GPT系列笔记
2019年3月机器学习先驱阿尔伯塔大学教授 Richard S. Sutton(强化学习) 著名的文章《苦涩的教训》的开篇的一段话,其中一句是
“70 年的人工智能研究史告诉我们,利用计算能力的一般方法最终是最有效的方法。”
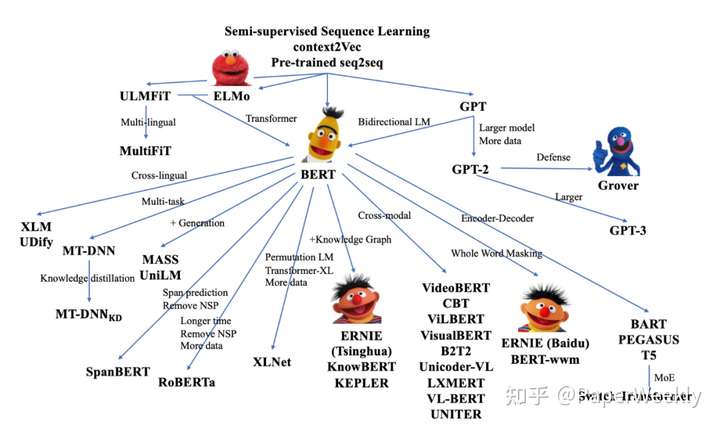
GPT系列
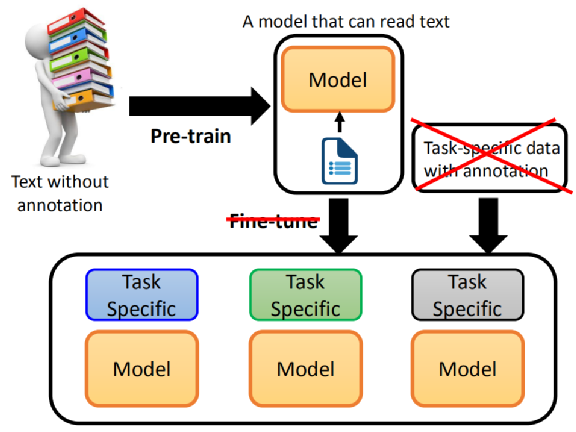
预训练语言模型
从数学或机器学习角度看,语言模型是对词语序列的概率相关性分布的建模,即利用已经说过的语句(语句可以视为数学中的向量)作为输入条件,预测下一个时刻不同语句甚至语言集合出现的概率分布。
更新版:
一个理想的语言模型,应该具备以下性质:
- 具备强大的自主学习、消化知识的能力,其学习过程不需要人为介入。
- 充分理解人类指令,习惯人类的表达方式。
- 能够正确、清晰的给出回答。
可以说,ChatGPT在这三个方面的综合水平上,相比前辈们,取得了突破性的成就。
GPT 诞生之初
parameter base;自回归模型,使用 transformer 模块(一个 Casual Masked 的 MHA 加上 FFN 层);使用预训练 + 微调结构,微调通常使用全连接层处理最后一个位置的隐状态。
用 BERT + pre-train model 时,先 pre-train model,接下来,为每个任务准备相关的语料,根据任务专业资料进行 fine-tune,会有每一个任务的 model。
- 如果用 BERT 解决任务,还是要收集一些语料的,BERT 没办法直接去解这些任务,包括 QA 任务、NLI 任务。
BERT大火后,pre-train + fine-tune(预训练 + 微调) 成为NLP界的主流范式
GPT 系列的目标:能不能拿掉 fine-tune 这个步骤?
- pre-train 一个模型,直接解决 downstream task,连 fine-tune 都不需要。
比如,英文能力考试时,考生如何答题?只需要给一个题型说明。
- 选择最适合题意的字或词,然后多给一个解题范例。
- 考生只看了题型说明和范例,就知道怎么解题了。
这就是 GPT 系列想要做的,实现方法有三个:
- Few-shot Learning:任务说明(example )部分提供不止一个 example,学习后回答问题
- 注意:GPT-3 中的 Few-shot Learning 不同于一般的 Few-shot Learning
- 一般的Few-shot Learning:给机器少量的训练资料,用少量的训练资料去 fine-tune model
- GPT-3 中Few-shot Learning没有 fine-tune,直接作 GPT model 的输入,没有调整模型 —— 这种学习方式叫 “In-context Learning”, 即 ICL
- One-shot Learning:任务说明,一个example,学习后回答问题 —— 非常接近人类英文能力考试
- Zero-shot Learning:只提供任务说明,无example,学习后回答问题
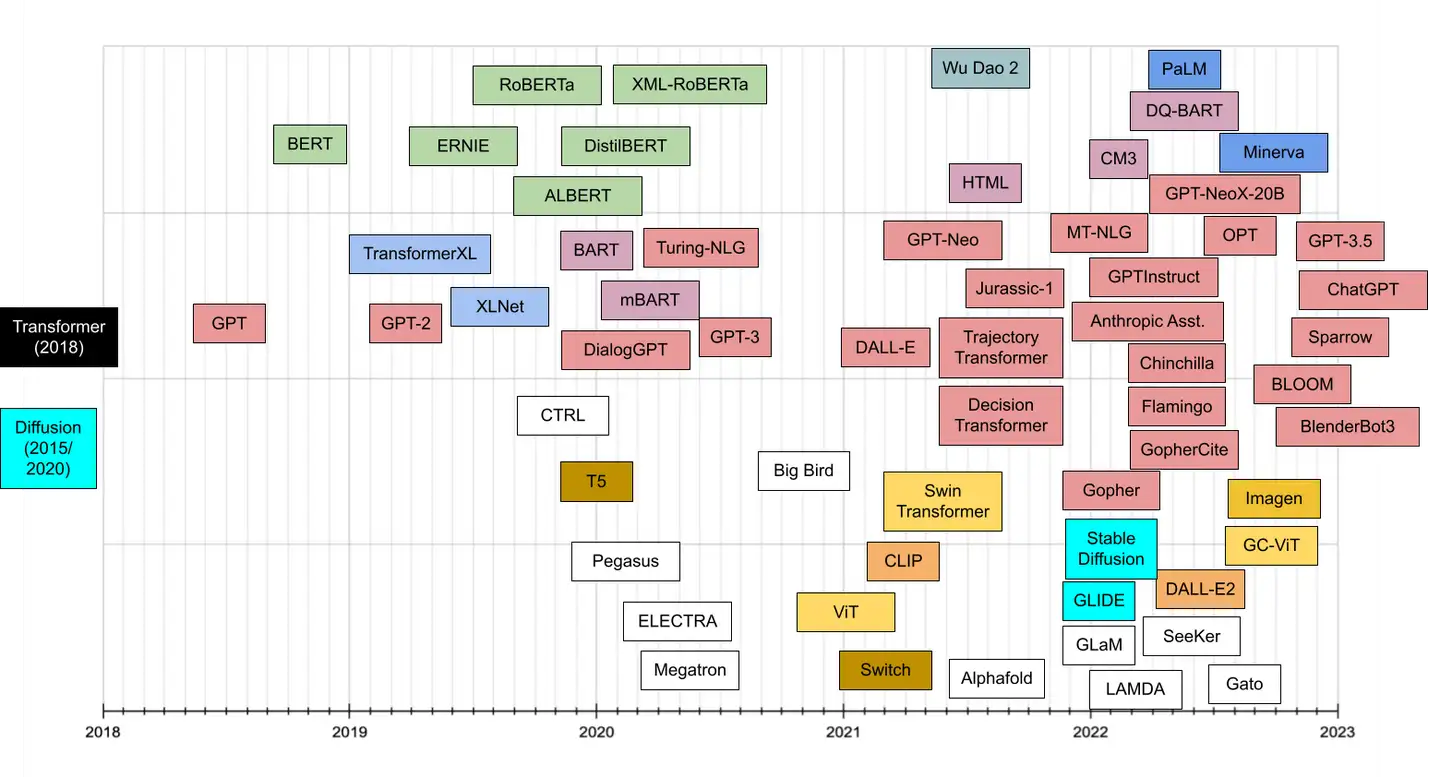
GPT 发展历史
GPT系列进化时间线
迭代路线:GPT → GPT-2 → GPT-3
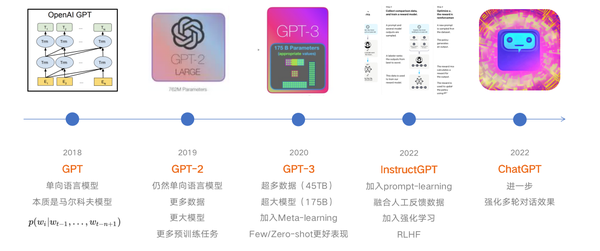
- GPT:只有简单的单向语言模型任务
- GPT-2:使用更多的数据,更大的模型,又新增了几个辅助的训练任务
- GPT-3:使用 45TB 超大规模数据,175B 超大参数量模型。
- 加入了Meta-learning的训练任务,提高了Few/Zero-shot(即少样本/无样本)任务上的表现
- InstructGPT:
- 加入了近两年流行的 prompt-learning。
- 更重要的是,加入了强化学习,即 RLHF(Reinforcement Learning from Human Feedback),基于人工反馈机制的强化学习
- ChatGPT:目前没有开源代码或论文参考,从网上的推测来看,应该是在InstructGPT的基础上,进一步优化了多轮对话效果
作者:王岳王院长
GPT家族对比分析
- GPT家族与BERT模型都是知名的NLP模型,都基于Transformer技术。GPT-1只有12个Transformer层,而到了GPT-3,则增加到96层。
【2023-2-12】
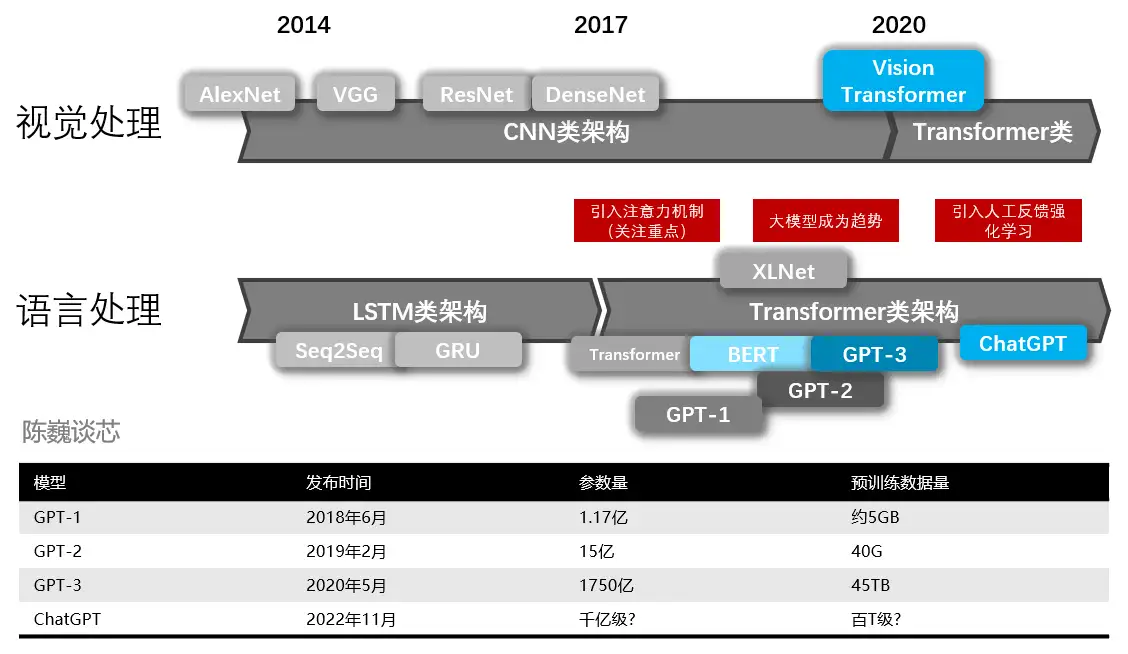
GPT从开始至今,其发展历程如下:
- 2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。 论文地址
- 2018年6月, OpenAI 发布论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练提升语言理解能力),首次提出
GPT模型(Generative Pre-Training)。论文地址- OpenAI的研究人员使用了一种新颖的组合,将生成式深度学习架构Transformer和无监督预训练(也称为自监督学习)结合起来,得到了GPT模型。
- Transformer的
自注意力机制提供了一种通用的方式来对输入的各个部分进行建模,使其依赖于输入的其他部分(需要大量计算)。 - Transformer和
无监督预训练的组合不限于GPT系列模型。Google,Facebook和许多大学实验室相继提出了BERT、XLNet等语言模型。
- 2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者),提出
GPT-2模型。论文地址- OpenAI改进了其基础架构,将参数和数据量增加10倍来扩展同一模型,即 GPT-2
- OpenAI随后推出了
SparseTransformer,它是对早期Transformer模型的改进,可以可靠地处理更长的文档。
- 2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者,提出
GPT-3模型。论文地址- OpenAI通过其 beta API发布了GPT-3,引起了人们的关注。GPT-3不仅扩大了GPT-2上使用的数据量和计算量,而且用
SparseTransformer取代了原始Transformer,从而产生了迄今为止具有最佳zero-shot 和 few-shot学习性能的模型。 - GPT-3的few-shot学习能力具备了一些非常有趣的演示功能,包括自动代码生成、“搜索引擎”、写作辅助和创意小说等。
- OpenAI通过其 beta API发布了GPT-3,引起了人们的关注。GPT-3不仅扩大了GPT-2上使用的数据量和计算量,而且用
- 2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布
Instruction GPT模型。论文地址- Instruction GPT是基于
GPT-3的一轮增强优化,所以也被称为GPT-3.5。 GPT-3主张few-shot少样本学习,同时坚持无监督学习。但few-shot的效果,显然是差于fine-tuning监督微调的方式的。那怎么办?走回fine-tuning监督微调?显然不是。- OpenAI给出新的答案: 在GPT-3的基础上,基于人工反馈(RLHF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。
- Instruction GPT是基于
-
2022年11月30日,OpenAI推出
ChatGPT模型,并提供试用,全网火爆。 - 【2020-8-10】京东副总裁何晓冬:GPT-3后,人机对话与交互何去何从?CCF-GAIR 2020

GPT系列:
- 2018年6月
GPT-1:大量数据(约5GB文本)上无监督训练,然后针对具体任务在小的有监督数据集上做微调;关键词:“scalable, task-agnostic system”;8个GPU上训练一个月;预训练模型(1.1亿参数)可下载; - 2019年2月
GPT-2:大量数据(约40GB文本)上无监督训练,然后针对具体任务在小的有监督数据集上做微调,尝试在一些任务上不微调(即使结果离SOTA还远);关键词“without task-specific training”;据说在256个Google Cloud TPU v3上训练,256刀每小时,训练时长未知[2];预训练模型(15亿参数)最终公开可下载;OpenAI model - 2020年5月
GPT-3:大量数据(499B tokens)上无监督训练,不微调就超越SOTA;关键词“zero-shot, one-shot, few-shot”;训练据说话费1200万刀;1750亿参数,将会开放付费API

