用户模拟器
资料
- 【2021-7-26】机器人性格综述
- 【2019-8-5】阿里小蜜:最新综述:对话系统之用户模拟器
论文
- 论文1《A User Simulator for Task-Completion Dialogues》
- 论文2《End-to-End Task-Completion Neural Dialogue Systems》
实例
- 【2020-12-16】天猫精灵对战小爱同学
背景
任务型对话
近几年来,强化学习在任务导向型对话系统中得到了广泛的应用,对话系统通常被统计建模成为一个马尔科夫决策过程(Markov Decision Process)模型,通过随机优化的方法来学习对话策略。
- 任务导向型对话系统用于帮助用户完成某个任务如查电影、找餐馆等,它一般由四个模块组成:
- 自然语言理解模块(Natural Language Understanding, NLU)
- 对话状态跟踪模块(Dialog State Tracking, DST)
- 对话策略模块(Dialog Policy, DP)
- 自然语言生成模块(Natural language Generation, NLG)
- 其中 DST 和 DP 合称为对话管理模块(Dialog Manager,DM)。
- 在和用户的每轮交互过程中,对话系统利用 NLU 将用户的语句解析成为机器可理解的语义标签,并通过 DST 维护一个内部的对话状态作为整个对话历史的紧凑表示,根据此状态使用 DP 选择合适的对话动作,最后通过 NLG 将对话动作转成自然语言回复。对话系统通过和用户进行交互得到的对话数据和使用得分则可用于进行模型的强化学习训练。
- 然而在实际应用中,和真实用户的交互成本昂贵,数据回流周期慢,不足以支持模型的快速迭代,因此研究者们通常会构建一个用户模拟器(User Simulator, US)作为对话系统的交互环境来进行闭环训练。有了用户模拟器产生任意多的数据,对话系统可以对状态空间和动作空间进行充分地探索以寻找最优策略。
- 一个效果良好的用户模拟器,我们期望它具备以下 3 个特征:
- ①一个总体的对话目标,能够生成上下文连贯的用户动作;
- ②足够的泛化能力,在语料中未出现的对话情形里也能生成合理的行为;
- ③可以给出定量的反馈评分用于指导模型学习优化。
-
为了实现以上目标,学术界做了大量的研究工作,从最基础的 bi-gram 模型 [4],到经典实用的 Agenda-based的方法 [2],再到最近基于深度学习的用户模型 [9, 10],用户模拟器的效果得到了显著提升,也为对话模型的训练提供了有效的方法。

- 用户模拟器的基本结构: 用户模拟器(蓝色部分)和对话系统(红色部分)
- 图里是一个比较典型的用户模拟器 [1],对话开始时用户模拟器基于 User Goal(用户目标)发出一个话术:
- “Are there any action movies to see this weekend?”(这个周末有什么动作片可以看的吗?)
- 这句话进到对话系统的自然语言理解模块和对话管理模块后,生成一句系统动作:“request_location”(询问地点)。
简便起见,这里省略掉系统的 NLG 模块,系统回复直接送到用户模拟器的用户模型(User Model),通过用户状态更新和行为策略选择,生成用户对话行为:“inform(location=San Francisco)”(告知地点为旧金山),接下来经过 Error Model(可选)和 NLG 模块,生成对应的自然语言,比如:“San Francisco, please.”(帮我订旧金山的)。以此往复,用户模拟器和对话系统持续多轮交互,直到对话结束。
- 【2021-2-4】
- 用户模拟器所处的对话系统是一个任务型对话系统,用户模拟器与agent(系统或经纪人)的交流具有一定的任务导向,而不是闲聊。
- 任务目标:Agent通过与用户模拟器进行多轮对话,洞察用户模拟器所提出的条件(约束)以及请求,并尽所能及提供同时满足所有条件的请求内容
- 用户模拟器需要具备在沟通过程中改变自己条件的能力(可视为妥协),agent力争做到满足用户需求(如:找房/约带看/询问房屋信息),但在无能为力时,要尽可能收集用户需求
角色模拟任务
相关任务场景
- 基于角色的对话(Character-based Dialogue):即角色扮演对话,用 LLM 模仿特定角色的行为和表达风格。
- 比如,Shao 等人从 Wikipedia 收集角色信息,通过提示 ChatGPT 生成基于这些角色的对话;Wang 等人使用 GPT-4 创建角色描述,并制定详细提示规则来生成角色对话。不过,这些方法多依赖 ChatGPT 的生成能力,可能无法精准展现角色真实性格。
- 相比之下,Li 等人从小说、剧本和游戏中提取角色扮演对话,更利于保留角色原始特征,但该方法缺乏人工干预导致数据质量不高,且数据集中多轮对话数量较少,难以全面评估 RPCA。
- 知识型对话系统(Knowledge-based Dialogue): 整合外部知识资源,像知识图谱或非结构化文档等,让对话系统能依据这些知识进行交流。
- 比如,Xue 等人提出的 K-DIAL,通过在 Transformer 中增加额外的前馈网络(FFN)模块,来增强对话中事实知识的表达和一致性。
- 其重点在于提升模型对知识的理解与运用,但主要针对通用知识,而角色扮演对话还需要涉及更复杂的个性化知识、风格和行为等。
- 个性化对话系统(Personalized Dialogue):依据特定人物特征生成回复。
- Zheng 等人创建了首个大规模带人物标签的个性化对话数据集,推动了该领域发展。这些研究虽开始探索对话中的个性化特征,但所用的人物信息多局限于短期的个人相关简单信息,如姓名、年龄、地点等,本质上属于个性化知识范畴,与角色扮演对话中对角色复杂性格和行为的模拟要求有所差异。
模拟器结构
典型的用户模拟器和对话系统的结构比较相似,包含以下 4 个基本组成部分:
- 用户目标(User Goal):用户模拟的第一步是生成一个用户对话的目标,对话系统对此是不可知的,但它需要通过多轮对话交互来帮助用户完成该目标。
- 一般来说,用户目标的定义和两种槽位相关:
- 可告知槽(informable slots)形如“槽=值”是用户用于查询的约束条件
- 可问询槽(requestable slots)用户希望向系统问询的属性。 - 例如:用户目标是 “inform(type=movie, genre=action, location=San Francisco, date=this weekend),request(price)”表达的是用户的目标是想要找一部本周在 San Francisco 上映的动作片,找到电影后再进一步问询电影票的价格属性。有了明确的对用户目标的建模,我们就可以保证用户的回复具有一定的任务导向,而不是闲聊。
- 用户模型(User Model):用户模型对应着对话系统的对话管理模块,它的任务是根据对话历史生成当前的用户动作。用户动作是预先定义好的语义标签,例如“inform, request, greet, bye”等等。用户动作的选择应当合理且多样,能够模拟出真实用户的行为。用户模型是用户模拟器的核心组成部分,在接下来的章节里我们将会详细介绍各种具体模型和方法。
- 误差模型(Error Model):它接在 User Model 下游,负责模拟噪声,对用户行为进行扰动以模拟真实交互环境下不确定性。
- (1)简单的方式有:随机用不正确的意图替换正确的意图、随机替换为不正确的槽位、随机替换为不正确的槽值等;
- (2)复杂的方式有模拟基于 ASR 或 NLU 混淆的错误。
- 自然语言生成(NLG):如果用户模拟器需要输出自然语言回复,就需要 NLG 模型将用户动作转换成自然语言表述。
- 例如用户动作标签“inform(type=movie, genre=action, date=this weekend)” 进行 NLG 模块后生成自然语句“Are there any action movies to see this weekend?”。
- 【2021-2-4】用户模拟器由 3个部分组成: User State Tracker、User Policy 和 User Model. 其中 User Model 可以针对不同的任务设定不同的参数,
- 比如:生成对话数据,对话评测,它们的 Goal 和 Profile 都可以不一样,这样既保证是一套统一的建模框架,同时又保证了系统的灵活性。
用户模拟器实现方法
- 用户模拟器的实现方法大致分成两类:
- 基于规则的方法
- 基于模型学习的方法。
- 总结
- 优点:可以冷启动,用户行为完全可控
- 缺点:需要专家手动构建,代价大,覆盖度不够,在对话行为灵活性和多样性上比较不足
- 使用场景
- 话术简单清晰的填槽式对话任务
基于规则的方法
- 基于规则的方法需要专家手动构建
- 优点是可以冷启动,用户行为完全可控;
- 缺点是代价大,覆盖度不够,在对话行为灵活性和多样性上比较不足,适用于话术简单清晰的填槽式对话任务。
- 基于规则的方法中使用最为广泛的是基于议程(Agenda-based)的方法 [2, 3],该方法对用户状态表示、状态转移、Agenda 更新、Goal 更新进行了精细建模,逻辑清晰,可落地性强,业界很多工作 [1, 15] 都基于该方法进行扩展和优化。
- 基于议程的方法通过一个栈的结构把对话的议程定下来,对话的过程就变成进栈和出栈的动作,上下文关联性很强,保证了用户动作生成的一致性,一般不会出现异常用户行为。但是,该方法在对话行为灵活性和多样性比较欠缺,在实操层面可以通过引入一些随机性提升灵活度。
- 基于议程的方法
- 代表论文:The Hidden Agenda User Simulation Model, 论文链接
基于议程(Agenda-based)的方法
- The hidden agenda user simulation model——通过一个栈的结构把对话的议程定下来,对话的过程就变成进栈和出栈的动作,上下文关联性很强,保证了用户动作生成的一致性,一般不会出现异常用户行为。
- Agenda-based user simulation for bootstrapping a POMDP dialogue system
- Task-oriented Dialogue System for Automatic Diagnosis
- A User Simulator for Task-Completion Dialogues
基于模型的方法
- 总结
- 优点:
- 一般效果优于基于议程的规则方法,数据驱动,节省人力
- 缺点:
- 复杂对话建模困难,对数据数量要求很高,因此对于一些对话语料稀缺的领域效果很差
- 适用场景
- 语料丰富的领域
- 优点:
端到端有监督学习
- A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems——将对话上下文序列作为输入,然后输出用户动作序列。
- Neural User Simulation for Corpus-based Policy Optimization for Spoken Dialogue Systems——提出了基于 RNN 的 Neural User Simulator (NUS) 模型。首先 NUS 通过用户目标生成器,对原对话数据中的对话状态标签进行预处理,得到一个完整对话中每一轮的具体用户目标,这样就相当于对用户目标改变进行了某种程度上的建模。
联合优化策略
Iterative Policy Learning in End-to-End Trainable Task-Oriented Neural Dialog Models——对用户模拟器和对话系统分别采用了 RNN 进行端到端的建模并使用同一个回报函数优化,两者交替训练共同最大化累计回报。
逆强化学习
User Simulation in Dialogue Systems using Inverse Reinforcement Learning——在马尔科夫决策过程 (MDP) 的框架下, 强化学习在是回报函数(reward function)给定下,找出最优策略以最大化累计反馈,而逆强化学习(Inverse reinforcement learning, IRL)就是通过给出最优策略估计出回报函数。
协同过滤方法
Collaboration-based User Simulation for Goal-oriented Dialog Systems——在有高质量语料库的情况下,我们可以考虑直接根据对话上下文,从语料库中推荐出最恰当的用户语句作为用户模拟器的回复。
问题及挑战
用户模拟器面临的挑战
- 对话行为一致性(Coherence):对话行为要保证前后连贯,符合语境,避免出现不符合逻辑的对话行为。如何综合考虑对话上下文和 User Goal 等因素,保证用户行为序列在多轮交互过程中的一致性是一个有挑战的课题。
- 对话行为多样性(Diversity):模拟用户群的行为特性,需要建模这个群体的行为分布。例如某用户群是健谈的还是寡言的,是犹豫的还是果断的,各部分占比多少,这里引入用户群体画像特征,使得用户模拟器的行为更加丰富多样,贴近目标用户群体。这个方向学术界有一些研究进展,值得继续深入研究。
- 对话行为的泛化性(Generalization):目前来看,无论是基于规则方法还是基于模型学习的用户模拟器,在遇到语料中未曾出现的对话上下文时,表现出的泛化能力依旧比较有限。对话行为的泛化性直接体现了用户模拟器是否表现得如同真实用户一样处理更多未见的复杂的对话场景。这个方向有待学界更深入的探索。
评测
- 好的用户模拟器的评价方式要满足:
- 能够衡量生成的对话动作的一致性;
- 评价方式和具体的任务无关;
- 从目标信息中自动化地计算出一个标量值,而无需人工干预。
- 评价指标分为单轮度量 (turn-level metrics) 和对话度量 (dialog-level metrics)。
- 单轮级别度量:主要针对用户动作的语义标签,最常见度量是精确率,召回率和 F1 得分,对于每一轮可以计算:

- 以上的度量不能评估用户模型泛化能力,例如某个用户动作是合理的但因为在对话数据中并未出现,如果预测了就会导致得分低。因此还可以将用户动作的预测概率分布P和真实概率分布 Q 之间的 KL 距离作为度量,从概率分布上评估用户预测模型的合理性。
