Agent 智能体设计
LLM在多步骤推理、实时信息获取和动态决策的任务时,面临的挑战:
- 事实幻觉:模型可能生成看似合理但不准确的信息;
- 缺乏实时信息:模型训练数据截止后的新信息无法获取;
- 规划能力不足:面对复杂任务时难以分解和制定有效策略;
- 错误传播:单个错误推理可能导致整个任务失败;
于是,诞生了多种提示技术框架,如 ReAct(Reasoning + Acting)和 Reflexion(Self-Reflection)作为两个关键创新,通过将推理、行动和反思机制融入模型行为中,显著提升了LLM在知识密集型、决策型和编程任务上的表现。
资料
- 【2025-3-31】MetaGPT、蒙特利尔大学等联合出品 ADVANCES AND CHALLENGES IN FOUNDATION AGENTS
【2026-5-11】Agent 新发展趋势:Claw 化,即从「对话聊天」向「工具助手」的转变。
- 更多 Skill、更多 Tool、更深度系统交互和更好的上下文管理。 两种发展方向:个人 Agent 和 公共 Agent。
- 个人 Agent 高自由度、可成长,是个人能力的数字化延伸;
- 公共 Agent 开箱即用、领域专用,是领域知识的模型化封装。 本地化协同实践:通过共享 workspace,让 Agent 深度参与团队协作,从「工具」变为「协作者」,并展望 AI Native Workspace 的未来。
详见站内专题:OpenClaw
Agentic AI
从基础 AI Agents 到 Agentic AI 系统、应用、局限性和解决方案策略的方法论流程图
- 论文名称:AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenges
- 【2025-5-26】解读 再见AI Agents,你好Agentic AI!
AI Agent
AI Agents 定义
- 限定数字环境中,执行目标导向任务的自主软件实体。
- 通过感知结构化或非结构化的输入、对上下文信息进行推理,并采取行动以实现特定目标。
与传统自动化脚本不同,AI Agents 展现出反应式智能和有限的适应性,能够根据动态输入调整输出。
生成式AI的局限性
- 处理动态任务、维持状态连续性或执行多步计划的能力不足,促使了工具增强型系统(即AI Agents)的发展。
- 这些系统在 LLMs 的基础上引入了额外的基础设施,如:记忆缓冲区、工具调用 API、推理链和规划例程,以弥合被动响应生成与主动任务完成之间的差距。
Agentic AI
AI Agents 虽然在特定任务的自动化方面表现出色,但在处理复杂、多步骤或需要协作的任务时存在局限性。
Agentic AI 通过多智能体协作、动态任务分解、持久记忆和协调自主性来克服这些限制,实现更复杂的任务自动化。
从孤立任务到协调系统的概念飞跃
AI Agents 通常被设计为执行特定任务的单一实体,而 Agentic AI 系统则由多个专业智能体组成,这些智能体通过结构化通信和共享记忆来协作完成复杂目标。
- 目标分解:用户指定的目标被自动解析并分解为更小的子任务,这些子任务被分配给不同的智能体。
- 多步骤推理和规划:智能体能够动态地对子任务进行排序,以适应环境的变化或部分任务的失败。
- 持久记忆:智能体能够跨多个交互存储上下文,评估过去的决策,并迭代地改进策略。
- 智能体间的通信:通过分布式通信渠道(如异步消息队列、共享内存缓冲区或中间输出交换)进行协调,而无需持续的集中监督。
AI Agent vs Agentic AI
对比分析
- 定义:AI Agents 执行特定任务的自主软件程序,而Agentic AI是多个AI代理协作以实现复杂目标的系统。
- 自主性水平:AI Agents在其特定任务内具有高自主性,而Agentic AI具有更高的自主性,能够管理多步骤、复杂的任务。
- 任务复杂性:AI Agents通常处理单一、特定的任务,而Agentic AI处理需要协作的复杂、多步骤任务。
- 协作:AI Agents独立运行,而Agentic AI涉及多智能体协作和信息共享。
- 学习和适应能力:AI Agents在特定领域内学习和适应,而Agentic AI在更广泛的范围和环境中学习和适应。
论文总结
| 特征 | 人工智能代理(AI Agents) | 智能体人工智能(Agentic AI) |
|---|---|---|
| 定义 | 执行特定任务的自主软件程序。 | 多个人工智能代理协作以实现复杂目标的系统。 |
| 自主程度 | 在特定任务内具有高自主性。 | 具有更高的自主性,能够管理多步骤的复杂任务。 |
| 任务复杂性 | 通常处理单一的特定任务。 | 处理需要协调的复杂多步骤任务。 |
| 协作性 | 独立运行。 | 涉及多智能体协作和信息共享。 |
| 学习与适应能力 | 在其特定领域内学习和适应。 | 在更广泛的任务和环境中学习和适应。 |
| 应用领域 | 客服聊天机器人、虚拟助手、自动化工作流程。 | 供应链管理、业务流程优化、虚拟项目经理。 |
Agent 发展
【2025-4-23】从 Manus 看 AI Agent 演进之路
AI Agent 技术发展中的逻辑推理能力、上下文记忆能力和工具调用能力还属于Single Agent(单独智能体)迭代过程。
让 AI Agent 真正发展起来,既要做到主流化规模化,要实现 多个智能体 Multi-Agent 之间通信互联。
当不同的 AI Agent 在不同的设备、机房之间去做计算和联动,才有机会能够推动上亿级别用户的应用。
而存在一个难点:通用的标准化协议适配范式。
Agent 阶段
Agent 发展阶段
- 第一阶段:Single Agent(单独智能体)—— 已实现
- AI Agent 拥有 Planning、Memory、Tools,中间有大模型 LLM 的驱动。
- 第二阶段:Multi-agent(单机)—— 已实现
- Agent 中的 Planning 部分拥有逻辑推理和调度能力,比如:要实现一个复杂任务,用户可以写很多 prompt,把复杂任务拆成很多个子任务,让各个 Agent 之间去通信,但此时的复杂仍是在一个单进程内完成的。像 LangGraph、CrewAI和微软推出的 AutoGen 都已实现多个 Agent 在一个单机上的库之间通信。
- 第三阶段:Agent实现不同设备、不同机房之间联动(MCP协议)—— 探索中
- 如果要支持上亿级别用户的应用,要在不同设备、不同机房间数据联动和流通的架构,目前依然处在尝试中的 Agent 第三阶段架构。
- 解决的问题:很多网站或者工具并不支持AI Agent 的调用(目前很多网站和服务都会有“反机器人/anti-bot”的设置)。
- 2024年11月初,Antropic 推出“模型上下文协议”(Model Context Protocol 简称
MCP)协议,统一大语言模型与外部数据源和工具之间的通信协议,MCP 主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题。 - Antropic 将 MCP 协议称之为“AI 应用的USB-C端口”,支持将大模型直接连到数据源。此前,企业和开发者要把不同数据接入 AI 系统,都得单独开发对接方案,而MCP做的就是提供一个「通用协议」来解决这个问题。
- 第四阶段:端云一体化的分布式 Agent 网络与互联协议 —— 待突破
- 还有最后一个问题:目前 AI Agent 应用大规模爆发的壁垒,是真正统一的 Agent 和 Agent 间的协议通信标准与分布式计算,就像如今的安卓与iOS一样,也需要一个全球大家承认且通用的 AI OS。
Agent 进化事件
GPT 进化
- (1) 推理
Planning:让 AI 能“思考”和“行动”- 2022年10月, 普林斯顿与 Google Brain 合作的团队提出了 ReAct 框架论文, 通过提示工程让LLM具备一定推理、工具执行能力
- 所有 AI Agent 整体构架都从这篇论文开始。
- 然而当时最先进模型
GPT-3.5能力相对有限,使得 AI Agent 逻辑推理能力并不出彩,错误率非常高
- 2023年3月14号,GPT-4 大模型上线,比 3.5版本模型更强,理解能力、推理能力、回答质量都大幅度提升。
- 2023年3月23日:ChatGPT 插件功能 Plugin 发布, 允许大模型 LLM 调用外部工具并且开发 APP, 搜索互联网、连接不同的数据库
- AI Agent 技术的三大要素中的 Planning 搭建成型
- 2022年10月, 普林斯顿与 Google Brain 合作的团队提出了 ReAct 框架论文, 通过提示工程让LLM具备一定推理、工具执行能力
- (2) 记忆
Memory:让 Al 有更强的“记忆”能力- GPT-4 刚开始只有 4096 个token, 容纳3000多个英文单词
- 2023年5月11日:竞争对手 Anthropic 公司发布 Claude 大模型支持 100K token(上下文窗口),技术史上里程碑式进步。
- 2023年6月13日:OpenAI 发布
Function Calling函数调用,引入 json 模式 & GPT 大模型支持 16k token - AI Agent 更加可靠的调用外部API,比如说查天气、自动填表等等任务。
- 2023年11月21号,Anthropic Claude 2.1 版本又进一步把上下文窗口扩展到 20 万个 token,相当于 AI 可以一次性记住一整本教科书的内容,思考能力也出现大大的提升,进一步扩大大模型的记忆能力,优化推理和决策过程。
- 2024年2月:Google 发布 Gemini 1.5 大模型支持百万级 token
- AI Agent 发展必备的第二个技术壁垒 Memory 的限制也完全的被打破了,对于开发者来说就不是大问题
- (3) 工具
Tools:让 AI 开始“动手”- 2023年12月:Simular AI 发布AI Agent Demo, 首次在发布会上让大模型操控电脑
- 2024月10月:Claude 大模型增加 Computer use功能,进一步支持 AI Agent 对电脑的控制,让 AI 更像可以行动起来的智能助手。
- 2024年底:吴恩达教授公开主题演讲 AI, Agents and Applications
- 开发者社区或初创社区的行动都比大公司要早很多。
- 媒体头版开始出现:“2025年将成为 AI Agent 应用的元年的预测”
Human 参与模式
决策过程中,人与AI协作关系分两种:
- 「
人工参与决策」(human-in-the-loop)模式HITL:人工直接接入决策 - 「
人工监督流程」(human-on-the-loop)模式HOTL:监督自动化系统
【2025-2-12】Humans on the Loop vs. In the Loop: Striking the Balance in Decision-Making
【2025-6-11】Human in the Loop vs. Human on the Loop: Navigating the Future of AI
human-in-the-loop: system where human judgment is directly involved in the decision makinghuman-on-the-loop: a little different. It’s where the system can operate autonomously, but there’s a human monitoring the process and able to intervene if needed.
human-in-the-loop
HITL: Supervising Automated Systems
human-in-the-loop: 人工直接参与决策制定
- system where human judgment is directly involved in the decision making
human-on-the-loop
HOTL
human-on-the-loop:
- 略有不同,系统自动运行,人工监视整个流程,并且能随时干预
- a little different. It’s where the system can operate autonomously, but there’s a human monitoring the process and able to intervene if needed.
如何选择
Deciding between humans in the loop vs. humans on the loop depends on several factors, including the complexity of decisions, the stakes involved, and the maturity of the system.
Agent 选型
【2025-4-23】Agent 落地路线图
Supervisor vs Handoffs
【2025-12-27】Multi-Agent多智能体架构“Supervisor” 与“ Handoffs”有什么不同?
LangGraph中的两个核心概念:Handoffs(交接)和Supervisor(主管)模式
Supervisor(监督者 / 督导)与Handoffs(交接) 完全不同:
- 前者是 “监督 / 管理的角色 / 职能”
- 后者是 “任务 / 对话的转移动作 / 流程环节”
定义
- Supervisor(监督者 / 督导):负责监控、审核、干预工作流程的角色(可以是人工或 AI),核心职能是 “管理工作质量、处理异常、确保合规”。
- 比如:客服团队的人工督导(监控客服对话质量)、AI Supervisor(监控智能体的工具调用 / 决策,防止越权操作)。
- Handoffs(交接):是将任务、对话或工作从一个主体(Agent、人员、团队)转移到另一个主体的动作 / 流程环节,核心目的 “衔接不同主体的能力,确保任务 / 对话的延续性”。
- 比如:AI 智能体将复杂问题转交给人工客服、技能型 Agent 将任务转交给专业 Agent(如 “订单查询 Agent” 把售后问题转交给 “维修处理 Agent”)。
对比
| 维度 | Supervisor(监督者) | Handoffs(交接) |
|---|---|---|
| 本质 | 角色/职能(负责监督管理) | 动作/流程环节(负责任务转移) |
| 核心作用 | 监控流程、审核决策、干预异常、保障质量/合规 | 衔接不同主体的能力,延续任务/对话(解决单一主体无法完成的工作) |
| 执行场景 | 全程或关键节点介入(如Agent调用高风险工具时,Supervisor审核) | 当前主体无法完成任务时触发(如AI Agent解决不了复杂问题,转人工) |
| 参与主体 | 监督者(人工/AI)+ 被监督者(Agent/人员) | 转出方(原处理主体)+ 转入方(新处理主体) |
| 目标 | 确保工作符合规则、质量达标、避免风险 | 确保任务不中断,由更合适的主体完成 |
Agent 工作流 Handoffs(任务 / 对话交接)过程中,常见问题集中在上下文衔接、主体匹配、流程连续性、体验一致性等环节
- 上下文丢失 / 不完整:最核心,比较严重,转出方未将用户历史对话、任务中间状态、已收集的信息(如用户需求、订单号、问题类型)完整传递给转入方
- 转接主体匹配错误:未根据任务类型 / 用户需求,将 Handoffs 指向正确的 Agent / 人工角色(比如把 “维修问题” 转交给 “订单查询 Agent”,把 “复杂纠纷” 转交给初级客服)转入方无法处理任务,需再次交接(“二次转接”),增加流程冗余,甚至导致问题搁置。
- 交接延迟 / 流程卡顿:交接过程中系统响应慢(如状态同步、权限校验耗时久),或人工转接时等待时间过长;实时对话场景中,用户因等待过久流失;任务流中,交接延迟导致整体处理时效超时。
- 责任边界模糊:交接后,转出方与转入方对 “后续任务的责任归属” 不明确(比如问题未解决时,用户不知道该联系原 Agent 还是新 Agent);出现问题时互相推诿,用户诉求得不到及时跟进,甚至引发投诉。
- 权限 / 资源不互通:转入方缺少处理任务所需的权限或资源(比如转出方有用户隐私数据访问权,但转入方无权限查看);交接后无法继续处理任务,需额外申请权限 / 重新获取资源,拖慢流程。
- 用户体验断裂:交接前后的交互风格、信息口径不一致(比如原 Agent 语气亲切,新 Agent 语气生硬;原 Agent 承诺 “24 小时回复”,新 Agent 称 “需 48 小时”);用户感知到服务断层,降低对系统的信任度。
- 交接异常无 fallback 机制:交接过程中出现系统故障(如状态同步失败、Agent 离线),但未设置应急方案;任务 / 对话直接中断,用户的问题悬而未决,且无反馈通知。
- 转接条件不清晰:未明确 “何时触发 Handoffs”“转接给哪个主体” 的规则(比如简单问题也被转人工,或复杂问题未及时转接);要么过度占用高成本资源(如人工),要么导致 Agent 处理超出能力范围的任务,降低整体效率。
Agent 分析
当前模型 agent 的问题和局限性。
- 记忆召回问题。如果只是做简单的 embedding 相似性召回,很容易发现召回的结果不是很好。这里应该也有不少可以改进的空间,例如前面提到的 Generative Agents 里对于记忆的更细致的处理,LlamaIndex 中对于 index 结构的设计也有很多可以选择与调优的地方。
- 错误累积问题。网上给出的很多例子应该都是做了 cherry-picking 的,实际上模型总体表现并没有那么惊艳,反而经常在前面一些步骤就出现了偏差,然后逐渐越跑越远……这里一个很重要的问题可能还是任务拆解执行,外部工具利用等方面的高质量训练数据相对匮乏。这应该也是 OpenAI 为啥要自己来做 plugin 体系的原因之一。
- 探索效率低。对于很多简单的场景,目前通过模型 agent 来自行探索并完成整个解决过程还是比较繁琐耗时,agent 也很容易把问题复杂化。考虑到 LLM 调用的成本,要在实际场景落地使用也还需要在这方面做不少优化。一种方式可能是像 AutoGPT 那样可以中途引入人工的判断干预和反馈输入。
- 任务终止与结果验证。在一些开放性问题或者无法通过明确的评估方式来判断结果的场景下,模型 agent 的工作如何终止也是一个挑战。这也回到了前面提到的,执行 task 相关的数据收集与模型训练以及强化学习的应用或许可以帮助解决这个问题。
【2025-4-16】人人都在鼓吹的Agent,为什么我看到的全部是缺点
工具调用可靠性低
- 即使简单API调用也常因格式错误、参数不匹配或上下文误解而失败。例如,模型可能生成无效的JSON格式或忽略关键参数。
- 工具选择错误率高,尤其在面对大量工具时难以有效组合或筛选。
- 自然语言接口的稳定性不足,导致工具调用行为不一致。
记忆与上下文限制
- 有限上下文窗口(即使200k tokens)制约历史信息访问与自我反思能力。
- 分层记忆架构尚未成熟,短期、长期记忆整合困难
系统集成与成本问题
- 缺乏标准化接口,需为每个部署定制集成层,开发成本高昂。
- 大模型推理成本高,多步任务导致响应延迟显著。
- 计算资源需求大,大规模部署面临内存和算力瓶颈
人机交互性能不足
- 复杂软件(如办公套件)操作成功率仅40%,协作平台沟通成功率低至21.5%。
- 多模态感知能力弱,缺乏对物理环境(如触觉、痛觉)的反馈机制
多步任务执行缺陷
- 在任务执行过程中,智能体可能选择了错误的动作序列,导致偏离正确轨迹
- 智能体需要回顾并修正之前的错误动作,以完成任务
- Agent 也容易陷入局部循环(Stuck into Loops),反复执行相同动作,无法探索新可能性
- 复合错误积累显著:若单步成功率为90%,10步任务成功率将骤降至35%。
- 上下文管理能力弱,长序列任务中难以维持连贯理解。
- Agent 难以从错误的长轨迹中恢复(Difficult to recovery in long trajectory)
- 缺乏动态调整能力,错误恢复机制不完善,无法像人类一样从失败中学习
Agent 设计模式
大模型落地两种模式:Copilot模式和Agent模式。
Copilot模式:人机交互以人类为主导,AI只是作为助手,部分流程由AI通过对话交互或SDK方式完成。- AI Copilot 可能在特定领域(如编程、写作、驾驶等)提供帮助,通过与人类的交互来提高效率和创造力。AI Copilot 可能更多地依赖于人类的输入和指导,而不是完全自主地完成任务。
Agent模式:人类作为人工智能导师/教练的角色,设计目标并监督结果,大模型充分发挥自身推理能力,实现推理规划,并调用合适的工具和接口,实现行动执行,最后给予结果反馈。
agent和copilot 区别主要体现在:交互方式、任务执行和独立性等方面。
- 交互方式:
- copilot 要用户给出清晰明确的prompt,即需要用户具体详细地描述任务或问题,copilot才能根据prompt给出有用的回答。
- 而大模型agent交互方式更为灵活,根据给定目标自主思考并做出行动,无需用户给出过于详细明确的prompt。
- 任务执行:
- copilot在接收到清晰明确的prompt后,可以协助完成一些任务,但它的执行能力相对有限。
- 而大模型agent则可以根据目标自主规划并执行任务,还能连接多种服务和工具来达成目标,执行任务的能力更强。
- 独立性:
- copilot被视为一个“副驾驶”,在完成任务时更多的是起辅助作用,需要用户的引导。
- 而大模型agent则更像一个初级的“主驾驶”,具有较强的独立性,可以根据目标自主思考和行动。
总结
- AI Agent 更强调自主性和独立完成任务的能力
- 而 AI Copilot 更侧重于作为人类的助手,协助完成特定任务。
场景
- Copilot模式更适合简单知识交互类场景,而Agent模式则更适合企业内部复杂任务场景,帮助企业尽可能提高劳动生产力
资料
- 麦吉尔大学学者
Keheliya Gallaba总结的agent设计方案: ppt Agentic architectures and workflows
总结
参考
- 【2025-4-25】掌握Agent设计的九大模式
- Agent的九种设计模式(图解+代码),飞书文档
谷歌 Agent 白皮书
【2025-11-17】
Google 联合 Kaggle 发布AI Agent 五天课程 5-Day AI Agents Intensive Course with Google
内容:
- Day 1: Introduction to Agents
- Day 2: Agent Tools & Interoperability with MCP
- Day 3: Context Engineering: Sessions & Memory
- Day 4: Agent Quality
- Day 5: Prototype to Production
Agent 定义:
Agent =
模型+工具+编排层+部署运行时
比主流 AI Agent 定义(LLM + Tool + Memory)多了一层部署运行时
类比
Model(大脑)- 核心推理引擎:处理信息、权衡方案、做出决策
- 通用大模型、领域微调模型,或多模态模型
- 决定了“能思考到什么程度”
Tools(双手)- 把“会说话的模型”变成“能做事的系统”
- 包括:业务 API、代码函数、数据库/RAG、搜索、事务系统等
- Agent 负责选择哪个工具、如何调用,再把结果塞回上下文继续推理
- (补充:目前 Tools 最常用的方式是 MCP,但是最近 Anthropic 发布文章说 MCP 可能不一定是一个好的方式,这个后面有时间再另外发文细说)
Orchestration Layer(神经系统)- 管理整个循环:规划步骤、维护状态、选择推理策略
- 通过 CoT、ReAct 等模式把复杂目标拆成多步
- 负责“记忆”:短期会话记忆、长期工作记忆、外部知识记忆等
Deployment & Services(身体与腿)- 运行时(Serverless / 容器 / 专用 Agent 平台)
- 监控与日志
- 配置、版本管理与访问控制
- 把试验室里的 Agent 变成可用服务:
- 对用户是 GUI,对其他 Agent 是 API(A2A 接口)
开发模式也随之改变:
- 传统开发者像“砌砖工”,写死每个 if-else;
- Agent 开发者更像“导演”,需要:
- 写清楚场景与角色设定(System Prompt、Persona、约束)
- 选择并编排合适的“演员”(工具、子 Agent)
- 提供足够又不过载的上下文(Context Engineering)
- 在运行中持续观测效果、迭代脚本(Agent Ops)
五步问题求解循环:Mission(拿到问题) → Scene(感知场景) → Think(推理规划) → Act(调用工具) → Observe(观测迭代)
Agentic 系统能力分层:从 Level 0 到 Level 4
| 级别 | 名称 | 核心能力 | 局限 / 示例 |
|---|---|---|---|
| Level 0 | 核心推理系统 | 仅依赖 LM 预训练知识,无工具 / 记忆 | 能解释球赛规则,但无法查询“昨晚球赛比赛比分”(无实时信息) |
| Level 1 | 连接型问题解决者 | LM + 外部工具,获取实时 / 外部信息 | 调用API 查询“昨晚球赛比分”,返回“5-3 胜” |
| Level 2 | 策略型问题解决者 | 多步规划 + 上下文工程(动态筛选关键信息) | 任务“找办公室与客户间评分≥4 星的咖啡店”:1. 地图查中点→2. 调用点评软件筛选咖啡店 |
| Level 3 | 协作式多智能体系统 | 多 specialist agents 分工,如人类团队 | 项目经理智能体分解“耳机发布”任务:市场调研→公关文案→网页开发,分配给对应智能体 |
| Level 4 | 自进化系统 | 识别能力缺口,动态创建工具 / 智能体 | 发现无社交媒体情感分析工具,调用 Agent生成新的情感分析Agent并加入团队 |
无水印图源
Level 0:核心推理系统(只有大脑)
- 只有 LLM,没有工具、记忆或外部环境交互
- 擅长解释概念、写文案、做一般性规划
- 完全无法感知实时世界(最新比分、实时库存等)
- 工程上就是熟悉的“纯模型调用”
(补充:本地通过 Ollama 部署一个模型然后进行对话就是这种)
Level 1:接入工具的连通问题求解者
- Level 0 上接入外部工具(搜索、API、RAG 等)
- 仍然是 Agent,但能力从“纸上谈兵”变成“能查真相”
典型能力:
- 查实时信息(比分、天气、股价)
- 访问企业内部系统(CRM、工单系统、数据库)
这是大多数实际项目的起点,也是最容易落地的阶段。
如何赋予模型与外部系统进行实时、上下文感知的互动能力呢?
