大模型意图识别
文本分类
详见站内专题:文本分类
评估指标
【2025-7-20】衡量 AI Agent 意图识别效果,不只是“识别对不对”,还要看“是不是有用”“能不能解决问题”
因此产品需从准确率、覆盖率、响应效果、用户行为四个维度全方位评估。
| 序号 | 指标名称(中文) | 定义 | 计算公式 | 例子 | 意义 |
|---|---|---|---|---|---|
| 1 | 意图准确率(Intent Accuracy) | Agent 识别出的意图是否与用户真实想法一致 | 准确意图数 / 总意图请求数 | 用户说“这个标题感觉没吸引力”,Agent判断为“需要优化标题”,且用户采纳推荐标题,则视为命中 | 衡量识别“对不对”,是核心指标 |
| 2 | 意图覆盖率(Intent Coverage) | Agent 能识别的意图数量,占业务中用户真实意图的比例 | Agent支持意图数 / 用户表达中出现的全部意图数 | 用户频繁提及“能不能换背景音乐”,但Agent没支持该意图,则视为未覆盖 | 覆盖率低会让用户觉得“问了也没用”,限制可用性 |
| 3 | 响应正确率(Response Match Rate) | Agent 给出的响应是否对症下药,解决了用户的问题 | 有效响应数 / 总识别成功的意图数 | 用户说“换个爆点”,Agent识别成“优化标题”没错,但推荐的标题毫不相关,则响应不正确 | 识别准确≠任务完成,反映实际价值 |
| 4 | 用户修正率(User Correction Rate) | 用户是否对Agent的理解结果进行修正或重说 | 用户主动更换意图 / 总次对话数 | 用户说“太普通了”,Agent推荐封面,用户马上说“我说的是标题”,属于一次修正 | 体现意图识别是否“贴心懂人话”,用户感知强 |
✅ 一、意图准确率(Intent Accuracy)
- 定义:Agent 识别出的意图是否与用户真实想法一致。
- 计算:准确意图数 / 总意图请求数。
- 例子:用户说“这个标题感觉没吸引力”,Agent判断为“需要优化标题”,且后续用户采纳了推荐标题,则视为命中。
- 意义:衡量识别“对不对”,是核心指标。
✅ 二、意图覆盖率(Intent Coverage)
- 定义:Agent 能识别的意图数量,占业务中用户真实意图的比例。
- 计算:Agent支持意图数 / 用户表达中出现的全部意图数。
- 例子:用户频繁提及“能不能换背景音乐”,但 Agent 没支持该意图,则视为未覆盖。
- 意义:覆盖率低会让用户觉得“问了也没用”,限制可用性。
✅ 三、响应正确率(Response Match Rate)
- 定义:Agent 给出的响应是否对症下药,解决了用户的问题。
- 计算:有效响应数 / 总识别成功的意图数。
- 例子:用户说“换个爆点”,Agent识别成“优化标题”没错,但推荐出的标题毫不相关,则响应不正确。
- 意义:识别准确≠任务完成,响应正确率反映实际价值。
✅ 四、用户修正率(User Correction Rate)
- 定义:用户是否对 Agent 的理解结果进行修正或重说。
- 计算:用户主动更换意图 / 总次对话数。
- 例子:用户说“太普通了”,Agent推荐封面,用户马上说“我说的是标题”,这属于一次修正。
- 意义:体现意图识别是否“贴心懂人话”,用户感知强。
智能客服
【2025-7-18】构建智能客服Agent:从需求分析到生产部署
智能客服Agent不仅仅是聊天机器人,而是集成自然语言理解(NLU)、对话管理(DM)、知识图谱(KG)、人机协作等多项核心技术的复杂系统。
- 传统规则驱动客服系统面对复杂业务场景时力不从心
- 用户意图识别准确率 65%左右,对话完成率更是低至40%。
- 智能客服Agent技术,引入深度学习模型、多轮对话状态跟踪(DST)、动态知识库更新等先进技术
- 最终将意图识别准确率提升至92%,对话完成率达到78%,用户满意度从3.2分提升至4.6分(满分5分)。
客服场景的需求建模、多轮对话的上下文维护、知识库的动态集成以及人机协作的智能切换机制。
通过详实的代码实现、丰富的技术图表和量化的性能评测,帮助读者构建一个真正适用于生产环境的智能客服Agent系统。这套技术方案已在多家大型企业成功落地,处理日均对话量超过10万次,为企业节省人力成本60%以上。
核心需求:
| 需求类型 | 具体描述 | 技术挑战 | 解决方案 |
|---|---|---|---|
| 意图识别 | 准确理解用户咨询意图 | 口语化表达、同义词处理 | BERT+BILSTM+CRF模型 |
| 实体抽取 | 提取关键业务信息 | 领域专有名词、嵌套实体 | 基于标注的NER模型 |
| 多轮对话 | 维护对话上下文状态 | 指代消解、话题切换 | DST+对话策略网络 |
| 知识检索 | 快速匹配相关知识 | 语义相似度计算 | 向量化检索+重排序 |
| 人机切换 | 智能判断转人工时机 | 置信度评估、用户情绪 | 多因子融合决策模型 |
整体架构
场景建模
意图识别
分层的意图分类体系
点击展开 Click to expand
```py
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
class IntentClassifier(nn.Module):
"""基于BERT的意图分类器"""
def __init__(self, bert_model_name, num_intents, dropout_rate=0.1):
super(IntentClassifier, self).__init__()
self.bert = BertModel.from_pretrained(bert_model_name)
self.dropout = nn.Dropout(dropout_rate)
self.classifier = nn.Linear(self.bert.config.hidden_size, num_intents)
# 意图层级定义
self.intent_hierarchy = {
"consultation": { # 咨询类
"product_info": ["产品功能", "价格查询", "规格参数"],
"service_policy": ["退换货", "保修政策", "配送方式"],
"account_issue": ["账号登录", "密码重置", "信息修改"]
},
"complaint": { # 投诉类
"product_quality": ["质量问题", "功能异常", "外观缺陷"],
"service_attitude": ["服务态度", "响应时间", "专业程度"],
"logistics_issue": ["配送延迟", "包装破损", "地址错误"]
},
"transaction": { # 交易类
"order_inquiry": ["订单状态", "物流跟踪", "配送信息"],
"payment_issue": ["支付失败", "退款查询", "发票申请"],
"after_sales": ["退货申请", "换货流程", "维修预约"]
}
}
def forward(self, input_ids, attention_mask):
"""前向传播"""
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
def predict_intent_with_confidence(self, text, tokenizer, device):
"""预测意图并返回置信度"""
self.eval()
with torch.no_grad():
encoding = tokenizer(
text,
truncation=True,
padding=True,
max_length=512,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
logits = self.forward(input_ids, attention_mask)
probabilities = torch.softmax(logits, dim=-1)
confidence, predicted_class = torch.max(probabilities, dim=-1)
return predicted_class.item(), confidence.item()
```
DST
对话状态跟踪(DST)实现
点击展开 Click to expand
```py
import json
from typing import Dict, List, Any
from collections import defaultdict
class DialogueStateTracker:
"""对话状态跟踪器"""
def __init__(self):
self.dialogue_state = {
"user_info": {}, # 用户信息
"current_intent": None, # 当前意图
"slots": {}, # 槽位信息
"context_history": [], # 上下文历史
"turn_count": 0, # 对话轮次
"last_action": None, # 上次动作
"confidence_scores": [] # 置信度历史
}
# 定义槽位依赖关系
self.slot_dependencies = {
"order_inquiry": ["order_number", "phone_number"],
"product_consultation": ["product_category", "specific_model"],
"complaint_handling": ["complaint_type", "order_number", "description"]
}
def update_state(self, user_input: str, intent: str, entities: Dict,
confidence: float, system_action: str):
"""更新对话状态"""
# 更新基本信息
self.dialogue_state["current_intent"] = intent
self.dialogue_state["turn_count"] += 1
self.dialogue_state["last_action"] = system_action
self.dialogue_state["confidence_scores"].append(confidence)
# 更新槽位信息
for entity_type, entity_value in entities.items():
self.dialogue_state["slots"][entity_type] = entity_value
# 维护上下文历史
turn_info = {
"turn": self.dialogue_state["turn_count"],
"user_input": user_input,
"intent": intent,
"entities": entities,
"confidence": confidence,
"system_action": system_action,
"timestamp": self._get_timestamp()
}
self.dialogue_state["context_history"].append(turn_info)
# 清理过期上下文(保留最近10轮)
if len(self.dialogue_state["context_history"]) > 10:
self.dialogue_state["context_history"] = \
self.dialogue_state["context_history"][-10:]
def check_slot_completeness(self, intent: str) -> Dict[str, bool]:
"""检查当前意图所需槽位是否完整"""
required_slots = self.slot_dependencies.get(intent, [])
slot_status = {}
for slot in required_slots:
slot_status[slot] = slot in self.dialogue_state["slots"]
return slot_status
def get_missing_slots(self, intent: str) -> List[str]:
"""获取缺失的槽位"""
slot_status = self.check_slot_completeness(intent)
return [slot for slot, filled in slot_status.items() if not filled]
def resolve_coreference(self, current_input: str) -> str:
"""指代消解处理"""
# 简化的指代消解逻辑
pronouns_map = {
"它": self._get_last_product_mention(),
"这个": self._get_last_entity_mention(),
"那个": self._get_previous_entity_mention(),
"我的订单": self._get_user_order()
}
resolved_input = current_input
for pronoun, reference in pronouns_map.items():
if pronoun in current_input and reference:
resolved_input = resolved_input.replace(pronoun, reference)
return resolved_input
def _get_last_product_mention(self):
"""获取最近提到的产品"""
for turn in reversed(self.dialogue_state["context_history"]):
if "product_name" in turn["entities"]:
return turn["entities"]["product_name"]
return None
def _get_timestamp(self):
"""获取当前时间戳"""
import time
return int(time.time())
def export_state(self) -> str:
"""导出对话状态用于调试"""
return json.dumps(self.dialogue_state, ensure_ascii=False, indent=2)
```
上下文感知回复
点击展开 Click to expand
```py
class ContextAwareResponseGenerator:
"""上下文感知的回复生成器"""
def __init__(self, dst: DialogueStateTracker):
self.dst = dst
self.response_templates = self._load_response_templates()
