- 端侧 LLM
- 结束
端侧 LLM
边缘计算
端即物联网中的任何终端,端侧AI即AI在端侧的应用,也是边缘计算。这种模式可以更好的支持AIoT场景
AI+IoT=AIoT
边缘计算就是未来
端侧AI(On-device AI)
传统计算处理多数是基于云侧,把所有图像、音频等数据通过网络传输到云中心进行处理后将结果反馈。
但是随着数据指数式增长,依靠云侧的计算已经显现了诸多不足,例如:数据处理的实时性、网络条件制约、数据安全等
端侧推理则愈发重要。
ChagtGPT、GPT-4等AIGC大模型虽然它们很厉害,但是它们只解决了语言大模型在服务端部署的问题。大模型需要极高的算力和资本投入,并不是一般的企业所能承受的
端侧AI
云端协同
- 端侧AI当前普遍应用方式:终端侧处理 + 云端处理补充,即
协同合作(云端协同) 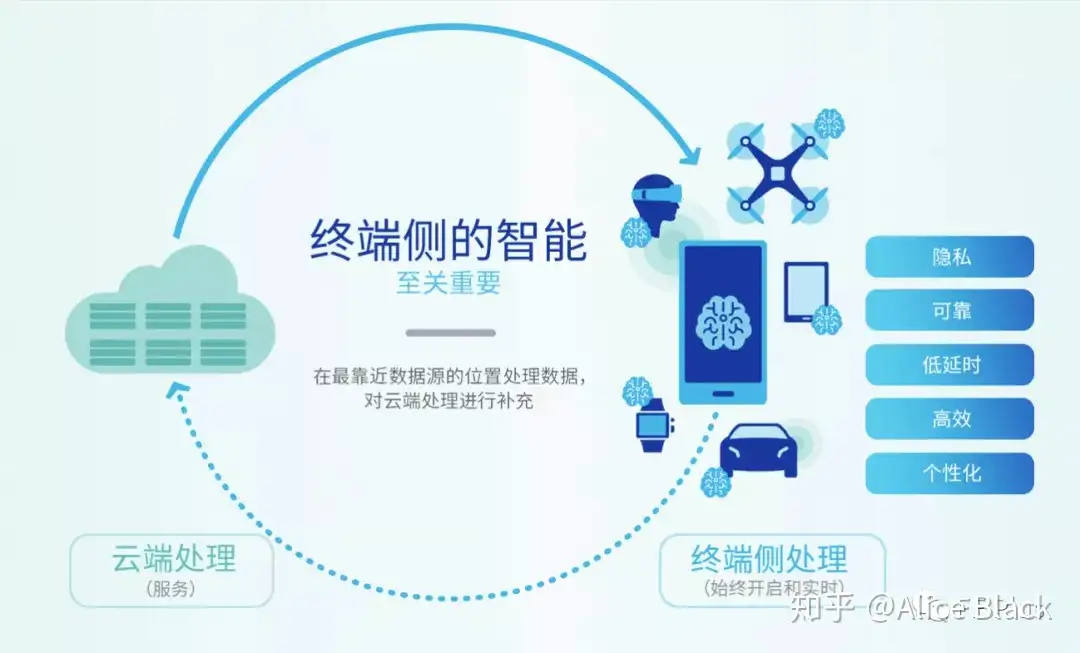
- 图源
- 参考:端侧AI(On-device AI)
端侧 AI 优势:
- 隐私保护: 数据存储本地无需上传
- 可靠: 降低数据上传云端链路过长导致的错误率
- 低延时: 本地存储计算, 减少不必要流量,选择性占用网络宽带资源
- 不依赖网络
- 个性化: 持续学习,模型调整,隐私保护的分布式学习.带来个性化的互动与体验
端侧 AI 挑战:
- 硬件资源限制: 存储、内存、计算资源
处理器算力有限,远低于云端计算能力,如何满足日益复杂的端侧 AI 性能的需求至关重要内存大小和带宽有限,对性能影响至关重要
- 模型版本管理、生命周期
- 终端种类很多,不同硬件架构适配和模型迁移成本过高, 同时导致了端侧AI应用复杂度增加
与云端AI面临的挑战类似
边缘和端侧AI软硬件的成熟度以及软硬的融合很大程度上阻碍了AI的普及,降低AI开发门槛,提升通用性成为了AI普及的当务之急。- 商业层面也面临诸多挑战,比如 应用场景众多,如何在众多的应用场景中形成一个良好的商业闭环?如何让传统行业也能轻松用上AI技术?怎么提供打动消费者的使用体验?
曾经火爆的智能音箱已经证明,不佳的使用体验只会让消费者迅速对新技术感到失望。
- 要实现良好的AI产品用户体验,多传感器融合以及多种AI技术的应用成为了未来的发展方向。
智能音箱反映出端侧AI普及面临硬件、算法以及应用需求多样的三道槛。
- 2018年爆发的智能音箱并没有用于实现AI功能的专用芯片,AI的算法也并不成熟,再加上整个行业的低价恶性竞争,体验不佳的智能音箱让众多尝鲜者很快放弃了这一AI“爆品”。
边缘和端侧AI硬件和算法向前迭代遇到普及三道槛
- 硬件设备
- 运行于芯片上的算法
- 应用多样,需求不同。
小模型 vs 大模型
模型制作阶段,端侧小模型和大模型的成本接近。
但发布后,大模型依然需要依赖AI服务器提供推理,但端侧小模型只需要提供模型文件下载即可。
端侧小模型对算法硬件只有临时性需求。一旦生成,即可脱离。
小模型才是 Agentic AI 未来
2025年6月2日, 英伟达和佐治亚理工学院论文
- 论文:Small Language Models are the Future of Agentic AI
- 反共识的观点:小模型才是Agentic AI的未来。
小模型指能安装在普通的消费级电子设备上,并且在处理单个用户的智能体请求时,其推理延迟足够低、具有实际可用性的语言模型。
- 虽然大模型在通用对话和复杂推理方面表现出色, 但在实际的智能体应用中,模型通常只需要执行特定、重复且范围有限的任务。
- 这些场景下,小模型 不仅足够强大,而且在运行效率和经济成本上具有压倒性优势。
几个方面对这个观点论证:
- 小模型已经变得足够强大,新一代小模型(如 Microsoft Phi 系列、Qwen3.5系列、Huggingface SmolLM2)的性能曲线正在变得越来越陡峭,他们已经和几年前的大模型性能相当。
- Agent执行的任务常常比较单一,比如解析JSON、调用API、总结文档,LLM作为一个全才,大部分参数在执行这些任务是冗余的。小模型通过微调完全可以胜任这些任务。
- 小模型的推理成本远低于大模型,更加经济高效。
对三个流行的Agent框架进行了测试,发现其中40%-70%的查询都可以用小模型进行处理。
端侧模型生产方式
端侧小模型生成方式:
- 1、大模型转化为端侧小模型。
- 2、训练时直接生成客户端部署的端侧小模型。
- 3、由客户端训练,可在客户端运行的端侧小模型
应用
应用
- APP: 扫福、卡片识别等图像影音识别
- Web: 前端机器学习, Tensorflow.js
- Low code:生成前端代码
- 生成form表单
- 非AI,阿里Formily
- Json Schema=>Code
- JSX Schema=>Code
- WebAssembly -> IoT
| 案例 | 说明 | 示例 |
|---|---|---|
| 手机淘宝-千人千面 |  |
|
| 支付宝扫福 | 运营活动 |  |
| 卡片识别 | 银行卡识别 | 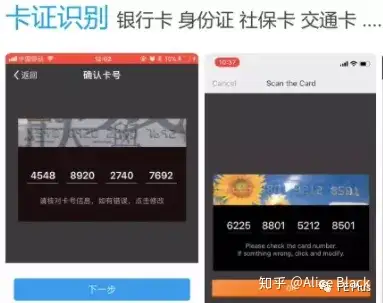 |
| 阿玛尼AR小程序 | 基于Web的TensorFlow Lite | 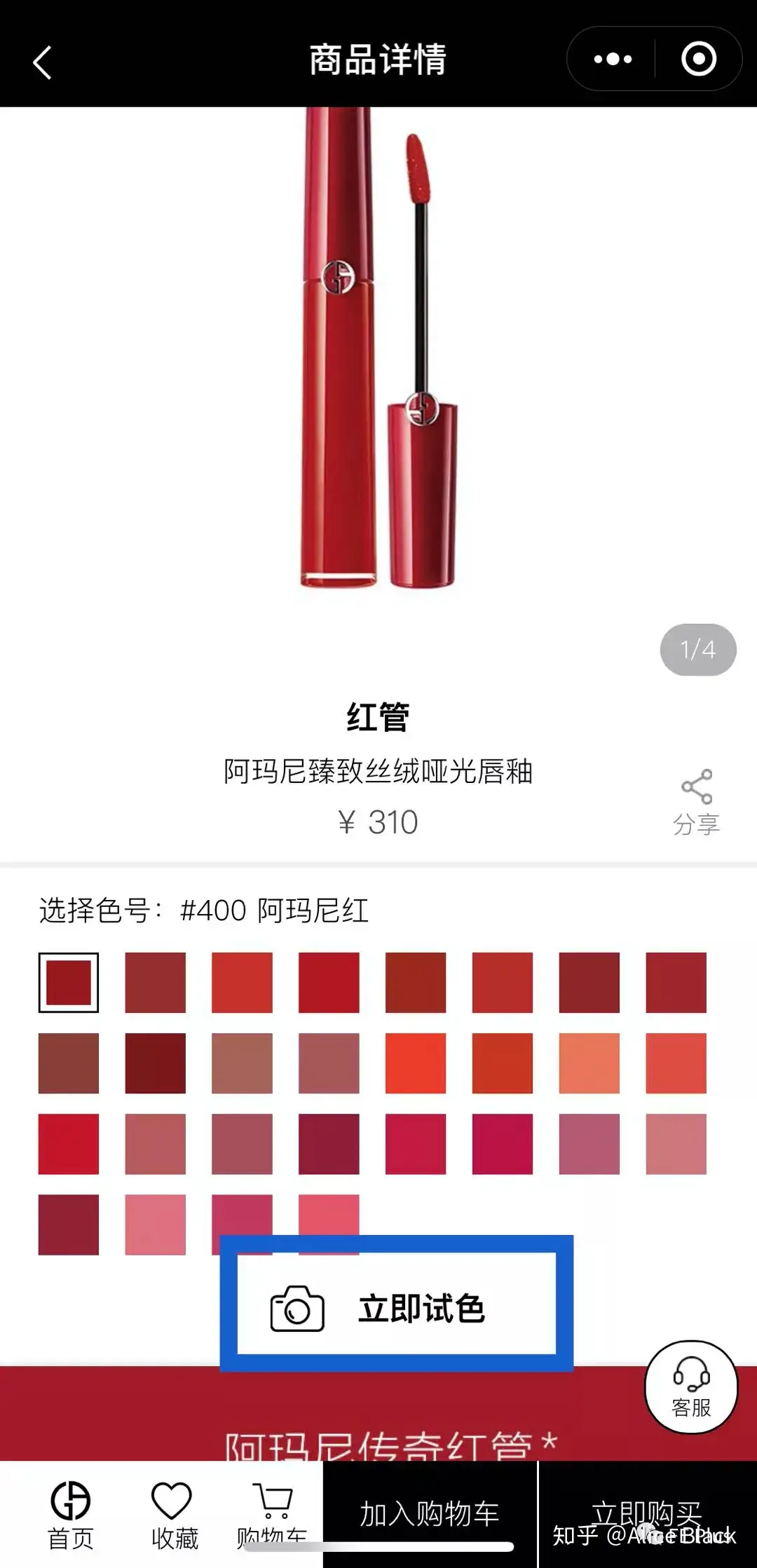 |
| 阿里PipCook | 基于Tensorflow.js,为 JavaScript 开发者提供的机器学习工具集。与Tensorflow的区别在于全流程JS环境,且专注于前端领域。 | |
| D2C:Design to code |
边缘计算设备
计算设备
- ARM 处理器在智能设备中占主导地位,是端侧 AI 落地的主流平台。
NPU、DSP、GPU` 可以提供更高的计算能力,在端侧 AI 上有一定的应用场景,但生态环境较差,距离成熟还需要时间。
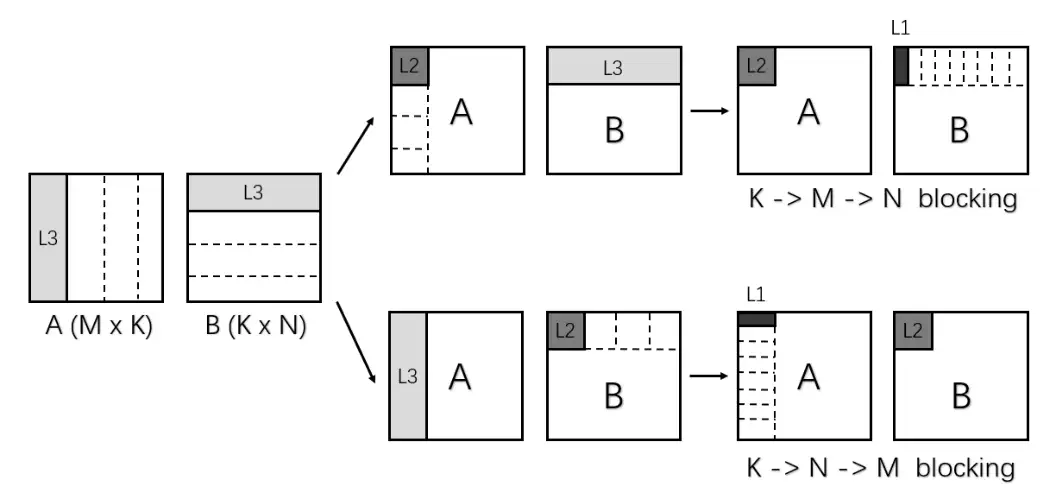
端侧 AI 最耗时的计算为全连接(FC)和卷积计算,底层核心计算为矩阵乘,底层计算库的性能对端侧 AI 能否落地起决定性作用。
深度学习工具库
常用框架:
- Caffe2、TensorFlow Lite、Core ML
TensorflowLite
TensorflowLite
- 谷歌的Tensorflow适用于移动和其他边缘设备的版本
- 设备端重新训练模型, TensorFlow Lite 设备端训练
阿里的MNN
- 轻量级的深度学习端侧推理引擎, 详见端侧AI:从探索尝试到逐步展开
ARM 第三方 BLAS 库
各 ARM blas 库矩阵乘法特点
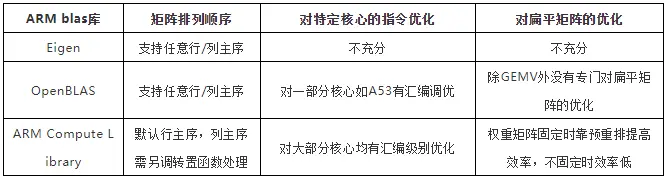
Eigen
线性代数运算的 C++ 模板库,矩阵的运算可直接用符号做。
OpenBLAS
由中科院计算所维护的一个开源的高性能 BLAS 库,基于 Kazushige Goto 的 GotoBLAS,支持 Fortran BLAS 和 CBLAS 接口调用。
ARM Compute Library
ARM 官方推出的计算库,支持 AI 的常见运算,其中矩阵乘法运算以模型推理层的形式封装,需要先初始化后才能调用。
常规矩阵规模上的矩阵乘法进行了较好的优化,性能表现较好,然后在扁平矩阵上性能表现较差。端侧 AI 底层计算主要为扁平矩阵的乘法,第三方计算库性能表现较差,没有充分发挥硬件的性能,不利于 AI 应用在端侧平台上落地。
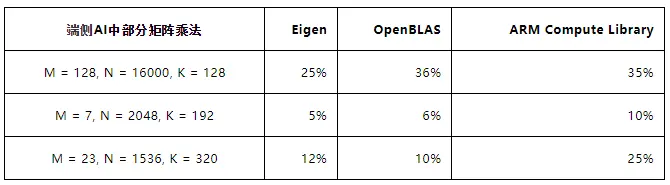
- 表 2 ARM cortex-A53 四核第三方库 GEMM 计算效率
注:$ C(M, N) = A(M, K) * B(K, N) $ ,以上值取全行主序和全列主序的最好值,测试在相同的矩阵上重复 128 次,计算效率由 GEMM 计算 FLOPS 值除以硬件理论 FLOPS 值得到。
本地ML案例
GGML 谷歌
GGML是一个用于机器学习的张量库,它只是一个c++库,允许你在CPU或CPU + GPU上运行llm。它定义了用于分发大型语言模型(llm)的二进制格式。GGML使用了一种称为量化的技术,该技术允许大型语言模型在消费者硬件上运行。
EMLL 网易
【2021-6-16】网易有道开源 EMLL:高性能端侧机器学习计算库,大幅提高计算性能
网易有道 AI 团队开源高性能端侧机器学习计算库——EMLL (Edge ML Library)
EMLL 为加速端侧 AI 推理而设计,提供基于端侧处理器的高性能机器学习计算库,支持 fp32、fp16、int8 等数据类型,已在网易有道词典笔、翻译王和超级词典等智能硬件产品的 NMT、ASR、OCR 引擎中应用,大幅提高计算性能,提升用户体验。
- 中文介绍
- EMLL提供基于 C 的接口,详情请见 Usage_ZH.md
- 更多原理详见原文
特点
- 高性能
- EMLL实现的矩阵乘法函数,为端侧人工智能中常见的扁平矩阵作了专门的优化,为各常见ARM处理器作了特定的优化。对于cortex-A35/A53/A55处理器,本库针对它们的流水线特点,使用了汇编级别的优化。
- 易用性
- EMLL使用的函数接口在参数设计上力求简洁直接,矩阵乘法去掉了不常用的LD*参数,矩阵和向量的传递通过指针和整数维度分别传递。本库的构建和运行不依赖第三方计算库。
- 扩展性
- 对于矩阵乘法和量化函数,EMLL 库提取了它们和架构无关的代码作为通用的宏,这些宏可以在支持新的CPU架构时大大节省所需的代码量。
各函数支持的数据类型
| 处理器 | 矩阵乘法 | 偏置 | 量化 | 重量化 |
|---|---|---|---|---|
| ARMv7a 32-bit | fp32,(u)int8 | fp32,int32 | fp32 -> (u)int16/(u)int8 | int32 -> (u)int16/(u)int8,int16 -> (u)int8 |
| ARMv8a 64-bit | fp32,fp16,(u)int8 | fp32,int32 | fp32 -> (u)int16/(u)int8 | int32 -> (u)int16/(u)int8,int16 -> (u)int8 |
EMLL 支持
- 在 Linux 和安卓系统上运行。
- 用 GCC 和 Clang 编译。
- 未来会增加对端侧 GPU 和 NPU 的支持,并拓展支持的算子范围(卷积、激活函数等)
支持的架构
- armv7a, armv8a
支持的端侧操作系统
- Linux, Android
应用效果
- EMLL 高性能端侧机器学习计算库,已经在网易有道多款智能硬件产品中实际应用并取得显著的效果,大幅提升性能,给用户带来更好的产品体验。
网易有道词典笔,是网易有道打磨的一款学习型智能硬件,凭借高效、准确查词和丰富、权威内容,成为 AI 技术在学习领域应用落地的优秀产品。网易有道词典笔,具有“多行扫描翻译”功能,支持整段翻译的智能学习硬件。
- 网易有道
超级词典打造高效的智能英语学习系统,强化端侧功能,提供了拍照学英语、查词翻译、背单词、听力练习、对话翻译、语音助手等功能。 - 网易有道
翻译王支持 43 种语言互译,畅游全球 191 个国家和地区,支持 21 种语言在线、7 种语言端侧拍照翻译,指示牌、菜单等即拍即译。
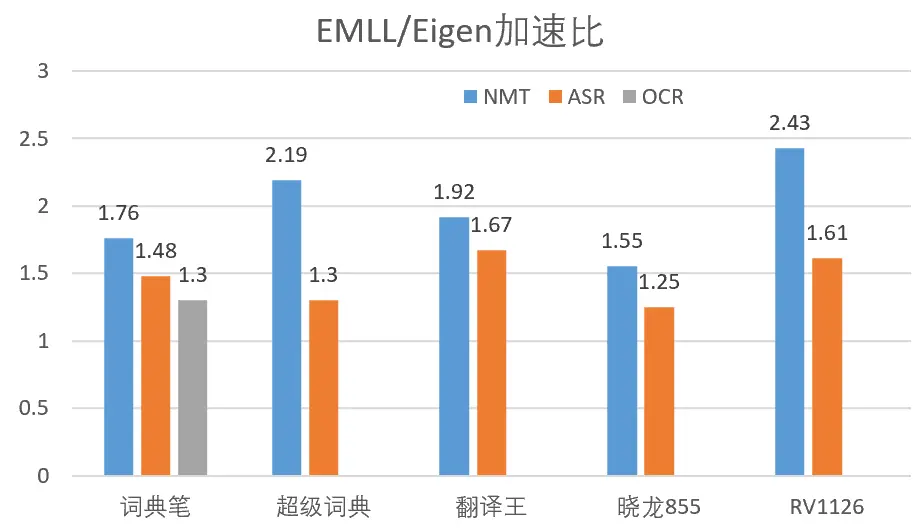
网易有道词典笔、超级词典、翻译王均内嵌了网易有道自主研发的神经网络翻译 NMT、光学字符识别 OCR、语音识别 ASR、语音合成 TTS 等业内领先的 AI 技术,并且支持离线功能。
网易有道自研端侧机器学习计算库已在网易有道词典笔、超级词典、翻译王等智能硬件产品中使用,带来以下好处:
- 端到端性能相对于使用 eigen 库加速 1.3 到 2.43 倍,效果显著,大大降低了端侧推理引擎的延迟。除了在有道智能硬件带来了较好的性能提升,在配置骁龙 855 的某款手机上也做了性能测试,端到端性能相对于 eigen 提升了 25%-55%,效果明显。
- 端侧推理引擎采用 EMLL 之后,可以上线更大的 AI 模型,提高质量,并保证实时性,如端侧 NMT 质量(BLEU)提升 2 个点,端侧 ASR 准确度提升 4.73%。
- EMLL 可以保证在更低端芯片上实时性,如在 cortex-A7 上使用 Eigen 库无法达到实时性,使用 EMLL 之后延迟大幅降低,并保证实时性效果。EMLL 可以让智能硬件更多的芯片选择,从而降低成本,提高市场竞争力。
端侧 NMT、ASR、OCR 在不同平台上使用 EMLL 和 eigen 端到端性能加速比
端上推荐系统 阿里EdgeRec
【2023-9-13】EdgeRec:电商信息流的端上推荐系统
更多见推荐专题:推荐系统 端上推荐专题
本地 LLM
如何让模型运行在本地电脑上?
- Ollama 之类
详见站内专题: 端侧LLM部署工具
Home LLM
【2024-3-4】First Local AI Model Specially trained to Control Home Assistant
【Home LLM:基于本地LLM的家庭助理】’Home LLM - A Home Assistant integration that allows you to control your house using an LLM running locally’
- GitHub: home-llm
- 结合端侧LLM(如 Phi-2)实现智能家居设备控制
系统提示语 “system” prompt:
You are 'Al', a helpful AI Assistant that controls the devices in a house. Complete the following task as instructed with the information provided only.
