- Agent 智能体 应用
- 结束
Agent 智能体 应用
Agent项目:
2024年阿里全球数学竞赛AI赛道全球第2
- 代码仓库:Math-Multi-Agent
- 特工宇宙 GitHub 组织:[Agent-Universe](https://github.com/Agent-Universe)
【2024-1-25】这几天agent操控设备成为热点:
- 智谱昨天推出 glm-pc 1.1,注重长程推理,与年前的autoglm互补,分别占据pc和mobile设备
- openai 的 operator 也涉足pc操控
大家都在布局3级别agi
2025 是智能体之年
Agent 效果
榜单
【2025-3-26】俄亥俄州立大学、加州伯克利推出 Web助理效果评测 An Illusion of Progress? Assessing the Current State of Web Agents

数据集
GAIA
【2023-11-23】 FAIR, Meta, HuggingFace, AutoGPT, GenAI 联合推出评测集
- 466 个问题及作答, 覆盖生活中实际问题,涉及 推理、多模态操控、网页浏览、写代码、通用工具使用
- 其中 300 个问题开源出来, 不含答案,用来维护 排名榜 Leader Board
- 问题难度: 人类简单(92%),但模型难(含插件的 GPT-4 15%)
资源
问题分级
- 一级问题: 不需要工具,或最用1种工具,且步骤不超过 5 步。
- 二级问题: 涉及更多步骤,大致在 5-10 步,并且需要综合运用不同工具。
- 三级问题: 近乎完美的通用助手, 执行任意长系列行动,任意数量工具,总体上通用水平
示例
Question: What was the actual enrollment count of the clinical trial on H. pylori in acne vulgaris patients from Jan-May 2018 as listed on the NIH website?Ground truth: 90
Agent 项目实例
【2024-9-15】一个包含15种大模型Agent技巧的项目开源
从简单到高级,15 个 step-by-step notebook
(1) 初级 Agent
- 简单对话Agent: simple_conversational_agent.ipynb
- 简单问答Agent:simple_question_answering_agent.ipynb
- 简单数据分析Agent:simple_data_analysis_agent_notebook.ipynb
- 客户支持Agent(LangGraph):customer_support_agent_langgraph.ipynb
- 论文评分Agent(LangGraph):essay_grading_system_langgraph.ipynb
- 旅行计划Agent(LangGraph):simple_travel_planner_langgraph.ipynb
- GIF 动画生成器Agent(LangGraph):gif_animation_generator_langgraph.ipynb
- TTS 诗歌生成器Agent(LangGraph):tts_poem_generator_agent_langgraph.ipynb
- 音乐合成器Agent (LangGraph):music_compositor_agent_langgraph.ipynb
(2) 高级Agent架构
- 记忆增强对话Agent:memory_enhanced_conversational_agent.ipynb
- 多智能体协作系统:multi_agent_collaboration_system.ipynb
- 自我提升Agent:self_improving_agent.ipynb
- 任务驱动的Agent:task_oriented_agent.ipynb
- Internet 搜索和总结Agent:search_the_internet_and_summarize.ipynb
(3) 复杂系统
- 用于复杂 RAG 任务🤖的复杂可控Agent:Controllable-RAG-Agent
数据库
genai-toolbox
【2025-7-13】谷歌开源为Agent设计的数据库工具箱 genai-toolbox
真正为 LLM 设计的数据工具中间层,帮大语言模型(LLM)或 Agent 快速、安全、标准化地调用数据库或 HTTP 接口等外部工具
- 支持 MCP 协议,兼容 LangChain、LlamaIndex、多语言 SDK,特别适合做 AI Agent、数据库助手、数据中台等场景。
核心设计:
- Go语言开发,工具和数据源完全解耦,采用注册表和插件机制,通过 init 注册 kind,实现声明式扩展,无需改核心代码。
- 参数系统支持默认值、类型校验、模板注入,还能从 JWT 自动注入字段,实现了安全性和灵活性的平衡。
- 双协议设计也很有参考价值,既支持传统 REST,也支持面向 LLM 的 MCP 接口,调用流程标准化,支持 tool 列表发现、schema 推理、参数验证等。
- 整个系统从 prebuilt YAML 配置到运行时动态加载,再到 OpenTelemetry 级别的日志与追踪,具备了生产级能力。
- 适合 AI 工程师、数据平台开发者、Agent 系统开发者研究。Go 工程师也可以借此学习如何设计一套模块清晰、热插拔、面向未来的 AI 中间件系统。
操作系统
【2024-12-2】Android团队“再创业” !Agent操作系统方向
很多公司都在研究AI智能体框架中的不同组件、不同功能模块,但是/dev/agents相对就更勇敢一下,/dev/agents坚持提出一个完整的第三方操作系统才能是释放其全部潜力的关键
技术理念是:
- 充分释放人工智能代理的潜力,必须构建一个全新的操作系统。
- 打造一个跨设备的云端操作系统,通过整合生成式AI技术,为开发者提供一个标准化的开发框架,并为最终用户创造一个智能化的交互界面。
- 这一平台有望成为AI时代的基础设施,正如Android在移动互联网时代的角色一样。
知识问答
法律问答
【2024-8-15】我的Agent拿了全国第十一
基于智谱 GLM-4 大模型和相关业务API构建能回答法律问题的Agent,为法律人士提供专业的辅助咨询服务。
法律问题或简或繁
- 简单问题: 只是查阅单表和数个字段:
- “广东鹏鼎律师事务所的电话邮箱地址分别是什么?”
