- 文本生成之序列解码
- 结束
文本生成之序列解码
序列解码
生成式任务比普通的分类、tagging等NLP任务复杂不少。
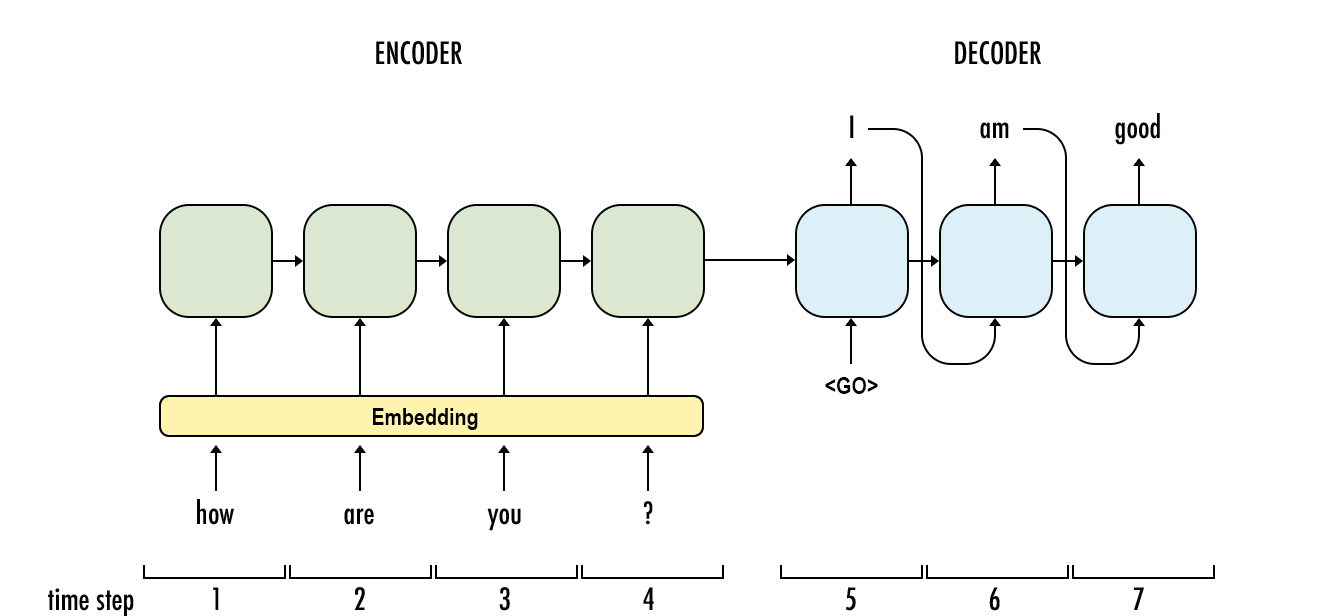
- Seq2Seq模型中,RNN Encoder对输入句子进行编码,生成一个大小固定的 hidden state $h_c$
- 结合先前生成的第1到t-1个词 $x_{1~t-1}$, RNN Decoder会生成当前第t个词的 hidden state $h_t$
- 最后通过softmax函数得到第t个词 $x_t$ 的 词汇概率分布 vocabulary probability distribution $P(x|x_{1:t-1})$
生成时模型一个时间步一个时间步依次输出,前面时间步的结果影响后面时间步的结果。即每一个时间步,模型给出的都是基于历史生成结果的条件概率。
- 生成完整的句子,需要一个称为
解码的额外动作来融合模型多个时间步的输出,使得最终序列的每一步条件概率连乘起来最大。 - 分析
- 每一个时间步可能的输出种类称为
字典大小(vocabulary size,用V表示) - 进行T步随机的生成可能获得的结果总共有$V_T$种。
- 以中文文本生成为例,V的值大约是5000-6000,即常用汉字的个数。
- 每一个时间步可能的输出种类称为
- 基数较大,遍历整个生成空间是不现实的。
详见站内专题: 文本生成及评价
LLM 解码
LLM 解码原理
大模型训练好之后,如何对训练好的模型进行解码(decode)?
- 生成输出文本:模型逐个预测每个 token ,直到达到终止条件(如终止符号或最大长度)。每一步模型给出一个概率分布,表示下一个单词预测。
- 循环迭代的自回归过程中,不断生成新词, 最后构成一段文本
- 【2023-8-4】大模型文本生成——解码策略(Top-k & Top-p & Temperature)
例如,如果输入文本是“我最喜欢的”,那么模型可能会给出下面的概率分布:

自回归问题
自回归解码存在的问题
- 错误级联放大: 一个词有误时, 错误会循环输入, 不断放大,导致模型难以拟合数据集
- 效率低:下一个词依赖上一次预测结果,每次预测都是串行计算,难以并行加速,导致效率低
Teacher Forcing (教师辅导)
- 每轮都仅将输入结果与“标准答案”(Ground Truth)拼接,作为下一轮输入
- 进而加速训练收敛
问题
- 曝光偏差(Exposure Bias): 训练过程与推理过程存在差异,因为推理环节没有标准答案可以参考,导致推理效果差
改进
- Bengio 针对 RNN 提出 Scheduled Sampling 方法: 训练时,循序渐进,部分使用模型自己生成的词,替代“标准答案”, 对推理环节无标准答案的情况进行预演。
采样策略
概率分布中选择下一个单词呢?
常用方法:
- (1) 概率最大化: 选择最常见的样本
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。
- 这种方法简单高效,但每次选择最常见的词,可能导致结果过于单调和重复,多样性不足——废话文学
- 怎么办?增加随机性
- Beam Search (集束搜索/波束搜索):维护一个大小为 k 的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k 个单词,然后保留总概率最高的 k 个候选序列。
- 这种方法可以平衡生成的质量和多样性
- 但是可能会导致生成的文本过于保守和不自然。
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。
- (2) 随机采样(Random Sampling):按照概率分布随机选择一个单词。
- 这种方法可增加多样性,但可能会导致不连贯和无意义。
- 折中: 通过指定候选词数量、划定候选词概率阈值方法来选择
Top-K采样: 指定候选词数量, 选择k个概率最高的词, softmax重新归一化- 优点: 增加文本新颖度
- 缺点: 固定值k的候选集无法容纳更多相近概率的词,导致不同轮次预测结果差异大, 可能导致生成概率小、不符合常规的词,即“胡言乱语”
Top-p采样: 又叫 Nucleus 采样, 解决 Top-p 问题. 划定候选词概率阈值- 优点: 避免选到概率小、不符合常理的词, 减少“胡言乱语”
Temperature机制:- 起因: Top-p 和 Top-k 采样的随机性由语言模型输出概率决定,不可自由调整,以适配不同业务场景。
- temperature 机制可以调节解码随机性。
- 原理: 对 softmax 函数自变量进行尺度变换, 再利用 softmax 非线性控制分布
T>1: 概率差异小,随机性增加0<T<1: 概率差距大, 确定性增加
这些方法各有各的问题,而 top-k 采样和 top-p 采样是介于贪心解码和随机采样之间,目前大模型解码策略中常用的方法。
{
"top_k": 10,
"temperature": 0.95,
"num_beams": 1,
"top_p": 0.8,
"repetition_penalty": 1.5,
"max_tokens": 30000,
"message": [
{
"content": "你好!",
"role": "user"
}
]
}
贪心策略,那么选择的 token 必然就是“女孩”
- 问题: 容易陷入重复循环
Top-k 采样: “贪心策略”的优化- 从排名前 k 的 token 中抽样,允许分数/概率较高的token 有机会被选中。这种抽样带来的随机性有助于提高生成质量。
- 每步只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
- 例如,如果 k=2,那么只从女孩、鞋子中选择一个单词,而不考虑大象、西瓜等其他单词。这样避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
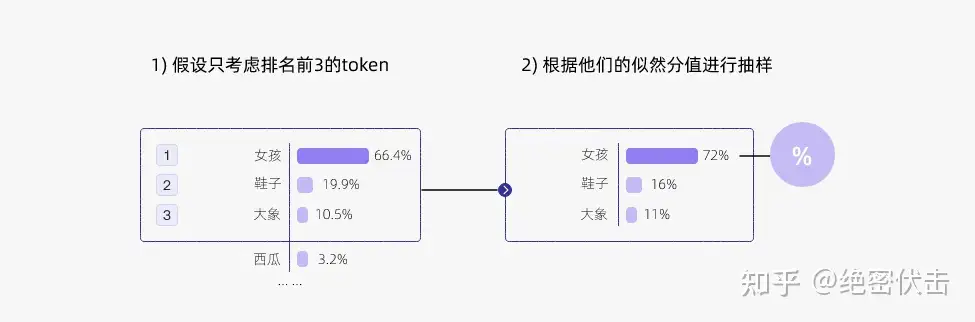
- 通过调整 k 的大小,即可控制采样列表的大小。“
贪心策略”其实就是 k = 1 的top-k 采样。 
LLM稳定输出
Temperature 控制模型输出内容稳定性,因为 LLM 的输出是通过“概率”来排序。
- 如果对同一个问题想要每次输出完全一致的内容,
temperature = 0。 - 而如果想提升 LLM 输出内容的“创意性”,把 temperature 往上增加
- 一般 temperature 在
[0,1]范围获得的结果可用,大于1可能结果就不可用。 - 最好是按不同场景来配置 temperature 的数值,例如写诗就需要更高的 temperature 数值
解码原理
【2019-6-16】文本生成中的decoding strategy整理
解码策略
文本生成 decoding strategy 主要分为两大类:
- (1)
Argmax Decoding: 主要包括 beam search, class-factored softmax 等- 如果vocabulary size较大,达到了50k甚至150k,在softmax层的运算量就会变得非常大, 需要降低复杂度
- ①
Class-factored Softmax:将原本的softmax layer扩展为两层:- 第一层为cluster层,每个cluster中包含一组语意相近的词,每个词只出现在一个cluster中;
- 第二层为word层,输出最后decode的词。
- 尽管cluster层和word层分别包含一个softmax layer,但每一层softmax的分母部分的计算量都大大缩小了。
- cluster的选取对decoding的效果有很大的影响,所以需要选择合适的聚类算法来pre-train高质量的cluster,论文中选用的是Brown cluster。
- 详见论文:Pragmatic Neural Language Modelling in Machine Translation
- ②
Pointer-generator Network- 一层softmax layer,但引入了一个非常强大的copy network,模型训练速度和生成句子的质量都显著高于Seq2Seq + Standard Softmax。
- 首先建立一个很小(如5k)的高频词vocabulary
- 然后建立一个Attention layer,得到输入句子的Attention distribution
- 在decoding阶段,若vocabulary中不存在需要decode的词 xt,则直接从输入句子的Attention distribution中copy xt 的attention weight作为 p(xt)。详见论文:Get To The Point: Summarization with Pointer-Generator Networks
- (2)
Stochastic Decoding: 主要包括 temperature sampling, top-k sampling等- 问题:Argmax Decoding常常会导致模型生成重复的句子,如 “I don’t know. I don’t know. I don’t know….“。
- 因为模型中:
p(know|I don't) < p(know|I don't know. I don't) - 解决:decoding过程中引入randomness
- 但是论文(The Curious Case of Neural Text Degeneration)指出,sampling from full vocabulary distribution生成的句子会非常的杂乱无章,因为当vocabulary size非常大时,每个词的probability都会变得很小,这时模型会有非常高的可能性sample到一个tail distribution中的词,一旦sample到了tail distribution中一个和前文非常不相关的词,很有可能接下来的词都受其影响,使得句子脱离原本的意思。
- 因此需要sampling from truncated vocabulary distribution,比较常见的算法主要有以下几种:
- ①
Temperature Sampling- softmax中引入一个temperature t来改变vocabulary probability distribution,使其更偏向high probability words
- 通过调整t的大小,就可以避免sampling from tail distribution。
- 当 t -> 0 时,就变成了greedy decoding;
- 当 t -> ∞ 时,就变成了uniform sampling。
- ②
Top-k Sampling- 更简单有效
- decoding过程中,从 概率分布P 中选取概率最高的前k个tokens,概率累加得到 p‘,再将 P 调整为 P’=P/p’, 最后从 P’ 中sample一个token作为output token
- 论文:Hierarchical Neural Story Generation
- 问题:常数k是提前给定的值,对于长短大小不一,语境不同的句子,我们可能有时需要比k更多的tokens。
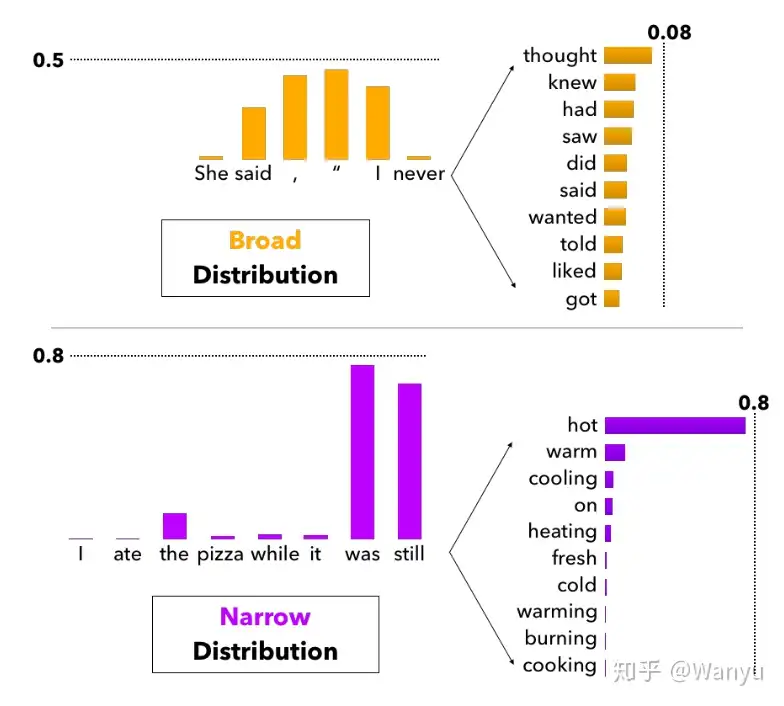
- 设k=10
- 第一句话”She said, ‘I never”后面可以跟的选项能有很大的diversity,此时10个tokens或许不足以包含全部可能的选择;
- 而第二句话”I ate the pizza while it was still”后面可以跟的选项则不能有太大的diversity,否则会使得整个句子含义表达错乱,此时10个tokens就变得过多了,会让模型陷入sample from tail distribution的风险。
- ③
Top-p Sampling(top k改进) – nuclear sampling- 针对top k的问题,Top-p Sampling 基于Top-k Sampling,将 p’ 设为一个提前定义好的常数 p’∈(0,1),而selected tokens根据句子history distribution的变化而有所不同。详见论文:The Curious Case of Neural Text Degeneration
- 本质上
Top-p Sampling和Top-k Sampling都是从truncated vocabulary distribution中sample token,区别在于置信区间的选择。
两类 decoding strategy 主要区别: 如何从vocabulary probability distribution $P(x|x_{1:t-1})$ 中选取一个词 $x_t$:
- Argmax Decoding的做法是选择词表中概率最大的词,即 $x_t=argmax P(x|x_{1:t-1})$;
- Stochastic Decoding则是基于概率分布随机sample一个词 $x_t$,即 $x_t~P(x|x_{1:t-1})$。
问题:top-k/top-p 与 beam search区别
- Top-p没有和beam search一样的候选序列,它仅在当前time step采样
【2021-1-2】翁丽莲的博客:Controllable Neural Text Generation
Since the final layer of the model predicts logits o over the vocabulary space, the next token can be sampled by applying softmax with temperature T. The probability of sampling the i-th token is
$p_i \propto \frac{\exp(o_i / T)}{\sum_j \exp(o_j/T)}$
A low temperature would make the distribution sharper and a high value makes it softer.
