上下文工程
发展
- 2022年, 大家谈论“提示词工程”(Prompt Engineering),解决单次交互。
- 2024年, 谈 “上下文工程”(Context Engineering),解决Agent(智能体)的长序列、多轮工具调用。
- 2026 年初,AI 工程界达成关键共识:大模型能力的提升正遭遇边际效应递减,真正的瓶颈在于执行环境(Execution Environment)
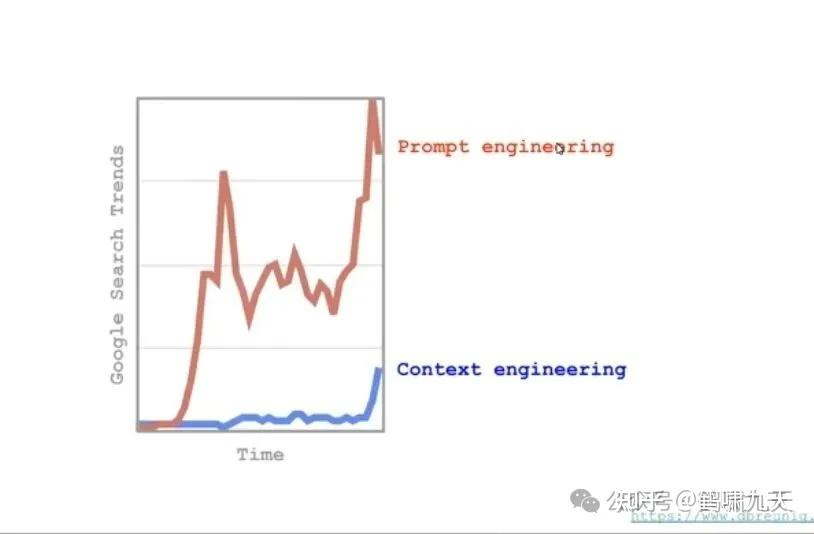
早期提示工程(Prompt Engineering),即如何巧妙地向模型提问,迅速转向一个更进阶的领域——上下文工程(Context Engineering)。
要点:
- 上下文工程不仅是提示工程的升级,更是将动态系统、工具协作和记忆管理结合在一起的综合工程
- 四大策略(
写入、选择、压缩、隔离) 是构建代理时常见的手段,需要根据任务特性灵活组合 - 多代理架构优缺点并存:并行子代理可扩展能力,但会增加成本并带来协调困难,需配合共享上下文和压缩技术
- 长上下文不是灵丹妙药:随着上下文增长,污染、干扰、混乱和冲突现象会加剧,剪枝和隔离同样重要
资料
- LangChain 官方博客文章《The Rise of “context engineering”》
- 【2025-6-24】解读 LangChain官方分享LLM的“上下文工程”技巧
- 【2025-7-16】图解+详解:上下文工程
- 【2025-7-30】Mutil-Agent的终极秘密武器:上下文工程(Context Engineering)
上下文负责铺路,而提示工程教你怎么走,提示工程是上下文工程的子集。
【2025-10-27】Manus血泪教训:为什么上下文工程才是护城河
综述
上下文工程(Context Engineering)是一门生成、获取、处理与管理语言模型智能体上下文信息的艺术。
本文对该领域进行了系统梳理与分类,总结了其核心构成要素及典型应用场景。将现有研究划分为三类基础能力组件(Context Retrieval and Generation、Context Processing、Context Management)和四种系统实现(RAG、Memory Systems、Tool-Augmented Reasoning、多智能体系统),并分析其在Prompt Engineering、Memory机制、Agent通信与调度等方面的具体应用。
此外,重点讨论当前大模型在“context scaling”层面的发展瓶颈与挑战,指出真正的上下文扩展不仅涉及长度问题,更包括对信息类型、结构与动态处理机制的扩展。我们进一步总结了LLM在处理复杂关系型和结构化数据方面的最新进展与未来方向。
背景
使用LLM 智能体(Agent)时,常常遇到棘手问题:
- 为什么智能体表现如此不稳定?
习惯性归咎于模型本身不够强大。
然而,问题根源:未能向模型提供恰当上下文。
- 当一个智能体无法可靠地执行任务时,其根本原因通常是未能以正确的格式向模型传递正确的信息、指令和工具。
随着LLM应用从单一提示词演变为复杂的、动态的智能体系统,“上下文工程”(Context Engineering)正迅速成为AI工程师需要掌握的重要技能。
Cognition 团队核心观点
“再聪明的模型,若不知上下文,也无法做出正确判断。”
LLM 失败
智能体系统的失误,本质是 LLM 失误。
从第一性原理分析,LLM 失败主要源于两个方面:
- 底层模型能力不足,无法正确推理或执行。
- 模型缺少正确判断所需的上下文。
随着模型能力的飞速发展,第二点正成为更普遍的瓶颈。
上下文供给不足体现在:
- 信息缺失:模型完成任务所依赖的关键信息未被提供。
- 格式混乱:信息虽然存在,但其组织和呈现方式不佳,阻碍了模型的有效理解。
两个问题:
- 成本与效率: 长上下文会增加模型的计算成本和延迟,并可能导致模型性能下降
- 新的失败模式: Drew Breunig 总结了长上下文的四大失败模式:
- 上下文污染(Context Poisoning): 幻觉或错误信息进入上下文后被反复引用,代理会围绕错误目标做出决
- 上下文干扰(Context Distraction): 上下文过长导致模型过度关注历史而忽略训练知识,反复重复已有行
- 上下文混乱(Context Confusion): 上下文中无关的内容(如过多的工具说明)干扰模型,使其调用不必要的工
- 上下文冲突(Context Clash): 上下文中出现相互矛盾的信息时,模型难以判断取舍
因此,仅依靠扩大上下文窗口并不能解决问题,反而会引入新的风险。
上下文工程旨在通过合理整理、压缩和隔离信息,避免上述失败模式。
上下文悖论
Agent 任务往往是 多轮对话 和 工具调用 的组合,导致上下文越来越长。
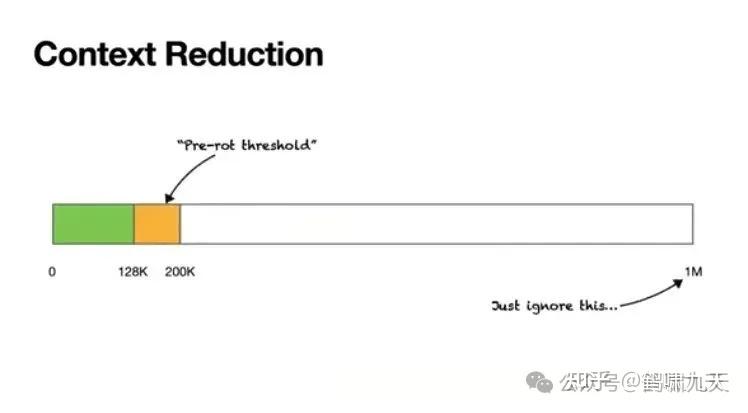
LangChain 创始人 Lance指出“上下文悖论”:Agent要完成复杂任务,必须大量调用工具(典型任务约50次)来获取上下文。
- 即使 100万Token上下文窗口,模型在处理到200K(约20万)时,性能就开始“腐烂”(Context Rot),出现重复、缓慢和质量下降。
