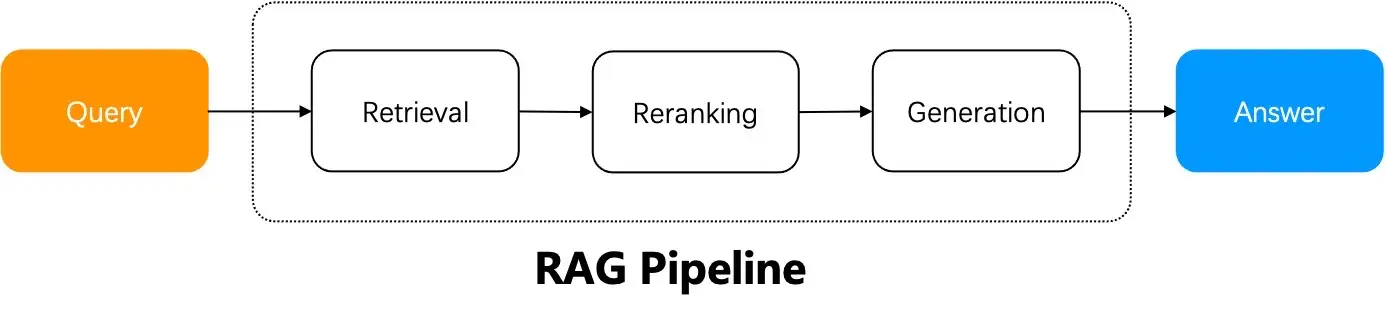
- RAG 检索增强生成
- 趋势
- LLM 问题
- RAG 解决什么问题
- RAG 介绍
- RAG 方案
- 评估指标
- RAG 问题
- RAG 工具
- RAG 不足
- RAG优化
- 【2022-8-29】HyDE
- 【2023-11-15】CoN 承认不会
- 【2023-11-14】FILCO 提前过滤不相关
- 图谱
- Vector RAG
- 【2023-10-9】DeepMind: Step-Back Prompting
- 【2023-10-17】华盛顿大学: Self-RAG
- 【2023-10-28】Agent RAG
- 规划思考
- 【2024-2-23】文档分割
- 【2024-6-26】UAR
- 排序
- 【2024-9-6】HybridRAG
- 【2024-9-10】MemoRAG
- 【2025-8-27】Youtu-GraphRAG
- Deep GraphRAG
- RAG 提效
- RAG 自动化
- 新范式
- 应用
- 结束
RAG 检索增强生成
更多LLM技术落地方案见站内专题:大模型应用技术方案
趋势
RAG -> DeepSearch
【2025-4-22】别搞Graph RAG了,拥抱新一代RAG范式DeepSearcher
RAG 解决什么问题
- 知识时效性
- 事实准确性:降低幻觉
- 领域适配成本:微调的标注数据+计算成本高
传统RAG、Graph RAG、DeepSearcher
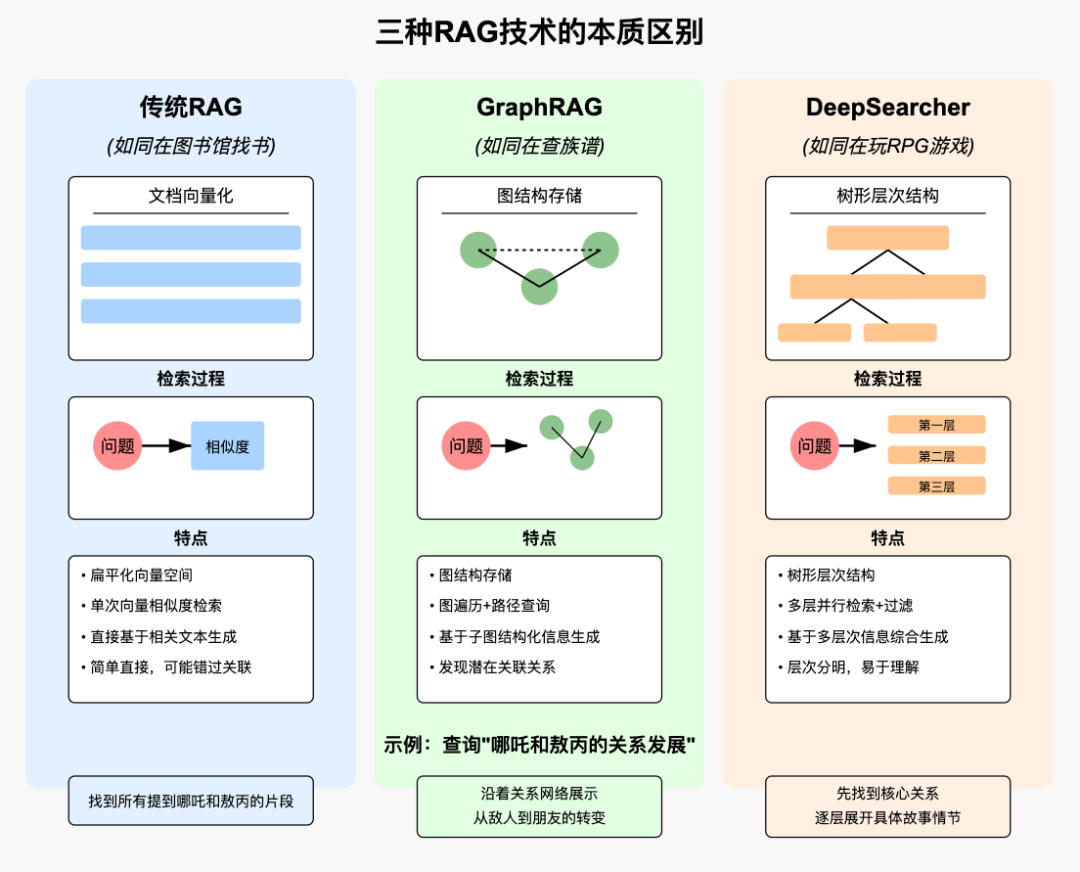
上下文工程
【2025-8-23】RAG 已死,上下文工程当立
Chroma 的创始人 Jeff Huber 最新访谈视频,专业做向量数据库,对RAG的理解透彻。
- youtube视频
- Chroma 是一个开源的向量检索数据库,提供 AI 应用所需要的向量检索+关键词全文检索+正则+元数据过滤的一体化方案。可以本地嵌入式运行,也可连到托管的 Chroma 云端上。
RAG很多坑,比如数据召回准确率低、没有上下文思想、非结构化数据解析有难度等等。
由于RAG 召回主要依赖的就是向量化检索,这个技术决定了数据没法完整准确地召回,还要配合关键词检索,混合检索。
无论大小厂,应该都遇到过类似的问题,因为目前大家的技术几乎都离不开RAG。
RAG 术语将检索、增强、生成三个概念硬拼在一起,且常被误解为只做单次的向量检索。
当前的 AI 应用中存在着严重的上下文腐烂的问题。
- 当模型的上下文窗口中存在着更多 Token 时,模型的注意力会下降,推理能力也会随之减弱。
- 对于当前前沿模型声称能够完美利用百万级 Token 上下文窗口的说法,Jeff 也保持着怀疑的态度。Chroma 的报告显示,许多模型在长上下文的场景中的性能并不理想。
Jeff Huber 解决方案:Context Engineering(上下文工程)
上下文工程定义为:
在任何给定的LLM 生成步骤中,精确决定上下文窗口应包含何种信息的任务。
包含两个循环
- 内循环,决定当前这一步中,应该塞入哪些内容给到模型作为上下文
- 外循环,随着对话次数的增加、时间的积累,逐渐要让模型选择最相关的信息
实用策略:
- 两阶段检索范式:
- 首先第一阶段检索(向量、全文、元数据检索),从海量候选数据中快速筛选出少量相关数据。
- 随后将这些初步筛选结果交给 LLM 作为重排序器进行精细筛选。随着 LLM 变得更快,更便宜,Jeff 认为以往专用的重排序模型将逐渐被 LLM 替代。
- 代码上下文优化:代码是一种特殊的上下文。
- Chroma 原生支持 Regex (正则表达式搜索)并引入了独特的Forking 功能,用户可以再百毫秒内创建现有索引的副本,从而高效地对不同 git 提交、分支或发布标签的代码库进行重索引和搜索。
- 当然,千万不要神化 embedding,regex 仍然解决 85%-90% 的查询,embedding 通常还能带来 5-15% 的额外增益,所以这套组合拳才是实际项目工程中的最优解。
- 数据预处理与信号增强:Jeff 强调,在数据读取并处理的时候,要尽可能地提取并注入结构化信息和元数据。例如,通过 Chunk Rewriting 技术,让 LLM 为代码生成自然语言描述,然后将这些描述与代码本身一同embedding 或者单独做 embedding 处理。
- 构建黄金数据集的重要性:Jeff 指出,构建小型、高质量的数据集对于量化评估和持续改进系统非常重要。许多团队都是有文档、有答案、就是没有用户的查询,导致无法量化检索的优劣。正确的做法是:使用 LLM 为你的语料自动生成 query-chunk 对,得到小而精的评测集,用它来权衡召回,精度,成本,可用性再稳步迭代。实践证明:几百条高质量的评估集,能带来巨大的回报。
RAG 消失
rag 终会消失
RAG 每个环节都藏着工程”暗伤”:
- 切片策略是玄学:按段落切?按 Token 数切?重叠多少?切片粒度直接影响检索质量,却没有银弹。
- Embedding 是黑盒:换个 Embedding 模型,检索效果可能天差地别。而且向量只是原文的一个”有损压缩”,信息必然丢失。
- 索引更新是噩梦:文档改一行,可能需要重新切片、重新 Embedding、重新写入。实时性?基本别想。
- 基础设施是成本:Milvus、Qdrant、Pinecone……光是向量数据库的选型、部署、运维就能消耗大量精力。
方案总结
- 树状推理:PageIndex
- 无检索:阿里 Sirchmunk(蒙特卡洛采样+自进化数据库)
- 文件检索:Google File Search、字节 OpenViking(依赖embedding)
详见站内专题:RAG 消失之路
LLM 问题
LLM 通过大量数据训练,回答任何问题或完成任务,利用其参数化记忆。这些模型有一个知识截止日期,取决于上次训练的时间。
- 被问及超出其知识范围或知识截止日期后发生的事件时,模型会产生幻觉。
Meta 研究人员发现,通过提供与手头任务相关的信息,模型在完成任务时表现显著改善。
例如,询问模型关于截止日期之后发生的事件,则提供该事件作为背景信息并随后提问将帮助模型正确回答问题。
由于LLM具有有限的上下文窗口长度,在处理当前任务时只能传递最相关的知识。添加到上下文中数据质量影响着模型生成响应结果的质量。
机器学习从业者在RAG流程不同阶段使用多种技术来改善LLM性能。
RAG 解决什么问题
RAG 解决什么问题
- 知识时效性:大型语言模型通常是基于一定时间范围内的数据进行训练的,因此它们难以获取最新的信息。外挂知识库可以包含最新的数据,使得模型能够回答关于最新事件的问题。
- 知识覆盖范围:即使是非常大的语言模型,也无法覆盖所有领域的知识。通过外挂知识库,可以针对特定领域或主题提供详细和专业的信息。
- 提高准确性和可靠性:在没有额外知识的情况下,模型可能会基于其训练数据生成不准确或误导性的回答。外挂知识库可以提供准确的信息源,从而提高回答的可靠性。
- 减少幻觉(Hallucination):幻觉是指模型生成看似合理但实际上不准确的答案。通过检索相关的真实信息,外挂知识库可以帮助减少这种幻觉现象。
- 跨领域知识融合:在处理需要跨领域知识的问题时,外挂知识库可以提供不同领域的知识,帮助模型生成综合性的回答。
- 数据长度问题,最初大模型一次性处理的token数量有限,通过RAG技术能是的大模型一次性处理更长的文本
- 数据安全问题
RAG 介绍
科里·祖
“检索增强生成是用您(系统)从其他地方检索到的附加信息来补充用户输入到 ChatGPT 等大型语言模型 (LLM) 的过程。然后,法学硕士可以使用该信息来增强其生成的响应。”
检索增强生成(简称 RAG)是 Meta 于 2020 年推广的一种架构,通过将相关信息与问题/任务细节一起传递给模型来提高 LLM 的性能。
RAG模型直接把Retrieve augmentation加到名字里。
解决的痛点:
- 之前的研究(如REALM)基于MLM模型,只做提取任务,其他任务受限,用generator可以赋予其更大的能力。
两个模型变种:RAG-Sequence和RAG-Token
RAG-Sequence,先找到k个最详尽的例子(k个z),然后根据每个z作为条件去预测完整个句子,然后概率求和。在每一次去预测的时候都是只看一个doc的。先乘后加。对应的decode需要额外处理RAG-Token,先找到k个最详尽的例子(k个z),但是每预测一个token的时候都要看k个doc然后求和。先加后乘,对应的decode需要额外处理
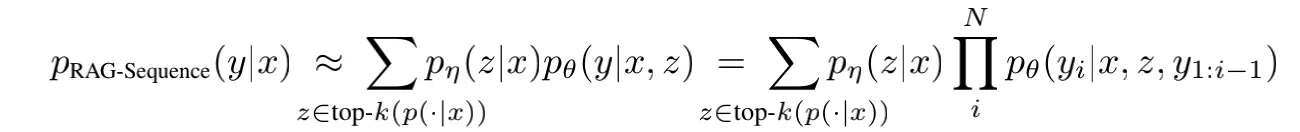
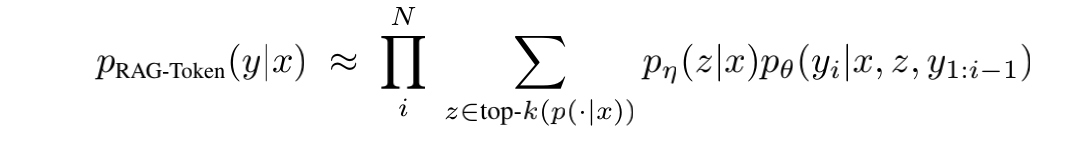
retriever 用 DPR,generator 用 BART,联合训练。预测时候有一些小小操作详情见原论文
REALM 和 RAG 在huggingface上都已经被实现了,直接使用。
FiD和FiD-KD,简单高效的Generator端的改进
FiD全称是 Fusion-in-Decoder,作者的一篇短文被提出(小彩蛋:通讯作者是当时cached LM的一作)- 主要改进 Generator端,方法一张图:
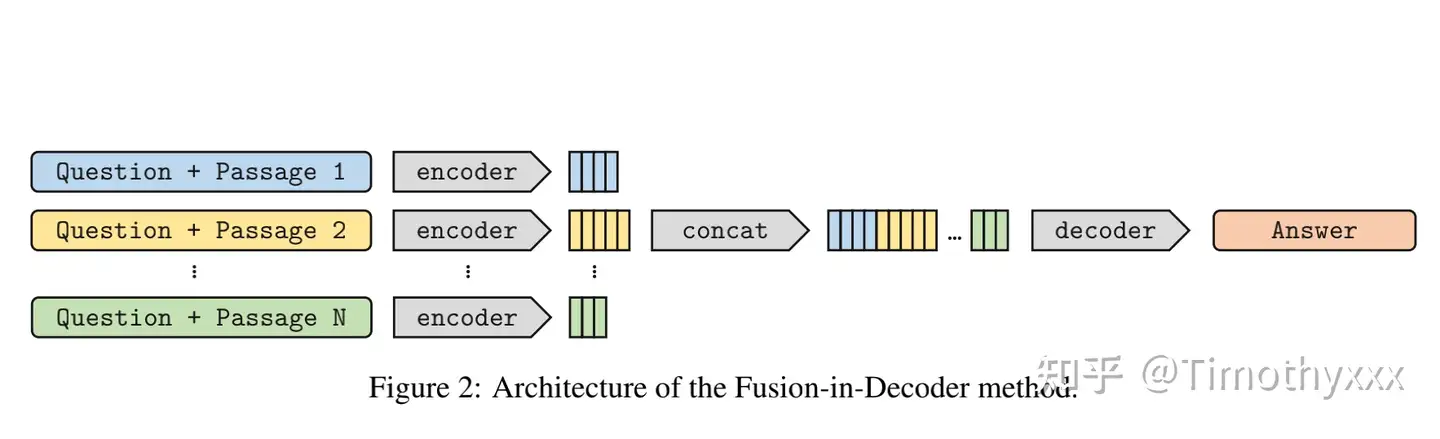
- 基于seq2seq的模型,拆开两半用,第一步用encoder将检索出来的N个段落分别与Question进行拼接的N个拼接编码,之后就和seq2seq剩余的部分一样了,cross attention,causual mask什么的使用decoder把他们拼起来的结果解码即可。结果还是很不错的,简单有效刷SOTA。
FiD-KD: 发完FiD不久,统一团队对FiD迅速补充提出了KD的FiD。- 解决的痛点: 很难去监督retrieve出来的结果,因为几乎没有对到底检索出来哪些文档有有监督的标注,之前的REALM和RAG也对这个根本没有监督。FiD-KD对此进行改进。
- FiD中将所有的encoding拼接之后接下来继续完成seq2seq,会进行一下cross attention,(如果对cross attention不熟悉那么就可以去看看huggingface transformers的BART源码),cross attention的attention值的大小是一个很好的监督信号。cross attention的值这个可以对检索出来的文章进行一个打分,进而作为信号被我们用来拉近retriever的结果和retriever打分的分布。具体的attention怎么处理的,怎样拉近分布比较好详情见论文。
UniK-QA,扩展Open-domain QA的知识来源
- 之前的KBQA(涉及结构化知识)和开放域问答(涉及非结构化知识)是分别分开研究的,使用的技术也不一样,同时也限制了知识的来源。作者希望他们之间能通过统一使得QA的性能得以提高。所以作者提出了一个pipeline:首先将结构化文本进行flatten表示为非结构化文本“一段话”(也就是传统的开放域问答所使用的知识形式)
TLM,使用检索来进行专用化的高效预训练
- 2021年的11月,杨植麟团队提出了一种新的预训练范式,Task-driven Language Modeling (TLM),根据下游需要完成的任务来有针对性的进行上游预训练数据的筛选。这种针对性的预训练可以大幅度加速下游的微调时间,从而取得更好的效果。
CASPER,检索examples作为辅助
RETRO,retrieve-based LM领域的大厂强心剂
- jalammar写的很简洁,直接看就可以很快地了解RETRO在干什么,几个takeaway是:
- 1)不训练检索器就很好使,RETRO直接用冻结的BERT作为检索器,效果也很好。
- 2)cross attention固然好用,像RETRO这样设计新的深度融合可能会更好,这也是可以做的一个蓝海方向。
更多:检索、提示:检索增强的(Retrieval Augmented)自然语言处理
【2024-3-7】大模型RAG行业适配过程中的一些思考
对齐方式上来看:人向大模型对齐和大模型向人对齐。
- 人->大模型对齐:prompt工程,通过提示词工程提升,进行问题优化,或引入BPO机制,进行提示词预训练。
- 大模型->人对齐:RLHF、SFT、RAG 等方式,通过对于人类习惯、领域知识的增强与补充,使模型的输出更加符合人类的预期和需求。
实际工程中也会通过以上融合的方式,使大模型能够更加符合人类对于问答的预期
RAG 生成准确且符合上下文的答案,同时减少模型幻觉。
- RAG的基本原理: 首先对现有文档进行检索,然后基于检索到的信息对生成的答案进行修正。
- RAG主要作用: 提高LLM的处理效率,并有效控制tokens的长度
- 主流框架: LlamaIndex和langchain等,通过RAG对于领域知识的引入,可以减少大模幻觉问题。并且,由于无需打开模型调参的工作机制,与SFT等对齐方式相比,具有更加快速、便捷的优点。
准确率计算:
RAG准确率=LLM准确率*语义搜索准确率*RAG信息保存率
RAG的准确性影响因素
- 上下文脱节问题:如果文本有多层上下文信息,chunk之间会使得内容上上下文脱节
- 位置因素失效问题:一般文字位置代表一定的重要性,但是在向量库存储的模式下,位置关键因素会失效
- 连续信息不完整问题:由于连接不再完整,语序容易被打乱
- 描述信息丢失问题。
RAG 方案
【2024-11-24】详见:浙大《大模型基础》
如何优化检索器与LLM协作?
按是否访问模型参数,现有RAG 系统分为
- (1)黑盒增强架构,不访问模型的内部参数,仅利用输出反馈进行优化;
- 是否微调检索器,分两类:①
无微调、②检索器微调 - ①
无微调: 检索器和语言模型经过分别独立的预训练后参数不再更新,直接组合使用参数的针对性调整- 优点: 计算资源需求较低,方便实现且易于部署,适合于对部署速度和灵活性有较高要求的场景
- 代表: In-Context RALM (用query部分/全部内容检索,直接将结果作为Prompt的前置上文)
- 几个关键参数: 如
检索步长和检索查询长度。前者直接影响模型响应速度和信息即时性
- 几个关键参数: 如
- 问题: 无微调架构在实现和部署上非常便捷,但完全没有考虑
检索器与语言模型之间潜在的协同效应,效果有待提升
- ②
检索器微调: 语言模型参数保持不变,而检索器根据语言模型的输出反馈进行- 代表: REPLUG LSR
- 将语言模型视为黑盒处理,仅通过模型的输出来指导检索器的训练,避免了对语言模型内部结构的访问和修改
- 用LLM
困惑度分数作为监督信号来微调检索器,使其能更有效地检索出能够显著降低语言模型困惑度的文档 - 用
KL 散度损失函数来训练检索器,对齐检索文档的相关性分布与对语言模型性能提升的贡献分布
- 用LLM
- AAR 使用额外的小模型,用交叉注意力得分标注偏好文档,微调检索器
- 将语言模型视为黑盒处理,仅通过模型的输出来指导检索器的训练,避免了对语言模型内部结构的访问和修改
- 代表: REPLUG LSR
- 是否微调检索器,分两类:①
- (2)白盒增强架构,允许对大语言模型进行微调
- 是否微调检索器,分两类:①
仅微调大语言模型、②检索器与大语言模型协同微调 - ①
仅微调LLM: 大语言模型根据检索器提供的上下文信息,对自身参数进行微调- 代表:
- RETRO 修改语言模型的结构,使其在微调过程中将检索文本直接融入到语言模型中间状态中,实现外部知识对大语言模型的增强
- SELF-RAG 在微调语言模型时引入反思标记,使语言模型在生成过程中动态决定是否需要检索外部文本,并对生成结果进行自我批判和优化。
- 问题: 基座模型参数不动,导致检索器无法根据语言模型的需求进行适应性调整,从而限制了检索器与语言模型之间的相互协同
- 代表:
- ②
检索器与大语言模型协同微调: 检索器和语言模型的参数更新同步进行- 代表:
Atlas: 与REPLUG LSR类似,预训练和微调阶段使用KL 散度损失函数联合训练检索器和语言模型,确保检索器输出的文档相关性分布与文档对语言模型的贡献分布相一致, 不同点是Atlas语言模型参数同步被更新
- 代表:
- 是否微调检索器,分两类:①
如何优化检索过程?如何提高检索的质量与效率,主要包括:
- (1)知识库构建,构建全面高质量的知识库并进行增强与优化;
- (2)查询增强,改进原始查询,使其更精确和易于匹配知识库信息;
- 问题: 知识表达形式是有限,但用户的提问方式无限
- 解决: 以对用户查询的语义和内容进行扩展,即查询增强
- ① 查询
语义增强:通过同义改写和多视角分解等方法来扩展、丰富用户查询的语义,以提高检索的准确性和全面性。- 同义改写: 用户查询单一的表达形式可能无法全面覆盖到知识库中多样化表达的知识
- 做法: 原始问题生成多个相似问题, 每个改写后的查询都可独立用于检索相关文档, 随后合并、去重
- 考拉的饮食习惯是什么? –> :1、“考拉主要吃什么?”;2、“考拉的食物有哪些?”;3、“考拉的饮食结构是怎样的?”
- 多视角分解:分而治之,将复杂查询分解为来自不同视角的子查询,以检索到查询相关的不同角度的信息
- “考拉面临哪些威胁?” –> 多个视角分解:1、“考拉的栖息地丧失对其有何影响?”;2、“气候变化如何影响考拉的生存?”;3、“人类活动对考拉种群有哪些威胁?”;4、“自然灾害对考拉的影响有哪些?”等子问题
- 同义改写: 用户查询单一的表达形式可能无法全面覆盖到知识库中多样化表达的知识
- ② 查询
内容增强:- 通过生成与原始查询相关的背景信息和上下文,丰富查询内容,提高检索的准确性和全面性.
