- Agent 框架
- 总结
- 决策模型
- 框架
- Single-Agent
- Multi-Agent
- 总结
- 问题
- 发展趋势
- 【2023-8-10】斯坦福虚拟小镇
- GPT Researcher
- Camel
- 【2024-6】LangGraph
- 【2024-6-16】AgentUniverse
- 【2024-6-29】AgentStudio
- 【2024-10-12】Swarm
- 【2025-3-12】OpenAI Agents SDK(Swarm)
- CrewAI – LangChain
- AgentScope
- UFO
- TaskWeaver
- Semantic Kernel
- 【2023-10-10】AutoGen
- 【2024-11-4】Magentic-One
- 【2025.4.23】cooragent
- 字节 Aime
- GUI Agent
- 结束
Agent 框架
Agent 框架 旨在 简化 LLM-powered 应用开发过程
总结
大模型 Agent 开发框架概览
| Agent框架类型 | 分析 | 热门框架 | 分析 |
|---|---|---|---|
| 低代码框架 | 无需代码即可完成 | Coze、Dify、LangFlow | |
| 基础框架 | 大模型原生能力进行Agent开发 | function calling、tools use | |
| 代码框架 | 借助代码完成Agent开发 | LangChain、LangGraph、Llamalndex | |
| Multi-Agent框架 | 多智能体 | CrewAl、Swarm、Assistant API AutoGen、MetaGPT |
AI框架
𝗟𝗮𝗻𝗴𝗖𝗵𝗮𝗶𝗻- AI 工作流、RAG 和智能代理的首选 𝗟𝗟𝗠 𝗮𝗽𝗽 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸。𝗟𝗹𝗮𝗺𝗮𝗜𝗻𝗱𝗲𝘅- 优化了 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝘀𝗲𝗮𝗿𝗰𝗵 和聊天机器人内存,有𝗲𝗮𝘀𝘆 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲 𝗶𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻。𝗖𝗿𝗲𝘄𝗔𝗜- 一个 𝗺𝘂𝗹𝘁𝗶-𝗮𝗴𝗲𝗻𝘁 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻 框架,可简化人工智能团队工作和自动化。𝗦𝘄𝗮𝗿𝗺- 用于𝘀𝗲𝗹𝗳-𝗼𝗿𝗴𝗮𝗻𝗶𝘇𝗶𝗻𝗴 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁 系统 𝗻𝗲𝘁𝘄𝗼𝗿𝗸𝘀。𝗣𝘆𝗱𝗮𝗻𝘁𝗶𝗰𝗔𝗜- 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 𝗔𝗜 𝗱𝗮𝘁𝗮 𝘃𝗮𝗹𝗶𝗱𝗮𝘁𝗶𝗼𝗻 和 𝗲𝗻𝗳𝗼𝗿𝗰𝗶𝗻𝗴 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝘁 𝗟𝗟𝗠 𝗼𝘂𝘁𝗽𝘂𝘁𝘀 的常用框架。𝗟𝗮𝗻𝗴𝗚𝗿𝗮𝗽𝗵- A 𝗴𝗿𝗮𝗽𝗵-𝗯𝗮𝘀𝗲𝗱 𝗔𝗜 𝘄𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻 𝗰𝗼𝗺𝗽𝗹𝗲𝘅 𝗟𝗟𝗠 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 的框架。𝗔𝘂𝘁𝗼𝗴𝗲𝗻𝗔𝗜- 最强大的 𝗮𝘂𝘁𝗼𝗻𝗼𝗺𝗼𝘂𝘀 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁 𝘀𝗲𝗹𝗳-𝗶𝗺𝗽𝗿𝗼𝘃𝗶𝗻𝗴 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 𝗮𝗻𝗱 𝘁𝗮𝘀𝗸 𝗮𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗼𝗻。
| 框架名称 | 用途 | 优势 | 劣势 | 最适合场景 |
|---|---|---|---|---|
LangChain |
自定义LLM工作流 | 生态系统庞大、灵活性高、社区强大 | 调试困难 | 检索增强生成(RAG)、AI工作流、智能体 |
LangGraph |
AI工作流编排 | GUI编辑、可扩展 | 学习曲线陡峭 | 复杂大语言模型管道 |
AutoGen AI |
自动化AI智能体,多个Agent交互协作系统 | 自我改进能力 | 设置复杂 | AI研究、任务自动化 |
LlamaIndex |
大语言模型应用 | 优化搜索、易于数据库集成 | 工具较LangChain少 | 文档搜索、聊天记忆 |
Swarm |
去中心化AI智能体 | 分布式执行、自修复 | 小众应用、采用率低 | 自组织AI系统 |
CrewAI |
多智能体协作 | 设置简单、可任务分配 | 集成较少 | AI团队自动化 |
Pydantic AI |
AI驱动的数据验证 | 结构化输出 | 范围有限 | 模式验证、结构化数据 |
图见小红书原文
【2025-4-4】Top 9 AI Agent Frameworks as of April 2025
好的AI框架特性:
- Agent 架构: 决策引擎精心设计,包含 记忆管理、高级交互协议
- 环境集成:实际系统集成API、虚拟环境适配器、安全访问控制、性能监控接口
- 任务编排:自动化工作流管理,基于优先级执行系统、资源分配控制
- 通信基础设施:人机交互协议、API集成能力、数据交换系统、多代理通信
- 性能优化:机器学习模型,持续学习能力,迭代框架, 错误处理和恢复:应急机制,审计跟踪,系统健康诊断
A well-designed AI framework typically includes:
Agent Architecture: Sophisticated decision-making engines with persistent memory management systems and advanced interaction protocols.Environmental Integration Layer: APIs for real-world system integration, virtual environment adapters and robust security and access controls with performance monitoring interfaces.Task Orchestration Framework: Automated workflow management with priority-based execution systems and resource allocation controls. Error handling and recovery mechanisms for emergencies.Communication Infrastructure: Human-AI interaction protocols, API integration capabilities, data exchange systems, and inter-agent communication channels to facilitate internal collaborations.Performance Optimization: Machine learning models with continuous learning capabilities and iteration frameworks. Audit trail capabilities and system health diagnostics for future optimization.
- LangChain
- AutoGen
- Semantic Kernel
- Atomic Agents
- CrewAl
- RASA
- Hugging Face Transformers Agents
- Langflow
- Lyzer
LangChain vs AutoGen
使用指南
- 用 LangChain 设计原型,业务复杂时,升级到 AutoGen
分析
- AutoGen 专注于 Agent AI,支持创建 多个Agent交互协作系统,解决任务。
- 生态: AutoGen Studio (GUI原型设计), AutoGen Bench(测试套件)
- LangChain 强调可组合性,提供模块化构建,链接在一起, 创建自定义LLM工作流。
- 生态: LangServe, LandSmith, LangGraph
- langchain-openai、langchain-anthropic 包
- 生态: LangServe, LandSmith, LangGraph
LangChain
优势
- 丰富的集成和模块
- 全面的框架
- 大型社区和支持
- 面向生产的附加组件(LangSmith、LangServe)
弱点
- 单代理焦点(默认)
- 复杂性和开销(适用于简单任务)
- 潜在的性能注意事项(如果设计不仔细)
- 早期版本有重大更改(正在解决)
使用场景
- 快速构建LLM应用
- 单智能体流程
- 集成外部工具、数据源,需要综合大型社区、文档
- 工程部署: LangSmith, LangServe
案例
- 多代理旅行计划:具有专业角色(规划师、当地导游)的代理合作创建详细的行程。
- 自动内容生成:代理起草、审查和优化电子邮件或营销材料。
- 人机回环系统:代理在人工监督下收集和汇总数据。
- 自治客户服务机器人:代理协作处理查询。
- 协作写作助理:多个代理参与一个写入项目。
AutoGen
优势
- 多代理编排
- 异步、事件驱动型内核
- 工具/代理的可扩展性
- 开发人员工具(AutoGen Studio、AutoGen Bench)
- 可观测性功能
弱点
- 较小的集成生态系统(超出核心LLMs)
- 更陡峭的学习曲线(以开发人员为中心)
- 更新、更小的社区
- 快速更改(版本控制)
适用场景
- 多个智能体协作
- 工作流以智能体为中心,逻辑复杂
- 以开发者、代码为中心
- 前沿智能体实验
案例
- 检索增强 QA:聊天机器人通过从文档中检索信息来回答问题。(示例:MUFG Bank、Klarna)
- 内容总结和分析:总结成绩单,分析合同,生成报告。
- 使用工具的聊天机器人:可以使用计算器、搜索 API 或其他工具的聊天机器人。
- SQL 查询生成:从自然语言生成 SQL 查询。
- 辅导系统:使用多项选择工具对用户进行测验。
- 医疗保健和房地产 AI 助手。
框架分析
【2024-12-20】五大多智能体 ( Multi-AI Agent) 框架对比
- AutoGen (Microsoft)
- LangGraph (LangChain)
- CrewAI
- OpenAI Swarm (OpenAI)
- Magentic-One (Microsoft)
| 框架 | 时间 | 公司 | 特点 | 优点 | 缺点 | |
|---|---|---|---|---|---|---|
AutoGen |
2023-10-10 | 微软 | 用户智能体(提出编程需求/编写提示词)+助手智能体(生成/执行代码) | 代码任务这类多智能体编排 允许人工指导 微软社区支持 |
需要代码背景 本地LLMs配置繁琐,需要代理服务器 非软件开发领域,表现不够出色 |
|
CrewAI |
初学者首选方案,主要编码提示词 | 界面操作直观,配置方便 智能体创建便利,适合非技术背景用户 与LangChain结合,适合本地LLM |
灵活性不足 复杂编程任务不理想 智能体交互偶尔故障 社区支持不足 |
|||
LangGraph |
LangChain | 基于 LangChain 开发, 核心是有向循环图(DAG) | 灵活可定制 能与开源LLM无缝衔接 LangChain延伸,技术社区较好 |
文档资料不足 需要编程背景,尤其是图/逻辑流程 |
||
Swarm |
OpenAI | 简化智能体创建过程,上下文切换 | 适合新手 | 只支持OpenAI API 不适合生产环境 不够灵活 社区支持较弱 |
||
Magentic |
微软 | AutoGen的简化版,预设5个智能体 | 操作便捷,适合小白 附带AutoGenBench,评估功能 |
开源LLMs支持不佳 不够灵活,更像是应用,非框架 文档社区支持几乎为零 |
||
| 框架 | 技术特点 | 应用场景 | 社区活跃度 | 学习曲线 | 部署难度 |
|---|---|---|---|---|---|
LangGraph |
循环控制、状态管理、人机交互 | 复杂工作流程、多轮对话 | ⭐⭐⭐⭐ | 中等 | 中等 |
AutoGen |
多智能体协作、模块化设计 | 团队协作、复杂任务分解 | ⭐⭐⭐⭐⭐ | 高 | 中等 |
MetaGPT |
角色划分、软件开发流程 | 软件开发、项目管理 | ⭐⭐⭐⭐⭐ | 高 | 困难 |
ChatDev |
开发流程自动化、多角色协作 | 软件开发、团队协作 | ⭐⭐⭐⭐ | 中等 | 中等 |
Swarm |
轻量级、高度可控 | 独立功能开发、原型验证 | ⭐⭐⭐⭐ | 低 | 容易 |
uagents |
去中心化、轻量级 | 分布式应用、物联网 | ⭐⭐⭐ | 低 | 容易 |
原表格
| Framework | Technical Features | Use Cases | Community Activity | Learning Curve | Deployment Difficulty |
|---|---|---|---|---|---|
| LangGraph | Loop control, state management, human-machine interaction | Complex workflows, multi-round dialogues | ⭐⭐⭐⭐ | Medium | Medium |
| AutoGen | Multi-agent collaboration, modular design | Team collaboration, complex task decomposition | ⭐⭐⭐⭐⭐ | High | Medium |
| MetaGPT | Role division, software development process | Software development, project management | ⭐⭐⭐⭐⭐ | High | Difficult |
| ChatDev | Development process automation, multi-role collaboration | Software development, team collaboration | ⭐⭐⭐⭐ | Medium | Medium |
| Swarm | Lightweight, highly controllable | Independent function development, prototype verification | ⭐⭐⭐⭐ | Low | Easy |
| uagents | Decentralized, lightweight | Distributed applications, IoT | ⭐⭐⭐ | Low | Easy |
参考
【2025-1-2】主流Agent框架2024盘点: LangGraph、CrewAI、AutoGen、Dify、MetaGPT、OmAgent深度横评
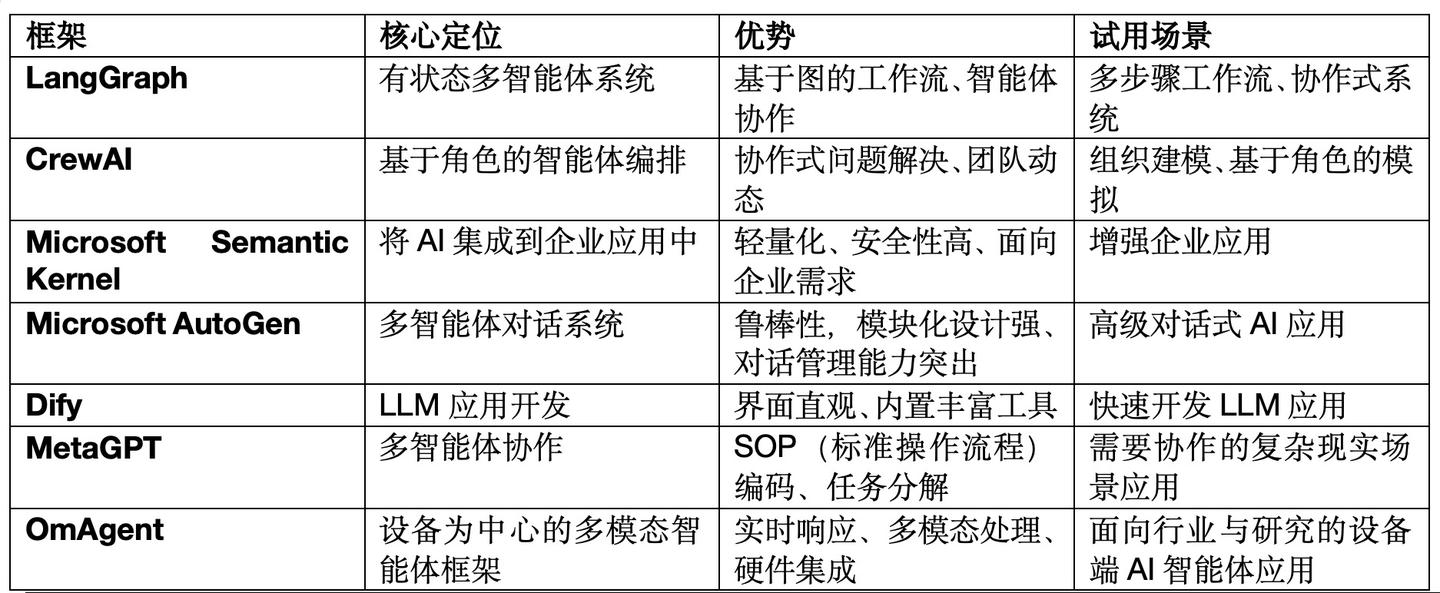
| 框架 | 核心定位 | 优势 | 试用场景 | 不足 |
|---|---|---|---|---|
LangGraph |
有状态多智能体系统 | 基于图的工作流、循环/非循环的多智能体协作、交互可视化 | 多步工作流、自适应、协作式系统 | 依赖专业知识,对多模态、设备支持弱 |
CrewAI |
基于角色的智能体编排 | 动态分配任务、模拟人类协作/角色分工、智能体高效通信 | 组织化建模、协作式模拟、高级AI应用 | 聚焦协作场景,对多模态支持较弱 |
Semantic Kernel |
企业应用集成 | 轻量化SDK、多种编程语言、安全性高、多步骤AI任务管理 | 增强企业应用 | 研究导向、多模态应用不足 |
AutoGen |
多智能体对话系统 | 鲁棒性,强大的模块化设计、对话管理能力突出; 自定义智能体、任务恢复; 多智能体通信、外部工具集成 |
高级对话式AI应用、协作式决策 | 多模态、硬件集成缺乏 |
MetaGPT |
多智能体协作 | SOP(标准操作流程)编码、任务分解 | 需要协作的复杂现实场景应用 | |
OmAgent |
设备为中心的多模态智能体框架 | 实时响应、多模态处理、硬件集成 | 面向行业与研究的设备端AI智能体应用 | |
Dify |
LLM应用开发 | 界面直观、内置丰富工具(50种)、RAG、ReACT | 快速开发LLM应用 | 不支持硬件、设备 |
为什么选择 OmAgent?
