- PyTorch 学习笔记
- PyTorch 教程
- pytorch 内部机制
- 结束
PyTorch 学习笔记
2017 年 1 月,FAIR(Facebook AI Research)发布 PyTorch。
PyTorch在Torch基础上用 python 语言重新打造的一款深度学习框架。- Torch 是采用 Lua 语言为接口的机器学习框架,但因为 Lua 语言较为小众,导致 Torch 学习成本高,因此知名度不高。
Pytorch 是基于 Python 的科学计算库,加速深度学习应用
- PyTorch 工作流程非常接近 科学计算库 NumPy
- PyTorch 提供类似 NumPy 的抽象方法来表征
张量(或多维数组),利用 GPU 来加速训练。
深度学习框架
【2022-4-8】中国开源深度学习框架第六年:百度飞桨国内综合份额第一,全球开发者超400万,和讯网地址
- 国际两大主流深度学习框架TensorFlow、PyTorch之外,中国的开源框架,发展怎么样?
- 百度飞桨(PaddlePaddle),深度学习开源框架的先头兵,在2016年就已率先对外发布。
- 2020年,国内开源框架迎来了第一波集中爆发。
- 独角兽旷视拿出工业级深度学习框架天元(MegEngine),一流科技OneFlow、华为昇思(MindSpore)也在同年登场。
- 学界方面,清华大学开源了支持即时编译的深度学习框架计图(Jittor)。
- 过去几年中,”开源”、”AI底层”成为了国内AI厂商们十分重视的发展战略。

发展历史
PyTorch 历史
PyTorch 发展
- 2017 年 1 月正式发布 PyTorch。
- 2018 年 4 月更新 0.4.0 版,支持 Windows 系统,caffe2 正式并入 PyTorch。
- 2018 年 11 月更新 1.0 稳定版,已成为 Github 上增长第二快的开源项目。
- 2019 年 5 月更新 1.1.0 版,支持 TensorBoard,增强可视化功能。
- 2019 年 8 月更新 1.2.0 版,更新 Torchvision,torchaudio 和torchtext,支持更多功能。
目前 PyTorch 超越 Tensorflow。
深度学习框架渊源
- 【2021-3-3】深度学习框架编年史:搞深度学习的那帮人,不是疯子,就是骗子!
- 2002年,瑞士是物理和数学领域的领跑者。也在2002年,瑞士戴尔莫尔感知人工智能(Idiap)研究所诞生了第一个机器学习库Torch。
- 机器学习库Torch,出自”葡萄酒产区”研究所的一份研究报告(三位作者分别是:Ronan Collobert、Samy Bengio、Johnny Mariéthoz)。其中一位作者姓本吉奥(Bengio),没错,这位眉毛粗粗的科学家,就是深度学习三巨头之一,约舒亚·本吉奥(Yoshua Bengio)的兄弟。2007年他跳槽去了谷歌。
- 2007年,加拿大蒙特利尔大学开发了第一个深度学习框架Theano(行业祖师爷)。框架和图灵奖获得者颇有渊源,约舒亚·本吉奥(Yoshua Bengio)和伊恩·古德费洛(Ian Goodfellow)都有参与Theano。
- 库和框架的不同之处,在于境界。库是兵器库,框架则是一套武林绝学的世界观,程序员在这个世界观的约束下去练(编)拳(程)法(序),结果被框架所调用。框架接管了程序的主控制流。有了框架,才能做到只关注算法的原理和逻辑,不用去费事搞定底层系统、工程的事。
- 2013年,著名的Caffe框架诞生,发音和”咖啡”相似,是”快速特征提取的卷积框架”论文的英文简称。贾扬清第一个C++项目
- 贾扬清已经在美国加州大学伯克利分校攻读博士学位,开启了计算机视觉的相关研究。那时候,他常被一个问题困扰:怎样训练和设计深度学习的网络?为此,贾扬清想造一个通用工具。
- 2013年,Parameter Server(参数服务器)的两位著名教授走向台前,邢波(Eric Xing)教授和Alex Smola教授,现在两位均在美国卡内基梅隆大学(CMU)任教。
- 参数服务器是个编程框架,也支持其他AI算法,对深度学习框架有重要影响。
- 高校实验室善于技术创新,深度学习框架的很多精髓创意源于此地。但是,深度学习框架复杂性高、工程量极大,长期负责复杂产品,高校并不擅长。多年后,高校出生的深度学习框架,都以某种方式”进入”企业,或者被企业赶超
- 2015年11月,谷歌大脑团队开发的TensorFlow开源,原创者之一是谷歌天才科学家,杰夫·迪恩(Jeff Dean)。谷歌的搜索、油管、广告、地图、街景和翻译的背后,都有其身影。
- TensorFlow直译,张量(tensor)在图中流动(flow)。由此也可获知,数据流图是框架的重要技术。数据流图由算子组成,算子又分为大算子和小算子。Caffe是大算子抽象,TensorFlow是小算子抽象。小算子好处是灵活,坏处是性能优化难。
- 在2000年下半年的时候,Jeff Dean的代码速度突然激增了40倍,原因是他把自己的键盘升级到了USB 2.0。编译器从来不会给Jeff Dean警告,但Jeff Dean会警告编译器。—— 段子
- 2015 年是一个重要的年份,何恺明等人的研究成果,突破了边界,在准确率上再创新高,风头一时无二。
- 2015年,谷歌AI研究员弗朗索瓦·乔莱特(Francois Chollet)几乎是独自完成了著名的Keras 框架的开发,为谷歌再添一条护城河,大有”千秋万代,一统江湖”的势头。
- 2016年,微软CNTK(Cognitive Toolkit)伸手接过女神(内部孵化项目Minerva)的接力棒,可惜魔障难消,用的人少,没有推广开,于2019年停止维护。
- 2016年,贾扬清从谷歌TensorFlow团队离职,跳槽到了Facebook公司。与谷歌挥手道别,四载光阴(实习两年,工作两年),往事依稀,他的内心充满感怀。
- 2016年5月,陈天奇读博二开发的MXNet(读作”mixnet”,mix是中文”混合”之意)开源,浓缩了当时的精华,合并了几个原来有的项目,陈天奇cxxnet、参数服务器、智慧女神、颜水成学生林敏的purine2。仅一年时间里,就做出了完整的架构。团队中还有一位闻名遐迩的大神,李沐(现任亚马逊公司资深主任科学家,principal scientist)。2017年9月,MXNet被亚马逊选为官方开源平台。
- 2017年,祖师爷Theano官宣退休。贾扬清借鉴谷歌TensorFlow框架里面的一些新思想,实现了一个全新的开源Caffe2。三十而立的他,成长为遍历世界级产品的第一高手。
- 2018年,PyTorch接纳Caffe2后,意外崛起,上演令谷歌框架王冠落地的戏剧性一幕。易用性确实可以抢客户,但谷歌没有想到脸书抢了这么多。后来者确实可以居上,但谷歌没有想到脸书仅用如此短的时间。
- 谷歌出发最早,为何没有独坐钓鱼台?为什么是脸书抢了市场?
- 谷歌野心非常大,初期想做很大很全的工具。虽然完备性很强,但是,系统过度复杂。虽然以底层操作为主,有很多基础的功能,但是这些功能没能封装得很好,需要开发者自己解决(定义),手动工作过多。
- 仅仅是丢市场还不够惨,PyTorch框架带火了背后的技术(动态执行等),脸书开始左右技术趋势。
- 微软在智慧女神和CNTK两次滑铁卢之后,依然斗志昂扬准备第三次入局。微软思路清奇地设计了ONNX(全称Open Neural Network Exchange),一种开放式深度学习神经网络模型的格式,用于统一模型格式标准。
- 2016 年8月,百度PaddlePaddle开源,PaddlePaddle作为国内唯一的开源深度学习框架,此后两年多,都是孤家寡人。2013年,百度第一位T11徐伟,同时也是百度深度学习框架PaddlePaddle的原创者和奠基人。
- 2019年,百度PaddlePaddle有了中文名,名叫”飞桨”。国外产品连个中文名都懒得起。
- 2019年2月,一流科技获得千万级Pre-A轮投资,袁进辉是创始人兼CEO。邢波教授团队和袁进辉团队双剑合璧开发了OneFlow
- 2014年,微软亚研院副院长马维英(现任清华大学智能产业研究院讲席教授、首席科学家)找到一位研究员,名叫袁进辉,他是清华大学计算机专业的博士,师从张钹院士。
- 来自美国CMU的教授,名叫邢波,此时任微软亚研院顾问一职,他擅长的领域包括大规模计算系统。
- 2020年,国产深度学习框架井喷。国产深度学习框架的”元年”。
- 3月20日,清华大学计图(Jittor)。
- 3月25日,旷视科技天元(MegEngine) 。
- 3月28日,华为MindSpore。
- 7月31日,一流科技OneFlow。OneFlow有两个创新点:一会自动安排数据通信。二把数据通信和计算的关系协调好,让整体效率更高。
- 守旧的经验是,既然国外开源了,就抓紧学。既然人家成了事实工业标准,就尽力参与。总是慢了好几拍,Linux这轮就是这样。
- 引用某游戏厂商的经典台词是:”别催了,在抄了,在抄了。”
- 可惜竞争从来不是游戏。
- 深度学习框架的台词是:”不能照抄,不能舔狗,舔到最后,一无所有。”
- 这世界上唯一能够碾压国内一线城市房价增速的,只有AI模型的规模,虽然硬件和软件的进步已经将每年的训练成本降低了37%;但是,AI模型越来越大,以每年10倍的速度增长。
- 前美国国防部咨询顾问,史蒂夫·马奎斯的说法是:”开源项目,来源于最纯粹的竞争。如果一个开源项目在商业世界获得了成功,那决不会是出于侥幸,决不会是因为其它竞争者恰好被规章制度所累、被知识产权法约束、被人傻钱多的金主拖垮。一个开源项目胜出了,背后只会有一个原因——它真的比其他竞争者都要好。”
PyTorch 优缺点
PyTorch 优点
PyTorch 优点
- 上手快,掌握 Numpy 和基本深度学习概念即可上手。
- 支持 Python:PyTorch 可与 Python 数据科学栈相结合
- 与 NumPy 一样简单,甚至都感觉不出区别
- 代码简洁灵活:
- 用
nn.Module封装, 网络搭建更加方便。 - 基于
动态图机制,更加灵活。
- 用
- 资源多
- arXiv 中新论文的算法大多有 PyTorch 实现。
- 开发者多
- Github 上贡献者(Contributors)已经超过 1100+
动态计算图:- PyTorch 不再采用特定函数预定义计算图,而是提供构建
动态计算图框架,甚至可在运行时修正。 - 这种动态框架在不知道所构建的神经网络需要多少内存时非常有用。
- PyTorch 不再采用特定函数预定义计算图,而是提供构建
- 其它:
- 还有多 GPU 支持、自定义数据加载器和极简的预处理过程等
Tensorflow v.s. Pytorch
结论:
- 如果是工程师,应该优先选TensorFlow2.
- 如果是学生/研究人员,应该优先选择Pytorch.
- 如果时间足够,最好TensorFlow2和Pytorch都要学习掌握。
- 理由如下:
- 1,在工业界最重要的是模型落地,目前国内的大部分互联网企业只支持TensorFlow模型的在线部署,不支持Pytorch。 并且工业界更加注重的是模型的高可用性,许多时候使用的都是成熟的模型架构,调试需求并不大。
- 2,研究人员最重要的是快速迭代发表文章,需要尝试一些较新的模型架构。而Pytorch在易用性上相比TensorFlow2有一些优势,更加方便调试。 并且在2019年以来在学术界占领了大半壁江山,能够找到的相应最新研究成果更多。
- 3,TensorFlow2和Pytorch实际上整体风格已经非常相似了,学会了其中一个,学习另外一个将比较容易。两种框架都掌握的话,能够参考的开源模型案例更多,并且可以方便地在两种框架之间切换。
- Keras库在2.3.0版本后将不再更新,用户应该使用tf.keras
总结:
- (1)模型可用性:pytorch更好
- (2)部署便捷性:TensorFlow更好
- Serving 和 TFLite 比 PyTorch 的同类型工具要稳健一些。而且,将 TFLite 与谷歌的 Coral 设备一起用于本地 AI 的能力是许多行业的必备条件。相比之下,PyTorch Live 只专注于移动平台,而 TorchServe 仍处于起步阶段。
- 既想用 TensorFlow 的部署基础设施,又想访问只能在 PyTorch 中使用的模型,作者推荐使用 ONNX 将模型从 PyTorch 移植到 TensorFlow。
- (3)生态系统对比:TensorFlow 胜出
2022年了,PyTorch和TensorFlow你选哪个?
选择指南:
- (1)
工程师- TensorFlow 强大的部署框架和端到端的 TensorFlow Extended 平台是很珍贵的。能在 gRPC 服务器上进行轻松部署以及模型监控和工件跟踪是行业应用的关键
- 仅在 PyTorch 中可用的 SOTA 模型,那也可以考虑使用 PyTorch(TorchServe)
- 移动应用,也可以用pytorch live
- 音频或视频输入,应该使用 TensorFlow
- 用 AI 的嵌入式系统或 IoT 设备,鉴于 TFLite + Coral 生态系统,用tf
- (2)
研究者- 大概率会使用 PyTorch,坚持使用,大多数 SOTA 模型都适用于 PyTorch;
- 但强化学习领域的一些研究应该考虑使用 TensorFlow。原生 Agents 库,并且 DeepMind 的 Acme框架和Sonnet
- 想用TPU训练,但不想用TensorFlow,那考虑探索谷歌的JAX。JAX 本身不是神经网络框架,而是更接近于具有自动微分能力的 GPU/TPU 的 NumPy 实现。
- 不用TPU 训练,那最好是坚持使用 PyTorch
- (3)
教授,因课程重点而已- 培养具备行业技能的深度学习工程师,胜任整个端到端深度学习任务,而不仅仅是掌握深度学习理论,那应该使用 TensorFlow
- 深度学习理论和理解深度学习模型的底层原理/高级课程/研究,那应该使用 PyTorch。
- (4)
职业转型- 对框架完全不熟悉,请使用 TensorFlow,因为它是首选的行业框架。
- (5)
业余爱好者- 大项目,部署到物联网/嵌入式设备,TensorFlow + TFLite
- 了解深度学习,PyTorch
- 入门即可,keras
HuggingFace 使得深度学习从业者仅借助几行代码就能将训练、微调好的 SOTA 模型整合到其 pipeline 中。
- HuggingFace中大约有85%的模型只能在PyTorch上用,剩下的模型还有一半也可以在 PyTorch 上用。
- 相比之下,只有16%的模型能在 TensorFlow 上用,只有 8% 是 TensorFlow 所独有的。
- Top 30 个模型中,能在 TensorFlow 上用的还不到 2/3,但能在 PyTorch 上用的却达到了 100%,没有哪个模型只能在 TensorFlow 上用。
- 8个顶级研究期刊论文中框架采用情况:PyTorch 的采用率增长迅速,几年时间就从原来的 7% 长到了近 80%。 很多转向 PyTorch 的研究者都表示 TensorFlow 1 太难用了。尽管 2019 年发布的 TensorFlow 2 改掉了一些问题,但彼时,PyTorch 的增长势头已经难以遏制。
- 2018 年还在用 TensorFlow 的论文作者中,有 55% 的人在 2019 年转向了 PyTorch,但 2018 年就在用 PyTorch 的人有 85% 都留了下来。
- Papers with Code 本季度创建的 4500 个库中,有 60% 是在 PyTorch 中实现的,只有 11% 是在 TensorFlow 中实现的。相比之下,TensorFlow 的使用率在稳步下降,2019 年 TensorFlow 2 的发布也没有扭转这一趋势。
大公司:
- Google AI:谷歌发布的论文自然会用 TensorFlow。鉴于在论文方面谷歌比 Facebook 更高产,一些研究者可能会发现掌握 TensorFlow 还是很有用的。
- DeepMind:DeepMind 也用 TensorFlow,而且也比 Facebook 高产。他们创建了一个名叫 Sonnet 的 TensorFlow 高级 API,用于研究目的。有人管这个 API 叫「科研版 Keras」,那些考虑用 TensorFlow 做研究的人可能会用到它。此外,DeepMind 的 Acme 框架可能对于强化学习研究者很有用。
- OpenAI:OpenAI 在 2020 年宣布了全面拥抱 PyTorch 的决定。但他们之前的强化学习基线库都是在 TensorFlow 上部署的。基线提供了高质量强化学习算法的实现,因此 TensorFlow 可能还是强化学习从业者的最佳选择。
- JAX:谷歌还有另一个框架——JAX,它在研究社区中越来越受欢迎。与 PyTorch 和 TensorFlow 相比,JAX 的开销要小得多。但同时,JAX 和前两个框架差别也很大,因此迁移到 JAX 对于大多数人来说可能并不是一个好选择。目前,有越来越多的模型 / 论文已经在用 JAX,但未来几年的趋势依然不甚明朗。
模型部署
TensorFlow Serving:
- TensorFlow Serving 用于在服务器上部署 TensorFlow 模型,无论是在内部还是在云上,并在 TensorFlow Extended(TFX)端到端机器学习平台中使用。Serving 使得用模型标记(model tag)将模型序列化到定义良好的目录中变得很容易,并且可以选择在保持服务器架构和 API 静态的情况下使用哪个模型来进行推理请求。
- Serving 可以帮用户轻松地在 gRPC 服务器上部署模型,这些服务器运行谷歌为高性能 RPC 打造的开源框架。gRPC 的设计意图是连接不同的微服务生态系统,因此这些服务器非常适合模型部署。Serving 通过 Vertex AI 和 Google Cloud 紧密地集成在一起,还和 Kubernetes 以及 Docker 进行了集成。
TensorFlow Lite:
- TensorFlow Lite 用于在移动或物联网 / 嵌入式设备上部署 TensorFlow 模型。TFLite 对这些设备上的模型进行了压缩和优化,并解决了设备上的 AI 的 5 个约束——延迟、连接、隐私、大小和功耗。可以使用相同的 pipeline 同时导出基于标准 Keras 的 SavedModels(和 Serving 一起使用)和 TFLite 模型,这样就能比较模型的质量。
- TFLite 可用于 Android、iOS、微控制器和嵌入式 Linux。TensorFlow 针对 Python、Java、C++、JavaScript 和 Swift 的 API 为开发人员提供了广泛的语言选项。
PyTorch 用户需要使用 Flask 或 Django 在模型之上构建一个 REST API,但现在他们有了 TorchServe 和 PyTorch Live 的本地部署选项。
TorchServe:
- TorchServe 是 AWS 和 Facebook 合作的开源部署框架,于 2020 年发布。它具有端点规范、模型归档和指标观测等基本功能,但仍然不如 TensorFlow。TorchServe 同时支持 REST 和 gRPC API。
PyTorch Live:
- PyTorch 于 2019 年首次发布 PyTorch Mobile,旨在为部署优化的机器学习模型创建端到端工作流,适用于 Android、iOS 和 Linux。
- PyTorch Live 于 12 月初发布,以移动平台为基础。它使用 JavaScript 和 React Native 来创建带有相关 UI 的跨平台 iOS 和 Android AI 应用。设备上的推理仍然由 PyTorch Mobile 执行。Live 提供了示例项目来辅助入门,并计划在未来支持音频和视频输入。
生态系统
PyTorch 2024 研讨会
【2024-10-14】PyTorch 2024 Conference-亮点内容
PyTorch 2024 研讨会议近期结束了,主要内容涵盖通用AI、LLM、分布式、边缘计算等,邀请了开发者、供应商和周边团队。
LLM 相关内容
- 原生接口LLM库:
TorchTian、TorchTune、TorchChat; - 编译库: torchao;FSDP2;vLLM
SD(Speculative Decoding)的内容,可以搜索一下(柳晓萱)的论文:Optimizing Speculative Decoding for Serving Large Language Models Using Goodput。
2024年推出torch原生三大件:TorchTian、TorchTune、TorchChat
TorchTian: Pre-Training 预训练阶段使用TorchTune: Fine-Tuning 微调阶段使用TorchChat: Inference 推理阶段使用
TorchTian
TorchTian 分布式训练服务模块,结合pytorch图编译complie以及ao量化。
主要特性:并行策略、分布式CKPT、高性能训练
- 并行策略, 还是三个:区分维度是GPU数量,而非模型参数量
- 数据并行:DDP+FSDP。 适配场景 <= 512 GPU 训练。
- FSDP承担了ZeRO功能
- 张量并行:TP/seq。 <=2K GPU;
- PP并行:解决超过2K场景训练;
- 数据并行:DDP+FSDP。 适配场景 <= 512 GPU 训练。
区别
- 原生支持 torch.compile,以及FSDP的进化->v2
追赶并超越 Megtron/Deepspeed/colossalAI 类的框架,可能得依靠原生(Native)这个力量。
TorchTune
TorchTune 库主打原生
tune 特点(或者说它期望的目标)侧重内存效率和性能:
目前支持主流模型,但还不支持如Deepseek、Claude、Yi等榜上有名的模型
TorchChat
Chat属于端侧部署模块,瞄准服务器以及小型终端(PC、手机)的部署的应用。
终端的算力体量虽然没有服务器的大,但是作为生态的一个重要板块能够很好的抓住用户。
当前已支持Llama 3.2 11B 模型部署,而且支持的硬件系统多:
- Linux (x86)
- Mac OS (M1/M2/M3)
- Android (Devices that support XNNPACK)
- iOS 17+ and 8+ Gb of RAM (iPhone 15 Pro+ or iPad with Apple Silicon)
Pytorch 生态
Hub:- PyTorch Hub 作为面向研究的官方平台,用于与预训练模型共享存储库。Hub 拥有广泛类别的模型,包括用于音频、视觉、NLP 任务的模型,还有用于生成任务的 GAN 模型。
SpeechBrain:- SpeechBrain 是 PyTorch 的官方开源语音工具包。SpeechBrain 能够完成自动语音识别(ASR)、说话人识别、验证和分类等任务。如果你不想构建任何模型,而是想要一个具有情感分析、实体检测等功能的即插即用工具,可以选择使用 AssemblyAI 的 Speech-to-Text API。
- 当然,PyTorch 的工具页面还有很多其他有用的库,包括为计算机视觉和自然语言处理量身定制的库,例如 fast.ai。
TorchElastic:- TorchElastic 是 AWS 和 Facebook 2020 年联合发布的分布式训练工具,可管理工作进程并协调重启行为,以便用户在计算节点集群上训练模型,这些节点可以动态变化而不会影响训练。因此,TorchElastic 可防止因服务器维护或网络问题等导致的灾难性故障,不会丢失训练进度。TorchElastic 具有与 Kubernetes 集成的特性,并已集成到 PyTorch 1.9+ 中。
TorchX:- TorchX 是一个用于快速构建和部署机器学习应用程序的 SDK。TorchX 包括 Training Session Manager API,可在支持的调度程序上启动分布式 PyTorch 应用程序。TorchX 负责启动分布式作业,同时原生支持由 TorchElastic 局部管理的作业。
Lightning:- PyTorch Lightning 有时被称为 PyTorch 的 Keras。虽然这种类比并不准确,但 Lightning 的确是简化 PyTorch 中模型工程和训练过程的有用工具,自 2019 年首次发布以来已经逐渐趋于成熟。Lightning 以面向对象的方式处理建模过程,定义了可重用和可跨项目使用的可共享组件。
【2023-7-9】 torchkeras 详见介绍
- torch4keras 功能: 像使用keras一样使用pytorch, 是从 bert4torch 中抽象出来的 trainer, 适用于一般神经网络的训练,用户仅需关注网络结构代码的实现,而无需关注训练工程代码
功能介绍
- 模型训练: 模型训练过程和keras很相似
- model.compile(optimizer,loss, scheduler,metric) 指定loss, 优化器,scheduler,mertrics;
- model.fit(train_dataloader, epoch, steps_per_epoch) 进行模型训练
- 特色功能:
- 进度条展示训练过程;
- 自带和自定义metric;
- 自带Evaluator, Checkpoint, Tensorboard, Logger等keras自带的Callback,也可自定义Callback;
- 支持dp和ddp的多卡训练
- 设计初衷:前期功能是作为bert4torch和rec4torch的Trainer,用户可用于各类pytorch模型训练
TorchServe
- 【2020-4-27】PyTorch 1.5 发布,与AWS联手推出TorchServe
- PyTorch 1.5 发布,升级了主要的 torchvision (视觉),torchtext(文本) 和 torchaudio(语音) 库,并推出将模型从 Python API 转换为 C++ API 等功能。
- Facebook 还和 Amazon 合作,推出了两个重磅的工具:TorchServe 模型服务框架 和 TorchElastic Kubernetes 控制器。
- TorchServe 旨在为大规模部署 PyTorch 模型推理,提供一个干净、兼容性好的工业级路径。
- TorchElastic Kubernetes 控制器,可让开发人员快速使用 Kubernetes 集群,在 PyTorch 中创建容错分布式训练作业。
- 【2021-1-19】pytorch模型部署工具TorchServe
如何评价 PyTorch 在 2020 年 4 月推出的 TorchServe?
- TorchServe 旨在为大规模部署 PyTorch 模型推理,提供一个干净、兼容性好的工业级路径。其主要的特点包括有:
- 原生态 API:支持用于预测的推理 API,和用于管理模型服务器的管理 API。
- 安全部署:包括对安全部署的 HTTPS 支持。
- 强大的模型管理功能:允许通过命令行接口、配置文件或运行时 API 对模型、版本和单个工作线程进行完整配置。
- 模型归档:提供执行「模型归档」的工具,这是一个将模型、参数和支持文件打包到单个持久工件的过程。使用一个简单的命令行界面,可以打包和导出为单个「.mar」文件,其中包含提供 PyTorch 模型所需的一切。该 .mar 文件可以共享和重用。
- 内置的模型处理程序:支持涵盖最常见用例,如图像分类、对象检测、文本分类、图像分割的模型处理程序。TorchServe 还支持自定义处理程序。
- 日志记录和指标:支持可靠的日志记录和实时指标,以监视推理服务和端点、性能、资源利用率和错误。还可以生成自定义日志并定义自定义指标。
- 模型管理:支持同时管理多个模型或同一模型的多个版本。你可以使用模型版本回到早期版本,或者将流量路由到不同的版本进行 A/B 测试。
- 预构建的图像:准备就绪后,可以在基于 CPU 和 NVIDIA GPU 的环境中,部署 TorchServe 的 Dockerfile 和 Docker 镜像。
- 综上可知,这次的 TorchServe 在推理任务上,将会有很大的使用空间,对于广大开发者来说是一件好事。这一点可以留着以后去慢慢验证。对于这次 Facebook 和 AWS 合作,明显可以看出双方在各取所长,试图打造一个可以反抗谷歌 TensorFlow 垄断的方案。
- 问题:
- 为什么 TorchServe 采用 Java 开发,而没有像 TensorFlow Serving 一样采用更好性能的C++,抑或是采用 Golang?
- TorchServe Architecture
- Model Server for PyTorch Documentation

Basic Features
- Serving Quick Start - Basic server usage tutorial
- Model Archive Quick Start - Tutorial that shows you how to package a model archive file.
- Installation - Installation procedures
- Serving Models - Explains how to use
torchserve. - Packaging Model Archive - Explains how to package model archive file, use
model-archiver. - Logging - How to configure logging
- Metrics - How to configure metrics
- Batch inference with TorchServe - How to create and serve a model with batch inference in TorchServe
- Model Snapshots - Describes how to use snapshot feature for resiliency due to a planned or unplanned service stop
Advanced Features
- Advanced settings - Describes advanced TorchServe configurations.
- Custom Model Service - Describes how to develop custom inference services.
- Unit Tests - Housekeeping unit tests for TorchServe.
- Benchmark - Use JMeter to run TorchServe through the paces and collect benchmark data
Default Handlers
- Image Classifier - This handler takes an image and returns the name of object in that image
- Text Classifier - This handler takes a text (string) as input and returns the classification text based on the model vocabulary
- Object Detector - This handler takes an image and returns list of detected classes and bounding boxes respectively
- Image Segmenter - This handler takes an image and returns output shape as [CL H W], CL - number of classes, H - height and W - width
端侧部署 ExecuTorch
【2023-10-18】端侧AI推理,高效部署PyTorch模型:官方新工具,Meta已经用上了
2023 年 PyTorch 大会宣布了一个用于在边缘和移动设备上实现 AI 推理的解决方案: ExecuTorch
ExecuTorch 理解成一个 PyTorch 平台,其能提供基础设施来运行 PyTorch 程序,从 AR/VR 可穿戴设备到标准的 iOS 和 Android 设备的移动部署。
ExecuTorch 最大优势是可移植性,能够在移动和嵌入式设备上运行。不仅如此,ExecuTorch 还可以提高开发人员的工作效率。
ExecuTorch 可以有效地将 PyTorch 模型部署到边缘设备。ExecuTorch 的优点包括:
- 可移植性:与各种计算平台兼容,从高端移动手机到高度受限的嵌入式系统和微控制器。
- 提高生产力:开发人员能够使用相同的工具链和 SDK,从而提高生产力。
- 提高性能:由于轻量级运行时和充分利用 CPU、NPU 和 DSP 等硬件功能,为最终用户提供了无缝和高性能的体验。
由于 ExecuTorch 严重依赖 PyTorch 相关知识,因而想要熟练掌握 ExecuTorch,还需提前补充相关知识。官方文档已经提供了入门级教程。例如,在构建 ExecuTorch Android 演示应用程序示例当中,大家可以跟随指导教程,从而熟悉如何使用 ExecuTorch。
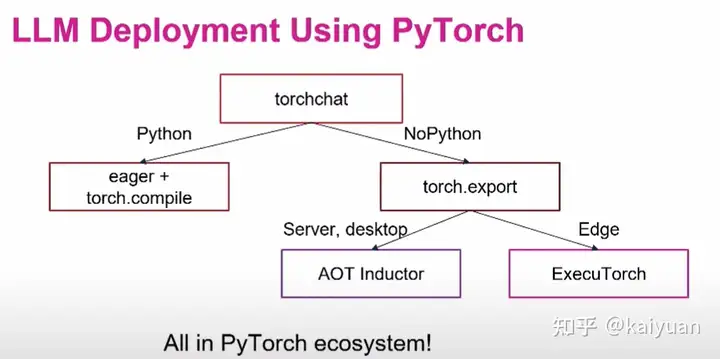
torchchat
【2024-7-30】 PyTorch 发布 torchchat,使得在本地运行 LLM 变得非常容易。 🔥
- 支持多种型号,包括 Llama 3.1。
- 可以在服务器、桌面甚至移动设备上使用它。
- 实现起来非常简单
- 提供 Python 和本机执行模式。它还支持 eval 和量化。
官方介绍
PyTorch 教程
PyTorch 的设计哲学是解决当务之急,也就是说即时构建和运行计算图。
PyTorch 基于python的科学计算包,针对两类受众:
- 代替Numpy从而利用GPU的强大功能;
- 提供最大灵活性和速度的深度学习研究平台。
PyTorch 是一个建立在 Torch 库之上的 Python 包,旨在加速深度学习应用。
- PyTorch 提供一种类似 NumPy 的抽象方法来表征张量(或多维数组),利用 GPU 来加速训练。
TorchRL
TorchRL 是一个基于PyTorch的强化学习(Reinforcement Learning, RL)库,专为研究人员和开发者设计,提供一个灵活、高效的框架来实现和实验各种RL算法。
- 与
PyTorch深度集成:TorchRL 充分利用了PyTorch 生态系统,使用户能够无缝地将RL算法与深度学习模型结合。 - 模块化设计:库提供了可组合的组件,允许用户轻松构建和定制RL算法。
- 高性能:TorchRL注重效率,支持GPU加速和并行化,以加快训练和推理速度。
- 多环境支持:兼容多种RL环境,包括 OpenAI Gym、DeepMind Control Suite等。
- 丰富的算法实现:内置多种流行的RL算法,如 DQN、PPO、SAC等。
- 扩展性:易于扩展和添加新的算法、环境和功能。
【2024-9-7】Python TorchRL 进行多代理强化学习
pytorch 提供的框架, 开发和实验多代理强化学习(MARL)算法
用 VMAS 模拟器,这是一个多机器人模拟器并且可以在 GPU 上进行并行训练
pip3 install torchrl
pip3 install vmas
pip3 install tqdm
PPO 中, 学习过程依赖于一个评论家(critic), 评估策略所采取行动的质量。
评论家估计给定状态的价值,通过比较预期回报与实际结果来指导策略优化。
在多代理设置中, 部署多个策略,每个代理一个,通常以分散方式运作。每个代理的策略仅根据其局部观察来决定其行动。但是评论家可以是集中或分散:
MAPPO: 评论家集中,以全局观察或连接的代理观察作为输入。这种方法在可获得全局状态信息的集中式训练场景中有益。IPPO: 评论家分散,仅依赖于局部观察。这种设置支持分散式训练,代理只需要局部信息。
集中式评论家有助于缓解多个代理同时学习时出现的非平稳性问题,但可能因输入的高维度性而面临挑战。
资料
资料
- PyTorch 学习笔记:Colab, GitHub
- 【2024-3-28】站内 pytorch手册
- w3c pytorch 入门系列教程
- 国外 PyTorch Zero to All
- PyTorch 中文教程, Deep-Learning-with-PyTorch-Tutorials, 含pdf
- 深度学习网络架构的pytorch实现, ppt, Google Docs
- 【2023-2-20】李宏毅学生萧淇元的pytorch ppt, 李宏毅春季机器学习课程, 含 GPT/扩散等知识
【2024-10-18】pytorch 学习指南
- DL-with-Python-and-PyTorch2
- 2018年, pytorch-tutorial 含 速成代码, 用 RNN/MLP/CNN 实现 mnist
git clone https://github.com/hpzhao/pytorch-tutorial.git
安装

