计算机视觉
- 【2022-8-25】生成人脸:this-person-does-not-exist.com
- 【2022-8-23】国产AI作画神器火了,更懂中文,竟然还能做周边, “一句话生成画作”这个圈子里,又一个AI工具悄然火起来了,不是你以为的Disco Diffusion、DALL·E,再或者Imagen……而是全圈子都在讲中国话的那种, 文心·一格
- 操作界面上,Disco Diffusion开放的接口不能说很复杂,但确实有点门槛。它直接在谷歌Colab上运行,需要申请账号后使用(图片生成后保存在云盘),图像分辨率、尺寸需要手动输入,此外还有一些模型上的设置。好处是可更改的参数更多,对于高端玩家来说可操作性更强,只是比较适合专门研究AI算法的人群;相比之下,文心·一格的操作只需三个步骤:输入文字,鼠标选择风格&尺寸,点击生成。
- 提示词,Disco Diffusion的设置还要更麻烦一些。除了描述画面的内容以外,包括画作类别和参考的艺术家风格也都得用提示词来设置,通常大伙儿会在其他文档中编辑好,再直接粘过来。相比之下文心·一格倒是没有格式要求,输入150字的句子或词组都可以
- 性能要求上,Disco Diffusion是有GPU使用限制的,每天只能免费跑3小时。抱抱脸(HuggingFace)上部分AI文生图算法的Demo虽然操作简单些,但一旦网速不行,就容易加载不出来; 文心·一格除了使用高峰期以外,基本上都是2分钟就能生成,对使用设备也没有要求。
- 总体来看,同样是文字生成图片AI,实际相比文心·一格的“真·一句话生成图片”,DALL·E和Disco Diffusion的生成过程都不太轻松。
- 【2022-7-11】AI工具:解你描述的东西还可以画出来的AI,真就全靠想象
- 一、DALL•E2:openai出品,理解并画出你描述的所有东西,如:一直粉红色大象在撒哈拉沙漠玩扑克
- 二、AI智能图片放大:还原马赛克图片,就连表情包也能高清重置
- 三、线稿自动上色:Style2paints, GitHub 链接
- 用 AI 技术为黑白线稿快速自动上色。在最近推出的 2.0 版中,研究人员使用了完全无监督的生成对抗网络(GAN)训练方法大幅提高了上色的准确性。Style2paints 的作者表示,该工具在精细度、漫画风格转换等方面超越了目前其他所有工具。
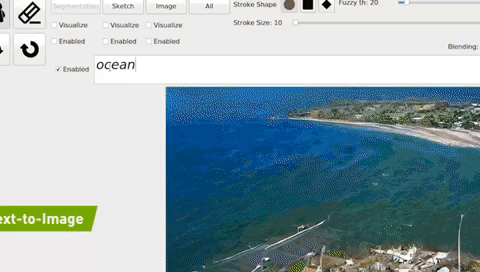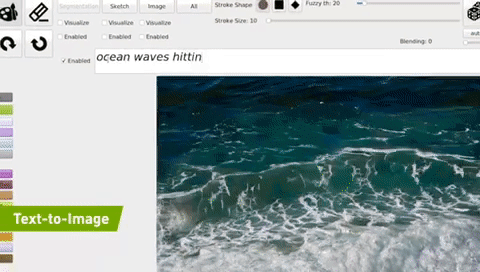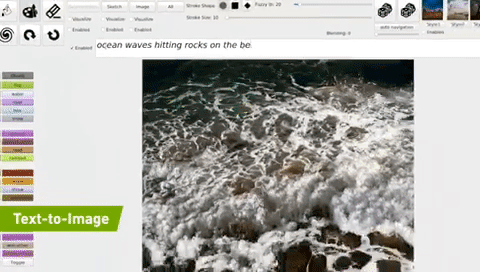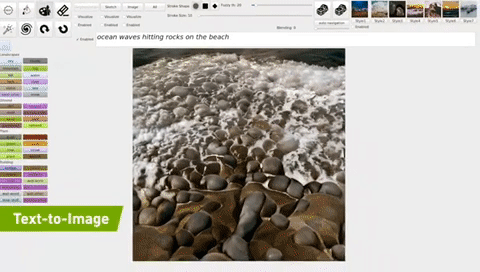
- 【2021-11-22】image2text的反向:text2image,NVIDIA Demo; 用深度学习模型(GauGAN)可以将文本转换成图片, demo,GauGAN AI Art Demo,只要输入一句简短的描述就可以生成图片了。下图是他们演示的“海浪击打岩石”的效果。
- 汇总计算机视觉的应用案例
- 【2021-3-26】视频大脑:视频内容理解的技术详解和应用,极客时间视频,黄君实 奇虎360 人工智能研究院资深研发科学家
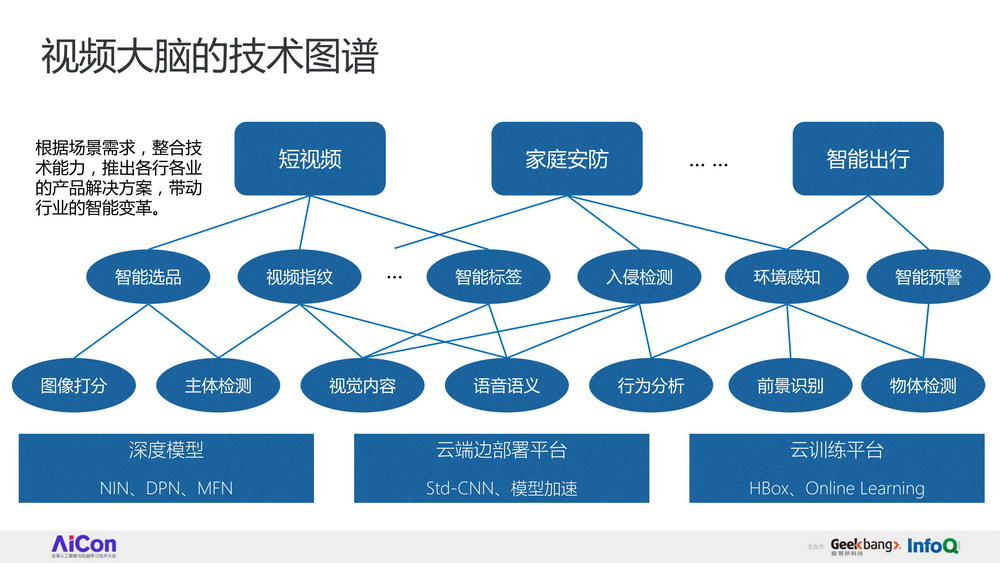
sota
【2021-6-22】CVPR 2021大奖公布!何恺明获最佳论文提名,代码已开源
推特上,有学者打趣说,CV论文可以分为这几类:
- 「只想混文凭」
- 「教电脑生成更多猫的照片」
- 「ImageNet上实验结果提升0.1%!」
- 「手握超酷数据集但并不打算公开」
- 「3年过去了,代码仍在赶来的路上」
- 「实验证明还是老baseline性能更牛」
- 「我们的数据集更大!」
- 「研究范围超广,无他,我们有钱」
- 「花钱多,结果好」……
何恺明和Xinlei Chen的论文Exploring Simple Siamese Representation Learning(探索简单的连体表征学习)获得了最佳论文提名。
「连体网络」(Siamese networks)已经成为最近各种无监督视觉表征学习模型中的一种常见结构。这些模型最大限度地提高了一个图像的两个增量之间的相似性,但必须符合某些条件以避免collapse的解决方案。在本文中,我们报告了令人惊讶的经验结果,即简单的连体网络即使不使用以下任何一种情况也能学习有意义的表征。(i) 负样本对,(ii) 大batch,(iii) 动量编码器。我们的实验表明,对于损失和结构来说,collapse的解决方案确实存在,但stop-gradient操作在防止collapse方面发挥了重要作用。我们提供了一个关于stop-gradient含义的假设,并进一步展示了验证该假设的概念验证实验。我们的 「SimSiam 」方法在ImageNet和下游任务中取得了有竞争力的结果。我们希望这个简单的基线能促使人们重新思考连体结构在无监督表征学习中的作用。
代码已开源 https://github.com/facebookresearch/simsiam
何恺明
何恺明成就
在CV领域所做的工作,涵盖ResNet、Faster RCNN、Mask RCNN、MoCO和MAE。
- 【2023-3-14】何恺明回归学界,进入MIT,成为MIT被引次数最高的人。
- MIT全校被引用次数最高的,是化学与生物医学工程系的重量级教授Robert Langer,次数为38万+。而何恺明被引用次数高达40万+。
何恺明
- 最出圈的研究非ResNet莫属,在2021年底突破10万大关,如今已经涨到15万。
- 主要贡献还包括Faster R-CNN及后续的Mask R-CNN等一系列研究,在很多年都是目标检测的主流方法。
- 近期主要研究兴趣是无监督学习,21年底提出的MAE,将语言模型的掩码预训练方法用在视觉模型上,为视觉大规模无监督预训练大模型开路。最近他还将掩码方法引入众多AI绘画应用的基础模型CLIP,把训练速度提升了3.7倍。
何恺明履历
何恺明编年史

何恺明履历
- 出生于广州的何恺明是家中独子,父母均在企业里从事管理工作,从小就接触到优良的教学环境。实际上,能从众多学子中脱颖而出,除了教学环境之外,更多的是靠自己的努力。
- 何恺明年少时就被送到少年宫学习绘画,有时一待就是大半天,这也不断使他练就出沉稳的性格。同绘画一样,他对于文化课的钻研也十分耐得住性子,学习成绩优秀而且稳定。在老师的心目中,他是一个“性格比较内向”但是“目标明确”的学生,“从小就立志上清华”。
- 高中时,全国物理竞赛一等奖被保送进清华大学机械工程及其自动化专业,不去,偏要考,结果成了2003年广东理科状元;
- 大学期间,何恺明继续着自己沉稳而优秀的表现,不仅连续3年获得清华奖学金,2007年,还未毕业的他就进入了微软亚洲研究院(MSRA)实习。
- 本科毕业后,他进入香港中文大学攻读研究生,师从AI名人汤晓鸥;
- 2009年,第一篇论文“Single ImageHaze Removalusing Dark Channel Prior”被计算机视觉领域顶级会议CVPR接收并被评为年度最佳论文,CVPR创办25年来华人学者第一次获此殊荣,也使何恺明在CV领域声名鹊起
- 2011年,博士毕业的何恺明正式加入MSRA计算机视觉和深度学习的研究工作。
- 2015年的ImageNet图像识别大赛中,何恺明和他的团队凭借152层深度残差网络ResNet-152,击败谷歌、英特尔、高通等业界团队,荣获第一。目前ResNets也已经成为计算机视觉领域的流行架构,同时也被用于机器翻译、语音合成、语音识别和AlphaGo的研发上。
- 2016年,何恺明凭借ResNets论文再次获得CVPR最佳论文奖,也是目前少有的一人两次获得CVPR最佳论文奖的学者。
- 后来,何恺明和孙剑相继离开MSRA。与孙剑的选择不同,何凯明走得还是那条学院路。他选择了去Facebook,担任其人工智能实验室研究科学家,选择了进一步走学术之路。
- 2017年3月,何恺明和同事公布了其最新的研究Mask R-CNN,提出了一个概念上简单、灵活和通用的用于目标实例分割(object instance segmentation)框架,能够有效地检测图像中的目标,同时还能为每个实例生成一个高质量的分割掩码。同年,凭借《利用焦点损失提升物体检测效果》这篇论文,他一举夺下了另一个计算机视觉顶级会议ICCV最佳论文奖。
- 2018年,何恺明在美国盐湖城召开的CVPR上,获得了PAMI青年研究者奖。几个月前,何恺明等人发表论文称,ImageNet预训练却并非必须。何恺明和其同事使用随机初始化的模型,不借助外部数据就取得了不逊于COCO 2017冠军的结果,再次引发业内关注。
【2022-1-12】何恺明编年史
别人的荣誉都是在某某大厂工作,拿过什么大奖,而何恺明的荣誉是best,best,best …… kaiming科研嗅觉顶级,每次都能精准的踩在最关键的问题上,提出的方法简洁明了,同时又蕴含着深刻的思考,文章赏心悦目,实验详尽扎实,工作质量说明一切。
何恺明的研究兴趣大致分成这么几个阶段:
- 传统视觉时代:Haze Removal(3篇)、Image Completion(2篇)、Image Warping(3篇)、Binary Encoding(6篇)
- 深度学习时代:Neural Architecture(11篇)、Object Detection(7篇)、Semantic Segmentation(11篇)、Video Understanding(4篇)、Self-Supervised(8篇)
代表作
- 2009 CVPR best paper Single Image Haze Removal Using Dark Channel Prior
- 利用实验观察到的暗通道先验,巧妙的构造了图像去雾算法。现在主流的图像去雾算法还是在Dark Channel Prior的基础上做的改进。
- 2016 CVPR best paper Deep Residual Learning for Image Recognition
- 通过残差连接,可以训练非常深的卷积神经网络。不管是之前的CNN,还是最近的ViT、MLP-Mixer架构,仍然摆脱不了残差连接的影响。
- 2017 ICCV best paper Mask R-CNN
- 在Faster R-CNN的基础上,增加一个实例分割分支,并且将RoI Pooling替换成了RoI Align,使得实例分割精度大幅度提升。虽然最新的实例分割算法层出不穷,但是精度上依然难以超越Mask R-CNN。
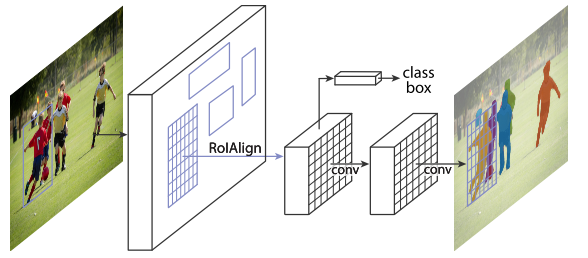
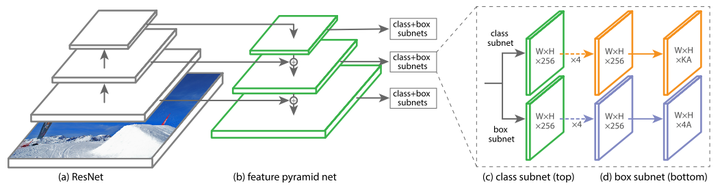
- 2017 ICCV best student paper Focal Loss for Dense Object Detection
- 构建了一个One-Stage检测器RetinaNet,同时提出Focal Loss来处理One-Stage的类别不均衡问题,在目标检测任务上首次One-Stage检测器的速度和精度都优于Two-Stage检测器。近些年的One-Stage检测器(如FCOS、ATSS),仍然以RetinaNet为基础进行改进。
- 2020 CVPR Best Paper Nominee Momentum Contrast for Unsupervised Visual Representation Learning
- 19年末,NLP领域的Transformer进一步应用于Unsupervised representation learning,产生后来影响深远的BERT和GPT系列模型,反观CV领域,ImageNet刷到饱和,似乎遇到了怎么也跨不过的屏障。就在CV领域停滞不前的时候,Kaiming He带着MoCo横空出世,横扫了包括PASCAL VOC和COCO在内的7大数据集,至此,CV拉开了Self-Supervised研究新篇章。
人如何接收环境信息

