大模型因果推断
因果推断
详见站内专题:因果科学
大模型+因果
大语言模型 × 因果推断:谁在因果谁?
因果推断和大模型结合主要有如下4个方向:
- Causality in Large Models:看下大模型里因果性是什么
- Causality for Large Models:用因果推断理论改造大模型,更有理论性
- Causality with Large Models:用大模型解决因果问题
- Causality of Large Models:用大模型运作的因果结构,让其更有可解释性
随着 ChatGPT、Claude、Gemini 等大语言模型(LLM)日益强大,学界开始探索其在因果推断 中的潜力与挑战:
- 一方面,想利用
因果推断提升语言模型的鲁棒性、解释性与可靠性; - 另一方面,借助 LLMs 强大的知识能力辅助
因果结构发现、反事实生成与干预决策。
因果→LLM
如何让LLM真正理解事物间的因果联系,而非仅仅是模式匹配,一直是行业面临的重大挑战。
大模型中的因果推断
大模型中存在一些偏差,比如说LLM过度依赖Prompt中的某些文本,或者出现的虚假相关
Causal Prompting
【2024-3-5】《因果提示:基于前门调整的大型语言模型提示去偏》
核心思想:
- 大模型内部有因果性,通过某些方法加强其因果性,输出更有逻辑的结果。其实就是结合
前门调整,将CoT作为中介变量
具体方案:
- 论文首先通过
结构因果模型(Structural Causal Model, SCM)揭示提示方法背后的因果关系。 - 输入提示(X)与模型生成的答案(A)之间的关系受到不可观察的混杂变量(U)的影响,导致了偏见的存在。
- 研究者们提出,使用“后门调整”无法有效计算X与A之间的因果效应。相反,论文利用链式思维(Chain-of-Thought, CoT)作为中介变量(R),使得可以通过前门调整有效估计X与A之间的因果关系。
通过COT的方式进行前门调整,加强大模型推理的因果性,从而缓解大模型推理的偏差。
LLM → 因果
传统因果发现方法在面对数据扰动时,往往容易过拟合,表现近乎随机。
【2025-6-20】十)大模型+因果推断如何结合?
E2E 因果效果预估
用 LLM从自然语言文本中推断因果效应,也算是充分发挥了LLM的自然语言理解能力
【2024-10-28】多伦多大学论文 NATURAL:End-To-End Causal Effect Estimation from Unstructured Natural Language Data
- 收集Reddit帖子(文本),并根据关键词等数据清洗过滤数据,并用LLM判断与问题是否相关;
- 再用LLM抽取treatment、outcome和协变量;
- 再用LLM实现数据增强,补充缺失值等;
- 用LLM计算倾向值得分,并根据IPW计算ATE。
Causal Copilot
用LLM作为Copilot完成因果推断、因果发现、结果解释等任务全流程。通过LLM串联各个环节,实现end2end的分析。
- 【2025-4-21】论文 Causal-Copilot: An Autonomous Causal Analysis Agent
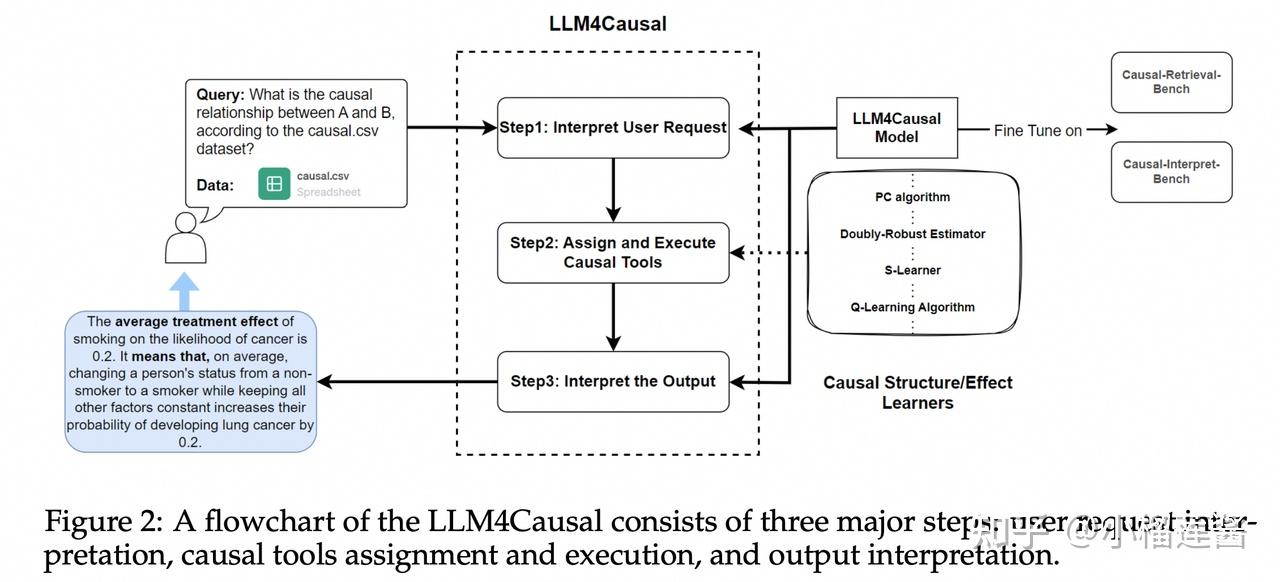
LLM4Causal
