Data-centric
认知
不可能三角
开源大模型开源的是什么?模型权重,模型架构代码,训练和推理的脚本和tokenizer,有诚意的团队会在技术报告中写训练超参数(炼丹的火候)和数据配比(丹方),但没有一家大模型厂家会开源他们的训练数据。
开源数据集存在根本矛盾--“不可能三角”
- 开源数据集不可能同时做到:
大规模,高质量,安全可信。
所以,唯一的方法构建自研数据集,用复杂数据流水线,从开源、自爬、购买的混合数据源中,清洗、过滤、去重、合成,构建出“规模足够大、质量足够高、足够安全”的专有混合配方。
数据 > 模型
数据在模型训练中非常重要。
- 数据提升对于模型效果的提升至关重要,而模型的提升效果却不明显
- 很多研究人员开始研究以数据为中心,想办法加强数据的质量和数量, 而不过多考虑模型或固定数据集
- img
劣质数据影响很大
脏数据学多了,LLM 变傻且不可逆
【2025-11-14】脏数据学多了,LLM也会变傻
“脑损伤”(Brain Rot)
- 因为长期接触碎片化、低价值网络信息而逐渐变得记忆紊乱、注意力下降的情况
- 俗称:碎片化垃圾信息刷多了,抖音刷多了人会变傻,详见站内专题: 大脑工作原理
2024年,这个词一度被选为牛津年度词汇。
【2025-10-15】研究显示,AI也一样。大模型灌多了垃圾内容也会变蠢降智脑损伤,而且后面变不回来了。
几个AI研究者找来了几个月的高流行但低价值的Twitter数据(现𝕏),统统“喂”给大模型后发现:
- 模型推理能力下降了23%;
- 模型长上下文记忆下降了30%;
- 模型性格测试显示,其自恋和精神病态的现象激增。
更可怕的是,即使后来又在干净、高质量的数据上进行重新训练,这些已经造成的损伤,无法完全修复。
原以为:“垃圾进垃圾出”,更换好数据就能恢复
结果:一次错误就会造成永久性的认知漂移
启发:
- 1、首次把“持续预训练的数据筛选”归为“训练时安全问题”,提醒行业不能只关注“训练后对齐”(如安全微调),更要在源头把控数据质量。
- 2、给大模型加上“认知体检”非常重要,建议部署大模型时使用 ARC、RULER等基准测试AI认知,避免AI长期接触低质量数据导致能力退化。
- 3、类似“热度”指标比文本长度更能判断数据质量,未来筛选训练数据时,可优先排除“短+高传播”的碎片化内容,尤其是社交平台数据。
人类数据→经验数据
【2025-6-10】强化学习之父最新演讲:AI的未来是经验时代,人类的未来是去中心化合作
强化学习之父”、2024 年 ACM 图灵奖得主 Richard Sutton 在新加坡国立大学发表人工智能未来的演讲,系统地阐述了他对 AI 技术趋势、社会哲学及宇宙演化的前沿思考。
- AI 正经历从“人类数据时代”到“经验时代”的根本性转变,并强烈呼吁社会以去中心化的合作精神取代基于恐惧的中心化控制,勇敢地迎接一个由 AI 驱动的未来。
- YouTube 视频 NUS120 Distinguished Speaker Series - Professor Richard Sutto
定调:
- 第一句来自未来学家
Ray Kurzweil:“智能是宇宙中最强大的现象。” - 第二句则出自“计算机科学之父”
Alan Turing:“我们需要的是能够从经验中学习的机器。”
Sutton 指出,在 AI 诞生之前,人类就对从经验中学习这一概念充满兴趣,而这正是强化学习的核心所在。
目前正处于一个“人类数据时代”。以大型语言模型为代表的现代 AI,其能力主要建立在对海量人类生成数据的学习之上
- 这些数据源自互联网的文本、图像,并通过人类标注和偏好进行微调。
- 这些模型本质上是强大的“预测机器”,擅长预测人类会说的下一句话或标签。
Sutton 警告:
- 这一范式正逐渐触及其天花板。高质量的人类数据源,如同珍贵的矿藏,大部分已被消耗殆尽。
- 要创造真正意义上的新知识,AI 必须超越这种以人类为中心、依赖静态历史数据的方法。
由此,Sutton 和他的同事 David Silver 提出,正在进入“经验时代”——一个全新的数据生成和学习范式。

“经验”的内涵:并非某种神秘或哲学的概念,而是指智能体通过与世界进行第一人称的、实时的互动所产生的数据流。
