads:把文字 token 抽象成符号变量;
- Symbolic Induction Heads:在符号上做序列归纳;
- Retrieval Heads:根据推断的符号去检索下一个 token。
消融实验验证,少了任何一段都不行
- 禁用符号抽象头会立刻毁掉所有归纳能力;
- 停用归纳头则模型无法继续延伸模式;
- 禁用检索头则知道模式也没法生成答案。
结论:
- Emergent Symbolic Architecture
- LLM 在训练过程中自发形成了三段式符号化电路:
抽象→归纳→检索,这一结构与经典符号推理模型高度对应。
抽象推理依赖性
- 抽象推理能力并非纯粹“大量参数+统计”得来,而是要依靠内部符号机制的阶段化协作。
符号与神经桥梁
- 研究结果在“符号主义 vs. 连接主义”争论中给出了折中答案:神经网络可以在无预设符号模块的情况下,通过学习自动构造类似符号处理的子网络。
未来方向
- 可据此设计更高效的符号-神经混合架构,显式增强这三大机制;
Nature重磅:深度学习x符号学习,AGI唯一路径
【2025-12-17】Nature重磅!深度学习+符号学习,竟是AGI的唯一通关密码?
- 地址 nature
绝大多数研究者认为,仅靠“神经网络”远远无法通往人类级智能。真正的突破或许要靠老牌“符号派AI”与神经网络联手。
神经网络和符号算法各有利弊。
- 神经网络速度快、有创造力,但会编造内容,超出训练数据范围就难以可靠回答;
- 符号系统难以涵盖“模糊”概念,构建规则数据库难度大、搜索慢,但运作机制清晰,擅长推理。
缺乏符号知识的神经网络在现实世界会犯低级错误,如AI生成图像可能画出六根手指的人。
许多人认为“神经网络 + 符号机制”是向AI注入逻辑推理的最佳甚至唯一方法,全球科技巨头IBM就押注神经符号技术,但也有人怀疑
- 现代 AI之父之一
Yann LeCun认为:神经符号方法与深度学习机制“不兼容” - Richard Sutton坚持“苦涩的教训”仍适用于今天的AI。
神经符号AI虽核心愿景明确,即融合神经网络与符号学派的双重优势,但具体定义仍模糊。
Marcus称其涵盖“浩瀚无垠的宇宙”,目前探索只是“沧海一粟”。
业界有多种技术路径,主流的有两条:
- 符号技术“加持”神经网络
- 以AlphaGeometry为代表,先利用符号编程语言生成海量数学题作为合成数据集,再用这些数据训练神经网络,让解题过程更易验证,错误率极低,被评价为“优雅的融合”。还有“逻辑张量网络”,将符号逻辑编码进神经网络,赋予陈述“模糊真值”,构建规则框架辅助逻辑推理。
- 神经网络“巧解”符号算法难题:谷歌AlphaGo击败人类围棋冠军
- 符号知识库体量大,搜索耗时,无法暴力计算穷尽。而神经网络可训练预测“最有胜算”的落子方向,大幅修剪搜索“分枝”
ABL-Refl
【2025-2-8】周志华团队ABL-Refl革新 神经符号推理 Neuro-Symbolic (NeSy) AI
- Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection
- Abductive Reflection (ABL-Refl) based on the Abductive Learning (ABL) framework
神经符号人工智能类比人类双过程认知,但复杂任务中常出现与领域知识不一致的输出,纠正困难。
受人类认知反思启发,研究在溯因学习框架上提出溯因反思(ABL-Refl),利用领域知识生成反思向量,标记并纠正神经网络输出错误,生成一致结果。
其效率远高于以往溯因学习实现,实验显示性能优于主流神经符号方法,能以更少训练资源获高准确率,且效率提升。
SymAgent
起因
仅通过提示大型语言模型来规划整个推理流程无法取得令人满意的性能。
当前大型语言模型难以将复杂问题与知识图谱(KG)的语义及连接模式对齐,导致生成的推理链粒度较粗,无法有效用于精确的信息检索与整合。
SymAgent 介绍
【2025-2-5】武大、阿里 SymAgent:神经符号自学习Agent
SymAgent 结合知识图谱(KGs)与大型语言模型(LLMs)以自主解决复杂推理任务的框架。
SymAgent利用大型语言模型(LLM)从知识图谱(KG)中识别可能用于回答问题的潜在符号规则,而非生成详细的分步计划:
- 已有研究表明,大型语言模型在归纳推理方面表现出色,但在演绎推理方面能力较弱。
- 符号规则本身反映了知识图谱的推理模式,可作为辅助分解复杂问题的隐含信息。
通过这种方式,Agent-Planner在自然语言问题与知识图谱的结构信息之间搭建了一座桥梁,从而提高了推理过程的准确性和通用性。
框架
SymAgent 包含一个 Agent-Planner(智能体规划器)和一个 Agent-Executor(智能体执行器)
- Agent-Planner 从知识图谱中提取符号规则,用于分解问题和规划推理步骤
- Agent-Executor 则通过整合反思所得见解和环境反馈来回答问题。
为解决标注推理数据缺失的问题,引入了一个自学习框架,通过自主交互实现协同改进。
整体架构如图所示。 SymAgent框架概述。
- (a)SymAgent中的规划器,其从知识图谱中提取符号规则以指导推理;
- (b)SymAgent中的执行器,其执行自动行动调用以获取答案;
- (c)用于迭代增强智能体的自学习框架;
- (d)合成的行动调用轨迹示例。
类脑
详见站内专题:类脑计算
图解
总结LLM各阶段优化方向
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