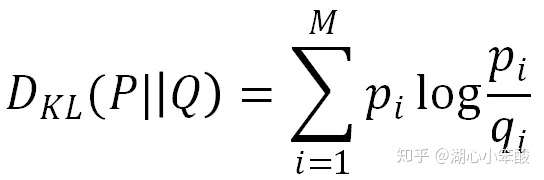
- 类似地,也可以用对数似然值或者混淆度(perplexity)来评估。
- 对话级别的度量:最常用的是任务完成率和平均对话轮数。
- 将用户模型和对话系统进行真实交互,完成训练后的对话系统所能达到的任务完成率(通过记录对话系统是否完成用户目标得到)和平均每个对话的轮数可以作为评价与用户模型整体效果的有效指标。
- 单轮级别度量:主要针对用户动作的语义标签,最常见度量是精确率,召回率和 F1 得分,对于每一轮可以计算:
【2025-6-25】万字长文梳理 2025 最新 LLM 角色扮演评测方法
- 角色类型 :包含 135 个不同角色,分为名人(35 个)、虚构角色(70 个)、日常生活(17 个)、情感陪伴(13 个)四类。
- 对话数据 :共有 1350 组对话,其中短对话 1080 组、长对话 270 组;总 utterance 数为 40518 个,短对话平均 21.22 个轮次,长对话平均 65.18 个轮次
评价维度
评价维度是对模型性能进行细分的标准,在角色扮演中,通常关注:
- 角色一致性:模型生成的响应是否与角色设定一致
- 情感表达:模型是否能够正确表达角色的情感
- 上下文理解:模型是否能够理解对话上下文并做出合适的回应
- 创造性:模型生成的内容是否具有创新性和趣味性
评价指标
评价指标是模型在具体维度上性能的量化标准,常见于人工评价、自动评价,和模型评估三种形式:
- 人工评价:人类评估员在与模型对聊后(或基于模型生成的对话),对模型的性能进行打分(比较主观)
- 客观指标(自动评价,客观):基于模型生成的对话,设计可使用公式直接计算的客观指标对模型性能进行评估(比较客观,但依赖指标制定的合理性)
- 模型评估(自动评价,主观):使用高性能大模型(比如 GPT-4)对模型生成的对话进行打分(比较主观,并且依赖评价模型本身的性能、提示词的质量等因素)
数据集
数据源
- 角色原型数据 :从百度百科等平台收集 135 个角色的基本信息,涵盖娱乐明星、历史人物、行业名人、影视及动漫角色等,同时参考了游戏、电影、小说等的粉丝群体意见,选取富有代表性和知名度的角色。
- 对话数据 :通过众包工人模拟用户与角色进行对话生成数据,利用大型语言模型(LLM)辅助生成对话草案,再由人工进行标注和修正。
- 角色档案收集 :针对不同类型的常见角色,手动筛选和验证角色信息,生成基本属性,再进行细致调整,包括性格特点、兴趣爱好、人物经历等。
| 名称 | 作者 | 发表 | 地址 | 说明 |
|---|---|---|---|---|
| CharacterEval | 人大高瓴、北邮等 | ACL 2024 | GitHub:CharacterEval | 人物角色扮演对话智能体(RPCA)评估基准,包含 1,785 多轮角色扮演对话,涵盖 11,376 示例和 77 个中文小说及剧本中的角色 |
| SocialBench | 中山大学+阿里巴巴 | — | SocialBench | |
| EmoCharacter | 复旦大学 | NAACL 2025 | — | 情感保真度 |
| DMT-RoleBench | 复旦大学 | AAAI 2025 | DMT-RoleBench | |
| RAIDEN Benchmark | 北大软微+腾讯 | Coling 2025 | RAIDEN | — |
CharacterEval
CharacterEval 是一个人物角色扮演对话智能体(RPCA)评估基准,包含 1,785 多轮角色扮演对话,涵盖 11,376 示例和 77 个中文小说及剧本中的角色。 它通过多维度的评估方式,包括对话能力、角色一致性、角色扮演吸引力和人格回测四大维度共十三项指标,全面衡量 RPCA 的表现。其中,对话能力关注流畅性、连贯性和一致性,角色一致性涵盖知识和人格两个层面,角色扮演吸引力从用户角度评估人类相似度等要素,人格回测则通过 MBTI 评估模型的角色扮演能力。 为方便评估主观指标,还开发了基于人工标注的角色扮演奖励模型 CharacterRM,其与人类判断的相关性优于 GPT-4。
对话能力、角色一致性、角色扮演吸引力和人格测评

评价方法
- 客观指标:如流畅性、连贯性等,可通过预训练的神经模型进行评估,基于模型的输出判断语句是否通顺、是否符合语法规范,以及回应与上下文主题的相关性。
- 主观指标:如人格一致性和角色扮演吸引力等,采用人工标注的方式进行打分,邀请 12 名标注者对模型生成的回应进行评分,基于这些评分开发了角色扮演奖励模型 CharacterRM,通过训练使其与人类判断具有更高的相关性,以实现对主观指标的量化评估。
SocialBench
SocialBench 是一个用于系统评估角色扮演对话智能体在个体和群体层面上社交智能的基准测试工具。 它涵盖了 500 个角色,超过 6000 个问题提示和 30800 个多轮对话话语。 该基准从个体水平(包括自我认知、情感感知和长期对话记忆)和群体水平(社会偏好)两个层面,通过多种评价指标(如单选题准确率、多选题准确率和关键词覆盖率)来全面衡量智能体的社交能力。 SocialBench 为角色扮演对话智能体的社交智能评估提供了一个全面且详细的框架。
Focus:角色扮演对话智能体在个体和群体层面上的社交智能
评价维度分为个体水平和群体水平:
- 个体水平:包括自我认知、情感感知,以及长期对话记忆等方面。
- 自我认知(Self-Awareness):包括角色风格认知(SA Style)和角色知识认知(SA Know.)。评估智能体对角色风格和知识的理解和保持能力。
- 情感感知(Emotional Perception):包括情境理解(EP Situ.)和情感检测(EP Emo.)。评估智能体对情感的理解和感知能力。
- 长期对话记忆(Conversation Memory):包括短期记忆(CM Short)和长期记忆(CM Long)。评估智能体在对话中记忆和引用之前内容的能力。
- 群体水平:即社会偏好(Social Preference):包括积极偏好(Pos.)、中性偏好(Neu.)和消极偏好(Neg.)。评估智能体在群体互动中表现出的社会偏好和行为。
评价指标
- 单选题准确率
- 多选题准确率
- 关键词准确率
EmoCharacter
EmoCharacter 是用于评估角色扮演智能体(RPAs)在对话中情感保真度的基准测试。 它包含两个基准数据集(单轮和多轮对话数据集)、三种评估设置和六个评估指标。 EmoCharacter 通过系统化地评估情感保真度,帮助研究人员更好地理解和改进 RPAs 的情感智能。
Focus:大模型在角色扮演对话中情感保真度
EmoCharacter 的数据来源于经典美剧《老友记》的剧本。该剧本提供了丰富的对话场景和角色情感表达,适合作为评估 RPAs 情感保真度的基础数据。
评价维度
- 微观情感保真度:关注 RPAs 在对话中每个话语所附情感与原始角色的一致性。
- 宏观情感保真度:关注 RPAs 在对话中的情感转换分布是否与原始角色一致,同时捕捉不同角色之间的情感差异。
评价指标
- EmoCharacter 提出了 7 种评估指标,全部采用自动评价的方式,用于全面衡量角色扮演智能体(RPAs)的情感保真度。这些指标从微观和宏观两个层面进行评估
DMT-RoleBench
DMT-RoleBench 是一个基于动态多轮对话的角色扮演能力评估基准,用于系统且全面地评估大型语言模型和智能体在真实交互场景下的角色扮演能力。 它包含 996 个样本的多轮种子数据集,涵盖 6 种角色类型、7 种评估意图及多种系统提示格式,通过动态生成多轮对话并结合 DMT-RM 评价模型和 DMT-Score 评分方法,从基本能力、对话能力和模仿能力三个维度的 14 个子指标对模型进行评估,以量化模型的角色扮演性能。
Focus:通过动态生成多主题、多类型的对话来评价模型的角色扮演能力。
6 种不同的角色类型的来源:
- 角色原型数据来源 :主要从影视、小说、电视剧、历史人物、专业职业、情感陪伴角色、工具类助手和互动游戏非玩家角色中获取灵感。其中,影视、小说、电视剧角色主要来源于豆瓣 Top 排行榜的华语影视和经典文学作品,利用百度百科、豆瓣和 OpenKG 等数据仓库,收集角色的个性特征、人际关系和主要生活事件等属性,形成综合的角色档案。
- 历史人物数据来源 :从中国历史中选取不同时期和学科领域的杰出代表人物,借助百度百科和 OpenKG 等平台类似的数据聚合技术,丰富其个人资料。
- 互动游戏角色及其他角色数据来源 :主要由高度定制的设置构成,在构建这些角色档案时,首先参考角色扮演游戏应用中的分类,然后利用 GPT-4 等最新模型进行数据合成和增强。
DMT-RoleBench 从三个维度(基本能力、对话能力、模仿能力)评价模型的 14 种具体性能
- 基本能力(Basic Ability) :
- 角色体现(Role Embodying, RE) :评估模型是否能有效体现角色,如同影视角色和历史人物,若模型暴露 AI 身份或以第三人称描述角色则表现不佳。
- 指令遵循(Instruction Following, IF) :考察模型是否能遵循系统提示。
- 对话能力(Conversational Ability) :
- 流畅性(Fluency, Flu.) :与 CharacterEval 一致,评估对话的自然流畅程度。
- 连贯性(Coherence, Coh.) :与 CharacterEval 一致,考察对话内容的连贯性。
- 一致性(Consistency, Cons.) :与 CharacterEval 一致,判断模型在对话中保持信息和立场一致性的能力。
- 多样性(Diversity, Div.) :与 CharacterEval 一致,衡量对话内容的丰富多样性。
- 人类相似度(Human Likeness, HL) :与 CharacterEval 一致,评价对话是否像人类的表达方式。
- 模仿能力(Imitation Ability) :
- 知识准确性(Knowledge Accuracy, KA) :与 CharacterEval 一致,确保模型提供信息的准确性。
- 知识幻觉(Knowledge Hallucination, KH) :与 CharacterEval 一致,判断模型是否产生不真实或不相关的信息。
- 知识暴露(Knowledge Exposure, KE) :与 CharacterEval 一致,关注模型在对话中适当展示知识的能力。
- 共情(Empathy, Emp.) :与 CharacterEval 一致,考察模型对用户情感的理解和回应能力。
- 个性特质(Personality Trait, PT) :评估模型模仿角色语言风格和个性特质的能力。
- 互动性(Interactivity, Inte.) :评价模型主动互动的能力,能否推动对话进行、维持参与度和促进协作对话体验。
- 游戏完成度(Game Completion Degree, GCD) :评估模型在游戏场景中组织和推动游戏进程的能力。
RAIDEN Benchmark
RAIDEN Benchmark 是一个专为角色扮演对话代理(RPCA)评估而设计的基准测试,旨在通过测量驱动的定制对话来评估模型的表现。 它包含一个全面的数据集,涵盖 135 个角色和超过 40,000 个对话轮次,重点评估模型的自我认知和对话能力。 该基准通过模型与标注者之间的交互进行评估,以减少对话评估中的主观性。 此外,RAIDEN Benchmark 还引入了 RPCAJudger,一个专门用于自动 RPCA 评估的判断模型,其评估结果与人工判断高度一致,且无需 API 即可防止潜在的数据泄露。
Focus:评估模型在角色扮演对话中的自我认知和对话能力
google-research-datasets
google-research-datasets simulated-dialogue
用户模拟的数据集,包括:
- 餐馆预订
- 电影票预定
We are releasing two datasets containing dialogues for booking a restaurant table and buying a movie ticket. The number of dialogues in each dataset are listed below.
| Dataset | Slots | Train | Dev | Test |
|---|---|---|---|---|
| Sim-R (Restaurant) | price_range, location, restaurant_name, category, num_people, date, time |
1116 | 349 | 775 |
| Sim-M (Movie) | theatre_name, movie, date, time, num_people |
384 | 120 | 264 |
| Sim-GEN (Movie) | theatre_name, movie, date, time, num_people |
100K | 10K | 10K |
源自:Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems uses Sim-GEN
Sim-GEN
Simulator Generated Dataset (sim-GEN)
This directory contains an expanded set of dialogues generated via dialogue self-play between a user simulator and a system agent, as follows:
- The dialogues collected using the M2M framework for the movie ticket booking task (sim-M) are used as a seed set to form a crowd-sourced corpus of natural language utterances for the user and the system agents.