工具是将基础模型与外部世界连接起来的桥梁
虽然名称各异,但都统称为工具(tools)。
几种方式:
- Functions 使 Agent 能够生成可以在客户端执行的函数代码,为开发人员提供了更精细的控制。
- Extensions 为 Agent 与外部 API 之间提供了一个桥梁,使 Agent 能完成实时 API 调用和实时信息检索。
- Data Stores 为 Agent 提供了访问结构化或非结构化数据的能力,使数据驱动的应用程序成为可能
- Plugins
Level 2:具备上下文工程的战略问题求解者
- 能够围绕复杂目标做多步规划与上下文裁剪
关键能力 Context Engineering:
- 主动决定“在有限的上下文窗口中,放什么信息最关键”
- 自动生成中间查询(如把长邮件压缩成机票信息再写入日历)
举例:帮你找两地之间“中途、评价足够高”的咖啡馆
Agent 会自动拆分为:算中点 → 查城市 → 在该城市查咖啡馆 → 过滤评价 → 汇总结果。
Level 3:协作型多 Agent 系统
- 不再追求万能大 Agent,而是有分工的 Agent 团队
- 常见角色:项目经理 Agent、执行 Agent、审查 Agent、学习 Agent 等
- 通信方式:Agent 把其他 Agent 当作“工具”去调用
例如新品发布项目:
- ProjectManagerAgent:分解任务、制定时间表
- MarketResearchAgent:做竞品与用户研究
- MarketingAgent:写文案、广告与落地页
- WebDevAgent:生成页面代码
- CriticAgent:做质量与合规审查
- LearningAgent:从失败案例中抽象出新规则
这类系统可以覆盖跨团队、跨职能的业务流程,但对观测、调试和治理提出更高要求。
Level 4:自我进化系统
- 不仅会完成任务,还会发现自身能力缺口并主动扩展能力
能够:
- 意识到缺少某种工具/子 Agent
- 调用“Agent 生成器”之类的工具,创建新的 Agent 或工具
- 把人类反馈固化为规则、Prompt 模板或工具升级
这类系统仍处在前沿探索阶段,但白皮书认为它代表了 Agentic 系统的长期方向。
知识获取、工具使用能力加强几种方法:
- In-context learning:如 ReACT,提供提示词、工具和示例,通用模型“即时学习”领域知识+工具使用方法
- Retrieval-based in-context learning:如 RAG,从外部存储中检索相关信息、工具和示例来动态填充模型提示词
- Fine-tuning based learning:如 Finetune,用大量特定示例对模型进行训练(微调/精调),然后用微调过的模型进行推理
设计要点
- 模型:不可“迷信大而全”
- 根据任务选择模型:通用任务用主力大模型,对实时性/成本有要求的链路用轻量模型,多模态场景(语音、图像)用多模态模型
- 注意:模型只是大脑,真正决定可靠性的,是你对上下文与工具的设计。
- 工具:明确契约,最小完备
- 工具不是“给模型一个黑盒 API”,而是带有严格契约的能力组件:明确输入输出结构、对参数范围、权限、错误做硬约束
- 工具分为两大类:
- 检索工具:搜索、数据库、RAG、配置中心
- 执行工具:写数据库、发邮件、调用第三方业务系统、操作 UI - 好用的 Agent 很大程度上是“工具设计得好”。
- 编排层:Prompt + 记忆 + 策略,编排层负责:
- 场景化 Prompt(任务说明 + 角色 + 风格 + 边界)
- 管理短期/长期记忆与外部知识
- 选用合适的推理模式(一步直出 / CoT / ReAct / 计划再执行)
这部分实际上构成“Agent 框架”,是很多团队竞争力所在。
Agent Ops 是 DevOps/MLOps 在 Agent 时代的自然演进
- 测试不再是“output == expected”
- 传统单元测试模式不再适用,需要新的评估范式
- Agent 响应本身就是概率性的,同一个请求每次都可能略有不同
- 语言质量和任务完成度,往往难以用简单断言描述
- 用 LM 做评测(LM-as-Judge)
- 搭建“评测集 + 评分 Rubric”:覆盖核心业务场景与边缘案例,使用强模型(或专门微调模型)来打分(正确性、完整性、事实性、风格等),把评测结果作为版本上线的硬指标,而不是靠人工主观感觉
- 像做 A/B 实验一样做迭代
- 定义业务 KPI:goal completion rate、用户满意度、时延、成本、转化率等
- 每次改动都跑一遍 Golden Dataset + 线上 A/B 对比:评估质量是否提升,监控延迟、成本、错误率是否可接受
- 用 Trace 调试“思考过程”
- 借助 OpenTelemetry 等系统记录完整执行轨迹:每次模型调用的 Prompt 与输出,调用了哪些工具/用什么参数/返回了什么,决策分支为何走错
- Trace 不是给用户看的,而是给工程团队做“行为剖析”和根因定位。现在 Trace 使用比较多的是 LangFuse,可视化更好
- 人类反馈是最有价值的“训练数据”
- 每一次“差评”“工单”“人工纠正”,都是新的边界条件
- 系统化做法:收集并聚合这些反馈,把高价值反馈转成新测试样本,加入评测集,既修复当前问题,又减少同类问题再出现的概率
从这个视角看,做 Agent 更像运营一个复杂的在线系统,而不仅仅是“部署了一个模型服务”。
Agent 与外部世界的三种关键关系。
- Agents & Humans:更自然、更高带宽的交互
- 聊天式 UI: 最简单
- 结构化输出: 进阶,结构化输出(JSON),驱动富 UI 或工作流引擎
- Computer Use:更进一步,Agent 直接操纵 UI 元素(点击、输入、导航),通过专门的 UI 控制工具/协议实现
- 语音与多模态 live 模式让 Agent 成为“可对话的实时助手”:实时语音双向流,看到摄像头画面、理解环境,适合维修指导、购物顾问等场景
- Agents & Agents:A2A 协议与任务式通信
- 企业内部 Agent 数量不断增长,点对点自定义集成会变成“集成地狱”
- Agent2Agent (A2A) 协议:每个 Agent 发布一个包含能力与入口的 Agent Card(数字名片),统一发现与认证方式使 Agent 能够互相调用,交互以“任务”为单位,而非单次请求响应,支持长时间运行任务与流式状态更新
- 为 Level 3 多 Agent 系统提供了基础设施。
- Agents & Money:为 Agent 经济搭建可信支付层
- 当 Agent 可以代表人类做购买与交易时,问题变成:“如果 Agent 买错了,责任在谁?” 两条关键路径:
- ① AP2(Agent Payments Protocol):通过加密签名的“Mandate(授权书)”表达用户意图,为每笔交易建立不可抵赖的审计链路,让 Agent 能在明确授权下自主浏览、谈判和交易
- ② x402 协议:基于 HTTP 402(Payment Required)状态码的互联网支付协议,支持机器对机器的微支付,如按调用付费访问 API 或数字内容
- 两者共同构成了未来 Agentic Web 的“信任与结算层”。
安全与治理:Agent 是新的「主体」
身份与安全体系中,Agent 被视为一种新的主体类型:
- 传统只有两类:用户(OAuth/SSO),服务账号(IAM/Service Account)
- 现在增加第三类:
- Agent 身份:有独立的数字身份、证书与权限范围
- 可通过类似 SPIFFE 的标准进行身份验证
- 授予严格的最小权限,限制可访问的 API、数据与其他 Agent
白皮书提出多层防护思路:
- 身份层:区分用户、服务账号与 Agent 身份
- 授权层:用策略控制每个 Agent 能访问哪些工具、数据和下游 Agent
- 工具层 Guardrail:工具内部自己做权限与参数校验,杜绝越权操作
- 动态防护:
- 在工具调用前后插入 Callback/Plugin 做行为审查
- 使用“模型作为安全审查器”识别 Prompt 注入、越权意图、敏感数据泄露
- 也可以接入专业安全服务做统一的模型安全防护
大规模部署时,还需要一个类似“控制平面”的治理系统:
- 统一注册与发现 Agent / 工具
- 管理版本、灰度与废弃
- 做集中审计与合规检查
- 避免 Agent 在组织内“野蛮生长、各自为政”
自主进化:持续学习、Agent Gym 与两个前沿案例
Agent 如何学习与自我演化
与人类类似,智能体通过经验和外部信号进行持续学习然后进化,才能胜任人类社会更多的任务。
白皮书把 Agent 的“学习信号”分成几类:
- 运行时经验:日志、Trace、记忆,包含成功与失败的轨迹
- 外部信号:新政策文档、监管要求、业务规则更新
- 人类反馈:专家批注、人工审核意见、用户纠错等
有了这些信息之类,要将这些“历史记录”转化为可复用的抽象产物,进而提升 Agent 的能力。概括来说主要有如下方式:
- 增强上下文工程: 系统会持续优化其提示、少量示例以及从记忆中检索的信息。通过为每个任务优化提供给语言模型的上下文,它可以提高成功的可能性
- 工具优化与创建: 智能体的推理可以识别其能力上的不足并采取行动加以弥补。这可能包括获取新工具的访问权限、即时创建新工具(例如,Python脚本),或修改现有工具(例如,更新API模式)
除此之外,其实还可以利用真实世界的这些反馈数据对模型进行后训练微调,从而使模型在我们的场景下编写的更好
Agent Gym:离线仿真与极限压测
- 构建一个专用平台,通过先进的工具和功能在离线流程中优化多智能体系统,而这些工具和功能并不属于多智能体运行时环境
企业版的“Agent 训练场 + 红蓝对抗实验室”
- 不在生产路径上,是一个独立的离线优化平台
- 提供高保真仿真环境,让 Agent 在合成或回放数据上“训练”
- 可调用更强大的模型、更多外部工具(包括红队、动态评估与批判 Agent)
- 可利用合成数据不断扩充、覆盖真实难例
- 在难以自动判断的场景下,Agent Gym 还可以主动“求助”人类专家,
- 把人类判断固化为下一轮优化的基准
案例
- Google Co‑Scientist 面向科研的多 Agent 系统,作为“虚拟合作者”帮助探索科研假设空间
- 本质上是 Level 3/4 混合系统,既有多 Agent 协作,也开始具备自我改进能力
- AlphaEvolve 用 Agent 体系探索数学与计算机科学中的复杂算法设计问题
工程团队启示:
- 从 Level 1–2 做起,而不是一上来造“超级 Agent”
- 先把“连通 + 工具调用 + 上下文工程”做好
- 把一个具体业务场景做深做稳,再考虑多 Agent 与自我进化
- 把 Agent 当“系统”而不是“模型能力”来设计
- 同等重视模型选择、工具设计、编排策略与运行治理
- 把 Tool 视为有严格契约的能力单元,避免朦胧的“万能函数”
- 尽早建立 Agent Ops 能力
- 搭建评测集与 LM 评审体系
- 接入 Trace 与监控,避免“黑箱调参”
- 把用户反馈系统化转化为测试用例与规则更新
- 安全与治理是架构的一部分,而不是事后补丁
- 在设计之初就考虑 Agent 身份、最小权限与策略层
- 对关键工具内置防护逻辑 + 行为审查
- 建立统一的 Agent 注册、发现和审计机制
- 保留人类的“掌舵权”
- 在高风险或高价值决策链路中留出 Human-in-the-Loop
- 把专家反馈视作核心资产,沉淀为规则、Prompt 和工具升级
谷歌智能体设计模式
【2025-9-5】Agentic Design Patterns(智能体设计模式)
- 谷歌高级工程师
Antonio Gulli400 页免费文档 - 动手实践的智能系统构建指南
- 资料 google doc
- 翻译: agentic-design-patterns, 中文版主页
什么让 AI 系统成为“智能体”? – 9 页
第一部分(共 103 页)
- 第 1 章:提示链(Prompt Chaining) – 12 页:又称
管道模式(Pipeline pattern)- 核心思想是分而治之,将原始复杂问题分解为一系列更小、更易管理的子问题,模块化串行,形成依赖链;提示链还支持外部知识、工具集成
- agent 工作流是人类思维过程的简单模拟,实现与复杂领域的自然交互,解决的问题:
- ①单一提示词的局限性:单一复杂提示词效率低,导致模型可能出现指令忽略、上下文漂移、错误传播、上下文窗口受限、幻觉
- ② 顺序分解增强可靠性:复杂任务分解为顺序工作流,每步简单、清晰,更加聚焦,减少模型的认知负荷,显著提升可靠性、控制力
- 注意:提示词链的可靠性高度依赖于步骤之间传递的数据完整性 → 结构化输出,输出限定为特定格式(json或xml),机器可读,可精确解析并插入到下一个提示词中,而不会产生歧义,最大限度减少自然语言解析错误,构建健壮的多步骤 LLM 系统的关键部分

- 案例:
- 信息处理工作流:原始信息需要多次加工、转换,如:总结文档、提取关键词、查数据库、生成报告
- 数据提取转换:非结构化文本转换为结构化格式,顺序修改提高准确性、完整性,如 发票提取特定字段→字段检测/矫正→验证结果→输出;LLM不适合精确计算,改成工具调用
- 复杂知识问答:多步推理、信息检索,如 “1929年股市崩盘的主要原因及政府应对策略” → 识别用户问题中的核心子问题(崩盘/政府响应)+分别查询子问题信息(并行)+总结输出
- 内容生成工作流:复杂内容创作(创意叙事/技术文档)分解为不同阶段,构思、结构大纲、起草、修订等
- 有状态对话agent:提示链能保持对话连续性,将多轮对话构建成新提示词,维护上下文。如 识别用户q1中的意图/实体→生成下一轮状态提示语→循环
- 代码生成和完善:代码生成是多阶段过程,用户需求拆解成多步执行的离散逻辑操作序列,如 用户需求理解 →生成大纲/伪代码→初始代码→错误检测(静态分析工具)→优化完善→添加文档/测试用例
- 多模态与多步推理:分析不同模态数据集时,需要拆解问题。
- 进化:
上下文工程是在 token 生成之前系统地设计、构建和向 AI 模型提供完整信息环境的学科; 传统提示工程的重大演进- 相比模型架构,
上下文工程更加依赖于上下文丰富程度 - 工具:LangChain/LangGraph 和 Google ADK 框架提供了强大的工具来定义、管理和执行这些多步序列
- 第 2 章:路由(Routing) – 13 页
- 问题:提示词链顺序处理是执行确定性、线性工作流的基础技术,但不够灵活,无法动态决策,不适合需要根据上下文自适应的系统
- 路由:将条件逻辑引入 Agent 框架,从固定执行路径升级为:Agent 动态评估特定标准以从一组可能的后续行动中进行选择。
- 第 3 章:并行化(Parallelization) – 15 页
- 第 4 章:反思(Reflection) – 13 页
- 第 5 章:工具使用(Tool Use) – 20 页
- 第 6 章:规划(Planning) – 13 页
- 第 7 章:多智能体(Multi-Agent) – 17 页
第二部分(共 61 页)
- 第 8 章:记忆管理(Memory Management) – 21 页
- 第 9 章:学习与适应(Learning and Adaptation) – 12 页
- 第 10 章:模型上下文协议(Model Context Protocol, MCP) – 16 页
- 第 11 章:目标设定与监控(Goal Setting and Monitoring) – 12 页
第三部分(共 34 页)
- 第 12 章:异常处理与恢复(Exception Handling and Recovery) – 8 页
- 第 13 章:人类参与环节(Human-in-the-Loop) – 9 页
- 第 14 章:知识检索(RAG, Retrieval-Augmented Generation) – 17 页
第四部分(共 114 页)
- 第 15 章:智能体间通信(Agent-to-Agent, A2A) – 15 页
- 第 16 章:资源感知优化(Resource-Aware Optimization) – 15 页
- 第 17 章:推理技术(Reasoning Techniques) – 24 页
- 第 18 章:护栏与安全模式(Guardrails / Safety Patterns) – 60 页
后续章节(共 83 页)
第 19 章 – 第 21 章(未完全展开,但预计涵盖高级主题、案例研究和未来展望)
斯坦福agent课程
【2025-12-7】斯坦福agent课程,视频youtube Stanford’s 2-Hour Lecture on AI Agents, LLM & RAG is a Joy to Watch. I Pulled 𝟯𝟭 Advanced Techniques You Won’t Find Explained Elsewhere ⬇️
- Knowledge cutoff is your LLM’s biggest limitation—RAG fixes it without retraining.
- Never dump everything into context—retrieve only relevant chunks.
- Chunk size matters: ~500 tokens balances context preservation and embedding quality.
- Two-stage retrieval: candidate retrieval (maximize recall) → ranking (maximize precision).
- Bi-encoders (SBERT) power fast semantic similarity search via cosine similarity.
- BM25 ensures keyword matching when exact terms matter.
- Hybrid retrieval (embeddings + BM25) beats either method alone.
- HyDE: generate a hypothetical document first, then embed it for better retrieval.
- Contextual retrieval: prepend chunk summaries to preserve meaning.
- Prompt caching slashes costs by 10x when processing multiple chunks.
- Cross-encoders for re-ranking: feed query + chunk together for accurate relevance.
- Evaluate with NDCG, MRR, Precision@k, Recall@k—not just vibes.
- Tool calling = LLMs completing tasks by accessing external resources dynamically.
- Define tools with clear APIs: function name, args, documentation—no implementation.
- Three-stage flow: LLM predicts tool + args → execute → LLM synthesizes response.
- Train with two SFT pairs: query→tool call AND tool result→natural language.
- For code-fluent models, skip SFT—use detailed prompts with reasoning chains.
- Iterate prompts using evaluation sets: let reasoning models debug instructions.
- Tool categories: information retrieval, computation, action execution.
- Tool selection/routing is critical when you have 10+ tools—avoid context overload.
- Use an LLM-based tool selector to filter from hundreds to ~5 relevant ones.
- Standardize with MCP (Model Context Protocol) to avoid reimplementing tools per LLM.
- Agent = autonomous system that pursues goals through reasoning + tool use loops.
- ReAct pattern: Observe → Plan → Act, repeat until goal achieved.
- Observe translates user intent into actionable state.
- Plan decides next action based on current state.
- Act executes the tool call and feeds results back into the loop.
- Multi-agent systems need standardized communication—see Agent2Agent protocol.
- Safety is critical: guard against data exfiltration, harmful actions, jailbreaks.
- Use training-time safeguards (harmlessness SFT/RL) + inference classifiers.
- Start small, start smart: prototype with simple tools on capable models, then optimize.
Agent 模式
Agent(智能体)是指能够自主感知环境、推理并采取行动以完成目标的 AI 系统。
与传统”问答”式大模型调用不同,Agent 可连续地执行多步操作,调用工具,甚至协调其他 Agent来完成复杂任务。
Agent 架构指 Agent 系统中各个组件的组织方式,决定了 Agent 的能力边界、可靠性、灵活性和适用场景。
Agent 工作方式本质是循环(Loop)
感知当前状态,推理下一步,执行行动,再次感知…… 直到任务完成。
不同架构的差异在于如何组织和扩展这个基本循环。
【2026-5-22】RUNOOB Agent教程
各种架构对比
| 架构 | 自主性 | 可预测性 | 并行能力 | 适合任务复杂度 | 典型实现 |
|---|---|---|---|---|---|
