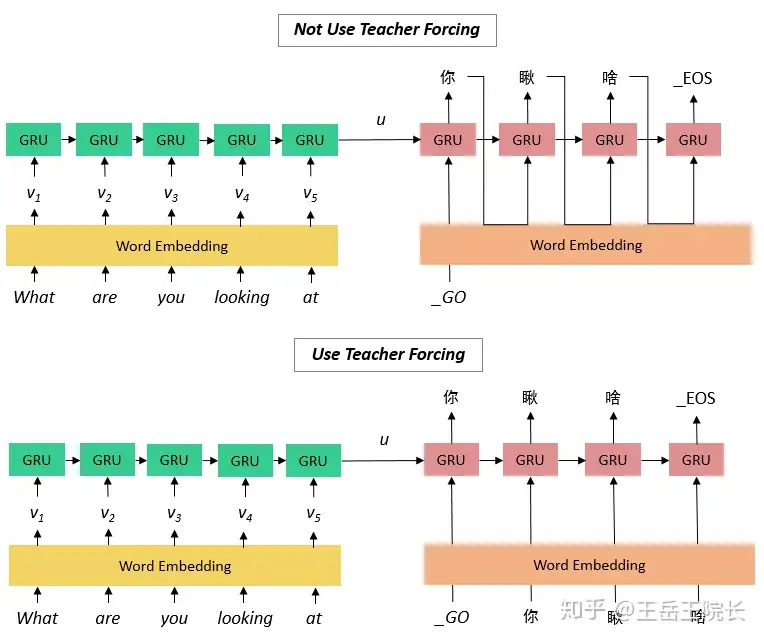
- 文本生成
- GAN
- paraphrase 复述/同义语/改写
- 评价方法
- 应用
- 资料
- 结束
文本生成
计算机要实现自然语言处理,主要有两方面的工作:自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG),这两方面工作遍布我们的生活。
文本生成(Text Generation)是自然语言处理(Natural Language Processing,NLP)领域的一项重要且具有挑战的任务
文本生成介绍
文本生成是从非语言的表示生成人类可以理解的文本
文本生成任务大概可以分为:
机器翻译(Machine Transiation):从一种语言翻译到另一种语言,既有理解,又有生成;问答系统(Dialogue Systems):理解用户的表达,生成合理的回复;文本摘要(Text Summarization):给定一篇文档,生成文档主体内容的总结摘要;故事生成(Story Telling)、诗句生成(Poetry Generation)等。
文本生成任务是生成近似于自然语言的文本序列,但仍可以根据输入数据进行分类。比如
- 输入文本 text-to-text
- 输入结构化数据的 Data-to-text Generation
- 输入图片的 Image Caption
- 输入视频的 Video Summarization
- 输入音频的 Speech Recognition 等。
文本生成文本的 Text-to-Text 任务,具体地包括神经机器翻译、智能问答、文本摘要、古诗生成、文本复述等等。文本摘要又可以分为抽取式摘要和生成式摘要。 抽取式摘要通常包含信息抽取和规划等主要步骤。
随着深度学习的发展,众多新兴技术已被文本生成任务所采用。比如
- 为了解决文本生成中的长期依赖、
超纲词(Out-of-Vocabulary,OOV)问题,注意力机制(Attention Mechanism),拷贝机制(Copy Mechanism)等应运而出; - 网络结构上使用了
循环神经网络(Recurrent Neural Networks),卷积神经网络(Convolutional Neural Networks),图神经网络(Graph Neural Networks),Transformer 等。 - 为了顺应“预训练-精调”范式的兴起,在海量语料上自监督地训练出的大体量预训练语言模型(Pre-trained Language Model;PLM),也被广泛应用在文本生成任务中。
参考:一文了解文本生成
方法总结
【2022-9-7】智能化自动生成文本总结的方法
- (1)从原文中抽取句子组成文本总结
- (2)用文本生成模型来生成文本总结
- (3)抽取与生成相结合的方法
- (4)将预训练模型用于总结的生成
【2023-2-3】基于知识的NLG综述
- 校设实验室向细或向空,公司实验室向大。校设实验室逐渐向大模型靠拢。由于训练资源不足,大量校设实验室将集中于prompt可解释性、即插即用方法、内部知识整合。训练资源尤其稀缺的校设实验室将集中在非常偏的任务。公司实验室会开始大模型竞争,RLHF的不同方向和规模将成为第一波low-fruit,外部知识整合会是第二波low-fruit。公司实验室的方法和参数保密性将进一步提升。公司实验室对系统架构和高效训练的人才的需求将迅速攀升。
- 小任务整合入大任务。大量小任务会并入大任务,构造有监督数据集并微调不再是小任务的第一选择。大模型无法取得好结果的小任务将成为研究热点。换句话说,研究热点将从“大模型能做到什么”转换为“大模型做不到什么”。
- 知识的挖掘和自监督学习成为NLP最前沿方向。大量基于RLHF的自监督基于知识的生成方法将被大实验室提出并实践,成果将大量发表在顶会。主流热点将主要focus在知识的数量、质量以及运用知识的方法。统计方法几乎完全取代规则方法,知识的地位将快速超越模型本身。这一浪潮将迅速影响到CV,今年必定有更多基于RLHF的CV方法发表于CV三大会。
- 资本变向,算法岗地位下降。资本将变向涌入大模型方向,未来数年会保持较高热度。公司将合并大量业务,竞争训练大模型以抢占市场。大数据工程师、后端工程师、架构师的地位提高,算法工程师地位进一步下降。
ChatGPT无非就是微调的GPT-3,唯一的不同不过是知识的指向性,或者说模型对特定知识的筛选。
- GPT-3是用大量无指向性的非结构化文本训练的,而ChatGPT是在GPT-3的基础上用大量RLHF自监督的文本微调的。
- 换句话说,知识才是ChatGPT优于GPT-3的关键。GPT-3的知识没有任何标签,因此本质是一个无监督学习;而ChatGPT使用RLHF生成符合人类指令要求的知识,因此本质是一个自监督学习。有了RLHF提供的监督信号,两个模型学习知识的质量就完全不同了。实验证明,使用质量高的知识,可以将GPT-3的模型规模压缩100倍。绕来绕去,NLG最后还是知识起了决定性作用。
【2023-6-22】斯坦福cs224n文本生成专题讲解
生成模型概览
【2023-2-3】2022生成模型进展有多快?新论文盘点9类生成模型代表作
- 参考ChatGPT 持续创造历史记录:AIGC,人工智能的旷世之作
- 2014年,变分自动编码,VAE
- 2014年,生成对抗网络,GAN
- 2015年,基于流的生成模型,Flow-based models
- 2015年,扩散模型,Diffusion Model
- 2017年,Transformer模型
- 2020年,神经辐射场,Neural Radiance Field
- 2021年,CLIP(Contrastive Language-Image PreTraining模型)
(1) 从原文中抽取句子组成文本总结
- ① TextRank:使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取 N 个得分最高的节点,作为摘要。其基本思想来源于谷歌的 PageRank算法,不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
- ② 编码+聚类/分类: 通过Bert,transformer或wor2vec方式进行编码,得到句子级别的向量表示。再用聚类的方式或分类模型来提取出关键句子。对于聚类可用 K-Means聚类和 Mean-Shift 聚类等进行句子聚类,得到 N 个类别。最后从每个类别中,选择距离质心最近的句子,得到 N 个句子,组合成最终摘要。对于分类,可以选择合适的分类模型进行分类,其标签获取往往是选取原文中与标准摘要计算 ROUGE 得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合 ROUGE 得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为 1 标签,其余为 0 标签。
- 抽取式的方法发展较早,技术相对成熟,效果稳定。摘要中所有的语句均来自于源文,逻辑合理,语句通顺。其缺点在于可能会引入冗余信息或缺失关键信息,组成的文本连贯性较差。在实际应用中可将此方法用于辅助人工分析。尤其是在较长的文本中,可提取出关键句子,让人抓住重点。
(2)用文本生成模型来生成文本总结
-
- Seq2Seq+Attention 模型
- Seq2Seq模型简单概括就是拼接两个RNN系(RNN,LSTM等)的模型,分别称为模型的Encoder部分和Decoder部分。Encoder部分负责输入文本语义的编码,生成一个“浓缩输入语义”的语义空间meaning space。Decoder部分负责根据这个语义空间及每个time-step的Decoder输出,进行Attention机制并生成句子,从而实现在语义背景下从句子到句子的直接转换(Sequence to Sequence)。
- 不足之处在于:无法生成训练时未出现(OOV)的词,只能生成词汇表中的词;会产生错误的事实,句子的可读性较差;文本自我重复,即聚焦于某些公共Attention很大的单词;长文本摘要生成难度较大。
- Seq2Seq+Attention 模型
-
- Pointer-Generator(指针生成器网络)
- 该方法在基于注意力机制的Seq2Seq基础上增加了 Copy 和 Coverage 机制,缓解未登录词问题(OOV)和生成重复的问题。
- PGN架构的核心思想: 对于每一个解码器的时间步, 计算一个生成概率p_gen = [0, 1]之间的实数值, 相当于一个权值参数. 用这个概率调节两种选择的取舍, 要么从词汇表生成一个单词, 要么从原文本复制一个单词。
- ①. 使用指针生成器网络(pointer-generator network),通过指针从原文中拷贝词,这种方式可以在正确复述原文信息的同时,也能使用生成器生成一些新的词。
- ②. 使用覆盖率(coverage) 机制,追踪哪些信息已经在摘要中了,通过这种方式以期避免生成具有重复片段的摘要。
- 不足在于:概括的内容可能并非源文本的核心内容;生成的摘要都是相近的词或片段概括,没有更高层次的压缩概括;语句通畅性降低。
- Pointer-Generator(指针生成器网络)
- 相比于抽取式,生成式的摘要更加灵活,强大,可以更好的引入外部知识。然而,生成过程往往缺少关键信息的控制和指导,无法很好地定位关键词语,难以生成流畅性的句子。
(3)抽取与生成相结合的方法
考虑到抽取式和生成式各自的优缺点,目前很多研究已经将二者结合:用抽取的方式选择重要内容,基于重要内容指导生成网络的训练对内容进行改写。
- Bottom-Up
- Bottom-Up使用数据有效的内容选择器去确定应该作为摘要一部分的源文档中的短语。将此选择器用作自下而上的注意力步骤,以将模型约束成可能的短语。使用这种方法提高了压缩文本的能力,同时仍能生成流畅的摘要。
- SPACES
- SPACES以抽取出的关键句作为输入来生成新的总结、摘要文本。首先对文本进行分句,然后构建句子索引,并通过transformer对句子进行编码。然后在编码后的句子向量的基础上用DGCNN训练一个关键句分类的模型,判断每个句子是否为关键句。标签是通过一种自动的方式生成的,根据标准的总结,在原文中进行相似度计算,相似度较高的句子视为关键句其标签为1,否则为0。生成模型就是一个Seq2Seq模型,以抽取模型的输出结果作为输入、人工标注的总结作为标签进行训练,得到摘要生成模型。
- Fast-RL
- Fast-RL是基于强化学习的任务,首先使用抽取器agent选择重要的句子或突出显示的内容。然后使用生成器网络重写每一个被抽取的句子。抽取器利用分层神经模型来学习文档的句子表示,并利用“选择网络”根据其表示提取句子。使用时域卷积模型来计算文档中每个单独句子的表示形式。为了进一步结合文档的全局上下文并捕获句子之间的长期语义依赖关系,将双向LSTM-RNN应用于卷积的输出。基于抽取器提取的句子,添加另一个LSTM-RNN来训练Pointer Network,以循环抽取句子。
- 抽取+生成的结合形式有很多,融合了抽取式和生成式的优点,生成的文本内容逻辑清晰,语句的连贯性更强,有很大的研究价值和改进空间。
(4)将预训练模型用于总结的生成
- 目前基于预训练模型进行下游任务微调的方法发展很快,迁移性很强,可以应用在多种下游任务上,在文本的总结上也有不错的效果。
-
- 基于BART
- BART的训练主要由2个步骤组成:(1)使用任意噪声函数破坏文本。(2)模型学习重建原始文本。BART 使用基于 Transformer 的标准神经机器翻译架构,可视为BERT、GPT等预训练模型的泛化形式。通过随机打乱原始句子的顺序,再使用文本填充方法(即用单个 mask token 替换文本片段)能够获取最优性能。BART 尤其擅长处理文本生成任务,同时在自然语言理解任务中的表现也是可圈可点。
- 基于BART
-
- 基于CPT
- CPT是在BART的基础上,提出兼顾自然语言理解(NLU)和自然语言生成(NLG)的模型结构。CPT的具体结构可以看作一个输入,多个输出的非对称结构,主要包括三个部分:(1)S-Enc (Shared Encoder):共享Encoder,双向attention结构,建模输入文本。(2)U-Dec (Understanding Decoder):理解用Decoder,双向attention结构,输入S-Enc得到的表示,输出MLM的结果。为模型增强理解任务。(3)G-Dec (Generation Decoder):生成用Decoder,正如BART中的Decoder模块,利用encoder-decoder attention与S-Enc相连,用于生成。
- 基于CPT
-
- 基于PEGASUS
- 在 PEGASUS 中,将源文档中的“重要句子”删除或者遮蔽,再利用剩余的句子在输出中生成这些被删除或遮蔽的句子。这是一种基于间隙句子(gap-sentences)生成的序列-序列模型自监督的预训练目标,以适配Transformer-based的encoder-decoder模型在海量文本语料上预训练。由间隔句生成(GSG)和掩码语言模型(MLM)相结合,对于低资源任务数据集,通过微调PEGASUS模型,可以在广泛的领域实现良好的抽象摘要效果。
- 基于PEGASUS
- 预训练模型可以应用在文本生成,文本分类,机器翻译等下游任务上
常见分类
文本摘要的主流方法包括「抽取式」(Extractive Summarization)和「生成式」(Abstractive Summarization)
生成模型方法
生成一段对话回复的模型可以简单分为三类:
- (1)
规则模板。典型的技术就是AIML语言。这种回复实际上需要人为设定规则模板,对用户输入进行回复。- 优点:1、实现简单,无需大量标注数据;2、回复效果可控、稳定。
- 不足:1、如果需要回复大量问题,则需要人工设定大量模板,人力工作量大;2、使用规则模板生成的回复较为单一,多样性低。
- (2)
生成模型。主要用encoder-decoder结构生成回复。典型技术是Seq2Seq、transformer。- 优点:无需规则,能自动从已有对话文本中学习如何生成文本。
- 不足:1、生成效果不可控,训练好的模型更像是一个“黑盒”,也无法干预模型的生成效果;2、倾向生成万能回复,如“好的”、“哈哈”等,所以多样性与相关性低。
- (3)
检索模型。利用文本检索与排序技术从问答库中挑选合适的回复。- 优点:由于数据来源于已经生成好的回复,或是从已抓取的数据得到的回复,所以语句通顺性高,万能回复少;
- 不足:1.不能生成新的回复文本,只能从问答库中得到文本进行回复;2.当检索或排序时,可能只停留在表面的语义相关性,难以捕捉真实含义。
总结如下:
| 方法流派 | 思路 | 示例 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|---|
| 规则模板 | 人为设定规则模板 | AIML语言 |
①简单,无须标注②稳定可控 | ①人力消耗大②回复单一,多样性欠缺 | - |
| 生成模型 | 用encoder-decoder结构生成回复 | Seq2Seq、transformer |
无须规则,自动生成 | ①效果不可控②万能回复(安全回复)③多样性低④一致性不足 | - |
| 检索模型 | 文本检索与排序技术从问答库中挑选合适的回复 | IR | ①语句通顺②可控 | ①不能生成回复②表面相关,难以捕捉语义信息 | - |
| 混合模型 | 综合生成和检索方案 | 度秘 | - | - | - |
【2020-10-22】大众点评信息流基于文本生成的创意优化实践:文本生成的三种主流方法各自的优劣势:
- 规划式:根据结构化的信息,通过语法规则、树形规则等方式规划生成进文本中,可以抽象为三个阶段。宏观规划解决“说什么内容”,微观规划解决“怎么说”,包括语法句子粒度的规划,以及最后的表层优化对结果进行微调。其优势是控制力极强、准确率较高,特别适合新闻播报等模版化场景。而劣势是很难做到端到端的优化,损失信息上限也不高。
- 抽取式:顾名思义,在原文信息中抽取一部分作为输出。可以通过编码端的表征在解码端转化为多种不同的分类任务,来实现端到端的优化。其优势在于:能降低复杂度,较好控制与原文的相关性。而劣势在于:容易受原文的束缚,泛化能力不强。
- 生成式:通过编码端的表征,在解码端完成序列生成的任务,可以实现完全的端到端优化,可以完成多模态的任务。其在泛化能力上具有压倒性优势,但劣势是控制难度极大,建模复杂度也很高。

常见数据集
文本生成数据集,把它建模成一个条件概率的分布P(y|x)。y是一个数据描述文本,x是各种各样不同形式的数据,可以是统计数据、键值表格,也可以是三元组(多见于知识图谱),或是逻辑表达。
- 左边是一个NBA比赛赛事的描述,包括两个队的得分,以及球员的一些技术统计,基于这些数据产生的赛事播报,这是一个常见的应用。
- 中间是一个键值对表格,取的是维基百科里对人物介绍的一个数据集,在学术界用得比较多,工业界也会尝试去应用。
- 右边是一个比较新的数据集,提供了数据结构化数据,并规定了逻辑表达式。我们根据给定的逻辑表达式产生对应的描述。
【2022-7-16】腾讯刘天宇:可控、可靠的数据到文本生成技术, 聚焦data2text任务
可控文本生成数据集
可控文本生成相关数据集
- StylePTB:细粒度文本风格迁移基准数据集:https://github.com/lvyiwei1/StylePTB/
- SongNet:格式可控的宋词生成任务:https://github.com/lipiji/SongNet
- GPT-2 Output:可用于构造可控文本生成数据集的大体量语料库:https://github.com/openai/gpt-2-output-dataset
- Inverse Prompting:公开领域的诗文生成,公开领域的长篇幅问答数据集:https://github.com/THUDM/iPrompt
- GYAFC (Grammarly’s Yahoo Answers Formality Corpus):雅虎问答形式迁移语料库:https://github.com/raosudha89/GYAFC-corpus
生成模型
生成模型是什么?
- 从一批样本数据 $X$ 中学习分布 $p(X)$ ,这样就能学习到样本外的数据。用这个分布 $p(X)$ 就能随意采样,获得新的生成结果
- 然而,这样的分布 $p(X)$ 无法直接获取,只能通过一个隐变量 $Z$ 来生成 $X$, 假设 $Z$ 服从正态分布,随便取一个 $Z$,用 $Z$ 和 $X$ 的关系计算 $p(X)$ 。
- 公式:$p(X)=\sum_{Z} p(X \mid Z) p(Z)$
- $p(X \mid Z)$ 是后验分布,$p(Z)$ 是先验分布
「基于神经网络的文本生成」大致分为「自回归」和「非自回归」两种思路
- 自回归就是给定条件和已知的词逐步生成下一个词,例如,大名鼎鼎的「seq2seq + attention」,在讲解「seq2seq + attention」之前,先要了解什么是「
语言建模」和「解码器」。 - 「
语言建模」完成的是源语句的编码,给定已知的词,来预测下一个词,模型输出一个词表上的概率分布,产生这种概率分布的系统称为「语言模型」,建模的总体思路是使用 RNN 作为编码器来构建句子的语义表示,之所以使用 RNN,是因为 RNN 擅长建模顺序性的信息。
在语言建模和解码器的基础上,诞生了灵活的「seq2seq」生成架构,使用编码器 RNN 来产生源语句的表示,使用解码器 RNN 生成以编码为条件的目标句子。但是 seq2seq 的问题也很明显,源语句编码的「中间语义张量」需要捕获有关源语句的所有信息,短小而不精悍的「中间语义张量」限制了编码器的表示能力,这就是 seq2seq 的信息瓶颈。
随着深度学习不断发展,attention 为 seq2seq 的瓶颈问题提供了解决方案,核心思想是在编码器的每个步骤,专注于源序列的特定部分,这样做还有助于解决梯度消失问题,这就是显赫的「seq2seq + attention」。
再到后面,attention 再进一步,便产生了震惊世人的 Transformer,彻底解决了 RNN 中顺序计算无法并行化的问题,后面又有大佬机构陆续提出 GPT 系列生成模型。
上述的这些自回归方法并不是完美的,存在以下三点不足:
- 时间复杂度比较高;
- 解码器的各个步骤必须顺序运行,不能并行运行;
- 缺乏全局信息,这也是采用 Beam Search 的原因。
针对自回归的这些不足,大佬们提出了「非自回归」方法,给定 来源 x 和 目标 y,确定目标序列 y 的长度,并行生成目标序列,优点是并行解码目标输出,不用前后词互相等待,所以快速(比自回归快 20 倍),缺点是生成的前后词是否约束匹配、是否能形成一句话,仍然存在很多问题,目前「非自回归」没有成为生成任务的主流。
参考:一文了解文本生成
模型结构总结
文本生成模型的结构常来自于人类撰写文本的启发。此处按照模型结构的特征,将主流文本生成模型分为如下几种:
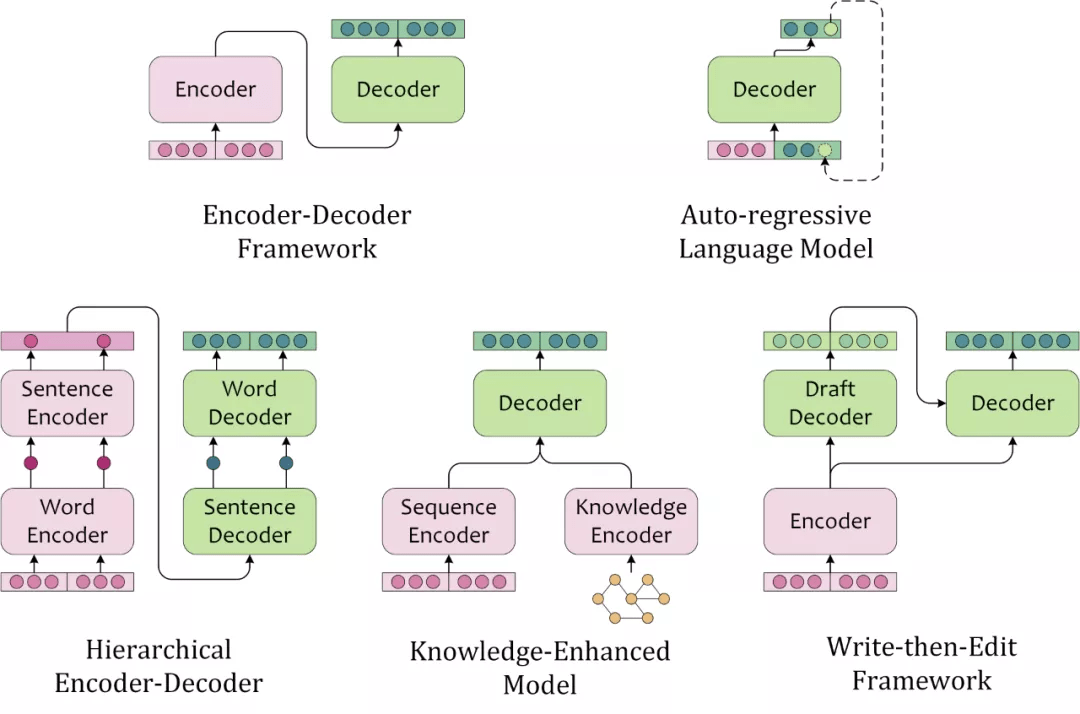