Decoding Strategies
- Greedy search: Always pick the next token with the highest probability, equivalent to setting temperature $T=0$. However, it tends to create repetitions of phrases, even for well-trained models.
- 贪心解码相当于 $T=0$, 容易导致短语重复
- Beam search: It essentially does breadth-first search, one token per tree level, but with a limited bandwidth. At each level of the search tree, beam search keeps track of n (named “beam width”) best candidates and expands all the successors of these candidates in the next level. Beam search could stop expanding a node if it hits the EOS (end-of-sentence) token.
- 宽度优先搜索, 遇到结束符(EOS)停止;集束搜索不保证最优生成结果
- However, maximization-based decoding does not guarantee high-quality generation.
- Fig. 1. The probability assigned to the next token by beam search versus by humans. The human selected tokens have much higher variance in predicted probability and thus more surprising. (Image source: Holtzman et al. 2019)
- Top-k sampling
Top-k采样(Fan et al., 2018): At each sampling step, only the top k most likely tokens are selected and the probability mass is redistributed among them. In Fan et al., 2018, the authors proposed to use top-k random sampling where the next token is randomly selected among the top k most likely candidates and they argued that this approach can generate more novel and less repetitive content than beam search.- 每步解码时,只选择 top-k 可能性的token,再重新计算概率分布。
- 好处:比beam search更容易生成新颖、少重复的内容
- Nucleus sampling
Top-p采样(Holtzman et al. 2019): Also known as “Top-p sampling”. One drawback of top-k sampling is that the predefined number k does not take into consideration how skewed the probability distribution might be. The nucleus sampling selects the smallest set of top candidates with the cumulative probability exceeding a threshold (e.g. 0.95) and then the distribution is rescaled among selected candidates.- Top-k采样的一个缺点是k值选取未考虑概率分布是否倾斜。
- Top-p采样选择超过一定阈值(如0.95)的最小字符集合,重新计算概率分布
- Both top-k and nucleus sampling have less repetitions with a proper set of hyperparameters.
- Penalized sampling (Keskar et al. 2019): To avoid the common failure case of generating duplicate substrings, the CTRL paper proposed a new sampling method to penalize repetitions by discounting the scores of previously generated tokens. The probability distribution for the next token with repetition penalty is defined as:
- $p_i = \frac{\exp(o_i / (T \cdot \mathbb{1}(i \in g)))}{\sum_j \exp(o_j / (T \cdot \mathbb{1}(j \in g)))} \quad \mathbb{1}(c) = \theta \text{ if the condition }c\text{ is True else }1$
- 一种惩罚重复子串的采样方法,考虑之前生成过的字符
- where g contains a set of previously generated tokens, 𝟙1(.) is an identity function. θ=1.2 is found to yield a good balance between less repetition and truthful generation.
GPT-2
huggingface 里的 GPT-2 代码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
import pandas as pd
input_txt = "Transformers are the"
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
iterations = []
n_steps = 8 # 进行8步解码
choices_per_step = 5 # 每一步候选数量
with torch.no_grad():# eval模式
for _ in range(n_steps):# 每步解码
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0]) # 提示文本
output = model(input_ids=input_ids) # 将提示文本输入到模型进行解码
# Select logits of the first batch and the last token and apply softmax
next_token_logits = output.logits[0, -1, :]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
# Store tokens with highest probabilities
for choice_idx in range(choices_per_step): # 概率最大的五个token
token_id = sorted_ids[choice_idx]
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = (
f"{tokenizer.decode(token_id)} ({100 * token_prob:.2f}%)" # 取百分号两位数
)
iteration[f"Choice {choice_idx+1}"] = token_choice
# Append predicted next token to input
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1) # 将概率最大的字符拼接到提示文本
iterations.append(iteration)
# 输出序列解码结果
pd.DataFrame(iterations)
详见站内专题: GPT-2
解码方法
总结
以 简化版 中英翻译任务为例
- 中文输入:”我” “恨” “你”
- 英文输出:”I” “H” “U”, 假设输出字典只有3个
- 目标:得到最优的翻译序列 I-H-U
解码方法
- (1)
exhaustive/brute search(穷举搜索/暴力搜索):遍历所有可能得输出序列,最后选择概率最大的序列输出- 示例:一共 $3^3=27$ 种排列组合
- 穷举搜索能保证全局最优,但计算复杂度太高,当输出词典稍微大一点根本无法使用。
- (2)
greedy search贪心搜索:每步选取概率最大的词,局部最优- 示例:1种组合
- 第1个时间步:翻译”我”,发现候选”I”的条件概率最大为0.6,所以第一个步长直接翻译成了”I”。
- 第2个时间步:翻译”我恨”,发现II概率0.2,IH概率0.7,IU概率0.1,所以选择IH作为当前步长最优翻译结果。
- 第3个时间步:翻译”我恨你”,发现IHI概率0.05,IHH概率0.05,IHU概率0.9,所以选择IHU作为最终的翻译结果。

- 贪心算法每步选择当前最好的选择,希望通过局部最优策略期望产生全局最优解。但是贪心算法没有从整体最优上考虑,并不能保证最终一定全局最优。但是相对穷举搜索,搜索效率大大提升。
- 示例:1种组合
- (3)
beam search集束搜索:使用条件概率,每步选取概率最大的top k个词(beam width)- beam search是对greedy search的一个改进算法,相对greedy search扩大了搜索空间,但远远不及穷举搜索指数级的搜索空间,是折中方案
- beam search有一个超参数 beam size(束宽),设为 k
- 每步选取当前条件概率最大的k个词,当做候选输出序列的第一个词。之后每个时间步,基于上步的输出序列,挑选出所有组合中条件概率最大的k个,作为该时间步下的候选输出序列。始终保持k个候选。最后从k个候选中挑出最优的。
- 第1步: I和H的概率是top2,所以将I和H加入到候选输出序列中。
- 第2步: 以I开头有三种候选 { II, IH, IU },以H开头有三种候选 { HI, HH, HU } 从这6个候选中挑出条件概率最大的2个,即IH和HI,作为候选输出序列
- 第3步: 同理以IH开头有三种候选 {IHI, IHH, IHU},以HI开头有三种候选 {HII, HIH, HIU}。从这6个候选中挑出条件概率最大的2个,即IHH和HIU,作为候选输出序列。
- 3步结束, 直接从IHH和IHU中挑选出最优值IHU作为最终的输出序列。

- (4)
温度采样方法(Temperature Sampling Methods) - 总结
- beam search不保证全局最优,但是比greedy search搜索空间更大,一般结果比greedy search要好。
- greedy search 可以看做是 beam size = 1时的 beam search。
贪心 Greedy Search
贪心搜索,每步都取条件概率最大的词输出,再将从开始到当前步的结果作为输入,获得下一个时间步的输出,直到模型给出生成结束的标志。
- 示例,生成序列: [A,B,C]

参数设置:
- do_sample = False, num_beams = 1
分析
- 优点: 原来指数级别的求解空间直接压缩到了与长度线性相关的大小。(指数级→线性级)
- 缺点:
- 1、生成文本重复
- 2、不支持生成多条结果。 当 num_return_sequences 参数设置大于1时,代码会报错,说greedy search不支持这个参数大于1
- 由于丢弃了绝大多数的可能解,这种关注当下的策略无法保证最终序列概率是最优的
def greedy_decode(model, input, max_length):
output = input
for _ in range(max_length):
# 为模型的下一个单词生成预测
predictions = model(output)
# 使用argmax来选择最可能的下一个单词
next_word = torch.argmax(predictions, dim=-1)
# 将选择的单词添加到输出中
output = torch.cat((output, next_word), dim=-1)
# 在生成完成后返回输出
return output
集束搜索 Beam Search
Beam search是对贪心策略一个改进。
- 思路:稍微放宽一些考察的范围。
- 每步不再只保留当前分数最高的1个输出,而是保留num_beams个。每步选择num_beams个词,并从中最终选择出概率最高的序列。
- 第1步选取当前条件概率最大的 k 个词。之后每个时间步基于上个步长的输出序列,挑选出所有组合中条件概率最大的 k 个,作为该时间步长下的候选输出序列。始终保持 k 个候选。最后从 k 个候选中挑出最优的。
- 当 num_beams=1 时集束搜索就退化成了贪心搜索。
- 示例
- 每个时间步有ABCDE共5种可能的输出,即v=5v=5,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列

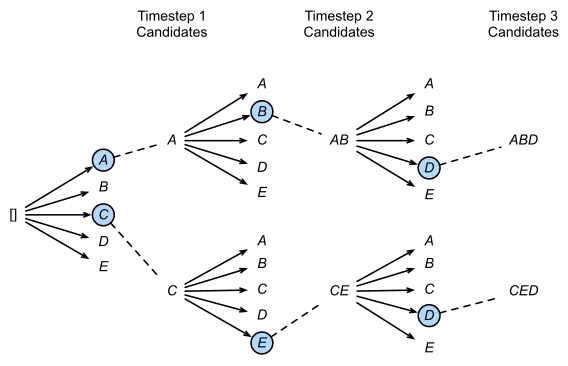
- 在第一个时间步,A和C是最优的两个,因此得到了两个结果[A],[C],其他三个就被抛弃了;
- 第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选人,[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排名,再保留最优的两个,即图中的[AB]和[CE];
- 第三步同理,也会从新的10个候选人里再保留最好的两个,最后得到了[ABD],[CED]两个结果。
参数设置:
- do_sample = False, num_beams>1
分析
- beam search在每步需要考察的候选人数量是贪心搜索的num_beams倍
- BS是一种时间换性能的方法。
- 会遇到诸如词语重复问题
缺点:
- 虽然结果比贪心搜索更流畅,但是仍然存在生成重复的问题
def beam_search_decode(model, input, max_length, k):
output = [(input, 0)] # initialize beam with the input and its score
for _ in range(max_length):
all_candidates = [] # list to store all sentence candidates at this step
for sentence, score in output:
# Get next word probabilities
predictions = model(sentence)
# Get the k most probable next words
top_k_scores, top_k_words = torch.topk(predictions, k, dim=-1)
# create new candidates with the top_k words and add their score
for i in range(k):
candidate = torch.cat((sentence, top_k_words[i].unsqueeze(0)), dim=-1)
all_candidates.append((candidate, score + top_k_scores[i]))
# Sort all candidates by score
ordered = sorted(all_candidates, key=lambda tup:tup[1], reverse=True)
# Select the best k candidates
output = ordered[:k]
# Return the sentence of the best candidate
return output[0][0]
代码实现
- tensorflow 把 decoder 从 BasicDecoder 换成 BeamSearchDecoder
- 因为用了 Beam Search,所以 decoder 的输入形状需要做 K 倍的扩展,tile_batch 就是用来干这个。如果和之前的 AttentionWrapper 搭配使用的话,还需要把encoder_outputs 和 sequence_length 都用 tile_batch 做一下扩展
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
if useBeamSearch > 1:
decoder_initial_state = tf.contrib.seq2seq.tile_batch(encoder_state, multiplier=useBeamSearch)
decoder = tf.contrib.seq2seq.BeamSearchDecoder(decoder_cell, decoder_embedding, tokens_go, w2i_target["_EOS"], decoder_initial_state , beam_width=useBeamSearch, output_layer=tf.layers.Dense(config.target_vocab_size))
else:
decoder_initial_state = encoder_state
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, decoder_initial_state, output_layer=tf.layers.Dense(config.target_vocab_size))
decoder_outputs, decoder_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder, maximum_iterations=tf.reduce_max(self.seq_targets_length))
序列扩展
- 序列扩展是beam search的核心过程

Multinomial sampling(多项式采样)
方式:
- 每步根据概率分布随机采样字(每个概率>0的字都有被选中的机会)。
参数:
- do_sample = True, num_beams = 1
优点:
- 解决了生成重复的问题,但是可能会出现生成的文本不准守基本的语法
Beam-search multinomial sampling
方式:
- 结合了Beam-search和multinomial sampling的方式,每个时间步从num_beams个字中采样
参数:
- do_sample = True, num_beams > 1
自回归
以llama模型为例
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# --------- 模型/分词器初始化 ----------
model_name = "llama-2-7b-hf" # 用你的模型的地址
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# --------- 分词 ----------
text = "say"
inputs = tokenizer(text, return_tensors="pt") # 分词后是1个token, 词表中位置是 1827
print(f"inputs:{inputs}")
# 结果
# inputs:{'input_ids': tensor([[ 1, 1827]]), 'attention_mask': tensor([[1, 1]])}
# --------- 直接生成 ----------
logits = model.forward(input_ids) # 模型输出, [batch_size, sequence_length, vocab_size]
print("Logits Shape:", logits.logits.shape) # Logits Shape: torch.Size([1, 2, 32000])
print(f"logits:{logits.logits}")
# logits:tensor([[[-12.9696, -7.4491, -0.4354, ..., -6.8250, -8.0804, -7.5782],
# [-11.3775, -10.1338, -2.3563, ..., -6.7709, -6.5252, -8.9753]]],
# device='cuda:0', grad_fn=<UnsafeViewBackward0>)
logits 是模型的最后输出,是一个张量(tensor),维度是[batch_size, sequence_length, vocab_size]
- 示例中, batch_size=1,sequence_length=2
问题: 只输入了一个say(1个token),为什么是2个token?