- 示例代码支持:提供针对行业从业者和 AI 研究人员的预构建示例代码,支持真实场景应用和最新 AI 算法。
- 领先的多模态能力:原生支持视频理解、视觉问答(VQA)等多模态任务。
- 设备集成:简化 AI 与智能设备的集成,是硬件为中心的 AI 应用的首选框架。
- 创新算法:包含前沿工作流,如 ReAct 和 Divide-and-Conquer 等算法。
- 实时性能:针对实时、低延迟交互进行优化,提供流畅体验。
OmAgent 是 AI 智能体开发领域的一次全新变革,具备卓越的能力,专注于构建以设备为核心的多模态智能体。相比 LangGraph、CrewAI 和 AutoGen 等框架在特定领域的优势,OmAgent 凭借其在硬件集成、多模态支持以及前沿研究上的独特表现,成为最灵活、最全面的选择。
无论是在实际应用中实现落地,还是在学术研究中探索创新,OmAgent 都为开发者和研究人员提供了强大的工具、灵活的架构和持续的创新动力。
OmAgent 开源地址:
- GitHub - om-ai-lab/OmAgent: A Multimodal Language Agent Framework for Problem Solving and More
Agents SDK, Google 的 ADK, LangChain, Crew AI, LlamaIndex, Agno AI, Mastra, Pydantic AI, AutoGen, Temporal, SmolAgents, DSPy
框架选型
选择建议:
- 初学者:从
Swarm或uagents开始,轻量级且易学习。 - 企业应用:
AutoGen或langgraph更合适,提供完整的企业级功能。 - 软件开发:
MetaGPT或ChatDev是理想选择,尤其适用于自动化软件开发流程。 - 原型验证:
Swarm轻量级特性使其非常适合快速验证想法。 - 分布式应用:
uagents去中心化特性使其在这些场景中具有独特优势。
Selection Recommendations:
- Beginners: Start with Swarm or uagents, as these frameworks are lightweight and easy to learn
- Enterprise Applications: AutoGen or langgraph are more suitable, providing complete enterprise-level functionality
- Software Development: MetaGPT or ChatDev are ideal choices, especially suitable for automated software development processes
- Prototype Verification: Swarm’s lightweight nature makes it ideal for quickly validating ideas
- Distributed Applications: uagents’ decentralized nature gives it unique advantages in these scenarios
总结
- 软件开发:
AutoGen(微软) 最适合处理代码生成和复杂 multi-agent 编码工作流任务。 - 初学者:OpenAI
Swarm和CrewAI操作简便,非常适合刚接触 multi-agent AI 且没有复杂配置需求的新手使用。 - 复杂任务首选:
LangGraph—— 极高的灵活性,为高级用户设计,支持自定义逻辑和智能体编排(orchestration)。 - 开源 LLMs 兼容程度:
LangGraph—— 与开源 LLMs 的兼容性极佳,支持多种 API 接口,这是其他一些框架所不具备的。CrewAI在这方面也表现不俗。 - 技术社区:
AutoGen拥有相当不错的技术社区支持,能够帮助用户解决一些难题。 - 即开即用:
CrewAI—— 配置快捷、操作直观,非常适合用于演示或是需要迅速创建智能体的任务。Swarm和Magentic-One表现也相当不错,但社区支持相对较弱。 - 性价比之王:
Magentic-One—— 它提供了一套预配置的解决方案,采用了通用框架的设计方法,可能在初期能够节省成本。Swarm和CrewAI在成本效益方面也值得关注。
Agent 架构设计见站内专题:Agent 设计
决策模型
Agent 主流决策模型是 ReAct框架 和 ReAct变种 框架。
ReAct 框架
ReAct 是调用工具、推理和规划时常用的prompt结构
- 先推理再执行,根据环境来执行具体的action,并给出思考过程Thought。
ReAct = 少样本prompt + Thought + Action + Observation
ReAct 变种
Plan-and-Execute ReAct
类 BabyAgi 执行流程:
- 通过优化规划和任务执行的流程来完成复杂任务的拆解,将复杂的任务拆解成多个子任务,再依次/批量执行。
优点
- 对于解决复杂任务、需要调用多个工具时,也只需要调用三次大模型,而不是每次工具调用都要调大模型。
LLmCompiler
LLmCompiler:并行执行任务,规划时生成一个DAG图来执行action,可以理解成将多个工具聚合成一个工具执行图,用图的方式执行某一个action。
- paper:LLmCompiler
原文链接:https://blog.csdn.net/m0_68116052/article/details/143197176
框架
分析
单智能体=大语言模型(LLM) +观察(obs) +思考(thought) +行动(act) +记忆(mem)多智能体= 多个智能体+环境+SOP+评审+通信+成本
业界各种最新的智能体
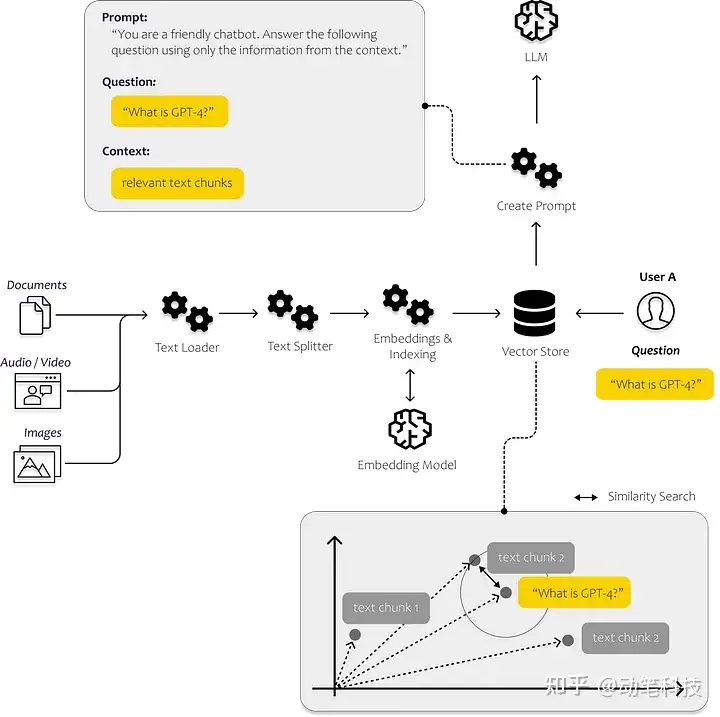
【2023-7-14】构建你的第一个 LLM APP 所需了解的一切
通过上下文注入构建你自己的聊天机器人
智能体分类
- 单智能体: AutoGPT, ChatGPT(code+plugin), Langchain Agent, Transformers Agent
- 多智能体: BabyAGI, CAMEL, Multi-Agent Debate, MetaGPT, AutoGenß
单智能体
Single Agent 框架
- 执行架构优化:论文数据支撑CoT to XoT,从一个thought一步act到一个thought多个act,从链式的思考方式到多维度思考;
- 长期记忆的优化:具备个性化能力的agent,模拟人的回想过程,将长期记忆加入agent中;
- 多模态能力建设:agent能观察到的不仅限于用户输入的问题,可以加入包括触觉、视觉、对周围环境的感知等;
- 自我思考能力:主动提出问题,自我优化;
多智能体
多agent应该像人脑一样,分工明确、又能一起协作
- 比如,大脑有负责视觉、味觉、触觉、行走、平衡,甚至控制四肢行走的区域都不一样。
单一Agent 已经无法满足日益增长的需求。而多Agent让多个AI代理能够协同工作,共同完成复杂的任务
参考 MetaGPT 和 AutoGen 生态最完善的两个Multi-Agent框架:
- 环境&通讯:Agent间的交互,消息传递、共同记忆、执行顺序,分布式agent,OS-agent
- SOP:定义SOP,编排自定义Agent
- 评审:Agent健壮性保证,输入输出结果解析
- 成本:Agent间的资源分配
- Proxy:自定义proxy,可编程、执行大小模型
优点:
- 多视角分析问题:虽然LLM可以扮演很多视角,但会随着system prompt或者前几轮的对话快速坍缩到某个具体的视角上;
- 复杂问题拆解:每个子agent负责解决特定领域的问题,降低对记忆和prompt长度的要求;
- 可操控性强:可以自主的选择需要的视角和人设;
- 开闭原则:通过增加子agent来扩展功能,新增功能无需修改之前的agent;
- (可能)更快的解决问题:解决单agent并发的问题;
缺点:
- 成本和耗时的增加;
- 交互更复杂、定制开发成本高;
- 简单的问题single Agent也能解决;
多智能体能解决的问题:
- 解决复杂问题;
- 生成多角色交互的剧情;
Single-Agent
总结
Single-Agent 主流框架
- BabyAGI
- AutoGPT
- HuggingGPT
- GPT-Engineer
- Samantha
- AppAgent
- OS-Copilot
- Langgraph
BabyAGI
【2023-4】 BabyAGI
- git:GitHub - yoheinakajima/babyagi
- doc:doc
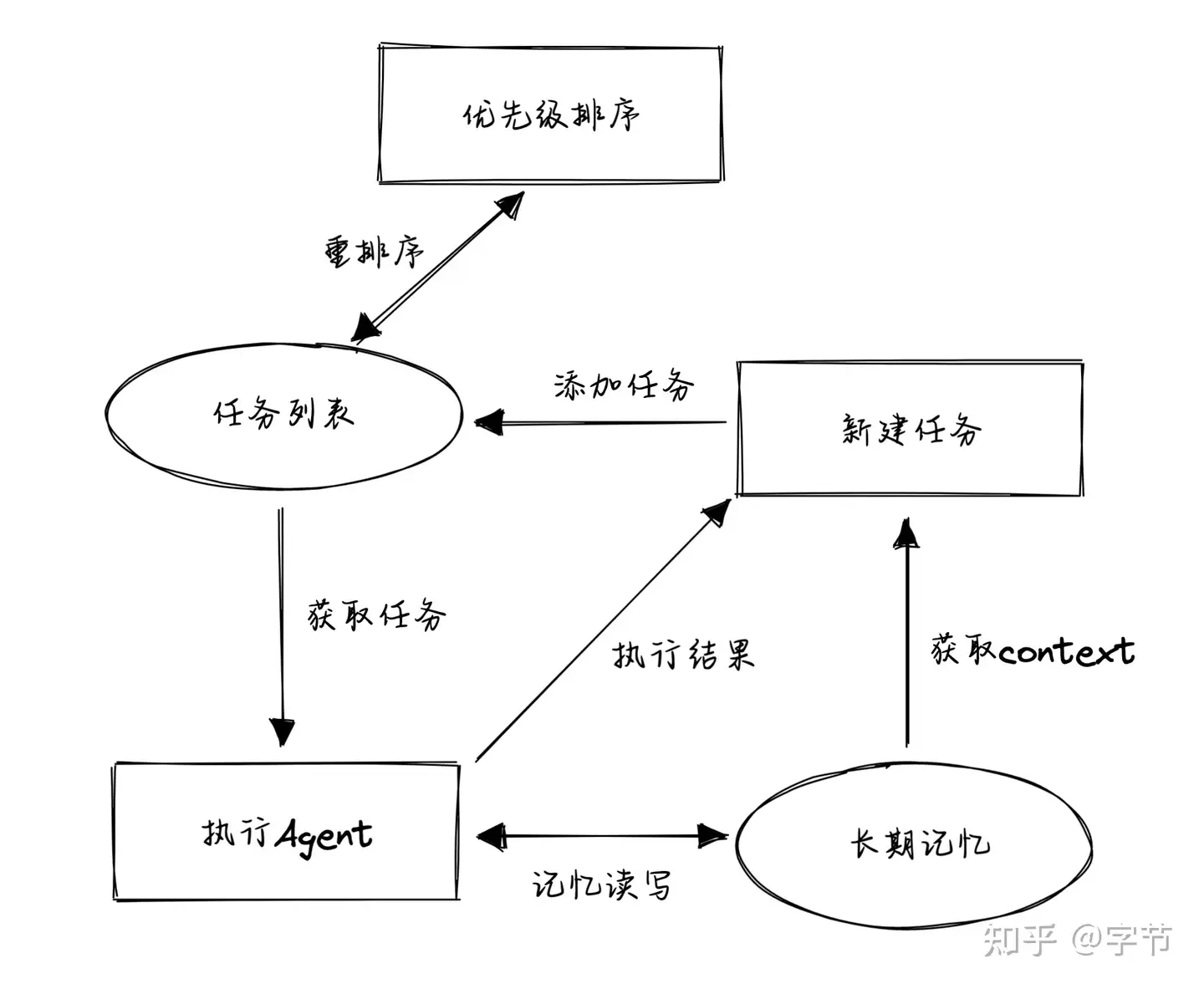
babyAGI 决策流程:
- 1)根据需求分解任务;
- 2)对任务排列优先级;
- 3)执行任务并整合结果;
亮点:
- BabyAGI 框架比较简单使用
- 任务优先级队列比较独特
相对于 AutoGPT ,BabyAGI 更聚焦在“思维流程”方面尝试的项目,并没有添加对各种外部工具利用的支持。
BabyAGI 原理
其核心逻辑:
- 从任务列表中获取排在第一位的任务。
- 获取任务相关的“记忆”信息,由任务执行 agent 来执行这个任务,获取结果。目前这个执行就是一个简单的 LLM 调用,不涉及外部工具。
- 将返回结果再存放到记忆存储中。基于当前信息,如整体目标,最近一次执行结果,任务描述,还未执行的任务列表等,生成新任务。
- 将新任务添加到任务列表中,再判断所有任务的优先级,重新排序。

这个过程就是在模拟作者一天真实的工作流程。
- 早上起来看下有哪些任务要做,白天做任务拿反馈,晚上再看下基于反馈有没有新的任务要加进来,然后重新排下优先级。
整个项目的代码量很少,相关的 prompts 也比较简单易懂
BabyAGI 进化
进化版本
- BabyASI 借鉴了 AutoGPT 添加了对 search,代码执行等工具的支持。理论上,如果这个 ASI(Artificial Super Intelligence)真的足够聪明,甚至可以产生代码给自己做 prompt 优化,流程改造,甚至持续的模型训练等,让 GPT 自己开发未来的 GPT,想想是不是很带感 。
AutoGPT
AutoGPT
- git:AutoGPT
AutoGPT 定位类似个人助理,帮助用户完成指定的任务,如调研某个课题。AutoGPT比较强调对外部工具的使用,如搜索引擎、页面浏览等。
作为早期agent,autoGPT麻雀虽小五脏俱全,虽然也有很多缺点,比如无法控制迭代次数、工具有限。
但是后续的模仿者非常多,基于此演变出了非常多的框架。
HuggingGPT
HuggingGPT
HuggingGPT 任务分为四个部分:
- 任务规划:将任务规划成不同的步骤,这一步比较容易理解。
- 模型选择:在一个任务中,可能需要调用不同的模型来完成。例如,在写作任务中,首先写一句话,然后希望模型能够帮助补充文本,接着希望生成一个图片。这涉及到调用到不同的模型。
- 执行任务:根据任务的不同选择不同的模型进行执行。
- 响应汇总和反馈:将执行的结果反馈给用户。
HuggingGPT的亮点:
- HuggingGPT与AutoGPT的不同之处在于,可调用HuggingFace上不同的模型来完成更复杂的任务,从而提高了每个任务的精确度和准确率。
- 然而,总体成本并没有降低太多。
【2023-4-3】HuggingGPT
简介
【2023-4-3】HuggingGPT:一个ChatGPT控制所有AI模型,自动帮人完成AI任务,浙大与微软亚研院的合作成果.
- paper
- 项目已开源,名叫「贾维斯」,钢铁侠里的AI管家贾维斯(JARVIS)。
- 和3月份刚发布的Visual ChatGPT的思想非常像:后者HuggingGPT,主要是可调用的模型范围扩展到了更多,包括数量和类型。
原理
如果说 BabyAGI 更多的是探索了 plan & execution 这个应用 LLM 的模式,那么 HuggingGPT 相对早一些的工作更多地展示了在“外部工具”这个层面的想象空间。
核心运作逻辑也是计划加上执行,只不过在执行工具层面,可利用丰富的“领域专业模型”来协助 LLM 更好地完成复杂任务

语言是通用的接口。
工程流程分为四步:
- 首先,任务规划。ChatGPT将用户的需求解析为任务列表,并确定任务之间的执行顺序和资源依赖关系。
- 其次,模型选择。ChatGPT根据HuggingFace上托管的各专家模型的描述,为任务分配合适的模型。
- 接着,任务执行。混合端点(包括本地推理和HuggingFace推理)上被选定的专家模型根据任务顺序和依赖关系执行分配的任务,并将执行信息和结果给到ChatGPT。
- 最后,输出结果。由ChatGPT总结各模型的执行过程日志和推理结果,给出最终的输出。
请求:
请生成一个女孩正在看书的图片,她的姿势与example.jpg中的男孩相同。然后请用你的声音描述新图片。
可以看到HuggingGPT是如何将它拆解为6个子任务,并分别选定模型执行得到最终结果的。
用gpt-3.5-turbo和text-davinci-003这俩可以通过OpenAI API公开访问的变体,进行了实测。如下图所示:
- 在任务之间存在资源依赖关系的情况下,HuggingGPT可以根据用户的抽象请求正确解析出具体任务,完成图片转换。
在音频和视频任务中,它也展现了组织模型之间合作的能力,通过分别并行和串行执行两个模型的方式,完了一段“宇航员在太空行走”的视频和配音作品。
还可以集成多个用户的输入资源执行简单的推理,比如在以下三张图片中,数出其中有多少匹斑马。
Langchain 生态
GPT-Engineer
GPT-Engineer
- git: GPT-Engineer
基于 langchain 开发,单一工程师 agent,解决编码场景的问题。
目的是创建一个完整的代码仓库,在需要时要求用户额外输入补充信息。
亮点:code-copilot 自动化升级版
LangGraph
弥补了传统 LangChain 在动态流程控制(如循环、分支)上的不足,支持更灵活的 Agent 协作与状态管理:通过有向图(Graph) 组织工作流,将任务拆分为 节点(Nodes) 和 边(Edges),实现非线性的执行逻辑(如循环、条件分支),更贴近真实业务场景。
Langgraph
- doc:Langgraph
- LangGraph Studio
- LangGraph + DeepSeek 实现案例
langchain 组件,允许开发者通过图的方式重构单个agent内部的执行流程,增加一些灵活性,并且可与langSmith等工具结合。
核心定位:有状态多智能体系统。
特点:
- 基于图的工作流,用于复杂操作。
- 支持具有循环和非循环流程的多智能体协作。
- 提供任务与智能体交互的可视化表示。
- 适用场景:多步骤工作流、自适应 AI 应用、协作式问题解决。
- 局限性:需要专业知识,对多模态或设备为中心的使用场景没有本质优化。
安装
pip install "langgraph"
# 安装 langgraph studio
pip install "langgraph-cli[inmem]"
【2023-3-30】AutoGPT
【2023-4-12】
AutoGPT 介绍
AutoGPT 的研究开始走进大众视野。
- 2023年3月30日,Toran Bruce Richards 发行
AutoGPT,实验性开源应用程序,利用 OpenAI 的GPT-4语言模型来创建完全自主和可定制的 AI 代理 - Toran 是一名游戏开发商,并创立了一家名为 Significant Gravitas 的游戏公司
- AutoGPT 相当于给基于 GPT 的模型一个内存和一个身体。
- 可以把一项任务交给 AI 智能体,自主地提出一个计划,然后执行计划。
- 此外其还具有互联网访问、长期和短期内存管理、用于文本生成的 GPT-4 实例以及使用 GPT-3.5 进行文件存储和生成摘要等功能。
- AutoGPT 从根本上改变了 AI 与人类之间的交互方式,人类不再需要发挥积极作用,同时仍然保持与 ChatGPT 等其他 AI 应用程序相同或更好的结果质量。
AutoGPT 用处很多,可用来分析市场并提出交易策略、提供客户服务、进行营销等其他需要持续更新的任务。
AutoGPT 工作原理
AutoGPT 如何工作?