def generate_response(self, intent: str, entities: Dict,
knowledge_result: Dict = None) -> Dict:
"""生成上下文感知的回复"""
# 检查槽位完整性
missing_slots = self.dst.get_missing_slots(intent)
if missing_slots:
# 生成槽位询问回复
return self._generate_slot_inquiry(intent, missing_slots)
else:
# 生成业务回复
return self._generate_business_response(intent, entities, knowledge_result)
def _generate_slot_inquiry(self, intent: str, missing_slots: List[str]) -> Dict:
"""生成槽位询问回复"""
slot_questions = {
"order_number": "请提供您的订单号,我来帮您查询订单状态。",
"phone_number": "请提供您注册时使用的手机号码进行身份验证。",
"product_category": "请告诉我您想了解哪类产品?",
"complaint_type": "请描述一下您遇到的具体问题。"
}
# 优先询问最重要的槽位
primary_slot = missing_slots[0]
question = slot_questions.get(primary_slot, f"请提供{primary_slot}信息。")
return {
"response_type": "slot_inquiry",
"text": question,
"missing_slots": missing_slots,
"next_action": "collect_slot_info"
}
def _generate_business_response(self, intent: str, entities: Dict,
knowledge_result: Dict) -> Dict:
"""生成业务回复"""
if knowledge_result and knowledge_result.get("success"):
# 基于知识库结果生成回复
template = self.response_templates.get(intent, {}).get("success")
response_text = template.format(**entities, **knowledge_result["data"])
return {
"response_type": "business_success",
"text": response_text,
"knowledge_source": knowledge_result.get("source"),
"next_action": "satisfaction_survey"
}
else:
# 处理失败情况
fallback_response = self.response_templates.get(intent, {}).get("fallback")
return {
"response_type": "business_fallback",
"text": fallback_response,
"next_action": "transfer_to_human"
}
def _load_response_templates(self) -> Dict:
"""加载回复模板"""
return {
"order_inquiry": {
"success": "您的订单{order_number}当前状态为:{status},预计{delivery_date}送达。",
"fallback": "抱歉,暂时无法查询到您的订单信息,正在为您转接人工客服。"
},
"product_consultation": {
"success": "{product_name}的主要特点:{features},当前价格:{price}元。",
"fallback": "关于这个产品的详细信息,我为您转接专业顾问。"
}
}
```
知识库
向量化检索
知识库是智能客服的核心组件。用向量检索+精确匹配的混合方案
点击展开 Click to expand
```py
import numpy as np
from sentence_transformers import SentenceTransformer
import faiss
from typing import List, Dict, Tuple
import json
class KnowledgeRetrievalSystem:
"""知识检索系统"""
def __init__(self, model_name: str = "distilbert-base-chinese"):
self.encoder = SentenceTransformer(model_name)
self.knowledge_base = []
self.knowledge_vectors = None
self.faiss_index = None
# 知识库结构
self.kb_structure = {
"product_info": {}, # 产品信息库
"policy_rules": {}, # 政策规则库
"faq_pairs": {}, # 常见问题库
"procedure_steps": {} # 操作流程库
}
def build_knowledge_base(self, knowledge_data: List[Dict]):
"""构建知识库"""
self.knowledge_base = knowledge_data
# 提取文本进行向量化
texts = [item["content"] for item in knowledge_data]
self.knowledge_vectors = self.encoder.encode(texts)
# 构建FAISS索引
dimension = self.knowledge_vectors.shape[1]
self.faiss_index = faiss.IndexFlatIP(dimension) # 内积检索
# 归一化向量
faiss.normalize_L2(self.knowledge_vectors)
self.faiss_index.add(self.knowledge_vectors)
print(f"知识库构建完成,包含{len(knowledge_data)}条知识")
def retrieve_knowledge(self, query: str, top_k: int = 5,
threshold: float = 0.7) -> List[Dict]:
"""检索相关知识"""
# 查询向量化
query_vector = self.encoder.encode([query])
faiss.normalize_L2(query_vector)
# FAISS检索
similarities, indices = self.faiss_index.search(query_vector, top_k)
results = []
for i, (similarity, idx) in enumerate(zip(similarities[0], indices[0])):
if similarity >= threshold:
knowledge_item = self.knowledge_base[idx].copy()
knowledge_item["similarity"] = float(similarity)
knowledge_item["rank"] = i + 1
results.append(knowledge_item)
# 二次排序:结合业务规则
results = self._rerank_results(query, results)
return results
def _rerank_results(self, query: str, initial_results: List[Dict]) -> List[Dict]:
"""基于业务规则的二次排序"""
# 定义业务权重
category_weights = {
"urgent": 1.3, # 紧急问题
"common": 1.1, # 常见问题
"product": 1.0, # 产品相关
"policy": 0.9 # 政策相关
}
for result in initial_results:
base_score = result["similarity"]
category = result.get("category", "common")
weight = category_weights.get(category, 1.0)
# 考虑知识的时效性
freshness_factor = self._calculate_freshness_factor(result)
# 综合评分
result["final_score"] = base_score * weight * freshness_factor
# 按综合评分排序
return sorted(initial_results, key=lambda x: x["final_score"], reverse=True)
def _calculate_freshness_factor(self, knowledge_item: Dict) -> float:
"""计算知识时效性因子"""
import time
current_time = time.time()
knowledge_time = knowledge_item.get("update_time", current_time)
# 30天内的知识权重为1.0,超过30天开始衰减
days_old = (current_time - knowledge_time) / (24 * 3600)
if days_old <= 30:
return 1.0
else:
return max(0.8, 1.0 - (days_old - 30) * 0.01)
def update_knowledge_item(self, knowledge_id: str, new_content: Dict):
"""动态更新知识条目"""
# 找到对应的知识条目
for i, item in enumerate(self.knowledge_base):
if item.get("id") == knowledge_id:
# 更新内容
self.knowledge_base[i].update(new_content)
# 重新计算向量
new_vector = self.encoder.encode([new_content["content"]])
faiss.normalize_L2(new_vector)
# 更新FAISS索引中的向量
self.knowledge_vectors[i] = new_vector[0]
self.faiss_index = self._rebuild_faiss_index()
return True
return False
def _rebuild_faiss_index(self):
"""重建FAISS索引"""
dimension = self.knowledge_vectors.shape[1]
new_index = faiss.IndexFlatIP(dimension)
new_index.add(self.knowledge_vectors)
return new_index
```
知识库动态更新
知识库动态更新机制流程图
人机协作
准确判断何时需要转接人工
多因子融合的决策模型
import numpy as np
from typing import Dict, List, Tuple
from enum import Enum
class HandoffReason(Enum):
"""转人工原因枚举"""
LOW_CONFIDENCE = "置信度过低"
COMPLEX_QUERY = "查询过于复杂"
EMOTIONAL_ESCALATION = "情绪升级"
REPEATED_FAILURE = "重复失败"
EXPLICIT_REQUEST = "明确要求"
BUSINESS_CRITICAL = "业务关键"
class HumanHandoffDecisionModel:
"""人机切换决策模型"""
def __init__(self):
# 决策权重配置
self.decision_weights = {
"confidence_score": 0.25, # 置信度权重
"emotion_score": 0.20, # 情绪权重
"complexity_score": 0.20, # 复杂度权重
"failure_count": 0.15, # 失败次数权重
"user_satisfaction": 0.10, # 用户满意度权重
"business_priority": 0.10 # 业务优先级权重
}
# 阈值设置
self.handoff_threshold = 0.6
# 情绪词典
self.emotion_keywords = {
"negative": ["生气", "愤怒", "不满", "投诉", "差评", "垃圾"],
"urgent": ["紧急", "急", "马上", "立即", "尽快"],
"confused": ["不懂", "不明白", "搞不清", "糊涂"]
}
def should_handoff_to_human(self, dialogue_context: Dict) -> Tuple[bool, str, float]:
"""判断是否需要转人工"""
# 计算各项评分
confidence_score = self._calculate_confidence_score(dialogue_context)
emotion_score = self._calculate_emotion_score(dialogue_context)
complexity_score = self._calculate_complexity_score(dialogue_context)
failure_score = self._calculate_failure_score(dialogue_context)
satisfaction_score = self._calculate_satisfaction_score(dialogue_context)
business_score = self._calculate_business_priority_score(dialogue_context)
# 加权计算总分
total_score = (
confidence_score * self.decision_weights["confidence_score"] +
emotion_score * self.decision_weights["emotion_score"] +
