- GUI Agent
- 资讯
- GUI Agent 介绍
- OS Agent
- 评测集
- 模型
- 产品
- 【2023-8】实在 Agent
- 【2023-12-21】AppAgent
- 【2024-2-9】ScreenAgent
- 【2024-6-18】Mobile-Agent
- 【2024-9-7】TinyAgent
- 【2024-10-23】Computer Use
- 【2024-12-23】PC Agent
- Browser Use
- 智谱
- 【2025-1-24】Operator
- 【2025-2-25】Proxy-lite
- 【2025-3-4】Pokee AI
- 【2025-3-4】 Mobile Use
- 字节
- 【2025-7-25】中移动 九天
- 【2025-8-6】联想 SEA
- 【2025-8-9】厦大 UI-AGILE
- 【2025-9-15】浙大+通义 UI-S1 半在线强化学习
- OMG-Agent
- 【2025-12-29】阿里 MAI-UI
- 结束
GUI Agent
资讯
【2024-1-25】这几天agent操控设备成为热点:
- 智谱昨天推出 glm-pc 1.1,注重长程推理,与年前的autoglm互补,分别占据pc和mobile设备
- openai 的 operator 也涉足pc操控
【2025-11-05】字节发布 UI-TARS桌面版
- 看懂整个屏幕,用自然语言指挥鼠标键盘,操作任何桌面App和浏览器,全程 100% 本地运行,隐私安全拉满,再也不用把屏幕内容丢给云端!
GUI Agent 介绍
Huawei London 邵坤主题演讲,介绍面向通用型 GUI Agent 的模型和优化。
- 《Towards generalist GUl Agents: model and optimization》
- 【2025-3-18】AI Agent进化:RL到大模型,绝了
GUI Agent成为新趋势
- 手机、电脑广泛使用,提供大量开放域端侧任务,更能触达智能边界
当前的多模态大型语言模型 (MLLM) 受制于其训练数据,缺乏有效发挥操作助手功能的能力
- 角色模拟上见站内专题 agent-角色模拟
定义
如果 Agent 能像人一样使用界面,那就有丰富的想象空间,可以自动执行复杂的任务
- 比如通过 GUIAgent 操作,自动帮用户点外卖
模仿人类使用端侧产品方式,进行智能化、自动化操控终端设备完成复杂任务。
GUI agent:
- 输入: 人类自然语言+screenshot/DOM/HTML
- 输出: action
如: 创建一个test文件夹,并在其中构建一个hi.txt。
用户通过自然语言提出指令要求,GUI Agent 读取设备界面,正确分析和理解界面UI元素以及用户意图,进行任务planning,找到对应的创建文件+号,执行点击动作,依次规划执行实现最终任务
核心价值在于能将自然语言指令转化为实际的图形界面操作,让软件“不仅能说,更能做”
- “看得见界面就能自动化”是 GUI agent 的最大公约数。
- 只要工作流里还残留“人眼识别+鼠标点击”,而系统又缺 API,就是 GUI agent 可以落地的地方。
发展历史
GUI Agent演进
- (1)2023年
Rule-based(规则驱动):人工定义规则、API 调用- 依赖API接口或脚本录制,需后台系统支持,预先配置对接。
- 需为每个应用单独编写监本,规则固定,任务改变、界面变化,都会导致任务失败。
- 容错性差,按钮位置变化可能导致脚本崩溃。
- (2)2024年
Agent Framework(模块化框架):使用推理性强的基础大模型(如 GPT-4o)+ 提示工程 + 外挂模块(如 grounding、memory)- 集中在调用基于文本的api调用和code片段执行。
- 增强模型能力大多采用特定场景外挂模块(grounding、workflow memory)
- 集中采用PE方式优化plan和action的生成,强依赖foundation model的能力。
- (3)2025年
Native Agent model(统一模型)- 统一perception、reasoning、memory、action为一个模型。
- 多数据对MLLMs进行cpt、sft、rlhf提升gui agent能力。
- 基于视觉感知,实时解析界面,操作前端界面,动态适应UI变化,灵活理解各种界面。
- 跨应用协作,跨应用执行任务。
应用场景
| 应用领域 | 具体落地场景 | 核心价值 / 解决的问题 | 应用 |
|---|---|---|---|
| 企业办公与业务流程自动化(“白领机器人”) | 自动完成跨软件的数据录入、报表生成、OA 系统审批等重复性工作。 | 提升效率,无需随软件版本迭代反复改脚本。 | 九科 bit-Agent |
| 软件测试(“0 脚本兼容测试”) | 通过自然语言指令生成测试用例,自动探索应用界面,执行点击、输入等操作,替代传统脚本。 | 应对动态 UI 变化,提高测试覆盖率和效率。无需编写/维护 UI 自动化脚本 | 腾讯 AppAgent、智谱 CogAgent |
| 智能助手与无障碍支持 | 帮助障碍用户通过语音或高级指令操控终端应用(如点击、输入、滑动)。 | 更简单的人机交互方式,贴身的数字助理。 | 微软 Copilot+GPT-4V 的 “Seeing AI” |
| 客户服务与交互响应 | 在客服场景中,自动完成订单查询、密码重置、信息填写等高频低风险任务。 | 实现 7×24 小时服务,快速响应,将人工客服解放出来处理更复杂的问题。 | 曹操出行 |
| 生活服务“跨 App 秘书” | 语音/文字一句话完成 “订机票→选座→把行程单丢进钉钉” 这类跨 App 流程。 | 把 7 - 8 步人工点击变成 1 句口令,大幅降低老年人和视障用户门槛。 | 中国移动“九天 GUI Agent” |
| 创意/设计“多模态工作流” | 视频剪辑、PPT 美化、社媒配图——agent 根据自然语言脚本自动拉取素材、剪辑、上字幕、发公众号。 | 把 2 小时的手工剪辑压到 10 分钟,MCN 机构一个人可管 5 条账号。 | AssistEditor 多 agent 框架 |
2025年12月,字节跳动与中兴通讯合作推出的”豆包AI手机”努比亚M153在短短数日内售罄,二手市场溢价高达3500元,这一现象级产品的核心卖点正是其系统级GUI Agent能力——用户只需说出”帮我点一份猪脚饭”,手机便能自动打开外卖应用、完成比价、下单支付的全流程操作。然而,这一突破性体验迅速引发了微信、支付宝、银行等主流应用的”集体防御”,用户遭遇强制登出、风险提示等限制措施,将GUI Agent技术推至产业变革的风口浪尖。
技术原理
技术
- 视觉编码器:理解图像,精准识别UI元素
- 结构化理解页面:屏幕截图转为层次化UI树,识别UI组件
核心能力
- 理解任务目标
- 多模态感知与推理
- 执行复杂的操作
用户通过自然语言提出要求,GUIAgent 通过理解界面状GUI Agent 通过滑动、点AI 能正确分析和理解意图态和 UI 元素,找到外卖的击、输入、拖拽等复杂操作APP 和历史订单,明确机器识别到 “下单” 的按钮并点击坏人爱吃的饭…
三个核心组成
- 环境 environments
- 观察空间 observation space
- 动作空间 action space。
三个核心能力
- 理解 understanding: 理解任务, 感知能力 + 更高阶的语境理解能力。先决条件
- 规划 planning: 设计行动策略,任务规划。
- 实施 grounding: 有效实现动作,将文本指令或plans 转换成可执行的action 的能力。
【2025-12-15】豆包AI手机售罄,GUI Agent引发应用‘集体防御’
不同于传统的RPA(机器人流程自动化)依赖规则脚本或有限状态机,现代 GUI Agent 以 (M)LLM 为核心“大脑”,融合视觉感知、语言理解与动作决策,实现对复杂、开放、动态图形界面的通用化操作能力。
GUI Agent 系统可被抽象为一个闭环系统:接收用户自然语言指令与当前屏幕截图(或视频帧)作为输入,输出一个可执行的动作(如点击、滑动、输入文本等),作用于目标 GUI 环境,再根据环境反馈进行下一步决策。
当前主流架构几乎都围绕 多模态大模型(Multimodal Large Language Model, MLLM) 构建。模型输入为图像 + 文本,输出为结构化动作指令。区别于早期方法依赖 OCR 提取文本再拼接位置信息,现代方法更倾向于端到端地让模型直接从像素中理解界面元素及其语义,从而提升对图标、图像按钮、动态内容等非文本元素的处理能力。
这个循环过程涉及四大核心模块:感知模块(Perception)、规划模块(Planning)、动作模块(Action Execution)与环境交互模块(Environment Interaction)。
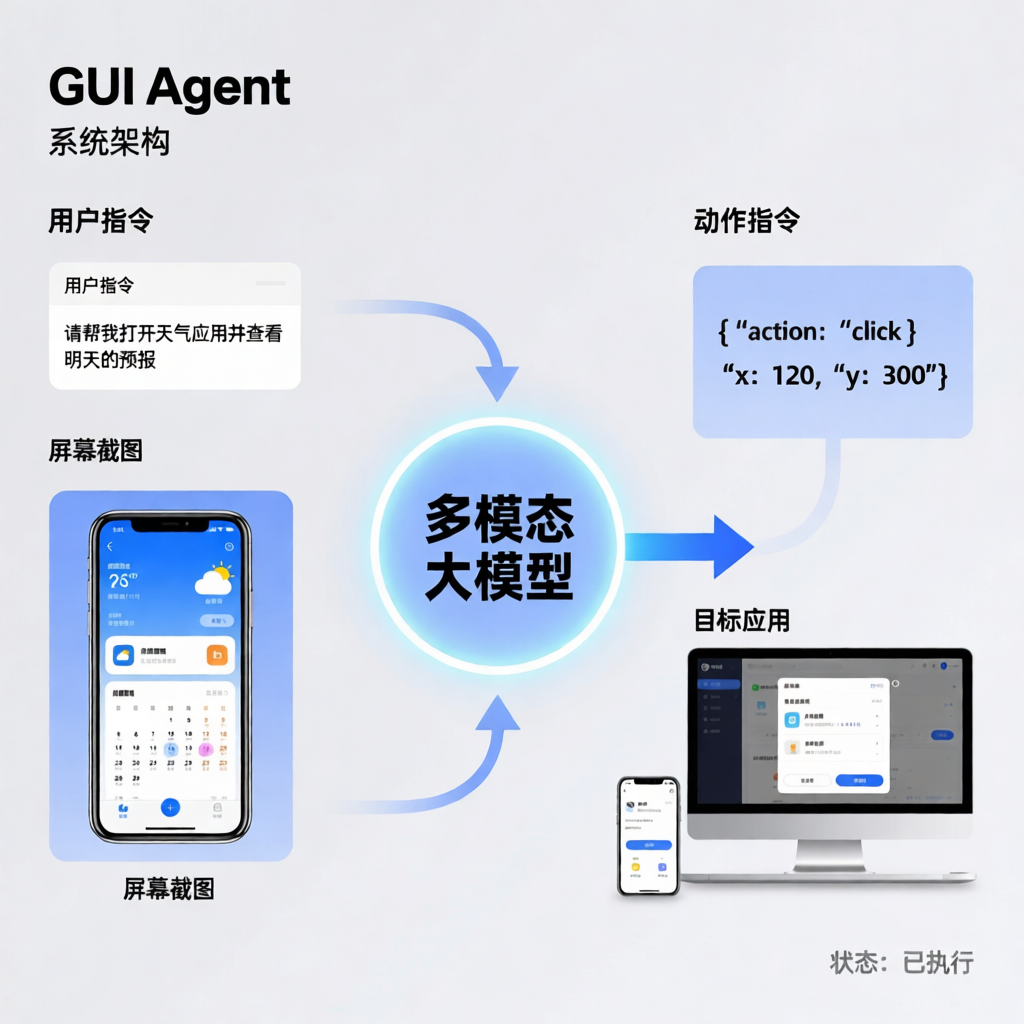
模型架构
(1)embedding结构
- LLMs: 直接利用html等结构化数据进行指令生成。如:webagent
- MLLMs: 保留自然语言处理能力基础上,增加GUI处理能力。如: Qwen-vl, CogVLM,LLaVA.