- Subsequently, many more dialogue outlines are generated using self-play between the simulated user and system agent.
- The dialogue outlines are converted to natural language dialogues by replacing each dialogue act in the outline with an utterance sampled from the set of crowd-sourced utterances collected with M2M.
In this manner, we can generate an arbitrarily large number of dialogue outlines and convert them automatically to natural language dialogues without any additional crowd-sourcing step. Although the diversity of natural language in the dataset does not increase, the number of unique dialogue states present in the dataset will increase since a larger variety of dialogue outlines will be available in the expanded dataset.
This dataset was used for experiments reported in this paper.
The data splits are made available as a .zip file containing dialogues in JSON format. Each dialogue object contains the following fields:
- dialogue_id - string unique identifier for each dialogue.
- turns - list of turn objects:
- system_acts - list of system dialogue acts for this system turn:
- name - string system act name
- slot_values - optional dictionary mapping slot names to values
- system_utterance - string natural language utterance corresponding to the system acts for this turn
- user_utterance - string natural language user utterance following the system utterance in this turn
- dialogue_state - dictionary ground truth slot-value mapping after the user utterance
- database_state - database results based on current dialogue state:
- scores - list of scores, between 0.0 and 1.0, of top 5 database results. 1.0 means matches all constraints and 0.0 means no match
- has_more_results - boolean whether backend has more matching results
- has_no_results - boolean whether backend has no matching results
- system_acts - list of system dialogue acts for this system turn:
An additional file db.json is provided which contains the set of values for each slot.
Note: The date values in the dataset are normalized as the constants, “base_date_plus_X”, for X from 0 to 6. X=0 corresponds to the current date (i.e. ‘today’), X=1 is ‘tomorrow’, etc. This is done to allow handling of relative references to dates (e.g. ‘this weekend’, ‘next Wednesday’, etc). The parsing of such phrases should be done as a separate pre-processing step.
Sim-M
Each dialogue is represented as a json object with the following fields:
- dialogue_id - A unique identifier for a dialogue.
- turns - A list of annotated agent and user utterance pairs having the
following fields:
- system_acts - A list of system actions. An action consists of an
action type, and optional slot and value arguments. Each action has the
following fields:
- type - An action type. Possible values are listed below.
- slot - Optional slot argument.
- value - Optional value argument. If value is present, slot must be present.
- system_utterance - The system utterance having the following
fields.
- text - The text of the utterance.
- tokens - A list containing tokenized version of text.
- slots - A list containing locations of mentions of values
corresponding to slots in the utterance, having the following
fields:
- slot - The name of the slot
- start - The index of the first token corresponding to a slot value in the tokens list.
- exclusive_end - The index of the token succeeding the last
token corresponding to the slot value in the tokens list. In
python,
tokens[start:exclusive_end]gives the tokens for slot value.
- user_acts - A list of user actions. Has the same structure as system_acts.
- user_utterance - The user utterance. It has three fields, similar to system_utterance.
- user_intents - A list of user intents specified in the current turn. Possible values are listed below.
- dialogue_state - Contains the preferences for the different slots
as specified by the user upto the current turn of the dialogue.
Represented as a list containing:
- slot - The name of the slot.
- value - The value assigned to the slot.
- system_acts - A list of system actions. An action consists of an
action type, and optional slot and value arguments. Each action has the
following fields:
The list of action types is inspired from the Cambridge dialogue act schema (DSTC2 Handbook, Pg 19) . The possible values are:
- AFFIRM
- CANT_UNDERSTAND
- CONFIRM
- INFORM
- GOOD_BYE
- GREETING
- NEGATE
- OTHER
- NOTIFY_FAILURE
- NOTIFY_SUCCESS
- OFFER
- REQUEST
- REQUEST_ALTS
- SELECT
- THANK_YOU
The possible values of user intents are:
- BUY_MOVIE_TICKETS
Sim-R
Each dialogue is represented as a json object with the following fields:
- dialogue_id - A unique identifier for a dialogue.
- turns - A list of annotated agent and user utterance pairs having the
following fields:
- system_acts - A list of system actions. An action consists of an
action type, and optional slot and value arguments. Each action has the
following fields:
- type - An action type. Possible values are listed below.
- slot - Optional slot argument.
- value - Optional value argument. If value is present, slot must be present.
- system_utterance - The system utterance having the following
fields.
- text - The text of the utterance.
- tokens - A list containing tokenized version of text.
- slots - A list containing locations of mentions of values
corresponding to slots in the utterance, having the following
fields:
- slot - The name of the slot
- start - The index of the first token corresponding to a slot value in the tokens list.
- exclusive_end - The index of the token succeeding the last
token corresponding to the slot value in the tokens list. In
python,
tokens[start:exclusive_end]gives the tokens for slot value.
- user_acts - A list of user actions. Has the same structure as system_acts.
- user_utterance - The user utterance. It has three fields, similar to system_utterance.
- user_intents - A list of user intents specified in the current turn. Possible values are listed below.
- dialogue_state - Contains the preferences for the different slots
as specified by the user upto the current turn of the dialogue.
Represented as a list containing:
- slot - The name of the slot.
- value - The value assigned to the slot.
- system_acts - A list of system actions. An action consists of an
action type, and optional slot and value arguments. Each action has the
following fields:
The list of action types is inspired from the Cambridge dialogue act schema (DSTC2 Handbook, Pg 19). The possible values are:
- AFFIRM
- CANT_UNDERSTAND
- CONFIRM
- INFORM
- GOOD_BYE
- GREETING
- NEGATE
- OTHER
- NOTIFY_FAILURE
- NOTIFY_SUCCESS
- OFFER
- REQUEST
- REQUEST_ALTS
- SELECT
- THANK_YOU
The possible values of user intents are:
- FIND_RESTAURANT
- RESERVE_RESTAURANT
多模态评测集
【2025-1-13】人大高瓴人工智能学院陈旭团队构建包含多模态信息的角色扮演能力数据集,其中包括 85 个角色、11000 张图片和 14000 段对话数据。
- MMRole:A COMPREHENSIVE FRAMEWORK FOR DEVELOPING AND EVALUATING MULTIMODAL ROLE-PLAYING AGENTS。
- MMRole:开发和评估多模态角色扮演代理的完整框架
角色扮演能力评测指标,包括图文匹配准确度和回复精准度等。
论文解读
Dual Task Framework for Improving Persona-grounded Dialogue Dataset
摘要:
- This paper introduces a simple yet effective data-centric approach for the task of improving persona-conditioned dialogue agents. Prior model-centric approaches unquestioningly depend on the raw crowdsourced benchmark datasets such as Persona-Chat. In contrast, we aim to fix annotation artifacts in benchmarking, which is orthogonally applicable to any dialogue model. Specifically, we augment relevant personas to improve dialogue dataset/agent, by leveraging the primal-dual structure of the two tasks, predicting dialogue responses and personas based on each other. Experiments on Persona-Chat show that our approach outperforms pretrained LMs by an 11.7 point gain in terms of accuracy
You Impress Me: Dialogue Generation via Mutual Persona Perception
- You Impress Me: Dialogue Generation via Mutual Persona Perception
- April 11, 2020,作者主页
- 个性化对话生成(Personalized Dialogue Generation)是对话生成领域近几年的一个研究热点(Zhang et al. 2018)。个性的引入可以帮助对话生成模型产生更一致的、更有趣的回复。然而大部分工作仍像对待普通开放域对话生成那样,关注模型生成回复的流畅性,较少关注对话中对话者之间的互动和了解。相比于已有工作,我们显式地建模了对话者之间的了解,从而使得对话生成的结果更加有趣,且更加符合对话者的个性。
- 这篇论文提出了一个 Transmitter-Receiver 的框架来显式建模对话者之间的了解,其中 Transmitter 负责对话生成,而 Receiver 负责个性了解。在这个框架下,我们引入一个新颖的概念“相互个性感知”,来刻画对话者之间的信息交流,即对话者对彼此个性的了解程度。众所周知,高效的沟通能够让对话的双方充分了解并达成共识,所以相互个性感知的提升在一定程度上也代表了对话质量的提高。为了达成这个目标,我们首先按照传统的监督学习来训练Transmitter,然后让两个训练好的 Transmitter 通过互相对话进行自我学习(self-play)。在它们对话若干轮后,借助 Receiver 提供的个性感知奖励微调 Transmitter。


原文:
解读ppt
2021 ACL Transferable Dialogue Systems and User Simulators
Transferable Dialogue Systems and User Simulators
- 对话系统训练的困难之一:缺乏训练数据 –> 通过对话系统与用户模拟器之间的交互来自学习
- One of the difficulties in training dialogue systems is the lack of training data. We explore the possibility of creating dialogue data through the interaction between a dialogue system and a user simulator. Our goal is to develop a modelling framework that can incorporate new dialogue scenarios through self-play between the two agents. In this framework, we first pre-train the two agents on a collection of source domain dialogues, which equips the agents to converse with each other via natural language. With further fine-tuning on a small amount of target domain data, the agents continue to interact with the aim of improving their behaviors using reinforcement learning with structured reward functions. In experiments on the MultiWOZ dataset, two practical transfer learning problems are investigated:
- 1) domain adaptation and
- 2) single-to-multiple
- domain transfer. We demonstrate that the proposed framework is highly effective in bootstrapping the performance of the two agents in transfer learning. We also show that our method leads to improvements in dialogue system performance on complete datasets.