- 根据提示分别选择系统(Linux、Mac 或者 Windows),安装方式(Conda,Pip,LibTorch 或者源码安装)、编程语言(Python 2.7 或者 Python 3.5,3.6,3.7 或者是 C++),
Python 版本和某些库版本不一致时,会导致冲突。
为了减少冲突,用 Anaconda 管理多个 Python 虚拟环境。
Pytorch
安装:
pip install torch
pip install torchvision # 视觉数据集
pip install torchtext # 文本数据集
pip install torchaudio # 音频数据集
验证:
python -c "import torch;x = torch.rand(5, 3);print(x)"
GPU
PyTorch 是一个张量和动态神经网络 Python 库,GPU 加速性能极其强大。
- 可直接定义 GPU 张量,或由 CPU 张量转化为 GPU 张量
CUDA 接口
PyTorch 优势之一是为张量和 autograd 库提供 CUDA 接口。
使用 CUDA GPU,不仅可以加速神经网络训练和推断,还可以加速任何映射至 PyTorch 张量的工作负载
cpu/gpu 检测
如何检查 PyTorch 是 GPU 还是 CPU版?
准备工作
- GPU 驱动检测: nvidia-smi, 显示 cuda 版本, 如 12.2
- 安装 PyTorch GPU 版: 官网选择对应环境信息后,出现安装命令
- pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu121 -i https://pypi.tuna.tsinghua.edu.cn/simple
以下命令:
import torch
torch.cuda.is_available() # True,是否启用gpu
cuda_gpu =torch.cuda.is_available()
if cuda_gpu:
print("Great, you have a GPU!")
print('GPU数目: ', torch.cuda.device_count())#1
print('当前GPU编号: ', torch.cuda.current_device())#0
print('GPU设备地址: ', torch.cuda.device(0))#<torch.cuda.device at 0x7efce0b3be0>
print('GPU型号: ', torch.cuda.get_device_name(0))#'GeForce GTX 950M'
else:
print("Life is short -- consider a GPu!")
gpu 信息获取
torch.cuda.device_count() # 1
torch.cuda.current_device() # 0
torch.cuda.device(0) # <torch.cuda.device at 0x7efce0b03be0>
torch.cuda.get_device_name(0) # 'GeForce GTX 950M'
gpu 加速
使用 cuda 加速
- 张量上调用
.cuda(),则将执行从 CPU 到 CUDA GPU 的数据迁移。 - 模型上调用
.cuda(),则不仅将所有内部储存移到 GPU,还将整个计算图映射至 GPU。 - 将张量或模型复制回 CPU,比如和 NumPy 交互,可以调用
.cpu()。
x = torch.cuda.HalfTensor(5, 3).uniform_(-1, 1)
if cuda_gpu:
x = x.cuda()
print(type(x.data))
x = x.cpu()
print(type(x.data))
# --------------
x = torch.cuda.HalfTensor(5, 3).uniform_(-1, 1)
y = torch.cuda.HalfTensor(3, 5).uniform_(-1, 1)
z = torch.matmul(x, y)
# CPU张量 -> GPU张量
x = torch.FloatTensor(5, 3).uniform_(-1, 1)
x = x.cuda(device=0) # cpu -> gpu
x = x.cpu() # gpu -> cpu
问题
【2023-2-20】安装GPU版本(CPU版本执行时报错,找不到CUDA,实际上路径存在)
# 如:cuda 11.3, python 3.7.3时
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
问题
gcc 版本低
【2024-3-27】GPU上启动InternLM训练时,中途报错
错误信息
You're trying to build PyTorch with a too old version of GCC. We need GCC 9 or later
原因
- PyTorch版本过高,而系统 gcc版本又太低(<9.0)
解决办法: 更新gcc
本地信息
gcc -v
# gcc version 8.3.0 (Debian 8.3.0-6)
cuda 11.6
pytorch 2.2.1
解法
- ① make 源码编译,参考
- ② conda
conda install -c 3dhubs gcc-5
fused_adam
【2024-3-27】GPU上启动InternLM训练时,中途报错
- gcc 版本低 → ninja 执行有误 → 构建 fused_adam 错误
# ① gcc 问题
You're trying to build PyTorch with a too old version of GCC. We need GCC 9 or later
# ② ninja 问题
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
# ③ fused_adam 问题
RuntimeError: Error building extension 'fused_adam'
数据集
【2023-1-28】PyTorch中的数据集Torchvision和Torchtext
Torchtext 数据集
IMDB:用于情感分类的数据集,其中包含一组 25,000 条高度极端的电影评论用于训练,另外 25,000 条用于测试。使用以下类加载这些数据torchtext:torchtext.datasets.IMDB()WikiText2:WikiText2语言建模数据集是一个超过 1 亿个标记的集合。- 从维基百科中提取的,并保留了标点符号和实际的字母大小写。它广泛用于涉及长期依赖的应用程序。
- 可从torchtext以下位置加载此数据:
torchtext.datasets.WikiText2()
除了上述两个流行的数据集,torchtext 库中还有更多可用的数据集,例如: SST、TREC、SNLI、MultiNLI、WikiText-2、WikiText103、PennTreebank、Multi30k 等。
数据模块细分为 4 个部分:
- 数据收集:样本和标签。
- 数据划分:训练集、验证集和测试集
- 数据读取:对应于PyTorch 的 DataLoader。
- DataLoader 包括
Sampler和DataSet。 - Sampler 生成索引
- DataSet 根据生成索引读取样本以及标签。
- DataLoader 包括
- 数据预处理:对应于 PyTorch 的 transforms

datasets
Torchvision 中的数据集
MNIST: 手写数字识别,超过 60,000 张训练图像和 10,000 张测试图像Fashion MNIST:类似于MNIST,但该数据集包含T恤、裤子、包包等服装项目,而不是手写数字,训练和测试样本数分别为60,000和10,000。EMNIST:EMNIST数据集是 MNIST 数据集的高级版本。它由包括数字和字母的图像组成。如果正在处理基于从图像中识别文本的问题,EMNIST是一个不错的选择。CIFAR:CIFAR数据集有两个版本,CIFAR10和CIFAR100。CIFAR10 由 10 个不同标签的图像组成,而 CIFAR100 有 100 个不同的类。这些包括常见的图像,如卡车、青蛙、船、汽车、鹿等。COCO:COCO数据集包含超过 100,000 个日常对象,如人、瓶子、文具、书籍等。这个图像数据集广泛用于对象检测和图像字幕应用IMAGE-NET:ImageNet 是用于训练高端神经网络的旗舰数据集之一。它由分布在 10,000 个类别中的超过 120 万张图像组成。通常,这个数据集加载在高端硬件系统上,因为单独的 CPU 无法处理这么大的数据集。
torch.utils.data.Dataset
功能:
- Dataset 是抽象类,所有自定义的 Dataset 都需要继承该类,并且重写
__getitem__()方法和__len__()方法 。__getitem__方法的作用是接收一个索引,返回索引对应的样本和标签,这是自己需要实现的逻辑。__len__()方法是返回所有样本的数量。
数据读取包含 3 个方面
- 读哪些数据:每个 Iteration 读取一个 Batchsize 大小的数据,每个 Iteration 应该读取哪些数据。
- 从哪里读取数据:如何找到硬盘中的数据,应该在哪里设置文件路径参数
- 如何读取数据:不同文件需要使用不同的读取方法和库
pytorch 数据读取流程图

- 首先在 for 循环中遍历 DataLoader
- 然后根据是否采用多进程,决定使用单进程或者多进程的 DataLoaderIter。
- 在DataLoaderIter 里调用Sampler生成 Index 的 list
- 再调用 DatasetFetcher 根据index获取数据。
- DatasetFetcher里会调用Dataset的
__getitem__()方法获取真正的数据。这里获取的数据是一个 list,其中每个元素是 (img, label) 的元组,再使用 collate_fn()函数整理成一个 list,里面包含两个元素,分别是 img 和 label 的tenser
- DatasetFetcher里会调用Dataset的
from torchvision.datasets import MNIST
# Download MNIST
data_train = MNIST('~/mnist_data', train=True, download=True)
torchvision.datasets.FashionMNIST() # fashion MNIST
torchvision.datasets.EMNIST()
torchvision.datasets.CIFAR10() # cifar10
torchvision.datasets.CIFAR100() # cifar100
torchvision.datasets.CocoCaptions() # COCO
torchvision.datasets.ImageNet() # imagenet
DataLoader
DataLoader, Sampler 和 Dataset 三者关系:
DataLoader包含Sampler(采样策略, 存数据索引) +Dataset(数据集, 存数据内容)- 两种sampler:
sampler和batch_sampler,都默认为None。sampler: 生成一系列的indexbatch_sampler: 将sampler生成的indices打包分组,得到一个又一个batch的index。
Epoch, Iteration, Batchsize: refer
Epoch: 所有训练样本都已经输入到模型中,称为1个 EpochIteration: 一批样本输入到模型中,称为1个 IterationBatchsize: 批大小,决定一个 iteration 有多少样本,也决定了1个 Epoch 有多少个 Iteration
torch.utils.data.DataLoader()
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)
加载原理
PyTorch 为数据分布式训练提供了多种选择。
随着应用从简单到复杂,从原型到产品,常见的开发轨迹可以是:
- 数据和模型能放入单个GPU,单设备训练,此时不用担心训练速度;
- 服务器上有多个GPU,且代码修改量最小,加速训练用单个机器多GPU
DataParallel; - 进一步加速训练,且愿意写点代码,用单个机器多个GPU
DistributedDataParallel; - 应用程序跨机器边界扩展,用多机器
DistributedDataParallel和启动脚本; - 预期有错误(比如OOM)或资源可动态连接和分离,使用
torchelastic来启动分布式训练。
要点 详见
- DataSet 把数据集数目发给 DistributedSampler。
- Sampler 按照某种规则发送数据indices给Loader。
- Loader 依据indices加载数据。
- Loader 把数据发给模型,进行训练。
参数
定义dataloader,一般接受3个重要参数
dataset: 数据集batch_size: 将数据集切分为多少份shuffle: 是否对数据集进行随机排序
DataLoader(object) 参数详解:
dataset(Dataset): 传入的数据集, Dataset 类,决定数据从哪里读取batch_size(int, optional): 每个batch有多少个样本shuffle(bool, optional): 在每个epoch开始时,对数据进行重新排序sampler(Sampler, optional): 自定义从数据集中采样策略,如果指定这个参数,那么shuffle必须为Falsebatch_sampler(Sampler, optional): 与sampler类似,但是1次只返回1个batch的indices(索引)- 一旦指定这个参数,那么
batch_size,shuffle,sampler,drop_last就不能再指定了(互斥——Mutually exclusive) - BatchSampler 是wrap一个sampler,生成mini-batch的索引(indices)的方式
- 一旦指定这个参数,那么
num_workers(int, optional): 是否多进程, 这个参数决定几个进程处理data loading。- 0 意味着所有数据都会被load进主进程。(默认为0)
collate_fn(callable, optional): 将list的sample组成一个mini-batch的函数;将1个batch的数据进行合并操作。- 默认的 collate_fn 将img和label分别合并成imgs和labels,所以如果
__getitem__方法只是返回 img, label,那么可用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。
- 默认的 collate_fn 将img和label分别合并成imgs和labels,所以如果
pin_memory(bool, optional):- 如果设置为True,那么data loader将会在返回之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
drop_last(bool, optional): 当样本数不能被 batchsize 整除时,是否舍弃最后一批数据- 如果设置为True:对最后的未完成的batch,比如 batch_size设置为64,而一个epoch只有100个样本,那么训练时, 后面的36个就被扔掉了…
- 如果为 False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
timeout(numeric, optional):- 如果是正数,等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。
- 这个numeric应总是大于等于0。默认为0
worker_init_fn(callable, optional): 每个worker初始化函数- If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
collate_fn 用法
- collate_fn 函数可对样本进一步处理(任何处理),返回值一个有结构的batch。
- 而DataLoader每次迭代的返回值就是collate_fn的返回值
indices = next(self.sample_iter)
batch = self.collate_fn([dataset[i] for i in indices])
源码
__init__()和__iter__():
(1)数据的shuffle和batch处理
- RandomSampler(dataset)
- SequentialSampler(dataset)
- BatchSampler(sampler, batch_size, drop_last)
(2)DataLoader只有__iter__()而没有实现__next__()
- 所以, DataLoader 是iterable, 而不是iterator。
- 这个iterator 实现在 _DataLoaderIter中。
class DataLoader(object):
__initialized = False
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None):
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
...
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with "shuffle"')
...
if batch_sampler is None:
if sampler is None:
if shuffle:
sampler = RandomSampler(dataset)
else:
sampler = SequentialSampler(dataset)
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
self.__initialized = True
...
def __iter__(self):
return _DataLoaderIter(self)
...
DataLoader 用法
【2023-9-12】Pytorch中DataLoader的基本用法
DataLoader支持的两种数据集
Map格式:即 key,value形式,例如{0: '张三', 1: '李四'}Iterator格式:例如数组,迭代器等- python中,只要是for循环的数据,都是Iterator格式的数据
# list 是一个迭代器,for循环本质上调用next函数
data = [0,1,2,3,4]
for item in data:
print(item, end=' ')
# 等效写法
data = [0,1,2,3,4]
data_iter = iter(data) # 返回一个迭代器
item = next(data_iter, None) # 获取迭代器的下一个值
while item is not None:
print(item, end=' ')
item = next(data_iter, None)
Map 格式
Map格式的DataLoader
dataset = {0: '张三', 1:'李四', 2:'王五', 3:'赵六'}
dataloader = DataLoader(dataset, batch_size=2)
for i, value in enumerate(dataloader):
print(i, value)
Iterator 格式
from torch.utils.data import DataLoader
data = [i for i in range(100)] # 定义数据集,需要是一个可迭代的对象
dataloader = DataLoader(dataset=data, batch_size=6, shuffle=False)
for i, item in enumerate(dataloader): # 迭代输出
print(i, item)
输入一个数据集0~99,通过dataloader将数据集分成100/6 =17份,每份6个数据,最后一份因为不满6个,所以只返回了4个。
自定义的IterableDataset
- 可迭代对象在初始化中会调用一次
__init__方法,在获取迭代器时会调用一次__iter__方法,之后在获取元素时,每获取一个元素都会调用一次__next__方法
from torch.utils.data import DataLoader
from torch.utils.data import IterableDataset
class MyDataset(IterableDataset):
# 自定义数据集
def __init__(self):
print('init...')
def __iter__(self):
print('iter...') # 获取迭代器
self.n = 1
return self
def __next__(self):
print('next...') # 获取下一个元素
x = self.n
self.n += 1
if x >= 100: # 当x到100时停止
raise StopIteration
return x
dataloader = DataLoader(MyDataset(), batch_size=5)
for i, item in enumerate(dataloader):
print(i, item)
数据采样 Sampler
Sampler 重点:
- 如何让每个 worker 在数据集中,只加载自己所属的部分,并且worker之间实现对数据集的正交分配
已实现的Sampler 有几种:(均在torch.utils.data下)
SequentialSamplerRandomSamplerWeightedSamplerSubsetRandomSampler- 新增:
DistributedSampler分布式采样
shuffle 参数
- 若shuffle=True,则若未指定sampler,默认使用
- 若shuffle=False,则未指定sampler,默认使用
注意, DataLoader 部分初始化参数之间存在互斥关系,见源码
- 如果自定义
batch_sampler, 参数都必须用默认值:batch_size, shuffle, sampler, drop_last. - 如果自定义
sampler,那么shuffle需要设置为False - 如果
sampler和batch_sampler都为None, 那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:- 若shuffle=True, 则sampler=
RandomSampler(dataset) - 若shuffle=False, 则sampler=
SequentialSampler(dataset)
- 若shuffle=True, 则sampler=
SequentialSampler
RandomSampler(dataset)、 SequentialSampler(dataset) 在 dataloader.py 同级目录下 torch/utils/data/sampler.py
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
sampler.py 中实现了一个父类Sampler,以及SequentialSampler,RandomSampler和BatchSampler等五个继承Sampler的子类
import torch
class Sampler(object):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an __iter__ method, providing a way
to iterate over indices of dataset elements, and a __len__ method that
returns the length of the returned iterators.
"""
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
class SequentialSampler(Sampler):
r"""Samples elements sequentially, always in the same order.
Arguments:
data_source (Dataset): dataset to sample from
"""
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
class RandomSampler(Sampler):
r"""Samples elements randomly, without replacement.
Arguments:
data_source (Dataset): dataset to sample from
"""
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(torch.randperm(len(self.data_source)).tolist())
def __len__(self):
return len(self.data_source)
if __name__ == "__main__":
print(list(RandomSampler(range(10))))
print(list(SequentialSampler(range(10))))
a = SequentialSampler(range(10))
from collections import Iterable
print(isinstance(a, Iterable))
from collections import Iterator
print(isinstance(a, Iterator))
for x in SequentialSampler(range(10)):
print(x)
print(next(a))
print(next(iter(a)))
假设有100个样本数据集,batch_size=4 时,以 SequentialSampler 和 BatchSampler 为例,Pytorch读取数据时,主要过程:
- SequentialSampler 类中的
__iter__方法返回iter(range(100))迭代器对象,对其进行遍历时,会依次得到range(100)中的每一个值,100个样本的下标索引。 BatchSampler类中__iter__使用for循环访问SequentialSampler类中的__iter__方法返回的迭代器对象,也就是iter(range(100))。当达到batch_size大小时,就使用yield方法返回。而含有yield方法为生成器也是一个迭代器对象,因此BatchSampler类中__iter__方法返回的也是一个迭代器对象,对其进行遍历时,会依次得到batch size大小的样本的下标索引。- DataLoaderIter 类会依次遍历类中的 BatchSampler 类中
__iter__方法返回的迭代器对象,得到每个batch的数据下标索引。
DistributedSampler
【2024-7-24】数据加载之DistributedSampler
对于数据并行和分布式训练,DistributedSampler 负责其数据采样的任务。
- DistributedSampler 是 Sampler 的派生类。
- 当 DistributedDataParallel 使用DistributedSampler 时,每个并行进程都会得到一个 DistributedSampler 实例,这个DistributedSampler 实例会给DataLoader发送指示,从而 DataLoader 加载具体数据。
- DistributedSampler 加载策略负责只提供加载数据集中的一个子集,这些DistributedSampler 提供的子集之间不重叠,不交叉。
自定义 sampler
如果现有 Dataset 不满足需求,可自定义 Dataset,通过继承 torch.utils.data.Dataset。
继承时,要 override 三个方法。
__init__: 初始化数据集__getitem__:给定索引值,返回该索引值对应的数据;- python built-in方法,让该类可以像list一样通过索引值对数据进行访问
__len__:用于 len(Dataset)时, 返回大小
整体结构
PyTorch 构建模型时的几大要素
- 数据:数据读取,数据清洗,数据划分和数据预处理
- 比如:读取图片如何预处理及数据增强。
- 模型:构建模型模块,组织复杂网络,初始化网络参数,定义网络层。
- 损失函数:创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。
- 优化器:根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。
- 迭代训练:组织4 个模块进行反复训练。
- 观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。
PyTorch由4个主要包装组成:
- 1、
Torch:类似于Numpy的通用数组库,可以在将张量类型转换为(torch.cuda.TensorFloat)并在GPU上进行计算。 - 2、torch.
autograd:用于构建计算图形并自动获取渐变的包 - 3、torch.
nn:具有共同层和成本函数的神经网络库 - 4、torch.
optim:具有通用优化算法(如SGD,Adam等)的优化包
流程概要
叶子节点
在反向传播过程中,只有叶子节点导数结果,会被最后保留下来
- requires_grad = False 的tensor,一定是
叶子节点 - requires_grad = True 时
- 当这个tensor是用户创建,是
叶子节点; - 当这个tensor是由其他运算操作产生时,不是
叶子节点
- 当这个tensor是用户创建,是
非叶子节点(即中间变量)是通过用户所定义的叶子节点,通过一系列运算生成的,用完后即被释放
- 叶子节点的 grad_fn属性都为空;
- 非叶子节点的 grad_fn不为空
inplace 操作
在不更改变量内存地址的情况下,直接修改变量的值
PyTorch 通过 tensor._version 来检测 tensor 是否发生了 inplace 操作。
- 每次 tensor 在进行
inplace操作时,变量_version就会加1,其初始值为0
组件图解
组件详解
深度学习任务中,PyTorch 程序主要包含以下这4个模块。
- 网络模型定义文件,如
network.py。 - 数据读取文件,如
dataset.py。 - 训练接口程序,如
train.py。 - 测试接口程序,如
evaluate.py。
除了 network,dataset,train 和 evaluate,还有定制的模块
- cal_metrics 用来计算实验指标
- cfg 用来设置某些超参数
- image_io_and_process 用来对图像进行预处理和后处理
- loss_functions 用来定义与实现某些损失
- utils 用来承载一些其他操作,比如读写txt文档。
详解:
- 网络模型定义文件,比如, 名为
network.py。- 定义Python类,并继承
torch.nn.Module。 - 重写构造函数
__init__来定义网络中使用的层,在定义层或者模块的时候,经常会使用到torch.nn这个库。 - 再重写父类的 forward 函数: 使用
__init__函数中定义的层, 实现网络的前传过程 - 问题: 所有单元都需要先在
__init__中定义吗?
- 定义Python类,并继承
- 数据读取文件,比如
dataset.py。- PyTorch 与其他框架差异: 数据读取接口非常规范。
- PyTorch 继承
torch.utils.data.Dataset类实现自己的数据集读取。 - 继承时,重写三个函数:
__init__函数,__getitem__函数和__len__函数。
__init__函数:初始化,比如, 读取所需记录数据的txt或者xml文件,传入一些预处理参数等等。__getitem__函数:规定每个batch训练给网络喂数据时,应该采用怎样的数据读取方式,以及怎样预处理。__len__函数:数据集中有多少数据 - 训练程序中只需使用torch.utils.data.DataLoader开始在每次训练中对数据集进行读取与遍历就行 - 除去 dataset,用的比较多的:batch_size,shuffle,num_workers和pin_memory这几个参数。batch_size指定一个批次的数据容量shuffle指定是否打乱数据num_workers指定用多少个线程对数据进行读取pin_memory指定是否将数据放入显存。
- 训练接口程序,比如
train.py。与其他深度学习框架类似,都是先搭建图(模型),然后在图上进行训练- 四个步骤,引用数据、引用模型、定义损失函数、定义优化器:
- ① 数据: 引用之前定义的数据读取接口。
- ② 模型: 引用model,即网络,需要的话就载入预训练参数。
- ③ 损失函数: 定义loss。
- ④ 优化器: 定义优化器。 - 然后, for循环中进行可训练参数更新了。
- 测试接口程序,比如名称为
evaluate.py。- 测试程序比训练程序简单很多,两个步骤:
- 定义网络
- 载入已训练参数
- 然后读取测试样本进行前传。
- 注意: 模型测试时,要将model置为测试模式,对应代码中
model.eval()
train_data_loader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,timeout=0, worker_init_fn=None)
训练注意
- 保存模型和加载预训练参数。
- 保存模型的已训练参数/整个模型: 通过
torch.save函数完成; - 加载预训练参数: 通过model的父类,即
torch.nn.Module的load_state_dict完成。
- “strict”参数: 是否需要将预训练模型里面的参数与model里面的完全对齐。
- 保存模型的已训练参数/整个模型: 通过
- 使用GPU训练
- 如果使用GPU训练时,用到
to(device) 函数,将数据或者模型放到GPU上面。
- 如果使用GPU训练时,用到
- 参数更新过程,分成三步:
- 将可训练参数梯度置零
optimizer.zero_grad() - 根据损失值求梯度
loss.backward() - 更新可训练参数
optimizer.step()
- 将可训练参数梯度置零
- 将model置为训练模式
- 对应代码中的
model.train() - 训练模式会对某些定义的网络模块有影响,比如 使用dropout层,在训练时会被激活。
- 对应代码中的
PyTorch 程序比较规范,简洁与清晰。
- 还使用到了非常多的面向对象规范,有许多操作都是通过继承Python类进行实现的。
模式 train/eval
PyTorch 训练和测试时, 一定要把实例化的model指定 train/eval
pytorch 切换训练和评估(推断)模式: model.train() 和 model.eval()
model.train():启用 BatchNormalization 和 Dropoutmodel.eval():不启用 BatchNormalization 和 Dropout
分析:
- bn:
model.train(): 保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差; - Dropout:
model.train()随机取一部分网络连接来训练更新参数,而model.eval()利用到了所有网络连接。 eval()时,框架会自动把BN和Dropout固定住,不会取平均,而是用训练好的值,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大
| 模式 | 切换方法 | 作用 | bn层 | dropout |
|---|---|---|---|---|
| 训练 | model.train() |
训练状态, 除了模型参数可变, 还有bn/droupout策略不同 | 均值/方差使用当前batch数值 | 按照参数随机选取部分连接 |
| 测试 | model.eval() |
推理/评估状态, 模型参数固定, 避免改变参数 | 均值/方差使用全部训练数据的数值 | 失效,使用全部网络连接 |
训练完train样本后,生成的模型model要用来测试样本。
model(test) 前,加上 model.eval(),否则,输入数据(即使不训练)会改变权值。
- model中含有batch normalization层所带来的的性质。
- one classification 时,训练集和测试集的样本分布是不一样,尤其需要注意这一点。