complexity_score * self.decision_weights["complexity_score"] +
failure_score * self.decision_weights["failure_count"] +
satisfaction_score * self.decision_weights["user_satisfaction"] +
business_score * self.decision_weights["business_priority"]
)
# 判断主要原因
main_reason = self._identify_main_reason({
"confidence": confidence_score,
"emotion": emotion_score,
"complexity": complexity_score,
"failure": failure_score,
"satisfaction": satisfaction_score,
"business": business_score
})
should_handoff = total_score >= self.handoff_threshold
return should_handoff, main_reason, total_score
def _calculate_confidence_score(self, context: Dict) -> float:
"""计算置信度评分"""
recent_confidences = context.get("confidence_scores", [])[-3:] # 最近3轮
if not recent_confidences:
return 0.5
avg_confidence = np.mean(recent_confidences)
# 置信度越低,转人工评分越高
if avg_confidence < 0.3:
return 1.0
elif avg_confidence < 0.5:
return 0.8
elif avg_confidence < 0.7:
return 0.4
else:
return 0.1
def _calculate_emotion_score(self, context: Dict) -> float:
"""计算情绪评分"""
recent_inputs = [turn["user_input"] for turn in context.get("context_history", [])[-3:]]
emotion_score = 0.0
for text in recent_inputs:
for emotion_type, keywords in self.emotion_keywords.items():
for keyword in keywords:
if keyword in text:
if emotion_type == "negative":
emotion_score += 0.4
elif emotion_type == "urgent":
emotion_score += 0.3
elif emotion_type == "confused":
emotion_score += 0.2
return min(emotion_score, 1.0)
def _calculate_complexity_score(self, context: Dict) -> float:
"""计算查询复杂度评分"""
current_intent = context.get("current_intent")
turn_count = context.get("turn_count", 0)
# 复杂意图映射
complex_intents = {
"complaint_handling": 0.8,
"refund_request": 0.7,
"technical_support": 0.6,
"product_consultation": 0.3
}
intent_complexity = complex_intents.get(current_intent, 0.2)
# 多轮对话增加复杂度
turn_complexity = min(turn_count * 0.1, 0.5)
return min(intent_complexity + turn_complexity, 1.0)
def _calculate_failure_score(self, context: Dict) -> float:
"""计算失败次数评分"""
context_history = context.get("context_history", [])
# 统计最近的失败次数
failure_count = 0
for turn in context_history[-5:]: # 最近5轮
if turn.get("system_action") in ["fallback", "unclear", "no_result"]:
failure_count += 1
return min(failure_count * 0.3, 1.0)
def _calculate_satisfaction_score(self, context: Dict) -> float:
"""计算用户满意度评分"""
# 这里可以集成实时满意度检测模型
# 简化实现:基于用户反馈关键词
recent_inputs = [turn["user_input"] for turn in context.get("context_history", [])[-2:]]
dissatisfaction_keywords = ["不行", "没用", "解决不了", "要人工", "转人工"]
for text in recent_inputs:
for keyword in dissatisfaction_keywords:
if keyword in text:
return 1.0
return 0.2
def _calculate_business_priority_score(self, context: Dict) -> float:
"""计算业务优先级评分"""
current_intent = context.get("current_intent")
# 高优先级业务
high_priority_intents = {
"payment_issue": 0.9,
"security_concern": 1.0,
"complaint_handling": 0.8,
"refund_request": 0.7
}
return high_priority_intents.get(current_intent, 0.2)
def _identify_main_reason(self, scores: Dict) -> str:
"""识别主要转人工原因"""
max_score_key = max(scores.keys(), key=lambda k: scores[k])
reason_mapping = {
"confidence": HandoffReason.LOW_CONFIDENCE.value,
"emotion": HandoffReason.EMOTIONAL_ESCALATION.value,
"complexity": HandoffReason.COMPLEX_QUERY.value,
"failure": HandoffReason.REPEATED_FAILURE.value,
"satisfaction": HandoffReason.EXPLICIT_REQUEST.value,
"business": HandoffReason.BUSINESS_CRITICAL.value
}
return reason_mapping.get(max_score_key, "未知原因")
详见站内专题:智能客服
LLM 意图识别
总结
【2024-8-19】怎样进行大模型应用程序中的意图识别
RAG 实际落地时,往往需要根据理解query意图。在 RAG 中路由控制流程,创建更有用、更强大的 RAG 应用程序
- 数据源多样性: query 路由到
- 非结构化文档: 语义检索,召回相关文档(图片/文本/pdf/word等)
- 结构化文档: Text2SQL, query转sql语句,从关系型数据库中查找相关信息,如 MySQL, PostgreSQL, Oracle, SQL Lite 等。
- API: 通过 Function Call 调用 Restful API
- 组件多样性: 相同数据用不同的向量存储, query 路由到:
- 向量库
- LLM
- Agent
- 提示模版多样性: 根据用户问题使用不同提示模版 Prompt Template
- query –(Router)–> Prompt1, Prompt2, …, Promptn —-> LLM —-> Response
- LLM 存在不确定性, 不可能100%稳定正确
路由 Router 分类
- 逻辑路由 Logical Router
- 自然语言路由 (Natural Language Router) 由不同 RAG 和 LLM 应用开发框架和库实现。
- LLM 路由 (LLM Router)
- LLM 补全路由 (LLM Completion Router): 从 prompt 里候选单词选择最佳, 作为 if/else条件控制流程, 案例 LlamaIndex Selector 原理 (LangChain 路由)
- LLM 函数调用路由 (LLM Function Calling Router): LLM 判断 query 对应哪个函数, 即路由,案例 LlamaIndex 中 Pydantic Router 原理,大多数 agent 工具选择方式
- 语义路由 (Semantic Routers): 利用 embedding 和 相似性搜索确定意图, 选择最佳
- 零样本分类路由 (Zero Shot Classification Routers): prompt 中指定分类集合, 直接进行分类
- 语言分类路由 (Language Classification Routers): 语种路由, langdetect python 包(朴素贝叶斯) 检测文本语种
- 关键字路由: query 匹配路由表中的关键字来路由
- LLM 路由 (LLM Router)
路由 Router vs 智能体 Agent
- 二者相似点多,Agent 将 Router 作为流程的一部分执行。
单轮
单轮意图识别指仅基于用户的单一输入判断其意图,不考虑历史对话内容。
技术方案
- 规则
- 优点:实现简单,可解释性强
- 缺点:缺乏灵活性,难以覆盖表达的多样性
- 向量检索方法
- 将用户输入与预先准备的意图示例转换为向量(如 SentenceTransformer),通过计算相似度确定最接近的意图。
- 优点:可以捕捉语义相似性,不局限于关键词匹配
- 缺点:依赖于示例的质量和数量,需要维护向量库
- 大模型
- 利用预训练大模型的强大语义理解能力来识别意图。
- 优点:语义理解能力强,部署简单,可处理复杂表述
- 缺点:响应延迟较高,成本较高,黑盒特性不便于调试
- 混合方案
- 结合多种方法的优势,构建更强大的意图识别系统。
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 规则 | 专家经验,规则匹配 | 实现简单,可解释性强 | 缺乏灵活性,难以覆盖表达的多样性 |
| 向量检索 | 将用户输入与预先准备的意图示例转换为向量,通过计算相似度确定最接近的意图 | 捕捉语义相似性,不局限于关键词匹配 | 依赖于示例的质量和数量,需要维护向量库 |
| 大模型 | 预训练大模型的强大语义理解能力 | 语义理解能力强,部署简单,可处理复杂表述 | 响应延迟较高,成本较高,黑盒特性不便于调试 |
| 混合 | 结合多种方法的优势,构建更强大的意图识别系统 | - | - |
多轮
与单轮对话相比,多轮对话具有以下特点:
- 上下文依赖性:后续轮次的意图理解依赖于前面轮次的内容
- 意图转换:用户可能在对话过程中切换话题或改变意图
- 省略现象:用户可能省略已在上文中提及的信息
- 指代现象:用户使用代词指代前面提到的实体
多轮意图识别比单轮更为复杂,需要考虑对话历史和上下文信息。它处理的是连续多轮对话中意图的变化和延续。
实现方法
- (1) 上下文窗口法
- 保留最近N轮对话作为上下文,综合考虑整个窗口内的信息
- (2) 对话状态追踪法
- 维护对话状态,跟踪意图变化和槽位填充情况。
- (3) 多轮对话意图识别的大模型方法
- 利用大模型的强大上下文理解能力,直接处理复杂多轮对话。
专题
长上文
【2025-3-21】大模型对话系统中的意图识别 含图解、代码
意图识别相关技术:基于规则、向量检索、深度学习、大模型等多种方法,以及处理多轮对话的上下文窗口法和对话状态追踪法。
以酒店预订对话为例展示了多轮意图识别的实际应用。
较小规模的模型在处理长对话时表现欠佳:
- 当对话超过3轮且每轮内容较多时,模型容易混淆上下文关系
- 对话长度增加,语义理解负担加重,回复质量明显下降
- 多意图交织的复杂对话场景下,准确率显著降低
常规做法
解决思路
- 思路1:截断历史对话
- 最简单的方法是保留最近几轮对话,舍弃更早的内容。这种方法虽然直接,但会导致上下文连贯性断裂,影响对话体验。
- 思路2:上下文语义分割和槽位关联
- 将对话分解为不同的语义单元,并建立关联关系,保留关键信息:
- 上下文语义分割:识别对话中的主题段落,保留关键信息
- 槽位关联:跟踪对话中出现的实体信息(如产品名称、数量等),便于后续使用
- 将对话分解为不同的语义单元,并建立关联关系,保留关键信息:
- 思路3:基于多路多轮数据的微调
- 针对大模型进行特定任务的微调,提升模型在多轮对话中的表现
文本转图像
人脑 工作机制
DeepSeek OCR 发布,详见站内专题 OCR-DeepSeek-OCR
DeepSeek OCR 同期工作
- 【2025-10-21】南京理工、中南大学 See the Text: From Tokenization to Visual Readin
- 【2025-10-20】清华:Glyph —— Scaling Context Windows via Visual-Text Compression
- 【2025-10-22】AI^2 和 芝加哥大学,EMNLP 2025 Findings,Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs
总结:让大模型“看”文本,而不是“读”文本。
- 【2025-10-20】清华:Glyph —— Scaling Context Windows via Visual-Text Compression
Glyph 从输入端出发,把长文本“画”成图像,让模型以视觉方式理解语义。这样就能用图像输入取代传统的文本 token,在不改变模型结构的前提下处理更长的上下文,轻松突破计算与显存的瓶颈。
在 LongBench、MRCR 等基准上,Glyph 在 3–4× 压缩 下依然表现强劲;在极致压缩下,128K 模型也能处理百万级 token,展示出巨大的上下文扩展潜力!