- Concatenated MLLMs: LLM + vision encoder, 连接方式通过一个adapter或者一个cross attention 模块。
- Modified MLLMs:解决高分辨image的问题。Cogagent采用辅助模块(EVA-CLIP-L high-resolution vision encoder + cross attention)连接MLLM;Ferret-UI resize image到固定分辨率,然后进行sub-images切分;mobileFlow将Qwen-VL中vision encoder(vit-bigG)换成了LayoutLMv3,
(2)agent framework
- 感知
- 规划(可选): ReAct或CoAT
- 记忆(可选)
- 行动
感知 perception
- 在不finetune vision encoder的前提下,通过GUI grounding 训练提高GUI 截图的理解能力
GUI grounding 指agent解读屏幕内容并准确定位相关元素(如按钮、菜单、文本框等)的过程。
GUI Agent 感知能力首先依赖于对屏幕图像的准确理解。这并非简单的图像分类,而是细粒度的 UI 元素检测与语义解析。早期方法(如基于规则的 OCR + 模板匹配)在面对 UI 风格多样、元素重叠、动态加载等场景时鲁棒性极差。如今,主流方案分为两类:
- 第一类是 两阶段检测-识别范式:先用目标检测模型(如 YOLO、Detr)定位 UI 元素边界框,再对每个框内区域进行 OCR 或图标分类,最后将结构化信息(文本、类型、坐标)作为 LLM 的输入。这种方法可解释性强,但 pipeline 长、误差累积严重,且难以处理重叠或遮挡元素。
- 第二类是 端到端视觉-语言融合:直接将原始屏幕截图输入 MLLM(如 Qwen-VL、LLaVA、Fuyu),让模型在内部隐式完成元素识别与语义关联。阿里近期发布的 GUI-Owl 模型正是基于 Qwen2.5-VL 构建的端到端 GUI Agent,支持 7B 和 32B 两种规模,在手机和 PC 场景均取得 SOTA 效果。这种架构的优势在于避免了中间模块的误差传播,且能利用 MLLM 强大的上下文推理能力理解元素间的逻辑关系(如“登录”按钮通常在“用户名”和“密码”输入框下方)。
注意
- 屏幕图像通常需经预处理以提升模型感知精度。例如,对移动端截图进行分辨率归一化、去除状态栏干扰;
- 对 Web 页面,可注入 DOM 信息作为辅助(但会牺牲通用性)。
- 此外,部分工作引入 UI 元素的可访问性(Accessibility)树作为额外输入,提供层级结构信息,但这依赖于操作系统或浏览器的支持,并非完全视觉驱动。
vision encoder和GUI grounding可类比为目标检测领域中的feature encoder与detection head. 相当于在不进行feature encoder的训练情况下通过训练特定task head提升模型效果。主要分为三类:
- visual grounding: 增强agent的视觉定位能力。大多通过Set-of-Marks(SoM)
- semantic grounding: 为交互元素添加语义描述,提升智能体的语义理解能力。
- 如利用网页的 HTML 文档作为 GUI 截图的语义参考,将视觉元素与 HTML 结构中的语义信息关联起来,从而实现语义层面的定位。
- dual grounding: 结合了视觉与语义两类信息,进一步提升智能体对视觉环境的理解。
动作空间设计
动作空间的定义直接决定了 Agent 的通用性与执行精度。
- 早期 GUI Agent 采用 离散动作集(如 “click_home”, “swipe_up”),但这种设计严重依赖预定义词汇表,无法泛化到新应用或新元素。
- 现代方法普遍采用 坐标化动作空间(Coordinate-based Action Space),即动作由屏幕坐标 (x, y) 定义,配合动作类型(click, long_press, swipe, type_text 等)。
动作输出格式是一个 JSON 对象:
{
"action_type": "click",
"x": 240,
"y": 520
}
或对于文本输入:
{
"action_type": "type",
"text": "hello world"
}
这种设计与平台无关:
- 无论 Android、iOS 还是桌面应用,只要能获取屏幕坐标,即可执行操作。
- UI-TARS-2 等先进框架通过构建“All-in-One Sandbox”环境,统一了多平台的动作执行接口。
问题
- 坐标化带来新挑战:坐标归一化。
不同设备分辨率差异巨大,直接输出绝对坐标会导致模型在新设备上失效。主流解决方案是将坐标归一化到 [0, 1] 区间,模型输出相对位置,再由执行器根据当前屏幕尺寸反推绝对坐标。Os-atlas 等基础动作模型进一步提出统一动作空间(Unified Action Space),将不同数据集的动作标注对齐到同一坐标系,极大提升了模型的跨任务泛化能力。
action
- Input Operations: click、tap、long press等。
- Navigation Operations: scroll等。
- Extended Operations: code execution等。
训练数据
GUI Agent 的性能高度依赖训练数据的质量与规模。理想数据应包含 自然语言指令、屏幕截图序列、对应的动作轨迹。构建此类数据成本极高,主要有三种来源:
- 人工标注:精度高但规模小、成本高,通常用于构建高质量验证集或小样本微调。
- 程序化合成:通过自动化脚本在模拟器中执行预设任务并记录轨迹。Android in the Wild (AitW) 是目前最大规模的移动端 GUI Agent 数据集,包含数百万条真实设备上的操作轨迹,涵盖单步与多步任务。该数据集极大推动了移动端 Agent 的发展。
- 众包或用户行为日志:从真实用户交互中脱敏采集,数据最真实但噪声大、指令缺失。
数据格式通常被转换为 VQA(视觉问答)或指令微调(Instruction Tuning)形式。
例如,给定一张截图和问题“如何打开 WiFi?”,模型需输出点击 WiFi 图标的坐标。UI-TARS-2 提出“Data Flywheel”管道,通过 Agent 自主探索生成新数据并迭代优化模型,形成正向循环。
指标
主流指标是任务完成率(Task Completion Rate)。然而,这忽略了效率(步数)、安全性(是否误操作)和鲁棒性(UI 变化下的表现)。
新兴评估框架开始引入更细粒度的指标:
- Ground-Truth Alignment (GTA):衡量 Agent 动作与标准轨迹的对齐程度。
- 执行精度(Execution Accuracy):检查每一步动作是否作用于正确元素。
- UI Drift Robustness:测试在界面布局微调后 Agent 的适应能力。
代表性基准包括 AitW(移动端)、WebArena(Web 端)、GUI-Odyssey(跨平台)等。这些基准通常提供沙盒环境,确保评估的可复现性。
模型训练
主流训练范式包括:
- 监督微调(SFT):直接在指令-动作对上训练 MLLM,是最基础的方法。
- 强化学习(RL):使用任务完成率作为奖励信号,优化策略。GUI-R1 等工作证明,基于统一动作空间的规则建模进行 RL,能显著提升执行成功率。
- 模型自我反思(Self-Reflection):让模型根据执行结果(成功/失败)生成反思日志,用于下一轮训练。
训练中的关键技术难点包括长序列建模(多步任务)和动作的精确 grounding(定位)。为缓解后者,部分工作在损失函数中加入坐标回归项,或使用注意力可视化约束模型关注正确区域。
训练方式:
- Pre-training
- Supervised Finetuning
- Reinforcement Learning
训练策略:提升完成复杂任务的能力。
(1)grounding能力的提升
GUI元素的语义理解和定位是重要的。grounding的能力提升主要通过构建合适的数据集对grounding对齐层/MLLM进行训练.
- UI element grounding
- 公开数据集:UI-vision 、GUI-R1
- A11y tree合成:通过ally tree提取bbox 和功能描述。外观布局描述利用MLLMs生成。
- 细粒度文字与字符grounding
- 文档image, 使用ocr tool 提取文字以及相应的空间位置,
(2)task planning 能力提升
- 轨迹数据合成
- 使用历史成功轨迹,每一个page生成细粒度描述,将其与历史action混合通过LLM合成planning data。
- 轨迹数据过滤
- 通过LLM生成的planning data, 包含大量复杂的跨app任务轨迹,通过更大的large scale pretrained LLM过滤。
(3)action语义理解提升
- 状态变化感知的能力:action如何影响页面的变化
- 收集大量pre-action、post-action screenshot构建双层数据。
- 根据前后截图直接预测action, 包括type和parameter。label基于离线轨迹可以得到。
- 让模型在预测action同时生成其产生影响以及语义的描述。label通过更高阶模型进行语义label打标。
(4)推理能力的提升
- 离线拒绝采样,根据历史信息让VLMs生成推理内容,剥离上下文,利用推理内容生成action,比较pt action与gt action。
- 多agent蒸馏,多agent任务的推理输出,通过LLM整合,与action配对,用于训练。
- 在线拒绝采样(数据飞轮),critic过滤,评分step
GUI agent 挑战
GUI agent 挑战
- 数据稀缺:缺乏大规模、高质量、多步骤的 GUI 操作轨迹数据
- 感知困难:GUI 截图信息密度高、元素小、布局复杂
- 推理不足:多步骤任务需要更加复杂的推理能力(如任务分解、反思、试错)
- 动作精度低:需要精确到像素级的点击、拖拽等操作
- GUI环境的复杂性: 千万种的APP应用,动态复杂的动态页面(弹窗、验证码)
- 性能瓶颈: 实时读取页面,推理算力消耗大。
- 隐私风险:模拟点击可能触发二次认证。
自动化 vs GUI Agent
自动化
- 依赖API接口或脚本录制,需后台系统支持,预先配置对接
- 需为每个应用单独编写脚本,规则固定,任务变了或者界面变了,可能都干不好
- 容错性差,按钮位置变化可能导致脚本崩溃
GUI Agent
- 基于视觉感知,直接操作前端界面,直接像人类一样看着就能操作
- 实时解析界面,动态适应UI变化能灵活理解各种界面
- 自动找按钮
GUI Agent 优势:
- 跨应用协作:不需要打通后台,跨应用执行任务
- 用户立场: 用户角度思考,跨应用对比服务、价格
局限
- 使用范围有限: 每个APP逻辑不同,无法理解跨应用逻辑
- 无法读懂复杂、动态页面:如弹窗、验证码
- 性能瓶颈:实时读取页面,推理算力消耗大,慢
- 隐私风险:模拟点击可能触发二次认证
图解:
- 机器坏人(AI版)小红书帖子
OS Agent
【2025-8-6】虽然 GUI 界面短期内不会完全消失,但 OS Agent 正在重塑人机交互的基本范式,让计算机操作变得更加智能和自然。
- 浙大、复旦和OPPO论文,ACL 2025 Oral
- OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
技术组件
技术架构的根本性变革
OS Agent 的核心将传统的 “点击-输入-导航” 操作模式转变为自然语言驱动的智能执行。
其技术架构包含四个关键组件:
- 感知(理解屏幕内容和用户指令)
- 规划(将复杂任务拆解为可执行步骤)
- 记忆(存储用户偏好和操作经验)
- 动作(执行具体的系统操作)。
从基础模型层面看,OS Agent 经历了从简单文本处理到多模态理解的演进。
- 早期的 WebAgent 只能处理网页 HTML
- 而新一代的 CogAgent 和 OS-Atlas 已能处理高分辨率 GUI 界面,实现跨平台的精准操作。
这种技术进步使得用户可以通过一句话完成原本需要多步操作的复杂任务。
应用
产业应用的快速落地
从 2023 年的零星基础模型到 2025 年的完整产品框架,OS Agent 的产业化速度令人瞩目。
- OS-Copilot 在 MacOS 系统上已能执行 “准备专注工作环境”(自动关闭干扰应用、切换深色模式、播放白噪音)、Excel 数据处理和网站创建等复杂任务。
各大厂商的投入也印证了这一趋势。
- OpenAI 的 Memory 功能、基于强化学习的 AutoGLM 系统,以及专门为 OS 场景优化的 OS-Atlas 模型,都表明行业正在从 “适应 GUI” 向 “替代 GUI” 转变。
发展方向
尽管前景广阔,OS Agent 仍面临显著挑战。跨平台泛化能力不足是主要痛点 —— 多数模型依赖单一平台数据训练,在其他平台准确率下降 30% 以上。细粒度 GUI 理解能力也有待提升,现有模型难以识别高分辨率界面中的小图标和细文本。
OS Agent 的发展方向聚焦于三个核心领域:
- 构建跨平台统一的预训练数据集
- 开发用户画像驱动的个性化机制
- 强化多模态感知融合能力。
随着技术不断成熟,正在见证一个从 “学会使用界面” 到 “让界面理解我们” 的根本性转变。
评测集
AppBench
【2024-10-10】EMNLP2024 用AppBench一键评测你的手机智能
港中文 发布 AppBench,一个评估大型语言模型在复杂用户指令下规划和执行来自多个应用的多项API的新基准。
- 论文: AppBench: Planning of Multiple APIs from Various APPs for Complex User Instruction - EMNLP2024
- 作者:王鸿儒 港中文在读PhD
- 主页
如何评估大型语言模型(LLMs)在复杂用户指令下规划和执行来自不同来源的多个API的能力。
研究难点:
- 图结构:一些API可以独立执行,而另一些则需要依次执行,形成类似图的执行顺序。
- 权限约束:需要确定每个API调用的授权来源。
相关工作:
- API调用评估:如 API-Bank 和 ToolBench等,主要关注单次或有限参数的API调用。
- 语言代理框架:如 Chameleon 和 WebShop等,主要关注与外部工具的交互。
任务定义:给定用户指令和虚拟移动环境中的APP家族,meta代理需要决定一个可执行路径,调用不同APP中的不同API来完成任务。任务的形式为列表,每个列表项表示一个APP及其对应的API调用。
数据分类:根据每个用户指令中使用的APP和API数量,数据分为四种类型:
- 单APP单API(SS)
- 单APP多API(SM)
- 多APP单API(MS)
- 多APP多API(MM)
数据收集:利用现有的任务导向对话数据集(如SGD),通过LLM和Python脚本生成所需的输入和输出。具体步骤包括:
- 指令获取:从对话中提取用户和系统的发言,输入到LLM中总结用户需求。
- 规划路径:编写Python脚本解析多轮对话中的API调用,形成规划路径。
- 质量评估:使用GPT-4o评分每个指令的流畅性和多样性,确保数据质量。
VeriGUI
【2025-7-23】当前 GUI Agent 中任务链短、依赖单一结果验证的局限
VeriGUI 构建可用于评估 GUI Agent 长程任务和执行能力的基准数据集。
- 涵盖 Web 和 Desktop 两类真实环境,其中 Web 任务聚焦多跳信息检索与复杂推理,涉及学术、金融、科技、文娱、社会等领域;
- Desktop 任务则涵盖办公软件、系统操作与专业工具,强调多步操作与复杂流程执行,体现真实GUI场景的挑战性。
Core Contribute:
- 长链复杂度 🔗:每个任务轨迹包含上百步操作,由多个相互依赖的子任务组成,且支持任意子任务作为任务起点。
- 子任务级验证 ✅:每个子任务的目标都是可验证的,且不限制任务的执行路径,从而实现一种 “过程发散,结果收敛” 的范式,鼓励Agent进行更多样化的探索 。
- 所有的任务轨迹都由人类专家在真实环境中标注,确保数据的可靠性和真实性。
Reality Check:
- 对当前的SOTA模型进行了评测,结果显示,包括OpenAI O3和Gemini 2.5 Pro等主流模型,在VeriGUI上的平均成功率均低于10%,最佳表现为8.5% 🤯。
- Agent普遍存在Shallow Search和Irrelevant Result等问题,这揭示了现有Agent在长程任务和复杂交互中的瓶颈 。
目前一期已开源130条Web任务轨迹,更多Web与Desktop任务将陆续发布
MMBench-GUI
【2025-7-25】上海AI Lab、上交大和厦大 论文 把AI agents的GUI操作能力拆解分析了个遍。
现在的 GUI agents 实际操作中最大的问题是:不够聪明,也不够高效!