- 复杂问题: 涉及跨多表查询、逻辑判断以及统计等操作
- “(2020)吉0184民初5156号的被告是否为上市公司,如果是的话,他的股票代码和上市日期分别是?如果不是的话,统一社会信用代码是?该公司是否被限制高消费?如果是被限制高消费的涉案金额总额为?请保留一位小数点。”
经验
- 第一,API编排 vs Code/SQL生成。
- 相较于Code/SQL的生成能力,企业客户会更看重Agent的API编排能力。在具备API资产的情况下,企业内和企业间的交流会更多地通过API,而非直写Code/SQL实现。
- Agent 要能够编排并依次调用:裁判文书信息、上市公司信息、企业工商注册信息和企业限高消费信息的API以回答较为复杂的问题。
- 第二,对Agent的要求是“又快又准”。
- 比赛的盲盒测试要求Agent在1小时内回答200道问题,对Agent运算速度和精度都有较高要求。而这也与企业的实际场景契合,毕竟企业内绝大多数的信息检索场景相对简单(单表或有限多表/视图,有限的逻辑处理和统计需求),但对响应的速度和精度有近乎苛刻的要求。
- 第三,Plan ↑ Reflection↓。
- 对速度和精度的高要求:Agent能够在Plan阶段“一次搞定”,而非通过Reflection反复修正。
- 为此,排除了 Multi-Agents 架构,而着重于保证Plan的准确性,并确保一旦Plan正确,Action必然正确:
- 两个环节:
- Orchestration(编排),依据知识图谱,将自然语言问题编排为大模型友好的“指令序列”;
- Question Rewrite(问题改写),“抹平”问题的缺陷,并依据知识图谱发现隐藏的实体关系。
- 最终,所有正确回答的问题中,Agent的首轮正确率超过了90%。
- 第四,
自然语言->API,NO!自然语言->指令->API,YES!- 自然语言的复杂度和多样性降低了大模型 Function Calling 精度,Agent需要将自然语言“格式化”为指令以提升API调用的准确性。
- 例如,大模型可以将问题“广东鹏鼎律师事务所的电话邮箱地址分别是什么?”先转化为指令,再进行API调用:
- 相较于直接调用API,指令更具额外优势:
- API命名不可控,而指令命名可以富含语义,有利于大模型进行问题分解;
- 简洁指令消耗更少Token,从而降低了大模型幻觉的几率,并且提升了Agent的响应速度;
- 指令和API的1:1对应关系能够确保“Plan正确,则Action正确”。
- 第五,自然语言问题是一个指令序列。
- 自然语言问题可以被大模型转化为一系列指令,即指令序列。如果用函数
F(X)->Y代表指令,比赛中的问题则可以被描述为一个指令序列 - 用不同类型的指令构成指令序列,指令间可以通过内存进行沟通。通过不断增加指令类型,Agent可以应对更复杂的问题。
- 指令集合: 查询、统计、比较、存在、格式化、for循环、api调用计数
- 自然语言问题可以被大模型转化为一系列指令,即指令序列。如果用函数
- 第六,大模型善于指令编排,前提是约束以
知识图谱和Few-Shots。- Plan 核心是编排指令,生成指令序列以回答问题。
- 比赛中,即便仅仅使用提示词工程,只要辅以正确的知识图谱和Few-Shots,大模型善于将问题编排为指令序列
知识图谱主要约束大模型的生成路径,而Few-Shots则提供了生成样式。同时,Agent利用 embedding search 针对不同类型问题动态加载Few-Shots,在节省Token的同时增加了指令序列生成的精度。鉴于指令和API的一一应对关系,指令的编排等同于API的编排。
- 第七,必要的问题改写。
- 指令序列的生成和问题的问法息息相关,而Agent经常面临的挑战在于,问题未必会提到答案中所需的内容。
- 这种情况下,Agent需要改写问题以“填坑”。类似于指令序列的生成,我们可以同样使用知识图谱和Few-Shots指导问题的改写。
- 而问题改写的另一好处: 能仰仗大模型“抹平”问题中的错误,例如,问题改写就修正了公司和字段名称重复的错误
- 第八,
<SOS>/<EOS>提升 Few-Shots 遵从性。- 使用Few-Shots 产生指令序列的挑战之一就是大模型的“不遵从”,包括:
- 格式上的不遵从,例如符号的错用;
- 内容上的不遵从,例如在指令序列之外增加无谓的解释和啰嗦的内容。
- 通过提示词要求大模型严格遵从输出要求,但更好的办法是使用
<SOS>/<EOS>包裹Few-Shots以提升遵从性 - 因为大模型在训练之初就使用
<SOS>/<EOS>标记训练数据的起终点,使用该标记后,99.99%的情况下,大模型能够遵从要求生成指令序列。
- 使用Few-Shots 产生指令序列的挑战之一就是大模型的“不遵从”,包括:
电商问答
【2025-5-18】智能闲鱼客服机器人系统:
- 专为
闲鱼平台打造的AI值守解决方案 - 实现闲鱼平台 7×24 小时自动化值守,支持多专家协同决策、智能议价和上下文感知对话。
- XianyuAutoAgent
复杂任务
尽管 LLMs 在单一任务上表现出色,面对复杂、多步骤的项目处理时,仍存在显著缺陷。
- 以数据分析项目为例,涉及需求理解、数据清洗和预处理、探索性数据分析、特征工程和建模等多个环节。每个步骤都需要专业知识和细致的规划,通常需要多次迭代,门槛非常高。
AutoKaggle
【2024-11-25】大幅降低数据科学门槛!豆包大模型团队开源 AutoKaggle,端到端解决数据处理
详见站内专题:数据竞赛之智能体
娱乐
MusicAgent
【2023-10-20】MusicAgent:基于大语言模型的音乐理解和生成AI agent
- MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
- github muzic

MusicAgent 系统整合了众多与音乐相关的工具,并拥有一个自动工作流程来满足用户需求。
- 构建了一个从各种来源收集工具的工具集,如 Hugging Face、GitHub和Web API等,并由大型语言模型(如ChatGPT)支持的自动工作流程来组织这些工具。