【2024-3-25】
- 训练阶段
model.train()让模型适应训练数据变化,并防止过拟合; - 而验证/测试阶段
model.eval()保证模型在新数据上的表现一致性,并且避免因为BN层在小批量数据上的不稳定统计,导致预测结果波动以及Dropout带来的不确定性。
网络单元在哪儿定义? __init__ 还是 forward ?
__init__: 训练时需要更新权重的单元forward: 不需要权重
# 定义一个网络
class Net(nn.Module):
def __init__(self, l1=120, l2=84):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, l1)
self.fc2 = nn.Linear(l1, l2)
self.fc3 = nn.Linear(l2, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 实例化这个网络
Model = Net()
# 训练模式使用.train()
Model.train(mode=True)
# 测试模型使用.eval()
Model.eval()
代码示例
代码示例
# (1)======= 模型定义 =======
class My_Network(nn.Module):
"""
模型定义: 继承自nn.Module, 实现 __init__ 和 forward 函数
"""
#
def __init__(self): # 重写构造函数定义网络结构
super(network, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) # 3×3卷积
self.bn1 = nn.BatchNorm2d(64) # BatchNorm
self.relu = nn.ReLU() # 激活
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2) # 最大池化
self.fc = nn.Linear(64 * 14 * 14, 512) # 全连接,将[n, (64*14*14)]变成[n, 512]
for m in self.modules(): # 对可训练参数进行初始化(上面定义的所有模块都存储在此)
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
def forward(self, x): # 重写forward实现前传, 定义网络结构
# 前传,输入x尺寸为[n, c, 28, 28]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(x.size(0), -1) # 将4维Tensor变成2维,作为全连接的输入
x = self.fc(x)
return x
# (2)======= 数据读取 =======
class My_Dataset(torch.utils.data.Dataset):
"""
数据集处理函数,重写函数:__init__, __getitem__, __len__
"""
def __init__(self, data_txt_path):
data_list = read_txt(data_txt_path) # 读取一下记录数据与标签的txt
self.data_list = np.random.permutation(data_list) # 打乱一下txt
self.transform = T.ToTensor() # 预处理,将数据转化成[n, c, h, w]的形式,并归一化到[0,1]
def __getitem__(self, index):
sample = self.data_list[index] # 读取txt中的一行,是一个数据对(image_path, label)
image_path = sample.split(' ')[0]
label = int(sample.split(' ')[-1])
resized_image = read_image(image_path) # 读取一下图像
image = self.transform(resized_image) # 转化成Tensor
return image.float(), label
def __len__(self):
# 数据量
return len(self.data_list)
# (3)======= 训练 ==========
from __future__ import print_function
import torch.nn
from torch.nn import DataParallel
import torch.optim
import torch.utils.data
import argparse
#import 所需的各种模块
parser = argparse.ArgumentParser(description="")
#添加各种自定义参数
args = parser.parse_args()
def main():
device = torch.device("cuda") # 注明用GPU
train_dataset = My_Dataset(txt_path) # 实例化数据集处理对象
train_data_loader = torch.utils.data.DataLoader(train_dataset, batch_size, shuffle, num_workers) # 读数据
model = My_Network() # 实例化模型
#若有预训练参数,可以载入预训练参数
model.load_state_dict(torch.load(ckpt_path), strict=False)
#定义损失,比如criterion = torch.nn.CrossEntropyLoss()
criterion = My_Loss # 损失函数
model.to(device)
model = DataParallel(model) # 将模型训练放在多张GPU上并行
optimizer = torch.optim.SGD(model.parameters(), lr, weight_decay) # 优化器
model.train() #将模型置为训练模式
# 开始训练
for i in range(epoch):
for ii, data in enumerate(train_data_loader):
data_input, label = data
data_input = data_input.to(device)
label = label.to(device).long()
output = model(data_input)
loss = criterion(output, label)
print("loss =: ", loss)
optimizer.zero_grad() #首先梯度置零
loss.backward() #然后求梯度
optimizer.step() #通过梯度更新参数
iters = i * len(train_data_loader) + ii
if iters % save_interval == 0:
torch.save(model.state_dict(), save_path) # 保存模型
if __name__ == "__main__":
main()
# (4)======= 测试 =======
from __future__ import print_function
import torch.nn
from torch.nn import DataParallel
import torch.optim
import torch.utils.data
import argparse
#import 所需的各种模块
parser = argparse.ArgumentParser(description="")
#添加各种自定义参数
args = parser.parse_args()
def main():
device = torch.device("cuda")
model = My_Network() # 模型实例化
model = DataParallel(model) # 多GPU
model.load_state_dict(torch.load(snapshot_path)) #载入参数
model.to(device)
model.eval() #将模型置为测试模式
for eval_data_path in eval_data_list:
eval_data = read_image(eval_data_path)
data = torch.from_numpy(eval_data) #将data转化为Tensor
data = data.to(device)
output = model(data) #前传得到结果
#自定义操作,比如计算精度
if __name__ == "__main__":
main()
网络结构
只需要定义forward函数,就可以使用autograd 定义backward函数(计算梯度)。forward函数中使用任何张量操作。
LR
单个神经元, LR 回归
y = sigmoid( w*x + b )
# 线性回归
lr = nn.Sequential(
nn.Linear(NUM_INPUTS, 1),
nn.Sigmoid()
)
# LR回归
lor = nn.Sequential(
nn.Linear(NUM_INPUTS, 1),
nn.Sigmoid()
)
MLP 全连接
全连接神经网络
m = 100
h = 1024
n = 20
# MLP
lor = nn.Sequential(
nn.Linear(m, h),
nn.Tanh(),
nn.Linear(h, h),
nn.Tanh(),
nn.Linear(h, n),
nn.LogSoftmax(dim=1)
)
LSTM
LSTM 解决 MNIST 识别问题
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.rnn = nn.LSTM(input_size=28, hidden_size=64, batch_first=True)
self.batchnorm = nn.BatchNorm1d(64)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(64, 32)
self.fc2 = nn.Linear(32, 10)
def forward(self, input):
# Shape of input is (batch_size,1, 28, 28)
# converting shape of input to (batch_size, 28, 28)
# as required by RNN when batch_first is set True
input = input.reshape(-1, 28, 28)
output, hidden = self.rnn(input)
# RNN output shape is (seq_len, batch, input_size)
# Get last output of RNN
output = output[:, -1, :]
output = self.batchnorm(output)
output = self.dropout1(output)
output = self.fc1(output)
output = F.relu(output)
output = self.dropout2(output)
output = self.fc2(output)
output = F.log_softmax(output, dim=1)
return output
CNN
CNN 卷积神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
示例
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square, you can specify with a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
# -> view -> linear -> relu -> linear -> relu -> linear
# -> MSELoss
# -> loss
# 模型定义
net = Net()
print(net)
# 网络参数
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
# 输入数据
input = torch.randn(1, 1, 32, 32)
# 输出数据
out = net(input)
print(out)
# 使用随机梯度将所有参数和反向传播的梯度缓冲区归零
net.zero_grad() # 将梯度缓冲区手动设置为零
out.backward(torch.randn(1, 10))
注意
- torch.nn仅支持小批量。 整个torch.nn包仅支持作为微型样本而不是单个样本的输入。
- 例如,nn.Conv2d将采用nSamples x nChannels x Height x Width的 4D 张量。
- 如果只有一个样本,只需使用input.unsqueeze(0)添加一个假批量尺寸。
回顾:
- torch.Tensor 一个多维数组,支持诸如backward()的自动微分操作。 同样,保持相对于张量的梯度。
- nn.Module 神经网络模块。 封装参数的便捷方法,并带有将其移动到 GPU,导出,加载等的帮助器。
- nn.Parameter 一种张量,即将其分配为Module的属性时,自动注册为参数。
- autograd.Function 实现自动微分操作的正向和反向定义。 每个Tensor操作都会创建至少一个Function节点,该节点连接到创建Tensor的函数,并且编码其历史记录。
AE
class AE(nn.Module):
def __init__(self, num_inputs=784):
super().__init__()
# 编码器: 压缩成一个向量 C
self.encoder = nn.Sequential(
nn.Linear(num_inputs, 400),
nn.ReLU(inplace=True),
nn.Linear(400,400),
nn.ReLU(inplace=True),
nn.Linear(400, 20)
)
# 解码器
self.decoder = nn.Sequential(
nn.Linear(20,400),
nn.ReLU(inplace=True),
nn.Linear(400,400),
nn.ReLU(inplace=True),
nn.Linear(400, num_inputs)
)
def forward(self, x):
return self.decoder(self.encoder(x))
ae = AE(784)
x = torch.randn(10, 784)
print('Input tensor x size: ', x.size())
y = ae(x)
print('Output tensor y size: ', y.size())
VAE
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
# 编码器
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
# 根据均值、方差,随机采样
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def decode(self, z):
# 解码器
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
# 随机抽样生成新的C
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
torch 知识点
torch.nn 模块
nn.xx 与 nn.functional.xx
- 实际功能相同,
nn.xx是包装好的类,nn.functional.xx是可直接调用的函数。
模块类型
【2023-1-14】PyTorch torch.nn 模块 Layer 总结
torch.nn 模块是 Pytorch 对 Layer 的总结
torch.nn 模块中的类分为 4 种:
- (1)
容器类,nn.modules.container是一系列层的组合。- 先通过索引先获取模块类,再按照模块类的方法
- 主要为
nn.Sequential()
- (2)
模型类,继承nn.module类,自行构建的神经网络模型,具体为 nn.modules.module.Module 类- 通过 .modules() 方法得到一个迭代器,获得模型中的所有模块类(可能有容器类)
- .modules()方法的第一个模型本身。对于嵌套的模块(即容器类),会以此往其子模块遍历
- (3)
模块类,nn.modules 类下除了容器类(nn.modules.container)和模型类(nn.modules.module.Module)均被划为此类,即层- 有学习参数的类:
nn.Linear(); - 无学习参数的类:
nn.Sigmoid()和nn.MSELoss()等 - 使用 type() 函数查看实例化对象,得到
<class 'torch.nn.modules....'>信息 - 通过特定属性,返回
nn.parameter类,再学习参数类的方法(即.data属性)得到,- 如:对于
nn.Linear()层,包括 2 种属性:.weight和.bias
- 如:对于
- 一些函数层(如:激活函数层,维度和尺寸改变层,损失函数层)可通过 torch 模块中或
torch.nn.functional模块中的函数实现;不需要先定义层,直接当做函数使用。- 激活函数层
nn.Sigmoid():torch.nn.functional.sigmoid() 和 torch.sigmoid(),但是 PyTorch 官方推荐使用后者 - 展平层
torch.nn.Flatten():torch.flatten() - 损失函数层
nn.MSELoss(): nn.functional.mse_loss()
- 激活函数层
- 有学习参数的类:
- (4)
学习参数类,nn.parameter类- 为了与函数或实例的传入参数区分,加上了限定词学习,即网络模型需要学习(即,训练,或优化)的参数
- 一般为
nn.Parameter()类初始化的实例 - 使用
type()函数查看实例化对象,可以得到<class 'torch.nn.parameter.Parameter'>的信息 - 直接通过
.data属性(或.detach()方法),得到学习参数值 - 返回 tensor 数据类型,且 autograd 启动
所有网络模型都是继承于nn.Module

注意
容器类(nn.modules.container)和模型类(nn.modules.module.Module)也是 nn.modules 类。
torch.nn 模块中类(即,层类)的使用:先定义,再输入
总结
- 一个 module 里可包含多个子 module。
- 比如 LeNet 是一个 Module,里面包括多个卷积层、池化层、全连接层等子 module
- module 相当于运算,必须实现
forward()函数 - 每个 module 都有 8 个字典管理自己的属性
通用层和容器层(Containers)
- torch.nn.
Parameter() 用于 wrap 待优化模型参数 Tensor - torch.nn.
Sequential() 将多个网络层,按照先后顺序串联起来 - torch.nn.
Module() 用来管理模型待优化的参数- nn.
ModuleList:像 pythonlist一样包装多个网络层,可以迭代; 包装一组网络层,以迭代方式调用网络层, 主要有以下 3 个方法:- append():在 ModuleList 后面添加网络层
- extend():拼接两个 ModuleList
- insert():在 ModuleList 的指定位置中插入网络层
- nn.
ModuleDict:像 pythondict一样包装多个网络层,通过 (key, value) 的方式为每个网络层指定名称。包装一组网络层,以索引的方式调用网络层,主要有以下 5 个方法:- clear():清空 ModuleDict
- items():返回可迭代的键值对 (key, value)
- keys():返回字典的所有 key
- values():返回字典的所有 value
- pop():返回一对键值,并从字典中删除
- nn.
容器总结
- nn.Sequetial:顺序性,各网络层之间严格按照顺序执行,常用于 block 构建,在前向传播时的代码调用变得简洁
- nn.ModuleList:迭代行,常用于大量重复网络构建,通过 for 循环实现重复构建
- nn.ModuleDict:索引性,常用于可选择的网络层
线性层
- torch.nn.Linear():对输入数据最后的一个维度上实现
- torch.nn.LazyLinear()
稀疏层 Sparse Layers
- torch.nn.Embedding() 用于词向量的嵌入
torch.nn.Module
torch.nn 专门为神经网络设计的模块化接口。nn构建于autograd之上,用来定义和运行神经网络。
nn.Module 是 nn 中十分重要的类,包含网络各层定义及forward方法。
一切自定义操作基本上都是继承nn.Module类来实现
nn.Module 方法
5 个方法:
clear():清空 ModuleDictitems():返回可迭代的键值对 (key, value)keys():返回字典的所有 keyvalues():返回字典的所有 valuepop():返回一对键值,并从字典中删除
自定义 Module
定义自已的网络:
- 需要继承
nn.Module类,并实现forward方法。 - 具有可学习参数层放在构造函数
__init__()中, - 不可学习参数层不限:
- 如
ReLU,dropout、BatchNormanation层, 可放在构造函数中,也可不放, (而在forward中使用nn.functional来代替)
- 如
- 只要在
nn.Module子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。 - forward函数中可用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用if,for,print,log等python语法.
调用
- 执行
model(x)时候,底层自动调用forward方法计算结果
注:
- Pytorch 基于 nn.Module 构建模型中,只支持 mini-batch 的 Variable输入方式
- forward方法必须重写,实现模型的功能,各个层之间的连接关系的核心。
farward 原理
farward 是 神经网络的核心,定义了输入数据通过网络时的前向传播过程
实例化一个继承自 torch.nn.Module 的自定义类, 并传入输入数据时,要通过调用该实例来实现前向传播计算, 这实际上会隐式地调用 forward 方法。
执行 output = model(input_data) 时
- 首先,尝试调用 自定义model的
__call__方法。- 因为
nn.Module对__call__进行了特殊处理,确保先将输入数据准备好,并设置模型的状态(如启用或禁用批量归一化层的追踪模式等)。
- 因为
- 然后,
__call__内部调用自定义forward方法 执行前向传播计算,从而得到输出结果。 - 最终,output变量将存储从forward方法返回的前向传播输出结果。
forward 虽然不是“自动执行”,但通过直接对模型实例应用输入数据的方式,像自动执行了 forward 函数。
- 通过直接对模型实例 model 赋值输入数据并获取结果的方式,隐式地调用了
model.__call__()方法
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定义网络层结构...
def forward(self, x):
# 定义前向传播的具体步骤
out = self.some_layer(x)
# 进行更多操作...
return out
# 实例化模型
model = MyModel()
# 准备输入数据
input_data = torch.randn(1, 3, 224, 224) # 假设是针对图像分类任务的数据
# 调用模型(此时会自动调用forward方法),隐式地调用了 model.__call__() 方法
output = model(input_data)
源码
调用一个继承自nn.Module的子类实例时,如model(input_data),Python解释器会调用model.call(input_data)。在这个过程中,__call__方法首先确保模型的状态正确(例如是否处于训练或验证模式),然后调用子类重写的forward方法执行前向传播计算,并返回结果
详见原文
# 注意,这并非完整的真实源代码,而是为了说明原理而简化的伪代码
class torch.nn.Module:
def __init__(self):
super(Module, self).__init__()
self._modules = OrderedDict()
self.training = True # 默认训练模式
def _apply(self, fn):
for module in self.children():
module._apply(fn)
fn(self)
return self
def train(self, mode=True):
self.training = mode
for module in self.children():
module.train(mode)
return self
def __call__(self, *input, **kwargs):
# 确保模型处于正确的训练/评估模式
self.train(self.training)
# 在某些情况下可能还会处理梯度、模型参数等其他设置
# ...(这部分根据实际需要执行相关逻辑)
# 调用用户定义的前向传播函数
output = self.forward(*input, **kwargs)
# 返回前向传播的结果
return output
def forward(self, *input):
raise NotImplementedError("Subclasses of 'Module' must implement the 'forward' method")
# 用户自定义模块示例
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layer1 = nn.Linear(10, 5)
self.layer2 = nn.ReLU()
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
model = MyModel()
input_data = torch.randn((64, 10))
# 这一行会调用MyModel实例的__call__方法
output = model(input_data)
常用 nn 模块
用 torch.nn 包构建神经网络,API 的表达及意义
- 线性层 - nn.Linear、nn.Bilinear
- 卷积层 - nn.Conv1d、nn.Conv2d、nn.Conv3d、nn.ConvTranspose2d
- 非线性激活函数 - nn.Sigmoid、nn.Tanh、nn.ReLU、nn.LeakyReLU
- 池化层 - nn.MaxPool1d、nn.AveragePool2d
- 循环网络 - nn.LSTM、nn.GRU
- 归一化 - nn.BatchNorm2d
- Dropout - nn.Dropout、nn.Dropout2d
- 嵌入 - nn.Embedding
- 损失函数 - nn.MSELoss、nn.CrossEntropyLoss、nn.NLLLoss
示例
import torch.nn as nn
import torch.nn.functional as F
# ------- 先定义,再输入 -------
layer = nn.Linear(params) # 先定义,设置层的参数
# 一般在 nn.Module 模型的初始化函数 __init__() 中定义
output_data = layer(input_data) # 输入数据,得到输出数据
# 一般在函数 forward() 中定义
# ------- 等效表达 -------
input = torch.rand((3, 5))
# 方法 1:
layer = nn.Sigmoid()
output1 = layer(input)
# 方法 2:
output2 = F.sigmoid(input)
# 方法 3:
output3 = torch.sigmoid(input)
# 输出
print(ouput1.size())
print(torch.sum(torch.abs(output2 - output1)))
# ------- parameter -------
w = nn.Parameter(torch.Tensor([1., 1.,]))
print(w.detach()) # 返回新的tensor
print(w.data) # tensor数值,与原tensor共用
print(w.grad) # tensor梯度值,与原tensor共用
# ------- sequential -------
# 构建输入层为5,隐含层为3,输出层为1,激活函数为sigmoid的神经网络
model = nn.Sequential(
nn.Linear(5, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid(),
nn.Flatten(0, -1)
)
# ------- 模型定义 -------
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 放入需要学习的参数
# 正向传播
def forward(self, x):
return y
# 损失函数
def loss_func(self, y_pred, y_true):
return loss
# 评估函数(准确率)
def metric_func(self, y_pred, y_true):
return metric
# 优化器
@property
def optimizer(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
1. 基本配置
导入包
import torch
import torch.nn as nn
#import torchvision
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.get_device_name(0))
可复现性
- 硬件设备(CPU、GPU)不同时,完全可复现性无法保证,即使随机种子相同。
- 但是,同一个设备上,应该保证可复现性。
具体做法
- 程序开始时,固定torch随机种子,同时也把numpy随机种子固定。
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
cuda 设置
# 判断当前环境GPU是否可用, 然后将tensor导入GPU内运行
if torch.cuda.is_available():
tensor = tensor.to('cuda')
# ------------
# 如果只需要一张显卡
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 常用语句:有GPU用GPU,没有用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# 如果需要指定多张显卡,比如0,1号显卡。
import os
# 方法1
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方法2
os.environ['CUDA_VISIBLE_DEVICE']='1'
# 方法3
torch.cuda.set_device(id)
# 清除显存
torch.cuda.empty_cache()
也可以在命令行运行代码时,设置显卡:
# 命令行指定显卡
CUDA_VISIBLE_DEVICES=0,1
python train.py
# 命令行重置GPU的指令(清楚显存)
nvidia-smi --gpu-reset -i [gpu_id]
张量移动
GPU加速可显著提高模型训练速度。在将数据传递给GPU之前,需要将其转换为GPU可用格式。
常见操作
- x.
cuda() 移到 gpu - x.
cpu() 移到 cpu - x.
to() 移到指定设备, 不限 cpu/gpu
函数原型
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
return self._apply(lambda t: t.cuda(device))
def cpu(self: T) -> T:
return self._apply(lambda t: t.cpu())
def to(self, *args, **kwargs):
...
def convert(t):
if convert_to_format is not None and t.dim() == 4:
return t.to(device, dtype if t.is_floating_point() else None, non_blocking, memory_format=convert_to_format)
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
return self._apply(convert)
Tensors 可用 x.to(device) 方法来将张量、模型移动到任意设备(CPU/GPU)上, 转为为可用格式.
- 将 x 复制一份到指定设备device(cpu, cuda)上, 之后的运算都在device上进行
张量
import torch
# 获取当前device序号
print('id: ', torch.cuda.current_device())
a = torch.Tensor([[2, 3], [4, 8], [7, 9]])
tensor = torch.randn(2, 2) # Initially dtype=float32, device=cpu
tensor.to(torch.float64) # to 的另一种用法, 类型转换
cuda0 = torch.device('cuda:0')
tensor.to(cuda0, dtype=torch.float64)
other = torch.randn((), dtype=torch.float64, device=cuda0)
tensor.to(other, non_blocking=True)
print(a)
if torch.cuda.is_available():
device = torch.device("cuda")
# torch.device('cuda', 0)
# torch.device('cuda:0')
y = torch.ones_like(a, device=device) # 显示创建在 GPU 上的一个 tensor
# 把 tensor a 放到GPU上
a_cuda = a.cuda() # 方法1: 将张量/模型转换为GPU可用格式
a_cuda = a.to(device) # 方法2 (建议)
print(a_cuda)
模型
import torch
from torch import nn
from torch import optim
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net()
# 将模型参数和优化器转换为GPU可用的格式
net = net.cuda() # 直接转换为 gpu 格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device.type) # 返回 设备类别, cuda, cpu
net = net.to(device) # 模型移到device
print(net)
optimizer = optim.SGD(net.parameters(), lr=0.01)
多设备操作
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model()
if torch.cuda.device_count() > 1:
# 多个设备
model = nn.DataParallel(model,device_ids=[0,1,2])
model.to(device)
问题
【2024-7-24】使用 to(device) 报错
to()received an invalid combination of arguments - got (module)
File "./llm/dschat/utils/utils.py", line 44, in to_device
output[k] = v.to(device)
TypeError: to() received an invalid combination of arguments - got (module), but expected one of:
* (torch.device device, torch.dtype dtype, bool non_blocking, bool copy, *, torch.memory_format memory_format)
* (torch.dtype dtype, bool non_blocking, bool copy, *, torch.memory_format memory_format)
* (Tensor tensor, bool non_blocking, bool copy, *, torch.memory_format memory_format)
2. 张量(Tensor)
张量概念
数学上,张量就是向量和矩阵的推广
PyTorch 张量是同类型元素组成的多维矩阵。
虽然 PyTorch 接口是 Python,但底层主要都是用 C++实现,而在 Python 中集成 C++代码通常被称为「扩展」
张量是一种包含某种标量类型(比如浮点数和整型数等)的 n 维数据结构。功能与 NumPy 的 ndarray 对象类似
Tensor 表面上像是 Python 列表,但是本质上完全不一样。图见文章
- Python 列表或元组是一些散落在内存块中的 Python 对象的集合
- Tensor 是原始 C 语言数字类型的连续内存块视图。无论 Tensor 的形状是什么(3行2列还是2行3列),其中的数据在底层都是分配在连续的内存块中。
张量由一些数据构成,以及描述属性的元数据
- 张量大小、所包含的元素类型(dtype)、步幅(stride)
- 张量所在的设备(CPU 内存?CUDA 内存?)
三个独立地确定张量类型的配套参数:
device(设备):实际存储张量的物理内存,比如在 CPU、英伟达 GPU(cuda)、AMD GPU(hip)或 TPU(xla)上。设备之间各不相同的特性是有各自自己的分配器(allocator),这没法用于其它设备。layout(布局):对物理内存进行逻辑解读的方式。最常用的布局是有步幅的张量(strided tensor),但稀疏张量的布局不同,其涉及到一对张量,一个用于索引,一个用于数据;MKL-DNN 张量的布局更加奇特,比如 blocked layout,仅用步幅不能表示它。dtype(数据类型):张量中每个元素实际存储的数据的类型,比如可以是浮点数、整型数或量化的整型数。
Tensor 总结
- (1)Tensor 和 Numpy都是矩阵,区别是前者可以在GPU上运行,后者只能在CPU上;
- (2)Tensor 和 Numpy互相转化很方便,类型也比较兼容
- (3)Tensor 可直接通过print显示数据类型,而Numpy不可以
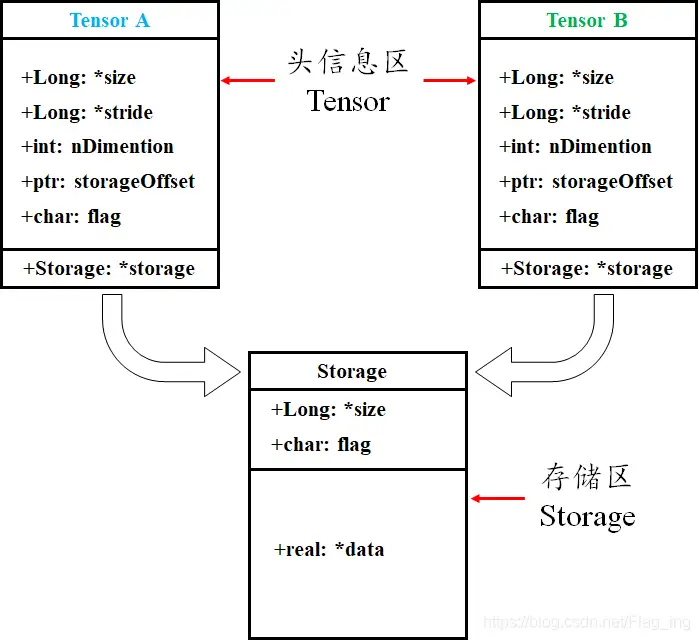
张量存储
Pytorch Tensor 分为头信息区 (Tensor) 和存储区 (Storage)。
- 信息区保存 tensor的形状 (size)、步长 (stride)、数据类型 (type) 等信息。
- 真正的数据则保存成连续数组,存储在存储区。
1个Tensor 都会有相对应的 Storage,但也有另一种情况时多个 Tensor 都对应着相同的一个 Storage,这几个 Tensor 只是头信息区不同。
tensor 数据采用头信息区(Tensor)和存储区 (Storage)分开存储;
- 定义张量A,其形状size、步长stride、索引信息都存储在头信息区,真实数据在存储区
- 对A进行修改操作,赋值给B,此时B的头信息区变化,但数据存储区与A共享 ——
浅拷贝</span>
import torch
# -------张量属性-----
a = torch.arange(5) # ③ 初始化张量 a 为 [0, 1, 2, 3, 4]
b = a[2:] # 截取张量a的部分值并赋值给b,b其实只是改变了a对数据的索引方式
# a: tensor([0, 1, 2, 3, 4])
# b: tensor([2, 3, 4])
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址, 两者共用存储区
# ptr of storage of a: 2862826251264
# ptr of storage of b: 2862826251264
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}") # 形状(维数) Shape of tensor: torch.Size([3, 4])
print(f"Datatype of tensor: {tensor.dtype}") # 数据类型 Datatype of tensor: torch.float32
print(f"Device tensor is stored on: {tensor.device}") # 存储设备 Device tensor is stored on: cpu
print('==================================================================')
b[1] = 0 # 修改b中索引为1,即a中索引为3的数据为0
# a: tensor([0, 1, 2, 0, 4])
# b: tensor([2, 0, 4])
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址,可以发现a的相应位置的值也跟着改变,说明两者是共用存储区
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址
# ==================================================================
# ptr of storage of a: 2862826251264
# ptr of storage of b: 2862826251264
张量存储方式:多维数组以一维展开的几种方式
- C/C++中使用的是行优先方式(row major)
- Matlab、Fortran使用的是列优先方式(column major)
- PyTorch中Tensor底层实现是C,也是使用行优先顺序。
t = torch.arange(12).reshape(3,4)
#tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
t.stride() # (4, 1) 连续
t.flatten()
#tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
t2 = t.transpose(0,1)
#tensor([[ 0, 4, 8],
# [ 1, 5, 9],
# [ 2, 6, 10],
# [ 3, 7, 11]])
t2.stride() # (1, 4) 不连续
t.data_ptr() == t2.data_ptr() # True 底层数据是同一个一维数组
t.is_contiguous(),t2.is_contiguous() # t连续,t2不连续
- 行
- 列


