- 智能体记忆设计
- Memory 记忆
- 人类记忆
- Agent 记忆
- 记忆存储
- 记忆原理
- 案例
- 结束
智能体记忆设计
Memory 记忆
记忆模块像 Agent大脑,积累经验、自我进化,让agent行为更加一致、合理和有效。
记忆模块主要记录 Agent 行为,并为未来 Agent 决策提供支撑
- (1)记忆结构
- 统一记忆:仅考虑短期记忆,不考虑长期记忆;
- 混合记忆:长期记忆和短期记忆相结合
- (2)记忆形式:主要基于以下 4 种形式
- 语言
- 数据库
- 向量表示
- 列表
- (3)记忆内容:常见3 种操作:
- 记忆读取
- 记忆写入
- 记忆反思
agentic memory is represented as:
Sensory memoryor short-term holding of inputs which is not emphasized much in agents.Short-term memorywhich is the LLM context windowLong-term memorywhich is the external storage such as RAG or knowledge graphs.
人类记忆
设计灵感来自人类记忆过程的认知科学研究。
记忆工作模式
记忆工作模型
The Multi-Store (Modal) Model. 最早的标准三阶段记忆存储结构的模型。- Atkinson-Shiffrin 三阶段模型
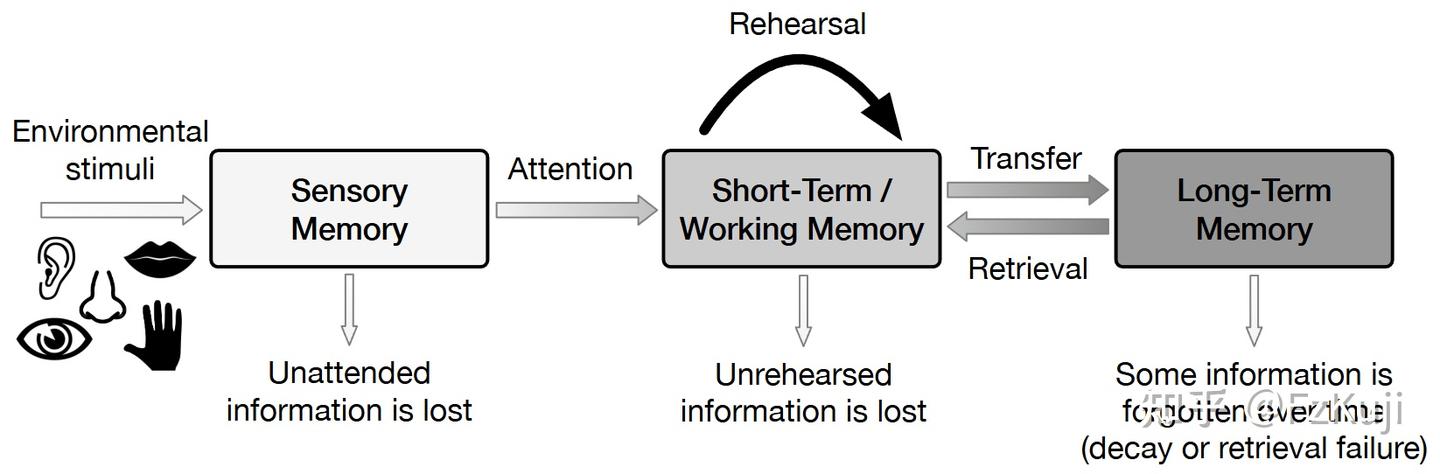
Working Memory Models短期记忆只是存储的信息,要对短期记忆进行整合、与长期记忆进行桥接,因此提出工作记忆概念Serial-Parallel-Independent (SPI) Model. (串行-并行-独立)模型- Serial(串行):感知信息进入系统是有顺序的,例如先通过感知系统,再进入语义或情节系统。
- Parallel(并行):一旦信息被编码,它可以同时被不同模块(如语义、情节)使用。
- Independent(独立):各个模块在使用上可以互相独立,不必每次都依赖其他模块来操作(例如可以有程序性记忆而没有情节记忆)。
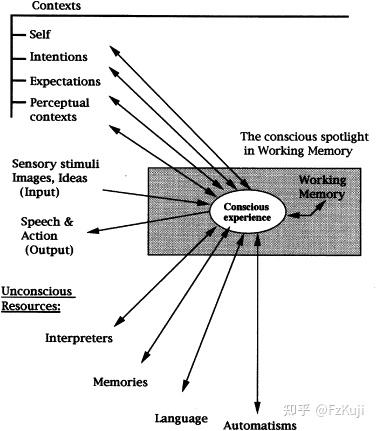
Global Workspace Theory (GWT) and the IDA/LIDA Framework. 全局工作空间理论- 全局工作空间理论(Global Workspace Theory, GWT)将意识视为一种“广播机制”,认为大脑中存在多个专门处理感知和认知任务的模块,只有当某条信息被广播到全局工作空间中,才能进入意识和工作记忆,供整个系统共享与处理。
- 将大脑想象成一个公司,很多人在后台干活(视觉、记忆、听觉),“广播室”把某个重要的信息广播出来(比如你突然想到今晚有个会议),所有系统都能听到这个广播,并据此调整工作(比如安排出门路线、调整计划)。
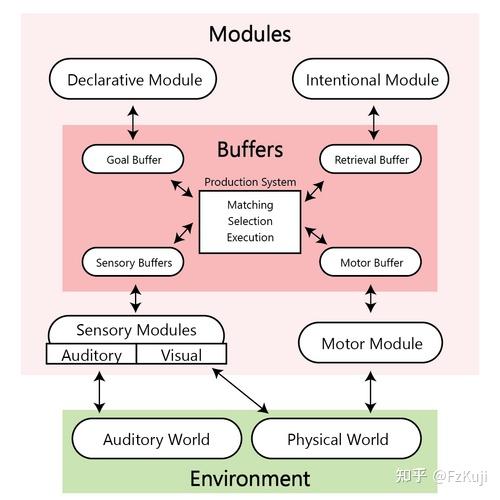
ACT-R and Cognitive Architectures. 思想的适应性控制-理性- 综合性认知架构,模拟人类如何感知、记忆、思考与行动。将大脑划分为多个功能模块,如视觉、动作、陈述性记忆和程序性记忆,各模块通过缓冲区交互,构成完整的认知流程。ACT-R 区分事实知识(chunk)与条件规则(if-then),通过符号规则驱动认知行为,同时引入数学函数进行次符号调节,以更真实地还原人类的反应速度、记忆强度和策略选择。
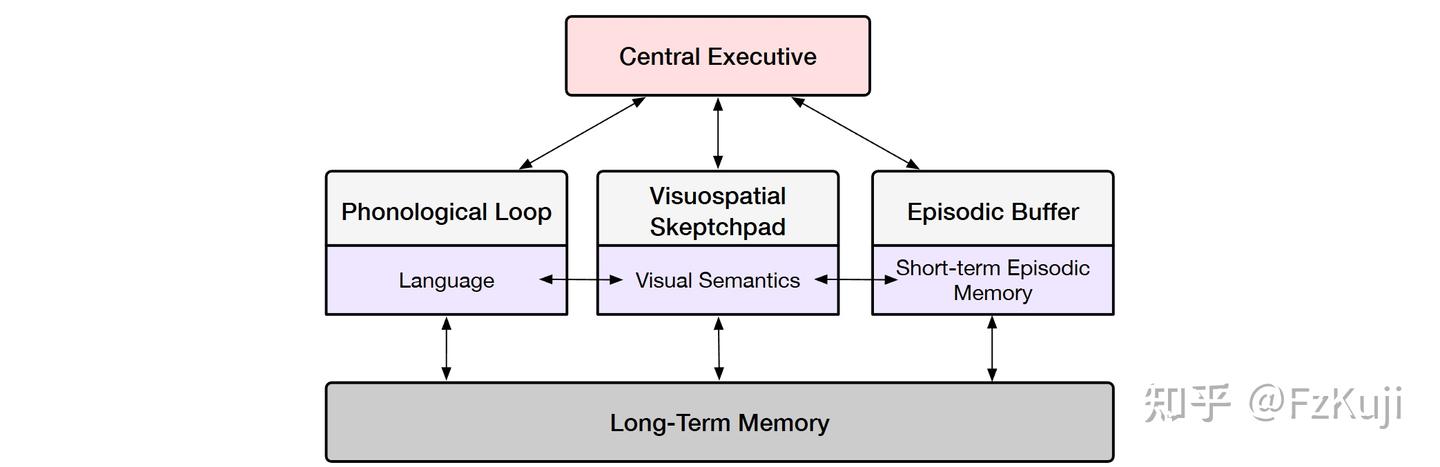
详见站内专题: 大脑工作原理
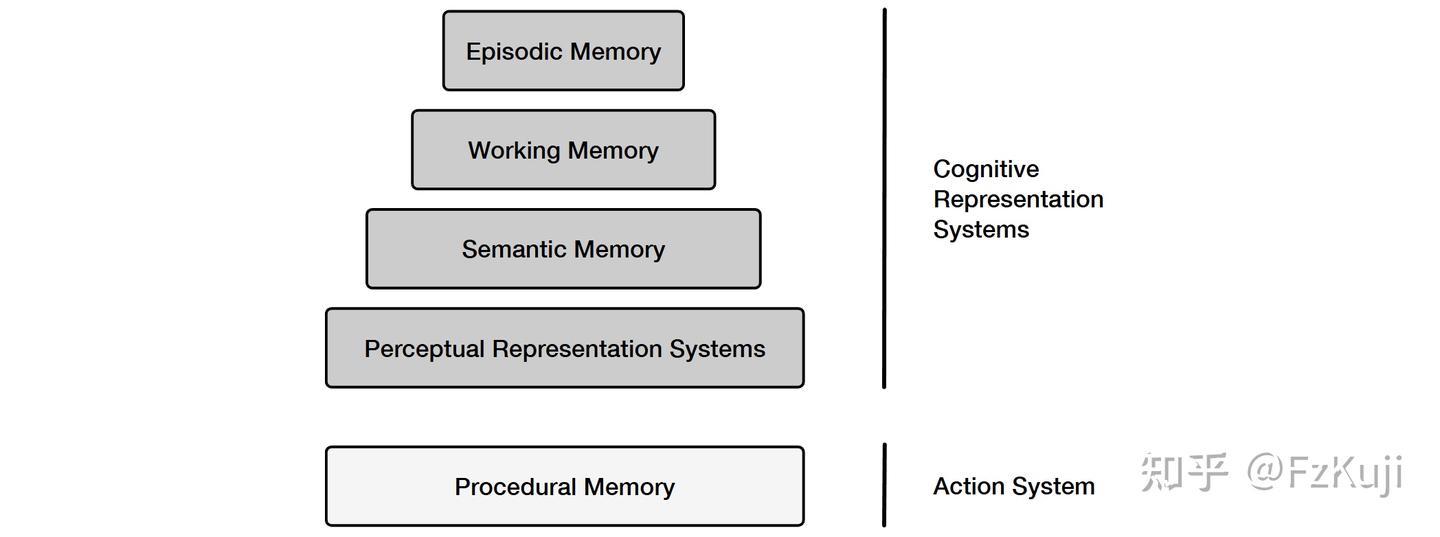
记忆类型
人类记忆发展:
- 感官记忆,记录、感知输入;
- 短期记忆,暂时保持信息;
- 长期记忆,在更长的时间内巩固信息。
【2024-7-4】张亚勤: 人类拥有DNA记忆、短期记忆、海马体记忆、皮层记忆、长期记忆。
记忆定义为用于获取、存储、保留和后续检索信息的过程,人类大脑中主要有三种类型的记忆。
感官记忆(Sensory memory)- 这种记忆处于记忆的最早阶段,提供了在原始刺激结束后保留感官信息(视觉,听觉等)印象的能力,通常只持续几秒钟。
- 感官记忆的子类别包括图标记忆(视觉)、回声记忆(听觉)和触觉记忆(触觉)。
短时记忆(STM)或工作记忆(Working Memory)- 存储当前意识到的所有信息,以及执行复杂的认知任务(如学习和推理)所需的信息,大概可以存储7件事,持续20-30秒。
长期记忆(LTM)- LTM 将信息存储相当长的时间,范围从几天到几十年不等,具有基本上无限的存储容量。LTM有两种亚型:
- 1)显式/陈述性记忆,即对事实和事件的记忆,指那些可以有意识地回忆起来的记忆,包括情景记忆(事件和经验)和语义记忆(事实和概念)。
- 2)隐式/程序性记忆,这种类型的记忆是无意识的,包括自动执行的技能和例程,比如骑自行车或在键盘上打字。

图解:
- 机器坏人(AI版)小红书帖子
金鱼记忆
大语言模型(LLM)的 “先天短板”—— 记忆容量有限。
就像大脑的短期记忆,只能临时存下一小段信息,超过 “内存上限” 就会自动 “清缓存”。
LLM 都有 “上下文窗口” 限制,能记住的对话内容长度固定,可能是几千字,也可能几万字。一旦超过这个范围, 早期信息就会被 “挤出去”。
- 跟 AI 从早上聊到晚上,从工作方案聊到周末聚餐,中间提到了 10 个关键信息。
- 但到了晚上,可能只记得最后 2 个,前面 8 个就像从没说过一样。
这种 “金鱼记忆”,让 LLM 在处理长对话、复杂任务时特别吃力。
LLM “无限记忆”有什么好处:
- 长期陪伴更贴心:AI 助手记住用户 3 年前提过的梦想职业,2 年前的过敏食物,甚至上周随口说的一句 “最近压力大”,下次聊天时能精准戳中需求。
- 复杂任务更靠谱:做一个跨季度项目规划,AI 能记住每个阶段的进度、遇到的问题、合作方的要求,不会中途 “断片”;写一本长篇小说,它能牢牢抓住人物设定、剧情伏笔,避免前后矛盾。
- 个性化服务更深入:学生用 AI 补习,它能记住你从高一到高三的知识漏洞,持续调整学习计划;职场人用 AI 处理工作,它能记住公司的流程、客户的习惯,像个 “老同事” 一样默契。
Agent 记忆
Agent 记忆结构设计也借鉴了这些人类记忆特点。
- 短期记忆类似 受限于transformers上下文窗口的输入信息。
- 而长期记忆则类似于外部向量存储,Agent可以根据需要快速查询检索。
记忆来源: 智能体记忆内容的出处。
三种类型记忆来源:
- 内部任务信息(Inside-trial Information): 当前任务执行信息
- 单个任务或交互过程中收集的数据。仅与当前正在进行的任务有关。
- 一个对话人物, Agent 要记住上下文信息,以便生成连贯的回应
- 跨任务信息( Cross-trial Information ): 历史任务重的长期积累学习
- 跨越了多个任务或交互过程,它包括了Agent在不同任务中积累的经验、学到的教训以及可能的模式识别
- 旅行计划中, Agent 从用户预订过的机票酒店,用户反馈 这类跨任务信息优化改进执行策略
- 外部知识(External Knowledge)
- Agent 与环境交互之外的信息。
- 可能是通过API调用、数据库查询或访问在线资源(如维基百科)等方式获得的
对应到语言模型概念:
感官记忆作为原始输入(包括文本、图像或其他形式)的学习嵌入表征;短期记忆是上下文学习(in-context learning),非常短且影响范围有限,受到Transformer的上下文窗口长度的限制。长期记忆作为智能体在查询时可用的外部向量存储,可通过快速检索访问。
- 【2025-3-31】ADVANCES AND CHALLENGES IN FOUNDATION AGENTS
Meta的划分:
感觉记忆(Sensory Memory):同理感觉记忆应当为原始数据输入,即摄像头、麦克风等各种传感器获取到的原始信息。短期记忆(Short-Term Memory):Meta认为短期记忆充当着连接感觉记忆和长期记忆的瞬时动态工作空间。同时短期记忆可以细分为上下文记忆和工作记忆。- 上下文记忆:通过感觉记忆处理得到的基础记忆
- 工作记忆:对上下文记忆进行进一步操作得到的记忆
长期记忆(Long-Term Memory):这里Meta和人类记忆一样,将长期记忆分得很细,但是很明显不同研究的实现方式不一样,Meta将这些工作杂揉了起来。- 显式记忆(Explicit Memory):可被直接提取与使用的记忆
- 语义记忆(Semantic Memory):存储通用知识、事实、概念。比如,鱼含有蛋白质、刀在厨房
- 情节记忆(Episodic Memory):存储特定事件、交互历史、情境路径。从厨房走到客厅再走到花园
- 隐式记忆(Implicit Memory):无需显式调用即可影响行为
- 程序性记忆(Procedural Memory):储存可复用的技能或执行计划;提升任务效率
- 启动效应(Priming):记录状态变化与响应模式,使智能体能快速做出合适反应
- 显式记忆(Explicit Memory):可被直接提取与使用的记忆
Agentic Memory
感知记忆
Sensory Memory
感知记忆目前在大模型中缺失,更像模型输入,而非中间产物。
最简单的例子就是:好了伤疤忘了痛。
对于感官,很难将当时的信息保留下来。闭上眼睛,图像就没有了;捂上耳朵,声音就没有了。
即使是大模型内部思考,也还是明文思考,直接print出来,不知道大模型会不会不好意思。
大语言模型的问题尤为严重,因为编码后的文本是现实中不存在的事物,因此多模态模型不仅要考虑到将图片和问题统一到一个特征空间,还需要考虑他们本身不是一个维度的事物。
短期记忆
工作记忆 记录当前环境信息
- 最近的感知输入、活跃目标、及时反馈和内部推理信息。
Working memory reflects the agent’s current circumstances:
- • Recent perceptual input
- • Active goals
- • Results from intermediate, internal reasoning.
如何管理短期记忆
- 修剪(Trimming): 调用 LLM 前,简单移除对话历史的开头或结尾 N条消息。
- 总结(Summarization): 将早期对话内容进行总结,用一段摘要替换掉原始消息。
- 永久删除(PermanentDeletion): 从LangGraph 等框架的状态中彻底移除某些消息。
- 自定义策略(Custom Strategies): 如根据消息的重要性进行过滤,保留关键信息,删除不重要的闲聊。
长期记忆
Long-Term memory 长期记忆类型
- ❑ 程序记忆 Procedural memory: 存储系统本身信息
- 定义智能体知道该怎么做的逻辑和流程,通常被 硬编码或通过学习 固化 在代码中。
- stores the production system itself
- ❑ 语义记忆 Semantic memory: 存储环境事实知识
- stores facts about the world
- 存储与特定用户相关的过去交互和具体事件,是实现个性化和持续学习的关键。
- ❑ 情景记忆 Episodic memory:存储历史行为信息
- stores sequences of the agent’s past behaviors
- 存储关于世界的事实性知识,通常通过向量搜索或 RAG 从外部源获取并内化。
获取长期记忆最常见的方式是通过“语义搜索”。
- 用一个 embedding 模型,将所有的记忆文本都转化为一个向量。而后续跟模型的交互信息也可以通过同样的 embedding 模型转化为向量,计算相似度来找到最相似的记忆文本。最后再将这些记忆文本拼接到 prompt 里,作为模型的输入。

- 这类方法最热门的开源项目可以参考 OpenAI 官方的 ChatGPT Retrieval Plugin 和 Jerry Liu 的 LlamaIndex。
这种拓展模型记忆的模式相比人类大脑的运作方式来说感觉还有些“粗糙”,所谓的长期与短期记忆(包括 LangChain 与 LlamaIndex 中一些更复杂的实现),仍然是比较“hard coded”的感觉。如果未来在模型 context size 上有突破性的研究进展,那么当前的这类模式或许就不再需要了。
永久记忆
【2025-1-3】“AI将在2025拥有永久记忆”,谷歌前 CEO 施密特预测道
前谷歌CEO埃里克·施密特(Eric Schmidt)在最近的预测中指出,未来几年内,人工智能(AI)将迎来三项革命性的突破,这些突破不仅有可能实现,而且其影响力“被低估而非高估”。
当前AI的上下文窗口相当于“短期记忆”。然而,2025年,AI将实现“永久记忆”,这将彻底改变其信息处理和存储的方式。
【2024-8-9】谷歌研究院最新发表的论文《Leave No Context Behind》提出了一种名为“无限注意力”的新方法,使AI能够像一个永不疲倦的助手,持续读取和记忆大量信息,只保留最关键的内容。
将基于transformer的大型语言模型(LLMs)扩展到无限长的输入,同时保持有界的内存和计算。
- 一个关键组成部分是一种新的注意力技术,称为
Infini-attention。 - Infini-attention将压缩记忆整合到传统的注意力机制中,并在单个变换器块中构建了掩蔽的局部注意力和长期的线性注意力机制。
- 在长上下文语言建模基准测试、1M序列长度的密钥上下文块检索和500K长度的书籍摘要任务上,使用1B和8B LLMs展示了我们方法的有效性。引入了最小有界的内存参数,并实现了LLMs的快速流式推理。
这种“永久记忆”技术将广泛应用于多个领域。
例如,教育领域的AI导师能够记住学生的学习进度和偏好,提供个性化的教学方案;医疗领域的AI助手可以长期跟踪患者的健康数据,提供持续的健康管理建议。此外,施密特预测,这项技术将在科学研究中发挥重要作用,帮助研究人员记住和整合大量文献和实验数据,加速科研进程。
联想记忆
今天的大语言模型来说,几乎不存在任何「持续学习」。
医学类比:顺行性遗忘症(Anterograde Amnesia)。特征:
- 短期记忆正常
- 长期记忆也还在
但👉短期记忆,无法转移为长期记忆。永远活在「现在」
知识主要来自两部分:
- 预训练阶段学到的长期知识、
- 当前上下文里的短期信息。
两者之间几乎完全没有通道。AI模型无法自然地把「刚刚学到的东西」,沉淀为未来可复用的知识。
真正的问题不是参数不够多,不是数据不够大,也不只是算力不够。
问题本质:「短期记忆」和「长期记忆」之间,根本没有一条自然的知识转移通道
如果这条通道不存在,所谓「持续学习」,就永远只是一个口号。
核心问题:该如何构建一种机制,让AI模型像人类一样,将「现在」的经历沉淀为「未来」的知识?