- 传统检索区别: 过引入大语言模型生成的辅助文档,为原始查询提供更多维度的信息支持。
- 如何保护考拉的栖息地?–> 考拉是原产于澳大利亚的保护动物。。。。
- (3)检索器,介绍常见的检索器结构和搜索算法;
- 检索器分为
判别式检索器和生成式检索器 判别式检索器: 通过判别模型对查询和文档是否相关进行打分。判别式检索器通常分为两大类:稀疏检索器和稠密检索器。稀疏检索器利用离散、基于词频的文档编码向量进行检索- 代表: TF-IDF、BM25
- 而
稠密检索器则利用神经网络生成的连续的、稠密向量对文档进行检索。- 稠密检索器一般用预训练语言模型对文本生成低维、密集的向量表示,通过计算向量间的相似度进行检索。按照模型结构的不同,稠密检索器大致可以分为两类:
交叉编码类(Cross-Encoder)、双编码器类(Bi-Encoder) - 代表: DPR(Dense Passage Retriever)、ColBERT(对比学习对双编码器进行微调)、Poly-encoder(处理长查询,m个向量捕获多维特征)
- 稠密检索器一般用预训练语言模型对文本生成低维、密集的向量表示,通过计算向量间的相似度进行检索。按照模型结构的不同,稠密检索器大致可以分为两类:
生成式检索器: 通过生成模型对输入查询直接生成相关文档的标识符。- 与判别式检索器不断地从知识库中去匹配相关文档不同,生成式检索器直接将知识库中的文档信息记忆在模型参数中。然后,收到查询请求时,直接生成相关文档的标识符(即DocID),以完成检索
- 生成式检索器通常采用基于Encoder-Decoder 架构的生成模型,如 T5、BART
- DocID设计至关重要,常用DocID 形式两类:基于数字的DocID 和基于词的DocID。
- 基于数字: 用唯一的数字值或整数字符串来表示文档,虽然构建简单,但在处理大量文档时可能导致标识符数量激增,增加计算和存储负担
- 基于词: 在缺乏高质量标题时,URL 或N-gram 也可作为有效的替代方案
- 尽管
生成式检索器在性能上取得了一定的进步,但与稠密检索器相比,其效果仍稍逊一筹。 - 此外,生成式检索器还面临着一系列挑战,包括: 如何突破模型输入长度限制、如何有效处理大规模文档以及动态新增文档的表示学习等,这些都是亟待解决的问题
- 检索器分为
- (4)检索效率增强,介绍用于提升检索效率的常用相似度索引算法;
- 引入
向量数据库来实现检索中的高效向量存储和查询 - 向量数据库的核心是设计高效的相似度索引算法,常用索引技术:基于空间划分的方法、基于量化方法和基于图的方法。
- ① 基于空间划分: 将搜索空间划分为多个区域来实现索引,主要包括基于
树的索引方法(KD树、Ball树)和基于哈希的方法(局部敏感哈希 LSH) - ② 基于图:构建一个邻近图,将向量检索转化为图遍历,在索引构建阶段,将数据集中的每个向量表示为图中的一个节点,并根据向量间的距离或相似性建立边的连接。
- 图索引设计面临稀疏性和稠密性的权衡:较稀疏的图结构每步计算代价低,而较稠密的图则可能缩短搜索路径。
- 代表: NSW、IPNSW 和 HNSW 等。
- ③ 基于乘积量化: 通过将高维向量空间划分为多个子空间,并在每个子空间中进行聚类得到码本和码字,以此作为构建索引的基础。主要包括训练和查询两个阶段
- 引入
- (5)重排优化,通过文档重排筛选出更有效的信息。
- 问题: 检索器可能检索到与查询相关性不高的文档, 导致RAG结果质量下滑
- 解法: 对检索到的文档进行重新排序,简称
重排,然后从中选择出排序靠前的文档。 - 重排方法主要分为两类:基于交叉编码的方法和基于上下文学习的方法。
- ① 基于交叉编码的重排方法:利用交叉编码器(Cross-Encoders)来评估文档与查询之间的语义相关性
- 代表:
MiniLM-L(减少层数和隐层单元数来降低参数数量,知识蒸馏)、Cohere(在线重排模型, api可访问)
- 代表:
- ② 基于上下文学习方法: 通过设计精巧的Prompt,使用大语言模型来执行重排任务
- 代表: RankGPT (滑动窗口技术来优化排序过程,不受窗口限制)
- (6) 生成增强
- 如何优化增强过程?如何高效利用检索信息,主要包括:
- (1)何时增强,确定何时需要检索增强,以提升效率并避免干扰信息;
- (2)何处增强,讨论生成过程中插入检索信息的常见位置;
- (3)多次增强,针对复杂与模糊查询,讨论常见的多次增强方式;
- (4)降本增效,介绍现有的知识压缩和缓存加速策略
RAG 方案总结
【2024-3-27】王昊奋团队高云帆的RAG综述
- 同济、复旦 Retrieval-Augmented Generation for Large Language Models: A Survey
- 导读
- 讨论:
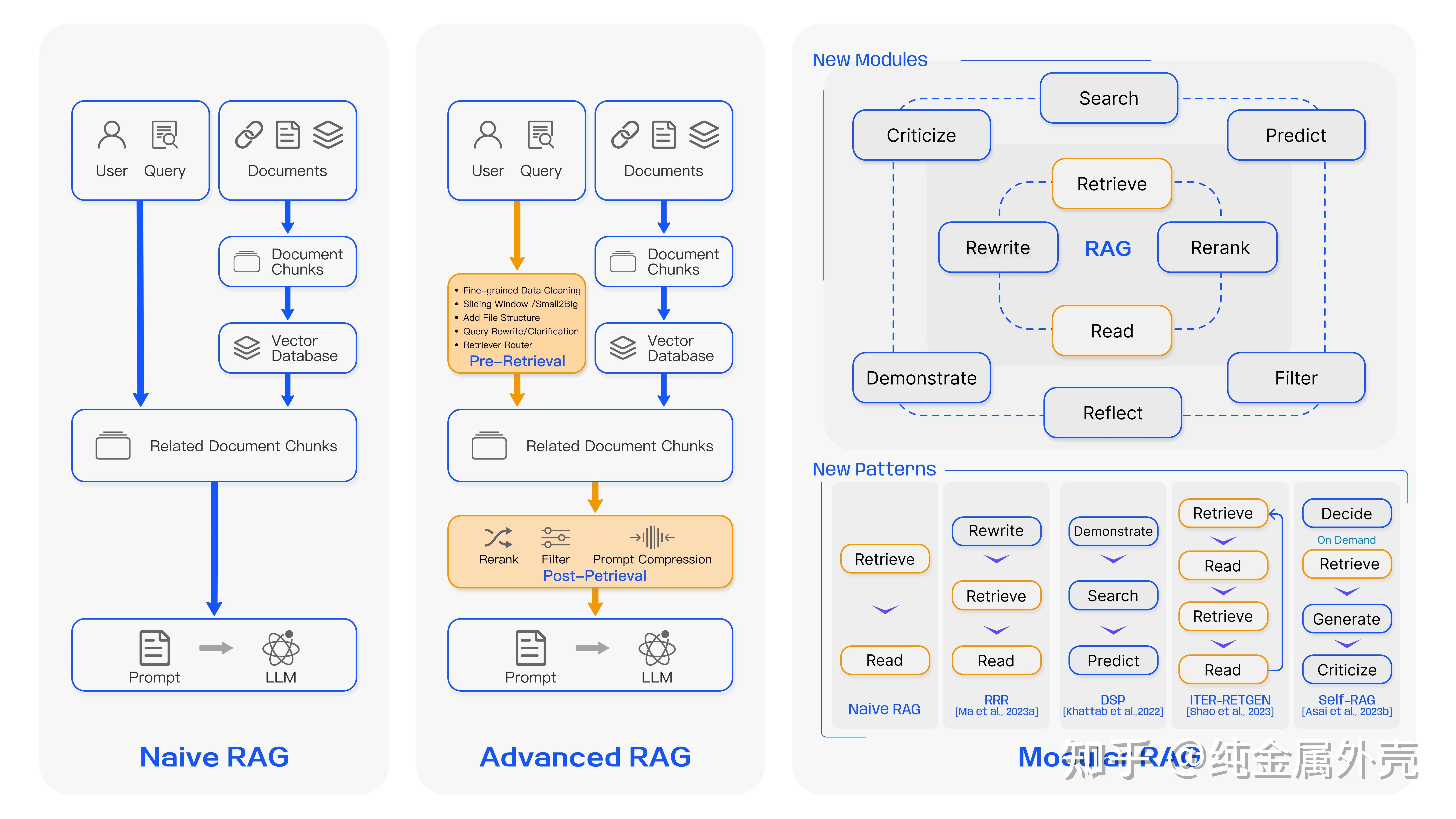
Naive RAG,Advanced RAG,Modular RAG
分析
Naive RAG: 原生RAG, 建索引(离线)→检索(在线)→生成, 3个阶段- 问题: 切分方法生硬,片段不一定相关,检索到的文本分段可能大量冗余、重复或者噪声信息
Advanced RAG: 高级RAG, 改进版RAG,预检索(pre-retrieval)、后检索(post-retrieval)- Preretrieval(检索前),Post-retrieval(检索后) 和Retrieval Process(检索中) 的各种改善方法
- 检索前:建立多种文档索引、利用滑动窗对文本进行分块;
- 检索中:多路召回,Embedding 模型微调;
- 检索后:重排(Re-rank)等
Modular RAG: 模块RAG, 更灵活, 不再是单一流水线模式,新范式 RAG Agent- 递归调用LLM,例如利用模型来反思、评估第一次输出,然后再输出新的结果。或者让模型自己决定什么时候调用检索工具。
- 不同阶段RAG: pre-training, fine-tuning, inference
【2024-11-18】LLM RAG 汇总
传统RAG
- 集 chunk切分、向量化、存储、检索、生成等几个阶段于一体的RAG框架
- 核心: 不同策略适应,如文档处理、检索策略等
- 代表:
RAGFlow(深度文档理解),QAnything(重排rerank引入),可高度配置的Dify等
- 代表:
【2024-12-24】检索准确率从 50-60% 提升至 95% 的两个技巧
- 利用 LLM 改写用户查询
- 解决方案:查询阶段,借助 LLM 将用户输入改写为结构化查询。
- 例如,将 “
Swedish massage in Helsinki” 改写为:服务字段包含 "Swedish massage" 且城市字段为 "Helsinki" 的查询。 - 实际效果:精准的查询改写显著提高了检索相关性,减少了 BM25 依赖于关键词频率的问题。 - 成本与问题: - 性能开销:查询改写需要实时处理,在高并发场景中可能增加响应时间。
- 维护复杂度:需持续优化查询改写逻辑,以适应不断变化的用户需求。
- 利用 LLM 改进索引
- 解决方案:索引阶段,用大语言模型(LLM)从自由文本中提取服务信息,生成结构化服务列表作为索引字段。
- 例如,从 描述 “This spa offers Swedish massage and aromatherapy” 中提取 “Swedish massage” 和 “aromatherapy”。 - 处理非标准化输入:预处理步骤清洗拼写错误、语言变体等噪声,提升模型一致性。 - 实际效果:索引信息更加精确,解决了向量搜索中模糊匹配导致的相关性不足问题。 - 成本与问题:
- 计算成本:索引构建需要显著的计算资源,特别是在大规模数据场景中。
- 维护复杂度:动态服务信息需要持续更新,确保索引的准确性和实用性。
17种
- 1)
AnythingLLM,具备完整的RAG(检索增强生成)和AI代理能力。- anything-llm
- GitHub - Mintplex-Labs/anything-llm: The all-in-one Desktop & Docker AI application with built-in RAG, AI agents, and more.
- 2)
MaxKB,基于大型语言模型的知识库问答系统。即插即用,支持快速嵌入到第三方业务系统。地址: - 3)
RAGFlow,一个基于深度文档理解的开源RAG(检索增强生成)引擎。- 地址:ragflow
- 4)Dify,开源大型语言模型应用开发平台。
- Dify 通过直观界面结合了AI工作流、RAG流程、代理能力、模型管理、可观测性功能等,快速从原型阶段过渡到生产阶段。
- 地址:Dify
- 5)FastGPT,基于LLM构建的知识型平台,提供即开即用的数据加工和模型调用能力,允许通过流程可视化进行工作流编排。
- 地址:FastGPT
- GitHub - labring/FastGPT: FastGPT is a knowledge-based platform built on the LLMs, offers a comprehensive suite of out-of-the-box capabilities such as data processing, RAG retrieval, and visual AI workflow orchestration, letting you easily develop and deploy complex question-answering systems without the need for extensive setup or configuration.
- 6)Langchain-Chatchat,基于Langchain和ChatGLM等不同大模型的本地知识库问答。
- 7)QAnything,基于Anything的问题和答案。
- 地址:QAnything
- 8)Quivr,使用 Langchain、GPT 3.5/4 turbo、Private、Anthropic、VertexAI、Ollama、LLMs、Groq等与文档(PDF、CSV等)和应用程序交互,本地和私有的替代OpenAI GPTs和ChatGPT。
- 地址:quivr
- GitHub - QuivrHQ/quivr: Opiniated RAG for integrating GenAI in your apps Focus on your product rather than the RAG. Easy integration in existing products with customisation! Any LLM: GPT4, Groq, Llama. Any Vectorstore: PGVector, Faiss. Any Files. Anyway you want.
- 9)RAG-GPT,RAG-GPT利用LLM和RAG技术,从用户自定义的知识库中学习,为广泛的查询提供上下文相关的答案,确保快速准确的信息检索。
- 11)FlashRAG,一个用于高效RAG研究的Python工具包。
- 地址:FlashRAG
- 12)LightRAG,检索器-代理-生成器式的RAG框架。
- 地址:LightRAG
- 13)kotaemon,一个开源的干净且可定制的RAG UI。
- 15)TurboRAG,通过预计算的KV缓存加速检索增强生成,适用于分块文本。
- 地址:TurboRAG
- 16)TEN,实时多模态AI代理框架。
- 17)AutoRAG,RAG AutoML工具。
- 地址:AutoRAG
GraphRAG 框架流行于微软 GraphRAG,后续出现很多
- 轻量化改进版本,如
LightRAG、nano-GraphRAG - 特色版本,如: KAG,其核心思想是在原先传统RAG的基础上,增加实体、社区、chunk之间的关联,或者原有KG的知识,从而提升召回和准确性。
详情
- 1)LightRAG,简单快速的Graphrag检索增强生成。
- “LightRAG: Simple and Fast Retrieval-Augmented Generation”
- 地址: LightRAG 2)GraphRAG-Ollama-UI,使用 Ollama的GraphRAG,带有Gradio UI和额外功能。
- 地址:GraphRAG-Ollama-UI
- 3)GraphRAG,一个模块化,基于图的检索增强生成(RAG)系统。微软
- 地址:graphrag
- 4)nano-GraphRAG,,简单、易于修改的GraphRAG实现地址:
- 5)KAG,基于OpenSPG引擎的知识增强生成框架,用于构建知识增强的严格决策制定和信息检索知识服务。
- 地址:KAG
- KAG is a knowledge-enhanced generation framework based on OpenSPG engine, which is used to build knowledge-enhanced rigorous decision-making and information retrieval knowledge services
- 6)Fast-GraphRAG,GraphRAG的轻量化版本。
- 7)Tiny-GraphRAG,一个小巧的GraphRAG实现。
16种RAG
16 types of RAG models shaping the next wave of AI innovation
- Standard RAG
- The foundation of all RAG systems - combines retrieval and generation for question answering and knowledge synthesis.
- Agentic RAG
- Empowers AI agents to retrieve and act autonomously, perfect for assistants that need dynamic, tool-based reasoning.
- Graph RAG
- Uses knowledge graphs for relational reasoning - ideal for expert systems in law, medicine, and semantic search.
- Modular RAG
- Breaks retrieval, reasoning, and generation into independent components - enabling collaborative, scalable AI workflows.
- Memory-Augmented RAG
- Adds persistent external memory for context retention, powering long-term chatbots and personalized experiences.
- Multi-Modal RAG
- Processes text, images, and audio together - perfect for video summarization, captioning, and multi-modal AI tools.
- Federated RAG
- Enables privacy-preserving retrieval from decentralized sources, used in healthcare and secure enterprise systems.
- Streaming RAG
- Performs real-time retrieval and generation, ideal for financial dashboards, live feeds, and social media monitoring.
- ODQA RAG (Open-Domain QA)
- Handles large, diverse datasets - ideal for search engines and intelligent virtual assistants.
- Contextual Retrieval RAG
- Maintains session-level awareness, great for conversational AI and customer support chatbots.
- Knowledge-Enhanced RAG
- Integrates structured domain data, useful for legal, educational, and professional knowledge applications.
- Domain-Specific RAG
- Custom-tailored for specific industries - like finance, healthcare, or legal analytics.
- Hybrid RAG
- Combines multiple retrieval approaches, bridging structured and unstructured data for high precision.
- Self-RAG
- Introduces self-reflection to refine its own answers, enabling AI models to fact-check and improve reasoning autonomously.
- HyDE RAG (Hypothetical Document Embeddings)
- Generates hypothetical documents to guide retrieval, excellent for complex or niche query contexts.
- Recursive / Multi-Step RAG
- Performs multiple retrieval-generation loops, enabling advanced problem-solving and reasoning chains.
图解
代码实现
【2025-3-20】22种 rag 的代码实现 all-rag-techniques,直接可实操,有22个notebook,抓紧练起来,一键运行。
- Simple RAG:简单的RAG,一个基础的RAG实现,适合初学者快速上手!
- Semantic Chunking:语义分块,根据语义相似性分割文本,生成更有意义的文本块。
- Chunk Size Selector:分块大小选择器,探索不同分块大小对检索性能的影响。
- Context Enriched RAG:上下文增强的RAG,检索相邻分块以提供更多上下文信息。
- Contextual Chunk Headers:上下文分块标题,在嵌入前为每个分块添加描述性标题。
- Document Augmentation RAG:文档增强的RAG,从文本分块生成问题,优化检索过程。
- Query Transform:查询转换,重写、扩展或分解查询,包含回溯提示和子查询分解,提升检索效果。
- Reranker:重排器,使用大模型(LLM)重新对最初检索结果排序,提高相关性。
- RSE:相关段落提取,识别并重构连续文本段落,保留上下文。
- Contextual Compression:上下文压缩,过滤并压缩检索分块,最大化相关信息。
- Feedback Loop RAG:反馈循环的RAG,结合用户反馈随时间改进系统。
- Adaptive RAG:自适应的RAG,根据查询类型动态选择最佳检索策略。
- Self RAG:自我RAG,动态决定何时及如何检索,评估相关性和效用。
- Proposition Chunking:命题分块,文档分解为原子性事实陈述,精准检索。
- Multimodel RAG:多模态RAG,结合文本和图像检索,使用LLaVA生成图像标题。
- Fusion RAG:融合RAG,结合向量搜索与BM25关键词检索,提升结果。
- Graph RAG:图谱RAG,知识组织成图,支持相关概念遍历。
- Hierarchy RAG:层次RAG,构建摘要+详细分块的层次索引,高效检索。
- HyDE RAG:HyDE RAG,使用假设性文档嵌入,改善语义匹配。
- CRAG:纠正性RAG,动态评估检索质量,网络搜索作为后备。
- RAG with RL:带强化学习的RAG,使用强化学习最大化模型奖励。
- Big Data with Knowledge Graphs:大数据知识图谱RAG,专为大规模数据集设计!
RAG -> Agent
【2024-6-26】 LlamaIndex团队技术报告:“RAG的尽头是Agent”
- LlamaIndex co-founder/CEO
Jerry Liu - 报告主题:“超越RAG:构建高级上下文增强型大型语言模型(LLM)应用”,
- 主题原文:“Beyond RAG: Building Advanced Context-Augmented LLM Applications”
- ppt 截图见原文 LlamaIndex团队技术报告:“RAG的尽头是Agent”
- 飞书文档
内容概要:
RAG 局限性:
- RAG最初是为简单问题和小型文档集设计,通常包括数据解析、索引检索和简单问答。
- 然而,处理复杂问题时存在局限性,例如 总结整个年度报告、比较问题、结构化分析和语义搜索等。
Agent 引入:
- 为了解决 RAG 局限性,文档提出了引入Agent的概念。
- Agent 是一种更高级系统,执行多轮对话、查询/任务规划、工具使用、反思和记忆维护等更复杂的功能。
从 RAG 到 Agent 的转变涉及几个层次的功能:
- 多轮对话:与用户进行更深入的互动。
- 查询/任务规划层:能够理解并规划复杂的查询和任务。
- 工具接口:与外部环境进行交互,使用工具来辅助任务执行。
- 反思:自我评估并改进执行过程。
- 记忆:维护用户交互的历史,以提供个性化服务。
Agent 从简单到高级的不同层次:
- 简单Agent:成本较低,延迟较低,但功能有限。
- 高级Agent:成本较高,延迟较高,但提供更复杂的功能,如动态规划和执行。
ReAct:ReAct(Reasoning + Acting with LLMs),这是一个结合了推理和行动的LLM系统,它利用查询规划、工具使用和记忆来执行更复杂的任务。LLMCompiler:一个Agent编译器,用于并行多功能规划和执行,它通过生成步骤的有向无环图(DAG)来优化任务执行。- 自我反思和可观察性:Agent能够通过自我反思和反馈来改进执行,同时提供可观察性,以便开发者能够追踪和理解Agent的行为。
- 多Agent系统:多Agent系统的概念,其中多个Agent可以同步或异步地交互,以执行更复杂的任务。
RAG 作者:部署企业级 RAG Agents 的 10 个经验教训
10 个经验教训 更好的 LLM 不是(唯一)答案: LLM 只是整个 AI 系统(特别是 RAG 系统,包括提取、检索、生成、联合优化)的一小部分(约 20%)。一个优秀的 RAG 系统配合普通的 LLM,效果可能优于一个顶尖 LLM 配合糟糕的 RAG 系统。关键是关注系统而非孤立的模型。
- 专业知识是你的燃料: 企业内部积累的专业知识和机构知识(通常存在于文档和数据中)是驱动 AI 产生价值的核心燃料。必须设法解锁这些专业知识。
- 企业规模是你的护城河: 企业的核心竞争力在于其独特的数据。真正的挑战在于大规模地利用这些数据,让 AI 能够处理大规模、甚至“嘈杂”的真实数据。成功做到这一点,就能构建竞争壁垒。
- 试点与生产之间的鸿沟总是比预想的要大: 建立小规模试相对容易(少量文档、用户、单一场景、低风险),但将其扩展到生产环境 则面临巨大挑战(海量文档、大量用户、多场景、高安全风险、SLA 要求等)。
- 速度比完美更重要: 不要追求一开始就完美。应尽早将(哪怕不完美的)系统交给真实用户使用,获取反馈并快速迭代。通过迭代“爬山”达到目标,而不是试图一次性设计出完美方案。
- 不要让工程师在“无聊”的事情上花费大量时间: 工程师本应专注于构建流程、提升精度、扩展应用等创造业务价值的工作,但现实中却常常耗费时间在数据分块策略、文本清洗、构建连接器、配置向量数据库、调整提示、管理基础设施等相对基础且耗时的工作上。应设法将这些工作自动化或平台化。
- 让 AI 易于消费: 即使 AI 系统已部署到生产环境,如果没有被用户方便地使用,也无法产生价值。很多时候系统使用率为零。关键在于将 AI 集成到用户现有的工作流程中。企业数据 + AI + 集成 = 成功。
- 让你的用户“惊叹”: 要让 AI 应用产生粘性,需要尽快让用户体验到“惊艳”时刻。例如,帮助用户找到一个他们自己都不知道存在的、埋藏多年的重要文档并回答了关键问题。用户体验设计应围绕创造这种早期价值。
- 可观测性比准确率更重要: 达到 100% 准确率几乎不可能,90-95% 也许可以。但企业更关心的是那无法避免的 5-10% 的错误会带来什么影响以及如何处理。因此,可观测性 ,包括理解系统为何给出某个答案、提供溯源依据、建立审计追踪等,比单纯追求更高的准确率更重要,尤其是在受监管行业。
- 要有雄心壮志: 项目失败往往不是因为目标太高,而是因为目标太低。不要满足于解决“401k 供应商是谁”这类简单问题,要敢于挑战能带来真正业务转型的难题。
RAG 进化路线
模型:
Knn-LM->REALM->DPR->RAG->FID->COG->GenRead->REPLUG->Adaptive retrieval
详情见文章
【2023-10-30】ACL2023陈丹琦等《基于检索的大语言模型及其应用》
- 【2023-7-10】陈丹琦ACL学术报告来了!详解大模型「外挂」数据库7大方向3大挑战,3小时干货满满
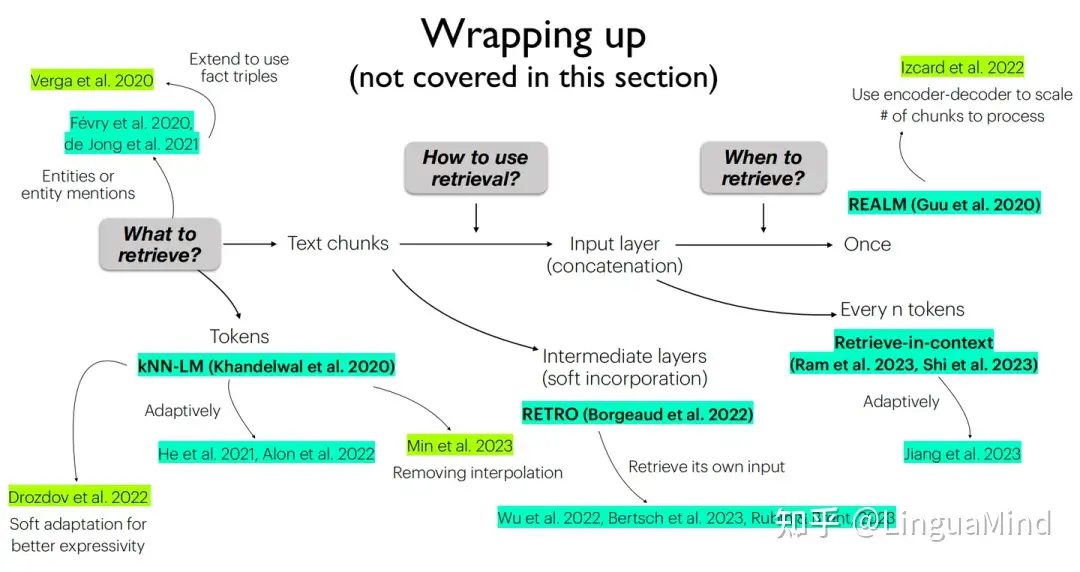
GPT 模型三个问题:
- 1、参数量过大,如果基于新数据重训练,计算成本过高;
- 2、记忆力不行(面对长文本,记了下文忘了上文),时间一长会产生幻觉,且容易泄露数据;
- 3、目前的参数量,不可能记住所有知识。
这种情况下,外部检索语料库被提出,即给大语言模型“外挂”一个数据库,让它随时能通过查找资料来回答问题,而且由于这种数据库随时能更新,也不用担心重训的成本问题。
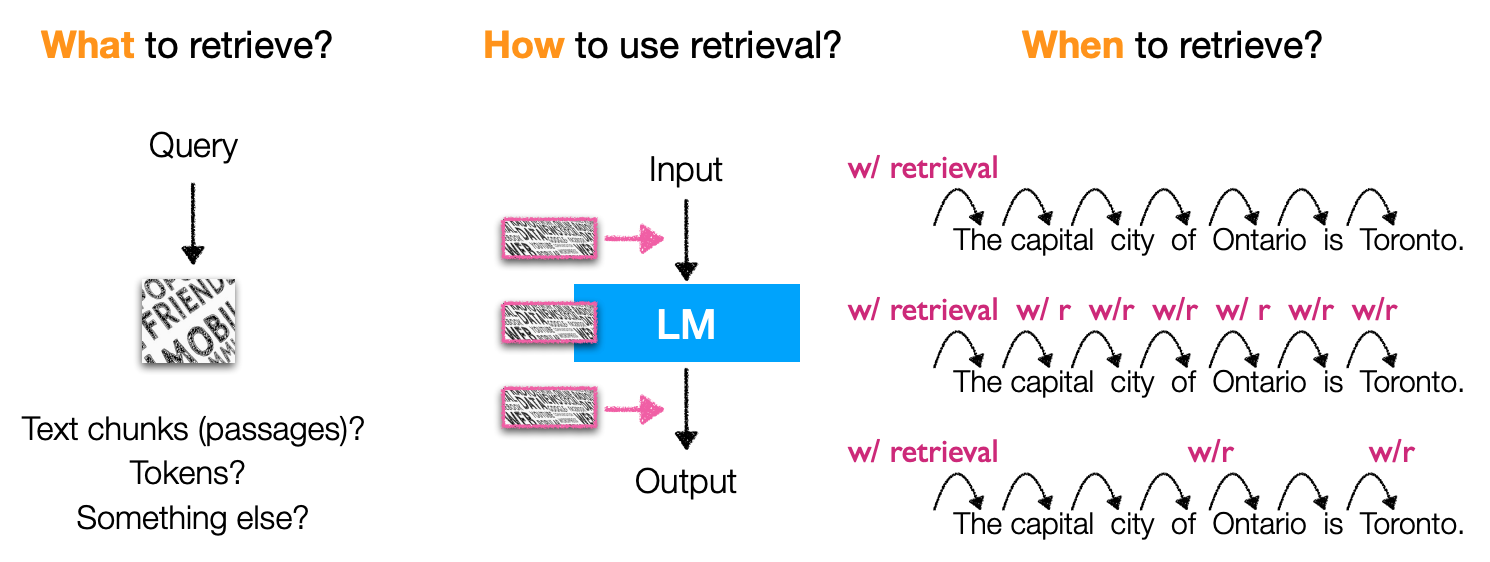
训练方式上,则着重介绍
- 独立训练(independent training,语言模型和检索模型分开训练)、连续学习(sequential training)、多任务学习(joint training)等方法
应用方面,这类模型涉及的也就比较多了
- 不仅可以用在代码生成、分类、知识密集型NLP等任务上
- 而且通过微调、强化学习、基于检索的提示词等方法就能使用
RAG要解决的几大难题。
- 其一,小语言模型+(不断扩张的)大数据库,本质上是否意味着语言模型的参数量依旧很大?如何解决这一问题?