张量定义
张量命名是一个非常有用的方法,可以方便地使用维度名字来做索引或其他操作,大大提高了可读性、易用性,防止出错。
- 注意:rand 和 rand_like 只能生成浮点型!
Tensor vs tensor
相同:
- Tensor 和 tensor 都用于生成新张量
异同:
torch.Tensor主要tensor类,所有tensor都是torch.Tensor的实例。torch.Tensor是torch.FloatTensor的别名。torch.Tensor([1,2])调用 Tensor类构造函数__init__,生成单精度浮点类型的张量
- 而
torch.tensor是一个函数,返回一个tensor.torch.tensor(data, dtype=None, device=None, requires_grad=False)- data 可以是:
list,tuple, NumPyndarray,scalar和其他类型。 torch.tensor从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的 torch.LongTensor、torch.FloatTensor和torch.DoubleTensor。
a = torch.Tensor([1,2]) # 直接生成 FloatTensor
a # tensor([1., 2.])
a.type() # 'torch.FloatTensor'
# ----------------
a = torch.tensor([1,2]) # 根据数据类型自动适配 int
a # tensor([1, 2])
a.type() # 'torch.LongTensor'
a = torch.tensor([1.,2.]) # 自动适配 float
a.type() # 'torch.FloatTensor'
a = np.zeros(2,dtype=np.float64)
a = torch.tensor(a) # 自动适配 double
a.type() # 'torch.DoubleTensor'
区别1
- torch.
Tensor(data) 将输入 data 转化 torch.FloatTensortorch.Tensor()只能指定数据类型为torch.float,所以torch.Tensor() 是 torch.empty() 的一个特殊情况
- torch.
tensor(data): (未指定dype的类型时) 将 data 自动转化为 torch.FloatTensor、torch.LongTensor、torch.DoubleTensor等类型,转化类型依据于data的类型或者dtype的值
区别2
- 使用如下语句:
tensor_without_data = torch.Tensor()可以创建一个空的FloatTensor - 而使用
tensor_without_data = torch.tensor()时候则会报错
如何创建一个空的tensor?
tensor_without_data = torch.Tensor() # tensor([])
tensor_without_data = torch.tensor(()) # tensor([])
tensor_without_data = torch.empty([]) # tensor(0.)
所以 torch.Tensor 同时具有 torch.tensor 和 torch.empty 的功能
- 但使用 torch.Tensor 可能会使代码 confusing,所以最好还是使用 torch.tensor 和 torch.empty,而不是 torch.Tensor。
Tensor vs numpy
Tensor 和 Numpy 数组可相互转换,并且共享在 CPU 内存空间
- 即: 改变其中一个的数值,另一个也随之改变。
Tensor(在CPU上) 与 numpy 数据共享基础内存位置, 改变其中一个的值, 另一个也会随之被改变.
- 除CharTensor外,CPU上所有张量都支持与 NumPy 相互转换。
- 用类似于Numpy的方式对张量进行操作, 可以像 numpy 一样 Tensor 切片
Tensor 与 numpy 互转
- 类似引用,没有新建内存,二者修改同步
# tensor → numpy
t = torch.ones(5)
n = t.numpy()
# numpy → tensor
n = np.ones(5)
t = torch.from_numpy(n)
代码
import numpy as np
import torch
# Numpy array --> Torch Tensor
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a) # [2. 2. 2. 2. 2.]
print(b) # tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
# Torch Tensor --> Numpy array
a = torch.ones(5) # a = tensor([1., 1., 1., 1., 1.])
b = a.numpy() # b = [1., 1., 1., 1., 1.]
a.add_(1)
print(a) # tensor([2., 2., 2., 2., 2.])
print(b) # [2. 2. 2. 2. 2.]
# tensor 切片
print(b[: 3]) # tensor([2., 2., 2.], dtype=torch.float64)
# ----- 索引 --------
# numpy 一样通过索引获取其中元素,同时改变它的值。
a = torch.zeros((3, 2))
print(a)
a[0, 1] = 100
print(a)
# tensor([[ 0., 100.],
# [ 0., 0.],
# [ 0., 0.]])
tensor = torch.ones(4,4)
print(tensor[0]) # 第一行(0开始)
print(tensor[;,0]) # 第一列(0开始)
print(tensor[...,-1]) # 最后一列
# 张量中只有一个元素, 可以用.item()将值取出, 作为一个python number
x = torch.randn(1) # 生成一个元素的张量
print(x) # tensor([0.5374])
print(x.item()) # 0.5374473929405212
x = torch.randn(2, 2)
print(x[1, 1]) # 输出张量:tensor(2.1489)
print(x[1, 1].item()) # 输出元素:2.1488616466522217
定义方法
张量创建方式
- ① 直接创建张量
- 随机创建,torch.rand()
- ② 从已有数据创建: 从 Python列表 或 NumPy数组 创建张量
- list: torch.tensor(a)
- numpy: torch.from_numpy(a)
- ③ 参考创建,据已有张量,创建类似张量
- torch.ones_like(a)
- torch.rand_like(a)
张量初始化
- 全 0 张量: torch.zeros(),torch.zeros_like
- 全 1 张量: torch.ones(),torch.ones_like()
- 全值张量(自定义): torch.full(),torch.full_like()
- 等差张量: torch.arange()
# 随机数矩阵
x1 = torch.rand(5,4) # 随机数矩阵
x2 = torch.empty(5,4) # 全0矩阵
x3 = torch.zeros(5, 3, dtype=torch.long) # 指定类型long
t = torch.full((3, 3), 5) # 都是5的 3*3 张量
t = torch.arange(2, 10, 2) # 等差张量, 区间为[start, end), 递增step(2), [2,4,6,8]
t= torch.linspace(2, 10, 6) # 等分张量, [ 2.0000, 3.6000, 5.2000, 6.8000, 8.4000, 10.0000]
t = torch.logspace(2, 10, 6, base=10) # 对数等分张量, 1.0000e+02, 3.9811e+03, 1.5849e+05, 6.3096e+06, 2.5119e+08, 1.0000e+10]
t = torch.eye(3,4) # 对角阵张量, 3*4 维
t_normal = torch.normal(0., 1., size=(4,)) # 概率张量, 均值mean(0),方差std(1),正态分布随机张量 1*4 维, 所有元素分布相同
mean = torch.arange(1, 5, dtype=torch.float)
std = torch.arange(1, 5, dtype=torch.float)
t_normal = torch.normal(mean, std) # 各个元素指定自己的mean和std
t = torch.randint(low=2, high=6, size=(3,4))
t = torch.randperm(n=4);t
#t = torch.bernoulli(input=(0.3, 0.1));t
概率分布
[0,1)均匀分布: torch.rand() 和 torch.rand_like()[0,1)正态分布: torch.randn() 和 torch.randn_like()[low, high]上整数均匀分布: torch.randint() 和 torch.randint_like()- 0 到 n-1 的随机排列。常用于生成索引: torch.randperm()
- 以 input 为概率,生成伯努利分布 (0-1 分布,两点分布): torch.bernoulli()
import torch
# ------- 张量定义 -------
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data) # ① 直接根据已有数据创建,python list 转 tensor
x = torch.tensor([5.5, 3]) # tensor方法直接用参数初始化
x = torch.Tensor(5, 3) # 注意区别:Tensor!未初始化
np_array = np.array(data)
x_np = torch.from_numpy(np_array) # ② numpy 转 tensor
# 继承已有张量的数据属性(结构、类型), 也可以重新指定新的数据类型
x_ones = torch.ones_like(x_data) # ③ 参照已有张量"画瓢",保留 x_data 的属性
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # 重写 x_data 的数据类型:int -> float
print(f"Random Tensor: \n {x_rand} \n")
# 利用randn_like方法得到相同张量尺寸的一个新张量, 并且采用随机初始化来对其赋值
y = torch.randn_like(x, dtype=torch.float)
# 利用news_methods方法得到一个张量
x = x.new_ones(5, 3, dtype=torch.double)
# 指定维度生成张量
shape = (2,3,)
rand_tensor = torch.rand(shape) # 随机数
rand_tensor = torch.rand(5, 3) # 随机数矩阵:5*3
x = torch.randn((2, 2)) # 服从标准正态分布
ones_tensor = torch.ones(shape) # 全1
zeros_tensor = torch.zeros(shape) # 全0
x = torch.zeros(5, 3, dtype=torch.long) # 指定数值类型
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
# ---- rand & rand_like 用法 ------
t = torch.rand(10)
t = torch.rand(3,3)
t = torch.rand(size = (3,3))
t = torch.rand(size = [3,3])
t = torch.rand(size=(3,3), dtype=torch.float32) # 指定data_type
# 使用种子
gen = torch.Generator()
gen.manual_seed(2947587447)
tensor = torch.rand(size=(4,3), generator = gen)
#z3 = torch.rand_like(z2) # Error ! torch.rand is only implemented for float types
z3 = torch.rand_like(z2, dtype=torch.float32)
# 未初始化矩阵,所分配的内存中的任何值都将显示为初始值
x = torch.empty(5, 3) # 趋近于0的随机数,如:1.5975e-43
# 在PyTorch 1.3之前,需要使用注释
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)
# PyTorch 1.3之后
NCHW = ['N', 'C', 'H', 'W']
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C') # 使用维度名字索引
images.select('C', index=0)
# 也可以这么设置
tensor = torch.rand(3,4,1,2,names=('C', 'N', 'H', 'W'))
# 使用align_to可以对维度方便地排序
tensor = tensor.align_to('N', 'C', 'H', 'W')
new_* 方法
new_*方法用于替换之前的new方法,从已有张量中创建新张量(相同类型、设备)- It seems that in the newer versions of PyTorch there are many of various new_* methods that are intended to replace this “legacy” new method.
- So if you have some tensor t = torch.randn((3, 4)) then you can construct a new one with the same type and device using one of these methods, depending on your goals:
t = torch.randn((3, 4)) # 原始张量
a = t.new_tensor([1, 2, 3]) # same type, device, new data
b = t.new_empty((3, 4)) # same type, device, non-initialized
c = t.new_zeros((2, 3)) # same type, device, filled with zeros
# 查看张量信息
for x in (t, a, b, c):
print(x.type(), x.device, x.size())
# torch.FloatTensor cpu torch.Size([3, 4])
# torch.FloatTensor cpu torch.Size([3])
# torch.FloatTensor cpu torch.Size([3, 4])
# torch.FloatTensor cpu torch.Size([2, 3])
基本信息
0.4.0 以后版本,Variable 消失, 融入 Tensor 中
因此, Tensor 除了具有 Variable 5个属性,还有另外 3个属性。
张量的变量属性:
data:保存张量的数据grad:保存反向传播过程中计算的梯度值- 非叶子节点梯度为空, 如果反向传播后,仍要保留梯度, 使用方法
retain_grad()
- 非叶子节点梯度为空, 如果反向传播后,仍要保留梯度, 使用方法
grad_fn:创建张量时使用的方法(函数),反向传播求导时要用到is_leaf:是否叶子节点requires_grad:- 如果对于某个操作,其所有输入张量的
requires_grad属性均为false,那么该操作的输出张量的 requires_grad属性也是false,同时也不会生成后向图,且输出张量也是叶子节点- 张量a和b都是 requires_grad=False, c=a*b 为 False
- 张量a是 requires_grad=True,张量b是False,c=a*b 为 True
- 如果对于某个操作,其所有输入张量的
还有3个属性
dtype: 张量数据类型,如 torch.FloatTensor,torch.cuda.FloatTensor。shape: 张量形状。如 (64, 3, 224, 224)device: 张量所在设备 (CPU/GPU),GPU 是加速计算的关键