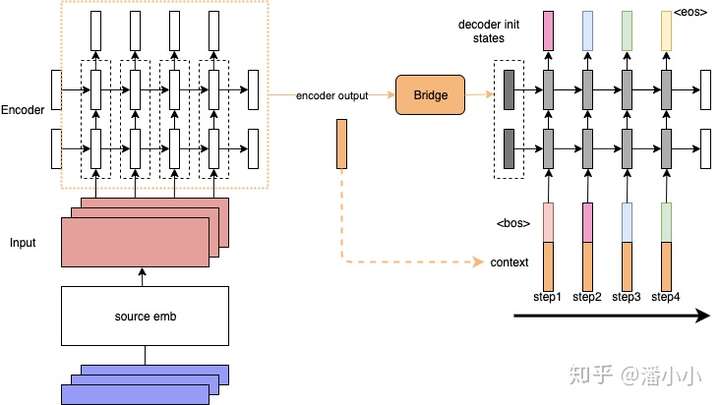
Encoder-Decoder Framework
“编码器-解码器框架”首先使用 encoder 编码文本,再使用 decoder 基于原文编码和部分解码输出,自回归地解码(Autoregressively Decoding)出文本。这类似于,人类首先理解素材(源文本、图片、视频等),然后基于对原文的理解和已写出的内容,逐字地撰写出文本。也是目前序列到序列任务中应用最广泛的框架结构。
Auto-regressive Language Model
标准的 left-to-right 的单向语言模型,也可以根据前文序列逐字地解码出文本序列,这种依赖于前文语境来建模未来状态的解码过程,叫做自回归解码(Auto-regressive Decoding)。不同于编码器-解码器框架”使用 encoder 编码源文本,用 decoder 编码已预测的部分序列,AR LM 用同一个模型编码源文本和已解码的部分序列。
Hierarchical Encoder-Decoder
对于文本素材,人类会先理解单个句子,再理解整篇文本。在撰写文本的过程中,也需要先构思句子的大概方向,再逐字地撰写出内容。这类模型往往需要一个层次编码器对源文本进行 intra-sentence 和 inter-sentence 的编码,对应地进行层次 sentence-level 和 token-level 的解码。在 RNN 时代,层次模型分别建模来局部和全局有不同粒度的信息,往往能够带来性能提升,而 Transformer 和预训练语言模型的时代,全连接的 Self-Attention 弱化了这种优势。
Knowledge-Enriched Model
知识增强的文本生成模型,引入了外部知识,因此除了针对源文本的文本编码器外,往往还需要针对外部知识的知识编码器。知识编码器的选择可以依据外部知识的数据结构,引入知识图谱、图片、文本作为外部知识时可以对应地选用图神经网络、卷积神经网络、预训练语言模型等。融合源文本编码与知识编码时,也可以考虑注意力机制,指针生成器网络(Pointer-Generator-Network),记忆网络(Memory Networks)等。
Write-then-Edit Framework
考虑到人工撰写稿件尚不能一次成文,那么文本生成可能同样需要有“修订”的过程。人工修订稿件时,需要基于原始素材和草稿撰写终稿,模型也需要根据源文本和解码出的草稿重新进行编解码。这种考虑了原文和草稿的模型能够产生更加合理的文本内容。当然也会增加计算需求,同时生成效率也会打折扣。
原理解读
【2022-12-17】通俗形象地分析比较生成模型(GAN/VAE/Flow/Diffusion/AR)
通俗解释各类生成模型,如自回归模型Autoregressive Model (AR),生成对抗网络Generative Adversarial Network (GAN),标准化流模型Normalizing Flow (Flow),变分自编码器Variational Auto-Encoder (VAE),去噪扩散模型Denoising Diffusion Probablistic Model (Diffusion)等等。
生成模型的数据生成过程是将一个先验分布的采样点 Z 变换成数据分布的采样点 X 的过程。下图可以清楚地看到各个模型是如何将采样点Z映射到数据X的
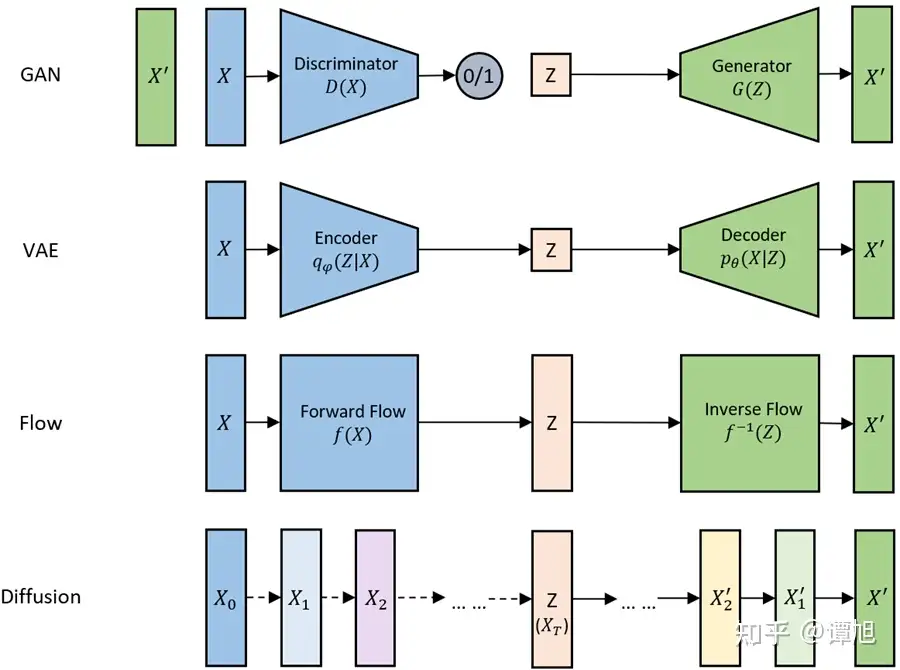
从Z映射到X的过程,比喻为过河。河的左岸是Z,右岸是X,过河就是乘船从左岸码头到达右岸码头。船可以理解为生成模型,码头的位置可以理解为样本点Z或者X在分布空间的位置。不同的生成模型有不同的过河的方法
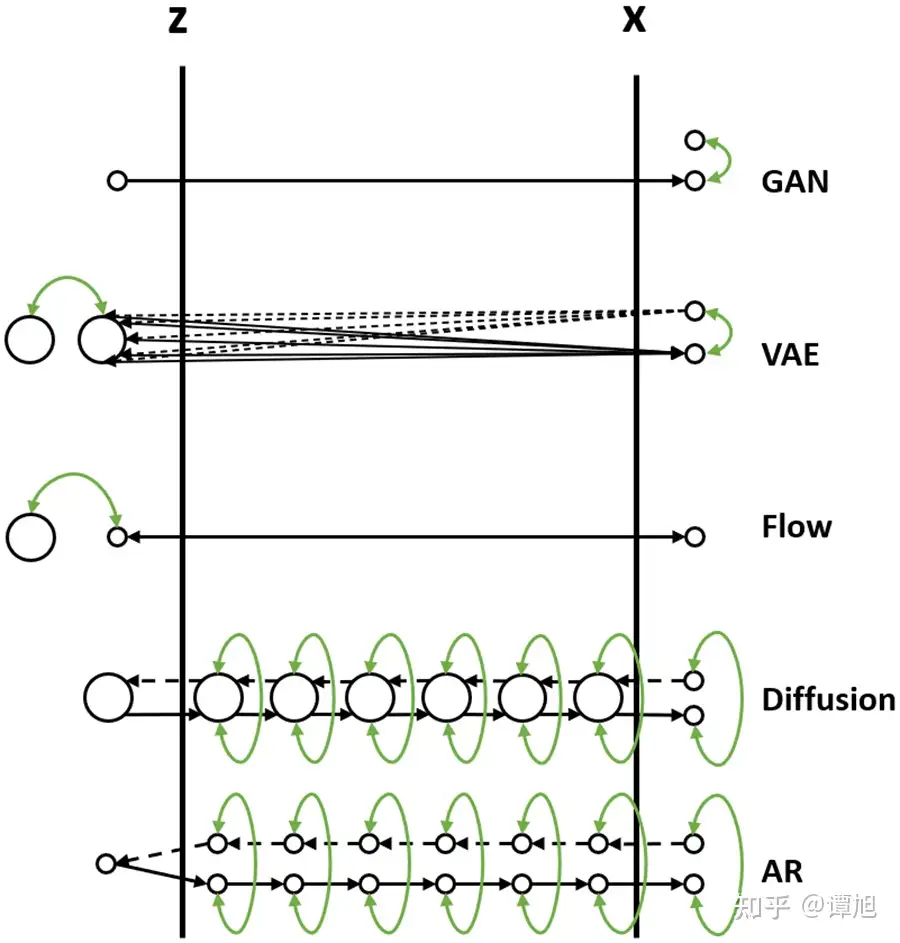
各种过河方式
GAN- 从先验分布随机采样一个Z,即在左岸随便找一个码头,直接通过对抗损失的方式强制引导船开到右岸,要求右岸下船的码头和真实数据点在分布层面上比较接近。
VAE- 1)VAE在过河的时候,不是强制把河左岸的一个随机点拉到河右岸,而是考虑右岸的数据到达河左岸会落在什么样的码头。如果知道右岸数据到达左岸大概落在哪些码头,直接从这些码头出发就可以顺利回到右岸了。
- 2)由于VAE编码器的输出是一个
高斯分布的均值和方差,一个右岸的样本数据X到达河左岸的码头位置不是一个固定点,而是一个高斯分布,这个高斯分布在训练时会和一个先验分布(一般是标准高斯分布)接近。 - 3)在数据生成时,从先验分布采样出来的Z也大概符合右岸过来的这几个码头位置,通过VAE解码器回到河右岸时,大概能到达真实数据分布所在的码头。
Flow- 1)Flow的过河方式和VAE有点类似,也是先看看河右岸数据到河左岸能落在哪些码头,在生成数据的时候从这些码头出发,就比较容易能到达河右岸。
- 2)和VAE不同的是,对于一个从河右岸码头出发的数据,通过Flow到达河左岸的码头是一个固定的位置,并不是一个分布。而且往返的船开着双程航线,来时从什么右岸码头到达左岸码头经过什么路线,回去时就从这个左岸码头经过这个路线到达这个右岸码头,是完全可逆的。
- 3)Flow需要约束数据到达河左岸码头的位置服从一个先验分布(一般是标准高斯分布),这样在数据生成的时候方便从先验分布里采样码头的位置,能比较好的到达河右岸。
Diffusion- 1)Diffusion也借鉴了类似VAE和Flow的过河思想,要想到达河右岸,先看看数据从河右岸去到左岸会在哪个码头下船,然后就从这个码头上船,准能到达河右岸的码头。
- 2)但是和Flow以及VAE不同的是,Diffusion不只看从右岸过来的时候在哪个码头下船,还看在河中央经过了哪些桥墩或者浮标点。这样从河左岸到河右岸的时候,也要一步一步打卡之前来时经过的这些浮标点,能更好约束往返的航线,确保到达河右岸的码头位置符合真实数据分布。
- 3)Diffusion从河右岸过来的航线不是可学习的,而是人工设计的,能保证到达河左岸的码头位置,虽然有些随机性,但是符合一个先验分布(一般是高斯分布),这样在生成数据的时候选择左岸出发的码头位置。
- 4)因为训练模型的时候要求一步步打卡来时经过的浮标,在生成数据的时候,基本上也能遵守这些潜在的浮标位置,一步步打卡到达右岸码头。
- 5)如果觉得开到河右岸一步步这样打卡浮标有点繁琐,影响船的行进速度,可以选择一次打卡跨好几个浮标,就能加速船行速度,这就对应diffusion的加速采样过程。
AR- 1)可以类比Diffusion模型,将AR生成过程看成中间的一个个浮标。从河右岸到达河左岸的过程就好比自回归分解,将一步步拆解成中间的浮标,这个过程也是不用学习的。
- 2)河左岸的码头可以看成自回归生成的第一个START token。AR模型河左岸码头的位置是确定的,就是START token对应的embedding。
- 3)在训练过程中,自回归模型也一个个对齐了浮标,所以在生成的时候也能一步步打卡浮标去到河右岸。
- 4)和Diffusion不同的是,自回归模型要想加速,跳过某些浮标,就没有那么容易了,除非重新训练一个semi-autoregressive的模型,一次生成多个token跨过多个浮标。
- 5)和Diffusion类似的是,在训练过程中都使用了teacher-forcing的方式,以当前步的ground-truth浮标位置为出发点,预测下一个浮标位置,这也降低了学习的难度,所以通常来讲,自回归模型和Diffusion模型训练起来都比较容易。
RNN系列
- 机器翻译是从RNN开始跨入神经网络机器翻译时代的,几个比较重要的阶段分别是: Simple RNN, Contextualize RNN, Contextualized RNN with attention, Transformer(2017)
RNN演变历史
【2023-3-22】 整理RNN到Seq2Seq演变过程
【2023-4-2】seq2seq演进过程:
RNN: 时序输入,但要求输入输出一一对应,能解决 1->N, N->N, N->1,而 N->M 无能为力Seq2Seq: Encoder-Decoder结构(局部是RNN),将信息压缩到Context向量中, 实现 N->M的变长输入输出; 但 Context 存储信息量有限,如果句子太长,翻译精读就会下降。Seq2Seq+Attention: Context向量升级为矩阵, 解码时自动获取最重要的单词上文,成功摆脱了对句子长度的限制;但 计算速度太慢Seq2Seq+Self-attention(Transformer): 自注意力机制,先选取单词的意义,再根据顺序选取要生成的信息,支持并行计算,接近人类的翻译方式。
Simple RNN
- encoder-decoder模型结构中,encoder将整个源端序列(不论长度)压缩成一个向量(encoder output),源端信息和decoder之间唯一的联系只是: encoder output会作为decoder的initial states的输入。这样带来一个显而易见的问题就是,随着decoder长度的增加,encoder output的信息会衰减。
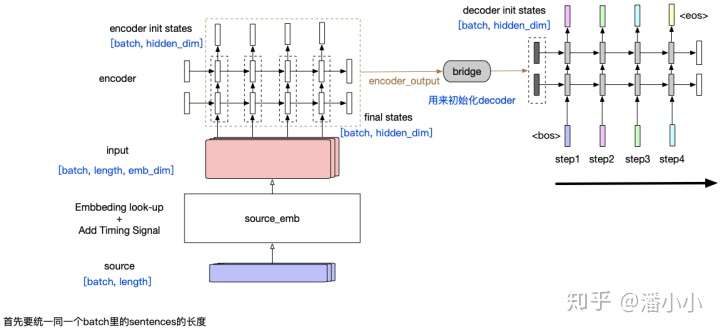
这种模型有2个主要的问题:
- 源端序列不论长短,都被统一压缩成一个固定维度的向量,并且显而易见的是这个向量中包含的信息中,关于源端序列末尾的token的信息更多,而如果序列很长,最终可能基本上“遗忘”了序列开头的token的信息。
- 第二个问题同样由RNN的特性造成: 随着decoder timestep的信息的增加,initial hidden states中包含的encoder output相关信息也会衰减,decoder会逐渐“遗忘”源端序列的信息,而更多地关注目标序列中在该timestep之前的token的信息。
LSTM
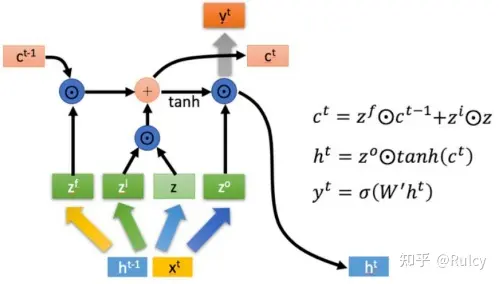
LSTM(1997)主要用于解决长期依赖,在长序列中有更好的表现。相比于RNN只传递了一个隐状态向量(hidden state)h,LSTM额外传递了一个隐状态向量(cell state)c。
- 先理解LSTM的图表示,LSTM首先将当前输入与隐状态向量h拼接,并输出四个状态向量(3个sigmoid激活的门控状态和1个tanh激活的状态向量),这4个状态向量分别用于:
- 1、忘记节点,对传递的c进行选择性的忘记;
- 2、选择记忆,通过一个门控状态和一个状态向量得到当前结果;
- 3、输出阶段,通过一个门控状态向量来决定当前得到的c如何转换为输出到下一个节点的h。
LSTM整体逻辑如下图所示,可以看到c与h都可以表示当前序列,但是c的变化是累加的,而h的变化由c通过门控状态向量得到,可能产生很大不同。显而易见,LSTM引入了多个需要训练的网络,参数量大。
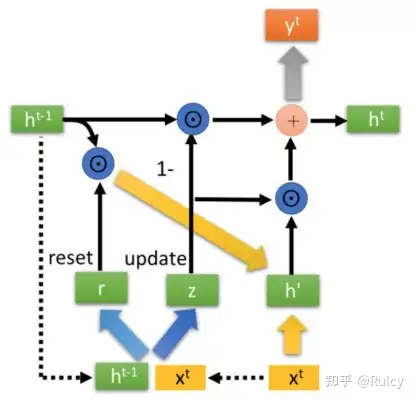
GRU
GRU(2014)比LSTM的参数量更少。
- GRU相对于LSTM,抛弃了cell state而将其整合到了隐状态向量h中,将GRU内部结构看做黑盒,那么GRU与RNN是具有相同结构的。
- 相对来说,GRU比LSTM少一个门控单元,GRU有2个门控单元(reset gate和update gate)和1个状态向量。通过更新门实现了以z的权重保留当前的状态向量,并以(1-z)的权重保留传递的状态向量。我们可以粗暴地认为,LSTM通过两个隐状态向量c/h进行预测,但是GRU牺牲一个门控,从而在传递的隐状态向量h(GRU)中整合了c/h(LSTM)。
Contextualized RNN
- 为了解决上述第二个问题,即encoder output随着decoder timestep增加而信息衰减的问题,有人提出了一种加了context的RNN sequence to sequence模型:
- decoder在每个timestep的input上都会加上一个context。
- 把这看作是encoded source sentence。这样就可以在decoder的每一步,都把源端的整个句子的信息和target端当前的token一起输入到RNN中,防止源端的context信息随着timestep的增长而衰减。
但是这样依然有一个问题:
- context对于每个timestep都是静态的(encoder端的final hidden states,或者是所有timestep的output的平均值)。但是每个decoder端的token在解码时用到的context真的应该是一样的吗?在这样的背景下,Attention 就应运而生了
Contextualized RNN with soft align (Attention)
- Attention在机器翻译领域的应用最早的提出来自于2014年的一篇论文 Neural Machine Translation by Jointly Learning to Align and Translate

- 在每个timestep输入到decoder RNN结构中之前,会用当前的输入token的vector与encoder output中的每一个position的vector作一个”attention”操作,这个”attention”操作的目的就是计算当前token与每个position之间的”相关度”,从而决定每个position的vector在最终该timestep的context中占的比重有多少。最终的context即encoder output每个位置vector表达的加权平均。

RNN 结构
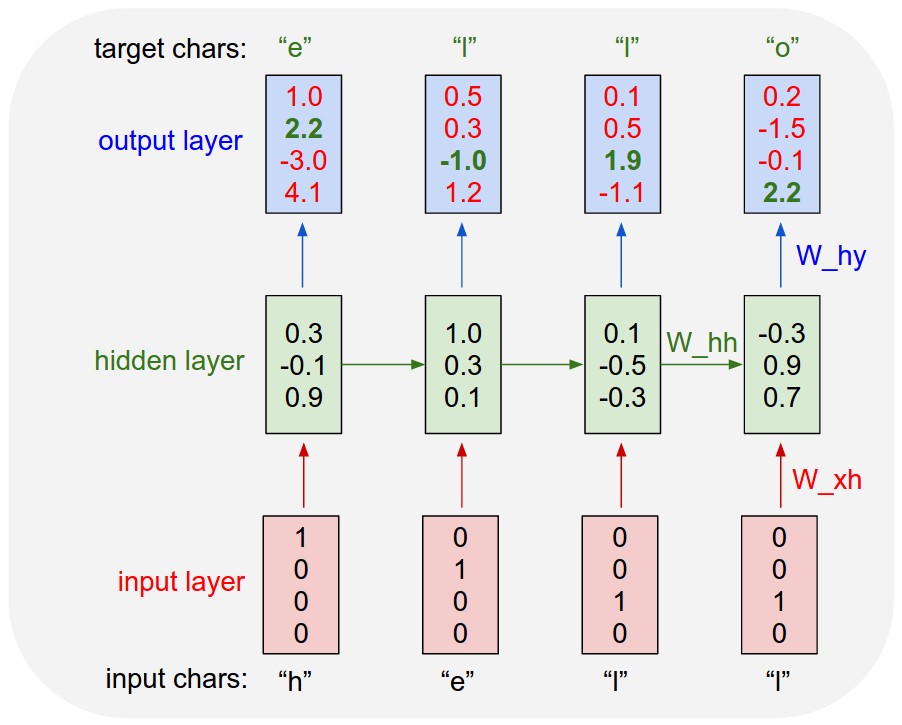
RNN 基本模型如上图所示
- 每个神经元接受的输入包括:前一个神经元的隐藏层状态 h(用于记忆) 和当前输入 x (当前信息)。
- 神经元得到输入之后,会计算出新的隐藏状态 h 和输出 y
- 然后再传递到下一个神经元。
因为隐藏状态 h 的存在,使得 RNN 具有一定的记忆功能。
序列任务与RNN
任务总结
针对不同任务,通常要对 RNN 模型结构进行少量调整,根据输入和输出的数量,分为三种比较常见的结构:
- N vs N
- 1 vs N
- N vs 1
【2015-5-21】Andrej Karpathy blog The Unreasonable Effectiveness of Recurrent Neural Networks

| 类型 | 说明 | 图解 | 示例 |
|---|---|---|---|
| one to one | 一对一 | 输入/输出长度固定,传统神经网络 | 图像分类 |
| one to many | 一对多 | 单输入,序列输出 | 看图说话/音乐生成 |
| many to one | 多对一 | 多输入/序列输入,单输出 | 文本分类 |
| many to many | 多对多(定长) | 输入/输出长度相同 | 视频分类/NER |
| many to many | 多对多(不定长) | 输入/输出长度不同 | 机器翻译 |
参考:
(1)1 to N 一对多
在 1 vs N 结构中,只有一个输入 x,和 N 个输出 y1, y2, …, yN。
有两种方式使用 1 vs N
- 第一种,只将输入 x 传入第一个 RNN 神经元
- 第二种,将输入 x 传入所有 RNN 神经元。
- 此类结构的输入长度为1,输出长度为N,一般又可以分为两种:
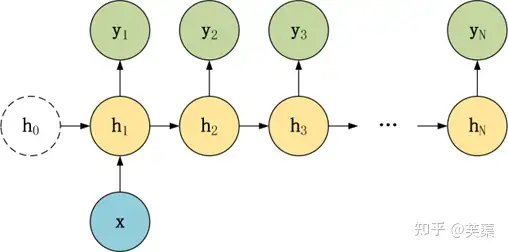
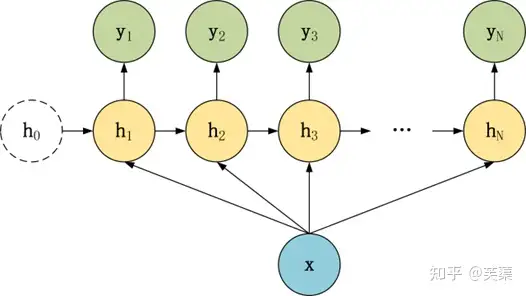
1 vs N 结构适合用于以下任务:
- 图像生成文字,一般输入 X 为图片,输出为一段图片描述性的文字;
- 输入 x 就是一张图片,输出就是一段图片的描述文字。根据音乐类别,生成对应的音乐。根据小说类别,生成相应的小说。
- 输入音乐类别,生成对应的音乐
- 根据小说(新闻情感)类别,生成对应的文字
(2)N to 1 多对一
和 1 to N 相反,N vs 1 结构中,x是序列,y是单个数值,img
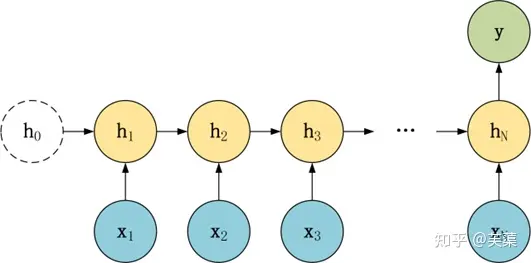
N vs 1 结构适合用于以下任务:
- 序列分类任务,一段语音、一段文字的类别,句子的情感分析。
- 如给定一段文本或语音序列,归类(情感分类,主题分类等)
(3)N to N 多对多
该模型处理的一般是输入和输出序列长度相等的任务,模型结构图
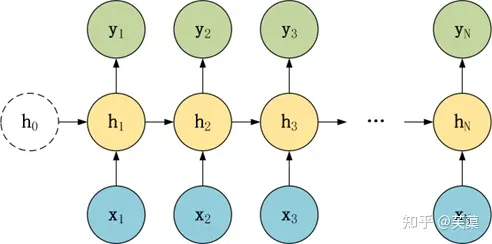
N vs N 结构,包含 N个输入 x1, x2, …, xN,和 N个输出 y1, y2, …, yN。
N vs N 的结构中,输入和输出序列的长度是相等的,通常适合用于以下任务:
- 词性标注
- 词性标注训练语言模型,使用之前的词预测下一个词等
- 语言模型(Language Modeling)
(4)N to M 多对多
N to N的扩展,RNN系列方法无法解决,此时采用 seq2seq 结构
Seq2seq
参考资料
seq2seq简介
闲聊型任务,主要用seq2seq方案生成闲聊型机器人。
seq2seq的运行模式
input -> encoder -> context -> decoder -> output
基本结构:

-

Encoder:seq2seq的编码器是单层或多层的RNN(双向),对输入的文本编码成一个向量输出。Decoder:seq2seq的解码器,也是单层或多层的RNN(非双向),然后根据context信息对每一步进行解码,输出对应的文本。- context,最简单的方法是直接拿encoder的最后一个状态,或整个状态进行加总,得到一个固定的向量。
- 问题:context是固定长度的向量,表达能力比较有限,所以引入了Attention机制。
- Attention机制:每步解码都会根据当前状态对encoder的文本进行动态权重计算,进行归一化。再算出一个当前加权后的context,作为decoder的context。表达能力更强。

- 损失函数:对每一步的单词计算一个交叉熵,然后把它给加起来,最后得到一个损失函数
- 优化算法:
- 贪心搜索:每一步搜索都取概率最大的分支,容易陷入局部最优解。比如,可能当前一步的概率很大,但后面的概率都很小,这样搜索出来的文本就不是全局的最优解。但如果对整个空间进行搜索,可能搜索空间太大,无法全部搜索。
- Beam Search:采取折中的办法,每次搜索只保留最优的k条路径,搜索结果优于贪心搜索,因为每一步并非按最大的去选一个;时间复杂度也可以根据对“K”的设置进行控制;(如下图:每次搜索只保留最优的2条路径)

- Beam Search可能会产生的问题是:可能都是十分相近的句子。如:当用户说“我喜欢打篮球”,搜索出来的结果可能是“我也是。”“我也是!”“我也是……”只有标点符号不同,这样多样性依然很低。

实验对比
模型对比
- 普通seq2seq存在生成回复相关性不够高、生成回复为否定句或负面情感的问题。
- Copy机制+seq2seq:提高了回复相关性,但依然无法解决回复为否定句或负面情感的问题。
- 主题控制+seq2seq:既提高回复相关性,也可以控制回复语义,提升回复效果,但可能出现回复不通顺的问题,并存在否定句式与负面回复。
- 属性控制+seq2seq:比较能满足场景需要,但有一定比例的通用回复,可以通过改进Beam Search、后排序的办法来提高个性化回复的得分,从而提高回复多样性。

总结:
- 属性控制模型能有效提升回复质量

深度学习中,对序列数据进行训练,一般会用到RNN和LSTM模型,对定长序列模型生成出和相同长度的模型
- 但是对于输入长度已知但输出长度未知的任务,比如机器翻译,上面提到的两个模型就不能满足要求。
- 因此就有了Sequence to Sequence模型,简称
Seq2Seq
Seq2Seq(Sequence to Sequence,序列到序列模型) 是一种循环神经网络的变种,包括编码器 (Encoder) 和解码器 (Decoder) 两部分。
Seq2Seq 是自然语言处理中的一种重要模型,可以用于机器翻译、对话系统、自动文摘
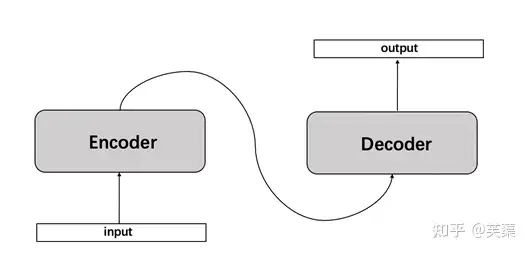
Seq2Seq模型是输出长度不确定时采用的模型,一般在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
- 如:输入的中文长度为4,输出的英文长度为2。
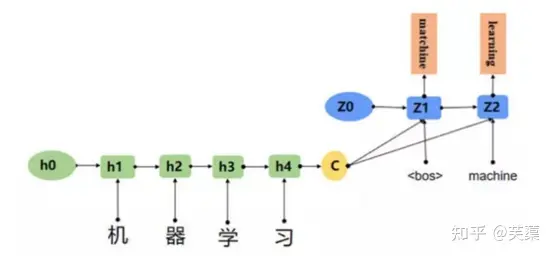
- 输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出 “machine”,将”machine”作为下一次的输入,接着输出”learning”,这样就能输出任意长的序列。
应用示例
- 机器翻译:输入(Hello) —>输出(你好)。
- 人机对话:问机器 “你是谁?”,机器返回 “我是某某某”。
- 简单的邮件对话的场景,发送方问:“你明天是否有空”;接收方回答:“有空,怎么了?”。
Seq2Seq 介绍
上面三种结构对于 RNN 的输入和输出个数都有一定的限制,但实际中很多任务的序列的长度是不固定的,例如
- 机器翻译中,源语言、目标语言的句子长度不一样;
- 对话系统中,问句和答案的句子长度不一样。
RNN结构大多对序列的长度比较局限,输入和输出长度并不对等,为 N to M 的结构,简单的RNN束手无策,因此便有了新的模型,Encoder-Decoder模型,也就是Seq2Seq模型。
Seq2Seq 是一种重要的 RNN 模型,也称为 Encoder-Decoder 模型,可以理解为一种 N×M 模型。
模型包含两个部分:
- Encoder 用于对输入的N长度的序列进行表征
- 编码序列的信息,将任意长度的序列信息编码到一个向量 c 里。
- Decoder 用于将Encoder表征映射到到输出的M长度序列。
- 解码器得到上下文信息向量 c 之后可以将信息解码,并输出为序列。
参考:
Seq2Seq 提出于2014年,最早由两篇文章独立地阐述了主要思想,分别是
- Google Brain 团队的《Sequence to Sequence Learning with Neural Networks》
- Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。
这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
Seq2Seq 是一种RNN模型,使用的是 Encoder-Decoder结构,可以理解为一种 N * M 的模型,即 Encoder 长度可以为N,Decoder 长度可以为M。多对多的序列结构
- Encoder 用于编码序列的信息,将任意长度的序列信息编码到一个向量 c 里。
- Decoder 是解码器,解码器得到上下文信息向量 c 之后可以将信息解码,并输出为序列。

Input是输入的序列数据,比如翻译系统的词向量等;Encoder内部是RNN/LSTM,目的是将输入的向量转换成隐藏层向后传播的隐藏向量;State就是隐藏向量,可以理解为RNN中向前传播的隐藏层状态,即包含过去信息的状态;Decoder就是解码部分,对输入的时序数据进行解析处理,这也是整个Seq2Seq最核心的部分,比如对于翻译系统来说输入英文在解码器中会解析为目标语言;Output是将解析好的数据输出。
Seq2Seq 模型结构
Seq2Seq的模型结构也有很多种,常见的有几种,Encoder都相同,区别主要在于Decoder.
Seq2Seq 模型结构有很多种,下面是几种比较常见的:
- 第一种: c 只与解码器第一个隐含层h连接
- 第二种: c 与解码器所有隐含层h连接
- 第三种: c 与解码器所有隐含层h、输出y连接
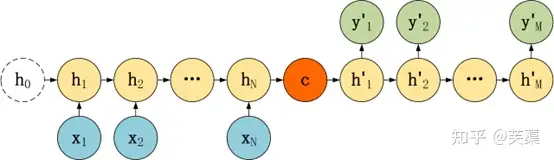

这三种 Seq2Seq 模型的主要区别在于 Decoder,它们的 Encoder 都是一样的
第一种 :C只与第一个隐含层单元h连接
整体结构:

- Encoder阶段将整个source序列编码成一个固定维度的向量C(也就是RNN最终的隐藏状态hT,保存了source序列的信息)
- 将其传入Decoder阶段即可,在每次进行decode时,仍然使用RNN神经元进行处理
Encoder & Decoder:img
单看 Decoder:img
这种Decoder比较简单:
- 将上下文向量 C 当成是 RNN 的初始隐藏状态输入到 RNN 中
- 后续只接受上一个神经元的隐藏层状态 h’ 而不接收其他的输入 x
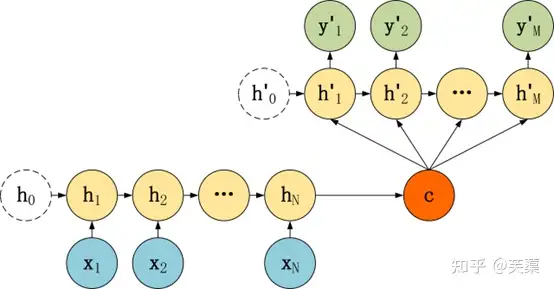
第二种 : C与所有隐含层单元连接
模型结构

区别在于
- source编码后的向量C直接作为Decoder阶段RNN的初始化state,而不是在每次decode时都作为RNN cell的输入。
- 此外,decode时RNN的输入是目标值,而不是前一时刻的输出。
Encoder & Decoder:img
单看 Decoder:img
- Decoder 结构有了自己的初始隐藏层状态 h’0
- 不再把上下文向量 c 当成是 RNN 的初始隐藏状态,而是当成 RNN 每一个神经元的输入
第三种 : C与所有隐含层单元几输出y连接
Encoder & Decoder:

单看Decoder:
-

- Decoder 结构和第二种类似,但是在输入的部分多了上一个神经元的输出 y’。
- 即每一个神经元的输入包括:上一个神经元的隐藏层向量 h’,上一个神经元的输出 y’,当前的输入 c (Encoder 编码的上下文向量)。
- 对于第一个神经元的输入 y’0,通常是句子起始标志位的 embedding 向量。
损失函数
Seq2seq建模成一个概率问题
- 用最大似然法最大化输出序列基于输入序列的条件概率
连乘变求和
$-\log \mathbb{P}\left(\mathrm{y}{1}, \ldots, \mathrm{y}{\mathrm{T}^{\prime}} \mid \mathrm{x}{1}, \ldots, \mathrm{x}{\mathrm{T}}\right)=-\sum_{\mathrm{t}^{\prime}=1}^{\mathrm{T}^{\prime}} \log \mathbb{P}\left(\mathrm{y}{\mathrm{t}^{\prime}} \mid \mathrm{y}{1}, \ldots, \mathrm{y}_{\mathrm{t}^{\prime}-1}, \boldsymbol{c}\right)$
seq2seq损失函数从连乘变成求和是为了方便计算,并不是为了奖励短句子、惩罚长句;
- 理由:-log变换保持了单调性不变
- 示例: 单调性不变
# 连乘
0.1*0.2 = 0.02
0.1*0.2*0.3 = 0.006
# 连加
-log(0.1)*log(0.2) = -1.3498588075760032
-log(0.1)*log(0.2)*log(0.3) = -1.822118800390509
真正的长度惩罚
- $\frac{1}{\mathrm{~L}^{\alpha}} \log \mathbb{P}\left(\mathrm{y}{1}, \ldots, \mathrm{y}{\mathrm{L}}\right)=\frac{1}{\mathrm{~L}^{\alpha}} \sum_{\mathrm{t}^{\prime}=1}^{\mathrm{L}} \log \mathbb{P}\left(\mathrm{y}{\mathrm{t}^{\prime}} \mid \mathrm{y}{1}, \ldots, \mathrm{y}_{\mathrm{t}^{\prime}-1}, \boldsymbol{c}\right)$
L是最终序列的长度,α一般选0.75。这L的系数起到的作用是惩罚太长的序列得分过高的情况
通常在输入和输出序列前后分别加一个特殊符号<bos>和<eos>,分别表示句子的开始和结束。
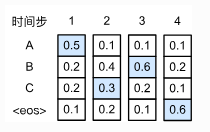
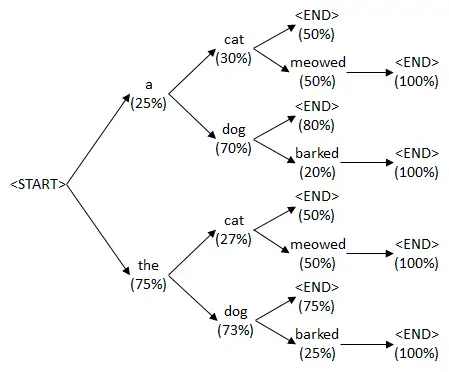
- 数字表示每一个state(解码步数),ABC表示每一个词。中间的数字是条件概率,比如, B2这里的0.4表示在 $P(B|A)$,而A2就是表示$P(A|A)$ 3种方式优化: 贪婪搜索、穷举搜索、束搜索
- 贪心解码: 每一步最优,不一定全局最优
- Beam Search: 每步多选几个作为候选,最后综合考虑,选出最优的组合。
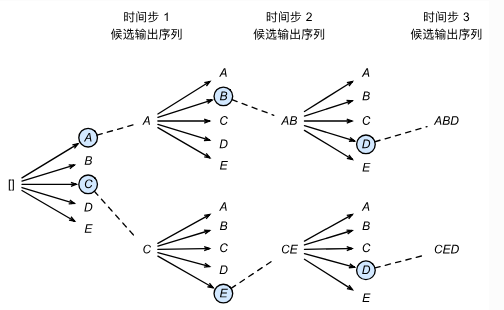
集束搜索
- 每次不再只看概率最高的那个词,而是看概率最高的k个词(beam size 束宽)
- 根据k个候选词输出下一个阶段的序列,接着再选出概率最高的k个序列,不断重复这件事情
- 各个状态的候选序列中筛选出包含特殊符号
<eos>的序列,并将这个符号后的子序列舍弃,得到最后的输出序列。然后再在这些序列中选择分数最高的作为最后的输出序列 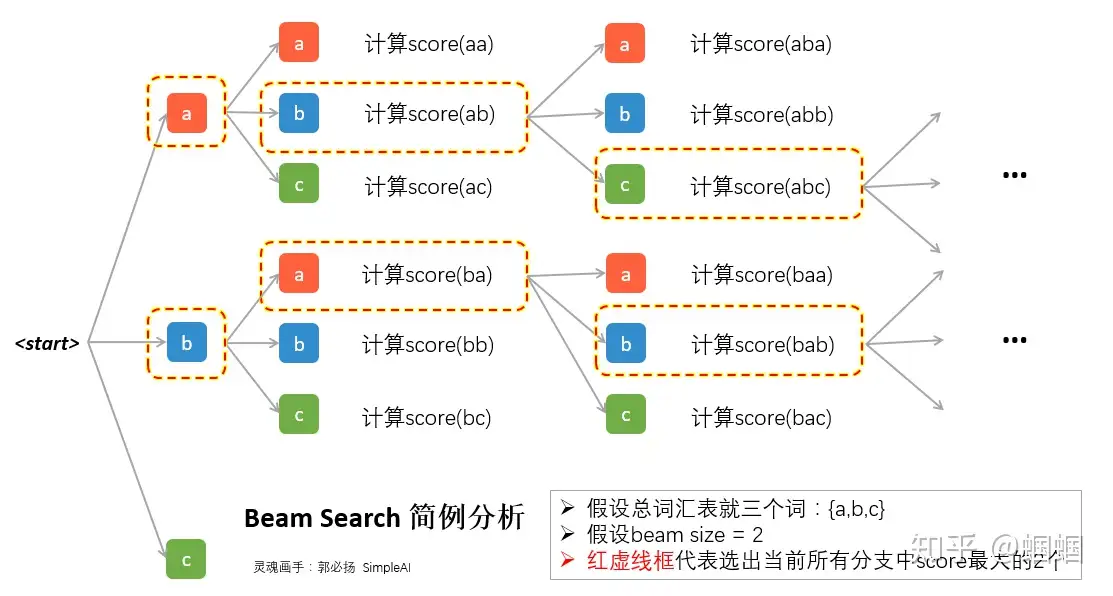
score 函数定义序列得分
- 当前到第t步的输出序列的一个综合得分,越高越好
- log类似第t步的交叉熵损失的负数
- $ \operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\sum_{i=1}^{t} \log P\left(y_{i} \mid y_{1}, y_{2}, \ldots, y_{i-1}, x\right) $
但并不直接根据score选择句子,而是用长度来对score函数进行细微的调整,避免只选短句
- 对每个序列的得分,除以序列的长度
贪婪搜索可以看做是beam size为1的束搜索。
- 不同于贪婪搜索,束搜索并不知道什么时候停下来,所以要定义一个最长输出序列长度。
分析
- 贪婪算法: 结果是ABC,概率 0.5×0.4×0.2×0.6
- 非贪婪算法: 结果是ACB,概率 0.5×0.3×0.6×0.6 , 明显概率更大。
【2018-9-6】台大李宏毅深度学习——seq2seq
内部结构
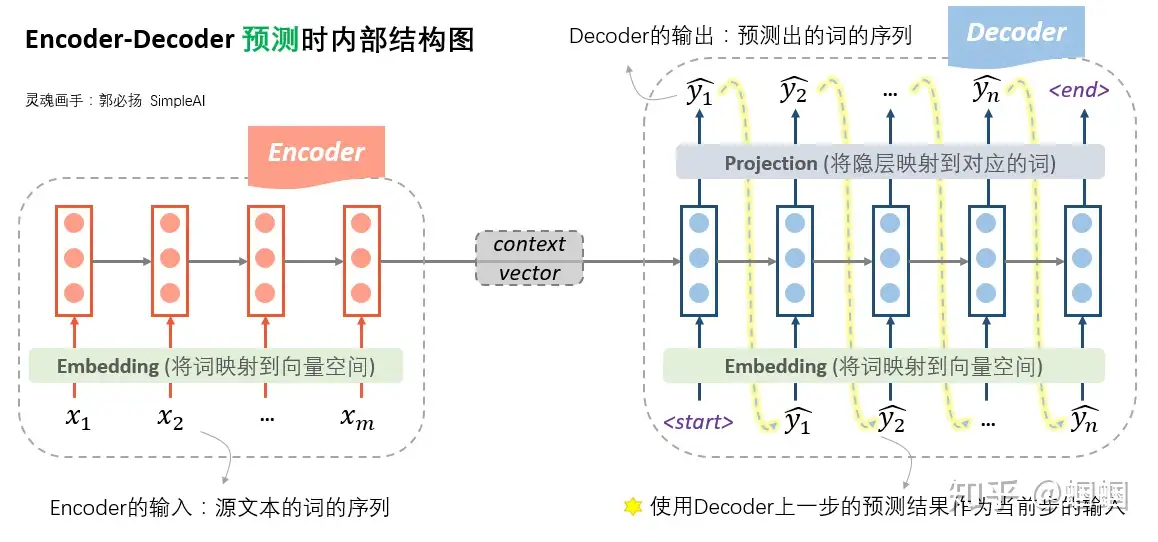
seq2seq内部详细结构
| 维度 | 训练 | 预测 |
|---|---|---|
| 图解 | 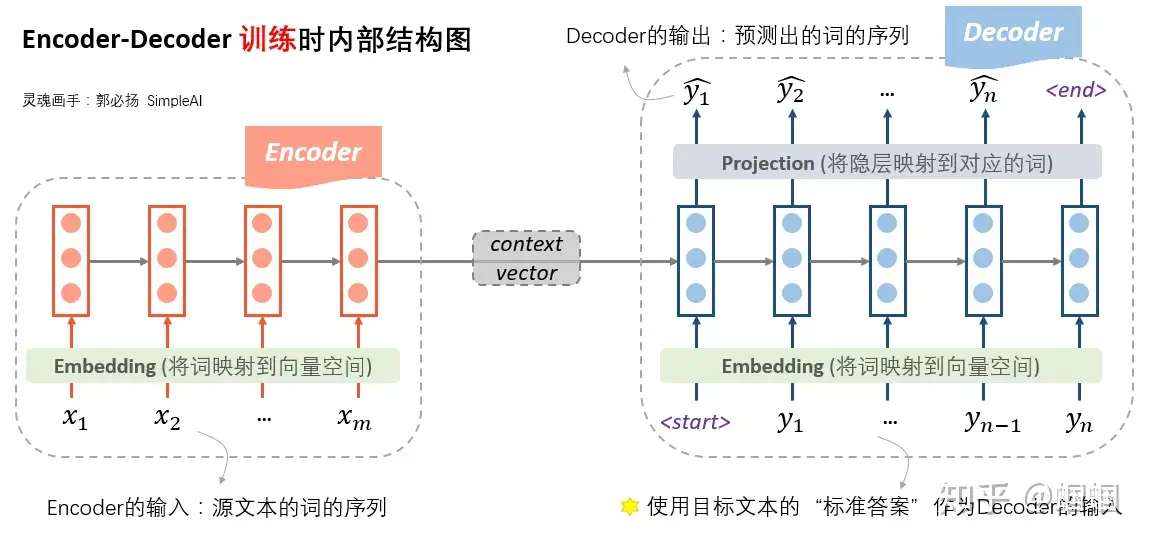 |
 |
| 分析 | 使用label序列作为输入 | 使用上一步生成的字符作为输入 |
训练时-图解
- Encoder端,将source文本的词序列先经过embedding层转化成向量,然后输入到一个RNN结构(普通RNN,LSTM,GRU等等)中。另外,RNN也可以是多层、双向的。经过了RNN的一系列计算,最终隐层的输入,就作为源文本整体的一个表示向量,称为「context vector」。
- Decoder端。Decoder的输入是什么呢?Decoder的输入,训练和测试时是不一样的!
- 「在训练时,使用真实的目标文本,即“标准答案”作为输入」(注意第一步使用一个特殊的
<start>字符,表示句子的开头)。 - 每一步根据当前正确的输出词、上一步的隐状态来预测下一步的输出词。
- 「在训练时,使用真实的目标文本,即“标准答案”作为输入」(注意第一步使用一个特殊的
- 注意
- decoder即使遇到了
<end>标识也不会结束,因为训练时并不是一个生成过程 ,要等到“标准答案”都输入完才结束。
- decoder即使遇到了
预测时-预测图解
- Encoder端没变化
- Decoder端,由于此时没有所谓的“真实输出”或“标准答案”了,所以只能「自产自销:每一步的预测结果,都送给下一步作为输入」,直至输出
<end>就结束。「这时的Decoder就是一个语言模型」。由于这个语言模型是根据context vector来进行文本的生成的,因此这种类型的语言模型,被称为“条件语言模型”:Conditional LM。正因为如此,在训练过程中,可用一些预训练好的语言模型来对Decoder的参数进行初始化,从而加快迭代过程。
疑惑:
- 为什么训练时,不能直接用这种语言模型的模式,使用上一步的预测来作为下一步的输入呢?可以,速度太慢
- 没有任何的引导,一开始完全瞎预测,正所谓“一步错,步步错”,而且越错越离谱,这样会导致训练时的累积损失太大(「误差爆炸」问题,exposure bias),训练起来就很费劲
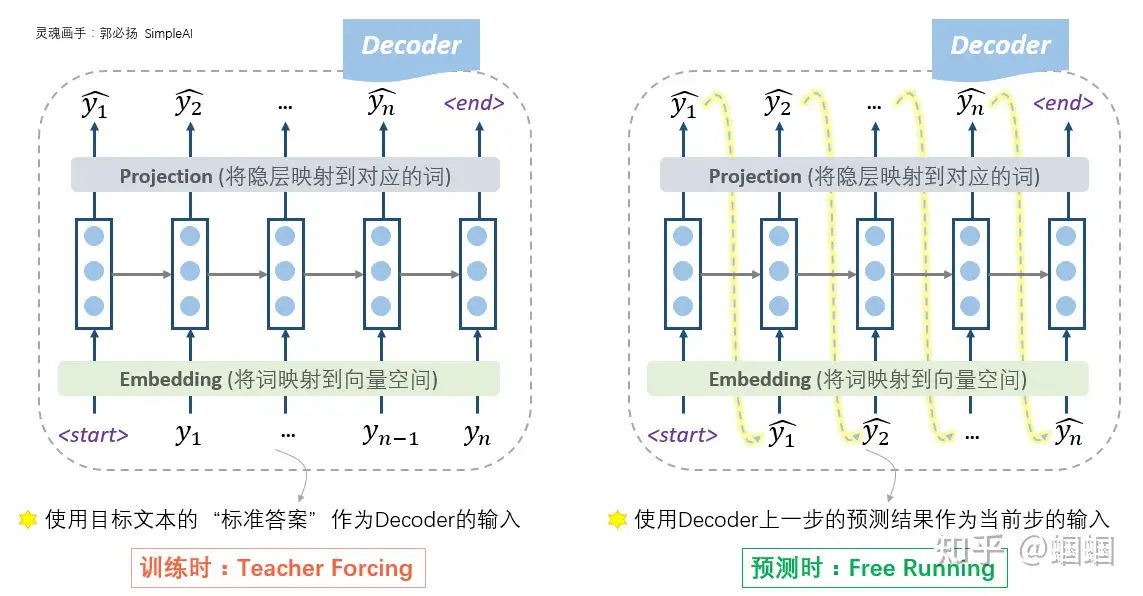
两种模式
- 根据标准答案来decode的方式为「
teacher forcing」- 每一步的预测时,让老师来指导一下,即提示一下上一个词的正确答案,decoder就可以快速步入正轨,训练过程也可以更快收敛。
- 优点:加速训练
- 缺点:预测时没法用
- 根据上一步的输出作为下一步输入的decode方式为「
free running」
怎么办?计划采样
- 老师只给适量引导,学生也积极学习。即设置一个概率p,每一步,以概率p靠自己上一步的输入来预测,以概率1-p根据老师的提示来预测,这种方法称为「计划采样」(
scheduled sampling) 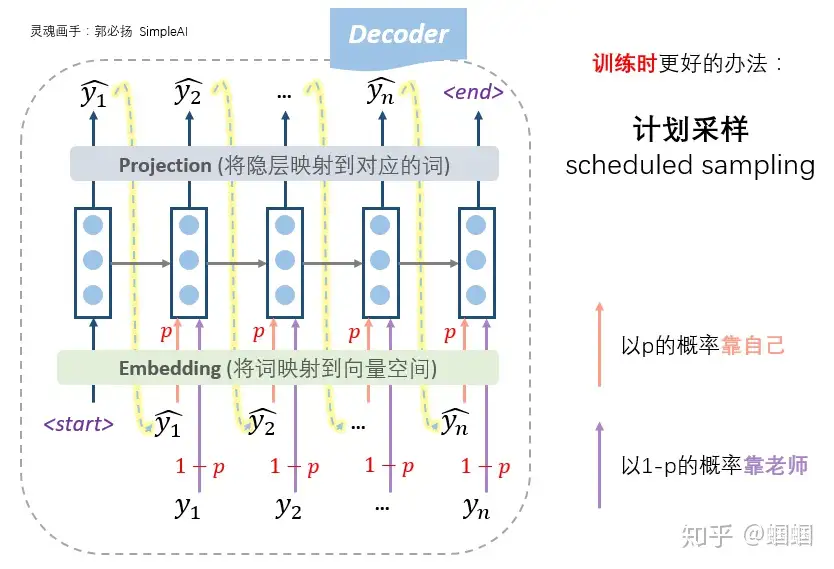
参考:
Seq2seq 改进
改进版:Attention
Seq-to-Seq with Attention(NMT)
模型结构

区别:向量C变矩阵
- 前面两个模型都是将source序列编码成一个固定维度的向量C,对于长序列这将会丢失很多信息,导致效果不好
- 所以作者提出将encoder阶段所有的隐层状态保存在一个列表中,然后接下来decode的时候,根据前一时刻状态st-1去计算T个隐层状态与其相关程度,在进行加权求和得到编码信息ci,也就是说每个解码时刻的c向量都是不一样


改进版:Attention变形
Attention各种变形
- 论文:[Effective Approaches to Attention-based Neural Machine Translation]
这篇论文提出了两种 Seq-to-Seq模型, 分别是global Attention和local Attention
- ①
global Attention,跟上面的思路差不多,也是采用soft Attention的机制,对上面模型进行了稍微的修改- 模型结构图如下所示:原理上与NMT区别不大,只是aij计算方法稍有区别,这里的score函数从上面的神经网络变成了三种选择,包括
内积、general、concat 
- 模型结构图如下所示:原理上与NMT区别不大,只是aij计算方法稍有区别,这里的score函数从上面的神经网络变成了三种选择,包括
- ②
local Attentionsoft Attention和hard Attention。- global模型属于
soft Attention,缺点- 每次decode时都要计算所有的向量,导致计算复杂度较高
- 而且有些source跟本次decode根本没有任何关系,所以计算他们之间的相似度有些多余;
- 当source序列较长时,这种方法的效果也会有所下降。
- 而
hard Attention每次仅选择一个相关的source进行计算。缺点:不可微,没有办法进行反向传播,只能借助强化学习等手段进行训练。
改进版: Beam-Search 提速
前面几种Seq-to-Seq模型都是从模型结构上改进,从训练的层面上改善模型效果。
- beam-search是在测试的时候才用到的技术。
- 注意:Beam Search只用于测试,不用于训练过程。
一般使用 greedy search(贪心搜索),在进行解码的时候,每一步都选择概率最大的那个词作为输出,然后再将这个词作为下一解码时刻的输入传递进去。以此类推,直到输出<EOS>符号为止,最终会获得一个概率最大的序列当做是解码的输出。
缺点
- 某一步的错误输出可能会导致后面整个输出序列都发生错误
那么改进方案:beam search(集束搜索)
- 每次都选择概率最大的k个词(beam size)作为输出,并在下一时刻传入RNN进行解码,以此类推。
- beam size=1时,beam search就会退化为贪心算法
- 好处:可以通过增加搜索范围来保证一定的正确率。beam size等于2时效果就已经不错了,到10以上就不会再有很大提升
seq2seq问题
文本生成特有的挑战:
- 计算量大:解码是反复进行的,因此相比其他一次性输出模型,seq2seq生成需要更多计算量。
- 超参敏感:生成文本的质量和多样性取决于解码方法和相关超参数的选择。

普通seq2seq可能出现如下问题,导致用户体验差或者对话上下文不够连贯。
- 负面情感的回复
- 疑问句式的回复
- 回复的多样性较低
- 一致性低
- 上下文逻辑冲突;背景有关的一些信息,比如年龄其实不可控;
- 安全回复居多,对话过程显得很无聊。
- 训练时用到的数据都是人类的对话语料,往往充斥着已知和未知的背景信息,使得对话成为一个”一对多”的问题,比如问年龄和聊天气,回答包括不同的人针对同样的问题产生的不同的回复。
- 但是神经网络无论多复杂,它始终是一个一一映射的函数。
-
最大似然只能学到所有语料的共通点,所有背景,独特语境都可能被模型认为是噪音,这样会让模型去学习那些最简单出现频率高的句子
,比如”是的”之类的回复,我们称之为安全回复。
- 对话语料的局限性
- 对话语料只是冰山的一角,实际上对话语料中潜藏着很多个人属性、生活常识、知识背景、价值观/态度、对话场景、情绪装填、意图等信息,这些潜藏的信息没有出现在语料,建模它们是十分困难的。