用 VLM 扩展长上下文确实是一条可行且潜力巨大的路径,希望未来能构建出千万token的模型
长文压缩
【2025-10-17】韩国科学技术学院(KAIST)、微软、剑桥, 压缩 Agent 多轮交互历史
- 【2025-10-1】发表,【2025-10-17】修改 ACON: Optimizing Context Compression for Long-horizon LLM Agents
- 代码 Acon
背景
- LLM agents 在执行如工作流自动化等长时程 (long-horizon) 任务时, 需要不断累积历史交互信息, 导致上下文 (context) 长度爆炸式增长, 从而带来了高昂的计算成本和效率问题。现有的上下文压缩技术大多针对单步或特定领域的任务, 无法很好地适用于复杂、动态的 agent 场景。
方法 🛠️
Agent Context Optimization (ACON) 统一框架, 系统性压缩 LLM agent 的交互历史和环境观测。
- 首先,训练任务上运行 agent, 分别使用完整上下文和经过压缩上下文。
- 对比两种情况下 agent 表现, 筛选出完整上下文中成功, 但在压缩上下文中失败的 “contrastive” 轨迹。
- 针对失败轨迹, 用强大”optimizer LLM” 来分析完整上下文和压缩上下文差异, 生成自然语言形式的 “feedback”。这个 feedback 指出了压缩过程中丢失了哪些关键信息。
- 接着, 将多条轨迹生成 feedback 聚合起来, 交给 optimizer LLM 来更新和优化最初的压缩指令。
为了进一步降低成本, 还引入了一个 “compression maximization” step。这一步只分析那些使用压缩上下文成功的轨迹, 让 LLM 判断哪些信息在执行过程中是真正必要的。
为了降低使用大型 LLM 作为 compressor 带来的推理开销, 将优化好的大型 compressor (teacher) 的能力 “distill” (蒸馏) 到一个更小的模型 (student) 中, 从而实现高效部署。
实验结果 📊
AppWorld, OfficeBench 和 Multi-objective QA 等多个长时程 agent benchmark 验证 ACON 有效性:
- ACON 基本保持任务性能, 将峰值内存使用 (peak tokens) 降低 26-54%, 显著优于 FIFO, Retrieval 等基线方法。
澄清
意图不明时,引入澄清机制,浅多轮,如 反问、澄清
Google ACT 多轮澄清
- 【2025-7-27】google,哥伦比亚大学 用 Action-Based Contrastive Self-Training (ACT) 做多轮训练(DPO),学会澄清
- 论文 Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training,
- 含代码
用人类反馈优化大模型(LLMs)已成为智能对话助手主流范式。
然而,基于LLM的智能体在对话技能方面仍有欠缺
- 歧义消除能力——信息模糊时,往往含糊其辞或暗自猜测用户的真实意图,而非主动提出澄清问题。
- 特定任务场景中,高质量的对话样本数量有限
这成为限制LLMs学习最优对话行动策略的瓶颈。
基于行动的对比自训练(ACT) 算法,基于直接偏好优化(DPO)的准在线偏好优化算法,在多轮对话建模中实现数据高效的对话策略学习。
ACT 训练过程
通过真实对话任务验证ACT在数据高效调优场景中的有效性,即使在没有行动标签的情况下依然表现优异,这些任务包括:
- 表格驱动的问答
- 机器阅读理解
- AmbigSQL(一种面向数据分析智能体的新型任务,用于消除复杂SQL生成中信息查询请求的歧义)。
ACT 显著优于 PE和SFT
此外,还提出评估LLMs作为对话智能体能力的方法
- 通过检验能否在对话中隐性识别并推理歧义信息。
- 结果表明,与监督微调、DPO等标准调优方法相比,ACT在对话建模方面有显著提升
改写
【2025-2-26】Query Rewriting查询改写方案汇总
用户查询输入不可控,而不同query质量直接影响召回结果。
一般查询语句中会出现各种意图问题,比如: 不明确、混淆、错误之类的
查询重写通过系列手段修正query的错误,提高query质量,以尽可能准确的识别用户的查询意图,匹配到关键的召回结果。
传统方法
常规流程
- 预处理→分词→纠错(Query改写)→Query分词(Term分析)→意图识别→敏感识别→人工干预
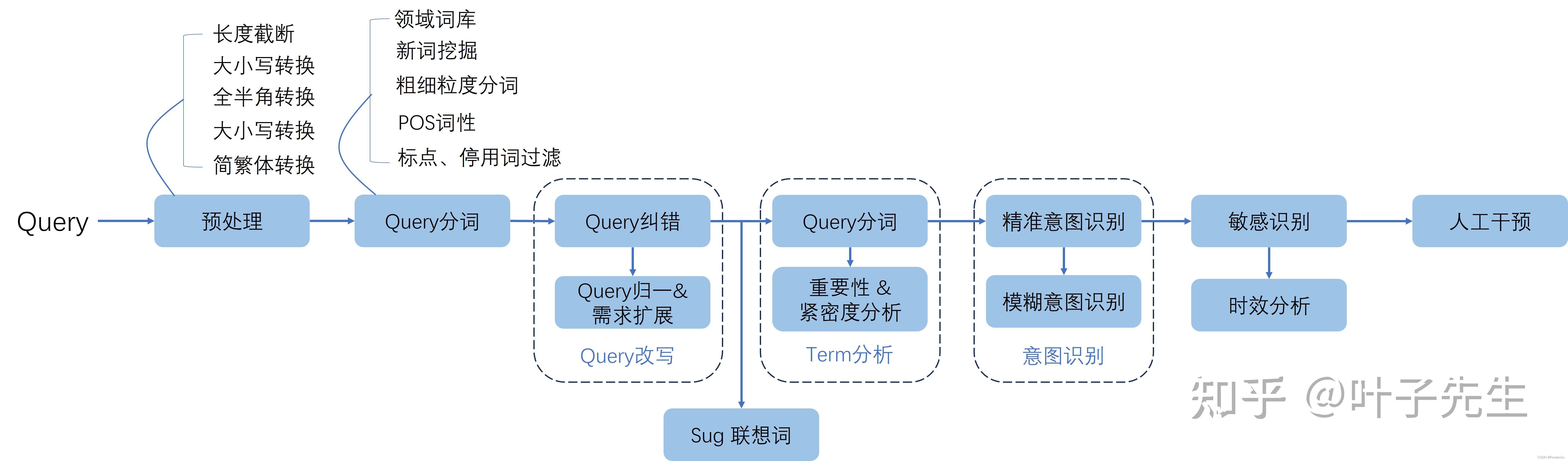
大模型改写
短查询和长查询的处理分开介绍
- 短查询本身没有那么多语义信息,而且意图并不准确,实际上处理方式都是数据增强,对query进行不同程度的扩写,相当于补充上下文,而不同的短查询有各自的特征,这些特征决定了数据增强的方案。
- 而长查询往往有相对精确的语义和意图,只是可能仍然存在语义信息不足的问题,需要对原文进行补充的同时不破坏原先的语义。
短查询和长查询的处理思路核心分别是“揣测”和“解释”
- 短查询由于没有明确上下文和语义信息,需要去猜测最可能的意图
- 长查询有一定上下文和相对精准的语义信息,只需要扩充和补充说明或者纠正。
短查询数据增强
- 意图多意
- 意图模糊
- 隐含信息
- 相关性扩充
长查询重写
- 样本重写:零样本重写、小样本重写、预训练重写
- 子查询拆分
- 后退提示词:将问题抽象出基本规则后再回答
- 假设文档嵌入:HyDE 是一种零样本的密集检索方法
【2026-1-20】视频号《划水的青蛙》query改写的正确姿势
Query 改写三大痛点:资源浪费、召回率下降、缺乏业务上下文
- 资源浪费(60%简单查询无需改写)
- 召回率下降(口语改书面语后与文档不匹配)
- 缺乏业务上下文(如HP指代不明)
五大解决方案:基础改写、多查询、子问题拆解、问题泛化、假设性文档嵌入。
核心是”通用策略+业务知识”双轮驱动,建议先分类再改写、控制改写数量(2-3个)、建立评估机制、尽早完善业务词典。
OOD
【2024-7-14】域外意图检测——解决“没见过”的问题
开放域意图识别时,模型总会遇到“没见过”样本,分类不可控,可能被关键词迷惑,也可能停留在阈值上下摇摆不定,而样本层面很难覆盖所有情况
这类问题叫“out-of-Scope intent detection”,域外意图检测,也叫 OOD(out of domain),更像是“拒识”,识别目前系统未覆盖的功能。
- 一般把意图内样本作为正类,例如,要做天气的意图识别,那就是把天气相关的句子作为正类,例如“今天天气如何”、“北京的天气”
- 而其他类目算作负类,如“周杰伦最近有什么新歌”、“深度学习入门”等,然后把他当做一个二分类问题做就好了。
问题
- 负类是无底洞,无法把“不是天气意图”的句子都梳理出来作为负样本
文本分类旨在把两个类目区分开,而域外意图识别更像拒绝,聚焦负类,把“不是正类”的找出来。
域外意图识别,用于做拒识
- 搜索、对话场景,未覆盖、无法解决的问题给拒绝掉
- 特点: 被拒识样本无法全覆盖
OOD 综述
【2023-12-14】Out-of-Distribution Detection(OOD)入门综述!