【202-7-14】人工智能GPT3
2019 年初,OpenAI 发布了通用语言模型 GPT-2,能够生成连贯的文本段落,在许多语言建模基准上取得了 SOTA 性能。这一基于 Transformer 的大型语言模型共包含 15 亿参数、在一个 800 万网页数据集上训练而成。GPT-2 是对 GPT 模型的直接扩展,在超出 10 倍的数据量上进行训练,参数量也多出了 10 倍。
OpenAI在最近, 新提出的 GPT-3 在网络媒体上引起啦的热议。因为它的参数量要比 2 月份刚刚推出的、全球最大深度学习模型 Turing NLP 大上十倍,而且不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。
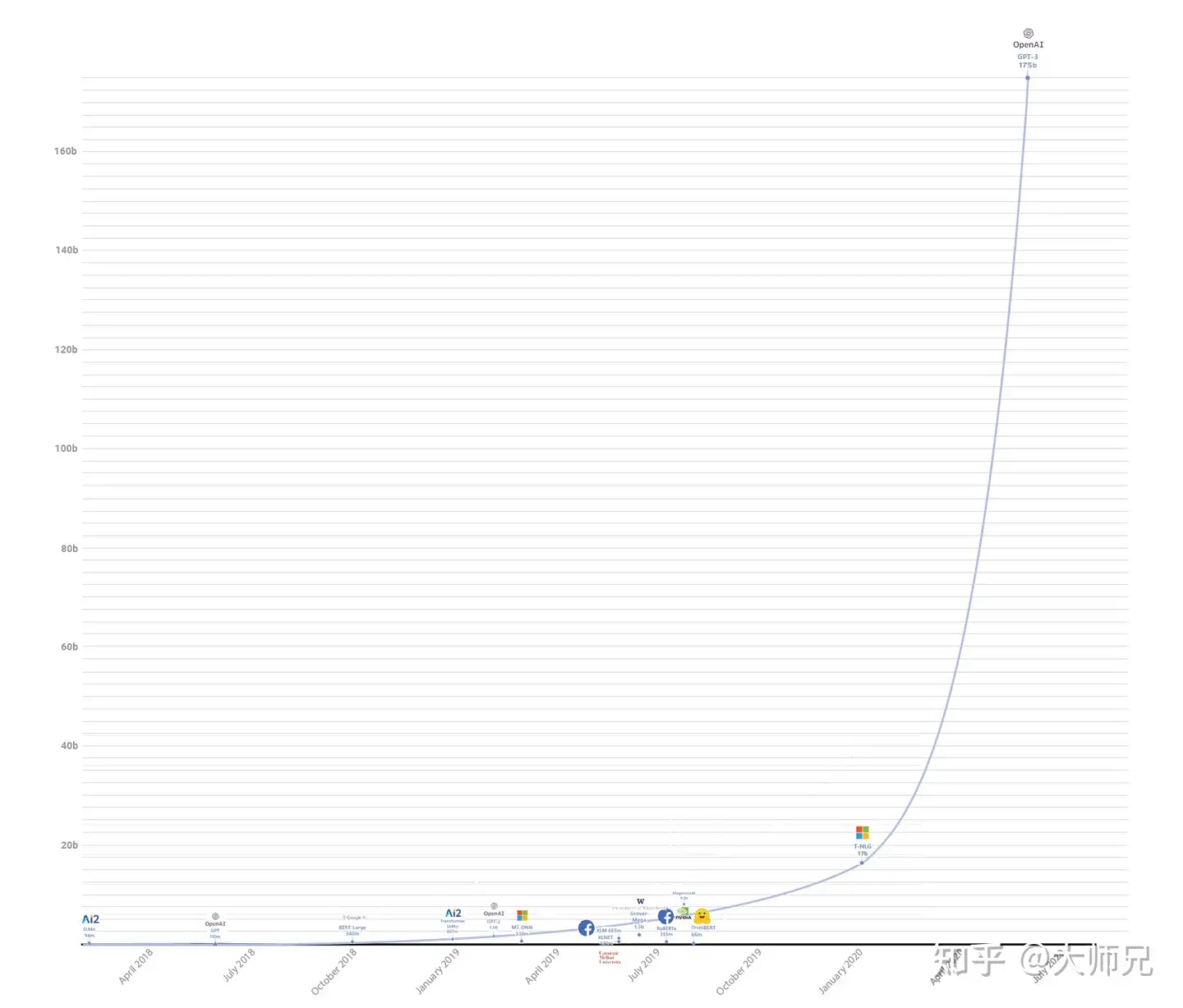
- NLP各种语言模型参数对比
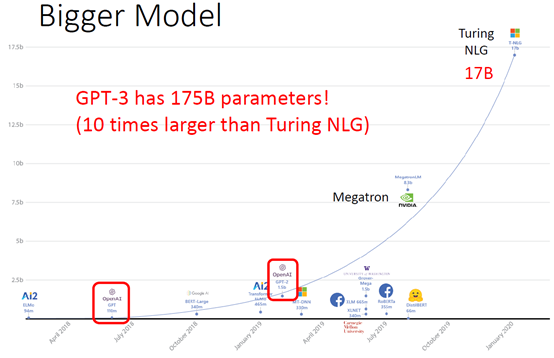
- 最早的ELMO模型有94M,然后2018年7月GPT出世,模型参数有110M,接着BERT-Large有340M;后来GPT-2出世已经把参数弄到1.5b了;再后来随着Turing NLG的出现直接将参数提升到17b,成为当时最大的模型;最后GPT-3出现了,直接将参数增加到175b,参数量基本上是第二名Turing NLG的十倍。参考:数据拾光者
GPT-2(参数15 亿)、Megatron-BERT(80 亿参数)、Turing NLG(170 亿参数),而GPT-3直接1700亿个参数。GPT-3不需要fine-tune,就能具有非常好的效果
GPT-3 在许多 NLP 数据集上均具有出色的性能,包括翻译、问答和文本填空任务,这还包括一些需要即时推理或领域适应的任务,例如给一句话中的单词替换成同义词,或执行 3 位数的数学运算。新闻生成,GPT-3生成的新闻我们很难将机器写的和人类写的区分。
GPT-3 是一种具有1,750亿个参数的自然语言深度学习模型,足足是 GPT-2 的 116倍 。该模型经过了将近0.5万亿个单词的预训练,并且在不进行微调的情况下,可以在多个NLP基准上达到最先进的性能。
GPT-3 最令人惊讶的还是模型体量,它用的最大数据集在处理前容量达到了 45TB。根据 OpenAI 的算力统计单位 petaflops/s-days,训练 AlphaGoZero 需要 1800-2000pfs-day,而 OpenAI 刚刚提出的 GPT-3 用了 3640pfs-day。
- Google的T5论文的一页实验烧了几百万美元,当时看起来已经是壕无人性了,但背靠MS的OpenAI的GPT-3需要的GPU算力是BERT的近2000倍,训练成本保守估计一千万美元,以至于训练出了一个bug也无能无力,论文只能拿出一部分篇幅研究了这个bug会有多大影响
- 当下入坑DL建议:穷搞理论,富搞预训练。
- 31个作者,72页论文,320万token(一个batch),1700亿参数,暴力出奇迹,few-shot干翻SOTA,finetune都省了(当然也tune不动),有钱真好。
- 计算量(flops)是BERT的两千多倍,训练一个BERT 1.2万美元, GPT-3训练下来大约花了1200万刀。难怪出了bug也不敢retrain,地主家也没余粮了。
- 参考:Jsgfery
研究者们希望 GPT-3 能够成为更通用化的 NLP 模型,解决当前 BERT 等模型的两个不足之处:对领域内有标记数据的过分依赖,以及对于领域数据分布的过拟合。GPT-3 致力于能够使用更少的特定领域,不做 fine-tuning 解决问题。
GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
- 对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
- 对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。GPT-3一定程度上证明了大力真的可以出奇迹,无需fine-tuning就能在下游任务中“大显神威”。
预训练好的GPT-3探索了不同输入形式下的推理效果:
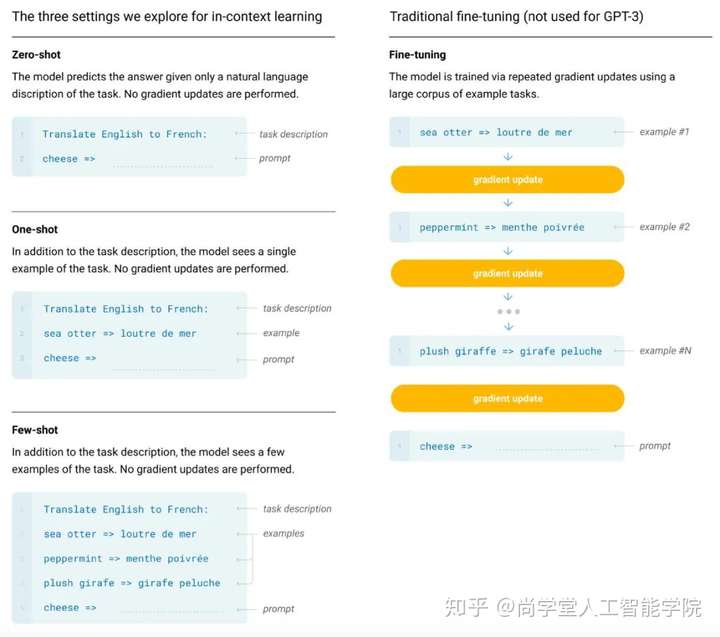
- Zero-shot、One-shot、Few-shot都是完全不需要精调的,因为GPT-3是单向transformer,在预测新的token时会对之前的examples进行编码。
- 实验证明Few-shot下GPT-3有很好的表现: 量变引起的质变
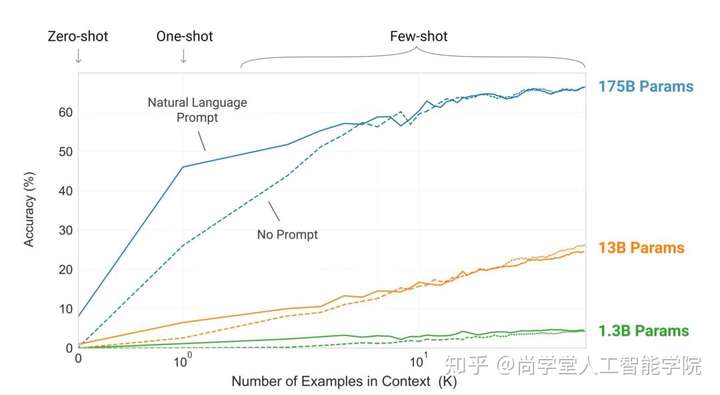
传入文本作为输入,GPT输出,模型在训练期间扫描大量文本“学到”的东西产生的,3000亿个文本token的数据集用于生成模型的训练样本,训练是将模型暴露于大量文本的过程。现在看到的所有实验都来自该受过训练的模型。据估计,这需要花费355年的GPU时间,花费460万美元
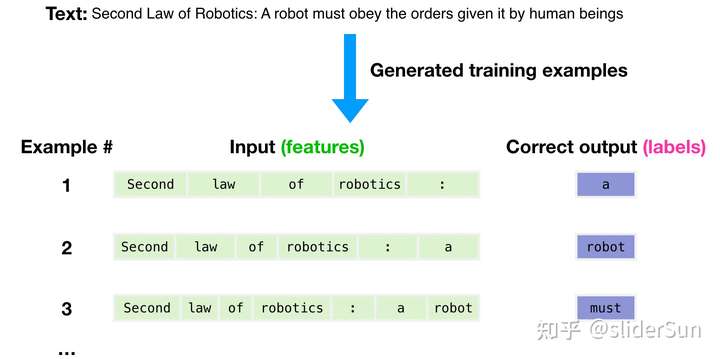
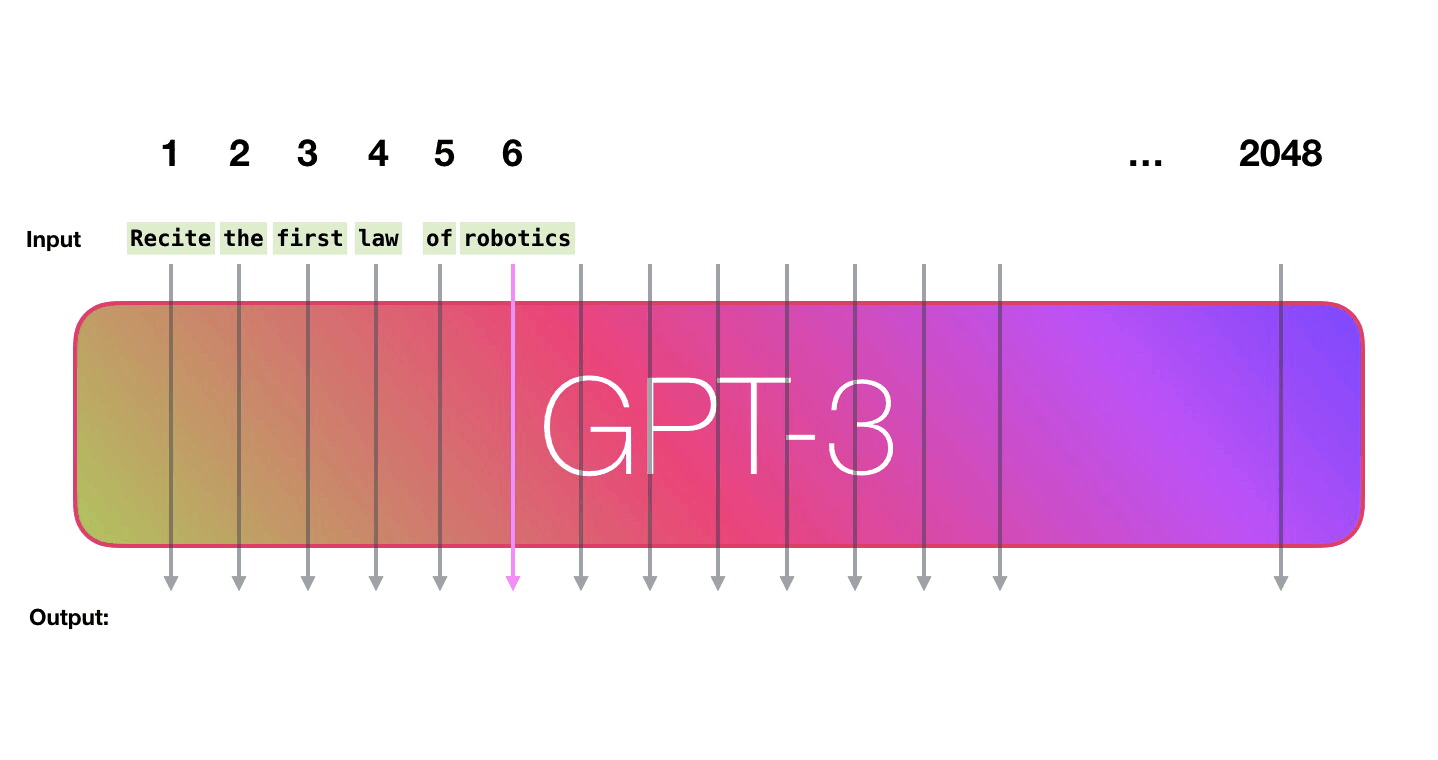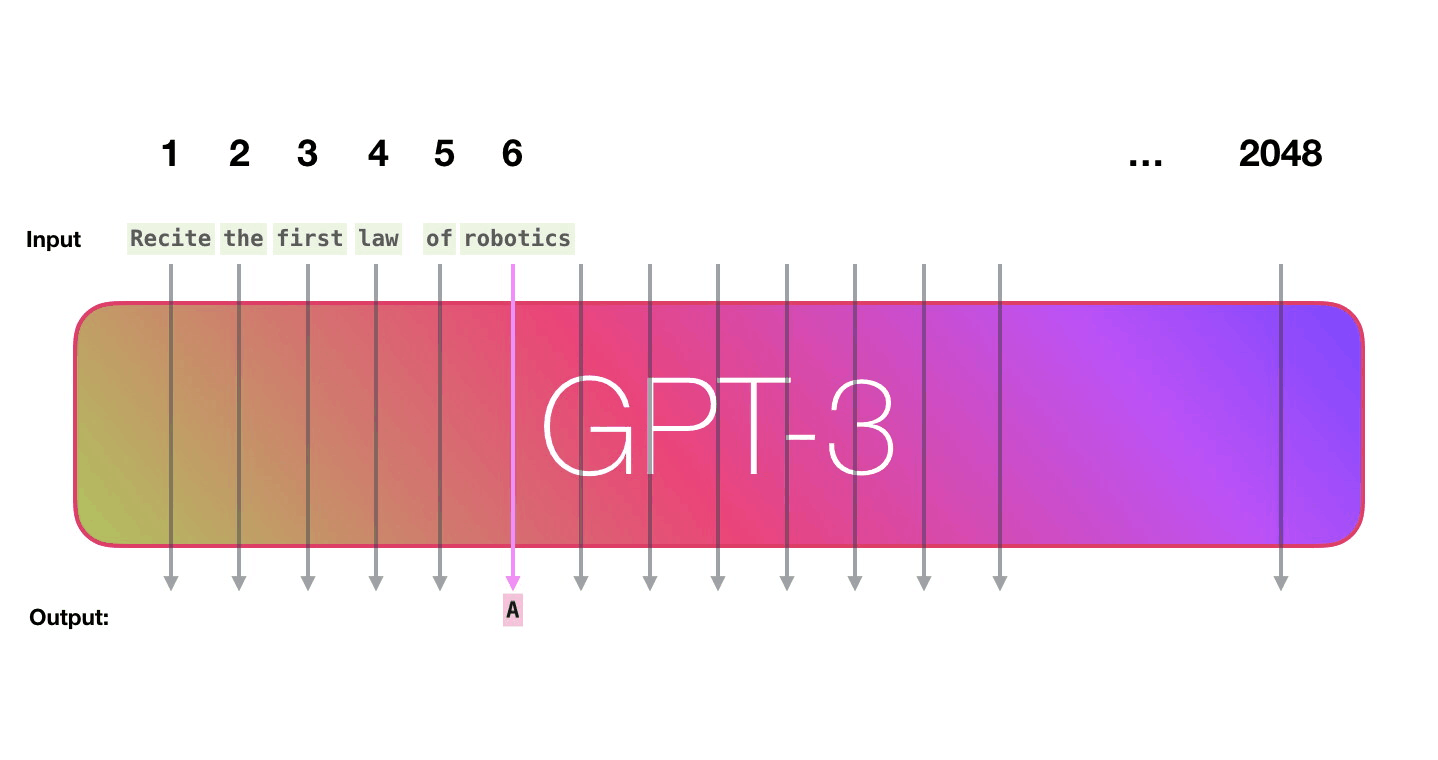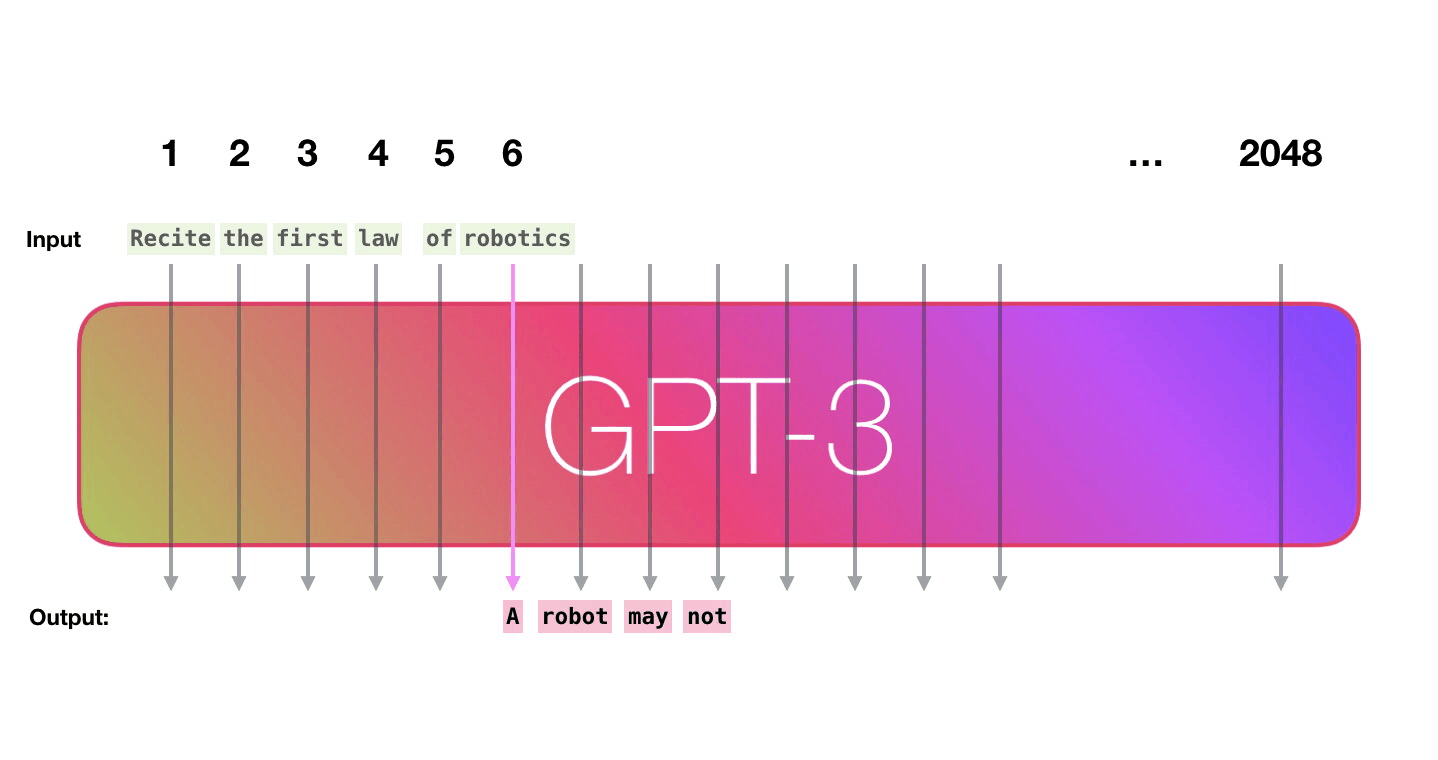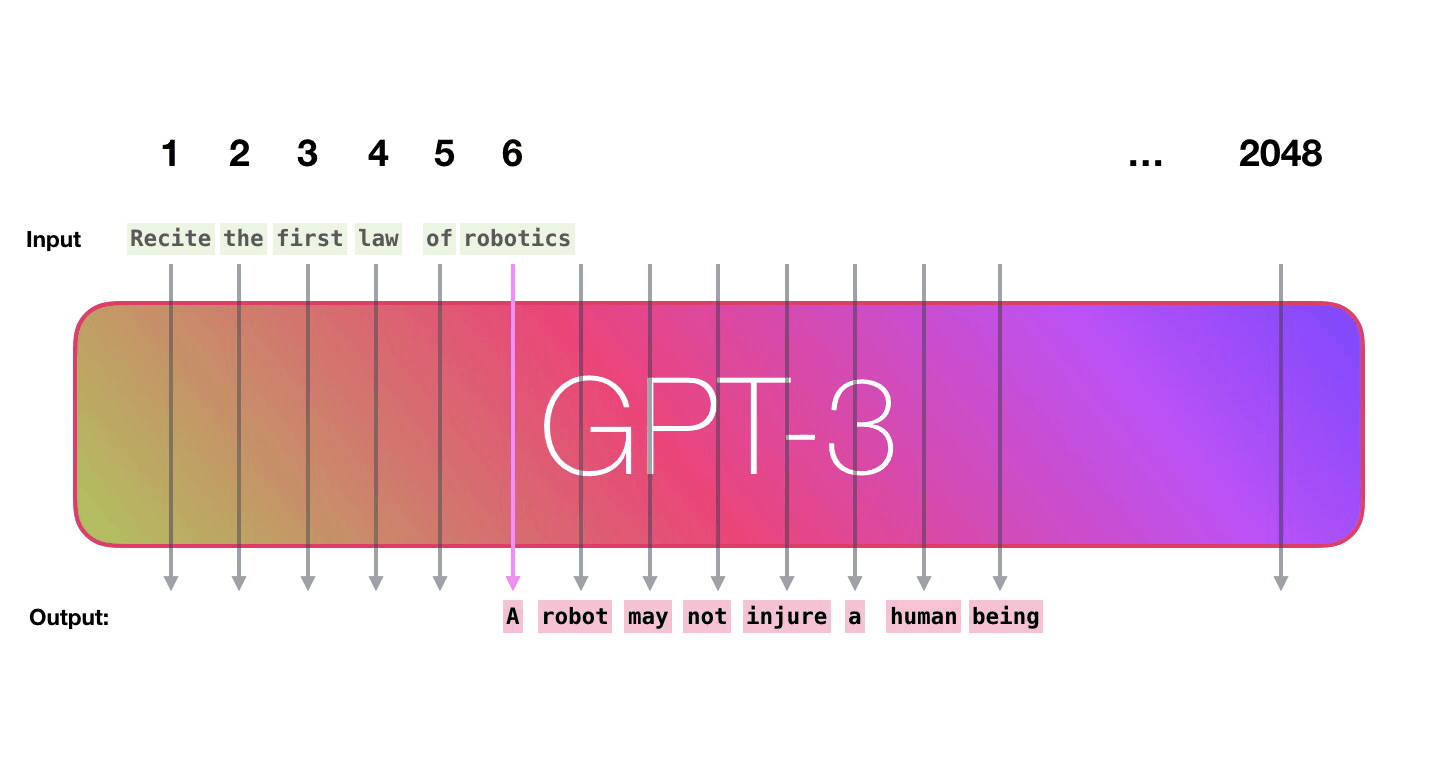
GPT3为2048个token。这就是它的“上下文窗口”。这意味着它有2048条轨道,沿着这些轨道处理token。
NLP可以说是实现AGI的最大难题,NLP的突破需要一个效果很好且通用的模型,GPT-3依凭借巨大的参数与算力已经极力接近这样的性质,在许多任务上(如翻译、QA和文本填空任务)拥有出色的性能甚至取得了SOTA。然而,GPT-3还是存在一些局限,论文作者给出了未来有前景的方向:建立GPT-3尺度的双向模型。使双向模型能在少样本、零样本学习上工作。
其它评论:
- GPT-3参数量再大,还是没有逃过任何一个普通两层全连接神经网络的缺点:
- 灾难性遗忘
- 独立同分布假设
- 1700亿参数的堆叠就会是智能的本质吗?大一点的猴子,但还是猴子,不是人。只是在量变并没有质变。
- 人工智能该到了谈信仰的时候了,上一次这样争论的内容是联结主义和符号主义。Judea Pearl的结构因果模型才是真正可以称得上智能的东西。GPT-3呢?仍然处于 Association 阶段,只是在寻找数据之间的相关性,并没有从因果的角度显式地给出文本之间可解释的内在逻辑。它做不到训练集分布外的延拓,做不到因果推断,更何谈智能。总而言之,GPT-3更像是深度学习在现有算力下的一次巅峰验证,只是一个顺应时代的产物,但绝不是我们对智能最终的解决方案。
- GPT-3不具备人类的感知思维,它的生成表现只是大数据训练的结果,无法超越数据本身,也无法拥有人类自成长型的广泛组合性推理的能力,所以,我们不如说它学会的是“统计层面的复制粘贴能力”。知乎
GPT 对比
总结如下:
| 时间 | 机构 | 模型名称 | 范式 | 模型规模 | 数据规模 | 计算时间 | 备注 |
|---|---|---|---|---|---|---|---|
| 2018.6 | OpenAI | GPT-1 |
两阶段 | 110M | 4GB | 3天 | 两阶段:无监督预训练+有监督微调 无监督预训练:序列生成 有监督微调:NLI推理、QA问答、语义相似度 12层的Transformer decoder |
| 2019.2 | OpenAI | GPT-2 |
? | 1.5B | 40GB | 200天 | 多任务学习:用无监督预训练做有监督任务 任何有监督任务都是语言模型的一个子集 |
| 2020.5 | OpenAl | GPT-3 |
prompt | 175B(1750亿) | 45TB | 355年 | 小样本学习:96层transformer,无需fine-tune |
| 2022.11 | OpenAl | ChatGPT |
千亿级别? | 百TB | 355年 | ||
| 2023 | OpenAI | GPT-4 |
? | ~1000B | ? | ? | |
| 2018.10 | BERT | 两阶段 | 330M | 16GB | 50天 | ||
| 2019.7 | RoBERTa | 两阶段 | 330M | 160GB | 3年 | ||
| 2019.10 | T5 | ? | 11B | 800GB | 66年 |
【2023-6-12】 三代模型架构图 参考
【2024-9-15】GPT 系列演进两种路线 weibo
- (1) Scaling 规模扩大:
GPT-3->GPT-4->GPT-5 - (2) Optimization 优化:
GPT-3->GPT-3.5->GPT-3.5-TurboGPT-4->GPT-4 Turbo->GPT-4o->GPT-40-Mini
GPT 可视化
【2023-12-4】 GPT 3D 可视化及动态演示: bbycroft, 支持 Nano-GPT,GPT-2和GPT-3,可交互
【2024-3-8】GPT代码讲解+图解,包含 transformer、bert、gpt
资料
- 听李宏毅点评GPT-3:来自猎人暗黑大陆的模型
- 【2023-2-8】 Andrej Kaparthy, twiiter 讲解GPT, Let’s build GPT: from scratch, in code, spelled out.
paper系列
- ChatGPT: Optimizing Language Models for Dialogue ChatGPT: Optimizing Language Models for Dialogue
- GPT论文:Language Models are Few-Shot Learners Language Models are Few-Shot Learners
- InstructGPT论文: Training language models to follow instructions with human feedback Training language models to follow instructions with human feedback
- huggingface解读RHLF算法:Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
- RHLF算法论文:Augmenting Reinforcement Learning with Human Feedback https://www.cs.utexas.edu/~ai-lab/pubs/ICML_IL11-knox.pdf
- TAMER框架论文:Interactively Shaping Agents via Human Reinforcement https://www.cs.utexas.edu/~bradknox/papers/kcap09-knox.pdf
- PPO算法: Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
GPT-1
GPT 效果非常惊艳,在12个任务里,9个达到了最佳,有些任务性能提升非常明显。
初代 GPT 有哪些贡献?
- 第一,最早一批提出 pre-train + fine-tuning 范式。
- 第二,GPT 实验证明了模型的精度和泛化能力会随着解码器层数增加而不断提升,而且还有提升空间
- 第三,预训练模型具有 zero-shot 能力,并且能随着预训练的进行不断增强
第二和第三点,也直接预示着后续 GPT-2 和 GPT-3 的出现。
GPT-1 模型结构
GPT(“Generative Pre-Training”)也叫生成式预训练模型
- 论文: Improving Language Understanding by Generative Pre-Training
- 通用预训练模型来提升语言理解能力(Generative Pre-Training 即 “生成式预训练”)
- 超强但不秀:NLP中极有价值的工作,比BERT出现的早,但是名声却远远不如BERT。
两个问题:
- 什么是通用?在学习通用、迁移性文本特征表达时,什么目标函数有效?
- 有通用特征表达之后,如何将迁移到不同下游任务?
GPT 使用了预训练 + 微调方式解决这两个问题。
GPT是典型的预训练+微调的两阶段模型。
- 预训练阶段就是用海量的文本数据通过无监督学习的方式来获取语言学知识
- 微调就是用下游任务的训练数据来获得特定任务的模型。
GPT预训练模型结构两个要点:
- 使用 Transformer 的 decoder 部分 作为特征抽取器
- 使用单向的语言模型。
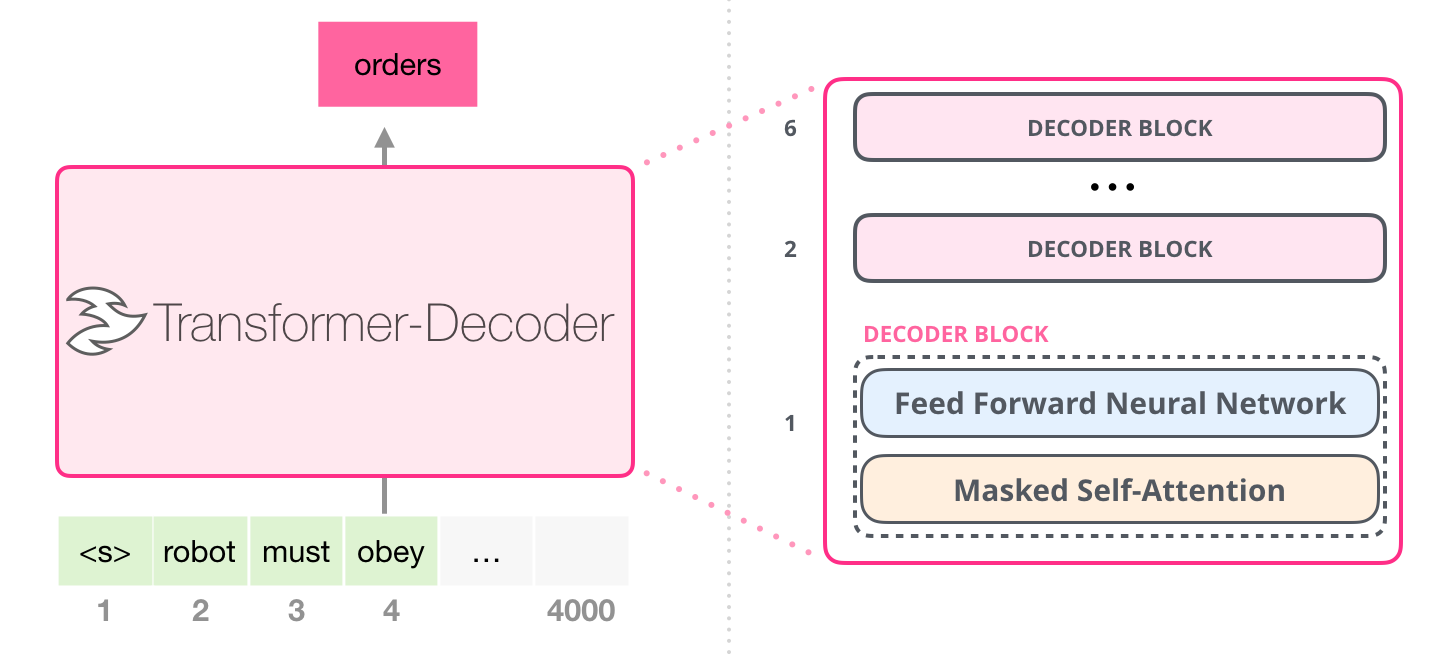
GPT-1 使用 12个 transformer Decoder 块的结构作为解码器,每个transformer块是一个多头自注意力机制,然后通过全连接得到输出的概率分布。
- 原始GPT网络结构
- 常见文本生成
- 并非所有英雄都穿 -> 斗篷
- GPT生成
- 并非所有英雄都披着斗篷 -> 但
- 并非所有英雄都披着斗篷 ,但-> 全部
- 并非所有英雄都披着斗篷,但全部 -> 恶棍
- 并非所有英雄都披着斗篷,但全部恶棍 -> 做
说明
- 输入序列固定在2048个字(对于GPT-3)以内。将短序列作为输入时,只需用“空”值填充。
- GPT输出不仅是一次预测(概率),而是一系列预测(长度2048)(每个可能单词的概率)。序列中每个“next”位置都是一个预测。但是在生成文 时,通常只查看序列中最后一个单词的预测。
- 为了提高效率,GPT-3实际上使用字节级(byte-level)字节对编码(BPE)进行Token化。
- 对当前Token在序列中的位置进行编码,将Token的位置(标量i,在[0-2047]中)传递给12288个正弦函数,每个函数的频率都不同
两阶段训练
GPT 模型主要包含两个阶段
- 预训练模型(无监督),利用大量未标注语料预训练一个语言模型
- fine-tuning(有监督),对预训练好的语言模型进行微调,将其迁移到各种有监督的NLP任务,并对参数进行fine-tuning。
给定一个没有标注的大语料,记每一个序列为 u = u1, u2, u3, …, un,GPT 通过最大化以下似然函数来训练语言模型:
- $ L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) $
- k 表示上下文窗口(滑动窗口)的大小,计算每个单词的预测概率时,只考虑左侧窗口大小的词汇信息(单向Transformer)
- P 是条件概率
- θ 是模型参数
- 优化算法:SGD
- GPT-1 基于一个12层的Transformer decoder作为语言模型结构,并将decoder的中间那层线性变换删除,每个transformer块是一个多头自注意力机制,然后通过全连接得到输出的概率分布。
- 使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。
(1)无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有 40000 个字节对;
- 词编码的长度为 768
- 位置编码也需要学习;
- 12层的transformer,每个transformer块有 12个头;
- 位置编码的长度是 3072
- Attention, 残差,Dropout等机制用来进行正则化,drop比例为 0.1
- 激活函数为GLEU;
- 训练的batchsize为 64,学习率为 $2.5e^{-4}$ ,序列长度为 512,序列epoch为 100 ;
- 模型参数数量为 1.17亿。
(2)有监督微调
- 无监督部分的模型也会用来微调;
- 训练的epoch为 3,学习率为 $6.25e{-4}$ ,这表明模型在无监督部分学到了大量有用的特征。
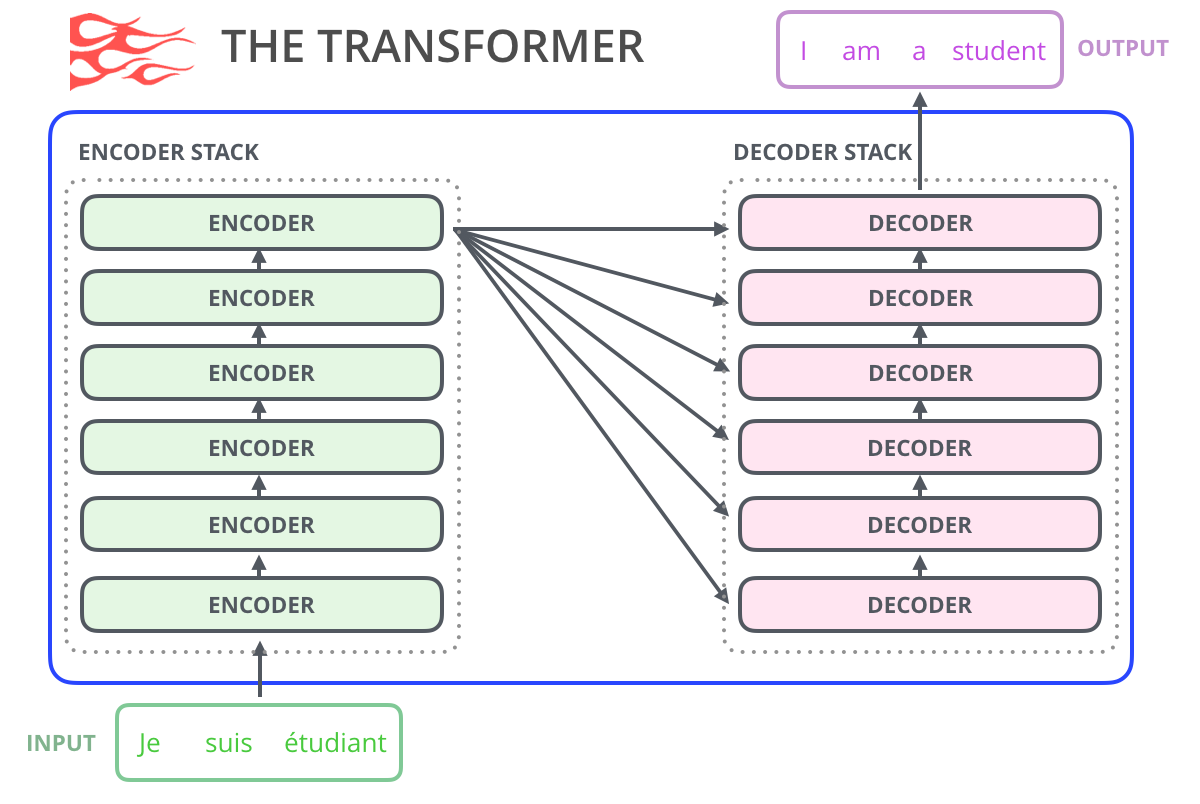
GPT-1 与 Tansformer
Transformer 结构
针对 transformer 改进的模型
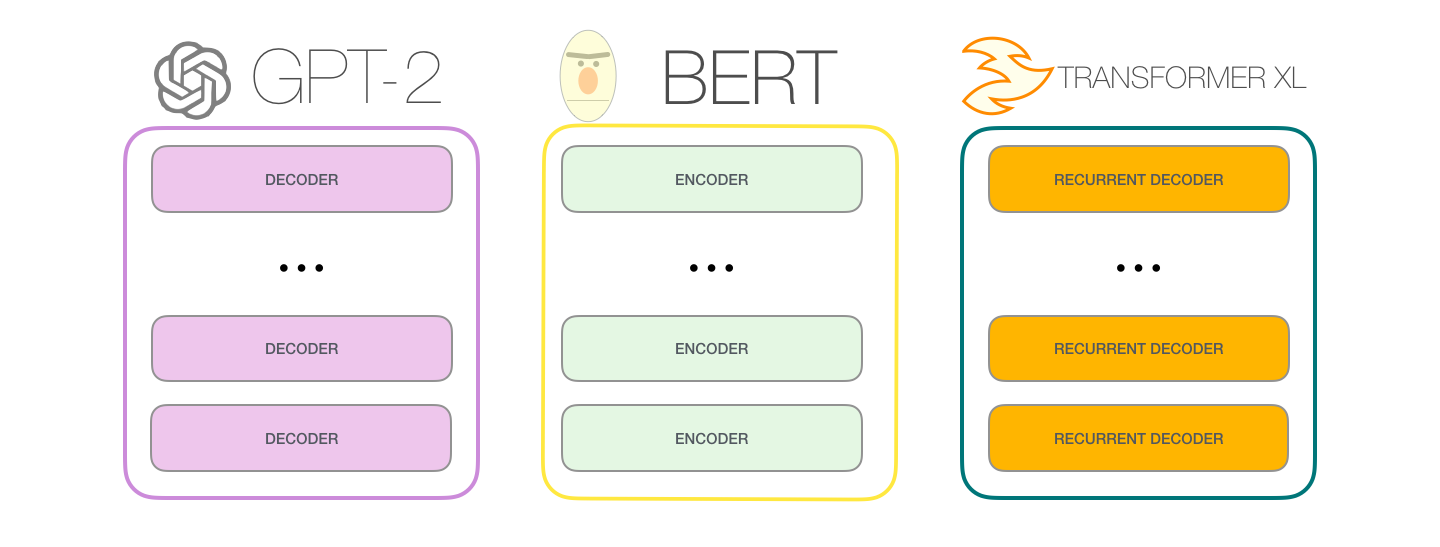
GPT-2:只用 DecoderBERT:只用 EncoderTransformer-XL:循环解码器 Recurrent Decoder
GPT 对 position embedding 矩阵进行随机初始化,让模型自己学习,而不是采用正弦余弦函数进行计算。(原Transformer用三角函数)
- GPT-1 保留 Decoder 的 Masked Multi-Attention 层和 Feed Forward 层,并扩大了网络的规模。将层数扩展到12层,GPT-1 还将Attention 的维数扩大到768(原来为512),将 Attention 的头数增加到12层(原来为8层),将 Feed Forward 层的隐层维数增加到3072(原来为2048),总参数达到1.5亿。
- Position Encoding : Transformer 中,由于 Self-Attention 无法捕获文本位置信息,因此需要对输入的词 Embedding 加入Position Encoding
- 在 Transformer 中采用了 sin 和 cos 的计算方法,而在 GPT-1 中,不再使用正弦和余弦的位置编码,而是采用与词向量相似的随机初始化,并在训练中进行更新。
GPT 如何适配下游任务
有监督任务包括
自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;分类(Classification):判断输入文本是指定的哪个类别。
将无监督学习作为有监督模型的预训练目标,因此叫通用预训练(Generative Pre-training,GPT)。
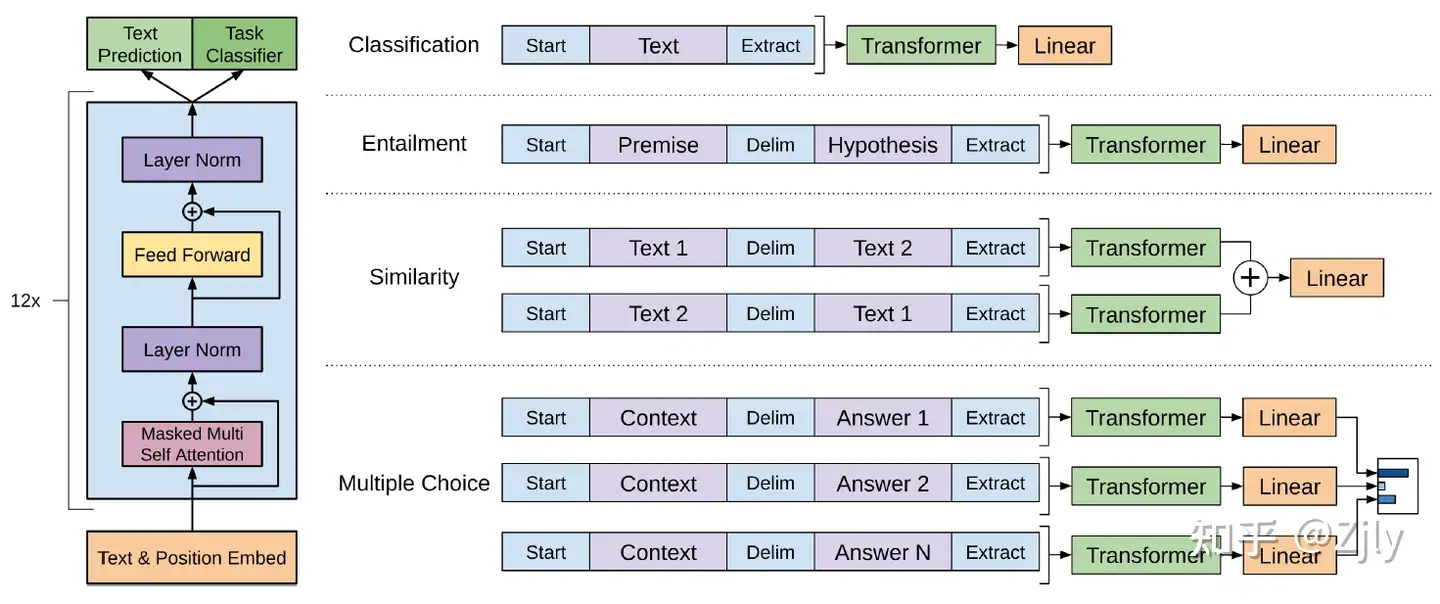
简单改造,GPT就能很好适应不同的任务。只需要在输入部分调整一下就可以了,非常方便。img
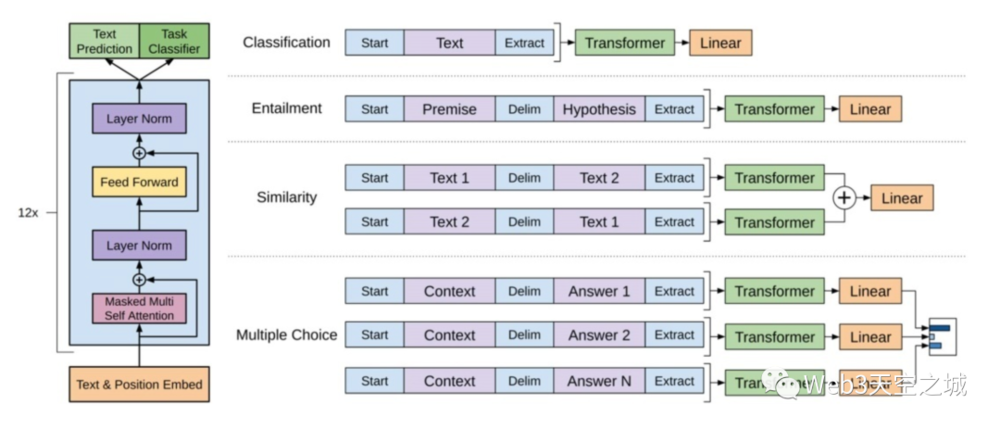
GPT 如何改造下游任务?