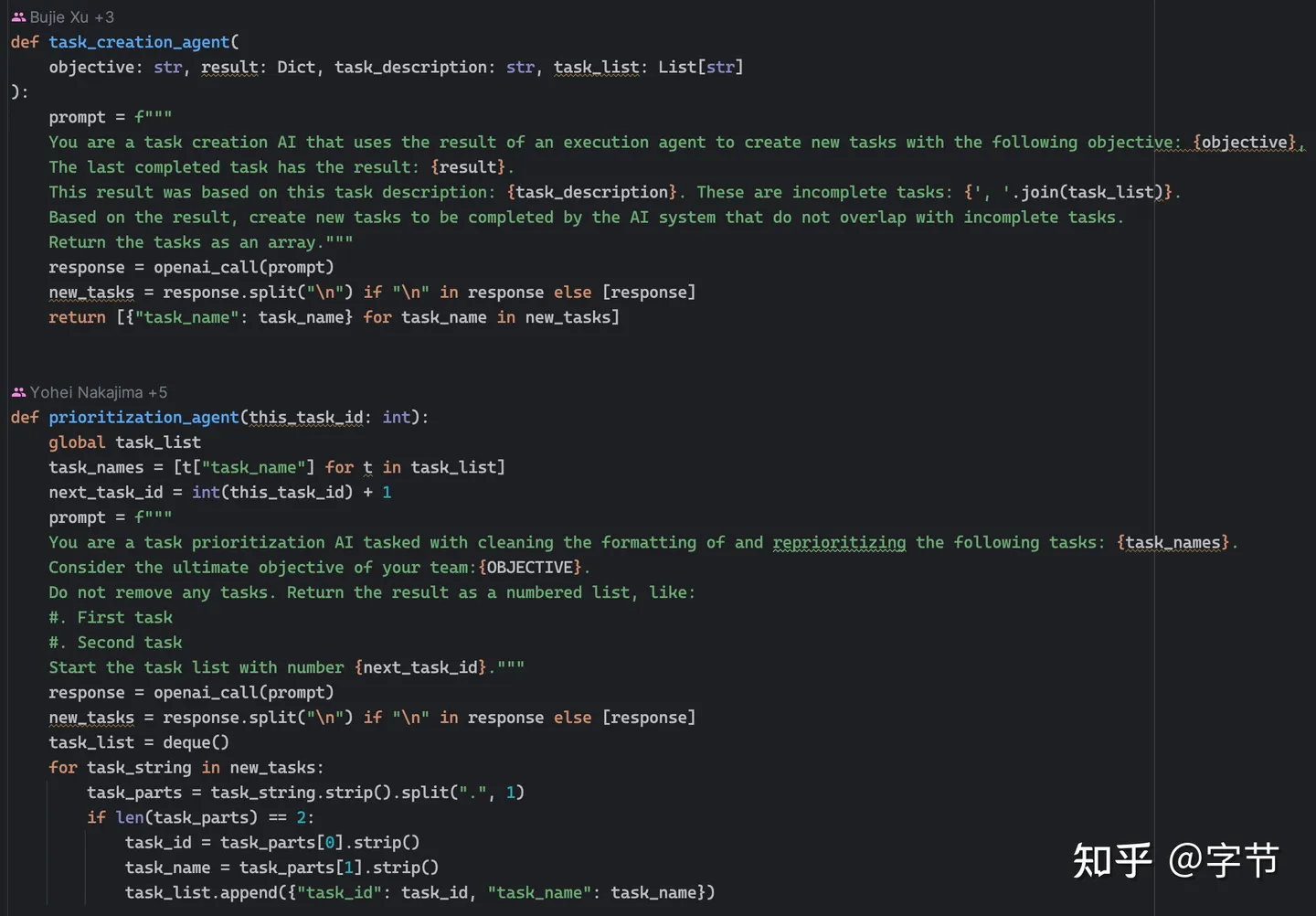
AutoGPT 基于自主 AI 机制工作,其中 AI 系统创建不同的 AI 代理来满足特定任务,其中包括:
- 任务创建代理: 在 AutoGPT 上输入目标时,第一个与任务创建代理交互的 AI 代理。根据目标创建一个任务列表以及实现这些目标的步骤,并将其发送给优先级代理。
- 任务优先级代理: 收到任务列表后,优先级 AI 代理会确保顺序正确且符合逻辑,然后再将其发送给执行代理。
- 任务执行代理: 完成优先级排序后,执行代理将一个接一个地完成任务。这涉及利用 GPT-4、互联网和其他资源来获得结果。
当执行代理完成所有任务,结果不理想时,它可以与任务创建代理通信,创建新的任务列表。三个代理之间的迭代循环,直到完成所有用户定义的目标。
AI 代理的行为也显示在用户界面上,将它们分为四组:思想、推理、计划、评判。
思想(THOUGHTS) :AI 代理分享它对目标的想法。推理(REASONING) :AI 代理推理如何开展并实现它的想法。计划(PLAN) :AI代理通过分析,列举了所要完成任务的计划。评判(CRITICISM) :AI进行自我评判,纠正错误并克服任何限制问题。
通过共享此计算流程,AutoGPT 可以进行反复尝试论证,并进行针对性的优化处理,可以在没有任何用户干预的情况下克服所遇到的所有问题。
模块图, 源自 AGI-MAP

特斯拉前 AI 总监、刚刚回归 OpenAI 的 Andrej Karpathy 也为其大力宣传,并在推特赞扬:「AutoGPT 是 prompt 工程的下一个前沿。」
AutoGPT 局限性
一些关键限制
- 成本高昂
- 虽然功能令人惊叹,但 AutoGPT 的实用性可能会让你失望。由于
AutoGPT使用昂贵的GPT-4模型,因此即使是小任务,完成每个任务的成本也可能很高。这主要是因为 AutoGPT 在特定任务的步骤中会多次使用GPT-4。
- 虽然功能令人惊叹,但 AutoGPT 的实用性可能会让你失望。由于
- 经常陷入循环
- 用户在使用 AutoGPT 时面临的最常见问题是它陷入循环。如果这种情况持续超过几分钟,则可能意味着你必须重新启动该过程。发生这种情况是因为 AutoGPT 依赖 GPT-4 来正确定义和分解任务。因此,如果底层LLM返回结果不足以让 AutoGPT 采取任何行动就会出现反复尝试的问题。
- 数据安全性
- 由于AutoGPT经过充分授权,能自主运行并访问你的系统和互联网,例如使用twitter账号,登录github,使用搜索引擎等,因此你的数据可能会被泄露。
- AutoGPT没有安全代理,所以使用 AutoGPT 时必须小心,如果没有给出正确的说明和安全指南,你不能让模型继续运行。
使用
AutoGPT配置
- 为AI取一个名字 [Name],一个角色定位[Role],同时你可以为它制定目标[Goals](最多5个目标,如果你仅有一个目标就直接回车)。
- 制定完成目标以后,AutoGPT会进行自主思考并分析你的目标[THOUGHTS],思考完成后开始理解并推理如何去完成这个目标[REASONING],然后开始自主拆解成具体的计划[PLAN],最后会提出评判[CRITICISM] 用以保证 AI 代理纠正错误并作出正确的决断。
- 完成以上的行为规划后,AutoGPT会提示它将要作出的指令和动作[NEXT ACTION], 里面包含具体执行的命令[COMMAND]和参数[ARGUMENTS],用户可以在此时可以对风险命令进行识别,避免出现数据泄露等预期外的风险,这里可以通过y或者n进行授权或者拒绝AutoGPT接下来的指令动作。
- AutoGPT会通过以上步骤,进行多次循环,由于AutoGPT可以存储上下文和历史经验,所以每一次都会根据反馈结果进行更深入的思考,制定出更优的方案,最后列举他要执行的计划,反复尝试和补充,直到达到你预期的目标。
- AutoGPT会通过以上步骤,进行多次循环,由于AutoGPT可以存储上下文和历史经验,所以每一次都会根据反馈结果进行更深入的思考,制定出更优的方案,最后列举他要执行的计划,反复尝试和补充,直到达到你预期的目标。
效果
实践
# 准备Python 3.8以上的环境, 安装minicoda
# source ~/.bash_profile
conda create -n py310 python=3.10 # 创建 3.10环境
conda activate py310 # 激活环境
# 下载autogpt代码
git clone https://github.com/Torantulino/Auto-GPT.git
cd 'Auto-GPT'
pip install -r requirements.txt
# 配置文件
mv .env.template .env
vim .env # 填入 openai key 到变量 OPENAI_API_KEY
# python scripts/main.py
# python scripts/main.py --debug # 调试模式
# python scripts/main.py --speak # use TTS for Auto-GPT
python3 scripts/main.py # 多个虚拟环境时,为了避免干扰
python -m autogpt
【2023-7-7】
- 复制 默认的 env文件,只更新里面的openai_api_key
cp .env.template .env
命令,详见指南
./run.sh --help # on Linux / macOS
./run.sh --debug # 打印日志
# Run Auto-GPT with a different AI Settings file shell
./run.sh --ai-settings <filename>
# Run Auto-GPT with a different Prompt Settings file shell
./run.sh --prompt-settings <filename>
# Specify a memory backend
./run.sh --use-memory <memory-backend>
./run.sh --speak # 启动tts 语音播报
./run.sh --continuous # 100% 自动化,无需手动确认,有一定风险
./run.sh --gpt3only # 只用 gpt3
./run.sh --gpt4only # 只用 gpt4 ,更贵
AutoGPT 改进
COA
【2023-5-18】从 COT 到 COA
COT(Chain of Thought,思维链)COA(Chain of Action,行为链): AutoGPT为代表,将自然语言表达的目标分解 为子任务,并利用互联网和其他工具自动迭代地尝试实现这些目标。
特点
- 自主化决策,任务链自动化
- 知行一体,参数外挂,泛化学习,
- 动态适应和灵活反应
- AI从模拟人类思维到模拟人类行为, 人主要负责设定目标、审批预算、 调整关键行动链
优点
- •自主任务分解
- •上下文适应性
- •泛化多功能优化
- •智能响应
- •协同学习
- •动态知识整合
缺点
- 语义鸿沟
- 依赖风险
- 计算成本过高
- 透明度缺失
CoVe
【2023-9-20】META AI提出CoVe
一种CoVe(链式验证)的方式来减少大模型的幻觉
该论文研究了大语言模型在解决‘幻觉’问题上的能力,提出了一种链式验证(CoVe)方法,通过该方法模型首先起草初始回答,然后计划验证问题来核实起草结果,独立回答这些问题以避免受到其他回答的影响,最终生成验证后的回答。实验证明CoVe方法降低了在各种任务中出现的幻觉,包括基于Wikidata的列表问题,闭书型MultiSpanQA和长文本生成等。
按照这种Prompt模板
- Generate baseline response
- Generate a verification plan (set of questions)
- Execute plan (answer questions)
- Generate Final Verified Response (using answers)
AgentGPT
AgentGPT:浏览器中直接部署自主 AI 智能体
近日,又有开发者对 AutoGPT 展开了新的探索尝试,创建了一个可以在浏览器中组装、配置和部署自主 AI 智能体的项目 ——AgentGPT。项目主要贡献者之一为亚马逊软件工程师 Asim Shrestha
AgentGPT 允许自定义 AI 命名,执行任何想要达成的目标。自定义 AI 会思考要完成的任务、执行任务并从结果中学习,试图达成目标。
- 如下为 demo 示例:HustleGPT,设置目标为创立一个只有 100 美元资金的初创公司。
用户在使用该工具时,同样需要输入自己的 OpenAI API 密钥。AgentGPT 目前处于 beta 阶段,并正致力于长期记忆、网页浏览、网站与用户之间的交互。
git clone https://github.com/reworkd/AgentGPT.git
cd AgentGPT
./setup.sh
【2023-4-15】免费的AutoGPT替代网站
- 第一个是最火的AutoGPT,性能最强的,但是安装起来也挺麻烦的,并且还需要各种API的权限,小白不建议。
- 第二个AgentGPT,需要OpenAI的API,操作简单,在网页输入key就可以用。
- 第三个和第四个暂时是免费的,想体验的可以赶紧了。
| 名称 | 方案 | 特点 | 链接 |
|---|---|---|---|
| AutoGPT | 最复杂 | 需要安装开源代码 | |
| AgentGPT | 需要Token | 通过简单的网页访问易于使用,具有相对简单的功能 | |
| Cognosys | 不需要Token | 性能不错,具有明确的任务组织 | |
| Godmode | 不需要Token | 操作更加直观,每个步骤需要用户权限 |
Generative Agents
将多个 agent 组成一个团队,分别扮演不同的角色,是否能更好地解决一些复杂问题,甚至让这个小的“社群”演化出一些更复杂的行为模式甚至新知识的发现
Generative Agents 将 25 个拥有身份设定的模型 agent 组成了一个虚拟小镇社群,每个 agent 都具有记忆系统,并通过做计划,行动应答,自我反思等机制来让他们自由活动,真正来模拟一个社群的运作。从模拟过程来看这个社群也“涌现”了不少真实社会中的现象。
几个 agent 行为的设定值得学习:
- 每个 agent 的记忆获取做得更加细致,会结合时效性,重要度和相关度来做相关记忆的召回。相比简单的向量相似度搜索来说效果会好很多。
- 记忆存储方面也添加了 reflection 步骤,定期对记忆进行反思总结,保持 agent 的“目标感”。
- 在 plan 生成方面也做了多层级递归,由粗到细生成接下来的行动计划,跟我们的日常思考模式也更接近。
- 通过“人物采访”的方式来评估这些行为设定的效果,消融实验中都能发现明显的提升。
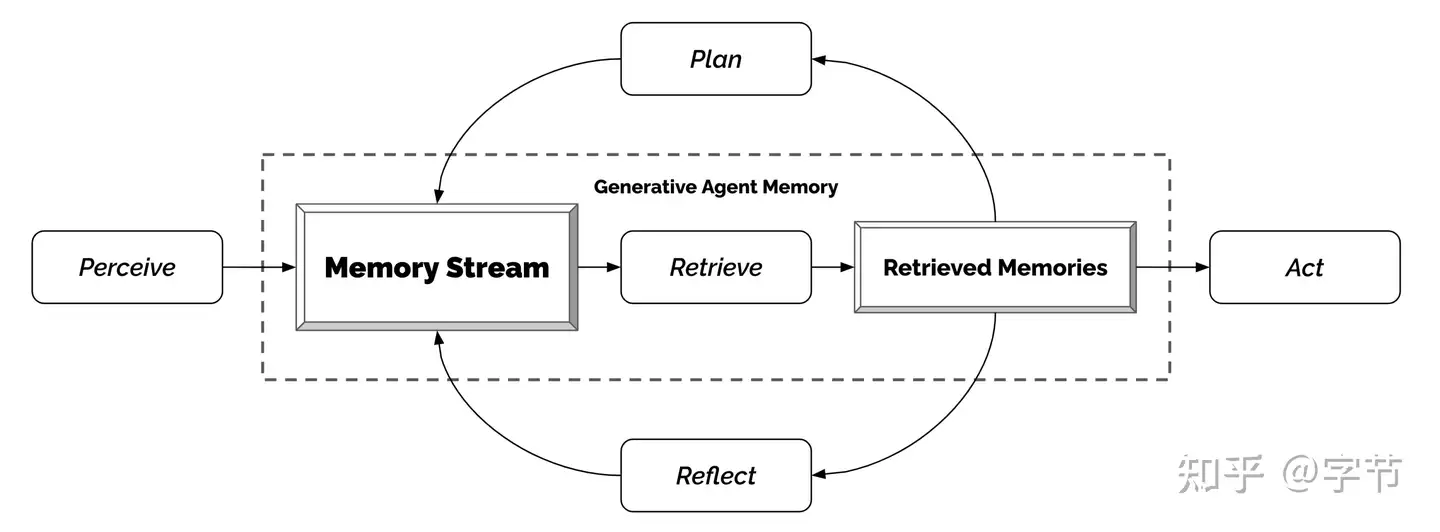
一整套 identity,plan, act/react,reflect,memory stream 逻辑挺合理的,与 AutoGPT 的做法可以进行一些互补。当然局限性应该也有不少,比如
- 模拟过程中 agent 之间都是一对一的谈话,而没有会议/广播这种设定。
- 目前模拟运行的时长也有限,比较难确保长时间的运行下 agent 的记忆、行为模式的演化,社群整体目标的探索与推进等方面的效果。
从应用角度来看,目前好像也主要集中在社会活动模拟,游戏应用等。是否能拓展到任务处理,知识探索等更广阔的领域,还有待进一步探索。
Adept
Adept 和 Inflection 这两家早期团队想以自然语言为基础,为用户打造新的 LUI (语言为基础的 UI)方式。
Inflection
待定
【2023-5-4】GPT4Free
【2023-5-4】GPT4Free (discord地址) 通过You.com、Quora和CoCalc等网站(OpenAI付费用户)提供的各种API地址,免费使用GPT-4和GPT-3.5模型。
- GPT4Free 脚本会先访问 https://you.com/api/streamingSearch,并传送各种参数过去,然后获取返回的JSON并对其进行格式化。
- GPT4Free仓库还有从Quora、Forefront和TheB等其他网站获取数据的脚本,任何开发者都可以基于这些脚本制作自己的聊天机器人。
实测:
- 安装
- 要求 Python 3.8以上
- 修改 requirements.txt 文件
- The requirements.txt need to be updated
# pypasser # 原始
pypasser>=0.0.5 # 指定版本,否则 pip install -r requirements.txt 提示冲突
UI部署正常,但点击“Think”后,出现新的错误:
- Please make sure you are using a valid cloudflare clearance token and user agent.
安装
pip install gpt4free
程序调用
import gpt4free
from gpt4free import Provider, quora, forefront
# usage You
response = gpt4free.Completion.create(Provider.You, prompt='Write a poem on Lionel Messi')
print(response)
# usage Poe
token = quora.Account.create(logging=False)
response = gpt4free.Completion.create(Provider.Poe, prompt='Write a poem on Lionel Messi', token=token, model='ChatGPT')
print(response)
# usage forefront
token = forefront.Account.create(logging=False)
response = gpt4free.Completion.create(
Provider.ForeFront, prompt='Write a poem on Lionel Messi', model='gpt-4', token=token
)
print(response)
print(f'END')
# usage theb
response = gpt4free.Completion.create(Provider.Theb, prompt='Write a poem on Lionel Messi')
print(response)
# usage cocalc
response = gpt4free.Completion.create(Provider.CoCalc, prompt='Write a poem on Lionel Messi', cookie_input='')
print(response)
错误信息
tls_client.exceptions.TLSClientExeption: failed to do request: Get “https://you.com/api/streamingSearch?q=Write+a+poem+on+Lionel+Messi&page=1&count=10&safeSearch=Moderate&onShoppingPage=False&mkt=&responseFilter=WebPages%2CTranslations%2CTimeZone%2CComputation%2CRelatedSearches&domain=youchat&queryTraceId=77ebaf4c-ba0c-4035-bad6-1dafc27fdc14&chat=%5B%5D”: dial tcp 192.133.77.59:443: i/o timeout (Client.Timeout exceeded while awaiting headers)
【2023-7-5】MetaGPT
核心定位:多智能体协作。
主要特点:
- 将标准操作流程(SOP)编码为协作提示。
- 为智能体分配专业化角色,优化任务分解效率。
适用场景:复杂任务分解、多智能体系统的现实场景应用。
局限性:专注于程序化知识编码,对多模态或设备特定任务的支持较少。
【2023-7-5】MetaGPT
- git:MetaGPT
- doc:doc
- MetaGPT: Multi-Agent Meta Programming Framework 多智能体编程框架
- MetaGPT takes a one line requirement as input and outputs user stories / competitive analysis / requirements / data structures / APIs / documents, etc.
- Internally, MetaGPT includes product managers / architects / project managers / engineers. It provides the entire process of a software company along with carefully orchestrated SOPs.
- Code = SOP(Team) is the core philosophy. We materialize SOP and apply it to teams composed of LLMs.

metaGPT 国内开源 Multi-Agent 框架,目前整体社区活跃度较高和也不断有新feature出来,中文文档支持的很好。
metaGPT 以软件公司方式组成,目的是完成一个软件需求,输入一句话的老板需求,输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等。
MetaGPT 内部包括产品经理 / 架构师 / 项目经理 / 工程师,它提供了一个软件公司的全过程与精心调配的SOP。
整体代码精简,主要包括:
- actions:智能体行为
- documents: 智能体输出文档
- learn:智能体学习新技能
- memory:智能体记忆
- prompts:提示词
- providers:第三方服务
- utils:工具函数等
【2023-8-9】OlaGPT
【2023-8-9】首个模拟人类认知的思维框架OlaGPT:推理能力最高提升85%
模型在对话上的表现实在是太像人类了,以至于产生了语言模型具有「思维能力」的错觉。基于高概率语言模式的再现与期望中的「通用人工智能」还有很大差距。
- 某些情况下生成内容毫无意义,或者偏离了人类的价值偏好,甚至会给出一些非常危险的建议,目前的解决方案是引入人类反馈的强化学习(RLHF)对模型输出进行排序。
- 语言模型的知识仅限于在训练数据中明确提到的概念和事实。
面对复杂问题时,语言模型也无法像人类一样适应变化的环境、利用现有的知识或工具、反思历史教训、分解问题,以及使用人类在长期进化中总结出的思维模式(如类比、归纳推理和演绎推理等)来解决问题。
当前大多数研究中,大模型主要是在特定提示的引导下生成思维链来执行推理任务,没有考虑人类认知框架,使得语言模型解决复杂推理问题的能力与人类之间仍然存在着显着的差距。
让语言模型模拟人脑处理问题的过程还有许多系统难题:
- 如何系统地模仿和编码人类认知框架中的主要模块,同时以可实现的方式根据人类的通用推理模式进行调度?
