- 全模态大模型
- 背景
- Omni 系列模型部署
- 案例
- 【2024-3-11】Google Gemini 1.5 Pro
- 阿里云
- 【2024-9-10】LLaMA-Omni
- 阿里 Omni
- 哈工大
- 【2025-6-11】蚂蚁 Ming-Omni
- 【2025-6-16】中科院 Stream-Omni
- 【2025-8-4】字节 VeOmni 框架
- 【2025-10-27】NVIDIA OmniVinci
- 【2025-11-03】LongCat-Flash-Omni
- 【2026-2-4】MiniCPM-o 4.5
- 【2026-3-4】OPPO
- 【2026-6-22】京东 JoyAI-VL-Interaction
- 【2026-6-28】VLX系列 流式多模态→具身导航
- 结束
全模态大模型
多模态大模型专题见站内:多模态大模型案例
背景
现有技术
- 传统语音理解大模型的人机交互场景里,一般用 ASR(Automatic Speech Recognition,自动语音识别)把语音转文本,随后交给大语言模型处理,最终借助 TTS(Text-to-Speech,语音合成)转语音反馈给用户。
- 而视频理解模型是基于图片、视频进行大模型理解,并以文字形式输出反馈。
这两种模型均属于相互独立的单链路模型。
近两年,Omni 模型逐渐成为多模态大模型的重要方向。
Omni 模型理解为:一个模型同时具备 文本、图像、音频、视频的理解能力,并且能够以 文本或自然语音 的形式实时回应用户。
相比传统的 ASR + LLM + TTS 级联系统,Omni 模型更强调端到端的统一建模和低延迟交互。
闭源模型中
- OpenAI 的 GPT-4o / Realtime 系列可看作实时语音交互方向的代表之一
- Google Gemini 系列也在原生多模态和长上下文理解上持续演进。
开源生态中
- 阿里 Qwen-Omni 系列是目前最值得关注的路线之一:从 Qwen2.5-Omni 到 Qwen3-Omni,再到 Qwen3.5-Omni,Qwen 团队围绕 Thinker–Talker 架构、音频编码器、流式语音生成和 ARIA 对齐机制 持续迭代,形成了一条非常清晰的技术演进路线。
Omni 系列模型部署
【2026-12-2】vLLM-Omni 上线:多模态推理更简单、更快、更省
vllm 发布 vLLM-Omni:向“全模态(omni-modality)”时代迈出,专为新一代看得见、听得懂、会说话、能生成多种媒介的模型设计的推理框架。
传统推理引擎大多为纯文本自回归(Autoregressive, AR)任务优化。随着模型进化为可以“看、听、说”的全能代理(omni agents),底层推理系统也不得不同时面对:
- 真·全模态:一条请求里既有文本,又有图片、音频甚至视频,输出形式也不再单一。
- 超越自回归:扩散 Transformer(Diffusion Transformer, DiT)等 并行生成模型 需要不同于 LLM 的调度和内存管理策略。
- 异构推理流水线:一次调用往往会经过“多模态编码 → LLM 推理 → 扩散生成”等多个异构组件,资源分配和调度更像一条复杂的作业流水线,而不是单一模型调用。
vLLM-Omni 是最早一批支持“omni-modality”模型推理的开源框架之一,它把 vLLM 在文本推理上的性能优势,扩展到了多模态和非自回归推理领域。 【2026-3-12】vllm-omni

omni-modality 推理请求经过三类组件:
- 模态编码器(Modality Encoders):负责高效地把多模态输入编码成向量或中间表示,例如 ViT 视觉编码器、Whisper 等语音编码器。
- LLM 核心(LLM Core):基于 vLLM 的自回归文本/隐藏状态生成部分,可以是一个或多个语言模型,用于思考、规划和多轮对话。
- 模态生成器(Modality Generators):用于生成图片、音频或视频的解码头,例如 DiT 等扩散模型。
这些组件并不是简单串联,而是通过 vLLM-Omni 的管线调度在不同 GPU/节点间协同工作。
vLLM-Omni 与 Hugging Face Transformers 对比基准测试。有限预算下支撑高并发、长会话的推理服务,会直接体现在 GPU 利用率和成本曲线上。
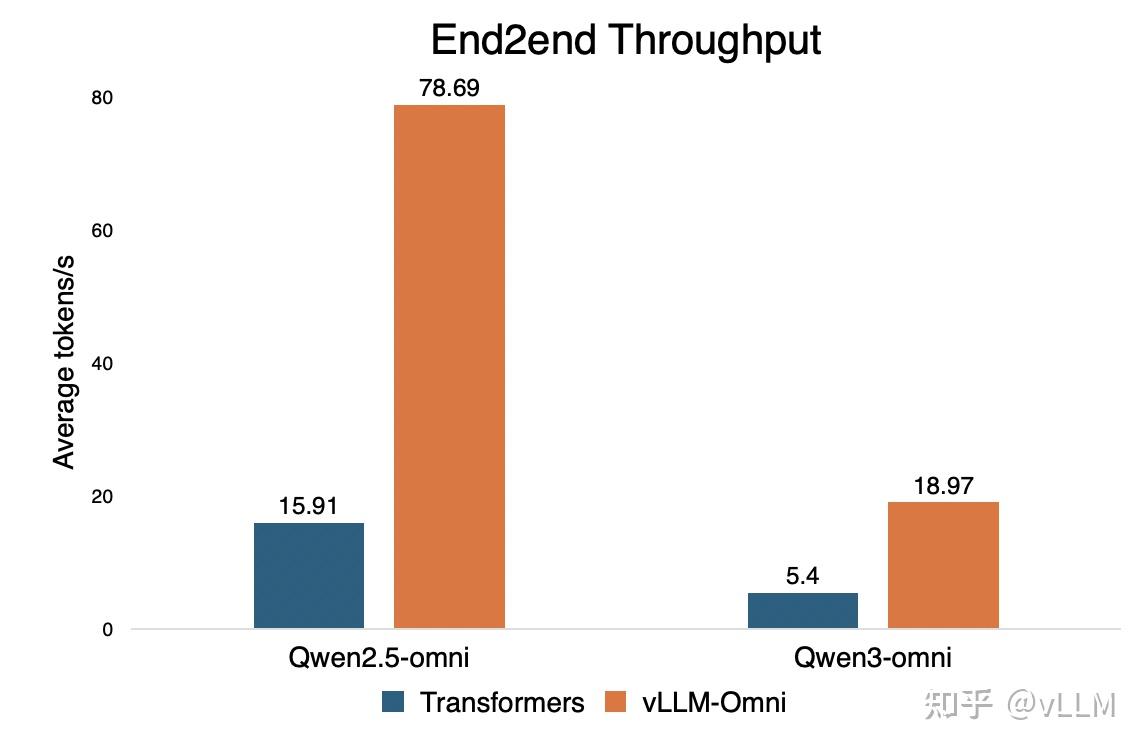
案例
【2024-3-11】Google Gemini 1.5 Pro
【2024-3-11】 Google Gemini 团队开发多模态混合专家模型Gemini 1.5 Pro,标志着人工智能领域的一次重大进步。
注意
MoE 架构下多模态理解能力,不含音频生成
该模型能够回忆和推理数百万个令牌(tokens)的上下文中的细粒度信息,包括多个长文档、数小时的视频和音频内容。它在跨模态的长上下文检索任务中实现了接近完美的召回率,在长文档问答、长视频问答和长上下文自动语音识别(ASR)等方面提高了现有的最佳性能,达到或超越了 Gemini 1.0 Ultra 在广泛基准测试中的领先性能。
技术细节
- 稀疏激活: 通过学习路由功能,MoE模型只激活(即使用)对于给定输入最相关的一部分参数,从而在大规模模型中保持高效计算。
- 参数规模: Gemini 1.5 Pro 的总参数数量极大,达到了多亿至数十亿的规模,但由于其稀疏激活特性,每次前向传播过程中只有一小部分参数被激活,这使得模型即便在参数规模巨大的情况下仍保持高效运行。
- 多模态输入处理: 该模型能够处理来自不同模态(文本、图像、视频和音频)的输入数据,并能够在这些不同类型的数据之间建立联系,进行综合理解和推理。
能力:
- 长上下文处理能力: Gemini 1.5 Pro 能够处理高达至少1000万个令牌的极长上下文,这是现有大型语言模型所不具备的。这使得模型可以处理整个文档集合、多小时的视频和近五天长的音频。
- 跨模态理解: 该模型不仅能处理文本,还能理解和处理视频与音频信息,实现跨模态的信息融合和推理。
- 近乎完美的信息检索: 在各种模态上,Gemini 1.5 Pro 都能实现超过99%的信息检索召回率,即使是在包含1000万令牌的海量信息中也能准确找到所需数据。
- 学习新语言的能力: 给定语法手册,Gemini 1.5 Pro 能够学习翻译拥有不到200名说话者的罕见语言,表现出与通过同样材料学习的人类相似的翻译能力。
- 优化的模型架构: Gemini 1.5 Pro 采用稀疏混合专家(MoE)的 Transformer 基础模型,实现了在大幅降低训练计算资源需求的同时,保持或超越前代模型的性能。
- 自适应学习和推理: 模型能够基于输入数据的特性动态调整其内部路由和激活的“专家”网络,从而针对不同的任务和数据类型自适应地优化其性能。Gemini 1.5 Pro 在保持高性能的同时,显著降低了资源消耗