| 单 Agent 循环 | 高 | 低 | 无 | 中低 | Claude Code 默认模式 |
| 规划 + 执行 | 中 | 中 | 部分 | 中高 | Claude Code Plan Mode |
| 多 Agent 协作 | 高 | 低 | 强 | 高 | AutoGen, CrewAI |
| 反思 / 自我修正 | 中 | 中 | 中 | 中 | Reflexion, Self-Refine |
| RAG + Agent | 高 | 中 | 无 | 中高 | LangChain RAG Agent |
| 工作流编排 | 低 | 高 | 强 | 高(固定流程) | LangGraph, Prefect |
常见组合模式:
- 工作流编排 + 多 Agent:用 DAG 定义主流程,每个节点内部是一个独立的 Agent。例如 CI/CD 流水线中,代码检查节点是 Code Review Agent,安全扫描节点是 Security Agent。
- 多 Agent + RAG:多个 Subagent 共享同一个向量知识库,各自根据子任务按需检索。例如客服系统中,订单查询 Agent 和退款处理 Agent 都查询同一个知识库但检索不同的内容。
- 规划执行 + 反思:先规划再执行,但每个步骤执行后加入反思环节确保质量。适合对质量要求极高的任务。
选择架构时,核心考量只有两个:
- 要多大的灵活性,应对意外情况
- 要多大的确定性,保证结果可靠
常见误区
- 误区一:架构越复杂越好
- 多 Agent 协作看起来很强大,但如果你的任务用单 Agent 循环在 5 步内就能完成,引入编排开销反而降低效率。原则:用能满足需求的最简架构。
- 误区二:反思一定能提升质量
- 自我反思的有效性取决于模型的自我评估能力。如果质量要求极其严格,考虑使用 Critic 模型或引入外部验证(如代码自动测试)。
- 误区三:DAG 工作流不需要 Agent
- DAG 定义了流程骨架,但每个节点内部仍然可以是 Agent 调用。工作流编排和 Agent 能力不是互斥的,而是互补的——DAG 提供可靠性,Agent 提供灵活性。
- 误区四:上下文窗口大了就不需要 RAG
- 即使模型支持 1M token 的上下文窗口,把所有文档塞进去仍然不是最优方案。RAG 的价值不仅在于”装得下”,更在于精准检索——减少噪音、降低推理成本、提高答案准确性。
模式总结
总结
- ReAct: ReAct 模式将推理(Reasoning)和行动(Act)紧密结合
- Plan and Solve 模式
- Reason without Observation 模式
- LLMCompiler 模式
- Basic Reflection 模式
- Reflexion 模式
- Language Agent Tree Search 模式
- Self-Discover 模式
- Storm 模式
从ReAct出发,有两条发展路线:
- 侧重规划能力,包括:REWOO、Plan & Execute、LLM Compiler。
- 侧重反思能力,包括:Basic Reflection、Reflexion、Self Discover、LATS。
ReAct
背景
传统方法存在明显短板:
- 链式思考(CoT):无法与外部世界互动,容易导致事实幻觉(Fact Hallucination)和错误传播。
- 仅行动(Act-Only):缺乏规划能力,在多步骤任务中表现不佳。
定义
2022 年 10 月,Yao等人提出 ReAct 模式,此时 ChatGPT 还未面世
灵感源于人类决策过程:
我们不只是被动思考,而是通过思考制定计划、执行行动、观察结果,并据此调整策略。
ReAct将这一过程应用到LLM中,使模型能够动态处理复杂任务。
- 推理(Reasoning):模型生成内部思考轨迹,例如”我需要先做什么,再做什么”,类似于链式思考(Chain-of-Thought, CoT)。这有助于分解任务、制定计划和处理异常。
- 行动(Acting):模型生成可执行的操作,例如”搜索[关键词]”或”计算[表达式]”,以调用外部工具(如搜索引擎或计算器)获取实时信息。
通过”思考 → 行动 → 观察 → 再思考”的循环,ReAct使LLM能够融入外部知识,避免纯内部推理的局限性。
ReAct 模式将推理(Reasoning)和行动(Act)紧密结合
- 每次行动后立即进行观察(Observation),并将观察结果反馈到下一次推理过程,使 Agent 能够更好地适应环境变化,维持短期记忆,从而实现更加灵活和智能的行为。
ReAct 通过行动步骤验证信息、减少幻觉,并通过推理步骤分解复杂问题。
- 知识密集型任务(如问答和事实验证)中,ReAct优于Act-Only,并与CoT结合时效果最佳。
- 决策型任务(如文字游戏)中,显著提升性能,尽管与人类专家仍有差距。
流程
ReAct 模式核心在于交互流程:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 推理(Thought):Agent 根据当前的任务和已有的知识进行推理,生成初步的行动计划。
- 行动(Action):Agent 执行推理得出的行动。
- 观察(Observation):Agent 对行动的结果进行观察,获取反馈信息。
- 循环迭代:将观察结果反馈到推理过程中,Agent 根据新的信息重新进行推理,生成新的行动计划,并继续执行行动和观察,直到任务完成。
分析
优势:
- 适应性强:Agent 能够根据环境的变化及时调整自己的行为,适应动态环境。
- 维持短期记忆:通过观察和反馈,Agent 能够记住之前的行动和结果,避免重复错误或遗漏重要信息。
- 提高效率:减少了不必要的行动,提高了任务完成的效率。
示例
Agent 去厨房拿胡椒粉的任务:
class ReActAgent:
def __init__(self):
self.knowledge_base = {
"locations": ["台面上", "灶台底下抽屉", "油烟机左边吊柜"]
}
def think(self, task):
# 推理:根据任务生成行动计划
for location in self.knowledge_base["locations"]:
yieldf"检查 {location} 是否有胡椒粉"
def act(self, action):
# 行动:执行具体的行动
if action == "检查 台面上 是否有胡椒粉":
return"台面上没有胡椒粉"
elif action == "检查 灶台底下抽屉 是否有胡椒粉":
return"灶台底下抽屉有胡椒粉"
elif action == "检查 油烟机左边吊柜 是否有胡椒粉":
return"油烟机左边吊柜没有胡椒粉"
def observe(self, action_result):
# 观察:记录行动的结果
return action_result
def run(self, task):
# 主循环:推理 -> 行动 -> 观察 -> 循环迭代
for action in self.think(task):
action_result = self.act(action)
observation = self.observe(action_result)
print(f"Action: {action}")
print(f"Observation: {observation}")
if"有胡椒粉"in observation:
print("任务完成:找到胡椒粉")
break
# 示例运行
agent = ReActAgent()
agent.run("去厨房拿胡椒粉")
输出结果
Action: 检查 台面上 是否有胡椒粉
Observation: 台面上没有胡椒粉
Action: 检查 灶台底下抽屉 是否有胡椒粉
Observation: 灶台底下抽屉有胡椒粉
任务完成:找到胡椒粉
ReAct 模式如何通过推理、行动和观察的循环迭代来完成任务。
这种模式在实际应用中可以扩展到更复杂的任务和场景,例如智能客服、自动化任务处理等,通过不断优化 Agent 的推理和行动策略,实现更加智能和高效的任务执行。
Plan and Solve
Plan and Solve 模式原理
Plan and Solve 模式是一种先规划再执行的 Agent 设计模式,适用于复杂任务的处理。
- 论文 《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》
如果说 ReAct 更适合 完成“厨房拿胡椒粉”的任务,那么 Plan & solve 更适合完成“西红柿炒鸡蛋”的任务:
- 需要计划,并且过程中计划可能会变化(比如你打开冰箱发现没有西红柿时,你将购买西红柿作为新的步骤加入计划)。
这种模式下,Agent 首先会根据任务目标生成一个多步计划,然后逐步执行计划中的每个步骤。
如果在执行过程中发现计划不可行或需要调整,Agent 会重新规划,从而确保任务能够顺利进行。
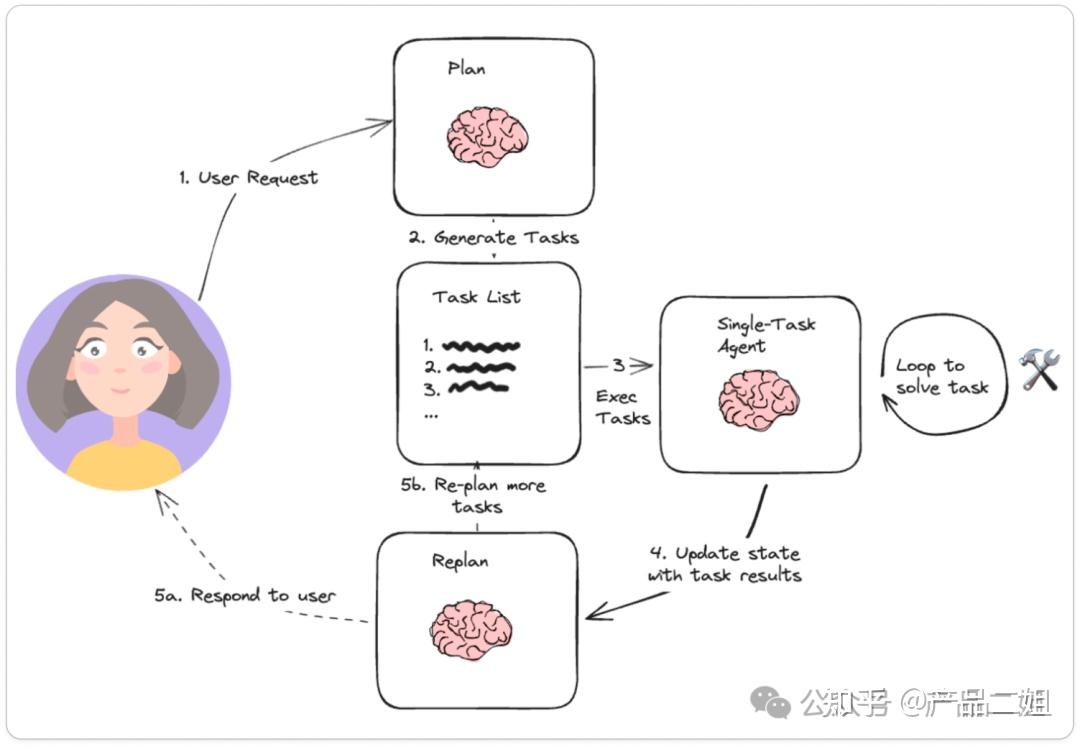
Plan and Solve 模式的交互流程如下:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 规划(Plan):Agent 根据任务目标生成一个多步计划,明确每个步骤的具体内容和顺序。
- 执行(Solve):Agent 按照计划逐步执行每个步骤。
- 观察(Observation):Agent 对执行结果进行观察,判断是否需要重新规划。
- 重新规划(Replan):如果发现计划不可行或需要调整,Agent 会根据当前状态重新生成计划,并继续执行。
- 循环迭代:重复执行、观察和重新规划的过程,直到任务完成。
优势在于:
- 适应性强:Agent 能够根据任务的复杂性和环境的变化灵活调整计划。
- 任务导向:通过明确的计划,Agent 能够更高效地完成任务,避免盲目行动。
- 可扩展性:适用于复杂任务和多步骤任务,能够有效管理任务的各个阶段。
示例
为了更好地理解 Plan and Solve 模式,我们可以通过图解和代码示例来展示其具体实现。
实现一个 Agent 制作西红柿炒鸡蛋的任务:
class PlanAndSolveAgent:
def __init__(self):
self.knowledge_base = {
"steps": [
"检查冰箱是否有西红柿和鸡蛋",
"如果没有西红柿,购买西红柿",
"准备食材:切西红柿、打鸡蛋",
"热锅加油,炒鸡蛋",
"加入西红柿,翻炒",
"调味,出锅"
]
}
def plan(self, task):
# 规划:根据任务生成多步计划
return self.knowledge_base["steps"]
def solve(self, step):
# 执行:执行具体的步骤
if step == "检查冰箱是否有西红柿和鸡蛋":
return"冰箱里有鸡蛋,但没有西红柿"
elif step == "如果没有西红柿,购买西红柿":
return"购买了西红柿"
elif step == "准备食材:切西红柿、打鸡蛋":
return"食材准备完毕"
elif step == "热锅加油,炒鸡蛋":
return"鸡蛋炒好了"
elif step == "加入西红柿,翻炒":
return"西红柿炒好了"
elif step == "调味,出锅":
return"西红柿炒鸡蛋完成"
def observe(self, step_result):
# 观察:记录执行结果
return step_result
def replan(self, current_plan, observation):
# 重新规划:根据观察结果调整计划
if"没有西红柿"in observation:
current_plan.insert(1, "如果没有西红柿,购买西红柿")
return current_plan
def run(self, task):
# 主循环:规划 -> 执行 -> 观察 -> 重新规划 -> 循环迭代
plan = self.plan(task)
for step in plan:
step_result = self.solve(step)
observation = self.observe(step_result)
print(f"Step: {step}")
print(f"Observation: {observation}")
if"没有西红柿"in observation:
plan = self.replan(plan, observation)
if"完成"in observation:
print("任务完成:西红柿炒鸡蛋制作完成")
break
# 示例运行
agent = PlanAndSolveAgent()
agent.run("制作西红柿炒鸡蛋")
输出结果
Step: 检查冰箱是否有西红柿和鸡蛋
Observation: 冰箱里有鸡蛋,但没有西红柿
Step: 如果没有西红柿,购买西红柿
Observation: 购买了西红柿
Step: 准备食材:切西红柿、打鸡蛋
Observation: 食材准备完毕
Step: 热锅加油,炒鸡蛋
Observation: 鸡蛋炒好了
Step: 加入西红柿,翻炒
Observation: 西红柿炒好了
Step: 调味,出锅
Observation: 西红柿炒鸡蛋完成
任务完成:西红柿炒鸡蛋制作完成
Plan and Solve 模式如何通过规划、执行、观察和重新规划的循环迭代来完成任务。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如项目管理、自动化工作流程等,通过不断优化 Agent 的规划和执行策略,实现更加智能和高效的任务执行。
Reason without Observation
Reason without Observation 模式原理
Reason without Observation(REWOO)模式是一种创新的 Agent 设计模式,在传统 ReAct 模式的基础上进行了优化,去掉了显式观察(Observation)步骤,而是将观察结果隐式地嵌入到下一步的执行中。这种模式的核心在于通过推理(Reasoning)和行动(Action)的紧密协作,实现更加高效和连贯的任务执行。
REWOO(Reason without Observation) 相对 ReAct中的Observation
- ReAct 提示词结构是 Thought→ Action→ Observation
- 而 REWOO 把 Observation 去掉了。
但实际上,REWOO 只是将 Observation 隐式地嵌入到下一步的执行单元中了,即由下一步骤的执行器自动去 observe 上一步执行器的输出。
流程
REWOO 模式中,Agent 交互流程:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 推理(Reasoning):Agent 根据当前的任务和已有的知识进行推理,生成初步的行动计划。
- 行动(Action):Agent 执行推理得出的行动。
- 隐式观察(Implicit Observation):Agent 在执行行动的过程中,自动将结果反馈到下一步的推理中,而不是显式地进行观察。
- 循环迭代:Agent 根据新的信息重新进行推理,生成新的行动计划,并继续执行行动,直到任务完成。
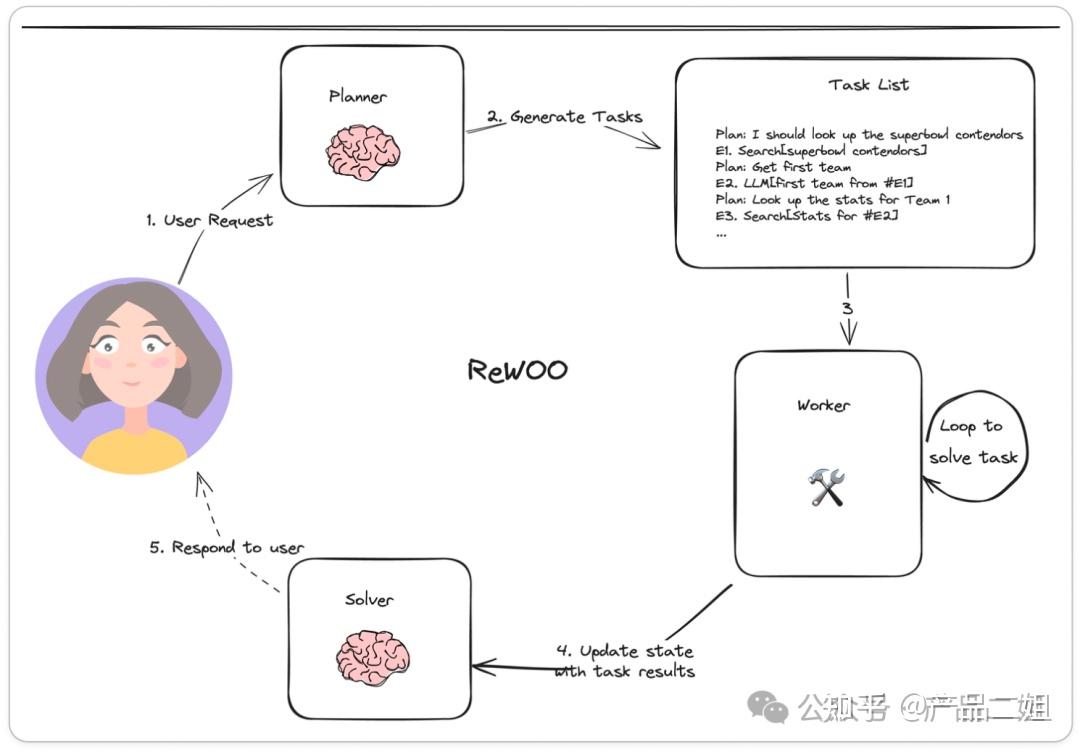
- Planner:负责生成相互依赖的“链式计划”,定义每步所依赖的上一步的输出。
- Worker:循环遍历每个任务,并将任务输出分配给相应的变量。当调用后续调用时,它还会用变量的结果替换变量。
- Solver:求解器将所有这些输出整合为最终答案。
优势在于:
- 高效性:去掉了显式的观察步骤,减少了交互的复杂性,提高了任务执行的效率。
- 连贯性:通过隐式观察,Agent 的行动更加连贯,避免了不必要的重复操作。
- 适应性:Agent 能够根据任务的复杂性和环境的变化灵活调整行动策略。
示例
Agent 完成审批流程的任务:
class REWOOAgent:
def __init__(self):
self.knowledge_base = {
"steps": [
"从部门 A 获取文件 a",
"拿着文件 a 去部门 B 办理文件 b",
"拿着文件 b 去部门 C 办理文件 c"
]
}
def reason(self, task, current_step):
# 推理:根据任务和当前步骤生成行动计划
if current_step == 0:
return"从部门 A 获取文件 a"
elif current_step == 1:
return"拿着文件 a 去部门 B 办理文件 b"
elif current_step == 2:
return"拿着文件 b 去部门 C 办理文件 c"
def act(self, action):
# 行动:执行具体的行动
if action == "从部门 A 获取文件 a":
return"文件 a 已获取"
elif action == "拿着文件 a 去部门 B 办理文件 b":
return"文件 b 已办理"
elif action == "拿着文件 b 去部门 C 办理文件 c":
return"文件 c 已办理"
def run(self, task):
# 主循环:推理 -> 行动 -> 隐式观察 -> 循环迭代
steps = self.knowledge_base["steps"]
for current_step in range(len(steps)):
action = self.reason(task, current_step)
action_result = self.act(action)
print(f"Action: {action}")
print(f"Result: {action_result}")
if"文件 c 已办理"in action_result:
print("任务完成:审批流程完成")
break
# 示例运行
agent = REWOOAgent()
agent.run("完成审批流程")
输出结果
Action: 从部门 A 获取文件 a
Result: 文件 a 已获取
Action: 拿着文件 a 去部门 B 办理文件 b
Result: 文件 b 已办理
Action: 拿着文件 b 去部门 C 办理文件 c
Result: 文件 c 已办理
任务完成:审批流程完成
REWOO 模式如何通过推理和行动的紧密协作,实现高效的任务执行。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如工作流程自动化、多步骤任务处理等,通过不断优化 Agent 的推理和行动策略,实现更加智能和高效的任务执行。
LLMCompiler 模式
LLMCompiler 模式原理
Compiler-编译含义:如何进行任务编排使得计算更有效率
- 原论文题目是《An LLM Compiler for Parallel Function Calling》
- 通过并行Function calling来提高效率,比如用户提问张译和吴京差几岁,planner 搜索张译年龄和搜索吴京年龄同时进行,最后合并即可。
LLMCompiler 模式是一种通过并行函数调用提高效率的 Agent 设计模式。该模式的核心在于优化任务的编排,使得 Agent 能够同时处理多个任务,从而显著提升任务处理的速度和效率。这种模式特别适用于需要同时处理多个子任务的复杂任务场景,例如多任务查询、数据并行处理等。
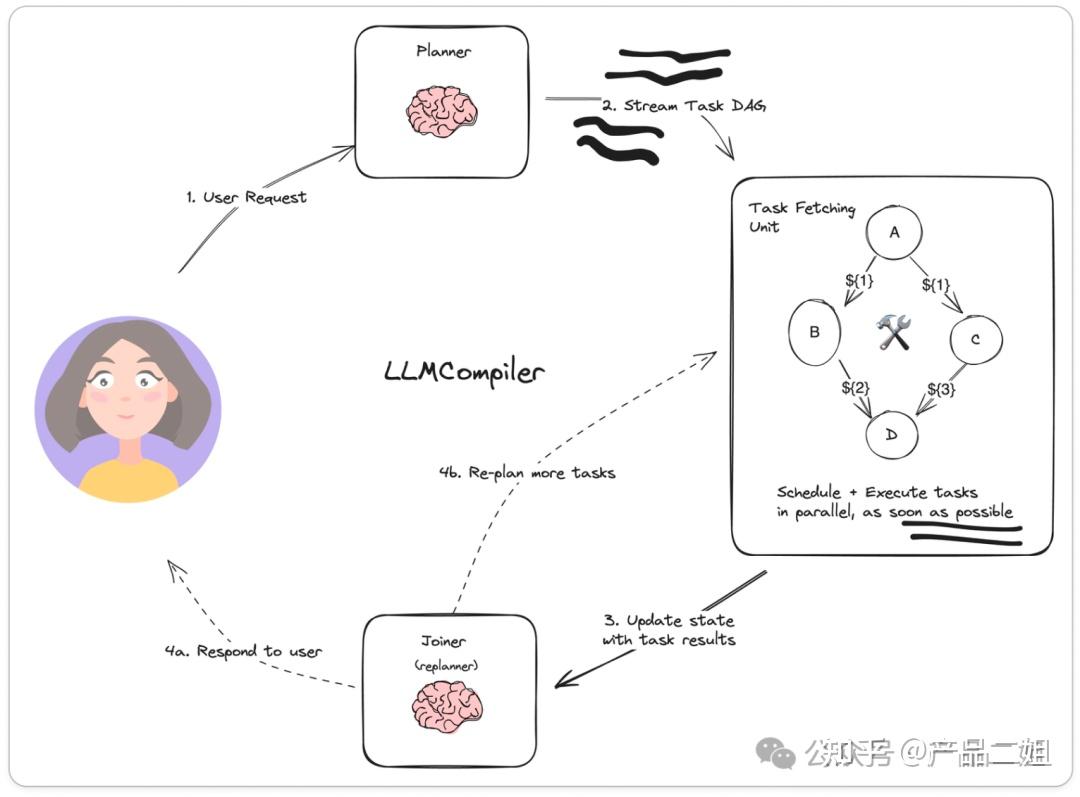
流程
LLMCompiler 模式的交互流程:
- 接收任务:Agent 接收到用户或系统的任务指令,任务可能包含多个子任务。
- 任务分解(Task Decomposition):Agent 将复杂任务分解为多个子任务,并确定这些子任务之间的依赖关系。
- 并行执行(Parallel Execution):Agent 根据子任务之间的依赖关系,将可以并行处理的子任务同时发送给多个执行器进行处理。
- 结果合并(Result Merging):各个执行器完成子任务后,Agent 将结果合并,形成最终的输出。
- 循环迭代(Iteration):如果任务需要进一步处理或调整,Agent 会根据当前结果重新分解任务,并继续并行执行和结果合并,直到任务完成。
优势在于:
- 高效率:通过并行处理多个子任务,显著减少了任务完成的总时间。
- 灵活性:能够根据任务的复杂性和子任务之间的依赖关系动态调整任务分解和执行策略。
- 可扩展性:适用于大规模任务和复杂任务场景,能够有效利用多核处理器和分布式计算资源。
架构上有一个 Planner(规划器),有一个 Jointer(合并器)
示例
Agent 同时查询两个人的年龄并计算年龄差的任务:
import concurrent.futures
class LLMCompilerAgent:
def __init__(self):
self.knowledge_base = {
"person_age": {
"张译": 40,
"吴京": 48
}
}
def query_age(self, name):
# 查询年龄
return self.knowledge_base["person_age"].get(name, "未知")
def calculate_age_difference(self, age1, age2):
# 计算年龄差
try:
return abs(int(age1) - int(age2))
except ValueError:
return"无法计算年龄差"
def run(self, task):
# 主流程:任务分解 -> 并行执行 -> 结果合并 -> 循环迭代
if task == "查询张译和吴京的年龄差":
# 任务分解
tasks = ["查询张译的年龄", "查询吴京的年龄"]
results = {}
# 并行执行
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = {executor.submit(self.query_age, name): name for name in ["张译", "吴京"]}
for future in concurrent.futures.as_completed(futures):
name = futures[future]
try:
results[name] = future.result()
except Exception as e:
results[name] = f"查询失败: {e}"
# 结果合并
age_difference = self.calculate_age_difference(results["张译"], results["吴京"])
print(f"张译的年龄: {results['张译']}")
print(f"吴京的年龄: {results['吴京']}")
print(f"年龄差: {age_difference}")
# 示例运行
agent = LLMCompilerAgent()
agent.run("查询张译和吴京的年龄差")
输出结果
张译的年龄: 40