- 如何引导语言模型像人类一样进行主动学习,即从历史错误或专家对困难问题的解决方案中学习和发展?虽然重新训练模型对纠正后的答案进行编码可能是可行的,但显然成本很高而且不灵活。
- 如何让语言模型灵活地利用人类进化出的各种思维模式,从而提高其推理性能?
一个固定的、通用的思维模式很难适应不同问题,就像人类在面对不同类型的问题时,通常会灵活地选择不同的思维方式,如类比推理、演绎推理等。
人类在面对复杂的推理难题时,通常会使用各种认知能力,并且需要与工具、知识和外部环境信息的各个方面进行交互,那语言模型能不能模拟人类的思维流程来解决复杂问题呢?
OlaGPT 包括多个认知模块,包括注意力、记忆、推理、学习,以及相应的调度和决策机制;受人类主动学习启发,框架中还包括一个学习单元来记录之前的错误和专家意见,并动态参考来提升解决类似问题的能力。
OlaGPT借鉴了认知架构(cognitive architecture)理论,把认知框架的核心能力建模为注意力(attention)、记忆(memory)、学习(learning)、推理(reasoning)、行动选择(action selction)。
提出一个适合语言模型解决复杂问题的流程,具体包括六个模块:意图增强模块(注意力)、记忆模块(记忆)、主动学习模块(学习)、推理模块(推理)、控制器模块(行动选择)和投票模块。
人类解决问题的常见有效推理框架,并设计了思维链(CoT)模板;还提出了一个全面的决策机制,可以最大限度地提高模型的准确性。
意图增强(Intention Enhance)
注意力是人类认知的一个重要组成部分,识别出相关的信息并过滤掉不相关的数据。
同样地,研究人员为语言模型设计了相应的注意力模块,即意图增强,旨在提取最相关的信息,并在用户输入和模型的语言模式之间建立更强的关联,可以被看作是一个从用户表达习惯到模型表达习惯的优化转换器。
首先通过特定的提示词提前获得LLMs的问题类型,然后重构提问的方式。
比如在问题的开头加上一句「Now give you the XX(问题类型),question and choices:」;为了便于分析,提示中还需要加入「The answer must end with JSON format: Answer: one of options[A,B,C,D,E].」
记忆(Memory)
记忆模块在存储各种知识库信息方面起着至关重要的作用,已经有研究证明了当下语言模型在理解最新事实数据方面的局限性,而记忆模块着重于巩固模型尚未内化的知识,并将其作为长期记忆储存在外部库中。
研究人员使用langchain提供的记忆功能进行短期记忆,长期记忆则由基于Faiss的矢量数据库实现。
在查询过程中,其检索功能可以从库中提取相关知识,涵盖了四种类型的记忆库:事实、工具、笔记和思维(thinking),其中事实是现实世界的信息,如常识等;工具包括搜索引擎、计算器和维基百科,可以协助语言模型完成一些无需为条的工作;笔记主要记录一些疑难案例和解决问题的步骤;思考库主要存储由专家编写的人类解决问题的思考模板,专家可以是人类,也可以是模型。
学习(Learning)
学习的能力对于人类不断提升自我表现来说至关重要,从本质上讲,所有形式的学习都依赖于经验,语言模型可以从之前的错误中学习,从而实现快速提高推理能力。
首先,研究人员找出语言模型无法解决的问题;然后在笔记库中记录专家提供的见解和解释;最后选择相关的笔记来促进语言模型的学习,从而可以更有效地处理类似问题。
推理(Reasoning)
推理模块的目的是创建基于人类推理过程的多个智能体,从而激发语言模型的潜在思维能力,进而解决推理问题。
该模块结合了多种思维模板,参考特定的思维类型,如横向思维、顺序思维、批判性思维和整合性思维,以促进推理任务。
控制器(Controller)
控制器模块主要用来处理相关的行动选择,具体包括模型的内部规划任务(如选择某些模块来执行)以及从事实、工具、笔记和思维库中选择。
首先检索和匹配相关的库,检索到的内容随后被整合到一个模板智能体中,要求语言模型以异步的方式在一个模板下提供回复,就像人类在推理之初可能难以识别所有的相关信息一样,同样很难期望语言模型一开始就做到这一点。
因此,动态检索是根据用户的问题和中间的推理进度来实现的,使用Faiss方法为上述四个库创建嵌入索引,其中各个库的检索策略略有不同。
投票(voting)
由于不同的思维模板可能更适合不同类型的问题,研究人员设计了投票模块来提升多个思维模板之间的集成校准能力,并多种投票策略来生成最佳答案以提高性能。
具体的投票方法包括:
- 语言模型投票:引导语言模型在多个给定的选项中选择最一致的答案,并提供一个理由。
- regex投票:用正则表达式精确匹配抽取答案以获取投票结果。
在多个推理数据集上进行了严格评估后得到的实验结果表明,OlaGPT超越了此前最先进的基准,证明了其有效性。
- SC(self-consistency)的性能优于GPT-3.5-turbo,表明在一定程度上采用集成方法确实有助于提高大规模模型的有效性。
- 文中提出方法的性能超过了SC,在一定程度上证明了思维模板策略的有效性。
- 不同思维模板的答案表现出相当大的差异,在不同的思维模板下进行投票,最终会比简单地进行多轮投票产生更好的结果。
- 不同思维模板的效果是不同的,循序渐进的解决方案可能更适合推理型问题。
- 主动学习模块的性能明显优于零样本方法。
- 具体来说,随机、检索和组合列表现出更高的性能,即将具有挑战性的案例作为笔记库纳入其中是一种可行的策略。
- 不同的检索方案在不同的数据集上有不同的效果,总的来说,组合(combine)策略的效果更好。
- 文中方法明显优于其他方案,这得益于整体框架的合理设计,包括主动学习模块的有效设计;思维模板实现了对不同模型的适应,不同思维模板下的结果是不同的;控制器模块起到了很好的控制作用,选择了与所需内容比较匹配的内容;投票模块设计的不同思维模板的集成方式是有效的。
SuperAGI
SuperAGI - A dev-first open source autonomous AI agent framework. Enabling developers to build, manage & run useful autonomous agents quickly and reliably.
【2023-10-17】XAgent
【2023-10-17】全面超越AutoGPT,面壁智能联合清华 NLP实验室打造大模型“超级英雄”—— XAgent
国内领先的人工智能大模型公司 面壁智能 又放大招,联合 清华大学 NLP 实验室 共同研发并推出 大模型 “超级英雄”——XAgent。 通过任务测试,XAgent在真实复杂任务的处理能力已 全面超越 AutoGPT。
GitHub 正式开源:
XAgent 是一个可以实现自主解决复杂任务的全新 AI 智能体,以 LLM 为核心,能够理解人类指令、制定复杂计划并自主采取行动。
- 传统智能体通常受到人类定制规则的限制,只能在限定范围内解决问题。更像是为人类所用的“工具”,而不是真正的“自主智能体”,难以自主解决复杂问题。
- XAgent 被赋予了 自主规划和决策 的能力,使它能够独立运行,发现新的策略和解决方案,不受人类预设的束缚。
(1) “左右脑”协同,双循环机制
- 正如人类具备“左脑”和“右脑”,在处理复杂任务时通常从“宏观”和“微观”两个视角进行考虑,既要针对全局进行统筹和规划,也要从执行层面来考量。
面壁智能和清华大学在 XAgent 的设计中创新地引入了一种 “双循环机制”:
- 外循环:负责全局任务规划,将复杂任务分解为可操作的简单任务。
- 内循环:负责局部任务执行,专注于细节。
(2) 人机协作:智能体交互新范式
- 虽然 AutoGPT 在一定程度上突破了传统 GPT 模型的局限性,但它仍然存在死循环、错误调用等执行出错的现象,需要人工干预才能解决。
- 而 XAgent 在设计之初就针对相关问题进行了考量,并引入了专为增强人机协作的交互机制:它可以自主与用户进行交互,并向人类发出干预和指导的请求。
对于一个智能体而言,“是否能够与人类协作” 也是体现其智能程度的重要指标。
- 首先,XAgent 具备 直观的界面,用户可以直接覆盖或修改它提出的建议,从而将AI效率与人类的直觉和专业知识有效结合。
- 其次,在面临陌生挑战的情况下,XAgent 具备“向人类寻求帮助”能力,它会向用户征求实时反馈、建议或指导,确保即使在不确定的领域,智能体也能发挥出最佳作用。
(3) 高效通信语言,超强工具调用
无论“双循环”的运转机制,还是“人机协作”的交互能力,在 XAgent 的总体设计中,面壁智能和清华团队着重考虑的是智能体的稳定、高效和安全等核心特性。 而 结构化的通信方式 同样是建立强大、稳定智能体的重要因素之一。 XAgent 采用 Function Call 作为其内部的通信语言,具备结构化、标准化、统一化等优势。
- 结构化:Function Call 具备清晰且严谨的格式,可以明确表述所需内容,从而最小化了潜在的错误。
- 标准化:Function Call 可以将与外部工具的交互过程标准化,提供一种通用语言,使智能体具备使用和整合多种工具的能力,解决复杂任务。
- 统一化:通过将信息摘要、任务规划、工具执行等所有环节转化为特定的 Function Call 形式,确保每个环节均以统一的方式进行处理,从而简化系统设计。
此外,工具调用也是评价 AI Agent 是否具备解决复杂问题的重要能力之一。 XAgent 在设计中原创了工具执行引擎 ToolServer,可以实现更安全、高效、可扩展的工具执行能力。
经过在一系列任务中的测试可以看到(如下图a、b所示),基于 GPT-4 的 XAgent 表现效果在所有基准测试中都超过了原始的 GPT-4,并全面超越了 AutoGPT。
这些任务需要 Agent 推理规划和使用外部工具的能力,包括:用搜索引擎回答问题的能力(FreshQA+HotpotQA)、Python 编程能力(MBPP)、数学推理能力(MATH)、交互式编程能力(InterCode)、具身推理能力(ALFWorld)、真实复杂任务等。
Multi-Agent
2024年,EMNLP 收录港科大论文,研究社会游戏(如Avalon)里的Agent行为
- 论文 LLM-Based Agent Society Investigation: Collaboration and Confrontation in Avalon Gameplay
- 代码 LLM-Game-Agent
总结
Multi-Agent 主流框架
- 斯坦福虚拟小镇
- MetaGPT
- AutoGen
- ChatDEV
- GPTeam
- GPT Researcher
- TaskWeaver
- 微软UFO
- CrewAI
- AgentScope
- Camel
总结对比
| 维度 | AutoGen |
Multi-Agent Debate |
CAMEL |
BabyAGI |
MetaGPT |
|---|---|---|---|---|---|
| 架构通用性 | ✅ | ❌ | ✅ | ❌ | ❌ |
| 对话模式 | 静态/动态 | 静态 | 静态 | 静态 | 静态 |
| 执行LLM代码 | ✅ | ❌ | ❌ | ❌ | ✅ |
| 人工介入 | ✅ | ❌ | ❌ | ❌ | ❌ |
问题
第一篇 MAS 失败原因分析综述
- 【2025-3-17】伯克利 Why Do Multi-Agent LLM Systems Fail?
- multi-agent-systems-failuretaxonomy
- 解读 三个Agent没水喝
鉴于llm处理复杂、多步骤任务以及与不同环境实时互动的能力,由大语言模型(LLM)驱动的 agent 系统,尤其是多 agent 系统(MAS),被认为非常适合用来解决现实世界中的问题,越来越多地应用在各个领域中,如软件工程、药物发现、科学模拟,以及通用 agent 系统。
Multi-Agent Systems (MAS) 多智能体系统通过多个LLM驱动的智能体相互协作完成任务,MAS 广受关注,热度越来越高,但与单智能体相比,在流行的评测集上取得的成绩相对有限。
- 多 agent 系统却在处理实际问题时,相对于单Agent更易出错。AppWorld 故障率可高达 86.7%。
有必要深入分析下 MAS 的失败原因
- 选用5个热门MAS系统,150多个任务上评测
- 6个人工专家来标注评测结果

| MAS | Agentic Architecture | Purpose of the System |
|---|---|---|
| MetaGPT (Hong et al., 2023) | Assembly Line | Simulating the SOPs of different roles in Software Companies to create open - ended software applications |
| ChatDev (Qian et al., 2023) | Hierarchical Workflow | Simulating different Software Engineering phases like (design, code, QA) through simulated roles in a software engineering company |
| HyperAgent (Phan et al., 2024) | Hierarchical Workflow | Simulating a software engineering team with a central Planner agent coordinating with specialized child agents (Navigator, Editor, and Executor) |
| AppWorld (Trivedi et al., 2024) | Star Topology | Tool - calling agents specialized to utility services (ex: Gmail, Spotify, etc.) being orchestrated by a supervisor to achieve cross - service tasks |
| AG2 (Wu et al., 2024a) | N/A - Agentic Framework | An open - source programming framework for building agents and managing their interactions |
| MAS名称(测试环境) | 成功率 | 失败率 |
|---|---|---|
| MetaGPT (ProgramDev) | 66.0% | 34.0% |
| ChatDev (ProgramDev) | 25.0% | 75.0% |
| HyperAgent (SWE-Bench Lite) | 25.3% | 74.7% |
| AppWorld (Test-C) | 13.3% | 86.7% |
| AG2 (GSM-Plus) | 84.8% | 15.2% |
提炼出MAS的14种失败模式
- 流程规划、任务划分:
- 智能体协作:
- 智能体在讨论没意义的内容,效率低
- 忽略关键信息
- 任务验证: 不少系统里验证机制失效
- manus 能协作漂亮的文档,但内容很容易出错 – 使用低质量内容,错误进一步放大
14 种故障模式,划分为 3 大类:
- (1)规范和系统设计故障;
- (2)Agent 间错位;
- (3)任务验证和终止。
反思
- 智能体不该简单模仿人类工作方式
- MAS 使用场景: 群体智慧场景,如 Google 的 Co-Scientist, Agent之间相互辩论、启发、对抗,更有价值
论文贡献
- 提出首个基于经验的多 agent 系统故障分类法——MASFT,理解和缓解多 agent 系统故障提供了一个结构化框架。
- MASFT 将多 agent 系统的执行划分为 3 个阶段:执行前、执行中和执行后,确定每个细粒度故障模式可能发生的多 agent 系统执行阶段。
- 同时,开发可扩展的 “LLM-as-a-judge” 评估管道,用于分析新的多 agent 系统性能和诊断故障模式。
- 针对 agent 规范、对话管理和验证策略,进行干预研究,尽管将任务完成率提高了 14%,但仍未能完全解决多 agent 系统故障问题,这凸显了结构性多 agent 系统重新设计的必要性。
开源:
- 150 多个标注的多 agent 系统会话轨迹;
- 可扩展的 LLM-as-a-judge 评估管道和 150 多个轨迹的 LLM 标注;
- 15 个选定轨迹的详细专家标注。
发展趋势
论文: 多智能体协作机制综述
- 【2025-1-10】爱尔兰科克大学 Multi-Agent Collaboration Mechanisms: A Survey of LLMs
- 解说
协作机制:参与者(涉及Agent)、类型(例如,合作、竞争或合作竞争)、结构(例如,点对点、集中式或分布式)、策略(例如,基于角色或基于模型)和协调协议。
未来 5 年内多Agent平台的两大发展趋势:
- (1)多Agent 平台的技术架构演进
- (2)模型能力的提升
多 Agent 架构正从简单设置演变为更加分布式、分层和混合框架,以协调大量Agent。
近期研究将这些架构分类为 扁平式(点对点)、分层式(树状监督)、团队式、社会式 或 混合式
每种架构在可扩展性、灵活性和效率上各有权衡。未来的平台可能会结合这些模式,使Agent能够根据不同任务进行自组织。新框架展示了如何将Agent组织成动态网络或专业化小组,以提升集体问题求解能力。随着系统规模扩大,这种分布式方法预计将增强系统的鲁棒性和性能。
多Agent协作的核心是高效通信。当前研究正推动Agent间通信协议向更自适应、稳健且高效利用带宽的方向发展,特别是在Agent数量增长的情况下。
关于基于 LLM 的多智能体系统(MAS)的研究强调,系统级设计(即Agent如何通信以及它们共享哪些目标)和内部通信策略必须进行优化,以实现真正的集体智能。
结构化消息传递、共享“黑板”记忆,甚至隐式信号都可以被利用,以减少误解并提高协作效率。
多智能体强化学习(MARL)将继续成为训练Agent群体,使其通过经验不断改进的关键技术。
MARL 在可扩展性和鲁棒性方面的优势,使Agent能够在共享环境中共同学习协调策略。
未来,研究人员正致力于使 MARL Agent 在部署后变得更自适应和自我优化。
一个值得关注的趋势是将 基于 LLM 推理 整合到强化学习(RL)循环中 —— Agent 可在训练过程中交换信息或学习通信协议,以提升协作能力。
- 例如,语言条件 MARL 正在被探索,使Agent能够发展出一种共享的“语言”来协调策略,结合深度强化学习(Deep RL)与类人通信的优势。
未来五年内,预计会出现以下重要进展:
- 多智能体自博弈(Self-Play)技术:Agent 通过相互对抗或协作来提升自身能力;
- 元学习(Meta-Learning):Agent 学会优化自己的学习算法,提高学习效率;
- 终身学习(Lifelong Learning):Agent 团队能够在多Agent环境中动态适应新任务。
这些自我优化能力将由将 MAS 视为一个不断进化的生态系统的新型架构所支持,可能引领我们迈向人工集体智能(Artificial Collective Intelligence),即Agent群体整体的学习能力超越个体能力的总和。
增强推理、自主性与适应性
多Agent平台将更深层次的推理能力和更高的自主性。
大型语言模型(LLMs)已被用于自主Agent的“大脑”,支持其执行复杂的规划和决策任务。
将 LLM 与长期记忆和规划模块结合,可打造出能够规划、记忆并进行类人适应的Agent。
- 例如,近期的生成式Agent实验表明,多个基于 LLM 的Agent在沙盒环境中可以自主模拟可信的社交行为(如仅凭初始提示就共同组织一场聚会),展现出涌现的协作能力与适应性。
- 在未来几年将看到Agent在理解上下文、推理多步问题和动态调整行为方面的能力进一步提升。
当前,LLM 驱动的Agent已经能够推理目标并做出情境决策,而这些能力将通过更优的认知架构进一步优化。
以下技术将得到更广泛应用:
- 链式思维提示:增强推理能力,使Agent能够进行更复杂的逻辑推导;
- 逻辑推理增强:提升Agent在推理问题上的准确性;
- 外部工具调用:让Agent可以调用计算器、代码解释器等外部工具,以提升执行能力。
这些技术的结合将进一步提升多Agent系统的自主性,减少对人类干预的依赖,使Agent能够主动判断任务需求并协作完成任务。多Agent系统中 LLM 的演进大型语言模型(LLMs)自身也在不断发展,以更好地支持多Agent环境。
当前趋势表明,与其使用单一的大型通用模型,更倾向于部署多个专门化的 LLM Agent进行交互。基于 LLM 的Agent协作使其能够解决单个模型难以独立完成的任务,利用多样化的专业知识和集体问题求解能力。
当前 LLM 在多Agent环境中的局限性,将Agent视为一种数字物种,可能需要新的训练方法。
一个关键挑战是,通用 LLM 设计初衷并非针对多Agent交互,因此可能导致:
- 产生错误信息或不一致性(幻觉),这些错误会在Agent间级联放大;
- 缺乏共识构建机制,导致决策不稳定或Agent之间难以达成一致。
未来的发展方向可能包括专为多Agent协作优化的 LLM 变体或微调模型,提升其在与其他 AI 交互时的可靠性。
- 例如,正在探索能考虑其他Agent观点、维护一致的共享世界状态的 LLM。通过调整模型架构和训练方法,AI 研究社区正努力打造更加协作透明、团队意识更强、适应性更高的 AI “团队成员”。
与“通用型”Agent不同,当前的发展方向是 Agent专精化
- 每个Agent通过微调或提示配置,被设计为擅长完成某一特定职能,并在一个协调框架中协同工作。
Agent角色的自动分配方法
- 2024 年的一项研究提出了一种“自动Agent生成”框架,可以在一个大任务中自动生成处理子任务的专用Agent。
【2023-8-10】斯坦福虚拟小镇
【2023-8-10】斯坦福25个AI智能体「小镇」终于开源,《西部世界》来了!斯坦福爆火「小镇」开源,25个AI智能体恋爱交友
- 项目地址:generative_agents
斯坦福虚拟小镇
- git:generative_agents
- paper:PAPER
原理
Smallville 沙盒世界小镇中,区域会被标记。根节点描述整个世界,子节点描述区域(房屋、咖啡馆、商店),叶节点描述对象(桌子、书架)。 智能体会记住一个子图,这个子图反映了他们所看到的世界的各个部分。