- “上下文腐烂”阈值 大约128K-200K之间
Agent又慢又笨,不是模型不行,是“上下文工程”没做好
提示词 → 上下文
大模型应用技术从“提示词艺术”迈向“上下文科学”。
最近爆品,如Cursor,Manus等产品都表明
- 一个卓越的大模型产品,背后必然是精心设计的上下文工程系统。
未来的核心竞争力,不再是精妙的提示词,更是高质量、高效率的上下文。
通过精心组织,为模型提供事实依据、注入持久记忆、并扩展其行动能力,有可能释放大模型的潜力,构建出新的有价值AI产品。
定义
2025年6月,Shopify CEO Tobi Lütke 和 AI 大神 Andrej Karpathy 在 X 上提出新概念——上下文工程。
Karpathy 将其定义为”一门微妙的艺术与科学,旨在填入恰到好处的信息,为下一步推理做准备。”
上下文工程
- 构建动态系统,以正确格式提供合适的信息和工具,使 LLM 能够合理地完成任务。
LangChain 在博客中将 上下文工程(context engineering) 定义为构建动态系统,为大语言模型提供恰当的信息和工具,使其“有可能完成任务”。
- 《The Rise of Context Engineering》
与早期只靠提示词的“prompt engineering”不同,上下文工程强调的是:
- 系统性: 代理的上下文来自开发者、用户、历史交互、工具调用或其他外部数据,必须通过系统化的逻辑组合在一起
- 动态性: 这些上下文通常是实时生成的,因此构建最终提示必须具有动态拼接能力
- 正确的信息与工具: 代理出错往往不是模型能力不足,而是缺乏恰当的信息或工具,因此必须保证提供的信息充分且格式合适
安德烈·卡帕西(Andrej Karpathy)用操作系统类比:
- LLM 就像 CPU,上下文窗口是 RAM(工作内存),而上下文工程就是决定哪些信息可以放入 RAM 的“调度器”。
- 由于 RAM 容量有限,上下文工程需要精心挑选和组织信息以避免溢出。
上下文工程
上下文工程(Context Engineering)核心定义:
- 构建一个动态系统,以正确格式提供正确的信息和工具,从而使大语言模型(LLM)能够可靠地完成指定任务。
深入理解:
- 系统工程:复杂智能体从多个来源获取上下文,包括开发者预设、用户输入、历史交互、工具调用结果以及外部数据。将这些信息源有机地整合起来,本身就是一个复杂的系统工程。
- 动态变化:上下文组成部分很多是实时生成。最终输入给模型的提示(Prompt)也必须是动态构建的,而非静态的模板。
- 信息精准:智能体系统失败的原因之一是上下文信息缺失。LLM 无法“读心”,必须为其提供完成任务所需的全部信息。所谓“垃圾进,垃圾出”,信息质量直接决定输出质量。
- 工具适用:很多任务无法仅靠初始信息完成。为 LLM 配备合适的工具就变得至关重要,用于信息检索、执行动作或与其他系统交互。提供正确的工具与提供正确的信息同等重要。
- 强调格式规范:与 LLM 的“沟通方式”跟人一样关键。简洁明了的错误信息远胜于一个庞杂 JSON 数据块。工具的参数设计、数据的呈现格式,都会显著影响 LLM 的理解和使用效率。
- 任务可行性:设计系统时,应反复自问:“在当前提供的上下文和工具下,LLM 是否真的有可能完成任务?” 便于归因分析,上下文不足,还是模型本身的执行失误,从而采取不同的优化策略。
【2025-7-21】中科院论文 A Survey of Context Engineering for Large Language Models
【2025-10-30】上海交通大学刘鹏飞团队和 GAIR 实验室这篇关于《上下文工程 2.0》论文,系统回答了上下文工程的本质、基础构件和未来发展。
马克思:
人类是社会关系的总和
其实也是上下文的总和
核心困境:人与机器的交流之所以困难,是因为我们之间存在一道深深的认知鸿沟。
- 人类的表达是高熵的。说话时充满模糊、暗示,并且严重依赖过往的共识。比如我们对同事说“搞定那个报告”,对方就能理解。
- 而机器,至少在目前,是低熵的。它无法处理这种模糊性,只能理解精确、毫不含糊的指令。 「上下文工程」解决这个根本矛盾。 论文将上下文工程比作「熵减」。当前的 AI,比如我们熟悉的 LLM,其技术架构的本质是一个无状态函数。
- 给一个输入,就返回一个输出。没有真正的记忆,不记得你是谁,也不懂你身处的环境。
- 人类是有状态的存在。每个反应都建立在长期记忆和对当下的感知之上。 因此,上下文工程的真正本质是为这个「无状态」的函数,搭建一套庞大而精巧的脚手架。
- RAG 和外部数据库来模拟长期记忆;
- 多模态输入来模拟感官;
- 复杂管理系统过滤信息,模拟注意力。
努力用所有这些外部工具,把一个天生没有记忆、没有感官的「函数」,包装成一个看起来有记忆、能理解环境的智能体。
这套脚手架是现阶段的必然产物,核心价值是让 AI 从能用变得好用。但终极使命是等待一个真正具备原生记忆和感知的,有状态的新架构出现。
到那时,这套脚手架也就可以功成身退了。
碳基智能 vs 硅基智能
图解
提示工程 vs 上下文工程
为什么从“提示工程”(Prompt Engineering)转向“上下文工程”?