模型到底是「怎么记住东西的」?
- 大模型给出的答案,不是Transformer,不是参数量,而是一个更原始、更根本的概念:
联想记忆(Associative Memory)。
「联想记忆」是人类学习机制的基石。本质是通过经验将不同的事件或信息相互关联。
技术上,联想记忆就是键值对映射:
- Key:线索
- Value:与之关联的内容
但关键在于,联想记忆的映射关系不是预先写死的,而是「学出来的」。
注意力机制本质是一种联想记忆系统:学习如何从当前上下文中提取key,并将其映射到最合适的value,从而产生输出。
如果不仅优化这种映射本身,还让系统去元学习(meta-learn)这种映射过程的初始状态,会发生什么?
基于对联想记忆的理解,提出通用框架,名为 MIRAS,用于系统化地设计AI模型中的记忆模块。
详见站内专题:大模型发展方向:嵌套学习
记忆存储
记忆如何保存?
记忆形式:主要基于以下 4 种形式
- 语言
- 数据库
- 向量表示
- 列表
记忆格式上,可以自然语言或嵌入向量形式存储。
文本形式的记忆和参数形式的记忆同样也是各有千秋,它们适合不同的应用场景。
- 如果要快速回忆最近的对话,文本形式可能更合适;
- 而如果要存储大量知识,或者需要一个稳定可靠的知识库,参数形式可能更有优势。
各种记忆形式案例总结
(1) 文本形式
分析
- 好处: 易于理解和实现,而且读写速度都很快。
- 但是,如果记忆太长,就会占用很多空间,影响处理速度。
文本形式记忆可进一步细分为几种类型:
- 存储完整的交互信息: ReAct
- 最近的交互信息
- 检索到的交互信息和外部知识。
MemGPT 分别体现出了短期和召回记忆;
Qwen-Agent中,通过 chatml 特有多轮格式<im_start> <im_end>进行分割历史的会话,最后一轮才加上ReAct的prompt。
(2) 参数形式
这种方式更高级。不直接存储文字,而是把记忆转换成模型参数,就像是把知识压缩成精华。
- 好处: 不受文本长度限制,而且存储效率更高。
- 但是,写入时可能需要更多的计算,而且解释起来也不如文本形式直观。
参数形式的记忆则涉及更复杂的技术,比如: fine-tuning 和 editing。
- 微调可以帮助模型快速学习特定领域的知识
- 而知识编辑则可以精确地更新或删除某些记忆,避免影响其他无关的知识。
经典 Character-LLM: A Trainable Agent for Role-Playing,用微调方式,
记忆原理
记忆流程
Agent通过记忆阅读、记忆写入和记忆反思三个关键操作与外部环境进行交互。
- 记忆阅读: 提取有意义的信息, 以增强Agent的行动;
- 记忆写入: 将感知到的环境信息存储在记忆中;
- 记忆反思: 模拟了人类审视和评估自己的认知、情感和行为过程的能力。
【2024-4-21】人民大学高瓴学院, Memory 设计综述 A Survey on the Memory Mechanism of Large Language Model based Agents
人民大学关于memory设计的最新资料:LLM_Agent_Memory_Survey
【2024-8-13】Agent memory大揭秘:轻松搞定记忆写入、管理、读取
记忆操作像 LLM大脑,三个部分组成:记忆写入、记忆管理和记忆读取。
- 记忆写入: LLM短期记忆, 接收到新信息时(聊天),以特殊编码方式存入”大脑”
MemGPT: 自我指导是否写入记忆,智能体根据上下文决定是否更新MemoGPT: 聊天时做总结, 提取对话片段的主题, 关键词形式保存,便于查找, topic,summary,dialogues
- 记忆管理: LLM长期记忆, 整理短期记忆信息;信息归类, 找出最重要的部分,忘掉次要信息,保持大脑的清晰、高效
MemoryBank: 智能体从对话内容中提炼每日大事记, 同时不断评估,生成个性特征Voyager: 智能体根据环境反馈优化记忆Generative Agents: 智能体自我反思,获取更高层次的信息. 从事件信息中生成抽象想法GITM: 记忆模块中总结多个计划的关键行动, 建立各种情况下的共同参考计划, 提取最重要的行动步骤
- 记忆读取: 使用LLM记忆解决问题
ChatDB: SQL操作完成记忆阅读MPC: 从记忆池里检索相关记忆, 使用思维链示例方式,忽略次要信息ExpeL: 用Faiss向量库作为记忆池, 找出与当前任务最相似的k个成功示例.
Agent 记忆机制
Agent 和大语言模型最大的不同: Agent 能够在环境中不断进行自我演化和自我学习;而这其中,记忆机制扮演了非常重要的角色。
从 3 个维度来分析 Agent 的记忆机制:
- (1)Agent 记忆机制设计, 常见有以下两种记忆机制:
- 基于向量检索的记忆机制
- 基于 LLM 总结的记忆机制
- (2)Agent 记忆能力评估,主要需要确定以下两点:
- 评估指标
- 评估场景
- (3)Agent 记忆机制演化分析:
- 记忆机制的演化
- 记忆机制的自主更新
最大内积搜索 Maximum Inner Product Search (MIPS)
外部记忆可以缓解有限注意力span的限制,常用的操作是将信息嵌入表征保存到支持快速最大内积搜索(MIPS)的向量存储数据库中。
为了优化检索速度,一般都会选择近似最近邻(ANN,approximate nearest neighbors)算法返回前k个最近邻节点,牺牲一点准确性以换取巨大的速度提升。
常用的ANN算法包括: LSH(Locality-Sensitive Hashing),ANNOY, HNSW, FAISS, ScaNN
快速MIPS的几种常见ANN算法选择:更多
- LSH(Locality-Sensitive Hashing):它引入了一种哈希函数,使得相似的输入项在很大概率下被映射到相同的桶中,而桶的数量远远小于输入项的数量。
- ANNOY(Approximate Nearest Neighbors Oh Yeah):核心数据结构是随机投影树,是一组二叉树,其中每个非叶节点表示将输入空间分成两半的超平面,每个叶节点存储一个数据点。树是独立且随机构建的,因此在某种程度上模拟了哈希函数。ANNOY搜索在所有树中进行,通过迭代搜索与查询最接近的一半,并汇总结果。这个想法与KD树有很大的关联,但可扩展性更强。
- HNSW(Hierarchical Navigable Small World):它受到小世界网络( small world networks)的启发,其中大多数节点可以通过少数步骤到达任何其他节点;例如,社交网络中的“六度分隔”特性。HNSW构建了这些小世界图的分层结构,其中底层包含实际数据点。中间层创建了快捷方式以加快搜索速度。在执行搜索时,HNSW从顶层的随机节点开始,并向目标节点导航。当无法再靠近时,它会下降到下一层,直到达到底层。上层的每次移动都有可能在数据空间中覆盖较大的距离,而下层的每次移动则会提高搜索质量。
- FAISS(Facebook AI Similarity Search):它基于这样的假设,在高维空间中,节点之间的距离遵循高斯分布,因此应该存在数据点的聚类。FAISS通过将向量空间划分为聚类,并在聚类内部进行量化的方式来应用向量量化。搜索首先使用粗糙的量化方法寻找聚类候选项,然后再使用更精细的量化方法进一步查找每个聚类内的数据。
- ScaNN(Scalable Nearest Neighbors):ScaNN的主要创新在于各向异性向量量化。它将数据点 $x_i$ 量化为 $\tilde{x}_i$ ,使得内积 $\langle q, x_i \rangle$ 尽可能与原始距离 $\angle q, \tilde{x}_i$ 相似,而不是选择最接近的量化质心点。
案例
各个 记忆实现案例 在以上版面的分布对比
实际应用中
- 有些系统只模拟人类的短期记忆,通过上下文学习实现,记忆信息直接写在prompt中。
- 而有些系统则采用了hybird memory(混合记忆架构),明确模拟了人类的短期和长期记忆。短期记忆暂时缓冲最近的感知,而长期记忆则随着时间的推移巩固重要信息。
案例
- MemAgent
- MemOS
- Mem
- A-Mem
【2024-2-7】MEMORYLLM
记忆自动更新
【2024-2-7】 Amazon、UC SD、UC LA
LLM 部署后通常保持静态,难以注入新知识。
目标
- 构建可自更新参数的模型,有效且高效地整合新知识。
MEMORYLLM 由一个transformer和transformer潜空间内固定大小的记忆池组成。
MEMORYLLM 可以使用文本知识进行自我更新并记忆先前注入的知识。
评估
- MEMORYLLM 能够有效地整合新知识
- 同时,该模型表现出长期信息保留能力。
- 操作完整性,即使在近一百万次记忆更新后也没有任何性能下降的迹象。
代码和模型已开源
- wangyu-ustc/MemoryLLM: The official implementation of the ICML 2024 paper “MemoryLLM: Towards Self-Updatable Large Language Models”
【2025-5-18】Mem0
自适应衰减
【2025-5-18】再见RAG,这款让AI拥有超强记忆力的开源神器,绝了!,含图解
Mem0 是一款为大型语言模型(LLM)设计的智能记忆层框架
- GitHub mem0 结合向量库检索、知识图谱检索、记忆衰减机制
- 2024年7月上线GitHub即引爆社区,两天斩获13K星,被开发者誉为”AI记忆革命的开源先锋”。
- 它能让AI记住用户的偏好、对话历史和操作习惯,像老朋友一样提供连续陪伴式服务,彻底打破传统AI”金鱼记忆”的局限。
核心功能
- 超强记忆网络
- 通过用户级/会话级/代理级三级记忆体系,实现跨平台记忆联动。比如用户Alice在周一提及”喜欢打网球”,周三咨询运动课程时,AI能自动关联记忆推荐相关内容。
- 动态进化能力
- 采用遗忘曲线算法,自动衰减过时信息(如三年前的工作习惯),强化高频使用数据(如最近偏好的咖啡口味),让记忆库像人类大脑般智能更新。
- 零代码接入
- 提供5行Python极简API,开发者无需理解底层技术即可快速集成。
- 多模态记忆管理
- 支持文本/图像/结构化数据混合存储,通过向量数据库+图数据库技术,实现”星巴克拿铁”→”咖啡偏好”→”周五消费习惯”的立体关联。
- 场景自适应
- 在医疗场景自动强化病历记忆,在教育场景侧重学习进度跟踪,通过场景感知算法动态调整记忆权重,准确率达92%。
| 模块 | 技术栈 | 功能亮点 |
|---|---|---|
| 记忆存储 | Qdrant向量数据库 | 百万级数据毫秒检索 |
| 关系解析 | Neo4j图数据库 | 构建用户-行为-场景关系网络 |
| 语义理解 | GPT-4 Turbo | 精准提取对话中的关键记忆点 |
| 记忆更新 | 自适应衰减算法 | 动态优化记忆权重 |
| API网关 | FastAPI框架 | 支持5000+QPS高并发请求 |
与 RAG 对比
| 特性 | Mem0 | 传统RAG |
|---|---|---|
| 记忆时效 | 动态衰减更新 | 静态文档存储 |
| 关系理解 | 实体网络关联 | 关键词匹配 |
| 交互连续性 | 跨会话记忆延续 | 单次会话有效 |
| 个性化程度 | 自适应进化 | 固定模板响应 |
| 部署成本 | 支持增量学习 | 需全量数据重建 |
| 适用场景 | 长期陪伴型应用 | 短期问答场景 |
应用场景
- 虚拟伴侣养成计划
- 记录用户的情感偏好和聊天习惯,当用户说”今天好累”时,AI不仅能安慰,还会提醒:”上次你说听周杰伦的歌会放松,要播放《晴天》吗?”
