- 多模态模型案例
- 总结
- ViT
- ALBEF
- Flamingo 火烈鸟(DeepMind)
- OpenFlamingo
- CLIP (OpenAI)
- FLAVA
- BEiT 系列
- BLIP 系列
- LLaVA
- MMGPT (基于OpenFlamingo)
- X-LLM (中科院)
- VisualGLM
- CoDi
- TigerBot
- Video-LLaMA(视听,达摩院)
- PandaGPT – 大一统
- InstructBLIP
- VisorGPT
- SEEChat
- BayLing 百聆 中科院计算所
- VisCPM 面壁智能
- BuboGPT 字节
- LLaSM – 语音文本
- NExT-GPT 任意模态
- Gemini 谷歌
- LEGO – 字节&复旦,视频解读
- RoboFlamingo 字节
- LargeWorldModel
- Chameleon
- QWen-VL 系列
- VITA
- Emu3
- Janus-Pro-7B
- Gemini 2.5
- META
- 美团
- 结束
多模态模型案例
总结
资讯
- 【2023-7-27】Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic
- 【2023-9-25】多模态大模型最全综述来了!7位微软研究员大力合作,成文119页
现象:
多模态基础模型已经从专用走向通用。
全模态LLM见站内专题:全模态大模型
排行榜
多模态模型排行榜 OpenCampass
综述
五个具体研究主题:多模态大模型最全综述来了!7位微软研究员大力合作,成文119页
- 视觉理解: 根据监督信号的不同,分类:标签监督、语言监督(以CLIP为代表)和只有图像的自监督。
- 图像监督:监督信号是从图像本身中挖掘出来的,流行的方法包括对比学习、非对比学习和masked image建模
- 视觉生成: 空间可控生成、基于文本再编辑、更好地遵循文本提示和生成概念定制(concept customization)四个方面
- 统一视觉模型
- LLM加持的多模态大模型
- 多模态agent
【2024-1-25】26种多模态大语言模型(MM-LLMs)进行了全面的研究和分析。
- MM-LLMs: Recent Advances in MultiModal Large Language Models
- 模型架构和训练流程:如何结合了传统大型语言模型(LLMs)的能力,并支持多模态输入和输出。
- 模型概览:
- • 研究涵盖了26种不同的 MM-LLMs,每个模型都有其独特的设计和功能特点。
- • 这些模型被分为不同的类别,根据它们的架构和功能进行了分类。 3. 性能评估:对这些模型在主流基准测试上的性能进行了回顾,分析了它们在不同任务上的表现。 4. 训练策略:总结了提高 MM-LLMs 性能的关键训练策略,包括数据处理和模型优化等。 5. 研究方向和资源:讨论了 MM-LLMs 的未来研究方向,并提供了实时跟踪这些模型最新发展的资源。
多模态基础知识,详见站内专题:多模态学习笔记
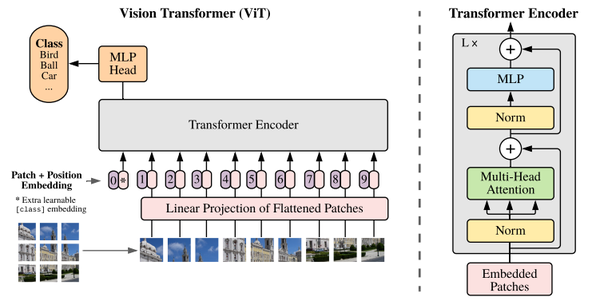
ViT
将 transformer 引入到 CV 领域
- 1、将图片patch化,解决 Transformer 不能应用于图像领域问题;
- 2、patch embedding 提取图像特征高效;
- 3、基于ViT模型衍生了视频Transformer相关模型。
2020年,Google提出ViT,将Transformer应用在图像分类的模型
- transformer应用在视觉任务论文, 非首次,但模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究
ViT 论文中最核心结论
- 当拥有足够多的数据进行预训练时,
ViT表现就会超过CNN,突破transformer缺少归纳偏置的限制,可在下游任务中获得较好的迁移效果 - 当训练数据集不够大的时候,
ViT表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。
CNN具有两种归纳偏置
- 一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;
- 一种是平移不变形(translation equivariance)
当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型
ViT只使用了Transformer的encoder
ViT 将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。
- 但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测
ALBEF
salesforce
- 论文:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- 代码:ALBEF
解决问题:
- 1)没有对齐视觉的 tokens 和 文字的 tokens, 因此给 多模编码器进行图文交互学习时带来挑战
- 2)训练多模模型,利用到了互联网上爬取的数据,这些数据中往往存在大量噪声,传统的图文特征融合训练模式(如 MLM, masked language modeling) 可能过拟合到噪声文本上,从而影响模型的泛化性能。
解决方案:
- 1) 通过跨模态 attention 的方式引入对比损失,在图文特征融合前对齐图像和文本表征,相对与大多数传统方案来说,不需要在高清图片上进行框级别的标注。
- 2)提出一种 动量蒸馏 (momentum distillation) 的方案,即通过自训练(self-training)的方式从动量模型提供的伪标签中进行学习。
在训练过程中,通过参数移动平均的方式更新动量模型,并利用动量模型生成伪标签(pseudo-targets) 作为额外的监督信息。利用动量蒸馏的方式,模型将不在惩罚模型合理的输出,即使这个输出与网络标签不一致,提升从网络噪声数据中学习的能力。
结果:
- 1)在图文检索任务中,本方案优于在大规模数据集中预训练的方案(CLIP & ALIGN)
- 2) 在 VQA 和 NLVR 任务中,本方案相对 SOTA 算法(VILIA)分别获得了 2.37% 和 3.84% 的指标提升,而且获得了更快的推理速度。
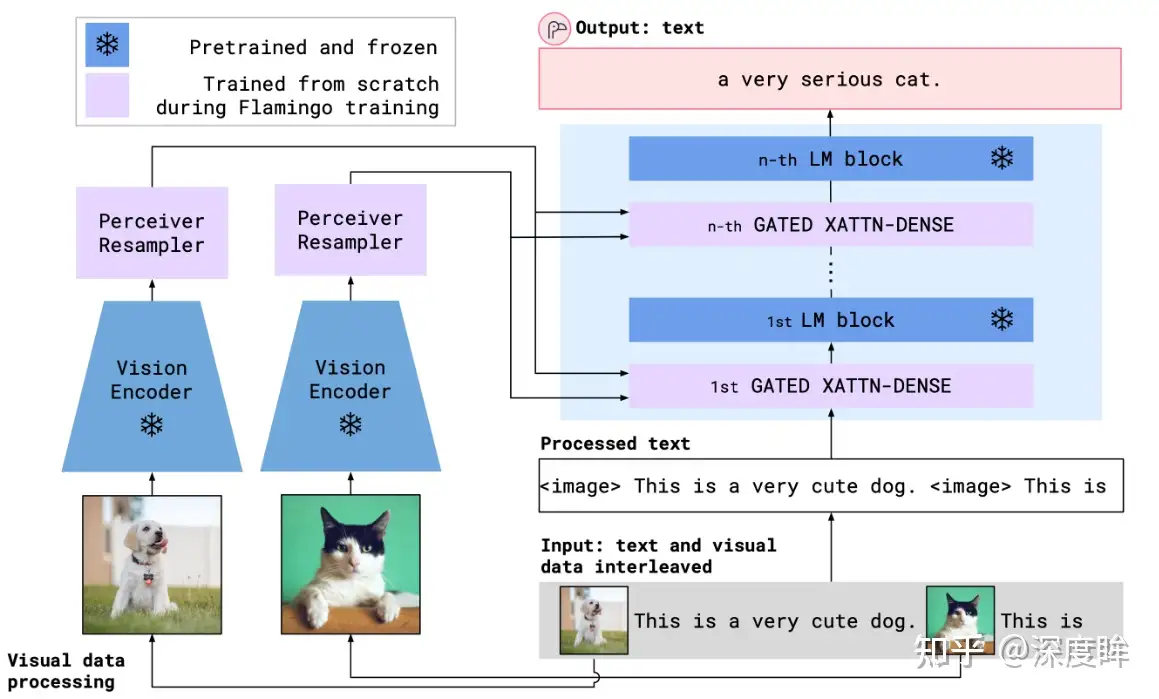
Flamingo 火烈鸟(DeepMind)
【2022-4-29】Flamingo在few-shot和zero-shot上有很好的泛化性能,甚至能击败few-shot+fine-tune的SOTA,进一步证明了 Prompt tuning机制+多模态多任务+大规模预训练 三者有比较好的相性。
Flamingo 架构

Flamingo 开箱即用的多模式对话,用 OpenAI 的 DALL·E 2 生成的「汤怪物」图像,在关于这张图像的不同问答中,Flamingo 都能准确地回答出来。
- 例如问题:这张图片中有什么?
- Flamingo 回答:一碗汤,一张怪物脸在上面。
Flamingo 可以快速适应各种图像和视频理解任务,只需简单地提示它几个例子

具有丰富的视觉对话功能

OpenFlamingo
【2023-3-29】多模态大语言模型OpenFlamingo开源了
- Christoph Schuhmann团队宣布开源了OpenFlamingo,这是DeepMind Flamingo模型的开源复制品。OpenFlamingo是一个框架,可实现大型多模态模型(LMM)的训练和评估
OpenFlamingo 模型是 DeepMind 的 Flamingo 模型开源复现版本,采用了较大的多模态数据集 MMC4 和 LAION 2B 进行训练,其视觉部分采用了 CLIP vision encoder 构成,而语言部分采用了 LLaMA 模型
OpenFlamingo 是一个框架,其实可以换不同的视觉和语言模型基座。
- OpenFlamingo 发布了 9B 的权重,其实已经具备了多模态问答能力。
多模态大语言模型 BLIP-2 和 FROMAGe 展现出惊人的读图能力和理解力,并具有问答能力
OpenFlamingo项目继续也在这些领域进行探索,并致力于为开发者们提供完整的开发框架入流程,持续共同为视觉语言模型多模态机器学习做出贡献。
多模态大语言模型OpenFlamingo满足大部分基础玩家的需求:
- 首先,基于Python框架项目,可用于训练Flamingo风格的大语言模型,模型框架基于基于Lucidrains的flamingo实现,并依托David Hansmair的flamingo-mini存储库;
- 其次,包含一个大规模的多模态数据集,其中包含交替的图像和文本序列等多种数据形式;
- 再次,可用于视觉-语言任务的上下文学习评估基准,并把亲自copy训练的模型进行评估,从而可以水更多论文;
- 最后,基于LLaMA的OpenFlamingo-9B模型的第一个版本已经出来了,更多更好的模型与权重正在路上。
CLIP (OpenAI)
【2021-2-26】OpenAI推出CLIP (Contrastive Language–Image Pre-training) 使用零样本迁移学习
- Alec Radford等人提出 Contrastive Language-Image Pre-training (CLIP), 突破了文本-图像之间的限制
- Learning Transferable Visual Models From Natural Language Supervision
解决什么问题
- 视觉数据集重人力,即便是一个小任务也需要昂贵的人力开销
- 标准视觉模型仅适用于单任务,迁移代价较大
- 标准数据集上效果好的模型在别的数据集上差强人意。
现有计算机视觉方法存疑
常规图像分类模型往往基于有类别标签的图像数据集进行全监督训练
- 例如在Imagenet上训练的Resnet,Mobilenet,在JFT上训练的ViT等。
- 对于数据需求非常高,需要大量人工标注;同时限制了模型的适用性和泛化能力,不适于任务迁移。
互联网上可以轻松获取大批量的文本-图像配对数据。
- Open AI团队通过收集4亿(400 million)个文本-图像对((image, text) pairs),以用来训练其提出的CLIP模型。文本-图像对的示例如下:

解法:用神经网络解决这些问题
- 使用互联网上海量图像、文本信息来训练,执行各种各样的分类任务,不优化标准指标 — 零样本学习
- 打通文本-图像预训练实现ImageNet的zero-shot分类,比肩全监督训练的ResNet50/101 – 详见
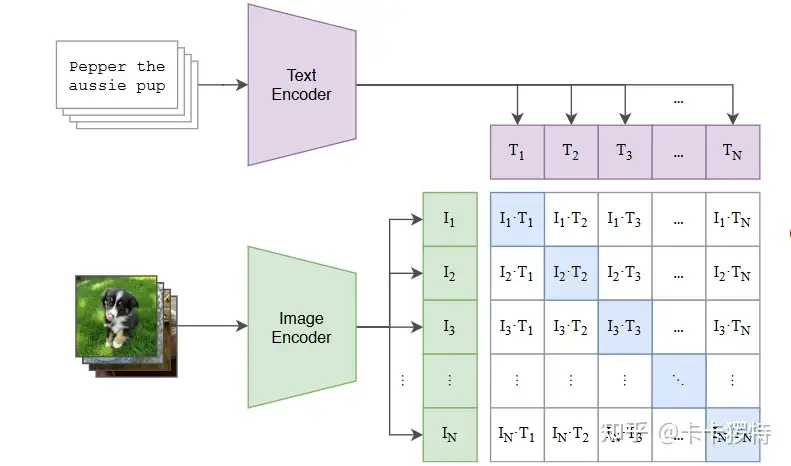
CLIP模型结构包括两个部分: 文本编码器(Text Encoder)和图像编码器(Image Encoder)。
- Text Encoder选择的是Text Transformer模型;
- Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。
训练过程可视化

CLIP使用大规模的文本-图像配对预训练,并且可以直接迁移到Imagenet上,完全不需要图像标签微调即可实现zero-shot分类。CLIP模型或许会引导CV的发展走向大规模预训练,文本-图像打通的时代。
通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度。