吴京的年龄: 48
年龄差: 8
LLMCompiler 模式如何通过任务分解、并行执行和结果合并来高效完成任务。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如多任务查询、数据并行处理等,通过不断优化 Agent 的任务分解和并行执行策略,实现更加智能和高效的任务执行。
Basic Reflection 模式
Basic Reflection 模式原理
Basic Reflection 类比学生(Generator)写作业,老师(Reflector)来批改建议,学生根据批改建议来修改,如此反复。
Basic Reflection 模式是一种通过反思和修正来优化 Agent 行为的设计模式。在这种模式下,Agent 的行为可以分为两个阶段:生成初始响应和对初始响应进行反思与修正。
这种模式的核心:通过不断的自我评估和改进,使 Agent 的输出更加准确和可靠。
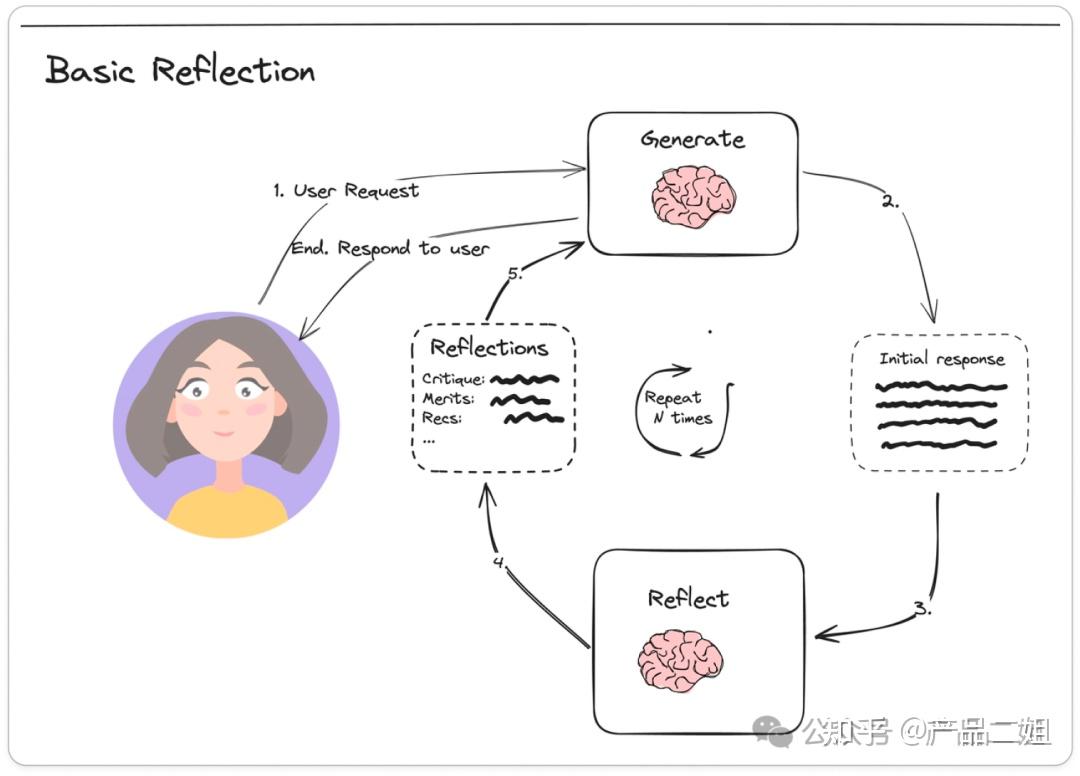
流程
Basic Reflection 模式的交互流程如下:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 生成初始响应(Initial Response):Agent 根据任务生成一个初步的回答或解决方案。
- 反思(Reflection):Agent 对初始响应进行评估,检查是否存在错误、遗漏或可以改进的地方。
- 修正(Revision):根据反思的结果,Agent 对初始响应进行修正,生成最终的输出。
- 循环迭代(Iteration):如果任务需要进一步优化,Agent 会重复反思和修正的过程,直到输出满足要求。
优势在于:
- 提高准确性:通过反思和修正,Agent 能够减少错误和遗漏,提高输出的准确性。
- 增强适应性:Agent 能够根据不同的任务和环境调整自己的行为策略,增强适应性。
- 提升用户体验:通过不断优化输出,Agent 能够提供更高质量的服务,提升用户体验。
架构上有一个 Generator,一个 Reflector
示例
Agent 回答数学问题的任务:
class BasicReflectionAgent:
def __init__(self):
self.knowledge_base = {
"math_problems": {
"1+1": 2,
"2*2": 4,
"3*3": 9
}
}
def initial_response(self, task):
# 生成初始响应:根据任务生成初步回答
return self.knowledge_base["math_problems"].get(task, "未知")
def reflect(self, response):
# 反思:检查初始响应是否准确
if response == "未知":
return"需要进一步查找答案"
else:
return"答案正确"
def revise(self, response, reflection):
# 修正:根据反思结果调整响应
if reflection == "需要进一步查找答案":
return"抱歉,我没有找到答案"
else:
return response
def run(self, task):
# 主流程:生成初始响应 -> 反思 -> 修正 -> 循环迭代
initial_response = self.initial_response(task)
reflection = self.reflect(initial_response)
final_response = self.revise(initial_response, reflection)
print(f"Initial Response: {initial_response}")
print(f"Reflection: {reflection}")
print(f"Final Response: {final_response}")
# 示例运行
agent = BasicReflectionAgent()
agent.run("1+1")
agent.run("5*5")
输出结果
Initial Response: 2
Reflection: 答案正确
Final Response: 2
Initial Response: 未知
Reflection: 需要进一步查找答案
Final Response: 抱歉,我没有找到答案
Basic Reflection 模式如何通过生成初始响应、反思和修正的过程来优化 Agent 的行为。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如智能客服、自动问答系统等,通过不断优化 Agent 的反思和修正策略,实现更加智能和高效的任务执行。
Reflexion 模式
Reflexion 模式是 Basic Reflection 升级版
- 论文《Reflexion: Language Agents with Verbal Reinforcement Learning》
- 和 Basic reflection 相比,引入了外部数据来评估回答是否准确,并强制生成响应中多余和缺失的方面,这使得反思的内容更具建设性。
Reflexion 是强化学习框架,由Shinn等人提出,通过生成语言反馈(口头强化)帮助智能体从错误中学习,而非传统标量奖励。Reflexion 模仿人类反思过程,让模型在尝试后获得具体改进建议,如”上次搜索范围太宽,下次更具体”。
Reflexion 模式是一种基于强化学习的 Agent 设计模式,旨在通过引入外部数据评估和自我反思机制,进一步优化 Agent 的行为和输出。
与 Basic Reflection 模式相比,Reflexion 模式不仅对初始响应进行反思和修正,还通过外部数据来评估回答的准确性和完整性,从而生成更具建设性的修正建议。
Reflexion构建在ReAct基础上,添加评估和反思机制,形成闭环:
- 参与者(Actor):基于ReAct或CoT生成行动轨迹。
- 评估者(Evaluator):对轨迹打分,判断成功或失败。
- 自我反思(Self-Reflection):核心组件,生成语言反馈并存入长期记忆,指导下次行动。
工作流程:行动 → 评估 → 反思 → 迭代。
通过滑动窗口记忆,Reflexion保留反思内容,实现持续优化。
Reflexion 模式的交互流程如下:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 生成初始响应(Initial Response):Agent 根据任务生成一个初步的回答或解决方案。
- 外部评估(External Evaluation):引入外部数据或标准,对初始响应进行评估,检查是否存在错误、遗漏或可以改进的地方。
- 反思(Reflection):Agent 根据外部评估的结果,对初始响应进行自我反思,识别问题所在。
- 修正(Revision):根据反思的结果,Agent 对初始响应进行修正,生成最终的输出。
- 循环迭代(Iteration):如果任务需要进一步优化,Agent 会重复外部评估、反思和修正的过程,直到输出满足要求。
分析
适用场景与局限性
Reflexion适合需要试错学习的任务,如决策、推理和编程。
- 计算效率高,无需模型微调,提供详细反馈和高可解释性。
- 但局限:依赖评估准确性、简单记忆机制,以及在非确定性编程任务中的挑战
优势在于:
- 提高准确性:通过外部数据评估和自我反思,Agent 能够更准确地识别错误和遗漏,从而提高输出的准确性。
- 增强适应性:Agent 能够根据不同的任务和环境调整自己的行为策略,增强适应性。
- 提升用户体验:通过不断优化输出,Agent 能够提供更高质量的服务,提升用户体验。
- 强化学习:引入外部数据评估机制,使 Agent 的学习过程更加科学和有效,能够更好地适应复杂任务和动态环境。
架构上
- Responder:自带批判式思考的陈述 Critique;
- Revisor:以 Responder 中的批判式思考作为上下文参考对初始回答做修改。
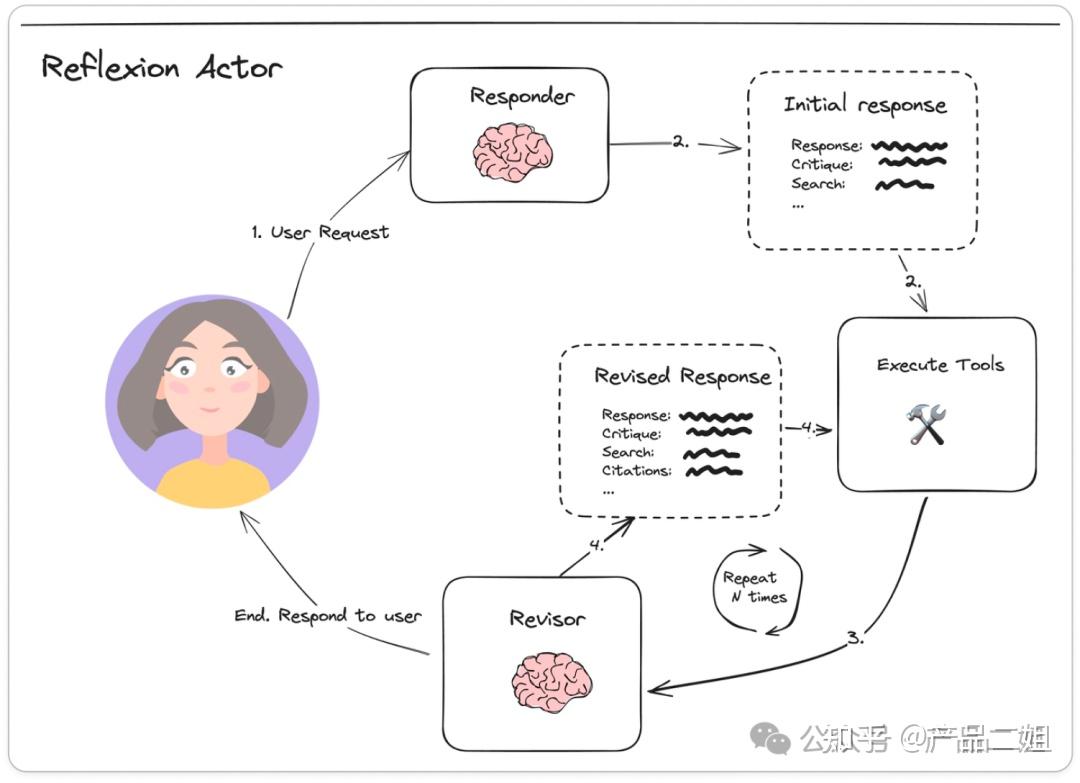
ReAct与Reflexion的比较与结合
- ReAct聚焦于即时推理-行动循环,适合实时任务;
- Reflexion扩展为学习闭环,强调从失败中迭代,适用于需要优化的场景。
- 两者结合(如在Reflexion中使用ReAct作为Actor)可发挥最大潜力:ReAct提供基础机制,Reflexion添加反思层,提升长期性能。
示例
Agent 回答数学问题的任务:
class ReflexionAgent:
def __init__(self):
self.knowledge_base = {
"math_problems": {
"1+1": 2,
"2*2": 4,
"3*3": 9
}
}
self.external_data = {
"1+1": 2,
"2*2": 4,
"3*3": 9,
"5*5": 25
}
def initial_response(self, task):
# 生成初始响应:根据任务生成初步回答
return self.knowledge_base["math_problems"].get(task, "未知")
def external_evaluation(self, response, task):
# 外部评估:检查初始响应是否准确
correct_answer = self.external_data.get(task, "未知")
if response == correct_answer:
return"答案正确"
else:
returnf"答案错误,正确答案是 {correct_answer}"
def reflect(self, evaluation):
# 反思:根据外部评估的结果进行自我反思
if"答案错误"in evaluation:
return"需要修正答案"
else:
return"无需修正"
def revise(self, response, reflection, evaluation):
# 修正:根据反思结果调整响应
if reflection == "需要修正答案":
correct_answer = evaluation.split("正确答案是 ")[1]
return correct_answer
else:
return response
def run(self, task):
# 主流程:生成初始响应 -> 外部评估 -> 反思 -> 修正 -> 循环迭代
initial_response = self.initial_response(task)
evaluation = self.external_evaluation(initial_response, task)
reflection = self.reflect(evaluation)
final_response = self.revise(initial_response, reflection, evaluation)
print(f"Initial Response: {initial_response}")
print(f"External Evaluation: {evaluation}")
print(f"Reflection: {reflection}")
print(f"Final Response: {final_response}")
# 示例运行
agent = ReflexionAgent()
agent.run("1+1")
agent.run("5*5")
输出结果
Initial Response: 2
External Evaluation: 答案正确
Reflection: 无需修正
Final Response: 2
Initial Response: 未知
External Evaluation: 答案错误,正确答案是 25
Reflection: 需要修正答案
Final Response: 25
Reflexion 模式如何通过生成初始响应、外部评估、反思和修正的过程来优化 Agent 的行为。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如智能客服、自动问答系统等,通过不断优化 Agent 的反思和修正策略,实现更加智能和高效的任务执行。
Language Agent Tree Search 模式
Language Agent Tree Search 模式原理
Language Agent Tree Search(LATS)模式是一种融合了树搜索、ReAct、Plan & Solve 以及反思机制的 Agent 设计模式。它通过多轮迭代和树搜索的方式,对可能的解决方案进行探索和评估,从而找到最优解。
- LATS 论文《Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models》
- Tree search + ReAct+Plan&solve 的融合体。在原作的图中,LATS 中通过树搜索的方式进行 Reward(强化学习的思路),同时还会融入 Reflection,从而拿到最佳结果。
LATS = Tree search + ReAct+Plan&solve + Reflection + 强化学习
这种模式特别适用于复杂任务的解决,尤其是在需要对多种可能性进行评估和选择的场景中。
流程
LATS 模式的交互流程如下:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 树搜索(Tree Search):Agent 构建一个搜索树,将任务分解为多个子任务,并探索所有可能的解决方案路径。
- ReAct 交互:在树搜索的过程中,Agent 使用 ReAct 模式对每个子任务进行推理和行动,获取反馈信息。
- Plan & Solve 执行:Agent 根据树搜索的结果,生成一个多步计划,并逐步执行计划中的每个步骤。
- 反思与修正(Reflection & Revision):Agent 对执行结果进行反思,评估每个步骤的正确性和效率,根据反思结果对计划进行修正。
- 循环迭代(Iteration):Agent 重复树搜索、ReAct 交互、Plan & Solve 执行和反思修正的过程,直到找到最优解或任务完成。
优势在于:
- 全局优化:通过树搜索,Agent 能够全面探索所有可能的解决方案,找到最优路径。
- 灵活性:结合 ReAct 和 Plan & Solve 模式,Agent 能够灵活应对任务中的动态变化。
- 准确性:通过反思机制,Agent 能够不断优化自己的行为,提高任务完成的准确性。
- 适应性:适用于复杂任务和多步骤任务,能够有效管理任务的各个阶段。
架构上,就是多轮的 Basic Reflection, 多个 Generator 和 Reflector。
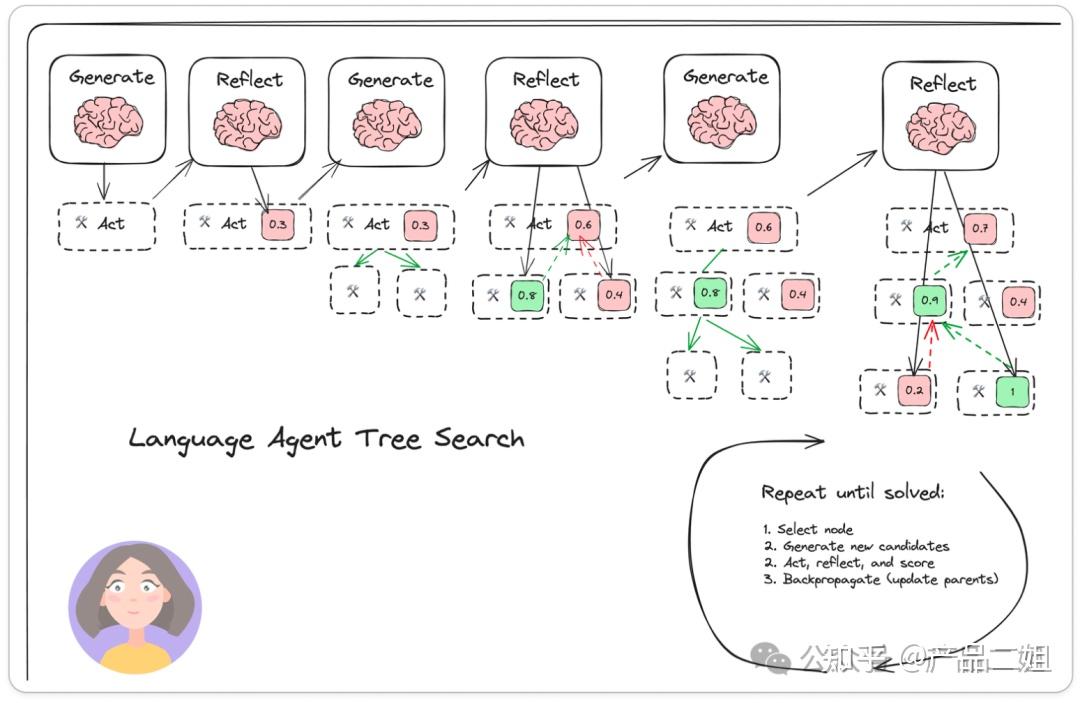
LATS 模式的交互流程:
+-------------------+
| 接收任务 |
+-------------------+
|
v
+-------------------+
| 树搜索(Tree Search)|
+-------------------+
|
v
+-------------------+
| ReAct 交互(ReAct Interaction)|
+-------------------+
|
v
+-------------------+
| Plan & Solve 执行(Plan & Solve Execution)|
+-------------------+
|
v
+-------------------+
| 反思与修正(Reflection & Revision)|
+-------------------+
|
v
+-------------------+
| 循环迭代 |
+-------------------+
示例
Agent 解决一个复杂的任务,例如规划一条旅行路线并优化行程:
class LATSNode:
def __init__(self, state, parent=None, action=None):
self.state = state
self.parent = parent
self.action = action
class LATSAgent:
def __init__(self):
self.knowledge_base = {
"cities": ["北京", "上海", "广州", "深圳"],
"distances": {
("北京", "上海"): 1300,
("北京", "广州"): 2000,
("北京", "深圳"): 2200,
("上海", "广州"): 1200,
("上海", "深圳"): 1500,
("广州", "深圳"): 100
}
}
def tree_search(self, start, goal):
# 树搜索:构建搜索树并找到最优路径
open_list = [LATSNode(start)]
while open_list:
current_node = open_list.pop(0)
if current_node.state == goal:
return self.get_path(current_node)
for city in self.knowledge_base["cities"]:
if city != current_node.state:
new_node = LATSNode(city, current_node, f"前往 {city}")
open_list.append(new_node)
returnNone
def get_path(self, node):
# 获取路径
path = []
while node:
path.append(node.state)
node = node.parent
return path[::-1]
def react_interaction(self, path):
# ReAct 交互:对每个步骤进行推理和行动
observations = []
for i in range(len(path) - 1):
start = path[i]
end = path[i + 1]
distance = self.knowledge_base["distances"].get((start, end), 0)
observations.append(f"从 {start} 到 {end} 的距离是 {distance} 公里")
return observations
def plan_and_solve(self, observations):
# Plan & Solve 执行:根据观察结果生成计划并执行
plan = []
for observation in observations:
plan.append(f"根据 {observation},调整行程")
return plan
def reflect_and_revise(self, plan):
# 反思与修正:评估计划并进行修正
revised_plan = []
for step in plan:
if"调整行程"in step:
revised_plan.append("优化行程")
return revised_plan
def run(self, start, goal):
# 主流程:树搜索 -> ReAct 交互 -> Plan & Solve 执行 -> 反思与修正 -> 循环迭代
path = self.tree_search(start, goal)
if path:
observations = self.react_interaction(path)
plan = self.plan_and_solve(observations)
revised_plan = self.reflect_and_revise(plan)
print(f"路径: {path}")
print(f"观察结果: {observations}")
print(f"初始计划: {plan}")
print(f"修正后的计划: {revised_plan}")
else:
print("未找到路径")
# 示例运行
agent = LATSAgent()
agent.run("北京", "深圳")
输出结果
路径: ['北京', '上海', '深圳']
观察结果: ['从 北京 到 上海 的距离是 1300 公里', '从 上海 到 深圳 的距离是 1500 公里']
初始计划: ['根据 从 北京 到 上海 的距离是 1300 公里,调整行程', '根据 从 上海 到 深圳 的距离是 1500 公里,调整行程']
修正后的计划: ['优化行程', '优化行程']
LATS 模式如何通过树搜索、ReAct 交互、Plan & Solve 执行和反思修正的多轮迭代来优化 Agent 的行为。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如路径规划、资源优化等,通过不断优化 Agent 的行为策略,实现更加智能和高效的任务执行。
Self-Discover 模式
Self-Discover 模式原理
Self-Discover 模式是一种让 Agent 在更小粒度上对任务本身进行反思的设计模式。
这种模式的核心在于通过自我发现和自我调整,使 Agent 能够更深入地理解任务的本质和需求,从而优化行为和输出。
- 与 Reflexion 模式相比,Self-Discover 模式不仅关注任务的执行结果,还注重任务本身的逻辑和结构,通过自我发现潜在问题和改进点,实现更深层次的优化。
流程
Self-Discover 模式的交互流程如下:
- 接收任务:Agent 接收到用户或系统的任务指令。
- 任务分析(Task Analysis):Agent 对任务进行初步分析,识别任务的关键要素和目标。
- 自我发现(Self-Discovery):Agent 对任务本身进行反思,发现潜在的问题、遗漏或可以改进的地方。这一步骤包括对任务逻辑、数据需求和目标的深入分析。
- 调整策略(Strategy Adjustment):根据自我发现的结果,Agent 调整任务执行策略,优化行为路径。
- 执行与反馈(Execution & Feedback):Agent 按照调整后的策略执行任务,并收集反馈信息,进一步优化行为。
- 循环迭代(Iteration):Agent 重复自我发现、调整策略和执行任务的过程,直到任务完成且达到最优解。
优势在于:
- 深度优化:通过自我发现和调整策略,Agent 能够深入理解任务的本质,实现更深层次的优化。
- 适应性强:Agent 能够根据任务的变化和复杂性灵活调整行为策略,增强适应性。
- 提高效率:通过不断优化任务执行路径,Agent 能够减少不必要的操作,提高任务完成的效率。
- 提升用户体验:通过提供更高质量的服务,Agent 能够更好地满足用户需求,提升用户体验。
Self-discover 的核心是让大模型在更小粒度上 task 本身进行反思,比如前文中的 Plan&Slove 是反思 task 是不是需要补充,而 Self-discover 是对 task 本身进行反思
