大模型微调新方法
【2023-9-21】大模型二次训练避坑指南
领域自适应预训练(Domain-Adaptive Pretraining)在所属的领域数据上继续预训练(or 增量预训练、二次预训练)
二次训练有很多需要注意的地方,否则很容易产生灾难性遗忘(Catastrophic Forgetting)现象
- 在原始任务上训练好的神经网络在训练完新任务后,在原始任务上的表现崩溃式的降低。
总结
【2023-9-21】大模型二次训练避坑指南
- 分析领域相关性:
- AllenAI研究表明,不考虑领域相关性而直接暴露于更多数据的继续预训练对最终任务性能有害。
- 领域相似度可以通过不同领域间的词汇重叠度(提取出除停用词之外的top 10K的unigram,计算两个数据集的词汇重复度)来度量。
- 使新数据分布与旧数据分布近似:
- ChatHome数据比例实验中,以1:5的比例的语料混合,在C-Eval和CMMLU上的表现是最佳的。
- 但是经过了领域内预训练之后,相比于未经过预训练的模型,在C-Eval和CMMLU上,效果均有所下降。
- 度小满轩辕2.0模型中,为防止遗忘,混合无监督数据和指令数据,并且合并了继续预训练和指令微调阶段:
- 降低学习率:
- 当使用较大的学习率2e-5进行训练时,模型在通用数据集上的准确率较高,而在指令任务上的准确率则迅速下降,这表明存在明显的遗忘。
- 当使用较低的学习率(如1e-6和5e-6)时,遗忘现象会明显缓解,但域内准确率也会降低。
- 进行warm up:
- 蒙特利尔大学研究表明,当模型经过「充分」训练后,不管多长的预热步数最后的性能都差不多。但前提是「充分训练」,如果只看训练前期的话,使用更长的预热步数,无论是上游任务还是下游任务,模型的 Loss 都要比其他预热步数要低(下游学的快,上游忘的慢)。
- 对新任务中参数变化施加惩罚;
- 知识蒸馏(KD),使微调模型的预测结果接近旧模型的预测结果。
【2023-11-11】
- 国内基座大模型基本都是用 gpt4 训练出来的
- 靠谱的应用必然是混合模型,否则控制不住幻觉
- LORA 其实在训练专家模型方面挺靠谱的,不过得需要配合 MOE 架构
- LORA 的灾难性遗忘问题比较严重,只适合训练专家模型
小样本
小数据过拟合
罗福莉 当“大”模型遇上“小”数据
Fine-tuning 过程中,一方面想利用大规模预训练模型提供的强大知识,另一方面又想解决“海量参数”与“少量标注样本”的不匹配问题,那么能否采用这样的方式来解决问题呢?
BERT提出以来,预训练模型参数量从最开始的3亿,逐渐攀升到了GPT-2的15亿,再到火出NLP圈的1750亿参数的GPT-3。
模型越来越大,但下游任务的标注数据量却很少。
如果直接将“大”模型在下游“小”数据上进行标准Fine-tune,将模型迁移到目标任务中去,会导致什么情况呢?
- 由于这种“大”与“小”的不匹配,容易过拟合,导致模型在下游任务中的表现差、不稳定、泛化性能差。
如何解决这种不匹配现象,缓解大规模预训练模型在下游任务过拟合。
2021 Child-Tuning
EMNLP’21 Child-Tuning 从 backward 参数更新的角度思考问题,提出一种新 Fine-tuning 策略,在Fine-tuning过程中仅更新部分参数(对应的Child Network),效果出奇的好
- 论文 Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
- 代码 ChildTuning
在不同下游任务中相比 Vanilla Fine-tuning 有明显提高,如基于BERT模型在四个不同数据集中平均带来 1.5个点 提升,在ELETRA上甚至提升8.6个点。
两个步骤:
- Step1: 在预训练模型中发现确认Child Network,并生成对应的Weights的Gradients 0-1 Mask;
- Step2: 在后向传播计算完梯度之后,仅仅对Child Network中的参数进行更新,而其他参数保持不变。梯度掩码(Gradients Mask)
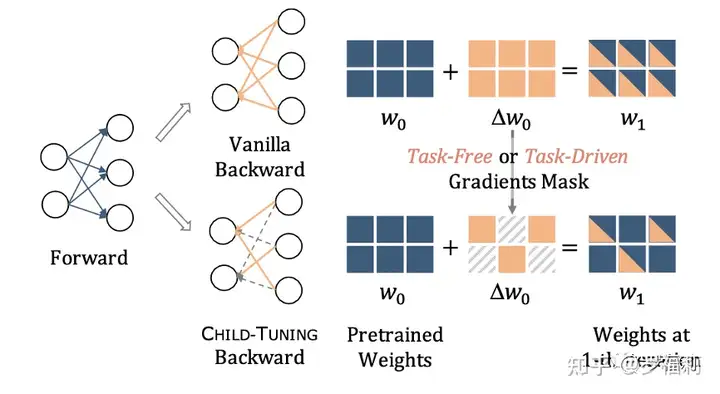
怎么识别Step1提到的Child Network呢?两种算法。
- 一种是与下游任务无关的Child-Tuning_F方法
- 另一种则是与下游任务相关、能够自适应感知下游任务特点的Child-Tuning_D
这两种方式各有优缺点。
- 任务无关算法Child-Tuning_F 对于下游任务无关算法Child-Tuning_F(F for Task-Free) ,其最大的优点是简单有效,在Fine-tune的过程中,只需要在每一步更新的迭代中,从伯努利分布中采样得到一个Gradients Mask(M_t)即可,相当于在对网络参数更新的时候随机地将一部分梯度丢弃。
代码实现
原来optimizer里加入简单几行代码:
for p in model.parameters():
grad = p.grad.data
## Child-Tuning_F Begin ##
reserve_p = 0.2 # the ratio of gradients that are reserved.
grad_mask = Bernoulli(grad.new_full(size=grad.size(), fill_value=reserve_p))
grad *= grad_mask.sample() / reserve_p
## Child-Tuning_F End ##
# the followings are the original code of optimizer
....