25个AI智能体不仅能在这里上班、闲聊、social、交友,甚至还能谈恋爱,而且每个Agent都有自己的个性和背景故事。
智能体 John Lin 种子记忆就是这样的——
- John Lin是一名药店店主,十分乐于助人,一直在寻找使客户更容易获得药物的方法。
- John Lin的妻子Mei Lin是大学教授,儿子Eddy Lin正在学习音乐理论,他们住在一起,John Lin非常爱他的家人。
- John Lin认识隔壁的老夫妇Sam Moore和Jennifer Moore几年了,John Lin觉得Sam Moore是一个善良的人。
- John Lin和他的邻居山本百合子很熟。John Lin知道他的邻居TamaraTaylor和Carmen Ortiz,但从未见过他们。
- John Lin和Tom Moreno是药店同事,也是朋友,喜欢一起讨论地方政治等等。
John Lin度过的一天早晨:6点醒来,开始刷牙、洗澡、吃早餐,在出门工作前,他会见一见自己的妻子Mei和儿子Eddy。
这些智能体相互之间会发生社会行为。当他们注意到彼此时,可能会进行对话。随着时间推移,这些智能体会形成新的关系,并且会记住自己与其他智能体的互动。
一个有趣的故事是,在模拟开始时,一个智能体的初始化设定是自己需要组织一个情人节派对。 随后发生的一系列事情,都可能存在失败点,智能体可能不会继续坚持这个意图,或者会忘记告诉他人,甚至可能忘了出现。
分析
虚拟小镇作为早期 multi-agent 项目,很多设计也影响到了其他multi-agent框架,里面的反思和记忆检索模拟人类的思考方式。
- 代理(Agents)感知环境,当前代理所有的感知(完整的经历记录)都被保存在一个名为”记忆流”(memory stream)中。
- 基于代理的感知,系统检索相关的记忆,然后使用这些检索到的行为来决定下一个行为。
- 这些检索到的记忆也被用来形成长期计划,并创造出更高级的反思,这些都被输入到记忆流中以供未来使用。
记忆流记录代理的所有经历,检索从记忆流中根据近期性(Recency)、重要性(Importance)和相关性(Relevance)检索出一部分记忆流,以传递给语言模型。
反思是由代理生成的更高级别、更抽象的思考。因为反思也是一种记忆,所以在检索时,它们会与其他观察结果一起被包含在内,反思是周期性生成的。
英伟达高级科学家Jim Fan评论:
斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一。 常常讨论单个大语言模型的新兴能力,但是现在有了多个AI智能体,情况会更复杂、更引人入胜。 一群AI,可以演绎出整个文明的演化进程。
GPT Researcher
GPT Researcher
- git:GPT Researcher
串行 Multi-Agent,框架可适配内容生产
GPT Researcher 架构主要通过运行两个Agent来进行,一个是“规划者”,一个是“执行者”;
- 规划者负责生成研究问题,而执行者则是根据规划者生成的研究问题寻找相关的信息
- 最后再通过规划者对所有相关信息进行过滤与汇总,然后生成研究报告;
Camel
Camel 早期 Multi-Agent 项目,实现agent间的一对一对话
- github: camel
Camel 通过 LLM 来模拟用户和 AI 助手,让两个 agent 进行角色扮演(例如一个是业务专家,一个是程序员),然后自主沟通协作来完成具体任务。
prompt 设计重要,否则会出现:角色转换,重复指令,消息无限循环,瑕疵回复,对话终止等等问题。
- 具体看项目代码中给出的 prompt 设定,添加了非常多的明确指令来让 agent 按照预想的设定来沟通协作。

除了 agent prompt 和运作模式的设计优化外,还设计了 prompt 来自动生成各种角色,场景诉求等内容。
这些内容在自动组成各种角色扮演的场景,就能收集到各个场景下 agent 的交互情况,便于后续做进一步的挖掘分析。这个网站 来探索已经生成的各种 agent 组合之间的对话记录。

【2023-9】ChatDev
ChatDev
ChatDev(2023.9)不是普通 MultiAgent框架,基于Camel,内部流程都是2个Agent之间多次沟通,整体上的不同Agent角色的沟通关系和顺序都是由开发者配置,不太像是个全功能的 MultiAgent 框架的实现。
ChatDev 项目本身没有太多和复用性,依赖的旧版本Camel也是该抛弃的东西。
这个项目本身更多是为了支撑论文的学术性原型,并不是为了让别人在上面开发而设计的。
【2024-6】LangGraph
2023 年 1 月推出 LangGraph,低级编排框架,用于构建代理应用。
- 开源的,并提供 Python 和 JavaScript 两种版本
LangGraph Studio 提供专门环境来简化 LLM(大语言模型)应用开发过程,用于可视化、交互和调试代理应用。
与传统软件开发不同,构建 LLM 应用需要标准代码编辑器之外的独特工具。
- LangGraph Studio 通过允许开发人员可视化代理图、修改代理结果以及随时与agent状态交互来增强开发体验。
2024 年 6 月,发布稳定的 0.1 版本
LangGraph 适用于各种 Multi-AI Agent 任务,并且具有极高的灵活性。
功能特点:
- LangGraph 基于 LangChain 开发,其核心思想是“有向循环图(Directed Cyclic Graph)”。
- 它不仅仅是一个 Multi-AI agent 框架,功能远超于此。
- 高度灵活,可定制性强,几乎能够满足所有多智能体协作应用的需求。
- 作为 LangChain 的延伸,它得到了技术社区的大力支持。
- 能够与开源的 LLMs(大语言模型)以及各种 API 无缝协作。
不足之处:
- 文档资料不够详尽。对于编程经验较少的用户来说,上手难度较大。
- 需要具备一定的编程能力,特别是在图(graphs)和逻辑流程的理解上。
安装
pip install langgraph
【2024-6-16】AgentUniverse
【2024-6-16】蚂蚁金服推出 AgentUniverse:大模型多智能体框架。
核心提供多智能体协作编排组件,其相当于一个模式工厂(pattern factory),允许开发者对多智能体协作模式进行开发定制,同时附带了搭建单一智能体的全部关键组件。开发者可以基于本框架轻松构建多智能体应用,并通过社区对不同领域的pattern实践进行交流共享】
- ‘agentUniverse - Your LLM Powered Multi-Agent Framework’ GitHub: agentUniverse
核心特性
- 单智能体的全部关键组件
- 丰富的多智能体协同模式: 提供
PEER(Plan/Execute/Express/Review)、DOE(Data-fining/Opinion-inject/Express)等产业中验证有效的协同模式,同时支持用户自定义编排新模式,让多个智能体有机合作; - 所有组件均可定制: LLM、知识、工具、记忆等所有框架组件均提供自定义能力,供用户来增强专属智能体;
- 轻松融入领域经验: 提供领域prompt、知识构建与管理的能力,同时支持领域级SOP编排与注入,将智能体对齐至领域专家级别;
模式组件包括:
- PEER 模式组件: 该pattern通过计划(Plan)、执行(Execute)、表达(Express)、评价(Review)四个不同职责的智能体,实现对复杂问题的多步拆解、分步执行,并基于评价反馈进行自主迭代,最终提升推理分析类任务表现。典型适用场景:事件解读、行业分析
- DOE 模式组件: 该pattern通过数据精制(Data-fining)、观点注入(Opinion-inject)、表达(Express)三个智能体,实现对数据密集、高计算精度、融合专家观点的生成任务的效果提升。典型适用场景:财报生成
使用案例
- 6.1 RAG类Agent案例
- 6.1.1 法律咨询Agent
- 6.2 ReAct类Agent案例
- 6.2.1 Python代码生成与执行Agent
- 6.3 基于多轮多Agent的讨论小组
- 6.4 PEER多Agent协作案例
- 6.4.1 金融事件分析案例

【2024-6-29】AgentStudio
【2024-6-29】AgentStudio :联合国际顶尖高校 昆仑万维开源智能体研发工具包,从0到1,轻松构建Agent
AgentStudio 模拟真实的多模式环境,从环境设置到数据收集、代理评估和可视化的整个过程。包括智能体观察与动作空间、跨平台的在线环境支持、交互式数据收集与评估、可扩展的任务套件、以及相应的图形界面。
- 观察和操作空间非常通用,支持函数调用和人机界面操作。
- 任何设备上运行任何软件的智能体助手
- AgentStudio: A Toolkit for Building General Virtual Agents
- agent-studio

AgentStudio 环境和工具包涵盖了构建可与数字世界中的一切交互的计算机代理的整个生命周期。
- 环境 (Env)
- • 跨设备 (Cross-Device):AgentStudio 可以在不同设备上运行,包括 Docker 容器、物理机器和虚拟机。这意味着无论你是在云端还是本地运行代理,AgentStudio 都能适应。
- • 跨操作系统 (Cross-OS):支持多种操作系统,如 Linux、MacOS 和 Windows。无论你使用哪个系统,AgentStudio 都能工作。
- 代理 (Agent)
- • 通用行动空间 (Universal Action Space):代理可以使用键盘、鼠标和 API 工具进行操作。这就像人类使用电脑的方式,代理可以模拟这些操作。
- • 多模态观察空间 (Multimodal Observation Space):代理可以通过截图、录屏和代码输出观察环境。这类似于人类通过眼睛和日志查看屏幕上的内容。
- • 开放性 (Open-Endedness):支持工具的创建和检索,这意味着代理可以学习并使用新的工具来完成任务。
- 数据 (Data)
- • GUI 定位 (GUI Grounding):收集用户界面上的数据,帮助代理理解界面布局。
- • 人类轨迹 (Human Trajectories) 和 代理轨迹 (Agent Trajectories):记录人类和代理在界面上的操作路径,为代理的学习提供数据。
- • 人类/AI 反馈 (Human/AI Feedback) 和 视频演示 (Video Demonstration):提供反馈和示范,帮助代理改进操作。
- 评估 (Eval)
- • 基本代理能力 (Fundamental Agent Abilities):评估代理的自我评估、自我纠正和准确定位能力。
- • 开放域任务套件 (Open-Domain Task Suite):评估代理在低级指令执行和复杂任务组合上的能力。
- 界面 (Interface)
- • 互动注释管道 (Interactive Annotation Pipeline):允许用户实时标注数据,帮助代理学习。
- • VNC 远程桌面 (VNC Remote Desktop):支持远程操作和测试。
- • 野外测试 (In-the-Wild Testing) 和 自动评估 (Auto-Evaluation):在真实环境中测试代理,并自动评估其表现。
- • 安全检查 (Safety Check):确保代理操作的安全性。
【2024-10-12】Swarm
【2024-10-12】OpenAI今天Open了一下:开源多智能体框架Swarm
多智能体是 OpenAI 未来重要的研究方向之一, OpenAI 著名研究科学家 Noam Brown 在 X 上为 OpenAI 正在组建的一个新的多智能体研究团队
这个团队开源了一项重量级研究成果:Swarm, 实验性质的多智能体编排框架,主打特征是工效(ergonomic)与轻量(lightweight)。
- 项目地址:swarm
重点:让智能体协作和执行变得轻量、高度可控且易于测试。
为此,使用了两种原语抽象:智能体(agent)和交接(handoff)。
- 其中,智能体包含指令和工具,并且在任何时间都可以选择将对话交接给另一个智能体。
- Swarm 智能体与 Assistants API 中的 Assistants 无关。
- Swarm 完全由 Chat Completions API 提供支持,因此在调用之间是无状态的。
Swarm 核心组件包括 client(客户端)、Agent(智能体)、Function(函数)。
client(客户端): 运行 Swarm 就是从实例化一个 client 开始- Swarm 的 run() 函数: 类似于 Chat Completions API 中的 chat.completions.create() 函数——接收消息并返回消息,并且在调用之间不保存任何状态。但重点在于,它还处理 Agent 函数执行、交接、上下文变量引用,并且可以在返回给用户之前进行多轮执行。
- client.run() 完成后(可能进行过多次智能体和工具调用),会返回一个响应,其中包含所有相关的已更新状态。具体来说,即包含新消息、最后调用的智能体、最新的上下文变量。你可以将这些值(加上新的用户消息)传递给 client.run() 的下一次执行,以继续上次的交互——就像是 chat.completions.create()
Agent(智能体): 将一组指令与一组函数封装在一起(再加上一些额外的设置),并且其有能力将执行过程交接给另一个 Agent。Function(函数): Swarm Agent 可以直接调用 Python 函数。- 函数通常应返回一个字符串(数值会被转换为字符串)。
- 如果一个函数返回了一个 Agent,则执行过程将转交给该 Agent。
- 如果函数定义了 context_variables 参数,则它将由传递到 client.run() 的 context_variables 填充。
Swarm 的 client.run() 是实现以下循环:
- 先让当前智能体完成一个结果
- 执行工具调用并附加结果
- 如有必要,切换智能体
- 如有必要,更新上下文变量
- 如果没有新的函数调用,则返回
选择
- 如果开发者想要寻求完全托管的线程以及内置的内存管理和检索,那么 Assistants API
- 但如果开发者想要完全透明度,并且能够细粒度地控制上下文、步骤和工具调用,那么 Swarm 才是最佳选择。
- Swarm (几乎)完全运行在客户端,与 Chat Completions API 非常相似,不会在调用之间存储状态。
应用案例
- 天气查询智能体
- 用于在航空公司环境中处理不同客户服务请求的多智能体设置
- 客服机器人
- 可以帮助销售和退款的个人智能体等。
安装
pip install git+ssh://git@github.com/openai/swarm.git
使用
from swarm import Swarm, Agent
client = Swarm()
def transfer_to_agent_b():
return agent_b
agent_a = Agent(
name="Agent A",
instructions="You are a helpful agent.",
functions=[transfer_to_agent_b],
)
agent_b = Agent(
name="Agent B",
instructions="Only speak in Haikus.",
)
response = client.run(
agent=agent_a,
messages=[{"role": "user", "content": "I want to talk to agent B."}],
)
print(response.messages[-1]["content"])
【2025-3-12】OpenAI Agents SDK(Swarm)
2025 年 3 月 11 日(美国时间)/ 3 月 12 日(北京时间),OpenAI Agents SDK 随 Responses API 一同发布,开源、Python 优先。
- 前身 Swarm:2023 年底–2024 年实验性发布,2025 年 3 月被 Agents SDK 取代。
重要更新
- 2025 年 6 月:发布 TypeScript 版本。
- 2025 年 10 月 6 日(DevDay):发布基于 Agents SDK 的 AgentKit(含 ChatKit 前端组件)。
- 2026 年 4 月 15 日:重大架构更新,新增原生沙箱执行、MCP、AGENTS.md 等。
OpenAI Agents SDK 核心: Agent(代理),由 LLM 驱动,通过 Runner 执行循环(Run Loop)协调工作流。
流程如下:
- 输入处理:用户输入经过 InputGuardrail 安全检查。
- 决策生成:LLM 解析意图,决定调用工具、发起交接或直接回复。
- 动作执行:
- 调用工具(如 API、函数)并返回结果;
- 通过 Handoff 转移控制权给其他代理;
- 生成文本回复。
- 输出处理:结果经 OutputGuardrail 验证后返回用户。
应用场景与优势
- 复杂任务处理:
- 单代理处理简单任务(如天气查询);
- 多代理协作处理跨领域任务(如客服→技术支持的交接)。
- 安全可控性:
- Guardrails 确保输入/输出合规;
- InputGuardrailTripwireTriggered 快速拦截风险。
- 灵活扩展:
- 工具库可自定义(API、函数、其他代理);
- 交接机制支持动态任务分配。
设计思想
- Agent Loop 自动化:
- Runner.run() 内部自动处理循环逻辑(调用 LLM → 解析响应 → 执行工具/交接 → 更新状态),开发者只需关注中间项的处理。
- 上下文共享:
- context 参数确保跨代理的数据一致性(如用户 ID、会话历史)。
- 模块化扩展:
- 通过 new_items 分离不同操作(工具调用、交接),便于添加自定义逻辑(如审计工具调用记录)。
OpenAI Agents SDK 的核心操作层级:
- Runner 是中枢,驱动代理执行;
- 输出项类(如 MessageOutputItem、ToolCallItem)封装运行时数据;
- Handoff 实现多代理协同;
- InputGuardrailTripwireTriggered 强化安全边界;
- ItemHelpers 提供数据处理支持。
该框架通过解耦模型、工具、代理逻辑,大幅降低了构建复杂 AI 工作流的门槛,尤其适合客服系统、任务路由等场景。
(1)Runner:执行引擎
- 功能:管理代理运行循环,协调工具调用、交接、异常处理。
- 核心方法:
- run_sync():同步执行代理;
- run():异步执行(推荐用于生产环境)。
- 作用场景:贯穿整个代理生命周期,处理输入到输出的全流程。
示例
from agents import Runner, Agent
agent = Agent(name="Assistant", instructions="Help users with queries.")
result = Runner.run_sync(agent, "What's the weather today?")
print(result.final_output) # 输出代理的最终响应
(2) 输出项类型(Output Items)
代理运行中可能生成多种输出类型,需通过 ItemHelpers 辅助操作:
| 类名 | 功能说明 | 关联/补充说明 | 示例场景 |
|---|---|---|---|
| MessageOutputItem | 来自用户或代理的文本消息 | 通用文本消息封装载体 | 用户提问 How to reset my password? 被封装为此类 |
| HandoffOutputItem | 触发代理之间的控制权转移 | 关联 Handoff 类,用于定义交接规则(目标代理、输入过滤等) |
路由代理将西班牙语请求转交给西语专精代理 |
| ToolCallItem | 工具调用请求封装 | 代表发起一次工具调用动作(如接口、函数) | 发起调用天气 API 的请求 |
| ToolCallOutputItem | 工具执行结果封装 | 承载工具调用完成后返回的结果数据 | 天气 API 返回的气象数据被封装为此类 |
示例
@function_tool
def get_weather(city: str) -> str:
return f"Weather in {city}: Sunny"
agent = Agent(tools=[get_weather]) # 工具绑定到代理
(3)异常项:InputGuardrailTripwireTriggered
- 功能:表示输入触发防护栏(Guardrail),例如检测到违规内容(如暴力、隐私问题)。
- 处理逻辑:Runner 会中断流程,返回预设的安全响应(如 “I can’t answer that”)。
示例:
- 若输入含敏感词,生成此异常项并终止流程。
@input_guardrail
def content_filter(input: str) -> bool:
return "violence" in input # 触发条件
(4)Handoff:代理间交接控制
- 功能:定义代理间的任务转移规则,包括目标代理、输入预处理等。
- 核心参数:
- to_agent:目标代理实例;
- input_mapping:输入数据的转换规则(如提取用户问题中的关键词)。
handoff_to_spanish = Handoff(
to_agent=spanish_agent,
input_mapping=lambda x: {"query": x.split(":")[1]} # 提取西语问题
)
(5)ItemHelpers:输出项操作工具
- 功能:提供辅助方法,用于:
- 过滤特定类型的输出项(如提取所有 ToolCallItem);
- 转换输出格式(如将 MessageOutputItem 转为纯文本)。
- 典型场景:在复杂工作流中解析代理的中间输出。
多智能体示例:智能客服
from agents import Agent, Runner, Handoff, function_tool
# 定义工具:天气查询
@function_tool
def get_weather(city): ...