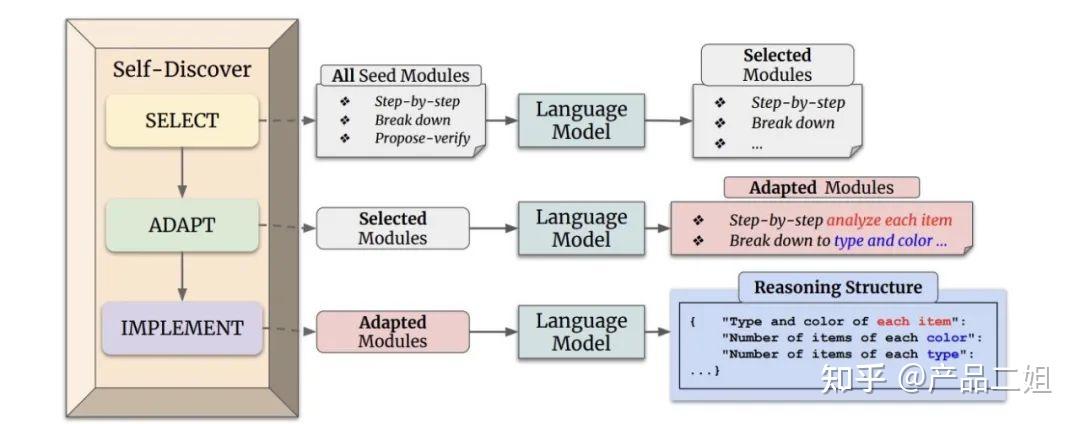
- Selector: 从众多反省方式中选择合适的反省方式;
- Adaptor: 使用选择的反省方式进行反省;
- Implementor: 反省后进行重新 Reasoning;
Self-Discover 模式的交互流程:
+-------------------+
| 接收任务 |
+-------------------+
|
v
+-------------------+
| 任务分析(Task Analysis)|
+-------------------+
|
v
+-------------------+
| 自我发现(Self-Discovery)|
+-------------------+
|
v
+-------------------+
| 调整策略(Strategy Adjustment)|
+-------------------+
|
v
+-------------------+
| 执行与反馈(Execution & Feedback)|
+-------------------+
|
v
+-------------------+
| 循环迭代 |
+-------------------+
示例
Self-Discover 模式代码示例,用于实现一个 Agent 优化一个简单的数据分类任务:
class SelfDiscoverAgent:
def __init__(self):
self.knowledge_base = {
"data": [
{"feature1": 1, "feature2": 2, "label": "A"},
{"feature1": 2, "feature2": 3, "label": "B"},
{"feature1": 3, "feature2": 4, "label": "A"},
{"feature1": 4, "feature2": 5, "label": "B"}
],
"initial_strategy": "simple_threshold"
}
def task_analysis(self, task):
# 任务分析:识别任务的关键要素和目标
returnf"任务分析:{task}"
def self_discovery(self, analysis):
# 自我发现:发现潜在的问题和改进点
if self.knowledge_base["initial_strategy"] == "simple_threshold":
return"发现:初始策略过于简单,可能无法准确分类"
else:
return"无需改进"
def strategy_adjustment(self, discovery):
# 调整策略:根据自我发现的结果优化行为路径
if"过于简单"in discovery:
return"调整策略:采用更复杂的分类算法"
else:
return"保持原策略"
def execute_and_feedback(self, strategy):
# 执行与反馈:执行任务并收集反馈信息
if strategy == "调整策略:采用更复杂的分类算法":
# 假设新策略提高了分类准确率
return"执行结果:分类准确率提高到90%"
else:
return"执行结果:分类准确率60%"
def run(self, task):
# 主流程:任务分析 -> 自我发现 -> 调整策略 -> 执行与反馈 -> 循环迭代
analysis = self.task_analysis(task)
discovery = self.self_discovery(analysis)
strategy = self.strategy_adjustment(discovery)
feedback = self.execute_and_feedback(strategy)
print(f"Task Analysis: {analysis}")
print(f"Self-Discovery: {discovery}")
print(f"Strategy Adjustment: {strategy}")
print(f"Execution & Feedback: {feedback}")
# 示例运行
agent = SelfDiscoverAgent()
agent.run("数据分类任务")
输出结果
Task Analysis: 任务分析:数据分类任务
Self-Discovery: 发现:初始策略过于简单,可能无法准确分类
Strategy Adjustment: 调整策略:采用更复杂的分类算法
Execution & Feedback: 执行结果:分类准确率提高到90%
Self-Discover 模式如何通过任务分析、自我发现、调整策略和执行反馈的多轮迭代来优化 Agent 的行为。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如机器学习模型优化、智能决策系统等,通过不断优化 Agent 的行为策略,实现更加智能和高效的任务执行。
Storm 模式
Storm 模式原理
Storm 模式是一种专注于从零开始生成复杂内容的 Agent 设计模式,特别适用于需要系统化构建和优化内容生成的任务,例如生成类似维基百科的文章、报告或知识库。其核心在于通过逐步构建大纲,并根据大纲逐步丰富内容,从而生成高质量、结构化的文本。
Storm 论文《 Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models》
从零生成一篇像维基百科的文章。主要思路是先让 agent 利用外部工具搜索生成大纲,然后再生成大纲里的每部分内容
流程
Storm 模式的交互流程:
- 接收任务:Agent 接收到用户或系统的任务指令,明确需要生成的内容主题。
- 构建大纲(Outline Construction):Agent 根据任务主题生成一个详细的大纲,明确内容的结构和各个部分的主题。
- 内容生成(Content Generation):Agent 根据大纲逐步生成每个部分的具体内容,确保内容的连贯性和准确性。
- 内容优化(Content Optimization):Agent 对生成的内容进行优化,包括语言润色、逻辑调整和信息补充,以提高内容的质量。
- 循环迭代(Iteration):Agent 重复内容生成和优化的过程,直到内容满足用户需求或达到预设的质量标准。
优势在于:
- 系统化生成:通过构建大纲和逐步填充内容,确保生成内容的结构化和系统性。
- 高质量输出:通过多轮优化,Agent 能够生成高质量、连贯且准确的内容。
- 适应性强:适用于多种内容生成任务,包括但不限于文章、报告、知识库等。
- 可扩展性:可以根据任务的复杂性和需求灵活调整大纲和内容生成策略。
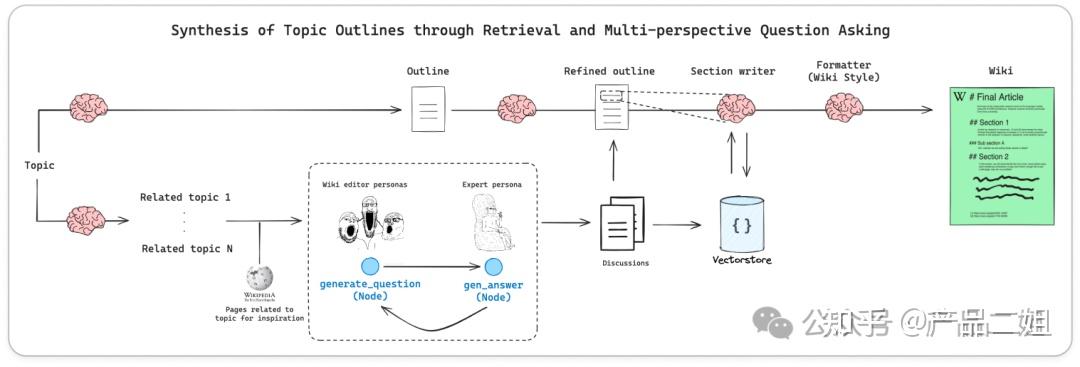
Storm 模式的交互流程可以用以下图示来表示:
+-------------------+
| 接收任务 |
+-------------------+
|
v
+-------------------+
| 构建大纲(Outline Construction)|
+-------------------+
|
v
+-------------------+
| 内容生成(Content Generation)|
+-------------------+
|
v
+-------------------+
| 内容优化(Content Optimization)|
+-------------------+
|
v
+-------------------+
| 循环迭代 |
+-------------------+
示例
Storm 模式代码示例,用于实现一个 Agent 生成一篇关于“人工智能”的维基百科风格文章:
class StormAgent:
def __init__(self):
self.knowledge_base = {
"topics": {
"人工智能": {
"定义": "人工智能(Artificial Intelligence, AI)是计算机科学的一个分支,旨在创建能够执行复杂任务的智能机器。",
"历史": "人工智能的发展可以追溯到20世纪40年代,当时科学家们开始探索如何使计算机模拟人类智能。",
"应用": "人工智能在医疗、金融、教育、交通等多个领域都有广泛的应用。",
"未来": "未来,人工智能有望在更多领域实现突破,推动社会的智能化发展。"
}
}
}
def outline_construction(self, topic):
# 构建大纲:根据主题生成大纲
outline = [
"定义",
"历史",
"应用",
"未来"
]
return outline
def content_generation(self, topic, section):
# 内容生成:根据大纲部分生成具体内容
return self.knowledge_base["topics"][topic][section]
def content_optimization(self, content):
# 内容优化:对生成的内容进行润色和调整
optimized_content = content.replace("有望", "有巨大潜力")
return optimized_content
def run(self, topic):
# 主流程:构建大纲 -> 内容生成 -> 内容优化 -> 循环迭代
outline = self.outline_construction(topic)
article = {}
for section in outline:
content = self.content_generation(topic, section)
optimized_content = self.content_optimization(content)
article[section] = optimized_content
return article
# 示例运行
agent = StormAgent()
article = agent.run("人工智能")
for section, content in article.items():
print(f"### {section}")
print(content)
输出结果
### 定义
人工智能(Artificial Intelligence, AI)是计算机科学的一个分支,旨在创建能够执行复杂任务的智能机器。
### 历史
人工智能的发展可以追溯到20世纪40年代,当时科学家们开始探索如何使计算机模拟人类智能。
### 应用
人工智能在医疗、金融、教育、交通等多个领域都有广泛的应用。
### 未来
未来,人工智能有巨大潜力在更多领域实现突破,推动社会的智能化发展。
Storm 模式如何通过构建大纲、内容生成和内容优化的多轮迭代来生成高质量的文章。这种模式在实际应用中可以扩展到更复杂的任务和场景,例如生成研究报告、知识库条目等,通过不断优化 Agent 的内容生成和优化策略,实现更加智能和高效的任务执行。
设计经验
RL
【2025-4-21】强化学习之于 AI Agent,是灵魂、还是包袱?
如何构建 Agent? 公认的技术路径:
- 一是拥有基础模型是构建 Agent 的起点
- 二是 RL 是赋予 Agent 连贯行为和目标感的“灵魂”
Agent 不能仅靠 Workflow 搭建
支持
Pokee AI 创始人、前 Meta AI应用强化学习团队负责人朱哲清,对 RL 始终坚定信仰的“长期主义者”。
- RL 核心优势在于目标驱动,不是简单地响应输入,而是围绕清晰目标,进行策略规划和任务执行。
- 一旦缺少了 RL 参与,Agent 就容易陷入“走一步看一步”的模式,缺乏内在驱动力,最终难以真正胜任复杂任务的完成。
真正的 Agent 核心: 执行力与影响力。
如果一个系统只是单纯地生成内容或文件,那更像是一个普通的工具,而非真正的 Agent。
而当它能够对环境产生不可逆的影响时,它才具备了真正的执行性。
只有与环境发生深度交互,且产生的影响不可逆,才能称之为真正的 Agent。
带有 Workflow 的产品是 Agent 发展的初期形态。
- 虽然有明确目标和流程,但仍需要人为干预。
- 真正的 Agent 不仅仅是按照预设的工具来操作,而是能够根据给定目标,自主选择和使用工具完成任务。
反对
香港科技大学(广州)博士生,DeepWisdom 研究员张佳钇对 RL 持保留态度, 追求跨环境的智能体:
- 现有RL技术虽能在特定环境中提升Agent能力,但这本质上是“任务特化”而非真正的智能泛化。
- 在实现跨环境数据的有效统一表征之前,RL面临的跨环境学习困境难以突破。
用 RL 对语言模型进行环境内优化本身没有问题,但问题在于:
- 目前很多研究使用的仍是能力较弱的基础模型(base model),即便训练到“最优”,也只是对单一环境的适配,缺乏跨环境的泛化能力。
- “使用 RL 训出一个适应某个环境的 Agent 已经很近,但距离训出通用跨环境的 Agent 还有很长的一段路要走。”
Agent 发展过程分为六个阶段:
- 第一阶段:构成 Agent 系统的最底层节点,语言模型被调用来执行基本任务;
- 第二阶段:在底层调用节点基础上,构建出固定的 agentic workflow,每个节点的角色与职责预设明确;
- 第三阶段:底层组件演化为具有自身逻辑和动作空间的 autonomous agent;
- 第四阶段:多个 autonomous agents 通过主动交流机制构建系统,形成 Multi Autonomous Agent Systems(MAS);
- 第五阶段:底层组件拥有与人类一致的环境空间,成为 Foundation Agent,开始协助人类跨环境完成任务;
- 第六阶段:Foundation Agent 基于人类目标与其他 Agent 产生联系,演化出具备自主协作能力的Foundation Agents 网络。真正实现以人类目标为核心的多智能体社会,达到Agent与人类共生的范式。
目前大多数 Agent 产品公司仍停留在第二到第三阶段之间,尚未迈过第四阶段的门槛,而“最大的瓶颈在于当前 Agent 仍严重依赖人类预设的 workflow 节点,缺乏真正的自主性。”
Anthropic
详见站内专题: LLM应用范式
从2025年2月发布”如何构建有效 Agent”的指南,到推出 Model Context Protocol(MCP),再到 Claude Code 和最新 Claude Agents SDK
Anthropic 在 2024 年走完了”Agents 之年”。但现在,他们却要告诉你一个完全不同的故事。
【2025-2-】Building Effective Agents
Anthropic 工程师 Barry Zhang 在 AI Engineer 工作坊分享: “如何构建有效的 Agent”
- 【2024-12-19】Anthropic 官方 Building Effective Agents
- 【2025-4-5】How We Build Effective Agents: Barry Zhang, Anthropic
Anthropic 官方 Building Effective Agents
Agent进化之路:
- Building block: The augmented LLM
- Workflow: Prompt chaining
- Workflow: Routing
- Workflow: Parallelization
- Workflow: Orchestrator-workers
- Workflow: Evaluator-optimizer
- Agent
| Type | 中文 | 示意图 |
|---|---|---|
| Building block: The augmented LLM | 堆积木: LLM增强 | 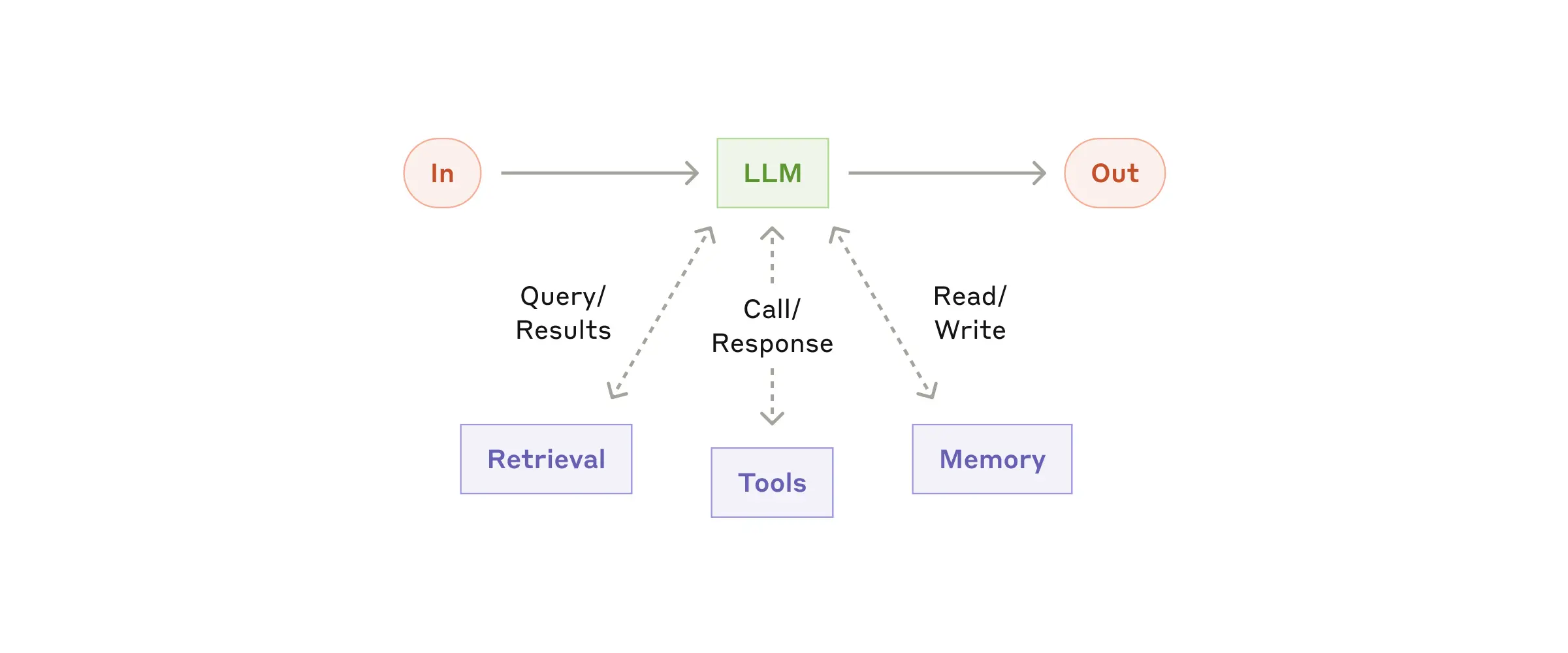 |
| Workflow: Prompt chaining | 工作流: 提示链 | 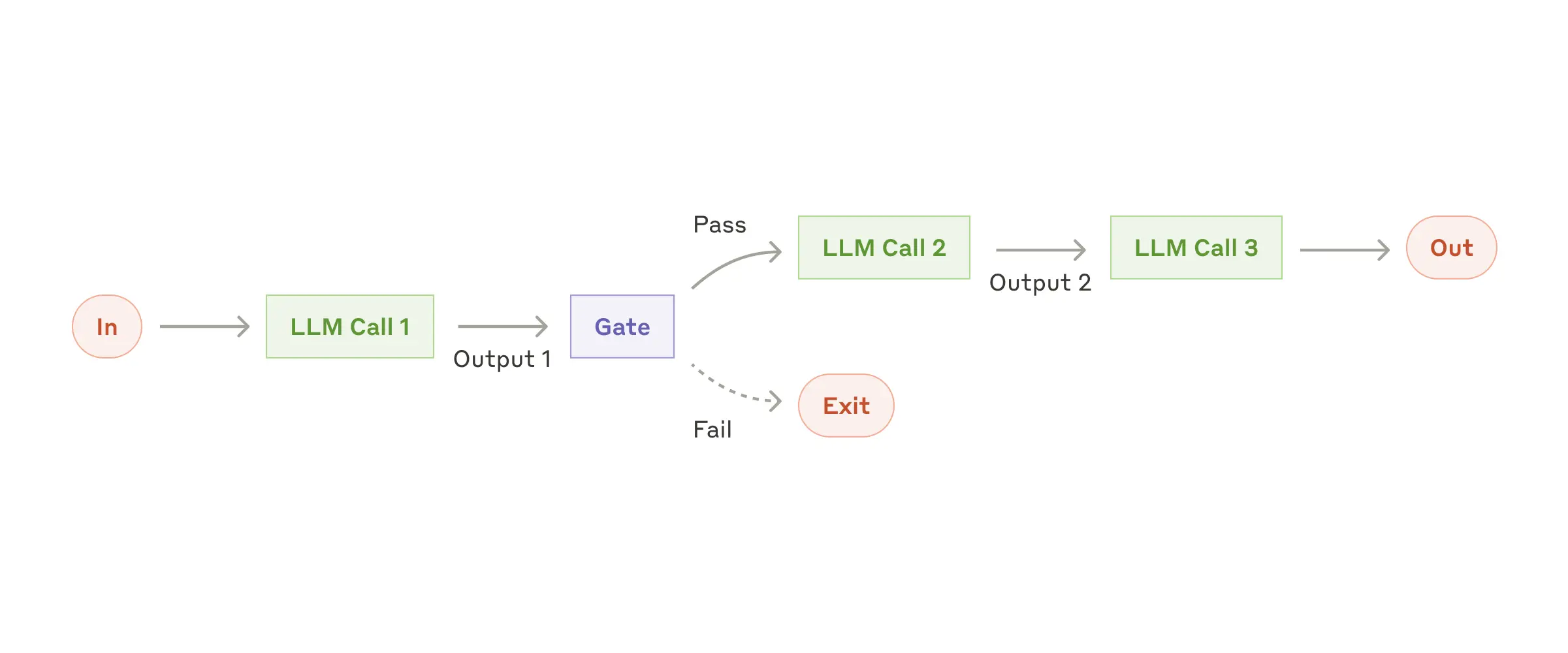 |
| Workflow: Routing | 工作流: 路由 | 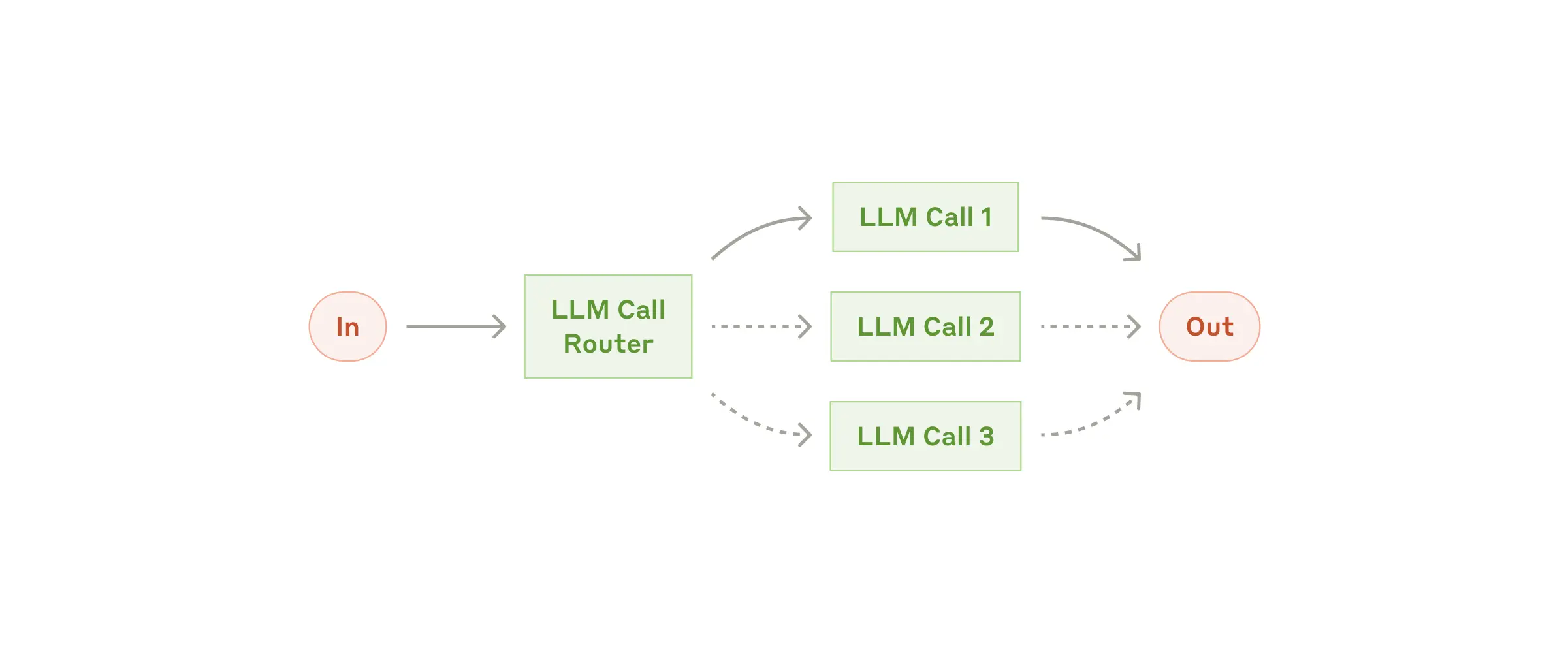 |
| Workflow: Parallelization | 工作流: 并行 | 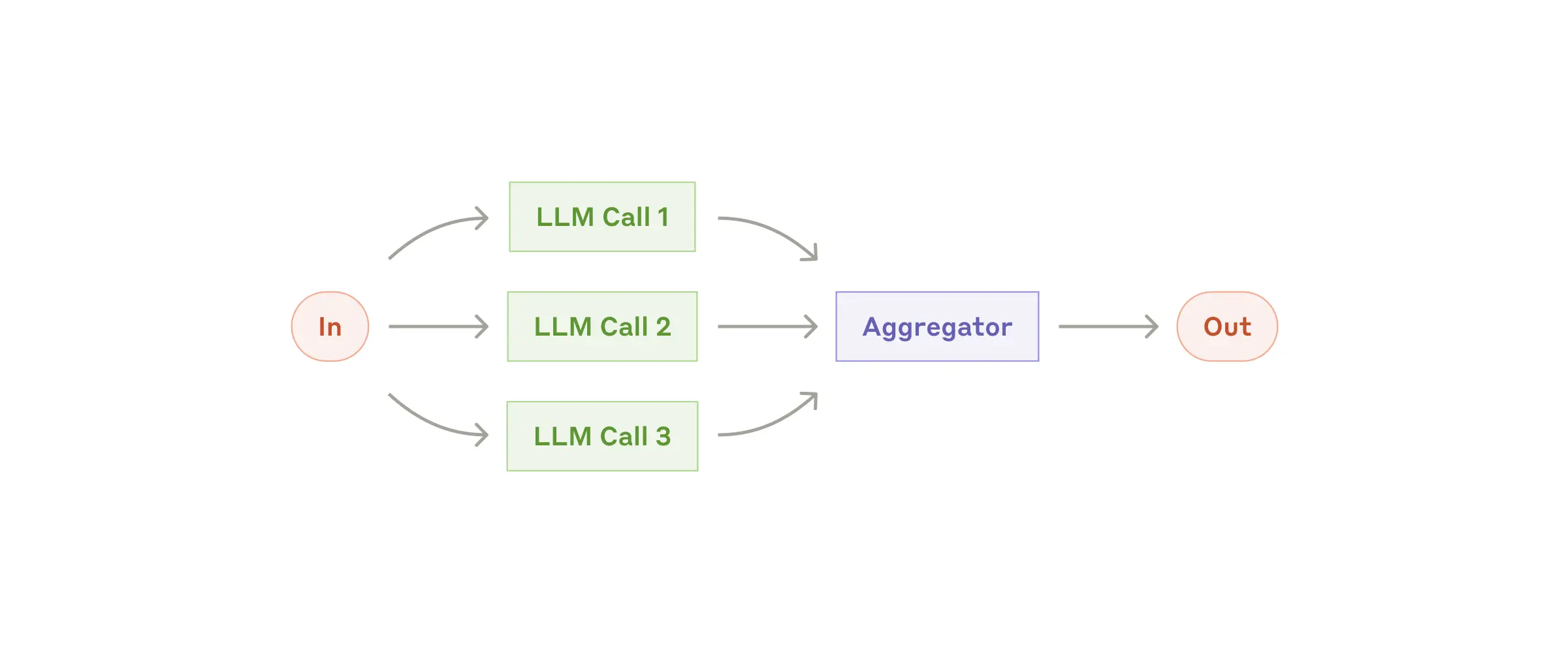 |
| Workflow: Orchestrator-workers | 工作流: 主从 | 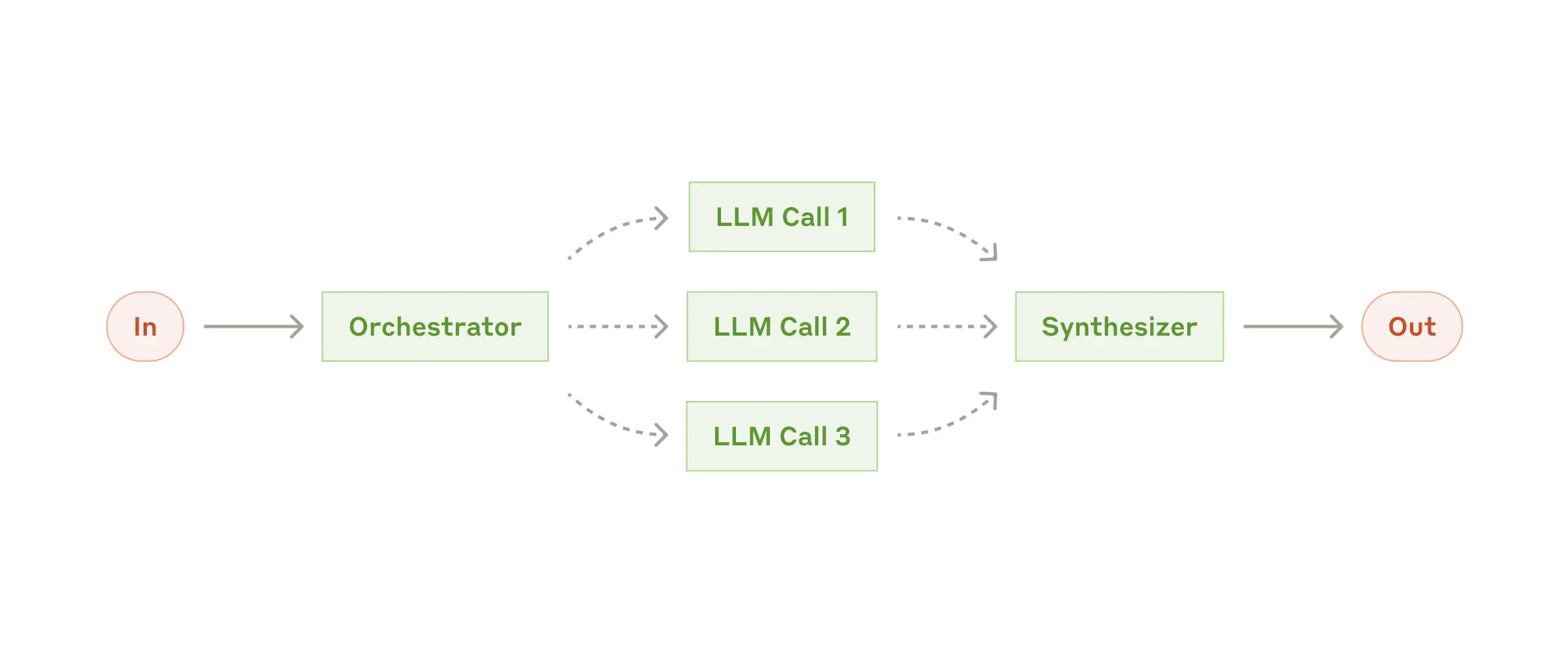 |
| Workflow: Evaluator-optimizer | 工作流: 评估优化 | 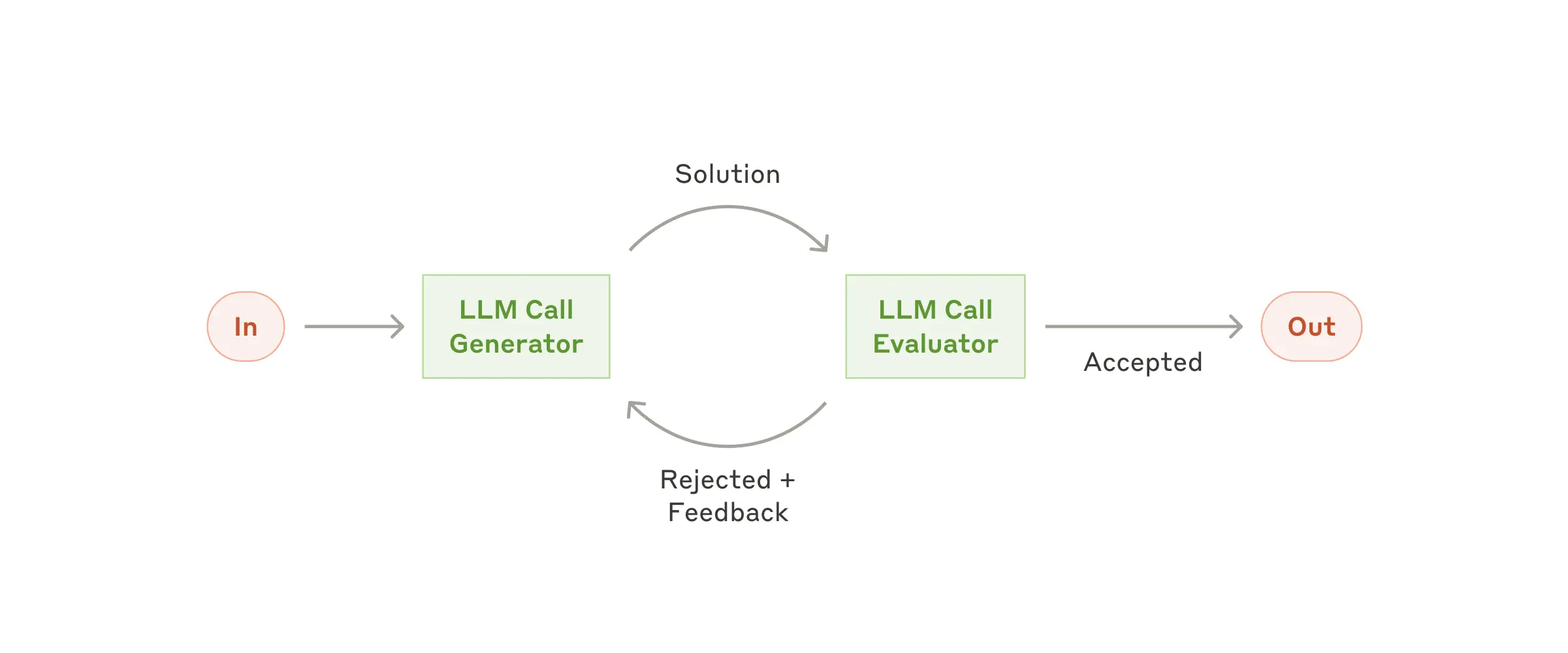 |
| Agent | 智能体 | 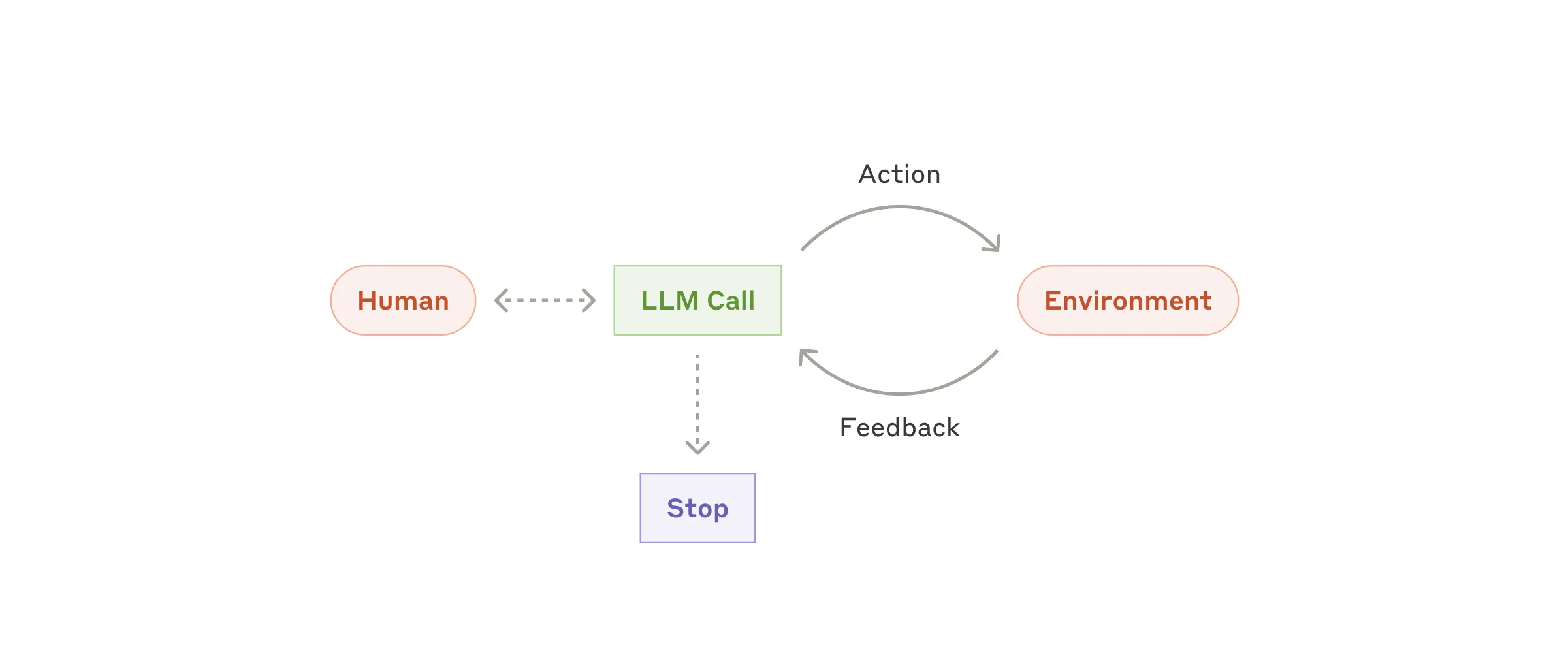 |
Agent 使用场景
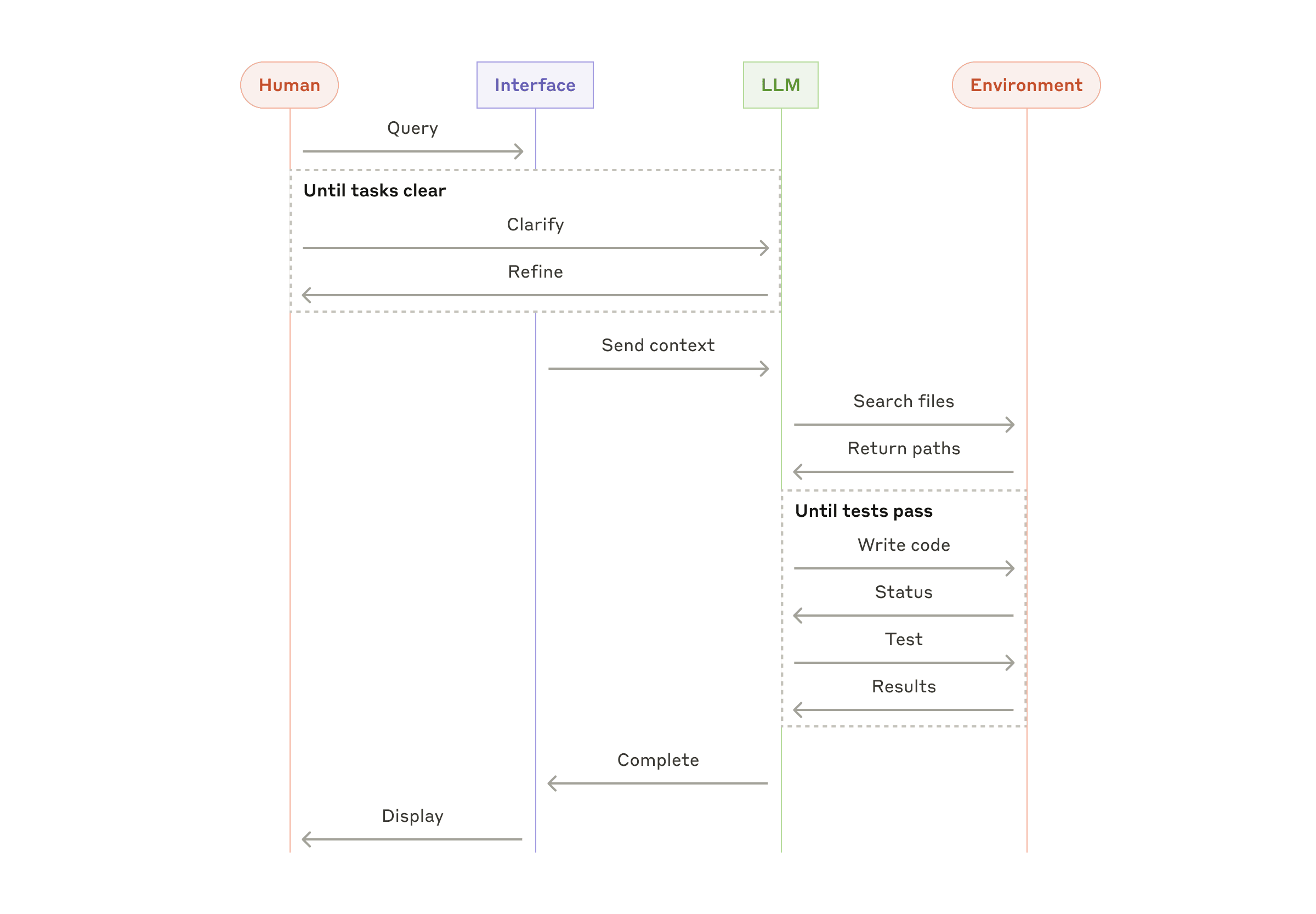
观点:Don’t build agents for everything,别做什么都能干的 Agent,那是大模型要干的事情😆
构建有效 Agent 的三大要点:
- 明智选择应用场景,并非所有任务都需要 Agent;
- 找到合适的用例后,尽可能长时间地保持系统简单;
- 在迭代过程中,尝试从 Agent 的视角思考,理解其局限并提供帮助;
Barry 主要负责 Agentic System,演讲内容基于他和 Eric 合著的一篇博文
Agent 系统演进
- 简单功能: 起初是简单任务,如摘要、分类、提取,这些在几年前看似神奇,现在已成为基础;
工作流(Workflows): 随着模型和产品成熟,开始编排多个模型调用,形成预定义的控制流,以牺牲成本和延迟换取更好性能。这被认为是 Agent 系统的前身;Agent: 当前阶段,模型能力更强,领域特定的 Agent 开始出现。与工作流不同,Agent 可以根据环境反馈自主决定行动路径,几乎独立运作;- 未来(猜测): 可能是更通用的单一 Agent,或多 Agent 协作。
- 趋势: 赋予系统更多自主权,使其更强大有用,但也伴随着更高的成本、延迟和错误后果。
核心观点一:Agent 并非万能
并非所有场景都适合构建 Agent (Don’t build agents for everything)
- Agent 主要用于扩展复杂且有价值的任务,成本高、延迟高,不应作为所有用例的直接升级。
- 对于可以清晰映射决策树的任务,显式构建
工作流(Workflow)更具成本效益和可控性。
- 对于可以清晰映射决策树的任务,显式构建
- 何时构建 Agent 的检查清单:
- 任务复杂度 :
Agent擅长处理模糊问题。如果决策路径清晰,应优先选择工作流; - 任务价值: Agent 探索会消耗大量 token,任务价值必须能证明其成本。
- 对于预算有限(如每任务 10 美分)或高容量(如客服)场景,
工作流可能更合适;
- 对于预算有限(如每任务 10 美分)或高容量(如客服)场景,
- 关键能力的可行性 :
- 确保 Agent 在关键环节(如编码 Agent 的编写、调试、错误恢复能力)不存在严重瓶颈,否则会显著增加成本和延迟。
- 如有瓶颈,应简化任务范围;
- 错误成本与发现难度: 如果错误代价高昂且难以发现,就很难信任 Agent 自主行动。可限制范围(如只读权限、增加人工干预)来缓解,但这也会限制其扩展性;
- 任务复杂度 :
- 写代码(Coding)是很好的 Agent 用例,因为任务复杂(从设计文档到 PR)、价值高、现有模型(如 Claude)在许多环节表现良好,且结果易于验证,例如单元测试、CI。
核心观点二 保持简单 (Keep it simple)
- Agent 的核心结构: 模型(Model)+ 工具(Tools)+ 循环(Loop)在一个环境(Environment)中运作。
- 三个关键组成部分:
- 环境:Agent 操作所在的系统;
- 工具集: Agent 采取行动和获取反馈的接口;
- 系统提示: 定义 Agent 的目标、约束和理想行为;
- 迭代方法: 优先构建和迭代这三个基本组件,能获得最高的投资回报率。避免一开始就过度复杂化,这会扼杀迭代速度。优化(如缓存轨迹、并行化工具调用、改进用户界面以增强信任)应在基本行为确定后再进行。
- 一致性: 尽管不同 Agent 应用(编码、搜索、计算机使用)在产品层面、范围和能力上看起来不同,但它们共享几乎相同的简单后端架构。
核心观点三:像 Agent 一样思考 (Think like your agents)
- 问题:
- 开发者常从自身角度出发,难以理解 Agent 为何会犯看似反常的错误;
- 解决方法:
- 将自己置于 Agent 的“上下文窗口”中。
- Agent 每步决策都基于有限的上下文信息(如 10k-20k token);
- 换位思考练习:
- 尝试从 Agent 的视角完成任务,体验其局限性
- 例如,只能看到静态截图,在推理和工具执行期间如同“闭眼”操作。
- 这有助于发现 Agent 真正需要哪些信息(如屏幕分辨率、推荐操作、限制条件)以避免不必要的探索;
- 利用模型自身:
- 直接询问模型(如 Claude):指令是否模糊?是否理解工具描述?为什么做出某个决策?如何帮助它做出更好的决策?这有助于弥合开发者与 Agent 之间的理解差距。
思考
- 预算感知 Agent (Budget-aware Agents): 控制 Agent 成本和延迟,定义和强制执行时间、金钱、token 预算,以便在生产环境中更广泛地部署。
- 自进化工具 (Self-evolving Tools): Agent 能设计和改进自己的工具(元工具),使其更具通用性,能适应不同用例的需求。
- 多 Agent 协作 (Multi-agent Collaboration): 预计2025年底将出现更多多 Agent 系统。
- 其优势包括并行化、关注点分离、保护主 Agent 上下文窗口等。
- 关键挑战:Agent 间通信方式,如何实现异步通信,超越当前的用户-助手轮流模式。
【2025-12-10】Agent→Skills
【2025-12-10】别折腾造 Agent 了,Anthropic 说你该造 Skills
- AI/Code大会演讲:
- 译文
Anthropic 核心工程师 Barry Zhang 和 Mahesh Murag 专场分享,主题很直接:
别再折腾造Agent了,你应该去造Skills。
问题:”谁来帮你报税?”
- 选项 A:Mahesh,一个智商 300 的数学天才
- 选项 B:Barry,一个经验丰富的税务专业人士
答案很明显——当然选 B。不希望数学天才从第一性原理去推导 2025 年的税法。要的是有经验的专家,按套路办事,稳稳当当搞定。
这就是AI Agent 的核心问题:”很聪明,但缺专业知识。”
什么是 Skills ?文件夹。
- 官方定义 What are Skills?