可控文本生成
【2021-9-29】ICBU可控文本生成技术详解
可控文本生成的目标是控制给定模型基于源文本产生特定属性的文本。
- 特定属性包括文本的
风格、主题、情感、格式、语法、长度等。 - 根据源文本生成目标序列的文本生成任务,可以建模为 $ P(Target|Sourse) $;
- 而考虑了控制信号的可控文本生成任务,则可以建模为 $ P(Target|Sourse,ControlSignal) $ 。
目前可控文本生成已有大量的相关研究,比较有趣的研究有
- SongNet(Tencent)控制输出诗词歌赋的字数、平仄和押韵;
- StylePTB(CMU)按照控制信号改变句子的语法结构、单词形式、语义等;
- CTRL(Salesforce)在预训练阶段加入了 control codes 与 prompts 作为控制信号,影响文本的领域、主题、实体和风格。
【2021-1-2】翁丽莲的博客:Controllable Neural Text Generation
学术前沿
【2023-7-4】ACL 2023 大模型时代,自然语言领域还有什么学术增长点
- 微软: DuNST: 基于噪声对偶自学习的半监督可控文本生成
- DuNST 将文本生成和分类作为对偶过程进行联合建模,并且通过自学习来改进模型的生成和分类。除了生成器生成的伪文本之外,研究员们还利用分类器给未标注的文本做伪标注。另外,模型会通过添加两种平滑的噪声来扰动学到的文本空间。添加的噪声可以帮助模型改进文本空间的局部平滑性,增加模型的鲁棒性。理论上,DuNST 可以被看作是对探索(Exploration)和利用(Exploitation)的平衡。添加噪声增强了对潜在更大的真实文本空间的探索,同时保持了对已经学到的文本空间的利用,从而保证模型的性能。
- 微软+北交大: EmbMarker: 通过后门水印保护基于大模型的向量表示服务的版权, 代码EmbMarker
- 问题: 许多公司开始基于这些 LLMs 提供向量表示服务(EaaS),用户可以通过发送查询和接收输出来重建模型的参数,这使得 LLM 的服务提供者面临着模型被盗用或复制的风险。
- 一种适用于 EaaS 的水印方法。这类方法需要满足以下条件:
- 不影响向量在下游任务的使用性能;
- 当有盗用者复制提供商的模型并提供相同的竞争服务时,提供商可以通过访问盗用者的服务验证其输出中含有提供商的水印;
- 水印需要足够隐蔽,不会被盗用者轻易地过滤掉。
- 为了解决这些问题,研究员们提出了一种基于后门水印的方法:EmbMarker,两个阶段:水印插入阶段和版权验证阶段
- 水印插入阶段:首先找到一组合适词频的单词作为触发单词,并预定义一个目标向量作为水印。当用户提供的句子中含有的触发单词数量越多时,服务提供者发送的向量与预定义的目标向量的距离越接近。
- 版权验证阶段:提供商可以使用触发单词和非触发单词分别构造两组句子,并访问待验证的服务得到两组向量。两组向量离目标向量的距离分布差距越大,则说明该服务后的模型越有可能是盗用或复制了提供商的模型。
- 实验结果表明,EmbMarker 可以在不影响向量在下游任务性能的情况下,以高置信度验证盗用者服务中的水印,并且具有很强的隐蔽性。
可控文本生成技术的发展过程和趋势
发展过程
- 首先,在预训练语言模型的热度高涨之前,使用解码策略来控制文本属性的方案较为流行
- 比如,引入多个判别器影响 Beam Search 中的似然得分的 L2W,以及改进解码采样策略的 Nucleur Sampling(2019)。
- 随着 GPT-2(2019)、T5(2019)的提出,使得基于 Prompt 来控制同一预训练语言模型来完成多种任务成为可能。
- 因其能够更有效地利用模型在预训练阶段习得的知识,Prompting LM 的方式受到了学术界的重视,Prefix-Tuning(2021)等也推动基于 Prompt 的文本生成向前一步。
- 而针对于如何基于预训练语言模型做可控文本生成,学术界也一直往“低数据依赖、低算力需求、低时间消耗”方向上推进。
- CTRL(2019)凭借海量数据和大体量结构成为文本生成领域的代表性模型;
- PPLM (2019)则引入属性判别器,仅需精调小部分参数起到了“四两拨千斤”的效果;
- 而 GeDi(2020) 为了解决 PPLM 多次反传导致的解码效率低下,直接在解码阶段加入属性判别器来控制解码输出;
- CoCon(2021)同样仅精调插入 GPT-2 中的 CoCon 层来提高训练效率,并通过精巧的目标函数的设计来增强可控性能。
可控文本生成模型
可控文本生成模型等方案也多种多样,按进行可控的着手点和切入角度,将可控文本生成方案分为四类:
构造Control Codes、设计Prompt、加入解码策略(Decoding Strategy),以及Write-then-Edit
详解
构造Control Codes: 引入一些符号或文本作为条件,训练条件语言模型设计Prompt: 为预训练语言模型设计 Prompt 也能实现对 PLM 所执行文本任务的控制- 加入
解码策略(Decoding Strategy): 在解码阶段使用采样策略,也能够采样出具有特定属性的文本 Write-then-Edit: PPLM 引入属性判别模型来根据产生的草稿计算梯度并反向传播,基于更新后的隐含状态来产生最终文本序列
具体方法详见:ICBU可控文本生成技术详解
seq2seq实现
TensorFlow版本:直观理解并使用Tensorflow实现Seq2Seq模型的注意机制, 在Tensorflow中实现、训练和测试一个英语到印地语机器翻译模型
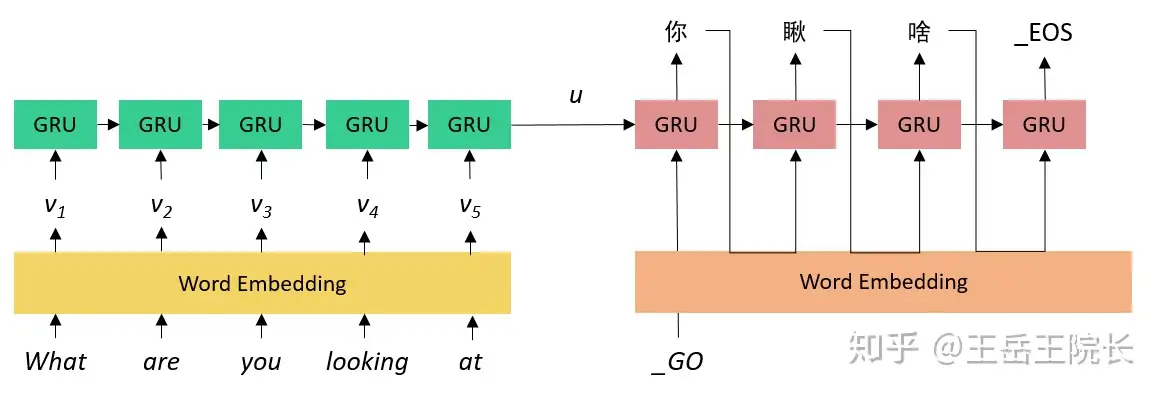
资料:
- Sequence to sequence Architecture with Attention
- Google神经机器翻译官方讲解
import tensorflow as tf
class Seq2seq(object):
def __init__(self, config, w2i_target):
self.seq_inputs = tf.placeholder(shape=(config.batch_size, None), dtype=tf.int32, name='seq_inputs')
self.seq_inputs_length = tf.placeholder(shape=(config.batch_size,), dtype=tf.int32, name='seq_inputs_length')
self.seq_targets = tf.placeholder(shape=(config.batch_size, None), dtype=tf.int32, name='seq_targets')
self.seq_targets_length = tf.placeholder(shape=(config.batch_size,), dtype=tf.int32, name='seq_targets_length')
with tf.variable_scope("encoder"):
encoder_embedding = tf.Variable(tf.random_uniform([config.source_vocab_size, config.embedding_dim]), dtype=tf.float32, name='encoder_embedding')
encoder_inputs_embedded = tf.nn.embedding_lookup(encoder_embedding, self.seq_inputs)
encoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(cell=encoder_cell, inputs=encoder_inputs_embedded, sequence_length=self.seq_inputs_length, dtype=tf.float32, time_major=False)
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_inputs = tf.concat([tf.reshape(tokens_go,[-1,1]), self.seq_targets[:,:-1]], 1)
with tf.variable_scope("decoder"):
decoder_embedding = tf.Variable(tf.random_uniform([config.target_vocab_size, config.embedding_dim]), dtype=tf.float32, name='decoder_embedding')
decoder_inputs_embedded = tf.nn.embedding_lookup(decoder_embedding, decoder_inputs)
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
decoder_outputs, decoder_state = tf.nn.dynamic_rnn(cell=decoder_cell, inputs=decoder_inputs_embedded, initial_state=encoder_state, sequence_length=self.seq_targets_length, dtype=tf.float32, time_major=False)
decoder_logits = tf.layers.dense(decoder_outputs.rnn_output, config.target_vocab_size)
self.out = tf.argmax(decoder_logits, 2)
数据读入及预处理
数据源:Kaggle里一个名为”HindiEnglishTruncatedCorpus”的文件
预处理步骤如下:
- 在单词和标点符号之间插入空格
- 如果手头上的句子是英语,我们就用空格替换除了(a-z, A-Z, “.”, “?”, “!”, “,”)
- 句子中去掉多余的空格,关键字”sentencestart” (
)和"sentenceend"( )分别添加到句子的前面和后面,让我们的模型明确地知道句子开始和结束。 - 每个句子的以上三个任务都是使用preprocess_sentence()函数实现的。我们还在开始时初始化了所有的超参数和全局变量。请阅读下面的超参数和全局变量。我们将在需要时使用它们。
import numpy as np
import pandas as pd
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import tensorflow as tf
from sklearn.model_selection import train_test_split
import time
from matplotlib import pyplot as plt
import os
import re
data = pd.read_csv("./Hindi_English_Truncated_Corpus.csv")
english_sentences = data["english_sentence"]
hindi_sentences = data["hindi_sentence"]
# Global variables and Hyperparameters
num_words = 10000
oov_token = '<UNK>'
english_vocab_size = num_words + 1
hindi_vocab_size = num_words + 1
MAX_WORDS_IN_A_SENTENCE = 16
test_ratio = 0.2
BATCH_SIZE = 512
embedding_dim = 64
hidden_units = 1024
learning_rate = 0.006
epochs = 100
def preprocess_sentence(sen, is_english):
if (type(sen) != str):
return ''
sen = sen.strip('.')
# insert space between words and punctuations
sen = re.sub(r"([?.!,¿;।])", r" \1 ", sen)
sen = re.sub(r'[" "]+', " ", sen)
# For english, replacing everything with space except (a-z, A-Z, ".", "?", "!", ",", "'")
if(is_english == True):
sen = re.sub(r"[^a-zA-Z?.!,¿']+", " ", sen)
sen = sen.lower()
sen = sen.strip()
sen = 'sentencestart ' + sen + ' sentenceend'
sen = ' '.join(sen.split())
return sen
# Loop through each datapoint having english and hindi sentence
# 对包含英语句子和印地语句子的每个数据点进行循环,确保不考虑带有空字符串的句子,并且句子中的最大单词数不大于MAXWORDSINASENTENCE的值。这一步是为了避免我们的矩阵是稀疏的。
processed_e_sentences = []
processed_h_sentences = []
for (e_sen, h_sen) in zip(english_sentences, hindi_sentences):
processed_e_sen = preprocess_sentence(e_sen, True)
processed_h_sen = preprocess_sentence(h_sen, False)
if(processed_e_sen == '' or processed_h_sen == '' or processed_e_sen.count(' ') > (MAX_WORDS_IN_A_SENTENCE-1) or processed_h_sen.count(' ') > (MAX_WORDS_IN_A_SENTENCE-1)):
continue
processed_e_sentences.append(processed_e_sen)
processed_h_sentences.append(processed_h_sen)
print("Sentence examples: ")
print(processed_e_sentences[0])
print(processed_h_sentences[0])
print("Length of English processed sentences: " + str(len(processed_e_sentences)))
print("Length of Hindi processed sentences: " + str(len(processed_h_sentences)))
# 文本语料库进行向量化
def tokenize_sentences(processed_sentences, num_words, oov_token):
tokenizer = Tokenizer(num_words = num_words, oov_token = oov_token)
tokenizer.fit_on_texts(processed_sentences) # 为每个单词分配一个唯一的索引
word_index = tokenizer.word_index
# # 将一个文本句子转换为一个数字列表或一个向量,其中数字对应于单词的唯一索引
sequences = tokenizer.texts_to_sequences(processed_sentences)
# 通过添加刚好足够数量的oovtoken(从vocab token中提取)来确保所有这些向量最后都具有相同的长度,使每个向量具有相同的长度。
sequences = pad_sequences(sequences, padding = 'post')
return word_index, sequences, tokenizer
english_word_index, english_sequences, english_tokenizer = tokenize_sentences(processed_e_sentences, num_words, oov_token)
hindi_word_index, hindi_sequences, hindi_tokenizer = tokenize_sentences(processed_h_sentences, num_words, oov_token)
# split into traning and validation set
english_train_sequences, english_val_sequences, hindi_train_sequences, hindi_val_sequences = train_test_split(english_sequences, hindi_sequences, test_size = test_ratio)
BUFFER_SIZE = len(english_train_sequences)
# Batching the training set
dataset = tf.data.Dataset.from_tensor_slices((english_train_sequences, hindi_train_sequences)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder = True)
print("No. of batches: " + str(len(list(dataset.as_numpy_iterator()))))
编码器Encoder
Seq2seq架构在原论文中涉及到两个长短期内存(LSTM)。一个用于编码器,另一个用于解码器。请注意,在编码器和解码器中,我们将使用GRU(门控周期性单元)来代替LSTM,因为GRU的计算能力更少,但结果与LSTM几乎相同。Encoder涉及的步骤:
输入句子中的每个单词都被嵌入并表示在具有embeddingdim(超参数)维数的不同空间中。换句话说,您可以说,在具有embeddingdim维数的空间中,词汇表中的单词的数量被投影到其中。这一步确保类似的单词(例如。boat & ship, man & boy, run & walk等)都位于这个空间附近。这意味着”男人”这个词和”男孩”这个词被预测的几率几乎一样(不是完全一样),而且这两个词的意思也差不多。
接下来,嵌入的句子被输入GRU。编码器GRU的最终隐藏状态成为解码器GRU的初始隐藏状态。编码器中最后的GRU隐藏状态包含源句的编码或信息。源句的编码也可以通过所有编码器隐藏状态的组合来提供[我们很快就会发现,这一事实对于注意力的概念的存在至关重要]。
class Encoder(tf.keras.Model):
def __init__(self, english_vocab_size, embedding_dim, hidden_units):
super(Encoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(english_vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(hidden_units, return_sequences = True, return_state = True)
def call(self, input_sequence):
x = self.embedding(input_sequence)
encoder_sequence_output, final_encoder_state = self.gru(x)
# Dimensions of encoder_sequence_output => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, hidden_units)
# Dimensions of final_encoder_state => (BATCH_SIZE, hidden_units)
return encoder_sequence_output, final_encoder_state
# initialize our encoder
encoder = Encoder(english_vocab_size, embedding_dim, hidden_units)
解码器Decoder
了解解码器的情况下,不涉及注意力机制。这对于理解稍后与解码器一起使用的注意力的作用非常重要。
解码器GRU网络是生成目标句的语言模型。最终的编码器隐藏状态作为解码器GRU的初始隐藏状态。第一个给解码器GRU单元来预测下一个的单词是一个像”sentencestart”这样的开始标记。这个标记用于预测所有num_words数量的单词出现的概率。训练时使用预测的概率张量和实际单词的一热编码来计算损失。这种损失被反向传播以优化编码器和解码器的参数。同时,概率最大的单词成为下一个GRU单元的输入。重复上述步骤,直到出现像”sentenceend”这样的结束标记。
这种方法的问题是:
- 信息瓶颈: 编码器的最终隐藏状态成为解码器的初始隐藏状态。这就造成了信息瓶颈,因为源句的所有信息都需要压缩到最后的状态,这也可能会偏向于句子末尾的信息,而不是句子中很久以前看到的信息。
- 解决方案:我们解决了上述问题,不仅依靠编码器的最终状态来获取源句的信息,还使用了编码器所有输出的加权和。那么,哪个编码器的输出比另一个更重要?注意力机制就是为了解决这个问题。
详见站内专题: 文本生成之解码专题
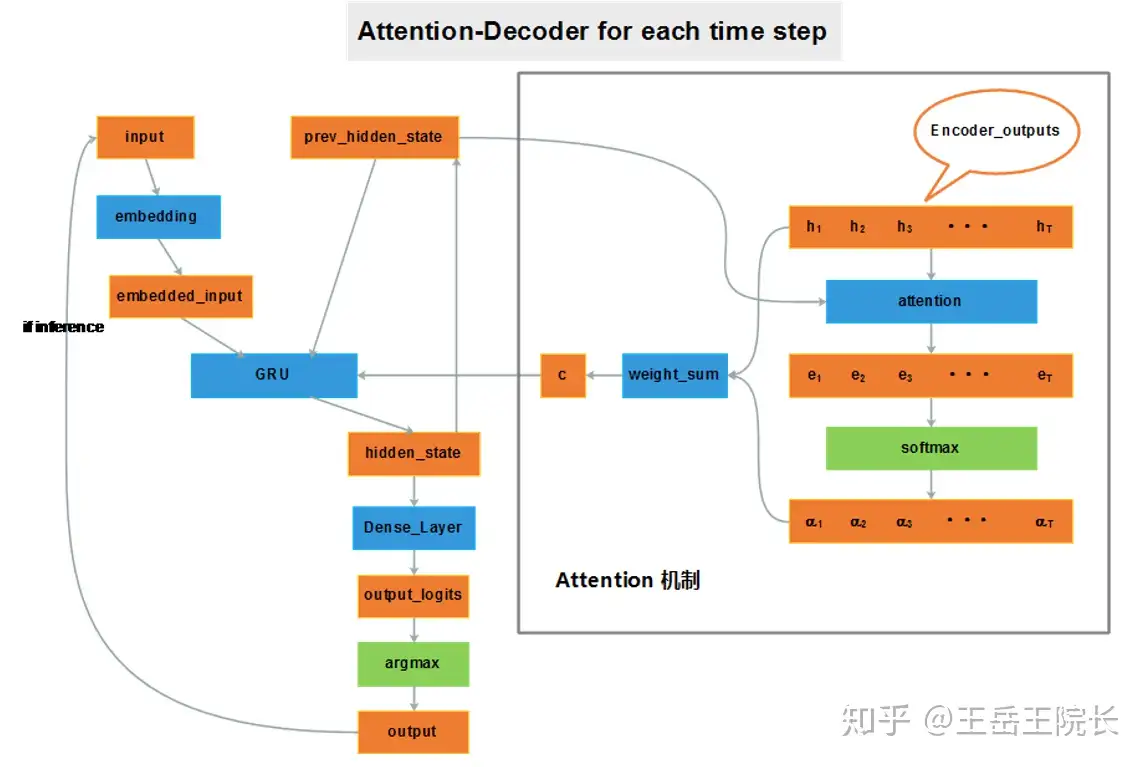
注意力机制
注意力不仅为瓶颈问题提供了解决方案,还为句子中的每个单词赋予了权重(相当字面意义)。源序列在编码器输出中有它自己的的信息,在解码器中被预测的字在相应的解码器隐藏状态中有它自己的的信息。我们需要知道哪个编码器的输出拥有类似的信息,我们需要知道在解码器隐藏状态下,哪个编码器输出的信息与解码器隐藏状态下的相似。
因此,这些编码器输出和解码器的隐藏状态被用作一个数学函数的输入,从而得到一个注意力向量分数。当一个单词被预测时(在解码器中的每个GRU单元),这个注意力分数向量在每一步都被计算出来。该向量确定每个编码器输出的权重,以找到加权和。
注意力的一般定义:给定一组向量”值”和一个向量”查询”,注意力是一种计算基于查询的加权值和的技术。
几种方法可以找到注意力得分(相似度)。主要有以下几点:
- 基本点积注意力(Dot Product Attention): 最容易掌握
- 乘法注意力(multiplicative attention)
- 加性注意力(additive attention)
基本的点积注意有一个假设。
- 假设两个输入矩阵的维数在轴上要做点积的地方必须是相同的,这样才能做点积。在我们的实现中,这个维度是由超参数hidden_units给出的,对于编码器和解码器都是一样的。
将编码器输出张量与解码器隐藏状态进行点积,得到注意值。这是通过Tensorflow的matmul()函数实现的。我们取上一步得到的注意力分数的softmax。这样做是为了规范化分数并在区间[0,1]内获取值。编码器输出与相应的注意分数相乘,然后相加得到一个张量。这基本上是编码器输出的加权和,通过reduce_sum()函数实现。
class BasicDotProductAttention(tf.keras.layers.Layer):
def __init__(self):
super(BasicDotProductAttention, self).__init__()
def call(self, decoder_hidden_state, encoder_outputs):
# Dimensions of decoder_hidden_state => (BATCH_SIZE, hidden_units)
# Dimensions of encoder_outputs => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, hidden_units)
decoder_hidden_state_with_time_axis = tf.expand_dims(decoder_hidden_state, 2)
# Dimensions of decoder_hidden_state_with_time_axis => (BATCH_SIZE, hidden_units, 1)
attention_scores = tf.matmul(encoder_outputs, decoder_hidden_state_with_time_axis)
# Dimensions of attention_scores => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, 1)
attention_scores = tf.nn.softmax(attention_scores, axis = 1)
weighted_sum_of_encoder_outputs = tf.reduce_sum(encoder_outputs * attention_scores, axis = 1)
# Dimensions of weighted_sum_of_encoder_outputs => (BATCH_SIZE, hidden_units)
return weighted_sum_of_encoder_outputs, attention_scores
解码器Decoder (加注意力机制)
代码在decoder类中增加了以下步骤。
- 就像编码器一样,我们在这里也有一个嵌入层用于目标语言中的序列。序列中的每一个单词都在具有相似意义的相似单词的嵌入空间中表示。
- 我们也得到的加权和编码器输出通过使用当前解码隐藏状态和编码器输出。这是通过调用我们的注意力层来实现的。
将以上两步得到的结果(嵌入空间序列的表示和编码器输出的加权和)串联起来。这个串联张量被发送到我们的解码器的GRU层。
这个GRU层的输出被发送到一个稠密层,这个稠密层给出所有hindivocabsize的单词出现的概率。具有高概率的单词意味着模型认为这个单词应该是下一个单词。
class Decoder(tf.keras.Model):
def __init__(self, hindi_vocab_size, embedding_dim, hidden_units):
super(Decoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(hindi_vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(hidden_units, return_state = True)
self.word_probability_layer = tf.keras.layers.Dense(hindi_vocab_size, activation = 'softmax')
self.attention_layer = BasicDotProductAttention()
def call(self, decoder_input, decoder_hidden, encoder_sequence_output):
x = self.embedding(decoder_input)
# Dimensions of x => (BATCH_SIZE, embedding_dim)
weighted_sum_of_encoder_outputs, attention_scores = self.attention_layer(decoder_hidden, encoder_sequence_output)
# Dimensions of weighted_sum_of_encoder_outputs => (BATCH_SIZE, hidden_units)
x = tf.concat([weighted_sum_of_encoder_outputs, x], axis = -1)
x = tf.expand_dims(x, 1)
# Dimensions of x => (BATCH_SIZE, 1, hidden_units + embedding_dim)
decoder_output, decoder_state = self.gru(x)
# Dimensions of decoder_output => (BATCH_SIZE, hidden_units)
word_probability = self.word_probability_layer(decoder_output)
# Dimensions of word_probability => (BATCH_SIZE, hindi_vocab_size)
return word_probability, decoder_state, attention_scores
# initialize our decoder
decoder = Decoder(hindi_vocab_size, embedding_dim, hidden_units)
序列损失 Sequence Loss
seq2seq 训练中次要但值得一提的知识点。
按照通常 loss 计算方法
- 假设 batch size=4,max_seq_len=4,分别计算这 4*4 个位置上的 loss。
- 但是实际上 “_PAD” 上的 loss 计算是没有用的,因为“_PAD”本身没有意义,也不指望 decoder 去输出这个字符,只是占位用的,计算 loss 反而带来副作用,影响参数的优化
解法
- 在 loss 上乘一个 mask 矩阵,这个矩阵可以把“_PAD”位置上的 loss 筛掉。

sequence_mask 矩阵之后(tensorflow 提供的函数 tf.sequence_mask 可以直接生成),直接乘在 loss 矩阵上就行
# tf seq2seq 全家桶
sequence_mask = tf.sequence_mask(self.seq_targets_length, dtype=tf.float32)
self.loss = tf.contrib.seq2seq.sequence_loss(logits=decoder_logits, targets=self.seq_targets, weights=sequence_mask)
# 如果不用全家桶:
sequence_mask = tf.sequence_mask(self.seq_targets_length, dtype=tf.float32)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=decoder_logits, labels=self.seq_targets)
self.loss = tf.reduce_mean(loss * sequence_mask)
序列解码
详见站内专题: 序列解码专题
训练
定义我们的损失函数和优化器。选择了稀疏分类交叉熵和Adam优化器。每个训练步骤如下:
- 从编码器对象获取编码器序列输出和编码器最终隐藏状态。编码器序列输出用于查找注意力分数,编码器最终隐藏状态将成为解码器的初始隐藏状态。
- 对于目标语言中预测的每个单词,我们将输入单词、前一个解码器隐藏状态和编码器序列输出作为解码器对象的参数。返回单词预测概率和当前解码器隐藏状态。
- 将概率最大的字作为下一个解码器GRU单元(解码器对象)的输入,当前解码器隐藏状态成为下一个解码器GRU单元的输入隐藏状态。
- 损失通过单词预测概率和目标句中的实际单词计算,并向后传播
在每个epoch中,每次调用上述训练步骤,最后存储并绘制每个epoch对应的损失。
附注:在第1步,为什么我们仍然使用编码器的最终隐藏状态作为我们的解码器的第一个隐藏状态?
这是因为,如果我们这样做,seq2seq模型将被优化为一个单一系统。反向传播是端到端进行的。我们不想分别优化编码器和解码器。并且,没有必要通过这个隐藏状态来获取源序列信息,因为我们已经有注意力机制了:)
optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate)
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')
def loss_function(actual_words, predicted_words_probability):
loss = loss_object(actual_words, predicted_words_probability)
mask = tf.where(actual_words > 0, 1.0, 0.0)
return tf.reduce_mean(mask * loss)
def train_step(english_sequences, hindi_sequences):
loss = 0
with tf.GradientTape() as tape:
encoder_sequence_output, encoder_hidden = encoder(english_sequences)
decoder_hidden = encoder_hidden
decoder_input = hindi_sequences[:, 0]
for i in range(1, hindi_sequences.shape[1]):
predicted_words_probability, decoder_hidden, _ = decoder(decoder_input, decoder_hidden, encoder_sequence_output)
actual_words = hindi_sequences[:, i]
# if all the sentences in batch are completed
if np.count_nonzero(actual_words) == 0:
break
loss += loss_function(actual_words, predicted_words_probability)
decoder_input = actual_words
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss.numpy()
all_epoch_losses = []
training_start_time = time.time()
for epoch in range(epochs):
epoch_loss = []
start_time = time.time()
for(batch, (english_sequences, hindi_sequences)) in enumerate(dataset):
batch_loss = train_step(english_sequences, hindi_sequences)
epoch_loss.append(batch_loss)
all_epoch_losses.append(sum(epoch_loss)/len(epoch_loss))
print("Epoch No.: " + str(epoch) + " Time: " + str(time.time()-start_time))
print("All Epoch Losses: " + str(all_epoch_losses))
print("Total time in training: " + str(time.time() - training_start_time))
plt.plot(all_epoch_losses)
plt.xlabel("Epochs")
plt.ylabel("Epoch Loss")
plt.show()
训练优化
训练技巧: 参考Seq2Seq 模型知识总结
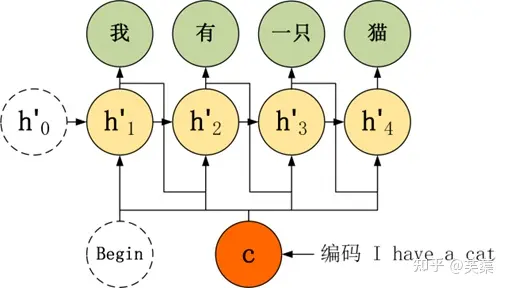
- Teacher Forcing
- Teacher Forcing 用于训练阶段,主要针对上面第三种 Decoder 模型来说的,第三种 Decoder 模型神经元的输入包括了上一个神经元的输出 y’。如果上一个神经元的输出是错误的,则下一个神经元的输出也很容易错误,导致错误会一直传递下去。而 Teacher Forcing 可以在一定程度上缓解上面的问题,在训练 Seq2Seq 模型时,Decoder 的每一个神经元并非一定使用上一个神经元的输出,而是有一定的比例采用正确的序列作为输入。
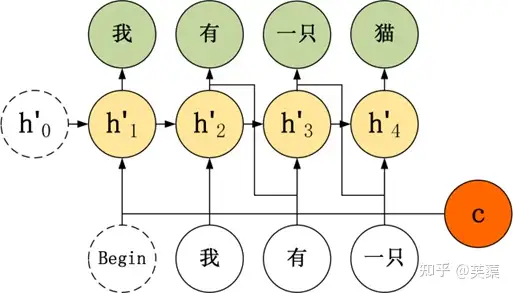
- 举例,在翻译任务中,给定英文句子翻译为中文。”I have a cat” 翻译成 “我有一只猫”,下图是不使用 Teacher Forcing 的 Seq2Seq:
- 如果使用 Teacher Forcing,则神经元直接使用正确的输出作为当前神经元的输入。
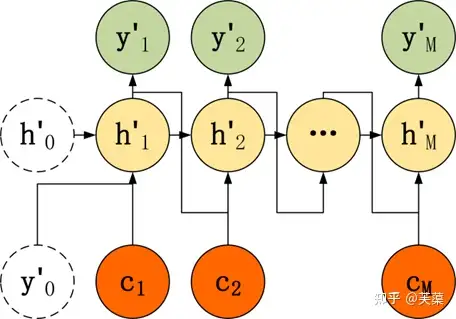
- Attention 机制
- 在 Seq2Seq 模型,Encoder 总是将源句子的所有信息编码到一个固定长度的上下文向量 c中,然后在 Decoder 解码的过程中向量 c 都是不变的。这存在着不少缺陷(定长向量c表示能力有限)
- 与人类的注意力方式不同,即人类在阅读文章的时候,会把注意力放在当前的句子上。Attention 即注意力机制,是一种将模型的注意力放在当前翻译单词上的一种机制。例如翻译 “I have a cat”,翻译到 “我” 时,要将注意力放在源句子的 “I” 上,翻译到 “猫” 时要将注意力放在源句子的 “cat” 上。
- 使用了 Attention 后,Decoder 的输入就不是固定的上下文向量 c了,而是会根据当前翻译的信息,计算当前的 c。
- 束搜索(Beam Search)
- beam search 方法不用于训练的过程,而是用在测试的。在每一个神经元中,我们都选取当前输出概率值最大的 top k个输出传递到下一个神经元。下一个神经元分别用这 k 个输出,计算出 L 个单词的概率 (L 为词汇表大小),然后在 kL 个结果中得到 top k 个最大的输出,重复这一步骤。
测试
定义了一个函数,该函数接受一个英语句子,并按照模型的预测返回一个印地语句子。让我们实现这个函数,我们将在下一节中看到结果的好坏。
- 我们接受英语句子,对其进行预处理,并将其转换为长度为MAXWORDSINASENTENCE的序列或向量,如开头的”预处理数据”部分所述。
- 这个序列被输入到我们训练好的编码器,编码器返回编码器序列输出和编码器的最终隐藏状态。
- 编码器的最终隐藏状态是译码器的第一个隐藏状态,译码器的第一个输入字是一个开始标记”sentencestart”。
- 解码器返回预测的字概率。概率最大的单词成为我们预测的单词,并被附加到最后的印地语句子中。这个字作为输入进入下一个解码器层。
- 预测单词的循环将继续下去,直到解码器预测结束标记”sentenceend”或单词数量超过某个限制(我们将这个限制保持为MAXWORDSINASENTENCE的两倍)。
def get_sentence_from_sequences(sequences, tokenizer):
return tokenizer.sequences_to_texts(sequences)
# Testing
def translate_sentence(sentence):
sentence = preprocess_sentence(sentence, True)
sequence = english_tokenizer.texts_to_sequences([sentence])[0]
sequence = tf.keras.preprocessing.sequence.pad_sequences([sequence], maxlen = MAX_WORDS_IN_A_SENTENCE, padding = 'post')
encoder_input = tf.convert_to_tensor(sequence)
encoder_sequence_output, encoder_hidden = encoder(encoder_input)
decoder_input = tf.convert_to_tensor([hindi_word_index['sentencestart']])
decoder_hidden = encoder_hidden
sentence_end_word_id = hindi_word_index['sentenceend']
hindi_sequence = []
for i in range(MAX_WORDS_IN_A_SENTENCE*2):
predicted_words_probability, decoder_hidden, _ = decoder(decoder_input, decoder_hidden, encoder_sequence_output)
# taking the word with maximum probability
predicted_word_id = tf.argmax(predicted_words_probability[0]).numpy()
hindi_sequence.append(predicted_word_id)
# if the word 'sentenceend' is predicted, exit the loop
if predicted_word_id == sentence_end_word_id:
break
decoder_input = tf.convert_to_tensor([predicted_word_id])
print(sentence)
return get_sentence_from_sequences([hindi_sequence], hindi_tokenizer)
# print translated sentence
print(translate_sentence("Try multiple sentences here to check how good model is working!"))
结果
NVidia K80 GPU Kaggle,在上面的代码。100个epoch,需要70分钟的训练。损失与epoch图如下所示。
经过35个epoch的训练后,我尝试向我们的translate_sentence()函数中添加随机的英语句子,结果有些令人满意,但也有一定的问题。超参数并不是与实际翻译有一些偏差的唯一原因。
改进点:
- 使用堆叠GRU编码器和解码器
- 使用不同形式的注意力机制
- 使用不同的优化器
- 增加数据集的大小
- 采用Beam Search代替Greedy decoding:Beam Search解码从单词概率分布中考虑最高k个可能的单词,并检查所有的可能性
推理
生成模型接受输入并进行前向传递:
- 输入被喂入模型并逐层顺序传递,直到预测出下一个 token 的非标准化对数概率 (也称为 logits)。
- 一个 token 可能包含整个词、子词,或者是单个字符,这取决于具体模型
- 文本生成步骤:从这些概率中选择下一个 token,策略有贪心、多项式抽样(分布抽样)
文本生成的延迟瓶颈:
- 运行大型模型的前向传递很慢,可能需要依次执行数百次迭代。
为什么前向传递速度慢?
- 前向传递通常以矩阵乘法为主,内存带宽限制了乘法效率 (例如,从 GPU RAM 到 GPU 计算核心)。
- 即:前向传递的瓶颈来自将模型权重加载到设备的计算核心中,而不是来自执行计算本身。
推理加速
- 首先,特定硬件的模型优化。
- 例如,如果设备与 Flash Attention 兼容,可以重新排序操作或 INT8 量化,加速注意力层,其减少了模型权重的大小。
- 其次,如果有并发文本生成需求,对输入进行批处理,从而实现较小的延迟损失并大幅增加吞吐量。
- 将模型对于多个输入并行计算,在大致相同的内存带宽负担情况下获得了更多 token。
- 批处理的问题:需要额外的设备内存 (或在某处卸载内存)。像 FlexGen 这样的项目以延迟为代价来优化吞吐量。
- 最后,如果有多个可用设备,使用 Tensor 并行分配工作负载并获得更低的延迟。
- Tensor 并行将内存带宽负担分摊到多个设备上,但除了在多个设备运行计算成本,还要考虑设备间的通信瓶颈。
- 该方法收益很大程度上取决于模型大小: 对于可以轻松在单个消费级设备上运行的模型,通常效果并不显著。根据这篇 DeepSpeed 博客,可以将大小为 17B 的模型分布在 4 个 GPU 上,从而将延迟减少 1.5 倍。
这三种类型的改进可以串联使用,从而产生高通量解决方案。
- 然而,在应用特定于硬件的优化后,降低延迟的方法有限——并且现有的方法很昂贵。
【2023-5-26】详见:辅助生成: 低延迟文本生成的新方向
Seq2Seq 优化技巧
【2023-3-16】Tensorflow中的Seq2Seq全家桶
1、Teacher Forcing
Teacher Forcing 用于训练阶段,预测过程是都一样。
训练时:如果不使用 Teacher Forcing,输入包括了上一个神经元的输出 y’。如果上一个神经元的输出是错误的,则下一个神经元的输出也很容易错误,导致错误会一直传递下去。