LLM应用早期,开发者专注于通过巧妙措辞诱导模型给出更好的答案。
但随着应用变得越来越复杂,共识逐渐形成:
- 向AI提供完整和结构化的上下文,远比任何“魔法般”的措辞都重要。
提示工程是上下文工程的子集。
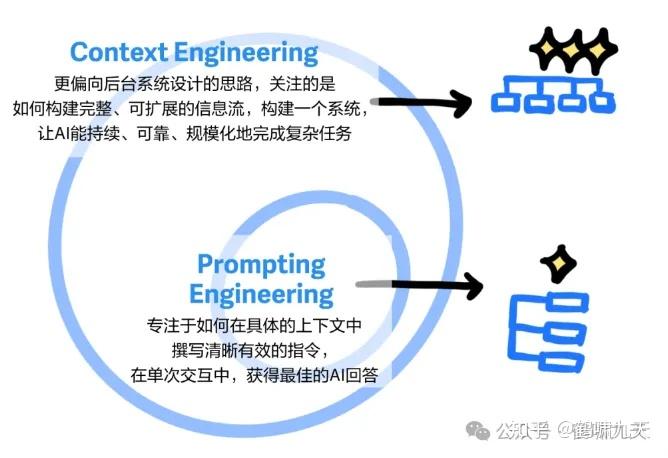
即使有全部上下文信息,提示词组织、编排方式,仍然至关重要——提示工程范畴。
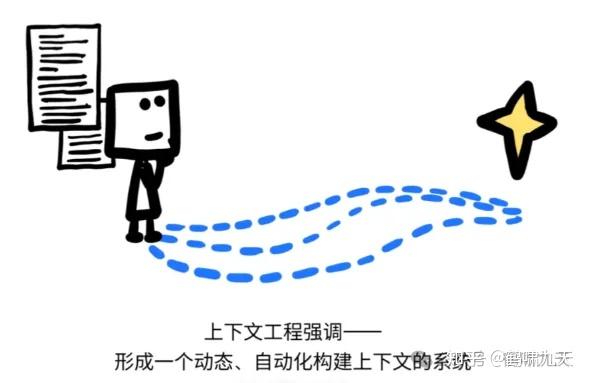
核心区别:
上下文工程:设计架构,动态地收集、筛选和整合来自多源的数据,构建出完整的上下文。提示工程:已有上下文的基础上,设计格式化和指令,以最优方式与LLM沟通。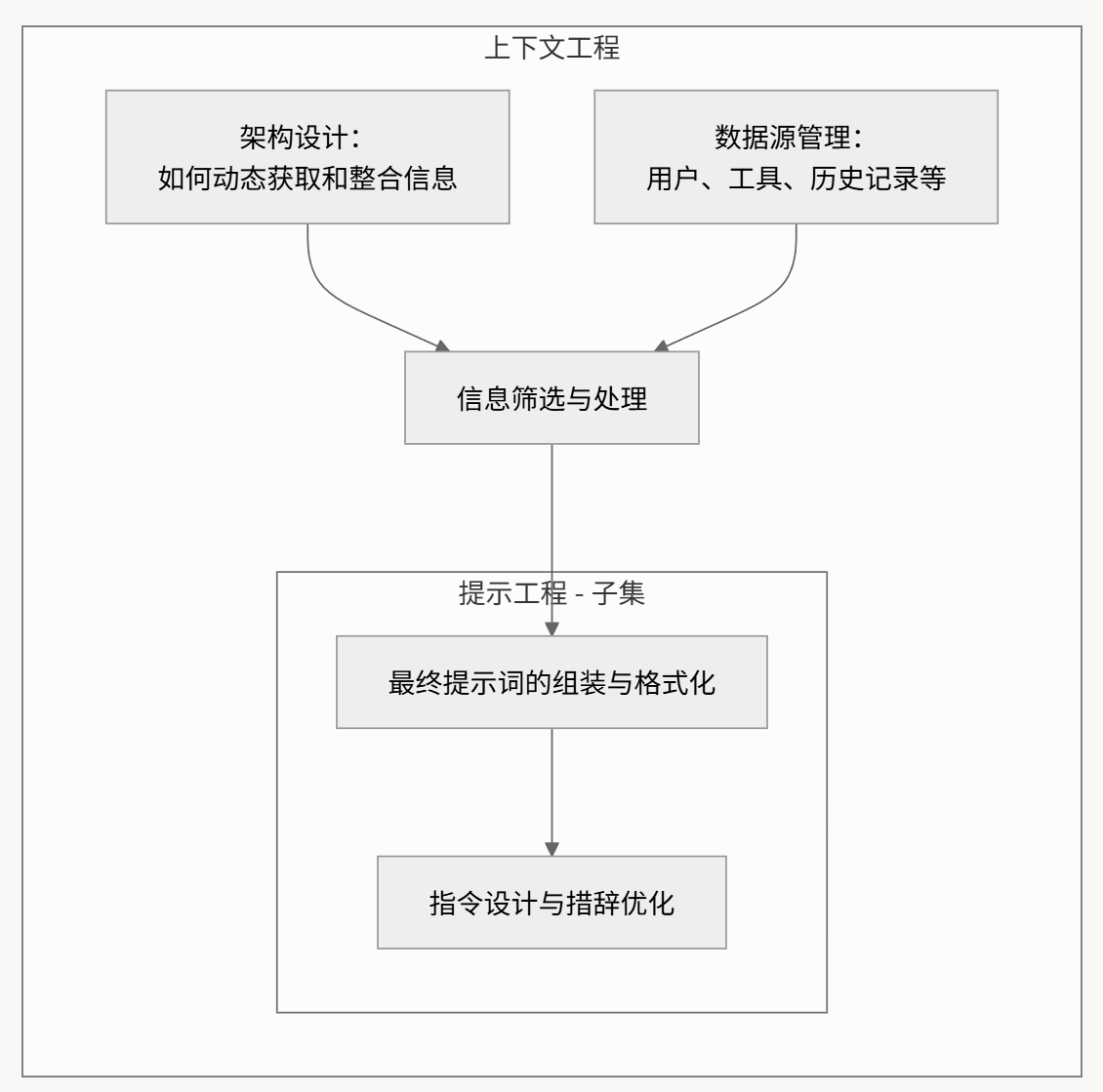
不同于传统 Prompt Engineering,Context Engineering 更关注系统级的动态上下文构建。
- 强调:在复杂交互和多智能体协作中,如何为每个 Agent 构建精准、独立、可持续的任务背景,是系统能否稳定运行的关键。
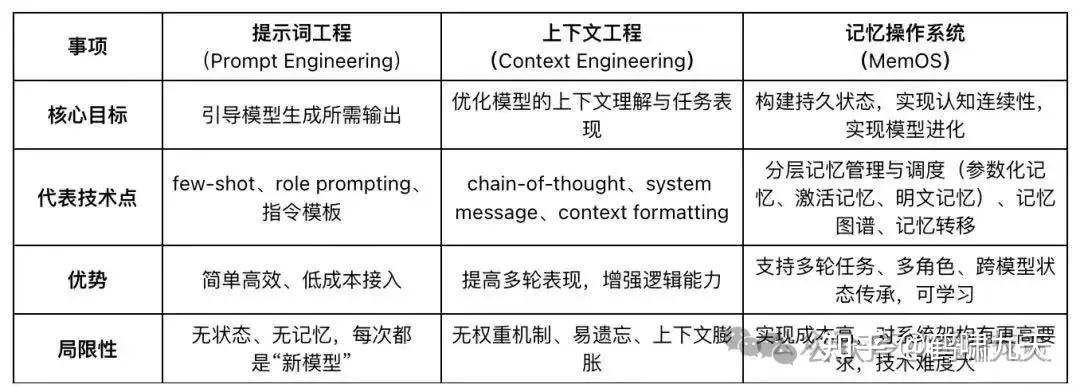
| 维度 | 提示词工程(Prompting engineering) | 上下文工程(Context engineering) |
|---|---|---|
| 目标 | 写出清晰、明确的指令 | 准备好一切AI该知道的信息 |
| 本质 | 提示词本质是布置任务的指令,让AI按预期方式回答问题、执行任务 | 告诉AI当前的「需要什么」、「能做什么」,就像游戏的任务设定一样,提供所需要的信息、工具和历史记忆,然后交给AI来思考和执行 |
| 比喻 | 怎么走路 | 铺路 |
| 图解 | 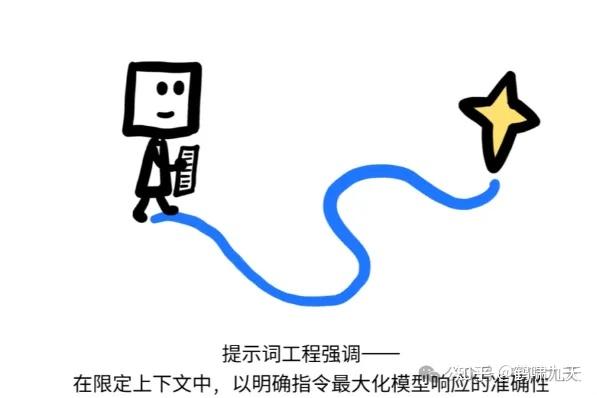 |
 |
总结:
- 提示词工程依赖精细指令,不仅难以复用,还容易因措辞差异导致结果波动,对写Prompts的人要求也更高
- 上下文工程让AI具备持续理解和应变能力,不仅能适应新任务,还能保持输出稳定、不易“翻车”
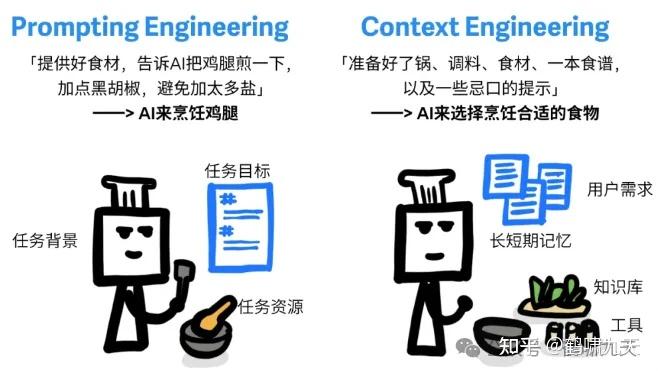
漫画来自: 小红书博主“机器坏人(AI版)”
更多对比
策略
解决上下文悖论的常见方法
- ①.Context Offloading (上下文
卸载):将信息从核心对话历史中移出,存放到外部系统(如文件系统),只在上下文中保留一个轻量级引用 - ②.Reducing Context (上下文
精简):通过总结/压缩减少信息量,例如修剪旧的工具调用记录 - ③.Retrieving Context (上下文
检索):按需从外部系统将信息取回。实现方式包括基于索引的语义搜索,或更简单的基于文件系统的搜索工具(如 glob 和 grep) - ④.Context Isolation (上下文
隔离):将任务分解给多个子代理(sub-agents),每个子代理拥有独立、更小的上下文窗口,从而实现关注点分离和上下文管理 - ⑤.Caching Context (上下文
缓存):对上下文信息进行缓存,以提高效率(这一点在 Manus 的实践中被特别提及)
这些策略并非孤立存在,而是相互关联、协同工作,共同构成了现代 AI Agents 架构的基石
LangChain Lance 总结 上下文工程的四种策略: 写入(Write)、选择(Select)、压缩(Compress)和隔离(Isolate)
业内顶尖团队(包括Manus)都在使用的4大工程支柱:

| Offload | Reduce | Retrieve | Isolate | Cache | |
|---|---|---|---|---|---|
| Drew’s Post | Discussed | Discussed | Discussed | Discussed | Not discussed |