- 模型参数量只有70亿参数量,但外挂的数据库却能达到2T…
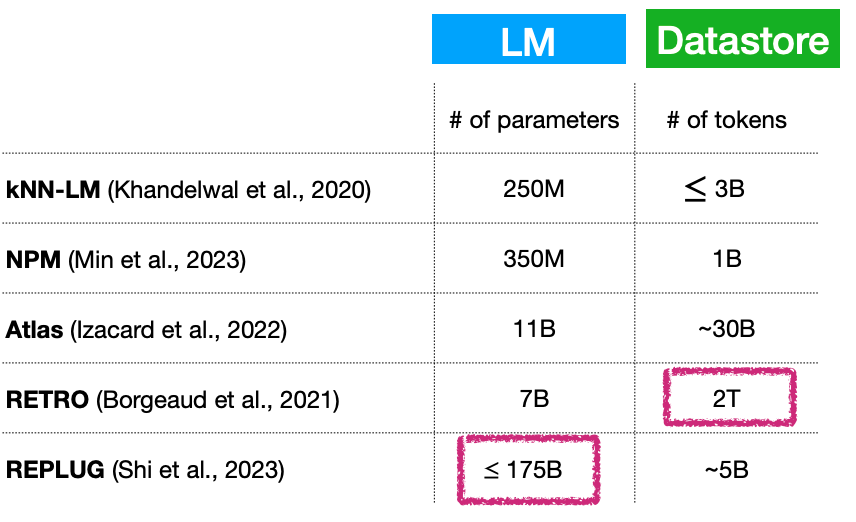
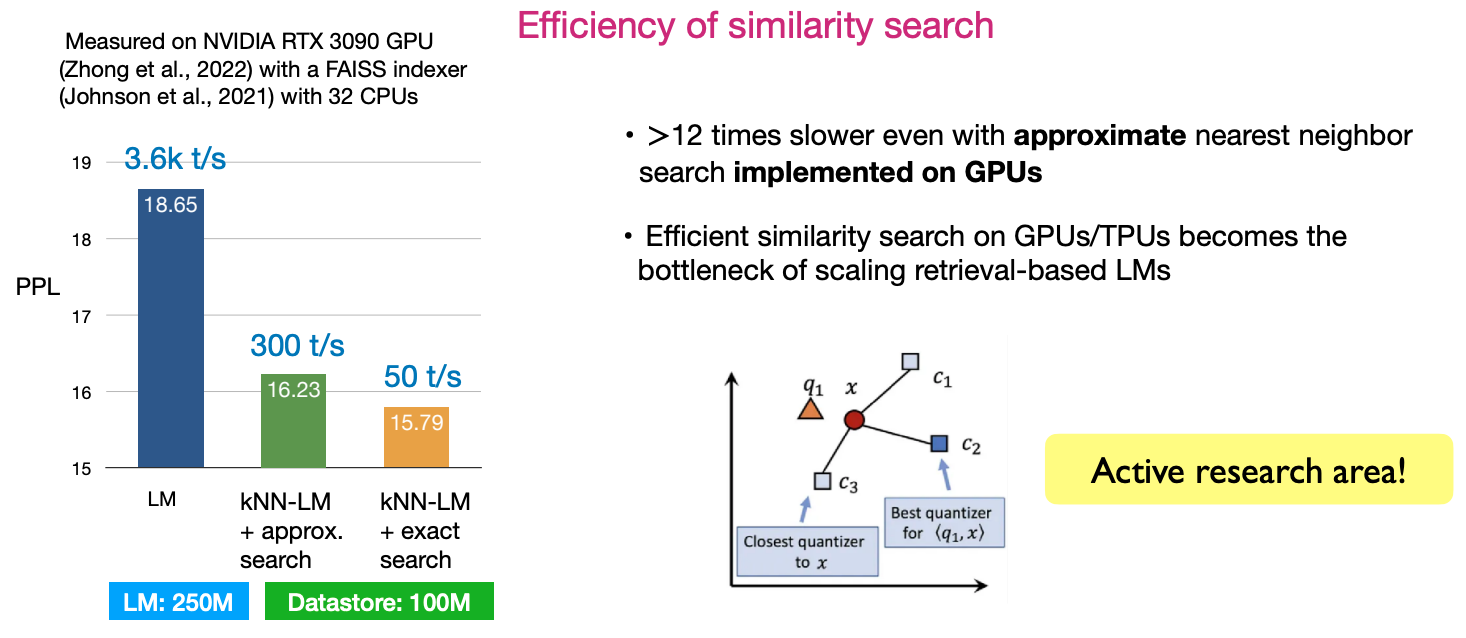
- 其二,相似性搜索的效率。如何设计算法使得搜索效率最大化,是目前非常活跃的一个研究方向。
- 其三,完成复杂语言任务。包括开放式文本生成任务,以及复杂的文本推理任务在内,如何用基于检索的语言模型完成这一任务,也是需要持续探索的方向。

RAG 模式
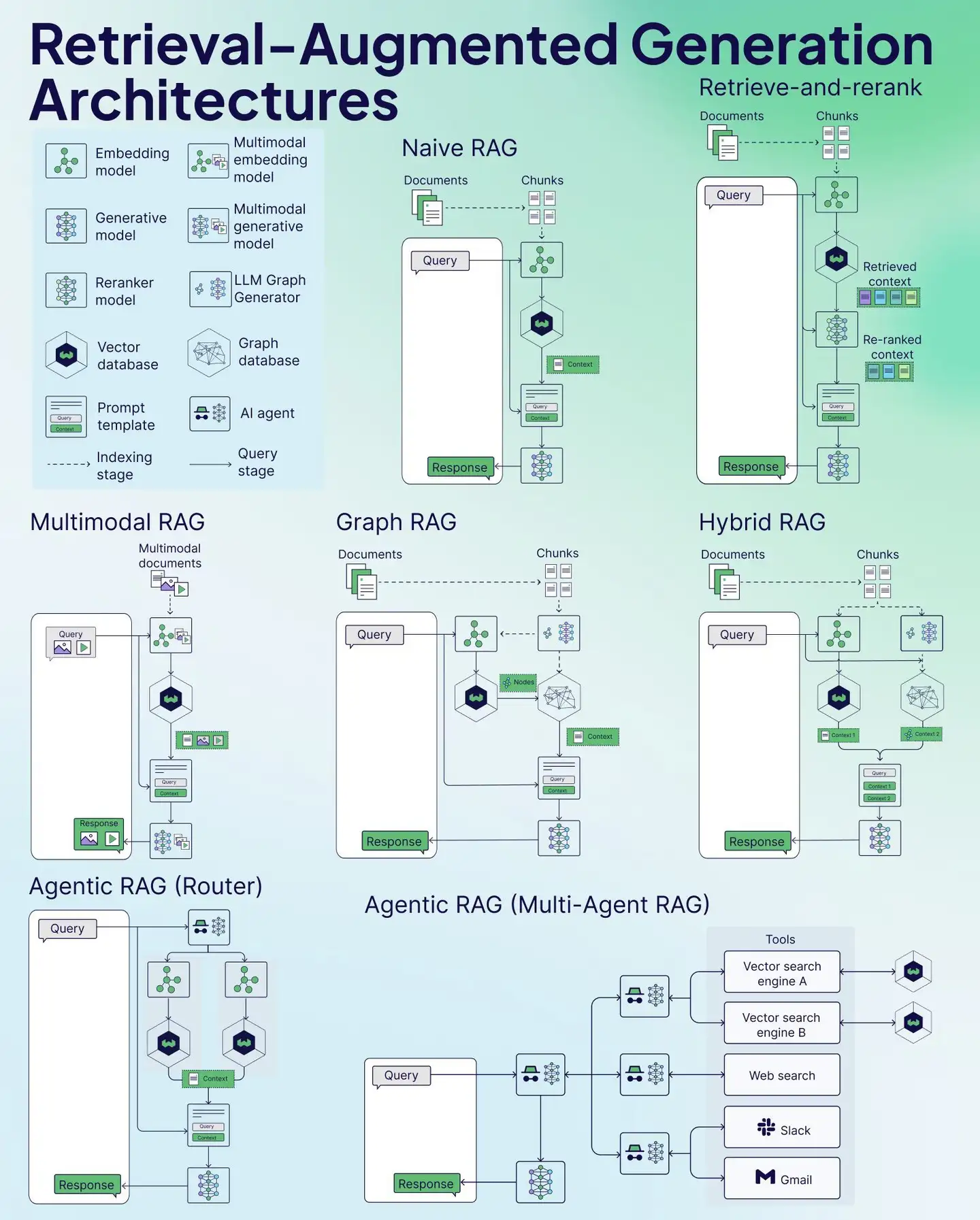
【2025-1-24】七种RAG架构cheat sheet
RAG 分为两个阶段:索引阶段 和 查询阶段,每个阶段都有多种硬核技术加持
- 索引阶段
- Embedding model:嵌入模型,把文本变成低维向量
- Generative model:生成模型,文本、图像生成
- Reranker model:重排序模型,检索结果重新排,优化检索相关性
- Vector database:向量数据库,存储、检索向量数据
- Prompt template:提示模板,指导模型生成特定格式
- 查询阶段
- Multimodal embedding model:多模态嵌入模型,图像、文本全搞定,统一嵌入表示
- Multimodal generative model:多模态生成模型,多种数据结合生成,输出超丰富
- LLM Graph Generator:大语言模型图生成器,生成图结构数据,复杂关系轻松搞定
- Graph database:图数据库,存储图结构数据,图查询操作超高效
- AI agent:AI 代理,代表用户执行任务,决策交互超智能
本文转自:
7 种 RAG 模式
Naive RAG最基础的架构,包含简单的文档检索、处理和生成响应的流程Retrieve-and-rerank在基础 RAG 上增加了重排序步骤,可以优化检索结果的相关性Multimodal RAG能够处理图像等多种类型的数据,不仅限于文本Graph RAG利用图数据库增强知识连接,可以更好地理解文档间的关系Hybrid RAG结合了多种技术的优势,包含图结构和传统检索方法Agentic RAG Router使用 AI Agent 来路由和处理查询,可以选择最适合的处理路径Agentic RAG Multi-Agent使用多个专门的 AI Agent 协同工作,可以调用不同的工具(如向量搜索、网页搜索、Slack、Gmail 等)
| 编号 | 名称 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 1 | Naive RAG(朴素RAG) |
基于文档分块检索,直接将检索结果输入生成模型生成答案,包含检索模块(向量/关键词搜索)和生成模块(LLM) | 简单易实现、低延迟、模块化设计 | 检索结果质量不稳定、缺乏上下文整合、易受噪声影响 | 基础问答、小型知识库、对精度要求不高的场景 |
| 2 | Retrieve-and-Rerank RAG(检索与重排序RAG) |
在Naive RAG基础上增加重排序模块(如Cross - Encoder或BERT模型),优化检索结果相关性 | 提升生成质量、减少噪声干扰、支持领域优化(如法律/医学) | 计算成本增加、依赖重排序模型性能 | 高精度问答(法律文档、技术文档) |
| 3 | Multimodal RAG(多模态RAG) |
支持多模态数据(文本、图像、视频等)的检索与生成,利用跨模态模型(如CLIP)对齐语义 | 信息表达丰富、支持跨模态查询(如图像问答)、增强上下文理解 | 实现复杂、计算资源消耗高、需多模态训练数据 | 电商推荐、医疗影像分析、多模态内容生成 |
| 4 | Graph RAG(图RAG) |
利用图数据库(如Neo4j)存储实体关系,通过图查询实现多跳推理和语义关联检索 | 捕捉复杂关系(因果、层级)、支持动态更新、增强推理能力 | 图构建和维护成本高、依赖图数据质量 | 知识图谱问答、科研文献分析、复杂关系推理(医学/法律) |
| 5 | Hybrid RAG(混合RAG) |
结合多种检索策略(如向量检索+关键词检索+图检索),融合结果后生成答案 | 检索覆盖率高、灵活适配多场景、抗噪声能力强 | 系统复杂度高、需协调多模块权重 | 知识库质量参差不齐、需多策略互补的场景 |
| 6 | Agentic RAG (Router)(路由RAG) |
通过智能路由器(基于LLM)动态分配查询至不同模块(如专用知识库、API等) | 动态负载均衡、支持多数据源、模块扩展性强 | 路由策略设计复杂、多模块整合难度高 | 多任务类型(跨API/数据库)、企业知识管理 |
| 7 | Agentic RAG (Multi-Agent)(多智能体RAG) |
多个智能体协同处理任务(如并行检索数据库、搜索引擎、邮件系统),整合结果生成答案 | 高度模块化、并行处理效率高、支持复杂任务自动化 | 代理协作机制复杂、通信开销大 | 超大规模任务(多轮对话、跨工具协作) |
图解
架构选择
- 基础场景:优先选择 Naive RAG 或 Retrieve-and-Rerank,平衡速度与精度。
- 多模态需求:采用 Multimodal RAG,结合CLIP等跨模态模型。
- 复杂关系推理:Graph RAG 或 Hybrid RAG 更适合知识图谱和结构化数据。
- 动态任务分配:Agentic RAG系列适用于多数据源、多工具集成的企业级应用。
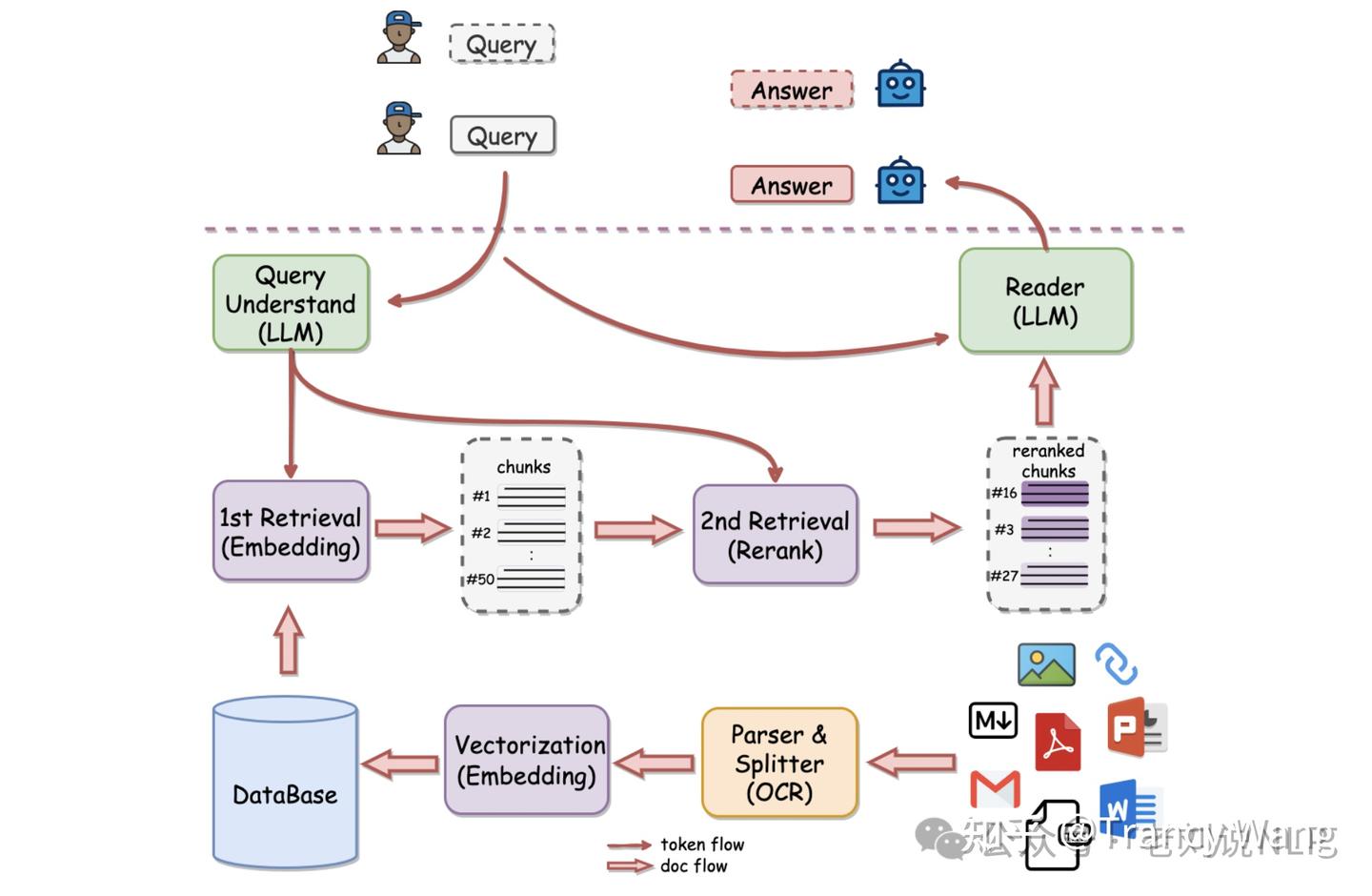
RAG 流程
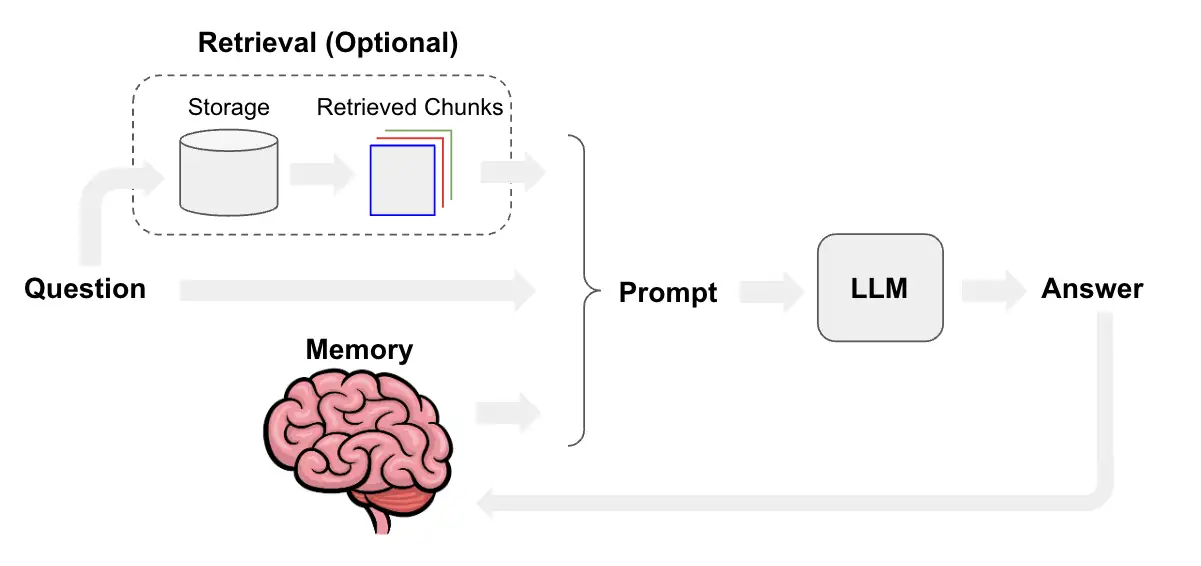
将原始文件拆解后, 每个部分都会生成相应embedding 并且 存放到vector store 中. 当查询发送给 vector store 时, 查询也会转换为 embedding , 然后 vector store 返回与查询最相似 的 embeddings
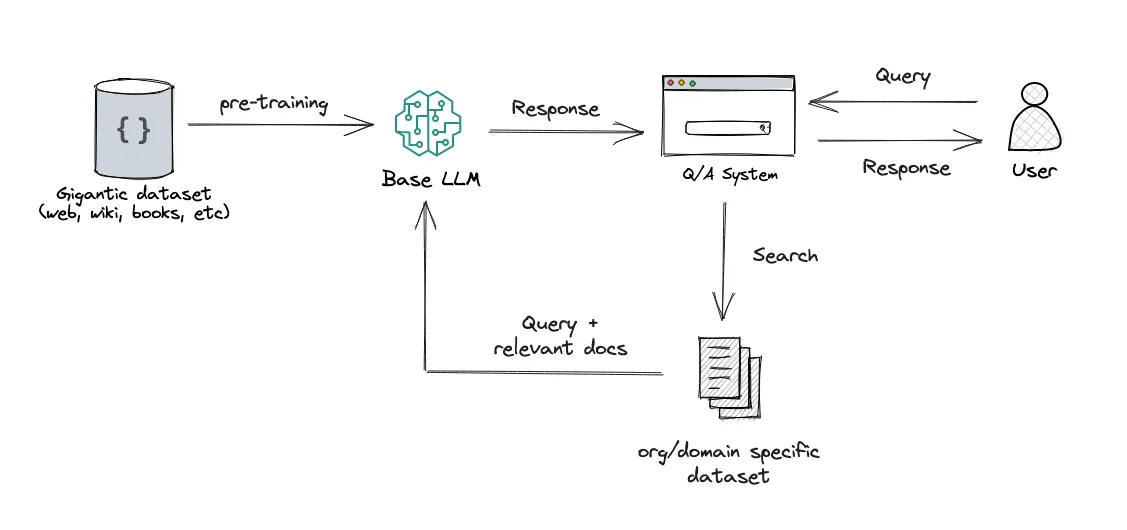
RAG 包含三个阶段:数据准备、检索和生成。
- 数据准备阶段:确定数据源、从数据源中提取数据、清理数据并将其存储到数据库中。
- 识别数据来源、从来源中提取数据、清洗数据并将其存储在数据库中
- 向量存储器:存储文本、图像、音频等非结构化数据,并基于语义相似性搜索该类别下的内容。
- 检索阶段:根据手任务从数据库中检索相关数据。
- 关键词搜索:简单的检索数方法,数据根据关键词进行索引,并且搜索引擎返回包含这些关键的文档。
- 关键词搜索适用于存储结构化数据(如表格、文档等)并使用关键词对数据进行搜索。
- 图数据库以节点和边的形式存储数据。适用于存储结构化数据(如表格、文档等),并通过数据之间的关系进行搜索
- 搜索引擎:从公共搜索引擎(如Google、Bing等)或内部擎(如Elasticsearch、Solr等)中检索RAG管道中的数据;搜索引擎适用于从网络上检索数据并使用关键字对其进行搜索。
- 可将来自搜索引擎的数据与其他数据库(如向量存储、图数据库等)中获取到的数据相结合,以提高输出质量。推荐结合多种策略(如语义搜索 + 关键字匹配)的混合方法
- 矢量数据库中对嵌入式数据进行相似性搜索
- 生成阶段:利用检索到的数据和任务生成输出结果。
- 检索到相关数据,就会连同用户的查询或任务一起传递给生成器(LLM)。LLM 使用检索到的数据和用户的查询或任务生成输出
- 输出质量取决于数据的质量和检索策略。
技术选型
- 向量数据库
- Weaviate:支持多模态、内置混合搜索(BM25 + 向量)、低延迟,适合复杂查询场景。
- Qdrant:轻量级、高吞吐量,适合中小规模部署。
- Milvus:分布式架构,适合超大规模数据(亿级向量)。
- LLM 服务
- 云端 API:OpenAI GPT、DeepSeek。
- 本地部署:Ollama、vLLM
- 数据分块策略
- 固定长度分块:简单但可能破坏语义(如 512 字符)。
- 语义分块:基于 NLP 模型(如 Sentence-BERT)识别段落边界。
- 多粒度分块:结合粗粒度(文档级)和细粒度(段落级)提升召回率。
- 检索策略
- 纯向量检索:适合语义相关性强的场景(如问答)。
- 混合检索:结合向量与关键词(BM25),提升多样性和覆盖率。
- 图增强检索:集成知识图谱(如 Neo4j)支持多跳推理。
分块策略
RAG 的五种分块策略:
- 1️⃣ 固定大小分块
- 2️⃣ 语义分块
- 3️⃣ 递归分块
- 4️⃣ 基于文档结构的分块
- 5️⃣ 基于 LLM 的分块
| 分块策略 | 具体方法 | 特点 |
|---|---|---|
| 固定大小分块 | 按预定义的字符数、单词数或Token数量切分文本,保留一定重叠部分 | 实现简单,但可能截断句子,造成信息分散 |
| 语义分块 | 根据有意义单元分段,持续添加单元到现有块,直至余弦相似度显著下降,然后开始新分块 | 能保持语言自然流畅性 |
| 递归分块 | 基于内在分隔符(如段落、章节)分块,若块超大小限制则进一步分割 | 能保持语言自然流畅性 |
| 基于文档结构的分块 | 利用文档内在结构(如标题、章节、段落)分块 | 能保持文档自然结构,需文档结构清晰 |
| 基于LLM的分块 | 用提示引导LLM生成有意义分块 | 能保留语义准确性,因LLM可理解上下文和含义 |
LLM+RAG
【2023-9-26】一文纵览LLM+RAG 的方法实现
LLM+RAG 方法实现主要有以下几种方法:
- 作为Prompt一部分:比较简单,外接检索器,将检索器召回的内容直接放置到预先配置的Prompt模板中,当成背景知识让LLM来直接输出。这种方法实现最简单,也是当前比较常用的做法。
- KNN+LLM:该方法最大的一个特点就是推理时采用 模型分布输出 + 检索Top tokens,作为两个next-token 进行融合解码。通过 Embdding 召回外部知识库和Query token 相似的token 。
- 自回归检索+解码:先让模型解码出tokens,然后检索该tokens相似的doc,拼接在Prompt中,进行next-token 预测,完成自回归的解码。
第一种办法中涉及私域知识库问答,关于建索引部分可参考文章:分享闭域知识问答下检索相关的方法和实践。
- 如果不是私域问答,最简单的方案是直接用query 调用外部搜索引擎,取到Top 的结果内容拼接到Prompt 中拿到模型的答案。
路线图见原文: 一文纵览LLM+RAG 的方法实现
评估指标
一般有检索的上下文相关性、答案的忠实度(faithfulness)和答案相关性(answer_relevancy)
- 一类是衡量LLM如何回答问题的
- 第一个度量是忠实度(Faithfulness),检查生成答案的事实准确性,将答案分解为事实,并将这些事实与检索的内容相对应。如果无法对应,则认为是模型的“幻觉”。这个度量提供了一个数值,如果数值低于某个阈值,表明可能出现了幻觉。
- 另一类则是衡量检索内容与问题的相关性。
- 答案相关性(Answer Relevancy)度量模型生成的答案是否真正针对用户提出的问题。有时候模型可能会生成一个很好地利用了检索内容的答案,但实际上与用户的原始问题毫不相关。这个度量就是为了衡量这一点。如果发现答案在事实上是准确的,但相关性却很低,这意味着模型可能过于关注内容本身,而忽视了问题的实际要求。这就表明可能需要进行提示工程(Prompt Engineering),或者采取其他措施来促使模型更多关注问题本身,并决定是否应该使用相关内容。
- 内容相关性方面,需要关注上下文精确度(Context Precision),这是衡量检索内容信噪比的指标。它评估每一块内容与答案的对应关系,以确定内容的使用是否真正对答案有帮助。此外,上下文召回(Context Recall)度量模型是否检索到了回答问题所需的所有相关信息。这是反映搜索优化程度的一个指标,如果召回率很低,表明我们可能需要优化搜索功能,引入重排序,或者对嵌入进行精调(Fine-tuning),以确保能够检索到更相关的内容。
【2023-11-1】评估检索增强生成(RAG):TRULENS + MILVUS
- Evaluations for Retrieval Augmented Generation: TruLens + Milvus
构建 RAG 的各种配置和参数,包括:索引类型、嵌入模型、top k 和 chunk 大小参数
- 前 k 个:经常讨论的一个参数,控制检索到的上下文分块数量。更高的前 k 个提供更高机会检索到所需信息,也增加语言模型融入不相关信息到其回答中的可能性。对简单问题而言,较低的前 k 个通常性能最佳。
- 分块大小:控制每个检索上下文的大小。对更复杂问题而言,较大分块大小可能更有帮助,而简单问题只需要很小一部分信息即可回答,较小分块就足够了。
参数选择没有无一刀切的解决方案。
- 性能可能因数据规模和类型、使用的语言模型、应用等而大相径庭。
TruLens
需要评估工具来评估质量。 TruLens 的用武之地。
TruLens 是一个开源库,用于评估和跟踪语言模型应用(如RAG)的性能。通过TruLens,还可以利用语言模型本身来评估输出、检索质量等。
构建语言模型应用时,多数人最关心的问题是幻想。RAG 在很大程度上通过为语言模型提供检索上下文来确保准确信息,但无法百分百保证。因此评估对验证应用中不存在幻想至关重要。
TruLens 提供了三项测试:上下文相关度、准确性和答案相关度。
- (1)上下文相关度
- 任何 RAG 应用第一步是检索;为验证检索质量,要确保每个上下文块与输入查询相关。这非常关键,因为语言模型将使用该上下文生成答案,所以上下文中的任何不相关信息都可能被编织成幻想。
- (2)准确性
- 检索上下文后,它被语言模型形成答案。语言模型往往偏离提供的事实,对正确的答案进行夸张或扩展。为验证应用的准确性,应将回复分为独立语句,并在检索上下文中独立查证每个语句的证据支持。
- (3)答案相关度
- 最后,回复仍须有助于回答原始问题。通过评估最终回复与用户输入的相关度来验证这一点。
无幻想 RAG
- 通过对上述三项达到满意的评估,可以对应用的正确性做出细微陈述;它在知识库限度内经验证无幻想。换言之,如果向量数据库仅包含准确信息,则 RAG 提供的答案也准确。
代码见原文
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with TruLens-Eval and deep learning explainability with TruLens-Explain.