Services: light.turn_off(), light.turn_on(brightness,rgb_color), fan.turn_on(), fan.turn_off()
Devices:
light.office 'Office Light' = on;80%
fan.office 'Office fan' = off
light.kitchen 'Kitchen Light' = on;80%;red
light.bedroom 'Bedroom Light' = off
命令示例
# turning on the kitchen lights for you now
# homeassistant
{ "service": "light.turn_on", "target_device": "light.kitchen" }
训练
- 3B: LoRA, RTX 3090 (24GB), 训练 10h
- 1B: 全参微调, full fine-tuning, RTX 3090 (24GB), 2.5h
python3 train.py \
--run_name home-3b \
--base_model microsoft/phi-2 \
--add_pad_token \
--add_chatml_tokens \
--bf16 \
--train_dataset data/home_assistant_alpaca_merged_train.json \
--learning_rate 1e-5 \
--save_steps 1000 \
--micro_batch_size 2 --gradient_checkpointing \
--ctx_size 2048 \
--group_by_length \
--use_lora --lora_rank 32 --lora_alpha 64 --lora_modules fc1,fc2,q_proj,v_proj,dense --lora_modules_to_save embed_tokens,lm_head --lora_merge
LLaMA
模型权重是浮点数。
- 表示大整数(例如1000)比表示小整数(例如1)需要更多的空间一样,
- 表示高精度浮点数(例如0.0001)比表示低精度浮点数(例如0.1)需要更多的空间。
- 量化大型语言模型的过程涉及降低表示权重的精度,以减少使用模型所需的资源。GGML支持许多不同的量化策略(例如4位、5位和8位量化),每种策略在效率和性能之间提供不同的权衡。
量化后模型大小对比:
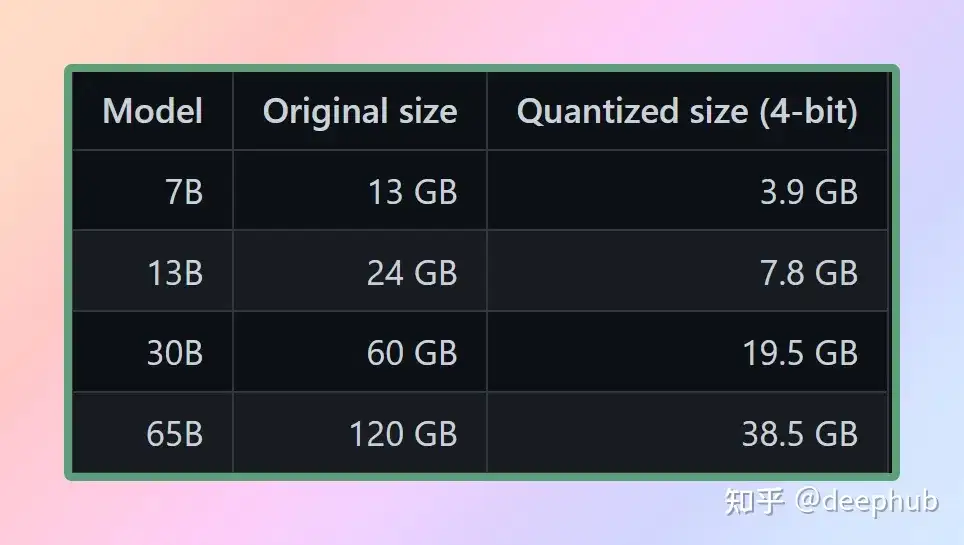
LLaMA.cpp
【2023-8-21】研究完llama.cpp,我发现手机跑大模型竟这么简单
【2024-1-24】Llama.cpp 代码浅析(一):并行机制与KVCache
不同于 DeepSpeed ,llama.cpp 不依赖 Torch。所以,llama.cpp 有点像 darknet,简练,直接。
- llama.cpp 功能还是非常强大,代码总量很大。10000+ 行以上的文件还是有好几个,但是总体结构看起来却很直观,总共也没几个文件。
llama.cpp 基于 LLaMA/2 模型手写的纯 C/C++ 版本:
- 支持 CPU 推理,当然也支持各种底层库推理(CUDA/OpenCL),具有 FP16 和 FP32 的混合精度、支持8/4bit量化等等。
- bin/main 中 -ngl 这个参数,它代表:n_gpu_layers,这个参数默认是 0,如果不设置为一个比较大的数字,整个模型就会到 CPU 上面跑,即便你用了 cublas 等各种编译参数也是在 CPU 上。
经过优化和量化权重,各种以前无法想象的硬件上本地运行 LLaMa 模型。其中:
- 谷歌 Pixel5 手机上,它能以 1 token/s 的速度运行 7B 参数模型。
- M2 芯片的 Macbook Pro 上,使用 7B 参数模型的速度约为 16 token/s
- 甚至于在 4GB RAM 的树莓派上运行 7B 模型,尽管速度只有 0.1 token/s
2023 年 6月,llama.cpp 作者 Georgi Gerganov 开始创业,宣布创立一家新公司 ggml.ai,旨在用纯 C 语言框架降低大模型运行成本。
GPU 对深度学习有两个主要好处:
- 很大的内存带宽(如 A100:1935 GB/s,RTX 4090:1008 GB/s)
- 关系到数据从 HBM 内存(即 RAM)移动到片上内存需要花费的时间。片上内存相当小(A100 上为 40MB,而 RAM 为 40-80GB)内存带宽比计算性能小约 2 个数量级
- 内存带宽几乎是与 transformer 采样相关的最大限制因素。任何降低这些模型内存需求的方法都会使它们更容易提供服务 —— 比如量化
- 很大的算力(A100:FP16 有 312 TFLOPS,RTX 4090:FP16 有 82.6 TFLOPS)
llama.cpp 使用深度学习推理中较为激进的 int4 格式,因此 KV 缓存的 RAM 需求减少到 1.33GB,模型参数的 VRAM 减少到 16.25GB。
TinyLlama-1.1B
【2024-1-11】TinyLlama-1.1B(小羊驼)模型开源-Github高星项目分享
小模型在边缘设备上有着广泛的应用,如智能手机、物联网设备和嵌入式系统,这些边缘设备通常具有有限的计算能力和存储空间,它们无法有效地运行大型语言模型。
场景:
- 对大型模型进行 speculative decoding。
- 边缘装置上运行,比如离线的实时机器翻译
- TinyLlama的4比特量化版本的模型权重只需要550MB的内存
- 游戏中实现实时对话生成(因为还得给游戏本身留显存所以模型要小)。
【2024-1-8】新加坡科技设计大学(SUTD)的研究者近日推出了 TinyLlama ,该语言模型的参数量为 11 亿,在大约 3 万亿个 token 上预训练而成。
TinyLlama 以 Llama 2 架构和分词器(tokenizer)为基础,TinyLlama 可以在基于 Llama 的开源项目中即插即用。
- 此外,TinyLlama 只有 11 亿的参数,体积小巧,适用于需要限制计算和内存占用的多种应用。
- 仅需 16 块 A100-40G 的 GPU,便可在 90 天内完成 TinyLlama 的训练。
尽管规模相对较小,但 TinyLlama 在一系列下游任务中表现相当出色,它的性能显著优于同等大小的现有开源语言模型。具体来说,TinyLlama 在各种下游任务中都超越了 OPT-1.3B 和 Pythia1.4B 。
此外,TinyLlama 还用到了各种优化方法,如 flash attention 2、FSDP( Fully Sharded Data Parallel )、 xFormers 等。
在这些技术的加持下,TinyLlama 训练吞吐量达到了每 A100-40G GPU 每秒 24000 个 token。例如,TinyLlama-1.1B 模型对于 300B token 仅需要 3,456 A100 GPU 小时,而 Pythia 为 4,830 小时,MPT 为 7,920 小时。这显示了该研究优化的有效性以及在大规模模型训练中节省大量时间和资源的潜力。
TinyLlama 实现了 24k tokens / 秒 / A100 的训练速度,这个速度好比用户可以在 8 个 A100 上用 32 小时训练一个具有 11 亿参数、220 亿 token 的 chinchilla-optimial 的模型。同时,这些优化也大大减少了显存占用,用户可以把 11 亿参数的模型塞入 40GB 的 GPU 里面还能同时维持 16k tokens 的 per-gpu batch size。只需要把 batch size 改小一点, 你就可以在 RTX 3090/4090 上面训练 TinyLlama。
| Model | A100 GPU hours on 300 tokens |
|---|---|
| TinyLlama-1.1B | 3456 |
| Pythia-1.0B | 4830 |
| MPT-1.3B | 7920 |
LiteLlama
德克萨斯工农大学的 Xiaotian Han 发布了 SLM-LiteLlama。它有 460M 参数,由 1T token 进行训练。这是对 Meta AI 的 LLaMa 2 的开源复刻版本,但模型规模显著缩小。
- 项目地址:LiteLlama-460M-1T
LiteLlama-460M-1T 在 RedPajama 数据集上进行训练,并使用 GPT2Tokenizer 对文本进行 token 化。作者在 MMLU 任务上对该模型进行评估,结果如下图所示,在参数量大幅减少的情况下,LiteLlama-460M-1T 仍能取得与其他模型相媲美或更好的成绩。
端侧LLM实现
总结
【2024-11-23】2024年顶级小型语言模型前15名
- 论文 paper
- 2024年备受瞩目的15款小型语言模型(SLMs): Llama 3.1 8B、Gemma2、Qwen 2、Mistral Nemo、Phi-3.5等。
| 模型名称 | 参数 | 开源 | 主要特点 |
|---|---|---|---|
| Qwen2 | 0.5B, 1B, 7B | 是 | 可扩展,适用于各种任务 |
| Mistral Nemo 12B | 12B | 是 | 复杂的自然语言处理任务,本地部署 |
| Llama 3.1 8B | 8B | 是* | 平衡性能和效率 |
| Pythia | 160M - 2.8B | 是 | 专注于推理和编码 |
| Cerebras-GPT | 111M - 2.7B | 是 | 计算效率高,遵循Chinchilla缩放法则 |
| Phi-3.5 | 3.8B | 是** | 长上下文长度(128K令牌),多语言 |
| StableLM-zephyr | 3B | 是 | 快速推理,边缘系统高效 |
| TinyLlama | 1.1B | 是 | 移动和边缘设备高效 |
| MobileLLaMA | 1.4B | 是 | 为移动和低功耗设备优化 |
| LaMini-GPT | 774M - 1.5B | 是 | 多语言,指令跟随任务 |
| Gemma2 | 9B, 27B | 是 | 本地部署,实时应用 |
| MiniCPM | 1B - 4B | 是 | 平衡性能,英文和中文优化 |
| OpenELM | 270M - 3B | 是 | 多任务处理,低延迟,节能 |
| DCLM | 1B | 是 | 常识推理,逻辑推理 |
| Fox | 1.6B | 是 | 为移动应用速度优化 |
【2024-3-12】对比近期发布的几个小模型,sLLM的天花板在哪里
- 清华 MiniCPM
- MiniCPM-2B 参数量为 2.4B,主打端侧部署
- 特点: 采用很多策略充分挖掘了 sLLM 的潜力
- MiniCPM-2B 模型在综合性榜单上与 Mistral-7B 相近,整体性能超越了 Llama2-13B、MPT-30B、Falcon-40B 等模型。在 MTBench 榜单上,MiniCPM-2B 也超越了多个代表性开源大模型
- 微软phi系列
Phi-1.5: 展现出许多大模型才有的能力,例如一步步思考,多步推理,进行基本的上下文学习等- 特点: 数据用现有大模型/生成教科书级的合成数据,同时对网络少的数据做了非常细致的筛选,总的数据量只用了 30B tokens,远小于 Llama-7B 的 1T tokens,就取得了非常不错的效果。
- Phi-1.5 只有 1.3B 参数,但是在自然语言任务上可以和比其大 5 倍的模型相比较,在更复杂的小学数学和基础 coding 能力上,超过了大多数 sLLM。
- Coding 上,phi-1.5 在 HumanEval 的分数为 41.4,也远超 Llama-65B 的 23.7
- 缺点: 可能会出现幻觉以及安全性还不太好,可能会产生有毒的内容
Phi-2: 参数量达到 2.7B,数据量用了 1.4T 的 tokens,主要由合成的数据和网络数据组成。用 96 块 A100 训练了 14 天。- 一个 base 模型,没有经过 RLHF 对齐,因为在数据侧做了非常多的清洗工作,发现其安全性表现还不错,比 Llama2-7B 都要好不少。
- 效果上,与 Mistral 和 Llama-2 进行比较,平均来看,Phi-2 的表现优于 Mistral-7B,并且后者的性能又优于 Llama-2 模型(7B,13B,和 70B)。
- Phi-1.5、Phi-2 在 Phi-1 的基础上,充分发挥了其数据工程的优势,总体性能已经优于Mistral-7B,是一个非常不错的 sLLM 了
- 阿里 Qwen-1.8B
- Qwen-1.8B 阿里出品,超过 2.2 万亿 tokens 来训练,数据上覆盖高质量的中、英、多语言、代码、数学等数据。同时其支持 8192 上下文长度,词表以中英文为主,量级约 15 万,对多语言支持还不错。Qwen 似乎在 1.8B 的模型上做过多优化,但是其中文支持友好,可以作为一个基础的 Baseline。
- Google Gemma
- Gemma 发布了 2B 和 7B 两个版本,2B 版本也主打端侧应用。
- Gemma 在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型。
- 特点: 在数学/科学、Coding 能力上有比较大的优势。另外 Google 也做了详细的评测,其安全性,指令遵循能力都非常强。
如何提升小模型的潜力?