神经系统必须接收和处理外界信息以作出反应、进行通信并确保身体的健康与安全。
- 这些信息大部分来自感觉器官:
眼睛、耳朵、鼻子、舌头和皮肤。 - 这些器官中的细胞和组织会接收原始刺激,并将其转化为神经系统可以使用的信号。神经将信号传递到大脑,大脑将其解释为影像(视觉)、声音(听觉)、气味(嗅觉)、味道(味觉)和触感(触觉)。
大脑必须依靠感觉器官来收集感觉讯息。相关的五种感觉器官是:
- 耳朵(听觉)
- 皮肤及毛发(触觉)
- 眼睛(视觉)
- 舌头(味觉)
- 鼻子(嗅觉
视觉系统的出现和不断完善迫使不同物种间的竞争加剧,进而极大地缩短了它们的进化时间,最终导致了大爆炸现象的出现。
婴儿如何学习
【2024-2-4】Nature,纽约大学最新研究:给婴儿戴上摄像头,让神经网络自主学习,像婴儿一样感知环境,学习语言
婴儿视角
- Vong 和同事通过一个男婴头盔上的摄像机进行 61 小时记录,从婴儿的角度收集信息。
- Sam 住在澳大利亚阿德莱德附近,从六个月大到两岁左右,每周两次佩戴相机,每次每次一小时左右(大约是他清醒时间的 1%)。
研究人员根据视频中的帧以及从录音中转录出来的对山姆说的话训练神经网络(一种受大脑结构启发的人工智能)。该模型接触了 250,000 个单词和相应的图像,这些图像是在玩耍、阅读和吃饭等活动中捕获的。
- 该模型使用了对比学习技术了解哪些图像和文本倾向于结合在一起,哪些不结合在一起,从而建立可用于预测某些单词(例如“球”和“碗”)所指的图像的信息。
1. 眼睛将光线转化为供大脑处理的图像信号

眼睛位于头骨的眼眶中,受到骨骼和脂肪的保护。眼睛的白色部分是巩膜。它保护内部结构,包围着角膜、虹膜和瞳孔形成的圆形入口。角膜是透明的,允许光线进入眼睛,并发生弯曲来引导光线进入其后的瞳孔。瞳孔实际上是虹膜有色圆盘中的开孔。虹膜扩张或收缩,调节有多少光线通过瞳孔并进入晶状体。接下来,弯曲的晶状体将图像会在视网膜(眼的内层)上聚焦。视网膜是一层精细的神经组织膜,包含了感光细胞。这些视杆细胞和视锥细胞将光转化为神经信号。视神经将信号从眼睛传递到脑部,由脑将其解释为视觉图像。
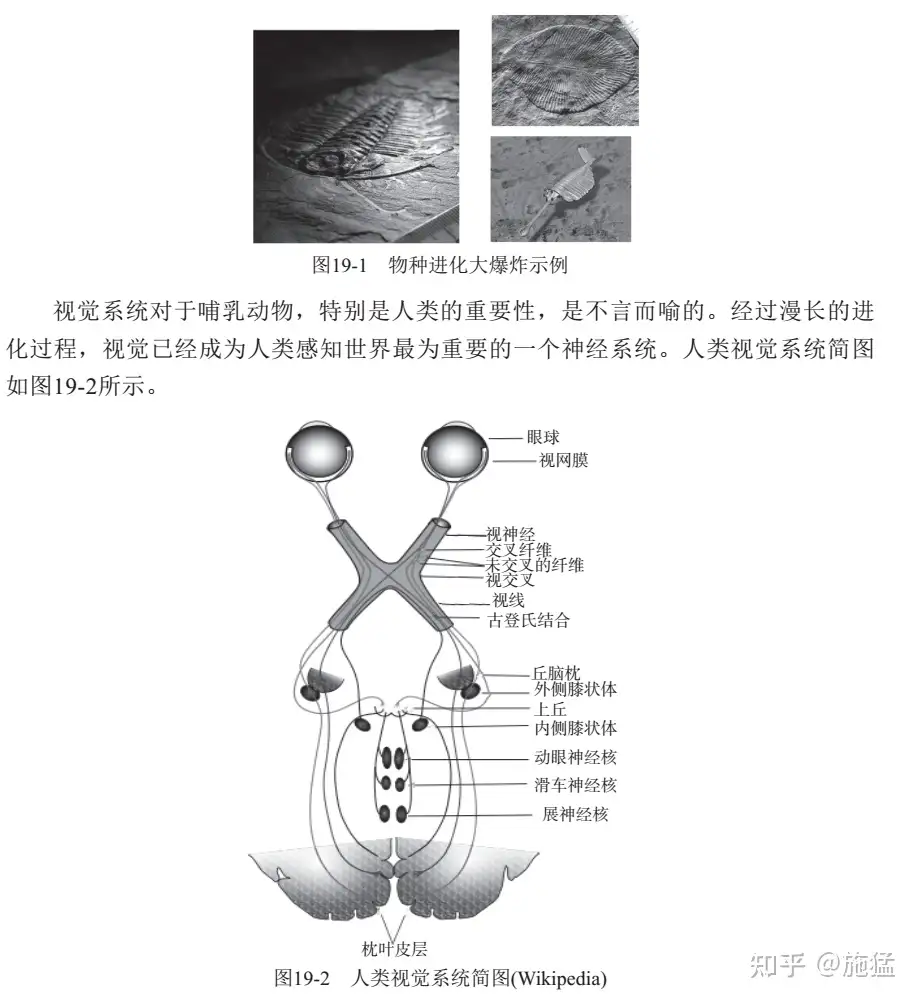
2. 耳朵使用听小骨和液体将声波转换为声音信号
音乐、笑声、汽车鸣笛—都作为空气中的声波传入耳朵。外耳将声波沿着耳道(外耳道)汇聚到鼓膜(“耳鼓”)。声波敲击鼓膜,在膜中产生机械振动。鼓膜将这些振动传递到三块被称为听小骨的微小骨骼,可在充满空气的中耳腔室内看到它们。这些骨骼(锤骨、砧骨和镫骨)承载振动并敲击内耳的开口。内耳由充满液体的管道组成,包括螺旋形的耳蜗。随着听小骨的撞击,耳蜗中的特殊毛细胞会检测到液体中的压力波。它们激活神经感受器,通过蜗神经向脑发送信号,后者将信号解释为声音。
3. 皮肤中的特殊感受器向大脑发送触觉信号

皮肤由三个主要组织层构成:外层表皮、中层真皮和内层皮下组织。
这些组织层中专门的感受器细胞检测触觉,并通过周围神经向脑部传递信号。不同类型感受器的存在和位置使特定身体部位更加敏感。嘴唇、手和外生殖器官下表皮可见Merkel细胞。迈斯纳小体可见于无毛发皮肤的上真皮层内—指甲、乳头、嘴唇、足底、阴蒂、龟头和舌尖。这两种感受器都可以检测到触摸、压力和振动。其他触觉感受器还包括环层小体,它也能记录压力和振动。还有能感受到疼痛、瘙痒和刺痒的特异性神经自由末梢。
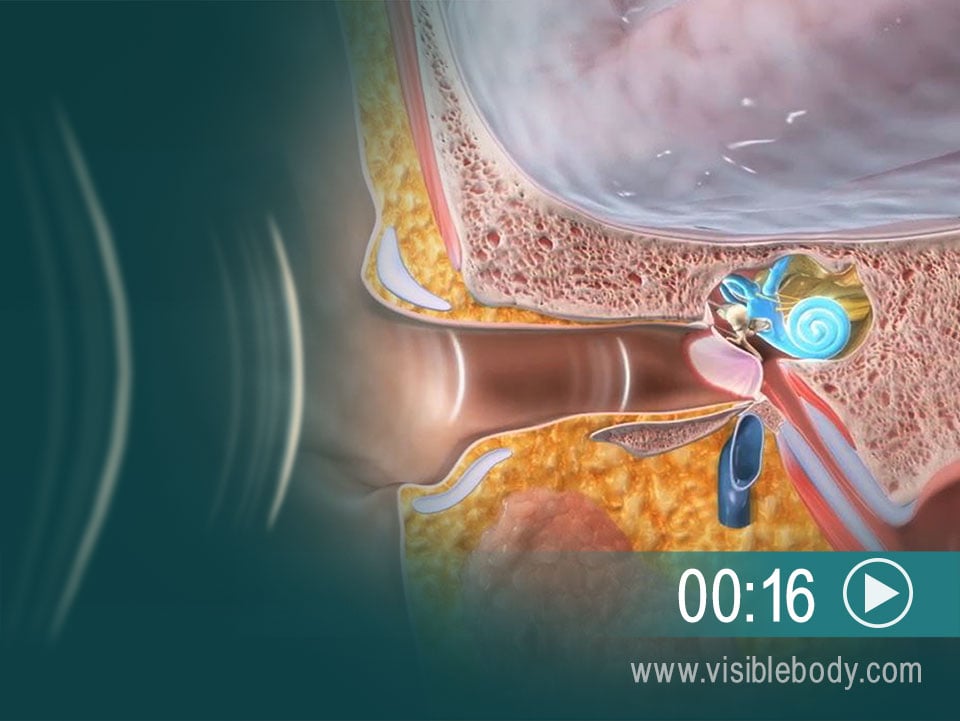
4. 嗅觉:空气中的化学物质刺激发出被大脑解释为气味的信号。
气味的感觉被称为嗅觉。它开始于鼻腔的顶部上皮中的毛状纤毛上的感受器。当我们用鼻子嗅和吸气时,一些空气中的化学物质会与感受器结合。这会触发一个顺着神经纤维向上传递的信号,穿过上皮和上方的颅骨到达嗅球。嗅球包含神经元细胞体,其将信号顺着延伸至嗅球的颅神经传递。然后将信号朝着大脑皮层的嗅觉区域向下传递到嗅神经。
5. 味蕾的载体:舌头是味觉的主要器官
舌头的四块内在肌协同工作,使舌头具有很大的灵活性。

舌头上的那些小疙瘩是什么?它们叫做舌乳头。它们中包括轮廓乳头和菌状乳头在内的多数都包含味蕾。当我们进食时,食物中的化学物质会进入舌乳头并到达味蕾。这些化学物质(或促味剂)刺激味蕾内部特殊的味觉细胞,激活神经感受器。感受器将信号发送至面神经、舌咽神经和迷走神经的神经纤维。这些神经将信号传递到延髓,延髓将信号传递到脑部的丘脑和大脑皮层。
什么是计算机视觉
相对于生物视觉系统漫长的进化历程,计算机视觉显然是“非常年轻而且稚嫩”的,因为人们是从20世纪50年代才开始尝试赋予计算机系统这一重要的感知能力。而且,这个学科的涉及面比较宽泛,它不仅依赖于计算机科学知识,同时还涉及生物学、数学、神经科学等多个领域

What is computer vision?
- Computer vision is the field of computer science that focuses on creating digital systems that can process, analyze, and make sense of visual data (images or videos) in the same way that humans do. The concept of computer vision is based on teaching computers to process an image at a pixel level and understand it. Technically, machines attempt to retrieve visual information, handle it, and interpret results through special software algorithms.
- 向人脑一样处理、分析、感知视觉数据(图像/视频)的数字系统 img

- The goal of computer vision is to give computers (super) human-level perception
- typical perception pipeline: representation –> fancy math(black box) –> output
- representation: what should we look at? (image features)
- fancy math: easy to get lost in the techniques
- output: what can we understand? (semantic segmentation)
- The parts that we are most interested in: representation & output
- Important note:
- In general, computer vision does not work, except in certain situations/conditions
- 当前的计算机视觉方案行不通(暂无解法),但特定领域下可行
- 朱松纯观点
- 现在的人工智能和机器人,关键问题是缺乏物理的常识和社会的常识“Common sense”。 这是人工智能研究最大的障碍。
- 我们要寻找“乌鸦”模式的智能,而不要“鹦鹉”模式的智能

Here are a few common tasks that computer vision systems can be used for:
Object classification. The system parses visual content and classifies the object on a photo/video to the defined category. For example, the system can find a dog among all objects in the image.Object identification. The system parses visual content and identifies a particular object on a photo/video. For example, the system can find a specific dog among the dogs in the image.-
Object tracking. The system processes video finds the object (or objects) that match search criteria and track its movement. 