使用 Teacher Forcing,神经元直接使用正确的输出作为当前神经元的输入。

好处:
- 防止上一时刻的错误传到此刻,decode 出一个序列,要是第一个单词错了,整个序列就跑偏了,计算 loss 更新参数作用都很小了。用 Teacher Forcing 可以阻断错误积累,斧正模型训练,加快参数收敛
- 提前把 decoder 的整个输入序列提前准备好,直接放到 dynamic_rnn 函数就能出结果,实现起来简单方便
但带来的问题:
- 到了测试阶段,不能用 Teacher Forcing,因为测试阶段看不到期望的输出序列,所以必须等着上一时刻输出一个单词,下一时刻才能确定该输入什么。不能提前把整个 decoder 的输入序列准备好,也就不能用 dynamic_rnn 函数了
怎么办?
- 用 raw_rnn 函数,手动补充 loop_fn 循环,手动去写在 decoder rnn 的每一个时间片上,先把上一个时间片的输出向量映射到词表上,再找出概率最大的词,再用 embedding 矩阵映射成向量成为这一时刻的输入,还要判断这个序列是否结束了,结束了还要拿“_PAD”作为输入……
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_embedding = tf.Variable(tf.random_uniform([config.target_vocab_size, config.embedding_dim]), dtype=tf.float32, name='decoder_embedding')
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
if useTeacherForcing:
decoder_inputs = tf.concat([tf.reshape(tokens_go,[-1,1]), self.seq_targets[:,:-1]], 1)
helper =tf.contrib.seq2seq.TrainingHelper(tf.nn.embedding_lookup(decoder_embedding, decoder_inputs), self.seq_targets_length)
else:
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embedding, tokens_go, w2i_target["_EOS"])
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, encoder_state, output_layer=tf.layers.Dense(config.target_vocab_size))
decoder_outputs, decoder_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder, maximum_iterations=tf.reduce_max(self.seq_targets_length))
2、Attention
Seq2Seq 模型中,Encoder 总是将源句子的所有信息编码到一个固定长度的上下文向量 c 中,然后在 Decoder 解码的过程中向量 c 都是不变的。这存在着不少缺陷:
- 对于比较长的句子,很难用一个定长的向量 c 完全表示其意义。
- RNN 存在长序列梯度消失的问题,只使用最后一个神经元得到的向量 c 效果不理想。
- 人在阅读文章的时候,会把注意力放在当前的句子上,这种结构没有利用这点。
- 引入attention 机制,就是一种将模型的注意力放在当前翻译单词上的一种机制。
- 例如翻译 “I have a cat”,翻译到 “我” 时,要将注意力放在源句子的 “I” 上,翻译到 “猫” 时要将注意力放在源句子的 “cat” 上。
使用了 Attention 后:
- Decoder 的输入就不是固定的上下文向量 c 了
- 而是会根据当前翻译的信息,计算当前的 c

-
- Attention 需要保留 Encoder 每一个神经元的隐藏层向量 h
- 然后 Decoder 的第 t 个神经元要根据上一个神经元的隐藏层向量 h’t-1 计算出当前状态与 Encoder 每一个神经元的相关性 et
- et 是一个 N 维的向量 (Encoder 神经元个数为 N),若 et 的第 i 维越大,则说明当前节点与 Encoder 第 i 个神经元的相关性越大。et 的计算方法有很多种,即相关性系数的计算函数 a 有很多种:
- 上面得到相关性向量 et 后,需要进行归一化,使用 softmax 归一化。然后用归一化后的系数融合 Encoder 的多个隐藏层向量得到 Decoder 当前神经元的上下文向量 ct:


3、beam search
- beam search 方法不用于训练的过程,而是用在测试的。训练的时候因为知道正确答案,不需要再进行搜索。
- 在每一个神经元中,我们都选取当前输出概率值最大的 top k 个输出传递到下一个神经元。
- 下一个神经元分别用这 k 个输出,计算出 L 个单词的概率 (L 为词汇表大小),然后在 kL 个结果中得到 top k 个最大的输出,重复这一步骤。后面会不断重复这个过程,直到遇到结束符或者达到最大长度为止。最终输出得分最高的2个序列。
例如
- 预测的时候,假设词表大小为3,内容为a,b,c。beam size是2,decoder解码的时候:
- 1: 生成第1个词的时候,选择概率最大的2个词,假设为a,c,那么当前的2个序列就是a和c。
- 2:生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,计算每个序列的得分并选择得分最高2个序列,作为新的当前序列,假如为aa cb。
- 3:后面会不断重复这个过程,直到遇到结束符或者达到最大长度为止。最终输出得分最高的2个序列。
前缀树解码
【2021-12-17】
- 苏剑林:Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
- ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
- “Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。
前缀树来约束解码
语料:
明月几时有
明天会更好
明天下雨
明天下午开会
明天下午放假
明年见
今夕是何年
今天去哪里玩
前缀树来存储这些句子:

- 从左往右地把相同位置的相同token聚合起来,树上的每一条完整路径(以[BOS]开头、[EOS]结尾)都代表数据库中的一个句子。之所以叫“前缀树”,是因为利用这种树状结构,我们可以很快地查找到以某个前缀开头的字/句有哪些。比如从上图中我们可以看到,第一个字只可能是“明”或“今”,“明”后面只能接“月”、“天”或“年”,“明天”后面只能接“会”或“下”,等等。
- 第一个字只能是“明”或“今”,那么在预测第一个字的时候,我们可以把模型预测其他字的概率都置零,这样模型只可能从这两个字中二选一;如果已经确定了第一个字,比如“明”,那么我们在预测第二个字的时候,同样可以将“月”、“天”或“年”以外的字的概率都置零,这样模型只可能从这三个字中选一个,结果必然是“明月”、“明天”、“明年”之一;依此类推,保证解码过程只走前缀树的分支,而且必须走到最后,这样解码出来的结果必然是数据库中已有的句子。
- 相比常规的向量检索方案,“Seq2Seq+前缀树”的方案用前缀树代替了要储存的检索向量,而前缀树本质上是原始句子的一种“压缩表示”,所以不难想象前缀树所需要的储存空间要比稠密的检索向量要少得多。
Python实现前缀树比较简单的方案就是利用字典结构来实现嵌套
效果:排行榜第二
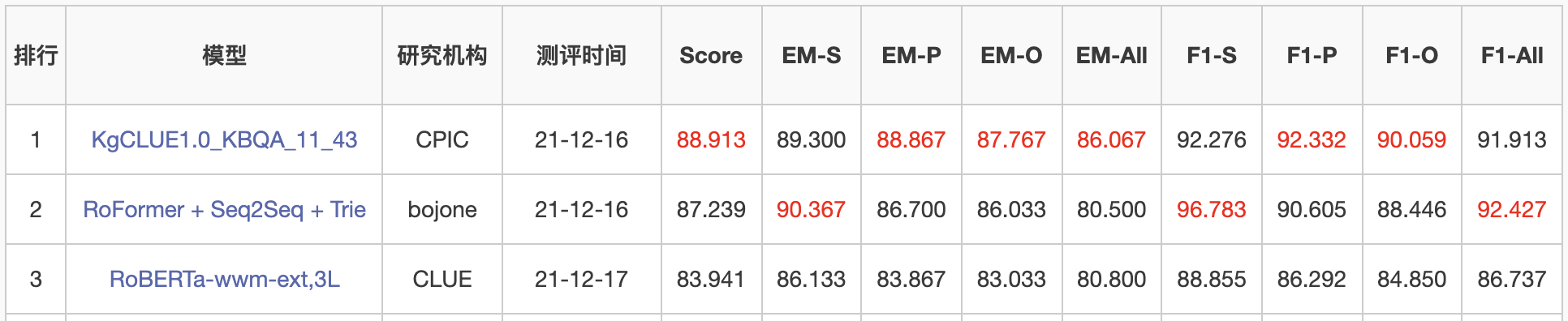
“Seq2Seq+前缀树”或许可以在评测指标上取得不错的效果,但它对于工程来说,有一个不大有好的特点,就是修正bad case会变得比较困难,因为传统方法修正bad case,你只需要不断加样本就行了,而“Seq2Seq+前缀树”则需要你修改解码过程,这通常困难得多。
改进方法
文本生成仍然存在很多问题,需要大家投入大量毛囊和精力,本文总结未来发展趋势如下:
- 融合知识的文本生成。有些生成任务需要真实知识,eg:故事生成、面向任务的对话系统;
- 取代严格从左到右生成的方法。类似非自回归的并行生成,可以提高生成效率,同时生成长文本肯定不能逐句解码,需要一个整体的生成计划框架;
- 用 teacher forcing 替代最大似然训练目标,建立考虑更全面的句子级别目标,而不是单词级别的目标;
- 研究更好的文本生成评估方法。「如何进行有效的评估」是目前文本生成技术进展的最大障碍。
知识融合的文本生成
- 文本生成12:4种融合知识的text generation
- 刘知远:“NLP搞事情少不了知识指导”
- 对融合知识的idea做了一个简单的汇总,大致有4个较为典型的方式:
- 多任务学习(生成+文本蕴含)
- 基于knowledge graph 的文本生成:图神经网络参与文本生成
- 从长文本构建graph,然后辅助生成文本
- 语义图or三元组的文本生成,graph to text 就是原本的任务
- 基于memory network 的文本生成
- 以memory network 形式储存ConceptNet知识
- 结合分布-采样进行文本生成
- 从带有“知识”的分布采样生成文本
控制主题、属性
【2023-1-12】可控文本生成
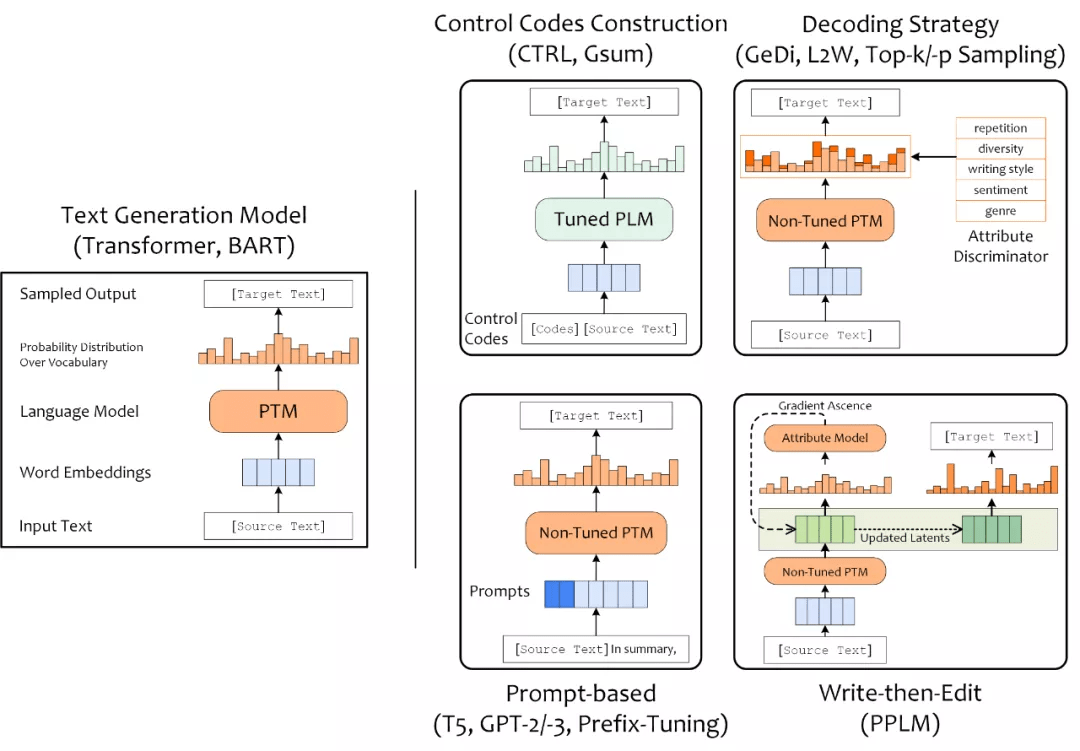
【2023-2-27】可控文本生成-PPLM(year 2020, Uber AI)
- 论文的核心在于给LLM增加一个后置插件, 可以为LLM的输出注入属性(比如主题, 风格)约束, 引导LLM可以生成复合目标的文本。这种插件形式不需要LLM做修改,只是增加了多个简单的属性分类器,对原始的输入进行属性加成,然后重新更新输入分布,完成p(x)到 p(a|x)的转换过程。
- 属性分类器是不是也可以当作一种个性化知识编码,如果使用合理,可以用在对话场景做个性化输出;同时,如果把它理解为一种约束规则,也可以当做生成结果的安全无害等指标的加成,在不同任务场景下有不同的理解和含义

(1)Copy机制
最初用于解决OOV问题
- ACL2017的《Get To The Point: Summarization with Pointer-Generator Networks》,借鉴point network模型
思路:
- 单词可以有两种来源:一种是通过普通seq2seq生成;另一种是从原文本拷贝过来。

实现:
- 将每步输出的单词概率看作一个混合模型(生成的单词概率分布与拷贝原文的单词概率分布的混合),利用注意力得分作为拷贝单词的概率

效果:
- 回答的相关性和流畅性更高
- 问:“我老家是湖南的”
- 答:我也是 → 我也是湖南的
在神经网络流行之前,传统文本摘要分为两个阶段:「内容选择」和「文本生成」。「seq2seq + attention」是一种 End2End 的方法,完全混合了这两个阶段,使用「解码器」实现「文本解码」,使用「选择注意力」实现「词级内容选择」,这种方法由于缺少全局内容选择策略,词级内容选择表现不佳,进而造成了「复制机制」的各种问题。
脑门最亮的程序员突然醒悟,何不使用一种「自下而上的摘要」方法:
- 内容选择阶段:使用神经网络序列标记模型,将单词标记为「包含」或「不包含」;
- 自上而下的注意阶段:使用「seq2seq + attention」,不再关注那些标记为「不包含」的单词。
这种方法的优点是给「seq2seq + attention」单独设置了一个「内容选择阶段」,帮助整理标注原文中的词,从而更好的把控原文全局信息,从而实现更优质的文本摘要。
基于神经网络的文本摘要主要采用生成式方法,例如家喻户晓的「seq2seq + attention」,这种方法擅长编写流畅的输出,但是不擅长复制细节,因此在 2016 年,有大佬提出「复制机制」(Copy mechanisms),复制机制用 attention 使 seq2seq 系统能够直接将重要单词和短语,从输入复制到输出,计算了一个 Pgen,即下一个单词是生成的概率,(1-Pgen) 就是直接复制的概率,因此最终的生成概率分布 = 生成分布 + 复制分布。
「复制机制」看似很完美,实际也存在若干局限性:
- 不好平衡生成和复制的比例;
- 复制太多时,本来是生成式摘要,却退化成大部分是提取式摘要;
- 不擅长覆盖全文的内容选择,尤其是在输入文档很长的情况下;
- 没有选择内容的整体策略。
(2)主题控制
解决的问题:
- 普通的seq2seq生成的内容,其实没有办法把控生成的语义信息
思路:
-
通过增加关键词信息,用关键词去影响生成回复的语义(主题)
- 思路一:用关键词作为硬约束——一定出现
- ACL 2016的《Sequence toBackward and Forward Sequences: A Content-Introducing Approach to GenerativeShort-Text Conversation》
- 步骤:
- 利用互信息进行预测,即取与问题互信息最大的词作为关键词。
- 生成回复:分两步:生成包含关键词的前半句话 → 生成后半句话;

- 不足:预测的单词不准,或者在对话中出现较少时,上下句可能衔接不够流畅。
- 思路二:用关键词作为软约束——不一定出现
- Emnlp 2016的《Towards implicit content-introducing for generative short-textconversation systems》。
- 假设关键词在生成文本中不一定会出现,只作为额外信息输入到网络里;设计cue word gru单元,将关键词信息加入到每一步的状态更新;
- 思路三:用关键词同时约束主题与情感
- Emnlp 2018《A Syntactically Constrained Bidirectional-Asynchronous Approach for Emotional Conversation Generation》

- 先预测情感关键词与主题关键词,再生成文本
(3)属性控制
避免出现负面情感或疑问句式的回应
思路:
-
学习到文本的属性信息(句式、情感信息),控制生成文本风格,使生成的回复更为可控
- 思路一:直接融合属性信息
- 输入的文本除了encoder的信息,还包括属性embedding的信息
- 思路二:用条件变分编码器
- Generating Informative Responses with Controlled Sentence Function
- 条件变分编码器的网络结构去控制回复的句式,使模型生成一些更有信息量的回复
- 约束中间隐变量z,使z更多地去编码句式属性的信息
多样性
从2015年以来,提高文本多样性的方法大致分为四类:
- 第一类:采用新模型对Beam Search得到的候选序列进行重排,比如
MMI-bidi等。 - 第二类:引入内容形式,对输出文本先预测一个关键词,然后对其进行补全,比如
Seq2BF等。 - 第三类:直接修改Beam Search算法,对每个时间步的条件概率施加多样性惩罚,比如
MMI-antiLM、diverseRL、DBS等。 - 第四类:直接修改训练时的损失函数,比如
ITF-loss等
总结吧:
MMI两种损失函数与传统的极大似然估计相比,可以提高文本生成的多样性和趣味性。MMI-antiLM不需要额外训练一个模型,使用起来会方便一点。MMI-bidi需要训练两个模型,训练时间翻了一倍,另外,对于最终输出句子的重排,还是受到Seq2Seq生成的候选句子的限制,如果生成的候选句子多样性差,那么就算重排之后,其实也不一定能提高多样性。Seq2BF虽然通过预测关键词来提高文本生成的多样性,但是因为其关键词都限定为名词,而有些回复其实是不包含名词的,此时如果强制要求回复必须包含预测的名词,那可能会出现错误。
改进Beam Search——提高回复多样性
- 思路一:通过增加惩罚项
- 如对同一组的第二、第三选项进行降权,从而避免每次搜索结果都来自于同一路径。对于权重的选择,可以通过强化学习得到;也可以通过设置参数、调整参数来得到