- 输入模型前 llama tokenizer自动添加一个bos token ——
<s>(开始符), 实际输入长度就是2个token(<s>+say) - llama 推理过程并没有增加(改变)输入序列长度,最后一个token的 logits 输出预测下一个token的概率,vocab_size 是词典的大小,llama 是32000,在第2个sequence里找到在32000词表中哪个token的概率最大
# 在最后一个维度上(32000)进行求最大值操作,返回具有最高分数的词汇索引
next_token = torch.argmax(logits.logits, dim=-1).reshape(-1)[1]
print(f"next_token:{next_token}")
# next_token:tensor([22172], device='cuda:0')
next_word = tokenizer.decode(next_token)
print(f"next_word:{next_word}") # next_word:hello
最后一个维度上(32000)进行求最大值操作,并返回具有最高分数的词汇索引,在词表中的位置是22172,接下来就是解码该token
将 next_word 预测出来后的流程:
- 将“hello”加到“say”后面变成“say hello”
- 迭代上述流程直到生成eos_token(终止词)
整个预测也就完成了,这就是自回归过程。
总结
Huggingface 共有8种解码策略
model.generate()
总结
- greedy decoding 贪心解码策略: 最原始、简单, 每步选择预测概率最高的token
- beam search 集束解码策略: 或束搜索, 每步选择多个候选, 简称 bs
- multinomial sampling 多项式采样解码策略:
- 通过各种改变 logits 参数(multinomial sampling,temperature,top_k,top_p等)实现生成文本的多样性
- contrastive search 对比搜索策略: 引入对比度惩罚的搜索方法
- 当前token与前面token相似性大,就减少生成概率,解决重复问题
- constrained beam-search decoding 受限束搜索解码
- 解码搜索过程中,引入自定义词表, 强制生成指定词表的token
- beam-search multinomial sampling: bs 改进, 引入多项式采样
- diverse beam-search decoding: 分组 beam-search 解码方式
- assisted decoding 辅助解码: 用另一个模型(称为辅助模型)的输出来辅助生成文本,一般是借助较小模型来加速生成候选 token
贪心解码 greedy decoding
贪心解码策略最经典、最原始
- 在
model.generate()中,当num_beams等于 1 且do_sample等于 False 时进入此模式 - 也可直接使用
model.greedy_search()
每步选择预测概率最高的token作为下一个token,从而生成文本,和之前的forword是一样的
问题
- 这种方法通常会导致生成的文本单一和局部最优。
注意
- 此策略不能用 temperature,top_k,top_p 等改变 logits 参数。
优缺点
贪婪搜索缺点:
- 倾向于产生重复序列
- 可能会错过整体概率较高的单词序列,只是因为高概率的单词刚好在低概率的单词之前。
解法:集束搜索
实现1
两种方案
- model.generate()
- model.greedy_search()
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_name = "llama-2-7b-hf" # 你模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
input_ids = inputs["input_ids"].to("cuda")
# 启动方式① model.generate
generation_output = model.generate(
input_ids=input_ids,
num_beams = 1,
do_sample = False,
return_dict_in_generate=True,
max_new_tokens=3,
)
# 启动方式②, 直接指定使用其函数 model.greedy_search
generation_output = model.greedy_search(
input_ids=input_ids,
num_beams = 1,
do_sample = False,
return_dict_in_generate=True,
max_length = 7
)
# 解码
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 结果
# query: say hello to
# Generated sequence 1: say hello to the newest
实现2
# (1)贪婪搜索
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))
# Transformers are the most popular toy line in the world,
# 扩大长度
max_length = 128
input_txt = """In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.\n\n
"""
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output_greedy = model.generate(input_ids, max_length=max_length, do_sample=False)
print(tokenizer.decode(output_greedy[0]))
# Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
# In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
集束解码 beam-search decoding
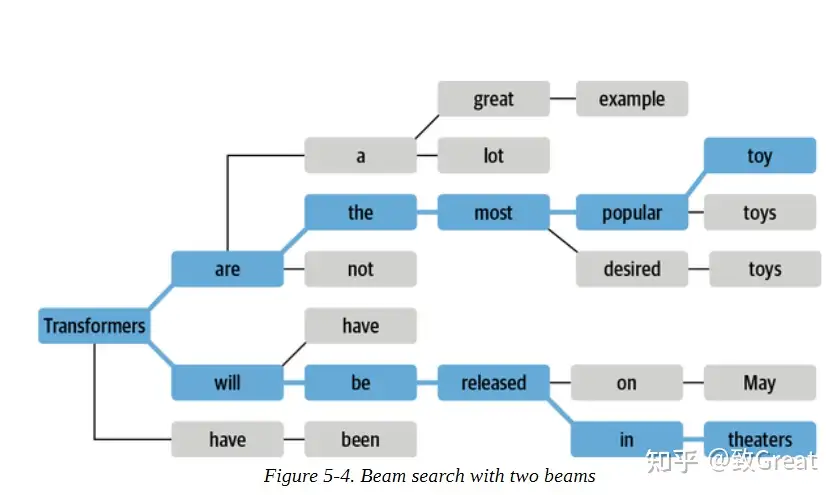
原理
集束搜索每步解码时, 不选概率最高标记,而是记录前b个最有可能的下一个标记,其中, b被称为波束或路径个数。
- 下一组集束的选择是考虑现有集束的所有可能的下一个标记的扩展,并选择b个最可能的扩展。
- 这个过程重复进行,直到达到最大长度或EOS标记
- 然后根据对数概率对b个波束进行排序,选择最可能的序列
为什么用对数概率而不是条件概率对序列进行评分?
- 计算一个序列的总体概率
P(y1,y2,...,yt|x)涉及计算条件概率P(yt|y < t,x)的乘积。由于每个条件概率通常是[0,1]范围内的小数字,取乘积会导致总概率很容易出现下溢。不能再精确地表示计算的结果。 
- 于是,使用
对数概率替换条件概率
BS流程:
- 初始化:设定一个宽度参数 beam width,表示每步保留的最优候选解的数量。
- 递归过程:从起始状态开始,模型会预测第一个词语的所有可能选项,并根据它们的概率保留前beam width个概率最高的选项作为候选路径。
- 扩展路径:对每个保留下来的候选路径,模型接着预测第二个词语,将当前词语添加到之前路径上,并计算新的完整路径的概率。再次保留概率最高的beam width条路径。
- 迭代求解:重复步骤3的过程,直到达到终止条件(如遇到结束符号或者达到预设的最大长度)。
- 最后,Beam Search返回的是整个搜索过程中找到的最高概率路径作为最终输出序列。
BS 与 直接采样
与直接采样(Sampling)的区别:
Beam Search:
- 一种确定性策略,总是选择概率最高的若干选项继续进行下一轮生成。
- 保证生成结果具有较高的概率质量,但可能会牺牲一定的多样性,因为不是所有低概率的序列都被考虑。
- 可能导致过拟合于训练数据中出现频率较高的模式,产生“僵化”或“机械”的输出。
直接采样(Random Sampling 或 Top-k Sampling 等):
- 一种随机策略,每次生成新词时,可以按照词汇表中每个词的概率分布进行随机抽样。
- 采样方法能够生成更加多样化的输出,更有可能探索到新颖和未见的序列组合,有助于解决Beam Search可能导致的过于保守的问题。
- 直接采样的不确定性较大,生成结果不一定是全局最优解,而且对于较差的概率分布可能出现生成结果质量较低的情况。
总结
- Beam Search 旨在寻找最大概率路径,确保生成结果的合理性和准确性
- 而直接采样则通过引入随机性来增强输出的多样性和创造性,两者在实际应用中可以根据需求权衡精度和多样性来进行选择。
BS 优缺点
优点:
- 生成多样性: 通过增加num_beams束宽,束搜索可以保留更多的候选序列,从而生成更多样化的结果。
- 找到较优解: 增加num_beams束宽有助于保留更多可能的候选序列,从而更有可能找到更优的解码结果,这在生成任务中有助于避免陷入局部最优解
- 控制输出数量: 通过调整num_beams束宽,可以精确控制生成的候选序列数量,从而平衡生成结果的多样性和数量。
缺点:
- 计算复杂度: 随着num_beams束宽的增加,计算复杂度呈指数级增长,较大的束宽会导致解码过程变得更加耗时,尤其是在资源有限的设备上。
- 忽略概率较低的序列: 增加num_beams束宽可能会导致一些低概率的候选序列被忽略,因为搜索过程倾向于集中在概率较高的路径上,从而可能错过一些潜在的优质解。
- 缺乏多样性: 尽管增加num_beams束宽可以增加生成结果的多样性,但束搜索仍然可能导致生成的结果过于相似,因为它倾向于选择概率较高的路径。
定义
步骤
- 定义一个 BeamSearchNode 类
- 然后给出接下来生成token的概率,简单起见给一个固定的概率
class BeamSearchNode:
def __init__(self, sequence, score):
self.sequence = sequence # 生成的序列
self.score = score # 分数(概率)
# 示例:下一个token的概率函数,简单使用固定概率
def simple_next_word_probs(sequence):
if sequence[-1] == "<end>":
return {}
return {"apple": 0.3, "like": 0.35, "peach": 0.2, "banana": 0.15}
def beam_search(initial_sequence, next_word_probs_func, num_beams, max_sequence_length):
# 初始化初始节点,且分数为1
initial_node = BeamSearchNode(sequence=initial_sequence, score=1.0)
candidates = [initial_node]
final_candidates = [] # 最终的候选序列
# 只要候选节点列表不为空,且 final_candidates 中的候选节点数量还没有达到指定的束宽度,就继续进行搜索
while candidates and len(final_candidates) < num_beams:
# 候选节点排序
candidates.sort(key=lambda x: -x.score)
current_node = candidates.pop(0)
# 当节点序列末尾生成结束符号(如"<end>"),或者当生成的序列长度达到最大限制时终止节点的扩展
if current_node.sequence[-1] == "<end>" or len(current_node.sequence) >= max_sequence_length:
final_candidates.append(current_node)
else:
# 获取下一个token的概率,我们的例子返回的是固定的概率
next_words_probs = next_word_probs_func(current_node.sequence)
# 生成新的候选序列,并计算分数
for next_word, next_word_prob in next_words_probs.items():
new_sequence = current_node.sequence + [next_word]
new_score = current_node.score * next_word_prob
new_node = BeamSearchNode(sequence=new_sequence, score=new_score)
candidates.append(new_node)
return [candidate.sequence for candidate in final_candidates]
使用
initial_sequence = ["<start>", "I"]
num_beams = 3
max_sequence_length = 3
result = beam_search(initial_sequence, simple_next_word_probs, num_beams, max_sequence_length)
for idx, sequence in enumerate(result):
print(f"Sentence {idx + 1}: {' '.join(sequence)}")
实现
beam search 集束解码策略
- 在
model.generate()中是当num_beams大于 1 且do_sample等于 False 时使用 - 也可调用
model.beam_search()来实现
import torch.nn.functional as F
# 对数概率
def log_probs_from_logits(logits, labels):
logp = F.log_softmax(logits, dim=-1)
logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)
return logp_label
# 序列总对数概率
def sequence_logprob(model, labels, input_len=0):
with torch.no_grad():
output = model(labels)
log_probs = log_probs_from_logits(output.logits[:, :-1, :], labels[:, 1:]) # 不算首尾标记,非模型生成
# 只需要将每个标记的对数概率相加
seq_log_prob = torch.sum(log_probs[:, input_len:])
return seq_log_prob.cpu().numpy()
# 调用
logp = sequence_logprob(model, output_greedy, input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
print(f"\nlog-prob: {logp:.2f}")
# beam search, 5个
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5, do_sample=False)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob: {logp:.2f}")
波束越多,得到的结果就越好;然而,生成过程会变得更慢
用集束搜索得到的对数概率(越高越好)比用简单的贪婪解码得到的要好。
- 然而,集束搜索也受到重复文本的影响。
一个解决方法
- 用 no_repeat_ngram_size 参数施加一个 n-gram惩罚,跟踪哪些n-gram已经被看到,并将下一个token的概率设置为零,如果它将产生一个以前看到的n-gram
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5, do_sample=False, no_repeat_ngram_size=2)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob: {logp:.2f}")
停止重复后,尽管产生了较低的分数,但文本仍然是连贯的。
带n-gram惩罚的集束搜索是一种很好的方法,可以在关注高概率标记(用束搜索)和减少重复(用n-gram惩罚)之间找到一个平衡点
- 通常用于总结或机器翻译等事实正确性很重要的应用中。当事实的正确性不如生成的输出的多样性重要时,例如在开放领域的闲聊或故事生成中,另一种减少重复同时提高多样性的方法是使用抽样。
多样式采样 multinomial sampling
多项式采样解码策略
- 在
model.generate()中,当num_beams等于 1 且do_sample等于 True 时进入此模式 - 也可用
model.sample()
该策略通过各种改变 logits 的参数(multinomial sampling,temperature,top_k,top_p等)从而实现生成文本的多样性。
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from transformers import (
LogitsProcessorList,
TopKLogitsWarper,
TopPLogitsWarper,
TemperatureLogitsWarper,
)
import torch
model_name = "llama-2-7b-hf" # 你模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
input_ids = inputs["input_ids"].to("cuda")
# 方式一: model.generate
generation_output = model.generate(
input_ids=input_ids,
num_beams = 1,
do_sample = True,
temperature = 1.2,
top_k = 100,
top_p = 0.6,
return_dict_in_generate=True,
max_length=7,
)
# 方式二: model.sample
# sample实现
logits_warper = LogitsProcessorList(
[
TopKLogitsWarper(100),
TemperatureLogitsWarper(1.2),
TopPLogitsWarper(0.6)
]
)
generation_output = model.sample(
input_ids=input_ids,
logits_warper=logits_warper,
return_dict_in_generate=True,
max_length=7,
)
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 注意这种方式每次结果都可能不一样
# query: say hello to
# Generated sequence 1: say hello to our new intern
对比搜索 contrastive search
对比搜索策略
- 在
model.generate()中,当penalty_alpha大于 0 且top_k>1大于 1 时使用
这是一种引入对比度惩罚的搜索方法,penalty_alpha 惩罚因子参数,只有在contrastive search是才会用到。
这种解码策略是 2022年 A Contrastive Framework for Neural Text Generation 论文中提出来的方法
Huggingface已经实现,简单原理:
- 生成的token 从模型预测的最佳候选(top k)中而来;
- 在生成token时,当前token应该能与前面生成的内容保持对比性(或差异性),其实现就是若当前生成的token 与之前的序列token相似度很大,就减少其整体概率值,进而减少它被解码出来的可能性,避免重复解码的问题。