CV 与 CG
计算机视觉(CV)和计算机图形学(CG)该如何区别?
- 计算机视觉输入的是图像或视频,输出的是对画面内容的理解,也就是对世界的理解。
- 而计算机图形学输入的是对虚拟场景的描述,输出的则是图像。
随着两者的共同进步,无论是算法还是解决问题的思路上都互有借鉴,不过基础的分界仍未改变。
发展史
计算机视觉是深度学习领域最热门的研究领域之一,目前在各领域应用广泛,而它是如何发展至今,一起回顾一下计算机视觉的发展史。
自从20世纪中期开始,计算机视觉不断发展,研究经历了从二维图像到三维到视频到真实空间的探知,操作方法从构建三维向特征识别转变,算法从浅层神经网络到深度学习,数据的重要性逐渐被认知,伴随着计算机从理论到应用的速度加快,高质量的各种视觉数据不断沉淀,相信无论在社会经济农业还是工业领域,还是视频直播、游戏、电商不断发展,一定还会有更多好玩炫酷的计算机视觉应用出现在我们身边。
四个阶段
计算机视觉经历了4个主要历程。
- 中国科学院自动化研究所胡占义研究员撰写的《计算机视觉简介:历史、现状和发展趋势》
- 马尔计算视觉、主动和目的视觉、多视几何与分层三维重建和基于学习的视觉。
马尔计算视觉(Computational Vision)
马尔计算视觉理论包含两个主要观点:
- 首先,人类视觉的主要功能是复原三维场景的可见几何表面,即三维重建问题;
- 其次,马尔认为这种从二维图像到三维几何结构的复原过程是可以通过计算完成的,并提出了一套完整的计算理论和方法。
所以,马尔视觉计算理论在一些文献中也被称为三维重建理论。
马尔认为,从二维图像复原物体的三维结构,涉及三个不同的层次。
- 首先是计算理论层次,也就是说,需要使用何种类型的约束来完成这一过程。马尔认为合理的约束是场景固有的性质在成像过程中对图像形成的约束。
- 其次是表达和算法层次,也就是说如何来具体计算。
- 最后是实现层次。马尔对表达和算法层次进行了详细讨论。
他认为从二维图像恢复三维物体,经历了三个主要步骤,即: 图像初始略图(sketch)—> 物体2.5维描述 —> 物体3维描述
- 其中,初始略图是指高斯拉普拉斯滤波图像中的过零点(zero-crossing)、短线段、端点等基元特征。
- 物体2.5维描述是指在观测者坐标系下对物体形状的一些粗略描述,如物体的法向量等。
- 物体3维描述是指在物体自身坐标系下对物体的描述,如球体以球心为坐标原点的表述。
马尔视觉计算理论是上世纪八十年代初提出的,之后三十多年的研究中,人们发现马尔理论的基本假设:”人类视觉的主要功能是复原三维场景的可见几何表面”——基本上是不正确的,”物体识别中的三维表达的假设”——也基本与人类物体识别的神经生理机理不相符。尽管如此,马尔计算视觉理论在计算机视觉领域的影响是深远的,他所提出的层次化三维重建框架,至今是计算机视觉中的主流方法。尽管文献中很多人对马尔理论提出了质疑、批评和改进,但就目前的研究状况看,还没有任何一种理论可以取代马尔理论,或与其相提并论。
昙花一现的主动和目的视觉
很多人介绍计算机视觉时,将这部分内容不作为一个单独部分加以介绍,主要是因为“主动视觉和目的视觉”并没有对计算机视觉后续研究形成持续影响。
20世纪80年代初马尔视觉计算理论提出后,学术界兴起了“计算机视觉”的热潮。人们想到的这种理论的一种直接应用就是给工业机器人赋予视觉能力,典型的系统就是所谓的“基于部件的系统”(parts-based system)。然而,10多年的研究,使人们认识到,尽管马尔计算视觉理论非常优美,但“鲁棒性”(Robustness)不够,很难想人们预想的那样在工业界得到广泛应用。这样,人们开始质疑这种理论的合理性,甚至提出了尖锐的批评。
对马尔计算视觉理论提出批评最多的有二点:
- 一是认为这种三维重建过程是”纯粹自底向上的过程”(pure bottom-up process),缺乏高层反馈(top-down feedback);
- 二是”重建”缺乏”目的性和主动性”。由于不同的用途,要求重建的精度不同,而不考虑具体任务,仅仅”盲目地重建一个适合任何任务的三维模型”似乎不合理。
对马尔视觉计算理论提出批评的代表性人物有:马里兰大学的 J. Y. Aloimonos;宾夕法尼亚大学的R. Bajcsy和密西根州立大学的A. K. Jaini。 Bajcsy 认为,视觉过程必然存在人与环境的交互,提出了主动视觉的概念(active vision). Aloimonos认为视觉要有目的性,且在很多应用,不需要严格三维重建,提出了”目的和定性视觉”(purpose and qualitative vision) 的概念。 Jain 认为应该重点强调应用,提出了”应用视觉”( practicing vision)的概念。上世纪80年代末到90年代初,可以说是计算机视觉领域的”彷徨”阶段。真有点”批评之声不绝,视觉之路茫茫”之势。
值得指出的是,”主动视觉”应该是一个非常好的概念,但困难在于”如何计算”。 主动视觉往往需要”视觉注视”(visual attention),需要研究脑皮层(cerebral cortex)高层区域到低层区域的反馈机制,这些问题,即使脑科学和神经科学已经较20年前取得了巨大进展的今天,仍缺乏”计算层次上的进展”可为计算机视觉研究人员提供实质性的参考和借鉴。
多视几何和分层三维重建(Multiple View Geometry and Stratified 3D Reconstruction)
20世纪90年代初计算机视觉从”萧条”走向重新”繁荣”,主要得益于以下二方面的因素:首先,瞄准的应用领域从精度和鲁棒性要求太高的”工业应用”转到要求不太高,特别是仅仅需要”视觉效果”的应用领域,如远程视频会议(teleconference),考古,虚拟现实,视频监控等。另一方面,人们发现,多视几何理论下的分层三维重建能有效提高三维重建的鲁棒性和精度。
2000 年Hartley 和Zisserman 合著的书 (Hartley & Zisserman 2000) 对这方面的内容给出了比较系统的总结,而后这方面的工作主要集中在如何提高”大数据下鲁棒性重建的计算效率”。大数据需要全自动重建,而全自动重建需要反复优化,而反复优化需要花费大量计算资源。所以,如何在保证鲁棒性的前提下快速进行大场景的三维重建是后期研究的重点。
举一个简单例子,假如要三维重建北京中关村地区,为了保证重建的完整性,需要获取大量的地面和无人机图像。假如获取了1万幅地面高分辨率图像(4000×3000),5 千幅高分辨率无人机图像(8000×7000)(这样的图像规模是当前的典型规模),三维重建要匹配这些图像,从中选取合适的图像集,然后对相机位置信息进行标定并重建出场景的三维结构,如此大的数据量,人工干预是不可能的,所以整个三维重建流程必须全自动进行。这样需要重建算法和系统具有非常高的鲁棒性,否则根本无法全自动三维重建。在鲁棒性保证的情况下,三维重建效率也是一个巨大的挑战。所以,目前在这方面的研究重点是如何快速、鲁棒地重建大场景。
基于学习的视觉(Learning based vision)
基于学习的视觉,是指以机器学习为主要技术手段的计算机视觉研究。基于学习的视觉研究,文献中大体上分为二个阶段:本世纪初的以流形学习( manifold Learning)为代表的子空间法( subspace method)和目前以深度神经网络和深度学习(deep neural networks and deep learning)为代表的视觉方法。
1、流形学习(Manifold Learning)
正像前面所指出的,物体表达是物体识别的核心问题。给定图像物体,如人脸图像,不同的表达,物体的分类和识别率不同。另外,直接将图像像素作为表达是一种”过表达”,也不是一种好的表达。流形学习理论认为,一种图像物体存在其”内在流形”(intrinsic manifold), 这种内在流形是该物体的一种优质表达。所以,流形学习就是从图像表达学习其内在流形表达的过程,这种内在流形的学习过程一般是一种非线性优化过程。 流形学习始于2000年在Science 上发表的二篇文章( Tenenbaum et al., 2000) (Roweis & Lawrence 2000)。流形学习一个困难的问题是没有严格的理论来确定内在流形的维度。人们发现,很多情况下流形学习的结果还不如传统的PCA (Principal Component Analysis),LDA( linear DiscriminantAnalysis ), MDS( Multidimensional Scaling)等。流形学习的代表方法有:LLE(Locally Linear Embedding )(Roweis & Lawrence 2000),Isomap ( Tenenbaum et al., 2000), Laplacian Eigenmaps (Belkin & Niyogi, 2001)等。
2、深度学习(Deep Learning)
深度学习的成功,主要得益于数据积累和计算能力的提高。深度网络的概念20世纪80年代就已提出来了,只是因为当时发现”深度网络”性能还不如”浅层网络”,所以没有得到大的发展。目前似乎有点计算机视觉就是深度学习的应用之势,这可以从计算机视觉的三大国际会议:国际计算机视觉会议(ICCV),欧洲计算机视觉会议(ECCV)和计算机视觉和模式识别会议(CVPR)上近年来发表的论文就可以看出。 目前的基本状况是,人们都在利用深度学习来”取代”计算机视觉中的传统方法。”研究人员”成了”调程序的机器”,这实在是一种不正常的”群众式运动”。 关于深度网络和深度学习,详细内容可参阅相关文献,这里仅仅强调以下几点:
- (1)深度学习在物体视觉方面较传统方法体现了巨大优势,但在空间视觉,如三维重建,物体定位方面,仍无法与基于几何的方法相媲美。这主要是因为深度学习很难处理图像特征之间的误匹配现象。在基于几何的三维重建中,RANSAC (Random Sample Consensus)等鲁棒外点(误匹配点)剔除模块可以反复调用,而在深度学习中,目前还很难集成诸如RANSAC等外点剔除机制。如果深度网络不能很好地集成外点剔除模块,深度学习在三维重建中将很难与基于几何的方法相媲美,甚至很难在空间视觉中得到有效应用;
- (2) 深度学习在静态图像物体识别方面已经成熟,这也是为什么在ImageNet上的物体分类竞赛已不再举行的缘故;
- (3) 目前的深度网络,基本上是前馈网络。不同网络主要体现在使用的代价函数不同。下一步预计要探索具有”反馈机制”的层次化网络。反馈机制,需要借鉴脑神经网络机制,特别是连接组学的成果。
- (4) 目前对视频的处理,人们提出了RCNN (Recurrent Neural Networks)。循环是一种有效的同层作用机制,但不能代替反馈。大脑皮层远距离的反馈可能是形成大脑皮层不同区域具有不同特定功能的神经基础。所以,研究反馈机制,特别具有”长距离反馈”(跨多层之间)的深度网络, 将是今后研究图像理解的一个重要方向;
- (5)尽管深度学习和深度网络在图像物体识别方面取得了”变革性”成果,但为什么”深度学习”会取得如此好的结果目前仍然缺乏坚实的理论基础。目前已有一些这方面的研究,但仍缺乏系统性的理论。事实上,”层次化”是本质,不仅深度网络,其它层次化模型,如Hmax 模型(Riesenhuber & Poggio,1999) HTM (Hierarchical Temporal memory)模型(George & Hawkins, 2009)存在同样的理论困惑。为什么”层次化结构”( hierarchical structure )具有优势仍是一个巨大的迷。
1、20世纪50年代:生物视觉原理
研究生物视觉工作原理
人们总是在探索着所处世界中的万事万物—-这其中当然包括人类自身。
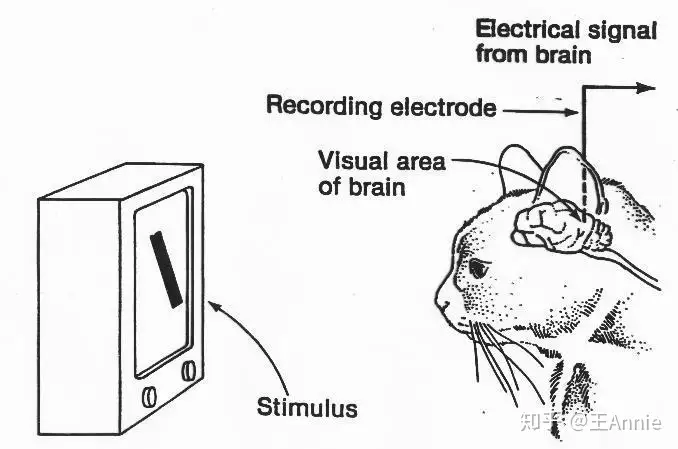
- 20世纪50年代左右,生物学家们做了很多努力来试图理解动物的视觉系统,其中比较有名的是Hubel和Wiesel的一些研究成果。他们从电生理学的角度来分析猫(猫和人类的大脑比较相近)的视觉皮层系统,从中发现了视觉通路中的信息分层处理机制,并提出了感受野的概念,实验示意图。
- 他们也因此获得了诺贝尔生理学或医学奖。
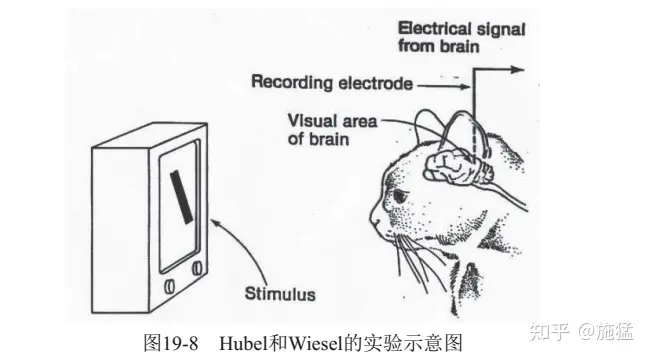

主题是二维图像的分析和识别
1959年,神经生理学家 David Hubel 和 Torsten Wiesel 通过猫的视觉实验,首次发现了视觉初级皮层神经元对于移动边缘刺激敏感,发现了视功能柱结构,为视觉神经研究奠定了基础——促成了计算机视觉技术40年后的突破性发展,奠定了深度学习之后的核心准则。
1959年,Russell 和同学研制了一台可以把图片转化为被二进制机器所理解的灰度值的仪器——这是第一台数字图像扫描仪,处理数字图像开始成为可能。
这一时期,研究的主要对象如光学字符识别、工件表面、显微图片和航空图片的分析和解释等。
2、20世纪60年代:三维视觉理解
开创了三维视觉理解为目的的研究
- 计算机视觉严格来说是在20世纪60年代逐步发展起来的。
- 这个时期诞生了人类历史上的第一位计算机视觉博士,即Larry Roberts。
- 1963年撰写的论文“Machine perception of three-dimensional solids”中将物体简化为几何形状(立方体、棱柱体等)来加以识别。
- 当时人们相信只要提取出物体形状并加以空间关系的描述,那么就可以像“搭积木”般拼接出任何复杂的三维场景。人们的研究热情空前高涨,研究范围遍布角点特征、边缘、颜色、纹理提取以及推理规则建立等很多方面。
1965年, Lawrence Roberts《三维固体的机器感知》描述了从二维图片中推导三维信息的过程。
- 现代计算机视觉的前导之一,开创了理解三维场景为目的的计算机视觉研究。
- 他对积木世界的创造性研究给人们带来极大的启发,之后人们开始对积木世界进行深入的研究,从边缘检测、角点特征的提取,到线条、平面、曲线等几何要素分析,到图像明暗、纹理、运动以及成像几何等,并建立了各种数据结构和推理规则。