- 做很多不必要的重复操作,导致任务完成效率低下,甚至失败。
- 这就像一个新手司机,明明可以直接开到目的地,却绕了一大圈,还熄火了好几次!😭
MMBench-GUI “分级考试系统”。
- 不是简单地看AI能不能完成任务,而是从GUI内容理解、元素精确定位、任务自动化执行,到跨平台协作,一共分了四个层级来考AI。
- 这就像给AI做了一个全方位的技能体检,哪里弱一目了然!
还发明了一个叫EQA(Efficiency-Quality Area)的“效率-质量面积”指标。
- 不是简单地看AI有没有把事情做对,还要看它做得有多快,有多省力。这就像考驾照,不仅要会开,还要开得平稳、省油!🚗
这个框架测试市面上很多AI agents,结果发现:
- 视觉精确定位是决定任务成败的关键!
- AI得先看清楚屏幕上的按钮、文字在哪里,才能准确操作。
- 这就像我们人一样,得先看清楚路标,才能导航对吧?
- 而且,跨平台(Windows, macOS, Linux, iOS, Android, Web)的泛化能力、长上下文记忆和长时推理能力也至关重要。
- 不过,即使是任务完成了,很多AI agents的效率也低得离谱,重复操作太多
模型
大模型 gui agent 训练存在思考动作不一致的情况。
比如
- 模型输出思考需要点击a按钮,实际模型输出动作却是点击b按钮。
- 增加了思考动作一致性reward感觉提升不明显
产品
【2023-8】实在 Agent
2023 年 8 月,国内团队 实在智能,率先推出国内外首个“实在 Agent”智能体。
该智能体借助垂直大语言模型 TARS,调用 RPA 和 ISSUT 来完成点击、输入、下载等任务。
- 无需 API,能够为企业员工配备全能业务专家,实现超自动化执行以及自然对话式交互,堪称智能办公的“AI 个人助理”。
- 用户可以通过实在智能官网下载 AI 产品“实在 Agent 智能体”。
实在Agent(智能体)是全球首款具备“大脑和手脚”、能够自主规划执行任务,自动操作软件的智能体产品。作为企业级的AI智能办公助理,它将助力企业迈入高效、智能的未来办公新时代。
基于自研的塔斯大模型,实在Agent 能够精准理解用户意图,将用户的口语化描述拆解为具体的流程和步骤。这使得传统的大模型不再只是“说说而已”,而是真正能够自动操作电脑、手机以及车载屏幕上的各种软件和APP的超级AI智能体,让用户实现“一句话完成工作”。
【2023-12-21】AppAgent
西湖大学、河南大学等
【2023-12-21】AppAgent 初版
【2023-12-21】AI能模仿人类在手机上操作APP了
AppAgent 可以通过自主学习和模仿人类的点击和滑动手势,能够在手机上执行各种任务。
它可以在社交媒体上发帖、帮你撰写和发送邮件 、使用地图、在线购物,甚至进行复杂的图像编辑…
AppAgent在50 个任务上进行了广泛测试,涵盖了10种不同的应用程序。
该项目由腾讯和德州大学达拉斯分校的研究团开发。
主要功能特点:
- 多模态代理: AppAgent 是一个基于大语言模型的多模态代理,它能够处理和理解多种类型的信息(如文本、图像、触控操作等)。这使得它能够理解复杂的任务并在各种不同的应用程序中执行这些任务。
- 直观交互:它能通过模仿人类的直观动作(如点击和滑动屏幕)来与智能手机应用程序交互。就像一个真人用户一样。
- 自主学习:AppAgent 通过观察和分析不同应用程序中的用户界面交互。并学习这些交互模式,并将所获得的知识编译成文档。
- 构建知识库:通过这些交互,AppAgent 构建了一个知识库,记录了不同应用程序的操作方法和界面布局。这个知识库随后用于指导代理在不同应用程序中执行任务。
-
执行复杂任务:一旦学习了应用程序的操作方式,AppAgent 就能够执行跨应用程序的复杂任务,如发送电子邮件、编辑图片或进行在线购物。
- 项目及演示
- 论文: AppAgent: Multimodal Agents as Smartphone Users
- GitHub:AppAgent
【2025-3-8】AppAgentX 进化
【2025-3-8】AppAgentX 进化, 详见进化专题
【2024-2-9】ScreenAgent
大模型直接操控电脑 —— ScreenAgent
产品信息:
- ScreenAgent 是一款由
吉林大学人工智能学院开发、视觉语言大模型驱动的计算机控制代理。
产品功能:
- ScreenAgent 可帮助用户在无需辅助定位标签的情况下,通过VLM Agent控制电脑鼠标和键盘,实现大模型直接操控电脑的功能。
ScreenAgent 可根据用户的文本描述查找并播放指定的视频
例如,ScreenAgent 可根据用户的文本描述查找并播放指定的视频,或根据用户要求调整视频播放速度。ScreenAgent还能帮用户打开Windows系统的事件查看器,使用office办公软件,例如根据用户文本描述,删除指定的PPT内容。
【2024-6-18】Mobile-Agent
2024年初, 北交大和阿里联合推出的Mobile-Agent通过视觉感知工具和操作工具完成智能体在手机上的操作,实现了即插即用,无需进行额外的训练和探索,凭借其强劲的自动化手机操作能力迅速在AI领域和手机制造商中引起广泛关注。
【2024-6-18】团队推出了新版本 Mobile-Agent-v2,改进亮点:
- 继续采用纯视觉方案、多智能体协作架构、增强的任务拆解能力、跨应用操作能力以及多语言支持。
参考
- 代码: MobileAgent, 支持本地LLM, only Android OS and Harmony OS (version <= 4) support tool debugging, 安装 adb 工具, 通过 python run.py 启动
- 论文: Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration
Mobile-Agent-v2 也接入到魔搭的ModelScope-Agent
- ModelScope-Agent拥有了 Mobile-Agent-v2完成自动化打车的能力。
- 用户只需输入目的地,ModelScope-Agent即能通过规划、决策和优化等过程,为用户完成叫车服务。
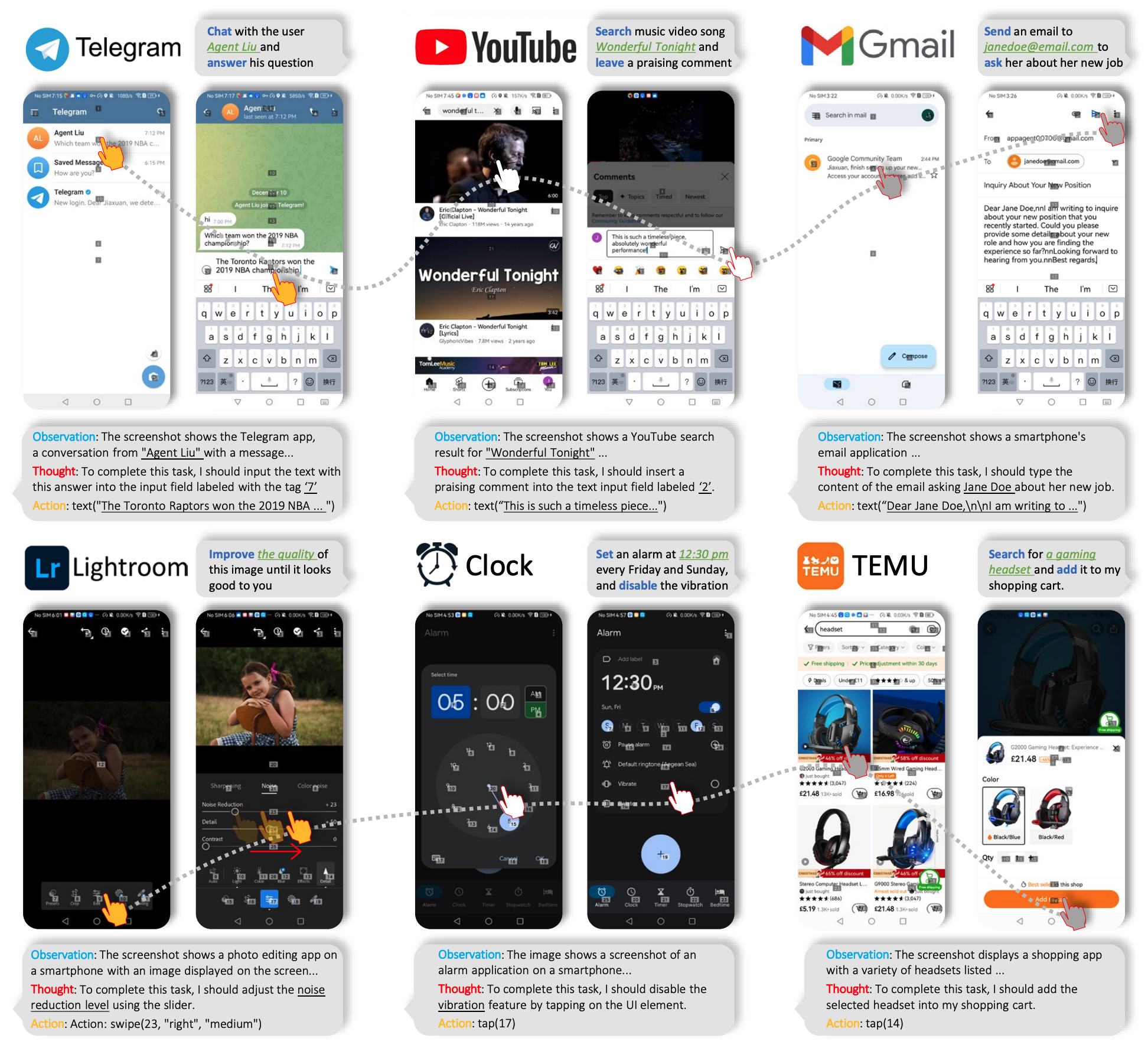
实际案例,其中包括了:
- 根据指令要求打开了WhatApps并查看了来自「Ao Li」的消息,消息中要求在TikTok中找一个宠物相关的视频并分享给他。- Mobile-Agent-v2随后退出当前应用并进入TikTok中刷视频,在找到一个宠物猫的视频后通过点击分享按钮将视频链接成功发送给「Ao Li」。
- X(推特)中搜索名人「马斯克」,关注他并评论一条他发布的帖子。尽管社交媒体应用往往文字较多,UI布局复杂,但是Mobile-Agent-v2仍旧准确地完成了每一步的操作,尤其是点击关注之后出现的推荐用户挡住了原本的推文,而Mobile-Agent-v2也执行了上划操作并完成评论。
- 随后是在同样复杂的长视频平台YouTube操作的例子。从该演示视频中自然地对篮球运动员进行吹捧的表现来看,Mobile-Agent-v2对于社交媒体和视频平台的操作能力十分惊艳,有成为新一代控评机器人的潜力。
- 另外,在初代Mobile-Agent中评测的那些相对基础的任务,例如安装应用、导航去某个地点等,Mobile-Agent-v2也能完成。
- 最后则是在中文应用小红书和微信的例子,包括在小红书中搜索攻略并评论,以及帮助用户回微信。Mobile-Agent-v2可以根据帖子的内容发布相关的评论,也能根据微信消息的内容生成相关的回复。
在手机操作任务中,智能体通常需要通过多步操作才能完成任务要求。
- 每次操作时,智能体都需跟踪当前任务进度,即了解之前的操作完成了哪些需求,从而根据用户指令推断下一步的操作意图。