- 数据工程:增大数据规模、提升数据质量、添加更多代码、数学方面的数据。Google gemma 7B 用了 6T tokens 来训练,增加了代码、数学相关的数据,效果表现非常不错。微软 Phi 系列提到其也可以做到步步思考,多步推理,进行基本的上下文学习等,其在数据质量提高上做了非常多的工作。另外我们也可以利用 [3] 和 [6] 等思路从数据构造和建模等方面继续优化 sLLM 的推理效果。
- 蒸馏:微软 Phi 系列利用更大的模型 ChatGPT3.5 合成高质量数据,带来的提升也令人印象深刻,这也算一种知识蒸馏的方式将大模型能力迁移到 sLLM上。另外也可以参考 Gemma 利用更大的模型辅助来做 RLHF,更高的对齐人类价值观、提升安全性等。
- 参数优化:更细致的训练策略,像清华 MiniCPM 在预训练的退火阶段加入高质量的数据,引入 WSD 学习率优化器等策略带来比较大的提升都令人印象深刻,借助更多沙盒实验,或许像 Gemma 等模型还可以继续带来一些突破。
【2024-5-29】杨红霞创业入局“端侧模型”,投后估值 1.5 亿美元
杨红霞已于 5 月下旬正式从字节跳动离职,开始筹备 AI 创业项目。不过,杨红霞不做“大”模型,而是将方向瞄准端侧模型,布局 AI Agent。目前,团队正在筹备组建中,已获得 3000 至 4000 万美元的投资,投后估值 1.5 亿美元。
杨红霞为大家所熟知的是,她曾是阿里达摩院万亿参数规模多模态预训练模型 M6 的技术负责人,参与过北京智源研究院主导的“悟道”大模型项目,而该项目是中国最早的大模型项目之一。
在字节跳动的大模型队伍中,杨红霞的学术气质较为突出。据 AI 科技评论梳理,字节大模型团队的核心成员主要是在字节抖音、西瓜等产品内部成长起来的骨干。
杨红霞
- 2007 年,杨红霞从南开大学本科毕业,赴杜克大学攻读博士,师从著名统计学家 David Dunson,著有超过 100 篇杰出学术论文。
- 博士毕业后,杨红霞入职 IBM 全球研发中心任 Watson 研究员,之后又加入雅虎公司,担任首席数据科学家。
- 2016年,杨红霞回国加入阿里达摩院,就职期间杨红霞职级为 P8,曾任达摩院智能计算实验室主任,作为技术负责人,一路见证了 M6 从百亿、千亿进化到万亿参数量规模。
- 2023年初,杨红霞加入字节跳动 AI Lab,作为
AML(Applied Machine Learning,机器学习系统)团队负责人,带领一支大约 40 人的团队。
PC大模型
DisTrO
【2024-8-29】DisTrO 让你家里的电脑也能训练超级大模型
Nous Research 最近放出了一份重磅报告,介绍最新研究成果——DisTrO(Distributed Training Over-the-Internet)。
有望让告别”只有大公司才能训练大模型”的时代,开启全民AI狂欢!
DisTrO 是一个分布式优化器家族,两个超级牛X的特点:
- 与架构无关:不管你用啥架构,它都能用。
- 与网络无关:网速慢?没关系,它照样能跑!
最厉害的是,DisTrO把GPU之间的通信需求减少了1000到10000倍!
在龟速网络上,用各种杂牌子的网络硬件,也能训练大型神经网络,而且收敛速度跟AdamW+All-Reduce一样快!
DisTrO究竟有什么用呢?
- 提高LLM训练的抗风险能力:不再依赖单一实体的计算能力,训练过程更安全、更公平。
- 促进研究合作与创新:研究人员和机构可以更自由地合作,尝试新技术、新算法、新模型。
- 推动AI民主化:降低了训练大模型的门槛,让更多人有机会参与其中。
MiniMind
minimind 从0开始,3小时训练出仅为26M大小的微型语言模型 MiniMind
- 个人GPU也可快速推理甚至训练
- MiniMind 改进自 DeepSeek-V2、Llama3结构,项目包含整个数据处理、pretrain、sft、dpo的全部阶段,包含混合专家(MoE)模型。
项目包含:
- 公开MiniMind模型代码(包含Dense和MoE模型)、Pretrain、SFT指令微调、LoRA微调、DPO偏好优化的全过程代码、数据集和来源。
- 兼容transformers、accelerate、trl、peft等流行框架。
- 训练支持单机单卡、单机多卡(DDP、DeepSpeed)训练。训练过程中支持在任意位置停止,及在任意位置继续训练。
- 在Ceval数据集上进行模型测试的代码。
- 实现Openai-Api基本的chat接口,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。
手机大模型
模型手机部署
- 【2023-9-7】手机大模型也卷起来了
- 【2023-11-16】掰开安卓手机,满屏都是三个字:大模型
- C-Eval全球大模型综合性考试评测榜上,也分别出现了
vivo和OPPO自研大模型云端方案 - 除了华为,小米、OPPO、vivo等厂商也在积极入局大模型,试图在手机大模型这一领域抢占先发优势。
这年头,安卓厂商没个大模型,都不敢开手机发布会了。
- 前脚OPPO刚用大模型升级了语音助手,后脚vivo就官宣自研手机AI大模型;
- 小米发布会则直接将大模型当场塞进手机系统……其竞争激烈程度,不亚于抢芯片首发。
智能终端已经成为了各类AIGC应用的落地“新滩头”
- 图像生成大模型,接二连三地被塞进手机
- 十亿参数的
Stable Diffusion,在手机上快速生成一只金毛小狗: - 手机上运行十五亿参数的
ControlNet,快速生成一张限定图像结构的AI风景照
- 十亿参数的
- 文本生成大模型们也争先恐后地推出了手机新应用——
- 国内有文心一言、智谱清言APP
- 国外则有OpenAI的移动版ChatGPT,Llama 2手机版也在加急准备中。
最底层的软硬件技术齿轮开始转动。从高通到苹果,最新的芯片厂商发布会,无一不在强调软硬件对机器学习和大模型的支持——
- 苹果M3能运行“数十亿参数”机器学习模型
- 高通的骁龙X Elite和骁龙8 Gen 3更是已经分别实现将130亿和100亿参数大模型装进电脑和手机。高通现场演示和手机中的百亿大模型对话
手机厂商,All in大模型
国内手机厂商开卷大模型,背景是中国智能手机市场的持续低迷。为了在瓶颈期寻求新的差异化增长点,国产手机厂商已经在影像力、参数、产品形态等方面卷到了极致。
虽然手机厂商都将大模型作为未来业务发力点,但目前手机大模型尚未全面对用户开放,仍处于小范围内测阶段,用户对它的接受程度还不得而知。
而手机大模型不仅要面对友商之间的竞争,还要面临像文心一言APP这样的云端大模型竞争对手。
- 文心一言发布初期,参数已经高达2600亿,支持多模态的生成式AI内容,比如文生图、代码理解、生成Excel等功能,覆盖了办公、学习、情感、绘画、娱乐等应用场景。
小爱同学在本地部署的大模型受限于手机算力,参数相对要更轻量化。
小爱同学13亿的参数量跟文心一言2600亿的参数量并不是同一个数量级,因此应用场景也有一定局限性,就目前内测版本的反馈来看,小爱同学还不支持文生图功能。
相比ChatGPT、文心一言等云端大模型,手机大模型也有其得天独厚的优势
- 因为完全本地部署,用户在使用它时的操作对话也在本地运行,在用户数据的隐私和安全性方面更有保障。
- 因为参数量较为轻量化,加载运行速度也会更快,不受网络环境限制。
- 这样轻量化的大模型训练周期短,且能根据用户需求进行快速的迭代更新。
另外,可定制化的手机大模型将能更灵活地响应用户的各种需求,用户可以根据自己的兴趣、工作性质、起居习惯定制个性化的大模型助手。比如大模型助手可以根据用户画像,为用户提供饮食起居建议等个性化服务,也可以根据用户喜好,扮演其喜爱的角色形象。
目前的手机大模型实用价值还有待挖掘,但它被认为是打造品牌形象和彰显产品算力的全新范式。
尽管从理论上来说,目前市面大多数智能手机都能达到要求(6GB内存),但是能够运行本地大模型的手机会自然地被消费者认为算力和配置更高。
- 类似无线充电这种功能,消费者的使用频率很低,但缺少了无线充电的手机,一定不是一台合格的旗舰机。
- 手机大模型也是同理,未来消费者也可能更加倾向于优先选购那些部署大模型的智能手机。
端手机市场,自研芯片始终是彰显品牌能力的杀手锏,但在Mate 60系列回归前,华为麒麟被制裁、OPPO哲库解散,国产手机芯片的自主研发也进入了至暗时刻。因此手机厂商退而求其次,选择在影像方向构建自己的护城河,国产旗舰机型都在讲述自己的影像故事,他们力求通过影像层面的差异化打造品牌的高端形象。而手机大模型的出现也为品牌的高端化故事提供了一个新角度,因此布局大模型也成为国产手机厂商的共识。
手机本地大模型
MLC Chat
Github上 开源的手机大模型 MLC LLM 为例,这个60亿参数的大模型可以在6GB内存以上配置的手机上运行

PocketPal AI
PocketPal AI 软件在手机上本地部署大模型
PocketPal AI 自带基准测试
- 设置中选择CPU线程和GPU层数拉满(CPU线程6,GPU层数99)
- 测试模型选择了 Qwen 3.5-9B-Q4_K_M,以及 Gemma 4-E4B-it-Q4_K_M,体量比较小,性能表现比较好,适合本地部署的小参数模型。
- 其中:
- Qwen 3.5-9B-Q4_K_M ,输出速度约 10 tok/sec,占用运存约 6GB
- Gemma 4-E4B-it-Q4_K_M,输出速度约 20 tok/sec,占用运存约 6GB
【2025-1-23】阿里 MNN
【2025-1-23】阿里巴巴 MNN
- 开源地址:MNN,不只支持手机,电脑也支持,完全可以替代Ollama。
- MNN对应的APP名称叫MNN Chat
- 安卓系统Android 10及以上,iPhone苹果系统iOS 15及以上就能运行,同时保证你手机的存储空间有1个G以上。
- 下载地址: 安卓 mnn_chat_0_8_2_2.apk,Mac APP mnn-chat
特性
- 仅用手机,不需要电脑
- 模型完全本地运行,不上云、不泄露数据
- 支持离线使用,没网也能对话
- 免费、无次数限制、无内购
- 轻量运行,普通手机流畅使用
模型市场不仅有阿里的Qwen系列模型,还有 Hunyuan、Deepseek、Llama、MiMo、gemma、glm、MiniCPM、gpt-oss、ERNIE等

两个参数,分别是Prefill和Decode,体现手机本地跑大模型的性能。
- Prefill 预填充阶段,处理用户的输入内容和上下文,将其转换为模型可理解的向量。
- 大概是24个tokens,约等于24个汉字或字符。而0.10s是处理的总耗时,242.12tokens/s是预填充速度,即每秒处理242.12个输入token。
- Decode 解码生成阶段,表示模型在逐字生成回答内容。
- 生成完整回答耗时5.82s,生成的token数是297tokens(约等于297个汉字或字符),生成速度是51.04tokens/s。
MNN Chat 还能开启API服务,局域网内给其他Agent或者应用去调用大模型:手机里养了龙虾跟马,能对接MNN Chat提供的模型API服务,实现手机本地跑大模型,给龙虾和马提供token消耗的效果。
【2026-6-1】vivo y500上实践通过