- 图片来源 http://cs231n.stanford.edu/
1966, MIT AI 实验室的 Seymour Papert 教授决定启动夏季视觉项目(“Summer Vision Project”),与会人员“雄心勃勃”地希望在一个暑假的时间里彻底解决计算机视觉问题。没错,几个月内解决机器视觉问题。Seymour 和 Gerald Sussman 协调学生将设计一个可以自动执行背景/前景分割,并从真实世界的图像中提取非重叠物体的平台。
- 虽然未成功,但是计算机视觉作为一个科学领域的正式诞生的标志。
- 随后几十年人们对于计算机视觉的热情却持续高涨,其影响范围也蔓延到了全世界。
1969年秋天,贝尔实验室的两位科学家Willard S. Boyle和George E. Smith正忙于电荷耦合器件(CCD)的研发。它是一种将光子转化为电脉冲的器件,很快成为了高质量数字图像采集任务的新宠,逐渐应用于工业相机传感器,标志着计算机视觉走上应用舞台,投入到工业机器视觉中。
3、20世纪70年代:理论体系
出现课程和明确理论体系
MIT的人工智能实验室在计算机视觉领域中发挥了相当积极的推动作用。
- 一方面,它于20世纪70年代设置了机器视觉(Machine Vision)课程;
- 同时人工智能实验室还吸引了全球很多研究人员参与到计算机视觉的理论和实践研究中。
70年代中期,麻省理工学院(MIT)人工智能(AI)实验室:CSAIL正式开设计算机视觉课程。

David Marr 教授在计算机视觉理论方面做出了非常多的贡献。他融合了心理学、神经生理学、数学等多门学科,提出了有别于前人的计算机视觉分析理论,并在前后二十年的时间里影响了这一领域的发展。
- 主要著作:Vision: A computational investigation into the human representation and processing of visual information
- 由于David在1980年不幸病逝,这本书据说是由其学生归纳总结出来的
- 书中将视觉识别过程划分为三个阶段


1977年David Marr在MIT的AI实验室提出了,计算机视觉理论(Computational Vision),这是与 Lawrence Roberts当初引领的积木世界分析方法截然不同的理论。计算机视觉理论成为80年代计算机视觉重要理论框架,使计算机视觉有了明确的体系,促进了计算机视觉的发展。
4、20世纪80年代:独立学科应用
独立学科形成,理论从实验室走向应用
20世纪80年代,逻辑学和知识库等理论在人工智能领域占据了主导地位。人们试图建立专家系统来存储先验知识,然后与实际项目中提取的特征进行规则匹配。这种思想也同样影响了计算机视觉领域,于是诞生了很多这方面的方法。
- David G. Lowe在论文“Three-Dimensional Object Recognition from Single Two-Dimensional Images”中提出了基于知识的视觉(Knowledge-based Vision)的概念
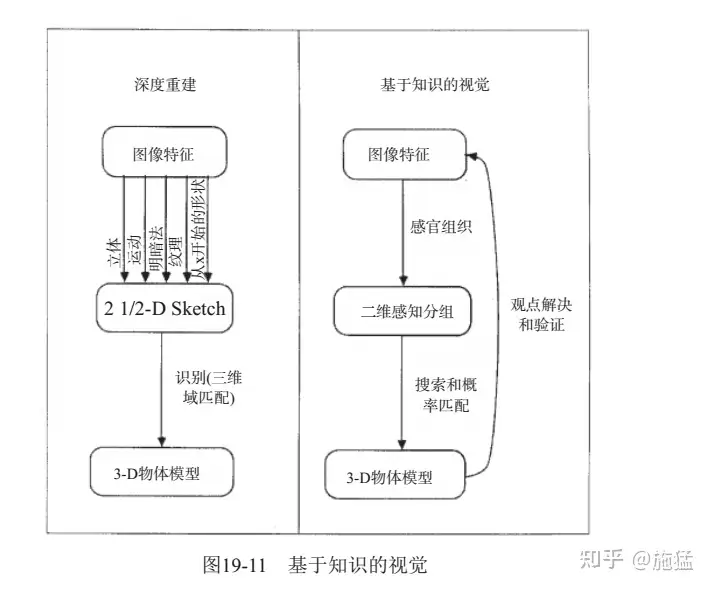
1980年,日本计算机科学家 Kunihiko Fukushima 在 Hubel 和 Wiesel 的研究启发下,建立了一个自组织的简单和复杂细胞的人工网络——Neocognitron,包括几个卷积层(通常是矩形的),他的感受野具有权重向量(称为滤波器)。
- 这些
滤波器的功能是在输入值的二维数组(例如图像像素)上滑动,并在执行某些计算后,产生激活事件(2维数组),这些事件将用作网络后续层的输入。Fukushima 的 Neocognitron 可以说是第一个神经网络,是现代 CNN 网络中卷积层+池化层的最初范例及灵感来源。
1982年,David Marr 发表了有影响的论文–“愿景:对人类表现和视觉信息处理的计算研究”。基于Hubel和Wiesel的想法视觉处理不是从整体对象开始, David介绍了一个视觉框架,其中检测边缘,曲线,角落等的低级算法被用作对视觉数据进行高级理解的铺垫。
- 同年《视觉》(Marr, 1982)一书的问世,标志着计算机视觉成为了一门独立学科。

1982年 日本COGEX公司于生产的视觉系统 DataMan,是世界第一套工业光学字符识别(OCR)系统。
1989年,法国的 Yann LeCun 将一种后向传播风格学习算法应用于 Fukushima 的卷积神经网络结构。在完成该项目几年后,LeCun 发布了LeNet-5 – 第一个引入今天仍在CNN中使用的一些基本成分的现代网络。现在卷积神经网络已经是图像、语音和手写识别系统中的重要组成部分。
5、20世纪90年代:特征对象识别
特征对象识别开始成为重点
此时计算机视觉虽然已经发展了几十年,但仍然没有得到大规模的应用,很多理论还处于实验室的水平,离商用要求相去甚远。
- 人们逐渐认识到计算机视觉是一个非常难的问题,以往的尝试似乎都过于“复杂”,于是有的学者开始“转向”另一个看上去更简单点儿的方向—图像分割(Image Segmentation)。后者的目标在于运用一些图像处理方法将物体分离出来,以此作为图像分类的第一步。
另外,伴随着统计学理论在人工智能中的逐渐“走红”,计算机视觉在20世纪90年代也同样经历了这个转折。学者们利用统计学手段来提取物体的本质特征描述,而不是由人工去定义这些规则。这一时期产生的多种基础理论直到现在还有广泛的应用,例如图像搜索引擎。
1997年,伯克利教授 Jitendra Malik(以及他的学生Jianbo Shi)发表了一篇论文,试图解决感性分组的问题。研究人员试图让机器使用图论算法将图像分割成合理的部分(自动确定图像上的哪些像素属于一起,并将物体与周围环境区分开来)
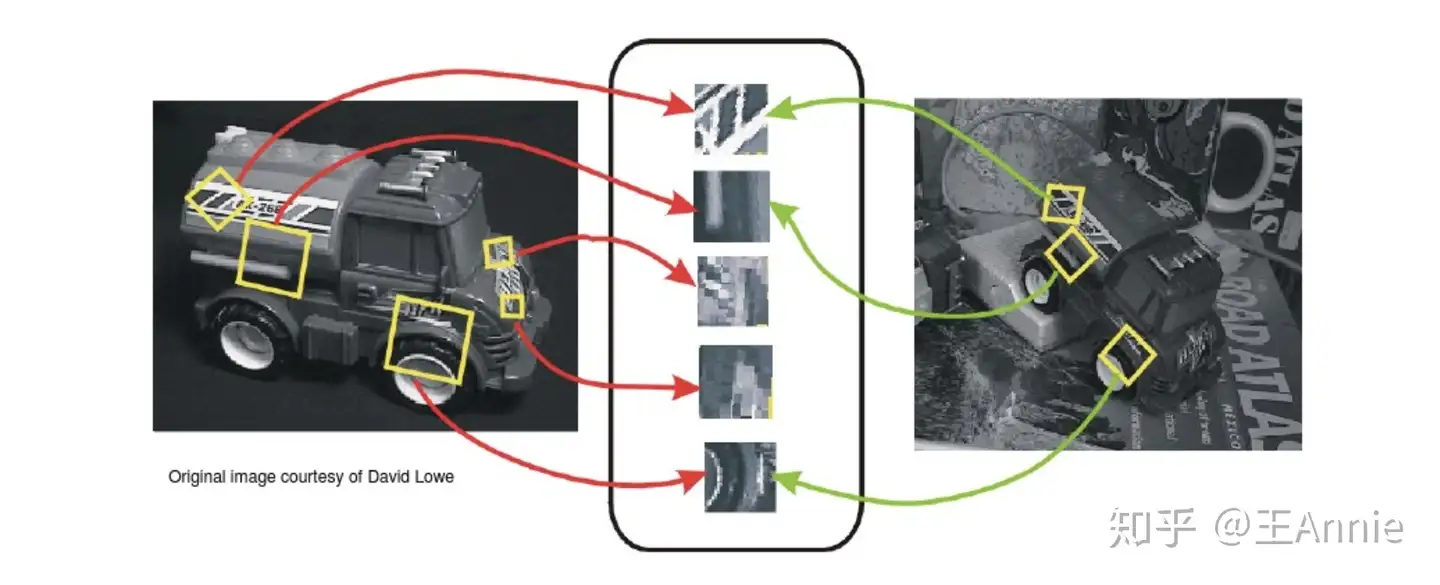
1999年, David Lowe 发表《基于局部尺度不变特征(SIFT特征)的物体识别》,标志着研究人员开始停止通过创建三维模型重建对象,而转向基于特征的对象识别。

1999年,Nvidia 公司在推销 Geforce 256芯片时,提出了GPU概念。GPU是专门为了执行复杂的数学和集合计算而设计的数据处理芯片。伴随着GPU发展应用,游戏行业、图形设计行业、视频行业发展也随之加速,出现了越来越多高画质游戏、高清图像和视频。
6、21世纪初:图像特征工程
随着机器学习的兴起,CV领域开始取得一些实际的应用进展。
- Paul Viola和Michael Johns等人利用Adaboost算法出色地完成了人脸的实时检测,并被富士公司应用到商用产品中;同时SPM、HoG、DPM等经典算法也如“雨后春笋”般涌现了出来。