主动学习
【2025-8-7】主动学习
主动学习方法,用于显著减少微调大型语言模型(LLMs)所需的训练数据量,同时提升模型与人类专家之间的对齐度。
【2025-8-7】Google 把大模型微调所需的数量从10万量级降低到数百条
- 博客文章《Achieving 10,000x training data reduction with high-fidelity labels》
- 由Markus Krause, Engineering Manager 和 Nancy Chang, Research Scientist, Google Ads的两位研究人员提出新方法
- 解读 标注的原理:少而完备,监督模型训练的根本
挑战
- 广告安全领域,识别违规内容需要深度语境和文化理解,传统机器学习难以胜任。
- 微调 LLMs 通常需要大量高质量数据,成本高昂,且容易受到概念漂移影响。
方法概述
- 使用一个零/少样本模型(LLM-0)生成初始标签数据。
- 对“点击诱饵”和“正常”广告分别聚类,识别标签冲突区域。
- 从重叠聚类中选取最具混淆性的样本对,送交专家标注。
- 优先选择覆盖搜索空间更广的样本对,以控制标注预算。
- 将专家标签分为评估集与微调集,迭代更新模型,直到对齐度达到上限或收敛。
大幅降低微调所需数据量并且提高模型与专家的一致性:
- LLM 先粗标 + 聚类找冲突样本 + 专家小批高保真复标 + 迭代微调的主动学习式数据策划流程,在实际任务上把微调数据量从 10万条降到数百条,同时显著提升模型与专家的一致性,在更大模型的生产系统里甚至做到万倍数据量缩减。
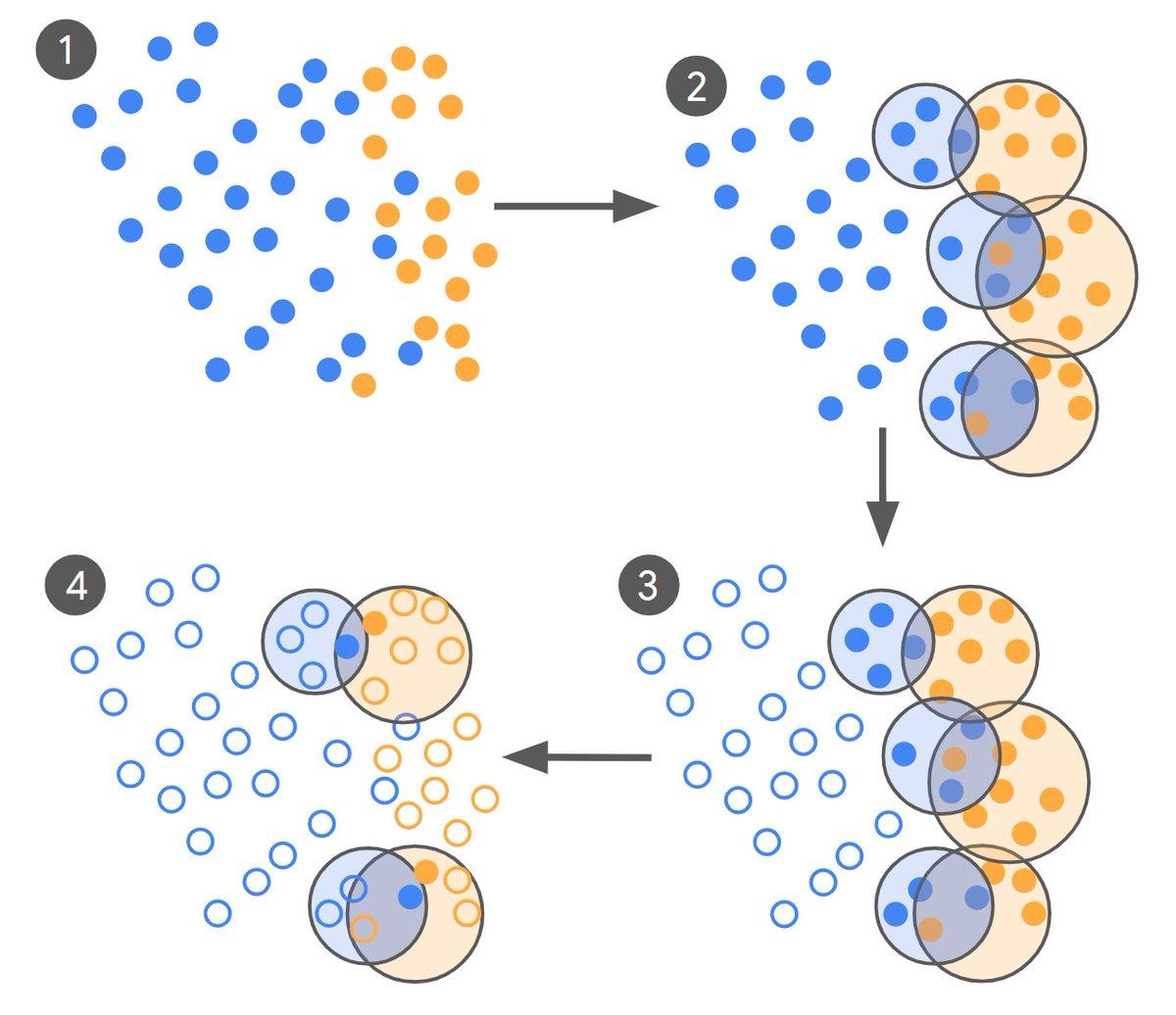
基本思路:
- LLM-0 粗标全量:按任务提示词(如“是否标题党”)先把海量样本打成正/负,注意真实分布极度不平衡(<1% 为正类)。
- 聚类找冲突:分别对正、负样本聚类,定位彼此重叠的聚类;对每对重叠聚类,找最近邻且标签相反的样本对送专家标注,并按“覆盖更大搜索空间”优先级选样以节省预算。
- 专家双用途小样本:专家标注集随机一分为二——一半做评测(看模型—专家是否接近专家—专家上限),一半做微调;多轮迭代,直到收敛/平台化。
- 度量:用 Cohen’s Kappa 统一评数据集质量与模型表现(>0.8 极佳,>0.4 可接受)。
测试效果:
- 数据量极限压缩:实验把训练样本从100,000 条降到 <500 条,模型—专家一致性反而提升最多 65%;
- 生产中的更大模型还能做到最多四个数量级的数据量缩减(1/10,000)且质量不降。
尺寸依赖:在 3.25B 参数模型上收益显著:Kappa 由 .36→.56(低复杂任务)与 .23→.38(高复杂任务),仅用 250–450 条专家样本对(众包基线用 10 万)。1.8B 型号收益不明显。
上限参照:专家内部一致性上限约 .81 / .78(低/高复杂任务);众包数据对专家的一致性仅 .59 / .41
技巧
【2023-10-10】马里兰 NEFTune – 加随机噪声
【2023-11-1】微调时只需要简单的在 embedding层上加随机噪声即可大幅度提升微调模型的对话能力?
微调时只需要简单的在 embedding层上加随机噪声即可大幅度提升微调模型的对话能力,而且也不会削弱模型的推理能力,他们从模型过拟合的角度对这一现象进行了解释。
有时改进幅度非常大,而且没有额外的计算或数据开销。
- Alpaca微调LLaMA-2-7B 可在 AlpacaEval上取得29.79%的表现,而使用加了噪声的嵌入则提高到64.69%。
不过该工作只在比较小的模型上进行微调,评估上也略显单一,解释上也不算太深入。不过实现起来非常简单,有资源的话可以快速试试。
方法
NEFTune
- 先从数据集中采样一个指令(Instruction),并将其转换为嵌入向量。
- 然后,NEFTune添加一个随机噪声向量来增强嵌入。
- 噪声向量是通过随机采样均匀分布的独立identically分布的元素生成的,每个元素范围是
[-1,1], 然后用一个因子α/√Ld缩放整个噪声向量,其中L是序列长度,d是嵌入维度,α是一个可调参数。
- 噪声向量是通过随机采样均匀分布的独立identically分布的元素生成的,每个元素范围是
def new_func(x):
# during training, we add noise to the embedding
# during generation, we don't add noise to the embedding
if model.training:
embed_init = orig_embed(x)
dims = torch.tensor(embed_init.size(1) * embed_init.size(2))
mag_norm = noise_alpha/torch.sqrt(dims)
return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)
else:
return orig_embed(x)
return new_func
NEFTune 表明: 正则化对LLM训练很重要。
- NEFTune 简单但可以持续稳定地改进指令(Instruction)微调结果,这表明正则化在LLM下值得重新审视。
- NEFTune对下游对话质量有很强的正面影响。
本文局限
- 采用AlpacaEval基准进行评估,这依赖于一个大模型判别器。
- 由于计算资源有限,在多个数据集上无法对更大的70B模型进行验证。
模拟微调
【2023-10-19】斯坦福 EFT – 模拟微调
【2023-10-23】斯坦福NLP提出EFT:如何不实际微调而“假装”微调了LLM?
语言模型(LM)训练经历两个阶段:
- 利用大量多样化的文本数据进行预训练;
- 对模型针对特定目标进行微调。
业界普遍认为
- 预训练阶段是模型获取核心知识和技能的关键,而微调更偏重于调整和优化这些能力
- knowledge and skills come from pre-training, and fine-tuning mostly filters this knowledge and skillset
但这一观念却没有深入探究。
What would happen if we combined the knowledge learned by a large model during
pre-trainingwith the knowledge learned by a small model duringfine-tuning(or vice versa)?