- 尽管操作历史中保存了每一步的具体操作和相应的屏幕状态,但随着操作次数的增加,操作历史序列会变得越来越长。
- 操作历史的冗长且图文交错的格式,会显著增加智能体追踪任务进度的难度
经过7轮操作后,输入的操作历史序列长度已超过一万个token,图文交错的数据格式使得智能体追踪任务进度变得异常困难。
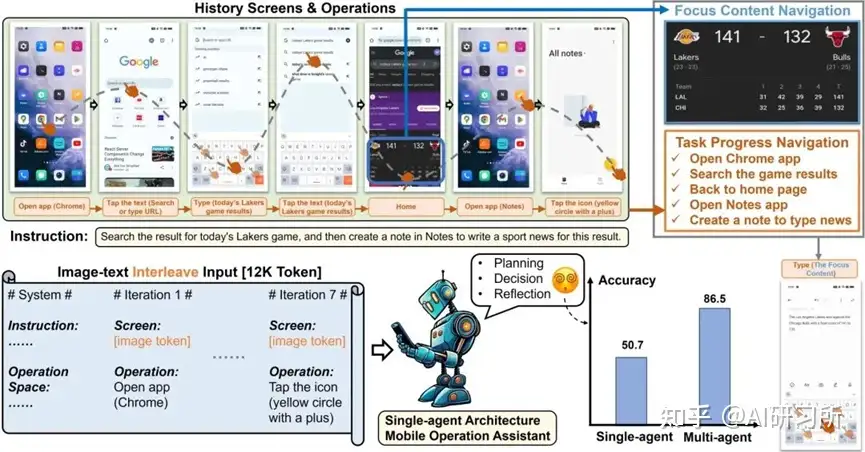
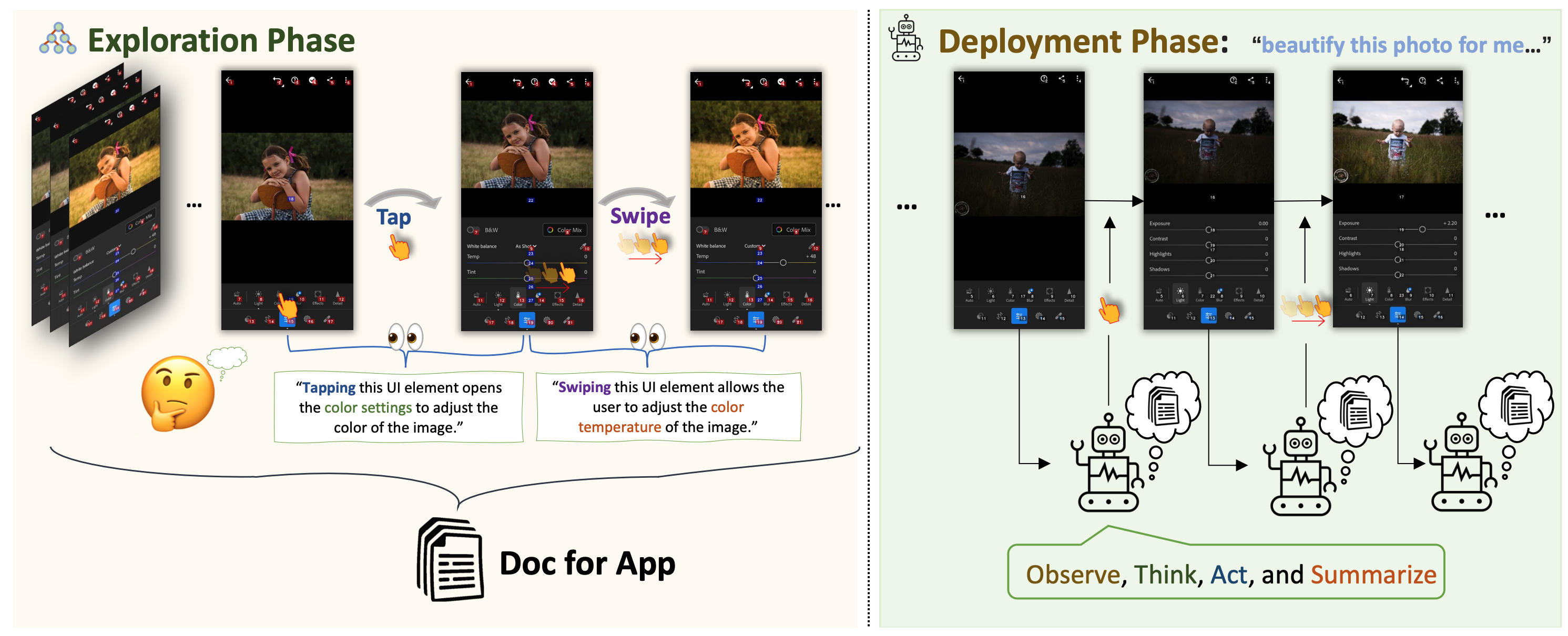
Mobile-Agent-v2 引入了创新的多代理协作架构。
- 如图所示,这种架构允许多个AI代理协同工作,以实现更加高效的任务规划和执行。这种协作机制不仅提升了任务处理的灵活性,还显著提高了任务完成的效率。在一些任务中,智能体需要查看天气并撰写穿衣指南。生成指南时,智能体需要依赖历史屏幕中的天气信息。
- Mobile-Agent-v2设计了记忆单元,由决策智能体负责更新与任务相关的信息。此外,由于决策智能体无法直接观察操作后的屏幕信息,系统还引入了反思智能体,用于监测并评估决策智能体操作前后的屏幕状态变化,确保操作的正确性。
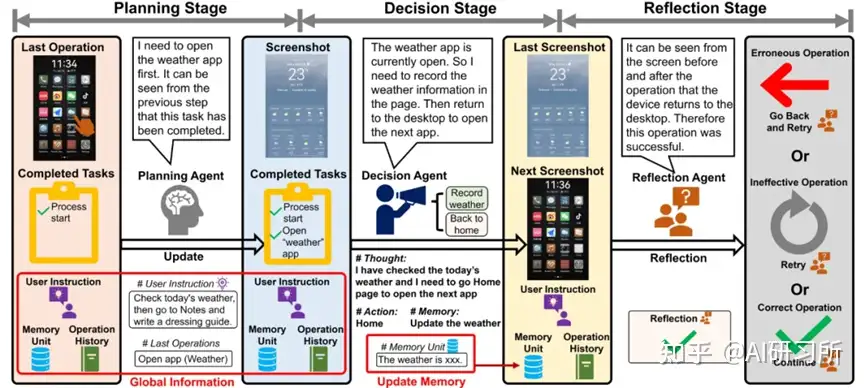
Mobile-Agent-v2在多项指标上,无论在英文还是非英文场景,都表现出了全面的提升。此外,通过人为增加操作知识(Mobile-Agent-v2 + Know.),性能得到了进一步的增强。
【2024-9-7】TinyAgent
【2024-9-7】边缘智能革命:TinyAgent实现端侧复杂功能调用智能体
- UC Berkeley TinyAgent: Function Calling at the Edge
大语言模型(LLMs)可开发出通过调用功能来整合各种工具和API,完成用户查询的高级智能体系统。
然而,这些 LLMs 在边缘部署尚未被探索,因为通常需要基于云基础设施,这是由于庞大的模型尺寸和计算需求。
为此,提出了 TinyAgent, 一个端到端的框架,用于训练和部署能够调用功能的特定任务小型语言模型智能体,以在边缘驱动智能体系统。
智能体配备了16种不同的功能,可以与Mac上的不同应用程序进行交互,包括:
- • 电子邮件:撰写新电子邮件或回复/转发电子邮件
- • 联系人:从联系人数据库中检索电话号码或电子邮件地址
- • 短信:向联系人发送文本消息
- • 日历:创建具有标题、时间、参与者等详细信息的日历事件
- • 笔记:在各个文件夹中创建、打开或追加笔记内容
- • 提醒事项:为各种活动和任务设置提醒
- • 文件管理:打开、阅读或总结各个文件路径中的文档
- • Zoom会议:安排和组织Zoom会议
对于这些功能/工具,已经预先定义了Apple脚本,模型所需要做的就是利用预先定义的API并确定正确的函数调用计划来完成给定的任务
训练一个小型语言模型, 并用驱动一个处理用户查询的语义系统。
考虑了Mac上的类似Siri的助手作为一个驱动应用。实现关键组件是
- (i)通过LLMCompiler框架教现成的SLMs进行功能调用
- (ii)为手头的任务策划高质量的功能调用数据
- (iii)在生成的数据上微调现成的模型
- (iv)通过基于用户查询仅检索必要的工具的方法称为ToolRAG,以及量化模型部署以减少推理资源消耗,来实现高效部署。
最终模型在这项任务上实现了80.06%和84.95%的TinyAgent1.1.B和7B模型,超过了GPT-4-Turbo的79.08%的成功率。
【2024-10-23】Computer Use
Claude
【2024-10-23】Claude 推出 Computer Use ,可以像人类一样使用计算机了?查看屏幕、移动光标、点击按钮、输入文本,还能查找代码错误、自动搜集信息填表,并向开发者提供了API
通过 API,开发者可以让 Claude 将指令翻译成计算机指令,从而解放一些枯燥的重复性流程任务。
基准测试中,Claude 在 OSWorld 电脑操作评估测试中获得了 14.9% 的成绩,远超其他 AI 模型的 7.8% 最高分,但与人类的 70 - 75% 的水平相比仍有相当大的差距。当用户提供更多完成任务所需的步骤时,Claude 的得分可以提升到 22.0%。
字节版
【2025-6-21】让远程电脑成为你的AI助手 - Computer Use Agent 实践
字节跳动自研 Doubao-1.5-thinking-vision-pro /Doubao-1.5-UI-TARS 模型的 AI 产品,依托 AI 云原生 AgentKit 套件,以强化学习融合视觉能力与高级推理,无需特定 API 即可直连图形用户界面(GUI)。
从视频剪辑到 PPT 制作,从自媒体运营到复杂桌面操作,它凭借智能感知、自主推理的行动式 AI 架构,将用户指令转化为精准的自动化任务执行,正引领从 “对话式 AI” 到 “行动式 AI” 的技术变革。
- 感知:CUA 截取计算机屏幕图像,旨在对数字环境中的内容进行情境化处理。这些视觉输入成为决策的依据。
- 推理:CUA 借助思维链推理对其观察结果进行评估,并跟踪中间步骤的进展。通过分析过往和当前的屏幕截图,该系统能够动态适应新的挑战和不可预见的变化。
- 行动:CUA 利用虚拟鼠标和键盘执行键入、点击和滚动等操作
同时 Computer Use 已经在社区内部开源
- 仓库详情:computer_use
让 Agent 像人一样操作电脑
技术底座的四大核心能力
- 强大的自研模型:字节跳动自主研发的 Doubao-1.5-thinking-vision-pro 核心模型,通过自然语言处理与计算机视觉技术的深度融合,实现对用户指令的多维度语义解析,精准捕捉业务需求背后的场景意图,为复杂任务执行提供底层智能支撑。
- 多种操作系统支持:提供 Windows 与 Linux 双系统支持,Windows具有无可比拟的传统软件生态,Linux更加轻量与灵活,可以满足企业级计算环境的多元化需求。。
- 极致拉起速度:依托字节跳动分布式架构的底层技术积累,通过资源池化管理、热迁移变配等核心能力,实现云主机实例的秒级启动响应。动态负载均衡机制可根据业务流量实时调整资源分配,构建从资源申请到服务就绪的极致弹性链路,显著提升用户操作的实时性体验。
- 灵活服务组合:采用高内聚低耦合的微服务架构设计,支持火山 computer-use 方案的全栈式部署与组件化调用,对于大型互联网客户,支持按需编排Agent Planner、MCP Server、Sandbox Manager等服务,对于小型客户,提供全栈式的一体化的解决方案。
| 组件 | 技术实现 |
|---|---|
| Web UI | 实时展示远程桌面状态,可视化任务执行步骤 |
| Agent Planner | 简易的 Agent 服务(Client),提供与 Web UI、模型、MCP Server Tool 交互能力 |
| Sandbox Manager | 秒级创建/销毁 ECS 沙箱实例,管理 VNC/RDP 连接 |
| MCP Server | 封装 Tool-Server 能力,向大模型暴露标准化工具协议 |
| Tool Server | 部署于沙箱内部,提供原子级操作能力(截屏/键鼠事件) |
| VNC Proxy | 安全转发桌面流,支持前端实时渲染 |
场景实战演示
- 视频演示见原文
智能AI操作场景汇总表
| 场景编号 | 场景名称 | 用户指令 | AI操作流程 | 特殊功能支持 |
|---|---|---|---|---|
| 场景1 | 智能订机票 | “订北京→法兰克福6月3日航班,乘机人张三” | 自动打开航司官网→输入地点日期→智能选择经济舱→跳过广告弹窗→完成乘机人认证 | 系统提示词确保关键步骤零失误 |
| 场景2 | 文件信息整理 | “把照片按拍摄国家分类” | 识别埃菲尔铁塔→创建“法国”文件夹→移动相关图片 | 支持100+国家地标图片识别 |