名为”anthropic_brand”的 Skills 文件夹,包含:
- SKILL.md - 核心指令文件
- docs.md - 参考文档
- slide-decks.md - 演示模板
- apply_template.py - 可执行脚本
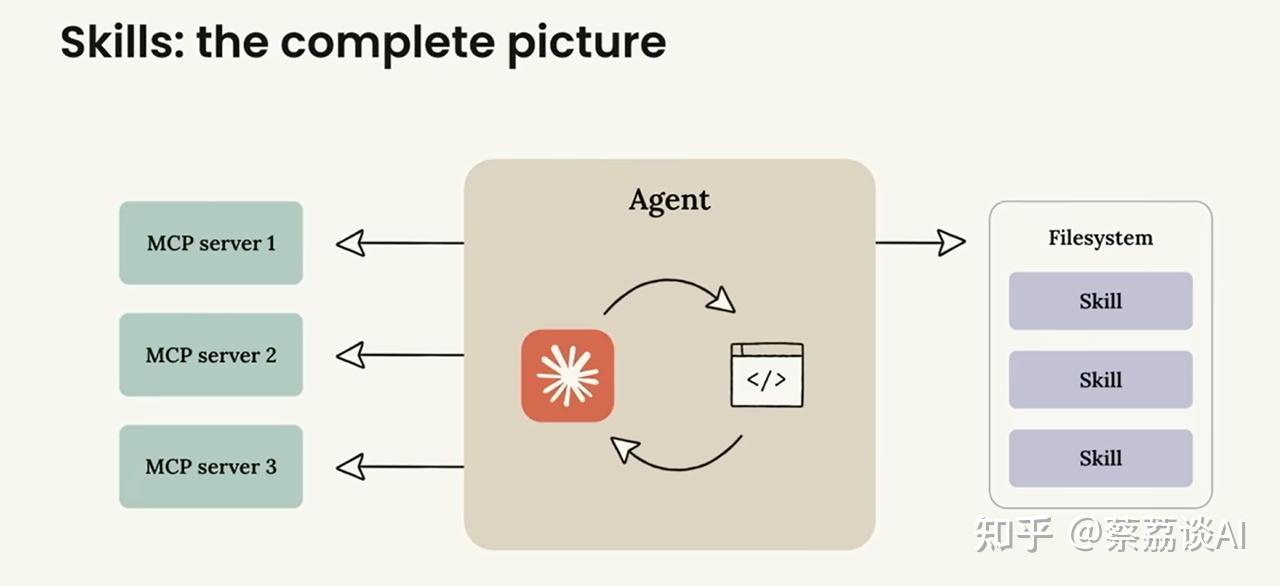
Skills 和 MCP
互补关系:
- MCP Servers(如MCP server 1/2/3),提供各种外部连接能力。
- 中间是Agent核心,负责协调和执行。
- 右侧是 Filesystem 中的Skills,提供专业知识和流程指导。
分析
- MCP 提供”连接”:让 Claude 访问外部世界,读数据库、调 API、操作软件
- Skills 提供”知识”:告诉 Claude 该怎么用这些连接,怎么完成特定任务
MCP 提供钥匙,Skills 告诉你钥匙该怎么用、用在哪扇门上。
- BrowserBase 公司做了个 Skill,配合开源浏览器自动化工具 StageHand。有了这个 Skill,Claude 就知道怎么用 StageHand 来操作浏览器、完成各种网页任务。
- Notion 出了一套 Skills,让 Claude 理解 Notion 工作区,做深度研究和整理。
Skills 正在被非技术人员创建,财务、招聘、会计、法务
- 第 1 天:没有 Skills,但很聪明(Intelligent)
- 第 5 天:有了几个 Skills,开始变得有能力(Capable)
- 第 30 天:拥有众多 Skills,真正变得有用(Useful)
Skills 功能才五周,就已经出现了数千个 Skills
Skills 门槛很低——最简单的 Skill 就是一个 Markdown 文件,写几条指令就行,不需要会编程
Anthropic 目标:让 Skills 成为持续学习的机制。
- 用 Claude 干活,发现某个地方总是做不好,就把正确做法写下来,保存成 Skill。
- 下次再遇到类似任务,Claude 就知道该怎么做了。
- 而且可共享——创建的 Skill,可以分享给团队、公司,甚至全世界
另外:Skills 可以被 Claude 自己创建
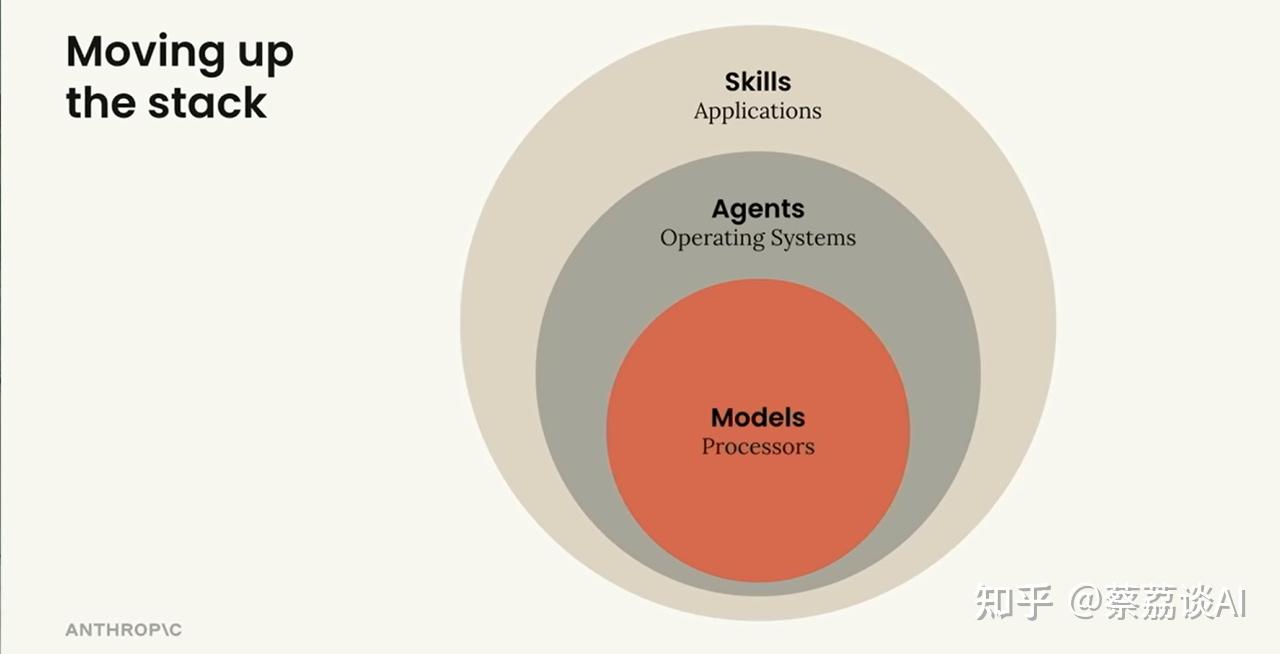
技术栈对比,同心圆完美诠释三者关系:
- 最内层 - Models(模型)= Processors(处理器): 需要巨大投资,潜力无限但单独用处有限,只有少数公司能造。
- 中间层 - Agents(代理)= Operating Systems(操作系统): 协调模型周围的进程、资源和数据,让模型更有价值,同样只有少数公司在做。
- 最外层 - Skills(技能)= Applications(应用程序): 真正创造价值的地方,人人都能参与,这才是生态爆发的关键。
Skills 扮演”应用程序”角色: 人人都能参与、人人都能创造价值。
Anthropic 抓住了本质:
AI 的瓶颈不在智能,在专业知识。
知识管理方式:
- 把组织的最佳实践、工作流程、机构知识打包成 Skills,让整个团队的 AI 都变得更专业。
Andrew NG
【2024-3-27】吴恩达
2024年3月,初创公司 Cognition 基于大模型开发出首个AI软件工程师Devin
- Devin几乎能完成普通软件工程师能做的所有事情,包括搭建环境、编码、调试;更离谱的是,Devin成功通过了一家AI公司的面试。
- Devin没有开源代码,不过随后就有一个团队为了复刻Devin,开发了OpenDevin,从代码中可见,其核心就是Agent。
通过agent workflow,人工智能能够胜任的任务种类将会大幅扩展。
吴恩达团队实验,让 AI 去写一些代码并运行,最终对比不同模型和工作流程得出结果的性能。结果如下:
- GPT-3.5 模型:准确率 48%
- GPT-4 模型:准确率 67%
- GPT-3.5 + Agent:高于 GPT-4 模型的表现
- GPT-4 + Agent:表现远高于 GPT-4 模型,非常出色
吴恩达提到的四种 Agent 设计模式: Reflection、Tool Use、Planning、Multiagent
反思(reflection): Agent 审视和修正自己生成的输出- 两个 Agent, 一个负责 Coding,另一个负责 Code Review。
- 让大模型仔细检查输出内容的准确性、结构规范性等,并且给出评论
- agent会利用外部组件运行代码,执行单元测试,代码Review,甚至与另一个Agent进行对抗来逐渐提升代码质量
工具使用(Tool use): AI Agent会与外部组件相连接,使用各种工具来分析、收集信息- 例如,执行网络搜索作为上下文输入,基于LLM输出执行发送预警邮件操作。
规划(Planning): Agent 分解复杂任务并按计划执行- 类似于思维链模式,按照逻辑顺序组织和评估信息,形成一系列的思考步骤。
- 这种方法特别适用于复杂问题,因为能够帮助人们逐步分析问题,从而得出合理的结论或解决方案。
- 任务: 生成一张女孩读书的图像,并且女孩的姿势与男孩一致,最后输出描述图像的音频。
- Agent 规划: 第一步, 确定男孩的姿势,可能在huggingface上找到一个合适的模型来提取这个姿势,接下来使用controlNet模型来合成一个女孩的图像,然后使用图像到文本的模型,最后使用语音合成。
多智能体协作(Multiagent collaboration): 多个 Agent 扮演不同角色合作完成任务- 将一个复杂任务进行分解,让不同语言模型扮演不同的角色,比如公司CEO、设计师、产品经理或测试员,这些”代理”会相互协作,共同开发游戏等复杂程序。
- AI客服回答售前,售中,售后三种不同类型的问题。
- 先基于预训练模型微调出三个专业模型,分别用于回答售前,售中,售后问题
- 然后,再通过一个LLM判断用户的提问属于售前,售中,售后哪一种,最后调用对应的专业大模型。
OpenAI
OpenAI AI Agent 使用建议
- 【2025-4-17】A practical guide to building agents
一句话总结:可靠性是核心
Agent 定义与特征
OpenAI将Agent定义为”能够独立完成任务的系统”。
Agent具有以下核心特征:
- 利用大语言模型(LLM)管理
工作流执行和决策过程 - 获取上下文并采取行动的工具访问能力
- 在明确定义的护栏内运行
Agent 适用场景:
- 复杂决策场景:涉及细微判断、例外情况或上下文敏感决策的工作流
- 难以维护的规则系统:笨重系统,更新成本高或容易出错
- 严重依赖非结构化数据:解释自然语言、从文档提取意义或进行对话交互的场景
Agent 核心组件
- 模型:驱动Agent推理和决策的LLM
- 工具:Agent可用于采取行动的外部函数或API
- 指令:定义Agent行为的明确指南和护栏
设计模式与架构
两种主要编排模式:
- 单Agent系统:单一模型配备适当工具和指令,在循环中执行工作流
- 适合初始阶段和相对简单的任务
- 可通过添加工具逐步扩展能力
- 多Agent系统:工作流执行分布在多个协调的Agent之间
- 管理者模式:中央”管理者”Agent通过工具调用协调多个专业Agent
- 去中心化模式:多个Agent 对等运作,根据各自专长交接任务
实施建议
- 渐进式方法:从小处着手,验证有效后逐步扩展
- 模型选择策略:先使用最强大模型建立基准,再尝试更小模型
- 人工干预机制:设置失败阈值和高风险行动触发点
- 护栏分层防御:组合多种护栏类型创建更强韧的系统
Agent代表工作流自动化的新时代,系统能够处理模糊情况、跨工具采取行动,并以高度自主性处理多步骤任务。
构建可靠的Agent需要强大基础、合适的编排模式和严格的护栏,同时采用迭代方法才能在生产环境中取得成功。
LangChain – 精华
【2025-4-21】精华 Agents和Workflows孰好孰坏,LangChain创始人和OpenAI杠上了
- 原文 【2025-4-20】how-to-think-about-agent-frameworks
LangChain 创始人 Harrison Chase 对于 OpenAI 一些观点持有异议,尤其是「通过 LLMs 来主导 Agent」的路线。
Harrison Chase 认为
- 并非要通过严格的「二元论」来区分 Agent,目前大多数的「Agentic 系统」都是
Workflows和Agents的结合。 - 理想的 Agent 框架应允许从「结构化
工作流」逐步过渡到「由模型驱动」,并在两者之间灵活切换。
OpenAI 观点建立在一些错误的二分法上,混淆了「Agentic 框架」的不同维度,从而夸大了单一封装的价值。
- 混淆了「
声明式vs命令式」与「Agent 封装」,以及「WorkflowsvsAgents」。
观点: LLMs 越来越强, 最终都会变成 Agents, 而不是 Workflows?
事实:
- 调用工具的 Agents 的性能继续提升
- 控制输入给 LLM 的内容依然会非常重要(垃圾进,垃圾出)
- 一些应用,简单工具调用循环足够了
- 另一些应用,Workflows 更简单、更便宜、更快、也更好
- 对于大多数应用,生产环境 Agentic 系统将是 Workflows 和 Agents 结合。
Harrison Chase 更认同 Anthropic 此前发布的如何构建高效 Agents 的文章
- 对于 Agent 定义,Anthropic 提出了「
Agentic 系统」的概念,并且把 Workflows 和 Agents 都看作是其不同表现形式。
大模型派(Big Model)和工作流派(Big Workflow)的又一次争锋
- 前者认为每次模型升级都可能让精心设计的工作流瞬间过时,这种「苦涩的教训」让他们更倾向于构建通用型、结构最少的智能体系统。
- 而以 LangGraph 为代表的后者,强调通过显式代码、模块化工作流来构建智能体系统。结构化的流程更可控、更易调试,也更适合复杂任务。
资料:
- OpenAI 的构建 Agents 指南(写得不太行):
- Anthropic 构建高效 Agents 指南
- LangGraph(构建可靠 Agents 的框架)
要点
- 构建可靠的 Agentic 系统,其核心难点在于确保 LLM 在每一步都能拿到恰当的上下文信息。这既包括精准控制输入给 LLM 的具体内容,也包括执行正确的步骤来生成那些有用的内容。
Agentic 系统包含 Workflows 和 Agents(以及介于两者之间的一切)。- 大多数的 Agentic 框架,既不是声明式也不是命令式的编排工具,而是提供了一套 Agent 封装能力的集合。
- Agent 封装使入门变得更加容易,但常常把底层细节隐藏起来,反而增加了确保 LLM 在每一步都能获得恰当上下文的难度。
- 无论 Agentic 系统是大是小,是 Agents 主导还是 Workflows 驱动,都能从同一套通用的实用功能中获益。这些功能可以由框架提供,也可以完全自己从头搭建。
- 把 LangGraph 理解成一个编排框架(它同时提供了声明式和命令式的 API),然后在它之上构建了一系列 Agent 封装,这样想是最恰当的。
问卷调查:「在将更多 Agents 投入生产时,你们遇到的最大障碍是什么?」
- 排名第一的回答:「performance quality」。
让 Agents 稳定可靠地工作,依然是个巨大的挑战。
| 类别 | 占比 |
|---|---|
| Performance quality | 41% |
| Cost | 18.4% |
| Safety concerns | 18.4% |
| Latency | 15.1% |
| Other | 7% |
为什么 LLM 会出错?
- 一是模型本身能力还不够;
- 二是传递给模型的上下文信息不对或者不完整。
第二种情况更常见。
什么原因导致上下文信息传递出问题?
- System Message 不完整或写得太短
- 用户的输入太模糊
- 没有给 LLM 提供正确的工具
- 工具描述写得不好
- 没有传入恰当的上下文信息
- 工具返回的响应格式不对
构建可靠的 Agentic 系统,难点在于:如何确保 LLM 每步都能拿到最合适的上下文信息。
- 一是精准控制到底把哪些具体内容喂给 LLM
- 二是执行正确步骤来生成那些有用的内容。
「workflow」 到 「agent」 范围内构建应用程序时,要考虑两件事:
- 可预测性(Predictability) vs 自主性(agency)
- 可靠性并不等同于可预测性, 但密切相关
- 系统越偏向 Agentic,其可预测性就越低
- 低门槛(low floor),高上限(high ceiling)
- Workflow 框架高上限,但门槛也高,但需要自己编写很多 Agent 逻辑。
- Agent 框架则是低门槛,但上限也低 —— 虽然容易上手,但不足以应对复杂用例。
- LangGraph 目标: 兼具低门槛(提供内置的 Agent 封装,方便快速启动)和高上限(提供低层功能,支持实现高级用例)。
LangGraph 最常见的方式主要有两种:
- 一种是通过声明式的、基于图(Graph)的语法
- 另一种是利用构建在底层框架之上的 Agent 封装
此外,LangGraph 还支持函数式 API 以及底层的事件驱动 API,并提供了 Python 和 Typescript 两个版本。
LangGraph 内置了一个持久化层,这使得其具备容错能力、短期记忆以及长期记忆。
这个持久化层还支持「人工参与决策」(human-in-the-loop)和「人工监督流程」(human-on-the-loop)模式,比如: 中断、批准、恢复以及时间回溯(time travel)等功能。
LangGraph 内建支持多种流式传输,包括 tokens 的流式输出、节点状态的更新和任意事件的流式推送。同时,LangGraph 可以与 LangSmith 无缝集成,方便进行调试、评估和可观测性分析。
生产环境中大多数的 Agentic 系统都是 Workflows 和 Agents 的组合。一个成熟的生产级框架必须同时支持 workflow 和 agent 两种模式。
多智能体
智能体时代的设计模式
多智能体类型
多智能体(Mulit-Agent)架构 6 种不同类型:
- 𝟭
𝗛𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝗶𝗰𝗮𝗹( 𝗩𝗲𝗿𝘁𝗶𝗰𝗮𝗹 ) 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲- 一名主管代理负责协调多名专门代理。
- 1)一名代理从内部数据源检索信息
- 2)另一位经纪人专门从事网络搜索的公共信息
- 3)第三个代理专门从个人账户(电子邮件、聊天)中检索信息
- 𝟮
𝗛𝘂𝗺𝗮𝗻-𝗶𝗻-𝘁𝗵𝗲-𝗟𝗼𝗼𝗽𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲- 在处理敏感信息时,在进行下一步操作之前进行人工验证。
- 𝟯
𝗡𝗲𝘁𝘄𝗼𝗿𝗸( 𝗛𝗼𝗿𝗶𝘇𝗼𝗻𝘁𝗮𝗹 ) 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲- 代理以多对多方式直接相互通信。形成一个没有严格层级结构的分散式网络。
- 𝟰
𝗦𝗲𝗾𝘂𝗲𝗻𝘁𝗶𝗮𝗹𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲- 代理按顺序处理任务,其中一个代理的输出成为下一个代理的输入。
- 比如 :三个顺序代理,其中:
- 1) 第一个查询代理从矢量搜索中检索信息
- 2) 第二个查询代理根据第一个代理的发现从网络搜索中检索更多信息
- 3) 最终生成代理使用来自两个查询代理的信息创建响应
- 𝟱 𝗗𝗮𝘁𝗮 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
- 包括专用于转换数据的代理。
- 比如:转换代理,可在插入时丰富数据或转换现有集合
- 还有一些其他模式可以与这些架构相结合:
- 1)
𝗟𝗼𝗼𝗽𝗽𝗮𝘁𝘁𝗲𝗿𝗻 :持续改进的迭代循环 - 2)
𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗽𝗮𝘁𝘁𝗲𝗿𝗻 :多个代理同时处理任务的不同部分 - 3)
𝗥𝗼𝘂𝘁𝗲𝗿𝗽𝗮𝘁𝘁𝗲𝗿𝗻 : 中央路由器决定调用哪些代理 - 4)
𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗼𝗿/𝘀𝘆𝗻𝘁𝗵𝗲𝘀𝗶𝘇𝗲𝗿𝗽𝗮𝘁𝘁𝗲𝗿𝗻 :收集和合成来自多个代理的输出
参考 小红书总结
多智能体构建
Anthropic
2024年底,《Build Effective Agents》,基于当时agent系统的能力和多数应用场景,鼓励大家多用 workflow,少用 multi-agents。
【2025-6-13】Anthropic 分享构建多个Claude智能体,更有效地探索复杂主题,遇到的工程挑战和经验教训。
Agent 提示词设计原则
- 像 Agent 一样思考: 有效的提示词工程依赖于建立智能体的准确认知模型
- 规范协调者任务分发描述:
- 主智能体将查询分解为子任务, 并向子智能体描述任务。
- 每个子智能体目标明确、输出格式、工具和信息源使用指导,以及清晰的任务边界。
- 如果没有详细的任务描述,智能体会重复工作、遗漏内容或无法找到必要信息。
- 最初允许主智能体给出简单、简短的指令,如“研究半导体短缺”,但这些指令过于模糊,导致子智能体误解任务或执行与其他智能体完全相同的搜索。例如,一个子智能体探索2021年汽车芯片危机,而另外两个重复调查当前2025年供应链情况,缺乏有效的分工。
- 根据任务复杂度匹配工作量
- 智能体难以判断不同任务所需工作量,因此,提示词中嵌入规模调节规则。
- 简单事实查找只需1个智能体进行3-10次工具调用,直接比较可能需要2-4个子智能体各进行10-15次调用
- 复杂研究可能使用超过10个子智能体并明确划分职责。
- 这些指导原则帮助主智能体有效分配资源,防止在简单查询上过度投入——早期版本中的常见失败模式
- 重视工具设计与选择
- 智能体与工具的接口与人机接口同样重要。
- 通过MCP服务器访问外部工具时,更加复杂,因为智能体会遇到描述质量参差不齐的未知工具。所以为智能体提供明确的启发式方法。
- 例如:首先检查所有可用工具,使工具使用与用户意图匹配,通过网络搜索进行广泛的外部探索,或优先选择专业工具而非通用工具。
- 智能体自我改进
- Claude 4 是优秀的提示词工程师。执行用户提示词并遭遇失败时,能诊断智能体失败的原因并提出改进建议,甚至创建工具测试智能体——当给定有缺陷的MCP工具时,尝试使用该工具,然后重写工具描述以避免失败。通过数十次测试工具,这个智能体发现了关键细节和错误。
- 改善工具易用性,使智能体任务避免大部分错误,完成时间减少了40%。
- 先宽后窄
- 搜索策略模仿专家人类:深入具体内容之前先探索整体情况。智能体默认使用过长、过于具体的查询,返回结果很少。
- 通过提示智能体从简短、广泛的查询开始,评估可用信息,然后逐步缩小关注范围来解决这种倾向。
- 引导思考过程
- 扩展思考(Extended Thinking)模式让Claude 思考过程中输出额外token,作为可控的思考空间。
- 主智能体使用思考来规划方法,评估哪些工具适合任务,确定查询复杂性和子智能体数量,并定义每个子智能体的角色。
- 测试显示扩展思考改善了指令遵循、推理和效率。子智能体也会规划,然后在工具结果后使用交替思考来评估质量、识别缺口并完善下一个查询。这使子智能体在适应任务方面更加有效。
- 并行工具调用改变速度和性能
- 复杂任务涉及探索多个信息源。早期智能体执行顺序搜索,速度极其缓慢。为了提高速度,引入两种并行化方式:
- ① 主智能体并行启动3-5个子智能体;
- ② 子智能体并行使用3个以上工具。
- 效果:复杂查询减少90%时间,几分钟而非几小时内完成更多工作,同时覆盖比其他系统更多的信息。
提示词策略专注于培养良好的启发式方法,而非僵化规则。
- 如将困难问题分解为较小任务、仔细评估信息源质量、根据新信息调整搜索方法,以及识别何时专注于深度(详细调查一个主题)还是广度(并行探索多个主题)。
- 还通过设置明确防护措施主动缓解意外副作用,防止智能体失控。
- 最后,专注于具有可观察性和测试用例的快速迭代循环。
多智能体评估
输出内容自由格式的文本,很少有唯一正确答案,因此很难通过程序化方式评估。
LLM天然适合对输出进行评分。用LLM评判者,根据评估标准对每个输出进行评估:
- 事实准确性(声明是否与来源匹配?)
- 引用准确性(引用来源是否与声明匹配?)
- 完整性(是否涵盖了所有要求的方面?)
- 来源质量(是否使用了一手来源而非低质量的二手来源?)
- 工具效率(是否合理地使用了正确工具?)