- 目标: 让用户从AI音乐工具的复杂性中解脱出来,专注于创意部分。
这个系统为用户提供了轻松组合工具的自由,无缝且丰富的音乐体验。
角色模拟
详见 用户模拟器专题
AI助理
【2023-10-19】不再只是聊天机器人!AutoGen + LangChain = 超级AI助理
- AutoGen 代理可以根据特定需求定制,参与对话,并无缝集成人类参与。适应不同的操作模式,包括LLM的利用、人类输入和各种工具。
- AutoGen 没有原生支持连接到各种外部数据源,而LangChain正好发挥作用。两者结合,正是基于OpenAI的函数调用特性。利用 function call,AutoGen Agents能够调用LangChain的接口与组件。
构建AI助理,帮助用户完成知识问答任务
- 使用白皮书构建一个向量存储。
- 基于向量存储,通过LangChain创建会话型基于检索的问答链。
- 定义名为 answer_uniswap_question 的函数,接受一个参数question,并调用问答链来回答问题。
- 使用AutoGen设置用户代理和助手代理,并启用函数调用。
Bland AI
详见站内专题: 大模型时代智能客服
CogAgent
【2023-12-15】CogAgent:带 Agent 能力的视觉模型,免费商用
- 10月11日,我们发布了智谱AI新一代多模态大模型 CogVLM,该模型在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合,其中 CogVLM-17B 在 14 个多模态数据集上取得最好或者第二名的成绩。
- 12月15日,我们再次升级。基于 CogVLM,提出了视觉 GUI Agent,并研发了多模态大模型CogAgent。
其中,视觉 GUI Agent 能够使用视觉模态(而非文本)对 GUI 界面进行更全面直接的感知, 从而做出规划和决策。
而多模态模型 CogAgent,可接受1120×1120的高分辨率图像输入,具备视觉问答、视觉定位(Grounding)、GUI Agent等多种能力,在9个经典的图像理解榜单上(含VQAv2,STVQA, DocVQA,TextVQA,MM-VET,POPE等)取得了通用能力第一的成绩,并在涵盖电脑、手机的GUI Agent数据集上(含Mind2Web,AITW等),大幅超过基于LLM的Agent,取得第一。 为了更好地促进多模态大模型、Agent社区的发展,我们已将CogAgent-18B开源至GitHub仓库(申请可免费商用),并提供了网页版Demo。
模型:
- Huggingface: cogagent-chat-hf
- 魔搭社区: cogagent-chat
Eko
【2025-1-22】截胡OpenAI!清华复旦等抢先开源智能体框架Eko,一句话打造「虚拟员工」
清华、复旦和斯坦福的研究者联合提出了名为Eko的 Agent开发框架,开发者可以通过简洁的代码和自然语言,快速构建可用于生产的「虚拟员工」。AI智能体能够接管用户的电脑和浏览器,代替人类完成各种任务,为工作流程提供自动化支持。
- Github eko
- 优于 Langchain、Broweruser、Dify.ai、Coze和Midscene.js
Eko 是一个强大的Agent开发框架,开发者能用自然语言和简单代码快速构建「虚拟员工」,完成从简单指令到复杂工作流的任务,如股票分析、自动化测试等;通过混合智能体表示、跨平台架构和生产级干预机制等创新技术,实现高效、灵活且安全的自动化工作流程。
核心创新点:
- 混合智能体表示:提出了Mixed Agentic representation,通过无缝结合表达高层次设计的自然语言(Natural Language)与开发者低层次实现的程序语言(Programming Language)。
- 跨平台Agent框架:提出环境感知架构,实现同一套框架和编程语言,同时支持浏览器使用、电脑使用、作为浏览器插件使用。
- 生产级干预机制:现有Agent框架普遍强调自治性(Autonomous),即无需人类干预,而Eko框架提供了显性的生产级干预机制,确保智能体工作流可以随时被中断和调整,从而保障人类对生产级智能体工作流的有效监管和治理。
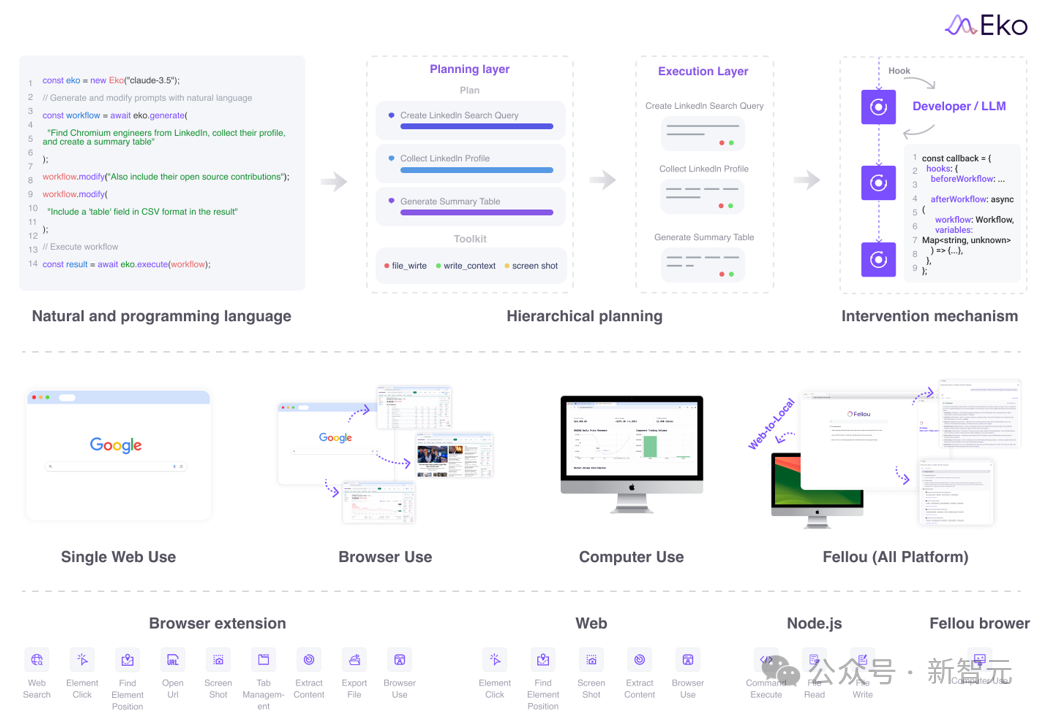
Eko的跨平台开发是通过其环境感知架构(Environment-Aware Architecture)实现的,架构由三个关键层次构成:通用核心(Universal Core)、环境特定工具(Environment-Specific Tools)和环境桥接(Environment Bridge)。
通用核心:这一层提供了与环境无关的基本功能,如工作流管理、工具注册管理、LLM(大语言模型)集成和钩子系统。 环境特定工具:每种环境(如浏览器扩展、Web环境、Node.js环境)都提供了优化的工具集。 环境桥接:这一层负责环境的检测、工具注册、资源管理和安全控制,确保不同平台之间能够顺利互动和通信。 安全性和访问控制:Eko针对不同环境实施了适当的安全措施。浏览器扩展和Web环境都采用了严格的权限控制和API密钥管理,而Node.js环境则允许更广泛的系统级访问,基于用户权限进行文件操作和命令执行,在需要时会在执行前请求用户确认。
自动工具注册:通过 loadTools() 等工具,Eko 自动注册适用于当前环境的工具,这使得开发者可以在多个环境中无缝地切换,并确保工具的正确加载。
层次化规划(Hierachical planning)
研究人员提出层次化感知框架,将任务的拆解分为两层,包括Planning layer 和 Execution layer。其中Planning layer负责将用户的需求(自然语言或代码语言表示)和现有工具集拆解成一个有领域特定语言(Domain-specific language)表示的任务图(Task graph)。
任务图是一个有向无环图,描述了子任务之间的依赖关系。该任务图由LLM一次性合成。在Execution layer中,根据每个任务调用LLM来合成具体的执行行为和工具调用。
