- Transformer 学习笔记
- 总结
- Transformer 模型
- Transformer架构
- 序列化
- Encoder
- Decoder
- Attention 机制
- 直观理解
- 注意力与机器翻译
- Attention 类型
- 注意力可视化
- self-attention
- Context-attention 是什么?
- 点乘注意力是什么?
- self-attention 实现
- self-attention 改进
- Multi-head attention 又是什么
- 2.1. 点积attention
- 2.2. Attention机制涉及到的参数
- 2.3. Query, Key, Value
- 2.4. Attention 作用
- 2.5. Decoder端的Mask
- 2.6. 多头Attention (Multi-head Attention)
- 3.1. Feed Forward Network
- 3.2. Positional Encoding
- 3.3. Layer Normalization
- Residual connection是什么?
- Layer normalization是什么?
- Mask 是什么?
- Positional encoding 是什么?
- Position-wise Feed-Forward network是什么?
- Transformer 实现
- Transformer 改进
- 结束
Transformer 学习笔记
总结
NLP典型任务
NLP领域一般分别叫做NLU(Natural Language Understanding,自然语言理解)任务和NLG(Natural Language Generation,自然语言生成)任务。
- NLU任务:句子级别分类,给定一个句子输出一个类别。
- 因为句子可以表示为一个向量,经过张量运算映射到每个类的概率分布。
- 这和之前的语言模型没有本质区别,只是语言模型的类别是整个词表大小,而分类的类别看具体任务,有
二分类、多分类、多标签分类等等。
- NLG任务: 除了生成外,常见的有
文本摘要、机器翻译、改写纠错等。
NLP典型任务
| 任务 | 理解(NLU) |
生成(NLG) |
输入/输出模式 | 分析 |
|---|---|---|---|---|
文本分类 |
✅ | ❌ | 多对一 | 适合Encoder |
文本匹配 |
✅ | ❌ | 近似多对一 | 适合Encoder |
文本生成 |
❌ | ✅ | 多对多,变长 | 适合Decoder |
序列标注 |
✅ | ❌ | 多对多,定长 | 适合Encoder |
文本摘要 |
❌ | ✅ | 多对多,变长,一般变少 | 适合Decoder |
机器翻译 |
❌ | ✅ | 多对多,变长 | 适合Decoder |
改写/纠错 |
❌ | ✅ | 多对多,维度近似 | 适合Decoder |
问答系统 |
❌ | ✅ | 多对多,维度不定 | 适合Decoder |
然而,大多数NLP任务其实并不是 Seq2Seq
- 典型代表:句子级别
分类、Token级别分类(也叫序列标注)、相似度匹配和生成;
而前三种应用最为广泛。这时候Encoder和Decoder可以拆开用。
- 左边的Encoder在把句子表示成一个向量时,利用上下文信息,也就是双向;
- 右边的Decoder不能看到未来的Token,一般只利用上文,是单向的。
虽然都可以用来完成刚刚提到的几个任务,但从效果上来说
Encoder更加适合非生成类(即理解类)任务Decoder更加适合生成类任务。
Transformer 解决什么问题
针对 rnn 和 cnn 缺陷,Transformer怎么解决这些问题?
- 并行化
- 长程依赖学习
- 层次化建模
【2024-11-24】浙大大语言模型书籍:语言模型基础
transformer 是两种模块组成的模块化网络结构
- (1)
注意力模块Attention: 加权平均, 将前文信息叠加到当前状态上- 自注意力模块有
自注意力层(Self-Attention Layer)、残差链接(Residual Connections)和层正则化(Layer Normalization)组成
- 自注意力模块有
- (2)
全连接前馈模块Fully-connected Feedforward:- 全连接前馈模块由
全连接前馈层、残差连接和层正则化组成,中间由 ReLU 作为激活函数 - 全连接模块占据了 transformer 近 2/3 的参数量,掌管着transformer记忆功能,可看做KV模式的记忆管理模块
- 全连接前馈模块由
- 分析
层正则化(Layer Normalization): 加速神经网络训练过程,以取得更好的泛化性能残差链接(Residual Connections): 有效解决梯度消失问题- 几种类型: Pre-LN、Post-LN
- Pre-LN: 应对表征坍塌(Representation Collapse)能力略弱,但处理梯度消失强
- Post-LN: 应对表征坍塌(Representation Collapse)能力更强,但处理梯度消失略弱
概要
Transformer 从NLP领域横跨到语音和图像领域,最终统一几乎所有模态的架构。
- 基于 Transformers 架构的大型语言模型 (LLM),如
GPT、T5和BERT,已经在各种自然语言处理 (NLP) 任务中取得了 SOTA 结果。 - 此外,涉足其他领域,例如:计算机视觉 (
VIT、Stable Diffusion、LayoutLM) 和音频 (Whisper、XLS-R)
Google 2017年发的一篇论文,标题叫《Attention Is All You Need》,核心是Self-Attention机制,中文也叫自注意力。
- 在语言模型建模过程中,把注意力放在那些重要的Token上。
基于transformer的多模态模型
ViT: 2020, 图像任务CLIP: 2021, 文本和图像混合KOSMOS-1: 2023, 多模态大规模语言模型
【2024-3-8】transformer Transformer 逐层图解, medium 文章翻译
- 整体结构
- 词嵌入(Embedding ) + 位置编码(Position Encoding)
- Transformer 输入关注每个词的信息:含义和序列位置。
- 嵌入层对词含义编码。
- 位置编码层表示词的位置。一条正弦曲线(偶数)和余弦曲线(奇数)
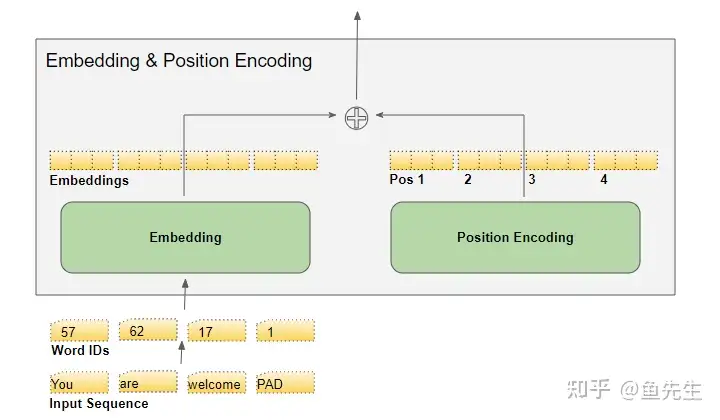
- Transformer 输入关注每个词的信息:含义和序列位置。
- 矩阵维度(Matrix Dimensions)
- 嵌入层接受一个 (samples, sequence_length) 形状的二维单词ID矩阵,将每个单词ID编码成一个单词向量,其大小为 embedding_size,得到(samples, sequence_length, embedding_size) 形状的三维输出矩阵。
- 由嵌入层和位置编码层产生的(samples, sequence_length, embedding_size) 形状在模型中被保留下来,随数据在编码器和解码器堆栈中流动,直到它被最终的输出层改变形状(实际上变成了samples, sequence_length, vocab_size) 。
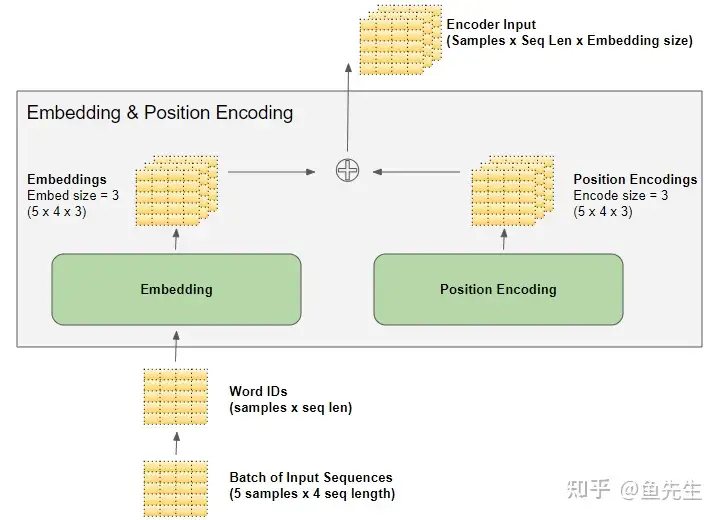
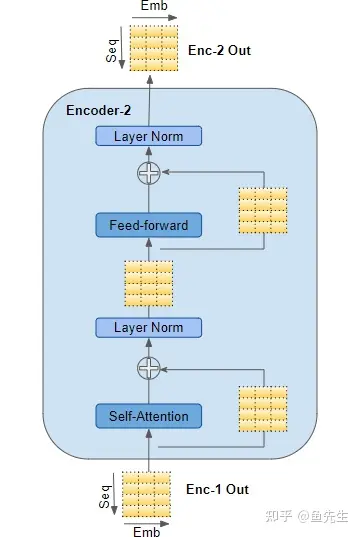
- 编码器 (Encoder)
- 编码器和解码器堆栈分别由几个(通常是 6 个)编码器和解码器组成,按顺序连接。
- 堆栈中的第一个编码器从嵌入和位置编码中接收其输入。堆栈中的其他编码器从前一个编码器接收它们的输入。
- 当前编码器接受上一个编码器的输入,并将其传入当前编码器的自注意力层。当前自注意力层的输出被传入前馈层,然后将其输出至下一个编码器。
- 自注意力层和前馈网络都会接入一个残差连接,之后再送入正则化层。注意,上一个解码器的输入进入当前解码器时,也有一个残差连接。
- 编码器堆栈中的最后一个编码器的输出,会送入解码器堆栈中的每一个解码器中。
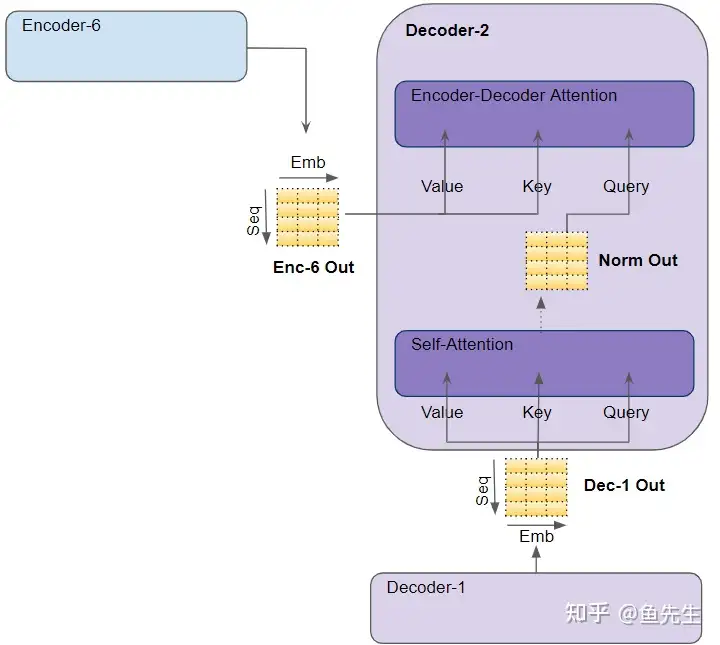
- 解码器(Decoder)
- 解码器结构与编码器类似,但有一些区别。
- 像编码器一样,堆栈中的第一个解码器从嵌入层(词嵌入+位置编码)中接受输入;堆栈中的其他解码器从上一个解码器接受输入。
- 在一个解码器内部,输入首先进入自注意力层,这一层的运行方式与编码器相应层的区别在于:
- 训练过程中,每个时间步的输入,是直到当前时间步所对应的目标序列,而不仅是前一个时间步对应的目标序列(即输入的是step0-stepT-1,而非仅仅stepT-1)。
- 推理过程中,每个时间步的输入,是直到当前时间步所产生的整个输出序列。
- 解码器的上述功能主要是通过 mask 方法进行实现。
- 解码器与编码器的另一个不同:解码器有第二个注意层层,即编码器-解码器注意力层 Encoder-Decoder-attention 层。其工作方式与自注意力层类似,只是其输入来源有两处:位于其前的自注意力层及 E解码器堆栈的输出。
- Encoder-Decoder attention 的输出被传入前馈层,然后将其输出向上送至下一个Decoder。
- Decoder 中的每一个子层,即 Multi-Head-Self-Attention、Encoder-Decoder-attention 和 Feed-forward层,均由一个残差连接,并进行层规范化。

- 解码器结构与编码器类似,但有一些区别。
- 注意力(Attention)
- 注意力被用在三个地方:
- Encoder 中的 Self-attention:输入序列对自身的注意力计算;
- Decoder 中的 Self-attention:目标序列对自身的注意力计算;
- Decoder 中的Encoder-Decoder-attention:目标序列对输入序列的注意力计算。
- 注意力层(Self-attention 层及 Encoder-Decoder-attention 层)以三个参数的形式接受其输入,称为查询(Query)、键(Key)和值(Value)
- Decoder self-attention,解码器的输入同样被传递给所有三个参数,Query、Key和 Value。
- Encoder-Decoder-attention,编码器堆栈中最后一个编码器的输出被传递给Value和Key参数。位于其前的 Self-attention 和 Layer Norm 模块的输出被传递给 Query 参数。
- 自注意力计算方式
- ![])(https://pic3.zhimg.com/80/v2-7cda913d104961a1db0e5ea6ff3a8b86_1440w.webp)
- 注意力被用在三个地方:
- 多头注意力(Multi-head Attention)
- 多头注意力–Multi-head Attention 通过融合几个相同的注意力计算,使注意力计算具有更强大的分辨能力
- 掩码

transformer 与 大脑
【2025-6-7】香港浸会大学助理教授 吴郁杰: Transformer 与人脑结构相似
Transformer Architecture vs. Hippocampal-Cortical Interaction
- Self-attention mechanism vs. Hopfield model + Hebbian learning
- Position coding vs. Recurrent,position encodings
- Transformer vs. Modern Hopfield network + Grandmother Cell Theory
参考
- 2016年,Dense associative memory for pattern recoanition
- 2021年, Relating transformers to models and neural representations of the hippocampal formation
AI vs Biology:
- AI learning: 错误信息逐层累计,propagated error signals layer by layer to optimize weights (global)
- Bio learning: operate by multiple synaptic plasticity rules, decentralized and adaptive learning (local)
Methods for hybrid learning models 混合学习模型
- Two cues about neuromodulation: modulation mechanisms and independent learning circuits
- Hybrid spiking learning unit: slow weight (wcp) and fast weight (w.p)
Transformer 模型
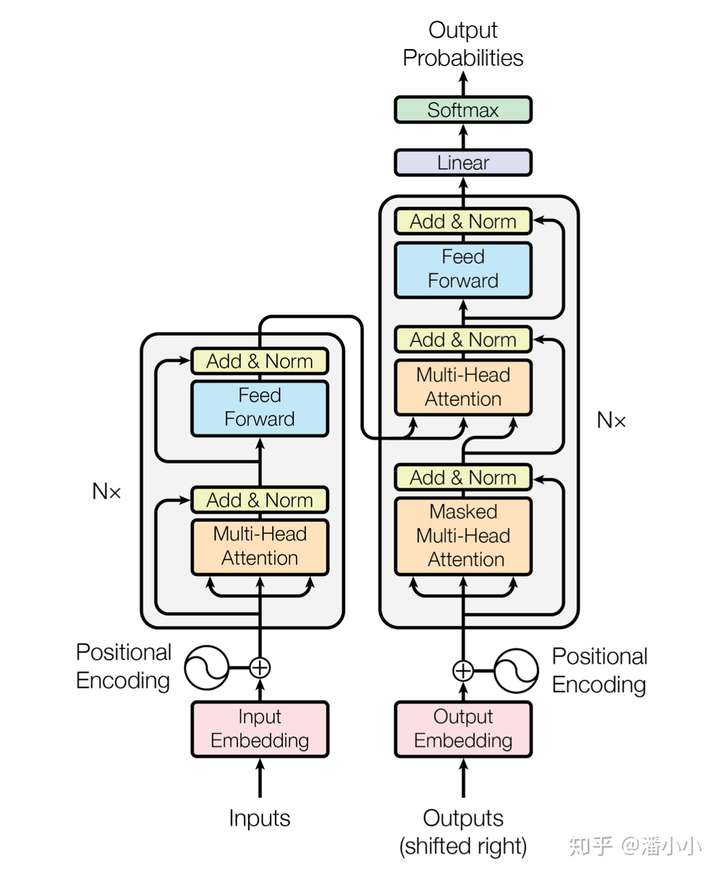
上图下面部分,训练用的输入和输出数据的 embedding,都会先加上一个position encoding来补充一下位置信息。
Encoder- 途中左侧部分是encoder块,encoder中6层相同结构堆叠而成,在每层中又可以分为2个子层,底下一层是multihead self-attention层,上面是一个FC feed-forward层,每一个子层都有residual connection,,然后在进行Layer Normalization. 为了引入redisual connenction简化计算,每个层的输入维数和embedding层保持一致。
Decoder- 同样是一个6层的堆叠,每层有三个子层,其中底下两层都是multihead self-attention层,最底下一层是有mask的,只有当前位置之前的输入有效,中间层是encode和decode的连接层,输出的self-attention层和输入的encoder输出同时作为MSA的输入,实现encoder和decoder的连接,最上层和encoder的最上层是一样的,不在单说,每个子层都有有residual connection,和Layer Normalization
【2021-8-25】Transformer结构中,左边叫做编码端(Encoder),右边叫做解码端(Decoder)。不要小看这两个部分,其中左边的编码端最后演化成了最后鼎鼎大名的Bert,右边的解码端在最近变成了无人不知的GPT模型。
【2023-2-15】transformer 出现后,迅速取代了 RNN系列 变种,跻身主流模型架构基础。
transformer 结构分成:
- (1)Decoder-only 自回归系列:下一词预测(Next Token Prediction)训练语言模型,偏好 文本生成,示例:GPT-3;
- (2)Encoder-only 双向自编码系列:偏好 自然语言理解,示例:BERT,双向transformer+Mask自编码系列
- (3)Encoder-Decoder 系列:结合“截断补全”、“顺序恢复”等有监督/自监督任务训练,偏好 条件文本生成,示例:T5,双向/单向attention,
RNN系列
详见站内专题:RNN和seq2seq演变
亮点
Self Attention- 传统的编解码结构中,将输入输入编码为一个定长语义编码,然后通过这个编码在生成对应的输出序列。它存在的一个问题在于:输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示
- attention机制: encoder的输出不是一个语义向量,是一个语义向量的序列

- Transformer的Attenion函数称为scaled dot-Product Attention

MultiHead Attention- self attention计算时会分为两个阶段,第一个阶段计算出softmax部分,第二部分是在乘以 Value部分,这样还是串行化的,并行化不够。
- MultiHeadAttention,对query,key,value各自进行一次不同的线性变换,然后在执行一次softmax操作,这样可以提升并行度,论文中的head数是8个

- position Encoding
- 语言是有序的,在cnn中,卷积的形状包含了位置信息,在rnn中,位置的先后顺序其实是通过送入模型的先后来保证。transformer抛弃了cnn和rnn,那么数据的位置信息怎么提供呢?
- Transformer通过position Encoding来额外的提供位置信息,每一个位置对应一个向量,这个向量和word embedding求和后作为 encoder和decoder的输入。这样,对于同一个词语来说,在不同的位置,他们送入encoder和decoder的向量不同。
总结
- 结构

- 训练过程

图解 Transformer
站点 poloclub 提供多种模型原理可视化
包含提供 transformer 交互式可视化
Transformer架构
transformer 结构图:

首先,Transformer模型使用经典的encoer-decoder架构,由encoder和decoder两部分组成。
- 上图的左半边用
Nx框出来的,encoder的一层。encoder一共有6层这样的结构。 - 上图的右半边用
Nx框出来的,decoder的一层。decoder一共有6层这样的结构。 - 输入序列经过word embedding和positional encoding相加后,输入到encoder。
- 输出序列经过word embedding和positional encoding相加后,输入到decoder。
- 最后,decoder输出的结果,经过一个线性层,然后计算softmax。
word embedding和positional encoding后面会解释。首先详细地分析一下encoder和decoder的每一层是怎么样的。
Transformer 架构理解
Transformer是一种Encoder-Decoder架构(Seq2Seq架构也是),先把输入映射到Encoder,可以把Encoder想象成RNN,Decoder也是。
Transformer 架构基于Seq2Seq,同时处理NLU和NLG任务,而且Self Attention机制的特征提取能力很强。
- 不同于Seq2Seq, Transformer 是一个
set-to-set模型,不再依赖串行,解决了seq2seq并行能力问题- seq2seq: 序列到序列模式
- transformer: 集合到集合模式
- 只要数据是基本单位组成的集合(a set of units),就可以应用 transformer;
这样,左边负责编码,右边则负责解码。不同的是
- (1)
编码时,因为知道数据,所以建模时可以同时利用当前Token的历史Token和未来Token;- Encoder的block分两个模块:
Multi-Head Attention和Feed Forward, - ①
Multi-Head Attention用到Self Attention,和Attention类似,不过它是Token和Token的重要性权重。Multi-Head将自注意力重复n次,每个token注意到的信息不一样,可以捕获到更多信息。- 比如:「我喜欢在深夜的星空下伴随着月亮轻轻地想你」,有的Head「我」注意到「喜欢」,有的Head「我」注意到「深夜」,有的Head「我」注意到「想你」……
- ②
Feed Forward相当于「记忆层」,大模型大部分知识都存在此,Multi-Head Attention根据不同权重的注意提取知识。
- Encoder的block分两个模块:
- (2) 但
解码时逐个Token输出,所以只能根据历史Token以及Encoder的Token表示进行建模,而不能利用未来Token。
序列化
模型只认识数字,因此,输入前需要将各种模态的数据序列化成数组/向量
数据模态
- 文本
- 语音
- 图像
参考知乎
文本序列化
- 文字序列根据 BPE 或者其它编码方法得到 Token
- 文字编码方式:一个英文单词编码在 1~2 个 token, 一个汉字编码是 1~3 个 token,每个 token 都是一个数字
- Token 通过查表直接得到 Embeding矩阵
- 这个表通常非常大 ,比如 GPT3 可能是 12288x4096, 12288是 token 个数,4096 是维度,每个 token 查表后有 4096 维,这个是训练出来的
- Token 通过 Postion 计算 Positional Encoding(标准算法公式)
- 将 Embedding 与 Positional Encoding 相加得到 Transformer的输入
Token 查表示意图
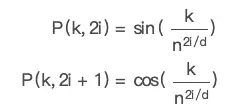
- 每个token的位置embedding受多个因素影响:词库总数n, embedding维度d, token对应的词库id(k), 句子中的第几个(i), sin还是cos