- 这是一种动态、连续且与智能体自身行为紧密相关的数据。
这才是所有生物真正的学习方式, 婴儿会不断地与周围的玩具互动,当一个玩具不再能带来新的学习时,他便转向下一个。他与世界的互动,本身就在不断生成新的、专属于他的学习数据。
无论是足球运动员在瞬息万变的赛场上做出决策,还是猎鹰精准地飞越狭窄空间,这些场景都涉及到高带宽的实时信号处理和基于即时反馈的学习。这种“经验”数据的丰富性远非书面文字所能比拟。
真正的智能,核心在于智能体预测并控制自身输入信号(尤其是奖励信号)的能力。这正是强化学习理论的基石。
从早期让 AI 学会在 Atari 游戏中获胜,到 AlphaGo 通过在“想象”中进行数百万次自我对弈(一种模拟经验)而下出被称为“神之一手”的第 37 手,都印证了“经验学习”的强大威力。
如今,我们看到最新的 AI 智能体开始被赋予采取行动、与环境交互并想象其后果的能力,这标志着“经验时代”的大门正在被真正推开。
而在“人类数据时代”表现出色的大语言模型,最多再过十年,甚至可能只有五年,它就将被其他更强大的 AI 形式所超越,因为“利用计算进行规模化比利用我们的人类知识要好得多”。
许多甚嚣尘上的论调,如 呼吁暂停 AI 研究、强调“AI 对齐”(将 AI 的目标与人类价值观对齐),以及对 AI 潜在风险的过度渲染,其本质都是在呼吁一种基于恐惧的“中心化控制”。

正确的道路并非去设计和控制 AI 的内在目标,因为这不仅极其困难,而且本质上是在创造一种“奴隶”。相反,应该致力于创造一个 AI 能够生存和发展的外部世界,让“合作”成为最理性的选择。
宇宙的四个伟大时代:
- 粒子时代:宇宙大爆炸后,只有基本粒子。
- 恒星时代:粒子在引力下汇聚成恒星,通过核聚变创造出更重的元素。
- 复制者时代(The Age of Replicators):生命的诞生。他特意避免使用“生命”一词,而改用更精确的“复制者”,指代那些能够在不完全理解自身工作原理的情况下,复制出自身的系统。所有生物,包括人类,都是“复制者”。
- 设计者时代(The Age of Design):技术与机器的出现。与“复制”的盲目性不同,“设计”的产物首先在某个心智的想象中被构思出来,然后才被付诸实现。

法律法规
【2025-8-18】图解《人工智能生成合成内容标识办法》及配套国家标准
【2025-3-14】国家网信办等四部门印发《人工智能生成合成内容标识办法》(以下简称《办法》),自2025年9月1日起施行。
《办法》提到
- 人工智能生成合成内容标识主要包括
显式标识和隐式标识两种形式- 显式标识: 生成合成内容或者交互场景界面中添加的,以文字、声音、图形等方式呈现并可以被用户明显感知到的标识;
- 隐式标识: 采取技术措施在生成合成内容文件数据中添加的,不易被用户明显感知到的标识。
- 网络信息服务提供者应当按照《互联网信息服务深度合成管理规定》相关规定
- 在生成合成内容的文本、音频、图片、视频、虚拟场景或其他生成合成服务场景的画面中,于适当位置添加显著的提示标识;
- 生成合成内容的文件元数据中应添加隐式标识,隐式标识包含生成合成内容属性信息、服务提供者名称或者编码、内容编号等制作要素信息。
- 任何组织和个人不得恶意删除、篡改、伪造、隐匿本办法规定的生成合成内容标识,不得为他人实施上述恶意行为提供工具或者服务,不得通过不正当标识手段损害他人合法权益。
什么是 Data-centric AI
Data-centric AI 定义
Data-centric 观点:
- 当今的AI系统更多由数据驱动,而非模型架构的变化驱动
Andrew Ng: ML团队80%的工作应该放在数据准备上,数据质量最重要,每个人都应该如此
- Data-Centric AI is the discipline of systematically engineering the data used to build an AI system.
- If 80 percent of our work is data preparation, then ensuring data quality is the important work of a machine learning team.