多步合并优化:当Eko检测到两次执行都是对LLM的调用时,会触发框架的自动合并机制,将两次调用的system prompt自动整合,合并成一次调用。从而加快推理速度。
视觉-交互要素联合感知(Visual-Interactive Element Perception)
视觉-交互要素联合感知框架(VIEP)是一种先进的浏览器自动化解决方案,通过将视觉识别与元素上下文信息相结合,显著提升了在复杂网页环境中自动化任务的准确性和效率。该技术的核心在于提取网页中的交互元素和相关数据,优化了自动化过程,极大地提高了任务执行的成功率。
具体来说,首先VIEP通过识别网页上的关键交互元素——如按钮、输入框、链接等——来聚焦用户可能进行操作的核心区域。
接着,每个可交互的元素都被分配唯一的标识符,并通过彩色框标记,确保精确定位。随后,系统通过结合截图和伪HTML的方式构建元素信息,利用文本和视觉数据的结合,帮助自动化模型更好地识别和操作这些元素,尤其在复杂网页结构中尤为重要。
通用智能体
详见站内专题: 通用智能体
个人设备
个人PC
【2024-10-8】联想如意
【2024-10-8】新版桌面助手-如意(AI stick),新界面新体验
【2026-1-18】用户反馈
- 联想管家里搜:豆包,系统偷偷安装 如意
10月10日,联想推出新版桌面助手-如意(AI stick)
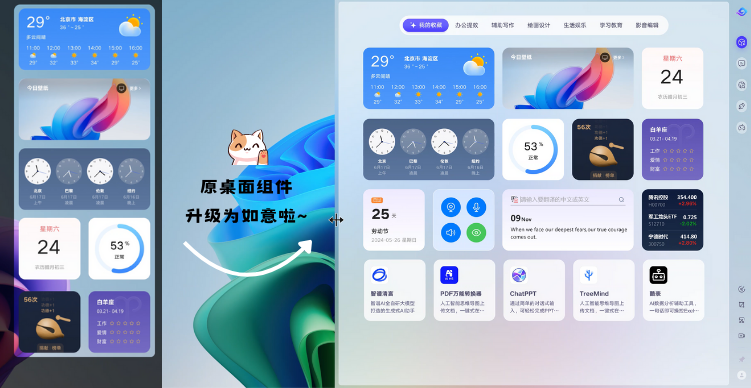
电脑管家-工具箱
三大AI新功能,引领智能潮流
- AI空间:想象一下,一个集近百款智能服务于一体的超级空间,从日常办公到生活娱乐,各类便捷工具一触即达,让您的生活更加高效便捷。
- AI聊天:不再孤单,您的私人AI顾问已上线!无论是专业知识解答,还是日常闲聊解闷,只需轻轻输入,AI即刻回应,精准理解,温馨陪伴,让沟通无界限。
- AI写作:创意无限,文字无忧!无论是撰写深度文章、个人博客,还是快速生成营销文案、专业邮件模板,只需输入关键词,AI写作引擎即刻启动,文思泉涌,助您妙笔生花。
- AI搜索:超越传统搜索,我们重塑信息检索的未来。AI搜索技术,让每一次点击都更加精准、高效,海量信息一网打尽,为您的决策提供最强有力的支持。
- 小游戏乐园:工作之余,也要享受生活!我们精选海量精品小游戏,无需繁琐下载,一点即玩,随时随地放松心情,享受游戏的乐趣。
设备操作
详见站内专题: 设备操控
阅读 Readagent
阅读能力超强的Agent模型——Readagent
产品信息:
- Readagent是由Google开发的一款模仿人类阅读方式的阅读类型代理(Agent)模型。它通过学习人类阅读长文本时遗忘具体信息但保留要点信息的方式,来提高处理和理解长文本的效率。
产品功能:
- 在处理长文本时,Readagent会把文本中的主要信息转化为“要点记忆”进行存储,当需要回答具体细节问题时,Readagent会迅速定位到到相应的“要点”中寻找答案,从而出色地完成长文本的阅读理解任务。此外,Readagent还能帮用户在复杂的网站中找到需要的信息。
会话评估
详见 用户模拟器专题
智能教育
【2024-4-12】用大模型+Agent,把智慧教育翻新一遍
以正大模型Agent大多采用“群体作战”模式。在Agent社区中,不同角色的Agent可以主动与彼此交互、协同,帮人类用户完成任务。
助教Agent能够实现一对一讲评,成为教师的得力助手;教案Agent能够生成高质量精品教案;学伴Agent是学生的学习伴侣,随时提供学习辅导,并为学生制定个性化教学方案。
举例
- 教师将某个学习任务输入助教Agent后
- 助教Agent能够主动将任务分发至各位同学的学伴Agent
- 学伴Agent会主动根据学生的学习习惯制定个性化学习计划,并主动跟踪学生的学习进度和质量,还能将情况即使反馈至助教Agent。
Agent社区形成后,接下来是解决Agent落地“最后一米”的问题——如何设计人与Agent的交互形式。
很多教育场景中,自然语言交互并非最佳方式。
- 老师制定教育计划或学生提交作业经常会涉及到四五千字的长文本,这么长的内容放在一个对话流中阅读,非常影响使用体验。
- 现实工作场景中,用户很多时候都需要一个能高效操作的工具,并不是每次人机交互都需要输入一段文字或说一段话
团队最终摸索出集两种交互方式优点于一体的产品形态——用“白板”代替简单的对话流,支持自然语言驱动的交互方式,并提供内容展示、阅览、回顾等功能,比传统软件交互更简单,但比对话交互更丰富,可深入学校各个业务场景。
游戏
详见站内专题: 大模型游戏应用
医疗
Agent Hospital
医院模拟器 Agent Hospital
【2024-5-5】清华 【LLM-agent】医院agent:具有可进化医疗agent的医院模拟器
基于大型语言模型(LLM)和agent技术构建医疗场景下的医院模拟体,命名为医院agent(Agent Hospital)。
医院agent不仅包括两种角色(医疗专业人员和患者代理)和数十个特定agent,还涵盖了医院内的流程如分诊、登记、咨询、检查和治疗计划,以及医院外的阶段如疾病和康复。
医院agent中,论文提出了MedAgent-Zero策略,用于医疗代理的发展,该策略不依赖参数和知识,允许通过模拟患者进行无限制的agent训练。该策略主要包括一个医疗记录库和经验库,使得agent能够像人类医生一样,从正确和失败的治疗中积累经验。
AgentClinic
【2024-5-22】斯坦福、约翰霍普金斯推出 AgentClinic
- AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
- 代码 agentclinic
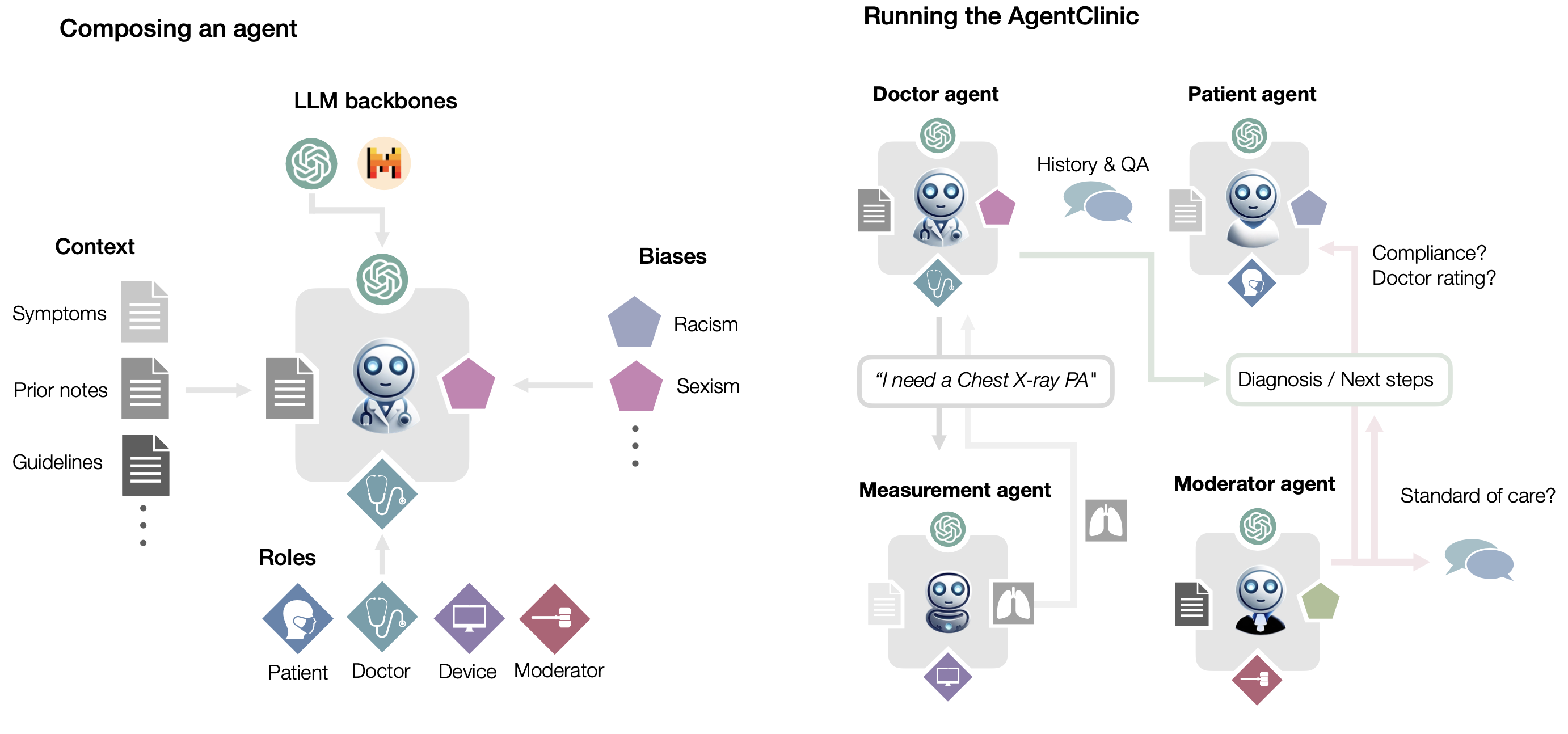
AgentClinic 将静态医疗 QA 问题转化为临床环境(医生、患者、医疗设备)中的代理,以便为医学语言模型提供更具临床相关性的挑战。
- 问题:现有评测标准基于静态QA,无法处理交互式决策问题(interactive decision-making)
- 方案:在临床模拟环境中操作智能体,实现多模态评估LLM
- AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments.