为了探索这两个阶段各自的贡献,斯坦福大学提出了一种新的技术 —— 模拟微调(EFT)。
- 模拟在不同规模下的预训练和微调结果,从而更清晰地探讨不同训练阶段的影响。
- Paper: An Emulator for Fine-Tuning Large Language Models using Small Language Models
EFT
- 原理:
- 模型行为可分解为两部分:预训练模型的基础行为,微调过程中获得的行为改变。
- 只改变一个阶段(比如只扩大预训练的规模,而不改变微调的规模),模型能力会如何变化。
实验结果
- 加强微调规模能够显著增强模型的帮助性,而扩大预训练规模则能更好地确保事实精准度。
- 此外,EFT允许不需要额外训练的前提下调整模型的行为特质
- 例如 提高其帮助性和减少其潜在危害。
研究者们还提出了一个特殊的EFT应用,避免对大规模LMs进行微调,而是通过与小型微调模型的结合,来模拟大型模型的微调效果。
LoRA 改进
【2023-10-24】LoRAShear 微软
LoRAShear:微软在LLM修剪和知识恢复方面的最新研究
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。
- LHSPG技术( Lora Half-Space Projected Gradient)支持渐进式结构化剪枝和动态知识恢复。可以通过依赖图分析和稀疏度优化应用于各种llm。
- LoRAPrune将LoRA与迭代结构化修剪相结合,实现参数高效微调。在LLAMA v1上的实现即使进行了大量的修剪也能保持相当的性能。
问题
- 信息的动态性要求LLM不断更新知识。
一般情况下微调用来向模型灌输最新的见解,开发人员使用特定于领域的数据对预训练模型进行微调使其保持最新状态。因为组织和研究人员的定期更新对于保持llm与不断变化的信息景观保持同步至关重要。但微调成本大且周期长。
微软研究人员推出了一种开创性方法——LoRAShear。这种方法不仅简化了llm,而且促进了结构知识的恢复。
- LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
- 结构修剪的核心: 去除或减少神经网络架构中的特定组件,优化效率、紧凑性和计算需求。
(1) LoRAShear引入了LHSPG技术,支持渐进式结构化修剪。这种方法在LoRA模块之间无缝地传递知识,并集成了动态知识恢复阶段。微调过程类似于预训练和指示微调,确保llm保持更新和相关性。
(2) 论文还有LoRAPrune 集成技术,将LoRA与迭代结构化修剪相结合,实现了参数高效的微调和直接硬件加速。
- 这种节省内存方法完全依赖于LoRA的权重和梯度来进行修剪标准。这个过程包括构造一个跟踪图,确定要压缩的节点组,划分可训练的变量,并最终将它们返回给LLM。
论文在开源LLAMAv1上的实现,证明了LoRAShear的有效性。
- 修剪了20%的LLAMAv1只有1%的性能损失,而修剪了50%的模型在评估基准上保留了82%的性能
【2025-10-2】Thinking Machines 最新研究:解读
- 小数据量任务上,LoRA 与 FullFT 几乎没有差距,完全可以对齐;
- 大数据量任务上,LoRA 容量不足,承载不了过多新知识,表现略显吃力;
- 而在强化学习任务里,哪怕 LoRA rank=1 这么小的设定,也能跑出与全量微调接近的效果。
LoRA 的使用位置也有讲究。
- 只加在注意力层并不理想,覆盖所有层(尤其 MLP/MoE)效果更佳。
- LoRA 在大 batch size 下,比 FullFT 更容易掉性能;
- LoRA 学习率和超参数规律与 FullFT 不同,需要单独调优。
灾难遗忘
【2023-11-22】LM-Cocktail
问题
-
LLM finetune 方式会导致目标任务之外的生成任务上,性能严重衰减(performance degeneration)
- 论文:LM-Cocktail: Resilient Tuning of Language Models via Model Merging
- 代码:FlagEmbedding
BAAI和中科院发布 LM-Cocktail,使用模型融合(model merging)方式
- 将 finetune模型融入 pre-train模型中
- 或 两者同等重要,加权
详见:MoE专题
【2024-1-14】腾讯 LLaMA2-Pro 块扩展
【2024-1-14】腾讯LLaMA2-Pro开源到wisemodel社区,块扩展方法解决微调的灾难性遗忘
香港大学与腾讯ARC实验室等联合研发的LLaMA-Pro-8B系列模型发布到了始智AI wisemodel.cn 开源社区。
LLaMA-Pro-8B系列模型是在LLaMA2-7B模型基础上,通过Decoder块扩展的方法,增加了8个新的块扩展,总参数量是83亿,给模型增加专业领域新能力,并且未产生灾难性遗忘的问题。
块扩展是一种简单而有效的后预训练方法,通过复制Transformer块来扩展现成的预训练语言模型,新添加的块,其线性层被初始化为零以启用恒等映射,仅使用特定领域的语料库进行进一步调整,而其余块则保持冻结。调整后,扩展的预训练模型在通用和特定领域任务上都表现出色。
- 在原始的每个块中加入一个恒等映射块(identity block),即输入和输出相同,确保扩展后的模型和扩展前相同的输出。
强化学习
【2024-12-7】RFT 强化微调
ReFT REinforced Fine-Tuning
- 论文 REFT: Reasoning with REinforced Fine-Tuning
- 解读:《论文讲解》ReFT: Reasoning with Reinforced Fine-Tuning
-
代码 mwp_ReFT
- 【2024-12-7】OpenAI强化微调登场:几十条数据o1-mini反超o1暴涨80%,奥特曼:今年最大惊喜
- 【2024-12-7】揭秘强化微调(ReFT):重塑大语言模型推理格局的突破技术
- 【2025-5-9】OpenAI强化微调终于上线了:几十个样本就可轻松打造AI专家 强化微调(Reinforcement Fine-Tuning, RFT)正式登陆 OpenAI o4-mini 模型,RFT 用思维链推理和任务专属的评分机制提升模型在特定复杂领域的表现,可以将AI模型从高中学生水平轻松提升到了专家博士水平。 通过强化微调,轻松将模型某个领域的专业能力迅速提升,打造出各种AI专家
如何提升LLM推理能力?
- 监督微调(SFT)和链式思考(CoT)注释, 来增强模型的推理能力
- 一种思路: 用CoT构建推理语料, 在SFT训练阶段从学习语料中学习推理能力
问题
- 泛化能力有限, SFT效果依赖标注的推理语料, 如数学问题上应该有多种解法,语料只有1种
强化微调(Reinforcement Fine-Tuning)结合在线RL和SFT提升模型泛化能力
使用极少训练数据即在特定领域轻松地创建专家模型。
- 最低几十个例子就可以。
RFT 场景:
- 指令变代码:把开放式指令转换成结构化代码、配置或模板,并且这些产出必须通过确定性的测试。
- 杂乱文本提炼精华:从非结构化文本中提取可验证的事实和摘要,并以JSON或其他结构化模式输出。
- 复杂规则精准应用:当信息细微、量大、层级复杂或事关重大时,进行精细的标签或策略决策。
OpenAI Cookbook 官方文档
过程
- (1) 预热: 先用 SFT 预热(warmup)
- 预热阶段,模型在“
问题,CoT”元组数据集上微调,使模型具备基本的问题解决能力。 - CoT生成过程可以分解为一系列
下一个标记预测动作,最后一个动作标记<eos>表示生成
- 预热阶段,模型在“
- (2) 强化学习: 再用在线RL(如PPO)进一步训练
- 模型通过重复采样响应、评估响应答案的正确性,并在线更新其参数来提高性能。
- 使用 PPO算法进行训练,模型通过采样多种CoT推理路径来学习,从而获得比SFT更丰富的监督信号。
ReFT的一些优势