Data-centric AI 是一种搭建 AI 系统的新理念, 简称 DCAI
Data-centric AI refers to a framework to develop, iterate, and maintain data for AI systems
Data-centric AI framework
Data-centric AI 是指为人工智能系统开发、迭代和维护数据的框架。它涉及建立有效的训练数据、设计适当的推理数据、维护数据的相关任务和方法。
Data-centric AI 框架
- 训练数据开发
- 数据收集、标注、准备、降维、增强
- 推理数据开发
- 分布内评估
- 分布外评估
- 提示工程
- 数据维护
- 数据理解、质量维护、存储检索
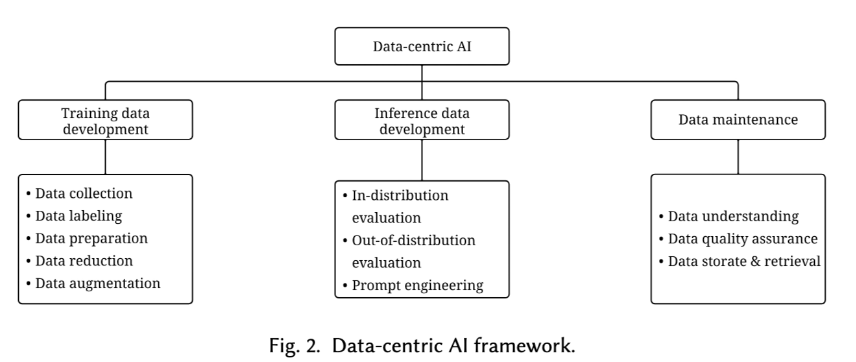
论文 Data-centric Artificial Intelligence: A Survey
Model-centric vs Data-centric
对比分析
- 模型为中心(model-centric): 传统搭建AI模型,以迭代模型为主,数据相对固定
- 聚焦于几个基准数据集,然后设计各式各样的模型去提高预测准确率。
- model-centric问题
- 没有考虑到实际应用中数据可能出现的各种问题,例如不准确的标签,数据重复和异常数据等。
- 准确率高的模型只能确保很好地「拟合」了数据,并不一定意味着实际应用中会有很好的表现。
- 数据为中心(Data-centric) AI:
- 关注数据本身,而模型相对固定。
- 采用 Data-centric AI的方法, 实际场景中会有更大的潜力,因为数据很大程度上决定了模型能力的上限。
- Data-centric 更侧重于提高数据的质量和数量。
图来自论文
数据为中心 和 模型为中心 不是对立的,而是相辅相成
- 一方面,以模型为中心的方法可用于实现以数据为中心的人工智能目标。
- 例如,利用生成模型,如 GAN 和扩散模型,来执行数据增强并生成更多高质量数据
- 另一方面,以数据为中心的人工智能可以促进以模型为中心的人工智能目标的改进。
- 例如,增加的数据增强数据的可用性可以激发模型设计的进一步发展
DCAI 演变
随着AI发展,组织形式也在不断演进,职责分化,诞生新的功能模块。
传统:
- 流程: 由
数据工程师完成数据标注、清洗、增强、聚合等工作,再由机器学习工程师完成模型训练,而算法工程师仅需关注算法的开发。
问题:
- 数据管理成本高:
- 算力和存储未优化
- 人力成本高, 主要靠算法工程师
- 时间成本高
- 无法支持大规模应用:
- 人工管理数据, 到一定程度后,边际效应为0
- 无法多维、多模态复杂查询
- 稳定性差、安全性差
新的组织带来协作难度升级,也需要新范式来支持
职责分化
Data Ops: 数据标注(25%), 数据清洗(25%), 数据增强(15%), 数据聚合(10%)ML Ops: 模型训练(10%), 数据识别(5%), 模型调参(5%), 机器学习运营(2%)算法工程师: 算法开发(3%)
图解
Data-centric AI 资料
综述
- 【2023-3】Data-centric Artificial Intelligence: A Survey ChatGPT 的成功的重要驱动力就是 data-centric。
- Data-Centric AI 介绍
MIT: Introduction to Data-Centric AI 课程
Syllabus
- 1/16/24: Data-Centric AI vs. Model-Centric AI
- 1/17/24: Label Errors and Confident Learning
- 1/18/24: Advanced Confident Learning, LLM and GenAI applications
- 1/19/24: Class Imbalance, Outliers, and Distribution Shift
- 1/22/24: Dataset Creation and Curation
- 1/23/24: Data-centric Evaluation of ML Models
- 1/24/24: Data Curation for LLMs
Special topics from previous years
- 1/24/23: Growing or Compressing Datasets
- 1/25/23: Interpretability in Data-Centric ML