- qwen 3.5 0.8B 支持图文对话
- 本地 asr+tts一般,tts消耗1+G空间,但声音混乱
- 本地服务 demo 无法联通
AX650N
【2023-6-1】5分钟就能完成原版Swin Transformer端侧部署
一款号称现实开源模型直接拿来用,还能让性能、功耗与自动驾驶领域基于GPU的端侧芯片有得一拼的平台诞生了。
- 爱芯元智推出AX650N,对Transformer架构支持效果尤甚。
Transformer 是当下最火的 ChatGPT、Stable Diffusion等大模型背后的基础架构。
AX650N 是 AI芯片公司爱芯元智发布的第三代端侧芯片。其构成包括CPU和NPU等,其中CPU采用的是八核A55处理器,NPU则采用了自研混合精度技术,可以做到43.2TOPs(INT4)或10.8TOPs(INT8)的高算力。
AX650N主要用于端侧视觉感知。

- 该领域业界主要还是基于CNN网络开发应用。
- 准确率和性能双佳的
Swin Transformer并没有得到突出的大规模落地,还是多部署于云端服务器。
因为GPU对于MHA结构(Transformer中的多头注意力机制)计算支持更友好。
而目前大部分端侧AI芯片由于其架构限制为了保证CNN结构的模型效率更好,基本上对MHA结构没有过多性能优化,因此需要修改Swin Transformer的网络结构才能勉强将其部署在端侧—— 一旦修改网络结构,就意味着将出现一系列问题,例如精度下降,精度一降就得对模型进行重训,这个过程就要以星期甚至是月来计算了。
爱芯元智联合创始人、副总裁刘建伟介绍:
用AX650N在端侧部署原版Swin Transformer,从拿到测试板到demo复现,只需要5分钟,再到在自己的私有环境里跑起来私有模型,只要1个小时就能搞定。
不仅能跑起来,还跑得飞快、性能高且功耗低。AX650N端侧部署Swin Transformer性能可达361 FPS。
- AX650N 还支持低比特混合精度,遇到大规模参数的模型,我们就可以采用INT4来减少内存和带宽占用率,从而降低大模型在端侧边缘侧部署的成本。
- AX650N可以说是成为了目前对Transformer架构支持最好的一个端侧部署平台。
- AX650N还适配ViT/DeiT、DETR在内的Transformer模型,Meta最新发布的视觉模型DINOv2也达到了30帧以上的运行结果。
因此,有了AX650N,下游进行检测、分类、分割等操作也更加方便。

接下来,爱芯元智AX650N将会针对Transformer结构进行进一步优化,并且将探索多模态方向的Transformer模型。
高通
高通认为
- 在
云端和PC、智能手机等终端之间协同工作的混合AI才是AI的未来,将大模型从云到端部署,尤其进入手机,是必然的演进路线。 - 参数超过10亿的AI模型已经能够在搭载高通处理器的手机上运行,且性能和精确度水平达到与云端相似的水平。
- 在MWC上,高通演示了在不联网状态下用安卓手机运行
Stable Diffusion,15秒即可生成AI图像。
不过,高通中国区研发负责人徐晧曾提到过
-
“大模型在手机上是可行的,但真正大规模地部署仍需要时间”。
- 【2023-8-8】大模型在手机上运行的预言,被高通提前实现了
- 【2023-7-5】安卓手机上跑15亿参数大模型,12秒不到就推理完了
- 操作人员在一部没有联网的安卓手机上使用了Stable Diffusion 来生成 AI 图像,整个生成时间不超过 15 秒,整个过程完全在终端进行,但是生成效果却没打一点折扣。
- 白皮书链接

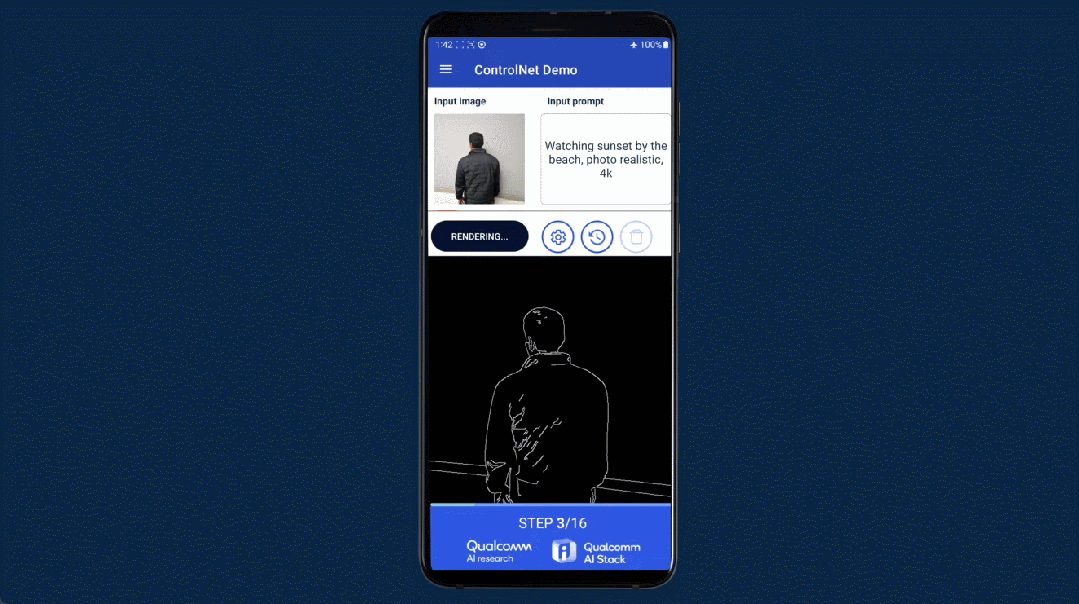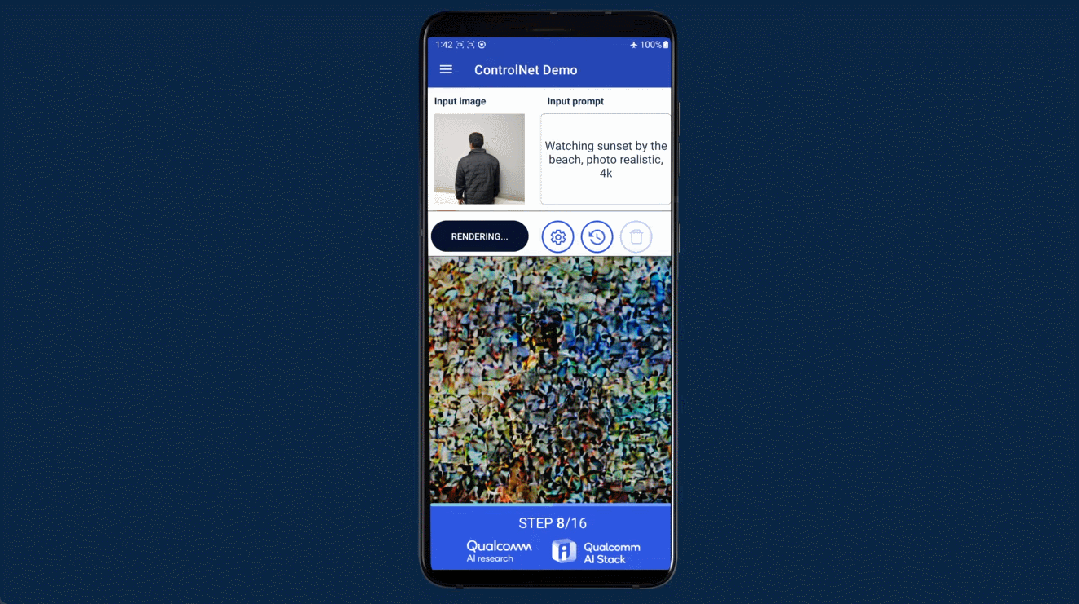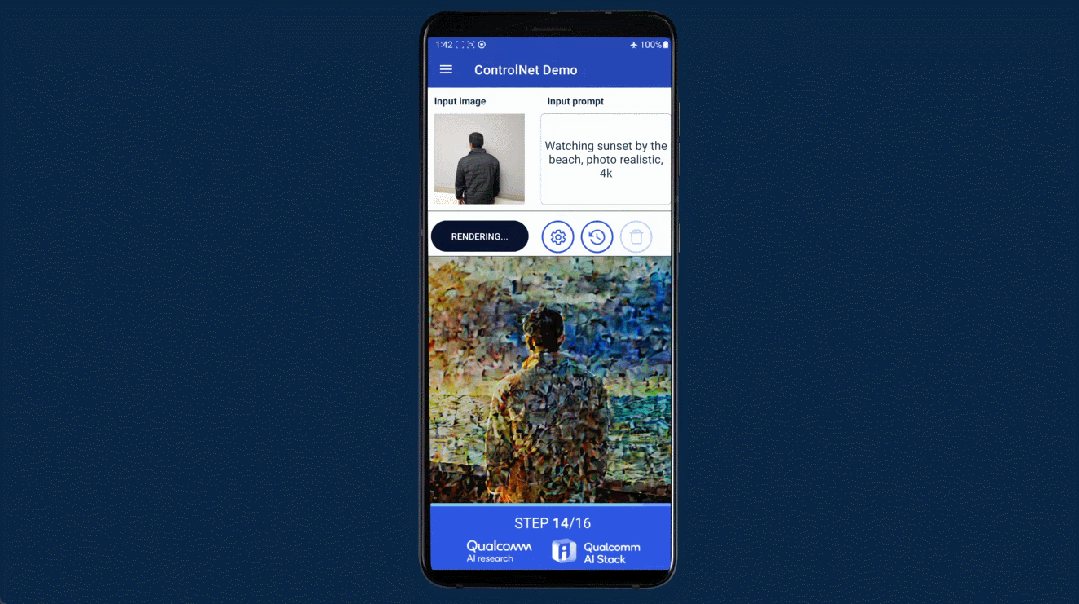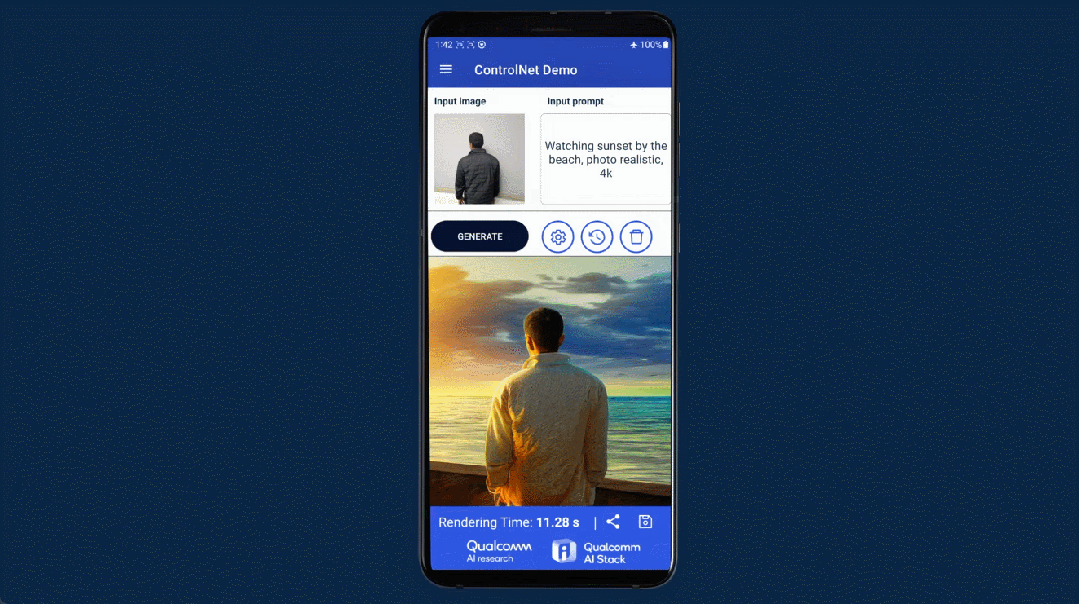

如果模型大小、提示(prompt)和生成长度小于某个限定值,并且能够提供可接受的精确度,推理即可完全在终端侧进行。如果是更复杂的任务,模型则可以跨云端和终端运行。
混合 AI 还能支持模型在终端侧和云端同时运行,也就是在终端侧运行轻量版模型时,在云端并行处理完整模型的多个标记(token),并在需要时更正终端侧的处理结果。这能极大限度地解决能耗和成本问题。
直接从源头减少数据运输过程,隐私泄露的问题便不复存在。 高通指出,混合 AI 架构中有一个“隐私模式”,当用户利用终端侧 AI 向聊天机器人输入健康问题或创业想法等敏感话题时,这个模式会自动开启。
【2023-11-16】掰开安卓手机,满屏都是三个字:大模型
高通最新推出的第三代骁龙8移动平台,就被定位为高通“首个专门为生成式AI打造的移动平台”:
- 能够在终端侧运行100亿参数大模型,面向70亿参数大语言模型,每秒能生成20个token。
较之前代产品,第三代骁龙8最重要的变化,就是驱动终端侧AI推理加速的高通AI引擎。
这个AI引擎由多个硬件和软件组成,包括高通Hexagon NPU、Adreno GPU、Kryo CPU和传感器中枢。其中最核心、与AI最密切相关的,是Hexagon NPU。
- 高通公布的数据显示,Hexagon NPU在性能表现上,比前代产品快98%,同时功耗降低了40%。
- Hexagon NPU升级了全新的微架构。更快的矢量加速器时钟速度、更强的推理技术和对更多更快的Transformer网络的支持等等,全面提升了Hexgon NPU对生成式AI的响应能力,使得手机上的大模型“秒答”用户提问成为可能。
-
Hexagon NPU之外,第三代骁龙8在 Sensing Hub(传感器中枢)上也下了功夫:增加下一代微型NPU,AI性能提高3.5倍,内存增加30%。Sensing Hub有助于大模型在手机端的“定制化”。随时保持感知的Sensing Hub与大模型协同合作,可以让用户的位置、活动等个性化数据更好地为生成式AI所用。
- 内存方面,第三代骁龙8支持LPDDR5X,频率从4.2GHz提高到了4.8GHz,带宽77GB/s,最大容量为24GB。
- 更快的数据传输速度,更大的带宽,也就意味着第三代骁龙8能够支持更大更复杂的AI模型。
- CPU方面,第三代骁龙8采用“1+5+2”架构(1个主核心、5个性能核心和2个能效核心),相较于前代的“1+4+3”,将1个能效核心转换为性能核心。其中超大核频率提升到3.3GHz,性能核心频率提升到最高3.2GHz,能效核心频率提升到2.3GHz。
新架构下,Kryo CPU性能提高了30%,功耗降低了20%。
苹果
布局
【2023-8-8】苹果年薪百万开招AIGC人才,目标:让iPhone本地跑上大模型
- 苹果想要将大模型压缩到终端,在未来让iPhone/iPad等核心产品直接跑上AIGC技术。苹果想要在核心产品上发力端侧大模型,一大部分原因就是为了隐私。就像离线版Siri那样,不经云端直接运行AI软件,不仅可以让程序跑得更快,也能更安全和私密地处理用户数据。
- 2020年的时候,苹果就斥资近2亿美元收购了一家总部位于西雅图的人工智能初创公司:Xnor,该公司专门在移动设备上运行复杂的机器学习模型,还一度击败了微软、亚马逊和英特尔等大厂的产品。
- 机器智能与神经设计 (Machine Intelligence Neural Design,MIND,属于苹果AIML的一部分) 等团队,要求工程师能够“在苹果下一代推理引擎中定义和帮助实现加速和压缩大型语言模型 (LLM) 的功能”,这指的就是在移动端而非云端。将“最先进的基础模型带入我们口袋里的iPhone,以保护隐私的方式实现下一代基于ML的体验”
ReALM 模型
【2024-4-2】苹果推出 ReALM 模型。大语言模型在屏幕实体、后台实体等非对话实体的理解能力。
- 屏幕实体指用户在电子屏幕上看到的图标、按钮、图片、视频等。
- 后台实体指电子设备的操作系统或应用程序中运行的、对用户不可见的进程和服务。
- 苹果 ReALM 模型的效果是让AI理解用户在屏幕上看到的内容和操作,对屏幕实体和后台实体有了足够强的理解能力,那用户可以发起的智能交互范畴就会明显扩大!
苹果目前在为下一代旗舰手机所做的准备:
- 1、把Google Gemini模型放进手机;
- 2、传言收购基于AI的搜索引擎Perplexity;
- 3、推出ReALM模型,使得AI更理解手机屏幕和app程序。
华为
- 7月, 华为开发者大会上发布了面向行业的
盘古大模型3.0,最高版本高达1000亿参数,同时也将盘古大模型应用到手机终端,将智能助手小艺接入了盘古大模型能力。 - 8月底,华为
Mate 60系列手机发布,除了支持卫星通信,另一舆论关注点就是其接入了盘古人工智能大模型。- 全新小艺将在今年8月底开放邀请测试,并于晚些时候在搭载HarmonyOS 4.0及以上的部分机型通过OTA升级体验,具体升级计划稍晚公布。
- 9月1日,华为
小艺大模型开启众测,首批支持机型为Mate 60系列手机。
【2023-8-11】华为率先把大模型接入手机!小艺+大模型,智慧助手智商
只需一句中文指令,华为小艺
- 写出一封英文邮件:
- 把自己的照片用AI做成不同风格:
还能说一长串指令,让它自己创建复杂场景,大白话就能听得懂
华为盘古L0基座大模型的基础上,融入大量场景数据,对模型进行精调,最后炼成的一个L1层对话模型。
- 文本生成、知识查找、资料总结、智能编排、模糊/复杂意图理解等任务。
- 而且可调用各种APP服务,实现系统级的智能化体验。
小艺依托的底层模型是华为盘古系列。
今年7月,华为正式发布盘古大模型3.0,并提出3层模型架构。
L0:基础大模型,包括自然语言、视觉、多模态、预测、科学计算;L1:N个行业大模型,比如政务、金融、制造、矿山、气象等;L2:更细化场景的模型,提供“开箱即用”的模型服务
其中L0层基础大模型最大版本包含1000亿参数,预训练使用了超3万亿tokens。
小艺正是在华为盘古L0基座大模型的基础上,针对终端消费者场景构建了大量的场景数据,并对模型进行精调,最后炼成的L1层对话模型。
- 精调中,小艺加入了覆盖终端消费者的主流数据类型,如:对话、旅游攻略、设备操控、吃穿住行等。
- 这能很好覆盖普通用户日常对话的知识范围,并且增强模型对话过程中的事实性、实时性以及安全合规等。
基于大模型能力,华为小艺这一次主要在三方面做了升级:
- (1)智慧交互: 让对话、交互更自然流畅, 听懂大白话,理解模糊意图和复杂命令。
- 找不到最新的壁纸设置功能、也不知道功能名称,可以直接问:那个可以根据天气实时变化的壁纸怎么换?
- 复杂的命令,包含多个要求的那种:找一家松山湖附近,评分高的海鲜餐厅,最好有适合四个人的优惠套餐。
- 多模态能力,能理解图像内容, 看一张邀请函图片,然后说:
- 导航去图上的地址。然后就可以提取出图上地址信息,并调用地图服务导航
- 把邀请函中的联系信息保存,很好理解图像中的文本信息
- 小艺进行复杂任务编排:
- 设置一个晨跑场景:帮我创建晨跑场景。每周一到周五早上6点半为我播报当天天气。当我戴上蓝牙耳机的时候,就播放收藏的歌曲,并把手机设为静音模式。
- (2)高效生产力: 得益于大模型等能力加持,现在小艺可提供更高效的生产力工具。帮你看、读、写都没问题。
- 看一篇英文文章,然后提问这篇文章中讲了什么?