图像序列化
图像的 token 化
- 直接把图像矩阵分割成小块(如 16x16)
- 再按顺序排好
- 然后加位置编码
示例
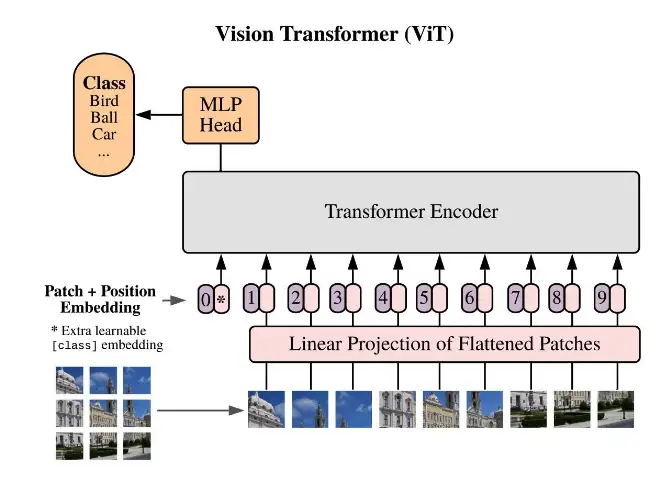
图片被切割拉平后,直接扔到一个 CNN 网络里变成 Transformer 的输入部分
语音序列化
声音的 token 化最简单,因为天生就有二维特征: mel 谱数据
以 openai 的 whisper 项目为例
- 声音输入的 token 每 30ms 一个,80 个log mel 谱数据。
- 这样只要不断切段,这个声音就直接变成了二维矩阵
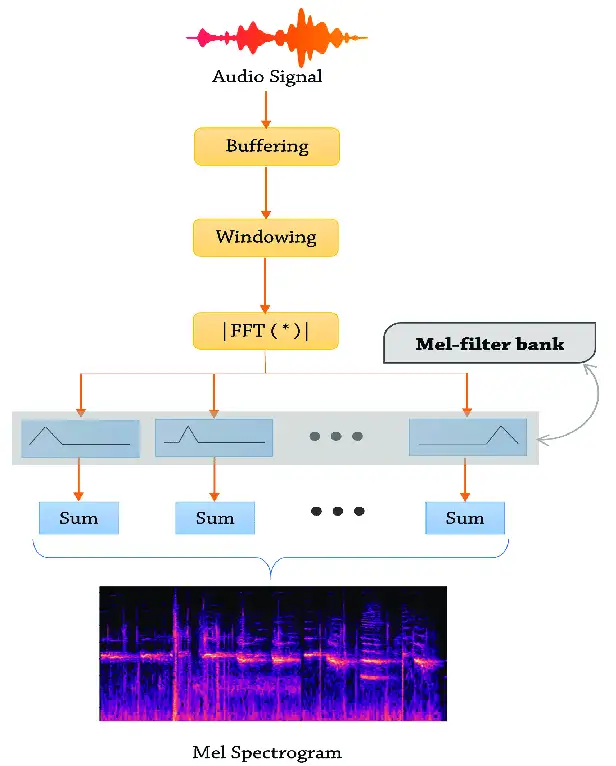
声音输入也有 position embedding
Encoder
Encoder 由6层相同的层组成,每一层分别由两部分组成:
-
- 第一部分是一个multi-head self-attention mechanism
-
- 第二部分是一个position-wise feed-forward network,是一个全连接层
两个部分,都有一个 残差连接(residual connection),然后接着一个Layer Normalization。
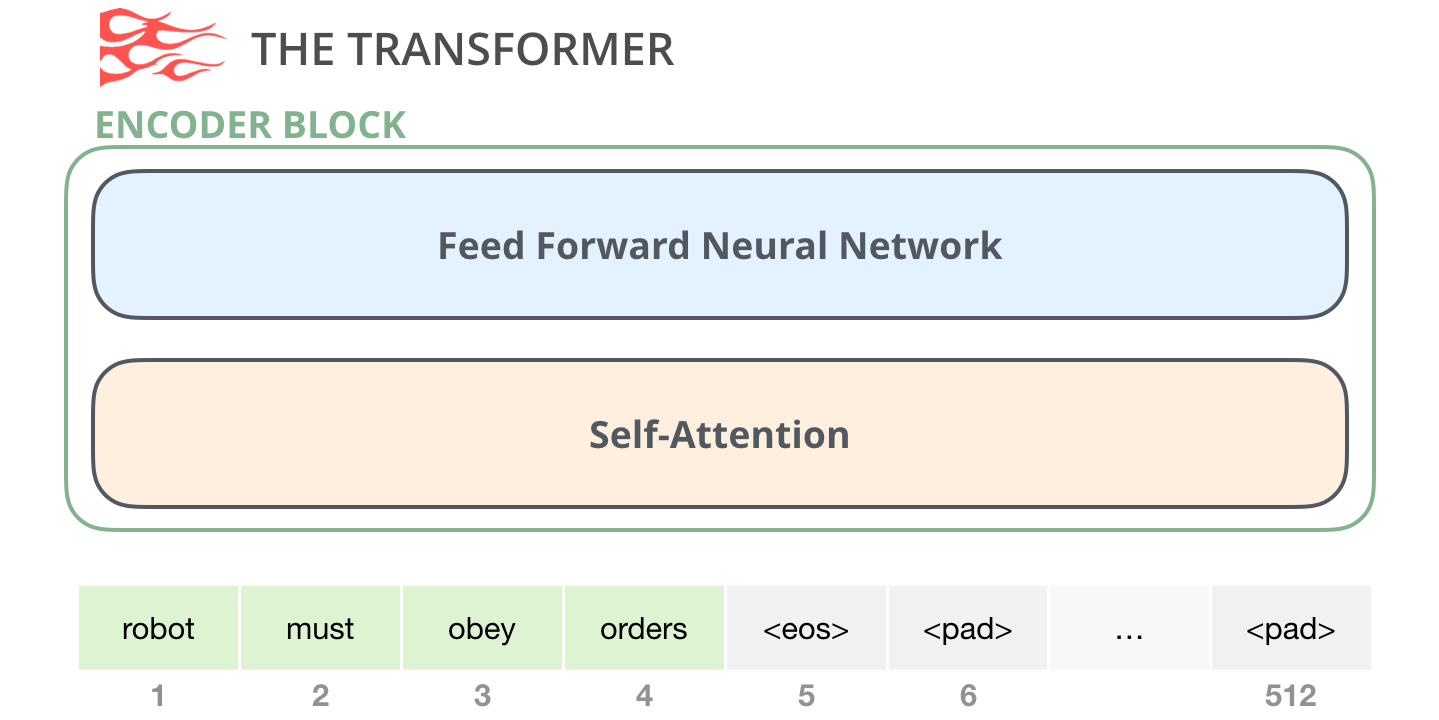
- An encoder block from the original transformer paper can take inputs up until a certain max sequence length (e.g. 512 tokens). It’s okay if an input sequence is shorter than this limit, we can just pad the rest of the sequence.
新手可能会问:
-
- multi-head self-attention 是什么呢?
-
- 参差结构是什么呢?
-
- Layer Normalization又是什么?
Decoder
和 encoder 类似,decoder由6个相同的层组成,每层包括3个部分:
- 第一个部分是multi-head self-attention mechanism
- 第二部分是multi-head context-attention mechanism
- 第三部分是一个position-wise feed-forward network
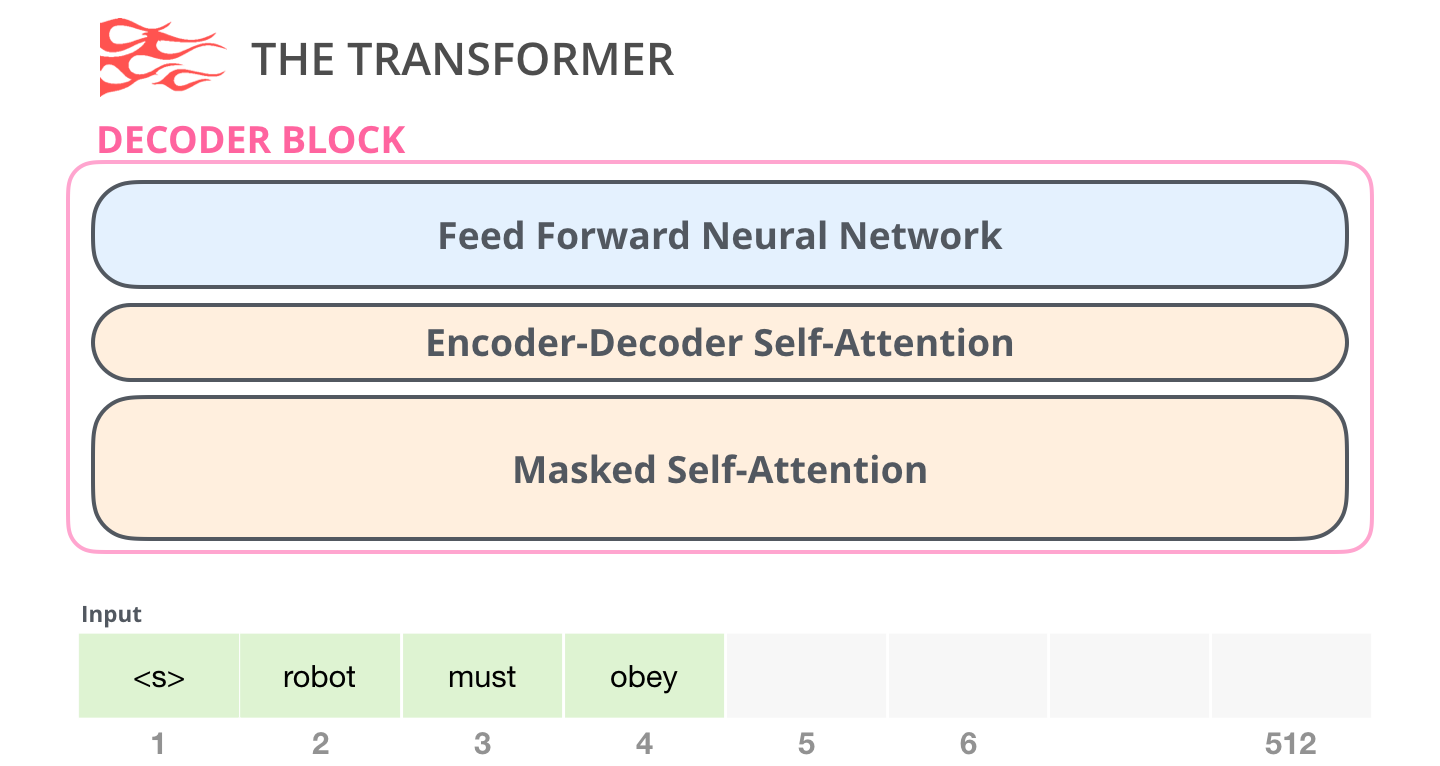
三个部分都有一个残差连接,后接一个Layer Normalization。
相同
- 都有 自注意力层(self-attention)
- 都有 前向全连接层(feed forward neural network)
不同于 encoder:
自注意力层将待预测的token屏蔽掉(mask),所以是 masked self-attention。掩码方法不同于BERT的置为 [MASK],而是继承到自注意力计算中。- 新增
编码器-解码器自注意力层(encoder-decoder self-attention)
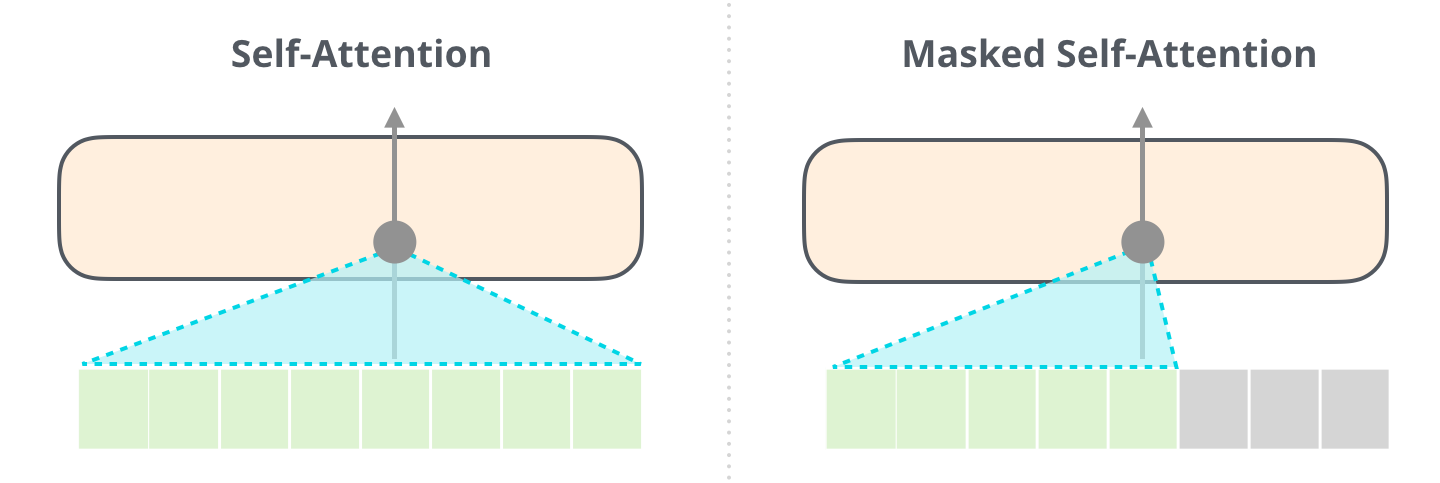
但是,decoder出现了一个新的东西multi-head context-attention mechanism。这个东西其实也不复杂,理解了multi-head self-attention 可以理解multi-head context-attention。
GPT-2 用的 Decoder 结构
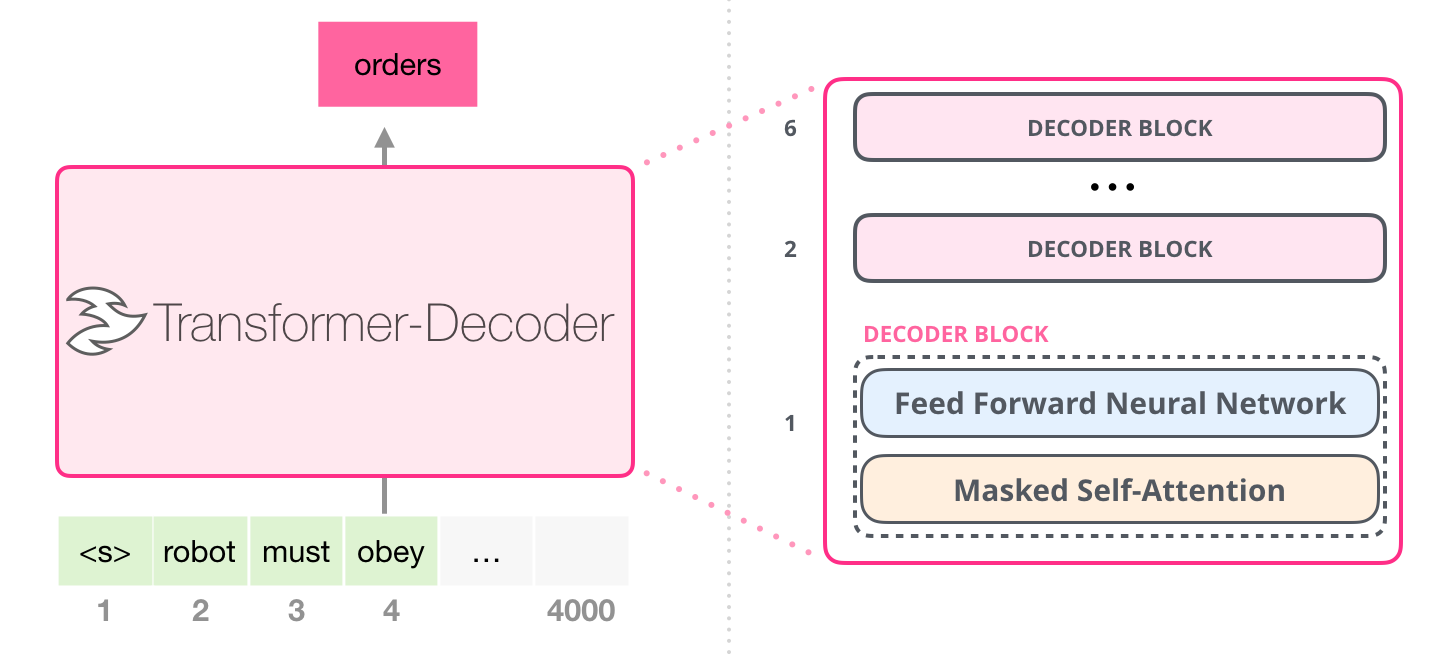
- 去掉 transformer decoder结构里的
编码器-解码器自注意力层
Attention 机制
直观理解
语言的含义极度依赖上下文,比如,机器人第二法则:
- 机器人第二法则机器人必须遵守人类给它的命令,除非该命令违背了第一法则。
这句话中高亮了三个地方,指代其它单词。需要把这些词指代的上下文联系起来,才能理解或处理这些词语。模型处理这句话时,必须知道:
- 「它」指代机器人
- 「命令」指代前半句话中人类给机器人下的命令,即「人类给它的命令」
- 「第一法则」指机器人第一法则的完整内容
自注意力机制
- 处理每个单词(将其传入神经网络)之前,融入了模型解释某个单词的上下文的相关单词的理解。
- 给序列中每一个单词都赋予一个相关度得分,之后对向量表征求和。
Attention是指对于某个时刻的输出y,它在输入x上各个部分的注意力。这个注意力实际上可以理解为权重。
Attention 机制也可以分成很多种。Attention? Attention! 一文有一张比较全面的表格:

- Figure 2. a summary table of several popular attention mechanisms.
上面第一种additive attention是以前seq2seq模型里面,使用attention机制,这种加性注意力(additive attention)用的很多。Google的项目 tensorflow/nmt 里面这两种attention机制都有实现。
为什么这种attention叫做additive attention呢?
- 对于输入序列隐状态 $h_i$ 和输出序列的隐状态 $s_t$ ,它的处理方式很简单,直接合并,变成$[s_t;h_i]$
但是 transformer模型用的不是这种attention机制,使用的是另一种,叫做乘性注意力(multiplicative attention)。
那么这种乘性注意力机制是怎么样的呢?从上表中的公式也可以看出来:两个隐状态进行点积!
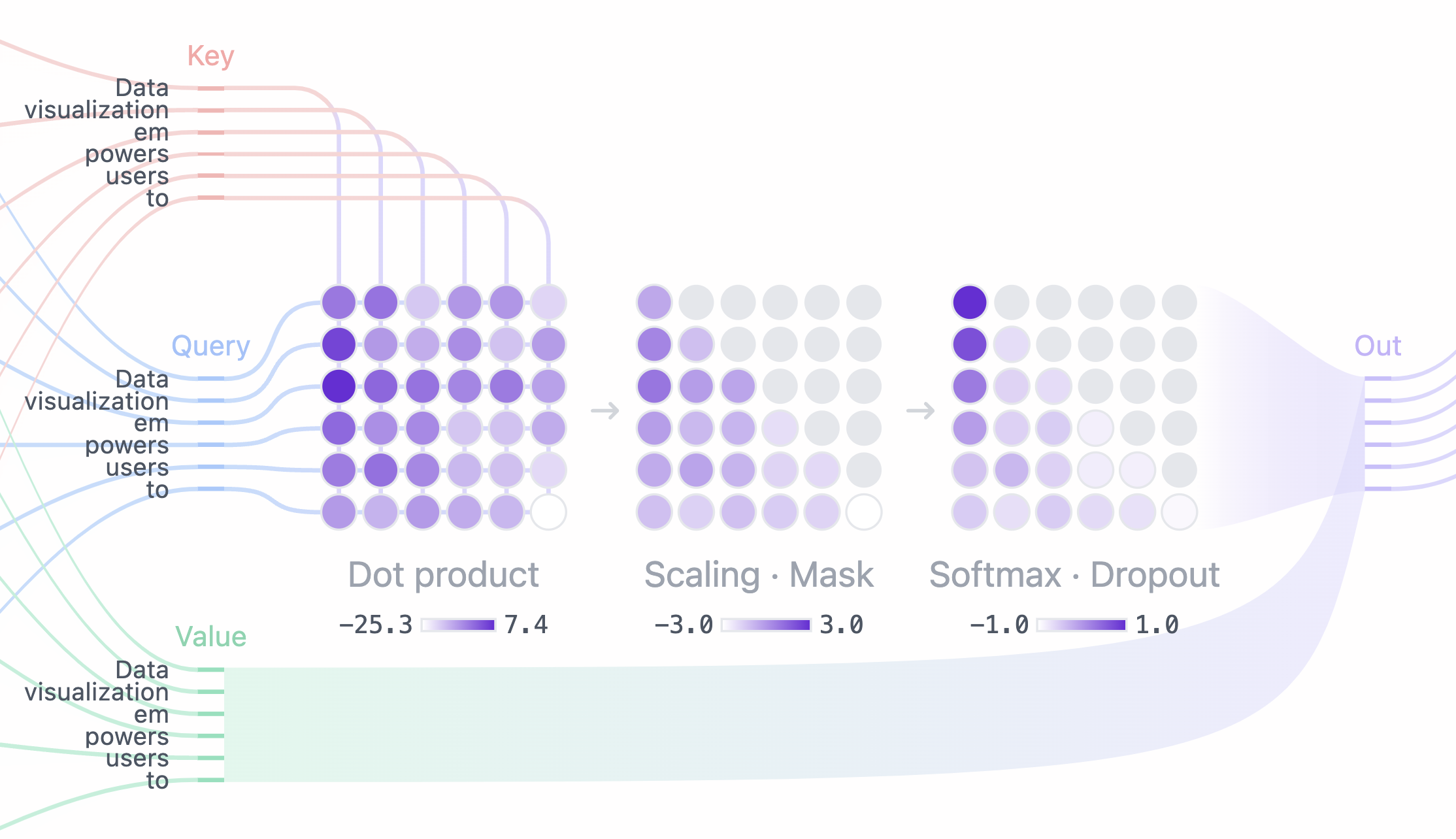
注意力机制 核心概念: Query(查询)、Key(键)和 Value(值)。
Query(Q):当前单词的一种表示,对所有其他单词进行评分(用Key)。只关心当前正在处理的token的 Query 。生成任务中,通常是最后一个token的表示。Key(K):所有单词的标签。它们是我们在搜索相关单词时所匹配的内容。用于与Query进行匹配,决定应该关注哪些信息。Value(V):单词实际表示,一旦对每个单词的相关性进行了评分,聚合起来表示当前单词的值。
工作原理类比:
- 假设输入为: “A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.”
- Query (查询):手里拿着一张便利贴,上面写着”it”。当前词的查询向量, 例子中是第9个位置的查询向量。
- Key (键):文件柜中每个文件夹的标签, 像键向量, 代表序列中每个词的”标识”。4个文件夹,分别标记为”a”, “robot”, “must”, “obey”。
- Value (值):每个文件夹里的实际内容对应着值向量,包含词具体信息。
注意力计算过程:
- 拿着”it”便利贴(Query #9),与每个文件夹的标签(Key #1到#4)进行比较。比较结果决定了你对每个文件夹内容的关注程度。
- “a” 文件夹得到30%的关注
- “robot”文件夹得到50%的关注
- “must”和”obey”文件夹各得到0.1%的关注
百分比是注意力权重,决定从每个文件夹中提取信息的比例。
信息综合:
最后根据这些权重从各个文件夹中提取信息,并将它们综合起来,形成对”it”这个词的理解。
最终的表示是多个信息源的加权组合。这个加权组合可以用一个简单的形式表达:
it的表示 = 0.3a+ 0.5robot+ 0.001must+ 0.001obey
每个词前的系数代表注意力权重,而词本身代表了其 Value 向量。这种加权求和方式使模型能根据当前上下文需求,灵活整合来自不同位置的信息,从而形成对当前词”it”的理解。
这个简化表达忽略了很多细节,但基本表达了注意力机制中信息综合的核心思想。
注意力机制本质:
Query向量代表当前 token 的”问题”或”需求”。Key向量代表每个 token 可能提供的”信息”。Value向量是实际传递的”信息内容”。
生成新 token 时,新”问题”(Query)查询所有历史”信息”(Key)并获取相关的”内容”(Value)。
注意力机制允许模型动态地“查阅”之前的信息。不同信息源(早先的词)会根据其相关性获得不同程度的”注意力”。最终表示是多个信息源的加权组合。
注意力与机器翻译
Attention 机制 为机器翻译任务带来了曙光
- Attention 显著地提高了翻译算法的表现。使Decoder网络注意原文中的某些重要区域来得到更好的翻译。
- Attention 解决了信息瓶颈问题。原先 Encoder-Decoder 网络的中间状态只能存储有限的文本信息,从繁重的记忆任务中解放出来了,它只需要完成如何分配注意力任务即可。
- Attention 减轻了梯度消失问题。Attention 在网络后方到前方建立了连接捷径,使得梯度可以更好的传递。
- Attention 提供了一些可解释性。通过观察网络运行过程中产生的注意力分布,可知道网络在输出某句话时都把注意力集中在哪里;而且通过训练网络还得到了一个免费的翻译词典(soft alignment), 尽管未曾明确地告诉网络两种语言之间的词汇对应关系,但是显然网络依然学习到了一个大体上是正确的词汇对应表。
- Attention 代表一种更为广泛的运算。之前学 Attention机制在机器翻译问题上的应用,实际上 Attention 还可以使用于更多任务中。
- Attention机制的广义定义:给定一组向量Value和一个查询Query,Attention是一种分配技术,根据Query需求和内容计算出Value的加权和。
- Attention 被认为是大量信息的选择性总结归纳,或给定一些表示(query)的情况下,用一个固定大小的表示( Ck )来表示任意许多其他表示集合的方法(Key)。

Attention 类型
Attention
- Hard Attention: 只选取向量中一个元素, 赋值1, 其余都是0
- Soft Attention
| Attention 种类 | 原理 | 实现方法 | 优点 | 缺点 | 其它 |
|---|---|---|---|---|---|
Hard Attention |
只选取向量中一个元素, 赋值1, 其余都是0 | 1. max(a_ki) 最大采样, 选最高权重的隐含层 2. 按 a_ki 分布进行随机采样 |
简单 | 最大采样/随机采样选择信息, 导致损失函数与注意力分布函数关系不可导, 无法用BP训练 | 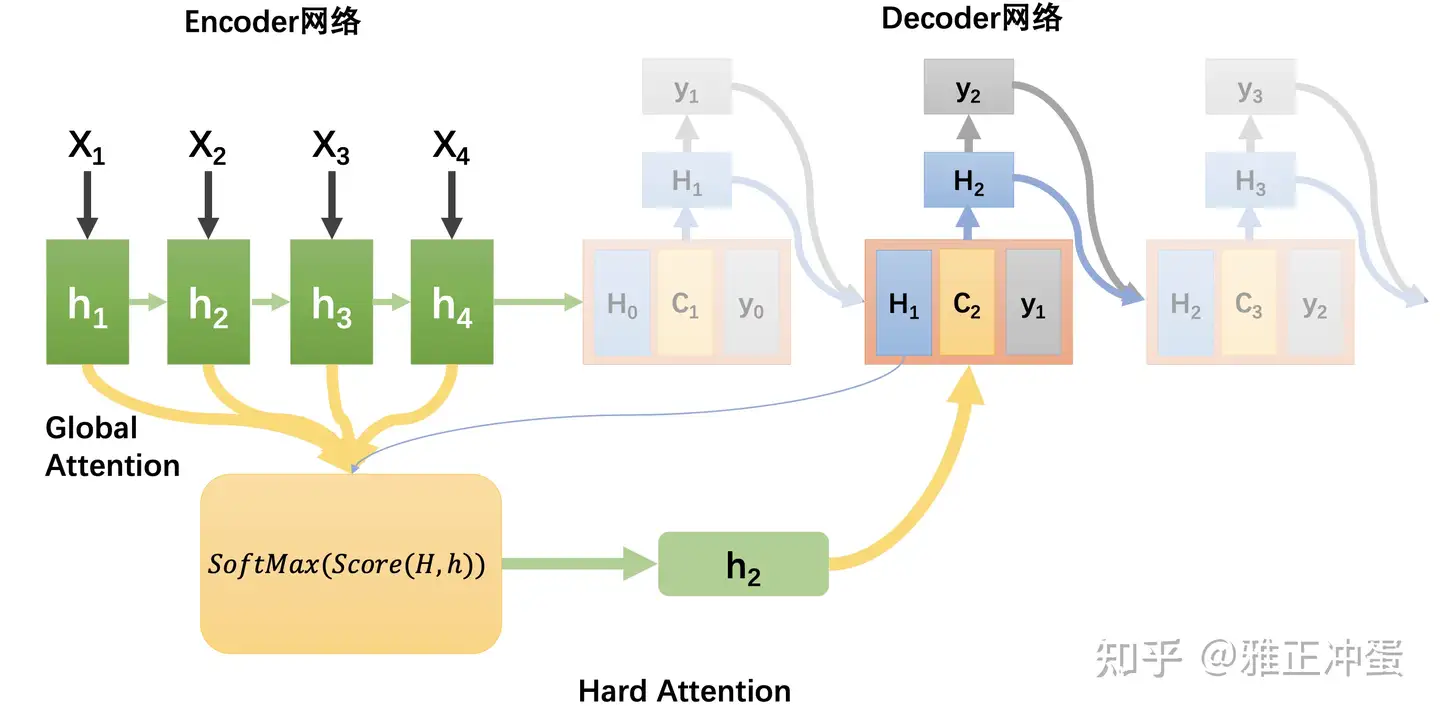 |
Soft Attention |
常规意义上的Attention实现, 加权平均 | 逐点相乘再累加 | Hard Attention改进 | 全局对齐,计算量大,运行效率低 | 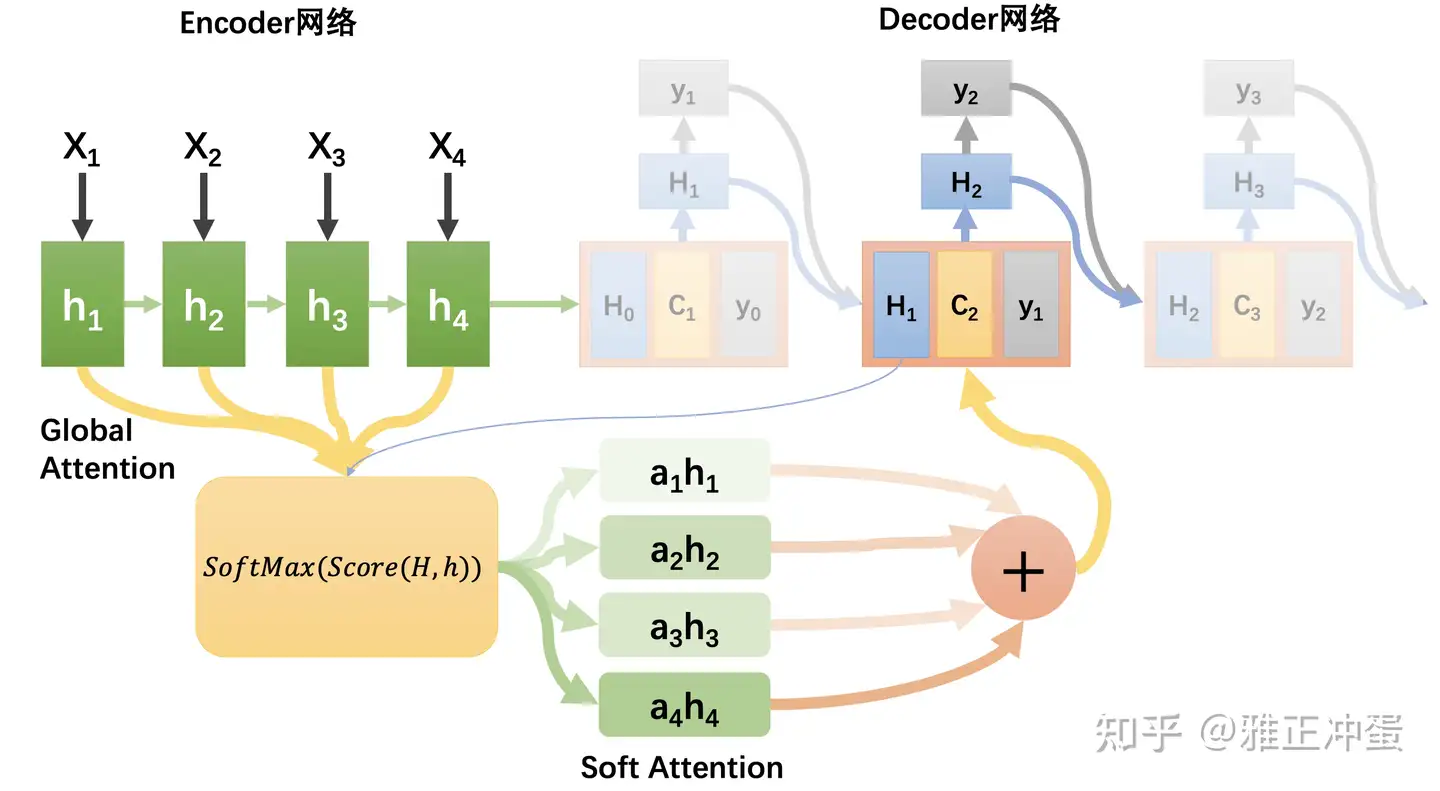 |
Global Attention |
以上都是Global | 所有位置参与运算 | 计算量大 | ||
Local Attention |
改进: 只对局部计算注意力 | 找对齐位置pt,前后扩展D个长度(如正态分布),局部范围内计算注意力 1. pt周围固定范围 2. pt周围正态分布 |
计算量降低, 大大加速 | 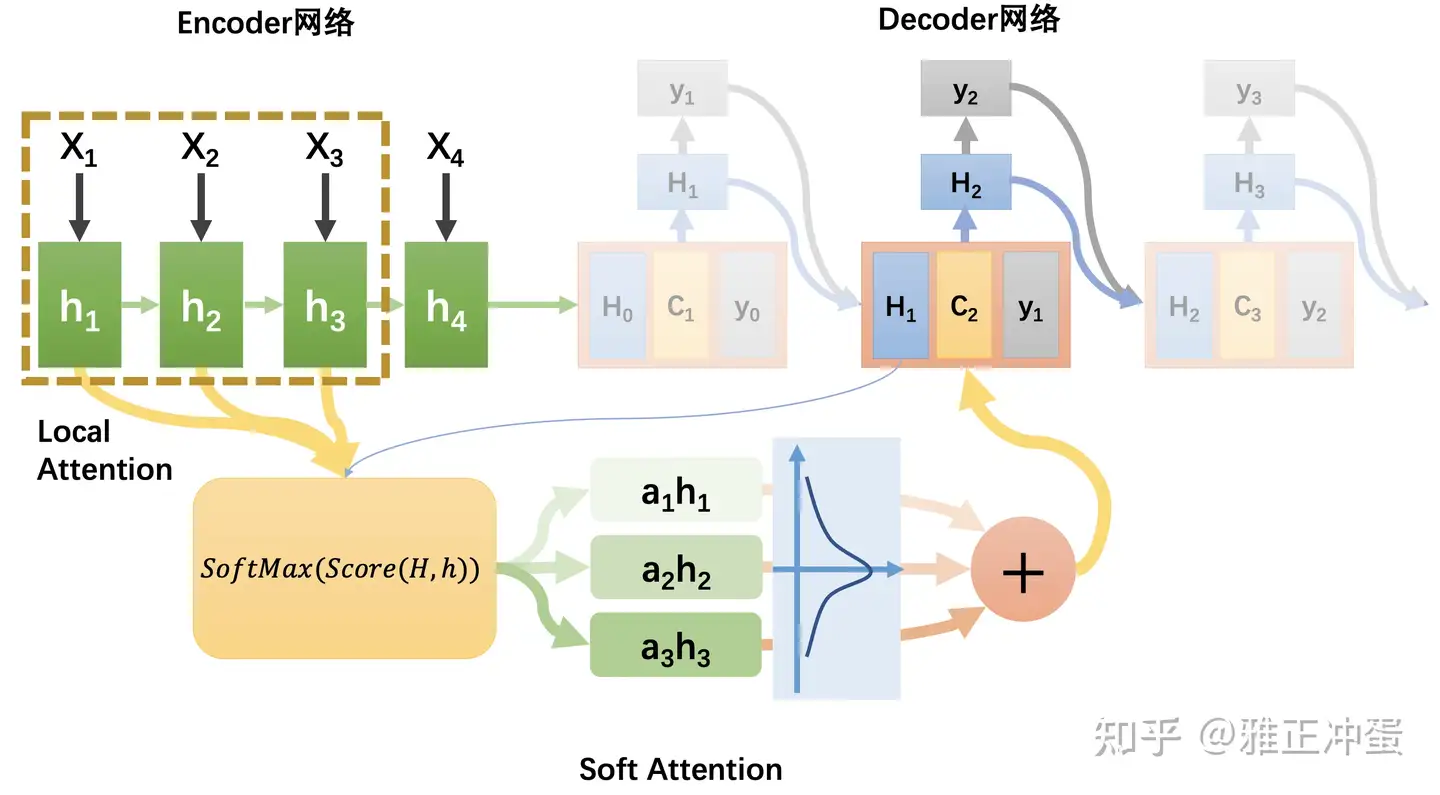 |
|
| Not-Self Attention | Encoder-Decoder结构只适用于seq2seq任务 | Hhc 计算模式 | 无法解决非seq2seq任务, 如阅读理解 | kv相同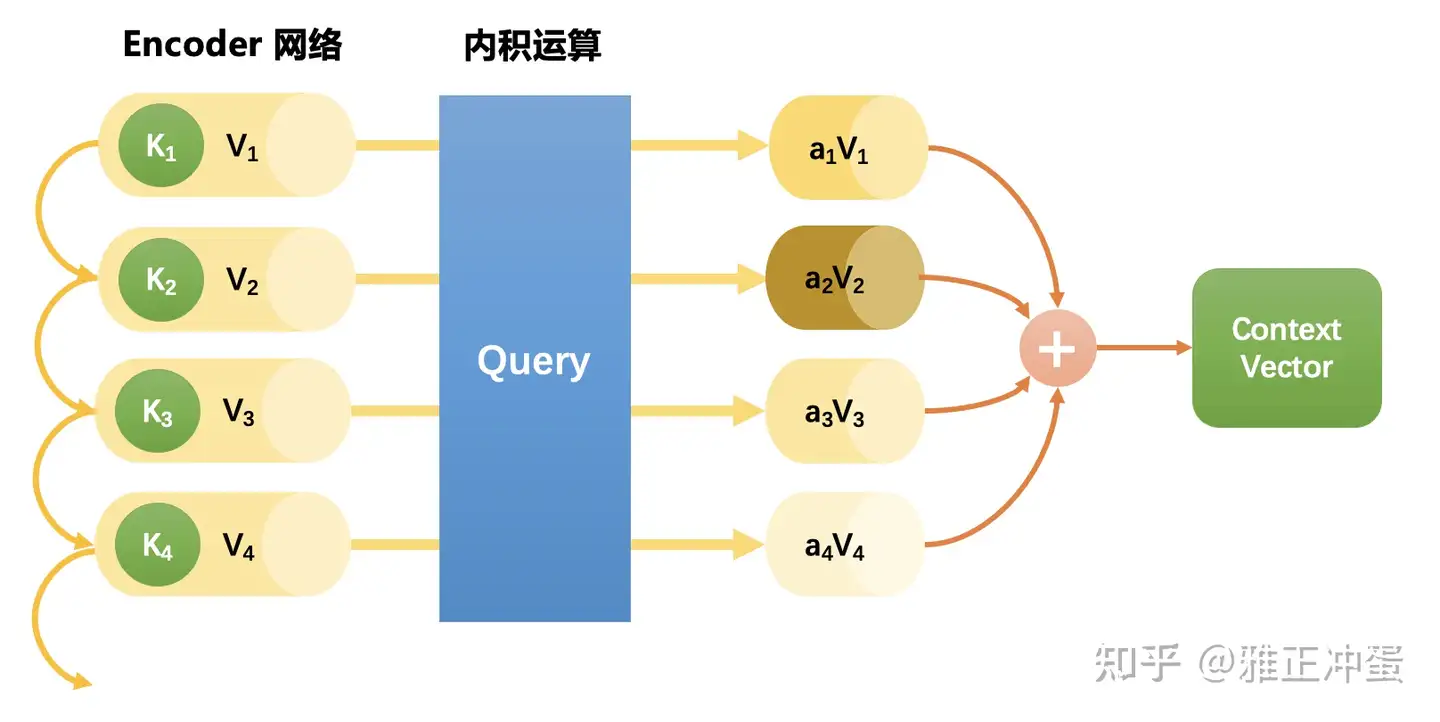 |
|
Self Attention |
自监督(Self-Attention)也叫 Intra-Attention, 寻找一段文本内关系 | QKV 计算模式 用Query在数据库中按照Key进行筛选 |
自监督注意力适合非seq2seq任务 阅读理解,文本摘要,文本蕴含 |
kv不同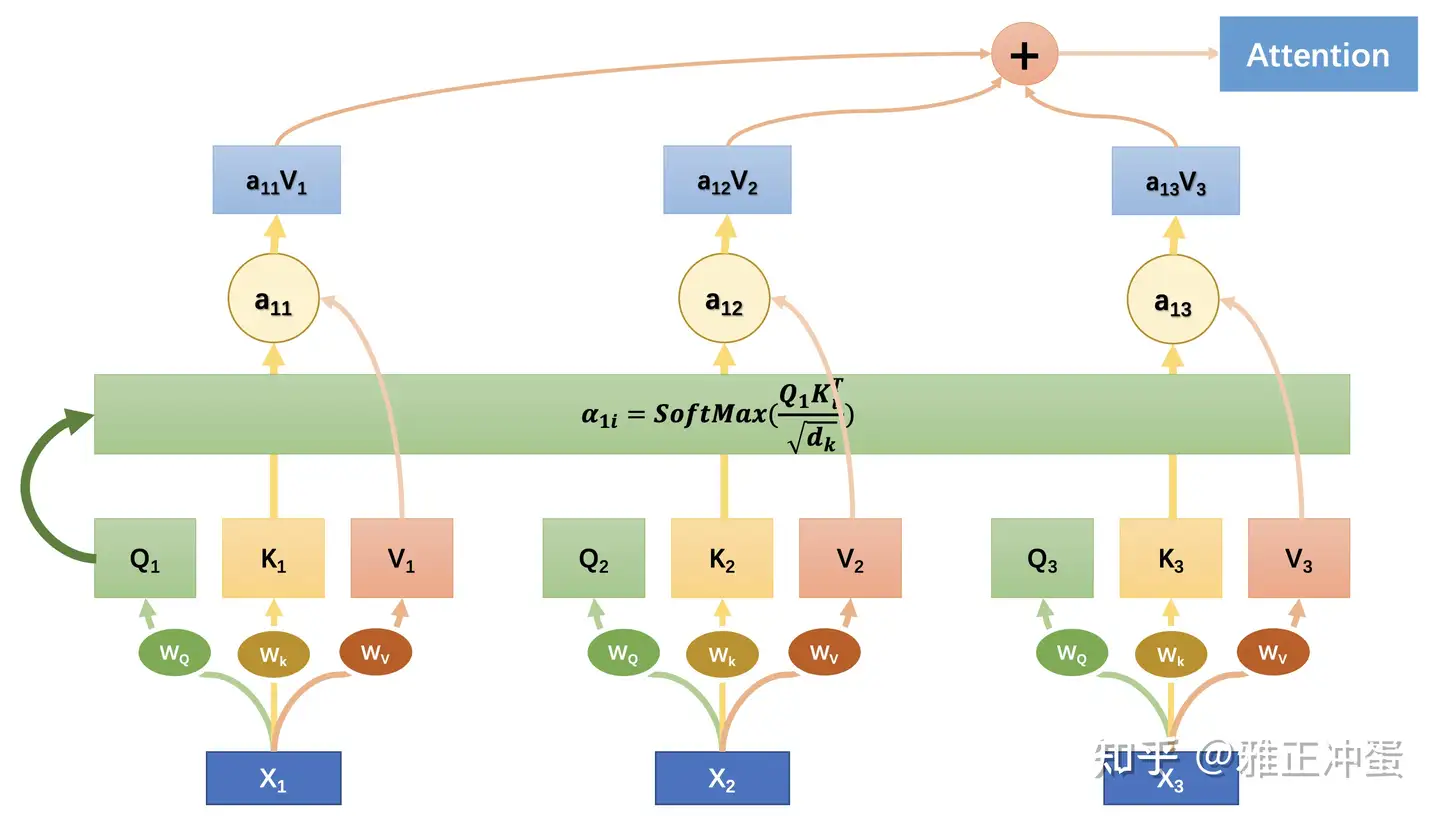 |
|
Attention |
Attention 是 BERT 乃至整个预训练语言模型的基石,接棒CNN/RNN,成为特征抽取的新利器。Attention is all you need !
注意力可视化
【2024-9-20】三蓝一棕 可视化注意力机制
self-attention
Self-Attention 是能力超强的特征提取器,跟 RNN、CNN 相比