核心代码
def ranking(context_hidden, next_hidden, next_top_k_ids, next_top_k_probs, alpha):
'''
该函数是实现Contrastive Search中next token预测中候选token的排序分数,分数最大对应token为输出结果
context_hidden: beam_width x context_len x embed_dim ,用于计算相似度,是公式中x_j集合表征向量
next_hidden: beam_width x 1 x embed_dim,用于计算相似度,是公式中候选token v 的表征向量
next_top_k_ids: beam_width x 1,记录候选token的编码
next_top_k_probs,候选token的模型预测概率
alpha,惩罚参数
'''
beam_width, context_len, embed_dim = context_hidden.size()
assert next_hidden.size() == torch.Size([beam_width, 1, embed_dim])
norm_context_hidden = context_hidden / context_hidden.norm(dim=2, keepdim=True)
norm_next_hidden = next_hidden / next_hidden.norm(dim=2, keepdim=True)
cosine_matrix = torch.matmul(norm_context_hidden, norm_next_hidden.transpose(1,2)).squeeze(-1) #计算相似度矩阵
assert cosine_matrix.size() == torch.Size([beam_width, context_len])
scores, _ = torch.max(cosine_matrix, dim = -1) #输出公式第二项值
assert scores.size() == torch.Size([beam_width])
next_top_k_probs = next_top_k_probs.view(-1) #输出公式第一项值
scores = (1.0 - alpha) * next_top_k_probs - alpha * scores #对应公式整体计算
_, selected_idx = torch.topk(scores, k = 1)
assert selected_idx.size() == torch.Size([1])
selected_idx = selected_idx.unsqueeze(0)
assert selected_idx.size() == torch.Size([1,1])
next_id = torch.gather(next_top_k_ids, dim = 0, index=selected_idx)
assert next_id.size() == torch.Size([1,1])
return next_id
使用方法
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_name = "llama-2-7b-hf" # 你模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
input_ids = inputs["input_ids"].to("cuda")
# (1) model.generate
generation_output = model.generate(
input_ids=input_ids,
penalty_alpha = 0.5,
top_k = 30,
return_dict_in_generate=True,
max_new_tokens=3,
)
# (2) 直接使用其函数 model.contrastive_search
generation_output = model.contrastive_search(
input_ids=input_ids,
penalty_alpha = 0.5,
top_k = 30,
return_dict_in_generate=True,
max_new_tokens=3,
)
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 结果
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
# query: say hello to
# Generated sequence 1: say hello to 20
辅助解码 Assisted decoding
辅助解码,用另一个模型(称为辅助模型)的输出来辅助生成文本,一般是借助较小模型来加速生成候选 token
- 辅助模型必须具有与目标模型完全相同的分词器(tokenizer)
属于推测解码的一种实现, 详见站内专题 LLM推理加速中的推测解码
实现
简单实现,通过llama7B辅助生成llama13B,一般来说辅助模型要很小,这里只是简单实验:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_name = "llama-2-13b-hf" # 你自己模型的位置
assistant_model_name = "llama-2-7b-hf" # 你自己模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
input_ids = inputs["input_ids"].to("cuda")
generation_output = model.generate(
assistant_model=assistant_model,
input_ids=input_ids,
num_beams = 1,
do_sample = False,
return_dict_in_generate=True,
max_length=7,
)
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 结果
# query: say hello to
# Generated sequence 1: say hello to the newest
Beam Search 改进
Beam Search 虽然比贪心有所改进,但还是会生成空洞、重复、前后矛盾的文本。
- 试图最大化序列条件概率的解码策略从根上就有问题
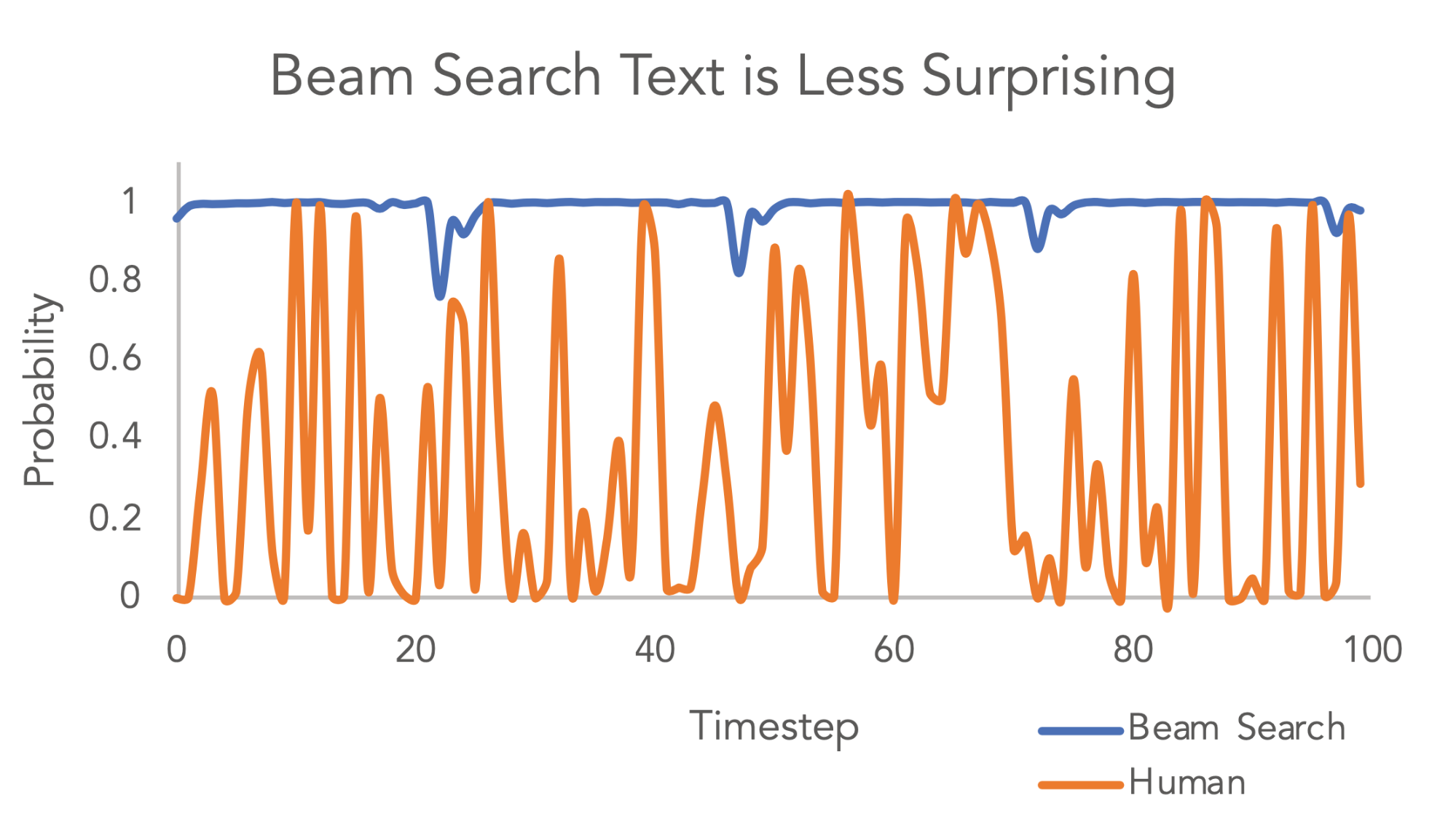
人类选择的词(橙线)并不是像机器选择的(蓝线)那样总是那些条件概率最大的词。
- 总是选择概率大的词会发生正反馈从而陷入重复,从生成的结果也可以看出,机器生成的结果有大量重复。

- 参考:解读Beam Search (2/2)
- 以下思路主要源自ICLR 2020论文:《The Curious Case of Neural Text Degeneration》
如何使用语言模型生成文本呢?用到了「解码器」:一种用于从语言模型生成文本的算法。
目前主流解码器有三种:「贪婪解码」(Greedy Decoding)、「集束搜索」(Beam Search)、「基于抽样」(Sampling-based)。
- 「
贪婪解码」解码器每一步采用 argmax 来生成目标句子,简单粗暴,但是由于缺乏回溯,输出可能会很差,会出现句子不合语法、不自然、没有意义等问题,主要是因为并不是每一步解码的概率最大,整体结果的概率就会最大,概率最大的句子,在其中某一步解码的概率可能不是最大的; - 「
集束搜索」解码器的每一步都要跟踪 Beam Size 个最有可能的部分序列,不只是寻找当前步概率最大的序列。达到停止条件后,选择概率最高的序列,当然最终结果也不一定是最佳序列,因为存在一个选择范围,所以优于贪婪解码。- 集束搜索的关键是 Beam Size 的确定,小的 Beam Size 会有与贪婪解码相似的问题(极限 Beam Size = 1),Beam Size 越大表示考虑的假设越多,计算量也就越大,大 Beam Size 会使输出太过通用、太万金油,聊天会很无聊、被终结,同时对于神经机器翻译(NMT),增大 Beam Size 过多会降低 BLUE 得分;
- 「
基于抽样」方法又可以分为「纯采样」(Pure Sampling)和「头部采样」(Top-n Sampling)- 纯采样是在每个步骤 t,从概率分布 Pt 中随机采样以获得下一个单词。
- 头部采样是在每个步骤 t,从 Pt 中随机抽样,仅限于前 n 个最可能的单词
- 当 n = 1 时,即为
贪婪解码,n = V 时,即为纯采样 - 增加 n 可以获得更加多样化、风险更高的输出,减少 n 可以获得更加安全、通用的输出。
这三种解码器中
贪婪解码是一种比较简单的方法,输出质量也比较低集束搜索输出质量比贪婪解码更高,但是如果 beam size 太大,将返回不合适的输出- 基于抽样的方法可以获得更多的多样性和随机性,适合开放式、创造性的创作,例如诗歌故事生成,通过 top-n 采样可以控制多样性的强弱。
受限束搜索 constrained beam-search decoding
受限束搜索解码
- 用
model.generate(): 当constraints不为 None 或force_words_ids不为 None 时进入该模式,而且要求num_beams要大于1(本质还是束搜索),do_sample为False,num_beam_groups为1,否则就会抛出:
"`num_beams` needs to be greater than 1 for constrained generation."
"`do_sample` needs to be false for constrained generation."
"`num_beam_groups` not supported yet for constrained generation."
这个解码策略核心是 beam search,只不过在search中加入自定义词表,强制其生成提供词表
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_name = "llama-2-7b-hf" # 你模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
input_ids = inputs["input_ids"].to("cuda")
# generate实现
generation_output = model.generate(
input_ids=input_ids,
num_beams = 3,
num_return_sequences=3,
return_dict_in_generate=True,
max_new_tokens=3,
)
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 结果
# query: say hello to
# Generated sequence 1: say hello to your new favorite
# Generated sequence 2: say hello to your new best
# Generated sequence 3: say hello to our newest
加上了约束之后,即给定词表["my"]:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_name = "llama-2-7b-hf" # 你模型的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "say hello to"
inputs = tokenizer(text, return_tensors="pt")
print(f"inputs:{inputs}")
input_ids = inputs["input_ids"].to("cuda")
force_words = ["my"] # 自定义词表
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids
generation_output = model.generate(
input_ids=input_ids,
force_words_ids = force_words_ids,
num_beams = 3,
num_return_sequences=3,
return_dict_in_generate=True,
max_new_tokens=3,
)
print("query:", text)
for i, output_sequence in enumerate(generation_output.sequences):
output_text = tokenizer.decode(output_sequence, skip_special_tokens=True)
print(f"Generated sequence {i+1}: {output_text}")
# 结果
# inputs:{'input_ids': tensor([[ 1, 1827, 22172, 304]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
# query: say hello to
# Generated sequence 1: say hello to my little friend
# Generated sequence 2: say hello to your new favorite
# Generated sequence 3: say hello to your new my
结果很明显,生成中出现了我们的限制词表“my”。
束搜索+多项式采样 beam-search multinomial sampling
beam-search 中在实现采样的方式
- 在 model.generate() 中,当 num_beams 大于 1 且 do_sample 等于 True 时使用,其实就是在 beam search 中加入了多样化采样方式
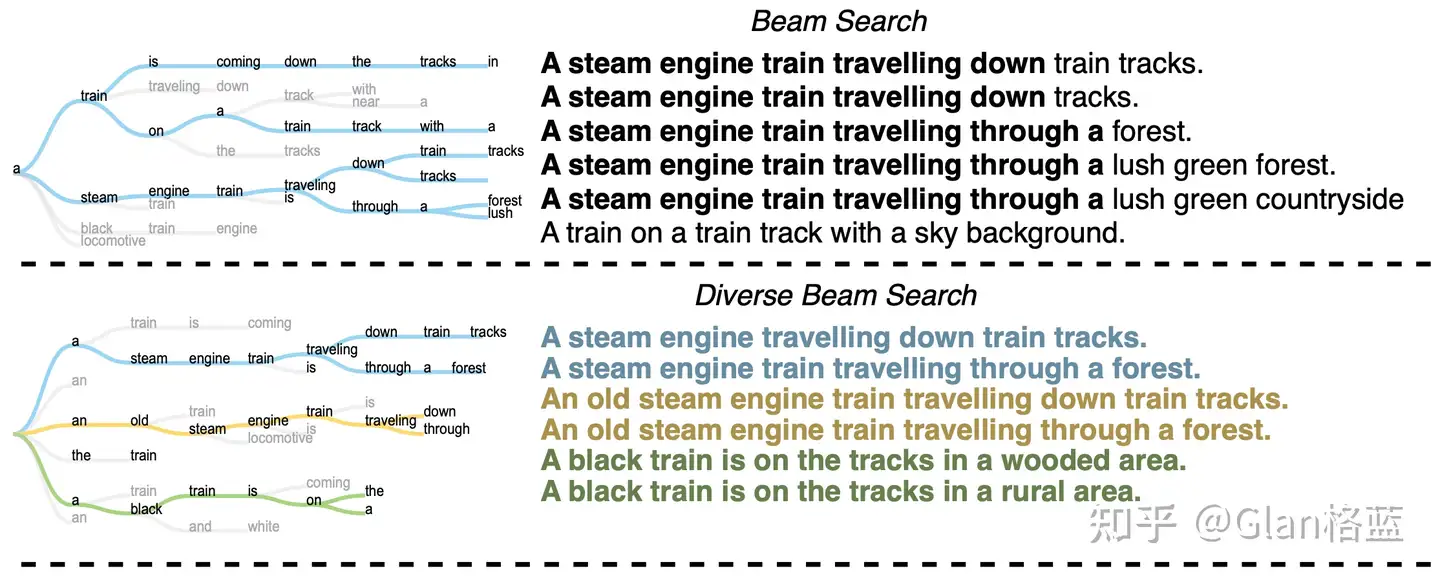
DBS diverse beam-search decoding
分组 beam-search 解码方式,上述在解释num_beam_groups
- 在 model.generate() 中,当 num_beams 大于 1 , num_beam_groups 大于 1 ,diversity_penalty 大于0,do_sample 等于 False 时进入此模式。
beam search算法的改进,叫做 Diverse Beam Search (DBS),核心就是分组机制
- num_beams=2, num_beam_groups=2, 分成2个组,每个组里的beam可以相似,但组和组之间要有足够的多样性,引入了多样性分数
论文图解
投机采样
2022年, Google DeepMind 推出大模型推理加速方法: 投机采样(Speculative Decoding)。
- deepmind 论文 Accelerating Large Language Model Decoding with Speculative Sampling
- google 论文 Fast Inference from Transformers via Speculative Decoding
- github LLMSpeculativeSampling
不损失生成效果前提下,获得3x以上加速比。GPT-4泄密报告也提到OpenAI线上模型推理使用了投机采样。
LLM 将模型输出logits的转换成概率,几种常用的采样方法,包括: argmax、top-k和top-n等
投机采样(Speculative Sampling)是一种推理加速策略
- 并行预测多个可能token,然后快速验证并采纳正确部分
解读
作用
- 不牺牲输出质量的前提下,减少语言模型生成 token 所需的时间
分析
- 传统语言模型,自回归生成是 串行,必须生成一个,再输入到模型中,才能生成下一个
- 投机采样核心思想:用”小模型”提前生成多个候选 token(投机结果),然后用”大模型”一起验证这批候选,并行加速。
使用两个模型:大模型 + 小模型
- 简单 token 生成交给小型模型处理,而困难的token则交给大型模型处理。
- 小型模型可采用与原始模型相同的结构,但参数更少,或者干脆使用n-gram模型。小型模型不仅计算量较小,还减少了内存访问需求。
投机采样过程:
- (1) 用小模型Mq做自回归采样连续生成 a 个tokens。
- (2) 把生成的a个tokens和前缀拼接一起送进大模Mp执行一次forwards。
- (3) 使用大、小模型logits结果做比对
- 如果发现某个token小模型生成的不好,重新采样这个token。重复步骤1。
- 如果小模型生成结果都满意,则用大模型采样下一个token。重复步骤1。
(2)中,过程和自回归相比,尽管计算量一样,但是a个tokens 同时参与计算,计算访存比显著提升。
示例
- prompt 是:”The weather today is”
- 小模型(Draft Model)快速生成多个候选 token
- 例如预测出:”The weather today is [sunny, and, warm, with, …]” 共 5 个 token
- 大模型(Target Model)验证这些 token
- 大模型并行地计算这 5 个 token 概率;
- 如果小模型结果和大模型前几个 token 一致(大模型在这个token上概率小于小模型的,即小模型”更有把握”),就”采纳”它;
- 如果中途发现不一致,就在那个位置停止,用大模型重新生成。
| 位置 | Token | 小模型预测 | 大模型验证 | 是否匹配 |
|---|---|---|---|---|
| 1 | sunny | ✅ | ✅ | ✅ |
| 2 | and | ✅ | ✅ | ✅ |
| 3 | warm | ✅ | ✅ | ✅ |
| 4 | with | ✅ | ❌ | ❌ |
第4个token被大模型拒绝。
下一轮 prompt 是: “The weather today is sunny and warm”, 循环往复
解码参数
大模型生成时的参数设置取决于具体任务和模型。
常见参数包括:
- 温度(Temperature):控制生成的文本的随机性。较低的温度值将导致生成更保守的文本,而较高的温度值将导致更多样化的文本。
- Top-k采样:仅从概率最高的k个词中采样,以减少生成文本的随机性。
- Top-p采样:从累积概率超过p的词中进行采样,这有助于生成更相关的文本。
- 最大生成长度:指定生成文本的最大长度。
最佳实践
【2025-6-26】LLM推理中的temperature、top_k、top_p的作用和原理、最佳实践
常见组合: Temperature + Top-p
- 例如:temperature=0.7, top_p=0.9。OpenAI API 和许多现代大模型应用的默认或推荐设置。
- 逻辑:先用 temperature 调整原始分布的“软硬”程度,再用 top-p 基于调整后的分布动态地筛选候选池。两者配合能更精细地控制生成的创造性、多样性、连贯性和事实性。 Top-k 和 Top-p 一般不同时用
- 如果同时设置,通常实现是两者都过滤一遍,取交集 (min_k, top_p)?还是分先后顺序?具体行为取决于实现,且效果可能冲突(比如 top-k 设很小,top-p 设很大相当于没作用)。通常建议只选用其中一个来控制候选池的范围,top-p 通常是首选。 如何调参? - 理解任务需求: 是严谨还是创意?需要事实准确还是引人入胜?目标输出是什么样的? - 从小开始实验: 先尝试默认值或常用范围(T=0.7-1.0, top_p=0.8-0.95)。观察生成结果。 - 过随机/荒谬? ➜ 降低 T 和/或降低 top_p(或如果只用top-k则减小k)。 - 过保守/重复/无聊? ➜ 提高 T 和/或提高 top_p(或如果只用top-k则增大k)。 - 观察长文本的连贯性: top-p 通常在维持长文本一致多样性方面更好。 没有万能值,不同模型、不同任务、不同提示词(Prompt)的最佳参数组合都不同。迭代实验是关键!