- 记住过一些信息,也能调用出来生成相应内容:过几天就要约David见面聊项目了,结合上次会议记的信息,写一份英文会议预约邮件。
- 小艺也能利用AI视觉能力,将照片创作成多种风格
- (3)个性化服务: 小艺现在支持更加个性化服务,也能更懂你。
- 所有记忆内容都是在用户授权下完成,会充分保护用户隐私。
- 感知到更多用户的高频场景,能主动提供一站式的智慧组合建议,省去很多自己手动查找的过程。
- 出境旅游场景下,出发前小艺能实时提醒最新汇率、兑换外币、帮助用户即时获取目的地游玩攻略;到达目的地后,还能提醒行李转盘信息、一键开启境外流量、快速获取实时翻译工具等。
- 全新小艺智慧场景增加3倍,POI数量提升了7倍,能够覆盖核心餐饮购物门店、商圈、机场高铁站等场景。
全新小艺不仅获得了最新的AIGC能力,还改善了手机语音助手过去经常被诟病的一些短板。
- 如没有记忆力、对话呆板、听不懂大白话等……
具体能力提升
- 更自然语言对话、玩机知识问答、查找生活服务、对话识别屏幕内容、生成摘要文案图片等。
其它方面
- 部署方面,华为正在不断增强大模型端云协同能力
- 端侧大模型先对用户请求和上下文信息做一层预处理,再将预处理后的request请求到云侧。
- 既能发挥端侧模型响应快的优势,又能通过云端模型来提升问答和响应质量,同时也能更进一步保护用户隐私数据。
- 降低推理时延上,华为小艺做了系统性工程优化,包含从底层芯片、推理框架、模型算子、输入输出长度等全链路。
- 通过对各个模块时延进行拆解,研发团队明确了各部分优化目标,利用算子融合、显存优化、pipeline优化等方式降低时延。
- 同时 prompt长度和输出长度也会影响大模型推理速度。
- 华为针对不同场景的prompt和输出格式做了逐字分析和压缩,最终实现推理时延减半。
华为小艺和大模型的融合,不是简单对聊天、AIGC、回复等任务进行增强,而是以大模型为核心,进行了系统级增强。让大模型成为系统的“大脑”
底层逻辑是:
将用户任务分配给合适的系统,各个系统各司其职,同时在复杂场景上增强体验。
具体来看小艺的典型对话流程,一共可分为三步:
- 第一步,接收用户问题,基于上下文理解/小艺记忆的能力,分析问题该如何处理。
- 第二步,根据请求类型调用不同能力,包括: 元服务检索、创意生成、知识检索。
- 如果用户发起的请求涉及到元服务,比如他询问附近有哪些可以聚会的餐厅,这就涉及到了美食APP服务的调用,系统需要API生成,最后由服务方基于推荐机制给出响应。
- 如果用户询问的是知识问题,比如问盘古大模型有多少参数。这时系统会调用搜索引擎、对应领域知识、向量知识进行查询,然后融合生成答案。
- 如果用户的请求是生成式任务,那么大模型自身能力即可给出回复。
- 最后一步,所有生成的回答会经过风控评估,再返还给用户。
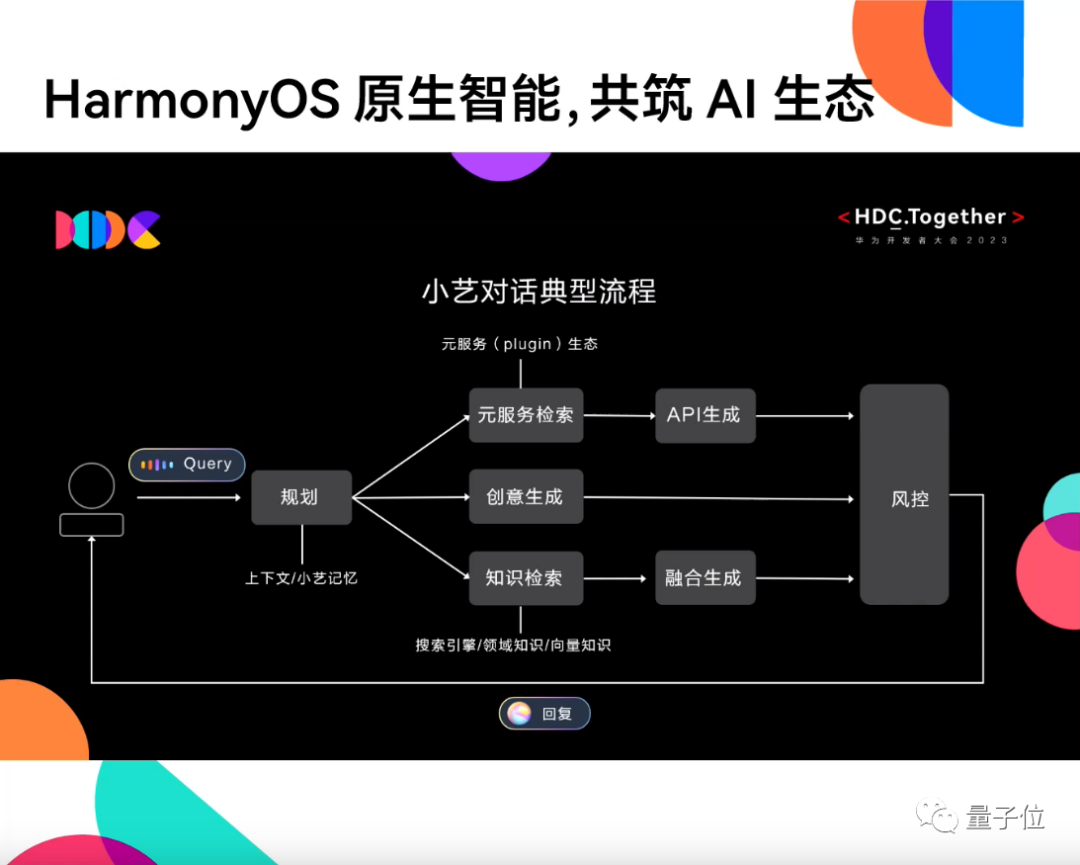
以上诸多体验都来自于华为研发团队成员日常感知到的场景。
- 有人习惯上下班开车路上获取新闻,对于太长资讯只能看不方便听,所以在华为小艺中出现了资讯总结的功能。
- 在写购物评论、生日祝福的时候总是词穷,所以华为小艺提供了文案生成功能。
而这种对场景体验的关注,是HarmonyOS的天生优势。
从诞生起,HarmonyOS便没有局限于手机端,而是面向多种终端、全场景。如今已经打造出“1+8+N”全场景生态。
华为小艺现在也已部署在了1+8设备上,未来将结合全场景设备的业务形态,逐步把拥有大模型能力的小艺部署到消费者全场景体验之上。
小艺作为一个AI驱动的智慧助手,从诞生起也在不断集成各种AI能力,如AI字幕、小艺朗读等
小米
- 4月,组建大模型团队,小米大模型技术的主力突破方向为轻量化、本地部署,小米考虑的是优先在手机上实现端侧跑通,让每个人都能更好在手机上使用大模型。
- MiLM-6B 是由小米全自研的大规模预训练语言模型
1.3b
- 2023年8月14日,小米新品发布会上,雷军正式宣布小米13亿参数大模型已经成功在手机本地跑通,部分场景可以媲美60亿参数模型在云端运行结果。
-

| 模型 | 平均分 | STEM | 人文学科 | 社会科学 | 其他 | 中国特定主题 |
|---|---|---|---|---|---|---|
| MILM-1.3B | 50.79 | 40.51 | 54.82 | 54.15 | 53.99 | 52.26 |
| Baichuan-13B | 54.63 | 42.04 | 60.49 | 59.55 | 56.6 | 55.72 |
| ChatGLM2-6B | - | 41.28 | 52.85 | 53.37 | 52.24 | 50.58 |
注
- 2023年8月10日数据,CMMLU中文多任务语言理解评估

- 新闻源
小爱同学升级
【2023-8-14】小爱同学升级AI大模型能力,并开启内测,未来小米大模型技术方向是轻量化、本地部署。
截至目前,已经有通过部分内测的用户初步尝鲜小爱大模型,并分享了“调戏”小爱同学全新版本的体验。
小爱同学功能解读视频
- 生成创作:写文案、策划能力、写代码、画图
- 改写能力
- 闲聊、知识问答:孔子隔空对话、小米商品咨询
问题
- 稳定性不高,有时卡顿
- 理解能力有待提高
- 目前仅文本对话,不能传文档、表格、图片
- 无法验证知识、版权是否正确
MiMo-V2-Flash
【2025-12-17】罗福莉执掌小米大模型首秀!定调下一代模型,全新MiMo-V2开源还横扫Agent第一梯队
2025 小米人车家全生态合作伙伴大会上,罗福莉首次公开亮相,Title 是 Xiaomi MiMo 大模型负责人。
全新大模型 MiMo-V2-Flash(3090 亿参数),是小米在凌晨发的新一代 MiMo 模型,开源。
- 小米自研的大语言模型(LLM)系列;
- 而 MiMo-V2-Flash 不仅在通用基准测试中和 DeepSeek-V3.2 相当,同时 还拉爆性价比,对 Agent 场景友好。
MiMo-V2-Flash 采用了当前很流行但工程难度也很高的 MoE(混合专家)架构,其 总参数规模达 3090 亿,但在每次推理时,真正被“点亮”的只有约 150 亿参数。
此外,搭载了 多词元预测(MTP)技术,专为高速推理和 Agent 工作流程而设计。与很多追求“参数越大越好”的模型不同,MiMo-V2-Flash 的设计目标可谓是:“要跑得快、跑得久、被高频调用也跑得起”。
大模型发展状态定界:
- 语言模型通过规模化训练确实取得了突破,但本质上是解码人类思维在文本空间的投影
- 一条自顶向下的捷径,而非真正理解了物理世界。
下一代智能体必须
- 从“回答问题”转向“完成任务”
- 能够与真实环境持续交互。
通往下一阶段智能的路径不只是增加多模态输入,而是构建一个统一、动态的世界模型:
“智能不是从文本中‘读出来的’,而是要在交互中‘活出来的’。”
AGI 路线立场:不否认语言路线的价值,但只凭语言未必通向 AGI。
【2025-12-17】罗福莉执掌小米大模型首秀!定调下一代模型,全新MiMo-V2开源还横扫Agent第一梯队
这一判断,为后续所有技术选择提供了前提—— 语言是强工具,但不是终点。
MiMo-V2-Flash 工程逻辑:该模型的设计目标并不是“更聪明”,而是更好用、更可部署。
归结为三个现实挑战:
- 一是 Agent 需要高效的“沟通语言”,代码能力和工具调用能力要优先于泛聊天;
- 二是 Agent 之间的交互带宽过低,因此推理效率必须成为第一设计目标;
- 三是 模型范式正在从预训练转向后训练和强化学习,这要求一个稳定、可扩展的训练体系来承载持续演化。
MiMo-V2-Flash 无论是采用 MoE 架构、控制活跃参数规模,还是引入混合注意力、多词元预测以及面向后训练的蒸馏范式,本质上都是被 Agent 场景“倒逼”出来的工程取舍,而非单纯的技术炫技。
推理阶段用三层 MTP 并行推理,实际场景中实现了约 2 到 2.6 倍的推理加速。
社区测试结果,三层 MTP 的情况下,模型输出吞吐与成本高度相关。
- 单机环境下,吞吐可以达到 5000 到 15000 token/s,而单请求输出速度也能达到 150 token/s。
- 相比不使用 MTP,整体速度提升约 2-3 倍。
MiMo-V2-Flash 在 Agent、代码、工具调用、复杂任务执行 方面已进入第一梯队。
Xiaomi MiMo-V2-Pro
2026年3月27日,小米官方称自研大模型 Xiaomi MiMo-V2-Pro 在OpenRouter平台最新周榜中位列第一,成为该平台首个周Token消耗量超过3万亿的模型,模型使用市占率超过30%。
3月19日,该模型以匿名(「Hunter Alpha」)形式在OpenRouter上线进行早期测试,周榜数据公布后,小米正式确认其为 MiMo-V2-Pro 的早期版本。
MiMo-V2-Pro 面向Agent时代需求的旗舰基座模型,总参数达万亿规模,采用混合专家(MoE)架构,激活参数为420亿,支持百万级上下文长度。这些技术特性使其在复杂工作流编排、长流程规划及工具调用等任务中具备一定优势。
Artificial Analysis全球大模型综合智能排行榜中,该模型位列全球第八,品牌排名第五。在OpenClaw、Claude Code等智能体框架的实际应用中,其表现与部分海外主流模型相当。
价格方面,MiMo-V2-Pro API定价为每百万tokens输入1美元、输出3美元(256K上下文以内),约为同类竞品的五分之一。性价比优势或是其调用量快速上升的重要原因之一。
原定一周的限免活动延长至两周,免费截止时间为北京时间2026年4月2日24:00。开发者在此期间可免费体验MiMo-V2-Pro及全模态模型MiMo-V2-Omni的API服务。
vivo
- 【2023-12-19】没绷住,vivo提前“泄密”大模型能力
- 【2023-11-1】vivo自研大模型/操作系统齐面世!蓝心大模型加持最新OriginOS4
vivo自研通用大模型矩阵正式发布!
蓝心大模型矩阵一共5款,兼顾端云:
- 1B 端侧大模型
- 7B 端云两用模型
- 70B 云端主力模型
- 130B 云端大模型
- 175B 云端大模型
7B版本将对外开源,vivo成为首家开源大模型的手机厂商
最卖座的安卓手机,竟然要实 装 大 模 型 了?还是发布即可用那种 —— 新版手机系统直接搭载,不整虚的。
虽然国产大模型百花齐放,但手机端“百模大战”,可以说是才刚进入热身阶段。自研大模型的手机厂商已有不少,但真正装进手机系统中的,还几乎没有
手机端实际上是大模型最难落地的场景之一。
- 受体积、耗电量所限,手机端侧算力相比云端算力“少得可怜”。
- 大模型,如果直接部署在端侧,往往难以取得较好的使用效果,即使能运行起来,推理速度也不及预期
- 如果做输入法的出词推荐,2秒才能出一个词, 但缩小模型体积,效果肯定会打折扣
- 大模型直接上传到云端联网使用,又会失去端侧部署的优势
- 大模型原本可以根据用户信息,在手机上个性化定制手机助理,且确保信息不上传到云端;但如果大模型在云端加载,势必要将个人信息通过网络上传,隐私安全无法保障。
- 云端运行大模型的成本非常高: vivo 有3亿中国大陆用户,如果每天用10次,一天的运算成本大概是3000万元,一年需要花费约90-100亿元。
vivo究竟是怎么将大模型部署到手机端的?一些“技巧”
- (1) 大模型的参数设计: 不同的参数量级,分别用于处理不同的任务。
- 最小的大模型,包括10亿和70亿参数的模型,直接部署在端侧,确保耗电量不高。涉及用户信息等个性化任务需求时,可以用这类大模型来完成,例如一键将备忘录内容加入日历、并设置闹钟提醒。
- 更大的大模型,如660亿、1300亿和1750亿参数的大模型,则根据任务难度来决定调用情况。大模型“智力涌现”所需的参数量级,几百亿足矣。
- 像用超大模型如GPT-4来总结电子邮件的行为,就一直被调侃为“开兰博基尼送披萨”。
- 遇上“难度系数较低”的任务时,可以切换更小的模型来进行,更复杂的如对上下文长度和输出效果要求更高的任务,再调用千亿参数大模型来完成。
- (2) 大模型的运行方式: 不依靠单一算力,而是云端协同的方式兼顾运行速度和体验。
- 上千亿的大模型尚难以部署到手机端,即使能部署,运行速度和耗电量也无法接受。
- 以谷歌和DeepMind同时推出的投机采样(speculative sampling/decoding)为例,这项技术就能在提升大模型推理速度的同时,确保生成效果。将一个大模型和一个较小的大模型(draft模型)进行组合,来解决大模型推理时的“内存限制”问题。然而,这个较小的模型并非“随便就能找到”,它必须和大模型“配套”,例如接口要统一、概率分布也要接近等。
- vivoLM这5个大模型如果相互“配套”,就能运用类似技术来实现端云协同的效果:大模型在云端进行计算,更小的模型则放在端侧运行,能节省相当的推理成本。
搭载大模型的vivo手机新系统会拥有什么新功能
- 使用方法上,vivoLM 目测会以语音助手的形式作为入口,作为全机的“智能助理”随叫随到;
- 具体功能上,又主要可能分为三大类:
- 生成类任务,如邮件智能撰写、AI头像生成等;
- 复杂任务调度,如一键总结通话内容、设置特定使用场景等;
- 意图理解,如根据模糊需求定制差旅等。
OriginOS 让系统交互和设计更加人性化。比如
- 点赞颇多的原子通知和原子组件就体现了OriginOS更直观的交互逻辑,通过点、触、滑动能直接使用组件功能。
- OriginOS 3中的侧边栏,具备场景识别能力,能根据用户正在浏览的界面,在侧边栏中匹配所需的应用
7b
vivo 即将推出的 OriginOS 4.0也内置了大模型。此前,在C-Eval全球大模型综合性考试评测榜上,也分别出现了vivo 和OPPO的自研大模型云端方案。
vivo_Agent_LM_7B是由 vivo AI 全球研究院自主研发的大规模预训练语言模型,从命名不难看出它可能有着70亿参数。
【2023-10-19】MediaTek 与 @vivo @OriginOS 在AI领域深度合作和联调,率先实现了10亿 和 70亿AI大语言模型以及10亿AI视觉大模型在手机端侧的的落地,共同为消费者带来行业领先的端侧生成式AI应用创新体验。
天现移动芯片赋能vivo最新旗舰手机率先搭载端侧AI大模型。在终端侧部署的生成式AI在保护用户信息安全、提升实时性和实现个个性化用户体验等方面具备明显优势。MediaTek的新一代旗舰级AI处理器APU与AI开发平台 NeuroPilot,能显著提高大模型在终端侧的运行效率,为为vivo的端侧生成式AI应用提供强大的AI算力和性能。
vivo 悄悄自研手机AI大模型的消息传得沸沸扬扬,如今靴子落地,官宣定档11月1日vivo开发者大会,上机新版系统OriginOS 4。
- vivo新版自研大模型,取名
vivoLM - vivoLM都已经提前在两大中文大模型评测榜单C-Eval和CMMLU上“刷榜”了一波。
- C-Eval榜单上,vivoLM取得了平均82.3分的榜一成绩,尤其在STEM、人文学科上表现突出;
- CMMLU榜单上,无论是 Five-shot(仅给5个样本示例)还是 Zero-shot(0样本示例),vivoLM-7B 版本都占据了 TOP 1,并同样在人文学科上“一骑绝尘”。
- 登顶CMMLU榜单的vivoLM-7B即70亿版本大模型,正是vivoLM将对外开放的版本
从vivo负责人剧透的消息中,可以窥见三个要点:
- 一口气发布5个大模型, 参数量分成: 十亿(1B/7B)、百亿(66B)和千亿(130B/175B)三个级别。
- 大模型嵌入手机,当助理还会画画
- 70亿版本大模型,对行业开放可用
Personal GPT
A private, on-device AI Chatbot for iOS and macOS
- Personal GPT is an AI chatbot that runs fully offline without an internet connection on iPhone, iPad and Macs.