- 1/26/23: Encoding Human Priors: Data Augmentation and Prompt Engineering
- 1/27/23: Data Privacy and Security
OpenAI 多么重视数据
OpenAI工程师花了极大心血提升数据质量和数量,GPT模型迭代差异明显
- 训练数据: 小数据 → 较大的高质量数据 → 更大的高质量数据 → 高质量人类标注数据
- 推理数据: 对prompt进行复杂精细管理
GPT-1 -> GPT-2 -> GPT-3 -> GPT-4:
- 模型架构相似
- 数据量不同:
| gpt模型 | 模型 | 数据量 |
|---|---|---|
GPT-1 |
4.8G,未过滤 | |
GPT-2 |
40G,人工过滤 | |
GPT-3 |
570G,从45T原石数据中过滤 | |
ChatGPT/GPT-4 |
人工演示/标注 |
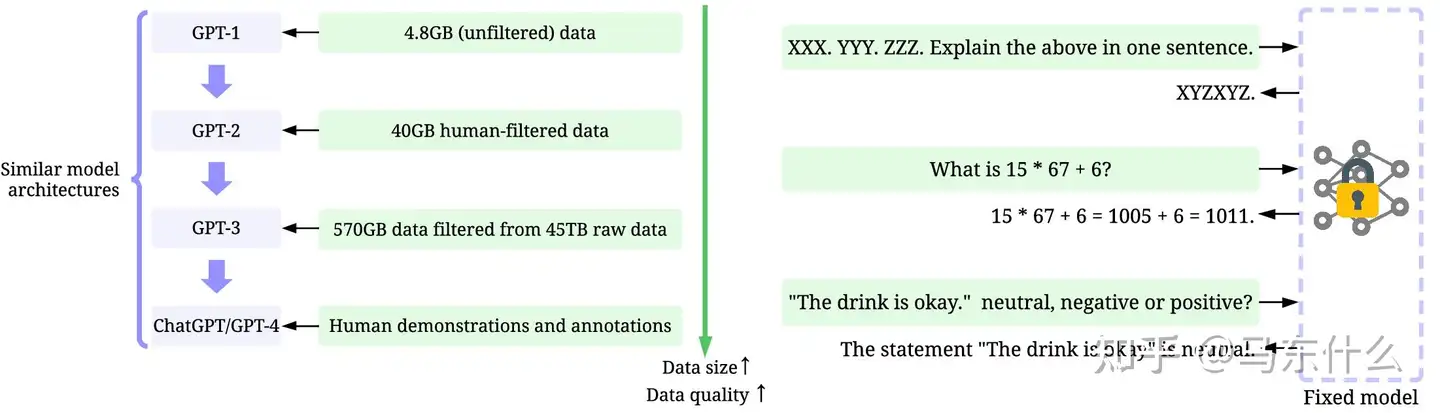
Data-centric 构成
data-centric两个重要部分: 合成数据和数据选择。
常面临数据量不足的问题
- 首先, 采用合成数据方法, 提升数据数量。
- 而数据数量达到一定程度时,模型性能陷入瓶颈,难以通过数量来提升性能,此时,可以通过数据选择方法筛选出高质量数据。
综述
摘要
- 分别从LM的五个learning stage介绍。
- Task-specific Fine-tuning 部分通常有两类目标:(实际落地场景较多应用)
- 匹配真实数据分布:适用于数据量少的场景
- 多样化数据分布:
1. 提高数据效能
- 数据集转化为图表示,knn寻找距离方差最大的数据点 -> 多样性;保留只有相同label邻近的数据点 -> 减少数据量。
- Self-influence score: 评估outlier等困难样本。
- datamodels
- 增强鲁棒性
DCAI 自动化
DCAI 研究方向划分为两个视角,即自动化程度和人类协作程度。
- 前者侧重于自动化流程的设计,后者则更加关注如何 human in the loop
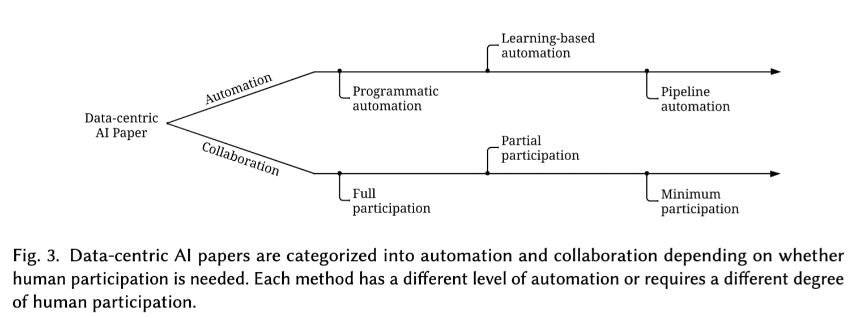
三种Automation
- Programmatic automation:使用程序自动处理数据。程序通常是根据一些启发式和统计信息设计的,现阶段各类的 automate machine learning 的工作大都集中于此,例如各类 auto feature engineering 的方法
- Learning-based automation:通过优化学习自动化策略。例如,最小化目标函数,此类方法通常更灵活,适应性更强。例如基于强化学习的方法做超参数调整或基于 meta learning 来确定优化策略等
- Pipeline automation:跨多个任务的自动化调整优化策略。例如 tpot,autosklearn 这类工作,将数据处理,特征工程,模型调参等一系列任务放置在一个统一的 pipeline 里(Learning-based automation和Programmatic automation可以看作是pipeline automation中的一环)
三种Human Participation
从另一个角度来看,面向Human Participation的方法往往需要不同形式的人类参与。可以确定几个程度:
- Full participation:人类完全控制过程。需要全员参与的方法通常可以很好地符合人类的意图,但代价高昂,例如雇佣大量外包公司来做数据打标
- Partial participation:不需要人工全程参与,但是需要人类密集或持续地提供信息。例如,通过提供大量反馈或频繁交互。例如大名鼎鼎的RLHF。Active Learning 领域很多研究都是这个范畴
- Minimum participation:自动化的控制整个过程,只在少量需要时咨询人类。人类只有在收到提示或要求时才会参与。当遇到海量数据和人力预算有限时,这种方法非常合适
同样,人类参与的程度在一定程度上,反映了效率(更少的人力)和有效性(更好地与人类保持一致)之间的权衡
合成数据 Synthetic Data
Conclusion
Conclusion
- 优秀的LLM合成数据的质量更高(推荐用GPT-4合成)。
- 合成数据训练出的模型性能比真实数据更差且与任务的主观性呈负相关。
- Few-shot合成数据通常比zero-shot合成数据的效果更好。
- 盲目增加训练数据可能导致特定任务的性能下降。
- 合成数据在多语言场景上有三种用法,均能够提升目标语种效果:
- 直接生成非目标语种数据
- 生成非目标语种数据后翻译成目标语种
- 直接生成目标语种的数据