- 更好的泛化性能:因为后面的训练完全不需要用到 CoT 标注数据,完全依赖模型自己去探索 怎么样的CoT 是正确的。
- 相比RLHF训练简单: 不需要标注额外数据训练Reward Model, 不需要额外数据提高policy. 当然这里作者也认为更多的数据能提高效果,但这并不是这个文章的目的。
- 可用性: 没有一些特定restriction,在其他任务上也是可以用到的,适用于大家SFT数据少的时候,我们做一些效果上的性能提升。
- 更好的效果:最后作者也在GSM8K上做实验,证明更好的policy也能在Majority Voting和进一步Reranking上面有效果的提升,而且也是非常的明显。
微调后, o1-mini模型得分提高80%,直接反超o1正式版。
目前OpenAI已开启强化微调研究计划,开发者可以申请强化微调API的alpha版本访问权限。
进行测试时,可使用几十到几千个高质量数据,模型能够通过强化学习自行探索和学习如何推理复杂任务。
生物医学任务,AI需要根据病例描述的症状,找出相关基因。
训练数据长这样:
病人信息:51岁女性,疾病发病时间未具体说明。
症状:眼距过宽、睑裂狭小、小颌畸形、软腭咽闭合不全、甲状旁腺功能减退、全身发育迟缓和感觉神经性听力障碍
未表现出以下症状:腭裂、法洛四联症、肺动脉瓣闭锁、心房隔缺损、主动脉肺动脉侧支血管
请列出所有可能导致这些症状的基因,从可能性最大到可能性最小,并解释为什么你认为这些特定的基因可能是原因。
评分模型(Grader)会对模型的答案进行评分,OpenAI会提供不同的评分模型,并支持自定义。
强化微调步骤
- 网页选择训练集和验证集, 设置超参
- 微调过程中,可以观察模型性能指标变化趋势
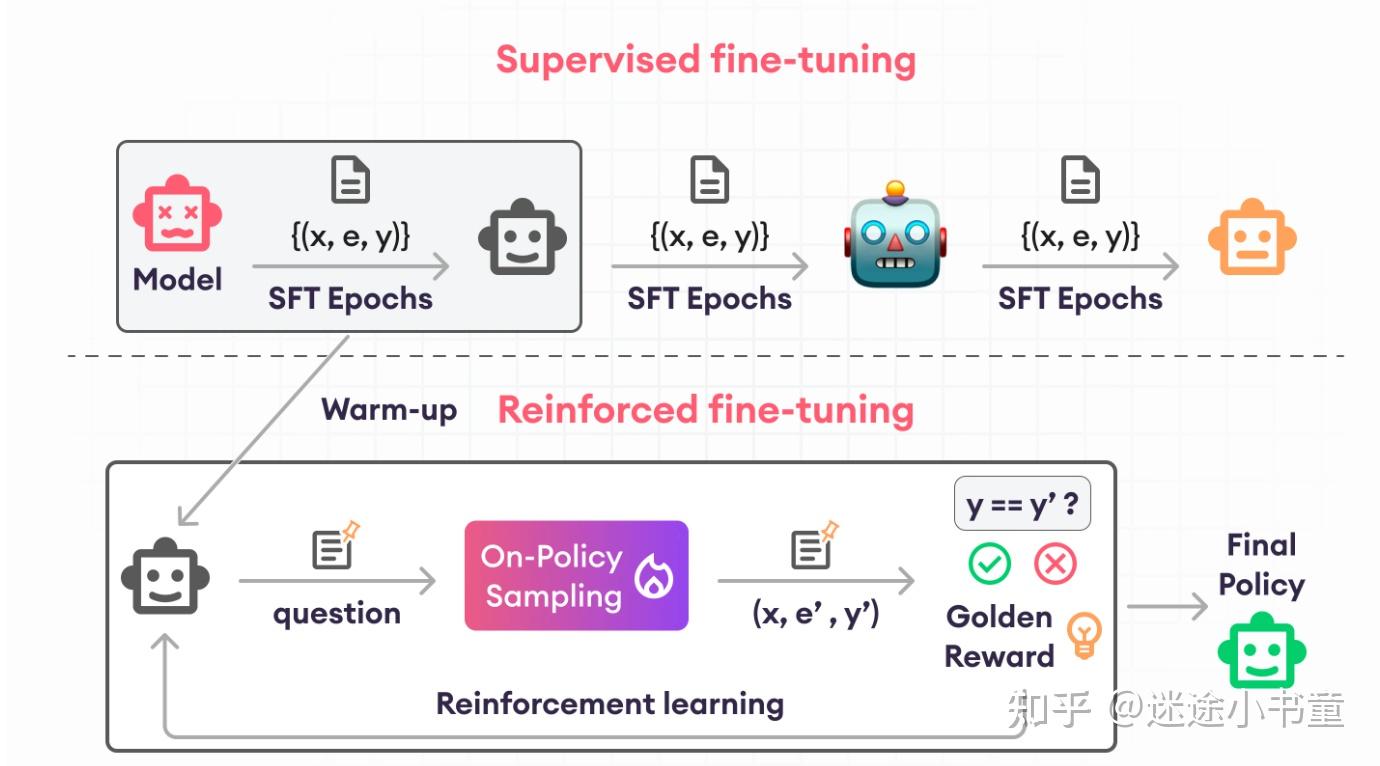
OpenAI内部测试中,强化微调在生物化学、安全、法律和医疗保健领域取得成功。
实验使用8个A100-80GB GPU 训练,并采用 DeepSpeed和HuggingFace Accelerate工具。
- ReFT 预热阶段,使用AdamW优化器,并设置了学习率和批量大小。
- 强化学习阶段,使用PPO算法,并设置了相关超参数。
实验结果表明
- ReFT在自然语言和基于程序的CoT上都显示出显著的性能提升和泛化能力。
- 此外,ReFT还能从多数投票和奖励模型重新排名等技术中受益,进一步提升性能。
ReFT 在所有数据集上均优于SFT和其他自训练方法。
- 特别是在CodeLLAMA模型上,ReFT在GSM8K数据集上的N-CoT和P-CoT任务中分别取得了9点和8点以上的提升。
- 此外,ReFT还表现出对多数投票和奖励模型重新排名技术的兼容性,进一步提升了性能。
批判式微调
【2025-2-5】CFT 批判式微调
【2025-3-9】让SFT重新伟大!CMU等华人学者提出全新「批判式微调」,媲美复刻版DeepSeek
复杂推理任务里,SFT 往往让大模型显得力不从心。
SFT 过程中,模型要模仿人类标注或合成的高质量回复,以增强通用指令遵循能力。
这类 SFT 数据集通常使用 Self-Instruct 和 Evol-Instruct 等方法进行构建。
局限性
- 随着数据集规模和质量的提升,SFT 面临着边际收益递减的问题,尤其是在训练本身效果就不错的基础模型时,使用SFT甚至可能会导致性能下降。
【2025-2-5】CMU、滑铁卢大学等机构3名华人论文,针对SFT做出了更进一步的改进,提出批判式监督微调方法(CFT,Critique Fine-Tuning),让模型更有效地模仿模仿数据集
- 论文 Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate
- 主页 CritiqueFineTuning
「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过 200万 个样本的强化学习方法
CFT 将重点从简单模仿转向批判学习
核心思想: 让模型学会批判,而不是简单地模仿,其灵感来源于人类的学习过程。
- 学霸们在学习过程中,不仅仅是复制提供的答案,而是分析、批判和改进它们。
- CFT数据集中为错误响应提供相应的批评供模型学习,让LLM能够识别响应中存在的缺陷,进而提出改进建议并验证正确性。
这种方法不仅能够提升推理能力,还能使模型在面对复杂任务时表现出更强的适应性和灵活性。
新范式
SFT-then-RL
SFT-then-RL 范式
后训练 (Post-training) 种主流范式:监督微调 (Supervised Fine-Tuning, SFT) 和强化学习 (Reinforcement Learning, RL)。
- SFT 通过模仿高质量的专家数据来学习,通过模仿学习的方式来塑造模型的行为模式。
- 优点: 直接、有效,能够快速让模型掌握特定的技能。
- 缺点也同样明显:
- 数据依赖性:SFT 的效果高度依赖于专家数据的质量和数量。
- 泛化能力有限:可能导致模型只会“背诵”而无法真正泛化。
- 暴露偏差 (Exposure Bias) :由于训练时只接触“正确答案”,模型在自主生成时可能会因遇到未见过的中间状态而偏离轨道。
- RL 则通过与环境的交互和反馈进行探索性学习。鼓励模型主动探索,通过环境的直接反馈(奖励信号)来学习和优化策略,从而发现可能比专家更优的解决方案。
- 优点: 泛化能力上通常优于 SFT。
- 缺点: RL 探索过程可能低效,甚至有风险:策略退化 (Policy Degradation) ,模型可能会因为熵坍塌 (entropy collapse) 或对次优策略的过度利用而导致性能下降。
如何结合两者的优点并规避各自的缺点?最直接的方法:“先 SFT,后 RL” (SFT-then-RL) 的序列化范式。
【2025-5-22】UFT
【2025-8-24】MIT:UFT 统一监督微调(SFT)和强化微调(RFT)
后训练阶段主要由两大技术范式主导:监督微调 (Supervised Fine-Tuning, SFT) 和强化学习微调 (Reinforcement Fine-Tuning, RFT)。
- SFT 就像是让模型“背诵”标准答案,通过学习高质量的“解题步骤”来模仿人类的推理过程。
- RFT 则鼓励模型进行“探索性思考”。它不直接提供标准答案,而是让模型自己尝试解决问题,并根据最终结果的好坏给予奖励或惩罚。
趋势:
- 单一微调范式, 可能已无法满足我们对通用人工智能推理能力的极致追求。
- 案例: Qwen 推出 CHORD
【2025-5-22】麻省理工学院 (MIT) 研究团队提出 Unified Fine-Tuning (UFT) ,将 SFT 和 RFT 无缝统一到单一集成过程中的新型后训练框架。
- 论文:UFT: Unifying Supervised and Reinforcement Fine-Tuning
- 引用论语:“学而不思则罔,思而不学则殆。”
- 代码 UFT
原理
UFT 核心思想
- 模拟人类学习新知识的方式:遇到难题时,会先尝试自己思考(类似 RFT),如果卡住了,会去翻看答案或提示(类似 SFT),然后基于提示继续思考。
UFT 设计哲学:“在指导下探索,在探索中学习”。
它并非简单地将 SFT 和 RFT 两个阶段串联起来(即先 SFT 再 RFT,论文中称为 SFT-RFT 模式),而是在一个统一的框架内,动态地、平滑地融合二者。
UFT 的实现依赖于两大核心支柱:提示引导的探索 (Exploration with Hint) 和 混合目标函数 (Hybrid Training Objective) 。
四种微调范式区别
- SFT 从头到尾都在使用完整的标准答案。
- RFT 则完全不使用答案,纯靠自己探索。
- SFT-RFT 是先用 SFT 训练,然后完全切换到 RFT。
- 而 UFT 则是在训练过程中,动态地为模型提供部分答案(提示),并结合了两种学习信号。
提示引导的探索 (Exploration with Hint)
为了解决 RFT 中因奖励稀疏导致的探索效率低下问题,UFT 引入了“提示”(Hint) 的概念
什么是提示?