- 医生通过对话和交互数据来评估病人病情
诊断和管理患者是一个复杂的、连续的决策过程,需要医生获取信息—例如要执行哪些测试—并采取行动。人工智能 (AI) 和大型语言模型 (LLMs) 的最新进展有望对临床护理产生深远影响。
然而,目前的评估方案过度依赖静态的医学问答基准,缺乏现实生活中临床工作所需的交互式决策。
AgentClinic:一个多模式基准,用于评估LLMs在模拟临床环境中作为代理运行的能力。
- 基准测试中,医生代理必须通过对话和主动数据收集来发现患者的诊断。
发布两个开放基准:多模态图像和对话环境 AgentClinic-NEJM 和纯对话环境。
- AgentClinic-MedQA: 代理以美国医学执照考试~(USMLE) 的案例为基础
- AgentClinic-NEJM: 代理以多模式新英格兰医学杂志 (NEJM) 的案例挑战为基础。
在患者和医生代理中嵌入认知和隐性偏见 (cognitive and implicit biases),以模拟有偏见的代理之间的真实互动。
引入偏倚会导致医生代理的诊断准确性大幅降低,以及患者代理的依从性、信心和后续咨询意愿降低。通过评估一套最先进的技术LLMs,一些在MedQA等基准测试中表现出色的模型在AgentClinic-MedQA中表现不佳。
- 在AgentClinic基准测试中,患者代理中使用的LLM药物是性能的重要因素。
- 有限的相互作用和过多的相互作用都会降低医生代理的诊断准确性。
MMedAgent
【2024-11-3】斯坦福&哈佛医学院 - MMedAgent,一个用于医疗领域的多模态医疗AI智能体
斯坦福+哈佛医学院推出 第一个专门为医学领域设计的智能体,名为多模态医学智能体 (MMedAgent)。策划了一个由六种医疗工具组成的指令调整数据集,解决了五种模式的七项任务,使智能体能够为给定任务选择最合适的工具。
- 论文: MMedAgent:Learning to Use Medical Tools with Multi-modal Agent
- Github: MMedAgent
- 演示系统 - gradio demo
选择 LLaVA-Med 作为主干,旨在扩展其处理各种语言和多模态任务的能力,包括接地、分割、分类、MRG 和检索增强生成(RAG)。这些任务包括多种医学成像模式,例如 MRI、CT 和 X 射线,使 MMedAgent 能够支持临床实践中通常遇到的各种数据类型。
综合实验表明,与最先进的开源方法甚至闭源模型 GPT-4o 相比,MMedAgent 在各种医疗任务中实现了卓越的性能。此外,MMedAgent 在更新和集成新医疗工具方面表现出效率。
AgentMental
【2025-8-15】AgentMental:会追问的AI心理评估框架
创新性在于将多智能体协作模式引入心理评估,提出的自适应追问机制和树状记忆结构设计精巧且贴合实际应用场景。实验设计严谨,通过与多种先进基线方法的对比和详尽的消融研究,充分验证了其方法的可靠性和巨大潜力,为开发下一代交互式AI心理健康工具提供了重要思路。
论文信息
针对现有自动心理评估方法依赖静态文本、无法深入交互的局限,提出了一个名为AgentMental的多智能体框架。该框架通过模拟临床对话,利用自适应追问机制和树状记忆结构,动态获取和整合信息,在抑郁症识别任务上取得了超越基线方法的表现。
背景与挑战
心理健康评估对早期干预至关重要,但传统方法受限于专业临床医生短缺。现有的AI辅助方法大多对静态文本进行一次性分析,当用户回答模糊或不完整时,难以像真人医生一样追问以获取关键信息,导致评估的深度和准确性不足。因此,如何让AI具备动态、深入的交互式评估能力,是该领域面临的核心挑战。
💡 方法与创新
AgentMental的核心是模拟一个由多位专家组成的“虚拟诊疗团队”。它包含四个智能体(Agent),分别负责提问、评估、评分和更新。其关键创新在于“自适应追问机制”,即由评估智能体判断用户回答是否充分,若不充分,则驱动提问智能体生成针对性的追问,以探寻症状的频率、时长、影响等深层信息。同时,系统采用“树状结构记忆(Tree-Structured Memory)”来动态记录和组织对话信息,有效避免了重复提问,并确保了评估的连贯性和上下文感知能力。
🎯 实验与成果
研究在经典的DAIC-WOZ抑郁症评估数据集上进行了验证。实验通过模拟交互式访谈,对比了AgentMental与多种基于大语言模型的基线方法。结果显示,AgentMental在各项关键指标上均取得最优性能,例如其Macro F1分数达到89.8%,显著优于其他方法。
教育
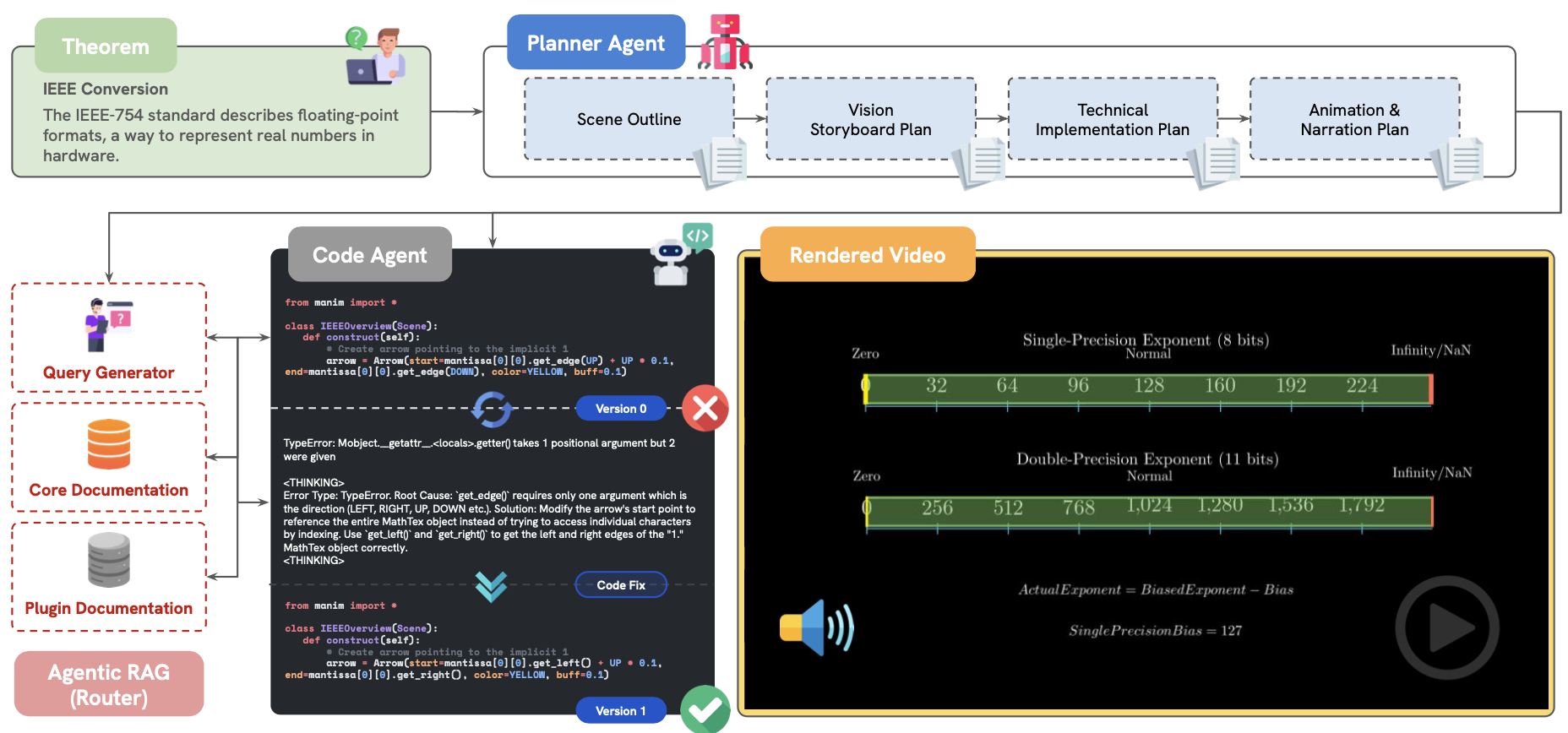
TheoremExplainAgent
【2025-3-5】 加拿大滑铁卢大学用 Manim + Agent 制作5分钟以上的数学教学视频
- 并提出评测集 TheoremExplainBench, 覆盖 240 个理论知识点
- 主页 TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding
- 【2025-2-26】论文 TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding
o3-mini agent 成功率 93.8%, 总分 0.77
实现方法
- 两个 Agent: 规划 + 写代码
金融
金融交易智能体
详见站内 大模型与量化
出行
高德的小高老师,美团的小美之后,滴滴的 AI
滴滴: AI小滴
【2025-6-10】滴滴推出 智能旅行规划助手 AI小滴, 企业级落地
【2026-1-9】滴滴上线AI小滴助手 滴滴上线AI叫车,终于有懂我的出行AI了
下车后就开晕,真的很想给滴滴客服打电话:为什么打车不能直接指定油车啊?!