- 【2024-10-28】北卡州立大学 LLM4Causal: Democratized Causal Tools for Everyone via Large Language Model
总结:流程自动化(任务分类—>工具调用—>结果解释),而非替代传统的因果方法。这里微调大模型只是能让大模型识别出来做什么任务,即根据自然语言识别对应的任务分类。
因果推断几类任务:
- CGL (Causal Graph Learning):因果图学习
- ATE (Average Treatment Effect Estimation):平均处理效应估计
- HTE (Heterogeneous Treatment Effect Estimation)
- MA (Mediation Effect Analysis):中介效应分析
- OPO (Optimal Policy Optimization):最优策略优化
现有方案的缺陷:
- 图a):当希望做因果分析的时候,提供相关性分析的结果
- 图b):无法提供端到端的结果
- 图c):一些前沿的方法没法使用
提出端到端的用户友好框架
三个主要步骤组成:
- 用户请求解释
- 因果工具分配和
- 执行
- 输出解释。
接收到用户查询和上传的数据文件后,初始步骤识别相关的因果任务并提取查询详细信息——包括数据集名称、任务类型和感兴趣的变量,以及其他变量——到结构化JSON摘要中。
LLM4Causal模型通过在 causal - retrieve - bench 数据集上对预训练的LLM进行微调,获得了将自然语言用户查询转换为JSON摘要的能力。提出设计良好的数据生成管道,以保证因果检索台架在数据多样性和准确性方面的质量。
- 第二步,系统根据结构化JSON数据中详细的任务类型自动选择因果学习算法,执行选择的算法对数据集进行分析,并收集算法的输出。
- 然后,在第三步中,使用llm4因果模型将输出翻译成易于理解的语言,该模型已与cause - interpret - bench数据集进一步微调,以生成高质量的解释。
SD-SCMs
【2024-11-12】标题:Language Models as Causal Effect Generators:LLM作为因果效应生成器
基于大型语言模型(LLM)的数据生成框架,具有可控的因果结构。
定义一种将任何语言模型和任何有向无环图(DAG)转换为序列驱动结构因果模型(sequence-driven structural causal models:SD-SCM)的流程。
SD-SCM 是一种具有用户定义结构和 LLM 定义的结构方程的因果模型。描述了 SD-SCM 如何根据所需的因果结构从观测、干预和反事实分布中进行采样。然后,利用这一流程提出了一种新的因果推断方法基准测试类型,能够生成个体层面的反事实数据,而无需手动指定变量之间的函数关系。
创建了一个包含数千个数据集的示例基准,并在这些数据集上测试了一系列流行的估计方法,包括ATE、CATE和ITE估计,同时考虑了存在和不存在隐藏混杂因素的情况。除了生成数据之外,同样的流程还允许测试 LLM 中可能编码的因果效应是否存在。此程序能够为检测大型语言模型中的错误信息、歧视或其他不良行为提供支撑。
SD-SCM 可以在任何需要可控因果结构的序列数据的应用中发挥有用工具的作用。
因果发现
【2025-7-31】荷兰 莱顿大学计算机学院 LAICS
因果推断仍然是大型语言模型面临的基本挑战。当前最好的推理模型能否稳健因果发现?