2021年10月21日, 新加坡南洋理工大学(NTU)和美国威斯康星大学Madison分校
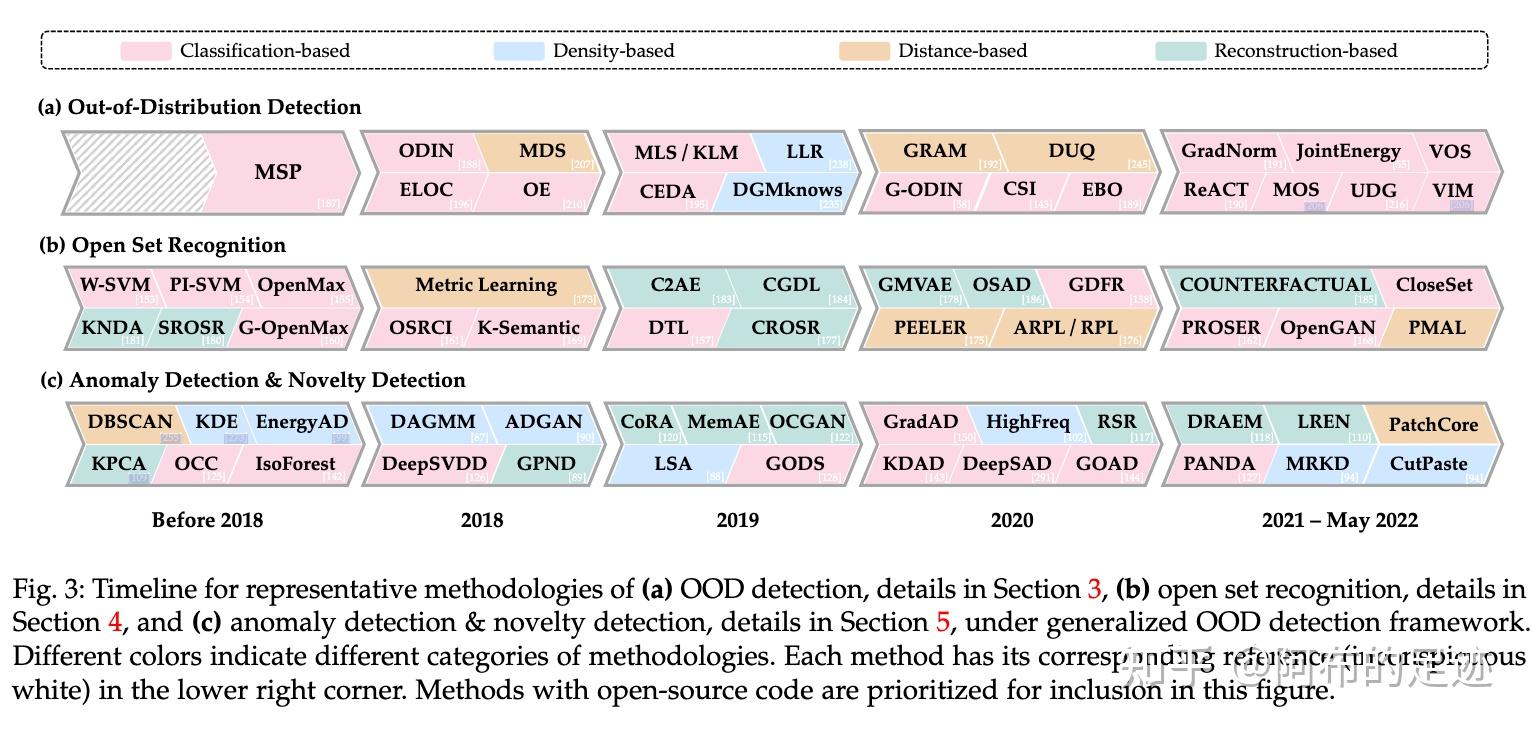
OOD 方法:
- 基于分类方法 classification-based
- 基于密度方法 density-based
- 基于距离方法 distance-based
- 基于重建方法
动机和方法论方面都与 OOD 检测密切相关
- 异常检测 (AD,anomaly detection)
- 新颖性检测 (ND,novelty detection)
- 开放集识别 (OSR,open set recognition)
- 异常值检测 (OD,outlier detection)
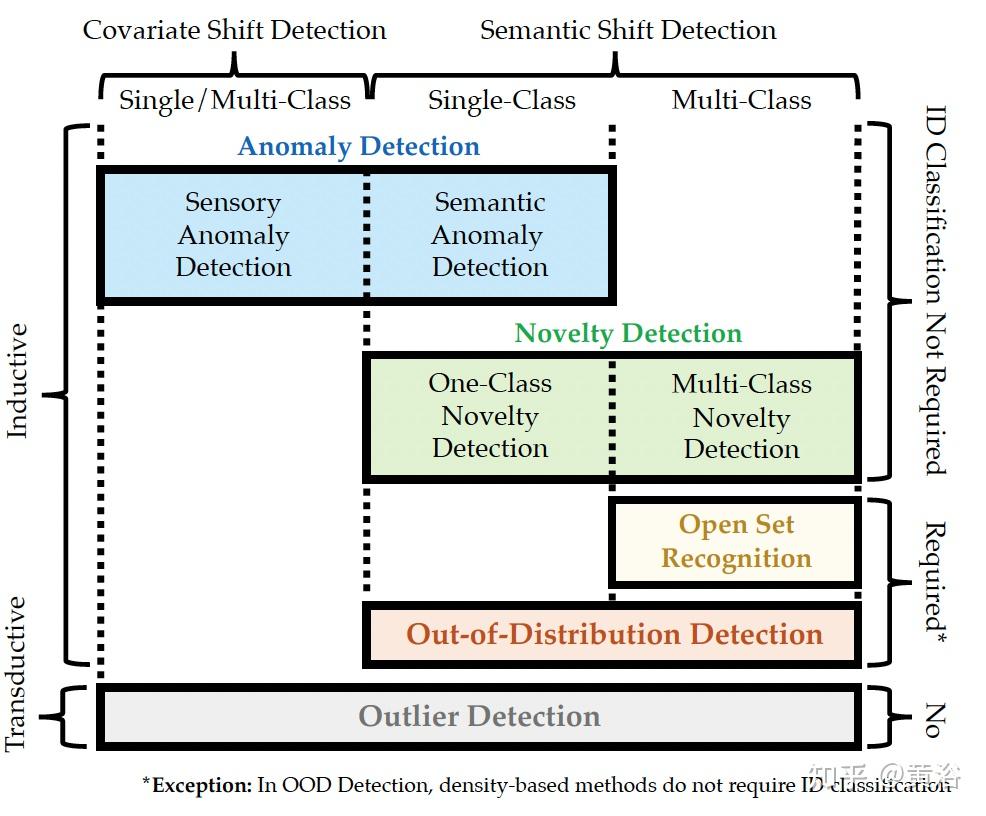
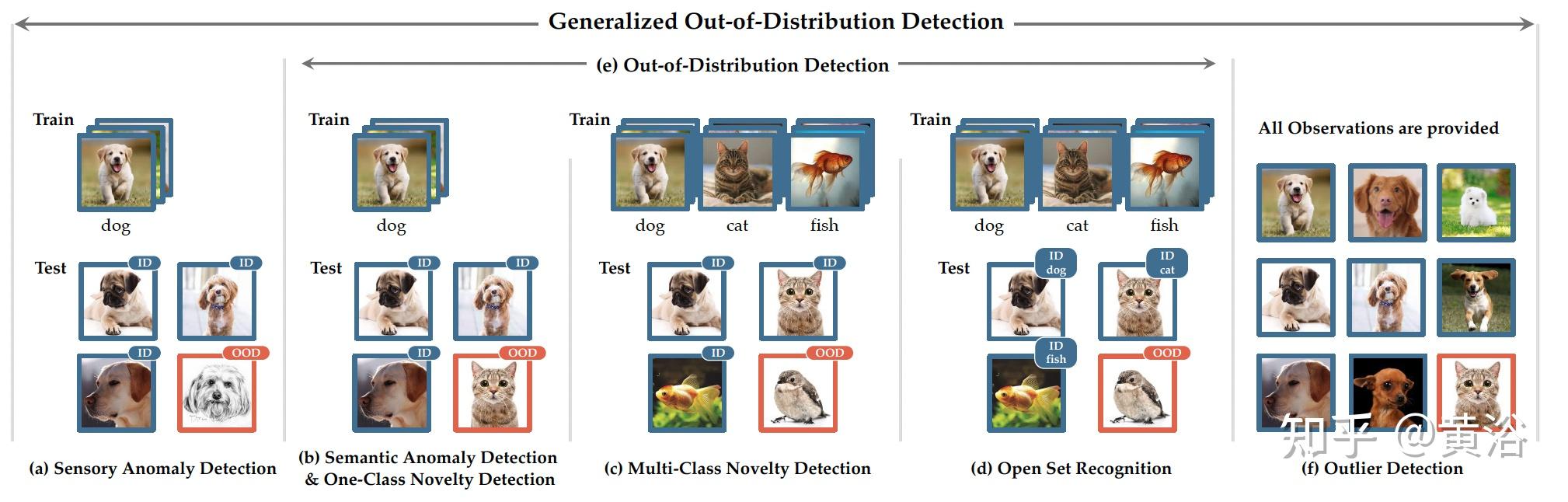
OOD样本偏移包括两类
- 第一类是 semantic shift (语义偏移),即OOD样本来自和ID(In-distribution)不同的类别。
- 另一类是 covariate shift(协方差偏移),即OOD样本来自于和ID样本不同 domain
上述方法主要是 semantic shift,即OOD样本和ID样本具有不同的类别
共同点:都定义了某种特定 in-distribution,具有在open-world假设下检测out-of-distribution样本的共同目标。
五种方法之间的区别和共同点。
- 1)检测什么样的shift;
- 2)ID的样本是单类还是多类;
- 3)是否需要对ID样本进行分类;
- 4)是否遵循train-test模式(是否为归纳问题)。
OSR和OOD 概念可以互换。
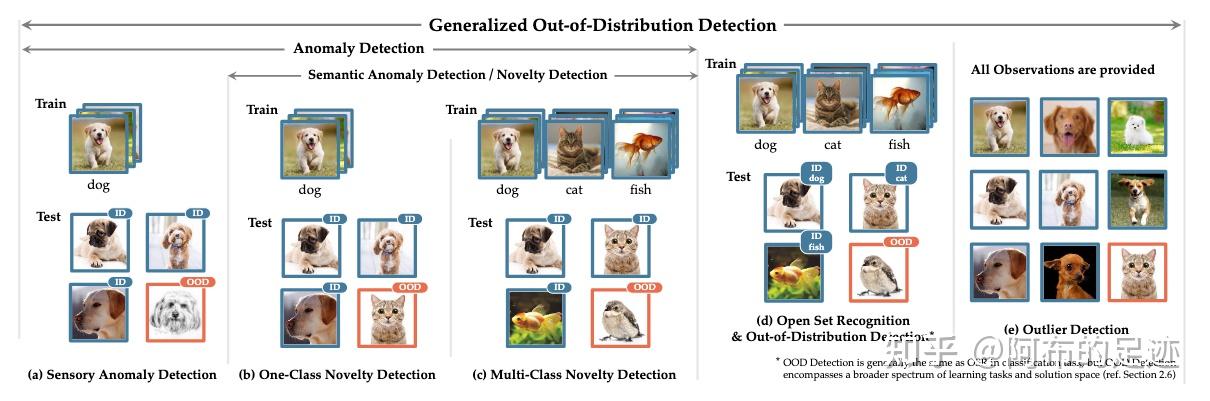
Anomaly Detection(AD) 关键是,要清晰的定义常态(正常)类样本,并且通常情况下,正常类下面没有子类(如将正常类定义为狗,下面不会再分泰迪、金毛或者德牧,都认为是一类)。目标是在某些特定的情境下,检测出所有可能的异常样本。
省流:Anomaly Detection对于ID内样本的分类并不关心,都认为是一类,只关心如何把ID样本和OOD样本分开,检测出OOD样本。
分为两类Sensory AD和Semantic AD,这里主要说一下后者,即检测属于新类的样本。现实的应用如犯罪监控、Active 图片爬虫。学术界一个标准,即使用MNIST中的某一类作为ID样本,其余9个类别作为OOD样本来检验模型的OOD检测能力。
评价标准:AUROC,AUPR,or F-scores
Novelty Detection(ND) 通常情况下,Novelty Detection是可以和Anomaly Detection互换的。Novelty detection又称为Novel class detection,表明它主要专注于Semantic shift。检测到的新类,会被ND方法存储起来加以运用,用于增量学习或者特殊的分析。注意,一类ND和多类ND都被表述为二元分类问题,即ND只关心辨别新类样本和旧类样本。
不考虑新类是恶意还是积极的,其实ND和Semantic AD是一样的。继续细究的话,ND是完全无监督的,AD有时候可能会有一些异常训练样本辅助训练。
评价标准:AUROC,AUPR,or F-scores
(1) Open Set Recognition(OSR)
不仅要求能够检测未知类别,还要求正确分类已知的类别。
评价标准:AUROC,AUPR,or F-scores,CCR@FPRx
(2) Out-of-Distribution Detection(OOD)
保证ID类测试样本的分类性能,拒绝OOD测试样本,ID样本往往具有多个类别,OOD的类别不能与ID的类别重合。
经常使用CIFAR-10作为ID样本进行训练,其他数据集如SVHN等作为OOD测试样本。
评价标准:AUROC,AUPR,or F-scores,FPR@TPRx,TNR@TPRx
和OSR的区别:
- 1)OSR常常用一个数据集,一部分类别作为ID一部分作为OOD。而OOD则是一个数据集作为ID样本,再用别的数据集作为OOD样本(仍要保证类别不重合)。
- 2)OOD检测方法的范围更广,如多标签分类,解空间更大。
OOD 检测主流 Detecting semantic shift。当然在一些领域中,也十分的关注covariate shift,即要拒绝和原本的ID样本具有不同分布的样本,即使类别可能一样。如医学图像或者隐私敏感的领域,就不能让模型对具有不同分布的样本进行泛化。
(3) Outlier Detection(OD)
AD、ND、OSR和OOD中的问题设置检测与训练数据分布不同的未见测试样本。相比之下,异常值检测直接处理所有观测数据,目的是从受污染的数据集中选择异常值。
OD不遵循训练-测试的模式,可以访问所有的观测数据,他不是一个归纳问题。
通常用于数据挖掘或者一些主任务的数据预处理。还可以通过主任务的效果检验OD方法的性能。
OOD 常见方法
域外检测常见方法
(1)样本空间度量
- 邱锡鹏论文: KNN-Contrastive Learning for Out-of-Domain Intent Classification 用对比学习常用的NT-Xent,还用了ArcFace相似的加入margin 损失函数;实现:以搜代分
- 把域外意图强行融成团或划分区域,非常不现实,应该用类似KNN的手段,只要落到正类比较密集的区域内,就可能是正类,否则是负类,这样更加符合域外意图的空间实际分布。
- 论文:Enhancing the generalization for Intent Classification and Out-of-Domain Detection in SLU 预测阶段增加了一个DRM(domain-regularized module),只需正样本,马氏距离能有效把IND和OOD的空间给拉开的更加明显。
(2)对抗和扰动
- 简单问题,通过样本层面的增强,挖掘对抗样本;复杂的通过embedding层面的增强,甚至训练策略上的对抗来实现,让正类的空间更加内聚稳定,此时域外检测就会更加精准。