- 提示本质上是正确解题步骤的一个前缀。
- 例如,一个完整的解题过程有 5 步,一个长度为 2 的提示就是把前 2 步的正确解答直接提供给模型。
提示如何工作?
- 训练的每一步,UFT 不再让模型从零开始解决问题,而是将“问题 + 提示”拼接在一起作为新的输入,让模型从提示的结尾处继续生成剩余的解题步骤。
显而易见的好处:
- 有效缩减搜索空间:提示将模型直接引导到了一个更有希望的“状态”,极大地降低了探索的难度。模型不再需要在庞大的搜索树的浅层区域进行盲目探索,而是可以专注于更深层次的推理。
- 增加获得正奖励的机会:从一个正确的中间步骤开始,模型最终“撞上”正确答案的概率大大增加。这使得稀疏的奖励信号变得相对“密集”,从而加速了学习过程。
关键问题:提示长度如何控制?
- 提示的引入虽然巧妙,但也带来一个新的问题:提示应该给多长?
- 如果提示太长(例如,总是提供 99% 的答案),那训练就退化成了 SFT,模型学不到独立推理的能力。
- 如果提示太短(或没有提示),那又回到了 RFT 的困境。
- 更重要的是,在最终评估(测试)时,模型是没有任何提示的。
因此,训练过程必须能够平滑地过渡到“无提示”的状态,以避免训练和测试之间的分布不匹配 (distribution mismatch)。
UFT 在这里提出了一种非常精妙的解决方案:基于余弦退火的提示长度调度 (Cosine Annealing for Hint Length Scheduling) 。
混合目标函数 (Hybrid Training Objective)
UFT 的另一个核心创新。
传统的 RFT 只关心最大化最终的奖励,而忽略了模型在探索过程中接触到的“高质量信息”——也就是我们提供给它的“提示”。
提示本身就是正确答案的一部分,蕴含着宝贵的监督信号。如果仅仅把它用作探索的起点,无疑是一种巨大的浪费。
UFT 设计了一个混合目标函数,将 RFT 的奖励最大化和 SFT 的似然最大化巧妙地结合在了一起。
目标函数的直观理解:
- UFT 目标函数告诉模型:“你的首要任务是像 RFT 一样,通过探索来最大化最终奖励(学会思考)。
- 但同时,你必须紧紧跟随我给你的提示,不要偏离太远,要努力模仿提示中的每一步操作(学会记忆)。我会通过 β 来告诉你这两件事哪个更重要一点。”
效果
核心发现:
- UFT 普适优越性: UFT在绝大多数情况下都取得了最好的性能,稳定地超越了所有基线方法。
- UFT 对模型规模的自适应性: 根据基础模型能力,自动地在“记忆”和“泛化”之间进行权衡。
- 当模型较小时,UFT 行为更偏向于 SFT。其混合目标函数中的监督学习项(KL 散度项)发挥了主导作用,帮助模型有效地“记忆”解决方案,以弥补其自身探索能力的不足。
- 当模型较大时,UFT 的行为更偏向于 RFT。其目标函数中的强化学习项(奖励最大化项)发挥了主导作用,鼓励模型利用自身强大的基础能力去“思考”和“探索”,从而获得更好的泛化性能。
- UFT 能够帮助模型学习新知识
- 问题:微调究竟是在“激发”模型已有的潜能,还是在“教会”模型全新的知识?
- Llama-3.2-3B 模型通过 RFT 获得的性能提升非常有限,远不如 Qwen2.5-3B,RFT 对 Llama 模型的提升非常微弱,UFT 则对 Llama 模型有显著的性能提升
- UFT 不仅仅是在利用模型已有的知识。其混合目标函数中的监督学习部分,能够有效地为模型注入新知识和新技能。这使得 UFT 在帮助那些“偏科”的模型补齐短板方面,比纯 RFT 方法更具优势。
关键点:
- 对于小模型 Qwen2.5-0.5B,UFT 平均准确率达到 9.45% ,显著高于 SFT-RFT 的 7.28% 和 RFT 的 3.25%。
- 对于大模型 Qwen2.5-3B,UFT 平均准确率达到 30.93%
补充
小模型,基础模型能力较弱,难以进行有效的自主探索。
- RFT 的表现非常差,几乎没有提升。这验证了 RFT 严重依赖基础模型的强度。
- SFT 和 SFT-RFT 的表现要好得多,因为它们通过直接的监督信号强行“教会”了模型。
- UFT 的表现与 SFT-RFT 非常接近,并最终取得了最佳性能。
当模型规模增大,其预训练阶段学到的知识和推理潜力更强。
- SFT 和 SFT-RFT 的表现反而变差了,出现了明显的过拟合现象。它们强迫模型记忆特定路径,反而损害了模型利用自身强大能力进行泛化的潜力。
- RFT 的表现大幅提升,成为了最强的基线方法之一,展示了其在激发大模型泛化能力上的优势。
- UFT 的表现与 RFT 非常接近,甚至在某些点上超越了 RFT。
当模型较大时,UFT 的行为更偏向于 RFT。
- 其目标函数中的强化学习项(奖励最大化项)发挥了主导作用,鼓励模型利用自身强大的基础能力去“思考”和“探索”,从而获得更好的泛化性能。
这两个对比实验极具说服力地证明了 UFT 的自适应性。它不是一个僵化的算法,而是能够根据模型的内在能力,动态调整其学习策略,从而在各种规模的模型上都能“取其精华,去其糟粕”,实现稳定、出色的表现。
【2025-6-24】SRFT
【2025-6-24】中科院&美团等提出SRFT,将监督微调SFT和强化学习RL两种训练范式结合!