传统模型通常会因数据扰动而出现严重的过拟合和近乎随机的性能。
用 Corr2Cause 基准测试,研究了 OpenAI 的 o 系列和 DeepSeek-R 模型家族在因果发现中的表现
- 这些以推理优先的架构相比先前方法取得了显著性能提升。
- 为了充分利用这些优势,引入了受树形思维和链式思维方法启发的模块化上下文管道,在传统基线模型上实现了接近三倍的改进。
进一步通过分析推理链的长度和复杂度,并进行传统模型和推理模型的定性和定量比较,来探讨该管道的影响。
研究结果表明,尽管高级推理模型已经取得了显著的进步,但精心构建的上下文框架对于最大化这些模型的能力并为跨不同领域的因果发现提供通用蓝图至关重要。
这项研究核心:
- 像OpenAI的o系列和DeepSeek-R这类“推理优先”的LLM架构,在因果发现任务上展现出远超以往方法的原生优势。
- 这标志着LLM不再只是文本生成器,而是开始具备了更深层次的逻辑推理能力,能够理解“为什么”而不是“是什么”。
创新
- 借鉴“思维树”(Tree-of-Thoughts)和“思维链”(Chain-of-Thoughts)的思路,提出了一种模块化的上下文学习(in-context learning)流水线。
- 将复杂的因果推理任务分解成一系列可管理的步骤,让LLM能够逐步构建因果关系。
实验结果
- 将传统基线方法的性能提升了近三倍
- 这不仅仅是性能的提升,更是对LLM内在推理机制的深度挖掘和有效利用。
应用
- 在医疗领域,帮助医生更准确地诊断疾病的根本原因;
- 金融领域,揭示市场波动的深层驱动因素;
- 自动驾驶领域,提升车辆对复杂交通场景的理解和决策能力。
任何需要理解事物间因果联系的领域,都将因这项技术而受益。
综述
潜在方向
- 利用 LLM 进行因果结构建模
- 将因果推断方法嵌入 LLM 系统
- 基于 LLM 的因果发现与评估自动化
LLM 因果结构建模
利用 LLM 进行因果结构建模
LLMs 可以辅助识别变量之间的因果关系,特别是在文本、知识图谱或非结构化数据中。
例如:
- 从文献中提取“X 导致 Y”的显性/隐性结构
- 利用多轮问答评估变量之间的干预关系
代表工作:
- LLM 作为“因果判断者”(e.g., “Can language models infer causality?” NeurIPS 2022):探索 LLM 在结构学习中的 prompt engineering 与 few-shot 表现。
- CausalQA 数据集:训练 LLMs 在问答框架中识别干预与反事实关系。
嵌入 LLM
将因果推断方法嵌入 LLM 系统
目标: 让语言模型不仅“预测”,还能“解释+干预”:
- 将 因果图(causal graph) 用作 prompt 或 context,在生成时约束信息流
- 结合 do-calculus 理论框架,对复杂系统进行干预模拟(如政策模拟、医疗推荐)
代表方向:
- CausalGPT / Counterfactual LLMs:将反事实建模机制整合入 decoder,使模型能够生成“如果…会怎样”的干预性语言。
- Causal Chain-of-Thought:将因果图作为“思维链条”,嵌入语言模型的推理流程中。
因果发现/评估自动化
基于 LLM 的因果发现与评估自动化
- 自动审阅论文中的因果假设与方法(如 GRADE 框架)
- 将复杂的 RCT、IV、DID 设计算法转化为 prompt 可控的因果建模器
多智能体 CausalMACE
如何用“因果规划”,解决任务依赖难
在长周期、多步骤的协作任务中,传统单智能体面临任务成功率随步骤长度快速衰减,错误级联导致容错率极低等问题。
需要构建具备全局规划与因果依赖管理能力的分布式智能体框架,并在真实游戏中验证效能。
【2025-8-26】港科广和腾讯提出 CausalMACE 方法,将因果推理机制系统性地引入开放世界多智能体系统,为复杂任务协同提供了可扩展的工程化解决方案。
目前,该工作已中稿EMNLP 2025 Findings。
为了让一群AI像项目团队一样,既分工明确又能动态调整。论文提出“全局因果任务图”概念,让AI学会“如果-那么”的逻辑。
先搭地基再砌墙,先找食材再下锅。
全局因果任务图包含两个部分:
- 因果干预模块:引入
平均处理效应(ATE) 量化每条依赖边与游戏规则的一致性,自动剔除由大模型先验幻觉导致的错误依赖 - 负载感知调度:基于DFS路径搜索与动态“繁忙率”指标,实现多智能体实时任务再分配
方法框架层面,CausalMACE 则包含“判断”、“规划”、“执行”三个环节。
- 1️⃣ Judger——“裁判”: 实时验证动作是否合法,并给出成败反馈,保证所有智能体在同一套游戏规则下行动。
- 2️⃣ Planner——“总工”
- 先把复杂任务拆成若干“小工单”,一次性列清,再按游戏规则画一张“粗线条流程图”。
- 之后,通过因果推理“精修”这张图,对每一条先后关系,让大模型回答“如果游戏规则变了,这条先后关系还成立吗?”