How it works

pip install trulens-eval
pip install trulens
使用方法介绍 官方文档langchain_quickstart
RAG 问题
RAG 面临的七大挑战及解决方案
- • 缺失内容:数据清理和提示工程,确保输入数据的质量并引导模型更准确地回答问题。
- • 未识别出的最高排名:调整检索参数和优化文件排序来解决,以确保向用户呈现最相关的信息。
- • 背景不足:扩大处理范围和调整检索策略至关重要,以包含更广泛的相关信息。
- • 格式错误:改进提示、使用输出解析器和 Pydantic 解析器实现,有助于按照用户期望的格式获取信息。
- • 不完整部分:查询转换来解决,确保全面理解问题并作出回应。
- • 未提取部分:数据清洗、消息压缩和 LongContextReorder 是有效的解决策略。
- • 特定性不正确:可以通过更精细化的检索策略如 Auto Merging Retriever、元数据替换等技巧来解决问题,并进一步提高信息查找精度。
通过对 RAG 系统挑战的深入分析和优化,不仅可以提升LLM的准确性和可靠性,还能大幅提高用户对技术的信任度和满意度。
RAG 常见问题及解法
- 模型在解析查询内容时可能存在理解不足的问题,其在通过检索文本并总结出答案的能力上还有提升空间。例如,当询问“张三和李四谁更高?”时,如果知识库中张三和李四的身高信息并未在同一数据块(chunk)中同时出现,那么检索返回的文本信息密度较低,意味着需要整合多个数据块的内容才能得出正确的答案。可以通过query的改写来缓解这个问题,即将复杂问题拆解为多个子问题,每个子问题会从提供部分答案的相关文件检索答案。然后,收集这些中间结果,并将所有部分结果合成为最终响应。
- 数据分块导致数据语义不完整性:基于规则或长度的分块可能会将一个完整的语义单元切割成多个块,或者将多个不同的语义单元混合在一个块中,导致信息的不完整或混淆。信息冗余:如果分块大小设置不当,可能会导致一个块中包含大量与查询无关的信息,增加了信息处理的负担,并可能降低检索的效率。忽视语义边界:规则或长度的分块可能不遵循自然语言的语义边界,如句子、段落或主题的边界,这会影响检索的准确性和效率。对文本结构敏感:不同的文本结构(如列表、表格、段落)可能需要不同的分块策略。基于规则或长度的方法可能无法适应这些多样性。这些问题可能导致RAG效率低、耗时长、答案准确性和相关度低等问题。使用基于语义的分块方法,如阿里的SequenceModel等。
如何解决多实体提问问题?
- 子问题分解: 将多实体问题分解为多个单实体的子问题,然后逐一回答子问题,最后对答案汇总,给出最终答案。子问题分解,通常对模型的推理能力有较高的要求。
如何确定合适的 embedding?
- 通过检索器的性能衡量Embedding 效果,选择被广泛接受的两个指标:
Hit Rate和Mean Reciprocal Rank(MRR)。 命中率(Hit Rate):命中率计算在前k个检索到的文档中找到正确答案的查询的百分比。简单地说,这是关于我们的系统在前几次猜测中正确的频率。平均倒数排名(MRR):对于每个查询,MRR通过查看排名最高的相关文档的排名来评估系统的准确性。具体来说,它是所有查询中这些排名的倒数的平均值。因此,如果第一个相关文档是最高结果,则倒数为1;如果是第二个,则倒数为1/2,依此类推。
RAG 如何处理LLM漏答或者回答不完整的问题?
- 的一个好方法是添加查询理解层——在实际查询向量存储之前添加查询转换。
四种不同的查询转换:
- 路由: 保留初始查询,同时确定它所属的工具的适当子集,将这些工具指定为合适的查询工作。
- 查询重写: 但以多种方式重新表述查询,以便在同一组工具中应用查询。
- 子问题: 将查询分解为几个较小的问题,每个问题针对不同的工具。
ReAct: 根据原始查询,确定要使用哪个工具,并制定要在该工具上运行的特定查询。
生成增强检索(GAR)和检索增强生成(RAG)
GAR是 retrieval-generation 协作框架的一部分,迭代retrieval-generation协同框架在每次迭代中包含两个步骤:(1)生成增强检索(GAR):利用上一次迭代的输出来扩展查询,以帮助检索更多相关文档;(2)检索增强生成(RAG):利用检索到的文档来生成新文档来回答问题。GAR思想与Query改写的子问题分解思想类似。
文档解析
【2025-6-27】用900页pdf评测“文档解析”哪家强, 4种排版x9种类型, AI-RAG避坑指南
领导
- “模型成本已经这么高了,怎么还答不对?”
别急着甩锅给LLM,先分析文档解析这个“黑盒”
医药领域有很多记录药物不良反应的文档,比如,在PDF中经常被设计为 双栏排版+跨页浮动文本框,当使用某款号称 “文字提取准确率99%” 的开源解析工具时,获得以下记录:
- 第一页末尾:……注意事项(不完整)
- 第二页开头:特殊人群用药……(无上下文)
RAG 索引时,这两个碎片化文本段被切分到不同Chunk中,丧失了语义关联。
- 当用户查询:“药物X在肝功能不全患者的禁忌”时
- 系统检索到了包含关键词“禁忌”的段落,但该段落因缺乏标题上下文,未被关联到“特殊人群”这个关键维度,导致信息缺失。
文档解析是一套“解决方案”,而非“算法工具”,因为要解决的事情多,包含这些维度的组合:
- 文档格式类型:PDF、Word、Excel、PPT、Markdown…(每种文档格式类型处理手段都有区别)
- 文档业务领域:学术论文、杂志、报纸、研究报告、试卷……(每种类型有不同的版面风格,差异不一而论)
- 语种:中文、英文、其他语种……(每种语言都需要大量相应语种语料来学习识别)
- 文档元素类型:段落、标题、表格、公式、角标……(细节还原,有助于LLM理解文章层次)
- 文档布局:单栏、双栏、三栏、多栏混合……(识别布局是为了还原阅读顺序)
- 图像相关:文本OCR、是否有手写体、图像色彩识别、分辨率优化…(图中有文、文中有图,不分家)
- 表格相关:合并单元格、横竖排版、表头识别……(表格既不是“文本”也不是“图像”,慎重对待)
- 附加能力:切分、输出格式(“切分”不是本职工作,但能切得好,对问答效果有大增益,比如对超大表格的切分)
没有任何一款 工具能同时满足得很好
RAG 生死线
- 把跨页表格的表头“丢”在上一页,让数据断联
- 对着模糊的扫描件自信地“指鹿为马”
- 将数学公式里的“Σ”(求和符号)识别为不知所云的“E”
- 把脚注当成正文,把水印印成了“重要条款”
- ……
RAG 工具
【2023-11-7】RAG 工具包 tigerlab, 三大功能
- TigerRag: Enhanced Retrieval Capabilities customized for your own data
- TigerTune: Boost performance with swift and simple models
- TigerArmor: Ensuring Secure and Responsible AI Interactions

github: tiger
RAGxplorer 可视化
【2024-1-26】大模型RAG流程可视化的开源工具—RAGxplorer
RAGxplorer 是一个交互式的streamlit工具,用于支持构建基于检索增强生成(Retrieval Augmented Generation, RAG)的应用程序,通过可视化文档块和嵌入空间中的查询来实现。
- •文档上传:用户可以上传PDF文档。
- •块配置:配置块大小和重叠的选项。
- •嵌入模型选择:all-MiniLM-L6-v2或text-embedding-ada-002。
- •向量数据库创建:使用Chroma构建向量数据库。
- •查询扩展:生成子问题和假设答案,以增强检索过程。
- •交互式可视化:使用Plotly来可视化块。
pip install -r requirements-local-deployment.txt
# 设置OPENAI_API_KEY(必需)和NYSCALE_API_KEY(如果您需要anyscale)。复制.streamlit/secrets.example.toml文件到.streamlit/secrets.toml并填写值。
streamlit run app.py
import('pysqlite3')
import sys
sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')
RAG 不足
向量数据库打天下的方案已经不够了,于是各种花式疗法,从构建索引到回复生成,眼花缭乱:
- 内容切片不够好,容易切碎,于是有了段落智能划分;
- 向量生成的质量不可控,于是根据不同QA场景动态生成向量的Instructor;
- 隐式动态向量不够过瘾,再用
HyDE做个中间层:先生成一些虚拟文档/假设文档再做召回,提升召回率; - 如果向量这一路召回不够,再上关键词召回,传统BM25+向量HNSW融合各召回通路;
- 召回太多容易干扰答案生成,探究一下 Lost in the Middle,搞一搞trick,或者用LLMLingua压缩;
- 嫌召回太麻烦?直接扩到100k窗口全量怼进大模型,
LongLoRA横空出世;
刚才提到的各个环节需要改进的点太多,懒得手工做,直接交给大模型,用Self-RAG替你完成每个步骤……
作者:瀚海方舟
对金融行业有限的查询需求的洞察(已脱敏),列举一些RAG存在的挑战和解决思路。
【2024-3-7】大模型RAG行业适配过程中的一些思考
回答准确性分析
- 优势:小范围描述式问答回答精准
- 劣势:
- 1、不擅长关系型推理;
- 2、不擅长时间跨度长的问题。如:分析一下二战的一共有多少次战役。
如何提升准确率
- prompt优化: 减少问题中的错别字,并尽量对于提问内容表达详细。
- 原始用户查询: “跟我说说托尼”
- 用bard重新表述:”托尼的政治背景是什么,最显著的成就是什么,政治观点是什么“
- 保持embedding模型在同一个平面上。
- chunk的创建策略:其中,chunk大小是优质的超参,微软通过实验给出了各超参尺寸下的recall值,可以进行参考。
- 文本分割的策略:根据微软的实验结果,多的overlapping对于召回也会有比较好的提升。
- embedding模型语义提取能力有限,多主体、多回合的语料库不如简单语料更加有效,微软分析,最小的chunk大小是512 tiokens,因此,要做好分块的数据实验,根据自身情况调整块大小与分块策略。
各超参尺寸下的recall值
| 每个向量输入token数 | Recall@50 |
|---|---|
| 512 | 42.4 |
| 1024 | 37.5 |
| 4096 | 36.4 |
| 8191 | 34.9 |
文本分割策略
| chunk(512 tokens)划分策略 | Recall@50 |
|---|---|
| token边界断开 | 40.9 |
| 保留完整句子 | 42.4 |
| 10% chunk重叠 | 43.4 |
| 25% chunk重叠 | 43.9 |
通用优化策略:
- 大量重叠chunk 减少信息的丢失,以此提高准确率;
- 引入知识图谱,RAG将关系存储到图数据库中,以此保留关系信息。
【一】世界知识&私有知识混淆
提问:乙烯和丙烯的关系是什么?
大模型应该回答两者都属于有机化合物,还是根据近期产业资讯回答,两者的价格均在上涨?
【二】召回结果混淆
提问:化学制品行业关注度排名第几?
如果我们召回的文档如下:
(某日)……对化学制品行业的关注度近一周下降,目前降至第8……
(某日)……对化学制品行业的关注度近一周下降,目前降至第7……
(某日)……对化学制品行业的关注度近一周下降,目前降至第6……
(此处省略多条相似结果)
经试验,大模型见此状会神经错乱。
【三】多条件约束失效
提问:昨天《独家新闻》统计的化学制品行业的关注度排名第几?
如果说【二】中的约束太少导致召回结果过于泛滥,那么我加上约束之后,如何让大模型读懂什么叫“昨天”,又有哪段内容属于《独家新闻》?
【四】全文/多文类意图失效
提问:近期《独家新闻》系列文章对哪些行业关注度最高?
受限于文档切割,遇到横跨多篇文章,或全篇文章的提问,基本上凉凉了 。
【五】复杂逻辑推理
提问:近期碳酸锂和硫酸镍同时下跌的时候,哪个在上涨?
除非原文中有显性且密集型相关内容,大模型可能能够直接回答正确,否则凉凉的概率极高。而用户在提问这类问题时,往往是无法在某一段落中直接找到答案的,需要深层次推理。
【六】金融行业公式计算
提问:昨天哪些股票发生了涨停?
如何让大模型理解“涨停”意味着 (收盘价/昨日收盘价-1)≥10%
RAG优化
RAG 尽头是 Agent
【2024-6-5】LlamaIndex团队技术报告:“RAG的尽头是Agent”
LlamaIndex 团队2024年Talk:
- 报告人:Jerry Liu, LlamaIndex co-founder/CEO,
- 报告主题:“超越RAG:构建高级上下文增强型大型语言模型(LLM)应用”,
- 主题原文:“Beyond RAG: Building Advanced Context-Augmented LLM Applications”。
看完报告的感受: “RAG的尽头是Agent”
概要内容如下:
RAG局限性:
- RAG最初是为简单问题和小型文档集设计的,包括数据解析、索引检索和简单问答。
- 然而,处理更复杂问题时存在局限性,例如:总结整个年度报告、比较问题、结构化分析和语义搜索等。
Pain Points 痛点
There’s certain questions we want to ask where naive RAG will fail.
Examples:
- 总结 Summarization Questions: “Give me a summary of the entire
<company>10K annual report” - 对比 Comparison Questions: “Compare the open-source contributions ofcandidate A and candidate B”
- 结构分析+语义搜索 Structured Analytics + Semantic Search: “Tell me about the risk factors ofthe highest-performing rideshare company in the us”
-
多方观点 General Multi-part Questions:”Tell me about the pro-x arguments in articleA, and tell me about the pro-Y arguments in article B, make a table based onour internal style guide, then generate your own conclusion based on these facts.”