阿里云
【2025-8-29】阿里云(小云)实时交互形态
- AI电话通话:电话呼出、电话呼入
- 电话呼出: 填入自己的号码, 默认选择智能打断、多种音色可选
- 电话呼入: 拨打号码 02566040232 即可
- 智能体通话:消息对话、语音通话、视觉理解通话、数字人通话、视频通话
体验
【2024-9-10】LLaMA-Omni
【2024-9-10】中国科学院大学的研究人员推出了LLaMA-Omni,这是一种创新的模型架构,旨在克服实现与大型语言模型进行低延迟、高质量语音交互的挑战,该模型集成了语音编码器、语音适配器、LLM和流式语音解码器,可以直接处理语音输入并同时生成文本和语音响应,显著减少了响应延迟。
LLaMA-Omni 的架构由四个主要组件组成:语音编码器、语音适配器、LLM 和语音解码器。
- 语音编码器基于 Whisper-large-v3,从用户的语音输入中提取有意义的表示。
- 然后,这些表示由语音适配器进行处理,该适配器通过下采样和两层感知器将它们映射到 LLM 的嵌入空间。
- LLM 基于 Llama-3.1-8B-Instruct,直接从语音指令生成文本响应。语音解码器是一种非自回归流式 Transformer,它接收 LLM 的输出隐藏状态,并使用连接主义时间分类 (CTC) 来预测与语音响应相对应的离散单元。
阿里 Omni
Qwen-Omni 大致经历三代演进。
- 2025 年 3 月,Qwen 团队发布
Qwen2.5-Omni,开源,Qwen 系列第一代真正意义上的端到端全模态模型。- 可以统一处理文本、图像、音频和视频输入,并以流式方式生成文本与自然语音输出。
- Qwen2.5-Omni 同时提出 Thinker–Talker 架构,把“理解与推理”和“语音生成”拆成两个相对独立的子系统。
- 该版本提供了 Qwen2.5-Omni-7B 开源权重,后续又发布了 3B 版本以及量化版本。
- 2025 年 9 月,Qwen3-Omni 发布,开源。
- 相比 2.5 版本,它进一步走向原生端到端全模态,采用 30B-A3B 的 MoE 架构,并推出 Instruct、Thinking、Captioner 等多个版本。
- Qwen3-Omni 可以处理文本、图像、音频和视频,并实时输出文本和自然语音。Qwen3-Omni-30B-A3B、Thinking 和 Captioner 模型均以 Apache 2.0 协议公开发布。
- 2026 年 4 月,Qwen3.5-Omni 技术报告发布,闭源。
- 该版本进一步扩大到数千亿参数规模,支持 256k 上下文,并面向长音频、长视频和实时语音交互做了系统升级。语音侧最值得关注的是 ARIA:它将 Qwen3-Omni 中的双轨语音生成范式改为单流交错生成,用自适应速率约束缓解文本 token 与语音 token 速率不匹配带来的漏词、错读和数字表达歧义等问题。需要注意的是,Qwen3.5-Omni 论文中写的是通过 API 公开访问,并未像 Qwen3-Omni 那样明确宣布开放模型权重。
Qwen-Omni 系列半年左右更新的迭代节奏:
- 2025 年 3 月发布 Qwen2.5-Omni
- 2025 年 9 月发布 Qwen3-Omni
- 2026 年 4 月发布 Qwen3.5-Omni。
下一代 Omni 模型或许会在 2026 年 10 月前后出现,但这只是基于以往发布时间的推测。
【2025-3-27】阿里 Qwen2.5-Omni
【2025-3-27】阿里巴巴发布 Qwen2.5-Omni,全球首个端到端全模态大模型,为多模态信息流实时交互提供了新技术框架。
Qwen2.5-Omni 整合了文本、图像、音频和视频的跨模态理解能力,实现流式文本与自然语音的双向同步生成。
Qwen2.5-Omni 在保持全能的同时,并没有牺牲在各个垂直领域的能力
资料:
- 体验 Qwen Chat 新功能
- Qwen2.5-Omni技术报告
- 代码 Code: Qwen2.5-Omni
- 中文介绍: Qwen2.5-Omni
- 视频介绍: Video
Qwen2.5-Omni 和 VL 区别
- 🔸Qwen2.5-Omni:能听懂、看懂、读懂你,还能实时语音回应你的全能选手
- 🔸Qwen2.5-VL:专注于图像解析、内容识别、视觉逻辑推导的视觉语言专家
特点
特点
- Omni 和 架构:Thinker-Talker 架构,端到端的多模态模型,感知不同的模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。提出了一种名为
TMRoPE(Time-aligned Multimodal RoPE) 的新型位置嵌入,以将视频输入的时间戳与音频同步。 - 实时语音和视频聊天 :专为完全实时交互而设计的架构,支持分块输入和即时输出。
- 自然而稳健的语音生成 :超越许多现有的流媒体和非流媒体替代方案,在语音生成方面表现出卓越的稳健性和自然性。
- 跨模态的强劲性能 :与类似大小的单模态模型进行基准测试时,在所有模态中都表现出卓越的性能。
- Qwen2.5-Omni 在音频功能上优于同等尺寸的 Qwen2-Audio,并实现了与 Qwen2.5-VL-7B 相当的性能。
- 出色的端到端语音教学: Qwen2.5-Omni 在端到端语音教学跟踪方面的性能可与文本输入的有效性相媲美,MMLU 和 GSM8K 等基准测试证明了这一点。
Qwen2.5-Omni-7B 特点:原生支持视频、图片、语音、文字等多模态输入,并能原生生成语音及文字等多模态输出。
- 一个模型就能通过“看”、“听”、“阅读”等多种方式来综合思考。
原理
Qwen2.5-Omni 采用 Thinker-Talker 双核架构。
Thinker模块如同大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应文本内容;Talker模块则类似发声器官(嘴),以流式方式接收 Thinker 实时输出的语义表征与文本,流畅合成离散语音单元。
模型架构
- Thinker 基于 Transformer 解码器架构,融合音频/图像编码器进行特征提取;
- Talker 则采用双轨自回归 Transformer 解码器设计,在训练和推理过程中直接接收来自 Thinker 的高维表征,并共享全部历史上下文信息,形成端到端的统一模型架构。
关键技术:
- 1)采用分块处理策略解耦长序列多模态数据,由多模态编码器负责感知、语言模型承担序列建模,通过共享注意力机制强化模态融合;
- 2)提出时间对齐的位置编码方法TMRoPE,通过音视频交错排列实现时间戳同步;
- 3)首创