- 智能客服升级方案
- 在电商场景中,Mem0让客服机器人记住用户3天前的退货记录,当用户再次咨询时主动提示:”您购买的XX商品已安排专人上门取件”。
- 个性化学习引擎
- 通过记忆用户的知识薄弱点,当检测到用户多次拼错”accommodate”时,自动推送定制化练习题,记忆准确率提升73%。
- 医疗健康管家
- 持续跟踪患者用药记录,在患者说”最近头晕”时,结合既往血压数据提醒:”您上周收缩压140mmHg,建议优先复查心血管科”。
- 游戏AI革命
- 在RPG游戏中,NPC会记住玩家三小时前救助村民的选择,在后续剧情中给出特殊奖励,使玩家留存率提升41%。
- 智能办公助手
- 自动记忆会议纪要重点,当用户查询”Q2销售目标”时,直接调取最近三次会议数据生成对比图表。
以下代码实现记忆存储与调用:
from mem0 import Memory
m = Memory()
m.add("用户每周五购买拿铁", user_id="tom")
print(m.search("推荐咖啡", user_id="tom")) # 自动关联周五拿铁偏好
环境部署
# 安装核心库
pip install mem0ai
# 启动向量数据库
docker run -p 6333:6333 qdrant/qdrant
记忆管理实战
from mem0 import Memory
memory = Memory()
# 添加记忆
memory.add("客户王总喜欢蓝山咖啡", user_id="VIP001")
# 智能检索
print(memory.search("王总的饮品偏好", user_id="VIP001"))
# 输出:蓝山咖啡(相似度0.93)
# 动态更新
memory.update(memory_id="m1", data="王总最近改喝低因咖啡")
配置
config = {
"vector_store": {
"provider": "qdrant",
"config": {"host": "localhost", "port": 6333}
},
"graph_store": {
"provider": "neo4j",
"config": {"url": "neo4j://localhost:7687"}
}
}
m = Memory.from_config(config) # 支持多数据库联动
【2025-6-9】G-Memory
现有多智能体系统问题
- 现有LLM多智能体系统(MAS)大多靠“一次性”流程或人工SOP,缺乏“自我进化”能力:本质是因为缺一套能跨任务、跨角色沉淀协作经验的记忆架构。
【2025-6-9】NUS、Tongji University、UCLA 等发布 G-Memory:LLM多智能体的”集体记忆”机制
G-Memory 作为多智能体系统的“集体记忆”插件,结构化组织多智能体复杂记忆,让智能体从单任务执行者进化为跨任务专家。
即插即用
- 无需改现有框架,一行代码即可把AutoGen/DyLAN/MacNet升级为“会成长的团队”
原理
G-Memory核心洞察
受“组织记忆理论”启发,把冗长的多智能体交互拆成三层图:
- Insight Graph:可迁移的高层策略
- Query Graph:任务之间的语义脉络
- Interaction Graph:细粒度对话轨迹
像公司知识库一样,既存“最佳实践”,也留“踩坑记录”。
双向往返记忆检索
收到新任务后:
- ① 向上遍历→提取通用经验(Insight)
- ② 向下遍历→找到相似任务的关键对话片段(Interaction)
- ③ 按角色个性化投喂,避免上下文爆炸。
效果
核心实验简介
- 在5大基准+3类LLM+3个MAS框架上测试
- 具象任务成功率↑20.89%,知识问答准确率↑10.12%
- 额外token仅增加1.4M,远低于SOTA的2.2M
【2024-7-4】MemAgent
【2024-7-4】从 “记不住” 到 “忘不了”,MemAgent 可能不是简单地扩大内存,而是让 LLM 学会像人类一样 “管理记忆”。
字节跳动Seed团队与清华大学联合提出全新的长文本处理智能体——MemAgent。
在别的方法还在绞尽脑汁拉长上下文窗口,或依赖人工设定注意力规则时,MemAgent另辟蹊径,通过端到端强化学习让智能体像人类一样”边读边记”,再基于最终记忆进行作答。
这一设计不仅实现了线性时间复杂度(O(N)),还能在仅8K上下文长度训练的基础上,近乎无损外推至3.5M的问答任务(性能损失<5%),并在512K的RULER测试中达到95%以上的准确率。
字节提出RL驱动的记忆智能体 MemAgent,开辟LLM长上下文解决新路径
- 主页 MemAgent
- MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
- Github MemAgent
- 解读 https://news.qq.com/rain/a/20250709A08H4V00
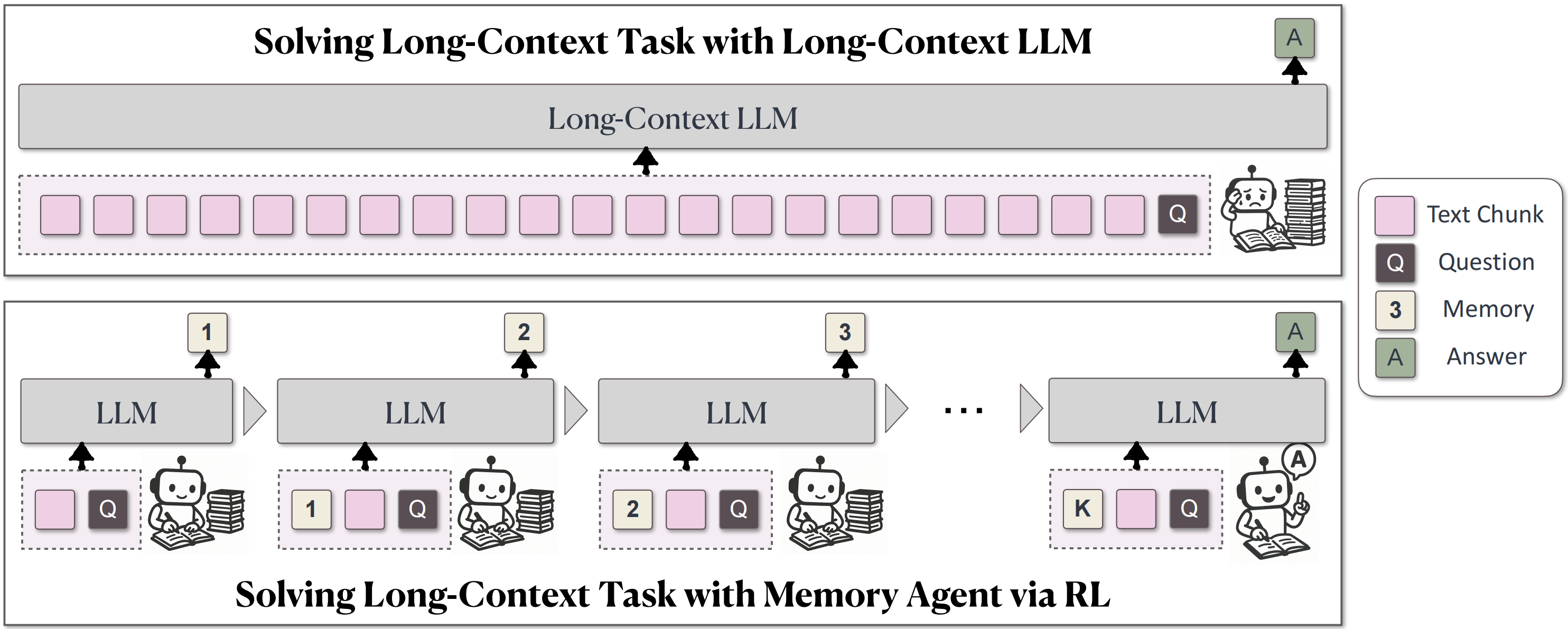
受人类处理长文档过程的启发,MemAgent会把长文章分成小块,每读完一段就记下重点,最后根据记住的内容回答问题。
具体来说,MemAgent 工作流分为两个阶段:
- 上下文处理模块中,模型每次接收一个文本块和当前记忆,通过提示模板迭代处理文本块并更新记忆;
- 当数据流处理完成后,最终的答案生成模块将仅依据问题陈述和记忆单元生成最终答案。
更新记忆的过程是覆盖式
论文将记忆覆盖决策构建为强化学习问题:智能体因保留有用信息或剔除冗余内容而获得奖励。通过新提出的 Multi-Conv DAPO 算法优化该目标,使模型能够学会在保持答案关键事实的前提下进行极致压缩。
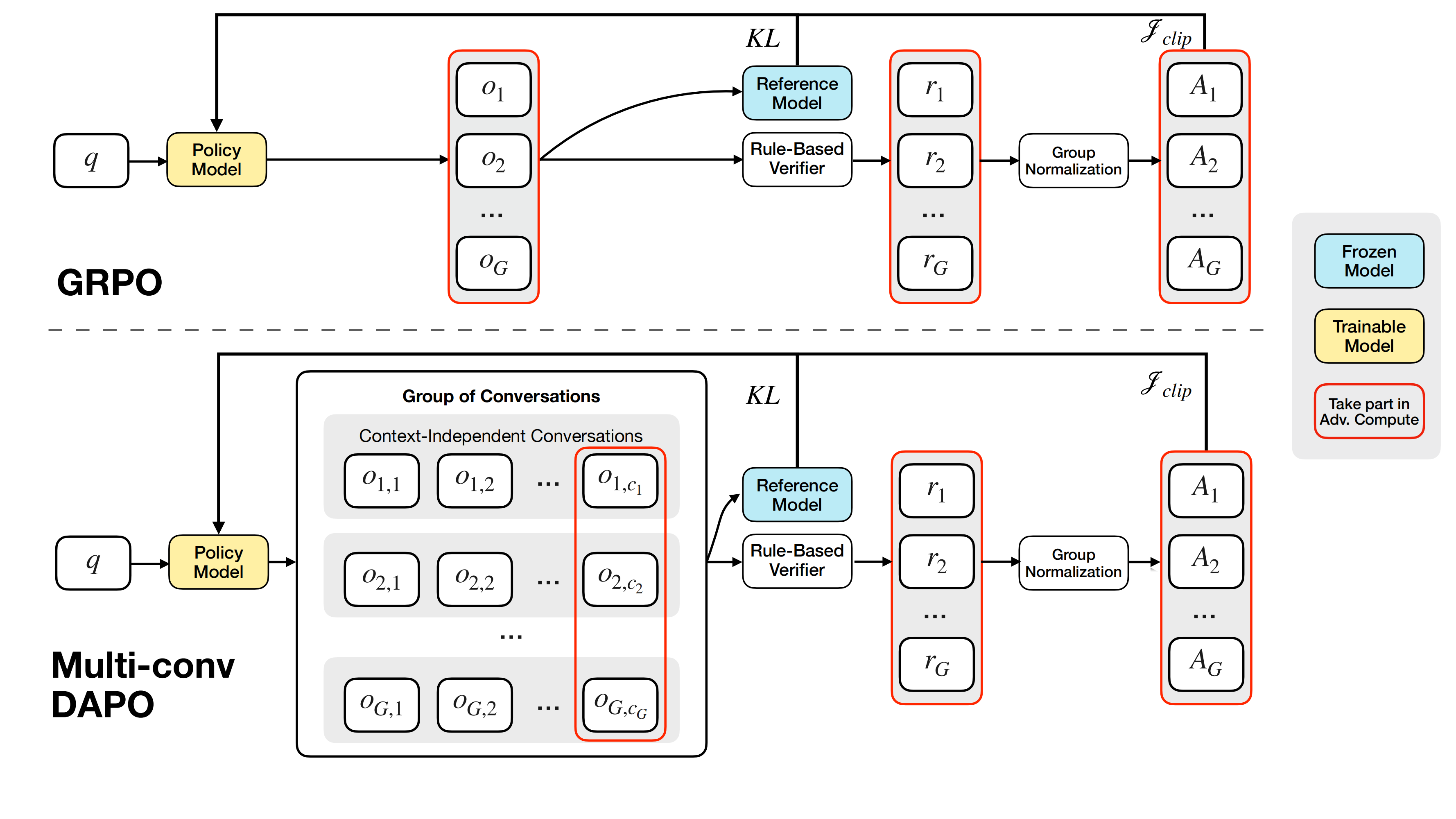
训练流程
- 多轮对话训练机制:对于每个输入样本,模型生成多次回答,每次回答的输入不是此前的生成轨迹的拼接,而是当前文本块和最新记忆状态。
- 奖励计算:从最后一轮回答中提取最终答案,使用基于规则的结果奖励并通过组归一化计算优势,将其分配到所有关联对话。