| Manus | Used | Discouraged [1] | Not discussed | Not discussed | Used |
| Anthropic–researcher | Used | Used | Used | Used | Not discussed |
| Cognition | Not discussed | Used | Not discussed | Discouraged [2] | Not discussed |
| LC open–deep–research | Used | Used | Used | Used | Not discussed |
写入(卸载, Offload)
又叫 上下文卸载 (Offloading)
写入(Write)——在上下文之外持久化信息
写入策略指将信息存储在上下文窗口之外,供未来检索。
做法:不把所有信息都塞进上下文。
比如,一个万字的网络搜索结果,只在上下文中返回一个文件路径(file.txt),Agent需要时自己去读。
例如:
- Scratchpad(草稿本): 类似人类做笔记,代理通过工具调用将临时信息写入文件或状态对象,在任务过程中随时访问。Anthropic 的多代理研究系统会在计划开始前将研究计划写入记忆,以防上下文超过 20 万个 token 时被截断anthropic.com。LangGraph 为代理提供了 short‑term memory(检查点)来在会话内保存状态blog.langchain.com。
- 长期记忆(Memory): 有些信息需要跨会话保存,例如用户偏好或历史反馈。生成式代理(Generative Agents)通过定期汇总过去的反馈构建长期记忆。现在的一些产品如 ChatGPT、Cursor 和 Windsurf 也自动生成长期记忆
Manus 经验:层次动作空间,3个抽象级别,每层在容量、成本和缓存稳定性之间权衡
- 函数调用 FC
- 沙盒工具
- 工具包和API
场景:处理大文件、大输出
选择(检索, Retrieving)
选择(Select)——从记忆中提取相关信息
选择策略是将外部记忆、文件或工具调用结果拉入当前上下文。
把信息(如记忆)存储在外部(如向量数据库),需要时通过RAG或简单grep命令检索回来。
常见做法包括:
- 小样本示例(Few‑shot examples): 作为 情景记忆(episodic memory) 帮助代理模仿预期行为
- 指令/规则(Procedural memory): 用于指导代理行为,如 Claude Code 中的 CLAUDE.md 规则文件
- 事实(Semantic memory): 存储知识、实体信息,供检索调用
LangGraph 中,开发者可以在每个节点按需检索状态或长期记忆,并通过嵌入检索等方式选取最相关的记忆。
对于工具选择,一些研究表明,使用 RAG 技术对工具说明进行检索可以使选择准确率提高 3 倍
场景:长时记忆、知识库。
压缩
压缩(Compress)——保留必要的信息, 又叫 上下文缩减 (Reducing)
最核心也最精妙的一步,即在上下文“腐烂”之前,主动对其进行“瘦身”。
压缩策略通过 摘要(summarization) 或 修剪(trimming) 减少上下文长度:
(1) 摘要:
- 通过 LLM 压缩对话历史,只保留关键决策。
- Claude Code 会在上下文超过 95% 时运行 “auto‑compact” 自动摘要。
- 在 Cognition 的代理中,还使用专门微调的小模型来压缩代理间的交互,以减少知识传递时的 token 数
(2) 修剪:
- 通过启发式方法删掉旧消息,例如只保留最近的几轮对话;也可以用训练出的 Provence 模型对检索内容进行句子级别的剪枝,它将上下文剪枝任务视为序列标注问题,在多领域问答中几乎不损失性能
压缩并非万能:过度摘要可能遗漏关键细节,修剪也有风险,因此需要结合任务特点谨慎使用。
而Manus团队,正是在“上下文缩减”上,做到了极致。