- 论文GOLD: Improving Out-of-Scope Detection in Dialogues using Data Augmentation 通过增强样本模型, 强化对OOD数据识别
- ① 用OOD样本在无标签样本中召回与之最接近的几个作为OOD数据
- ② 通过对话中的同话题多轮数据中挖掘,这种方案其实对标注数据的数量和质量都是有一定要求。
- 采用对抗学习,论文 Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
- 通过对抗,压缩正类的空间提升正类空间的密度和准度
解决方法:
- 空间层面,把正类转化为样本层面的封闭空间,而把负类放在空间之外。只有命中这个空间以内,才能认为是正类。
- 强调表征的重要性
- 一方面通过数据样本、embedding交叉还是训练策略的对抗和增强,来让表征朝着更有利于空间划分的方向走
- 另一方面通过特定距离计算,把两类或者多类样本空间尽可能分离。
【2025-12-01】普林斯顿 RL OOD
【2025-12-01】普林斯顿 用 RL 做 OOD
尽管RL提升了LLM 推理能力,但促进组合泛化(即从已知组件中合成新技能的能力)方面往往与单纯的长度泛化相混淆。
强化学习后训练在技能组合效果,及组合结构如何影响技能迁移。
聚焦于COUNTDOWN任务(给定n个数字和一个目标值,构建结果等于该目标值的表达式),并将模型解决方案视为表达式树进行分析——其中每个子树对应可复用的子任务,因此可被视为一项“技能”。
通过追踪训练过程中树的结构及其成功率,发现:
- (i)模型能实现分布外(OOD)泛化,既适用于更大的n,也适用于未见过的树结构,这表明子任务的组合复用;
- (ii)存在依赖结构的可学习性层级——模型先掌握浅层平衡树(子任务间工作量均衡),再掌握深层非平衡树,且在右重结构上存在持续的脆弱性(即便组合深度与某些左重结构相同)。诊断揭示了模型学到了什么、学习顺序如何以及泛化在何处失效,进而阐明了仅基于强化学习的后训练如何诱导分布外泛化。
RL 意图识别
【2025-4-18】腾讯+哈工大 GRPO+RCS
【2025-5-16】Intent Detection via RLVR:通过强化学习让对话系统更懂你的心思
任务导向型对话中,意图识别(Intent Detection)是核心模块,精准地理解用户查询背后的意图,以确保对话状态跟踪和后续API执行的准确性。
然而,TOD系统面临挑战:
- 这些工具之间存在复杂关系,如功能相似、重叠甚至包含关系。意图识别模型必须灵活适应新工具以处理未见过的任务,而且往往没有及时的增量训练过程。
- 过去,研究者尝试通过引入外部常识知识、将任务重新格式化为自然语言推理(NLI)格式以实现零样本能力,或者利用大语言模型(LLM)的零样本能力动态识别未知任务。
- 然而,这些方法在面对未见过的意图时,性能往往显著下降,导致系统错误地将用户意图分配给不匹配的代理。
Deepseek R1推动了RLVR技术发展,腾讯(PCG,平台内容组)和哈工大提出基于强化学习(RL)的意图识别方法,结合组相对策略优化(GRPO)和奖励驱动的课程采样(RCS)。不仅提升模型在已知任务上的性能,更重要的是显著增强了模型在未见任务、细分任务、组合任务以及跨语言场景下的泛化能力
- 【2025-4-18】论文:Improving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling
两种基于规则的奖励函数:格式奖励(Rformat)和答案奖励(Ranswer)。
- 格式奖励确保模型输出严格遵循预定义的格式
- 而答案奖励则评估模型预测的意图是否与真实标签完全匹配。
通过这两种奖励函数的加权组合,引导模型在训练过程中既关注输出的结构正确性,又注重意图识别的准确性。
GRPO训练早期,模型快速收敛到与监督微调(SFT)相当的性能水平,但随后奖励方差变得极小,模型对挑战性样本的关注度降低。
为此,引入离线奖励驱动的课程采样策略。
- 首先,用GRPO方法对整个训练数据集进行训练,记录每个样本在训练过程中的奖励值。
- 然后,将数据分为简单样本和挑战性样本,先在简单样本上进行初步训练,再在挑战性样本上进行深入训练。
这种课程学习方法使模型能够持续关注那些尚未完全掌握的样本,从而提高整体性能。
RCS方法在训练过程中优先选择更具信息量的训练实例,有效地解决了GRPO训练框架中简单样本引入的冗余问题。
- RCS方法仅用60%完整训练数据集的情况下,仍能取得与使用完整数据集的SFT和GRPO方法相当的性能。
- 随着正例比例的增加,模型总体性能呈现下降趋势。这表明,挑战性数据在第二训练阶段的相对集中度对模型解决困难案例的能力至关重要。
这种方法不仅能提升模型在已知任务上的性能,更重要的是显著增强了模型在未见任务(OOD)、细分任务、组合任务以及跨语言场景下的泛化能力。
基于RL的模型在泛化能力上显著优于监督微调(SFT)模型。Qwen2.5-7B-Instruct
例如,在TODAssistant的三个泛化测试集上,SFT模型的性能显著下降,而GRPO模型在所有三个测试集上都保持了超过90%的准确率。这表明GRPO模型能够有效地学习指令理解和推理,从而具备更强的泛化能力。
- 域内测试集: SFT/GRPO模型都能显著提升意图识别的性能。然而,仅使用RL(GRPO)在相同训练数据上并未能超越SFT的性能。这表明,在已知任务上,SFT可能更加高效。
- 泛化场景:GRPO 展现出了显著优势
思考
- 推理才能获得泛化优势?不包含思维过程模型,域内测试表现更好,但其泛化能力显著降低。然而,与预训练模型和SFT训练的模型相比,这些模型的泛化能力仍然有显著提升,表明强化学习方法本身对模型泛化提供了内在优势。
- 一定要用instruct模型?Base Model基础模型在经过GRPO训练后,其性能与指令模型相当。模型能力主要是在预训练阶段获得的,后续训练只是帮助模型更好地利用其固有能力。
研究方向:
- 将离线RCS转变为在线RCS,以更高效地选择优质样本;
- 从单意图检测扩展到多意图检测任务,以应对现实对话任务的复杂性;
- 探索强化学习在TOD系统的其他方面(如对话策略和响应生成)的应用;
- 深入研究“顿悟时刻”现象的深层次原因,逐步增加更加贴近复杂场景的意图识别、Function Call等问题,探索在任务型对话模型的自我反思、自我纠正和自我指导能力。
客服意图识别
面试题:智能客服中意图识别怎么优化?