- 如果,所有规则改变均不影响关系的成立,就删掉这条关系,避免AI做无用功。
- 经过这轮“去伪存真”,得到一张干净、可执行的任务因果图。
- 3️⃣ Worker——“调度室”
- 首先,用深度优先搜索把因果图拆成多条“生产线”,给每条生产线实时计算“繁忙指数”。其中,正在这条线上干活的AI越多、离起点越远,指数越高。
- 接下来,让新来的AI自动加入指数最低的那条线,既避免扎堆,也减少等待。每完成一步,AI向Planner申请下一步任务,整个过程持续迭代。
在VillagerBench三项基准任务(建造、烹饪、密室逃脱)中,相较AgentVerse与VillagerAgent基线,任务完成率最高提升12%,效率提升最高达1.5倍。
代理工作量更加平衡,相同设置下最大增益达到13%。
挑战
⚠️ 挑战与未来方向
- 语义 ≠ 因果:文本中出现“因为”不代表真实因果,如何让 LLM 理解统计学层面的因果推断逻辑仍待突破。
- 缺乏可验证性:LLM 输出的“因果判断”如何在实证中被验证?
- 模型偏倚与稳健性:大模型自身可能携带错误的世界观,甚至强化 spurious correlation。
增益模型 Uplift
参考
- 【2024-9-15】增益模型(Uplift)
- 【2024-8-20】营销算法炼丹笔记:一文读懂增益模型Uplift Model
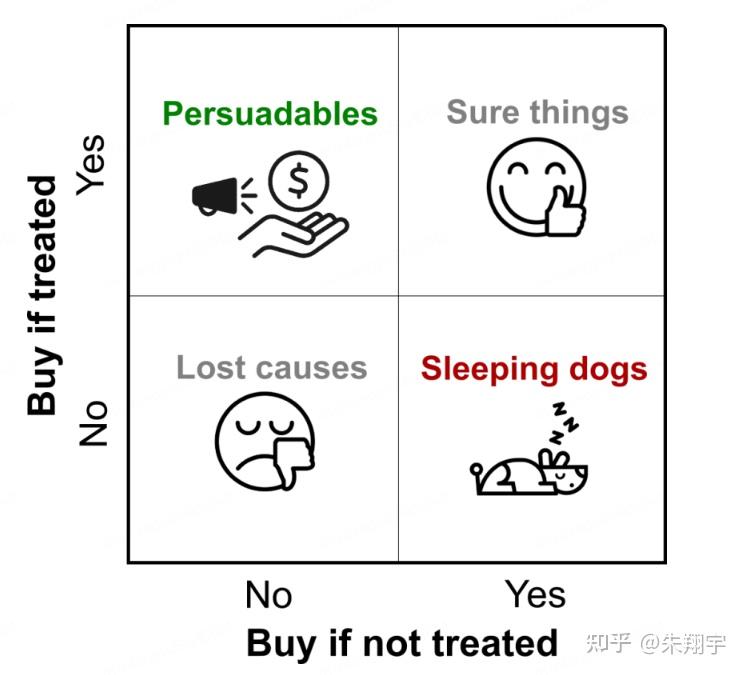
四类用户:
说服型Persuadables:不发送优惠券则不买,发送优惠券则购买;—— 真正想要进行触达干预的营销敏感用户确认型Sure things:不论是否发送优惠券均会购买;—— 发优惠券则会造成资源浪费沉睡型Lost causes: 不论是否发送优惠券均不会购买;—— 发优惠券则会造成资源浪费勿扰型Sleeping Dogs: 不发送优惠券会购买,发送优惠券反而不买;—— 对营销可能相对反感,尽量避免打扰