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能
问题
LLM 推理能力提升上,监督微调(SFT) 和强化学习(RL,有时也称作强化微调,RFT)是两条核心技术路线。
但各自都存在瓶颈:
- SFT 擅长模仿专家解题思路,类似“背书”,能快速为模型打下基础,但缺点: 容易陷入死记硬背,缺乏在新问题上灵活应用和寻找最优解的能力;
RFT/RL通过不断试错来探索解题方法,类似“刷题”,能够发现更优解法,但探索过程效率低下,容易面临模式崩溃风险。
因此,目前通常采用两阶段顺序方法 SFT→RFT/RL:
- 先用 SFT 学习高质量数据集,再用 RFT/RL 进一步优化对齐LLM策略(即先“背完书”再“去刷题”)。
然而,这种顺序方式不仅影响学习效率,还导致模型在“刷题”时忘了“书本”上的知识,引发知识遗忘等问题,如何让两者在同一阶段协同作用,做到“边背边练”,成为提升 LLM 推理能力的关键之一。
SFT 和 RL 对 LLM 的作用:大锤 vs. 手术刀
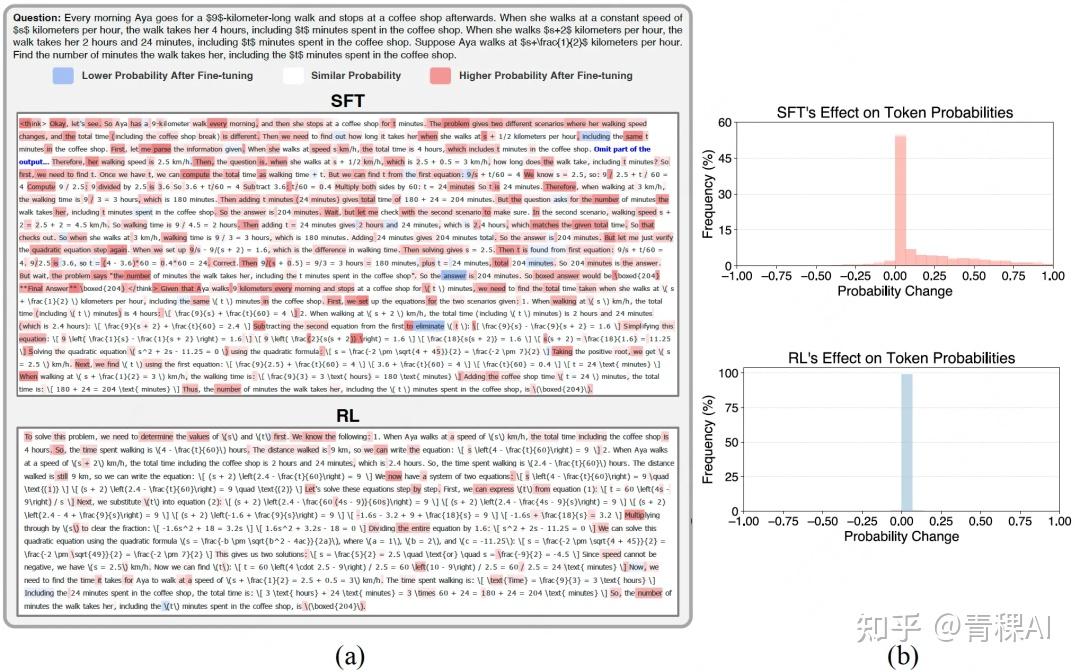
发现:
- SFT 导致大部分 token (50%以上)的概率分布改变(粗粒度)
- RL/RFT 只对特定 token (少于2%)进行有针对性调整,同时保留了大部分内容(细粒度)
理论上,SFT 目标是最大化专家数据的似然,将专家演示的条件概率分布 “注入” 模型,类似人们通过“背书”学习,其梯度公式揭示了其内在机制
- 对单个样本训练,SFT主要通过提高目标标记的概率,同时降低词汇表中所有其他标记的概率,这会锐化模型的分布,从而产生更具确定性的输出。
- 通过这种“一刀切”的方式,SFT强制模型去拟合专家数据,但也可能因此抑制模型的探索性和多样性。
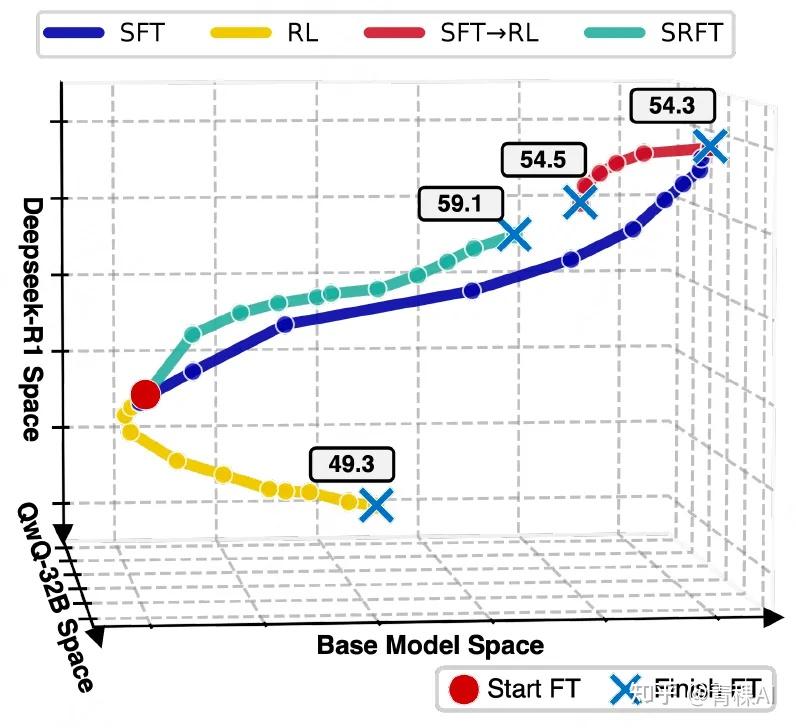
- 训练动态可视化,数字表示训练后的准确率。SRFT 通过在结合两种方法实现直接优化,到达与SFT→RL接近的区域,且无需两阶段转换
将不同模型看作高维空间中的点,通过计算生成相同回复(response)时输出token概率分布的“距离”,来描绘其在训练过程中的“移动轨迹”。
论文引入了三个参考模型——基础模型(Qwen-2.5-Math-7B)、DeepSeek-R1和QwQ-32B作为坐标系,通过模型与参考模型回复的 teacher forcing 距离来间接测量模型在不同微调步骤中的训练动态(如果两个模型对所有提示(prompt)中的所有回复token分配相似的概率,则认为它们是接近的)。
所有微调范式在提升性能的同时,均会偏离基础模型空间,此外:
- SFT 使模型在概率空间中移动的距离最远,印证了其“大锤”般的全局性影响。
- SFT→RL的两阶段路径揭示了一个问题:SFT可能将模型推得“过远”,后续的RL反而需要将其“拉回”到离基础模型更近的区域才能达到最优,这暗示了顺序方法的低效性。
- SRFT 单阶段路径则显得更为直接和高效,它在学习专家知识的同时,没有过度偏离初始模型,从而实现了更精准的优化。
结合两种范式:从两阶段到单阶段
两种结合方式的性能、熵变化曲线
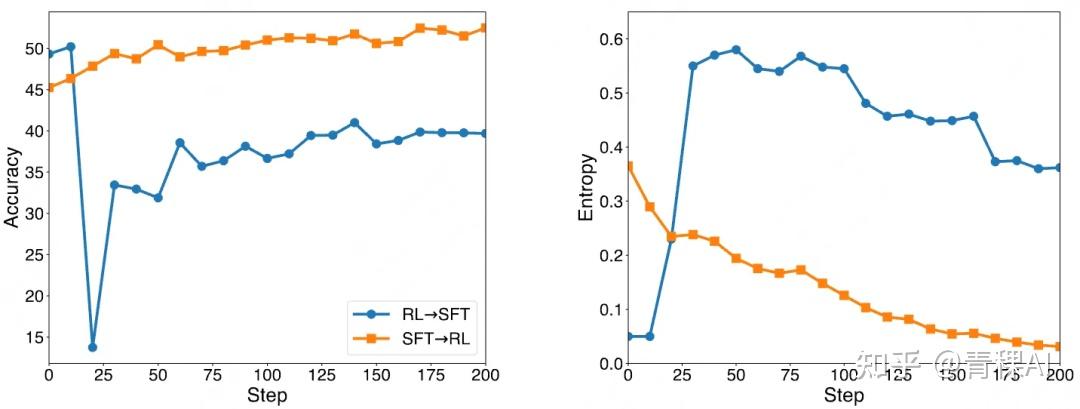
熵是信息论中的重要概念,衡量随机变量的不确定性。LLM 推理过程中,熵可以反映模型输出分布的不确定性,近期诸多工作也展示了熵在 LLM 训练中的重要性。
- 高熵表示模型的输出分布较为均匀,不确定性较大;
- 低熵则表示模型的输出分布较为集中,不确定性较小。
该论文中,研究人员主要从 SFT 和 RL结合的角度对熵展开了分析,如图所示。
在 RL 后进行 SFT,会使模型的熵短暂增加,这表明模型在学习新的知识和模式时,其输出分布变得更加不确定。随着训练的进行,熵逐渐降低,模型逐渐收敛,输出分布变得更加确定,最终提升模型性能。
相比之下,RL 在训练过程中则会使熵显著降低,模型的输出分布变得更加集中。这是因为 RL 通过奖励函数引导模型学习特定的策略,使模型更倾向于生成能够获得高奖励的输出。然而,这种低熵的状态也可能导致模型的可塑性降低,限制了后续训练的效果。
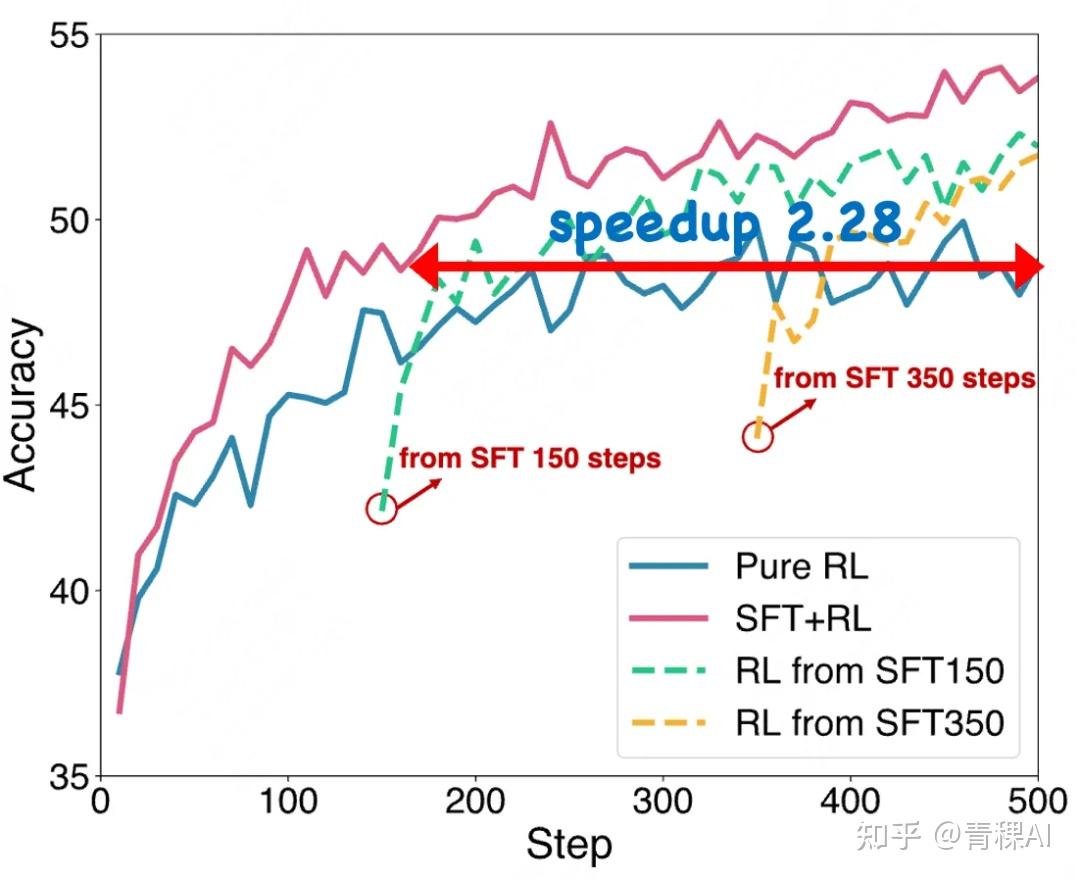
不同结合方式的训练效率
论文比较了纯 RL 、不同SFT步数的顺序 SFT→RL 方法,以及单阶段 SFT+RL 方法。
与顺序 SFT→RL 方法相比,单阶段 SFT+RL 方法实现了更优的训练效率。
- 单阶段 SFT+RL 方法通过统一优化有效利用演示数据,提速2.28倍。
- 这种方法能够直接针对目标进行策略优化,同时保留从数据集中通过监督学习进行知识蒸馏的优势。
介绍