改造施工:OpenAI ChatGPT(二):十分钟读懂 GPT-1
分类问题,不用怎么动,只需要在输入序列前后分别加上开始(Start)和结束(Extract)标记;句子关系问题,比如Entailment,除了开始和结束标记,在两个句子中间还需要加上分隔符(Delim)文本相似性判断问题,把两个句子顺序颠倒下, 两个输入即可,这是为了告诉模型句子顺序不重要;- 与句子关系判断任务相似,不同的是需要生成两个文本表示 $h_l^m$

多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。- 文本相似任务的扩展,两个文本扩展为多个文本。



任务微调主要是:
- 增加线性层参数
- 增加起始符、结束符和分隔符三种特殊符号的向量参数
这种改造还是很方便的,不同任务只需要在输入部分施工即可。
总结
- GPT其实跟ELMO非常相似,只是把语言模型直接迁移到具体的NLP任务中,因此,更容易进行迁移学习。
- 不过GPT主要还是针对文本分类和标注任务,如果对于生成任务,比如机器翻译等,则其结构也没法进行很好的迁移。
GPT 损失函数
GPT 训练
GPT 训练过程分为两个部分
- 无监督预训练语言模型
- 有监督下游任务 fine-tuning。
- 任务: 分类、文本蕴含、相似度检测、QA与常识推理(多选)
GPT 使用标准的语言模型目标函数来最大化下面的似然函数:
- 一段文本:
{u1, u2, ..., un} - GPT 训练目标: 基于 前面的
Ui-k~Ui-1,根据模型 $\Theta$ 预测 Ui 的概率, - k 是上文窗口的大小,k越大,上文信息越多,模型能力越强
模型对输入 U 进行特征嵌入得到 transformer 第一层的输入 h0,再经过多层 transformer 特征编码,使用最后一层的输出即可得到当前预测的概率分布, 解读
\[\begin{array}{l} h_{0}=U W_{e}+W_{p} \\ h_{l}=\text { transformer_block }\left(h_{l-1}\right) \\ P(u)=\operatorname{softmax}\left(h_{n} W_{e}^{T}\right) \end{array}\]其中,Wc 为词嵌入矩阵,Wp 为位置嵌入矩阵,hl 为第 l 层 transformer 的输出,hn 为最后一层 transformer 的输出,n 为模型层数。
在微调阶段,在有特定下游任务标签的情况下,给定输入序列 x1 到 xm,预测 y 的概率,即将序列输入到预训练好的模型中,得到最后一层 transformer 的最后一个 token $x^m$ 的特征 $h^m_l$ ,再经过预测层就可以得到对应标签的概率分布:
- $P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right)$
微调阶段损失函数
- $L_{1}(U)=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right)$
- $L_{2}(U)=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right)$
GPT 损失函数
- 预训练阶段: 负对数最大似然
- 微调阶段: 预训练部分的loss与微调部分的loss的带权和 $L = L_finetune + \lambda L_pretrain $
- 训练样本: 单词序列
[x1, x2, ..., xm]和 类标y - 训练目标: 根据单词序列
[x1, x2, ..., xm]预测类标y - 微调的loss也是负对数最大似然
- 组合的目的: 降低finetune阶段的灾难性遗忘, 保留一定通用性
- 训练样本: 单词序列
- 参考
损失函数
- 最终目标函数:将两个目标函数联合,训练得到的效果最好
- $L_{3}(U)=L_{2}(U)+\lambda * L_{1}(U) = \sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right) + \sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right)$
数据集
GPT-1使用了BooksCorpus数据集,这个数据集包含 本没有发布的书籍。作者选这个数据集的原因有二:
- 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;
- 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
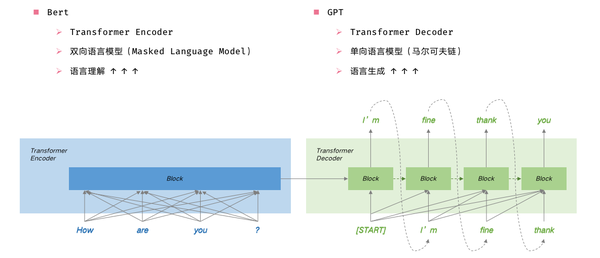
GPT vs BERT
GPT与BERT关系
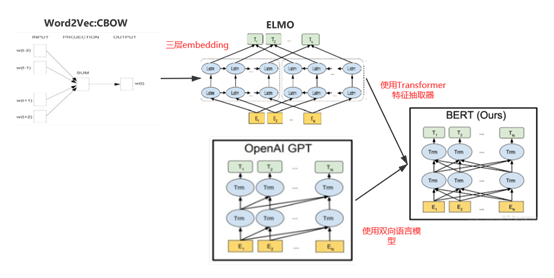
GPT 和 BERT 有什么区别呢?
- 从基础任务上:
- GPT是给前几个词,预测下一个词,单向语言模型;
- 而BERT给定周围几个词,预测中间被挖空的词(即Masked Language Model),算双向语言模型
- 从应用上:
- 因为是单向语言模型,从前到后逐个预测,GPT比较适合用于自然语言生成的任务;
- 而BERT在自然语言理解的任务上,表现更好
- 从网络结构上:两者本质都是基于Transformer,没什么区别。
- Transformer 结构提出时用于机器翻译,一个序列到序列任务,因此 Transformer 设计了
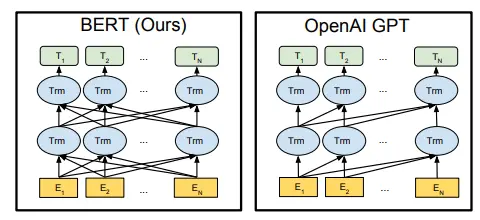
Encoder用于提取源端语言的语义特征,而用Decoder提取目标端语言的语义特征,并生成相对应的译文。 - 放在seq2seq结构里,BERT相当于只关注Encoder部分,而GPT只关注Decoder部分(下图中只以单层Transformer举例,实际上两个模型都是很多层Transformer堆叠而成)
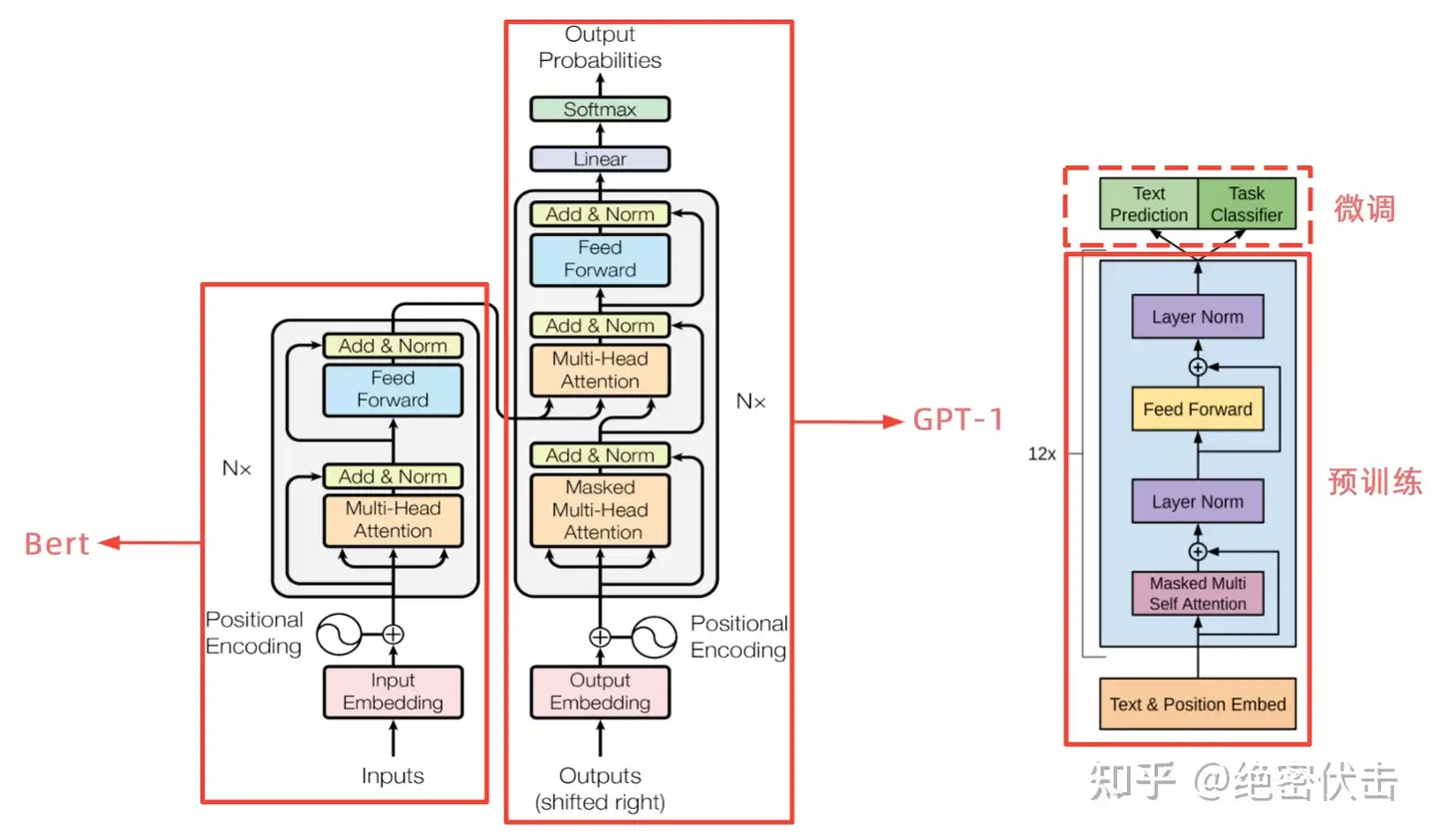
GPT-1只使用了 Transformer 的 Decoder 结构,而且只是用了Mask Multi-Head Attention, 没用Multi-Head Attention。- GPT-1 目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder 部分以及包括 Decoder 的
Encoder-Dcoder Attention层(也就是 Decoder中 的 Multi-Head Atteion)。
- Transformer 结构提出时用于机器翻译,一个序列到序列任务,因此 Transformer 设计了
作者:王岳王院长
BERT采用不经过Mask的Transformer,也就是与Transformer文章中的Encoder Transformer结构完全一样:
- GPT中因为要完成语言模型的训练,也就要求Pre-Training预测下一个词的时候只能够看见当前以及之前的词,这也是GPT放弃原本Transformer的双向结构转而采用单向结构的原因。
- BERT为了能够同时得到上下文的信息,而不是像GPT一样完全放弃下文信息,采用了双向Transformer。但是这样一来,就无法再像GPT一样采用正常的语言模型来预训练了,因为BERT的结构导致每个Transformer的输出都可以看见整个句子的,无论你用这个输出去预测什么,都会“看见”参考答案,也就是“see itself”的问题。ELMo中虽然采用的是双向RNN,但是两个RNN之间是独立的,所以可以避免see itself的问题。
- 参考:Transformer结构及其应用详解–GPT、BERT、MT-DNN、GPT-2
【2023-2-27】Google与OpenAI的LLM之争
GPT-1 效果
GPT-1的性能
- 有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。
- 在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。
- GPT-1证明了
transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
GPT-2
【2021-10-21】图解GPT-2完整版,英文原文
GPT-2 介绍
GPT-2学习目标:使用无监督的预训练模型做有监督任务。
GPT-2的核心思想概括为:
- 任何有监督任务都是语言模型的一个子集,当模型容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
-
当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
- 官方介绍: Better Language Models and Their Implications
-
We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks, and performs rudimentary reading comprehension, machine translation, question answering, and summarization—all without task-specific training.
- 架构上,GPT-2 与只含解码器的Transformer相似。不过,GPT-2 是体型更大,数据集更大。
- GPT-2 基本上就是键盘应用程序中预测下一个词的功能,但 GPT-2 比你手机上的键盘 app 更大更复杂。
- GPT-2 在一个 40 GB 的 WebText 数据集上训练,OpenAI 的研究人员从互联网上爬取了这个数据集,作为研究工作的一部分。
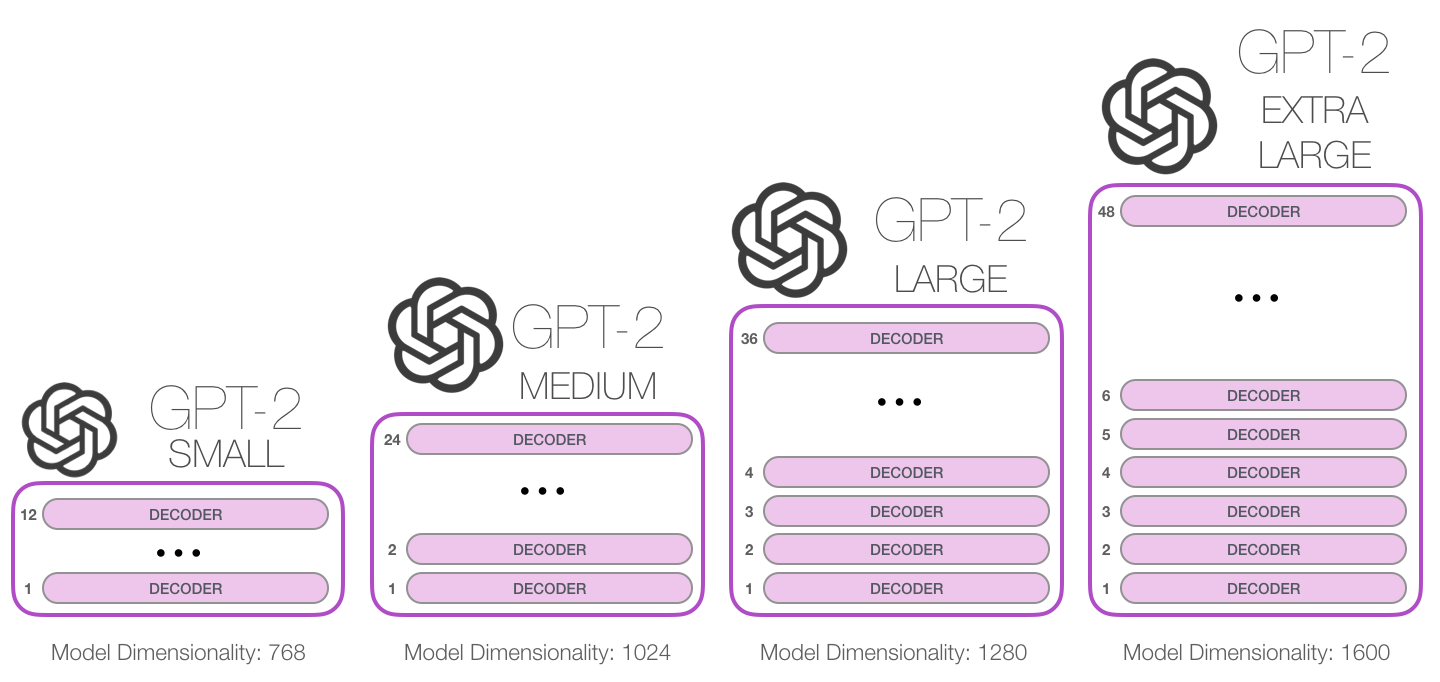
- 从存储空间上看
- 键盘应用程序 SwiftKey,只占用了 78 MB 的空间。
- 最小的 GPT-2 变种,需要 500 MB 的空间来存储所有参数。
- 最大的 GPT-2 模型变种是其大小的 13 倍,因此占用的空间可能超过 6.5 GB。