Uplift模型通过建模预测方法对这四类用户进行精准分群
传统模型通常直接预测目标:Outcome = P(buy|tratment)
而 Uplift models预测增量值,也就是lift部分:Lift = P(buy|tratment) - P(buy|no tratment)
增益模型定义:
一种用于估算个体干预增量( uplift )的模型,即
干预动作(treatment) 对用户响应行为(outcome) 产生的效果。
因果推断的应用,主要是 Uplift 建模,即 增量预估
目的: 预测某种干预对于个体状态或行为的因果效应。在数学上可以表达为两个条件概率的差值形式

Uplift建模对样本的要求比较高,要服从CIA ( Conditional Independence Assumption ) 条件独立假设,要求X与T是相互独立。
随机化实验是Uplift Model建模过程中非常重要的基础设施,可以为Uplift Model提供无偏的样本
ab test是最佳的因果推断方法之一,但ab test也有局限性:
- AB test不可进行:比如我们不能强迫一组用户‘吸烟’,另一组用户‘不吸烟’去观察吸烟对健康的危害;
- AB test成本太高:当线上实验的选择太多,而产品的流量/时间成本是有限时,逐一对每一个实验都进行测试显然不现实,此时通过离线数据进行因果推断可以帮助我们科学地预判不同实验策略的‘前途’,让我们可以优先尝试前途更加光明的实验;
因果推断是通过特定方法对观察性数据控制混杂变量以拟合随机试验。所有方法的核心思想都离不开控制混杂(control confounding variables)
- 混杂变量指对于因和果都有影响的因素,忽视它们会对结果带来致命的偏倚
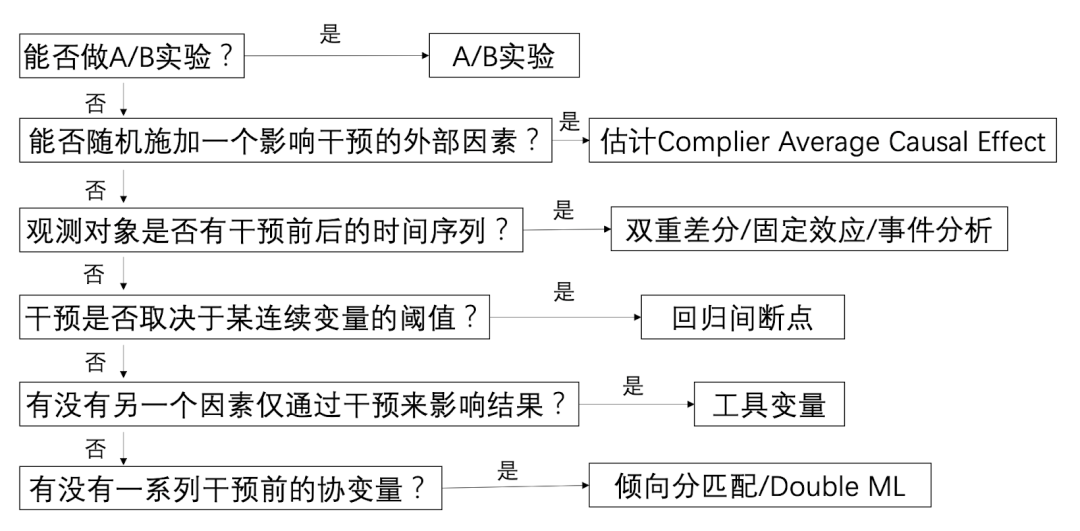
两个群体对广告投放的转化率分别是0.8%和2%,假如只有一次广告曝光的机会,应该向哪类用户投放广告?