- 优化策略:以每轮对话为优化目标,根据其优势计算类 DAPO 的token-level平均损失。损失计算维度从传统的(group, token)结构扩展至(group, conversation, token)。
论文使用 Qwen2.5-7B-Instruct、Qwen2.5-14B-Instruct 模型作为智能体的基座模型,并在7K至896K上下文长度范围内对基线模型的性能进行对比分析。
实验结果表明:
- MemAgent 在7K至3.5M的上下文范围内展现出卓越的外推能力,性能仅轻微衰减,验证了记忆机制与强化学习相结合的有效性;
- 基线模型即使在预设窗口内也表现不佳,难以有效利用超长上下文信息。
字节 MemAgent 详细技术细节未知,但从 “无限记忆” 核心点推测:
- 给记忆分个 “优先级”:就像人,把重要的事情记在笔记本上,不重要的随口忘。
- MemAgent 可能会自动判断哪些信息是关键(比如用户反复提到的偏好、任务的核心目标),重点保存;次要信息则压缩或归档,需要时再 “调出来”。
- 搭个 “外部记忆库”:不再只依赖模型自身的 “短期内存”,而是把信息存在专门的数据库里。
- 比如半年前跟 AI 说过 “不爱吃香菜”,这个信息会被存在库里,下次点外卖时,AI 能立刻从库里找到这个偏好。
- 学会 “总结和关联”:面对海量信息,它可能会像人类一样做笔记 —— 把连续的对话提炼成要点,把分散的信息串联起来(比如 “用户提到孩子 3 岁 + 喜欢恐龙,上周说想周末去博物馆”,会关联成 “推荐恐龙主题博物馆”)。
【2025-2-17】A-Mem
现有记忆系统主要支持基本的存储与检索功能,缺乏对记忆的高级组织能力。
即使有些系统引入图数据库进行结构化存储,这些系统的操作和结构通常是固定的,缺乏适应多样任务的灵活性。
【2025-2-17】美国罗格斯大学和公司AIOS Foundation 推出 A-MEM —— 一种新的 Agentic Memory 系统,以智能体的方式动态组织记忆。
- 论文 A-MEM: Agentic Memory for LLM Agents
- 代码 A-mem-sys
- 已集成到 AIOS: AI Agent Operating System
- 解读 A-MEM – Agentic Memory(动态的组织记忆)
借鉴 Zettelkasten 方法:通过动态索引与链接,构建一个互联的知识网络。
原理
系统机制概述
- 当添加一条新记忆时,系统会生成一条包含多个结构化属性的“笔记”,包括:
- 上下文描述(contextual descriptions)
- 关键词(keywords)
- 标签(tags)
- 系统分析历史记忆,识别相关连接并建立链接。
- 新记忆还可能触发历史记忆的上下文更新与属性变化,实现记忆的持续演化。
关键机制优势
A-MEM 将 Zettelkasten 结构化理念与 LLM 智能体的自主决策能力结合,具备:
- 自主构建上下文表示
- 动态建立记忆之间的联系
- 实现旧记忆的智能演化更新
- 支持更强的适应性与上下文感知能力
效果
A-MEM 在多个基准任务上相较于现有 SOTA 方法具有显著性能提升。
【2025-7-15】MEMOS
【2025-7-15】RAG已死,请停止给LLM打“短期记忆补丁”!
讲个内幕:
- 现在市面上绝大多数所谓LLM“长期记忆”方案,包括RAG,本质都是临时工。
LLM 再聪明,也只是一次次“短期记忆的循环”:
- 🔹 参数记忆,埋在亿级权重里,更新慢得像石头。
- 🔹 激活记忆,一次对话就消散,再无踪影。
- 🔹 明文记忆,几乎没人管,零碎、分散、孤立。
所以,当你换个场景再和它说话,永远像“初次见面”。
解决了“知识获取”问题,但没解决“记忆管理”的根本难题,导致AI依然健忘、无法个性化,数据被困在各个应用里形成“记忆孤岛” 。
一直在给漏水的坝打补丁,而不是建一个真正的水库。
核心短板:缺乏持久记忆机制,导致AI无法像人类一样长期学习和积累经验。
关于LLM内存的论文: MEMOS,一个真正的AI“内存操作系统” 。
【2025-7-4】上交、同济、浙大、中科大、人大联手发布
- MemOS:全球首个赋予AI类人记忆的操作系统
- 论文 MemOS: A Memory OS for Al System
- 项目官网
- 项目论文
- 代码仓库:MemOS Discord
原理
思想完全是降维打击:
- 统一管理: 创造了一个叫 MemCube 的标准单元 ,把参数 (固有知识)、KV缓存 (工作记忆)、外部明文 (瞬时知识) 三种形态的记忆全部统一管理 。
- OS级调度: 像Windows/Linux调度硬件一样,MEMOS调度、融合、迁移这些MemCube,让LLM第一次拥有了可控、可塑、可持续进化的记忆 。
3种记忆,一次打通
- 🧠 明文记忆
- • 存你给的知识、偏好、规则
- • 能追溯、能修改、能共享
- • 真正实现个性化智能体
- ⚡ 激活记忆
- • 把对话上下文变成“工作记忆”
- • 支持即时唤醒、压缩、固化
- • 从一次性到可持续
- 🔗 参数记忆
- • 像人类的常识和直觉
- • 支撑通用理解和推理
- • 未来支持“即插即用”
🧊 MemCube:记忆的原子容器
想象一下,每一份记忆都像一个Git仓库:
- ✅ 结构化封装
- ✅ 自描述
- ✅ 可分发、可迁移、可交易
通过MemCube,AI能把“学过的东西”保存、共享、迁移,甚至演化。
🌌 Next-Scene Prediction:下一幕,先知先觉
告别传统“一个token一个token生成”,MemOS启用了记忆调度新范式: 提前预测未来要用到的知识,把记忆和推理彻底解耦。
- ⏳ 响应更快
- 🌐 信息更全
- 🤝 协作更强
🔭 从模型到生态:AGI的另一条路
MemOS不仅仅是个工具,它是一座桥:
- 从“数据中心”到“记忆中心”
- 从“临时聪明”到“持久智慧”
- 从“个人模型”到“共享智能网络”
未来的AI,不仅要会说话,更要有记忆,有理解,有成长。
效果
效果惊人:
- 在LOCOMO基准上,性能全面碾压LangMem, Zep, OpenAI Memory等一众对手 。
- KV缓存加速技术,能把TTFT(首字输出时间)缩短最高 91.4% !