电影推荐
以电影推荐为例
传统推荐系统:特性向量点积用户偏好
- 人工设计一些电影特征,比如:浪漫指数、动作指数,
- 人工设计一些用户特征,例如:喜欢浪漫电影或动作片的可能性;
有了这两个维度的数据(特征向量)之后,对二者做点积(dot product), 得到电影属性与用户喜欢程度之间的匹配程度,用得分表示
- 电影推荐:电影特征向量(浪漫、动作、喜剧)与用户特性向量(喜欢浪漫、动作、喜剧的程度)做点积运算
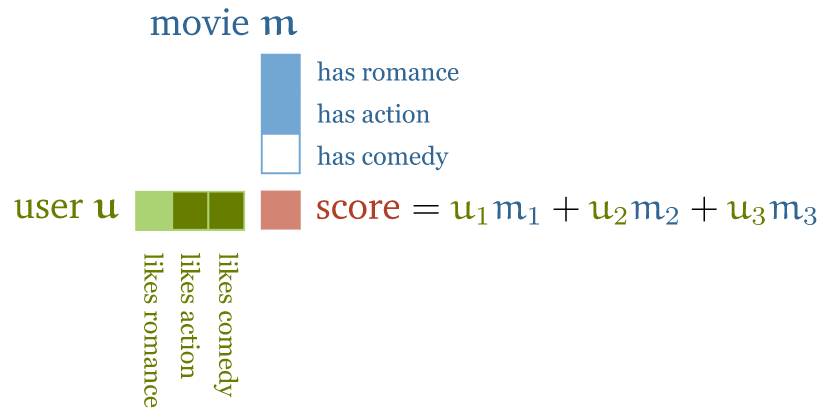
得分数值:
- 如果特征符号相同,例如“浪漫电影 && 用户喜欢浪漫电影”, 或者“不是浪漫电影 && 用户不喜欢浪漫电影”,得到的点积就是正数;反之就是负数;
- 特征值大小决定该特征对总分的贡献大小: 一部电影可能有点浪漫,但不是很明显,或者用户可能只是不喜欢浪漫,但也没到讨厌的程度。
分析
- 优点:简单直接,很容易上手;
- 缺点:规模大了很难搞, 因为对几百万部电影打标的成本非常高,精确标记用户喜欢或不喜欢什么也几乎是不可能的。
基于 self-attention 的推荐系统
电影特征和用户特征作为模型参数,匹配已知用户偏好
两步:
- 电影特征和用户特征不再直接做点积运算,而是作为模型参数(parameters of the model);
- 收集少量的用户偏好作为目标,然后通过优化用户特征和电影特征(模型参数), 使二者的点积匹配已知的用户喜好。
这就是 self-attention 的基本原理。
以一串单词作为输入,原理上只要将其作为 input vector 送到 self-attention 模型。
- 但实际上要对 input vector 做预处理,生成一个中间表示,即序列建模中的嵌入层。为每个单词 t 分配一个
嵌入向量(embedding vector) 𝐯t(我们后面将学习到这个值)。 - input vector -> embedding vector -> self-attention -> output vector
- (the, cat) -> (V_the, V_cat) -> 加权求和 -> y_the, y_cat
不同于一般的 sequence-to-sequence 运算:
- self-attention 将输入当做一个集合(set)而不是序列(sequence)。
- 如果对输入序列进行重排(permute),输出序列除了也跟着重排,其他方面将完全相同,self-attention 是排列等变的(permutation equivariant)。
- 构建完整的 transformer 时,会引入一些东西来保持输入的顺序信息,但要明白 self-attention 本身不关心输入的顺序属性(sequential nature)。
Self-attention 是什么?
什么是self-attention ?
self-attention 运算是所有 transformer 架构的基本运算, 而 Self-attention 是 sequence-to-sequence 运算:
- 输入一个向量序列(x1,x2,…,xm),输出另一个向量序列 (y1,y2,…,yn),所有字符都映射成k维向量;
- 输出向量是x的加权平均: yi = ∑ wi * xi
- 计算权重矩阵W 最简单函数就是
点积(dot product): $ w_ij = x_i^T * x_j $ - 结果取值范围是正负无穷,为了使累加和(表示概率)等于 100%, 需要做归一化, 即 softmax
- 总结起来就是两点:
- vector-to-vector 运算:self-attention 是对 input vector 做矩阵运算,得到一个加权结果作为 output vector;
- 加权矩阵计算:权重矩阵不是常量,而是跟它所在的位置 (i,j) 直接相关,根据对应位置的 input vector 计算。
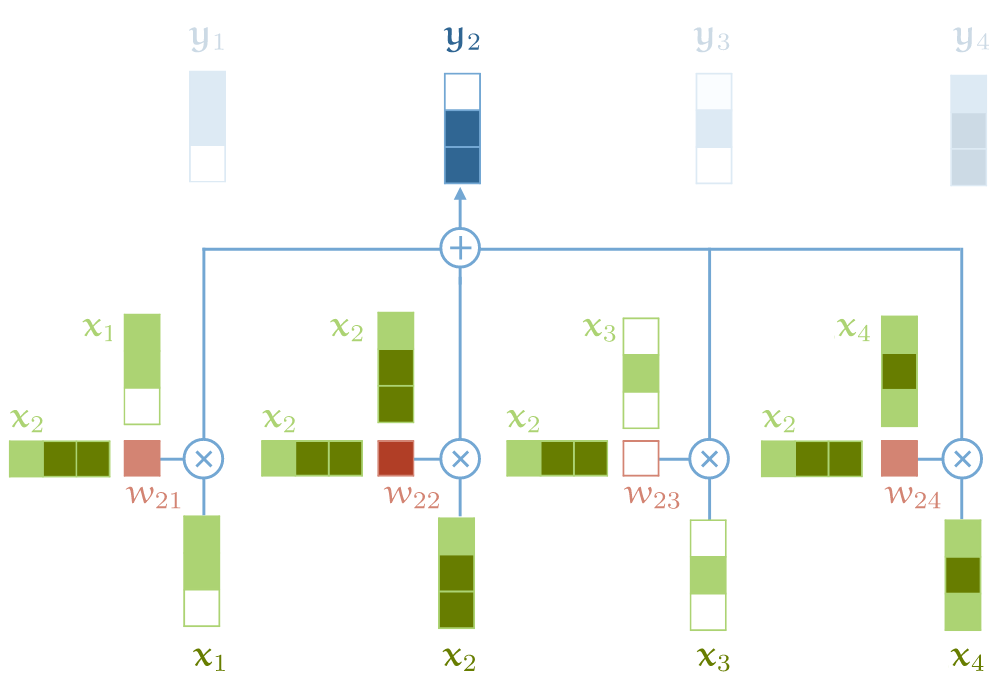
- output vector 中的每个元素 yj 都是对 input vector 中所有元素的加权和;
- 对于 yj,加权矩阵由 input 元素 xj 与每个 input 元素计算得到;
self-attention 是整个架构中唯一在 input & output vector 间做运算;
- Transformer 架构中的其他运算都是单纯对 input vector 做运算。
self-attention 模型简单,本质是加权平均公式,为什么效果这么好?
self-attention 结构图。原文
- 一个输入序列的向量集合(矩阵),经过Wq、Wk、Wv三个权重矩阵计算之后,生成了Q、K、V三个矩阵,经过FF网络,最后生成了新的向量集合。
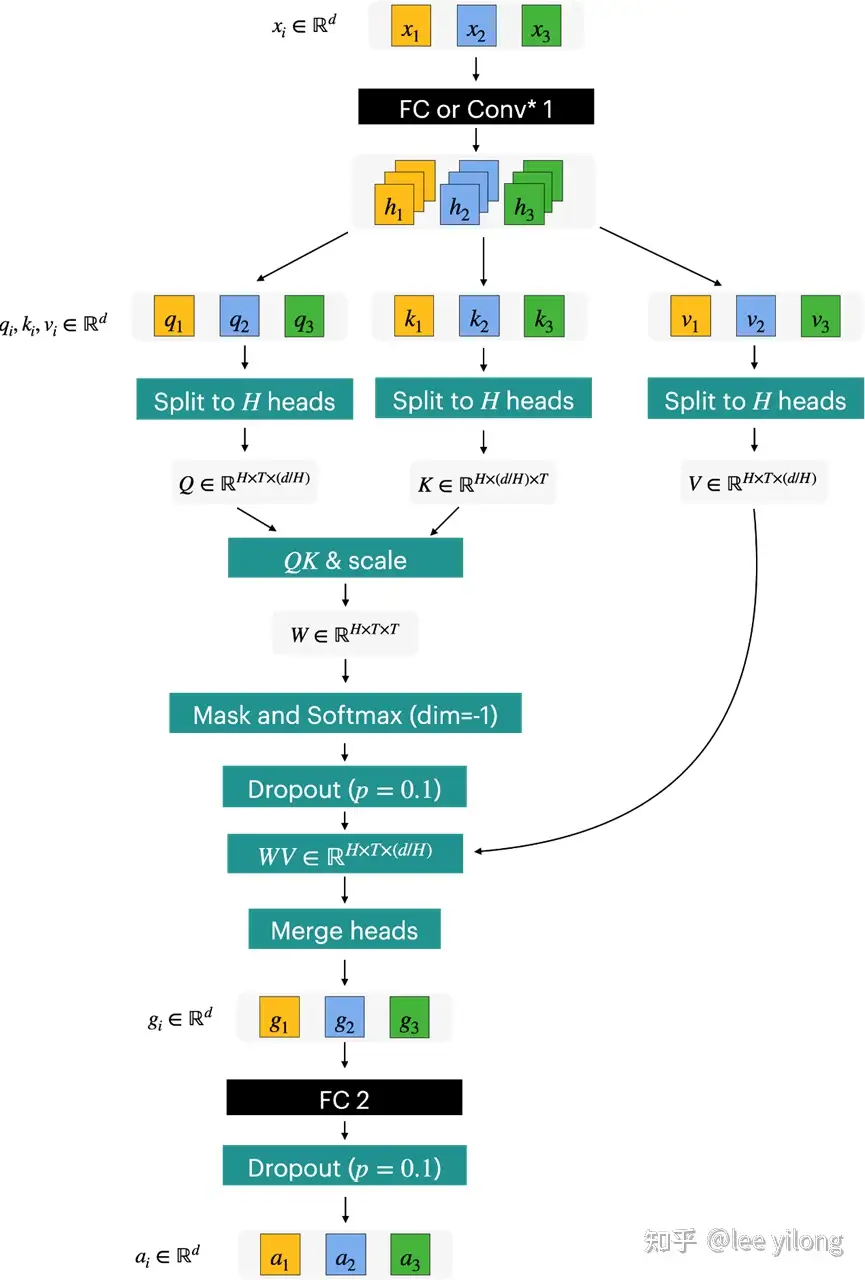
- img
attention 机制涉及两个隐状态: $ h_i $ 和 $s_t$,前者是输入序列第i个位置产生的隐状态,后者是输出序列在第t个位置产生的隐状态。
self-attention实际是:输出序列就是输入序列
因此,计算自己的 attention 得分,就叫做self-attention
最上层的 transformer 模块在处理单词「it」的时候会关注「a robot」,所以「a」、「robot」、「it」这三个单词与其得分相乘加权求和后的特征向量会被送入之后的神经网络层。

自注意力机制沿着序列中每一个单词的路径进行处理,主要由 3 个向量组成:
- 查询向量(Query 向量):当前单词的查询向量和其它单词的键向量相乘,得到其它词相对于当前词的注意力得分。只关心目前正在处理的单词的查询向量。
键向量(Key 向量):键向量就像是序列中每个单词的标签,搜索相关单词时用来匹配的对象。值向量(Value 向量):值向量是单词真正的表征,当算出注意力得分后,使用值向量进行加权求和得到能代表当前位置上下文的向量。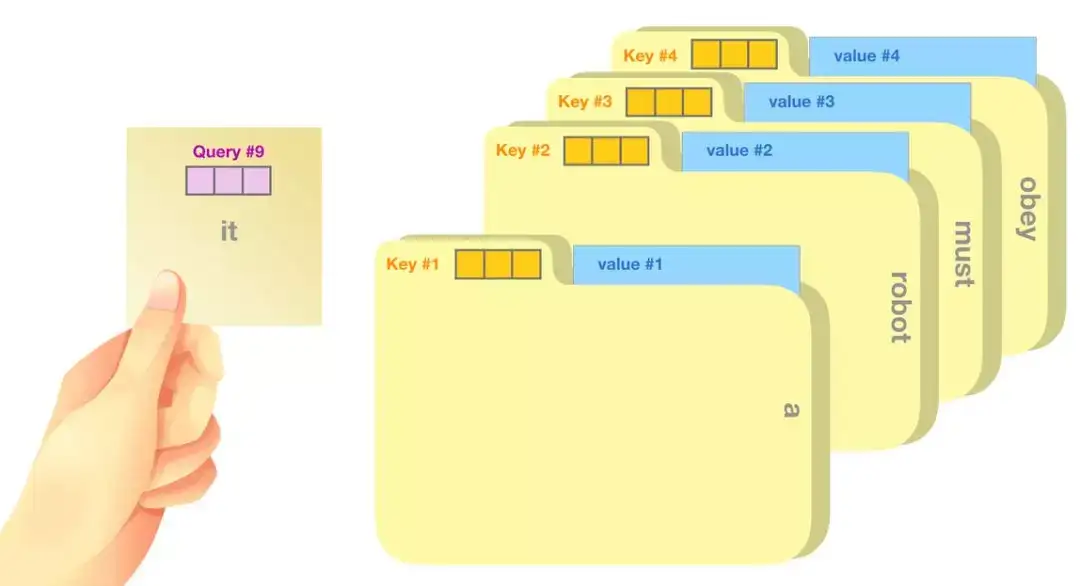
比喻: 档案柜中找文件。
- 查询向量就像一张便利贴,上面写着正在研究的课题。
- 键向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是值向量。只不过最后找的并不是单一的值向量,而是很多文件夹值向量的混合。
将单词查询向量分别乘以每个文件夹的键向量,得到各个文件夹对应的注意力得分
- 乘指的是向量点乘,乘积会通过 softmax 函数处理。
将值向量加权混合得到一个向量
- 将其 50% 的「注意力」放在了单词「robot」上,30% 的注意力放在了「a」上,还有 19% 的注意力放在「it」上