| 维度 | 叶子节点(requires_grad都是false) | 非叶子节点(requires_grad有true) |
|---|---|---|
| c=a*b | 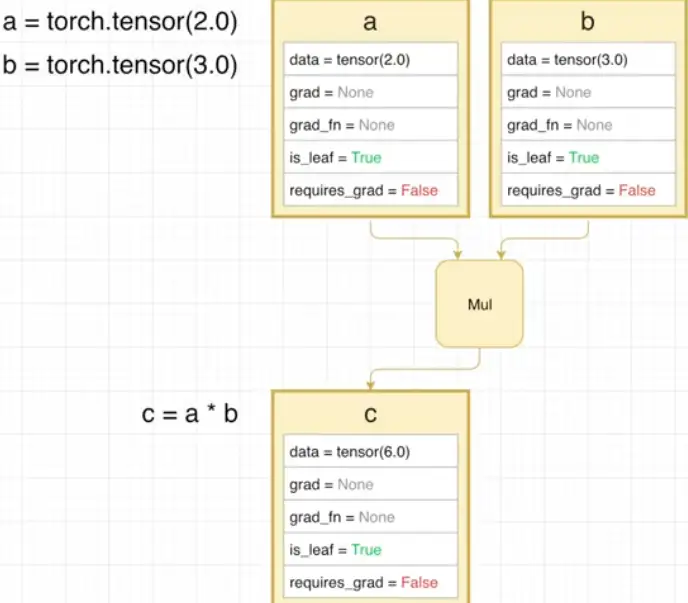 |
 |
torch tensor 也有步长属性。tensor 步长是从索引中的一个维度跨到下一个维度中间的跨度
- 卷积神经网络中卷积核对特征图的卷积操作也是有stride属性,但这两个stride可完全不是一个意思
Tensor 索引和 Python 列表索引一样, 但 Tensor 还支持更高级的索引方式。
t[t>3]
代码示例
import torch
tensor = torch.randn(3,4,5)
t = torch.randn(3,4,5)
print(t.shape, t.dtype, t.device)
print(tensor.type()) # 数据类型
print(tensor.size()) # 张量的shape,是个元组
print(tensor.dim()) # 维度的数量
print('size of a:', a.size()) # 查看a的shape
print('stride of a:', a.stride()) # 查看a的stride
print(a.storage_offset()) # 初始偏移量
print(a.storage()) # 打印a的储存区真实的数据
print('ptr of storage of a: ', a.storage().data_ptr()) # 查看a的storage区的地址
a = torch.arange(6).reshape(2, 3) # 初始化张量 a
b = torch.arange(6).view(3, 2) # 初始化张量 b
print('a:', a)
print('stride of a:', a.stride()) # 打印a的stride
print('b:', b)
print('stride of b:', b.stride()) # 打印b的stride
# 运行结果
# a: tensor([[0, 1, 2],
# [3, 4, 5]])
# stride of a: (3, 1)
#
# b: tensor([[0, 1],
# [2, 3],
# [4, 5]])
# stride of b: (2, 1)
张量类型
PyTorch有9种CPU张量类型和9种GPU张量类型。
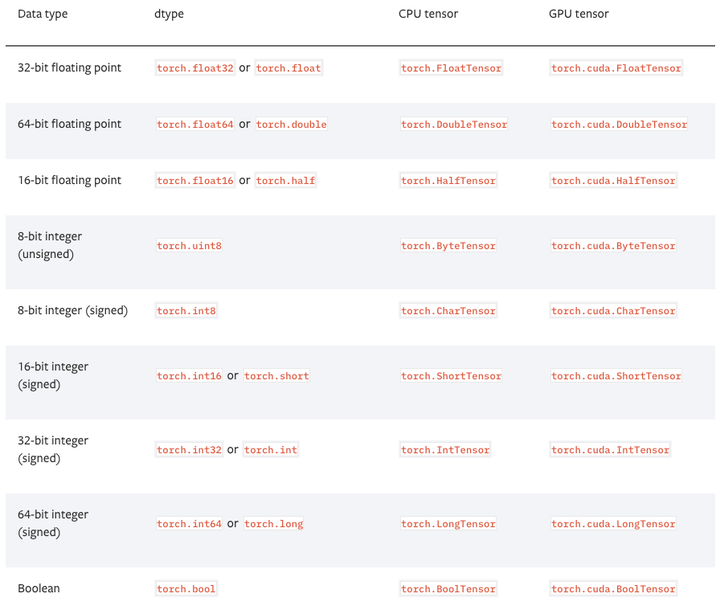
torch.Tensor 是一种包含单一数据类型元素的多维矩阵。
- torch.Tensor 是默认的tensor类型(torch.FlaotTensor)的简称。
类型介绍
Torch定义了7种CPU tensor类型和8种GPU tensor类型:
| Data type | CPU tensor | GPU tensor |
|---|---|---|
| 32-bit floating point | torch.FloatTensor |
torch.cuda.FloatTensor |
| 64-bit floating point | torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 16-bit floating point | N/A | torch.cuda.HalfTensor |
| 8-bit integer (unsigned) | torch.ByteTensor |
torch.cuda.ByteTensor |
| 8-bit integer (signed) | torch.CharTensor |
torch.cuda.CharTensor |
| 16-bit integer (signed) | torch.ShortTensor |
torch.cuda.ShortTensor |
| 32-bit integer (signed) | torch.IntTensor |
torch.cuda.IntTensor |
| 64-bit integer (signed) | torch.LongTensor |
torch.cuda.LongTensor |
每个张量tensor都有相应的torch.Storage用来保存其数据。
- 类tensor提供了一个存储的多维的、横向视图,并且定义了在数值运算。
Tensor 数据类型
- torch.float32 或 torch.float:32位浮点,默认数据类型
- torch.float64 或 torch.double:64位双精度浮点
- torch.float16 或 torch.half:16位半精度浮点
- torch.int8:有符号8位整数
- torch.uint8:无符号8位整数
- torch.int16 或 torch.short:有符号16位整数
- torch.int32 或 torch.int:有符号32位整数
- torch.int64 或 torch.long:有符号64位整数
注意:
- 改变tensor 函数操作会用一个下划线后缀来标示。
- 否则 不会改变原tensor值!
- torch.FloatTensor.
abs_() 会在原地计算绝对值,并返回改变后的tensor - tensor.FloatTensor.
abs() 会在一个新的tensor中计算结果。 - 类似的,in-place 运算还有:
acos_,asin_,add_,addbmm_,addcmul_,ceil_ - 更多信息,参考官网
# 通过list或序列构建tensor
a = torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
print(a[1][2]) # 6.0
a[0][1] = 8 # 索引和切片来获取和修改张量
print(a)
# 指定大小,创建tensor
torch.IntTensor(2, 4).zero_()
张量类型
- torch.
Tensor相当于torch.FloatTensor,32位浮点型 - torch.
DoubleTensor64位浮点型 - torch.
ShortTensor16位整型 - torch.
IntTensor32位整型 - torch.
LongTensor64位整型
类型转换
- 浮点型变化: 精度提升
- 32位与64位合并的tensor为64位
- 整型变化:
- 16位与64位合并的tensor为64位
- 浮点型+整型向更大的变化
- 浮点与整型合并为浮点
示例
import torch
# Tensor相当于FloatTensor
a = torch.Tensor([[1, 2], [3, 4], [5, 6]])
print(a)
print(a.type())
# 指定数据类型为64位浮点型
a = torch.DoubleTensor([[1, 2], [3, 4], [5, 6]])
print(a)
print(a.type())
# 16位整型
a = torch.ShortTensor ([[1, 2], [3, 4], [5, 6]])
print(a)
print(a.type())
# 32位整型
a = torch.IntTensor ([[1, 2], [3, 4], [5, 6]])
print(a)
print(a.type())
# torch.LongTensor:64位整型
a = torch.LongTensor ([[1, 2], [3, 4], [5, 6]])
print(a)
print(a.type())
# 类型转化
a = torch.ShortTensor ([[1, 2], [3, 4]])
b = torch.LongTensor([[5, 6], [7, 8]])
result = torch.cat([a,b], 0) # 拼接两个tensor
print(result)
print(result.dtype) # 64位
类型转换图解
转换方法
方法
- 直接转换:直接使用 float, long转换
- tensor.int()
- tensor.type(torch.IntTensor)
- 参考转换:
- type_as 转成指定变量同类型
# 设置默认类型,pytorch中的FloatTensor远远快于DoubleTensor
torch.set_default_tensor_type(torch.FloatTensor)
# 类型转换
tensor = tensor.cuda()
tensor = tensor.cpu()
newtensor = tensor.char() # char
tensor = tensor.float()
newtensor = tensor.byte() # short类型
tensor = tensor.long()
newtensor = tensor.half() # 半精度浮点类型
newtensor = tensor.int() # 整型
newtensor = tensor.double()
# type_as 转换为指定变量的类型
tensor1=torch.FloatTensor(4)
tensor2=torch.IntTensor(3)
tensor1=tensor1.type_as(tensor2) # type_as转换
tensor1.type(torch.FloatTensor) # type 转换
torch.Tensor 与 np.ndarray 转换
- 除了 CharTensor,其他所有CPU上的张量都支持转换为numpy格式然后再转换回来。
ndarray = tensor.cpu().numpy()
tensor = torch.from_numpy(ndarray).float()
tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride.
Torch.tensor 与 PIL.Image 转换
# pytorch中的张量默认采用[N, C, H, W]的顺序,并且数据范围在[0,1],需要进行转置和规范化
# torch.Tensor -> PIL.Image
image = PIL.Image.fromarray(torch.clamp(tensor*255, min=0, max=255).byte().permute(1,2,0).cpu().numpy())
image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way
# PIL.Image -> torch.Tensor
path = r'./figure.jpg'
tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2,0,1).float() / 255
tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently way
# np.ndarray与PIL.Image的转换
image = PIL.Image.fromarray(ndarray.astype(np.uint8))
ndarray = np.asarray(PIL.Image.open(path))
# 从只包含一个元素的张量中提取值
value = torch.rand(1).item()
张量索引
张量索引方法
- Python 风格索引,按step采样
- 指定特定索引
index_select - 任意维度索引
... - mask 索引:
masked_select条件筛选 - take 索引:
take打平后再索引
import torch
# 譬如:4张图片,每张三个通道,每个通道28行28列的像素
a = torch.rand(4, 3, 28, 28) # 4张图片数据, 3个通道
print(a[0].shape) #取到第一个维度 torch.Size([3, 28, 28])
print(a[0, 0].shape) # 取到二个维度 torch.Size([28, 28])
print(a[1, 2, 2, 4]) # 具体到某个元素 tensor(0.1076)
# 在第一个维度上取后0和1,等同于取第一、第二张图片
print(a[:2].shape)
# 在第一个维度上取0和1,在第二个维度上取0,等同于取第一、第二张图片中的第一个通道
print(a[:2, :1, :, :].shape)
# 在第一个维度上取0和1,在第二个维度上取1,2,等同于取第一、第二张图片中的第二个通道与第三个通道
print(a[:2, 1:, :, :].shape)
# 在第一个维度上取0和1,在第二个维度上取1,2,等同于取第一、第二张图片中的第二个通道与第三个通道
print(a[:2, -2:, :, :].shape)
# 使用step隔行采样
# 在第一、第二维度取所有元素,在第三、第四维度隔行采样 等同于所有图片所有通道的行列每个一行或者一列采样
# 注意:下面的代码不包括28
print(a[:, :, 0:28:2, 0:28:2].shape)
print(a[:, :, ::2, ::2].shape) # 等同于上面语句
# ------- index_select()选择特定索引 ----------
# 选择第一张和第三张图 torch.Size([2, 3, 28, 28])
print(a.index_select(0, torch.tensor([0, 2])).shape)
# 选择R通道和B通道 torch.Size([4, 2, 28, 28])
print(a.index_select(1, torch.tensor([0, 2])).shape)
# 选择图像的0~8行 torch.Size([4, 3, 8, 28])
print(a.index_select(2, torch.arange(8)).shape)
# ------- 任意多维度 ----------
# 等与a torch.Size([4, 3, 28, 28])
print(a[...].shape)
# 第一张图片的所有维度 torch.Size([3, 28, 28])
print(a[0, ...].shape)
# 所有图片第二通道的所有维度 torch.Size([4, 28, 28])
print(a[:, 1, ...].shape)
# 所有图像所有通道所有行的第一、第二列 torch.Size([4, 3, 28, 2])
print(a[..., :2].shape)
# -------- mask 索引: masked_select --------
a = torch.randn(3, 4)
print(a)
# 生成a这个Tensor中大于0.5的元素的掩码
mask = a.ge(0.5)
print(mask)
# 取出a这个Tensor中大于0.5的元素
val = torch.masked_select(a, mask)
print(val)
print(val.shape)
# ---------- take索引 --------------
# take索引是在原来Tensor的shape基础上打平,然后在打平后的Tensor上进行索引
a = torch.tensor([[3, 7, 2], [2, 8, 3]])
print(a)
print(torch.take(a, torch.tensor([0, 1, 5]))) # tensor([3, 7, 3])
张量运算
有超过100种张量相关的运算操作, 例如转置、索引、切片、数学运算、线性代数、随机采样等
- 所有运算都可以在GPU上运行(更高的运算速度)。如果是Google的Colab环境, 可以通过 Edit > Notebook Settings 来分配一个GPU使用。
加减法
几种实现方式
- +/-
- torch.
add/torch.sub - a.
_add/a._sub
import torch
# 初始化矩阵M和矩阵N
M = torch.tensor([[1, 2, 3]]) # 1x3矩阵
N = torch.tensor([[4], [5]]) # 2x1矩阵
# 方式1:直接使用"-"进行减法
result1 = M - N
print(result1)
# tensor([[-3, -2, -1],
# [-4, -3, -2]])
# 方式2:使用torch.sub()函数
result2 = torch.sub(M,N)
print(result2)
# tensor([[-3, -2, -1],
# [-4, -3, -2]])
# 方式3:使用sub_()函数
N.sub_(M)
print(N) # 报错
用Tensor初始化两个维度不同的矩阵,进行减法操作时
- ”
-“和torch.sub()函数可利用广播机制完成计算,并且原矩阵中的数据不变;- 由于M维度为1×3,N维度2×1,两矩阵会被广播成维度为2×3的矩阵(
[[1,2,3],[1,2,3]]和[[4,4,4],[5,5,5]]),然后对应位置相减,得到维度为2×3的结果矩阵。
- 由于M维度为1×3,N维度2×1,两矩阵会被广播成维度为2×3的矩阵(
sub_()函数操作触发广播机制,由于计算出的结果矩阵与原矩阵维度不匹配,所以出现报错。
import torch
# 索引
a = torch.ones(4, 4)
a[:,1] = 0 # 将第1列(从0开始)的数据全部赋值为0
# 加法操作
x = torch.rand(5, 3)
y = torch.rand(5, 3)
# 加法运算
print(x + y) # 第一种
print(torch.add(x, y)) # 第二种
result = torch.empty(5, 3) # 第三种,未初始化
# 或
result = torch.Tensor(5, 3) # 未初始化,默认torch.FloatTensor,也可定义torch. LongTensor(5,3),变换数据类型也可以用result.int(),即后面直接加类型
# (1)张量加法:结果复制
torch.add(x, y, out=result)
print(result)
# (2)原地加法
y.add_(x) # 第四种
np.add(x, 1, out=x) # numpy的等效实现,与tensor共享存储空间,所以一起变化
print(y)
注意
- 所有in-place 操作函数都有一个下划线的后缀. 比如
x.copy_(y),x.add_(y), 都会直接改变x的值.
+运算符
torch.add(tensor1, tensor2, [out=tensor3])
tensor1.add_(tensor2) # 直接修改 tensor 变量
乘除
乘除法
- torch.mul(x, y): 乘法, 对两个张量进行逐元素乘法运算。
- torch.div(x, y): 除法, 对两个张量进行逐元素除法运算。
import torch
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
result = torch.mul(x, y)
print(result)
x = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor([4.0, 5.0, 6.0])
result = torch.div(x, y)
print(result)
矩阵运算 – 重点
矩阵乘法三种办法,类似于运算符重载、成员函数和非成员函数
@ 和 * 代表矩阵的两种相乘方式:
@表示数学上定义的矩阵乘法;*表示点乘,两个矩阵对应位置处的两个元素相乘
总结
pytorch里的矩阵运算:
- ① 点乘:逐个元素相乘
mul和*, 还有dot- 广播 broadcast: 当a, b维度不一致时,会自动填充到相同维度相点乘
- torch.dot(a,b) 一维张量点乘
- mul : 两个维度必须相等, 可广播
- ② 矩阵乘法:
matmul和@, 以及mm和bmm- 矩阵相乘有 torch.mm 和 torch.matmul 两个函数。
mm只用于二维矩阵,当torch.mm用于大于二维时将报错。matmul是高维, 兼容多种- 都是一维矩阵: 功能同
torch.dot(), 返回两个一维tensor的点乘结果 - 都是二维矩阵: 功能与
torch.mm()一样,返回两个二维矩阵的矩阵乘法 - 一维 + 二维: 广播运算, 一维度上预填充一个1,执行二维矩阵乘法,最后将预填充的维度1去掉
- 二维或以上 + 一维: 执行矩阵-向量乘法。
- 三维 + 一维: 批处理矩阵乘法。
- 都是一维矩阵: 功能同
bmm两个输入必须是3-D矩阵且第一维相同(batch size)。
mm和bmm不 广播(broadcast)
- 矩阵相乘有 torch.mm 和 torch.matmul 两个函数。
# (1) torch.dot 两个1-D 张量的点乘(内乘)
torch.dot(torch.tensor([2, 3]), torch.tensor([2, 1])) # tensor(7)
# (2) torch.mm 只用于两个2-D矩阵的矩阵乘法
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
torch.mm(mat1, mat2)
# tensor([[ 0.4851, 0.5037, -0.3633],
# [-0.0760, -3.6705, 2.4784]])
# (3) torch.bmm 必须3-D矩阵且第一维相同(batch size)
input = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(input, mat2)
res.size() # torch.Size([10, 3, 5])
# (4) torch.matmul 两个tensors之间的矩阵乘法, 泛化
# 一维张量运算, 等效 dot
tensor1 = torch.randn(4)
tensor2 = torch.randn(4)
torch.matmul(tensor1, tensor2).size() # torch.Size([])
# 二维张量运算, 等效 mm
tensor1 = torch.randn(3,4)
tensor2 = torch.randn(4,5)
torch.matmul(tensor1, tensor2).size() # torch.Size([3, 5])
# 一维*二维, 广播再矩阵乘法,最后再恢复
tensor1 = torch.randn(4)
tensor2 = torch.randn(4,5)
torch.matmul(tensor1, tensor2).size() # 1*4 × 4*5=1*5→5, torch.Size([5])
# 多维*一维, 矩阵-向量乘法
a = torch.randn(4,5)
b = torch.randn(5)
torch.matmul(a, b).size() # torch.Size([4])
a = torch.randn(10, 3, 4)
b = torch.randn(4)
torch.matmul(a, b).size() # torch.Size([10, 3])
# 多维*多维, 批处理矩阵乘法, bmm
a = torch.randn(10, 3, 4)
b = torch.randn(10, 4, 5)
torch.matmul(tensor1, tensor2).size() # torch.Size([10, 3, 5])
# 第一个1维: 填充低维,按批处理算, 再删除
a = torch.randn(6)
b = torch.randn(2,6,3)
print(torch.matmul(tensor1, tensor2).size()) # torch.Size([2, 3])
# 第二个1维:
a = torch.randn(10, 3, 4)
b = torch.randn(4)
torch.matmul(a, b).size() # torch.Size([10, 3])
# 第二个2维
tensor1 = torch.randn(10, 3, 4)
tensor2 = torch.randn(4,2)
print(torch.matmul(tensor1, tensor2).size()) # torch.Size([10, 3, 2])
# 非矩阵维度会广播, 矩阵维度指最后两个
a = torch.randn(2,5,3)
b = torch.randn(1,3,4)
print(torch.matmul(a, b).size()) # torch.Size([2, 5, 4])
# 非矩阵维度会广播
a = torch.randn(2,1,3,4)
b = torch.randn(5,4,2)
print(torch.matmul(a, b).size()) # torch.Size([2, 5, 3, 2])
# (5) 点乘
a = torch.randn(3)
print(torch.mul(a, 100)) # tensor([0.1287, 0.7827, 0.2674])
# tensor([12.8663, 78.2685, 26.7358])
a = torch.randn(4, 1)
b = torch.randn(1, 4)
print(torch.mul(a, b))
区别:mm、matmul、bmm
mm只能进行二维矩阵乘法, 输入的两个tensor维度只能是( n × m ) 和 ( m × p )bmm是两个三维张量相乘, 两个输入tensor维度是( b × n × m ) 和( b × m × p ) , 第一维b代表batch size,输出为( b × n × p )matmul张量乘法, 输入可以是高维.
import torch
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[2, 1], [4, 3]])
print(x.shape, y.shape) # torch.Size([2,2])
# ① 点乘:* 或 mul,逐元素相乘
z1 = x * y
z2 = x.mul(y)
z3 = torch.rand_like(z2, dtype=torch.float32)
torch.mul(x, y, out=z3) # 输出到新的张量
print("*: ", z1.shape, z1.data)
print("mul: ", z2.shape, z2.data)
# ② 矩阵乘法: @ 或 matmul
y1 = x @ y
y2 = x.matmul(y.T)
y3 = torch.rand_like(x, dtype=torch.float32)
torch.matmul(x, y.T, out=y3)
# 单元素tensor求值
agg = x.sum()
agg_item = agg.item()
print(agg_item,type(agg_item))
# In-place 操作(会改变成员内容的成员函数,以下划线结尾)
x.add_(5) #每个元素都+5
# ---- rand & rand_like 用法 ------
t = torch.rand(10)
t = torch.rand(3,3)
t = torch.rand(size = (3,3))
t = torch.rand(size = [3,3])
t = torch.rand(size=(3,3), dtype=torch.float32) # 指定data_type
# 使用种子
gen = torch.Generator()
gen.manual_seed(2947587447)
tensor = torch.rand(size=(4,3), generator = gen)
#z3 = torch.rand_like(z2) # Error ! torch.rand is only implemented for float types
# ---------------------------------
代码
# ① 逐元素相乘结果
# Element-wise multiplication.
result = tensor1 * tensor2
print(f"tensor.mul(tensor): \n {tensor.mul(tensor)} \n")
# 等价写法:
print(f"tensor * tensor: \n {tensor * tensor}")
# ② 矩阵运算
print(f"tensor.matmul(tensor.T): \n {tensor.matmul(tensor.T)} \n")
# 等价写法:
print(f"tensor @ tensor.T: \n {tensor @ tensor.T}")
# Matrix multiplcation: (m*n) * (n*p) * -> (m*p).
result = torch.mm(tensor1, tensor2)
# Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p)
result = torch.bmm(tensor1, tensor2)
# torch.bmm() 是批量矩阵乘法(batched matrix multiplication)函数,对一批矩阵执行乘法操作
raw_weights = torch.bmm(x, x.transpose(1, 2))
计算两组数据之间的两两欧式距离
- 利用broadcast机制
dist = torch.sqrt(torch.sum((X1[:,None,:] - X2) ** 2, dim=2))
统计
- torch.
sum(input): 求和, 计算张量中所有元素的和。 - torch.
max(input): 求最大值, 找出张量中所有元素的最大值。 - torch.
mean(input): 求平均值, 计算张量中所有元素的平均值。 - torch.
min(input): 求最小值, 找出张量中所有元素的最小值。 - torch.
std(input): 求标准差, 计算张量中所有元素的标准差。 - torch.
var(input): 求方差, 计算张量中所有元素的方差。
import torch
tensor = torch.tensor([[1, 2], [3, 4]])
result = torch.sum(tensor)
result = torch.max(tensor)
result = torch.min(tensor)
print(result)
tensor = torch.tensor([[1, 2], [3, 4]], dtype=torch.float)
result = torch.mean(tensor)
result = torch.std(tensor)
result = torch.var(tensor)
print(result)
指数/幂
- torch.
pow(base, exponent): 幂运算 - torch.
exp(tensor): 指数运算, 计算张量中所有元素的指数。 - torch.
sqrt(tensor): 开方运算, 计算张量中所有元素的平方根。
import torch
tensor = torch.tensor([1.0, 2.0, 3.0])
result = torch.exp(tensor)
print(result)
base = torch.tensor([1, 2, 3])
exponent = 2
result = torch.pow(base, exponent)
print(result)
tensor = torch.tensor([1.0, 4.0, 9.0])
result = torch.sqrt(tensor)
print(result)
张量形变 view
view 介绍
改变张量形状,可用 torch.view()
x = torch.randn(4, 4) # 标准正态分布
# tensor.view()操作需要保证数据元素的总数量不变
y = x.view(16)
# -1代表自动匹配个数
z = x.view(-1, 8)
print(x.size(), y.size(), z.size()) # torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
view vs reshape vs resize_
维度重塑 view、reshape、reszie_
view 和 reshape 都可以重塑 tensor shape。
view只适合对满足连续性条件(contiguous)的tensor进行操作- 注:
is_contiguous是Tensor底层一维数组元素的存储顺序与Tensor按行优先一维展开的元素顺序是否一致。
- 注:
reshape适用范围更广, 可对不满足连续性条件的tensor进行操作。- view 能干的, reshape 都能干,如果view不能干, 可用reshape来处理—— view < reshape
- 满足tensor连续性条件时,
a.reshape返回的结果与a.view()相同,否则, 返回结果与a.contiguous().view()相同
如果不满足连续性条件
contiguous()方法原始tensor转换为满足连续条件的tensor,然后就可以使用view方法进行shape变换了。- 直接使用 reshape 方法进行维度变换,但变换后的tensor就不是与原始tensor共享内存了,而是被重新开辟了一个空间。
最后总结一下view()、reshape()、reszie_()三者的关系和区别。
- view()只能对满足连续性要求的tensor使用。
- 当tensor满足连续性要求时,reshape() = view(),和原来tensor共用内存。
- 当tensor不满足连续性要求时,reshape() = contiguous() + view(),会产生新的存储区的tensor,与原来tensor不共用内存。
- resize_()可以随意获取任意维度的tensor,不用在意真实数据的个数限制,但是不推荐使用。
引用和副本:
- view 并非原始数据的新拷贝,副本产生原始数据的新拷贝
- view 视图是数据的一个别称或引用,可访问、操作原有数据,但原有数据不会产生拷贝。
- 对视图进行修改会影响到原始数据,物理内存在同一位置,这样避免了重新创建张量的高内存开销。
张量的大部分操作是视图操作!
副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
view 重构张量维度,相当于numpy中resize的功能,但是用法可能不太一样
- view 先出现, reshape 后出现, 二者共存
import torch
import copy
a = torch.arange(5) # 初始化张量 a 为 [0, 1, 2, 3, 4]
b = copy.deepcopy(a) # b 是 a 的副本
print('a:', a)
print('b:', b)
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址,可以发现两者不是共用存储区
b[0]+=1
print('a:', a)
print('b:', b)
tt=torch.tensor([-0.3623, -0.6115, 0.7283, 0.4699, 2.3261, 0.1599])
result=tt.view(3,2) # 将一维的tt1重构成3x2维的张量
result=tt.view(-1) # 变成1维
result=tt.view(2,-1) # 变成2行,列数不定,由元素总数而定
# 在将卷积层输入全连接层的情况下通常需要对张量做形变处理,
# 相比torch.view,torch.reshape可以自动处理输入张量不连续的情况。
tensor = torch.rand(2,3,4)
shape = (6, 4)
tensor = torch.reshape(tensor, shape)
# 打乱顺序
tensor = tensor[torch.randperm(tensor.size(0))] # 打乱第一个维度
# 水平翻转
# pytorch不支持tensor[::-1]这样的负步长操作,水平翻转可以通过张量索引实现
# 假设张量的维度为[N, D, H, W].
tensor = tensor[:,:,:,torch.arange(tensor.size(3) - 1, -1, -1).long()]
变维
操作
- torch.squeeze() 降维
- torch.unsqueeze() 升维
unsqueeze_ 和 unsqueeze 区别
unsqueeze_和unsqueeze实现一样的功能- 区别在于
unsqueeze_是 in_place 操作, 即 unsqueeze 不会对使用 unsqueeze 的 tensor 进行改变,想要获取 unsqueeze 后的值必须赋予个新值, unsqueeze_ 则会对自己改变。
PyTorch中的 XXX_ 和 XXX 功能相同,唯一不同: 前者 in_place 操作。
降维(squeeze)
squeeze(): 降维,将输入张量形状中的1 去除并返回。
- 如果输入是形如(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)
- 当给定dim时,那么挤压操作只在给定维度上。
- 例如,输入形状为: (A×1×B), squeeze(input, 0) 将会保持张量不变,只有用 squeeze(input, 1),形状会变成 (A×B)。
- 注意: 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。
- 参数:
- input (Tensor) – 输入张量
- dim (int, optional) – 如果给定,则input只会在给定维度挤压
- out (Tensor, optional) – 输出张量
# ------------------
m = torch.zeros(2, 1, 2, 1, 2) # 5维张量
print(m.size()) # torch.Size([2, 1, 2, 1, 2])
n = torch.squeeze(m) # 降维:去除1维部分
print(n.size()) # torch.Size([2, 2, 2])
n = torch.squeeze(m, 0) # 当给定dim时,那么挤压操作只在给定维度上
print(n.size()) # torch.Size([2, 1, 2, 1, 2])
n = torch.squeeze(m, 1) # 只作用在第2维(刚好是1,所以第2维消失)
print(n.size()) # torch.Size([2, 2, 1, 2])
n = torch.squeeze(m, 2) # 只作用在第3维(不是1,所以维持现状)
print(n.size()) # torch.Size([2, 1, 2, 1, 2])
n = torch.squeeze(m, 3) # 只作用在第4维(刚好是1,所以第4维消失)
print(n.size()) # torch.Size([2, 1, 2, 2])
p = torch.zeros(2, 1, 1)
print(p)
# tensor([[[0.]],
# [[0.]]])
print(p.numpy())
# [[[0.]]
# [[0.]]]
print(p.size()) # torch.Size([2, 1, 1])
q = torch.squeeze(p)
print(q) # tensor([0., 0.])
print(q.numpy()) # [0. 0.]
print(q.size()) # torch.Size([2])
print(torch.zeros(3, 2).numpy())
# [[0. 0.]
# [0. 0.]
# [0. 0.]]
升维(unsqueeze)
unsqueeze(): 升维, 返回一个新的张量,对输入的既定位置插入维度 1
- 注意:
- 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。
- 如果dim为负,则将会被转化dim+input.dim()+1
- 参数:
- tensor (Tensor) – 输入张量
- dim (int) – 插入维度的索引
- out (Tensor, optional) – 结果张量
import torch
# torch.Tensor是默认的tensor类型(torch.FlaotTensor)的简称。
x = torch.Tensor([1, 2, 3, 4]) # 定义1维张量
print(x) # tensor([1., 2., 3., 4.])
print(x.size()) # torch.Size([4])
print(x.dim()) # 1
print(x.numpy()) # [1. 2. 3. 4.]
print('-' * 50)
print(torch.unsqueeze(x, 0)) # 升维:第1个位置,tensor([[1., 2., 3., 4.]])
print(torch.unsqueeze(x, 0).size()) # torch.Size([1, 4])
print(torch.unsqueeze(x, 0).dim()) # 2
print(torch.unsqueeze(x, 0).numpy()) # [[1. 2. 3. 4.]]
print(torch.unsqueeze(x, 1)) # 升维:第2个位置
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
print(torch.unsqueeze(x, 1).size()) # torch.Size([4, 1])
print(torch.unsqueeze(x, 1).dim()) # 2
print(torch.unsqueeze(x, -1)) # 升维:最后1个位置
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
print(torch.unsqueeze(x, -1).size()) # torch.Size([4, 1])
print(torch.unsqueeze(x, -1).dim()) # 2
print(torch.unsqueeze(x, -2)) # 升维:倒数第2个位置tensor([[1., 2., 3., 4.]])
print(torch.unsqueeze(x, -2).size()) # torch.Size([1, 4])
print(torch.unsqueeze(x, -2).dim()) # 2
# 边界测试
# 说明:A dim value within the range [-input.dim() - 1, input.dim() + 1) (左闭右开)can be used.
# print('-' * 50)
# print(torch.unsqueeze(x, -3))
# IndexError: Dimension out of range (expected to be in range of [-2, 1], but got -3)
# print('-' * 50)
# print(torch.unsqueeze(x, 2))
# IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
# 为何取值范围要如此设计呢?
# 原因:方便操作
# 0(-2)-行扩展
# 1(-1)-列扩展
# 正向:我们在0,1位置上扩展
# 逆向:我们在-2,-1位置上扩展
# 维度扩展:1维->2维,2维->3维,...,n维->n+1维
# 维度降低:n维->n-1维,n-1维->n-2维,...,2维->1维
# 以 1维->2维 为例,从【正向】的角度思考:
# torch.Size([4])
# 最初的 tensor([1., 2., 3., 4.]) 是 1维,我们想让它扩展成 2维,那么,可以有两种扩展方式:
# 一种是:扩展成 1行4列 ,即 tensor([[1., 2., 3., 4.]]),针对第一种,扩展成 [1, 4]的形式,那么,在 dim=0 的位置上添加 1
# 另一种是:扩展成 4行1列,即
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
# 针对第二种,扩展成 [4, 1]的形式,那么,在dim=1的位置上添加 1,从【逆向】的角度思考:
# 原则:一般情况下, "-1" 是代表的是【最后一个元素】
# 在上述的原则下,
# 扩展成[1, 4]的形式,就变成了,在 dim=-2 的的位置上添加 1
# 扩展成[4, 1]的形式,就变成了,在 dim=-1 的的位置上添加 1
# ------------------
print("-" * 50)
a = torch.Tensor([1, 2, 3, 4])
print(a) # tensor([1., 2., 3., 4.])
b = torch.unsqueeze(a, 1)
print(b)
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
print(a) # a 不变!
# tensor([1., 2., 3., 4.])
print("-" * 50)
a = torch.Tensor([1, 2, 3, 4])
print(a) # # tensor([1., 2., 3., 4.])
print(a.unsqueeze_(1))
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
print(a) # a 变化!
# tensor([[1.],
# [2.],
# [3.],
# [4.]])
维度互换
permute,transpose,contiguous
permute(dims): 将tensor的维度换位
(1)transpose与permute的异同
- Tensor.permute(a,b,c,d, …):permute函数可以对任意高维矩阵进行转置,但没有 torch.permute() 这个调用方式, 只能 Tensor.permute()
- torch.transpose(Tensor, a,b):transpose只能操作2D矩阵的转置,有两种调用方式
- 连续使用transpose也可实现permute的效果
- permute相当于可以同时操作于tensor的若干维度,transpose只能同时作用于tensor的两个维度;
(2)permute函数与contiguous、view函数之关联
- contiguous:view只能作用在contiguous的variable上,如果在view之前调用了transpose、permute等,就需要调用contiguous()来返回一个contiguous copy;
- 一种可能的解释是:有些tensor并不是占用一整块内存,而是由不同的数据块组成,而tensor的view()操作依赖于内存是整块的,这时只需要执行contiguous()这个函数,把tensor变成在内存中连续分布的形式;
判断ternsor是否为contiguous,可以调用torch.Tensor.is_contiguous()函数
import torch
x = torch.randn(2, 3, 5)
x.size() # torch.Size([2, 3, 5])
x.permute(2, 0, 1).size() # torch.Size([5, 2, 3])
torch.randn(2,3,4,5).permute(3,2,0,1).shape # torch.Size([5, 4, 2, 3])
torch.randn(2,3,4,5).transpose(3,0).transpose(2,1).transpose(3,2).shape # torch.Size([5, 4, 2, 3])
torch.randn(2,3,4,5).transpose(1,0).transpose(2,1).transpose(3,1).shape # torch.Size([3, 5, 2, 4])
x = torch.ones(10, 10)
x.is_contiguous() # True
x.transpose(0, 1).is_contiguous() # False
x.transpose(0, 1).contiguous().is_contiguous() # True
a=np.array([[[1,2,3],[4,5,6]]])
unpermuted=torch.tensor(a)
print(unpermuted.size()) # ——> torch.Size([1, 2, 3])
permuted=unpermuted.permute(2,0,1)
print(permuted.size()) # ——> torch.Size([3, 1, 2])
view_test = unpermuted.view(1,3,2)
print(view_test.size()) # ——> torch.Size([1, 3, 2])
张量赋值
自动赋值运算通常在方法后有 _ 作为后缀, 例如: x.copy_(y), x.t_()操作会改变 x 的取值。
- 自动赋值运算虽然可以节省内存, 但在求导时会因为丢失了中间过程而导致一些问题, 所以并不鼓励使用它
| Operation | New/Shared memory | Still in computation graph |
|---|---|---|
| tensor.clone() | New | Yes |
| tensor.detach() | Shared | No |
| tensor.detach.clone()() | New | No |
import torch
a = torch.ones(4, 4)
print(tensor, "\n")
tensor.add_(5)
print(tensor)
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy() # tensor -> numpy
print(f"n: {n}")
n = np.ones(5)
t = torch.from_numpy(n) # numpy -> tensor
t.add_(1) # 所有元素+1(原地)
张量拼接
torch.cat 方法将一组张量按照指定的维度进行拼接, 参考 torch.stack 方法
- 张量拼接:
- 多个已有张量拼接: torch.
cat() - 新增维度上拼接: torch.
stack()
- 多个已有张量拼接: torch.
- 张量切分: 将张量按照维度 dim 切分
- 平均切分, 尾部留余: torch.
chunk() - 指定各个维度: torch.
split()
- 平均切分, 尾部留余: torch.
cat vs stack
torch.cat 和 torch.stack 区别:
- torch.
cat沿着给定的维度拼接, - 而 torch.stack 会新增一维。
当参数是3个10x5的张量
- torch.cat 结果是 30x5 张量,
- 而torch.stack 结果是 3x10x5 张量。
cat/stack
t1 = torch.cat([a, a, a], dim=1)
tensor = torch.cat(list_of_tensors, dim=0)
tensor = torch.stack(list_of_tensors, dim=0)
# 将整数标签转为one-hot编码
# pytorch的标记默认从0开始
tensor = torch.tensor([0, 2, 1, 3])
N = tensor.size(0)
num_classes = 4
one_hot = torch.zeros(N, num_classes).long()
one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())
chunk/split
t = torch.ones((2, 3))
print('[cat]: 已有维度上拼接(不改变维度)')
t_0 = torch.cat([t, t], dim=0) # torch.Size([4, 3])
t_1 = torch.cat([t, t], dim=1) # Size([2, 6])
print("t_0:{} shape:{}\nt_1:{} shape:{}".format(t_0, t_0.shape, t_1, t_1.shape))
print("[stack]: 新增维度上拼接(改变维度)")
# 第一次指定拼接的维度 dim =2,结果的维度是 [2, 3, 3]。
# 后面指定拼接的维度 dim =0,由于原来的 tensor 已经有了维度 0,因此会把tensor 往后移动一个维度变为 [1,2,3],再拼接变为 [3,2,3]。
# dim =2
t_stack = torch.stack([t, t, t], dim=2)
print("\nt_stack.shape:{}".format(t_stack.shape)) # Size([2, 3, 3])
# dim =0
t_stack = torch.stack([t, t, t], dim=0)
print("\nt_stack.shape:{}".format(t_stack.shape)) # [3, 2, 3]
print("[张量切分]: [chunk]")
a = torch.ones((2, 7)) # 7
list_of_tensors = torch.chunk(a, dim=1, chunks=3) # 第2个维度上切分成3份: 3 + 3 + 1 = 7
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
print("[张量切分]: [split]")
list_of_tensors = torch.split(a, [2, 3, 2], dim=1)
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
张量筛选
张量切片
# 张量分隔
t = torch.rand(2, 4, 3, 5)
a = t.numpy()
pytorch_slice = t[0, 1:3, :, 4]
numpy_slice = a[0, 1:3, :, 4]
print ('Tensor[0, 1:3, :, 4]:\n', pytorch_slice)
print ('NdArray[0, 1:3, :, 4]:\n', numpy_slice)
条件选择
# 张量masking
t = t - 0.5
a = t.numpy()
pytorch_masked = t[t > 0]
numpy_masked = a[a > 0]
得到非零元素
torch.nonzero(tensor) # index of non-zero elements
torch.nonzero(tensor==0) # index of zero elements
torch.nonzero(tensor).size(0) # number of non-zero elements
torch.nonzero(tensor == 0).size(0) # number of zero elements
判断两个张量相等
torch.allclose(tensor1, tensor2) # float tensor
torch.equal(tensor1, tensor2) # int tensor
张量扩展
扩展方法
- reshape
- expand
- repeat
# Expand tensor of shape 64*512 to shape 64*512*7*7.
tensor = torch.rand(64,512)
torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)
# repeat 将张量重复指定次数, 如 3行2列
torch.tensor([11, 10]).repeat(3,2)
# tensor([[11, 10, 11, 10],
# [11, 10, 11, 10],
# [11, 10, 11, 10]])
特殊矩阵
torch.manual_seed(10)
a = torch.triu(torch.ones(4,4)) # 上三角矩阵
a = torch.tril(torch.ones(4,4)) # 下三角矩阵
爱因斯坦求和数
【2023-7-13】【深度学习中的神仙操作】einsum爱因斯坦求和
爱因斯坦求和约定(Einstein Notation)
- 数学中,
爱因斯坦求和约定是一种标记法,也称为Einstein Summation Convention,在处理关于坐标的方程式时十分有效。 - 简单来说,
爱因斯坦求和就是简化掉求和式中的求和符号,即 $\sum$ ,这样就会使公式更加简洁- $a_{i} b_{i}=\sum_{i=0}^{N} a_{i} b_{i}=a_{0} b_{0}+a_{1} b_{1}+\ldots+a_{N} b_{N}$
工具包实现
- Numpy率先将
爱因斯坦求和以扩展函数的方式引入(np.einsum),而多维数组的特性又非常符合深度学习中张量(Tensor)的特性 - 因此,基于Numpy,TensorFlow、PyTorch等深度学习框架也纷纷将einsum作为其拓展函数,与Numpy相比,tf和torch中参与运算的张量具有梯度,可以进行反向传播。
对于张量/矩阵运算,einsum几乎无所不能,以Numpy为例说明其典型用法,PyTorch和TensorFlow中的用法大同小异
import numpy as np
a = np.arange(0, 9).reshape(3, 3)
print(a)
b = np.einsum('ij->ji', a) # 转置
b = np.einsum('ij->', a) # 全元素求和
b = np.einsum('ij->i', a) # 某一维度求和
c = np.einsum('ij,j->ij', a, b) # 矩阵对应维度相乘
c = np.einsum('ij,j->i', a, b) # 矩阵对应维度相乘-求和形式
c = np.einsum('ij,ij->', a, b) # 矩阵点乘
c = np.einsum('ik,kj->ij', a, b) # 矩阵外积(相乘)
print(b)
神奇函数: torch.einsum()
- torch.einsum():爱因斯坦求和约定, 非常神奇的函数,满足一切需求
a = torch.arange(6).reshape(2,3)
# tensor([[0, 1, 2],
# [3, 4, 5]])
b=torch.arange(15).reshape(3,5)
# tensor([[0, 1, 2],
# [3, 4, 5]])
# 矩阵转置
torch.einsum('ij->ji',[a])
# 求和
torch.einsum('ij->',[a]) # tensor(15)
# 列求和(行维度不变,列维度消失)
torch.einsum('ij->j',[a]) # tensor([ 3., 5., 7.])
# 行求和(列维度不变,行维度消失)
torch.einsum('ij->i', [a]) # tensor([ 3., 12.])
# 矩阵-向量相乘
b=a[0]
torch.einsum('ik,k->i',[a,b]) # tensor([ 5., 14.])
# 矩阵-矩阵乘法
torch.einsum('ik,kj->ij',[a,b])
# tensor([[ 25, 28, 31, 34, 37],
# [ 70, 82, 94, 106, 118]])
# 点积
b=torch.arange(6,12).reshape(2,3)
torch.einsum('ij,ij->',[a,b]) # tensor(145.)
# 外积
a=torch.arange(3) # tensor([0, 1, 2])
b=torch.arange(3,7) # tensor([3, 4, 5, 6])
torch.einsum('i,j->ij',[a,b])
# tensor([[ 0., 0., 0., 0.],
# [ 3., 4., 5., 6.],
# [ 6., 8., 10., 12.]])
# batch矩阵乘
a=torch.randn(3,2,5)
b=torch.randn(3,5,3)
torch.einsum('ijk,ikl->ijl',[a,b])
# 多张量计算
A = torch.randn(3,5,4)
l = torch.randn(2,5)
r = torch.randn(2,4)
torch.einsum('bn,anm,bm->ba', l, A, r) # compare torch.nn.functional.bilinear
# tensor([[-0.3430, -5.2405, 0.4494],
# [ 0.3311, 5.5201, -3.0356]])
C = torch.einsum('ijklno,ijlmno->ijkmno', [A, B])
张量梯度
- tensor.
requires_grad_(): 标记张量需要计算梯度, 标记张量以便在反向传播中计算梯度。 - tensor.
grad: 获取张量的梯度, 获取张量的梯度值,前提是该张量需要计算梯度。 - tensor.
backward(): 计算梯度, 计算张量的梯度值,前提是该张量需要计算梯度。
import torch
# 标记张量运算时要计算梯度
tensor = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
tensor.sum().backward() # 计算梯度
print(tensor.grad) # 获取梯度
变量 Variable
PyTorch 变量是张量的简单封装
- 帮助建立计算图
- Autograd(自动微分库)的必要部分
- 将关于变量的梯度保存在
.grad中
PyTorch 0.4.0 前,torch.autograd 包中存在 Variable 数据类型
- 用于封装 Tensor,进行自动求导。
Variable 主要包含下面几种属性。
- data: 被包装的 Tensor。
- grad: data 的梯度。
- grad_fn: 创建 Tensor 所使用的 Function,是自动求导的关键,因为根据所记录的函数才能计算出导数。
- requires_grad: 指示是否需要梯度,并不是所有的张量都需要计算梯度。
- is_leaf: 指示是否叶子节点(张量),叶子节点的概念在计算图中会用到
PyTorch 0.4.0 后,Variable 消失, 并入了 Tensor。
变量定义
from torch.autograd import Variable
import torch.nn.functional as F
# 不算梯度
x = Variable(torch.randn(4, 1), requires_grad=False)
y = Variable(torch.randn(3, 1), requires_grad=False)
# requires_grad=True 要自动计算梯度,用于反向传播
w1 = Variable(torch.randn(5, 4), requires_grad=True)
w2 = Variable(torch.randn(3, 5), requires_grad=True)
# 模型构建
def model_forward(x):
return F.sigmoid(w2 @ F.sigmoid(w1 @ x))
print (w1)
print (w1.data.shape)
print (w1.grad) # Initially, non-existent
import torch.nn as nn
# 损失函数:描述模型的预测距离目标还有多远;
criterion = nn.MSELoss()
import torch.optim as optim
# 优化算法:用于更新权重;
optimizer = optim.SGD([w1, w2], lr=0.001)
# 反向传播步骤:
for epoch in range(10):
loss = criterion(model_forward(x), y)
optimizer.zero_grad() # Zero-out previous gradients
loss.backward() # Compute new gradients
optimizer.step() # Apply these gradients
print (w1)
拟合 Sin 函数
【2024-3-25】参考
(1) 准备数据集
用 pytorch 变量绘制曲线
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 创建数据
x = torch.linspace(0, 1, 100)
y = torch.sin(2 * np.pi * x)
# 添加随机噪声
np.random.seed(20)
y_noisy = y + 0.05 * torch.randn(size=x.shape)
# 绘图开始
plt.figure()
plt.plot(x, y, label='True function', color='g')
plt.scatter(x, y_noisy, edgecolor='b', s=20, label='Noisy samples')
plt.legend()
plt.tight_layout()
plt.show()
(2) 定义模型
定义模型:用多项式函数来拟合sin函数
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc=nn.Linear(100,5) # 全连接层
def forward(self,x):
output=F.tanh(x) # 激活函数 tanh
output=self.fc(output) # MLP 层
# 定义四阶多项式模型
output= output[0]+output[1]*x+output[2]*x**2+output[3]*x**3+output[4]*x**4
return output
# 网络实例化
net=Net()
# 损失函数
criterion = nn.MSELoss()
# 优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
(3) 模型训练
- 训练 3w 次后,测试效果
for i in range(30000):
y_pred=net(x)
loss=criterion(y_pred,y)
if i % 2000 == 1999:
print("epoch:{},mse:{}".format(i+1,loss.item()))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试效果
x_test=torch.linspace(0, 1, 100)
y_pred=net(x_test)
# 画图
plt.figure()
plt.plot(x_test.detach().numpy(), y_pred.detach().numpy(), label='Regressor', color='#FFA628')
plt.plot(x, y, label='True function', color='g')
plt.scatter(x, y_noisy, edgecolor='b', s=20, label='Noisy samples')
plt.legend()
plt.tight_layout()
plt.show()
3. 模型定义和操作
MLP 多层感知机
【2022-9-21】pytorch教程:层和块
定义模型结构的几种方法
- 直接顺序组装:nn.Sequential,不用定义网络结构
- 自定义网络结构:nn.Sequential,使用forward函数组装
- 根据参数顺序组装
快捷定义
import torch
from torch import nn
from torch.nn import functional as F
# x -> FC -> Relu -> FC
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)
自定义
- nn.Sequential定义了一种特殊的Module
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.out = nn.Linear(256, 10)
def forward(self, X):
return self.out(F.relu(self.hidden(X)))
# 实例化模型
net = MLP()
net(X)
参数传入各组件,顺序组装
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
# 依次遍历、组装各个传入的组件
for idx, module in enumerate(args):
self._modules[str(idx)] = module
def forward(self, X):
for block in self._modules.values():
X = block(X)
return X
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)
前向传播中执行代码
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
X = F.relu(torch.mm(X, self.rand_weight) + 1)
X = self.linear(X)
while X.abs().sum() > 1:
X /= 2
return X.sum()
net = FixedHiddenMLP()
net(X)
混合搭配各种方法
class NestMLP(nn.Module): # 嵌套结构
def __init__(self):
super().__init__()
# 顺序结构
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
# 自定义
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
chimera(X)
Embedding 词嵌入
nn.Embedding用法
- 一个简单的存储固定大小的词典的嵌入向量的查找表
- 给一个编号,嵌入层返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
- 输入为一个编号列表,输出为对应的符号嵌入向量列表。每个句子结尾要加EOS
- input: [‘i’, ‘am’, ‘a’, ‘boy’]
- output: [3, 6, 5, 10]
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None,
max_norm=None, norm_type=2.0, scale_grad_by_freq=False,
sparse=False, _weight=None)
# 建立词向量层
# 随机初始化建立了词向量层后,建立了一个"二维表",存储了词典中每个词的词向量
embed = torch.nn.Embedding(n_vocabulary, embedding_size)
参数解释
- num_embeddings (python:int) – 词典大小,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
- embedding_dim (python:int) – 嵌入向量维度,即用多少维来表示一个符号。
- padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
- max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
- norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
- scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
- sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
import torch
import torch.nn as nn
# an Embedding module containing 10 tensors of size 3
embedding = nn.Embedding(10, 3) # 10个单词的词库,每个词语3维
# a batch of 2 samples of 4 indices each
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
print('默认填充:', embedding(input))
# example with padding_idx 加填充
embedding = nn.Embedding(10, 3, padding_idx=0)
input = torch.LongTensor([[0,2,0,5]])
print('padding填充:', embedding(input))
# example of changing `pad` vector 改变填充向量
padding_idx = 0
embedding = nn.Embedding(3, 3, padding_idx=padding_idx)
embedding.weight
with torch.no_grad():
embedding.weight[padding_idx] = torch.ones(3)
print('自定义填充:', embedding.weight)
卷积网络
一个简单两层卷积网络的示例
# convolutional neural network (2 convolutional layers)
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model = ConvNet(num_classes).to(device)
卷积层的计算和展示可以用这个网站辅助。
双线性汇合(bilinear pooling)
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization
多卡同步 BN(Batch normalization)
当使用 torch.nn.DataParallel 将代码运行在多张 GPU 卡上时,PyTorch 的 BN 层默认操作是各卡上数据独立地计算均值和标准差,同步 BN 使用所有卡上的数据一起计算 BN 层的均值和标准差,缓解了当批量大小(batch size)比较小时对均值和标准差估计不准的情况,是在目标检测等任务中一个有效的提升性能的技巧。
sync_bn = torch.nn.SyncBatchNorm(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
将已有网络的所有BN层改为同步BN层
def convertBNtoSyncBN(module, process_group=None):
'''Recursively replace all BN layers to SyncBN layer.
Args:
module[torch.nn.Module]. Network
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
sync_bn = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum,
module.affine, module.track_running_stats, process_group)
sync_bn.running_mean = module.running_mean
sync_bn.running_var = module.running_var
if module.affine:
sync_bn.weight = module.weight.clone().detach()
sync_bn.bias = module.bias.clone().detach()
return sync_bn
else:
for name, child_module in module.named_children():
setattr(module, name) = convert_syncbn_model(child_module, process_group=process_group))
return module
类似 BN 滑动平均
如果要实现类似 BN 滑动平均的操作,在 forward 函数中要使用原地(inplace)操作给滑动平均赋值。
class BN(torch.nn.Module)
def __init__(self):
...
self.register_buffer('running_mean', torch.zeros(num_features))
def forward(self, X):
...
self.running_mean += momentum * (current - self.running_mean)
torch.nn.functional
建图过程中往往有两种层
- 一种含参数、有Variable,如全连接层,卷积层、Batch Normlization层等;
- 另一种不含参数、无Variable,如Pooling层,Relu层,损失函数层等。
阅读源码发现
- nn.里的函数继承自 nn.module 初始化为实例化一个类,如果含参数,则会帮你初始化好参数。
- nn.functional.里的函数,则是相当于直接一个函数句柄给你,如果需要参数,则需要自己输入参数,且并不会”记住”这个参数。
选择
- 如果要涉及到参数计算的,那用nn.里的;
- 如果不需要涉及更新参数,只是一次性计算,那用nn.functional.里面的。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(512, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(F.dropout(self.fc2(x), 0.5))
x = F.dropout(self.fc3(x), 0.5)
return x
三层网络为例。需要维持状态的主要是三个线性变换,所以在构造Module是,定义了三个nn.Linear对象,而在计算时,relu,dropout之类不需要保存状态的可以直接使用。
- 注:dropout的话有个坑,需要设置自行设定training的state。
对比示例
- 用nn.Xxx定义一个CNN
- 用nn.function.xxx定义一个与上面相同的CNN
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5,padding=0)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, padding=0)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.linear1 = nn.Linear(4 * 4 * 32, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
out = self.maxpool1(self.relu1(self.cnn1(x)))
out = self.maxpool2(self.relu2(self.cnn2(out)))
out = self.linear1(out.view(x.size(0), -1))
return out
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1_weight = nn.Parameter(torch.rand(16, 1, 5, 5))
self.bias1_weight = nn.Parameter(torch.rand(16))
self.cnn2_weight = nn.Parameter(torch.rand(32, 16, 5, 5))
self.bias2_weight = nn.Parameter(torch.rand(32))
self.linear1_weight = nn.Parameter(torch.rand(4 * 4 * 32, 10))
self.bias3_weight = nn.Parameter(torch.rand(10))
def forward(self, x):
x = x.view(x.size(0), -1)
out = F.conv2d(x, self.cnn1_weight, self.bias1_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.conv2d(x, self.cnn2_weight, self.bias2_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.linear(x, self.linear1_weight, self.bias3_weight)
return out
两种定义方式得到CNN功能都是相同的,但PyTorch官方推荐:
- 有学习参数的(例如,conv2d, linear, batch_norm)采用nn.Xxx方式
- 没有学习参数的(例如,maxpool, loss func, activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。
但关于dropout,强烈推荐使用 nn.Xxx方式,因为一般情况下只有训练阶段才进行dropout,在 eval阶段都不会进行dropout。使用nn.Xxx方式定义dropout,在调用 model.eval()之后,model中所有的dropout layer都关闭,但以nn.function.dropout方式定义dropout,在调用model.eval()之后并不能关闭dropout。
计算模型整体参数量
num_parameters = sum(torch.numel(parameter) for parameter in model.parameters())
查看网络中的参数
- 通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数)
params = list(model.named_parameters())
(name, param) = params[28]
print(name)
print(param.grad)
print('-------------------------------------------------')
(name2, param2) = params[29]
print(name2)
print(param2.grad)
print('----------------------------------------------------')
(name1, param1) = params[30]
print(name1)
print(param1.grad)
模型可视化(使用pytorchviz)
szagoruyko/pytorchviz 类似 Keras 的 model.summary() 输出模型信息(使用pytorch-summary ), sksq96/pytorch-summary
模型权重初始化
注意 model.modules() 和 model.children() 的区别:model.modules() 会迭代地遍历模型的所有子层,而 model.children() 只会遍历模型下的一层。
# Common practise for initialization.
for layer in model.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out',
nonlinearity='relu')
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.BatchNorm2d):
torch.nn.init.constant_(layer.weight, val=1.0)
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.Linear):
torch.nn.init.xavier_normal_(layer.weight)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
# Initialization with given tensor.
layer.weight = torch.nn.Parameter(tensor)
提取模型中的某一层
modules()会返回模型中所有模块的迭代器,它能够访问到最内层,比如self.layer1.conv1这个模块,还有一个与它们相对应的是name_children()属性以及named_modules(),这两个不仅会返回模块的迭代器,还会返回网络层的名字。
# 取模型中的前两层
new_model = nn.Sequential(*list(model.children())[:2]
# 如果希望提取出模型中的所有卷积层,可以像下面这样操作:
for layer in model.named_modules():
if isinstance(layer[1],nn.Conv2d):
conv_model.add_module(layer[0],layer[1])
部分层使用预训练模型
注意如果保存的模型是 torch.nn.DataParallel,则当前的模型也需要是
model.load_state_dict(torch.load('model.pth'), strict=False)
将在 GPU 保存的模型加载到 CPU
model.load_state_dict(torch.load('model.pth', map_location='cpu'))
导入另一个模型的相同部分到新的模型
模型导入参数时,如果两个模型结构不一致,则直接导入参数会报错。用下面方法可以把另一个模型的相同的部分导入到新的模型中。
# model_new代表新的模型
# model_saved代表其他模型,比如用torch.load导入的已保存的模型
model_new_dict = model_new.state_dict()
model_common_dict = {k:v for k, v in model_saved.items() if k in model_new_dict.keys()}
model_new_dict.update(model_common_dict)
model_new.load_state_dict(model_new_dict)
4. 数据处理
计算数据集的均值和标准差
import os
import cv2
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
def compute_mean_and_std(dataset):
# 输入PyTorch的dataset,输出均值和标准差
mean_r = 0
mean_g = 0
mean_b = 0
for img, _ in dataset:
img = np.asarray(img) # change PIL Image to numpy array
mean_r += np.mean(img[:, :, 0])
mean_g += np.mean(img[:, :, 1])
mean_b += np.mean(img[:, :, 2])
mean_r /= len(dataset)
mean_g /= len(dataset)
mean_b /= len(dataset)
diff_r = 0
diff_g = 0
diff_b = 0
N = 0
for img, _ in dataset:
img = np.asarray(img)
diff_r += np.sum(np.power(img[:, :, 0] - mean_r, 2))
diff_g += np.sum(np.power(img[:, :, 1] - mean_g, 2))
diff_b += np.sum(np.power(img[:, :, 2] - mean_b, 2))
N += np.prod(img[:, :, 0].shape)
std_r = np.sqrt(diff_r / N)
std_g = np.sqrt(diff_g / N)
std_b = np.sqrt(diff_b / N)
mean = (mean_r.item() / 255.0, mean_g.item() / 255.0, mean_b.item() / 255.0)
std = (std_r.item() / 255.0, std_g.item() / 255.0, std_b.item() / 255.0)
return mean, std
得到视频数据基本信息
import cv2
video = cv2.VideoCapture(mp4_path)
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(video.get(cv2.CAP_PROP_FPS))
video.release()
TSN 每段(segment)采样一帧视频
K = self._num_segments
if is_train:
if num_frames > K:
# Random index for each segment.
frame_indices = torch.randint(
high=num_frames // K, size=(K,), dtype=torch.long)
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.randint(
high=num_frames, size=(K - num_frames,), dtype=torch.long)
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), frame_indices)))[0]
else:
if num_frames > K:
# Middle index for each segment.
frame_indices = num_frames / K // 2
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), torch.arange(K - num_frames))))[0]
assert frame_indices.size() == (K,)
return [frame_indices[i] for i in range(K)]
常用训练和验证数据预处理
其中 ToTensor 操作会将 PIL.Image 或形状为 H×W×D,数值范围为 [0, 255] 的 np.ndarray 转换为形状为 D×H×W,数值范围为 [0.0, 1.0] 的 torch.Tensor。
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
5. 模型训练和测试
分布式 DDP
DistributedDataParallel(DDP)是依靠多进程来实现数据并行的分布式训练方法
- 简单说,能够扩大batch_size,每个进程负责一部分数据
在使用DDP分布式训练前,有几个概念或者变量需要弄清楚:
- group: 进程组,一般就需要一个默认的
- world size: 所有的进程数量
- rank: 全局的进程id
- local rank:某个节点上的进程id
- local_word_size: 某个节点上的进程数 (相对比较少见)
这些概念的基本单元都是进程,与GPU没有关系,一个进程可以对应若干个GPU。 所以 world_size 并不是等于所有的GPU数量,而是人为设定的。只不过平时用的最多的情况是一个进程使用一块GPU,这种情况下 world_size 可以等于所有节点的GPU数量。
假设所有进程数即 world_size 为W,每个节点上的进程数即local_world_size为L,则每个进程上的两个ID:
- rank的取值范围:[0, W-1],rank=0的进程为主进程,会负责一些同步分发的工作
- local_rank的取值:[0, L-1]
假定有2个机器或者节点,每个机器上有4块GPU。图中一共有4个进程,即world_size=4,那这样每个进程占用两块GPU,其中rank就是[0,1,2,3],每个节点的local_rank就是[0,1]了,其中local_world_size 也就是2。 这里需要注意的是,local_rank是隐式参数,即torch自动分配的。比如local_rank 可以通过自动注入命令行参数或者环境变量来获得) 。
从torch1.10开始,官方建议使用环境变量的方式来获取local_rank, 在后期版本中,会移除命令行的方式
示例:test.py
import torch.distributed as dist
import argparse, os
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=ine, default=0)
args = parser.parse_args()
dist.init_process_group("nccl")
rank = dist.get_rank()
local_rank_arg = args.local_rank # 命令行形式ARGS形式
local_rank_env = int(os.environ['LOCAL_RANK']) # 在利用env初始ENV环境变量形式
local_world_size = int(os.environ['LOCAL_WORLD_SIZE'])
print(f"{rank=}; {local_rank_arg=}; {local_rank_env=}; {local_world_size=}")
执行
python3 -m torch.distributed.launch --nproc_per_node=4 test.py # 在一台4卡机器上执行
一般的分布式训练都是为每个进程赋予一块GPU,这样比较简单而且容易调试。 这种情况下,可以通过local_rank作为当前进程GPU的id。
分布式训练场景: 单机多卡,多机多卡,模型并行,数据并行等等。
常见的单机多卡的情况进行记录。
更多资讯见原文: Pytorch DDP分布式训练介绍
分类模型训练代码
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i ,(images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch: [{}/{}], Step: [{}/{}], Loss: {}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
分类模型测试代码
# Test the model
model.eval() # eval mode(batch norm uses moving mean/variance
#instead of mini-batch mean/variance)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test accuracy of the model on the 10000 test images: {} %'
.format(100 * correct / total))
损失函数
MSE = torch.nn.MSELoss()
MAE = torch.nn.L1Loss()
自定义loss
继承torch.nn.Module类写自己的loss。
class MyLoss(torch.nn.Moudle):
def __init__(self):
super(MyLoss, self).__init__()
def forward(self, x, y):
loss = torch.mean((x - y) ** 2)
return loss
标签平滑(label smoothing)
写一个label_smoothing.py的文件,然后在训练代码里引用,用LSR代替交叉熵损失即可。label_smoothing.py内容如下:
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
"""
Convert labels to one hot vectors
Args:
labels: torch tensor in format [label1, label2, label3, ...]
classes: int, number of classes
value: label value in one hot vector, default to 1
Returns:
return one hot format labels in shape [batchsize, classes]
"""
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth
them.
Args:
target: target in form with [label1, label2, label_batchsize]
length: length of one-hot format(number of classes)
smooth_factor: smooth factor for label smooth
Returns:
smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1 - smooth_factor)
one_hot += smooth_factor / (length - 1)
return one_hot.to(target.device)
def forward(self, x, target):
if x.size(0) != target.size(0):
raise ValueError('Expected input batchsize ({}) to match target batch_size({})'
.format(x.size(0), target.size(0)))
if x.dim() < 2:
raise ValueError('Expected input tensor to have least 2 dimensions(got {})'
.format(x.size(0)))
if x.dim() != 2:
raise ValueError('Only 2 dimension tensor are implemented, (got {})'
.format(x.size()))
smoothed_target = self._smooth_label(target, x.size(1), self.e)
x = self.log_softmax(x)
loss = torch.sum(- x * smoothed_target, dim=1)
if self.reduction == 'none':
return loss
elif self.reduction == 'sum':
return torch.sum(loss)
elif self.reduction == 'mean':
return torch.mean(loss)
else:
raise ValueError('unrecognized option, expect reduction to be one of none, mean, sum')
或者直接在训练文件里做label smoothing
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
score = model(images)
log_prob = torch.nn.functional.log_softmax(score, dim=1)
loss = -torch.sum(log_prob * smoothed_labels) / N
optimizer.zero_grad()
loss.backward()
optimizer.step()
Mixup训练
beta_distribution = torch.distributions.beta.Beta(alpha, alpha)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
# Mixup images and labels.
lambda_ = beta_distribution.sample([]).item()
index = torch.randperm(images.size(0)).cuda()
mixed_images = lambda_ * images + (1 - lambda_) * images[index, :]
label_a, label_b = labels, labels[index]
# Mixup loss.
scores = model(mixed_images)
loss = (lambda_ * loss_function(scores, label_a)
+ (1 - lambda_) * loss_function(scores, label_b))
optimizer.zero_grad()
loss.backward()
optimizer.step()
L1 正则化
l1_regularization = torch.nn.L1Loss(reduction='sum')
loss = ... # Standard cross-entropy loss
for param in model.parameters():
loss += torch.sum(torch.abs(param))
loss.backward()
不对偏置项进行权重衰减(weight decay)
pytorch里的weight decay相当于l2正则
bias_list = (param for name, param in model.named_parameters() if name[-4:] == 'bias')
others_list = (param for name, param in model.named_parameters() if name[-4:] != 'bias')
parameters = [{'parameters': bias_list, 'weight_decay': 0},
{'parameters': others_list}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
梯度裁剪(gradient clipping)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=20)
得到当前学习率
# If there is one global learning rate (which is the common case).
lr = next(iter(optimizer.param_groups))['lr']
# If there are multiple learning rates for different layers.
all_lr = []
for param_group in optimizer.param_groups:
all_lr.append(param_group['lr'])
另一种方法,在一个batch训练代码里,当前的lr是optimizer.param_groups[0][‘lr’]
学习率衰减
# Reduce learning rate when validation accuarcy plateau.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)
for t in range(0, 80):
train(...)
val(...)
scheduler.step(val_acc)
# Cosine annealing learning rate.
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)
# Reduce learning rate by 10 at given epochs.
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)
for t in range(0, 80):
scheduler.step()
train(...)
val(...)
# Learning rate warmup by 10 epochs.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)
for t in range(0, 10):
scheduler.step()
train(...)
val(...)
优化器链式更新
从1.4版本开始,torch.optim.lr_scheduler 支持链式更新(chaining),即用户可以定义两个 schedulers,并交替在训练中使用。
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR, StepLR
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = StepLR(optimizer, step_size=3, gamma=0.1)
for epoch in range(4):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()
模型训练可视化
PyTorch可以使用tensorboard来可视化训练过程。
安装和运行TensorBoard。
pip install tensorboard
tensorboard --logdir=runs
使用SummaryWriter类来收集和可视化相应的数据,放了方便查看,可以使用不同的文件夹,比如’Loss/train’和’Loss/test’。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
保存与加载断点
为了能够恢复训练,要同时保存模型和优化器的状态,以及当前的训练轮数。
涉及保存模型的几个函数:
- torch.save
- torch.load
- state_dict()
- load_state_dict()
结论:
- pth文件不一定保存了模型的图结构;
- 加载没保存图结构的pth时,需要先初始化模型结构,即把架子搭好;
- 保存模型时,如果不想保存图结构,可以单独保存 model.state_dict()
方式一: 全部模型信息(图结构+参数)
import torch
model = torch.load('my_model.pth')
torch.save(model, 'new_model.pth')
pth文件直接包含了整个模型结构。灵活加载模型参数时,比如只加载部分参数,pth文件读取进来还得额外解析出”参数文件”。
方式二: 部分模型信息(不含图结构)
pytorch 把所有模型参数用一个内部定义的dict保存,自称为”state_dict”, 即不带模型结构的模型参数
保存和加载方式如下:
import torch
model = MyModel() # init your model class, build the graph shape
torch.save(model.state_dict(), 'model_state_dict1.pth') # 保存
state_dict = torch.load('model_state_dict.pth')
model.load_state_dict(state_dict)
# --------
import torch
# save: 保存多种状态(模型,优化器,轮数)
torch.save(model.state_dict(), PATH)
# load
model = MyModel(*args, **kwargs)
# 分两步:先用load加载模型权重, 再用load_state_dict 加载其他参数
model.load_state_dict(torch.load(PATH))
model.eval()
model.state_dict() 返回一个 OrderDict,存储了网络结构的名字和对应的参数
start_epoch = 0
# Load checkpoint.
if resume: # resume为参数,第一次训练时设为0,中断再训练时设为1
model_path = os.path.join('model', 'best_checkpoint.pth.tar')
assert os.path.isfile(model_path)
checkpoint = torch.load(model_path)
best_acc = checkpoint['best_acc']
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('Load checkpoint at epoch {}.'.format(start_epoch))
print('Best accuracy so far {}.'.format(best_acc))
# Train the model
for epoch in range(start_epoch, num_epochs):
...
# Test the model
...
# save checkpoint
is_best = current_acc > best_acc
best_acc = max(current_acc, best_acc)
checkpoint = {
'best_acc': best_acc,
'epoch': epoch + 1,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
model_path = os.path.join('model', 'checkpoint.pth.tar')
best_model_path = os.path.join('model', 'best_checkpoint.pth.tar')
torch.save(checkpoint, model_path)
if is_best:
shutil.copy(model_path, best_model_path)
提取 ImageNet 预训练模型某层的卷积特征
# VGG-16 relu5-3 feature.
model = torchvision.models.vgg16(pretrained=True).features[:-1]
# VGG-16 pool5 feature.
model = torchvision.models.vgg16(pretrained=True).features
# VGG-16 fc7 feature.
model = torchvision.models.vgg16(pretrained=True)
model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])
# ResNet GAP feature.
model = torchvision.models.resnet18(pretrained=True)
model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
with torch.no_grad():
model.eval()
conv_representation = model(image)
提取 ImageNet 预训练模型多层的卷积特征
class FeatureExtractor(torch.nn.Module):
"""Helper class to extract several convolution features from the given
pre-trained model.
Attributes:
_model, torch.nn.Module.
_layers_to_extract, list<str> or set<str>
Example:
>>> model = torchvision.models.resnet152(pretrained=True)
>>> model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
>>> conv_representation = FeatureExtractor(
pretrained_model=model,
layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image)
"""
def __init__(self, pretrained_model, layers_to_extract):
torch.nn.Module.__init__(self)
self._model = pretrained_model
self._model.eval()
self._layers_to_extract = set(layers_to_extract)
def forward(self, x):
with torch.no_grad():
conv_representation = []
for name, layer in self._model.named_children():
x = layer(x)
if name in self._layers_to_extract:
conv_representation.append(x)
return conv_representation
微调全连接层
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, 100) # Replace the last fc layer
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)
以较大学习率微调全连接层,较小学习率微调卷积层
model = torchvision.models.resnet18(pretrained=True)
finetuned_parameters = list(map(id, model.fc.parameters()))
conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)
parameters = [{'params': conv_parameters, 'lr': 1e-3},
{'params': model.fc.parameters()}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
6. 其他注意事项
- 不要使用太大的线性层。因为nn.Linear(m,n)使用的是 O(mn) 的内存,线性层太大很容易超出现有显存。
- 不要在太长的序列上使用RNN。因为RNN反向传播使用的是BPTT算法,其需要的内存和输入序列的长度呈线性关系。
- model(x) 前用 model.train() 和 model.eval() 切换网络状态。
- 不需要计算梯度的代码块用 with torch.no_grad() 包含起来。
- model.eval() 和 torch.no_grad() 的区别在于,model.eval() 是将网络切换为测试状态,例如 BN 和dropout在训练和测试阶段使用不同的计算方法。torch.no_grad() 是关闭 PyTorch 张量的自动求导机制,以减少存储使用和加速计算,得到的结果无法进行 loss.backward()。
- model.zero_grad()会把整个模型的参数的梯度都归零, 而optimizer.zero_grad()只会把传入其中的参数的梯度归零.
- torch.nn.CrossEntropyLoss 的输入不需要经过 Softmax。torch.nn.CrossEntropyLoss 等价于 torch.nn.functional.log_softmax + torch.nn.NLLLoss。
- loss.backward() 前用 optimizer.zero_grad() 清除累积梯度。
- torch.utils.data.DataLoader 中尽量设置 pin_memory=True,对特别小的数据集如 MNIST 设置 pin_memory=False 反而更快一些。num_workers 的设置需要在实验中找到最快的取值。
- 用 del 及时删除不用的中间变量,节约 GPU 存储。
- 使用 inplace 操作可节约 GPU 存储,如
- x = torch.nn.functional.relu(x, inplace=True)
- 减少 CPU 和 GPU 之间的数据传输。例如如果你想知道一个 epoch 中每个 mini-batch 的 loss 和准确率,先将它们累积在 GPU 中等一个 epoch 结束之后一起传输回 CPU 会比每个 mini-batch 都进行一次 GPU 到 CPU 的传输更快。
- 使用半精度浮点数 half() 会有一定的速度提升,具体效率依赖于 GPU 型号。需要小心数值精度过低带来的稳定性问题。
- 时常使用 assert tensor.size() == (N, D, H, W) 作为调试手段,确保张量维度和你设想中一致。
- 除了标记 y 外,尽量少使用一维张量,使用 n*1 的二维张量代替,可以避免一些意想不到的一维张量计算结果。
- 统计代码各部分耗时
with torch.autograd.profiler.profile(enabled=True, use_cuda=False) as profile:
...
print(profile)
# 或者在命令行运行
python -m torch.utils.bottleneck main.py
使用TorchSnooper来调试PyTorch代码,程序在执行的时候,就会自动 print 出来每一行的执行结果的 tensor 的形状、数据类型、设备、是否需要梯度的信息。
# pip install torchsnooper
import torchsnooper
# 对于函数,使用修饰器
@torchsnooper.snoop()
# 如果不是函数,使用 with 语句来激活 TorchSnooper,把训练的那个循环装进 with 语句中去。
with torchsnooper.snoop():
原本的代码
https://github.com/zasdfgbnm/TorchSnooper 模型可解释性,使用captum库
half 半精度
half 是PyTorch框架提供的trick:开启半精度。
- 直接加快运行速度、减少GPU占用,并且只有不明显的accuracy损失。
之前硬件加速,尝试过多种精度的权重和偏置。
- 在FPGA里用8位精度和16位精度去处理MNIST手写数字识别,完全可以达到差不多的准确率,并且可以节省一半的资源消耗。
- 这一思想用到GPU里完全可行。即将pytorch默认的32位浮点型都改成16位浮点型。
model.half() # ① 模型载入GPU之前,启动半精度
model.cuda() # 载入 GPU
model.eval()
# ② 模型改为半精度以后,输入也需要改成半精度。
img = torch.from_numpy(image).float()
img = img.cuda()
img = img.half() # 输入变半精度
res = model(img)
测试结果为:
- 速度提升25%~35%,显存节约40~60%,而accuracy几乎没变
计算图
Autograd 在由函数对象组成的有向无环图(DAG)中记录数据(张量)和所有已执行的操作(以及由此产生的新张量)。
示例:
- 只有1个layer的网络,输入x,参数w和b,以及一个loss function
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
# 设置 原地可变
w.requires_grad_(True)
b.requires_grad_(True)
# 偏导
print(z.grad_fn)
print(loss.grad_fn)
# 计算Loss对w和b的偏导,只需要使用
loss.backward() # 第一次执行正常
loss.backward(retain_graph=True) # 更正,加参数 retain_graph,这次多次调用 backward不出错
print(w.grad)
print(b.grad)
loss.backward() # 再次执行会出错!因为中间变量已经释放
注意
- 只能计算图里叶子的梯度,内部的点不能算
- 一张图只能计算1次梯度,要保留节点的话,backward 要传 retain_graph=True
得到的计算图(Computational Graph): DAG(有向无环图)
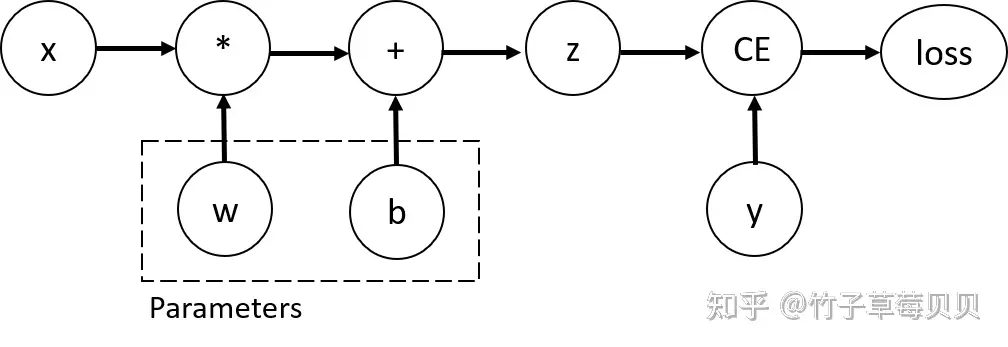
在DAG 中,叶子是输入张量,根是输出张量。 通过从根到叶跟踪此图,可以使用链式规则自动计算梯度。
在正向传播中,Autograd 同时执行两项操作:
- 运行请求的操作以计算结果张量,并且
- 在 DAG 中维护操作的梯度函数。
当在 DAG 根目录上调用 .backward() 时,反向传递开始。 autograd然后:
- 从每个 .grad_fn 计算梯度,
- 将它们累积在各自的张量的 .grad 属性中,然后
- 使用链式规则,一直传播到叶子张量。
下面是示例中 DAG 的直观表示。 在图中,箭头指向前进的方向。 节点代表正向传播中每个操作的反向函数。 蓝色的叶节点代表我们的叶张量a和b。