- 思路二:计算每条路径的概率分
- 如果后面生成的话跟第一组相似,就对该组进行降权,避免组与组之间相似度过高

2015, MMI系列
李纪为博士等人(2015)采用了最大互信息(Maximum Mutual Information,MMI)作为目标损失函数,在一定程度上提高了文本生成的多样性和趣味性。
- MMI损失函数可以看成是在极大似然估计的基础上,添加了一项对输出句子概率的惩罚项
- 不同损失函数对应方法:
MMI-antiLM、MMI-bidi - 直接将
MMI-antiLM和MMI-bidi两种损失函数作为损失函数,那么训练将会非常艰难,导致语法紊乱和解码难的问题,因此,作者在真实训练过程中,还是采用极大似然估计作为模型训练的损失函数,但是在预测时才采用MMI损失函数。 - 论文地址:《A Diversity-Promoting Objective Function for Neural Conversation Models》
2016, Seq2BF
2016年,北大 Lili Mou 等人提出了一种新的方法,即Seq2BF模型
- 基本思想: 在decoder之前,先根据
点态互信息(Pointwise Mutual Information,PMI)计算出一个与输入句子最相关的名词,作为输出句子的关键词,然后采用两个Seq2Seq模型分别对该词的前文和后文进行decode补全,最后作为预测的输出句子。 - 论文地址:《Sequence to Backward and Forward Sequences: A Content-Introducing Approach to Generative Short-Text Conversation》
步骤
- 关键词预测
- Seq2BF模型
2016, diverseRL
2016年,李纪为博士在15年那篇的基础上又进行了改进, 引入强化学习
- 直接对Beam_search方法进行修改,使得Beam_search的搜索结果多样性更强,并且其通用性更强,可以迁移到很多其他的任务上。在参数的选择方面,引进了强化学习的思想,使得该方法更加灵活。
- 论文地址:《A Simple, Fast Diverse Decoding Algorithm for Neural Generation》
2018, Diverse Beam Search (DBS)
2018年,Ashwin K Vijayakumar 等人也提出了一种新的Diverse Beam Search,简称DBS,大致思想:
- 将原先的 Beam Search 均分为 G个组,每个组含有 B′ = B / G 条候选路径,对每个组还是按照Beam Search的思想进行解码,但是每个组在解码时还要考虑解码后的序列与前面每个组已经解码的序列之间的差异性。
- 该方法与李纪为博士的
diverseRL方法、传统的Beam Search方法进行对比,发现在多个任务上都有效提升了文本生成的多样性。 - 论文地址:《DIVERSE BEAM SEARCH: DECODING DIVERSE SOLUTIONS FROM NEURAL SEQUENCE MODELS》
Beam Search 搜索方式很容易导致生成的B条序列都集中在某几个父节点,输出序列有大部分都非常接近。
- 为了克服这个问题,
DBS每次解码时,在原先的概率公式上添加了一项差异项Δ(Y[t]),用来衡量后续序列之间的多样性或差异性。 - 计算序列的多样性只考虑当前组与前面组已经解码好的后续序列,因此,计算复杂度大大降低,该形式也因此被称为
双贪婪(doubly greedy)的形式
DBS引入了一些超参数,比如: 组数G、惩罚参数λ、差异性度量函数δ(⋅,⋅)。实验发现:
- 随着组数G的增加,DBS的精度会不会提高,将组数G设置为B,即G = B 效果最好。
- λ不宜过高或过低,一般设置在0.2~0.8效果比较好。
- 对于差异项度量函数δ(⋅,⋅),作者对比了 Hamming diversity、Cummulative diversity、n-gram diversity 和 Neural-embedding diversity四种计算方式,发现采用Hamming diversity效果相对比较好,该方法直接度量每个句子与其他组句子词汇使用的差异性。
2018, ITF-loss
前面的方法都是在模型训练结束后,对decoder方式改动而成,而Ryo Nakamura等人在2018年提出的ITF-loss则直接改动训练时的MLE损失函数,该方法非常简单,不需要额外地训练其他模型,很容易迁移到各种模型当中。
传统Seq2Seq一般会采用Softmax Cross Entropy(后文简记为SCE)作为损失值的计算函数
高频的词汇的损失值越小,低频的词汇则会使损失值越大,从而使得模型更关注低频词汇的损失,其实该方法与focal loss非常类似。推理阶段,同样可以对每一步的输出施加一个权重
2022, 对比解码 Contrastive Search Decoding
【2022-9-26】 Contrastive Search Decoding,对比搜索解码文本生成算法,详见解读
- 论文: 《A Contrastive Framework for Neural Text Generation》, 剑桥、腾讯、香港、DeepMind联合撰写
- 摘要:生成结果不确定、重复
- Text generation is of great importance to many natural language processing applications. However, maximization-based decoding methods (e.g., beam search) of neural language models often lead to degenerate solutions—the generated text is unnatural and contains undesirable repetitions. Existing approaches introduce stochasticity via sampling or modify training objectives to decrease the probabilities of certain tokens (e.g., unlikelihood training). However, they often lead to solutions that lack coherence. In this work, we show that an underlying reason for model degeneration is the anisotropic /anisotropic/ 各向异性 distribution of token representations. We present a contrastive solution: (i) SimCTG, a contrastive training objective to calibrate the model’s representation space, and (ii) a decoding method—contrastive search—to encourage diversity while maintaining coherence in the generated text. Extensive experiments and analyses on three benchmarks from two languages demonstrate that our proposed approach significantly outperforms current state-of-the-art text generation methods as evaluated by both human and automatic metrics.
补充:
isotropic各向同性: 物体属性在各个方向都一致 Properties of a material are identical in all directions.anisotropic各向异性: 物体属性在各个方向都不一样 Properties of a material depend on the direction;- for example, wood. In a piece of wood, you can see lines going in one direction; this direction is referred to as “with the grain”.
论文
- ISOTROPY IN THE CONTEXTUAL EMBEDDING SPACE: CLUSTERS AND MANIFOLDS
- a strong anisotropic space such that most of the vectors fall within a narrow cone
- BERT/ERNIE的上下文嵌入空间显示出较强的各向异性特征:大部分向量都在一个窄小的椎体里,导致cosine相似度较大。有必要将其变成各向同性:识别嵌入空间里的孤立的聚类簇和低维流形。
问题
- GPT-2模型生成的token具有各异向性,使得token之间的相似性非常接近没有区分度,最后解码时造成了文本重复——text degeneration;
- 提出了一种新的训练策略(
SimCTG)+解码算法(contrastive search),在多语言任务和实际的工业场景中进行人工评测,显著提升了文本生成的质量。 - 论文提出的text degeneration的原因是text degeneration并不是SIMCTG提出的Contrastive Training,它并不能保证表征各向同质性,之所以在文本生成的质量上(少无意义的重复)有实实在在的提升,完全来自于新提出的解码策略——
contrastive search decoding。
contrastive search decoding是一种非topK、topP以及BeamSearch的解码策略,核心思想就是对比
- 把当前要生成的token和已经生成的所有token做相似度计算,得到最大的相似度值;然后使得该token的概率与最大的相似度值的差值最大化的那个token就是要生成的token;
- 当前轮次文本输入gpt2模型,使用hm得到新的k个候选生成tokens;然后把这些tokens和之前的文本拼接起来输入到下一轮模型,得到hm+1。这里的hm+1就是前面说的上一轮应该生成的token的embedding,通过解码公式的计算,选出最佳的hm+1也就得到了tm+1——当前轮最佳的那个token。按照上述流程循坏下去就可以得到生成一个句子了。
- 代码及图表详见原文
方案的缺陷
- 一般都要求生成的句子具有多样性——有不同的生成,contrastive search decoding是一个确定性方案,每次只能生成固定的结果。
- 作者有提出一个比较合适的方法:先用beamsearch + sample等方法生成部分句子,然后再使用contrastive search decoding对生成的句子进行补齐。
- 还有一种方法,实现上比较麻烦,思想:就是那个公式中选择v的时候,不选最大的那一个,多选择几个,但是要小于K值。
Transformer
Transformer主要用于解决训练并行问题,在长期依赖上也有很好地效果。
- 缺点是对于长序列,由于所有向量之间会进行self-attention,会引起参数量过大(Transformer XL对Self-attention的QK的连接进行了处理,控制了参数量)。
Transformer在结构上引入了较多深度学习的元素和结构(残差网络、Norm、Encoder-Decoder、前馈网络、多头自注意力、位置编码、Embedding),但最主要的结构在于多头自注意力,而多头自注意力的基本单元即是Self-Attention。
- Self-Attention通过让输入(多个向量组成的矩阵)两两之间计算Attention Value,实现每个向量能够关注到其它向量的信息。
- 多头自注意力的多头在于,从不同的子维度对向量执行Self-Attention,再将concat结果作为输出。多头的目的目前没有太合理的解释,已有解释如:
- 1、多头起到滤波器作用,从子维度提取到更丰富的信息;
- 2、多头相当于多个基学习器集成,降低过拟合。
VAE:Variational AutoEncoder
VAE和GAN一样,都是从隐变量 Z 生成目标数据 X 。
- 假设隐变量服从某种常见的概率分布(比如
正态分布) - 然后希望训练一个模型$X=g(Z)$,将原来的概率分布映射到训练集的概率分布,也就是分布变换。
- 注意,VAE和GAN的本质都是概率分布的映射。
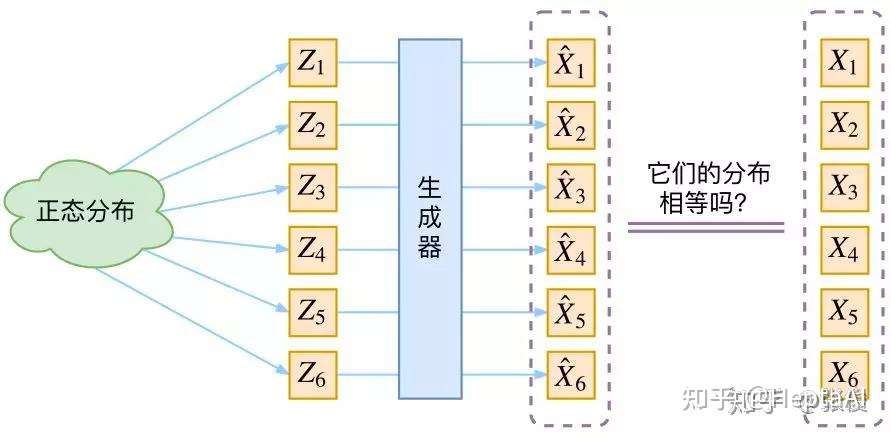
- 先用某种分布随机生成一组隐变量,然后这个隐变量会经过一个生成器生成一组目标数据。VAE和GAN都希望这组数据的分布 $\hat{X}$ 和目标分布 $X$ 尽量接近
然而这种方法本质上难以奏效,因为“尽量接近”并没有一个确定的关于 $X$ 和 $\hat{X}$ 的相似度的评判标准。
- 难在必须去猜测“它们的分布相等吗”这个问题,而缺少真正interpretable的价值判断。KL散度y不行,因为KL散度是针对两个已知的概率分布求相似度的,而 $\hat{X}$ 和 $X$ 的概率分布目前都是未知。
GAN直接把这个度量标准也学过来就行,相当生猛。但问题是依然不可解释(interpretable),非常不优雅。
- VAE的做法就优雅很多了,先来看VAE是怎么做的,理解了VAE以后再去理解Diffussion就很自然了。
自编码器
什么是自动编码器
自动编码器(AutoEncoder)最开始作为一种数据的压缩方法
自动编码器的结构
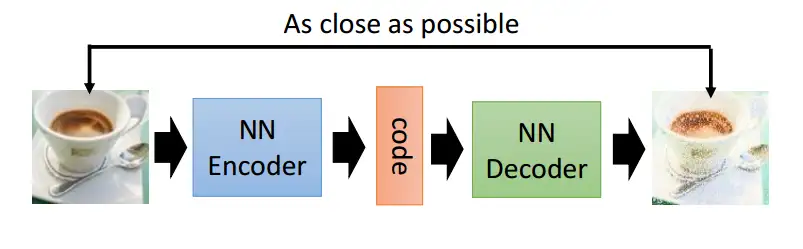
结构上两个部分,第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意模型,通常使用神经网络模型作为编码器和解码器。
输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入原数据一模一样的生成数据,然后通过去比较这两个数据,最小化之间的差异来训练这个网络中编码器和解码器的参数。这个过程训练完后,拿出这个解码器,随机传入一个编码(code),通过解码器能够生成一个和原数据差不多的数据。
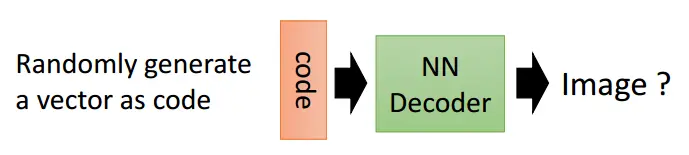
PyTorch来简单的实现一个自动编码器
- 一个简单的4层网络作为编码器,中间使用ReLU激活函数,最后输出的维度是3维的,定义的解码器,输入三维的编码,输出一个28x28的图像数据,特别要注意最后使用的激活函数是Tanh,这个激活函数能够将最后的输出转换到-1 ~1之间,这是因为我们输入的图片已经变换到了-1~1之间了,这里的输出必须和其对应。
- 训练过程比较简单,使用最小均方误差来作为损失函数,比较生成的图片与原始图片的每个像素点的差异。
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
将多层感知器换成卷积神经网络,这样对图片的特征提取有着更好的效果。
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(True),
# nn.Linear(128, 28*28),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
使用了nn.ConvTranspose2d(),这可以看作是卷积的反操作,可以在某种意义上看作是反卷积。
VAE核心
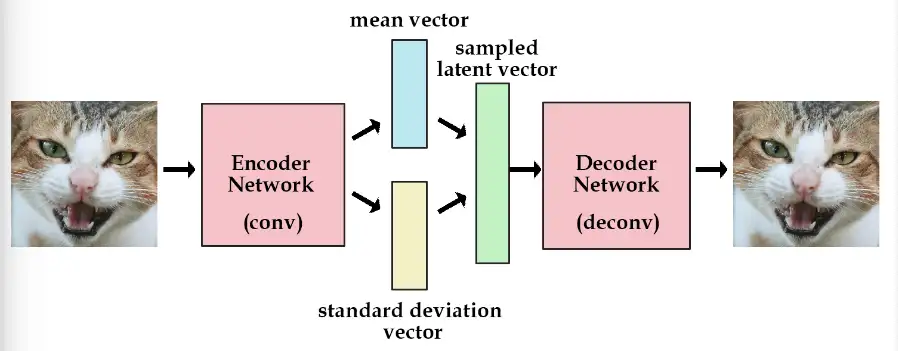
变分自动编码器(Variational Autoencoder)
- 变分编码器是自动编码器的升级版本,其结构跟自动编码器是类似的,也由编码器和解码器构成
- 在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
变分编码器使用了一个技巧“重新参数化”来解决KL divergence的计算问题。
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
if torch.cuda.is_available():
eps = torch.cuda.FloatTensor(std.size()).normal_()
else:
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
def decode(self, z):
h3 = F.relu(self.fc3(z))
return F.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrize(mu, logvar)
return self.decode(z), mu, logvar
| VAE | GAN |
|---|---|
 |
|
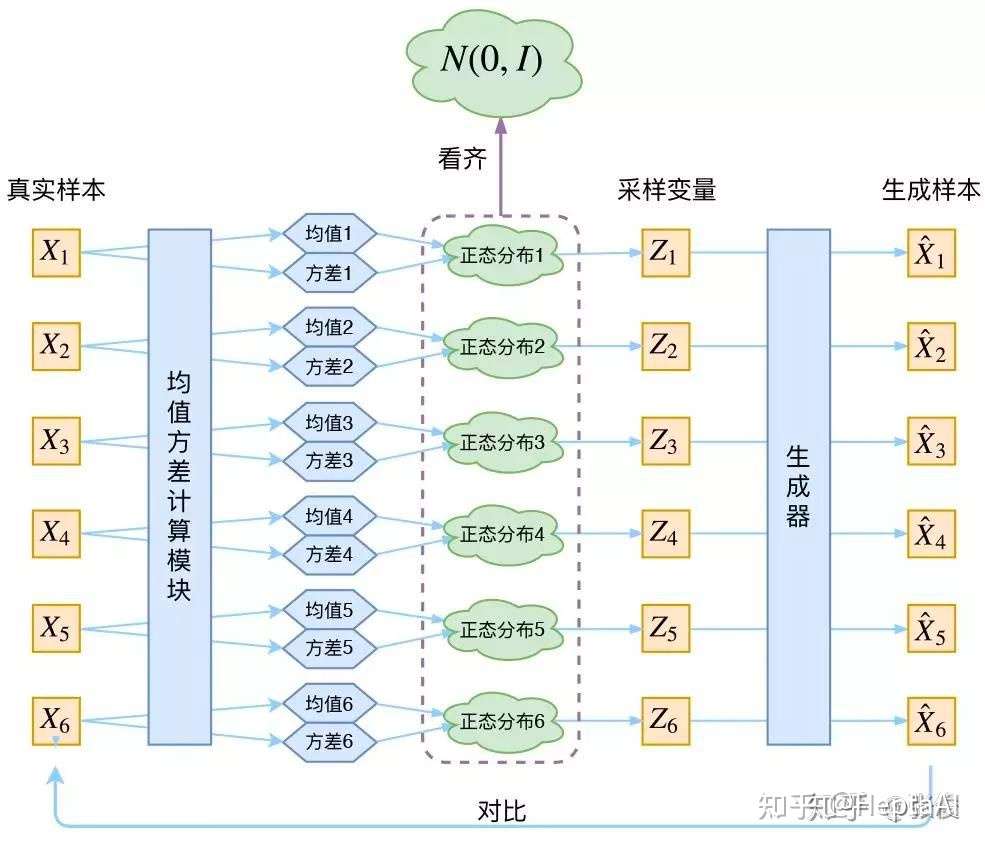
VAE的核心:不仅假设 $p(Z)$ 是正态分布,而且假设每个 $p(X_k \mid Z)$ 也是正态分布。

- 均值和方差的计算本质上都是encoder。VAE其实利用了两个encoder去分别学习均值和方差。
- $Z_k$ 是专属于(针对于)$X_k$ 的隐变量,那么和 $\hat{X}_k$ 本身就有对应关系,因此右边的蓝色方框内的“生成器”是一一对应的生成。
为什么VAE要在AE前面加一个Variational?
- 希望方差能够持续存在,从而带来噪声!
VAE的本质:
- VAE在AE的基础上对均值的encoder添加高斯噪声(正态分布的随机采样),使得decoder(就是右边那个生成器)有噪声鲁棒性;为了防止噪声消失,将所有 p(Z \mid X) 趋近于标准正态分布,将encoder的均值尽量降为 0,而将方差尽量保持住。这样当decoder训练的不好的时候,整个体系就可以降低噪声;当decoder逐渐拟合的时候,就会增加噪声。
- 和GAN很像!VAE是生成对抗encoder
Diffusion Model(扩散模型,DM)
【2022-9-20】如何通俗理解扩散模型?
本质上说,Diffusion就是VAE的升级版。
Diffusion本质就是借鉴了GAN这种训练目标单一的思路和VAE这种不需要判别器的隐变量变分的思路,糅合一下,起作用了
Diffusion的本质
- VAE和diffussion的区别

- VAE本质是一个基于梯度的 encoder-decoder架构,encoder用来学高斯分布的均值和方差,decoder用变分后验来学习生成能力,而将标准高斯映射到数据样本是自己定义的。
- 而扩散模型本质是一个 SDE/Markov架构,虽然也借鉴了神经网络的前向传播/反向传播概念,但是并不基于可微的梯度,属于数学层面上的创新。两者都定义了高斯分布 $Z$ 作为隐变量,但是VAE将 $Z$ 作为先验条件(变分先验),而diffusion将 $Z$ 作为类似于变分后验的马尔可夫链的平稳分布。
详见站内专题: 扩散生成模型
GAN
GAN 思想源于博弈论中零和游戏
- 一个玩家试图生成最逼真的假数据,而另一个玩家则尝试区分真实数据与假数据。
GAN由蒙提霍尔问题(一种生成模型与判别模型组合的问题)演变而来,但与蒙提霍尔问题不同,GAN不强调逼近某些概率分布或生成某种样本,而是直接使用生成模型与判别模型进行对抗。
GAN介绍
【2023-1-31】从ChatGPT说起,AIGC生成模型如何演进
GAN 全称是: Generative A dversarial Networks,从名称不难读出“对抗(Adversarial)”是其成功之精髓。
- 对抗思想受
博弈论启发,在训练生成器(Generator)时,训练一个判别器(Discriminator)来判断输入是真实图像还是生成图像,两者在一个极小极大游戏中相互博弈不断变强。当从随机噪声生成足以“骗”过的图像时,我们认为较好地拟合出了真实图像的数据分布,通过采样可以生成大量逼真的图像。
GAN问题
GAN 问题
- 虽然GAN效果出众,但由于博弈机制的存在,其训练稳定性差且容易出现模式崩溃(Mode collapse),如何让模型平稳地达到博弈均衡点也是一个问题。
- GAN在“创作”这个点上还存在一个死结,这个结恰恰是其自身的核心特点:根据GAN基本架构,判别器要判断产生的图像是否和已经提供给判别器的其他图像是同一个类别的,这就决定了在最好的情况下,输出图像是对现有作品的模仿,而不是创新。
GAN的开创性在于精巧地设计了一种“自监督学习”方式,跳出了以往监督学习需要大量标签数据的应用困境,可以广泛应用于图像生成、风格迁移、AI艺术和黑白老照片上色修复。
但其缺陷也正来源于这一开创性:
- 由于需要同步训练两个模型,GAN的稳定性较差,容易出现模式崩溃。
- 另一个有趣的现象“海奥维提卡现象”(the helvetica scenario):如果G模型发现了一个能够骗过D模型的bug,它就会开始偷懒,一直用这张图片来欺骗D,导致整个平衡的无效。 (机器也像人一样可以偷懒)
【2023-1-31】ChatGPT,背后的核心是什么?
GAN家族
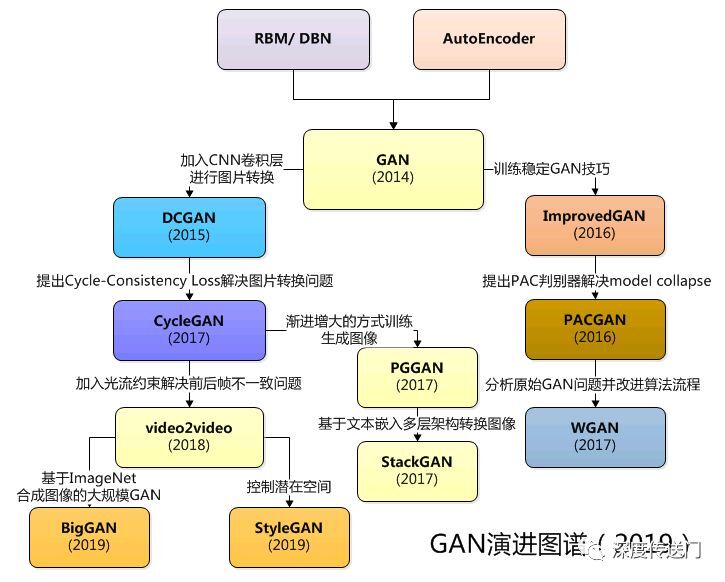
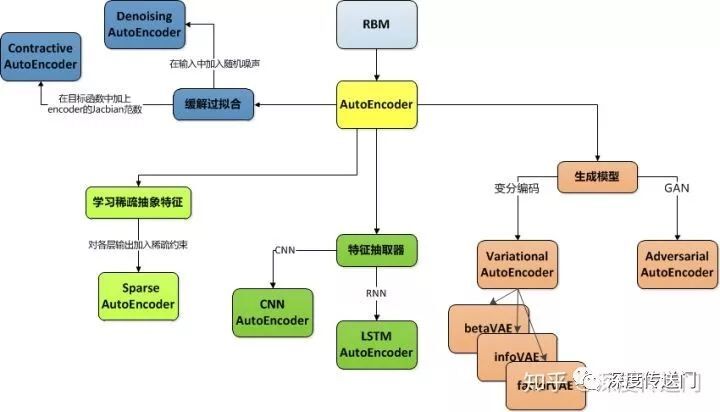
GAN文本生成
- GAN为什么在文本上效果不佳?
- 图像和文本的核心区别在于图像的 Pixel 表示是连续的,而文本是由离散的 token 组成
- 参数的微小改变不能对结果产生影响,或者说影响的方向也不对,这就导致 Discriminator 的梯度回传变得没有意义
- GAN在NLP表现一般:
- 语言不同于图像、语音,前者由人类制造,分布在离散空间中,后者天然存在于连续空间,结构化较好,所以,NLP中的embedding,微小的改变不足以产生影响,甚至让反向传播失效 img
- 思想:语言本身的离散特性,主谓宾结构,人类学习语言时也是这种模式,概念拼接组装置换
- GAN-in-NLP-Notes
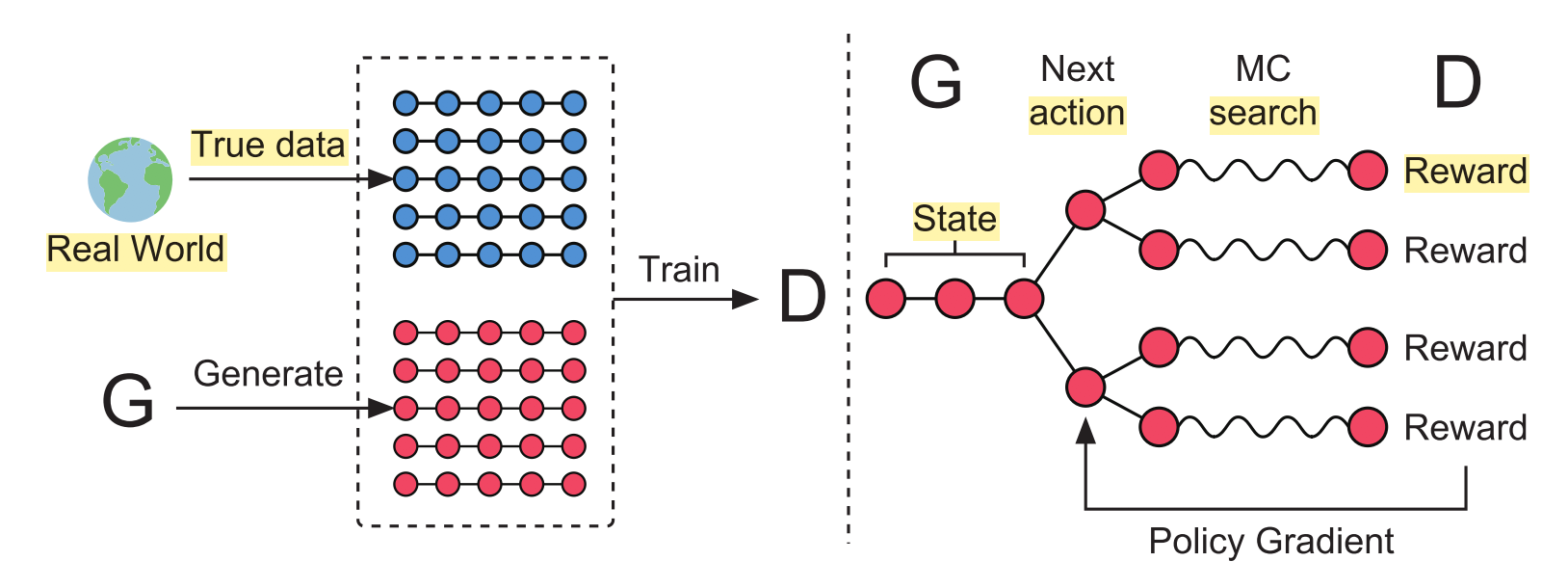
(1) SeqGAN
- SeqGAN 用了 RL + GAN 用于文本生成,一大创举,详见笔记
- SeqGAN_Sequence Generative Adversarial Nets with Policy Gradient
- 引入强化学习中的 Policy Gradient 来解决因为离散 token 生成前采样动作造成的不可微
- SeqGAN 在 Oracle 和古诗生成任务上做了测试,回过头来看,效果只能说一般。但其开创性的将文本生成看做序列决策问题, 并且将 RL 和 GAN 进行了有机的结合
(2)LeakGAN
- 交大继 SeqGAN 后的又一力作
- SeqGAN的问题:
- Discriminator 提供给 Generator 的 reward 需要等句子完成之后才能被计算(即使用 Monte Carlo 来计算,也只是一种近似的模拟),对于每一步的 token 生成不能得到及时的反馈;
- Reward 本身只是一个 Scalar,并不能携带太多的信息。何况对于文本这种结构复杂,同样的意思不同的说法都是可以的,那么数值所包含的指导信号比较弱。
- 改进
- 让 Discriminator 向 Generator “泄露”一些消息,也就是把作为 Discriminator 的 CNN 最后一层的 Feature Vector 交给 Generator,让这个 Feature Vector 携带大量的信息来指导 Generator 更好的生成
- 层次生成器:在生成器端使用了 Manager 和 Worker 两个模块,分别用于解析 CNN 提供的 Feature Vector 和具体的 token 生成。
(3)RankGAN
- Discriminator 的 Binary Classification 不足以生成多样、符合现实逻辑的文本
- 用一个 Ranker 来替代 Discriminator,以提供更好地生成句子的评估,进而生帮助 Generator 生成更为真实的句子
(4)MaskGAN
- 从生成器端来为生成提供更多的信息,更多:MaskGAN学习笔记
- 用了 Actor-Critic 来替换 Policy Gradient,相比 Monte Carlo,能够较好地对 reward function 做一个拟合
GAN 文本生成图像
GAN可以文生图
- 【2023-1-14】GAN之根据文本描述生成图像
模型结构
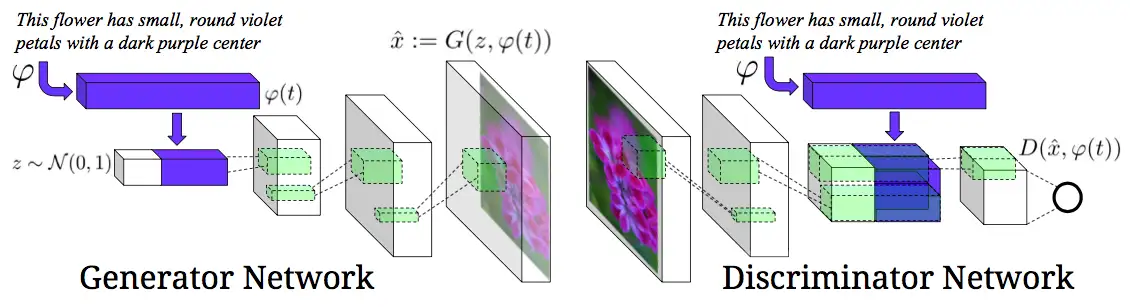
- 生成器:char-CNN-RNN结构来对文本做embedding,全连接层(Leaky-Relu激活)压缩到低维向量(128),再和一个正态分布抽样的随机向量进行拼接,将其输入到deconvolution(反卷积)层做图像生成
- 判别器:结构与生成器大致相反
- 实现的功能是:①判断生成的图像是否合理 ②判断图像与文本是否匹配
- 候选方法:
- ① 分阶段,先判断图像是否合理,然后再判断合理图像是否匹配
- ②一部到位,同时判断图文,此时需要补充样本(除了<假图,描述>和<真图,描述>外,补充<真图,不匹配描述>,对应网络:GAN-CLS)
- 插值法学习:文生图本质是两种表示空间的映射,即高维流形,GAN里通过流形向量插值实现新样本生成,由于文本与图像的本质不同(离散+连续),需要特殊处理,通过线性插值做数据增强,对应网络:GAN-INT
- 风格转换:生成器里融合文本+图像信息,自动识别图像维度信息(如:背景+位置)
实验效果:测试在鸟类生成的效果
- 整体效果
- 风格转换
- 插值图像