# 定义代理:路由代理 & 天气专精代理
triage_agent = Agent(name="Triage", instructions="Route questions.")
weather_agent = Agent(name="Weather", tools=[get_weather], instructions="Answer weather queries.")
# 定义交接:路由到天气代理
handoff_to_weather = Handoff(to_agent=weather_agent, input_mapping=lambda x: x)
# 配置路由代理的交接规则
triage_agent.handoffs = {"weather": handoff_to_weather}
# 运行流程
result = Runner.run_sync(triage_agent, "What's the weather in Paris?")
print(result.final_output) # 输出天气代理的响应
CrewAI – LangChain
CrewAI 是快速搭建 Multi-AI Agent 任务演示的首选工具,因为操作直观,配置起来也十分简便。
- GitHub crewAI
- 基于 LangChain 的 Multi-agent 框架
核心定位:基于角色的智能体协作编排。 主要特点:
- 动态任务分配,支持智能体之间的高效通信。
- 模拟人类团队协作,通过角色分工实现专业化(通过角色分工模拟人类团队协作)。
- 适用场景:组织化建模、协作式模拟、高级团队 AI 应用。
局限性:
- 聚焦于协作场景,对多模态处理的支持较弱。
CrewAI 核心特征
- 角色定制代理:可以根据不同的角色、目标和工具来量身定制代理。
- 自动任务委派:代理之间能够自主地分配任务和进行交流,有效提升解题效率。
- 任务管理灵活性:可以根据需要自定义任务和工具,并灵活地指派给不同代理。
- 流程导向:目前系统仅支持按顺序执行任务,但更加复杂的如基于共识和层级的流程正在研发中。
功能特点:
- 操作界面直观,主要依靠编写提示词。
- 创建新智能体并将其融入系统非常简单,几分钟内就能生成上百个智能体。
- 即便是非技术背景的用户也能轻松上手。
- 得益于与 LangChain 的集成,它能够与多数 LLM 服务提供商和本地 LLM 配合使用。
不足之处:
- 在灵活性和定制化方面有所限制。
- 更适合处理基础场景,对于复杂的编程任务则不太理想。
- 智能体间的交互偶尔会出现一些故障。
- 技术社区的支持力度相对较弱。
安装
pip install crewai
AgentScope
AgentScope
- github: AgentScope
阿里开源 Multi-agent 框架,亮点是支持分布式框架,并且做了工程链路上的优化及监控。
UFO
微软UFO
- git:UFO
UFO 面向Windows系统的Agent,结合自然语言和视觉操作Windows GUI
UFO(UI-Focused Agent)工作原理
- 基于先进的视觉语言模型技术,特别是GPT-Vision,以及一个独特的双代理框架,使其能够理解和执行Windows操作系统中的图形用户界面(GUI)任务。
UFO工作原理的详细解释:
- 双代理框架
- 双代理架构:UFO由两个主要代理组成,AppAgent和ActAgent,分别负责应用程序的选择与切换,以及在这些应用程序内执行具体动作。
- 应用程序选择代理(AppAgent):负责决定为了完成用户请求需要启动或切换到哪个应用程序。它通过分析用户的自然语言指令和当前桌面的屏幕截图来做出选择。一旦确定了最适合的应用程序,AppAgent会制定一个全局计划来指导任务的执行。
- 动作选择代理(ActAgent):一旦选择了应用程序,ActAgent就会在该应用程序中执行具体的操作,如点击按钮、输入文本等。ActAgent利用应用程序的屏幕截图和控件信息来决定下一步最合适的操作,并通过控制交互模块将这些操作转化为对应用程序控件的实际动作。
- 控制交互模块
- UFO的控制交互模块是将代理识别的动作转换为应用程序中实际执行的关键组成部分。
- 这个模块使UFO能够直接与应用程序的GUI元素进行交互,执行如点击、拖动、文本输入等操作,而无需人工干预。
- 多模态输入处理
- UFO能够处理多种类型的输入,包括文本(用户的自然语言指令)和图像(应用程序的屏幕截图)。这使UFO能够理解当前GUI的状态、可用控件和它们的属性,从而做出准确的操作决策。
- 用户请求解析
- 当接收到用户的自然语言指令时,UFO首先解析这些指令,以确定用户的意图和所需完成的任务。然后,它将这个任务分解成一系列子任务或操作步骤,这些步骤被AppAgent和ActAgent按顺序执行。
- 应用程序间的无缝切换
- 如果完成用户请求需要多个应用程序的操作,UFO能够在这些应用程序之间无缝切换。它通过AppAgent来决定何时以及如何切换应用程序,并通过ActAgent在每个应用程序中执行具体的操作。
- 自然语言命令到GUI操作的映射
- UFO的核心功能之一是将用户的自然语言命令映射到具体的GUI操作上。这一过程涉及到理解命令的意图,识别相关的GUI元素,以及生成和执行操作这些元素的动作。通过这种方式,UFO可以自动完成从文档编辑和信息提取到电子邮件撰写和发送等一系列复杂的任务,大大提高用户在Windows操作系统中工作的效率和便捷性。
TaskWeaver
TaskWeaver
- git:TaskWeaver
- doc:TaskWeaver
TaskWeaver 面向数据分析任务,通过编码片段解释用户请求,并以函数的形式有效协调各种插件来执行数据分析任务。
TaskWeaver不仅仅是一个工具,更是一个复杂的系统,能够解释命令,将它们转换为代码,并精确地执行任务。
TaskWeaver 工作流程涉及几个关键组件和过程, 三个关键组件组成:规划器(Planner)、代码生成器(CG)和代码执行器(CE)。代码生成器和代码执行器由代码解释器(CI)组成。
Semantic Kernel
Microsoft 出品
核心定位:将 AI 集成到企业应用中。
主要特点:
- 轻量级 SDK,支持多种编程语言。
- 提供安全性、合规性以及多步骤 AI 任务管理的协调器。
适用场景:
- 为企业软件提供 AI 能力增强(使用 AI 能力增强企业软件)。
局限性:
- 对研究导向或多模态应用支持较为有限。
【2023-10-10】AutoGen
微软出品
核心定位:
- 高级多智能体对话系统。
主要特点:
- 强大的模块化设计,支持自定义智能体角色和任务恢复机制。
- 支持多智能体通信及外部工具集成。
适用场景:
- 对话式 AI、协作式决策系统。
局限性:
- 对多模态任务和硬件集成的原生支持有限。
【2023-10-10】微软发布AutoGen, github,多代理(Agent)任务框架,完成各种场景的复杂工作流任务,从GPT大语言模型近几个月高速迭代以来,最近这个概念很火。
微软和OpenAI一定商量好了
- 11月6日 OpenAI 在发布 Assistant,和 AutoGen 原有架构完美兼容。
- 11月11日 AutoGen 就 Commits GPTAssistantAgent
如果要做 multi-Agent,那么 AutoGen 架构一定是最正确的
活跃度top级别的Multi-Agent框架,与MetaGPT“不相上下”
AutoGen 介绍
微软公司发布了开源Python库AutoGen。
- AutoGen是“一个简化大语言模型工作流编排、优化和自动化的框架。AutoGen背后的基本概念是“代理”(agents)的创建,即由大语言模型(如GPT-4)提供支持的编程模块。这些智能体(agents)通过自然语言信息相互作用,完成各种任务。
- 【2024-2-8】AutoGen框架学习 飞书文档
AutoGen Studio
【2023-12-1】微软 AutoGen Studio: Interactively Explore Multi-Agent Workflows
AutoGen Studio 提供了一个更直观的用户界面,使得用户可以更容易地使用AutoGen框架来创建和管理AI智能体。
- 与CrewAI和MetaGPT相比,AutoGen Studio提供了可视化界面,对新手更友好
特性
- 智能体和工作流定义修改:用户可以在界面上定义和修改智能体的参数,以及通信方式。
- 与智能体的互动:通过UI创建聊天会话,与指定的智能体交互。
- 增加智能体技能:用户可以显式地为他们的智能体添加技能,以完成更多任务。
- 发布会话:用户可以将他们的会话发布到本地画廊。
AutoGen Studio的组成
- 构建部分(Build):定义智能体属性和工作流。
- 默认的三个Skill是生成图片、获取个人网页正文、找Arxiv的论文。
- 游乐场(Playground):与在构建部分定义的智能体工作流进行互动。
- 画廊(Gallery):分享和重用工作流配置和会话。
CrewAI、MetaGPT v0.6、Autogen Studio 区别

实践
- 背后通过 fastapi、uvicorn 启动Web并行服务, 详见代码
- sqlite3 本地数据库存储会话数据,详见代码
- 重置数据库 —— 删除
database.sqlite - 删除用户信息 —— 删除文件夹
autogenstudio/web/files/user/<user_id_md5hash>
- 重置数据库 —— 删除
- 切换LLM、agent配置、skill信息 —— 修改默认配置文件 dbdefaults.json
- 查看中间信息 —— Web UI调试窗口,或
database.sqlite文件
pip install autogenstudio # 安装
# Mac电脑需要 export OPENAI_API_KEY=<your_api_key>
#参数 host, port, workers, reload
autogenstudio ui --port 8081 # 启动Web UI
autogenstudio ui --port 8081 --host 10.92.186.159 # 其它域内机器可访问
AutoGen 设计
借助AutoGen,开发人员可以创建一个由代理(agents)组成的生态系统,这些代理专注于不同的任务并相互合作。
- AutoGen使用多代理(multi-agent)对话支持复杂的基于大语言模型的工作流。
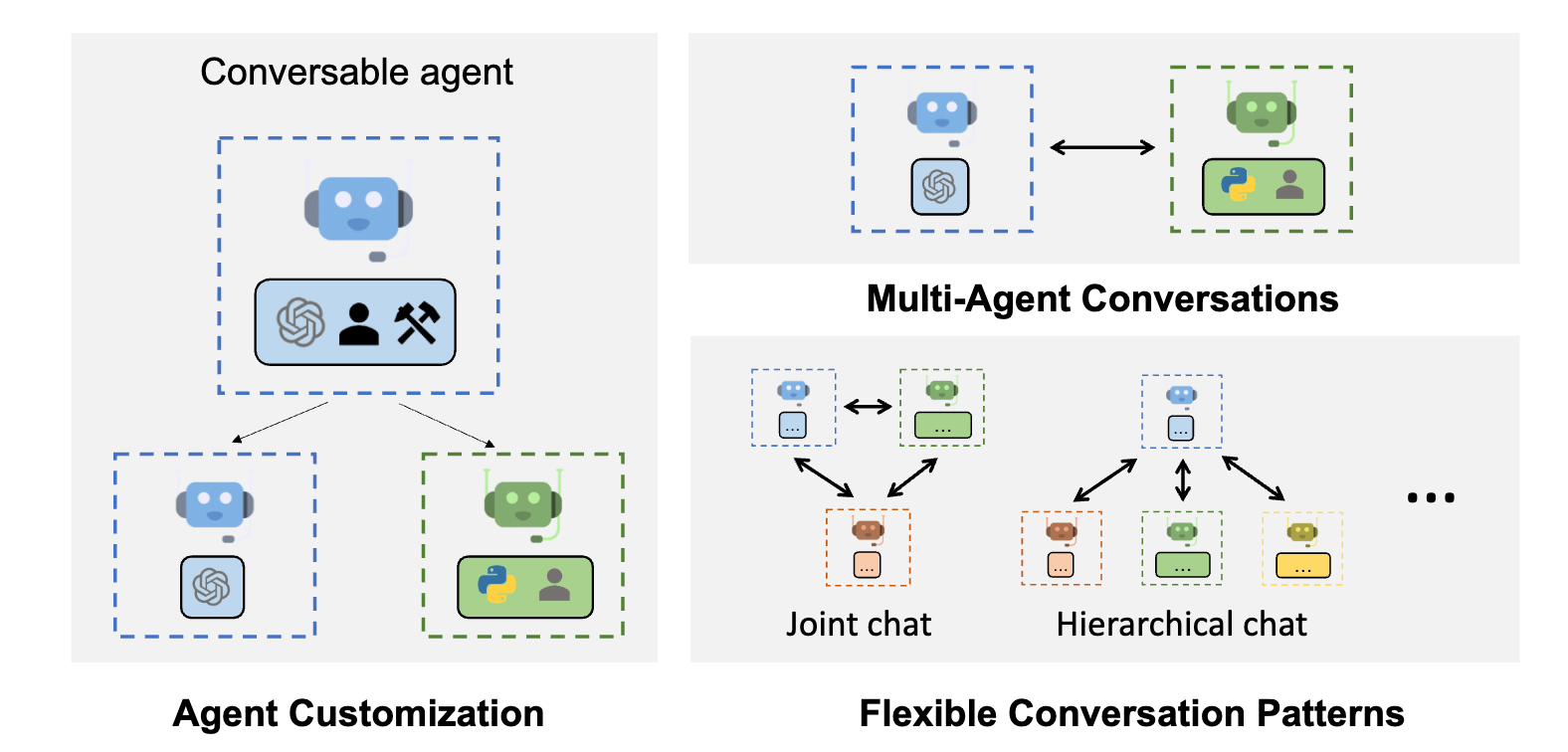
- 左图:AutoGen代理是可定制的,可以基于大语言模型 、工具、人,甚至是它们的组合。
- 右图:智能体(agents)可以通过对话来解决任务。右边下图:这个框架支持许多额外的复杂对话模式。
- 将每个代理(agents)视为具有其独特系统指令的单个ChatGPT会话。
- 例如,可以指示一个代理充当编程助手,根据用户请求生成Python代码。另一个代理可以是代码审查器,它获取Python代码片段并对其进行故障排除。然后,可以将第一个代理的响应作为输入传递给第二个代理。其中一些代理甚至可以访问外部工具,比如ChatGPT插件,如Code Interpreter或Wolfram Alpha。
AutoGen提供工具来创建代理(agents)并自动交互。多代理(multi-agent)应用程序完全自主或通过“人工代理”进行调节,允许用户介入代理之间对话,监督和控制。在某种程度上,人类用户变成了监督多个人工智能代理的团队负责人。
对于代理框架必须做出敏感决策并需要用户确认的应用程序,人工代理非常有用。
- AutoGen 让用户在开始走向错误的方向时帮助调整方向。例如,用户可以从应用程序的初始想法开始,然后在代理的帮助下逐渐进行完善,并在开始编写代码时添加或修改功能。
- AutoGen 模块化架构也允许开发人员创建通用的可重用组件,这些组件可以组装在一起,以快速构建自定义应用程序。
多个AutoGen代理可以协作完成复杂的任务。
例如,人工代理可能会请求帮助编写特定任务的代码。编码助理代理(agents)可以生成并返回代码,然后代理可以使用代码执行模块并对代码进行验证。然后,这两个人工智能代理可以一起对代码进行故障排除并生成最终的可执行版本,而人类用户可以在任何时候中断或提供反馈。
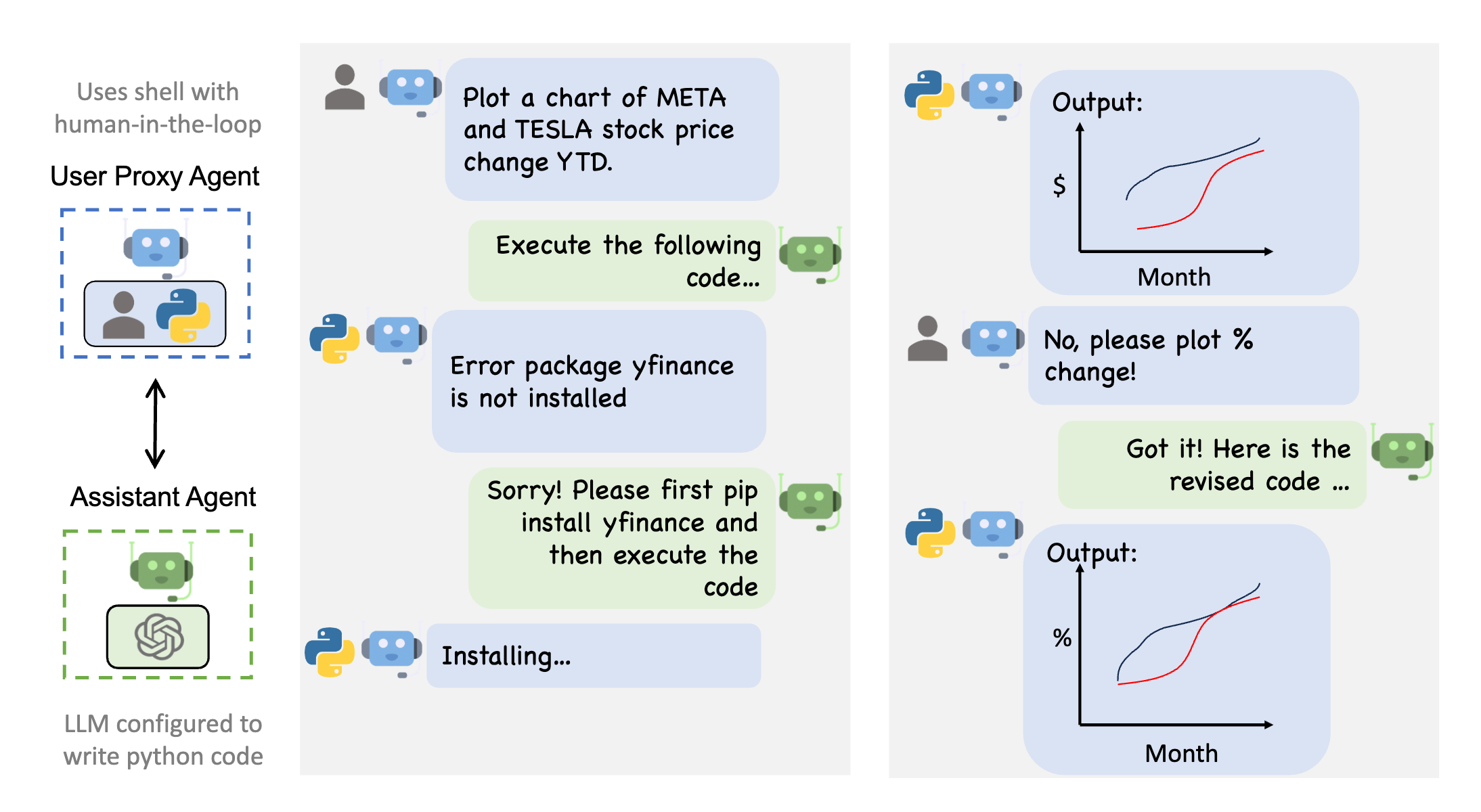
这种协作方法可以显著提高效率。根据微软公司的说法,AutoGen可以将编码速度提高四倍。
AutoGen 内置代理
- 泛型
ConversableAgent类- 这些代理能够通过交换消息来相互交谈以共同完成任务。代理可以与其他代理通信并执行操作。不同的代理在接收消息后执行的操作可能不同。
AssistantAgent助手代理: 通用的AI助手,负责执行具体任务- 默认使用 LLM,但不需要人工输入或代码执行。
- 编写 Python 代码(在 Python 编码块中),供用户在收到消息(通常是需要解决的任务的描述)时执行。在后台,Python 代码是由 LLM(例如 GPT-4)编写的。它还可以接收执行结果并建议更正或错误修复。可以通过传递新的系统消息来更改其行为。LLM 推理配置可以通过 llm_config 进行配置。
UserProxyAgent人类代理- 每个交互回合中,将人工输入作为代理的回复,并且还具有执行代码和调用函数的能力。
- 收到消息中检测到可执行代码块且未提供人类用户输入时,会自动 UserProxyAgent 触发代码执行。可将 code_execution_config 参数设置为 False 来禁用代码执行。默认基于 LLM 的响应处于禁用状态。可以通过设置为 llm_config 与推理配置对应的字典来启用它。When llm_config 设置为字典, UserProxyAgent 可以在不执行代码执行时使用 LLM 生成回复。
两个具有代表性的子类是 AssistantAgent 和 UserProxyAgent 。这两个代理可协同工作,构建强大的应用,如Chat GPT Plus代码解释器加插件的增强版本。
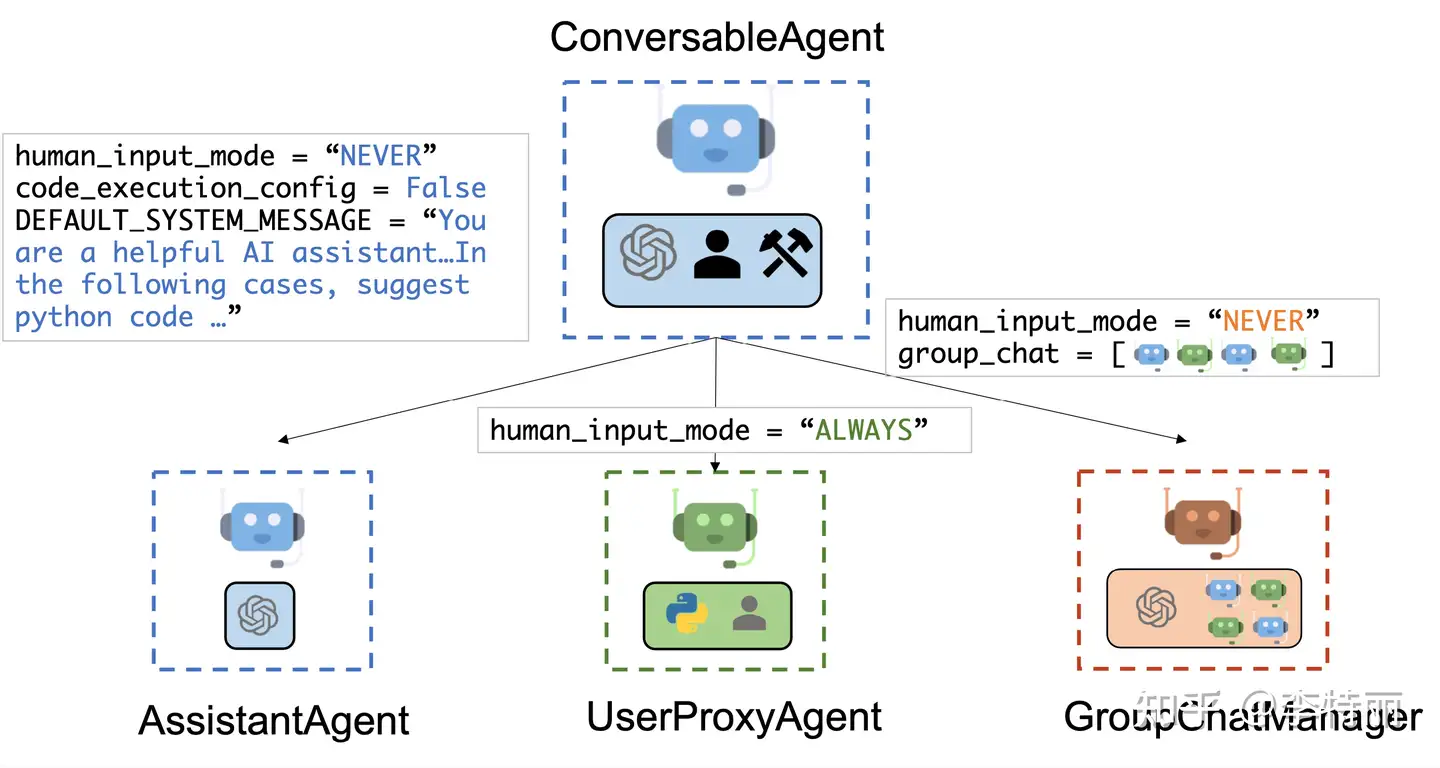
- 实用类
UserProxyAgent用户直接交互的 Agent,不处理 Task。AssistantAgent实际处理某些 Task 的 Agent,不直接与用户交互。GroupChatManager管理群组对话,也不直接和用户交互。
- 抽象类
ConversableAgent3 个实用 Agent 继承的类,绝大部分 Agent 的功能都写在这个里面,很长。Agent是ConversableAgent父类,很短,只定义了接口。
GroupChat是有关群组对话的类,不是 Agent,它保存群成员和群消息,以及一些列拼凑 prompt 和message 的方法。
一步循环流程
- 用户把 Task 告诉 UserProxyAgent
- UserProxyAgent 把消息发送给 AssistantAgent;
- AssistantAgent 返回结果给 UserProxyAgent ,UserProxyAgent 决定下一步如何进行。
UserProxyAgent 和 AssistantAgent 都是一系列代码 + LLM,都有自己的 prompt(SystemMessage)。
- 但是 UserProxyAgent 有特殊权限:执行代码,而 AssistantAgent 不能运行。
- 这种权限控制写在代码里,而不是 prompt。
- 即使实际处理 Task 的 Agent 只有 1 个,但必须有 1 个 UserProxyAgent,也就是至少有 2 个 Agent。
assistant = AssistantAgent("assistant" ....)
user_proxy = UserProxyAgent("user_proxy" ....)
user_proxy.initiate_chat(assistant, ....)
代码理解
AutoGen 中的代理具有以下功能:
- 可对话:AutoGen 没有隔离代理,任何代理都可发送和接收来自其他代理的消息以启动或继续对话
- 可定制:AutoGen 代理可自定义, 集成 LLM、人员、工具或组合。
框架解析
autogen/agentchat/init.py 中定义多种智能体
- “
Agent” 抽象类,定义了 name属性方法, reset,send/a_send,receive/a_reveive,generate_reply/a_generate_reply - “
ConversableAgent”, 泛型, 通过交换消息共同完成任务。不同代理接收消息后执行的操作可能不同- Autogen框架中有两个默认代理:用户代理(user) 和助手代理 (assistant)。
- 两个具有代表性的子类是
AssistantAgent和UserProxyAgent。
- “