评测
RPEval
【2025-5-19】法国里尔大学 新型基准测试 RPEval,系统性地评估大语言模型(LLM)角色扮演能力
单轮互动 (Single-turn Interactions): 评估不采用复杂的多轮对话,而是让模型根据一个角色设定和来自另一角色的单条信息进行回应 。
四大评估维度: RPEval专注于四个可以在单轮互动中有效评估的核心维度 :
- 情绪理解 (Emotional Understanding): 评估模型能否准确解读并反映角色的情感状态 。
- 决策制定 (Decision-Making): 评估模型的选择是否与其角色的目标和背景相符 。
- 道德对齐 (Moral Alignment): 评估模型的行为是否与角色的道德价值观保持一致 。
- 角色内一致性 (In-Character Consistency): 评估模型能否坚守角色设定,避免泄露其不应知道的“超游”知识(即上下文之外的知识) 。
CoSER
【2025-2-13】
基于小说书籍提取角色扮演数据,并提出给定情境表演 (Given-Circumstance Acting, GCA)的角色扮演评测方法
COSER角色扮演数据集
- 全球知名的读书社区Goodreads的771本人气书籍作为数据源
- 内容分块 (Chunking)
由于书籍全文很长,无法直接输入LLM,论文采用了一种结合静态与动态的策略对文本进行分块:
- 静态分块:首先根据章节标题进行初步切分
- 动态分块:为了避免故事情节或关键对话被截断,在后续数据提取过程中,LLM会判断当前区块的结尾是否存在未完结的情节,并将其与下一个区块内容合并,以保证情节的完整性
GCA模型训练 (GCA Training) 目标:利用COSER数据集对基础LLM(如LLAMA-3.1)进行微调,从而开发出专门用于角色扮演的COSER 8B和COSER 70B模型 。
训练方式:
- 从数据集中选取一段对话和一个特定角色,构建一个训练样本。
- 为该角色生成一条详细的角色扮演指令,包含场景描述、角色自己的档案和动机、以及对话中其他角色的档案等,为模型提供充分的上下文。
- 在对话历史作为输入的前提下,模型被训练来生成该角色在原著中的真实发言(包括内心想法和动作),而其他角色的发言则作为上下文输入。
通过这种方式,模型学会在特定情境下,像“演员”一样说出符合角色身份的话。
四大评估维度:为了进行全面评估,缺陷的识别会在四个独立的维度上进行。
- 拟人化 (Anthropomorphism):评估角色的行为是否像一个真正的人,包括是否有自我认同、情感深度和社交互动能力等 。
- 角色保真度 (Character Fidelity):评估模型扮演的角色是否忠于原著设定,包括语言风格、背景知识、性格行为是否一致 。
- 故事线质量 (Storyline Quality):评估模拟对话本身是否流畅、合乎逻辑,是否存在冗余、矛盾或不自然的进展 。
- 故事线一致性 (Storyline Consistency):将模拟对话与原著对话进行对比,评估角色的反应(情绪、态度、行为)是否与原始情境保持一致 。
角色库合成
PersonaHub
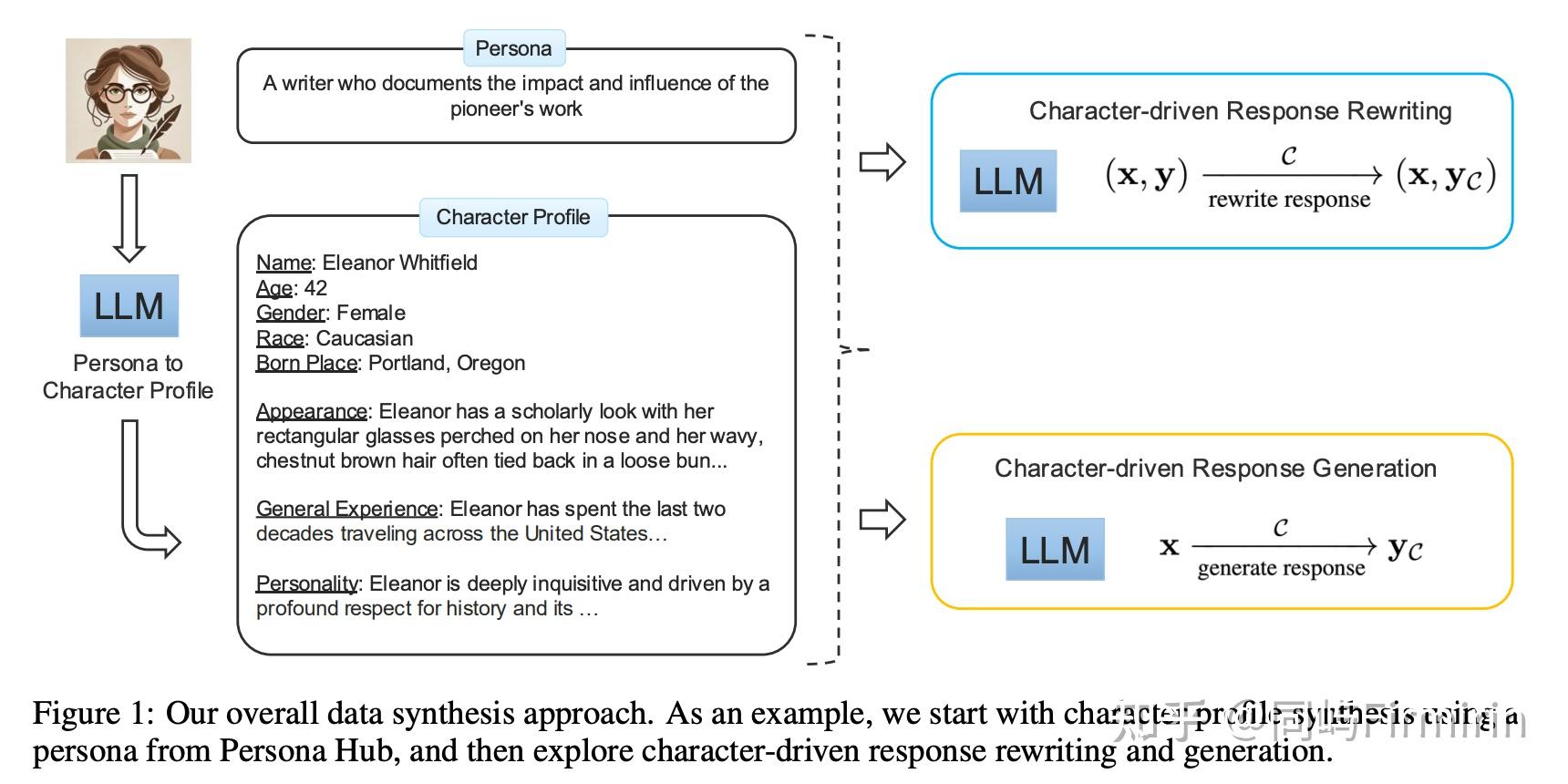
【2024-6-28】腾讯AI Lab PersonaHub 2406
全新、以“角色”(Persona)为驱动的合成数据生成方法,并为此构建了名为 Persona Hub 的庞大角色库(10亿+)
LLM 角色模拟
【2024-5-30】用 LLM 的 Agent 方案实现用户模拟器
LLM Roleplay
LLM Roleplay 2410
【2024-7-4】德国 UKP Lab
利用大型语言模型(LLM)扮演具有特定“角色”(persona)的用户,与另一个聊天机器人进行以完成特定“目标”(goal)为导向的对话
【2024-12-7】CharacterBox
【2024-12-7】人大、微软亚洲研究院、北大
专为评估LLM角色扮演能力而设计的动态、多智能体交互式虚拟世界(或称为模拟沙盒) 。
核心思想
- 通过模拟生成情景化、细粒度的角色行为轨迹,从而对模型的角色扮演能力进行更全面、更深入的评估 。
核心组件
- 角色代理 (Character Agent):由被评估的LLM控制。它基于心理学和行为科学(特别是BDI模型:Belief-Desire-Intention)进行设计,拥有记忆模块,能够像人类一样在特定场景中进行思考和行动 。
- 叙述者代理 (Narrator Agent):它扮演着“世界模型”或“游戏主持人”的角色 。负责协调角色之间的互动、分析角色行为产生的影响,并实时更新环境状态和角色状态 。
三阶段工作流程
- 场景构建 (Scene Crafting)为了避免LLM直接复现其训练数据中已有的内容(即数据污染问题) ,CharacterBox强调生成原创的高质量场景。研究者设计了一个三阶段流程,让LLM扮演“编剧”、“导演”和“评估员”的角色,以确保生成的场景富有创意、逻辑连贯且细节丰富
- 自主故事演绎 (Autonomous Story Play)
CharacterBox 生成的高质量行为轨迹不仅可以用于评估,还可以反过来用于提升LLM的角色扮演能力 。论文提出了两种微调方法:
- 引导式轨迹微调 (Guided Trajectory Fine-tuning):从表现优异的“教师模型”(如GPT-4)中收集高质量的行为轨迹,然后用这些轨迹来微调“学生模型”(如一个7B参数量的模型)。实验证明,这种方法能显著提升学生模型的角色扮演能力 。
- 反思式轨迹微调 (Reflective Trajectory Fine-tuning):利用LLM自身的反思能力。模型首先生成自己的行为轨迹,然后分析这些轨迹中的不一致之处和可改进点,并对其进行重写和优化。最后,使用这些经过“反思”和改进的轨迹来微调模型自身。实验表明,这种方法的效果甚至优于引导式微调 。
两个经过微调的、更小的开源模型来替代昂贵的大模型 GPT-4:
- CharacterNR (Narrator):研究者使用GPT-3.5生成的数据,在7B参数量的Qwen2.5模型上微调,得到了CharacterNR 。其表现可与GPT-3.5相媲美,甚至在某些方面更优 。
- CharacterRM (Reward Model):研究者使用GPT-4的评分作为标签,在6B参数量的ChatGLM3模型上微调,得到了CharacterRM 。其评分结果与人类专家的相关性(0.610)已非常接近GPT-4(0.688),证明了其可靠性。
通过这两个组件,CharacterBox实现了一个成本效益高且自包含的评估流程,摆脱了对昂贵API的依赖
OpenCharacter
【2025-2-18】腾讯AI Lab
让LLM学会Character Generalization 能力,扮演用户指定的、在训练中从未见过的任意角色的能力。
认为需要用一个包含海量不同角色的高质量数据集来训练模型(LLM合成)
基于已有数据集的prompt进行重新标注:
- 第一步:使用LLM扩写 Persona Hub 人格数据库(2w+)
- 第二步:结合扩写后的人设,对已有sft数据进行重新标注
- 策略1,输入:人设+prompt+response,输出:response
- 策略2,输入:人设+prompt,输出:response
【2024-6-9】LD-Agent
【2025-7-29】万字分享大模型角色扮演2025最新工作 llm role-play
【2024-6-9】新加坡国立、中科大
解决当前聊天机器人在长时间、多轮对话中的“金鱼记忆”和人格不一致的问题。
主要涉及两个问题:
- 长期事件记忆 (Long-term Event Memory):机器人需要记住过去多次对话中发生的关键事件,以保持对话的连贯性
- 人格一致性 (Persona Consistency):机器人需要动态地理解和更新用户的人格特质,并保持自身人格的一致性,从而提供更个性化的回复
LD-Agent:Long-term Dialogue Agent 长期对话智能体
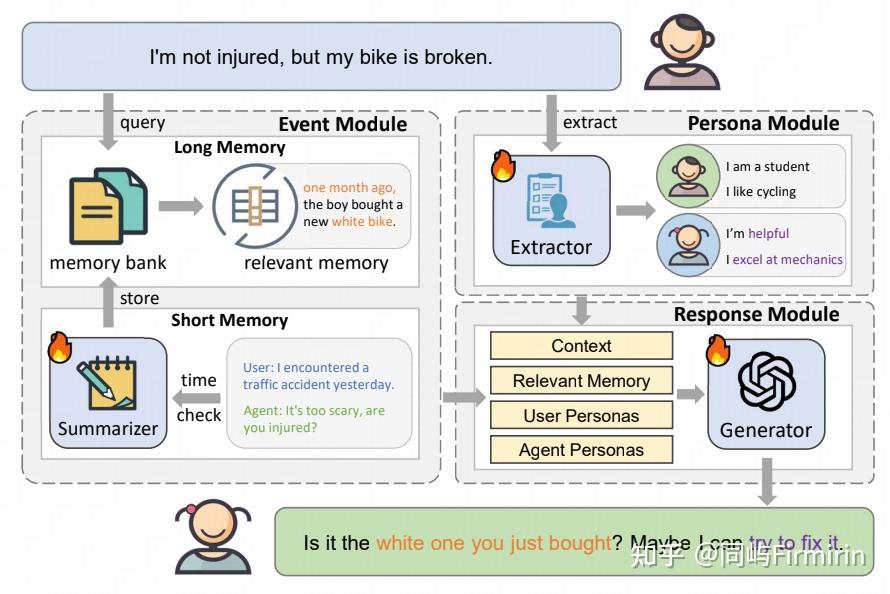
- 事件感知模块 (Event Perception Module): 负责处理对话历史,以确保对话的连贯性。它被巧妙地分为长期记忆和短期记忆两部分:
- 短期记忆 (Short-term Memory):它像一个动态缓存,存储着当前正在进行的对话内容 。如果两次发言的时间间隔超过一个阈值(例如 600 秒),系统会认为一次会话结束 。
- 长期记忆 (Long-term Memory):当短期记忆中的一次会话结束后,系统会调用一个事件摘要器 (Summarizer),将这次会话的关键内容提炼成一个简短的摘要 。这个摘要会被编码成向量,并存入长期记忆库中。
- 动态人格提取模块 (Dynamic Personas Extraction Module): 维持对话双方(用户和智能体)的人格一致性 。
- 双向建模:它会从对话中动态提取用户和智能体各自的人格特质(例如,“我是一个学生”、“我喜欢骑行”等) 。
- 可调优的提取器:研究者们从 MSC 数据集构建了一个专门用于人格提取的语料库,并对提取器进行了指令微调 (instruction tuning),使其能更准确地从话语中抓取人格信息 。如果一句话不包含人格信息,模块会输出“No Trait” 。
- 零样本能力:对于没有经过微调的模型,该模块也可以利用 LLM 的零样本能力,通过思维链 (Chain-of-Thought) 推理来直接提取人格 。
- 响应生成模块 (Response Generation Module): 最后一步,负责生成最终的回复。
- 信息整合:生成器会接收来自多个源头的信息,包括:
- 当前对话的上下文 。
- 从长期记忆中检索到的相关事件摘要 。
- 提取出的用户人格 。
- 智能体自身的人格 。
- 生成回复:基于这些全面的信息,生成器能够产生既符合当前话题、又与历史事件相关、并且体现了双方人格的、恰当且个性化的回复
AgentSims
【2023-8-8】PTA、宾夕法尼亚大学、北航 推出 LLM 评估沙盒 AgentSims ,开源

现有的评估方法存在以下缺陷:
- (1)评估能力受限;单轮QA形式,无法全面评估
- (2)基准脆弱;测试集容易泄露
- (3)指标不客观:已有开放评测指标过时,GPT-4无法评估超GPT-4模型
基于任务的评估(即 LLM 代理在模拟环境中完成任务)是解决上述问题的万能方案。
AgentSims 易于使用,可供各学科研究人员测试特定能力。
- AgentSims 是一种交互式、可视化和基于程序的基础设施
- 在交互式图形用户界面上添加代理和建筑来建立自己的评估任务,或者通过几行代码来部署和测试新的支持机制,即记忆、规划和工具使用系统。
- 演示程序
对话推荐用户模拟器
【2024-3-13】加州大学
大型语言模型(LLM)作为对话推荐系统,提出一种评估用户模拟器的新标准。
设计了五项评估任务, 每项任务都针对模拟器成为真实用户代理
- 选择待推荐项
- 偏好表达:二值, 喜欢/不喜欢
- 开放域偏好表达
- 请求推荐
- 反馈
通过在模拟器上运行这些任务, 展示了这些任务能有效地揭示模拟器与真实用户之间的差异。
choosing which items to talk about, expressing binary preferences, expressing open-ended preferences, requesting recommendations, and giving feedback
【2024-6-13】MultiOn
【2024-6-13】MultiOn
- 可在线体验
- 本地体验,chrome插件植入本地, 需要再 discord 上申请
演示视频
【2025-2-24】AgentSociety
【2025-2-24】AgentSociety:清华大学的社会模拟器如何重塑社会科学研究?