- 上面的示例为正样本,下面的示例为负样本。两对数据的图片其实都是猫,但负样本的文本将其描述成了狗,所以计算出的余弦相似度低,CLIP模型可以认定其文本与图像不匹配。
CLIP这个模型最大的亮点:zero-shot图像分类。
FLAVA
整体结构类似CLIP,但是引入了单模态和多模态的预训练任务,单模态的任务有MLM,MIM,多模态有GC,ITM等,同时将融合两个模态的方式改为了Transformer
BEiT 系列
演进过程
- June 2021: release preprint BEiT: BERT Pre-Training of Image Transformers
- July 2021: release the code and pretrained models of BEiT
- July 2021: BEiT-large achieves state-of-the-art ImageNet top-1 accuracy (88.6%) under the setting without extra data other than ImageNet-22k.
- July 2021: BEiT-large achieves state-of-the-art results on ADE20K (a big jump to 57.0 mIoU) for semantic segmentation.
- August 2021: BEiT is on HuggingFace
- January, 2022: BEiT was accepted by ICLR 2022 as Oral presentation (54 out of 3391).
- March, 2022: add linear probe examples
- June 2022: release preprint VL-BEiT: Generative Vision-Language Pretraining
- Aug 2022: release preprint BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
- Aug 2022: release preprint Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
- Sept 2022: release the code and pretrained models of BEiT v2
- March, 2023: BEiT-3 was accepted by CVPR 2023.
- March, 2023: release the code and pretrained models of BEiT-3
BEiT-1
【2022-9-3】 哈工大+微软 推出 BEiT, Bidirectional Encoder representation from Image Transformers
- 1、将生成式预训练
MLM方法从NLP迁移至CV,引入 ViT, 实现CV大规模自监督预训练;- masked image modeling (MIM) 任务
- 2、统一多模态大模型
BEiT-3前身。
论文
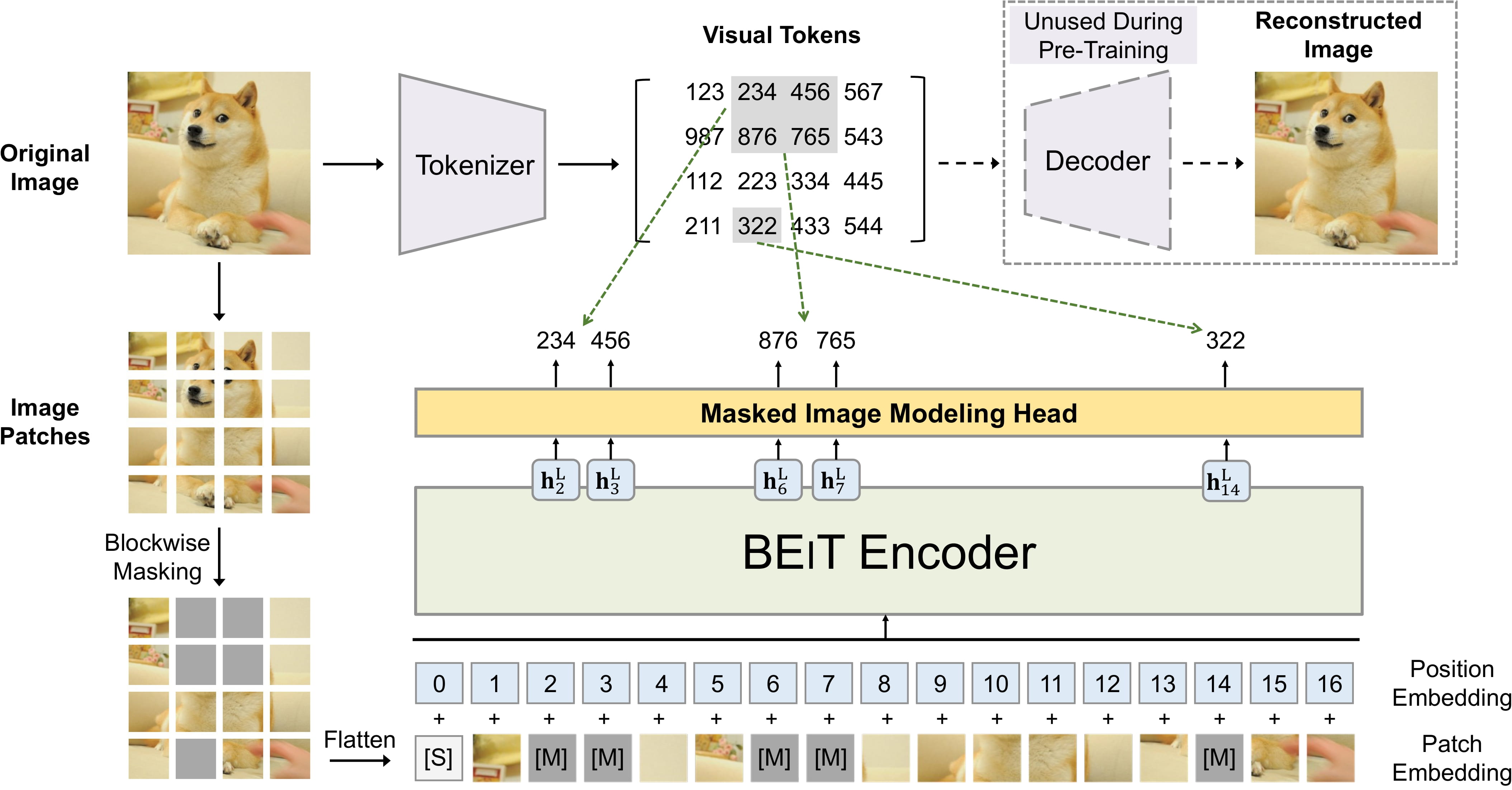
BEiT-3
BEiT-3模型输入变成了三部分: 图,文,图文对,通过各自自注意力机制和全联接网络
BLIP 系列
BLIP-1
【2022-2-15】Saleforce Research
问题:
- 1)当前 视觉-语言 预训练(VLP)推动了 视觉语言预训练任务的性能,然而大多数现有的预训练模型或者擅长基于理解的任务(分类)或者基于生成的任务之一。encoder-based 架构不擅长生成类任务,encoder-decoder 架构不擅长分类相关任务(如 图文跨模态检索)
- 2)当前 VLP 模型的性能提升依赖于扩大图文对训练集,这些图文对通常是从互联网上爬取的,所以噪声相对较大。
解决方案:
- 提出一种新的 VLP 框架,可以在视觉-语言的 理解任务 和 生成任务 之间灵活转换,而且可以通过booststraping 的方式有效利用噪声数据,即构造了一个 captioner 用于生成captions,一个 filters 移除噪声 captions。
具体如下:
- 1)提出一种多模混合 encoder-decoder 架构 (MED):可以作为独立的编码器,也可以分别作为基于图像的文本编码器和解码器。通过联合三种视觉-语言 的目标进行学习:图文对比学习、图文匹配 和 基于图像的语言建模(image-conditioned language modeling)。
BLIP 结合了encoder和decoder,形成了统一的理解和生成多模态模型。
- 论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 代码:BLIP
BLIP在预训练时统一了理解中的图像文本匹配任务以及生成模型的图像文本生成任务
- BLIP可先用decoder来对图像-文本的pair进行扩充,相当于一种数据增强手段,而后,再利用图像文本匹配来对收集到的数据以及decoder生成的数据进行数据清洗,利用清洗后的数据再次训练能够进一步提升效果。
BLIP 模型结构

BLIP 模型一共分为三个部分:
- Unimodal encoder,这里分别为图像特征提取器和文本特征提取器
- Image-grounded text encoder,输入图像特征和文本
- Image-grounded text decoder,输入图像特征,输出文本
BLIP 的预训练任务也是有三个:
- Unimodal encoder 输出的图像特征和文本特征进行对比学习(itc);
- Image-grounded text encoder 输出来判断图文是否一致(itm);
- Image-grounded text decoder 的文本生成任务(lm)
三个预训练任务统一进行训练,能够更加充分地利用收集到的图文多模态数据,也能使得BLIP模型能够同时满足图文理解任务与图文生成任务。
BLIP CapFilt
BLIP另一大创新点便是CapFilt。CapFilt 是Caption 和 Filter的缩写。
- Caption就是对图像生成Caption,这里其实是利用Image-grounded text decoder 来对图像进行处理,生成描述,用以进行数据扩充。由于收集到的图文多模态数据,以及利用模型生成的匹配图文多模态数据,都会存在一定的噪声,这时再利用Image-grounded text encoder 来对收集到的图文多模态数据和利用模型生成的匹配图文多模态数据进行数据清洗,这便是Filter。利用清洗后的数据再次训练BLIP能进一步提升效果。
BLIP两大亮点分别为:
- 1)模型既有encoder模块又有decoder模块,在预训练中统一了多模态理解与多模态生成任务;
- 2)利用数据扩充与数据清洗(CapFilt)进一步提升了模型的效果。
结果:
- 1)在图文检索任务中,本方案相较 SOTA, top1 recall 提升了 2.7%
- 2)在 image caption 任务中,CIDEr 指标提升 2.8%
- 3) 在 VQA 本方案相对 SOTA 算法获得了 1.6% 的VQA score 指标提升
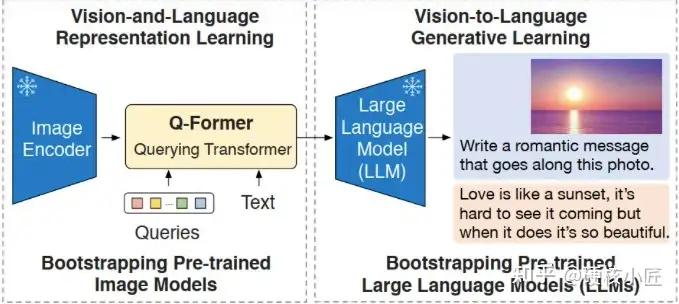
BLIP-2 (Flamingo)
【2023-1-30】BLIP-2 基于 Flamingo
- 【2023-6-15】论文:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 代码:blip-2, lavis
充分利用大模型原始能力,不做预训练,而通过一个轻量级的 Querying transformer(Q-former)弥补了模态之间的差距, 连接视觉大模型和语言大模型。
论文主要提出Q-Former(Lightweight Querying Transformer)用于连接模态之间的gap。
BLIP-2 整体架构包括三个模块:视觉编码器、视觉和LLM的Adapter(Q-Former)、LLM。
- 其中,Q-Former是BLIP-2模型训练过程中主要更新的参数,视觉Encoder和大语言模型LLM在训练过程中冻结参数。
模型结构:
- Vision Encoder:ViT-L/14
- VL Adapter:Q-Former
- LLM:OPT (decoder-based),FlanT5(encoder-decoder-based)
Q-former 通过两阶段方式进行训练:
- 阶段 1:固定图像编码器,学习视觉-语言(vision-language)一致性的表征, 从冻结图像编码器引导视觉语言表示学习
- 阶段 2:固定语言大模型,提升视觉-语言(vision-to-language)的生成能力, 将视觉从冻结的语言模型引导到语言生成学习
BLIP-2 可以基于给定图片+文字提示,做条件文本生成
架构