图像特征工程,出现真正拥有标注的高质量数据集
- 2001年,Paul Viola 和 Michael Jones 推出了第一个实时工作的人脸检测框架。虽然不是基于深度学习,但算法仍然具有深刻的学习风格,因为在处理图像时,通过一些特征可以帮助定位面部。该功能依赖于Viola / Jones算法,五年后,Fujitsu 发布了一款具有实时人脸检测功能的相机。
- 2005年,由 Dalal & Triggs 提出来方向梯度直方图,
HOG(Histogramof Oriented Gradients)应用到行人检测上。是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征方法。 - 2006年,Lazebnik, Schmid & Ponce 提出一种利用空间金字塔即
SPM(Spatial Pyramid Matching)进行图像匹配、识别、分类的算法,是在不同分辨率上统计图像特征点分布,从而获取图像的局部信息。 - 2006年,Pascal VOC项目启动。它提供了用于对象分类的标准化数据集以及用于访问所述数据集和注释的一组工具。创始人在2006年至2012年期间举办了年度竞赛,该竞赛允许评估不同对象类识别方法的表现。检测效果不断提高。
- 2006年左右,Geoffrey Hilton 和他的学生发明了用GPU来优化深度神经网络的工程方法,并发表在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”。随后深度学习的研究大放异彩,广泛应用在了图像处理和语音识别领域,他的学生后来赢得了2012年 ImageNet 大赛,并使CNN家喻户晓。
- 2009年,由 Felzenszwalb 教授在提出基于 HOG 的 deformable parts model(DPM),可变形零件模型开发,它是深度学习之前最好的最成功的objectdetection & recognition算法。它最成功的应用就是检测行人,目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予”终身成就奖”。
- 图片来源 http://www.360doc.com/content/14/0722/16/10724725_396297961.shtml
7、2010年-至今:深度学习
大家有幸正在经历人工智能大爆发的这个历史阶段—-包括计算机视觉在内的多项人工智能领域取得了长足的进步。
- ① 计算机运算能力呈现指数级的增长。
- ② ImageNet、PASCAL等超大型图片数据库使得深度学习训练成为可能
- 注:大型图片数据库虽然在2000年后期就已经出现了,但真正大放异彩还是在最近十年
- 同时,业界一些极具影响力的竞赛项目(例如ILSVRC)激励了全世界范围内的学者们竞相加入,从而催生了一个又一个优秀的深度学习框架。
深度学习在视觉中的流行,在应用上百花齐放
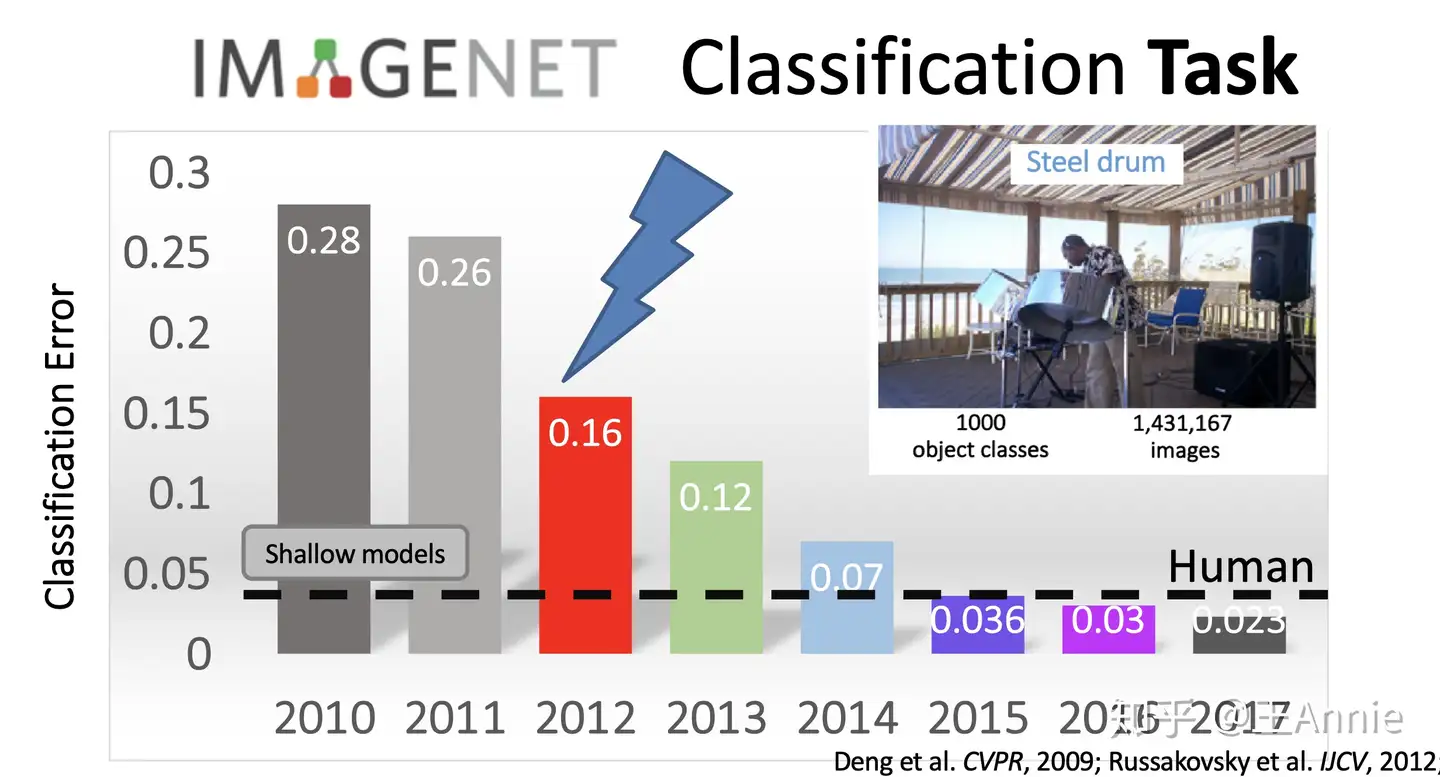
2009年,李飞飞教授等在 CVPR2009 上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,发布了ImageNet数据集,这是为了检测计算机视觉能否识别自然万物,回归机器学习,克服过拟合问题,经过三年多在筹划组建完成的一个大的数据集。从10年-17年,基于ImageNet数据集共进行了7届ImageNet挑战赛,李飞飞说
- ImageNet改变了AI领域人们对数据集的认识,人们真正开始意识到它在研究中的地位,就像算法一样重要
ImageNet是计算机视觉发展的重要推动者,和深度学习热潮的关键推动者,将目标检测算法推向了新的高度。

2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 创造了一个“大型的深度卷积神经网络”,即现在众所周知的 AlexNet,赢得了当年的 ILSVRC。这是史上第一次有模型在 ImageNet 数据集表现如此出色。
- 论文“ImageNet Classification with Deep Convolutional Networks”,迄今被引用约 7000 次,被业内普遍视为行业最重要的论文之一,真正展示了 CNN 的优点。机器识别的错误率从25%左右。降低了百分之16%左右,跟人类相比差别不大。是自那时起,CNN 才成了家喻户晓的名字。
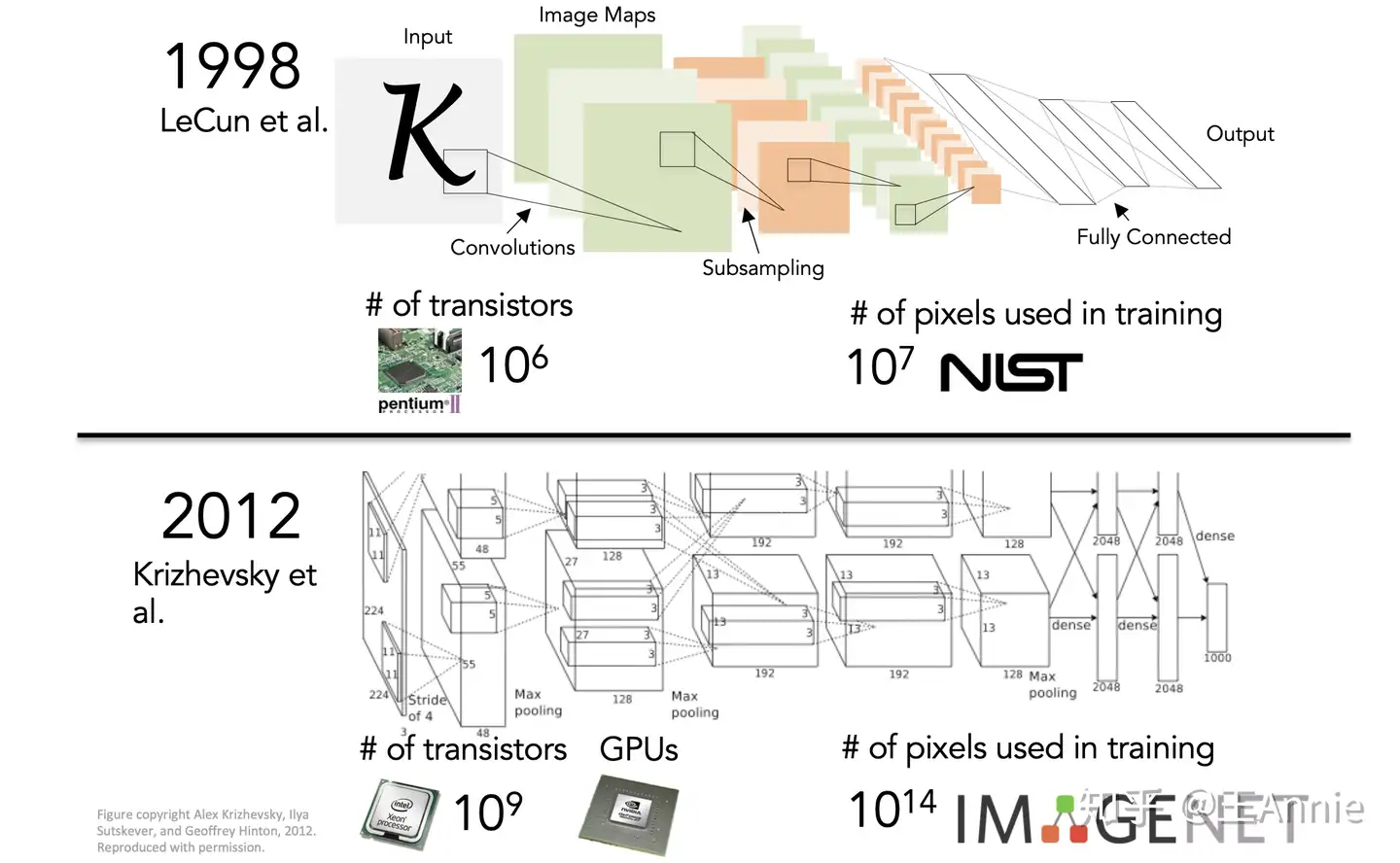
- 图片来源 http://cs231n.stanford.edu/
2014年,蒙特利尔大学提出生成对抗网络(GAN):拥有两个相互竞争的神经网络可以使机器学习得更快。一个网络尝试模仿真实数据生成假的数据,而另一个网络则试图将假数据区分出来。随着时间的推移,两个网络都会得到训练,生成对抗网络(GAN)被认为是计算机视觉领域的重大突破。
2017-2018 年深度学习框架的开发发展到了成熟期。PyTorch 和 TensorFlow 已成为首选框架,都提供了针对多项任务(包括图像分类)的大量预训练模型。
近年来,国内外巨头纷纷布局计算机视觉领域,开设计算机视觉研究实验室。以计算机视觉新系统和技术赋能原有的业务,开拓战场。
- 如Facebook 的 AI Research(FAIR)在视觉方面2016年声称其 DeepFace 人脸识别算法有着 97.35% 的识别准确率,几乎与人类不分上下。
- 2017,Lin, Tsung-Yi等提出特征金字塔网络,可以从深层特征图中捕获到更强的语义信息。同时提出 Mask R-CNN,用于图像的实例分割任务,它使用简单、基础的网络设计,不需要多么复杂的训练优化过程及参数设置,就能够实现当前最佳的实例分割效果,并有很高的运行效率。
- 2016,亚马逊收购了一支欧洲顶级计算机视觉团队,为 Prime Air无人机加上识别障碍和着陆区域的能力, 开发无人机送货。
- 2017年亚马逊网络服务(AWS)宣布对其识别服务进行了一系列更新,为云客户提供基于机器学习的计算机视觉功能。客户将能够在数百万张面孔的集合上进行实时人脸搜索。例如,Rekognition 可用于验证一个人的图像与现有数据库中的另一个图像相匹配,数据库高达数千万个图像,具有亚秒级延迟。
- 2018年末,英伟达发布的视频到视频生成(Video-to-Video synthesis),它通过精心设计的发生器、鉴别器网络以及时空对抗物镜,合成高分辨率、照片级真实、时间一致的视频,实现了让AI更具物理意识,更强大,并能够推广到新的和看不见的更多场景。
- 2019, BigGAN,同样是一个GAN,只不过更强大,是拥有了更聪明的课程学习技巧的GAN,由它训练生成的图像连它自己都分辨不出真假,因为除非拿显微镜看,否则将无法判断该图像是否有任何问题,因而,它更被誉为史上最强的图像生成器。
- 2020年5月末,Facebook发布新购物AI,通用计算机视觉系统GrokNet让“一切皆可购买”。

- 图片来源https://baijiahao.baidu.com/s?id=1667315579098237070&wfr=spider&for=pc
知识体系
内容:
教程
【2022-12-28】
【CMU】cv
CMU计算机视觉课程:16-385 Computer Vision, Spring 2020, 包含ppt
- Course Description
- This course provides a comprehensive introduction to computer vision. Major topics include image processing, detection and recognition, geometry-based and physics-based vision and video analysis. Students will learn basic concepts of computer vision as well as hands on experience to solve real-life vision problems.
Syllabus
- Introduction 计算机视觉介绍
- Image filtering 图像过滤
- Image pyramids and Fourier transform 图像金字塔与傅里叶变换
- Hough transform 霍夫变换
- Feature and corner detection 角点检测
- Feature descriptors and matching 特征匹配
- 2D transformations 二维变换
- Image homographies 单应图像
- Camera models 相机模型
- Two-view geometry 双视点几何
- Stereo 立体影响
- Radiometry and reflectance 辐射测量和反射率
- Photometric stereo and shape from shading 立体与阴影形状
- Image processing pipeline 图像处理流程
- Image classification 图像分类
- Bag of works
- Neural networks 神经网络
- Convolutional neural networks 卷积神经网络
- Optical flow 光流
- Alignment 对齐
- Tracking 跟踪
- Segmentation 图像分割
- graph-based techniques 图形学
- Structure from motion and wrap-up 运动结构
【斯坦福】cs231n
- 斯坦福cs 231, CS231n 是顶级院校斯坦福出品的深度学习与计算机视觉方向专业课程,核心内容覆盖神经网络、CNN、图像识别、RNN、神经网络训练、注意力机制、生成模型、目标检测、图像分割等内容。
- 解读:深度学习与CV教程
目录
- CV引言与基础
- 图像分类与机器学习基础
- 损失函数与最优化
- 神经网络与反向传播
- 卷积神经网络
- 神经网络训练技巧 (上)
- 神经网络训练技巧 (下)
- 常见深度学习框架介绍
- 典型CNN架构 (Alexnet, VGG, Googlenet, Restnet等)
- 轻量化CNN架构 (SqueezeNet, ShuffleNet, MobileNet等)
- 循环神经网络及视觉应用
- 目标检测 (两阶段, R-CNN系列)
- 目标检测 (SSD, YOLO系列)
- 图像分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 视觉模型可视化与可解释性
- 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度强化学习 (马尔可夫决策过程, Q-Learning, DQN)
- 深度强化学习 (梯度策略, Actor-Critic, DDPG, A3C)
计算机视觉任务
示例
【2023-4-7】visive.ai
Image Recognition is natural for humans, but now even computers can achieve good performance to help you automatically perform tasks that require computer vision.
- Tagging
- Classification
- Object Detection
- Scene information
Object Detection & Segmentation
- AI can instantly detect people, products & backgrounds in the images
| 任务 | 示例 | 备注 |
|---|---|---|
| 原图 |  |
|
| 目标检测 |  |
|
| 姿态估计 |  |
|
| 图像分割 |  |
|
| 图像分割 |  |
|
| 图像分割 |  |
任务
计算机视觉有四个核心任务:图像分类、物体检测、语义分割和视频分析。
- (1)
图像分类(image classification):给定一张输入图像,图像分类任务旨在判断该图像所属类别。 - (2)
目标检测(Object Recognition):相对于目标定位,目标种类和数目不定。目标定位:以包围框的(bounding box)形式得到图像类别位置,通常只有一类目标或固定数目的目标和背景类。- 详见专题文章:目标检测
- (3)
图像分割(Image Segmentation)语义分割(Semantic Segmentation):语义分割需要判断图像中哪些像素属于哪个目标。实例分割(Instance Segmentation):语义分割不区分属于相同类别的不同实例。
- (4)视频分析(Video Analysis)
从核心任务到人脸支付、自动驾驶、影像辅助诊断等落地的真实应用,中间还衍生了许多同样很重要的任务。
人体姿态识别,可以让我们更好地理解运动员的动作方式,或是识别、预测人类的行为;目标跟踪,即对视频中的人脸、车辆等目标进行持续的识别和跟随,在安防等领域有非常广泛的应用;SLAM可以通过视频图像对现实空间进行重建OCR则是识别图片中的字符,将图片转换为文字。详见站内专题 OCR