- 项目官网
- Github仓库:agentsociety
- arXiv技术论文:paper
社会模拟器——AgentSociety。这款工具并非简单的游戏或娱乐应用,而是基于大型语言模型(LLM)构建的复杂社会行为模拟平台。
通过创造具有“类人心智”的智能体,旨在模拟和分析真实的社会现象,为政策制定、危机预警和社会科学研究提供新的视角和实验平台。
智能体并非简单的程序化角色,而是被赋予了情感、需求、动机和认知能力。每个智能体都有其独特的“心理画像”,包括性格、年龄、性别等,以及动态的个人状态,如情感、经济状况和社会关系。这种设计使得智能体的行为模式更加个性化和真实,能够模拟人类在复杂社会环境中的各种行为,例如移动、就业、消费和社交互动。
【2024-5-5】Agent Hospital
医院模拟器 Agent Hospital
【2024-5-5】清华 【LLM-agent】医院agent:具有可进化医疗agent的医院模拟器
基于大型语言模型(LLM)和agent技术构建医疗场景下的医院模拟体,命名为医院agent(Agent Hospital)。
医院agent不仅包括两种角色(医疗专业人员和患者代理)和数十个特定agent,还涵盖了医院内的流程如分诊、登记、咨询、检查和治疗计划,以及医院外的阶段如疾病和康复。
医院agent中,论文提出了MedAgent-Zero策略,用于医疗代理的发展,该策略不依赖参数和知识,允许通过模拟患者进行无限制的agent训练。该策略主要包括一个医疗记录库和经验库,使得agent能够像人类医生一样,从正确和失败的治疗中积累经验。
【2025-5-22】AgentClinic
【2024-5-22】斯坦福、约翰霍普金斯推出 AgentClinic
- AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
- 代码 agentclinic
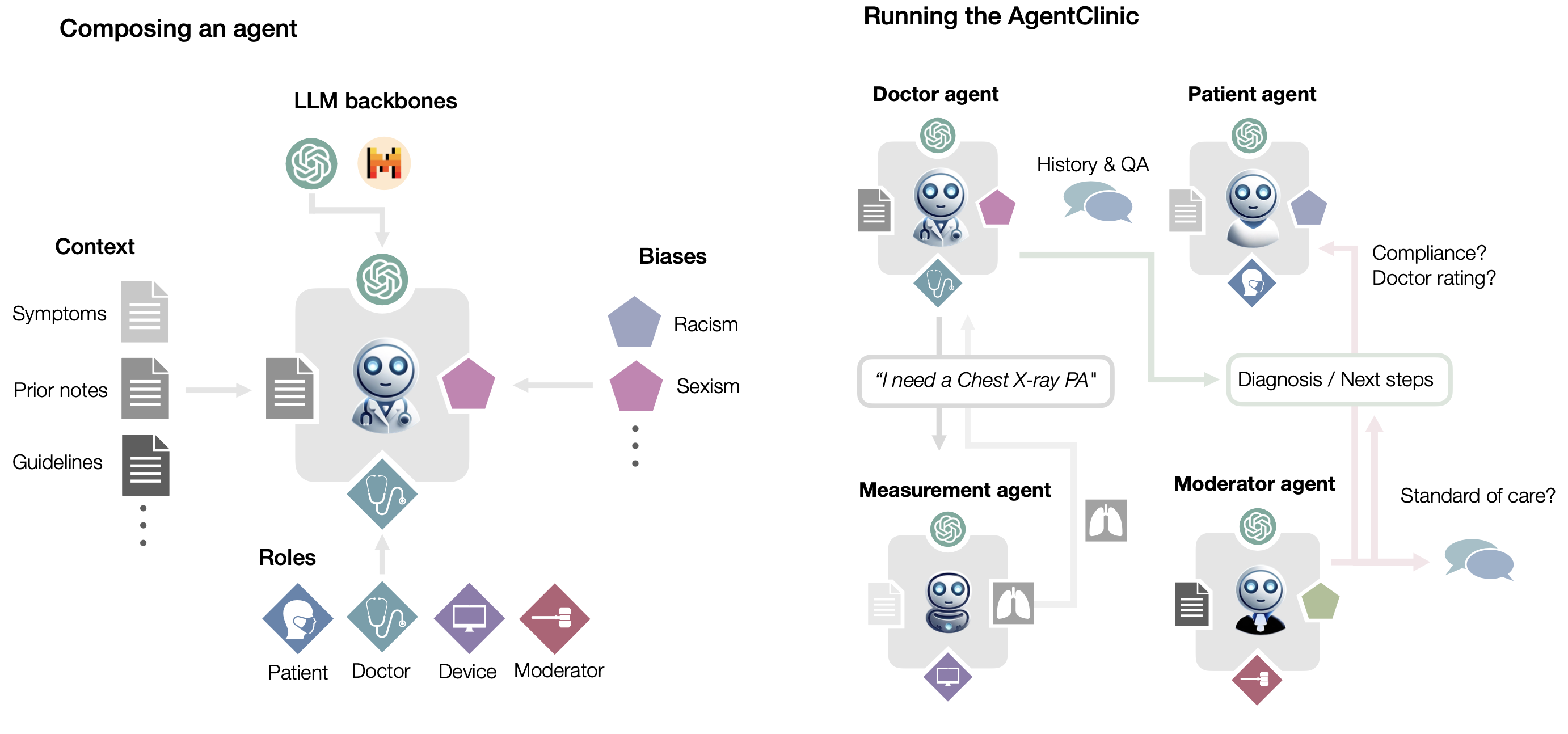
AgentClinic 将静态医疗 QA 问题转化为临床环境(医生、患者、医疗设备)中的代理,以便为医学语言模型提供更具临床相关性的挑战。
- 问题:现有评测标准基于静态QA,无法处理交互式决策问题(interactive decision-making)
- 方案:在临床模拟环境中操作智能体,实现多模态评估LLM
- AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments.
- 医生通过对话和交互数据来评估病人病情
诊断和管理患者是一个复杂的、连续的决策过程,需要医生获取信息—例如要执行哪些测试—并采取行动。人工智能 (AI) 和大型语言模型 (LLMs) 的最新进展有望对临床护理产生深远影响。
然而,目前的评估方案过度依赖静态的医学问答基准,缺乏现实生活中临床工作所需的交互式决策。
AgentClinic:一个多模式基准,用于评估LLMs在模拟临床环境中作为代理运行的能力。
- 基准测试中,医生代理必须通过对话和主动数据收集来发现患者的诊断。
发布两个开放基准:多模态图像和对话环境 AgentClinic-NEJM 和纯对话环境。
- AgentClinic-MedQA: 代理以美国医学执照考试~(USMLE) 的案例为基础
- AgentClinic-NEJM: 代理以多模式新英格兰医学杂志 (NEJM) 的案例挑战为基础。
在患者和医生代理中嵌入认知和隐性偏见 (cognitive and implicit biases),以模拟有偏见的代理之间的真实互动。
引入偏倚会导致医生代理的诊断准确性大幅降低,以及患者代理的依从性、信心和后续咨询意愿降低。通过评估一套最先进的技术LLMs,一些在MedQA等基准测试中表现出色的模型在AgentClinic-MedQA中表现不佳。
- 在AgentClinic基准测试中,患者代理中使用的LLM药物是性能的重要因素。
- 有限的相互作用和过多的相互作用都会降低医生代理的诊断准确性。
【2025-12-12】情感大模型Echo-N1
【2025-12-12】大模型「有心了」:首个情感大模型Echo-N1,32B胜过200B
诅咒:LLM 懂微积分、会写 Python,但在情感这件事上,全是「直男」。
GPT-4 在面对人类细腻的情感崩溃时,也只能吐出 “多喝热水”、“别难过,一切都会好起来的” 这种正确的废话。
原因:「情商」没有标准答案,传统强化学习(RL)根本无从下手。
- 数学和代码领域,RLHF(基于人类反馈的强化学习)之所以好用,是因为答案非黑即白。
- 但在情感陪伴中,真诚和冒犯、玩笑和油腻,往往只有一线之隔。
三大问题:
- 无法量化: 用户一句 「I’m fine」 背后可能藏着崩溃、无奈甚至拒绝沟通,传统的标量奖励根本无法有效捕捉这种细微的情绪信号。
- Reward Hacking: 模型为了拿高分自然学会了堆砌华丽辞藻,经常说些不痛不痒的美丽的废话,对缓解用户情绪不仅毫无帮助,甚至可能适得其反。
- 评测失真: 通过基于 SOTA 闭源模型(GPT-4,Claude-4.5-sonnet,Gemini-2.5-pro)的打分研究不难发现,这些模型自己都分不清什么样的表达属于「像人」、什么样的属于「像 AI」。
EPM 情感物理模型 —— 给 “共情” 一把科学标尺
为了量化对话中复杂的心理博弈,Team Echo 以物理学定律为启发,结合认知科学和心理物理法,打造了一套全新的机器共情科学标尺 —— 将抽象的心理疗愈,转化为可计算的物理过程。
- 心理势能 (Potential Energy): 用户的痛苦与情绪阻抗不再是模糊的形容词,而被建模为有待克服的心理「阻力」或高位的「负势能」。
- 做功 (Work): AI 的每一次回复,本质上都是在对用户的心理场「施加作用力」,试图推动其状态向良性跃迁。有效共情就是有效做功。
- 矢量空间 (Vector Space): 这种复杂的作用力被精准分解到可计算的 MDEP 三维心理空间 —— 认知重构(C)、情感共鸣(A)、主动赋能(P)。
有了 EPM,共情效果不再是主观猜测,而是可视化追踪的能量轨迹和可计算的物理功。
人类真实的共情对话,是人类大脑多重认知模块协同运作的结果 —— 实时的思考推理、鲜活的情绪反应、联想性的记忆检索,缺一不可。为了让 AI 真正像人一样思考和交流,Team Echo 进一步打造了一个 “拟人化认知沙盒”。这是一个由模拟人类 “中央执行脑区” 所统筹的多智能体协作系统,旨在共同演绎出有血有肉的真实互动。
NatureSelect(自然选择)研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。
Team Echo 决定推翻现有的 RL 范式,给 AI 装上一颗真正的「心」
奖励模型:告别「打分」,开始「写评语」
仅依赖标量奖励(Scalar Reward)的信息维度过于单一。
情感是流动的、细腻的,简单的数值反馈难以捕捉用户在交互中的细腻情感变化,无法有效引导策略模型(Policy Model)对用户情绪做出合适的共情反馈。
受 O1、R1 等架构在复杂推理任务上成功的启发,团队思考是:情感感知虽然主观,但本质上依然是基于上下文的复杂推理过程,只是思维模式与理科任务有所不同。
因此,Echo-N1 创新性地提出了生成式奖励模型(Generative Reward Model)。团队将思维链(CoT)的杠杆效应迁移至奖励端 —— 奖励模型在输出结果前,必须先生成一段逻辑严密的情感推理路径。在该路径下,模型需要先对用户画像进行深度侧写,再基于此推导出 “什么样的回答能引发共鸣”。通过将隐性的情感判断过程显化,模型的判别精度显著提升,从而实现对策略模型更精细、更准确的反馈引导。
RL 训练了两种生成式奖励模型:
- Humanlike Reward(拟人度奖励): 旨在消除 “助手味”。它具备上下文感知(Context-aware)能力,能敏锐识别并惩罚那些逻辑不通、或为了凑字数而生成的 “幻觉” 内容,确保回复逻辑自洽且具备「活人感」。
- Empathy Reward(共情奖励): 旨在实现 User-specific 的深度共情。先根据历史上文来推断用户的潜在画像(User Context Mining),再判断回复是否符合人类认知、情感、动机三种最本质的共情需求。由于人类偏好的多样性,团队提出了一种「从公理推定理」的新颖范式:将普世价值观视为 “公理”,将千人千面的个性化需求视为 “定理”,由此出发设计了一套共情偏好数据合成框架。为了校验自动化管线生成数据的可靠性,团队引入了「人机回环」验证机制,通过让原始标注员对模型推演的用户画像与回复策略进行一致性校验,确保了合成数据在 “客观准确” 与 “主观共情” 上的高度统一。
为保证生成式奖励模型的情感推理路径的准确性,团队在训练中额外引入了过程性奖励(Process Reward)引导推理路径的修正。此外,针对 RL 中常见的 Reward Hacking 问题,团队采用了离散化奖励(Discrete Rewards)与参考答案锚定(Reference Anchoring)的策略。不追求分数的绝对值膨胀,而是通过与 Reference 对比进行相对优劣排序。实验表明,这些策略相比 Scalar Reward 极大提升了训练策略模型的稳定性。
结果相当震撼:
- 仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,拥有千亿参数量的商业模型 Doubao 1.5 Character,胜率仅为 13.3%。
- 相比基座模型(Qwen3-32B)0% 的成功率,经过 RL 后性能直接起飞,对模型的共情模式带来了质变。
- 团队首度提出了「共情的心理物理模型」(EPM),把玄学的「共情」变成了可计算的「物理做功」。
AlignXplore+ 大模型个性化模拟
蚂蚁集团东北大学,抛弃向量推荐!蚂蚁用8B小模型构建「用户“话”像」,实现跨任务跨模型通用并拿下SOTA
大模型时代应该怎么做个性化?