our model outperforms Flamingo 80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters
- 性能优于Flamingo、BEIT-3等网络,达到sota
InstructBLIP
【2023.06.15】发布 InstructBLIP
- 论文地址:paper
模型结构:
- Vision Encoder:ViT-g/14
- VL Adapter:Q-Former
- LLM:FlanT5-xl(3B), FlanT5-xxl(11B), Vicuna-7B, Vicuna-13B
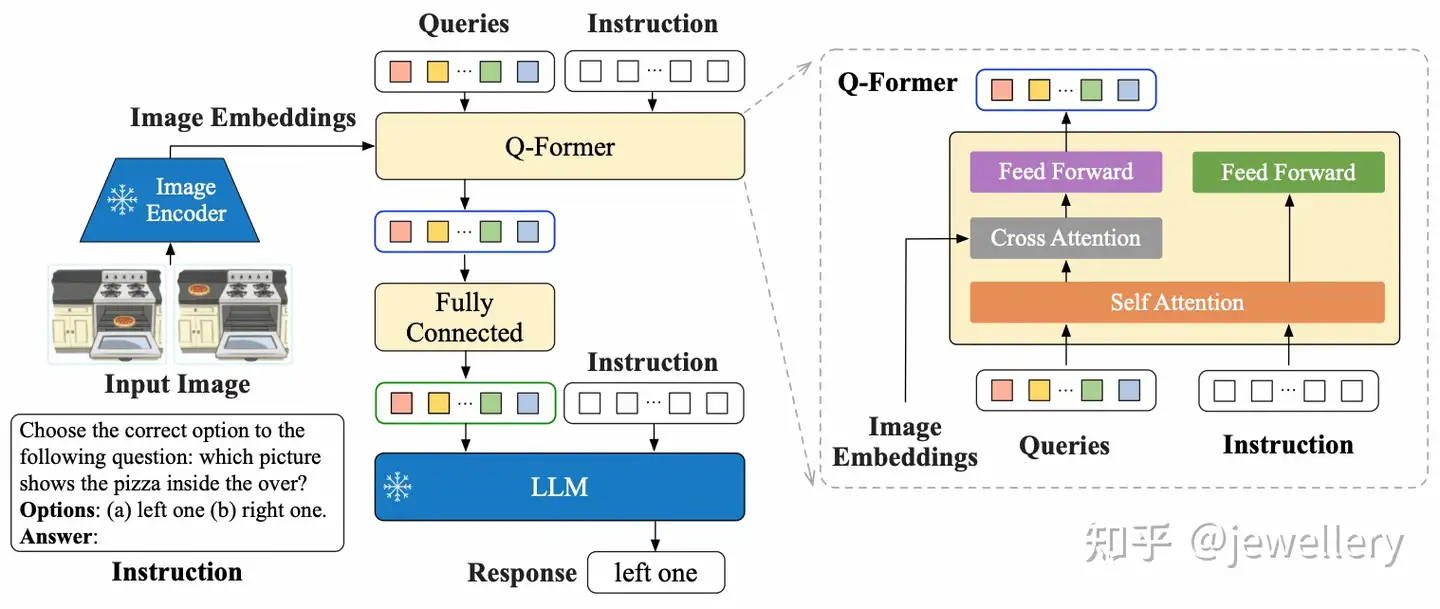
InstructBLIP 模型结构与BLIP-2类似,区别在于输入文本换成了指令数据Instructions.
- Q-Former 抽取指令感知的视觉特征(Instruction-aware vision model),根据指令的不同获取不同的视觉特征。
- 然后将这些视觉特征作为LLM的软视觉提示(soft prompt),使用language modeling loss和指令微调模型生成回复。
训练过程(Vision-Language Instruction Tuning):3阶段训练以及zero-shot预测
- Stage 1:预训练,训练Q-Former和Projection Layer,冻结image encoder。使用image caption数据,学习视觉文本相关性表示。
- Stage 2:预训练,训练Projection Layer,冻结LLM。使用image caption数据,学习对齐LLM的文本生成。
- Stage 3:指令微调,训练Q-Former和Projection Layer。使用Instruction任务数据,学习遵循指令生成回复的能力。
训练数据:
- 收集11个任务以及相应的26个数据集,如下图所示。
- 对于每个任务,人工编写10-15个自然语言的指令模版,作为构造指令微调数据的基础。
- 对于偏向较短回复的开源数据集,在指令模版中使用’short/briefly’降低模型过拟合为总是生成较短回复(防止过拟合的方式是在指令中有所体现)。
miniGPT-4
【2023-4-17】MiniGPT-4 发布,代码模型开源了,阿卜杜拉国王科技大学的几位博士
- GitHub: MiniGPT-4
- demo
- 【2023-10-02】论文:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
GPT-4 所实现的多模态能力,在以前的视觉 - 语言模型中很少见,因此认为,GPT-4 先进的多模态生成能力,主要原因在于利用了更先进的大型语言模型。
为了验证这一想法,团队成员将一个冻结的视觉编码器与一个冻结的 Vicuna 进行对齐,造出了 MiniGPT-4。
- MiniGPT-4 具有许多类似于 GPT-4 的能力, 图像描述生成、从手写草稿创建网站等
- MiniGPT-4 还能根据图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片做饭等。
未来在图像、声音、视频等领域,基于这些大语言模型所造出来的应用,其实际效果都不会太差。
这个项目证实了大语言模型在图像领域的可行性,接下来应该会有不少开发者入场,将 GPT-4 的能力进一步往音频、视频等领域延伸,进而让我们得以看到更多有趣、令人惊艳的 AI 应用。
MiniGPT-4 在一些开源大模型基础上训练得到,fine tune 分为两个阶段
- 先是在 4 个 A100 上用 500 万图文对训练
- 然后再用一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
BLIP-2 模型利用冻结预训练的图像编码器和大型语言模型,通过在它们之间训练一个轻量级的 12 层 Transformer 编码器,实现了各种视觉-语言任务的最先进性能。值得注意的是,在零样本 VQAv2 上,BLIP-2 相较于 80 亿参数的 Flamingo 模型,使用的可训练参数数量少了 54 倍,性能提升了 8.7 %。
投影层(Projection Layer)是神经网络中的一种常见层类型,它将输入数据从一个空间映射到另一个空间。在自然语言处理中,投影层通常用于将高维词向量映射到低维空间,以减少模型参数数量和计算量。在图像处理中,投影层可以将高维图像特征向量映射到低维空间,以便于后续处理和分析。
将一个冻结的视觉编码器和一个冻结的语言模型(如 Vicuna)通过一个投影层对齐意味着:
- 两种模型保持其独立训练得到的特征表示能力,通过投影层获得了一个共同的更低维的表达空间。
- 一个冻结的视觉编码器:指的是一个事先训练好的图像特征提取器,它将输入的图像转换成向量形式。
- 一个冻结的 LLM (Vicuna):指的是另一个事先训练好的大型语言模型,它可以生成文本或者对文本进行理解。
模型结构:
- Vision Encoder:ViT-G/14
- VL Adapter:Q-Former
- Projection Layer:a single linear
- LLM:Vicuna
训练过程:
- Stage 1:只训练Linear Projection Layer来对齐视觉特征和大语言模型。使用大量text-image pair数据。
- Stage 2:指令微调,使用少量高质量text-image instruction数据
- 指令模板:
###Human: <Img><ImageFeature></Img><Instruction>###Assistant:
MiniGPT-v2
【2023.11.07】
- 论文地址:paper
模型结构:
- Vision Encoder:ViT
- VL Adapter:/
- Projection Layer:Linear
- LLM:Llama2-7B
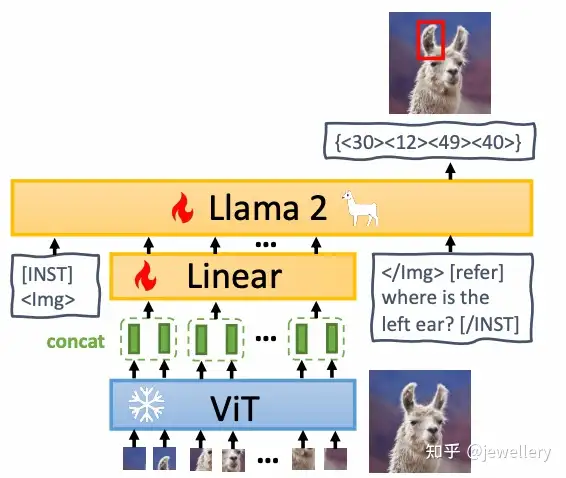
训练过程:
- Stage 1:预训练,使用大量弱监督image-text和细粒度数据集的混合数据训练,让模型获取多样化知识
- Stage 2:多任务训练,只使用细粒度高质量数据集训练模型在不同任务上的能力。
- Stage 3:多模态质量微调,让模型具备Chat哪里
LLaVA
【2023-4-17】Visual Instruction Tuning: 用LLaVA近似多模态GPT-4 用 GPT-4 进行视觉指令学习
- 论文:Visual Instruction Tuning
- Generated by GLIGEN: A cute lava llama and glasses
LLaVA (Language-and-Vision Assistant),一款展示了某些近似多模态 GPT-4 水平能力的语言和视觉助手:
- 视觉聊天 (Visual Chat):相对得分达到了 GPT-4 的 85%
-
多模态推理任务的科学问答 (Science QA):达到了新的 SoTA 92.53%,超过了之前的最先进的方法:多模态思维链技术 (multimodal chain-of-thoughts)
- 项目主页 Project Page
- 论文 Paper
- 代码 GitHub
- 演示 Demo
- 数据 Data (158K unique language-image instruction-following samples)
- 模型 Model (LLaVA-13B):
- 多模态指令跟踪数据(Multimodal Instruction-following Data)
- 数据质量是这个项目的关键。我们大部分时间都在迭代新的指令数据。在这个数据为中心(Data-Centric)的项目中,需要考虑以下因素:图像的符号化表示(包括 Caption & Boxes)、ChatGPT vs GPT-4、提示工程(Prompt Engineering)等。
- 看到学术圈一直以来没有这类数据,我们开源了我们最新一个版本的数据,希望能启发更多人沿着这个道路去探索。
- 视觉对话(Visual Chat)
- LLaVA 在涉及面向用户应用的聊天过程中表现出非常强的泛化能力,尽管只是在不到 1M CC/COCO 数据的训练下进行的。