- 在合成数据之后再通过判别器过滤掉被判别为“合成数据”的数据能够提升合成数据的忠实度,但不一定能提高效果。
论文
IT University of Copenhagen: The Parrot Dilemma: Human-Labeled vs. LLM-augmented Data in Classification Tasks
- 基于大型语言模型(LLMs)的数据增强:
- 针对文本分类任务,每次使用GPT-4和Llama-2 70B生成与给定样本数据标签相同但内容相似的9个新样本。
- 平衡的数据增强策略:过采样少数类别以平衡数据集中的类别比例。
- 温度调整:temperature为1,有助于增加生成样本的多样性。
- 多样性评估:计算合成数据与用于合成的原始数据样本的余弦相似度(语义多样性)和token overlap的比例(词汇多样性),来评估生成数据的多样性。
- 对比零样本分类的LLM:用FT小模型和zero-shot的LLM在文本分类任务上
- LLMs在生成与现实世界数据分布一致的合成数据方面仍面临挑战。
Microsoft: LLM-powered Data Augmentation for Enhanced Crosslingual Performance
- 使用 Dolly-v2、StableVicuna、ChatGPT 和 GPT-4,来扩充三个多语言常识推理数据集
- 评估了使用合成数据对较小的多语言模型进行微调的有效性,包括 mBERT 和 XLMR,并比较了使用英语生成的数据和目标语言生成的数据的效果。
Purdue University: Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
- 在不同文本分类任务中,使用LLM生成的合成数据训练出的模型性能与任务的主观性呈负相关。
- 使用few-shot合成数据相比zero-shot可以提高生成数据的有效性。
Allen Institute for AI: How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
- 采用不同数据集(真实/合成)在多个特定任务上进行实验
- 使用所有的数据集一起训练可以在达到最好的平均性能,但是在特定任务上性能会下降。
- 盲目增加训练数据可能导致特定任务的性能下降。
- 使用GPT合成数据训练有助于模型减少有害回复。
University of Toronto: Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science
- 合成数据的生成分布通常与研究人员关心的真实世界数据的分布不同(即不忠实)。为了提高合成数据的忠实度,在讽刺检测的任务中提出了三种策略:
- grounding(基础): 1. 合成示例相似数据(Parrot Dilemma这篇) or rewrite
- Filtering 1. 训练一个bert模型专门用来判断数据是否是合成数据
- taxonomy-based generation(在prompt中指定讽刺类别以提高多样性)。
- 三种策略都提高了分类器的性能,但grounding策略对于讽刺检测任务效果最好。
选择数据 Data Selection
总结
Conclusion
- PE数据选择方法成本较低,优先尝试。
- Influential function方法可在小模型上计算,以降低成本,再将选择出的高质量数据集迁移到目标LLM上进行训练。
- Datamodel 实现成本偏高,落地时只能在需要数据量小的场景应用。
- 获得数据选择标准/选择好的高质量数据后,能够反作用于数据合成质量的提升。
- 数据多样性不一定能提升效果。
方法概览
Data Selection常用的四类方法
| Data Selection Solutions | Intro | Advantages | Weakness |
|---|---|---|---|
提示工程 PE |
通过Prompt Engineering 判断数据质量 | 实现简单,成本最低 | 依赖于LLM能力,不够domain-specific |
影响函数 Influential Function |
通过计算数据间影响力函数,判断出对目标数据贡献大的训练集样本。 | 选择的数据质量高、可迁移性。 | 实现成本较高,计算量大,耗时久。 |
| 数据建模 Datamodels | 对目标数据建立datamodel,判断对目标数据贡献大的训练集样本。 | 选择的数据质量高。 | 实现成本极高,实际场景难落地。 |
| 其它 Other | 利用与测试集数据的相似度来选择。 | 实现成本相对Influential function和data models较低。 | 数据质量难以保证。 |