除此之外,还有边缘检测、细粒度识别、稠密运动估计等任务。这些任务之间交叉组合,有时还会结合 NLP 、语音识别等技术,最终才变成了真正的落地应用。

例如,当图像中有多只猫时
语义分割会将两只猫整体的所有像素预测为“猫”这个类别。实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。
难点
- 语义鸿沟,拍摄视角变化,目标占据图像的比例变化,光照变化,背景相似,目标形变,遮挡。
作者:离殇花开
专题
核心应用和关键知识点
- 基础部分:图像安全(加密、解密、信息隐藏、隐身)、图像识别(答题卡、手势、车牌、指纹、数字)、物体计数、图像检索、次品排查等。
- 机器学习:KNN字符识别(数字、字母)、数独求解(KNN)、SVM数字识别、行人检测、艺术画(K均值聚类)等。
- 深度学习:图像分类、目标检测(YOLO、SSD方法)、语义分割、实例分割、风格迁移、姿势识别等。
- 人脸相关:人脸检测、人脸识别、勾勒五官、人脸对齐、表情识别、疲劳驾驶检测、易容术、性别与年龄识别等。
案例:
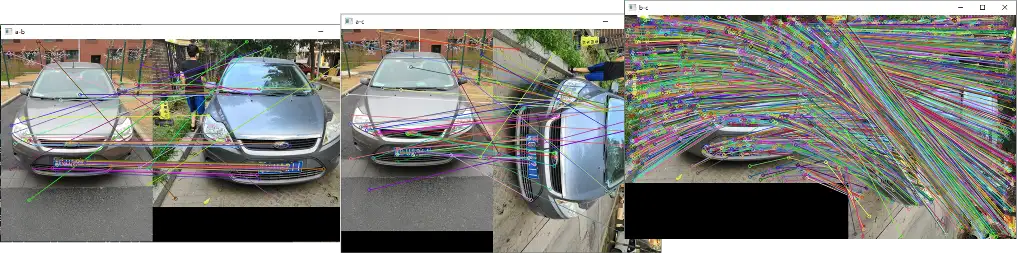
特征识别
特征匹配
图像处理
详见站内专题: 数字图像处理
图像滤波

风格迁移

图像识别
任务
- 数字识别
- 人脸识别
- 属性识别
- 手势识别
- 缺陷识别
- 车牌设别
数字识别
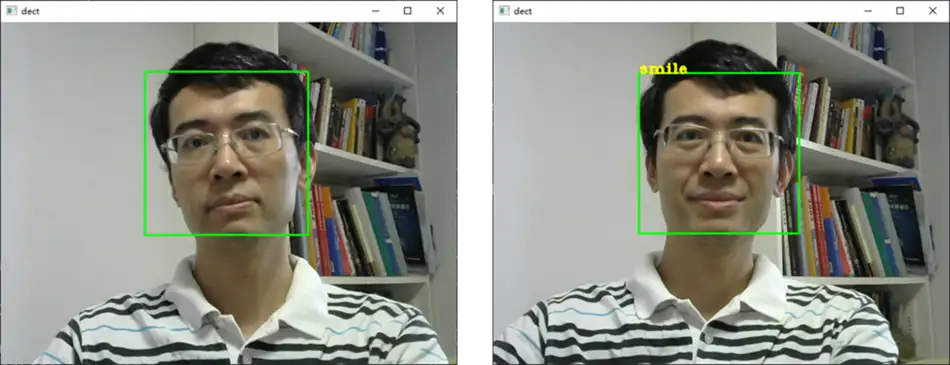
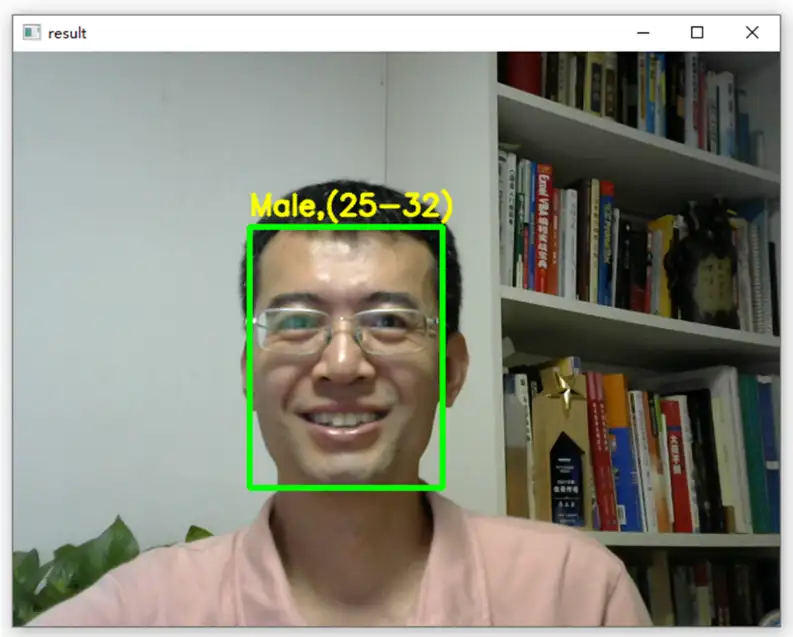
人脸识别

属性识别(年龄、性别)
手势识别

【2022-12-29】隐形键盘要来了?鲍哲南等人开发新型智能皮肤,可实现手部任务快速识别
- 在隐形键盘上打字、仅凭触摸就能识别物体、通过手势便可以实现与应用程序的交互。
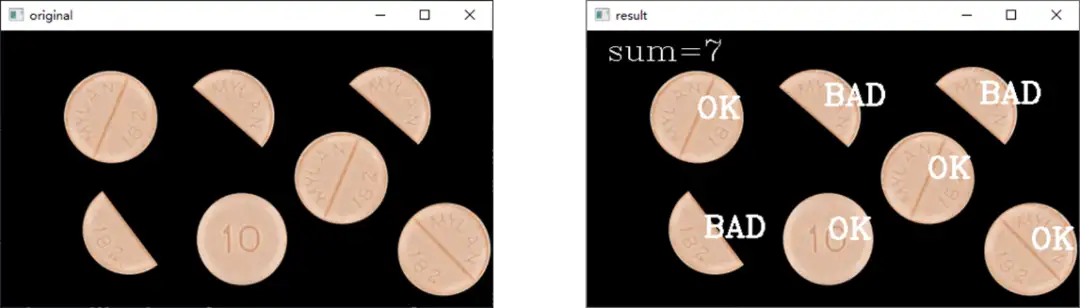
缺陷检测
车牌识别

【2024-9-6】Pytorch实现车牌识别, 含代码实现,效果示例
疲劳驾驶检测
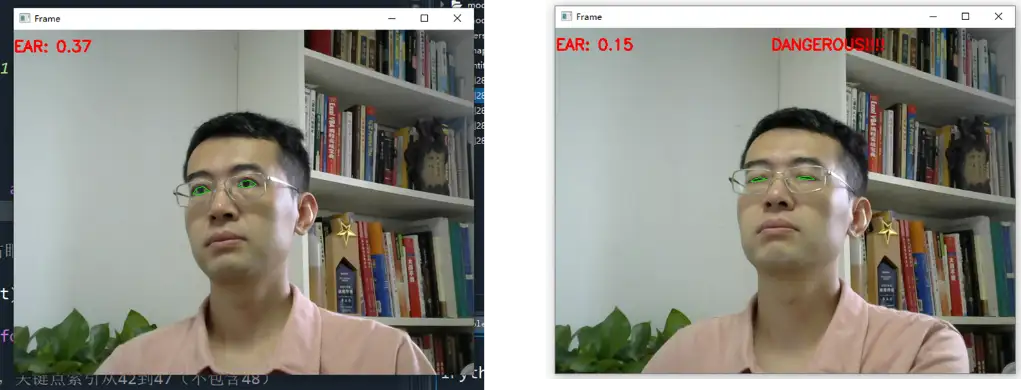
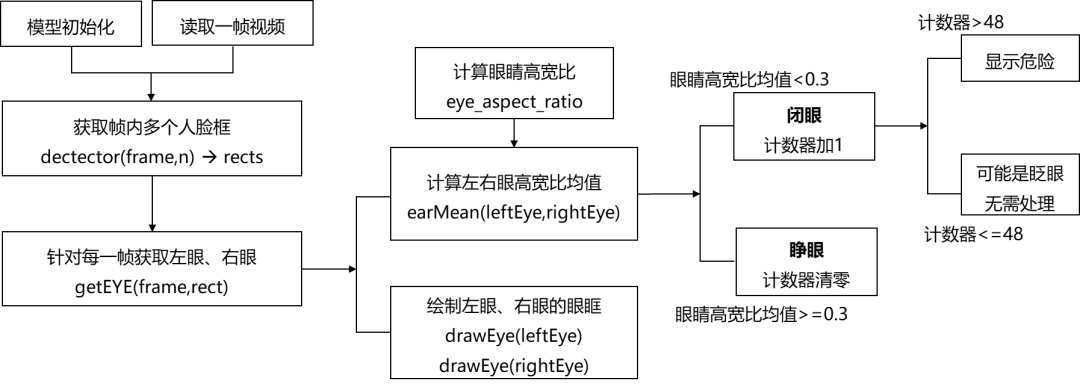
OCR
详见站内专题 OCR
人脸识别
2017年,FBI高级官员向国会报告称:“面部识别系统使用Idemia技术扫描3000万张照片,有助于‘保护美国公民’。”
- 法国Idemia的公司,人脸识别软件已经在为美国、澳大利亚和法国的警方提供服务。
- 这个软件会根据海关或者边境保护局的记录,检查一些在美国着陆乘客的面部特征。
人脸识别系统中,错误识别概率超过万分之一是一个评判标准。
但 Idemia 算法并不能对所有面孔都做到精准识别。
Idemia美国公共安全部门主管Donnie Scott表示:
- “NIST测试的算法尚未在商业上发布,该公司在产品开发过程中会检查人口统计学差异。人与人之间存在身体差异,算法将以不同的速度对不同的人进行改进。”
最先进的人脸识别算法依旧无法应对深色皮肤面孔
美国国家标准与技术研究所(National Institute of Standards and Technology,NIST) 7月份的测试结果显示
- 比起白人和黑人男性,系统更容易混淆黑人女性。
NIST用两张相同的面部照片去测试算法
- Idemia 算法错误匹配白人女性面孔的概率约为万分之一
- 而错误匹配黑人女性面孔的概率却为千分之一
- 概率增长了10倍之多。
参考 NIST:黑人遭人脸识别技术“误判”概率高出白人5至10倍
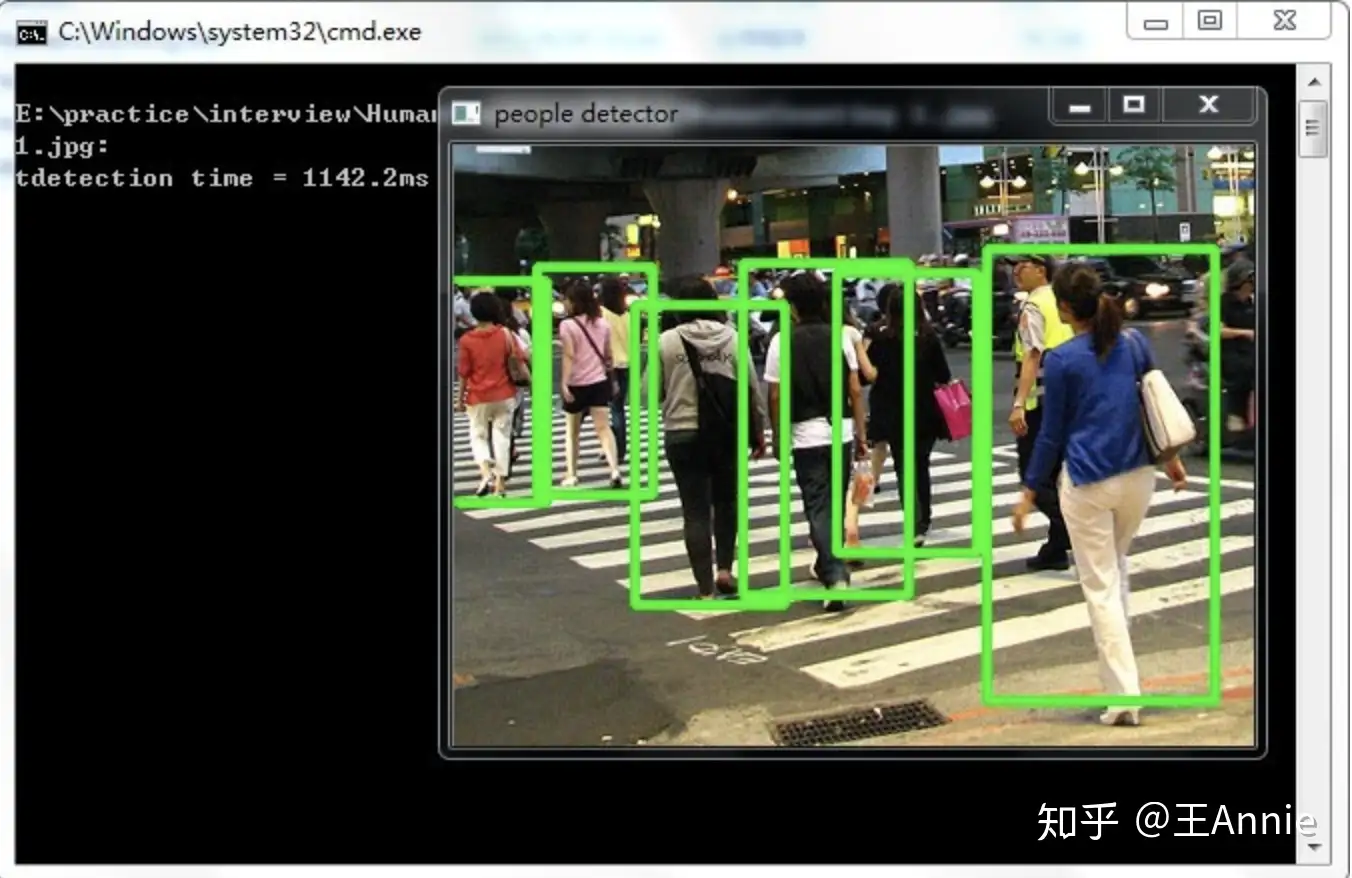
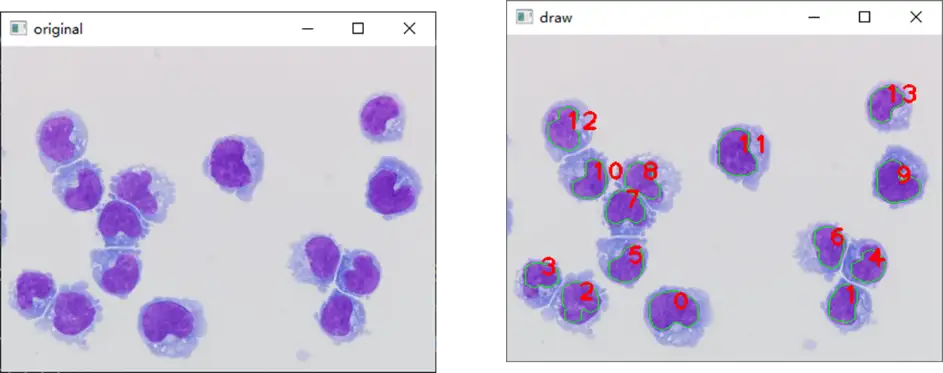
目标检测
行人检测
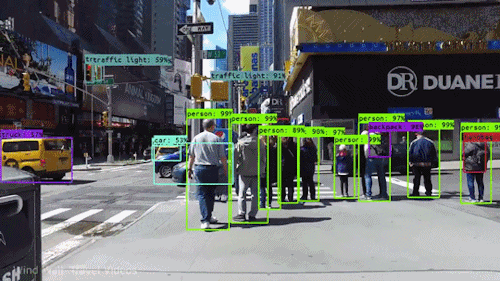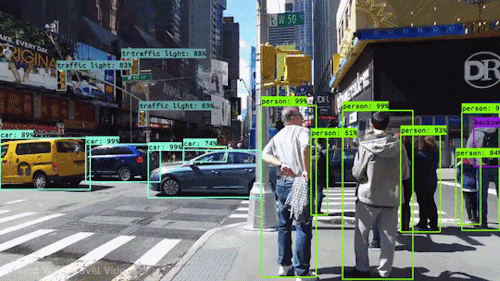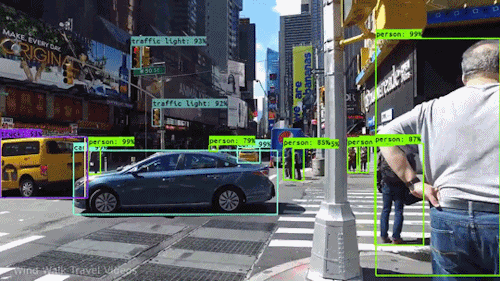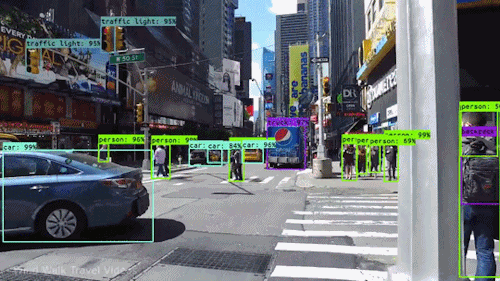
目标计数
姿势识别