🛠️主要步骤:
- 意图体系建立,搭建一整套标准化拆解任务,结合相似挖掘、异常检测等工具,提升效果。
- 意图理解,对线上各个意图理解模块进行说明。
- 长尾问题识别,抽象出一套完备的框架,保证每一部分的识别结果。
- 数据回流,提升意图识别和槽位抽取的准确性。
- 领域预训练模型,复盘整体流程,使预训练模型在智能客服领域充分发挥效果。
🎯意图识别难点
目前业界小模型,如果对话轮数过长,例如超过3轮,且每轮对话字数较多,模型回复易陷入混乱,回复质量降低。
- 解决思路1:粗暴解法是删掉历史对话,仅保留最新,但这样又会影响对话的流畅度。
- 解决思路2:基于上下文语义分割 + 基于上下文槽位关联
- 解决思路3:基于多路多轮数据的微调
⭕单轮意图识别
- 仅针对用户的单句输入进行意图判断。例如,在一个问答系统中,用户问 “今天的天气如何?”,系统只需要分析这一个句子,就能识别出用户是想查询天气信息的意图。
- 单轮意图识别相对简单,因为只处理一个句子的语义理解。通常可以通过关键词匹配、简单的语法分析和基于单句的机器学习模型来实现。
👉5种常见的方案:基于规则、向量检索、深度学习、大模型、融合方案
⭕多轮意图识别
- 涉及对用户在一系列对话轮次中的意图进行识别。
- 多轮意图识别要复杂得多,要考虑对话的历史信息,包括之前轮次的意图、对话的主题转移、用户情绪的变化等诸多因素。
- 多轮意图识别系统需要能够及时捕捉到这种意图的转变,并准确理解每个意图在整个对话流程中的作用。
👉比如在一个智能客服对话场景下,用户先问 “我买的商品坏了怎么办?”,客服回答后,用户又问 “那维修需要多长时间?”。
指标
| 指标 | 商用 | 自研 | 备注 |
|---|---|---|---|
| 识别准确率 | 74% | 86% | |
| 响应时间 | 2s | 0.5~1s |
意图识别难题
【2025-8-6】Agent意图识别有哪些挑战?深度解析8大难题
智能Agent理解用户需求的核心环节,意图识别始终被用户表达的灵活性、场景复杂性所困扰。
案例
- “苹果多少钱”的歧义
- “改到周五”的上下文依赖
- “查订单+取消订单”的多意图混合
深度拆解8大核心挑战
- 从自然语言的模糊歧义
- 长对话信息稀释
- 到长尾意图冷启动
- 专业领域知识依赖
- 动态意图演化等痛点
均对应给出可落地的技术方案:
- 从BERT/GPT的深层语义建模
- 会话状态追踪(DST)的上下文管理
- 少样本学习解决长尾问题
- 知识图谱融合适配专业领域……
解决意图识别难题
- 本质是“理解用户表达的复杂性”和“适配场景多样性”的平衡
- 解决方案:结合语义理解(预训练模型)、上下文建模(DST)、领域适配(微调/知识图谱)、动态学习(增量学习)等技术
- 精准识别+用户体验质检找到平衡
- 从用户交互场景出发,让模型不仅“能识别”,更能“懂人心”
- 既是难点,也是agent落地核心竞争力
| 难题 | 难度 | 说明 | 示例 | 分析 | 解决方案 |
|---|---|---|---|---|---|
| 自然语言模糊/歧义 | 高 | 用户表达含糊、歧义、不完整,字面含义与真是意图脱节 | 苹果多少钱:水果还是手机? 订明天的票:机票/火车票/电影票 太吵了:关音乐/调小空调/换安静环境 |
字面意思无法定位意图,需要结合语境/外部知识消歧 | 深度语义建模+知识融合 上下文工程辅助大模型理解用户表达的深层逻辑,如:订明天的票,结合用户历史出行记录,推断出高铁票 引入领域知识图谱:实体关联业务知识,辅助消解指代、多义,如:乔丹很厉害,图谱中乔丹曾效力于公牛队,识别出迈克尔乔丹,而不是演员乔丹 高歧义表达设置规则校验,订票场景,根据出发目的地距离判断类型,地铁票/机票 |
| 上下文依赖与多轮对话信息稀释 | 中 | 历史对话中早期信息容易遗忘 | 周三去北京,改造周五,两句话间隔越远(超过5轮),越容易淹没 | 动态追踪上下文,提取关键信息 | 会话状态跟踪(DST)+长上下文压缩 DST记录关键实体(北京,周三), 检索历史会话补全意图,改造周五→时间改造周五 长对话使用上下文压缩技术,保留核心实体与意图,transformer注意力机制 引入记忆网络,对话历史存储为记忆槽位,历史会话有“过敏”,“这个要能吃吗”关联“无过敏成分”校验 |
| 多意图与复合查询 | 高 | 用户在单轮/多轮中,同时表达多个意图,需要拆解、排序 | “查下订单,没发货就取消”包含两个意图 “订上海机票,再查后天天气” |
多意图区分主次顺序,避免遗漏/误判 | 多标签分类+图神经网络(GNN) 多标签分类模型输出多意图概率,查询订单(0.95),取消订单(0.8) GNN建模意图顺序关系,“订单查询”是“取消订单”的前提,优先处理 复合意图按任务依赖拆解子步骤,依次处理 |
| 长尾意图与冷启动问题 | 低 | 高频意图数据过剩(查天气),而低频意图样本稀缺,长尾意图(颐和园停车场容量) | 电商客服:退货/改地址,占80%,保税仓发货时间/发票抬头修改,占20%,新上线的宠物托运业务没标注数据 | 新业务缺乏标注数据,模型难以适配 | 少样本学习+数据合成 prompt tuning, 长尾/新意图设计提示模版 大模型合成数据,扩充数据集 新业务预设基础意图体系,宠物托运包含证件查询+价格咨询,结合用户反馈不断迭代,“狗能托运吗” |
| 域外意图识别 | 中 | 超出范围的意图,需得体拒绝,而不强行匹配 | 问天气机器人,“如何修电脑” | 明确区分域内/域外意图,生成合理拒绝话术 | 专门分类器+置信度阈值 域内/域外分类器,用域外样本增强识别能力 对识别结果设置阈值:过低(<0.7)触发拒绝机制,”这个问题暂时无法回答” 结合用户反馈优化阈值:用户频繁问“修电脑”,人工设置高频域外意图,拒绝话术 |
| 隐含意图深层推理 | 高 | 语言背后潜藏真实意图,需要读懂弦外之音 | 最近有点忙→找代办事项代理 这个方案不太对→修改方案 孩子明天上学→订早起闹钟 |
规则/基础模型难以捕捉开放域隐含意图,预设类别无法覆盖所有可能性 | 大模型推理+行为序列分析 GPT-4/Claude深度推理,通过因果链分析挖掘隐含意图,忙→没时间处理→需要代办 结合用户行为序列,如多次设置闹钟、查上学路线,将上学与闹钟意图关联 低置信度隐含意图,通过多轮追问澄清,“最近很忙,是要帮忙安排日程吗” |
| 领域知识依赖 | 中 | 金融/医疗等垂类意图识别需要专业术语/规则,模型缺乏会出错 | 金融领域,“赎回理财”要区分“定期理财”/”活期理财” .=医疗场景,“查报告”要关联业务规则“检验项目→科室→出报告时间” |
如何让大模型获得并遵循领域知识 | 融合知识图谱+领域微调 构建领域知识图谱:金融“产品类型-赎回规则”,医疗里“检验项目-科室”,意图识别结合知识检索,领域知识作为上下文,改写原文 领域数据微调:金融对话、医疗病例,预训练、微调模型(bert→finbert),强化术语理解 加入合规校验模块:金融领域需要反洗钱规则过滤,避免推荐高风险操作 |
| 动态意图烟花与用户目标跳转 | 高 | 用户意图动态变化,甚至前后矛盾,需要实时调整方向 | “我想定明天上海机票”,接着“算了还是高铁吧”,“下周走也行” “能不能改下,感觉哪里不对” 未明确修改标题/封面/内容 |
模型要跟踪意图变化,避免被旧意图束缚 | 增量学习+引导式对话 增量学习:弹性权重巩固(EWC)学习新意图时(改高铁)保留旧意图(订机票)关键参数,避免学新忘旧 引导式提问,拆解模糊意图:“你想改标题,还是封面”,复杂意图拆解成清晰的任务路径 会话状态动态更新:实时刷新用户目标,确保匹配最新意图,“出行方式机票→高铁,时间明天→下周” |
案例
亚马逊
【2024-10-2】 多轮场景中的意图识别方案: cot 方法 + SetFit(transformer微调)
hybrid system that combines SetFit and LLM by conditionally routing queries to LLM based on SetFit’s predictive uncertainty determined using Monte Carlo Dropout.