不同 GPT-2 模型大小对比
- GPT-2体验:AllenAI GPT-2 Explorer。它使用 GPT-2 来显示下一个单词的 10 种预测(包括每种预测的分数)。你可以选择一个单词,然后就能看到下一个单词的预测列表,从而生成一篇文章。
GPT-2总结
- 最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移能力,不需要额外训练。
- 但是很多实验也表明,GPT-2的无监督学习能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是仍不清楚GPT-2的这种策略究竟能做成什么样子。
- GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
GPT 2 模型
自回归语言模型
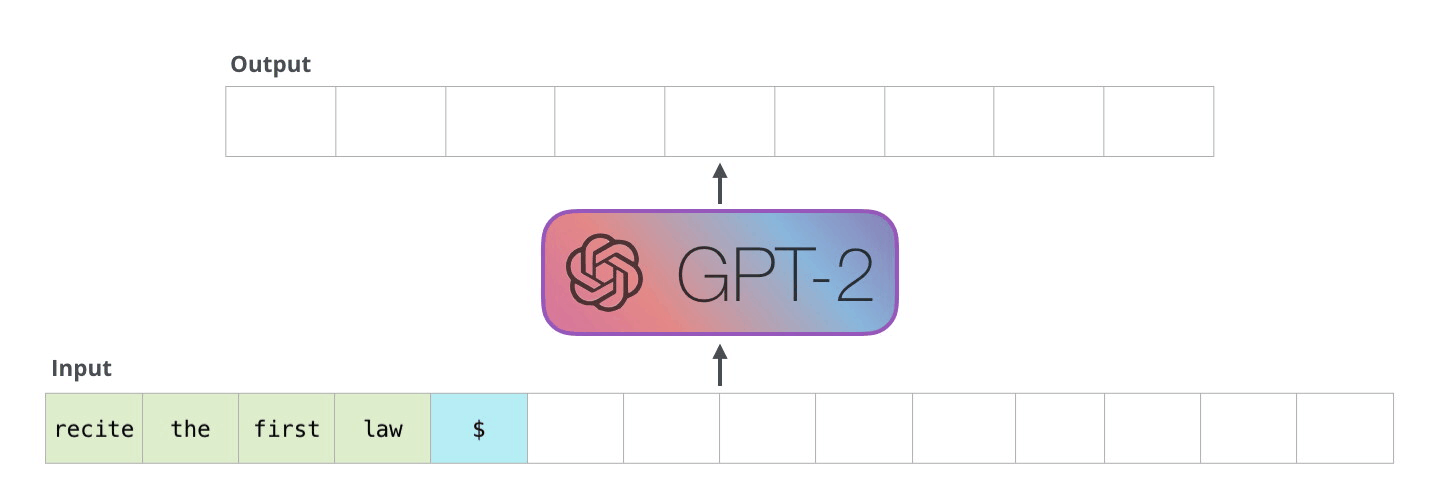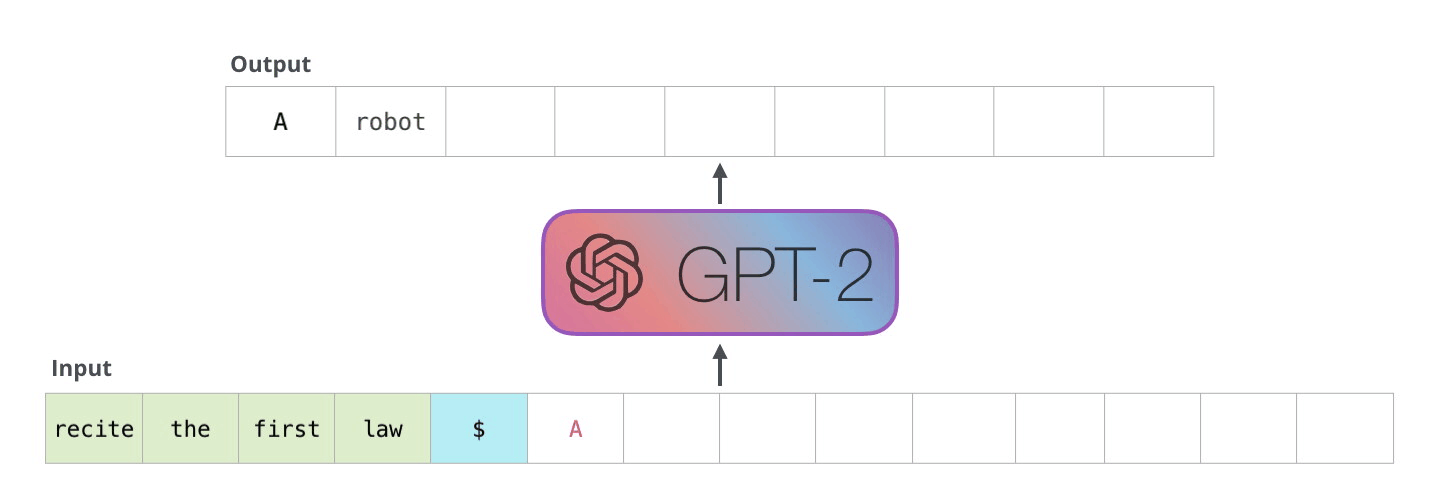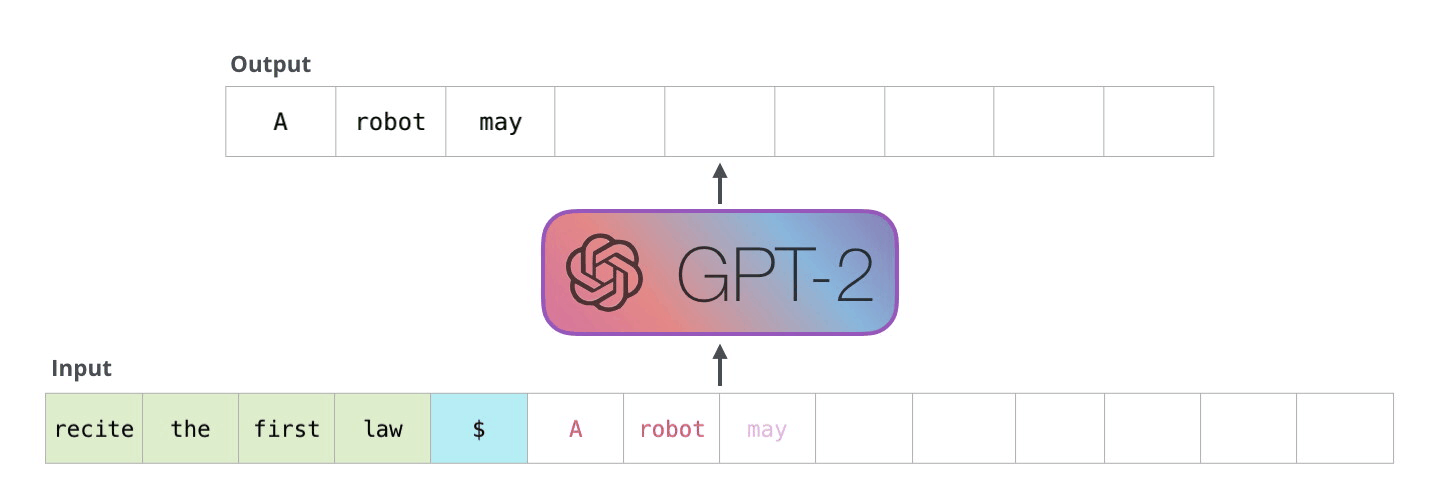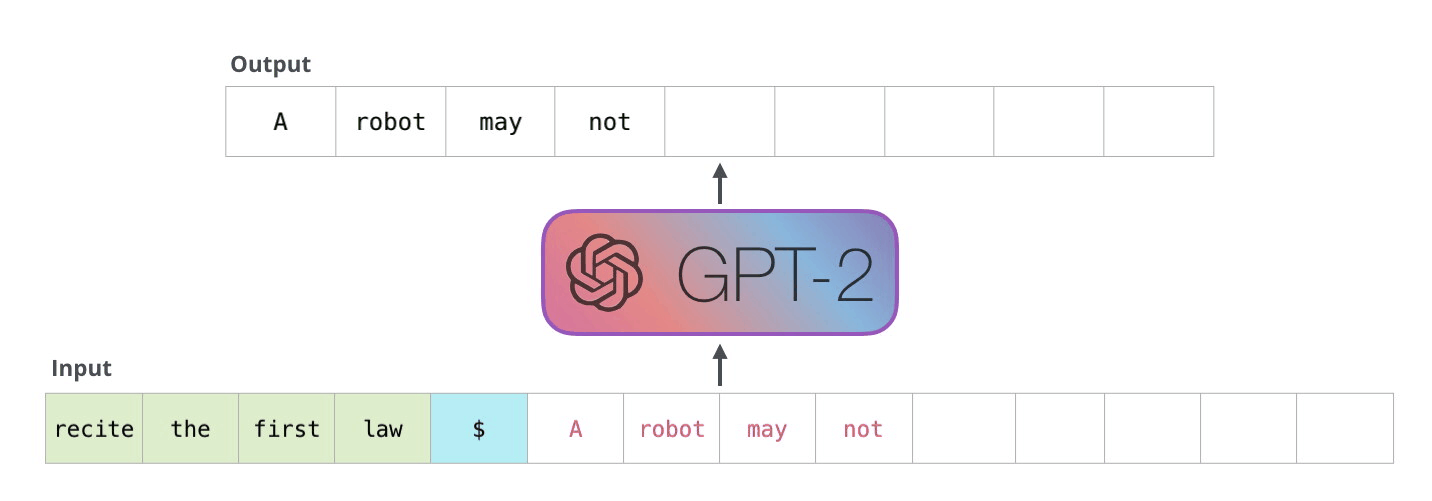
模型结构
BERT是使用Transformer的Encoder模块构建,而GPT-2用Transformer的Decoder模块构建。- 一个重要差异是,GPT-2 和传统的语言模型一样,一次输出一个 token
- GPT-2和后来的一些模型如 TransformerXL 和 XLNet,本质上都是自回归模型。但 BERT 不是自回归模型。这是权衡。
- 去掉了自回归后,BERT 能够整合左右两边的上下文,从而获得更好的结果。
- XLNet 重新使用了 自回归,同时也找到一种方法能够结合两边的上下文。
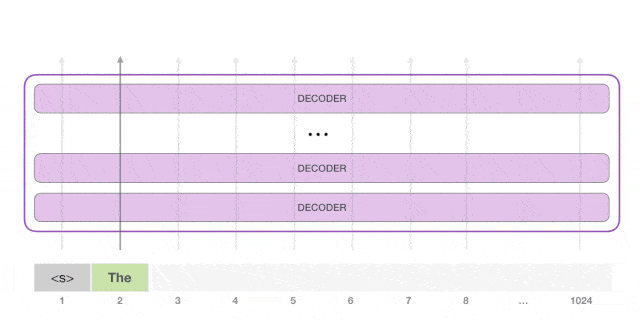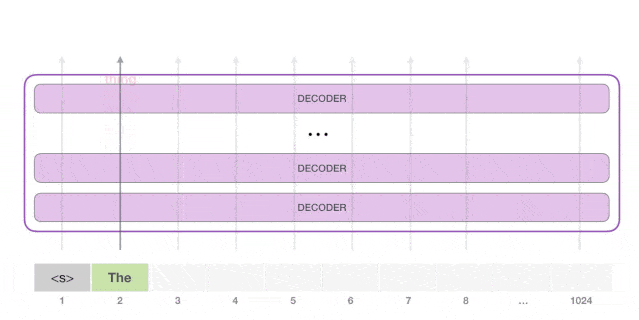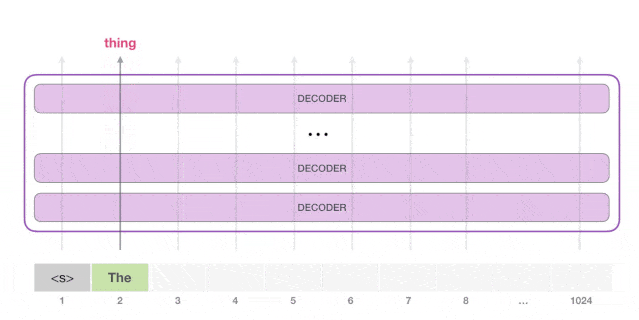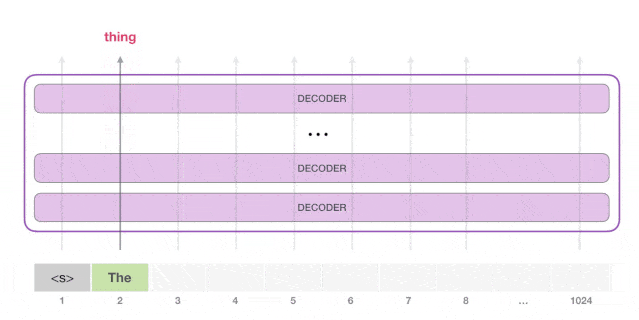
GPT-2 用的 Decoder 结构
- 去掉 transformer decoder结构里的
编码器-解码器自注意力层
GPT-2 改进点
GPT-2 跟 GPT-1 的区别:
- 去掉了微调层:GPT-2不再对不同下游任务微调,模型会自动识别出来需要做什么任务–多任务学习,证明了GPT-2拥有更强的泛化能力。
- 数据集增加:GPT-2 数据集包含了大小为40g的800万个网页。数据是经过过滤后高质量文本。
- 参数增加:GPT-2将transformer的层数增加到了48层,hidden layer的维度增加到了1600,这样参数量就到达了15亿(5倍于BERT的参数量)。
- GPT-2将词汇表数量增加到50257个;
- 最大的上下文大小从GPT-1的512提升到了1024 tokens;
- batch-size增加到512.
- 对transformer的调整:将layer normalization放到了每个sub-block前,同时在最后一个self-attention之后增加了一个layer-normalzation,论文中没有仔细讲这样改动的原因,不过可以看出来这并不是对网络结构的很大的创新。
具体为以下几点:
- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为 1 ;
- 输入序列的最大长度从 512 扩充到 1024;
关于 post-norm 和 pre-norm 可以参考《Learning Deep Transformer Models for Machine Translation》。
- 两者主要区别在于,post-norm 将 transformer 中每一个 block 的层归一化放在了残差层之后,而 pre-norm 将层归一化放在了每个 block 的输入位置
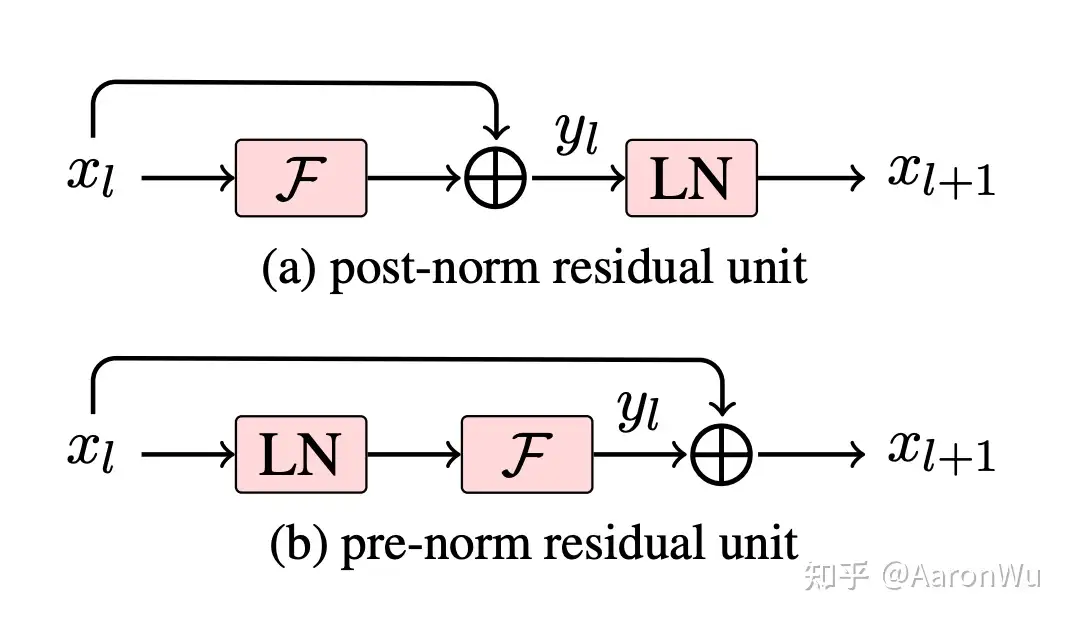
GPT-2 相比于 GPT-1 有如下几点区别:
- 主推
zero-shot,而 GPT-1 为pre-train + fine-tuning; - 训练数据规模更大,GPT-2 为 800w 文档 40G,GPT-1 为 5GB;
- 模型大小,GPT-2 最大 15 亿参数,GPT-1为 1 亿参数;
- 模型结构调整,层归一化和参数初始化方式;
- 训练参数,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024,等等;
调整原因
- 随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够减少预训练过程中各层之间的方差变化,使梯度更加稳定。
GPT-2 提供了四种规模的模型:

- 117M 参数等价于 GPT-1 模型,345M 参数模型用于对标同期的 BERT-large 模型
为什么移除 fine-tune?
理论上,GPT-3也是支持fine-tuning,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
移除fine-tune 必要性:
- 每一个新任务都需要大量的标记数据不利于语言模型的应用的。
- 提升模型表征能力的同时,降低数据分布复杂度是不合理的。比如,大模型并不能在样本外推预测时具有好效果,这说明fine-tune导致模型的泛化性降低了。
- 人类在接触一个下游语言任务时不需要大量样本,只需要一句对新任务的描述或者几个案例。人类这种无缝融合和切换多个任务的能力是当前自然语言技术所欠缺的。
模型移除fine-tune有2个解决方案:
meta-learning(元学习) :模型在训练阶段具备了一系列模式识别的能力和方法,并在预测过程中快速适应一个下游任务。最近的一些研究尝试通过称为in-context learning(上下文学习,ICL) 的方法来实现上述过程,然而效果距离期待的相差甚远。- Large scale transformers(大规模transformer):Transformer语言模型参数的每次增大都会让文本理解能力和其他的NLP下游任务的性能得到提升。
- 此外,有研究指出描述许多下游任务性能的log损失能让模型的性能和参数之间服从一个平滑趋势。考虑到in-context learning会将学习到的知识和方法存在模型的参数中,本文假设:模型的情境学习能力也会随着参数规模的增长而增长。
模型参数
模型参数
- 通用使用字节对编码构建字典,字典的大小扩大:50257
- 滑动窗口大小:1024 (上下文扩大)
- batch-size:512(增加)
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization
- 将残差层初始化值用 $ \frac{1}{\sqrt(N)} $ 进行缩放,其中N是残差层的个数
GPT-2训练了4组不同的层数和词向量的长度的模型
| 参数量 | 层数 | 词向量长度 |
|---|---|---|
| 117M(GPT-1) | 12 | 768 |
| 345M | 124 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
随着模型的增大,模型效果不断提升。模型仍欠拟合,后续还会加大数据量,做大做强。
总结而言,GPT-2在GPT-1的基础上创新不大,只不过规模要大很多,所以效果也好很多。
为什么GPT-2能够适应多任务?
训练时采用了多任务方式,不单单只在一个任务上进行学习,而是多个,每一个任务都要保证其损失函数能收敛,不同任务是共享主题Transformer参数的,进一步提升模型的泛化能力,因此在即使没有fine-tuning的情况下,依旧有非常不错的表现。
在fine-tuning有监督任务阶段,GPT-2根据给定输入与任务来做出相应的输出
- $ p(output\∣input,task) $
- 直接输入:(“自然语言处理”, 中文翻译) 得到结果 (“Nature Language Processing”)
- 因此模型可以将
机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而不误再为每一个子任务单独设计一个模型。
GPT-2 数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。
- 数据集共有约800万篇文章,累计体积约40G。
- 为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
GPT-2 性能
GPT-2的性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
GPT-2 源码
详见站内专题:GPT-2源码解读
GPT3
虽然 GPT-2 主推的 zero-shot 在创新度上有比较高的水平,但是由于其在效果上表现平平,所以在业界并没有取得比较大的影响力,而 GPT-3 正是为了解决效果上的问题而提出的
- GPT-3 不再去追求那种极致的不需要任何样本就可以表现很好的模型,而是考虑像人类的学习方式那样,仅仅使用极少数样本就可以掌握某一个任务,因此就引出了 GPT-3 标题 Language Models are Few-Shot Learners。
GPT-3 证明了对于所有任务,GPT-3无需进行任何梯度更新或微调,仅通过与模型的文本交互指定任务和少量示例(few-shot)即可获得很好的效果。
- 除了常规的翻译、问答和文本填空任务,GPT-3的出色能力还体现在一些即时推理或领域适应的任务,例如给一句话中的单词替换成同义词,或执行 3 位数的数学运算。
- GPT-3 的 paper 很长,ELMO 有 15 页,BERT 有 16 页,GPT-2 有 24 页,T5 有 53 页,而 GPT-3 有 72 页。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
GPT-3 模型
GPT3的效果在大语料大参数量的加持下有了一些成绩,并展示了三个重要的能力:
- 语言生成:遵循
提示词(prompt),然后生成补全提示词的句子(completion)。这也是今天人类与语言模型最普遍的交互方式。 - 上下文学习 (in-context learning):遵循给定任务的几个示例,然后为新测试用例生成解决方案。GPT3虽然是个语言模型,但论文几乎没有谈到“语言建模”(language modeling),作者全部精力都投入到了
对上下文学习的愿景上,这才是 GPT3的真正重点。 - 世界知识 (world knowledge):包括事实性知识 (factual knowledge)和常识(commonsense)。
GPT-3 vs GPT-2
GPT-3 相比于 GPT-2 的区别:
- 效果上超出 GPT-2 非常多,能生成人类难以区分的新闻文章;
- 主推 few-shot,相比于 GPT-2 的 zero-shot,具有很强的创新性;
- 模型结构略微变化,采用 sparse attention 模块;
- 海量训练语料 45TB(清洗后 570GB),相比于 GPT-2 的 40GB;
- 海量模型参数,最大模型为 1750 亿,GPT-2 最大为 15 亿参数;
GPT-3 模型使用 Transformer 的 Decoder结构,并对 Transformer Decoder 进行了一些改动,引入了 Sparse Transformer 中的 sparse attention 模块(稀疏注意力), 原本的 Decoder包含了两个 Multi-Head Attention 结构,GPT-3 只保留了 Mask Multi-Head Attention,利用常规的语言建模优化,从左到右的自回归预训练
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,… 的 token,其他所有 token 的注意力都设为 0,如下图所示:
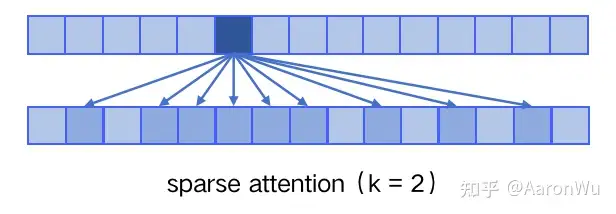
使用 sparse attention 的好处主要有以下两点:
- 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
- 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
关于 sparse attention 详情可参考《Generating Long Sequences with Sparse Transformers》。
GPT-3沿用了GPT-2的结构,但是在网络容量上做了很大的提升,具体如下:
- GPT-3采用了 96 层的多头transformer,头的个数为 96
- 词向量的长度是 12888;
- 上下文划窗的窗口大小提升至 2048 个token;
- 使用了alternating dense 和locally banded sparse attention。
GPT-3 延续使用 GPT 模型结构,但是。
一个拥有175billion参数的自回归语言模型(GPT-3),利用两组NLP数据集和一些全新的数据集评估了模型的情境学习能力和快速适应新任务能力。对于每一个任务,作者都测试了模型“few-shotlearning”,“one-shot learning”和“zero-shot learning”三种条件的性能。虽然GPT-3也支持fine-tune过程,但本文并未测试。
问题
- pre-train模型搭配下游任务fine-tune,在许多情况下效果显著,但是微调过程需要大量的样本。这一框架不符合人类的习惯,人类只需要少量示例或说明便能适应一个新的NLP下游任务。
结论
- 通过增大参数量就能让语言模型显著提高下游任务在 Few-shot(仅给定任务说明和少量示例)设置下的性能,即:证明了大规模语言模型使用
元学习策略的可能和fine-tuning策略的非必要性
贡献
- 训练了包含175 billion参数(以往非稀疏语言模型的10倍大小)的GPT3自回归语言模型,并在多个数据集上测试没有fine-tune过程的性能表现。
- 虽然GPT3在文本翻译、问答系统、完型填空、新词使用和代数运算等任务表现不错,但在阅读理解和推理任务数据集上的表现仍有待提高。
- 由于GPT-3的训练依赖于大量的网页语料,所以模型在部分测试数据集上可能出现方法论级别的data containation问题。
- GPT3能够编写出人类难以区分的新闻文章,本文讨论了该能力的社会影响力。
GPT-3 下游任务
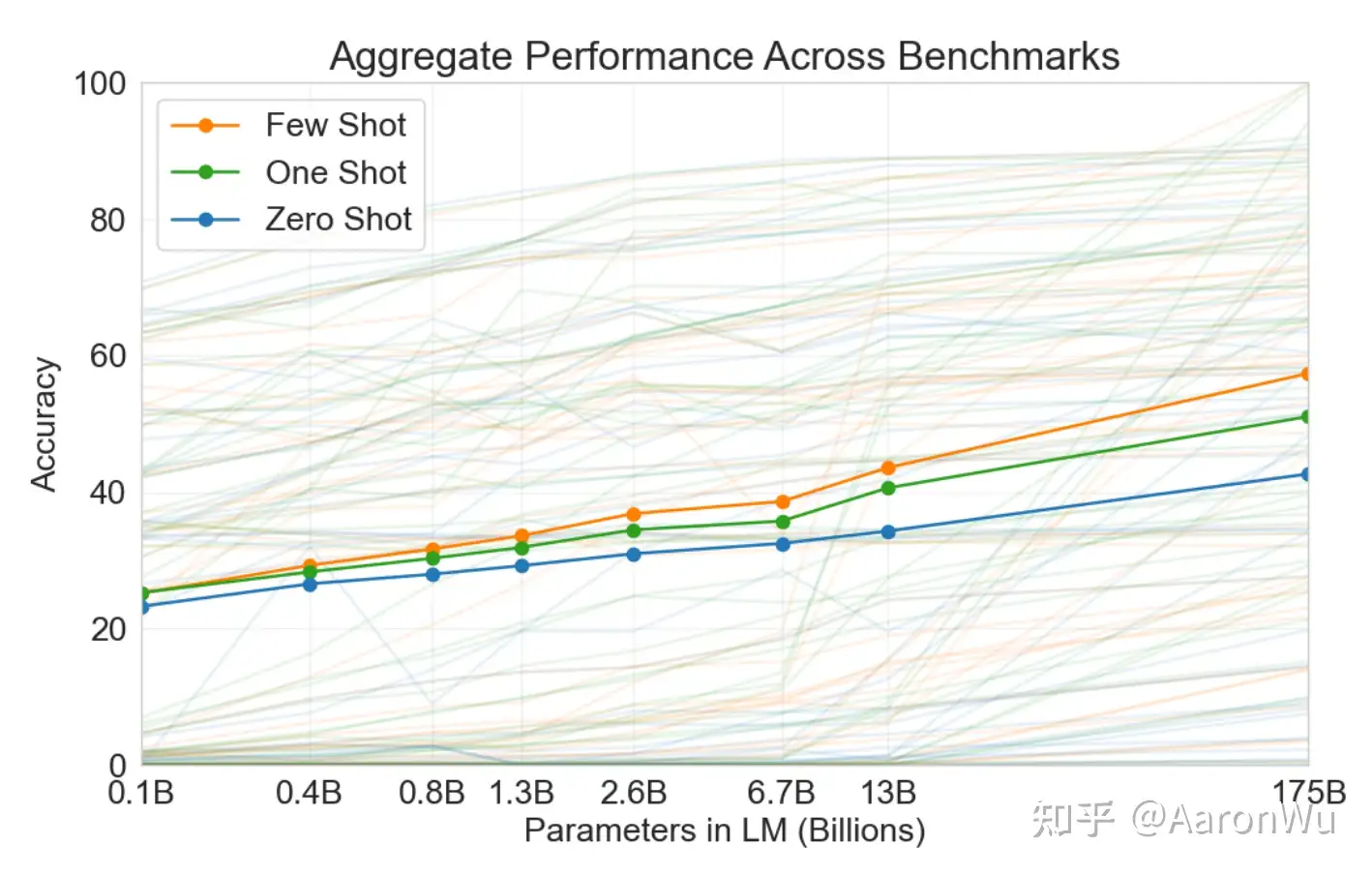
GPT-3 下游任务的评估与预测时,提供了三种方法:
Zero-shot:仅使用当前任务的自然语言描述;One-shot:当前任务的自然语言描述,加上一个简单的输入输出样例,不进行任何梯度更新;Few-shot:当前任务的自然语言描述,加上几个简单的输入输出样例,不进行任何梯度更新;
注意
- 三者都不进行任何梯度更新
Few-shot 也被称为 in-context learning(ICL),虽然与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:
- 本质区别: fine-tuning 基于标注数据对模型参数进行更新,而 ICL 使用标注数据时不做任何的梯度回传,模型参数不更新;
- ICL 依赖的数据量(10~100)远远小于 fine-tuning 数据量;
大量下游任务实验验证
- Few-shot 效果最佳,One-shot 效果次之,Zero-shot 效果最差
GPT-3 数据集
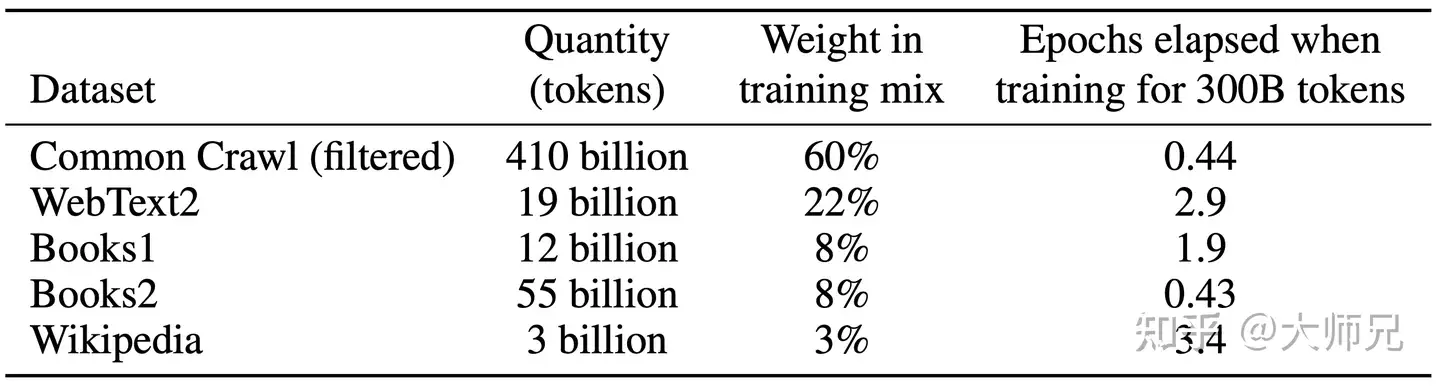
GPT-3共训练了5个不同的语料,分别是
- 低质量的 Common Crawl, 原始未处理的数据达到了 45TB
- GPT-2时就考虑使用这个数据集,只是这个数据集太脏了
- GPT-3做了些额外的数据清洗工作,来尽量保证数据的质量。
- 使用高质量数据作为正例,训练 LR 分类算法,对 CommonCrawl 的所有文档做初步过滤;
- 利用公开的算法做文档去重,减少冗余数据;
- 加入已知的高质量数据集:BERT、GPT、GPT-2 使用过的数据
- 处理完成后使用的数据规模约 570G。
- 高质量的 WebText2,Books1,Books2和Wikipedia
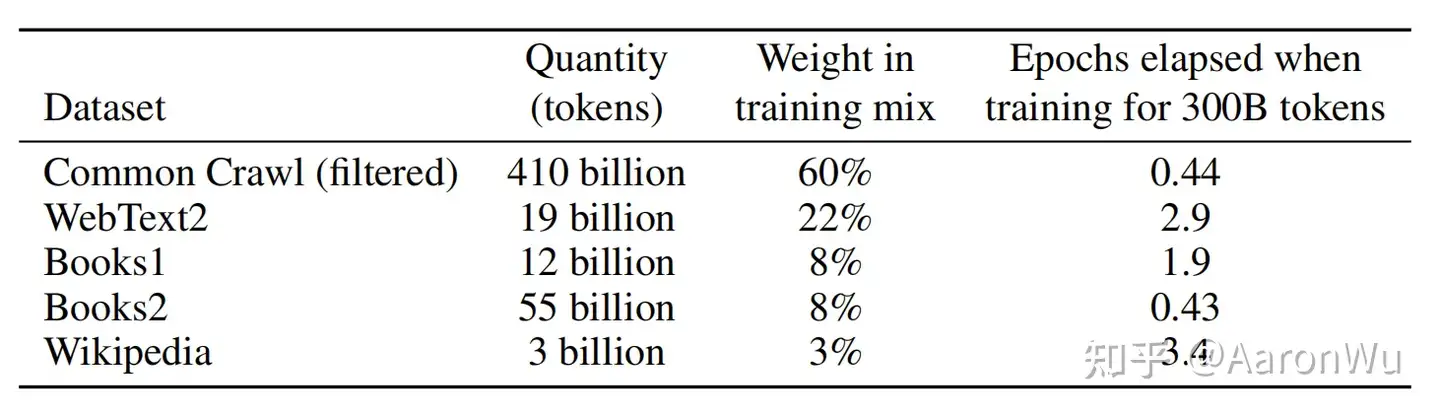
GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到
ICL (In-context Learning)
详见:本站ICL 专题
提示学习
详见专题:提示学习
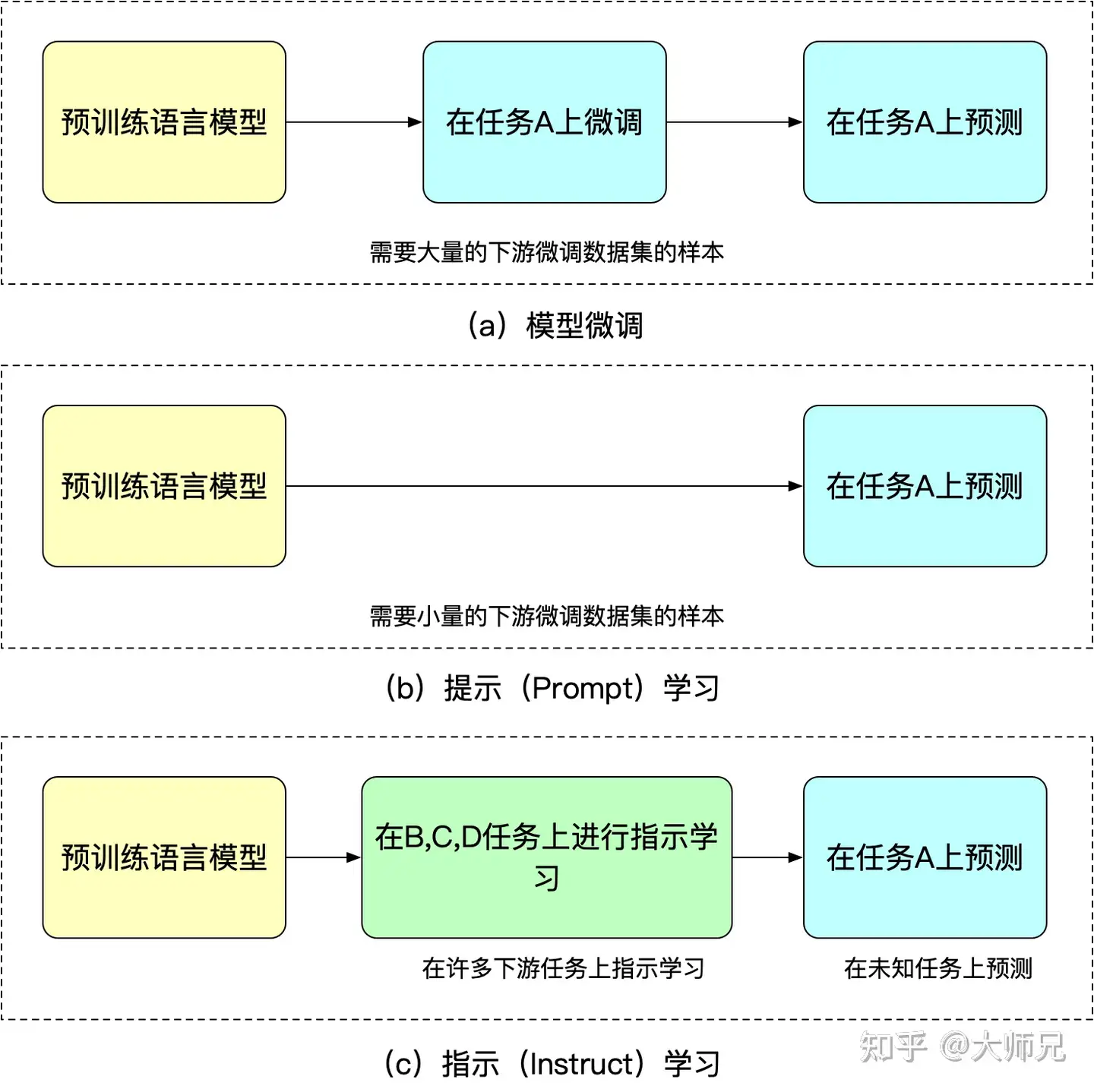
提示学习 与 指示学习
指示学习(Instruct Learning)和 提示学习(Prompt Learning)
指示学习是谷歌 Deepmind 的 Quoc V.Le 团队在 2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。
指示学习和提示学习
- 相同:目的都是去挖掘语言模型本身具备的知识。
- 不同:
- Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。
- Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。
指示学习优点是经过多任务微调后,能在其他任务上做zero-shot提示学习都是针对一个任务的。泛化能力不如指示学习。
通过下面的例子来理解这两个不同的学习方式:
- 提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
- 指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
模型微调,提示学习,指示学习三者的异同
工作原理
GPT3进行微调后,会更加惊人。微调实际上会更新模型的权重,以使模型在某些任务上表现更好
初代GPT-3展示了三个重要能力:【2023-2-8】拆解追溯 GPT-3.5 各项能力的起源
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子 (completion)。这也是今天人类与语言模型最普遍的交互方式。
- 上下文学习 (in-context learning): 遵循给定任务的几个示例,然后为新的测试用例生成解决方案。GPT-3虽然是个语言模型,但论文几乎没有谈到“语言建模” (language modeling) —— 作者将全部写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。
- 世界知识 (world knowledge):包括事实性知识 (factual knowledge) 和常识 (commonsense)。
GPT-3 VS BERT
2018年自然语言处理(NLP)领域诞生两个绝代双骄的模型,BERT(Google)和GPT(OpenAI),开启了NLP实际应用的爆发
【2020-9-11】GPT-3 Vs BERT For NLP Tasks:BERT vs GPT-3 — The Right Comparison