(1)温度 (Temperature):给概率“加热”还是“降温” - 形象比喻: 模型输出下一个词概率分布是一杯浓稠的糖浆(高概率词像糖块沉在杯底,低概率词像水分子浮在上面)。Temperature 就是给这杯糖浆加热的温度计。 - 高温 (T > 1.0): 猛火加热!糖浆变稀变均匀(概率分布更平坦/平滑)。模型对“不太可能但也可行”的词给予更多“宽容”。结果是输出更加随机、多样、有创意,甚至可能跑题、荒谬、出现小错误。就像一个喝了点酒、思维跳脱的作家。 - 低温 (T < 1.0): 放入冰箱冷却!糖浆变稠变“锋利”(概率分布更尖锐/集中)。模型更加保守,只偏爱那几个最高概率的词。结果是输出更加确定、可预测、准确、连贯,但也可能更乏味、重复。像一个严谨的科学家在写报告。 - 常温 (T = 1.0): 原汁原味。模型保持原始的预测概率分布,不做任何修改。
场景: - 高 T (e.g., 0.8 - 1.2): 创意写作(诗歌、故事、歌词)、头脑风暴、生成多样化答案、增加趣味性。当模型陷入重复时救场。 - 低 T (e.g., 0.1 - 0.5): 代码生成、事实性问答、摘要生成、需要高度准确性和连贯性的场景、技术文档编写。避免模型“胡言乱语”。 - 默认 T=1.0: 一个平衡点,适用于大多数通用场景。
(2)Top-k 采样:划定“精英候选词”范围,只保留概率最高的前 k 个词。 - 形象比喻: 考试结束后,老师只看前 K 名高分学生的卷子,然后根据他们的分数高低(对应概率大小),随机抽一个学生作为“标准答案”。Top-k 就是设定这个 K 值。 - K 小 (e.g., 10): 只看最顶尖的几个“学霸”(高概率词),从他们中选。输出更安全、更集中、更可预测,但也可能错过一些潜在的、有趣的“偏科天才”(中低概率但有意义的词)。 - K 大 (e.g., 50, 100): 允许更多“中等生”(中低概率词)进入候选池。输出更丰富、更多样化、更有惊喜,但也可能抽到一些“学渣”(极低概率的、不靠谱的词)导致输出质量不稳定。
场景: - 小 k (10-20): 需要高确定性、高连贯性的任务。适合短文本生成。 - 中等 k (40-100): 平衡多样性和质量的通用场景。 - 不推荐非常大 k (接近词表大小): 基本退化回纯随机采样,失去控制意义。 有时会与 temperature 联用: 先用 temperature 调整原始分布,再用 top-k 过滤。
(3)Top-p (Nucleus Sampling):按概率累积“招生”
只保留累积概率和首次达到或超过 p 的那部分词(即核心词 nucleus)
- 形象比喻: 大学招生不只看绝对排名(top-k),而是设定一个“最低录取分数线”:把所有申请学生按成绩(概率)从高到低排队,录取到累积分数(概率和)刚好超过分数线 p 为止的那批学生。然后在这批“合格学生”(一个动态变化大小的群体)中,按成绩比例随机录取一人。Top-p 就是设定这个分数线 p。 - p 小 (e.g., 0.5): 只有顶尖的、概率累积占整体很小一部分的词能进入候选池。输出非常保守。 - p 大 (e.g., 0.9, 0.95): 允许更多中高概率的词进入候选池。输出更丰富、更多样化。 - 关键特性:动态词表大小, 候选词的数量 V 不固定,完全取决于当前预测步骤中概率分布的集中程度。如果分布集中(比如前几个词就占了95%概率),则 V 会很小;如果分布平坦(比如前几十个词累积才到90%),则 V 会很大。
场景:
- p 在 0.7 - 0.95 之间比较常用。
- p=0.9 或 0.92 通常是不错的起点,被认为在许多任务中提供了良好的多样性-质量平衡。
- 适合需要长文本连贯性、创意写作、对话生成等强调整体质量和自然多样性的场景。 - 常与 temperature 配合使用(如 GPT 系列 API),效果更佳。
超参
【2024-4-26】LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现
LLM大语言模型Generate/Inference生成或者说推理时,有很多的参数和解码策略
Huggingface 常用参数
- temperature: 温度, 通过调整模型输出的logits概率分布来控制生成文本的随机性和多样性
- top_p
- top_k
- repetition_penalty
- no_repeat_ngram_size
- do_sample
- num_beams
- num_beam_groups
- diversity_penalty
- length_penalty
- use_cache
其他简单、少见参数
- num_return_sequences
- max_length
- max_new_tokens
- min_length
- min_new_tokens
- early_stopping
- bad_words_ids
- force_words_ids
- constraints
BS
BS 相关参数
num_beams
num_beams 用于束搜索(beam search)算法,其用途是控制生成的多个候选句子的数量,该
参数控制的是每个生成步要保留的生成结果的数量,用于在生成过程中增加多样性或生成多个可能的结果。
主要步骤如下:
- 在每个生成步,对于前一个生成中的所有生成结果,分别基于概率保留前 k 个最可能的结果(k 即 num_beams 参数的值)。
- 将所有扩展后的生成结果,按照其对应的概率分数重新计算分数并进行排序,并保留前 k 个最可能的结果。
- 如果已经生成了结束符,则将其对应的结果保留下来。
- 重复上述过程直到生成所有的结果或达到最大长度。
num_beam_groups
num_beam_groups 是 DBS 相关参数, 表示分成多少组
diversity_penalty
DBS 相关参数
diversity_penalty 多样性惩罚参数
- 只有启用“num_beam_groups”(组束搜索)时才有效,在这些组之间应用多样性惩罚,以确保每个组生成的内容尽可能不同。
length_penalty
长度惩罚参数 length_penalty 也用于束搜索过程中
- 候选序列的得分通过对数似然估计计算得到,即得分是负对数似然。
length_penalty 作用: 将生成序列的长度应用于得分的分母,从而影响候选序列的得分
- 当 length_penalty > 1.0 时,较长的序列得到更大的惩罚,鼓励生成较短的序列;
- 当 length_penalty< 1.0 时,较短的序列得到更大的惩罚,鼓励生成较长的序列
- 默认为1,不受惩罚。
随机采样(sampling)
- 随机采样:根据解码器输出的词典中每个词的概率分布随机抽样。
- 相比于按概率“掐尖”,这样会增大所选词的范围,引入更多的随机性。
谷歌开放式聊天机器人Meena采用的方式,论文结论是:
- 这种随机采样的方法远好于Beam Search。
- 但这其实也是有条件的,随机采样容易产生前后不一致的问题。
- 而在开放闲聊领域,生成文本的 长度都比较短 ,这种问题就被自然的淡化了。
do_sample
是否对模型计算出来的概率进行多项式采样
多项式采样(Multinomial Sampling)是一种用于从一个具有多个可能结果的离散概率分布中进行随机抽样的方法
多项式采样的步骤如下:
- 首先,根据概率分布对应的概率,为每个可能结果分配一个抽样概率。这些抽样概率之和必须为1。
- 然后,在进行一次抽样时,会根据这些抽样概率来选择一个结果。具体地,会生成一个随机数,然后根据抽样概率选择结果。抽样概率越高的结果,被选中的概率也就越大。
- 最终,被选中的结果就是这次抽样的输出。
在多项式采样中,概率高的结果更有可能被选中,但不同于确定性的选择,每个结果仍然有一定的概率被选中。这使得模型在生成文本时具有一定的随机性,但又受到概率的控制,以便生成更加多样且符合概率分布的文本。
import torch
probs = torch.tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
next_token = torch.multinomial(probs, num_samples=1)
print("next_token:", next_token)
# 结果
next_token: tensor([[1]])
do_sample 参数通过多样式采样会有一定的随机性,这种随机性导致了生成的文本更加多样化,因为模型有机会选择概率较低但仍然可能的词,这种方法可以产生丰富、有趣、创新的文本,但可能会牺牲一些文本的准确性。
注
- do_sample=False,不进行采样。在Huggingface中,do_sample 参数有更高的含义, 即做不做多样化采样
- do_sample=False,temperature,top_k,top_p 这些参数是不能够被设置的,只有 do_sample=True 时才能够被设置
温度 Temperature
Temperature Parameter 超参数直译为“温度系数”
Temperature 采样受统计热力学启发,高温意味着更可能遇到低能态。
- 将计算过程看做烧水,温度越高,水沸腾越剧烈,类比信息熵增减
Temperature 采样中的温度与玻尔兹曼分布有关.
- 概率模型中,logits 扮演着能量角色,通过将 logits 除以温度来实现温度采样,然后将其输入 Softmax 并获得采样概率。
- 本质: 在 Softmax 函数上添加了温度(T)这个参数。Logits 根据温度值进行缩放,然后传递到 Softmax 函数以计算新的概率分布。
- 越低温度使模型对其首选越有信心,而高于1的温度会降低信心。
- 0温度相当于 argmax 似然,而无限温度相当于均匀采样。
特性
- 温度系数越大,熵就越高,混乱程度越高,那么函数输出的各类别概率差距会越来越小(因为差距越小那么看出最优结果也就越困难,对应于熵越高),曲线也会愈发平滑。
- 相反,温度系数越小,函数曲线也会愈发陡峭。
“我喜欢漂亮的___” 例子中,初始温度 T=1 ,直观看一下 T 取不同值下概率会发生什么变化:
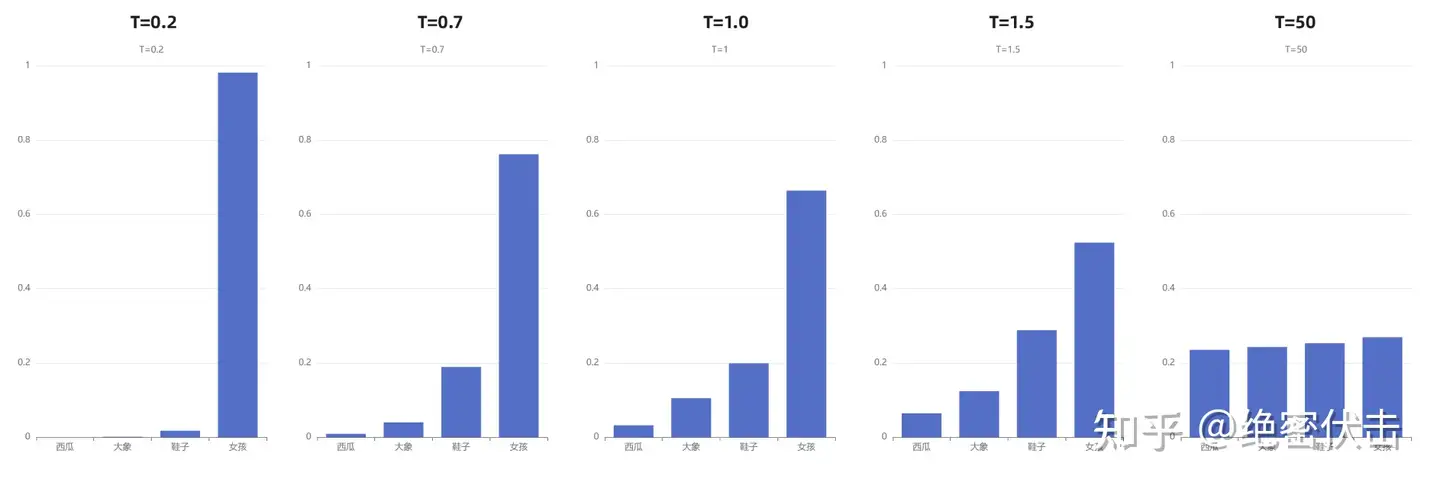
- 随着温度的降低,模型愈来愈越倾向选择”女孩“;
- 随着温度的升高,分布变得越来越均匀。
- 当 T=50 时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。

温度与模型的“创造力”有关?