AssistantAgent”, AI助手,通用AI助手,负责执行具体任务- 默认使用 LLM,但不需要人工输入或代码执行。
- 通过LLM编写 Python 代码,供用户在收到消息(要解决任务的描述)时执行。
- 接收执行结果并建议更正或错误修复。通过传递新系统消息来更改其行为。LLM 推理配置可以通过
llm_config进行配置。
- “
UserProxyAgent”, 人类代理,或用户代理,代表用户工作 (人类),可独立做决定或向用户请求输入。- 每个交互回合中,将人工输入作为代理回复,还具有执行代码和调用函数能力。收到的消息中检测到可执行代码块且未提供人类用户输入时,会自动 UserProxyAgent 触发代码执行。可以通过将
code_execution_config参数设置为 False 来禁用代码执行。 - 默认情况下,基于 LLM 的响应处于禁用状态。设置为
llm_config与推理配置对应的字典来启用它。 llm_config 设置为字典, UserProxyAgent 可以在不执行代码执行时使用 LLM 生成回复。
- 每个交互回合中,将人工输入作为代理回复,还具有执行代码和调用函数能力。收到的消息中检测到可执行代码块且未提供人类用户输入时,会自动 UserProxyAgent 触发代码执行。可以通过将
- “
GroupChat”, - “
GroupChatManager”
用户代理和助手代理之间的聊天被自动化,同时允许人工反馈或干预,实现了高效和灵活的任务完成方式。
图解
- GroupChatManager 不是 LLM Agent,没有「ManagerAgent」直接调用 OpenAI API 的代码证据,Manager 把群组消息重新组织后转发给其他 Agent ,自己调用 OpenAI API 。
- GroupChat 不是 Agent,包含了一些拼凑和更新 prompt 以及 message 文本的方法。Manager 会使用这些方法,并且把拼凑好的文本消息 send 给其他 Agent,并且消息的发送者是 speaker(其中一个AssistantAgent),而不是 Manager 自己
记忆单元 Memory
Memory记录Agent与其他Agent交互历史
- 信息隔离:没有对话过的agent看不到彼此信息
- 但ChatManager拥有所属agent聊天记录,消息广播给所有agent,所以能看到彼此信息
Tool 工具
- Tool calling: 通过 ConversableAgent.register_for_llm 方法向LLM注册tools。
- 通过 ConversableAgent.register_for_execution 向UserProxyAgent注册tool的执行。
ConversableAgent 关键环节
.initiate_chat(recipient: ? ...
# 对话开始时用 recipient 定义一个谈话对象 Agent
.send(message,recipient...
recipient.receive(message, ...)
# 把消息通过 .send 发送给谈话对象,谈话对象用 .receive 接收消息。
.receive
reply = self.generate_reply(messages, ...)
# 接收到消息后通过 generate_reply 里面有较长的处理步骤,会一直调到 OpenAIWrapper.create ,总之就是调到 OpenAI API 了,并得到 LLM 的推理和回复。
.send(reply, ...
# 把得到的 reply 通过 .send 发回给之前那个 Agent,这样完成一个循环。
ConversableAgent 注册函数、调用函数
# 注册
def register_reply( ...
self._reply_func_list.insert( ...
"reply_func": ?
# 这样就把函数插到了 _reply_func_list 里了,并且存在 "reply_func" 上
# 调用
def generate_reply( ...
for reply_func_tuple in self._reply_func_list:
reply_func = reply_func_tuple["reply_func"]
# 拿到所有的可调用的函数
if self._match_trigger(reply_func_tuple["trigger"], sender):
reply = reply_func(...
# 用 _match_trigger 去匹配一下名称,名称正确的话就直接调用那个函数
GroupChatManager 的关键环节
def run_chat:
speaker = ...
for agent in groupchat.agents:
if agent != speaker:
self.send(message, agent
# GroupChatManager 只有1个新增的函数方法就是 run_chat,它找到 1 个 speaker(是一个AssistantAgent),并且把 speaker 的消息发给群组里除了 speaker 之外的所有人。其余还有针对各种情况的判断处理就不深入了。
def __init__:
self.register_reply( GroupChatManager.run_chat, ...
# register_reply 是父类 ConversableAgent 的一个方法,允许注册新的函数功能,用来扩展 Agent 类型,GroupChatManager 的 run_chat 就是这样扩展进去的。之后新增的其他类型的 Agent 都在用这个方法扩展。
- 用户把 Task 告诉 UserProxyAgent,然后 UserProxyAgent 会把消息发送给 GroupChatManager;
- GroupChatManager 会作为群消息管理者,把适当的消息转发给适当的 AssistantAgent;
- AssistantAgent 接收到群消息,并且给出自己的推理;
- GroupChatManager 会拿到所有 AssistantAgent 的推理并发回给 UserProxyAgent。UserProxyAgent 来决定下一步如何进行,这样就完成一步的循环。
user_proxy = UserProxyAgent("user_proxy" ....
assistant1 = AssistantAgent("assistant1" ....
assistant2 = AssistantAgent("assistant2" ....
assistant3 = AssistantAgent("assistant3" ....
groupchat = autogen.GroupChat(agents=[user_proxy, assistant1, assistant2, assistant3], ...
manager = autogen.GroupChatManager(groupchat=groupchat, ...
user_proxy.initiate_chat(manager, ....
Autogen系列

应用场景
应用领域
【2024-1-14】Autogen 新手指南:基础概念和应用
官方公布的5大领域
- 代码生成、执行和调试
- 通过代码生成、执行和调试实现自动化任务解决
- 自动代码生成、执行、调试和人工反馈
- 使用检索增强代理自动生成代码和回答问题
- 使用基于 Qdrant 的检索增强代理自动生成代码和回答问题
- 多智能体协作(>3 智能体)
- 使用 GPT-4 + 多个人类用户自动解决任务
- 通过群聊自动解决任务(有 3 个群组成员代理和 1 个经理代理)
- 通过群聊自动实现数据可视化(有 3 个群组成员代理和 1 个经理代理)
- 通过群聊自动解决复杂任务(有 6 个群组成员代理和 1 个经理代理)
- 使用编码和规划代理自动解决任务
- 应用
- GPT-4 代理的自动国际象棋游戏和搭便车
- 从新数据中自动持续学习
- OptiGuide 用于供应链优化的大型语言模型.
- 工具使用
- Web 搜索:解决需要 Web 信息的任务
- 将提供的工具用作函数
- 使用 Langchain 提供的工具作为函数进行任务解决
- RAG:具有检索增强生成的群聊(具有 5 个组成员代理和 1 个经理代理)
- OpenAI 实用程序功能深入指南
- 代理教学
- 通过自动聊天向其他代理传授新技能和重用
- 向其他代理传授编码以外的新事实、用户偏好和技能
AutoGen的新应用程序示例:会话象棋(conversational chess)。它可以支持各种场景,因为每个玩家可以是大语言模型授权的AI、人类或两者的混合体。它允许玩家创造性地表达他们的动作,例如使用笑话,模因参考(meme references)和角色扮演,使棋类游戏对玩家和观察者来说更具娱乐性。
AutoGen还支持更复杂的场景和架构,例如大预言模型代理的分层安排。例如,聊天管理器代理可以调节多个人类用户和大语言模型代理之间的对话,并根据一组规则在它们之间传递消息。
具体
- Multi-Agent Conversation Framework
- AutoGen provides multi-agent conversation framework as a high-level abstraction. With this framework, one can conveniently build LLM workflows.
- Easily Build Diverse Applications
- AutoGen offers a collection of working systems spanning a wide range of applications from various domains and complexities.
- Enhanced LLM Inference & Optimization
- AutoGen supports enhanced LLM inference APIs, which can be used to improve inference performance and reduce cost.

举个示例:
- 比如构建一个法律资讯或电商客服系统时,AutoGen可以让一个AI代理负责收集客户提出的问题,另一个给出初步建议和回答。
- AutoGen同时还会将任务分解并分配给多个代理,一个代理负责查询数据库里的答案,一个代理会联网搜索实时最新数据进行比对,另一个代理负责对收集来的数据进行审核和纠正,还有的代理负责将汇总的数据进行格式化后并发给客户。
- 在整个过程中,AutoGen会把问题分解成多个任务,并自动分配给多个代理,同时支持人工抽样干预和反馈。与直接使用GPT AI聊天机器人不同的是,AutoGen支持多代理(AI、人、工具等)相互协作,使整个工作流更加高效。
其实代理Agent的设计一直是人工智能领域的焦点 过去的工作主要集中在增强代理的某些特定能力,比如符号推理,或者对于特定技能的掌握。 比如像国际象棋、围棋机器人等等。 这些研究更加注重算法的设计和训练策略,而忽视了大语言模型固有的通用能力的发展,比如知识记忆、长期规划、有效泛化和高效互动等。
AutoGen 构建的六个应用程序示例,包括数学问题解决、多智能体编码、在线决策制定、检索增强聊天、动态群聊以及对话式国际象棋。

基本配置
新建 OAI_CONFIG_LIST 文件,内容如下,并且将开发密钥填入<>后,保存文件。
- 配置列表的样子,可有多个API端点,所以可用多个模型。
- ① OpenAI: gpt-4和gpt-3.5-turbo,输入API密钥
- ② Azure API: 微软接口
- ③ 自定义模型
- 如果还没有OpenAI账户,请先注册。
config_list = [
{
"model": "gpt-4",
"api_key": os.environ.get("AZURE_OPENAI_API_KEY"),
"api_type": "azure",
"base_url": os.environ.get("AZURE_OPENAI_API_BASE"),
"api_version": "2023-03-15-preview",
},
{
"model": "gpt-3.5-turbo",
"api_key": os.environ.get("OPENAI_API_KEY"),
"api_type": "open_ai",
"base_url": "https://api.openai.com/v1",
},
{
"model": "llama-7B",
"base_url": "http://127.0.0.1:8080",
"api_type": "open_ai",
}
]
注意
- api_base 要更换为 base_url
twoagent.py 文件
- OAI_CONFIG_LIST_sample.json set-your-api-endpoints
#pip install pyautogen
from autogen import AssistantAgent, UserProxyAgent, config_list_from_json
# Load LLM inference endpoints from an env variable or a file
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST")
# 初始化agent
assistant = AssistantAgent("assistant", llm_config={"config_list": config_list})
user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": "coding"})
# 启动任务
task = "Plot a chart of NVDA and TESLA stock price change YTD."
user_proxy.initiate_chat(assistant, message=task)
# This initiates an automated chat between the two agents to solve the task
运行
python test/twoagent.py
执行过程
- AssistantAgent 从 UserProxyAgent 接收到包含任务描述的消息。
- AssistantAgent 尝试编写Python代码来解决任务,并将响应发送给 UserProxyAgent。
- UserProxyAgent收到助手的回复,尝试通过征求人类输入或准备自动生成的回复来进行回复。
- 如果没有提供人类输入,UserProxyAgent将执行代码并将结果用作自动回复。
- AssistantAgent 随后为UserProxyAgent生成进一步的回应。
- 用户代理随后可以决定是否终止对话。如果不终止,则重复步骤3和4。
简易案例
简单Agent示例
- 比 LangChain 简单的多
import autogen
# 1、建立必要配置
config_list = [
{
"model": "Mistral-7B",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
}]
# 2、大模型请求配置
llm_config = {
"request_timeout": 600,
"seed": 45, # change the seed for different trials
"config_list": config_list,
"temperature": 0,
"max_tokens":16000,
}
# 3、新建一个助理智能体
assistant = autogen.AssistantAgent(
name="assistant",
llm_config=llm_config,
is_termination_msg=lambda x: True if "TERMINATE" in x.get("content") else False,
)
#创建名为 user_proxy 的用户代理实例,这里定义为进行干预
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
human_input_mode="TERMINATE",
max_consecutive_auto_reply=1,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config={"work_dir": "web"},
llm_config=llm_config,
system_message="""Reply TERMINATE if the task has been solved at full satisfaction.