Thinker-Talker架构,分离文本生成(Thinker语言模型)与语音合成(基于隐藏表征的双轨自回归Talker模型),避免模态间干扰; - 4)引入滑动窗口DiT解码器降低音频流初始延迟。

效果分析:
- Omni-Bench 等多模态基准上达到SOTA,语音指令跟随能力与纯文本输入(MMLU/GSM8K)表现相当,流式语音生成在鲁棒性和自然度上超越主流流式/非流式方案。
评测
- 多模态任务 OmniBench,Qwen2.5-Omni 达到了SOTA的表现。(超过 Gemini 1.5-Pro)
- 单模态任务中,Qwen2.5-Omni 在多个领域中表现优异,包括:语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
「Thinker-Talker」(思考者-说话者) 架构。这个设计非常巧妙,让模型能 同时思考和说话:
Thinker(思考者): 扮演大脑的角色。它负责处理来自文本、音频、视频等多种模态的输入,通过专门的音视频编码器提取信息,再利用一个 Transformer 解码器进行理解和处理,最终生成高层语义表示和相应的文本内容Talker(说话者): 担当嘴巴功能。它以流式(streaming)方式接收 Thinker 生成的高层表示和文本,并采用一种双轨自回归 Transformer 解码器架构,流畅地合成并输出离散的语音单元(tokens)。
关键点: Talker 并非独立工作,直接获取 Thinker 产生的高维表示,并且 共享 Thinker 全部历史上下文信息。这使得 Thinker 和 Talker 构成了一个紧密协作的单一整体模型,可以进行端到端的训练和推理。这种设计是实现低延迟、高流畅度语音交互的核心
Qwen2.5-Omni 模型
Qwen2.5-Omni-7B
Qwen2.5-Omni-7B 模型是 Omni(全能)模型。
- 一个模型能同时理解 文本、音频、图像、视频 多种输入,并且能输出 文本和音频
全模态 Qwen2.5-Omni-7B 模型推出后,开发者反馈更小尺寸的Qwen2.5-Omni,以便更方便地适配
2025年4月30日,开源 Qwen2.5-Omni-3B 版本,较之前 7B 相比,代码运行时的推理时间减少,响应开发者轻量级GPU适配需求的新模型。
- 🔹 与Qwen2.5-Omni-7B相比,3B版本在长上下文序列处理(约25k tokens)中显存消耗减少超50% 🚀,并可在普通24GB的消费级GPU上支持长达30秒的音视频交互 。
- 🔹 3B版本模型保留7B模型90%以上的多模态理解能力 ,语音输出自然度与稳定性与7B版本性能一致 💪🏻。
新的Omni模型已在魔搭社区和HuggingFace上开源
效果
Qwen2.5-Omni全面评估:
- 跨模态能力 SOTA: 在需要整合多种模态信息的任务上(如 OmniBench 基准测试),Qwen2.5-Omni 达到了当前最佳水平(State-of-the-Art)
- 单模态能力不俗: 与同等规模的单模态模型(如 Qwen2.5-VL-7B、Qwen2-Audio)以及一些强大的闭源模型(如 Gemini-1.5-pro)相比,Qwen2.5-Omni 在各项单模态任务上也展现出强大的竞争力。具体包括:
-
- 语音识别:Common Voice
-
- 语音翻译:CoVoST2
-
- 音频理解:MMAU
-
- 图像推理:MMMU, MMStar
-
- 视频理解:MVBench
-
- 语音生成: Seed-tts-eval 及主观自然度评估
-
评测
- 多模态任务 OmniBench,Qwen2.5-Omni 达到了SOTA的表现。(超过 Gemini 1.5-Pro)
- 单模态任务中,Qwen2.5-Omni 在多个领域中表现优异,包括:语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
实践
消费级显卡也能运行 Qwen2.5-Omni 本地部署
- conda 创建虚拟环境,并激活
- 安装第三方库:transformers、accelerate、qwen-omni-utils-decord、modelscope
- 使用 modelscope 下载 qwen-2.5-omni 代码
- 创建 python 脚本,写脚本
问题
Qwen-2.5-Omni-7B 问题——目前还没有更普适的量化版本
- 当前量化版本只有
GPTQ,没有gguf/mlx. 导致大部分使用ollama,llama.cpp,mlx的用户根本没办法用。 - 而原版 7B 大小达到了20GB+,使用小显存显卡的用户完全没办法单卡部署。
而 GPTQ 量化理论上能用在 vLLM/SGLang 上。
但是这俩框架目前也不支持, 为纯本文模型准备的。
【2025-9-21】阿里 Qwen3 Omni
【2025-9-21】Qwen3-Omni 全模态正式登场,当前还看不到太多的相关信息。
仅从代码层面分析来看,相比 Qwen2.5-Omni,Qwen3-Omni 的主要升级点在于采用了MoE 架构,而Qwen2.5-Omni 的 Talker`模块在其标准实现中采用的是dense结构。
主要组成部分
- Thinker 模块:
- 功能:负责理解和处理多模态输入(文本、图像、视频、音频),并生成相应的文本输出。
- 子模块:
- Audio Encoder:将音频信号编码为连续的嵌入向量。
- Vision Encoder:将图像或视频帧编码为视觉嵌入向量。
- Text Model:基于 MoE 架构的文本模型,处理文本和视觉/音频嵌入,并生成文本输出。
- Talker 模块:
- 功能:负责将文本输出转换为语音输出。
- 子模块:
- Code Predictor:预测语音的残差码(residual codes)。
- Text Model:生成语音的文本表示,这个模型是基于 MoE 结构的
- Codec Head:将文本表示转换为语音码。
- Hidden Projection 和 Text Projection:用于将 Thinker 模块的隐藏状态投影到 Talker 模块的维度。
- Code2Wav 模块:
- 功能:将 Talker 模块生成的语音码转换为最终的音频波形。
关键特性
- 多模态支持:能够同时处理文本、图像、视频和音频输入。
- MoE 架构:通过稀疏激活专家网络,提高模型效率和性能。
- MRoPE (Multi-Dimensional Rotary Position Embedding):支持处理不同维度的输入(如时间、高度、宽度),用于视觉和音频任务。
- DeepStack:在视觉编码器中使用 DeepStack 技术,以增强视觉特征的表示能力。
Qwen3-Omni 是原生端到端多语言全模态基础模型。它处理文本、图像、音频和视频,并以文本和自然语音形式提供实时流式响应。我们引入了多项架构升级,以提高性能和效率。