- 非也。温度只是调整单词的概率分布。
- 宏观效果: 低温模型更具确定性,而高温不那么确定。
温度系数取值设计类比自信心大小:
- 温度系数大(曲线变得平滑,T>1): 对于算法结果不自信 –
知识蒸馏- 不相信当前的结果是最优的,通过添加大的温度系数,将 softmax 输出后的曲线变得平滑,那么稍微陡峭的结果和不陡峭的结果所体现出来的效果是差别不大。因此想要明确获得结果, 需要进行进一步训练,直到模型训练得到一个非常陡峭的输出,经过softmax之后才能获得一个相对陡峭的结果。
- 知识蒸馏是为了节省计算资源,将原模型中比较“没用”的参数给蒸发掉,本质上将原始数据集上训练的重量级模型作为教师,然后取相对更轻量的模型作为学生,令学生输出的概率分布尽可能的逼近教师输出的分布,从而达到知识提纯的目的。
- 蒸馏本质: 让学生网络去学习教师网络的泛化能力. 训练好的模型本身会出现过度自信的问题,softmax输出的概率分布熵很小,top k的优势过于明显。因此添加一个大的温度系数,来令结果不那么自信(也就是我们对当前结果不自信)。因此通过除以 T>1 来令分布变得平滑,进而来令学生模型学到的结果更加准确。
- 温度系数小的情况(曲线变得陡峭,T<1): 对于当前模型是很自信 –
对比学习- 模型变得更加敏感: softmax 对上一步的输入很敏感,稍微陡峭的结果经过损失函数之后变得非常陡峭。
- 添加小的温度系数来突出计算的优势,就可以有效加快模型收敛速度。
- 对比学习从本质上讲,以自监督学习为例,更多的是处理样本正对与负对的问题,也就是令正对更近,负对更远。
- 典型的NCE损失, 子项都除以一个温度系数 T(小于1)。原因:首先对比学习应用这种损失形式本身可以挖掘负样本,经过softmax操作后,会给距离更近的负样本更多的惩罚。那么为了控制对困难样本的惩罚程度,当 T 越小,softmax就会越陡峭,输出差异就被放得越大,那么对困难负样本的惩罚更大(loss更大)SLL综述
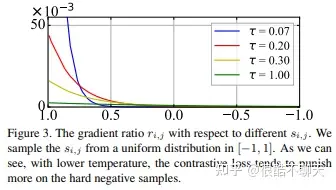
注意: T 不能太小! 无监督学习的对比学习均匀性-容忍性困境:
- “均匀性”:小温度系数更关注于将与本样本相似的困难样本分开,因此希望得到一个分布均匀的表征空间,从而令负对更远(综述提到这种表征或许是成功的关键)。所以说 T 应当小。
-
“容忍性”:困难样本往往是与本样本相似程度较高的,同类别的狗,但是萨摩耶和吉娃娃这两种不同实例。很多困难负样本其实是潜在的正样本,所以不能过度地分开“困难样本”导致破坏潜在语义结构。所以说 T 不能太小。
- 采样时有个可控超参数,称为温度(temperature, T)。
- 模型蒸馏里用到
- 解码器的输出层后面通常会跟一个softmax函数来将输出概率归一化,通过改变T可以控制概率的形貌。
- softmax的公式如下
- 当T大的时候,概率分布趋向平均,随机性增大;
- 当T小的时候,概率密度趋向于集中,即强者俞强,随机性降低,会更多地采样出“放之四海而皆准”的词汇。
公式
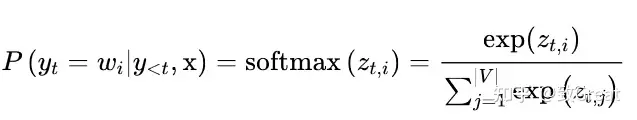
|V|表示词汇的cardinality。- 通过添加一个温度参数T来轻松控制输出的多样性,该参数在采取softmax之前重新调整对数:
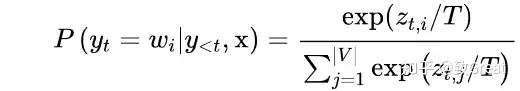
通过调整T控制概率分布的形状。
- 当 T≪1 时,分布在原点周围变得尖锐,罕见的标记被压制。
- 当 T≫1 时,分布变得平缓,每个令牌的可能性相同。
温度对标记概率的影响。
- 当 temperature→0,就变成
greedy search; - 当 temperature→∞,就变成
均匀采样(uniform sampling)。 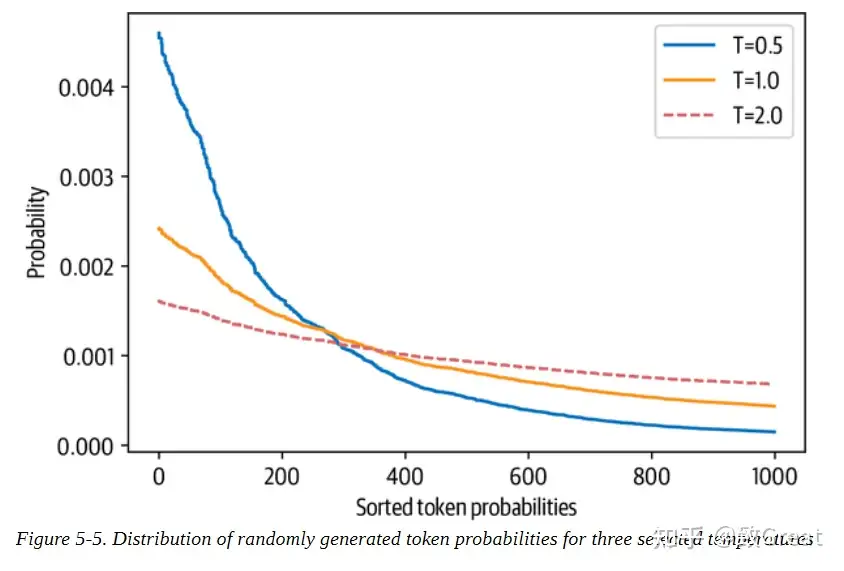
- 详见论文:The Curious Case of Neural Text Degeneration
generate() 函数中设置温度参数temperature,top_k,以T=2为例进行采样
import matplotlib.pyplot as plt
import numpy as np
def softmax(logits, T=1):
e_x = np.exp(logits / T)
return e_x / e_x.sum()
logits = np.exp(np.random.random(1000))
sorted_logits = np.sort(logits)[::-1]
x = np.arange(1000)
for T in [0.5, 1.0, 2.0]:
plt.step(x, softmax(sorted_logits, T), label=f"T={T}")
plt.legend(loc="best")
plt.xlabel("Sorted token probabilities")
plt.ylabel("Probability")
plt.show()
调用
torch.manual_seed(42);
# 高温
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True, temperature=2.0, top_k=0)
# 温度降下来
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True, temperature=0.5, top_k=0)
print(tokenizer.decode(output_temp[0]))
高温产生了大部分的胡言乱语;
- 通过调大罕见词汇出现的概率,使模型产生了奇怪的语法和相当多的生造词
- 降温后,更有连贯性
控制样本质量(一致性和多样性)的方法, 在一致性(低温)和多样性(高温)之间总有一个权衡
- 温度
- 截断词汇的分布
随着温度自由地调整多样性,在更有限的范围内,排除那些在语境中过于奇怪的词(即低概率词)。有两种主要的方法:top-k和nucleus(或top-p)采样。
tempreature 选择呈现如下规律:
- 当 temperature 设置为较小或者0的值时, Temperature Sampling 等同于 每次选择最大概率的 Greedy Search。
- 小的temperature 会引发极大的 repetitive 和predictable文本,但是文本内容往往更贴合语料(highly realistic),基本所有的词都来自与语料库。 当temperatures较大时, 生成的文本更具有随机性(random)、趣味性(interesting),甚至创造性(creative); 甚至有些时候能发现一些新词(misspelled words) 。
- 当 设置高 temperature时,文本局部结构往往会被破坏,大多数词可能会时 semi-random strings 的形式。
- 实际应用中,往往experiment with multiple temperature values! 当保持了一定的随机性又能不破坏结构时,往往会得到有意思的生成文本。
Top-k和nucleus(top-p)抽样是两种流行的替代方法/使用温度的扩展。
- 基本思想: 限制每个时间步长中可以取样的可能标记数量。
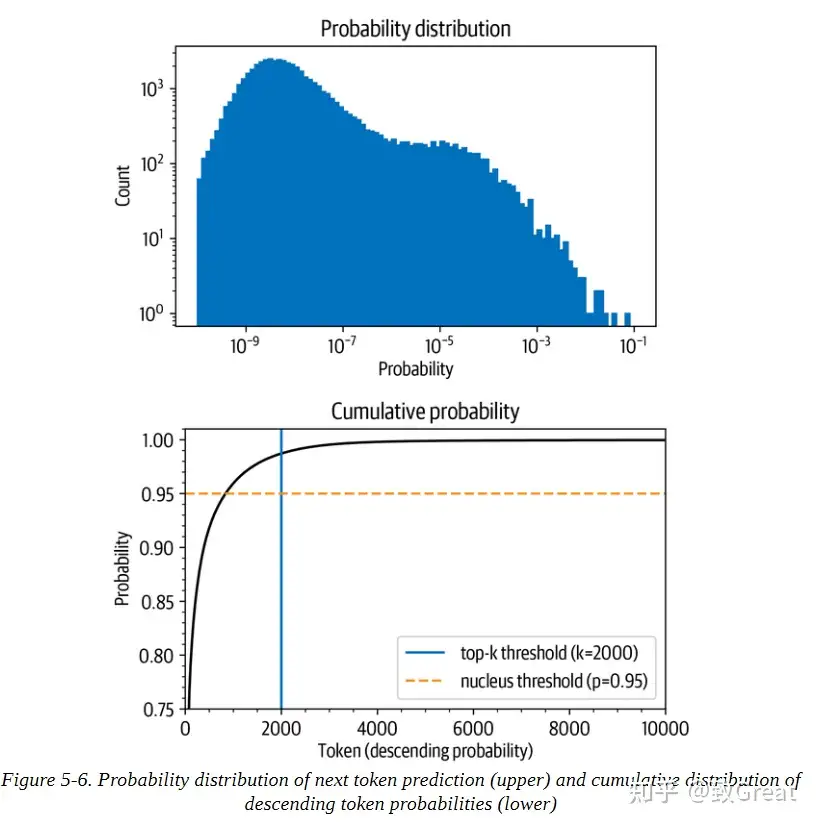
- 上图挑选概率最高的字符(10^-1处的孤立条)的概率是1/10。
- 按概率降序排列标记,并计算前10,000个标记的累积总和(GPT-2的词汇中总共有50,257个标记)
- 在概率最高的1,000个标记中,大约有96%的机会挑选任何一个标记。该概率迅速上升到90%以上,但在几千个标记之后才饱和,接近100%。该图 显示,有1/100的概率没有选到任何甚至不在前2000名的标记。
这些数字乍看很小,但很重要,因为在生成文本时
- 对每个标记取样一次, 只有1/100或1/1000的机会
- 如果取样数百次,就有很大的机会在某一时刻选到一个不可能的标记,而且在取样时选到这样的标记会严重影响生成文本的质量。
因此, 通常希望避免这些非常不可能的标记。top-k和top-p采样发挥作用的地方
top-k抽样
- 在Top-K Sampling中,将挑选出K个最有可能的下一个单词,并且仅在这K个下一个单词之间重新为它们分配概率。
- GPT2就是采用了这种采样方案,这也是其生成故事效果不错的原因之一。
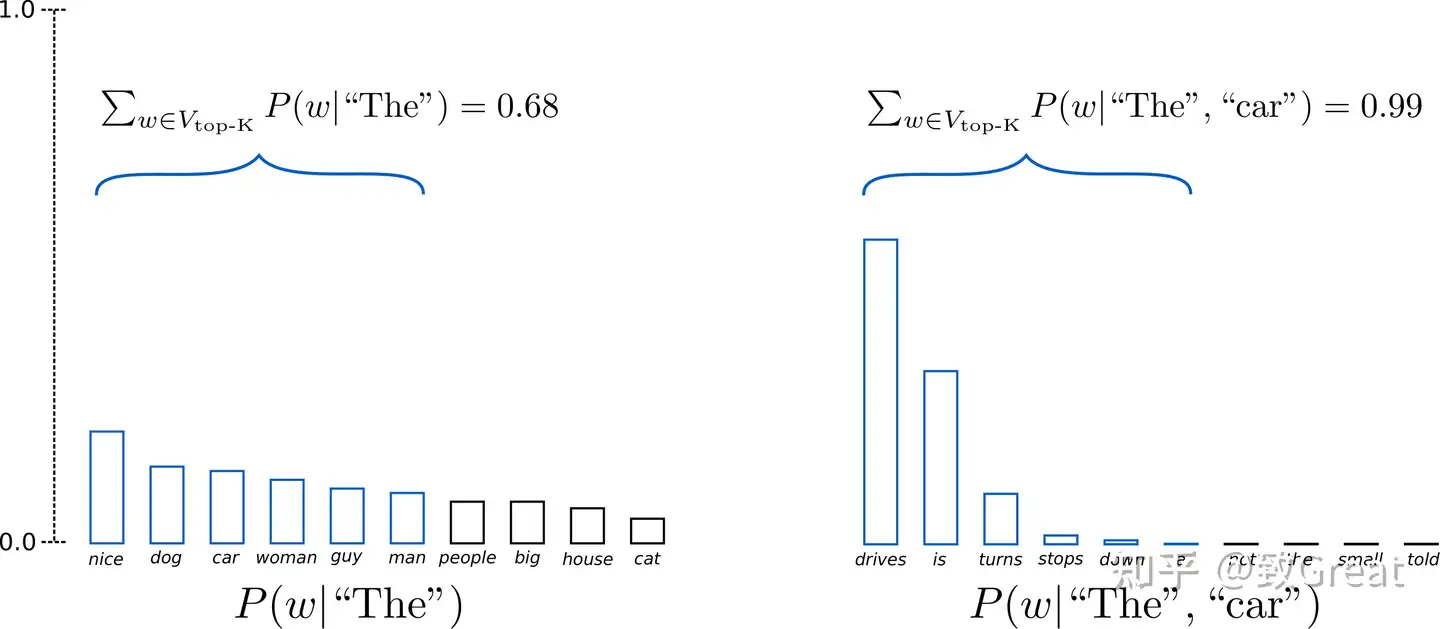
- K=6,将采样最有可能的6个单词,记为V top-K . 在第一步采样中,V top-K 包含了整体的2/3,第二步采样则包含了几乎全部,但是有效地去除了一些奇奇怪怪的单词。
top-k抽样背后的想法
- 通过只从概率最高的k个标记中抽样来避免低概率的选择。
- 这就在分布的长尾上设置了一个固定的切口,确保我们只从可能的选择中取样。
- top-k抽样相当于定义一条垂直线并从左边的标记中抽样。
同样,generate() 函数通过top_k参数提供了一个简单的方法来实现这一点:
output_topk = model.generate(input_ids, max_length=max_length, do_sample=True, top_k=50)
print(tokenizer.decode(output_topk[0]))
最终得到最像人类的文本
如何选择k呢?