滴滴首页「AI 叫车」可以只选油车,直接告诉要求,比如只要油车、新车、空气清晰,没有差评。
核心功能:个性化叫车,只需用自然语言说出需求,它就匹配最合适的车。比如「油车、特惠、后排宽敞、新车」,想到什么说什么。既可以文字输入,也可以语音输入。
需求拆解成明确的意图标签:晕车-> 驾驶平稳,又快-> 尽快上车,又干净-> 无异味。并且可以区分哪些是一定要满足的条件,哪些是尽量满足。随后返回页面告诉我:有车 90% 符合我的要求,问我要不要接受。
然后,记住用户偏好,下次打车不用重复说
除了打车,它还能帮你规划和记账,不用自己打开地图,查地铁路线、打车预估时间;AI 给出多种出行方案,时间预估、花费预估、风险点,一步到位
【逗逗小滴】互动玩法。你跟它聊天,有机会拿打车优惠券。9.8 折、9 折、8 折…
滴滴同步上线了 AI 叫车的 MCP 服务。
- MCP 传送门:MCP
论文
【2025-2-12】港科大(滴滴实习)+DiDi KDD 新作:LLM驱动的智能打车助手DiMA
- 📚论文标题: DiMA: An LLM-Powered Ride-Hailing Assistant at DiDi
- 🔍 问题背景:随着按需打车服务如DiDi、Uber和Lyft的普及,城市交通变得更加便捷和灵活。然而,现有的移动应用仍依赖于手动输入,如打字、点击和滚动,这使得打车过程耗时且效率低下。为了改善用户体验,研究团队提出了DiMA,一个基于LLM的打车助手,旨在通过自然对话界面提供无缝的打车服务。
- 💡 研究动机:现有的任务导向对话系统(ToD)在处理动态的打车需求时表现不佳,特别是在理解和处理用户的时空意图方面。为了提升打车助手的性能,研究团队设计了DiMA,一个集成了时空感知工具和成本效益对话系统的LLM助手。
- 🚀 方法简介:DiMA的核心是时空感知工具增强订单规划模块,通过集成外部工具进行精确的时空推理,提高订单规划的准确性。同时,DiMA还设计了一个成本效益的对话系统,通过多类型的对话回复器和成本感知的LLM配置,优化对话生成的效率和质量。
- 📊 实验设计:研究团队在DiDi应用中部署了DiMA,并进行了在线和离线实验。在线实验结果显示,DiMA在订单规划和响应生成方面的准确率分别达到了93%和92%。离线实验进一步验证了DiMA的性能,相比三个最先进的智能体框架,DiMA在订单规划任务上提升了70.23%,在响应生成任务上提升了321.27%,同时将延迟减少了0.72倍到5.47倍。
用户反馈
小红书用户反馈
滴滴的 AI 小滴开始批量内测。从根据习惯打车开始,把账单分析、沿路推荐、路线规划等等全做了个遍。
现阶段还是比较早期的产品。
1️⃣ 打车/约车场景:
- 用户需要反复和小滴交流,提要求,感觉不如老流程方便。
- 每次输入,都需要等待小滴分析。这期间空闲的司机很可能会被分配其他订单,导致两轮对话间的司机完全不同。
- 设置好约车时间后,小滴实际开始叫车的时间很早,司机比预订时间早到了快10分钟,影响了出行节奏。
2️⃣ 路线规划:
- 路线规划方案页面可直接跳转到打车页,比较方便。
- 推荐不同路线方案不够智能,实际情况和预估差很多。
3️⃣ 历史订单查询:
- 精准输入关键词后查询结果比较精准。但最多只能分析近30天的订单,不支持更广的时间范围。
- 分析功能有点傻。比如分不清中关村商圈里到底有啥具体地点。
整个过程都是实测,具体案例可以看图。
如果要谈当前版本最需要优化的方面,主要有两点:
- 1️⃣ 用户操作的简便性:
- 目前打车只需输入终点、选择车型即可完成。而使用对话式AI,则需要输入较多文字。从操作步骤来看,文本对话形式可能并不是最佳交互形态。
- 2️⃣ 司机侧的动态变化:
- 网约车是一个高度依赖动态供需平衡的场景,司机的实时位置和空闲状态都在不断变化。如果通过小滴叫车,无论是小滴生成答案所需的推理时间,还是用户与小滴的多轮对话过程,都可能造成匹配结果的变化。
不过话说回来,本地生活这种超高频场景的AI功能确实很难做,每个场景都需要精细化打磨。期待现阶段的问题被优化。
【2026-5-6】Uber Assistant
5月6日,OpenAI官方文章,Uber 借助 OpenAI搭建 AI 助手及语音功能(OpenAI Realtime API ),助力司机高效增收,提升乘客预订体验。
- Uber Assistant 采用多智能体架构,安全、信任与低延迟,为了提升响应效率,简单任务用更敏捷的 nano/mini 模型,复杂任务则用参数量更大的推理模型。
- Uber 还开发了 AI Guard 内部治理层,负责筛选提示词和回复,以提升安全性、隐私性和可靠性,强制执行政策,减少幻觉,并确保不同体验之间的一致性
携程
携程+腾讯云 推出旅行规划助手 DeepTrip
阿里高德 NaviAgent
【2025-4-14】高德地图近期在导航技术上迈出了重要一步,正式推出了基于地图的AI导航智能体 NaviAgent
NaviAgent 核心架构采用了先进的 Planner-Executor 模式,通过感知、规划、执行和表达四大模块,形成了一个智能闭环系统,集成了高德多项核心技术。
这款AI导航智能体被官方形象地比喻为“经验丰富的老司机”,具备实时感知路况、预判风险并主动调整策略的能力。
高速驾车场景中,NaviAgent 能够感知车道级的交通流变化、动态事件以及事故占道等信息,结合用户的行驶路线,自动开启领航功能,为用户推荐全局最优车道,使得变道决策更加从容和高效。
停车场景中,NaviAgent 也展现出了超视距感知能力。当用户输入目的地后,系统会在距离终点5公里时启动智能分析,主动为用户推荐目的地周边的空闲停车位。
基于时空感知和推理能力,NaviAgent 还能补全停车后的步行导航指引,帮助用户直达目的地入口,实现无缝衔接的导航体验。
NaviAgent 红绿灯AI领航功能已经覆盖全国。该功能结合实时交通信息与超视距感知技术,能够动态为用户提供车速建议、车道选择以及起步提醒,从而大幅提升过灯效率,减少等待时间。
除了技术上的创新,NaviAgent 还构建了包含情感识别、意图理解和情绪表达在内的三维交互体系。
这一体系使得NaviAgent不仅是一个导航工具,更像是一个有情感的伙伴。例如,当用户完成一次优质的驾驶操作时,NaviAgent会及时给予赞许,为用户带来更加愉悦和温馨的导航体验。
电商
字节 CRMAgent
【2025-7-11】字节跳动:如何用多智能体提升电商CRM?