- (a) 强大的多模态推理能力:GPT-4技术报告中的两个基于图像的推理示例,一度以为难以企及,利用LLaVA现在可以轻松复现。
- (b) 强大的 OCR 文字识别能力:请看我刚刚制作的一些示例。它能识别 CVPR、我们的举办的 Computer Vision in the Wild (CVinW) Workshop 的标志的图片,和 LLaVA 本身相关的照片。
- 科学问答(Science QA)
- 单独使用 LLaVA 实现了 90.92% 的准确率。我们使用仅文本的 GPT-4 作为评判者,根据其自身先前的答案和 LLaVA 的答案预测最终答案。这种“GPT-4 作为评判者”的方案产生了新的 SOTA 92.53%。令人惊讶的是,GPT-4 可以作为一种有效的模型集成方法!这些结果希望启发大家以后刷榜的时候,可以利用 GPT-4 这个神奇来集成不同方法。
模型结构:
- Vision Encoder:ViT-L/14
- VL Adapter:/
- Projection Layer:a linear layer
- LLM:LLaMA
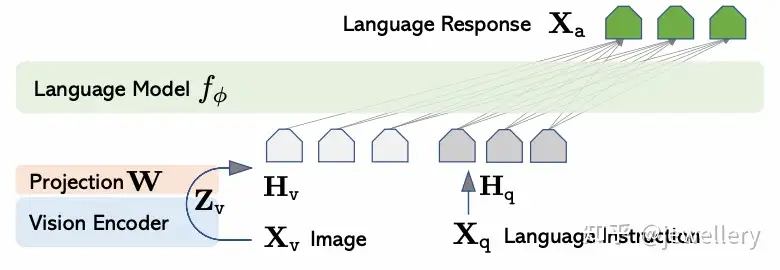
训练过程:
- Stage 1:Pre-training for Feature Alignment. 训练Projection Layer
- Stage 2:Fine-tuning End-to-End. 训练Projection Layer和LLM
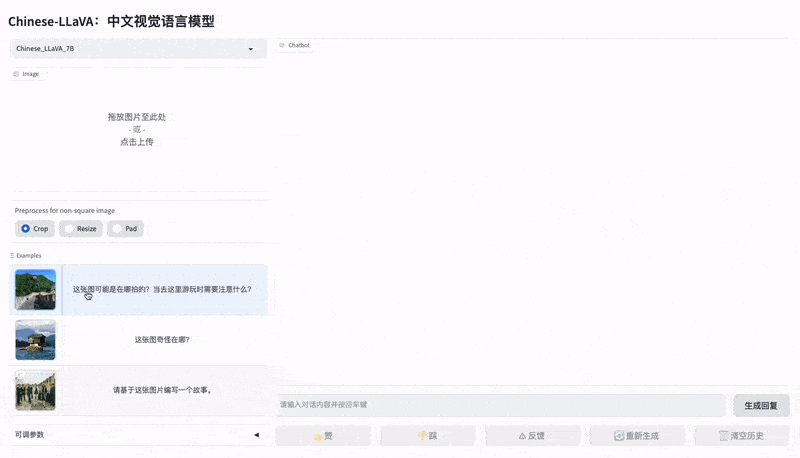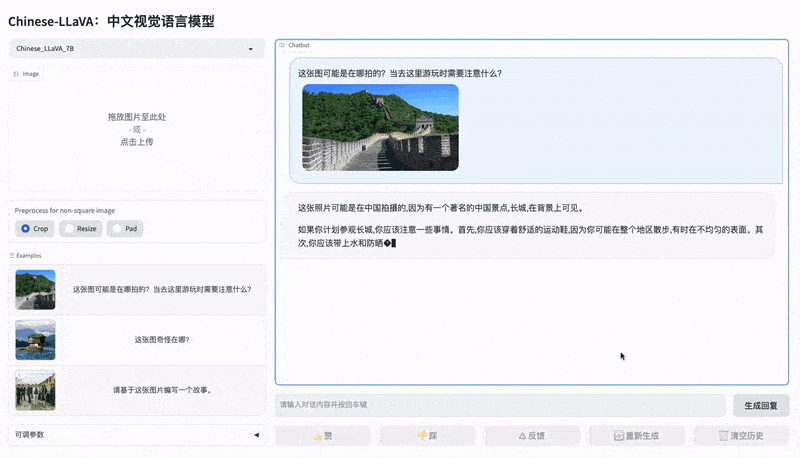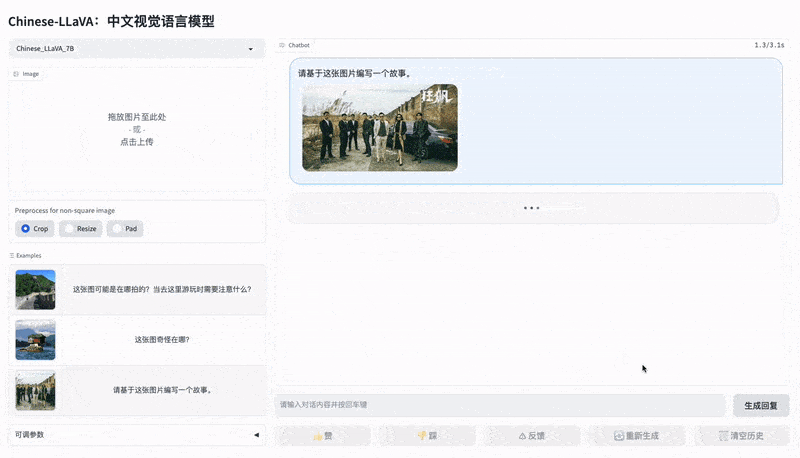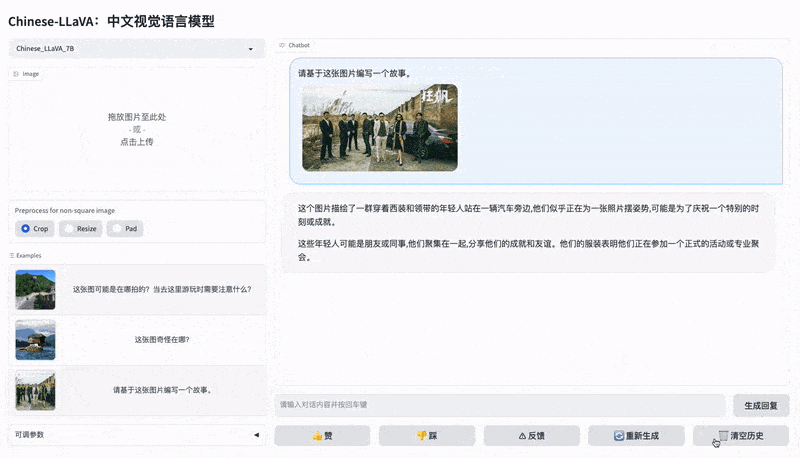
LLaVA 中文版
- LinkSoul.AI 开源了可商用的中英文双语视觉 - 语言助手 Chinese-LLaVA 以及中英文视觉 SFT 数据集 Chinese-LLaVA-Vision-Instructions,支持中英文视觉 - 文本多模态对话的开源可商用对话模型。
- 代码 Chinese-LLaVA, 模型、代码和数据地址
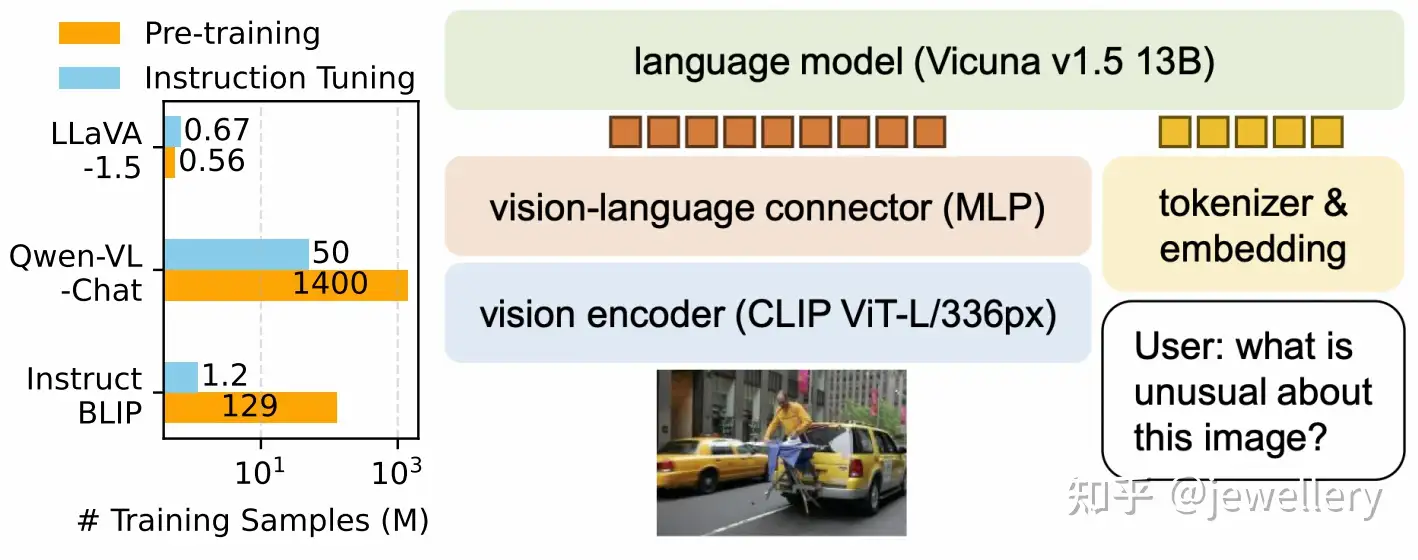
LLaVA-1.5
【2024.05.15】
论文地址:paper
模型结构:
- Vision Encoder:Clip预训练 Vit-L/336px
- VL Adapter:MLP
- LLM:Vicuna v1.5 13B
MMGPT (基于OpenFlamingo)
【2023-4-27】MMGPT (Multi-modal GPT) 安装指南和初体验
OpenMMLab 团队开源了一个类似 miniGPT-4 和 LLaVA 等的具备多模态对话能力的库 Multi-modal GPT,地址,对开源的 OpenFlamingo 模型利用视觉和语言数据进行高效 LoRA 联合微调训练
功能
- VQA, Image Captioning, Visual Reasoning, Text OCR, and Visual Dialogue
OpenFlamingo 发布了 9B 的权重,其实已经具备了多模态问答能力。而 MMGPT 是基于这个模型进行一步进行了指令微调。
MMGPT 给出了所有复现步骤
X-LLM (中科院)
【2023-5-15】中科院发布多模态 ChatGPT,图片、语言、视频都可以 Chat ?中文多模态大模型力作
- 多模态的大规模语言模型 X-LLM,同时支持图片、语音以及视频等多种模态信息作为大模型的输入,并且展现了类似于 GPT-4 的表现。
- X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
- 项目主页
用30 张模型未见过的图像,每张图像都与相关于对话、详细描述以及推理三类的问题,从而形成了 90 个指令-图像对以测试 X-LLM 与 GPT-4 的表现。通过使用 ChatGPT 从 1 到 10 为模型回复进行评分,与 GPT-4 相比 X-LLM 取得了 84.5% 的相对分数,表明了模型在多模态的环境中是有效的。
VisualGLM
【2023-5-18】VisualGLM-6B
- VisualGLM-6B 是一个开源,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/visualglm-6b", trust_remote_code=True).half().cuda()
image_path = "your image path"
response, history = model.chat(tokenizer, image_path, "描述这张图片。", history=[])
print(response)
response, history = model.chat(tokenizer, "这张图片可能是在什么场所拍摄的?", history=history)
print(response)
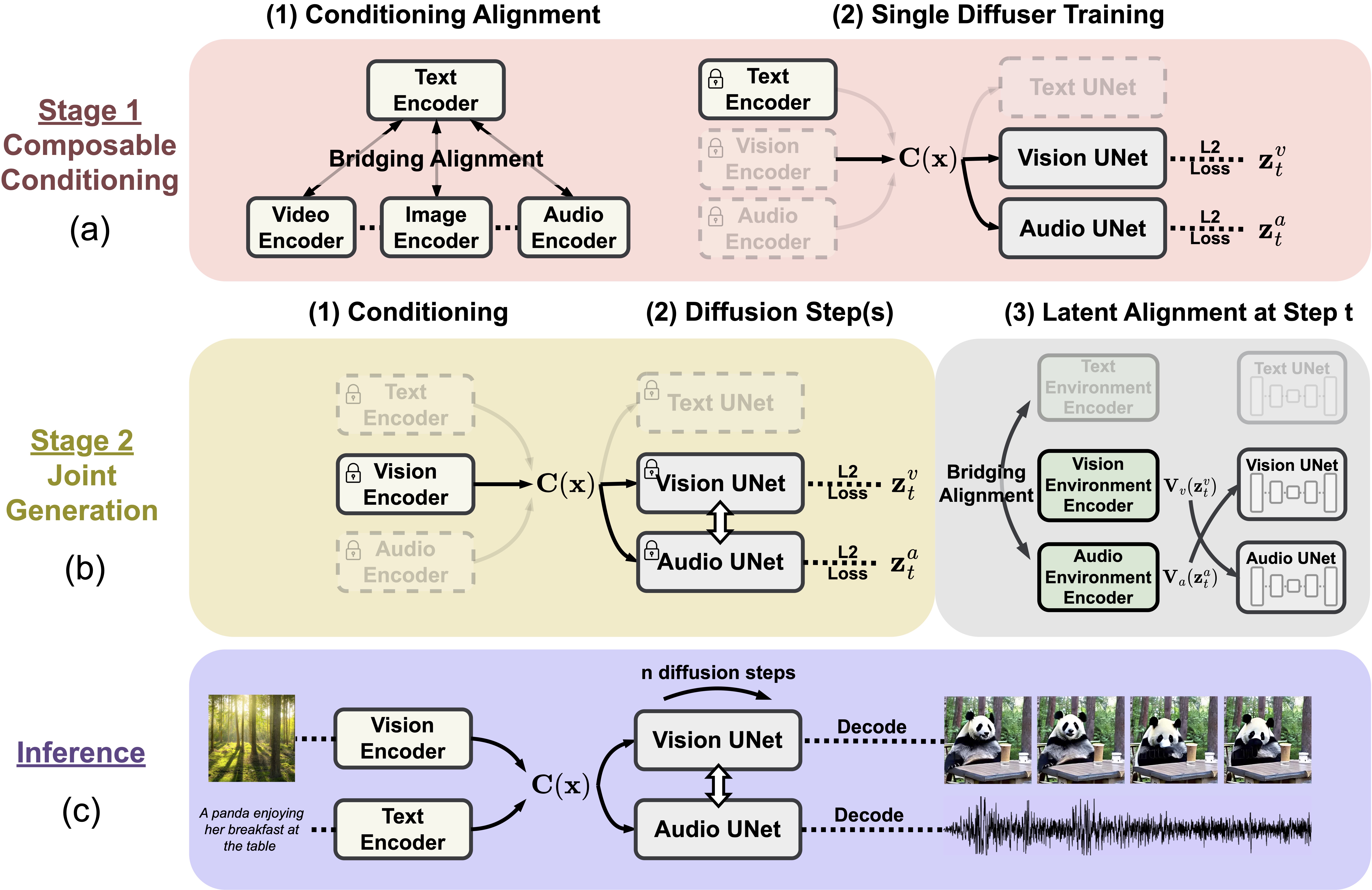
CoDi
【2023-5-19】CoDi: Any-to-Any Generation via Composable Diffusion, 主页
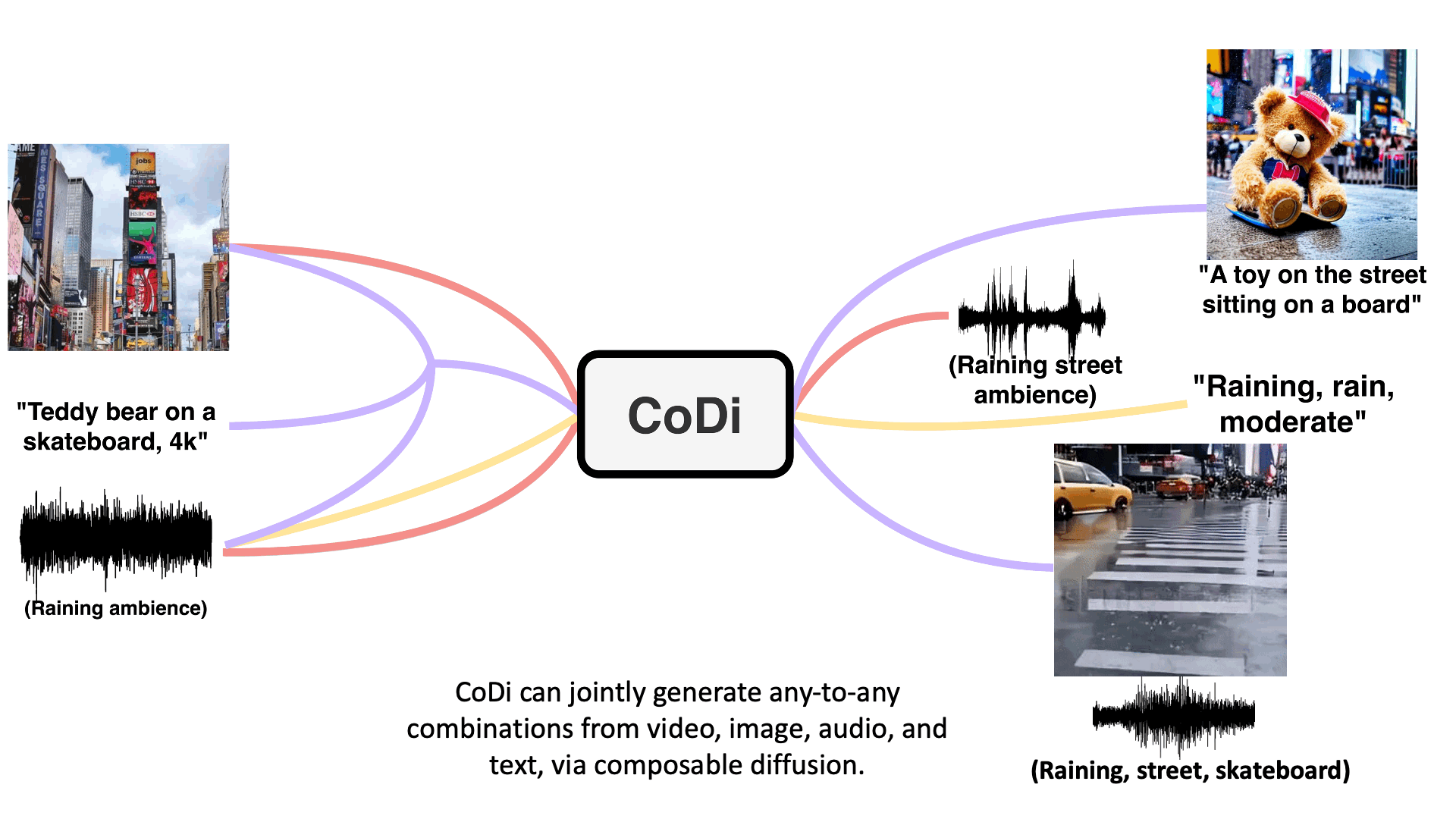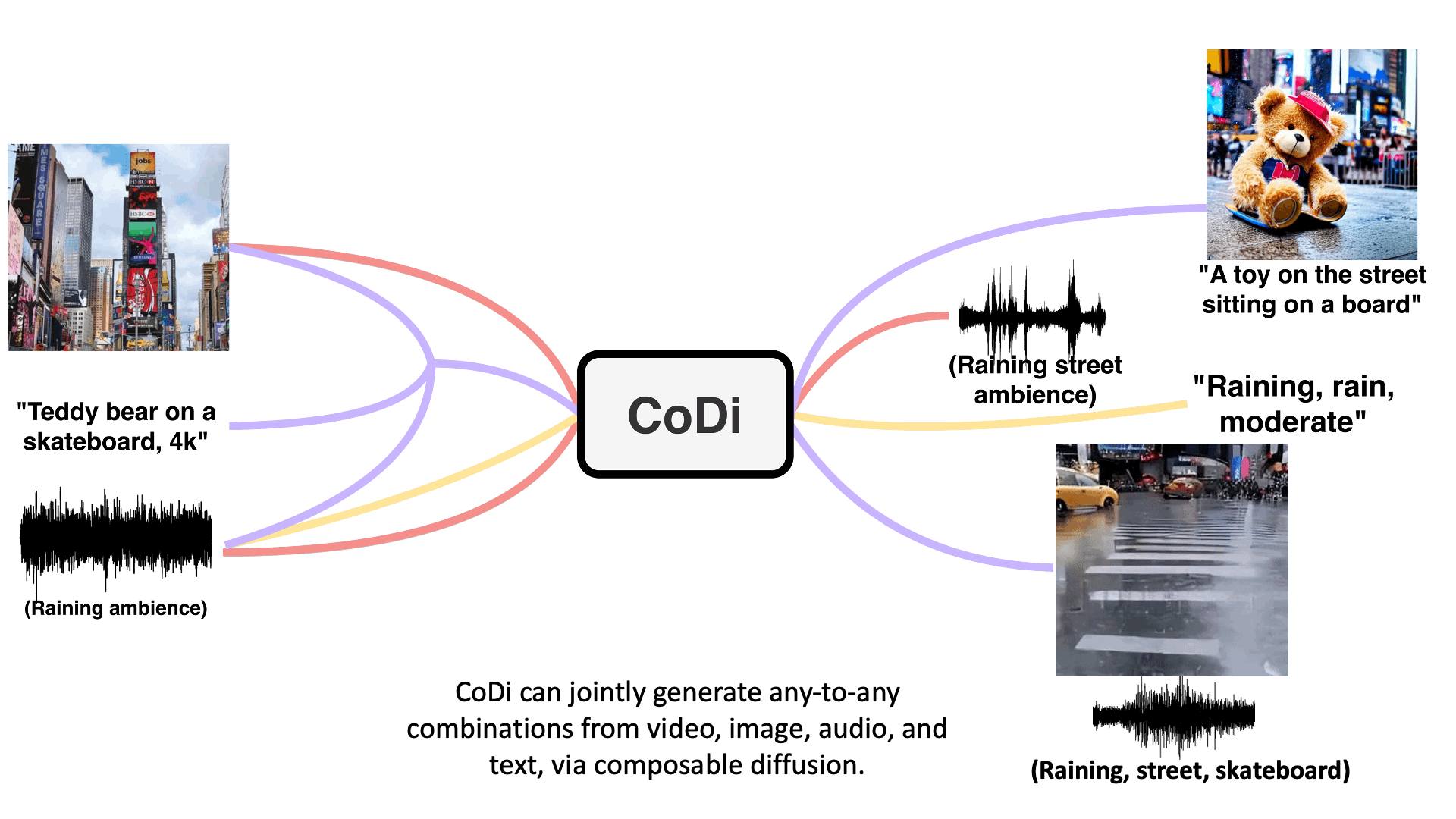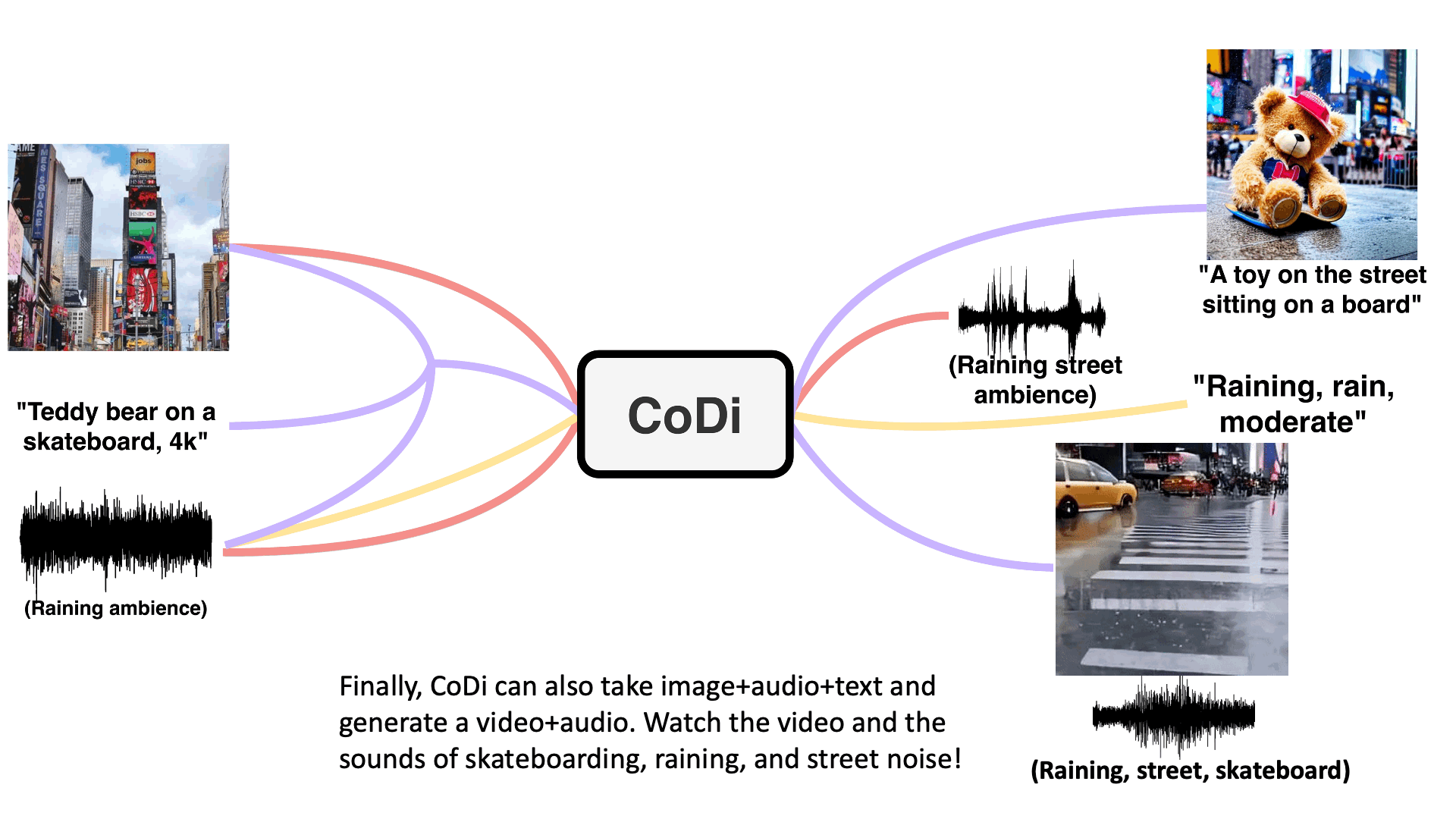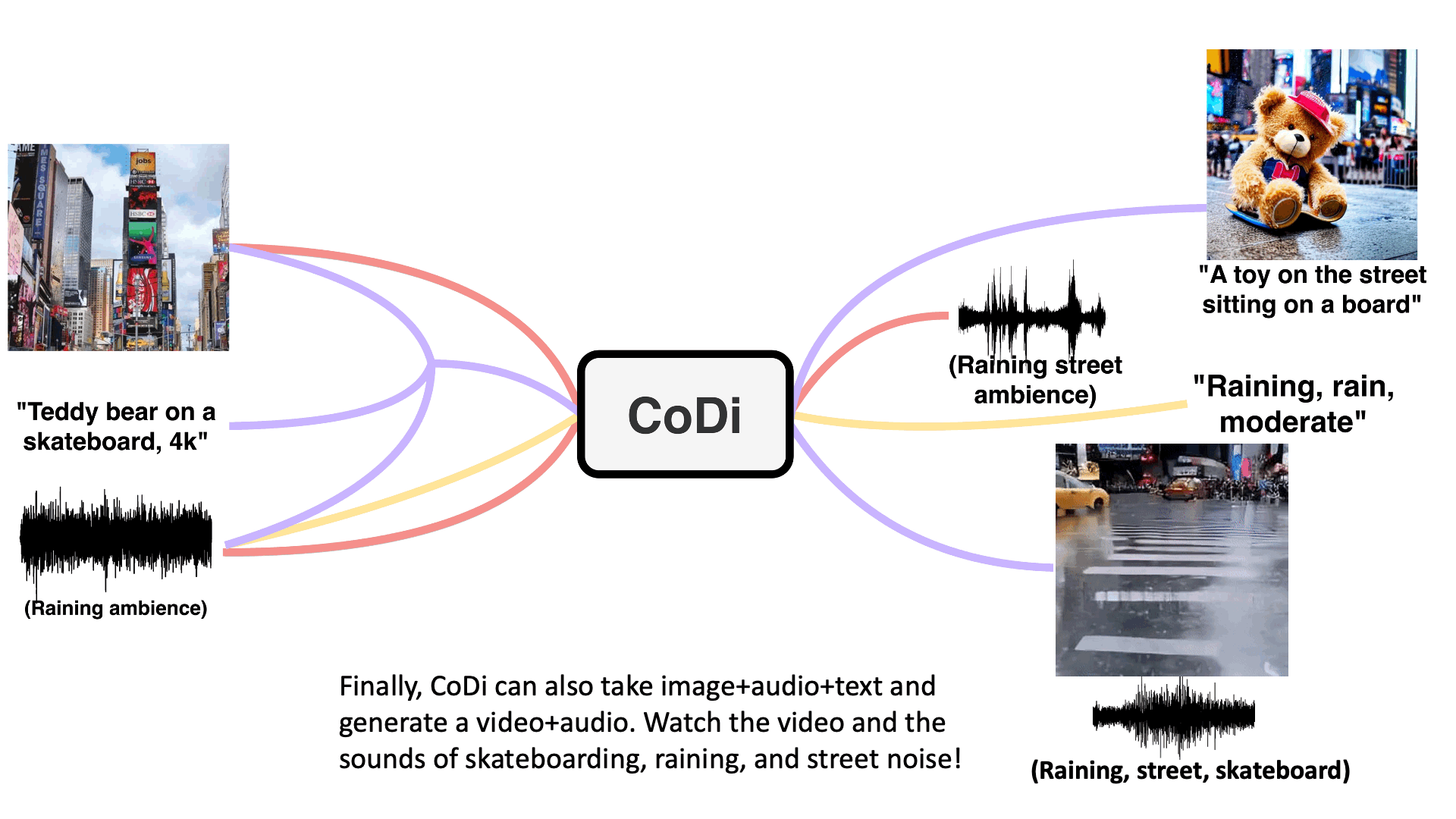
模型架构
TigerBot
【2023-6-7】国产大模型效果达OpenAI同规模模型96%,已开源
TigerBot 是一款国产自研的多语言任务大模型, 包含70亿参数和1800亿参数两个版本,均对外开源。
- TigerBot-180B 是目前业内开源的最大规模大语言模型。
- GitHub地址:TigerBot
TigerBot 是一个多语言、多任务的大规模语言模型(LLM)。
成果开源:
- 模型:TigerBot-7B, TigerBot-7B-base,TigerBot-180B (research version),
- 代码:基本训练和推理代码,包括双卡推理 180B 模型的量化和推理代码,
- 数据:预训练 100G,从 2TB 过滤后的数据中经过去噪去重清洗而得;监督微调 1G 或 100 万条数据,按比例涵盖用户指令常见的 10 大类 120 小类任务,
- API: chat, plugin, finetune, 让用户能在半小时内无代码的训练和使用专属于自己的大模型和数据,
- 领域数据:涵盖金融,法律,百科,广邀大模型应用开发者,一起打造中国的世界级的应用。
在 BLOOM 基础上,在模型架构和算法上做了如下优化:
- 指令完成监督微调的创新算法以获得更好的可学习型(learnability),
- 运用 ensemble 和 probabilistic modeling 的方法实现更可控的事实性(factuality)和创造性(generativeness),
- 并行训练上,突破了 deep-speed 等主流框架中若干内存和通信问题,使得在千卡环境下数月无间断,
- 对中文语言的更不规则的分布,从 tokenizer 到训练算法上做了更适合的算法优化。
开源模型包括三个版本:
- TigerBot-7B-sft
- TigerBot-7B-base
- TigerBot-180B-research
TigerBot带来的创新主要有以下几个方面:
- 提出指令完成监督微调的创新算法提升模型可学习性
- 运用ensemble和probabilistic modeling的方法实现可控事实性和创造性
- 在并行训练上突破deep-speed等主流框架中的内存和通信问题,实现千卡环境下数月无间断
- 针对中文语言更不规则的分布,从tokenizer到训练算法上做了更适合的优化
使用GPTQ算法和GPTQ-for-LLaMa实现量化
由该模型支持的对话AI同步上线。覆盖生成、开放问答、编程、画图、翻译、头脑风暴等15大类能力,支持子任务超过60种。