- k的值是手动选择的,对序列中的每个选择都是一样的,与实际的输出分布无关。
- 通过查看一些文本质量指标来找到一个好的k值
动态截断
- 在核抽样或顶抽样中,不选择一个固定的截断值,而是设定一个截断的时间条件。在选择中达到一定的概率质量时。
top-p 采样
- 在 Top-p 采样中,不是从仅最可能的K个单词中采样,而是从其累积概率超过一个阈值p的最小可能单词集合中进行选择,然后将这组单词重新分配概率。
- 这样,单词集合的大小(也就是集合中单词的数量)可以根据下一个单词的概率分布动态地增加或减少。
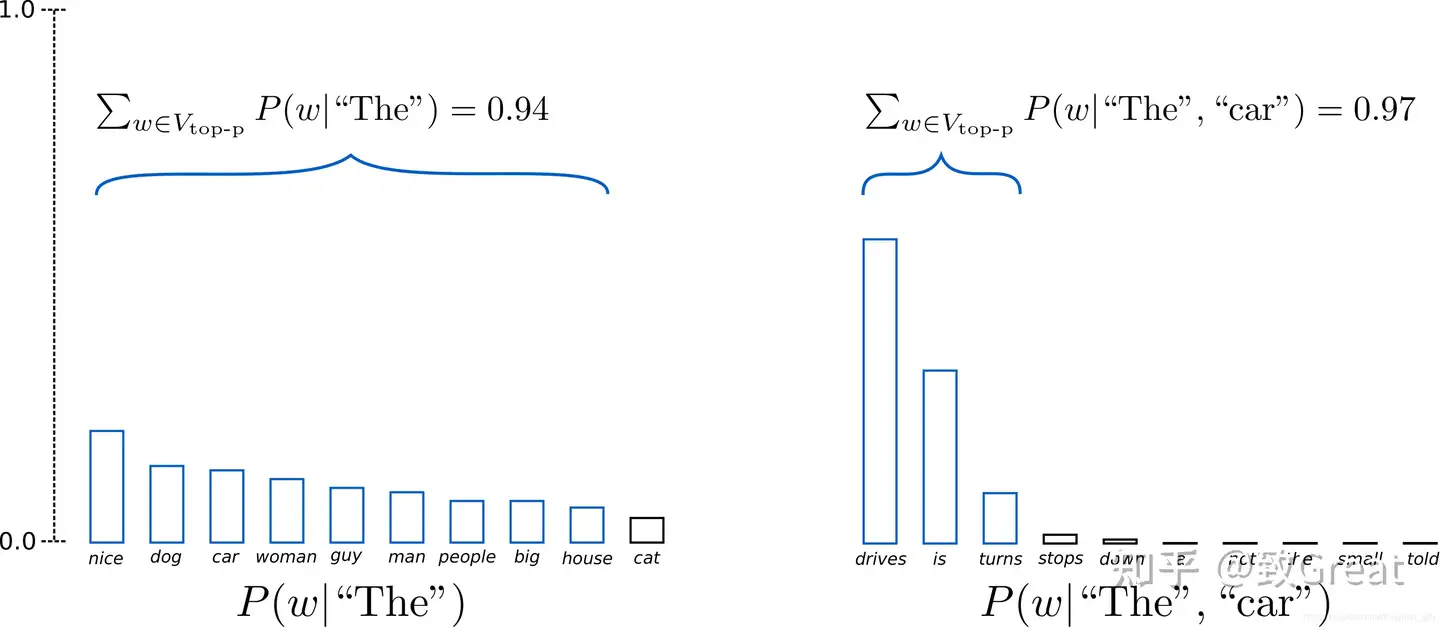
- 设置 p = 0.92,定义为 V top-p ,所有单词累计概率超过0.92的最小单词子集。 在第一步采样中,包括了9个最有可能的单词,而在第二步采样中,只需选择前3个单词即可超过92%。
- 当下一个单词的可预测性不确定时,保留了较多的单词
generate() 函数也提供了一个激活 top-p 抽样的参数
torch.manual_seed(42)
output_topp = model.generate(input_ids, max_length=max_length, do_sample=True, top_p=0.90)
print(tokenizer.decode(output_topp[0]))
Top-p 采样也产生了一个连贯的故事。把这两种抽样方法结合起来以获得最佳效果。
- 设置 top_k=50 和 top_p=0.9,相当于从最多50个标记的池子里选择概率质量为90%的标记的规则。
使用抽样时,也可以用束搜索。与其贪婪地选择下一批候选标记,可以对它们进行抽样,并以同样的方式建立起波束。
参考:关于文本生成(text generation),有哪些提高生成多样性的方法?
示例
大小为[1, 4]的logits张量,例子中其实是[1, 32000],然后, 将logits输入到softmax函数中,分别计算多种情况下的概率分布:
- 没有temperature
- temperature=0.5
- temperature=2
import torch
logits = torch.tensor([[0.5, 1.2, -1.0, 0.1]])
# 无temperature
probs = torch.softmax(logits, dim=-1)
# temperature low 0.5
probs_low = torch.softmax(logits / 0.5, dim=-1)
# temperature high 2
probs_high = torch.softmax(logits / 2, dim=-1)
print(f"probs:{probs}")
print(f"probs_low:{probs_low}")
print(f"probs_high:{probs_high}")
# 结果
# probs: tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
# probs_low: tensor([[0.1800, 0.7301, 0.0090, 0.0809]])
# probs_high: tensor([[0.2695, 0.3825, 0.1273, 0.2207]])
分析
- temperature 较高时,会更平均地分配概率给各个token,这导致生成的文本更具随机性和多样性;
- temperature 较低接近0时,会倾向于选择概率最高的token,从而使生成的文本更加确定和集中。
- temperature=1 时,不用此方式。
pytorch 实现
Temperature 采样代码实现:
import torch
from torch.distributions import Categorical
from labml_nn.sampling import Sampler
class TemperatureSampler(Sampler):
"""
## Sampler with Temperature
"""
def __init__(self, temperature: float = 1.0):
"""
:param temperature: is the temperature to sample with
"""
self.temperature = temperature
def __call__(self, logits: torch.Tensor):
"""
Sample from logits
"""
# Create a categorical distribution with temperature adjusted logits
dist = Categorical(logits=logits / self.temperature)
# Sample
return dist.sample()
Top-k 采样
生成下一个token时,限制模型只能考虑前k个概率最高的token
- 这个策略可以降低模型生成无意义或重复的输出概率,同时提高模型的生成速度和效率。
采样前将输出的概率分布截断,取出概率最大的k个词构成一个集合,然后将这个子集词的概率再归一化,最后重新的概率分布中采样词汇。
- 据说可以获得比Beam Search好很多的效果,但有个问题,就是这个k不太好选。
- 概率分布变化比较大,有时候可能很均匀(flat),有的时候比较集中(peaked)。
- 图

- 对于集中的情况还好说,当分布均匀时,一个较小的k容易丢掉很多优质候选词。
- 但如果k定的太大,这个方法又会退化回普通采样。
import torch
filter_value = -float("Inf")
top_k = 2
probs = torch.tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
indices_to_remove = probs < torch.topk(probs, top_k)[0][..., -1, None]
new_probs = probs.masked_fill(indices_to_remove, filter_value)
print("new_probs:", new_probs)
# 结果
# new_probs: tensor([[0.2559, 0.5154, -inf, -inf]])
top k 实现
def top_k_sampling(model, input, max_length, k):
output = input
for _ in range(max_length):
predictions = model(output)
# 取最可能的k个单词
top_k_scores, top_k_words = torch.topk(predictions, k, dim=-1)
# 对最可能的k个单词进行softmax操作以得到概率分布
probabilities = F.softmax(top_k_scores, dim=-1)
# 根据概率分布抽样一个单词
next_word = torch.multinomial(probabilities, 1)
# 将抽样的单词添加到输出中
output = torch.cat((output, next_word), dim=-1)
# 在生成完成后返回输出
return output
Top-k 采样: “贪心策略”的优化
- 从排名前 k 的 token 中抽样,允许分数/概率较高的token 有机会被选中。这种抽样带来的随机性有助于提高生成质量。
- 每步只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
- 例如,如果 k=2,那么只从女孩、鞋子中选择一个单词,而不考虑大象、西瓜等其他单词。这样避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
- 通过调整 k 的大小,即可控制采样列表的大小。“
贪心策略”其实就是 k = 1 的top-k 采样。
import torch
from labml_nn.sampling import Sampler
# Top-k Sampler
class TopKSampler(Sampler):
# k is the number of tokens to pick
# sampler is the sampler to use for the top-k tokens
# sampler can be any sampler that takes a logits tensor as input and returns a token tensor; e.g. `TemperatureSampler`.
def __init__(self, k: int, sampler: Sampler):
self.k = k
self.sampler = sampler
# Sample from logits
def __call__(self, logits: torch.Tensor):
# New logits filled with −∞; i.e. zero probability
zeros = logits.new_ones(logits.shape) * float('-inf')
# Pick the largest k logits and their indices
values, indices = torch.topk(logits, self.k, dim=-1)
# Set the values of the top-k selected indices to actual logits.
# Logits of other tokens remain −∞
zeros.scatter_(-1, indices, values)
# Sample from the top-k logits with the specified sampler.
return self.sampler(zeros)
top k 优缺点
top-k 优点:
- 根据不同输入文本动态调整候选单词的数量,而不是固定为 k 个。这是因为不同的输入文本可能会导致不同的概率分布,有些分布可能比较平坦,有些分布可能比较尖锐。如果分布比较平坦,那么前 k 个单词可能都有相近的概率,那么我们就可以从中进行随机采样;如果分布比较尖锐,那么前 k 个单词可能会占据绝大部分概率,那么我们就可以近似地进行贪心解码。
- 通过调整 k 的大小来控制生成的多样性和质量。一般来说,k 越大,生成的多样性越高,但是生成的质量越低;k 越小,生成的质量越高,但是生成的多样性越低。因此,我们可以根据不同的任务和场景来选择合适的k 值。
- 与其他解码策略结合使用,例如 温度调节(Temperature Scaling)、重复惩罚(Repetition Penalty)、长度惩罚(Length Penalty)等,来进一步优化生成的效果。
但是 top-k 一些缺点:
- 生成文本不符合常识或逻辑。
- top-k 采样只考虑了单词概率,而没有考虑单词之间的语义和语法关系。
- 例如,如果输入文本是“我喜欢吃”,那么即使饺子的概率最高,也不一定是最合适的选择,因为可能用户更喜欢吃其他食物。
- 生成文本过于简单或无聊。
- top-k 采样只考虑了概率最高的 k 个单词,而没有考虑其他低概率但有意义或有创意的单词。
- 例如,如果输入文本是“我喜欢吃”,那么即使苹果、饺子和火锅都是合理的选择,也不一定是最有趣或最惊喜的选择,因为可能用户更喜欢吃一些特别或新奇的食物。
通常会考虑 top-k 和其它策略结合,比如 top-p。
Top-p 采样
又称 核采样 Nucleus sampling
top-k 有个缺陷
- “k 值取多少是最优的?” 非常难确定。
于是,出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)
- 不再取一个固定的k,而是固定候选集合的概率密度和在整个概率分布中的比例
- 选出来这个集合之后也和top-k采样一样,重新归一化集合内词的概率,并把集合外词的概率设为0。
- 这种方式也称为top-p采样。
top-p 全名是”top probability“,通常用一个介于 0 ~ 1 之间值,表示生成下一个token时,在概率分布中选择的最高概率的累积阈值
top-p 采样思路
- 每步只从累积概率超过某个阈值 p 的最小单词集合中随机采样,而不考虑其他低概率的单词。
- 这种方法也被称为核采样(nucleus sampling),只关注概率分布的核心部分,而忽略了尾部部分。
- 例如,如果 p=0.9,只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。这样避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
下图展示了 top-p 值为 0.9 的 Top-p 采样效果:
top-p 值通常设置为比较高的值(如0.75),目的是限制低概率 token 的长尾。可同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
示例
分析
- 当top_p较高时,比如 0.9,前 90% 的概率的token会被考虑在抽样中,这样会允许更多的token参与抽样,增加生成文本的多样性;
- 当top_p较低时,比如比如 0.1,只有前 10% 最高概率的token会被考虑在抽样中,这样会限制生成文本的可能性,使生成的文本更加确定和集中。
- top_p=1时,表示不使用此方式。
疑问
- 当top-p设置的很小,累加的概率没超过怎么办?一般代码中都会强制至少选出一个token。
import torch
# 样例:probs: tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
probs = torch.tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
# 第一步进行排序
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
# 结果
# probs_sort: tensor([[0.5154, 0.2559, 0.1716, 0.0571]])
# probs_idx: tensor([[1, 0, 3, 2]])
# 第二步概率的累积和
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 结果
# probs_sum: tensor([[0.5154, 0.7713, 0.9429, 1.0000]])
# 第三步找到第一个大于阈值p的位置,假设p=0.9,并将后面的概率值置为0:
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
# 结果
# probs_sort: tensor([[0.5154, 0.2559, 0.1716, 0.0000]])
# 第四步复原原序列
new_probs = probs_sort.scatter(1, probs_idx, probs_sort)
# 结果
# new_probs: tensor([[0.2559, 0.5154, 0.0000, 0.1716]])
# 注:在真实实现中一般会把舍弃的概率置为-inf,即
zero_indices = (new_probs == 0)
new_probs[zero_indices] = float('-inf')
# 结果
# new_probs: tensor([[0.2559, 0.5154, -inf, 0.1716]])
# 完整代码
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
new_probs = probs_sort.scatter(1, probs_idx, probs_sort)
zero_indices = (new_probs == 0)
new_probs[zero_indices] = float('-inf')
return new_probs
实现
def top_p_sampling(model, input, max_length, p):
output = input
for _ in range(max_length):
predictions = model(output)
# 对预测进行排序并计算累积概率
sorted_logits, sorted_indices = torch.sort(predictions, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# 删除累积概率大于p的单词
sorted_indices_to_remove = cumulative_probs > p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
predictions[indices_to_remove] = float('-inf')
# 对剩下的单词进行抽样
next_word = torch.multinomial(F.softmax(predictions, dim=-1), 1)
# 将抽样的单词添加到输出中
output = torch.cat((output, next_word), dim=-1)
# 在生成完成后返回输出
return output
import torch
from torch import nn
from labml_nn.sampling import Sampler
class NucleusSampler(Sampler):
"""
## Nucleus Sampler
"""
def __init__(self, p: float, sampler: Sampler):
"""
:param p: is the sum of probabilities of tokens to pick $p$
:param sampler: is the sampler to use for the selected tokens
"""
self.p = p
self.sampler = sampler
# Softmax to compute $P(x_i | x_{1:i-1})$ from the logits
self.softmax = nn.Softmax(dim=-1)
def __call__(self, logits: torch.Tensor):
"""
Sample from logits with Nucleus Sampling
"""
# Get probabilities $P(x_i | x_{1:i-1})$
probs = self.softmax(logits)
# Sort probabilities in descending order
sorted_probs, indices = torch.sort(probs, dim=-1, descending=True)
# Get the cumulative sum of probabilities in the sorted order
cum_sum_probs = torch.cumsum(sorted_probs, dim=-1)