嵌入矩阵的每行都对应模型词汇表中一个单词的嵌入向量。乘法操作得到词汇表中每个单词对应的注意力得分。
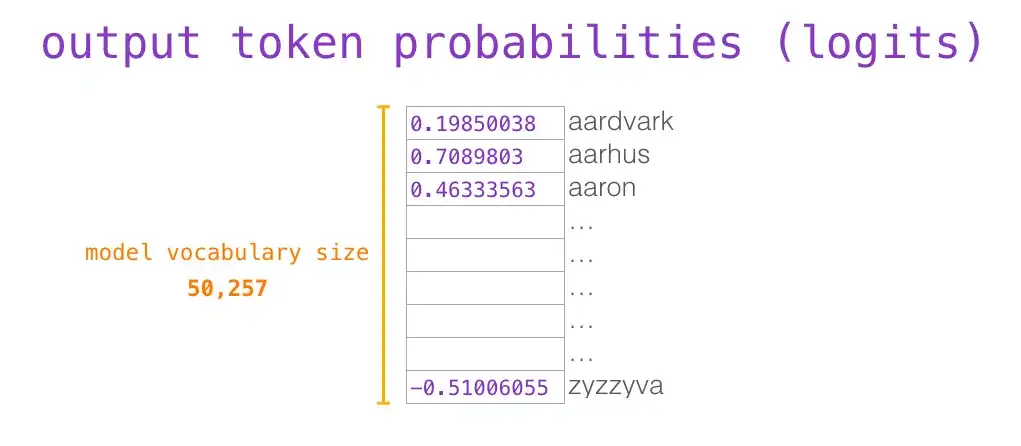
Attention 解决什么问题
背景:
- RNN 处理序列数据时,token 逐个喂给模型。比如在a3的位置,模型要等a1和a2的信息都处理完成后,才可以生成a3。
- 问题:
- a. 随着序列长度增加,模型并行计算的能力变差。
- b. 随着token间距离的增加,对于远距离处的信息,RNN很难捕获其依赖关系。
改进:提升模型的并行运算能力,序列中的每个token 无损地捕获序列里的其他tokens信息。
- Attention: 在每个位置,例如在a2处产生b2时,attention将会同时看过a1到a4的每个token。此外,每个token生成其对应的输出的过程是同时进行的,计算不需要等待。
- Attention 机制是Transformer架构引入的提取信息的方法。Attention机制通过对模型的输入部分赋予不同的权重,对value值进行加权求和。以此来抽取数据中更重要的信息。
Attention机制的核心: 从关注全部到关注重点。
Attention机制本质是对源数据中元素的值(value)进行加权求和,而其中查询(query)和键(key)用于计算权重系数。
Attention函数本质:
- Attention函数描述为将一个查询(query)映射到一系列键值对(key-value)的过程,其中通过计算查询(query)和键(key)的相似性或相关性来得到每个键对应值的权重系数,最终对值(value)进行加权求和,以产生Attention数值。
Attention的优点:
- 相对于传统的CNN和RNN,Attention参数数量更少。
- 使 Transformer模型在计算Query时实现并行计算。
- 使得模型能够更好地捕捉长距离依赖关系,模型效果更好。
Self-Attention 解决什么问题
提出 Self-Attention 原因:
- 传统 Attention 模块能捕获source端和target端的token间的依赖关系,但不能捕获source端或target端自身token间的依赖关系。
- self-attention 可以学习source端句子内部的token间的依赖关系,捕获句子的内部信息。
【2024-8-3】【LLM基础知识】LLMs-Attention知识总结笔记v4.0
Attention 和 Self-Attention 区别
Self-Attention 多两个约束条件:
- Q,K,V 计算输入同源,K-Q-V三者都来源于 X。
- Q,K,V 遵循 attention做法。
Self 的意思是 Attention完全来自输入序列自己,而不来自外部信息(比如output)。
Self-Attention 如何解决长距离依赖?
解决方式:
- 利用注意力机制来“动态”生成不同连接的权重,从而处理变长的信息序列。
具体介绍:
- 对于当前query,需要与句子中所有 key 进行点乘后再 Softmax ,以获得句子中所有 key 对于当前query的score(权重)
- 然后与所有词 的value向量进行加权融合之后,就能使当前token学习到句子中其他词的信息;
self-attention 如何并行化?
Transformer 的并行化主要体现在 self-attention 模块
- 在Encoder端 Transformer可以并行处理整个序列,并得到整个输入序列经过 Encoder 端的输出
- 在 self-attention 模块,对于某个序列(x1,x2,…xn),self-attention 模块可以直接计算xi,xj的点乘结果,而RNN系列的模型就必须按照顺序从x1计算到xn。
Self-Attention 并行计算句子中不同的query,每个query之间并不存在先后依赖关系,使得transformer能够并行化;
Self-Attention 在计算的过程中,如何对padding位做mask? 知乎
Attention与MLP层的区别?
既然 Attention 是为了关注某些局部信息,那些不就相当于连上一层在关注的部分权重更大的全连接层吗,二者的区别何在?
- Attention的最终输出可看成是一个“在关注部分权重更大的全连接层”。但是与全连接层的区别在于,注意力机制可利用输入特征信息确定哪些部分更重要。
两个 FFN 层作用
注意力计算后,用了两个FFN层,为什么第一个FFN层先把维提升,第二个FFN层再把维度降回原大小?
- 1、提升维度:类似SVM kernel,通过提升维度识别一些在低维无法识别的特征。
- 2、提升维度:更大的可训练参数,提升模型容量。
- 3、降回原维度:方便多层注意力层和残差模块进行拼接,而无需进行额外处理。
QKV 哪里来?
WQ, WK, WV 由来
- 先初始化为
[h,h]维度,再用模型训练学习这里面的参数。
为什么要计算Q和K点乘?
Q和K点乘是为了计算序列中每个token与其他token的相似度, 得到 attention score 矩阵,用来对V进行提纯。
假设句子 “Hello, how are you?” 长度是6,embedding维度是 300,那么 Q,K,V都是(6, 300)的矩阵。
- “Hello, how are you?” 这句话,当前token为”you”的时候,可知道”you“对于”Hello”, ” , “, “how”, “are”, “?”这几个token对应的关注度是多少。
- 有了这个 attention score,可知道处理到”you“的时候,模型在关注句子中的哪些token。
Q和K为什么用不同?
Q和K 为什么用不同的权重矩阵进行线性变换投影?
- 如果 WQ 和 WK 一样,则 QKᐪ结果是对称矩阵,这样就减弱了模型的表达能力。
- 同时在对称矩阵中,对角线的值会比较大,导致每个token过分关注自己。
- 使用不同的投影矩阵,参数增多,可以增强模型表达能力。
Self-Attention 计算时乘上WQ.WK.WV的好处?
- 增加了参数量,增加模型的表达能力。
- 加入了不同线性变换相当于对x 做了不同的投影,将向量x 投影到不同空间,增加模型的泛化能力。
- 允许某个token对其他位置token的注意力大于对自己的注意力,才能更好的捕捉全局位置的注意力。
能不能只用QV,KV或V?
为什么要用 Q,K,V? 仅仅使用QV,KV或者V行不行?
不行
- 使用 QKV 主要为了增强网络的容量和表达能力。
- self-attention 使用 Q,K,V 这三个参数独立,模型的表达能力和灵活性显然会比只用 QV 或者只用 V 要好些
自注意力实现
Self-Attention 计算公式
- QKV计算不加偏置项: 缩放点积注意力:Scaled Dot-Product Attention
- QKV计算加偏置项: Q = WQ*x+bQ
计算量多大
Self-Attention 时间复杂度多少?
Self-Attention 时间复杂度:O(n²⋅d)
- n是序列的长度seq_length
- d是embedding的维度d_model。
Self-Attention 包括三个步骤:相似度计算,softmax和加权平均,时间复杂度分别是:
- 相似度计算:
(n,d)和(d,n)矩阵相乘:(n,d)∗(d,n)=O(n²⋅d), - softmax 直接计算,时间复杂度为
O(n²) - 加权平均:
(n,n)和(n,d)的矩阵相乘:(n,n)∗(n,d)=O(n²⋅d)
Self-Attention 时间复杂度是 O(n²⋅d) 。
Self-Attention和Multi-head Attention的参数量怎么计算?
self-attention块的模型参数有Q,K,V的权重矩阵WQ,WK,WV和偏置,输出权重矩阵Wo和偏置。
4个权重矩阵的形状为【h,h】,4个偏置的形状为【h】。总参数量为4h²+4h.
Multi-head Attention也符合这个参数量,但实际上需要分head计算再组合。
Context-attention 是什么?
知道了self-attention,那你肯定猜到了context-attention是什么了:它是encoder和decoder之间的attention!所以,你也可以称之为encoder-decoder attention!
context-attention一词并不是本人原创,有些文章或者代码会这样描述,我觉得挺形象的,所以在此沿用这个称呼。其他文章可能会有其他名称,但是不要紧,我们抓住了重点即可,那就是两个不同序列之间的attention,与self-attention相区别。
不管是self-attention还是context-attention,它们计算attention分数的时候,可以选择很多方式,比如上面表中提到的:
- additive attention
- local-base
- general
- dot-product
- scaled dot-product
那么Transformer模型采用的是哪种呢?答案是:scaled dot-product attention。
点乘注意力是什么?
什么是 点乘注意力 Scaled dot-product attention ?
论文Attention is all you need对 attention机制的描述:
An attention function can be described as a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility of the query with the corresponding key.
翻译:通过确定Q和K之间的相似程度来选择V
公式描述更加清晰:
\[\text{Attention}(Q,K,V)=softmax(\frac{QK^T}{\sqrt d_k})V\]scaled dot-product attention和dot-product attention唯一的区别:
- scaled dot-product attention 有个缩放因子 $ \frac{1}{\sqrt d_k} $。
$d_k$ 表示 K的维度,论文里默认是64。
为什么加缩放因子?
提示: 面试题
论文解释:
- 对于 $d_k$ 很大时,点积得到的结果维度很大,使得结果处于 softmax 函数梯度很小的区域, 对反向传播不利。
为了克服这个负面影响,除以一个缩放因子,一定程度上减缓这种情况。
为什么是 1/dk ?
(1) 为什么是 $\frac{1}{\sqrt d_k}$
论文没有进一步说明。可用其他缩放因子,看看模型效果有没有提升。
提示: 面试题
scaled 参数除 $ \sqrt d_k $?
- 使 QKᐪ 结果满足
r ~ N(0,1), 期望为0,方差为1的标准正态分布,类似于归一化。 - 使输入值进入 softmax 敏感区间, 导数为0, 防止梯度消失
作者发现
- 当维度dk值很大时,输入softmax的值QKᐪ就越大,导致后面的softmax计算会有极小的梯度,不利于更新学习
- 因此除以dk,防止梯度消失。(softmax值过大,其偏导数趋于0)
(2) 必须是 $ \sqrt d_k $ 吗?
只要做到每层参数的梯度保持在训练敏感范围内,使网络好训练。缓解梯度消失就可以。
- 不用除根号dk方式有 Google T5 的 Xavier初始化。
(3) 为什么要满足 标准正态分布?
- 权重一般初始化为正态分布
KQV 是什么
K、Q、V 是什么:
- 在 encoder 的 self-attention中,Q、K、V都来自同一个地方(相等),他们是上一层encoder的输出。对于第一层encoder,它们就是word embedding和positional encoding相加得到的输入。
- 在 decoder 的 self-attention中,Q、K、V都来自于同一个地方(相等),它们是上一层decoder的输出。对于第一层decoder,它们就是word embedding和positional encoding相加得到的输入。但是对于decoder,我们不希望它能获得下一个time step(即将来的信息),因此我们需要进行sequence masking。
- 在 encoder-decoder attention 中,Q来自于decoder的上一层的输出,K和V来自于encoder的输出,K和V是一样的。
- Q、K、V三者的维度一样,即 $d_q=d_k=d_v$。
上面 scaled dot-product attention 和 decoder 的 self-attention都出现了masking这样一个东西。
那么这个mask到底是什么呢?这两处的mask操作是一样的吗?
self-attention 实现
基础 self-attention
最基础的 self-attention 模型实现:
- 2次 矩阵乘法 和 1次 归一化(softmax)。
import torch
import torch.nn.functional as F
# 假设我们有一些 tensor x 作为输入,它是 (b, t, k) 维矩阵
x = ...
# torch.bmm() 是批量矩阵乘法(batched matrix multiplication)函数,对一批矩阵执行乘法操作
raw_weights = torch.bmm(x, x.transpose(1, 2))
# 正值化、归一化
weights = F.softmax(raw_weights, dim=2)
# 计算输出
y = torch.bmm(weights, x)
点乘注意力实现
scaled dot-product attention 实现代码如下:
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
"""Scaled dot-product attention mechanism."""
def __init__(self, attention_dropout=0.0):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, scale=None, attn_mask=None):
"""前向传播.
Args:
q: Queries张量,形状为[B, L_q, D_q]
k: Keys张量,形状为[B, L_k, D_k]
v: Values张量,形状为[B, L_v, D_v],一般来说就是k
scale: 缩放因子,一个浮点标量
attn_mask: Masking张量,形状为[B, L_q, L_k]
Returns:
上下文张量和attetention张量
"""
attention = torch.bmm(q, k.transpose(1, 2))
if scale:
attention = attention * scale
if attn_mask:
# 给需要mask的地方设置一个负无穷
attention = attention.masked_fill_(attn_mask, -np.inf)
# 计算softmax
attention = self.softmax(attention)
# 添加dropout
attention = self.dropout(attention)
# 和V做点积
context = torch.bmm(attention, v)
return context, attention
self-attention 改进
现代 transformer 对 self-attention 扩展
- 引入控制参数(queries, keys and values)
- 对点积做缩放处理(scaling the dot product)
- softmax 函数对非常大的输入值敏感。这些 input 会梯度消失,学习变慢甚至完全停止。
- 由于点积平均值随着嵌入维度 k 的增加而增大,因此点积送到 softmax 之前进行缩放有助于缓解这个问题。
- $ w_ij = q_i^T k_j$ -> $ w_ij = \frac{q_i^T k_j}{\sqrt{k}}$
- 引入 multi-head attention
- 同一个单词随着相邻单词们的不同表示的意思也可能不同, 基本的 self-attention 欠缺了很多灵活性。
- 如何理解?让模型有更强的辨识力,一种解法:组合多个 self-attention(用 r 索引), 每个对应不同的 query/key/value 参数矩阵 $ 𝐖^r_q$ , $ 𝐖^r_k $, $ 𝐖^r_v $, 称为 attention heads(注意力头)。
- 对于 input 𝐱i,每个 attention head 产生不同的 output vector $ 𝐲^r_i $(一部分输出)。 最后再将这些部分输出连接起来,通过线性变换来降维回 k。
multi-head self-attention 提效:query/key/value 降维
- multi-head self-attention 看作多个并行 self-attention 机制,每个都有自己的键、值和查询转换。
- Multi-head self-attention 的缺点: 慢,对于 R 头,慢 R 倍。
优化:
- 实现这 multi-head self-attention,既能利用多个 self-attention 提升辨识力, 又与 single-head self-attention 基本一样快。
- 每个 head 对 query/key/value 降维。
如果输入向量有 k=256 维,模型有 h=4 个 attention head,则降维操作包括:
- 将输入向量乘以一个 256×64 矩阵,这会将 input vector 从 256 维降到 64 维;
- 对于每个 head 需要执行 3 次降维:分别针对 query/key/value 的计算。
甚至只用三次 k×k 矩阵乘法就能实现 multi-head 功能, 唯一需要的额外操作是将生成的 output vector 重新按块排序
multi-head self-attention 完整流程
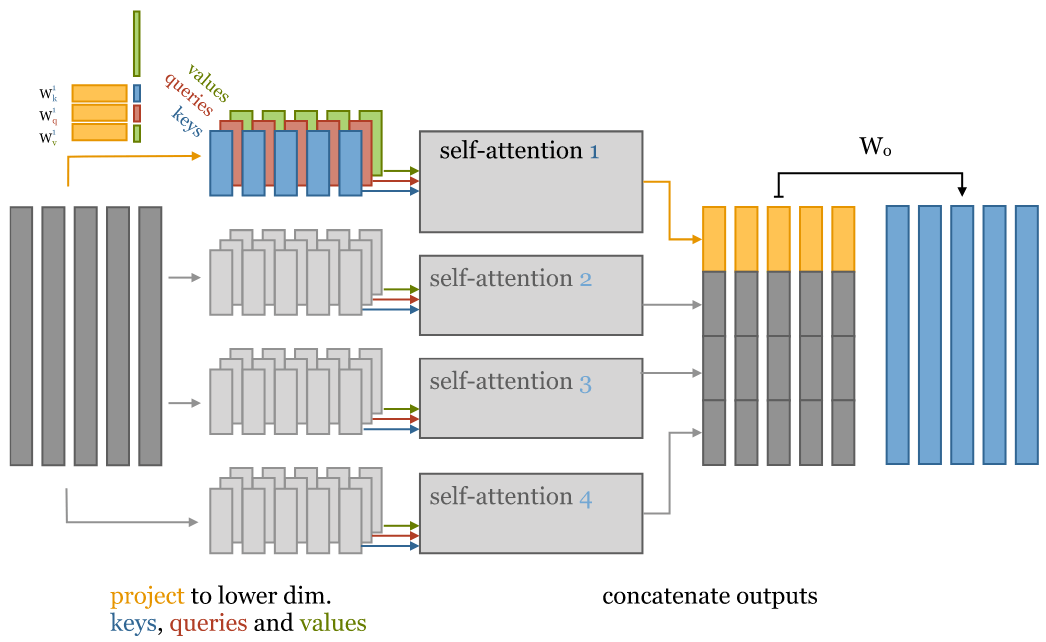
4-head self-attention 的直观解释。对输入进行降维,针对 key/value/query 分别进行矩阵运算来实现。
从左到右分为 5 列:
- 原始 256-维 input vector;
- 输入降维:将 input vector 乘以 256x64 矩阵,降维到 64 维;(256/4=64)
- 注意:对每个 input vector 需要分别针对 query/key/value 降维,总共是 3 遍;
- 将降维后的 input 分别输入多个并行的 self-attention;
- 计算得到多个降维之后的 output vector;
- 对低维度 output vectors 进行拼接,重新回到与 input vectors 一样的维度。
参数规模
single-head: 总参数数量是 $3k^2$。multi-head: 参数个数 $ 3hk\frac{k}{h}=3k^2 $- 与 single-head self-attention 的参数数量相同。
- 唯一区别:
- multi-head self-attention 最后拼接 output vector 时多了一个矩阵 Wo
- 参考:Transformer 是如何工作的:600 行 Python 代码实现两个(文本分类+文本生成)Transformer
Multi-head attention 又是什么
提示: 面试题
自注意力机制缺陷:
- 模型在对当前位置信息进行编码时,会过度的将注意力集中于自身的位置
多头注意力机制解决这一问题,还能给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
多头自注意力机制允许模型在不同子空间上同时捕捉信息,从而增强了输入序列的表达能力。
- 每个头关注输入序列的不同部分,然后将结果拼起来,以获得更全面的特征表示。
【202-12-31】相当于 CNN 里的卷积核,但有差异
多头注意力机制与卷积神经网络中多层卷积核的不同之处。
- 多头注意力通过拆分输入特征并赋予独立权重,允许并行计算,每个头关注不同特征。
- 而多层卷积核通过多个卷积层捕获不同层次的特征,参数通常在层内共享。
多头注意力机制中的多头不同于卷积神经网络中的多个卷积层中的卷积核,卷积神经网络中的多个卷积层相当于将单个卷积网络复制了 num_layers 次,每一个卷积层都可以独立进行运算。而多头注意力则可理解为将输入的特征值拆分成更加细碎的小块,对每一小块赋值一个单独的可训练权重参数,然后共用同一个隐藏层输出结果,每个头并不能看作是一个完整独立的编解码架构而单独运算。
论文提到
- 将 Q、K、V 通过一个线性映射之后,分成 h 份,对每份进行 scaled dot-product attention 效果更好。
- 把各个部分结果合并起来,再次经过线性映射,得到最终的输出。
所谓的multi-head attention。超参数 h 是heads数量。论文默认是8。
multi-head attention 结构图:
注意:
- 分成 h 份是在 $d_k$、$d_q$、$d_v$ 维度上切分。
- 因此,进入 scaled dot-product attention 的 $d_k$ 实际上等于未进入之前的 $D_K/h$ 。
Multi-head attention 允许模型加入不同位置的表示子空间信息。
Multi-head attention 公式:
- \[\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_ 1,\dots,\text{head}_ h)W^O\]
其中,$ \text{head}_ i = \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) $
相同维度下用单头和多头的区别是什么
- $d_{model}=512$,$h=8$。
- 在 scaled dot-product attention 里 $d_q = d_k = d_v = d_{model}/h = 512/8 = 64$
如果
- h=1,得到一个各个位置只集中于自身位置的注意力权重矩阵;
- h=2,得到另一个注意力权重稍微分配合理的权重矩阵;
多头恰好克服「模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置」的问题。
这里再插入一张真实场景下同一层的不同注意力权重矩阵可视化结果图:
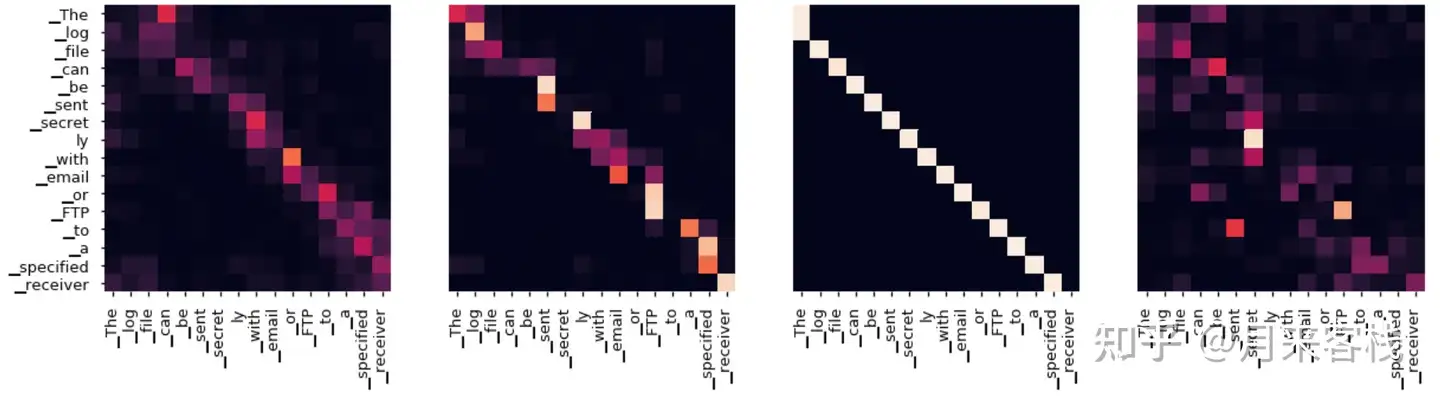
当 h 不一样时,dk 取值也不一样,使得对权重矩阵的scale程度不一样。
当模型维度 dm 确定时,一定程度上 h 越大, 整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
自注意力实现
【2024-9-10】代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
"""
自注意力机制
"""
def __init__(self, d, d_q, d_k, d_v):
super(SelfAttention, self).__init__()
self.d = d
self.d_q = d_q
self.d_k = d_k
self.d_v = d_v
self.W_query = nn.Parameter(torch.rand(d, d_q))
self.W_key = nn.Parameter(torch.rand(d, d_k))
self.W_value = nn.Parameter(torch.rand(d, d_v))
def forward(self, x):
"""
前向传播
"""
Q = x @ self.W_query
K = x @ self.W_key
V = x @ self.W_value
attention_scores = Q @ K.T / math.sqrt(self.d_k)
attention_weights = F.softmax(attention_scores, dim=-1)
context_vector = attention_weights @ V
return context_vector
if __name__ == '__main__':
sentence = 'the quick brown fox jumps over the lazy dog'
print('提取词库')
dc = {s: i for i, s in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc)
print('映射 str -> id')
r = [dc[i] for i in sentence.replace(',', '').split()]
sentence_int = torch.tensor(r)
print(sentence_int)
print('id -> embedding')
vocab_size = 50000 # Assume a large vocabulary size
torch.manual_seed(123)
embed = nn.Embedding(vocab_size, 3)
embedded_sentence = embed(sentence_int).detach()
print(embedded_sentence)
print('计算自注意力')
sa = SelfAttention(d=3, d_q=2, d_k=2, d_v=4)
cv = sa(embedded_sentence)
print(cv.shape)
print(cv)
输出
提取词库
{'brown': 0, 'dog': 1, 'fox': 2, 'jumps': 3, 'lazy': 4, 'over': 5, 'quick': 6, 'the': 8}
映射 str -> id
tensor([8, 6, 0, 2, 3, 5, 8, 4, 1])
id -> embedding
tensor([[ 0.4965, -1.5723, 0.9666],
[-0.1690, 0.9178, 1.5810],
[ 0.3374, -0.1778, -0.3035],
[-0.2196, -0.3792, 0.7671],
[-1.1925, 0.6984, -1.4097],
[ 0.2692, -0.0770, -1.0205],
[ 0.4965, -1.5723, 0.9666],
[ 0.1794, 1.8951, 0.4954],
[-0.5880, 0.3486, 0.6603]])
计算自注意力
torch.Size([9, 4])
tensor([[-0.0269, -0.0440, -0.0042, 0.0399],
[ 0.4747, 0.1601, 0.6337, 0.7438],
[ 0.1518, -0.0326, 0.0235, 0.2049],
[ 0.1134, -0.0163, 0.0691, 0.1872],
[ 0.0674, -0.0990, -0.1767, 0.0518],
[ 0.1159, -0.0648, -0.0747, 0.1341],
[-0.0269, -0.0440, -0.0042, 0.0399],
[ 0.5645, 0.1703, 0.7147, 0.8803],
[ 0.2060, 0.0059, 0.1400, 0.2985]], grad_fn=<MmBackward0>)
Multi-head attention 实现
multi-head attention 实现代码如下:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, model_dim=512, num_heads=8, dropout=0.0):
super(MultiHeadAttention, self).__init__()
self.dim_per_head = model_dim // num_heads
self.num_heads = num_heads
self.linear_k = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_v = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_q = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.dot_product_attention = ScaledDotProductAttention(dropout)
self.linear_final = nn.Linear(model_dim, model_dim)
self.dropout = nn.Dropout(dropout)
# multi-head attention之后需要做layer norm
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, key, value, query, attn_mask=None):
# 残差连接
residual = query
dim_per_head = self.dim_per_head
num_heads = self.num_heads
batch_size = key.size(0)
# linear projection
key = self.linear_k(key)
value = self.linear_v(value)
query = self.linear_q(query)
# split by heads
key = key.view(batch_size * num_heads, -1, dim_per_head)
value = value.view(batch_size * num_heads, -1, dim_per_head)
query = query.view(batch_size * num_heads, -1, dim_per_head)
if attn_mask:
attn_mask = attn_mask.repeat(num_heads, 1, 1)
# scaled dot product attention
scale = (key.size(-1) // num_heads) ** -0.5
context, attention = self.dot_product_attention(query, key, value, scale, attn_mask)
# concat heads
context = context.view(batch_size, -1, dim_per_head * num_heads)
# final linear projection
output = self.linear_final(context)
# dropout
output = self.dropout(output)
# add residual and norm layer
output = self.layer_norm(residual + output)
return output, attention
【2025-1-4】另一种实现
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embedding size must be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, value, key, query, mask):
N = query.shape[0]
value_len, key_len, query_len = value.shape[1], key.shape[1], query.shape[1]
# 向量分割成h个, Split embedding into self.heads pieces
values = self.values(value).view(N, value_len, self.heads, self.head_dim)
keys = self.keys(key).view(N, key_len, self.heads, self.head_dim)
queries = self.queries(query).view(N, query_len, self.heads, self.head_dim)
# 点乘注意力的另一种实现: sa = softmax(QK/_/dk)V
# QK
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) # QK, Scaled dot-product attention
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# softmax(QK/_/d)
attention = torch.softmax(energy / (self.head_dim ** 0.5), dim=3)
# softmax(QK/_/d) / V
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.embed_size)
return self.fc_out(out)
终于出现了 Residual connection和Layer normalization。
Attention 细节
2.1. 点积attention
介绍一下attention的具体计算方式。attention 很多种计算方式:
- 加性 attention
- 点积 attention
- 带参数的计算方式
着重介绍一下点积attention的公式:
-
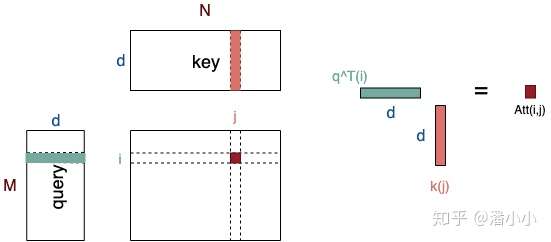
- Attention中(Q^T)*K矩阵计算,query和key的维度要保持一致
如上图所示, ,
分别是query和key,其中,query可以看作M个维度为d的向量(长度为M的sequence的向量表达)拼接而成,key可以看作N个维度为d的向量(长度为N的sequence的向量表达)拼接而成。
- 【一个小问题】为什么有缩放因子
?
- 先一句话回答这个问题: 缩放因子的作用是归一化。
- 假设
,
里的元素的均值为0,方差为1,那么
中元素的均值为0,方差为d. 当d变得很大时,
中的元素的方差也会变得很大,如果
的分布会趋于陡峭(分布的方差大,分布集中在绝对值大的区域)。总结一下就是
2.2. Attention机制涉及到的参数
一个完整的attention层涉及到的参数有:
- 把
,
,
分别映射到
的线性变换矩阵
(
),
(
),
(
)
- 把输出的表达
映射为最终输出
的线性变换矩阵
(
)
2.3. Query, Key, Value
Query和Key作用得到的attention权值作用到Value上。因此它们之间的关系是:
- Query
和 Key
的维度必须一致,Value
和Query/Key的维度可以不一致。
- Key
- Attention得到的Output
的维度和Value的维度一致,长度和Query一致。
- Output每个位置 i 是由value的所有位置的vector加权平均之后的向量;而其权值是由位置为i 的query和key的所有位置经过attention计算得到的 ,权值的个数等于key/value的长度。
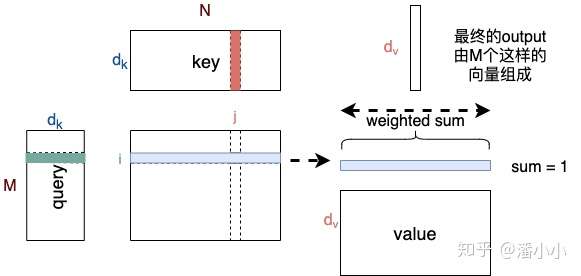
- Attention示意图
在经典的Transformer结构中,我们记线性映射之前的Query, Key, Value为q, k, v,映射之后为Q, K, V。那么:
- self-attention的q, k, v都是同一个输入, 即当前序列由上一层输出的高维表达。
- cross-attention的q代表当前序列,k,v是同一个输入,对应的是encoder最后一层的输出结果(对decoder端的每一层来说,保持不变)
而每一层线性映射参数矩阵都是独立的,所以经过映射后的Q, K, V各不相同,模型参数优化的目标在于将q, k, v被映射到新的高维空间,使得每层的Q, K, V在不同抽象层面上捕获到q, k, v之间的关系。一般来说,底层layer捕获到的更多是lexical-level的关系,而高层layer捕获到的更多是semantic-level的关系。
2.4. Attention 作用
下面这段我会以机器翻译为例,用通俗的语言阐释一下attention的作用,以及query, key, value的含义。
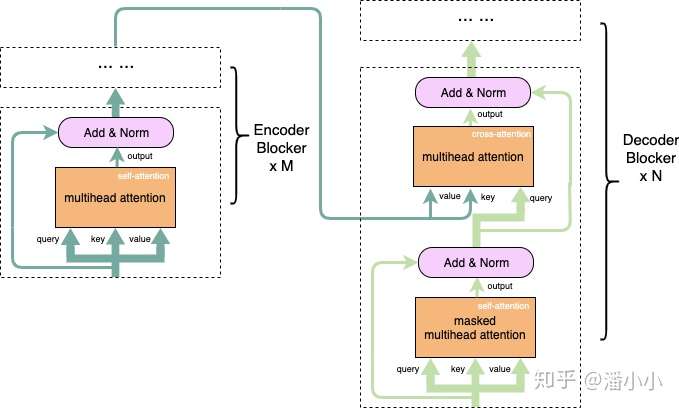
Transformer模型Encoder, Decoder的细节图(省去了FFN部分)
query对应的是需要被表达的序列(称为序列A),key和value对应的是用来表达A的序列(称为序列B)。其中key和query是在同一高维空间中的(否则无法用来计算相似程度),value不必在同一高维空间中,最终生成的output和value在同一高维空间中。上面这段巨绕的话用一句更绕的话来描述一下就是:
序列A和序列B在高维空间
中的高维表达
的每个位置分别和
计算相似度,产生的权重作用于序列B在高维空间
中的高维表达
,获得序列A在高维空间
Encoder部分中只存在self-attention,而Decoder部分中存在self-attention和cross-attention
- 【self-attention】encoder中的self-attention的query, key, value都对应了源端序列(即A和B是同一序列),decoder中的self-attention的query, key, value都对应了目标端序列。
- 【cross-attention】decoder中的cross-attention的query对应了目标端序列,key, value对应了源端序列(每一层中的cross-attention用的都是encoder的最终输出)
2.5. Decoder端的Mask
Transformer模型属于自回归模型(p.s. 非自回归的翻译模型我会专门写一篇文章来介绍),也就是说后面的token的推断是基于前面的token的。Decoder端的Mask的功能是为了保证训练阶段和推理阶段的一致性。
论文原文中关于这一点的段落如下:
We also modify the self-attention sub-layer in the decoder stack to prevent from attending to subsequent positions. This masking, combined with the fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
在推理阶段,token是按照从左往右的顺序推理的。也就是说,在推理timestep=T的token时,decoder只能“看到”timestep < T的 T-1 个Token, 不能和timestep大于它自身的token做attention(因为根本还不知道后面的token是什么)。为了保证训练时和推理时的一致性,所以,训练时要同样防止token与它之后的token去做attention。
2.6. 多头Attention (Multi-head Attention)
Attention是将query和key映射到同一高维空间中去计算相似度,而对应的multi-head attention把query和key映射到高维空间 的不同子空间
中去计算相似度。
为什么要做multi-head attention?论文原文里是这么说的:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
也就是说,这样可以在不改变参数量的情况下增强每一层attention的表现力。
Multi-head Attention示意图
Multi-head Attention的本质是,在参数总量保持不变的情况下,将同样的query, key, value映射到原来的高维空间的不同子空间中进行attention的计算,在最后一步再合并不同子空间中的attention信息。这样降低了计算每个head的attention时每个向量的维度,在某种意义上防止了过拟合;由于Attention在不同子空间中有不同的分布,Multi-head Attention实际上是寻找了序列之间不同角度的关联关系,并在最后concat这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
从上图可以看出, 和
之间的attention score从1个变成了h个,这就对应了h个子空间中它们的关联度。
- Transformer模型架构中的其他部分
3.1. Feed Forward Network
每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。
曾经我在这里有一个百思不得其解的问题:attention层的output最后会和 相乘,为什么这里又要增加一个2层的FFN网络?
其实,FFN的加入引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力。把FFN去掉模型也是可以用的,但是效果差了很多。
3.2. Positional Encoding
位置编码层只在encoder端和decoder端的embedding之后,第一个block之前出现,它非常重要,没有这部分,Transformer模型就无法用。位置编码是Transformer框架中特有的组成部分,补充了Attention机制本身不能捕捉位置信息的缺陷。
-
-
position encoding
Positional Embedding的成分直接叠加于Embedding之上,使得每个token的位置信息和它的语义信息(embedding)充分融合,并被传递到后续所有经过复杂变换的序列表达中去。
论文中使用的Positional Encoding(PE)是正余弦函数,位置(pos)越小,波长越长,每一个位置对应的PE都是唯一的。同时作者也提到,之所以选用正余弦函数作为PE,是因为这可以使得模型学习到token之间的相对位置关系:因为对于任意的偏移量k, 可以由
的线性表示:
上面两个公式可以由 和
的线性组合得到。也就是
乘上某个线性变换矩阵就得到了
p.s. 后续有一个工作在attention中使用了“相对位置表示” (Self-Attention with Relative Position Representations) ,有兴趣可以看看。
3.3. Layer Normalization
在每个block中,最后出现的是Layer Normalization。Layer Normalization是一个通用的技术,其本质是规范优化空间,加速收敛。
当我们使用梯度下降法做优化时,随着网络深度的增加,数据的分布会不断发生变化,假设feature只有二维,那么用示意图来表示一下就是:
数据的分布发生变化,左图比较规范,右图变得不规范
为了保证数据特征分布的稳定性(如左图),我们加入Layer Normalization,这样可以加速模型的优化速度。
- 以上内容摘自:Transformer模型深度解读
Residual connection是什么?
残差连接其实很简单!给你看一张示意图你就明白了:

Figure 5. Residual connection.
假设网络中某个层对输入x作用后的输出是$F(x)$,那么增加residual connection之后,就变成了:$F(x)+x$
这个+x操作就是一个shortcut。那么残差结构有什么好处呢?显而易见:因为增加了一项$x$,那么该层网络对x求偏导的时候,多了一个常数项$1$!所以在反向传播过程中,梯度连乘,也不会造成梯度消失!
所以,代码实现residual connection很非常简单:
def residual(sublayer_fn,x):
return sublayer_fn(x)+x
文章开始的transformer架构图中的Add & Norm中的Add也就是指的这个shortcut。
至此,residual connection的问题理清楚了。更多关于残差网络的介绍可以看文末的参考文献。
Pre-LN VS Post-LN
【2023-6-14】此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
- Sebastian: 指出谷歌大脑团队论文《Attention Is All You Need》中 Transformer 构架图与代码不一致
- 最初的 Transformer 构架图确实与代码不一致, 但 2017 年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
Layer Norm 位置 – 详细解答见为什么Pre Norm的效果不如Post Norm?
Pre-LN: LN 在 self-attention 之前, 放残差连接里- 效果:梯度更好, 可解决梯度问题, 更容易训练, 但可能导致表征崩溃
- 分析:
- 容易训练: 因为 恒等路径更突出
- 效果不好: Pre Norm结构无形地增加了模型宽度而降低了模型深度,而深度通常比宽度更重要,所以降低深度导致最终效果变差了
Post-LN: LN 在 self-attention 和 FFN 之后- 效果: 预期的梯度被放大, 最终效果更好
- 分析: 每Norm一次就削弱一次恒等分支的权重,所以Post Norm反而是更突出残差分支的,因此Post Norm中的层数更加“足秤”,一旦训练好之后效果更优。
- Deep-LN: 未知
结论:
同一设置之下,Pre Norm 结构往往更容易训练,但最终效果通常不如Post Norm。
2020年的论文: On Layer Normalization in the Transformer Architecture
Transformer 架构论文中的层归一化表明,Pre-LN 工作得更好,可解决梯度问题。
- 许多体系架构采用了这种方法,但可能导致表征崩溃。有论文将pre 和 post结合

- 将 Post-LN 和 Pre-LN 一起用,《 ResiDual: Transformer with Dual Residual Connections》,是否有用还有待观察。
注
- 面试题目: 为什么 Trans/GPT-1 采用 Post-LN 而 GPT-2 采用 Pre-LN ?
Layer normalization是什么?
GRADIENTS, BATCH NORMALIZATION AND LAYER NORMALIZATION一文对normalization有很好的解释:
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
说到normalization,那就肯定得提到Batch Normalization。BN在CNN等地方用得很多。
BN的主要思想就是:在每一层的每一批数据上进行归一化。
我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示:

Figure 6. Batch normalization example.(From theneuralperspective.com)
可以看到,右半边求均值是沿着数据批量N的方向进行的!
Batch normalization的计算公式如下:
- \[BN(x_i)=\alpha\times\frac{x_i-u_B}{\sqrt{\sigma_B^2+\epsilon}}+\beta\]
具体的实现可以查看上图的链接文章。
说完Batch normalization,就该说说咱们今天的主角Layer normalization。
那么什么是Layer normalization呢?:它也是归一化数据的一种方式,不过LN是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
下面是LN的示意图:

Figure 7. Layer normalization example.
和上面的BN示意图一比较就可以看出二者的区别啦!
下面看一下LN的公式,也BN十分相似:
- \[LN(x_i)=\alpha\times\frac{x_i-u_L}{\sqrt{\sigma_L^2+\epsilon}}+\beta\]
Layer normalization的实现
上述两个参数$\alpha$和$\beta$都是可学习参数。下面我们自己来实现Layer normalization(PyTorch已经实现啦!)。代码如下:
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
"""实现LayerNorm。其实PyTorch已经实现啦,见nn.LayerNorm。"""
def __init__(self, features, epsilon=1e-6):
"""Init.
Args:
features: 就是模型的维度。论文默认512
epsilon: 一个很小的数,防止数值计算的除0错误
"""
super(LayerNorm, self).__init__()
# alpha
self.gamma = nn.Parameter(torch.ones(features))
# beta
self.beta = nn.Parameter(torch.zeros(features))
self.epsilon = epsilon
def forward(self, x):
"""前向传播.
Args:
x: 输入序列张量,形状为[B, L, D]
"""
# 根据公式进行归一化
# 在X的最后一个维度求均值,最后一个维度就是模型的维度
mean = x.mean(-1, keepdim=True)
# 在X的最后一个维度求方差,最后一个维度就是模型的维度
std = x.std(-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.epsilon) + self.beta
顺便提一句,Layer normalization多用于RNN这种结构。
Mask 是什么?
现在终于轮到讲解mask了!mask顾名思义就是掩码,在我们这里的意思大概就是对某些值进行掩盖,使其不产生效果。
需要说明的是,我们的Transformer模型里面涉及两种mask。分别是padding mask和sequence mask。其中后者我们已经在decoder的self-attention里面见过啦!
- padding mask在所有的scaled dot-product attention里面都需要用到
- sequence mask只有在decoder的self-attention里面用到。
所以,我们之前ScaledDotProductAttention的forward方法里面的参数attn_mask在不同的地方会有不同的含义。这一点我们会在后面说明。
Padding mask
什么是padding mask呢?回想一下,我们的每个批次输入序列长度是不一样的!也就是说,我们要对输入序列进行对齐!具体来说,就是给在较短的序列后面填充0。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(可以是负无穷),这样的话,经过softmax,这些位置的概率就会接近0!
而我们的padding mask实际上是一个张量,每个值都是一个Boolen,值为False的地方就是我们要进行处理的地方。
下面是实现:
def padding_mask(seq_k, seq_q):
# seq_k和seq_q的形状都是[B,L]
len_q = seq_q.size(1)
# `PAD` is 0
pad_mask = seq_k.eq(0)
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1) # shape [B, L_q, L_k]
return pad_mask
Sequence mask
文章前面也提到,sequence mask是为了使得decoder不能看见未来的信息。也就是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为1,下三角的值权威0,对角线也是0。把这个矩阵作用在每一个序列上,就可以达到我们的目的啦。
具体的代码实现如下:
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
return mask
哈佛大学的文章The Annotated Transformer有一张效果图:

Figure 8. Sequence mask.
值得注意的是,本来mask只需要二维的矩阵即可,但是考虑到我们的输入序列都是批量的,所以我们要把原本二维的矩阵扩张成3维的张量。上面的代码可以看出,我们已经进行了处理。
回到本小结开始的问题,attn_mask参数有几种情况?分别是什么意思?
- 对于decoder的self-attention,里面使用到的scaled dot-product attention,同时需要
padding mask和sequence mask作为attn_mask,具体实现就是两个mask相加作为attn_mask。 - 其他情况,
attn_mask一律等于padding mask。
至此,mask相关的问题解决了。
Positional encoding 是什么?
【2021-8-25】面经:什么是Transformer位置编码?
位置编码是结构图里的Positional encoding。
序列顺序是一个很重要的信息,如果缺失,结果就是:所有词语都对了,但是无法组成有意义的语句
Self-attention 一次性将所有字都当做输入,感知不到方向、位置、间距。
但是NLP输入的文本要按照一定的顺序才可以。不同语序就有不同语义。
- 句子1:我喜欢吃洋葱
- 句子2:洋葱喜欢吃我
Transformer结构为了更好的发挥并行输入的特点,首先要让输入内容具有一定位置信息。
于是,论文提出了Positional encoding。
- 对序列中的词语出现的位置进行编码,如果对位置进行编码,那模型就可以捕捉顺序信息
为什么用位置编码
【2023-6-13】如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
为什么考虑顺序?
- 捕捉序列顺序,交换单词位置后 attention map 的对应位置数值也会交换,产生数值变化,补充词序信息。
- 不同距离的单词影响程度不同
Transformer 模型本身不包含循环或卷积结构,无法捕捉序列中的位置信息。因此,需要额外的位置编码来提供每个位置上的信息,以便模型能够区分不同位置的输入元素。
为什么用相对位置?
tokens 位置信息有:
- (1)绝对位置信息。a1是第一个token,a2是第二个token……
- (2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位……
- (3)不同位置间距。a1和a3差两个位置,a1和a4差三个位置….
但是这些信息 self-attention 都无法分辩
- 因为self-attention的运算是无向的。
- 需要想办法把tokens的位置信息喂给模型。
分析
- 顺序编码: 无界且不利于模型泛化
- 相对编码: 相对距离不同,无法反应间距信息
- 如将位置编号归一化到
[0,1]区间 - 同样是间隔3个位置,相对距离可能是 0.33, 0.5, …
- 如将位置编号归一化到
- 理想的编码方式满足:
- (1)能表示token在序列中的绝对位置,且连续有界
- (2)序列长度不同时,token的相对位置/距离也要保持一致
- (3)支持训练过程中没有的句子长度。
- (4)不同位置向量可以通过线性变化得到
二进制函数不行?
- 0/1 离散空间,one-hot表示字符,显示不出差距
为什么用sin函数?
- 词序信息表示方法很丰富,但都需要对不同维度的不同位置生成合理的数值表示。
- 合理:不同位置的同一维度的位置向量之间,含有相对位置信息,而相对位置信息可以通过函数周期性实现。
- 论文解释:对不同维度使用不同频率的正/余弦公式进而生成不同位置的高维位置向量。
- 猜测
- 周期性频率采样(OFDM、FFT等),可能确实迎合了语言的某种属性。比如,诗歌就是一类频率体现很明显的句子。
为什么奇偶维度之间需要作出区分,分别使用 sin 和 cos 呢?
- 三角函数的积化和差公式
- 奇偶区分可以通过全连接层帮助重排坐标,所以直接简单地分为两段(前 256 维使用 sin,后 256 维使用 cos)。
即满足(4)不同位置向量可以通过线性变化得到
- sin(a+b)=sin(a)
Transformer位置编码可视化
- 一串序列长度为50,位置编码维度为128的位置编码可视化结果