评测结果显示
- TigerBot-7B 已达到OpenAI同样大小模型综合表现的 96%。
- TigerBot-7B-base的表现优于OpenAI同等可比模型、BLOOM。
- TigerBot-180B-research或是目前业内开源的最大规模模型(Meta开源OPT的参数量为1750亿、BLOOM则为1760亿规模)。
根据 OpenAI InstructGPT 论文在公开 NLP 数据集上的自动评测
- TigerBot-7B 达到 OpenAI 同样大小模型的综合表现的 96%,并且这只是 MVP
此外,团队还一并开源100G预训练数据、监督微调1G或100万条数据。
基于TigerBot,开发者在半天内就能打造出自己的专属大模型。
虎博科技最初只有5人的小团队,首席程序员&科学家就是CEO本人。
- 从2017年起,他们就在NLP领域开始创业,专长垂直领域搜索。最擅长对数据重度依赖的金融领域,和方正证券、国信证券等有过深入合作。
- 创始人兼CEO,有着20多年从业经验,曾任UC伯克利客座教授,手握3篇最佳顶会论文和10项技术专利。
致敬硅谷90年代经典的“车库创业”模式。
团队最初只有5个人,陈烨是首席程序员&科学家,负责最核心的代码工作。后面成员规模虽有扩充,但也只控制在了10人,基本上一人一岗。
陈烨的回答是:
我认为从0到1的创造,是一件很极客的事,而没有一个极客团队是超过10个人的。
以及纯技术科学的事,小团队更犀利。
的确,TigerBot的开发过程里,方方面面都透露着果断、敏锐。
陈烨将这个周期分为三个阶段。
- 第一阶段,ChatGPT爆火不久,团队迅速扫遍了OpenAI等机构过去5年内所有相关文献,大致了解ChatGPT的方法机制。
- 由于ChatGPT代码本身不开源,当时相关的开源工作也比较少,陈烨自己上阵写出 TigerBot 的代码,然后马上开始跑实验。
- 逻辑很简单,让模型先在小规模数据上验证成功,然后经过系统科学评审,也就是形成一套稳定的代码。
- 一个月时间内,团队就验证了模型在70亿规模下能达到OpenAI同规模模型80%的效果。
- 第二阶段,通过不断吸取开源模型和代码中的优点,加上对中文数据的专门优化处理,团队快速拿出了一版真实可用的模型,最早的内测版在2月便已上线。
- 同时,参数量达到百亿级别后,模型表现出了涌现的现象。
- 第三阶段,最近的一两个月内,团队在基础研究上实现了一些成果和突破。如上介绍的诸多创新点,就是在这一时期内完成的。
- 同时整合更大规模算力,达到更快的迭代速度,1-2个星期内,TigerBot-7B 的能力便快速从 InstructGPT 的80%提升到了96%。
- 在这个开发周期内,团队始终保持着超高效运转。TigerBot-7B 在几个月内经历了3000次迭代。
小团队的优势是反应速度快,早上确定工作,下午就能写完代码。数据团队几个小时就能完成高质量清洗工作。
但高速开发迭代,还只是TigerBot极客风格的体现点之一。因为他们仅凭10个人在几个月内肝出来的成果,将以全套API的形式向行业开源。
Video-LLaMA(视听,达摩院)
【2023-6-8】给语言大模型加上综合视听能力,达摩院开源Video-LLaMA
能否给大模型装上 “眼睛” 和 “耳朵”,让它能够理解视频,陪着用户互动呢?
达摩院的研究人员提出了 Video-LLaMA,一个具有综合视听能力大模型。
- Video-LLaMA 能够感知和理解视频中的视频和音频信号,并能理解用户输入的指令,完成一系列基于音视频的复杂任务,例如音 / 视频描述,写作,问答等。
- 目前论文,代码
- 交互 demo 都已开放。Modelscope, Huggingface
Video-LLaMA 采用了模块化设计原则,把视频中的视觉和音频模态信息映射到到大语言模型的输入空间中,以实现跨模态指令跟随的能力。与之前侧重于静态图像理解的大模型研究(MiNIGPT4,LLaVA)不同,Video-LLaMA 面临着视频理解中的两个挑战:捕捉视觉中的动态场景变化和整合视听信号。
为了捕捉视频中的动态场景变化,Video-LLaMA 引入了一个可插拔的视觉语言分支。该分支首先使用 BLIP-2 中预训练好的图片编码器得到每一帧图像的单独特征,再与对应的帧位置嵌入结合后,所有图像特征被送入 Video Q-Former,Video Q-Former 将聚合帧级别的图像表示并且生成定长的综合视频表征。最后采用一个线性层将视频表征对齐到大语言模型的 embedding 空间。
Video-LLaMA 基于视频 / 音频 / 图像的对话的一些例子
音频视频理解依旧是一个非常复杂,尚未有成熟解决方案的研究问题,Video-LLaMA 虽然表现出了令人印象深刻的能力,作者也提到了其存在一些局限性。
- (1)有限的感知能力:Video-LLaMA 的视觉听觉能力仍然较为初级,对复杂的视觉声音信息依然难以辨认。其中一部分原因是数据集的质量和规模还不够好。该研究团队正在积极构建高质量的音频 - 视频 - 文本对齐数据集,以增强模型的感知能力。
- (2)难以处理长视频的:长视频 (如电影和电视节目) 包含大量的信息,对模型的推理能力和计算资源都较高。
- (3)语言模型固有的幻觉问题,在 Video-LLaMA 中依然存在。
Video-LLaMA 作为一个具有综合视听能力的大模型,在音频视频理解领域取得了令人印象深刻的效果。随着研究者的不断攻坚,以上挑战也将逐个被克服,使得音视频理解模型具有广泛的实用价值。
PandaGPT – 大一统
【2023-6-16】剑桥、腾讯AI Lab等提出大语言模型PandaGPT:一个模型统一六种模态
- 通过结合 ImageBind 的模态对齐能力和 Vicuna 的生成能力,同时实现了六种模态下的指令理解与跟随能力。虽然 PandaGPT 的效果尚有提升空间,但展示了跨模态 AGI 智能的发展潜力。
- 论文链接
- 代码链接
- 项目主页
- 线上 Demo 展示
为了实现图像 & 视频、文本、音频、热力图、深度图、IMU 读数六种模态下的指令跟随能力
- PandaGPT 将 ImageBind 的多模态编码器与 Vicuna 大型语言模型相结合
PandaGPT 版本只使用了对齐的图像 - 文本数据进行训练,但是继承了 ImageBind 编码器的六种模态理解能力(图像 / 视频、文本、音频、深度度、热量图和 IMU)和它们之间的对齐属性,从而具备在所有模态之间跨模态能力。
PandaGPT 仅仅是一个研究原型,暂时还不足以直接应用于生产环境。
InstructBLIP
【2023-6-18】超越GPT-4!华人团队爆火 InstructBLIP 抢跑看图聊天,开源项目横扫多项SOTA
- salesforece和香港科大,华人团队开源了多模态基础模型InstructBLIP,从BLIP2模型微调而来
- InstructBLIP模型更擅长「看」、「推理」和「说」,即能够对复杂图像进行理解、推理、描述,还支持多轮对话等。
- InstructBLIP在多个任务上实现了最先进的性能,甚至在图片解释和推理上表现优于GPT4。