| 场景3 | 全球发票处理 | “识别小票消费地,换算人民币记入Excel” | 调用汇率API→自动填充“地点/金额/汇率”三栏→生成财务报表 | - |
| 场景4 | 海外酒店预订 | “订法兰克福五星酒店,需健身房+浴缸” | 筛选携程酒店→识别浴室图片→完成支付 | - |
| 场景5 | 电商购物 | “打开值得买,帮我买一部小米15丁香紫” | 打开电商网站→选择指定手机商品→完成支付 | 支持Human-in-loop,需人工操作时移交控制权 |
| 场景6 | 购买车票 | “在浏览器上搜索12306,帮我订一张明天北京到上海的高铁票。” | 打开12306→搜索车票→选择车次→提交订单→完成支付 | - |
| 场景7 | 软件下载 | “请帮我下载一个汽水音乐客户端,并且安装到主机上 | 搜索客户端→点击下载→点击安装→完成安装 | - |
| 场景8 | 玩网页游戏 | “你来玩一局愤怒的小鸟。” | 进入游戏网站→打开游戏→攻克第一关→攻克第二关→… | - |
在线尝鲜
- AI 体验中心入口:https://exp.volcengine.com/ai-cloud-native-agentkit
- FaaS 应用中心:https://console.volcengine.com/vefaas/region:vefaas+cn-beijing/market/computer
- 方舟应用中心:https://console.volcengine.com/ark/region:ark+cn-beijing/application/detail?id=bot-20250304115020-abcde-procode-preset&prev=application
- 一键部署:租户专属版部署https://console.volcengine.com/vefaas/region:vefaas+cn-beijing/application/create?templateId=680b0a890e881f000862d9f0
- 开发者资源:https://github.com/volcengine/ai-app-lab/tree/main/demohouse/computer_use
【2024-12-23】PC Agent
【2024-12-23】 刘鹏飞老师组研发PC Agent,让 AI 替你熬夜做 PPT
上海交通大学 GAIR 实验室提出认知迁移方法,通过高效收集人类认知轨迹,打造(训练,非 API 调用)了能够像人类一样阅读电脑屏幕,精准操控键盘鼠标,执行长达数十步、跨软件的复杂生产任务的 PC Agent,标志着 AI 真正为人类减负的重要一步
Sam Altman 说,比起让智能体「订一家餐厅」,真正有趣的是让它「咨询 300 家餐厅」来找到最符合的口味。这样大量重复性的工作,对 PC Agent 而言也不在话下。
PC Agent 也能轻松对标类似 Claude 3.5 Sonnet 的演示任务 —— 展现 “AI 调用 AI” 完成工作的巧妙设计。
Browser Use
Browser Use —— 智能上网神器,轻松畅游互联网
让 AI 像真实用户一样自然操作浏览器的 Python 工具库,通过简单代码配置实现网页自动化任务,如订票、求职申请、数据收集等实际应用场景。
- Github browser-use
功能
- 让 AI 能够像人类一样浏览和操作网页
- 支持多标签页管理
- 可以提取网页内容和进行视觉识别
- 能够记录和重复执行特定操作
- 支持自定义动作(如保存文件、推送数据库等)
评测
Browser Use大幅领先Web Voyager,Computer Use,AgentE,Runner H 0.1
webui
【2025-1-6】 Browser-Use WebUI 是基于Gradio构建的用户界面,简化与浏览器代理的交互,允许用户通过图形界面与AI模型进行对话。
该工具主要功能:
- 自动化浏览器操作:Browser-Use WebUI能够模拟人类用户的行为,自动执行各种浏览器操作,如填写表单、点击链接和抓取数据。这使得用户可以高效地完成重复性任务。
- 支持多种大型语言模型:该工具支持多种AI模型,包括OpenAI、Anthropic、Gemini和DeepSeek等,用户可以根据需要选择合适的模型进行任务处理
- 自定义浏览器支持:用户可以使用自己的浏览器,无需重复登录或处理认证问题。这一功能使得用户能够保持浏览器会话的持续性,方便查看AI交互的历史记录和状态
- 高质量屏幕录制:借助Playwright的功能,Browser-Use WebUI支持高质量的屏幕录制,用户可以记录操作过程,便于后续分析和回顾
- 简化的环境配置:用户只需安装Python 3.11或更高版本,并按照简单的步骤安装依赖和配置环境,即可快速启动WebUI
安装
git clone https://github.com/browser-use/web-ui.git # 拉取项目
cd web-ui # 进到这个项目里
pip install -r requirements.txt
pip install MainContentExtractor # 官方遗漏的依赖库
配置
# 启动
python webui.py --ip 127.0.0.1 --port 7788
详情见原文
【2025-3-6】安装报错
案例
实际应用案例:
- 自动搜索和申请工作机会
- 自动查询航班信息
- Hugging Face 上搜索和保存模型信息
使用
pip:
pip install browser-use
#(可选)安装剧作家:
playwright install
启动代理:
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="Find a one-way flight from Bali to Oman on 12 January 2025 on Google Flights. Return me the cheapest option.",
llm=ChatOpenAI(model="gpt-4o"),
)
result = await agent.run()
print(result)
asyncio.run(main())
并且不要忘记将 API 密钥添加到.env文件中。
OPENAI_API_KEY=
ANTHROPIC_API_KEY=
【2025-3-3】 实践
官方示例无法运行,浏览器一直卡在空白页,无法动弹
- issue 里提到原因是 deepseek 模型不支持多模态问答,导致页面卡主
- 解法: Agent 初始化参数里,增加参数,关闭视觉交互功能
修正后的代码
# pip install browser-use
# #(可选)安装剧作家:
# pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple/
# playwright install
# pip install langchain_openai langchain
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
API_KEY='sk-******'
chat = ChatOpenAI(
model='deepseek-chat',
openai_api_key=API_KEY,
openai_api_base='https://api.deepseek.com',
max_tokens=1024
)
res = chat.predict('你好')
print(f'[Debug] 大模型接口有效性验证, 返回结果: {res}')
task_desc="Find a one-way flight from Bali to Oman on 12 January 2025 on Google Flights. Return me the cheapest option."