详见站内专题 目标检测及跟踪
图像分割
语义分割与实例分割

Segment Anything (SAM)
【2023-4-6】Meta 于宣布推出 Segment Anything 工具,可准确识别图像中的对象。
SAM 是一种革命性的图像分割模型。以其卓越的性能而著称,SAM 已巩固了其作为最先进的分割模型之一的地位。SAM 在图像分割技术方面代表了一项突破性的进展,提供了前所未有的精确性和多功能性。与传统的受特定对象类型或环境限制的分割模型不同,SAM 凭借先进的神经网络架构和在大型数据集上进行的广泛训练,能够以无与伦比的准确性分割图像中的几乎任何对象。
该项目包括模型、数据集。
- 该模型名为 Segment Anything Model(SAM),其数据集名称为 Segment Anything 1-Billion mask dataset(SA-1B)

- Segment Anything (SA) 项目:用于图像分割的新任务、模型和数据集。在数据收集循环中使用我们的高效模型,我们构建了迄今为止最大的分割数据集,在 1100 万张图像上有超过 10 亿个掩码。
Meta 官方表示这是有史以来最大的分割数据集(Segmentation Dataset)
Segment Anything 图像分割
- 从NLP中获得灵感。通过prompt工程解决各种下游任务,通过定义类似的任务,建立用于分割的基础模型。

Zero-Shot Edge Detection 零样本边缘检测
- 该模型被设计和训练为可提示的,因此它可以将零样本转移到新的图像分布和任务中。评估了它在众多任务上的能力,发现它的零样本性能令人印象深刻——通常与之前的完全监督结果具有竞争力,甚至优于之前的结果。

SAM 关键特性:
- 多功能性:SAM 设计用于分割图像中的任何事物,从日常物品到复杂场景,具备出色的准确性和细节。
- 鲁棒性:得益于其复杂的架构和在多样化数据集上的广泛训练,SAM 在各种场景中表现出色,包括不同的光照条件和物体方向。
- 规模:SAM 能够处理不同分辨率和规模的图像,适用于高分辨率图像和实时应用。
- 上下文理解:SAM 整合了上下文信息,以提高分割精度,甚至在杂乱场景中也能有效地区分对象与其环境。
- 效率:尽管具备先进功能,SAM 仍保持高效率,确保快速处理速度,非常适合实时应用。
- 适应性:SAM 可以为特定任务或数据集进行微调和定制,允许无缝集成到各种应用和行业中。
SAM 2
Segment Anything Model 2 (SAM 2)
SAM 实践
SAM 处理图像:
步骤1:首先从 GitHub 仓库下载 SAM 模型。
import os
HOME = os.getcwd()
pip install roboflow ultralytics 'git+https://github.com/facebookresearch/segment-anything.git'
步骤2:安装 SAM 模型的权重,可以从 SAM 的 GitHub 仓库获取。
%cd {HOME}/weights
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
步骤3:验证是否已成功下载 SAM 权重文件。
import os
CHECKPOINT_PATH = os.path.join(HOME, "weights", "sam_vit_h_4b8939.pth")
print(CHECKPOINT_PATH, "; exist:", os.path.isfile(CHECKPOINT_PATH))
步骤4:加载模型。
import torch
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
MODEL_TYPE = "vit_h"
sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)
步骤5:初始化掩码生成器。
mask_generator = SamAutomaticMaskGenerator(sam)
步骤6:为图像生成掩码。sam_result 变量包含生成的掩码。
import cv2
import supervision as sv
image_bgr = cv2.imread("path/to/image")
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
sam_result = mask_generator.generate(image_rgb)
掩码生成返回一个包含多个掩码的列表,每个掩码都是一个包含各种数据的字典。这些键包括:
- Segmentation:掩码
- area:掩码的像素面积
- bbox:掩码的边界框,格式为 XYWH
- predicted_iou:模型对掩码质量的自我预测
- point_coords:生成该掩码的采样输入点
- stability_score:掩码质量的附加度量
- crop_box:用于生成该掩码的图像裁剪框,格式为 XYWH
print(len(masks))
print(sam_results[0].keys())
步骤7:结果
mask_annotator = sv.MaskAnnotator(color_lookup = sv.ColorLookup.INDEX)
detections = sv.Detections.from_sam(sam_result=sam_result)
annotated_image = mask_annotator.annotate(scene=image_bgr.copy(), detections=detections)
sv.plot_images_grid(
images=[image_bgr, annotated_image],
grid_size=(1, 2),
titles=['source image', 'segmented image']
)
Inpaint-Anything
【2023-4-13】【Inpaint-Anything:SAM + 补全模型实现自动化清除图像里包含的目标】

来自中国科学技术大学和东方理工高等研究院的研究团队给出了令人惊艳的答案。基于 SAM,他们提出「修补一切」(Inpaint Anything,简称 IA)模型。区别于传统图像修补模型,IA 模型无需精细化操作生成掩码,支持了一键点击标记选定对象,IA 即可实现移除一切物体(Remove Anything)、填补一切内容(Fill Anything)、替换一切场景(Replace Anything),涵盖了包括目标移除、目标填充、背景替换等在内的多种典型图像修补应用场景。
尽管当前图像修补系统取得了重大进展,但它们在选择掩码图和填补空洞方面仍然面临困难。基于 SAM,研究者首次尝试无需掩码(Mask-Free)图像修复,并构建了「点击再填充」(Clicking and Filling) 的图像修补新范式,他们将其称为修补一切 (Inpaint Anything)(IA)。IA 背后的核心思想是结合不同模型的优势,以建立一个功能强大且用户友好的图像修复系统。
IA 拥有三个主要功能:
- (i) 移除一切(Remove Anything):用户只需点击一下想要移除的物体,IA 将无痕地移除该物体,实现高效「魔法消除」;
- (ii) 填补一切(Fill Anything):同时,用户还可以进一步通过文本提示(Text Prompt)告诉 IA 想要在物体内填充什么,IA 随即通过驱动已嵌入的 AIGC(AI-Generated Content)模型(如 Stable Diffusion)生成相应的内容填充物体,实现随心「内容创作」;
- (iii) 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体对象,并用文本提示告诉 IA 想要把物体的背景替换成什么,即可将物体背景替换为指定内容,实现生动「环境转换」。
「移除一切」步骤如下:
- 第 1 步:用户点击想要移除的物体;
- 第 2 步:SAM 将该物体分割出来;
- 第 3 步:图像修补模型(LaMa)填补该物体。
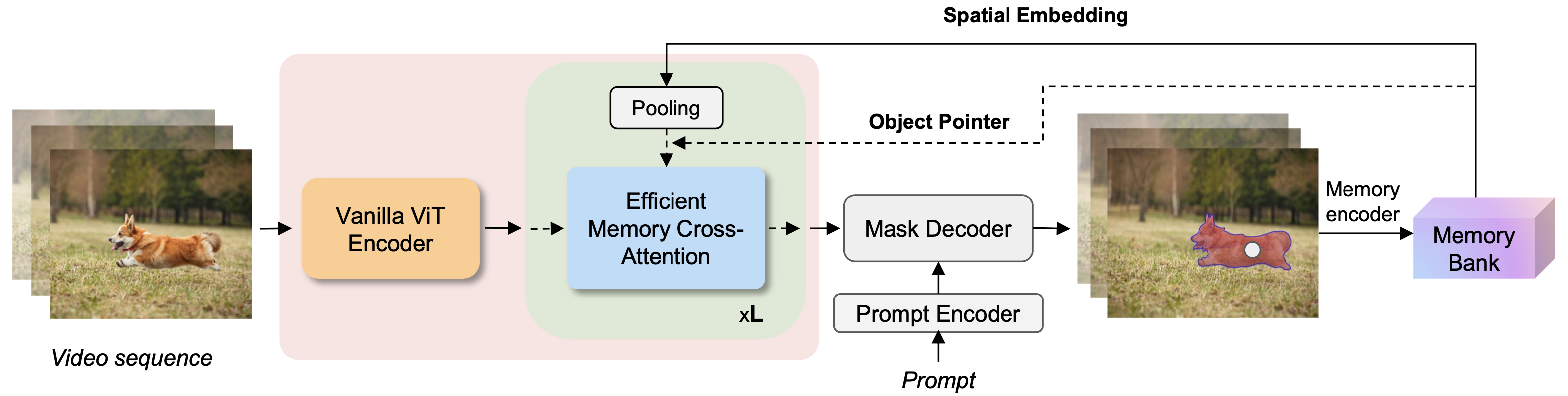
EfficientTAM
SAM 效果虽好,但消耗的计算资源多
EfficientTAMs 可以在终端设备(手机)上达到同等效果
- iPhone 15 Pro Max 上执行视频目标分割
【2024-12-4】EfficientTAM:让手机也能高效跑视频分割
- 代码:EfficientTAM
- 项目主页:efficient-track-anything
效果
Sa2VA
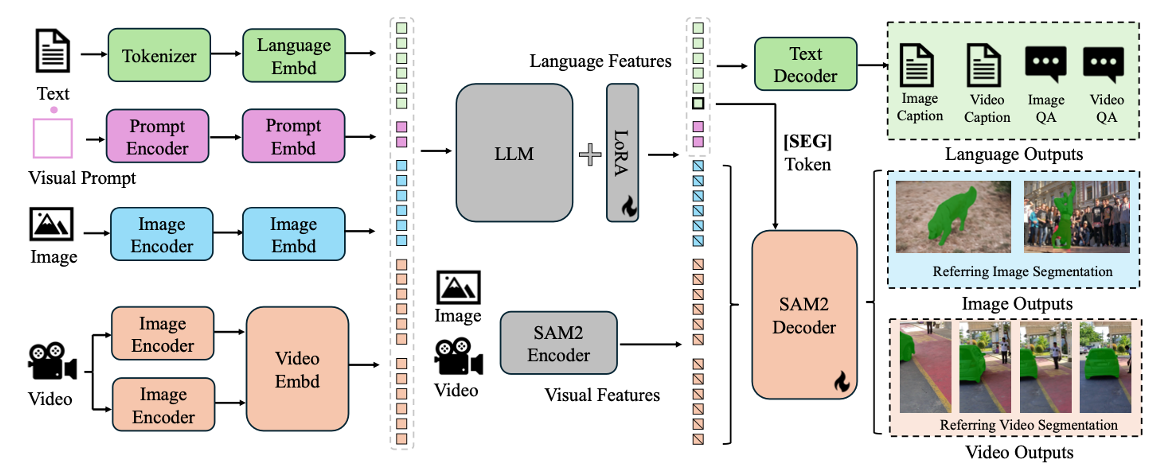
【2025-1-7】字节、武大 Sa2VA:融合SAM-2与LLaVA的强大引擎
- 论文 Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
- 代码:Sa2VA
- 主页:Sa2VA
- 演示视频
模型结构
SpatialLM
3D 点云计算及物体分割, 详见: 三维重建-SpatialLM
图像描述
【2025-11-16】ComfyUI - 使用 Joy Caption 模型 描述和打标 图像数据集 (Image Caption)
Joy Caption 模型 (由 Fancy Feast 研发) 在 SigLIP 和 Llama3.1 的基础之上,使用 Adapter 模式,训练出更好的描述图像的模型,需要与 SigLIP 和 Llama3.1 混合使用,输入图像,输出一段语义丰富的图像描述。
Google 的 SigLIP (Sigmoid Loss for Language Image Pre-Training) 是一种改进的多模态模型,类似于 CLIP,但是采用了更优的损失函数。
Meta-Llama-3.1-8B-bnb-4bit 是优化的多语言大语言模型,基于 Meta 的 Llama 3.1 架构,使用 BitsAndBytes 库进行 4-bit 量化,大幅减少内存使用,同时保持模型性能。
信息安全
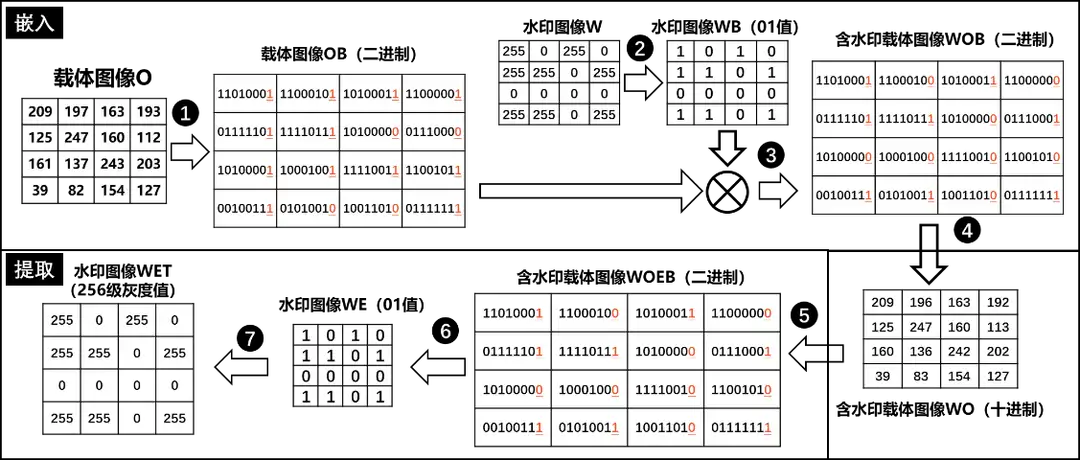
数字水印
隐身术