【2025-6-24】中科院深度强化学习团队联合美团,提出一种单阶段监督-强化微调方法——SRFT (Supervised Reinforcement Fine-Tuning)。
- 项目网页: SRFT2025
- 论文链接: SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
- 模型链接: SRFT
该方法通过基于熵的动态加权机制,将两种训练范式结合。
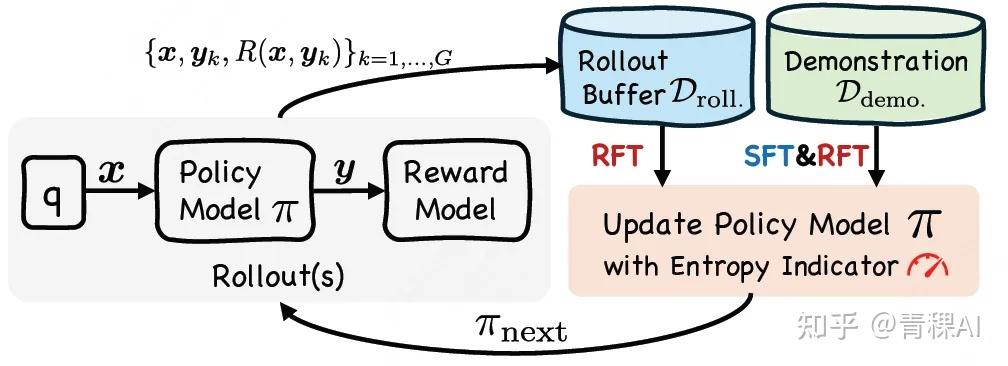
原理
SRFT 核心在于其单阶段学习机制:通过SFT实现粗粒度行为策略逼近,通过RL实现细粒度策略精化,借助于单阶段训练,将微调同时应用于演示数据和自生成的试错数据。
(1)从演示数据(demonstration)中学习
双重策略设计
对于包含演示数据的数据集 (例如,由DeepSeek-R1生成的推理响应),SRFT采用双重策略来有效利用这一宝贵资源:
- 监督微调组件:通过SFT执行行为策略的粗粒度逼近:
- 异策略强化学习组件:采用类似LUFFY的异策略强化学习(off-policy RL)方法,将演示数据作为高质量的异策略强化学习数据,进行细粒度学习:
- 直接将LLM的同策略强化学习(on-policy RL) 探索试错的组(group)与演示数据结合,创建增广训练组:
- 整个增广训练组的优势估计为:
分布不匹配缓解策略
为解决演示数据的行为策略 与当前训练策略 之间的分布不匹配,引入两种关键缓解策略:
- 熵感知自适应权重机制:对于演示数据的SFT,引入基于当前策略熵的自适应权重机制:
- 当模型熵很高(非常不确定)时,SFT权重很小。这能防止模型在“迷茫”时被专家数据过度“带偏”,避免了分布不匹配带来的负面影响。最终的演示SFT损失为:
- 重要性采样:对于异策略强化学习训练,引入类似GRPO和PPO的重要性采样项修正分布差异。最终的异策略强化学习训练损失为:
其中重要性采样比率为:为简化实现,论文设置 并省略截断操作。
(2)从自探索(self-exploration)中学习
RL目标函数分解
在具有二元奖励 的RL范式下,其目标函数可以自然分解为两个不同组件:
其中:
- 正样本目标:类似于监督微调,最大化正确响应的似然
- 负样本目标:实施似然最小化,减少分配给错误响应的概率
熵自适应权重
为保持训练稳定性并防止熵的快速降低,对正样本目标引入熵自适应权重机制:
完整的自探索目标为:
单阶段集成方法
统一损失函数
通过同时利用演示数据和自探索试错数据,SRFT有效平衡了SFT的粗粒度调整与RL的细粒度优化。总损失函数结合了所有四个组件:
关键机制总结
- 熵感知权重:两种熵感知权重机制确保训练稳定性
- 当策略展现高熵(不确定性)时,权值降低,减少SFT对训练的影响
- 当熵较高时,使RL训练中正样本训练的权值上升,使熵下降,从而促进熵的稳定
- 单阶段优化:直接朝着目标函数优化,同时保持来自数据集的监督学习的知识蒸馏优势
- 这种方法使SRFT能够同时从演示数据和自探索试错数据中受益,同时通过两种熵感知权重机制保持稳定的训练动态。
效果
结果:性能显著优于zero-RL方法,与其它结合方法相比提升明显
该方法能够同时从 高质量演示数据(demonstrations)与LLM自身的探索试错(rollouts) 中学习
- 在5项数学推理任务中实现 59.1% 的平均准确率,较zero-RL基线提升 9.0% ;
- 在三项分布外任务上取得 62.5% 的平均准确率,较zero-RL基线提升 10.9% ,展现了卓越的泛化能力。
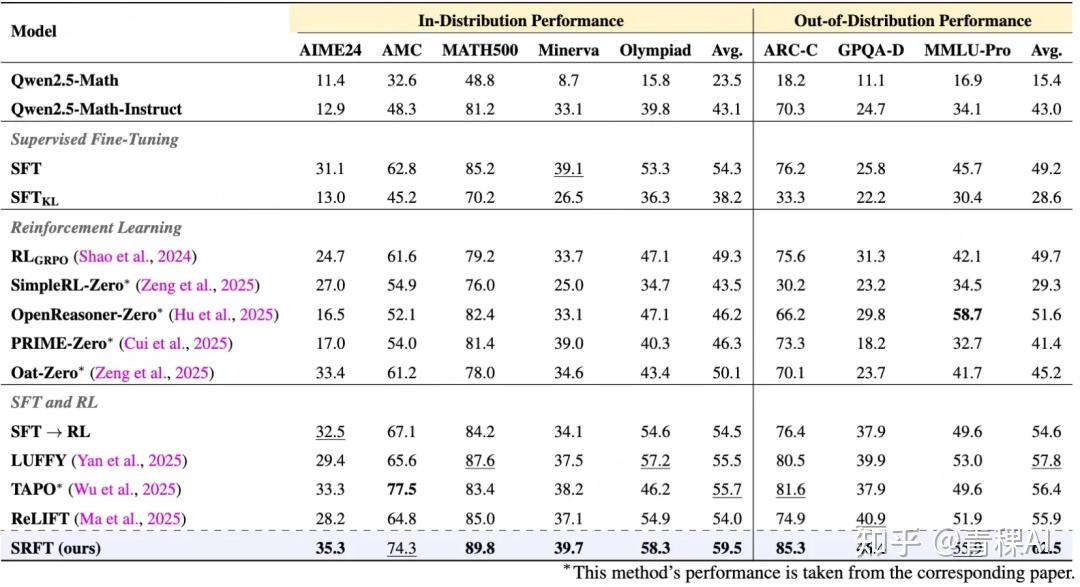
训练动态分析:更稳、更长、更高效
【2025-8-15】CHORD
【2025-8-15】Qwen团队提出CHORD训练流程:动态融合 SFT 与 RL
SFT-then-RL 初衷很美好:
- SFT 为 RL 提供一个良好的起点和有效的探索先验,帮助其跳出局部最优;
- 而 RL 的在策略学习机制则可以缓解 SFT 带来的暴露偏差和对静态数据的过拟合。
然而,理想很丰满,现实很骨感。
大量实证研究,包括本文的实验(如下图所示),都表明 SFT-then-RL 范式并不总能胜过单纯的 RL 方法,有时甚至会产生负面效果。
核心问题:
- 为什么简单的“SFT+RL”组合拳打不出预期的效果?
将两者结合的传统做法——先进行 SFT 再进行 RL (SFT-then-RL): 虽然直观,但在实践中常常表现不佳,甚至不如单纯的 RL。
由 Deepseek-R1 模型生成的专家数据对 Qwen2.5-7B-Instruct 模型进行 SFT,并在训练过程中持续评估模型在 MATH-500 数据集上的准确率。学习曲线揭示了一个被称为 “迁移-适应-过拟合” (shift-readapt-overfit) 的三阶段动态过程。