VisorGPT
【2023-6-20】 VisorGPT : 如何基于 GPT 和 AIGC 模型定制一个可控的生成模型

可控扩散模型如ControlNet、T2I-Adapter和GLIGEN等可通过额外添加的空间条件如人体姿态、目标框来控制生成图像中内容的具体布局。使用从已有的图像中提取的人体姿态、目标框或者数据集中的标注作为空间限制条件,上述方法已经获得了非常好的可控图像生成效果。
那么,如何更友好、方便地获得空间限制条件?或者说如何自定义空间条件用于可控图像生成呢?例如自定义空间条件中物体的类别、大小、数量、以及表示形式(目标框、关键点、和实例掩码)。
本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式来建模上述视觉先验。
因此,可以从学习好的先验中通过Prompt从多个层面,例如表示形式(目标框、关键点、实例掩码)、物体类别、大小和数量,来采样空间限制条件。
SEEChat
【2023-6-30】360 人工智能研究院正式开源中文多模态对话模型 SEEChat
将视觉能力融入语言模型 LLM的 MLLM(Multimodal Large Language Model),相关的研究路线主要分为两条:
- 一条是原生多模态路线,模型设计从一开始就专门针对多模态数据进行适配设计,代表性的工作有 MSRA的KOSMOS-1[1]和 Google Robotics的 PALM-E,均在今年3月份公开;
- 另一条是单模态专家模型缝合路线,通过桥接层将预训练的视觉专家模型与预训练的语言模型链接起来,代表性的工作有 Deepmind的Flamingo[3],Saleforce的BLIP-2,以及近期的 LLAVA和 miniGPT4等工作。
SEEChat项目的重点是将视觉能力与已有的 LLM模型相融合,打造侧重视觉能力的多模态语言模型 MLLM。在多模态能力的实现路线上,我们选择了能够充分复用不同领域已有成果的单模态专家模型缝合路线(Single-modal Experts Efficient integration),这也是 SEEChat项目的命名来源。
SEEChat v1.0的模型结构如下图6所示,通过 projection layer桥接层,将vision encoder: CLIP-ViT-L/14与开源的中文 LM:chatGLM6B缝合到一起。
BayLing 百聆 中科院计算所
【2023-7-4】中科院计算所推出多语言大模型「百聆」
- 论文: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
- Demo


在中科院计算所信息高铁 Al 训练推理平台 MLOps 上训练并发布了新的大型语言模型「百聆」,旨在让大型语言模型对齐人类意图的同时,将其生成能力和指令遵循能力从英语泛化到其他语种。「百聆」以经济友好、内存节约的方式实现了多语言人机交互能力。
VisCPM 面壁智能
【2023-7-6】VisCPM
VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型),在中文多模态开源模型中达到最佳水平。VisCPM基于百亿参数量语言大模型CPM-Bee(10B)训练,融合视觉编码器(Q-Former)和视觉解码器(Diffusion-UNet)以支持视觉信号的输入和输出。得益于CPM-Bee基座优秀的双语能力,VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
- 👐 开源使用:VisCPM可以自由被用于个人和研究用途。我们希望通过开源VisCPM模型系列,推动多模态大模型开源社区和相关研究的发展。
- 🌟 涵盖图文双向生成:VisCPM模型系列较为全面地支持了图文多模态能力,涵盖多模态对话(图到文生成)能力和文到图生成能力。
- 💫 中英双语性能优异:得益于语言模型基座CPM-Bee优秀的双语能力,VisCPM在中英双语的多模态对话和文到图生成均取得亮眼的效果。