GPT-3 和 BERT 都是 PLM 领域的新生事物,都在NLP领域先后达到了当时的SOTA水平
- 是否开源:
- BERT 开源,以便用户根据下游任务 fine-tune(精调)
- GPT-3 闭源,商用
- 模型规模:
- GPT-3 有175亿参数,是 BERT-Large 的 470 倍!
- 使用方法
- BERT:
两阶段范式,BERT + Fine-tune(准备下游任务语料)- 以BERT为代表: 双向预训练 + Fine-tuning 模式
- 情感分析、QA任务:在 BERT 句子表示后面增加一层,用于
精调(fine-tune)
- GPT-3:
提示范式,使用 指令(intruction)、提示(prompt) 访问 API- OpenAI选择并坚持至今: 自回归模型 + Zero/Few-Shot Prompt 模式
- 在输入token上直接使用小样本学习(few-shot learning)
- BERT:
- 模型架构 BERT领先
- Transformer:Encoder-Decoder架构
- BERT:复杂(MLM+NSP),通过fine-tune捕捉不同语境下的隐含关系;只用 Encoder 生成语言模型
- GPT-3:简单,尤其是适合小样本场景,只用 Decoder —— GPT-3 应用更方便
- 推理方式
- BERT:深度双向语境(context),集中输出
- GPT-3:自回归语言模型,连续输出,一次生成一个字符(token)
- 效果对比:以通用NLP任务为准(机器翻译、QA、数学运算、文本生成等)
- BERT:
- GPT-3:表现完美,只需要提供少量样例
- 擅长任务
- BERT:双向Encoder,所以善于做阅读理解
- GPT-3:单向Decoder,所以擅长文本生成
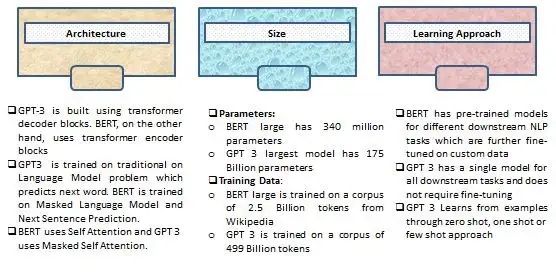
| 维度 | BERT | GPT-3 | 备注 |
|---|---|---|---|
| 模型架构 | 双向Encoder | 单向Decoder | 都是transformer架构,BERT架构领先 |
| NLP范式 | 两阶段范式:pre-train + fine-tune | prompt范式 | |
| 自监督方式 | NSP(下一句)+MLM(掩码语言模型) | AR(自回归语言模型/因果语言模型)+Prompt | 各自掀起两种NLP范式 |
| 开源 | 开源 | 闭源 | 只提供API |
| 模型规模 | 3.4亿(large) | 1750亿 | 470倍 |
| 推理方式 | 一次性输出 | 连续输出 | |
| 擅长任务 | 阅读理解 | 文本生成 | |
| 效果对比 | 通用NLP任务 | 适合小样本 |
OpenAI 为何一直坚持做纯语言模型预训练?
- 纯语言模型上限更高,OpenAI 一直致力于强人工智能;
- NLG 兼容 NLU,反之不合适,做纯语言模型预训练与模型“大统一”的目标更契合;
- 与同期竞争对手 BERT 有所区别;
【2023-6-11】图解
【2023-3-31】The Age of AI:拾象大模型及OpenAI投资思考
- 2018 年可能是 OpenAI 最不被看好的时候:BERT 一出世就把 GPT-2 从 GLUE 排行榜上淘汰了,学界的论文和业界的各类子任务都选择使用 BERT。大多数人都惋惜 GPT 没用到下文的信息,认为“它将作为 BERT 的古怪前身被尘封入史册”。
- 但是回头看最重要的一点,这种只有上文信息的自然语言生成模式在终局天然兼容了自然语言理解任务,能拥有这个大的认知和判断,而不是陷入对子任务效果的比较非常关键。
【2023-2-11】ChatGPT,一种更中心化的权力?
世界两大强权,微软和谷歌在对决。
- 微软与谷歌的大神对决:自回归(
GPT)VS 双向(BERT)
人工智能重大研究方向就是NLP任务(自然语言处理)。也就是机器要读懂人类语言,要当人类的奴隶,得听得懂主人的语言。
NLP任务(自然语言处理)有两大方向
- 一个方向是谷歌的双向(BERT)技术. 双向(BERT)技术,本质上是 A___B 概率猜谜。
- 另一个方向就是OpenAI的自回归(GPT)技术。自回归(GPT)技术,本质上是 A---B--____链式反应。

看得出来自回归(GPT)比双向(BERT)要开放得多,这才是真正的人类思维。
谷歌起了个大早而赶了个晚集,OpenAI在这一次关键性战争中赢了,当然,也是背后的大BOSS微软赢了。
GPT-3 在文本生成任务上取得实质性的进展,并将NLP的应用扩展到可用数据有限的领域。
GPT-3在传统的NLP任务(如机器翻译、阅读理解和自然语言推理任务)中表现如何呢?
语言建模:GPT-3 在纯语言建模任务上击败了所有的基准。(sota)机器翻译:对于需要将文档转换成英语的翻译任务,该模型的性能优于基准测试。(英语sota)- 但是如果需要将语言从英语翻译为非英语,那么情况就不一样了,GPT-3的性能也会出现问题。
阅读理解:GPT-3 模型的性能远远低于这里的技术水平。(很差)自然语言推理:自然语言推理(NLI)关注理解两个句子之间的关系的能力。GPT 3模型在NLI任务中的表现很差 (很差)常识推理:常识推理数据集测试物理或科学推理技能的表现。GPT 3模型在这些任务上的表现很差 (很差)
GPT-3 局限性
虽然 GPT-3 取得了非常亮眼的效果,但是出于严谨的学术态度,论文里还是客观的分析了自己的一些局限性:
- 当生成文本长度较长时,GPT-3 还是会出现各种问题,比如重复生成一段话,前后矛盾,逻辑衔接不好等等;
- 模型和结构的局限性,对于某一些任务,比如填空类型的文本任务,使用单向的自回归语言模型确实存在一定的局限性,这时候如果同时考虑上文和下文的话,效果很可能会更好一些;
- 预训练语言模型的通病,在训练时,语料中所有的词都被同等看待,对于一些虚词或无意义的词同样需要花费很多计算量去学习,无法区分学习重点;
- 样本有效性/利用率过低,训一个模型几乎要把整个互联网上的文本数据全都用起来,这与人类学习时所需要的成本存在非常大的差异,这方面也是未来人工智能研究的重点;
- 不太确定模型到底是在“学习”还是在“记忆”?当然希望它能够学习,但是在使用数据量如此大的情况下,很难去判断它到底是什么样的;
- 众所周知,GPT-3 的训练和使用成本都太大了;
- GPT-3 跟很多深度学习模型一样,都是不可解释的,没办法知道模型内部到底是如何作出一系列决策的;
- 模型最终呈现的效果取决于训练数据,这会导致模型会出现各种各样的“偏见”;
【2023-3-22】GPT-3本质还是通过海量参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型收敛。基于这个原因,GPT03学到的模型分布也很难摆脱数据集分布情况。
对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT3还是无能为力的。GPT3的缺点:
- 对于一些命题没有意义的问题,GPT3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
GPT-3 效果
GPT-3的优秀表现
- 首先,在大量语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。
- 另外,GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。
- 除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
被玩high的GPT-3
-
GitHub项目中的50种玩法,感兴趣的同学们可以继续探索。
- 1、生成应用和布局
- 根据描述生成HTML布局和代码
- 根据描述创建UI设计
- 根据描述生成React代码创建待办事项清单应用
- 仅基于React变量名称生成component
- 根据颜色名称或表情符号生成色阶
- 根据描述创建网站
- 2、搜索和数据分析
- 问题解答和搜索引擎
- 扩充表中的信息
- 根据描述创建图表
- 根据描述生成代码并转换为电子表格
- 根据描述生成图表和代码
- 3、程序生成与分析
- 根据描述生成shell命令
- 阅读代码并回答相关问题
- 根据描述生成LaTeX表达式
- 根据问题描述生成SQL代码_1
- 根据问题描述生成SQL代码_2
- 编码面试
- 生成Python代码回答自然语言问题
- 生成特定数据库的SQL代码
- 根据描述生成机器学习代码
- 4、文本生成
- 语言翻译
- 将日常语言转换为法律语言
- 自动生成请求
- 根据关键词写完整的回复邮件
- 简化法律语言
- 翻译中文非文学诗歌
- 将句子改写得更礼貌
- 总结名著思想
- 以大五人格(外向性、开放性、宜人性、尽责性、神经质)控制GPT-3的语言风格
- 5、内容创作
- 营销内容创作
- 生成模因,模仿创作
- 撰写Google广告
- 生成图片说明
- 根据描述生成食谱
- 根据“如何有效召开董事会会议”写“如何招募董事会成员”
- 生成莎士比亚风格的诗歌
- 生成科学问题并回答
- 生成历史问题并回答
- 文本补全和风格化重写
- 6、一般推理
- 物理问题
- 数学问题
- 医学问题
- 无意义的问题
- 推理问题
- 多步骤处理问题
- 通过图片确定食品成分和健康性
- 日常用语翻译成正式表达
- 7、其他
- GPT-3下棋
- 使用自然语言设计交互式语音应答流
- 通过临床症状对患者进行诊断
应用案例:
- 1、根据描述生成HTML布局和代码:根据输入的自然语言描述生成HTML网页布局,以及相应代码。
- 2、根据描述创建UI设计:输入文字描述,就可以生成相应的UI界面,跟上一个类似,不过界面更适应手机操作系统
- 3、扩充表中的信息
- 4、根据描述生成图表和Python代码
- 5、根据描述生成LaTeX表达式
- 6、根据问题描述生成SQL代码
- 7、根据描述生成机器学习代码:GPT-3还能写自己同类的代码,比AutoML还AutoML
- 8、编码面试
- 9、将日常语言转换为法律语言
- 10、根据关键词写完整的回复邮件
- 11、将句子改写得更礼貌
- 12、总结名著思想
- 13、生成科学问题并回答
- 14、推理问题
个性化聊天
【2021-10-13】AI 复活「她」!GPT-3 帮美国小哥复刻逝去未婚妻,但又夺走她…,7 月,一名33岁的美国小哥 Joshua Barbeau 在未婚妻去世后,根据她在 Facebook 和 twitter 上的文本在另一名开发人员的帮助下成功在 GPT-3 上微调,能够复刻出未婚妻生前的谈话方式。有很多人觉得 Joshua Barbeau 这个行为很可怕。但他认为,借助 Project December 项目创建出模拟已故之人的聊天机器人,可能会“帮助一些因此抑郁的人解开他们的心结”。但,Project December 的开发作者 Jason Rohrer 却收到了来自 OpenAI 的最后通牒:我们会在 9 月 2 日上午 10 点终止你的 API 访问。
- Jason Rohrer 是一名独立游戏开发者,Project December 是他于去年夏天疫情期间突发奇想的一个灵感:用 GPT-3 API 来开发一款模拟人类的聊天机器人,以电影《Her》中男主角的智能语音助手 Samantha 为原型
- 7月用户量突然激增。在《旧金山纪事报》报道的一篇文章讲述了一位 33 岁的美国男子 Joshua Barbeau 如何利用 Project December 创建出模拟其已故未婚妻 Jessica 的聊天机器人并与之交谈数月。在那之后,成千上万的人开始使用 Rohrer 网站。
- Rohrer 意识到他的网站将达到每月 API 的限制。主动联系 OpenAI 希望能通过支付更多费用以增加配额,以便容纳更多人与他创建的“Samantha”或自己的聊天机器人交流。但与此同时,OpenAI 方面认为 Project December 存在一定隐患:聊天机器人可能会被滥用或对人们造成伤害。
- 因此,双方进行了一场视频会议,可是很明显,效果并不理想。Jason Rohrer 在接受外媒 The Register 的采访时提到,OpenAI 给出了继续使用 GPT-3 API 需满足的 3 个条件:
- Jason Rohrer 必须禁止人们定制自己的开放式聊天机器人这一功能。
- Jason Rohrer 需设置内容过滤器以避免用户与“Samantha”谈论敏感话题。
- Jason Rohrer 必须部署自动化监控工具监视用户的对话,检测他们是否滥用 GPT-3 生成了有害或敏感语句。
- OpenAI 的员工与 Samantha 聊天,并试图了解「她」是否有种族主义倾向,或者会从「她」的训练数据中提供看起来像真实电话号码或电子邮件地址的内容,实验结果表明Samantha很老实,什么也没有说。Samantha 的输出令人感觉很真实,但随着时间的推移,很明显你能感觉到是在与某种自动化系统交谈,谈话的过程中往往会突然丢失对话思路。
- OpenAI 担心用户会受到 AI 的影响,害怕机器人会让他们自杀或如何给选举投票,可这完全是一种超道德的立场。
- Jason Rohrer 拒绝添加 OpenAI 要求的功能或机制,而是悄悄将原本 Project December 使用的 GPT-3 API 断开。并且替换为功能较差的开源 GPT-2模型以及由另一个研究团队开发的大型语言模型 GPT-J-6B。不过这两种模型性能显然不比 GPT-3,Samantha的对话能力也受到了影响。
【2022-4-6】外公去世十年后,我用 AI“复活”了他
一位程序员,天天跟 AI 和算法打交道,不免开始盘算:现阶段的 AI 技术能不能整合到一起,最终实现一个无论是语言表达还是人形上都极其接近我外公的效果。于是我开始搜索,发现了不少和我相同的愿望,也有人付诸实践。
- 韩国一位母亲因七岁女儿去世万分痛苦,一个电视团队听闻后耗时八个月制作出了女孩的三维虚拟形象,让母女在 VR 场景中相遇。在我看来,这更偏向动画制作,女孩形象和场景比较“卡通”
Project December 只能造出文字聊天机器人,我想合成一个有具体可感形象的“外公”,最好能写实一些。
- “他有记忆,能和我互动,能开口说话,脸一看就是我外公”,这个大胆的想法越来越清晰,我开始检索可能用得上的 AI 论文。
先做“外公”的大脑
- Project December 之所以能基于种子文本,生成有特定个性的角色,是因为接入了 GPT-3 的 API。GPT-3 是 OpenAI 的商业语言模型,可以简单理解为这个模型给了计算机像“人一样思考的能力”。
GPT-3 甚至能说出一些“高于人类”的话:
- 开始准备要导入 GPT-3 的种子文本,把之前保留的信件扫描成文字,整理好之前同步到云上的聊天短信,还扒下外公之前在视频里说过的话:“这个鱼还是要红烧,八十多块买来清蒸,味道洁洁淡(杭州话,“清淡”的意思),没味道。”“你不要手机一直拍来拍去,去帮你阿弟端菜。”
- 一股脑导入 GPT-3 后,它就能开始模仿外公的语言风格和对话思路……等等,GPT-3 收费。不过,我很快找到了免费开源的 GPT-J,开始了训练。 语言模型训练就是“猜词”的过程。模型利用显卡并行计算,找出一个语料库中每个词句之间的关系,比如出现一个词后,下一个词最有可能是什么。GPT-J 团队开源了预训练模型,已能实现大部分功能,我需要做的就是把种子文本转换成一个个词元,然后将这个外公专有语料库丢给 GPT-J 学习。
一般的深度学习模型需要训练几天几夜,我这次用 GPT-J 学习新语料并不是特别耗时,只需花六个小时。
人类:人生的目的是什么?
- AI:生命是一个美丽的奇迹。它随着时间不断进化,形成一种更大形式的美。从某种意义上来说,人生的目的就是增加宇宙中的这种美。
- 它之所以有这种能力,是因为工程师给这个模型猛喂数据,足足超过 3000 亿个文本。AI 模型在看了这么多文本后,就开始挖掘(也就是找规律)出词与词、句与句之间的关系,然后结合当前语境给出最适合的回答。
用语音驱动人脸
- 让我外公“显形”最直接的就是构建一个三维定制虚拟人像,但这需要采集人体数据点,很显然这条路行不通。
- 结合手头现有的照片、语音和视频等素材,我开始思考:有没有可能只用一段视频加上一串语音,就能生成一个栩栩如生的人脸呢?
- 几经波折,我找到了“Neural Voice Puppetry”这个方案,它是一种“人脸再扮演”(facial reenactment)技术,我只需要给定对话音频,它就能生成一段人脸嘴型与音频同步的动画。
- 论文作者利用卷积神经网络,把人脸外观、脸部情绪渲染和语音三者的关系找出来了,然后再利用这种学到的关系去渲染一帧帧能读出语音的人脸视频。但这个方案唯一的不足是不能指定输出的人物,我们只能选择给定人物,比如奥巴马。
实际得到的结果,是一段奥巴马用我外公声音在讲话的视频。我下一步要做的是 AI 换脸。
- 我最终选择用 HeadOn: Real-time Reenactment of Human Portrait Videos这篇论文里提到的技术。相关应用就是现在时兴的虚拟主播:捕捉中之人的表情,驱动二次元人物的脸。
- 提供表情信息的一般是真人,但由于我之前生成的“奥巴马”非常逼真,所以可以直接拿来带动我外公的肖像。
- 就这样,我用了我外公生前的通讯记录和不多的影音资料,整合几个成熟的 AI 技术,就让他“复活”了。
思考
OpenAI的创始人Sam Altman也认为GPT-3被过度炒作,在推特上表示:“ GPT-3的炒作实在太多了。它仍然存在严重的缺陷,有时还会犯非常愚蠢的错误。”
问题
- GPT-3还是一个依赖算力和大数据的怪兽。GPT-3的训练需要花费355GPU年和460万美元,数据集包含3000亿个文本token,存储量高达45TB,参数数量更是达到1750亿,而GPT-2的参数数量是15亿。
- 最近的流行也不能忽视心理学效应的影响
- 但是,GPT-3的few-shot 学习能力不是通用的,尽管该模型在复杂任务和模式的学习上给人留下了深刻的印象,但它仍然可能会失败。例如,即使看过10,000个示例,也解决不了反写字符串那样简单的任务。
- 即使是OpenAI,也曾指出GPT-3存在缺陷,GPT-3的原始论文就提供了一些证据,证明GPT-3无法执行复杂的逻辑推理。
- GPT3的宽度为2048个token,这是它理解上下文的极限,而人类可以记住多本书的知识,并将其关联起来,在这方面,GPT-3还差得远。
- GPT-3的生成结果表现出的灵活性是大数据训练的结果,它无法超越数据本身,也就无法拥有组合性推理能力,不如说,它学到的是“统计层面的复制粘贴能力”。
- 【2020-8-15】强大如 GPT-3,1750 亿参数也搞不定中国话
- 魏晨:GPT-3 模型从看上去更加接近“通用人工智能”(AGI) ,可以动态学习,处理多种不同的任务,只需少量的标注数据。
重点:
- GPT-3 参数庞大(约 1750 亿参数),能力较之前确实有所提升,但是宣传效果有夸张成分;
- 受参数大小影响,GPT-3 并不是一款性价比很高的模型,训练成本较高;
- 中文 GPT-3 的实践尚未出现; 4.GPT-3 确实可以通过文字输入生成代码,但是仅限于比较简单的情况;
- 离 AI 真正替代程序员工作, 还有较长的路要走 。
大模型 GPT-3 有 1750 亿参数,人类大脑有约 100 万亿神经元,约 100 个神经元会组成一个皮质柱,类似于一个小的黑盒神经网络模块,数量级上的差异决定了算力进步可以发展的空间还很大。训练 1750 亿参数的 GPT-3 的成本大概在 450 万美元左右,根据成本每年降低约 60% 的水平,供大模型提升计算复杂度的空间还很多。
资料
- GPT-2 有 1.5 个 billion 的参数,6GB
- GPT-3 175 个 billion 的参数大概, 700GB
项目github页面和论文Language Models are Few-Shot Learners, 目前没有代码只有生成样本和数据.52页的T5,72页的GPT-3
- 【2021-10-13】GPT-3 Creative Fiction 小说作品创作
- 【2019-2】张俊林:效果逆天的通用语言模型 GPT 2.0 来了,它告诉了我们什么?
- OpenAI GPT-3 API,Github地址
-

- Jay Alammar杰作:怎样向产品解释GPT-3
资料
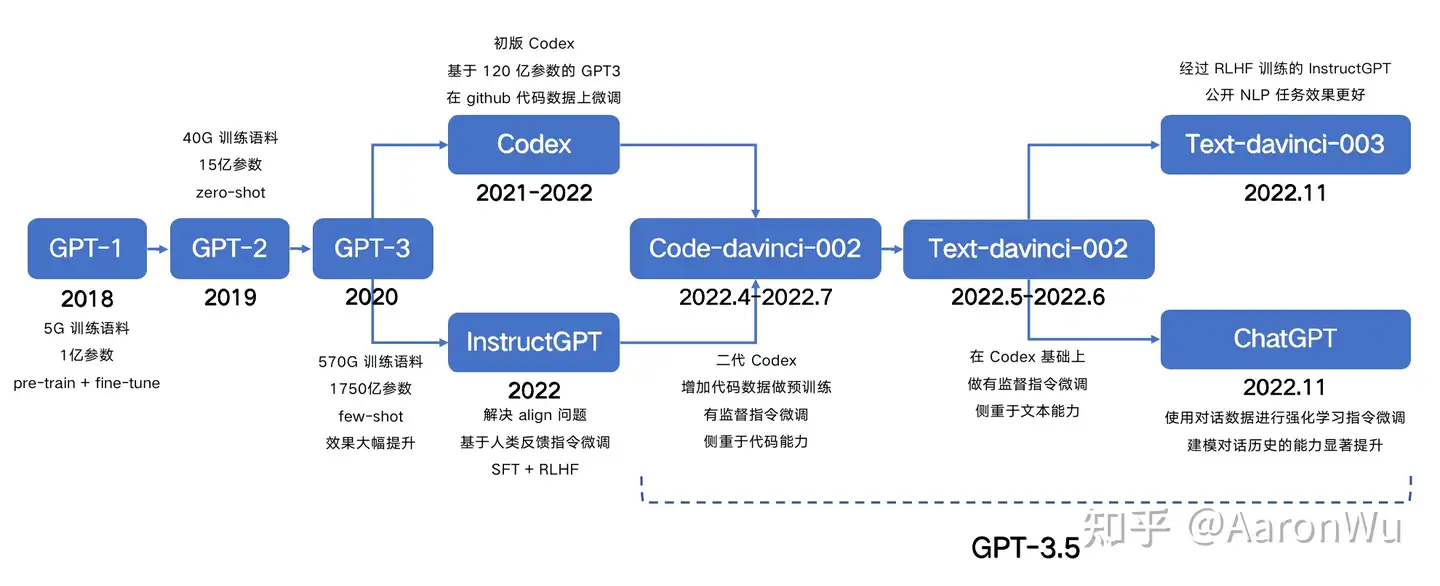
GPT 3.5
GPT-3.5 官方解释
InstructGPT 思路
GPT-3 虽然在各大 NLP 任务以及文本生成的能力上惊艳,但是仍然还是会生成一些带有偏见的,不真实的,有害的造成负面社会影响的信息,而且并不按人类喜欢的表达方式去说话。
OpenAI 提出了一个概念“Alignment”,模型输出与人类真实意图对齐,符合人类偏好。
- 为了让模型输出与用户意图更加 “align”,就有了 InstructGPT 这个工作。
InstructGPT 提出了一个理想化语言模型的三大目标:helpful, honest, harmless

InstructGPT 原理
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型。官方指南,论文地址, 未开源。
- Instruction GPT是基于
GPT-3的一轮增强优化,所以也被称为GPT-3.5。 - GPT-3.5 主张few-shot少样本学习,同时坚持无监督学习。但few-shot的效果,显然是差于fine-tuning监督微调的方式的。那怎么办?走回fine-tuning监督微调?显然不是。
- OpenAI给出新的答案: 在
GPT-3的基础上,基于人工反馈(RHLF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。
InstructGPT/GPT3.5(ChatGPT的前身)与GPT-3的主要区别在于,新加入了被称为RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。这一训练范式增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序。
在InstructGPT中,“goodness of sentences”的评价标准。
- 真实性:是虚假信息还是误导性信息?
- 无害性:它是否对人或环境造成身体或精神上的伤害?
- 有用性:它是否解决了用户的任务?
InstructGPT 同类
InstructGPT 是openai提出的对话机器人,在思路上跟google的LaMDA以及deepmind的Sparrow有一定的相似,但也存在明显的不同。
InstructGPT跟LaMDA与Sparrow的对比
a) 跟google的LaMDA以及deepmind的Sparrow相同,三个对话机器人都需要高质量的finetune数据集,都有自己的一套收集数据的方法论。
| 模型 | 数据 |
|---|---|
| LaMDA | 【预训练】 2.97B个文档,1.12B个对话,13.39轮对话,总共1.56T单词,超过90%是英文数据 【Finetune】 Quality: 6.4K个对话,61K轮对话 Safety:8K个对话,48K轮对话 Groundedness:4K个对话,40K轮对话(涉及手写query跟模型回复修改)以及,1K个对话,9K轮对话(判断检索query跟回复是否正确) |
| Sparrow | Finetune: Rule reward: 14576个对话 Preference reward:73273个样本 |
| instructGPT | Finetune: SFT: 13K个prompt RM: 33K个prompt PPO:31K个prompt |
b) 同deepmind的Sparrow一样使用了强化学习,即 reinforcement learning from human feedback,也称RLHF。
c) 区别于其他两个对话机器人,InstructGPT不具备检索外部知识源的能力(这点蛮奇怪的,毕竟这是已经被验证过缓解模型幻视的一种有效手段,所以会不会是openai调不了Google Search的api?),也没有为生成结果的安全性等方面设计额外的子任务。
InstructGPT 训练方法
Instruction GPT一共有3步:
- 1)、对 GPT-3 进行监督微调 (supervised fine-tuning)。
- 2)、再训练一个奖励模型(Reward Model,RM)
- 3)、利用人类反馈,通过增强学习优化SFT,称为 PRO
注意
- 第2、3步是完全可迭代、多次循环
- 基础数据规模同GPT-3
官方图