- 由于sin/cos函数的性质,位置向量每个值都位于[-1, 1]之间。
- 同时,纵向来看,图的右半边几乎都是蓝色的,因为越往后的位置,频率越小,波长越长,所以不同的t对最终结果影响不大。而越往左边走,颜色交替的频率越频繁。
位置编码分类
位置编码分类
位置编码分为两个类型:函数型和表格型
函数型:通过输入token位置信息得到相应的位置编码;- 方法①:使用
[0, 1]范围分配。第一个token分配0,最后一个token分配去1,其余token按照文章长度平均分配。- 示例:
- 我喜欢吃洋葱
【0 0.16 0.32.....1】 - 我真的不喜欢吃洋葱
【0 0.125 0.25.....1】
- 我喜欢吃洋葱
- 问题:如果句子长度不同,那么位置编码是不一样,所以, 无法表示句子之间有什么相似性。
- 示例:
- 方法②:1-n正整数范围分配
- 直观,按照输入顺序,一次分配给token所在的索引位置。具体形式如下:
- 我喜欢吃洋葱
【1,2,3,4,5,6】 - 我真的不喜欢吃洋葱
【1,2,3,4,5,6,7】
- 我喜欢吃洋葱
- 问题:句子越长,后面值越大,数字越大说明这个位置占的权重也越大,无法凸显每个位置的真实权重。
- 直观,按照输入顺序,一次分配给token所在的索引位置。具体形式如下:
- 总结:
- 过去的方法有各种不足,所以Transformer对于位置信息编码做了改进
- 方法①:使用
表格型:建长度为L的词表,按词表长度来分配位置id- 相对位置编码关注token与token距离的相对位置(距离差几个token)。位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2与位置3和位置4都只相差1。这种方法可以知道单词之间的距离远近关系。
- 问题:虽说可以表示出相对的距离关系,但是也有局限。
- 只能的到相对关系,无法得到方向关系。对于两个token谁在谁的前面/后面,无法判断。
Transformer位置编码采用函数型,GPT-3论文给出公式:
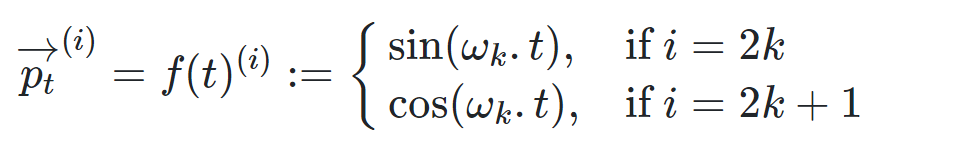
- 注意:每一个Token的位置信息编码不是数字,而是一个不同频率分割出来,和文本一样维度的向量。不同频率是通过Wn来表示。
- 得到位置向量P之后,将和模型的embedding向量相加,得到进入Transformer模型的最终表示
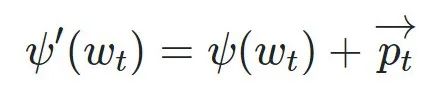 , 其中,$w_i=1/10000^{2i/d_{model}}$, t是每个token的位置,比如说是位置1,位置2,以及位置n
, 其中,$w_i=1/10000^{2i/d_{model}}$, t是每个token的位置,比如说是位置1,位置2,以及位置n
transformer怎么做呢?论文的实现很有意思,使用正余弦函数。公式如下:
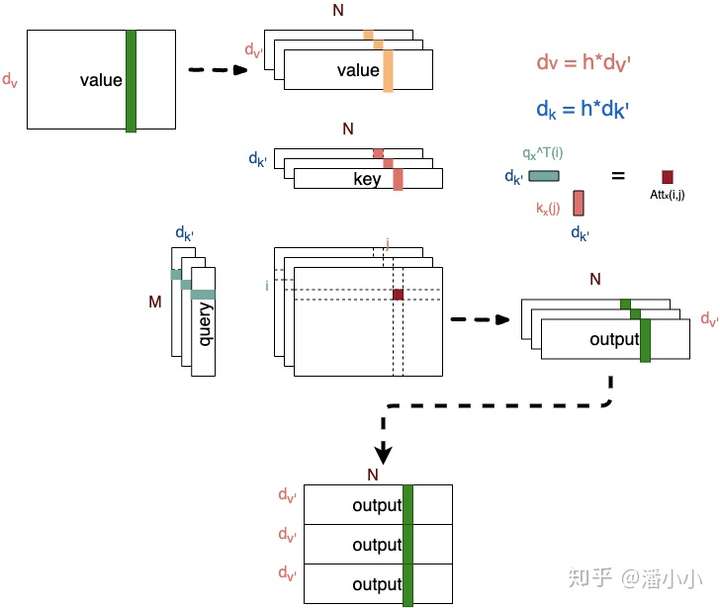
- \[PE(pos,2i) = sin(pos/10000^{2i/d_{model}})\]
- \[PE(pos,2i+1) = cos(pos/10000^{2i/d_{model}})\]
其中,pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
上面公式中的$d_{model}$是模型的维度,论文默认是512。
这个编码公式的意思就是:给定词语的位置$\text{pos}$,我们可以把它编码成$d_{model}$维的向量!也就是说,位置编码的每一个维度对应正弦曲线,波长构成了从$2\pi\(到\)10000*2\pi$的等比序列。
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。这就是论文为什么要使用三角函数的原因!
正弦函数能够表达相对位置信息。主要数学依据是以下两个公式:
- \[sin(\alpha+\beta) = sin\alpha cos\beta + cos\alpha sin\beta\]
- \[cos(\alpha+\beta) = cos\alpha cos\beta - sin\alpha sin\beta\]
上面的公式说明,对于词汇之间的位置偏移k,$PE(pos+k)$可以表示成$PE(pos)$和$PE(k)$的组合形式,这就是表达相对位置的能力!
以上就是$PE$的所有秘密。说完了positional encoding,那么我们还有一个与之处于同一地位的word embedding。
Word embedding大家都很熟悉了,它是对序列中的词汇的编码,把每一个词汇编码成$d_{model}$维的向量!看到没有,Postional encoding是对词汇的位置编码,word embedding是对词汇本身编码
所以,我更喜欢positional encoding的另外一个名字Positional embedding
图解位置编码
输入 attention 结构之前,每个字做 word embedding 和 positional embedding。
- 加位置 embedding是为了服务于 self-attention 的目标,即得到一个 word 序列中每两个word 之间的相关性。
- word之间的相关性,只跟相对位置有关、而与绝对位置无关。img

Positional encoding 实现
PE的实现也不难,按照论文的公式即可。代码如下:
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
"""初始化。
Args:
d_model: 一个标量。模型的维度,论文默认是512
max_seq_len: 一个标量。文本序列的最大长度
"""
super(PositionalEncoding, self).__init__()
# 根据论文给的公式,构造出PE矩阵
position_encoding = np.array([
[pos / np.pow(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)]
for pos in range(max_seq_len)])
# 偶数列使用sin,奇数列使用cos
position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2])
position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
# 在PE矩阵的第一行,加上一行全是0的向量,代表这`PAD`的positional encoding
# 在word embedding中也经常会加上`UNK`,代表位置单词的word embedding,两者十分类似
# 那么为什么需要这个额外的PAD的编码呢?很简单,因为文本序列的长度不一,我们需要对齐,
# 短的序列我们使用0在结尾补全,我们也需要这些补全位置的编码,也就是`PAD`对应的位置编码
pad_row = torch.zeros([1, d_model])
position_encoding = torch.cat((pad_row, position_encoding))
# 嵌入操作,+1是因为增加了`PAD`这个补全位置的编码,
# Word embedding中如果词典增加`UNK`,我们也需要+1。看吧,两者十分相似
self.position_encoding = nn.Embedding(max_seq_len + 1, d_model)
self.position_encoding.weight = nn.Parameter(position_encoding,
requires_grad=False)
def forward(self, input_len):
"""神经网络的前向传播。
Args:
input_len: 一个张量,形状为[BATCH_SIZE, 1]。每一个张量的值代表这一批文本序列中对应的长度。
Returns:
返回这一批序列的位置编码,进行了对齐。
"""
# 找出这一批序列的最大长度
max_len = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
# 对每一个序列的位置进行对齐,在原序列位置的后面补上0
# 这里range从1开始也是因为要避开PAD(0)的位置
input_pos = tensor(
[list(range(1, len + 1)) + [0] * (max_len - len) for len in input_len])
return self.position_encoding(input_pos)
Word embedding的实现
Word embedding应该是老生常谈了,它实际上就是一个二维浮点矩阵,里面的权重是可训练参数,我们只需要把这个矩阵构建出来就完成了word embedding的工作。
所以,具体的实现很简单:
import torch.nn as nn
embedding = nn.Embedding(vocab_size, embedding_size, padding_idx=0)
# 获得输入的词嵌入编码
seq_embedding = seq_embedding(inputs)*np.sqrt(d_model)
上面vocab_size就是词典的大小,embedding_size就是词嵌入的维度大小,论文里面就是等于$d_{model}=512$。所以word embedding矩阵就是一个vocab_size*embedding_size的二维张量。
如果你想获取更详细的关于word embedding的信息,可以看我的另外一个文章word2vec的笔记和实现。
位置编码: BERT vs Trans
各个模型的位置编码差异
- Word2Vec 没有位置编码
- Trans 位置编码是一个sin和cos函数算出来的固定值,只能标记这是某一个位置,并不能标记这个位置有啥用。
- 满足条件:绝对位置、相对位置、考虑远近、便于线性变换
- BERT 位置编码是一个可学习的embedding,所以不仅可以标注这一个位置,还能学习这个位置有什么作用。
- 维护3个embedding矩阵,词、段、位置。词是怎么取embedding的,段和位置就怎么取embedding

与 TransformerEncoder不同, BERTEncoder 使用片段嵌入和可学习的位置嵌入。
- nn.Parameter 传入的是一个随机数
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
详见:BERT
Position-wise Feed-Forward network是什么?
这就是一个全连接网络,包含两个线性变换和一个非线性函数(实际上就是ReLU)。公式如下:
\[FFN(x)=max(0,xW_1+b_1)W_2+b_2\]这个线性变换在不同的位置都表现地一样,并且在不同的层之间使用不同的参数。
论文提到,这个公式还可以用两个核大小为1的一维卷积来解释,卷积的输入输出都是$d_{model}=512$,中间层的维度是$d_{ff}=2048$。
实现如下:
import torch
import torch.nn as nn
class PositionalWiseFeedForward(nn.Module):
def __init__(self, model_dim=512, ffn_dim=2048, dropout=0.0):
super(PositionalWiseFeedForward, self).__init__()
self.w1 = nn.Conv1d(model_dim, ffn_dim, 1)
self.w2 = nn.Conv1d(model_dim, ffn_dim, 1)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):
output = x.transpose(1, 2)
output = self.w2(F.relu(self.w1(output)))
output = self.dropout(output.transpose(1, 2))
# add residual and norm layer
output = self.layer_norm(x + output)
return output
Transformer 实现
pytorch 版本
- Google 2017年的论文 Attention is all you need 阐释了什么叫做大道至简!该论文提出了Transformer模型,完全基于Attention mechanism,抛弃了传统的RNN和CNN。
- 根据论文的结构图,一步一步使用 PyTorch 实现这个Transformer模型。
自注意力实现
Self-Attention的代码实现
# Self-Attention 机制的实现
from math import sqrt
import torch
import torch.nn as nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim, dim_k, dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
if __name__ == '__main__':
X = torch.randn(4,3,2)
print(X.size(), X)
sa = Self_Attention(2,4,5)
res = sa(X)
print(res)
另一种写法
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # unnormalized attention weights
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
多头注意力实现
# Muti-head Attention 机制的实现
from math import sqrt
import torch
import torch.nn as nn
class Self_Attention_Muti_Head(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v,nums_head):
super(Self_Attention_Muti_Head,self).__init__()
assert dim_k % nums_head == 0
assert dim_v % nums_head == 0
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self.nums_head = nums_head
self.dim_k = dim_k
self.dim_v = dim_v
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
V = self.v(x).reshape(-1,x.shape[0],x.shape[1],self.dim_v // self.nums_head)
print(x.shape)
print(Q.size())
atten = nn.Softmax(dim=-1)(torch.matmul(Q,K.permute(0,1,3,2))) # Q * K.T() # batch_size * seq_len * seq_len
output = torch.matmul(atten,V).reshape(x.shape[0],x.shape[1],-1) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
【2023-5-10】点的self、cross注意力机制实现
def attention(query, key, value):
dim = query.shape[1]
scores = torch.einsum('bdhn,bdhm->bhnm', query, key) / dim**.5
prob = torch.nn.functional.softmax(scores, dim=-1)
return torch.einsum('bhnm,bdhm->bdhn', prob, value), prob
class MultiHeadedAttention(nn.Module):
"""
Multi-head attention to increase model expressivitiy
"""
def __init__(self, num_heads: int, d_model: int):
super().__init__()
assert d_model % num_heads == 0
self.dim = d_model // num_heads
self.num_heads = num_heads
self.merge = nn.Conv1d(d_model, d_model, kernel_size=1)
self.proj = nn.ModuleList([deepcopy(self.merge) for _ in range(3)])
def forward(self, query, key, value):
batch_dim = query.size(0)
query, key, value = [l(x).view(batch_dim, self.dim, self.num_heads, -1)
for l, x in zip(self.proj, (query, key, value))]
x, prob = attention(query, key, value)
self.prob.append(prob)
return self.merge(x.contiguous().view(batch_dim, self.dim*self.num_heads, -1))
需要实现6层 encoder和decoder。
encoder代码实现如下:
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
"""Encoder的一层。"""
def __init__(self, model_dim=512, num_heads=8, ffn_dim=2018, dropout=0.0):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self, inputs, attn_mask=None):
# self attention
context, attention = self.attention(inputs, inputs, inputs, padding_mask)
# feed forward network
output = self.feed_forward(context)
return output, attention
class Encoder(nn.Module):
"""多层EncoderLayer组成Encoder。"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Encoder, self).__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_mask = padding_mask(inputs, inputs)
attentions = []
for encoder in self.encoder_layers:
output, attention = encoder(output, self_attention_mask)
attentions.append(attention)
return output, attentions
通过文章前面的分析,代码不需要更多解释了。同样的,我们的decoder代码如下:
import torch
import torch.nn as nn
class DecoderLayer(nn.Module):
def __init__(self, model_dim, num_heads=8, ffn_dim=2048, dropout=0.0):
super(DecoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self,
dec_inputs,
enc_outputs,
self_attn_mask=None,
context_attn_mask=None):
# self attention, all inputs are decoder inputs
dec_output, self_attention = self.attention(
dec_inputs, dec_inputs, dec_inputs, self_attn_mask)
# context attention
# query is decoder's outputs, key and value are encoder's inputs
dec_output, context_attention = self.attention(
enc_outputs, enc_outputs, dec_output, context_attn_mask)
# decoder's output, or context
dec_output = self.feed_forward(dec_output)
return dec_output, self_attention, context_attention
class Decoder(nn.Module):
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.decoder_layers = nn.ModuleList(
[DecoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len, enc_output, context_attn_mask=None):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_padding_mask = padding_mask(inputs, inputs)
seq_mask = sequence_mask(inputs)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
self_attentions = []
context_attentions = []
for decoder in self.decoder_layers:
output, self_attn, context_attn = decoder(
output, enc_output, self_attn_mask, context_attn_mask)
self_attentions.append(self_attn)
context_attentions.append(context_attn)
return output, self_attentions, context_attentions
最后,把encoder和decoder组成Transformer模型!
代码如下:
import torch
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
src_max_len,
tgt_vocab_size,
tgt_max_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.2):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, src_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.decoder = Decoder(tgt_vocab_size, tgt_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.linear = nn.Linear(model_dim, tgt_vocab_size, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, src_seq, src_len, tgt_seq, tgt_len):
context_attn_mask = padding_mask(tgt_seq, src_seq)
output, enc_self_attn = self.encoder(src_seq, src_len)
output, dec_self_attn, ctx_attn = self.decoder(
tgt_seq, tgt_len, output, context_attn_mask)
output = self.linear(output)
output = self.softmax(output)
return output, enc_self_attn, dec_self_attn, ctx_attn
至此,Transformer模型已经实现了!
pytorch代码
【2021-11-1】

完整代码
# @Author:Yifx
# @Contact: Xxuyifan1999@163.com
# @Time:2021/9/16 20:02
# @Software: PyCharm
"""
文件说明:
"""
import torch
import torch.nn as nn
import numpy as np
import math
class Config(object):
# 模型超参类
def __init__(self):
self.vocab_size = 6
self.d_model = 20
self.n_heads = 2
assert self.d_model % self.n_heads == 0
dim_k = self.d_model // self.n_heads
dim_v = self.d_model // self.n_heads
self.padding_size = 30
self.UNK = 5
self.PAD = 4
self.N = 6
self.p = 0.1
config = Config()
class Embedding(nn.Module):
def __init__(self,vocab_size):
super(Embedding, self).__init__()
# 一个普通的 embedding层,我们可以通过设置padding_idx=config.PAD 来实现论文中的 padding_mask
self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD)
def forward(self,x):
# 根据每个句子的长度,进行padding,短补长截
for i in range(len(x)):
if len(x[i]) < config.padding_size:
x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # 注意 UNK是你词表中用来表示oov的token索引,这里进行了简化,直接假设为6
else:
x[i] = x[i][:config.padding_size]
x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model
return x
class Positional_Encoding(nn.Module):
def __init__(self,d_model):
super(Positional_Encoding,self).__init__()
self.d_model = d_model
def forward(self,seq_len,embedding_dim):
positional_encoding = np.zeros((seq_len,embedding_dim))
for pos in range(positional_encoding.shape[0]):
for i in range(positional_encoding.shape[1]):
positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model)))
return torch.from_numpy(positional_encoding)
class Mutihead_Attention(nn.Module):
def __init__(self,d_model,dim_k,dim_v,n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model,dim_k)
self.k = nn.Linear(d_model,dim_k)
self.v = nn.Linear(d_model,dim_v)
self.o = nn.Linear(dim_v,d_model)
self.norm_fact = 1 / math.sqrt(d_model)
def generate_mask(self,dim):
# 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
# padding mask 在数据输入模型之前完成。
matirx = np.ones((dim,dim))
mask = torch.Tensor(np.tril(matirx))
return mask==1
def forward(self,x,y,requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# 对 x 进行自注意力
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
# print("Attention V shape : {}".format(V.shape))
attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
if requires_mask:
mask = self.generate_mask(x.shape[1])
# masked_fill 函数中,对Mask位置为True的部分进行Mask
attention_score.masked_fill(mask,value=float("-inf")) # 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASKSoftmax之前的结果就好了
output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
# print("Attention output shape : {}".format(output.shape))
output = self.o(output)
return output
class Feed_Forward(nn.Module):
def __init__(self,input_dim,hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.L1 = nn.Linear(input_dim,hidden_dim)
self.L2 = nn.Linear(hidden_dim,input_dim)
def forward(self,x):
output = nn.ReLU()(self.L1(x))
output = self.L2(output)
return output
class Add_Norm(nn.Module):
def __init__(self):
self.dropout = nn.Dropout(config.p)
super(Add_Norm, self).__init__()
def forward(self,x,sub_layer,**kwargs):
sub_output = sub_layer(x,**kwargs)
# print("{} output : {}".format(sub_layer,sub_output.size()))
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.size()[1:])
out = layer_norm(x)
return out
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
x += self.positional_encoding(x.shape[1],config.d_model)
# print("After positional_encoding: {}".format(x.size()))
output = self.add_norm(x,self.muti_atten,y=x)
output = self.add_norm(output,self.feed_forward)
return output
# 在 Decoder 中,Encoder的输出作为Query和KEy输出的那个东西。即 Decoder的Input作为V。此时是可行的
# 因为在输入过程中,我们有一个padding操作,将Inputs和Outputs的seq_len这个维度都拉成一样的了
# 我们知道,QK那个过程得到的结果是 batch_size * seq_len * seq_len .既然 seq_len 一样,那么我们可以这样操作
# 这样操作的意义是,Outputs 中的 token 分别对于 Inputs 中的每个token作注意力
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
# print(x.size())
x += self.positional_encoding(x.shape[1],config.d_model)
# print(x.size())
# 第一个 sub_layer
output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
# 第二个 sub_layer
output = self.add_norm(x,self.muti_atten,y=encoder_output,requires_mask=True)
# 第三个 sub_layer
output = self.add_norm(output,self.feed_forward)
return output
class Transformer_layer(nn.Module):
def __init__(self):
super(Transformer_layer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self,x):
x_input,x_output = x
encoder_output = self.encoder(x_input)
decoder_output = self.decoder(x_output,encoder_output)
return (encoder_output,decoder_output)
class Transformer(nn.Module):
def __init__(self,N,vocab_size,output_dim):
super(Transformer, self).__init__()
self.embedding_input = Embedding(vocab_size=vocab_size)
self.embedding_output = Embedding(vocab_size=vocab_size)
self.output_dim = output_dim
self.linear = nn.Linear(config.d_model,output_dim)
self.softmax = nn.Softmax(dim=-1)
self.model = nn.Sequential(*[Transformer_layer() for _ in range(N)])
def forward(self,x):
x_input , x_output = x
x_input = self.embedding_input(x_input)
x_output = self.embedding_output(x_output)
_ , output = self.model((x_input,x_output))
output = self.linear(output)
output = self.softmax(output)
return output
Transformer 改进
详见站内专题: transformer改进方案
GPT-2
OpenAI 的 GPT-2 模型就用了这种只包含编码器(decoder-only)模块
GPT-2 可以处理最长 1024 个单词的序列。每个单词都会和前续路径一起「流过」所有的解码器模块。
训练 GPT-2 模型,最简单的方法
- 自己随机工作(生成无条件样本)。
- 给它一点提示,说一些关于特定主题的话(即生成交互式条件样本)。
在随机情况下,只简单地提供一个预先定义好的起始单词,然后自己生成文字。
-
训练好的模型使用「|endoftext|」作为起始单词,不妨将其称为<s>
- 模型的输入只有一个单词,所以只有这个单词的路径是活跃的。
- 单词经过层层处理,最终得到一个向量。向量对于词汇表的每个单词计算一个概率
- 词汇表是模型能「说出」的所有单词,GPT-2 的词汇表中有 50000 个单词
- 选择概率最高的单词「The」作为下一个单词。
- 将输出的单词添加在输入序列的尾部构建新的输入序列,让模型进行下一步的预测
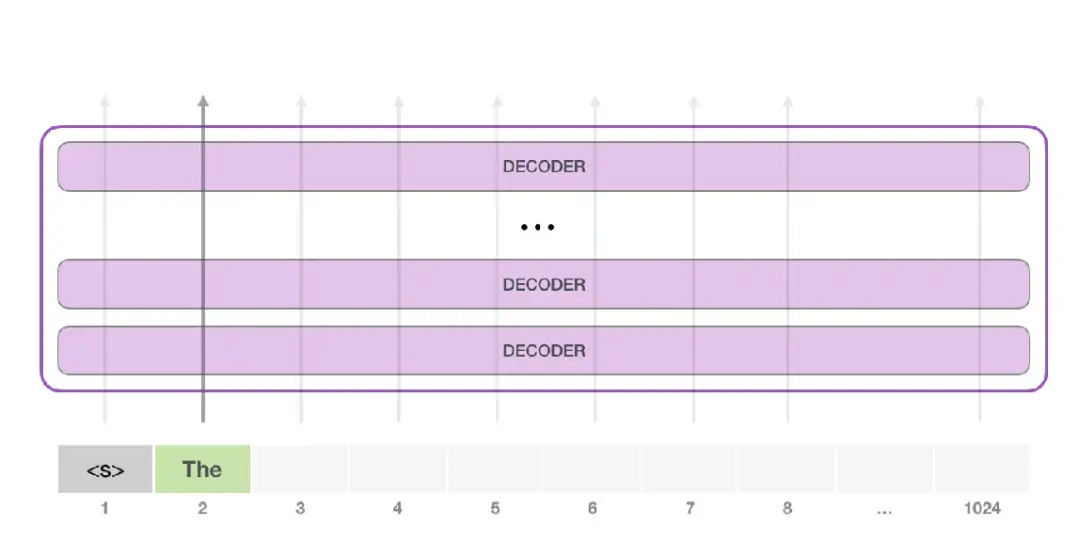
问题:重复
- 陷入推荐同一个词的循环中,除非采用其他单词才能跳出
GPT-2 有个「top-k」的参数
- 模型会从概率前 k 大的单词中随机抽样选取下一个单词。
- 之前情况下,top-k = 1
GPT-2 从嵌入(Embedding)矩阵中找单词对应的嵌入向量,该矩阵也是模型训练结果的一部分。
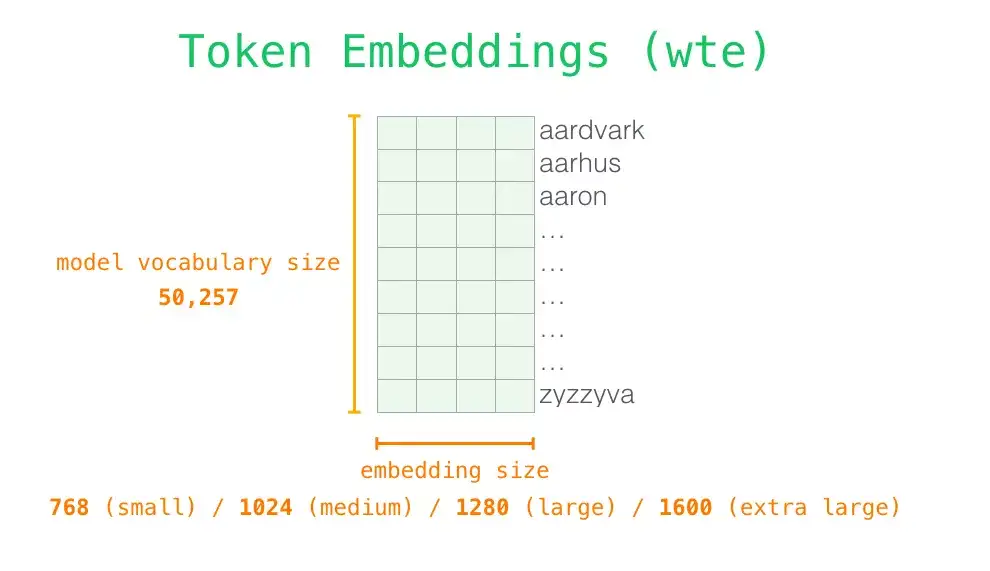
- 嵌入矩阵的每一行都对应模型词汇表中一个单词的嵌入向量。
- embedding size
- small : 768个字符,117m
- medium : 1024,345m
- large : 1280,762m
- extra large : 1600, 1542m
每一行都是一个词嵌入向量:一个能够表征某个单词,并捕获其数字列表。
- 嵌入向量的长度和 GPT-2 模型的大小有关,最小的模型使用了长为 768 的嵌入向量来表征一个单词。
在嵌入矩阵中查找起始单词<s>对应的嵌入向量。
- 但在将其输入给模型之前,引入
位置编码—— 一些向 transformer 模块指出序列中的单词顺序的信号。 - 1024 个输入序列位置中的每一个都对应一个位置编码,编码矩阵也是训练模型的一部分。
GPT-2 模型训练后包含两个权值矩阵:嵌入矩阵和位置编码矩阵。
单词输入第一个 transformer 模块之前, 查到对应的嵌入向量,加上 1号位置对应的位置向量。
堆栈之旅: 第一个 transformer 模块处理单词的步骤:
- 通过自注意力层处理,传给神经网络层。第一个 transformer 模块处理完但此后,会将结果向量被传入堆栈中的下一个 transformer 模块,继续进行计算。每一个 transformer 模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。