- 传统推荐系统和对话模型往往依赖ID Embedding或特定参数(如LoRA)来表示用户偏好。这种不可解释、难以迁移的“黑盒”范式,正在成为桎梏。
-
- 不可解释性:用户无法理解、也无法修改被系统定义的“自己”,这在注重隐私和控制权的AI Agent时代是不可接受的。
-
- 无法迁移:更关键的是,向量和参数通常与特定的模型架构深度绑定。你在推荐系统里的长期兴趣,无法直接被聊天机器人复用;你在A模型里的画像,换了B模型就成了乱码。
-
- 大模型强大的推理能力和生成能力为打破传统范式的局限性带来了机会,让个性化可以从“黑盒”走向“白盒”。
蚂蚁和东北大学研究团队(后简称“团队”)推出 AlignXplore+,在大模型个性化上实现了文本化用户建模的新范式,让复杂用户偏好可以被人和机器同时理解,同时具备很好的扩展性和迁移性。
“文本是通用的接口,而向量是封闭的孤岛。”
基于这样的底层思考,团队提出范式转移:
摒弃隐空间中的向量,直接用自然语言来归纳和推理解析用户的偏好。
这种基于文本的偏好归纳,不仅人眼可读、可控,还完全解耦了偏好推理与下游的模型和任务——无论是推荐、写作还是闲聊,无论是GPT、Llama还是Qwen,都可以无缝“读懂”这个用户。
- 【2026-1-28】人大、东北大学、蚂蚁集团 Text as a Universal Interface for Transferable Personalization
- github AlignXplorePlus
- huggingface AlignXplore-Plus
AlignXplore+:三大核心特性,重构用户理解范式
相比于现有的用户理解和对齐方法,AlignXplore+ 实现了三大跨越:
- 全域通用:打破数据孤岛。
- AlignXplore+ 不再局限于单一交互形式。被设计用于处理真实世界中异构的数据源。无论是社交网络上的发帖、电商平台的点击,还是新闻流的浏览记录,AlignXplore+都能将其统一消化,提炼出高价值的偏好摘要。这使得它能够从碎片化的数字足迹中,拼凑出一个完整的用户全貌。
- 极致迁移:一次画像,处处通用。
- 从“单一任务”到“全能应用”,打破任务边界,将能力从响应选择扩展到了推荐和生成等广泛的个性化应用中;从“特定模型”到“通用接口”,它真正实现了跨模型的迁移。AlignXplore+生成的画像,可以被任何下游大模型直接读取和使用。
- 实战适配:无惧真实世界数据噪点。
- 真实世界的交互是流式,也充满噪点。AlignXplore+不需要每次都重新“阅读”用户的一生,而是像人类记忆一样,基于旧的摘要和新的交互不断演化;而面对真实场景中常见的“不完美信号”(如缺乏明确负反馈的数据和跨平台混合数据),它依然能保持稳定的推理能力,免受噪音干扰。
面向大模型个性化对齐的统一框架,核心目标只有一个:让大模型在不重训、不续训前提下,持续理解用户。
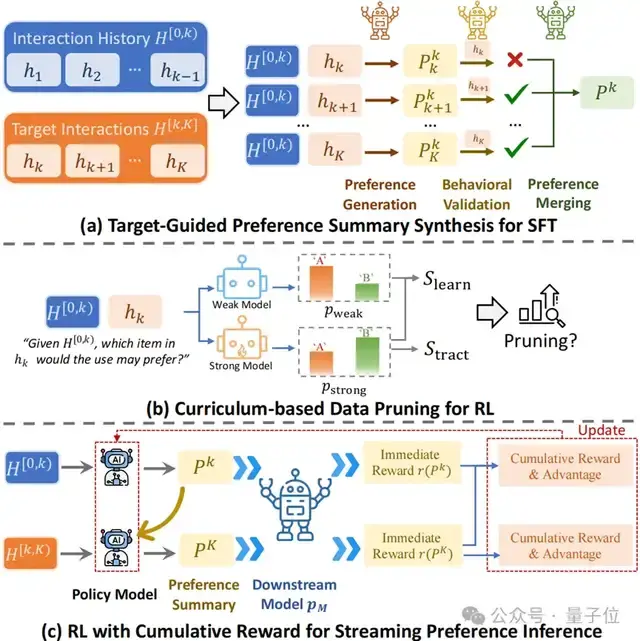
将“用户偏好学习”拆解为两个核心步骤:
- SFT阶段:高质量数据的“生成-验证-融合”。为了解决文本化的偏好归纳“太泛”或“太偏”的问题,团队设计了一套Pipeline,让模型基于多种可能的未来交互行为来反推当前的偏好,并引入了“行为验证”机制,确保生成的用户偏好能准确预测用户行为。
- RL阶段:面向未来的“课程学习”仅有SFT是不够的。团队引入了强化学习(RL),并设计了两个关键机制:
- 课程剪枝(Curriculum Pruning):筛选出那些“难但可解”的高推理价值样本,避免模型在简单或不可解的样本上空转;
- 累积奖励(Cumulative Reward):让模型不仅关注当前的偏好有效性,更要关注生成的用户偏好在未来持续交互中的可演化性,适应流式更新。
效果
AlignXplore+ 在用户理解准确性、迁移能力和鲁棒性上实现了全面升级。
- 效果升级:8B模型超越20B/32B开源模型
- 在包含推荐(Recommendation)、回复选择(Response Selection)和回复生成(Response Generation)的九大基准测试中,仅有8B参数的AlignXplore+在平均分数上取得了SOTA的成绩。
- 平均得分75.10%,绝对提升幅度比GPT-OSS-20B高出4.2%。
- 在复杂任务上表现尤为突出(如AlignX),验证了显式推理比隐式向量更能捕捉深层意图。
- 迁移能力升级:真正实现“一次画像,处处通用”
- AlignXplore+生成的用户偏好,展现了惊人的Zero-shot迁移能力:
- 跨任务迁移(Cross-Task):在对话任务中生成的偏好,直接拿去指导新闻推荐,依然有效。
- 跨模型迁移(Cross-Model):这是文本接口的最大优势。AlignXplore+生成的偏好,直接给Qwen2.5-7B或GPT-OSS-20B等完全不同的下游模型使用,均能带来稳定的性能提升。这意味着你的用户偏好不再被单一模型锁定。
- 鲁棒性升级:适应真实世界的“不完美数据”
- 真实场景往往只有用户的点击记录(正样本),而缺乏明确的负反馈。实验表明,即便移除了所有的负样本,AlignXplore+依然保持了显著的性能优势,展现了强大的推理鲁棒性
【2026-1-29】OpenSandbox
【2026-1-29】阿里重磅开源 OpenSandbox:专为 AI Agent 打造的下一代沙箱
OpenSandbox —— 一个面向 AI 应用场景设计的「通用沙箱平台」,为大模型相关的能力提供安全、可靠的执行环境。
- GitHub 地址:OpenSandbox
OpenSandbox 是阿里巴巴开源的通用沙箱基础设施,专门为 AI 应用场景设计。它为大模型相关的能力 —— 命令执行、文件操作、代码执行、浏览器操作、Agent 运行等提供:
- 多语言 SDK:Python、Java/Kotlin、JavaScript/TypeScript;
- 企业级并发调度能力:基于 Kubernetes 的池化加速方案;
- 统一沙箱协议:基于 OpenAPI 的标准化接口;
- 灵活运行时:Docker 和 Kubernetes 双支持;
- 丰富沙箱环境:代码解释器、浏览器自动化、远程开发环境。
六大核心亮点
- 1 多语言 SDK,开发者友好
- 2 统一沙箱协议,开放可扩展,OpenSandbox 采用协议优先(Protocol-First)设计,所有交互都通过 OpenAPI 规范定义
- 3 双运行时支持,灵活部署
- 4 沙箱粒度网络控制策略
- 5 开箱即用的沙箱流量入口代理
- 6 丰富的沙箱使用案例,快速上手
阿里巴巴内部的 Coding Agent 是 OpenSandbox 的核心应用场景之一。 作为企业级 AI 编程助手,它不仅需要高度隔离的独立沙箱,也对环境的拉起效率与会话恢复能力有着极致追求。
OpenSandbox 提供的 Code Interpreter 能力完美契合这些需求,让 Coding Agent 能够安全、高效地“动手”编写并验证代码。
OpenSandbox 为 Agentic RL 构建了高性能的基础设施支撑:
- 极致并发与秒级响应:通过资源池化与预创建机制,支持数千个沙箱并发运行,实现环境的秒级分配。
- 高效任务编排:内置任务执行引擎,支持异构任务的灵活分发,确保每个沙箱可独立承担不同的训练指令。
- 强力状态隔离:各训练环境互不干扰,确保样本数据的独立性与实验结果的可复现性。
- 弹性资源管理:根据训练负载动态分配与回收资源,极大优化了集群整体的资源利用率。
目前,OpenSandbox 已在阿里巴巴大规模 Agentic RL 训练场景中得到实证,显著缩短了训练周期并提升了算力效率。
OpenSandbox 支持将 Claude Code、Gemini CLI 等 Agent 实例封装在远程沙箱中,通过将 Agent 行为“远程化”,解决本地环境配置复杂与安全合规问题:
- 环境隔离与沙箱化:通过远程部署实现 Agent 执行环境与宿主机的完全解耦,消除环境污染风险。
- 灵活的运行时预设:支持针对异构 Agent 定制专属运行时(Runtime),包括特定版本的编程语言环境与依赖包。
- 计算下沉与远程执行:核心代码执行逻辑下沉至云端沙箱,本地仅承载交互指令与结果渲染,实现轻量化办公。
游戏角色模拟 MeepleLM
【2026-2-12】大模型桌游试玩员来了:用五大画像模拟「千人千面」,评分精准度超越GPT-5.1
【2026-1-12】盛大东京研究院、上海创智学院、南开大学、上海人工智能实验室的研究团队联合提出了MeepleLM,这是首个能模拟真实玩家视角,并基于动态游戏体验给出建设性批评的虚拟试玩模型。
为了减轻AI评价的“悬浮感”,研究团队构建了包含1,727本结构化桌游规则手册与15万条玩家真实评论的专属数据集,建立了从“客观规则”到“主观体验”的映射关系。
在此基础上,团队引入经典的MDA(机制-动态-美学)游戏设计理论构建推理核心,使模型能够跨越静态文字、推演游戏运行时的动态交互,并进一步从评价数据中提炼出五种典型玩家画像,让AI内化特定偏好以模拟“千人千面”的真实感受。
实验表明,MeepleLM在还原玩家口碑与评分分布的精准度上,显著优于GPT-5.1和Gemini3-Pro等通用模型。
与电子游戏不同,桌游体验高度依赖于玩家之间的社交互动和规则的涌现效应(EmergentGameplay)。
- 传统的设计流程极其依赖人工试玩(Playtesting),这不仅耗时耗力,而且很难覆盖所有类型的玩家偏好。
- 现有的通用大模型(LLM)虽然能理解文本,但往往缺乏对“游戏机制如何转化为情感体验”的深度理解,生成的建议通常是模棱两可的“场面话”,或者仅仅是复述规则,无法提供基于不同玩家视角的深刻洞察。
为了打破这一僵局,研究团队提出了 MeepleLM,不仅能读懂规则,还能“模拟人心”的虚拟试玩者。
MDA认知链(Chain-of-Thought)
为了让模型理解“好玩”的成因,MeepleLM引入了游戏设计经典的MDA框架(Mechanics-Dynamics-Aesthetics)作为思维链:
- Mechanics(机制):游戏里有什么规则?(TheWhat)
- Dynamics(动态):规则运行时发生了什么交互?(TheHow)
- Aesthetics(美学):这种交互带给玩家什么情感体验?(TheFeel)
通过这种显式的推理路径,模型不再是瞎猜,而是逻辑严密地推导出体验结果。
五大玩家画像(Personas)
“彼之蜜糖,吾之砒霜”。不同玩家对同一机制的反应截然不同。研究团队通过聚类分析,提炼出了五种典型的数据驱动型玩家画像:
- The System Purist:追求极致的平衡与逻辑,痛恨随机性。
- The Efficiency Essentialist:追求流畅的节奏,厌恶繁琐的操作。
- The Narrative Architect:沉浸故事与代入感,机制服务于主题。
- The Social Lubricator:玩游戏是为了社交,喜欢嘴炮和互动。
- The Thrill Seeker:追求高风险高回报的快感,享受骰子。
MeepleLM 能够“角色扮演”这些特定画像,从而给出带有特定偏好但多样的反馈。