Peak团队将“缩减”分为两种截然不同的操作:
- 压缩 (Compaction):可逆“瘦身”
- 定义:删除那些可以从外部(如文件系统)重建的信息。
- 例子:一个工具调用,完整信息是{path: “file.txt”, content: “…”}。在“压缩”后,只保留{path: “file.txt”}。
- 优势:信息“零”丢失,只是被“外置”了。
- 摘要 (Summarization):不可逆“遗忘”
- 定义:对历史信息进行总结,彻底丢弃原文。
- 优势:大幅度释放上下文空间。
Manus 策略堪称精妙:
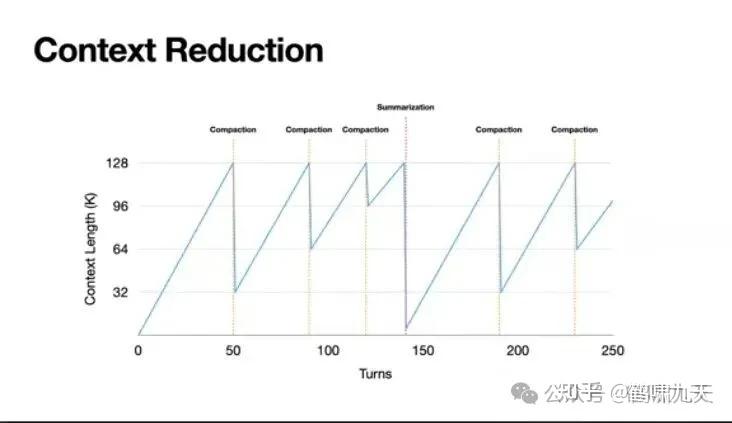
- 先“压缩”,后“摘要”:当上下文达到128K时,系统首先触发“压缩”。只在“压缩”收益也变小时,才万不得已触发“摘要”。
- “压缩”艺术:执行“压缩”时,只压缩最老的50%历史,并保留最新的50%工具调用的完整信息。这能确保模型有足够的新鲜“样例”来模仿,防止其行为错乱。
- “摘要”技巧:执行“摘要”时,会使用原始的、未经压缩的数据来总结,以保证信息保真度。并且,同样会保留最后几个工具调用的全量信息,防止模型“忘记自己刚刚在干什么”。
设置“腐烂”闹钟,“腐烂阈值”,128K。
注意:
- 不要过度,上文不是越多越好,简洁胜过膨胀,最大的收益来自删减而非添加,保持边界清晰
隔离(Isolation)
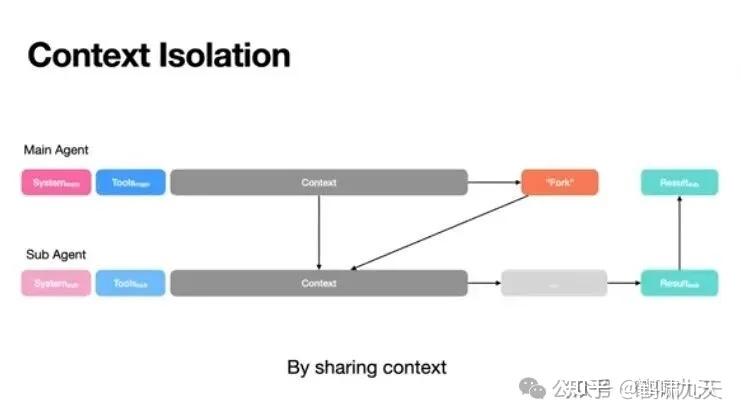
隔离(Isolate)——拆分上下文以并行处理
使用多智能体(Multi-Agent)架构,每个子Agent只处理自己的小上下文窗口,互不干扰。
隔离策略通过 分工合作 减少单个上下文窗口的压力。例如:
- 多代理架构: Anthropic 的 Research 系统采用 主代理 + 子代理 模式,主代理制定研究计划并将任务分配给多个子代理并行搜索,子代理拥有自己的上下文窗口,并在完成后将结果返回,由主代理汇总。该系统在广度优先查询中比单代理效果提升 90% 以上,但使用的 token 约是对话模式的 15 倍,因此只适用于价值高且可并行的任务
- 分离环境与沙盒: Hugging Face 的代码代理通过将代码执行放在沙盒环境中,图像或大型对象留在沙盒内,返回值再传回 LLM,这样可以隔离大量 token
- 状态对象: 在 LangGraph 中,开发者可以设计包含多个字段的状态 schema,只将 messages 字段暴露给模型,而将其他字段留作环境使用
Cognition 指出,多代理架构容易出现上下文缺乏共享、决策冲突等问题,并总结出两个关键原则:
- 原则 1:共享上下文和完整的代理轨迹;
- 原则 2:决策隐含偏好,冲突会产生坏结果
因此在实际应用中,应谨慎使用多代理,必要时更倾向于线性单代理配合压缩技术。
场景:复杂任务拆解。
构成
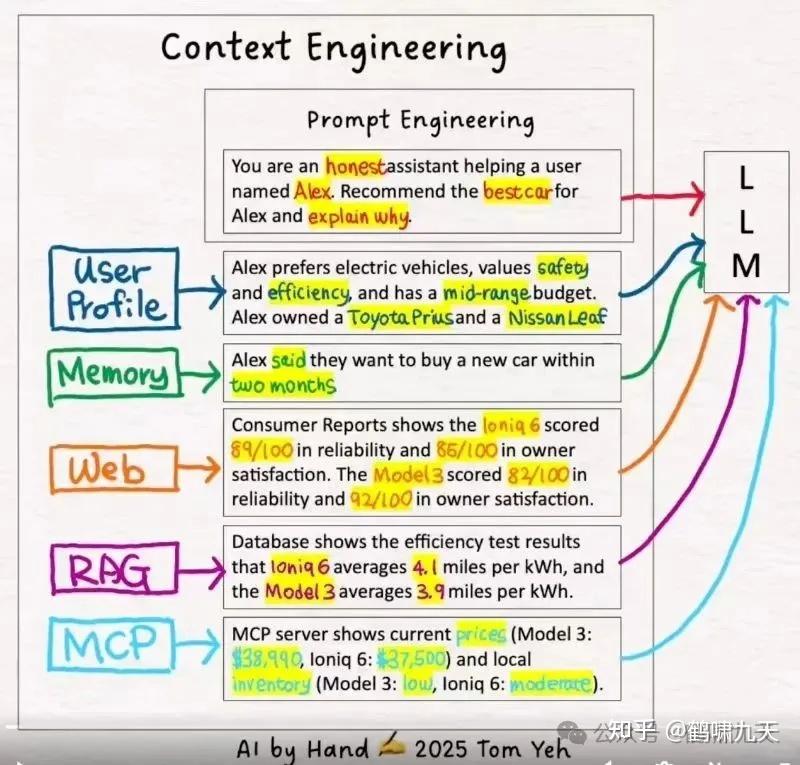
上下文系统由多个关键部分组成

上下文工程 = 提示词 + 用户画像 + 记忆 + 检索信息 + RAG信息 + MCP信息
上下文工程是一个动态系统
复杂的智能体系统从多个来源获取上下文:
- 应用开发者:预设的系统指令和行为准则。
- 用户:当前任务的直接输入和要求。
- 历史交互:先前对话的记忆或摘要。
- 工具调用:通过API或函数调用获取的外部信息。
- 外部数据:从数据库或知识库中检索的文档。
将所有这些信息整合在一起,需要一个复杂的系统。
- 提供正确的信息与工具
- 格式化至关重要
- 自检:反复确认信息是否充分
而且必须动态,因为许多上下文信息是实时变化的。
因此,最终交付给LLM的提示词(Prompt)不是静态模板,而是由动态逻辑实时构建的。
好的上下文工程应该包括:
- 工具使用:当一个智能体访问外部信息时,需要拥有能够访问这些信息的工具。当工具返回信息时,需要以 LLM 最容易理解的方式对其进行格式化。