# Find the cumulative sums less than $p$.
nucleus = cum_sum_probs < self.p
# Prepend ones so that we add one token after the minimum number
# of tokens with cumulative probability less that $p$.
nucleus = torch.cat([nucleus.new_ones(nucleus.shape[:-1] + (1,)), nucleus[..., :-1]], dim=-1)
# Get log probabilities and mask out the non-nucleus
sorted_log_probs = torch.log(sorted_probs)
sorted_log_probs[~nucleus] = float('-inf')
# Sample from the sampler
sampled_sorted_indexes = self.sampler(sorted_log_probs)
# Get the actual indexes
res = indices.gather(-1, sampled_sorted_indexes.unsqueeze(-1))
#
return res.squeeze(-1)
联合采样
通常将 top-k、top-p、Temperature 联合使用。
先后顺序:
top-k->top-p->Temperature
设置 top-k = 3,表示保留概率最高的3个 token。
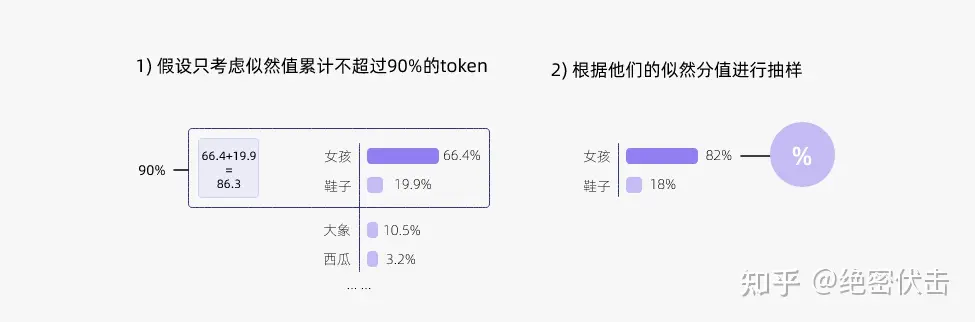
这样就会保留女孩、鞋子、大象这3个 token。
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
接下来使用 top-p 方法,保留概率的累计和达到 0.8 的单词
- 选取女孩和鞋子这两个 token。
接着使用 Temperature = 0.7 进行归一化,变成:
- 女孩:0.660
- 鞋子:0.340
接着,从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
示例
top k 和 top p 联合
# 代码输入的是logits,而且考虑很周全(我感觉漏了考虑k和p都给了的情况,这应该是不合适的)
# 巧妙地使用了torch.cumsum
# 避免了一个词都选不出来的尴尬情况
def top_k_top_p_filtering(logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1):
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
Args:
logits: logits distribution shape (batch size, vocabulary size)
if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
Make sure we keep at least min_tokens_to_keep per batch example in the output
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
"""
if top_k > 0:
top_k = min(max(top_k, min_tokens_to_keep), logits.size(-1)) # Safety check
# Remove all tokens with a probability less than the last token of the top-k
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p < 1.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# Remove tokens with cumulative probability above the threshold (token with 0 are kept)
sorted_indices_to_remove = cumulative_probs > top_p
if min_tokens_to_keep > 1:
# Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)
sorted_indices_to_remove[..., :min_tokens_to_keep] = 0
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
# scatter sorted tensors to original indexing
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
logits[indices_to_remove] = filter_value
return logits
惩罚重复
为了解决重复问题,还有可以通过惩罚因子将出现过词的概率变小或者强制不使用重复词来解决。
repetition_penalty 目标
- 对重复生成的token进行惩罚(降低概率),以减少生成文本中的重复性
惩罚重复
方式:
- 每步对出现过的词的概率做出惩罚,即降低出现过的字的采样概率,让模型趋向于解码出没出现过的词
repetition_penalty
参数:
repetition_penalty(float,取值范围>0)。- 默认为1,即代表不进行惩罚。
- 值越大,即对重复的字做出更大的惩罚
代码实现逻辑:
- 如果字的概率score<0,则 score = score*penalty, 概率会越低;
- 如果字的概率score>0, 则则score = score/penalty,同样概率也会变低。
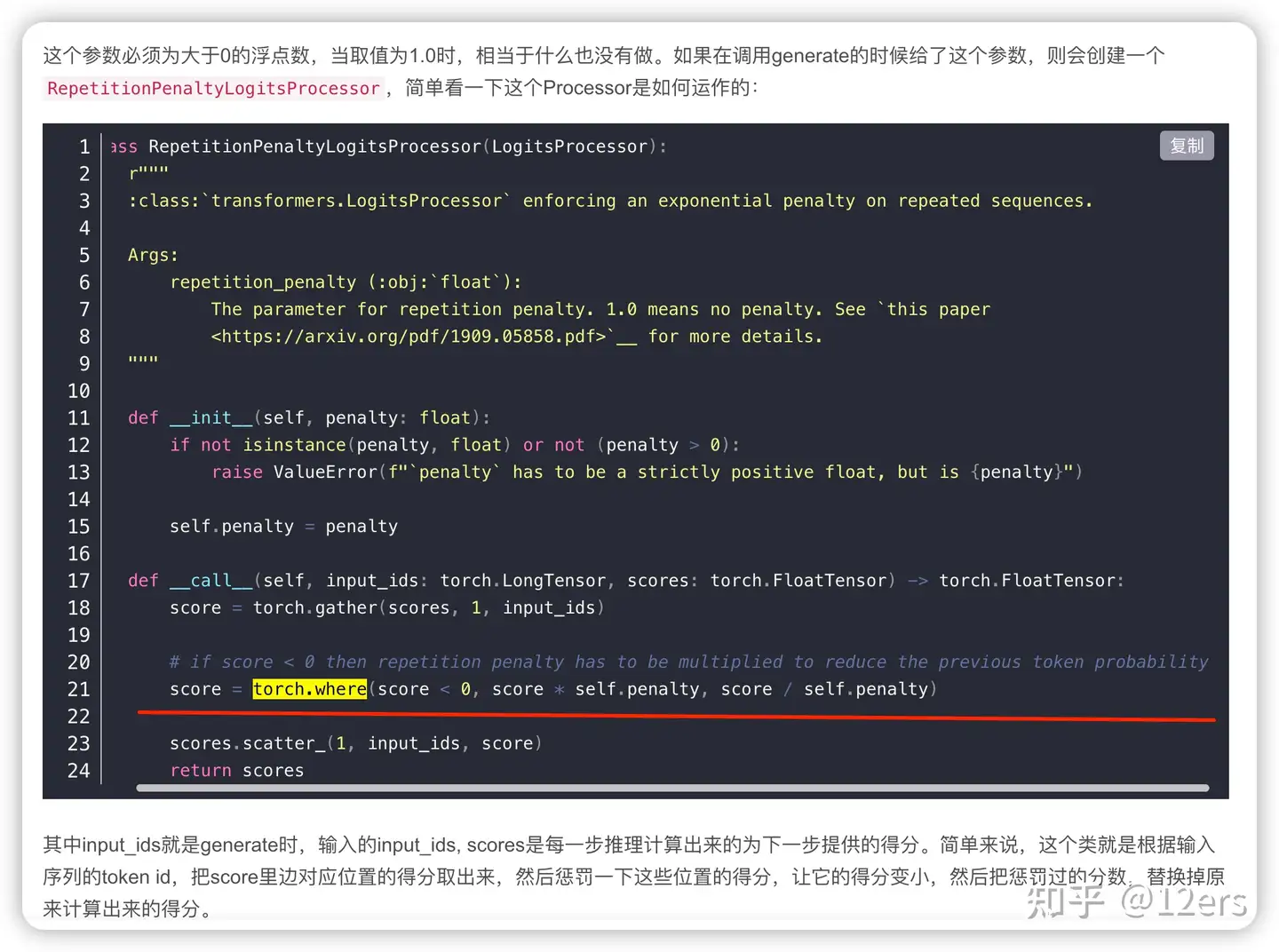
import numpy as np
def apply_repetition_penalty(probs, repetition_penalty, prev_tokens):
adjusted_probs = np.copy(probs)
for token in set(prev_tokens):
adjusted_probs[token] *= (1/repetition_penalty)
adjusted_probs /= np.sum(adjusted_probs)
return adjusted_probs
# 示例概率分布,索引对应不同词语
original_probs = np.array([0.3, 0.1, 0.3, 0.1, 0.2])
# 示例先前生成的词语
previous_tokens = [2, 4, 2]
# 重复惩罚系数
repetition_penalty = 1.25
# 应用重复惩罚,得到调整后的概率分布
adjusted_probs = apply_repetition_penalty(original_probs, repetition_penalty, previous_tokens)
print("原始概率分布:", original_probs)
print("调整后的概率分布:", adjusted_probs)
# 结果
# 原始概率分布: [0.3 0.1 0.3 0.1 0.2]
# 调整后的概率分布: [0.33333333 0.11111111 0.26666667 0.11111111 0.17777778]
出现过的 token 概率变低了,未出现过的token的概率变高了。
惩罚n-gram
方式:
- 限制n-gram在生成结果中出现次数
参数:
- no_repeat_ngram_size,限制n-gram不出现2次。 (no_repeat_ngram_size=6即代表:6-gram不出现2次)
no_repeat_ngram_size
no_repeat_ngram_size 这个参数
- 当设为大于0的整数时,生成的文本不会出现指定大小的重复n-gram(n个连续的token)
可以使生成的文本更加多样化,避免出现重复的短语或句子结构。
实现原理和 repetition_penalty 差不多,只不过这里是n个连续的token。
注
- 默认不设置
use_cache
该参数如何设置为True时,则模型会利用之前计算得到的注意力权重(key/values attentions)的缓存,这些注意力权重是在模型生成文本的过程中,根据输入上下文和已生成部分文本,计算出来的,当下一个token需要被生成时,模型可以通过缓存的注意力权重来重用之前计算的信息,而不需要重新计算一次,有效地跳过重复计算的步骤,从而减少计算负担,提高生成速度和效率
MoE
问题
- 解码任务中常用的Beam Search生成序列条件概率最大的句子,很容易导致生成句子的多样性不足
现有解法
- Diverse Beam Search通过对生成结果分组并加入相似性惩罚来提高多样性,一定程度缓解单一性问题,但并不彻底。
- 另外,Sampling解码算法(如topp、topk)生成结果的随机性更大,多样性更好一些,但相应准确率也更差。
MoE使用多个模型组合训练不同分布的数据,很适合解决多样性问题
- 有工作用MoE结构来学习推荐中多任务模型各任务之间的相关性,解决不相关的任务导致模型效果差的问题。
【2019-5-24】MoE in Text Generation – 用于 byte push
- Mixture Models for Diverse Machine Translation: Tricks of the Trade
- 用多种不同MoE策略,提出生成多样性的评估指标,在生成质量基本不降的情况下,多样性得到了很大改善。
MoE (Mixture of Experts)模型的基本思想
- 训练多个神经网络,每个网络(作为Expert)训练时使用数据集不同部分。
- 数据集内部分布可能不同,单模型往往善于处理其中一部分数据,不善于处理另一部分数据,而多专家系统解决了这个问题:系统中每个Expert都会有一个擅长的数据区域,在这组区域上其要比其他Expert表现得好。
常用的encoder-decoder结构,通过encoder得到hidden states,再输入进decoder得到生成结果
- 鉴于诸如Beam Search解码导致的生成多样性问题,作者引入Multinomial Latent Variable 并分解生成模型的边际似然函数(z表示一个expert)
- 训练阶段使用EM算法
- 解码时用生成概率最大的那个Expert的结果作为最终结果
实际使用中,这会导致两个严重的问题:
- 在训练中可能只有一个Expert会被迭代,导致rich gets richer的问题;
- Latent Variable失效;
作者提出了两个改进方式:
- hard/soft selection,即如何使用expert的权重进行迭代
- learned/uniform prior,prior即前面提到的p(z|x; θ)
- learned:设置一个gate网络,模型自己去学;
- uniform:所有experts权重统一
作者提出Pairwise-BLEU,用于衡量多样性的指标,纵轴是bleu。
- Pairwise-BLEU是对生成的多个结果两两计算BLEU,多样性越好,两两就越不相似,分数就越低
少见参数
少见参数
- num_return_sequences 模型返回不同的文本序列的数量,要和 beam search 中的 num_beams 一致,在贪心解码策略中,num_return_sequences只能为1,默认也为1。
- max_length 生成的token的最大长度。它是输入prompt的长度加上max_new_tokens的值。如果同时设置了max_new_tokens,则会覆盖此参数,默认为20。
- max_new_tokens 生成的最大token的数量,不考虑输入prompt中的token数,默认无设置
- min_length 生成的token的最小长度。它是输入prompt的长度加上min_new_tokens的值。如果同时设置了min_new_tokens,则会覆盖此参数,默认为0。
- min_new_tokens 生成的最小token的数量,不考虑输入prompt中的token数,默认无设置
- early_stopping 控制基于束搜索(beam search)等方法的停止条件,接受以下值:
- True:生成会在出现num_beams个完整候选项时停止。
- False:应用启发式方法,当很不可能找到更好的候选项时停止生成。
- never:只有当不能找到更好的候选项时,束搜索过程才会停止(经典的束搜索算法)。
- 默认为False
- bad_words_ids 包含词汇id的列表,这个参数用于指定不允许在生成文本中出现的词汇,如果生成的文本包含任何在这个列表中的词汇,它们将被被替换或排除在最终生成的文本之外。
- force_words_ids 包含词汇id的列表,用于指定必须包含在生成文本中的词汇,如果给定一个列表,生成的文本将包含这些词汇。
- constraints 自定义约束条件,可以指定约束条件,这些约束条件可以是必须出现的关键词、短语、特定术语或其他文本元素,其实和force_words_ids是差不多的意思,在代码实现也是一样的。
资料
- NLP界著名Python包Transformers
- 解析过程见:解读Beam Search (1/2)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