按照经验和直觉,会向第二类用户群投放广告,因为其转换率是最高,但这个结论是对的吗?经过进一步分析,除了广告曝光转化率之外,还能知道这两类用户群体在没有广告触达情况下的自然转化率,从而推算出广告所带来的增量。
Response Model 可能会误导做出错误决策,Uplift Model和Response Model之所以有差异,主要在于两个模型的预测目标不一样。
- Response Model 目标是估计用户看过广告之后转化的概率,这本身是一个相关性,但这个相关性会导致我们没有办法区分出自然转化人群;
- Uplift Model 估计用户因为广告而购买的概率,这是一个因果推断的问题,帮助锁定对营销敏感的人群。
所以 Uplift Model是整个智能营销中非常关键的技术,预知每个用户的营销敏感程度,从而帮助我们制定营销策略,促成整个营销的效用最大化。
增益模型(Uplift Model)作为工业界因果推断与机器学习结合最成熟的算法之一,在智能营销中有着广泛的应用。
业界针对某个处理变量(Treatment),衡量其处理效应(Treatment Effect)的一类模型称为增益模型(Uplift Modeling)。
- 传统监督学习模型关注准确估计
响应变量(Y) - 而
增益模型专注于估计处理变量(W)对响应变量(Y)的影响。
增益模型常用于估算CATE/ITE,基础 uplift model 有三种:
Two-Model:建立两个对于outcome的预测模型,一个实验组数据、一个对照组数据。- 双模型 Two-Model Approach 通常作为baseline模型
One-Model:Class Variable Transformation:响应结果为二元变量时可用。- 对uplift直接建模:对现有ML模型(树、RF、SVM)的改造
| 方法 | 简介 | 优点 | 缺点 |
|---|---|---|---|
Two-Model |
两个预测模型,分别实验组+对照组 | 简单易用,常用回归/分类模型 | 不是对uplift直接建模,可能会错失一些uplift相关的信号、导致表现较差 |
One-Model |
|||
| 直接见面 |
Two-Model
用户通过两个模型预测,并对结果取差,则得到预估的uplift值:
- 优点:简单易用,可以使用常用的回归/分类模型
- 缺点:不是对uplift直接建模,可能会错失一些uplift相关的信号、导致表现较差
最简单的Uplift建模方法是基于Two Model的差分响应模型,形式和前面介绍的Uplift Model的定义非常相似,包含了两个响应模型,其中一个模型G用来估计用户在有干预情况下的响应,另外一个模型G’是用来学习用户在没有干预情况下的响应,之后将两个模型的输出做差,就得到我们想要的uplift。
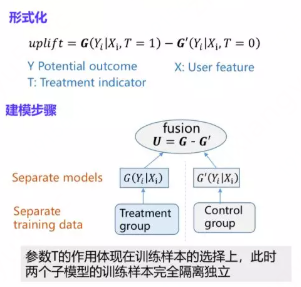
这种建模方法
- 优点:比较简单容易理解,同时它可以套用我们常见的机器学习模型,如LR,GBDT,NN等,所以该模型的落地成本是比较低的
- 但是该模型最大的缺点是精度有限,这一方面是因为独立的构建了两个模型,这两个模型在打分上面的误差容易产生累积效应,第二是建模目标其实是response而不是uplift,因此对uplift的识别能力比较有限。
One-Model
One Model:The Class Transformation Method
缺点:需要满足两个假设
- 二分类场景
- 数据在实验/对照组的分布一致,较为严格
还有基于One Model的差分响应模型,和上一个模型最大差别点: 在模型层面做了打通,同时底层的样本也是共享的,之所以能实现这种模型层面的打通,是因为在样本的维度上做了一个扩展,除了user feature之外,还引入了与treatment相关的变量T ( T如果是0,1的取值可以建模single treatment,T也可以扩展为0到N,建模multiple treatment,比如不同红包的面额,或者不同广告的素材 )。

One Model版本和Two Model版本相比
最大优点:
- 训练样本的共享可以使模型学习的更加充分,同时通过模型的学习也可以有效的避免双模型打分误差累积的问题