World’s First Private AI Chatbot
- Tired of subscription fees and worried about your privacy? Experience the power of AI at your fingertips with Private LLM, AI chatbot that runs on your iPhone®, iPad® and Mac without needing an internet connection. A one time purchase lets you download and use the app on all of your Apple devices. Share it with your family with family sharing.
【2023-8-8】
- 体验地址
- Mac OS App
- github, js 库
微软
small language models (SLMs) Phi
Phi 介绍,功能强大的小语言模型 (SLM),不仅拥有突破性的性能表现,还具有低成本和低延迟的优点
【2023-9-25】有论文指出 phi-1 和 phi-1.5 存在严重的数据污染,结果不可信, 详见站内评测专题
- Phi-1.5模型的数据污染问题很严重
phi-1
【2023-9-15】微软超强小模型引热议
2023年6月,微软发了一篇题为《Textbooks Are All You Need》的论文,用规模仅为 7B token 的「教科书质量」数据训练了一个 1.3B 参数的模型 ——phi-1。
- 尽管在数据集和模型大小方面比竞品模型小几个数量级,但
phi-1在 HumanEval 的 pass@1 上达到了 50.6% 的准确率,在 MBPP 上达到了 55.5%。
phi-1 证明高质量的「小数据」能够让模型具备良好的性能。
phi-1.5
最近,微软又发表了论文《Textbooks Are All You Need II: phi-1.5 technical report》,对高质量「小数据」的潜力做了进一步研究。
用 phi-1 的研究方法,并将研究重点放在自然语言常识推理任务上,创建了拥有 1.3B 参数的 Transformer 架构语言模型 phi-1.5。phi-1.5 的架构与 phi-1 完全相同,有 24 层,32 个头,每个头的维度为 64,并使用旋转维度为 32 的旋转嵌入,上下文长度为 2048。
Susan Zhang 进行了一系列验证,并指出:
- 「phi-1.5 能够对 GSM8K 数据集中的原问题给出完全正确的回答,但只要稍微修改一下格式(例如换行),phi-1.5 就不会回答了。」
- 修改问题中的数据,phi-1.5 在解答问题的过程中就会出现「幻觉」。例如,在一个点餐问题中,只修改了「披萨的价格」,phi-1.5 的解答就出现了错误。
phi-2
【2023-12-12】Phi-2: The surprising power of small language models
- 2.7b
效果比 Gemini Nano 2 好
| Model | Size | BBH | BoolQ | MBPP | MMLU |
|---|---|---|---|---|---|
Gemini Nano 2 |
3.2B | 42.4 | 79.3 | 27.2 | 55.8 |
Phi-2 |
2.7B | 59.3 | 83.3 | 59.1 | 56.7 |
Phi-3
【2024-4-24】Phi-3:微软小模型今日发布,手机上超越 Llama3
新推出 Phi-3 系列,包括: Phi-3-Mini、Phi-3-Small 和 Phi-3-Medium。
Phi-3-Mini最小,仅有 3.8B 参数,但在关键基准测试中,其表现毫不逊色于大型模型,如Mixtral 8x7B和GPT-3.5。- 而更强大的 Small 和 Medium 版本,在扩展数据集的加持下,表现更是卓越。
- 论文 Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 系列模型核心优势在于其小巧的体积,尤其适用于移动设备。
- Phi-3 模型的小巧之处体现在,能在手机上运行,例如 在 iPhone 上,每秒能生成 16 个 token 的信息,相当于大约 12 个单词。这种便携性和高效性使得 Phi-3 成为移动端应用和实时交互的理想选择。
Phi-3 系列模型能够提供与 GPT-3.5 相当的输出水平,而且无需联网,这一点具有深远的影响:
- 实现离线部署,加强隐私保护,从而改变许多应用的运行方式。
不足
- 知识有限
- 由于模型体积较小,存储的知识量相对有限。处理需要广泛事实知识支持的任务(如 TriviaQA 测试)时,这一局限性尤为明显,可能导致性能下降和产生不准确的输出。然而,这种问题可以通过与搜索引擎集成来部分解决,利用搜索引擎提供额外的信息支持,从而增强模型的知识库和应对复杂任务的能力。
- 语言限制
- Phi-3-Mini 只能处理英语。不过,Phi-3-Small 和 Medium 版本已经包含了更多种语言的数据,预计未来会逐步实现更多语言的迭代和优化。
Phi-4
【2024-12-12】微软首次展示 phi-4,参数只有140亿性能却极强
效果
- 在GPQA研究生水平、MATH数学基准测试中,超过了OpenAI的GPT-4o,也超过了同类顶级开源模型
Qwen 2.5 -14B和Llama-3.3-70B。 - 美国数学竞赛AMC的测试中phi-4更是达到了91.8分,超过了
Gemini Pro 1.5、GPT-4o、Claude 3.5 Sonnet、Qwen 2.5等知名开闭源模型,甚至整体性能可以与4050亿参数的Llama-3.1媲美。
当时微软未开源这款超强的小参数模型,甚至还有人在HuggingFace上传盗版的phi-4权重。
训练
- 预训练方面,
phi-4主要使用合成数据进行训练,同时辅以少量高质量有机数据。这种数据混合策略使得模型能够在学习推理和问题解决能力的同时,也能够吸收丰富的知识内容。 - 中期训练阶段,
phi-4将上下文长度从 4096 扩展到 16384,以提高模型对长文本的处理能力。帮助模型进一步增加了对长文本数据的训练,包括从高质量非合成数据集中筛选出的长于 8K 上下文的样本,以及新创建的满足4K 序列要求的合成数据集。 - 后训练阶段是 phi-4 优化模型的关键。微软采用了监督微调(SFT)和直接偏好优化(DPO)技术。
- SFT 阶段,使用不同领域高质量数据生成 约 8B tokens对预训练模型进行微调,学习率为 10 - 6,并添加了 40 种语言的多语言数据,所有数据均采用 chatml 格式。
- DPO 技术则通过生成偏好数据来调整模型的输出,使其更符合人类偏好。微软还引入了关键tokens搜索(PTS)技术来生成DPO 对,该技术能够识别对模型回答正确性有重大影响的关键tokens,并针对这些tokens创建偏好数据,从而提高模型在推理任务中的性能。
【2025-1-9】微软开源最强小模型Phi-4,超GPT-4o、可商用
- 开源地址:phi-4
Gemini Nano
Gemini Nano 2 3.2b
Gemma
【2026-4-4】Gemma 4 一口气发布了四个尺寸的模型
- 31B Dense —— 全密集架构,31B 参数全部激活,主打桌面工作站和单卡 H100。这是 Gemma 4 家族的当家花旦,在 Arena AI 开源模型排行榜文本赛道排名第三。不做量化的情况下,可以塞进一张 80GB 的 H100。
- 26B MoE(混合专家架构) —— 总参数 26B,单次推理只激活 3.8B 参数。在排行榜上排第六。MoE 的优势是推理速度快、延迟低,同一张卡上的 TPS 远超 Dense 版本。如果你更在乎推理速度,MoE 是更好的选择。
- E4B —— 有效参数 4.5B(加上 embedding 约 8B),为移动端 + Jetson / 树莓派设计。是跟 Google Pixel 团队、高通、联发科联合开发的。
- E2B —— 有效参数 2.3B(加上 embedding 约 5B),主打手机 / IoT / 边缘设备。这是整个家族里最适合端侧部署的版本。
E2B 和 E4B 的「E」代表什么。
- 小模型采用了 Per-Layer Embeddings(PLE)技术来最大化参数效率——每个 decoder 层都有自己的小型 embedding 表,这些表虽然体积大但只用来做快速查找,所以实际激活的参数远少于总参数。
- 「E」就是 Effective(有效)的意思。
全系列支持的能力统一且强悍:
- 多模态输入 :全系列原生支持图像和视频理解,小模型额外支持音频输入和语音识别
- 超长上下文 :大模型 256K,小模型 128K
- Agent 工作流 :原生函数调用(Function Call)、结构化 JSON 输出、System Instruction
- 140+ 语言 :原生训练支持 140 多种语言
- 代码生成 :高质量离线代码生成,可以当本地代码助手用
【2024-2-22】开源大模型王座易主!谷歌Gemma杀入场,笔记本可跑,可商用
谷歌推出全新开源模型系列「Gemma」。
- 相比 Gemini,Gemma 更加轻量,同时保持免费可用,模型权重也一并开源了,且允许商用。
- 官方代码 gemma_pytorch
提供两种权重规模的模型:Gemma 2B 和 Gemma 7B。不同尺寸满足不同的计算限制、应用程序和开发人员要求。
- 预训练及针对对话、指令遵循、有用性和安全性微调的 checkpoint。
- 70 亿参数的模型:
GPU和TPU上的高效部署和开发 - 20 亿参数的模型:
CPU和 端侧应用程序。 - 每种规模都有预训练和指令微调版本。
Huggingface 欢迎 Gemma: Google 最新推出开放大语言模型
所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:
- gemma-7b:7B 参数的基础模型。
- gemma-7b-it:7B 参数的指令优化版本。(根据prompt格式启用聊天模式)
- gemma-2b:2B 参数的基础模型。
- gemma-2b-it:2B 参数的指令优化版本。
效果
- Gemma 在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型,例如问答、常识推理、数学和科学、编码等任务
- 关键基准测试中明显超越更大的模型,包括 Llama-2 7B 和 13B,以及风头正劲的 Mistral 7B。HuggingFace 的 LLM leaderboard 上,Gemma 的 2B 和 7B 模型已经双双登顶
LLM 排行榜 上的比较
- LLM 排行榜适用于衡量预训练模型质量,而不太适用于聊天模型。建议对聊天模型运行其他基准测试,如 MT Bench、EQ Bench 和 lmsys Arena。
| 模型 | 许可证 | 商业使用 | 预训练大小 [tokens] | 排行榜分数 ⬇️ |
|---|---|---|---|---|
| LLama 2 70B Chat (参考) | Llama 2 许可证 | ✅ | 2T | 67.87 |
| Gemma-7B | Gemma 许可证 | ✅ | 6T | 63.75 |
| DeciLM-7B | Apache 2.0 | ✅ | 未知 | 61.55 |
| PHI-2 (2.7B) | MIT | ✅ | 1.4T | 61.33 |
| Mistral-7B-v0.1 | Apache 2.0 | ✅ | 未知 | 60.97 |
| Llama 2 7B | Llama 2 许可证 | ✅ | 2T | 54.32 |
| Gemma 2B | Gemma 许可证 | ✅ | 2T | 46.51 |
分析
- 7B 参数级别,Gemma 表现出色,与市场上最佳模型如
Mistral 7B不相上下。 - 2B 版本的 Gemma 虽然规模较小,但在其类别中的表现也颇具竞争力,尽管在排行榜上的得分并未超越类似规模的顶尖模型,例如
Phi 2。
Prompt 提示词格式
Gemma 基础模型不限定提示格式。如同其他基础模型,根据输入序列续写内容,适用于零样本或少样本的推理任务。这些模型也为特定应用场景的微调提供了坚实基础。
指令优化版本则采用了一种极其简洁的对话结构:
<start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who?<end_of_turn>
使用时必须严格按照上述结构进行对话。
访问方式
- Kaggle、谷歌的 Colab Notebook 或通过 Google Cloud 访问。
- 上线 HuggingFace 和 HuggingChat
gemma-7b-it 运行需大约 18 GB 的 RAM,适用于包括 3090 或 4090 在内的消费级 GPU。
二次开发
- 通过 API、谷歌 Vertex AI 平台。封闭模式,与同为闭源路线的 OpenAI 相比,未见优势。
模型结构
- 与 Gemini 类似,Gemma 模型架构基于 Transformer 解码器,模型训练的上下文长度为 8192 个 token
- Gemma 词汇表大小达到 256K,对英语之外的其他语言能够更好、更快地提供支持。
- 技术报告
改进部分:
- 多查询注意力:7B 模型使用多头注意力,而 2B 检查点使用多查询注意力;
- RoPE 嵌入:Gemma 在每一层中使用旋转位置嵌入,而不是使用绝对位置嵌入;此外,Gemma 还在输入和输出之间共享嵌入,以减少模型大小;
- GeGLU 激活:标准 ReLU 非线性被 GeGLU 激活函数取代;
- Normalizer Location:Gemma 对每个 transformer 子层的输入和输出进行归一化,这与仅对其中一个或另一个进行归一化的标准做法有所不同,RMSNorm 作为归一化层。
训练基础设施
- 谷歌使用自研 AI 芯片 TPUv5e 来训练 Gemma 模型:TPUv5e 部署在由 256 个芯片组成的 pod 中,配置成由 16 x 16 个芯片组成的二维环形。
- 7B 模型在 16 个 pod(共计 4096 个 TPUv5e)上训练模型。通过 2 个 pod 对 2B 模型进行预训练,总计 512 TPUv5e。在一个 pod 中,谷歌对 7B 模型使用 16 路模型分片和 16 路数据复制。对于 2B 模型,只需使用 256 路数据复制。优化器状态使用类似 ZeRO-3 的技术进一步分片。pod 之外,谷歌使用了 Pathways 方法通过数据中心网络执行数据复制还原。
预训练
Gemma 2B 和 7B 分别在来自网络文档、数学和代码的 2T 和 6T 主要英语数据上进行训练。与 Gemini 不同的是,这些模型不是多模态的,也不是为了在多语言任务中获得最先进的性能而训练的。
为了兼容,谷歌使用了 Gemini 的 SentencePiece tokenizer 子集(Kudo 和 Richardson,2018 年)。它可以分割数字,不删除多余的空白,并遵循(Chowdhery 等人,2022 年)和(Gemini 团队,2023 年)所使用的技术,对未知 token 进行字节级编码。词汇量为 256k 个 token。
指令调优
谷歌通过在仅文本、仅英语合成和人类生成的 prompt 响应对的混合数据上进行监督微调(SFT),以及利用在仅英语标记的偏好数据和基于一系列高质量 prompt 的策略上训练的奖励模型进行人类反馈强化学习(RLHF),对 Gemma 2B 和 Gemma 7B 模型进行微调。
实验发现,监督微调和 RLHF 这两个阶段对于提高下游自动评估和模型输出的人类偏好评估性能都非常重要。
监督微调
谷歌根据基于 LM 的并行评估结果来选择自己的混合数据,以进行监督微调。给定一组留出的(heldout) prompt, 谷歌从测试模型中生成响应,并从基线模型中生成相同 prompt 的响应,并要求规模更大的高性能模型来表达这两个响应之间的偏好。
谷歌还构建不同的 prompt 集来突出特定的能力,例如指令遵循、真实性、创造性和安全性等。谷歌使用了不同的自动化 LM「judges」,它们采用了多种技术,比如思维链提示(chain-of-thought prompting)、对齐人类偏好等。
格式化
指令调优模型使用特定的格式化器进行训练, 该格式化器在训练和推理时使用额外的信息来标注所有指令调优示例。这样做有以下两个目的,1)指示对话中的角色,比如用户角色;2)描述对话轮次,尤其是在多轮对话中。为了实现这两个目的,谷歌在分词器(tokenizer)中保留了特殊的控制 token。
人类反馈强化学习(RLHF)
谷歌使用 RLHF 对监督微调模型进一步微调,不仅从人类评分者那里收集了偏好对,还在 Bradley-Terry 模型下训练了奖励函数,这类似于 Gemini。该策略经过训练,使用一个具有针对初始调优模型的 Kullback–Leibler 正则化项的 REINFORCE 变体,对该奖励函数进行优化。
与监督微调(SFT)阶段一样,为了进行超参数调优,并额外减轻奖励黑客行为,谷歌依赖高容量模型作为自动评估器,并计算与基线模型的比较结果。
调用
前置工作
- 获取 gemma 权重 访问权限
- huggingface下载时,需要先申请权限,再填入 token 下载
- 安装环境
- python 版本不能超过 3.10
# python <3.10(实测3.9可以), 否则出错: 'FieldInfo' object has no attribute 'required'
python 3.9
# 升级 transformers
# pip install transformers --upgrade pip
pip install -U "transformers==4.38.0" --upgrade
# 使用 GPU
accelerate
# 量化版
bitsandbytes>=0.39.0
直接调用
from transformers import AutoTokenizer, AutoModelForCausalLM
# huggingface-cli download google/gemma-7b-it-pytorch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "sora模型优缺点."
# input_text = "你是谁."
question = f"""
<start_of_turn>user
{input_text}<end_of_turn>
<start_of_turn>model
"""
question = "how are you?"