注意
- DAG 在 PyTorch 中是动态的。
- 图是从头开始重新创建的;
- 在每个.backward()调用之后,Autograd 开始填充新图。 所以允许用户在模型中使用控制流语句。 用户可以根据需要在每次迭代中更改形状,大小和操作。
如果使用.grad_fn属性向后跟随loss,您将看到一个计算图
# input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
# -> view -> linear -> relu -> linear -> relu -> linear
# -> MSELoss
# -> loss
# 调用loss.backward()时,整个图将被微分。 损失,并且图中具有requires_grad=True的所有张量将随梯度累积其.grad张量
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
模型格式
保存哪些信息
提供哪些模型信息,让对方能够完全复现模型?
- 模型代码:
- (1)如何定义模型结构,包括模型有多少层/每层有多少神经元等等信息;
- (2)如何定义的训练过程,包括epoch batch_size等参数;
- (3)如何加载数据和使用;
- (4)如何测试评估模型。
- 模型参数:提供了模型代码之后,对方确实能够复现模型,但是运行的参数需要重新训练才能得到,而没有办法在我们的模型参数基础上继续训练,因此对方还希望我们能够把模型的参数也保存下来给对方。
- (1)包含 model.state_dict(),这是模型每一层可学习的节点的参数,比如weight/bias;
- (2)包含 optimizer.state_dict(),这是模型的优化器中的参数;
- (3)包含 其他参数信息,如epoch/batch_size/loss等。
- 数据集:
- (1)包含 训练模型使用的所有数据;
- (2)可以提示对方如何去准备同样格式的数据来训练模型。
- 使用文档:
- (1)根据使用文档的步骤,每个人都可以重现模型;
- (2)包含了模型的使用细节和我们相关参数的设置依据等信息。
根据提供的模型代码/模型参数/数据集/使用文档,就有理由相信对方是有手就会了,目的就达到了。
模型重现的关键:模型结构/模型参数/数据集,分享模型时需要一个交流规范,而 .pt .pth .bin 以及 .onnx 就是约定格式。
模型格式类型
【2023-9-26】Pytorch格式 .pt .pth .bin .onnx 详解
- 支持的模型保存格式包括:
.pt和.pth.bin.onnx
不同后缀只是用于提示文件可能包含的内容,但是具体内容要看模型提供者编写的README.md才知道。
- 使用
torch.load()方法加载模型信息时,不是根据文件后缀进行读取,而是根据文件的实际内容自动识别的 - 因此对于
torch.load()方法而言,不管把后缀改成是什么,只要文件是对的都可以读取。
“一切皆文件” 是正确打开计算机世界的思维方式
文件后缀只作为提示作用
- Windows系统中也会用于提示系统默认如何打开或执行文件
- 除此之外,文件后缀不是认识和了解文件阻碍。
| 格式 | 解释 | 适用场景 | 可对应的后缀 |
|---|---|---|---|
.pt 或 .pth |
PyTorch 默认模型文件格式,保存和加载完整 PyTorch 模型,包含模型结构和参数等信息。 | 需要保存和加载完整的 PyTorch 模型的场景,例如在训练中保存最佳的模型或在部署中加载训练好的模型。 | .pt 或 .pth |
.bin |
一种通用的二进制格式,可以用于保存和加载各种类型的模型和数据。 | 需要将 PyTorch 模型转换为通用的二进制格式的场景。 | .bin |
ONNX |
一种通用的模型交换格式,可以用于将模型从一个深度学习框架转换到另一个深度学习框架或硬件平台。PyTorch 中,可用 torch.onnx.export 函数将 PyTorch 模型转换为 ONNX 格式。 |
需要将 PyTorch 模型转换为其他深度学习框架或硬件平台可用的格式的场景。 | .onnx |
TorchScript |
PyTorch 提供的一种序列化和优化模型的方法,可以将 PyTorch 模型转换为一个序列化的程序,并使用 JIT 编译器对模型进行优化。在 PyTorch 中,可以使用 torch.jit.trace 或 torch.jit.script 函数将 PyTorch 模型转换为 TorchScript 格式。 | 需要将 PyTorch 模型序列化和优化,并在没有 Python 环境的情况下运行模型的场景。 | .pt 或 .pth |
导出哪些信息,就取决于场景,务必在readme.md中写清楚
- 公共部分: model = Net()
| 保存场景 | 保存方法 | 文件后缀 |
|---|---|---|
| 整个模型 | torch.save(model, PATH) | .pt .pth .bin |
| 仅模型参数 | torch.save(model.state_dict(), PATH) | .pt .pth .bin |
| checkpoints使用 | torch.save({‘epoch’: 10, ‘model_state_dict’: model.state_dict(), ‘optimizer_state_dict’: optimizer.state_dict(), ‘loss’: loss,}, PATH) | .pt .pth .bin |
| ONNX通用保存 | model.load_state_dict(torch.load(“model.bin”)) example_input = torch.randn(1, 3) torch.onnx.export(model, example_input, “model.onnx”, input_names=[“input”], output_names=[“output”]) |
.onnx |
| TorchScript 无python环境使用 | model_scripted = torch.jit.script(model) # Export to TorchScript model_scripted.save(‘model_scripted.pt’) 使用时: model = torch.jit.load(‘model_scripted.pt’) model.eval() |
.pt .pth |
# 模型定义
model = Net()
# 整个模型
torch.save(model, PATH)
# 仅模型参数
torch.save(model.state_dict(), PATH)
# checkpoint
torch.save(
{ 'epoch': 10,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, PATH)
# ONNX 通用保存
model.load_state_dict(torch.load("model.bin"))
example_input = torch.randn(1, 3)
torch.onnx.export(
model, example_input,
"model.onnx",
input_names=["input"],
output_names=["output"]
)
# TorchScript: 无python环境使用
model_scripted = torch.jit.script(model) # Export to TorchScript model_scripted.save('model_scripted.pt')
# 使用时:
model = torch.jit.load('model_scripted.pt')
model.eval()
.pt/.pth 格式
完整的Pytorch模型文件包含如下参数:
model_state_dict: 模型参数optimizer_state_dict: 优化器状态epoch: 当前训练轮数loss: 当前损失值
.pt文件的保存和加载示例(注意,后缀也可以是 .pth ):
.state_dict():包含所有参数和持久化缓存的字典,model 和 optimizer 都有这个方法torch.save():将所有的组件保存到文件中
import torch
import torch.nn as nn
# 定义一个简单的模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.fc2 = nn.Linear(5, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
model = Net()
# 保存模型
torch.save({
'epoch': 10,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, PATH)
# 加载模型
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
.bin 格式
.bin 文件是二进制文件,可保存Pytorch模型的参数和持久化缓存。
- .bin 文件较小,加载速度较快,因此在生产环境中使用较多。
import torch
import torch.nn as nn
# 定义一个简单的模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.fc2 = nn.Linear(5, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
model = Net()
# 保存参数到.bin文件
torch.save(model.state_dict(), PATH)
# 加载.bin文件
model = Net()
model.load_state_dict(torch.load(PATH))
model.eval()
.onnx 格式
上述文件可以通过 PyTorch 的torch.onnx.export函数转化为ONNX格式,其他深度学习框架中使用PyTorch训练的模型。
详见站内专题: onnx
保存完整模型
之前的方式都是保存了.state_dict(),但是没有保存模型结构,在其他使用时,必须先重新定义相同结构的模型(或兼容模型),才能够加载模型参数进行使用,如果想直接把整个模型都保存下来,避免重新定义模型,可以按如下操作:
# 保存模型
PATH = "entire_model.pt"
# PATH = "entire_model.pth"
# PATH = "entire_model.bin"
torch.save(model, PATH)
# 加载模型
model = torch.load("entire_model.pt")
model.eval()
ByteCheckpoint
【2024-8-20】 字节跳动豆包大模型团队与香港大学于近期公开了最新的研究成果—— ByteCheckpoint 。
PyTorch 原生,兼容多个训练框架,支持 Checkpoint 的高效读写和自动重新切分的大模型 Checkpointing 系统。与基线方法相比,ByteCheckpoint
- 在 Checkpoint 保存上性能提升高达 529.22 倍
- 在 加载上,性能提升高达 3.51 倍。
- 极简的用户接口和 Checkpoint 自动重新切分功能,显著降低了用户上手和使用成本,提高了系统的易用性。
- 论文 ByteCheckpoint: A Unified Checkpointing System for LLM Development
损失函数
PyTorch torch.nn 模块有多个标准损失函数。
- 平均绝对误差损失(
MAE):又称L1损失,计算实际值和预测值之间的绝对差之和的平均值。 $\operatorname{loss}(x, y)=|x-y|$ - 均方误差损失(
MSE):又称L2损失,计算实际值和预测值之间的平方差的平均值。惩罚大误差。 $\operatorname{loss}(x, y)=(x-y)^{2}$ - 负对数似然损失(
NLL):负对数似然损失函数 (NLL) 仅适用于以 softmax 函数作为输出激活层的模型。- Softmax 是指计算层中每个单元的归一化指数函数的激活函数。
- NLL 使用否定含义,因为概率(或可能性)在0和1之间变化,并且此范围内值的对数为负。 最后,损失值变为正值。
- 模型因做出正确预测的概率较小而受到惩罚,并因预测概率较高而受到鼓励。 对数执行惩罚。NLL 不仅关心预测是否正确,还关心模型对高分预测的确定性。
- 适用场景:多分类问题
- 交叉熵损失(
CE):衡量两个概率分布之间的差异- 用于计算一个分数,体现预测值和实际值之间的平均差异
- 与负对数似然损失(NLL)不同,交叉熵惩罚不正确但置信度高的预测,以及正确但置信度较低的预测。
- 交叉熵函数有多种变体,最常见的是二元交叉熵 (BCE)。 BCE Loss主要用于二元分类模型
- 适用场景:
- ① 二元分类任务,Pytorch 中的默认损失函数。
- ② 创建有信心的模型——预测将是准确的,而且概率更高。
- 铰链嵌入损失(
Hinge):Hinge Embedding Loss 用于计算输入张量 x 和标签张量 y 时的损失。- Hinge Loss 函数,只要实际类别值和预测类别值之间的符号存在差异,就可以给出更多错误。
- 适用场景:目标值介于 {1, -1} 之间,这使其适用于二元分类任务
- ① 分类问题,尤其是在确定两个输入是不同还是相似时。
- ② 学习非线性嵌入或半监督学习任务。
- 边际排名损失(
MRL):Margin Ranking Loss 计算一个标准来预测输入之间的相对距离。- 直接从一组给定的输入进行预测。
- $ \operatorname{loss}(x, y)=\max (0,-y *(x 1-x 2)+\operatorname{margin}) $
- 适用场景:排名问题
- 三元组边际损失(
TML):Triplet Margin Loss 计算衡量模型中三重态损失的标准。- 此损失函数可以计算损失,前提是输入张量 x1、x2、x3 以及值大于零的边距。
- 三元组由 a(锚点)、p(正例)和 n(负例)组成。
- $ \mathrm{L}(\mathrm{a}, \mathrm{p}, \mathrm{n})=\max \left{\mathrm{d}\left(\mathrm{a}{\mathrm{i}}, \mathrm{p}{\mathrm{i}}\right)-\mathrm{d}\left(\mathrm{a}{\mathrm{i}}, \mathrm{n}{\mathrm{i}}\right)+\operatorname{margin}, 0\right} $
- 适用场景
- ① 确定样本之间存在的相对相似性。
- ② 用于基于内容的检索问题
- Kullback-Leibler 散度(
KL):Kullback-Leibler 散度,缩写为 KL 散度,计算两个概率分布之间的差异。- 计算在预测概率分布用于估计预期目标概率分布的情况下丢失的信息量(以位表示)。
- 输出两个概率分布的接近程度。
- 如果预测的概率分布与真实的概率分布相差甚远,就会导致很大的损失。
- 如果 KL Divergence 的值为零,则意味着概率分布相同。
- KL 散度的行为就像交叉熵损失,它们在处理预测概率和实际概率的方式上存在关键差异。 Cross-Entropy 根据预测的置信度对模型进行惩罚,而 KL Divergence 则不会。 KL 散度仅评估概率分布预测与地面实况分布有何不同。
- $\operatorname{loss}(x, y)=y \cdot(\log y-x)$
- 适用场景
- 逼近复杂函数
- 多类分类任务
- 如果想确保预测的分布与训练数据的分布相似
详见站内专题: 损失函数
Autograd 微分
神经网络(NN)是在某些输入数据上执行的嵌套函数的集合。 这些函数由参数(由权重和偏差组成)定义,这些参数在 PyTorch 中存储在张量中。
训练 NN 分为两个步骤:
- 正向传播:在正向传播中,NN 对正确的输出进行最佳猜测。 它通过其每个函数运行输入数据以进行猜测。
- 反向传播:在反向传播中,NN 根据其猜测中的误差调整其参数。 它通过从输出向后遍历,收集有关函数参数(梯度)的误差导数并使用梯度下降来优化参数来实现。
torch.autograd 是 PyTorch 的自动差分引擎,求向量微积分
- torch.autograd 是用于计算向量雅可比积的引擎