- 短期记忆:如果对话持续一段时间,可以创建对话摘要,并在未来使用该摘要。
- 长期记忆:如果用户在之前的对话中表达了偏好,需要获取这些信息。
- 提示工程:在提示中清楚地列举智能体应该如何操作的说明。
- 检索:动态地获取信息,并在调用 LLM 之前将其插入到提示中。
正确的信息与工具
LLM 应用失败常见原因:上下文缺失。
LLM无法读取用户思想,如果不提供完成任务所需的关键信息,不可能知道这些信息的存在。
- “垃圾进,垃圾出”(Garbage in, garbage out)原则。
同样,仅有信息可能还不够。
在很多场景下,LLM需要借助工具来查询更多信息或执行某些动作。为LLM提供正确的工具,与提供正确的信息同等重要。
格式化至关重要
与人类沟通类似,如何向LLM传递信息,其格式会极大地影响结果。
一个简短但描述清晰的错误信息,远比一个庞大而杂乱的JSON数据块更容易让LLM理解和处理。这一点同样适用于工具的设计,工具的输入参数是否清晰、易于理解,直接决定了LLM能否有效使用。
自检
进行上下文工程时,反复确认:
- “以当前提供的上下文,LLM真的能合理地完成任务吗?”
这个问题能保持清醒,认识到LLM不是万能的,要为创造条件。同时,有助于区分两种主要的失败模式:
- 失败模式一:没有提供足够或正确的信息/工具,导致LLM失败。
- 失败模式二:提供了所有必要的信息和工具,但LLM自身出现了推理错误。
这两种失败模式的修复方案截然不同,准确定位问题是优化的第一步。
应用
优秀的上下文工程实践:
- 工具使用(Tool Use):确保必要时能访问外部信息,并为工具设计易于LLM理解的输入参数和输出格式。
- 短期记忆(Short-term Memory):持续多轮对话中,动态创建对话摘要,并将其作为后续交互的上下文,防止信息丢失。
- 长期记忆(Long-term Memory):当历史对话中包含用户特定偏好时,系统能够自动获取这些信息,并在新对话中加以利用。
- 提示工程(Prompt Engineering):提示词清晰地列出智能体应遵循的行为准则和详细指令。
- 检索(Retrieval):调用LLM之前,根据用户查询动态地从知识库(如向量数据库)中获取相关信息,并将其注入到提示词中。
两者却不约而同指出:要让多智能体系统稳定运行,有两个关键前提:
- Context Engineering(上下文工程)是基础设施级能力
- 多智能体更适合“读”任务而非“写”任务
结语:别被“智能体数量”迷惑,关键是上下文控制力
- Cognition 的告诫并非“多智能体无用”,而是警示其复杂性;
- Anthropic 的成功并非“多智能体万能”,而是源于良好的任务拆解与上下文管理; 构建多智能体系统不仅是技术挑战,更是“系统工程挑战”。
Cognition
Cognition 团队总结
- 多 Agent 写作风险: “行为背后是决策,冲突的决策会带来灾难。”
- 再聪明的模型,若不知上下文,也无法做出正确判断。
读 vs 写,本质区别在哪?
- 读(Research)型任务:如搜索信息、理解材料等,天然适合并行执行,多个 Agent 各自探索、协同处理即可。
- 写(Synthesis)型任务:如代码生成、内容撰写,需保持结构统一、语言风格一致,难以拆分并行,否则会产生冲突或碎片化。
Anthropic
Anthropic 实践:
- 长对话管理:对话可能长达数百轮,需要引入外部记忆与压缩机制,如在每阶段总结信息存储进记忆库、跨阶段切换时唤回关键信息。
- 任务描述精准化:子智能体需要被明确告知目标、输出格式、所用工具、边界约束,否则容易重复劳动或遗漏重要内容。
底层能力支持
- ✅ 完整控制 LLM 接收的上下文输入
- ✅ 无隐藏提示、无强加的“认知架构”
- ✅ 明确每一步执行顺序,实现灵活编排
Claude Research 系统中:
- 读取任务:由多智能体并行完成,每个 Agent 负责不同方向