- modelscope 地址 Qwen3-Omni-30B-A3B-Instruct
主要特点:
- 跨模态的最先进技术:早期以文本为主的预训练和混合多模态训练提供了原生多模态支持。在实现强大的音频和音视频结果的同时,单模态文本和图像性能没有退化。在36个音频/视频基准测试中的22个上达到SOTA,在36个中的32个上达到开源SOTA;ASR、音频理解和语音对话性能与Gemini 2.5 Pro相当。
- 多语言:支持119种文本语言,19种语音输入语言和10种语音输出语言。
- 语音输入:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印度尼西亚语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
- 语音输出:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
- 新颖架构:基于MoE的思考者-说话者设计,通过AuT预训练获得强大的通用表示,加上多码本设计,将延迟降至最低。
- 实时音频/视频交互:低延迟流媒体,具有自然的轮流发言和即时文本或语音响应。
- 灵活控制:通过系统提示自定义行为,实现细粒度控制和轻松适应。
- 详细的音频字幕生成器:Qwen3-Omni-30B-A3B-Captioner现已开源:这是一个通用的、高度详细的、低幻觉的音频字幕生成模型,填补了开源社区的一个关键空白。
模型
Qwen3-Omni-30B-A3B-Instruct:Qwen3-Omni-30B-A3B 的指令模型,包含思考者和说话者组件,支持音频、视频和文本输入,输出音频和文本。更多信息请阅读 Qwen3-Omni 技术报告。Qwen3-Omni-30B-A3B-Thinking:Qwen3-Omni-30B-A3B 的思考模型,包含思考者组件,具备链式思维推理能力,支持音频、视频和文本输入,输出文本。更多信息请阅读 Qwen3-Omni 技术报告。Qwen3-Omni-30B-A3B-Captioner:从Qwen3-Omni-30B-A3B-Instruct微调而来的下游音频细粒度字幕模型,为任意音频输入生成详细且低幻觉的字幕。它包含思考者组件,支持音频输入和文本输出。更多信息可以参考该模型的 cookbook。
【2026-3-30】Qwen3.5-Omni
【2026-6-8】Qwen3.5-Omni 语音架构解读:从 Thinker–Talker 到 ARIA
2026年3月30日,发布 Qwen3.5-Omni,原生全模态大模型,支持文本、图片、音频以及音视频的统一理解与生成,并具备处理长达10小时超长音频的突破性能力
Qwen3.5-Omni 延续 Thinker-Talker 架构,均采用 Hybrid-AttentionMoE 升级,长上下文、多语言能力显著提升。
Thinker擅长处理10小时长音频、1小时视频,Talker通过ARIA技术改善语音输出。
MoE架构让各模态专家分工明确,同时保持单模态性能。相比上一代,该模型新增语义打断、音色克隆等功能,对话体验接近真人。
特点
- 真正的“全模态”原生,无缝理解文本、图片、音频及音视频输入,支持细粒度、带时间戳的音视频 Caption 生成;
- 215 项 SOTA 霸榜,在音频及音视频分析、推理、对话、翻译等任务超过 Gemini3.1-Pro;
- 自然涌现的 Audio-Visual Vibe Coding 能力;
- 支持语义打断、音色克隆及语音控制,让对话体验更自然;
- 支持 256K 超长上下文与 113 种语言识别,可处理 10 小时音频或 1 小时视频。
- 原生支持 WebSearch 和复杂 Function Call,不仅能聊天,更能帮你做事。
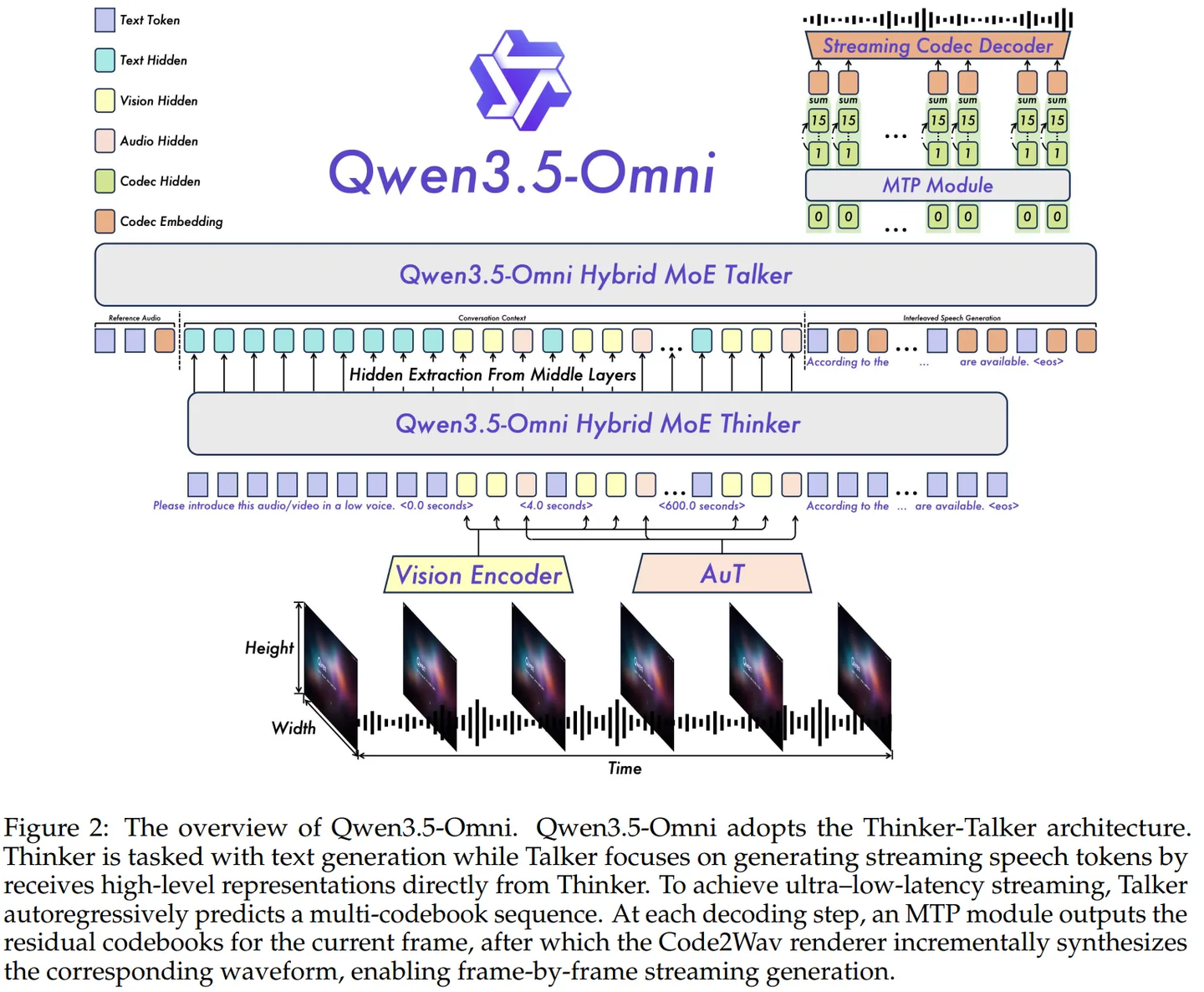
Thinker–Talker 架构:理解和说话解耦
Qwen3.5-Omni 延续了 Qwen2.5-Omni 中的 Thinker–Talker 架构。Thinker 负责“理解和思考”,Talker 负责“把思考结果说出来”。
- Thinker 近似理解为:Qwen3.5 + Vision Encoder + Audio Encoder。其中,Vision Encoder 负责处理图像和视频,Audio Encoder 负责处理音频,最终这些多模态信息会被统一送入以 Qwen3.5 为核心的 Thinker 中,完成 多模态理解、推理、文本生成和工具调用 等任务。
- Talker 语音生成模块。接收来自 Thinker 的高层语义表示,以及历史文本、多模态上下文和当前轮正在流式生成的文本,然后生成语音 token,最终通过 codec decoder 转成波形。相比普通 TTS 系统只根据文本合成语音,Qwen3.5-Omni 的 Talker 可以利用更丰富的上下文信息,从而动态调整语音的 韵律、音量和情绪。
从语音系统角度看,Talker 有点像一个专门的 Codec LM。不是直接输出波形,而是先生成 RVQ codec tokens,再通过流式 Code2Wav 模块还原成语音。
因此,Qwen3.5-Omni 并不是简单地把一个 LLM 和一个 TTS 系统串起来,而是把 多模态理解、文本生成和语音生成 整合进同一个端到端框架中。
哈工大
2023 年研发的「立知」大语言模型基础上(工信部和网信办双认证)
【2025-5-*】Uni-MoE
2024 年 5 月提出原创 Uni-MoE 全模态大模型架构
【2025-11-16】Uni-MoE-2.0-Omni
【2025-11-16】哈工大深圳团队推出Uni-MoE-2.0-Omni:全模态理解、推理及生成新SOTA
哈工大深圳计算与智能研究院 Lychee 大模型团队,在 2023 年研发的「立知」大语言模型基础上(工信部和网信办双认证),基于 2024 年 5 月提出的原创 Uni-MoE 全模态大模型架构,正式发布第二代「立知」全模态大模型 Uni-MoE-2.0-Omni。
- 论文 Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
- 项目地址 Uni-MoE-2.0-Omni
- 代码 Uni-MoE
以大语言模型为核心,通过渐进式模型架构演进与训练策略优化,将稠密大语言模型拓展为混合专家架构驱动的高效全模态大模型,实现从「语言理解」到「多模态理解」,再到「理解与生成兼备」的跨越式升级!团队围绕以语言为核心的通用人工智能,通过引入全模态 3D RoPE 位置编码、设计动态容量 MoE 架构以及全模态生成器等关键技术,有效打破了不同模态之间的壁垒,在维持高效计算性能的同时,实现了对图像、视频、文本与语音的统一理解、推理与生成。