根据链式规则,向量-雅可比积将是l相对于x的梯度:

- 示例中使用的是 vector-Jacobian 乘积的这一特征。 external_grad 表示 v
torch.autograd 跟踪所有将其 requires_grad 标志设置为True的张量的操作。
- 对于不需要梯度的张量,将此属性设置为False会将其从梯度计算 DAG 中排除。
- 即使只有一个输入张量具有
requires_grad=True,操作的输出张量也将需要梯度。
import torch
# requires_grad 提示 autograd 跟踪该张量的所有操作
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2 # 损失函数示例,对a的偏导 9a^2,对b的偏导 -2b
# Q上调用.backward()时,Autograd 将计算这些梯度并将其存储在各个张量的.grad属性中
external_grad = torch.tensor([1., 1.])
# 在Q.backward()中显式传递gradient参数,因为是向量。 gradient是与Q形状相同的张量,它表示Q相对于本身的梯度
Q.backward(gradient=external_grad)
# check if collected gradients are correct, 梯度现在沉积在a.grad和b.grad中
print(9*a**2 == a.grad) # tensor([True, True])
print(-2*b == b.grad) # tensor([True, True])
x = torch.rand(5, 5)
y = torch.rand(5, 5)
z = torch.rand((5, 5), requires_grad=True)
a = x + y
print(f"Does `a` require gradients? : {a.requires_grad}") # False 不需要剃度
b = x + z
print(f"Does `b` require gradients?: {b.requires_grad}") # True 需要剃度
NN 中,不计算梯度的参数通常称为冻结参数。 如果事先知道不需要参数梯度,则”冻结”模型的一部分很有用(通过减少自动梯度计算,这会带来一些性能优势)。
- 微调中,我们冻结了大部分模型,通常仅修改分类器层以对新标签进行预测。
from torch import nn, optim
model = torchvision.models.resnet18(pretrained=True)
# Freeze all the parameters in the network
for param in model.parameters(): # 模型中的所有参数都将冻结
param.requires_grad = False
# 10 个标签的新数据集中微调模
# 新增 分类器的新线性层
model.fc = nn.Linear(512, 10) # (默认情况下未冻结)
# 计算梯度的唯一参数是model.fc的权重和偏差
# Optimize only the classifier
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
不算梯度
模型已经训练后,不算剃度,节省时间
- no_grad
- detach
z = torch.matmul(x, w)+b
print(z.requires_grad) # True
with torch.no_grad(): # False
z = torch.matmul(x, w)+b
print(z.requires_grad)
# 另一个办法是用.detach()
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
当输出 tensor、雅可比积时,也不能计算梯度
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
Variable
autograd.Variable 是 autograd 包的核心类. 包裹着Tensor, 支持几乎所有Tensor的操作,并附加额外的属性. 一旦完成前向计算,可以通过.backward() 方法来自动计算所有的梯度.
- tensor变成variable之后才能进行反向传播求梯度
- 用变量.backward()进行反向传播之后,var.grad中保存了var的梯度
- Variable的运算结果也是
Variable,但是,中间结果反向传播中不会被求导(),这和TensorFlow不太一致,TensorFlow中中间运算果数据结构均是Tensor
Variable 有三个比较重要的组成属性: data , grad, grad_fn。
datatensor 数值,存储了Tensor,是本体的数据grad反向传播梯度,保存了data的梯度,本事是个Variable而非Tensor,与data形状一致grad_fn操作,比如通过加减还是乘除来得到的;指向Function对象,用于反向传播的梯度计算之用
自动求导的实现还有一个非常重要的类,即函数(Function).
变量(Variable)和函数(Function)是相互联系的, 并形成一个非循环图来构建一个完整的计算过程.- 每个变量有一个
.grad_fn属性, 指向创建该变量的一个Function, 用户自己创建的变量的grad_fn属性为None.
# py
import torch
from torch.autograd import Variable
# x = Variable(tensor, requires_grad = True)
x = Variable(torch.one(2,2), requires_grad = True)
print(x)#其实查询的是x.data,是个tensor
y = torch.cos(x) # 传入Variable
x_tensor_cos = torch.cos(x.data) # 传入Tensor
y = x.sum()
y.backward() # 反向传播
x.grad # Variable的梯度保存在Variable.grad中
# 所以要归零
x.grad.data.zero_() # 归零梯度,注意,在torch中所有的inplace操作都是要带下划线的,虽然就没有.data.zero()方法
Variable 和 tensor 的区别和联系
- Variable 是篮子,而 tensor 是鸡蛋,鸡蛋应该放在篮子里才能方便拿走(定义variable时一个参数就是tensor)
- Variable 这个篮子除了装了 tensor 外, 还有 requires_grad 参数,表示是否需要对其求导,默认为 False
Variable有一些属性
grad,梯度 variable.grad 是 d(y)/d(variable) 保存的是变量 y 对 variable 变量的梯度值,如果 requires_grad 参数为 False,所以variable.grad 返回值为None,如果为 True,返回值就为对 variable 的梯度值grad_fn,对于用户自己创建的变量 Variable() grad_fn 是为 none 的,也就是不能调用 backward 函数,但对于由计算生成的变量,如果存在一个生成中间变量的 requires_grad 为 true,那其的 grad_fn 不为 none,反则为nonedata,这个就很简单,这个属性就是装的鸡蛋(tensor)
import numpy as np
import torch
from torch.autograd import Variable
x = Variable(torch.ones(2,2), requires_grad = False)
temp = Variable(torch.zeros(2,2), requires_grad = True)
y = x + temp + 2
y = y.mean() #求平均数
y.backward() #反向传递函数,用于求y对前面的变量(x)的梯度
print(x.grad) # d(y)/d(x)
print(temp.grad) # d(y)/d(temp)
# 每次backward后,grad值是会累加的,所以利用BP算法,每次迭代是需要将grad清零的。
x.grad.data.zero_() # in-place操作需要加上_,即zero_
训练
总结
最简单的更新规则是随机梯度下降(SGD):
weight=weight-learning_rate*gradient
# 更新权重
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
超参
三个超参数
- Epochs:数据集迭代次数
- Batch size:单次训练样本数
- Learning Rate:学习速度
优化器
torch.optim 中实现了多种优化算法
Optimizer
- 初始化优化器,给它需要优化的参数,和超参数Learning Rate
optimizer = torch.optim.SGC(model.parameters(),lr = learning_rate)
# 优化器在每个epoch里做三件事
optimizer.zero_grad() # 将梯度清零
loss.backward() # 进行反向传播
optimizer.step() # 根据梯度更新参数
模型保存
加载/保存
如何保存和加载训好的模型?
保存和加载模型权重
- 通过
torch.save方法,将模型保存到state_dict类型的字典里。
import torch
import torchvision.models as models
model = models.vgg16(pretrained=True)
# 保存模型
torch.save(model.state_dict(), 'model_weights.pth')
# gpu中的模型保存到 cpu
torch.load('classifier.pt', map_location=torch.device('cpu'))
先构造相同类型的模型,然后把参数加载进去 load_state_dict
# 实例化模型
model = models.vgg16() # we do not specify pretrained=True, i.e. do not load default weights
# 导入权重
model.load_state_dict(torch.load('model_weights.pth'))
model.eval() # 必须步骤
注意
- 一定要调一下
model.eval(),防止后续出错
保存和加载模型,先实例化模型,再导入权值
有没有办法直接保存和加载整个模型呢?
- 不传
mode.state_dict()参数,改为 model
# 保存方式
torch.save(model,'model.pth')
# 直接加载方式
model = torch.load('model.pth')
自动保存最佳模型
best_loss=float('inf') #初始化最好的损失为无穷大
for epoch in range(num_epochs):
# 训练模型
# 评估模型
val_loss = evaluate_model(model, val_loader)
# 保存最好的模型
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict), 'best_model.pth')
demo
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
案例
线性回归
线性回归 分析一个变量 ($y$) 与另外一 (多) 个变量 ($x$) 之间的关系
- 公式: $y=wx+b$
- 目的: 求解参数$w, b$
求解步骤:
- 确定模型:$y=wx+b$
- 选择损失函数,均方误差 MSE:$\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-\hat{y}{i}\right)^{2}$。
- 其中 $ \hat{y}{i} $ 是预测值,$y$ 是真实值。
- 梯度下降法求解梯度 (其中 $lr$ 是学习率),并更新参数:
- $w = w - lr * w.grad$
- $b = b - lr * b.grad$
训练 80 次时,Loss 已经小于 1 了,因此停止训练

代码
import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.05 # 学习率
# 创建训练数据 y = 2x + 5 + e
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1)
# torch.randn(20, 1) 用于添加噪声
y = 2*x + (5 + torch.randn(20, 1)) # y data (tensor), shape=(20, 1)
# 构建线性回归参数
w = torch.randn((1), requires_grad=True) # 设置梯度求解为 true
b = torch.zeros((1), requires_grad=True) # 设置梯度求解为 true
# 迭代训练 1000 次
for iteration in range(1000):
# model: y = wx +b
# 前向传播,计算预测值
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad) # 求导, 计算梯度
w.data.sub_(lr * w.grad) # 求导, 计算梯度
# 每次更新参数之后,都要清零张量的梯度
w.grad.zero_()
b.grad.zero_()
# 绘图,每隔 20 次重新绘制直线
if iteration % 20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
# 如果 MSE 小于 1,则停止训练
if loss.data.numpy() < 1:
break
LR回归
PyTorch 构建模型需要 5 大步骤:
数据:包括数据读取,数据清洗,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强。模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层。损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。- 迭代
训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。

代码示例:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
torch.manual_seed(10)
# ============================ step 1/5 生成数据 ============================
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums, 2)
# 使用正态分布随机生成样本,均值为张量,方差为标量
x0 = torch.normal(mean_value * n_data, 1) + bias # 类别0 数据 shape=(100, 2)
# 生成对应标签
y0 = torch.zeros(sample_nums) # 类别0 标签 shape=(100, 1)
# 使用正态分布随机生成样本,均值为张量,方差为标量
x1 = torch.normal(-mean_value * n_data, 1) + bias # 类别1 数据 shape=(100, 2)
# 生成对应标签
y1 = torch.ones(sample_nums) # 类别1 标签 shape=(100, 1)
train_x = torch.cat((x0, x1), 0) # 拼接两类数据集
train_y = torch.cat((y0, y1), 0)
# ============================ step 2/5 选择模型 ============================
class LR(nn.Module):
"""
定义 LR 模型结构
"""
def __init__(self):
super(LR, self).__init__()
# 基本组件
self.features = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 模型结构
x = self.features(x)
x = self.sigmoid(x)
return x
lr_net = LR() # 实例化逻辑回归模型
# ============================ step 3/5 选择损失函数 ============================
loss_fn = nn.BCELoss()
# ============================ step 4/5 选择优化器 ============================
lr = 0.01 # 学习率
optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
# ============================ step 5/5 模型训练 ============================
for iteration in range(1000):
# 前向传播
y_pred = lr_net(train_x)
# 计算 loss
loss = loss_fn(y_pred.squeeze(), train_y)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 清空梯度
optimizer.zero_grad()
# 绘图
if iteration % 20 == 0:
mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类
correct = (mask == train_y).sum() # 计算正确预测的样本个数
acc = correct.item() / train_y.size(0) # 计算分类准确率
plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0')
plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1')
w0, w1 = lr_net.features.weight[0]
w0, w1 = float(w0.item()), float(w1.item())
plot_b = float(lr_net.features.bias[0].item())
plot_x = np.arange(-6, 6, 0.1)
plot_y = (-w0 * plot_x - plot_b) / w1
plt.xlim(-5, 7)
plt.ylim(-7, 7)
plt.plot(plot_x, plot_y)
plt.text(-5, 5, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))
plt.legend()
# plt.savefig(str(iteration / 20)+".png")
plt.show()
plt.pause(0.5)
# 如果准确率大于 99%,则停止训练
if acc > 0.99:
break
pytorch可视化
详见站内专题
pytorch 内部机制
斯坦福大学博士生与 Facebook 人工智能研究所研究工程师 Edward Z. Yang 是 PyTorch 开源项目的核心开发者之一。他在 5 月 14 日的 PyTorch 纽约聚会上做了一个有关 PyTorch 内部机制的演讲,本文是该演讲的长文章版本。
选自ezyang博客,作者:Edward Z. Yang,机器之心编译,参与:panda。

大家好!今天我想谈谈 PyTorch 的内部机制。
这份演讲是为用过 PyTorch并且有心为 PyTorch 做贡献但却被 PyTorch 那庞大的 C++ 代码库劝退的人提供的。没必要说谎:PyTorch 代码库有时候确实让人难以招架。
本演讲的目的是为你提供一份导航图:为你讲解一个「支持自动微分的张量库」的基本概念结构,并为你提供一些能帮你在代码库中寻路的工具和技巧。我预设你之前已经写过一些 PyTorch,但却可能还没有深入理解机器学习软件库的编写方式。

本演讲分为两部分:
- 在第一部分中,我首先会全面介绍张量库的各种概念。我首先会谈谈你们知道且喜爱的张量数据类型,并详细讨论这种数据类型究竟能提供什么,这能让我们更好地理解其内部真正的实现方式。
- 如果你是PyTorch高级用户,可能已经熟悉其中大部分材料了。我们也会谈到「扩展点(extension points)」的三个概念:布局(layout)、设备(device)和数据类型(dtype),这能引导我们思考张量类的扩展的方式。在 PyTorch 纽约聚会的现场演讲中,我略过了有关自动梯度(autograd)的幻灯片,但我在这里会进行一些讲解。
- 第二部分会阐述用PyTorch写代码时所涉及的基本细节。如何在 autograd 代码中披荆斩棘、什么代码是真正重要的以及怎样造福他人,我还会介绍 PyTorch 为你写核(kernel)所提供的所有炫酷工具。
概念
张量
张量是 PyTorch 中的核心数据结构。张量是一种包含某种标量类型(比如浮点数和整型数等)的 n 维数据结构。可以将张量看作是由一些数据构成的,还有一些元数据描述了张量的大小、所包含的元素的类型(dtype)、张量所在的设备(CPU 内存?CUDA 内存?)
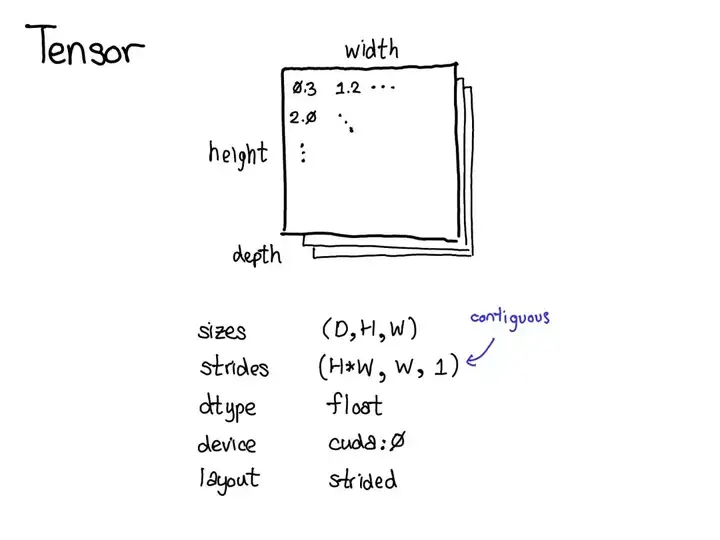
另外还有一个没那么熟悉的元数据:步幅(stride)。stride 实际上是 PyTorch 最别致的特征之一,所以值得稍微多讨论它一些。
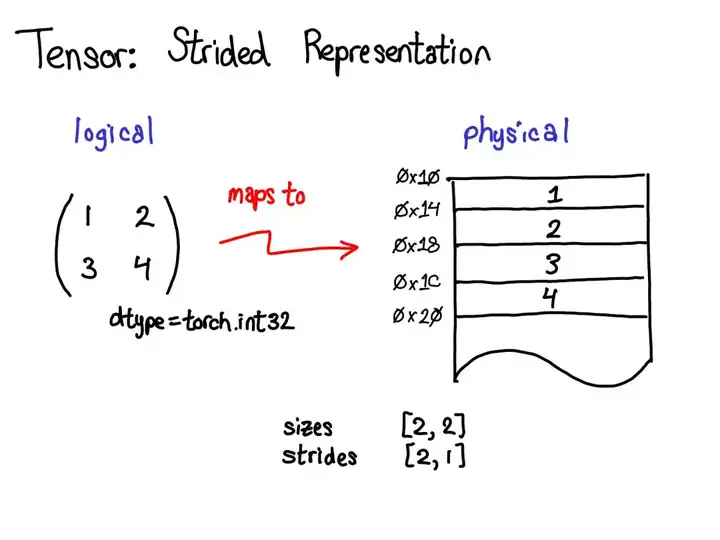
张量是一个数学概念。但要在我们的计算机中表示它,我们必须为它们定义某种物理表示方法。最常用的表示方法是在内存中相邻地放置张量的每个元素(这也是术语「contiguous(邻接)」的来源),即将每一行写出到内存,如上所示。在上面的案例中,我已经指定该张量包含 32 位的整型数,这样你可以看到每一个整型数都位于一个物理地址中,每个地址与相邻地址相距 4 字节。为了记住张量的实际维度,我们必须将规模大小记为额外的元数据。
所以这幅图与步幅有什么关系?

假设我想要读取我的逻辑表示中位置张量 [0,1] 的元素。我该如何将这个逻辑位置转译为物理内存中的位置?步幅能让我们做到这一点:要找到一个张量中任意元素的位置,我将每个索引与该维度下各自的步幅相乘,然后将它们全部加到一起。在上图中,我用蓝色表示第一个维度,用红色表示第二个维度,以便你了解该步幅计算中的索引和步幅。进行这个求和后,我得到了 2(零索引的);实际上,数字 3 正是位于这个邻接数组的起点以下 2 个位置。
(后面我还会谈到 TensorAccessor,这是一个处理索引计算的便利类(convenience class)。当你使用 TensorAccessor 时,不会再操作原始指针,这些计算过程已经为你隐藏了起来。)
步幅是我们为 PyTorch 用户讲解方法的基本基础。举个例子,假设我想取出一个表示以上张量的第二行的张量:
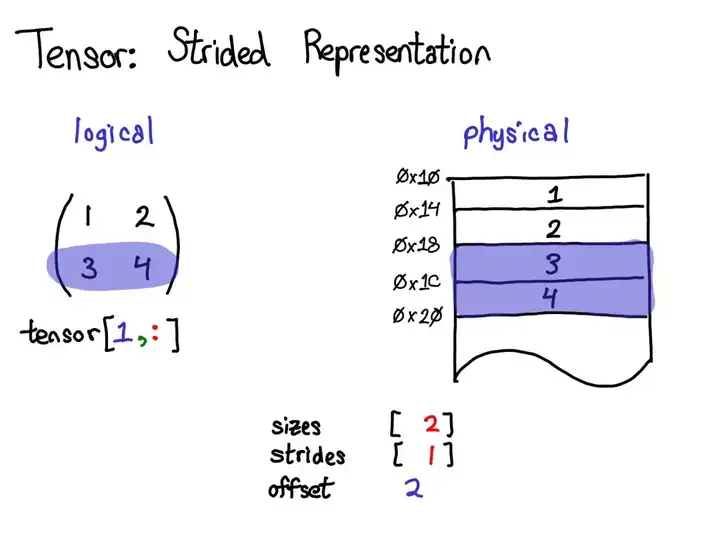
使用高级的索引支持,我只需写出张量 [1, :] 就能得到这一行。重要的是:当我这样做时,不会创建一个新张量;而是会返回一个基于底层数据的不同域段(view)的张量。这意味着,如果我编辑该视角下的这些数据,它就会反映在原始的张量中。
在这种情况下,了解如何做到这一点并不算太困难:3 和 4 位于邻接的内存中,我们只需要记录一个说明该(逻辑)张量的数据位于顶部以下 2 个位置的偏移量(offset)。(每个张量都记录一个偏移量,但大多数时候它为零,出现这种情况时我会在我的图表中省略它。)
演讲时的提问:如果我取张量的一个域段,我该如何释放底层张量的内存?
答案:你必须制作该域段的一个副本,由此断开其与原始物理内存的连接。你能做的其它事情实际上并不多。另外,如果你很久之前写过 Java,取一个字符串的子字符串也有类似的问题,因为默认不会制作副本,所以子字符串会保留(可能非常大的字符串)。很显然,Java 7u6 将其固定了下来。
如果我想取第一列,还会更有意思:
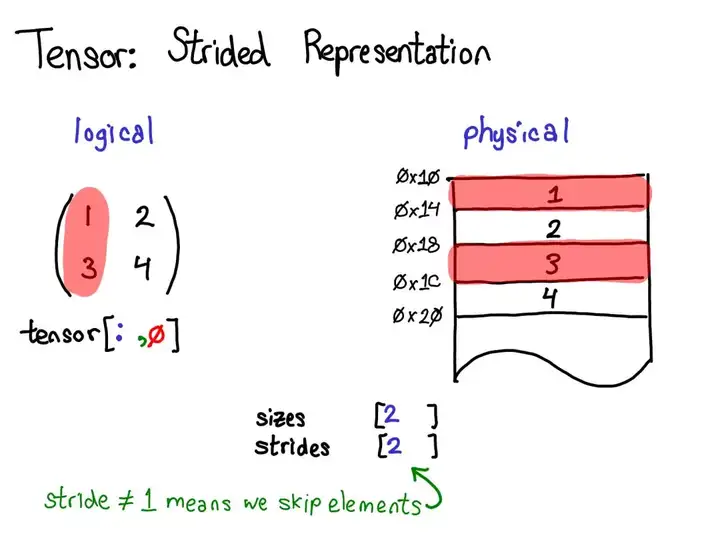
当我们查看物理内存时,可以看到该列的元素不是相邻的:两者之间有一个元素的间隙。步幅在这里就大显神威了:我们不再将一个元素与下一个元素之间的步幅指定为 1,而是将其设定为 2,即跳两步。(顺便一提,这就是其被称为「步幅(stride)」的原因:如果我们将索引看作是在布局上行走,步幅就指定了我们每次迈步时向前多少位置。)
步幅表示实际上可以让你表示所有类型的张量域段;如果你想了解各种不同的可能做法,请参阅 https://ezyang.github.io/stride-visualizer/index.html
我们现在退一步看看,想想我们究竟如何实现这种功能(毕竟这是一个关于内部机制的演讲)。如果我们可以得到张量的域段,这就意味着我们必须解耦张量的概念(你所知道且喜爱的面向用户的概念)以及存储张量的数据的实际物理数据的概念(称为「存储(storage)」):
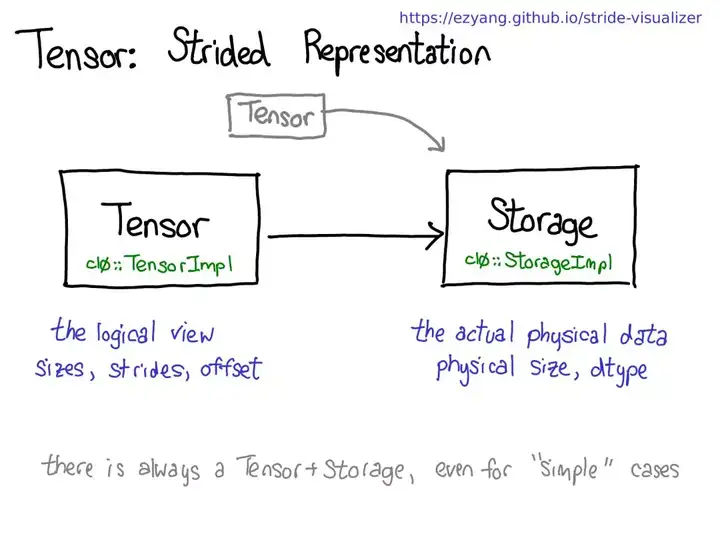
也许会有多个张量共享同一存储。存储会定义张量的 dtype 和物理大小,同时每个张量还会记录大小、步幅和偏移量,这定义的是物理内存的逻辑解释。
有一点需要注意:总是会存在一个张量-存储对,即使并不真正需要存储的「简单」情况也是如此(比如,只是用 torch.zeros(2, 2) 划配一个邻接张量时)。
顺便一提,我们感兴趣的不是这种情况,而是有一个分立的存储概念的情况,只是将一个域段定义为有一个基张量支持的张量。这会更加复杂一些,但也有好处:邻接张量可以实现远远更加直接的表示,而没有存储造成的间接麻烦。这样的变化能让 PyTorch 的内部表示方式更接近 Numpy。
上面已经介绍了一些张量的数据布局,但还是有必要谈谈如何实现对张量操作。在最抽象的层面上,当你调用 torch.mm 时,会发生两次调度:
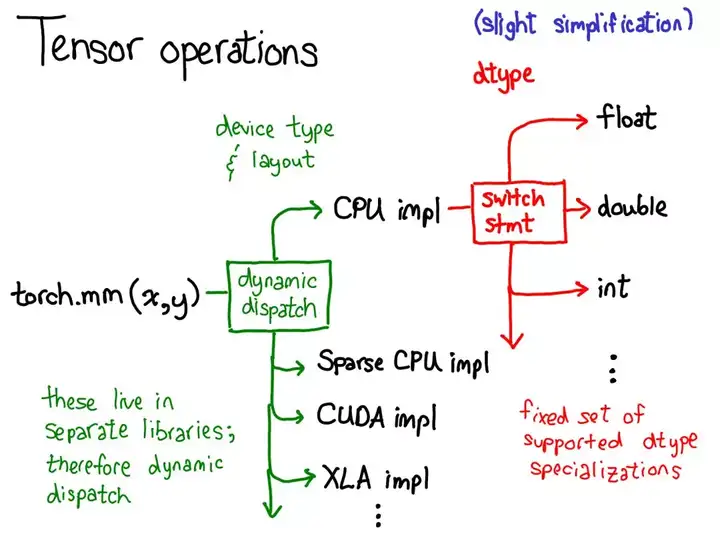
- 第一次调度基于设备类型和张量布局:比如是 CPU 张量还是 CUDA张量,是有步幅的张量还是稀疏的张量。这个调度是动态的:这是一个虚函数(virtual function)调用(这个虚函数调用究竟发生在何处是本演讲后半部分的主题)。
- 这里需要做一次调度应该是合理的:CPU 矩阵乘法的实现非常不同于 CUDA 的实现。这里是动态调度的原因是这些核(kernel)可能位于不同的库(比如 libcaffe2.so 或 libcaffe2_gpu.so),这样你就别无选择:如果你想进入一个你没有直接依赖的库,你必须通过动态调度抵达那里。
- 第二次调度是在所涉dtype上的调度。这个调度只是一个简单的 switch 语句,针对的是核选择支持的任意 dtype。这里需要调度的原因也很合理:CPU 代码(或 CUDA 代码)是基于 float 实现乘法,这不同于用于 int 的代码。这说明你需要为每种 dtype 都使用不同的核。
如果想理解 PyTorch 中算子的调用方式,这可能就是你头脑中应有的最重要的知识。后面当我们更深入代码时还会回到这里。