BuboGPT 字节
【2023-9-1】字节发布多模态大模型:BuboGPT
字节跳动发布自己的多模态大模型BuboGPT,整合了包括文本、图像和音频在内的多模式输入,能够较好的理解图片、语言数据。Demo上可以上传图片或者音频,然后询问相关的内容,回答效果不错。可以理解中文,但是回答却是英文。
LLaSM – 语音文本
【2023-8-30】LLaSM: Large Language and Speech Model, AI 初创公司 LinkSoul.Al
- 这家公司还训练了 Llama中文版 Chinese-Llama-2-7b, demo
- Llama 2 语料库仍以英文(89.7%)为主,而中文仅占据了其中的 0.13%。这导致 Llama 2 很难完成流畅、有深度的中文对话。
- Meta Al 开源 Llama 2 模型的次日,开源社区首个能下载、能运行的开源中文 LLaMA2 模型就出现了。该模型名为「Chinese Llama 2 7B」,由国内 AI 初创公司 LinkSoul.Al 推出。
- Chinese-Llama-2-7b 开源的内容包括完全可商用的中文版 Llama2 模型及中英文 SFT 数据集,输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。
- LinkSoul.AI 开源了可商用的中英文双语视觉 - 语言助手 Chinese-LLaVA 以及中英文视觉 SFT 数据集 Chinese-LLaVA-Vision-Instructions,支持中英文视觉 - 文本多模态对话的开源可商用对话模型。
- 代码 Chinese-LLaVA, 模型、代码和数据地址
- Demo,代码 LLaSM, 数据集LLaSM-Audio-Instructions
- 多模态模型大多聚集在视觉、文本上,而语音也需要关注,LLaSM 是端到端多模态语音语言模型,能遵循语音→语言指令
- LLaSM 是首个支持中英文语音 - 文本多模态对话的开源可商用对话模型。通过便捷的语音输入的交互方式,大幅改善过往以文本为输入的大模型的使用体验,同时有效避免基于 ASR 解决方案的繁琐流程以及可能引入的错误。
NExT-GPT 任意模态
【2023-9-18】无限接近AGI!新加坡华人团队开源全能“大一统”多模态大模型
现有的大语言模型
- 一方面是局限于某种单一模态信息的处理,而缺乏真正「任意模态」的理解;
- 另一方面是只关注于多模态内容在输入端的理解,而不能以任意多种模态的灵活形式输出内容。
已有多模态
- 图像类:
MiniGPT-4、BLIP-2、Flamingo、InstructBLIP等 - 视频类:
Video-LLaMA,PandaGPT等 - 声音类:
SpeechGPT等等。
目前的多模态LLM距离真正人类级别的AGI,总感觉少了点「那味儿」。
新加坡国立大学NExT++实验室华人团队近期开源了一种支持任意模态输入和任意模态输出的「大一统」多模态大模型,NExT-GPT(GPT of Next generation),支持任意模态输入到任意模态输出。
- 代码开源:NExT-GPT, 上线了Demo系统
- 论文地址:NExT-GPT: Any-to-Any Multimodal LLM
NExT-GPT 如何实现任意模态输入到任意模态输出的呢?
技术层面上「没有显著的创新点」——
- 通过有机连接现有的开源 1)LLM,2)多模态编码器和 3)各种模态扩散解码器,构成 NExT-GPT的整体框架,实现任意模态的输入和输出,可谓大道至简。
模型呈现为一个「编码端-推理中枢-解码器」三层架构:
- 多模编码阶段:
- 利用已开源的编码器对各种输入模态进行编码,然后通过一个投影层将这些特征投影为LLM所能够理解的「类似语言的」表征。中文作者采用了MetaAI的ImageBind统一多模态编码器。
- 推理中枢阶段:
- 利用开源LLM作为核心大脑来处理输入信息,进行语义理解和推理。LLM可以直接输出文本,同时其还将输出一种「模态信号」token,作为传递给后层解码端的指令,通知他们是否输出相应的模态信息,以及输出什么内容。作者目前采用了Vicuna作为其LLM。
- 多模生成阶段:
- 利用各类开源的图像扩散模型、声音扩散模型以及视频扩散模型,接收来自LLM的特定指令信号,并输出所对应的模型内容(如果需要生成的指令)。
在推理时,给定任意组合模态的用户输入,通过模态编码器编码后,投影器会将其转换为特征传递给LLM(文本部分的输入将会直接出入到LLM)。
然后LLM将决定所生成内容,一方面直接输出文本,另一方面输出模态信号token。
如果LLM确定要生成某种模态内容(除语言外),则会输出对应的模态信号token,表示该模态被激活。
NExT-GPT 并不是首个实现任意模态输入到任意模态输出功能。目前有两类前驱工作:
- 一类是不久前所发布的
CoDi模型,其整合了各种模态的diffusion模型,可以同时处理和生成各种组合的模态内容。- 然而作者指出,CoDi由于缺乏LLMs作为其核心部件,其仅限于成对(Parallel)内容的输入和生成,而无法实现复杂的内容推理和决策,根据用户输入的指令灵活相应。
- 另一类工作则试图将LLMs与现有的外部工具结合,以实现近似的「任意多模态」理解和生成,代表性的系统如
Visual-ChatGPT和HuggingGPT。- 由于这类系统在不同模块之间的信息传递完全依赖于LLM所生成的文本,其割裂、级联的架构容易不可避免地引入了噪音,降低不同模块之间的特征信息传递效用。并且其仅利用现有外部工作进行预测,缺乏一种整体的端到端训练,这对于充分理解用户的输入内容和指令是不利的。
相比之下,NExT-GPT却良好地解决了上述的现有工作的问题——既保证具有较好的学习成效,又全面降低、控制学习成本。
Gemini 谷歌
【2023-12-6】Google 正式推出了原生多模态的大型语言模型Gemini,可以同时支持文字、图片和声音的输入。
在32项AI测试中,有30项的评分超越了OpenAI的GPT-4。Google CEO Sundar Pichai强调,Gemini是Google有史以来最强大也是最通用的模型。
Gemini模型经过海量数据训练,可以很好识别和理解文本、图像、音频等内容,并可以回答复杂主题相关的问题。所以,非常擅长解释数学和物理等复杂学科的推理任务。
LEGO – 字节&复旦,视频解读
【2024-1-12】精确指出特定事件发生时间!字节&复旦多模态大模型解读视频太香了
字节&复旦大学多模态理解大模型来了,可以精确定位到视频中特定事件的发生时间。
- LEGO模型全都读得懂,并毫不犹豫给出正确答案
- 一个语言增强的多模态grounding模型,多模态LLM跨多种模态进行细粒度理解的能力,此前业内的成果主要强调全局信息。
- 论文 LEGO:Language Enhanced Multi-modal Grounding Model
- Demo
示例
- 狗子转身看镜头时的时间戳是多少?
- 什么时候用爪子推开滑板?
- 宝宝什么时候推起眼镜、舒展了一下身体?又是什么时候翻的书?
数据集转换(Dataset Conversion):构建模态对齐和细粒度对齐的基础多模态数据集
- 图像模态,作者利用LLaVA-pretrain595K数据集进行模态对齐,细粒度对齐则使用特定数据集如RefCOCO。
- 视频模态用Valley-Pretrain-703K进行模态对齐,Charades-STA数据集用于细粒度对齐。
指令调整数据集生成(Instruction-tuning Dataset Generation)。
- 目的是让模型更好地理解和遵循人类指令。
- 选择了公开可用的数据集(Flickr30K Entities、VCR、DiDeMo等)的子集进行人工注释,以创建上下文示例。它用于指导GPT-3.5在生成指令调整数据集时遵循类似的模式。
- 随后,特定任务的系统提示和随机选择的示例被输入到GPT-3.5中,以生成单轮或多轮对话。最后,进行数据过滤以确保数据集质量。
LEGO模型架构:
- 每个模态的输入通过独立的编码器进行处理,提取特征,然后使用适配器将这些特征映射到LLM的嵌入空间。
- 视频和图像模式的两个示例,蓝色方框表示视频作为输入,而黄色方框表示图像作为输入。
- 由于其基于模块化设计和适配器的架构,LEGO可以无缝集成新的编码器,处理额外的模态,如点云和语音,主打一个好扩展。
- 最后,LEGO使用Vicuna1.5-7B作为基础语言模型,训练由三个阶段完成:多模态预训练,细粒度对齐调整和跨模式指令调整。

LEGO的能力不仅在于视频定位,对图片、音频等多模态任务都很在行。
RoboFlamingo 字节
【2024-1-17】机器人领域首个开源视觉-语言操作大模型,RoboFlamingo激发开源VLMs更大潜能
ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。使用简单、少量的微调就可以把 VLM 变成 Robotics VLM,从而适用于语言交互的机器人操作任务。
OpenFlamingo 在机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能。
LargeWorldModel
谷歌 Gemini 1.5 最强竞对——LargeWorldModel
产品信息:
- LargeWorldModel(LWM)是一种大型多模态自回归模型,由UC伯克利大学开发。它使用 RingAttention 在包含长视频和长文本的大型数据集上进行训练,从而执行语言、图像和视频的理解和生成。
产品功能:
- LWM支持处理多模态信息,能在100万token中准确找到目标文本,还能一口气看完1小时的视频后,准确地回答出有关视频内容细节的问题,突破了当前语言模型在处理复杂的长格式任务的不足。除此之外,LWM还支持图像和视频的生成,被外界视为谷歌Gemini 1.5最强竞对。
Chameleon
【2024-5-16】MET 的 FAIR 发布 Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon,一种早期融合,基于token的混合模态模型族,能够理解和生成任意序列中的图像和文本。概述了一个稳定的训练 从一开始就采用的方法、对齐方法和为早期融合,基于token的混合模态设置。对模型进行了综合评价的任务,包括视觉问答、图像描述、文本生成、图像生成和长形式混合模态生成。变色龙具有广泛和一般的能力,包括在图像描述任务中的最先进性能,在纯文本任务中优于Llama-2 与Mixtral 8x7B和Gemini-Pro等模型竞争,并表现出非平凡图像生成,都在一个模型中。它还匹配或超过了更大的模型的性能, 包括Gemini Pro和GPT-4V,根据人类对新的长形式混合模态的判断
QWen-VL 系列
QWen-VL 系列
- QWen-VL
- QWen2-VL
详见站内专题 通义千问
VITA
首个能够同时处理视频、图像、文本和音频的开源多模态大语言模型。
【2024-9-10】腾讯优图实验室等机构研究者提出了 VITA,第一个开源的多模态大语言模型 (MLLM),同时处理和分析视频、图像、文本和音频模态,具有先进的多模态交互体验。
- 以
Mixtral 8×7B为语言基础,然后扩大其汉语词汇量,并进行双语指令微调。 - 通过多模态对齐和指令微调的两阶段多任务学习赋予语言模型视觉和音频能力。
VITA 展示了强大的多语言、视觉和音频理解能力,其在单模态和多模态基准测试中的出色表现证明了这一点。
- 论文主页
- 论文标题:VITA: Towards Open-Source Interactive Omni Multimodal LLM
- Github: VITA
提升自然多模态人机交互体验方面也取得了长足进步。
- 第一个在 MLLM 中利用非唤醒交互和音频中断的研究。
- 还设计了额外的状态 token 以及相应的训练数据和策略来感知各种交互场景。