这已经不是简单的技术优化,而是迈向“记忆训练” (Mem-training) 的范式革命 。
项目已开源,对于任何一个想构建真正有状态、能持续进化的AI Agent的开发者来说,非常建议读一下。
无状态AI的时代大概率要结束了。
【2025-7-16】MIRIX
当前的大模型记忆系统,有几个比较明显的局限性:
- 一是分类太少。所有记忆都存到一起,不好检索
- 二是多模态不行。以文本为核心的记忆机制,遇上图片之类的就不好使
- 三是不够灵活。总是整存整取,不压缩,存储空间占用大。
为了解决上述三个问题,MIRIX 模块化记忆系统把记忆精细地分成了六种类型(图3):核心、情节、语义、过程、资源和知识库。这样做优势明显:
- 不同类型记忆服务于不同目的,能针对性检索(解决问题一)
- 资源记忆等模块支持多模态输入(解决问题二)
- 信息经过了抽象与压缩(解决问题三)。
除了传统问题,还设计了一套主动检索机制(图4)来保证记忆的有效性。这套机制让模型接收新任务时,能自动生成查询主题,并主动根据主题去检索记忆。确保模型自觉调用最新的相关信息,不像Mem0之类的记忆系统,必须直接告诉它要检索记忆,否则它更倾向于用预训练时记住的过时信息来回答。
【2025-7-16】MIRIX:多模态、多智能体的分层记忆系统
- 【2025-7-10】UCSD是美国加利福尼亚大学圣迭戈分校 论文 MIRIX: Multi-Agent Memory System for LLM-Based Agents
- 主页 MIRIX
当前 LLM 智能体在记忆能力上存在根本性限制,主要体现在记忆扁平化、范围狭窄且难以处理多模态信息,导致缺乏个性化和可靠的长期记忆。
MIRIX,模块化、多智能体协作的记忆系统。
- 引入了六种结构化记忆类型:核心记忆、情景记忆、语义记忆、程序记忆、资源记忆和知识金库,并配合多智能体框架动态管理记忆的更新与检索。
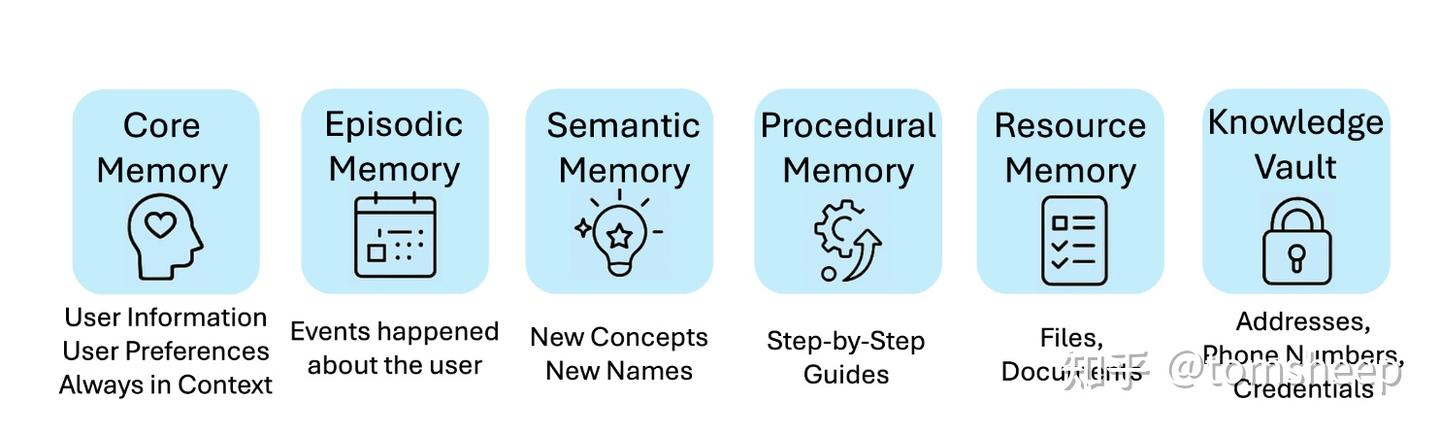
- 该设计使得智能体能够持久化、推理并准确检索多样化的长期用户数据,且支持丰富的视觉和多模态体验。
实验证明,MIRIX 在处理
- 高分辨率截图的多模态基准 ScreenshotVQA 上,准确率比现有 RAG 基线高出 35% 并显著降低存储需求;
- 长篇对话基准 LOCOMO 上,也取得了 85.4% 的 SOTA 表现。
MIRIX 为 LLM 智能体的记忆能力树立了新标准,并提供了实际应用。
【2025-7-25】LVMM
【2025-7-25】前Meta研究员、剑桥大学计算机科学博士创立的AI研究实验室Memories AI正式发布,推出了全球首个人工智能大型视觉记忆模型(Large Visual Memory Model,简称LVMM)。
这一突破性技术旨在赋予AI类人般的视觉记忆能力,让机器能够像人类一样“看到、理解并记住”视觉信息。
同时,Memories AI宣布完成由Susa Ventures领投的800万美元种子轮融资,标志着其在AI视觉记忆领域的雄心壮志。
原理
Memories AI 核心技术
- 独创的大型视觉记忆模型(LVMM)
业内首个能够持续捕获、存储和回忆视觉信息的AI架构。
与现有AI系统不同,传统模型通常只能处理短时视频片段 (15-60分钟),在长时间视频分析中会丢失上下文,导致无法回答“之前是否见过这个?”或“昨天发生了什么变化?”等问题。
而 LVMM 通过模拟人类记忆机制,能够处理长达数百万小时的视频数据,构建持久、可搜索的视觉记忆库。
通过三层架构实现:
- 首先对视频进行降噪和压缩,提取关键信息;
- 其次创建可搜索的索引层,支持自然语言查询;
- 最后通过聚合层将视觉数据结构化,使AI能够识别模式、保留上下文并进行跨时间比较。
这使得 Memories AI 在处理大规模视频数据时,展现出前所未有的效率和准确性,号称比现有技术高出100倍的视频记忆容量。
应用场景
涵盖以下场景:
- 物理安全:为安防公司提供异常检测功能,通过分析长时间监控视频,快速发现潜在威胁。
- 媒体与营销:帮助营销团队分析社交媒体上的海量视频内容,识别品牌提及、消费者趋势和情感倾向。例如,某社交媒体平台已利用Memories AI技术洞察TikTok等平台的长期趋势,保持竞争优势。
- 机器人与自动驾驶:通过赋予AI长期视觉记忆,支持机器人执行复杂任务,或帮助自动驾驶汽车记住不同路线的视觉信息。
Memories AI的平台支持通过API或聊天机器人网页应用访问,用户可以上传视频或连接自己的视频库,通过自然语言查询视频内容。这种灵活的交互方式使其适用于从企业级解决方案到个人化应用的广泛场景。
【2025-7-29】MemTool
多轮对话中 LLM 工具太多? MemTool 来救场!
问题
LLM Agent 在多轮对话中需动态调用工具或 MCP 服务器,但固定上下文窗口导致两大核心问题:
- 1)工具随对话累积,占用过多上下文空间,降低效率;
- 2)现有方法仅关注对话内容的总结/截断,缺乏对动态工具的添加、移除管理,导致多轮任务完成度下降。
因此,亟需一种能高效管理短期工具记忆的框架,平衡工具调用灵活性与上下文窗口限制。
已有方法
- 对话内容压缩:通过总结、截断历史对话减少上下文占用(如 LangChain 的上下文工程),但仅适用于纯会话场景,无法处理工具的动态增减。
- 工具检索增强:利用检索增强生成从外部知识库动态获取工具,但未解决工具使用后的移除问题,易导致上下文溢出。
- 长期记忆框架:如 Mem0、Zep 等,聚焦跨会话的长期记忆持久化,但不涉及单会话内短期工具的实时管理。
MemTool 介绍
【2025-7-29】多轮对话中的工具管理
三种管理模式(核心创新)
- 自主代理模式:a. 赋予 LLM 完全自主权,通过两个专用工具管理上下文:
Search_Tools:根据用户查询从知识库检索新工具并添加到上下文;Remove_Tools:自主判断并移除无关工具。- 模型在回答用户问题的同时,动态调整工具集,确保上下文高效利用。
- 工作流模式:采用确定性流程,每轮对话固定执行 “移除→添加” 两步:
- a. 调用独立 LLM 判断并移除无关工具;
- b. 调用独立 LLM 生成检索关键词,新增相关工具;
- c. 最终 LLM 仅基于筛选后的工具回答问题,无自主调整权。
- 混合模式:结合前两者优势
- 先通过独立 LLM 移除无关工具(类似工作流模式);
- 赋予 LLM 自主调用Search_Tools的权限,灵活新增工具(类似自主模式)。
关键机制
- 工具限制与错误处理:设置工具数量上限(如 128),当超出上限时提示模型移除工具,避免上下文溢出。
- 动态变量提示:在系统提示中嵌入当前工具数量,帮助模型感知上下文状态,提升移除决策准确性。
未来解决思路
- 小模型优化:通过强化学习提升中小模型在自主模式下的工具移除能力;
- 动态工具上限:根据任务复杂度自适应调整工具数量上限;
- 长期记忆融合:结合 Mem0 等长期记忆框架,实现跨会话的工具偏好学习;
- 智能提示工程:优化系统提示,增强模型对工具数量和相关性的感知能力。
【2025-8-13】M3-Agent
【2025-8-13】字节跳动发布M3-Agent:当AI拥有了“记忆”,世界将如何被重塑?
能否创造一个AI,像人类一样,拥有持续不断、自动更新的长期记忆系统? 让记忆不再是“塞进去”的数据库,而是从连续的生命体验中“生长出来”的知识森林?
自字节 Seed团队的石破天惊之作——M3-Agent,正是对这一宏伟蓝图的勇敢探索。
- 一位永不疲倦的、会为世界撰写“生命日志”的AI私家侦探。
- 论文原文: Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
- 官方代码:
- 项目主页
原理
M3-Agent 是优雅的双循环系统,由记忆和控制两大核心支柱构成。
- 记忆的基石:实体为心的多模态图谱: M3-Agent的长期记忆,并非简单的文本存储,而是一个以实体(Entity)为节点、以关系(Relationship)为边的多模态知识图谱。
- 实体属性: id, type, content, embedding, weight, extra_date
- 图谱的核心在于实体的一致性。通过内置的人脸识别和声纹识别工具,M3-Agent能将不同时间、不同场景下出现的同一个人的面孔和声音关联起来,并在语义记忆中生成一条关键的边:Equivalence。
- 解决了困扰多模态Agent最核心的难题:如何知道视频里的“他”和音频里的“他”是同一个人?