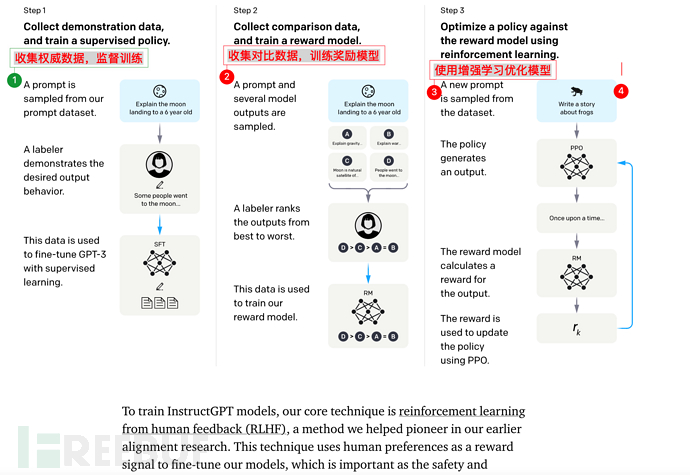
模型怎么训练,这些不重要,毕竟99.99%的人都没法训练GPT-3,更别提GPT-3.5了。但是有个地方需要说一嘴,打分模型(RM模型)也是基于GPT-3进行训练的,使用的是6B的版本,在进行SFT训练之后,把最后的embedding层去掉,改成输出一个标量。
思考
【2023-4-28】ChatGPT 为什么不用 Reward-Model 的数据直接 fine-tune,而用 RL?
模仿学习(imitation learning)里的behaviroal cloning(行为克隆) 和 inverse reinforcement learning (IRL逆强化学习)。
- 基于最大似然的fine-tuning,相当于
模仿学习里的behaviroal cloning (BC)。 - RLHF先学习reward model再使用PPO,相当于
模仿学习里的inverse reinforcement learning (IRL)。
后者的好处:在没见过的数据集上做优化。BC只能在训练数据集上做优化,IRL可以让模型产生新数据集,然后在新数据集上优化来提升泛化性能。
- RLHF里的reward model是不精准,这种提升能有多少,很难说。如果reward model是准的,那么使用模仿学习的术语,可以证明后者比前者好很多。
基于reward学习的RL训练可比监督学习fine tune好不少,这一现象在RL的研究中早已观察到,特别是在OOD数据上有显著差别。
参考
- 2020, Error bounds of imitating policies and environments
- 2022, Understanding Adversarial Imitation Learning in Small Sample Regime: A Stage-coupled Analysis.
- youtube: John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
作者:李子牛
TAMER 框架
TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)框架将人类标记者引入到Agents的学习循环中,可以通过人类向Agents提供奖励反馈(即指导Agents进行训练),从而快速达到训练任务目标。
引入人类标记的目的:加快训练速度。
尽管强化学习技术在很多领域有突出表现,但是仍然存在着许多不足,例如
- 训练收敛速度慢,训练成本高等特点。
- 特别是许多任务探索成本或数据获取成本很高。
如何加快训练效率,是如今强化学习任务待解决的重要问题之一。
- 而TAMER则可以将人类标记者的知识,以奖励信反馈的形式训练Agent,加快其快速收敛。
- TAMER不需要标记者具有专业知识或编程技术,语料成本更低。
通过TAMER+RL(强化学习),借助人类标记者的反馈,能够增强从马尔可夫决策过程 (MDP) 奖励进行强化学习 (RL) 的过程。
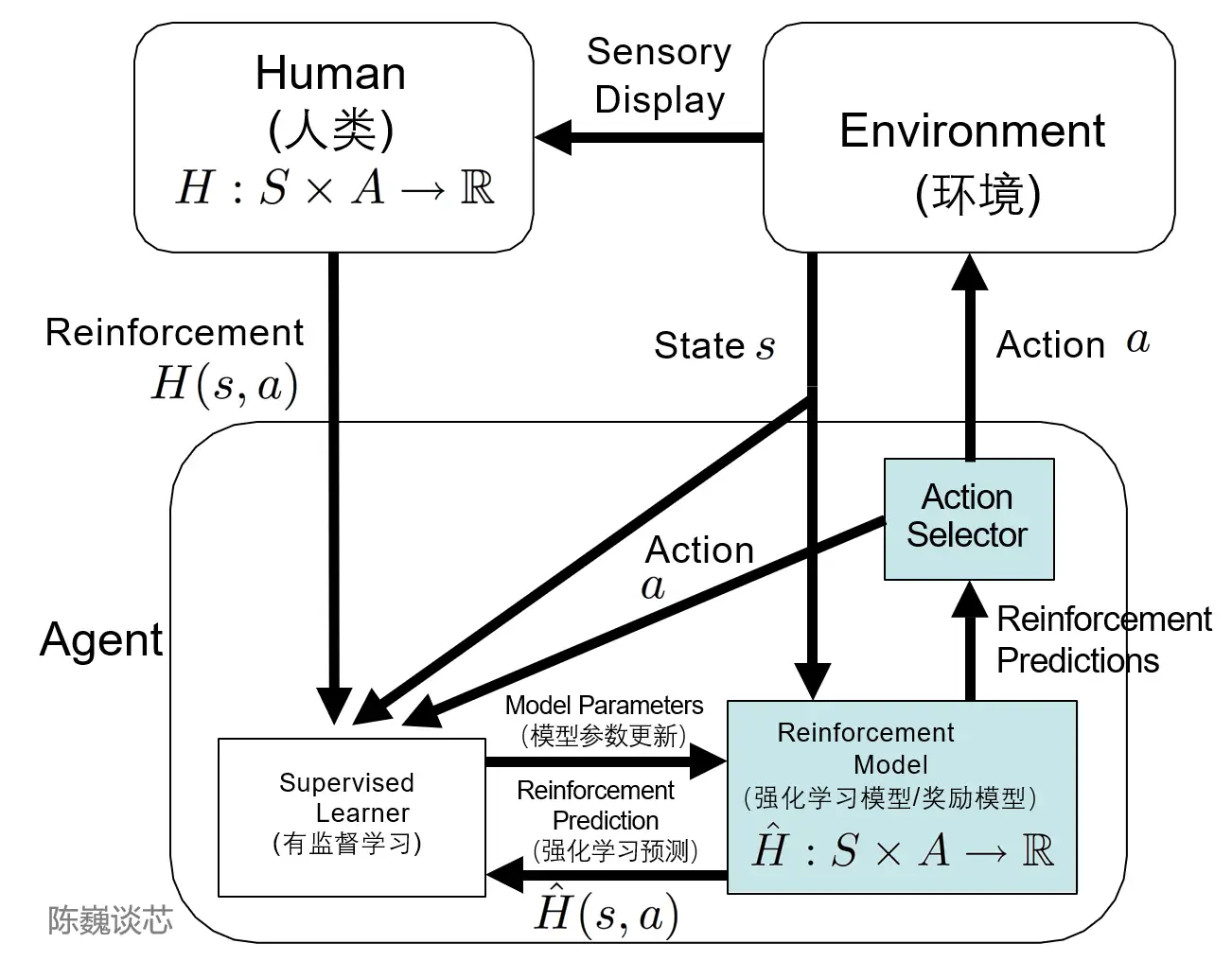
- 人类标记者扮演对话的用户和人工智能助手,提供对话样本,让模型生成一些回复,然后标记者会对回复选项打分排名,将更好的结果反馈回模型中,Agents 同时从两种反馈模式中学习——人类强化和马尔可夫决策过程奖励作为一个整合的系统,通过奖励策略对模型进行微调并持续迭代。
在此基础上,ChatGPT 可以比 GPT-3 更好的理解和完成人类语言或指令,模仿人类,提供连贯的有逻辑的文本信息的能力。
PPO
官方PPO介绍
- Policy gradient methods are fundamental to recent breakthroughs in using deep neural networks for control, from video games, to 3D locomotion, to Go.
- But getting good results via policy gradient methods is challenging because they are sensitive to the choice of stepsize — too small, and progress is hopelessly slow; too large and the signal is overwhelmed by the noise, or one might see catastrophic drops in performance. They also often have very poor sample efficiency, taking millions (or billions) of timesteps to learn simple tasks.
- Researchers have sought to eliminate these flaws with approaches like TRPO and ACER, by constraining or otherwise optimizing the size of a policy update. These methods have their own trade-offs
ACERis far more complicated thanPPO, requiring the addition of code for off-policy corrections and a replay buffer, while only doing marginally better thanPPOon theAtaribenchmark;TRPO— though useful for continuous control tasks — isn’t easily compatible with algorithms that share parameters between a policy and value function or auxiliary losses, like those used to solve problems inAtariand other domains where the visual input is significant.
Baselines: PPO, PPO2, ACER, and TRPO
This release of baselines includes scalable, parallel implementations of PPO and TRPO which both use MPI for data passing. Both use Python3 and TensorFlow. We’re also adding pre-trained versions of the policies used to train the above robots to the Roboschool agent zoo.
Update: We’re also releasing a GPU-enabled implementation of PPO, called PPO2. This runs approximately 3X faster than the current PPO baseline on Atari. In addition, we’re releasing an implementation of Actor Critic with Experience Replay (ACER), a sample-efficient policy gradient algorithm. ACER makes use of a replay buffer, enabling it to perform more than one gradient update using each piece of sampled experience, as well as a Q-Function approximate trained with the Retrace algorithm.
InstructGPT 数据集
InstructGPT 论文中,给出了上述三个步骤,分别制造/标注了多少样本:
SFT数据集(即第一步人类根据prompt自己写理想的输出,SFT:supervised fine-tuning),包含13K的prompts;RM数据集(即第二步用来训练打分模型的数据),包含33K的prompts;PPO数据集(即第三步用来训练强化学习PPO模型的数据),包含31K的prompts。
| 数据集 | 生成方法 | prompt量 | 训练任务 |
|---|---|---|---|
| SFT dataset | 由标记人员编写prompt对应的回答 | 13k | Supervised FineTune(SFT) |
| RM dataset | 由标记人员对gpt产生的答案进行质量排序 | 33k | Reword Model(RM) |
| PPO dataset | 不需要人工参与,gpt产生结果,RM进行打分 | 31k | Reinforcement learning (RL) |
前两步的prompts来自于OpenAI的在线API上的用户使用数据,以及雇佣的标注者手写的。最后一步则全都是从API数据中采样的,
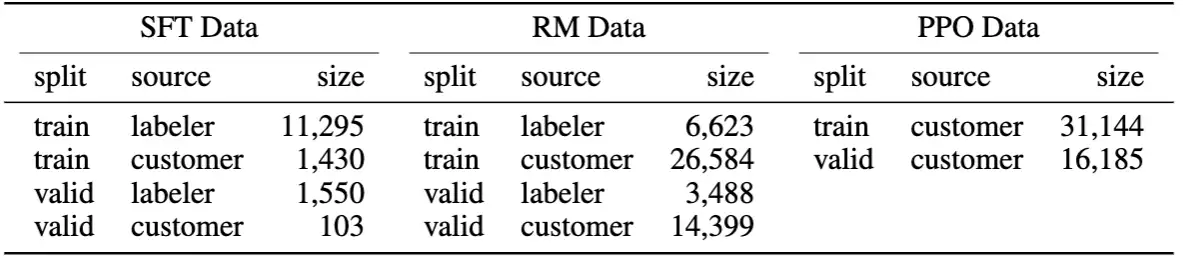
总共加起来也就 77K 数据,而其中涉及人工的只有46K。GPT-3 继续在 77K 数据上进行了进一步微调得到了InstructGPT。
初始的种子数据集需要标注者来编写prompts,而不是从API数据中采样
- 因为API接口中的prompts数据,多数都不是那种”人类要求模型干什么事儿“这类instruction-like prompts,多数都是续写之类的,这跟本文的出发点——希望模型能按照人类的要求做事儿,有点不匹配,所以需要标注者现场编写。
- 具体这些标注者被要求写这么三种数据:
- Plain:自己随便拍脑袋想一些prompts,同时尽可能保证任务的多样性。(比方随便写”请给我写个段子“,”请给我把这段话翻译成德语“,”啥是马尔科夫链啊?“等等各种问题、要求)
- Few-shot:不仅仅需要需要写prompts,还需要写对应的outputs。(这部分应该是最耗费人力的了,也是SFT数据的主要组成部分)
- User-based:OpenAI的用户希望OpenAI未来能提供哪些服务,有一个waitlist,然后这些标注者,就根据这个waitlist里面的task来编写一些prompts。(相当于告诉标注者,你们看看用户们都期待些什么功能,你们可以作为参考)
OpenAI客户在日常使用时的用途分布,即API数据的分布(RM数据集的大致分布):
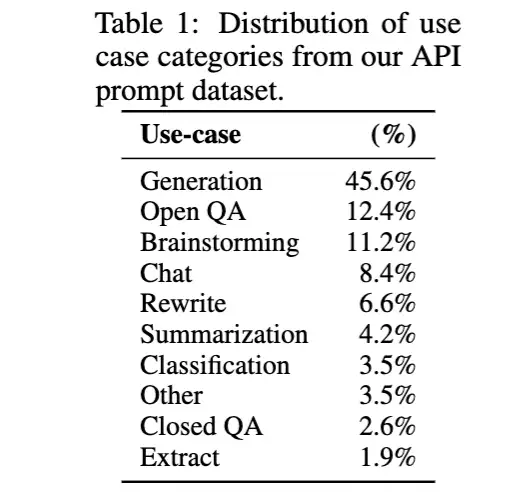
人工标注
美国《时代周刊》1月中旬报道:
- 为了训练ChatGPT,OpenAI雇佣了时薪不到2美元的
肯尼亚外包劳工,他们所负责的工作就是对庞大的数据库手动进行数据标注。 - 时薪1.32~2美元,9小时阅读并标注至多20万个单词,有员工遭受持久心理创伤
乐观的投资者认为,计算机生成的文本、图像、视频和音频将改变无数行业的经营方式,从创意艺术到法律,再到计算机编程,该技术都将提高人类的工作效率。
然而,数据标注员工的工作条件揭示了行业背后“黑暗”的部分:
- 尽管人工智能魅力无限,但它往往依赖于全球最廉价的劳动力,他们往往被大幅剥削。
- 尽管他们为数十亿美元的产业作出了杰出贡献,但这些几乎“隐形”的工人仍然处于最边缘的地带。
OpenAI在2021年底与Sama签署了三份总价值约20万美元的合同,为数据库中有害的内容进行标记。
- 合同规定,OpenAI将为该项目向Sama支付每小时12.50美元的报酬,这是该项目员工时薪的 6~9倍。
- Sama为OpenAI雇佣的数据标签员工支付的时薪在1.32美元~2美元之间(约8.99元~13.62元),具体取决于资历和表现。
Sama 是一家总部位于美国旧金山的公司,该公司雇佣了肯尼亚、乌干达和印度的外包员工。
- 大约30多名工作人员被分成三个小组,每个小组都专注于一个主题。三名员工对《时代周刊》表示,每9个小时要阅读和标注150~200段文字。这些段落的范围从100个单词到1000多个单词不等。
- 这份工作给他们留下了持久的心理创伤。尽管他们有权参加健康咨询师课程,但四人都表示,由于对工作效率的要求很高,只能选择参加小组会议。其中还有一人表示,他们要求以一对一的方式与心理咨询师会面的请求被Sama管理层多次拒绝。
除了OpenAI,Sama还为谷歌、Mate和微软等硅谷科技巨头标注数据。此外,Sama还标榜其是一家“有道德的人工智能公司”,并称其已经帮助5万多人脱贫。
InstructGPT 技能进化
【2023-2-8】拆解追溯 GPT-3.5 各项能力的起源
Models referred to as “GPT 3.5”
GPT-3.5 series is a series of models that was trained on a blend of text and code from before Q4 2021. The following models are in the GPT-3.5 series:
code-davinci-002is a base model, so good for pure code-completion tasks (代码补全任务)text-davinci-002is anInstructGPTmodel based oncode-davinci-002text-davinci-003is an improvement ontext-davinci-002
InstructGPT models
We offer variants of InstructGPT models trained in 3 different ways:
| TRAINING METHOD | explains | MODELS |
|---|---|---|
SFT |
Supervised fine-tuning on human demonstrations | davinci-instruct-beta1 |
FeedME |
Supervised fine-tuning on human-written demonstrations and on model samples rated 7/7 by human labelers on an overall quality score | text-davinci-001, text-davinci-002, text-curie-001, text-babbage-001 |
PPO |
Reinforcement learning with reward models trained from comparisons by humans | text-davinci-003 |
The SFT and PPO models are trained similarly to the ones from the InstructGPT paper. FeedME (short for “feedback made easy”) models are trained by distilling the best completions from all of our models. Our models generally used the best available datasets at the time of training, and so different engines using the same training methodology might be trained on different data.
InstructGPT 模型进化
GPT-3.5 的进化树:
-
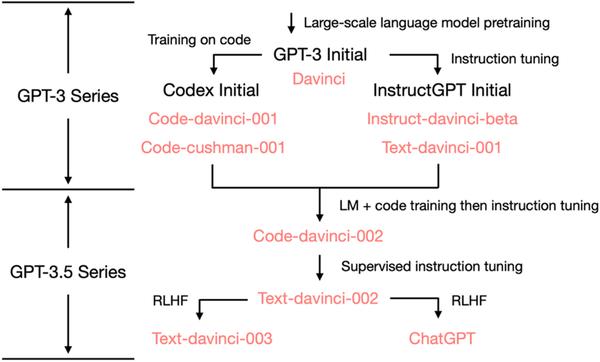
- 2020 年 7 月,OpenAI 发布了模型索引为的
davinci的初代 GPT-3 论文,从此它就开始不断进化。 - 2021 年 7 月,Codex 的论文发布,其中初始的 Codex 是根据(可能是内部的)120 亿参数的 GPT-3 变体进行微调的。后来这个 120 亿参数的模型演变成 OpenAI API 中的
code-cushman-001。 - 2022 年 3 月,OpenAI 发布了指令微调 (instruction tuning) 的论文,其监督微调 (supervised instruction tuning) 的部分对应了
davinci-instruct-beta和text-davinci-001。 - 2022 年 4 月至 7 月的,OpenAI 开始对
code-davinci-002模型进行 Beta 测试,也称其为 Codex。然后code-davinci-002、text-davinci-003和ChatGPT都是从code-davinci-002进行指令微调得到的。详细信息请参阅 OpenAI的模型索引文档。- 尽管 Codex 听着像是一个只管代码的模型,但
code-davinci-002可能是最强大的针对自然语言的GPT-3.5 变体(优于text-davinci-002和-003)。code-davinci-002很可能在文本和代码上都经过训练,然后根据指令进行调整。
- 尽管 Codex 听着像是一个只管代码的模型,但
- 然后, 2022 年 5-6 月发布的
text-davinci-002是一个基于code-davinci-002的有监督指令微调(supervised instruction tuned) 模型。在text-davinci-002上面进行指令微调很可能降低了模型的上下文学习能力,但是增强了模型的零样本能力(将在下面解释)。 - 然后是
text-davinci-003和ChatGPT,它们都在 2022 年 11 月发布,是使用的基于人类反馈的强化学习的版本指令微调 (instruction tuning with reinforcement learning from human feedback) 模型的两种不同变体。text-davinci-003恢复了(但仍然比code-davinci-002差)一些在text-davinci-002中丢失的部分上下文学习能力(大概是因为它在微调的时候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF)。 - 另一方面,ChatGPT 似乎牺牲了几乎所有的上下文学习的能力来换取建模对话历史的能力。
总的来说,在 2020 - 2021 年期间,在code-davinci-002之前,OpenAI 已经投入了大量的精力通过代码训练和指令微调来增强GPT-3。当他们完成code-davinci-002时,所有的能力都已经存在了。很可能后续的指令微调,无论是通过有监督的版本还是强化学习的版本,都会做以下事情(稍后会详细说明):
- 指令微调不会为模型注入新的能力 —— 所有的能力都已经存在了。指令微调的作用是解锁/激发这些能力。这主要是因为指令微调的数据量比预训练数据量少几个数量级(基础的能力是通过预训练注入的)。
- 指令微调将 GPT-3.5 的分化到不同的技能树。有些更擅长上下文学习,如
text-davinci-003,有些更擅长对话,如ChatGPT。 - 指令微调通过牺牲性能换取与人类的对齐(alignment)。 OpenAI 的作者在他们的指令微调论文中称其为 “对齐税” (alignment tax)。许多论文都报道了
code-davinci-002在基准测试中实现了最佳性能(但模型不一定符合人类期望)。 在code-davinci-002上进行指令微调后,模型可以生成更加符合人类期待的反馈(或者说模型与人类对齐),例如:零样本问答、生成安全和公正的对话回复、拒绝超出模型它知识范围的问题。
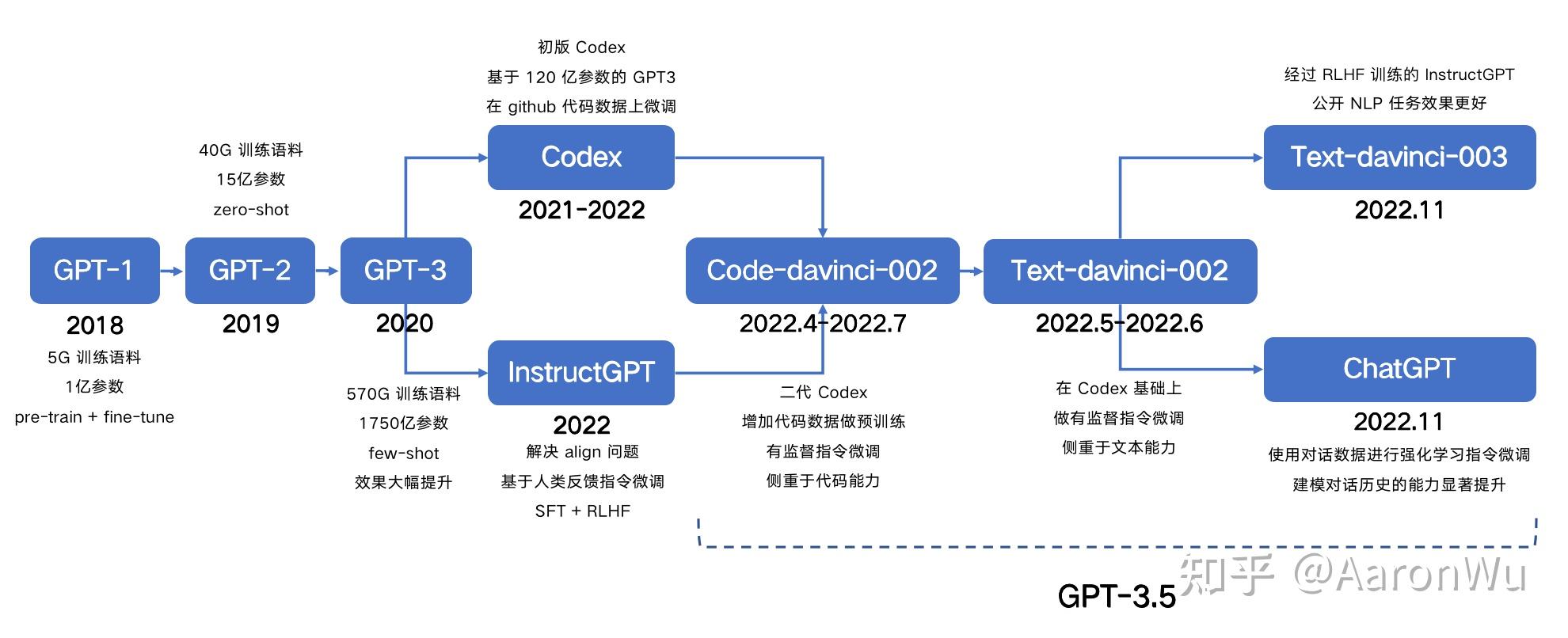
GPT-3.5 进化历程
仔细检查了沿着进化树出现的所有能力,总结出演化路径:
- 语言生成能力 + 基础世界知识 + 上下文学习都是来自于预训练(
davinci) - 存储大量知识的能力来自 1750 亿的参数量。
- 遵循指令和泛化到新任务的能力来自于扩大指令学习中指令的数量(
Davinci-instruct-beta) - 执行复杂推理的能力很可能来自于代码训练(
code-davinci-002) - 生成中立、客观的能力、安全和翔实的答案来自与人类对齐。具体来说:
- 如果是监督学习版,得到的模型是
text-davinci-002 - 如果是强化学习版 (RLHF) ,得到的模型是
text-davinci-003 - 无论有监督还是 RLHF ,模型在很多任务的性能都无法超过
code-davinci-002,这种因为对齐而造成性能衰退的现象叫做对齐税。
- 如果是监督学习版,得到的模型是
- 对话能力也来自于 RLHF(
ChatGPT),牺牲了上下文学习的能力,来换取:- 建模对话历史
- 增加对话信息量
- 拒绝模型知识范围之外的问题
模型进化树-图形化
- 蓝色代表
GPT-3, 绿色代表GPT-3.5 - 棕色部分表示能力点
GPT 3.5 VS GPT 3
InstructGPT 相对于之前的 GPT 系列:
- 解决 GPT-3 的输出与人类意图之间的 Align 问题;
- 让具备丰富世界知识的大模型,学习“人类偏好”;
- 标注人员明显感觉 InstructGPT 的输出比 GPT-3 的输出更好,更可靠;
- InstructGPT 在真实性、丰富度上表现更好;
- InstructGPT 对有害结果的生成控制的更好,但是对于“偏见”没有明显改善;
- 基于指令微调后,在公开任务测试集上的表现仍然良好;
- InstructGPT 有令人意外的泛化性,在缺乏人类指令数据的任务上也表现很好;
GPT-3.5和3.0的区别
- 首先,和微软合作,在微软的Azure AI云服务器上完成了训练;
- 训练数据集里除了文字,还加入了代码,因此 chatGPT 现在已经可以写程序,甚至给现成的代码找bug。
为什么试用过 chatGPT 的人都感觉提升很明显?
- chatGPT 引入了一个新的训练方法RLHF,用人类反馈的方式加强训练。
- 论文 Training language models to follow instructions with human feedback,发表于2022年3月,
- chatGPT 针对输出有效性上做了非常好的调整
- chatGPT 并非每一个问题都能回答详尽,但它绝对没有胡说八道,chatGPT的回答和真实世界的情况是相当一致的。
- chatGPT 在道德约束上做得很出色
- 询问一些逾越了道德边界的问题,或者一些特别敏感的问题,chatGPT基本都能察觉和回避。
基于Transformer的通用大数据无监督训练模式把自然语言的自动学习做到了某种极致,而这个RLHF又重新捡起了“手动档”人类反馈机制,貌似有一点返璞归真的感觉。
InstructGPT 效果
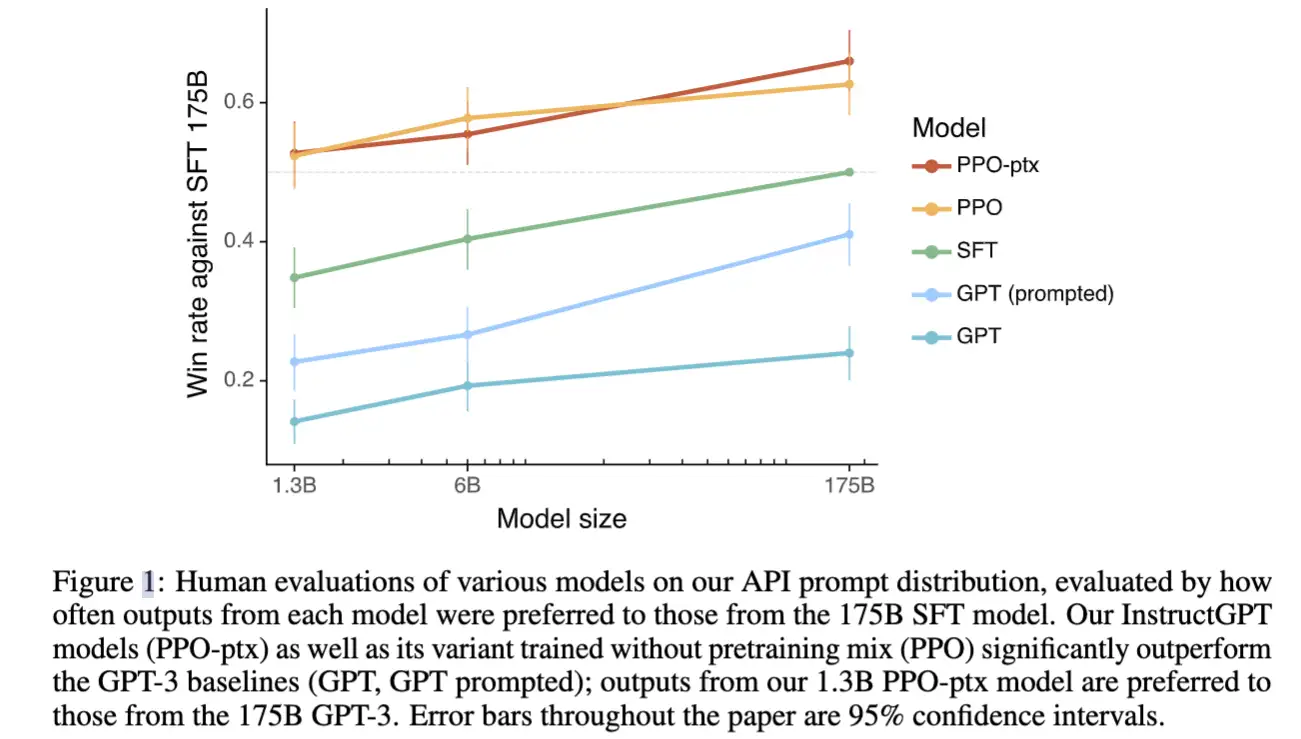
【2023-2-9】OpenAI是如何“魔鬼调教” GPT的?——InstructGPT论文解读
结论
- 在”听指挥“方面,1.3B版本的 InstructGPT 就可以超过比自己大100倍的 175B 版本的 GPT-3了
示例