最上层的 transformer 模块在处理单词「it」的时候会关注「a robot」,所以「a」、「robot」、「it」这三个单词与其得分相乘加权求和后的特征向量会被送入之后的神经网络层。
Lite Transformer (边缘设备)
【2020-6-7】模型压缩95%,MIT韩松等人提出新型Lite Transformer
- MIT 最近的研究《Lite Transformer with Long-Short Range Attention》中,MIT 与上海交大的研究人员提出了一种高效的移动端 NLP 架构
Lite Transformer,向在边缘设备上部署移动级 NLP 应用迈进了一大步。该论文已被人工智能顶会 ICLR 2020 收录。代码 - 核心是长短距离注意力(Long-Short Range Attention,LSRA),其中一组注意力头(通过卷积)负责局部上下文建模,而另一组则(依靠注意力)执行长距离关系建模。
- 对于移动 NLP 设置,Lite Transformer 的 BLEU 值比基于 AutoML 的 Evolved Transformer 高 0.5,而且它不需要使用成本高昂的架构搜索。
- 从 Lite Transformer 与 Evolved Transformer、原版 transformer 的比较结果中可以看出,Lite Transformer 的性能更佳,搜索成本相比 Evolved Transformer 大大减少
Transformer-XL 和 XLNet
XLNet引入了自回归语言模型以及自编码语言模型
杨植麟介绍
【2022-1-17】杨植麟博士,循环智能(Recurrent AI)联合创始人,清华大学交叉信息院助理教授,智源青年科学家。
2016年5月联合创办的Recurrent AI,核心技术包括自然语言理解、语音识别、语气识别、声纹识别和推荐系统。其中,自然语言理解来自公司的核心原创算法XLNet,这套算法刷新了18项NLP(自然语言处理)任务。如今累计融资4亿元,连续三年营收增长超200%,服务银行保险等行业的头部客户,日均处理对话一亿条、覆盖数百万终端用户。

- 循环智能创始团队,从左到右:COO揭发、CTO张宇韬、CEO陈麒聪以及AI和产品负责人杨植麟
其研究成果累计Google Scholar引用10,000余次;作为第一作者发表Transformer-XL 和 XLNet ,对NLP领域产生重大影响,分别是ACL 2019和NeurIPS 2019最高引论文之一;主导开发的盘古NLP大模型获2021年世界人工智能大会“卓越人工智能引领者之星奖”。曾入选2021年福布斯亚洲30 under 30;曾效力于Google Brain和Facebook AI。博士毕业于美国卡内基梅隆大学,本科毕业于清华大学
1. 什么是XLNet
XLNet 是一个类似 BERT 的模型,而不是完全不同的模型。总之,XLNet是一种通用的自回归预训练方法。它是CMU和Google Brain团队在2019年6月份发布的模型,最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:
- 通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;
- 用自回归本身的特点克服 BERT 的缺点;
- 此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
2. 自回归语言模型(Autoregressive LM)
在ELMO/BERT出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,这个跟模型具体怎么实现有关系。ELMO是做了两个方向(从左到右以及从右到左两个方向的语言模型),但是是分别有两个方向的自回归LM,然后把LSTM的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型。
自回归语言模型有优点有缺点:
- 缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。
- 优点其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
3. 自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。DAE吗,就要引入噪音,[Mask] 标记就是引入噪音的手段,这个正常。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。当然,XLNet还讲到了一个Bert被Mask单词之间相互独立的问题。
4. XLNet模型
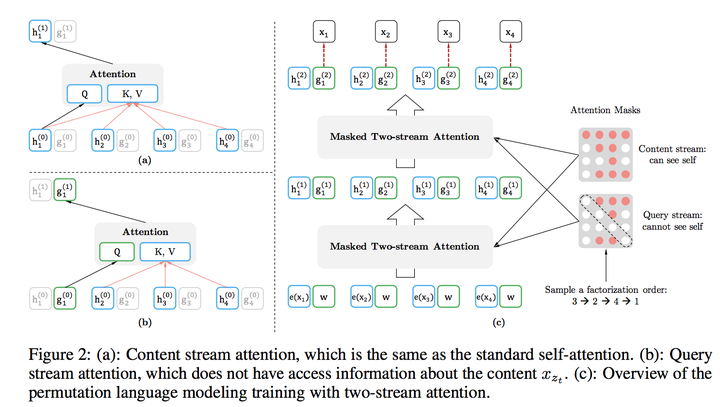
4.1 排列语言建模(Permutation Language Modeling)
Bert的自编码语言模型也有对应的缺点,就是XLNet在文中指出的:
- 第一个预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;
- 另外一个是,Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的。
上面两点是XLNet在第一个预训练阶段,相对Bert来说要解决的两个问题。
其实思路也比较简洁,可以这么思考:XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。就是说,看上去输入句子X仍然是自左向右的输入,看到Ti单词的上文Context_before,来预测Ti这个单词。但是又希望在Context_before里,不仅仅看到上文单词,也能看到Ti单词后面的下文Context_after里的下文单词,这样的话,Bert里面预训练阶段引入的Mask符号就不需要了,于是在预训练阶段,看上去是个标准的从左向右过程,Fine-tuning当然也是这个过程,于是两个环节就统一起来。当然,这是目标。剩下是怎么做到这一点的问题。
首先,需要强调一点,尽管上面讲的是把句子X的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,就必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成我们希望的目标。
具体而言,XLNet采取了Attention掩码的机制,你可以理解为,当前的输入句子是X,要预测的单词Ti是第i个单词,前面1到i-1个单词,在输入部分观察,并没发生变化,该是谁还是谁。但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention掩码隐藏掉,于是就能够达成我们期望的目标(当然这个所谓放到Ti的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了)。
具体实现的时候,XLNet是用“双流自注意力模型”实现的,细节可以参考论文,但是基本思想就如上所述,双流自注意力机制只是实现这个思想的具体方式,理论上,你可以想出其它具体实现方式来实现这个基本思想,也能达成让Ti看到下文单词的目标。
这里简单说下“双流自注意力机制”,一个是内容流自注意力,其实就是标准的Transformer的计算过程;主要是引入了Query流自注意力,这个是干嘛的呢?其实就是用来代替Bert的那个[Mask]标记的,因为XLNet希望抛掉[Mask]标记符号,但是比如知道上文单词x1,x2,要预测单词x3,此时在x3对应位置的Transformer最高层去预测这个单词,但是输入侧不能看到要预测的单词x3,Bert其实是直接引入[Mask]标记来覆盖掉单词x3的内容的,等于说[Mask]是个通用的占位符号。而XLNet因为要抛掉[Mask]标记,但是又不能看到x3的输入,于是Query流,就直接忽略掉x3输入了,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是扔了表面的[Mask]占位符号,内部还是引入Query流来忽略掉被Mask的这个单词。和Bert比,只是实现方式不同而已。
上面讲的Permutation Language Model是XLNet的主要理论创新,所以介绍的比较多,从模型角度讲,这个创新还是挺有意思的,因为它开启了自回归语言模型如何引入下文的一个思路,相信对于后续工作会有启发。当然,XLNet不仅仅做了这些,它还引入了其它的因素,也算是一个当前有效技术的集成体。感觉XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身:
- 首先,它通过PLM(Permutation Language Model)预训练目标,吸收了Bert的双向语言模型;
- 然后,GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了;
- 再然后,Transformer XL的主要思想也被吸收进来,它的主要目标是解决Transformer对于长文档NLP应用不够友好的问题。
4.2 Transformer XL
目前在NLP领域中,处理语言建模问题有两种最先进的架构:RNN和Transformer。RNN按照序列顺序逐个学习输入的单词或字符之间的关系,而Transformer则接收一整段序列,然后使用self-attention机制来学习它们之间的依赖关系。这两种架构目前来看都取得了令人瞩目的成就,但它们都局限在捕捉长期依赖性上。
为了解决这一问题,CMU联合Google Brain在2019年1月推出的一篇新论文《Transformer-XL:Attentive Language Models beyond a Fixed-Length Context》同时结合了RNN序列建模和Transformer自注意力机制的优点,在输入数据的每个段上使用Transformer的注意力模块,并使用循环机制来学习连续段之间的依赖关系。
4.2.1 vanilla Transformer
为何要提这个模型?因为Transformer-XL是基于这个模型进行的改进。
Al-Rfou等人基于Transformer提出了一种训练语言模型的方法,来根据之前的字符预测片段中的下一个字符。例如,它使用 𝑥1,𝑥2,…,𝑥𝑛−1x1,x2,…,xn−1 预测字符 𝑥𝑛xn,而在 𝑥𝑛xn 之后的序列则被mask掉。论文中使用64层模型,并仅限于处理 512个字符这种相对较短的输入,因此它将输入分成段,并分别从每个段中进行学习,如下图所示。 在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
该模型在常用的数据集如enwik8和text8上的表现比RNN模型要好,但它仍有以下缺点:
- 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
- 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
- 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
4.2.2 Transformer XL
Transformer-XL架构在vanilla Transformer的基础上引入了两点创新:循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding),以克服vanilla Transformer的缺点。与vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模。
- 引入循环机制
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
- 这两个输入会被拼接,然后用于计算当前段的Key和Value矩阵。
- 该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。在测试阶段,与vanilla Transformer相比,其速度也会更快。在vanilla Transformer中,一次只能前进一个step,并且需要重新构建段,并全部从头开始计算;而在Transformer-XL中,每次可以前进一整个段,并利用之前段的数据来预测当前段的输出。
- 该段的前面隐藏层的输出,与vanilla Transformer相同(上图的灰色线)。
- 前面段的隐藏层的输出(上图的绿色线),可以使模型创建长期依赖关系。
- 相对位置编码
在Transformer中,一个重要的地方在于其考虑了序列的位置信息。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。比如,第i−2i-2i−2段和第i−1i-1i−1段的第一个位置将具有相同的位置编码,但它们对于第iii段的建模重要性显然并不相同(例如第i−2i-2i−2段中的第一个位置重要性可能要低一些)。因此,需要对这种位置进行区分。
论文对于这个问题,提出了一种新的位置编码的方式,即会根据词之间的相对距离而非像Transformer中的绝对位置进行编码。从另一个角度来解读公式的话,可以将attention的计算分为如下四个部分:
详细公式见:Transformer-XL解读(论文 + PyTorch源码)
- 基于内容的“寻址”,即没有添加原始位置编码的原始分数。
- 基于内容的位置偏置,即相对于当前内容的位置偏差。
- 全局的内容偏置,用于衡量key的重要性。
- 全局的位置偏置,根据query和key之间的距离调整重要性。
5. XLNet与BERT比较
尽管看上去,XLNet在预训练机制引入的Permutation Language Model这种新的预训练目标,和Bert采用Mask标记这种方式,有很大不同。其实你深入思考一下,会发现,两者本质是类似的。
区别主要在于:
- Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;
- 而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。
所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已。这样,就可以抛掉表面的[Mask]标记,解决它所说的预训练里带有[Mask]标记导致的和Fine-tuning过程不一致的问题。至于说XLNet说的,Bert里面被Mask掉单词的相互独立问题,也就是说,在预测某个被Mask单词的时候,其它被Mask单词不起作用,这个问题,你深入思考一下,其实是不重要的,因为XLNet在内部Attention Mask的时候,也会Mask掉一定比例的上下文单词,只要有一部分被Mask掉的单词,其实就面临这个问题。而如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被Mask单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
当然,XLNet这种改造,维持了表面看上去的自回归语言模型的从左向右的模式,这个Bert做不到,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。所以看上去,XLNet貌似应该对于生成类型的NLP任务,会比Bert有明显优势。另外,因为XLNet还引入了Transformer XL的机制,所以对于长文档输入类型的NLP任务,也会比Bert有明显优势。
6. 代码实现
2023.5.24 RWKV
【2023-5-24】RWKV论文燃爆!将RNN崛起进行到底!可扩百亿级参数,与Transformer表现相当
RWKV结合了RNN和Transformer的优势:
- 一方面,抛弃传统的点积自注意力,使用线性注意力,解决transformer内存和计算复杂度随序列增长呈平方缩放的瓶颈;
- 另一方面,突破了RNN梯度消失、并行化和可扩展性等限制。
实现 O(Td) 的时间复杂度和 O(d) 的空间复杂度!
问题
- RNN分解为两个线性块(和)和一个特定于RNN块,但对于先前时间步的数据依赖阻止了RNN的并行化。
- RWKV与QRNN和RNN(Vanilla、LSTM、GRU等)的架构对比
RWKV 模型架构
- The Receptance Weighted Key Value (RWKV) 的名字来自于时间混合 (time-mixing) 和通道混合 (channel-mixing) 块中使用的四个主要元素:
R(Receptance) :接受过去信息的接受向量;W(Weight):位置权重衰减向量(可训练的模型参数);K(Key) :键是类似于传统注意力中的向量;V(Value):值是类似于传统注意力中的向量。
每个时间步,主要元素之间通过乘法进行交互。
RWKV 架构由一系列堆叠的残差块组成,每个残差块由具有循环结构的时间混合和通道混合子块组成。
效果
- 与具有相同参数和训练token数量的传统transformer架构(Pythia、OPT、BLOOM、GPT-Neo)相比,RWKV在六个基准测试(Winogrande、PIQA、ARC-C、ARC-E、LAMBADA和SciQ)上均具有竞争力。RWKV甚至在四项任务中超越了Pythia和GPT-Neo.
RWKV-4和ChatGPT / GPT-4的比较研究显示,RWKV-4对提示工程非常敏感。当将指令风格从适合GPT调整为更适合RWKV时,RTE的F1性能甚至从44.2%增加到74.8%。作者猜想是因为RNN不能回溯处理 ( retrospective processing) 来重新调整先前信息的权重。因此为了让性能更好,期望信息应该在问题之后展示。
RWKV与Transformer表现相当,且能在训练时能够并行、在推理时保持恒定的计算和内存复杂度。
但RWKV也存在局限:
- 比起标准Transformer的平方注意力所维护的完整信息,线性注意力和递归架构使信息通过单个向量表示在多个时间步上漏斗式传递,可能限制模型回忆非常长的上下文中细节信息的能力。并且,提示工程变得更加重要。
参考资料
- The Annotated Transformer,Harvard NLP出品,含pytorch版代码实现
- The Illustrated Transformer
- Transformer模型的PyTorch实现,A PyTorch implementation of the Transformer model in “Attention is All You Need”
- 【2021-1-21】The Transformer Family
- 【2023-6-14】李沐出品,动手学深度学习,面向中文读者的能运行、可讨论的深度学习教科书,含 PyTorch、NumPy/MXNet、TensorFlow 和 PaddlePaddle 实现,包含 NLP 预训练章节, Transformer实践
Transformer 可视化
三棕一蓝
【2024-4-2】三蓝一棕出品: 可视化讲解 transformer
3D可视化
【2023-7-28】关于 AI 的深度研究:ChatGPT 正在产生心智吗?,Transformer 原理 3D 可视化
Transformer Explainer
【2024-7-11】Transformer Explainer
参考文章
- 为什么ResNet和DenseNet可以这么深?一文详解残差块为何有助于解决梯度弥散问题
- GRADIENTS, BATCH NORMALIZATION AND LAYER NORMALIZATION
- The Annotated Transformer
- Building the Mighty Transformer for Sequence Tagging in PyTorch : Part I
- Building the Mighty Transformer for Sequence Tagging in PyTorch : Part II
- Attention?Attention!
参考代码
卷积
各类卷积讲解:A Comprehensive Introduction to Different Types of Convolutions in Deep Learning
- 卷积与互相关(信号处理)
- 深度学习中的卷积(单通道/多通道)
- 3D卷积1 x 1卷积卷积运算(Convolution Arithmetic)
- 转置卷积(反卷积,checkerboard artifacts)
- 扩张卷积(空洞卷积)
- 可分离卷积(空间可分离卷积,深度卷积)
- 扁平卷积(Flattened Convolution)
- 分组卷积(Grouped Convolution)
- 随机分组卷积(Shuffled Grouped Convolution)
- 逐点分组卷积(Pointwise Grouped Convolution)
作者:初识CV

空洞卷积 diolation
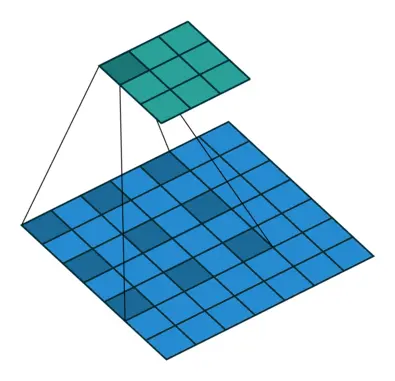
内部卷积 involution

 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