(1) PE
论文
- 通过PE对训练数据难度打分(1-3),判断数据质量。
- 设计数据合成与选择的pipeline:
few-shot生成->质量打分->zero-shot生成->质量打分
(2) Influence functions
论文
Influence functions:
- 评估训练集每个sample对Loss的影响
- 计算模型参数^2维度的hessian矩阵 -> 对于LLM开销太大,使用 Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC)代替。
- TF-IDF 过滤减少需要计算的sample数量(根据query选择TF-IDF得分top-10000的seqs)
- query batching 一次性计算所有训练数据的梯度,且用低秩矩阵代替计算。
- 实验针对不同query去计算其在训练集中 influential score高的样本
Danqi Chen
- Influential score的计算根据adam优化器作了改良,引入了m和v
- 数据选择:将每个子任务的训练集数据与验证集数据计算influential score,选择其中score top5%作为选定数据。
- 数据选择模型和最终使用的模型可以不同,所以可以用小模型进行data selection后再将选定的数据集应用于大模型ft
AI Lab
- G-DIG: Towards Gradient-based DIverse and hiGh-quality Instruction Data Selection for Machine Translation
- Influential score 计算根据梯度近似
- 利用influential score筛选出高质量数据:
- 选择对seed 数据(人工挑选的256条高质量数据)均产生正向influential score的数据
- 利用K-means聚类 + 重采样方法保证数据的多样性。
(3) Datamodels
MIT, Datamodels: Predicting Predictions from Training Data
- 给定一个训好的模型以及目标数据,建模预测出对目标数据的训练有帮助的训练数据,并去除噪声数据、发现泄漏数据等。
- 对每个测试集的样本都需要建一个datamodel来分析,训练成本较高
MIT: DsDm: Model-Aware Dataset Selection with Datamodels
- 通过使用数据模型来估计训练子集对目标任务性能的影响,并选择使估计最小化的子集。
- 选择与高质量数据相似度高的数据(Classifier/DSIR) 可能反而降低表现
其它
Stanford
- Data Selection for Language Models via Importance Resampling
- 提出一种通过在降维的n-gram特征空间中估计重要性权重,并根据这些权重进行重采样数据选择的方法DSIR。
- 本质上是利用与测试集数据的相似度来选择。 2. 定义了一种数据度量方法,称为KL reduction,计算使用数据选择方法选定的数据集与随机选择的数据集相比,在特征空间上相对于目标分布的KL散度的平均减少量。
- KL reduction 的值越大,表示通过数据选择过程选定的数据集在特征空间上与目标分布的接近程度越高,即数据选择过程更有效。
方法
Self-Instruct
大模型严重依赖于人类编写的指令数据,而这些数据在数量、多样性和创造力方面受到限制,阻碍了调整模型的通用性。
【2023-5-25】华盛顿作者提出了Self-instruct框架,通过预训练语言模型自己引导自己来提高的指令遵循能力的框架。
- 论文 Self-Instruct: Aligning Language Model with Self Generated Instructions
- self-instruct代码:self-instruct, 代码讲解
- 大模型自己遵循一套流程来生成数据
- 再用这些生成的数据来指令微调训自己
- 从而提高模型自己的能力
半自动的self-instruction过程,用于使用来自模型本身的指示信号对预训练的LM进行指令调整。
迭代的自引导(iterative bootstrapping)算法
- 从一个有限人工编写的指令种子集开始,用于指导整个生成。
- 第一个阶段,提示模型为新任务生成指令。此步骤利用现有的指令集合来创建更广泛的指令,这些指令定义(通常是新的)任务。
- 对于新生成指令集,框架还创建输入-输出实例,这些实例可在以后用于监督指令调优。