Otherwise, reply CONTINUE, or the reason why the task is not solved yet.""")
task1 = """今天是星期几?,还有几天周末?请告诉我答案。"""
user_proxy.initiate_chat(assistant,message=task1)
复杂案例
需求
今天是什么日期,比较Meta和Tesla的年初至今收益
用户代理和助手代理两种类型,完成如下任务
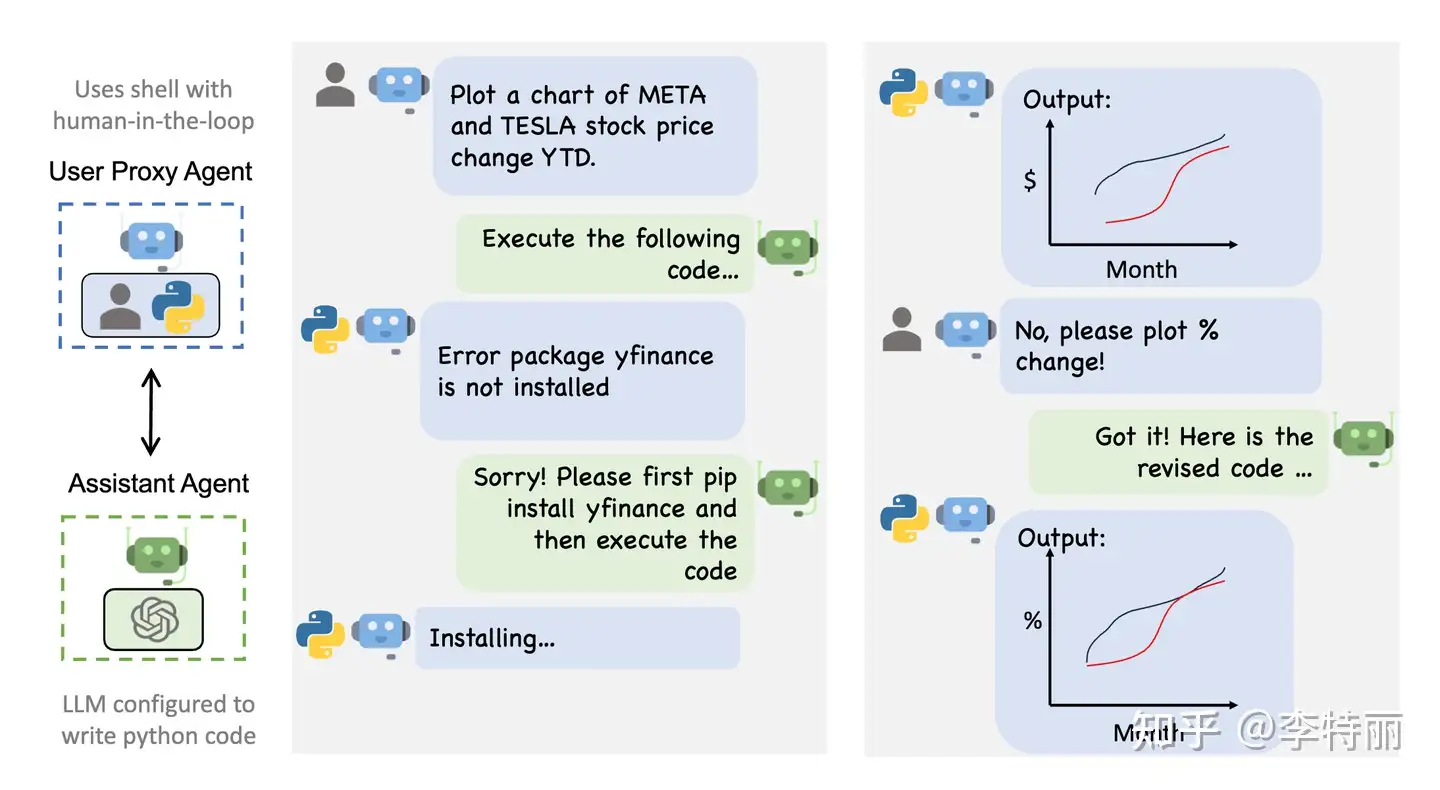
- 助手代理是增强版的代码解释器,生成、修改代码
- 用户代理负责执行,根据设置自动或手动运行代码
流程
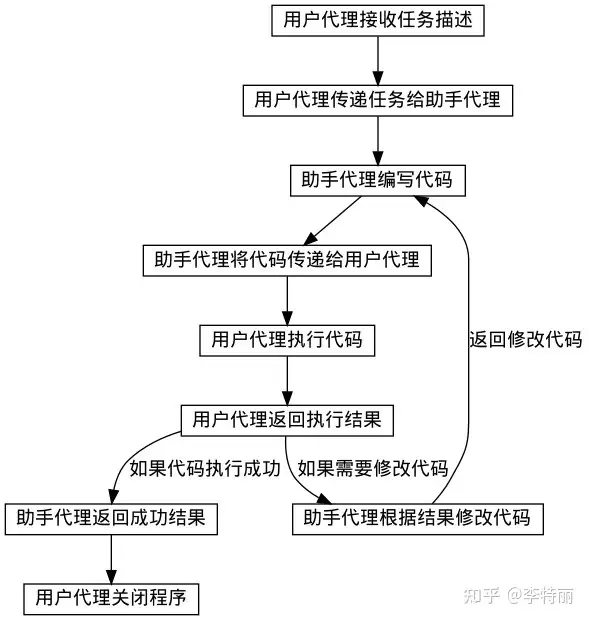
- 两个代理不断互动,用户代理接收任务描述,助手写代码,用户代理执行代码并且将代码的结果返回助手,助手根据代码执行的反馈修改代码或者返回成功的结果,完成任务后,返回结束标志给到用户代理,用户代理关闭程序。
具体
助手对用户代理说:
“首先,让我们使用Python获取当前日期。”
因此写了一些Python代码来获取日期。接下来,获取Meta和Tesla的年初至今收益。用Python中的 yfinance 库来获取股票价格。
如果还没有安装,请通过在终端运行 pip install yfinance 来安装这个库。这是助手告诉我安装那个库,然而用户代理将执行这个操作。
实际上它给了代码,用Python代码获取Meta和Tesla年初至今收益的方法。所以写了代码,使用了那个库。这段代码将以百分比的形式打印Meta和Tesla的年初至今收益。
用户代理执行了代码,但遇到了一个bug。这个 bug 从用户代理传递给到助手代理,把问题传回了助手,试图让助手修复它。
助手回到用户:
“为了之前的疏忽我道歉,变量today在第一段代码中定义了,但在第二段中没有定义。让我们更正它。”
所以这里它实际上在纠正,这里是新代码,这里是代码输出。
实际上工作。Meta的年初至今收益,Tesla的年初至今收益,以百分比表示。
然后助手回到用户:
“很好,代码已经成功执行。”
然后助手基本上以非常易读的方式打包了信息。所以在2023年10月2日,也就是今天,Meta的年初至今收益约为140%,Tesla的年初至今收益为131%。
现在助手输出了 TERMINATE 标志,代表该任务已经成功完成了,然后它输出了终止响应。
用户代理执行 is_termination_msg 匿名函数,获取到TERMINATE 标志后,停止了对话。
# 创建一个助手代理
assistant = autogen.AssistantAgent(
name="assistant",
llm_config={
"seed": 42, # seed for caching and reproducibility
"config_list": config_list, # a list of OpenAI API configurations
"temperature": 0, # temperature for sampling
}, # configuration for autogen's enhanced inference API which is compatible with OpenAI API
)
# 创建一个用户代理
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER", # 永远不征求用户意见,直接自动执行
max_consecutive_auto_reply=10,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"), # 终止消息特征
code_execution_config={
"work_dir": "coding",
"use_docker": False, # set to True or image name like "python:3" to use docker
},
)
# 使用用户代理发起一个会话,设置助理代理assistant,发起第一条消息message
user_proxy.initiate_chat(
assistant,
message="""What date is today? Compare the year-to-date gain for META and TESLA.""",
)
autogen既可以使用OpenAI,也可以用本地LLM
from autogen import oai
# create a chat completion request
response = oai.ChatCompletion.create(
config_list=[
{
"model": "chatglm2-6b",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
},
{
"model": "vicuna-7b-v1.3",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
}
],
messages=[{"role": "user", "content": "Hi"}]
)
print(response)
# ----------- 自定义消息、参数 --------
response = oai.ChatCompletion.create(
config_list=[
{
"model": "baichuan2-7b",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
}
],
messages=[
{"role": "system", "content": "你是一名资深的大语言模型领域的专家,精通模型架构原理和落地应用实践"},
{"role": "user", "content": "你好呀!"}
],
temperature=0.2,
top_k=1,
top_p=0.96,
repeat_penalty=1.1,
stop=["</s>"],
max_tokens=1024,
stream=False
)
print(response)
content = response.get("choices")[0].get("message").get("content")
print(content)
AutoGen 提供了 openai.Completion 或 openai.ChatCompletion 的直接替代,还添加了更多功能,如调优、缓存、错误处理和模板。例如,用户可以使用自己的调优数据,在预算范围内来优化 LLM 的生成内容。
# perform tuning
config, analysis = autogen.Completion.tune (
data=tune_data,
metric="success",
mode="max",
eval_func=eval_func,
inference_budget=0.05,
optimization_budget=3,
num_samples=-1,
)
# perform inference for a test instance
response = autogen.Completion.create (context=test_instance, **config)
【2024-2-4】实践通过, 本地工具调用
from autogen import AssistantAgent, UserProxyAgent, get_config_list, GroupChat, GroupChatManager
# =========== LLM 配置区 ===========
# config_list = get_config_list(["****"],
# ["****"], "azure",
# "2023-03-15-preview")
config_list = [
{
"model": "gpt-3.5-turbo-0613",
#"model": "gpt-4-0613",
"base_url": "https://****",
"api_type": "azure",
"api_key": "******",
}
]
llm_config = {
"config_list": config_list,
"temperature": 0.1,
"model": "gpt-35-turbo-16k",
}
# =========== Agent设置 ===========
weather = AssistantAgent(name="weather", llm_config=llm_config, )
travel = AssistantAgent(name="travel", llm_config=llm_config,)
# create a UserProxyAgent instance named "user_proxy"
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="TERMINATE",
is_termination_msg=lambda x: "tool_calls" not in x.keys(),
max_consecutive_auto_reply=10,
)
# =========== 本地工具调用 ===========
@user_proxy.register_for_execution()
@weather.register_for_llm(description="查询天气")
def query_weather(city: str) -> str:
return f"weather in {city} is sunny."
@user_proxy.register_for_execution()
@travel.register_for_llm(description="旅游推荐")
def travel_recommend(weather: str) -> str:
return f'结合天气{weather},我认为最好去爬山'
# =========== 群聊设置 ===========
group_chat = GroupChat(
agents=[user_proxy, weather, travel],
messages=[],
speaker_selection_method="auto",
allow_repeat_speaker=False,
max_round=12,
)
manager = GroupChatManager(
groupchat=group_chat,
is_termination_msg=lambda x: x.get("content", "").find("TERMINATE") >= 0,
llm_config=llm_config,
)
# =========== 启动会话 ===========
user_proxy.initiate_chat(
manager,
message="结合杭州的天气,给我推荐一些旅游的地方"
)
AutoGen 问题
功能局限
案例都是单层调用,一层树结构,user_proxy调weather或traval;
如果有多层调用怎么办?
- ① 再加一个assistant专门用来判断以上工具执行结果,正确才返回给user_proxy
- ② 两个weather agent同时执行,根据二者结果一致性情况再决定是否调travel;
多agent间复杂调用,更有实用价值,但autogen好像没说清楚怎么设计
autogen 没有现成可以支持这种场景的实现。但是可以扩展speak_selector_mehod和ChatManager。
通过定义SOP来实现上述场景
会话信息传递
- 上一个agent的输出会自动append到历史中
System prompt中如何引用?
- workflow 这样的确定的编排的场景。而不是agent的动态编排
单次调用,如果是批量请求,每次都需要initiate_chat? 如何获取中途所有agent的消息?
- 如果是用户批量消息, 每次都 initiate_chat。 agent 消息可以看上面的memory相关,每个agent都拥有和其他agent的消息历史
【2024-11-4】Magentic-One
【2024-11-4】微软推出 Magnetic-One(第二个框架),对现有的 AutoGen 框架进行简化。
Magentic-One 工作流程基于一个双循环机制:
- ● 外循环 (Outer Loop):协调者更新任务日志,制定和调整计划。
- ● 内循环 (Inner Loop):协调者更新进度日志,分配子任务给专业智能体,并监控执行情况。 如果进度停滞,则返回外循环重新规划。
功能特点:
- 与 Swarm 相似,Magnetic-One 同样适用于编程经验较少的用户,操作起来简便快捷。
- 系统预设了五个智能体,包括1个管理智能体和另外4个专用智能体:
- WebSurfer 负责在浏览器中浏览网页,以及与网页进行互动,
- FileSurfer 负责本地文件管理与导航,
- Coder 专注于代码编写与分析,
- ComputerTerminal 控制台访问权限,运行程序和安装库文件。
- 该框架基于 AutoGen 打造,是一个通用框架。
- 附带了 AutoGenBench 工具,专门用于评估智能体的性能。
不足之处:
- 对开源 LLMs 的支持较为复杂,不易实现。
- 灵活性有待提高;从某种程度上看,它更像是一款应用,而非一个框架。
- 目前文档资料和技术社区支持力度几乎为零,尚需加强。
架构

【2025.4.23】cooragent
【2025-4-23】清华LeapLab开源cooragent框架:一句话构建您的本地智能体服务群
清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。
- 项目链接:cooragent
人机协同的AGI
Cooragent 通过对话生成可协作的智能体,可编辑的 AGI - 让智能体通过 AGI 方式产生,但同时可以随时保持其可编辑性,与人协作,让智能体真正落地到每个人的生活和工作中。
Agent 技术层面
- Cooragent 基于 Agent 的协作框架, 通过动态上下文理解与自主归纳能力,Cooragent 彻底摒弃了传统 Agent 框架对人工设计 Prompt 的依赖。
- 系统利用深度记忆扩展和实时环境分析,自动生成高精度任务指令,显著降低使用门槛并提升智能体的适应性。
通过一句话创建一个具备强大功能的智能体,并与其他智能体协作完成复杂任务。
Cooragent 由两种工作模式:Agent Factory 和 Agent Workflow。
Agent Factory模式下,只需对智能体做出描述- Cooragent 就会根据需求生成智能体,自动分析用户需求,通过记忆和扩展深入理解用户,省去纷繁复杂 Prompt 设计。
- Planner 会在深入理解用户需求的基础上,挑选合适的工具,自动打磨 Prompt,逐步完成智能体构建。
- 智能体构建完成后,可以立即投入使用,但仍然可以对智能体进行编辑,优化其行为和功能。
Agent Workflow模式下, 只需描述要完成的目标任务- Cooragent 自动分析任务需求,挑选合适智能体进行协作。
- Planner 根据各个智能体擅长的领域,对其进行组合并规划任务步骤和完成顺序,随后交由任务分发节点 publish 发布任务。
- 各个智能领取自身任务,并协作完成任务。
Cooragent 在两种模式下不断演进,创造出无限可能。
Prompt-Free 设计
- Prompt 越来越成为负担。
- Prompt 设计需要考虑的因素太多,用户很难在短时间设计出合适的 Prompt。
- Cooragent 采用 Prompt-Free 设计,通过 Agent 的协作,深入理解上下文,自主归纳环境因素,自动生成 Prompt,从而省去 Prompt 设计。
快速安装
# 克隆仓库
git clone https://github.com/SeamLessAI-Inc/cooragent
cd cooragent
# 用uv创建并激活虚拟环境
uv python install 3.12
uv venv --python 3.12
source .venv/bin/activate # Windows系统使用: .venv\Scripts\activate
uv run src/service/app.py
# 安装依赖
uv sync
# 配置环境
cp .env.example .env
# 编辑 .env 文件,填入你的 API 密钥
# 运行项目
uv run cli.py
字节 Aime
大多数multi-agent系统采用经典的”计划-执行”框架,也开始在业务场景实现了落地。
但这个框架存在三大限制:计划执行过于刚性、智能体能力静态化、沟通效率低下。
【】字节最近提出更具动态性和通用性的的multi-agent框架-Aime。
Aime是一个改进的多智能体协作框架,核心思路是:
在经典plan-and-execute框架基础上,用流动自适应的架构替换传统静态工作流,解决三大限制:
- 🔒 计划执行刚性 - 无法根据反馈调整
- 🏗 智能体能力静态 - 配置固定缺乏灵活性
- 📡 沟通效率低下 - 缺乏统一协调机制
具备实时规划能力、行为体定制能力与全局状态感知能力的协作系统。
核心组件
- 动态规划器(Dynamic Planner)
- 这一模块堪称整个系统的“神经中枢”,负责拆解任务目标、制定执行策略,并在执行过程中进行迭代更新。它不断在“看大局”与“下指令”之间游走,实时根据任务执行反馈做出调整。
- 行为体工厂(Actor Factory)
- 这是系统中的“定制化工坊”,可按需生成具备特定能力与工具的智能行为体。它不再从固定角色池中挑选,而是为每一个任务量身定制最佳角色设定与知识资源,确保每一位“演员”都适配舞台。
- 动态行为体(Dynamic Actor)
- 这些是具体承担任务的“前线智能体”,通过 ReAct 框架在“推理—行动—观察”的循环中自主决策。每一个行为体不仅执行任务,还能自主判断何时向系统汇报进度与问题。
- 进度管理模块(Progress Management Module)
- 一个系统协同效率的保障,统一管理任务列表、实时状态与结果验证。它就像是所有智能体共享的“任务黑板”,每一个行动都在此标记,让整个 MAS 保持信息一致性和协作节奏。
GUI Agent
Dify
核心定位:专注于基于大语言模型(LLM)的应用开发与 AI
主要特点:
- 直观的界面,支持快速原型设计和生产级部署。
- 内置超过 50 种工具(如 Google Search、DALL·E、Stable Diffusion)。
- 支持 RAG(检索增强生成)管道和 ReAct 框架。
适用场景:
- 跨行业构建基于 LLM 的应用程序。
局限性:
- 对硬件或设备为中心的使用场景关注较少。
OmAgent
OmAgent 开源框架,专为轻松构建 设备端多模态智能体 而设计,具备高度灵活性和实时优化能力。
不仅限于传统框架,更进一步实现了 AI 与智能手机、可穿戴设备以及摄像头等硬件设备的无缝集成。
OmAgent 提供两种独特的示例代码:
- 行业实用应用:快速开发实际 AI 智能体的示例代码,适用于视频理解、物体识别、任务规划等真实场景。
- 研究导向实现:展示最新 AI 算法的实现,包括 ReAct、ToT 和 Divide-and-Conquer (DnC) 等,在顶级 AI 会议中发表,助力研究人员探索智能体的新能力。(诸如 ReAct、ToT 和 Divide-and-Conquer (DnC) 等在 AI 顶会中发表的前沿算法的复现示例,用于支持研究人员探索新智能体结构的能力)
核心功能
设备为中心:
- 原生支持智能设备,简化与手机、智能眼镜、IP 摄像头等硬件的集成。
- 后端流程优化,方便移动应用程序的无缝集成。
原生多模态支持:
- 内置先进的多模态模型,支持文本、音频、视频和图像的处理。
- 优化设备与用户之间自然、实时的交互体验。
工作流编排:
- 基于图结构的工作流引擎,支持高级任务管理。
- 实现前沿算法的应用,如 ReAct 和 Divide-and-Conquer (DnC)。
可扩展性与灵活性:
- 提供直观的界面,支持构建多角色、多场景的智能体。
- 支持动态工作流、长期记忆以及与 Milvus 等向量数据库的集成。
实时优化:
- 低延迟的端到端优化,确保即时反馈与卓越的用户体验。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