阿里云
阿里云 PAI 平台
【2025-2-19】基于LLM的意图识别解决方案
场景
- 智能语音助手领域,用户通过简单的语音命令与语音助手进行交互。
- 例如,当用户对语音助手说“我想听音乐”时,系统需要准确识别出用户的需求是播放音乐,然后执行相应操作。
- 智能客服场景中,挑战则体现在如何处理各种客户服务请求,并将它们快速准确地分类至例如退货、换货、投诉等不同的处理流程中。
- 例如,在电子商务平台上,用户可能会表达“我收到的商品有瑕疵,我想要退货”。
- 这里,基于LLM的意图识别系统要能够迅速捕捉到用户的意图是“退货”,并且自动触发退货流程,进一步引导用户完成后续操作。
基于LLM的意图识别解决方案
- 准备训练数据
- 参照数据格式要求和数据准备策略并针对特定的业务场景准备相应的训练数据集。您也可以参照数据准备策略准备业务数据,然后通过智能标注(iTAG)进行原始数据标注。导出标注结果,并转换为PAI-QuickStart支持的数据格式,用于后续的模型训练。
- 训练及离线评测模型
- 快速开始(QuickStart)中,基于Qwen1.5-1.8B-Chat模型进行模型训练。模型训练完成后,对模型进行离线评测。
- 部署及调用模型服务
- 当模型评测结果符合您的预期后,通过快速开始(QuickStart)将训练好的模型部署为EAS在线服务
流程图

阿里小蜜
2024年05月,Multi-Agent 智能对话链路
项目背景:
- 原小蜜对话链路存在理解能力差、无法对方案进行解释等问题,导致用户对机器人不信任(无交互指令人工高),交互后即时解决率低,转人工率高;
新链路采用多智能体协同方案,每个Agent中采用ReAct模式进行推理、工具调用和回复。
项目内容:
首问Agent:通过用户行为轨迹(与商家、人工客服、机器人的历史语聊),对用户本次进线问题进行预测方案前Agent:引导用户表达自己遇到的问题和诉求,给用户提供解决方案工具调用:知识诉求定位工具,意图识别工具,轨迹总结工具等工具
项目成果:
- 业务指标:用户无交互指令人工 下降7w/每日,进线即时解决率提升7pt,转人工率下降6pt
- 算法指标:首问Agent和方案前Agent对话合理率85%,轨迹总结工具准确率93%,知识诉求定位工具准确率94%,意图识别工具准召双90%
2025年04月,Multi-Agent 降RT专项
项目背景:
- 针对大模型Cot推理高延迟(均值12s,10%超过20s)进行全链路优化
项目内容:
- 应用DeepSearch方法:从
ReAct模式改成DeepSearch模式,降低循环调用LLM推理时间 - 动态召回提示词:基于用户query动态召回服务策略,降低prompt token数,提升指令跟随能力
- 投机采样:训练小参数蒸馏模型辅助大模型推理,有效降低大模型推理时间
- 强化学习:利用rule-base lcpo 方式训练qwq-32B,保持准确率的前提下, 控制生成的token长度
项目成果:
- 平均响应时间降至 10s(12s->10s),长尾请求(>20s)占比从10%降至0.1%。
- LLM prompt平均token数降低30%
抖音
抖音社区客服:意图识别从bert 70%提升到87%,qwen-7b
- eva小模型分级预测:准确率不足,迭代成本高
- 融合框架:RAG+SFT+GRPO
- 数据:结构化知识库(标签+解释+示例),引入对比数据、cot数据
专项
- 知识库改造:标签+解释+示例,形成结构化知识库
- 训练数据构造:引入语义对比、cot
- 训练方法:先通过RAG召回,再进行SFT+GRPO
伯克利 RouteLLM
模型与成本间,寻找平衡点
【2024-7-1】加州伯克利 基于偏好数据的大语言模型路由框架
选择哪个模型时,要在性能和成本之间做出权衡。更强大的模型虽然有效,但成本更高,而能力较弱的模型则更具成本效益。
论文提出了几种高效的路由模型,推理过程中动态选择更强大或较弱的LLM,旨在优化成本与响应质量之间的平衡。
利用人类偏好数据和数据增强技术的训练框架来提升这些路由器的性能。
论文的方法在某些情况下显著降低了成本——超过2倍——同时不牺牲响应质量。
腾讯PCG+哈工大 RL
【2025-4-18】腾讯+哈工大提出 组相对策略优化(GRPO)和奖励驱动的课程采样(RCS)
- 解读:腾讯研究团队提出意图检测新范式:强化学习+奖励机制,泛化能力显著提升 (暴涨47%)
AI 智能助手准确理解用户的意图(Intent Detection)并路由至下游工具链是实现这些功能的第一步, 而工具的快速迭代、多样化、工具之间关系的复杂化,给意图识别带来新的挑战
- 模型在应对新意图时普遍存在性能衰减问题。
- 如何在开源的轻量级 LLMs 上训练泛化性更好、鲁棒性更强的意图识别模型,使得模型能够更准确理解未见场景的意图至关重要。
腾讯 PCG 社交线的研究团队,针对 AI 智能助手在意图识别方面临的泛化性难题,创新性地采用强化学习(RL)训练方法,结合分组相对策略优化(GRPO)算法和基于奖励的课程采样策略(Reward-based Curriculum Sampling, RCS), 将其创新性地应用在意图识别任务上,显著提升模型在未知意图上的泛化能力,攻克了工具爆炸引发的意图泛化难题,推动大模型在意图识别任务上达到新高度。
实验表明,相比于传统的监督微调(SFT)方法,该方法在未见意图和跨语言能力上表现更佳。除了完全新的未见意图,该工作还比较了对已知意图进行拆分、合并等实际产品场景会遇到的真实问题
此外,研究还发现引入思考(Thought)以及选择预训练或指令微调模型作为基础,对模型性能影响不大,但严格的输出格式约束至关重要。
贡献
- 证明在意图检测问题上,通过强化学习(RL)训练的模型在泛化能力上显著优于通过监督微调(SFT)训练的模型,体现在对未见意图和跨语言能力的泛化性能大幅提升。
- 除了完全新的未见意图,该工作还比较了对已知意图进行拆分、合并等实际产品场景会遇到的真实问题。
- 通过基于奖励的课程采样策略进一步增强了 GRPO 训练效果,有效引导模型在训练过程中聚焦于更具挑战性的样例。
- 强化学习过程中引入思考(Thought),显著提升了模型在复杂意图检测任务中的泛化能力。在更具挑战性的场景中,Thought 对于提升模型的泛化能力至关重要。
- 在意图识别任务中,无论选择预训练模型(Pretrain)还是指令(Instruct)微调模型作为基础,经过相同轮次的 GRPO 训练后,两者性能相近。这一结果与传统训练经验有所不同。
该研究为解决工具爆炸背景下的意图识别难题提供了新思路。
方法
GRPO:强化学习优化意图识别
- 用GRPO方法对意图识别模型进行训练。
- 训练过程中,设计了两种基于规则的奖励函数:
格式奖励(Rformat)和答案奖励(Ranswer)。- 格式奖励确保模型输出严格遵循预定义的格式,而答案奖励则评估模型预测的意图是否与真实标签完全匹配。
- 通过这两种奖励函数的加权组合,引导模型在训练过程中既关注输出的结构正确性,又注重意图识别的准确性。
RCS:聚焦挑战性样本
- GRPO训练早期,模型能够快速收敛到与监督微调(SFT)相当的性能水平,但随后奖励方差变得极小,模型对挑战性样本的关注度降低。
两阶段训练方法,重点根据样本的难度选择训练样本:
- 第一阶段:整个数据集上训练模型,限制步数,避免使用较简单的数据,以确保模型从具有挑战性的示例中学习。
- 第二阶段:集中于通过评分机制识别的难样本,使模型能够在具有挑战性的案例上得到改善。
为此,引入了离线奖励驱动的课程采样策略。
- 首先,用GRPO方法对整个训练数据集进行训练,记录每个样本在训练过程中的奖励值。
- 然后,将数据分为简单样本和挑战性样本,先在简单样本上进行初步训练,再在挑战性样本上进行深入训练。
- 这种课程学习方法使模型能够持续关注那些尚未完全掌握的样本,从而提高整体性能。
思考
(1)RCS 是否必要
RCS方法通过在训练过程中优先选择更具信息量的训练实例,有效地解决了GRPO训练框架中简单样本引入的冗余问题。
实验表明,RCS方法在仅使用60%完整训练数据集的情况下,仍能取得与使用完整数据集的SFT和GRPO方法相当的性能。
(2)难易样本比例
随着正例比例的增加,模型的总体性能呈现下降趋势。
这表明,挑战性数据在第二训练阶段的相对集中度对模型解决困难案例的能力至关重要。
(3)thinking是否必要
强化学习过程中引入“Thinking”(思维链)过程是否必要。
- TODAssistant数据集上,不包含思维过程的模型在域内测试中表现更好,但其泛化能力显著降低。
- 然而,与预训练模型和SFT训练的模型相比,这些模型的泛化能力仍然有显著提升,表明强化学习方法本身对模型泛化提供了内在优势。
(4)instruct模型必要?
尽管意图检测需要模型具备强大的任务理解和分类能力,但 Base Model基础模型在经过GRPO训练后,其性能与指令模型相当。
- 模型的能力主要是在预训练阶段获得的,后续训练只是帮助模型更好地利用其固有能力。
- 基础模型在宽松格式奖励下先减少后增加的完成长度,但这种增加并没有引入有价值的信息,而是增加了与任务无关的内容。相比之下,指令模型在两种奖励函数下的完成长度保持不变。
这表明
- 类似于R1的强化学习训练确实试图增加长度以获得更高的奖励,但在相对简单的意图检测任务中,真正的“顿悟时刻”不太可能出现,因为上下文逻辑有限,不需要模型进行深入推理。
效果
不仅能提升模型在已知任务上的性能,更重要的是显著增强了模型在未见任务、细分任务、组合任务以及跨语言场景下的泛化能力。
MultiWOZ 2.2和TODAssistant两个数据集上进行了广泛的实验。实验结果表明,基于RL的模型在泛化能力上显著优于SFT模型。
(1)域内测试集
- 无论是SFT还是GRPO训练的模型,都能显著提升意图识别的性能。
- 然而,仅使用RL(GRPO)在相同训练数据上并未能超越SFT的性能。
(2)泛化场景下,GRPO模型展现出显著优势。
TODAssistant 三个泛化测试集上
- SFT模型的性能显著下降,尤其在细分和组合测试集上,SFT模型的预测被限制在训练期间见过的10个类别中。
- 相比之下,GRPO模型在所有三个测试集上都表现出色,保持了超过90%的准确率。
跨语言和跨任务场景中,GRPO方法仍能保持强大的性能,进一步凸显了其相对于SFT方法的优越性。
另一个数据集上,GRPO训练的模型在大多数类别上的表现比SFT训练的模型高出20%以上。
这表明
- 已知任务上,SFT可能更加高效。
- 未知任务上,GRPO模型能够有效地学习指令理解和推理,从而具备更强的泛化能力
展望
研究:
- 将离线RCS转变为在线RCS,以更高效地选择优质样本;
- 从单意图检测扩展到多意图检测任务,以应对现实对话任务的复杂性;
- 探索强化学习在TOD系统的其他方面(如对话策略和响应生成)的应用;
- 深入研究“顿悟时刻”现象的深层次原因,逐步增加更加贴近复杂场景的意图识别、Function Call等问题,探索在任务型对话模型的自我反思、自我纠正和自我指导能力。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