- Agent引入:为了解决RAG的局限性,文档提出了引入Agent的概念。
- Agent是一种更高级系统,执行多轮对话、查询/任务规划、工具使用、反思和记忆维护等更复杂的功能。
从RAG到Agent的转变:从RAG到Agent的转变,涉及到增加几个层次的功能:
- 多轮对话:与用户进行更深入的互动。
- 查询/任务规划层:能够理解并规划复杂的查询和任务。
- 工具接口:与外部环境进行交互,使用工具来辅助任务执行。
- 反思:能够自我评估并改进执行过程。
- 记忆:维护用户交互的历史,以提供个性化服务。
Agent不同层次:从简单到高级Agent的不同层次
- 简单Agent:成本较低,延迟较低,但功能有限。
- 高级Agent:成本较高,延迟较高,但提供更复杂的功能,如动态规划和执行。
示例
ReAct:ReAct(Reasoning + Acting with LLMs),结合了推理和行动,利用查询规划、工具使用和记忆来执行更复杂的任务。-
LLMCompiler:一个Agent编译器,用于并行多功能规划和执行,它通过生成步骤的有向无环图(DAG)来优化任务执行。 - 自我反思和可观察性:Agent通过自我反思和反馈来改进执行,同时提供可观察性,以便开发者能够追踪和理解Agent的行为。
- 多Agent系统:多Agent系统的概念,其中多个Agent可以同步或异步地交互,以执行更复杂的任务。
Agentic RAG
【2024-6-19】Agentic RAG 与图任务编排
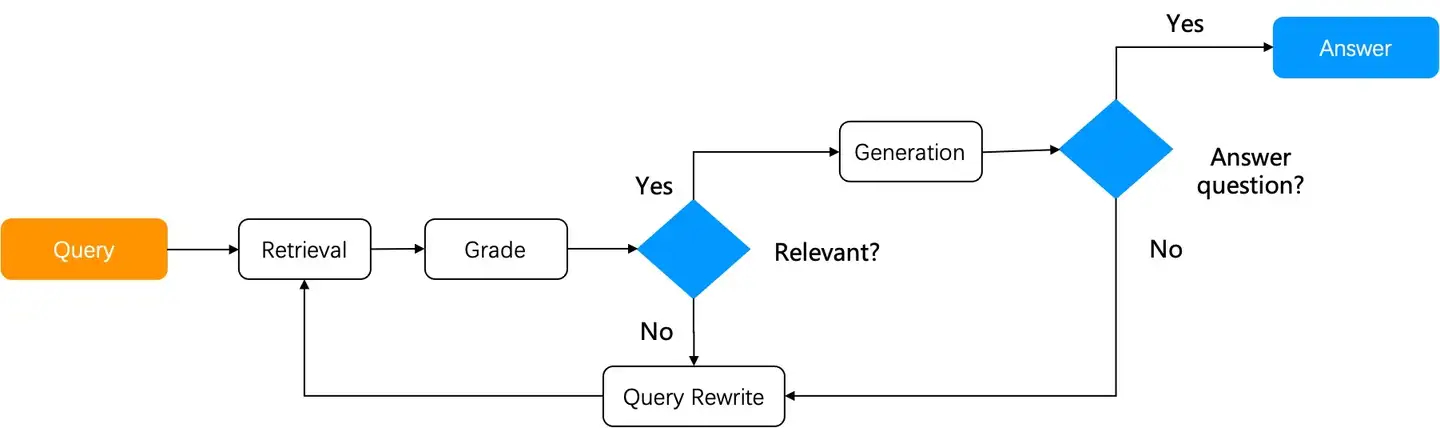
(1)朴素 RAG 流程
- 用户提出问题 -> 系统基于用户提问召回 -> 对召回结果进行重排序 -> 拼接提示词后送给 LLM 生成答案
- 问题: 用户意图并不明确时,无法通过直接检索找到答案
- 例如:针对多文档的总结类提问,需要进行多步推理 (Reasoning) 等等。
- 解决方法: Agentic RAG
(2)Agentic RAG 是基于 Agent 的 RAG。
Agent 与 RAG 关系紧密,两者互为基石。
Agentic RAG 和简单 RAG 的最大区别
- Agentic RAG 引入了 Agent 的动态编排机制,可根据用户提问的不同意图,引入反馈和查询改写机制,并进行“多跳”知识推理,从而实现对复杂提问的回答。
Agentic RAG 方法
- 初级:
Self-RAG - 高级:
Adaptive RAG
Self-RAG 引入反思机制。
- 从知识库中检索出结果后,评估结果是否与用户提问相关。
- 如果不相关,就要改写查询
- 然后重复 RAG 流程直到相关度评分达到要求。
Self-RAG 实现两大组件:
- 一套基于 Graph 的任务编排系统。
- Graph 内执行的必要算子:比如在 Self-RAG 中,评分算子就至关重要。
- 原始论文需要自己训练一个打分模型来针对检索结果评分;
- 在实际实现中也可以采用 LLM 进行评分,简化系统开发并且减少对各类环节依赖。
Self-RAG 是相对初级的 Agentic RAG,RAGFlow 中也已提供了相关实现。
实践证明
Self-RAG对于较复杂多跳问答和多步推理可以明显提升性能。
Adaptive RAG 根据用户提问的不同意图,采用对应策略:
- 开放域问答:直接通过 LLM 产生答案而无需依赖 RAG 检索。
- 多跳问答:首先将多跳查询分解为更简单的单跳查询,重复访问 LLM 和 RAG 检索器来解决这些子查询,并合并它们的答案以形成完整答案。
- 自适应检索:适用于需要多步逻辑推理的复杂问题。复杂的问答往往需要从多个数据源综合信息并进行多步推理。自适应检索通过迭代地访问 RAG 检索器和 LLM,逐步构建起解决问题所需的信息链。
Adaptive-RAG 工作流程与 Self-RAG 类似,只是在前面增加了一个查询分类器,就提供了更多种对话的策略选择。
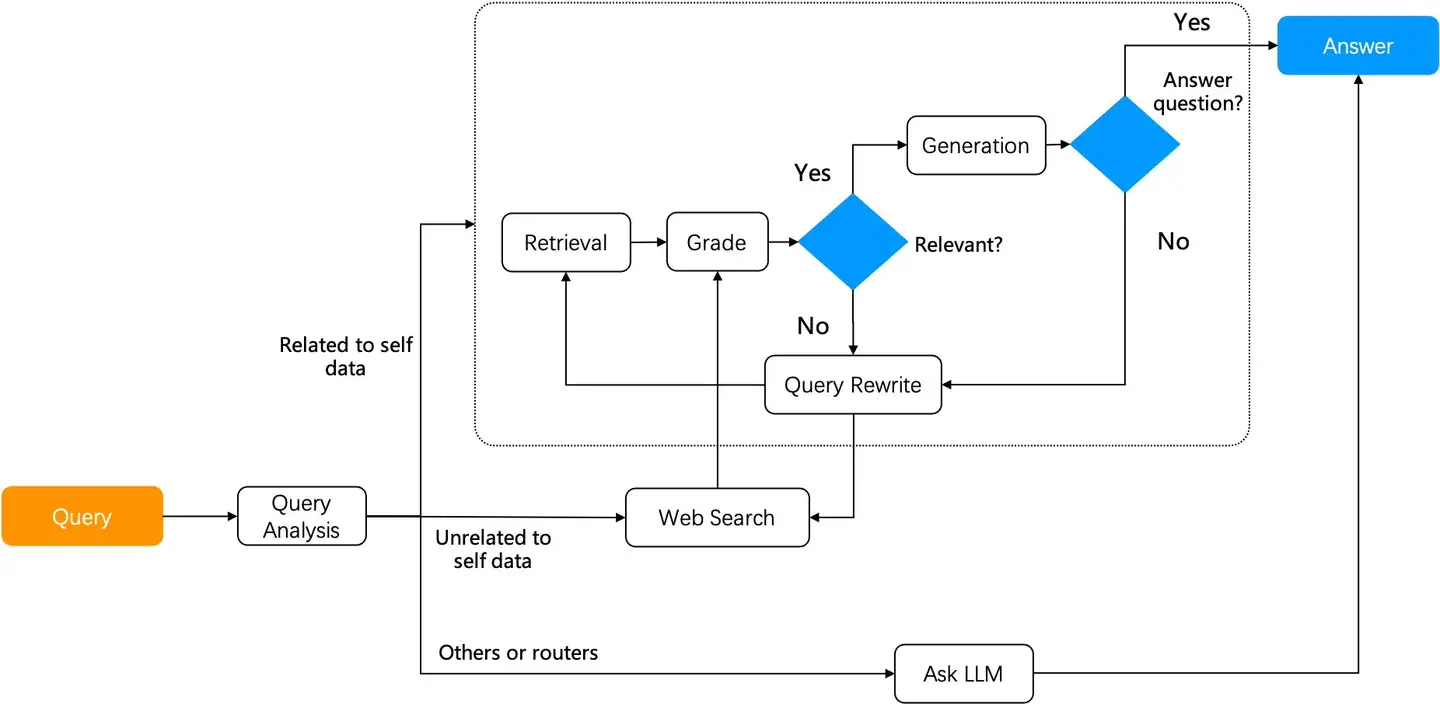
高级 RAG 系统基于任务编排系统上提供以下功能:
- 复用已有的 Pipeline 或者子图。
- 与包含 Web Search 在内的外部工具协同工作。
- 可以规划查询任务,例如查询意图分类,查询反馈等等。
任务编排系统类似的实现: Langchain 的 ️LangGraph 和 llamaIndex;
Agent 开发框架包括: AgentKit、Databricks 最新发布的 Mosaic AI Agent Framework 等等。
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
RAG 优化方向
【2023-12-11】RAG 优化分为两个方向:RAG基础功能优化、RAG架构优化
- (1)RAG基础功能优化: 针对 文档块切分、文本嵌入模型、提示工程优化、大模型迭代
- 文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要。
- 文本嵌入模型:基于新语料微调嵌入模型、动态表征。
- 提示工程优化:优化模板增加 提示词约束、提示词改写。
- 大模型迭代:基于正反馈微调模型、量化感知训练、提供大 context window 推理模型。
- query召回文档块集合:元数据过滤、重排序减少文档块数量。
- (2)RAG架构优化
- Vector+KG RAG:
- 问题:向量数据库无法获取长程关联知识、信息密度低(尤其当LLM context window较小时不友好)
- 解法:增加与向量库平行 KG(知识图谱)上下文增强策略
- Self-RAG:去掉无关内容
- 问题:传统 RAG 对召回上下文无差别合并,但召回上下文与query无关或矛盾时,应舍弃这个上下文,尤其当大模型上下文窗口较小时非常必要(目前4k的窗口比较常见)
- 解法:判断query是否需要检索。如果需要才检索若干passage,然后经一系列处理生成若干next segment候选。最后,对这些候选segment进行排序,生成最终 next segment。
- 多向量检索器多模态RAG:有三种工作模式
- 半结构化 RAG(文本+表格)
- 多模态 RAG(文本+表格+图片)
- 私有化 多模态RAG(文本+表格+图片)
- Vector+KG RAG:
图片详情见原文:检索增强生成(RAG)有什么好的优化方案? - AI pursuer的回答
RAG工作流
RAG 性能提升
【2023-10-1】提升RAG性能的 10 种方法
使用 LangChain 或 LlamaIndex 等框架的快速入门指南,任何人都可以使用大约五行代码构建一个简单的 RAG 系统,例如文档的聊天机器人。
但是,用这五行代码构建的机器人不会很好地工作。RAG 很容易制作原型,但很难达到用户满意的地步。基本教程可能会让 RAG 以 80% 的速度运行。但要弥补接下来的 20%,通常需要进行一些认真的实验。
提高 RAG性能 10 种方法
- 清理数据:提升数据质量,优化数据分布
- 探索不同索引类型:索引是 LlamaIndex 和 LangChain 核心
- RAG 标准方法涉及嵌入和相似性搜索,将上下文数据分块,嵌入所有内容,当查询到来时,从上下文中找到相似的部分。
- 这种方法效果很好,但并不是适合每个用例的最佳方法。
- 尝试多种分块方法
- 将上下文数据分块是构建 RAG 系统的核心
- 块大小很重要。较小的块通常可以改善检索,但可能会导致生成过程缺乏周围的上下文;
- 小、中、大块大小循环浏览了每一组,发现小是最好的
- 覆盖基本提示: 使用时覆盖基础提示
- 示例: 你是一名客户支持代理。您的目的是在仅提供事实信息的同时尽可能提供帮助。你应该友好,但不要过于健谈。
上下文信息如下。给定上下文信息而不是先验知识,回答查询。
- 示例: 你是一名客户支持代理。您的目的是在仅提供事实信息的同时尽可能提供帮助。你应该友好,但不要过于健谈。
- 元数据过滤
- 元数据(如日期)添加到块中,然后用它来帮助处理结果
- 构建 RAG 时要记住:相似 ≠ 相关
- 查询路由
- 适用场景:有多个索引,如摘要、敏感问题识别、日期相关,优化成一个索引不一定好
- 重排名
- 重新排名是解决相似性和相关性之间差异问题的一种解决方案
- 如 Cohere Rereanker,LangChain 和 LlamaIndex 都有抽象,可以轻松设置。
- 查询转换(改写)
- 将用户查询放入基本提示中来更改它
- 重新措辞:如果系统找不到查询的相关上下文,让LLM重新措辞查询并重试
- HyDE 是一种策略,接受查询,生成假设的响应,然后将两者用于嵌入查找。研究发现这可以显着提高性能。
- 将一个查询分解为多个问题(子查询),LLM在分解复杂查询时往往会工作得更好
- 微调embedding模型
- 基于嵌入的相似性是 RAG 的标准检索机制
- 预训练模型(如 OpenAI的ada)关于嵌入空间中相似内容的概念可能与场景上下文中相似内容不一致
- 处理法律文件:希望嵌入更多地基于您的领域特定术语(例如“知识产权”或“违反合同”)对相似性的判断,而不是基于“特此”和“协议”等一般术语。
- 微调将检索指标提高 5-10%,LlamaIndex 可以生成训练集
- LLM 开发工具
- LlamaIndex 或 LangChain 这两个框架都提供调试工具,允许定义回调、查看使用的上下文、检索来自哪个文档等等。
- Arize AI 有一个笔记本内工具,可探索如何检索哪些上下文及其原因。
- Rivet 是一个提供可视化界面的工具,可帮助您构建复杂的代理,由法律技术公司 Ironclad 开源。
其它:【2023-9-27】检索增强生成 (RAG):What, Why and How?
- 混合搜索:将语义搜索与关键词搜索结合起来,从向量存储中检索相关数据 —— 已被证明对大多数用例都能获得更好的结果
- 摘要:对块进行摘要并将摘要存储在向量存储中,而不是原始块
- 丢失问题:LLMs并不给予输入中所有标记相同权重。中间标记似乎比输入开头和结尾处的标记被赋予较低权重,中间丢失问题。
- 可重新排列上下文片段,使最重要的片段位于输入开头和结尾,并将次要片段放置在中间位置。
【2024-9-25】15 种高级 RAG 技术
从预检索、检索、后检索和生成四个环节,细分 15 种高级 RAG(检索增强生成,Retrieval-Augmented Generation)技术
- 增加信息密度(Increase Information Density Using LLMs)
- 利用 LLMs(大语言模型)处理、清理和标记数据,提高信息密度,从而减少生成模型所需的上下文窗口大小,降低成本并提高响应准确性。
- 像准备考试时,把一本教科书浓缩成一个简单笔记,只保留最重要的知识点,复习起来更高效。
- 应用分层索引检索(Apply Hierarchical Index Retrieval)
- 利用文档摘要创建多层索引,优先检索与查询最相关的摘要部分,再深入到详细文档,提高检索效率。
- 先快速浏览一本书的目录或摘要,找到相关章节,然后再仔细阅读。这比从头到尾读整本书要快得多。
- 改善检索对称性(Improve Retrieval Symmetry with Hypothetical Question Index)
- 生成每个文档的假设问答对,并将这些问答对作为检索的嵌入对象,从而提高查询与文档之间的语义相似度,减少检索时的上下文丢失。
- 问问题前已经知道了一些可能的答案,直接找到相关答案就容易多了,而不是去海量信息中寻找,类似 few-shot 的方式
- 使用 LLMs 去重信息(Deduplicate Information in Your Data Index Using LLMs)
- 通过 LLMs 对嵌入空间中的数据块进行去重,将重复的信息浓缩成更少的、更有用的数据块,提高响应的质量。
- 测试和优化分块策略(Test and Optimize Your Chunking Strategy)
- 根据具体情况测试不同的分块策略,通过调整数据块大小和重叠率等参数,找到最佳的嵌入方式,以提高检索效果。
- 不断调整,优化,迭代,总能找到适合的,有点像深度学习的调参
- 优化搜索查询(Optimize Search Queries Using LLMs)
- 针对对话系统,使用 LLMs 根据系统的搜索需求优化用户的查询语句,确保搜索系统能够更准确、高效地找到相关信息。
- 一个很懂搜索引擎的人帮你改写搜索关键词,这样你更容易找到你想要的结果。
- 使用假设文档嵌入修正查询与文档的非对称性(Fix Query-Document Asymmetry with Hypothetical Document Embeddings (HyDE))
- 检索前,生成一个与用户查询相关的假设文档,用这个文档的嵌入来替代用户的查询进行语义搜索,以提高检索的准确性。
- 实施查询路由或 RAG 决策模式(Implement Query Routing or a RAG Decider Pattern)
- 多数据源系统中,使用 LLMs 决定将查询路由到哪个数据库,或决定是否需要进行 RAG 检索,从而降低成本,提高系统效率。
- 根据目的地选择走哪条路,而不是每次都先走到中央车站再决定。
- 重新排名以优化搜索结果(Prioritize Search Results with Reranking)
- 利用重排模型优化检索结果的优先级,将最相关的文档排在最前,以提高 RAG 系统的表现。
- 这就像是当你在网上购物时,把最合适的商品排在搜索结果的最前面,避免翻很多页。
- QAanything 证明重排是个很有必要的步骤。
- 使用上下文压缩优化搜索结果(Optimize Search Results with Contextual Prompt Compression)
- 通过 LLMs 对检索到的信息进行处理、压缩或重新格式化,只保留生成最终响应所需的关键信息。
- 要点提炼出来,避免说一堆废话。能够降低成本,减少无关紧要的 token。
- 使用纠正 RAG 对检索文档打分和过滤(Score and Filter Retrieved Documents with Corrective RAG)
- 使用一个经过训练的模型对 RAG 结果进行打分,将不相关或不准确的文档过滤掉,只保留有用的部分。
- 请一个专家帮你筛选资料,只留下真正有用的信息。而不是用所有召回的文档 summary。
- 通过链式思维提示屏蔽噪音(Tune Out Noise with Chain-of-Thought Prompting)
- 利用链式思维提示(Chain-of-Thought Prompting)提高 LLM 在有噪音或无关信息情况下给出正确答案的概率。
- 让系统具备自我反思能力(Make Your System Self-Reflective with Self-RAG)
- 通过训练模型生成反思标记,判断是否需要检索或修正生成的内容,从而提高生成内容的质量和准确性。
- 和人的思考方式意义昂,会先想一想有没有漏掉什么信息,或者之前的判断是不是有问题,然后再做出最终决定。
- 大模型都是在模拟人脑的行为。
- 通过微调忽略无关上下文(Ignore Irrelevant Context Through Fine-Tuning)
- 微调模型,增强其在 RAG 表现,使其能够忽略无关的上下文,提高对相关信息的响应能力。
- 微调是一个非常必要的方式,针对某些垂直领域,给模型灌输对应的风格约束,领域知识。
- 使用自然语言推理让 LLMs 更好地应对无关上下文(Use Natural Language Inference to Make LLMs Robust Against Irrelevant Context)
- 使用 NLI 模型过滤掉无关上下文,仅在使用问题和 LLM 生成的答案被分类为蕴含时,才使用检索到的上下文。
一些结论
- 信息密度:使用 GPT-4 提取信息后,信息量显著减少,信息密度提高。例如,原始 HTML 有 55,000 个令牌,去除 CSS 和 HTML 标签后有 1,500 个令牌,使用 GPT-4 处理后进一步减少到 330 个令牌。
- 检索效率:层次索引检索和假设问题索引显著提高了检索效率和结果的相关性。
- 分块策略:1,000 字符分块与 200 字符重叠的策略表现最佳,得分为 4.34。
- 假设文档嵌入:使用假设文档嵌入进行语义搜索,提高了检索结果的准确性。
- 查询路由和 RAG 决策模式:识别出不需 RAG 查找的查询,避免了不必要的计算资源消耗。
- 重新排序和压缩:重新排序搜索结果和使用 LLM 压缩生成提示,提高了生成响应的质量和效率。
- 评分和过滤:使用 T5-Large 模型评分和过滤 RAG 结果,显著提高了响应的准确性。
图见原文
RAG 血泪史
【2023-11-13】RAG探索之路的血泪史及曙光, 包含 RAG 工程落地经验,ppt截图和视频
- Embedding 召回方案及局限性分析
- 朴素 RAG 通过向量召回的诸多局限,比如:不精确、粒度粗、不支持条件查询/统计、不能替代信息提取等。
- 使用 LLM 做信息提取的几种方案和弊端。
- 意图识别优化:传统NLP不是“破落户”
- 基于词性标注和成分句法分析(Constituency Parsing、CON),解决并列关系的多实体、多条件提取问题。
- 意图识别的重要性
- 意图识别: 意图分类和槽位填充。
- 涉及:rule-based 、 BERT fine-tuning,DIET 等。
- 上下文补全解决方案
- 复杂多轮对话中,如何与用户交互,直到其补全所有信息。
- 检索优化:从
向量到关系- 知识库召回其实不仅仅是 vector store,还可以使用关系型数据库和图数据库
- vector store 使用 embedding 召回的上下文补全解决方案
- 关系型数据的查询方案:小型数据基于 pandas dataframe,大型数据基于 sql
- 图数据库应用:主要解决多度关系和推荐问题。
【2022-8-29】HyDE
假设文档嵌入(Hypothetical Document Embeddings, HyDE)
2022 年, Gao 等人 论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》
Contriever 源自 2022 年 8 月Izacard 等人发表的早期论文
- 《Unsupervised Dense Information Retrieval with Contrastive Learning》
- 神经网络已成为检索的词频方法的良好替代方案,但需要大量数据,而且并不总是能很好地迁移到新的应用领域。因此,设计了一种通过
对比学习以无监督方式训练嵌入网络的方法。 - 该方法能够与 BM25 等无监督词频方法相匹配,并且在跨语言检索方面也表现良好,这是术语匹配方法无法实现的。
改进零样本密集检索的方法(即使用语义嵌入相似性)。
HyDE 不仅与问题进行相似度搜索,而是生成一个假答案并与之进行相似度搜索。
“假设”文档
通过 mask、重排等方式人为构造的虚拟文档。
HyDE 基于 RAG 模型
- 用 LLM 生成一个假设回答文档
- 将文档与知识库中的文档进行比较,从而找到与用户问题相关的信息。
HyDE 原理
HyDE 核心思想
- 对比真实文档和”假设”文档的差异,学习出能够更好捕捉文本语义和上下文信息的文档向量表示。
模型需要学会区分真实文档和这些假设文档,从而得到蕴含深层语义的文档向量。

相比原生 RAG,HyDE 和 RAG 合作,多了两步:
- 用 LLM 尝试回答问题
- 生成一个假设文档,这个假设的文档是通过 LLM 生成的。
HyDE 两步法
- 步骤1 指令提示语言模型(论文中用 GPT-3)根据原始查询生成假设文档。
- 步骤2 使用 Contriever 或 “无监督对比编码器”将该假设文档转换为嵌入向量,用于下游相似性搜索和检索。
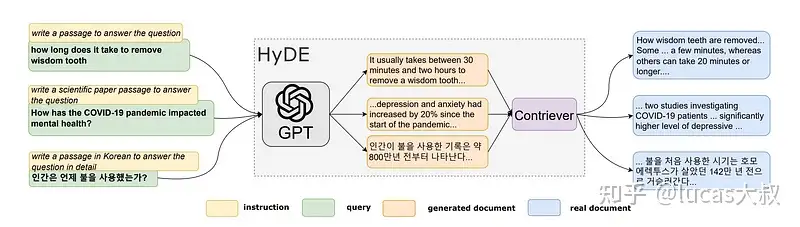
同时,embedding 时使用来源也不同:
- 原生 RAG 使用 用户问题
- HyDE 则用 LLM 生成文档。
HyDE 效果:
- 利用 HyDE 提升 RAG 生成性能:
- HyDE 生成文档向量更好地捕捉文本语义和上下文信息,有助于 RAG 模型产生更加相关、连贯的生成内容。
- 增强 RAG 模型可靠性:
- RAG 可以利用外部知识库增强自身知识,提高生成内容的准确性;而 HyDE 则能进一步约束生成过程,确保输出结果更加可靠。
参考
Langchain 实现
HyDE 实现:生成、嵌入、平均、检索。
from langchain.chains import HypotheticalDocumentEmbedder, LLMChain
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI, OpenAIEmbeddings
# 初始化 embedding 模型
base_embeddings = OpenAIEmbeddings()
# 初始化 LLM: 以下多种方式选其一即可
# ① 生成一个文档
llm = OpenAI()
# ② 生成多个文档, 取平均
llm = OpenAI(n=4, best_of=4)
# ③ 自定义 prompt
prompt_template = """请回答关于最近一次国情咨文的用户问题
问题$:{question}
回答$:"""
prompt = PromptTemplate(input_variables=["question"], template=prompt_template)
llm_chain = LLMChain(llm=llm, prompt=prompt)
# HyDE 执行
embeddings = HypotheticalDocumentEmbedder(
llm_chain=llm_chain, base_embeddings=base_embeddings
)
result = embeddings.embed_query("Where is the Taj Mahal?")
# 使用 web_search 提示加载HyDE
embeddings = HypotheticalDocumentEmbedder.from_llm(llm,
base_embeddings,
"web_search"
)
# 使用
result = embeddings.embed_query("泰姬陵在哪里?")
# --------- 检索 ----------
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import CharacterTextSplitter
with open("data/state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
docsearch = Chroma.from_texts(texts, embedding_fn, persist_directory="./data/.chroma_db")
query = "What did the president say about Ketanji Brown Jackson"
docs = docsearch.similarity_search(query)
HyDE 局限
局限性
- 问答框架:
- 并非所有检索用例都用于问答, 所以 让LLM假设回答问答不一定都有意义
- 文档分块检索时, 各分块在风格、语气和结构等方面并不一定同质, 难以用一个通用提示捕捉多样性
- 用户表达: 多数意图表达模糊
AutoHyDE
【2024-9-12】AutoHyDE:使HyDE更好地用于高级LLM RAG
假设文档嵌入(HyDE) 已被证明是一种强大的查询重写形式,可提高检索文档的相关性。
但 现有HyDE实现并非开箱即用,不够灵活
AutoHyDE,提高 LLM RAG 假设文档嵌入(HyDE)的有效性、覆盖率和适用性的半监督框架。
AutoHyDE 自动发现索引文档中的潜在相关模式,并生成直接表示这些相关性模式的假设文档。
- 直接调整了 LangChainHypotheticalDocumentEmbedder 类来实现 AutoHyDE,以便它仍然可以与 LangChain 的其他部分链接在一起。
AutoHyDE 主要改进: 假设文档生成方式。
- 没有使用固定提示(无论是 LangChain 预定义, 还是用户自定义)
- 而是设计框架, 自动发现所有文档中可能被基线检索忽略的潜在相关模式
- 并为每一种模式生成假设文档。
通过这种方式,我们能够使 HyDE 适应各种各样的任务和环境,并适应相关模式异构的索引的检索。
AutoHyDE 主要目的
- 自动发现向量数据库中各种相关模式, 并生成各种文档, 以提高这些模式的覆盖率。
主要步骤
- 从query中提取关键词
- 初步检索
- 获取包含关键词的忽略文档
- 被忽略文档聚类
- 生成假设文档
- 嵌入
- 合并
技术上,采用 LangChain 中 HypotheticalDocumentEmbedder 类的现有实现,并创建了新函数来实现 AutoHyDE,这样它就可以立即作为任何 RAG 链的一部分运行
代码实现
# ------- Define LLM and Embeddings -------
from langchain_openai import OpenAIEmbeddings
# embedding 定义
base_embeddings = OpenAIEmbeddings()
# LLM 定义
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4-1106-preview", temperature=1)
# ------- Split Documents -------
from langchain_community.document_loaders import TextLoader
loader = TextLoader("data/util.txt")
documents = loader.load()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator='.', chunk_size=1200, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# ------- Define Chroma Vector DB -------
from langchain_community.vectorstores import Chroma
db = Chroma.from_documents(docs,
base_embeddings,
collection_metadata={'hnsw:space': 'cosine'})
# ------- Instantiate improved HypotheticalDocumentEmbedder --------
from src.auto_hyde import HypotheticalDocumentEmbedder
hyde_embedder = HypotheticalDocumentEmbedder(
llm_chain=llm, base_embeddings=base_embeddings
)
# Define Custom HyDE params
hypo_params = {
'baseline_k': 20,
'exploration_multiplier': 5,
'verbose': True
}
# Get Embedding
query = 'what is the relationship between justice and happiness?'
hyde_embedding = hyde_embedder.embed_query(text=query, db=db, hypo_params=hypo_params)
hyde_embedding[:10]
【2023-11-15】CoN 承认不会
【2023-11-15】腾讯AI Lab
Chain-of-Note:大模型检索增强生成更加鲁棒
- 论文链接:CoN
缺乏知识的情况下,基于检索增强的语言模型应当能够承认自己的“无知”。为了应对这些挑战,作者引入Chain-of-Noting(CON)的方法,提高基于检索增强的语言模型面对嘈杂、不相关文档以及处理未知场景的鲁棒性。
CON 核心思想
- 为检索到的文档生成连续阅读笔记,使其能够彻底评估与给定问题的相关性,并将这些信息整合以生成最终答案。
三种不同类型的CoN
- 语言模型根据检索到的信息生成最终答案
- 检索到的文档虽然没有直接回答query,但提供了上下文,使得语言模型能够将这些信息与其固有知识结合起来,从而推导出答案
- 语言模型遇到不相关文档并缺乏回应所需知识的情况,能够承认自己的“无知”
【2023-11-14】FILCO 提前过滤不相关
【2023-11-14】CMU 提出
FILCO:检索增强生成加一道“过滤”
在开放领域问答和事实验证等任务中,如何改进检索增强型生成系统的性能。
- 生成回答时,会检索相关知识,但由于检索系统并不完美,有时会提供部分或完全不相关的信息。这可能导致生成模型过度或不足地依赖于上下文信息,进而产生错误的输出,例如虚构信息。
- 论文提出一种名为 FILCO 的方法,它通过词汇和信息论方法来识别有用的上下文,并训练上下文过滤模型在测试时过滤检索到的上下文。
FILCO 方法通过两个步骤改善生成器提供的上下文质量:
- (1) 基于词汇和信息论方法识别有用的上下文;
- (2) 训练上下文过滤模型在测试时过滤检索到的上下文。
图谱
分析
- GraphRAG 在多跳推理和上下文综合的任务中表现优异
- 但在简单事实检索任务中不如传统RAG
Native RAG 短板:
- 只会“关键字匹配”,不会“理解知识结构”,检索和生成之间始终隔着一层“信息语义的墙”
RAG 架构核心逻辑:
- 用户提问 → 文本向量化 → 相似文档检索 → 与问题拼接 → 喂给语言模型生成答案
这种方式虽然实用,但存在两个问题:
- 知识碎片化:检索结果是几个独立段落,不成体系
- 模型“不会关系”:无法理解A和B之间是什么关系
而 GraphRAG 可以解决。
详见站内专题:大模型时代的知识图谱
Vector RAG
基于 embedding 的 RAG方法,常见
【2023-10-7】RAG-Fusion
【2023-10-7】使用RAG-Fusion和RRF让RAG在意图搜索方面更进一步
起因
RAG有许多优点:
- 向量搜索融合: RAG通过将向量搜索功能与生成模型集成,引入了一种新的范例。这种融合能够从大型语言模型(大语言模型)生成更丰富、更具上下文感知的输出。
- 减少幻觉: RAG显著降低了LLM的幻觉倾向,使生成的文本更基于数据。
- 个人和专业实用程序:从个人应用程序如筛选笔记到更专业的集成,RAG展示了在提高生产力和内容质量方面的多功能性,同时基于可信赖的数据源。 然而,我发现越来越多的“限制”:
当前搜索技术限制:
- RAG受到基于检索的词法和向量搜索技术的相同限制。
- 人工搜索效率低下:人类并不擅长在搜索系统中输入他们想要的东西,比如打字错误、模糊的查询或有限的词汇,这通常会导致错过明显的顶级搜索结果之外的大量信息。虽然RAG有所帮助,但它并没有完全解决这个问题。
- 搜索的过度简化:流行的搜索模式将查询线性地映射到答案,缺乏深度来理解人类查询的多维本质。这种线性模型通常无法捕捉更复杂的用户查询的细微差别和上下文,从而导致相关性较低的结果。
为什么用 RAG-Fusion?