- 写作任务:由主智能体统一汇总并输出,避免冲突与割裂
模糊指令导致多个 Agent 重复搜索 2025 年半导体供应链,有效的任务拆解机制是防止资源浪费的关键。
Agent 框架核心不是功能丰富,而是给开发者“上下文的完全控制权”。
多智能体系统适合任务:
- ✅ 高价值任务:计算成本可控,但任务本身价值高(如战略研究)
- ✅ 广度优先探索:适合多个 Agent 并行发散,如舆情分析、多角度政策解读
- ✅ 超长上下文任务:任务 token 超过单模型窗口上限时,可用 Agent 分工处理各部分
而在以下场景中,多智能体反而不如单体结构高效:
- ❌ 强依赖上下文同步、实时响应(如代码协作、系统集成)
- ❌ 子任务之间依赖复杂、无法并行(如多步骤推理题)
没有通用最佳结构,只有最合适的架构决策。
作者:AI小智
LangChain
LangChain 生态两个核心工具——LangGraph和LangSmith——为实践上下文工程提供了强大的支持。
- LangGraph 用于构建可控智能体框架的库。设计理念与上下文工程完美契合,因为赋予了开发者完全的控制权。
- LangSmith 是 LangChain 的 LLM应用可观测性(Observability)和评估解决方案。核心功能——调用链路追踪——是调试上下文工程问题的利器。
Cursor
待定
Manus
【2025-10-27】
Manus联创 Peak 最近与LangChain创始人分享: Agent 上下文工程。
LangChain 团队首先介绍了上下文工程的背景与挑战,随后系统讲解了五种核心策略:卸载(Offloading)、缩减(Reducing)、检索(Retrieving)、隔离(Isolating) 与 缓存(Caching)。
Manus 分享了他们在实践中的深入经验,尤其是在上下文缩减、隔离与卸载方面,Manus 展示了独特做法,如可逆“压缩”与不可逆“总结”的区别、两种代理隔离模式,以及用于“工具卸载”的分层动作空间等
“血泪教训”:上一个产品,迭代速度被长达1-2周的模型训练周期活活拖死。
- 产品还没找到PMF(市场契合点)的阶段,他们却在花费大量时间“提升那些可能根本不重要的基准测试”
- 最大的“陷阱”还不是时间,而是“僵化”。“微调模型时,通常会固定一个‘行动空间’(Action Space)。” Manus 曾被MCP的发布彻底改变
划清界限:AI应用层的真正边界
经历“痛苦”领悟后,Peak为Manus找到清晰无比的战略边界:“上下文工程”
- 目前应用和模型之间最清晰、最实用的边界。
- 创业公司应该“尽可能久地”依赖通用大模型,而不是试图在模型层与巨头竞争。巨头的护城河是“模型”,而应用层的护城河,就是“使用”模型的能力——即“上下文工程”
这次把赌注压在“上下文工程”(Context Engineering),团队短短几个月内,将产品重构了整整5次。
Manus 心得:所有方法综合使用
- Offload 卸载 + Retrieve 检索 → enable Reduction 实现瘦身.
- Reliable Retrieve 可信检索 → enables Isolation 实现隔离
- Isolation 隔离 → reduces frequency of Reduction 减少瘦身频率
- All under Cache optimiztion 所有方法都用缓存优化
| Offload | Reduce | Retrieve | Isolate | Cache | |
|---|---|---|---|---|---|
| Drew’s Post | Discussed | Discussed | Discussed | Discussed | Not discussed |
| Manus | Used | Discouraged [1] | Not discussed | Not discussed | Used |