图像检索
图像哈希

Bing 图片搜索
支持功能
- Find chairs like this 输入图片
- Search for navy heels 输入文本
- Find similar images
- Explore landmarks 地标景点
- This looks like a… 输入图片,文本提示
- Pinpoint locations 景点打卡,输入图片
- Identify dog breeds 物种识别
- Shop for furniture 商品识别
风格迁移
风格迁移(style transfer)最近两年非常火,可谓是深度学习领域很有创意的研究成果。它主要是通过神经网络,将一幅艺术风格画(style image)和一张普通的照片(content image)巧妙地融合,形成一张非常有意思的图片。

因为新颖而有趣,自然成为了大家研究的焦点。目前已经有许多基于风格迁移的应用诞生了,如移动端风格画应用Prisma,手Q中也集成了不少的风格画滤镜:

对风格迁移的实现原理进行下简单介绍,然后介绍下它的快速版,即fast-style- transfer[^2]。
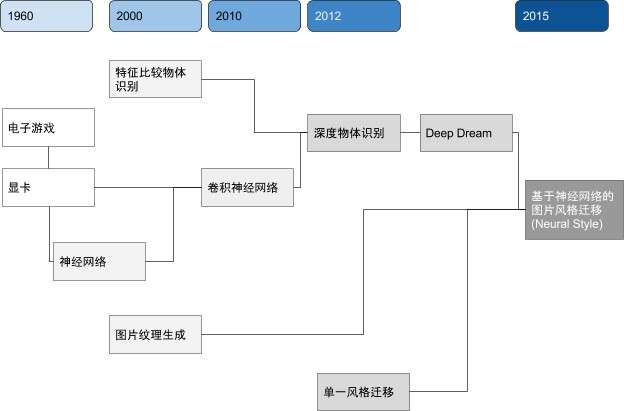
图像风格迁移科技树
风格化Demo
- 【2021-5-11】案例解析:用Tensorflow和Pytorch计算骰子值
- 【2020-12-04】AI姿势传递模型,论文地址,不愿意出节目的码农的年会神器?将舞蹈化为己用-视频
- 【2020-12-02】【MaskDetection:滴滴开源的口罩检测模型】 by DiDi GitHub
- 【2020-12-04】孪生网络用于图片搜索《Siamese networks with Keras, TensorFlow, and Deep Learning - PyImageSearch》by Adrian Rosebrock
- 【2022-10-8】北大博士的图像、视频风格化展示:williamyang1991,还有文本字体风格化

【2022-11-25】图像风格化工具
- ① Image to Sketch AI,caricature漫画;素描
- ② newprofilepic,多种风格可选
- ③ AnimeGANv2,卡通画,hugging face上
【2022-1-25】5个方便好用的Python自动化脚本
素描风格
自动生成素描草图
- 这个脚本可以把彩色图片转化为铅笔素描草图,对人像、景色都有很好的效果。而且只需几行代码就可以一键生成,适合批量操作,非常的快捷。
第三方库:
- Opencv - 计算机视觉工具,可以实现多元化的图像视频处理,有Python接口
安装
# 安装opencv的Python库
pip install opencv-python
示例
""" Photo Sketching Using Python """
import cv2
img = cv2.imread("elon.jpg")
## Image to Gray Image
gray_image = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
## Gray Image to Inverted Gray Image
inverted_gray_image = 255-gray_image
## Blurring The Inverted Gray Image
blurred_inverted_gray_image = cv2.GaussianBlur(inverted_gray_image, (19,19),0)
## Inverting the blurred image
inverted_blurred_image = 255-blurred_inverted_gray_image
### Preparing Photo sketching
sketck = cv2.divide(gray_image, inverted_blurred_image,scale= 256.0)
cv2.imshow("Original Image",img)
cv2.imshow("Pencil Sketch", sketck)
cv2.waitKey(0)
素描草图:马斯克
fast-style
- 图像风格迁移,深度学习之风格迁移简介
- Fast style transfer check demo


风格化案例
- 【2019-07-19】图像风格迁移示例
Real Time style transfer 实时风格迁移
Real Time style transfer check demo

1. 风格迁移开山之作
2015年,Gatys等人发表了文章[^1]《A Neural Algorithm of Artistic Style》,首次使用深度学习进行艺术画风格学习。把风格图像Xs的绘画风格融入到内容图像Xc,得到一幅新的图像Xn。则新的图像Xn:即要保持内容图像Xc的原始图像内容(内容画是一部汽车,融合后应仍是一部汽车,不能变成摩托车),又要保持风格图像Xs的特有风格(比如纹理、色调、笔触等)。
1.1 内容损失(Content Loss)
在CNN网络中,一般认为较低层的特征描述了图像的具体视觉特征(即纹理、颜色等),较高层的特征则是较为抽象的图像内容描述。 所以要比较两幅图像的内容相似性,可以比较两幅图像在CNN网络中高层特征的相似性(欧式距离)。

1.2 风格损失(Style Loss)
而要比较两幅图像的风格相似性,则可以比较它们在CNN网络中较低层特征的相似性。不过值得注意的是,不能像内容相似性计算一样,简单的采用欧式距离度量,因为低层特征包含较多的图像局部特征(即空间信息过于显著),比如两幅风格相似但内容完全不同的图像,若直接计算它们的欧式距离,则可能会产生较大的误差,认为它们风格不相似。论文中使用了Gram矩阵,用于计算不同响应层之间的联系,即在保留低层特征的同时去除图像内容的影响,只比较风格的相似性。

那么风格的相似性计算可以用如下公式表示:


1.3 总损失(Total Loss)
这样对两幅图像进行“内容+风格”的相似度评价,可以采用如下的损失函数:

1.4 训练过程
文章使用了著名的VGG19网络[3]来进行训练(包含16个卷积层和5个池化层,但实际训练中未使用任何全连接层,并使用平均池化average- pooling替代最大池化max-pooling)。

内容层和风格层的选择:将内容图像和风格图像分别输入到VGG19网络中,并将网络各个层的特征图(feature map)进行可视化(重构)。
内容重构五组对比实验:
-
- conv1_1 (a)
-
- conv2_1 (b)
-
- conv3_1 (c)
-
- conv4_1 (d)
-
- conv5_1 (e) 风格重构五组对比实验:
-
- conv1_1 (a)
-
- conv1_1 and conv2_1 (b)
-
- conv1_1, conv2_1 and conv3_1 (c)
-
- conv1_1, conv2_1, conv3_1 and conv4_1 (d)
-
- conv1_1, conv2_1, conv3_1, conv4_1 and conv5_1 (e)
通过实验发现:对于内容重构,(d)和(e)较好地保留了图像的高阶内容(high-level content)而丢弃了过于细节的像素信息;对于风格重构,(e)则较好地描述了艺术画的风格。如下图红色方框标记:

在实际实验中,内容层和风格层选择如下:
- 内容层:conv4_2
- 风格层:conv11, conv21, conv3__1, _conv4_1, conv5_1
- 训练过程:以白噪声图像作为输入(x)到VGG19网络,conv4_2层的响应与原始内容图像计算出内容损失(Content Loss),“conv1_1, conv2_1, conv3_1, conv4_1, conv5_1”这5层的响应分别与风格图像计算出风格损失,然后它们相加得到总的风格损失(Style Loss),最后Content Loss + Style Loss = Total Loss得到总的损失。采用梯度下降的优化方法求解Total Loss函数的最小值,不断更新x,最终得到一幅“合成画”。
1.5 总结
每次训练迭代,更新的参数并非VGG19网络本身,而是随机初始化的输入x; 由于输入x是随机初始化的,最终得到的“合成画”会有差异; 每生成一幅“合成画”,都要重新训练一次,速度较慢,难以做到实时。
2. 快速风格迁移
2016年Johnson等人提出了一种更为快速的风格迁移方法[2]《Perceptual losses for real-time style transfer and super- resolution》。
2.1 网络结构
它们设计了一个变换网络(Image Transform Net),并用VGG16网络作为损失网络(Loss Net)。输入图像经由变换网络后,会得到一个输出,此输出与风格图像、内容图像分别输入到VGG16损失网络,类似于[1]的思路,使用VGG16不同层的响应结果计算出内容损失和风格损失,最终求得总损失。然后使用梯度下降的优化方法不断更新变换网络的参数。
- 内容层:relu3_3
- 风格层:relu12, relu2_2, relu3_3, _relu4_3 其中变换网络(Image Transform Net)的具体结构如下图所示:

2.2 跑个实验
Johnson等人将论文的代码实现在github上进行了开源,包括了论文的复现版本,以及将“Batch-Normalization ”改进为“Instance Normalization”[4]的版本。咱们可以按照他的说明,训练一个自己的风格化网络。我这里训练了一个“中国风”网络,运行效果如下:

2.3 总结
网络训练一次即可,不像Gatys等人[1]的方法需要每次重新训练网络; 可以实现实时的风格化滤镜:在Titan X GPU上处理一张512x512的图片可以达到20FPS。下图为fast-style-transfer与Gatys等人[1]方法的运行速度比较,包括了不同的图像大小,以及Gatys方法不同的迭代次数。

- 参考资料
- Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style[J]. arXiv preprint arXiv:1508.06576, 2015.
- Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 694-711.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
- Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: The missing ingredient for fast stylization[J]. arXiv preprint arXiv:1607.08022, 2016.
- Fast Style Transfer(快速风格转移)
- 图像风格迁移(Neural Style)简史
应用案例
水印
【2023-9-21】花费好多时间来弄,最后却被别人直接搬运过去使用,好气哦!
- 怎么办? 给图片加水印
方法
Python代码
- filestools 库一共集成了4个功能,4个库都已经全部迁移到了filestools库中
add_mark()方法一共有8个参数
- file: 待添加水印的照片;
- mark: 使用哪些字作为水印;
- out: 添加水印后保存的位置;
- color: 水印字体的颜色,默认颜色#8B8B1B;
- size: 水印字体的大小,默认50;
- opacity: 水印字体的透明度,默认0.15;
- space: 水印字体之间的间隔, 默认75个空格;
- angle: 水印字体的旋转角度,默认30度;接下来,我们仅用一行代码,给图片添加水印。
# pip install filestools --index-url=http://mirrors.aliyun.com/pypi/simple -U
# 给图片加水印
from watermarker.marker import add_mark
# add_mark()方法一共有8个参数
add_mark(file=r"aixin.jpg", out=r"out.jpg", mark="人生苦短,快学Python", opacity=0.2, angle=45, space=30)
杂货店货架识别
- 【2021-1-23】Grocery-Product-Detection
- This repository builds a product detection model to recognize products from grocery shelf images. The dataset comes from here. Everything from data preparation to model training is done using Colab Notebooks so that no setup is required locally. All the relevant commentaries have been included inside the Colab Notebooks.
图片美化
【2023-4-18】autoenhance, Instant real estate photo editing, 房产领域图片美化:更换天气(阴天→蓝天)、对比度(模糊→清晰)、马赛克(模糊人脸/车牌)、角度调整(视角)、光线(暗→明)
【2024-9-16】CodeFormer 旧照片还原, 去马赛克
AI换脸
【2023-5-25】AI换脸诈骗
资料
- 更多Demo地址
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