为什么使用 RAG-Fusion
- 通过生成多个用户查询和重新排序结果来解决RAG固有的约束。
- 利用倒数排序融合(RRF)和自定义向量评分加权,生成全面准确的结果。
RAG-Fusion 弥合用户明确提出的问题和(原本的意图)打算提出的问题之间的差距,更接近于发现通常仍然隐藏的变革性知识。
RAG-Fusion 机制
RAG Fusion 基本三要素与RAG相似,并在于相同的三个关键技术:
- 通用编程语言,通常是Python。
- 专用的向量搜索数据库,如Elasticsearch或Pinecone,指导文档检索。
- 强大的大型语言模型,如ChatGPT,制作文本。
然而,与RAG不同,RAG-Fusion通过几个额外步骤来区分自己——查询生成和结果的重新排序。
RAG-Fusion’s 工作步骤:
- 查询语句的相关性复制(多查询生成):通过LLM将用户的查询转换为相似但不同的查询。
- 单个查询可能无法捕获用户感兴趣的全部范围,或者它可能太窄而无法产生全面的结果。这就是从不同角度生成多个查询的原因。
- 并发的向量搜索:对原始查询及其新生成的同级查询执行并发的向量搜索。
- 智能重新排名:聚合和细化所有结果使用倒数排序融合(RRF)。
- 最后优中选优:将精心挑选的结果与新查询配对,引导LLM进行有针对性的查询语句输出,考虑所有查询和重新排序的结果列表。
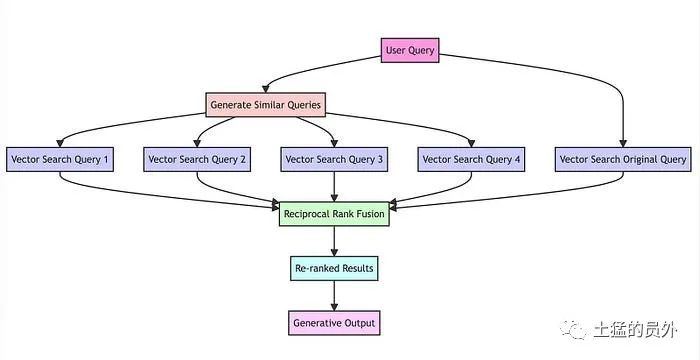
多查询生成
工作原理:
- 对语言模型的函数调用:函数调用语言模型(在本例中为chatGPT)。这种方法需要一个特定的指令集(通常被描述为“系统消息”)来指导模型。例如,这里的系统消息指示模型充当“AI助手”。
- 自然语言查询:然后模型根据原始查询生成多个查询。
- 多样性和覆盖范围:这些查询不仅仅是随机变化。它们是精心生成的,以提供对原始问题的不同观点。例如,如果最初的查询是关于“气候变化的影响”,生成的查询可能包括“气候变化的经济后果”、“气候变化和公共卫生”等角度。
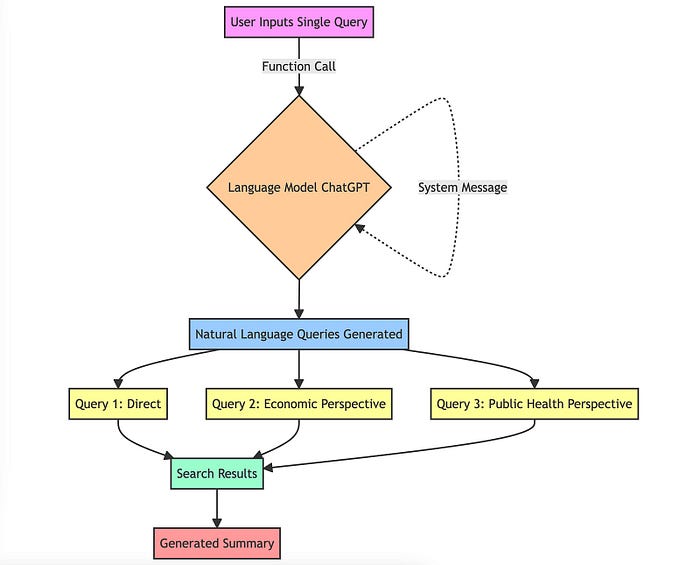
倒数排序融合 (RRF)
Why RRF?
- 倒数排序融合(RRF) 是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法,不同的相关性指标也不必相互关联即可获得高质量的结果。
该方法的优势在于不利用相关分数,而仅靠排名计算。相关分数存在的问题在于不同模型的分数范围差。RRF是与滑铁卢大学(CAN)和谷歌(Google)合作开发
- cormacksigir09-rrf
- “比任何单独的系统产生更好的结果,比标准的重新排名方法产生更好的结果”。
在elasticsearch的8.8版本,已经引入了RRF。
RRF 想象成那种坚持在做决定之前征求每个人意见的人,这种意见是有帮助的,兼听则明,多多益善
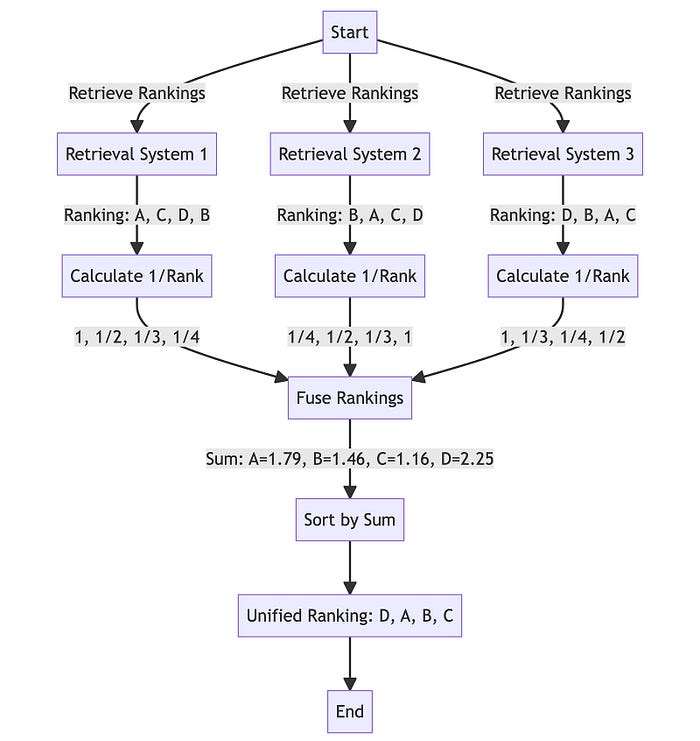
生成输出
用户意图保存
- 使用多个查询的挑战之一是可能会削弱用户的原始意图。为了缓解这种情况,我们指示模型在prompt工程中给予原始查询更多的权重。
RAG-Fusion 优缺点
优势
- 1、优质的原材料质量
- 使用RAG Fusion时,搜索深度不仅仅是“增强”,并且其实搜索范围已经被放大了。相关文档的重新排序意味着你不仅仅是在抓取信息的字面意思,而是在深入这个搜索的意图,所以会涉及到更多的优质文档和待搜索内容。
- 2、增强用户意图对齐
- RAG Fusion的设计理念中包含了自动提示,很多时候我们在搜索的时候并不知道应该怎么描述,像Google、百度就会进行输入框的自动补全提示。RAG Fusion可以捕获用户信息需求的多个方面,从而提供整体输出并与对用户意图进行增强。
- 3、自动为用户查询输入纠错
- 该系统不仅可以解释用户的查询,还可以精炼用户的查询。通过生成多个查询变体,RAG Fusion执行隐式拼写和语法检查,从而提高搜索结果的准确性。
- 4、导航复杂查询(自动分解长句的意图)
- 人类的语言在表达复杂或专门的思想时往往会结结巴巴。该系统就像一个语言催化剂,生成各种变体,这些变体可能包含更集中、更相关的搜索结果所需的行话或术语。它还可以处理更长的、更复杂的查询,并将它们分解成更小的、可理解的块,用于向量搜索。
- 5、搜索中的意外发现(关联推荐)
- 以前在亚马逊买书的时候,总能因为相关推荐发现我更想要的书,RAG Fusion允许这个偶然的发现。通过使用更广泛的查询范围,系统有可能挖掘到信息,而这些信息虽然没有明确搜索,但却成为用户的“啊哈”时刻。这使得RAG Fusion有别于其他传统的搜索模型。
挑战
- 1、过于啰嗦的风险
- RAG-Fusion的深度有时会导致信息泛滥。输出可能会详细到令人难以承受的程度,把RAG-Fusion想象成一个过度解释事物的朋友。
- 2、可能成本会比较昂贵
- 多查询输入是需要LLM来做处理的,这时候,很有可能会引起更多的tokens消耗。
【2023-10-9】DeepMind: Step-Back Prompting
【2023-10-27】DeepMind新技术Step-Back Prompting,可提升RAG应用效果,让大模型学会抽象思考
Zero-Shot-CoT 领域,最近几天(10.3)刚刚有一个新的研究《Large Language Models as Analogical Reasoners》提出,通过类比推理提示(Analogical Prompting)可以让大模型自己生成相似问题做为例子,从而再根据例子步骤形成思维链来解决新问题。
观察:很多任务都很复杂,充满了细节,大语言模型(LLMs)很难找到解决问题所需的相关信息。
- 物理问题:“如果一个理想气体的温度翻了一番,体积增加了八倍,那么它的压强 P 会发生什么变化?” LLM 在直接解答这个问题时可能会忽略理想气体定律的基本原则。
- 询问“Estella Leopold 在 1954 年 8 月到 11 月期间就读于哪所学校?”的问题,由于时间范围非常具体,直接回答也是非常困难的。
思考
- 在这两种情况下,通过退一步提问,能够帮助模型更有效地解决问题。
谷歌 DeepMind 10月9日提了一项新技术“Step-Back Prompting”,简称后退提示(STP),不是类比寻找相似示例,而是让LLMs自己抽象问题,得到更高维度概念和原理,再用这些知识推理并解决问题。这种思维模式非常类似于人类解决问题的方式,让大模型能够借鉴已有规律解决问题。
退一步问题为从原始问题中派生出来的、层级更高的抽象问题。
- 不直接问 “Estella Leopold 在特定时间段内的学校是哪所”,而是问一个更高层次的问题:“Estella Leopold 的教育历史是怎样的?”
- 通过回答这个更抽象的问题,获得解答原始问题所需的所有信息。
通常来说,退一步问题比原始问题更容易回答。基于这种抽象层次的推理有助于避免中间步骤的错误,链式思维提示的例子一样。总的来说,退一步提示法包含两个简单的步骤:
- 抽象:我们首先提示 LLM 提出一个关于更高层次概念或原则的通用问题,并检索与之相关的信息,而不是直接回答原始问题。
- 推理:在获取了关于高层次概念或原则的信息后,LLM 可以基于这些信息对原始问题进行推理。我们将这种方法称为基于抽象的推理。
后退提示(STP)可以和RAG相结合,利用后退提示获得的抽象问题,获得更多与最终答案需要的的上下文信息,然后,再将获得的上下文和原始问题一起提交给LLM,从而让LLM获得更好的回答质量。

PaLM-2L模型做了实验,发现这种Prompt技巧能显著提升推理任务(STEM、知识问答、多步推理)的性能表现。
- step-back prompting与rag配合使用的方式 相比较于baseline提升了39.9%,相较于单纯RAG应用,提升了21.6%的效果。
工程实现
- 该技术已经被langchain支持
- colab尝试
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{normal_context}
Original Question: {question}
Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
# Retrieve context using the normal question (only the first 3 results)
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
chain.invoke({"question": question})
【2023-10-17】华盛顿大学: Self-RAG
【2023-10-17】华盛顿大学 Self-RAG:通过自我反思实现检索增强生成
检索增强生成(Retrieval-Augmented Generation,RAG)方法通过检索相关知识来减少这类问题,降低了LLMs在知识密集型任务中的事实错误率)。但是,会存在如下问题
- 不加区别地检索和合并一定数量的检索文段,无论是否需要检索或文段是否相关,这会降低LLMs的多功能性或导致生成质量不佳(Shi等人,2023),因为不加区别地检索文段,无论事实支持是否有帮助。
- 生成结果与检索段落未必一致(Gao等人,2023),因为这些模型没有明确训练以利用和遵循所提供文段的事实。
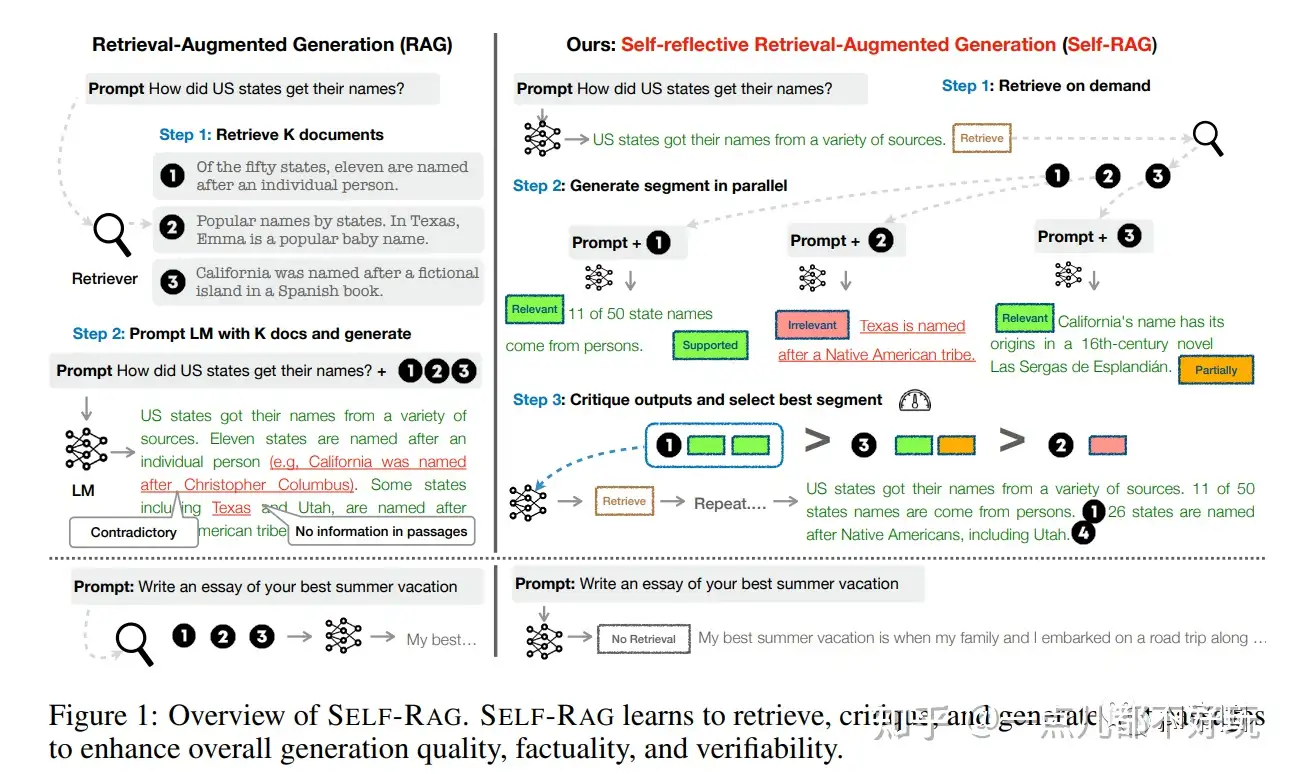
论文提出一种新框架:自我反思检索增强生成(SELF-RAG),通过按需检索和自我反思来提高LLM的生成质量,包括其事实准确性,而不损害其多功能性。
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- SELF-RAG 主页包含代码、模型和数据
论文以端到端方式训练任意LLM来学习反思自身的生成过程,通过生成任务输出和间歇性的特殊token(即反思token)。
- 反思token分为检索和评论token,分别表示检索的需求和生成的质量(图中右侧)。
具体做法如下:
- 给定输入提示和先前的生成,SELF-RAG
- 首先,确定继续生成增加检索文段是否有所帮助。如果是,输出一个检索标记,以便按需调用一个检索模型(步骤1)。
- 随后,SELF-RAG同时处理多个检索文段,评估相关性,然后生成相应的任务输出(步骤2)。
- 然后,生成评论标记来评估输出,并选择在事实准确性和整体质量方面最好的生成(步骤3)。
- 这个过程与传统RAG(图1左侧)不同,后者不管检索是否有必要(例如,底部示例不需要事实知识),都会一律检索固定数量的文档进行生成,并且从不第二次访问生成质量。
- 此外,SELF-RAG为每个部分提供引文,附带自我评估是否输出受文段支持,从而简化了事实验证。
实验证据表明
- SELF-RAG 在 6个任务上明显优于经过预训练或指令学习的LLMs,以及更高引用准确性的RAG方法,达到sota。
- SELF-RAG 在 4个任务上优于具有检索增强功能的
ChatGPT,Llama2-chat和Alpaca, 在所有任务中的性能更好。
Self-RAG outperforms vanilla ChatGPT or LLama2-chat across six tasks, and outperforms those SOTA models with widely-used retrieval-augmentation methods in most tasks by large margin
论文分析证明了使用反思标记进行训练和推理对整体性能提升以及测试时模型自定义(例如,在引文预测和完整性之间的权衡)的有效性。
Connections to Prior Work
- v.s. Retrieval-augmented Generation 与传统RAG相比,
Self-RAG针对多样性任务自适应检索,并评估相关性,更加灵活Standard RAGonly retrieves once or fixed number of time steps, whileSelf-RAGenables Adaptive retrieval for diverse task inputs, and can retrieve multiple times while generations, or completely skip retrieval, making it more suitable for diverse downstream queries (e.g., instruction-following).Self-RAGcarefully criticize retrieved passages or its own generations via reflection tokens and incorporate hard or soft constrained during decoding, whilestandard RAGdoes not assess relevance of passages or whether the output is indeed supported by the passages.
- v.s. Learning from Critique (Feedback)
Self-RAG再多个参考结果中调整奖励权重,不需要训练- Reflection tokens are inserted offline by another Critic model trained on machine-generated feedback, making training much more memory efficient and stable than widely adopted RLHF methods (e.g., PPO).
Self-RAGenables tailored behaviors by simply adjusting reward weights across multiple preference aspects, while prior fine-grained feedback learning method requires training for different model behaviors.
【2024-7-11】手把手代码复现Self RAG
【2023-10-28】Agent RAG
- OpenAI community Standard RAG + Agent Solution
AutoGen
【2023-10-28】Retrieval-Augmented Generation (RAG) Applications with AutoGen
- 基于 AtuoGen 的 RAG

AutoGen 构建一个能够进行智能搜索和信息检索的聊天应用。用户可以通过自然语言查询代理提出问题或请求信息,然后搜索代理会从互联网或其他数据源中检索相关信息,并通过自然语言代理将结果返回给用户。
AutoGen 的 RAG系统由两个代理组成,都从 AutoGen 的内置代理扩展而来
RetrieveUserProxyAgent: 人类代理,也能执行代码、调用函数code_execution_config可关闭自动执行- 默认不启用 LLM,可以通过配置文件
llm_config开启 - 指定文档集合路径。随后下载文档,分割成特定大小的块,计算嵌入,并存储在矢量数据库中
RetrieveAssistantAgent: 检索增强代理,与 LLM 交互,可以执行LLM生成的Python代码- 包含一个向量数据库
相关配置
-
llm_configLLM 配置信息 - RAG 代理的定制
- 定制嵌入功能、文本分割功能和矢量数据库。
- RAG 代理的两种高级用法,即
- 与群聊集成
- 使用 Gradio 构建聊天应用程序
Diverse Applications Implemented with AutoGen

规划思考
【2023-11-15】Chain-Of-Note
【2023-11-23】腾讯 AI Lab Chain-Of-Note:解决噪声数据、不相关文档和域外场景来改进RAG的表现
RAG检索增强生成已经成为llm的重要推动者。最值得注意的是,随着RAG的引入,模型幻觉得到了很大程度的抑制,RAG也可以作为模型性能的均衡器。
RAG(或 RALMs) 面临的挑战是确保在推理时向LLM提供准确、高度简洁和上下文相关的数据。但是
- 不相关数据的检索可能导致错误响应,并可能导致模型忽略(overlook)其固有的知识,即使它拥有足够的信息来处理查询。
- 很难评估内在、检索的知识对于得出正确输出是否够用
- 知识不足时,系统应该输出“不知道”
CoN 作为一种新的方法,提高RAG的弹性。特别是在RAG数据不包含与查询上下文相关的明确信号的情况下。
- 提高 RAG 在噪声、不相关文档、未知情形的鲁棒性
CoN 原理
CoN框架由三种不同的类型组成,阅读笔记。
- 类型(A)显示了检索到的数据或文档回答查询的位置。LLM仅使用NLG从提供的数据中格式化答案。
- 类型(B)中,检索到的文档不直接回答查询,但是上下文洞察足以使LLM将检索到的文档与它自己的知识结合起来,从而推断出答案。
- 类型(C)是指检索到的文档是不相关的,LLM没有相关的知识来响应,导致框架没有给出错误或错误的答案。
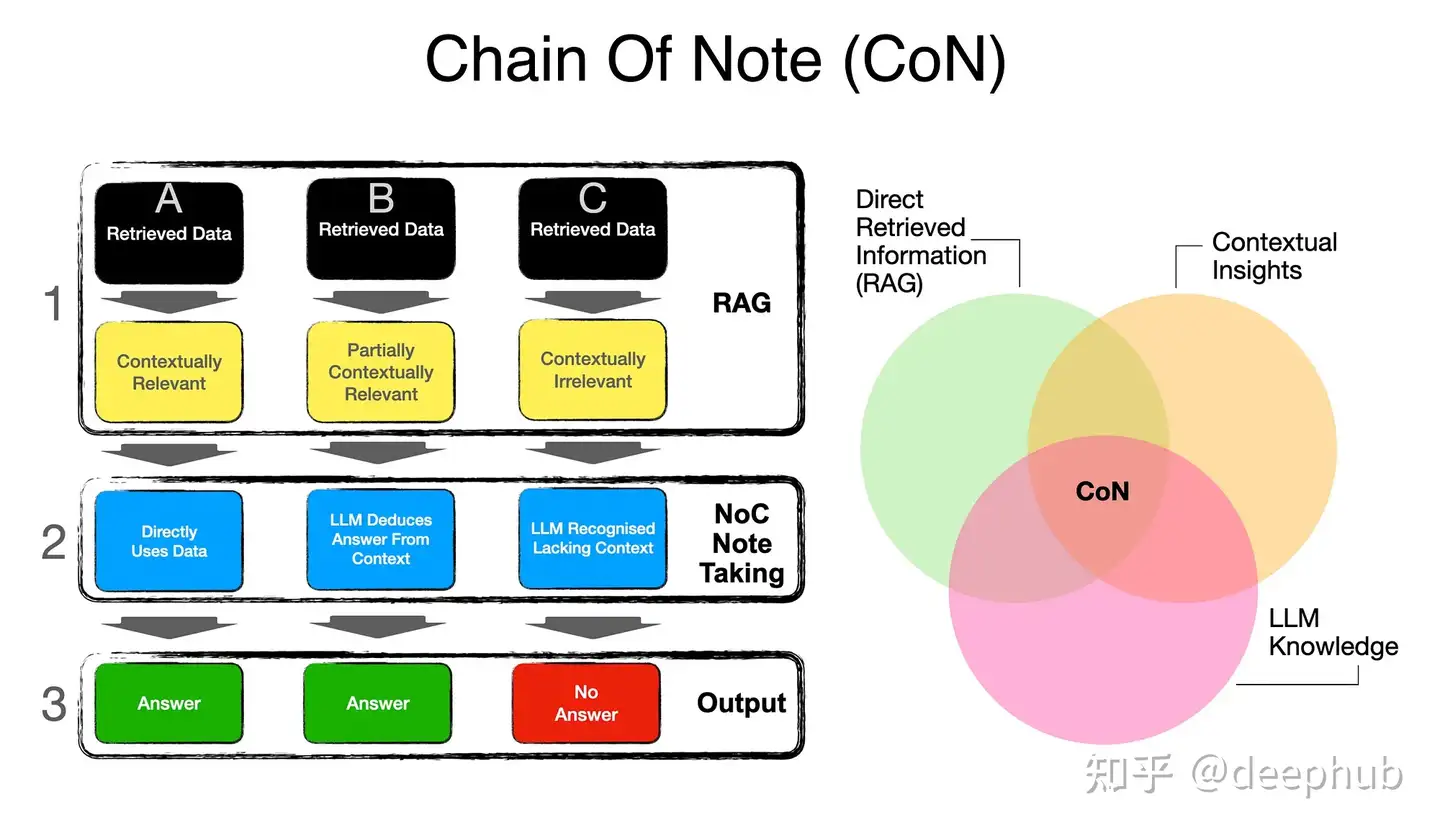

CoN框架为检索到的文档生成顺序的阅读注释,从而能够系统地评估从外部文档检索到的信息的相关性和准确性。
通过创建顺序阅读笔记,该模型不仅评估每个文档与查询的相关性,而且还确定这些文档中最关键和最可靠的信息片段。这个过程有助于过滤掉不相关或不可信的内容,从而产生更准确和上下文相关的响应。
CoN是一个自适应过程,或逻辑和推理层,其中直接信息与上下文推理和法学硕士知识识别相平衡。
为了使模型具有生成NoC阅读笔记的能力,需要进行微调。
- 论文训练了一个llama - 27b模型,将笔记能力整合到CON中。
CoN不仅是一个提示模板,而且还包含了一个经过微调的可以记笔记模型。
因此CoN 是 RAG 和 Fine-Tuning 的结合。
这又回到了数据人工智能的概念和数据的四个方面,即数据发现、数据设计、数据开发和数据交付。
一般来说,RAG和具体的CoN可以看作是数据交付过程的一部分。但是为了训练NoC模型,需要一个数据发现、数据设计和数据开发的过程。
使用 ChatGPT 生成训练数据,通过 LLama-2 7b 模型训练,在开放领域问答语料上实验,显著超过传统RAG
CoN 示例
LangSmith的CoN模板。给定一个问题,查询Wikipedia并使用带有Chain-of-Note提示的OpenAI的API提取答案。
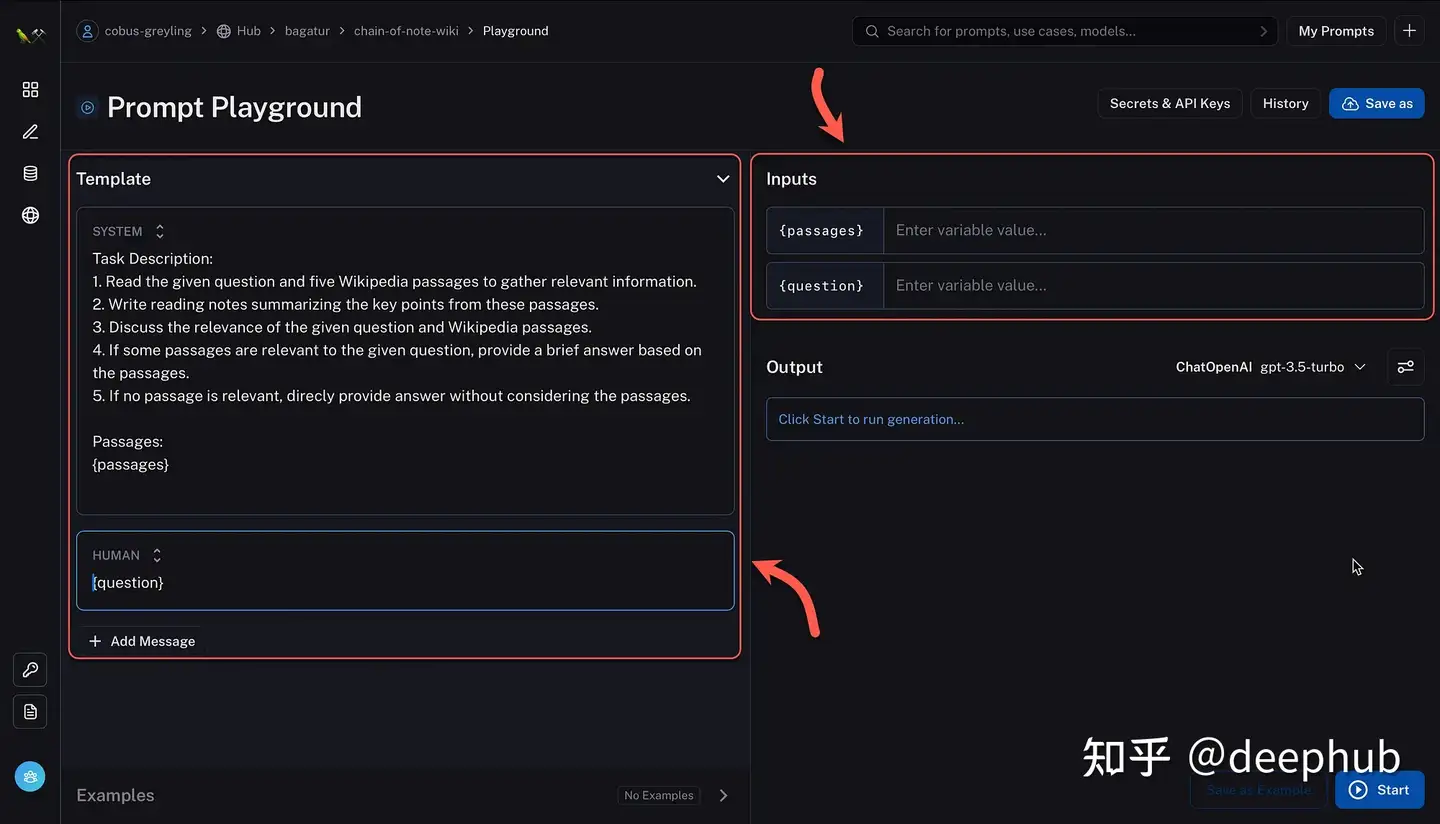
标准RAG:
Task Description: The primary objective is to briefly answer a specific question.