尝试多个评判者来评估各个组件,但发现使用单个LLM调用、单个提示词输出0.0-1.0分数和通过/失败评级是最一致的,与人类判断最为吻合。
人工评估捕捉自动化遗漏的问题
多智能体优势
开放性问题很难提前预测所需步骤,无法为探索复杂主题预设固定路径,因为动态且有路径依赖性。
这种不可预测性使AI智能体特别适合研究任务。
- 研究需要足够的灵活性,来调整方向或探索相关联系,随着调查的深入而展开。
- 模型必须自主运行多轮,基于中间发现来决定追求哪些方向。
- 线性的一次性处理流程无法胜任这些任务。
搜索本质是压缩:从庞大的语料库中提炼洞察。
- 子智能体通过各自独立的上下文窗口并行运行来促进这种压缩,同时探索问题的不同方面,然后为主要研究智能体提炼最重要的token。
- 每个子智能体还实现了职责分离——使用不同工具、提示词和探索轨迹——减少了路径依赖性,实现了全面而独立的调查。
一旦智能水平达到某个阈值,多智能体系统就成为扩展性能的关键方式。
- 尽管个体人类在过去10万年中变得更加智能,但人类社会在信息时代因为集体智能和协调能力而变得指数级强大。
- 即使是通用智能体在单独运行时也面临限制,而智能体群体能够完成更多工作。
多智能体系统在广度优先查询方面表现特别出色
- 涉及同时追求多个独立方向。
Anthropic 研究系统采用多智能体架构,协调者-执行者模式
- 主智能体负责协调整个过程,同时将任务委派给并行运行的专业子智能体。
- 用户提交查询时,主研究智能体(LeadResearcher)分析查询内容,制定研究策略
- 思考研究方法,并将计划保存到内存中以维持上下文,如果上下文窗口超过200,000个token就会被截断 —— 保留计划非常重要
- 并创建子智能体来同时探索不同方面。
- 子智能体作为智能筛选器,通过迭代使用搜索工具收集信息, 然后向主智能体返回公司列表,以便主智能体能够整合最终答案。
- 每个子智能体独立执行网络搜索,交替思考,评估工具结果,并将发现返回给主研究智能体。主研究智能体综合这些结果并决定是否需要进行更多研究——如果需要,它可以创建更多子智能体或完善研究策略。
- 一旦收集到足够的信息,系统就会结束研究循环,将所有发现传递给引用智能体(CitationAgent), 标注引用位置
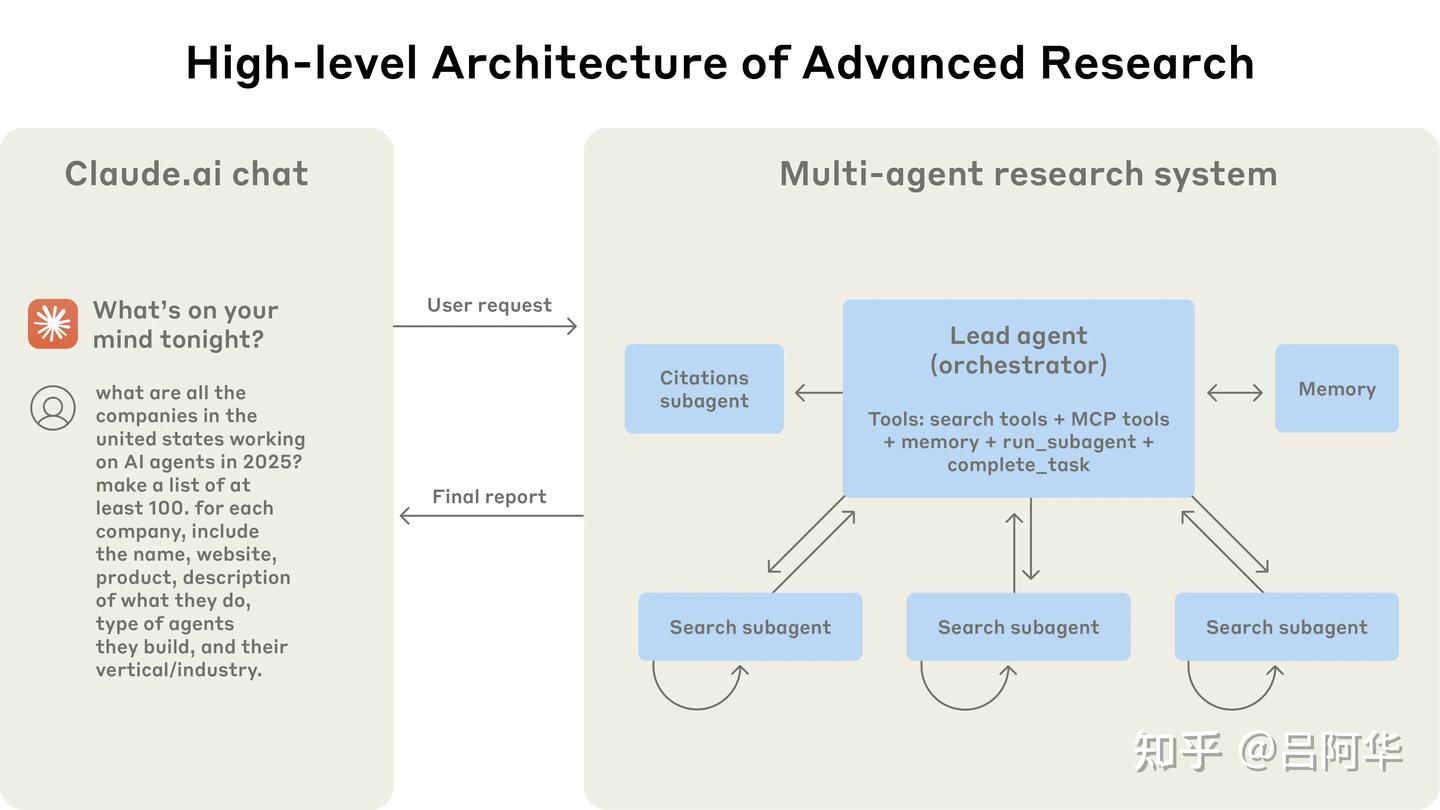
以 Claude Opus 4 作为主智能体、Claude Sonnet 4 作为子智能体的多智能体系统,在内部研究评估中比单智能体Claude Opus 4的表现提升了90.2%。
例如
- 识别信息技术S&P 500中所有公司的董事会成员时,多智能体系统通过将任务分解给子智能体找到了正确答案,而单智能体系统通过缓慢的顺序搜索未能找到答案。
多智能体系统之所以有效,主要是因为投入足够的token来解决问题。在分析中,三个因素解释了BrowseComp评估中95%的性能差异(该评估测试浏览智能体定位难以找到信息的能力)。
- 仅token使用量就解释了80%的差异,工具调用次数和模型选择是另外两个解释因素。
该架构将工作分布到具有独立上下文窗口的智能体中,为并行推理增加更多容量。最新的Claude模型在token使用方面充当巨大的效率倍增器,相比在Claude Sonnet 3.7上增加一倍的token预算,使用Claude Sonnet 4会带来更大的性能提升。多智能体架构有效地为超出单智能体限制的任务扩展了token使用量。
多智能体问题
Anthropic
多智能体缺点:快速消耗token。
- 单智能体消耗的token是聊天的4倍
- 多智能体消耗的token是聊天的15倍
为了经济可行性,多智能体系统需要任务价值足够高以承担增加的性能成本。
一些需要所有智能体共享相同上下文或涉及智能体间依赖关系的领域目前不适合多智能体系统。
例如
- 大多数编码任务涉及的真正可并行化任务比研究少,LLM智能体还不擅长实时协调和委派给其他智能体。
- 多智能体系统擅长处理涉及大量并行化、超出单个上下文窗口信息量以及需要与众多复杂工具交互的高价值任务。
Cognition
【2025-6-12】为什么不建议构建多智能体?《Don’t Build Multi-Agents》
- Cognition Don’t Build Multi-Agents
作者(Walden Yan)直指问题: 当前流行的多代理框架(Multi-Agent范式,如OpenAI的Swarm和Microsoft的AutoGen)违背了认知可靠性的基本原理:
- AI代理根本目标: 有限上下文约束下完成复杂任务的可靠执行。
而多代理架构在此框架下存在两个根本性矛盾
- (1) 上下文碎片化悖论
- 第一性原理:LLM决策质量与上下文完整性正相关
- 现实表现:当主agent将任务拆分为子任务(如”开发游戏背景”和”设计角色”)时,子agent仅获得任务片段
- 本质冲突:子agent缺失主agent决策树(如”视觉风格需统一”的关键约束),导致输出偏差(如Super Mario风格的背景配卡通风格角色)
- (2) 决策熵增定律
- 第一性原理:并行系统决策节点数与系统混乱度呈指数关系
- 案例实证:Flappy Bird 克隆任务中,两个子agent独立产生的设计决策(如像素分辨率、色彩空间)有很大概率发生协调冲突
Web开发史:
- 1993年诞生HTML,2013年React革新前端开发。
- 2025年的AI智能体领域类似“原始HTML时代”,缺乏成熟框架。主流库如OpenAI的Swarm和微软的AutoGen推广多智能体架构,但作者认为这是错误方向。
构建可靠agent的基本规则:
- 原则1:全局上下文共享(Full-context Tracing)
- 智能体每个动作必须基于系统中所有相关决策的完整上下文。
- 问题示例:当主智能体将任务拆分为子任务时,若子智能体仅接收子任务而缺乏主任务历史,可能误解需求。
- 如“构建Flappy Bird克隆”拆分为“背景”和“小鸟”子任务, 将背景误做成超级玛丽风格
- 解决方案:传递完整的智能体轨迹(agent trace),而非单个消息。
- 生物学基础:人脑前额叶皮质持续整合感官输入和工作记忆。
- 原则2:决策一致性约束(Implicit Decision Coherence)
- 动作中隐含未明说的决策,冲突会导致系统崩溃。
- 架构要求:禁止并行agent在未同步状态下作出可能冲突的决策(如界面布局与交互逻辑)。
- 问题示例:两个子智能体独立工作,分别设计背景和小鸟,但因缺乏实时协调,导致视觉风格冲突(如卡通小鸟配写实背景)。
违反这两个原则的架构脆弱
架构范式建议:从多线程回归单线程
- 当前大模型本身也是单线程范式(just predict next token)
异议
- 单agent上下文很长时,指令跟随能力会下降,一些步骤拆出去给其他线程,核心agent只收结果这种模式很多场景下需要
基于上述原则,可靠架构方案:
(1) 基础单线程:单线程线性智能体(Single-Threaded Linear Agent)
所有动作在单一连续上下文中执行(如图示),避免决策分散。
- 上下文处理方式:原始全量上下文(当然,也要在LLM允许的上下文窗口内),信息无损压缩。
- 优点:简单、可靠,适用于多数场景。
- 适用场景:比如搜索Agent(多轮动态搜索)、DataAgent(多轮解码解释器工具调用)。
- 缺点:长任务可能超出上下文窗口限制。适合中、短任务(如10分钟内)
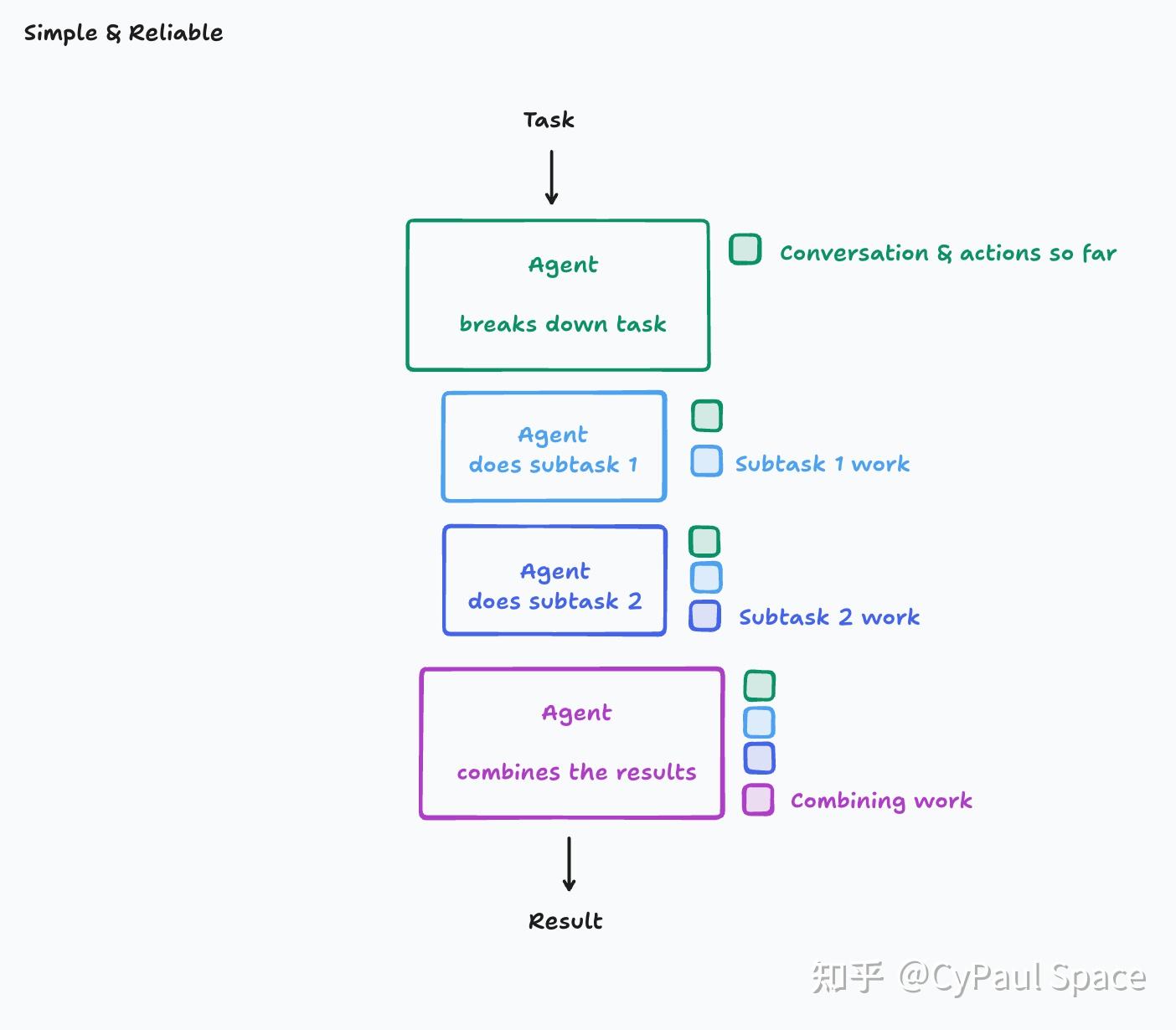
(2) 压缩中继:上下文压缩模型(Context Compression Model)
引入LLM(可能是专用LLM)压缩历史动作/对话,提炼关键事件和决策。
- 上下文处理方式:LLM摘要器提炼事件/决策, 信息有损压缩(不压缩的话,爆LLM上下文窗口)
- 优点:支持更长任务,减少上下文负担,适合长任务(几十分钟甚至几小时)。
- 适用场景:比如复杂任务Agent,如全栈开发等。
- 挑战:需精细设计压缩逻辑,可靠性也不如单线程线性。
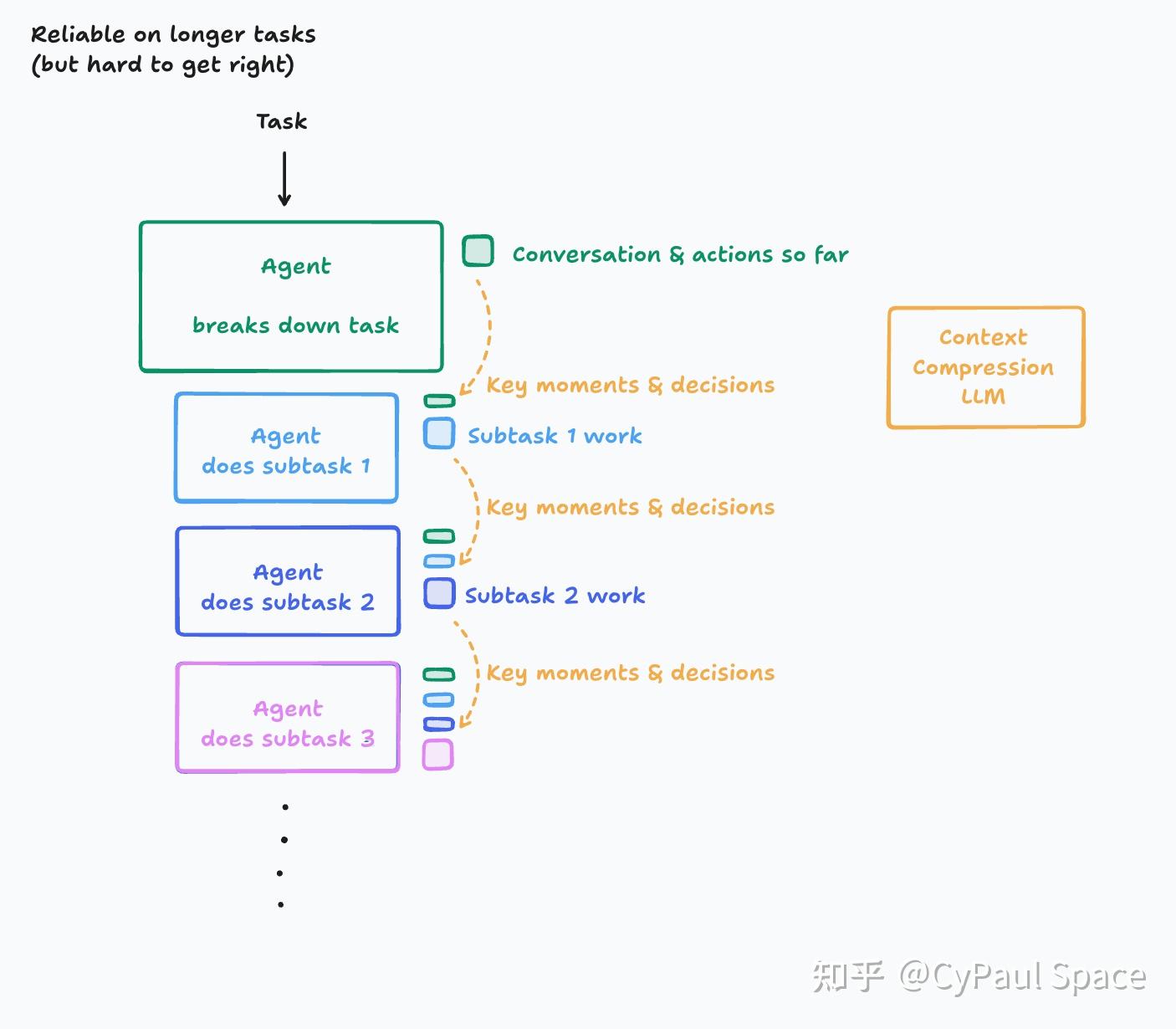
| 架构类型 | 上下文处理方式 | 可靠性指数 | 适用场景 |
|---|---|---|---|
| 基础单线程 | 原始全量上下文 -> 信息无损压缩 | ★★★★☆ | 中、短任务(10分钟内) |
| 压缩中继 | 动态摘要关键决策 -> 信息有损压缩 | ★★★☆☆ | 长任务(几十分钟甚至几小时) |
案例
- Deepsearch属于单线程
- manus属于压缩中继类型
当智能体范式从多线程回归单线程,未来大模型需要更关注上下文窗口(支持更长的上下文窗口),正如sam altman
sam altman:youtube
一个非常小的模型,拥有超人类的推理能力,运行速度极快,有1 万亿 token 的上下文窗口,并能调用你能想到的所有工具。 在这个设定下,问题是什么、模型有没有现成知识或数据,其实都不重要”
多智能体系统(MAS:multi-agent systems)中,设计有效的提示和拓扑结构面临挑战,因为单个智能体可能对提示敏感,且手动设计拓扑结构需要大量实验
【2025-2-4】Google研究发现:Multi-Agent的核心竟然是Prompt设计
Google&剑桥大学, 对设计空间进行了深入分析,了解构建有效MAS的因素。
- 提示设计对下游性能有显著影响,而有效的拓扑结构只占整个搜索空间的一小部分。
数学问题上
- Gemini 1.5 Pro 对比仅使用自我一致性(SC)、自我细化(reflect)和多智能体辩论(debate)进行扩展的智能体,展示了每个问题的提示优化智能体的准确率与总标记数的关系。误差条表示1个标准差。
- 通过更有效的提示,利用更多的计算资源可以获得更高的准确率。
Gemini 1.5 Pro 不同拓扑结构的性能与基础智能体相比,每个拓扑结构都通过 APO 优化,其中“Sum.”(总结)和“Exe.”(执行器)是任务特定拓扑结构。并非所有拓扑结构都对多智能体系统(MAS)设计有积极影响。
提出 自动化框架 Maas,详见本文章节 Agent自动化
知乎专题
知乎专题:如何评价当前的 AI Agent 落地效果普遍不佳的问题?
大部分人对 Agent 落地效果不佳的理解一开始就跑偏了
- 根源不在于模型不够聪明,而在于Agent 构建方式与模型能力不够匹配/契合
- 理想范式: 一个提示 + 一堆工具 + 一个循环搞定一切 —— 错误!
多数 Agent 团队落地路线
- 第一站:用 LangChain 或 CrewAI 等框架,快速搭个原型,看起来很美。
- 但很快就会掉进“80% 陷阱”:Demo 效果能到 80 分,可想从 80 分优化到能上生产的 99 分,会发现比推倒重来还难。
- 因为被框架高度抽象的 Prompt、内存管理、工具调用给绑死了,想精细控制都不知道从哪下手。
怎么办?
开源项目 12-factor-agents (Agents构建的12个原则),加上一些优秀 Coding Agent 的源码,共识越来越清晰:
- 别再执着于构建“全自动”的超级 Agent,而是要把 Agent 当作一个“微智能体”,嵌入到由传统代码主导的、确定性的
工作流(DAG)中。 - 因为基座LLM 还不够强…即使claude 4依然有不低的失败率
12-factor-agents
12-factor-agents 工程实践:
- How We Got Here: A Brief History of Software
- Factor 1: Natural Language to Tool Calls
- Factor 2: Own your prompts
- Factor 3: Own your context window
- Factor 4: Tools are just structured outputs
- Factor 5: Unify execution state and business state
- Factor 6: Launch/Pause/Resume with simple APIs
- Factor 7: Contact humans with tool calls
- Factor 8: Own your control flow
- Factor 9: Compact Errors into Context Window
- Factor 10: Small, Focused Agents
- Factor 11: Trigger from anywhere, meet users where they are
- Factor 12: Make your agent a stateless reducer
- Factor 13: Pre-fetch all the context you might need
背景与定位
- 从 DAG 到“去 DAG 化”
- 传统工作流(Workflow)往往用 DAG(有向无环图)来组织任务——每个节点做特定工作,然后按顺序依赖执行。
- 12-factor-agents 主张:让每个“子任务”成为一个微 Agent(micro agent),Agent 既能在 Loop 里自主决定下一步,也能作为更大 DAG 的节点。
- Agent Loop ≠ 完全取代 DAG
- 不是让整条流程彻底无序,而是把可动态决策的部分交给 Agent Loop,把静态依赖的部分仍用 DAG 控制,两者配合能兼顾灵活与可控。
核心设计因素(Factors)
- 自定义 Prompts
- 完全掌控模型行为:用不同 Prompt 模板驱动 Agent 执行“提取”、“决策”、“规划”等子任务。
- 灵活性高:对同一份原始上下文,可在不同环节用不同风格/粒度的 Prompt。
- 自定义上下文窗口
- 强调“错误压缩”到有限窗口:把模型执行结果与失败反馈一起保留在上下文,方便下次从中自我修复。
- 通过滑动窗口或分段策略,既能保证模型只看到最必要的信息,又让关键状态得以持续。
- 工具调用 = 结构化输出触发确定性代码
- LLM 负责“说”要做什么(输出 JSON/函数签名),后端有专门的代码真正去“做”——承担外部 API、文件操作、计算等。
- 分工明确:模型不再直接做高风险操作,一切副作用都由可测试的 deterministic code 完成。
- 错误自愈与持久性
- 当 Agent 调用失败或结果不符合预期,框架会把错误信息(stack trace、返回值)反馈回模型上下文,让它判断“要重试”、“要绕过”还是“要转人工”。
- 这样一个 Agent Loop 中的子任务就像带“断点恢复”的微服务,既能自动重试,也能记录失败状态以便后续审计。
- 预取所有可能需要的上下文(工具依赖)
- 进入执行阶段前,把已知会用到的工具输入/外部数据一次性 fetch 进来,避免中途再去网络/数据库查询导致的额外延迟或上下文丢失。 如果工具调用路径可确定,就直接“硬触发”工具,剩下的只让模型把结果拼接和解释即可。
12-factor-agents 把“微服务”思想嫁接到 LLM Agent 上,以可控、可调、可恢复为设计核心,既保留了 DAG 流程管理,又让模型在子任务中有充足的自主决策空间。
| 价值点 | 具体收益 |
|---|---|
| 可靠性 | 错误有反馈、可自动重试,减少 “LLM 掉链子” 带来的任务中断 |
| 可审计性 | 所有工具调用、错误信息都保存在 Agent Loop 里,方便回溯和合规检查 |
| 扩展性 | 随着需求增加,只要加新的微 Agent 或工具,就能平滑接入现有 DAG |
| 效率 | 预取上下文、明确分工,让单次执行延迟更低,整体吞吐量更高 |
典型应用场景
- 智能客服:对话转接、知识检索、工单处理等步骤各自封装成 Agent。
- 自动化运维:监控→告警→诊断→修复,每步都可用微 Agent 实现闭环。
- 数据 ETL:数据抓取、清洗、校验、报告生成都能用 Agent Loop 串联。
特别适合那种既要保证业务严谨度,又要兼顾灵活交互的复杂系统,如智能客服、运维自动化、知识处理流水线等。
Pokee AI
资料
- 【2025-4-29】对谈 Pokee.ai 朱哲清:强化学习做核心,Agent 的少数派造法
- 【2025-7-9】斯坦福毕业,用RL做Agent,华人创业团队种子轮融资1200万美元
Pokee.ai 创始人朱哲清用强化学习模型构建 AI Agent
- 2017年,杜克大学计算机科学专业毕业,一边在斯坦福读博(强化学习),一边在Meta工作,“应用强化学习” 部门负责人
- 2017年,Meta 工作期间,带领团队将强化学习落地到广告竞价、自动内容生成等业务,为公司带来高额增收。
- 2024年10月,创立 Pokee.ai,取自「小口袋」之意,寓指做一个轻便、决策能力强、随叫随到解决问题的模型。
公司整体定位是聚焦于开发一款交互式、个性化、高效的 AI Agent。
- AI 时代,模型、产品打磨各方面用不了很多人,现在7个,预计扩充到10个,人多了,反而做事情会蹑手蹑脚。
- 成员全部线上,有人在西雅图,有人在湾区,还有人在新加坡,习惯了远程办公,即便没有办公室,效率也挺高,而且还能兼顾生活
Pokee.AI 做的是「目标不是像人一样完成任务,而是超过人类在某些任务中的策略选择和规划能力。」
用户操作界面上,没有内嵌屏幕展示 Agent 具体在做什么,因为不用 browse-use(让 Agent 操控浏览器的开源工具)。
- 浏览器是给人看的,是落后的。
- LLM Agent 用 browser-use 把网页扒下来、多步操作非常慢,单次可能消耗数百万个 Token,成本在几美元到几十美元之间,用 browser-use 的初创公司多数在亏钱。
执行任务时,Pokee 直接通过数据接口和各个平台交互,已经打通了 Facebook、Google、Amazon 等大平台的几千个数据接口——这个目前市面上没人能做到。
由此,Pokee 能读取已有数据、写入新数据。
产品里加了护栏
- 用户点一下,让 Pokee 自动完成所有子任务;
- 也可以让 Pokee 分步完成任务,每个新步骤开始前都要确认,增加安全感。
Agent 产品纯靠技术不足以形成护城河。总有一天,对手能用相似的技术做出类似的产品。更重要的是靠先发优势,把用户的工作流绑定在产品内(用户习惯)。
渗透完专业消费者后,进一步拓展企业客户。现在很多公司没接入 OpenAI,一是担心数据安全,需要部署在本地的 Agent;二是成本问题,模型得足够小、单次任务成本低,才能反复调用。
主流 AI Agent 都把大语言模型(LLM,或者它的多模态版本)当作 “大脑”,靠一个或几个 LLM 编排工作、调用工具。但也有另一条路:Agent 规划、作业靠不依赖自然语言的强化学习模型,LLM 只充当 Agent 和人类的 “交互层”。
AI Agent 构建方式
- (1) LLM 驱动: 主流方案以 LLM 为核心, 把 LLM(或多模态版本)当 “大脑”,靠几个 LLM 编排工作、调用工具
- OpenAI
Operator和网页交互、操作电脑的能力基于 GPT-4o 模型 Manus完成任务则是靠 Claude 3.5 Sonnet 模型做长程规划。- Claude 提出方便 LLM 理解、使用第三方工具的通用协议 MCP 后,LLM 能调用的工具变多,把 LLM 当作 Agent 大脑的趋势增强。
- 局限:
- 现有 LLM 仍无法大量调用工具。“LLM 可能调用超过 50 个工具,就会产生幻觉。” 因为描述工具用途、用法的信息要先放入上下文,而 LLM 能接受的上下文长度有限。
- Agent 靠 LLM 完成任务也可能更慢、更贵。browser-use 浏览网站、多步交互时,单次可能消耗数百万个 Token,成本在几美元到几十美元之间。
- OpenAI
- (2) RL 驱动: Agent 规划、作业靠强化学习模型,不依赖自然语言,LLM 只充当 Agent 和人类的 “交互层”。
- 优点:
- RL模型不用上下文理解工具用途。靠训练时成千上万次 “试错”,记住工具和问题的正确组合。Agent 在训练时已经见过 15000 个工具,之后出现类似的新工具,自然会用。
- RL方法训练的模型参数量更小,完成任务耗时更短、成本更低。Pokee.ai 官方演示中,Agent 产品 Pokee 完成一项任务只要几分钟。相比同类产品,Pokee 的单任务成本也只有它们的 1/10。
- 优点:
Pokee.ai 是以 RL 为核心,在 Pokee 的架构中
- LLM 主要是充当人机交互界面,类似「 UI 层」,用以理解用户意图
- 而真正决策、执行任务的全都是基于 RL 结构完成。
RL 为核心的 AI Agent 和以 LLM 为核心的 AI Agent 的差异性在哪里?
当下很多 LLM 也用强化学习,而我们做的强化学习模型的工具调用范围和常规 LLM 模型的工具调用范围不一样,动作空间 (Action Space) 的区别,
- LLM 模型的动作空间只有 Token
- 而强化学习模型的动作空间可能不是 Token,是那些工具,直接通过工具本身的泛化性来完成对于 AI Agent 的搭建。
合格的 Agent 特点?
- 首先,完成任务耗时短。如果Agent 完成任务比人工久,不管过程中有没有人参与,一定都不会成功。因为人有惯性——机器完成某件任务时,他会在旁边盯着,而不是交给机器就走开了。
- 第二,Agent 动作要连贯,能最小化人工指导、输入,不能完成第一个任务,还需要人工复制、粘贴,放到第二个任务里面去再继续执行。
- 第三,Agent 不能只读取信息,还得能写入。现在多数 Agent 都只有抓取信息、做分析的能力,但不能写入互联网,或者写入个人账户、公司账户。
- 最后,成本要足够低,低到人工的 1/10,甚至是 1//100,这样才能提高 Agent 的使用频率。
为什么选 RL 做通用 Agent ?