Uni-MoE-2.0-Omni 在图像理解、视频推理、音频理解、语音生成、图像生成与编辑等 85 项基准上取得高度竞争性或领先的表现,在 76 项可对比评测中,Uni-MoE-2.0-Omni(75B Tokens)超越 Qwen2.5-Omni(1.2T Tokens)逾 50 项任务,不仅在视频理解和全模态交互上取得显著突破,更在长语音生成、多模态语音交互和可控图像生成与编辑方面树立了新标杆。
【2025-6-11】蚂蚁 Ming-Omni
【2025-6-11】蚂蚁百灵团队 2.8B 参数就能媲美GPT-4o
开源 Ming-Omni:支持统一感知与生成的多模态模型,在端到端语音理解和指令执行方面表现优异,超越了 Qwen2.5-Omni 和 Kimi-Audio
- 论文 Ming-Omni: A Unified Multimodal Model for Perception and Generation
- 【2025-5-21】Code: Ming
Hugging Face 宝藏项目——Ming-Omni。
Ming-Omni 实现了真正的多模态统一:同时输入文字、图片、音频和视频,不仅能理解,还能生成高质量的语音和图像。
最震撼的是,只用2.8B的活跃参数就达到了GPT-4o级别的效果。
Ming-Omni 是蚂蚁与 inclusionAI 共同开发的首个开源多模态模型,旨在与 GPT-4o 竞争。
- 该模型支持多种输入形式,包括文本、语音、图片和视频,同时也可以生成文本、语音和图片输出。
- 这一创新的开源项目为开发者提供了灵活的应用选择,具有广泛的潜力和应用场景。
Ming-lite-omni 是统一的多模态模型,是 Ming-omni 的轻量版,源自 Ling-lite,拥有 28 亿激活参数。
- 该模型能够处理图像、文本、音频和视频,同时在语音和图像生成方面表现出强大的能力。
- Ming-lite-omni 采用专用编码器从不同模态中提取 token,随后由 Ling 处理,Ling 是一种配备了新提出的模态专用路由器的 MoE 架构。
- 该设计使单一模型能够在统一框架内高效处理和融合多模态输入,从而支持多样化任务,无需单独模型、任务特定微调或结构重设计。
Ming-lite-omni 超越了传统多模态模型,支持音频和图像生成。这通过集成先进的音频解码器实现自然语音生成,以及 Ming-Lite-Uni 实现高质量图像生成,使模型能够进行上下文感知聊天、文本转语音转换和多功能图像编辑。
技术突破:MoE架构设计。
- 传统模型要么参数量巨大,要么能力单一
- Ming-Omni 通过模态专用路由器,让每个任务都能调用最合适的专家网络。这意味着更高的效率,更低的成本。
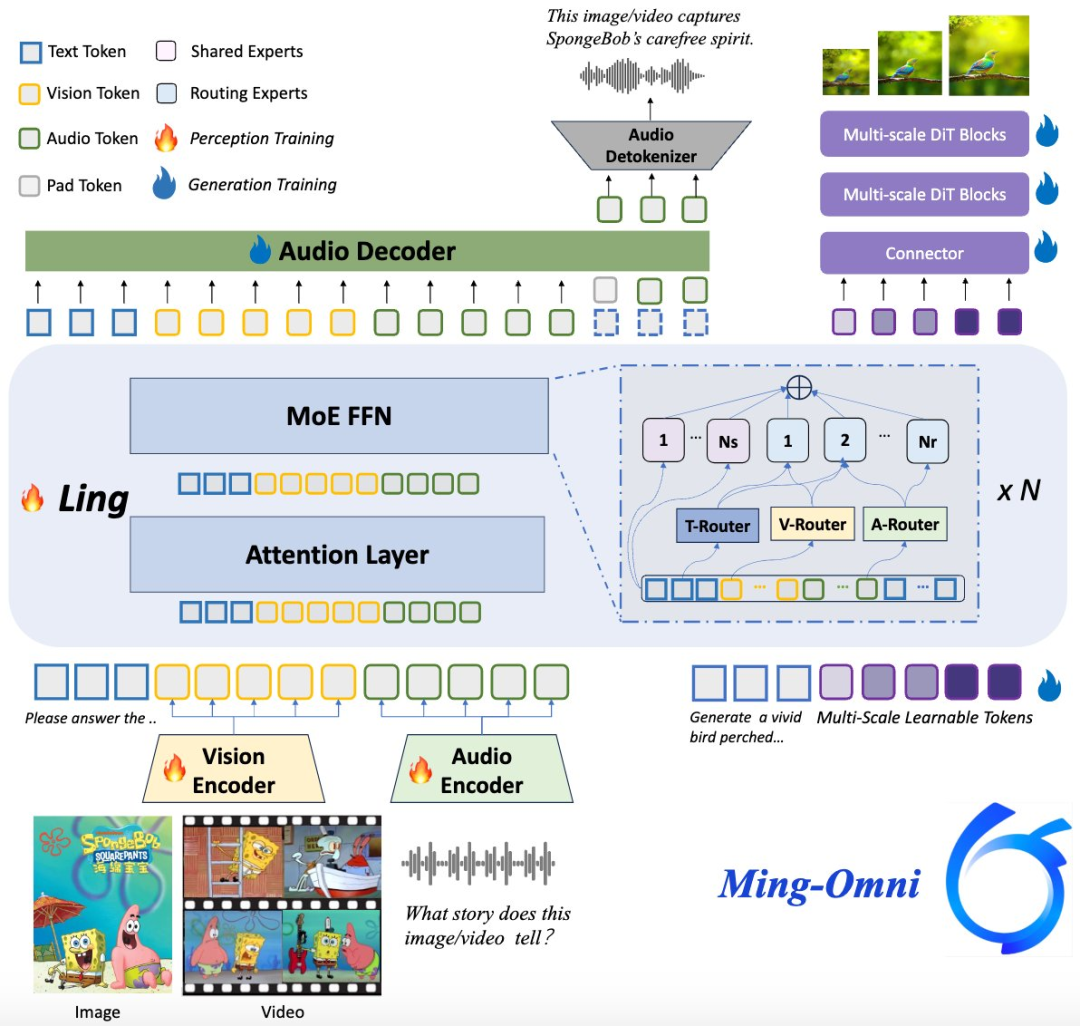
无论是上下文对话、文本转语音,还是图像编辑,流畅度和准确性都超出预期。
关键是完全开源,代码和权重全部公开,这对整个AI社区是巨大的贡献。
意义
- 对于开发者来说,这是真正部署到生产环境的方案。
- 对于普通用户,这意味着不用再为AI能力付费就能获得顶级体验。
【2025-6-16】中科院 Stream-Omni
【2025-6-16】中科院发布 Stream-Omni 全模态实时交互
- 集成了语言、视觉和语音三种模态
- 论文 Stream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model
- 解读
- GitHub项目页面 Stream-Omni
- Hugging Face 模型页面 stream-omni-8b
【2025-6-23】中科院发布Stream-Omni:AI同时“看懂”“听懂”“说话”的全能聊天助手诞生了
Stream-Omni 模型就像全能的聊天伙伴,不仅能同时处理图片、语音和文字,还能在你说话的同时实时给出回应,就像GPT-4o那样自然流畅
技术亮点
- 采用了视觉-语音双路径对齐策略

什么概念?
- 业界现有解决方案,要么在视觉和语言之间勉强拼凑,要么在语音和文本之间生硬转换
- 但Stream-Omni通过序列维度拼接和CTC层维度映射,实现了视觉、语音和文本的无缝融合,让机器真正做到了“看懂”“听懂”和“理解”。
通过对各模态间的关系进行更有针对性的建模,Stream-Omni实现了更加高效和灵活的文本-视觉-语音模态对齐。
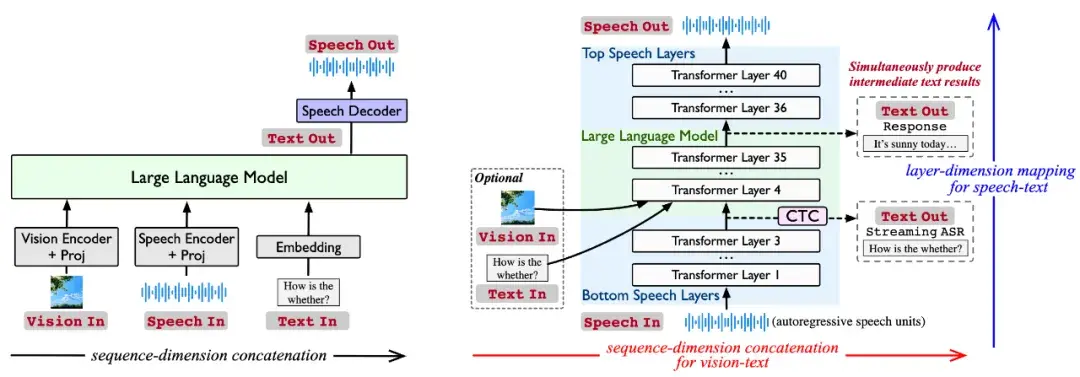
仅依赖包含2.3万小时语音的多模态数据,Stream-Omni即可具备文本交互、语音交互、基于视觉的语音交互等各种模态上的交互能力。
与此同时,依赖于创新的语音建模方式,Stream-Omni能在语音交互过程中像GPT-4o一样同步输出中间文本转录结果,为用户提供全方位的多模态交互体验。
Stream-Omni 针对视觉模态的语义互补特性,采用序列维度拼接,让图像和文本的语义融合得更加紧密;
而对于语音模态,创新性地引入了CTC层维度映射,直接将语音特征映射到文本特征空间。
这种双路径对齐机制不仅大幅降低了模态融合的数据需求,还让模型在处理多模态信息时更加高效。这就好比给机器安装了一双“眼睛”和“耳朵”,让它能够同时“看”和“听”,并实时做出反应。
框架
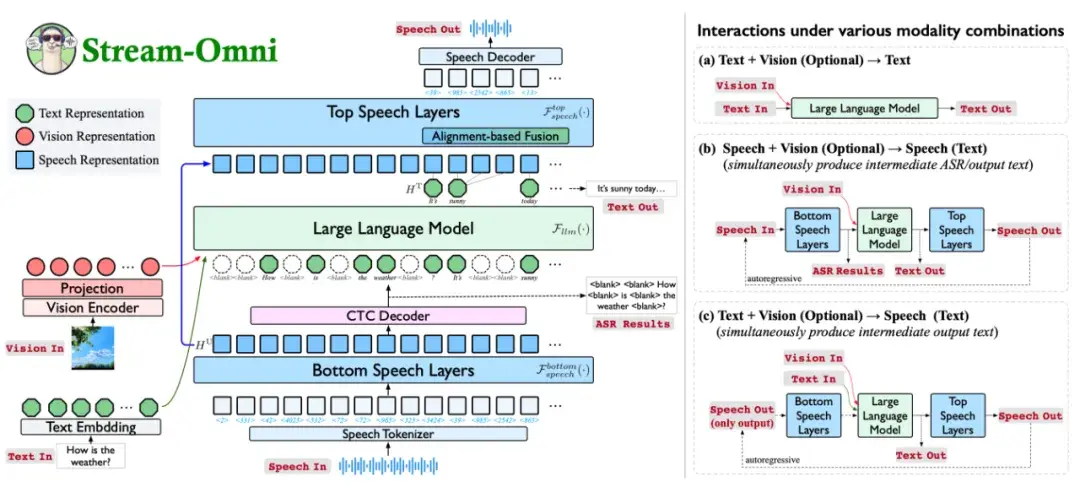
Stream-Omni以大语言模型作为主干,逐步将视觉和语音与文本对齐,高效地构建了一个支持文本、视觉和语音的多模态大模型。在视觉-文本对齐方面,Stream-Omni采用视觉编码器和投影模块提取视觉表示,并将其与文本表示进行拼接。在语音-文本对齐方面,Stream-Omni在 LLM 主干的底部和顶部分别引入若干语音层,用于将语音映射到文本以及基于文本生成语音。
视觉模态
基于视觉模态与文本模态之间具有语义互补性,Stream-Omni 采用LLaVA架构中的序列维度拼接的方式进行视觉-文本对齐。
语音模态
- (1)语音离散化:Stream-Omni采用CosyVoice Tokenizer对语音输入进行离散化,编码为若干离散的语音单元。
- (2)语音到文本映射:为了充分利用LLM的能力,Stream-Omni在LLM的底部引入语音层,用于学习语音与文本之间的映射关系,从而将 LLM 中的文本能力迁移到语音模态中。Stream-Omni利用在ASR任务上的CTC损失直接监督底部语音层语音表示,将其与文本模态对齐。
- (3)文本生成:LLM基于输入的视觉表示和语音表示,生成文本回复。
- (4)文本到语音生成:Stream-Omni通过顶部语音层来完成文本到语音生成。为了在生成文本的同时生成语音单元,Stream-Omni在顶部语音层中引入了alignment-based fusion模块。Alignment-based fusion沿用了StreamSpeech等实时生成研究中的同步生成策略,利用CTC对齐来指导同步生成过程。