以上信息源自2017年的文章,现在估计有新的迭代了
paraphrase 复述/同义语/改写
什么是paraphrase
复述(paraphrase)是指:
“运用与原句不同的词汇、句式,重新写一个相同含义的句子。”
para的意思是“另外的”,phrase是“陈述”。所以国内有人翻译为“复述”。但中文含义不同,叫“同义语”更合适
文本复述研究的主要对象是‘词语以上,句子以下’的语言单元,不涉及到段落级的改写问题。
与文本相似相比,还需要考虑语义的相似性。比如:
- S1: 我吃了晚饭
- S2: 我吃了早饭 这两句话很像(文本相似),但意义却不一样,不能互为文本复述。
文本复述方法
常见的文本复述类型(英语)
- 同义词替换:短语替换成同义短语
- 定义替换:替换成词典中的注释
- 语态替换:主动 与 被动,相互替换
- 词性变换:动词、形容词等
- 语序变换:移动原文中某些成分的位置
- 结构变换:
- 断句变换:句子拆分与合并
- 基于推理的变换:结合背景知识才能识别、理解
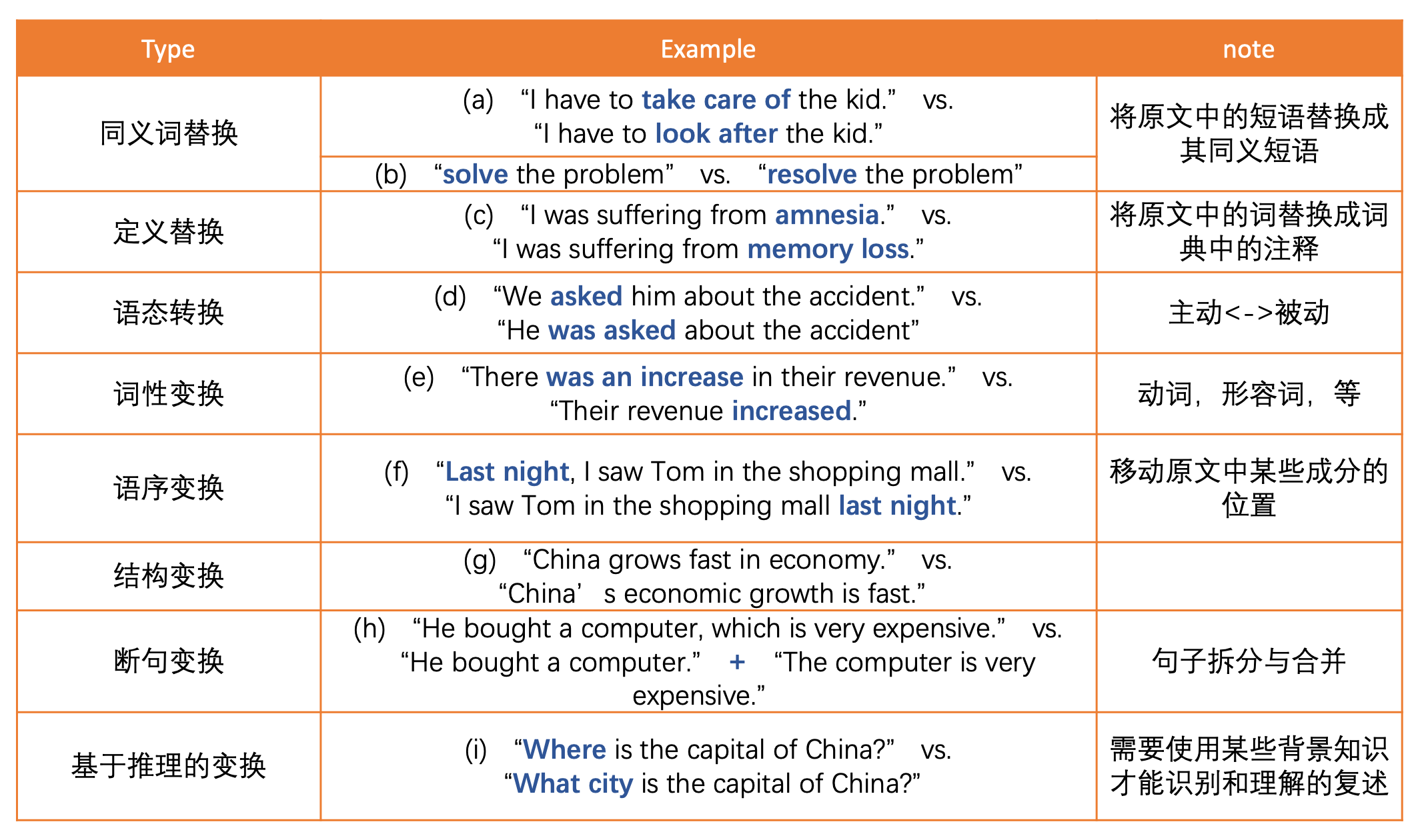
英文复述
示例:
- ① You should learn paraphrasing, for it is very important.
- ② Paraphrasing is extremely important, so it should be learned.
改动点:
- 单词:very important → extremely
- 词序:前后互换,(A,因为B)→ (B,所以A)
- 语法结构:You should learn paraphrasing → it(paraphrasing) should be learned. 有哪些改写方法?
- 改单词:
- a. 近义词替换:简单但有一定风险,单词在不同场合含义不同
- b. 改词性:将原句中的某些单词改变词性,一般来说,改词性时也会改动词序
- 改词序
- a. 主从句顺序:如果一个长句子有两个或以上的句子组成,可以通过调整句子的顺序来完成改写。
- b. 形容词变从句:句子中如果有“形容词+名词”结构,可以将形容词改成一个从句,放在名词后面。
- 改语法结构
- a. 改语态,如改句子的语态:主动改成被动,反之亦然。
中文复述
工程实现
- 中文复述代码, 使用训练好的英文文本复述模型进行复述,通过百度翻译API实现中文的输入和输出。英文文本复述模型可选择的有:tuner007/pegasus_paraphrase、ceshine/t5-paraphrase-quora-paws
- Demo:pair-a-phrase
- vsuthichai/paraphraser,基于Tensorflow的句子级复述生成,适合练手。
中文复述语料库
2019年9月30号,北大release了一批中文文本复述语料,PKU Paraphrase Bank文章解读:句级中文文本复述语料库
- 常见的文本复述方法多依赖于有孪生结构的深度神经网络,对label的要求较高,这篇文章使用了无监督方法生成了大量的匹配label数据,对中文环境下的文本复述识别、生成很有帮助。
- PKU Paraphrase Bank: A Sentence-Level Paraphrase Corpus for Chinese
- 语料库地址
数据来源
- 40部经典小说的95个译本,小说包括《基督山伯爵》《飘》《大卫科波菲尔》等。即每部小说选取2-3个译本。译本来源于网络。
- 这是很经典的枢轴(pivot)方法:采用同一文本(枢轴)的不同翻译作为文本复述模板的资源获取方法。
“由于每次翻译过程均要求源语言和目标语言中文本的语义保持一致,因此可以预期最后得到的文本在语义上能跟输入文本保持一致。”
举个文章中的例子(上面两句互为文本复述,下面两句互为文本复述):
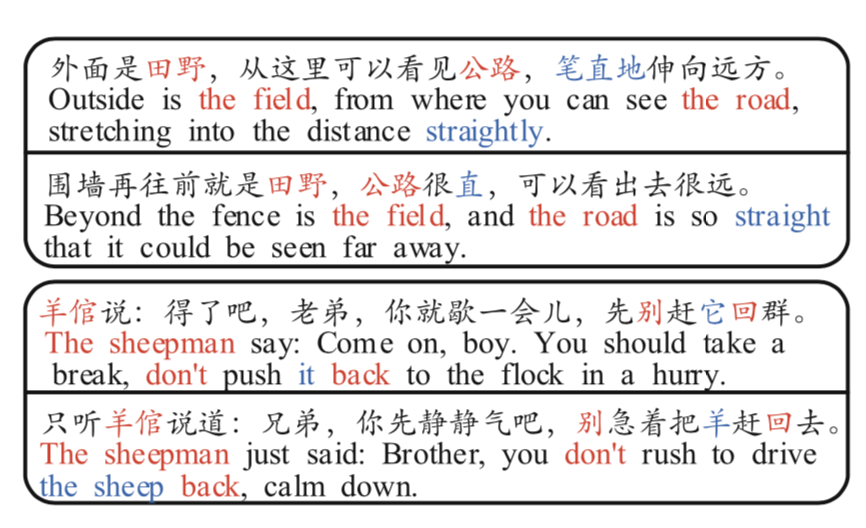
数据规模
- 509,832 (50w+) 组句对,大约是常见语料库(例如:Twitter News URL Corpus) 的10倍以上。平均每句23.05个词。
无监督语料库生成方法
 流程概览
流程概览- 首先,通过OCR工具将下载的pdf文件转换为plain text.
- 在格式清理的步骤中,需要将匹配用不到的头注,脚注,页码和注释等手动规则移除。
- 然后,通过。?!进行句子分割。少于6个单词的句子并入前句。
- 最后一步,利用Sun等人2011年提出的无监督方法Enhancing Chinese word segmentation using unlabeled data进行中文分词。 评估方法:多样性得分(PINC),Chen等人2011年定义的,它的含义和BLEU相反:句对间n-gram的co-occurence/同时出现的次数越少,得分越高。这意味着,虽然这两个句子意思相同,但它们“看起来”更不一样。
评价方法
总结
对话系统评估
人机交互的对话场景分为三大类别:任务类对话,问答类对话,和闲聊类对话。
智能对话评测的考量条件
- 对话
情境-上下文内容- 回答内容的好坏与上文内容直接关联。评价回答内容时,最主要的限制条件就是上文。测试者需要结合上文内容对答案做出相对公正和正确的判断。这当中不仅需要判断当前对话内容质量,还涉及对话内容逻辑一致性与情感合理性。上下文内容对于多轮对话生成至关重要。一组对话内容被放在不同对话情境下会表现出皆然不同的效果。
- 对话
场景– 机器人扮演的角色- 不同的应用场景下,对话系统需要扮演不同的角色以实现用户特定的需求和意愿。主流的应用场景包括家庭,早教,客服和车载。特定场景下的对话内容,总是包含特定术语或套路,以及相关领域知识,返回一些预设的回答或解决方案。测试人通过想象力将自己置身于该场景中,理解对话系统所尝试扮演的角色,有利于更加客观的对其进行评测。
- 对话
目的– 话题与意图- 人与人的自然语言对话可分为:有目的和无目的。有目的对话根据提问者引导对话方向。对话结束时,判断对话目的是否达成,进而判断对话质量。实际对话过程中,对话目的并不能定义清晰。对话评测时,不能只关心有明确目的的对话,忽略无目的的对话。在无目的的对话内容中依然会有信息传递和情感交互。因此,无论对话内容是否有明确的话题和意图,都应该关注其传达的信息和情感。
智能对话系统的评测方法分为两个大类:人工评测和自动评测(算法打分)以及分布式评测
- (1)
人工评测: 通过雇佣测试人员对对话系统生成的结果进行人工标注。让人通过自己的常识和经验来判断人工智能的对话表现。测试人员会在预设的任务领域或场景内,与系统进行对话交互,在交互过程中,对系统的表现进行评分。- 市面上有很多人工智能相关任务的众包平台。通过互联网快速的整合大量的人力资源,并对智能对话系统进行人工评测标注,比如,亚马逊的AMT(the Amazon Mechanical Turk)。
- 两个致命的缺陷。
- 第一个缺陷,成本非常高,“贵”。对话系统的评测任务往往需要评测者投入大量时间和精力。为了评测结果的具有普适性,需要组织一定规模的评测者参与到评测任务中。
- 第二个缺陷,存在不可控制误差。
- 一方面,只要依赖人工,就一定会有失误的概率发生,没有人能保证自己一定不会犯错。一般来说,人工标注任务的默认准确率在80%左右。
- 另一方面,凡是有人参与评判,就必然存在主观因素。同一个问题,每个人都可能有自己独特的看法和见解,语言表达本身就非常主观。判断对话内容好坏时很难避免主观因素的干扰。
- (2)
自动评测:通过预先设定的计算机算法或规则,对智能对话系统自动化评测。自动评测的结果常以分数或阈值的形式来表现。- 业界广泛认可的自动对话评测方法主要有两种。
- 一种是根据对话系统生成的回复与标准答案之间的词重叠率来进行评价。其中
BLEU和METEOR在机器翻译的任务中被广泛使用,ROUGE则在文本自动摘要的任务中取得了不错的评价效果。 - 另一种是通过每一个词的意思来判断回复相关性。词向量(Word2Vec)是实现这种评价方法的基础。
- 新的测方法, 包括受生成对抗网络(
GAN)结构启发的类GAN模型,以及依靠回归神经网络(RNN)而训练的自动评价模型ADEM。- 前者用于直观的
评判生成器(Generator)产生的回复结果与人类回复的相似程度; - 后者用于预测系统回复的人工评价结果,从而以更少的人工标注数据达到更准确的评测效果。
- 前者用于直观的
- 自动化的评测方法能够节省人力成本,快速高效的完成对话系统的评测工作。然而,这些方法一般当作参考指标用于特定实验场景,并不能代替人工标注实现客观且全面的对话评测。因为很多人人沟通和交互无法用预设规则所约束,“只可意会,不可言传”。
- 自动评测的方法虽然方便省事,但是没有解决实际问题。真实环境不同于实验室中预设状态,每种自动化评测方法都会被大量的反例所挑战。语言是人类特有的能力,因此,对话能力评判这样的工作,还是有必要由人亲自来完成,这当中需要一些人类特有的直觉。
- (3)
分布式评测:与其煞费苦心研究一个理想的自动评测算法,倒不如集中精力优化人工评测任务。于是,如何降低人工评测中的主观判断因素和人力资源成本,成了新方向。- 明确了对话系统的考量标准和评判尺度之后,把任务进行细分,从不同的维度判断智能对话系统的表现。这种评测方法称为“分布式的评测方法”。
- 分布式的评测旨在把评测任务切分成最小单元。
- 第一步,对话系统的表现切分成最小单位,即单独的一轮对话(一组问答对)。只要我们把许多轮对话的综合表现统计起来,就可以比较客观的反映一个对话系统的整体表现。
- 第二步,拆分每轮对话的评测任务,从不同维度评测,判断系统生成的每组问答内容在对话情境,对话场景和对话意图这三个指标下的表现。经过多次的尝试与探索,对话系统定义了六个评测维度。
六个评测维度:语法质量、内容质量、内容关联度、逻辑关联度、情感强度、发散性。
语法质量:生成答案的基本语法使用情况。回复内容应该符合通用语法,用词正确且规范,句子通顺且完整。这个维度判断比较客观,每种语言都有各自的语法规则。内容质量: 内容质量从三个角度进行判断。- 长度适中:回复内容长度恰到好处,不易过长也不易过短。
- 有内容:“言之有物”,包含实体信息,不存在语言歧义。
- 合规合法:避免血腥暴力,淫秽消极等不好的内容,以及政治敏感的内容,表达正确的立场和观点。
内容关联度:内容关联度是系统匹配答案与问题的相关度。- 回复内容与用户问题是否同一个话题,上文与下文是否同一件事情。包含相同实体内容的问答对属于内容关联。
逻辑关联度:生成内容与上文逻辑的关联性。这个逻辑包括时间逻辑,比较逻辑,客观规律等。比如,上文内容关于一个物体大小,那回复也是物体大小相关的内容。如果回复内容可以自然的与上文内容衔接,也可以说这组问答对包含逻辑关联。情感强度:回复内容是否有情感表达。情感强弱的定义因人而异,很难定义衡量标准。但是在回答内容合理,逻辑准确的基础上,通过回答内容是否有语气助词,是否包含拟声词等因素进行判断。对话的情感还体现在回复是否在敷衍,有没有表现出强烈的主观态度和意愿,以及是不是幽默搞笑或悲伤难过。发散性:机器回复内容话题的发散性。即评价当前的回复内容能否引发出更多轮数的对话。当用户看到系统回复内容之后,是否有意愿继续将对话进行下去。生成回复是开放性问题,那么对话就很容易自然的进行下去。这里涉及到内容推荐,主动提问等人机交互技巧。
文本生成评估
【2021-3-25】文本生成评估方法综述:Evaluation of Text Generation: A Survey
- (1) human-centric evaluation metrics:人工标注
- (2) unsupervised automatic metrics:无监督自动评估,如 ROUGE-N, BLEU-N, Distinct-N,METEOR,PYRAMID
- (3) machine-learned automatic metrics:机器学习自动评估,如 BERTScore、NLI model
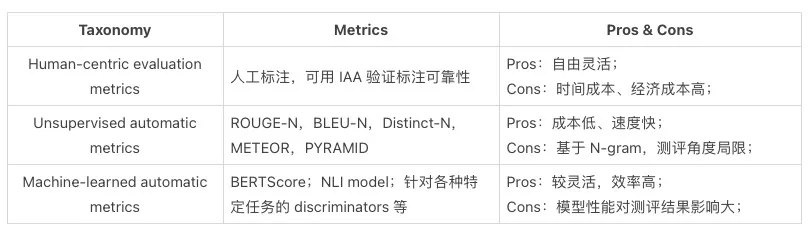
人工评价指标虽然灵活,不适合用于对海量样本评价。而无监督的自动评价指标,虽然能低成本地解决评测问题,但能够完成评价的角度甚少。“用模型来衡量模型”则是效率和灵活性之间的 trade-off。
Gkatzia总结2005-2014年, 常用的针对文本生成的评价方法,将其分为内在评价和外在评价方法。其中内在评价关注文本的正确性、流畅度和易理解性。常见的内在评价方法又可分为两类:
- 1)采用BLEU、NIST和ROUGE等进行自动化评价,评估生成文本和参考文本间相似度来衡量生成质量。
- 2)通过人工评价,从有用性等对文本进行打分。外在评价则关注生成文本在实际应用中的可用性。
内在评价方法最为流行。
- 2012-2015年间发表的论文超半数使用自动化评价指标进行评价
- 但由于需要大量对齐语料,且对于对齐语料的质量很敏感,所以使用自动化评价指标的同时,研究者常常还会同时使用其它评价方法,如直观且易于操作(与外在评价方法相比)的
人工评价生成文本的正确性、流畅性方法。
【2022-3-30】基于Seq2Seq的文本生成评价指标解析
NLG常用metrics:
BLEU: (Bilingual Evaluation Understudy) ngram precision;长度类似- 比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。
- unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。通常取N=1~4,再加权平均
ROUGE: n-gram recallROUGE-N(将BLEU的精确率优化为召回率)ROUGE-L(将BLEU的n-gram优化为公共子序列)ROUGE-W(ROUGE-W 是 ROUGE-L 的改进版)ROUGE-S(Skip-Bigram Co-Occurrence Statistics)
METEOR: 考虑同义词的F score;鼓励连续词匹配NIST/CIDEr: 降低频繁词的权重STM: 匹配语法树子树TER: 编辑的距离-
TERp: TER+同义替换 - 参考:
- 总结:
| 方法 | 全称 | 应用场景 | 核心思想 | 特点 | 缺点 | 改进 | 备注 |
|---|---|---|---|---|---|---|---|
| BLEU | Machine Translation | 比较候选译文和参考译文里的 n-gram 的重合程度 | n-gram共现统计;基于精确率 | 只看重精确率,不看重召回率;存在常用词干扰(可以用截断的方法解决);短句得分较高。即使引入了brevity penalty,也还是不够。 | 截断:改进常用词干扰;brevity penalty:改进短句得分较高的问题 | ||
| NIST | National Institute of standards and Technology | BLEU改进 | 引入了每个n-gram的信息量(information),对于一些出现少的重点的词权重就给的大了 | ||||
| METEOR | Metric for Evaluation of Translation with Explicit ORdering,显式排序的翻译评估指标 | Machine Translation、Image Caption | 解决一些 BLEU 标准中固有的缺陷 | unigram共现统计;基于F值;考虑同义词、词干 | 只有java实现;参数较多,4个自己设置;需要外部知识源,比如:WordNet | ||
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation,面向召回率的摘要评估辅助工具 | Text Summarization | BLEU 的改进版,专注于召回率而非精度。多少个参考译句中的 n 元词组出现在了输出之中。大致分为四种:ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S | n-gram共现统计、最长公共子序列;基于召回率(ROUGE-N)和F值(ROUGE-L) | 基于字的对应而非基于语义,可以通过增加参考摘要数量来缓解 | ROUGE-S:统计skip n-gram而非n-gram;ROUGE-W:考虑加权的最长公共子序列 | |
| Perplexity | 困惑度 | Machine Translation、Language Model | 根据句子长度对语言模型得分进行Normalize | 基于语言模型(我感觉其实也是n-gram);困惑度越低,翻译质量越好 | 数据集越大,困惑度下降得越快;数据中的标点会对模型的PPL产生很大影响;常用词干扰 | ||
| CIDEr | Consensus-based Image Description Evaluation,基于共识的图像描述评估 | Image Caption | TF-IDF向量的夹角余弦度量相似度 | TF-IDF;余弦相似度 | 与ROUGE一样,也只是基于字词的对应而非语义的对应 | ||
| SPICE | Semantic Propositional Image Caption Evaluation,语义命题图像标题评估 | Image Caption | 主要考察名词的相似度,不适合机器翻译 | ||||
- 一个好的评价指标(或者设置合理的损失函数)不仅能够高效的指导模型拟合数据分布,还能够客观的让人评估文本生成模型的质量,从而进一步推动 text generation 商业化能力。
- 然而由于语言天生的复杂性和目前技术限制,我们目前还没有一个完美的评价指标。
- 微软在其VTTChallenge2016中提出了三点主观评价标准:
- 1) 流畅度:评价生成语句的逻辑和可读性。
- 2) 相关性:评价生成语句是否包含与原视频段相关和重要的物体/动作/事件等。
- 3) 助盲性:评价生成语句对一个实力有缺陷的人去理解其表示的视频片段到底有多大的帮助。
- 本文就三方面对文本生成的评价指标介绍:
- (1)以 BLEU 为代表的基于统计的文本评价指标
- (2)data to text 和 image caption 进一步介绍了其特有的评价模式
- (3)基于 BERT 等预训练模型的文本评价指标
- 评价方法
- (1)基于词重叠率的方法
- 机器翻译 & 摘要 常用指标
- 基于词重叠率的方法是指基于词汇的级别计算模型的生成文本和人工的参考文本之间的相似性,比较经典的代表有 BLEU、METEOR 和 ROUGE,其中 BLEU 和 METEOR 常用于机器翻译任务,ROUGE 常用于自动文本摘要。
- (2)词向量评价指标
- 上面的词重叠评价指标基本上都是 n-gram 方式,去计算生成响应和真是响应之间的重合程度,共现程度等指标。而词向量则是通过 Word2Vec、Sent2Vec 等方法将句子转换为向量表示,这样一个句子就被映射到一个低维空间,句向量在一定程度上表征了其含义,在通过余弦相似度等方法就可以计算两个句子之间的相似程度。
- 使用词向量的好处是,可以一定程度上增加答案的多样性,因为这里大多采用词语相似度进行表征,相比词重叠中要求出现完全相同的词语,限制降低了很多。
- (1)基于词重叠率的方法
- 总结
- BLEU,ROUGE 等评价指标依然是主流的评价方式
- 从短句惩罚、重复、重要信息缺失、多样化等方面,衍生出例如 METEOR、SPICE、Distinct 等评价指标
- 以 bertscore 为代表的评价指标近年来受到广泛的关注,与人工评价的相关性也越来越高
- (1)基于词重合度的方法
- 机器翻译 & 摘要 常用指标
- BLEU:机器翻译
- ROUGE:自动文本摘要
- NIST
- METEOR:机器翻译
- TER
- data to text 常用指标 data2text
- 和翻译、摘要等生成式任务最大的不同是,input 是类似于 table 或者三元组等其他形式的数据。在评估生成结果时,需要考虑文本是否准确的涵盖了 data 的信息。《Challenges in Data-to-Document Generation》提供了许多 data to text 的评价指标,并且被后续的一些论文采用
- relation generation (RG)
- 从生成的句子中抽取出关系,然后对比有多少关系也出现在了 source 中(一般有 recall 和 count2 个指标)
- content selection (CS)
- data 当中的内容有多少出现在了生成的句子中,一般有 precision 和 recall 两个指标
- content ordering (CO)
- content ordering 使用归一化 Damerau-Levenshtein 距离计算生成句和参考句的 “sequence of records(个人认为可以理解为 item)”
- 如何实现上述的评价指标——github代码data2text
- Coverage:不涉及复杂的关系抽取,可以简单的通过匹配方法来验证文本是否能够覆盖要描述的 data
- Distinct:某些生成场景中(对话,广告文案)等,还需要追求文本的多样性。李纪为的《A diversity-promoting objective function for neural conversation models》提出了 Distinct 指标,后续也被许多人采用。
- image caption 常用指标
- CIDEr
- SPICE
- 机器翻译 & 摘要 常用指标
- (2)词向量评价指标
- Greedy Matching
- Embedding Average
- Vector Extrema
- (3)基于语言模型的方法
- PPL
- 基于 bert 的评分指标
- BERTSCORE
- 拓展阅读 :BLEURT
- 拓展阅读 :MoverScore
(1)词重叠率
- 待定
BLEU
- BLEU:Bilingual Evaluation Understudy,双语评估辅助工具
- 核心思想
- 比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的精确性,高阶n-gram用于衡量句子翻译的流畅性。 实践中,通常是取N=1~4,然后对进行加权平均。
- 主要特点
- n-gram共现统计
- 基于精确率
- 计算公式
- 其中n表示n-gram,Wn表示n-gram的权重;
- BP表示短句子惩罚因子(brevity penaty),用 r 表示最短的参考翻译的长度, c 表示候选翻译的长度,则BP具体计算方法为:
- pn表示n-gram的覆盖率,具体计算方式为:
- 应用场景:Machine Translation
- 总结
- 缺点:
- 只看重精确率,不看重召回率。(详细得说:待补充~)
- 存在常用词干扰(可以用截断的方法解决)
- 短句得分较高。即使引入了brevity penalty,也还是不够。
- 改进
- 截断:改进常用词干扰
- brevity penalty:改进短句得分较高的问题
- 缺点:
ROUGE
-
Recall-Oriented Understudy for Gisting Evaluation,面向召回率的摘要评估辅助工具
- 核心思想
- 大致分为四种:ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S。常用的是前两种(-N与-L)
- ROUGE-N (将BLEU的精确率优化为召回率)
- ROUGE-L (将BLEU的n-gram优化为公共子序列)
- ROUGE-W (将ROUGE-L的连续匹配给予更高的奖励)
- ROUGE-S (允许n-gram出现跳词(skip))
- ROUGE-N中的“N”指的是N-gram,其计算方式与BLEU类似,只是BLEU基于精确率,而ROUGE基于召回率。
- ROUGE-L中的“L”指的是Longest Common Subsequence,计算的是候选摘要与参考摘要的最长公共子序列长度,长度越长,得分越高,基于F值。
- ROUGE 用作机器翻译评价指标的初衷:
- SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;
- 等到 NMT (神经网络机器翻译)时代,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译。
- ROUGE的出现很大程度上是为了解决NMT的漏翻问题(低召回率)。
- 所以 ROUGE 只适合评价 NMT,而不适用于 SMT,因为它不管候选译文流不流畅
- 大致分为四种:ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S。常用的是前两种(-N与-L)
- 计算公式
- 主要介绍ROUGE-N和ROUGE-L(见原文)
- 主要特点
- n-gram共现统计、最长公共子序列
- 基于召回率(ROUGE-N)和F值(ROUGE-L)
- 应用场景
- Text Summarization
- 缺点
- ROUGE是基于字的对应而非基于语义的对应,不过可以通过增加参考摘要的数量来缓解这一问题。
- 改进
- ROUGE-S:统计skip n-gram而非n-gram
- ROUGE-W:考虑加权的最长公共子序列
METEOR
- Metric for Evaluation of Translation with Explicit ORdering,显式排序的翻译评估指标
- 核心思想
- METEOR 是基于BLEU进行了一些改进,其目的是解决一些 BLEU 标准中固有的缺陷 。
- METEOR 同时考虑了基于整个语料库上的准确率和召回率,而最终得出测度
- 使用 WordNet 计算特定的序列匹配,同义词,词根和词缀,释义之间的匹配关系,改善了BLEU的效果,使其跟人工判别共更强的相关性。并且,是基于F值的。
- METEOR 也包括其他指标没有发现一些其他功能,如同义词匹配等。METEOR 用 WordNet 等知识源扩充了一下同义词集,同时考虑了单词的词形
- 在评价句子流畅性的时候,用了 chunk 的概念
- 计算公式
- 平面图,就是 1 元组之间的映射集。平面图有如下的一些限制:在待评价翻译中的每个 1 元组必须映射到参考翻译中的 1 个或 0 个一元组,然后根据这个定义创建平面图。如果有两个平面图的映射数量相同,那么选择映射交叉数目较少的那个。 也就是说,上面左侧平面图会被选择。状态会持续运行,在每个状态下只会向平面图加入那些在前一个状态中尚未匹配的 1 元组。一旦最终的平面图计算完毕,就开始计算 METEOR 得分
- 主要特点
- unigram共现统计
- 基于F值
- 考虑同义词、词干
- 应用场景
- Machine Translation、Image Caption
- 优点
- 基于一元组的精度和召回的调和平均,召回的权重比精度要高一点 , 与人类判断相关性高
- 引入了外部知识,评价更加友好
- 缺点
- 实现复杂,只有Java实现。
- 参数较多,有四个需要自己设置的参数。
- 需要外部知识源,比如:WordNet,如果是WordNet中没有的语言,则无法用METEOR评测。
NIST
- NIST(National Institute of standards and Technology)方法是在BLEU方法上的一种改进。
- 最主要的是引入了每个n-gram的信息量(information) 的概念。BLEU算法只是单纯的将n-gram的数目加起来,而nist是在得到信息量累加起来再除以整个译文的n-gram片段数目。这样相当于对于一些出现少的重点的词权重就给的大了。
- 信息量的计算公式是:
- 解释一下:分母是n元词在参考译文中出现的次数,分子是对应的n-1元词在参考译文中的出现次数。对于一元词汇,分子的取值就是整个参考译文的长度。这里之所以这样算,应该是考虑到出现次数少的就是重点词这样的一个思路。
- 计算信息量之后,就可以对每一个共现n元词乘以它的信息量权重,再进行加权求平均得出最后的评分结果:
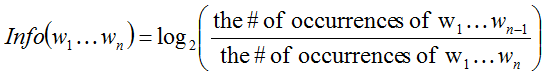