花点时间谈谈张量扩展。毕竟,除了密集的 CPU 浮点数张量,还有其它很多类型的张量,比如 XLA 张量、量化张量、MKL-DNN 张量;而对于一个张量库,还有一件需要思考的事情:如何兼顾这些扩展?
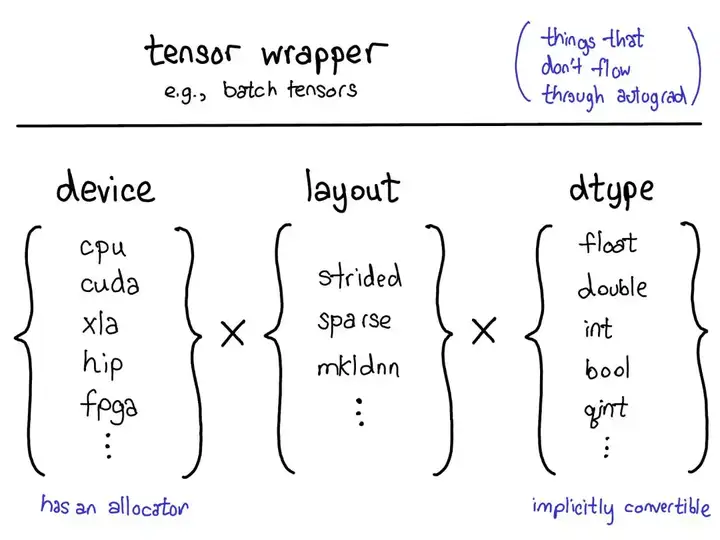
当前的用于扩展的模型提供了张量的四个扩展点。首先,有三个独立地确定张量类型的配套参数:
- device(设备):实际存储张量的物理内存,比如在 CPU、英伟达 GPU(cuda)、AMD GPU(hip)或 TPU(xla)上。设备之间各不相同的特性是有各自自己的分配器(allocator),这没法用于其它设备。
- layout(布局):对物理内存进行逻辑解读的方式。最常用的布局是有步幅的张量(strided tensor),但稀疏张量的布局不同,其涉及到一对张量,一个用于索引,一个用于数据;MKL-DNN 张量的布局更加奇特,比如 blocked layout,仅用步幅不能表示它。
- dtype(数据类型):张量中每个元素实际存储的数据的类型,比如可以是浮点数、整型数或量化的整型数。
如果你想为 PyTorch 张量添加一种扩展,你应该思考扩展这些参数中的哪几种。这些参数的笛卡尔积定义了你可以得到的所有可能的张量。现在,并非所有这些组合都有核(谁为 FPGA 上的稀疏量化张量用核?),但原则上这种组合可能有意义,因此我们至少应该支持表达它。
要为张量的功能添加「扩展」,还有最后一种方法,即围绕能实现的目标类型的 PyTorch 张量编写一个 wrapper(包装)类。这可能听起来理所当然,但有时候人们在只需要制作一个 wrapper 类时却跑去扩展那三个参数。wrapper 类的一个突出优点是开发结果可以完全不影响原来的类型(out of tree)。
你何时应该编写张量 wrapper,而不是扩展 PyTorch 本身?关键的指标是你是否需要将这个张量传递通过 autograd(自动梯度)反向通过过程。举个例子,这个指标告诉我们稀疏张量应该是一种真正的张量扩展,而不只是一种包含一个索引和值张量的 Python 对象:当在涉及嵌入的网络上执行优化时,我们想要嵌入生成稀疏的梯度。
 我们对扩展的理念也会影响张量本身的数据布局。对于我们的张量结构,我们真正想要的一件事物是固定的布局:我们不想要基本操作(这个说法很常见),比如「一个张量的大小是多少?」来请求虚调度。
我们对扩展的理念也会影响张量本身的数据布局。对于我们的张量结构,我们真正想要的一件事物是固定的布局:我们不想要基本操作(这个说法很常见),比如「一个张量的大小是多少?」来请求虚调度。
所以当你查看一个张量的实际布局时(定义为 TensorImpl 结构),会看到所有字段的一个公共前缀——我们认为所有类似「张量」的东西都会有;还有一些字段仅真正适用于有步幅的张量,但它们也很重要,所以我们将其保留在主结构中;然后可以在每个张量的基础上完成有自定义字段的后缀。比如稀疏张量可将其索引和值存储在这个后缀中。
自动梯度(autograd)
PyTorch 如有只有张量,就不过是 Numpy 的克隆。
PyTorch 显著特性是其在最初发布时就已提供对张量的自动微分(还有 TorchScript 等炫酷功能)
autograd 提供了对 Tensors 上所有运算操作的自动微分功能,计算梯度。
- 属于 define-by-run 类型框架,即反向传播操作的定义是根据代码的运行方式,因此每次迭代都可以是不同的。
自动微分是做啥?这是负责运行神经网络的机制:

……以及填充实际计算你的网络的梯度时所缺少的代码:

花点时间看看这幅图。其中有很多东西需要解读,我们来看看:
- 首先将你的目光投向红色和蓝色的变量。PyTorch 实现了反向模式自动微分,这意味着我们可以「反向」走过前向计算来有效地计算梯度。查看变量名就能看到这一点:在红色部分的底部,我们计算的是损失(loss);然后在这个程序的蓝色部分,我们所做的第一件事是计算 grad_loss。loss 根据 next_h2 计算,这样我们可以计算出 grad_next_h2。从技术上讲,我们加了 grad_ 的变量其实并不是梯度,它们实际上左乘了一个向量的雅可比矩阵,但在 PyTorch 中,我们就称之为 grad,基本上所有人都知道这是什么意思。
- 如果代码的结构保持一样,而行为没有保持一样:来自前向的每一行都被替换为一个不同的计算,其代表了前向运算的导数。举个例子,tanh 运算被转译成了 tanh_backward 运算(这两行用图左边一条灰线连接)。前向和反向运算的输入和输出交换:如果前向运算得到 next_h2,反向运算就以 grad_next_h2 为输入。
autograd 的意义就在于执行这幅图所描述的计算,但却不用真正生成这个源。PyTorch autograd 并不执行源到源的变换(尽管 PyTorch JIT 确实知道如何执行符号微分(symbolic differentiation))。
要做到这一点,我们需要在张量上执行运算时存储更多元数据。让我们调整一下我们对张量数据结构的图:现在不只是一个指向存储的张量,我们还有一个包装这个张量的变量,而且也存储更多信息(AutogradMeta),这是用户在自己的 PyTorch 脚本中调用 loss.backward() 执行 autograd 时所需的。
这张幻灯片的内容在不久的将来就会过时。Will Feng 在简单融合了 PyTorch 的前端端口之后,正在推动 C++ 中变量和张量的融合:https://github.com/pytorch/pytorch/issues/13638。
我们也必须更新上面关于调度的图:
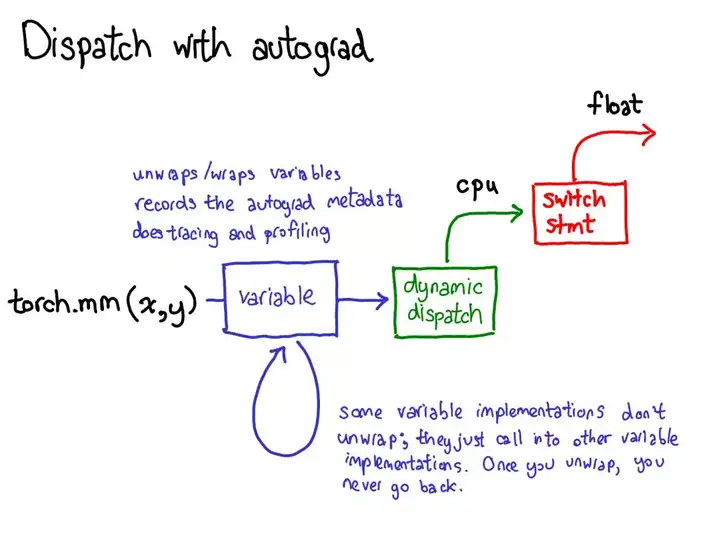
在我们调度到 CPU 或 CUDA 实现之前,还有另一个对变量的调度,其负责打开(unwrap)变量,调用底层实现(绿色),然后再重新将结果包装进变量并为反向过程记录必需的 autograd 元数据。
某些实现不会 unwrap;它们只是调用其它变量实现。所以你可能要在变量宇宙中花些时间。但是,一旦你 unwrap 并进入了非变量张量宇宙,你就到达终点了;你再也不用退回变量(除非从你的函数返回)。
在我的纽约聚会演讲中,我跳过了以下七页幻灯片。对它们的文本介绍还要等一段时间。

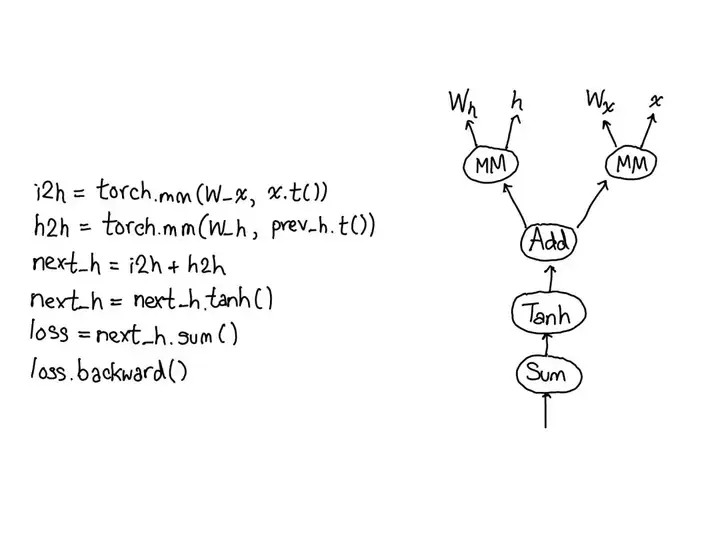


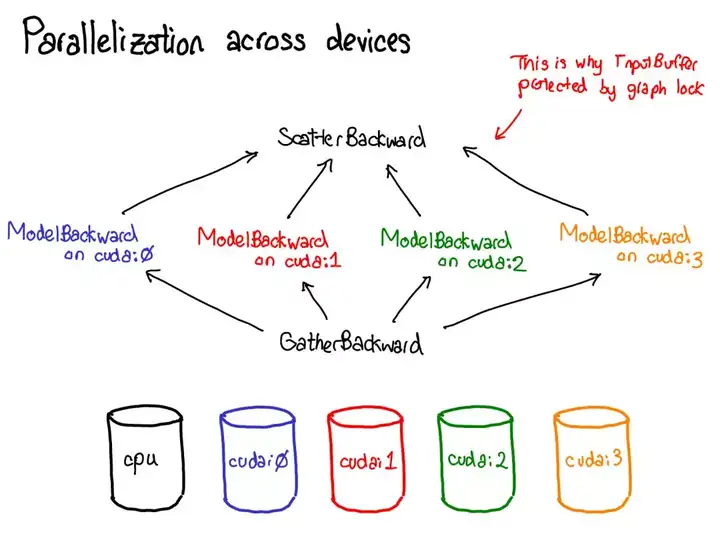
张量
当设置 torch.Tensor的属性 .requires_grad=True,就开始追踪该变量上的所有操作
- 完成计算后,调用
.backward()并自动计算所有的梯度,得到的梯度都保存在属性.grad中。 - 调用
.detach()方法分离出计算的历史,停止一个 tensor 变量继续追踪其历史信息,同时也防止未来的计算会被追踪。 - 如果是希望防止跟踪历史(以及使用内存),将代码块放在
with torch.no_grad():内,模型评估时非常有用,因为模型会包含一些带有requires_grad=True的训练参数,但实际上并不需要梯度信息。
Function
Tensor 和 Function 两个类是有关联, 并建立了一个非循环图,可编码一个完整的计算记录。
- 每个 tensor 变量都带有属性
.grad_fn,引用创建这个变量的Function(除了由用户创建的 Tensors,它们的grad_fn=None - 如果要进行求导运算,可调用一个 Tensor 变量的方法
.backward()。 - 如果该变量是一个标量,即仅有一个元素,那么不需要传递任何参数给方法
.backward() - 当包含多个元素的时候,就必须指定一个
gradient参数,表示匹配尺寸大小的 tensor。
import torch
# Tensor 变量默认 requires_grad 是 False
x = torch.ones(2, 2, requires_grad=True)
print(x)
y = x + 2
print(y)
print(y.grad_fn)
z = y * y * 3
out = z.mean()
print('z=', z)
print('out=', out)
梯度
计算梯度,进行反向传播的操作。
- out 变量是一个标量,因此
out.backward()相当于out.backward(torch.tensor(1.))
out.backward()
# 输出梯度 d(out)/dx
print(x.grad)
求梯度
# 定义变量 x,且x=1,并设置 requires_grad=True 以便追踪梯度
x = torch.tensor(1.0, requires_grad=True)
y_1 = x**2
# 使用 with torch.no_grad() 中断 y_2 = x^3 的梯度追踪
with torch.no_grad():
y_2 = x**3
y_3 = y_1 + y_2
# 计算 y_3 对 x 的梯度
y_3.backward()
# 输出梯度
print("y_3 对 x 的梯度 (dy_3/dx):", x.grad)
# y_3 对 x 的梯度 (dy_3/dx): tensor(2.)
分析:
- 计算 y_2 = x^3 时, 中断了梯度追踪,因此只会计算 y_1 = x^2 对 x 的梯度,即 (dy_1)/dx=2 。当 x = 1 时,梯度为 2 * 1 = 2。
工程开发
说够了概念,我们来看看代码。
找到你的路径
PyTorch 有大量文件夹,在 CONTRIBUTING.md 文档中有对它们的非常详细的描述,但实际上你只需知晓 4 个目录:
-
- 首先,torch/ 包含你最熟悉的东西:你导入和使用的实际的 Python 模块。这些东西是 Python 代码而且易于操作(只需要进行修改然后查看结果即可)。但是,如果太过深入……
- torch/csrc/:实现了你可能称为 PyTorch 前端的 C++ 代码。用更描述性的术语讲,它实现了在 Python 和 C++ 间转换的绑定代码(binding code);另外还有一些相当重要的 PyTorch 部分,比如 autograd 引擎和 JIT 编译器。它也包含 C++ 前端代码。
- aten/:这是「A Tensor Library」的缩写(由 Zachary DeVito 命名),是一个实现张量运算的 C++ 库。如果你检查某些核代码所处的位置,很可能就在 ATen。ATen 本身就分为两个算子区域:「原生」算子(算子的现代的 C++ 实现)和「传统」算子(TH、THC、THNN、THCUNN),这些是遗留的 C 实现。传统的算子是其中糟糕的部分;如果可以,请勿在上面耗费太多时间。
- c10/:这是「Caffe2」和「A”Ten”」的双关语,包含 PyTorch 的核心抽象,包括张量和存储数据结构的实际实现。
找代码需要看很多地方;我们应该简化目录结构,就是这样。如果你想研究算子,你应该在 aten 上花时间。
我们看看在实践中是如何分离这些代码的:

当你调用一个函数时,比如 torch.add,会发生什么?如果你记得我们的有关调度的讨论,你脑中应该已有了这些基础:
- 我们必须从 Python 国度转换到 C++ 国度(Python 参数解析)。
- 我们处理变量调度(VariableType—Type,顺便一提,和编程语言类型并无特别关联,只是一个用于执行调度的小工具)。
- 我们处理设备类型/布局调度(Type)。
- 我们有实际的核,这要么是一个现代的原生函数,要么是传统的 TH 函数。
其中每一步都具体对应于一些代码。让我们开路穿过这片丛林。

我们在 C++ 代码中的起始着陆点是一个 Python 函数的 C 实现,我们已经在 Python 那边见过它,像是 torch._C.VariableFunctions.add。THPVariable_add 就是这样一个实现。
对于这些代码,有一点很重要:这些代码是自动生成的。如果你在 GitHub 库中搜索,你没法找到它们,因为你必须实际 build PyTorch 才能看到它们。另外一点也很重要:你不需要真正深入理解这些代码是在做什么,你应该快速浏览它,知道它的功能。
我在上面用蓝色标注了最重要的部分:你可以看到这里使用了一个 PythonArgParser 类来从 Python args 和 kwargs 取出 C++ 对象;然后我们调用一个 dispatch_add 函数(红色内联);这会释放全局解释器锁,然后调用在 C++ 张量自身上的一个普通的旧方法。在其回来的路上,我们将返回的 Tensor 重新包装进 PyObject。
(这里幻灯片中有个错误:我应该讲解变量调度代码。我这里还没有修复。某些神奇的事发生了,于是……)

当我们在 Tensor 类上调用 add 方法时,还没有虚调度发生。相反,我有一个内联方法,其调用了一个内联方法,其会在「Type」对象上调用一个虚方法。这个方法是真正的虚方法(这就是我说 Type 只是一个让你实现动态调度的「小工具」的原因)。
在这个特定案例中,这个虚调用会调度到在一个名为 TypeDefault 的类上的 add 的实现。这刚好是因为我们有一个对所有设备类型(CPU 和 CUDA)都一样的 add 的实现;如果我们刚好有不同的实现,我们可能最终会得到 CPUFloatType::add 这样的结果。正是这种虚方法的实现能让我们最终得到实际的核代码。
也希望这张幻灯片很快过时;Roy Li 正在研究使用另一种机制替代 Type 调度,这能让我们更好地在移动端上支持 PyTorch。
值得再次强调,一直到我们到达核,所有这些代码都是自动生成的。
道路蜿蜒曲折,一旦你能基本上把握方向了,我建议你直接跳到核部分。
编写核(kernel)
PyTorch 为有望编写核的人提供了大量有用工具。在这一节我们会了解其中一些。但首先,编写核需要什么?

我们一般将 PyTorch 中的核看作由以下部分组成:
- 首先有一些我们要写的有关核的元数据,这能助力代码生成并让你获取所有与 Python 的捆绑包,同时无需写任何一行代码。
- 一旦你到达了核,你就经过了设备类型/布局调度。你首先需要写的是错误检查,以确保输入的张量有正确的维度。(错误检查真正很重要!不要吝惜它!)
- 接下来,我们一般必须分配我们将要写入输出的结果张量。
- 该到写核的时候了。现在你应该做第二次 dtype 调度,以跳至其所操作的每个 dtype 特定的核。(你不应该过早做这件事,因为那样的话你就会毫无用处地复制在任何情况下看起来都一样的代码。)
- 大多数高性能核都需要某种形式的并行化,这样就能利用多 CPU 系统了。(CUDA 核是「隐式」并行化的,因为它们的编程模型构建于大规模并行化之上。)
- 最后,你需要读取数据并执行你想做的计算!
在后面的幻灯片中,我将介绍 PyTorch 中能帮你实现这些步骤的工具。

要充分利用 PyTorch 的代码生成能力,你需要为你的算子写一个模式(schema)。这个模式能提供你的函数的 mypy 风格类型,并控制是否为 Tensor 上的方法或函数生成捆绑包。你还可以告诉模式针对给定的设备-布局组合,应该调用你的算子的哪种实现。
有关这种格式的更多信息,请参阅:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/README.md

你可能也需要为你在 derivatives.yaml 中的操作定义一个导数。

错误检查可以在低层 API 完成,也能通过高层 API 实现。低层 API 只是一个宏 TORCH_CHECK,其接收的是一个布尔值,然后还有任意数量的参数构成错误字符串(error string)以便得出结论看该布尔值是否为真。
这个宏有个很好的地方:你可以将字符串与非字符串数据混合起来;每一项都使用它们的 operator« 实现进行格式化,PyTorch 中大多数重要的数据类型都有 operator« 实现。
高层 API 能让你免于反复编写重复的错误消息。其工作方法是;你首先将每个张量包装为 TensorArg,这包含有关张量来处的信息(比如其参数名称)。然后它提供了一些预先装好的用于检查多种属性的函数;比如 checkDim() 测试的是张量的维度是否是一个固定数值。如果不是,该函数就基于 TensorArg 元数据提供一个用户友好的错误消息。

在用 PyTorch 写算子时,有一点很重要:你往往要注册三个算子:abs_out(其操作的是一个预分配的输出,其实现了 out= keyword 参数)、abs_(其操作的是 inplace)、abs(这只是一个算子的普通的旧功能版本)。
大部分时间,abs_out 是真正的主力,abs 和 abs_ 只是围绕 abs_out 的薄弱 wrapper;但有时候也可为每个案例编写专门的实现。

要执行 dtype 调度,你应该使用 AT_DISPATCH_ALL_TYPES 宏。这会获取你想要进行调度操作的张量的 dtype,并还会为可从该宏调度的每个 dtype 指定一个 lambda。通常而言,这个 lambda 只是调用一个模板辅助函数。
这个宏不只是「执行调度」,它也会决定你的核将支持的 dtype。这样,这个宏实际上就有相当多一些版本,这能让你选取不同的 dtype 子集以生成特定结果。大多数时候,你只需要 AT_DISPATCH_ALL_TYPES,但也要关注你可能需要调度其它更多类型的情况。

在 CPU 上,你通常需要并行化你的代码。过去,这通常是通过直接在你的代码中添加 OpenMP pragma 来实现。

某些时候,你必须真正访问数据。PyTorch 为此提供了相当多一些选择。
- 如果你只想获取某个特定位置的值,你应该使用 TensorAccessor。张量存取器就像是一个张量,但它将张量的维度和 dtype 硬编码为了模板参数。当你检索一个存取器时,比如 x.accessor();,我们会做一次运行时间测试以确保张量确实是这种格式;但那之后,每次存取都不会被检查。张量存取器能正确地处理步幅,因此你最好使用它们,而不是原始的指针访问(不幸的是,很多传统的核是这样做的)。另外还有 PackedTensorAccessor,这特别适用于通过 CUDA launch 发送存取器,这样你就能从你的 CUDA 核内部获取存取器。(一个值得一提的问题:TensorAccessor 默认是 64 位索引,这比 CUDA 中的 32 位索引要慢得多!)
- 如果你在用很常规的元素存取编写某种算子,比如逐点运算,那么使用远远更高级的抽象要好得多,比如 TensorIterator。这个辅助类能为你自动处理广播和类型提升(type promotion),相当好用。
- 要在 CPU 上获得真正的速度,你可能需要使用向量化的 CPU 指令编写你的核。我们也有用于这方面的辅助函数!Vec256 类表示一种标量向量,并提供了一些能在它们上一次性执行向量化运算的方法。然后 binary_kernel_vec 等辅助函数能让你轻松地运行向量化运算,然后结束那些没法用普通的旧指令很好地转换成向量指令的东西。这里的基础设施还能在不同指令集下多次编译你的核,然后在运行时间测试你的 CPU 支持什么指令,再在这些情况中使用最佳的核。

PyTorch 中大量核都仍然是用传统的 TH 风格编写的。(顺便一提,TH 代表 TorcH。这是个很好的缩写词,但很不幸被污染了;如果你看到名称中有 TH,可认为它是传统的。)传统 TH 风格是什么意思呢?
- 它是以 C 风格书写的,没有(或很少)使用 C++。
- 其 refcounted 是人工的(使用了对 THTensor_free 的人工调用以降低你使用张量结束时的 refcounts)。
- 其位于 generic/ 目录,这意味着我们实际上要编译这个文件很多次,但要使用不同的 #define scalar_t
这种代码相当疯狂,而且我们讨厌回顾它,所以请不要添加它。如果你想写代码但对核编写了解不多,你能做的一件有用的事情:将某些 TH 函数移植到 ATen。
工作流程效率

最后我想谈谈在 PyTorch 上的工作效率。如果 PyTorch 那庞大的 C++ 代码库是阻拦人们为 PyTorch 做贡献的第一只拦路虎,那么你的工作流程的效率就是第二只。如果你想用 Python 习惯开发 C++,那可能会很艰辛:重新编译 PyTorch 需要大量时间,你也需要大量时间才能知道你的修改是否有效。
如何高效工作本身可能就值得做一场演讲,但这页幻灯片总结了一些我曾见过某些人抱怨的最常见的反模式:「开发 PyTorch 很困难。」
- 如果你编辑一个 header,尤其是被许多源文件包含的 header(尤其当被 CUDA 文件包含时),可以预见会有很长的重新 build 时间。尽量只编辑 cpp 文件,编辑 header 要审慎!
- 我们的 CI 是一种非常好的零设置的测试修改是否有效的方法。但在获得返回信号之前你可能需要等上一两个小时。如果你在进行一种将需要大量实验的改变,那就花点时间设置一个本地开发环境。类似地,如果你在特定的 CI 配置上遇到了困难的 debug 问题,就在本地设置它。你可以将 Docker 镜像下载到本地并运行:https://github.com/pytorch/ossci-job-dsl
- 贡献指南解释了如何设置 ccache:https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#use-ccache ;强烈建议这个,因为这可以让你在编辑 header 时幸运地避免大量重新编译。当我们在不应该重新编译文件时重新编译时,这也能帮你覆盖我们的 build 系统的漏洞。
- 最后,我们会有大量 C++ 代码。如果你是在一台有 CPU 和 RAM 的强大服务器上 build,那么会有很愉快的体验。特别要说明,我不建议在笔记本电脑上执行 CUDA build。build CUDA 非常非常慢,而笔记本电脑往往性能不足,不足以快速完成。
参与进来!
这就是我们旋风一般的 PyTorch 内核之旅了!其中省略了很多很多东西;但希望这里的描述和解释至少能帮你消化其代码库中相当大一部分。
接下来该做什么?你能做出怎样的贡献?我们的问题跟踪器是个开始的好地方:https://github.com/pytorch/pytorch/issues。
从今年开始,我们一直在分类鉴别问题;标注有「triaged」的问题表示至少有一个 PyTorch 开发者研究过它并对该问题进行了初步评估。你可以使用这些标签找到我们认为哪些问题是高优先级的或查看针对特定模块(如 autograd)的问题,也能找到我们认为是小问题的问题。(警告:我们有时是错的!)
即使你并不想马上就开始写代码,也仍有很多其它有用的工作值得去做,比如改善文档(我很喜欢合并文档 PR,它们都很赞)、帮助我们重现来自其他用户的 bug 报告以及帮助我们讨论问题跟踪器上的 RFC。没有我们的开源贡献者,PyTorch 不会走到今天
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