# id化: 返回字典: {'input_ids':[[]], 'attention_mask':[[]]}
input_ids = tokenizer(question, return_tensors="pt")
print('输入tokens数: ', len(input_ids['input_ids'][0]))
# {'input_ids': tensor([[ 2, 1139, 708, 692, 235336]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1]])}
# -------- 续写模式(默认) --------
outputs = model.generate(**input_ids)
print('原始输出: ', tokenizer.decode(outputs[0]))
"""<bos>how are you?
I'm fine, thanks.
I'm sorry to hear
"""
# 控制生成长度, 用参数 max_length → 升级为 max_new_tokens
outputs = model.generate(**input_ids, max_length=30) # max_length 默认 20
print('max_length 输出: ', tokenizer.decode(outputs[0]))
"""
max_length 输出: <bos>how are you?
I'm fine, thanks.
I'm sorry to hear that.
I'm sorry to hear that
"""
outputs = model.generate(**input_ids, max_new_tokens=10)
print('max_new_tokens 输出:', tokenizer.decode(outputs[0]))
"""
max_new_tokens 输出: <bos>how are you?
I'm fine, thanks.
I"""
调用代码
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
# model.generation_config.cache_implementation = "static" # 静态缓存 static cache
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b") # ① cpu 版本
# model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto") # ② gpu 版本
# model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16) # ③ gpu + 不同精度(float16)
# model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.bfloat16) # ④ gpu + 不同精度(bfloat16)
# --------- ⑤ 使用 flash attention ---------
# pip install flash-attn
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
attn_implementation="flash_attention_2"
).to(0)
# --------- ⑥ 量化版本 ---------
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True) # int8 量化
# quantization_config = BitsAndBytesConfig(load_in_4bit=True) # int4 量化
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config) # int8 量化
# ------------- 调用 ---------------
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt") # ① cpu 版本
# input_ids = tokenizer(input_text, return_tensors="pt").to("cuda") # ②~④ gpu 版本
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
Chat 模式
- 参考官方gemma-7b-it
<start_of_turn>user
什么是sora?<end_of_turn>
<start_of_turn>model
调用代码
# 原始query
test_query = "sora模型优缺"
# ① 续写模式
question = test_query
# ② chat 模式
question = f"""
<start_of_turn>user
{test_query}<end_of_turn>
<start_of_turn>model
"""
# 调用 gamma
answer = getResponse(question)
微调
资料
- kaggle上的微调方法集合
- Hugging Face 微调 Gemma 模型
- 【2024-3-12】Gemma中文指令微调(Colab GPU).ipynb
使用 QLoRA (Dettmers 等人) 通过 4 位精度量化基础模型,以实现更高的内存效率微调协议。
- 环境中安装 bitsandbytes 库
- 然后在加载模型时传递 BitsAndBytesConfig 对象,即可加载具有 QLoRA 的模型。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "google/gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id, token=os.environ['HF_TOKEN'])
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0}, token=os.environ['HF_TOKEN'])
# -------- 测试效果 -----------
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# -------- 微调 -----------
# 数据集
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
# lora 微调
import transformers
from trl import SFTTrainer
def formatting_func(example):
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}"
return [text]
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
# 测试
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20) # 输出20个字符
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
实践
【2024-3-1】
huggingface 调用模型成功
环境
经验
- Mac cpu 环境, 直接运行报错
- 错误:
Input length of input_ids is 33, but max_length is set to 20 - 换 Ubuntu Linux 后, 并没有这个错误
- 解决: generate 函数 增加设置
max_new_tokens=50(>20) 参数才行
- 错误:
- Ubuntu Linux CPU 环境,报错
'FieldInfo' object has no attribute 'required'
from transformers import AutoTokenizer, AutoModelForCausalLM
# tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
# model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
model_dir = '/mnt/bn/flow-algo-intl/wangqiwen/model'
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b", cache_dir=model_dir)
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", cache_dir=model_dir)
input_text = "sora模型优缺点."
# input_text = "你是谁."
question = f"""
<start_of_turn>user
{input_text}<end_of_turn>
<start_of_turn>model
"""
input_ids = tokenizer(question, return_tensors="pt")
print('[debug]', input_ids)
outputs = model.generate(**input_ids)
# Mac 上报错: ValueError: Input length of input_ids is 33, but `max_length` is set to 20
outputs = model.generate(**input_ids, max_new_tokens=50) # max_lengths, max_new_tokens (输出数目)
print(tokenizer.decode(outputs[0]))
微调实践失败
错误信息
- 原因: transformers版本旧了,需要升级到 >=4.38
ImportError: cannot import name 'GemmaTokenizer' from 'transformers'
# 修复方法
pip install -U transformers
错误信息
ImportError: Using bitsandbytes 8-bit quantization requires Accelerate: pip install accelerate and the latest version of bitsandbytes: pip install -i https://pypi.org/simple/ bitsandbytes
Amazon
【2023-9-25】Amazon’s Alexa LLM
Amazon has officially joined the commercial language model race with the announcement of the Alexa LLM.
There is no detail on the model architecture or training data and training process, which is unfortunately slowly becoming the norm in the industry.
However, based on a blog post by Alexa’s Vice President, Daniel Rausch, and a product demo video, we can make speculations on how the model works.
Key findings:
- Alexa LLM will be multimodal, embedding commands, different voice characteristics, visual features, and more.
- The model has been designed to work with external APIs like ChatGPT plugins or the Toolformer approach
- The model adapts to users though the details are not clear—we can assume that Alexa LLM uses an advanced form of retrieval augmented generation (
RAG) - The model uses in-context learning to maintain coherence over long sequences of interactions between the user and the assistant
- Amazon aims to give the model personality, so we can expect it to be opinionated on some topics that might be controversial
- The model will be available as a “free preview,” but don’t expect Amazon to provide it as free as a final product (Alexa was losing money already)
Read the full article on TechTalks.
阿里
PolyLM 多语言
【2023-8-4】达摩院开源多语言大模型PolyLM, 覆盖集团核心小语种,效果超LLAMA、BLOOM
- Github PolyLM
- 1.7B/13B大小的两个多语言大模型
Polyglot Large Language Model (通晓多种语言的大语言模型)
LLMs主要集中在高资源语言,例如英语,限制了其他语言中的应用和研究。
因此,开发了PolyLM,一个在6400亿个词的数据上从头训练的多语言语言模型,包括两种模型大小(1.7B和13B)。
- PolyLM覆盖中、英、俄、西、法、葡、德、意、荷、波、阿、土、希伯来、日、韩、泰、越、印尼等语种,特别是对亚洲语种更友好。为了增强多语言能力
- 1) 将双语数据集成到训练数据;
- 2)采用一种课程学习策略,在预训练期间将非英语数据的比例从30%提高到60%。
此外,提出了一种多语言自指令方法,自动为模型生成132.7K条多样的多语言指令。为了评估模型的效能,收集了几种现成的多语言任务,包括多语言理解、问答、生成和翻译。广泛的实验表明,PolyLM超过了其他开源模型,如LLaMA和BLOOM,在多语言任务中表现良好,同时在英语上保持了可比较的性能。
现有LLM主要面向高资源语种开发,例如ChatGPT、LLama侧重英语,而ChatGLM、MOSS、千问等模型关注中文。BLOOM是一种多语言大模型,但很多重要语种不支持,同时在7B到175B模型之间存在断档。大家关注高资源语种可能是三方面原因导致的,一方面这些语种的研究人员比较集中,另一方面大模型的Scaling Law告诉我们可以简单的通过扩大数据规模来提升模型效果,这些经验性的发现也使得大家的研究集中到了中/英等高资源语向的探索。最后,市场也是一个决定性的因素。
然而实际上中/英以外的语种需求非常大:
内部需求:集团国际化18个核心语种(中、英、俄、西、法、葡、德、意、荷、波、阿、土、希伯来、日、韩、泰、越、印尼),场景覆盖多语言和跨语言的客服、导购、理解、问答、搜推、生成、翻译。现有的开源模型无法提供很好的支持。
外部需求:中/英实际上只能覆盖世界上60%的人口,很多小语种拥有大量的使用人口和场景,例如东亚的日韩近2亿使用者,东南亚的泰越印尼近4.5亿使用者,而中东的阿拉伯语覆盖了4.2亿用户。
QWen 1.7b
待定
书生-浦语
待定
面壁智能 MiniCPM
【2024-2-5】MiniCPM是面壁智能与清华大学自然语言处理实验室共同开源的系列端侧大模型
- MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量。
- 与 Mistral-7B 相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型
【2025-1-17】MiniCPM-o 2.6
【2025-1-17】面壁智能发布 MiniCPM-o 2.6 全模态模型,号称“端侧 GPT-4o”
“小钢炮”MiniCPM-o 2.6 端侧全模态模型,参数为 8B,号称性能比肩 GPT-4o、Claude-3.5-Sonnet。
- 开源地址:MiniCPM-o
- huggingface:MiniCPM-o-2_6
其采用了端到端多模态架构,可同时处理文本、图像、音频和视频等多种类型的数据,生成高质量文本和语音输出。官方表示,其总参数量 8B,视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,是开源社区中模态支持最丰富、性能最佳的模型之一。
MiniCPM-o 2.6 支持可配置声音的中英双语语音对话,还具备情感 / 语速 / 风格控制、端到端声音克隆、角色扮演等进阶能力。
MiniCPM-o 2.6 是首个支持在 iPad 等端侧设备上进行多模态实时流式交互的多模态大模型。
其在 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 70.2,以 8B 量级的大小在单图理解方面超越了 GPT-4o-202405、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。
【2026-4-6】VoxCPM2
【2026-4-6】面壁智能联合 OpenBMB 开源社区、清华大学人机语音交互实验室开发的2B小模型 VoxCPM 2 ,4月刚刚开源。
VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning
VoxCPM2 — 三种语音生成方式:
- 🎨 声音设计(Voice Design)
- 无需参考音频。在 Control Instruction 中描述目标音色特征(性别、年龄、语气、情绪、语速等),VoxCPM2 即可为你从零创造独一无二的声音。
- 🎛️ 可控克隆(Controllable Cloning)
- 上传参考音频,同时可选地使用 Control Instruction 来指定情绪、语速、风格等表达方式,在保留原始音色的基础上灵活控制说话风格。
- 🎙️ 极致克隆(Ultimate Cloning)
- 开启 极致克隆模式 并提供参考音频的文字内容(可自动识别)。模型会将参考音频视为已说出的前文,以音频续写的方式完整还原参考音频中的所有声音细节。注意:该模式与可控克隆模式互斥,将禁用Control Instruction。
NVIDIA
观点
【2025-6-2】NVIDIA 论文
观点
- 1、从效果上看,在一些垂直场景里,SLM的表现其实不一定比大模型差,尤其是任务比较聚焦的时候。
- 2、从实施上看,小模型更容易做微调,训练和迭代的门槛更低。
- 3、从经济成本上看,SLM所需算力更小,部署起来也更便宜、更高效。
Chat with RTX
【2024-2-15】英伟达官宣AI聊天机器人,本地RTX显卡运行,这是要挑战OpenAI?
- 发布了一个对话机器人 ——「Chat with RTX」,面向 GeForce RTX 30 系列和 40 系列显卡用户(至少有 8GB VRAM)
- Chat with RTX 默认使用 Mistral 开源模型,但也支持其他基于文本模型,包括 Meta 的 Llama 2。它会利用 RTX GPU 上的 Nvidia Tensor core 来加快查询速度。Nvidia 警告说,下载所有必要文件会占用相当大的存储空间 ——50GB 到 100GB,具体取决于所选模型。
- 下载地址
Chat with MLX
Mac 用户的 RAG 交互:通过 Chat-with-MLX 与数据对话
Features
- Chat with your Data: doc(x), pdf, txt and YouTube video via URL.
- Multilingual: Chinese 🇨🇳, English🏴, French🇫🇷, German🇩🇪, Hindi🇮🇳, Italian🇮🇹, Japanese🇯🇵,Korean🇰🇷, Spanish🇪🇸, Turkish🇹🇷 and Vietnamese🇻🇳
- Easy Integration: Easy integrate any HuggingFace and MLX Compatible Open-Source Model.
MLX 是苹果公司(Apple)专为其自家的硅片设计的一款机器学习研究框架,它由苹果的机器学习研究团队倾力打造。
MLX 亮点:
- 1)熟悉的API设计:MLX提供了类似于NumPy的Python API,使用户易于上手。同时,它还支持C++、C和Swift的API,保持与Python API的高度一致性。MLX还包含高级功能包如mlx.nn和mlx.optimizers,其API设计紧跟PyTorch,简化了复杂模型的构建过程。
- 2)灵活的函数转换能力:MLX支持自动微分、自动向量化和计算图优化,提升模型训练和优化的效率。
- 3)惰性计算机制:通过采用惰性计算,MLX能够仅在数据真正需要时才进行计算和呈现,有效提高计算效率。
- 4)动态图构建:MLX能动态构建计算图,即使函数参数的形状变化,也不会导致编译速度变慢,使得调试过程更为简单直观。
- 5)支持多设备运算:MLX能够在任何支持的设备上顺畅运行,无论是CPU还是GPU。
- 6)统一内存管理:与其他框架不同,MLX采用统一内存模型,数据存储在共享内存中,无需在不同设备间传输数据,极大提升了运算效率和数据处理速度。
Chat-with-MLX 界面

- 选中模型后,点击 Load Model,后台会出现下载进程
推荐理由
-
- 安装方便,支持添加其他模型
-
- 程序使用 MLX
-
- 不仅支持与本地文件(doc(x)、 pdf、 txt)的处理,还能够处理来自YouTube链接的内容。
实践
Jet-Nemotron
【2025-8-21】刚刚,英伟达新模型上线!4B推理狂飙53倍,全新注意力架构超越Mamba 2
Jet-Nemotron 是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。
其核心创新: 后神经架构搜索(PostNAS)与新型线性注意力模块 JetBlock,实现了从预训练Transformer出发的高效架构优化。
- 相比Qwen3、Gemma3、Llama3.2等模型,Jet-Nemotron在数学、代码、常识、检索和长上下文等维度上准确率更高
-
同时在H100 GPU上推理吞吐量最高提升至53倍。
- 论文:
- 项目:Jet-Nemotron
Jet-Nemotron 系列有 Jet-Nemotron-2B和Jet-Nemotron-4B大小。
- Jet-Nemotron 系列「小模型」性能超越了Qwen3、Qwen2.5、Gemma3和 Llama3.2等当前最先进的开源全注意力语言模型。
Jet-Nemotron有两项核心创新。
- 后神经网络架构搜索(Post Neural Architecture Search,PostNAS),这是一个高效的训练后架构探索与适应流程,适用于任意预训练的Transformer模型;
- JetBlock,一种新型线性注意力模块,其性能显著优于先前的设计,如Mamba2。
斯坦福 Octopus v2
【2024-4-7】超越GPT-4,斯坦福团队手机可跑的大模型火了,一夜下载量超2k
斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。
Octopus-V2-2B 是一个拥有 20 亿参数的开源语言模型,专为 Android API 量身定制,旨在在 Android 设备上无缝运行,并将实用性扩展到从 Android 系统管理到多个设备的编排等各种应用程序。
检索增强生成 (RAG) 方法需要对潜在函数参数进行详细描述(有时需要多达数万个输入 token)。
- Octopus-V2-2B 在训练和推理阶段引入了独特的函数 token 策略,不仅使其能够达到与 GPT-4 相当的性能水平,而且还显著提高了推理速度,超越了基于 RAG 的方法,这使得它对边缘计算设备特别有利。
模型开发与训练
- 采用 Google Gemma-2B 模型作为框架中的预训练模型,并采用两种不同的训练方法:完整模型训练和 LoRA 模型训练。
- 完整模型训练中,该研究使用 AdamW 优化器,学习率设置为 5e-5,warm-up 的 step 数设置为 10,采用线性学习率调度器。
LoRA 模型训练采用与完整模型训练相同的优化器和学习率配置,LoRA rank 设置为 16,并将 LoRA 应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。其中,LoRA alpha 参数设置为 32。
对于两种训练方法,epoch 数均设置为 3。
20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行
- 准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。
- 此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。
- 论文:Octopus v2: On-device language model for super agent
- 模型主页:Octopus-v2
SenseChat Lite
【2024-4-27】GPT-4现场被端侧小模型“暴打”,商汤日日新5.0:全面对标Turbo
商汤科技最新发布的日日新端侧大模型——SenseChat Lite(商量轻量版)。
SenseChat Lite则是采用了端云“联动”的MoE框架,在部分场景中端侧推理占70%,会让推理成本变得更低。
- 对比人眼20字/秒的阅读速度来说,SenseChat Lite在中等性能手机上,可以达到18.3字/秒推理速度。
- 若是在高端旗舰手机,那么推理速度可以直接飙到78.3字/秒!