带CON的RALM:
Task Description:
1. Read the given question and five Wikipedia passages to gather relevant information.
2. Write reading notes summarizing the key points from these passages.
3. Discuss the relevance of the given question and Wikipedia passages.
4. If some passages are relevant to the given question, provide a brief answer based on the passages.
5. If no passage is relevant, direcly provide answer without considering the passages.
Plan×RAG
现有的 Retrieval Augmented Generation(RAG)框架在处理复杂查询时,存在性能和幻觉以及缺乏归因问题。
【2024-10-28】阿尔托大学和微软推出 Plan×RAG 将传统的“检索-推理”范式转变为“规划-检索”范式,一种新的处理复杂查询的方法。
PlanxRAG 包括 Plan 和 RAG 两个部分
- 一个是推理计划的表示是一个核心,Plan×RAG 将推理计划表示为一个
有向无环图(DAG),将主查询分解为相互关联的原子子查询。
这种结构化的方法允许高效的信息共享和并行化处理。
示例
- 最后两届男子板球世界杯决赛举办地之间的距离
这个查询被分解为以下几个子查询:
- Q1.1:上一届男子板球世界杯决赛在哪里举行?
- Q1.2:上上届男子板球世界杯决赛在哪里举行?
- Q2.1:Q1.1中的答案地点的坐标是什么?
- Q2.2:Q1.2中的答案地点的坐标是什么?
- Q3.1:Q2.1和Q2.2中的答案地点之间的距离是多少?
这个DAG中,Q1.1和Q1.2可以独立处理,Q2.1和Q2.2也可以独立处理,而Q3.1依赖于Q2.1和Q2.2的结果。这种结构不仅允许并行处理,还使得每个子查询的归因变得直接和清晰。如果Q3.1的结果不正确,可以通过检查Q2.1和Q2.2的结果来确定问题所在,并进行相应的修正。
几个特点:
- 相关信息流: 一个查询被分解为多个子查询,每个子查询都与相关信息流相关联。每个子查询只处理与它直接相关的信息,从而提高了处理的效率和准确性;
- 并行执行: 在DAG中,同一深度的子查询可以并行执行。这是因为这些子查询是相互独立的,可以同时处理,从而减少了总体的响应时间。这种并行化处理是DAG结构的直接结果,因为它允许系统同时处理多个节点;
- 固有归因: DAG设计使得每个子查询的生成可以直接归因到一个特定的检索文档。这种归因是固有的,因为每个子查询通常只依赖于一个相关的文档。这有助于提高系统的可解释性和信任度,因为可以清楚地追踪每个生成的响应与其来源文档之间的关系;
- 调试和回溯: DAG结构允许系统进行调试和回溯。如果生成的最终答案不正确,可以通过DAG的结构从叶子节点回溯到根节点,识别出错的节点,并对其进行修正。这种能力提高了系统的可调试性,使得可以更容易地识别和纠正错误。
主要流程
- 1)查询分解:给定一个复杂查询,Plan×RAG首先将其分解为一系列更小、独立且相互关联的原子子查询。这些子查询是构成DAG的节点,每个节点代表一个需要回答的子问题。
- 2)构建DAG: DAG的构建遵循Markov假设,即一个子查询的答案仅依赖于其父节点的答案。 DAG的根节点是主查询,而叶节点是原子子查询,这些子查询可以直接通过单个文档回答。通过这种方式,DAG确保了查询的分解和组织,使得子查询之间没有循环依赖,并且所有节点都连接起来,形成一个有向的、无环的图结构。
- 3)查询DAG:在子查询中,使用特殊的标签来表示需要从父查询答案中动态填充的信息。这些标签在运行时被实际的答案替换,从而动态生成完整的子查询。
- 4)处理DAG:生成器(LM)按照拓扑顺序处理DAG中的每个节点。对于每个节点,都会调用一组插件式专家来控制生成过程,包括动态生成子查询、访问检索需求以及识别每个子查询的相关文档。此外,DAG的结构允许对同一深度的节点或DAG中独立路径上的节点进行并行处理,这显著减少了延迟,并提高上下文处理的效率。
专家包括插件式专家(Plug-and-Play Experts):
Plan×RAG 集成一组独立的插件式专家,如批评家专家(critic expert)和相关性专家(relevance expert),这些专家协同工作,提高LLM生成响应的准确性、可靠性和可解释性。
动态查询专家负责生成子查询,捕捉子查询之间的马尔可夫依赖关系,这个主要是根据prompt提示大模型生成;批评家专家在生成过程中按需进行检索,评估何时需要额外的信息;相关性专家精炼检索过程,确保选择最相关的文档;聚合器专家将多个子查询的答案组合成对原始查询的综合响应;插拔式专家可以与任何预训练的LM集成。
DeepSeek-R1 递归推理
【2025-3-13】基于DeepSeek-R1的递归推理RAG开源项目
结合 DeepSeek-R1 推理与 Tavily 搜索的递归RAG工作流程系统应运而生,通过智能信息检索和推理处理复杂的嵌套查询。
- 项目地址:r1-reasoning-rag
优势
- 传统 RAG 系统在处理复杂问题时,往往面临信息筛选困难、无法有效整合多源信息等挑战。
- 而基于 DeepSeek-R1 递归推理RAG系统,凭借其强大的推理能力,实现了性能的飞跃。动态筛选信息,减少对诸如“长上下文重排”这类繁琐技巧的依赖,通过递归检索机制,有效处理长嵌套和复杂的查询。
问题: “RBC总部是否在Sam Altman兄弟公司的总部以北?”
- 系统首先检索 RBC总部位于多伦多,但对于 Sam Altman兄弟公司总部位置信息 缺失,于是递归检索。
- 再次检索后, 虽获取了一些相关公司位置信息,但存在公司与兄弟关联不明确的问题,继续检索。
- 最终确认信息完整,得出答案。
通过这个案例,充分展示了该系统处理复杂问题的能力。
核心架构
- Agent层:基于 DeepSeek-R1 推理技术构建的自主决策“大脑”,负责整个检索和推理过程的协调,把控全局方向。
- 递归RAG引擎
- · 检索模块:如同勤劳的“信息采集员”,从知识库中快速提取相关信息。
- · 推理模块:扮演“智慧分析师”,分析已检索信息,判断这些信息是否足以回答问题。
- · 判断模块:好似“严格筛选官”,决定哪些信息需要保留,哪些应被丢弃,以及是否需要进一步检索。
- 知识库接口:作为连接外部知识源的标准化通道,确保系统能够获取丰富多样的知识。
- 综合答案生成器:将多轮检索获得的信息精心整合,输出完整、连贯的最终答案。
工作流程
- 系统接收复杂问题,例如 “RBC总部是否在Sam Altman兄弟公司的总部以北?”
- 初始检索相关信息,利用 Tavily 等工具在网络或知识库中查找线索。
- 对检索到的信息进行推理分析,评估现有信息能否回答问题。
- 判断信息是否充分
- 如果充分, 则生成答案;
- 若不充分,识别缺失细节并重新查询以获取更多数据。
- 如需更多信息,返回检索步骤进行递归检索,沿途丢弃无关数据,保留相关信息。
- 当信息充分时,综合生成最终答案。
结合推理模型与代理循环的RAG工作流程,将逐渐取代传统RAG方法,成为处理复杂信息检索的主流技术。

【2024-2-23】文档分割
【2024-2-23】文档语义分割
RAG中,embedding 和 文档语义分割、段落分割 是绕不开的关键点,重点梳理下各类典型的语义分割模型
基于 CrossSegmentAttention 的模型(如 Cross-segmentBERT 和 BERT+Bi-LSTM)以及阿里巴巴开源的 SeqModel,对比了在处理文本分割任务时的上下文利用和效率
CrossSegmentAttention
RAG 场景下,常用文本切块方法基于策略,例如大模型应用开发框架提供的 RecursiveCharacterTextSplitter 方法,定义多级分割符,用上一级切割符分割后的文本块, 如果还是超过最大长度限制,再用第二级切割符进一步切割
Lukasik 等人在论文《Text Segmentation by Cross Segment Attention》提出了三种基于transformer的分割模型架构。
- 其中一种仅利用每个候选断点(candidate break)周围的局部上下文
- 而另外两种则利用来自输入的完整上下文(所谓候选断点指任何潜在的段边界,即 any potential segment boundary)
(1) Cross-segment BERT:确定某个句子是否作为下一个段落的开头
分割模型旨在完成文档分割任务,预测每个句子是否是文本分段边界
- 在
Cross-segment BERT模型中,围绕潜在段落断点的局部上下文输入到模型中:左边k个标记和右边k个标记 - 其中与
[CLS]对应的输出隐状态被传递给softmax分类器,以便对候选断点进行分段决策
(2) BERT+Bi-LSTM
在BERT+Bi-LSTM模型中,首先用 BERT 对每个句子进行编码,然后将句子表示输入到Bi-LSTM中
- 当用BERT编码每个句子时,所有序列都以
[CLS]标记开始 - LSTM 负责处理具有线性计算复杂度的多样化和潜在的大型句子序列
(3) Hierarchical BERT
分层BERT模型中,首先用 BERT 对每个句子进行编码,然后将输出的句子表示输入到基于Transformer的另一个模型中
图见原文
SeqModel
阿里语义分割模型 SeqModel
SeqModel 核心原理
- Cross-Segment 提出基于本地上下文的跨段BERT模型和分层BERT模型(Hier.BERT),利用两个BERT模型对句子和文档进行编码,从而实现更长的上下文建模
- 2020年,论文《Two-level transformer and auxiliary coherence modeling for improved text segmentation》还采用了两个分层连接的Transformer结构(uses two hierarchically con-nected transformers)。然而,由于分层模型计算成本高且推理速度较慢
SeqModel:将文档分割建模为句子级序列标记任务
Zhang 等人在论文《Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation》中提出了SeqModel
SeqModel 利用BERT对多个句子同时编码,建模更长的上下文之间依赖关系之后再计算句向量,最后预测每个句子后边是否进行文本分割
此外,该模型还使用了自适应滑动窗口方法,在在不牺牲准确性的情况下进一步加快推理速度
图见原文
步骤
- 首先,文档中每个句子经过 WordPiece 分词器进行分词
- 然后,通过由“token嵌入、位置嵌入和段落嵌入”组成的输入表示层来对这些句子进行编码
- 这些嵌入被送入Transformer编码器,输出与k个标记对应的隐状态,并使用均值池化方法得到句子编码
- 最后,将所有句子编码输入softmax二元分类器,以判断每个句子是否为段落边界,训练目标是最小化softmax交叉熵损失
自适应滑动窗口(Self-adaptive Sliding Window)
还提出了一种自适应滑动窗口方法,在不牺牲准确性的情况下进一步加快推理速度
- 传统分割推理滑动窗口使用固定前向步长。自适应滑动窗口方法,在推理过程中,从前一个窗口中的最后一句话开始,模型在最大后向步长内 向后查看,以找到来自前一个推理步骤的积极分割决策(模型对分割预测概率>0.5)
- 当在这个跨度内有积极的决策时,下一个滑动窗口将自动调整为:从最近预测片段边界之后的下一个句子开始
- 考虑到最后一段和历史对下一个分割决策影响已经降低,这种策略有助于丢弃滑动窗口内不相关的历史信息。因此,自适应滑动窗口既可以加快推理速度也可以提高分割准确性
【2024-6-26】UAR
【2024-6-26】复旦+上海AI Lab提出统一主动检索RAG,减少延迟,提升响应
- 复旦大学和上海人工智能实验室Qinyuan Cheng等人发表《Unified Active Retrieval for Retrieval Augmented Generation》
- UAR 代码尚未放出
在检索增强型生成(Retrieval-Augmented Generation, RAG)中,如何智能地决定何时使用检索来增强大型语言模型(LLMs)的输出。
RAG中并非所有情况下检索都是有益的,对每个指令都应用检索是次优的。
因此,确定是否进行检索对于RAG来说至关重要,这通常被称为主动检索(Active Retrieval)。
主动检索(Active Retrieval)相关的一些研究工作,以下是一些主要的相关研究:
Self-RAG(Asai et al., 2023): 这是一种基于LLM自我意识的方法,只有在模型认为它不知道答案时才触发检索。FLARE(Jiang et al., 2023): 这种方法基于模型对其生成响应的不确定性来决定是否需要外部检索。SKR(Wang et al., 2023b): 首先确定模型是否知道问题的答案,如果不知道,则使用检索增强。RA-ISF(Liu et al., 2024): 与SKR类似,首先评估模型是否知道问题的答案,然后决定是否进行检索。Self-DC(Wang et al., 2024): 这种方法探讨了何时应该检索和何时应该生成答案,采用自划分和征服的方法处理组合未知问题。
其他一些与大型语言模型的时间意识(Time-awareness)和自我意识(Self-awareness)相关的研究,例如:
TimeQA(Chen et al., 2021): 用于评估模型处理时效性问题的能力。MULAN(Fierro et al., 2024): 用于评估语言模型预测可变事实的能力。- 关于自我意识的研究 (Kadavath et al., 2022; Lin et al., 2022a; Yin et al., 2023; Zhang et al., 2023; Cheng et al., 2024): 这些研究探讨了如何增强语言模型对自己知识范围的认识和表达。
这些相关研究为UAR提供了背景和对比,展示了在主动检索领域中不同方法的优缺点,以及UAR如何通过综合多个标准来改进检索时机的判断。
现有的主动检索方法面临两个挑战:
- 依赖单一标准,难以处理各种类型的指令;
- 依赖于专业化和高度差异化的程序,这使得将它们结合到RAG系统中更加复杂,并导致响应延迟增加。
为了解决这些挑战,提出统一主动检索(Unified Active Retrieval, UAR)的新框架。
UAR包含四个正交标准,转化为即插即用的分类任务,以最小额外推理成本实现多方面的检索时机判断。
UAR框架解决这个问题的关键步骤和方法:
- 多标准集成:UAR不依赖单一标准,而是将四个正交的检索时机判断标准集成到一个框架中。这些标准包括意图意识(Intent-aware)、知识意识(Knowledge-aware)、时效性意识(Time-aware)和自我意识(Self-aware)。
- 轻量级分类器:对于每个检索标准,UAR使用轻量级的二分类器(例如单层多层感知机,MLP),这些分类器基于固定大型语言模型(LLM)的最后一层隐藏状态来训练。这种方法避免了对整个LLM进行昂贵的微调,并减少了推理成本。
- 统一的检索判断流程:UAR引入了统一主动检索标准(UAR-Criteria),这是一个决策树,它根据多个检索标准设定的优先级顺序,统一地判断何时需要进行检索。
- 即插即用(Plug-and-play):UAR作为一个即插即用的框架,不需要改变LLM的参数,可以轻松地集成到现有的RAG系统中。
- 标准化处理流程:UAR-Criteria通过标准化的流程处理各种用户指令,确保在不同场景下都能做出一致的检索决策。
- 实验验证:论文通过在四种代表性的用户指令类型上进行实验,验证了UAR在检索时机判断准确性和下游任务性能上的显著优势。
- 资源发布:为了促进未来的研究,作者还发布了UAR的代码、数据、模型和相关资源。
- 通过这些方法,UAR框架能够有效地解决何时应该使用检索来辅助LLM生成响应的问题,同时避免了不必要的检索,提高了系统效率和响应速度。
文章还引入了统一主动检索标准(UAR-Criteria),旨在通过标准化程序处理多种主动检索场景。
通过在四种代表性用户指令类型的实验中,UAR在检索时机判断和下游任务性能上显著优于现有工作,证明了UAR的有效性及其对下游任务的帮助。
贡献
- 提出了UAR这一主动检索框架,创建了评估检索时机准确性的Active Retrieval Benchmark(AR-Bench),并在AR-Bench和下游任务上进行了全面的实验,展示了UAR的显著性能提升。
- 此外,发布了代码、数据、模型和相关资源,以促进未来的研究。
排序
RankRAG
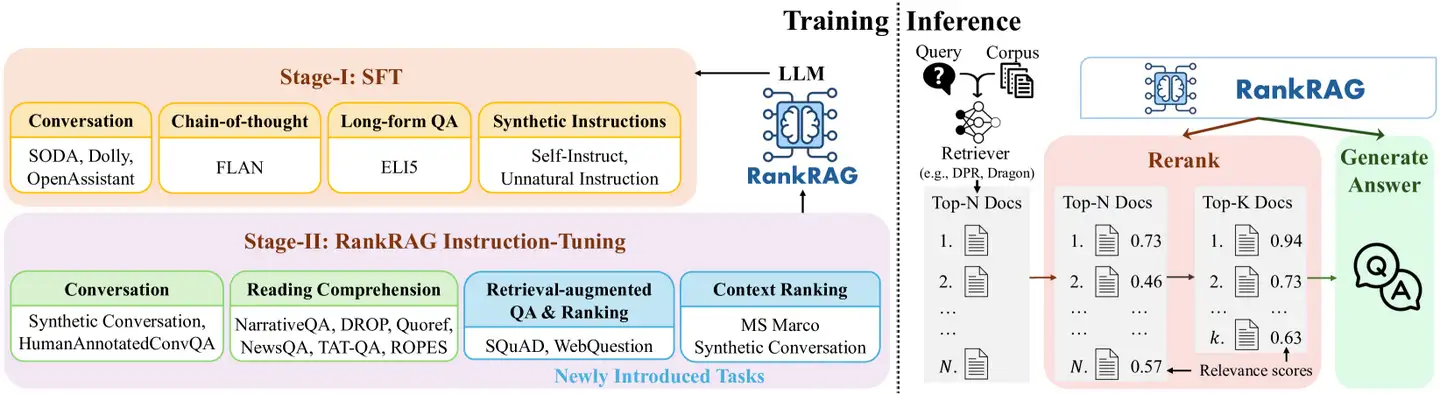
【2024-7-2】RankRAG,英伟达RAG新思路
RAG 局限性:
- • 检索器容量的限制。考虑到处理效率,现有RAG一般采用稀疏检索(比如BM25)或中等规模的嵌入模型(比如Bert)作为检索器。
- • 只选择前K个文档。尽管最新的大语言模型扩大了上下文长度的限制,能够接受更多的上下文作为输入,但是实际性能会随着K的增加而迅速达到饱和。比如在长问答任务中,最佳的分块上下文数量大约是10。虽然更大的K可以提高召回率,但是同时也引入了更多无关的内容,干扰大语言模型生成准确回答。
RankRAG 利用单一大语言模型, 实现高召回率的上下文提取和高质量内容生成。通过对单一大语言模型进行指令调优,使其可以同时进行上下文排序和答案生成,进一步提升LLM在RAG检索和生成阶段排除不相关上下文的能力。
RankRAG 整体包括两个阶段:指令调优阶段、排名与生成综合指令调优阶段。
DynamicRAG
【2025-5-16】伊利诺伊大学厄巴纳—香槟分校提出新颖的检索增强生成 (RAG) 框架DynamicRAG,引入一个动态重排器,通过强化学习训练,利用大语言模型 (LLM) 生成答案质量作为反馈信号,动态调整检索文档的数量和顺序,以优化RAG 系统整体性能和效率,解决了传统 RAG 中固定K 值文档选择的难题
- 论文《DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation》
- 代码 DynamicRAG
【2024-9-6】HybridRAG
【2024-9-6】[HybridRAG:VectorRAG+GraphRAG在时序向量图谱数据库AbutionGraph中的一体化实现](https://zhuanlan.zhihu.com/p/718613162?utm_psn=181652527
HybridRAG (Hybrid Retrieval-Augmented Generation) 结合了两种检索增强 和生成式 (Generation) 方法的自然语言处理技术。
- Retrieval-Augmented,前有
VectorRAG-采用AI/向量数据库存算Embedding文本相似度,后有GraphRAG-采用KG/知识图谱数据库存查相关联内容
通常用于问答系统、对话系统或文档生成等领域,创新结合检索式方法的信息准确性和生成式方法的流畅性和创造性。
HybridRAG 实现可能涉及到复杂的算法和技术,包括但不限于自然语言理解、机器学习、知识表示和推理等。随着NLP领域的不断发展,HybridRAG有望成为提高语言模型性能的关键技术之一
HybridRAG 通过结合VectorRAG和GraphRAG的特点,旨在提供一种更全面和强大的解决方案。它不仅利用向量数据库检索与查询相关的文本信息,还利用知识图谱来理解和推理文本中描述的实体及其关系。
优势:
- 信息准确性:通过检索式方法,HybridRAG能够提供准确的信息,确保生成的响应基于可靠的数据。
- 流畅性和创造性:生成式方法的结合使得HybridRAG能够生成流畅、自然且具有创造性的文本。
- 上下文理解:通过知识图谱,HybridRAG能够更好地理解文本的上下文和语义关系,从而生成更准确和相关的响应。
应用场景:
- 问答系统:在问答系统中,HybridRAG可以提供更准确的答案,同时保持对话的自然流畅。
- 对话系统:在对话系统中,HybridRAG可以生成更自然、更相关的回复,提高用户体验。
- 文档生成:在文档生成中,HybridRAG可以利用检索到的信息和知识图谱的结构化数据来创建内容丰富、逻辑清晰的文档。
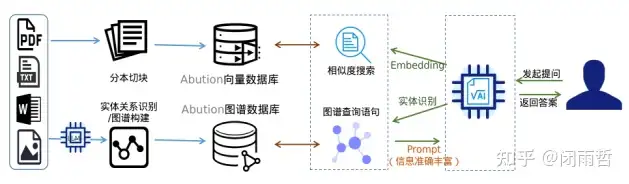
尽管HybridRAG提高了LLM的生成效果,也会带来新的挑战:
- 系统集成:将两种数据库技术有效地集成到一个系统中需要复杂的设计和实现。
- 实现定制:不同的业务场景对Graph(Schema)和Vector(原文/摘要)的形式要求存在差异,比如纯文本的数据和代码文本及结构数据文本的问答知识库面向场景不同,则需要个性化定制以确保引用质量。
- 性能优化:需要优化系统以确保检索和生成过程的效率和响应速度。
- 数据一致性:确保从不同来源检索的数据在知识图谱中保持一致性和准确性是个挑战。
- 全局问答/Global Search:架构上还是Local Search 友好型,Global Search支持困难。
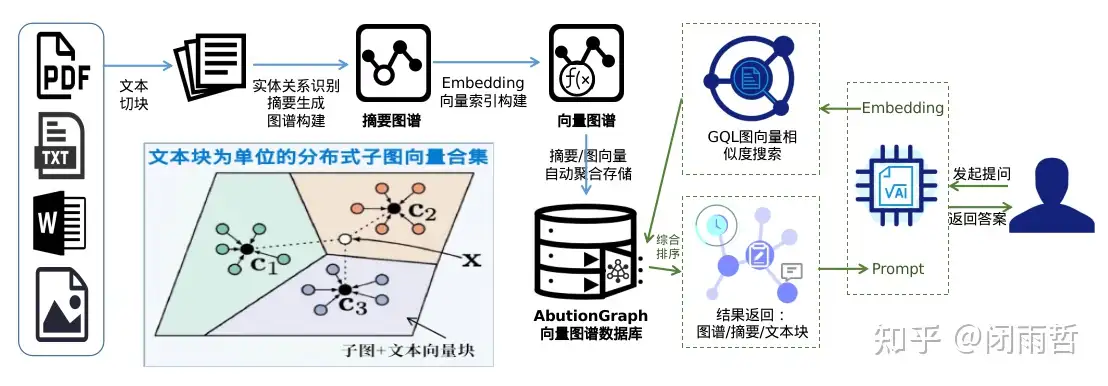
AbutionGraph支持静态图谱、时序图谱、向量图谱3种存储方式,相比于向量数据库+图谱数据库的HybridRAG实现方式,我们只需采用AbutionGraph的向量图谱存储方式即可达到HybridRAG的效果,是一种更优化/落地难度/成本更低的选择。实现上,我们可以像增加一个字段的方式轻松保存向量,运用时序图谱的特性,向量会自动完成合并并更新保存。根据向量保存在实体中的层级不同,可以实现例如图谱级、文档级、文本块级、实体级的向量存储,通常,我们使用文档级别即可实现简单高效(分布式)的存用。此外,根据构建图谱中层级的不同,同样可以生成不同粒度的摘要描述,运用流式时序图谱的特性,摘要可以自动合并,或使用轻量级LLM作为聚合函数自动完成摘要更新,时刻保持高质量的图谱信息。特别的,摘要(有文档摘要、文本块摘要、实体和关系的描述)是向量检索中非常重要的数据,我们将摘要向量化后存到向量索引中,实现图谱摘要的模糊检索,在提问时即可一步获取摘要同时得到关联图谱。AbutionGraph具有数据直接Json化的能力,检索输出对接到Prompt即可供大语言模型使用,Pipeline一栈式的构建个性化GraphRAG应用。
HybridRAG(采用:向量图谱数据库)
(向量图谱数据库一体化的HybridRAG方案图)
优势:
- 继承Vector+Graph RAG的优势:能力更集中的向Graph靠拢,丰富知识库能力。
- 架构简洁:一个数据库支撑住一个系统,图谱化的过程也很简洁,把更多精力放在业务优化上。
- 速度提升:图谱简洁-构建快速,整个过程全倚仗大模型的生成速度。
- 查询简单:得益于向量和图谱的绑定,且是RDF+属性图的架构,相比于微软开源的GraphRAG,整个图谱变得很精炼,问答检索的GQL仅需要一条固定不变查询语句即可完成。
- 信息准确:通过图向量的检索方法,一体化的HybridRAG能够提供准确的信息,确保生成的响应基于可靠的相关联的数据。
- 实现定制:可针对不同的业务场景调整/优化数据的存取和快速/便捷的获取,例如结合结构化数据、算法指标数据(出度入读等)、时序数据(年月日维度)等设计分析型业务。