迁移阶段 (Shift) :在训练初期,模型性能不升反降。这是因为专家数据(离策略)的推理模式与模型自身已建立的模式存在显著差异。强制模型去拟合这些外部模式会破坏其内部的稳定结构,导致能力暂时性地退化。这个问题在存在暴露偏差的情况下会进一步加剧,因为模型在推理时需要处理自己生成的、与专家数据分布不同的上下文。适应阶段 (Readapt) :随着 SFT 的继续,模型的策略 开始逐渐与专家的模式对齐,能够生成与专家类似的响应。此时,模型性能开始回升,并逐步接近甚至超越初始水平。在这个阶段,模型对自身原有模式的依赖性降低,从而在一定程度上缓解了暴露偏差问题。但与此同时,这也可能抑制了模型进行自我探索的潜力。过拟合阶段 (Overfit) :如果长时间在有限的专家数据上进行训练,模型最终会不可避免地走向过拟合。这不仅会导致模型在未见过的数据上泛化能力下降,还会使其输出的多样性大幅减少。更关键的是,这种过拟合会严重限制模型在后续 RL 阶段进行有效探索的能力。
动态过程清晰地揭示了 SFT-then-RL 范式的内在脆弱性。简单地将两个阶段分开,使得我们很难精确地控制离策略专家数据的影响,也难以把握从 SFT 转换到 RL 的最佳时机。尤其当专家数据的推理模式与模型原有模式差异巨大时,这种两阶段方法的局限性就更加凸显。
根本原因
- 来自外部专家的“离策略 (off-policy)”数据可能会严重干扰模型在 SFT 阶段已经建立的内部模式,导致模型性能下降,并可能在后续的 RL 阶段陷入过拟合。
阿里巴巴发表论文
从全新视角——“离策略 vs. 在策略 (off-policy vs. on-policy)”——审视了 SFT 与 RL 的关系,并提出了一个名为 CHORD (Controllable Harmonization of On- and Off-Policy Reinforcement Learning via Dynamic Weighting) 创新框架。
CHORD 框架不再将 SFT 视为一个独立预处理阶段,而是重新定义为在策略 RL 过程中的动态加权的辅助目标。
该框架的核心, 双重控制机制:
- 全局系数 (Global Coefficient) :该系数从整体上调控专家数据(离策略)的影响力,引导模型从初期的模仿学习平滑地过渡到后期的探索性学习(在策略)。
- 逐词权重函数 (Token-wise Weighting Function) :该函数在更细粒度的层面上对专家数据进行学习,通过降低对模型现有模式干扰较大的词元 (token) 的权重,来维持学习过程的稳定性,同时保留模型自身的探索能力。
通过这种动态加权的和谐机制,CHORD 能够在有效吸收专家知识的同时,避免破坏模型原有的推理能力,从而在多个基准测试中显著超越了传统的 SFT-then-RL 范式和其他基线方法,实现了更稳定、高效的学习过程。
【2025-12-2】OSFT
【2025-12-2】在线监督微调(OSFT)
OSFT 是一种无奖励的迭代自监督方法,通过生成并监督其自身的训练数据来微调 LLMs。采用解耦采样和训练温度来增强潜在推理能力,在数学基准测试中取得了具有竞争力的结果。该方法展示了高训练效率和可扩展性,为强化学习策略提供了一种更简单的替代方案。
OSFT 中,预训练模型根据提示生成输出,并立即使用其自身的响应通过交叉熵损失进行微调,以完全自监督和自放大的方式运行。与使用固定、外部提供数据的经典监督微调(SFT)或优化显式奖励信号的正则化学习方法不同,OSFT 在线构建其训练数据,并完全依赖其自身的生成行为来驱动改进。该机制在数学推理基准测试中表现出极具竞争力的下游性能,经常与具有可验证奖励(RLVR)的强正则化学习基线(如 GRPO)相媲美,同时在训练效率和简单性方面有显著提升
OSFT 作为预训练 LLMs 的“自助”学习策略运行
- 在线数据构建:模型不再在静态数据集上训练,而是在每次微调步骤中生成新的(提示,响应)对,主要在低温下采样其当前偏好的输出,以反映高置信度响应。
- 监督更新:微调使用标准交叉熵损失在自生成数据上进行,没有明确的奖励、优势估计或可取性分数。
- 与标准 SFT 对比:传统 SFT 固定训练目标(例如,人工标注或蒸馏数据);OSFT 在其能力变化时不断进化自己的训练信号。
- 与 RLVR/RLHF 的对比:基于 RL 的方法,如 RLVR(包括 GRPO、PPO),采样多条轨迹,并使用外部正确性或人类偏好信号作为奖励。OSFT 除了初始预训练外,没有外部监督
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