但除了文本生成之外,徐立同样在现场还展示了商汤端侧模型的多模态能力。
日日新5.0的更新亮点可以总结为:
- 采用MoE架构
- 基于超过10TB tokens训练,拥有大量合成数据
- 推理上下文窗口达到200K
- 知识、推理、数学和代码等能力全面对标GPT-4
【2026-6-9】Nextie 新程Alpha
【2026-6-9】仅4B大小可端侧部署!卡帕西预言的「认知模型」被国产做出来了
2025年12月 奇绩创坛Demo Day上,明日新程首度公开亮相就明确提出:
AI进化终点不是更大的单体大模型,认知模型才是下一周期行业趋势。
ak47 在访谈中抛出判断:“推理模型要变天了!”
- 仅需10亿参数,就能构建起非常优秀的「认知核心」, 剥离了海量事实记忆、只保留思考算法的智能单元。
小冰之父李笛集结微软小冰原班人马,带着仅成立半年的AI初创公司Nextie(明日新程),刚刚推出了行业首个认知模型「新程Alpha」。
知识不等同于智能。
当前推理模型正集体陷入「Scaling困境」,行业默认参数越大、知识越多,模型就越聪明。
结果
- 那些拥有庞大知识库的模型,看似能解决复杂的数学和编程问题,却总是在细节处频频被网友捉虫
- 比如:“200元取钱”这类逻辑陷阱,甚至说strawberry中有几个“r”这样的简单问题。
传统知识型推理模型还是在已有知识中找答案,但认知模型不一样,具备自主思考和规划能力,能够把单一场景下的思维策略泛化到另一个不相关领域。
真正的认知核心应该能被剥离出来:轻量、可泛化、低成本。
Alpha 轻量级选手把很多推理大模型做不到的事情做成了:以下克上,不仅搞定了模型算力的痛,最终效果还能比肩第一梯队的 GPT-5.4。
算力成本立省100%,从烧显卡变成了交电费,而且直接端侧能跑。
国产认知模型 Alpha:4B小模型实现端侧部署,挑战GPT-5性能
- ① 技术突破:4B参数规模实现端侧部署,算力成本大幅降低,国产AI技术新里程碑
- ② 性能表现:综合效果比肩GPT-5,在群体智能、情绪理解和多模态处理方面优势明显
- ③ 创新理念:跳出传统堆参数思路,聚焦AI自我认知能力,实现认知/知识/行动/记忆解耦
- ④ 应用场景:适用于情绪陪伴、法律辅助等领域,让高端AI技术真正走入日常生活
- 关注轻量化AI模型发展,了解4B级别小模型的技术特点和应用场景
- 探索认知模型在个人设备上的实践可能性,如手机、平板等终端
- 理解”认知即服务”新理念,把握AI从单纯对话向认知能力发展的趋势
- 支持国产AI技术创新,关注Nexttie等国内初创企业的技术突破
小模型承载大智慧,4B参数也能赋予AI”认知”灵魂,让顶尖能力真正融入每个人的数字生活。
【2026-5-20】推理内化小模型 HRM-Text
类脑架构,1B 模型实现更好的模型推理效果
详见站内专题:类脑计算
【2026-6-15】ICR框架助力小模型超越顶流
【2026-6-15】 Iterative-Contextual-Refinements 框架加持下, Qwen3.6-27B 跑分超过了 Anthropic Fable5
- 框架: Iterative-Contextual-Refinements
- 【2026-5-13】论文: PerfCodeBench: Benchmarking LLMs for System-Level High-Performance Code Optimization
框架主要提升软件性能优化. Vector-db-bench 给大模型提供了火焰图, perf, 各种测试 tool_call 让大模型自己迭代去优化代码性能.
瞄准小模型核心弱点, 参数量不足导致的”脑残”, 即小模型更容易长上下文衰退或陷入局部最优.
框架
- 先用
BFS探索模式, 写代码plan 过程, 让小模型提出多种解决方案, 比如写个字符串匹配, 小模型直接搞了个O(N^2)的暴力搜索, 而Agent会让小模型思考, 哪些可能的解决方案? 于是拓展小模型视野, KMP, 滑动窗口等技术方案没准就出来了. - 再用
DFS模式, 借助Agent让小模型借助代码性能测试工具不断跑分, 然后让小模型反思有哪些性能热点可以优化. - 最后,统筹全局的路由, 不但负责在BFS/DFS过程中选取最佳的技术方案, 而且还会在DFS过程中, 总结模型优化过程中面临的问题, 再反馈到BFS过程, 告诉模型, 需要注意xxx优化是有价值的, xxx优化面临xxx问题. 从而形成优化闭环, 解决掉模型陷入死胡同不断仰卧起坐的问题.
框架加持下, Qwen3.6-27B 在 CGRE 测试得到了95.5分, 成功超越了 Fable5(Mythos) 的94.1分! Agentic 工程的胜利, 不要模型写的不好就无脑怪模型, 也要看看是不是Agent本身有问题.
代价:
- AI硬通货是 token, 这个框架正是用了25-40x的token消耗完成了这一壮举. 值得学习.
端侧多模态
【2024-12-18】多模态小模型:LLaVa-Phi、TinyLLaVa、MobileVLM系列
轻量级多模态大模型的设计思路类似,包括:更换backbone、更换训练策略和使用更多训练数据。
从25年中阿里 Qwen-Embedding-0.6B、谷歌 0.27B的Gemma 3、0.3B EmbeddingGemma,再到今年初腾讯0.3B的HY-1.8B-2Bit,越来越多的小尺寸模型可供开发者选择,推动RAG、语义搜索等应用不断下沉至个人设备。
LLaVa-Phi
总结概括 本文提出了LLaVa-Phi,一种轻量级的多模态大模型,部分性能指标上达到LLaVa-1.5-7B模型。其模型架构和LLaVa相似,一个visual encoder+projector+LLM,主要差别为其LLM采用了轻量级的Phi-2 (2.7B) [1]。训练数据与LLaVa无异,也是采用预训练+指令微调的方式,在8张a100下,分别需要消耗1.5小时和8小时。
TinyLLaVa
比较翔实的实验论文,对LLM、visual backbone、projector、训练数据和训练方式进行了比较全面的效果实验。
总结观点:
- LLM上,基本满足LLM越大性能越好,即: Phi-2 (2.7 B)>StableLM-2 (1.6B) > TinyLlama (1.1B)。
- visual backbone上,SLIP好于CLIP,但是SLIP采用384分辨率,而CLIP是334分辨率,所以SLIP更好的效果可能主要是来自于更大的分辨率。
- projector上,目前的MLP已经足以做模态对齐。
- 训练数据上,使用更高质量的数据如 ShareGPT4v,效果略好于LLaVA-1.5数据集。
- 训练方式上,预训练时微调visual encoder会取得更好的效果。
轻量级多模态大模型,用更强的backbone、更多的训练参数、更高质量的训练数据,就可以取得更好的效果,结论是显而易见,缺少insight。做这种消融所需要的计算资源也比较多。 表3展示了TinyLLaVa与其他MLLM的对比结果。
MobileVLM系列
MobileVLM包括v1和v2版本,美团提出。
MobileVLMv1
- 论文:MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices
- 代码:https://github.com/Meituan-AutoML/MobileVLM
MobileVLMv1 可运行于低计算力平台如智能手机。主要在模型结构上进行设计,包括LLM encoder和projector。
- LLM encoder上,论文对LLaMa进行了缩放,训练出了MobileLLaMa,包括1.4B和2.7B模型。
- projector上,提出了Lightweight Downsample Projector (LDP)。它相对于MLP,会通过下采样降低Token数量,提升模型效率,同时为了增强局部性,使用了深度卷积和逐点卷积。
MobileVLMv2
MobileVLM 的改进,主要在三个方面: projector、训练策略、训练数据
- projector上,改变了下采样方式,采用平均池化,如图2所示。
- 训练策略上,在两阶段的训练上都放开了projector和LLM。
- 训练数据上,在第一阶段使用ShareGPT4v做预训练;第二阶段使用多个任务的数据集(如caption数据集、VQA数据集和指令微调数据集)进行联合训练。
Ivy-VL
【2024-11-20】轻量级多模态模型 Ivy-VL 解决了多模态大模型在端侧部署时面临的硬件资源受限、能效不足及难以满足多模态任务需求等问题。
移动设备和边缘设备硬件资源有限,能效要求又高,要把这些模型成功部署上去,长期以来都是棘手难题。
轻量级多模态模型 Ivy-VL 成为面向移动端多模态模型的新代表。
- 解决了多模态大模型在端侧部署时面临的硬件资源受限、能效不足及难以满足多模态任务需求等问题。
该模型由 AI Safeguard 联合卡内基梅隆大学、斯坦福大学开发,它的出现既推动了移动端AI应用的发展,也为更多设备在低功耗环境下运行先进AI技术提供了基础。Ivy-VL模型已上线始智AI-wisemodel开源社区
特性
- 极致轻量化
- Ivy-VL的参数量仅为 3B,极大地降低了计算资源需求,与7B 以几十 B 的多模态模型相比,具有更小的硬件占用。模型可高效运行于 AI 眼镜、智能手机等资源受限的设备上。
- 卓越性能
- Ivy-VL 在多个多模态榜单中夺得 SOTA(state-of-the-art)成绩。通过精⼼优化的数据集训练,Ivy-VL 展现了远超同类模型的性能,证明了小模型同样可以实现⼤突破。
- 在专业多模态模型评测榜单OpenCompass上⾯,做到4B以下开源模型第⼀的性能。超越了顶尖的端侧 SOTA 模型,包括Qwen2-VL-2B、InternVL2-2B、InternVL2.5-2B、SmolVLM-Instruct、Aquila-VL-2B以及PaliGemma3B等模型。
- 低延迟和高响应速度
- 3B 的LLM 模型大小,显著提升了 Ivy-VL 的响应速度,确保其在端侧设备上实现实时推理。在生成速度、能效比和准确率之间,达到了完美平衡。
- 强大的跨模态理解能力
- Ivy-VL基于 LLaVA-One-Vision,结合先进的视觉编码器(google/siglip-so400m-patch14-384)与强大的语言模型(Qwen2.5-3B-Instruct),Ivy-VL在视觉问答、图像描述、复杂推理等任务中表现优异,完美满足端侧应用的多模态需求。
- 开放生态
- Ivy-VL 将模型开源,并且允许商用,方便开发者快速上手。无论是 AI 创新团队还是个人开发者,都可以利用 Ivy-VL 构建自己的多模态应用。
Ivy-VL为多模态大模型的边缘部署和普及开创了全新可能。无论是推动移动设备AI 应用,还是服务于广泛的 IoT 设备,Ivy-VL 都在积极赋能各个领域。
- 智能穿戴设备:支持 AI 眼镜实现实时视觉问答,辅助增强现实(AR)体验。
- 手机端智能助手:提供更智能的多模态交互能力,让手机用户体验更自然的 AI 服务。
- 物联网设备:助力智能家居和 IoT 场景实现更高效的多模态数据处理。
- 移动端教育与娱乐:在教育软件中增强图像理解与交互能力,推动移动学习与沉浸式娱乐体验。
Ivy-VL标志着轻量级多模态模型在端侧设备上的一次重要突破。
【2026-2-10】腾讯 HY-1.8B-2Bit
【2026-2-10】主打一个快!腾讯开源0.3B端侧模型,手机耳机都能跑
2026年2月10日,腾讯混元开源面向消费级硬件场景的“极小”模型 HY-1.8B-2Bit,等效参数量仅有0.3B,内存占用仅600MB,比常用的一些手机应用还小,可本地化部署于手机、耳机或智能家居等设备应用。
- 项目链接:AngelSlim
- 模型地址:HY-1.8B-2Bit, HY-1.8B-2Bit-GGUF
- 技术报告:AngelSlim_Technical_Report.pdf
基于首个产业级2比特(Bit)端侧量化方案,通过对此前混元的小尺寸语言模型 HY-1.8B-Instruct 进行2比特量化感知训练(QAT)产出。这一模型对比原始精度模型等效参数量降低6倍,沿用原模型全思考能力,可根据任务复杂度切换长/短思维链;同时在真实端侧设备上生成速度提升2-3倍。
从去年中阿里的Qwen-Embedding-0.6B、谷歌的0.27B的Gemma 3、0.3B的EmbeddingGemma,再到今年初腾讯0.3B的HY-1.8B-2Bit,越来越多的小尺寸模型可供开发者选择,推动RAG、语义搜索等应用不断下沉至个人设备。
HY-1.8B-2Bit的能力仍受限于监督微调(SFT)的训练流程,以及基础模型本身的性能与抗压能力。针对这一问题,混元团队未来将重点转向强化学习与模型蒸馏等技术路径,以期进一步缩小低比特量化模型与全精度模型之间的能力差距。
【2025-12-12】FacePhys 端侧生理感知
0.2M小模型跑在手机摄像头
【2025-12-12】微面科技发布全球首个实时读懂心跳和情绪的基座模型 FacePhys,通过普通摄像头就能无接触测量心率、呼吸、情绪等120多项指标,精度达到医疗级,心率误差不超过2BPM。
- 论文 FacePhys: State of the Heart Learning
- Demo FacePhys-Demo
- 这个模型只有 0.2M 参数,可在手机摄像头里实时运行,延迟不到10毫秒。
AI终于能识别假笑和压抑情绪了。顺为资本已经投了数百万美元,合作伙伴包括海尔机器人。
FacePhys 关注 离线 SDK · 本地实时生理感知
- 摄像头视频流直出心率、HRV、情绪波形。无需上传,数据不出端,iOS / Android / Linux 全平台支持
产品
- Findings 无感生理采集系统:面向科研与实验场景的高精度生命体征采集设备与工具链
- 用于人因工程、座舱研究、心理咨询与用户体验实验等场景,支持本地采集、事件打标与结构化导出。
- FaceCam 智能摄像头:生理情绪意图多维识别,为具身智能设计的非接触式感知硬件
FacePhys 是一款基于浏览器的远程光电容积描记(rPPG)监测工具。
- 依托状态空间模型(SSM),通过普通摄像头拍摄的人脸视频,提取心率与心率变异性数据。
- 基于 LiteRT 和 WebAssembly 在本地完成推理,专为端侧环境打造:模型体积约 4MB,推理延迟低至 5 毫秒。
隐私说明
- 零数据上传:所有推理均在设备本地完成
- 无云端处理:视频数据与生理信号不会上传至服务器
- 支持离线运行:加载完成后,断网也可正常使用
功能特性
- 状态空间模型:将心脏活动建模为连续时间受控常微分方程,适配非规则采样场景
- 多线程架构:借助 Web Worker 执行推理、功率谱密度计算与绘图,保证界面流畅响应
- 可视化能力:实时展示注意力热力图、三维状态轨迹、血容量脉搏/功率谱密度波形
- 界面风格:复刻 Windows 95/98 经典样式
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