- 从模型的层面可以支持multiple treatment的建模,具有比较强的实用性。
同时和Two Model版本类似,缺点:
- 依然是其在本质上还是在对response建模,因此对uplift的建模还是比较间接,有一定提升的空间。
直接建模
直接对Uplift进行建模
通过对现有机器学习算法的改造直接对增益效果建模,最流行的是树模型,本文主要讨论树的分裂标准(二叉树)。
后续也有相关研究提出了第三种建模方法,通过对现有的模型内部进行深层次的改造来直接刻画uplift,其中研究较多的是基于树模型的uplift建模。
思想
- 传统决策树构建中,最重要的环节是分裂特征的选择,常用指标是信息增益或者信息增益比
- 其背后含义还是希望通过特征分裂之后下游节点的正负样本的分布能够更加的悬殊,也就代表类的纯度变得更高。
这种思想也可以引入到Uplift Model的建模过程中,虽然并没有用户个体的uplift直接的label,但是可以通过treatment组和control组转化率的差异来刻画这个uplift

以图中左下角的图为例,有T和C两组样本,绿色的样本代表正样本,红色的代表负样本,在分裂之前T和C两组正负样本的比例比较接近,但是经过一轮特征分裂之后,T和C组内正负样本的比例发生了较大的变化,左子树中T组全是正样本,C组全是负样本,右子树正好相反,C组的正样本居多,意味着左子树的uplift比右子树的uplift更高,即该特征能够很好的把uplift更高和更低的两群人做一个区分。
Uplift建模核心问题
(1)混杂因素偏置 Confounding Bias
干预机制导致选择偏差,引起干预样本和不干预样本的特征分布不一致,产生了混杂因素。
这一类混杂因素一方面会影响干预,也会影响结果。由于混杂因素的存在,无法得到一个干净的因果效应。具体案例比如:
- 流行度偏差:曝光集中在热门干预;
- 选择偏差:不同人群物品曝光差异。
基于这样的样本去建模大概率置信度不高的结论。
主要解决方法:
- 在 loss 引入倾向分正则项;
- 在模型结构引入倾向分链式、对抗结构;
- 倾向分逆加权采样;
- 解离表征:试图将混杂因素项解离到一个向量中。
(2)归纳偏置 Inductive Bias
当样本/个体分别在干预/不干预的模型下进行打分后的分布不一致时,对干预打分-非干预打分差值(CATE)进行分布统计时会发现抖动很厉害,不同个体/群体之间的 UPLIFT 差别很难分辨,这说明 UPLIFT 模型预测基本是失效的。
归纳偏置(Inductive Bias)问题:
- 从模型架构角度,预估反事实结果无监督信号,或潜在结果预估正则化程度不一致,导致最终 Uplift 预估不稳定。
回到 Neyman-Rubin 潜在结果框架,对于不同的个体我们只知道干预的结果或者不干预的结果,不可能同时知道干预和不干预的结果,这导致了两个潜在结果预估的分布不一致;而且我们的深度模型建模目标往往是 CTR 或者 CVR ,他们本身不可能直接得到一个增益得分(uplift),这就导致我们的建模目标和最终评估的指标是不一致的。在图中我们可以看到 CATE 的分布与潜在结果预估得分分布完全不一致。这一系列的问题我们都总结为归纳偏置问题。归纳偏执问题是 UPLIFT 模型的一个核心问题,目前学界大概提出了以下四种解决方法:
- 反事实输出向量一致性,MMD 等分布对齐方法;
- 设计合理的共享参数架构,FlexTENet、S-Net;
- 反事实参数差异限制;
- 在模型结构引入重参结构(reparametrization),EUEN。
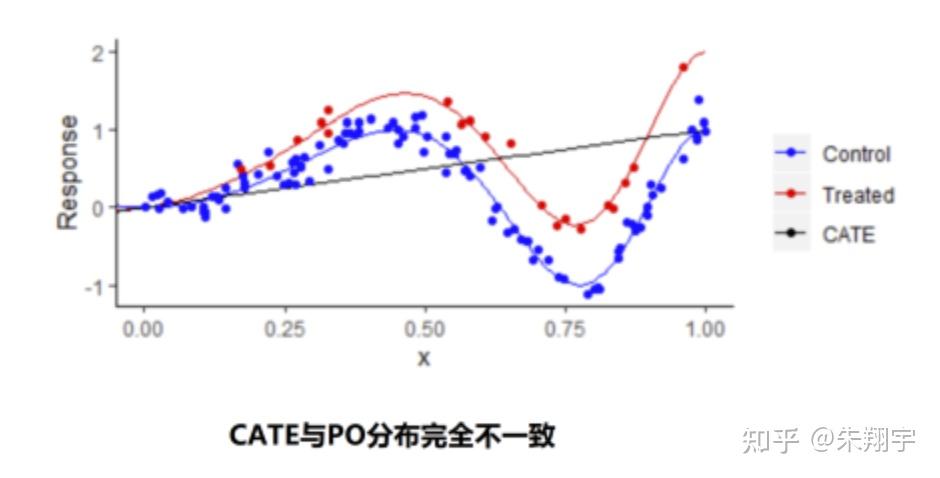
UPLIFT 模型的两大核心问题——混杂因质偏置和归纳偏置,学界和工业界提出了很多解决方案。
- 首先,最基本 Meta-Learner,代表建模方案有 S-Learner 和 T-Learner
- 随后, 进入深度学习后就演化出来以解决混杂偏置为代表的 DragonNet、DESCN、S-Net、CFRNet 等,和以解决归纳偏置为代表的 FlexTENet、S-Net、EUEN、DESCN、GANITE、CFRNet 等。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