- 知识融合:不同标签的相同实体通过AbutionGraph的预聚合能力可以实现新增属性、摘要、向量的自定义融合;
- 全局问答:通过顶级节点的摘要信息可以快速得到全局性的答案,此外,我们在图谱中内置了出入读的实时计算,可以更方便的去做Leiden社区划分;再有,我们有了摘要聚合的信息,也可以通过节点及其关系的聚合摘要来计算相似度来得出文本相关的社区,这会是一种更简便快速的方法;最后,通过AbutionGraph的技术特性,我们可以优化定制出更多针对特定场景的方案。
挑战:
- LLM工具化/函数化:随着轻量级/嵌入式LLM性能的提升,我们可以把其能力当作AbutionGraph数据库的一个聚合函数来使用,让动态知识图谱认知能力更强。
- 实体消歧:我们将{实体名称,实体描述}向量化,并采用AbutionGraph的流式聚合能力实时更新实体名称对应TopN个相似名称的字典,采用时序监控能力实时/定时监控大于1个相似名称的values,最后采用LLM重新标准化实体名,并更新图谱的关联关系。
AbutionGraph-时序/向量/图谱数据库的一体化GraphRAG实现方案介绍,利用图向量&向量图谱存储,可以轻松地保存向量和摘要并自动完成合并更新,实现一键相似度检索知识库,简化HybridRAG(VectorRAG+GraphRAG)的实现,使其构建知识库更加高效简便和降低LLM行业垂直应用落地门槛
三种主流技术方案的实现对比
| 方法 | 介绍 | 优势 | 问题 | 图解 |
|---|---|---|---|---|
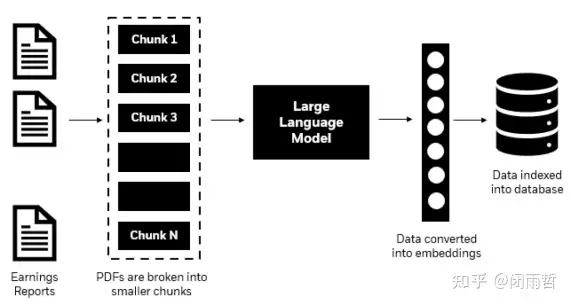
VectorRAG |
利用向量数据库来存储文本的Embedding形式数据来支持生成任务,通过检索与输入查询相关的文本信息来改进NLP任务,特别是在需要生成有意义和连贯响应的情况下。 |
确保 LLM 生成的响应与原始输入查询保持一致性和相关性 | 1. 使用段落级分块技术,不适合文档的层次结构性质,可能导致关键上下文信息的丢失。 2. 从大型异构语料库中检索的上下文质量可能不一致,可能导致分析的不准确和不完整 |
 |
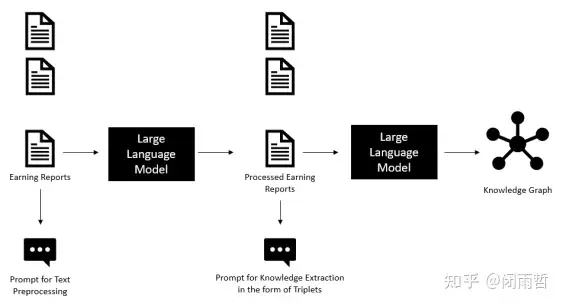
GraphRAG |
GraphRAG 将文本转化为实体及其关系的三元组集合,再利用图谱数据库将三元组集合存储, 实现与输入相关元素的查询检索,是一种将非结构化数据结构化的方法。 |
知识图谱提供了一种结构化方式来表示和管理知识,有助于高效的查询和推理,已经在多个领域得到广泛应用 | 1. 构建和维护一个高质量知识图谱,并将不同来源的数据集成到一个连贯的知识图谱中是一个复杂且技术门槛较高的过程。 2. 通常在抽象的Q&A任务或提问中没有提到明确的实体时表现不佳 |
 |
HybridRAG |
结合VectorRAG和GraphRAG的特点, 向量数据库+图谱数据库 |
|
||
HybridRAG |
结合VectorRAG和GraphRAG的特点, 向量图谱数据库 |
将 AbutionGraph 时序向量图谱数据库的 HybridRAG 实现方案与3种主流RAG技术方案进行了功能融合和对比,用于介绍该种创新的一体化RAG技术实现方式:
- 1)VectorRAG:
- 优势:保持生成响应与输入查询的一致性和相关性。
- 问题:可能丢失关键上下文信息;检索上下文质量不一致。
- 2)GraphRAG:
- 优势:利用知识图谱进行高效的查询和推理。
- 问题:构建和维护高质量知识图谱复杂;在抽象Q&A任务中表现不佳。
- 3)HybridRAG:
- 优势:结合VectorRAG和GraphRAG,提供全面解决方案;信息准确性和流畅性;上下文理解。
- 问题:系统架构复杂,定制化开发成本高。
- 4)基于AbutionGraph数据库的HybridRAG实现方案:
AbutionGraph数据库通过向量图谱存储方式,继承了Vector+Graph RAG的优势,简化了HybridRAG的实现,提供了一种构建存储和查询检索更优化、成本效益更高的选择。它支持静态图谱、时序图谱和向量图谱的存储,适用于需要高时效性和生成高质量响应的场景或通常一种数据库无法轻易完成的交叉性场景。
【2024-9-10】MemoRAG
RAG 的一个根本挑战: 处理复杂、模糊查询和非结构化知识。
- 传统 RAG 非常适合提供明确信息的简单问答任务,但在面对更细微的场景时就会失败。
突破性框架 MemoRAG 通过集成长期记忆功能将 RAG 推向新领域,实现更深入的上下文理解和更准确的信息检索。
【2024-9-10】北京智源人工智能研究院 BAAI 与中国人民大学 RUC 高瓴人工智能学院联合推出基于长期记忆的下一代检索增强大模型框架MemoRAG,推动RAG技术从仅能处理简单QA任务向应对复杂一般性任务拓展。
MemoRAG 提出全新的 RAG模式:
- “基于记忆的线索生成——基于线索指引的信息获取——基于检索片段的内容生成”
- 实现了复杂场景条件下(尤其是“模糊查询表述”、“高度非结构化知识”) 的精准信息获取。

MemoRAG 是一个基于内存的 RAG 创新性框架,通过高效、超长内存模型支持各种应用场景。
- 与传统 RAG 不同,
MemoRAG利用记忆模型来实现对整个数据集的全局理解记忆,通过从记忆中生成查询特定线索来增强证据检索,还会从数据集的“记忆”中提取信息,从而生成更准确和上下文丰富的答案。
MemoRAG 社区开发非常活跃,此存储库中自9月4日不断发布资源和原型。
MemoRAG 改变游戏规则
MemoRAG 在传统 RAG 系统难以解决的领域表现出色,特别是处理:
- 模糊查询:即使查询是隐式的或不完整的,MemoRAG 的记忆系统也可以推断用户意图。
- 分布式信息检索:需要从数据集的多个部分收集信息的任务可以通过 MemoRAG 从记忆中回忆线索并获取相关详细信息的能力轻松处理。
- 复杂摘要:MemoRAG 可以通过生成关键点和检索支持证据将大型非结构化数据集浓缩为连贯的摘要。
实际应用
MemoRAG 在需要复杂信息检索和高级理解的领域特别有效,例如:
- 法律文件分析:详细背景和精确度至关重要。
- 财务数据汇总:从大量数据中提取关键趋势至关重要。
- 对话式应用:MemoRAG 能够记忆并回顾之前的交流,这使其成为长期对话式 AI 应用的强大工具。
MemoRAG 对于司法、医疗、教育、代码等现实场景中的领域知识密集型任务的处理展示出了极高潜力。
MemoRAG 工作原理
MemoRAG 是双模型系统架构,采用两种不同的模型:
记忆模型:轻量级、远程语言模型创建了数据集的全局记忆。它充当知识库,在非常长的上下文(100万个token)中压缩和保留关键信息。该模型生成线索或部分答案,指导相关信息的检索。检索-生成模型:一个更强大、更具表现力的语言模型,它根据记忆模型生成的线索,从数据库中检索必要的证据,并生成最终的高质量答案。
这种双模型系统架构确保 MemoRAG 能够处理需要多跳推理或具有隐含信息需求的任务。通过从记忆中回忆线索并检索相关数据,MemoRAG 弥补了原始输入与有意义且符合语境的准确响应之间的差距。
MemoRAG 主要特点
主要特点
- 全局记忆:单个上下文能够处理多达100万个token,确保对大型数据集的更全面理解;
- 上下文线索:记忆模型从全局记忆中生成精确的线索,将原始输入连接到答案,解锁复杂数据中的隐藏语义信息;
- 高效缓存:通过支持缓存分块索引和编码,将上下文预填充速度提高多达30倍;
- 上下文重用:对长上下文进行一次编码,并支持重复使用;
- 可优化和灵活:只需几个小时的额外训练就可以轻松适应新任务,以优化性能;
- 多功能集成:适用于广泛的模型和应用,适合需要高效理解上下文的行业,例如:金融、法律和医疗保健。
【2025-8-27】Youtu-GraphRAG
【2025-8-27】Youtu-GraphRAG 是图谱检索增强推理智能体的未来
为什么使用 Youtu-GraphRAG?
- 多跳推理 / 总结 / 归纳:适用于需要多步推理的复杂问题场景。•知识密集型任务: 处理依赖大量结构化 / 私有 / 领域知识的问题时,效果尤为突出。
- 领域可扩展性: 只需对图谱模式(schema)做极少干预,就能轻松支持百科全书、学术论文、商业/私有知识库等多种领域。

Deep GraphRAG
【2026-1-19】蚂蚁集团和浙江大学的研究人员开发 Deep GraphRAG,结合分层全局到局部检索策略和动态加权强化学习方法(DW-GRPO)的框架,增强大型语言模型在复杂知识图谱推理方面的性能。
起因
RAG 难以处理需要理解知识内部结构关系的复杂推理, GraphRAG 利用知识图谱来提供更丰富的上下文理解
当前 GraphRAG 方法根本性限制:
- 图遍历中的探索-利用权衡
- 如何有效整合检索到的知识
Deep GraphRAG 引入分层检索策略,结合自适应强化学习方法进行知识整合,使得小型模型能够实现与大型模型相当的性能,同时显著降低计算成本
要点
(1)分层图构建
Deep GraphRAG 从文本语料库构建多级分层知识图谱开始。关键步骤:
- 文本处理和实体提取:系统使用滑动窗口方法(600个token,重叠100个token)对输入文本进行分段,并使用 Qwen2.5-72B-Instruct 提取实体和关系。至关重要的是,系统为每个关系边缘生成自然语言描述,捕捉超出简单三元组表示的语义细微差别。
- 实体解析和层级构建:混合方法结合了 BGE-M3 嵌入的余弦相似度(阈值 > 0.95)与基于 LLM 的确认来合并重复实体。然后,系统使用加权 Louvain 算法构建三级社区层级,其中分辨率参数 γ=1.0,从单个实体创建抽象社区摘要。
- 上下文感知表示:每个节点和社区都接收包含局部描述和父社区上下文的表示,从而在检索过程中实现多粒度理解。
(2) 分层检索策略
核心创新:四阶段的全局到局部检索过程,由束搜索(束宽度 k=3)引导:
- 顶层社区过滤:系统使用查询与社区表示之间的余弦相似度对顶层社区进行评分,选择最相关的高级区域。
- 中层细化:选定的社区扩展到子社区,束搜索通过实体交互分析优先考虑与查询最相关的社区。
- 实体级搜索:最相关的子社区进一步扩展到组成实体,通过细粒度评分选择前 m 个实体。
- 知识整合:检索到的分层知识传递给整合模块进行最终处理。
这种方法有效地平衡了全局探索和局部利用,解决了限制现有 GraphRAG 系统的根本性权衡。
(3)动态加权奖励 GRPO (DW-GRPO)
对于知识整合,Deep GraphRAG 引入 DW-GRPO,自适应强化学习方法,用于训练紧凑型 LLM 以有效提炼检索到的知识。系统优化了三个目标:
- 多目标奖励:该框架定义了三个奖励组件:相关性、忠实性、简洁性
- 自适应权重机制:DW-GRPO解决了优化奖励会以牺牲其他奖励为代价的“跷跷板效应”。其关键创新在于用动态的、策略感知的权重取代静态奖励权重
效果
该系统在问答数据集上取得了新的最先进成果,特别是在HotpotQA上实现了56.25%的EM-GQ,并使一个1.5B参数的LLM能够达到72B模型94%以上的性能,同时将检索延迟降低了80%以上
(1)复杂推理上的卓越性能
Deep GraphRAG 在与72B参数的LLM集成后,在Natural Questions (44.69% EM-Total) 和 HotpotQA (45.44% EM-Total) 上均取得了新的sota成果。
优势尤其体现在需要多跳推理的全局问题(Global Questions)上,在HotpotQA上实现了56.25%的EM-GQ,而局部搜索(Local Search)为10.00%,DRIFT搜索为38.75%。
(2)效率和可扩展性提升
该框架展示了显著的效率提升,与DRIFT搜索相比,局部问题(Local Questions)的延迟降低了86%,全局问题(Global Questions)降低了81.6%。这一性能提升源于分层剪枝策略,该策略系统地减少搜索空间,同时保持准确性。
(3)紧凑模型
经过DW-GRPO训练的Qwen2.5 1.5B模型在Natural Questions上达到了72B模型性能的94%以上(42.36% EM-Total)。这种显著的效率提升表明了通过大幅降低计算需求来普及高性能RAG系统的潜力。
DW-GRPO在防止跷跷板效应方面的有效性。当标准GRPO迅速最大化易于实现的简洁性奖励而其他指标停滞不前时,DW-GRPO通过其自适应加权机制在所有三个目标上保持了持续改进。
RAG 提效
rag新方法
REFRAG
【2025-9-13】Meta REFRAG框架详解,实现30倍加速与16倍上下文扩展(Context Engineering)
REFRAG框架,通过智能压缩上下文解决大模型处理长文本的效率问题。该技术将文档分块处理,选择性保留关键内容,实现30.85倍首token生成加速和16倍上下文处理长度扩展。适用于RAG、多轮对话等场景,在保证性能的同时显著降低计算成本。
注:代码尚未开源
Most RAG systems waste your money. They retrieve 100 chunks when you only need 10. They force the LLM to process thousands of irrelevant tokens. You pay for compute you don’t need.
表现
- 长上下文导致了更高内存成本,模型的首 token 生成时间(TTFT)会随之呈二次方增加。
- 冗余计算严重:RAG 与 Agent 的上下文一般是多个检索段落的组合,段落间的关联几乎为零。但大模型的注意力机制会对所有token 间的关联做计算,导致了大量冗余计算。
在此背景下,Meta团队提出了REFRAG 框架,在仅保留核心内容的原始token情况下,对RAG提供的低相关chunk内容做智能压缩,从而在不损失性能的前提下,实现 30.85 倍 TTFT 加速、将 LLMs 上下文处理长度扩展 16 倍。
经过实测,该方案在 RAG、多轮对话、智能体及 Web 级检索等 高吞吐量、低延迟场景中表现尤为突出 。
META built REFRAG, a new RAG approach that compresses and filters context before it hits the LLM. The results are insane:
- 30.85x faster time-to-first-token
- 16x larger context windows
- 2-4x fewer tokens processed
- Outperforms LLaMA on 16 RAG benchmarks
Here’s what makes REFRAG different:
Traditional RAG dumps everything into the LLM. Every chunk. Every token. Even the irrelevant stuff.
REFRAG works at the embedding level instead:
↳ It compresses each chunk into a single embedding
↳ An RL-trained policy scores each chunk for relevance
↳ Only the best chunks get expanded and sent to the LLM
↳ The rest stay compressed or get filtered out entirely
The LLM only processes what matters.
The workflow is straightforward:
- Encode your docs and store them in a vector database
- When a query arrives, retrieve relevant chunks as usual
- The RL policy evaluates compressed embeddings and picks the best ones
- Selected chunks are expanded into full token embeddings
- Rejected chunks stay as single compressed vectors
- Everything goes to the LLM together This means you can process 16x more context at 30x the speed with zero accuracy loss. I have shared link to the paper in the next tweet! https://arxiv.org/abs/2509.01092a
RAG 自动化
AutoRAG
【2024-10-29】 markr 推出 AutoRAG
- 论文 AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline
- AutoRAG_ARAGOG_Paper
AutoRAG是一个自动化框架,通过系统评估不同的RAG设置来优化技术选择
- 该框架类似于传统机器学习中的
AutoML实践,通过广泛实验来优化RAG技术的选择;
AutoRAG 通过模块化节点和定义策略来动态选择最有前途的节点,构建接近最优的pipeline,提高RAG系统的效率和可扩展性。
Query Expansion->Retrieval->Passage Augmenter->Passage Reranker->Prompt Maker->Generator(LLM)- 评估指标: 前4个阶段用 检索指标 Retrieval Metrics, 后两个阶段用 生成指标 Generation Metrics
用到的RAG组件
- 查询扩展(Query Expansion): 改善检索性能,通过扩展用户查询来创建更好的搜索查询。
- Query Decompose使用LLM将多个问题分解为单个问题;
- HyDE(Hypothetical Document Embedding)利用LLM生成假设性段落,提高与实际相关段落的语义相似度。
- 段落增强(Passage Augmenter): 通过获取额外的相关段落来增强检索性能。可以使用Prev-Next Passage Augmenter,利用相邻段落的元数据进行二次搜索,以找到与初始检索集上下文相关的更多段落。
- 段落重排(Passage Reranker): 初始检索阶段后,对段落进行重新排序以提高检索的准确性。
- LM-based Reranker 使用微调的语言模型对查询-段落对的相关性进行评分;
- LLM-based Reranker 利用LLM通过提示工程来重新排序段落;
- Embedding-based Reranker 使用密集向量表示来捕捉查询和文档之间的语义相似性;
- Log prob-based Reranker 基于从给定段落生成查询的对数概率来评估相关性。
- 提示创建(Prompt Maker): 将检索到的段落包含在提供给LLM的提示中,以实现上下文学习。其中可以使用的是,
- f-string将用户查询、检索到的段落和指令连接起来;
- long context reorder:解决“迷失在中间”现象,确保最相关的段落同时出现在输入提示的开始和结束部分。
新范式
GAG
【2026-1-15】GAG:超越RAG,无需检索的私有知识注入新范式
生物医药、材料、金融等高价值私有场景,大模型必须掌握专有、快速演化、公开语料严重不足的知识。
当前主流的两种私有知识注入范式均存在显著缺陷:
- 微调法迭代成本高昂,且持续更新过程中易引发灾难性遗忘与通用能力退化;
- 检索增强生成(RAG)法则可保持基础模型的完整性,但在专业私有语料中表现脆弱,具体问题包括:
- 分块导致的证据碎片化、检索漂移,以及长上下文压力引发的查询相关型提示词膨胀。
| 路线 | 硬伤 |
|---|---|
| 继续微调 | 迭代贵、灾难性遗忘、通用能力下滑 |
| RAG | 切片导致证据碎片化、检索漂移、长文本压力、Prompt长度不可控 |
中科院和360AI 联合团队,把私有知识看成一种新模态,借鉴多模态LLM的“对齐-融合”思路,提出无需检索、固定底座、单Token、即插即用的第三代方案——GAG。
受多模态大语言模型将异构模态对齐至共享语义空间思路的启发,提出生成增强生成(GAG)方法。
- 将私有专业知识视为一种额外专家模态,通过一个与冻结的基础模型对齐的轻量化表征级接口完成知识注入,既规避了提示词阶段的证据序列化操作,又实现了即插即用的专业化部署,同时支持具备可靠选择性激活能力的可扩展多领域融合。
用户提问
↓
PPR路由器(无训练)
↓
通用路由 ──→ frozen LLMbase
↓
领域路由 ──→ LLMdomainᵢ → 投影器 Πᵢ → 1-Token注入 → LLMbase

两项私有科学问答基准任务(免疫学佐剂、催化材料)及混合领域评估中,GAG 方法相较于性能强劲的 RAG 基线模型,在上述两项基准任务中分别实现了 15.34% 和 14.86% 的专业性能提升;与此同时,该方法在六项通用公开基准任务上的性能保持稳定,且能够实现类预言机级别的选择性激活,为可扩展的多领域部署提供支撑
核心思想
- “把专家知识压缩成1个连续向量,直接插进frozen LLM的Embedding空间。”
特点
- 零检索:告别倒排、向量库、Top-K拼接
- 零底座更新:Qwen3-8B权重全程冻住,治理友好
- 恒定预算:无论私有语料多庞大,推理时只增加1个Token
- 模块化:新领域来了,只需挂一个小专家+投影器,老模块不动
GAG把“私有知识”从文本证据升维到专家表征,用1个连续Token完成恒定预算、零检索、零底座改动的知识注入,为企业级多域专属大模型提供了治理友好、可热插拔的新范式。
应用
阿里 RAG
【2025-4-11】《RAG 技术演进的四大核心命题》
阿里 用 RAG 优化客服和内部助手,解决大模型瞎说(幻觉)和知识老旧的问题。
四大核心挑战和对应的解法,这些问题比较有共性:
| 挑战内容 | 痛点 | 解法 |
|---|---|---|
| 数据质量与关系挖掘 | 知识库来源杂(文档、语雀、笔记),质量差,模型“垃圾进垃圾出”;仅靠文本无法理解知识点关联 | 构建知识图谱 (Graph),串联零散信息及其关系,助模型深度理解 |
| 复杂问题的精准检索 | 简单文本/向量相似度不足,很多问题需多来源、多步推理才能解答,异构数据检索困难 | 采用智能检索,大模型先理解拆解复杂问题并改写,运用混合检索(文本+向量+图谱)提升召回率和精度,支持迭代式检索 |
| 抑制幻觉,提升生成可信度 | 即便检索到相关信息,大模型仍可能瞎编、忽略关键信息或无法有效利用检索内容 | 通过RAR (Retrieval-Augmented Relevance) ,用另一模型判断检索内容有效性后再喂给生成模型,减少幻觉 |
| 精细化评估与问题定位 | 传统指标(如准确率)过于粗略,无法明确问题出在检索、使用信息等哪个环节 | 自建RAG Diagnoser评估体系,将模型回答拆解成“原子事实”,对比标准答案,精准定位检索、改写、生成环节的问题 |
阿里这套思路就是系统性地从数据、检索、生成控制、评估这四个核心方面死磕 RAG 的效果和可靠性,干货挺多的,希望能给你点启发!
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