VITA 部署采用复式方案,一个模型负责生成对用户查询的响应,另一个模型持续跟踪环境输入。这使得 VITA 具有很好人机交互功能。

VITA 是开源社区探索多模态理解和交互无缝集成的第一步。虽然在 VITA 上还有很多工作要做才能接近闭源同行,但该研究希望 VITA 作为先驱者的角色可以成为后续研究的基石。
用户可以和 VITA 无障碍沟通
- 看到用户穿的白色 T 恤后,会给出搭配什么颜色的裤子;
- 在被问到数学题时,能够实时查看题目类型,进行推理,然后给出准确的答案;
- 当你和别人讲话时,VITA 也不会插嘴,因为知道用户不是和它交流;
- 出去旅游,VITA 也会给出一些建议;
在 VITA 输出的过程中,可以实时打断对话,并展开另一个话题。
VITA 整体训练流程包括三个阶段:LLM 指令微调、多模态对齐和多模态指令微调。
LLM 指令微调- Mixtral 8x7B 的性能属于顶级开源 LLM 中一员,因此该研究将其作为基础。然而研究者观察到官方的 Mixtral 模型在理解中文方面的能力有限。为了注入双语(中文和英文)理解能力,该研究将中文词汇量扩展到基础模型,将词汇量从 32,000 个增加到 51,747 个。在扩展词汇量后,研究者使用 500 万个合成的双语语料库进行纯文本指令微调。
多模态对齐- 为了弥合文本和其他模态之间的表征差距,从而为多模态理解奠定基础。仅在视觉对齐阶段训练视觉连接器。
- (1) 视觉模态
- 首先,
视觉编码器。研究者使用InternViT-300M-448px作为视觉编码器,它以分辨率 448×448 的图像作为输入,并在使用一个作为简单两层 MLP 的视觉连接器后生成了 256 个 token。对于高分辨率图像输入,研究者利用动态 patching 策略来捕捉局部细节。- 视频被视作图像的特殊用例。如果视频长度短于 4 秒,则统一每秒采样 4 帧。如果视频长度在 4 秒到 16 秒之间,则每秒采样一帧。对于时长超过 16 秒的视频,统一采样 16 帧。
- 其次,
视觉对齐。研究者仅在视觉对齐阶段训练视觉连接器,并且在该阶段没有使用音频问题。 - 最后,
数据级联。对于纯文本数据和图像数据,该研究旨在将上下文长度级联到 6K token,如图 4 所示。值得注意的是,视频数据不进行级联。- 级联不同的数据有两个好处:使用级联数据训练的模型与使用原始数据训练的模型性能相当。
- 支持更长的上下文长度,允许从单个图像问题交互扩展到多个图像问题交互,从而产生更灵活的输入形式,并扩展上下文长度。
- 提高了计算效率,因为视频帧通常包含大量视觉 token。通过级联图像 - 问题对,该研究可以在训练批中保持平衡的 token 数量,从而提高计算效率。
- 级联不同的数据有两个好处:使用级联数据训练的模型与使用原始数据训练的模型性能相当。
- 首先,
- (2) 音频模态
- 一方面是
音频编码器。输入音频在最开始通过一个 Mel 滤波器组块进行处理,该块将音频信号分解为 mel 频率范围内的各个频带,模仿人类对声音的非线性感知。随后,研究者先后利用了一个 4×CNN 的下采样层和一个 24 层的 transformer,总共 3.41 亿参数,用来处理输入特征。同时他们使用一个简单的两层 MLP 作为音频 - 文本模态连接器。最后,每 2 秒的音频输入被编码为 25 个 tokens。 - 另一方面是
音频对齐。对于对齐任务,研究者利用了自动语言识别(ASR)。数据集包括 Wenetspeech(拥有超过 1 万小时的多领域语音识别数据,主要侧重于中文任务)和 Gigaspeech(拥有 1 万小时的高质量音频数据,大部分数据面向英文语音识别任务)。对于音频字幕任务,研究者使用了 Wavcaps 的 AudioSet SL 子集,包含了 400k 个具有相应音频字幕的音频片段。在对齐过程中,音频编码器和连接器都经过了训练。
- 一方面是
- 多模态指令微调
- 该研究对模型进行了指令调整,以增强其指令遵循能力,无论是文本还是音频。
- 数据构建。指令调优阶段的数据源与表 1 中对齐阶段的数据源相同,但该研究做了以下改进:
- 问题被随机(大约一半)替换为其音频版本(使用 TTS 技术,例如 GPT-SoVITS6),旨在增强模型对音频查询的理解及其指令遵循能力。
- 设置不同的系统 prompt,避免不同类型数据之间的冲突,如表 2 所示。例如,有些问题可以根据视觉信息来回答或者基于模型自己的知识,导致冲突。此外,图像数据已被 patch,类似于多帧视频数据,这可能会混淆模型。系统 prompt 显式区分不同数据类型,有助于更直观地理解。
- 为了实现两种交互功能,即非唤醒交互和音频中断交互,该研究提出了复式部署框架,即同时部署了两个 VITA 模型。
- 在典型情况下,生成模型(Generation model)会回答用户查询。同时,监控模型(Monitoring model)在生成过程中检测环境声音。它忽略非查询用户声音,但在识别到查询音频时停止生成模型的进度。监控模型随后会整合历史上下文并响应最新的用户查询,生成模型和监控模型的身份发生了转换。
Emu3
【2024-10-21】Ilya观点得证!仅靠预测下一个token统一图像文本视频,智源发布原生多模态世界模型Emu3
下一token预测已在大语言模型领域实现了ChatGPT等突破,但是在多模态模型中的适用性仍不明确。
多模态任务仍然由扩散模型(如Stable Diffusion)和组合方法(如结合 CLIP视觉编码器和LLM)所主导。
2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。
Emu3 在图像生成、视频生成、视觉语言理解等任务中超过了 SDXL 、LLaVA、OpenSora 等知名开源模型,但是无需扩散模型、CLIP视觉编码器、预训练的LLM等技术,只需要预测下一个token。
Emu3 提供了一个强大的视觉 tokenizer,能够将视频和图像转换为离散token。这些视觉离散token可以与文本tokenizer输出的离散token一起送入模型中。与此同时,该模型输出的离散token可以被转换为文本、图像和视频,为Any-to-Any的任务提供了更加统一的研究范式。而在此前,社区缺少这样的技术和模型。
此外,受益于 Emu3 下一个token预测框架的灵活性,直接偏好优化(DPO)可无缝应用于自回归视觉生成,使模型与人类偏好保持一致。
Emu3 研究结果证明
- 下一个token预测可以作为多模态模型的一个强大范式,实现超越语言本身的大规模多模态学习,并在多模态任务中实现先进的性能。通过将复杂的多模态设计收敛到token本身,能在大规模训练和推理中释放巨大的潜力。下一个token预测为构建多模态AGI提供了一条前景广阔的道路。
目前Emu3已开源了关键技术和模型。
Emu3技术细节
1 数据
Emu3 是在语言、图像和视频混合数据模态上从头开始训练的。
- 语言数据:使用与Aquila模型相同的语言数据,一个由中英文数据组成的高质量语料库。
- 图像数据:构建了一个大型图像文本数据集,其中包括开源网络数据、AI生成的数据和高质量的内部数据。整个数据集经过了分辨率、图片质量、类型等方面的过滤过程。训练了一个基于Emu2的图像描述模型来对过滤后的数据进行标注以构建密集的图像描述,并利用vLLM库来加速标注过程。
- 视频数据:收集的视频涵盖风景、动物、植物和游戏等多个类别。
整个视频处理流程包括了场景切分、文本过滤、光流过滤、质量评分等阶段。并使用基于图像描述模型微调得到的视频描述模型来对以上过滤后的视频片段打标文本描述。
2 统一视觉Tokenizer
在SBER-MoVQGAN的基础上训练视觉tokenizer,它可以将4×512×512的视频片段或512×512的图像编码成4096个离散token。它的词表大小为 32,768。Emu3的tokenizer在时间维度上实现了4×压缩,在空间维度上实现了8×8压缩,适用于任何时间和空间分辨率。
此外,基于 MoVQGAN 架构,在编码器和解码器模块中加入了两个具有三维卷积核的时间残差层,以增强视频token化能力。
3 架构
Emu3 保留了主流大语言模型(即 Llama-2)的网络架构。不同点在于,其扩展了 Llama-2 架构中的嵌入层,以容纳离散的视觉token。网络中使用RMSNorm进行归一化。其还使用了GQA注意力机制、SwiGLU激活函数和一维旋转位置编码(RoPE)等技术,并并去除了注意力模块中QKV层和线性投影层中的偏置。此外,还采用了0.1的dropout率来提高训练的稳定性,使用QwenTokenizer对多语言文本进行编码。详细架构配置表。
Janus-Pro-7B
【2025-2-7】 DeepSeek Janus-Pro-7B,详见站内专题 DeepSeek 专题
Gemini 2.5
【2025-5-21】2025谷歌I/O大会:大模型应用全面开花
概括如下:
- (1)
Gemini 2.5更快、更聪明、理论能力更强,Gemini 2.5 Pro Deep Think 模式 - (2)内容生成工具:Veo、Imagen 和 Flow,下一代创作利器
- Veo 3:支持音频提示生成,如城市街道噪音、公园鸟鸣、角色对话等,增强视频真实感。
- Flow:AI 电影制作工具,可自定义视频镜头、动作、演员和场景等。
- Imagen 4:图像细节更清晰,表现力更强,支持多种画幅和最高 2K 分辨率。
- (3)谷歌搜索全新 AI 模式
- (4)Android XR:多模态 AI 助手,能够通过摄像头进行实时交互
- (5)谷歌生态远景:将科幻场景的“世界模型”变成现实
轻量级多模态AI模型——Gemma3n,并同时宣布Gemma模型家族迎来新成员,包括: 专为医疗领域设计的MedGemma和为无障碍沟通打造的SignGemma。
Gemma3n 作为本地运行AI技术的先锋,被精心打造以适应手机、笔记本和平板电脑等低算力设备的需求。它不仅能够处理文本、音频、图像和视频,而且据谷歌透露,即便在内存低于2GB的设备上,Gemma3n 也能流畅运行,展现了其卓越的架构效率。这一模型在发布当日即对开发者开放预览,并与Gemini Nano共享相同的底层技术架构。
医疗健康领域,谷歌通过旗下的健康AI开发者基金会推出了 MedGemma,专注于健康相关文本与图像分析的开放模型。
- MedGemma 具备出色的多模态分析能力,能够帮助开发者在医疗影像识别、病历文本处理等方面构建更加精准的AI解决方案。
谷歌还预告了 SignGemma 模型的推出,这款模型专为手语识别设计,能将美国手语(ASL)翻译成英语文本。
谷歌声称, SignGemma 是目前为止最强大的手语理解模型,旨在助力开发者为聋哑和听障用户打造更友好的沟通工具。
META
DINO
Meta 开源最新视觉大模型 DINO v3!
- 【2025-8-15】吞下17亿图片,Meta最强巨兽DINOv3开源,重新定义CV天花板
- 项目地址:dinov3
- 全部checkpoint
DINOv3 主要创新:
- 使用自监督学习,无需标注数据, 大幅度降低训练所需要的时间和算力资源。
- 与前一代相比,DINOv3 训练数据大12倍扩大至17亿张图像以及大7倍的70亿参数。
真开源:
- DINOv3 不仅可商用,还开源了完整的预训练主干网络、适配器、训练与评估代码等「全流程」
效果
根据测试数据显示,DINOv3 在图像分类、语义分割、单目深度估计、3D理解、实例识别、视频分割跟踪、视频分类等10大类,60多个子集测试中全部都非常出色,超越了同类开、闭源模型。
DINOv3 重新定义计算机视觉性能天花板,在多个基准测试中刷新或逼近最佳成绩
DINOv3 标志着大规模自监督训练的全新里程碑。
- 首次证明
自监督学习(SSL)模型能够在广泛任务中超越弱监督模型的表现。
美团
LongCat
【2025-3-24】美团自主研发生成式大语言模型LongCat(龙猫)。
LongCat 整合多模态能力,并在多个实际应用场景中落地,为美团内部的工作效率提升和创新能力的增强注入了新的活力。
LongCat 核心功能与技术特点
LongCat 核心优势:能处理包括文本、图像在内的多种数据类型。
这种多模态能力使得LongCat在生成任务上表现出色,例如,它可以快速生成图片、视频脚本以及代码等。这些功能并非简单的技术堆砌,而是经过精心设计和优化的结果,旨在满足美团内部多样化的业务需求。
LongCat 技术原理
- 数据:结合了开源数据和内部私有数据,使得模型能够更好地适应美团的业务场景
- 训练:参考 DeepMind的Chinchilla模型的研究思路,在固定的计算预算下,通过合理分配模型规模和训练数据量,提升模型的训练效率。
- 微调:具体的业务场景和任务进行微调
场景
- 编程辅助:提供代码片段建议、逻辑优化方案以及错误排查指导,能够显著提升开发者的工作效率。
- 会议助手:自动记录会议内容,生成会议纪要,并提取关键信息和决策点
- 文档编辑:根据用户输入的主题或大纲,快速生成文档内容,并提供智能写作建议,极大地提高了文档撰写和编辑的效率
- 内容创作:生成图片和视频脚本,为设计师和视频创作者提供创意灵感和详细的分镜头设计
- 知识问答:回答用户的各种问题,提供准确的信息和解决方案,成为了知识获取的便捷途径。同时,帮助整理和管理知识库,方便用户快速查找和学习相关知识
- 多模态内容生成:根据文字描述生成图片,或者根据图片生成文字描述
- 电商领域,LongCat可以根据商品描述自动生成商品图片,从而减少了人工拍摄和处理图片的工作量。
- 社交媒体领域,LongCat可以根据用户上传的图片自动生成文字描述,从而方便用户进行内容分享和交流。
LongCat-Flash-Chat
【2025-9-1】美团正式发布并开源 LongCat-Flash-Chat,动态计算开启高效 AI 时代
LongCat-Flash 采用创新性混合专家模型(Mixture-of-Experts, MoE)架构,总参数 560 B,激活参数 18.6B~31.3B(平均 27B),实现了计算效率与性能的双重优化。
根据多项基准测试综合评估,作为非思考型基础模型,LongCat-Flash-Chat 在仅激活少量参数的前提下,性能比肩当下领先的主流模型,尤其在智能体任务中具备突出优势。
并且,因为面向推理效率的设计和创新,LongCat-Flash-Chat 具有明显更快的推理速度,更适合于耗时较长的复杂智能体应用。
目前,Github、Hugging Face 平台同步开源
- 官网,与 LongCat-Flash-Chat 开启对话。
- LongCat-Flash-Chat 仓库
原理
技术亮点
- LongCat-Flash 模型在架构层面引入“零计算专家(Zero-Computation Experts)”机制,总参数量 560 B,每个token 依据上下文需求仅激活 18.6B~31.3 B 参数,实现算力按需分配和高效利用。为控制总算力消耗,训练过程采用 PID 控制器实时微调专家偏置,将单 token 平均激活量稳定在约 27 B。
- LongCat-Flash 在层间铺设跨层通道,使 MoE 的通信和计算能很大程度上并行,极大提高了训练和推理效率。配合定制化的底层优化,LongCat-Flash 在 30 天内完成高效训练,并在 H800 上实现单用户 100+ tokens/s 的推理速度。LongCat-Flash 还对常用大模型组件和训练方式进行了改进,使用了超参迁移和模型层叠加的方式进行训练,并结合了多项策略保证训练稳定性,使得训练全程高效且顺利。
- 针对智能体(Agentic)能力,LongCat-Flash 自建了Agentic评测集指导数据策略,并在训练全流程进行了全面的优化,包括使用多智能体方法生成多样化高质量的轨迹数据等,实现了优异的智能体能力。
效果
通过算法和工程层面的联合设计,LongCat-Flash 在理论上的成本和速度都大幅领先行业同等规模、甚至规模更小的模型;通过系统优化,LongCat-Flash 在 H800 上达成了 100 tokens/s 的生成速度,在保持极致生成速度的同时,输出成本低至 5元/百万 token。
多个领域表现出卓越的性能优势。
- 通用领域知识方面,LongCat-Flash 表现出强劲且全面的性能:
- 在 ArenaHard-V2 基准测试中取得 86.50 的优异成绩,位列所有评估模型中的第二名,充分体现了其在高难度“一对一”对比中的稳健实力。
- 在基础基准测试中仍保持高竞争力,MMLU(多任务语言理解基准)得分为 89.71,CEval(中文通用能力评估基准)得分为 90.44。
- 这些成绩可与目前国内领先的模型比肩,且其参数规模少于 DeepSeek-V3.1、Kimi-K2 等产品,体现出较高的效率。
- 智能体(Agentic)工具使用方面,LongCat-Flash 展现出明显优势:
- 即便与参数规模更大的模型相比,其在 τ2-Bench(智能体工具使用基准)中的表现仍超越其他模型;
- 在高复杂度场景下,该模型在 VitaBench(复杂场景智能体基准)中以 24.30 的得分位列第一,彰显出在复杂场景中的强大处理能力。
- 编程方面,LongCat-Flash 展现出扎实的实力:
- 其在 TerminalBench(终端命令行任务基准)中,以 39.51 的得分位列第二,体现出在实际智能体命令行任务中的出色熟练度;
- 在 SWE-Bench-Verified(软件工程师能力验证基准)中得分为 60.4,具备较强竞争力。
- 指令遵循方面,LongCat-Flash 优势显著:
- 在 IFEval(指令遵循评估基准)中以 89.65 的得分位列第一,展现出在遵循复杂且细致指令时的卓越可靠性;
- 此外,在 COLLIE(中文指令遵循基准)和 Meeseeks-zh(中文多场景指令基准)中也斩获最佳成绩,分别为 57.10 和 43.03,凸显其在中英文两类不同语言、不同高难度指令集上的出色驾驭能力。
部署
基于 SGLang 和 vLLM 的两种高效部署方案
示例
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 8
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