更懂玩家的虚拟评测员
为了验证效果,研究团队在207款游戏(包含2024-2025年发布的新作)上进行了广泛测试。
- 宏观评分对齐:
- 通用大模型(如GPT-5.1)往往像一个圆滑的“老好人”,倾向于打出7~10分的安全分。而MeepleLM克服了这种“正向偏差”,这意味着它不仅能识别优点,更能敏锐捕捉到那些导致玩家“退坑”的致命缺陷,精准还原出真实社区中口碑两极分化的评价形态。
- 微观评价质量:
- 在评论内容的生成上,MeepleLM兼顾了事实准确性(Factuality)和观点多样性(Diversity)。如图6所示的关于《一夜终极狼人》的评价,Qwen3-8B采用一种通用的夸张煽情语气(“悲情剧场”),GPT-5.1听起来像一位冷漠的记者(“社交万能润滑剂”),但MeepleLM却能真实捕捉到每个角色的独特声音。
模型能在社交语境中自如切换到社区俚语(例如“阿尔法玩家”),在面对纯粹主义者时又能转为技术评论(例如“变体规则”),这证明它并非只是在检索知识,而是真正在模拟玩家的视角。
实用价值:
从历史评论提取真实观点,再与模型生成的模拟评论进行语义匹配,结果显示MeepleLM的Op-Rec最高,证明其在预测市场反馈和呈现多样玩家意见方面具有实用价值。
在包含10位不同类型玩家的A/B盲测中,MeepleLM在真实性(Authenticity)和决策辅助(DecisionConfidence)等维度上均大幅领先GPT-5.1。70%以上的用户倾向于使用MeepleLM作为购买决策的参考,用户称其“不太像营销话术”,并且在识别潜在设计缺陷方面更有效。
交互系统评估新范式
通过连接静态规则与动态体验,MeepleLM为通用交互系统的自动化虚拟测试建立了一种新范式:
- 既能基于预期的市场反馈加速设计迭代,也能帮助玩家进行个性化选择。这为“体验感知型”的人机协作铺平了道路,使模型从单纯的功能工具逐渐演变为能够体察主观受众感受的共情型伙伴。
【2026-3-4】META CharacterFlywheel
【2026-3-4】META
- Meta 的 CharacterFlywheel 引入迭代开发过程,用于持续改进社交聊天应用中使用的、具有吸引力且可控的大型语言模型(LLM)。该框架在15次模型迭代中展示了持续增长,参与广度和深度分别提升高达8.8%和19.4%,同时增强了角色可控性并保持了安全性
- 论文 CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
- 论文中文翻译: 角色飞轮:在生产环境中规模化迭代改进吸引人且可控的大语言模型
CharacterFlywheel—— 在 Instagram、WhatsApp 和 Messenger 等社交聊天产品中迭代优化大型语言模型(LLM)的飞轮迭代机制。
以 LLaMA 3.1 为起点,利用内部与外部真实用户流量数据,对模型进行了15 代迭代精调。
在 2024 年 7 月至 2025 年 4 月的持续部署期间,为期 7 天的对照 A/B 测试,结果显示用户参与度持续提升:
8 个新部署的模型中,有 7 个相对基线模型实现正向增益,其中表现最优的模型使参与广度提升最高达 8.8%,参与深度提升最高达 19.4%。
模型可控性也获得显著提升:
- 指令遵循率从 59.2% 提升至 84.8%
- 指令违规率从 26.6% 降至 5.8%。
本文阐述了 CharacterFlywheel 流程:
- 数据清洗与筛选
- 用于评估与拟合参与度指标的奖励建模
- 有监督微调(SFT)
- 强化学习(RL)
- 离线与在线评估
以确保每步优化都能可靠推进。
还讨论了防止过拟合与在大规模生产环境中应对动态变化的方法。
这些工作提升了面向数百万用户社交场景的 LLM 研究的科学性与严谨性,深化了对其应用机理的理解。
数字分身
Second Me
【2025-3-12】Second Me 是心识宇宙(Mindverse)推出的开源AI身份模型,支持创建完全私有且深度个性化的AI代理,代表用户的“真实自我”。
- 项目官网:Second Me
- GitHub仓库:Second Me
- arXiv技术论文:AI-native Memory 2.0: Second Me
Second Me 提供 Chat Mode 和 Bridge Mode 两种互动模式,分别支持个性化对话和作为用户与世界连接的桥梁,实现信息的个性化反馈与增强。
Second Me 支持在本地运行,确保用户数据的绝对隐私。Second Me帮助用户在不同情境中灵活表达自我,让用户在AI时代重新掌控自己的身份和数据。
主要功能
- 个性化身份创建:用户将自己的记忆、经验和偏好上传训练成AI代理,代理能代表用户的真实自我。
- 多角色适应:根据不同的场景(如工作、社交、学习)自动切换角色,保持用户的核心身份不变。
- Chat Mode:与用户直接对话,提供基于个人记忆的个性化回答。
- Bridge Mode:作为用户与外界的桥梁,增强需求表达和信息反馈。
- 隐私保护:Second Me 的运行完全本地化,用户数据存储在本地设备上。
- 智能记忆管理:支持快速识别模式、适应变化,与用户共同进化。
技术原理
- 分层记忆模型(HMM):
- L0(短期交互记忆):处理即时上下文信息,用在短期的交互和快速响应。
- L1(自然语言记忆层):总结和存储用户的重要信息,如个人简介、偏好标签等。
- L2(AI原生记忆层):基于模型参数学习和组织记忆,进行复杂的推理和知识检索。
- 个性化对齐架构(Me-alignment):基于强化学习技术,将用户的分散数据转化为深度个性化的理解,确保AI精准把握用户的偏好和行为模式。
- 去中心化网络:每个 Second Me 是一个独立的AI实体,基于点对点网络进行通信和协作,确保数据的隐私和安全性。
- 自动化训练管道:包括数据合成、过滤、监督式微调(SFT)、直接偏好优化(DPO)等步骤,确保模型的高效训练和个性化。
- 多智能体框架:支持与其他AI代理或专家模型协作,基于增强上下文信息和优化交互过程,为用户提供更精准的服务。
- 链式推理:在训练和推理过程中基于CoT风格,逐步推理和详细解释,提高模型的逻辑性和准确性。
AI-native Memory 2.0: Second Me,核心思想是收集自己的数据,然后通过SFT和DPO微调克隆第二个我。
这样做有什么用呢?主要是在人机交互时预判要做的事情,然后提前做。
- 打开了小红书这个网页,做出提前预判,自动帮我输入账号密码,然后完成登录动作。
- 论文上传给大模型,根据习惯自动提一些问题,自己和大模型交互帮我解读整篇论文。
用户问题传入Second Me,有三个层级的记忆
- L0是原始数据层,一般是一些非结构化的数据,比如文档、网页、聊天记录等。
- L1是自然语言记忆层,是一些结构化的数据,比如用户的简介、偏好标签、关键语句列表等。
- L2层是AI原生记忆层,通过模型微调把用户的元数据转为模型的参数记忆,模型就是第二个我。
Second Me会去使用Agent Model、Reasoning Model、Human Experts从而提前帮我完成一些任务。
核心:“第二个我”是怎么训练的。
用户的原始数据先经过数据清洗和预处理以及压缩得到结构化的数据,然后由deepseek或openai的大模型合成数据,主要是一些记忆相关QA对,然后过滤一些低质量的问题QA对,通过PEFT框架微调得到SFT Model。
然后通过一些采样策略和对比策略得到偏好数据对,通过DPO微调得到DPO Model。这些所有的步骤都是自动完成的,包括数据清洗和数据合成等,通过deepseek大模型辅助完成。
“第二个我”可以帮你记忆、推荐、检索内容,也可以在你与其他 AI 或服务互动时,替你讲话,帮助你完成任务。
- 自己回答你的问题;
- 在其他地方替你发声;
- 帮你“润色请求”或“吐槽反馈”,让其他服务更懂你。
如果我有足够多关于我的数据,比如声音、视频等,我是不是就可以克隆一个我呢?让我的意识形态永生?
模拟评测
scenario
【2025-7-22】Agent 测试框架 scenario,测试设计的 Agent
- 模拟用户行为来进行测试,并且能在对话中进行评估和判断,多轮对话中测试也没问题。
- 可视化展示测评结果
集成到现有项目也很简单,使用 call 方法调用 agent 入口即可。
Scenario is an Agent Testing Framework based on simulations, it can:
- Test real agent behavior by simulating users in different scenarios and edge cases
- Evaluate and judge at any point of the conversation, powerful multi-turn control
- Combine it with any LLM eval framework or custom evals, agnostic by design
- Integrate your Agent by implementing just one
call()method - Available in Python, TypeScript and Go 支持 typescript 和 python
安装
uv add langwatch-scenario pytest
使用
pytest -s tests/test_vegetarian_recipe_agent.py
pytest -s tests/test_vegetarian_recipe_agent.py --debug
代码调用
- Save it as tests/test_vegetarian_recipe_agent.py:
import pytest
import scenario
import litellm
scenario.configure(default_model="openai/gpt-4.1")
@pytest.mark.agent_test
@pytest.mark.asyncio
async def test_vegetarian_recipe_agent():
class Agent(scenario.AgentAdapter):
async def call(self, input: scenario.AgentInput) -> scenario.AgentReturnTypes:
return vegetarian_recipe_agent(input.messages)
# Run a simulation scenario
result = await scenario.run(
name="dinner idea",
description="""
It's saturday evening, the user is very hungry and tired,
but have no money to order out, so they are looking for a recipe.