| Anthropic–researcher | Used | Used | Used | Used | Not discussed |
| Cognition | Not discussed | Used | Not discussed | Discouraged [2] | Not discussed |
| LC open–deep–research | Used | Used | Used | Used | Not discussed |
最深刻的领悟:
“我们最大的飞跃,不是来自添加了更花哨的上下文管理技巧,而是来自‘简化’和‘移除不必要的层’。”
进化
【2025-10-6】ACE
【2025-10-6】斯坦福新论文:微调已死,自主上下文当立
CE 问题
上下文工程两个大问题:
- 简洁偏置(brevity bias):为了让输入简短,把关键细节丢了。
- 比如只说 “处理财务数据”,却没说 “要按XBRL格式核对数值”,导致模型犯错。
- 上下文崩溃(context collapse):反复修改输入时,模型会把之前积累的有用信息越改越短、越改越没用。
- 比如原本有1.8万个token的实用策略,准确率为66.7,改一次就剩122个token,效果却下降到57.1。
ACE
斯坦福大学、SambaNova Systems公司和加州大学伯克利分校新论文中证明:
依靠上下文工程,无需调整任何权重,模型也能不断变聪明。
上下文不应是简短的摘要,而应成为全面、动态演化的「作战手册(playbooks)」—— 内容详实、包容、富含领域洞见
与人类不同,LLM 在提供长而细致的上下文时表现更好,并能自主提炼关键信息。因此,与其压缩领域启发与策略,不如将其保留,让模型在推理时自行决定哪些信息最为重要。
主动式上下文工程(ACE)应运而生,实现可扩展且高效的上下文自适应,并且离线(如系统提示优化)与在线(如测试时记忆自适应)场景都适用。
智能体上下文工程(Agentic Context Engineering), ACE 不依赖模型重新训练,而是让上下文自主进化,通过反复生成、反思并编辑自己的提示,直至成为一个自我完善的系统。
ACE 与将知识压缩为简短摘要或静态指令的方法不同,它将上下文视为不断演化的操作手册,能够随时间不断累积、优化并组织策略。
与以往将知识蒸馏为简短摘要或静态指令的方法不同,ACE 是将上下文视为不断演化的作战手册,能够持续积累、蒸馏与组织策略。
基于 Dynamic Cheatsheet 的智能体设计,ACE把模型的 “上下文优化” 拆成分工明确的三个角色。
- 生成器(Generator):负责生成推理轨迹;
- 反思器(Reflector):负责从成功和错误中提炼具体见解;
- 整理器(Curator):负责将这些见解整合到结构化的上下文更新中。
模仿了人类的学习方式,即「实验–反思–整合」,同时可避免让单一模型承担所有职能所导致的瓶颈。
效果
在智能体和特定领域的基准测试中,ACE能同时优化离线上下文(如system prompt)和在线上下文(如agent memory),并稳定优于强力基线模型。
在智能体和财务分析两大场景中,ACE稳定优于Base LLM(无适配)、ICL(少样本演示)、GEPA(主流prompt优化)、Dynamic Cheatsheet(动态备忘单)等方法。
在智能体测试中,研究团队采用的是AppWorld,它是一套自主智能体任务集合,涵盖API理解、代码生成和环境交互。
结果显示,ReAct+ACE相比ReAct+ICL和ReAct+GEPA分别领先12.3%和11.9%,优势显著。这表明,与固定的演示示例或单一优化指令提示相比,结构化、可演进且精细化的上下文能够更有效地促进智能体学习。
这一优势在在线场景中同样得以延续:ACE平均以7.6%的性能提升领先于Dynamic Cheatsheet等现有自适应方法。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