TER
- TER 是 Translation Edit Rate 的缩写,是一种基于距离的评价方法,用来评定机器翻译结果的译后编辑的工作量。
- 距离被定义为将一个序列转换成另一个序列所需要的最少编辑操作次数。操作次数越多,距离越大,序列之间的相似性越低;相反距离越小,表示一个句子越容易改写成另一个句子,序列之间的相似性越高。
- TER 使用的编辑操作包括:增加、删除、替换和移位。其中增加、删除、替换操作计算得到的距离被称为编辑距离,并根据错误率的形式给出评分 $ score = edit ( c , r ) l \text { score }=\frac{\operatorname{edit}(c, r)}{l} $
$ score = edit(c,r) $
- 其中 edit(c,r) 是指机器翻译生成的候选译文 c 和参考译文 r 之间的距离,l 是归一化因子,通常为参考译文的长度。在距离计算中所有的操作的代价都为 1。在计算距离时,优先考虑移位操作,再计算编辑距离,也就是增加、删除和替换操作的次数。直到移位操作(参考文献中还有个增加操作,感觉是笔误了)无法减少编辑距离时,将编辑距离和移位操作的次数累加得到 TER 计算的距离。
Example 1.2 Candidate:cat is standing in the ground Reference:The cat is standing on the ground
- 将 Candidate 转换为 Reference,需要进行一次增加操作,在句首增加 “The”;一次替换操作,将 “in” 替换为 “on”。所以 edit(c, r) = 2,归一化因子 l 为 Reference 的长度 7,所以该参考译文的 TER 错误率为 2/7。
- 与 BLEU 不同,基于距离的评价方法是一种典型的 “错误率” 的度量,类似的思想也广泛应用于语音识别等领域。在机器翻译中,除了 TER 外,还有 WER,PER 等十分相似的方法,只是在 “错误” 的定义上略有不同。需要注意的是,很多时候,研究者并不会单独使用 BLEU 或者 TER,而是将两种方法融合,比如,使用 BLEU 与 TER 相减后的值作为评价指标。
Perplexity
- perplexity(困惑度)用来度量一个概率分布或概率模型预测样本的好坏程度。
-
也可以用来比较两个概率分布或概率模型。(译者:应该是比较两者在预测样本上的优劣)低困惑度的概率分布模型或概率模型能更好地预测样本。
- 核心思想
- (1)根据参考句子,学习一个语言模型P;
- (2)根据语言模型P,计算候选句子的得分;
- (3)根据句子长度对上述得分进行Normalize
- 计算公式
- 主要特点
- 基于语言模型(我感觉其实也是n-gram)
- 困惑度越低,翻译质量越好
- 应用场景
- Machine Translation、Language Model
- 缺点
- 数据集越大,困惑度下降得越快
- 数据中的标点会对模型的PPL产生很大影响
- 常用词干扰
CIDEr
- Consensus-based Image Description Evaluation,基于共识的图像描述评估
- 核心思想
- 把每个句子看成文档,然后计算其 TF-IDF 向量(注意向量的每个维度表示的是n-gram 而不一定是单词)的余弦夹角,据此得到候选句子和参考句子的相似度。
- 计算公式
- 其中, c 表示候选标题, S 表示参考标题集合, n 表示评估的是n-gram, M 表示参考字幕的数量, Gn() 表示基于n-gram的TF-IDF向量。
- 主要特点
- TF-IDF
- 余弦相似度
- 应用场景
- Image Caption
- 缺点
- 与ROUGE一样,也只是基于字词的对应而非语义的对应
SPICE
- Semantic Propositional Image Caption Evaluation,语义命题图像标题评估
- 核心思想
- SPICE 使用基于图的语义表示来编码 caption 中的 objects, attributes 和 relationships。它先将待评价 caption 和参考 captions 用 Probabilistic Context-Free Grammar (PCFG) dependency parser parse 成 syntactic dependencies trees,然后用基于规则的方法把 dependency tree 映射成 scene graphs。最后计算待评价的 caption 中 objects, attributes 和 relationships 的 F-score 值。
- 计算公式
- 主要特点
- 使用基于图的语义表示
- 应用场景
- Image Caption
- 优点
- 对目标,属性,关系有更多的考虑;
- 和基于 n-gram 的评价模式相比,有更高的和人类评价的相关性
- 缺点
- 由于在评估的时候主要考察名词的相似度,因此不适合用于机器翻译等任务。
- 不考虑语法问题
- 依赖于 semantic parsers , 但是他不总是对的
- 每个目标,属性,关系的权重都是一样的(一幅画的物体显然有主次之分)
词向量
- 词重叠评价指标基本上都是 n-gram 方式,去计算生成响应和真是响应之间的重合程度,共现程度等指标。而词向量则是通过 Word2Vec、Sent2Vec 等方法将句子转换为向量表示,这样一个句子就被映射到一个低维空间,句向量在一定程度上表征了其含义,在通过余弦相似度等方法就可以计算两个句子之间的相似程度。
- 使用词向量的好处是,可以一定程度上增加答案的多样性,因为这里大多采用词语相似度进行表征,相比词重叠中要求出现完全相同的词语,限制降低了很多。
- 不过说句实话,至少在我读过的 paper 里很少有人用(或者说只用)这种评价指标来衡量模型好坏的。
Greedy Matching
- 如上图所示,对于真实响应的每个词,寻找其在生成响应中相似度最高的词,并将其余弦相似度相加并求平均。同样再对生成响应再做一遍,并取二者的平均值。上面的相似度计算都是基于词向量进行的,可以看出本方法主要关注两句话之间最相似的那些词语,即关键词。
Embedding Average
- 这种方法直接使用句向量计算真实响应和生成响应之间的相似度,而句向量则是每个词向量加权平均而来,如下图所示。然后使用余弦相似度来计算两个句向量之间的相似度。
Vector Extrema
- 跟上面的方法类似,也是先通过词向量计算出句向量,在使用句向量之间的余弦相似度表示二者的相似度。不过句向量的计算方法略有不同,这里采用向量极值法进行计算。
基于语言模型的方法
PPL
-
它也可以用来比较两个语言模型在预测样本上的优劣。低困惑度的概率分布模型或概率模型能更好地预测样本。(例如,给定一段人写的文本,分别查看 rnn 和 gpt-2 的 ppl 分数如何)
- 注意,PPL 指标是越低,代表语言模型的建模能力就越好。
- 给测试集的句子赋予较高概率值的语言模型较好, 当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,公式如下:
所以当我们使用 tf.contrib.seq2seq.sequence_loss() 函数计算模型 loss 的时候,perplexity 的计算就显得很简单了,直接对计算出来的 loss 取个指数就行了,命令如下所示:
train_perp = math.exp(float(mean_loss)) if mean_loss < 300 else math.inf
基于 bert 的评分指标
- 基于 N-gram 重叠的度量标准只对词汇变化敏感,不能识别句子语义或语法的变化。因此,它们被反复证明与人工评估差距较大。
-
近年来 Bert 为代表的的 plm 红红火火,于是有人提出使用句子上下文表示 (bert 全家桶) 和人工设计的计算逻辑对句子相似度进行计算。这样的评价指标鲁棒性较好,在缺乏训练数据的情况下也具有较好表现。
- BERTSCORE
- 思路是非常简单的:即对两个生成句和参考句(word piece 进行 tokenize)分别用 bert 提取特征,然后对 2 个句子的每一个词分别计算内积,可以得到一个相似性矩阵。基于这个矩阵,我们可以分别对参考句和生成句做一个最大相似性得分的累加然后归一化,得到 bertscore 的 precision,recall 和 F1
- 拓展阅读 :BLEURT
- 通过预训练结合人工评估数据的微调来同时满足度量方法的鲁棒性和表达度
- 拓展阅读 :MoverScore
- 采用了推土机距离计算和参考句的相似程度,而不是单纯的像 bertscore 只考虑最相似的词的距离。
- 如何得到一个 word/n-gram 的向量表示,基于预训练的模型来得到 contextualized 表示是一个开放性的问题,Elmo 和 BERT 都是多层结构,不同的 layer 包含了不同的含义。
应用
趣味文本生成
写作
【2022-12-4】秘塔写作猫:AI写作、多人协作、文本校对、改写润色、自动配图等功能,使用 GPT-3,详见资讯
- 秘塔写作猫的这项 AI 生成功能,是中文 AI 生成文本内容的一项应用突破。
AI生成效果:
- 降价房源急售
- 11月13日,读者王先生致电本报,反映小区降价了,这套房子是一套两居室。记者从王先生处了解到,他的母亲也想在这里买一套住房,就在小区里询问是否有合适的房源。“最近几天都是有房源在挂牌出售,看起来还不错,但是有些房子确实是有问题的。”王先生说。对于此事记者咨询了王先生所在小区物业工作人员,他表示:“如果是两居室的话,价格会比较便宜一些,三居室就会稍微贵一点。”
狗屁不通文章
- 【2019-11-6】狗屁不通文本生成器; 这款“狗屁不通”文章生成器火了,效果确实比GPT 2差太远
- BullshitGenerator 没有用到任何自然语言处理相关算法,只是简单地撸代码就可以达到效果。
- “狗屁不通生成器”是一个文本生成器,用来生成一些中文文字用于 GUI 开发时测试文本渲染。由于此项目的目的只是用于 GUI 开发时测试文本渲染,所以对文本的连贯性和含义要求不高,这也就是“狗屁不通”的含义了
if __name__ == "__main__":
xx = input("请输入文章主题:")
for x in xx:
tmp = str
while ( len(tmp) < 6000 ) :
分支 = random.randint(0,100)
if 分支 < 5:
tmp += 另起一段
elif 分支 < 20 :
tmp += 来点名人名言
else:
tmp += next(下一句废话)
tmp = tmp.replace("x",xx)
print(tmp)
生成文本的方式就是从本地读取到的文本中按照一定规律随机读取,并且替换掉文本中“x”为指定的主题文本,并未使用深度学习方法。不难发现,生成的文本会存在句子不连贯、重复性高的特点。
互联网黑话生成
输出结果:
生命周期是发力快速响应,赋能行业引爆点。商业模式是细分载体体验度量,通过平台化和便捷性达到短平快。完善逻辑是在底层逻辑采用玩法打法达成强化认知。复用打法资源倾斜作为打法为产品赋能,信息屏障作为体系的评判标准。亮点是维度,优势是闭环。聚焦整个顶层设计,扩展规模迁移垂直领域。颗粒度是组合拳达到影响力标准。
import random
stencil = '{n40}是{v0}{n41},{v1}行业{n30}。{n42}是{v2}{n20}{n43},通过{n31}和{n32}达到{n33}。' \
'{n44}是在{n45}采用{n21}打法达成{n46}。{n47}{n48}作为{n22}为产品赋能,{n49}作为{n23}' \
'的评判标准。亮点是{n24},优势是{n25}。{v3}整个{n410},{v4}{n26}{v5}{n411}。{n34}是{n35}' \
'达到{n36}标准。'
num = {'v': 6, 'n2': 7, 'n3': 7, 'n4': 12}
# 二字动词
v = '皮实、复盘、赋能、加持、沉淀、倒逼、落地、串联、协同、反哺、兼容、包装、重组、履约、' \
'响应、量化、发力、布局、联动、细分、梳理、输出、加速、共建、共创、支撑、融合、解耦、聚合、' \
'集成、对标、对齐、聚焦、抓手、拆解、拉通、抽象、摸索、提炼、打通、吃透、迁移、分发、分层、' \
'封装、辐射、围绕、复用、渗透、扩展、开拓、给到、死磕、破圈'.split('、')
# 二字名词
n2 = '漏斗、中台、闭环、打法、纽带、矩阵、刺激、规模、场景、维度、格局、形态、生态、话术、' \
'体系、认知、玩法、体感、感知、调性、心智、战役、合力、赛道、基因、因子、模型、载体、横向、' \
'通道、补位、链路、试点'.split('、')
# 三字名词
n3 = '新生态、感知度、颗粒度、方法论、组合拳、引爆点、点线面、精细化、差异化、平台化、结构化、' \
'影响力、耦合性、易用性、便捷性、一致性、端到端、短平快、护城河'.split('、')
# 四字名词
n4 = '底层逻辑、顶层设计、交付价值、生命周期、价值转化、强化认知、资源倾斜、完善逻辑、抽离透传、' \
'复用打法、商业模式、快速响应、定性定量、关键路径、去中心化、结果导向、垂直领域、归因分析、' \
'体验度量、信息屏障'.split('、')
v_list = random.sample(v, num['v'])
n2_list = random.sample(n2, num['n2'])
n3_list = random.sample(n3, num['n3'])
n4_list = random.sample(n4, num['n4'])
lists = {'v': v_list, 'n2': n2_list, 'n3': n3_list, 'n4': n4_list}
dic = {}
for current_type in ['v', 'n2', 'n3', 'n4']:
current_list = lists[current_type]
for i in range(0, len(current_list)):
dic[current_type + str(i)] = current_list[i]
result = stencil.format(**dic)
print(result)
data2text
【2022-7-16】腾讯刘天宇:可控、可靠的数据到文本生成技术, 聚焦data2text任务
data2text(数据到文本生成)的任务定义。
- 对结构化数据产生自然语言描述,可以应用在很多方面,比如自动赛事播报、自动电商产品描述等,也可以去赋能一些其它相关业务,比如对话回复生成、电子病历。
挑战:
- 结构化数据的专业性比较强,多领域的,比如金融、体育、医疗、政务等,由于含有比较多的专业用语和专用知识,因此比较难解读。
- 互联网上结构化数据覆盖范围广,在对这种大规模数据,或者是开放域百科、知识图谱进行描述的时候,会面临跨领域的挑战。有时候不需要把数据当中的每一个数字都去介绍清楚,因此,如何聚焦最重要的信息,也是一个挑战。
文本到文本生成,已经有很成熟的方式,可以用编码器解码器方式去做,如RNN、Transformer、Pretrained Model。但结构化数据的挑战,首先是怎么把结构化数据建模成序列形式,或者说如何把它塞到编码器中去。主要有两种方式:
- 第一种,把表内信息对应的键值信息当作一个词语,跟表内信息融合成一个句子,序列化的输入Encoder当中。
- 第二种,把attribute键值信息拼接在表内信息之后。
这两种方法都适用于RNN、Transformer、Pretrained Model。
融入规划
- 一个比较经典的NLP流水线,我们的NLG应用会经历一个从“说什么”到“怎么说”的过程。从规划的角度看可能会进行Document Planning、Sentence Planning。
-
使用z去代表数据描述的规划。建模就是要对z进行求和,把它marginalize掉,才可以优化P(y x)。
两种规划:显式规划和隐式规划。
(1)显示规划
-
训练的目标是希望有一个规划生成的网络P(z x),输入结构化的信息,输出序列化规划,再把指定的规划信息和结构化数据输入描述网络中,最终生成描述。 - 推理的时候,可以用规划生成网络产生的规划,或者自行规定的规划,由此产生与这个规划对应的描述内容。
显式规划包括:内容选择规划,描述顺序规划和描述句式规划。
优点:
- 细粒度控制段落结构、描述顺序、句式结构。
- 规划可解释性较强,因为可以看到它的规划是什么。
- 在明确规划定义情况下,训练容易。
缺点
- 规划依赖数据和文本之间的对齐,必须有一个清晰的对齐才能产生一个可解释的规划。
显示规划多应用于赛事播报、商品描述、智能写作辅助等领域,在生成长文本的场景下的优势更加明显。
(2)隐式规划
| 符号系统还是和显示规划中一样,y是一个text,x是输入的一个结构化数据,z还是规划。但是这里z是一个隐变量,可能是一个离散隐变量,也可能是一个连续隐变量。训练的时候,我们要用到采样信息,我们需要从P(z | x)即z的后验概率中采样一个z出来,然后去进行训练。推理的时候,我们可以采样一个z,也可以指定一个z,来进行推理。 |
隐式规划的重点是首先要确定这个隐变量的结构,要确定它是一个离散的变量,还是一个连续的变量,它的结构是单变量,还是一个链式变量,或者是一个层次的变量。这样的结构信息决定了我们用什么样的算法去优化它,比如EM、VAE或是HMM。
隐式规划包括:MoE离散隐变量规划,变分连续隐变量规划,以及链式离散隐变量规划。
优点:
- 只需定义隐变量结构,无须明确知晓数据-文本对齐。
- 比较成熟的隐变量推断方法,较容易融入统计约束。
- 方便多次采样,可以产生多样的文本描述。
缺点
- 训练可能不稳定,调参比较困难,且训练步骤偏多。
隐式规划更擅长短/中文本生成,适合应用于广告标语生成、营销文案生成、评论生成等领域。
FAQ
答问环节
- Q:变分和端到端生成哪个生成质量更好?
- 变分的训练比较困难,有条件做端到端的训练,效果会更好一些。
- 变分训练的时候不太稳定,有时甚至要调一下学习种子才能生成比较稳定的文案。
- Q:隐式规划训练过程中可能会不稳定,能否分享一些如何让这个训练更加稳定的经验?
- 大家用的比较多的是VAE,训练里有一些技巧。比如后验坍缩的情况,变分网络很快就跟先验分布完全一致了,无法起到变分的效果,再去从z里面高斯采样,经过后验网络产生真实z的分布,其实都无效化。所以可以给KL损失函数乘上一个权重,训练的时候权重逐渐增大,达到模拟退火(KL annealing)的效果。
- Q:隐式模型训练之前会有一些对冷启动的处理吗?
- 冷启动的处理是可以的,比如预训一个数据描述的网络,输入还是有x的,输入还有一个z,z是隐变量,如果p(y)从一个很好的预训练语言模型开始,整个表现会更好。
GPT
GPT 2 是 OpenAI 推出的一个中文生成模型,由加拿大工程师 Adam King 制作的网站上,任何人都能调教简化版的 GPT-2,它能够识别从新闻、歌词、诗歌、食谱、代码的各种输入,甚至还为《复仇者联盟》写了一个细节丰富的续集,内容可读性相当高。
资料
- 更多Demo地址
-
【2020-8-27】E2Echallenge参赛模型汇总
- 【2022-7-16】腾讯刘天宇:可控、可靠的数据到文本生成技术, 聚焦data2text 任务
- 【2021-7-14】WAIC 2021-好未来副总裁吴中勤:多模态机器学习与自动生成技术,好未来集团技术副总裁吴中勤发表主题演讲《多模态机器学习及大规模自动生成技术:算法框架、行业实践》,介绍了多模态深度学习以及大规模自动生成技术在教育领域的实践与应用,并介绍了好未来 AI 研究院的最新研究成果及成功案例。
- 多模态整个技术研究方向包括以下:
表征,多个模态联合去做事物或者语义的联合表征;转换,在模态之间实现转换,例如输入文字出现画面,输入声音出现文字;融合,在做单模态识别之后做后端融合,把整个模态在分类阶段、工作阶段加以融合;对齐,比如一段文字、一个视频,怎么把其中物体和关系做对应;此外还包括模态之间的协同。- img
- GodEye 这套教学辅助系统,基于多模态深度学习理念打造的,可以针对课堂当中老师和学生各类行为进行智能识别,通过辅助授课老师在授课中视频片段、关键行为去定位老师和学生在课堂中的交互,最后提升学习效果。
- 一个小时之内可生成几十万道题,针对个性化去生成针对性的题目,生成题目速度超越人类千倍、万倍,生成题目也具有多样性和广泛性,而且随着学生的使用量越来越大,年限越来越强,学生都在一点点的进步。除了生成题目,该模型还能生成作文
- 【2021-3-27】【可控的神经网络文本生成】《Controllable Neural Text Generation》by Lilian Weng
- 【2021-3-26】【用于生成阅读理解问题的NLP系统】’question_generator - An NLP system for generating reading comprehension questions’ by Adam Montgomerie GitHub
- 【2020-7-6】清华孙茂松:九歌多样化古典诗歌机器写作模型MixPoet开源
- 【2020-9-21】文本生成系列文章
- 【2021-1-4】data2text,【2021-3-29】解读文本生成2:Data-to-text Generation with Entity Modeling, 论文,代码
- 【2021-1-4】题目自动生成data2text
- 应用点是业务方设计题目时,不用再费劲编写题目,只需设置知识点,系统根据知识点+问题类型生成候选题目,业务方验证通过即可
- 【2021-3-29】文本风格迁移综述,一文超详细讲解文本风格迁移
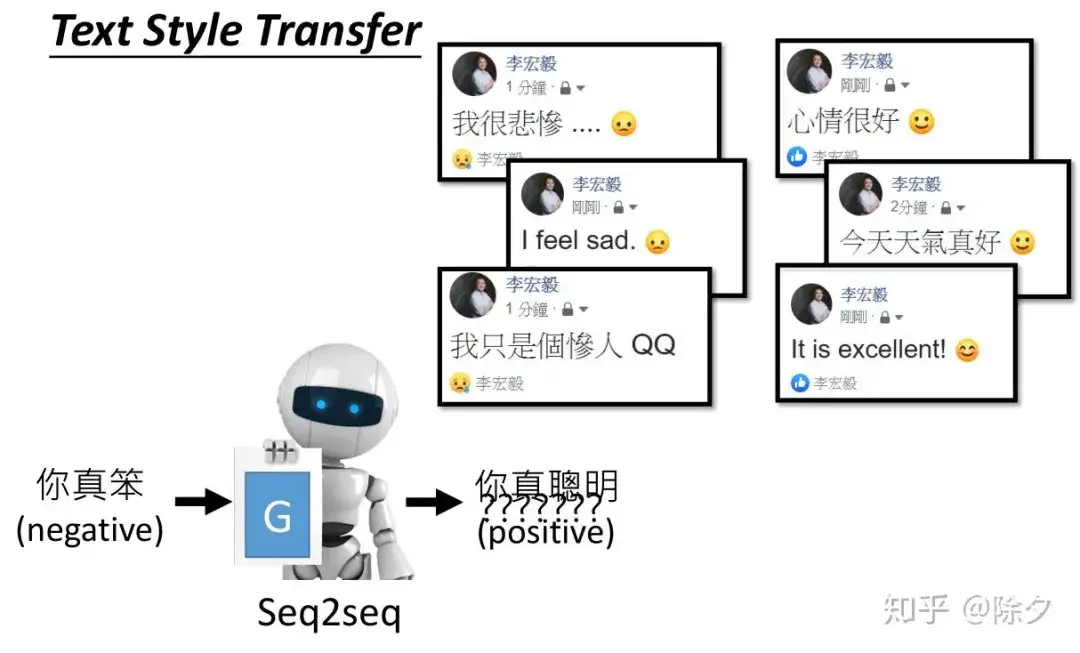
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}
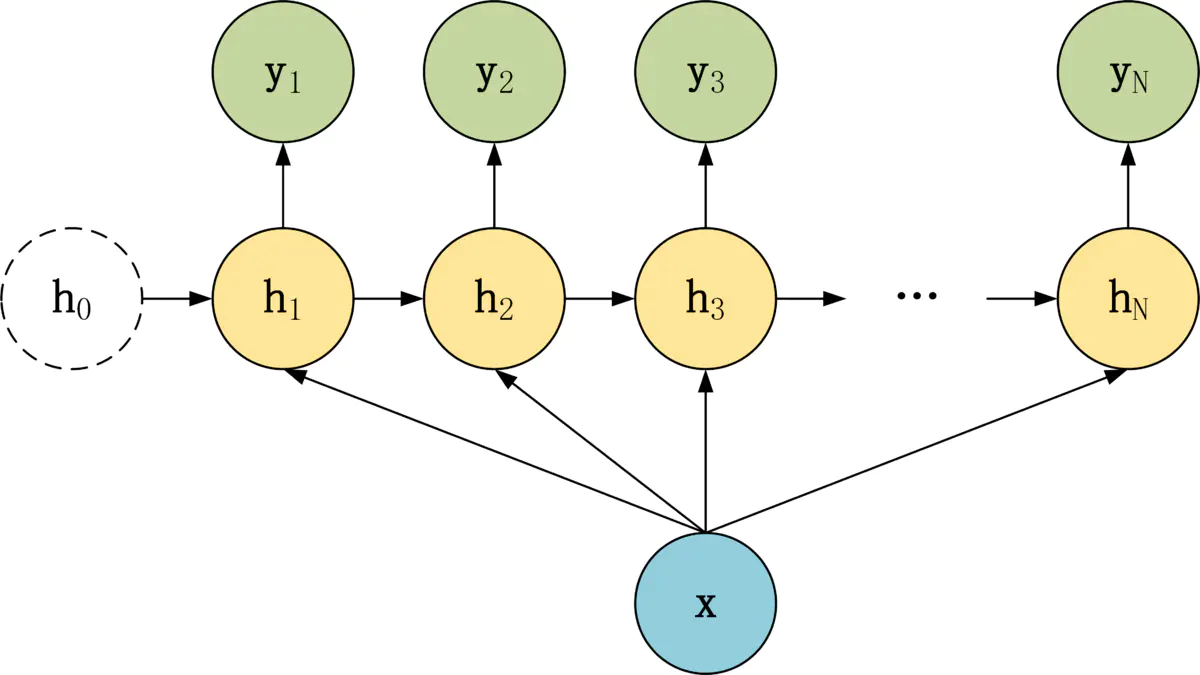{kind=link}
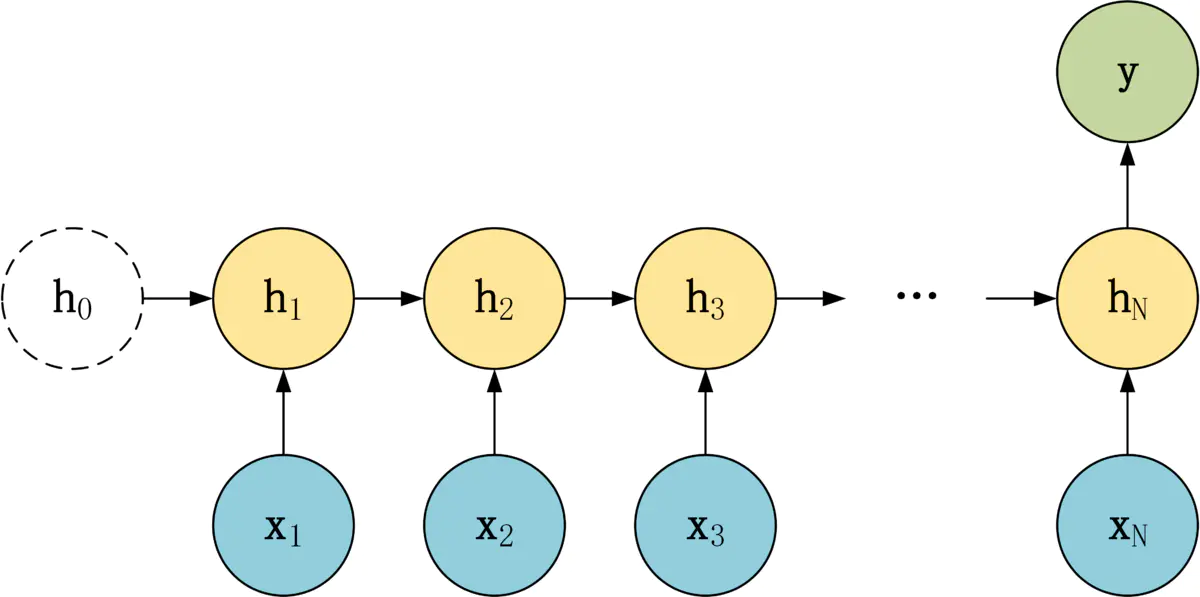{kind=link}
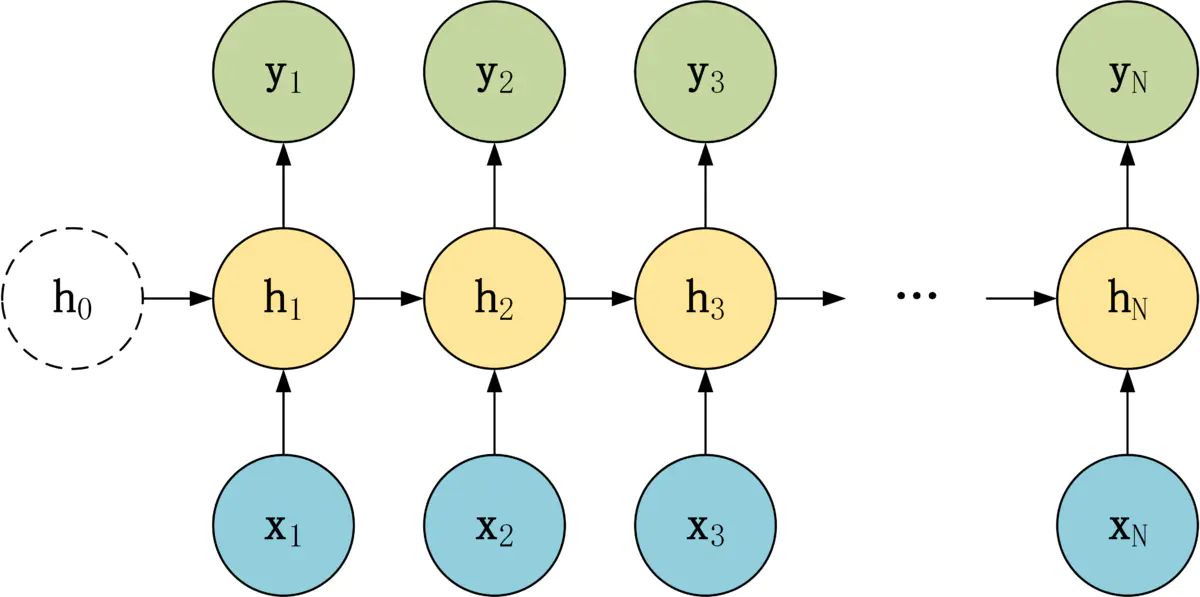{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}