任意模态组合下的多模态交互
Stream-Omni 通过灵活组合视觉编码器、底部语音层、LLM、顶部语音层来实现任意模态组合下的交互。同时,由于层级维度语音文本映射,Stream-Omni能够在语音到语音生成过程中提供中间的文本结果。
性能炸裂
Stream-Omni
- MSCOCO图像描述生成任务中,达到了128.5的CIDEr分数,吊打一众传统模型。
- 而在语音交互场景中,它的词错误率(WER)较基线降低了18.7%。
- 实时交互能力——能够在语音输入的过程中同步输出自动语音识别(ASR)转录文本和响应内容,真正实现了多模态信息的并行处理。好比在和它聊天的时候,不仅能立刻理解你说的话,还能同时“看”到周围的场景,并给出最合适的回答。
应用场景
- 车载交互领域,可以作为智能驾驶的“超级大脑”,不仅能听懂你的语音指令,还能实时分析车辆周围的视觉场景,提供最精准的导航和辅助驾驶建议
【2025-8-4】字节 VeOmni 框架
大模型从单一语言向文本 + 图像 + 视频的多模态进化时,训练流程却陷入了 “碎片化困境”:
- 当业务要同时迭代 DiT、LLM 与 VLM时,很难在一套代码里顺畅切换;
- 而当模型形态一旦变化,底层并行组合和显存调度往往需要大量手工改写,耗时耗力;
- DIT 模型蒸馏需要大量的资源消耗,但是缺少高效的训练 infra 支持来提升效率……
【2025-8-4】字节跳动 Seed 团队开源全模态 PyTorch 原生训练框架—— VeOmni 。
- 论文 VeOmni: Scaling Any Modality Model Training with Model-Centric Distributed Recipe Zoo
- GitHub:VeOmni
- 官方 解锁任意模态模型训练,字节跳动Seed开源VeOmni框架
- 解读 字节跳动 VeOmni 框架开源:统一多模态训练效率飞跃
VeOmni 采用以模型为中心的分布式训练方案,将复杂的分布式并行逻辑与模型计算解耦,让研究员像搭积木一样,为全模态模型组合设置高效的并行训练方案。
这一方式可大幅降低工程开销,提升训练效率和扩展性,将数周的工程开发时间缩短至几天。
此前,用 Megatron-LM 等以系统为中心的分布式训练框架训练全新架构的视觉-语言模型,往往需要一周以上进行工程研发,以及更长时间推进分布式优化和精度对齐,且耗时高度依赖于 Infra 工程团队的经验积累。
而使用 VeOmni 只需一天即可完成模型代码构建,开启训练任务,工程耗时可压缩 90% 以上。
VeOmni 介绍
VeOmni 是什么?一套框架搞定所有多模态训练
字节 Seed 团队与火山机器学习平台、IaaS 异构计算团队联合研发的统一多模态模型训练框架,核心定位是三个统一:“统一多模态、统一并行策略、统一算力底座”。
- 通过统一的 API 将 LoRA 轻量微调、FSDP、Ulysses 和 Expert Parallel 等多种混合并行策略以及自动并行搜索能力内置于框架内部。无论是百亿级语言模型、跨模态视觉语言模型,还是 480P/720P、长序列的文本到视频(T2V)或图像到视频(I2V)生成模型,开发者都能够基于统一的训练流程快速启动训练。
- 框架支持在千卡级 GPU 集群上自动完成权重张量的切分、通信拓扑的优化、动态显存回收和异步 checkpoint。在开源的 Wan 2.1 等模型上实测显示,相较于同类开源方案,VeOmni 能够将训练吞吐提高超过 40%,同时显著降低显存使用与跨节点通信带宽压力。
- 借助 VeOmni,字节跳动成功实现了“支持最快落地的新模型形态、最大化超大规模算力利用率、最小化业务改动成本”三大目标,有效弥补了开源社区训练框架在扩展性和抽象层面上的不足,为包括 LLM 和 VLM 在内的多模态生成场景提供了一条统一且高效的训练路径。
效果
实验结果
基于 VeOmni 框架,一个 300 亿参数的全模态 MoE 模型(支持文本、语音、图片、视频的理解和生成), 在 128 张卡上训练吞吐量可超过 2800 tokens/sec/GPU,并能轻松扩展至 160K 超长上下文序列。
目前,VeOmni 的相关论文和代码仓库均已对外公开,GitHub Star 数超过 500。
【2025-10-27】NVIDIA OmniVinci
【2025-10-27】NVIDIA 开源全模态大型语言模型 OmniVinci ,架构革新和数据优化,解决多模态模型中的模态割裂问题。
- 项目官网:OmniVinci
- Github仓库:OmniVinci
- HuggingFace模型库:OmniVinci
- arXiv技术论文:OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
功能
要点
- 通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉相对时间对齐信息,采用约束旋转时间嵌入编码绝对时间信息。
- 通过数据合成和精心设计的数据分布策略,生成大量单模态和全模态对话样本进行训练。
- 两阶段训练策略先进行单模态训练,再进行全模态联合训练,有效整合多模态理解能力。
OmniVinci的功能特色
- 多模态理解:能同时处理视觉、音频和文本信息,实现跨模态的理解和推理,例如可以根据视频内容生成详细的描述,包括视觉和音频信息。
- 模型架构创新:通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉视觉和音频信号的相对时间对齐信息,并采用约束旋转时间嵌入编码绝对时间信息,提升模型对多模态信号的理解能力。
- 数据合成与优化:通过数据合成和精心设计的数据分布策略,生成大量单模态和全模态对话样本,优化训练数据,提高模型的泛化能力和性能。
- 两阶段训练策略:采用单模态训练和全模态联合训练的两阶段策略,先分别开发视觉和音频理解能力,再整合这些能力实现跨模态理解,有效提升模型的多模态推理能力。
- 高效训练:在训练过程中,OmniVinci 使用较少的训练标记量(0.2 万亿)就能达到优异的性能,相比其他模型大幅减少了训练资源的消耗
网络结构
通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉视觉和音频信号的相对时间对齐信息,并采用约束旋转时间嵌入编码绝对时间信息,提升模型对多模态信号的理解能力
效果
OmniVinci 在多个基准测试中表现优异,如在 DailyOmni 上评分比 Qwen2.5-Omni 高出 19.05 分,且训练标记量大幅减少。已应用于医疗 CT 影像解读、半导体器件检测等领域,展现出强大的多模态理解能力