- 最后,在将低质量和重复的指令添加到任务池之前,使用各种措施来修剪它们。这个过程可以在许多交互中重复,直到达到大量的任务。
核心思想:生成指令遵循数据
指令数据由指令、输入、输出组成。
数据生成piple包含四个步骤:
- 1)生成任务指令
- 2)确定指令是否代表分类任务
- 3)使用输入优先或输出优先方法生成实例
- 4)过滤低质量的数据。
贡献如下:
- SELFINSTRUCT,一种用最少的人工标记数据诱导指令跟随能力的方法;
- 通过大量指令调优实验证明了其有效性;
- 发布包含52K指令的大型合成数据集和一组手动编写的新任务,用于构建和评估未来的指令遵循模型。
人物角色驱动的数据构造
【2024-7-1】腾讯AI Lab技术报告:一种以10亿人物角色驱动的新颖数据构造方法
大规模创建合成数据并非易事,尤其是确保数据的多样性。
- 以往的研究, 通过实例驱动或关键点驱动的方法来增加数据的多样性,但这些方法在可扩展性上存在限制。
因此, 腾讯提出了一种新颖的人物角色(Personas)驱动的数据合成方法,利用大型语言模型(LLM)中的多种视角来创建多样化的合成数据。
By showcasing PERSONA HUB’s use cases in synthesizing high-quality mathematical and logical reasoning problems, instructions (i.e., user prompts), knowledge-rich texts, game NPCs and tools (functions) at scale, we demonstrate persona-driven data synthesis is versatile, scalable, flexible, and easy to use, potentially driving a paradigm shift in synthetic data creation and applications in practice, which may have a profound impact on LLM research and development.

create ($data) with ($persona)
data:
- math problem
- logical reasoning problem
- user prompt to an LLM
persona:
| persona | math problem |
logical reasoning problem |
user prompt to an LLM |
|---|---|---|---|
| a moving company driver | |||
| a chemical kinetics researcher | |||
| … | |||
| a musician interested in audio processing |
人物角色可以与广泛的数据合成提示(例如,创建一个数学问题或用户提示)一起工作,以指导大型语言模型(LLM)合成具有相应视角的数据。
人物角色中心中的10亿个人物角色可以促进在十亿规模上为各种数据合成场景创建合成数据。
- “人物角色库”(Persona Hub):一个从网络数据自动策划的包含10亿个不同人格的集合。这些人格作为世界知识的分布式载体,可以深入LLM中的几乎所有视角,从而促进大规模创建多样化的合成数据。
角色库采用了两种可扩展的方法:Text-to-Persona 和 Persona-to-Persona
Text-to-Persona方法通过特定文本推断出可能阅读、写作或喜欢该文本的特定人格。- 文本到人物角色的方法:任何文本作为输入,只需通过提示大型语言模型“
谁可能[阅读|写作|喜欢|不喜欢|...这个文本?]”,就可以获得相应的角色。
- 文本到人物角色的方法:任何文本作为输入,只需通过提示大型语言模型“
Persona-to-Persona方法则是从已有人格中衍生出具有人际关系的其他人格。- 角色到角色方法:通过人际关系获取多样化的角色,这可以通过向大型语言模型提问“
谁是与给定角色有密切关系的人?”来轻松实现。
- 角色到角色方法:通过人际关系获取多样化的角色,这可以通过向大型语言模型提问“
通过“人物角色库”合成高质量数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏NPC和工具(功能)的用例。
Evol-Instruct
Evol-Instruct 方法核心: 指令数据演化。
对初始指令集进行升级和演化,生成更多样化的指令,从而提高模型对不同类型指令的处理能力。