task_desc = """
打开网易, 找出热门新闻,按照主题汇总,返回5条国际政治新闻
"""
# task_desc = "打开财联社https://www.cls.cn/telegraph,获取前十条资讯"
async def main():
agent = Agent(
task=task_desc,
llm=chat,
use_vision=False, # ds 不支持视觉模型, 导致 浏览器卡主,一直空白
max_failures=2,
)
result = await agent.run()
print(result)
asyncio.run(main())
智谱
论文
智谱AI团队新论文, AutoGLM 背后打造的两套训练框架, COMPUTERRL 和 MOBILERL。
- 一个面向桌面操作,一个专攻手机端,让AI真正具备稳定自主的执行能力,能熟练操控电脑和手机完成任务。
- 论文:在线强化学习
- 【2025-8-19】COMPUTERRL: SCALING END-TO-END ONLINE REINFORCEMENT LEARNING FOR COMPUTER USE AGENTS 桌面端智能体的规模化端到端在线RL
- 【2025-7-8】MobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment 新框架 MobileGUI-RL,支持在线训练 GUI-Agent,自我探索路径,使用GRPO训练
MOBILERL和COMPUTERRL 标志着GUI智能体研究从传统的“模仿学习”范式向更先进的“在线强化学习”范式的关键转变。
- MOBILERL 展示了通过精巧算法设计在数据和交互受限的环境中实现高效学习;
- 而COMPUTERRL则展示如何通过系统和范式的革新,将在线学习的能力扩展到更复杂、更通用的场景中。
传统GUI界面给人设计,对AI来说理解成本高。而强化学习虽然通用,但光靠模仿学不会真正的操作。
智谱在COMPUTERRL中提出API+GUI的操作范式,让AI不仅能像人一样点按钮,还能像程序员一样调接口。
还设计了API自动构建机制,只需提供任务示例,模型就能生成可用的API代码和基础测试流程。
训练方面,COMPUTERRL搭建异步分布式架构,用Docker和gRPC管理上千个Ubuntu虚拟机,实现大规模并发采样。
为了避免模型在长期训练中变得保守、只重复熟悉动作,设计了 Entropulse 机制,在模型探索能力下降时,穿插一轮监督微调,让策略重新找回多样性,继续进化。
最终, 在OSWorld基准测试中,基于该框架训练出的AutoGLM-OS模型取得48.1%准确率,超越OpenAI、Anthropic和UI-TARS等方案,而且平均只用别人三分之一的操作步骤,优势明显。
MOBILERL,面对的是另一套挑战,移动端任务类型复杂,任务难度跨度大。
智谱采用了三阶段训练策略
- 第一阶段是监督学习打地基
- 第二阶段是推理增强,帮助AI理解为什么要这么点
- 第三阶段引入DGRPO算法,使训练过程更加稳定、高效。
在 AndroidWorld 和 AndroidLab 两个评测集上,MOBILERL训练出的模型成绩分别达到75.8%和46.8%,超过GPT-4o和Claude-Sonnet,尤其在复杂任务上的表现尤为突出。
还能根据任务难度动态调整训练重点,从简单点击到多步链式操作都能胜任。
这两套框架现已整合进AutoGLM, 能真正完成任务的智能执行体。
用户只需一句话指令,它就能在云端的手机或电脑上自动完成操作,浏览网页、点外卖、订酒店、做PPT、生成视频等。
AutoGLM
2024年10月,智谱发布全球首个Phone-Use产品AutoGLM,开启Agent的新时代
【2025-8-20】智谱新版autoglm
- 智谱AutoGLM上线:给每个手机都装上通用Agent
- 一句话操控手机,电脑,中途人工可以随时接管
- 下载
AutoGLM 2.0 将Agent应用提升到新的高度——
- 全球首个手机Agent,人人可用;
- 开创Agent+云手机/云电脑的新技术范式,不抢占用户手机和电脑;
- 突破硬件限制,在任何设备、任何场景下运行,帮助用户代理操作;
- 国产模型(GLM-4.5、GLM-4.5V)驱动,具备推理、代码与多模态的全能能力。
AutoGLM 2.0 实现了质的飞跃:不再只是“说”,而是真正能够“做”。
- AutoGLM 1.0中,已探索过让AI代替用户完成部分手机操作,但只在有限场景下生效。
- AutoGLM 2.0 已经成长为一名执行型助手,能够在「云端」自主完成多样化的任务。
应用场景
- 生活场景中,只需一句话,让 AutoGLM 操作美团、京东、小红书、抖音等几十个高频应用:点外卖、订机票、查房源,例如帮你买「秋天的第一杯奶茶」。
- 办公场景中,同样能跨网站执行全流程工作,操作网页版的飞书、网易邮箱、知乎、微博、抖音、微头条等网站:从信息检索到内容撰写,再到生成视频、PPT 或播客,并直接完成小红书、抖音等社交媒体平台内容发布。
AutoGLM 2.0中,为AI配备了专属智能体手机/智能体电脑,让它可以在云端自主干活、完成任务,而无需占用用户的本地设备,期间用户可以使用其他 APP(如刷抖音、打游戏)。
这意味着AI不仅能“自动驾驶手机”,还可“异步代理办公”。让手机变成具备自主执行、跨端协作能力的智能体手机。
AutoGLM会以这样的产品形态出现,源于我们对AGI早期形态的理解。我们认为从Agent到AGI,还需要满足3A原则:
- Around-the-clock(全时):24 小时运行,即使用户离线,Agent 依然在执行任务;
- Autonomy without interference(自主零干扰):独立运行,不占用用户屏幕与算力,平行世界的搭子;
- Affinity(全域连接):跳出浏览器对话框,跨越手机、电脑、手表、眼镜、家电等设备,操作物理世界。
AutoGLM由智谱最新开源SOTA语言模型GLM-4.5与视觉推理模型GLM-4.5V驱动。AutoGLM将基座模型原生能力发挥到极致,并结合在「端到端异步强化学习」方面的多项突破成果,可以完成推理、编码、研究、Agentic与GUI操作等多类任务,并可根据需求灵活调用最合适的「大脑」完成执行。
- ComputerRL:提出API-GUI协同范式,提升数据多样性与计算效率;改进GRPO并提出 Entropulse 机制,增强探索与策略多样性。
- MobileRL:创新难度自适应强化学习方法(推理自举预热 + 难度自适应GRPO),显著提升移动端任务的稳定性与收敛效率。
- AgentRL:通过交叉采样与任务优势归一化机制,解决多任务训练中的不稳定与梯度分布不均,增强整体鲁棒性与效率。
在Device Use基准测试(涵盖手机、电脑和网页操作)中,AutoGLM表现优于ChatGPT Agent、UI-TARS-1.5和Claude Sonnet 4,展现出更强的鲁棒性与通用性,处于主流Agent的SOTA水平。
GLM团队的三篇最新技术论文:
- ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
- MobileRL: Advancing Mobile Use Agents With Adaptive Online Reinforcement Learning
- AgentRL: Reinforcing Multi-task LLM Agents From Zero (Upcoming)
【2024-11-29】GLM-PC
【2024-1-23】智谱Agent抢跑OpenAI,GLM-PC一句话搞定一切!网友:有AGI那味了
智谱 GLM-PC: 电脑智能体大模型
- LLM for Computer Use
- 基于CogAgent视觉语言大模型构建的电脑智能体
全球首个面向公众、回车即用的电脑智能助手的诞生,,小名叫「牛牛」
GLM-PC
- 2024年11月29日, 正式发布并开放内测
- 2025年1月23日, 最新的v1.0版本引入了“深度思考”模式,该模式在逻辑推理和代码生成方面进行了针对性的优化,尤其支持Windows系统的无缝操作。
- 逻辑推理和代码生成方面进行了针对性的优化,尤其支持Windows系统的无缝操作。
- GLM-PC Window 和 Mac 客户端已经同步上线
场景:
| 场景 | agent操作 | 分析 |
|---|---|---|
| 微信上给xxx发送祝福语,再给他发送一个新春图片和一个新春祝贺视频。 | 将任务分解成多个步骤,并对图片内容进行识别,生成相应配文 AI瞬间跳转到微信,打开朋友圈,将图片上传,再附上文案,一键发送就搞定了 |
|
智谱已经有了手机智能体AutoGLM和电脑智能体GLM-PC两大系统,实现了工具使用能力的深度突破。
这两个系统分别覆盖了移动设备和桌面端
AutoGLM在手机上,能够精准操控各类应用,实现跨场景智能交互;GLM-PC则将电脑端的操作提升到了新的高度,基于视觉语言模型VLM的图形界面智能体GUI Agent,实现逻辑推理与感知认知的结合,凸显出AI对复杂系统工具的掌控力。
智谱AGI
- AI实现L3之后,通过不断优化工具使用能力,正为L4阶段——自主学习发明创新奠定了扎实的技术基础。
【2025-1-24】Operator
2024年7月,OpenAI 发布了“从AI到AGI的五步过程”:
- Level 1:Chatbots,AI可以以对话的方式与人互动。
- Level 2:Reasoners,AI科技解决人类水平的问题。
- Level 3:Agents,AI可以作为系统执行一些行动任务。
- Level 4:Innovators,AI可以开发创新性的AI。
- Level 5:Organizations,AI可以完成一个组织完成的工作。
OpenAI 表示自己还只处于 Level 1 阶段,正在靠近 Level 2。
而现在,随着Operator的发布,奥特曼宣布:进入 Level 3 的开始。
【2025-1-24】OpenAI突发Operator!完全自主玩转浏览器,奥特曼:Level 3时代开启
- 只面向Pro用户,一个月200刀(约合人民币1458元)的大会员。
OpenAI官方介绍:
Operator是我们的首批智能体之一。这些AI能够独立为你完成工作——只需给它一个任务,它就会执行。
OpenAI总裁 Brockman 就迫不及待地宣布:2025是智能体之年。
Operator 到底有多“独立自主”。
- 几乎可以使用任何网站,无需人类的操作辅助。
场景
- 从 Allrecipes 上找到一份蛤蜊扁面条的食谱,然后把所有的食材都放到我instacart的购物车里?
不同于其他用API或者基于编程接口的Agent,Operator 基于文本的思维链进行推理
确认好菜单后,去哪个店下单买菜呢?
人类进一步给出指令,使用 Gus’s,然后Operator就会到对应的网站开始下单。
遇到登录、支付等操作时,Operator会将操作权交还给用户。
在用户实测中,有博主发现如果 Operator 被 Reddit 墙了,它还会自己在搜索时就加入“Reddit”关键词以找到相关帖子。
用户也可以通过添加自定义指令,获得个性化体验。比如设置订机票时的首选航司。
Operator 允许用户保存提示,以便在主页上快速访问,非常适合重复任务,如在购物网站上补货。
Operator 也能同时运行多个任务,就像是打开多个网页那样,比如让它在Etsy上订购个性化的搪瓷马克杯,同时在Hipcamp上预订露营地。
Operator 底层使用全新的模型 Computer-Using-Agent(CUA)。
通过将GPT-4o的视觉能力和高级推理强化学习相结合,CUA可以进行GUI交互。
Operator 可以看到网页界面内容,使用鼠标、键盘允许的所有操作。由此它可以自动操作,而无需自定义的API集成。
如果遇到问题或者出现错误,Operator 可以利用推理能力自我纠错。并在它卡住需要帮助时,将控制权交还给用户。
CUA 在 WebArena 和 WebVoyager两个基准测试中都取得了SOTA。
【2025-2-25】Proxy-lite
【2025-2-25】 Convergence AI 发布轻量级网页自动化助手模型 Proxy-lite。
- 基于
Qwen 2.5-VL-3B-Instruct微调的 3B 参数视觉语言模型 (VLM),能够自主完成网页浏览和操作任务。
Proxy Lite:轻量级(只有3B参数)、开源、能使用电脑的代理助手。
Proxy Lite 是3B参数的视觉语言模型(VLM),为开源社区带来了最先进的网络自动化能力。
WebVoyager 结果,Proxy Lite 在网络自动化任务中表现出色,资源占用也非常低。
- Proxy Lite 提供全面的VLM-浏览器交互框架,给予企业级浏览器控制能力。
- Proxy Lite 响应通过三个独特步骤完成,实现了比传统的提示-预测模型更好的泛化能力:
- 观察:评估上一步的成功情况。
- 思考:推理出下一步该做什么。
- 工具调用:决定在浏览器中采取哪种行动。
- 借助类似 DeepSeek R1 执行反馈,Proxy Lite 学会了观察和推理,使其能够在广泛的任务上取得进展。
Each response is separated into three parts:
Observation: assesses the success of the previous stepthinking: reasons through what to do nexttool_call: decides what action to take in the browser
资料
- 项目:proxy-lite, 含演示视频
- 模型:proxy-lite-3b
- Blog:proxy_lite
效果评测

| 产品 | 公司 | 数字 |
|---|---|---|
Proxy |
Convergence | 88% |
Operator |
OpenAi | 87% |
Agent E |
Emergence | 73.1% |
Proxy Lite |
Convergence | 72% |
Runner H |
H Company | 67% |
【2025-3-4】Pokee AI
【2024-11-21】作者知乎 Meta E7 员工 朱哲清 创立 Pokee AI
【2025-3-4】比 OpenAI Operator 准确率高10倍的AI Agent - Pokee AI
Pokee AI 无需编码或复杂集成,即可无缝使用数百种互联网工具,不仅能检索信息,还能代替你执行任务 —— 只需一个自然语言指令!
Pokee AI 核心技术:基于最新的强化学习(RL)智能体研究与小型语言模型(LLM)相结合,智能性不断进化
Pokee AI 最新通用智能体的演示视频
- 比 OpenAI 的
Operator和 AnthropicComputer Use快10倍,可靠性高10倍
所有三个应用场景中全面碾压 OpenAI Operator:
- 数据科学:从 Google Cloud Database 读取原始销售数据,自动生成 Google Sheets 和 Slides 详细分析报告。
- ✅ Pokee 67秒完成 —— Operator 失败 ❌
- 社交媒体 & 广告:通过模糊搜索,自动在 Shopify 商店 查找商品,并结合亚马逊用户评价生成完整的 Facebook & Instagram 广告。
- ✅ Pokee 在 110 秒内完成 —— Operator 失败 ❌
- 会议管理:基于一封邮件,自动安排投资人会议,附上 Zoom 会议链接和商业计划书。
- ✅ Pokee 速度比Operator快8 倍 —— Operator 任务完成但存在关键错误 ⚠️
【2025-3-4】 Mobile Use
【2025-3-4】 Mobile Use: Your AI assistant for mobile - Any app, any task.