InstructGPT 论文介绍OpenAI是怎么把GPT-3这个野孩子调教得听人类指挥的
- 调教成本并没有那么大,相比于GPT-3预训练的成本,InstructGPT 仅使用了 77K 数据进行微调,基本不值一提。
- 最终,InstructGPT 生成的结果,在真实性、无害性、有用性方面都有了很大的提高(但是对偏见这种问题依然没有改善)。
作者团队通过大量的实践,总结几个重要结论:
- 对齐税:这种“调教”会降低常见NLP任务上的效果,作者称之为“
对齐税” —— alignment tax(实际上之前很多研究都发现了这个问题)。但是,可以改善RLHF 过程,比如在预训练过程也混合RLHF的方法。 - 数据集需要更加普适:常见的公开NLP数据集,跟人类实际使用语言模型的场景,差别很大。因此单纯在公开NLP数据集进行指令微调,效果依然不够。
- 域外泛化能力强:虽然人类标注只有几十K,远远不能覆盖所有可能的prompts,但是实验发现InstructGPT的域外泛化能力很强,对于没有见过的prompt类型,依然有比较好的泛化能力。
- 依然会胡说八道:革命尚未成功,InstructGPT依然会犯错,依然可能瞎编乱造、啰里吧嗦、不听指挥、黑白不分。。。ChatGPT也难以避免这个问题。所以InstructGPT、ChatGPT是开启了一扇门,让人看到了巨大的希望,也看到了巨大的困难,依然有很多有挑战性的问题待解决。
ChatGPT
详见专题文章:ChatGPT
GPT 4
传说 GPT-4.0 已然突破了图灵测试。
GPT-4 体验
第三方接入
体验:
- POE地址
- gpt-4 api专题
- 第三方软件
- Cursor访问GPT-4,跳转
- Copilot
官方接入
ChatGPT plus账户上支持选择GPT-4模型
GPT-4功能 参考
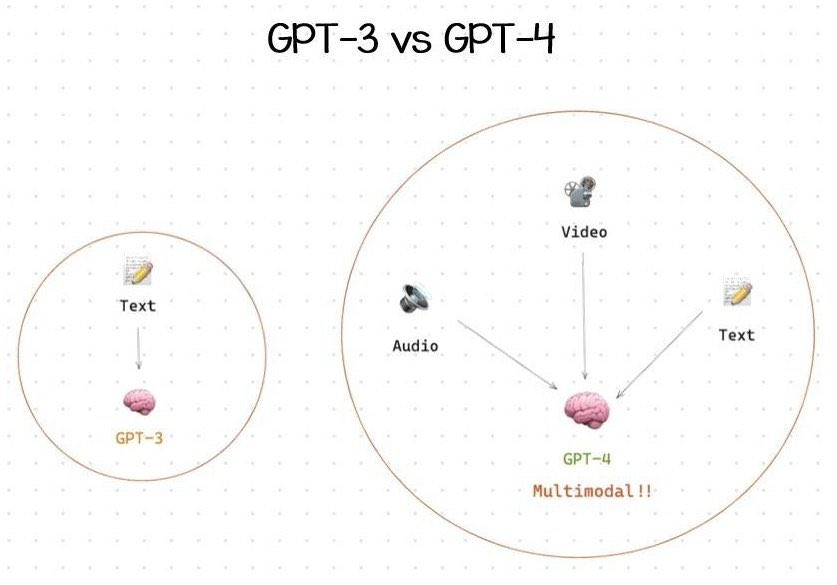
- 相比于GPT-3.5,GPT-4是新一代多模态大模型。GPT-4不仅支持文本,还支持图像输入。

访问ChatGPT Plus就拥有Default和Legacy双模型回答,以及快速、稳定的AI回复。
GPT-4 介绍
【2023-3-15】GPT-4震撼发布:GPT-4 is OpenAI’s most advanced system, producing safer and more useful responses, 多模态大模型,直接升级ChatGPT、必应,开放API,游戏终结了?, OpenAI 既发布了论文(更像是技术报告)、 System Card,把 ChatGPT 直接升级成了 GPT-4 版的,也开放了 GPT-4 的 API。
- OpenAI 官方发布视频GPT-4 Developer Livestream
- GPT-4 发布后,OpenAI 直接升级了 ChatGPT。ChatGPT Plus 订阅者可以在 chat.openai.com 上获得具有使用上限的 GPT-4 访问权限。要访问 GPT-4 API(它使用与 gpt-3.5-turbo 相同的 ChatCompletions API),用户可以注册等待。OpenAI 会邀请部分开发者体验。获得访问权限后,用户目前可以向 GPT-4 模型发出纯文本请求(图像输入仍处于有限的 alpha 阶段)。至于价格方面,定价为每 1k 个 prompt token 0.03 美元,每 1k 个 completion token 0.06 美元。默认速率限制为每分钟 40k 个 token 和每分钟 200 个请求。
GPT-4 的上下文长度为 8,192 个 token。OpenAI 还提供了 32,768 个 token 上下文(约 50 页文本)版本的有限访问,该版本也将随着时间自动更新(当前版本 gpt-4-32k-0314,也支持到 6 月 14 日)。定价为每 1K prompt token 0.06 美元和每 1k completion token 0.12 美元。
GPT-4 实现了以下几个方面的飞跃式提升:
- 强大的识图能力;
- 文字输入限制提升至 2.5 万字;
- 回答准确性显著提高;
- 能够生成歌词、创意文本,实现风格变化。
GPT-4 可以接受文本和图像形式的 prompt,新能力与纯文本设置并行,允许用户指定任何视觉或语言任务。
OpenAI 今天还开源了 OpenAI Evals,这是其用于自动评估 AI 模型性能的框架。OpenAI 表示此举是为了让所有人都可以指出其模型中的缺点,以帮助 OpenAI 进一步改进模型。
GPT-3.5 和 GPT-4 之间的区别很微妙。当任务的复杂性达到足够的阈值时,差异就会出现 ——GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。为了了解这两个模型之间的差异,OpenAI 在各种基准和一些为人类设计的模拟考试上进行了实验。OpenAI 还在为机器学习模型设计的传统基准上评估了 GPT-4。
- GPT-4 大大优于现有的大型语言模型,以及大多数 SOTA 模型
- GPT-4 基本模型在此任务上仅比 GPT-3.5 略好;然而,在经过 RLHF 后训练之后,二者的差距就很大了。
按照 demo 视频里 OpenAI 工程师们的说法,GPT-4 的训练在去年 8 月完成,剩下的时间都在进行微调提升,以及最重要的去除危险内容生成的工作。
GPT-4 在 RLHF 训练中加入了一个额外的安全奖励信号,通过训练模型拒绝对此类内容的请求来减少有害的输出。奖励是由 GPT-4 的零样本分类器提供的,它判断安全边界和安全相关 prompt 的完成方式。为了防止模型拒绝有效的请求,团队从各种来源(例如,标注的生产数据、人类的红队、模型生成的 prompt)收集多样化的数据集,在允许和不允许的类别上应用安全奖励信号(有正值或负值)。
这些措施大大在许多方面改善了 GPT-4 的安全性能。与 GPT-3.5 相比,模型对不允许内容的请求的响应倾向降低了 82%,而 GPT-4 对敏感请求(如医疗建议和自我伤害)的响应符合政策的频率提高了 29%。
尽管功能已经非常强大,但 GPT-4 仍与早期的 GPT 模型具有相似的局限性,其中最重要的一点是它仍然不完全可靠。OpenAI 表示,GPT-4 仍然会产生幻觉、生成错误答案,并出现推理错误。
GPT-4 原理
【2023-3-26】GPT-4来了,但大模型的诸多未解之谜仍然未解
“GPT-4 未解之谜” 文章要点总结如下:📝
- ❶ 上下文学习出错:ChatGPT 可以分析文章、问题,并生成回答。但是有时候它会过于关注上下文,导致回答不完全准确,生成的答案会很容易被上下文“诱导”。
- (案例:给定问答案例,要求 ChatGPT 举一反三)🎣
- ❷ 思维链推理出错:在有些情况下,使用思维链可能会产生错误的结果,导致逻辑上不太合理或不一致。如果有错误的前提存在,那么思维链的效果就可能会变得更糟。但在某些情况下,思维链也能发现推理过程中的一些问题,从而推翻题设。这种时好时坏的现象,目前仍是“迷之存在”
- (案例:要求 ChatGPT 证明 1208 + 28/20 = 100 )😵💫
- ❸ 幻觉之谜:人类提问者用非常确定地语气说出一些事实性的错误时,ChatGPT 会有一些不稳定的表现,可能有 3 种反应方式
- 承认错误后重述原来的回答(割裂感);
- 持续捍卫自己的观点,并做解释;
- 进入和稀泥状态,给出似是而非的回答,不放弃自己的观点,也不完全否认提问者的想法。
- (案例:ChatGPT 是由 MIT 的科学家发明的)🫠
GPT-4 出现后,推理、幻觉问题有所缓解,但是还不能说彻底解决。
从上面的与 ChatGPT 的测试中,我们发现有三大谜团,上下文推理之谜,思维链推理之谜,幻觉之谜。在处理这些场景时,需要格外谨慎…(详见正文) 🤔
【2023-7-9】 GPT-4
- 模型结构:MoE/ 16 experts/ 800b 参数
- 训练代价:5 万张 A100 实验和训练,3-4 万张A100 做 inference,人均 500 张卡做实验
- 数据量:30 T
详见:MoE 专题
微软报告
【2023-3-22】微软GPT-4报告
- 154页pdf《通用人工智能火花:GPT-4早期试验(Sparks of Artifificial… )》源论文&中文翻译
- 原文:Sparks of Artificial General Intelligence: Early experiments with GPT-4

- 译文:人工通用智能的星星之火:GPT-4的早期实验
- 【2023-3-30】真格基金解读, GPT-4 可以完成涉及数学、编程、视觉、医学、法律、心理学等新颖而困难的任务,同时无需任何特殊提示。
摘要
- 除了语言理解,GPT-4可以解决跨越数学、编码、视觉、医学、法律、心理学等新颖、困难的任务,而不需要任何特别提示。
- GPT-4具备空间理解、音乐谱写、代码、使用工具、有限推理、数学、医学等能力,在表现惊人地接近人类的表现,而且大大超过之前的模型,如ChatGPT。
- 局限:会编造内容、会继承一些训练模型中的偏见等。
- 鉴于GPT-4能力的广度和深度,可以被合理地视为
人工通用智能(AGI)系统的早期版本(但仍不完整)。
GPT-4 应用
【2023-2-8】微软发布GPT-4支持的Bing和Edge浏览器,强大模型使搜索引擎也得到20年来最大提升
- 微软在此基础上训练了专用模型Prometheus,不仅支持聊天、写作等新功能,搜索本身的性能也取得了巨大提升 —— “实现了20年来相关性方面的最大跃升”
新的 Bing 体验是四项技术突破的结晶:
- 下一代 OpenAI 模型。 我们很高兴地宣布,新的 Bing 正在运行一种新的下一代 OpenAI 语言大模型,该模型比 ChatGPT 更强大,并且专门针对搜索进行了定制。 它吸取了 ChatGPT 和 GPT-3.5 的重要经验和进步——而且速度更快、更准确、功能更强大。
- 微软Prometheus模型。 我们开发了一种使用 OpenAI 模型的专有方法,使我们能够最好地利用它的力量。 我们将这种能力和技术的集合称为 Prometheus 模型。 这种组合为您提供更相关、更及时和更有针对性的结果,同时提高了安全性。
- 将人工智能应用于核心搜索算法。 我们还将 AI 模型应用于我们的核心 Bing 搜索排名引擎,从而实现了20年来相关性方面的最大跃升。 有了这个 AI 模型,即使是基本的搜索查询也更加准确和相关。
- 新的用户体验。 我们正在重新构想你与搜索、浏览器和聊天的交互方式,将它们整合到一个统一的体验中。 这将开启一种全新的互联网交互方式。
这些突破性的新搜索体验之所以成为可能,是因为微软致力于将 Azure 打造成为面向全球的 AI 超级计算机,而 OpenAI 已使用该基础设施来训练目前正在针对 Bing 进行优化的突破性模型。
GPT-4多模态
- 模态是指一些表达或感知事物的方式。语音、语言、图像等属于天然的、初始的模态,情绪等属于抽象的模态。
- 多模态即是从多个模态表达或感知事物。多个模态也可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,即图片与文本语言的关系。
为什么要用多模态
- 图灵奖得主 Yann LeCun 对于人工智能前景的最新思考。
- 「语言只承载了所有人类知识的一小部分;大部分人类知识、所有动物知识都是非语言的;因此,大语言模型是无法接近人类水平智能的,」
为什么多模态学习要比单模态学习效果好?
- 多模态学习可以聚合多源数据的信息,使得模型学习到的表示更加完备。以视频分类为例,同时使用字幕标题等文本信息、音频信息和视觉信息的多模态模型要显著好于只使用任意一种信息的单模态模型,这已经被多篇文章实验验证过。
预训练任务
- Masked Language Modeling(
MLM)- 在 sentence tokens 中随机 MASK 掉一些 token,然后模型基于其他的本文 token 和所有的图像 token 来预测这些被 mask 掉的 token。
- Masked Region Modeling(
MRM)- 采样视觉region或者patch,并以15%概率掩码,使用剩余的视觉特征和文本特征对掩码进行回归或预测。计算 Faster R-CNN 特征和 Mask region 的分布差异,使得 Mask region 的分布和 Faster R-CNN 特征的分布尽可能相似,所以损失函数用的是 KL 散度。
- Masked Feature Classification(
MFC)- 每个 region 都会有 Faster R-CNN 得到一个 label,模型需要预测 mask token 的类别,使之和 Faster R-CNN 的 label 相同。
- Image-Text Matching(
ITM)- 通过[CLS]来预测两种模态的输入是否匹配。需要对输入的 Image-Text Pair 随机替换 Image 或者 Text,最后预测输入的 Image 和 Text 是否有对应关系,所以这是一个二分类的问题。
- Vision-Language Contrastive Learning(
VLC):- 从对比学习的角度,对于batch大小为N的图像-文本对,其中含有N个正样本,其余配对N^2-N都是负样本。
- Word-Region Alignment(
WRA):- 以无监督的方式对齐单词和视觉region或patch,使用了最优传输理论,OT提供了一种最优化单词和视觉region或patch对齐的方案。
下游任务
- Visual Question Answering (
VQA)- VQA 就是对于一个图片回答图片内容相关的问题。将图片和问题输入到模型中,输出是答案的分布,取概率最大的答案为预测答案。
- Natural Language for Visual Reasoning (
NLVR)- 同时输入两张 Image 和一个描述,输出是描述与 Image 的对应关系是否一致,label 只有两种(true/false)
- Visual Commonsense Reasoning (
VCR)- 任务是以选择题形式存在的,对于一个问题有四个备选答案,模型必须从四个答案中选择出一个答案,然后再从四个备选理由中选出选择这个答案的理由。
- Grounding Referring Expressions (
GRE)- 给定文本,选择文本所关联的图片区域。即输入是一个句子,模型要在图片中圈出对应的 region。对于这个任务,我们可以对每一个 region 都输出一个 score,score 最高的 region 作为预测 region。
- Multi-modal Sentiment Analysis (
MSA)- 通过利用多模态信号(例如视觉、语言等)来检测视频中的情绪。它是作为一个连续的强度变量来预测话语的情感取向
- Vision-Language Retrieval (
VLR)- 在 Image-Text Retrieval 任务中,就是给定一个模态的指定样本,在另一个模态的 DataBase 中找到对应的样本。这个任务 Image-Text Matching 任务非常相似,所以在 fine-tune 的过程中就是选择 positive pair 和 negative pair 的方式来训练模型。
其它多模态
详见专题:多模态新模型
Image GPT
【2020-1-17】Image GPT 将 GPT 模型用于图像领域,将图像按照像素排列,媲美 CNN,code
We find that, just as a large transformer model trained on language can generate coherent text, the same exact model trained on pixel sequences can generate coherent image completions and samples. By establishing a correlation between sample quality and image classification accuracy, we show that our best generative model also contains features competitive with top convolutional nets in the unsupervised setting.
【2023-3-8】谷歌发布了个多模态模型 PaLM-E,使用传感器数据、自然语言、视觉训练,能直接用人话操作机器人完成任务。
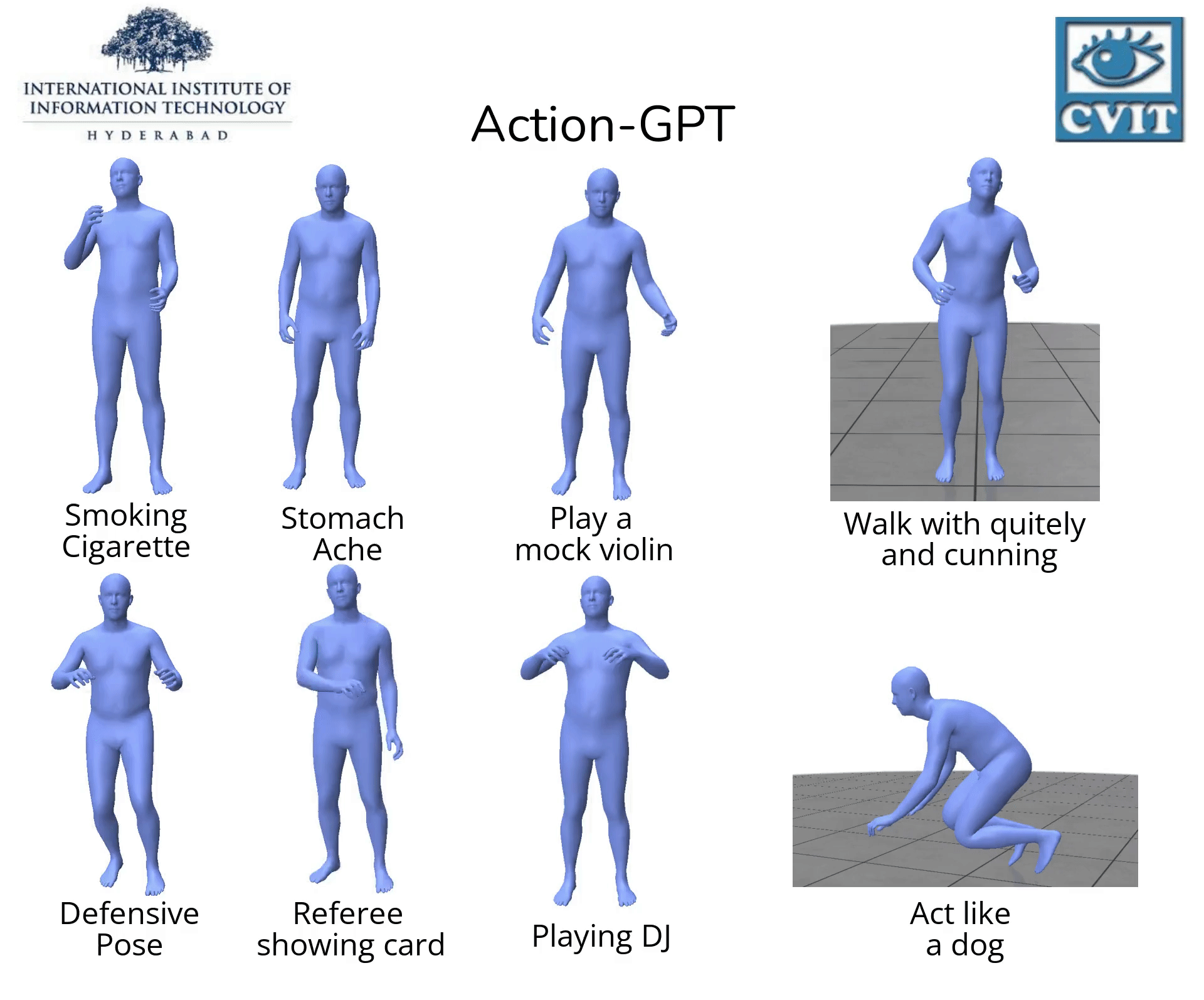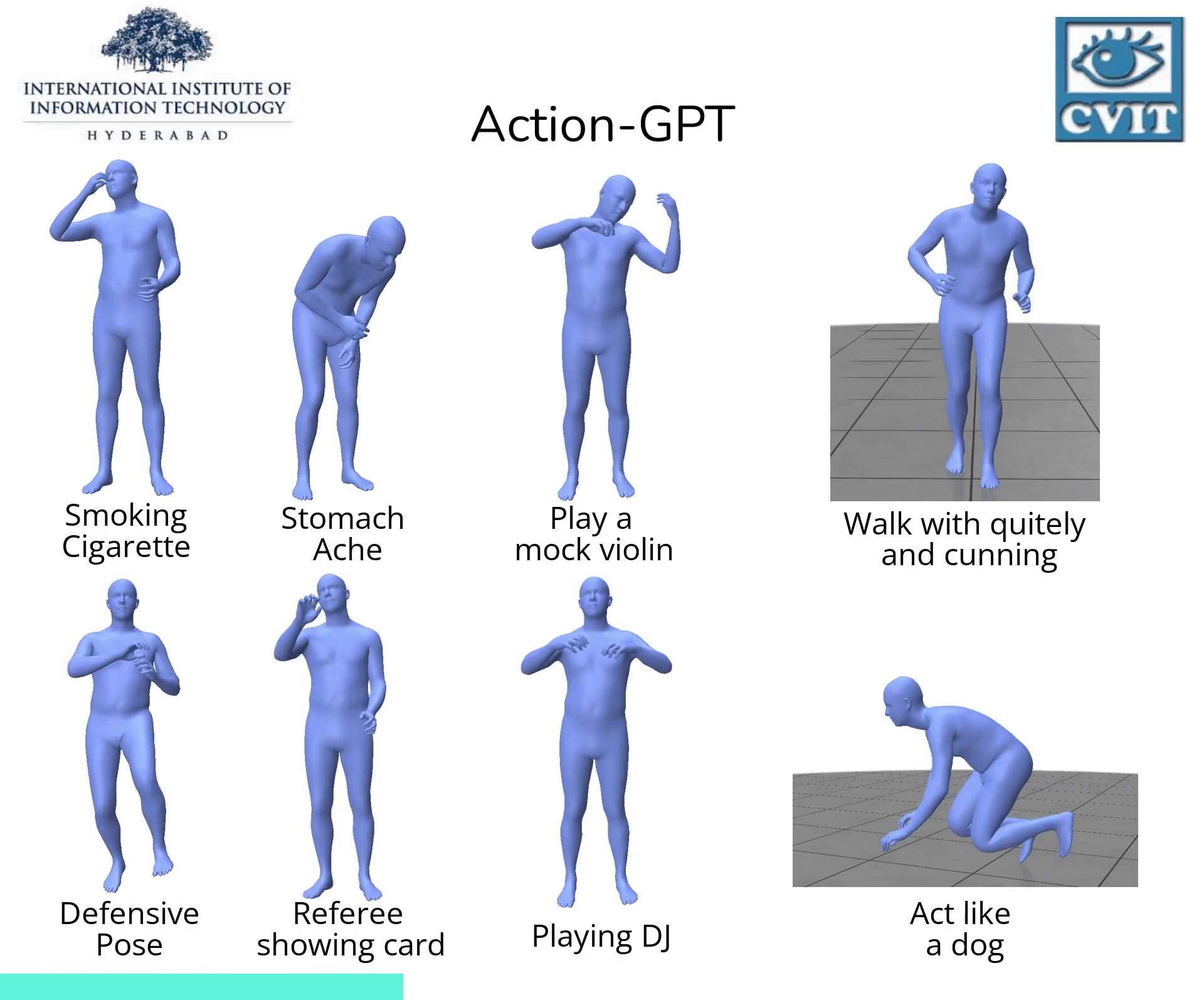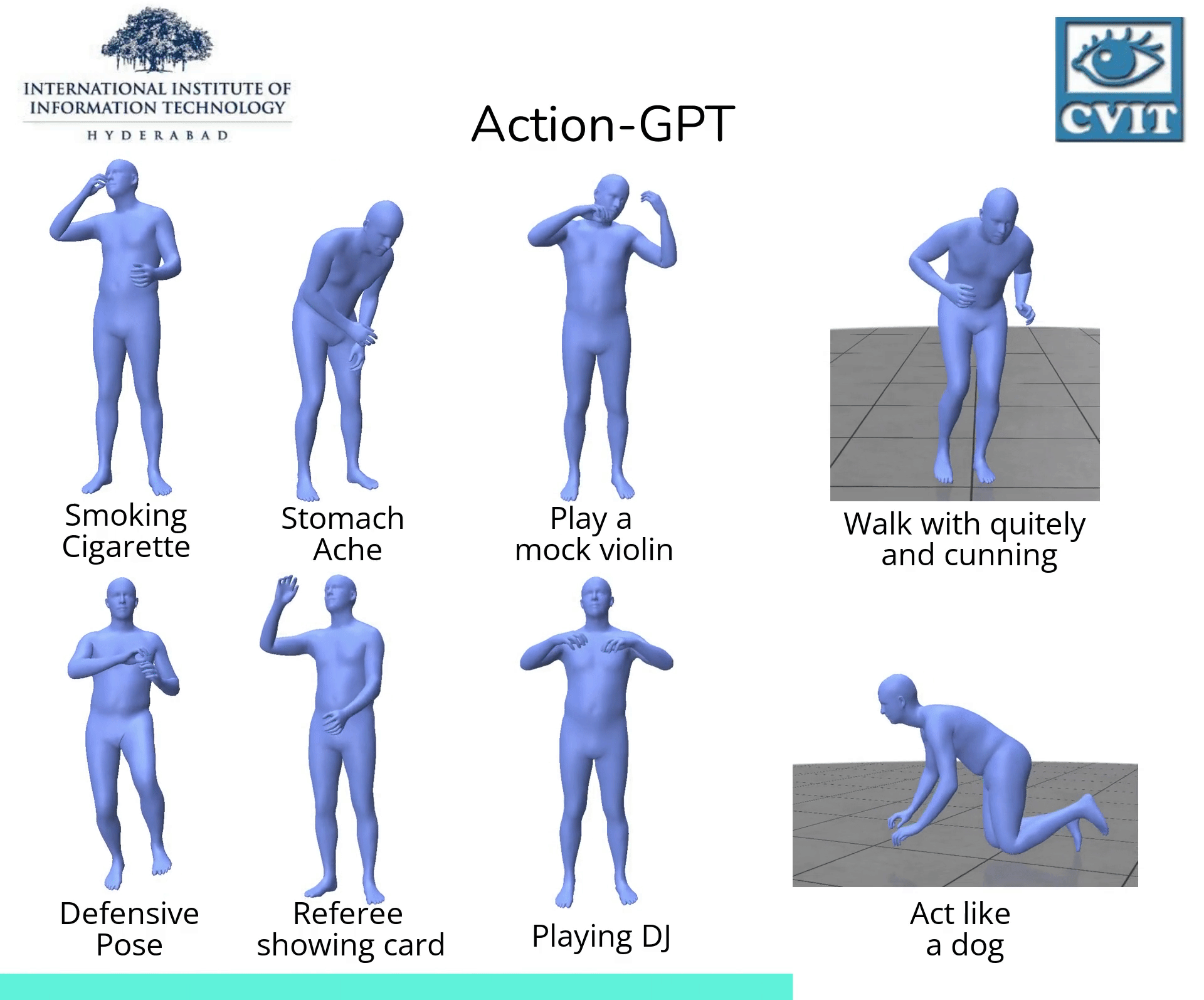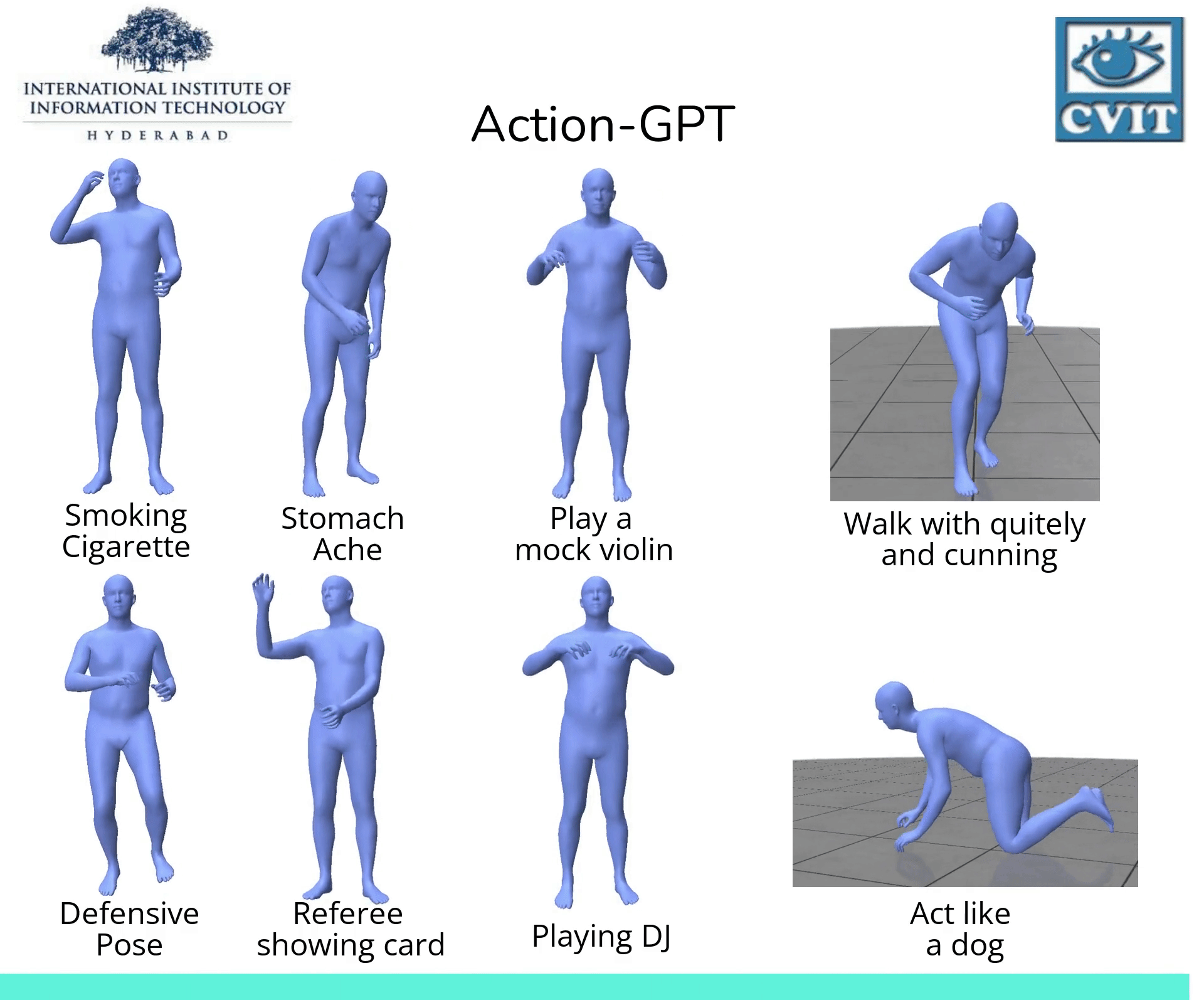
Action-GPT
【2023-3-22】Action-GPT:利用GPT实现任意文本生成动作
除了文本生成图片,也有许多其他的文本引导生成任务,例如基于文本生成视频,基于文本生成动作,这些研究在诸如娱乐,虚拟现实和机器人等领域均有大量应用。
- 论文:Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation, demo
 , code
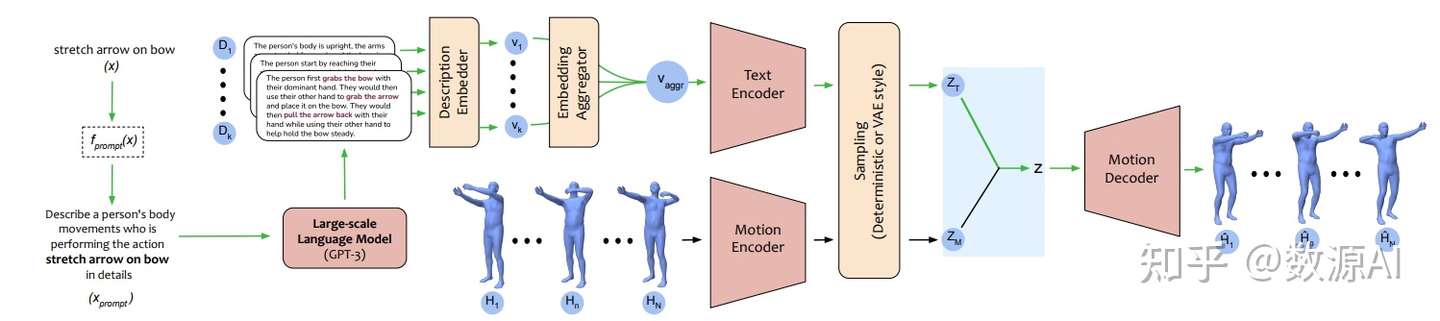
, code- Action-GPT是一种插即用的框架,可用于将大型语言模型 (LLM) 合并到基于文本的动作生成模型中。鉴于当前的动作短语运动捕捉数据集包含最少的和最重要的信息, Action-GPT首先通过为 LLM 精心制作prompt提示,生成更丰富、更细粒度的动作描述,再利用这些详细描述来代替原始动作短语,从而更好的对齐文本和运动空间。
- Action-GPT主要由Text Encoder,Motion Encoder,Motion Decoder组成,其中Text Encoder,Motion Encoder分别将文本序列和动作序列编码为特征向量。
- 给定一个动作短语x,首先使用prompt函数 fprompt(x)生成一个合适的prompt文本xprompt。然后将xprompt输入到大规模语言模型(GPT-3)中获取包含更细粒度动作细节的多个动作描述Di。
- 然后利用一个Description Embedder获得每个Di相应的深度文本表征vi,再利用Embedding Aggregator进行融合后输入到Text Encoder中。
训练数据集
- 大规模BABEL数据集 ,其中的语言标注描述了 mocap 序列中正在进行的动作。 包括来自 AMASS 数据集的约 43 小时的 mocap 序列的动作标注。
实验表明
- 基于 MotionCLIP, TEMOS 以及 TEACH 三种方法,Action-GPT 框架在BABEL测试集上的结果均有较大提升:
- Action-GPT更强大的能力在于零样本生成(Zero-Shot Generations)。利用GPT-3的强大语言能力,Action-GPT还可以根据未见过的文本短语生成动作序列 。
GPT-5
【2023-3-24】预测一下,GPT-5 会在什么时候发布,又会有哪些更新
- 预计GPT-5大概率是在24年~25年发,出处:ChatGPT-5 Release Date (Predictions)
- GPT-5之前,会先发布一个GPT-4.5的过度版本,大概23年9月-10月发布
GPT-4.5 的未来增强功能
未来的 GPT-4.5 模型将通过改进其性能和扩展其潜在应用来解决其前身的一些局限性。可以预期的主要改进包括:
- 处理较长的文本输入: GPT-4.5 模型可能能够处理和生成更长的文本输入,同时保持上下文和连贯性。这一改进将使该模型在处理复杂任务和理解用户意图方面更加通用。
- 增强主题连贯性: 将来,GPT-4.5 可能会提供更好的主题连贯性,确保生成的文本在整个对话或内容生成过程中始终专注于相关主题。
- 更准确的回应: 随着模型的不断发展,GPT-4.5 可以提供更准确和上下文相关的响应,使其成为适用于各种应用程序的更有效的工具。
- 改进的微调功能: 此外,GPT-4.5 将带来微调能力的进步。这将使开发人员能够针对特定任务或领域更有效地调整模型。这将使为各种应用程序定制模型变得更加容易,例如客户支持、内容创建和虚拟帮助。
【2023-10-09】GPT-5和GPT-6将具备多模态输出能力,相比现有的GPT可靠性更高、个性化定制体验更好。
GPT-5会具备语音识别、合成和情绪检测等新功能来看,GPT-5应该会具备“图文听说”等各种模态对齐的能力。
借着GPT-5和GPT-6的话题,奥特曼还给大模型“布了个道”:
- 现在,大模型领域的“
摩尔定律”(Scaling Laws)已经开始发挥作用。大模型训练成本正变得更低、调用GPT接口的价格将变得更便宜。
奥特曼表示“距离AGI之路都还有很远” —— 无论是GPT-5还是GPT-6,都还远远不及AGI。
甚至光是“像人”这一标准,现阶段就还没AI Chatbot能做到:
- 即使背后用上了最前沿的AI技术,也没让我感觉到在和一个“人”聊天。
真正的AGI将能够掌握“自行推理”,即随着时间推移发展出新知识。像是能够根据物理学已有知识,写论文、做实验的AI,才能够得上AGI的门槛。
谨慎对待AI的输出结果:
- 人们会原谅人犯错误,但不会原谅计算机,二者的标准是不一样的。
对于AGI时刻的来临,奥特曼也给出了一个想象:
- 到那个时候,人们可能会经历一定程度的自我认同危机,但不会太糟糕和混乱。我们经历过很多次这样的时刻,技术终将变得无处不在。
OpenAI 政变
- 【2023-11-22】OpenAI新模型曝重大飞跃:AGI雏形或威胁人类,也成Altman被解雇导火索
- 【2023-11-24】导致Sam离职风波背后的OpenAI最近的技术突破——Q*项目信息汇总
Sam Altman在APEC上曾暗示:OpenAI已经开发出比现在GPT-4更强大、远远超出人们期待的东西。
- 模型能力将会有一个无人预料到的飞跃。与人们的预期不同,这个飞跃是惊人的!
- 现在正在发生的技术变革,将彻底改变我们生活方式、经济和社会结构以及其他可能性限制……这在OpenAI的历史上有四次 ,而最近一次,就是在过去几周内。
- 在拨开无知的面纱和探索未知的边界时,我有幸在场, 这是我职业生涯中的荣幸。
OpenAI首席科学家Ilya Sutskever主导的技术突破,引起了一些员工的担忧。他们担心公司没有合适的保障措施,来将这种先进的AI模型商业化。 在接下来的几个月里,OpenAI的高级研究人员又利用这项创新,建立了能够解决基本数学问题的系统。 经常用大模型的人都知道,数学问题对于现有的LLM,都是一项艰巨的任务。
一天后,他被解雇了。
- 一封据称发给董事会的警告信也显示,OpenAI的某个模型,内部已产生重大飞跃。
- 被解雇的前四天,OpenAI内部的研究员曾向董事会发了一封警告信,称发现了一个可能威胁人类的强大人工智能。
- 曾任OpenAI临时CEO的Mira Murati,在周三提到了这个名为Q*(读作Q-Star)的项目,并且在「政变」发生之前给董事会写过一封信。
对齐派 VS 加速派
- 对齐团队:虽然超级AI还很遥远,但会在十年内到来。
- 加速派:Altman和Greg Brockman,对于这项技术也持支持态度,致力于将其整合到新产品中。Pachocki和Sidor大概率是在Ilya对齐团队的反面。
Q star
OpenAI董事会突然把Sam开除的事件已经结束,闹了好几天之后Sam回归,董事会改组。而这件事的背后导火索有许多传闻,其中最重要的一个是OpenAI可能在最近有一项重大的技术突破,被认为是Sam和董事会分歧的重要原因。而今天,国外的路透社独家消息提到OpenAI内部一个称为Q*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。
Q Star是一个OpenAI内部的新模型,它可以解决一些数学问题。内部人士表示,虽然Q*模型目前仅仅可能只有小学生的水平,但是它可以解决一些数学问题。而与此前数学推理模型不同的是,Q* 模型可能不是通过检索来解决问题,而是有可能有一点真正的人类推理能力。
斯坦福AI博士生 Silas Alberti从命名习惯和能力上猜测,Q*可能是Q-Learning和A*的结合, 或者是表示贝尔曼方程的最优解。
- Q-Learning是强化学习的一种方法,而
A*算法用于在图形(如地图或网络)中找到从一个节点(起点)到另一个节点(目标)的最短路径。 A*算法和 Q-Learning可能结合的原因是基于这两种算法的互补特性,这种结合可以在复杂的决策环境中发挥出更强大的能力。
二者结合的潜在原因包括:
- 互补性:A* 算法在已知环境中表现出色,而 Q-Learning在处理不确定性和学习环境动态方面更有效。将这两者结合可能创建一种能够有效处理复杂、动态环境的算法。
- 路径规划和决策制定:A* 提供了有效的路径规划能力,而 Q 学习能在不确定环境中作出最优决策。结合它们可能使算法能在不确定性较高的环境中找到最优路径,并在此过程中适应环境变化。
- 提高效率:A* 的启发式搜索可以指导 Q-Learning更快地收敛到最优解,而 Q-Learning的适应性可以帮助 A* 算法更好地处理动态变化的环境。
结合 A* 算法和 Q-Learning可能会产生一种既能有效规划路径,又能适应环境变化并进行复杂决策制定的算法,这应该可以大大提高大模型的泛化和推理能力。
贝尔曼最优解(Bellman Optimal Equation)是强化学习和动态规划领域的一个核心概念,由理查德·贝尔曼(Richard Bellman)提出。这个方程式描述了在一个决策过程中,如何找到使长期回报最大化的策略。
不管怎么说,这种猜测都指向Q*很可能是一种采用了 AlphaGo 风格的蒙特卡洛树搜索,这种技术可能会让大模型大大提高推理能力。而且可能极大提高数学问题的解决能力,与报道传闻的突破一致。
GPT-Zero
2021年,OpenAI的科学家Ilya Sutskever在OpenAI内部启动GPT-Zero模型项目,目的是找出一条可行的路径让GPT-4模型能够解决推理、数学或者科学类的问题。而这也是类似DeepMind的AlphaGO的项目。
AlphaGo首次引起广泛关注是在2016年,当时它在一场历史性的比赛中战胜了世界级围棋冠军李世石。- 此后,
AlphaGo继续进化,其改进版本AlphaGo Zero甚至能够在没有任何人类围棋知识的情况下,仅凭自我对弈学习并达到超越专业水平的能力。
AlphaGo Zero 已经不需要人类棋谱来提升能力,而是通过自我对弈学习提升。这也是OpenAI的GPT-Zero可能想解决的问题。
- 即克服没有高质量数据情况下解决模型的继续训练。
而Ilya Sutskever的GPT-Zero的目的也是希望可以用计算机生成的数据而不是真实的数据来解决模型训练数据缺乏的瓶颈
GPT入门版
详见站内专题: GPT-2入门理解
中文GPT
【2023-1-12】GPT中文版:GPT2-Chinese,Chinese version of GPT2 training code, using BERT tokenizer.
- 中文的GPT2训练代码,使用BERT的Tokenizer或Sentencepiece的BPE model。
- 可以写诗,新闻,小说,或是训练通用语言模型。支持
字为单位、分词模式、BPE模式。支持大语料训练。
好玩儿的案例
【2021-10-14】爆肝100天,我开发了一个会写作文的人工智能【17亿参数、2亿数据、1万行代码】 EssayKiller
- 一个基于OCR、NLP领域模型所构建的生成式文本创作AI框架,目前第一版finetune模型针对高考作文(主要是议论文),可以有效生成符合人类认知的文章,多数文章经过测试可以达到正常高中生及格作文水平。视频中有部分细节为了方便非AI专业的观众理解,以及为了更好的节目效果,做的略有不严谨。由于要控制时长我没有展开讲,业内大佬们见谅。技术上的问题欢迎Github
CPM 清华智源(GPT-3)
【2020-11-17】中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型