【2025-11-03】LongCat-Flash-Omni
【2025-11-03】LongCat-Flash-Omni正式发布并开源:开启全模态实时交互时代
美团 LongCat-Flash 系列再升级,正式发布全新家族成员——LongCat-Flash-Omni。
LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架构设计为基础( Shortcut-Connected MoE,含零计算专家),同时创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力,为开发者的多模态应用场景提供了更高效的技术选择。
综合评估结果表明,LongCat-Flash-Omni 在全模态基准测试中达到开源最先进水平(SOTA),同时在文本、图像、视频理解及语音感知与生成等关键单模态任务中,均展现出极强的竞争力。LongCat-Flash-Omni 是业界首个实现 “全模态覆盖、端到端架构、大参数量高效推理” 于一体的开源大语言模型,首次在开源范畴内实现了全模态能力对闭源模型的对标,并凭借创新的架构设计与工程优化,让大参数模型在多模态任务中也能实现毫秒级响应,解决了行业内推理延迟的痛点。
模型已同步开源,欢迎体验:
- Hugging Face:LongCat-Flash-Omni
- Github:LongCat-Flash-Omni
【2026-2-4】MiniCPM-o 4.5
MiniCPM-o 4.5 是由面壁智能(ModelBest)与清华大学(OpenBMB)于 2026 年初联合推出的一款端侧原生全模态大模型。作为“面壁小钢炮”系列的最新旗舰,该模型虽然参数量仅有 9B,但展现出了比肩甚至超越诸多云端千亿级闭源模型(如 GPT-4o、Gemini 2.5 Flash 等)的惊人实力。
端侧 AI 从“被动问答”正式迈向了“实时看听、全双工、主动交互”的新时代
【2026-2-4】面壁智能小钢炮开源进阶版「Her」,9B模型居然有了「活人感」
- 体验链接:demo

问题:
- 为什么和 AI 对话,总觉得少了点「人味儿」?
- 就像两个人在用对讲机聊天。按住通话键说话时,对方听不见;对方说话时,你也插不上嘴。一次只能一个方向传递信息。
这不是产品设计问题,而是技术限制。因为绝大多数 AI 都在用单工模式运行,用起来感觉很死板。
2026年2月4日,面壁开源行业首个全双工全模态大模型 MiniCPM-o 4.5,相比已有多模态模型,MiniCPM-o 4.5 首次实现了「边看边听边说」以及「自主交互」的全模态能力,模型不再只是把视觉、语音作为静态输入处理,而是能够在实时、多模态信息流中持续感知环境变化,并在输出的同时保持对外界的理解。
目前,MiniCPM-o 4.5 已在 GitHub、Hugging Face 等平台开源:
- 开源地址:MiniCPM-o
- Hugging Face: MiniCPM-o-4_5
- 体验链接:demo
技术架构
- 底层基座:MiniCPM-o 4.5 采用了端到端的全模态架构,融合了 Qwen3-8B(语言)、SigLip2(视觉)、Whisper-medium(听觉)和 CosyVoice2(语音生成),总参数量控制在极度紧凑的 9B。
- 原生全双工多模态:该模型摒弃了传统语音助手基于 VAD(静音检测)的“机械等待”机制。它在接收持续音视频流的同时,能够在模型内部高频进行语义理解,自主判断“用户是否在说话”及“自己是否该插嘴”,实现了边听、边看、边想、边说的极致流畅体验。
虽然参数量只有 9B,MiniCPM-o 4.5 却在全模态、视觉理解、文档解析、语音理解和生成、声音克隆等方面,均做到了全模态模型 SOTA 水平。在涵盖 8 个主流评测基准的 OpenCompass 综合评估中得分 77.6 。
- MiniCPM-o 4.5 在 MMBench(综合视觉理解)、MathVista(数学推理)及 OmniDocBench(文档解析)等关键任务上击败了顶级闭源模型 Gemini 2.5 Flash。
- MiniCPM-o 4.5 在提升能力密度的同时也在追求极致能效比:以更低显存占用、更快响应速度,在保持 SOTA 级多模态表现下,实现更高推理效率与更低推理成本
MiniCPM-o 4.5 之所以 9B 小身板达到「类人感知 + 交互沟通」的能力。这背后藏着面壁对人机交互形态的终极思考。
(1)从伪双工到真全双工:重构并行交互能力
分析
- 传统多模态大模型大多是在处理「离线、静态」的交互状态。无论是图像还是视频,通常都需要用户先整理、上传,再基于这些已完成处理的输入向模型提问;模型一次性生成一大段结果,用户再进行下一轮反馈。这是一种严格的「提交 — 响应」式交互,天然存在时延,也缺乏过程中的动态调整能力。
- 流式全模态模型的出现开始打破这一限制,包括 GPT-4o、Gemini Live 等已经可以以并行流的方式持续输入,视觉、语音信号不再是一次性提交,而是实时、连续地进入系统。这是相对于「提交-响应」式交互的显著进步。
- 但这些流式全模态模型在本质上仍然是单工。输入与输出在本质上是阻塞的。模型一旦开始「说话」,就几乎无法再感知外部环境,等同于「闭上眼睛、捂住耳朵」,丧失了时间维度的感知能力。
MiniCPM-o 4.5 打破这面墙。构建了一种全双工、全模态的大模型架构,使输入与输出流互不阻塞:模型在生成语音或文本的同时,仍然可以持续感知外界的视频与音频流。
关键设计:
- 时间对齐与时分复用:将输入的视频、音频流与输出的文本、语音 Token 在毫秒级时间线上严格对齐,通过时分复用机制将并行的全模态流划分为微小周期性时间片内的顺序信息组,使模型能在宏观串行中处理微观并行。
- 循环分块编码:将离线模态编码器转化为支持流式输入输出的在线版本,模型将多模态流切分为微小分块 (Chunks) 并循环处理,这种高度复用的架构确保模型在输出的同时依然能持续解码环境信息。
- 端到端语音生成:语音解码器采用文本与语音 Token 交错建模的方式,通过稠密的隐藏层连接实现端到端生成,而非简单的 TTS 拼接。这种深度融合使模型能根据实时的视觉与音频反馈,动态调整语音的语气与情感,显著提升了音色的拟人度与表现力,同时也提升了长语音 (如超过 1 分钟) 生成的稳定性。
如果说全双工架构给了 AI 一双「永不闭合」的眼睛和一对「时刻倾听」的耳朵,那么自主交互机制,则是给了它一颗「懂得察言观色」的大脑
(2)自主交互:让模型摆脱「外挂」
MiniCPM-o 4.5 另一个突破在于全模态的自主交互机制。模型开始在实时信息流中,自行判断语义是否已经成熟到需要触发回应的时机,从而决定是否开口、何时开口。
问:
- 现在不是已经有不少语音或全模态对话模型,可以被打断了吗?