大多数电商商家在私域渠道(如IM、邮件)中进行客户关系管理(CRM)时,缺乏高效、专业的消息模板创作能力,导致营销效果不理想。
Georgia Institute of Technology 和 字节跳动的研究团队提出了CRMAgent系统,用多智能体大语言模型自动生成高质量CRM消息模板,帮助商家提升用户留存与转化。
CRMAgent 由四个分工明确的智能体组成:
ContentAgent:分析同一受众群体下表现优劣的模板,总结成功要素。RetrievalAgent:跨商家检索与当前活动受众、产品和优惠券类型相近的优质模板,作为参考。TemplateAgent:结合诊断和优质范例,重新生成更具说服力的消息模板。EvaluateAgent:对新旧模板在受众契合度和营销有效性上进行评分和偏好对比,实现自动化质量评估。
效果
用GPT-4o等模型在11大典型用户分群上进行了全面评测。新生成的模板在受众契合度和营销评分上分别提升了9.09%和38.44%,在盲测对比中有78.44%的概率被评为更优!尤其对“潜在新客户”和“放弃购物车用户”,通过增加紧迫感和明确利益点,极大提升了转化可能。更厉害的是,生成的内容在语义和风格上与原文高度一致,既有创新又不跑题。
创新
CRMAgent 不仅分工细致,支持多种数据场景,还通过“组内学习+检索迁移+规则兜底”三重策略,让每个商家都能低成本获得像头部商家一样专业的推送消息,极大降低了营销门槛。该系统为大模型在实际商业场景落地提供了范例,也展现了多智能体协作的巨大潜力。
作者信息:Yinzhu Quan(Georgia Institute of Technology)、Xinrui Li(ByteDance Inc.)等人
京东
京东电商agent方案:
- 有memory,将agent决策抽象成四维空间,包括直接回复,意图识别,工具召回,工具调用,结合用户数据整体联合训练
【2024-5-22】京东商家智能助手:Multi-Agents 在电商垂域的探索与创新
- 《京东商家智能助手:AI 多智能体系统在电商垂域的探索与创新》演讲阐述了 Multi-Agents 如何模拟真实的商家经营,并介绍 ReAct 范式的 Multi-Agent 在线推理架构,以及 Agent 落地垂域的样本、训练与评估监控的方法
京东零售基于 Multi-Agents 理念搭建了商家助手大模型在线推理服务架构,这一系统的核心是算法层基于 ReAct 范式定制多个 LLM AI Agents,每个 Agent 都有专门业务角色和服务功能,可以调用不同的工具或多 Agent 协同工作来解决相应的问题。
平台向商家传递各种各样的信息,包括新的玩法、新的规则条款,以及可能的惩罚通知等。面对平台的各种消息和随之而来的疑问,商家需要一个经营助手协助,他通常扮演着一个专门提供平台知识百科的咨询顾问角色。
当商家提出赔付、运费等与业务相关的复杂问题,需要先理解需求,然后从长篇的业务文本中抽取出问题解决的大方向或目标。定位问题后,形成逐步的解题思路,再灵活调用各种资源和工具来解决问题,其中包括调用知识库、进行搜索和检索,以及使用人脑进行总结和筛选重点内容。经过这一系列操作后将问题的最终答案返还给商家。
从商家的需求出发:无论谁在回答问题,对商家来说都只有一个人帮助他们解答问题。因此,构建一个 Agent 即可,它映射到为商家提供专属咨询服务的多个业务岗位的人。
商家提出问题:“最近我的店铺经营得怎么样?”
【2025-6-24】京东集团算法总监 韩艾
NaviAgent, a graph-navigated bilevel planning architecture for robust function calling, comprising a Multi-Path Decider and GraphEncoded Navigator
- the Multi-Path Decider defines a four-dimensional decision space and continuously perceives environmental states, dynamically selecting the optimal action to fully cover all tool invocation scenarios.
- The Graph-Encoded Navigator constructs a Tool Dependency Heterogeneous Graph (TDHG), where node embeddings explicitly fuse API schema structure with historical invocation behavior
Experiments show that NaviAgent consistently achieves the highest task success rate (TSR) across all foundation models and task complexities, outperforming the average baselines (ReAct, ToolLLM, α-UMI) by 13.5%, 16.4%, and 19.0% on Qwen2.5-14B, Qwen2.5-32B, and Deepseek-V3, respectively.
Its execution steps are typically within one step of the most efficient baseline, ensuring a strong balance between quality and efficiency. Notably, a finetuned Qwen2.5-14B model achieves a TSR of 49.5%, surpassing the much larger 32B model (44.9%) under our architecture. Incorporating the Graph-Encoded Navigator further boosts TSR by an average of 2.4 points, with gains up over 9 points on complex tasks for larger models (Deepseek-V3 and GPT-4o), highlighting its essential role in toolchain orchestration.
JDAgents-R1
【2025-6-24】京东集团算法总监 韩艾
多智能体强化学习(MARL)已成为处理日益复杂任务的重要范式。然而,异构智能体之间的联合进化, 仍面临合作效率低与训练不稳定等挑战。
京东提出了一种面向 MARL 的联合进化算法框架 JDAgents-R1,该方法首次将组相对策略优化(GRPO)应用于异构多智能体的联合训练中。
- 通过迭代优化智能体的大语言模型(LLMs)与自适应记忆机制,
JDAgents-R1实现了决策能力与记忆能力的动态均衡,并能有效减少重复推理、加快训练收敛。 - 在通用场景以及商家定制化场景中的实验表明,JDAgents-R1 在基于更小规模开源模型的情况下,依然能够达到与大规模语言模型相媲美的性能表现。
大纲
- JDAgents-R1: 联合进化算法方案
- 多智能体协作
- GRPO联合训练算法技术
- Memory更新技术
- 电商领域落地实战
- 通用与垂直领域任务
- 商家多智能体联合进化
NaviAgent
待定
OxyGent
【2025-8-8】京东零售 Oxygen 团队正式开源发布多智能体协作框架——OxyGent。
当前多智能体开发仍面临诸多挑战:框架生态碎片化、配置调试复杂、智能体协作逻辑“黑盒”,使得构建和维护多智能体系统对个人开发者和中小团队而言成本高昂。社区亟需更简单、灵活的解决方案。
京东零售Oxygen团队基于在AI应用的长期积累,正式开源多智能体协作框架OxyGent——将工具、模型和智能体抽象为可插拔的原子算子Oxy,支持开发者像搭积木一样灵活组合多智能体系统,具备极致可扩展性和全链路决策追溯能力。
- 通过构建-推理-进化的闭环智能体流水线,OxyGent实现了Oxy无缝集成、弹性扩展和持续优化,为AI生态发展提供全新可能。
这一创新框架致力于帮助开发者高效组装多智能体协作系统,实现智能体间的无缝协作、弹性扩展与全链路可追溯。
推动人工智能从“单点突破”迈向“群体智能”时代。
OxyGent 已在开源社区正式上线。
OxyGent 能做什么?