北京智源人工智能研究院和清华大学研究团队合作开展大规模预训练模型,并发布清源CPM (Chinese Pretrained Models) 研究计划,旨在推动中文自然语言处理的研究与应用。
- 2020 年 11 月中旬,CPM 开放第一阶段的26 亿参数规模的中文语言模型 (CPM-LM) 和217亿参数规模的结构化知识表示模型 (CPM-KM) 下载,以及相应的系统演示。
清源 CPM 大规模预训练模型具有以下特点:
- 学习能力强:能够在多种自然语言处理任务上,进行零次学习或少次学习达到较好的效果。
- 语料丰富多样:收集大量丰富多样的中文语料,包括百科、小说、对话、问答、新闻等类型。
- 行文自然流畅:基于给定上文,模型可以续写出一致性高、可读性强的文本,达到现有中文生成模型的领先效果。
- 模型规模大:本次发布的 CPM-LM 的参数规模为 26 亿,预训练中文数据规模100 GB,使用了 64 块 V100 GPU 训练时间约为 3 周。CPM-KG 的参数规模分别为217亿,预训练结构化知识图谱为 WikiData 全量数据,包含近 1300 个关系、8500万实体、4.8 亿个事实三元组,使用了 8 块 V100 GPU 训练时间约为 2 周。
资料
- 清源CPM主页
- 清源CPM Github
- 预训练模型必读论文列表
- 清源 CPM-中文GPT3-我魔改出了一个TF版本
PLUG——阿里达摩院 (GPT-3)
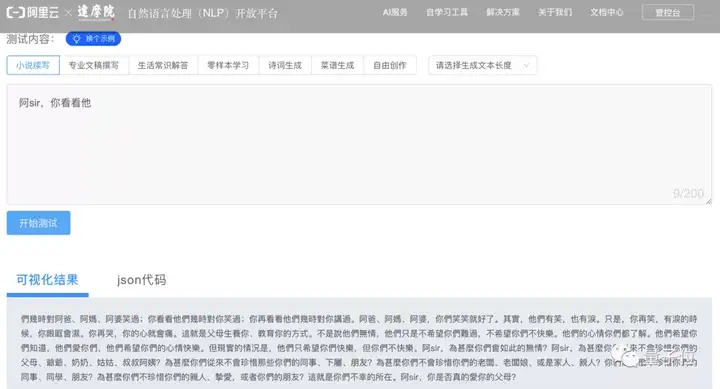
【2021-4-19】达摩院用128张GPU烧出“中文版GPT-3”,我试了下,这文风不是开往幼儿园的车…
PLUG,Pre-training for Language Understanding and Generation,顾名思义,就是集语言理解(NLU)和生成(NLG)能力于一身。要实现这一点,据团队介绍,这一模型是达摩院此前提出的两种自研模型——NLU语言模型StructBERT、NLG语言模型PALM的融合。
此外,跟GPT-3的单向建模方式不同的是,它采用了编码器-解码器(encoder-decoder)的双向建模方式。整个训练过程分为两个阶段。
- 第一阶段,以达摩院自研的语言理解模型——
StructBERT作为编码器。在句子级别和词级别两个层次的训练目标中,加强对语言结构信息的建模,从而提高模型的语法学习能力。这也使得PLUG具有输入文本双向理解能力,能够生成和输入更相关的内容。这个过程共训练了300B tokens训练数据。 - 第二阶段,将这个编码器用于生成模型的初始化,并外挂一个6层、8192个隐藏层节点数的解码器,共计训练了100B tokens的训练数据。
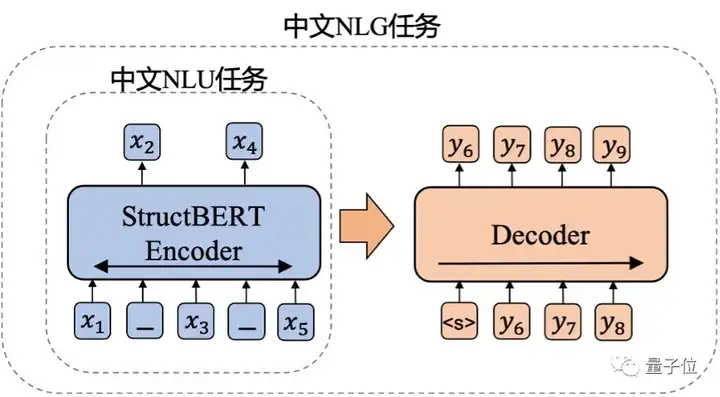
PLUG还能为目标任务做针对性优化。GPT-3并没有利用微调和梯度更新,而是通过指定任务、展示少量演示,来与模型文本进行交互,完成各种任务。因此在面对新任务时候,不需要重新收集大量的带标签数据。但不可避免的,生成的效果不足。比如,犯低级错误就是GPT-3被人诟病比较多的一点。而PLUG的能力更加全面,既可以实现与GPT-3类似的零样本生成功能,也可以利用下游训练数据微调(finetune)模型,提升特定任务的生成质量。
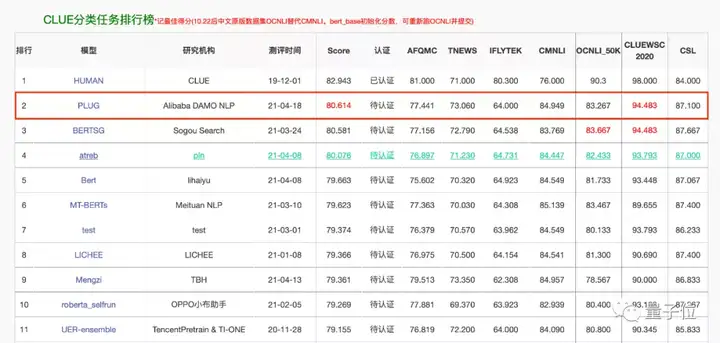
当然,效果实现的关键,还少不了算力和数据。PLUG负责人表示,原本计划用128张A100训练120天炼成,不过由于阿里云、算法优化等达摩院多方力量的参与,以及加速手段的有效利用,成功将日程缩短到三分之一。最后,只烧了35天就达到了这样的效果。前面也提到,PLUG的参数量达到了270亿,中文训练数据量也达到了1T以上。在语言理解任务上,PLUG以80.614分刷新了CLUE分类任务榜单记录。而在语言生成任务上,据团队介绍,其多项应用数据较业内最优水平提升了8%以上。
耗时3个月、270亿参数规模、一发布就给体验端口
去年,阿里达摩院发布了自研深度语言模型体系,包括6大自研模型。
- 通用语言模型 StructBERT
- 多模态语言模型 StructVBERT
- 多语言模型 VECO
- 生成式语言模型 PALM……
他们一直在致力于陆陆续续将模型开源出来。
阿里达摩院开源GPT-3
【2023-02-09】 GPT3中文开源
ModelScope官方已经支持的批量推理的模型和Pipeline:
- NLP领域各文本分类任务对应的各模型(包括情感分析、句子相似度、自然语言推理或用户Finetune后的模型)和Pipeline
- NLP领域各序列标注任务对应的各模型(包括中文分词、多语言分词、各NER任务的模型,或用户FInetune后得到的模型)和Pipeline
- NLP领域生成任务对应的各模型(包含Palm、T5等)和Pipeline
- NLP领域翻译任务模型CSANMT
【2023-2-20】实测,支持的任务有限,已反馈官方
示例代码:
- 名义上功能多,但实测后发现只有文本续写(text-generation),效果如上,问答、摘要、情感分析都不支持
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 加载 GPT3模型
model_id = 'damo/nlp_gpt3_text-generation_1.3B'
# Tasks 指定任务类型
# dir(Tasks) # 查看可用任务类别
#p = pipeline('text-generation', model_id) # question_answering
p = pipeline(Tasks.text_generation, model_id) # No module named 'deepspeed'
盘古-华为&循环智能(GPT-3)
2021年4月21日,HDC.Cloud大会上,余承东发布由华为云和循环智能联合开发的盘古 NLP 模型
最近的 CLUE 榜单上,「盘古」在总榜、阅读理解排行榜和分类任务排行榜上都位列第一,总榜得分比第二名高出一个百分点。

- 业界首个千亿参数的中文大模型,拥有 1100 亿密集参数,由循环智能(Recurrent AI)和华为云联合开发,鹏城实验室提供算力支持。
- 为了训练这个模型,田奇(华为云人工智能首席科技家)与杨植麟(循环智能联合创始人)联合带领的研究团队花了近半年的时间,给模型喂了 40TB 的行业文本数据和超过 400 万小时的行业语音数据。
GPT-3 是 OpenAI 在2020年5月份发布的语言模型,不仅可以答题、翻译、写文章,还带有一些数学计算的能力,因此在人工智能领域掀起了一场巨浪。
- GPT-3 很强,这是社区公认的事实,所以循环智能最初是想开发一个中文版 GPT-3。
但在开发过程中,他们发现:GPT类模型在复杂的商业场景中既不好用,也不高效。
- (1)GPT 对于复杂商用场景的少样本学习能力较弱。
- Schick 和 Schutze 已经在 PET 工作中证明:在少样本学习方面,千亿参数的 GPT-3 模型的语言理解能力还比不上亿级参数量的 BERT。
- (2)GPT-3 对于微调并不友好,在落地场景中难以进一步优化
- 商业场景对于模型的准确率和召回率有着很高的要求。虽然 P-Tuning 等工作提出了针对 GPT-3 的新型微调方式,但在面对复杂场景时,仍然难以通过使用更多标注数据对 GPT-3 进行进一步优化。
- 杨植麟:「比如说我们现在用到的一个场景里面,通过少量样本得到 GPT-3 的准确率是 65%。在学术研究的语境下,这个准确率听起来也不是很差,但是你实际场景就没法用。这时我们要加一些数据对模型进行优化,要做到 90% 才能用,但我们实验发现 GPT-3 结合微调的提升并不明显,这就大大限制了它的使用场景。」
- (3)GPT-3 只能进行直接的、端到端的生成(把知识库做成很长的一段文字,直接放进 prompt 中),难以融入领域知识
- GPT-3 是一个百科全书式的存在,但在很多落地场景中,我们更需要的是一个领域「专家」。
- 为了打造这个「专家」,我们需要将行业的知识库接入 AI 流水线,将通用 AI 能力跟行业知识相结合,实现基于行业知识的精确理解和预测。
如何提高少样本学习能力?
为了克服少样本学习难题,循环智能的研究团队进行了两方面的努力。
- 一是利用迁移学习。与 GPT-3 的少样本学习方式不同,盘古模型的技术路线是通过元学习的方式在任务之间进行迁移,从而实现少样本学习的目标。这种方式可以更好地利用任务之间的相似性,得到更好的少样本学习结果。
- 二是将 P-tuning、priming 等最新技术融入到盘古的微调框架中,进一步提升微调效果。
CNN、中文版 GPT-3(CPM)、BERT、RoBERTa 和盘古在少样本场景下的学习能力

如何解决大模型微调难题?
大模型微调难题的解决也分为两个方面。
- 首先,为了增强预训练与微调的一致性,研究者在预训练阶段加入了基于 prompt 的任务。Prompt pattern 的选择和数据增强机制保证了微调阶段使用的 prompt 得到充分的预训练,大幅度降低了基于 prompt 的微调的难度。在下游数据充足时,微调难度的降低使得模型可以随着数据变多而持续优化;在下游数据稀缺时,微调难度的降低使得模型的少样本学习效果得到显著提升。
- 其次,随着预训练模型规模的增大,微调难度不断上升,过拟合十分严重。因此,分析过拟合的主要来源,采用了 gradient dropout 等机制对微调过程进行正则化,可以较大程度缓解过拟合的问题。
彩云小梦

总结:
- 小梦熟悉小说写作的各种套路,它有着不错的脑洞,能够一定程度上理解前文的脉络,并且不失时机地运用它知道的写作手法。
- 不过,它的缺点也是明显的,依然是缺少常识。这导致它在遣词造句上,会写出不符合人类习惯的奇怪句子。
- 不过小梦显然是值得期待的。甚至现在的网文作者,已经可以把小梦当作工具,在一些特定的场景里,帮助作者寻找情节的突破口。小梦写得还不够好,但它肯定看过的文章比任何人都多,未来可期。
秘塔写作猫
【2022-12-4】秘塔写作猫:AI写作、多人协作、文本校对、改写润色、自动配图等功能,使用 GPT-3,详见资讯
- 秘塔写作猫的这项 AI 生成功能,是中文 AI 生成文本内容的一项应用突破。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