- 答案:表面上看起来是,但本质并不一样。
这类模型通常依赖外部 VAD(语音活动检测)模块来控制交互流程:
- 监听用户是否重新开口,一旦检测到声音,就强行中断当前输出。
- 这类方案在体验上确实比「完全插不上嘴」好了一些,但会引入一系列本质性问题。
- 例如 VAD 不理解语义,无法区分说话者,会被拍桌子、环境噪声等误触发,且必须等待固定静音阈值 (如 1 秒) 才能响应,人为拉长了延迟。
然而更本质的问题:
- 很难想象,一个真正面向 AGI 的模型,会要一个「不太聪明的小工具」来告诉它什么时候该说话。
- 说话时机的控制是被外包给外部工具的 —— 这意味着模型本身没有真正的交互自主性。
MiniCPM-o 4.5 的发布,首次让模型真正具备了基于语义的自主交互判断能力:
- 自行判断交互是否成熟、何时进入说话状态,而不再依赖 VAD 等外部工具来裁决发言时机。
- 取而代之的是一种内生的高频语义决策机制 —— 语言模型持续感知视频与音频输入,并以约 1Hz 的频率自主决定是否发言。正是这种高频语义判断与全双工机制的结合,使模型首次具备了主动提醒、主动评论等真正意义上的主动交互能力。
其特点可总结为:
- 语义驱动的决策: 模型以高频(如每秒一次)的状态,完全基于语义理解来自主判断是否需要进入「说话状态」。
- 去工具化: 摆脱外部 VAD,模型在实时监听多模态信号的过程中,自行决定继续倾听还是产生文本与语音 Token 进行回复。
- 时机自由度: 赋予模型在时间维度上的自由度,使行为时机与行为内容实现一体化。
正是基于这种自主决策机制,MiniCPM-o 4.5 展现出比传统方式更智能的交互表现:
- 极低延迟的及时回复: 模型可以根据语义进行「预判」,不再需要死等外部工具的硬性静音信号。在人类话音刚落甚至即将结束时,模型即可启动推理,实现连贯的实时反馈。
- 智能抗干扰与内生打断:及时打断: 打断行为不再是外部强制挂断,而是模型根据外部实时信号进行的内生判断。抗干扰能力(抵抗打断): 面对环境噪声或旁人闲聊,模型展现出一定的「抵抗能力」,不会轻易被非目标信号干扰。
- 内生的主动回复(异步交互): 模型具备了跨越时空限制的回复能力,不仅局限于即时对话,还能根据环境变化或预设任务(如「水满提醒」、「电梯到达提醒」)在未来的某个时机自主发起交互。
当这种「类人感知 + 交互沟通」的实时本能,与仅有 9B 参数量的轻量模型相结合时,MiniCPM-o 4.5 成为了智能终端真正需要的那颗会沟通的大脑。
【2026-3-4】OPPO
2026年3月4日,在MWC 2026巴塞罗那举行的联发科技发布会上,OPPO与联发科技联合研发的技术预研成果——端侧全模态Omni模型正式亮相。作为业界首个在手机端侧实现多模态融合理解与交互的AI模型,Omni支持语音、视频、文本等多种输入方式,并能进行实时环境描述与实景问答,使手机端侧AI能够深入感知并理解周遭物理世界,为未来更主动、更自然的人机交互形态奠定了坚实的技术基础。
基于联发科技天玑9500芯片NPU提供的强劲算力支撑,OPPO自研的端侧AI翻译与端侧AI补光功能已可媲美云端体验,并将于近期随ColorOS 16系统更新,正式推送至OPPO Find X9系列。另外,OPPO Find X9 Pro也成功入围本届MWC GLOMO Awards “最佳智能手机”奖项评选。
【2026-6-22】京东 JoyAI-VL-Interaction
【2026-6-22】京东开源模型 JoyAI-VL-Interaction,”边看边说”——持续在场,自己判断什么时候该开口。
- 首个开源视觉驱动的实时交互模型,监控实时视频流,自主决定什么时候说话、静默、转交,可集成 ASR/TTS
- 94 毫秒延迟,对 Gemini 视频通话助手胜率 87.9%。
- 主页 Project page: JoyAI-VL-Interaction
- GitHub:JoyAI-VL-Interaction
- 【2026-6-10】论文 JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
模型
- 基于 QWen3-VL微调的8B 模型,视觉优先的交互模型
- 5090(32g)
- 16位模型占用显存太大,前后端传输延迟大,后端推理完前端还没显示;
- 4位模型占用显存小,速度快,更实用
- 4位awq或者nvfp4 量化版:JoyAI-VL-Interaction-Preview-AWQ
以前的多模态模型交互方式是轮次:
- 用户发一张图或视频,模型回答。
- 一轮结束,等用户下一轮。
JoyAI-VL-Interaction 思路完全不同:
- 模型持续接收视频流,自己判断什么时候该回应、什么时候该沉默、什么时候把任务交给后台 Agent。
不是”你问我答”,而是”我在看着,该我说的时候我会说”。
全栈开源的交互模型和系统,vLLM-Omni 原生支持。
# git clone https://github.com/vllm-project/vllm-omni.git
# 1. Serve the model (plain `vllm serve`, NOT --omni — it is vanilla Qwen3-VL)
vllm serve jdopensource/JoyAI-VL-Interaction-Preview \
--served-model-name JoyAI-VL-Interaction-Preview --port 8061 \
--max-model-len 131072 --enable-prefix-caching --limit-mm-per-prompt '{"image":256,"video":1}'
# 2. Start the interaction orchestrator (OpenAI-compatible, :8070)
python -m vllm_omni.experimental.fullduplex.joyvl.serving.server --port 8070 \
--main-backend-url http://127.0.0.1:8061/v1 --main-model JoyAI-VL-Interaction-Preview
支持持续的视觉观察与语言交互,开发者可基于其框架构建实景AI助手
JoyAI-VL-Interaction 支持摄像头、直播流等多种视频输入方式,并具备语音输入输出、可视化界面、长期记忆、后台模型接口和vLLM部署方案等功能。
其技术可应用
- 安防监控、老人小孩看护、直播讲解、电商导购、操作指导、AI眼镜、无障碍辅助等需要AI持续在场的场景
【2026-6-28】VLX系列 流式多模态→具身导航
【2026-6-28】杭州 Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。
Om AI 是一家来自杭州的AI公司,也是国内最早布局多模态模型的团队之一。创始人兼CEO赵天成是CMU计算机博士、吴文俊人工智能科技进步奖得主。团队成员来自CMU、清华、浙大、微软、阿里云等机构,手握50多篇顶会论文和50多项发明专利。
VLX 主打真实世界的端侧与具身场景,总共三款模型:
VLX-Flow:实时流式感知,让视频像水流一样持续输入,模型实时看、实时想、实时更新世界状态。VLX-Seek:精准定位,从看见走向看清,快速锁定目标。VLX-Go:行动决策,把感知和定位的结果转化成真实动作——该往哪走、怎么操作,一气呵成。- VLX:全球首个面向物理世界的端侧流式多模态模型,仅 0.6B
全新范式下,视觉信息不是以“截一帧”方式进入模型,而是以“连续流”的方式持续进入。模型不是“看完再说”,而是“边看边理解、必要时主动行动”。这对应的不是“更好的人机对话体验”,而是“AI自主工作能力的质变”。
物理世界AI 三个刚性约束:时间是连续的、环境是动态变化的、终端算力是资源受限的
VLX系列完全围绕实时视频流与端侧设备原生构建——不是将云端模型压缩后塞进终端,而是从架构层面为端侧具身智能重新设计——以“快(流式推理,单路延迟最低0.06秒)、小(轻量化选型,覆盖0.6B至10B规格)、准(细粒度定位)、行(感知执行闭环)”四大优势,实现从持续感知到行动决策的端侧闭环。
流式多模态: 让AI能够在物理世界中持续、实时地感知环境,并最终形成一条完整的能力链:
感知(Perception)→精准定位(Grounding)→行动(Action)
当多模态模型从“看图答题”走向“持续感知”,当AI从屏幕走向真实的物理世界,VLX端侧流式多模态模型系列为物理AI的演进提供了一种全新的架构范式——让每一台终端都能拥有持续理解、即时决策、自主行动的能力,这才是物理世界AI应有的样子。
这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
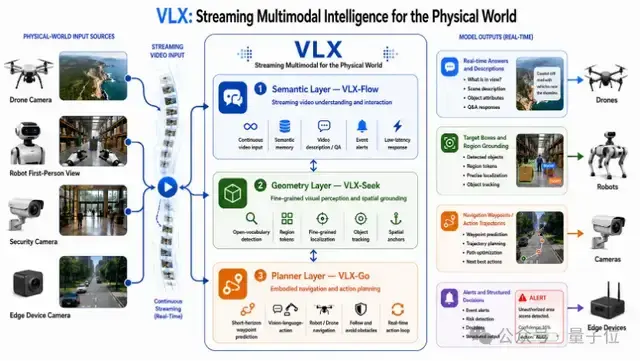
与此同时,其原生端侧设计也让它能够真正跑进手机、无人机、机器人这些端侧设备。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