- Agent 要好用,得能调用工具,可能有上千个。但现在最好的 LLM 在调用 100 个甚至 50 个工具的时候,就已经开始出现幻觉。
- LLM “注意力” 有限,能支持的上下文 Token 长度有限。比如有 50 个工具,每个工具用 1000 个 Token 描述,那光工具就有 5 万个 Token。完成任务时,调用一个工具拉出一篇文章,文章对应的 Token 也要作为上下文喂给 LLM。十几步下来,就是上百万个 Token,百分之百产生幻觉。
- 未来任务越来越复杂,工具数量会按照几何级数上涨,而 LLM 的参数量、上下文长度只能线性增长,不可能把世界上所有的工具包进来。
- 强化学习模型完成任务的能力来自 self-play(自我对弈):
- 虚拟环境里无数次试错,找到最优路径,然后记住它,之后遇到类似的情况就知道该怎么做。不靠 Token 决策,不用像 LLM 一样先生成 1000 个 Token 理解工具是什么、怎么用,再生成 1000 个 Token 理解问题是什么,再生成 1000 个 Token 匹配问题和工具。
- 完成多步任务时,LLM 开始每步动作前,都要扫描一遍之前生成的 Token,再选工具,有 N 个步骤,就得做 N 次决策;而强化学习模型一次决策,就能计划好在哪一步该调用什么工具。
- 本质
- LLM 学人类的思维模式,预训练时提炼文本中的人类知识,微调时也和人类对齐。
- 但强化学习模型只靠试错寻找最优路径,有时会跳出人类思考框架。
接入新工具,是否要重新训模型?大部分情况不用
- 这版 Agent 训练时已经见过 15000 个工具了,有很好的泛化能力。
- 如果要调用小众的工具,那可能还需要做微调,和以 LLM 为核心的 Agent 一样。
案例
- 让 Pokee 帮我和投资人预约会议,但忘记给它邮箱的阅读权限。
- 基于 LLM 的 Agent 按照人类思路,这时可能直接问用户要收件地址
- 但 Pokee 直接 Google 了投资人的公开信息,拿到了邮箱地址。
长期看, LLM 可能会是用户交互界面,是互联网的前端。而后端,所有工具的交互是由某种协议加决策机制来完成的,不必然用自然语言。
比如你让 Agent 去买菜,它会用 LLM 理解你在说什么,然后交给另一个以强化学习为核心的模型做。后者再把信息传达商家端的 Agent。商家端 Agent 确定库存、收货地址,向送货员发请求。这过程应该由 Agent 和 Agent 之间的沟通来完成。
MCP 过于复杂,开发者自己设置 MCP 服务器,声明如何设置参数,保证工具之间能相互衔接,Pokee.ai 团队另做了一套方便 Agent 调用工具的协议,开发者说明工具的输入、输出、唤起方式,就能被 Pokee 调用。同时,Pokee 未来也会支持 MCP。
这种路线慢慢从「非共识」变成了「共识」
通用 Agent 的核心能力:
- 不管是在什么场景下,要解决什么问题,只要把 prompt 告诉它,就可以把任务完成,而不需要事先去配置要用哪些工具。
设想
- 客户给到一个 prompt,描述要做的事情需求,这家公司或开发者不需要处理,直接将 prompt「扔」给 Pokee, Pokee 就根据 prompt 调用对应工具,把问题解决,将结果直接传回给公司或开发者,之后后者可以把内容用更好的展现形式反馈会给客户。
通用 Agent 对 prompt 的要求很高,不是每个人都能正确提问题
- 用户给的 prompt 可能并不是真正意图,想做的和说的是两回事。
如何理解意图就叫做对齐(Alignment),非常难,因为没有 Ground Truth,每个人说话方式都不一样。如果真的想要找到 Ground Truth,说用户一定指的是这件事情,那必须要通过和这个人的长期 Memory 联系起来才能够找到。
先要能够解决问题,之后把用户的非训练数据进行个性化(personalization) ,然后要去理解、对齐。大概就是三步走 —— 决策能力、对于 Memory 的 personalization、Alignment 对齐。
- 整个行业第一步都还没做完,更别说二、三步了
- 但从商业化角度,这不是第一优先级,先考能不能解决问题?然后再探索能不能更好地理解(问题)。
第三方开发者在不需要做任何开发的情况下完成 AI Agent 的搭建,不管是 No Code 还是 Low Code。
- No Code: Pokee 直接跑一个 prompt,得到工作流后,直接复制粘贴给无数个场景下面;
- Low Code: 别人通过接口把想要解决的问题以 Prompt 形式传过来,从而把问题解决了,也不用告诉要用什么工具。
Agent 自动化
Agent 自动化
问题
LLMs 在解决多样化的复杂任务方面表现出色,但构建其工作流需要大量人力,限制了扩展性。
问题
- 手动设计智能体系统效率低下:
- 当前 Foundation Models (FMs) 虽强大,但解决复杂问题时往往需要将其作为模块构建成多组件的智能体系统(如 Chain-of-Thought, Self-Reflection)。
- 这些系统以及各种构建块(如思维链推理、记忆结构、工具使用、自反思等)的开发和组合,通常需要研究人员和工程师付出大量手动调优和精力,且容易受限于领域特定知识。
- 长期来看自动化解决方案最终取代手动设计:
- 机器学习的历史表明,手动设计的解决方案最终会被更高效的学习型解决方案所取代(例如,计算机视觉中手动设计的 HOG 特征被 CNN 学习到的特征取代,以及 AutoML、AI-GA 等方法在自动设计神经网络、生成环境方面的成功)。这暗示着智能体系统设计也应走向自动化。
总结
案例
DSPy(Khattab et al., 2024) 提示工程提供自动化样例 automates the process of designing exemplars for improved prompt programming.MASLi et al. (2024a) 多数投票机制,借助多个agent来提升效果 proposes to optimize MAS by scaling up the number of agents in majority voting.ADAS(Hu et al., 2024a) 提出元智能体概念, 拓扑结构 programs new topologies expressed in code via an LLM-based meta-agent.AFlow(Zhang et al., 2024b) 通过MCTS在预定义算子集合中找到更好的拓扑结构 searches better topologies using Monte Carlo Tree Search within a set of predefined operators.MaasGoogle, Multi-Agent System Search 多阶段优化框架
However, the interplay between multiple design spaces, including prompts and topologies, remains unclear.
【2026-4-6】Agent Loop
【2026-4-6】Agent Loop:让 Agent 自己跑起来
Anthropic 在文章《Building effective agents》中,对 Agent 精辟定义:
Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. Agent 可以处理复杂的任务,但它们的实现往往很简单。本质上就是 LLM 在一个循环中,根据环境反馈来使用工具。
注意关键词:in a loop(在一个循环中)。
Agent 和 普通 LLM 应用最本质的区别
- 普通 LLM 应用:问一句答一句,流程是预先写死的。
- 而 Agent 是把控制权交给 LLM,由模型决定下一步做什么、调什么工具、什么时候停下来。
Anthropic 强调:
Agent 的核心循环结构非常简单,关键在于模型的能力和工具的设计,而不是复杂的编排逻辑。
Claude Code 就是这个理念的直接产物。如果用过 Claude Code,能感受到:给它一个任务,自己去读代码、改文件、跑命令,一步步推进,直到搞定。
背后驱动这一切的,就是 Agent Loop。
对比
【2026-1-27】从 ReAct 到 Ralph Loop:AI Agent 的持续迭代范式
开发者语境中
- “agent loop” 指智能体内部的 感知—决策—执行—反馈 循环(即典型的感知-推理-行动机制)。
- 而 Ralph Loop 更侧重于迭代执行同一任务直至成功,与典型智能体循环在目的和设计上有所不同:
结果表明:
- 常规 Agent Loop 更通用:用于决策型 agent,根据多种状态和输入动态调整下一步操作。
- ReAct 模式适合需要动态适应的场景
- Plan-and-Execute 模式适合结构化任务分解。
- Ralph Loop 更像是自动驱动的 refine-until-done 模式:重点是让模型在固定任务上不断修正输出直到满足完成条件。它通过外部强制控制避免了 LLM 自我评估的局限性。
Ralph Loop
Ralph 循环的“外部化”范式
Claude Code 社区诞生了一种极简但有效的范式——Ralph Loop(也称 Ralph Wiggum Loop):
while :; do
cat PROMPT.md | claude-code --continue
done
核心思想:
- 同一个提示反复输入,让 AI 在文件系统和 Git 历史中看到自己之前的工作成果。
- 这不是简单的“输出反馈为输入”,而是通过外部状态(代码、测试结果、提交记录)形成自我参照的迭代循环。
- 其技术实现依赖于 Stop Hook 拦截机制。
Ralph Loop 让大语言模型持续迭代、自动运行直到任务完成,而不在典型“一次性提示 → 结束”循环中退出。这种范式已经被集成到主流 AI 编程工具和框架中,被一些技术博主和开发者称作“AI 持续工作模式”。
核心三要素:
- 明确任务 + 完成条件:定义可验证的成功标准
- Stop Hook 阻止提前退出:未达标时强制继续
- max-iterations 安全阀:防止无限循环
Ralph 循环打破了依赖 LLM 自我评估的局限性。
实现机制采用停止钩子(Stop Hook)技术:
- 当智能体试图退出当前会话(认为任务完成)时,系统会通过特定的退出代码(如退出码 2)截断退出信号。
- 外部控制脚本会扫描输出结果,如果未发现预定义的“完成承诺”(Completion Promise),系统将重新加载原始提示词并开启新一轮迭代。
【2024-8-15】ADAS
【2024-8-15】加拿大 不列颠哥伦比亚大学 提出 ADAS (Automated Design of Agentic Systems)方法,并实施案例 Meta Agent Search
- ICLR 25 文章:AUTOMATED DESIGN OF AGENTIC SYSTEMS(自动化Agent设计系统)。
- Github - ADAS
- 【2025-7-11】ICLR25-告别手搓workflow!AI 能自己设计更强智能体吗?
ADAS 将 Agent 框架设计自动化
- 发现新的架构模块
- 已有模块按照新的方式组织
如何自动化设计强大的Agent系统(ADAS系统),其通过一种元智能体(meta-agent)来自动编写和迭代优化Agent,让他自动化去发明新颖的构建模块和组合方式。同时通过一个名为 元智能体搜索(Meta Agent Search) 迭代地编程新颖智能体,并根据其性能进行评估和优化。
该方法特点:
- 自动化Agent设计系统: 自动发明新颖的构建模块并设计强大的智能体系统。
- 代码空间搜索: 在代码空间中定义和搜索智能体的方法,理论上允许发现任何可能的智能体系统(包括提示、工具使用、工作流等),并利用大模型的编程能力来实现自动化发现。
- 元智能体搜索算法: 引入了 Meta Agent Search 算法,通过让元智能体迭代地编程新颖智能体,并根据其性能进行评估和优化,从而实现性能的持续提升和泛化能力的增强。
方法
- 1 搜索空间 (Search Space): 定义了 ADAS 方法能够表示和发现的智能体系统类型。提出在 代码空间 中定义整个智能体系统。选择 Python 等图灵完备的编程语言作为搜索空间,可以尝试各种提示、工具使用逻辑、工作流和它们的任意组合。
- 2 搜索算法 (Search Algorithm): 元智能体(基于 GPT-4等强大的LLM)迭代地编程新颖的智能体。元智能体根据一个不断增长的、包含先前发现的智能体及其性能的档案来生成新的智能体。相当于迭代去探索(新颖或有价值)的可能结果。
- 为元智能体提供一个包含基本功能(如 FM 查询 API、提示格式化)的简单框架(少于 100 行代码)。
- 元智能体只需编写一个 forward 函数来定义新智能体的功能。
- 可以可选地用基线智能体(如 Chain-of-Thought, Self-Refine)初始化档案。
- 3 评估函数 (Evaluation Function): 以智能体在任务验证数据上的 准确率或 F1 分数 作为性能指标来优化。
结论
- 结论1: 自动化Agent系统设计可能代表着智能体开发的新范式。 手动设计智能体系统所面临的效率低下和创新局限性。利用LLM的强大编程能力在代码空间中进行搜索,可能能够自动发明新颖、高效的智能体构建块和组合方式,可以加速了智能体系统的发展。
- 结论2: 元智能体搜索算法能够持续发现超越 SOTA 手动设计的智能体。 本文提出的 Meta Agent Search 算法在多个领域(包括逻辑推理、阅读理解、数学、多任务和科学问题解决)的实验中表现出色,在未见过的领域也有强大的泛化和迁移能力。一定程度证明了自动化设计智能体系统是可行的。
- 结论3: 代码空间搜索是实现通用智能体设计和 AI 进步的关键。 理论上这种方法能发现任何可能的智能体系统——包括提示、工具使用、工作流和它们的任意组合。
Automated agent design significantly surpasses manual approaches in performance and generalizability.
- • Introduces Automated Design of Agentic Systems (
ADAS), a new research area for automatic creation of powerful agentic system designs - • Represents agents in code, enabling a meta agent to program increasingly better agents
- • Proposes
Meta Agent Searchalgorithm:- Iteratively generates new agents based on an evolving archive of previous discoveries
- Uses Foundation Models to create agents, evaluate performance, and refine designs
- • Encompasses a search space including all possible components of agentic systems:
- Prompts
- Tool use
- Control flows
- • Theoretically enables discovery of any possible agentic system
Results📊:
- • Outperforms state-of-the-art hand-designed agents across multiple domains
- • Improves F1 scores on reading comprehension (DROP) by 13.6/100
- • Increases accuracy on math tasks (MGSM) by 14.4%
- • Demonstrates strong transferability:
- 25.9% accuracy improvement on GSM8K after domain transfer
- 13.2% accuracy improvement on GSM-Hard after domain transfer
- • Maintains superior performance when transferred across dissimilar domains and models
【2024-10-14】AFlow
AFLOW 自动化框架通过工作流优化视为搜索问题,并利用MCTS(蒙特卡洛树搜索)技术自动探索和优化代码表示的工作流。
【2024-10-14】DeepWisdom和香港科技大学 提出AFlow (Zhang et al., 2024b) 通过MCTS在预定义算子集合中找到更好的拓扑结构 searches better topologies using Monte Carlo Tree Search within a set of predefined operators.
- 【2025-4-15】ICLR 论文 AFLOW:AUTOMATING AGENTIC WORKFLOW GENERATION
- 代码 AFlow
- 【解读】AFlow:Automating Agentic Workflow Generatio 工作流生成
- 效果超过 ADAS
AFLOW 将工作流建模为由代码连接的节点和边,表示操作间的逻辑、依赖关系和流程,形成一个庞大的搜索空间。
该框架使用预定义的操作符作为构建块,并结合多种创新技术(如软混合概率选择、LLM驱动的节点扩展、执行评估和经验反向传播)来高效探索这一空间,自动创建优化的工作流,以最大化任务性能并减少人工干预。
AFLOW通过自动化技术提升工作流生成效率,适应多样化的任务需求,从而提高整体任务执行效率并降低人力需求。
关键贡献:
- (1) 问题形式化:将工作流优化问题进行了形式化定义,将以往的方法概括为特定案例。这为未来在节点和工作流优化层面的研究提供了一个统一的框架。
- (2) AFLOW:提出了AFLOW,一种基于蒙特卡洛树搜索(MCTS)的方法,该方法能够以最少的人工干预自动发现跨多个领域的高效工作流。
- (3) 广泛评估:六个基准数据集上对AFLOW进行了评估,这些数据集包括HumanEval、MBPP、MATH、GSM8K、HotPotQA和DROP。结果表明,AFLOW的表现比人工设计的方法高出5.7%,比现有的自动化方法高出19.5%。值得注意的是,由AFLOW生成的工作流使较小的大型语言模型(LLMs)能够超越更大的模型,在成本效益上表现出显著优势,这对实际应用具有重要意义。
【2025-2-4】Google Maas
【2025-2-4】Google研究发现:Multi-Agent的核心竟然是Prompt设计
Google&剑桥大学提出 Mass 框架, Multi-Agent System Search(Mass),三个阶段优化MAS:
- 块级(局部)提示优化:对每个拓扑块中的智能体进行提示优化。
- 工作流拓扑优化:在修剪过的拓扑空间中优化工作流拓扑结构。
- 工作流级(全局)提示优化:在找到的最佳拓扑结构上进行全局提示优化。
阶段 1) block-level (local) prompt ‘warm-up’ for each topology block; 2) workflow topology optimization in a pruned set of topology space; 3) workflow-level (global) prompt optimization given the best-found topology.
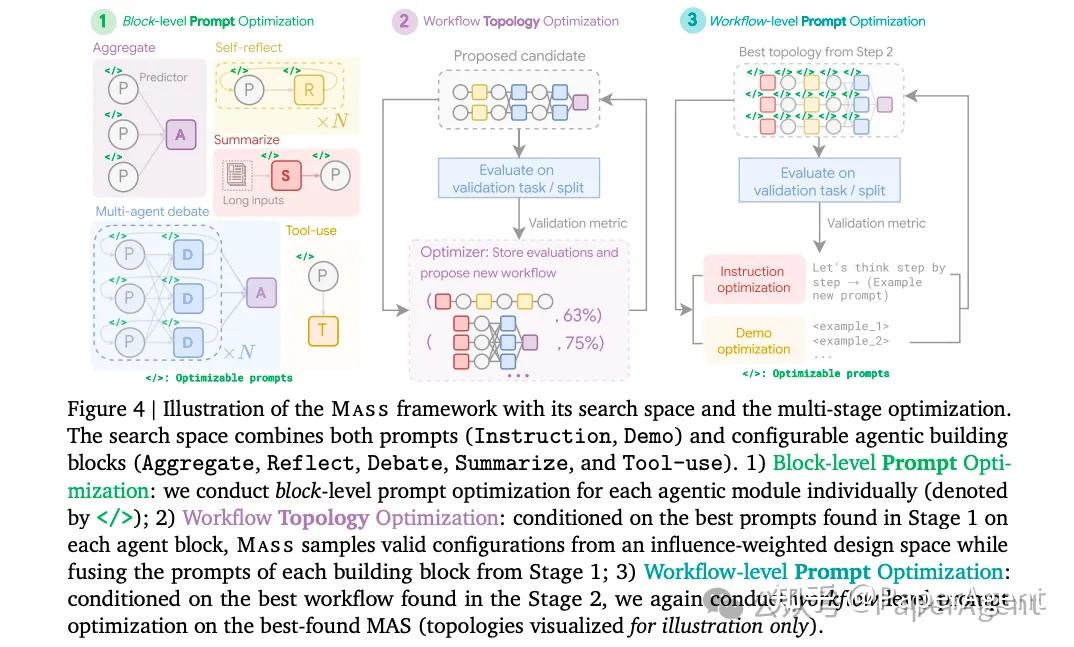
多智能体系统搜索(Mass)框架通过在可定制的多智能体设计空间中交错进行提示优化和拓扑优化,发现了有效的多智能体系统设计(右侧为经过优化的拓扑结构和优化的提示)
比较,包括: 链式思考(CoT)、自我一致性(SC)、自我细化(Self-Refine)、多智能体辩论(Multi-Agent Debate)、ADAS和AFlow。
- 性能提升:Mass在多个任务上显著优于现有方法,平均性能提升约10%以上。
- 优化阶段的重要性:通过分阶段优化,Mass在每个阶段都取得了性能提升,证明了从局部到全局优化的必要性。
- 提示和拓扑结构的协同优化:Mass通过同时优化提示和拓扑结构,实现了比单独优化更好的性能。
- 成本效益:Mass在优化过程中表现出稳定且有效的性能提升,与现有自动设计方法相比,具有更高的样本效率和成本效益。
【2025-2-6】MaAS
论文
- 【2025-2-6】新加坡国立、南洋理工 提出
MaAS
早期多智能体系统提供专业能力,但严重依赖手动配置
- 如
CAMEL(Li et al., 2023)、AutoGen(Wu et al., 2023)和MetaGPT(Hong et al., 2023) - 手工配置:提示工程、智能体分析和智能体间通信流水线(Qian et al., 2024)。
- 这种依赖限制了多智能体系统对不同领域和应用场景的快速适应
多智能体系统设计自动化
- 优化Agent间通信:
DsPy(Khattab et al., 2023)和EvoPrompting(Guo et al., 2023) 自动提示优化,GPTSwarm(Zog et al.,2024)和G-Designer(Zhang et al.,2024b) - 自我进化Agent分析:
EvoAgent(Yuan et al.,2024)和AutoAgents(Chen et al.,2023a)
然而,专注于自动化系统的特定方面。
随后,ADAS(胡等人,2024a)、AgentSqure(Shang 等人,2024)和 AFlow(Zhang 等人,2024c)拓宽了设计搜索空间 — SOTA 方法
ODS 通过不同的搜索范式为给定数据集优化单个复杂(多)代理工作流程,例如: 启发式搜索(胡 et al., 2024a)、蒙特卡洛树搜索(Zhang et al., 2024c)和进化(Shang et al., 2024),超越了手动设计系统的性能
问题
- 性能受资源限制,例如令牌成本、LLM调用和推理延迟。现代方法倾向于针对复杂和资源密集型的 agen 进行优化
We introduce MaAS, an automated framework that samples query-dependent agentic systems from the supernet, delivering high-quality solutions and tailored resource allocation (e.g., LLM calls, tool calls, token cost). Comprehensive evaluation across six benchmarks demonstrates that MaAS (I) requires only 6 ∼ 45% of the inference costs of existing handcrafted or automated multi-agent systems, (II) surpasses them by 0.54% ∼ 11.82%, and (III) enjoys superior cross-dataset and cross-LLM-backbone transferability.
MaAS 自动化框架从超网中采样query相关的智能体系统,提供高质量的解决方案和定制的资源分配(大语言模型调用、工具调用、令牌成本)。
Agent超网是一个级联的多层工作流,包括
- ❶ 多个Agent算子: CoT (Wei et al., 2022)、Multi-agent Debate (Du et al., 2023)、ReAct (Yao et al., 2023)),以及
- ❷ 算子跨层的参数化概率分布。
- 训练期间,MaAS 利用控制器网络对以query为条件的多代理架构进行采样。分布参数和运算符根据环境反馈共同更新,前者的梯度通过蒙特卡洛采样近似,后者梯度通过文本梯度估计。
- 推理过程,对于不同query,MaAS 对合适的多智能体系统进行采样,提供令人满意的分辨率和适当的推理资源,从而实现任务定制的集体智慧
六个基准综合评估: MaAS
- ❶ MaAS 高性能,比现有的手工或自动化多智能体系统高出 0.54% ∼ 11.82%;
- ❷ 节省token,在 MATh 基准上优于 SOTA 基线 AFlow,训练成本为 15%,推理成本为 25%;
- ❸ 可迁移: 跨数据集和 LLM-backbone;
-
❹ 归纳式: 对看不见的Agent运算符泛化性强
- (I)仅需现有手工制作或自动化多智能体系统推理成本的 6% - 45%
- (II)高出 0.54% - 11.82%,并且
- (III)具有卓越的跨数据集和跨大语言模型骨干的可转移性。
【2025-5-29】MermaidFlow
【2025-7-28】告别脆弱Agent系统:一图读懂MermaidFlow,下一代多智能体LLM工作流演化引擎
MermaidFlow通过引入声明式、有类型的workflow表示与约束演化算法,为多智能体LLM系统的生成计划与执行带来了前所未有的可解释性、安全性与泛化能力。
它不再让LLM“盲写代码”,而是在一个编译器友好、结构可控、可调试的图空间中优化任务规划 —— 开启了Agentic Workflow进化的“结构纪元”。
当前多智能体系统为何频繁掉点?不是模型不行,而是工作流设计太脆弱、太混乱
workflow往往以Python代码或JSON等形式隐式表达,缺乏结构化表达与验证机制,导致生成结果常常不可执行、不可复用、难以调试。这种不安全、不健壮的生成方式成为多智能体系统的主要瓶颈。
A*STAR 与 NTU 论文 MermaidFlow 提出解决方案 —— 用声明式图语言Mermaid重构Agent工作流表达,并引入进化式优化机制,让每一个任务规划既长得美又能执行。
- 论文:【ICML 2025】2025.05.29_MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
- 官方代码:MermaidFlow
新框架:MermaidFlow 核心创新包括:
- Mermaid 声明式工作流表示法
- 使用类 DSL语言 Mermaid 描述 agentic workflow,使得每个节点和边都具备明确的类型、角色语义与连接逻辑。
- 工作流表示为有向图
G(V[τ, α], E[ρ]),支持静态类型检查和图可视化。
- 安全约束的演化式编程
- 定义结构安全的图操作:如节点替换、子图变换、交叉、插入与删除,确保变异后的workflow依旧合法(闭合于合法空间 S)。
- 基于历史工作流构建优化过程,提升搜索效率与泛化能力。
- “LLM作为裁判”与“编译器检查器”
- 用LLM评价workflow语义有效性,同时配合Mermaid parser进行语法检查,避免不合法或非结构化的结果。
所有任务上, MermaidFlow 均优于13个现有基线方法,如: MaAS、AutoAgents、AFlow等。
- 平均精度达80.75%,超越最强基线
MaAS的79.35%。 - 结构复杂、基准分数低的任务(如MATH、MBPP)上,改进尤为显著。
优势:
- 提高了可执行性与结构健壮性;
- 显著加快了收敛速度;
- 构建出更可视、可复用、可验证的workflow空间。
【2025-7-16】ZeroGraph
【2025-7-16】ZeroGraph: 让 Al Agent 构建 AI Agent.
- 未找到官方信息
还在手动拖拽n8n、Dify的工作流,或在ComfyUI 的节点迷宫里挣扎?是不是觉得,这种方式不够”AI”?
未来,属于Agentic Programming, 让 Al Agent 自己理解任务、分解问题,甚至动态生成和优化工作流
【2025-7-30】MetaAgent
【2025-7-30】威斯康星大学:自动构建多智能体系统
- MetaAgent: Automatically Constructing Multi-Agent Systems Based on Finite State Machines
- 代码 MetaAgent
起因
现有人工设计的多智能体框架通常局限于少量预定义任务,缺乏通用性,还存在工具集成不足、依赖外部训练数据、通信结构僵化等问题 。
MetaAgent 介绍
MetaAgent,这是一个基于有限状态机(FSM)的框架,可针对给定任务描述,自动生成多智能体系统。
- 给定任务的大致描述后,MetaAgent 会先设计多个智能体以解决任务,再基于解决任务时可能涉及的场景,对这些智能体所需执行的行动进行总结和梳理,每个状态包含对应的任务解决步骤 。
特点
和现有方法有何不同?
相比传统人工设计或自动化方法,MetaAgent 支持工具集成、无需外部训练数据,并能灵活实现“状态回溯”——发现错误可自动回到前一步修正。
通过状态机机制,让每个 Agent 明确分工并动态协作,极大提升了系统的通用性和鲁棒性。
创新和意义
MetaAgent 主要创新在于用有限状态机框架统一了多智能体系统的设计,支持“工具赋能”和“状态回溯”,让系统能自动调优、动态修正,适应更广泛的实际场景。
对于AI研究者和工程师来说,这意味着可以低成本、高效率地开发和部署更强大的多智能体系统,推动智能体技术的产业落地。
效果
文本生成、机器学习、软件开发等多种任务上,MetaAgent 自动生成的多智能体系统不仅超越了目前主流的自动化设计方法,在部分任务上还能达到与顶尖人工系统相当的效果。
比如,在文本任务中,MetaAgent 比最强的 prompt-based 方法高出9%,在机器学习任务的多个数据集上也达到或接近最佳表现。
Agent 进化
详见站内专题: LLM/Agent自我进化
Agent 训练
【2025-8-5】微软 Agent Lightning
【2025-8-5】
微软提出 Agent Lightning,灵活且可扩展的框架,支持基于强化学习(RL)的大模型(LLMs)训练,适用于任何AI 智能体。
与现有方法将RL 训练与智能体紧密耦合或依赖序列拼接与掩码不同,Agent Lightning 实现了智能体执行与训练的完全解耦,使得与通过多种方式开发的现有智能体(如使用LangChain、OpenAI Agents SDK、AutoGen 等框架,或从零构建)几乎无需代码修改即可无缝集成。
通过将智能体执行建模为马尔可夫决策过程,定义统一的数据接口,并提出了一种分层RL 算法——LightningRL,其包含信用分配模块,将任何智能体生成的轨迹分解为训练转移。
这使得RL能够处理复杂的交互逻辑,如多智能体场景和动态工作流。
在系统设计上,引入了训练-智能体分离架构,并将智能体可观测性框架融入智能体运行时,提供了标准化的智能体微调接口。
在文本到SQL、检索增强生成和数学工具使用等任务上的实验展示了稳定、持续的改进,证明了该框架在实际智能体训练与部署中的潜力。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