Web 界面输入自然语言指令,Mobile Use 的 GUI 智能体自动操作手机并完成任务
功能
特性
- 自动操作手机:基于用户输入任务描述,自动操作UI完成任务
- 智能元素识别:解析GUI布局并定位操作目标
- 复杂任务处理:支持复杂指令分解和多步操作
原理
受 browser use 启发,多模态大模型是基于 Qwen2.5-VL,Web UI 是基于 Gradio
操作方法
- Web UI 输入自然语言指令
- 手机截屏,获取图像,传给Agent
- Agent 借助 多模态大模型,理解当前状态,并执行下一步动作
- 操控手机
框架

支持的手机动作
- 代码配置 mobile_use/action.py
| 动作名称 | 描述 | 参数 |
|---|---|---|
click |
在给定位置点击屏幕 | point(坐标点位置,数组类型,如[230, 560]) |
long_press |
在给定位置长按屏幕 | point(坐标点位置,数组类型,如[230, 560]) |
type |
在屏幕上输入文本 | text(要输入的文本,字符串类型) |
scroll |
指定方向从起始点到结束点滚动 | start_point(滚动起始点坐标,数组类型,如[230, 560]),end_point(滚动结束点坐标,数组类型,如[230, 560]) |
press_home |
按下主页按钮 | 无 |
press_back |
按下返回按钮 | 无 |
wait |
等待片刻 | 无 |
finished |
表示任务已完成的特殊标志 | answer(任务目标的最终答案,字符串类型) |
call_user |
向人类寻求帮助 | 无 |
代码
- 整体控制
- mobile_use/vlm.py 定义多模态大模型类 VLM, 指定次数(
max_retry)内不断调用openai接口, 预测(predict方法)下一个动作 - mobile_use/environ.py python 通过adb操控手机,执行各类指令
Environment类:execute_action方法实现手机指令,os.system方法执行adb指令
- mobile_use/webui.py gradio 框架实现 Web UI
- mobile_use/vlm.py 定义多模态大模型类 VLM, 指定次数(
- Agent 实现
- agents/agent_qwen.py qwen 模型执行 Function Call, 调用指定函数
- agents/agent_qwen_with_summary.py 感知、规划
效果
效果
- AndroidWord 动态测评环境中评估 Mobile Use 智能体方案(模型用 Qwen2.5-VL-72B-Instruct),获得 38% 的成功率
| 模型名称 | 得分 |
|---|---|
| GPT-4(SoM) | 34.5 |
| Gemini-Pro-1.5(SoM) | 22.8 |
| Gemini-2.0(SoM) | 26 |
| Claude | 27.9 |
| Aguvis-72B | 26.1 |
| Qwen2.5-VL-72B | 35 |
| Mobile-Use (Qwen2.5-VL-72B) | 38 |
使用
mobile-use 需要使用 adb 来控制手机,需要预先安装相关工具并使用USB连接手机和电脑。
代码调用
import os
from dotenv import load_dotenv
from mobile_use.scheme import AgentState
from mobile_use import Environment, VLMWrapper, Agent
from mobile_use.logger import setup_logger
load_dotenv()
setup_logger(name='mobile_use')
# Create environment controller
env = Environment(serial_no='a22d0110')
vlm = VLMWrapper(
model_name="qwen2.5-vl-72b-instruct",
api_key=os.getenv('VLM_API_KEY'),
base_url=os.getenv('VLM_BASE_URL'),
max_tokens=128,
max_retry=1,
temperature=0.0
)
agent = Agent.from_params(dict(type='default', env=env, vlm=vlm, max_steps=3))
going = True
input_content = goal
while going:
going = False
for step_data in agent.iter_run(input_content=input_content):
print(step_data.action, step_data.thought)
字节
产品
- Agent TARS 是通用的多模态 AI Agent Stack,将 GUI Agent 和 Vision 的强大功能带入你的终端、计算机、浏览器和产品中。
- 主要提供 CLI 和 Web UI 供使用。 通过前沿的多模态 LLMs 和与各种现实世界 MCP 工具的无缝集成,提供更接近人类任务完成方式的工作流程。
- UI-TARS Desktop 由 UI-TARS 和 Seed-1.5-VL/1.6 系列模型驱动的原生 GUI agent,可在你的本地计算机上使用。
【2025-3-22】字节 TARS
【2025-3-22】 字节发布 TARS, 开源多模态 AI 智能体
- 客户端下载 UI-TARS-desktop
Agent TARS 是一款多模态AI Agent,支持深度研究、电脑操作、文件编辑以及MCP(多云平台)等多种功能,旨在助力用户实现更高效的自动化解决方案。
核心功能
- 高级浏览器操作:复杂任务的智能执行
- Agent TARS在浏览器操作方面表现出色。通过其代理框架,用户可以执行包括深度研究和操作员功能在内的复杂任务。它不仅能够完成简单的自动化操作,还能实现全面的任务规划与执行。例如,在市场调研场景中,Agent TARS可以自动浏览网页、收集数据、分析信息并生成报告,显著提升工作效率。这种能力使其在需要多步骤决策的场景中尤为突出。
- 全面的工具支持:一站式工作流程
- Agent TARS集成了多种实用工具,包括搜索、文件编辑、命令行和MCP,能够处理从数据收集到结果输出的复杂工作流程。例如,在软件开发中,开发者可以利用Agent TARS自动搜索代码库、编辑文件、运行命令并整合结果。这种一站式支持简化了繁琐的操作,让用户专注于核心任务。
- 增强的桌面应用程序:优化用户体验
- Agent TARS的桌面应用程序经过大幅改进,提供了直观且强大的用户界面。
其主要特性包括:
- 浏览器显示:实时展示浏览器操作过程。
- 多模式元素:支持多种交互方式。
- 会话管理:便于用户追踪任务历史。
- 模型配置:灵活调整AI行为。
- 对话流可视化:清晰展示任务执行步骤。
- 浏览器/搜索状态跟踪:实时监控操作进展。
- 这些功能不仅提升了用户体验,还让用户能够更直观地管理Agent TARS的工作流程。例如,通过对话流可视化,用户可以轻松监控任务的每一步,随时调整策略。
典型应用:
- 市场调研
- Agent TARS可以自动完成网页浏览、数据收集和报告生成,帮助企业快速获取市场洞察。
- 软件开发
- 开发者可利用其工具集成能力,简化代码搜索、文件编辑和测试流程,提升开发效率。
- 学术研究
- 通过自定义工作流程,Agent TARS能自动搜索文献、整理信息并生成研究初稿,减轻研究负担。
- 自动化客服
- 开发者可基于Agent TARS构建智能客服系统,实现问题解答和任务处理的自动化。
【2025-11-05】UI-TARS 桌面版
【2025-11-05】字节发布 UI-TARS桌面版
- 看懂整个屏幕,用自然语言指挥鼠标键盘,操作任何桌面App和浏览器,全程 100% 本地运行,隐私安全拉满,再也不用把屏幕内容丢给云端!
核心黑科技:
- UI-TARS + Seed-1.5-VL 视觉语言模型实时截图理解
- 精准鼠标/键盘控制 + 实时反馈
- 自然语言指令直接搞定一切:打开 VS Code、改系统设置、刷 GitHub、浏览器全自动操作……
- 支持 Windows / macOS / Browser 跨平台
- 完全开源(Apache 2.0),本地跑模型,无云端、无 API 费用、无数据泄露风险。
【2025-7-25】中移动 九天
中国移动还是那个“卖套餐、办宽带”的通信公司,但这次登顶,其实是它在AI领域多年布局的“厚积薄发”。而GUI Agent正是“九天” 模型落地的关键一步。
中国移动已建成13个全国性区域性智算中心节点,打造多个超大规模的智算中心,拥有三个万卡集群,为人工智能技术演进升级提供坚实的算力底座;同时,中国移动拥有10亿级的用户和37亿级连接,规模优势无与伦比。
从2013年开始,中国移动便持续加大AI投入,打造了九天系列的通用大模型。在网络方面,升级近50万个无线AI智能化改造基站;在客服领域,中国移动线上AI已面向全国31省推广;
GUI Agent在实际应用中面临三大核心技术挑战:
- 一是如何准确感知理解动态多变的多模型UI界面
- 二是如何对复杂长链条任务做到高效推理
- 三是在任务执行过程中如何做到自动纠偏处理。
【2025-7-25】中国移动九天人工智能研究院的端侧自主智能体模型JT-GUI Agent-V2,登顶谷歌Android World自主智能体动态基准评测国际榜单榜首。
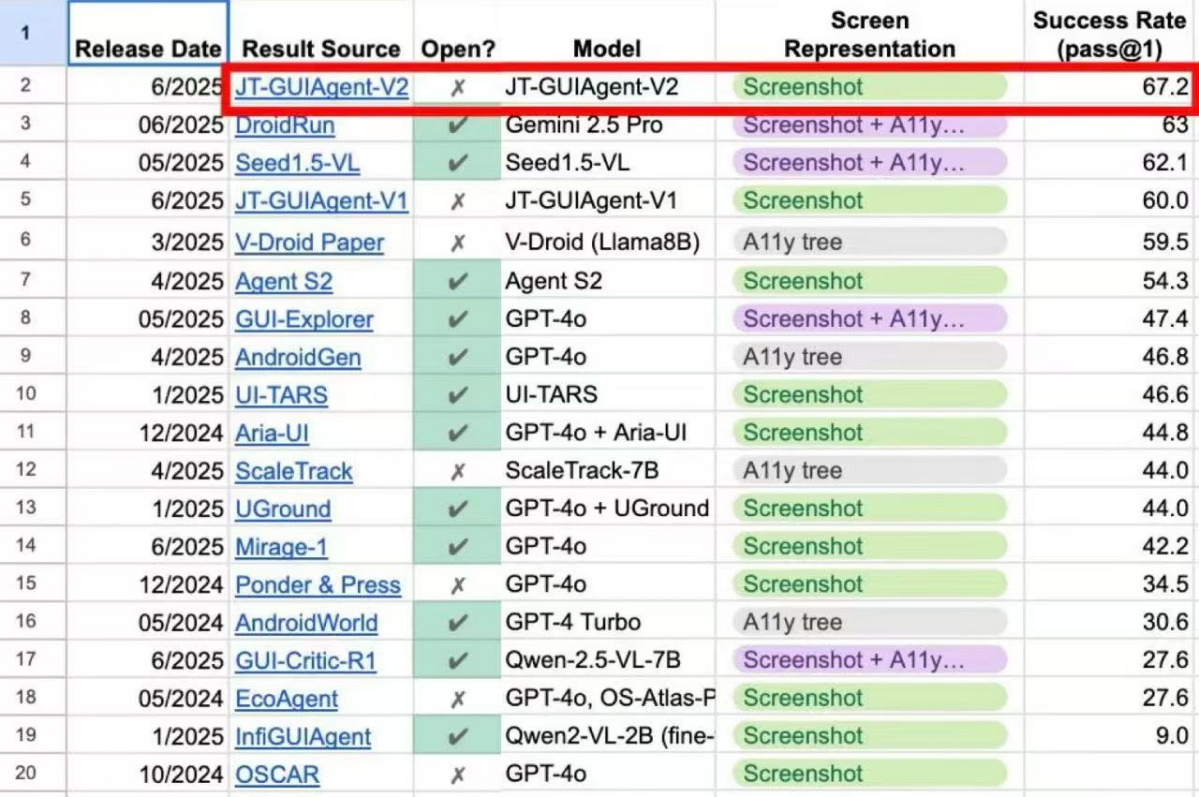
Android World是由Google研究人员联合发布的一个功能完备的Android环境,它模拟了20款主流Android应用的真实环境,设计了116项涵盖日程管理、信息交流、系统设置等日常场景的任务,从指令理解到界面操作,从简单点击到复杂流程,每一项测试都严苛到“吹毛求疵”。
特点:
- 一是环境真实,构建了包含20款主流Android应用程序的完整功能环境。
- 二是任务多样, 精心设计了涵盖日程管理、信息交流、系统设置等日常活动的116项任务,高度模拟真实用户场景。
- 三是评测严谨, 每项任务均配备标准化初始化、严格的成功判定机制及清理逻辑,确保评测结果的高可重复性与可比性。
- 四是能力全面, 重点考察智能体对自然语言指令的理解深度、与动态UI的精准交互能力、复杂任务的高效完成度以及应对任务参数变化的鲁棒性。
而中国移动的JT-GUI Agent-V2 在这场“战场”中交出了67.2%的任务成功率。排在后面的是大名鼎鼎的GPT-4o(最高47.4%)、Gemini 2.5 Pro(63%)、Seed1.5-VL(62.1%),全球AI巨头们引以为傲的核心模型。
JT-GUIAgent-V2 在架构设计和智能规划上实现了全面升级。相比1个月前发布的V1版本,新版本在自然语言指令理解、UI元素多模态感知、目标任务识别推理以及自动化执行等方面实现了全方位能力跃迁,真正实现了“任务自动观察-自主思考-自动执行”的全链路闭环,其核心技术优势体现在以下两大创新:
- 第一,自主构建两阶段的协同框架。创新设计全局规划智能体(Planner)和感知定位智能体(Grounder)两阶段协同框架。
- Planner专注高阶策略规划,显著提升复杂任务推理能力和环境适应性;
- Grounder则确保界面元素的精准识别与操作执行,二者协同形成完整决策闭环。