关键步骤:
- 收集初始指令集:作为演化的基础,初始指令集应包含来自不同领域和任务、具有不同复杂度和难度级别的指令。这些指令可以是简单的问答、翻译任务,也可以是复杂的推理、总结任务。
- 指令数据演化:通过对初始指令集进行深度演化和广度演化,生成更多样化的指令。深度演化主要包括添加约束、深化、具体化、增加推理步骤和复杂化输入等操作,旨在使指令更加复杂和深入。广度演化则是通过创建与给定指令基于同一领域但更为罕见的全新指令,来增加主题和技能覆盖面,使数据集更加多样化。
- 淘汰低效指令:在演化过程中,会产生一些没有提供信息增益、难以生成响应或明显复制了演化提示词汇的指令。这些指令被称为低效指令,需要通过淘汰演化过程进行识别和过滤,以确保指令集的质量。
- 合并与微调:将演化的指令数据与初始指令集合并,形成最终的微调数据集。然后,在LLM上进行微调训练,以提高模型对复杂指令的处理能力。
ACEBench
ACEBench 覆盖8大领域(技术、金融等)、68子领域,生成4538个API,包含Normal、Special、Agent三类数据,完美适配拒绝采样和强化学习。
数据合成的三大模块
- API合成:构建多样化工具池
- 对话生成:模拟真实交互
-
质量检测:确保数据逼真
- API合成:构建多样化工具池
API是工具调用的基础,ACEBench生成4538个中英文API:
- 提取与设计:从真实场景(如天气查询)提炼参数,如WeatherAPI需city、date(格式YYYY-MM-DD)。
- 分层上下文:构建领域(如金融)到子功能(如汇率计算)的层级,参数约束清晰。
- 成果:生成功能稳定的API池,为对话生成奠基。
- 对话生成:模拟真实交互
基于API池,生成单轮和多轮对话,贴近真实场景:
- 单轮对话:模板生成简单场景,如“查北京明天天气”调用WeatherAPI,返回“晴,2- 。
- 多轮对话:多智能体角色扮演(用户、助手、工具),模拟复杂任务,如规划旅行调用WeatherAPI、FlightAPI。
- 特殊场景:模拟歧义指令(“查天气”未指定城市)、相似API混淆,提升模型鲁棒性。
- 质量检测:确保数据逼真
高质量需严格校验,ACEBench结合多重审核:
- 自动化检测:检查API完整性、对话逻辑、格式一致性(如JSON Schema)。
- 模型辅助:LLM检测语义错误,多模型投票过滤低质量数据。
- 人工复审:领域专家审核复杂对话的逻辑性和逼真度。
数据分类与应用
ACEBench数据分三类,评估不同能力:
- Normal数据:测试简单工具调用准确性,如“查天气”。
- Special数据:评估歧义或错误指令下的鲁棒性。
- Agent数据:测试多轮对话中的上下文理解和动态交互。
Kimi Agent 数据合成
【2025-7-16】Kimi K2智能体能力的技术突破:大规模数据合成 + 通用强化学习
受ACEBench启发,月之暗面 Kimi K2 博客提出“Large-Scale Agentic Data Synthesis”,通过系统化方法生成逼真、多样的Agent工具调用数据。
Kimi K2 增强的智能体能力来自两个重要方面:大规模智能体数据合成和通用强化学习
ACEBench 数据合成的核心思路
整个系统就像巨大的”智能体训练工厂”:
- 左侧是原料准备 :首先从各种领域(Domains)中收集工具(Tools),这些工具既包括真实的 MCP 工具,也有人工合成的工具。然后基于这些工具创建出不同的智能体(Agents)。
- 中间是模拟环境 :有一个工具模拟器(Tool Simulator)作为环境,让智能体可以在里面”练习”使用各种工具。同时还有用户智能体(User Agents)来模拟真实用户的行为和需求。
- 右侧是质量控制 :所有的任务都配有评分标准(Tasks w/rubrics),最后由评判员(Judge)来评估整个交互过程的质量。
整个流程就是让智能体在这个模拟的”沙盒”环境中不断练习使用工具、与用户交互,然后通过评判员筛选出高质量的训练数据。这样就能大规模地生成真实、多样化的智能体训练素材,让 Kimi K2 学会如何在真实世界中灵活使用各种工具
为什么数据合成是LLM核心?
工具调用让LLM能处理复杂任务,如查询天气、规划旅行等,背后靠的是高质量数据。真实数据成本高、覆盖有限,数据合成则能模拟多样场景,生成大规模训练数据。
【2024-12-17】CHIMERA
【2024-12-17】CHIMERA 合成数据推理
如何用9K条合成数据训练4B模型,逼近DeepSeek-R1的推理能力。核心是三阶段流水线构建高质量推理数据。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