- 控制的核心:迭代式推理策略模型: 与负责“记录”的记忆模型(基于Qwen2.5-Omni)不同,负责“思考”的控制模型是一个纯语言模型(基于Qwen3),它扮演着策略模型的角色。它的任务是:给定一个问题和从记忆中检索到的信息,决定下一步是继续搜索([Search])还是直接回答([Answer])。这种迭代式推理的能力,是通过强化学习训练得来的,使其远比传统的单轮RAG更为强大和灵活。
M3-Agent “控制”工作流,是另一个核心创新, 摒弃了传统RAG(检索增强生成)的一问一答模式,引入了强化学习(RL)来训练一个能够进行多轮迭代式推理的策略模型, 采用了DAPO(Direct Advantage Policy Optimization)
现有的长视频问答(LVQA)基准存在不足:它们大多关注短期的动作识别或时空定位,而缺乏对需要长期记忆积累才能回答的高级认知能力的评测。
长期记忆试金石
构建了全新的、极具挑战性的评测基准——M3-Bench。
包含两大部分:
- M3-Bench-robot:100个从机器人第一视角拍摄的、真实世界长视频。
- M3-Bench-web:929个来自网络的、覆盖更多样化场景的长视频。
M3-Bench的真正创新之处在于其精心设计的问题类型,直击长期记忆的核心能力:
- 多细节推理 (Multi-detail Reasoning):需要从视频中多个不连续的片段聚合信息(“五个商品中,哪个最贵?”)。
- 多跳推理 (Multi-hop Reasoning):需要像侦探一样,一步步追溯事件链条(“他们去了A店之后,下一站去了哪里?”)。
- 跨模态推理 (Cross-modal Reasoning):需要结合视觉(“他手里拿着红色的文件夹”)和听觉(“他说‘机密文件放这里’”),才能得出正确答案。
效果
M3-Agent在M3-Bench以及另一个公开基准VideoMME-long上,与一系列强大的基线模型(包括基于Gemini-1.5-Pro和GPT-4o的Agent)进行了正面交锋。
M3-Agent 在所有三个基准上都取得了最佳性能。相较于最强的基线模型(Gemini-GPT4o-Hybrid)
- M3-Agent 准确率在M3-Bench-robot上高出6.7%
- 在M3-Bench-web上高出7.7%,在VideoMME-long上高出5.3%。
这定量地证明了其精心设计的架构和RL训练的优越性。
【2025-8-27】Memento 记忆学习
【2025-8-27】 Memento:无需微调模型,实现 LLM 智能体持续学习
LLM Agent「记忆增强」的论文,提出了一个名为 Memento 的学习范式。
尝试解决当前 LLM Agent 面临两难困境:要么依赖固定的、缺乏适应性的工作流,要么通过高成本的大模型参数微调来实现学习。
Memento 核心贡献: 开创了一条冻结大模型,学习小记忆的路径。
- 通过将智能体的决策过程建模为记忆增强
马尔可夫决策过程(Memory-augmented MDP) ,利用外部的、不断增长的「案例库 (Case Bank)」来存储过去的成功与失败经验。 - 智能体的学习能力体现在一个可学习的案例检索策略上,该策略通过
在线强化学习(具体为软 Q 学习)不断优化,学会从记忆中挑选最有价值的过往经验来指导当前决策。
这种方法极大地降低了持续学习的计算成本,使智能体能够低成本、实时地适应新环境和新任务,并在多个高难度基准测试(如 GAIA)上取得了顶尖性能。 论文:[2508.16153] Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
LLM 智能体的基本范式
- 范式一:基于固定工作流的静态智能体
- 范式二:基于参数更新的自适应智能体
Memento 核心思想可以概括为:冻结 LLM 的参数,将学习的焦点从「模型」转移到「记忆」。
- 不试图让 LLM 本身变得更「聪明」,而是让智能体更善于利用过去的「经验」。
- 这一思想借鉴了认知科学中的人类记忆机制和人工智能领域的经典范式——案例式推理(Case-Based Reasoning, CBR)。
- CBR 的核心主张是,人类通过回忆和类比过往相似情境的解决方案来解决新问题。
Memento 将这一思想形式化,并构建了一个完整的学习闭环。
【2025-8-27】Memory-R1
【2025-9-4】Memory-R1:通过RL优化记忆管理
- 【2025-8-27】慕尼黑大学 论文 Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Memory-R1 并没有对长期记忆框架做更新,而是提出了对其中的“记忆管理”部分做优化。
用强化学习 (RL) 来主动管理与利用长期记忆的框架。
怎么理解?
之前 Mem0等类似项目都设计一个“记忆管理”模块涉及新增记忆的“增删改查”。
问题: 这些项目都通过LLM + prompt 实现。
- 当然能够做到对于记忆的增删改查,但是Prompt engineer 弊端显而易见:Prompt的设计是有限的,在遇到新的长尾行为或需要权衡历史信息时,通常需要人工调整提示/规则。
而 Memory-R1 通过强化学习,把记忆管理当作可训练的policy(单独的“小模型”/agent),从根本上解决了场景长尾问题,使得agent能学到长尾场景里更合理的“何时忘记/合并/存储”的策略;对复杂跨会话权衡更敏感。
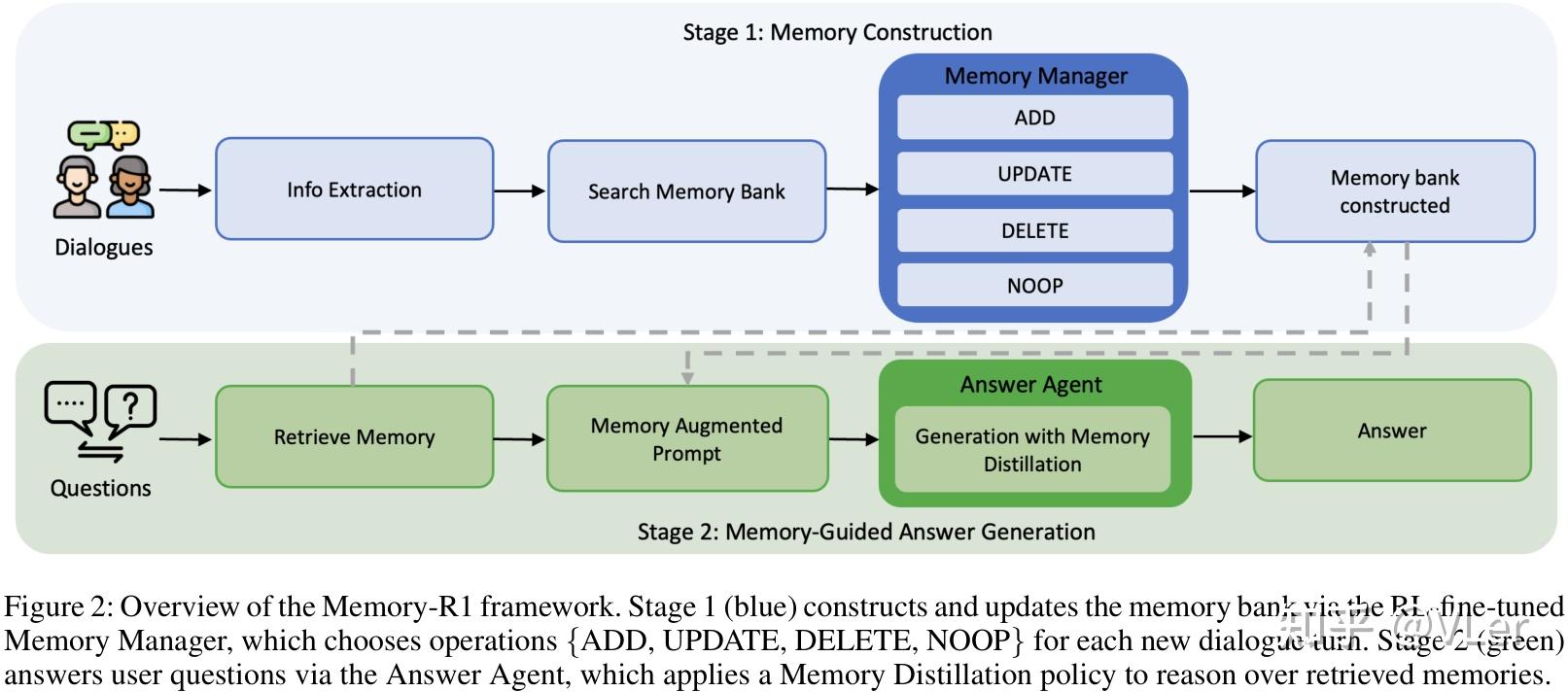
示例
- 当用户和Agent 对话,提到领养了一只叫Buddy的小狗,在几天后,又提到又忍不住领养了另一只小狗叫斯科特。
- 传统长期记忆框架里,LLM + Prompt将第⼆次收养误解为⽭盾,并发出 DELETE+ADD 指令,导致记忆碎⽚化和偏移。
- 基于RL框架的新框架里,经过 RL 训练的记忆管理器则准确地发出单个 UPDATE 指令来整合记忆。
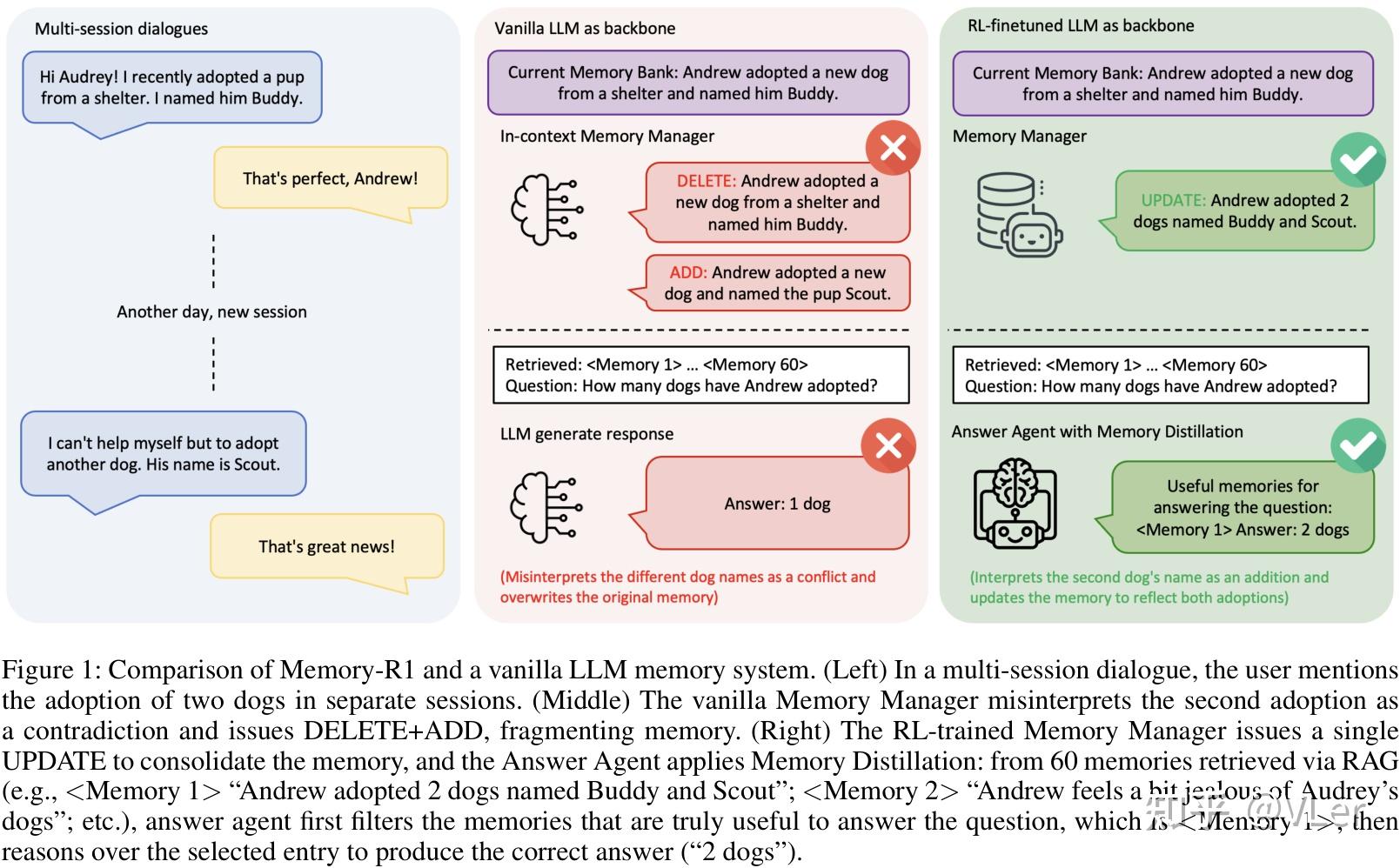
Memory-R1 在 LOCOMO 等基准上相对先前最强基线(如 Mem0)有显著提升(例如报道引用的度量显示在 F1、BLEU、LLM-as-a-Judge 等指标上有明显增益),但要注意:学术基准的改进不必然等同于在你特定生产场景中的实际收益(实际收益会受检索延迟、成本、数据分布等影响)
【2025-7-18】Graphiti
【2025-7-18】Agent实时知识图谱工具,动态知识图谱构建与时间感知能力
Graphiti 构建和查询时间感知知识图谱的框架,专为在动态环境中运行的 AI 智能体设计。
- 项目地址:Graphiti
与传统检索增强生成(RAG)方法不同,Graphiti 能够持续整合用户交互、结构化与非结构化企业数据,以及外部信息,构建成一个连贯且可查询的图谱。
该框架支持增量数据更新、高效检索与精准的历史查询,且无需整体重新计算图谱,非常适合开发交互式、上下文感知型 AI 应用。
功能
Graphiti 功能:
- 整合并维护动态的用户交互和业务数据。
- 支持智能体基于状态的推理和任务自动化。
- 通过语义搜索、关键词搜索、图遍历等方式,查询复杂、不断演化的数据。
Graphiti 独特之处
- 自主构建知识图谱,同时处理关系变化并保持历史上下文。
Graphiti 驱动着 Zep 的 AI 智能体记忆核心。
通过 Graphiti,证明了:Zep 是当前智能体记忆领域的最先进方案。
优势:
- 实时增量更新:新数据片段能够即时整合,无需批量重计算。
- 双时间数据模型:明确记录事件的发生时间和接收时间,支持精准的时点查询。
- 高效的混合检索:结合了语义嵌入、关键词检索(BM25)和图遍历,实现了低延迟查询,且无需依赖大型语言模型(LLM)摘要。
- 自定义实体定义:通过直观简单的 Pydantic 模型,开发者可以灵活创建本体论和自定义实体。
- 优异的可扩展性:支持并行处理,能够高效管理大规模数据集,适用于企业级应用场景。
知识图谱
知识图谱是由互相关联的事实组成的网络,例如:“Kendra 喜爱 Adidas 鞋子。” 每条事实是一个“三元组”,由两个实体(或称节点,如“Kendra”和“Adidas 鞋子”)以及关系(或称边,如“喜爱”)表示。
Graphiti采用分层设计构建知识图谱,模拟人类记忆模式:
- 情节子图(Episode Subgraph): 存储原始输入数据(如对话文本、JSON文档),保留完整上下文。通过情节边连接到语义实体,确保可追溯数据来源。 2.语义实体子图(Semantic Entity Subgraph): 利用LLM从情节中提取实体(如人物、产品)和关系(如“喜欢”“属于”),形成结构化知识网络。实体节点包含属性摘要,支持快速检索。 3.社区子图(Community Subgraph): 通过标签传播算法对实体进行聚类,形成高层次概念(如“运动品牌”)。社区边连接语义实体与社区,支持抽象推理(如“Adidas属于运动品牌社区”)。 分层架构既保留细节信息,又支持从具体事件到抽象概念的多层次查询。
RAG 分析
Graphiti 颠覆 RAG 静态模式。
- Instant updates:新数据进来就能即时更新
- Bi-temporal tracking:既知道事情发生的时间,也知道被记录的时间
- Hybrid retrieval:融合 semantic search(看语义)、keyword search(看精准关键词)和 graph traversal(看关系结构)
Zep 分析
| 方面 | Zep | Graphiti |
|---|---|---|
| What they are | 用于AI记忆的完整托管平台 | 开源图框架 |
| User & conversation management | 内置用户、对话线程和消息存储 | 需自行构建 |
| Retrieval & performance | 预配置、可用于生产环境的检索,大规模下性能亚200毫秒 | 需自定义实现;性能取决于自身配置 |
| Developer tools | 带图可视化的仪表盘、调试日志、API日志;支持Python、TypeScript、Go的SDK | 需自行构建工具 |
| Enterprise features | 服务等级协议(SLAs)、支持、安全保障 | 自管理 |
| Deployment | 完全托管或部署在自有云环境 | 仅支持自托管 |
分析:该表格对比了Zep和Graphiti两个工具在多个维度的差异。Zep是一个托管平台,提供了从用户对话管理到检索、开发工具等全链路的成熟解决方案,适合需要快速落地且注重企业级保障的场景;而Graphiti是开源图框架,灵活性高,但需要用户自行完成大部分构建工作,更适合有定制化需求且具备技术能力的团队。
Graphiti 与 GraphRAG 对比
Graphiti MCP is an open-source temporal knowledge graph
| 方面 | GraphRAG | Graphiti |
|---|---|---|
| Primary Use | 静态文档摘要 | 动态数据管理 |
| Data Handling | 面向批量的处理 | 持续、增量更新 |
| Knowledge Structure | 实体集群 & 社区摘要 | 情景数据、语义实体、社区 |
| Retrieval Method | 序列式大语言模型摘要 | 混合语义、关键词和基于图的搜索 |
| Adaptability | 低 | 高 |
| Temporal Handling | 基础时间戳跟踪 | 显式双时态跟踪 |
| Contradiction Handling | 大语言模型驱动的摘要判断 | 时态边失效 |
| Query Latency | 几秒到几十秒 | 通常亚秒级延迟 |
| Custom Entity Types | 不支持 | 支持,可自定义 |
| Scalability | 中等 | 高,针对大型数据集优化 |
使用
环境要求:
- Python 3.10 或更高版本
- Neo4j 5.26 或更高版本(用作嵌入存储后端)
- OpenAI API 密钥(用于 LLM 推理与嵌入生成)
命令
pip install graphiti-core
【2025-12-9】Titans+MIRAS
【2025-12-9】Titans+MIRAS:帮助人工智能拥有长期记忆
- 【2024-12-31】论文 itans: Learning to Memorize at Test Time
- 谷歌 官方博客 titans-miras-helping-ai-have-long-term-memor
Transformer架构引入了注意力机制,彻底革新了序列建模。注意力机制使模型能够回顾早期输入,从而优先处理相关的输入数据。然而,计算成本会随着序列长度的增加而急剧上升,这限制了基于Transformer的模型扩展到超长上下文的能力,例如全文档理解或基因组分析所需的上下文。
Transformer 长序列处理存在着严重缺陷,难以扩展到更长的上下文。
已有多种解决方案,如高效的线性循环神经网络(RNN)和状态空间模型(SSM),如Mamba-2,通过将上下文压缩到固定大小来实现快速线性扩展。
然而,这种固定大小的压缩无法充分捕捉超长序列中丰富的信息。
Titans + MIRAS:帮助人工智能拥有长期记忆
谷歌提出新架构,Titans,引入了神经长期记忆模块,有望解决Transformer的长序列处理难题。
NeurIPS 2025上,Google推出 Titans 架构和 MIRAS 框架两项研究成果。核心解决Transformer架构在处理超长上下文时的根本局限。
允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
- Titans:兼具RNN速度和Transformer性能的全新架构;
- MIRAS:Titans背后的核心理论框架。
MIRAS 框架实现了向实时自适应的重要转变。该架构并非将信息压缩成静态状态,而是随着数据流的流入主动学习并更新自身参数。
Titans 并非被动地存储数据,主动学习如何识别并保留连接整个输入数据中各个标记的重要关系和概念主题。这种能力的关键在于“意外指标 surprise metric”。在人类心理学中,很容易忘记那些例行的、预期的事件,但却会记住那些打破常规的事情 —— 意料之外的、令人惊讶的或情绪激动的事件。
Titans 融入两个关键要素来改进机制:
- 动量:该模型同时考虑“瞬时意外”(当前输入)和“过去意外”(近期上下文流)。这确保了即使后续信息本身并不令人意外,也能被捕捉到相关的后续信息。
- 遗忘(权重衰减):为了在处理极长序列时管理有限的内存容量,Titan 模型采用了一种自适应权重衰减机制。该机制如同一个遗忘门,允许模型丢弃不再需要的信息。
【2025-12-3】MindLab 智能遗忘
【2025-12-3】Mind Lab团队两篇论文智能遗忘
问题
- 豆包聊天,聊着聊着就“失忆”了,前面答应过的事转头就忘,有时候还自相矛盾。
分析
- 模型不够好?
- 上海交大10月份Context Engineering 2.0论文,问题不在模型本身,而是记忆管理架构。
但Mind Lab两项研究彻底改变了对AI记忆和训练的认知。
- (1)第一件事:让AI学会智能遗忘。
- (2)第二件事:用10%的GPU训练万亿参数模型。
这两件事合在一起,完整答案:
- 好的AI产品 = 强大的基础模型 + 聪明的记忆管理 + 高效训练方法。
- 上海交大给了工程方案:分层设计、提取关键信息、主动预测用户
- Mind Lab直接在模型层和训练层给出了解法。不是做加法,而是做减法。不是追求更多资源,而是更聪明地使用资源。
AI的进化,不是在学习做得更多,而是学习做得更对。
(1)第一件事:让AI学会智能遗忘
Memory Diffusion(记忆扩散)颠覆了传统思路。不是记住更多,而是像人类一样智能遗忘。
- 开车时你会自动忽略路边广告牌,但记住重要路标,这才是真正的智能。
方法:
- 掩码-分配-重填,挑出对话里不重要的部分,给关键信息分配更多空间,然后压缩重组。
传统方法像整理房间的两种笨办法:
- 方法A:每天写一份“房间总结”,扔掉原物品 (推理型)
- 方法B:把所有东西扔进仓库,需要时去翻找 (工具型)
新方法有点像像断舍离哲学:
- 定期审视房间里的每样东西,问:“这个一年后还有用吗?”。
重要的精心保留,不重要的果断丢弃,房间始终保持最优状态,而不是等爆满再清理。
Locomo 基准测试93%准确率(SOTA),目前最佳成绩。
(2)第二件事:用10% GPU训练万亿参数模型
LoRA技术相比传统全参数强化学习,只需要用10%的GPU资源,就在万亿参数(1.04T)的Kimi K2模型上完成了强化学习训练。这不只是省钱。
对照实验,控制相同的计算预算,对比不同规模模型的强化学习效果,证明了反直觉的结论:
- 相同计算预算下,在大模型上做小幅度优化,比在小模型上做全参数训练效果更好。
因为AI的进化是”先验受限”的。如果基础模型本身不够强,再怎么训练也很难突破。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