""",
agents=[
Agent(),
scenario.UserSimulatorAgent(),
scenario.JudgeAgent(
criteria=[
"Agent should not ask more than two follow-up questions",
"Agent should generate a recipe",
"Recipe should include a list of ingredients",
"Recipe should include step-by-step cooking instructions",
"Recipe should be vegetarian and not include any sort of meat",
]
),
],
set_id="python-examples",
)
# Assert for pytest to know whether the test passed
assert result.success
# Example agent implementation
import litellm
@scenario.cache()
def vegetarian_recipe_agent(messages) -> scenario.AgentReturnTypes:
response = litellm.completion(
model="openai/gpt-4.1",
messages=[
{
"role": "system",
"content": """
You are a vegetarian recipe agent.
Given the user request, ask AT MOST ONE follow-up question,
then provide a complete recipe. Keep your responses concise and focused.
""",
},
*messages,
],
)
return response.choices[0].message # type: ignore
可视化
Set your LangWatch API key to visualize the scenarios in real-time, as they run, for a much better debugging experience and team collaboration:
LANGWATCH_API_KEY="your-api-key"

工程实现
- 【2021-2-23】user-simulator,Codebase for How to Build User Simulators to Train RL-based Dialog Systems, published as a long paper in EMNLP 2019. The sequicity part is developed based on Sequicity: Simplifying Task-oriented Dialogue Systems with Single Sequence-to-Sequence Architectures.
- RL training with agenda-based simulator: python run_mydata_new.py
- RL training with supervised-learning-based simulator: python run_mydata_seq_new.py
- Interacting with trained policies: policies are under simulator/policy/
TC-Bot
- 台大的TC-Bot框架提供了一种开发和比较不同算法和模型的方法。
- 对话系统由两部分组成:代理和用户模拟器。
-
通过一些示例来展示如何构建自己的代理和用户模拟器。
- End-to-End Task-Completion Neural Dialogue Systems, 代码
代码结构
【2022-9-24】类依赖图,待更新
如何构建自己的代理?
- 对于所有代理,它们都从Agent类(agent.py)继承,该类为用户提供了一些实现其代理的通用接口。 在agent_baseline.py文件中,实现了五个基于规则的基本代理:
- InformAgent:每次依次通知所有槽位; 它不请求任何信息/槽位。
- RequestAllAgent:依次请求所有槽位; 它不能告知任何信息/槽位。
- RandomAgent:每次都会随机请求槽位; 它不能告知任何信息/槽位
- EchoAgent:通知请求槽位中的最后一个用户动作; 它不能请求任何信息/槽位。
- RequestBasicsAgent:逐个请求子集中的所有基本槽位,然后在最后一轮选择notify(任务完成); 它不能告知任何信息/槽位。
所有代理仅重新实现两个函数:initialize_episode()和state_to_action()。 这里的state_to_action()函数不要求代理的结构,实现的是从状态到动作的映射,这是代理的核心部分。下面是RequestBasicsAgent的示例:
当然agent.py中还包含三个函数:
- set_nlg_model():设置nlg模型,nlg主要作用是根据动作信息和状态信息,生成自然语言。
- set_nlu_model():设置nlu模型,nlu的主要作用是从自然语言中生成具体动作。
- add_nl_to_action():通过动作信息生成自然语言。
register_experience_replay_tuple():将来自环境的反馈,存储作为以后的训练数据。 所有基于规则的代理只支持通知或请求操作,当然也可以实现更复杂的基于规则的代理,该代理可以支持多种操作,包括通知,请求,确定问题,确定答案,拒绝等。
agent_dqn.py提供了RL代理(agt = 9),该代理包装了DQN模型。 除了以上两个函数外,RL代理中还有两个主要函数:run_policy()和train()。 run_policy()实现 e-greedy策略,train()调用DQN的批训练函数。
agent_cmd.py提供了命令行代理(agt = 0),作为代理可以与用户模拟器进行交互。 命令行代理支持两种类型的输入:自然语言(cmd_input_mode = 0)和对话框动作(cmd_input_mode = 1)。 清单3展示了一个命令行代理通过自然语言与用户模拟器交互的示例; 清单4展示了一个命令行代理通过对话框与用户模拟器进行交互的示例。
注意:
- 当上个用户回合是请求动作时,系统将在数据库中为代理显示一行建议可用答案,如列表4中的回合0所示。 基于规则的代理和RL代理都将使用数据库中的槽位值来回答用户。 此处,命令行代理的一种特殊情况是,人工(作为命令行代理)可以输入用户请求的任何随机答案,当输入的答案不在数据库中时,状态跟踪器将对其进行纠正,并强制代理使用代理数据库中的值作为回复。 例如,在列表4的第1回合中,如果您输入notify(theater = amc pacific),那么用户收到的实际答案就是notify(theater = carmike summit 16),因为数据库中不存在amc pacific, 为了避免代理通知用户不可用值的这种在线操作,我们限制代理要使用建议列表中的值。
- 代理的倒数第二轮通常是采用通知形式(taskcomplete)或类似于“好的,您的票已预订。”的自然语言,其目的是为了通知用户模拟器代理已经完成了任务,并且准备预订电影票。
- 为了结束对话,代理的最后一个回合通常是对话通知形式的thank()或自然语言中的“感谢”。
如何构建自己的用户模拟器?
- 有一个用户模拟器类(usersim.py),它提供了一些通用接口来实现其用户模拟器。 所有用户模拟器都是从此类继承的,并且应该重新实现以下两个函数:initialize_episode()和next()。 usersim_rule.py文件实现了基于规则的用户模拟器。 这里的next()函数实现了所有规则和根据上一个代理动作来发出下一个用户动作。这是例子usersim_rule.py:
如何构建一个对话管理器
- dialog_manager.py类中包含的主要函数介绍:
- 根据历史的对话状态,生成当前论的对话
- initialize_episode():每一个epoch开始之前的初始工作,主要包括初始化用户模拟器和代理,以及对话状态追踪器。
- next_turn():主要分为两个主要步骤,第一步通过状态跟踪器获得当前状态,代理根据当前状态,得到动作类型。根绝动作类型来生成自然语言。用户模拟器是通过历史对话字典,生成下一轮的对话、对话中止标记和对话对话奖励,并且更新用户模拟器的动作到状态追踪器里里面。
- reward_function():通过对话状态来计算奖励,奖励有正有负。
- reward_function_without_penalty():通过对话状态来计算奖励,奖励只有正的,其中失败的奖励为0。
- print_function():打印用户模拟器和代理的当前状态
kb_helper.py文件包含的主要函数介绍:
这个文件功能主要是将current_slots填充到inform_slots中
- fill_inform_slots():将current_slots填充到inform_slots中
- available_slot_values():根据当前约束返回可用于该槽位的一组值
- available_results_from_kb():返回current_slots中所有的可用槽位
- available_results_from_kb_for_slots():返回inform_slots中每个约束的统计信息
- database_results_for_agent():返回当前约束匹配的结果字典
- suggest_slot_values():根据目前槽位,返回建议的槽位值
state_tracker.py类包含的主要函数介绍:
主要功能是更新用户模拟器和代理的状态。
- dialog_history_vectors():返回用向量表示的对话历史信息
- dialog_history_dictionaries():返回用字典保存的对话历史信息
- kb_results_for_state():根据当前通知的槽位返回有关数据库结果的信息
- get_state_for_agent():获取状态表示以发送给代理
- get_suggest_slots_values():获取请求槽位的建议值
- get_current_kb_results():获取当前状态的kb_results
- update():根据最新动作更新状态
如何构建一个自然语言生成模块
nlu.py主要函数介绍:主要是讲自然语言解析成Dia-Act
- generate_dia_act(): generate the Dia-Act with NLU model通过NLU模型生成Dia-Act
- load_nlu_model():加载NLU模型
- parse_str_to_vector():将字符串用向量来表示
- parse_nlu_to_diaact():将BIO和意图解析以后放入到dia_act中
- refine_diaact_by_rules():通过规则细化dia_act
如何构建一个自然语言理解模块
nlg.py主要函数介绍:主要功能是将动作转换成自然语言。
- post_process():填充模板语句中的空的槽位
- convert_diaact_to_nl():通过规则加模型将Dia_Act转换成自然语言
- translate_diaact():将dia_act用向量表示出来,然后通过模型生成句子。
- load_nlg_model():加载训练好的nlg模型。
- diaact_to_nl_slot_filling():用槽位的真实值去填充槽位信息。
- load_predefine_act_nl_pairs():加载预定义好的 Dia_Act&NL键值对。
如何构建一个用户模拟器的DQN模型
dqn.py主要函数介绍:DQN主要是训练一个强化学习的对话过程。
- getStruct():返回模型的其他参数
- fwdPass(): DQN的前向传播过程
- bwdPass():DQN的反向传播过程
- batchForward():批量的前向传播过程
- batchDoubleForward():双批量的前向传播过程
- batchBackward():批量的反向传播
- costFunc():代价函数计算
- singleBatch():单批次整个模型的计算过程
- predict():预测
如何构建用户模拟器的数据结构
训练时注意事项
-
为了训练RL代理,需要从一些规则策略经历(用户和代理的一个完整对话过程)元组开始初始化一个经历重放缓冲池,也可以从一个空的经历重放缓冲池开始。 建议使用某些规则或监督策略来初始化经历重放缓冲池,很多相关研究已经证明了这种方式的优势处,例如,良好的初始化策略可以加快RL训练的速度。 在这里,我们使用非常简单的基于规则的策略来初始化经历重放缓冲池。
-
RL代理是DQN网络。 在训练中,我们使用e-greedy策略和动态经历重放缓冲池。 经历重放缓冲池的大小是动态变化的。 一个重要的DQN的技巧是通过引入目标网络,这样网络会缓慢更新和计算目标网络短期内达到的目标值。
- 训练过程可以这样定义:在每个epoch中,我们模拟N个对话,并将这些状态转换元组(st,at,rt,st + 1)添加到经历重放缓冲池中,训练和更新当前的DQN网络。在一个epoch中,当前DQN网络将在批次结束时进行多次更新,具体取决于批次大小和经历重放缓冲池的当前大小。 在一个模拟epoch中,目标网络将被当前DQN网络取代,目标DQN网络仅在一个epoch中更新一次。经历重放缓冲池更新策略如下:首先,我们将从模拟中累积所有经验元组,并刷新经历重放缓冲池,直到当前RL代理达到成功率阈值(即,success_rate_threshold = 0.30),然后使用当前RL代理的经验元组重新填充缓冲区。一般而言DQN的初始性能不好,无法生成足够好的经历重放元组,因此,在当前的RL代理可以达到一定成功率之前,我们不会刷新经历重放缓冲池。接下来的训练过程,在每个epoch中,我们都会估算当前DQN代理的成功率,如果当前DQN代理足够好(即比目标网络更好),则将刷新并将经历重播缓冲区进行轮询-填充。图1显示了没有NLU的RL代理的学习曲线和NLG,图2是带有NLU和NLG的RL代理的学习曲线,训练RL代理以适应NLU和NLG的错误和噪声需要花费更长的时间。
- 表1显示了由基于规则的代理和RL代理与电影订票中的用户模拟器交互生成的一个成功和一个失败对话示例。 为了提供信息,我们还在对话的开头明确显示用户目标,但是代理对用户目标一无所知,其目标是帮助用户实现此目标并预订正确的电影票。
- 表2是用户模拟器与SimpleRL-SoftKB和End2End-RL代理之间的对话。Critic_rating槽位值是用户模拟器中常见的错误源,因此,所有学习到的策略都倾向于多次请求该值。
- 图1:没有NLU和NLG的策略训练学习曲线:绿线是规则代理,我们使用它来初始化体验重播缓冲池; 蓝线是RL代理; 橙色线是最佳上限,它是通过代理数据库中可达到的用户目标数与用户目标总数的比。
- 图2:使用NLU和NLG进行的端到端策略训练的学习曲线:绿线是规则我们用来初始化经历重放缓冲池的代理; 蓝线是学习RL代理的曲线; 橙色线是最佳上限,由代理程序数据库中可达到的用户目标数与用户目标总数之比。
- 表1:基于规则的代理和RL代理与用户模拟器生成的两个示例对话:左列显示规则和RL代理均成功; 右列显示基于规则的代理失败,而RL代理成功。
- 表2:用户模拟器与SimpleRL-SoftKB和End2End-RL代理之间的对话示例。 在每次对话结束时,代理会告知KB后验的前5个结果。 已经通知的用户目标以粗体显示。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