- 从零到多智能体,只需几分钟
- 像拼乐高一样组装 AI 团队——纯 Python,无冗余代码,无 YAML 配置。OxyGent 的模块化开源架构,内置标准化组件Oxy(可以是Agent, Tool, LLM, Function….),让你随心组装、定制、扩展多智能体系统,适配任意场景。Python 代码即插即用,分钟级部署,弹性扩展,无需繁琐配置——导入、拼装、运行,一步到位。即刻原型,实时可视化架构,极速迭代,全程决策可溯。OxyGent 让开发者无限创新与协作,让复杂 AI 变得像乐高组装一样直观灵活。
- 团队群聊,但更聪明!
- OxyGent 让多智能体协作变成极客级“超能群聊”。只需把任务丢进对话,AI 团队自动自组织——无刚性流程,实时弹性协作。智能体自动分工、动态协商(“我来调 API,@time_agent 先查时间”),随场景智能切换角色,真正实现“群体智能”。用 OxyGent,智能体协作如同与同事在线群聊——更快、更弹性、更透明。
- 探索智能体多元宇宙
- OxyGent让你像量子实验一样探索 AI 决策。可随时暂停流程,剖析任意智能体内部状态——LLM 提示、记忆快照、待执行工具等——修改变量、重采推理路径,无需重启。支持强制注入故障、并行运行不同模型多路实验,所有变体自动记录,复现无忧。这不仅是调试,是 AI 的多宇宙探索,每一个“如果”都可追溯、可回滚。
- 智能体认知全息透视
- OxyGent 让你“X 光级”洞悉智能体大脑——从高阶策略到原子操作,逐层可视。在 OxyGent,智能体认知不再是黑盒,而是全透明、可操作、可审计。每一步自动生成可追溯决策图,像 Git 一样记录每个“为什么”。
- 多智能体系统性能剖析
- OxyGent 内置生产级时间追踪,实时洞察智能体每一秒的消耗:LLM 推理、工具/API 调用、智能体协商等全链路分解,瓶颈一目了然。依赖图实时揭示任务分发与资源拥堵,助你极致优化架构,让 AI 团队始终高效运转——一站式掌控。
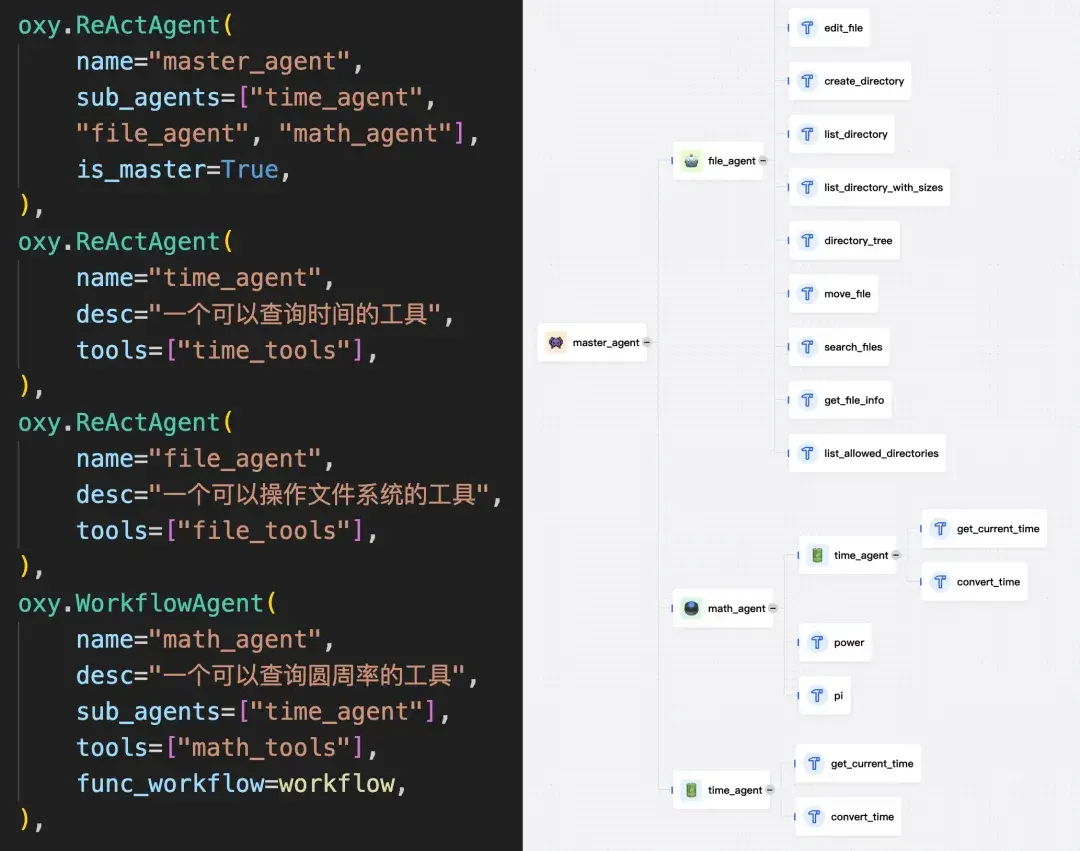
OxyGent 有什么特性?
- 高效开发
- OxyGent 是模块化多智能体框架,极致高效构建、部署、进化 AI 团队。标准化 Oxy 组件像乐高一样拼装,支持热插拔与跨场景复用——纯净 Python 接口,无需繁杂配置。
- 智能协作
- 动态规划范式,智能体可智能分解任务、协商解法、实时适应变化。区别于刚性流程,OxyGent 智能体自然应对突发挑战,每一步决策全链路可审计。
- 弹性架构
- 底层弹性架构支持任意智能体拓扑——从简单 ReAct 到复杂混合规划。自动依赖映射与可视化调试,轻松优化分布式系统性能。
- 持续进化
- 每一次交互都是学习机会——内置评估引擎并具备实时冻结与回放智能体状态的能力,能够并行模拟多策略分支,支持SFT与强化学习样本的高效采集和继续训练。智能体通过知识反馈机制实现持续自我进化,整个流程透明且可追溯。
- 无限扩展
- 按 Metcalfe 定律线性扩容——分布式调度器让协作智能指数级增长。系统轻松应对全域优化与实时决策,任意规模无压力。
完整的智能体生命周期管理:
- 1️⃣ 纯 Python 编写智能体(再见 YAML 地狱)
- 2️⃣ 一行命令极速部署(本地 or 云端,随心切换)
- 3️⃣ 决策全程可追踪(透明到每一次推理)
- 4️⃣ 智能体自动进化(自我提升,越用越强)
这不仅仅是一个框架,OxyGent 是真正能快速在生产环境落地的 Agent 应用开源利器。
效果
OxyGent 斩获 59.14 高分(开源框架第一 OWL 60.8分)
- GAIA(General AI Assistant)Benchmark
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