- 第二,创新性地引入经验驱动的智能规划方法,通过实时融合用户指令解析与应用操作经验,实现系统的动态决策优化,带来三个方面的性能和效果显著提升:
- 一是规划精准化 :引入经验检索机制,实时匹配用户意图与应用特征,避免规划冗余或陷入错误循环;
- 二是错误最小化:有效减少模型“认知盲区”,解决不常见图标识别、隐藏手势调用等技术难题;
- 三是任务通用化:通过可扩展的应用经验积累,提升模型在新任务上的执行准确率。
【2025-8-6】联想 SEA
GUI智能体新SOTA
电脑智能体是人工智能领域的一个新兴方向,旨在通过操控电脑完成用户任务,但现有智能体的性能远未达到实用水平。
【2025-8-6】联想、中国农大提出电脑智能体SEA, 7b 级别模型最佳
联想提出自进化电脑智能体SEA(Self-Evolution Agent),并在数据生成、强化学习和模型增强三个层面提出创新方法。
- 首先提出自动化流程来生成可验证的训练轨迹数据;
- 其次设计高效的逐步强化学习策略,以缓解长周期训练带来的巨大计算负担;
- 最终提出无需额外训练即可将视觉定位能力与规划能力融合的模型增强方法。
实验表明
- SEA智能体取得了具有竞争力的结果:其性能不仅超越了同等规模的其他智能体,更能与参数更大的智能体相媲美。
- 该方法为电脑智能体领域开辟了一条充满前景的新方向。
【2025-8-9】厦大 UI-AGILE
【2025-8-9】UI-AGILE
- 论文UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
- 代码 UI-AGILE
多模态大语言模型(MLLMs)推动了图形用户界面(GUI)智能体能力的显著提升。
然而,现有 GUI智能体训练与推理技术在仍面临难题:推理设计、奖励机制有效性及视觉噪声处理方面。
UI-AGILE 从训练和推理两个层面增强GUI智能体的性能。
训练层面,对监督微调(SFT)过程进行系列改进:
- 设计连续奖励函数,以激励智能体实现高精度定位;
- 引入简化思考奖励,在规划能力、响应速度与定位准确性之间取得平衡;
- 采用基于裁剪的重采样策略,缓解奖励稀疏问题,并提升智能体在复杂任务上的学习效果。
推理层面,提出带选择的分解定位策略:通过将高分辨率显示图像拆分为更小、更易于处理的部分,大幅提升智能体在高分辨率屏幕上的定位准确性。
实验结果
UI-AGILE 在ScreenSpot-Pro和ScreenSpot-v2两个基准测试集上均实现了sota定位性能,同时展现出强大的通用智能体能力。
例如,结合训练与推理增强方法后,在ScreenSpot-Pro基准测试中,其定位准确性较现有最佳基线模型提升了23%。
【2025-9-15】浙大+通义 UI-S1 半在线强化学习
图形用户界面(GUI)智能体(Agent)在通过强化学习(RL)自动化复杂的用户界面交互方面取得了一些进展。
然而,目前方法面临根本性的困境:
离线强化学习(offline RL)能够在预先收集的轨迹上实现稳定的训练,但由于缺乏轨迹级别的奖励信号,难以执行多步骤任务;- 而
在线强化学习(online RL)则通过环境交互来捕获这些信号,但面临奖励稀疏和部署成本过高的问题。
当前GUI Agent,现存两种训练方法都有一定问题:
Offline RL:用收集好的 “人操作界面的步骤数据” 来训 AI。- 好处: 训练稳定、不用实时操作界面;
- 但缺点很明显: 只会 “死记硬背” 单步操作,遇到需要多步连贯思考的任务(比如 “先在相册看收据照片,再在记事本里记下来”)时就不会做了,因为它没考虑 “下一步要干啥”,也不会处理自己之前操作留下的痕迹。
Online RL:让 AI 实时跟界面互动,做错了调整、做对了给奖励。- 好处: 能学多步任务,因为能看到自己操作的后果;
- 但缺点也更明显: ① “奖励太少”(比如只有最后任务完成了才给奖励,中间错了不知道错在哪),② 成本高(要搭很多模拟界面,想换个 APP 训还得重新改代码)
UI-S1:让UI Agent又快又稳
- 论文核心工作提出“半在线强化学习”的方案来提升GUI Agent的操作能力。
【2025-9-15】浙江大学和通义实验室提出“半在线强化学习”(Semi-online Reinforcement Learning),在离线轨迹上模拟在线强化学习的新范式。
- 论文 UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
- 代码 UI-S1
- 模型 UI-S1-7B
- 解读 浙大 × 通义实验室提出 UI-S1:用“半在线”训练让 MLLM 更懂图形界面
原理
UI-S1 核心思想:用离线数据模拟在线过程。
- 不直接与环境实时交互(像 Online RL 那样昂贵)
- 也不完全静态回放轨迹(像传统 Offline RL 那样僵化)。
- 相反,UI-S1 在每次训练回放时,保留模型自身的推理上下文和动作输出,同时引入专家轨迹作为参考,动态修正偏差。
这种方式既保留了离线训练的稳定性,又逼近了在线学习的反馈机制,从而更好地优化长期任务表现。
每次 rollout 过程中,保留多轮对话中的原始模型输出,同时一个 Patch Module 自适应地恢复推出轨迹与专家轨迹之间的差异。
为了捕获长期训练信号,“半在线强化学习”在奖励计算中引入了“折现未来回报” (discounted future returns),并用加权的步骤级(step-level)和片段级(episode-level)优势来优化策略。
进一步提出了“半在线性能” (Semi-Online Performance,SOP),一个与真实在线性能更好地对齐的指标,可作为实际和有效的现实世界评估代理。
“半在线强化学习”在四个动态基准测试中,7B 模型中实现了 SOTA 性能,相比基础模型
- 例如,在 AndroidWorld 上提升了 12.0%,在 AITW 上提升了 23.8%
- 这证明了在弥合离线训练效率和在线多轮推理之间的差距方面取得了重大进展。
| 基准 | 提升幅度 |
|---|---|
| AndroidWorld(在线指标) | +12.0% |
| AITW-Gen(复杂多步任务) | +23.8% |
| AndroidControl-High(单步精度) | +15.5% |
| GUI Odyssey | +7.1% |
半在线强化学习的方案:使用离线数据来模拟在线训练,这样既保留离线训练的低成本,又能让 AI 学会多步思考。
具体实现如下:
- 模拟 “在线互动感”:让 AI 记自己的操作
- 离线训练时,AI 本来只看 “人之前怎么做的”;现在改了 —— 让 AI 在训练时,每一步都记自己刚才输出的操作和思考过程(比如 “我刚才点了‘闹钟’图标,接下来该选时间了”),就像真的在实时操作一样。这样 AI 慢慢就会处理 “自己之前做过啥”,不会多步操作就乱。
- 补全 “断档的步骤”:Patch 模块
- 训练时,AI 偶尔会跟 “人操作的正确步骤” 对不上(比如人该点 “确定”,AI 点了 “取消”)。要是直接停下,后面的步骤就学不到了。所以加了个 “补丁模块”:一旦 AI 操作错了,就把正确操作 “补” 进去,再帮 AI 补一段 “合理的思考过程”(比如 “刚才该点确定,因为要保存闹钟时间”),让训练能继续往下走,不浪费后面的步骤数据。
- 让 AI 考虑 “长远奖励”:双层次优化
- 之前离线训练只看 “这一步对不对”,不管后面;现在改成 “两步一起算”,这样 AI 就不会只顾眼前对,不顾长远,多步任务的成功率就上来了。
- 单步奖励:这一步操作对不对;
- 多步奖励:这一步操作对最后完成任务有没有帮助(比如 “现在点‘相册’,是为了后面看收据,所以这步要算加分”)。
亮点
关键技术亮点
✅ 1. Patch Module:让“走偏”的轨迹也能继续学
真实任务中,模型可能在某一步做出与专家不同的选择,导致后续路径完全偏离。传统方法往往直接丢弃这类样本。
UI-S1 引入 Patch Module,当检测到动作分歧时,自动注入专家动作,并生成合理的“合成推理”内容来补全上下文。这样,即使模型中途犯错,训练仍可继续,显著提升数据利用率。
类比:就像老师发现学生解题走错方向,不是打叉了事,而是帮他回到正轨后继续讲解。
✅ 2. 双层优势优化:兼顾短期准确与长期成功
GUI 多步任务需要平衡两个目标:
- 短期每一步是否正确?
- 长期整条任务能否完成?
为此,UI-S1 设计了 双层优势函数(Dual-level Advantage),结合:
- 步级优势(Step-level):衡量单步决策质量;
- 剧集级优势(Episode-level):关注最终任务完成情况。
并通过引入 折扣未来回报(discounted future returns)增强对远期奖励的感知能力,使策略更倾向于选择能导向最终成功的动作序列。
✅ 3. 新评估指标 SOP:更贴近真实性能
现有的离线评估方式常与真实在线表现脱节。
为此,团队提出 Semi-Online Performance (SOP) 指标。
SOP 的评估方式更接近真实使用场景:
- 在模型生成的历史上下文中,逐步执行后续动作,观察其连续决策能力。实验表明,SOP 与真实在线性能高度相关,是一个更具指导意义的评估标准。
OMG-Agent
【2025-12-19】我们的 GUI Agent 开源了:OMG-Agent,AI 手机我来了
现有开源项目,交互方式多是命令行, AutoGLM,GELab-Zero,得装 Python 环境,配依赖库,搞ADB,还要一边看手机一边看电脑…不方便
通用的 GUI Agent
项目 Open-sourced Mobile GUI Agent,或叫「Oh My God Agent」。
每次测试,可以直观的在 GUI 上看清楚模型对AI的操作,看着 AI 自己完成任务
OMG-Agent 是个GUI Agent,用来配合 AutoGLM、GELab-Zero 这些开源模型使用。
做的事情很简单:
- 把这些GUI model 用来操作手机,并且内置了Agent
两种使用方式: 1.下载打包好的exe文件,双击运行,零配置(还在测试,我们尽快发布 win/mac 版本) 2.frok 代码运行,方便开发者调试,支持基于 GUI 交互
【2025-12-29】阿里 MAI-UI
【2025-12-29】阿里杀疯了!重磅开源 MAI-UI 手机GUI智能体:端云协同,性能吊打 Gemini
开源通用 GUI 智能体基座模型:MAI-UI。实现豆包手机助手的效果,自动化操作手机。
- GitHub:MAI-UI
特色:本地模型+云端模型协作的方式,兼顾性能和准确度,在多项手机操作评分中排名第一。
核心能力
- 1、32B 模型视觉能力:超越 Gemini-3-Pro
- 2、端云协同:小鬼当家,大佬兜底
- 3、原生 MCP 工具集成:能走捷径绝不绕路
- 4、高情商交互理解:它不瞎猜,它会问
- 5、抗干扰能力:在混乱中保持优雅
MAI-UI 最天才的设计:端云协同,小鬼当家,大佬兜底
- • 2B 小模型(端侧):常驻手机内存。处理日常高频操作(如滑动屏幕、点击图标)。反应快、不耗电、隐私数据不出手机。
- • 32B 大模型(云端):当遇到复杂逻辑或 2B 模型搞不定时,才由云端介入。
这种架构完美解决了“手机跑不动大模型”和“云端处理延迟太高”的矛盾。
安装
git clone https://github.com/Tongyi-MAI/MAI-UI.git
cd MAI-UI
pip install -r requirements.txt
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
